Время на прочтение
5 мин
Количество просмотров 166K
Цель данной статьи:
В данной статье я хочу рассказать о том, как происходит компиляция программ, написанных на языке C++, и описать каждый этап компиляции. Я не преследую цель рассказать обо всем подробно в деталях, а только дать общее видение. Также данная статья — это необходимое введение перед следующей статьей про статические и динамические библиотеки, так как процесс компиляции крайне важен для понимания перед дальнейшим повествованием о библиотеках.
Все действия будут производиться на Ubuntu версии 16.04.
Используя компилятор g++ версии:
$ g++ --version
g++ (Ubuntu 5.4.0-6ubuntu1~16.04.9) 5.4.0 20160609Состав компилятора g++
- cpp — препроцессор
- as — ассемблер
- g++ — сам компилятор
- ld — линкер
Мы не будем вызывать данные компоненты напрямую, так как для того, чтобы работать с C++ кодом, требуются дополнительные библиотеки, позволив все необходимые подгрузки делать основному компоненту компилятора — g++.
Зачем нужно компилировать исходные файлы?
Исходный C++ файл — это всего лишь код, но его невозможно запустить как программу или использовать как библиотеку. Поэтому каждый исходный файл требуется скомпилировать в исполняемый файл, динамическую или статическую библиотеки (данные библиотеки будут рассмотрены в следующей статье).
Этапы компиляции:
Перед тем, как приступать, давайте создадим исходный .cpp файл, с которым и будем работать в дальнейшем.
driver.cpp:
#include <iostream>
using namespace std;
#define RETURN return 0
int main() {
cout << "Hello, world!" << endl;
RETURN;
}1) Препроцессинг
Самая первая стадия компиляции программы.
Препроцессор — это макро процессор, который преобразовывает вашу программу для дальнейшего компилирования. На данной стадии происходит происходит работа с препроцессорными директивами. Например, препроцессор добавляет хэдеры в код (#include), убирает комментирования, заменяет макросы (#define) их значениями, выбирает нужные куски кода в соответствии с условиями #if, #ifdef и #ifndef.
Хэдеры, включенные в программу с помощью директивы #include, рекурсивно проходят стадию препроцессинга и включаются в выпускаемый файл. Однако, каждый хэдер может быть открыт во время препроцессинга несколько раз, поэтому, обычно, используются специальные препроцессорные директивы, предохраняющие от циклической зависимости.
Получим препроцессированный код в выходной файл driver.ii (прошедшие через стадию препроцессинга C++ файлы имеют расширение .ii), используя флаг -E, который сообщает компилятору, что компилировать (об этом далее) файл не нужно, а только провести его препроцессинг:
g++ -E driver.cpp -o driver.iiВзглянув на тело функции main в новом сгенерированном файле, можно заметить, что макрос RETURN был заменен:
int main() {
cout << "Hello, world!" << endl;
return 0;
}driver.ii
В новом сгенерированном файле также можно увидеть огромное количество новых строк, это различные библиотеки и хэдер iostream.
2) Компиляция
На данном шаге g++ выполняет свою главную задачу — компилирует, то есть преобразует полученный на прошлом шаге код без директив в ассемблерный код. Это промежуточный шаг между высокоуровневым языком и машинным (бинарным) кодом.
Ассемблерный код — это доступное для понимания человеком представление машинного кода.
Используя флаг -S, который сообщает компилятору остановиться после стадии компиляции, получим ассемблерный код в выходном файле driver.s:
$ g++ -S driver.ii -o driver.sdriver.s
.file "driver.cpp"
.local _ZStL8__ioinit
.comm _ZStL8__ioinit,1,1
.section .rodata
.LC0:
.string "Hello, world!"
.text
.globl main
.type main, @function
main:
.LFB1021:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl $.LC0, %esi
movl $_ZSt4cout, %edi
call _ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKc
movl $_ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_, %esi
movq %rax, %rdi
call _ZNSolsEPFRSoS_E
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1021:
.size main, .-main
.type _Z41__static_initialization_and_destruction_0ii, @function
_Z41__static_initialization_and_destruction_0ii:
.LFB1030:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
cmpl $1, -4(%rbp)
jne .L5
cmpl $65535, -8(%rbp)
jne .L5
movl $_ZStL8__ioinit, %edi
call _ZNSt8ios_base4InitC1Ev
movl $__dso_handle, %edx
movl $_ZStL8__ioinit, %esi
movl $_ZNSt8ios_base4InitD1Ev, %edi
call __cxa_atexit
.L5:
nop
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1030:
.size _Z41__static_initialization_and_destruction_0ii, .-_Z41__static_initialization_and_destruction_0ii
.type _GLOBAL__sub_I_main, @function
_GLOBAL__sub_I_main:
.LFB1031:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl $65535, %esi
movl $1, %edi
call _Z41__static_initialization_and_destruction_0ii
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1031:
.size _GLOBAL__sub_I_main, .-_GLOBAL__sub_I_main
.section .init_array,"aw"
.align 8
.quad _GLOBAL__sub_I_main
.hidden __dso_handle
.ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.9) 5.4.0 20160609"
.section .note.GNU-stack,"",@progbitsМы можем все также посмотреть и прочесть полученный результат. Но для того, чтобы машина поняла наш код, требуется преобразовать его в машинный код, который мы и получим на следующем шаге.
3) Ассемблирование
Так как x86 процессоры исполняют команды на бинарном коде, необходимо перевести ассемблерный код в машинный с помощью ассемблера.
Ассемблер преобразовывает ассемблерный код в машинный код, сохраняя его в объектном файле.
Объектный файл — это созданный ассемблером промежуточный файл, хранящий кусок машинного кода. Этот кусок машинного кода, который еще не был связан вместе с другими кусками машинного кода в конечную выполняемую программу, называется объектным кодом.
Далее возможно сохранение данного объектного кода в статические библиотеки для того, чтобы не компилировать данный код снова.
Получим машинный код с помощью ассемблера (as) в выходной объектный файл driver.o:
$ as driver.s -o driver.oНо на данном шаге еще ничего не закончено, ведь объектных файлов может быть много и нужно их всех соединить в единый исполняемый файл с помощью компоновщика (линкера). Поэтому мы переходим к следующей стадии.
4) Компоновка
Компоновщик (линкер) связывает все объектные файлы и статические библиотеки в единый исполняемый файл, который мы и сможем запустить в дальнейшем. Для того, чтобы понять как происходит связка, следует рассказать о таблице символов.
Таблица символов — это структура данных, создаваемая самим компилятором и хранящаяся в самих объектных файлах. Таблица символов хранит имена переменных, функций, классов, объектов и т.д., где каждому идентификатору (символу) соотносится его тип, область видимости. Также таблица символов хранит адреса ссылок на данные и процедуры в других объектных файлах.
Именно с помощью таблицы символов и хранящихся в них ссылок линкер будет способен в дальнейшем построить связи между данными среди множества других объектных файлов и создать единый исполняемый файл из них.
Получим исполняемый файл driver:
$ g++ driver.o -o driver // также тут можно добавить и другие объектные файлы и библиотеки5) Загрузка
Последний этап, который предстоит пройти нашей программе — вызвать загрузчик для загрузки нашей программы в память. На данной стадии также возможна подгрузка динамических библиотек.
Запустим нашу программу:
$ ./driver
// Hello, world!Заключение
В данной статье были рассмотрены основы процесса компиляции, понимание которых будет довольно полезно каждому начинающему программисту. В скором времени будет опубликована вторая статья про статические и динамические библиотеки.
Make
Для кого и для чего
Для всех. Для автоматизации сборки вашего проекта.
Сборка – это когда из файликов вашего проекта собирается исполняемый файл.
Этапы компиляции
Препроцессинг
Это макро процессор, который преобразовывает вашу программу для дальнейшего компилирования. На данной стадии происходит работа с препроцессорными директивами. Например, препроцессор добавляет заголовочные файлы в код (#include), убирает комментирования, заменяет макросы (#define) их значениями, выбирает нужные куски кода в соответствии с условиями #if, #ifdef и #ifndef.
На этом этапе не происходит компиляция как такова. Происходит вставка все заголовочных файлов, дефайнов и уже полученный файл потом компилируется.
Используем флаг -E
gcc -E main.c -o 1.txt
В файле 1.txt будет настоящий код вашей программки, который будет компилироваться.
Компиляция
На данном шаге компилятор выполняет свою главную задачу — компилирует, то есть преобразует полученный на прошлом шаге код без директив в ассемблерный код. Это промежуточный шаг между высокоуровневым языком и машинным (бинарным) кодом.
Ассемблирование
Так как x86 процессоры исполняют команды на бинарном коде, необходимо перевести ассемблерный код в машинный с помощью ассемблера.
Ассемблер преобразовывает ассемблерный код в машинный код, сохраняя его в объектном файле (файле с расширением .о)
Компоновка (Линкова)
Компоновщик (линкер) связывает все объектные файлы и статические библиотеки в единый исполняемый файл, который мы и сможем запустить в дальнейшем.
bin – исполняемый файл
Объединение этапов
Когда мы пишем
И получаем из файлика с исходным кодом исполняемый файл.
Но мы же не пишем руками все эти флаги, верно?
Потому что, если в явном виде не указан один из флагов выше, то выполняются все четыере этапа сборки в исполняемый файлы.
Если у нас все в одном файле, то проблем нет. А если в проекте несколько файлов?
Руками каждый раз компилировать и линковать файлы каждый достаточно грустно.
Давайте автоматизирум?
Сборка проекта
В качествет тестового примера предлагаю скачать данные из репозитория:
https://github.com/Klavishnik/How_to_fuzz_lab
Там уже есть Makefile. Мы напишем свой.
В данном проекте есть три файлика
project
│
├── lib
│ └──string.c
│ └──string.h
│── main.c
Нам нужно отдельно скомпилировать файлы нашей папки lib и main.c
Выполним следующие команды (будем использовать компилятор clang. Он круче)
clang -c main.c -o main.o
clang -c lib/string.c -o string.o
clang main.o string.o -o bin -lreadline
Флагом -c мы объединяем два этапа – компиляция и ассемблирования. Из файла с исходным кодом получаем объектный файлик.
Флагом -o в янвном виде указываем название файла, который у нас получится в результате выполнения команды.
На этапе линковки мы также подключаем динамические (shared) библиотеки.
Так для этой задачи мы заиствовали фнукцию из билиотки readline.
Данная библиотека есть в системе. Чтобы использовать функцию, мы должны прилинковать данную библиотеку флагом -lreadline
Автоматизация сборки
Для автоматизации сборки есть ряд программ, но все они инкапсулируют работу программы make.
Данная утилитка принимает на вход Makefile (именно с таким названием).
Создаем данный флайик и пишем туда следующее:
all:
clang -c main.c -o main.o
clang -c lib/string.c -o string.o
clang main.o string.o -o bin -lreadline
Сохраняеем файл.
Теперь, если находясь внутри папки мы запустим make
make
То просиходит следующее:
make начинает искать внутри директории Makefile и если находит, выполянет стадию all.
Все, простейший makefile написан. Вы автоматизировали сборку своего проекта.
Копаем глубже
Что же такое all ?
Make работает стадиями, которые принимает в качестве аргумента.
Если аргумента нет, то make выполняет стадию all.
Т.е. в Makefile должна быть стадия all.
Как описать стадию?
Добавим к файлику выше еще одну стадию.
Пишем название, например clean
Далее, нажимет Enter и tab (табаемся).
Все что внутри стадии должно быть с отступом.
Пишем:
Если выполнить
То внутри папки будут удалены все файлики с расширением .o, а также исполняемый файлик bin.
Т.е. make в качестве аргумента примет название той стадии, которую нужно выполнить.
А как выполнить несколько стадий?
Изменим Makefile вот так:
all: build clean
build:
clang -c main.c -o main.o
clang -c lib/string.c -o string.o
clang main.o string.o -o bin -lreadline
clean:
rm -rf *.o
rm bin
Старую стадию all мы заменили на стадию build.
В стадии all появился вызов стадий build и clean
Теперь, вызвав просто make мы выполним обе стадии, т.е. скопмилируем проект и удалим все новые файлы.
Напоминаю, чтобы вызвать конкретную стадию, пишем:
Так мы по очереди вызвали обе стадии.
Пример Makefile
Пишем Make
all: build clean
build:
clang -c main.c -o main.o
clang -c lib/string.c -o string.o
clang main.o string.o -o bin -lreadline
debug:
clang -c main.c -o main.o -g
clang -c lib/string.c -o string.o -g
clang main.o string.o -o bin -lreadline
clean:
rm -rf *.o
rm bin
Тут мы добавили стадию debug – в ней добавлены отладочные стадии при компиляции.
Это пригодится, если придется отлаживать программу с помощью gdb .
Makefile который не Makefile
А если у нас Makefile имеет другое название? Например file_make?
Используй флаг -f
make -f file_make
make debug -f file_make
Going depper.
Слышали про переменные?
Раскрою секрет – в make они тоже есть.
Стандатный переменные
Переменная CC
CC – так мы назвали переменную. Вообще это стандартное название ( CC – compiler C) для переменной, которая хранит компилятор для Си.
CC=clang
all: build clean
build:
$(CC) -c main.c -o main.o
$(CC) -c lib/string.c -o string.o
$(CC) main.o string.o -o bin -lreadline
debug:
$(CC) -c main.c -o main.o -g
$(CC) -c lib/string.c -o string.o -g
$(CC) main.o string.o -o bin -lreadline
clean:
rm -rf *.o
rm bin
Тут мы заменили clang на переменную CC. Чтобы make подставил значение переменной, при её вызове нужно использовать значок доллара $.
Переменная CFLAGS
Некоторые флаги, например флаг -g или 02 – это флаги компилятора. Их нужно ставить на этапе компиляции .
Для флагов компилятора есть стандартная переменная CFLAGS.
Сделаем ткаой код:
CC=clang
CFLAGS=-g
all: build clean
build:
$(CC) -c main.c -o main.o
$(CC) -c lib/string.c -o string.o
$(CC) main.o string.o -o bin -lreadline
debug:
$(CC) -c main.c -o main.o $(CFLAGS)
$(CC) -c lib/string.c -o string.o $(CFLAGS)
$(CC) main.o string.o -o bin -lreadline
clean:
rm -rf *.o
rm bin
Переменная LD и LDFLAGS
LD – это линковщик. В нашей ситуации компилятор и линковщик – одинаковы, поэтому данной переменной переопределять его не будем.
А вот LDFLAGS – это флаги линковки. Это -lm и -lreadline
CC=clang
CFLAGS=-g
LDFLAGS=-lreadline
all: build clean
build:
$(CC) -c main.c -o main.o
$(CC) -c lib/string.c -o string.o
$(CC) main.o string.o -o bin -$(LDFLAGS)
debug:
$(CC) -c main.c -o main.o $(CFLAGS)
$(CC) -c lib/string.c -o string.o $(CFLAGS)
$(CC) main.o string.o -o bin -lreadline
clean:
rm -rf *.o
rm bin
Собственные переменные
Переменная на то и переменная, что её можно определить любую.
Например, я хочу добавить санитайзеры к нашему проектуи под это дело сделаю свою переменную ASAN
CC=clang
CFLAGS=-g
LDFLAGS=-lreadline
ASAN=-fsanitize=address
all: build clean
build:
$(CC) -c main.c -o main.o
$(CC) -c lib/string.c -o string.o
$(CC) main.o string.o -o bin -$(LDFLAGS)
debug:
$(CC) -c main.c -o main.o $(CFLAGS) $(ASAN)
$(CC) -c lib/string.c -o string.o $(CFLAGS) $(ASAN)
$(CC) main.o string.o -o bin -lreadline $(ASAN)
clean:
rm -rf *.o
rm bin
Переопредление переменных из системы
Удалим из Makefile’a переменную СС
CC=clang <---- Вот эту строку удалить
CFLAGS=-g
и выполним make.
Ошибок не будет – код соберется.
Почему?
Потому что СС это стандартная переменная и она определена в системе.
На сервере это сс (а это clang).
Переменные можно переоределить внутри системы
Допустим, хочу не clang, а gcc в качестве компилятора
Пишу в консоли (не в Makefile)
Данной коммандой мы переоделели переменную оболочки.
Выполним make
И видим, что сборка пошла с gcc.
Чтобы убрать переменную в оружении
Успехов
Учимся компилировать C++ программу -12
Программирование, C++, Блог компании OTUS. Онлайн-образование
Рекомендация: подборка платных и бесплатных курсов системной аналитики – https://katalog-kursov.ru/
В преддверии старта нового потока по курсу «Разработчик C++» подготовили перевод еще одного полезного материала. Данный материал не является хардкорным, но наверняка будет интересен джунам.
Одна из самых сложных тем, с которыми я столкнулся в начале изучении C++, помимо указателей и управления памятью, заключалась в том, как успешно компилировать код с использованием сторонних библиотек.
Как разработчик игр, вы часто полагаетесь на библиотеки для реализации разных аспектов вашей игры, например, таких как рендеринг или физика, а успешная компиляция пустого проекта с включением этих библиотек может оказаться на удивление сложной.
По крайней мере, у меня были с этим трудности, потому что я просто не понимал, как программы на C++ собираются и распространяются по интернету. Я не понимал, как мой исходный код превращается в исполняемый файл или библиотеку, и не понимал, как компилировать платформо-независимый код.
На практике это означало, что я просто не имел понятия, как включить библиотеку в свой код, или же я бился головой об стену, пытаясь устранить ошибки, возникающие при попытке компиляции. На самом деле, это не должно быть трудной частью создания вашей игры.
Эти знания не из тех, которые обычно входят в обучающие программы. Основное внимание уделяется решению проблем и синтаксису C++, и, тем не менее, если вы хотите заниматься серьезным программированием игр на C++ без написания всего с нуля, эти знания необходимы.
Поэтому я решил написать серию статей, в которых рассматриваются эти, обсуждаемые мной, вопросы. Первая статья будет посвящена изучению того, как скомпилировать программу на C++.
Трехэтапный процесс
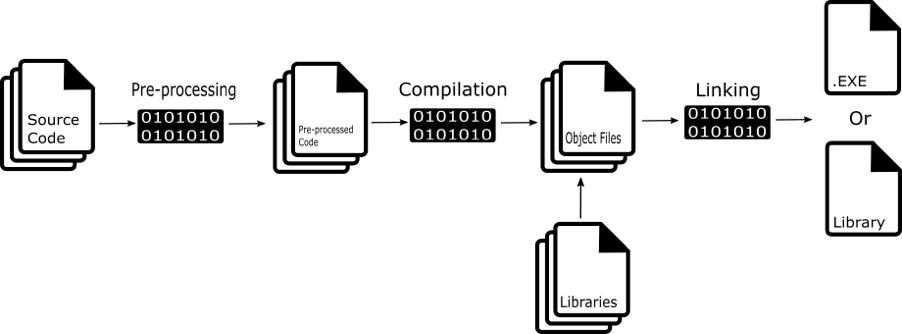
Компиляция программы на C++ включает взятие написанного нами исходного кода (файлы .cpp, .c, .h, .hpp) и преобразование их в исполняемый файл или библиотеку, которая может работать на указанной платформе.
Этот процесс можно разделить на три основных этапа:
- Препроцесинг
- Компиляция
- Компоновка
Препроцесинг
В C++ есть директивы препроцессора (идентифицируются в коде префиксом #), определяющие преобразования, которые должны выполняться в исходном коде до его компиляции.
Вы можете узнать больше о директивах препроцессора здесь. Первый этап компиляции программы на C++ с использованием препроцессора предполагает выполнение этих преобразований.
Что именно делает препроцессор, зависит от директивы.
Например, мы часто разбиваем код на отдельные файлы, чтобы упростить организацию и чтение. Чтобы связать код в одном файле с кодом из другого мы используем директиву #include.
При компиляции нашей программы на C++ препроцессор берет этот #include и копирует код, определенный в хедере, в файл, который его включает. Это экономит наше время и исключает возможность возникновения ошибок, которые могли бы возникнуть при ручном копировать кода между файлами.
Директива include является лишь одним примером предопределенных директив, другие примеры вы можете посмотреть в этой статье.
К концу стадии препроцессинга все директивы препроцессора в вашем коде будут обработаны препроцессором компилятора, и результирующий код будет готов к компиляции.
Компиляция
Компиляция является следующим этапом в процессе и связана с превращением исходного кода, который мы пишем, в нечто, понятное компьютеру — машинный код.
Компиляция C++ сама по себе является двухэтапным процессом. Во-первых, компилятор берет исходный код и конвертирует его в язык ассемблера. Ассемблер является языком программирования низкого уровня, который в большей степени похож на машинные инструкции процессора.
Во-вторых, исходный код, преобразованный в язык ассемблера, снова преобразуется в машинный код с использованием ассемблера. В результате получается набор файлов, хранящихся в промежуточном файловом формате, известном как объектный файл.
Примечание: машинный код состоит из команд, написанных в двоичном формате, в терминах машинного языка, потому что именно это тот код, который фактически понимает процессор.
Объектный файл имеет расширение .obj или .o и создается для каждого файла исходного кода. Объектный файл содержит все инструкции машинного уровня для этого файла. Он упоминается как промежуточный файл, потому что только на заключительном этапе, компоновке, создается фактический исполняемый файл или библиотека, которую мы можем использовать.
На этапе компиляции мы будем предупреждены о любых ошибках в нашем коде, которые приводят к тому, что наш код не компилируется. Все ошибки на этом этапе вызваны тем, что компилятор не понимает написанный нами код.
Код не будет распознаваемым C++, если мы где-то перепутали наш синтаксис. В типичных примерах неудачной компиляции не хватает точки с запятой, неправильно написано ключевое слово C++ или добавлено слишком многих фигурных скобок в конце метода.
Если обнаружена ошибка, компиляция полностью останавливается. Вы не сможете скомпилировать свой C++ код, пока все ошибки не будут исправлены.
Компоновка
Завершающим этапом процесса является компоновка, которая связана с извлечением наших результатов из предыдущего шага и связыванием всего этого вместе для создания фактического исполняемого файла или библиотеки.
Первым шагом на этом этапе является компиляция всех объектных файлов в исполняемый файл или библиотеку. Как только этот шаг будет успешно завершен, следующим шагом будет связывание этого исполняемого файла с любыми внешними библиотеками, которые мы хотим использовать в нашей программе.
Примечание: библиотека — это просто повторно используемая коллекция функций, классов и объектов, которые имеют общее назначение, например, математическая библиотека.
Наконец, компоновщик должен разрешить все зависимости. Это место, где происходят все ошибки, связанные с компоновкой.
Среди распространенных ошибок можно выделить невозможность найти указанную библиотеку или попытку связать два файла, которые, например, могут иметь классы с одинаковыми именами.
Предполагая, что на этом этапе ошибок не возникнет, компилятор предоставит нам исполняемый файл или библиотеку.
Сборка
Я думаю, стоит упомянуть еще одну вещь: в IDE, такой как Visual Studio, описанные шаги компиляции сгруппированы в процесс, называемый сборка (build). Типичный рабочий процесс при создании программы — сборка, а затем отладка (debug).
Происходит следующее: сборка создает исполняемый файл (путем компиляции и компоновки кода) или список ошибок в зависимости от того, насколько хорошо мы справились с написанием кода со времени нашей последней сборки. Когда мы нажмем Start Debugging, Visual Studio запустит созданный исполняемый файл.
Компиляция простой программы на C++
Теперь мы знаем основные этапы компиляции C++ программ. Я подумал, что мы могли бы закончить эту статью, рассмотрев простой пример, который поможет закрепить то, что мы только что изучили.
В этом примере я планирую использовать набор инструментов MSCV и собирать его из командной строки разработчика.
Это не руководство по настройке и использованию набора инструментов MSCV из командной строки, поэтому, если вам это интересно, вы можете найти больше информации здесь.
Шаги, которые мы собираемся выполнить:
- Создадим папку для нашей C++ программы.
- Перейдем в эту папку.
- Создадим нашу C++ программу в редакторе (я использовал Visual Studio Code).
- Скомпилируем наш исходный код в объектные файлы.
- Скомпонуем наши объектные файлы, чтобы создать исполняемый файл.
Создаем место для хранения нашей C++ программы

Все, что мы делаем на этом шаге, это используем команду Windows md для создания каталога по указанному пути с именем HelloWorld. Мы могли бы просто создать папку из проводника, но это не так круто.
Переходим в папку
Все, что мы делаем на этом шаге, — это перемещаемся в нашу папку с помощью команды cd, за которой следует путь, по которому мы хотим перейти. В нашем случае это папка, которую мы создали на предыдущем шаге.
Мы делаем это, чтобы облегчить себе жизнь.
Если мы не переходим к папке для каждого файла, который мы хотим скомпилировать, нам нужно указать полный путь, но если мы находимся в соответствующей папке, то нам достаточно указать только имя файла.
Пишем код на C++
class HelloWorld
{
public:
void PrintHelloWorld();
};
#include "HelloWorld.h"
#include <iostream>
using namespace std;
void HelloWorld::PrintHelloWorld()
{
std::cout << "Hello World";
}
#include "HelloWorld.h"
int main()
{
HelloWorld hello;
hello.PrintHelloWorld();
return 0;
}
Приведенный выше код представляет собой очень простую программу, содержащую три файла: main.cpp, HelloWorld.h, и HelloWorld.cpp.
Наш заголовочный файл HelloWorld определяет единственную функцию PrintHelloWorld(), реализация этой функции определена в HelloWorld.cpp, а фактическое создание объекта HelloWorld и вызов его функции выполняется из main.cpp.
Примечание. Эти файлы сохраняются в папке, которую мы создали ранее.
Компиляция программы
Чтобы скомпилировать и скомпоновать нашу программу, мы просто используем команду cl, за которой следуют все файлы .cpp, которые мы хотим скомпилировать. Если мы хотим скомпилировать без компоновки, нужно использовать команду cl /c.
Примечание: мы не включаем файл .h в компиляцию, потому что его содержимое автоматически включается в main.cpp и HelloWorld.cpp препроцессором благодаря директиве препроцессора #include.


На изображении выше показаны объектные файлы для наших двух исходных файлов .cpp. Также обратите внимание, что у нас нет исполняемого файла, потому что мы не запускали компоновщик.
Компоновка
На этом финальном этапе нам нужно скомпоновать наши объектные файлы для получения окончательного исполняемого файла.
Для этого мы используем команду LINK, за которой указываем созданные объектные файлы.


Теперь все, что нам нужно сделать, это дважды кликнуть по helloworld.exe, чтобы запустить нашу программу.
Стоит отметить, что, учитывая, что наша программа производит вывод в консоль как раз перед вызовом return из main, консоль может не появиться, или же она будет отображена очень недолго.
Распространенным решением для обеспечения того, чтобы консоль оставалась открытой, является запрос пользовательского ввода в конце программы с использованием cin.
Это очень примитивный пример, но я надеюсь, что он поможет понять, как компилируется программа на C++.
Есть еще много вещей, которые мы не рассмотрели, например, как скомпоновать внешние библиотеки, как наш код может быть скомпилирован на нескольких платформах, и как лучше справляться с компиляцией больших программ на C++.
Существует также гораздо лучший способ компилировать и компоновать программы, нежели вводить каждый файл в командную строку, и нет, это не просто запуск сборки в вашей IDE.
Резюме
Компиляция программы на C++ — это трехэтапный процесс: препроцессинг, компиляция и компоновка.
Препроцессор обрабатывает директивы препроцессора, такие как #include, компиляция преобразует файлы исходного кода в машинный код, хранимый в объектных файлах, а компоновка связывает ссылки на объектные файлы и внешние библиотеки для создания исполняемого файла или файла библиотеки.
Ссылки
- en.wikipedia.org/wiki/C%2B%2B
- stackoverflow.com/questions/6264249/how-does-the-compilation-linking-process-work
- faculty.cs.niu.edu/~mcmahon/CS241/Notes/compile.html
- www.learncpp.com/cpp-tutorial/introduction-to-the-compiler-linker-and-libraries
Пройти тестирование и узнать подробнее о курсе.
C++ course notes
Процесс компиляции программ
- Запись лекции №1
- Запись лекции №2
- Запись лекции №3
- Практика
Зачем нам нужно это изучать?
- У студентов часто возникают с этим проблемы — когда компилятор пишет ошибку, а человек не понимает, что ему говорят.
- Если вы делаете ошибку в организации программы, причём такую ошибку, которая сразу к проблеме не приводит, то бывает такое, что при компиляции чуть-чуть по-другому всё сломается. Причём даже в крупных компаниях
такое случается.
Самое интересное, что ни в одной литературе про компиляцию не рассказывается (в совсем базовой считается что это сложно, а в продвинутой — что вы всё знаете), а все кто это знает,
говорят, что пришло с опытом.
Базовые знания об этапах компиляции.
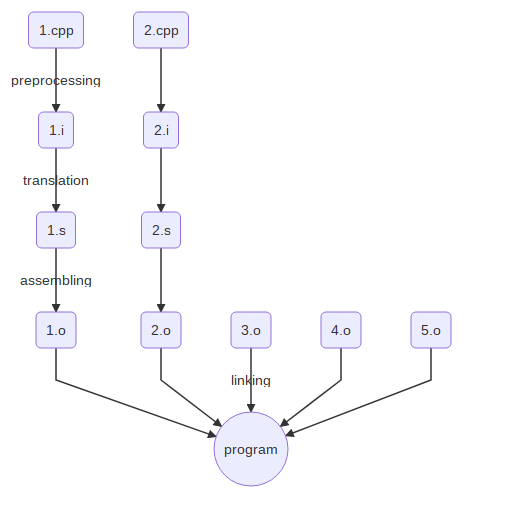
Обычно мы компилируем программу как g++ program.cpp. А вот чего мы пока не знаем, так это того, что g++ не делает всю работу самостоятельно, а вызывает другие команды, которые выполняют компиляцию по частям. И если посмотреть, что там, то происходит cc1plus, потом as, в конце collect2, который вызывает ld. Давайте попытаемся это повторить.
Дальше будет перечисление стадий с указанием двух моментов: как их можно выполнить руками и какое расширение обычно имеет результат этой стадии.
- Препроцессирование. Выполняется при помощи g++ -E (если дополнительно передать ключ -P, то вывод будет чуть короче), выходной файл обычно имеет расширение .i. На файл с расширением .i можно и глазами посмотреть — в нём будет куча текста вместо
#include, а потом наш код. Собственно,#include— директива препроцессора, которая тупо вставляет указанный файл в то место, где написана. Также препроцессор занимается макросами (#define). О них позже. - Трансляция. Выполняется при помощи g++ -S, выходной файл обычно имеет расширение .s. «Трансляция» — это (с английского) «перевод». Кого и куда переводим? Наш язык в ассемблер. Если передать параметр -masm=intel, можно уточнить, в какой именно ассемблер переводить (как было сказано в 01_asm, ассемблеры отличаются в зависимости от инструмента).
- Ассемблирование. Выполняется специальной утилитой as, выходной файл обычно имеет расширение .o (и называется объектным файлом). На данном этапе не происходит ничего интересного — просто инструкции, которые были в ассемблере, перегоняются в машинный код. Поэтому файлы .o бесполезно смотреть глазами, они бинарные, для этого есть специальные утилиты, например, objdump. Про него будет рассказано чуть позже.
- Линковка. Выполняется простым вызовом g++ от объектного файла. На выходе даёт исполняемый файл. Нужна, если файлов несколько: мы запускаем препроцессор, трансляцию и ассемблирование независимо для каждого файла, а объединяются они только на этапе линковки. Независимые .cpp файлы называют единицами трансляции. Разумеется, только в одной единице должен быть
main. В этомmain‘е, кстати, можно не делатьreturn 0, его туда вставит компилятор.
Сто́ит сказать, что информация о линковке верна до появления модулей в C++20, где можно доставать данные одного файла для другого. Там появляется зависимость файлов друг от друга, а значит компилировать их надо в определённом порядке.
Классическая схема этапов компиляции выглядит так:
Есть похожая статья на хабре по теме.
Объявление и определение.
Очень хочется слинковать вот это:
// a.cpp:
int main() {
f();
}
// b.cpp:
#include <cstdio>
void f() {
printf("Hello, world!n");
}
Это не компилируется, а точнее ошибка происходит на этапе трансляции a.cpp. В тексте ошибки написано, что f не определена в области видимости. Всё потому, что для того чтобы вызвать функцию, надо что-то про неё знать. Например, если мы передаём в функцию int — это один ассемблерный код, а если double — то совершенно другой (потому что разные calling convention’ы могут быть). Поэтому на этапе трансляции нужно знать сигнатуру функции. Чтобы указать эту сигнатуру, в C++ есть объявления:
// a.cpp:
void f(); // Вот это объявление.
int main() {
f();
}
// b.cpp:
#include <cstdio>
void f() {
printf("Hello world");
}
Когда мы пишем функцию и точку с запятой — это объявление/декларация (declaration). Это значит, что где-то в программе такая функция есть. А когда мы пишем тело функции в фигурных скобках — это определение (definition).
Кстати, написать объявление бывает полезно даже если у нас один файл. Например, в таком файле:
#include <cstdio>
int main() {
f();
}
void f() {
printf("Hello, worldn");
}
Это не компилируется, и дело в том, что компилятор смотрит файл сверху вниз, и когда доходит до вызова функции f внутри main, он ещё не дошёл до её определения. Тут можно переставить функции местами, да, но если у нас есть взаиморекурсивные функции, то там переставить их не получится — только написать декларацию.
Ошибки линковки. Инструменты nm и objdump. Ключевое слово static.
Рассмотрим такой пример:
// a.cpp
#include <cstdio>
void f()
{
printf("Hello, a.cpp!n");
}
// b.cpp
#include <cstdio>
void f()
{
printf("Hello, b.cpp!n");
}
// main.cpp
void f();
int main()
{
f();
}
Тут вам на этапе линковки напишут, что функция f() определяется дважды. Чтобы красиво посмотреть, как это работает, можно использовать утилиту nm. Когда вы сгенерируете a.o и вызовете nm -C a.o, то увидите что-то такое:
U puts
0000000000000000 T f()
Что делает ключ -C, оставим на потом. На то что тут находится puts вместо printf, тоже обращать внимание не надо, это просто такая оптимизация компилятора — когда можно заменить printf на puts, заменяем.
А обратить внимание надо на то, что puts не определена (об этом нам говорит буква U), а функция f() — определена в секции .text (буква T). У main.cpp, понятно, будет неопределённая функция f() и определённая main. Поэтому, имея эти объектные файлы, можно слинковать main.cpp и a.cpp, а можно — main.cpp и b.cpp. Без перекомпиляции. Но нельзя все три вместе, ведь f() будет определена дважды.
Если мы хотим посмотреть на объектные файлы поподробнее, нам понадобится утилита objdump. У неё есть бесчисленное много ключей, которые говорят, что мы хотим увидеть. Например -x — выдать вообще всё. Нам сейчас нужно -d — дизассемблирование и -r — релокации. Когда мы вызовем objdump -dr -Mintel -C main.o, мы увидим, что на месте вызова функции f находится call и нули. Потому что неизвестно, где эта функция, надо на этапе линковки подставить её адрес. А чтобы узнать, что именно подставить, есть релокации, которые информацию об этом и содержат. В общем случае релокация — информация о том, какие изменения нужно сделать с программой, чтобы файл можно было запустить.
Давайте теперь вот на что посмотрим. Пусть в нашем файле определена функция f(). И где-то по случайному совпадению далеко-далеко также определена функция f(). Понятно, что оно так не слинкуется. Но мы можем иметь ввиду, что наша функция f нужна только нам и никак наружу не торчит. Для этого имеется специальный модификатор: static. Если сделать на такие функции nm, то можно увидеть символ t вместо T, который как раз обозначает локальность для единицы трансляции. Вообще функции, локальные для одного файла сто́ит помечать как static в любом случае, потому что это ещё помогает компилятору сделать оптимизации.
Глобальные переменные.
Для глобальных переменных всё то же самое, что и для функций: например, мы также можем сослаться на глобальную переменную из другого файла. Только тут другой синтаксис:
extern int x; // Объявление.
int x; // Определение.
И точно также в глобальных переменных можно писать static. А теперь пример:
// a.cpp
extern int a;
void f();
int main()
{
f();
a = 5;
f();
}
// b.cpp
#include <cstdio>
int a;
void f()
{
printf("%dn", a);
}
В первый раз вам выведут 0, потому что глобальные переменные инициализируются нулями. Локальные переменные хранятся на стеке, и там какие данные были до захода в функцию, те там и будут. А глобальные выделяются один раз, и ОС даёт вам их проинициализированные нулём (иначе там могут быть чужие данные, их нельзя отдавать).
Декорирование имён. extern "C".
Обсуждённая нами модель компиляции позволяет использовать несколько разных языков программирования. Пока ЯП умеет транслироваться в объектные файлы, проблемы могут возникнуть только на этапе линковки. Например, никто не мешает вам взять уже готовый ассемблерник и скомпилировать его с .cpp файлом. Но в вызове ассемблера есть одна проблема. Тут надо поговорить о такой вещи как extern "C". В языке C всё было так: имя функции и имя символа для линковщика — это одно и то же. Если мы скомпилируем файл
// a.c <-- C, не C++.
void foo(int)
{
// ...
}
То имя символа, которое мы увидим в nm будет foo. А в C++ появилась перегрузка функций, то есть void foo(int) и void foo(double) — это две разные функции, обе из которых можно вызывать. Поэтому одно имя символа присвоить им нельзя. Так что компилятор mangle’ит/декорирует имена, то есть изменяет их так, чтобы символы получились уникальными. nm даже может выдать вам эти имена (в данном случае получится _Z3fooi и _Z3food). Но у вас есть и возможность увидеть их по-человечески: для этого существует уже упомянутый ключ -C, который если передать программе nm, то она раздекорирует всё обратно и выдаст вам имена человекочитаемо. objdump‘у этот ключ дать тоже можно. А ещё есть утилита
c++filt, которая по имени символа даёт сигнатуру функции.
Так вот, extern "C" говорит, что при линковке нам не нужно проводить декорацию. И если у нас в ассемблерном файле написано fibonacci:, то вам и нужно оставить имя символа как есть:
extern "C" uint32_t fibonacci(uint32_t n);
У функций с разными сигнатурами, но помеченных как extern "C", после компиляции не будет информации об типах их аргументов, поэтому это слинкуется, но работать не будет (ну либо будет, но тут UB, так как, например, типы аргументов ожидаются разные).
Линковка со стандартной библиотекой.
Возьмём теперь объявление printf из cstdio и вставим его объявление вручную:
extern "C" int printf(const char*, ...);
int main() {
printf("Hello, world!");
}
Такая программа тоже работает. А где определение printf, возникает вопрос? А вот смотрите. На этапе связывания
связываются не только ваши файлы. Помимо этого в параметры связывания добавляются несколько ещё объектных файлов и несколько библиотек. В нашей модели мира хватит информации о том, что библиотека — просто набор объектных файлов. И вот при линковке вам дают библиотеку стандартную библиотеку C++ (-lstdc++), математическую библиотеку (-lm), библиотеку -libgcc, чтобы если вы делаете арифметику в 128-битных числах, то компилятор мог вызвать функцию __udivti3 (деление), и кучу всего ещё. В нашем случае нужна одна — -lc, в которой и лежит printf. А ещё один из объектных файлов, с которыми вы линкуетесь, содержит функцию _start (это может быть файл crt1.o), которая вызывает main.
Headers (заголовочные файлы). Директива #include.
Если мы используем одну функцию во многих файлах, то нам надо писать её сигнатуру везде. А если мы её меняем, то вообще повеситься можно. Поэтому так не делают. А как делают? А так: декларация выделяется в отдельный файл. Это файл имеет расширение .h и называется заголовочным. По сути это же происходит в стандартной библиотеке. Подключаются заголовочные файлы директивой #include <filename>, если они из какой-то библиотеки, или #include "filename", если он ваш. В чём разница? Стандартное объяснение — тем, что треугольные скобки сначала ищут в библиотеках, а потом в вашей программе, а кавычки — наоборот. На самом желе у обоих вариантов просто есть список путей, где искать файл, и эти списки разные.
Но с заголовками нужно правильно работать. Например, нельзя делать #include "a.cpp". Почему? Потому что все определённые в a.cpp функции и переменные просочатся туда, куда вы его подключили. И если файл у вас один, то ещё ничего, а если больше, то в каждом, где написано #include "a.cpp", будет определение, а значит определение одного и того же объекта будет написано несколько раз.
Аналогичной эффект будет, если писать определение сразу в заголовочном файле, не надо так.
К сожалению, у директивы #include есть несколько нюансов.
Предотвращение повторного включения.
Давайте поговорим про структуры. Что будет, если мы в заголовочном файле создадим struct, и подключим этот файл? Да ничего. Абсолютно ничего. Сгенерированный ассемблерный код будет одинаковым. У структур нет определения по сути, потому что они не генерируют код. Поэтому их пишут в заголовках. При этом их методы можно (но не нужно) определять там же, потому что они воспринимаются компилятором как inline. А кто такой этот inline и как он работает — смотри дальше. Но со структурами есть один нюанс. Рассмотрим вот что:
// x.h:
struct x {};
// y.h:
#include "x.h"
// z.h:
#include "x.h"
// a.cpp:
#include "y.h" // --> `struct x{};`.
#include "z.h" // --> `struct x{};` ошибка компиляции, повторное определение.
Стандартный способ это поправить выглядит так:
// x.h:
#ifndef X_H // Если мы уже определили макрос, то заголовок целиком игнорируется.
#define X_H // Если не игнорируется, то помечаем, что файл мы подключили.
struct x {};
#endif // В блок #ifndef...#endif заключается весь файл целиком.
Это называется include guard. Ещё все возможные компиляторы поддерживают #pragma once (эффект как у include guard, но проще). И на самом деле #pragma once работает лучше, потому что не опирается на имя файла, например. Но его нет в стандарте, что грустно.
Есть один нюанс с #pragma once‘ом. Если у вас есть две жёстких ссылки на один файл, то у него проблемы. Если у вас include guard, то интуитивно понятно, что такое разные файлы — когда макросы у них разные. А вот считать ли разными файлами две жёстких ссылки на одно и то же — вопрос сложный. Другое дело, что делать так, чтобы источники содержали жёсткие
или символические ссылки, уже довольно странно.
Forward-декларации.
// a.h
#ifndef A_H
#define A_H
#include "b.h" // Nothing, then `struct b { ... };`
struct a {
b* bb;
};
#endif
// b.h
#ifndef B_H
#define B_H
#include "a.h" // Nothing, then `struct a { ... };`
struct b {
a* aa;
};
#endif
// main.cpp
#include "a.h" // `struct b { ... }; struct a { ... };`
#include "b.h" // Nothing.
Понятно, в чём проблема заключается. Мы подключаем a.h, в нём — b.h, в нём, поскольку мы уже зашли в a.h, include guard нам его блокирует. И мы сначала определяем структуру b, а потом — a. И при просмотре структуры b, мы не будем знать, что такое a.
Для этого есть конструкция, называемая forward-декларацией. Она выглядит так:
// a.h
#ifndef A_H
#define A_H
struct b;
struct a {
b* bb;
};
#endif
// b.h
#ifndef B_H
#define B_H
struct a;
struct b {
a* aa;
};
#endif
Чтобы завести указатель, нам не надо знать содержимое структуры. Поэтому мы просто говорим, что b — это некоторая структура, которую мы дальше определим.
Вообще forward-декларацию в любом случае лучше использовать вместо подключения заголовочных файлов (если возможно, конечно). Почему?
- Во-первых, из-за времени компиляции. Большое количество подключений в заголовочных файлах негативно влияет на него, потому что если меняется header, то необходимо перекомпилировать все файлы, которые подключают его (даже не непосредственно), что может быть долго.
- Второй момент — когда у нас цикл из заголовочных файлов, это всегда ошибка, даже если там нет проблем как в примере, потому что результат компиляции зависит от того, что вы подключаете первым.
Пока структуру не определили, структура — это incomplete type. Например, на момент объявление struct b; в коде выше, b — incomplete. Кстати, в тот момент, когда вы находитесь в середине определения класса, он всё ещё incomplete.
Все, что можно с incomplete типами делать — это объявлять функции с их использованием и создавать указатель. Становятся полным типом после определения.
Пока что информация об incomplete-типах нам ни к чему, но она выстрелит позже.
Правило единственного определения.
А теперь такой пример:
// a.cpp
#include <iostream>
struct x {
int a;
// padding
double b;
int c;
int d;
};
x f();
int main() {
x xx = f();
std::cout << xx.a << " "
<< xx.b << " "
<< xx.c << " "
<< xx.d << std::endl;
}
// b.cpp
struct x {
int a;
int b;
int c;
int d;
int e;
};
x f() {
x result;
result.a = 1;
result.b = 2;
result.c = 3;
result.d = 4;
result.e = 5;
return result;
};
Тут стоит вспомнить, что структуры при линковке не играют никакой роли, то есть линковщику всё равно, что у нас структура x определена в двух местах. Поэтому такая программа отлично скомпилируется и запустится, но тем не менее она является некорректной. По стандарту такая программа будет работать неизвестно как, а по жизни данные поедут. А именно 2 пропадёт из-за выравнивания double, 3 и 4 превратятся в одно число (double), а 5 будет на своём месте, а x::e из файла a.cpp будет просто не проинициализирован. Правило, согласно которому так нельзя, называется one-definition rule/правило единственного определения. Кстати, нарушением ODR является даже тасовка полей.
Inlining.
int foo(int a, int b) {
return a + b;
}
int bar(int a, int b) {
return foo(a, b) - a;
}
Если посмотреть на ассемблерный код для bar, то там не будет вызова функции foo, а будет return b;. Это называется inlining — когда мы берём тело одной функции и вставляем внутрь другой как оно есть. Это связано, например, со стилем программирования в текущем мире (много маленьких функций, которые делают маленькие вещи) — мы убираем все эти абстракции, сливаем функции в одну и потом оптимизируем что там есть.
Но есть один нюанс…
Модификатор inline.
// a.c
void say_hello();
int main() {
say_hello();
}
// b.c
#include <cstdio>
void say_hello() {
printf("Hello, world!n");
}
Тут не произойдёт inlining, а почему? А потому что компилятор умеет подставлять тело функций только внутри одной единицы трансляции (так как inlining происходит на момент трансляции, а тогда у компилятора нет функций из других единиц).
Тут умеренно умалчивается, что модель компиляции, которую мы обсуждаем — древняя и бородатая. Мы можем передать ключ -flto в компилятор, тогда всё будет за’inline’ено. Дело в том, что при включенном режиме linking time optimization, мы откладываем на потом генерацию кода и генерируем его на этапе линковки. В таком случае линковка может занимать много времени, поэтому применяется при сборке с оптимизациями. Подробнее о режиме LTO — сильно позже.
Но тем не менее давайте рассмотрим, как без LTO исправить проблему с отсутствием inlining’а. Мы можем написать в заголовочном файле тело, это поможет, но это, как мы знаем, ошибка компиляции. Хм-м, ну, можно не только написать функцию в заголовочном файле, но и пометить её как static, но это, даёт вам свою функцию на каждую единицу трансляции, что, во-первых, бывает просто не тем, что вы хотите, а во-вторых, кратно увеличивает размер выходного файла.
Поэтому есть модификатор inline. Он нужен для того, чтобы линковщик не дал ошибку нарушения ODR. Модификатор inline напрямую никак не влияет на то, что функции встраиваются.. Если посмотреть на inline через nm, то там увидим W (weak) — из нескольких функций можно выбрать любую (предполагается, что все они одинаковые).
По сути inline — указание компилятору, что теперь за соблюдением ODR следите вы, а не он. И если ODR вы нарушаете, то это неопределённое поведение (ill-formed, no diagnostic required). ill-formed, no diagnostic required — это ситуация, когда программа некорректна, но никто не заставляет компилятор вам об этом говорить. Он может (у GCC есть такая возможность: если дать g++ ключи -flto -Wodr, он вам об этом скажет), но не обязан. А по жизни линковщик выберет произвольную из имеющихся функций (например, из первой единицы трансляции или вообще разные в разных местах):
// a.cpp
#include <cstdio>
inline void f() {
printf("Hello, a.cpp!n");
}
void g();
int main() {
f();
g();
}
// b.cpp
inline void f() {
printf("Hello, b.cpp!n");
}
void g() {
f();
}
Если скомпилировать этот код с оптимизацией, обе функции f будут за’inline’ены, и всё будет хорошо. Если без, то зависит от порядка файлов: g++ a.cpp b.cpp может вполне выдавать Hello, a.cpp! два раза, а g++ b.cpp a.cpp — Hello, b.cpp! два раза.
Если нужно именно за’inline’ить функцию, то есть нестандартизированные модификаторы типа __forceinline, однако даже они могут игнорироваться компилятором. Inlining функции может снизить производительность: на эту тему можно послушать доклад Антона Полухина на C++ Russia 2017.
Остальные команды препроцессора.
#include обсудили уже вдоль и поперёк. Ещё есть директивы #if, #ifdef, #ifndef, #else, #elif, #endif, которые дают условную компиляцию. То есть если выполнено какое-то условие, можно выполнить один код, а иначе — другой.
Определение макроса.
И ещё есть макросы: определить макрос (#define) и разопределить макрос (#undef):
#define PI 3.14159265
double circumference(double r) {
return 2 * PI * r;
}
Текст, который идет после имени макроса, называется replacement. Replacement отделяется от имени макроса пробелом и распространяется до конца строки. Все вхождения идентификатора PI ниже этой директивы будут заменены на replacement. Самый простой макрос — object-like, его вы видите выше, чуть более сложный — function-like:
#define MIN(x, y) x < y ? x : y
printf("%d", MIN(4, 5));
Что нам нужно про это знать — макросы работают с токенами. Они не знают вообще ничего о том, что вы делаете. Вы можете написать
#include <cerrno>
int main() {
int errno = 42;
}
И получить отрешённое от реальности сообщение об ошибке. А дело всё в том, что это на этапе препроцессинга раскрывается, например, так:
int main() {
int (*__errno_location()) = 42;
}
И тут компилятор видит более отъявленный бред, нежели называние переменной так, как нельзя.
Что ещё не видит препроцессор, так это синтаксическую структуру и приоритет операций. Более страшные вещи получаются, когда пишется что-то такое:
#define MUL(x, y) x * y
int main() {
int z = MUL(2, 1 + 1);
}
Потому что раскрывается это в
int main() {
int z = 2 * 1 + 1;
}
Это не то что вы хотите. Поэтому когда вы такое пишите, нужно во-первых, все аргументы запихивать в скобки, во-вторых — само выражение тоже, а в-третьих, это вас никак не спасёт от чего-то такого:
#define max(a, b) ((a) < (b) ? (a) : (b))
int main() {
int x = 1;
int y = 2;
int z = max(x++, ++y);
}
Поэтому перед написанием макросов три раза подумайте, нужно ли оно, а если нужно, будьте очень аккуратны. А ещё, если вы используете отладчик, то он ничего не знает про макросы, зачем ему знать. Поэтому в отладчике написать «вызов макроса» Вы обычно не можете. Cм. также FAQ Бьярна Страуструпа о том, почему макросы — это плохо.
Ещё #define позволяет переопределять макросы.
#define STR "abc"
const char* first = STR; // "abc".
#define STR "def"
const char* second = STR; // "def".
Replacement макроса не препроцессируется при определении макроса, но результат раскрытия макроса препроцессируется повторно:
#define Y foo
#define X Y // Это не `#define X foo`.
#define Y bar // Это не `#define foo bar`.
X // Раскрывается `X` -> `Y` -> `bar`.
Также по спецификации препроцессор никогда не должен раскрывать макрос изнутри самого себя, а оставлять вложенный идентификатор как есть:
#define M { M }
M // Раскрывается в { M }.
Ещё пример:
#define A a{ B }
#define B b{ C }
#define C c{ A }
A // a{ b{ c{ A } } }
B // b{ c{ a{ B } } }
C // c{ a{ b{ C } } }
Условная компиляция. Проверка макроса.
Директивы #ifdef, #ifndef, #if, #else, #elif, #endif позволяют отпрепроцессировать часть файла, лишь при определенном условии. Директивы #ifdef, #ifndef проверяют определен ли указанный макрос. Например, они полезны для разной компиляции:
#ifdef __x86_64__
typedef unsigned long uint64_t;
#else
typedef unsigned long long uint64_t;
#endif
Директива #if позволяет проверить произвольное арифметическое выражение.
#define TWO 2
#if TWO + TWO == 4
// ...
#endif
Директива #if препроцессирует свой аргумент, а затем парсит то, что получилось как арифметическое выражение. Если после препроцессирования в аргументе #if остаются идентификаторы, то они заменяются на 0, кроме идентификатора true, который заменяется на 1.
Одно из применений #ifndef — это include guard, которые уже обсуждались ранее.
Константы.
Понадобилась нам, например, $pi$. Традиционно в C это делалось через #define. Но у препроцессора, как мы знаем, есть куча проблем. В случае с константой PI ничего не случится, вряд ли кто-то будет называть переменную так, особенно большими буквами, но всё же.
А в C++ (а позже и в C) появился const. Но всё же, зачем он нужен, почему нельзя просто написать глобальную переменную double PI = 3.141592;?
- Во-первых, константы могут быть оптимизированы компилятором. Если вы делаете обычную переменную, компилятор обязан её взять из памяти (или регистров), ведь в другом файле кто-то мог её поменять. А если вы напишете
const, то у вас не будет проблем ни с оптимизацией (ассемблер будет как при#define), ни с адекватностью сообщений об ошибках. - Во-вторых, она несёт документирующую функцию, когда вы пишете
constс указателями. Если в заголовке функции написаноconst char*, то вы точно знаете, что вы передаёте в неё строку, которая не меняется, а еслиchar*, то, скорее всего, меняется (то есть функция создана для того, чтобы менять). - В-третьих, имея
const, компилятор может вообще не создавать переменную: если мы напишемreturn PI * 2, то там будет возвращаться константа, и никакого умножения на этапе исполнения.
Кстати, как вообще взаимодействует const с указателями? Посмотрим на такой пример:
int main() {
const int MAGIC = 42;
int* p = &MAGIC;
}
Так нельзя, это имеет фундаментальную проблему: вы можете потом записать *p = 3, и это всё порушит. Поэтому вторая строка не компилируется, и её надо заменить на
const int* p = &MAGIC;
Но тут нужно вот на что посмотреть. У указателя в некотором смысле два понятия неизменяемости. Мы же можем сделать так:
int main() {
const int MAGIC = 42;
const int* p = &MAGIC;
// ...
p = nullptr;
}
Кто нам мешает так сделать? Да никто, нам нельзя менять содержимое p, а не его самого. А если вы хотите написать, что нельзя менять именно сам указатель, то это не const int*/int const*, а int* const. Если вам нужно запретить оба варианта использования, то, что логично, const int* const или int const* const. То есть
int main() {
int* a;
*a = 1; // ok.
a = nullptr; // ok.
const int* b; // Синоним `int const* b;`
*b = 1; // Error.
b = nullptr; // ok.
int* const c;
*c = 1; // ok.
c = nullptr; // Error.
const int* const d; // Синоним `int const* const d;`
*d = 1; // Error.
d = nullptr; // Error.
}
Теперь вот на что посмотрим:
int main() {
int a = 3;
const int b = 42;
int* pa = &a; // 1.
const int* pca = &a; // 2.
int* pb = &b; // 3.
const int* pcb = &b; // 4.
}
Что из этого содержит ошибку? Ну, в третьем точно ошибка, это мы уже обсудили. Также первое и четвёртое точно корректно. А что со вторым? Ну, нарушает ли второе чьи-то права? Ну, нет. Или как бы сказали на парадигмах программирования, никто не нарушает контракт, мы только его расширяем (дополнительно обещая неизменяемость), а значит всё должно быть хорошо. Ну, так и работают неявные преобразования в C++, вы можете навешивать const везде, куда хотите, но не можете его убирать.
Константными могут быть и составные типы (в частности, структуры). Тогда у этой структуры просто будут константными все поля.
Введение
Язык С++ является компилируемым, то есть трансляция кода с языка высокого уровня на инструкции машинного кода происходит не в момент выполнения, а заранее — в процессе изготовления так называемого исполняемого файла (в ОС Windows такие файлы имеют расширение .exe, а в ОС GNU/Linux чаще всего не имеют расширения).
hello.cpp
Пример простой программы на С++, которая печатает “Привет, Мир!”:
#include <iostream> int main() { std::cout << "Hello, World!" << std::endl; return 0; }
Для вывода здесь используется стандартная библиотека iostream, поток вывода std::cout.
Исполняемые операторы в программах на С++ не могут быть сами по себе — они должны быть обязательно заключены в функции.
Функция main() — это главная функция, выполнение программы начинается с её вызова и заканчивается выходом из неё.
Возвращаемое значение main() в случае успешных вычислений должно быть равно 0, что значит “ошибка номер ноль”, то есть “нет ошибки”. В противном процесс, вызвавший программу, может посчитать её выполнившейся с ошибкой.
Чтобы выполнить программу, нужно её сохранить в текстовом файле hello.cpp и скомпилировать следующей командой:
Опция -o сообщает компилятору, что итоговый исполняемый файл должен называться hello. g++ — это компилятор языка C++, входящий в состав проекта GCC (GNU Compiler Collection). g++ не является единственным компиляторм языка C++. Помимо него в ходе курса мы будет использовать компилятор clang, поскольку он обладает рядом преимуществ, из которых нас больше всего интересует одно — этот компилятор выдаёт более понятные сообщения об ошибках по сравнению с g++.
Упражнение №1
Скомпилируйте и выполните данную программу.
Ввод и вывод на языке С++
В Python и в С ввод и вывод синтаксически оформлены как вызов функции, а в С++ — это операция над объектом специального типа — потоком.
Потоки определяются в библиотеке iostream, где определены операции ввода и вывода для каждого встроенного типа.
Вывод
Все идентификаторы стандартной библиотеки определены в пространстве имен std, что означает необходимость обращения к ним через квалификатор std::.
std::cout << "mipt"; std::cout << 2018; std::cout << '.'; std::cout << true; std::cout << std::endl;
Заметим, что в С++ мы не прописываем типы выводимых значений, компилятор неким (пока непонятным) способом разбирается в типе выводимого значения и выводит его соответствующим образом.
Вывод в один и тот же поток можно писать в одну строчку:
std::cout << "mipt" << 2018 << '.' << true << std::endl;
Для вывода в поток ошибок определён поток std::cerr.
Ввод
Поток ввода с клавиатуры называется std::cin, а считывание из потока производится другой операцией — >> :
Тип считываемого значения определяется автоматически по типу переменной x.
Для всех типов, кроме char, считывание будет производиться с пропуском символов-разделителей и до следующего символа-разделителя. При этом пробел и табуляция так же, как и символ перевода каретки, являются корректными разделителями. Считывание в char происходит посимвольно независимо от типа символа.
Например для введенной строки “Иван Иванович Иванов”,
std::string name; std::cin >> name;
считает в name только первое слово “Иван”.
Считать всю строку целиком можно с помощью функции getline():
std::string name; std::getline(std::cin, name);
Считывать несколько значений можно и в одну строку:
Упражнение №2
Напишите программу, которая считает гипотенузу прямоугольного треугольника по двум катетам. Ввод и вывод стандартные.
| Ввод | Вывод |
| 3 4 | 5 |
Сумма первых n натуральных чисел
Пример программы, которая подсчитывает сумму первых n натуральных чисел:
#include <iostream> int main() { int n = 0; std::cin >> n; int sum = 0; for (int i = 1; i <= n; i++) { sum += i; } std::cout << sum << std::endl; return 0; }
Как известно, если сложную задачу разбить на несколько простых подзадач, то её решение сильно упрощается. Поэтому не стоит писать весь код в одной функции main(). Лучше разбивать код на отдельные функции, каждая из которых решает свою несложную подзадачу, но делает это хорошо. Например, в предыдущем примере можно вынести функциональность подсчёта суммы первых n натуральных чисел в отдельную функцию:
#include <iostream> int GetNaturalsSum(const int n) { int sum = 0; for (int i = 1; i <= n; i++) { sum += i; } return sum; } int main() { int n = 0; std::cin >> n; std::cout << GetNaturalsSum(n) << std::endl; return 0; }
Эмперическое правило: каждая функция не должна превышать по размеру 1 экран вашего монитора.
Этапы сборки: препроцессинг, компиляция, компоновка
Компиляция исходных текстов на Си в исполняемый файл происходит в три этапа.
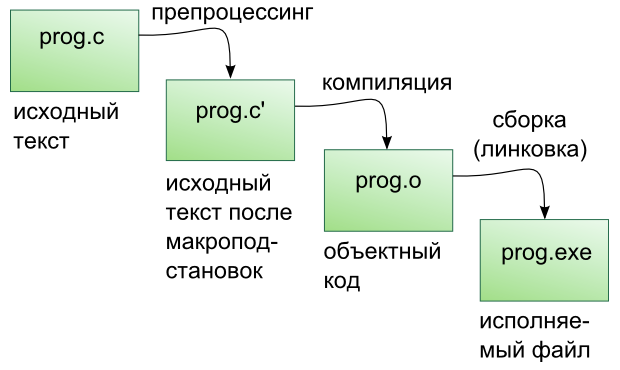
Препроцессинг
Эту операцию осуществляет текстовый препроцессор.
Исходный текст частично обрабатывается — производятся:
- Замена комментариев пустыми строками
- Текстовое включение файлов —
#include - Макроподстановки —
#define - Обработка директив условной компиляции —
#if,#ifdef,#elif,#else,#endif
Компиляция
Процесс компиляции состоит из следующих этапов:
- Лексический анализ. Последовательность символов исходного файла преобразуется в последовательность лексем.
- Синтаксический анализ. Последовательность лексем преобразуется в дерево разбора.
- Семантический анализ. Дерево разбора обрабатывается с целью установления его семантики (смысла) — например, привязка идентификаторов к их декларациям, типам, проверка совместимости, определение типов выражений и т. д.
- Оптимизация. Выполняется удаление излишних конструкций и упрощение кода с сохранением его смысла.
- Генерация кода. Из промежуточного представления порождается объектный код.
Результатом компиляции является объектный код.
Объектный код — это программа на языке машинных кодов с частичным сохранением символьной информации, необходимой в процессе сборки.
При отладочной сборке возможно сохранение большого количества символьной информации (идентификаторов переменных, функций, а также типов).
Компоновка
Компоновка также называется связывание или линковка. На этом этапе отдельные объектные файлы проекта соединяются в единый исполняемый файл.
На этом этапе возможны так называемые ошибки связывания: если функция была объявлена, но не определена, ошибка обнаружится только на этом этапе.
Упражнение №3
Выполните в консоли для ранее созданного файла hello.cpp последовательно операции препроцессинга, компиляции и компоновки:
- Препроцессинг:
$ g++ -E -o hello1.cpp hello.cpp
- Компиляция:
$ g++ -c -o hello.o hello1.cpp
- Компоновка:
Принцип раздельной компиляции
Компиляция — алгоритмически сложный процесс, для больших программных проектов требующий существенного времени и вычислительных возможностей ЭВМ. Благодаря наличию в процессе сборки программы этапа компоновки (связывания) возникает возможность раздельной компиляции.
В модульном подходе программный код разбивается на несколько файлов .cpp, каждый из которых компилируется отдельно от остальных.
Это позволяет значительно уменьшить время перекомпиляции при изменениях, вносимых лишь в небольшое количество исходных файлов. Также это даёт возможность замены отдельных компонентов конечного программного продукта, без необходимости пересборки всего проекта.
Пример модульной программы с раздельной компиляцией на С++
Рассмотрим пример: есть желание вынести часть кода в отдельный файл — пользовательскую библиотеку.
program.cpp
#include "mylib.hpp" const int MAX_DIVISORS_NUMBER = 10000; int main() { int number = read_number(); int Divisor[MAX_DIVISORS_NUMBER]; int Divisor_top = 0; factorize(number, Divisor, &Divisor_top); print_array(Divisor, Divisor_top); return 0; }
Подключение пользовательской библиотеки в С++ на самом деле не так просто, как кажется.
Сама библиотека должна состоять из двух файлов: mylib.hpp и mylib.cpp:
mylib.hpp
#ifndef MY_LIBRARY_H_INCLUDED #define MY_LIBRARY_H_INCLUDED #include <cstdlib> //считываем число int read_number(); //получаем простые делители числа // сохраняем их в массив, чей адрес нам передан void factorize(int number, int *Divisor, int *Divisor_top); //выводим число void print_number(int number); //распечатывает массив размера A_size в одной строке через TAB void print_array(int A[], size_t A_size); #endif // MY_LIBRARY_H_INCLUDED
mylib.cpp
#include <iostream> #include "mylib.hpp" //считываем число int read_number() { int number; std::cin >> number; return number; } //получаем простые делители числа // сохраняем их в массив, чей адрес нам передан void factorize(int x, int *Divisor, int *Divisor_top) { for (int d = 2; d <= x; d++) { while (x%d == 0) { Divisor[(*Divisor_top)++] = d; x /= d; } } } //выводим число void print_number(int number) { std::cout << number << std::endl; } //распечатывает массив размера A_size в одной строке через TAB void print_array(int A[], size_t A_size) { for(int i = A_size-1; i >= 0; i--) { std::cout << A[i] << 't'; } std::cout << std::endl; }
Препроцессор С++, встречая #include "mylib.hpp", полностью копирует содержимое указанного файла (как текст) вместо вызова директивы. Благодаря этому на этапе компиляции не возникает ошибок типа Unknown identifier при использовании функций из библиотеки.
Файл mylib.cpp компилируется отдельно.
А на этапе компоновки полученный файл mylib.o должен быть включен в исполняемый файл program.
Cреда разработки обычно скрывает весь этот процесс от программиста, но для корректного анализа ошибок сборки важно представлять себе, как это делается.
Упражнение №4
Давайте сделаем это руками:
$ g++ -c mylib.cpp # 1 $ g++ -c program.cpp # 2 $ g++ -o program mylib.o program.o # 3
Теперь, если изменения коснутся только mylib.cpp, то достаточно выполнить только команды 1 и 3.
Если только program.cpp, то только команды 2 и 3.
И только в случае, когда изменения коснутся интерфейса библиотеки, т.е. заголовочного файла mylib.hpp, придётся перекомпилировать оба объектных файла.
Утилита make и Makefile
Утилита make предназначена для автоматизации преобразования файлов из одной формы в другую.
По отметкам времени каждого из имеющихся объектных файлов (при их наличии) она может определить, требуется ли их пересборка.
Правила преобразования задаются в скрипте с именем Makefile, который должен находиться в корне рабочей директории проекта. Сам скрипт состоит из набора правил, которые в свою очередь описываются:
- целями (то, что данное правило делает);
- реквизитами (то, что необходимо для выполнения правила и получения целей);
- командами (выполняющими данные преобразования).
В общем виде синтаксис Makefile можно представить так:
# Отступ (indent) делают только при помощи символов табуляции,
# каждой команде должен предшествовать отступ
<цели>: <реквизиты>
<команда #1>
...
<команда #n>
То есть, правило make это ответы на три вопроса:
{Из чего делаем? (реквизиты)} —> [Как делаем? (команды)] —> {Что делаем? (цели)}
Несложно заметить что процессы трансляции и компиляции очень красиво ложатся на эту схему:
{исходные файлы} —> [трансляция] —> {объектные файлы}
{объектные файлы} —> [линковка] —> {исполнимые файлы}
Простейший Makefile
Для компиляции hello.cpp достаточно очень простого мэйкфайла:
hello: hello.cpp gcc -o hello hello.cpp
Данный Makefile состоит из одного правила, которое в свою очередь состоит из цели — hello, реквизита — hello.cpp, и команды — gcc -o hello hello.cpp.
Теперь, для компиляции достаточно дать команду make в рабочем каталоге. По умолчанию make станет выполнять самое первое правило, если цель выполнения не была явно указана при вызове:
$ make <цель>
Makefile для модульной программы
program: program.o mylib.o g++ -o program program.o mylib.o program.o: program.cpp mylib.hpp g++ -c program.cpp mylib.o: mylib.cpp mylib.hpp g++ -c hylib.cpp
Попробуйте собрать этот проект командой make или make hello.
Теперь измените любой из файлов .cpp и соберите проект снова. Обратите внимание на то, что во время повторной компиляции будет транслироваться только измененный файл.
После запуска make попытается сразу получить цель program, но для ее создания необходимы файлы program.o и mylib.o, которых пока еще нет. Поэтому выполнение правила будет отложено и make станет искать правила, описывающие получение недостающих реквизитов. Как только все реквизиты будут получены, make`вернется к выполнению отложенной цели. Отсюда следует, что `make выполняет правила рекурсивно.
Фиктивные цели
На самом деле в качестве make целей могут выступать не только реальные файлы. Все, кому приходилось собирать программы из исходных кодов, должны быть знакомы с двумя стандартными в мире UNIX командами:
Командой make производят компиляцию программы, командой make install — установку. Такой подход весьма удобен, поскольку все необходимое для сборки и развертывания приложения в целевой системе включено в один файл (забудем о скрипте configure). Обратите внимание на то, что в первом случае мы не указываем цель, а во втором целью является вовсе не создание файла install, а процесс установки приложения в систему. Проделывать такие фокусы нам позволяют так называемые фиктивные (phony) цели. Вот краткий список стандартных целей:
all — является стандартной целью по умолчанию. При вызове make ее можно явно не указывать;
clean — очистить каталог от всех файлов полученных в результате компиляции;
install — произвести инсталляцию;
uninstall — и деинсталляцию соответственно.
Для того чтобы make не искал файлы с такими именами, их следует определить в Makefile, при помощи директивы .PHONY. Далее показан пример Makefile с целями all, clean, install и uninstall:
.PHONY: all clean install uninstall
all: program
clean:
rm -rf mylib *.o
program.o: program.cpp mylib.hpp
gcc -c -o program.o program.cpp
mylib.o: mylib.cpp mylib.hpp
gcc -c -o mylib.o mylib.cpp
program: program.o mylib.o
gcc -o mylib program.o mylib.o
install:
install ./program /usr/local/bin
uninstall:
rm -rf /usr/local/bin/program
Теперь мы можем собрать нашу программу, произвести ее инсталлцию/деинсталляцию, а так же очистить рабочий каталог, используя для этого стандартные make цели.
Обратите внимание на то, что в цели all не указаны команды; все что ей нужно — получить реквизит program. Зная о рекурсивной природе make, не сложно предположить, как будет работать этот скрипт. Также следует обратить особое внимание на то, что если файл program уже имеется (остался после предыдущей компиляции) и его реквизиты не были изменены, то команда make ничего не станет пересобирать. Это классические грабли make. Так, например, изменив заголовочный файл, случайно не включенный в список реквизитов (а надо включать!), можно получить долгие часы головной боли. Поэтому, чтобы гарантированно полностью пересобрать проект, нужно предварительно очистить рабочий каталог:
P.S. Неплохая статья с описанием мейкфайлов.
