Кто не делится найденным, подобен свету в дупле секвойи (древняя индейская пословица)
Библиографическая запись:
Создание собственного корпуса. — Текст : электронный // Myfilology.ru – информационный филологический ресурс : [сайт]. – URL: https://myfilology.ru//177/sozdanie-sobstvennogo-korpusa/ (дата обращения: 16.05.2023)
Многие лингвисты работают с уже существующими масштабными корпусами — например, с British National Corpus или с корпусом Cobuild Project. Тем не менее, часто возникает необходимость изучить какие-то тексты, до сих пор не вошедшие в известные корпусы. Кроме того, не всегда есть возможность использовать эти «гиганты». В этом случае лингвист может составить свой собственный корпус из своих источников и исследовать уже его. В этой лекции мы рассмотрим некоторые вопросы, связанные с созданием своего корпуса — в основном, те, которые могут вызвать сложности при работе над проектом на зачёт.
Планирование
Лингвистический корпус — это некое собрание текстов, в основе которого лежит логический замысел, логическая идея, объединяющая тексты. Тип корпуса и его структура зависят от его предназначения. Это означает, что прежде чем начать планирование корпуса, необходимо определиться, что же именно мы хотим исследовать. Например, нам интересны лингвистические особенности рекламных текстов в журнале Cosmopolitan в 2007 году. Здесь уже определена тематика текстов, а так же место и время их размещения. Это вполне конкретная лингвистическая задача. В данном случае корпус будет синхроническим, но вполне можно себе представить соответствующее диахроническое исследование — например, сравнение рекламных текстов в этом же журнале в 80-х годах и в 2000-ых. Отметим, что изучать просто «тексты из Cosmopolitan» было бы, наверное, некорректно, поскольку они принадлежат к разным категориям с разными коммуникативными интенциями. Для такого исследования нужно было бы сначала категоризировать все тексты этого журнала и затем собирать корпус с учётом этой классификации.
Принципиальным так же является решение об устном или письменном наполнении корпуса. Устные тексты сложнее разбить на категории, поэтому даже планирование устного корпуса связано с немалыми трудностями. Но, скорее всего, большинство студентов будут сдавать на зачёт письменный корпус, так что им это не грозит.
Важное значение имеет и размер корпуса. Ранее в лекциях говорилось об устоявшемся стандарте в 1 миллион словоупотреблений (word tokens, running words). На зачёт вам необходимо собрать корпус всего лишь не менее 10 тысяч словоупотреблений. Но это не значит, что он будет «неполноценным». Такой размер корпуса вполне достаточен для многих лингвистических исследований — разве что кроме изучения масштабных дискурсивных связей в длинных текстах. Есть хорошая фраза: «Не пытайтесь сочинить идеальный корпус — лучше подробно опишите имеющийся.»
При наборе текстов в корпус всегда желательно учитывать такие экстралингвистические факторы, как источники текстов, их авторы (их пол, возраст, профессия, национальность), носитель текста, место действия, тематика, дата публикации, возраст и размер предполагаемой аудитории и т.д.
Продолжим наш пример с Cosmopolitan. После того, как мы определились с тематикой и временем (рекламные тексты, 2007 год), нам нужно выбрать собственно сами тексты. И тут мы встаём перед выбором: либо взять в корпус все рекламные тексты журнала за этот год, либо провести выборку (sampling) нескольких текстов, на базе анализа которых можно будет делать выводы о всех остальных. Выборку применяют очень часто, поскольку редко когда можно внести в корпус все интересующие нас тексты. В данном случае выборка играет роль модели явления. Выборка должна быть строго случайной, не зависящей от субъективных моментов. Например, мы можем выбирать 5 рекламных текстов из каждого номера за этот год, причём эти 5 текстов должны быть равномерно распределены по журналу (к примеру, быть расположенными на 10, 30, 50, 70 и 90 страницах). Аналогичным образом выборка осуществляется и в других случаях. Ещё раз отметим, что если явление, которое мы анализируем, является сложным, состоящим из нескольких классов, то и наша выборка (модель) должна отражать это деление.
Итак, перед тем, как начать составлять корпус, нам нужно знать следующее:
- 1. Какова логическая идея которая положена в основу корпуса?
- 2. С каким объёмом данных мы будем работать при составлении корпуса? Насколько это необходимо и реалистично?
- 3. Используем отрывки из текстов, полные тексты или то и другое?
- 4. Какова процедура отбора текстов в корпус?
Сбор и оцифровка данных
В качестве источников текстов для корпуса можно использовать как цифровые, так и не цифровые носители. Естественно, в последнем случае понадобится каким-то образом ввести текст в компьютер: заново набрать его, либо отсканировать и распознать (конечно, с последующим редактированием). Например, в нашем случае с Cosmopolitan у нас нет электронных версий рекламных текстов, поэтому нам придётся приложить усилия для их оцифровки (приведения в computer-readable вид).
Однако в настоящее время большинство корпусов составляются из текстов, которые уже находятся в цифровой электронной форме (благодаря нарастающей компьютеризации). Для проекта на зачёт вам так же, скорее всего, будет логично использовать уже существующие электронные версии необходимых документов. Это резко снижает сложность составления корпуса.
Один из очевидных источников уже оцифрованных текстов — Интернет, который сам по себе является титаническим текстовым корпусом. В первую очередь, это, конечно, веб- страницы, но не нужно забывать и про другие интернет-каналы, по которым циркулируют огромные объёмы текстов: электронная почта, общение в ICQ и других мессенджерах, в социальных сетях, чаты, IRC и т.п. Можно использовать и другие источники текстов в электронном виде, если составитель корпуса может обосновать их привлечение.
Ввод в компьютер звуковых данных (в случае с устным корпусом) ещё более затруднён, но и результаты, которые может дать такой корпус более интересны.
Формат и кодировка текста
Храните тексты для корпуса в простом текстовом формате (plain text, *.txt). Во-первых, он занимает меньше места, чем сложные форматы типа MS Word. Во-вторых, хотя современные программы анализа корпусов обычно могут работать с документами в формате HTML (XML), но всё-таки это менее надёжно, чем простой текст. Plain text — это простая последовательность букв, пробелов и знаков пунктуации. Такие файлы будет понимать любая программа везде и всегда, а при необходимости вы в любой момент сможете сконвертировать их в любой другой формат по своему выбору. Не храните ваши корпусы в MS Word — это не имеет никакого смысла! Кстати, не забывайте про резервные копии.
Ещё один тонкий момент — кодировка ваших файлов. Дело в том, что компьютеры создавались для работы на английском языке (точнее, с латинскими алфавитами). Отсюда многочисленные проблемы, связанные с тем, что нет чёткого договора, как именно компьютер должен обрабатывать и отображать символы других алфавитов (например, кириллицу, которой пользуется русский язык). Многие наверняка сталкивались с этим, когда видели в Интернете страницы, на которых текст представлен нечитаемыми «иероглифами» или вместо текста на экране оказывается бессмысленная последовательность кириллических букв. Это происходит из-за того, что существует несколько так называемых «кодировок» (англ. encodings), которые описывают русский алфавит — среди них koi8-r или cp1251. Ни одну из них нельзя назвать стандартом. Кроме того, не так давно появилась кодировка Unicode, которая поддерживает символы всех алфавитов всех языков мира, включая даже египетские иероглифы. Но пока не все программы готовы с ней работать.
Любой текстовый файл сохранён в одной из этих кодировок. Соответственно, если программа анализа корпуса считает, что кодировка одна, а на самом деле она другая — то файл будет прочитан неверно и вместо слов вы получите те самые бессмысленные наборы символов. Что тут можно посоветовать? Мы рекомендуем пользоваться либо Unicode (предпочтительнее), либо CP-1251. CP-1251 является стандартной кодировкой для MS Windows, а Unicode удобнее, поскольку может использоваться для любого языка. Когда вы сохраняете файл как «кодированный текст» в MS Word или в OpenOffice.org, то вам будет предложено выбрать кодировку.
Если вы анализируете текст в AntConc, то там вы можете указать кодировку для файлов, которые загружаете в него (в меню Global Settings — Encodings). Corsis воспринимает кириллические тексты только если они сохранены в кодировке Unicode. Dialing, напротив, считает, что кириллические тексты должны быть только в CP-1251. Но у вас всегда есть выход — вы можете сохранять один и тот же текст сколько угодно раз в различных кодировках.
С английскими текстами таких проблем нет, они будут нормально читаться и анализироваться вне зависимости от кодировки.
Разметка (аннотирование) корпуса
Вы можете разметить свой корпус, то есть, добавить в тексты какие-то служебные пометки (например, части речи). В этом случае внимательно перечитайте лекцию номер пять, в которой говорилось о лингвистической разметке корпусов. Разметка поможет вам искать какие-то специфические места в текстах, но, учитывая небольшой размер корпусов, вряд ли имеет смысл разрабатывать масштабную систему разметки. Если же она всё-таки понадобится, то, скорее всего, нужно будет использовать при её создании стандарты XML и TEI.
Хранение и презентация корпуса
Окончательный корпус должен соответствовать отраслевым стандартам и быть представлен, как продукт, готовый к отправке заказчику. То есть, он должен быть адекватно оформлен.
Курс «Корпусная лингвистика» (А.Б. Кутузов), ТюмГУ
Лицензия Creative commons Attribution Share-Alike 3.0 Unported
 07.06.2016, 17794 просмотра.
07.06.2016, 17794 просмотра.
Технологический
процесс создания корпуса можно представить
в виде следующих шагов или этапов.
1. Определение
перечня источников.
2.
Оцифровка текстов (преобразование в
компьютерную форму). Следует сказать,
что насколько раньше задача ввода
текстов в компьютер была тяжела и
трудоемка, настолько сегодня эта проблема
решается довольно легко, по крайней
мере, что касается современных текстов
и в современной орфографии. Эта легкость
базируется на успехах в оптическом
вводе (сканирование) и распознавании
текстовой информации и на глобальной
компьютеризации современной жизни, в
том числе и в областях, связанных с
обработкой текстовой информации. Тексты
в электронном виде для создания корпусов
могут быть получены самыми разными
способами — ручной ввод, сканирование,
авторские копии, дары и обмен, Интернет,
оригинал-макеты, предоставляемые
составителям корпусов издательствами
и проч.
3.
Предобработка текста. На этом этапе все
тексты, полученные из разных источников,
проходят филологическую выверку и
корректировку. Также осуществляется
подготовка библиографического и
экстралингвистического описания текста.
4.
Конвертирование и графематический
анализ. Некоторые тексты проходят также
через один или несколько этапов
предварительной машинной обработки, в
ходе которых осуществляются различного
рода перекодировка (если требуется),
удаление или преобразование нетекстовых
элементов (рисунки, таблицы), удаление
из текста переносов, «жёстких концов
строк», обеспечение единообразного
написания тире и проч. Как правило, эти
операции выполняются в автоматическом
режиме. Обычно на этом же этапе
осуществляется сегментирование текста
на его структурные составляющие.
5.
Разметка текста. Разметка текста
заключается в приписывании текстам и
их компонентам дополнительной информации
(метаданных). Метаописание
текстов корпуса включает как содержательные
элементы данных (библиографические
данные, признаки, характеризующие
жанровые и стилевые особенности текста,
сведения об авторе), так и формальные
(имя файла, параметры кодирования, версия
языка разметки, исполнители этапов
работ). Эти данные обычно вводятся
вручную. Структурная разметка документа
(выделение абзацев, предложений, слов)
и собственно лингвистическая разметка
обычно осуществляются автоматически.
6.
На следующем этапе осуществляется
корректировка результатов автоматической
разметки: исправление ошибок и снятие
неоднозначности (вручную или
полуавтоматически).
7. Заключительный
этап – конвертирование размеченных
текстов в структуру специализированной
лингвистической информационно-поисковой
системы (corpus manager), обеспечивающей быстрый
многоаспектный поиск и статистическую
обработку.
8. И, наконец,
обеспечение доступа к корпусу. Корпус
может быть доступен в пределах дисплейного
класса, может распространяться на CD-ROM
и может быть доступен в режиме глобальной
сети. Различным категориям пользователей
могут предоставляться разные права и
разные возможности.
Конечно, в каждом
конкретном случае состав и количество
процедур могут отличаться от выше
перечисленных, и реальная технология
может оказаться гораздо сложнее.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
(Решено) Что такое корпус, как его создать и как с ним работать?…
Вопрос от пользователя:
Что такое корпус, как его создать и как с ним работать?
Подождите!
Не закрывайте страницу. Нейросеть пишет ответ. Он появится тут.
Этот ответ написан нейросетью.
Искуственный интеллект во многом преуспевает, но в некоторых областях может давать неточные ответы.
Если вам не понравился ответ, попробуйте задать его более развёрнуто и конкретно, используя точные параметры.
Ответ нейросети:
Корпус – это набор текстов, связанных общей темой или жанром, который используется для лингвистических исследований и анализа языка. Создание корпуса может потребовать много времени и усилий, поскольку он должен содержать достаточно текстов, чтобы ученый мог проводить статистические исследования и анализ свойств языка, таких как лексика, синтаксис или контекст. В то же время, корпус должен быть достаточно малым, чтобы его можно было обработать на компьютере. Например, корпус может содержать тексты, написанные на определенном языке, жанре или объеме.
Есть несколько способов создания корпуса. Один из наиболее распространенных способов – это ручной сбор текстов из различных источников, таких как книги, статьи, списки речей и т.д. Тексты могут быть сохранены в электронном формате, что позволяет исследователю быстро и эффективно обрабатывать тексты на компьютере.
Еще один способ – это использование веб-скрейпинга, который позволяет автоматически собирать данные из интернета. Веб-скрейпинг позволяет собирать данные определенного типа, таких как текстовые документы, файлы PDF, мультимедийные файлы и т.д. для последующего использования в корпусном анализе.
После того, как корпус создан, его можно использовать для проведения различных лингвистических исследований, таких как анализ частотности слов, зависимости между лексикой и контекстом, анализ синтаксиса и т.д. Для этого исследователь может использовать программа с открытым исходным кодом, такие как Python или R, либо определенное программное обеспечение, такое как AntConc. Исследователь может также использовать методы машинного обучения для анализа корпуса, такие как моделирование тем и классификация текстов.
Таким образом, корпус – это важный инструмент для лингвистических исследований и анализа языка. Его создание может быть трудоемким процессом, однако при использовании корпуса для анализа языка можно получить много интересных результатов и улучшить понимание свойств языка.
⚠️Зарепортить пост!
Чтобы оставить комментарий, необходимо авторизоваться.
Задай любой вопрос нейросети!
она справится с любой поставленной задачей быстрее чем поиск в Яндекс.
Последние вопросы
(c) ChatGPT по русски 2023. Все права защищены. При обнаружении неправомерного контента пишите на [email protected]
1. Как работает тематическое моделирование?
Тематическое моделирование (topic modeling) — это способ научить машину выделять в текстах содержательные темы. Например, проанализировав массив новостных и публицистических текстов о протестных митингах, машина может выделить там темы (топики) «полицейское насилие», «география Москвы», «требования и лозунги» и др.
Естественно, компьютеры не могут понять смысл статей напрямую. Но если есть большая коллекция текстов с разными темами, то вероятности совместного употребления слов позволяют нам выделить отдельные тематические пласты — примерно, как химики разделяют нефть на фракции: бензин, керосин, солярка, мазут, асфальт…
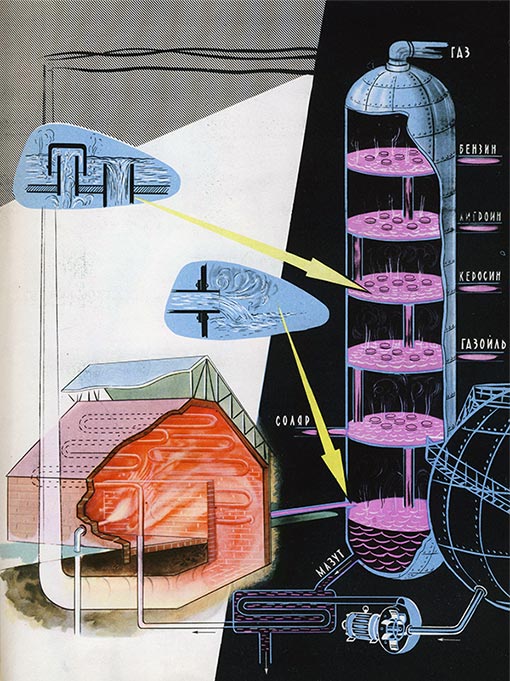
Как выглядит в чистом виде такой тематический пласт, «отфильтрованный» из множества текстов? Это просто набор слов, характерных для темы. Слова в наборе отсортированы по важности для данной темы. Посмотрите, к примеру, на такой набор слов:

Это явно про отношения между полами! А вот такой набор слов:

— это про музыкальную индустрию и звукозапись.
И тот, и другой пример реальные — они получены нами на корпусе 6700 текстов одного из современных русских СМИ. Размеры слов на визуализации пропорциональны тому, насколько они значимы для темы, насколько хорошо они характеризуют ее. Этот показатель как раз и рассчитывает алгоритм тематического моделирования.
Разумеется, слова нельзя просто так «склеить» друг с другом по признаку частого совместного упоминания — тогда получится много довольно бессмысленных тем типа таких:

Чтобы темы были осмысленными, нужно определять слова, которые не просто частотны, а именно характерны для одних контекстов, но при этом практически не употребляются в других. Для этого используется хитрая математика, о которой мы уже рассказывали вот здесь. Не будем в нее углубляться — вместо этого поработаем с готовым инструментом для тематического моделирования. В этом инструменте все математические хитрости уже реализованы — от нас требуется только освоить нужные команды.
2. Да, хватит уже бла-бла. Как это сделать самому?
Приведенные выше примеры содержательных тем (условно назовем их «межполовые отношения» и «музыка») мы получили с помощью Mallet — старой, но по-прежнему очень популярной программы для тематического моделирования. Mallet выделяет темы при помощи латентного размещения Дирихле (LDA) — это классический способ, придуманный в 2003 году и остающийся популярным по сей день.
2.1 Подготовка
Первым делом Mallet нужно скачать — программа распространяется свободно и доступна для всех операционных систем. Но пользователям Windows придется пострадать чуть больше других.
Решаем траблы с Windows (маководы и линуксоиды могут сразу переходить к следующему разделу — установке JDK)
Во-первых, на Windows скачанный вами архив с Mallet желательно распаковывать непосредственно в корень одного из системных дисков — т.е. чтобы путь к папке был вроде «D:mallet-2.0.8» или «C:mallet-2.0.8». C более длинными путями бывают проблемы (на юникс-подобных системах — Mac OS и Linux — с такими сложностями мы не сталкивались).
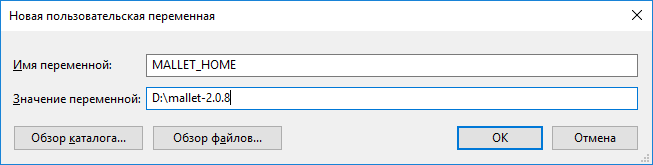
Во-вторых, на Windows нужно будет установить т.н. переменную среды (environment variable), которая даст системе путь к тому месту, куда вы установили Mallet. Имя переменной (variable name) — MALLET_HOME, значение переменной (variable value) — собственно путь (например «D:mallet-2.0.8» или «C:mallet-2.0.8»).
Можно сделать это через панель управления, найдя в разделе «Система» в «Продвинутых настройках системы» кнопочку «Переменные среды»:
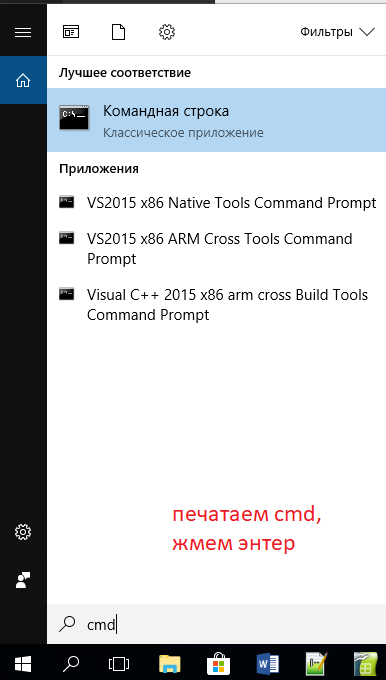
А можно сделать то же самое по-хакерски — и честно говоря, так проще всего — через командную строку. Ведь дальше нам все равно потребуется работать именно с командной строкой. Поэтому идем в меню «Пуск» — и вводим там в окошке поиска три буквы: cmd, а затем жмем enter:
Оказавшись в командной строке, пишем: setx MALLET_HOME «D:mallet-2.0.8». Эта команда установит для переменной среды MALLET_HOME значение D:mallet-2.0.8.
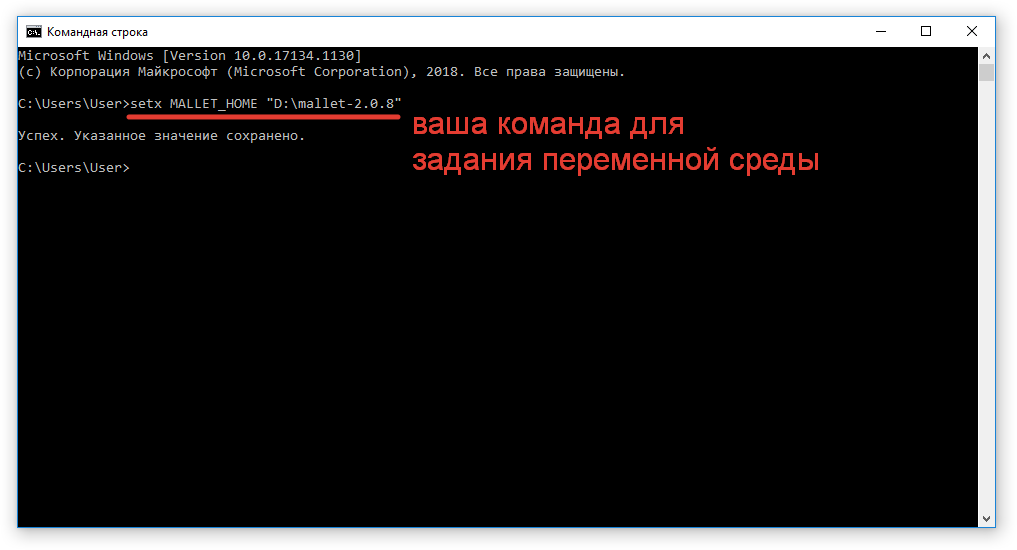
Если у вас путь отличается, измените его в команде.
На этом борьба с проблемами Windows должна закончиться — попробуем запустить программу.
Ставим JDK
Еще одна небольшая техническая деталь: для работы маллет нужен Java Development Kit — пакет разработчика программ для Java. Если вы не программируете на Java, скорее всего, у вас он не установлен. Просто установите его отсюда.
2.2 Подбираем корпус текстов
Тематическое моделирование может сработать хорошо и на небольшом наборе текстов, если в них действительно присутствует тематическая разнородность. Но все-таки его применение более осмысленно на больших коллекциях, которые просто так не прочитаешь. Вот, например, мы взяли корпус текстов одного сетевого издания, и попробовали выделять темы в нем. Наш корпус содержит 6700 текстов, ваш может содержать меньше или больше. Для начала предлагаем вам поработать вот с этим корпусом новостей — популярный набор данных для тематического моделирования. Или используйте примеры, поставляющиеся вместе с mallet — они лежат в папке sample-data, которая уже есть у вас после распаковки mallet.
Поместим корпус (т.е. просто множество txt-файлов) в отдельную папку внутрь папки, с которой мы работаем:
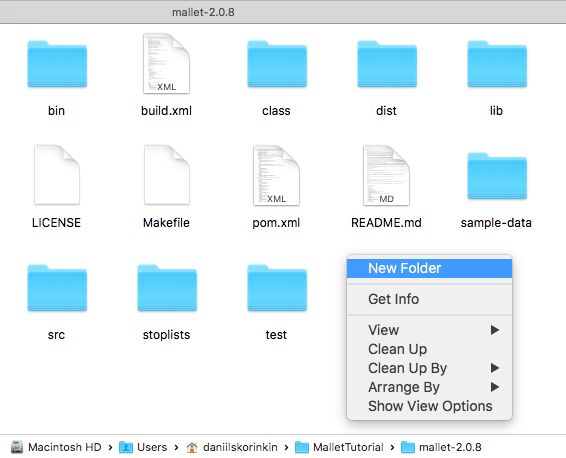
(на Windows процедура ничем не отличается)
Тематическое моделирование в Mallet осуществляется в два шага. На первом шаге надо перевести все ваши текстовые файлы во внутренний бинарный формат .mallet. Второй шаг — непосредственное моделирование, когда алгоритм ищет в корпусе заданное нами число тем и выводит их, а также выдает распределение тем по документам.
2.3 Работаем с Mallet
Mallet — это очень просто устроенная программа, у нее даже нет графического интерфейса. Поэтому все команды мы будем отдавать через ту же самую командную строку. На Mac OS и Linux это называется терминалом (Terminal).
Для начала пропишем путь к папке, в которой лежит программа (это просто наш распакованный архив). В командной строке (или в терминале) это делается с помощью команды cd. Эта команда понимает как абсолютные, так и относительные пути. Например, если у вас Windows и распакованный архив с mallet лежит у вас в D:mallet-2.0.8, вы можете сделать так:
cd D:MalletTutorialmallet-2.0.8
- Для перехода командной строки между дисками может предварительно понадобиться выполнить команду /d D: (если по умолчанию ваша командная строка работает с диском С, например)
Если у вас Линукс или Mac OS, и вы, например, положили mallet в папку vasya в папке Users, то попасть в нее можно точно так же, с помощью cd:
cd users/vasya/mallet-2.0.8
В папку нам нужно попасть, чтобы потом было недалеко ходить за самим исполняемым файлом, т.е. программой, которая непосредственно «делает» тематическое моделирование.
Перевод файлов в формат .mallet
Для того, чтобы программа могла работать с текстами из нашего корпуса, необходимо привести их в формат .mallet. Для этого нам нужно воспользоваться командой
import-dir. Этой команде нужно сообщить, откуда брать файлы (параметр). Вот так выглядит «голая» команда в командной строке:

А вот наши пояснения к ее частям:

Внимание: в Windows разделителем пути в командной строке служит не слэш (/), а двойной бэкслэш (). Т.е. если вы работаете из командной строки Windows, путь из папки с mallet к исполняемому файлу будет иметь вид binmallet.
Для того, чтобы mallet смог выдавать вам слова, характеризующие все топики, нужно указать еще один параметр: —keep-sequence. Это позволяет программе помнить, в какой последовательности шли слова в текстах. А чтобы наши темы получились более осмысленными и не замусоривались служебными словами вроде и, на, в, про и т.п., можно еще передать Mallet список стоп-слов. Это делается в той же команде import-dir с помощью опции —stoplist-file, после которой через пробел вводится путь к файлу со стоп-словами:

В папке stoplists (находится прямо в основной рабочей папке —там же, где мы создавали папку с корпусом и куда прописывали путь) у Mallet уже лежат готовые списки стопслов для нескольких языков, русского среди них нет, но скачать русский список можно много где (раз, два). Мы скачали такой список, назвали его stop_ru.txt и положили его в папку stoplists, поэтому можем теперь его использовать.
Все, теперь в нашей папке появился нужный нам файл с расширением .mallet:
Можно приступать непосредственно к тематическому моделированию.
Получение топиков
Для обучения тематической модели и получения нам понадобится вторая — и последняя в этом тьюториале — команда для Mallet, которая так и называется: —train-topics, т.е. обучить топики. Ей надо передать тот самый файл .mallet, полученный нами на предыдущем этапе, но теперь уже в качестве входных данных:
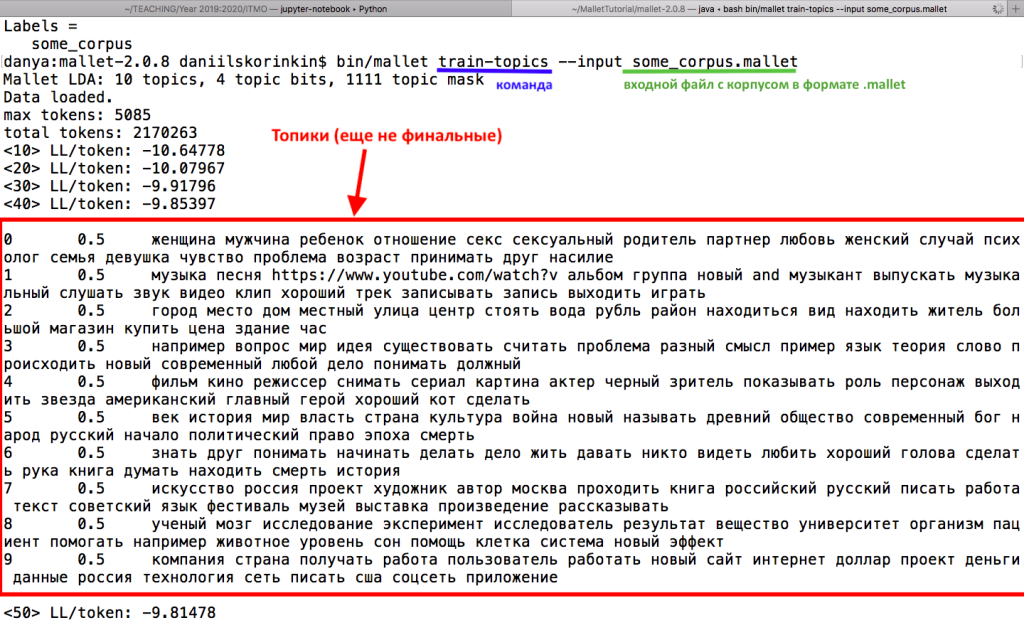
У команды train-topics есть много параметров, которые вы можете изучить самостоятельно с помощью опции —help:

Расскажем про несколько самых важных.
—num-topics позволяет указать, сколько тем должен выделить Mallet. Необходимость задавать число тем вручную — слабое место большинства алгоритмов тематического моделирования. Зато регулировка этого параметра позволяет получать более общие, абстрактные, или наоборот более дробные, конкретные темы. Вот, например, в «Войне и мире» при попытке выделить 2 темы выделяется что-то похожее на «военную» и «мирную» темы.
—output-topic-keys — сюда указываем путь к файлу, в который надо сложить темы. В файле будет просто 20 строчек с темами в виде мешка слов, то же самое, что выдаст вам командная строка:

—topic-word-weights-file — а вот тут можно указать путь к файлу, в который Mallet сложит полные данные: какие слова обладают какой значимостью для какого топика. На основе данных из этого файла уже можно делать облака слов для любого из ваших топиков — например, с помощью wordclouds.com, как это делаем мы:

Все! Остальные параметры команды для обучения тематических моделей мы призываем вас исследовать самостоятельно. Удачного тематического моделирования!
«Он видел их семью своими глазами»
Время на прочтение
6 мин
Количество просмотров 64K
Можешь выбрать подходящую к заголовку поста картинку?

Тогда научи робота! Он тоже хочет.
Команда проекта Открытый корпус просит хабралюдей помочь разметить свободно доступный (CC-BY-SA) корпус текстов. Под катом мы расскажем о том, что такое корпус, зачем он нужен, как обстоят дела с корпусами в России и за рубежом, почему так плохо и какой у нас план.
Корпус текстов — это лингвистическая база данных, включающая тексты, разные метаданные, относящиеся к этим текстам, а также грамматические разборы входящих в них слов и предложений. Метаданные и грамматические разборы — это разметка. Она бывает разных уровней: морфологическая, синтаксическая, семантическая, и т.д. Без размеченных корпусов текстов трудно (или даже невозможно) разрабатывать софт для анализа текста. Для программ, использующих машинное обучение, из размеченного корпуса берётся обучающая выборка. В остальных случаях корпус нужен для тестирования.
Размеченные корпуса существуют для многих языков мира. Чаще всего корпус текстов доступен через специализированные поисковые машины, позволяющие выбирать примеры употребления различных языковых конструкций. Эти сервисы предназначены для лингвистов. Скачивать корпуса целиком оттуда нельзя, т.к. входящие в них тексты чаще всего защищены копирайтом. Для разработки лингвистического софта нужны корпуса, которые можно скачивать целиком, вместе с разметкой. На Хабре уже писали об этом здесь (про POS-tagging) и здесь (про синтаксис).
Корпуса текстов в России и за рубежом
Здесь у русского языка всё не так хорошо, как, например, у английского, для которого есть несколько разных доступных и вручную размеченных корпусов текстов. Это не удивительно как минимум потому, что на английском говорит больше людей, чем на русском. Удивительно, что даже для венгерского языка, на котором говорят в 10 раз меньше людей, чем на русском, есть доступный и размеченный корпус размером больше 1 млн. слов.
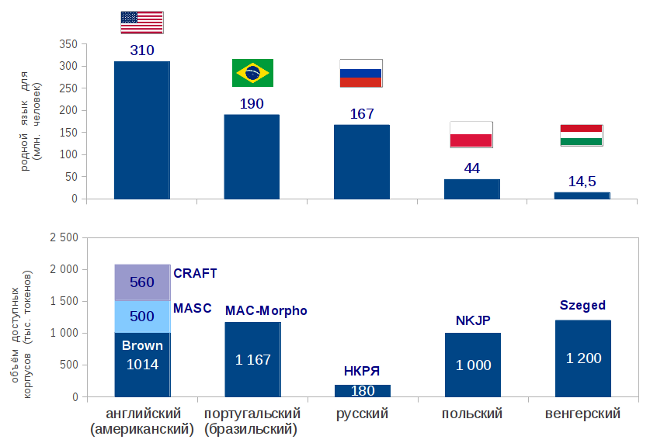
А что у нас?
Национальный корпус русского языка (НКРЯ), создаваемый совместными усилиями многих организаций (включая Институт русского языка РАН), доступен только в режиме поиска по корпусу. Из 6 млн. слов, размеченных вручную, можно скачать только выборку размером 180 тысяч слов, в которой предложения идут с нарушенным порядком. Если вы хотите сделать морфологический анализатор со снятием неоднозначности, то вам придётся либо воспользоваться этими 180 тысячами, которых чаще всего будет недостаточно для машинного обучения, либо попробовать какой-нибудь другой язык, например, польский. Такое положение дел, очевидно, не способствует развитию компьютерной лингвистики в нашей стране.
Для того, чтобы русский язык не попадал в категорию «under-resourced languages», мы решили сделать новый Открытый корпус русского языка, учитывая опыт создания НКРЯ и других проектов. Поскольку Национальный корпус предоставляет хороший интерфейс поиска, и, таким образом, решает задачи связанные с поиском примеров употребления различных слов и конструкций, мы решили сфокусироваться на создании свободно доступного корпуса для разработчиков: его можно скачать и использовать для машинного обучения или для тестирования. Поиска по нему нет, но это не страшно, т.к. он есть в НКРЯ. Чтобы вопрос копирайта не мешал распространению в корпус включаются только тексты либо доступные на условиях лицензии Creative Commons, либо находящиеся в общественном достоянии. Разметка создаётся на условиях CC-BY-SA.
На предыдущем этапе нашей работы (в 2011 году) мы собрали корпус в 700 тыс. слов и расставили вручную границы слов и предложений. Эти данные уже можно скачивать. Сейчас нашей основной целью является снятие неоднозначности в морфологической разметке. Эту работу тоже нужно делать вручную, её много, и мы просим вас нам помочь.
Вспомним школу или что такое морфологическая разметка
Морфологическая разметка (tagging, part-of-speech tagging) — это сопоставление каждому слову в тексте его словарной формы («большого» — «БОЛЬШОЙ», «столу» — «СТОЛ», «читал» — «ЧИТАТЬ») и указание грамматических характеристик слова: род, число, падеж, время и др. Первичная морфологическая разметка делается по словарю автоматически. Мы используем словарь проекта АОТ, доработанный для наших целей. Для большинства слов разметка получается неоднозначной, т. е. для многих слов в тексте в словаре находится несколько гипотез. Чаще всего только одна из гипотез является правильной. Бывают и неоднозначные предложения, имеющие несколько вариантов разбора. Например:
«Эти типы стали есть в цехе»
СТАЛЬ (существительное) или СТАТЬ (глагол)?«Он видел их семью своими глазами»
СЕМЬЯ (существительное) или СЕМЬ (числительное)?
Такие примеры встречаются редко. Морфологический разбор становится однозначным в контексте предложения: прочитав его целиком, мы можем определить, в какой именно форме стоит то или иное слово. Например, для предложения «Мама мыла раму» в конечном итоге должен быть построен вот такой разбор:

Проведя морфологический анализ при помощи словаря, только одно из слов мы сможем разобрать однозначно. Для слов «МЫЛА» и «РАМУ» мы получим четыре и две гипотезы соответственно:
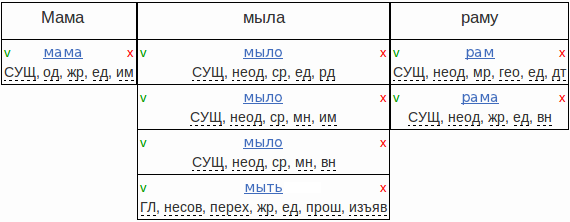
Снять морфологическую неоднозначность — это значит выбрать одну правильную гипотезу для каждого слова. Для носителей языка это, чаще всего, не представляет трудности.
У нас есть план!
Чтобы упростить задачу снятия неоднозначности, мы разделили её на простые вопросы, которые вместе представляют собой дерево решений для каждого примера неоднозначности. В случае со словом «МЫЛА», первый вопрос будет «Существительное или глагол?». Для предложения «Мама мыла раму» снятие неоднозначности на этом закончится, т. к. это глагол, а глагольная гипотеза только одна. В других случаях нужно будет ответить ещё на один или, в худшем случае, ещё на два вопроса.
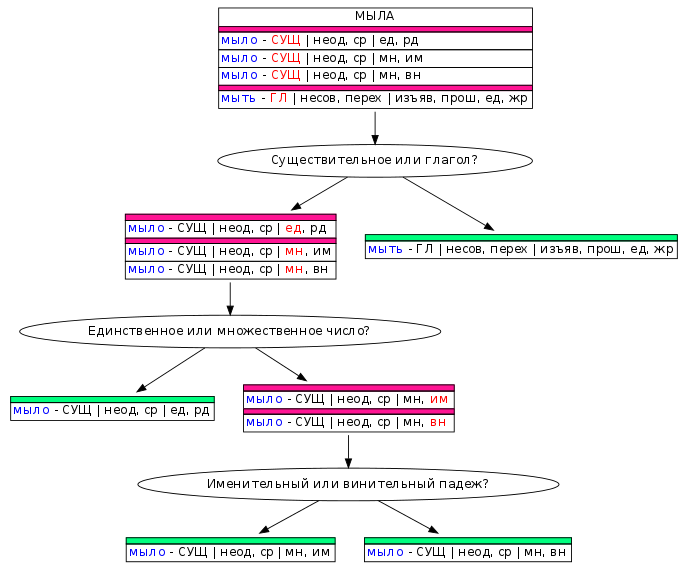
Однотипные вопросы мы объединили в группы. Участник может выбрать тип вопросов и отвечать только на вопросы этого типа про случайно выбранные слова в их контекстах, сфокусировавшись, таким образом, на одной задаче. Так размечать быстрее, т.к. не тратится время на переключение между разными типами вопросов.
Чтобы разметка была достаточно точной, каждый вопрос задаётся трём разным людям, и только если ответы полностью совпадают, и никто не написал комментариев, они используются без перепроверки. Если один ответ отличается от двух других, или если оставлен комментарий, то этот пример проверяет модератор.
Сколько у нас этого плана?
По грубым подсчётам, чтобы снять неоднозначность в собранной на настоящий момент коллекции текстов, с учётом того, что вопросы задаются трижды, нужно ответить на 4 миллиона 3.75 миллиона вопросов (на 250 тысяч вопросов ответы уже получены). Если в этом будут участвовать 100 человек, то получится по 40 тысяч вопросов на человека. 40 тысяч — это много, а человеческие жертвы нам не нужны. Если 1000 человек, то по 4 тысячи. Это несколько часов работы. Если 10000, то по 400 вопросов, что занимает 20-30 минут.
Для участия в проекте можно использовать приступы прокрастинации, время по дороге на работу (интерфейс разметки работает на смартфонах) и другие вынужденные паузы в полезной деятельности. В этом смысле разметка корпуса похожа на пасьянс, только полезнее. Поскольку никаких особенных лингвистических знаний не требуется, то каждый дочитавший до этого места может принять участие, и мы вместе создадим морфологический слой разметки корпуса. На этой странице находится пошаговая инструкция по разметке.
Недавно мы начали собирать и публиковать подмножество предложений, в которых вся неоднозначность уже снята. Этот подкорпус пока очень маленький — около 9500 слов. По мере того, как идёт разметка, он становится больше, и, в дальнейшем, эти данные можно будет использовать для создания свободно доступных морфологических анализаторов, умеющих снимать неоднозначность.
Открытый корпус. Не стесняйтесь снимать неоднозначность!
Ссылки на упомянутые корпуса
Русский
[НКРЯ] Национальный корпус русского языка: ruscorpora.ru (23 октября об этом проекте будет лекция в лектории Политехнического музея в Москве)
[OpenCorpora] Статьи и презентации об Открытом корпусе: opencorpora.org/?page=publications
Английский
[Brown] Брауновский корпус: en.wikipedia.org/wiki/Brown_Corpus
[MASC] Manually Annotated Sub-Corpus (часть Американского национального корпуса, размеченная вручную): www.anc.org/MASC/Home.html
[CRAFT] The Colorado Richly Annotated Full Text Corpus (67 статей по био-медицинской тематике с лингвистической и онтологической разметками): bionlp-corpora.sourceforge.net/CRAFT/index.shtml
Португальский, польский, венгерский
[MAC-Morpho] Тексты из газеты «Folha de São Paulo» на бразильском португальском: www.nilc.icmc.usp.br/lacioweb/english/plancamento.htm
[NKJP] Narodowy Korpus Języka Polskiego. Подкорпус NKJP, доступный на условиях лицензии GNU GPL v.3: nkjp.pl/index.php?page=14&lang=1
[Szeged] Szeged Corpus, корпус текстов на венгерском языке: www.inf.u-szeged.hu/projectdirs/hlt/index_en.html
Картинки в начале поста: «Family portrait» и «Totem moster».
