Время на прочтение
8 мин
Количество просмотров 30K
Не являясь специалистом в обозначенной области я, тем не менее, прочитал много специализированной литературы для знакомства с предметом и прорываясь через тернии к звёздам набил, на начальных этапах, немало шишек. При всём изобилии информации мне не удалось найти простые статьи о кодировании как таковом, вне рамок специальной литературы (так сказать без формул и с картинками).
Статья, в первой части, является ликбезом по кодированию как таковому с примерами манипуляций с битовыми кодами, а во второй я бы хотел затронуть простейшие способы кодирования изображений.
0. Начало
Поскольку я обращаюсь к новичкам в этом вопросе, то не посчитаю зазорным обратиться к Википедии. А там, для обозначения кодирования информации, у нас есть такое определение – процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
Чего мне не хватало в 70-80-е, так это в школе, пусть не на информатике, а, например, на уроках математики – базовой информации по кодированию. Дело в том, что кодированием информации каждый из нас занимается ежесекундно, постоянно и в целом – не концентрируясь на самом кодировании. То есть в быту мы это делаем постоянно. Так как это происходит?
Мимика, жесты, речь, сигналы разного уровня – табличка с надписью, знак на дороге, светофоры, и для современного мира – штрих- и бар-коды, URL, хэш-тэги.
Давайте рассмотрим некоторые более подробно.
1.1 Речь, мимика, жесты
Удивительно, но всё это – коды. С помощью них мы передаём информацию о своих действиях, ощущениях, эмоциях. Самое важное, чтобы коды были понятны всем. Например, родившись в густых лесах у Амазонки и не видя современного городского человека, можно столкнуться с проблемой непонимания кода – улыбка, как демонстрация зубов, будет воспринята как угроза, а не как выражение радости.
Следуя определению, что же происходит когда мы говорим? Мысль – как форма, удобная для непосредственного использования, преобразуется в речь – форму удобную для передачи. И, смотрите, так как у звука есть ограничение как на скорость, так и на дальность передачи, то, например, жест, в какой-то ситуации, может быть выбран для передачи той же информации, но на большее расстояние.
Но мы всё еще будем ограничены дальностью остроты нашего зрения, и тогда – человек начинает придумывать другие способы передачи и преобразования информации, например огонь или дым.
1.2 Чередующиеся сигналы

В примитивном виде кодирование чередующимися сигналами используется человечеством очень давно. В предыдущем разделе мы сказали про дым и огонь. Если между наблюдателем и источником огня ставить и убирать препятствие, то наблюдателю будет казаться, что он видит чередующиеся сигналы “включено/выключено”. Меняя частоту таких включений мы можем выработать последовательность кодов, которая будет однозначно трактоваться принимающей стороной.
Наряду с сигнальными флажками на морских и речных судах, при появлении радио начали использовать код Морзе. И при всей кажущейся бинарности (представление кода двумя значениями), так как используются сигналы точка и тире, на самом деле это тернаный код, так как для разделения отдельных кодов-символов требуется пауза в передаче кода. То есть код Морзе кроме “точка-тире”, что нам даёт букву “A” может звучать и так – “точка-пауза-тире” и тогда это уже две буквы “ET”.

1.3 Контекст
Когда мы пользуемся компьютером, мы понимаем, что информация бывает разной – звук, видео, текст. Но в чем основные различия? И до того, как начать информацию кодировать, чтобы, например, передавать её по каналам связи, нужно понять, что из себя представляет информация в каждом конкретном случае, то есть обратить внимание на содержание. Звук – череда дискретных значений о звуковом сигнале, видео – череда кадров изображений, текст – череда символов текста. Если мы не будем учитывать контекст, а, например, будем использовать азбуку Морзе для передачи всех трёх видов информации, то если для текста такой способ может оказаться приемлемым, то для звука и видео время, затраченное на передачу например 1 секунды информации, может оказаться слишком долгим – час или даже пара недель.
2. Кодирование текста
От общего описания кодирования перейдём к практической части. Из условностей мы за константу примем то, что будем кодировать данные для персонального компьютера, где за единицу информации приняты – бит и байт. Бит, как атом информации, а байт – как условный блок размером в 8 бит.
Текст в компьютере является частью 256 символов, для каждого отводится один байт и в качестве кода могут быть использованы значения от 0 до 255. Так как данные в ПК представлены в двоичной системе счисления, то один байт (в значении ноль) равен записи 00000000, а 255 как 11111111. Чтение такого представления числа происходит справа налево, то есть один будет записано как 00000001.
Итак, символов английского алфавита 26 для верхнего и 26 для нижнего регистра, 10 цифр. Так же есть знаки препинания и другие символы, но для экспериментов мы будем использовать только прописные буквы (верхний регистр) и пробел.
Тестовая фраза “ЕХАЛ ГРЕКА ЧЕРЕЗ РЕКУ ВИДИТ ГРЕКА В РЕЧКЕ РАК СУНУЛ ГРЕКА РУКУ В РЕКУ РАК ЗА РУКУ ГРЕКУ ЦАП”.

2.1 Блочное кодирование
Информация в ПК уже представлена в виде блоков по 8 бит, но мы, зная контекст, попробуем представить её в виде блоков меньшего размера. Для этого нам нужно собрать информацию о представленных символах и, на будущее, сразу подсчитаем частоту использования каждого символа:
|
Символ |
Количество |
|---|---|
|
ПРОБЕЛ |
18 |
|
Р |
12 |
|
К |
11 |
|
Е |
11 |
|
У |
9 |
|
А |
8 |
|
Г |
4 |
|
В |
3 |
|
Ч |
2 |
|
Л |
2 |
|
И |
2 |
|
З |
2 |
|
Д |
1 |
|
Х |
1 |
|
С |
1 |
|
Т |
1 |
|
Ц |
1 |
|
Н |
1 |
|
П |
1 |
Всего нами использовано 19 символов (включая пробел). Для хранения в памяти ПК будет затрачено 18+12+11+11+9+8+4+3+2+2+2+2+1+1+1+1+1+1+1=91 байт (91*8=728 бит).
Эти значения мы берём как константы и пробуем изменить подход к хранению блоков. Для этого мы замечаем, что из 256 кодов для символов мы используем только 19. Чтобы узнать – сколько нужно бит для хранения 19 значений мы должны посчитать LOG2(19)=4.25, так как дробное значение бита мы использовать не можем, то мы должны округлить до 5, что нам даёт максимально 32 разных значения (если бы мы захотели использовать 4 бита, то это дало бы лишь 16 значений и мы не смогли бы закодировать всю строку).
Нетрудно посчитать, что у нас получится 91*5=455 бит, то есть зная контекст и изменив способ хранения мы смогли уменьшить использование памяти ПК на 37.5%.
К сожалению такое представление информации не позволит его однозначно декодировать без хранения информации о символах и новых кодах, а добавление нового словаря увеличит размер данных. Поэтому подобные способы кодирования проявляют себя на бОльших объемах данных.
Кроме того, для хранения 19 значений мы использовали количество бит как для 32 значений, это снижает эффективность кодирования.
2.2 Коды переменной длины
Воспользуемся той же строкой и таблицей и попробуем данные закодировать иначе. Уберём блоки фиксированного размера и представим данные исходя из их частоты использования – чем чаще данные используются, чем меньше бит мы будем использовать. У нас получится вторая таблица:
|
Символ |
Количество |
Переменный код, бит |
|---|---|---|
|
ПРОБЕЛ |
18 |
0 |
|
Р |
12 |
1 |
|
К |
11 |
00 |
|
Е |
11 |
01 |
|
У |
9 |
10 |
|
А |
8 |
11 |
|
Г |
4 |
000 |
|
В |
3 |
001 |
|
Ч |
2 |
010 |
|
Л |
2 |
011 |
|
И |
2 |
100 |
|
З |
2 |
101 |
|
Д |
1 |
110 |
|
Х |
1 |
111 |
|
С |
1 |
0000 |
|
Т |
1 |
0001 |
|
Ц |
1 |
0010 |
|
Н |
1 |
0011 |
|
П |
1 |
0100 |
Для подсчёта длины закодированного сообщения мы должны сложить все произведения количества символов на длины кодов в битах и тогда получим 179 бит.
Но такой способ, хоть и позволил прилично сэкономить память, но не будет работать, потому что невозможно его раскодировать. Мы не сможем в такой ситуации определить, что означает код “111”, это может быть “РРР”, “РА”, “АР” или “Х”.
2.3 Префиксные блочные коды
Для решения проблемы предыдущего примера нам нужно использовать префиксные коды – это такой код, который при чтении можно однозначно раскодировать в нужный символ, так как он есть только у него. Помните ранее мы говорили про азбуку Морзе и там префиксом была пауза. Вот и сейчас нам нужно ввести в обращение какой-то код, который будет определять начало и/или конец конкретного значения кода.
Составим третью таблицу всё для той же строки:
|
Символ |
Количество |
Префиксный код с переменными блоками, бит |
|---|---|---|
|
ПРОБЕЛ |
18 |
0000 |
|
Р |
12 |
0001 |
|
К |
11 |
0010 |
|
Е |
11 |
0011 |
|
У |
9 |
0100 |
|
А |
8 |
0101 |
|
Г |
4 |
0110 |
|
В |
3 |
0111 |
|
Ч |
2 |
10001 |
|
Л |
2 |
10010 |
|
И |
2 |
10011 |
|
З |
2 |
10100 |
|
Д |
1 |
10101 |
|
Х |
1 |
10110 |
|
С |
1 |
10111 |
|
Т |
1 |
11000 |
|
Ц |
1 |
11001 |
|
Н |
1 |
11010 |
|
П |
1 |
11011 |
Особенность новых кодов в том, что первый бит мы используем для указания размера следующего за ним блока, где 0 – блок в три бита, 1 – блок в четыре бита. Нетрудно посчитать, что такой подход закодирует нашу строку в 379 бит. Ранее при блочном кодировании у нас получился результат в 455 бит.
Можно развить этот подход и префикс увеличить до 2 бит, что позволит нам создать 4 группы блоков:
|
Символ |
Количество |
Префиксный код с переменными блоками, бит |
|---|---|---|
|
ПРОБЕЛ |
18 |
000 |
|
Р |
12 |
001 |
|
К |
11 |
0100 |
|
Е |
11 |
0101 |
|
У |
9 |
0110 |
|
А |
8 |
0111 |
|
Г |
4 |
10000 |
|
В |
3 |
10001 |
|
Ч |
2 |
10010 |
|
Л |
2 |
10011 |
|
И |
2 |
10100 |
|
З |
2 |
10101 |
|
Д |
1 |
10110 |
|
Х |
1 |
10111 |
|
С |
1 |
11000 |
|
Т |
1 |
11001 |
|
Ц |
1 |
11010 |
|
Н |
1 |
11011 |
|
П |
1 |
11100 |
Где 00 – блок в 1 бит, 01 – в 2 бита, 10 и 11 – в 3 бита. Подсчитываем размер строки – 356 бит.
В итоге, за три модификации одного способа, мы регулярно уменьшаем размер строки, от 455 до 379, а затем до 356 бит.
2.4 Код Хаффмана
Один из популярнейших способов построения префиксных кодов. При соблюдении определенных условий позволяет получить оптимальный код для любых данных, хотя и допускает вольные модификации методов создания кодов.
Такой код гарантирует, что для каждого символа есть только одна уникальная последовательность значений битов. При этом частым символам будут назначены короткие коды.
|
Символ |
Количество |
Код |
|---|---|---|
|
ПРОБЕЛ |
18 |
00 |
|
Р |
12 |
101 |
|
К |
11 |
100 |
|
Е |
11 |
011 |
|
У |
9 |
010 |
|
А |
8 |
1111 |
|
Г |
4 |
11011 |
|
В |
3 |
11001 |
|
Ч |
2 |
111011 |
|
Л |
2 |
111010 |
|
И |
2 |
111001 |
|
З |
2 |
111000 |
|
Д |
1 |
1101011 |
|
Х |
1 |
1101010 |
|
С |
1 |
1101001 |
|
Т |
1 |
1101000 |
|
Ц |
1 |
1100011 |
|
Н |
1 |
1100010 |
|
П |
1 |
110000 |
Считаем результат – 328 бит.
Заметьте, хоть мы и стали использовать коды в 6 и 7 бит, но их слишком мало, чтобы повлиять на исход.
2.5.1 Строки и подстроки
До сих пор мы кодировали данные, рассматривая их как совокупность отдельных символов. Сейчас мы попробуем кодировать целыми словами.
Напомню нашу строку: “ЕХАЛ ГРЕКА ЧЕРЕЗ РЕКУ ВИДИТ ГРЕКА В РЕЧКЕ РАК СУНУЛ ГРЕКА РУКУ В РЕКУ РАК ЗА РУКУ ГРЕКУ ЦАП”.
Составим таблицу повторов слов:
|
Слово |
Количество |
|---|---|
|
ПРОБЕЛ |
18 |
|
ГРЕКА |
3 |
|
В |
2 |
|
РАК |
2 |
|
РЕКУ |
2 |
|
РУКУ |
2 |
|
ВИДИТ |
1 |
|
ГРЕКУ |
1 |
|
ЕХАЛ |
1 |
|
ЗА |
1 |
|
РЕЧКЕ |
1 |
|
СУНУЛ |
1 |
|
ЦАП |
1 |
|
ЧЕРЕЗ |
1 |
Для кодирования нам нужно придумать концепцию, например – мы создаём словарь и каждому слову присваиваем индекс, пробелы игнорируем и не кодируем, но считаем, что каждое слово разделяется именно символом пробела.
Сначала формируем словарь:
|
Слово |
Количество |
Индекс |
|---|---|---|
|
ГРЕКА |
3 |
0 |
|
В |
2 |
1 |
|
РАК |
2 |
2 |
|
РЕКУ |
2 |
3 |
|
РУКУ |
2 |
4 |
|
ВИДИТ |
1 |
5 |
|
ГРЕКУ |
1 |
6 |
|
ЕХАЛ |
1 |
7 |
|
ЗА |
1 |
8 |
|
РЕЧКЕ |
1 |
9 |
|
СУНУЛ |
1 |
10 |
|
ЦАП |
1 |
11 |
|
ЧЕРЕЗ |
1 |
12 |
Таким образом наша строка кодируется в последовательность:
7, 0, 12, 3, 5, 0, 1, 9, 2, 10, 0, 4, 1, 3, 2, 8, 4, 6, 11
Это подготовительный этап, а вот то, как именно нам кодировать словарь и данные уже после подготовительного кодирования – процесс творческий. Мы пока останемся в рамках уже известных нам способов и начнём с блочного кодирования.
Индексы записываем в виде блоков по 4 бита (так можно представить индексы от 0 до 15), таких цепочек у нас будет две, одна для закодированного сообщения, а вторая для соответствия индексу и слову. Сами слова будем кодировать кодами Хаффмана, только нам еще придется задать разделитель записей в словаре, можно, например, указывать длину слова блоком, самое длинное слово у нас в 5 символов, для этого хватит 3 бита, но так же мы можем использовать код пробела, который состоит из двух бит – так и поступим. В итоге мы получаем схему хранения словаря:
|
Индекс / биты |
Слово / биты |
Конец слова / биты |
|---|---|---|
|
0 / 4 |
ГРЕКА / 18 |
ПРОБЕЛ / 2 |
|
1 / 4 |
В / 5 |
ПРОБЕЛ / 2 |
|
2 / 4 |
РАК / 10 |
ПРОБЕЛ / 2 |
|
3 / 4 |
РЕКУ / 12 |
ПРОБЕЛ / 2 |
|
4 / 4 |
РУКУ / 12 |
ПРОБЕЛ / 2 |
|
5 / 4 |
ВИДИТ / 31 |
ПРОБЕЛ / 2 |
|
6 / 4 |
ГРЕКУ / 17 |
ПРОБЕЛ / 2 |
|
7 / 4 |
ЕХАЛ / 20 |
ПРОБЕЛ / 2 |
|
8 / 4 |
ЗА / 10 |
ПРОБЕЛ / 2 |
|
9 / 4 |
РЕЧКЕ / 18 |
ПРОБЕЛ / 2 |
|
10 / 4 |
СУНУЛ / 26 |
ПРОБЕЛ / 2 |
|
11 / 4 |
ЦАП / 17 |
ПРОБЕЛ / 2 |
|
12 / 4 |
ЧЕРЕЗ / 21 |
ПРОБЕЛ / 2 |
и само сообщение по 4 бита на код.
Считаем всё вместе и получаем 371 бит. При этом само сообщение у нас было закодировано в 19*4=76 бит. Но нам всё еще требуется сохранять соответствие кода Хаффмана и символа, как и во всех предыдущих случаях.
Послесловие
Надеюсь статья позволит составить общее впечатление о кодировании и покажет, что это не только военный-шифровальщик или сложный алгоритм для математических гениев.
Периодически сталкиваюсь с тем, как студенты пытаются решить задачи кодирования и просто не могут абстрагироваться, подойти творчески к этому процессу. А ведь кодирование, это как причёска или модные штаны, которые таким образом показывают наш социальный код.
UPD:
Так как редактор Хабра уничтожил написанную вторую часть, а администрация не отреагировала на моё обращение, то продолжение (написанное еще в январе) скорее всего никогда не увидит свет (две недели непрерывной работы). Писать снова, считать таблицы, писать софт для проверки и скриншотов стимулов у меня нет, как нет желания писать что-то на ресурсе, на котором несогласные с “линией партии” получают отрицательную карму.
Кодирование строк
Кодирование строк


![]()
Чтобы компьютер смог отобразить передаваемые ему символы, они должны быть представлены в конкретной кодировке. Навряд ли найдется человек, который никогда не сталкивался с кракозябрами: открываешь интернет-страницу, а там – набор непонятных знаков; хочешь прочесть книгу в текстовом редакторе, а вместо слов получаешь сплошные знаки вопроса. Причина заключается в неверной процедуре декодирования текста (если сильно упростить, то программа пытается представить американцу, например, букву «Щ», осуществляя поиск в английском алфавите).
Возникают вопросы: что происходит, кто виноват? Ответ не будет коротким.
1. Компьютер – человек
Так сложилось, что компьютерная техника оперирует единицами и нулями. На вашей же клавиатуре представлено не менее 100 клавиш. Все, что вы вводите при печати, в итоге преобразуется в те самые бинарные величины.
В этом суть кодировки. ПК запоминает любые буквы, числа и знаки в виде определенного значения из единиц и нулей. Для примера: английская буква «Y» в двоичном коде выглядит как «0b1011001», а в шестнадцатеричном как «0x59».
Для осмысленного диалога пользователя и компьютера требуется двусторонний переводчик:
– «человеческие» строки необходимо перекодировать в байты;
– «компьютерную» речь требуется преобразовать в воспринимаемые пользователем осмысленные структуры.
В языке Python за это отвечают функции encode / decode. Важно кодировать и декодировать сообщение в одинаковой кодировке, чтобы не столкнуться с проблемой бессмысленных наборов символов.
Так как первые вычислительные машины были малоемкими, для представления в их памяти всего набора требуемых знаков хватало 7 бит (или 128 символов). Сюда входил весь английский алфавит в верхнем и нижнем регистрах, цифры, знаки, вспомогательные символы.

Поначалу этого вполне хватало. Кодировка получила имя ASCII (читается как «аски» или «эски»). В Пайтоне вы и сегодня можете посмотреть на символы ASCII. Для этого имеется встроенный модуль string.
import string
print(string.ascii_letters)
print(string.digits)
print(string.punctuation)
Результат выполнения кода
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
0123456789
!"#$%&'()*+,-./:;<=>?@[]^_`{|}~С другими свойствами модуля можете ознакомиться самостоятельно.
Время шло, компьютеризация общества ширилась, 128 символов стало не хватать. Оставшийся последний 8-ой бит также выделили для кодирования (а это еще 128 знаков). В итоге появилось большое количество кодировок (кириллическая, немецкая и т.п.). Такая ситуация привела к проблемам. Уже в то время англичанин, получающий электронное письмо из России, мог увидеть не русские буквы, а набор непонятных закорючек.
Потребовалось указание кодировок в заголовках документов.
3. Юникод-стандарт
Как вы считаете, сколько нужно символов, чтобы хватило всем и навсегда? 10_000? Конечно, нет. Уже сегодня более 100_000 знаков имеет свое числовое представление. И это не предел. Люди постоянно придумывают новые «буквы».
Откройте свой телефон и создайте пустое сообщение. Зайдите в раздел «смайликов». Да их тут больше сотни! И это не картинки в большинстве своем. Они являются символами определенной кодировки. Если вы застали времена, когда SMS-технологии только начинали развиваться, то этих самых «смайлов» было не более десятка. Лет через 10 их количество станет «неприличным».
Упомянутая выше кодировка ASCII в своем расширенном варианте породила большое количество новых. Основная беда: имея 128 вариантов обозначить символ, мы никак не сумеем внедрить туда буквы других языков. В частности, какой-нибудь символ под номером 201 в кириллице даст совсем не русскую букву, если отослать его в Румынию. Следовательно, говоря кому-то «посмотри на 201-ый символ» мы не даем никакой гарантии, что собеседник увидит то же.
Для решения задачи был разработан стандарт Unicode. Отметим, что это не определенная кодировка, а именно набор правил. Суть юникода – связь символа и определенного числа без возможного повторения. Если мы кого-то попросим показать символ, скрытый под номером «1000», то в любой точке планеты он будет одним и тем же графическим элементом.

Всего в Unicode стандарте на сегодня имеется место под более чем 1,1 млн знаков:
- UTF-8 – кодировка символов юникод в двоичном виде. Использует от 1 до 4 байт. Так как наиболее часто используемые символы занимают 1 байт (в частности, аски-символы), то UTF-8 оптимальна для английского текста, но не для азиатского.
- UTF-16 используется для кодирования 2-мя или 4-мя байтами. Считается удобным способом для пользователей азиатских стран с иероглифическим письмом.
- UTF-32 представляет все символы при помощи 4 байт. Используется редко, так как потребляет много памяти. Тем не менее, быстро работает при наличии мощностей.
4. Кодирование и декодирование строк
Пользователям Python 3 версии повезло. Все символы и документы заранее приводятся к кодировке UTF-8. И если где-то в коде вы напишете строку «Ёжик в тумане» или «אֱלִיעֶזֶר וְהַגֶזֶר», то будьте уверены, они не превратятся в абракадабру и не приведут к ошибкам.
Тем не менее, строковые методы decode / encode не потеряли свою актуальность. По умолчанию все преобразования осуществляются в кодировке UTF-8, но никто не мешает задать нужную вам.
Пример – Интерактивный режим
>>> 'Ёжик'.encode()
b'xd0x81xd0xb6xd0xb8xd0xba'
>>> 'Ёжик в тумане'.encode().decode()
'Ёжик в тумане'
>>> 'Ёжик в тумане'.encode().decode('utf-16')
'臐뛐룐뫐퀠₲苑菑볐냐뷐뗐'Поясним полученные результаты и принцип работы этих методов.
Задача encode() – представить строку в виде объекта типа bytes (предваряется литералом b). Если знак относится к ASCII, то его байтовое представление будет выглядеть как оригинальный символ. В случае когда он выходит за пределы ASCII, то заменяется байтовым представлением (x – эскейп-последовательность для обозначения 16-ричных чисел в языке Python).
Пример – интерактивный режим
>>> 'Python'.encode()
b'Python'
>>> 'Пайтон'.encode()
B'xd0x9fxd0xb0xd0xb9xd1x82xd0xbexd0xbd'Метод decode() преобразует последовательность байтов в привычную нам строку. Если задать другую кодировку, то можем получить либо неожиданный результат (как в последнем примере, где русские слова превратились в набор корейских иероглифов), либо ошибку UnicodeDecodeError, если в требуемой кодировке нет такого сочетания байтов или они выходят за ее границы.
Читайте также
5. Инструментарий для работы с кодировками
В Python встроено большое разнообразие функций и методов для работы с кодированием-декодированием строк. Часть из них менее актуальна, но на практике могут встречаться.
Перечислим те, которые вам могут понадобиться, а затем опробуем их на практике:
6. Практические примеры
Для усвоения материала попрактикуемся в применении изученного.
А. Функция ascii
Примеры – Интерактивный режим
>>> ascii(12)
'12'
>>> ascii('cat')
"'cat'"
>>> ascii('шапка')
"'\u0448\u0430\u043f\u043a\u0430'"Экранирование русского слова связано с тем, что ни один из символов не включен в стандартный набор знаков ascii (т.е. не имеет 1-байтового представления).
Б. Применение функции str для получения строк
Примеры – Интерактивный режим
>>> str(123)
'123'
>>> str(b'xd0x9fxd0xb0xd0xb9xd1x82xd0xbexd0xbd', 'utf8')
'Пайтон'В. Функция bytes
Превращает в объект bytes не только строки или числа, но и последовательности чисел (каждое из которых соответствует определенному символу).
Примеры – Интерактивный режим
>>> bytes('well done', 'ascii')
b'well done'
>>> bytes('Юта', 'utf16')
b'xffxfe.x04Bx040x04'
>>> bytes((80, 77, 99, 101))
b'PMce'Г. Модуль unicodedata
Позволяет узнать имя любого юникод-символа, а также отобразить его по имени. С другими свойствами можете ознакомиться самостоятельно.
Примеры – Интерактивный режим
>>> import unicodedata
>>> unicodedata.name('Я')
'CYRILLIC CAPITAL LETTER YA'
>>> unicodedata.lookup('GIRL')
'????'
>>> unicodedata.lookup('Trigram for Heaven')
'☰'Задачи по темам
Решаем задачи и отвечаем на вопросы по теме “Целые числа”: работаем с типом данных int
Решаем задачи и отвечаем на вопросы по теме “Числа с плавающей точкой”: работаем с типом данных float
Решаем задачи и отвечаем на вопросы по теме “Логический тип данных”: работаем с типом данных bool
Строки как тип данных в Python. Основные методы и свойства строк. Примеры работы со строками, задачи с решениями.
Д. Отображение любого Юникод-символа
Функция chr() может принимать числа любой стандартной системы счисления (десятичной, двоичной, восьмеричной или шестнадцатеричной).
Функция ord() возвращает десятичное число, соответствующее символу юникод. Если требуется, мы это число можем преобразовать к любому иному основанию.
Примеры – Интерактивный режим
>>> chr(0o144)
'd'
>>> chr(0b1100100)
'd'
>>> chr(0x64)
'd'
>>> chr(100)
'd'
>>> ord('d')
100Также попробуем немного экзотики. Если какой-то из символов не отображается, у вас нет шрифта в системе, который поддерживает эти знаки.
Примеры – Интерактивный режим
>>> chr(0x131B0) # Египетский иероглиф
????
>>> chr(0x1F5A4) # Черное сердечко
'????'
>>> chr(0x265E) # Черный конь
'♞'
>>> chr(0x111E1) # Сингальское число 1
????
>>> chr(0x4E78) # Китайский иероглиф
'乸'Воспользовавшись базой данных символов юникод, вы сумеете просмотреть все доступные варианты на сегодняшний день с указанием имени, кода, принадлежности.
Как вам материал?


Читайте также

Дмитрий Михайлович Беляев
Эксперт по предмету «Информатика»
Задать вопрос автору статьи
Чаще всего кодированию подвергаются тексты, написанные на естественных языках (русском, немецком и др.).
Основные способы кодирования текстовой информации
Существует несколько основных способов кодирования текстовой информации:
- графический, в котором текстовая информация кодируется путем использования специальных рисунков или знаков;
- символьный, в котором тексты кодируются с использованием символов того же алфавита, на котором написан исходник;
- числовой, в котором текстовая информация кодируется с помощью чисел.
Процесс чтения текста представляет собой процесс, обратный его написанию, в результате которого письменный текст преобразуется в устную речь. Чтение – это ничто иное, как декодирование письменного текста.
А сейчас обратите внимание на то, что существует много способов кодирования одного и того же текста на одном и том же языке.
![]()
Сделаем домашку
с вашим ребенком за 380 ₽
Уделите время себе, а мы сделаем всю домашку с вашим ребенком в режиме online
Бесплатное пробное занятие
*количество мест ограничено
Пример 1
Поскольку мы русские, то и текст привыкли записывать с помощью алфавита своего родного языка. Однако тот же самый текст можно записать, используя латинские буквы. Иногда это приходится делать, когда мы отправляем SMS по мобильному телефону, клавиатура которого не содержит русских букв, или же электронное письмо на русском языке за границу, если у адресата нет русифицированного программного обеспечения. Например, фразу «Здравствуй, дорогой Саша!» можно записать как: «Zdravstvui, dorogoi Sasha!».
Стенография
Определение 1
Стенография — это один из способов кодирования текстовой информации с помощью специальных знаков. Она представляет собой быстрый способ записи устной речи. Навыками стенографии могут владеть далеко не все, а лишь немногие специально обученные люди, которых называют стенографистами. Эти люди успевают записывать текст синхронно с речью выступающего человека, что, на наш взгляд, достаточно сложно. Однако для них это не проблема, поскольку в стенограмме целое слово или сочетание букв могут обозначаться одним знаком. Скорость стенографического письма превосходит скорость обычного в $4-7$ раз. Расшифровать (декодировать) стенограмму может только сам стенографист.
«Кодирование текстовой информации» 👇
Пример 2
На рисунке представлен пример стенографии, в которой написано следущее: «Говорить умеют все люди на свете. Даже у самых примитивных племен есть речь. Язык — это нечто всеобщее и самое человеческое, что есть на свете»:
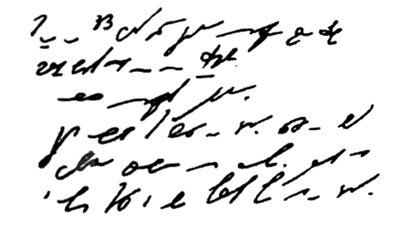
Рисунок 1.
Стенография позволяет не только вести синхронную запись устной речи, но и рационализировать технику письма.
Замечание 1
Приведёнными примерами мы проиллюстрировали важное правило: для кодирования одной и той же информации можно использовать разные способы, при этом их выбор будет зависеть от цели кодирования, условий и имеющихся средств.
Если нам нужно записать текст в темпе речи, сделаем это с помощью стенографии; если нужно передать текст за границу, воспользуемся латинским алфавитом; если необходимо представить текст в виде, понятном для грамотного русского человека, запишем его по всем правилам грамматики русского языка.
Также немаловажен выбор способа кодирования информации, который, в свою очередь, может быть связан с предполагаемым способом её обработки.
Пример 3
Рассмотрим пример представления чисел количественной информации. Используя буквы русского алфавита, можно записать число «тридцать пять». Используя же алфавит арабской десятичной системы счисления, запишем: $35$. Допустим нам необходимо произвести вычисления. Естественно, что для выполнения расчётов мы выберем удобную для нас запись числа арабскими цифрами, хотя можно примеры описывать и словами, но это будет довольно громоздко и не практично.
Замечание 2
Заметим, что приведенные выше записи одного и того же числа используют разные языки: первая — естественный русский язык, вторая — формальный язык математики, не имеющий национальной принадлежности. Переход от представления на естественном языке к представлению на формальном языке можно также рассматривать как кодирование.
Криптография
В некоторых случаях возникает потребность засекречивания текста сообщения или документа, для того чтобы его не смогли прочитать те, кому не положено. Это называется защитой от несанкционированного доступа. В таком случае секретный текст шифруется. В давние времена шифрование называлось тайнописью.
Определение 2
Шифрование представляет собой процесс превращения открытого текста в зашифрованный, а дешифрование — процесс обратного преобразования, при котором восстанавливается исходный текст. Шифрование — это тоже кодирование, но с засекреченным методом, известным только источнику и адресату. Методами шифрования занимается наука криптография.
Определение 3
Криптография — это наука о методах и принципах передачи и приема зашифрованной с помощью специальных ключей информации.
Ключ — секретная информация, используемая криптографическим алгоритмом при шифровании/расшифровке сообщений.
Числовое кодирование текстовой информации
В каждом национальном языке имеется свой алфавит, который состоит из определенного набора букв, следующих друг за другом, а значит и имеющих свой порядковый номер.
Каждой букве сопоставляется целое положительное число, которое называют кодом символа. Именно этот код и будет хранить память компьютера, а при выводе на экран или бумагу преобразовывать в соответствующий ему символ. Помимо кодов самих символов в памяти компьютера хранится и информация о том, какие именно данные закодированы в конкретной области памяти. Это необходимо для различия представленной информации в памяти компьютера (числа и символы).
Используя соответствия букв алфавита с их числовыми кодами, можно сформировать специальные таблицы кодирования. Иначе можно сказать, что символы конкретного алфавита имеют свои числовые коды в соответствии с определенной таблицей кодирования.
Однако, как известно, алфавитов в мире большое множество (английский, русский, китайский и др.). Соответственно возникает вопрос, каким образом можно закодировать все используемые на компьютере алфавиты.
Чтобы ответить на данный вопрос, нам придется заглянуть назад в прошлое.
В $60$-х годах прошлого века в американском национальном институте стандартизации (ANSI) была разработана специальная таблица кодирования символов, которая затем стала использоваться во всех операционных системах. Эта таблица называется ASCII (American Standard Code for Information Interchange, что означает в переводе с английского «американский стандартный код для обмена информацией»).
В данной таблице представлен $7$-битный стандарт кодирования, при использовании которого компьютер может записать каждый символ в одну $7$-битную ячейку запоминающего устройства. При этом известно, что в ячейке, состоящей из $7$ битов, можно сохранять $128$ различных состояний. В стандарте ASCII каждому из этих $128$ состояний соответствует какая-то буква, знак препинания или же специальный символ.
В процессе развития вычислительной техники стало ясно, что $7$-битный стандарт кодирования достаточно мал, поскольку в $128$ состояниях $7$-битной ячейки нельзя закодировать буквы всех письменностей, имеющихся в мире.
Чтобы решить эту проблему, разработчики программного обеспечения начали создавать собственные 8-битные стандарты кодировки текста. За счет дополнительного бита диапазон кодирования в них был расширен до $256$ символов. Во избежание путаницы, первые $128$ символов в таких кодировках, как правило, соответствуют стандарту ASCII. Оставшиеся $128$ – реализуют региональные языковые особенности.
Замечание 3
Как мы знаем национальных алфавитов огромное количество, поэтому и расширенные таблицы ASCII-кодов представлены множеством вариантов. Так для русского языка существует также несколько вариантов, наиболее распространенные Windows-$1251$ и Koi8-r. Большое количество вариантов кодировочных таблиц создает определенные трудности. К примеру, мы отправляем письмо, представленное в одной кодировке, а получатель при этом пытается прочесть его в другой. В результате на экране у него появляется непонятная абракадабра, что говорит о том, что получателю для прочтения письма требуется применить иную кодировочную таблицу.
Существует и другая проблема, которая заключается в том, что алфавиты некоторых языков содержат слишком много символов, которые не позволяют помещаться им в отведенные позиции с $128$ до $255$ однобайтовой кодировки.
Следующая проблема возникает тогда, когда в тексте используют несколько языков (например, русский, английский и немецкий). Нельзя же использовать обе таблицы сразу.
Для решения этих проблем в начале $90$-х годов прошлого столетия был разработан новый стандарт кодирования символов, который назвали Unicode. С помощью этого стандарта стало возможным использование в одном тексте любых языков и символов.
Данный стандарт для кодирования символов предоставляет $31$ бит, что составляет $4$ байта за минусом $1$ бита. Количество возможных комбинаций при использовании данной кодировочной таблицы очень велико: $231 = 2 147 483 684$ (т.е. более $2$ млрд.). Это возможно стало в связи с тем, что Unicode описывает алфавиты всех известных языков, даже «мертвых» и выдуманных, включает многие математические и другие специальные символы. И все-таки информационная емкость $31$-битового Unicode слишком велика, И как следствие, наиболее часто используют именно сокращенную $16$-битовую версию ($216 = 65 536$ значений), в которой представлены все современные алфавиты.
В Unicode первые $128$ кодов совпадают с таблицей ASCII.
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме
Бухарбаева Нэркэс Айнуровна
Магнитогорский государственный технический университет имени Г.И. Носова
студентка первого курса группы ИПОб-16-1, направление «Русский язык и литература»
Аннотация
Статья посвящена теме кодирования текстовой информации, в ней ставится проблема целостности информации, возникающей в процессе электронного документооборота, автор предлагает пути ее решения.
Библиографическая ссылка на статью:
Бухарбаева Н.А. Кодирование текстовой информации // Современные научные исследования и инновации. 2017. № 5 [Электронный ресурс]. URL: https://web.snauka.ru/issues/2017/05/83194 (дата обращения: 11.05.2023).
Актуальность. Внедрение информационных технологий отразилось на технологии документооборота внутри организаций и между ними, и между отдельными пользователями. Большое значение в данной сфере приобретает электронный документооборот, позволяющий отказаться от бумажных носителей (снизить их долю в общем потоке) и осуществлять обмен документами между субъектами в электронном виде. Преимущества данного подхода очевидны: снижение затрат на обработку и хранение документов и их быстрый поиск. Однако отказ от бумажного документооборота поставил ряд проблем, связанных с обеспечением целостности передаваемого документа и аутентификации подлинности его автора.
Цель работы. Дать основные понятия по теме «Кодирование текстовой информации», отразить возможности злоумышленника при реализации угроз, направленных на нарушение целостности передаваемых сообщений, предложить пути решения проблемы.
Что такое код? Код – это система условных знаков для представления информации.
Кодирование – это представление информации в удобном альтернативном виде с помощью некоторого кода для передачи, обработки или хранения, а декодирование – это процесс восстановления первоначальной формы представления информации.
Персональный компьютер обрабатывает числовую, текстовую, графическую, звуковую и видео – информацию. В компьютере она представлена в двоичном коде, так если используется алфавит в два символа – 0 и 1. В двоичном коде ее легче всего представить как электрический импульс, его отсутствие (0) и присутствие (1). Подобный вид кодирования называется двоичным.
Элементы кодируемой информации:
– Буквы, слова и фразы естественного языка;
– Знаки препинания, арифметические и логические операции, и т.д;
– Числа;
– Наследственная информация и т.д.
Сами знаки операций и операторы сравнения – это кодовые обозначения, представляющие собой буквы и сочетания букв, числа, графические обозначения, электромагнитные импульсы, световые и звуковые сигналы и т.д.
Способы кодирования: числовой (с помощью чисел), символьный (с помощью символов алфавита исходного текста) и графический (с помощью рисунков, значков)
Цели кодирования:
А) Удобство хранения, обработки, передачи информации и обмена ей между субъектами;
Б) Наглядность отображения;
В) Идентификация объектов и субъектов;
Г) Сокрытие секретной информации.
Различают одноуровневое и многоуровневое кодирование информации. Одноуровневое кодирование–это световые сигналы светофора. Многоуровневое- представление визуального (графического) образа в виде файла фотографии. Bначале визуальная картинка разбивается на пиксели, каждая отдельная часть картинки кодируется элементарным элементом, а элемент, в свою очередь, кодируется в виде набора цветов (RGB: англ.red – красный, green – зеленый, blue – синий) соответствующей интенсивностью, которая представляется в виде числового значения (наборы этих чисел кодируются в форматах jpeg, png и т.д.). Наконец, итоговые числа кодируются в виде электромагнитных сигналов для передачи по каналам связи или областей. Сами числа при программной обработке представляются в соответствии с принятой системой кодирования чисел.
Различают обратимое и необратимое кодирование. При обратимом можно однозначно восстановить сообщение без потери качества, например, кодирование с помощью азбуки Морзе. При необратимом однозначное восстановление исходного образа невозможно. Например, кодирование аудиовизуальной информации (форматы jpg, mp3 или avi) или хеширование.
Существуют общедоступные и секретные системы кодирования. Первые используются для облегчения обмена информацией, вторые – в целях ее сокрытия от посторонних лиц.
Кодирование текстовой информации. Пользователь обрабатывает текст, состоящий из букв, цифр, знаков препинания и других элементов.
Для кодирования одного символа необходим 1 байт памяти или 8 бит. Cпомощью простой формулы, связывающей количество возможных событий (К) и количество информации (I), вычисляем, сколько не одинаковых символов можно закодировать: К = 2^I = 28 = 256. Для кодирования текстовой информации используют алфавит мощностью в 256 символов.
Принцип данного кодирования заключается в том, что каждому символу (букве, знаку) соответствует свой двоичный код от 00000000 до 11111111.
Для кодирования букв российского алфавита есть пять разных кодировочных таблиц (КОИ – 8, СР1251, СР866, Мас, ISO). Тексты, закодированные одной таблицей, не будут корректно отображаться в другой кодировке:
Для одного двоичного кода в разных таблицах соответствуют разные символы:
Таблица 1 – Соответствие разных символов двоичному коду
| Двоичный код | Десятичный код | КОИ8 | СР1251 | СР866 | Мас | ISO |
| 11000010 | 194 | Б | В | – | – | Т |
Перекодированием текстовых документов занимаются программы, встроенные в текстовые редакторы и процессоры. С начала 1997 года Microsoft Office поддерживает новую кодировку Unicode, в ней можно закодировать не 256, а 655369 символов (под каждый символ начали отводить 2 байта).
Биты и байты. Цифра, воспринимаемая машиной, таит в себе некоторое количество информации. Оно равно одному биту. Это касается каждой единицы и каждого нуля, которые составляют ту или иную последовательность зашифрованной информации. Соответственно, количество информации в любом случае можно определить, просто зная количество символов в последовательности двоичного кода. Они будут численно равны между собой. 2 цифры в коде несут в себе информацию объемом в 2 бита, 10 цифр – 10 бит и так далее. Принцип определения информационного объема:

Рисунок 1 – определение информационного объема
Проблема целостности информации. Проблема целостности информации с момента ее появления до современности прошла довольно долгий путь. Изначально существовало два способа решения задачи: использование криптографических методов защиты информации и хранения данных и программно-техническое разграничение доступа к данным и ресурсам вычислительных систем. Стоит учесть, что в начале 80–х годов компьютерные системы были слабо распространены, технологии глобальных и локальных вычислительных сетей находились на начальной стадии своего развития, и указанные задачи удавалось достаточно успешно решать.
Современные методы обработки, передачи и накопления информационной безопасности способствовали появлению угроз, связанных с возможностью потери, искажения и раскрытия данных, адресованных или принадлежащих другим пользователям. Поэтому обеспечение целостности информации является одним из ведущих направлений развития ИТ [1, с.10].
Под информационной безопасностью понимают защищенность информации от незаконного ее потребления: ознакомления, преобразования и уничтожения.
Различают естественные (не зависящие от деятельности человека) и искусственные (вызванные человеческой деятельностью) угрозы информационной безопасности. В зависимости от их мотивов искусственные подразделяют на непреднамеренные (случайные) и преднамеренные (умышленные).
Гарантия того, что сообщение не было изменено в процессе его передачи, необходима и для отправителя, и для получателя электронного сообщения. Получатель должен иметь возможность распознать факт искажений, внесенных в документ.
Проблема аутентификации подлинности автора сообщения заключается в обеспечении гарантии того, что никакой субъект не сможет подписаться ни чьим другим именем, кроме своего. В обычном бумажном документообороте информация в документе и рукописная подпись автора жестко связана с физическим носителем (бумагой). Для электронного же документооборота жесткая связь информации с физическим носителем отсутствует.
Рассмотрим методы взлома компьютерных систем, все попытки подразделяют на 3 группы:
1. Атаки на уровне операционной системы: кража пароля, сканирование жестких дисков компьютера, сборка “мусора” (получение доступа к удаленным объектам в “мусорной” корзине), запуск программы от имени пользователя, модификация кода или данных подсистем и т.д.
2. Атака на уровне систем управления базами данных: 2 сценария, в первом случае результаты арифметических операций над числовыми полями СУБД округляются в меньшую сторону, а разница суммируется в другой записи СУБД, во втором случае хакер получает доступ к статистическим данным
3. Атаки на уровне сетевого программного обеспечения. Сетевое программное обеспечение (СПО) наиболее уязвимо: перехват сообщений на маршрутизаторе, создание ложного маршрутизатора, навязывание сообщений, отказ в обслуживании
Перечислим возможности злоумышленника при реализации угроз, направленных на нарушение целостности передаваемых сообщений и подлинности их авторства:
А) Активный перехват. Нарушитель перехватывает передаваемые сообщения, изменяя их.
Б) Маскарад. Нарушитель посылает документ абоненту B, подписываясь именем абонента A.
В) Ренегатство. Абонент А заявляет, что не посылал сообщения абоненту B, хотя на самом деле посылал. В этом случае абонент А – злоумышленник.
Г) Подмена. Абонент B изменяет/формирует новый документ, заявляя, что получил его от абонента A. Недобросовестный пользователь – получатель сообщения B.
Для анализа целостности информации используется подход, основанный на вычислении контрольной суммы переданного сообщения и функции хэширования (алгоритма, позволяющего сообщение любой длины представить в виде короткого значения фиксированной длины).
Hа всех этапах жизненного цикла существует угроза ЦИ (целостности информации):
При обработке информации нарушение ЦИ возникает вследствие технических неисправностей, алгоритмических и программных ошибок, ошибок и деструктивных действий обслуживающего персонала, внешнего вмешательства, действия разрушающих и вредоносных программ (вирусов, червей).
В процессе передачи информации – различного рода помехи как естественного, так и искусственного происхождения. Возможно искажение, уничтожение и перехват информации.
В процессе хранения основная угроза – несанкционированный доступ с целью модификации информации, вредоносные программы (вирусы, черви, логические бомбы) и технические неисправности.
В процессе старения – утеря технологий, способных воспроизвести информацию, и физическое старение носителей информации.
Угрозы ЦИ возникают на протяжении всего жизненного цикла информации с момента ее появления до начала утилизации.
Мероприятия по предотвращению утечки информации по техническим каналам включают в себя обследования помещений на предмет обнаружения подслушивающих устройств, а также оценку защищенности помещений от возможной утечки информации с использованием дистанционных методов перехвата и исследование ТС, где ведутся конфиденциальные разговоры[2, с.15].
Обеспечение целостности информации. Для обеспечения ЦИ необходимым условием является наличие высоконадежных технических средств (ТС), включающие в себя аппаратную и/или программную составляющие, и различные программные методы, значительно расширяющие возможности по обеспечению безопасности хранящейся информации [3, с.150]. ТС обеспечивает высокую отказоустойчивость и защиту информации от возможных угроз. K ним относят средства защиты от электромагнитного импульса (ЭМИ). Наиболее эффективный метод уменьшения интенсивности ЭМИ – это экранирование – размещение оборудования в электропроводящем корпусе, который препятствует проникновению электромагнитного поля.
К организационным методам относят разграничение доступа, организующий доступ к информации к используемому оборудованию и предполагающий достаточно большой перечень мероприятий, начиная от подбора сотрудников и заканчивая работой с техникой и документами. Среди них выделяют технологии защиты,обработки и хранения документов, аттестацию помещений и рабочих зон, порядок защиты информации от случайных/несанкционированных действий. Особое внимания уделяют защите операционных систем (ОС), обеспечивающих функционирование практически всех составляющих системы. Наиболее действенный механизм разграничения доступа для ОС – изолированная программная среда (ИПС). Устойчивость ИКС к различным разрушающим и вредоносным программам повышает ИПС, обеспечивая целостность информации.
Антивирусная защита. В настоящее время под компьютерным вирусом принято понимать программный код, обладающий способностью создавать собственные копии и имеющие механизмы, внедряющие эти копии в исполняемые объекты вычислительной системы [1, с.354]. Вредоносные программы (вирусы) имеют множество видов и типов, отличаясь между собой лишь способами воздействия на различные файлы, размещением в памяти ЭВМ или программах, объектами воздействия. Главное свойство вирусов, выделяющее их среди множества программ и делающее наиболее опасным, это способность к размножению.
ЦИ обеспечивает использование антивирусных программ, однако ни одна из них не гарантирует обнаружение неизвестного вируса. Применяемые эвристические сканеры не всегда дают правильный диагноз. Пример подобных ошибок – две антивирусные программы, запущенные на одном компьютере: файлы одного антивируса принимаются за вредоносную программу другим антивирусом.
Использование локальных сетей, не имеющих связи с интернетом – лучший способ защиты от вирусов. При этом необходимо жестко контролировать различные носители информации с прикладными программами, с помощью которых можно занести вирус [4, с. 231].
Помехоустойчивое кодирование. Наиболее уязвимой информация бывает в процессе ее передачи. Разграничение доступа снимает многие угрозы, но она невозможна при использовании в канале
связи беспроводных линий. Информация наиболее уязвима именно на таких участках ИКС. Обеспечение ЦИ достигается засчет уменьшения объема передаваемой информации. Это уменьшение можно достичь за счет оптимального кодирования источника.
Метод динамического сжатия. При таком подходе структура сжатого сообщения включает в себя словарь и сжатую информацию. Однако, если в словаре при передаче или хранении есть ошибка, то возникает эффект размножения ошибок, приводящий к информационному искажению/уничтожению.
Стеганография. С этим термином знаком тот,кто занимается криптографией. Выделяют три направления стеганографии: сокрытие данных, цифровые водяные знаки и заголовки. При скрытой передаче информации одновременно с обеспечением конфиденциальности решается и вопрос обеспечения ЦИ. Нельзя изменить того, чего не видишь – главный аргумент использования стеганографии. Ее главный недостаток – больший объем контейнера. Но это можно нивелировать, передавая в качестве контейнера полезную информацию, не критичную к ЦИ.
Резервирование используется при передаче и хранении информации. При передаче возможен многократный повтор сообщения в одно направление либо его рассылка во все возможные направления. Данный подход можно рассматривать как один из методов ПКИ. При хранении идея резервирования достаточно проста – создание копий полученных файлов и их хранение отдельно от первоначальных документов. Зачастую такие хранилища создаются в географически разнесенных местах.
Недостаток резервирования – возможность ее несанкционированного снятия, т.к. информация, располагаемая на внешних устройствах хранения, является незащищенной.
Заключение. Любая информация, выводящаяся на монитор компьютера, прежде чем там появиться, подвергается кодированию, которое заключается в переводе информации на машинный язык. Он представляет собой последовательность электрических импульсов – нулей и единиц. Для кодирования различных символов существуют отдельные таблицы.
К методам обеспечения ЦИ в ИК Сотносят обеспечение надежности ТС, разграничение доступа, стеганография (скрытие факта передачи), помехоустойчивое кодирование, антивирусная защита, сжатие данных и резервирование.
В каждом из рассмотренных методов выделены наиболее существенные угрозы ЦИ и показаны возможные пути их устранения. Практическая реализация этих методов зависит от угроз, которые возникают в процессе жизненного цикла информации, и вида используемой информации.Обеспечение ЦИ можно достичь только комплексным использованием рассмотренных методов.
Библиографический список
- Шаньгин, В.Ф. Информационная безопасность компьютерных систем и сетей: учеб. пособие. — М.: ИД «ФОРУМ»: ИНФРА-М, 2011. — 416с.
- Баранов, А.П. Проблемы обеспечения информационной безопасности в информационно-телекоммуникационной систем специального назначения и пути их решения // Информационное общество. — 1997. вып.1. — с. 13-17.
- Андрианов, В.И. «Шпионские штучки» и устройства для защиты объектов и информации: справ. пособие / В.И. Андрианов, В.А. Бородин, А.В. Соколов. С- Пб.: Лань, 1996. – 272с.
- Баранов, А.П. Проблемы обеспечения информационной безопасности в информационно-телекоммуникационной систем специального назначения и пути их решения // Информационное общество. — 1997. вып.1. — с. 13-17.
Количество просмотров публикации: Please wait
Все статьи автора «Бухарбаева Нэркэс Айнуровна»
