Создание понятных отчетов о тестировании
Время на прочтение
6 мин
Количество просмотров 112K
Введение
Данная статья будет полезна для специалистов не только в тестировании, но и из других областей.
Я думаю, все понимают, что отчётность — это, зачастую, та часть, которая обязательна на проекте, но составлять ее всегда проблематично. Каждый, рано или поздно, сталкивается с проблемой «как это описать?», «что написать?» и главное «зачем и кто это будет читать?».
На самом деле, отчет — это важная и лаконичная форма передачи информации от исполнителя к заказчику. Это ответ на его технические требования и одновременно информация о проделанной работе.
Сегодня мы поговорим об отчетах в тестировании. В статье Вы найдет акценты на важные моменты при создании отчётов.
Понятный отчёт о тестировании
Создание понятного отчёта о тестировании (test-report) на практике.
Для начала, давайте вспомним определение:
Отчёт — это документ, содержащий информацию о выполненных действиях, результатах проведённой работы. Обычно он включает в себя таблицы, графики, списки, просто описывающую информацию в виде текста. Их пропорция и содержание определяют пользу и понятность отчета.
Нам важно понять, для кого, для чего и в каких условиях мы это делаем и на сколько это улучшит восприятие излагаемой нами информации. Надо помнить, что каждое действие преследует определенную цель. В случае отчета нам важно понять, для кого, для чего и в каких условиях мы это делаем.
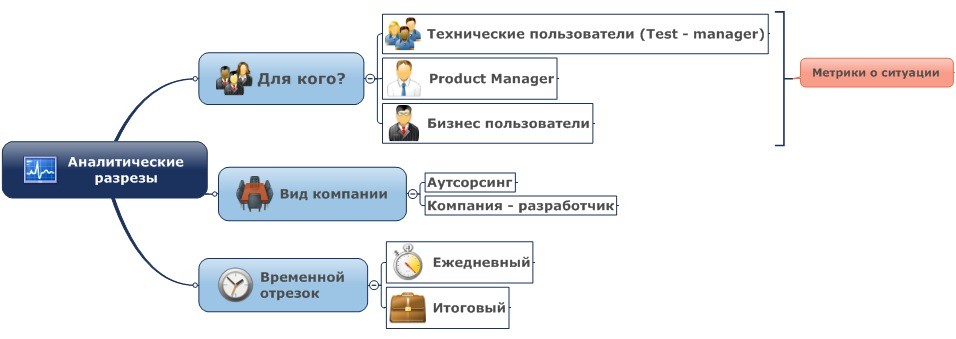
Давайте посмотрим на схему:
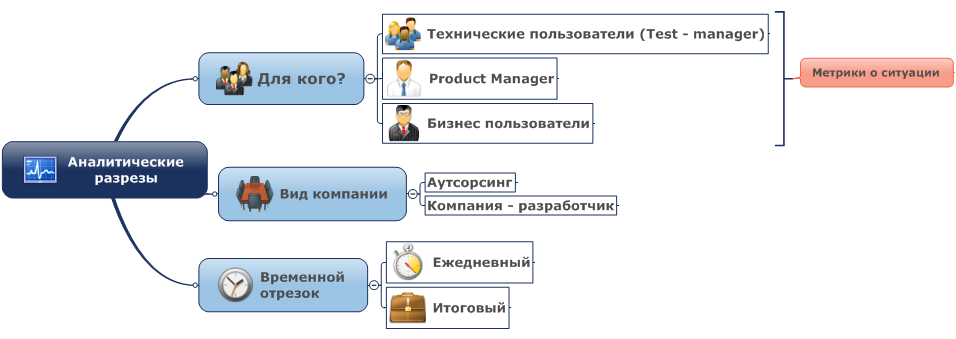
Аналитические разрезы – это и есть наш отчет. В нем мы даем анализ нашей работе и оценку тестируемому продукту.
Вид компании, в идеальной ситуации, не должен влиять на качество и смысловую ёмкость отчетности. В реальном же мире, к сожалению, отчетность аутсорсинговых компаний является, как правило, более качественной и емкой, чем отчетность штатных отделов тестирования (бывают и приятные исключения).
Мы, как и любая другая аутсорсинговая компания, вынуждены уделять большое внимание качеству и прозрачности отчетности, потому что она является ключевой видимой заказчику метрикой оценки нашей работы.
Саму отчетность можно разделить на финальную и регулярную – дневную, недельную, месячную, версионную (для каждой версии продукта) и т.п. Различия заключаются в глубине временнОй выборки.
Итак, перед написанием отчета, сначала нам надо определиться для кого мы его пишем.
Для кого формируем отчет?
При создании отчета важно понимать, для кого он создаётся, и кто будет его читать.
Исходя из приоритетов целевой аудитории, мы должны определить, какую информацию должен содержать отчёт. Соответственно, в ходе проекта, информация должна консолидироваться по тому направлению, которое необходимо отразить.
Мы можем выделить три группы целевых аудиторий:
1. Технические пользователи — Test-manager. Для них приоритетно понимание хода тестирования, какие возникают проблемы, как они решаются, построение самого процесса тестирование, описание применяемых методов и технологий.
2. Product Manager, они же Менеджеры продукта. Их фокус сконцентрирован на сроках выполнения, выжимки из результатов тестирования без излишних технических подробностей и на общую статистику (цифровые и сравнительные метрики).
3. Бизнес-пользователи. Обычно это и есть те люди, которые принимают решения по завершению тестирования. Они же определяют качество проделанной работы. Для них, в первую очередь, важен конечный результат в максимально кратком и ясном формате (данет), наглядное представление информации (графики, диаграммы), экспертное мнение о возможности выпуска продукта в промышленную среду и т. п., без углубления в детали.
Вывод: Написать отчет, который устроит все группы, практически невозможно. Прежде чем писать отчет, обязательно определите целевую аудиторию. В зависимости от нее, содержание будет сильно отличаться своей структурой и содержать разные детали, необходимые конкретной группе.
Какова глубина временной выборки?
Отчёты могут делиться на два вида относительно времени:
1. (Недельный, дневной, месячный)/ промежуточный.
В общем, это практически тот же финальный отчет, но с измененными приоритетами фокуса и уменьшенной глубиной временной выборки. В нем обязательно должны содержаться две главных метрики:
— Оценка степени готовности продукта.
— Оценка проведённых работ по тестированию за время между отчетностями (прогресс).
Этот отчет должен показать какова динамика вашей работы.
Важно помнить, что прогресс – величина не постоянная, а динамическая, она определяется за счёт сравнения состояния проекта на прошлой неделе и настоящей. Соответственно прогресс – этот совокупность метрик, позволяющих понять в каком состоянии находится проект.
Они создаются для каждого проекта индивидуально, основываясь на целях, которые ставятся для успешного проведения тестирования. Метрики ставятся при создании ТК (тест-кейсов), прохождении ТК (проваленпройден), обнаружении дефектов (критичность). Они позволяют доступно и достаточно быстро составить общую сравнительную картину по проекту. Если вы, например, используете TestLink, то понимаете, что метрики позволяют делать быструю выборку по проблемам, составлять статистику проваленных ТК и т. п.
Данная информация полезна и необходима для Product Manager, её составляют и контролируют Test-manager, а также QE и SQE.
Есть еще один важный и часто используемые тип временного отчета – версионный (отчет по итерации).
Он схож с итоговым. В нём описываются те задачи, которые были выполнены командой тестирования для конкретной версии продукта.
2. Конечный /финальный.
В финальном отчете важно показать общий взгляд на проделанную работу (в контексте установленных метрик) и эволюцию продукта.
Так же, надо дать исчерпывающую информацию о статусе продукта в данный момент (количество оставшихся неисправленных ошибок, полностью ли протестирован продукт или требуется дополнительный цикл тестирования, оценка возможности выпуска продукта во «внешний мир» и т.д).
Вывод: Ведите статистику, используя метрики в течении всего проекта. Она поможет вам в нужный момент предоставить любую информацию заказчику и избавит от страха перед вопросами «А что конкретно вы сделали на четвертой неделе?» и «Что у нас со сроками?».
Какие приёмы представления информации и данных использовать в отчёте?
Когда технический специалист пишет для другого технического специалиста, вопрос о применении тех или иных приемов отражения информации возникает редко. Термины, формулы, профессиональный сленг – это привычно и понятно. Гораздо сложнее писать отчеты для людей, которые относительно далеки от специфики тестирования.
Для Бизнес-пользователей, зачастую, используют представление информации в виде графиков. Они наглядно показывают на сколько продукт готов к выпуску в промышленную среду, на сколько процентов проект выполнен.
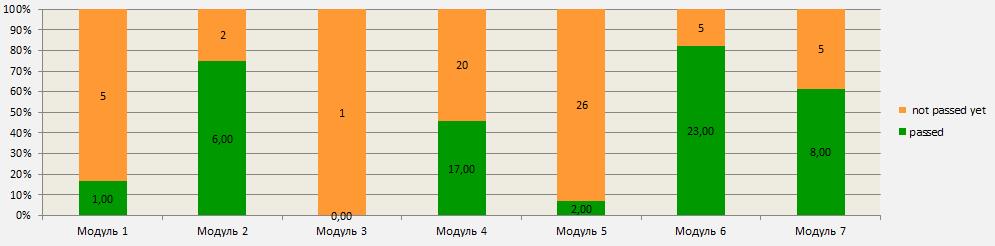
Это может быть, к примеру, график пройденных ТК п о модулям. Он наглядно покажет, какой объем работы в каждом модуле уже проделан и поможет вычленить проблемы.
Так же, очень полезным может быть график отношения созданных тикетов (обнаруженных багов) и закрытых (исправленных багов). Не даром он является основным во многих таск-трекерах.
В случае продуктивной работы программистов над исправлением дефектов и написанием качественного кода кривая критических ошибок с выходом нового релиза стремиться к низу, при этом приоритет и важность ошибок тоже уменьшается.
Но, если разработчиками или тестировщиками уделяется мало внимания существующим дефектам, то кривая закрытых багов растет медленнее, чем не закрытых.
В идеальном случае кривая незакрытых багов (найденных, но не исправленных) должна сойтись с кривой исправленных. Другими словами, к финальному релизу необходимо, что бы все дефекты были устранены. Если это не так, то руководство может принять решение о продлении разработки и тестирования с целью устранения всех дефектов или выпустить продукт в «прод», беря на себя возможные риски.
В дополнение к графику необходимо оформлять сводную таблицу. График строится на основании этих данных.
Вот пример таблицы, на основании которой был построен график пройденных ТК по модулям:

Вывод: График для бизнес-пользователей — обязательная часть отчетности. Он информативен, доступен и понятен конечному пользователю, демонстрирует динамику активности на проекте или, в худшем случае — застой.
Так же, использование графиков в отчетах для любых пользователей и технических специалистов целесообразно тогда, когда надо быстро и наглядно сравнить цифры и показать динамику.
ЧТО НУЖНО УКАЗЫВАТЬ В ОТЧЕТЕ ВСЕГДА?
Может показаться, что отчеты разных типов сильно отличаются.
Тем не менее, в них есть схожие черты и данные, которые стоит указывать всегда.
Вот они:
1. Состав команды;
2. Сроки выполнения, за которые составляется отчет;
3. Описание процессов тестирования;
4. Изменения тестовой модели, дополнение ТК;
5. Процент пройденных ТК;
6. Критичные и блокирующие проблемы и принятые меры по их устранению;
7. Результаты регресса (плюс акцент на сохранившихся проблемах);
8. План на следующую итерацию неделю месяц;
Пункты 3, 4, 6 и 8 стоит писать с оглядкой на целевую аудиторию отчета.
Седьмой пункт стоит указывать тогда, когда проводилось «регресс-тестирование». Обычно этот пункт фигурирует в «версионных» отчетах.
Пункт 8 из итогового отчета исключается.
Заключение
Итак, мы поняли нашу целевую аудиторию, обозначили период, за который мы будем писать отчет, определили содержание и блоки. На самом деле — это практически все, что надо, чтобы сформировать понятный документ, который обязательно найдет отклик в головах тех, кому он адресован.
Пишите ваши отчеты детально, грамотно и с удовольствием, ведь хороший отчет – это как минимум треть работы и единственная ее часть, которая видна кому-то, кроме тестировщиков и программистов.
Автор: Ефремова Дарья
← Предыдущий урок
(Перед вами перевод бесплатного курса по A/B тестированию от компании Dynamic Yield. Если вы здесь впервые, то лучше начните сначала)
Автор английской версии: Шана Пилевски, директор по маркетингу, Dynamic Yield
На большинстве платформ для проведения экспериментов есть встроенная функция аналитики, чтобы отслеживать нужные метрики и KPI. Но прежде чем смотреть в отчеты и начинать что-то анализировать, важно понять суть двух ключевых метрик:
- Рост (аплифт, uplift): разница (в процентах) между показателями вариации и базовой (контрольной) версии. К примеру, если для вариации доход на пользователя составил 5$, а для контрольной версии — 4$, значит рост составил 25%.
- Вероятность того, что одна версия лучше другой (P2BB, Probability to Be Best): показывает, каковы шансы, что конкретная вариация будет более эффективной в долгосрочной перспективе. Эта метрика самая полезная во всем отчете с практической точки зрения — ее используют для определения победителя A/B теста. Если рост (аплифт) может варьироваться в зависимости от размера выборки, то показатель P2BB (вероятность, что одна версия лучше) учитывает размер выборки (основываясь на байесовском подходе). P2BB не начинает вычисляться, пока выборка не достигнет 1000 или не наберется 30 конверсий. Проще говоря, показатель P2BB отвечает на вопрос “Какая версия лучше?”, а рост показывает “Насколько?”
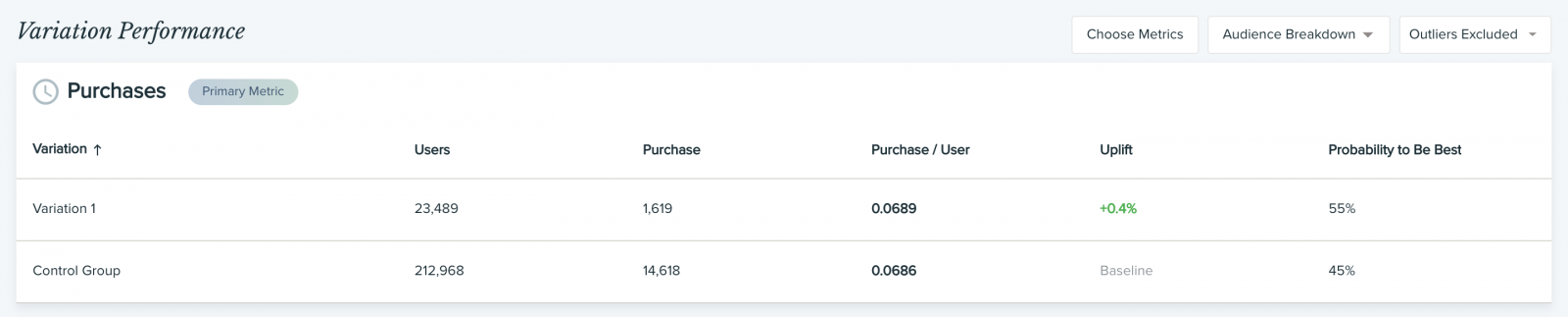
Базовый анализ
Начните с проверки результатов A/B теста: возможно, уже выделился конкретный победитель или хотя бы есть информация, какая вариация побеждает на данный момент. Если ваша платформа для тестирования не рассчитывает метрику P2BB (вероятность, что одна версия лучше другой), можете воспользоваться нашим байесовским калькулятором для A/B тестирования, чтобы обработать данные и выявить статистически значимые результаты.
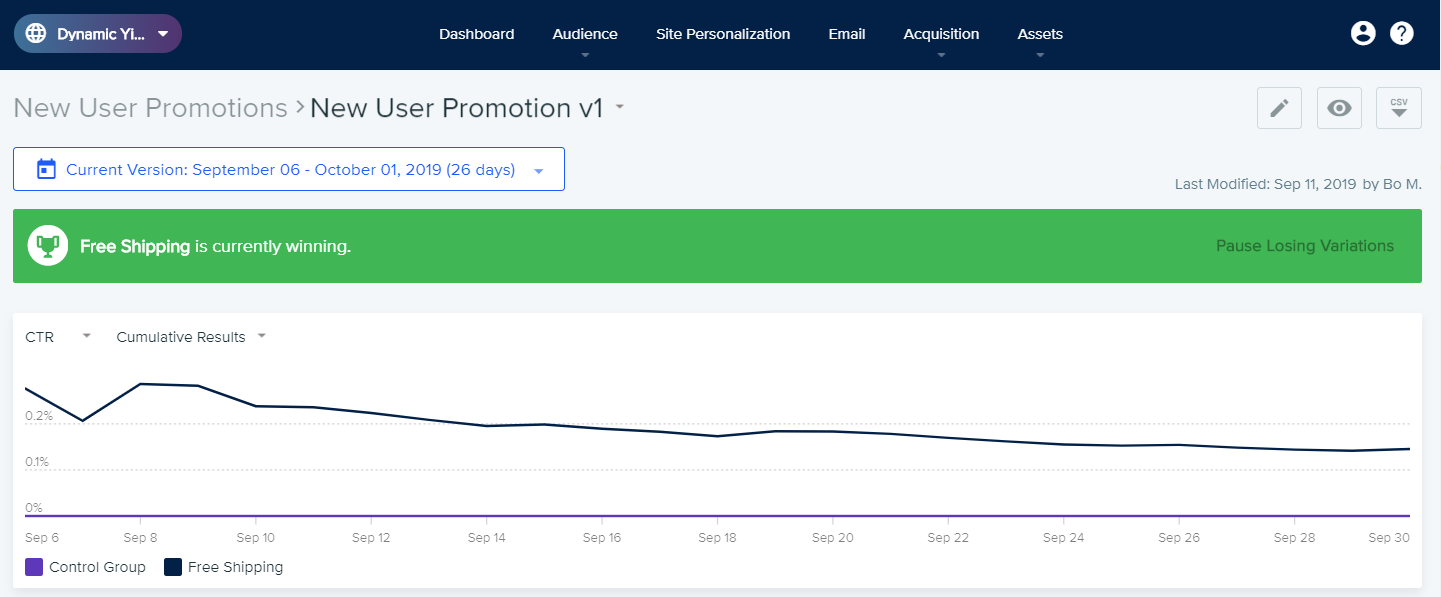
Обычно, победитель объявляется, когда соблюдены следующие условия:
- Для одной из вариаций показатель P2BB превысил 95% (некоторые платформы позволяют менять порог этого показателя через настройку уровня значимости победителя).
- Прошло минимальное время тестирования (по умолчанию это 2 недели). Это делается, чтобы застраховать результаты от влияния сезонных колебаний.
Анализ вторичных метрик
Обычно победитель тестирования определяется на основании одной ключевой метрики. Однако некоторые платформы (и Dynamic Yield в их числе) также отслеживают и дополнительные, так называемые вторичные метрики. Прежде чем вы завершите эксперимент и начнете масштабировать вариацию-победителя на всю аудиторию, рекомендуем всегда анализировать вторичные метрики, и вот почему:
- Перестраховаться от ошибки (например, победившая вариация обеспечила рост вашей ключевой метрики CTR, но повлекла падение количества покупок, объема дохода или средней стоимости заказа (AOV)).
- Раскопать ценную информацию (например, доля покупок на пользователя сократилась, но средняя стоимость заказа выроста, из чего следует, что пользователи делают покупки реже, но приобретают более дорогие товары — следовательно, генерируют больше прибыли).
По каждой вторичной метрике мы рекомендуем отслеживать рост (аплифт) и P2BB, чтобы отслеживать эффективность вариаций в сравнении.
После такого анализа будет понятно, стоит ли выкатывать одну победившую вариацию на весь трафик или лучше скорректировать распределение на основании новых данных.
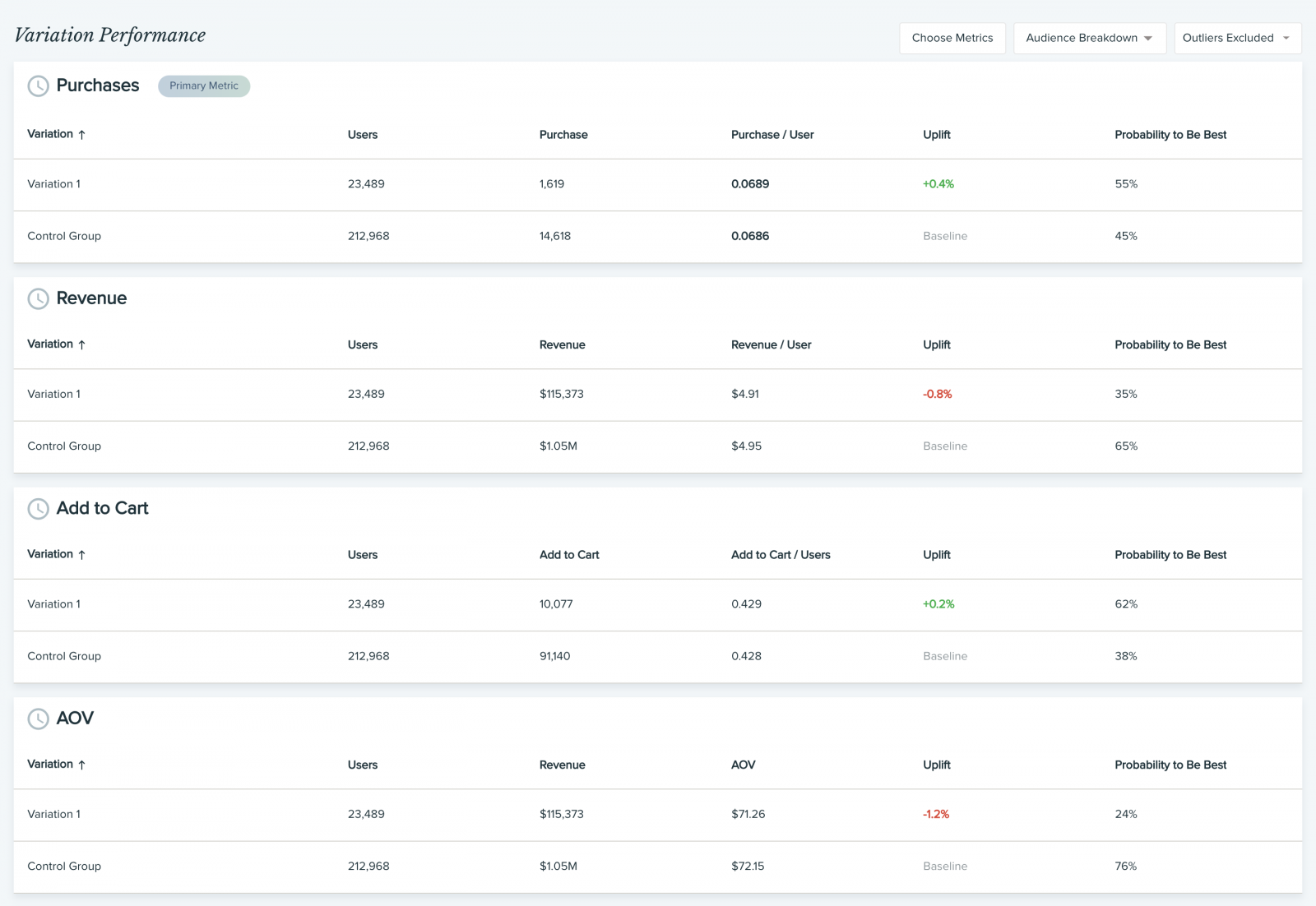
Анализ состава аудитории
Еще одно направление, в которое стоит углубиться — это разбивка результатов по сегментам аудитории. Это поможет ответить на следующие вопросы:
- Как вел себя трафик из разных источников в процессе эксперимента?
- Какая вариация победила среди мобильных пользователей/ пользователей десктопов?
- Какая вариация лучше сработала для новых пользователей?
Рекомендую выделить пользователей, наиболее значимых для бизнеса, в отдельный сегмент, а также сгруппировать тех пользователей, чье поведение отличается от общей аудитории.
Опять же, по каждой аудитории нужно отслеживать рост (аплифт) и P2BB, чтобы оценить эффективность каждой вариации. Это тоже поможет определиться, стоит ли выкатывать изменения сразу на всю аудиторию.
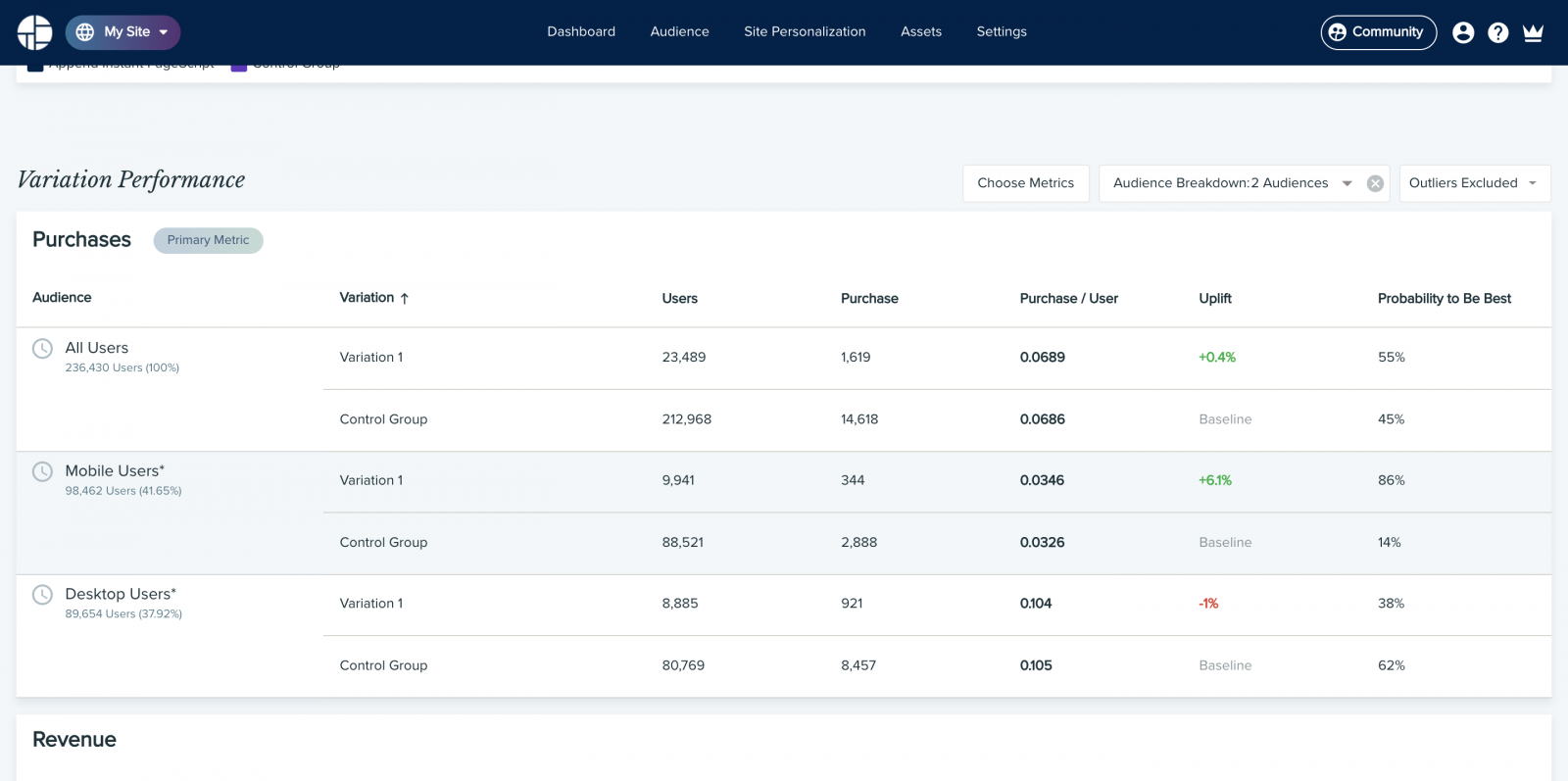
Но иногда проигрыш в A/B тесте — это на самом деле победа!
Нет никаких сомнений, что оптимизация конверсии (CRO) и A/B тестирование работают. Они всегда помогали маркетологам, которые находятся в контакте с аудиторией и в целом знают, чего хотят посетители, выбирать максимально эффективные варианты подачи контента и существенно поднимать конверсию и доход. Однако сегодня в игру вступает персонализация. По мере того, как пользовательский опыт становится все более персонализированным, результаты экспериментов, которые не учитывают индивидуальные особенности пользователей, уже нельзя назвать однозначными; кроме того, становится все сложнее добиваться статистической значимости.
В этом сложном новом мире персонализации, где “среднестатистические пользователи” уже не могут говорить за “всех пользователей”. Это означает, что старый подход, когда мы искали некий “лучший” опыт и пытались масштабировать его на всю аудиторию, больше не работает, хотя мы и пытаемся выжать из него максимум: вычисляем нужный размер выборки, совершенствуем гипотезы и оптимизируем KPI.Сегодня мы уже не можем просто положиться на успешный эксперимент и использовать вариацию-победителя для всех. Нужно понимать, что в этом случае мы все равно игнорируем интересы определенного процента пользователей, для которых наша “лучшая” вариация таковой не является — а такой процент всегда будет. Если принять как данность эту особенность A/B тестов, становится очевидно, что даже проигрыш в A/B тесте может обернуться победой. Неудачный тест иногда помогает выявить скрытые возможности, которые при должном (персонализированном) подходе могут принести блестящие результаты. Ниже приведены результаты настоящего эксперимента, который длился порядка 30 дней. На первый взгляд тут почти ничья, и контрольная версия даже кажется эффективнее экспериментальной.
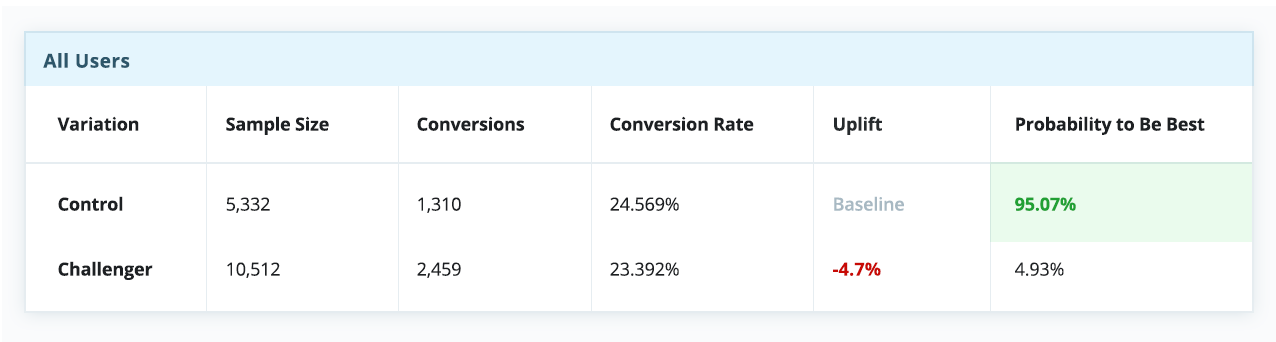
Однако если разбить эксперимент на сегменты по типам устройства — а это довольно простой и распространенный тип сегментации — история в корне меняется. Очевидно, что контрольная версия побеждает для десктопов, но сильно проигрывает среди пользователей телефонов и планшетов.
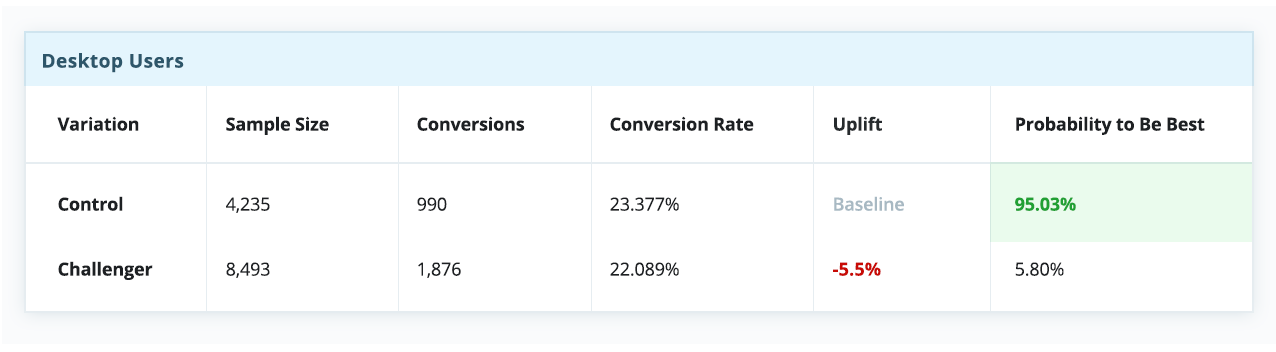
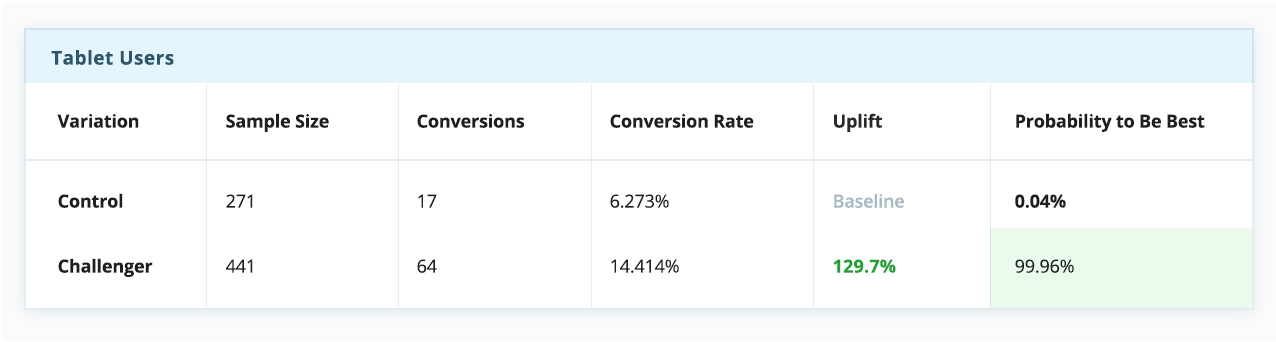
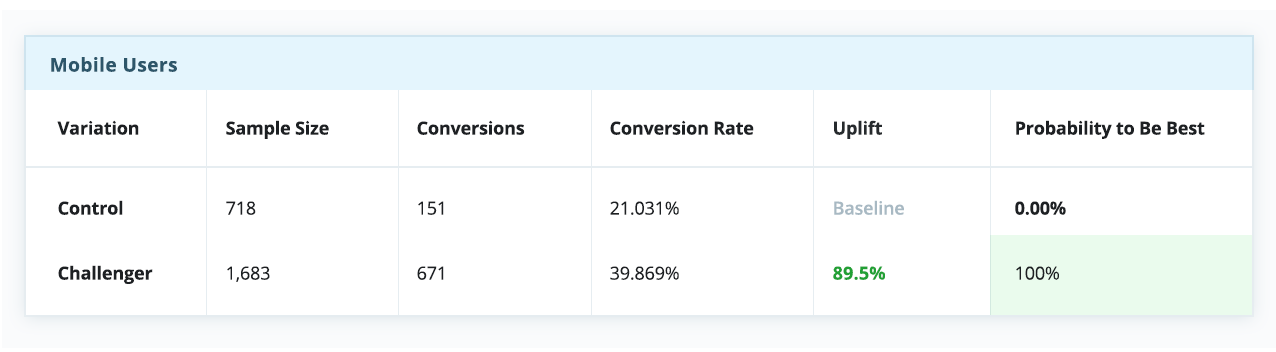
В контексте этого примера, если бы мы выбрали стратегию “winner takes all” (а многие так и делают), всей аудитории пришлось бы довольствоваться единым пользовательским опытом, якобы оптимизированным под среднестатистического пользователя — несмотря на то, что пользователи мобильных устройств явно предпочли экспериментальную вариацию.
А вот еще один пример, в котором контрольная вариация, казалось бы, проигрывает по результатам эксперимента в масштабе всей аудитории. Однако дальнейший анализ показал, что эффективнее будет показывать победившую вариацию (v2) наиболее многочисленному сегменту “прямого трафика”, а остальным пользователям продолжать показывать контрольную вариацию.
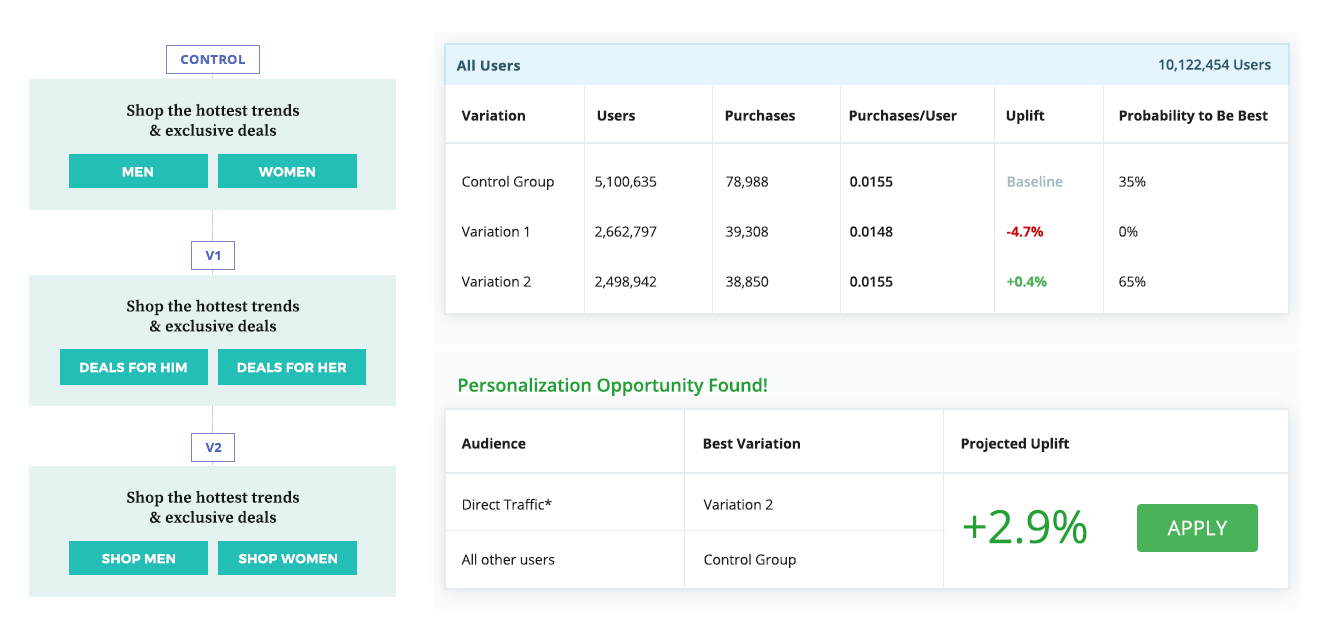
Эти примеры подчеркивают важность исследования и тщательного анализа результатов тестирования в разрезе разных сегментов аудитории. Только так вы сможете выявить скрытые возможности для оптимизации даже в тех экспериментах, где тестирование с ориентацией на среднестатистического пользователя (такого, кстати, не существует) не принесло ожидаемых результатов.
В большинстве ситуаций бывает достаточно быстрого анализа, но когда циклы тестирования идут один за другим, а приоритеты постоянно меняются бывает трудно выкроить время даже на это. Однако с ростом количества тестов, вариаций и сегментов проблема лишь усугубляется, и в результате анализ становится очень объемной задачей. Ну что, с этими знаниями, все еще хочется и дальше сохранять статус кво, читать результаты поверхностно и не делать ни шагу в сторону?
← Назад | Продолжение (Глава 15) →
Анализ итогового
тестирования.
Дата
проведения:______________________
Предмет:____________________
Класс:______________________
Всего
в классе:________
Присутствовало:
______
|
№ |
|
Оценка |
|
1 |
||
|
2 |
||
|
3 |
||
|
4 |
||
|
5 |
Количество
учащихся, выполнивших работу на
«5»
_____чел_______%
«4»
______чел_______%
«3»
______чел_______%
Количество учащихся, не справившихся с работой
___чел____%
Успеваемость в %: _______________
Качество знаний в %:__________
Степень обученности в %: _________
Средний балл: _____________
Типичные ошибки
обучающихся:_________________________________________________
_______________________________________________________________________________________________________________________________________________________________________________________________________________________________________
Вывод:__________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
Учитель: А.А. Баринова.
ДИАГНОСТИКА
В. И. Тесленко
МЕТОДИКА АНАЛИЗА И ОЦЕНКА РЕЗУЛЬТАТОВ ТЕСТИРОВАНИЯ
Научно обоснованный тест — это метод, соответствующий установленным стандартам валидности и надежности. Качество педагогической информации о результатах тестирования оказывается зависимым от качества используемого для этого инструментария.
Результаты каждого тестирования необходимо приводить в определенную систему, делать анализ и проводить их обработку.
Выбор технологии обработки результатов выполнения теста определяется целями тестирования. Информация, содержащаяся в ответах, позволяет не только судить о результатах учения каждого из испытуемых, но и делать достаточно обоснованные выводы об особенностях процесса преподавания, о технологии обучения, провести диагностику и прогнозирование процесса обучения.
Выделяют две группы методов анализа заданий: экспертные и математические. Математические методы применяются после проведения тестирования на основании полученного эмпирического материала, поэтому о них речь пойдет ниже. Экспертные методы позволяют не только оценить, в какой степени они измеряют именно те знания, умения и навыки, для которых разрабатывается тест, но и оценить задания с точки зрения их формы. В основе экспертных методов лежит соотнесение содержания и форм заданий с требованиями, изложенными в спецификации. Задания, к которым ни один из экспертов не высказал замечаний, включаются в тест. Такие задания считаются объективными и корректно сформулированными. Остальные задания переформулируются или совсем убираются из теста. После разработки и проведения экспертного анализа заданий получается первый вариант теста. Чтобы повысить его качество, используются математические методы. Для применения этих методов нужны результаты экспериментального апробирования теста. Такое тестирование называют предварительным.
Если математической обработке подвергаются оценки, выраженные в баллах, по которым судят об эффективности педагогического процесса, то нельзя забывать, что они являются суммарным выражением знаний, умений и навыков, исключающим возможность выявления связей между преподавателем и испытуемыми во всем их многообразии.
При использовании математического метода обработки данных перед тестирующими встает вопрос о точности, достоверности педагогических выводов, вы-
текающих из математических формул. Это несет в себе большую долю относительности применительно к процессу обучения. Поэтому недопустимо неумелое, формальное использование математических методов.
Использование математической статистики, как показывают исследования, — одно из эффективных средств познания объективных законов обучения, воспитания и развития. Оно оправданно и действенно только тогда, когда опирается на умелый и разносторонний качественный анализ, когда математические формулы представляют собой конкретное выражение качественных особенностей сформированности знаний, умений. Все это предполагает установление определенных отношений между показателями и факторными признаками, характеризующими различные стороны подготовки испытуемых. Знание функциональной зависимости между ними позволяет спрогнозировать уровень подготовки для каждого испытуемого.
Следует отметить, что человек как объект исследования слишком сложен в своих проявлениях, чтобы его поведение можно было уложить в определенные формулы, поэтому главное внимание уделяют исследованию статистических связей. Но в любом случае основой для выводов служит оценка достижений отдельных испытуемых. Поэтому остановимся вначале именно на этом.
Успешность работы с тестом означает выполнение его заданий. Поскольку тест есть система заданий, то предстоит сопоставить результаты выполнения различных заданий между собой.
При выполнении задания закрытой формы перед испытуемым встают две взаимосвязанные задачи: определить верные ответы (их может быть несколько) и найти ошибки в неверных ответах.
Дополнительные трудности испытуемому при распознавании верных ответов создает то, что их может быть несколько к одному заданию и они могут находиться в разных отношениях. Варианты ответов подбираются правдоподобными, ошибки в них замаскированы. Иногда обнаружение ошибки в ответе оказывается делом более сложным, чем узнавание верного (может быть, хорошо известного) ответа. При оценке сложности задания нельзя не учитывать трудностей распознавания ошибочных ответов.
При оценке результатов выполнения заданий испытуемыми перед составителем теста встает целый ряд проблем. Нет проблем только в том случае, если ответ абсолютно совпадает с правильным эталонным ответом. Как поступать, если определены не все верные ответы? Решение может быть различным: если эти верные ответы равноправны, то можно считать задание выполненным, например, когда найден хоть один правильный ответ; если ответы находятся в отношении дополнения друг друга и только вместе дают законченный, полный ответ, то составителю предстоит определить свое отношение к каждому из конкретных случаев и отобразить это в специально составленной эталонной таблице ответов к тесту, о которой речь пойдет ниже.
Иногда испытуемый наряду с правильными ответами может отобрать ошибочные. Как оценить в этом случае выполнение задания? По-видимому, следует учитывать характер допущенной ошибки. Самое простое было бы считать в любом подобном случае задание невыполненным. Но ведь ошибка ошибке рознь. Они могут носить второстепенный характер, не иметь принципиального значе-
ния с точки зрения основных целей измерения. В то же время не учитывать ошибку нельзя. Было бы справедливо при наличии незначительных ошибок считать задание выполненным, но оценку испытуемому снизить.
Ошибки, содержащиеся в ответах к заданию, могут носить существенный характер, свидетельствуя о наличии пробелов у испытуемого в контролируемом учебном материале. Наличие такого рода ошибок является основанием для того, чтобы считать задание невыполненным или же оценку значительно понизить. Ответы теста могут содержать и грубые ошибки как свидетельство явного непонимания испытуемым сущности контролируемого. В этом случае задание считается безусловно невыполненным.
Такой подход к ошибкам в ответах испытуемых сильно осложняет обработку результатов тестирования, и его можно реализовать только в том случае, если процесс обработки результатов происходит при помощи компьютера.
Рассмотрим сначала простой способ оценки теста по результатам выполнения его заданий.
В качестве критерия оценки результата выполнения теста может быть выбрано число правильно выполненных заданий (n+). Для того чтобы можно было сопоставлять результаты работы с тестами, включающими в себя различное число заданий (n), за достижение испытуемого (Д) принимается:
Дг=(п+) tin.
Что означает этот результат? Плохо это или хорошо? Необходимо интерпретировать результаты тестирования. В настоящее время существуют два основных подхода к интерпретации результатов.
Нормативно-ориентированный подход (по-английски norm-referenced) позволяет сравнивать учебные достижения отдельных учащихся друг с другом. Критериально-ориентированный подход (по-английски criterion-referenced) позволяет оценивать, в какой степени учащиеся овладели необходимым учебным материалом.
Подход к интерпретации тестового балла является основным критерием для разделения тестов на критериально- и нормативно-ориентированные, различающиеся по методам конструирования и особенностям применения.
Результаты выполнения различных тестов следует оценивать в зависимости
n
от их сложности СТ = XC3i / n, а при помощи специальной нормировочной таб-
i=1
лицы (табл. 1) можно сравнить итоги выполнения тестов различной сложности.
Дадим пояснения к нормировочной таблице. При репродуктивном тесте (ТР) испытуемому для получения отметки «5» необходимо иметь достижение не менее 0,9, т. е. правильно выполнить не менее 90 % всех заданий теста. Отметка «4» ставится при достижении не менее 0,7 и т. д. Если же выполняется тест повышенной сложности (ТП), то при таком же достижении 0,7 испытуемый получит оценку «5» и т. д. Нормировочную таблицу несложно продолжить для информационного и творческого тестов.
Таблица 1
Оценка результатов выполнения тестов различной сложности
Д=(п+)/п 1 0,9 0,8 0,7 0,6 0,5 0,4 0,3 0,2 0,1 0
ТР 1,3<СТ<1,6 «5» «4» «3» «2» «1»
ТБ 1,7<СТ<2,4 «5» «4» «3» «2» «1»
ТП 2,2<СТ<2,4 «5» «4» «3» «2»
Следует отметить, что система оценивания испытуемых по результатам тестирования содержит максимальное количество стереотипов, домыслов и ошибок. Одни считают, что отличную оценку можно ставить только в том случае, когда испытуемый справился со всеми заданиями. Другие — для получения положительной оценки достаточно ответить более чем на половину заданий в тесте. Среди рекомендаций можно встретить и такие, когда вопрос оценивания целиком перекладывается на пользователя.
В этой связи следует отметить, что педагогические тесты имеют основания для сравнения. Для критериально-ориентированных тестов — это полученный на основе экспертных оценок критерий значимости, превысив который, как считается, тестируемый справился, готов, прошел и т. д., в зависимости от целей тестирования. Для нормативно-ориентированных тестов основанием для сравнения служат статистические нормы.
Тестовые нормы представляют собой установленные на базе репрезентативной выборки эмпирические усредненные количественные данные о результатах выполнения теста, полученные в стандартных условиях. Выделяют следующие нормы по широте охвата испытуемых:
– универсальные (устанавливаются для широкого контингента людей);
– национальные;
– региональные;
– локальные.
Нормирование дает качественный способ корректного сравнения оценок, полученных в результате изменения различных тестов и выставления оценок в школьных баллах.
Следует признать более эффективным использование для оценки результатов тестирования не пятибалльной, а двенадцатибалльной шкалы.
Так можно сравнивать между собой уровни подготовленности испытуемых, выполнявших один и тот же вариант по определенной теме, но сравнивать эти результаты с результатами участников тестирования, решавших другие варианты тестов по этой теме, нельзя. Для одного и того же количества верно решенных заданий соответствующие интервалы тестовых баллов для разных вариантов тестов будут различны.
Для того чтобы иметь возможность сравнивать между собой все оценки уровней подготовленности испытуемых и все оценки сложности тестовых заданий, необходимо все шкалы привести к единой для всех вариантов шкале.
Для сопоставления результатов тестирования учащихся по разным вариантам теста в пределах определенной темы учебного предмета необходимо наличие перекрытия вариантов, то есть различные варианты должны иметь определенную часть общих заданий. Такие задания называют узловыми, или якорными. Здесь в качестве единой шкалы в самом простом случае можно выбрать шкалу параметров какого-либо из вариантов или промежуточную шкалу, началом которой является среднее арифметическое значение оценок трудностей общих заданий.
Методика оценки результатов тестирования складывается из следующих этапов.
1. Для выбранного теста составляется эталонная таблица.
Приведем фрагмент подобной таблицы и дадим к ней необходимые пояснения.
Таблица 2
п
СТ = 2 СЗ / п .
г=1
В задании 1 два равноправных ответа — «б» и «г». Задание репродуктивного характера (СЗ=1,5) будет считаться выполненным, если указан хотя бы один из верных ответов.
В задании 2 верный ответ «б» и его сложность 2 (базовый уровень).
Задание 3 считается выполненным только в том случае, если выбраны оба ответа «а» и «в». Сложность задания повышенная — 2,5. Фигурная скобка указывает на то, что должны быть определены обязательно оба верных ответа.
В задании 4 — три верных ответа, прямые скобки указывают на то, что при выборе испытуемым любых двух задание считается выполненным. Это задание творческого характера (СЗ = 3).
По сложности теста (СТ) определяется его характер. Он может быть репродуктивным, базовым, творческим и т. п. Отсюда становится ясным, какая часть нормировочной таблицы оценок (табл. 1) должна быть использована при выставлении окончательных отметок испытуемым.
2. Для анализа результатов с целью диагностики составляется аспектная таблица оценки результатов тестирования (табл. 3).
Т а б л и ц а 3
Аспектная таблица оценки результатов тестирования
(тест по теме: Скорость движения тела)
Аспекты тестирования Задания Общее число заданий
1. Цели введения понятия 1, 2, 7 3
2. Определение понятия 2, 3, 4, 9, 10, 12 6
3. Специфические особенности понятия «скорость» 5, 6, 7, 12 4
4. Применение понятия 4, 8, 9, 10, 11, 12 6
Сравнивая число верно выполненных заданий испытуемыми, по аспекту тестирования можно определить его аспектное достижение (ДАО и по нормировочной таблице (табл. 1) выставить отметку, более того, сделать определенные выводы диагностического характера. Следует обратить внимание на то, что выполнение отдельных заданий теста может быть одновременно связано с несколькими из выделенных аспектов контроля.
3. Оценка эффективности технологии или методики обучения.
Одним из критериев, позволяющих оценить технологию или методику обучения, является достижение группы испытуемых, под которым подразумевается среднее достижение испытуемых в группе:
дг=2 д , / п,
где п — число испытуемых в группе.
Как и для отдельного испытуемого, достижения, относящиеся ко всей группе, могут быть представлены в виде отметки, учитывающей сложность теста, с которым работала группа испытуемых. Для этого следует воспользоваться нормировочной таблицей (табл. 1).
Перечислим этапы применения педагогического теста и анализа результатов тестирования.
В распоряжении преподавателя имеется некоторый тест, к которому составлены аспектная таблица (табл. 3), эталонная таблица ответов (табл. 2) и определена сложность теста. Кроме того, имеется нормировочная таблица оценок (табл. 1).
Каждый из испытуемых, выполняя тест, заполняет стандартную рабочую таблицу ответов на задания теста (табл. 4).
Испытуемому предстоит проставить к каждому из заданий теста буквы, относящиеся к правильным ответам. Результаты тестирования, представленные испытуемыми в такой форме, очень удобны для сопоставления с эталонной таблицей ответов к тесту. В результате этого сопоставления при минимальных затратах времени оценивается достижение каждого из испытуемых и по нормировочной таблице выставляются оценки.
Таблица 4
Стандартная рабочая таблица ответов
Ф.И.О., группа Задания теста № … 1 2 3 п п+ Д = П± п
Ответы а
б
в
г
Отказ
Вычисляется достижение всей группы тестируемых (или отдельных групп) по формуле:
п
IД
ДГ = ,
п
где п — число испытуемых.
Сравнительно много времени потребуется для проведения диагностики. С помощью аспектной таблицы оценки результатов для каждого из испытуемых (табл. 3) находится аспектное достижение ДА^ на основании которого выставляются отметки по каждому из аспектов тестирования (ОА^:
(п+) А
ДА} .
ПА
Суммируя эти отметки для всей группы тестируемых, можно сделать выводы об эффективности выбранной технологии обучения.
Наибольшую ценность для проведения диагностики результатов обучения по использовавшейся технологии представляет таблица, в которой сведены ответы всей группы испытуемых по каждому из заданий теста (табл. 5). Данная таблица приводится в качестве примера.
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Т а б л и ц а 5
Распределение ответов группы испытуемых по заданиям теста
Задания Число ответов^^ 1 2 3 4 5 6 7 8 9 10 11 12
а 13 2 29 21 40 60 26 8 3 25 58 61
б 56 59 44 13 34 19 62 16 45 15 5 40
в 33 9 21 59 28 30 43 32 10 5 3 56
г 7 2 40 8 2 4 31 52 20 25 10 0
Отказ 1 1
Верные ответы 24 59 26 18 44 21 30 11 43 25 8 44
Общее число испытуемых: N=69.
Анализ приведенной выше таблицы дает возможность установить наиболее распространенные ошибки испытуемых по выделенным аспектам тестирования, сделать обоснованные выводы о причинах их появления.
Какое бы число подобных факторов не влияло на конкретные случаи, общая закономерность обязательно проявит себя. С учетом других факторов результаты обработки собранных данных (табл. 4, 5) помогут только в конечном итоге сделать обоснованные выводы об эффективности той или иной технологии или методики обучения, так как сложный многогранный характер обучения не позволяет делать однозначные утверждения относительно его результатов при планировании этого процесса. О результатах можно говорить как о вероятных, возможных. Есть все основания рассматривать результат обучения как вероятностный процесс.
Центр тестирования Минобразования и науки РФ для оценки уровня подготовленности выпускников школ использует тесты, состоящие из нескольких вариантов. Процесс вычисления тестовых баллов участников тестирования состоит из двух этапов.
Первый этап заключается в оценивании параметров заданий и уровней подготовленности участников тестирования по каждому из вариантов в отдельности.
Например, вариант теста, состоящий из п заданий, был предложен N участникам тестирования. Ответ тестируемого на каждое задание оценивается по дихотомному принципу, то есть за верный ответ ставится единица, а за неверный — ноль, причем за пропущенные задания также ставится ноль.
Матрица тестовых результатов имеет размерности N х п, где на пересечении 1-й строки и ^го столбца (1 е [1.^, j е [1..п) стоит результат (то есть ноль или единица) выполнения 1-м участником тестирования ,]-го задания. Как правило, число строк в матрице ответов во много раз превышает число столбцов.
Используя полученную матрицу тестовых результатов, вычисляют оценки параметров заданий варианта теста и оценки уровня подготовленности участников тестирования, решающих данный вариант.
Один из возможных подходов к решению данной задачи состоит в применении метода наибольшего правдоподобия. Кратко данный метод изложен в работе В.В. Овчинникова [1].
После завершения первого этапа, уровень подготовленности каждого участника тестирования характеризуется некоторым числом. Но проблема заключается в том, что эти числа для участников тестирования, решавших разные варианты, находятся на разных шкалах. Можно сравнивать между собой уровни подготовленности участников тестирования, выполняющих один и тот же вариант, но сравнивать эти результаты с результатами испытуемых, решавших другие варианты, не представляется возможным. Аналогичная ситуация происходит и с оценками параметров тестовых заданий.
Для каждого из вариантов теста существует своя шкала, на которой располагаются оценки параметров заданий, и сравнивать оценки параметров заданий из разных вариантов считается некорректным.
Сравнивать между собой все оценки уровней подготовленности испытуемых и все оценки параметров заданий можно лишь при условии приведения получившихся шкал к одной, единой для всех вариантов шкале.
Второй этап вычисления тестовых баллов заключается в нанесении полученных оценок параметров участников и заданий на единую для всех вариантов шкалу и преобразовании получившейся шкалы в стобалльную. При этом результаты тестирования, определенные по каждому варианту теста, приводятся в сопоставимый вид с учетом свойств каждого варианта теста. В связи с этим возникают вопросы:
Что выбрать в качестве единой шкалы?
Как нанести оценки всех параметров на единую шкалу?
В качестве единой шкалы можно выбрать или шкалу параметров какого-либо из вариантов, или промежуточную вспомогательную шкалу. Полученные единые шкалы преобразуются в стобалльную. Делается это следующим образом. На единой шкале результатов вычисляются среднее значение уровня подготовленности испытуемых и соответствующее среднее квадратичное отклонение. После этого уровень подготовленности каждого участника тестирования (1 = 1, …, N преобразовывается в окончательный тестовый балл В1 по формуле:
в. -в
В. = 50 +у—–, где
! а
у — определяется исходя из того, что значения Вг должны находиться в промежутке от 0 до 100;
в — уровень подготовленности 1-участника;
в — среднее значение уровня подготовленности участников тестирования, вычисленного по формуле:
– 1 V
в = V , где
м 1=1
N — общее число испытуемых.
Вычисление тестового балла по указанной формуле производится только для тех испытуемых, которые верно выполнили часть заданий теста. Участникам тестирования, верно выполнившим все задания без каких-либо вычислений ставится максимальный тестовый балл, то есть 100, участникам тестирования, не решившим верно ни одного задания, ставится минимальный балл.
Для установления достоверности полученных результатов вычисляют также определенные статистические показатели.
1. Дисперсия каждого задания. Это произведение доли правильных ответов (р^ и доли неправильных ответов (^) в каждом столбце по каждому отдельному заданию. Извлечение корня из значения pjgi дает стандартное отклонение результатов испытуемых по каждому заданию. Эта величина является показателем рассеивания от их средней величины.
2. Средняя арифметическая величина – х. Является обобщающей по всему тесту. Выражая одним числом определенную совокупность, она как бы ослабля-
ет влияние случайных индивидуальных отклонений. В простейшем случае этот показатель вычисляется путем сложения всех полученных индивидуальных баллов и деления суммы на число испытуемых:
N
_ £ х Х=■ где
X – знак суммирования;
хг — индивидуальный балл каждого испытуемого;
N — число испытуемых.
По этой формуле вычисляется так называемая простая средняя арифметическая величина, применяющаяся в тех случаях, когда имеется небольшое число испытуемых.
При большом числе тестируемых прибегают к вычислению взвешенной средней арифметической величины. С этой целью результаты тестирования упорядочиваются по строкам (по всей совокупности заданий) и по столбцам (по каждому отдельному заданию) по принципу «от больших значений (количество правильных ответов) к меньшим», или наоборот. Таким образом получают вариационный ряд, который представляет собой ряд вариант и их частот.
Для упрощения числовых операций весь ряд разбивается на группы в зависимости от количества выполненных заданий. После разбивки вариант в каждой группе определяется срединная варианта «Ус», для каждой из которых проставляется число испытуемых, выполнивших задания. Примеры этих операций приведены в таблице 6.
В таблице 6 графы 1 и 3 представляют собой вариационные ряды, которые можно изобразить графически для дальнейшего анализа результатов тестирования. Применяется несколько способов графического изображения вариационных рядов в зависимости от их вида и поставленной задачи.
Для нашего случая (табл. 6) строится соответствующий полигон: на оси абсцисс прямоугольной системы координат откладываются интервалы значений баллов, полученных испытуемыми, а на оси ординат — число испытуемых, соответствующих этим интервалам.
Из полигона можно получить гистограмму того же распределения, если на оси абсцисс прямоугольной системы координат отложить интервалы значений баллов и на них, как на основаниях, построить прямоугольники с высотами, пропорциональными числу испытуемых в этих интервалах.
Взвешенная средняя арифметическая величина вычисляется по формуле:
— Ек ■ N 811,75 Х = ——= —^» 8,46 .
N 96
Таблица 6
Результаты тестирования, упорядоченные по строкам и по столбцам по принципу распределения больших значений (количество правильных ответов) к меньшим
Количество баллов Середина интервала, Уе Число испытуемых, N Уе^ Ус – х = й а2
0-2 1 3 3,0 -7,46 55,65 166,95
3-4 3,5 5 17,5 -4,96 22,80 114,00
5-6 5,5 8 30,25 -2,96 8,76 70,08
7-8 7,5 14 105,0 -0,96 0,92 12,88
9-10 9,5 27 256,5 1,04 1,08 29,16
11-12 11,5 25 287,5 3,04 9,24 231,00
13-14 13,5 7 94,5 5,04 25,40 177,80
15-16 15,5 5 77,5 7,04 49,56 247,80
17-18 17,5 2 35,0 9,04 8,17 16,34
96 811,75 1066,01
Полученная величина позволяет сравнивать и оценивать группы испытуемых в целом. Однако для характеристики группы испытуемых только этой величины недостаточно, так как размер колебаний вариант, из которых она складывается, может быть различным. Поэтому в характеристику группы испытуемых необходимо ввести такой показатель, который давал бы представление о величине колебаний вариант около их средней величины. Целесообразно каждую вычисленную среднюю арифметическую дополнять соответствующим данному распределению средним квадратическим отклонением.
3. Среднее квадратическое отклонение. Этот статистический параметр называется еще стандартным отклонением, или просто стандартом. Условное обозначение его — а. Величина среднего квадратического отклонения является показателем рассеивания (т. е. отклонений вариант, которые получены в исследовании, от их средней величины) и призвана дополнять характеристику группы испытуемых.
Пример вычисления этого параметра приведен в таблице 6. Среднее квадратическое отклонение вычисляется по формуле:
а=±
£ й /1066,01
= ±Л—гг— ~±3,33.
N V 96
При малом числе испытуемых среднее квадратическое отклонение рекомендуется вычислять по следующей формуле:
а=±-
£ й2 N
N -1
Закон нормального распределения говорит, что подавляющее большинство значений в однородной группе вариант встречается в интервале, расположенном около средней арифметической величины. При нормальном распределении варианты расположены в определенных границах. Например, в границах х ± 3а расположено 99,7 % всех вариант признака.
Величина стандартного отклонения (а) служит также средством оценки характера распределения результатов тестирования. Для этого величину средней арифметической (х) соотносят со значением а, взятым три раза. Если х примерно равняется произведению 3а, то это является одним из признаков распределения, близкого к нормальному.
Рассматривается и другое мнение. «Применение тестов, сконструированных в соответствии с традиционным критерием, согласно которому “хороший” тест должен давать «нормальное» (то есть гауссово) распределение, имеет еще и побочный результат. Он состоит в том, что такие тесты крайне неэффективны для оценки качества системы образования в целом или какой-либо его части (подсистемы) с точки зрения достижения стоящих перед ней важных целей» [2].
4. Средняя ошибка среднего арифметического. Вычисление средней ошибки среднего арифметического производится по формуле:
а
т=±7^ ’ где
т — средняя ошибка среднего арифметического; о – среднее квадратическое отклонение;
N — число испытуемых.
Для приведенного примера (табл. 6) величина средней ошибки среднего арифметического будет равна:
3,33
т = ± I— ~ ±0,34. л/96
Следовательно, (х ± т) = (8,46 + 0,34). Это означает, что полученная средняя арифметическая величина (х =8,46) может иметь значение от 8,12 (8,46 + 0,34 = 8,12) до 8,80 (8,46 + 0,34 = 8,80).
Средняя ошибка показывает отличие среднего арифметического, полученного на выборочной совокупности (в нашем примере на 96 испытуемых), от истинной средней арифметической величины.
Следует отметить, что если тест предназначается для более узкого использования (в одном классе, группе), то процесс разработки теста упрощается. Не проводится предварительное тестирование, а в тест включается большое количество заданий, из которого после анализа исключаются неудачные. Такой тест совершенствуется из года в год.
Применение компьютерной технологии в практике педагогического тестирования не только значительно облегчает этот процесс и позволяет гибко, но с единых позиций подходить к формированию тестов и оценке получаемых ре-
зультатов, но и обеспечивает обоснованный, точный, надежный диагноз подготовки испытуемого.
Тестирование может быть основано на работе испытуемых как с тестом на печатной основе, так и с компьютером. Современные средства программирования позволяют создавать достаточно универсальные компьютерные тесты многоцелевого назначения.
Известно, что в процессе тестирования можно выделить ряд основных этапов:
1) ознакомление испытуемых с содержанием заданий теста;
2) выполнение испытуемыми заданий и оформление результатов;
3) обработка результатов тестирования;
4) обсуждение с испытуемыми результатов тестирования с целью внесения корректив в процесс обучения.
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Поэтому в организации тестирования могут и должны найти свое место компьютеры. Более того, весь процесс тестирования может быть построен на основе применения компьютеров, широкого использования их дидактических возможностей.
Во-первых, использование компьютера для ознакомления испытуемого с содержанием теста имеет целый ряд преимуществ по сравнению с применением для этой цели печатных форм. Компьютер как бы оживляет содержание заданий теста, показывая рассматриваемые в них ситуации в динамике, развитии. Испытуемые «видят» движения тел, происходящие изменения в их состояниях. Более того, на экране дисплея могут моделироваться не только процессы, но и физические измерения, эксперимент. Испытуемый, проводя «измерения» на экране дисплея, самостоятельно находит исходные данные для выполнения задания. При этом, как и в реальных условиях измерений, могут обсуждаться вопросы расчета погрешностей в проводимых измерениях, проводиться учет вводимых упрощений. Практически ЭВМ применяется как средство наглядности.
Во-вторых, компьютер может использоваться при выполнении заданий теста. Речь идет об использовании компьютера не только для выполнения необходимых вычислений или как средства оформления результатов, но и как средства решения, например, определенных педагогических ситуаций.
В-третьих, незаменимы компьютеры и в статистической обработке результатов тестирования. Результаты массового выполнения теста содержат огромную по объему информацию не только о достижениях в учении каждого из испытуемых, но и об эффективности тех технологий, по которым велось обучение. Детальный анализ результатов тестирования позволяет объективно диагностировать учебный процесс и результаты обучения, вскрывая сильные и слабые стороны в учении конкретных испытуемых, а также высказывать достаточно обоснованно причины пробелов в обучении. Вся сложность извлечения этой полезнейшей информации связана с необходимостью выполнения такого значительного числа операций, что без компьютера не обойтись.
Говоря о ближайшем будущем применения компьютера в контроле процесса обучения, следует упомянуть о возможности создания программ тестирования, адаптированных к индивидуальным особенностям испытуемых. Основной це-
лью адаптивного тестирования является повышение точности измерения достижений испытуемых в условиях сокращения времени тестирования и выделения определенного числа заданий. В отличие от традиционного подхода к организации тестового контроля достижений, где один и тот же набор заданий используется для измерения достижений различных испытуемых, в адаптивном контроле тестирование осуществляется путем подбора оптимальных по трудности тестовых заданий. Имея такой банк заданий, с помощью компьютера можно подбирать оптимальные задания и предъявлять их индивидуально каждому испытуемому. Такие программы можно отнести к гибким, предоставляя испытуемому право выбора теста любого уровня сложности.
Гибкие программы тестирования (ГТ) содержат системы заданий, в которых характер каждого последующего задания зависит от результата выполнения испытуемым предыдущего. В зависимости от индивидуальных результатов испытуемого варьируется не только характер, но и число заданий. Реализация такого рода программ возможна только в форме компьютерного тестирования, диалога «компьютер – испытуемый».
Остановимся на особенностях компьютерной технологии обработки результатов тестирования. Наличие компьютера позволяет выдвинуть ряд дополнительных требований к технологии обработки результатов выполнения теста, обеспечивающих более объективную их оценку и позволяющих получить дополнительную информацию диагностического характера.
Вспомним предложенную ранее технологию обработки результатов. В качестве основного критерия оценки достижения испытуемого выбрано отношение числа правильно выполненных заданий теста к общему числу заданий в тесте: Д =(п+) 1/п. Этот критерий имеет определенные недостатки. Первый из них связан с тем, что задания в тесте могут быть различной сложности. При подсчете общего числа правильно выполненных заданий (п+) не учитывалось, какие именно задания выполнены верно, какова их сложность. Второй: было принято правило – включение испытуемым в число верных ответов хотя бы одного ошибочного, независимо от того, определены ли верно правильные ответы, служит основанием считать задание невыполненным. Иными словами, не учитывается характер ошибок, допущенных испытуемыми, а ошибки могут быть грубыми, более или менее существенными и незначительными.
В компьютер вводится эталонная таблица ответов, несколько отличная от предложенной ранее таблицы 2. В ней каждому из ответов к заданию теста можно приписывать число в соответствии со следующими правилами: 1) верным ответам – положительное, неверным – отрицательное или нуль; 2) сумма оценок положительных ответов совпадает с оценкой сложности всего задания;
3) более сложному ответу приписывается большее число; 4) выбор ответа, помеченного нулем, является свидетельством грубой ошибки, и в этом случае задание считается невыполненным; 5) оценка выполнения испытуемым задания находится как сумма положительных и отрицательных оценок выбранных им ответов к заданию.
Приведем для примера фрагмент эталонной таблицы оценок (табл. 7).
Сумма сложностей всех заданий теста: ЕСЗ = 28. Это максимальное число, которое может получить испытуемый при работе с 12-ю заданиями теста. Таким образом, сложность теста (как средняя сложность его задания) определяется:
п
СТ = £сд. / п = 28/12 = 2,3.
(=1
Таблица 7
Эталонная таблица ответов к тесту
^’^^^Задания Ответьі^^^^ 1 2 3 4 5 6 7 8 9 10 11 12
а 0 0 0,5 1 1,5 0 0 0 0 0,5 1 0
б 1 2 -1 1,5 1 1 2 1 2,5 0,5 0 0
в 1 0 1 0,5 0 1,5 0 0 1 0,5 1 2
г 0 0 1 -1 0 0 0 3 0 0,5 0 0
СЗ 2 2 2,5 3 2,5 2,5 2 3 2,5 2 2 2
Это тест повышенной сложности (ТП), поэтому в компьютер вводится нормировочная таблица оценок (табл. 8).
Таблица 8
Нормировочная таблица оценок результатов тестирования
Отметки «5» «4» «3» «2»
Верхняя граница достижений (ВГД) 1,00 0,69 0,49 0,29
Нижняя граница достижений 0,70 0,50 0,30 0,00
Для диагностики результатов тестирования в компьютер вводится эталонная аспектная таблица ответов (табл. 9).
Максимальная оценка аспекта может быть получена как сумма сложностей заданий, в которых проверяется рассматриваемый аспект. Для первого аспекта его максимально возможная оценка (ОМАї):
ОМАї = 2 + 2 + 2,5 + 3 + 2,5 = 12.
Результаты работы с тестом каждый из испытуемых вводит в специальную таблицу (табл. 10).
Таблица 9
Эталонная аспектная таблица ответов
№ п/п Аспекты тестирования Задания по аспектам Максимально возможная оценка
1 Прямолинейность распространения света. Тень, полутень и т. д. 1, 2, 3, 4, 5 12
На основании сравнения таблицы ответов каждого из испытуемых с эталонной, аспектной эталонной и нормировочной таблицами компьютер позволяет получить результаты тестирования для каждого из испытуемых: достижение (Д) и соответствующую отметку (0); достижения и оценки испытуемого по каждому из аспектов тестирования (ДА1 и ОАО (табл. 11).
Сопоставляя результаты отдельных групп испытуемых с помощью компьютера, получаем данные, позволяющие сделать определенные выводы об эффективности той технологии, по которой велось обучение испытуемых в группе: достижение группы в целом (ДГ) как среднее достижение испытуемого:
N
IД
ДГ = ПТ, где
N — число испытуемых в группе; соответствующую отметку группы (ОГ) по нормировочной шкале; аспектные достижения группы (ДГА) и отметки (ГА) (табл. 12).
Таблица 10
Ответы испытуемого
^’^^^Ответы ЗаданИЯ^^^ 1 2 3 4 5 6 7 8 9 10 11 12
а 1 1 1 1
б 1 1 1 1 1 1 1
в 1 1 1 1 1 1
г 1 1
Отказ
Кроме того, компьютер позволяет получить и таблицу распределения выбора ответов всей группы испытуемых по каждому заданию теста (табл. 5).
Таблица 11
Результаты работы испытуемых с тестом
№ п/п Ф.И.О. Достижение, Д Отметка, О Аспектные достижения и отметки
1 2 3
ДА1 (ОА)1 ДА2 (ОА)2 ДАз (ОА)з
1 Цветков Н. и т. д. 0,45 3 0,54 (4) 0,47 (3) 0,35 (3)
Таблица 12
Результаты работы группы испытуемых с тестом
№ Группа ДГ ОГ Аспектные достижения группы, отметки
п/п 1 2 3
1 17 и т. д. 0,37 3 0,48 (3) 0,35 (3) 0,27 (2)
Компьютер позволяет получить среднее отклонение достижений испытуемых от достижения группы:
ддт = X(Д – ДГI) п
Таким образом, компьютерная обработка в результате тестирования отличается от других видов тем, что:
1) контроль и диагностика достижений испытуемых происходят без вмешательства преподавателя; тем самым обеспечивается объективная оценка достижений;
2) можно получить дополнительную информацию диагностического характера об испытуемом;
3) требует разработки специальных приемов регистрации наблюдаемых явлений и фактов;
4) позволяет фиксировать достижения испытуемых в данный момент времени;
5) можно оперативно проводить статистическую обработку результатов тестирования.
В заключение хотелось бы отметить, что эффективность тестирования зависит не только от качества тестов, но и от методов сравнения тестовых результатов. Объем информации о том или ином полученном балле заметно возрастает, если известны среднее арифметическое значение и стандартное отклонение. Соотношение полученного тестового балла с этими статистическими показате-
лями позволяет уточнить место, занимаемое тем или иным испытуемым в ряду других. Использование математической статистики в педагогических исследованиях не самоцель, а одно из эффективных средств познания объективных законов обучения и воспитания.
Библиографический список
1. Овчинников, В.В. Оценивание учебных достижений учащихся при проведении централизованного тестирования. — М.: Центр тестирования МО РФ, 2001. — 27 с.
2. Равен, Дж. Педагогическое тестироавние: проблемы, заблуждения, перспективы : пер. с англ. / Джон Равен. – М.: Когито-Центр, 1999. – 144 с.
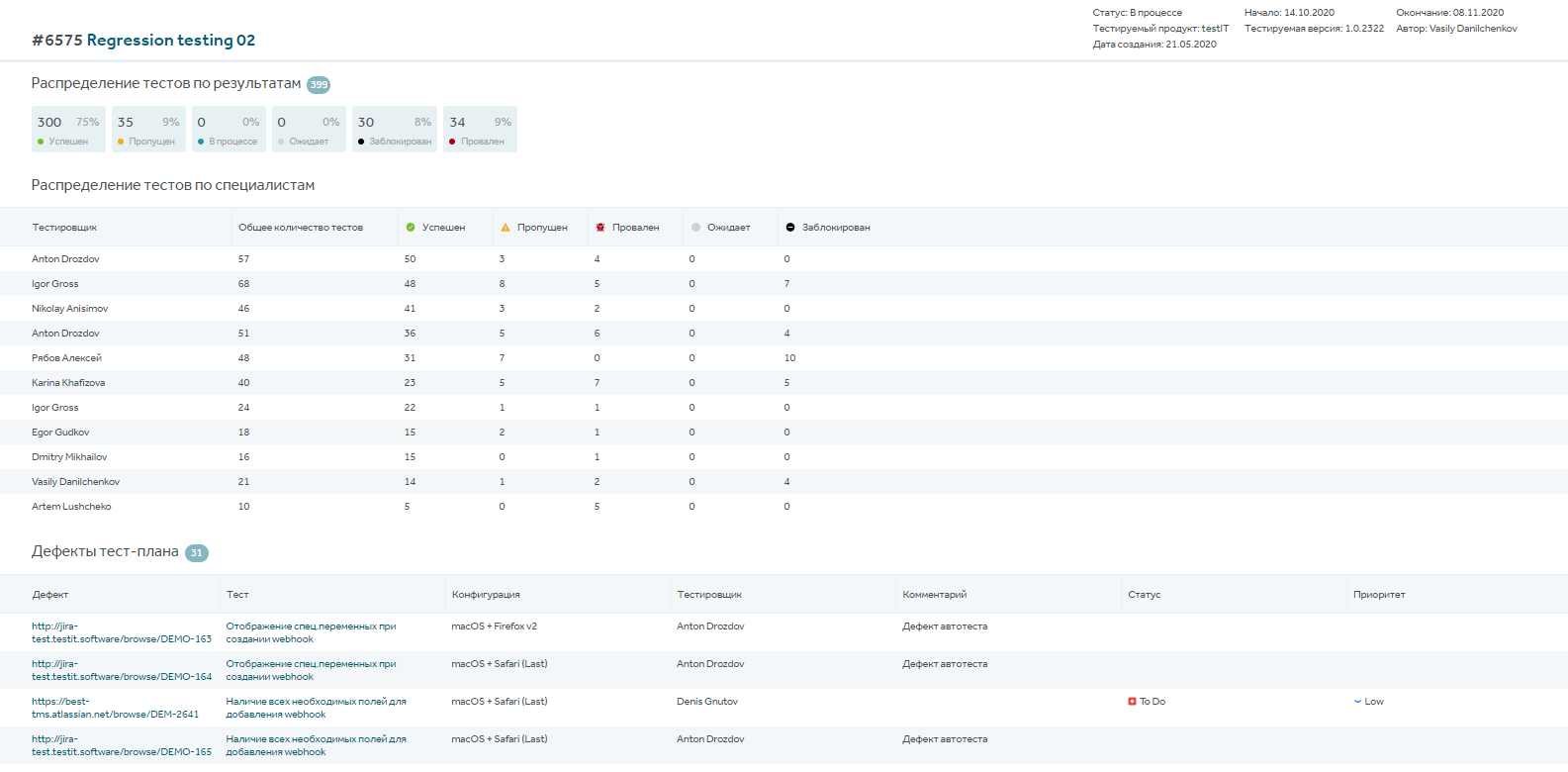
Отчетность в тестировании — обязательная часть работы на проекте. Различные отчеты о результатах тестирования могут быть полезны для работы многих специалистов в команде, от QA-инженера до CEO компании. В этой статье постараемся ответить, кому какие отчеты в Test IT могут быть нужны, и как их составлять.
Система Test IT — не только система управления тестированием, но также единый инструмент для взаимодействия всей команды разработки. Условно объединим тех, кто может использовать Test IT, в группы, и расскажем об отчетах для каждой:
-
QA-инженеры, ручные тестировщики,
-
Автоматизатори и разработчики,
-
QA-лиды, тест-менеджеры,
-
PM, Product Owner, CEO
Отчет — это документ, содержащий информацию о выполненных действиях, результатах проведённой работы. Включает в себя таблицы, графики, списки, описания в виде текста. Их пропорция и содержание определяют пользу и понятность отчета.
 Источник: habr.com
Источник: habr.com
Какие отчеты есть в Test IT?
Концептуально в системе существует шесть типов представления информации для создания виджета отчетности:
-
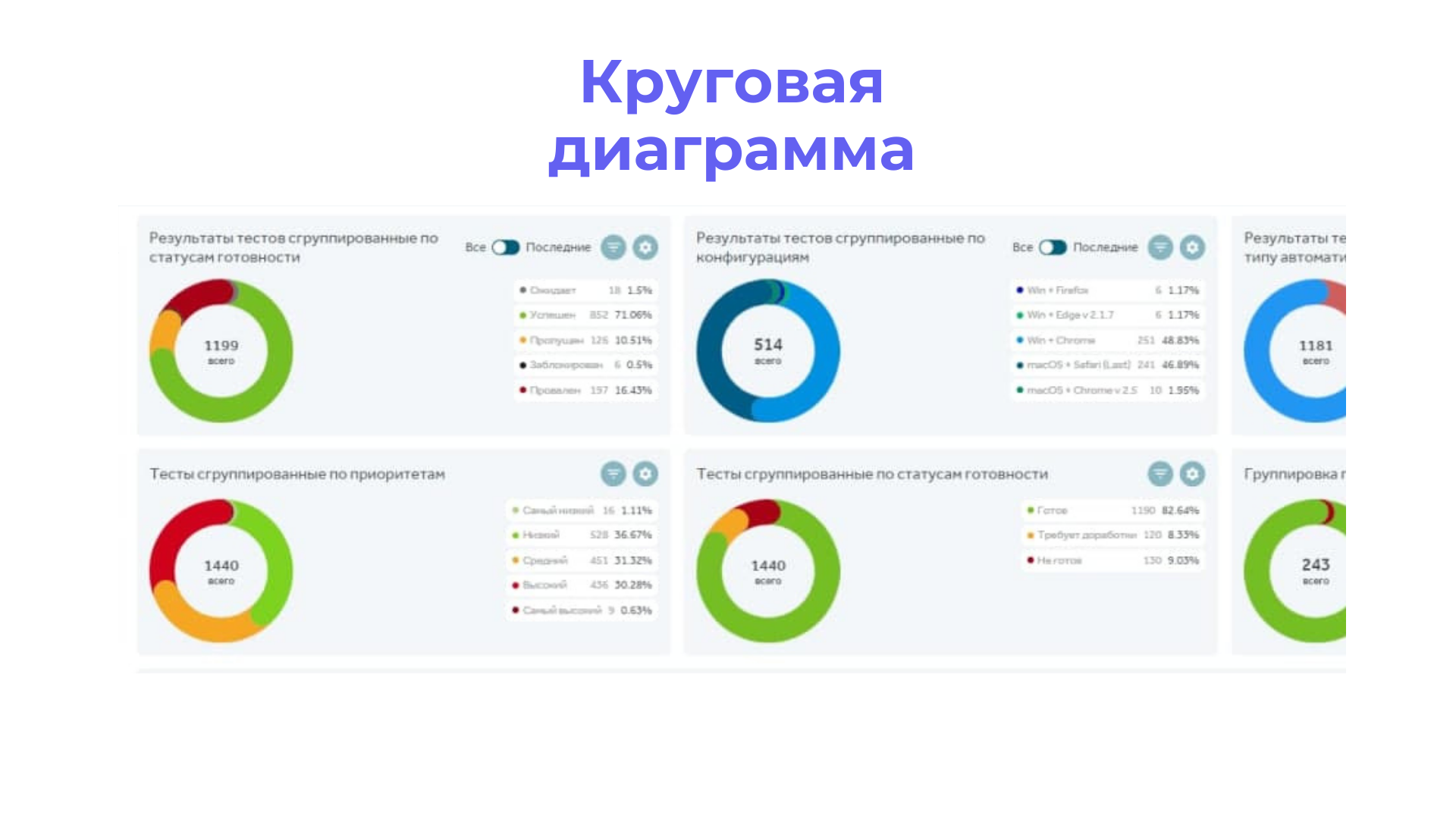
Круговая диаграмма – может выводить результаты тестов, тесты и автотесты, и группировать их по статусам, по приоритетам, по типу автоматизации или по авторам.
-
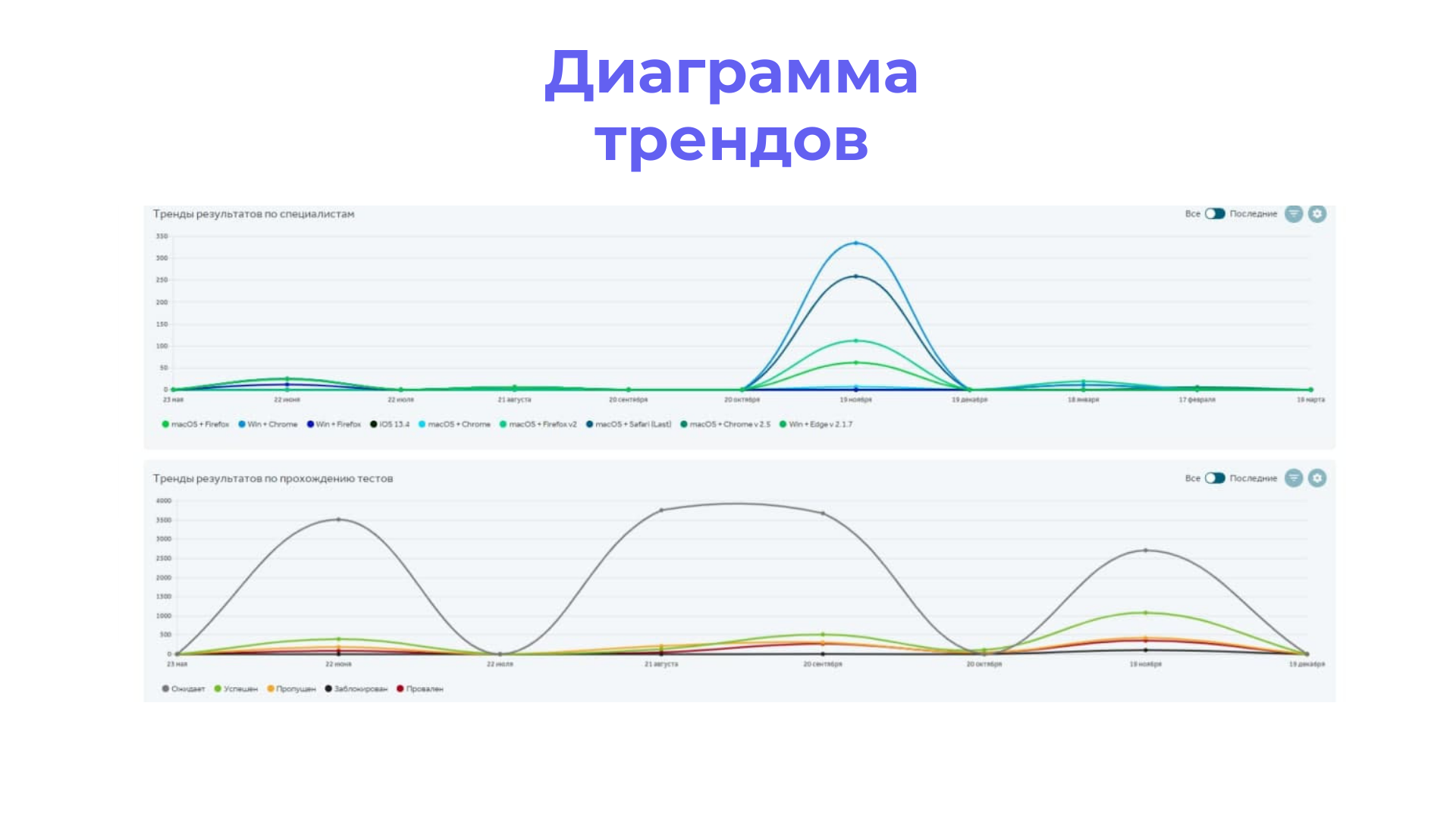
Тренды – то же самое, что круговая, но имеет другое графическое представление.
-
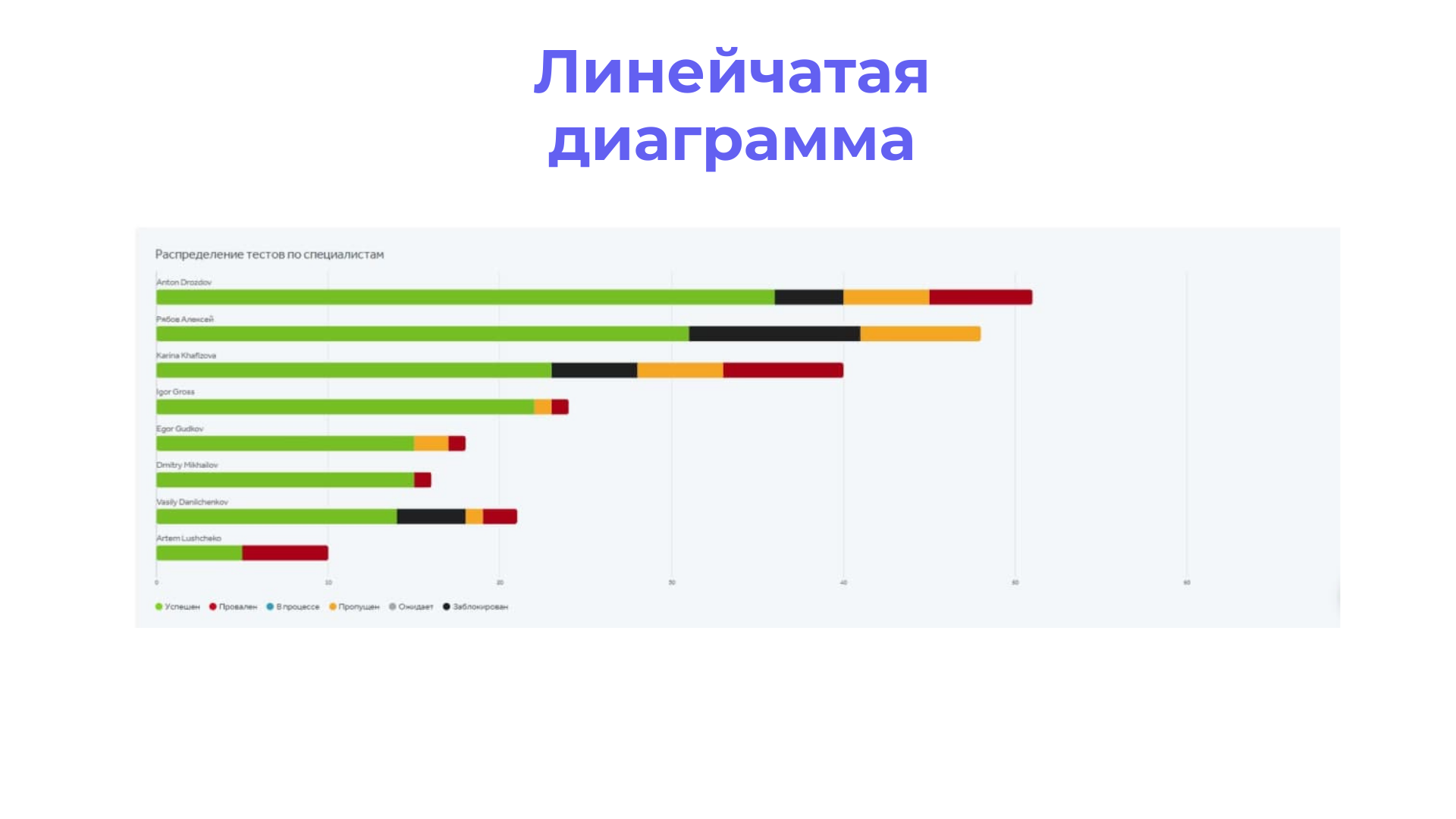
Линейчатая диаграмма умеет выводить результаты по тест-планам и тест-ранам.
-
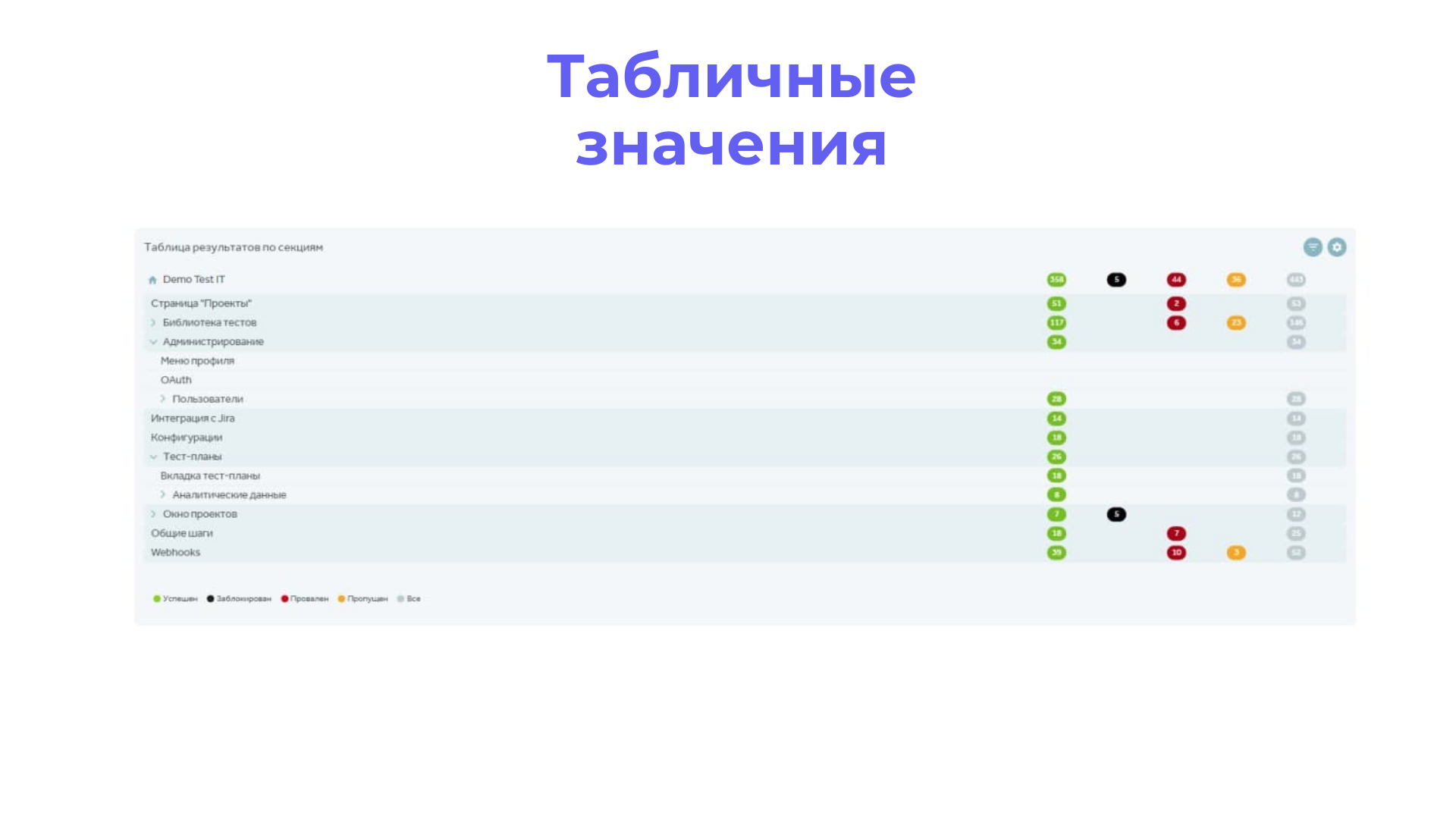
Таблица выводит результаты по результатам тестов и тестам.
-
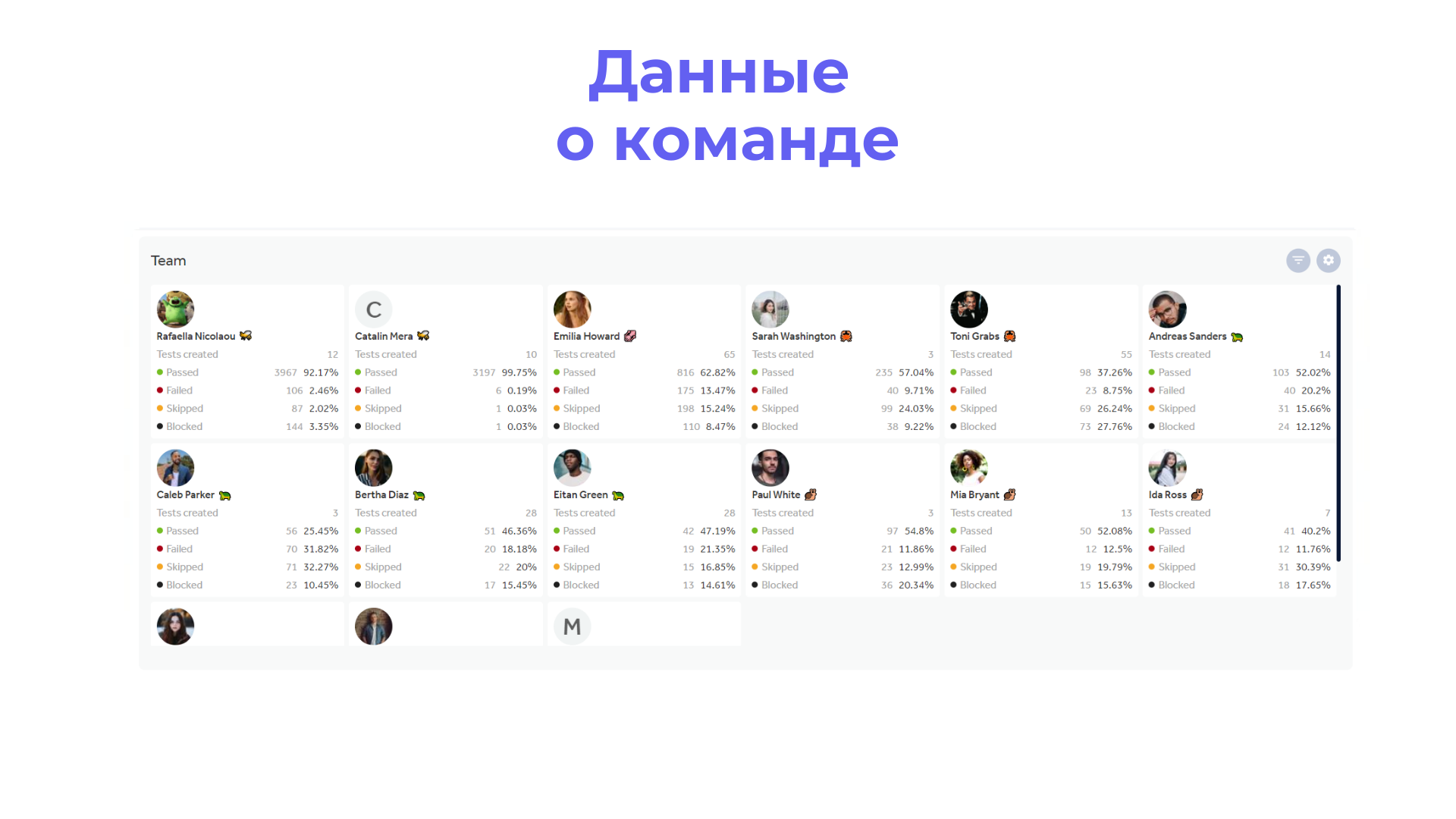
Команда – отчет по сотрудникам проекта, которые принимали участие в тестировании.
-
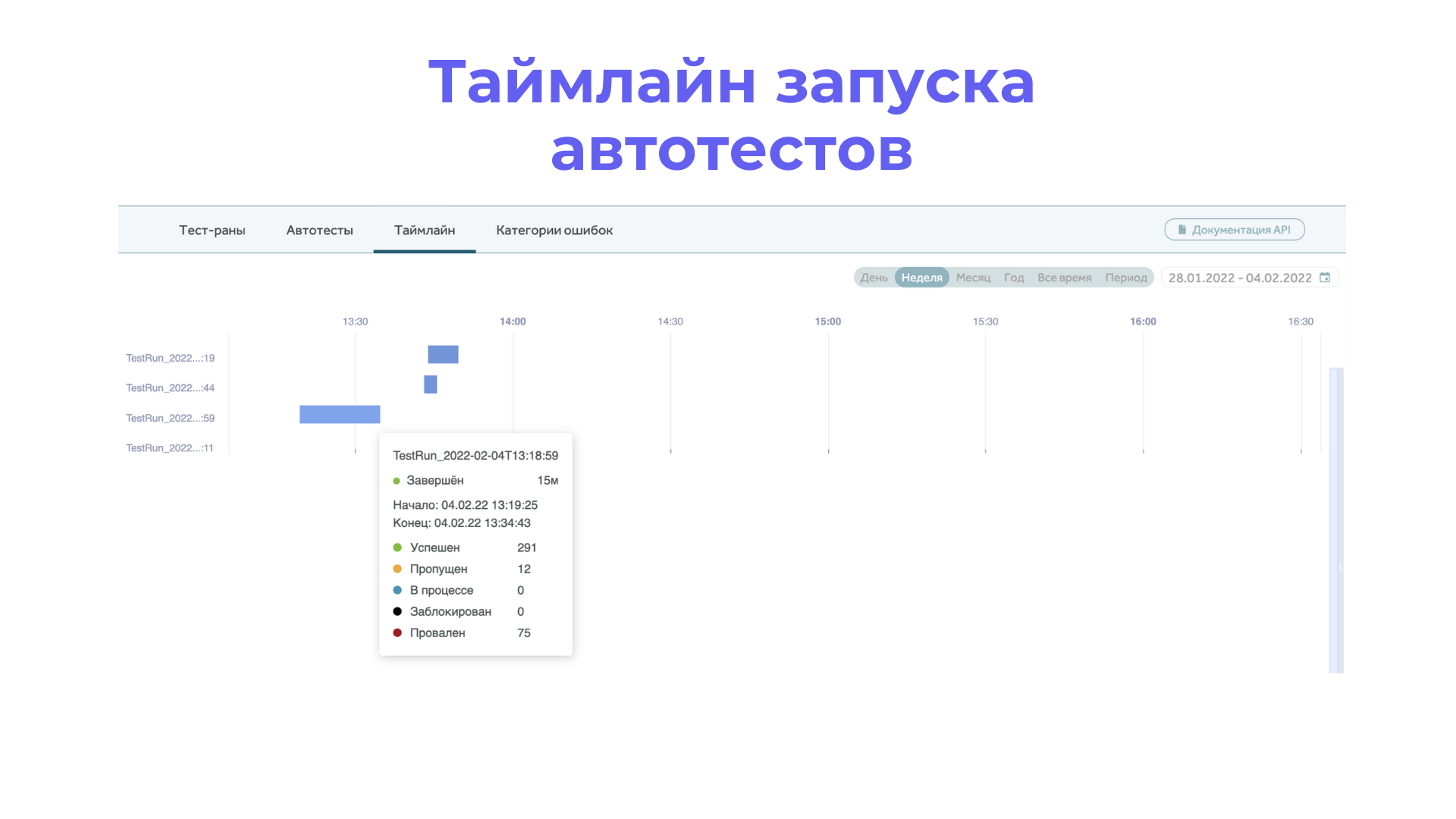
Таймлайн – график запущенных тест-ранов.
Некоторые типы отчетов доступны внутри модулей (автотесты и тест-планы), и абсолютно все типы отчетов можно вывести в модуль Дашбордов для удобства. Отчеты можно фильтровать по множесту параметров: по типу данных, конфигурациям, приоритетам, временным параметрам, отслеживать продуктивность команды от регресса к регрессу.
Все виджеты и отчёты можно прямо сейчас попробовать в облачной версии Test IT Cloud.
Отчеты для ручных QA-инженеров
Обычно основная обязанность QA-инженеров или тестировщиков на проекте – писать, а затем проходить тесты. В крупных компаниях эти обязанности могут быть разделены между несколькими специалистами. Выходят новые фичи, новые требования, нуждающиеся в покрытии тестами, старые тесты требуют поддержания и обновления. Работа всегда кипит.
Какие метрики интересны QA-инженеру?
-
Статус теста (готов/не готов/требует доработки)
-
Приоритет теста
-
Автоматизирован тест или нет.
Также полезно отслеживать так называемые smoke-наборы (highest), те тесты, которые необходимо проходить ежедневно для проверки работоспособности системы. Хорошим показателем считается, когда таких тестов 5-10% от общего числа.

Вышеуказанные метрики также удобно смотреть в виде диаграммы трендов или круговой диаграммы.
Как построить такой отчет:
В выбранном проекте перейдите в модуль Дашборды, нажмите на плюсик справа внизу и выберите нужное представление данных.

Если документация в порядке, система Test IT это покажет. Например, если мы видим картину, что не менее 95% тестов готовы, то мы можем начинать регрессионное тестирование. В противном случае требуется поддержание тестовой модели.
В самих тест-планах также есть отчеты: зайдите в модуль “Тест-планы” выбранного проекта, выберите тест-план, раздел отчеты. В этом разделе можно отследить свой личный прогресс, посмотреть распределенные на себя тесты, а также общую картину по тест-плану.
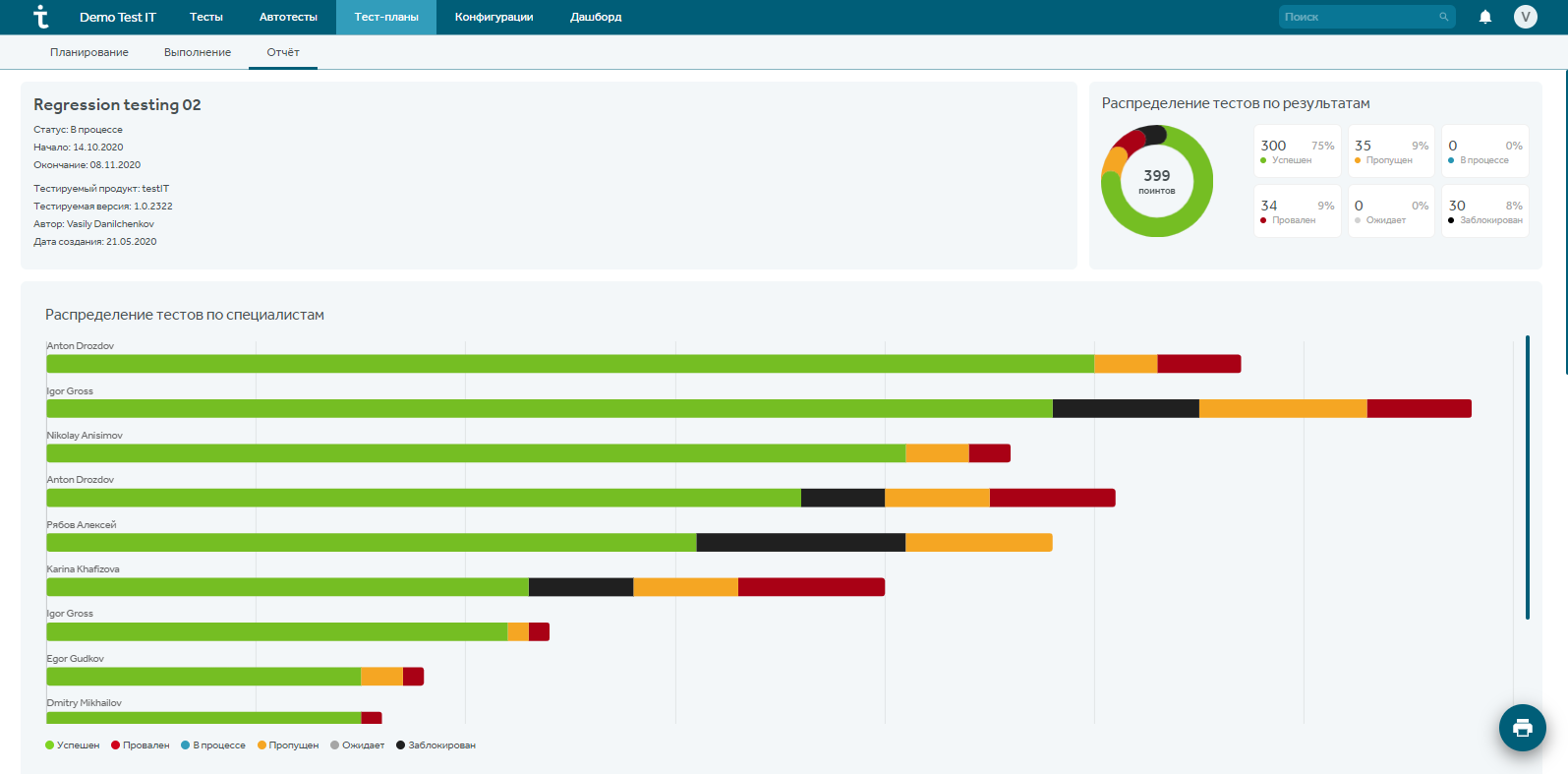
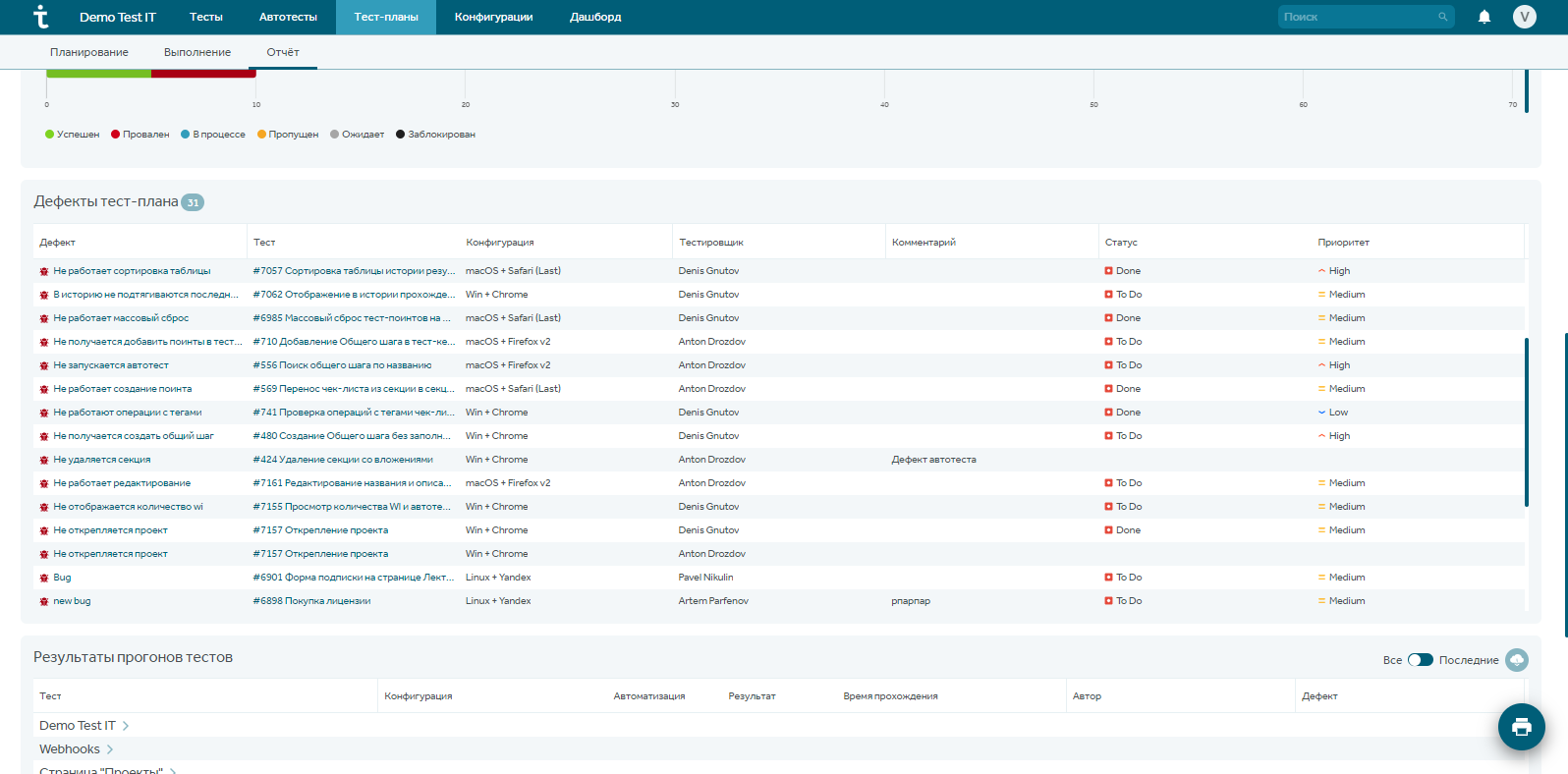
Ниже есть отчет по дефектам, который также может быть полезен ручным тестировщикам. Например, чтобы не дублировать баги в Jira.
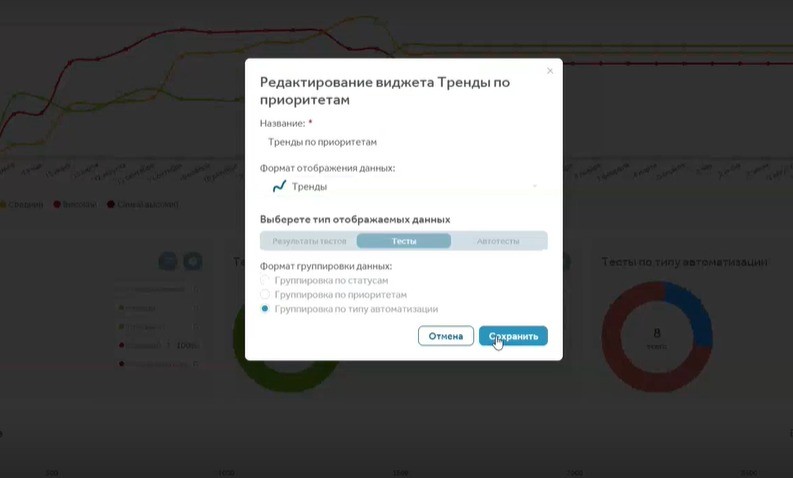
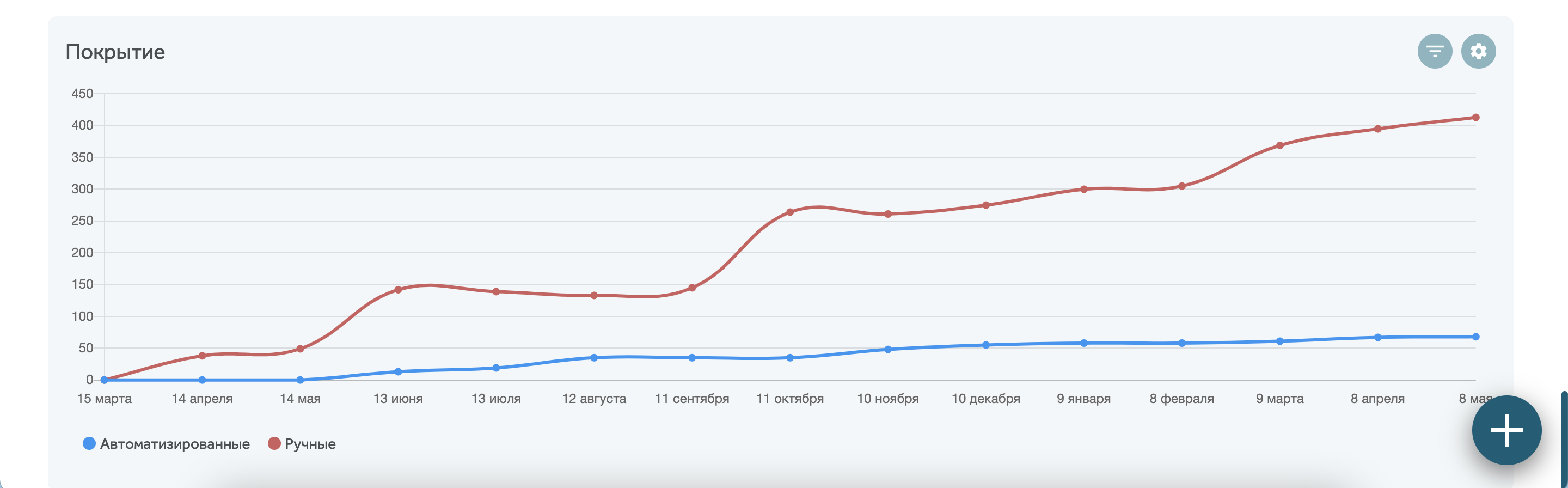
Также ручным тестировщикам при взаимодействии с автотестерами пригодится отчет, показывающий процент покрытия автотестами. Для этого, создавая отчет, в представлении “Тренды” выберите группировку тестов по типу автоматизации.
Какие отчеты нужны автоматизатору тестирования
QA-автоматизатора могут интересовать метрики:
- по тест-ранам,
- времени запуска,
- данные о причинах падения автотестов,
- отчет по стабильности тестов,
- процент автотестов от общего числа тестов.
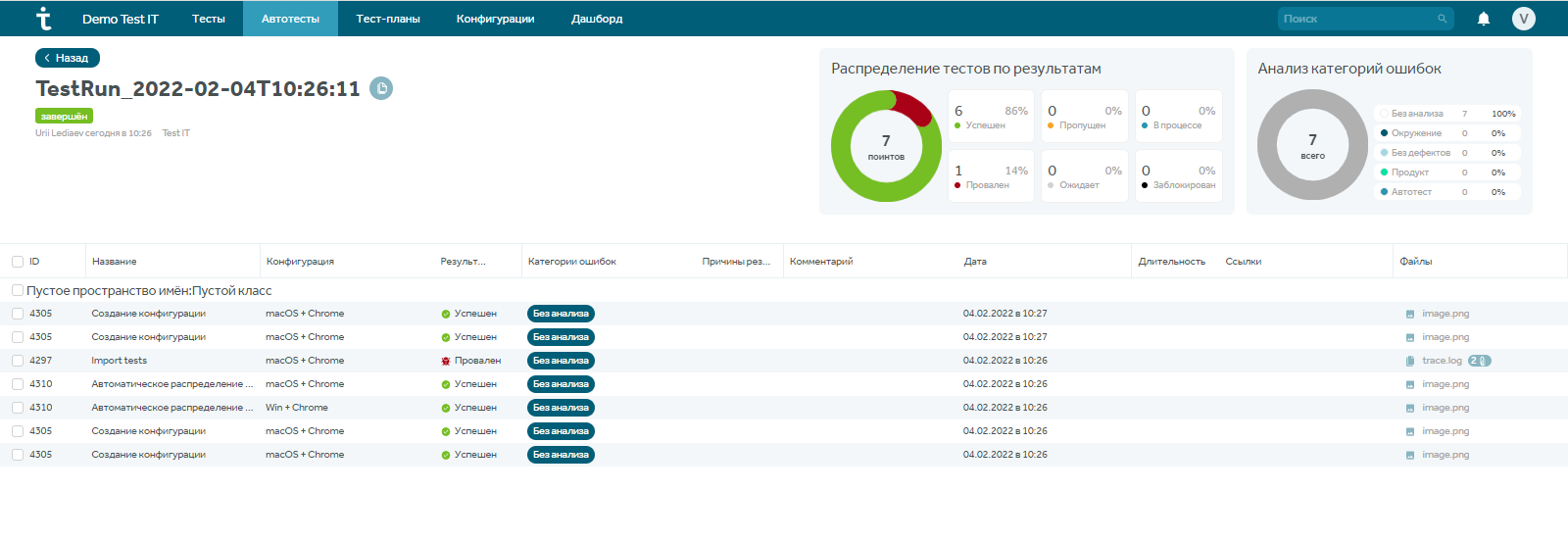
В модуле “Автотесты” есть свои отчеты по запускам автотестов, где отображается информация о времени запуска, количестве, результатах и причинам падения:
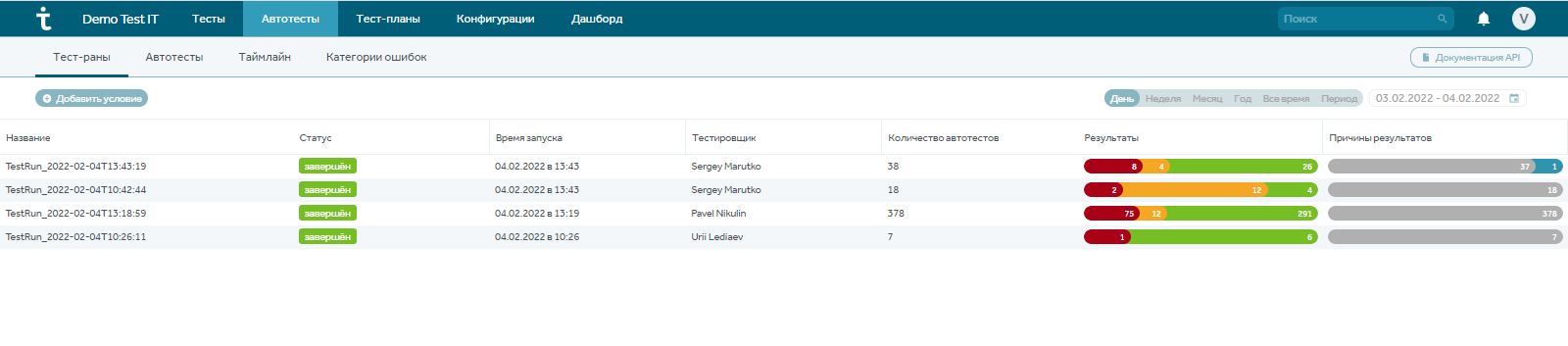
Можно кликнуть по любому из тест-ранов и получить полную информацию, где будет представлено распределение тестов по результатам, анализ категории ошибок, датам, тестировщикам.
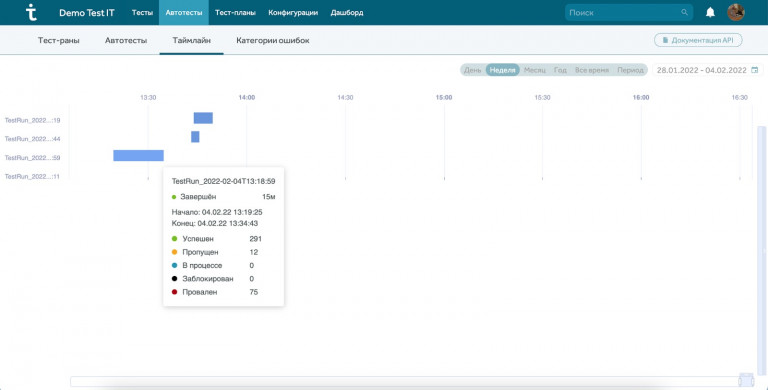
В модуле “Автотесты”, начиная с версии Taurus, доступен раздел таймлайнов, который визуализирует информацию о том, когда запускались автотесты и сколько времени это заняло:
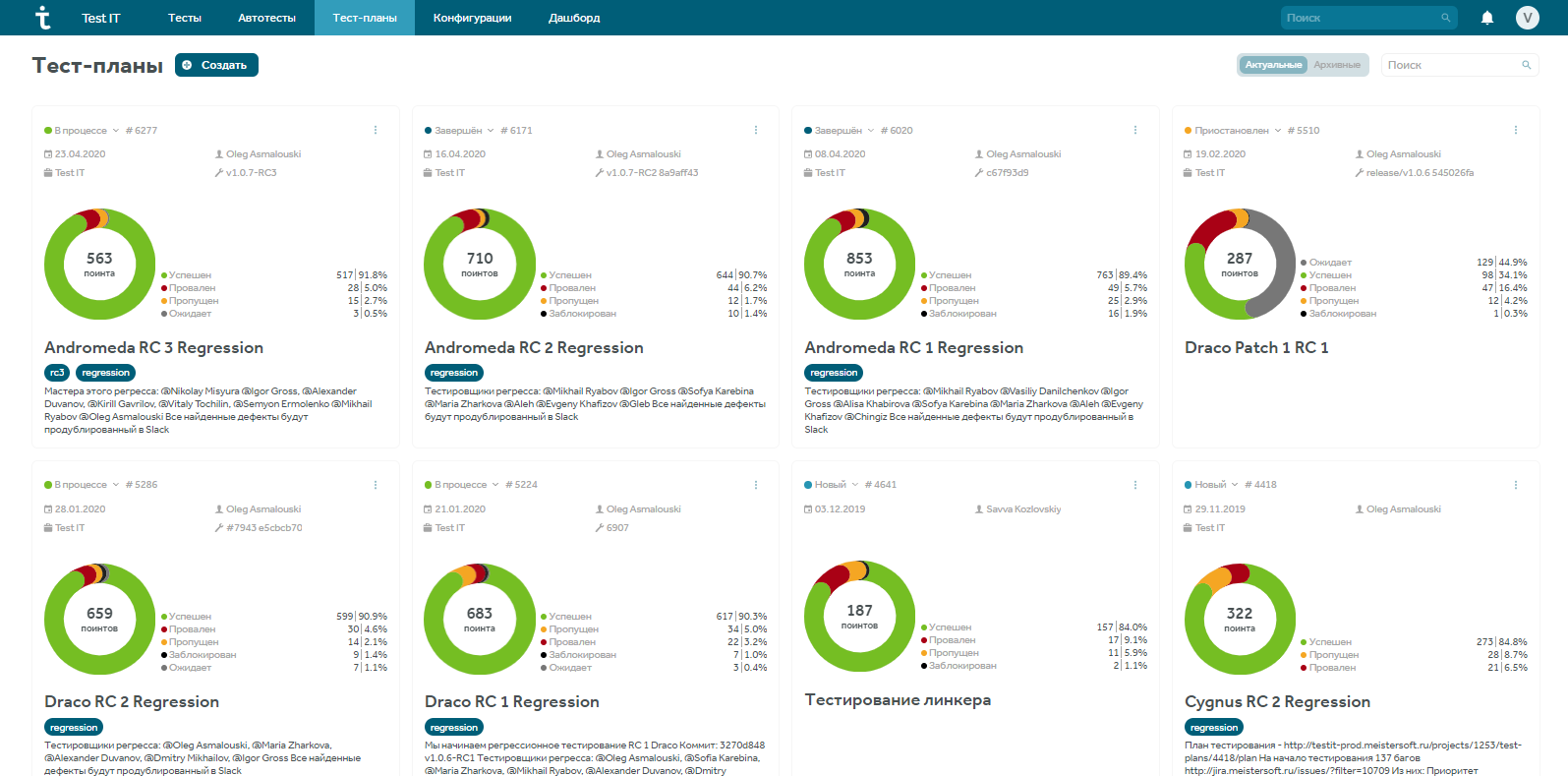
Раздел тест-планы сам по себе представляет свод отчетов по проведенным или проходящим процессам тестирования. В этом модуле пересекаются интересы ручных тестировщиков и специалистов по автоматизации.
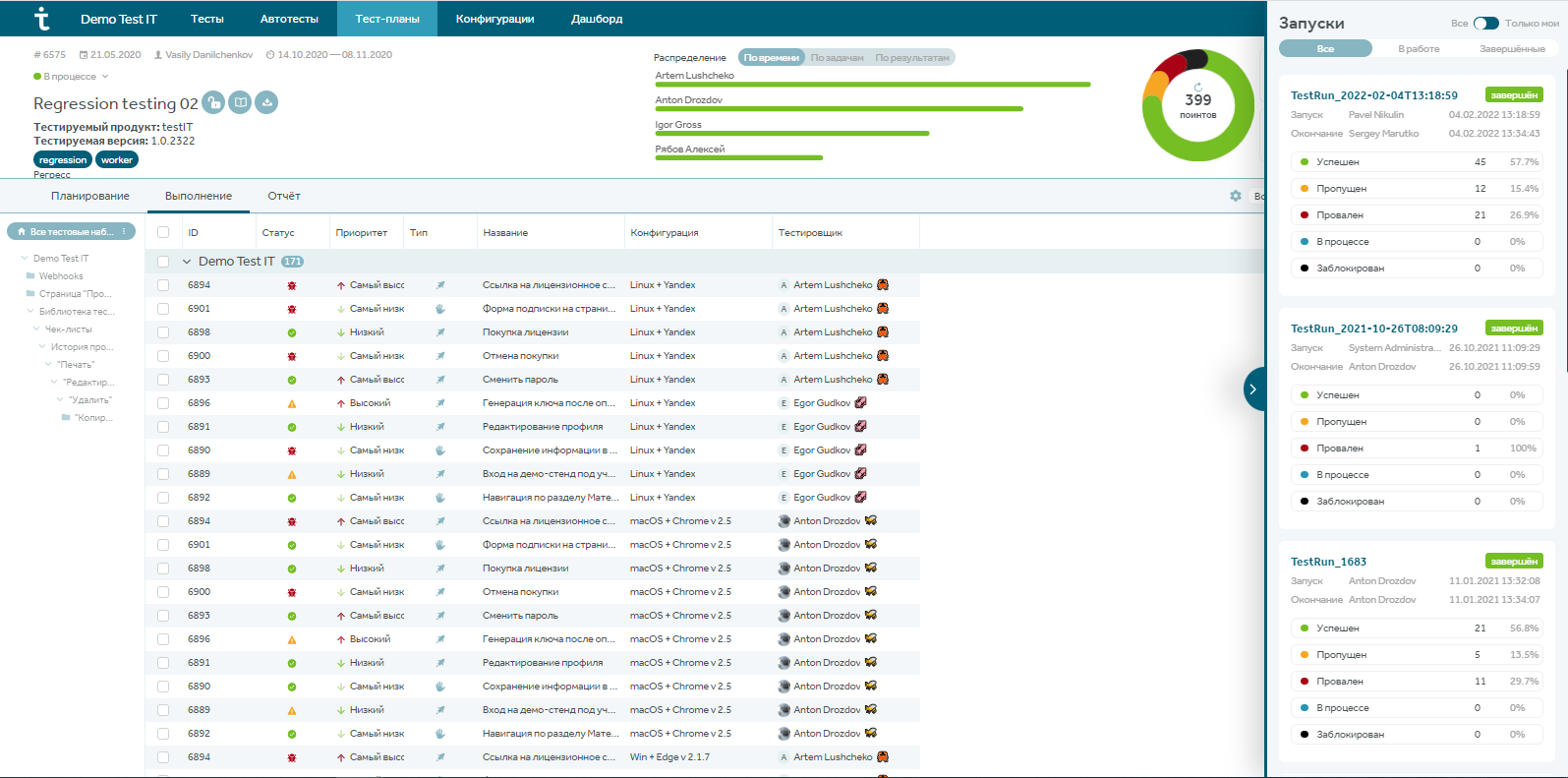
В тест-планах есть также отчет по запускам автотестов. Практика показывает, что именно в этом разделе автоматизаторы работают чаще всего:
В разделе Дашборды можно вывести отчет по причинам падения автотестов в виде линейчатой диаграммы (не определена, проблема окружения, продукта или автотеста):
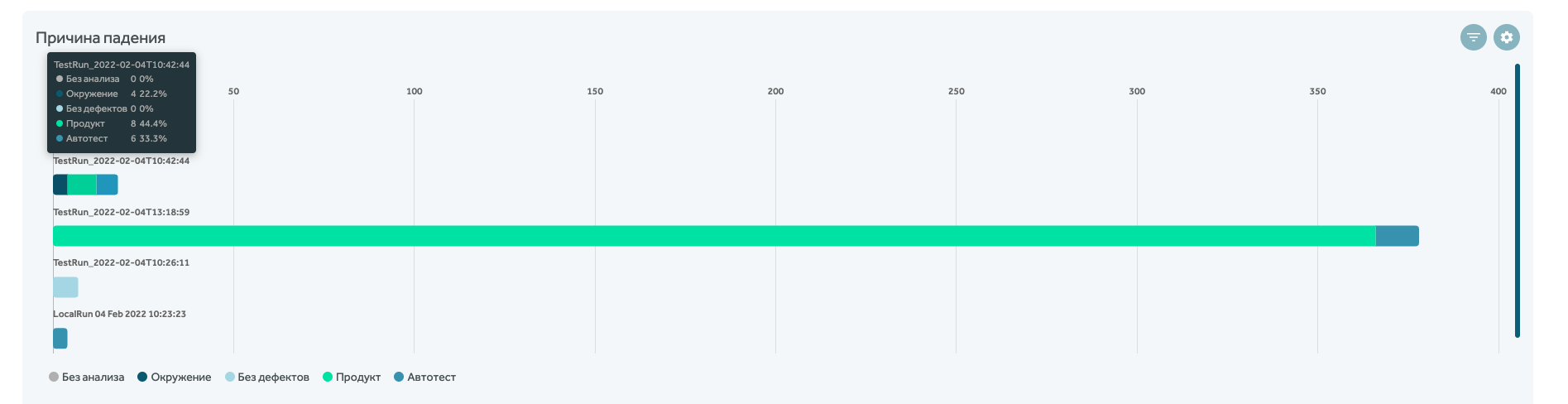
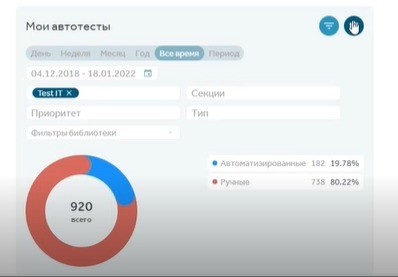
На дашборды также можно вывести отчет по соотношению тестов и автотестов, а также по конфигурациям, на которых прогонялись тесты:
Чтобы построить отчет по стабильности автотестов, необходимо в библиотеке автотестов выделять такие группы тестов и отметить их как нестабильные. При этом в библиотеке есть две колонки, обозначающие стабильность: одна выводится автоматически и показывает процент успешных запусков по мнению системы Test IT, вторая выводит данные, введенные вручную автоматизатором.
Напоминаем, что всю информацию, которая может быть отображена в виде трендов, можно представить в виде круговой диаграммы – это зависит от личных предпочтений.
С помощью линейчатой диаграммы можно показать запуски автотестов, и отслеживать их результаты в режиме реального времени.
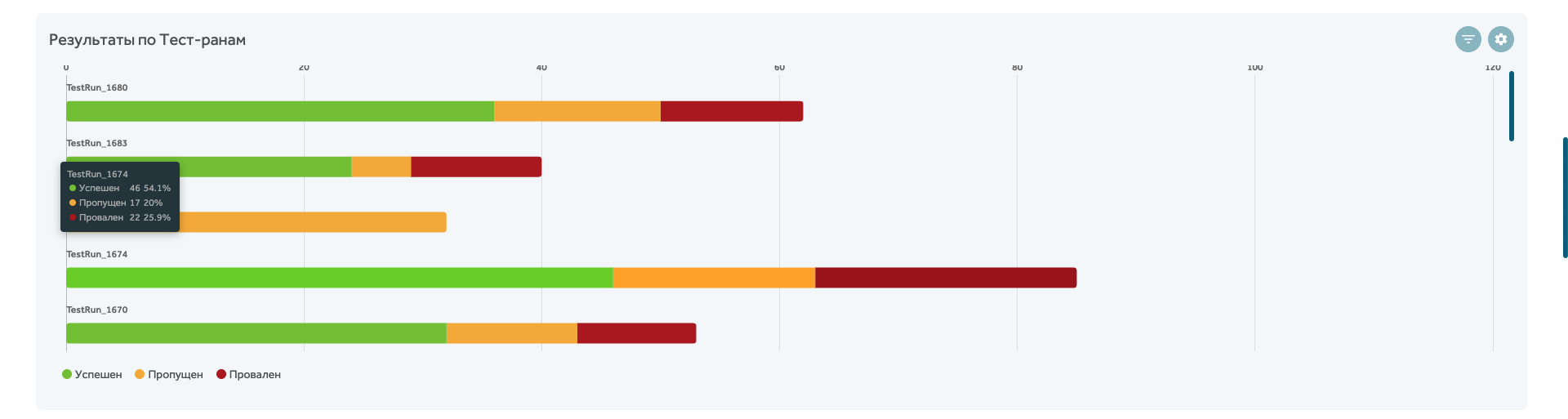
С помощью таблицы с фильтром по автоматизации и конфигурациям можно смотреть, в каком модуле автотесты падают чаще всего:

Разработчики, как правило, редко заходят в Test IT, но и для них есть полезная информация, например, шаги тест-кейсов или информация по автотестам.
Какие отчеты нужны тест-менеджеру
Менеджера в первую очередь интересуют отчеты по тест-планам, где отражена информация о результатах и статусе тест-плана, на основе которых делается вывод о том, нужен ли еще один регресс или нет.
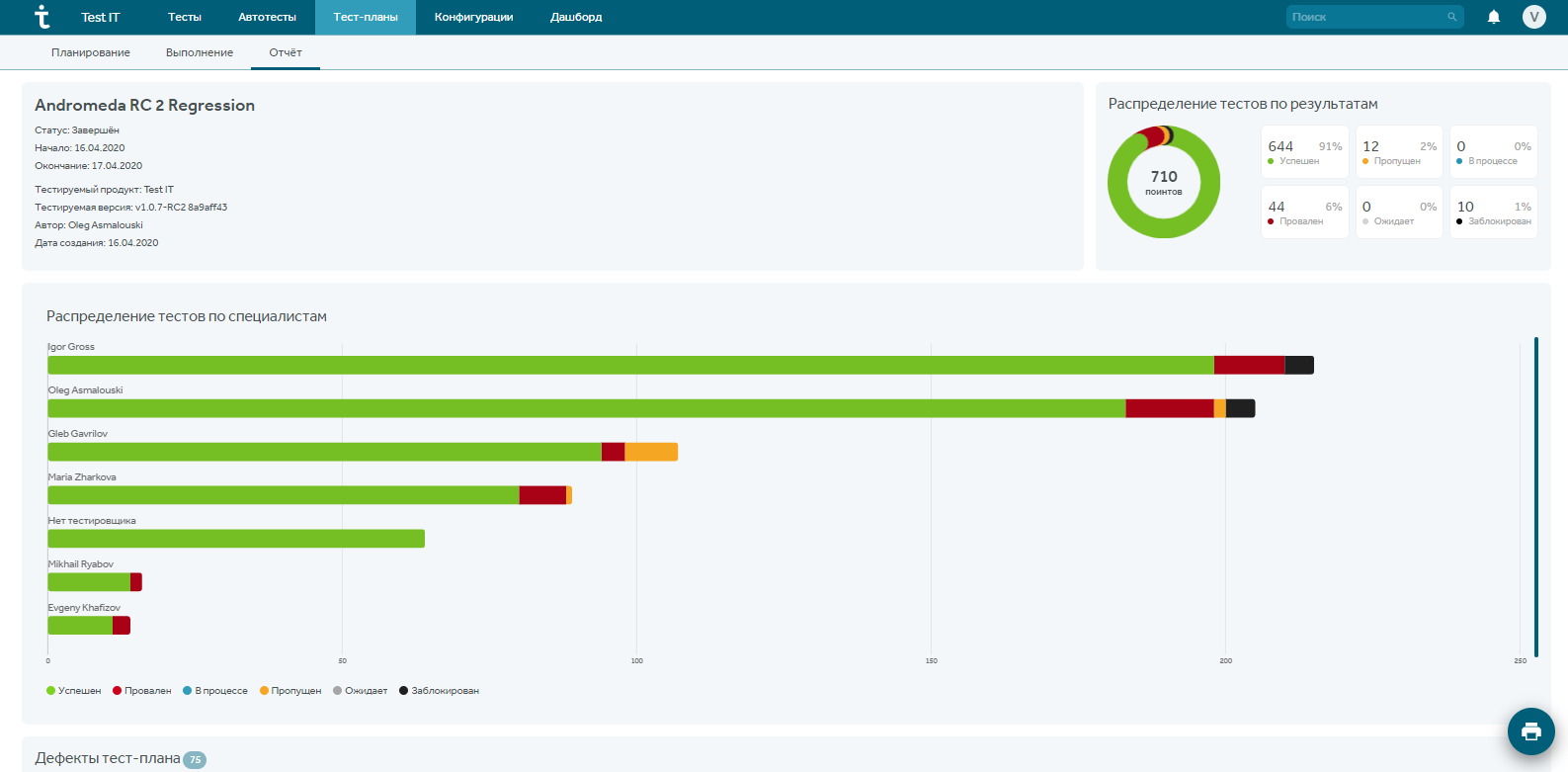
Менеджеру нужна вся информация, о которой упоминалось ранее (включая ручного тестировщика и автоматизатора). Также менеджеру важно смотреть отчеты по результатам работы команды, отслеживать нагрузку на каждого тестировщика и т.д.
Заходим в раздел отчетов по тест-плану и создаем отчеты в любом необходимом представлении: тренды, круговая, линейчатая, таблицы и люди…
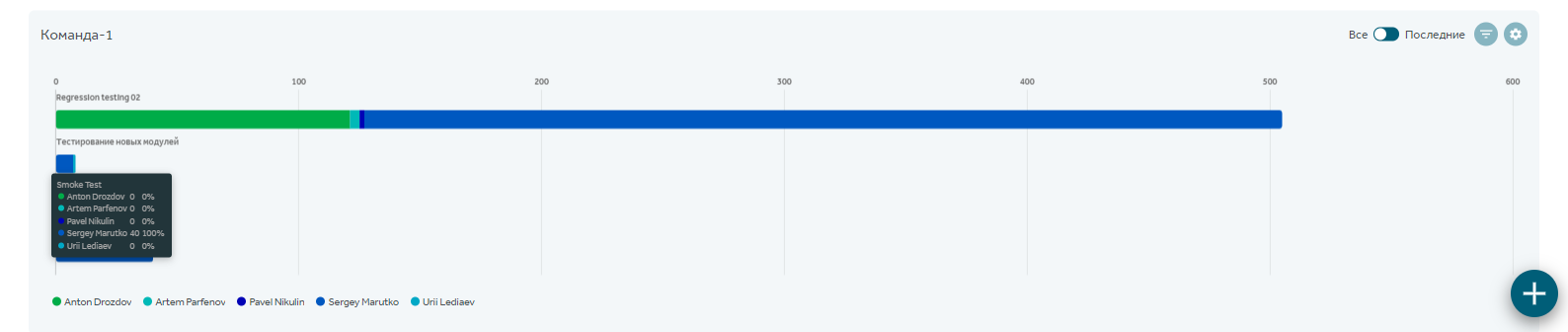
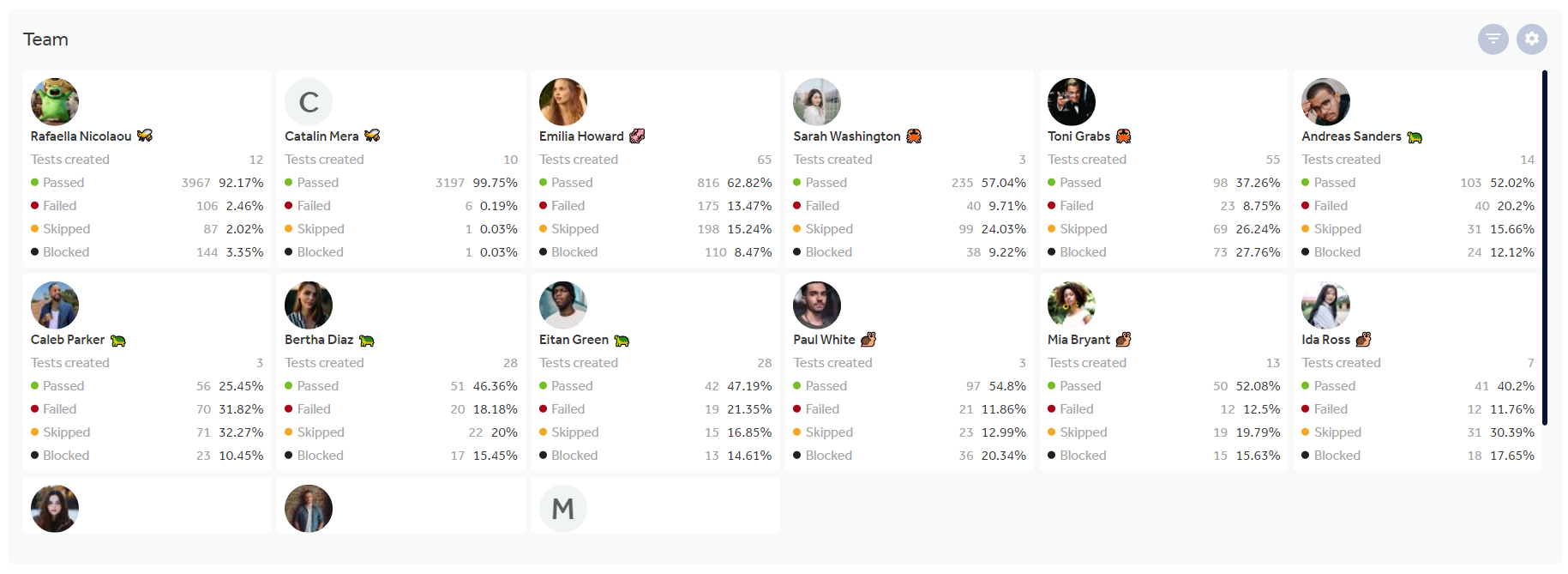
Можно отслеживать результаты от регресса к регрессу, определять приоритетность конфигураций, процент покрытия тестами и автотестами и многое другое.
Как понять, когда будет релиз? Чем меньше упавших тестов на регрессе, тем лучше. Это зависит от специфики проекта и от тест-менеджера, но обычно не допускается падение более чем 3-5% тестов. Эту информацию также можно получить в отчете по тест-плану.
Что может быть интересно CEO компании?
Что интересно CEO (иногда ГД) на самом деле 🙂
- тренд по количеству багов на прод среде(качество тестирования и разработки)
- тренд по хотфиксам (сколько пересборок)
- тренд по сделаным сторипойнтам в релиз (скорость разработки), тренд по времени регрессивного тестирования (скорость тестирования).
В отчете по тест-плану можно посмотреть дефекты, чтобы понимать, в каком модуле проблемы. Если, например, в регрессе отваливаются старые модули, которые раньше работали, нужно разбираться, что им помешало:
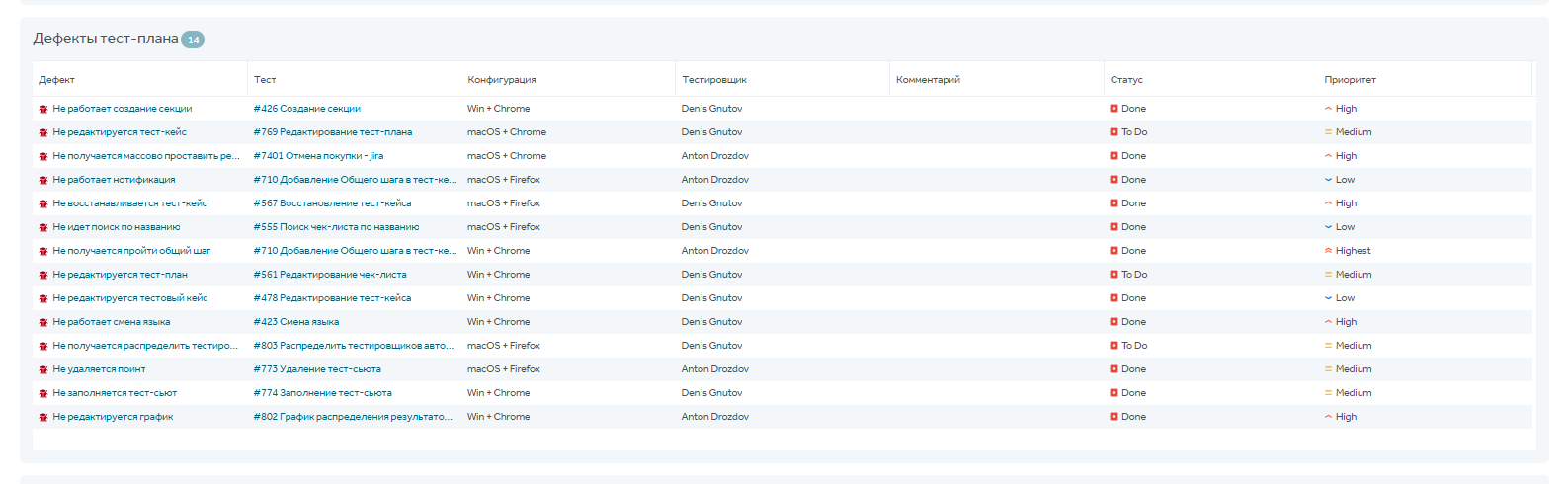
Эту информацию можно также смотреть в отчете по результатам прогонов тестов. Например, мы делаем релиз по определенному модулю системы, к которому будет приковано внимание всех пользователей, и важно, чтобы он работал без проблем. Данный отчет работает в онлайн-режиме и постоянно обновляется:
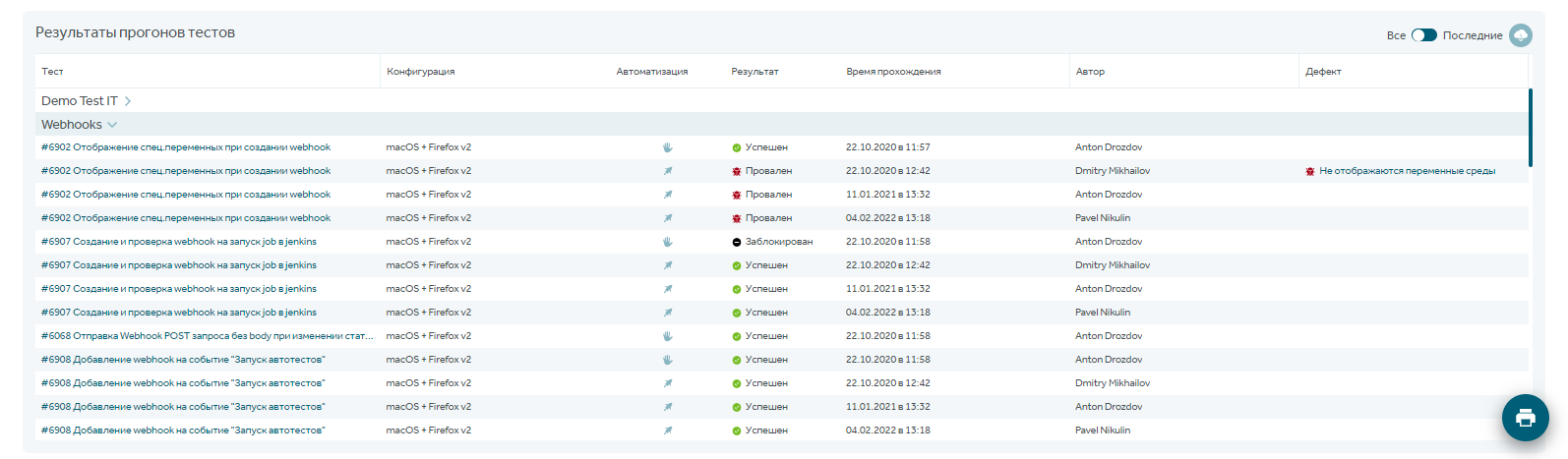
В разделе Дашборды важен отчет по трендам, который можно отфильтровать по интересующим данным.
Для высшего руководства может быть интересно, как в целом работает отдел тестирования, есть ли прогресс, много ли ошибок находится. Эту информацию можно посмотреть в сводных отчетах в разделе Дашборды.
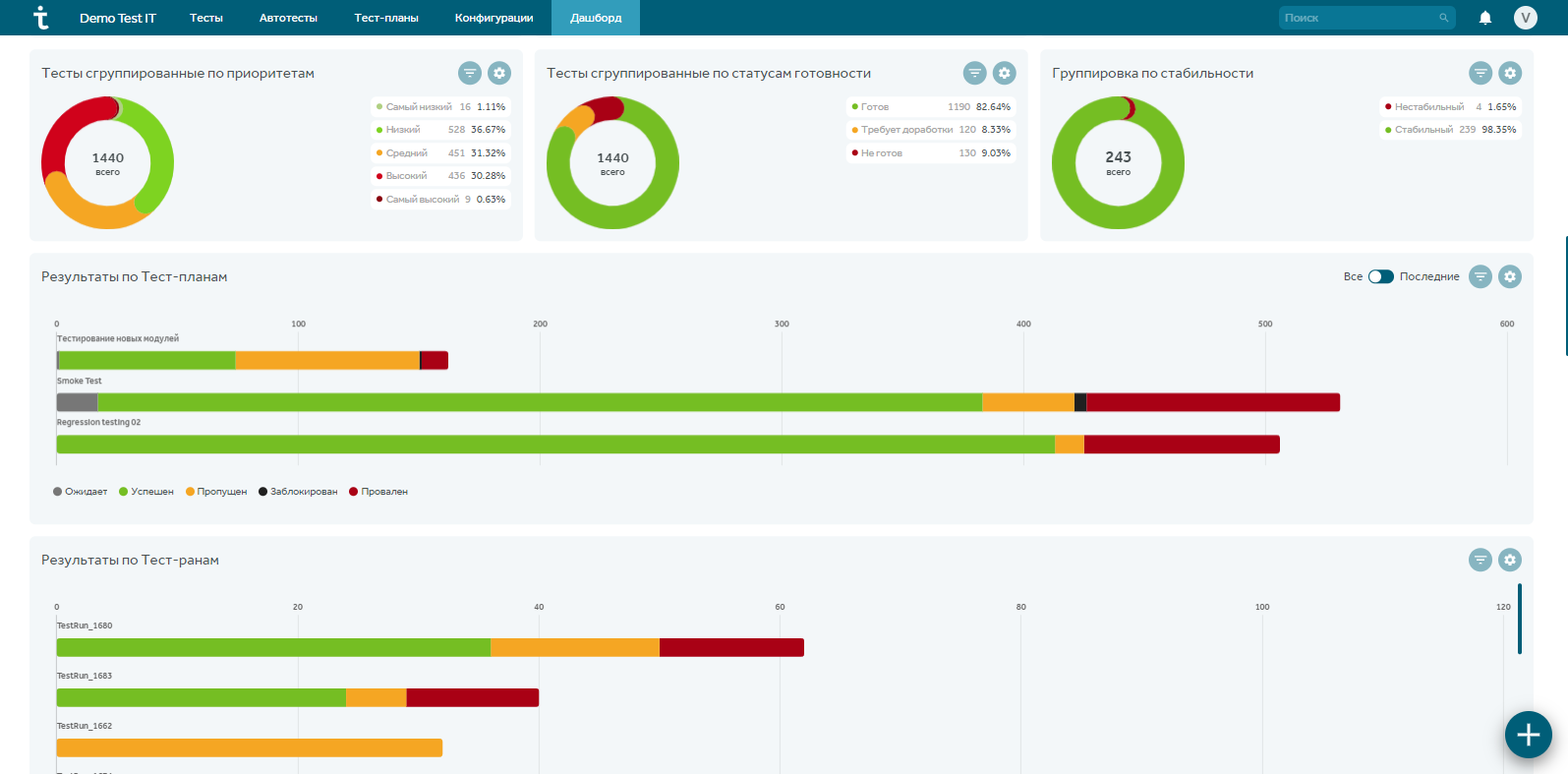
Любым отчетом по тест-плану можно поделиться: сохранить в pdf, распечатать или отправить заинтересованной стороне. Для этого зайдите в модуль “Тест-планы”, выберите тест-план, зайдите в его отчет и нажмите на “принтер” вправа внизу. Получите отчет в виде сводной информации: