Библиографическая ссылка:
Столяров А.И. Построение концептуальной схемы баз данных // Портал научно-практических публикаций [Электронный ресурс]. URL: https://portalnp.snauka.ru/2014/06/2064 (дата обращения: 24.02.2023)
Столяров Александр, студент 2 курса, направление подготовки прикладная информатика
ФГБОУ ВПО Федеральное государственное бюджетное образовательное учреждение высшего профессионального образования «МГТУ имени Носова»
Аннотация
В статье даётся определение базы данных и понятия концептуальной модели. Рассматриваются основные компоненты, относящиеся к концептуальной модели, этапы её создания, а так же её значение и применение.
Develop a conceptual database model
Stolyarov Alexandr, 2nd year student, specialty Applied Informatics,
Magnitogorsk State Technical University of a name Nosov
Annotation
The article defines database concepts and conceptual model. The basic components related to the conceptual model, the stages of its creation, as well as its meaning and application.
§1. База Данных и её проектирование
База данных – это объединение взаимосвязанных данных при малой крайней избыточности, допускающей их рациональное использование в различной областях человеческой деятельности. Это модель, позволяющая сохранять информацию о наборе объектов, обладающих сходной группой свойств, в определенном порядке.
В зависимости от способа описания данных и отношений между ними, базы данных могут иметь реляционную, сетевую или иерархическую структуры.
Реляционная база данных является множеством взаимосвязанных таблиц, которые содержат информацию об объектах определенного вида. Строка таблицы, называемая записью, содержит данные об одном объекте (компьютере, сотруднике и т. д.), а столбцы таблицы содержат какие-либо характеристики этих объектов – атрибуты (адрес клиента, IP-адрес компьютера и так далее.).
Иерархические базы данных представляются графически перевернутым деревом, состоящим из объектов, относящимся к различным уровням. 1-й уровень занимает один объект, 2-й – объекты второго уровня и т. д. Между объектами существуют связи. Объекты в иерархической структуре находятся в отношении предка к потомку. Объекты, которые имеют общего предка, называют близнецами.
Сетевая модель организует данные в виде сетевой структуры. Структура называется сетевой, если в отношениях между данными порожденный элемент имеет более одного исходного.
На эффективность базы данных с различными структурами влияют условия её применения. Реляционные базы данных широко используется в документах и отчётах, поскольку они удобны и позволяют наглядно представлять различного рода данные.
Можно выделить несколько этапов проектирования БД:
1. Концептуальное проектирование – это сбор, анализ, редактирование требований к данным. Осуществляют следующие мероприятия:
a. исследование предметной области и изучение ее структуры;
b. выявление всех фрагментов, характеризующиеся пользовательским представлением атак же информационными объектами и связями между ними, процессами над информационными объектами;
c. интеграция атак же моделирование всех представлений.
По окончании этого этапа получаем концептуальную модель. Обычно она представляет собой модели “сущность-связь”.
2. Логическое проектирование – это преобразование требований к данным в структуры данных. На выходе получаем СУБД-ориентированную структуру базы данных. На этом этапе создают модель базы данных применительно к конкретным СУБД и проводят сравнительный анализ моделей.
3. Физическое проектирование – это определение особенностей хранения данных и методов доступа к ним.
§2. Концептуальная модель и её основные определения.
Создание семантической модели предметной области является начальной стадией проектирования системы баз данных, в основе которой лежит анализ свойств объектов предметной области и информационных потребностей тех, кто будет эксплуатировать систему. Эта стадия называется концептуальным проектированием системы, а ее результат – концептуальной моделью предметной области. Объектом моделирования является предметная область будущей системы.
Концептуальная модель – модель предметной области, состоящей из перечня связанных понятий, используемых для описания области, вместе со свойствами и характеристиками, классификацией этих понятий, по видам, ситуациям, признакам в данной области и алгоритмов протекания процессов в ней.
Есть две понятийные области в концептуальной модели. Каждая из них построена по принципу иерархии. 1-я область – это дерево типов данных, 2-я – дерево данных.
Дадим основные определения:
Уровень упрощения – уровень детализации представления об объекте реального мира для его описания и последующей эксплуатации. Для того чтобы максимально полно представить объект и использовать на практике представления о нем нам предельно упростить объект реального мира.
Свойство объекта – информация о характеристике реального мира, которую мы будем хранить в базе данных.
События – совокупность реакций объекта на изменения внешней среды, описанных в базе данных.
Тип – совокупность свойств и событий объекта, описанных как единая группа.
Объект – группа типов и свойств, объединенных в один тип, достаточный для описания объекта реального мира.
Связь – свойство типа или свойства типа, характеризующее взаимосвязь типов в дереве данных а так же способ изменения значения свойства объектного типа. Различают три вида связей:
1. включение в дереве данных,
2. вставка из другого типа значения свойства.
3. ссылка на экземпляр типа в дереве данных. Включение позволяет строить дерево данных.
Наследование – это способ описания дерева типов. Вы можете описать тип транспорт, от которого наследовать типы: грузовой автомобиль, трамвай, самолёт и т.д. При этом поддерживается полиморфизм (свойство, которое позволяет одно и то же имя использовать для решения двух или более схожих, но технически разных задач).
§ 3. Создание концептуальной модели.
Целью концептуального проектирования является построение концептуальной модели данных в основе которой лежат представления о предметной области каждого отдельного типа пользователей. Концептуальная модель являет собой описание основных сущностей и связей между ними без учета принятой модели БД и синтаксиса конечной СУБД. Как правило на такой модели отображаются только имена сущностей, не указывая их атрибутов. Представление пользователя включает в себя данные, необходимые конкретному пользователю для принятия решений или выполнения задания.
Ниже рассматривается последовательность шагов при концептуальном проектировании:
1. Выделение сущностей.
Заключается в определении главных объектов, которые могут интересовать пользователя и должны храниться в БД. При наличии функциональной модели IDEF0 прообразами таких объектов являются входы, управления и выходы. Так же для этих целей можно использовать DFD. Прообразами объектов в этом случае будут накопители данных. Накопитель данных является совокупностью таблиц или непосредственно таблицей. Возможные трудности в определении объектов связаны с использованием постановщиками задачи:
– примеров и аналогий при описании объектов;
– синонимов;
– омонимов.
Каждая сущность должна обладать следующими свойствами:
– должна иметь уникальное имя;
– обладать одним или несколькими атрибутами, которые либо принадлежат сущности, либо наследуются через связь;
– обладать одним или несколькими атрибутами, которые делают уникальной каждую строку таблицы;
– обладать произвольным количеством связей с другими сущностями.
2. Определение атрибутов.
Выявленные атрибуты могут быть следующих видов:
– простой (или атомарный, неделимый) – состоящий из одного компонента с независимым существованием;
– составной (псевдоатомарный) – состоящий из нескольких компонентов;
– однозначный – содержащий только одно значение для одного экземпляра;
– многозначный – содержащий несколько значений;
– производный (или вычисляемый) – значение атрибута может быть определено по значениям других атрибутов;
– ключевой – служащий для уникальной идентификации экземпляра сущности;
– неключевой (или описательный) – не входящий в первичный ключ;
– обязательный – при вводе нового экземпляра в сущность или редактировании обязательно указывается допустимое значение атрибута. После редактирования оно не может быть неопределенным (NOT NULL).
После определения атрибутов задаются их домены, иначе говоря, области допустимых значений.
Задание доменов определяет набор допустимых значений, тип, размер и формат атрибута.
Ключ – один или несколько атрибутов сущности, служащих для однозначной идентификации ее экземпляров или для их быстрого поиска. Выделяют следующие типы ключей:
– суперключ (superkey) – это атрибут или множество атрибутов, идентифицирующий экземпляр сущности;
– потенциальный ключ (potential key) – это суперключ, не содержащий подмножества, являющегося суперключом данной сущности;
– первичный ключ (primary key) – это потенциальный ключ, выбранный для идентификации экземпляров;
– альтернативные ключи (alternative key) – это потенциальные ключи, не выбранные в качестве первичного ключа;
– внешний ключ (foreign key) — это столбец или сочетание столбцов, применяемые для принудительного установления связи между данными в двух таблицах.
3. Определение связей.
Наиболее типичными видами связей между сущностями являются:
– связи типа «часть–целое»;
– классифицирующие связи;
– производственные связи;
– функциональные связи, определяемые глаголами.
Внешний вид связи на диаграммах IDEF1X указывает на ее мощность, тип и обязательность.
4. Определение суперклассов и подклассов.
Когда две и более сущности по набору атрибутов отличаются друг от друга, применяется иерархия наследования, включающая в себя суперклассы и подклассы.
Суперкласс – сущность, включающая в себя подклассы.
Иерархия наследования создается, когда несколько сущностей имеют общие по смыслу атрибуты и связи.
Так же для каждой категории указывается дискриминатор – атрибут родового предка, показывающий, как отличить одну сущность от другой.
Иерархии категорий можно разделить на два типа: неполные и полные.
Полная категория: одному экземпляру родового предка обязательно соответствует экземпляр в каком-либо потомке.
Неполная категория: из за того, что категория еще не выстроена полностью и в родовом предке могут существовать экземпляры, не имеющие соответствующих экземпляров в потомках.
§4. Значение
Моделирование предметных областей выполняется с разными целями, например для реинжиниринга бизнесс-процессов, для прогнозирования развития предметной области, при проектировании баз данных и программного обеспечения и т.п.
Концептуальная модель имеет множество преимуществ:
Продумывание концептуальной модели вынуждает рассматривать только наиболее важные задачи. Поэтому создаются продукты, наиболее полно поддерживающие задачи пользователя.
Создание списка всех объектов и действий даёт возможно сть обнаруживать действия, общие у некоторых объектов, что позволяет унифицировать интерфейс при работе с похожими объектами.
Словарь пользователя помогает достичь целостности в терминологии.
Прописывание вариантов использования и создание базовых контекстных сценариев помогает не только в проектировании интерфейса программы, но и в подготовке функционального тестирования.
Источники
- «Киберфорум»URL-Доступ: http://citforum.ru/cfin/prcorpsys/infsistpr_09.shtml
- Создание схемы данных для сервера Oracle с помощью AllFusion Data Modeler Махмутова М.В., Махмутов Г.Р. Сборник научных трудов Sworld. 2010. Т. 3. № 2. С. 58a-61.
- Концептуальные модели данных. Модель «сущность-связь». Сущности, атрибуты, связи. Сущности-связи и мощности связей. Примеры.[Электронный ресурс] E-educ.ru – заботясь об образовании; URL-Доступ: http://e-educ.ru/bd12.html
- Разработка информационной модели URL-Доступ: http://edu.dvgups.ru/METDOC/GDTRAN/YAT/ITIS/PROEK_INF_SIS/METOD/UMK_DO/frame/UMK_DO/M4/L7.htm
- Концепции и терминология для концептуальной схемы и информационной базы [Текст]: ГОСТ 34.320 96; Введ. 03.10.1996
Количество просмотров публикации: –
Проектирование
структуры базы данных начнем с построения
концептуальной модели. Концептуальная
модель представляет собой высокоуровневый
взгляд на предметную область. На данном
этапе не учитывается модель данных и
физические аспекты представления и
хранения данных, проектирование одинаково
для любой базы данных.
Одним
из самых распространённых способов
проектирования базы данных является
построение модели «сущность-связь»,
также известных как ER-модели (англ.
entity-relationship model). Модель, построенная
таким образом, называется ER-диаграммой.
В данной курсовой работе для этой цели
используется нотация «Crow’s Foot».
Моделирование
с использованием модели «сущность-связь»
предполагает:
-
выделение
в предметной области важных сущностей; -
описание
их атрибутов и взаимосвязей.
Связи
характеризуют в том числе мощность
отношений между объектами сущностей.
Наиболее важными типами таких отношений
являются функциональные бинарные
отношения:
-
«один-к-одному»,
-
«один-ко-многим»,
-
и
«многие-ко-многим».
При
рассмотрении предметной обрасти
деятельности туристических агентств
можно выделить семь информационных
сущностей:
-
Страны;
-
Города;
-
Виды
транспорта; -
Туристы;
-
Отели;
-
Туры;
-
Путевки.
Опишем
детально предназначение каждой сущности
и ее атрибутов.
Сущность
«Страны».
Отвечает
за хранение перечня стран мира, в которые
совершаются туристические туры. Важным
атрибутом этой сущности является
«Название страны».
Сущность
«Города».
Отвечает
за хранение перечня городов, в которые
совершаются туристические туры. Важными
атрибутами этой сущности являются:
-
Название
города; -
Название
страны, которой принадлежит город.
Атрибут
сущности «Название страны» имеет связь
«один-ко-многим» с сущностью «Страны».
Сущность
«Виды транспорта».
Отвечает
за хранение перечня видов транспорта,
которым туристы доставляются от
транспортных развязок к отелям. Важным
атрибутом этой сущности является
«Название транспорта».
Сущность
«Туристы».
Отвечает
за хранение перечня туристов, которые
совершили туристические туры. Важными
атрибутами этой сущности являются:
-
ФИО
туриста; -
Возраст.
Сущность
«Отели».
Отвечает
за хранение перечня отелей, которые
принимают туристов на отдых. Важными
атрибутами этой сущности являются:
-
Название
отеля; -
Класс
обслуживания; -
Суточная
плата за проживание в отеле; -
Название
города, где размещен отель.
Атрибут
сущности «Название города» имеет связь
«один-ко-многим» с сущностью «Города».
Сущность
«Туры».
Отвечает
за хранение перечня туров в отелях, с
указанием продолжительности заезда.
Важными атрибутами этой сущности
являются:
-
Название
тура; -
Продолжительность;
-
Описание;
-
Вид
транспорта для доставки туристов в
отель.
Атрибут
сущности «Вид транспорта» имеет связь
«один-ко-многим» с сущностью « Виды
транспорта».
Сущность
«Путевки».
Основная
сущность информационной системы,
хранящая информацию о распределении
туристов по отелям и заездам. Важными
атрибутами этой сущности являются:
-
Дата
вылета на отдых; -
Тур;
-
Отель;
-
Турист.
Атрибут
сущности «Тур» имеет связь «один-ко-многим»
с сущностью «Туры».
Атрибут
сущности «Отель» имеет связь
«один-ко-многим» с сущностью «Отели».
Атрибут
сущности «Турист» имеет связь
«один-ко-многим» с сущностью «Туристы».
Построенная
ER-модель в графической нотации «Crow’s
Foot» представлена на рис. 3.
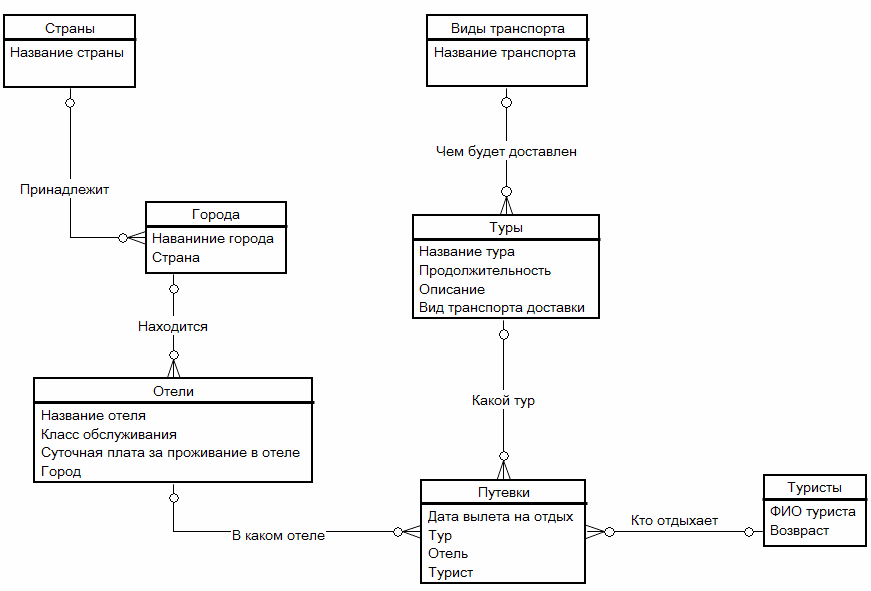
Рис.
3. ER-модель информационной системы
Таким
образом, при помощи модели «сущность-связь»
на высоком уровне проанализирована
предметная область, выявлены её важнейшие
сущности, а также их атрибуты и характер
взаимосвязей. Результат представлен в
соответствующей графической нотации.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Концептуальная модель базы данных это
Концептуальная модель базы данных это некая наглядная диаграмма, нарисованная в принятых обозначениях и подробно показывающая связь между объектами и их характеристиками. Создается концептуальная модель для дальнейшего проектирования базы данных и перевод ее, например, в реляционную базу данных. На концептуальной модели в визуально удобном виде прописываются связи между объектами данных и их характеристиками.
Принятые определения в концептуальной базе данных
Для единообразия программирования баз данных введены следующие понятия для концептуальных баз данных:
- Объект или сущность. Это фактическая вещь или объект (для людей) за которой пользователь (заказчик) хочет наблюдать. Например, Иванов Иван Иванович;
- Атрибут это характеристика объекта, соответствующая его сущности. Например. Задаем себе вопрос: Какую информацию нужно хранить об Иванове Иване Ивановиче? Ответы на этот вопрос и будут атрибуты объекта Иванов Иван Иванович;
- Третье понятие в проектировании концептуальной базы данных это связь или отношения между объектами.
Лексически более правильно говорить связь между объектами КБД и отношения между сущностями КБД (концептуальная база данных), но встретить можно самые различные сочетания сущности, объекта, связи и отношения (огрехи переводов).
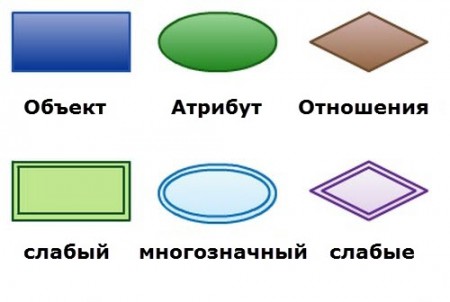
Концептуальная модель базы данных: принятые графические обозначения
Диаграмма сущность/отношения (объект/связь) называют ER-диаграммой или EDR (entity-relationship diagram). Сама модель сущность-связь была предложена профессором Peter Pin-Shen Chen (Питер Чен) в 1976 году. Правила написания и условные обозначения ER-диаграммы называют нотацией. Распространены две основные нотации ER-диаграмм:
- Нотация Питера Чена;
- Нотация Gordon Everest (Гордона Эверста). Под назаванием Crow’s Foot или Fork (вилка).
Обозначения ER-диаграммы по Питеру Чену
Чен предложил и это приняли следующие условные обозначения для ER-диаграмм:
- Сущность или объект обозначать прямоугольником;
- Отношения обозначать ромбом;
- Атрибуты объектов, обозначаются овалом;
- Если сущность связана с отношением, то их связь обозначается прямой линией со стрелкой. Необязательная связь обозначается пунктирной линией. Мощная связь обозначается двойной линией.
Каждый атрибут может быть связан с одним объектом (сущностью).
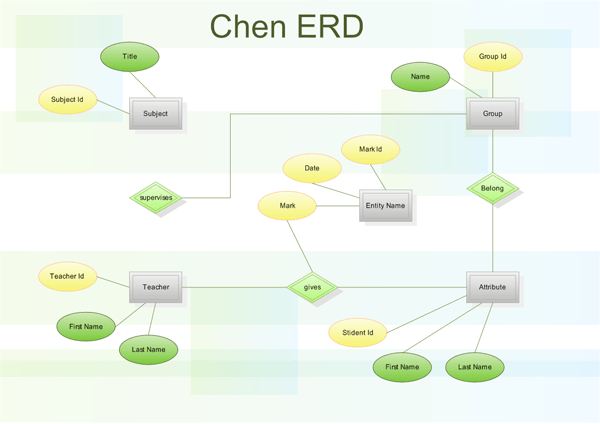
Нотация Gordon Everest
Gordon Everest ввел новое обозначение связей, которые получили название вилка или воронья лапа. Также он ввел, что объект должен обозначаться прямоугольником с названием типа объекта в виде имени существительного внутри прямоугольника. Причем, это имя должно быть уникальным в пределах создаваемой базы данных.
Атрибуты не выделяются в отдельную фигуру, а вписываются в прямоугольник объекта именем существительным с уточняющим словом.
Связь между объектами обозначается прямой линией. Множественные связи обозначаются вилкой на конце. Сама связь подписывается глаголом, типа «Включает» или «Принадлежит».
Дополнения
Атрибуты в ER диаграмме, могут иметь свои собственные атрибуты (композитный) атрибут.
Как нарисовать ER-диаграмму-советы
Простую ER диаграмму нарисовать достаточно просто. Другое дело насыщенная, объемная ER диаграмма. Ниже приведены некоторые советы, которые помогут вам построить эффективные ER схемы:
- Определите все объекты в данной системе и определите отношения между этими объектами;
- Объект должен появиться только один раз в определенном месте схемы;
- Определите точное и подходящее имя для каждого объекта, атрибута и отношений в диаграмме. Выберите простые и понятные слова. Условия, которые просты и знакомы всегда побеждает смутные, технические звучащие слова. Для объектов имена существительные, для связей глаголы (можно с пояснениями). Не забываем про уникальность имен объектов;
- Удалите неявные, избыточные или ненужные отношения между объектами;
- Никогда не подключайте отношения к другим отношениям;
- Используйте цвета, чтобы классифицировать однотипные объекты или выделить ключевые области в диаграмме.
©WebOnTo.ru
Другие статьи раздела: СУБД
Похожие статьи:
From Wikipedia, the free encyclopedia
A conceptual schema or conceptual data model is a high-level description of informational needs underlying the design of a database.[citation needed] It typically includes only the main concepts and the main relationships among them. Typically this is a first-cut model, with insufficient detail to build an actual database. This level describes the structure of the whole database for a group of users. The conceptual model is also known as the data model that can be used to describe the conceptual schema when a database system is implemented.[citation needed] It hides the internal details of physical storage and targets on describing entities, datatypes, relationships and constraints.
Overview[edit]
A conceptual schema is a map of concepts and their relationships used for databases. This describes the semantics of an organization and represents a series of assertions about its nature. Specifically, it describes the things of significance to an organization (entity classes), about which it is inclined to collect information, and its characteristics (attributes) and the associations between pairs of those things of significance (relationships).
Because a conceptual schema represents the semantics of an organization, and not a database design, it may exist on various levels of abstraction. The original ANSI four-schema architecture began with the set of external schemata that each represents one person’s view of the world around him or her. These are consolidated into a single conceptual schema that is the superset of all of those external views. A data model can be as concrete as each person’s perspective, but this tends to make it inflexible. If that person’s world changes, the model must change. Conceptual data models take a more abstract perspective, identifying the fundamental things, of which the things an individual deals with are just examples.
The model does allow for what is called inheritance in object oriented terms. The set of instances of an entity class may be subdivided into entity classes in their own right. Thus, each instance of a sub-type entity class is also an instance of the entity class’s super-type. Each instance of the super-type entity class, then is also an instance of one of the sub-type entity classes.
Super-type/sub-type relationships may be exclusive or not. A methodology may require that each instance of a super-type may only be an instance of one sub-type. Similarly, a super-type/sub-type relationship may be exhaustive or not. It is exhaustive if the methodology requires that each instance of a super-type must be an instance of a sub-type. A sub-type named “Other” is often necessary.
Example relationships[edit]
- Each PERSON may be the vendor in one or more ORDERS.
- Each ORDER must be from one and only one PERSON.
- PERSON is a sub-type of PARTY. (Meaning that every instance of PERSON is also an instance of PARTY.)
- Each EMPLOYEE may have a supervisor who is also an EMPLOYEE.
Data structure diagram[edit]

A data structure diagram (DSD) is a data model or diagram used to describe conceptual data models by providing graphical notations which document entities and their relationships, and the constraints that bind them.
See also[edit]
- Concept mapping
- Conceptual framework
- Conceptual graphs
- Conceptual model (computer science)
- Data modeling
- Entity-relationship model
- Object-relationship modelling
- Object-role modeling
- Knowledge representation
- Logical data model
- Mindmap
- Ontology
- Physical data model
- Semantic Web
- Three schema approach
References[edit]
Further reading[edit]
- Perez, Sandra K., & Anthony K. Sarris, eds. (1995) Technical Report for IRDS Conceptual Schema, Part 1: Conceptual Schema for IRDS, Part 2: Modeling Language Analysis, X3/TR-14:1995, American National Standards Institute, New York, NY.
- Halpin T, Morgan T (2008) Information Modeling and Relational Databases, 2nd edn., San Francisco, CA: Morgan Kaufmann.
External links[edit]
- A different point of view, as described by the agile community
Основано на этих лекциях.
Основы проектирования баз данных.
Традиционно процедуру проектирования базы данных разбивают на три этапа, каждый из которых завершается созданием соответствующей информационной модели.
Этап 1-й. Концептуальное проектирование – создание схемы БД, включающего определение важнейших сущностей (таблиц) и связей между ними, но не зависящего от модели БД (иерархической, сетевой, реляционной и т.д.) и физической реализации (целевой СУБД).
Этап 2-й. Логическое проектирование – развитие концептуальной схемы БД с учетом принимаемой модели (иерархической, сетевой, реляционной и т.д.).
Этап 3-й. Физическое проектирование – развитие логической схемы БД с учетом выбранной целевой СУБД.
Концептуальное и логическое проектирование вместе называют также инфологическим или семантическим проектированием.
В настоящее время для проектирования БД активно используются CASE-средства, в основном ориентированные на использование ERD (Entity – Relationship Diagrams, диаграммы «сущность–связь»). С их помощью определяются важные для предметной области объекты (сущности), отношения друг с другом (связи) и их свойства (атрибуты). Следует отметить, что средства проектирования ERD в основном ориентированы на реляционные базы данных (РБД), и если существует необходимость проектирования другой системы, скажем объектно-ориентированной, то лучше избрать другие методы проектирования.
ERD были впервые предложены П. Ченом в 1976 г. Основные элементы ERD перечислены ниже.
Сущность (таблица, в РБД – отношение) – набор (класс) однотипных реальных либо воображаемых объектов, имеющих существенное значение для рассматриваемой предметной области, информация о которых подлежит хранению. Примеры сущностей: работник, деталь, ведомость, результаты сдачи экзамена и т.д.
Экземпляр сущности (запись, строка, в РБД – кортеж) – уникально идентифицируемый объект.
Связь – некоторая ассоциация между двумя сущностями, значимая для рассматриваемой предметной области. Примерами связей могут являться родственные отношения «отец–сын», производственные – «начальник-подчиненный» или произвольные – «иметь в собственности», «обладать свойством».
Атрибут (столбец, поле) – свойство сущности или связи.
При использовании CASE-средств вначале обычно строится логическая схема БД в виде диаграммы с указанием сущностей и связей между ними. Логической схемой называется универсальное описание структуры данных, независимое от конечной реализации базы данных и аппаратной платформы. На основании полученной логической схемы переходят к физической схеме данных. Физическая схема представляет собой диаграмму, содержащую всю необходимую информацию для генерации БД для конкретной СУБД или даже конкретной версии СУБД. Если в логической схеме не имеет значения, какие идентификаторы носят таблицы и атрибуты, тип данных атрибутов и т.д., то в физической схеме должно быть полное описание БД в соответствии с принятым в ней синтаксисом, с указанием типов атрибутов, триггеров, хранимых процедур и т.д. По одной и той же логической схеме можно создать несколько физических. Например, на основании логической схемы сформировать физические для промышленных СУБД (ORACLE, MySQL, DB2, MS SQL Server и др.) и их различный версий. На основании физической схемы можно сгенерировать либо саму БД или DDL-скрипт, который, в свою очередь, может быть использован для генерации БД.
Система управления базами данных, СУБД — система (базирующаяся на программном и аппаратном обеспечении) для описания, создания, использования, контроля и управления базами данных.
Упрощённо: программное средство, управляющее базами данных.
Стоит отметить важный для начинающих факт (т.к. очень часто можно услышать просьбу «показать СУБД»): подавляющее большинство СУБД не имеет никакого «человеческого интерфейса», представляет собой сервис (демон в *nix-системах) и взаимодействует с внешним миром по специальным протоколам (чаще всего, построенным поверх TCP/IP). Такие известные продукты как MySQL Workbench, Microsoft SQL Server
Management Studio, Oracle SQL Developer и им подобные — это не СУБД, это лишь клиентское программное обеспечение, позволяющее нам взаимодействовать с СУБД.
Следует отметить, что современные СУБД обладают своими встроенными средствами визуального моделирования данных. Некоторые из них даже поддерживают классические нотации ERD. Недостатками такого моделирования является построение только физической схемы данных и невозможность быстрого перехода на другую СУБД, если такое решение принято. Достоинством этого подхода является более полное использование потенциала СУБД, ведь разработчики СУБД лучше других знают ее особенности и возможности.
Концептуальное проектирование
Цель концептуального проектирования – создание концептуальной схемы данных на основе представлений о предметной области каждого отдельного типа пользователей. Концептуальная схема представляет собой описание основных сущностей (таблиц) и связей между ними без учета принятой модели БД и синтаксиса целевой СУБД. Часто на такой схеме отображаются только имена сущностей (таблиц) без указания их атрибутов. Представление пользователя включает в себя данные, необходимые конкретному пользователю для принятия решений или выполнения некоторого задания.
Ниже рассматривается последовательность шагов при концептуальном проектировании.
-
Выделение сущностей.
Первый шаг в построении концептуальной схемы данных состоит в определении основных объектов (сущностей), которые могут интересовать пользователя и, следовательно, должны храниться в БД.
Возможные трудности в определении объектов связаны с использованием постановщиками задачи:
-
примеров и аналогий при описании объектов (например, вместо обобщающего понятия «работник» они могут упоминать его функции или занимаемую должность: «руководитель», «ответственный», «контролер», «заместитель»);
-
синонимов (например, «допускаемая скорость» и «установленная скорость», «разработка» и «проект», «барьерное место» и «ограничение скорости»);
-
омонимов (например, «программа» может обозначать компьютерную программу, план предстоящей работы или программу телепередач).
Далеко не всегда очевидно то, чем является определенный объект – сущностью, связью или атрибутом. Например, как следует классифицировать «семейный брак»? На практике это понятие можно вполне обоснованно отнести к любой из упомянутых категорий. Анализ является субъективным процессом, поэтому различные разработчики могут создавать разные, но вполне допустимые интерпретации одного и того же факта. Выбор варианта в значительной степени зависит от здравого смысла и опыта проектировщика.
Каждая сущность должна обладать некоторыми свойствами:
-
должна иметь уникальное имя, и к одному и тому же имени должна всегда применяться одна и та же интерпретация;
-
обладать одним или несколькими атрибутами, которые либо принадлежат сущности, либо наследуются через связь;
-
обладать одним или несколькими атрибутами (первичным ключом), которые однозначно идентифицируют каждый экземпляр сущности, т. е. делают уникальной каждую строку таблицы;
-
может обладать любым количеством связей с другими сущностями.
В графической нотации IDEF1X для отображения сущности используются обозначения, изображенные на следующем рисунке.
-
-
Определение атрибутов.
Самый простой способ определения атрибутов – после идентификации сущности, задать себе вопрос «Какую информацию требуется хранить о …?». Существенно помочь в определении атрибутов могут различные бумажные и электронные формы и документы, используемые в организации при решении задачи. Это могут быть формы, содержащие как исходную информацию (например, «Ведомость возвышений наружного рельса в кривых»), так и результаты обработки данных (например, «Форма № 1»).
Выявленные атрибуты могут быть следующих типов:
-
простой (атомарный, неделимый) – состоит из одного компонента с независимым существованием (например, «должность работника», «зарплата», «норма непогашенного ускорения», «радиус кривой» и т.д.);
-
составной (псевдоатомарный) – состоит из нескольких компонентов (например, «ФИО», «адрес» и т. д.). Степень атомарности атрибутов, закладываемая в модель, определяется разработчиком. Если от системы не требуется выборки всех клиентов с фамилией Иванов или проживающих на улице Комсомольской, то составные атрибуты можно не разбивать на атомарные;
-
однозначный – содержит только одно значение для одного экземпляра сущности (например, у кривой в плане может быть только одно значение радиуса, угла поворота, возвышения наружного рельса и т.д.);
-
многозначный – содержит несколько значений (например, у одного отделения компании может быть несколько контактных телефонов);
-
производный (вычисляемый) – значение атрибута может быть определено по значениям других атрибутов (например, «возраст» может быть определен по «дате рождения» и текущей дате, установленной на компьютере);
-
ключевой – служит для уникальной идентификации экземпляра сущности (входит в состав первичного ключа), быстрого поиска экземпляров сущности или задания связи между экземплярами родительской и дочерней сущностей;
-
неключевой (описательный);
-
обязательный – при вводе нового экземпляра в сущность или редактировании обязательно указывается допустимое значение атрибута, т.е. после указанных действий оно не может быть неопределенным (NOT NULL). Атрибуты, входящие в первичный ключ сущности, являются обязательными.
После определения атрибутов задаются их домены (области допустимых значений), например:
-
наименование участка – набор из букв русского алфавита длиной не более 60 символов;
-
поворот кривой – допустимые значения «Л» (влево) и «П» (вправо);
-
радиус кривой – положительное число не более 4 цифр.
Задание доменов определяет набор допустимых значений для атрибута (нескольких атрибутов), а также тип, размер и формат атрибута (атрибутов).
-
-
Определение ключей.
На основании выделенного множества атрибутов для сущности определяется набор ключей. Ключ – один или несколько атрибутов сущности, служащих для однозначной идентификации её экземпляров, их быстрого поиска или задания связи между экземплярами родительской и дочерней сущностей. Ключи, используемые для однозначной идентификации экземпляров, подразделяются на следующие типы:
-
суперключ (superkey) – атрибут или множество атрибутов, которое единственным образом идентифицирует экземпляр сущности. Суперключ может содержать «лишние» атрибуты, которые необязательны для уникальной идентификации экземпляра. При правильном проектировании структуры БД суперключом в каждой сущности (таблице) будет являться полный набор ее атрибутов;
-
потенциальный ключ (potential key) – суперключ, содержащий минимально необходимый набор атрибутов, единственным образом идентифицирующих экземпляр сущности. Сущность может иметь несколько потенциальных ключей. Если ключ состоит из нескольких атрибутов, то он называется составным ключом. Среди всего множества потенциальных ключей для однозначной идентификации экземпляров выбирают один, так называемый первичный ключ, используемый в дальнейшем для установления связей с другими сущностями;
-
первичный ключ (primary key) – потенциальный ключ, который выбран для уникальной идентификации экземпляров внутри сущности;
-
альтернативные ключи (alternative key) – потенциальные ключи, которые не выбраны в качестве первичного ключа.
Рассмотрим пример. Пусть имеется таблица, содержащая сведения о студенте, со следующими столбцами:
- фамилия;
- имя;
- отчество;
- дата рождения;
- место рождения;
- номер группы;
- ИНН;
- номер пенсионного страхового свидетельства (НПСС);
- номер паспорта;
- дата выдачи паспорта;
- организация, выдавшая паспорт.
Для каждого экземпляра (записи) в качестве суперключа может быть выбран весь набор атрибутов. Потенциальными ключами (уникальными идентификаторами) могут быть:
- ИНН;
- номер пенсионного страхового свидетельства;
- номер паспорта.
В качестве уникального идентификатора можно было бы выбрать совокупность атрибутов «Фамилия»+«Имя»+«Отчество», если вероятность учебы в вузе двух полных тезок была бы равна нулю.
Если в сущности нет ни одной комбинации атрибутов, подходящей на роль потенциального ключа, то в сущность добавляют отдельный атрибут – суррогатный ключ (искусственный ключ, surrogate key). Как правило, тип такого атрибута выбирают символьный или числовой. В некоторых СУБД имеются встроенные средства генерации и поддержания значений суррогатных ключей. Также стоит отметить, что некоторые разработчики вместо поиска потенциальных ключей и выбора из них первичного в каждую сущность добавляют искусственный атрибут, который в дальнейшем и используют в качестве первичного ключа.
Если потенциальных ключей несколько, то для выбора первичного ключа рекомендуется придерживаться следующих правил:
-
количество атрибутов, входящих в ключ, должно быть минимальным (желательно, чтобы ключ был атомарным, т.е. состоял из одного атрибута);
-
размер ключа в байтах должен быть как можно короче;
-
тип домена ключа – числовой. При выборе символьных атрибутов в ключ часто возникают проблемы с вводом ошибочных значений (путают регистр букв; добавляют лишние пробелы; используют буквы, пишущиеся на разных языках одинаково). В числовых атрибутах вероятность ошибки при вводе значения меньше;
-
вероятность изменения значений ключа была наименьшей (например, «Номер пенсионного страхового свидетельства» более постоянный параметр, чем «ИНН» или «Номер паспорта»);
-
с ключом проще всего работать пользователям (например, «Номер пенсионного страхового свидетельства» – это набор из 11 цифр, а «Номер паспорта» зависит от его вида: гражданина СССР, гражданина РФ или зарубежный).
Если некий атрибут (набор атрибутов) присутствует в нескольких сущностях, то его наличие обычно отражает наличие связи между экземплярами этих сущностей. В каждой связи одна сущность выступает как родительская, а другая – в роли дочерней. Это означает, что один экземпляр родительской сущности может быть связан с несколькими экземплярами дочерней. Для поддержки этих связей обе сущности должны содержать наборы атрибутов, по которым они связаны. В родительской сущности это первичный ключ. В дочерней сущности для моделирования связи должен присутствовать набор атрибутов, соответствующий первичному ключу родительской. Этот набор атрибутов в дочерней сущности принято называть внешним ключом (foreign key).
-
-
Определение связей.
Наиболее характерными типами связей между сущностями являются:
-
связи типа «часть–целое», определяемые обычно глаголами «состоит из», «включает» и т.п.;
-
классифицирующие связи (например, «тип – подтип», «множество – элемент», «общее – частное» и т. п.);
-
производственные связи (например, «начальник–подчиненный»);
-
функциональные связи, определяемые обычно глаголами «производит», «влияет», «зависит от», «вычисляется по» и т. п.
Среди них выделяются только те связи, которые необходимы для удовлетворения требований к разработке БД.
Связь характеризуется следующим набором параметров:
-
именем – указывается в виде глагола и определяет семантику (смысловую подоплеку) связи;
-
кратностью (кардинальность, мощность): один-к-одному (1:1), один-ко-многим (1:N) и многие-ко-многим (N:M, N = M или N <> M). Кратность показывает, какое количество экземпляров одной сущности определяется экземпляром другой. Например, на одном участке (описывается строкой таблицы «Участки») может быть один, два и более путей (каждый путь описывается отдельной строкой в таблице «Пути»). В данном случае связь 1:N. Другой пример: один путь проходит через несколько раздельных пунктов и через один раздельный пункт может проходить несколько путей – cвязь N:M;
-
типом: идентифицирующая (атрибуты одной сущности, называемые внешним ключом, входят в состав дочерней и служат для идентификации ее экземпляров, т.е. входят в ее первичный ключ) и неидентифицирующая (внешний ключ имеется в дочерней сущности, но не входит в состав первичного ключа);
-
обязательностью: обязательная (при вводе нового экземпляра в дочернюю сущность заполнение атрибутов внешнего ключа обязательно и введенные значения должны совпадать со значениями атрибутов первичного ключа какого-либо экземпляра родительской сущности) и необязательная (заполнение атрибутов внешнего ключа в экземпляре дочерней сущности необязательно или введенные значения не совпадают со значениями атрибутов первичного ключа ни одного экземпляра родительской сущности);
-
степенью участия – количеством сущностей, участвующих в связи. В основном между сущностями существуют бинарные связи, т.е. ассоциации, связывающие две сущности (степень участия равна 2). Например, «Участок» состоит из «Путей». В то же время по степени участия возможны следующие типы связей:
-
унарная (рекурсивная) – сущность может быть связана сама с собой. Например, в таблице «Работники» могут быть записи и по подчиненным, и по их начальникам. Тогда возможна связь «начальник» – «подчиненный», определенная на одной таблице;
-
тернарная – связывает три сущности. Например, «Студент» на «Сессии» получил «Оценку по дисциплине»;
-
кватернарная и т.д.
-
В методологии IDEF1X степень участия может быть только унарной или бинарной. Связи большей степени приводятся к бинарному виду.
Внешний вид связи на диаграммах IDEF1X указывает на ее мощность, тип и обязательность.
-
Логическое проектирование
Цель логического проектирования – развить концептуальную схему БД с учетом принимаемой модели БД (иерархической, сетевой, реляционной и т. д.).
Примем в качестве модели реляционную БД в третьей нормальной форме (набор нормализованных отношений с кратностью связей 1:N). Поэтому необходимо будет проверить концептуальную схему с помощью методов нормализации и контроля выполнения транзакций. Транзакция – одно действие или их последовательность, выполняемых как единое целое одним или несколькими пользователями (прикладными программами) с целью осуществления доступа к БД и изменению ее содержимого.
-
Удаление и проверка элементов, не отвечающих принятой модели данных.
-
Удаление связей N:M.
Если в концептуальной схеме присутствуют связи N:M, то их следует устранить путем определения промежуточной сущности. Связь N:M заменяется двумя связями типа 1:M, устанавливаемыми со вновь созданной сущностью.
-
Удаление связей с атрибутами.
Связи с атрибутами должны быть преобразованы в сущности.
-
Удаление сложных связей (со степенью участия более 2).
Сложную связь заменяют необходимым количеством бинарных связей 1:N со вновь созданной сущностью, которая и показывает эту связь.
-
Удаление рекурсивных связей (со степенью участия 1).
Рекурсивную связь заменяют, определив дополнительную сущность и необходимое количество связей.
-
Удаление многозначных атрибутов (атрибутов имеющих несколько значений).
Многозначность устраняется путем введения новой сущности и связи 1:N. Например, несколько номеров организации выводятся в отдельную сущность “Телефоны”. Данное преобразование, помимо соответствия реляционной модели данных, также позволяет хранить любое количество телефонов по одному филиалу.
-
Удаление избыточных связей.
Связь является избыточной, если одна и та же информация может быть получена не только через нее, но и с помощью другой связи.
-
Перепроверка связей 1:1.
В процессе определения сущностей могли быть созданы сущности, которые на самом деле являются одной. В этом случае их следует объединить. Например, сущности «Филиал» и «Руководитель филиала» лучше объединить.
В то же время не всегда можно выполнить такое объединение.

Офисный пакет состоит из строго определенного набора компонентов, причем каждый из них характеризуется большим количеством атрибутов. Кроме этого, некоторые компоненты могут отсутствовать в офисном пакете (например, почтовый клиент) или они не входят в его состав (выступают в качестве самостоятельного продукта). В описанных случаях рекомендуется не объединять сущности.
-
-
Проверка модели с помощью правил нормализации.
Основная идея нормализации заключается в том, чтобы каждый факт хранился в одном месте, т. е. чтобы не было дублирования данных. Многие из требований нормализации, как правило, уже учитываются при выполнении предыдущих шагов проектирования.
Ниже приводятся краткие сведения из теории нормализации.
Проектирование реляционной БД представляет собой пошаговый процесс создания набора отношений (таблиц, сущностей), в которых отсутствуют нежелательные функциональные зависимости.
Функциональная зависимость определяется следующим образом. Пусть A и B – произвольные наборы атрибутов отношения. Тогда B функционально зависит от A (A → B), в том и только в том случае, если каждому значению A соответствует в точности одно значение B. Левая часть функциональной зависимости (A) называется детерминантом, а правая (B) – зависимой частью. В частности, в отношении А может быть первичным ключом, а B – набором неключевых атрибутов, так как одному значению первичного ключа в точности соответствует одно значение набора неключевых атрибутов.
Если в БД отсутствуют нежелательные функциональные зависимости, то это обеспечивает минимальную избыточность данных, что в свою очередь ведет к уменьшению объема памяти, необходимой для хранения данных. Процесс устранения таких зависимостей получил название нормализация. Она выполняется в виде последовательности тестов для некоторого отношения (таблицы, сущности) с целью проверки его соответствия (или несоответствия) набору ограничений для заданной нормальной формы.
Процесс нормализации впервые был предложен Э.Ф. Коддом в 1972 г. Сначала было предложено три вида нормальных форм (1NF, 2NF и 3NF). Затем Р. Бойсом и Э.Ф. Коддом (1974 г.) было сформулировано более строгое определение третьей нормальной формы, которое получило название нормальная форма Бойса–Кодда (BCNF). Вслед за BCNF появились определения четвертой (4NF) и пятой (5NF или PJNF) нормальных форм (Р. Фагин, 1977 и 1979 г.). На практике нормальные формы более высоких порядков используются крайне редко. При проектировании БД, как правило, ограничиваются третьей нормальной формой, что позволяет предотвратить возможное возникновение избыточности данных и аномалии обновлений.
1НФ. Отношение находится в первой нормальной форме (сокращённо 1НФ), если все его атрибуты атомарны, то есть если ни один из его атрибутов нельзя разделить на более простые атрибуты, которые соответствуют каким-то другим свойствам описываемой сущности.
Степень неделимости (атомарности), т.е. решение о том, следует разбивать неатомарный атрибут на атомарные или оставить его псевдоатомарным, определяется проектировщиком БД исходя из конкретных условий. Если при обработке таблиц нет необходимости различать атомарные составляющие псевдоатомарного атрибута, то его можно не делить (например, атрибуты «Фамилия, имя, отчество», «Адрес» и т. д.).
2NF. Отношение находится во 2NF, если оно находится в 1NF, и каждый неключевой атрибут характеризуется полной функциональной зависимостью от первичного ключа.
Полная функциональная зависимость определяется следующим образом. В некотором отношении атрибут В полностью зависит от атрибута А, если атрибут В функционально зависит от полного значения атрибута А и не зависит от какого-либо подмножества полного значения атрибута А.
Например, таблица «Оценки по экзаменам» характеризуется следующим набором атрибутов {Номер зачетной книжки, Дисциплина, Дата сдачи, ФИО студента, № группы, Оценка}. Очевидно, что первичным ключом является набор {Номер зачетной книжки, Дисциплина, Дата сдачи}. Полной функциональной зависимостью обладает только один неключевой атрибут «Оценка». Атрибуты «ФИО студента» и «№ группы» могут быть однозначно определены по части первичного ключа – «Номер зачетной книжки». Таким образом, требуется разбиение исходной таблицы на две.

3NF. Отношение находится в 3NF, если оно находится во 2NF и никакой неключевой атрибут функционально не зависит от другого неключевого атрибута, т. е. нет транзитивных зависимостей.
Транзитивная зависимость. Если для атрибутов А, В и С некоторого отношения существуют зависимости вида А → В и В → С, то атрибут С транзитивно зависит от атрибута А через атрибут В.
Например, таблица «Работник» характеризуется набором атрибутов {Табельный номер, Фамилия, Имя, Отчество, Должность, Зарплата, …}, первичный ключ – {Табельный номер}. В этой таблице от первичного ключа («Табельный номер») зависит неключевой атрибут «Должность», а от «Должности» другой неключевой атрибут «Зарплата». Для приведения к 3NF необходимо добавить новую таблицу.

-
Определение требований поддержки целостности данных.
Ограничения целостности данных представляют собой ограничения, которые вводятся с целью предотвращения помещения в базу противоречивых данных.
К этим ограничениям относятся:
-
обязательные данные – атрибуты, которые всегда должны содержать одно из допустимых значений (NOT NULL). Например, поворот кривой (влево или вправо) должен быть обязательно задан. Обязательными также являются все атрибуты, входящие в первичный ключ сущности;
-
домены – наборы допустимых значений для атрибута. Например, радиус кривой должен быть положительным числом не более 4 цифр или поворот кривой может принимать одно из двух допустимых значений – «Л» (влево) или «П» (вправо);
-
бизнес-правила (бизнес-ограничения) – ограничения, принятые в рассматриваемой предметной области. Например, сумма длин переходных кривых не должна быть более длины всей кривой, километраж начала или конца кривой должен быть в пределах общего километража пути и т.д.;
-
ссылочная целостность – набор ограничений, определяющих действия при вставке, обновлении и удалении записей (экземпляров сущности). Например:
-
при наличии обязательной связи вставка записи в дочернюю сущность требует обязательного заполнения атрибутов внешнего ключа, и введенному значению должна соответствовать запись родительской сущности;
-
аналогичное требование выдвигается при обновлении внешнего ключа в дочерней сущности;
-
удаление записи из дочерней сущности или вставка записи в родительскую не вызывают нарушения ссылочной целостности;
-
удаление записи в родительской сущности может требовать удаления всех связанных записей в дочерней сущности.
-
Автоматическая поддержка всех видов ограничений целостности возможна за счет использования операторов SQL.
Ссылочная целостность может быть обеспечена за счет использования триггеров. Триггер – это хранимая в БД процедура, исполняемая СУБД автоматически при удалении (DELETE), вставке (INSERT) или обновлении (UPDATE) записи. Набор команд, входящих в триггер, зависит от принятой стратегии (типа триггера) поддержания целостности:
-
RESTRICT или NO ACTION – на выполнение действия накладываются ограничения (условия). Под NO ACTION обычно понимаются триггеры, срабатывающие на изменение данных в родительской таблице. При соблюдении условий изменения в БД принимаются, в противном случае отклоняются;
-
CASCADE – каскадное удаление или обновление данных;
-
SET NULL – установка неопределенного значения (NULL) в атрибутах внешнего ключа дочерней таблицы;
-
SET DEFAULT – установка значения по умолчанию в атрибутах внешнего ключа дочерней таблицы;
-
NO CHECK, NONE или IGNORE – поддержка ссылочной целостности встроенными средствами СУБД не предусмотрена, но может быть выполнена за счет клиентских программ, работающих с БД. Данная стратегия принята в СУБД по умолчанию.
-
Физическое проектирование
Цель физического проектирования – преобразование логической схемы с учетом синтаксиса, семантики и возможностей выбранной целевой СУБД.
В связи с тем, что методология физического проектирования существенно зависит от выбранной целевой СУБД, ограничимся лишь общими рекомендациями.
-
Анализ необходимости введения контролируемой избыточности.
При реализации проекта часто для достижения большей эффективности системы требуется снизить требования к уровню нормализации отношений, т.е. внести некоторую избыточность данных. Процесс внесения таких изменений в БД называется денормализацией.
Рассмотрим некоторые виды денормализации, которые в определенных случаях могут существенно повысить производительность системы.
-
Использование производных данных.
С точки зрения физического проектирования любой производный атрибут либо может сохраняться в БД, либо при каждом обращении к нему его значение будет вычисляться заново. Например, длина пути может каждый раз вычисляться по таблицам «Действительный километраж» и «Неправильные пикеты» либо храниться как атрибут в таблице «Пути».
Проектировщик при использовании производных данных должен оценить:
-
дополнительную стоимость хранения производных данных и поддержки согласованности с текущими значениями тех данных, на основании которых они вычисляются, т.е. минусы хранения производных данных;
-
издержки на выполнение вычислений значений производных атрибутов при каждом обращении к ним – плюсы.
-
-
Дублирование атрибутов.
-
Объединение отношений, связанных 1:1.
Даже в тех случаях, когда связь между двумя сущностями необязательная, стоит подумать об их объединении, с учетом того, что часть полей в записях не будет заполняться. Руководствоваться в таких случаях надо из тех же соображений, что и при использовании производных данных. В частности, на рис. 7.4 и 7.5 показана иерархия наследования для сущности «Сотрудник». Если эту иерархию оставить без изменений, то в БД будет четыре сущности (Сотрудник, Постоянный сотрудник, Совместитель и Консультант), согласованность которых надо будет поддерживать. При выполнении запросов по сотрудникам надо будет оперировать четырьмя таблицами. Таким образом, лучше в БД вместо иерархии запроектировать одну таблицу, в которую добавить атрибуты «Ставка» и «Организация». В атрибуте «Ставка» для постоянного сотрудника всегда будет значение «1», а атрибут «Организация» будет заполняться только для консультантов. Несмотря на избыточность, такая замена с точки зрения обработки данных и эксплуатации более выгодна.
-
Дублирование атрибутов в связях типа 1:M.
Например, при запросе к таблице «Раздельные пункты на пути» очень часто будет требоваться наименование самих раздельных пунктов. С целью уменьшения нагрузки на БД следует рассмотреть возможность включения атрибута в эту таблицу.
-
Использование служебных таблиц (справочных таблиц, классификаторов, типовых списков значений).
Служебные таблицы, как правило, создаются для атрибутов символьного типа, значения которых могут выбираться из строго определенного и ограниченного списка. Например, значениями атрибута «Род балласта» могут быть только «Щебеночный», «Песчаный», «Гравийный» и «Асбестовый».
Обычно служебные таблицы содержат два атрибута: идентификатор (код, шифр) и описание (наименование). Например, в БД можно предусмотреть служебные таблицы «Вид раздельного пункта», «Род балласта» и т.д. с атрибутами {ID, Наименование}. Эти таблицы связываются неидентифицирующей обязательной связью с исходной, при этом в ней вместо наименования параметра будет содержаться идентификатор этого наименования.
Использование служебных таблиц дает следующие преимущества:
-
значительно снижается вероятность ошибки при указании значений для этих атрибутов. Если не использовать служебные таблицы, то разные пользователи могут вносить рассогласованные значения, в том числе и с ошибками. Например, «Щебеночный», «щебеночный», «Щебен.», «Шебеночный», «Щ» и т.д. Несмотря на то, что по смыслу это все один и тот же род балласта, программа будет их воспринимать как разные;
-
уменьшается размер исходной таблицы. Например, если непосредственно хранить наименование рода балласта в таблице «План пути», то в каждой записи на этот атрибут будет расходоваться не менее 10 байт (длина слова «Щебеночный» 10 букв), а если использовать идентификатор, то достаточно всего одного байта. Экономия в 10 раз;
-
если описание параметра может измениться, то значительно проще изменить одно значение в служебной таблице, чем корректировать множество записей в исходной. Например, если принято решение вместо полного наименования рода балласта отображать только начальную букву (Щ, П, Г и А), то изменениям подвергнется только служебная таблица, а исходные таблицы «План пути» и «ВСП на прямых участках» останутся без изменений.
-
-
Введение повторяющихся (многозначных) атрибутов.
Для достижения большей производительности при выполнении часто вызываемых запросов может быть целесообразным подход сохранения многозначных атрибутов, чем вынесение их в отдельную таблицу. Например, если количество контактных телефонов у филиала компании невелико (до 10), эта величина постоянная и не увеличится со временем, то в таблице «Филиал» можно предусмотреть атрибуты «Номер телефона 1», …, «Номер телефона 10».
-
Создание сводных таблиц.
Если нагрузка на БД в часы пик велика, а период актуальности отчетов, составляемых на основании данных, – сутки и более, то следует подумать о включении в БД сводных таблиц, обновляемых в часы минимальной нагрузки на БД.
-
-
-
Перенос логической схемы данных в среду целевой СУБД.
Данная стадия включает в себя проектирование таблиц и связей между ними с учетом возможностей целевой СУБД. При этом проектировщик должен хорошо ориентироваться в функциональных возможностях СУБД, а именно поддерживает ли СУБД задание:
- доменов;
- первичных, альтернативных и внешних ключей;
- неопределенных (NULL) и обязательных (NOT NULL) значений;
- значений по умолчанию (DEFAULT);
- правил контроля целостности;
- хранимых процедур и триггеров.
Кроме этого, целевая СУБД должна поддерживать требуемые типы данных или иметь возможность адекватного их хранения. Стадия переноса также включает в себя модификацию логической схемы с учетом семантики и синтаксиса, принятой в целевой СУБД, а именно, соблюдение правил наименования таблиц, атрибутов, типов данных, описания триггеров, хранимых процедур и т. д.
-
Реализация бизнес-правил и анализ транзакций.
Реализацию бизнес-правил (сумма длин переходных кривых не должна быть более длины всей кривой) можно включить в SQL-операторы создания таблиц (CREATE TABLE опция CHECK для полей или таблицы в целом) или в триггеры (CREATE TRIGGER).
После реализации бизнес-правил необходимо проверить выполнимость и эффективность (время отклика, скорость выборки, объем задействованных данных) выполнения всех транзакций.
-
Разработка механизмов защиты.
Ввиду того, что работают с системой, как правило, несколько пользователей, необходимо продумать механизмы защиты данных от несанкционированного просмотра и модификации. В частности, с системой определения скоростей планируется работа разных пользователей: инженера службы пути; начальника службы пути, представителей других служб дороги и Департамента пути и сооружений ОАО «РЖД». Каждый из них должен быть наделен соответствующими полномочиями. Так, например, инженер службы пути «головой отвечает» за достоверность исходных данных и результаты расчетов. В связи с этим он должен быть наделен самыми широкими полномочиями. Другие пользователи должны иметь возможность только просмотра результатов расчета и формирования ведомостей.
Ниже рассматриваются два наиболее популярных способа обеспечения защиты данных.
-
Разработка пользовательских представлений (видов).
Представление пользователя включает в себя данные, необходимые конкретному пользователю для принятия решений или выполнения некоторого задания.
Представление в БД – динамический результат одной или более операций, выполненных над таблицами БД с целью получения новой сводной таблицы. Представление является виртуальной таблицей, которая реально в БД не существует, но создается по запросу (SELECT) определенного пользователя в результате выполнения этого запроса.
В БД представления создаются для упрощения запросов и для организации защиты. Например, с помощью представления можно ограничить доступ к отдельным атрибутам или записям некоторых типов пользователей.
-
Определение прав доступа (привилегий).
В СУБД, поддерживающих SQL, возможно выполнение запросов от имени определенного пользователя, которое задается администратором БД. Каждый пользователь обладает строго определенным набором прав (привилегий) в отношении конкретной таблицы или представления. Наделение правами выполняется с помощью оператора GRANT, отмена – REVOKE. Операции, на которые можно назначить права: SELECT, INSERT, DELETE и UPDATE. Кроме того, возможно задание передачи прав от одного пользователя к другому.
-
-
Организация мониторинга и настройка функционирования системы.
Мониторинг функционирования и достигнутого уровня производительности системы необходим с целью устранения ошибочных проектных решений или изменения требований к системе.
Первоначальный физический проект БД не следует понимать как нечто статическое. Он, скорее, является промежуточным звеном, предназначенным для оценки достигнутого уровня производительности системы. Большинство коммерческих СУБД предоставляет в распоряжение администратора БД набор утилит, предназначенных для наблюдения за функционированием системы и ее настройки.
На практике настройку БД никогда нельзя считать завершенной. На протяжении всего жизненного цикла системы необходимо постоянно вести наблюдение за уровнем ее производительности, что позволит своевременно реагировать на изменения, происходящие в окружающей среде. Внесение в БД изменений, предназначенных для повышения производительности одного из приложений, может отрицательно отразиться на работе другого приложения, возможно, более важного. Таким образом, внесение любых изменений в БД должно проводиться обдумано и осторожно с обязательным их тестированием.
Дополнительная литература
- Нормализация баз данных простыми словами
- Нормализация базы данных и ее формы
