Содержание:
Корреляционный анализ:
Связи между различными явлениями в природе сложны и многообразны, однако их можно определённым образом классифицировать. В технике и естествознании часто речь идёт о функциональной зависимости между переменными x и у, когда каждому возможному значению х поставлено в однозначное соответствие определённое значение у. Это может быть, например, зависимость между давлением и объёмом газа (закон Бойля—Мариотта).
В реальном мире многие явления природы происходят в обстановке действия многочисленных факторов, влияния каждого из которых ничтожно, а число их велико. В этом случае связь теряет свою однозначность и изучаемая физическая система переходит не в определённое состояние, а в одно из возможных для неё состояний. Здесь речь может идти лишь о так называемой статистической связи. Статистическая связь состоит в том, что одна случайная переменная реагирует на изменение другой изменением своего закона распределения. Следовательно, для изучения статистической зависимости нужно знать аналитический вид двумерного распределения. Однако нахождение аналитического вида двумерного распределения по выборке ограниченного объёма, во-первых, громоздко, во-вторых, может привести к значительным ошибкам. Поэтому на практике при исследовании зависимостей между случайными переменными X и У обычно ограничиваются изучением зависимости между одной из них и условным математическим ожиданием другой, т.е. 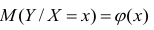
Вопрос о том, что принять за зависимую переменную, а что — за независимую, следует решать применительно к каждому конкретному случаю.
Знание статистической зависимости между случайными переменными имеет большое практическое значение: с её помощью можно прогнозировать значение зависимой случайной переменной в предположении, что независимая переменная примет определенное значение. Однако, поскольку понятие статистической зависимости относится к осредненным условиям, прогнозы не могут быть безошибочными. Применяя некоторые вероятностные методы, как будет показано далее, можно вычислить вероятность того, что ошибка прогноза не выйдет за определенные границы.
Введение в корреляционный анализ
Связь, которая существует между случайными величинами разной природы, например, между величиной X и величиной Y, не обязательно является следствием прямой зависимости одной величины от другой (так называемая функциональная связь).
В некоторых случаях обе величины зависят от целой совокупности разных факторов, общих для обеих величин, в результате чего и формируется связанные друг с другом закономерности. Когда связь между случайными величинами обнаружена с помощью статистики, мы не можем утверждать, что обнаружили причину происходящего изменения параметров, скорее мы лишь увидели два взаимосвязанных следствия.
Например, дети, которые чаще смотрят по телевизору американские боевики, меньше читают. Дети, которые больше читают, лучше учатся. Не так-то просто решить, где тут причины, а где следствия, но это и не является задачей статистики.
Статистика может лишь, выдвинув гипотезу о наличии связи, подкрепить ее цифрами. Если связь действительно имеется, говорят, что между двумя случайными величинами есть корреляция. Если увеличение одной случайной величины связано с увеличением второй случайной величины, корреляция называется прямой.
Например, количество прочитанных страниц за год и средний балл (успеваемость). Если, напротив рост одной величины связано с уменьшением другой, говорят об обратной корреляции. Например, количество боевиков и количество прочитанных страниц. Взаимная связь двух случайных величин называется корреляцией, корреляционный анализ позволяет определить наличие такой связи, оценить, насколько тесна и существенна эта связь. Все это выражается количественно.
Как определить, есть ли корреляция между величинами? В большинстве случаев, это можно увидеть на обычном графике. Например, по каждому ребенку из нашей выборки можно определить величину 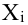 (число страниц) и
(число страниц) и 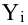 (средний балл годовой оценки), и записать эти данные в виде таблицы. Построить оси X и Y, а затем нанести на график весь ряд точек таким образом, чтобы каждая из них имела определенную пару координат (,) из нашей таблицы. Поскольку мы в данном случае затрудняемся определить, что можно считать причиной, а что следствием, не важно, какая ось будет вертикальной, а какая горизонтальной.
(средний балл годовой оценки), и записать эти данные в виде таблицы. Построить оси X и Y, а затем нанести на график весь ряд точек таким образом, чтобы каждая из них имела определенную пару координат (,) из нашей таблицы. Поскольку мы в данном случае затрудняемся определить, что можно считать причиной, а что следствием, не важно, какая ось будет вертикальной, а какая горизонтальной.
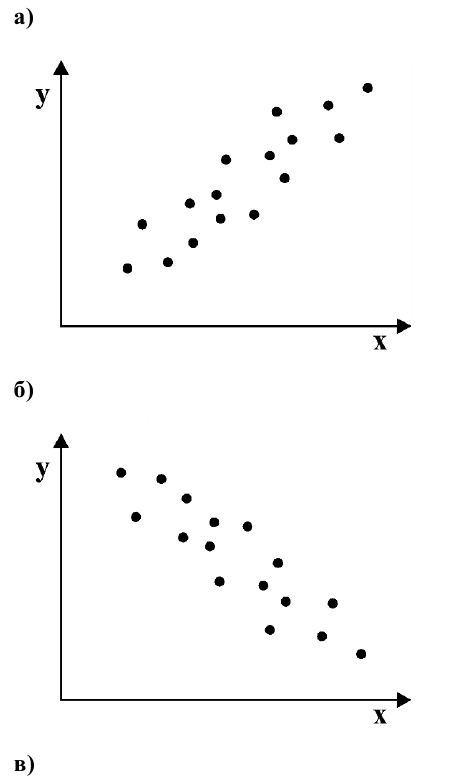
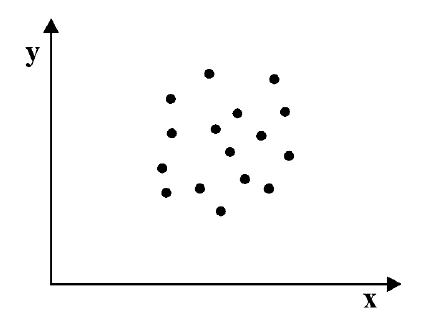
Если график имеет вид а), то это говорит о наличии прямой корреляции, в случае, если он имеет вид б) – корреляция обратная. Отсутствие корреляции тоже можно приблизительно определить по виду графика – это случай в).
С помощью коэффициента корреляции можно посчитать насколько тесная связь существует между величинами.
Пусть, существует корреляция между ценой и спросом на товар. Количество купленных единиц товара в зависимости от цены у разных продавцов показано в таблице:  Видно, что мы имеем дело с обратной корреляцией. Для количественной оценки тесноты связи используют коэффициент корреляции:
Видно, что мы имеем дело с обратной корреляцией. Для количественной оценки тесноты связи используют коэффициент корреляции: 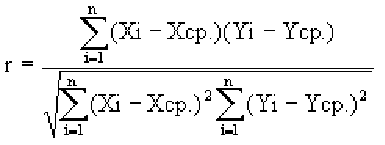
Коэффициент r мы считаем в Excel, с помощью функции 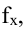 далее статистические функции, функция KOPPEЛ. По подсказке программы вводим мышью в два соответствующих поля два разных массива (X и Y). В нашем случае коэффициент корреляции получился r = -0,988.
далее статистические функции, функция KOPPEЛ. По подсказке программы вводим мышью в два соответствующих поля два разных массива (X и Y). В нашем случае коэффициент корреляции получился r = -0,988.
Надо отметить, что чем ближе к 0 коэффициент корреляции, тем слабее связь между величинами. Наиболее тесная связь при прямой корреляции соответствует коэффициенту r, близкому к +1. В нашем случае, корреляция обратная, но тоже очень тесная, и коэффициент близок к -1.
Что можно сказать о случайных величинах, у которых коэффициент имеет промежуточное значение? Например, если бы мы получили r = 0,65. В этом случае, статистика позволяет сказать, что две случайные величины частично связаны друг с другом. Скажем на 65% влияние на количество покупок оказывала цена, а на 35% – другие обстоятельства. И еще одно важное обстоятельство надо упомянуть.
Поскольку мы говорим о случайных величинах, всегда существует вероятность, что замеченная нами связь – случайное обстоятельство. Причем вероятность найти связь там, где ее нет, особенно велика тогда, когда точек в выборке мало, а при оценке Вы не построили график, а просто посчитали значение коэффициента корреляции на компьютере. Так, если мы оставим всего две разные точки в любой произвольной выборке, коэффициент корреляции будет равен или +1 или -1. Из школьного курса геометрии мы знаем, что через две точки можно всегда провести прямую линию. Для оценки статистической достоверности факта обнаруженной Вами связи полезно использовать так называемую корреляционную поправку: 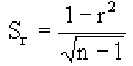
Связь нельзя считать случайной, если: 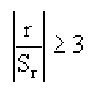
В то время как задача корреляционного анализа – установить, являются ли данные случайные величины взаимосвязанными, цель регрессионного анализа – описать эту связь аналитической зависимостью, т.е. с помощью уравнения. Мы рассмотрим самый несложный случай, когда связь между точками на графике может быть представлена прямой линией. Уравнение этой прямой линии 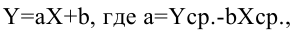
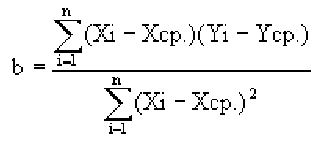
Зная уравнение прямой, мы можем находить значение функции по значению аргумента в тех точках, где значение X известно, a Y – нет. Эти оценки бывают очень нужны, но они должны использоваться осторожно, особенно, если связь между величинами не слишком тесная. Отметим также, что из сопоставления формул для b и r видно, что коэффициент не дает значение наклона прямой, а лишь показывает сам факт наличия связи.
Определение формы связи. Понятие регрессии
Определить форму связи — значит выявить механизм получения зависимой случайной переменной. При изучении статистических зависимостей форму связи можно характеризовать функцией регрессии (линейной, квадратной, показательной и т.д.).
Условное математическое ожидание 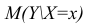 случайной переменной К, рассматриваемое как функция х, т.е.
случайной переменной К, рассматриваемое как функция х, т.е. 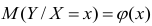 , называется
, называется
функцией регрессии случайной переменной Y относительно X (или функцией регрессии Y по X). Точно так же условное математическое ожидание
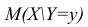 случайной переменной X, т.е.
случайной переменной X, т.е. 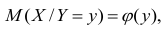 называется функцией регрессии случайной переменной X относительно Y (или функцией регрессии X по Y).
называется функцией регрессии случайной переменной X относительно Y (или функцией регрессии X по Y).
На примере, дискретного распределения найдём функцию регрессии.
Функция регрессии имеет важное значение при статистическом анализе зависимостей между переменными и может быть использована для прогнозирования одной из случайных переменных, если известно значение другой случайной переменной. Точность такого прогноза определяется дисперсией условного распределения.
Несмотря на важность понятия функции регрессии, возможности её практического применения весьма ограничены. Для оценки функции регрессии необходимо знать аналитический вид двумерного распределения (X, Y). Только в этом случае можно точно определить вид функции регрессии, а затем оценить параметры двумерного распределения. Однако для подобной оценки мы чаще всего располагаем лишь выборкой ограниченного объема, по которой нужно найти вид двумерного распределения (X, Y), а затем вид функции регрессии. Это может привести к значительным ошибкам, так как одну и ту же совокупность точек на плоскости можно одинаково успешно описать с помощью различных функций. Именно поэтому возможности практического применения функции регрессии ограничены. Для характеристики формы связи при изучении зависимости используют понятие кривой регрессии.
на плоскости можно одинаково успешно описать с помощью различных функций. Именно поэтому возможности практического применения функции регрессии ограничены. Для характеристики формы связи при изучении зависимости используют понятие кривой регрессии.
Кривой регрессии Y по X (или Y на А) называют условное среднее значение случайной переменной У, рассматриваемое как функция определенного класса, параметры которой находят методом наименьших квадратов по наблюдённым значениям двумерной случайной величины (х, у), т.е.
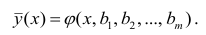
Аналогично определяется кривая регрессии X по Y (X на Y):
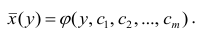
Кривую регрессии называют также эмпирическим уравнением регрессии или просто уравнением регрессии. Уравнение регрессии является оценкой соответствующей функции регрессии.
Возникает вопрос: почему для определения кривой регрессии
используют именно условное среднее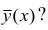 Функция у(х) обладает одним замечательным свойством: она даёт наименьшую среднюю погрешность оценки прогноза. Предположим, что кривая регрессии — произвольная функция. Средняя погрешность прогноза по кривой регрессии определяется математическим ожиданием квадрата разности между измеренной величиной и вычисленной по формуле кривой регрессии, т.е.
Функция у(х) обладает одним замечательным свойством: она даёт наименьшую среднюю погрешность оценки прогноза. Предположим, что кривая регрессии — произвольная функция. Средняя погрешность прогноза по кривой регрессии определяется математическим ожиданием квадрата разности между измеренной величиной и вычисленной по формуле кривой регрессии, т.е. 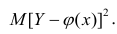 . Естественно потребовать вычисления такой кривой регрессии, средняя погрешность прогноза по которой была бы наименьшей. Таковой является
. Естественно потребовать вычисления такой кривой регрессии, средняя погрешность прогноза по которой была бы наименьшей. Таковой является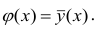 Это следует из свойств минимальности рассеивания около центра распределения
Это следует из свойств минимальности рассеивания около центра распределения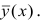
Если рассеивание вычисляется относительно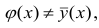 то средний квадрат отклонения увеличивается. Поэтому можно сказать, что кривая регрессии, выражаемая как
то средний квадрат отклонения увеличивается. Поэтому можно сказать, что кривая регрессии, выражаемая как 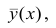 минимизирует среднеквадратическую погрешность прогноза величины Y по X.
минимизирует среднеквадратическую погрешность прогноза величины Y по X.
Основные положения корреляционного анализа
Статистические связи между переменными можно изучать методом корреляционного и регрессионного анализа. С помощью этих методов решают разные задачи; требования, предъявляемые к исследуемым переменным, в каждом методе различны.
Основная задача корреляционного анализа — выявление связи между случайными переменными путём точечной и интервальной оценки парных коэффициентов корреляции, вычисления и проверки значимости множественных коэффициентов корреляции и детерминации, оценки частных коэффициентов корреляции. Корреляционный анализ позволяет также оценить функцию регрессии одной случайной переменной на другую.
Предпосылки корреляционного анализа следующие:
- 1) переменные величины должны быть случайными;
- 2) случайные величины должны иметь совместное нормальное распределение.
Рассмотрим простейший случай корреляционного анализа — двумерную модель. Введём основные понятия и опишем принцип проведения корреляционного анализа. Пусть X и Y — случайные переменные, имеющие совместное нормальное распределение. В этом случае связь между X и Y можно описать коэффициентом корреляции p;. Этот коэффициент определяется как ковариация между X и Y, отнесённая к их среднеквадратическим отклонениям:
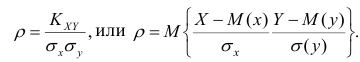 (1.1)
(1.1)
Оценкой коэффициента корреляции является выборочный коэффициент корреляции r. Для его нахождения необходимо знать оценки следующих параметров: 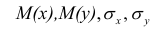 . Наилучшей оценкой
. Наилучшей оценкой
математического ожидания является среднее арифметическое, т.е.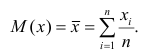
Оценкой дисперсии служит выборочная дисперсия, т.е.
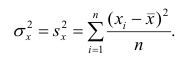
Тогда выборочный коэффициент корреляции
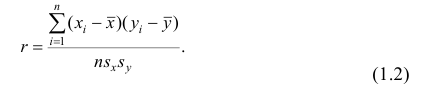
Коэффициент р называют также парным коэффициентом корреляции, а r— выборочным парным коэффициентом корреляции.
При совместном нормальном законе распределения случайных величин X и Y, используя рассмотренные выше параметры распределения и коэффициент корреляции, можно получить выражение для условного математического ожидания, т. е, записать выражение для функции регрессии одной случайной величины на другую. Так, функция регрессии Y на X имеет вид:
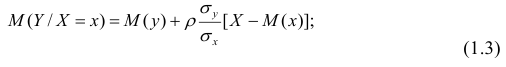
функция регрессии X на Y — следующий вид:
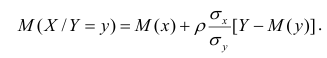
Выражения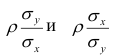 — называют коэффициентами регрессии.
— называют коэффициентами регрессии.
Подставив в (1.3) соответствующие оценки параметров, получим уравнения регрессии, график которых — прямая линия, проходящая через точку 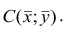 Запишем уравнение регрессии у на х и х на у:
Запишем уравнение регрессии у на х и х на у:
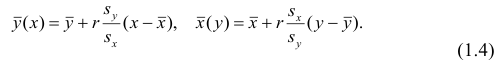
Таким образом, в корреляционном анализе на основе оценок параметров двумерной нормальной совокупности получаем оценки тесноты связи между случайными переменными и можем оценить регрессию одной переменной на другую. Особенностью корреляционного анализа является строго линейная зависимость между переменными. Это обусловливается исходными предпосылками. На практике корреляционный анализ можно применять для обработки наблюдений, сделанных на предприятиях при нормальных условиях работы, если случайные изменения свойства сырья или других факторов вызывают случайные изменения свойств продукции.
Свойства коэффициента корреляции
Коэффициент корреляции является одним из самых распространенных способов измерения связи между случайными переменными. Рассмотрим некоторые свойства этого коэффициента.
Теорема 1. Коэффициент корреляции принимает значения на интервале (-1, +1).
Доказательство. Докажем справедливость утверждения для случая дискретных переменных. Запишем явно неотрицательное выражение:
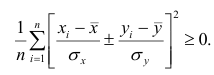
Возведём выражение под знаком суммы в квадрат:
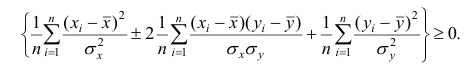
Первое и третье из слагаемых равны единице, поскольку из определения дисперсии следует, что 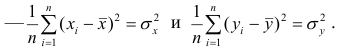
Таким образом, окончательно получаем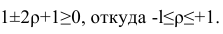
Если коэффициент корреляции положителен, то связь между переменными также положительна и значения переменных увеличиваются или уменьшаются одновременно. Если коэффициент корреляции имеет отрицательное значение, то при увеличении одной переменной уменьшается другая.
Приведём следующее важное свойство коэффициента корреляции: коэффициент корреляции не зависит от выбора начала отсчёта и единицы измерения, т. е. от любых постоянных 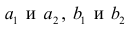 таких, что
таких, что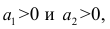 т.е.
т.е.
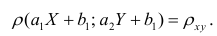
Таким образом, переменные X и У можно уменьшать или увеличивать в а раз, а также вычитать или прибавлять к значениям X и У одно и то же число b. В результате величина коэффициента корреляции не изменится.
Если коэффициент корреляции 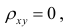 то случайные переменные некоррелированы. Понятие некоррелированности не следует смешивать с понятием независимости, независимые величины всегда некоррелированы. Однако обратное утверждение невероятно: некоррелированные величины могут быть зависимы и даже функционально, однако эта связь не линейная.
то случайные переменные некоррелированы. Понятие некоррелированности не следует смешивать с понятием независимости, независимые величины всегда некоррелированы. Однако обратное утверждение невероятно: некоррелированные величины могут быть зависимы и даже функционально, однако эта связь не линейная.
Выборочный коэффициент корреляции вычисляют по формуле (1.2). Имеется несколько модификаций этой формулы, которые удобно использовать при той или иной форме представления исходной информации. Так, при малом числе наблюдений выборочный коэффициент корреляции удобно вычислять по формуле
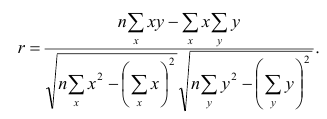
Если информация имеет вид корреляционной таблицы (см. п 1.5), то удобно пользоваться формулой
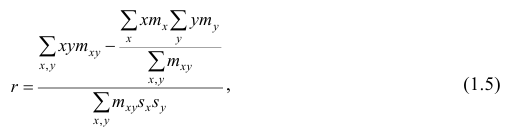
где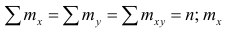 — суммарная частота наблюдаемого значенияпризнака х при всех значениях
— суммарная частота наблюдаемого значенияпризнака х при всех значениях  — суммарная частота наблюдаемого значения признака упри всех значениях х;
— суммарная частота наблюдаемого значения признака упри всех значениях х; 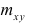 — частота появления пары признаков (x, у).
— частота появления пары признаков (x, у).
Из формулы (1.2) очевидно, что 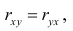 т.е. величина выборочного коэффициента корреляции не зависит от порядка следования переменных, поэтому обычно пишут просто r.
т.е. величина выборочного коэффициента корреляции не зависит от порядка следования переменных, поэтому обычно пишут просто r.
Поле корреляции. Вычисление оценок параметров двумерной модели
На практике для вычисления оценок параметров двумерной модели удобно использовать корреляционную таблицу и поле корреляции. Пусть, например, изучается зависимость между объёмом выполненных работ (у) и накладными расходами (x). Имеем выборку из генеральной совокупности, состоящую из 150 пар переменных 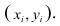 Считаем, что предпосылки корреляционного анализа выполнены.
Считаем, что предпосылки корреляционного анализа выполнены.
Пару случайных чисел 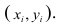 можно изобразить графически в виде точки с координатами
можно изобразить графически в виде точки с координатами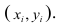 . Аналогично можно изобразить весь набор пар случайных чисел (всю выборку). Однако при большом объёме выборки это затруднительно. Задача упрощается, если выборку упорядочить, т.е. переменные сгруппировать. Сгруппированные ряды могут быть как дискретными, так и интервальными.
. Аналогично можно изобразить весь набор пар случайных чисел (всю выборку). Однако при большом объёме выборки это затруднительно. Задача упрощается, если выборку упорядочить, т.е. переменные сгруппировать. Сгруппированные ряды могут быть как дискретными, так и интервальными.
По осям координат откладывают или дискретные значения переменных, или интервалы их изменения. Для интервального ряда наносят координатную сетку. Каждую пару переменных из данной выборки изображают в виде точки с соответствующими координатами для дискретного ряда или в виде точки в соответствующей клетке для интервального ряда. Такое изображение корреляционной зависимости называют полем корреляции. На рис. 1.1 изображено поле корреляции для выборки, состоящей из 150 пар переменных (ряд интервальный).
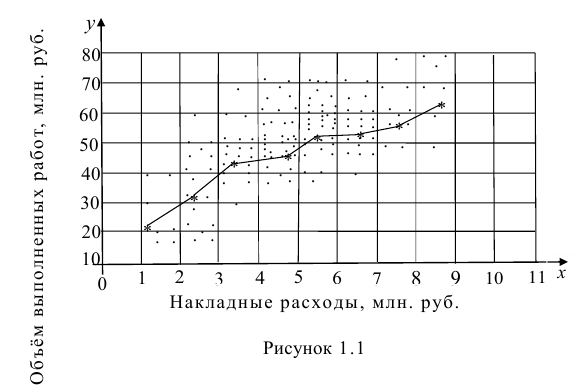
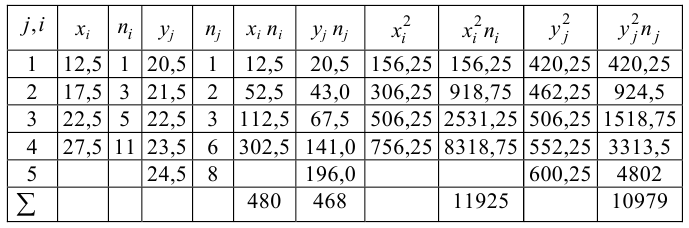
Если вычислить средние значения у в каждом интервале изменения х [обозначим их 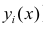 )], нанести эти точки на рис. 1.1 и соединить между собой, то получим ломаную линию, по виду которой можно судить, как в среднем меняются у в зависимости от изменения х. По виду этой линии можно также сделать предположение о форме связи между переменными. В данном случае ломаную линию можно аппроксимировать прямой линией, так как она достаточно хорошо приближается к ней. По выборочным данным можно построить также корреляционную табл. 1.1.
)], нанести эти точки на рис. 1.1 и соединить между собой, то получим ломаную линию, по виду которой можно судить, как в среднем меняются у в зависимости от изменения х. По виду этой линии можно также сделать предположение о форме связи между переменными. В данном случае ломаную линию можно аппроксимировать прямой линией, так как она достаточно хорошо приближается к ней. По выборочным данным можно построить также корреляционную табл. 1.1.
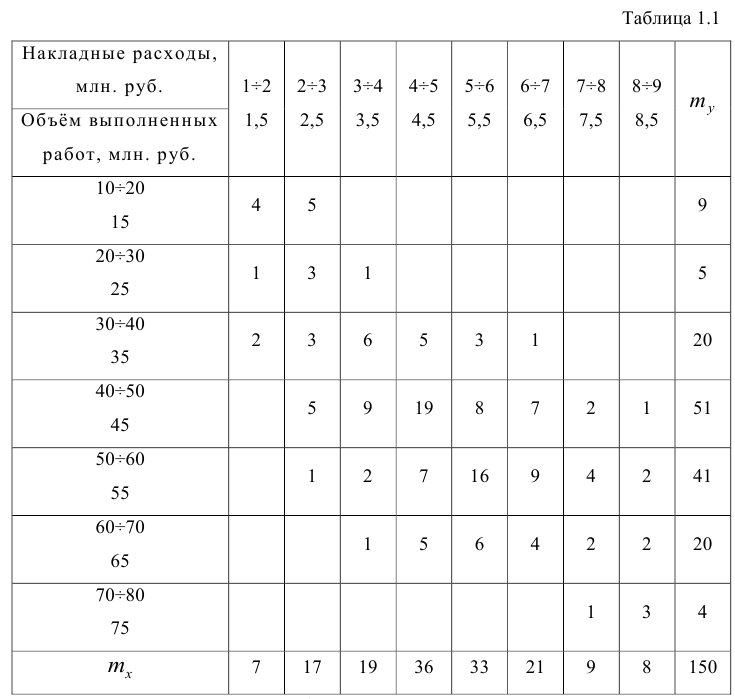
Корреляционную таблицу, как и поле корреляции, строят по
сгруппированному ряду (дискретному или интервальному). Табл. 1.1 построена на основе интервального ряда. В первой строке и первом столбце таблицы помещают интервалы изменения х и у и значения середин интервалов. Так, например, 1,5 — середина интервала изменения *=1-2,15— середина интервала изменения у= 10-20. В ячейки, образованные пересечением строк и столбцов, заносят частоты попадания пар значений (л у) в соответствующие интервалы по х и у. Например, частота 4 означает, что в интервал изменения у от 10 до 20 попало 4 пары наблюдавшихся значений. Эти частоты обозначают 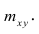 В 9-й строке и 10-м столбце находятся значения
В 9-й строке и 10-м столбце находятся значения 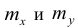 – суммы
– суммы 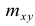 по соответствующим столбцу и строке.
по соответствующим столбцу и строке.
Как будет показано в дальнейшем, корреляционно таблицей удобно пользоваться при вычислении коэффициентов корреляций и параметров уравнений регрессии.
Корреляционная таблица построена на основе интервального ряда, поэтому для оценок параметров воспользуемся формулами гл. 1 для вычисления средней арифметической и дисперсии. Имеем:
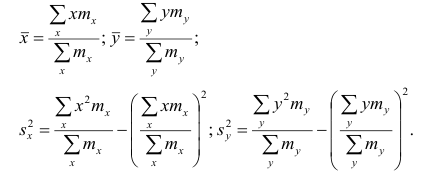 (1.6)
(1.6)
Проверка гипотезы о значимости коэффициента корреляции
На практике коэффициент корреляции р обычно неизвестен. По результатам выборки может быть найдена его точечная оценка — выборочный коэффициент корреляции r.
Равенство нулю выборочного коэффициента корреляции ещё не свидетельствует о равенстве нулю самого коэффициента корреляции, а следовательно, о некоррелированности случайных величин X и Y. Чтобы выяснить, находятся ли случайные величины в корреляционной зависимости, нужно проверить значимость выборочного коэффициента корреляции г, т.е. установить, достаточна ли его величина для обоснованного вывода о наличии корреляционной связи. Для этого проверяют нулевую гипотезу 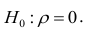 . Предполагается наличие двумерного нормального распределения случайных переменных; объём выборки может быть любым. Вычисляют
. Предполагается наличие двумерного нормального распределения случайных переменных; объём выборки может быть любым. Вычисляют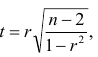
которая имеет распределение Стьюдента с k=n-2
степенями свободы. Для проверки нулевой гипотезы по уровню значимости а и числу степеней свободы к находят по таблицам распределения Стьюдента (t-распределение; см. табл. 1 приложения) критическое значение 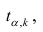 удовлетворяющее условию
удовлетворяющее условию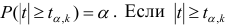 , то нулевую гипотезу об отсутствии корреляционной связи между переменными X и Y следует отвергнуть. Переменные считают зависимыми. При
, то нулевую гипотезу об отсутствии корреляционной связи между переменными X и Y следует отвергнуть. Переменные считают зависимыми. При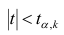 нет оснований отвергать нулевую гипотезу.
нет оснований отвергать нулевую гипотезу.
В случае значимого выборочного коэффициента, корреляции есть смысл построить доверительный интервал для коэффициента корреляций р. Однако для этого нужно знать закон распределения выборочного коэффициента корреляции r.
Плотность вероятности выборочного коэффициента корреляции имеет сложный вид, поэтому прибегают к специально подобранным функциям от выборочного коэффициента корреляции, которые сводятся к хорошо изученным распределениям, например нормальному или Стьюдента. Чаще всего для подбора функции применяют преобразование Фишера. Вычисляют статистику:
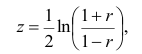
где r=thz — гиперболический тангенс от z.
Распределение статистики z хорошо аппроксимируется нормальным распределением с параметрами
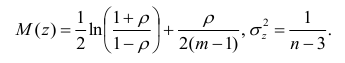
В этом, случае доверительный интервал для римеетвид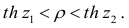 Величины
Величины 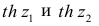 находят по таблицам по следующим значениям:
находят по таблицам по следующим значениям:
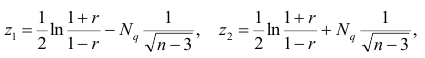
где 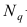 — нормированная функция Лапласа для q % доверительного интервала (см. табл. 2 приложений значение функции
— нормированная функция Лапласа для q % доверительного интервала (см. табл. 2 приложений значение функции 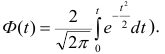
Если коэффициент корреляции значим, то коэффициенты регрессии также значимо отличаются от нуля, а интервальные оценки для них можно получить по следующим формулам:
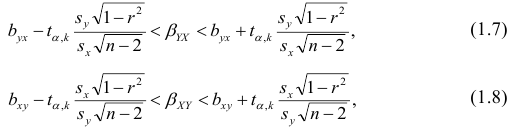
где 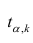 имеет распределение Стьюдента с k=n—2 степенями свободы.
имеет распределение Стьюдента с k=n—2 степенями свободы.
Корреляционное отношение
На практике часто предпосылки корреляционного анализа нарушаются: один из признаков оказывается величиной не случайной, или признаки не имеют совместного нормального распределения. Однако статистическая зависимость между ними существует. Для изучения связи между признаками в этом случае существует общий показатель зависимости признаков, основанный на показателе изменчивости — общей (или полной) дисперсии.
Полной называется дисперсия признака относительно его математического ожидания. Так, для признака Y это 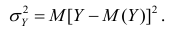 Дисперсию
Дисперсию 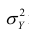 можно разложить на две составляющие, одна из которых характеризует влияние фактора X на Y, другая — влияние прочих факторов.
можно разложить на две составляющие, одна из которых характеризует влияние фактора X на Y, другая — влияние прочих факторов.
Очевидно, чем меньше влияние прочих факторов, тем теснее связь, тем более приближается она к функциональной. Представим 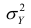 в следующем виде:
в следующем виде:
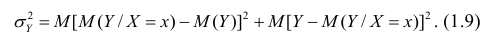
Первое слагаемое обозначим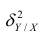 Это дисперсия функции регрессии относительно математического ожидания признака (в данном случае признака У);.она измеряет влияние признака X на Y. Второе слагаемое обозначим
Это дисперсия функции регрессии относительно математического ожидания признака (в данном случае признака У);.она измеряет влияние признака X на Y. Второе слагаемое обозначим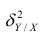 . Это дисперсия признака Y относительно функции регрессии. Её называют также средней из условных дисперсий или остаточной дисперсией
. Это дисперсия признака Y относительно функции регрессии. Её называют также средней из условных дисперсий или остаточной дисперсией 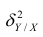 измеряет влияние на Y прочих факторов.
измеряет влияние на Y прочих факторов.
Покажем, что 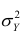 действительно можно разложить на два таких слагаемых:
действительно можно разложить на два таких слагаемых:
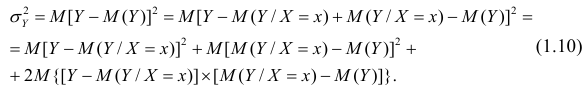
Для простоты полагаем распределение дискретным. Имеем 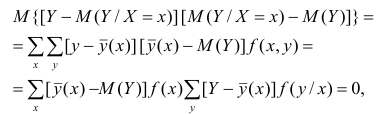
так как при любом х справедливо равенство
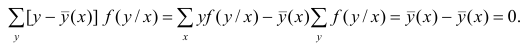
Третье слагаемое в равенстве (1.10) равно нулю, поэтому равенство (1.9) справедливо. Поскольку второе слагаемое в равенстве (1.9) оценивает влияние признака X на Y, то его можно использовать для оценки тесноты связи между X и Y. Тесноту связи удобно оценивать в единицах общей дисперсии 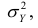 т.е. рассматривать отношение
т.е. рассматривать отношение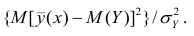 . Эту величину обозначают
. Эту величину обозначают 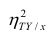 и называют теоретическим корреляционным отношением. Таким образом,
и называют теоретическим корреляционным отношением. Таким образом,
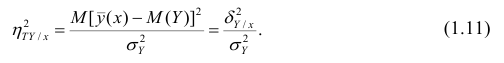
Разделив обе части равенства (1.9) на 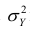 получим
получим
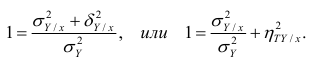
Из последней формулы имеем

Поскольку 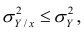 так как
так как 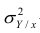 — составная часть
— составная часть 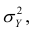 то из равенства (1.12) следует, что значение
то из равенства (1.12) следует, что значение 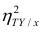 всегда заключено между нулем и единицей.
всегда заключено между нулем и единицей.
Все сделанные выводы справедливы и для 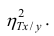 Из равенства (1.12)
Из равенства (1.12)
следует, что 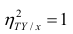 только тогда, когда
только тогда, когда 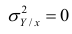 , т.е. отсутствует влияние прочих факторов и всё распределение сконцентрировано на кривой регрессии
, т.е. отсутствует влияние прочих факторов и всё распределение сконцентрировано на кривой регрессии 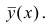 . В этом случае между Y и X существует функциональная зависимость.
. В этом случае между Y и X существует функциональная зависимость.
Далее, из равенства (1.12) следует, что 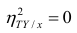 тогда и только тогда, когда
тогда и только тогда, когда
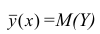 = const, т.е. линия регрессии У по X — горизонтальная прямая, проходящая через центр распределения. В этом случае можно сказать, что переменная У не коррелирована с X (рис. 1.2,а, б, в).
= const, т.е. линия регрессии У по X — горизонтальная прямая, проходящая через центр распределения. В этом случае можно сказать, что переменная У не коррелирована с X (рис. 1.2,а, б, в).
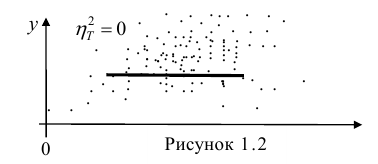
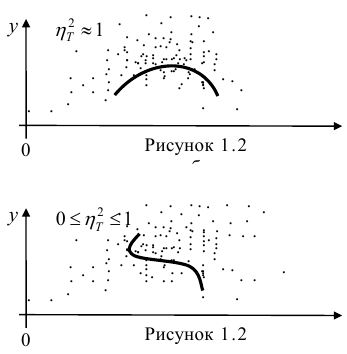
Аналогичными свойствами обладает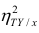 — показатель тесноты связи между X и У.
— показатель тесноты связи между X и У.
Часто используют величину

Считают, что она не может быть отрицательной. Значения величины 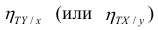 также могут находиться лишь в пределах от нуля до единицы. Это очевидно из формулы (1.13).
также могут находиться лишь в пределах от нуля до единицы. Это очевидно из формулы (1.13).
Значения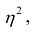 лежащие в интервале
лежащие в интервале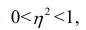 являются показателями тесноты группировки точек около кривой регрессии независимо от её вида (формы связи). Корреляционное отношение
являются показателями тесноты группировки точек около кривой регрессии независимо от её вида (формы связи). Корреляционное отношение 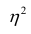 связано
связано 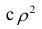 следующим образом:
следующим образом: 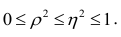 В случае линейной зависимости между переменными
В случае линейной зависимости между переменными 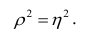
Разность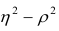 может быть использована как показатель нелинейности связи между переменными.
может быть использована как показатель нелинейности связи между переменными.
При вычислении 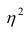 по выборочным данным получаем выборочное корреляционное отношение. Обозначим его
по выборочным данным получаем выборочное корреляционное отношение. Обозначим его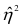 . Вместо дисперсий в этом случае используются их оценки. Тогда формула (1.12) принимает вид
. Вместо дисперсий в этом случае используются их оценки. Тогда формула (1.12) принимает вид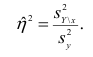
Понятие о многомерном корреляционном анализе
Частный коэффициент корреляции. Основные понятия корреляционного анализа, введенные для двумерной модели, можно распространить на многомерный случай. Задачи и предпосылки корреляционного анализа были сформулированы в п. 1.3. Однако если при изучении взаимосвязи переменных по двумерной модели мы ограничивались рассмотрением парных коэффициентов корреляции, то для многомерной модели этого недостаточно. Многообразие связей между переменными находит отражение в частных и множественных коэффициентах корреляции.
Пусть имеется многомерная нормальная совокупность с m признаками 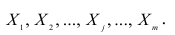 В этом случае взаимозависимость между признаками
В этом случае взаимозависимость между признаками
можно описать корреляционной матрицей. Под корреляционной матрицей будем понимать, матрицу, составленную из парных коэффициентов корреляции (вычисляются по формуле (1,1)):
где 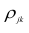 — парные коэффициенты корреляции; m — порядок матрицы.
— парные коэффициенты корреляции; m — порядок матрицы.
Оценкой парного коэффициента корреляции является выборочный парный коэффициент корреляции, определяемый по формуле (1.2), однако для m признаков формула (9.2) принимает вид
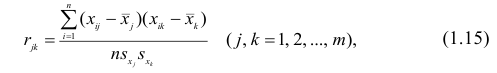
где 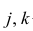 — порядковые номера признаков.
— порядковые номера признаков.
Как и в двумерном случае, для оценки коэффициента корреляции необходимо оценить математические ожидания и дисперсии. В многомерном корреляционном анализе имеем т математических ожиданий и m дисперсий, а также m(m—1)/2 парных коэффициентов корреляции. Таким образом, нужно произвести оценку 2m+m(m—1)/2 параметров.
В случае многомерной корреляции зависимости между признаками более многообразны и сложны, чем в двумерном случае. Одной корреляционной матрицей нельзя полностью описать зависимости между признаками. Введём понятие частного коэффициента корреляции l-го порядка.
Пусть исходная совокупность состоит из т признаков. Можно изучать зависимости между двумя из них при фиксированном значении l признаков из m-2 оставшихся. Рассмотрим, например, систему из 5 признаков. Изучим зависимости между 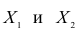 при фиксированном значении признака
при фиксированном значении признака 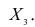 В этом случае имеем частный коэффициент корреляции первого порядка, так как фиксируем только один признак.
В этом случае имеем частный коэффициент корреляции первого порядка, так как фиксируем только один признак.
Рассмотрим более подробно структуру частных коэффициентов корреляции на примере системы из трёх признаков 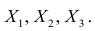 . Эта система позволяет изучить частные коэффициенты корреляции только первого порядка, так как нельзя фиксировать больше одного признака. Частный коэффициент корреляции первого порядка для признаков
. Эта система позволяет изучить частные коэффициенты корреляции только первого порядка, так как нельзя фиксировать больше одного признака. Частный коэффициент корреляции первого порядка для признаков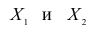 при фиксированном значении
при фиксированном значении 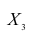 выражается через парные коэффициенты
выражается через парные коэффициенты
корреляции и имеет вид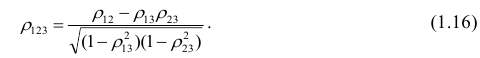
Частный коэффициент корреляции, так же как и парный коэффициент корреляции, изменяется от —1 до +1, В общем виде, когда система состоит из m признаков, частный коэффициент корреляции l-го порядка может быть найден из корреляционной матрицы. Если 1=m—2, то рассматривается матрица порядка m, при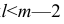 — подматрица порядкаl+2, составленная из элементов матрицы
— подматрица порядкаl+2, составленная из элементов матрицы 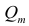 , которые отвечают индексам коэффициента частной
, которые отвечают индексам коэффициента частной
корреляции. Например, корреляционная матрица системы из пяти признаков имеет вид
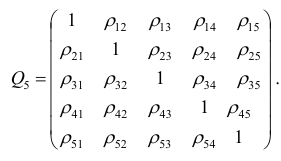
Для определения частного коэффициента корреляции второго порядка, например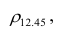 следует использовать подматрицу четвертого порядка,
следует использовать подматрицу четвертого порядка,
вычеркнув из исходной матрицы 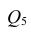 третью строку и третий столбец, так как признак
третью строку и третий столбец, так как признак 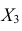 не рассматривают.
не рассматривают.
В общем виде формулу частного коэффициента корреляции l-го порядка (1=m—2) можно записать в виде
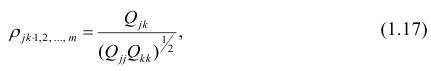
где 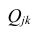 — алгебраические дополнения к элементу
— алгебраические дополнения к элементу 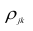 корреляционной
корреляционной
матрицы 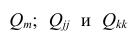 — алгебраические дополнения к элементам
— алгебраические дополнения к элементам 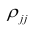 и ркк корреляционной матрицы
и ркк корреляционной матрицы 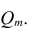
Очевидно, что выражение (1.16) является частым случаем выражения (1.17), в чём легко убедиться, рассмотрев корреляционную матрицу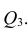
Оценкой частного коэффициента корреляции l-го порядка является выборочный частный коэффициент корреляции l-го порядка. Он вычисляется на основе корреляционной матрицы, составленной из выборочных парных коэффициентов корреляции:
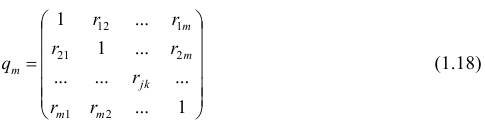
Формула выборочного частного коэффициента корреляции имеет вид

где 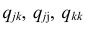 — алгебраические дополнения к соответствующим элементам матрицы (1.18).
— алгебраические дополнения к соответствующим элементам матрицы (1.18).
Частный коэффициент корреляции l-го порядка, вызволенный на основе п наблюдений над признаками, имеет такое же распределение, что и парный коэффициент корреляции, вычисленный  наблюдениям. Поэтому значимость частных коэффициентов корреляции оценивают так же, как и в п. 1.6.
наблюдениям. Поэтому значимость частных коэффициентов корреляции оценивают так же, как и в п. 1.6.
Множественный коэффициент корреляции
Часто представляет интерес оценить связь одного из признаков со всеми остальными. Это можно сделать с помощью множественного, или совокупного, коэффициента корреляции

где 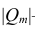 —определитель корреляционной матрицы
—определитель корреляционной матрицы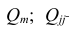 —алгебраическое
—алгебраическое
дополнение к элементу 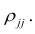
Квадрат коэффициента множественной корреляции 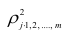 называется
называется
множественным коэффициентом детерминации. Коэффициенты множественной корреляции и детерминации — величины положительные, принимающие значения в интервале Оценками этих
Оценками этих
коэффициентов являются выборочные множественные коэффициенты корреляции и детерминации, которые обозначают соответственно 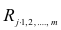 и
и
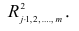 Формула для вычисления выборочного множественного коэффициента корреляции имеет вид
Формула для вычисления выборочного множественного коэффициента корреляции имеет вид

где 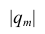 —определитель корреляционной матрицы, составленной из выборочных парных коэффициентов корреляции;
—определитель корреляционной матрицы, составленной из выборочных парных коэффициентов корреляции; 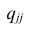 алгебраическое дополнение к элементу
алгебраическое дополнение к элементу 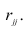
Многомерный корреляционный анализ позволяет получить оценку функции регрессии — уравнение регрессии. Коэффициенты в уравнении регрессии можно найти непосредственно через выборочные парные коэффициенты корреляции или воспользоваться методом многомерной регрессии, который мы рассмотрим в вопросе 2.7. В этом случае все предпосылки регрессионного анализа оказываются выполненными и, кроме того, связь между переменными строго линейна.
Ранговая корреляция
В некоторых случаях встречаются признаки, не поддающиеся количественной оценке (назовём такие признаки объектами). Попытаемся, например, оценить соотношение между математическими и музыкальными способностями группы учащихся. «Уровень способностей» является переменной величиной в том смысле; что он варьирует от одного индивидуума к другому. Его можно измерить, если выставлять каждому индивидууму отметки. Однако этот способ лишен объективности, так как разные экзаменаторы могут выставить одному и тому же учащемуся разные отметки. Элемент субъективизма можно исключить, если учащиеся будут ранжированы. Расположим учащихся по порядку, в соответствии со степенью способностей и присвоим каждому из них порядковый номер, который назовем рангом. Корреляция между рангами более точно отражает соотношение между способностями учащихся, чем корреляция между отметками.
Тесноту связи между рангами измеряют так же, как и между признаками. Рассмотрим уже известную формулу коэффициента корреляции
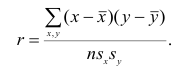
Пусть 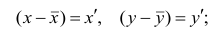 тогда, учитывая,
тогда, учитывая,
что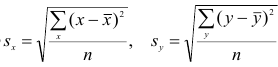 ,можно записать
,можно записать

В зависимости от того, что принять за меру различия между величинами 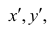 можно получить различные коэффициенты связи между рангами. Обычно используют коэффициент корреляции рангов Кэнделла
можно получить различные коэффициенты связи между рангами. Обычно используют коэффициент корреляции рангов Кэнделла 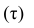 и коэффициент корреляции рангов Спирмэна р.
и коэффициент корреляции рангов Спирмэна р.
Введём следующую меру различия между объектами: будем считать 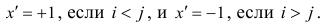 Поясним сказанное на примере. Имеем две последовательности:
Поясним сказанное на примере. Имеем две последовательности:
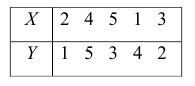
Рассмотрим отдельно каждую из них. В последовательности X первой паре элементов —2; 4 припишем значение +1, так как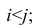 второй паре 2; 5 также припишем значение +1, третьей паре 2; 1 припишем значение —1, поскольку
второй паре 2; 5 также припишем значение +1, третьей паре 2; 1 припишем значение —1, поскольку 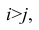 и т.д. Последовательно перебираем все пары, причём каждая пара должна быть учтена один раз. Так, если учтена пара 2; 1, то не следует учитывать пару 1; 2. Аналогичные действия проделаем с последовательностью У, причём порядок перебора пар должен в точности повторять порядок перебора пар в последовательности X. Результаты этих действий представим в виде табл. 1.3.
и т.д. Последовательно перебираем все пары, причём каждая пара должна быть учтена один раз. Так, если учтена пара 2; 1, то не следует учитывать пару 1; 2. Аналогичные действия проделаем с последовательностью У, причём порядок перебора пар должен в точности повторять порядок перебора пар в последовательности X. Результаты этих действий представим в виде табл. 1.3.
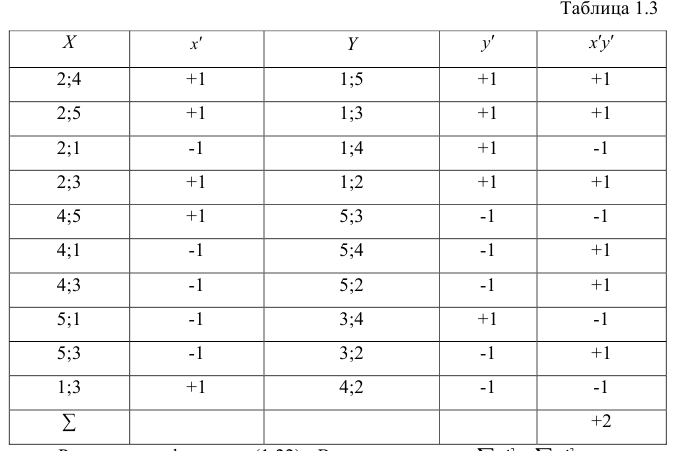
Рассмотрим формулу ( 1 .22). В нашем случае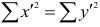 и равна
и равна
количеству пар, участвовавших в переборе. Каждая пара встречается только один раз, поэтому их общее количество равно числу сочетаний из n по 2, т.е.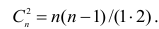 Обозначая
Обозначая 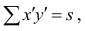 получаем формулу коэффициента корреляции рангов Кэнделла:
получаем формулу коэффициента корреляции рангов Кэнделла:
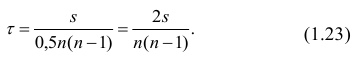
Теперь рассмотрим другую меру различия между объектами. Если обозначить через 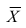 средний ранг последовательности X, через
средний ранг последовательности X, через 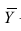 — средний ранг последовательности Т, то
— средний ранг последовательности Т, то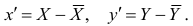 Поскольку ранги последовательности X и Y есть числа натурального ряда, то их сумма равна
Поскольку ранги последовательности X и Y есть числа натурального ряда, то их сумма равна 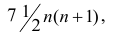 а средний ранг
а средний ранг 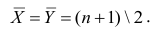
Тогда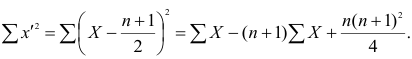 Сумма
Сумма
чисел натурального ряда равна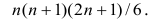
Тогда 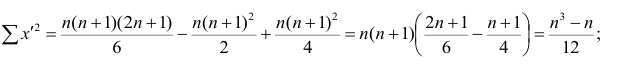
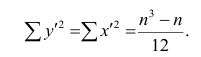
Введём новую величину d, равную разности между рангами: d=X—Y, и определим через неё величину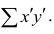 . Имеем:
. Имеем: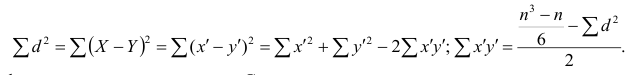
Коэффициент корреляции рангов Спирмэна

У коэффициентов 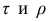 разные масштабы, они отличаются шкалами измерений. Поэтому на практике нельзя ожидать, что они совпадут. Чаще всего, если значения обоих коэффициентов не слишком, близки к 1, p; по абсолютной величине примерно на 50% превышает
разные масштабы, они отличаются шкалами измерений. Поэтому на практике нельзя ожидать, что они совпадут. Чаще всего, если значения обоих коэффициентов не слишком, близки к 1, p; по абсолютной величине примерно на 50% превышает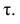 Выведены неравенства, связывающие
Выведены неравенства, связывающие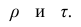 Например, при больших n можно пользоваться следующим приближённым соотношением:
Например, при больших n можно пользоваться следующим приближённым соотношением: 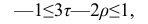 или
или
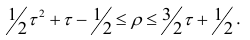 Коэффициент p легче рассчитать, однако с теоретической точки зрения больший интерес представляет коэффициент
Коэффициент p легче рассчитать, однако с теоретической точки зрения больший интерес представляет коэффициент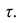
При вычислении коэффициента корреляций рангов Кэнделла для подсчёта s можно использовать следующий приём: одну из последовательностей упорядочивают так, чтобы её элементы были числами натурального ряда; соответственно изменяют и другую последовательность. Тогда сумму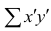 можно подсчитывать лишь по последовательности К, так как все
можно подсчитывать лишь по последовательности К, так как все 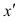 равны +1.
равны +1.
Если нельзя установить ранговое различие нескольких объектов, говорят, что такие объекты являются связанными. В этом случае объектам приписывается средний ранг. Например, если связанными являются объекты 4 и 5, то им приписывают ранг 4.5; если связанными являются объекты 1, 2, 3, 4 и 5, то их средний ранг (1+2+3+4+5)/5=3. Сумма рангов связанных объектов должна быть равна сумме рангов при ранжировании без связей. Формулы коэффициентов корреляции для 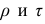 в этом случае также можно вывести из формулы обобщённого коэффициента корреляции, только знаменатель выражения (1.21) в этом случае не равен n(n—1)/2. Если / последовательных членов связаны, то все оценки, относящиеся к любой вобранной из них паре, равны нулю; число таких пар t(t—1), Следовательно,
в этом случае также можно вывести из формулы обобщённого коэффициента корреляции, только знаменатель выражения (1.21) в этом случае не равен n(n—1)/2. Если / последовательных членов связаны, то все оценки, относящиеся к любой вобранной из них паре, равны нулю; число таких пар t(t—1), Следовательно,
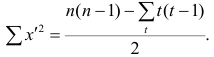 Соответственно для другой последовательности
Соответственно для другой последовательности
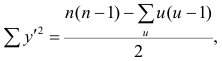
где t и u—число связанных пар в последовательностях.
Обозначая 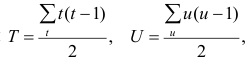 получаем
получаем
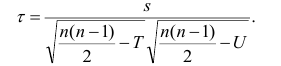
Аналогично находим выражение для р. Только в этом случае
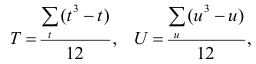 , где е и г – число связанных пар в
, где е и г – число связанных пар в
последовательностях, а
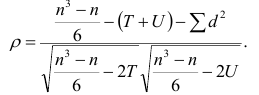
Если имеется несколько последовательностей, то возникает необходимость определить общую меру согласованности между ними. Такой мерой является коэффициент копкордации.
Пусть ь — число последовательностей, т — количество рангов в каждой последовательности. Тогда коэффициент конкордации

где d — фактически встречающееся отклонение от среднего значения суммы рангов одного объекта.
Коэффициент корреляции рангов может быть использован для быстрого оценивания взаимосвязи между признаками, не имеющими нормального распределения, и полезен в тех случаях, когда признаки поддаются ранжированию, но не могут быть точно измерены.
Пример:
Для данных табл. 13 найти выборочный коэффициент корреляции, проверить его значимость на уровне 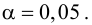
Решение. Для вычислений составим таблицу. Находим суммы
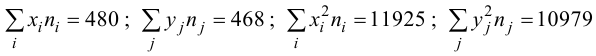 и заносим их в таблицу. Вычислим
и заносим их в таблицу. Вычислим
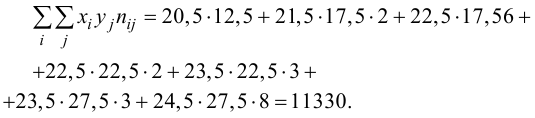
Подставляя полученные значения сумм в (8), найдем выборочный коэффициент корреляции
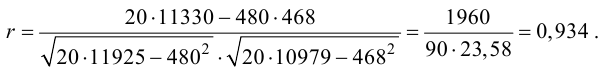
Проверим значимость 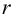 на уровне
на уровне 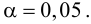 Для этого вычислим статистику
Для этого вычислим статистику
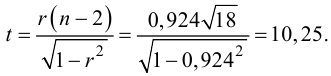
По таблице распределения П6 Стьюдента 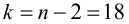 находим критическое значение
находим критическое значение 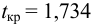 Так как
Так как 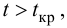 то считаем
то считаем 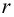 значимым.
значимым.
Пример:
Для данных табл. 13 найти корреляционное отношение 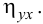
Для вычисления эмпирического корреляционного отношения найдем групповые средние 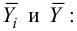
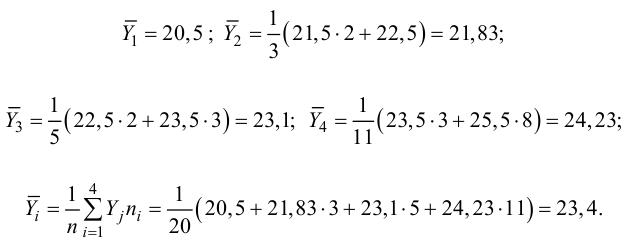
Тогда
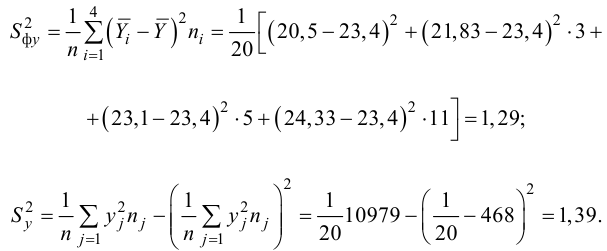
Вычисляем корреляционное отношение
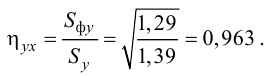
- Статистические решающие функции
- Случайные процессы
- Выборочный метод
- Статистическая проверка гипотез
- Доверительный интервал для математического ожидания
- Доверительный интервал для дисперсии
- Проверка статистических гипотез
- Регрессионный анализ
Термин «корреляция» активно используется в гуманитарных науках, медицине; часто мелькает в СМИ. Ключевую роль корреляции играют в психологии. В частности, расчет корреляций выступает важным этапом реализации эмпирического исследования при написании ВКР по психологии.
Материалы по корреляциям в сети слишком научны. Неспециалисту трудно разобраться в формулах. В то же время понимание смысла корреляций необходимо маркетологу, социологу, медику, психологу – всем, кто проводит исследования на людях.
В этой статье мы простым языком объясним суть корреляционной связи, виды корреляций, способы расчета, особенности использования корреляции в психологических исследованиях, а также при написании дипломных работ по психологии.
Содержание
Что такое корреляция
Численное выражение корреляционной связи
- Прямая и обратная корреляция
- Сильная и слабая корреляция
Корреляционный анализ в психологии
Коэффициенты корреляции Пирсона и Спирмена
Как рассчитать коэффициент корреляции
- Расчет корреляций с помощью электронных таблиц Microsoft Excel
- Как вычислить значение корреляции с помощью статистической программы STATISTICA
Использование корреляционного анализа в дипломных работах по психологии
Что такое корреляция
Корреляция – это связь. Но не любая. В чем же ее особенность? Рассмотрим на примере.
Представьте, что вы едете на автомобиле. Вы нажимаете педаль газа – машина едет быстрее. Вы сбавляете газ – авто замедляет ход. Даже не знакомый с устройством автомобиля человек скажет: «Между педалью газа и скоростью машины есть прямая связь: чем сильнее нажата педаль, тем скорость выше».
Это зависимость функциональная – скорость выступает прямой функцией педали газа. Специалист объяснит, что педаль управляет подачей топлива в цилиндры, где происходит сжигание смеси, что ведет к повышению мощности на вал и т.д. Это связь жесткая, детерминированная, не допускающая исключений (при условии, что машина исправна).
Теперь представьте, что вы директор фирмы, сотрудники которой продают товары. Вы решаете повысить продажи за счет повышения окладов работников. Вы повышаете зарплату на 10%, и продажи в среднем по фирме растут. Через время повышаете еще на 10%, и опять рост. Затем еще на 5%, и опять есть эффект. Напрашивается вывод – между продажами фирмы и окладом сотрудников есть прямая зависимость – чем выше оклады, тем выше продажи организации. Такая же это связь, как между педалью газа и скоростью авто? В чем ключевое отличие?
Правильно, между окладом и продажами заисимость не жесткая. Это значит, что у кого-то из сотрудников продажи могли даже снизиться, невзирая на рост оклада. У кого-то остаться неизменными. Но в среднем по фирме продажи выросли, и мы говорим – связь продаж и оклада сотрудников есть, и она корреляционная.
В основе функциональной связи (педаль газа – скорость) лежит физический закон. В основе корреляционной связи (продажи – оклад) находится простая согласованность изменения двух показателей. Никакого закона (в физическом понимании этого слова) за корреляцией нет. Есть лишь вероятностная (стохастическая) закономерность.
Численное выражение корреляционной зависимости
Итак, корреляционная связь отражает зависимость между явлениями. Если эти явления можно измерить, то она получает численное выражение.
Например, изучается роль чтения в жизни людей. Исследователи взяли группу из 40 человек и измерили у каждого испытуемого два показателя: 1) сколько времени он читает в неделю; 2) в какой мере он считает себя благополучным (по шкале от 1 до 10). Ученые занесли эти данные в два столбика и с помощью статистической программы рассчитали корреляцию между чтением и благополучием. Предположим, они получили следующий результат -0,76. Но что значит это число? Как его проинтерпретировать? Давайте разбираться.
Полученное число называется коэффициентом корреляции. Для его правильной интерпретации важно учитывать следующее:
- Знак «+» или «-» отражает направление зависимости.
- Величина коэффициента отражает силу зависимости.
Прямая и обратная
Знак плюс перед коэффициентом указывает на то, что связь между явлениями или показателями прямая. То есть, чем больше один показатель, тем больше и другой. Выше оклад – выше продажи. Такая корреляция называется прямой, или положительной.
Если коэффициент имеет знак минус, значит, корреляция обратная, или отрицательная. В этом случае чем выше один показатель, тем ниже другой. В примере с чтением и благополучием мы получили -0,76, и это значит, что, чем больше люди читают, тем ниже уровень их благополучия.
Сильная и слабая
Корреляционная связь в численном выражении – это число в диапазоне от -1 до +1. Обозначается буквой «r». Чем выше число (без учета знака), тем корреляционная связь сильнее.
Чем ниже численное значение коэффициента, тем взаимосвязь между явлениями и показателями меньше.
Максимально возможная сила зависимости – это 1 или -1. Как это понять и представить?
Рассмотрим пример. Взяли 10 студентов и измерили у них уровень интеллекта (IQ) и успеваемость за семестр. Расположили эти данные в виде двух столбцов.
|
Испытуемый |
IQ |
Успеваемость (баллы) |
|
1 |
90 |
4,0 |
|
2 |
91 |
4,1 |
|
3 |
92 |
4,2 |
|
4 |
93 |
4,3 |
|
5 |
94 |
4,4 |
|
6 |
95 |
4,5 |
|
7 |
96 |
4,6 |
|
8 |
97 |
4,7 |
|
9 |
98 |
4,8 |
|
10 |
99 |
4,9 |
Посмотрите внимательно на данные в таблице. От 1 до 10 испытуемого растет уровень IQ. Но также растет и уровень успеваемости. Из любых двух студентов успеваемость будет выше у того, у кого выше IQ. И никаких исключений из этого правила не будет.
Перед нами пример полного, 100%-но согласованного изменения двух показателей в группе. И это пример максимально возможной положительной взаимосвязи. То есть, корреляционная зависимость между интеллектом и успеваемостью равна 1.
Рассмотрим другой пример. У этих же 10-ти студентов с помощью опроса оценили, в какой мере они ощущают себя успешными в общении с противоположным полом (по шкале от 1 до 10).
|
Испытуемый |
IQ |
Успех в общении с противоположным полом (баллы) |
|
1 |
90 |
10 |
|
2 |
91 |
9 |
|
3 |
92 |
8 |
|
4 |
93 |
7 |
|
5 |
94 |
6 |
|
6 |
95 |
5 |
|
7 |
96 |
4 |
|
8 |
97 |
3 |
|
9 |
98 |
2 |
|
10 |
99 |
1 |
Смотрим внимательно на данные в таблице. От 1 до 10 испытуемого растет уровень IQ. При этом в последнем столбце последовательно снижается уровень успешности общения с противоположным полом. Из любых двух студентов успех общения с противоположным полом будет выше у того, у кого IQ ниже. И никаких исключений из этого правила не будет.
Это пример полной согласованности изменения двух показателей в группе – максимально возможная отрицательная взаимосвязь. Корреляционная связь между IQ и успешностью общения с противоположным полом равна -1.
А как понять смысл корреляции равной нулю (0)? Это значит, связи между показателями нет. Еще раз вернемся к нашим студентам и рассмотрим еще один измеренный у них показатель – длину прыжка с места.
|
Испытуемый |
IQ |
Длина прыжка с места (м) |
|
1 |
90 |
2,5 |
|
2 |
91 |
1,2 |
|
3 |
92 |
2,0 |
|
4 |
93 |
1,7 |
|
5 |
94 |
1,9 |
|
6 |
95 |
1,3 |
|
7 |
96 |
1,7 |
|
8 |
97 |
2,3 |
|
9 |
98 |
1,1 |
|
10 |
99 |
2,6 |
Не наблюдается никакой согласованности между изменением IQ от человека к человеку и длинной прыжка. Это и свидетельствует об отсутствии корреляции. Коэффициент корреляции IQ и длины прыжка с места у студентов равен 0.
Мы рассмотрели крайние случаи. В реальных измерениях коэффициенты редко бывают равны точно 1 или 0. При этом принята следующая шкала:
- если коэффициент больше 0,70 – связь между показателями сильная;
- от 0,30 до 0,70 – связь умеренная,
- меньше 0,30 – связь слабая.
Если оценить по этой шкале полученную нами выше корреляцию между чтением и благополучием, то окажется, что эта зависимость сильная и отрицательная -0,76. То есть, наблюдается сильная отрицательная связь между начитанностью и благополучием. Что еще раз подтверждает библейскую мудрость о соотношении мудрости и печали.
Приведенная градация дает очень приблизительные оценки и в таком виде редко используются в исследованиях.
Чаще используются градации коэффициентов по уровням значимости. В этом случае реально полученный коэффициент может быть значимым или не значимым. Определить это можно, сравнив его значение с критическим значением коэффициента корреляции, взятым из специальной таблицы. Причем эти критические значения зависят от численности выборки (чем больше объем, тем ниже критическое значение).
Корреляционный анализ в психологии
Корреляционный метод выступает одним из основных в психологических исследованиях. И это не случайно, ведь психология стремится быть точной наукой. Получается ли?
В чем особенность законов в точных науках. Например, закон тяготения в физике действует без исключений: чем больше масса тела, тем сильнее оно притягивает другие тела. Этот физический закон отражает связь массы тела и силы притяжения.
В психологии иная ситуация. Например, психологи публикуют данные о связи теплых отношений в детстве с родителями и уровня креативности во взрослом возрасте. Означает ли это, что любой из испытуемых с очень теплыми отношениями с родителями в детстве будет иметь очень высокие творческие способности? Ответ однозначный – нет. Здесь нет закона, подобного физическому. Нет механизма влияния детского опыта на креативность взрослых. Это наши фантазии! Есть согласованность данных (отношения – креативность), но за ними нет закона. А есть лишь корреляционная связь. Психологи часто называют выявляемые взаимосвязи психологическими закономерностями, подчеркивая их вероятностный характер – не жесткость.
Пример исследования на студентах из предыдущего раздела хорошо иллюстрирует использование корреляций в психологии:
- Анализ взаимосвязи между психологическими показателями. В нашем примере IQ и успешность общения с противоположным полом – это психологические параметры. Выявление корреляции между ними расширяет представления о психической организации человека, о взаимосвязях между различными сторонами его личности – в данном случае между интеллектом и сферой общения.
- Анализ взаимосвязей IQ с успеваемостью и прыжками – пример связи психологического параметра с непсихологическими. Полученные результаты раскрывают особенности влияния интеллекта на учебную и спортивную деятельность.
Вот как могли выглядеть краткие выводы по результатам придуманного исследования на студентах:
- Выявлена значимая положительная зависимость интеллекта студентов и их успеваемости.
- Существует отрицательная значимая взаимосвязь IQ с успешностью общения с противоположным полом.
- Не выявлено связи IQ студентов с умением прыгать с места.
Таким образом, уровень интеллекта студентов выступает позитивным фактором их академической успеваемости, в то же время негативно сказываясь на отношениях с противоположным полом и не оказывая значимого влияния на спортивные успехи, в частности, способность к прыгать с места.
Как видим, интеллект помогает студентам учиться, но мешает строить отношения с противоположным полом. При этом не влияет на их спортивные успехи.
Неоднозначное влияние интеллекта на личность и деятельность студентов отражает сложность этого феномена в структуре личностных особенностей и важность продолжения исследований в этом направлении. В частности, представляется важным провести анализ взаимосвязей интеллекта с психологическими особенностями и деятельностью студентов с учетом их пола.
Коэффициенты Пирсона и Спирмена
Рассмотрим два метода расчета.
Коэффициент Пирсона – это особый метод расчета взаимосвязи показателей между выраженностью численных значений в одной группе. Очень упрощенно он сводится к следующему:
- Берутся значения двух параметров в группе испытуемых (например, агрессии и перфекционизма).
- Находятся средние значения каждого параметра в группе.
- Находятся разности параметров каждого испытуемого и среднего значения.
- Эти разности подставляются в специальную форму для расчета коэффициента Пирсона.
Коэффициент ранговой корреляции Спирмена рассчитывается похожим образом:
- Берутся значения двух индикаторов в группе испытуемых.
- Находятся ранги каждого фактора в группе, то есть место в списке по возрастанию.
- Находятся разности рангов, возводятся в квадрат и суммируются.
- Далее разности рангов подставляются в специальную форму для вычисления коэффициента Спирмена.
В случае Пирсона расчет шел с использованием среднего значения. Следовательно, случайные выбросы данных (существенное отличие от среднего), например, из-за ошибки обработки или недостоверных ответов могут существенно исказить результат.
В случае Спирмена абсолютные значения данных не играют роли, так как учитывается только их взаимное расположение по отношению друг к другу (ранги). То есть, выбросы данных или другие неточности не окажут серьезного влияния на конечный результат.
Если результаты тестирования корректны, то различия коэффициентов Пирсона и Спирмена незначительны, при этом коэффициент Пирсона показывает более точное значение взаимосвязи данных.
Как рассчитать коэффициент корреляции
Коэффициенты Пирсона и Спирмена можно рассчитать вручную. Это может понадобиться при углубленном изучении статистических методов.
Однако в большинстве случаев при решении прикладных задач, в том числе и в психологии, можно проводить расчеты с помощью специальных программ.
Расчет с помощью электронных таблиц Microsoft Excel
Вернемся опять к примеру со студентами и рассмотрим данные об уровне их интеллекта и длине прыжка с места. Занесем эти данные (два столбца) в таблицу Excel.
Переместив курсор в пустую ячейку, нажмем опцию «Вставить функцию» и выберем «КОРРЕЛ» из раздела «Статистические».
Формат этой функции предполагает выделение двух массивов данных: КОРРЕЛ (массив 1; массив»). Выделяем соответственно столбик с IQ и длиной прыжков.

Далее нажимаем галочку (то есть, рассчитать) и получаем значение , в нашем случае 0,038. Как видим, коэффициент не равен нулю, хотя и очень близок к нему.
В таблицах Excel реализована формула расчета только коэффициента Пирсона.
Расчет с помощью программы STATISTICA
Заносим данные по интеллекту и длине прыжка в поле исходных данных. Далее выбираем опцию «Непараметрические критерии», «Спирмена». Выделяем параметры для расчета и получаем следующий результат.

Как видно, расчет дал результат 0,024, что отличается от результата по Пирсону – 0,038, полученной выше с помощью Excel. Однако различия незначительны.
Использование корреляционного анализа в дипломных работах по психологии (пример)
Большинство тем выпускных квалификационных работ по психологии (дипломов, курсовых, магистерских) предполагают проведение корреляционного исследования (остальные связаны с выявлением различий психологических показателей в разных группах).
Сам термин «корреляция» в названиях тем звучит редко – он скрывается за следующими формулировками:
- «Взаимосвязь субъективного ощущения одиночества и самоактуализации у женщин зрелого возраста»;
- «Особенности влияния жизнестойкости менеджеров на успешность их взаимодействия с клиентами в конфликтных ситуациях»;
- «Личностные факторы стрессоустойчивости сотрудников МЧС».
Таким образом, слова «взаимосвязь», «влияние» и «факторы» – верные признаки того, что методом анализа данных в эмпирическом исследовании должен быть корреляционный анализ.
Рассмотрим кратко этапы его проведения при написании дипломной работы по психологии на тему: «Взаимосвязь личностной тревожности и агрессивности у подростков».
1. Для расчета необходимы сырые данные, в качестве которых обычно выступают результаты тестирования испытуемых. Они заносятся в сводную таблицу и помещаются в приложение. Эта таблица устроена следующим образом:
- каждая строка содержит данные на одного испытуемого;
- каждый столбец содержит показатели по одной шкале для всех испытуемых.
|
№ испытуемого |
Личностная тревожность |
Агрессивность |
|
1 |
12 |
24 |
|
2 |
14 |
25 |
|
3 |
11 |
13 |
|
4 |
17 |
19 |
|
5 |
21 |
29 |
|
6 |
26 |
29 |
|
7 |
13 |
16 |
|
8 |
16 |
20 |
|
8 |
13 |
24 |
|
9 |
18 |
21 |
|
10 |
23 |
31 |
2. Необходимо решить, какой из двух типов коэффициентов – Пирсона или Спирмена – будет использоваться. Напоминаем, что Пирсон дает более точный результат, но он чувствителен к выбросам в данных Коэффициенты Спирмена могут использоваться с любыми данными (кроме номинативной шкалы), поэтому именно они чаще всего используют в дипломах по психологии.
3. Заносим таблицу сырых данных в статистическую программу.

4. Рассчитываем значение.

5. На следующем этапе важно определить, значима ли взаимосвязь. Статистическая программа подсветила результаты красным, что означает, что корреляция статистически значимы при уровне значимости 0,05 (указано выше).
Однако полезно знать, как определить значимость вручную. Для этого понадобится таблица критических значений Спирмена.
Таблица критических значений коэффициентов Спирмена
|
Уровень статистической значимости |
|||
|
Число испытуемых |
р=0,05 |
р=0,01 |
р=0,001 |
|
5 |
0,88 |
0,96 |
0,99 |
|
6 |
0,81 |
0,92 |
0,97 |
|
7 |
0,75 |
0,88 |
0,95 |
|
8 |
0,71 |
0,83 |
0,93 |
|
9 |
0,67 |
0,8 |
0,9 |
|
10 |
0,63 |
0,77 |
0,87 |
|
11 |
0,6 |
0,74 |
0,85 |
|
12 |
0,58 |
0,71 |
0,82 |
|
13 |
0,55 |
0,68 |
0,8 |
|
14 |
0,53 |
0,66 |
0,78 |
|
15 |
0,51 |
0,64 |
0,76 |
Нас интересует уровень значимости 0,05 и объем нашей выборки 10 человек. На пересечении этих данных находим значение критического Спирмена: Rкр=0,63.
Правило такое: если полученное эмпирическое значение Спирмена больше либо равно критическому, то он статистически значим. В нашем случае: Rэмп (0,66) > Rкр (0,63), следовательно, взаимосвязь между агрессивностью и тревожностью в группе подростков статистически значима.
5. В текст дипломной нужно вставлять данные в таблице формата word, а не таблицу из статистической программы. Под таблицей описываем полученный результат и интерпретируем его.
Таблица 1
Коэффициенты Спирмена агрессивности и тревожности в группе подростков
|
Агрессивность |
|
|
Личностная тревожность |
0,665* |
* – статистически достоверна (р≤0,05)
Анализ данных, приведенных в таблице 1, показывает, что существует статистически значимая положительная связьмежду агрессивностью и тревожностью подростков. Это означает, что чем выше личностная тревожность подростков, тем выше уровень их агрессивности. Такой результат дает основание предположить, что агрессия для подростков выступает одним из способов купирования тревожности. Испытывая неуверенность в себе, тревогу в связи с угрозами самооценке, особенно чувствительной в подростковом возрасте, подросток часто использует агрессивное поведение, таким непродуктивным способом снижая тревогу.
6. Можно ли при интерпретации связей говорить о влиянии? Можно ли сказать, что тревожность влияет на агрессивность? Строго говоря, нет. Выше мы показали, что корреляционная связь между явлениями носит вероятностный характер и отражает лишь согласованность изменений признаков в группе. При этом мы не можем сказать, что эта согласованность вызвана тем, что одно из явлений является причиной другого, влияет на него. То есть, наличие корреляции между психологическими параметрами не дает оснований говорить о существовании между ними причинно-следственной связи. Однако практика показывает, что термин «влияние» часто используется при анализе результатов корреляционного анализа.
© СтудентуПсихологу.рф
Корреляционная связь, ее признаки, виды. Коэффициент корреляции, определение, свойства, методы вычисления. Метод корреляции рядов Пирсона. Метод корреляции рангов Спирмена.
Многие
явления в медицине, так же как в природе
и обществе, взаимосвязаны между
собой. При проведении статистического
исследования часто возникает необходимость
проанализировать выявленные связи
между различными явлениями и дать
обобщающую характеристику. Различают
2 формы проявления связей между явлениями:
функциональную
и корреляционную.
Функциональная
связь означает
строгую зависимость одного признака
от другого, когда определенному значению
одной величины соответствует строго
определенное значение другой. Например,
радиусу круга соответствует определенная
площадь круга; скорость свободно
падающего тела определяется величиной
ускорения, силой тяжести и временем
падения. Функциональная связь характерна
для физико-химических процессов.
Корреляционная
связь
—
это такая связь, когда одной и
той
же величине одного признака
соответствует несколько значений
другого взаимосвязанного с ним
признака. Врачи и биологи хорошо знакомы
с этим видом связи: при одинаковой
температуре у различных людей наблюдаются
индивидуальные колебания частоты
пульса; при одинаковом росте отмечаются
различные колебания масс тела.
По
форме корреляционная связь:
Прямолинейная
связь
—
равномерные изменения одного признака
соответствуют равномерным изменениям
второго признака при незначительных
отклонениях.
Криволинейная
связь
—
равномерные изменения одного признака,
соответствуют неравномерным изменениям
второго признака, причем неравномерность
имеет определенную закономерность.
Общая тенденция в определенном
моменте изменяет свос направление, дает
изгиб.
Направление
связи:
Прямая
связь (положительная)
—
если с
увеличением
одного признака второй также увеличивается
или с уменьшением одного признака другой
тоже уменьшается. Обратная
связь (отрицательная)
—
когда с увеличением одного признака,
другой, корреляционно связанный с
ним признак, уменьшается.
Под
силой связи
следует
понимать степень корреляции (степень
сопряженности между признаками).
Измерение
силы связи и определение ее направления
осуществляется путем вычисления
коэффициента
корреляции.
Существуют следующие методы вычисления
коэффициента корреляции: рядов,
рангов, путем составления корреляционной
решетки.
|
Степень |
Величина |
|
|
При |
При |
|
|
Связь |
0 |
0 |
|
Связь |
от |
от |
|
Связь |
от |
от |
|
Связь |
от |
от |
|
Связь |
+1 |
-1 |
Коэффициент
корреляции рядов (rxy)
(Пирсона):
rxy
=
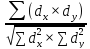 ,
,
гдеd
= V-
M.
Для
оценки достоверности коэффициента
корреляции вычисляется средняя
ошибка коэффициента
корреляции:
mr
=
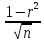 – при числе наблюдений более 100;
– при числе наблюдений более 100;
mr
=
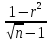 – при числе наблюдений от 30 до 100;
– при числе наблюдений от 30 до 100;
mr
=
 – при числе наблюдений менее 30.
– при числе наблюдений менее 30.
Для
оценки величины полученной ошибки
следует использовать критерий
достоверности (t).
t
=
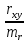
Значение
критерия (t)
оценивается
по специальной таблице Стьюдента. Если
полученное значение t
больше
табличного для выбранного уровня
доверия и числа степеней свободы, то
коэффициент корреляции считается
достоверным.
Коэффициент
корреляции рангов (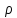 )
)
(Спирмена):
Коэффициент
корреляции рангов относится
к непарамегрическим критериям. Он
используется при необходимости получения
быстрого результата, при малом числе
наблюдений, а также в тех случаях, когда
изучаемые признаки не имеют точных
количественных значений или носят
описательный характер. Этот метод
основан на определении ранга (места)
каждого из значений ряда.
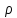
=
1 –
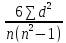 ,
,
гдеd
—
разность между ранговыми номерами;
n
— число парных членов в коррелируемых
рядах
Вычисления
проводятся по следующему алгоритму:
1)
Определить ранги по значению каждой
величины ряда. (1,2,3,4…) Если первый ряд
(x)
ранжируется от меньшего значения к
большему, то второй ряд (у) следует
ранжировать в том же порядке.
2)
Определить разность рангов каждой пары
ряда (х) и ряда (у): (dxy)=
(x)
– (у). Они в сумме с учетом знаков равны
нулю.
3)
Возвести в квадрат полученные разности
и суммировать их.
4)
Рассчитать коэффициент корреляции
рангов по формуле.
Прежде
чем судить о степени связи между
изучаемыми признаками, необходимо
оценить достоверность коэффициента
корреляции рангов.
t
=
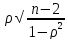
Полученное
значение критерия t
оценивается по таблице t-критерия
Стьюдента для
числа степеней свободы n’
=
n-2.
Коэффициент корреляции незначим, если
рассчитанное значение меньше табличного.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Постановка задачи
При статистическом анализе зависимостей между количественными переменными возникают ситуации, когда представляет интерес расчет и анализ такого показателя как корреляционное отношение (η).
Данный показатель незаслуженно обойден вниманием в большинстве доступных для пользователей математических пакетов.
В данном разборе рассмотрим способы расчета и анализа η средствами Python.
Не будем углубляться в теорию (про η достаточно подробно написано, например, в [1, с.73], [2, с.412], [3, с.609]), но вспомним основные свойства η:
-
η характеризует степень тесноты любой корреляционной связи (как линейной, так и нелинейной), в отличие от коэффициента корреляции Пирсона r, который характеризует тесноту только линейной связи. Условие r=0 означает отсутствие линейной корреляционной связи между величинами, но при этом между ними может существовать нелинейная корреляционная связь (η>0).
-
η принимает значения от 0 до 1; при η=0 корреляционная связь отсутствует, при η=1 связь считается функциональной; степень тесноты связи можно оценивать по различным общепринятым шкалам, например, по шкале Чеддока и др.
-
Величина η² характеризует долю вариации, объясненной корреляционной связью между рассматриваемыми переменными.
-
η не может быть меньше абсолютной величины r: η ≥ |r|.
-
η несимметрично по отношению к исследуемым переменным, то есть ηXY ≠ ηYX.
-
Для расчета η необходимо иметь эмпирические данные эксперимента с повторностями; если же мы имеем просто два набора значений переменных X и Y, то данные нужно группировать. Этот вывод, в общем-то, очевиден – если предпринять попытку рассчитать η по негруппированным данным, получим результат η=1.
Группировка данных для расчета η заключается в разбиении области значений переменных X и Y на интервалы, подсчет частот попадания данных в интервалы и формирование корреляционной таблицы.
Важное замечание: особенности методики расчета корреляционного отношения, особенно при форме связи, близкой к линейной, и η близком к единице, могут привести к результатам, в общем-то абсурдным, например:
-
когда нарушается условие η ≥ |r|;
-
когда r окажется значим, а η нет;
-
когда нижняя граница доверительного интервала для η окажется меньше 0 или верхняя граница – больше 1.
Это нужно учитывать при выполнении анализа.
Итак, перейдем к расчетам.
Формирование исходных данных
В качестве исходных данных рассмотрим зависимость расхода среднемесячного расхода топлива автомобиля (л/100 км) (FuelFlow) от среднемесячного пробега (км) (Mileage).
Загрузим исходные данные из csv-файла (исходные данные доступны в моем репозитории на GitHub):
fuel_df = pd.read_csv(
filepath_or_buffer='data/fuel_df.csv',
sep=';',
index_col='Number')
dataset_df = fuel_df.copy() # создаем копию исходной таблицы для работы
display(dataset_df.head())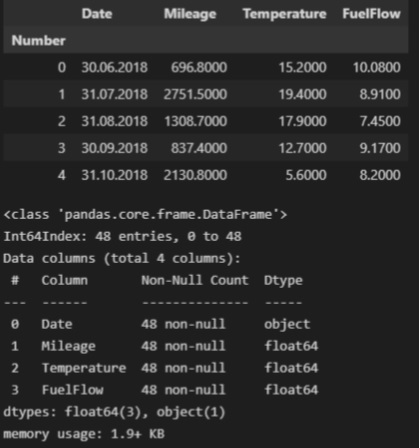
Загруженный DataFrame содержит следующие столбцы:
-
Month — месяц (в формате Excel)
-
Mileage – месячный пробег (км)
-
Temperature – среднемесячная температура (°C)
-
FuelFlow – среднемесячный расход топлива (л/100 км)
Сохраним нужные нам переменные Mileage и FuelFlow в виде numpy.ndarray.
X = np.array(dataset_df['Mileage'])
Y = np.array(dataset_df['FuelFlow'])Для удобства дальнейшей работы сформируем сформируем отдельный DataFrame из двух переменных – X и Y:
data_XY_df = pd.DataFrame({
'X': X,
'Y': Y})Настройка заголовков отчета (для дальнейшего формирования графиков):
# Общий заголовок проекта
Task_Project = "Расчет и анализ корреляционного отношения средствами Python"
# Заголовок, фиксирующий момент времени
AsOfTheDate = ""
# Заголовок раздела проекта
Task_Theme = "Анализ расхода топлива автомобиля"
# Общий заголовок проекта для графиков
Title_String = f"{Task_Project}n{AsOfTheDate}"
# Наименования переменных
Variable_Name_X = "Среднемесячный пробег (км)"
Variable_Name_Y = "Среднемесячный расход топлива автомобиля (л/100 км)"Визуализация и первичная обработка данных
Предварительно отсеем аномальные значения (выбросы). Подробно не будем останавливаться на этой процедуре, она не является целью данного разбора.
mask1 = data_XY_df['X'] > 200
mask2 = data_XY_df['X'] < 2000
data_XY_df = data_XY_df[mask1 & mask2]
X = np.array(data_XY_df['X'])
Y = np.array(data_XY_df['Y'])Описательная статистика исходных данных:
data_XY_df.describe()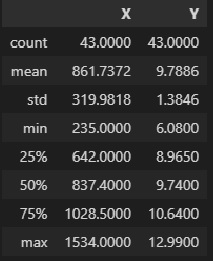
Выполним визуализацию исходных данных:
fig, axes = plt.subplots(figsize=(297/INCH, 210/INCH))
fig.suptitle(Task_Theme)
axes.set_title('Зависимость расхода топлива от пробега')
data_df = data_XY_df
sns.scatterplot(
data=data_df,
x='X', y='Y',
label='эмпирические данные',
s=50,
ax=axes)
axes.set_xlabel(Variable_Name_X)
axes.set_ylabel(Variable_Name_Y)
#axes.tick_params(axis="x", labelsize=f_size+4)
#axes.tick_params(axis="y", labelsize=f_size+4)
#axes.legend(prop={'size': f_size+6})
plt.show()
fig.savefig('graph/scatterplot_XY_sns.png', orientation = "portrait", dpi = 300)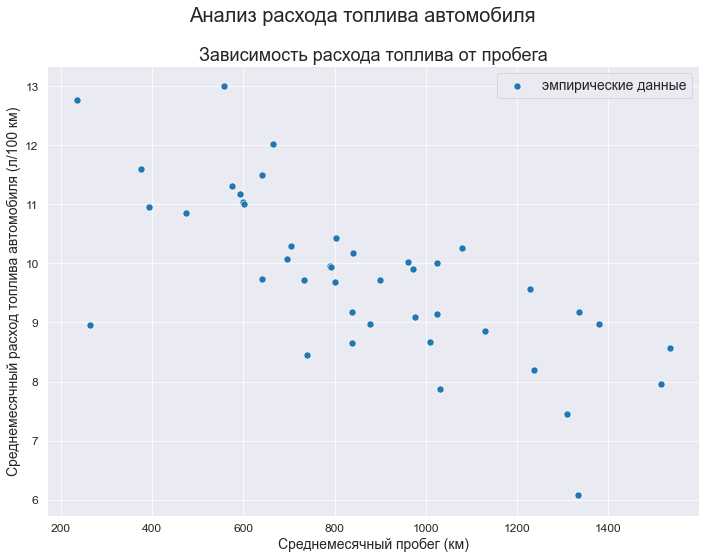
Для визуальной оценки выборочных данных построим гистограммы и коробчатые диаграммы:
fig = plt.figure(figsize=(420/INCH, 297/INCH))
ax1 = plt.subplot(2,2,1)
ax2 = plt.subplot(2,2,2)
ax3 = plt.subplot(2,2,3)
ax4 = plt.subplot(2,2,4)
fig.suptitle(Task_Theme)
ax1.set_title('X')
ax2.set_title('Y')
# инициализация данных
data_df = data_XY_df
X_mean = data_df['X'].mean()
X_std = data_df['X'].std(ddof = 1)
Y_mean = data_df['Y'].mean()
Y_std = data_df['Y'].std(ddof = 1)
bins_hist = 'sturges' # выбор числа интервалов ('auto', 'fd', 'doane', 'scott', 'stone', 'rice', 'sturges', 'sqrt')
# данные для графика плотности распределения X
xmin = np.amin(data_df['X'])
xmax = np.amax(data_df['X'])
nx = 100
hx = (xmax - xmin)/(nx - 1)
x1 = np.linspace(xmin, xmax, nx)
xnorm1 = sps.norm.pdf(x1, X_mean, X_std)
kx = len(np.histogram(X, bins=bins_hist, density=False)[0])
xnorm2 = xnorm1*len(X)*(xmax-xmin)/kx
# данные для графика плотности распределения Y
ymin = np.amin(Y)
ymax = np.amax(Y)
ny = 100
hy = (ymax - ymin)/(ny - 1)
y1 = np.linspace(ymin, ymax, ny)
ynorm1 = sps.norm.pdf(y1, Y_mean, Y_std)
ky = len(np.histogram(Y, bins=bins_hist, density=False)[0])
ynorm2 = ynorm1*len(Y)*(ymax-ymin)/ky
# гистограмма распределения X
ax1.hist(
data_df['X'],
bins=bins_hist,
density=False,
histtype='bar', # 'bar', 'barstacked', 'step', 'stepfilled'
orientation='vertical', # 'vertical', 'horizontal'
color = "#1f77b4",
label='эмпирическая частота')
ax1.plot(
x1, xnorm2,
linestyle = "-",
color = "r",
linewidth = 2,
label = 'теоретическая нормальная кривая')
ax1.axvline(X_mean, color='magenta', label = 'среднее значение')
ax1.axvline(np.median(data_df['X']), color='orange', label = 'медиана')
ax1.legend(fontsize = f_size+4)
# гистограмма распределения Y
ax2.hist(
data_df['Y'],
bins=bins_hist,
density=False,
histtype='bar', # 'bar', 'barstacked', 'step', 'stepfilled'
orientation='vertical', # 'vertical', 'horizontal'
color = "#1f77b4",
label='эмпирическая частота')
ax2.plot(
y1, ynorm2,
linestyle = "-",
color = "r",
linewidth = 2,
label = 'теоретическая нормальная кривая')
ax2.axvline(Y_mean, color='magenta', label = 'среднее значение')
ax2.axvline(np.median(data_df['Y']), color='orange', label = 'медиана')
ax2.legend(fontsize = f_size+4)
# коробчатая диаграмма X
sns.boxplot(
#data=corn_yield_df,
x=data_df['X'],
orient='h',
width=0.3,
ax=ax3)
# коробчатая диаграмма Y
sns.boxplot(
#data=corn_yield_df,
x=data_df['Y'],
orient='h',
width=0.3,
ax=ax4)
# подписи осей
ax3.set_xlabel(Variable_Name_X)
ax4.set_xlabel(Variable_Name_Y)
plt.show()
fig.savefig('graph/scatterplot_boxplot_X_Y_sns.png', orientation = "portrait", dpi = 300)
Перед тем, как приступать к дальнейшим расчетам, проверим исходные данные на соответствие нормальному закону распределения.
Выполнять такую проверку нужно обязательно, так как только для нормально распределенных данных мы можем в дальнейшем использовать общепринятые статистические процедуры анализа: проверку значимости корреляционного отношения, построение доверительных интервалов и т.д.
Для проверки нормальности распределения воспользуемся критерием Шапиро-Уилка:
# функция для обработки реализации теста Шапиро-Уилка
def Shapiro_Wilk_test(data):
data = np.array(data)
result = sci.stats.shapiro(data)
s_calc = result.statistic # расчетное значение статистики критерия
a_calc = result.pvalue # расчетный уровень значимости
print(f"Расчетный уровень значимости: a_calc = {round(a_calc, DecPlace)}")
print(f"Заданный уровень значимости: a_level = {round(a_level, DecPlace)}")
if a_calc >= a_level:
conclusion_ShW_test = f"Так как a_calc = {round(a_calc, DecPlace)} >= a_level = {round(a_level, DecPlace)}" +
", то гипотеза о нормальности распределения по критерию Шапиро-Уилка ПРИНИМАЕТСЯ"
else:
conclusion_ShW_test = f"Так как a_calc = {round(a_calc, DecPlace)} < a_level = {round(a_level, DecPlace)}" +
", то гипотеза о нормальности распределения по критерию Шапиро-Уилка ОТВЕРГАЕТСЯ"
print(conclusion_ShW_test)# проверка нормальности распределения переменной X
Shapiro_Wilk_test(X)
# проверка нормальности распределения переменной Y
Shapiro_Wilk_test(Y)
Итак, гипотеза о нормальном распределении исходных данных принимается, что позволяет нам в дальнейшем пользоваться статистическим инструментарием для интервального оценивания величины η, проверки гипотез и т.д.
Переходим собственно к расчету корреляционного отношения.
Переходим собственно к расчету корреляционного отношения.
Расчёт и анализ корреляционного отношения
1. Выполним группировку исходных данным по обоим признакам X и Y:
Создадим новую переменную matrix_XY_df для работы с группированными данными:
matrix_XY_df = data_XY_df.copy()Определим число интервалов группировки (воспользуемся формулой Стерджесса); при этом минимальное число интервалов должно быть не менее 2:
# объем выборки для переменных X и Y
n_X = len(X)
n_Y = len(Y)
# число интервалов группировки
group_int_number = lambda n: round (3.31*log(n_X, 10)+1) if round (3.31*log(n_X, 10)+1) >=2 else 2
K_X = group_int_number(n_X)
K_Y = group_int_number(n_Y)
print(f"Число интервалов группировки для переменной X: {K_X}")
print(f"Число интервалов группировки для переменной Y: {K_Y}")Выполним группировку данных средствами библиотеки pandas, для этого воспользуемся функцией pandas.cut. В результате получим новые признаки cut_X и cut_X, которые показывают, в какой из интервалов попадает конкретное значение X и Y. Полученные новые признаки добавим в DataFrame matrix_XY_df:
cut_X = pd.cut(X, bins=K_X)
cut_Y = pd.cut(Y, bins=K_Y)
matrix_XY_df['cut_X'] = cut_X
matrix_XY_df['cut_Y'] = cut_Y
display(matrix_XY_df.head())
Теперь мы можем получить корреляционную таблицу с помощью функции pandas.crosstab:
CorrTable_df = pd.crosstab(
index=matrix_XY_df['cut_X'],
columns=matrix_XY_df['cut_Y'],
rownames=['cut_X'],
colnames=['cut_Y'])
display(CorrTable_df)
# проверка правильности подсчета частот по интервалам
print(f"sum = {np.sum(np.array(CorrTable_df))}")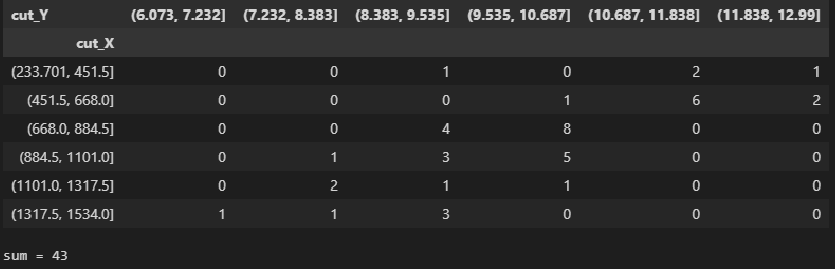
Функция pandas.crosstab также позволяет формировать более ровные и удобные для восприятия границы интервалов группировки путем задания их вручную. Для расчета η это принципиального значения не имеет, но в отдельных случаях может быть полезно.
Например, зададим вручную границы интервалов группировки для X и Y:
bins_X = pd.IntervalIndex.from_tuples([(200, 400), (400, 600), (600, 800), (800, 1000), (1000, 1200), (1200, 1400), (1400, 1600)])
cut_X = pd.cut(X, bins=bins_X)
bins_Y = pd.IntervalIndex.from_tuples([(6.0, 7.0), (7.0, 8.0), (8.0, 9.0), (9.0, 10.0), (10.0, 11.0), (11.0, 12.0), (12.0, 13.0)])
cut_Y = pd.cut(X, bins=bins_Y)
CorrTable_df2 = pd.crosstab(
index=pd.cut(X, bins=bins_X),
columns=pd.cut(Y, bins=bins_Y),
rownames=['cut_X'],
colnames=['cut_Y'])
display(CorrTable_df2)
# проверка правильности подсчета частот по интервалам
print(f"sum = {np.sum(np.array(CorrTable_df2))}")
Есть и другой способ получения корреляционной таблицы – с помощью pandas.pivot_table:
matrix_XY_df.pivot_table(
values=['Y'],
index='cut_X',
columns='cut_Y',
aggfunc=len,
fill_value=0)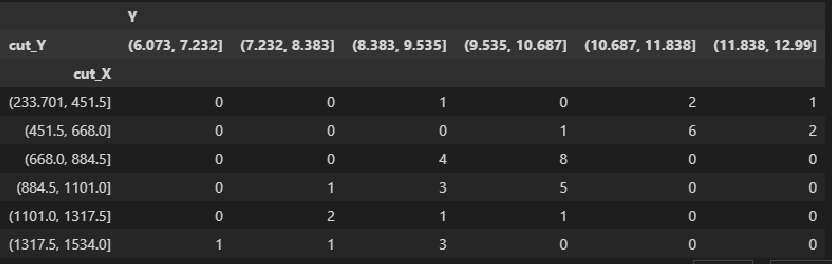
2. Выполним расчет корреляционного отношения:
Для дальнейших расчетов приведем корреляционную таблицу к типу numpy.ndarray:
CorrTable_np = np.array(CorrTable_df)
print(CorrTable_np, type(CorrTable_np))
Итоги корреляционной таблицы по строкам и столбцам:
# итоги по строкам
n_group_X = [np.sum(CorrTable_np[i]) for i in range(K_X)]
print(f"n_group_X = {n_group_X}")
# итоги по столбцам
n_group_Y = [np.sum(CorrTable_np[:,j]) for j in range(K_Y)]
print(f"n_group_Y = {n_group_Y}")![]()
Также нам необходимо получить среднегрупповые значения X и Y для каждой группы (интервала). При этом нужно помнить, что функция pandas.crosstab при группировании расширяет крайние диапазоны на 0.1% с каждой стороны, чтобы включить минимальное и максимальное значения.
Для доступа к данным – границам интервалов, полученным с помощью pandas.cut – существуют методы right и left:
# Среднегрупповые значения переменной X
Xboun_mean = [(CorrTable_df.index[i].left + CorrTable_df.index[i].right)/2 for i in range(K_X)]
Xboun_mean[0] = (np.min(X) + CorrTable_df.index[0].right)/2 # исправляем значения в крайних интервалах
Xboun_mean[K_X-1] = (CorrTable_df.index[K_X-1].left + np.max(X))/2
print(f"Xboun_mean = {Xboun_mean}")
# Среднегрупповые значения переменной Y
Yboun_mean = [(CorrTable_df.columns[j].left + CorrTable_df.columns[j].right)/2 for j in range(K_Y)]
Yboun_mean[0] = (np.min(Y) + CorrTable_df.columns[0].right)/2 # исправляем значения в крайних интервалах
Yboun_mean[K_Y-1] = (CorrTable_df.columns[K_Y-1].left + np.max(Y))/2
print(f"Yboun_mean = {Yboun_mean}", 'n')![]()
Находим средневзевешенные значения X и Y для каждой группы:
Xmean_group = [np.sum(CorrTable_np[:,j] * Xboun_mean) / n_group_Y[j] for j in range(K_Y)]
print(f"Xmean_group = {Xmean_group}")
Ymean_group = [np.sum(CorrTable_np[i] * Yboun_mean) / n_group_X[i] for i in range(K_X)]
print(f"Ymean_group = {Ymean_group}")![]()
Общая дисперсия X и Y:
Sum2_total_X = np.sum(n_group_X * (Xboun_mean - np.mean(X))**2)
print(f"Sum2_total_X = {Sum2_total_X}")
Sum2_total_Y = np.sum(n_group_Y * (Yboun_mean - np.mean(Y))**2)
print(f"Sum2_total_Y = {Sum2_total_Y}")![]()
Межгрупповая дисперсия X и Y (дисперсия групповых средних):
Sum2_between_group_X = np.sum(n_group_Y * (Xmean_group - np.mean(X))**2)
print(f"Sum2_between_group_X = {Sum2_between_group_X}")
Sum2_between_group_Y = np.sum(n_group_X * (Ymean_group - np.mean(Y))**2)
print(f"Sum2_between_group_Y = {Sum2_between_group_Y}")![]()
Внутригрупповая дисперсия X и Y (возникает за счет других факторов – не связанных с другой переменной):
print(f"Sum2_within_group_X = {Sum2_total_X - Sum2_between_group_X}")
print(f"Sum2_within_group_Y = {Sum2_total_Y - Sum2_between_group_Y}")![]()
Эмпирическое корреляционное отношение:
corr_ratio_XY = sqrt(Sum2_between_group_Y / Sum2_total_Y)
print(f"corr_ratio_XY = {corr_ratio_XY}")
corr_ratio_YX = sqrt(Sum2_between_group_X / Sum2_total_X)
print(f"corr_ratio_YX = {corr_ratio_YX}")![]()
Итак, мы получили результат – значение корреляционного отношения.
Оценим тесноту корреляционной связи по шкале Чеддока, для удобства создадим пользовательскую функцию:
def Cheddock_scale_check(r, name='r'):
# задаем шкалу Чеддока
Cheddock_scale = {
f'no correlation (|{name}| <= 0.1)': 0.1,
f'very weak (0.1 < |{name}| <= 0.2)': 0.2,
f'weak (0.2 < |{name}| <= 0.3)': 0.3,
f'moderate (0.3 < |{name}| <= 0.5)': 0.5,
f'perceptible (0.5 < |{name}| <= 0.7)': 0.7,
f'high (0.7 < |{name}| <= 0.9)': 0.9,
f'very high (0.9 < |{name}| <= 0.99)': 0.99,
f'functional (|{name}| > 0.99)': 1.0}
r_scale = list(Cheddock_scale.values())
for i, elem in enumerate(r_scale):
if abs(r) <= elem:
conclusion_Cheddock_scale = list(Cheddock_scale.keys())[i]
break
return conclusion_Cheddock_scale![]()
Шкала Чеддока изначально предназначалась для оценки тесноты линейно корреляционной связи (на основе коэффициента корреляции Пирсона r), но мы ее применим и для корреляционного отношения η (не забывая про свойство η ≥ r!). В выводе функции Cheddock_scale_check можно указать символ, обозначающий величину – аргумент name=chr(951) выводит η вместо r.
В современных исследованиях шкала Чеддока теряет популярность, в последние годы все чаще применяется шкала Эванса (в психосоциальных, медико-биологических и др.исследованиях) ( более подробно про шкалы Чеддока, Эванса и др. – см.[4]). Оценим тесноту корреляционной связи по шкале Эванса, для удобства также создадим пользовательскую функцию:
def Evans_scale_check(r, name='r'):
# задаем шкалу Эванса
Evans_scale = {
f'very weak (|{name}| < 0.19)': 0.2,
f'weak (0.2 < |{name}| <= 0.39)': 0.4,
f'moderate (0.4 < |{name}| <= 0.59)': 0.6,
f'strong (0.6 < |{name}| <= 0.79)': 0.8,
f'very strong (0.8 < |{name}| <= 1.0)': 1.0}
r_scale = list(Evans_scale.values())
for i, elem in enumerate(r_scale):
if abs(r) <= elem:
conclusion_Evans_scale = list(Evans_scale.keys())[i]
break
return conclusion_Evans_scale
print(f"Оценка тесноты корреляции по шкале Эванса: {Evans_scale_check(corr_ratio_XY, name=chr(951))}")![]()
Итак, степень тесноты корреляционной связи может быть оценена как высокая (по шкале Чеддока), сильная (по шкале Эванса).
3. Проверка значимости корреляционного отношения:
Рассмотрим нулевую гипотезу:
H0: ηXY = 0
H1: ηXY ≠ 0Для проверки нулевой гипотезы воспользуемся критерием Фишера:
# расчетное значение статистики критерия Фишера
F_corr_ratio_calc = (n_X - K_X)/(K_X - 1) * corr_ratio_XY**2 / (1 - corr_ratio_XY**2)
print(f"Расчетное значение статистики критерия Фишера: F_calc = {round(F_corr_ratio_calc, DecPlace)}")
# табличное значение статистики критерия Фишера
dfn = K_X - 1
dfd = n_X - K_X
F_corr_ratio_table = sci.stats.f.ppf(p_level, dfn, dfd, loc=0, scale=1)
print(f"Табличное значение статистики критерия Фишера: F_table = {round(F_corr_ratio_table, DecPlace)}")
# расчетный уровень значимости
a_corr_ratio_calc = 1 - sci.stats.f.cdf(F_corr_ratio_calc, dfn, dfd, loc=0, scale=1)
print(f"Расчетный уровень значимости: a_calc = {round(a_corr_ratio_calc, DecPlace)}")
print(f"Заданный уровень значимости: a_level = {round(a_level, DecPlace)}")
# вывод
if F_corr_ratio_calc < F_corr_ratio_table:
conclusion_corr_ratio_sign = f"Так как F_calc = {round(F_corr_ratio_calc, DecPlace)} < F_table = {round(F_corr_ratio_table, DecPlace)}" +
", то гипотеза о равенстве нулю корреляционного отношения ПРИНИМАЕТСЯ, т.е. корреляционная связь НЕЗНАЧИМА"
else:
conclusion_corr_ratio_sign = f"Так как F_calc = {round(F_corr_ratio_calc, DecPlace)} >= F_table = {round(F_corr_ratio_table, DecPlace)}" +
", то гипотеза о равенстве нулю корреляционного отношения ОТВЕРГАЕТСЯ, т.е. корреляционная связь ЗНАЧИМА"
print(conclusion_corr_ratio_sign)
4. Доверительный интервал для корреляционного отношения:
# число степеней свободы
f1 = round ((K_X - 1 + n_X * corr_ratio_XY**2)**2 / (K_X - 1 + 2 * n_X * corr_ratio_XY**2))
f2 = n_X - K_X
# вспомогательные величины
z1 = (n_X - K_X) / n_X * corr_ratio_XY**2 / (1 - corr_ratio_XY**2) * 1/sci.stats.f.ppf(p_level, f1, f2, loc=0, scale=1) - (K_X - 1)/n_X
z2 = (n_X - K_X) / n_X * corr_ratio_XY**2 / (1 - corr_ratio_XY**2) * 1/sci.stats.f.ppf(1 - p_level, f1, f2, loc=0, scale=1) - (K_X - 1)/n_X
# доверительный интервал
corr_ratio_XY_low = sqrt(z1) if sqrt(z1) >= 0 else 0
corr_ratio_XY_high = sqrt(z2) if sqrt(z2) <= 1 else 1
print(f"{p_level*100}%-ный доверительный интервал для корреляционного отношения: {[round(corr_ratio_XY_low, DecPlace), round(corr_ratio_XY_high, DecPlace)]}")![]()
Важное замечание: при значениях η близких к 0 или 1 левая или правая граница доверительного интервала может выходить за пределы отрезка [0; 1], теряя содержательный смысл (см. [1, с.80]). Причина этого – в аппроксимационном подходе к определению границ доверительного интервала. Подобные нежелательные явления возможны, и их нужно учитывать при выполнении анализа.
5. Проверка значимости отличия линейной корреляционной связи от нелинейной:
Оценим величину коэффициента линейной корреляции:
corr_coef = sci.stats.pearsonr(X, Y)[0]
print(f"Коэффициент линейной корреляции: r = {round(corr_coef, DecPlace)}")
print(f"Оценка тесноты линейной корреляции по шкале Чеддока: {Cheddock_scale_check(corr_coef)}")
print(f"Оценка тесноты линейной корреляции по шкале Эванса: {Evans_scale_check(corr_coef)}")
Проверим значимость коэффициента линейной корреляции:
# расчетный уровень значимости
a_corr_coef_calc = sci.stats.pearsonr(X, Y)[1]
print(f"Расчетный уровень значимости коэффициента линейной корреляции: a_calc = {a_corr_coef_calc}")
print(f"Заданный уровень значимости: a_level = {round(a_level, DecPlace)}")
# вывод
if a_corr_coef_calc >= a_level:
conclusion_corr_coef_sign = f"Так как a_calc = {a_corr_coef_calc} >= a_level = {round(a_level, DecPlace)}" +
", то гипотеза о равенстве нулю коэффициента линейной корреляции ПРИНИМАЕТСЯ, т.е. линейная корреляционная связь НЕЗНАЧИМА"
else:
conclusion_corr_coef_sign = f"Так как a_calc = {a_corr_coef_calc} < a_level = {round(a_level, DecPlace)}" +
", то гипотеза о равенстве нулю коэффициента линейной корреляции ОТВЕРГАЕТСЯ, т.е. линейная корреляционная связь ЗНАЧИМА"
print(conclusion_corr_coef_sign)
Теперь проверим значимость отличия линейной корреляционной связи от нелинейной. Для этого рассмотрим нулевую гипотезу:
H0: η² - r² = 0
H1: η² - r² ≠ 0Для проверки нулевой гипотезы воспользуемся критерием Фишера:
print(f"Корреляционное отношение: {chr(951)} = {round(corr_ratio_XY, DecPlace)}")
print(f"Коэффициент линейной корреляции: r = {round(corr_coef, DecPlace)}")
# расчетное значение статистики критерия Фишера
F_line_corr_sign_calc = (n_X - K_X)/(K_X - 2) * (corr_ratio_XY**2 - corr_coef**2) / (1 - corr_ratio_XY**2)
print(f"Расчетное значение статистики критерия Фишера: F_calc = {round(F_line_corr_sign_calc, DecPlace)}")
# табличное значение статистики критерия Фишера
dfn = K_X - 2
dfd = n_X - K_X
F_line_corr_sign_table = sci.stats.f.ppf(p_level, dfn, dfd, loc=0, scale=1)
print(f"Табличное значение статистики критерия Фишера: F_table = {round(F_line_corr_sign_table, DecPlace)}")
# расчетный уровень значимости
a_line_corr_sign_calc = 1 - sci.stats.f.cdf(F_line_corr_sign_calc, dfn, dfd, loc=0, scale=1)
print(f"Расчетный уровень значимости: a_calc = {round(a_line_corr_sign_calc, DecPlace)}")
print(f"Заданный уровень значимости: a_level = {round(a_level, DecPlace)}")
# вывод
if F_line_corr_sign_calc < F_line_corr_sign_table:
conclusion_line_corr_sign = f"Так как F_calc = {round(F_line_corr_sign_calc, DecPlace)} < F_table = {round(F_line_corr_sign_table, DecPlace)}" +
f", то гипотеза о равенстве {chr(951)} и r ПРИНИМАЕТСЯ, т.е. корреляционная связь ЛИНЕЙНАЯ"
else:
conclusion_line_corr_sign = f"Так как F_calc = {round(F_line_corr_sign_calc, DecPlace)} >= F_table = {round(F_line_corr_sign_table, DecPlace)}" +
f", то гипотеза о равенстве {chr(951)} и r ОТВЕРГАЕТСЯ, т.е. корреляционная связь НЕЛИНЕЙНАЯ"
print(conclusion_line_corr_sign)
Создание пользовательской функции для корреляционного анализа
Для практической работы целесообразно все вышеприведенные расчеты реализовать в виде пользовательских функций:
-
функция corr_coef_check – для расчета и анализа коэффициента линейной корреляции Пирсона
-
функция corr_ratio_check – для расчета и анализа корреляционного отношения
-
функция line_corr_sign_check – для проверка значимости линейной корреляционной связи
Данные функции выводят результаты анализа в виде DataFrame, что удобно для визуального восприятия и дальнейшего использования результатов анализа (впрочем, способ вывода – на усмотрение каждого исследователя).
# Функция для расчета и анализа коэффициента линейной корреляции Пирсона
def corr_coef_check(X, Y, p_level=0.95, scale='Cheddok'):
a_level = 1 - p_level
X = np.array(X)
Y = np.array(Y)
n_X = len(X)
n_Y = len(Y)
# оценка коэффициента линейной корреляции средствами scipy
corr_coef, a_corr_coef_calc = sci.stats.pearsonr(X, Y)
# несмещенная оценка коэффициента линейной корреляции (при n < 15) (см.Кобзарь, с.607)
if n_X < 15:
corr_coef = corr_coef * (1 + (1 - corr_coef**2) / (2*(n_X-3)))
# проверка гипотезы о значимости коэффициента корреляции
t_corr_coef_calc = abs(corr_coef) * sqrt(n_X-2) / sqrt(1 - corr_coef**2)
t_corr_coef_table = sci.stats.t.ppf((1 + p_level)/2 , n_X - 2)
conclusion_corr_coef_sign = 'significance' if t_corr_coef_calc >= t_corr_coef_table else 'not significance'
# доверительный интервал коэффициента корреляции
if t_corr_coef_calc >= t_corr_coef_table:
z1 = np.arctanh(corr_coef) - sci.stats.norm.ppf((1 + p_level)/2, 0, 1) / sqrt(n_X-3) - corr_coef / (2*(n_X-1))
z2 = np.arctanh(corr_coef) + sci.stats.norm.ppf((1 + p_level)/2, 0, 1) / sqrt(n_X-3) - corr_coef / (2*(n_X-1))
corr_coef_conf_int_low = tanh(z1)
corr_coef_conf_int_high = tanh(z2)
else:
corr_coef_conf_int_low = corr_coef_conf_int_high = '-'
# оценка тесноты связи
if scale=='Cheddok':
conclusion_corr_coef_scale = scale + ': ' + Cheddock_scale_check(corr_coef)
elif scale=='Evans':
conclusion_corr_coef_scale = scale + ': ' + Evans_scale_check(corr_coef)
# формируем результат
result = pd.DataFrame({
'notation': ('r'),
'coef_value': (corr_coef),
'coef_value_squared': (corr_coef**2),
'p_level': (p_level),
'a_level': (a_level),
't_calc': (t_corr_coef_calc),
't_table': (t_corr_coef_table),
't_calc >= t_table': (t_corr_coef_calc >= t_corr_coef_table),
'a_calc': (a_corr_coef_calc),
'a_calc <= a_level': (a_corr_coef_calc <= a_level),
'significance_check': (conclusion_corr_coef_sign),
'conf_int_low': (corr_coef_conf_int_low),
'conf_int_high': (corr_coef_conf_int_high),
'scale': (conclusion_corr_coef_scale)
},
index=['Correlation coef.'])
return result # Функция для расчета и анализа корреляционного отношения
def corr_ratio_check(X, Y, p_level=0.95, orientation='XY', scale='Cheddok'):
a_level = 1 - p_level
X = np.array(X)
Y = np.array(Y)
n_X = len(X)
n_Y = len(Y)
# запишем данные в DataFrame
matrix_XY_df = pd.DataFrame({
'X': X,
'Y': Y})
# число интервалов группировки
group_int_number = lambda n: round (3.31*log(n_X, 10)+1) if round (3.31*log(n_X, 10)+1) >=2 else 2
K_X = group_int_number(n_X)
K_Y = group_int_number(n_Y)
# группировка данных и формирование корреляционной таблицы
cut_X = pd.cut(X, bins=K_X)
cut_Y = pd.cut(Y, bins=K_Y)
matrix_XY_df['cut_X'] = cut_X
matrix_XY_df['cut_Y'] = cut_Y
CorrTable_df = pd.crosstab(
index=matrix_XY_df['cut_X'],
columns=matrix_XY_df['cut_Y'],
rownames=['cut_X'],
colnames=['cut_Y'])
CorrTable_np = np.array(CorrTable_df)
# итоги корреляционной таблицы по строкам и столбцам
n_group_X = [np.sum(CorrTable_np[i]) for i in range(K_X)]
n_group_Y = [np.sum(CorrTable_np[:,j]) for j in range(K_Y)]
# среднегрупповые значения переменной X
Xboun_mean = [(CorrTable_df.index[i].left + CorrTable_df.index[i].right)/2 for i in range(K_X)]
Xboun_mean[0] = (np.min(X) + CorrTable_df.index[0].right)/2 # исправляем значения в крайних интервалах
Xboun_mean[K_X-1] = (CorrTable_df.index[K_X-1].left + np.max(X))/2
# среднегрупповые значения переменной Y
Yboun_mean = [(CorrTable_df.columns[j].left + CorrTable_df.columns[j].right)/2 for j in range(K_Y)]
Yboun_mean[0] = (np.min(Y) + CorrTable_df.columns[0].right)/2 # исправляем значения в крайних интервалах
Yboun_mean[K_Y-1] = (CorrTable_df.columns[K_Y-1].left + np.max(Y))/2
# средневзевешенные значения X и Y для каждой группы
Xmean_group = [np.sum(CorrTable_np[:,j] * Xboun_mean) / n_group_Y[j] for j in range(K_Y)]
Ymean_group = [np.sum(CorrTable_np[i] * Yboun_mean) / n_group_X[i] for i in range(K_X)]
# общая дисперсия X и Y
Sum2_total_X = np.sum(n_group_X * (Xboun_mean - np.mean(X))**2)
Sum2_total_Y = np.sum(n_group_Y * (Yboun_mean - np.mean(Y))**2)
# межгрупповая дисперсия X и Y (дисперсия групповых средних)
Sum2_between_group_X = np.sum(n_group_Y * (Xmean_group - np.mean(X))**2)
Sum2_between_group_Y = np.sum(n_group_X * (Ymean_group - np.mean(Y))**2)
# эмпирическое корреляционное отношение
corr_ratio_XY = sqrt(Sum2_between_group_Y / Sum2_total_Y)
corr_ratio_YX = sqrt(Sum2_between_group_X / Sum2_total_X)
try:
if orientation!='XY' and orientation!='YX':
raise ValueError("Error! Incorrect orientation!")
if orientation=='XY':
corr_ratio = corr_ratio_XY
elif orientation=='YX':
corr_ratio = corr_ratio_YX
except ValueError as err:
print(err)
# проверка гипотезы о значимости корреляционного отношения
F_corr_ratio_calc = (n_X - K_X)/(K_X - 1) * corr_ratio**2 / (1 - corr_ratio**2)
dfn = K_X - 1
dfd = n_X - K_X
F_corr_ratio_table = sci.stats.f.ppf(p_level, dfn, dfd, loc=0, scale=1)
a_corr_ratio_calc = 1 - sci.stats.f.cdf(F_corr_ratio_calc, dfn, dfd, loc=0, scale=1)
conclusion_corr_ratio_sign = 'significance' if F_corr_ratio_calc >= F_corr_ratio_table else 'not significance'
# доверительный интервал корреляционного отношения
if F_corr_ratio_calc >= F_corr_ratio_table:
f1 = round ((K_X - 1 + n_X * corr_ratio**2)**2 / (K_X - 1 + 2 * n_X * corr_ratio**2))
f2 = n_X - K_X
z1 = (n_X - K_X) / n_X * corr_ratio**2 / (1 - corr_ratio**2) * 1/sci.stats.f.ppf(p_level, f1, f2, loc=0, scale=1) - (K_X - 1)/n_X
z2 = (n_X - K_X) / n_X * corr_ratio**2 / (1 - corr_ratio**2) * 1/sci.stats.f.ppf(1 - p_level, f1, f2, loc=0, scale=1) - (K_X - 1)/n_X
corr_ratio_conf_int_low = sqrt(z1) if sqrt(z1) >= 0 else 0
corr_ratio_conf_int_high = sqrt(z2) if sqrt(z2) <= 1 else 1
else:
corr_ratio_conf_int_low = corr_ratio_conf_int_high = '-'
# оценка тесноты связи
if scale=='Cheddok':
conclusion_corr_ratio_scale = scale + ': ' + Cheddock_scale_check(corr_ratio, name=chr(951))
elif scale=='Evans':
conclusion_corr_ratio_scale = scale + ': ' + Evans_scale_check(corr_ratio, name=chr(951))
# формируем результат
result = pd.DataFrame({
'notation': (chr(951)),
'coef_value': (corr_ratio),
'coef_value_squared': (corr_ratio**2),
'p_level': (p_level),
'a_level': (a_level),
'F_calc': (F_corr_ratio_calc),
'F_table': (F_corr_ratio_table),
'F_calc >= F_table': (F_corr_ratio_calc >= F_corr_ratio_table),
'a_calc': (a_corr_ratio_calc),
'a_calc <= a_level': (a_corr_ratio_calc <= a_level),
'significance_check': (conclusion_corr_ratio_sign),
'conf_int_low': (corr_ratio_conf_int_low),
'conf_int_high': (corr_ratio_conf_int_high),
'scale': (conclusion_corr_ratio_scale)
},
index=['Correlation ratio'])
return result # Функция для проверка значимости линейной корреляционной связи
def line_corr_sign_check(X, Y, p_level=0.95, orientation='XY'):
a_level = 1 - p_level
X = np.array(X)
Y = np.array(Y)
n_X = len(X)
n_Y = len(Y)
# коэффициент корреляции
corr_coef = sci.stats.pearsonr(X, Y)[0]
# корреляционное отношение
try:
if orientation!='XY' and orientation!='YX':
raise ValueError("Error! Incorrect orientation!")
if orientation=='XY':
corr_ratio = corr_ratio_check(X, Y, orientation='XY', scale='Evans')['coef_value'].values[0]
elif orientation=='YX':
corr_ratio = corr_ratio_check(X, Y, orientation='YX', scale='Evans')['coef_value'].values[0]
except ValueError as err:
print(err)
# число интервалов группировки
group_int_number = lambda n: round (3.31*log(n_X, 10)+1) if round (3.31*log(n_X, 10)+1) >=2 else 2
K_X = group_int_number(n_X)
# проверка гипотезы о значимости линейной корреляционной связи
if corr_ratio >= abs(corr_coef):
F_line_corr_sign_calc = (n_X - K_X)/(K_X - 2) * (corr_ratio**2 - corr_coef**2) / (1 - corr_ratio**2)
dfn = K_X - 2
dfd = n_X - K_X
F_line_corr_sign_table = sci.stats.f.ppf(p_level, dfn, dfd, loc=0, scale=1)
comparison_F_calc_table = F_line_corr_sign_calc >= F_line_corr_sign_table
a_line_corr_sign_calc = 1 - sci.stats.f.cdf(F_line_corr_sign_calc, dfn, dfd, loc=0, scale=1)
comparison_a_calc_a_level = a_line_corr_sign_calc <= a_level
conclusion_null_hypothesis_check = 'accepted' if F_line_corr_sign_calc < F_line_corr_sign_table else 'unaccepted'
conclusion_line_corr_sign = 'linear' if conclusion_null_hypothesis_check == 'accepted' else 'non linear'
else:
F_line_corr_sign_calc = ''
F_line_corr_sign_table = ''
comparison_F_calc_table = ''
a_line_corr_sign_calc = ''
comparison_a_calc_a_level = ''
conclusion_null_hypothesis_check = 'Attention! The correlation ratio is less than the correlation coefficient'
conclusion_line_corr_sign = '-'
# формируем результат
result = pd.DataFrame({
'corr.coef.': (corr_coef),
'corr.ratio.': (corr_ratio),
'null hypothesis': ('ru00b2 = ' + chr(951) + 'u00b2'),
'p_level': (p_level),
'a_level': (a_level),
'F_calc': (F_line_corr_sign_calc),
'F_table': (F_line_corr_sign_table),
'F_calc >= F_table': (comparison_F_calc_table),
'a_calc': (a_line_corr_sign_calc),
'a_calc <= a_level': (comparison_a_calc_a_level),
'null_hypothesis_check': (conclusion_null_hypothesis_check),
'significance_line_corr_check': (conclusion_line_corr_sign),
},
index=['Significance of linear correlation'])
return resultdisplay(corr_coef_check(X, Y, scale='Evans'))
display(corr_ratio_check(X, Y, orientation='XY', scale='Evans'))
display(line_corr_sign_check(X, Y, orientation='XY'))
Сделаем выводы по результатам расчетов:
-
Между величинами существует значимая (acalc<0.05) корреляционная связь, корреляционное отношение η = 0.7936 (т.е. связь сильная по Эвансу).
-
Линейная корреляционная связь между величинами также значимая (acalc<0.05), отрицательная, коэффициент корреляции r = -0.7189 (связь сильная по Эвансу); линейная корреляция между переменными объясняет 51.68% вариации.
-
Гипотеза о равенстве корреляционного отношения и коэффициента корреляции отвергается (acalc<0.05), то есть отличие линейной формы связи от нелинейной значимо.
ИТОГИ
Итак, мы рассмотрели способы построения корреляционной таблицы, расчета корреляционного отношения, проверки его значимости и построения для него доверительных интервалов средствами Python. Также предложены пользовательские функции, уменьшающие размер кода.
Исходный код находится в моем репозитории на GitHub (https://github.com/AANazarov/Statistical-methods).
ЛИТЕРАТУРА
-
Айвазян С.А. и др. Прикладная статистика: исследование зависимостей. – М.: Финансы и статистика, 1985. – 487 с.
-
Айвазян С.А., Мхитарян В.С. Прикладная статистика. Основы эконометрики: В 2 т. – Т.1: Теория вероятностей и прикладная статистика. – М.: ЮНИТИ-ДАНА, 2001. – 656 с.
-
Кобзарь А.И. Прикладная математическая статистика. Для инженеров и научных работников. – М.: ФИЗМАТЛИТ, 2006. – 816 с.
-
Котеров А.Н. и др. Сила связи. Сообщение 2. Градации величины корреляции. – Медицинская радиология и радиационная безопасность. 2019. Том 64. № 6. с.12–24 (https://medradiol.fmbafmbc.ru/journal_medradiol/abstracts/2019/6/12-24_Koterov_et_al.pdf).
Post Views:
10 602
Корреляционный анализ (КА) — это статистический инструмент, позволяющий установить связь между двумя различными переменными, а также оценить, насколько сильна взаимосвязь между этими переменными. Такой анализ применим исключительно для количественных данных. Исчисляется с помощью коэффициента корреляции, также известного как коэффициент Пирсона.
Коэффициент корреляции Пирсона — это ковариация двух переменных, деленная на произведение их стандартных отклонений. Коэффициент может иметь значение в диапазоне от (+1) до (-1), которое отражает степень взаимосвязи между переменными.
Результаты корреляционного анализа
Если результат корреляционного анализа положительный, то взаимосвязь двух переменных прямо пропорциональная. Это означает, что при увеличении одной переменной, вторая будет также увеличиваться. Как правило, такой результат принято называть “позитивной корреляцией”.
Если результат корреляционного анализа отрицательный, то взаимосвязь двух переменных обратно пропорциональная. Это означает, что при увеличении одной переменной, вторая будет уменьшаться. Такой эффект называется “отрицательной корреляцией”.
Таким образом, чем ближе значение КА к (+1) или (-1), тем сильнее взаимосвязь между двумя переменными. Соответственно, если результат анализа стремится к нулю, то взаимосвязь между двумя переменными отсутствует. Статистически значимыми принято считать значения, результат которых выше 0,5 в обоих направлениях.
Корреляционный анализ следует использовать, когда вы считаете, что есть связь между двумя переменными и вы хотите в этом убедиться. Также, КА можно использовать между несколькими переменными, проводя последовательную оценку, для определения наибольшей взаимосвязи.
Применение корреляционного анализа
Применение КА широко распространено, поскольку он позволяет выявить неожиданные взаимосвязи, которые позволяют делать более глубокий анализ и использовать полученные результаты для извлечения выгоды. Анализ полезен при тестировании гипотез ценообразования и продаж, развития стратегии и продуктового портфеля.
Например, корреляционный анализ поможет ответить на такие вопросы:
- Влияет ли скидка на увеличение продаж?
- Влияет ли уменьшение цены на увеличение продаж?
- Являются ли лояльные клиенты самыми прибыльными?
Самый простой пример: такие факторы, как жаркая погода и продажи мороженного можно подвергнуть корреляционному анализу. Логично сделать заключение, что жаркая погода является причиной того, что люди покупают больше мороженного. При этом, жаркая погода может стать причиной увеличения продаж хлора для бассейнов. Но при этом продажа мороженного никак не коррелируется с продажей хлора.
Более того, корреляционный анализ применяется в рамках концепции Lean SixSigma для поиска коренных причин проблемы и их взаимного влияния друг на друга.
Корреляционный анализ: формула

Порядок расчета коэффициента корреляции:
- Собрать данные исследуемых переменных — “X” и “Y”.
- Сгруппировать данные двух исследуемых переменных в столбцы (см. пример ниже).
- Добавить столбцы “ХХ”, “XY”, “YY”.
- Провести расчеты для столбцов (перемножение данных: Х*Х; Х*У; У*У).
- Просуммировать данные столбцов.
- Внести полученные данные в формул расчета.
Пример расчета коэффициента корреляции
Рассмотрим пример взаимосвязи цены и проданных единиц продукции, потому что самое популярное предположение — чем ниже цена, тем больше количество проданных единиц продукции. Учитывая, важность получаемой выручки, проверим данную гипотезу по формуле, которая указана выше. В таблице представлена условная цена и количество проданных единиц продукции по заданной цене. Рассчитаем последовательно остальные данные необходимые для коэффициента корреляции.


Полученные расчеты используем в формуле и получаем значение корреляции, равное (-0,412). Данный результат будет означать, что взаимосвязь между ценой и количеством проданных единиц товара не существенная.

Корреляционный анализ в MS Excel
Рассчитаем коэффициент корреляции для вышеприведенного примера в MS Excel. Для это необходимо занести два столбца с переменными данными.

Далее, открываем меню “Формулы”, нажимаем кнопку “Вставить функцию” и через мастера функций находим функцию PEARSON.

Выделяем область данных для полей “Массив1” и “Массив 2”, то есть столбец “Х” и столбец “У”. В левом нижнем углу видим результат, равный ( ‑0,412), что полностью соответствует вышеприведенным расчетам.

