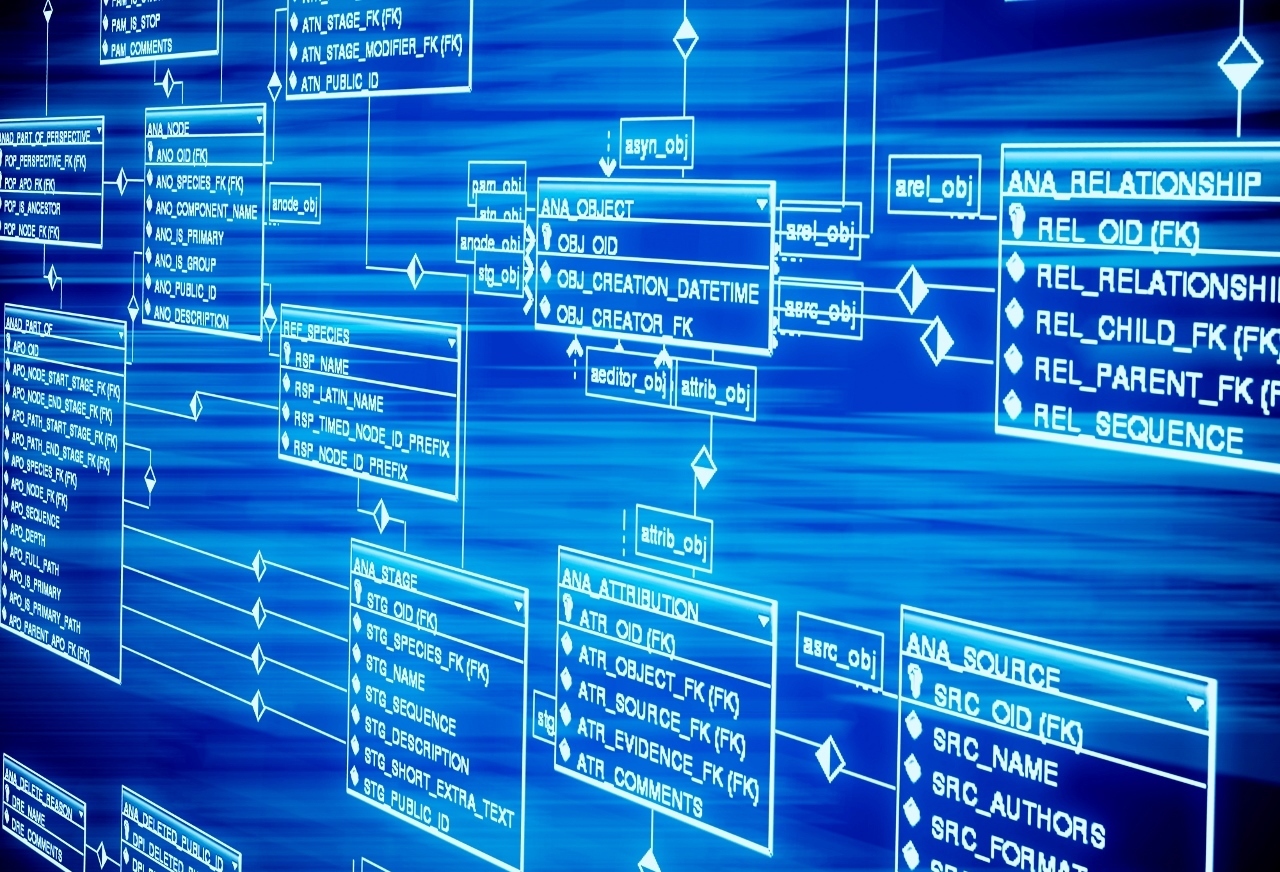
В этой статье мы изучим особенности и структуру реляционных данных, а также увидим пример создания этих БД.

Рассмотрим проектирование, составим концептуальную модель данных. Узнаем, что такое объект и нормализация данных, обсудим, на что обратить внимание на этапе проектирования баз данных. Скучно не будет!
Таблица как важная часть реляционной БД
Всем известно, что реляционная база данных состоит из таблиц. При этом каждая таблица включает в себя столбцы (поля либо атрибуты) и строки (записи либо кортежи).
Таблицы в таких БД обладают следующими свойствами:
– столбцы размещаются в определённом порядке, формируемом при создании таблицы. Таблица может не иметь ни одной строки, однако хотя бы один столбец должен быть обязательно;
– в таблице не может быть 2-х одинаковых строк. Если вспомнить математику, то такие таблицы называют отношениями (relation). Именно поэтому данные БД и считаются реляционными;
– каждый столбец в пределах таблицы имеет уникальное имя, а все значения в одном столбце должны быть одного типа (дата, текст, число и т. п.);
– на пересечении строки и столбца может быть только атомарное значение (значение, не состоящее из группы значений). Таблицы, которые удовлетворяют этим условиям, считаются нормализованными.
Приведём пример
Допустим, вы хотите создать базу данных для интернет-форума. На форуме есть зарегистрированные пользователи, создающие темы и оставляющие сообщения в данных темах. Вся эта информация и должна размещаться в базе данных.
В теории всё можно расположить в одной таблице, а именно:
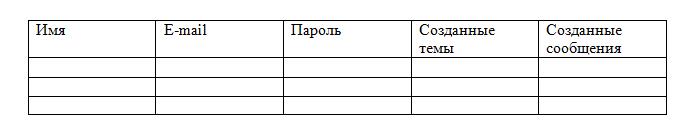
Однако такое расположение противоречит атомарности, причём в столбцах «Созданные сообщения» и «Созданные темы» возможно неограниченное число значений. Целесообразнее всего разбить таблицу на три:
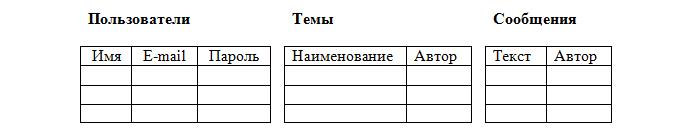
Теперь таблица «Пользователи» соответствует правилам. Но вот таблицы «Сообщения» и «Темы» — нет, т. к. не должно быть 2-х одинаковых строк. В нашем же случае один и тот же пользователь может написать 2 одинаковых сообщения:
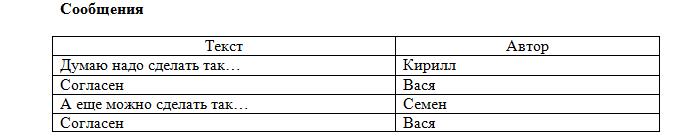
А ещё давайте вспомним о том, что каждое сообщение должно относиться к какой-нибудь теме. Для решения этого вопроса в реляционных базах данных используют ключи.
Ключи в БД
Первичный ключ (РК, primary key) — столбец, значения которого различны во всех строках. РК бывают логические (естественные) и суррогатные (искусственные).
Например, для таблицы «Пользователи» первичным ключом может быть столбец e-mail, т. к. не бывает 2-х пользователей с одним и тем же e-mail.
На практике для хранения и обработки данных рекомендуют применять суррогатные ключи (их использование позволит абстрагировать РК от реальных данных). Это важно, если пользователь, вдруг, сменит e-mail, а ведь первичные ключи нельзя менять.
Суррогатный ключ — это дополнительное поле в БД. Обычно это уникальный id (порядковый номер записи), хотя принцип может быть и другой, главное — уникальность.
Вносим первичные ключи в наши таблицы:

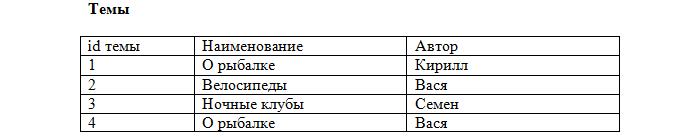
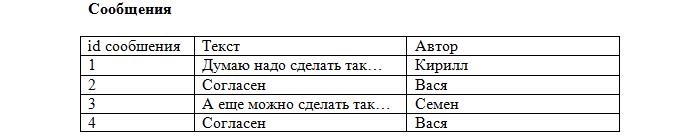
Заметьте, что каждая запись в таблице уникальна. Осталось лишь установить соответствие между сообщениями и темами, используя первичные ключи. Добавляем в таблицу с сообщениями ещё одно поле:

Теперь становится ясно, что сообщение id=2 относится к теме «О рыбалке» (id=4), которая создана Васей, а остальные принадлежат теме «О рыбалке», созданной Кириллом (id=1). Такое поле будет называться внешний ключ (FK, foreign key). При этом каждое значение данного поля сопоставляется с каким-либо первичным ключом из таблицы «Темы». В результате устанавливается однозначное соответствие между темами и сообщениями.
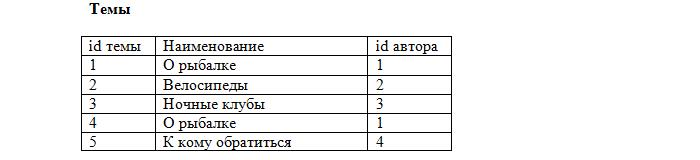
Ещё момент: допустим, добавляется новый пользователь по имени Вася.

Как узнать, какой же из «Васей» оставил сообщение? Для этого поля «Автор» в наших таблицах «Сообщения» и «Темы» мы тоже сделаем внешними ключами:

Итак, наша база данных фактически готова. Схематично она выглядит так:
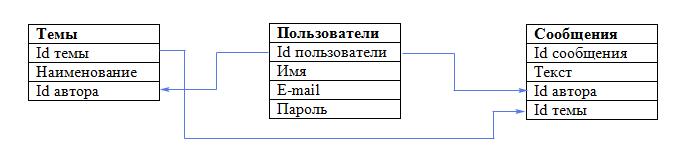
В этой небольшой базе данных лишь 3 таблицы. А что делать, если их 10 либо 200? Ясно, что всё не так просто. Именно поэтому любое проектирование реляционных баз данных начинается с разработки концептуальной модели данных.
Концептуальная модель базы данных
Под концептуальной моделью понимают отражение предметной области для разрабатываемой базы данных. Если не вдаваться в теорию, то речь идёт о некой диаграмме с общепринятыми обозначениями:
– вещи обозначаются прямоугольниками;
– атрибуты объекта овалами;
– связи в таблицах ромбами;
– мощность и направление связей стрелками (одинарными, двойными).
Простой пример — интернет-магазин. В нём есть товары, поставляемые поставщиками и заказываемые покупателями. Это три объекта и две связи:

Делая поставку, поставщик подтверждает её документами. Аналогично и с покупателем. Таким образом, и поставку, и покупку можно рассматривать в качестве самостоятельных объектов.
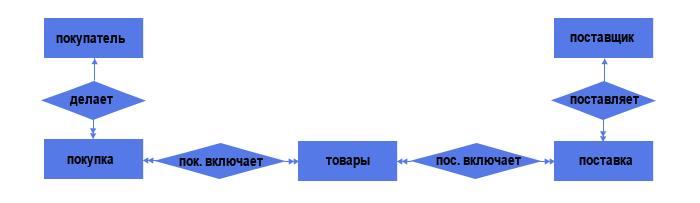
Итого 5 объектов и 4 связи. Из них:
– 2 связи типа «один ко многим» (один поставщик может делать несколько поставок; один покупатель может делать несколько покупок);
– 2 связи типа «многие ко многим» (каждая поставка может включать несколько товаров, причём одинаковый товар может быть в нескольких поставках; аналогичная ситуация по линии «Покупка — Товар»).
Но давайте вспомним, что связи типа «многие ко многим» недопустимы в реляционных моделях данных, поэтому такие связи надо менять на связи типа «один ко многим». Делаем это, добавляя промежуточный объект:
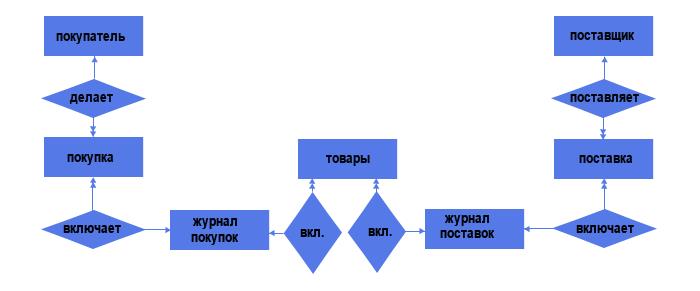
Видим, что в структуре появились ещё 2 объекта — «Журнал поставок» и «Журнал покупок» со связями типа «один ко многим» (каждый журнал может включать несколько поставок/покупок, но каждая поставка/покупка включает лишь один журнал).
Атрибуты таблицы
Каждый объект интернет-магазина имеет свои атрибуты:
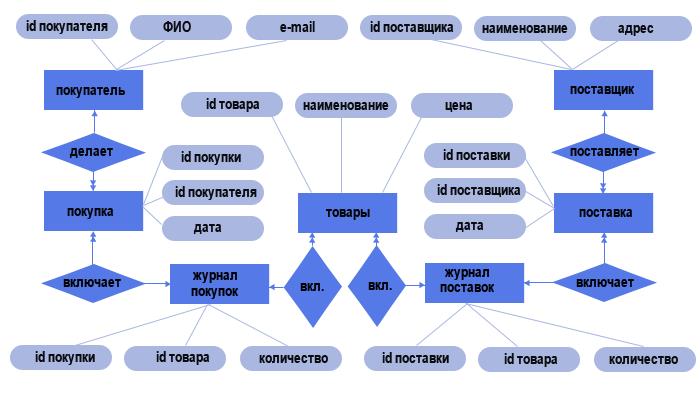
В результате мы создали концептуальную модель будущей базы данных. Точнее говоря, речь идёт лишь о части БД, т. к. мы не учли склады, сотрудников и т. п. Собственно, при обширной предметной области данные лучше разбить на несколько локальных областей. Как правило, объём должен быть в пределах 5-7 объектов. И лишь после создания локальных моделей выполняется их объединение в общую сложную схему. В нашем случае ограничимся созданной моделью. Однако теперь давайте преобразуем её в реляционную модель данных.
Проектирование реляционной базы данных. Преобразование модели в реляционную
Преобразование концептуальной модели данных в реляционную — важная часть проектирования БД. Процесс включает в себя:
– построение набора предварительных таблиц;
– указание РК;
– выполнение нормализации.
Из набора таблиц состоят наши объекты, а из полей таблиц — атрибуты объектов:
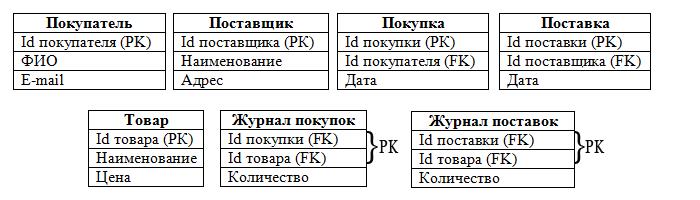
Итак, мы определились с таблицами, полями, РК и FK. Следует отметить, что в таблицах «Журнал покупок» и «Журнал поставок» РК составные, т. к. состоят из 2-х полей.
Что касается нормализации, то под ней понимают обратимый и пошаговый процесс, при котором исходная схема меняется другой схемой, в которой таблицы характеризуются более простой и логичной структурой. Это нужно по следующим причинам:
1. Устранение избыточности данных. Вспомним нашу таблицу:

Очевидно, что в поле «Темы» одни и те же названия встречаются регулярно. Для хранения таких данных нужны дополнительные ресурсы памяти. Кроме того, при дублировании данных можно допустить ошибку во время ввода значений атрибута, вследствие которой БД перейдёт в состояние несогласованности.
2. Устранение различных аномалий, связанных с обновлением, удалением, модификацией и пр. Пример аномалии модификации — чтобы поменять название темы, нам придётся смотреть все строки и менять название в каждой из них.
Нормализация бывает:
– 1-й нормальной формы (1НФ);
– 2НФ;
– 3НФ;
– НФБК (нормальной формы Бойса-Кодда);
– 4НФ;
– 5НФ.
Каждая форма накладывает определённые ограничения на данные разного уровня. В ходе нормализации база данных становится всё строже, подверженность аномалиям снижается.
Если говорить о реляционных базах данных, то минимум — это 1НФ. Однако в процессе проектирования специалисты по СУБД стремятся нормализовать базу хотя бы до уровня 3НФ, исключив тем самым избыточность данных и аномалии. Это важно, если мы стремимся получить качественный результат проектирования. Однако подробное описание нормализации данных выходит за рамки нашей статьи, поэтому давайте просто посмотрим, как будет выглядеть наша база на уровне 3НФ:
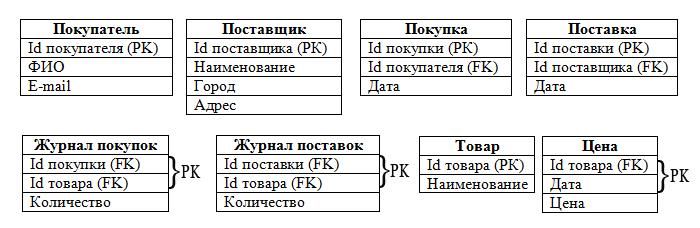
Итак, в процессе проектирования мы преобразовали концептуальную модель в реляционную. Следующий этап — реализация её в конкретной СУБД. Для этого потребуется как сама СУБД, так и знание языка SQL. Например, прекрасно подойдёт СУБД MySQL или какая-нибудь другая СУБД.
Подводим итоги проектирования
Проектирование БД — процесс небыстрый и достаточно трудоёмкий. Во время проектирования надо хорошо знать предметную область, учитывать все нюансы. Вся информация должна отображаться в виде таких элементов, как объекты, атрибуты, связи, причём проектирование успешно лишь тогда, когда всё сделано максимально рационально.
Вообще, взгляды на проектирование среди разработчиков могут различаться. Некоторые игнорируют теорию, руководствуясь лишь опытом и здравым смыслом. Другие во время проектирования отводят главную роль интуиции, считая проектирование искусством, которым владеют далеко не все. Как бы там ни было, знания никогда не бывают лишними.
Да, реляционная база данных — это не более чем хранилище, где хранятся данные. Однако от того, как грамотно вы его организуете, будет зависеть стабильность работы всего приложения, где используются эти самые данные.
В заключение, добавим, что умение проектировать базы вам никогда не помешает. А научиться всему этому вы сможете на нашем курсе «Реляционные СУБД». Ждём вас!

Концептуальная модель базы данных это
Концептуальная модель базы данных это некая наглядная диаграмма, нарисованная в принятых обозначениях и подробно показывающая связь между объектами и их характеристиками. Создается концептуальная модель для дальнейшего проектирования базы данных и перевод ее, например, в реляционную базу данных. На концептуальной модели в визуально удобном виде прописываются связи между объектами данных и их характеристиками.
Принятые определения в концептуальной базе данных
Для единообразия программирования баз данных введены следующие понятия для концептуальных баз данных:
- Объект или сущность. Это фактическая вещь или объект (для людей) за которой пользователь (заказчик) хочет наблюдать. Например, Иванов Иван Иванович;
- Атрибут это характеристика объекта, соответствующая его сущности. Например. Задаем себе вопрос: Какую информацию нужно хранить об Иванове Иване Ивановиче? Ответы на этот вопрос и будут атрибуты объекта Иванов Иван Иванович;
- Третье понятие в проектировании концептуальной базы данных это связь или отношения между объектами.
Лексически более правильно говорить связь между объектами КБД и отношения между сущностями КБД (концептуальная база данных), но встретить можно самые различные сочетания сущности, объекта, связи и отношения (огрехи переводов).
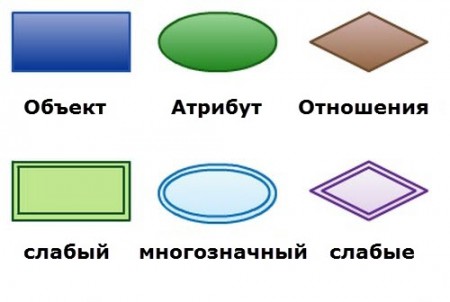
Концептуальная модель базы данных: принятые графические обозначения
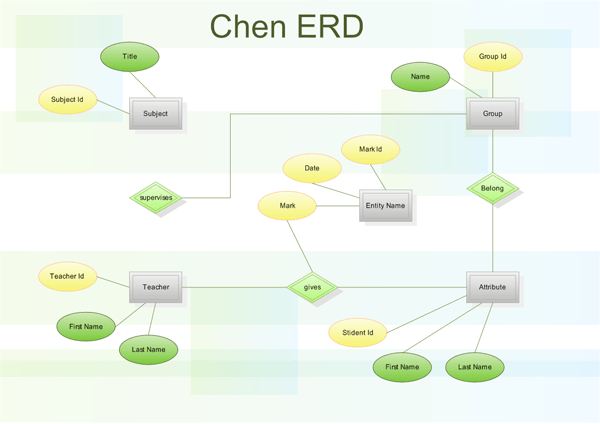
Диаграмма сущность/отношения (объект/связь) называют ER-диаграммой или EDR (entity-relationship diagram). Сама модель сущность-связь была предложена профессором Peter Pin-Shen Chen (Питер Чен) в 1976 году. Правила написания и условные обозначения ER-диаграммы называют нотацией. Распространены две основные нотации ER-диаграмм:
- Нотация Питера Чена;
- Нотация Gordon Everest (Гордона Эверста). Под назаванием Crow’s Foot или Fork (вилка).
Обозначения ER-диаграммы по Питеру Чену
Чен предложил и это приняли следующие условные обозначения для ER-диаграмм:
- Сущность или объект обозначать прямоугольником;
- Отношения обозначать ромбом;
- Атрибуты объектов, обозначаются овалом;
- Если сущность связана с отношением, то их связь обозначается прямой линией со стрелкой. Необязательная связь обозначается пунктирной линией. Мощная связь обозначается двойной линией.
Каждый атрибут может быть связан с одним объектом (сущностью).
Нотация Gordon Everest
Gordon Everest ввел новое обозначение связей, которые получили название вилка или воронья лапа. Также он ввел, что объект должен обозначаться прямоугольником с названием типа объекта в виде имени существительного внутри прямоугольника. Причем, это имя должно быть уникальным в пределах создаваемой базы данных.
Атрибуты не выделяются в отдельную фигуру, а вписываются в прямоугольник объекта именем существительным с уточняющим словом.
Связь между объектами обозначается прямой линией. Множественные связи обозначаются вилкой на конце. Сама связь подписывается глаголом, типа «Включает» или «Принадлежит».
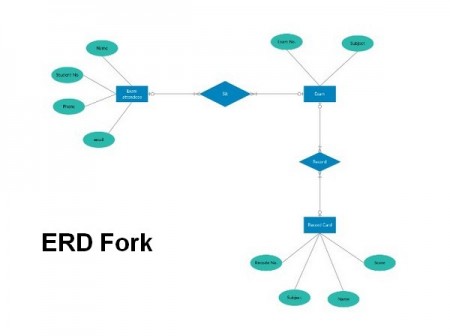
Дополнения
Атрибуты в ER диаграмме, могут иметь свои собственные атрибуты (композитный) атрибут.
Как нарисовать ER-диаграмму-советы
Простую ER диаграмму нарисовать достаточно просто. Другое дело насыщенная, объемная ER диаграмма. Ниже приведены некоторые советы, которые помогут вам построить эффективные ER схемы:
- Определите все объекты в данной системе и определите отношения между этими объектами;
- Объект должен появиться только один раз в определенном месте схемы;
- Определите точное и подходящее имя для каждого объекта, атрибута и отношений в диаграмме. Выберите простые и понятные слова. Условия, которые просты и знакомы всегда побеждает смутные, технические звучащие слова. Для объектов имена существительные, для связей глаголы (можно с пояснениями). Не забываем про уникальность имен объектов;
- Удалите неявные, избыточные или ненужные отношения между объектами;
- Никогда не подключайте отношения к другим отношениям;
- Используйте цвета, чтобы классифицировать однотипные объекты или выделить ключевые области в диаграмме.
©WebOnTo.ru
Другие статьи раздела: СУБД
Похожие статьи:
В качестве примера спроектируем несложную базу данных информационной системы кинотеатра. При этом, решим следующие задачи:
- анализ предметной области для определения состава и содержания информации, обрабатываемой информационной системой, а также пользовательских потребностей;
- построение концептуальной модели предметной области, заключающееся в выявлении сущностей и связей между ними, а также отображение этой информации в виде ER-диаграммы;
- физическое проектирование базы данных и ее реализация в MS SQL Server.
1 Анализ предметной области
Зачастую, кинотеатр состоит из нескольких залов разной конфигурации, а посетителю предоставляется возможность выбора билета, для этого ему отображается текущее состояние зала. Выбранные места посетитель сообщает кассиру, который вводит их в систему и места помечаются как «проданные». Это «основной» сценарий использования информационной системы, однако надо учесть следующее:
- репертуар и расписание проката кинотеатра должен кто-то вносить в систему — соответствующую роль назовем «Менеджер»;
- посетитель и кассир должны иметь возможность просматривать расписание, при этом интересно расписание, начиная с некоторого момента времени (например, текущего времени). Составлять оно может по-разному:
- расписание показа всех фильмов, упорядоченное по времени;
- расписание прокатов в отдельных залах кинотеатра;
- расписание проката определенного фильма.
Из этого описания понятны основные функции системы, изображенные на рисунке с помощью нотации диаграммы прецедентов UML. На диаграмме не отображена роль администратора базы данных, так как администратор обычно взаимодействует с системой не через интерфейс, а через выполнение SQL-запросов.

Несмотря на то, что мы не будет разрабатывать интерфейс информационной системы и текстовые описания прецедентов, дальше нас будут интересовать данные, необходимые для выполнения того или иного прецедента, а для этого надо выделить и описать сущности. Иначе, невозможно определить «какие данные должен вводить менеджер при добавлении фильма». Основные сущности, данные которых потребуются во время работы, показаны на рисунке, при этом используется нотация диаграммы классов UML. Каждый прямоугольник соответствует одной сущности, внутри записаны поля и типы данных.

Каждая сущность, кроме hall_row содержит поле id, которое идентифицирует объект. У сущности hall_row поле id не нужно, так как в одном и том же зале кинотеатра (id_hall) не могут повторяться номера рядов (number).
Когда пользователь выберет зал и прокат — система должна отобразить заполненность зала, при этом надо отобразить конфигурацию зала с пометкой занятых и свободных мест. Под конфигурацией зала тут имеется ввиду, что разные залы имеют разный размер, а ряды зала могут иметь различное количество мест. Поэтому в базе данных зал (hall) составляется из рядов (hall_row), одним из параметров которых является вместимость (capacity).
2 Построение концептуальной модели
Выше были отображены основные сущности, но не отображены роли пользователей, хотя их тоже должна хранить система. Они показаны ниже на ER-диаграмме в нотации Чена [1].

На диаграмме выделены роли кассира и менеджера, а также основные отношения между сущностями. На диаграмме нет роли администратора, но его роль заключается в:
- создании всех таблиц базы;
- добавлении залов и рядов в них;
- добавлении кассиров и менеджеров.
На диаграмме не отражена роль посетителя, так как:
- билет не содержит информации о том, кто его купил (посетитель может подарить билет другу);
- система вообще не хранит информацию о посетителях;
- покупку билета он осуществляет через общение с кассиром вне системы;
- никакие данные в базе посетитель самостоятельно изменить не может.
На диаграмме проставлены кратности связей, например, видно, что один менеджер может добавить много (N) прокатов. В этой базе не оказалось связей типа N:M, сложных или рекурсивных связей — такие связи являются препятствиями в проектировании и решаются изменением ее структуры.
Для формирования схемы данных необходимо сначала дополнить ER-диаграмму реквизитами сущностей (уточнить ее) — результат приведен на рисунке.

В ходе анализа этой диаграммы были найдены несколько недочетов, допущенных при выделении сущностей системы:
- система не должна позволять продавать несколько билетов на одно и то же место при одном показе фильма. Это значит, что вторичным ключем для Билета должен быть кортеж (id_screening, row, seat). Однако, тогда нет необходимости в id билета — на билеты не ссылается ни одна таблица, это поле может быть удалено. Изначально id был добавлен потому, что обычно на билетах в кинотеатрах печатается номер;
- билет хранит поле id_hall, это было сделано для того, чтобы посетитель кинотеатра мог найти свой кинозал. Однако, билет, выдаваемый пользователю — это не тоже самое, что информация о билетах, хранимая в базе данных. Билет базы данных хранит также поле id_screening, а Показ уже ссылается на id_hall. Таким образом, в базе нет смысла хранить id_hall в таблице билетов.
Исправленная ER-диаграмма приведена ниже:

Таблица менеджеров и кассиров не объединены в таблицу Users так как вопросы разграничения прав доступа в различных СУБД решаются по-разному. Так, в MS SQL пользователи добавляются с помощью специальных запросов типа:
CREATE LOGIN Manager_Name WITH PASSWORD='Some Passwrd';
при этом вообще нет необходимости хранить информацию об их логинах и паролях в таблицах. Однако, вопросы разграничения доступа решаются позже — на этапе физического проектирования.
3 Физическое проектирование
ER-диаграмма отражает основные таблицы, связи и атрибуты, на ее основе можно построить модель БД. На ER-диаграммы нет стандарта, но есть ряд нотаций (Чена, IDEFIX, Мартина и т.п.) [2], но на модель предметной области не удалось найти ни стандарта, ни нотаций. Однако, в ходе построения такой диаграммы обязательно выделяются ключевые поля (внешние и внутренние), иногда — индексы и типы данных. Схема базы данных, приведенная на рисунке, выполнена с использованием открытого инструмента plantuml [3], при этом:
- для связей используется нотация Мартина («вороньи лапки»);
- таблицы изображены прямоугольниками, разделенными на 3 секции:
- имя таблицы;
- внутренние ключи (помечаются маркером);
- остальные поля, при этом обязательные поля помечаются маркером.

3.1 Составление и нормализация реляционных отношений
Схема отношения «Билеты» (tickets):
|
Наименование поля |
Тип поля |
Размер поля |
Значение по умолчанию |
Ограничения |
Ключ или индекс |
|
id_screening |
int |
4 |
|
обязательное поле |
первичный ключ (составной) |
|
row |
smallint |
2 |
— |
обязательное поле |
первичный ключ (составной) |
|
seat |
smallint |
2 |
— |
обязательное поле |
первичный ключ (составной) |
Схема отношения «Прокаты» (screening):
|
Наименование поля |
Тип поля |
Размер поля |
Значение по умолчанию |
Ограничения |
Ключ или индекс |
|
id |
int |
4 |
|
обязательное поле |
Первичный ключ, уникальный |
|
hall_id |
int |
4 |
— |
обязательное поле |
Внешний ключ к hall |
|
film_id |
int |
4 |
— |
обязательное поле |
Внешний ключ к film |
|
time |
datetime |
8 |
— |
обязательное поле |
— |
Схема отношения «Кинозалы» (hall):
|
Наименование поля |
Тип поля |
Размер поля |
Значение по умолчанию |
Ограничения |
Ключ или индекс |
|
id |
int |
4 |
|
обязательное поле |
первичный ключ |
|
name |
varchar |
100 |
— |
обязательное поле |
первичный ключ |
Схема отношения «Ряд кинозала» (hall_row):
|
Наименование поля |
Тип поля |
Размер поля |
Значение по умолчанию |
Ограничения |
Ключ или индекс |
|
id_hall |
int |
4 |
|
обязательное поле |
первичный ключ (составной) |
|
number |
smallint |
2 |
— |
обязательное поле |
первичный ключ (составной) |
|
capacity |
smallint |
2 |
— |
обязательное поле |
— |
Схема отношения «Фильмы» (film):
|
Наименование поля |
Тип поля |
Размер поля |
Значение по умолчанию |
Ограничения |
Ключ или индекс |
|
id |
int |
4 |
|
обязательное поле |
первичный ключ |
|
name |
varchar |
255 |
— |
обязательное поле |
— |
|
description |
varchar |
2000 |
NULL |
необязательное поле |
— |
При выборе типов данных и описании их размеров использовалась документация [4]. Для ряда полей, где известно что значениями будут целые числа в небольшом диапазоне используется тип smallint. Для строковых полей используется varchar, однако мог бы использоваться и тип char, критично это только для поля film.description. Дело в том, что описания фильмов бывают длинными, поэтому при создании таблицы надо указать заранее «достаточный» размер поля, например 2000 символов. Однако, согласно документации, при использовании типа char, под все описания фильмов будет выделено 2000 символов, а при использовании varchar более короткие описания будут потреблять меньше памяти — ровно столько, сколько необходимо.
Разработанная схема БД находится в:
- первой нормальной форме, так как в качестве доменов выступают только скалярные значения и информация в таблицах не дублируется. Почти во всех таблицах есть идентификатор (id), а в остальных — в качестве первичного ключа выступает кортеж (набор полей);
- во второй и третьей нормальных формах, так как каждый не ключевой атрибут неприводимо и нетранзитивно зависит от первичного ключа. Для всех таблиц нашей БД это очевидно — количество мест в ряду зависит только от пары (номер зала, номер ряда) и никаким другим образом вывести его из информации в базе нельзя.
Таким образом, схема базы данных находится в нормальной форме Бойса-Кодда [5].
3.2 Инсталляция MS SQL Server и создание пустой базы
Был скачан и проинсталлирован MS SQL Server 2014 [6], так как работа выполнялась на 32х-разрядном компьютере, а более новые версии программы не поддерживают такую архитектуру. При установке была выбрана «Установка нового изолированного экземпляра SQL Server» с параметрами по умолчанию. Как показано на рисунке, при установке задано имя экземпляра «my_project».

В результате, на компьютер была установлена программа SQL Server Management Studio, внутри которой выбирается имя сервера, как показано ниже:

После выбора сервера в обозревателе объектов отобразились компоненты сервера, в том числе вкладка «базы данных». В контекстом меню был выбран пункт добавления базы, в качестве имени указано «my_db», как показано на рисунке:

3.3 Формирование таблиц
После создания базы данных в обозревателе объектов появилась возможно добавить в базу данных таблицы. На рисунке ниже показан процесс добавления таблицы hall — видно, что указываются имена полей и их типы, а для ключевого поля указано «начальное значение» и «шаг приращения».

Ключевые поля добавляются в таблицы с помощью контекстоного меню, выпадающего после клика по полю правой кнопкой. Однако, для таблиц с составными и внешними ключами, например hall_row сделать это через графический интерфейс не получилось. В нем были созданы только заготовки таблиц, для них были сгенерированы скрипты T-SQL и дополнены соответствующими параметрами. Для генерации T-SQL скрипта для таблицы в меню выбирается «создать скрипт для таблицы -> используя DROP и CREATE». Сгенерированные скрипты были поправлены, в результате получено следующее:
USE [my_db]
GO
DROP TABLE [dbo].[hall_row]
GO
DROP TABLE [dbo].[tickets]
GO
DROP TABLE [dbo].[screening]
GO
DROP TABLE [dbo].[hall]
GO
DROP TABLE [dbo].[film]
GO
CREATE TABLE [dbo].[film](
id int IDENTITY(1,1) NOT NULL,
name varchar(255) NOT NULL,
description varchar(2000) NOT NULL,
CONSTRAINT [PK_film] PRIMARY KEY CLUSTERED
(
id ASC
)
)
GO
CREATE TABLE [dbo].[hall](
id int IDENTITY(1,1) NOT NULL,
name nvarchar(100) NOT NULL,
CONSTRAINT [PK_hall] PRIMARY KEY CLUSTERED
(
id ASC
)
)
GO
CREATE TABLE [dbo].[screening](
id int IDENTITY(1,1) NOT NULL,
hall_id int NOT NULL,
film_id int NOT NULL,
time datetime NOT NULL,
FOREIGN KEY (hall_id) REFERENCES hall (id),
FOREIGN KEY (film_id) REFERENCES film (id),
CONSTRAINT [PK_screening] PRIMARY KEY CLUSTERED
(
id ASC
)
)
GO
CREATE TABLE [dbo].[hall_row](
id_hall int NOT NULL,
number smallint NOT NULL,
capacity smallint NOT NULL,
FOREIGN KEY (id_hall) REFERENCES hall (id),
CONSTRAINT [PK_hall_row] PRIMARY KEY CLUSTERED
(
id_hall, number
)
)
GO
CREATE TABLE [dbo].[tickets](
id_screening int NOT NULL,
row smallint NOT NULL,
seat smallint NOT NULL,
cost int NOT NULL,
FOREIGN KEY (id_screening) REFERENCES screening (id),
CONSTRAINT [PK_ticket] PRIMARY KEY CLUSTERED
(
id_screening, row, seat
)
)
GO
Измененный скрипт был запущен в MS SQL Management Studio, в результате были обновлены таблицы. Затем, на их основе сгенерирована схема базы данных:

3.4 Наполнение базы
Для наполнения базы был создан такой запрос (приведен фрагмент):
INSERT INTO [dbo].[film] (name, description)
VALUES ('Багратион', '«Багратион» — советский двухсерийный историко-биографический фильм 1985 года о жизни прославленного российского полководца Петра Ивановича Багратиона — героя Отечественной войны 1812 года. Совместное производство «Грузия-фильм» и «Мосфильм». Режиссёры Гиули Чохонелидзе и Караман Мгеладзе. Премьера — декабрь 1985 года. ')
INSERT INTO [dbo].[hall] (name) VALUES ('красный зал')
INSERT INTO [dbo].[hall] (name) VALUES ('желтый зал')
INSERT INTO [dbo].[hall] (name) VALUES ('синий зал')
INSERT INTO [dbo].[hall_row] (id_hall ,number ,capacity) VALUES (1, 1, 10)
INSERT INTO [dbo].[hall_row] (id_hall ,number ,capacity) VALUES (1, 2, 15)
INSERT INTO [dbo].[hall_row] (id_hall ,number ,capacity) VALUES (1, 3, 20)
INSERT INTO [dbo].[screening] (hall_id ,film_id, time) VALUES (1, 1, '20210101 10:35:00 AM')
INSERT INTO [dbo].[screening] (hall_id ,film_id, time) VALUES (1, 1, '20210101 00:00:00 AM')
INSERT INTO [dbo].[screening] (hall_id ,film_id, time) VALUES (1, 2, '20210101 1:35:00 PM')
INSERT INTO [dbo].[tickets] (id_screening ,row ,seat ,cost) VALUES (1, 2, 3, 150)
INSERT INTO [dbo].[tickets] (id_screening ,row ,seat ,cost) VALUES (1, 3, 3, 200)
INSERT INTO [dbo].[tickets] (id_screening ,row ,seat ,cost) VALUES (1, 3, 5, 150)
% ...
Запрос выполняется успешно, а результаты его выполнения проверялись с помощью SELECT-запросов:

3.5 Проектирование наиболее востребованных запросов
Как отмечалось в разделе 1, при продаже билета посетитель кинотеатра устно передает кассиру номер и место. Кассир вводит эти данные в систему, которая не должна позволить продать билеты на несуществующие места. Для этого программа-клиент кассира должна получить вместимость ряда конкретного зала. Чтобы получить количество мест во втором ряду третьего зала надо выполнить запрос:
SELECT capacity FROM hall_row WHERE id_hall = 3 AND number = 2
программа клиент получит набор строк, соответствующих условию запросу. Если запрос выполнился успешно — в этом наборе всегда будет одна строка, иначе — пустое множество строк.
Затем, программа-клиент должна проверить не продано ли это место. Для этого можно выполнить отдельный SELECT, но можно попробовать выполнить INSERT INTO и если место было ранее продано — запрос завершится с ошибкой, ведь на таблицу билетов наложены соответствующие ограничения.
Чтобы сформировать расписание показов фильмов, прокатываемых с определенного момента (обычно в запрос будет поставляться текущее время) можно использовать такой запрос:
SELECT * FROM film, screening WHERE time > '20210101 11:00:00 AM' AND screening.film_id = film.id;
в данном случае в запросе используется две таблицы, которые связываются по идентификатору. Выбираются названия фильмов, показ которых начинается после 11 часов 01.01.2021. Результат выполнения запроса:

Для получения расписания проката в конкретном зале кинотеатра надо добавить в запрос связь с третьей таблицей и ограничения на эту таблицу:
SELECT film.name, hall.id, screening.time FROM film, screening, hall WHERE time > '20210101 11:00:00 AM' AND screening.film_id = film.id AND screening.hall_id = hall.id AND hall.id = 2;
При соединении нескольких таблиц в вывод попадают лишние столбцы, чтобы этого избежать в приведенном запросе явно указаны интересующие нас столбцы — название фильма, номер зала и время.
Для получения расписания проката конкретного фильма — можно вставить в запрос его идентификатор:
SELECT film.name, hall.name, screening.time FROM film, screening, hall WHERE time > '20210101 11:00:00 AM' AND screening.film_id = film.id AND screening.hall_id = hall.id AND film.id = 2;
Если вдруг нас интересуют фильмы, названия которых соответствует определенному шаблону — можно использовать оператор LIKE. Так, приведенный ниже запрос выбирает все фильмы, прокатываемые с определенного момента, названия которых начинаются с символа 'Б', шаблон '%' задает в T-SQL любое количество любых символов.
SELECT film.name, hall.name, screening.time FROM film, screening, hall WHERE time > '20210101 11:00:00 AM' AND screening.film_id = film.id AND screening.hall_id = hall.id AND film.name LIKE 'Б%';
Чтобы вывести расписание прокатов, упорядоченное по залу и дате нужно применить конструкцию ORDER BY:
SELECT film.name, hall.name, screening.time FROM film, screening, hall WHERE time > '20210101 11:00:00 AM' AND screening.film_id = film.id AND screening.hall_id = hall.id ORDER BY hall.name, screening.time;
Список полезной литературы
- Учимся проектированию Entity Relationship — диаграмм // Хабр URL: https://habr.com/ru/post/440556/ (дата обращения: 02.01.2021).
- Технологии баз данных. Лекция 3. Модель «Сущность-связь». URL: https://docplayer.ru/27886777-Model-sushchnost-svyaz-tehnologii-baz-dannyh-lekciya-3.html (дата обращения: 02.01.2021).
- Entity Relationship Diagram. URL: https://plantuml.com/ru/ie-diagram (дата обращения: 03.01.2021).
- Transact-SQL Reference (Database Engine) // Microsoft Docs URL: https://docs.microsoft.com/ru-ru/sql/t-sql/language-reference?view=sql-server-ver15 (дата обращения: 05.01.2021).
- Нормализация отношений. Шесть нормальных форм // Хабр URL: https://habr.com/ru/post/254773/ (дата обращения: 05.01.2021).
- Материалы для скачивания по SQL Server // Microsoft URL: https://www.microsoft.com/ru-ru/sql-server/sql-server-downloads (дата обращения: 05.01.2021).
- Другой пример проектирования базы данных (MySQL). URL: https://pro-prof.com/forums/topic/db_example
Концептуальная модель – это отражение предметной области, для которой разрабатывается база данных. Не вдаваясь в теорию, отметим,
что это некая диаграмма с принятыми обозначениями элементов. Так, все объекты, обозначающие вещи, обозначаются в виде прямоугольника.
Атрибуты, характеризующие объект – в виде овала, а связи между объектами – ромбами. Мощность связи обозначаются стрелками
(в направлении, где мощность равна многим – двойная стрелка, а со стороны, где она равна единице – одинарная).
Давайте в качестве примера рассмотрим интернет-магазин. У магазина есть товары, которые поставляются поставщиками и
покупаются покупатели. Это можно представить тремя объектами и двумя связями:

Но как поставщик поставляет товары? Он делает поставку, которая подтверждается документом. Аналогично и покупатель делает
покупку, которая также может подтверждаться документом. Таким образом, поставка и покупка могут рассматриваться, как самостоятельные
объекты:

Теперь у нас пять объектов и четыре связи. Две связи “один ко многим” (один поставщик может осуществить несколько поставок, но
каждая поставка осуществляется только одним поставщиком, аналогично и для связи Покупатель – Покупка) и две связи “многие ко
многим” (каждая поставка может содержать несколько товаров, а один и тот же товар может содержаться в нескольких поставках,
аналогично и для связи Покупка – Товар).
Но связи “многие ко многим” недопустимы в реляционной модели, поэтому каждую такую связь надо заменить на две связи “один
ко многим”. Делается это добавлением промежуточного объекта:

Таким образом, у нас появилось еще два объекта – журнал покупок и журнал поставок, со связями “один ко многим” (один журнал
поставок может включать несколько поставок, но каждая поставка может входить только в один журнал, аналогично и для остальных).
Каждый объект нашего магазина имеет свои атрибуты:

Вот собственно мы и создали концептуальную модель базы данных магазин, вернее ее части, ведь в магазине еще есть сотрудники, склады,
доставка товаров и т.д.
Вообще, если предметная область обширная, то ее полезно разбить на несколько локальных предметных областей
(наша концептуальная модель отражает именно локальную предметную область). Объем локальной области выбирается таким образом, чтобы
в нее входило не более 6-7 объектов. После создания моделей каждой выделенной предметной области производится объединение
локальных концептуальных моделей в одну общую, как правило, довольно сложную схему.
Для наших учебных целей, мы ограничимся созданной моделью. Теперь нашу концептуальную модель надо преобразовать в реляционную
модель данных, т.е. в уже известные нам таблицы, поля, ключи и т.д. Этим мы и займемся на следующем уроке.
Предыдущий урок
Вернуться в раздел
Следующий урок
Научись программировать на Python прямо сейчас!
- Научись программировать на Python прямо сейчас
- Бесплатный курс
Если этот сайт оказался вам полезен, пожалуйста, посмотрите другие наши статьи и разделы.
|
|
Код кнопки: |

Теперь нажмите кнопку, что бы не забыть адрес и вернуться к нам снова.
Концептуальная
модель
отражает ИЛМ предметной области с учетом
ограничений, которые накладывает
конкретная СУБД. При преобразовании
ИЛМ в концептуальную модель БД
проектировщики должны обеспечить
возможность реализации всех функциональных
связей, определенных в ИЛМ и удовлетворить
все требования по обработке информации.
Поэтому, прежде чем приступить к
логическому проектированию базы данных,
необходимо изучить особенности
реляционных СУБД и уточнить ограничения,
которые они налагают на концептуальную
модель БД.

Рис.2.2
Для реляционной
модели БД ограничениями СУБД могут
быть: 1) общее количество отношений. 2)
количество столбцов таблицы (мерность
отношения) и др.
Этап построения
концептуальной модели обычно
декомпозируется на следующие подэтапы:
1) построение
начального варианта реляционной модели;
2) устранение
дублирования информации в отношениях;
3) составление
схемы базы данных.
/.
Построение
начального варианта реляционной модели.
Из
рис.2.2 видно, что ИЛМ является иерархической,
т.е. многоуровневой. Первоначально
необходимо представить рассматриваемую
информационно-логическую модель одним
отношением, в которое сведем все атрибуты
по объекту учета “Слушатели” и по
объекту “Дисциплина”.
2.
Устранение дублирования информации в
отношениях.
Анализ
полученной таблицы позволяет сделать
вывод, что использовать это
отношение в качестве завершенного
нельзя. Это обусловлено дублированием
данных, которое состоит в том, что одна
и та же фамилия слушателя может встречаться
в нескольких строках (кортежах).
Дублирование данных приводит к проблеме
удаления существующих кортежей. Например,
если необходимо удалить информацию из
базы данных по имеющемуся в таблице
слушателю Петрову, то в отношении
“Слушатели” должны быть удалены
все кортежи, относящиеся к Петрову.
Дублирование
создает также трудности с обновлением
значений атрибутов в отношениях. Пример,
в случае изменения формы отчетности на
новую необходимо скорректировать
значения формы отчетности во всех
картежах, относящихся к дисциплине.
Корректировка одного значения приведет
к противоречивости данных в базе данных.
Наличие повторяющейся
информации приводит также к неоправданному
увеличению размера базы данных . В
результате чего снижается оперативность
выполнения запросов и нерационально
используется память на магнитном диске.
В процессе разработки
базы данных должны быть выявлены такие
отношения и исключена необходимость
дублирования значений атрибутов и
отношений.
Устранение
дублирования информации
в
базе данных
называется нормализацией.
В теории нормализации баз данных
разработаны достаточно формальные
подходы по устранению этого недостатка
в реляционных БД, эти вопросы излагаются
в специальной литературе.
Теория нормализации
оперирует с пятью нормальными формами
таблиц. При практическом проектировании
баз данных используется, как правило,
первая нормальная форма.
Таблица в первой
нормальной форме должна удовлетворять
следующим требованиям:
1.
В отношении
должны отсутствовать повторяющиеся
значения атрибутов.
-
Отношение не
должно иметь повторяющихся записей. -
Строки и столбцы
должны быть не упорядочены
Рассмотрим
удовлетворение первого
требования.
Основным путем устранения повторяющихся
значений в ненормализованном отношении
является размещение данных в нескольких
отношениях. Для этого выявляются
атрибуты, в которых существует избыточность
данных. С этой целью приведем анализ
записей по любому слушателю. Дублирование
здесь получается за счет атрибутов,
определяющих обучение различным
дисциплинам. Такими атрибутами являются
форма отчетности, кафедра, телефон. На
основе этого можно сделать вывод, что
в самостоятельное отношение необходимо
вынести информацию о дисциплинах. Анализ
других записей показывает, что причиной
дублирования информации являются
атрибуты, характеризующие домашний
адрес. Исходя из сказанного в самостоятельное
отношение необходимо включить
перечисленные выше атрибуты. Таким
образом, исходное отношение разбивается
на три отношения. Каждая запись в первом
отношении будет содержать сведения об
одном из слушателей, а во втором –
информацию о дисциплинах, которыми он
занимался в процессе обучения.
Что
бы удовлетворить второе
требование
необходимо иметь первичный ключ. Для
отношения “Слушатели” в качестве
ключа целесообразно использовать
несколько атрибутов “Ф.И.О.” т к.
вероятность совпадения этих атрибутов
у двух слушателей чрезвычайно мала.
Третье
требование
выполняется для обеих таблиц, т. к записи
в таблицах не упорядочены.
После тою как
выполнили все требования, считается
что отношение находится в 1 НФ.
Анализ содержания
отношения показывает, что избавиться
от избыточности в полном объеме не
удалось, а именно, в поле “код”
таблицы наименование кафедры повторяется
столько раз, сколько будет отчетностей
по ней.
3.
Составление
схемы базы данных.
Схема
базы данных разрабатывается на входном
языке конкретной СУБД. В качестве
входного языка предлагается использовать
язык СУБД Access,
которая функционирует как в локальных
вычислительных сетях, так и на отдельных
ПЭВМ.
__________________________«
» 200__г.
Соседние файлы в папке ЗАДАНИЕ
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
