Разработка концептуальной и логической схемы при создании базы данных
NovaInfo 75, с.1-8, скачать PDF
Опубликовано 1 декабря 2017
Раздел: Физико-математические науки
Просмотров за месяц: 78
Аннотация
На примере разработки информационной системы для сервис-центра были рассмотрены инфологический и логический этапы проектирования.
Ключевые слова
ИНФОЛОГИЧЕСКАЯ МОДЕЛЬ, ЛОГИЧЕСКАЯ СХЕМА, БАЗЫ ДАННЫХ, ИНФОРМАЦИОННАЯ СИСТЕМА
Текст научной работы
В ходе выполнения данной работы была разработана информационная система для сервис-центра.
Инфологической моделью можно назвать описание базы данных, которое состоит из таких элементов как формулы, графики, таблиц и диаграмм, а также других средств. Смысл такой модели состоит в реальном описании процессов, информационных потоков, функций системы с помощью общедоступного всем языка, понятного всем [1-3].
Результаты инфологического проектирования могут быть выражены в виде инфологической или концептуальной модели, которая представляет структуру данных. Для построения концептуальной модели используется метод моделирования «Сущность — связь» или ER-диаграмма.
После того, как было проведено исследование предметной области сервис-центра и проведен анализ структуры системы были выделены сущности, атрибуты и первичный ключ.
|
№ |
Название и обозначение сущности |
Ключ сущности и его обозначение |
Атрибуты сущности и их обозначение |
|
1 |
Запчасти |
код_запчасти |
категория наименование серийный номер марка количество цена в наличии |
|
2 |
Типы |
код_типа |
категория описание |
|
3 |
Сотрудники |
код_сотрудника |
ФИО_сотрудника дата_рождения паспорт должность телефон пол образование |
|
4 |
Ремонт |
код_ремонта |
дата_ремонта название имя_клиента имя_сотрудника запчасти стоимость_ремонта статус |
|
5 |
Клиенты |
код_клиента |
ФИО телефон адрес е-mail |
|
№ |
Связь |
|
1 |
Запчасти СОСТОЯТ из Типов |
|
2 |
Запчасти ИСПОЛЬЗУЮТСЯ при Ремонте |
|
3 |
Сотрудники ВЫПОЛНЯЮТ Ремонт |
|
4 |
Клиенты ЗАКАЗЫВАЮТ Ремонт |
На основе сущностей и связи между ними получаем ER-диаграмму предметной области (рис.1):

Следующим этапом проектирования является логическая схема — это модель данных конкретной области вопросов, выраженная в терминах технологии управления данными. При проектировании логической структуры реляционной базы данных определяется оптимальный состав таблиц для хранения исходной информации. Для каждой таблицы указывается ее название, перечень полей и первичный ключ. Идентифицируются связи между таблицами. После использования правила отображения ER-диаграммы на логическую схему, получаем примерно такие таблицы:
|
Ключевое поле |
Название поля |
Тип поля |
|
Ключ |
код_запчасти |
Счетчик |
|
Наименование |
Текстовый |
|
|
Серийный номер |
Числовой |
|
|
Марка |
Текстовый |
|
|
Количество |
Числовой |
|
|
Цена |
Числовой |
|
|
В наличии |
Текстовый |
|
Ключевое поле |
Название поля |
Тип поля |
|
Ключ |
код_типа |
Счетчик |
|
Категория |
Текстовый |
|
|
Описание |
Поле МЕМО |
|
Ключевое поле |
Название поля |
Тип поля |
|
Ключ |
код_сотрудника |
Счетчик |
|
ФИО_сотрудника |
Текстовый |
|
|
дата_рождения |
Дата/время |
|
|
Паспорт |
Текстовый |
|
|
Должность |
Текстовый |
|
|
Телефон |
Текстовый |
|
|
Пол |
Текстовый |
|
|
Образование |
Текстовый |
|
Ключевое поле |
Название поля |
Тип поля |
|
Ключ |
код_ремонта |
Счетчик |
|
Дата_заказа |
Текстовый |
|
|
ФИО_сотрудника |
Текстовый |
|
|
ФИО_клиента |
Текстовый |
|
|
Запчасти |
Текстовый |
|
|
Стоимость_ремонта |
Денежный |
|
Ключевое поле |
Название поля |
Тип поля |
|
Ключ |
код_клиента |
Счетчик |
|
ФИО_клиента |
Текстовый |
|
|
Телефон |
Текстовый |
|
|
Адрес |
Текстовый |
|
|
|
Текстовый |
Для физической реализации разработки базы данных была выбрана программа Microsoft Access, так как она позволяет быстро создавать таблицы и заполнять их без использования специальных конструкций [4].
На рисунке 2 представлена схема разработанной базы данных, в которой показаны таблицы и связи таблиц между собой.

Таблицы создавались с учетом оптимального использования памяти и простоты представляемых данных согласно ER-модели. Была проведена нормализация ER-модели для последующей оптимальной работы с базой данной.
В ходе разработки структуры базы были созданы следующие таблицы:
1. Ремонт — таблица предназначена для хранения информации об ремонте. На рисунке 3 показана заполненная таблица Ремонт, где ключевым полем объявлено поле «КодРемонта», имеющее тип счетчика, а остальные поля используются для задания значения фамилии и данных клиентов.

2. Клиенты — таблица предназначена для хранения информации о клиентах, такой как ФИО клиента, телефон, адрес и электронная почта.
Для таблицы Клиенты задано ключевое поле, которое отвечает за уникальный номер группы для сохранения однозначности в связях с другими таблицами. На рисунке 4 показана заполненная таблица «Клиенты».

3. Типы — таблица предназначена для хранения информации о типах запчастей.
На рисунке 5 показана таблица «Типы».

4. Запчасти — таблица предназначена для хранения информации о запчастях, которые могут пригодиться при ремонте. На рисунке 6 представлена таблица «Запчасти».

5. Сотрудники — таблица предназначена для хранения информации о сотрудниках, которые работают в данном сервисном центре. На рисунке 7 представлена таблица «Сотрудники».

В ходе выполнения данной работы была разработана информационная система для сервис-центра и были решены следующие задачи:
- Проведен тщательный анализ предметной области сервисного центра;
- Обработана и систематизирована полученная информация;
- Построена ER-диаграмму и получена логическая схема базы данных в Microsoft Office Access;
- Создано приложение для работы базой данных в Embarcadero Rad Studio;
- Разработан удобный интерфейс для пользователей приложения и предоставлена возможность обработки информации: создание, удаление, изменение записей.
Спроектированная информационная система дает возможность удобного ввода, редактирования, удаления и хранения данных. Для реализации данного программного обеспечения были использованы Microsoft Access и Embarcadero Rad Studio и изученERWin.
Читайте также
-
Применение Borland Delphi для разработки интерфейса
- Хусаинова Г.Я.
-
Разработка информационной системы средствами MS Access
- Хусаинова Г.Я.
-
Математическое моделирование барабанного нефтесборщика с рифленой поверхностью
- Хусаинова Г.Я.
-
Исследование полей температуры вязкопластичных жидкостей при плоскорадиальном фильтрационном течении
- Хусаинова Г.Я.
-
Автоматизированное рабочее место администратора фитнес-клуба
- Хусаинова Г.Я.
Список литературы
- Айнуров К.И. Использование информационных технологий в обучении. – Магнитогорск.: МГПУ, 2014. – 85 с.
- Викторов С.У. Развитие информационных технологий.– Пермь: ЛНА, 2011. – 74 с.
- Хусаинов И.Г., Рахимова Р.А. Роль интерактивных технологий на уроках информатики в развитии этического воспитания учащихся // Современные проблемы науки и образования. – 2015. – № 3. – С. 488.
- Хусаинова Г.Я. Исследование температурных полей при стационарном течении аномальных жидкостей // Автоматизация. Современные технологии. 2016. № 7. С. 13-16.
Цитировать
Хусаинова, Г.Я. Разработка концептуальной и логической схемы при создании базы данных / Г.Я. Хусаинова. — Текст : электронный // NovaInfo, 2017. — № 75. — С. 1-8. — URL: https://novainfo.ru/article/14280 (дата обращения: 19.05.2023).
Поделиться
Время от времени я заглядываю на Toster.ru и иногда даже отвечаю там на вопросы. Чаще всего люди спрашивают две вещи — как стать программистом и как правильно спроектировать схему базы данных. Мне лично кажется очень странным, что так много людей задают последний вопрос. Мне почему-то всегда казалось, что это такая простая вещь, которую умеют вообще все. Но, раз так много людей интересуются, здесь я постараюсь дать достаточно развернутый и в то же время краткий ответ.
Дополнение: Также вас могут заинтересовать заметки Начало работы с PostgreSQL, Потоковая репликация в PostgreSQL и пример фейловера, Некоторые интересные отличия PostgreSQL от MySQL и Обратная совместимость и изменение схемы базы данных.
Я предполагаю, что SQL вы знаете. То есть, объяснять, что такое таблицы, строки, индексы, первичные ключи и ссылочная целостность, не требуется. Если это не так, боюсь, я вынужден отправить вас к соответствующей литературе. Благо, ее сейчас очень много.
Рисуем диаграмму
Допустим, требуется спроектировать схему базы данных, в которой хранится информация о музыкальных исполнителях, альбомах и песнях. На начальном этапе, когда у нас еще совсем ничего нет, удобно начать с рисования диаграммы будущей схемы. Можно начать с наброска ручкой на листе бумаги, можно сразу взять специализированный редактор. Их сейчас очень много, все они устроены довольно похожим образом. При подготовке этой заметки я воспользовался DbSchema. Это платная программа, но мне кажется, что она стоит своих денег. К тому же, в нормальных компаниях обычно оплачивают стоимость софта, необходимого для работы. Триал у DbSchema, если что, составляет две недели.
Нарисовать следюущую диаграмму заняло у меня порядко десяти минут:
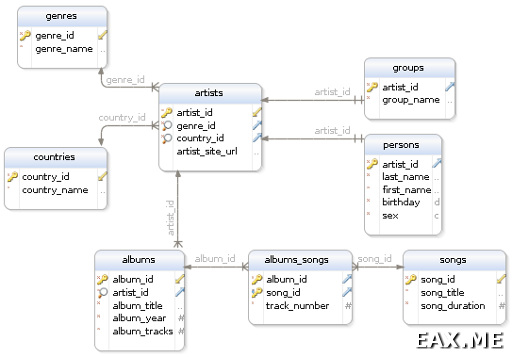
Если раньше вам не доводилось работать с такими диаграммами, не пугайтесь, тут все просто. Прямоугольнички — это таблицы, строки в прямоугольничках — имена столбцов, стрелочками обозначаются внешние ключи, а ключиками — первичные ключи. При желании тут можно разглядеть даже индексы, типы столбцов и обязательность их заполнения (null / not null), но для нас сейчас это не так важно.
Дополнение: Аналогичную диаграмму можно построить при помощи открытого инструмента PlantUML.
Генерируем SQL и скармливаем его СУБД
Нетрудно заметить, что данная диаграмма легко отображается в код для создания схемы базы данных на языке SQL. В DbSchema сгенерировать SQL можно, сказав Schema → Generate Schema and Data Script. Затем полученный скрипт можно скормить используемой вами СУБД:
cat music.sql | psql -hlocalhost test_database test_user
Я использовал PostgreSQL. Информацию о том, как установить эту СУБД, вы найдете в этой заметке.
Итак, чем же я руководствовался при проектировании схемы?
Нормальные формы
Процесс устранения избыточности и ликвидации противоречивости базы данных называется нормализацией. Выделяют так называемые нормальные формы, из которых на практике редко кто помнит больше первых трех.
Грубо говоря, таблица находится в первой нормальной форме (1НФ), если на пересечении любой строки и любого столбца в таблице находится ровно одно значение. В современных РСУБД это условие всегда выполняется. Даже если СУБД поддерживает множества или массивы, на пересечении строки и столбца хранится ровно одно значение типа множество или массив. Но в таблице (user varchar(100), phone integer) не может быть строки alex - 1234, 5678. В 1НФ может быть только две сроки — alex - 1234 и alex - 5678.
Вторая нормальная форма (2НФ) означает, что таблица находится в первой нормальной форме, и каждый неключевой атрибут неприводимо зависит от значения первичного ключа. Неприводимость означает следующее. Если первичный ключ состоит из одного атрибута, то любая функциональная зависимость от него неприводима. Если первичный ключ является составным, то в таблице не может быть атрибута, значение которого однозначно определяется значением подмножества атрибутов первичного ключа.
Таблица находится в третьей нормальной форме, если она находится в 2НФ и ни один неключевой атрибут не находится в транзитивной функциональной зависимости от первичного ключа. Например, рассмотрим таблицу (employee varchar(100) primary key, department varchar(100), department_phone integer). Очевидно, что она находится в 2НФ. Но телефон отдела находится в транзитивной функциональной зависимости от имени сотрудника, так как сотрудник однозначно задает отдел, а отдел однозначно задает телефон отдела. Для приведения таблицы в 3НФ нужно разбить ее на две таблицы — employee - department и departmnet - phone.
Легко видеть, что нормализация уменьшает избыточность базы данных и препятствует внесению случайных ошибок. Например, если оставить таблицу из последнего примера в 2НФ, то можно по ошибке прописать одному и тому же отделу разные телефоны. Или рассмотрим компанию с пятью отделами и 1000 сотрудниками. Если у отдела поменялся номер телефона, то для его обновления в базе данных в случае 2НФ потребуется просканировать 1000 строк, а в случае с 3НФ только пять.
Как я уже отмечал, есть и более строгие нормальные формы, но на практике обычно используются только первые три.
Отношение один ко многим
На приведенной диаграмме можно заметить, что каждый исполнитель относится к какой-то стране, и каждый альбом принадлежит какому-то исполнителю. Это и есть отношение один ко многим. Например, к одной стране относится множество исполнителей, и каждый исполнитель может иметь множество альбомов. Но приведенная схема, например, запрещает одному альбому принадлежать множеству исполнителей. Хотя в реальной жизни, конечно, это возможно, например, в случае со сборниками.
Для моделирования такого типа отношения в каждом альбоме указывается id исполнителя, и в каждом исполнителе указывается id страны. Понятное дело, мы не просто пишем туда какую-то циферку, а возлагаем ответственность по контролю ссылочной целостности на нашу СУБД:
ALTER TABLE albums ADD CONSTRAINT fk_albums_artists FOREIGN KEY ( artist_id ) REFERENCES artists( artist_id );
Это часто оказывается большим сюрпризом для тех, кто всю жизнь работал с MySQL и его бэкендом MyISAM, который так не умеет. Я не вижу причин не проверять ссылочную целостность, если только вы не пишите супер-пупер высоконагруженный проект, у которого исполнители хранятся на одном сервере, а альбомы — на другом. В противном случае вас ждет много часов увлекательной отладки вашего приложения в ночь с субботы на воскресенье, потому что как-то так получилось, что кто-то создал альбом с несуществующим исполнителем.
Жанры и страны в приведенной схеме иногда еще называют «словарями». Это сравнительно небольшие таблицы, состоящие из двух столбцов — id и названия. Если, например, мы захотим переименовать страну Russia в Russian Federation, нам придется поменять всего лишь одну строчку в таблице countries, а не править кучу строк в таблице artists, что может привести к очень большому количеству дисковых операций. Кроме того, если требуется отобразить в диалоге создания нового исполнителя выпадающий список с выбором страны, нам не придется делать дорогих группировок по таблице artists, достаточно сделать простую выборку из countries.
Отношение многие ко многим
Один альбом, как правило, содержит множество песен. Кроме того, нет веских причин, почему одна песня не может находится сразу в нескольких альбомах. Здесь мы имеем место с типичным отношением многие ко многим.
Оно моделируется путем введения дополнительной таблицы. В нашем примере эта таблица называется albums_songs. Первичный ключ в этой таблицы состоит из двух внешних ключей — album_id и song_id. Теперь нетрудно с помощью пары join’ов получить все песни, входящие в данный альбом или все альбомы, в которые входит заданная песня. Кроме того, ничто не мешает завести в связующей таблице дополнительные столбцы. Например, столбец, хранящий номер трека, под которым песня входит в заданный альбом.
На практике связаны могут быть не две, а три и более таблиц. Например, некий пользователь сделал некий заказ, выбрав указанный способ оплаты, адрес и способ доставки — пожалуйста, пять таблиц как с куста.
Отношение родитель-потомок (или общее-частное)
Исполнители могут быть разных типов. Это может быть отдельно взятый(ая) певец/певица, или же группа. У всех исполнителей, независимо от конкретного типа, есть что-то общее. Например, страна, адрес официального сайта и так далее. Но кроме того, есть некоторые свойства, характерные только для данного типа. У певицы явно нет никакого названия группы, а у группы нет имени, фамилии и пола. Аналогичная ситуация возникает, скажем, если у вас есть сотрудники, занимающие различные должности и свойства сотрудников зависят от занимаемых должностей.
Один из способов моделирования такой ситуации заключается в введении по отдельной таблице на каждый из возможных подтипов. В приведенном примере это таблицы groups и persons. В качестве первичного ключа в каждой из этих таблиц используется artist_id, первичный ключ родительской таблицы artists. Кто-то при использовании такой схемы предпочитает добавить в родительскую таблицу столбец type, но, строго говоря, он является избыточным. Недостаток этого метода заключается в том, что можно создать исполнителя, являющегося как группой, так и человеком одновременно.
Есть и другие подходы. В PostgreSQL, например, есть наследование таблиц, предназначенное для решения как раз такой вот проблемы. Если вы работаете с PostgreSQL, нет причин не использовать этот механизм. Кто-то предпочитает ввести одну таблицу для всех типов с дополнительным столбцом type. Если некий столбец не имеет смысла для заданного типа, в него пишется null. Но это, как вы можете подозревать, не очень-то удобно, если у вас 10 типов, каждый из которых имеет по дюжине столбцов, характерных только для этого типа, а также парочку собственных подтипов. Кроме того, можно опрометчиво реализовать смену типа, как простое обновление столбца type, и получить массу интереснейших эффектов.
Что еще нужно принять во внимание
Принцип при моделировании других отношений тот же. Например, один человек имеет двух родителей и при этом один человек может иметь сколько угодно детей. Казалось бы, связь 2:N, этого мы не проходили. На самом деле, это просто две связи 1:N. Вводим столбцы mother_id, father_id и вперед. Да, связь в рамках одной таблицы, ну и что?
Иногда на практике можно столкнутся с древовидными структурами. На самом деле, это то же самое отношение один ко многим, один родитель имеет много потомков. В общем, вводится столбец parent_id, куда пишется «внешний» первичный ключ из этой же таблицы. В корневом элементе устанавливается parent_id равный null. Главное при работе с этим хозяйством — не наплодить случайно циклов.
В общем, все, что нужно, это немного здравого смысла.
Также при проектировании схемы базы данных нужно уделять внимание индексам. Тут все сильно зависит от конкретной СУБД, поддерживает ли она составные индексы, частичные индексы, функциональные индексы, bitmap scans и так далее. Кое-что по этой теме я писал здесь, а вообще — курите мануалы по вашей СУБД. Также за кадром остались вьюхи, триггеры и многое другое.
В высоконагруженных проектах в целях оптимизации иногда прибегают к денормализации, то есть, процессу, обратному нормализации. Действительно, в некоторых случаях намного эффективнее держать все в одной таблице, чем делать несколько десятков джоинов. Иногда данные распределяют между несколькими серверами. Понятно, что в этом случае ссылочная целостность никем не проверяется и может быть случайно нарушена. Сплошь и рядом базы данных содержат в себе некоторую избыточность. Например, стоимость заказа можно однозначно определить, сложив стоимость товаров в корзине. Но иногда эффективнее хранить уже посчитанную стоимость, особенно если речь идет не об одной корзине, а о месячном отчете по всей системе. Иногда избыточность добавляется, чтобы данные можно было починить в случае программных ошибок. Например, все критичные операции сопровождаются записью в таблицу-журнал.
Ну и нельзя не отметить, что приведенный здесь пример с исполнителями и альбомами довольно игрушечный. В реальных условиях база данных может запросто содержать сотню таблиц, каждая из которых имеет многие десятки столбцов и миллионы строк. Или, например, одну таблицу, имеющую пару сотен столбцов. Примите также во внимание, что схема базы данных имеет свойство довольно часто меняться, что, разумеется, приводит к необходимости мигрировать данные, и вы получите более-менее правдоподобную картину того, с чем на самом деле вам предстоит столкнуться.
Заключение
Все приходит с опытом. Самостоятельно спроектируйте две-три схемы, и картинка сама сложится у вас в голове. В качестве ДЗ можете спроектировать базу данных блога, интернет-магазина или базу с сотрудниками компании, их должностями и контактами. Отталкивайтесь от задачи. Учитывайте, кто и какие действия будет совершать с базой данных. Например, с базой интернет-магазина работают не только клиенты, но и, например, отдел доставки.
Проект для DbSchema, а также сгенерированный из него SQL, вы можете скачать здесь. Как всегда, если у вас есть вопросы или дополнения, не стесняйтесь писать их в комментариях.
Метки: Разработка, СУБД.
После
описания таблиц выполняется последний
этап проектирования
– разработка взаимосвязи между Таблицами,
составляющими
одну БД
СКЛАД. Результатом
выполнения этого этапа будет
схема, называемая логической
структурой БД СКЛАД (см.
рис, 4.2).
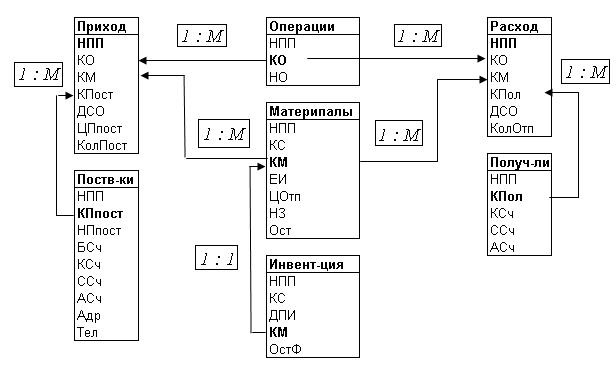
Рис. 4.2. Логическая
структура БД СКЛАД
Как
отмечалось выше, при создана формы
связи между таблицами: «один ко многим»
и «сдан к одному».
В
схеме данных связь между
таблицами
устанавливается на основе
общего
поля, которое
в одной из таблиц обязательно является
ключевым,
то
есть содержит уникальное, неповторяющиеся
значения, и поэтому представляет сторону
«один»; а в другой таблице оно будет
полем
связи, значения
которого могут повторяться, и поэтому
оно обозначает
сторону «многие».
Смысл
логических отношений между таблицами
(описан в разделе 4.2.2)*
Материалы – Приход;
Материалу – Расход;
Инвентаризация – материалы;
Поставщик – Приход;
Получатель – Расход;
Операции – Приход;
Операции – Расход.
Разработкой
схемы данных заканчивается проектирование
таблиц БД
так ютшщсм1ттй «бумажный», этап их
создания. Схему данных полезно
согласовать с пользователем, после чего
можно приступить непосредственно к
созданию БД
См
приложения
5. Создание базы данных склад
Создание
реляционной БД СКЛАД осуществляется в
полном соответствии
с ее структурой, разработанной в
результате проектирования
и определенной составом таблиц и их
взаимосвязями.
БД
создается как новая,
то
есть «с нуля», что определяет стадии ее
формирования:
-
формирование
структуры таблиц; -
загрузка таблиц;
-
создание
межтабличных связей.
5.1. Формирование структуры таблиц
На
этой стадии по материалам
проектирования
формируется состав
полей и задается их описание.
Однако
прежде чем приступить к этой работе
необходимо создать
файл базы данных, так как все реляционные
таблицы хранятся в одном файле.
5.1.1 Создание файла бд склад
1. Сразу
после запуска ПП ACCESS
открывается первое диалоговое
окно Создание
БД
Рис.
5.1. Окно Создание
БД
Если по какой-либо
причине окно не выводится, то следует
выполнить команду Файл
→ Создание
или воспользоваться кнопкой создать
базу данных на панели инструментов.
-
В окне СОЗДАНИЕ
базы данных выбрать закладку Новая
база данных. -
В появившемся
окне Файл
новая база данных
(рис.5.2.) следует выбрать палку для
размещения файла (по умолчанию файл
будет сохранен в папке Мои документы
– воспользуемся ею) или создать свою,
затем задать имя файла новой базы данных
– СКЛАД и нажать кнопку Создать
(тип файла по умолчанию имеет значение
База данных,
что придает файлу расширение .mdb).
Рис. 5.2. Окно Файл
новой базы данных
-
В
результате выполнения команды Создать
открывается окно СКЛАД: база
данных
(рис. 5.3)
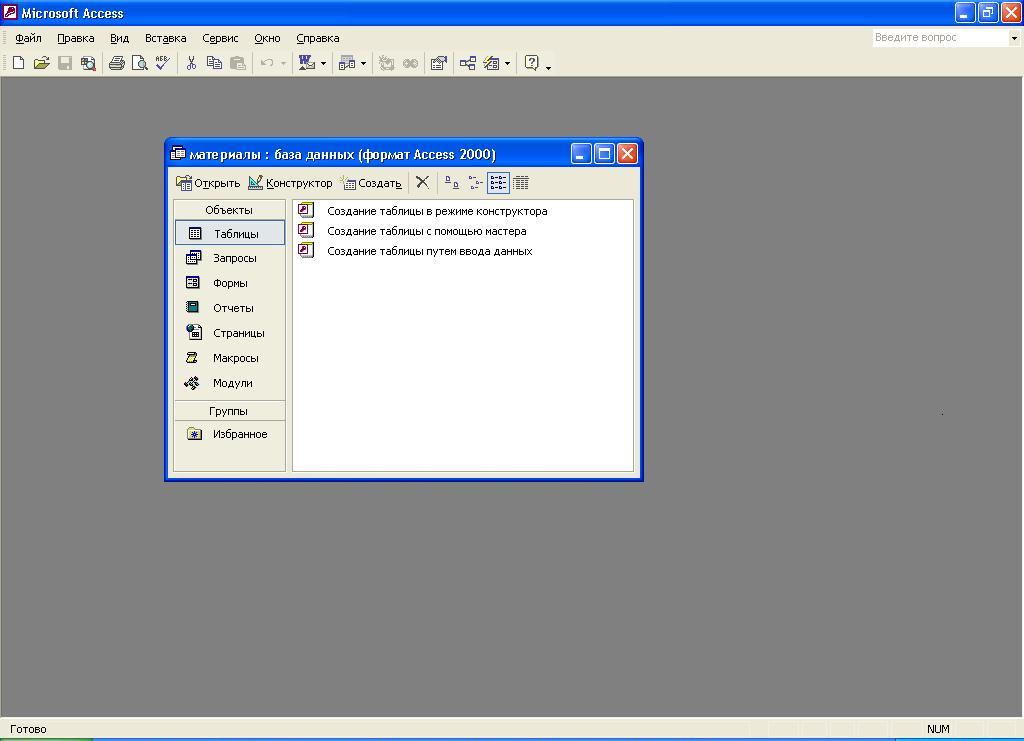
Рис.
5.3. Окно Базы
данных СКЛАД
Именно
с этого окна начинается работа с любыми
объектами базы
данных, в том числе и с таблицами.
5.1.2. Создание структуры таблиц бд
На
этом этапе по каждой таблице задается
состав полей, определяется
последовательность их размещения,
выделяется ключевое поле
и дается описание свойств полей.
1.
Для создания новой таблицы в окне Базы
данных СКЛАД
(рис.5.3)
необходимо выбрать вкладку Таблицы
и
нажать кнопку
![]()
Создать.
В
результате открывается окно Новая
таблица
(рис.5.4),
в котором
представлены режимы создания таблиц.
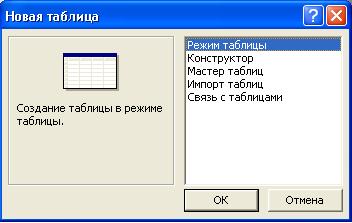
Рис.
5.4. Окно Новая
таблица
Не
рассматривая особенности каждого
режима, выберем Конструктор.
Он
является основным способом создания
таблиц, так как
отличается наглядностью и, позволяет
пользователю самому указывать
параметры всех элементов таблицы.
2.
Выбранный режим Конструктор
открывает
окно Таблица
1: таблица
(рис.5.5).

Рис.
5.5. Окно Конструктора
таблицы –
Таблица
1: таблица
Окно
Конструктора таблицы напоминает
графический бланк, удобный
для создания и редактирования структуры
таблиц. Первоначально
он пуст.
В
верхней части бланка должен; быть
представлен перечень всех полей
(гр. «Имя поля»), их типы (гр. «Тип данных»)
и подсказки к полям
(гр. «Описание»); последние не являются
обязательными к заполнению.
Нижняя
часть бланка содержит список свойств
поля, выделенного
или заполняемого в верхней части.
Некоторые из свойств уже заданы по
умолчанию, однако их можно изменить.
Теперь
подробно опишем порядок формирования
структуры таблиц
БД СКЛАД.
Очередность
создания таблиц значения не имеет.
Поэтому рассмотрим
их в той последовательности, в которой
они разрабатывались
на этапе проектирования.
Начнем
с главной таблицы – Материалы.
Описание ее
структуры представлено в разделе 4.2.
Поле
НПП
*
В первую ячейку гр. «Имя поля» окна
Конструктора таблицы (Таблица
1: таблица) введем
имя поля – НПП.
• Для
того чтобы задать тип
поля надо
щелкнуть мышью в соответствующей
ячейке гр. «Тип данных», что приведет к
появлению
символа списка
![]()
справа
в выбранной ячейке. Щелкнув по этой
кнопке, раскроем список
типов данных и выберем в нем нужный
Счетчик
(рис.5.6а).
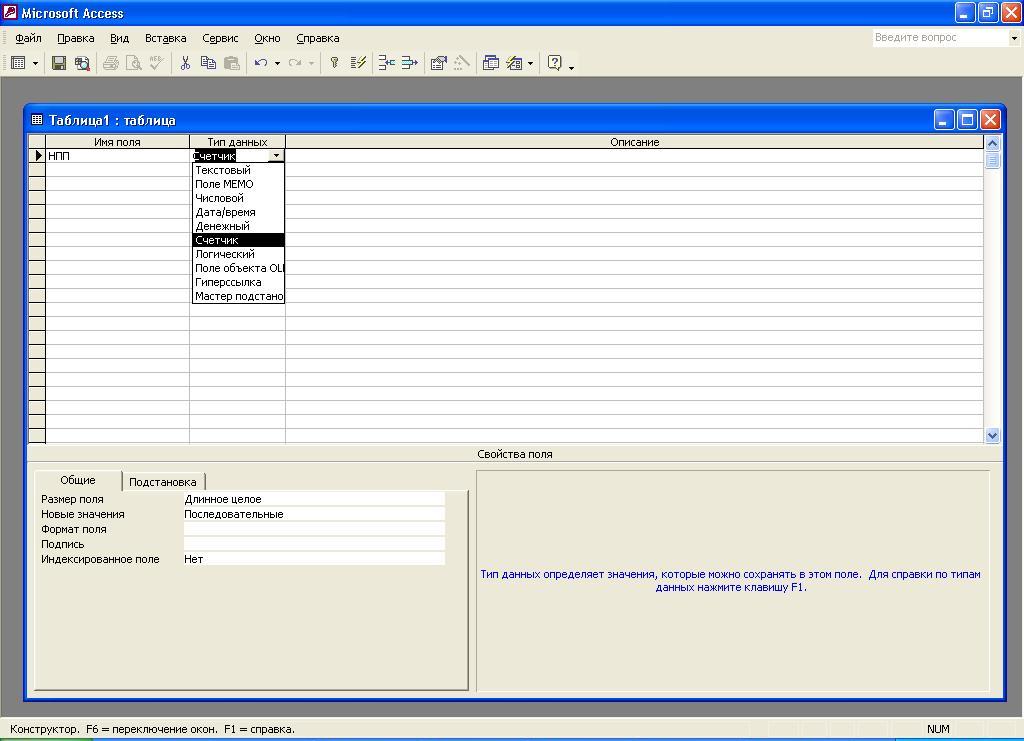
Рис.5.6а.
Окно Конструктора таблицы со
спискам типов данных
После
щелчка по выбранной позиции – счетчик
это
сообщение переносится в ячейку гр. «Тип
данных», которая
соответствует полю НПП.
Одновременно с этим занесением в нижней
части бланка (раздел «Свойства
поля») на
вкладке Общие
автоматически
появляется список свойств
полей типа счетчик
(рис.
5.6б).
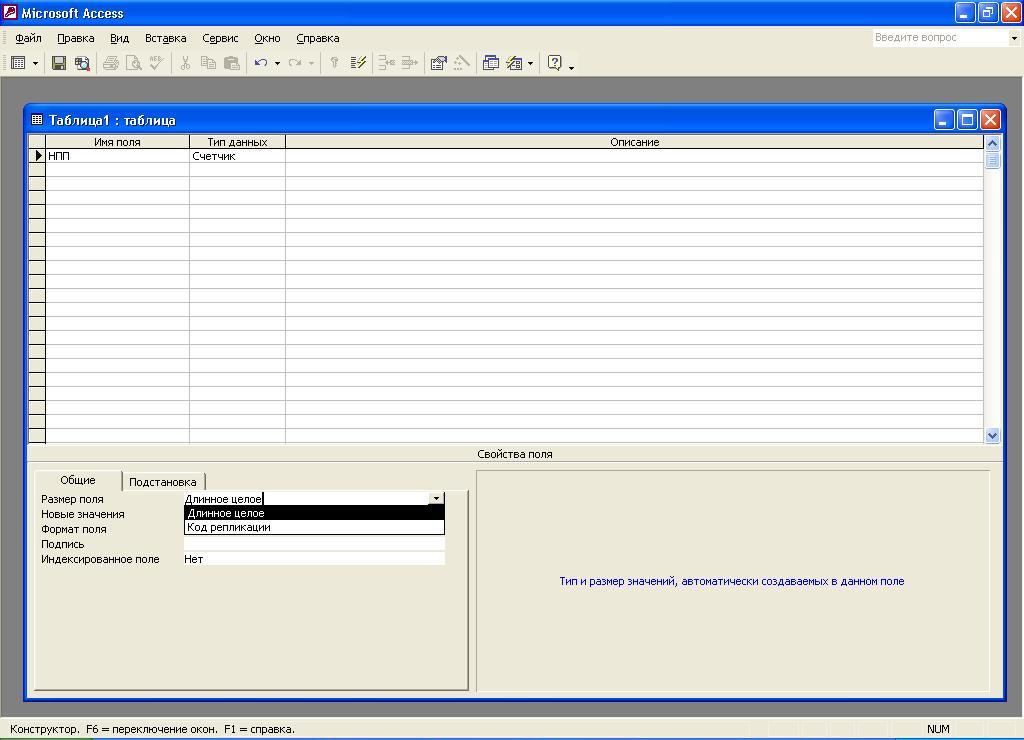
Рис. 5.6б. Окно
Конструктора таблицы со спискам свойств
паля типа счетчик
* Теперь дадим
описание свойств поля НПП типа счетчик:
Размер паля.
Данные шля типа счетчик выполняют;
определенную функцию – автоматическую
идентификацию записей таблицы. Поэтому,
во-первых, счетчик – всегда целое число;
во-вторых, оно может быть как угодно
велико. Эти особенности должны быть
учтены при описании свойства Размер
поля.
Для занесения
размера поля
необходимо:
-
щелкнув по строке
Размер шля, вызвать значок (символ)
списка -
щелкнув по значку
список, вызвать список типов числовых
полей; -
выбрать тип поля
– Длинное
целое.
Новые значения.
Наращивание значения поля происходит
автоматически. Есть два варианта
изменения счетчика: последовательный
и случайный. Нас устраивает первый. Он
устанавливается по умолчанию. При втором
варианте сдерет вызвать список новых
значений и выбрать нужный.
Подпись поля
– заносится: № записи.
Индексированное
поле –
поскольку оно не ключевое, автоматически
После
занесения свойств
поля НПП
окно Конструктора таблицы будем иметь
вид, представленный на рис. 5.6 в.
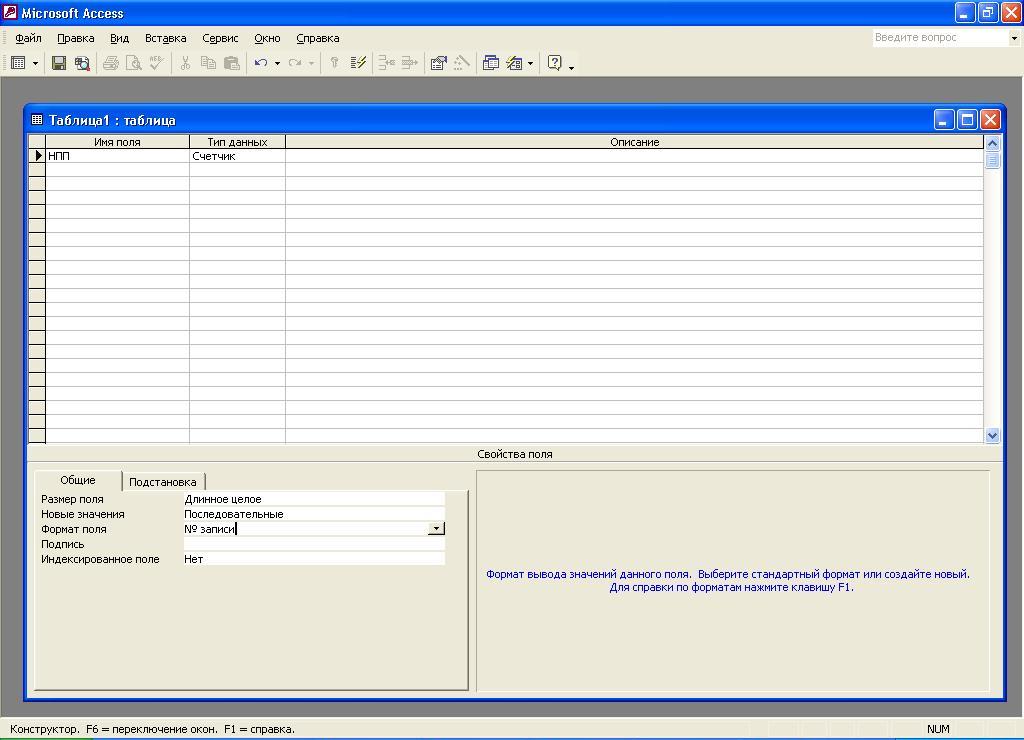
Рис.
5.6 в. Окно
Конструктора
таблицы со
свойствами поля НПП
Поле КС
Описание
поля в окне Конструктора таблицы (Таблица
1: таблица)
занимает вторую строку верхней части
бланка.
Занесение
имени
поля –
КС
и
выбор типа
данных –
текстовый
выполняются
аналогично описанию работы с полем НПП.
Одновременно
с занесением типа поля на вкладке Общие
(раздел «Свойства
поля») автоматически
появляется список свойств полей типа
текстовый
(рис.
5.7а).
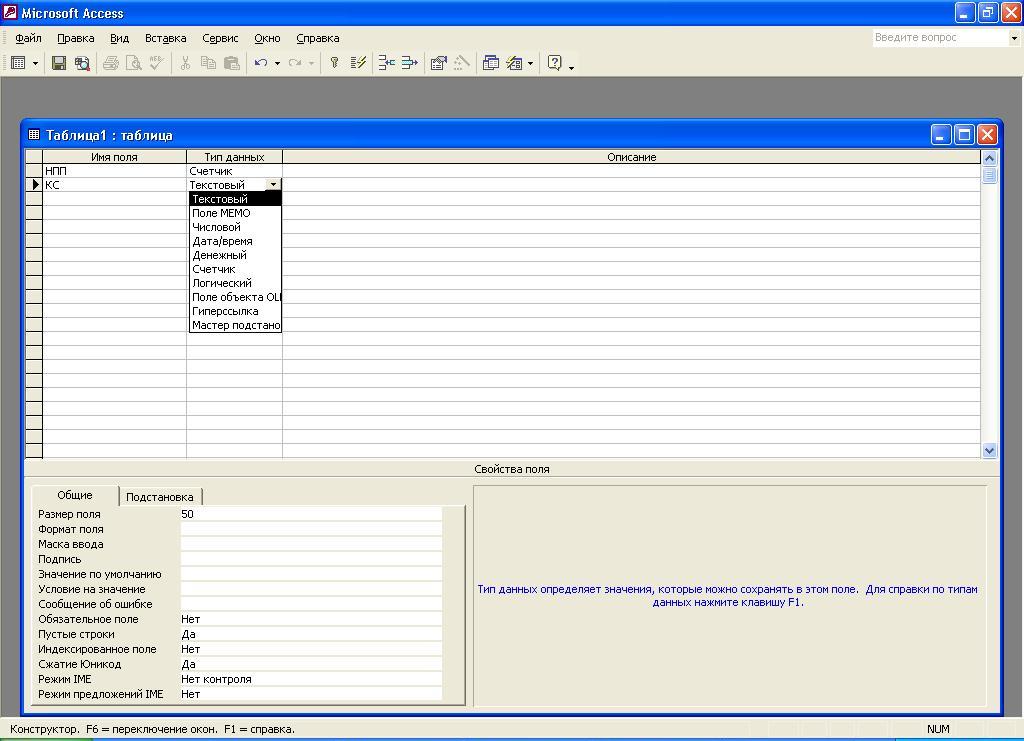
Рис. 5.7а. Окно
Конструктора таблицы со
списком свойств поля типа текстовый
Описание свойств
поля КС:
Размер поля.
Автоматически устанавливается равным
50. Снимем эту размерность и установим
нужную – 2.
Подпись поля –
склад.
Обязательное поле
– нет (устанавливается по умолчанию).
Индексированное
поле- нет (устанавливается по умолчанию).
После занесения
свойств поля КС окно Конструктора
таблицы будет иметь вид, представленный
на рис. 5.76.
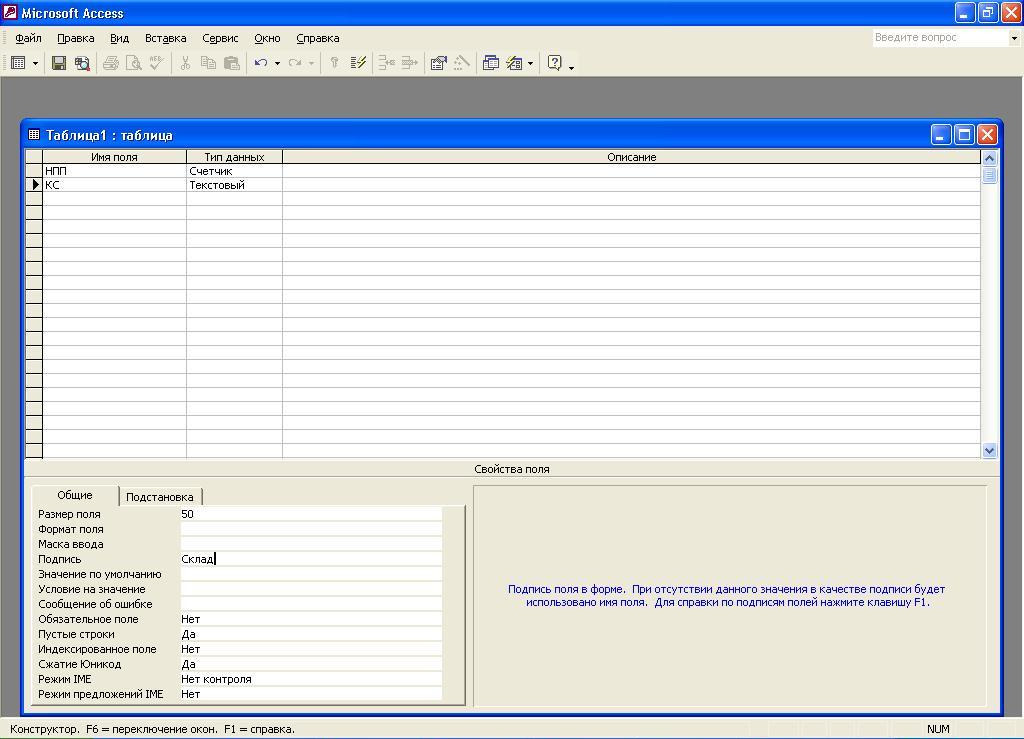
Рис.
5.76. Окно Конструктора таблицы со
свойствами поля КС
Поле
КМ.
Описание
поля в окне Конструктора таблицы занимает
третью строку
верхней части бланка.
Имя
поля –
КМ,
тип данных –
текстовый,
размер поля –
6,
подпись
поля –
код
материала заносятся
так же, как для поля КС.
Поле КМ -ключевое.
Для
задания ключевого поля следует в бланке
установить курсор на
строку поля КМ и на панели инструментов
щелкнуть кнопку
![]()
Ключевое
поле или,
щелкнув правой кнопкой мыши, вызвать
контекстное
меню и в нем выбрать команду Ключевое
поле. Признаком
установки ключа будет его изображение
слева от имени поля.
Обязательное
поле – Да. Для
ключевого поля другого ответа быть
не может: иначе не установить логические
связи. Ответ Да
выбирается
из списка значений этого свойства.
Индексированное
поле – Да (совпадения не допускаются).
Для
ключевого
поля другого ответа не может быть по
определению. Ответ выбирается
из списка значений этого свойства.
После
занесения свойств
поля КМ окно
Конструктора таблицы будет
«меть вид, представленный на рис. 5.8.
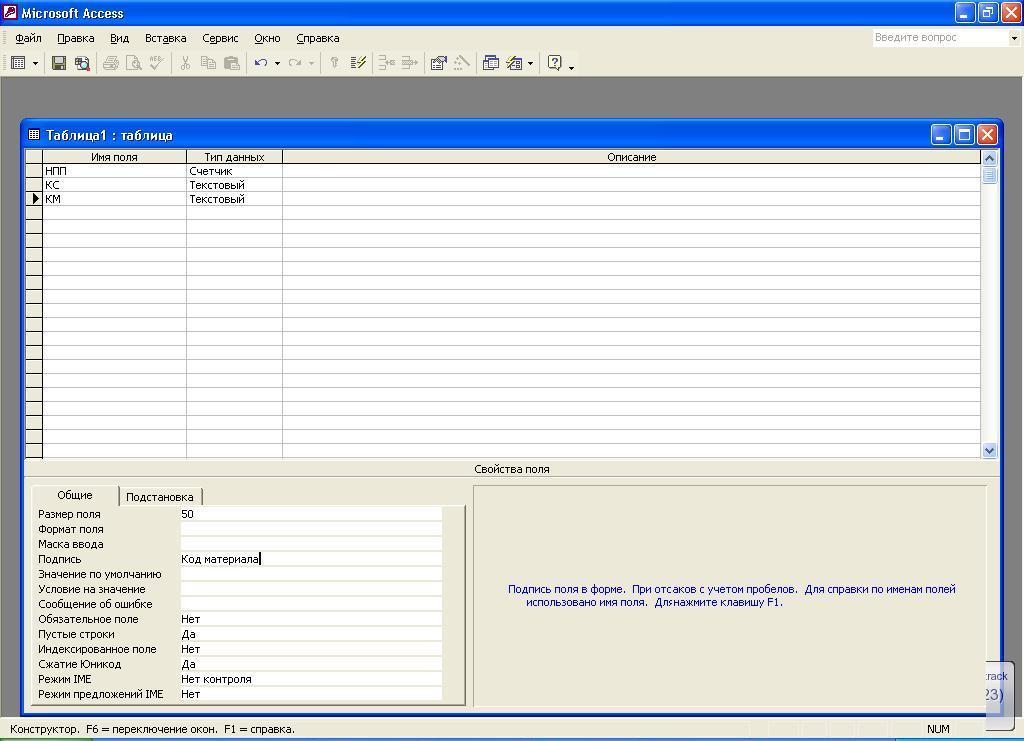
Рис.
5.8. Окно Конструктора таблицы со
свойствами поля КМ
Поля
НМ и ЕИ. Порядок
описания этих полей аналогичен описанию
КС.
Поля
ЦОтп, НЗ, Ост Порядок
описания этих полей аналогичен описанию
предыдущих с той лишь разницей, что из
списка типа данных для
них выбирается – числовой,
а
для свойства Размер
поля из
списка типов
числовых полей выбираются соответственно:
Длинное
целое; Целое;
Целое.
После
описания всех полей таблицы и их свойств
окно Конструктора
таблицы будет иметь вид, представленный
на рис. 5.9.
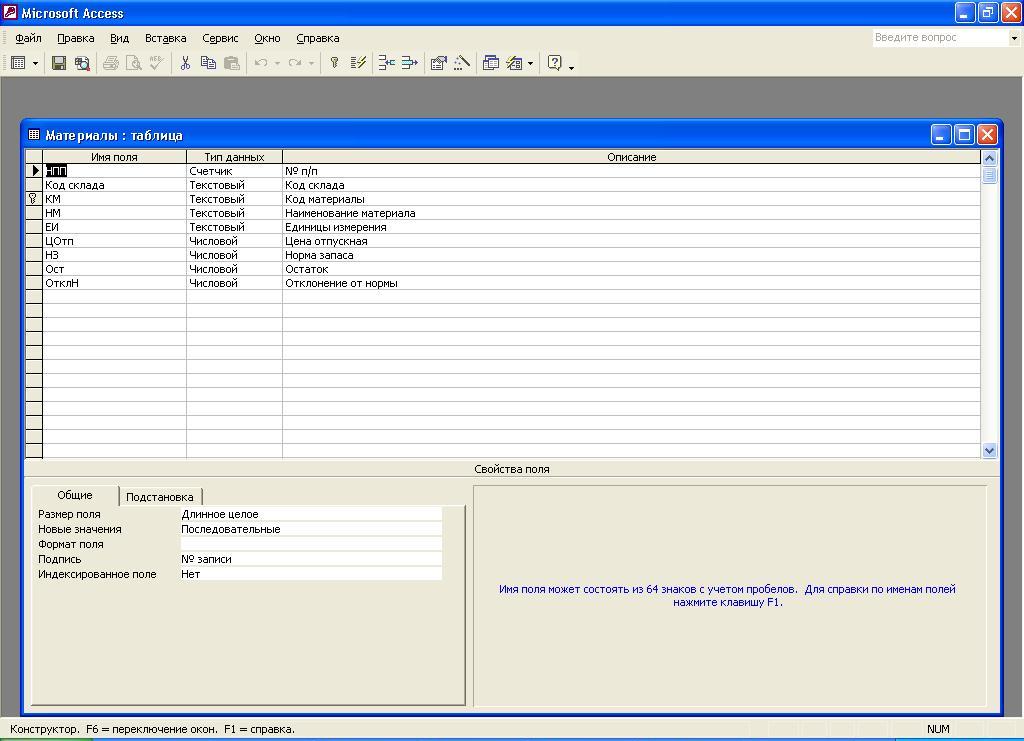
Рис.
5.9. Окно Конструктора таблицы с
описанием структуры таблицы Материалы
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
На чтение 10 мин Просмотров 7.6к. Опубликовано 19.05.2021
При создании серверной части приложения необходимо учитывать, как интерфейс будет взаимодействовать с серверной частью. Однако более важным является построение и дизайн вашей базы данных. Отношения между вашими формами данных приведут к построению вашей схемы базы данных.
Схема базы данных является абстрактным дизайн, который представляет собой хранение ваших данных в базе данных. Он описывает как организацию данных, так и отношения между таблицами в данной базе данных. Разработчики заранее планируют схему базы данных, чтобы знать, какие компоненты необходимы и как они будут соединяться друг с другом.
В этом руководстве мы узнаем, что такое схема базы данных и почему они используются. Мы рассмотрим несколько распространенных примеров, чтобы вы могли узнать, как настроить схему базы данных самостоятельно.

Содержание
- Что такое схемы базы данных?
- Типы схемы базы данных
- Логический
- Физический
- Пример NoSQL
- Пример SQL-сервера
- Пример PostgreSQL
- Что изучать дальше
Что такое схемы базы данных?
Когда дело доходит до выбора базы данных, одна из вещей, о которой вы должны подумать, — это форма ваших данных, модель, которой они будут следовать, и то, как сформированные отношения помогут нам при разработке схемы.
Схема базы данных — это план или архитектура того, как будут выглядеть наши данные. Он не содержит самих данных, а вместо этого описывает форму данных и то, как они могут быть связаны с другими таблицами или моделями. Запись в нашей базе данных будет экземпляром схемы базы данных. Он будет содержать все свойства, описанные в схеме.
Думайте о схеме базы данных как о типе структуры данных. Он представляет собой структуру и структуру содержимого данных организации.
Схема базы данных будет включать:
- Все важные или важные данные
- Единое форматирование для всех записей данных
- Уникальные ключи для всех записей и объектов базы данных
- Каждый столбец в таблице имеет имя и тип данных.
Размер и сложность схемы вашей базы данных зависит от размера вашего проекта. Визуальный стиль схемы базы данных позволяет программистам правильно структурировать базу данных и ее взаимосвязи, прежде чем переходить к коду. Процесс планирования дизайна базы данных называется моделированием данных.
Схемы важны для проектирования систем управления базами данных (СУБД) или систем управления реляционными базами данных (СУБД). СУБД — это программное обеспечение, которое хранит и извлекает пользовательские данные безопасным способом в соответствии с концепцией ACID.
Во многих компаниях ответственность за проектирование базы данных и СУБД обычно ложится на роль администратора базы данных (DBA). Администраторы баз данных несут ответственность за обеспечение беспрепятственного доступа к информации аналитикам данных и пользователям баз данных. Они работают вместе с командами менеджеров для планирования и безопасного управления базой данных организации.
Примечание. Некоторыми популярными СУБД являются MySQL, Oracle, PostgreSQL, Microsoft Access, MariaBB и dBASE, а также другие.
Типы схемы базы данных
Существует два основных типа схемы базы данных, которые определяют разные части схемы: логическую и физическую.

Логический
Схема логической базы данных представляет, как данные организованы в виде таблиц. Он также объясняет, как атрибуты из таблиц связаны друг с другом. В разных схемах используется разный синтаксис для определения логической архитектуры и ограничений.
Примечание. Ограничения целостности — это набор правил для СУБД, которые поддерживают качество вставки и обновления данных.
Чтобы создать логическую схему базы данных, мы используем инструменты для иллюстрации отношений между компонентами ваших данных. Это называется моделированием сущности-отношения (моделирование ER). Он определяет отношения между типами сущностей.
Схема ниже представляет собой очень простую модель ER, которая показывает логический поток в базовом коммерческом приложении. Он объясняет продукт покупателю, который его покупает.

Идентификаторы в каждом из трех верхних кружков указывают первичный ключ объекта. Это идентификатор, который однозначно определяет запись в документе или таблице. FK на схеме — это внешний ключ. Это то, что связывает отношения от одной таблицы к другой.
- Первичный ключ: идентифицировать запись в таблице
- Внешний ключ: первичный ключ для другой таблицы
Модели сущностей-отношений могут быть созданы всевозможными способами, и существуют онлайн-инструменты, которые помогают в построении диаграмм, таблиц и даже SQL для создания вашей базы данных из существующей модели ER. Это поможет создать физическое представление схемы вашей базы данных.
Физический
Схема физической базы данных представляет, как данные хранятся на диске. Другими словами, это реальный код, который будет использоваться для создания структуры вашей базы данных. Например, в MongoDB с мангустом это примет форму модели мангуста. В MySQL вы будете использовать SQL для создания базы данных с таблицами.
По сравнению с логической схемой она включает имена таблиц базы данных, имена столбцов и типы данных.
Теперь, когда мы знакомы с основами схемы базы данных, давайте рассмотрим несколько примеров. Мы рассмотрим наиболее распространенные примеры, с которыми вы можете столкнуться.
Пример NoSQL
Базы данных NoSQL в первую очередь называются нереляционными или распределенными базами данных. Разработка схемы для NoSQL является предметом некоторых дискуссий, поскольку они имеют динамическую схему. Некоторые утверждают, что привлекательность NoSQL заключается в том, что вам не нужно создавать схему, но другие говорят, что дизайн очень важен для этого типа базы данных, поскольку он не предоставляет одно решение.
Этот фрагмент является примером того, как будет выглядеть физическая схема базы данных при использовании Mongoose (MongoDB) для создания базы данных, представляющей приведенную выше диаграмму отношения сущность. Просматривайте вкладки кода, чтобы увидеть различные части.
CustomerSchema.js
const mongoose = require(‘mongoose’);
const Customer = new mongoose.Schema({
name: {
type: String,
required: true
},
zipcode: {
type: Number,
}
})
module.exports = mongoose.model(«Customer», Customer);
ProductSchema.js
const mongoose = require(‘mongoose’);
const Product = new mongoose.Schema({
name: {
type: String,
required: true
},
price: {
type: String,
required: true
}
})
module.exports = mongoose.model(«Product», Product);
TransactionSchema.js
const mongoose = require(‘mongoose’);
const Transaction = new mongoose.Schema({
date: {
type: String,
required: true
},
cust_id: {
type: mongoose.Schema.Types.ObjectId, // signifies relationship to Customer Schema
ref: ‘Customer’
},
products: [{
type: mongoose.Schema.Types.ObjectId, // signifies relationship to Product Schema
ref: ‘Product’
}]
})
module.exports = mongoose.model(«Transaction», Transaction);
Здесь важно помнить, что в базах данных NoSQL, таких как MongoDB, нет внешних ключей. Другими словами, между схемами нет отношений. ObjectIdПросто представляет собой _id(идентификатор, который Монго автоматически присваивает при создании) документа в другой коллекции. На самом деле это не создает соединение.
Пример SQL-сервера
База данных SQL содержит такие объекты, как представления, таблицы, функции, индексы и представления. Нет никаких ограничений на количество объектов, которые мы можем использовать. Схемы SQL определяются на логическом уровне, и пользователь, владеющий этой схемой, называется владельцем схемы.
SQL используется для доступа, обновления и управления данными. MySQL — это СУБД для хранения и организации.
Мы можем использовать SQL Server CREATE SCHEMAдля создания новой схемы в базе данных. В MySQL схема является синонимом базы данных. Вы можете заменить ключевое слово SCHEMAдля DATABASEсинтаксиса MySQL SQL.
Некоторые другие продукты баз данных различаются. Например, в продукте Oracle Database схема представляет только часть базы данных: таблицы и другие объекты принадлежат одному пользователю.
Примечание. В SQL представление — это виртуальная таблица, основанная на наборе результатов оператора. Представление содержит как строки, так и столбцы.
Первичные ключи и внешние ключи оказываются здесь полезными, поскольку они представляют отношения от одной таблицы к другой.
CREATE DATABASE example;
USE example;
DROP TABLE IF EXISTS customer;
CREATE TABLE customer (
id INT AUTO_INCREMENT PRIMARY KEY,
postalCode VARCHAR(15) default NULL,
)
DROP TABLE IF EXISTS product;
CREATE TABLE product (
id INT AUTO_INCREMENT PRIMARY KEY,
product_name VARCHAR(50) NOT NULL,
price VARCHAR(7) NOT NULL,
qty VARCHAR(4) NOT NULL
)
DROP TABLE IF EXISTS transactions;
CREATE TABLE transactions (
id INT AUTO_INCREMENT PRIMARY KEY,
cust_id INT,
timedate TIMESTAMP,
FOREIGN KEY(cust_id)
REFERENCES customer(id),
)
CREATE TABLE product_transaction (
prod_id INT,
trans_id INT,
PRIMARY KEY(prod_id, trans_id),
FOREIGN KEY(prod_id)
REFERENCES product(id),
FOREIGN KEY(trans_id)
REFERENCES transactions(id)
Пример PostgreSQL
PostgreSQL — это бесплатная система управления реляционными базами данных с открытым исходным кодом, которая отличается высокой расширяемостью и соответствует требованиям SQL. В PostgreSQL схема базы данных — это пространство имен с именованными объектами базы данных.
Сюда входят таблицы, представления, индексы, типы данных, функции и операторы. В этой системе схемы являются синонимами каталогов, но они не могут быть вложены в иерархию.
Примечание. В программировании пространство имен — это набор знаков (называемых именами), которые мы используем для идентификации объектов. Пространство имен гарантирует, что всем объектам присваиваются уникальные имена, чтобы их было легко идентифицировать.
Итак, хотя база данных Postgres может содержать несколько схем, уровень будет только один. Посмотрим на визуальное представление:

В PostgreSQL кластер баз данных содержит одну или несколько баз данных. Пользователи совместно используются в кластере, но данные не передаются. Вы можете использовать одно и то же имя объекта в нескольких схемах.
Мы используем это выражение CREATE SCHEMAдля начала. Обратите внимание, что PostgreSQL автоматически создаст общедоступную схему. Здесь будет размещаться каждый новый объект.
CREATE SCHEMA name;
Чтобы создать объекты в схеме базы данных, мы пишем полное имя, которое включает имя схемы и имя таблицы:
schema.table
В следующем примере из документации Postgres вызывается CREATE SCHEMAновая схема scm, вызывается таблица deliveriesи вызывается представление delivery_due_list.
CREATE SCHEMA scm
CREATE TABLE deliveries(
id SERIAL NOT NULL,
customer_id INT NOT NULL,
ship_date DATE NOT NULL
)
CREATE VIEW delivery_due_list AS
SELECT ID, ship_date
FROM deliveries
WHERE ship_date <= CURRENT_DATE;
Что изучать дальше
Поздравляю! Теперь вы знаете основы схем баз данных и готовы вывести свои навыки проектирования баз данных на новый уровень. Схемы баз данных жизненно важны для создания баз данных. Независимо от того, используете ли вы базу данных на основе NoSQL или SQL, схемы баз данных составляют основу ваших приложений.
Чтобы продолжить обучение, вам необходимо рассмотреть следующие темы:
- Архитектура с тремя схемами
- Модели сущности-отношения
- Понятия реляционной модели
- Функциональные зависимости
- Нормализация
Основано на этих лекциях.
Основы проектирования баз данных.
Традиционно процедуру проектирования базы данных разбивают на три этапа, каждый из которых завершается созданием соответствующей информационной модели.
Этап 1-й. Концептуальное проектирование – создание схемы БД, включающего определение важнейших сущностей (таблиц) и связей между ними, но не зависящего от модели БД (иерархической, сетевой, реляционной и т.д.) и физической реализации (целевой СУБД).
Этап 2-й. Логическое проектирование – развитие концептуальной схемы БД с учетом принимаемой модели (иерархической, сетевой, реляционной и т.д.).
Этап 3-й. Физическое проектирование – развитие логической схемы БД с учетом выбранной целевой СУБД.
Концептуальное и логическое проектирование вместе называют также инфологическим или семантическим проектированием.
В настоящее время для проектирования БД активно используются CASE-средства, в основном ориентированные на использование ERD (Entity – Relationship Diagrams, диаграммы «сущность–связь»). С их помощью определяются важные для предметной области объекты (сущности), отношения друг с другом (связи) и их свойства (атрибуты). Следует отметить, что средства проектирования ERD в основном ориентированы на реляционные базы данных (РБД), и если существует необходимость проектирования другой системы, скажем объектно-ориентированной, то лучше избрать другие методы проектирования.
ERD были впервые предложены П. Ченом в 1976 г. Основные элементы ERD перечислены ниже.
Сущность (таблица, в РБД – отношение) – набор (класс) однотипных реальных либо воображаемых объектов, имеющих существенное значение для рассматриваемой предметной области, информация о которых подлежит хранению. Примеры сущностей: работник, деталь, ведомость, результаты сдачи экзамена и т.д.
Экземпляр сущности (запись, строка, в РБД – кортеж) – уникально идентифицируемый объект.
Связь – некоторая ассоциация между двумя сущностями, значимая для рассматриваемой предметной области. Примерами связей могут являться родственные отношения «отец–сын», производственные – «начальник-подчиненный» или произвольные – «иметь в собственности», «обладать свойством».
Атрибут (столбец, поле) – свойство сущности или связи.
При использовании CASE-средств вначале обычно строится логическая схема БД в виде диаграммы с указанием сущностей и связей между ними. Логической схемой называется универсальное описание структуры данных, независимое от конечной реализации базы данных и аппаратной платформы. На основании полученной логической схемы переходят к физической схеме данных. Физическая схема представляет собой диаграмму, содержащую всю необходимую информацию для генерации БД для конкретной СУБД или даже конкретной версии СУБД. Если в логической схеме не имеет значения, какие идентификаторы носят таблицы и атрибуты, тип данных атрибутов и т.д., то в физической схеме должно быть полное описание БД в соответствии с принятым в ней синтаксисом, с указанием типов атрибутов, триггеров, хранимых процедур и т.д. По одной и той же логической схеме можно создать несколько физических. Например, на основании логической схемы сформировать физические для промышленных СУБД (ORACLE, MySQL, DB2, MS SQL Server и др.) и их различный версий. На основании физической схемы можно сгенерировать либо саму БД или DDL-скрипт, который, в свою очередь, может быть использован для генерации БД.
Система управления базами данных, СУБД — система (базирующаяся на программном и аппаратном обеспечении) для описания, создания, использования, контроля и управления базами данных.
Упрощённо: программное средство, управляющее базами данных.
Стоит отметить важный для начинающих факт (т.к. очень часто можно услышать просьбу «показать СУБД»): подавляющее большинство СУБД не имеет никакого «человеческого интерфейса», представляет собой сервис (демон в *nix-системах) и взаимодействует с внешним миром по специальным протоколам (чаще всего, построенным поверх TCP/IP). Такие известные продукты как MySQL Workbench, Microsoft SQL Server
Management Studio, Oracle SQL Developer и им подобные — это не СУБД, это лишь клиентское программное обеспечение, позволяющее нам взаимодействовать с СУБД.
Следует отметить, что современные СУБД обладают своими встроенными средствами визуального моделирования данных. Некоторые из них даже поддерживают классические нотации ERD. Недостатками такого моделирования является построение только физической схемы данных и невозможность быстрого перехода на другую СУБД, если такое решение принято. Достоинством этого подхода является более полное использование потенциала СУБД, ведь разработчики СУБД лучше других знают ее особенности и возможности.
Концептуальное проектирование
Цель концептуального проектирования – создание концептуальной схемы данных на основе представлений о предметной области каждого отдельного типа пользователей. Концептуальная схема представляет собой описание основных сущностей (таблиц) и связей между ними без учета принятой модели БД и синтаксиса целевой СУБД. Часто на такой схеме отображаются только имена сущностей (таблиц) без указания их атрибутов. Представление пользователя включает в себя данные, необходимые конкретному пользователю для принятия решений или выполнения некоторого задания.
Ниже рассматривается последовательность шагов при концептуальном проектировании.
-
Выделение сущностей.
Первый шаг в построении концептуальной схемы данных состоит в определении основных объектов (сущностей), которые могут интересовать пользователя и, следовательно, должны храниться в БД.
Возможные трудности в определении объектов связаны с использованием постановщиками задачи:
-
примеров и аналогий при описании объектов (например, вместо обобщающего понятия «работник» они могут упоминать его функции или занимаемую должность: «руководитель», «ответственный», «контролер», «заместитель»);
-
синонимов (например, «допускаемая скорость» и «установленная скорость», «разработка» и «проект», «барьерное место» и «ограничение скорости»);
-
омонимов (например, «программа» может обозначать компьютерную программу, план предстоящей работы или программу телепередач).
Далеко не всегда очевидно то, чем является определенный объект – сущностью, связью или атрибутом. Например, как следует классифицировать «семейный брак»? На практике это понятие можно вполне обоснованно отнести к любой из упомянутых категорий. Анализ является субъективным процессом, поэтому различные разработчики могут создавать разные, но вполне допустимые интерпретации одного и того же факта. Выбор варианта в значительной степени зависит от здравого смысла и опыта проектировщика.
Каждая сущность должна обладать некоторыми свойствами:
-
должна иметь уникальное имя, и к одному и тому же имени должна всегда применяться одна и та же интерпретация;
-
обладать одним или несколькими атрибутами, которые либо принадлежат сущности, либо наследуются через связь;
-
обладать одним или несколькими атрибутами (первичным ключом), которые однозначно идентифицируют каждый экземпляр сущности, т. е. делают уникальной каждую строку таблицы;
-
может обладать любым количеством связей с другими сущностями.
В графической нотации IDEF1X для отображения сущности используются обозначения, изображенные на следующем рисунке.
-
-
Определение атрибутов.
Самый простой способ определения атрибутов – после идентификации сущности, задать себе вопрос «Какую информацию требуется хранить о …?». Существенно помочь в определении атрибутов могут различные бумажные и электронные формы и документы, используемые в организации при решении задачи. Это могут быть формы, содержащие как исходную информацию (например, «Ведомость возвышений наружного рельса в кривых»), так и результаты обработки данных (например, «Форма № 1»).
Выявленные атрибуты могут быть следующих типов:
-
простой (атомарный, неделимый) – состоит из одного компонента с независимым существованием (например, «должность работника», «зарплата», «норма непогашенного ускорения», «радиус кривой» и т.д.);
-
составной (псевдоатомарный) – состоит из нескольких компонентов (например, «ФИО», «адрес» и т. д.). Степень атомарности атрибутов, закладываемая в модель, определяется разработчиком. Если от системы не требуется выборки всех клиентов с фамилией Иванов или проживающих на улице Комсомольской, то составные атрибуты можно не разбивать на атомарные;
-
однозначный – содержит только одно значение для одного экземпляра сущности (например, у кривой в плане может быть только одно значение радиуса, угла поворота, возвышения наружного рельса и т.д.);
-
многозначный – содержит несколько значений (например, у одного отделения компании может быть несколько контактных телефонов);
-
производный (вычисляемый) – значение атрибута может быть определено по значениям других атрибутов (например, «возраст» может быть определен по «дате рождения» и текущей дате, установленной на компьютере);
-
ключевой – служит для уникальной идентификации экземпляра сущности (входит в состав первичного ключа), быстрого поиска экземпляров сущности или задания связи между экземплярами родительской и дочерней сущностей;
-
неключевой (описательный);
-
обязательный – при вводе нового экземпляра в сущность или редактировании обязательно указывается допустимое значение атрибута, т.е. после указанных действий оно не может быть неопределенным (NOT NULL). Атрибуты, входящие в первичный ключ сущности, являются обязательными.
После определения атрибутов задаются их домены (области допустимых значений), например:
-
наименование участка – набор из букв русского алфавита длиной не более 60 символов;
-
поворот кривой – допустимые значения «Л» (влево) и «П» (вправо);
-
радиус кривой – положительное число не более 4 цифр.
Задание доменов определяет набор допустимых значений для атрибута (нескольких атрибутов), а также тип, размер и формат атрибута (атрибутов).
-
-
Определение ключей.
На основании выделенного множества атрибутов для сущности определяется набор ключей. Ключ – один или несколько атрибутов сущности, служащих для однозначной идентификации её экземпляров, их быстрого поиска или задания связи между экземплярами родительской и дочерней сущностей. Ключи, используемые для однозначной идентификации экземпляров, подразделяются на следующие типы:
-
суперключ (superkey) – атрибут или множество атрибутов, которое единственным образом идентифицирует экземпляр сущности. Суперключ может содержать «лишние» атрибуты, которые необязательны для уникальной идентификации экземпляра. При правильном проектировании структуры БД суперключом в каждой сущности (таблице) будет являться полный набор ее атрибутов;
-
потенциальный ключ (potential key) – суперключ, содержащий минимально необходимый набор атрибутов, единственным образом идентифицирующих экземпляр сущности. Сущность может иметь несколько потенциальных ключей. Если ключ состоит из нескольких атрибутов, то он называется составным ключом. Среди всего множества потенциальных ключей для однозначной идентификации экземпляров выбирают один, так называемый первичный ключ, используемый в дальнейшем для установления связей с другими сущностями;
-
первичный ключ (primary key) – потенциальный ключ, который выбран для уникальной идентификации экземпляров внутри сущности;
-
альтернативные ключи (alternative key) – потенциальные ключи, которые не выбраны в качестве первичного ключа.
Рассмотрим пример. Пусть имеется таблица, содержащая сведения о студенте, со следующими столбцами:
- фамилия;
- имя;
- отчество;
- дата рождения;
- место рождения;
- номер группы;
- ИНН;
- номер пенсионного страхового свидетельства (НПСС);
- номер паспорта;
- дата выдачи паспорта;
- организация, выдавшая паспорт.
Для каждого экземпляра (записи) в качестве суперключа может быть выбран весь набор атрибутов. Потенциальными ключами (уникальными идентификаторами) могут быть:
- ИНН;
- номер пенсионного страхового свидетельства;
- номер паспорта.
В качестве уникального идентификатора можно было бы выбрать совокупность атрибутов «Фамилия»+«Имя»+«Отчество», если вероятность учебы в вузе двух полных тезок была бы равна нулю.
Если в сущности нет ни одной комбинации атрибутов, подходящей на роль потенциального ключа, то в сущность добавляют отдельный атрибут – суррогатный ключ (искусственный ключ, surrogate key). Как правило, тип такого атрибута выбирают символьный или числовой. В некоторых СУБД имеются встроенные средства генерации и поддержания значений суррогатных ключей. Также стоит отметить, что некоторые разработчики вместо поиска потенциальных ключей и выбора из них первичного в каждую сущность добавляют искусственный атрибут, который в дальнейшем и используют в качестве первичного ключа.
Если потенциальных ключей несколько, то для выбора первичного ключа рекомендуется придерживаться следующих правил:
-
количество атрибутов, входящих в ключ, должно быть минимальным (желательно, чтобы ключ был атомарным, т.е. состоял из одного атрибута);
-
размер ключа в байтах должен быть как можно короче;
-
тип домена ключа – числовой. При выборе символьных атрибутов в ключ часто возникают проблемы с вводом ошибочных значений (путают регистр букв; добавляют лишние пробелы; используют буквы, пишущиеся на разных языках одинаково). В числовых атрибутах вероятность ошибки при вводе значения меньше;
-
вероятность изменения значений ключа была наименьшей (например, «Номер пенсионного страхового свидетельства» более постоянный параметр, чем «ИНН» или «Номер паспорта»);
-
с ключом проще всего работать пользователям (например, «Номер пенсионного страхового свидетельства» – это набор из 11 цифр, а «Номер паспорта» зависит от его вида: гражданина СССР, гражданина РФ или зарубежный).
Если некий атрибут (набор атрибутов) присутствует в нескольких сущностях, то его наличие обычно отражает наличие связи между экземплярами этих сущностей. В каждой связи одна сущность выступает как родительская, а другая – в роли дочерней. Это означает, что один экземпляр родительской сущности может быть связан с несколькими экземплярами дочерней. Для поддержки этих связей обе сущности должны содержать наборы атрибутов, по которым они связаны. В родительской сущности это первичный ключ. В дочерней сущности для моделирования связи должен присутствовать набор атрибутов, соответствующий первичному ключу родительской. Этот набор атрибутов в дочерней сущности принято называть внешним ключом (foreign key).
-
-
Определение связей.
Наиболее характерными типами связей между сущностями являются:
-
связи типа «часть–целое», определяемые обычно глаголами «состоит из», «включает» и т.п.;
-
классифицирующие связи (например, «тип – подтип», «множество – элемент», «общее – частное» и т. п.);
-
производственные связи (например, «начальник–подчиненный»);
-
функциональные связи, определяемые обычно глаголами «производит», «влияет», «зависит от», «вычисляется по» и т. п.
Среди них выделяются только те связи, которые необходимы для удовлетворения требований к разработке БД.
Связь характеризуется следующим набором параметров:
-
именем – указывается в виде глагола и определяет семантику (смысловую подоплеку) связи;
-
кратностью (кардинальность, мощность): один-к-одному (1:1), один-ко-многим (1:N) и многие-ко-многим (N:M, N = M или N <> M). Кратность показывает, какое количество экземпляров одной сущности определяется экземпляром другой. Например, на одном участке (описывается строкой таблицы «Участки») может быть один, два и более путей (каждый путь описывается отдельной строкой в таблице «Пути»). В данном случае связь 1:N. Другой пример: один путь проходит через несколько раздельных пунктов и через один раздельный пункт может проходить несколько путей – cвязь N:M;
-
типом: идентифицирующая (атрибуты одной сущности, называемые внешним ключом, входят в состав дочерней и служат для идентификации ее экземпляров, т.е. входят в ее первичный ключ) и неидентифицирующая (внешний ключ имеется в дочерней сущности, но не входит в состав первичного ключа);
-
обязательностью: обязательная (при вводе нового экземпляра в дочернюю сущность заполнение атрибутов внешнего ключа обязательно и введенные значения должны совпадать со значениями атрибутов первичного ключа какого-либо экземпляра родительской сущности) и необязательная (заполнение атрибутов внешнего ключа в экземпляре дочерней сущности необязательно или введенные значения не совпадают со значениями атрибутов первичного ключа ни одного экземпляра родительской сущности);
-
степенью участия – количеством сущностей, участвующих в связи. В основном между сущностями существуют бинарные связи, т.е. ассоциации, связывающие две сущности (степень участия равна 2). Например, «Участок» состоит из «Путей». В то же время по степени участия возможны следующие типы связей:
-
унарная (рекурсивная) – сущность может быть связана сама с собой. Например, в таблице «Работники» могут быть записи и по подчиненным, и по их начальникам. Тогда возможна связь «начальник» – «подчиненный», определенная на одной таблице;
-
тернарная – связывает три сущности. Например, «Студент» на «Сессии» получил «Оценку по дисциплине»;
-
кватернарная и т.д.
-
В методологии IDEF1X степень участия может быть только унарной или бинарной. Связи большей степени приводятся к бинарному виду.
Внешний вид связи на диаграммах IDEF1X указывает на ее мощность, тип и обязательность.
-
Логическое проектирование
Цель логического проектирования – развить концептуальную схему БД с учетом принимаемой модели БД (иерархической, сетевой, реляционной и т. д.).
Примем в качестве модели реляционную БД в третьей нормальной форме (набор нормализованных отношений с кратностью связей 1:N). Поэтому необходимо будет проверить концептуальную схему с помощью методов нормализации и контроля выполнения транзакций. Транзакция – одно действие или их последовательность, выполняемых как единое целое одним или несколькими пользователями (прикладными программами) с целью осуществления доступа к БД и изменению ее содержимого.
-
Удаление и проверка элементов, не отвечающих принятой модели данных.
-
Удаление связей N:M.
Если в концептуальной схеме присутствуют связи N:M, то их следует устранить путем определения промежуточной сущности. Связь N:M заменяется двумя связями типа 1:M, устанавливаемыми со вновь созданной сущностью.
-
Удаление связей с атрибутами.
Связи с атрибутами должны быть преобразованы в сущности.
-
Удаление сложных связей (со степенью участия более 2).
Сложную связь заменяют необходимым количеством бинарных связей 1:N со вновь созданной сущностью, которая и показывает эту связь.
-
Удаление рекурсивных связей (со степенью участия 1).
Рекурсивную связь заменяют, определив дополнительную сущность и необходимое количество связей.
-
Удаление многозначных атрибутов (атрибутов имеющих несколько значений).
Многозначность устраняется путем введения новой сущности и связи 1:N. Например, несколько номеров организации выводятся в отдельную сущность “Телефоны”. Данное преобразование, помимо соответствия реляционной модели данных, также позволяет хранить любое количество телефонов по одному филиалу.
-
Удаление избыточных связей.
Связь является избыточной, если одна и та же информация может быть получена не только через нее, но и с помощью другой связи.
-
Перепроверка связей 1:1.
В процессе определения сущностей могли быть созданы сущности, которые на самом деле являются одной. В этом случае их следует объединить. Например, сущности «Филиал» и «Руководитель филиала» лучше объединить.
В то же время не всегда можно выполнить такое объединение.

Офисный пакет состоит из строго определенного набора компонентов, причем каждый из них характеризуется большим количеством атрибутов. Кроме этого, некоторые компоненты могут отсутствовать в офисном пакете (например, почтовый клиент) или они не входят в его состав (выступают в качестве самостоятельного продукта). В описанных случаях рекомендуется не объединять сущности.
-
-
Проверка модели с помощью правил нормализации.
Основная идея нормализации заключается в том, чтобы каждый факт хранился в одном месте, т. е. чтобы не было дублирования данных. Многие из требований нормализации, как правило, уже учитываются при выполнении предыдущих шагов проектирования.
Ниже приводятся краткие сведения из теории нормализации.
Проектирование реляционной БД представляет собой пошаговый процесс создания набора отношений (таблиц, сущностей), в которых отсутствуют нежелательные функциональные зависимости.
Функциональная зависимость определяется следующим образом. Пусть A и B – произвольные наборы атрибутов отношения. Тогда B функционально зависит от A (A → B), в том и только в том случае, если каждому значению A соответствует в точности одно значение B. Левая часть функциональной зависимости (A) называется детерминантом, а правая (B) – зависимой частью. В частности, в отношении А может быть первичным ключом, а B – набором неключевых атрибутов, так как одному значению первичного ключа в точности соответствует одно значение набора неключевых атрибутов.
Если в БД отсутствуют нежелательные функциональные зависимости, то это обеспечивает минимальную избыточность данных, что в свою очередь ведет к уменьшению объема памяти, необходимой для хранения данных. Процесс устранения таких зависимостей получил название нормализация. Она выполняется в виде последовательности тестов для некоторого отношения (таблицы, сущности) с целью проверки его соответствия (или несоответствия) набору ограничений для заданной нормальной формы.
Процесс нормализации впервые был предложен Э.Ф. Коддом в 1972 г. Сначала было предложено три вида нормальных форм (1NF, 2NF и 3NF). Затем Р. Бойсом и Э.Ф. Коддом (1974 г.) было сформулировано более строгое определение третьей нормальной формы, которое получило название нормальная форма Бойса–Кодда (BCNF). Вслед за BCNF появились определения четвертой (4NF) и пятой (5NF или PJNF) нормальных форм (Р. Фагин, 1977 и 1979 г.). На практике нормальные формы более высоких порядков используются крайне редко. При проектировании БД, как правило, ограничиваются третьей нормальной формой, что позволяет предотвратить возможное возникновение избыточности данных и аномалии обновлений.
1НФ. Отношение находится в первой нормальной форме (сокращённо 1НФ), если все его атрибуты атомарны, то есть если ни один из его атрибутов нельзя разделить на более простые атрибуты, которые соответствуют каким-то другим свойствам описываемой сущности.
Степень неделимости (атомарности), т.е. решение о том, следует разбивать неатомарный атрибут на атомарные или оставить его псевдоатомарным, определяется проектировщиком БД исходя из конкретных условий. Если при обработке таблиц нет необходимости различать атомарные составляющие псевдоатомарного атрибута, то его можно не делить (например, атрибуты «Фамилия, имя, отчество», «Адрес» и т. д.).
2NF. Отношение находится во 2NF, если оно находится в 1NF, и каждый неключевой атрибут характеризуется полной функциональной зависимостью от первичного ключа.
Полная функциональная зависимость определяется следующим образом. В некотором отношении атрибут В полностью зависит от атрибута А, если атрибут В функционально зависит от полного значения атрибута А и не зависит от какого-либо подмножества полного значения атрибута А.
Например, таблица «Оценки по экзаменам» характеризуется следующим набором атрибутов {Номер зачетной книжки, Дисциплина, Дата сдачи, ФИО студента, № группы, Оценка}. Очевидно, что первичным ключом является набор {Номер зачетной книжки, Дисциплина, Дата сдачи}. Полной функциональной зависимостью обладает только один неключевой атрибут «Оценка». Атрибуты «ФИО студента» и «№ группы» могут быть однозначно определены по части первичного ключа – «Номер зачетной книжки». Таким образом, требуется разбиение исходной таблицы на две.

3NF. Отношение находится в 3NF, если оно находится во 2NF и никакой неключевой атрибут функционально не зависит от другого неключевого атрибута, т. е. нет транзитивных зависимостей.
Транзитивная зависимость. Если для атрибутов А, В и С некоторого отношения существуют зависимости вида А → В и В → С, то атрибут С транзитивно зависит от атрибута А через атрибут В.
Например, таблица «Работник» характеризуется набором атрибутов {Табельный номер, Фамилия, Имя, Отчество, Должность, Зарплата, …}, первичный ключ – {Табельный номер}. В этой таблице от первичного ключа («Табельный номер») зависит неключевой атрибут «Должность», а от «Должности» другой неключевой атрибут «Зарплата». Для приведения к 3NF необходимо добавить новую таблицу.

-
Определение требований поддержки целостности данных.
Ограничения целостности данных представляют собой ограничения, которые вводятся с целью предотвращения помещения в базу противоречивых данных.
К этим ограничениям относятся:
-
обязательные данные – атрибуты, которые всегда должны содержать одно из допустимых значений (NOT NULL). Например, поворот кривой (влево или вправо) должен быть обязательно задан. Обязательными также являются все атрибуты, входящие в первичный ключ сущности;
-
домены – наборы допустимых значений для атрибута. Например, радиус кривой должен быть положительным числом не более 4 цифр или поворот кривой может принимать одно из двух допустимых значений – «Л» (влево) или «П» (вправо);
-
бизнес-правила (бизнес-ограничения) – ограничения, принятые в рассматриваемой предметной области. Например, сумма длин переходных кривых не должна быть более длины всей кривой, километраж начала или конца кривой должен быть в пределах общего километража пути и т.д.;
-
ссылочная целостность – набор ограничений, определяющих действия при вставке, обновлении и удалении записей (экземпляров сущности). Например:
-
при наличии обязательной связи вставка записи в дочернюю сущность требует обязательного заполнения атрибутов внешнего ключа, и введенному значению должна соответствовать запись родительской сущности;
-
аналогичное требование выдвигается при обновлении внешнего ключа в дочерней сущности;
-
удаление записи из дочерней сущности или вставка записи в родительскую не вызывают нарушения ссылочной целостности;
-
удаление записи в родительской сущности может требовать удаления всех связанных записей в дочерней сущности.
-
Автоматическая поддержка всех видов ограничений целостности возможна за счет использования операторов SQL.
Ссылочная целостность может быть обеспечена за счет использования триггеров. Триггер – это хранимая в БД процедура, исполняемая СУБД автоматически при удалении (DELETE), вставке (INSERT) или обновлении (UPDATE) записи. Набор команд, входящих в триггер, зависит от принятой стратегии (типа триггера) поддержания целостности:
-
RESTRICT или NO ACTION – на выполнение действия накладываются ограничения (условия). Под NO ACTION обычно понимаются триггеры, срабатывающие на изменение данных в родительской таблице. При соблюдении условий изменения в БД принимаются, в противном случае отклоняются;
-
CASCADE – каскадное удаление или обновление данных;
-
SET NULL – установка неопределенного значения (NULL) в атрибутах внешнего ключа дочерней таблицы;
-
SET DEFAULT – установка значения по умолчанию в атрибутах внешнего ключа дочерней таблицы;
-
NO CHECK, NONE или IGNORE – поддержка ссылочной целостности встроенными средствами СУБД не предусмотрена, но может быть выполнена за счет клиентских программ, работающих с БД. Данная стратегия принята в СУБД по умолчанию.
-
Физическое проектирование
Цель физического проектирования – преобразование логической схемы с учетом синтаксиса, семантики и возможностей выбранной целевой СУБД.
В связи с тем, что методология физического проектирования существенно зависит от выбранной целевой СУБД, ограничимся лишь общими рекомендациями.
-
Анализ необходимости введения контролируемой избыточности.
При реализации проекта часто для достижения большей эффективности системы требуется снизить требования к уровню нормализации отношений, т.е. внести некоторую избыточность данных. Процесс внесения таких изменений в БД называется денормализацией.
Рассмотрим некоторые виды денормализации, которые в определенных случаях могут существенно повысить производительность системы.
-
Использование производных данных.
С точки зрения физического проектирования любой производный атрибут либо может сохраняться в БД, либо при каждом обращении к нему его значение будет вычисляться заново. Например, длина пути может каждый раз вычисляться по таблицам «Действительный километраж» и «Неправильные пикеты» либо храниться как атрибут в таблице «Пути».
Проектировщик при использовании производных данных должен оценить:
-
дополнительную стоимость хранения производных данных и поддержки согласованности с текущими значениями тех данных, на основании которых они вычисляются, т.е. минусы хранения производных данных;
-
издержки на выполнение вычислений значений производных атрибутов при каждом обращении к ним – плюсы.
-
-
Дублирование атрибутов.
-
Объединение отношений, связанных 1:1.
Даже в тех случаях, когда связь между двумя сущностями необязательная, стоит подумать об их объединении, с учетом того, что часть полей в записях не будет заполняться. Руководствоваться в таких случаях надо из тех же соображений, что и при использовании производных данных. В частности, на рис. 7.4 и 7.5 показана иерархия наследования для сущности «Сотрудник». Если эту иерархию оставить без изменений, то в БД будет четыре сущности (Сотрудник, Постоянный сотрудник, Совместитель и Консультант), согласованность которых надо будет поддерживать. При выполнении запросов по сотрудникам надо будет оперировать четырьмя таблицами. Таким образом, лучше в БД вместо иерархии запроектировать одну таблицу, в которую добавить атрибуты «Ставка» и «Организация». В атрибуте «Ставка» для постоянного сотрудника всегда будет значение «1», а атрибут «Организация» будет заполняться только для консультантов. Несмотря на избыточность, такая замена с точки зрения обработки данных и эксплуатации более выгодна.
-
Дублирование атрибутов в связях типа 1:M.
Например, при запросе к таблице «Раздельные пункты на пути» очень часто будет требоваться наименование самих раздельных пунктов. С целью уменьшения нагрузки на БД следует рассмотреть возможность включения атрибута в эту таблицу.
-
Использование служебных таблиц (справочных таблиц, классификаторов, типовых списков значений).
Служебные таблицы, как правило, создаются для атрибутов символьного типа, значения которых могут выбираться из строго определенного и ограниченного списка. Например, значениями атрибута «Род балласта» могут быть только «Щебеночный», «Песчаный», «Гравийный» и «Асбестовый».
Обычно служебные таблицы содержат два атрибута: идентификатор (код, шифр) и описание (наименование). Например, в БД можно предусмотреть служебные таблицы «Вид раздельного пункта», «Род балласта» и т.д. с атрибутами {ID, Наименование}. Эти таблицы связываются неидентифицирующей обязательной связью с исходной, при этом в ней вместо наименования параметра будет содержаться идентификатор этого наименования.
Использование служебных таблиц дает следующие преимущества:
-
значительно снижается вероятность ошибки при указании значений для этих атрибутов. Если не использовать служебные таблицы, то разные пользователи могут вносить рассогласованные значения, в том числе и с ошибками. Например, «Щебеночный», «щебеночный», «Щебен.», «Шебеночный», «Щ» и т.д. Несмотря на то, что по смыслу это все один и тот же род балласта, программа будет их воспринимать как разные;
-
уменьшается размер исходной таблицы. Например, если непосредственно хранить наименование рода балласта в таблице «План пути», то в каждой записи на этот атрибут будет расходоваться не менее 10 байт (длина слова «Щебеночный» 10 букв), а если использовать идентификатор, то достаточно всего одного байта. Экономия в 10 раз;
-
если описание параметра может измениться, то значительно проще изменить одно значение в служебной таблице, чем корректировать множество записей в исходной. Например, если принято решение вместо полного наименования рода балласта отображать только начальную букву (Щ, П, Г и А), то изменениям подвергнется только служебная таблица, а исходные таблицы «План пути» и «ВСП на прямых участках» останутся без изменений.
-
-
Введение повторяющихся (многозначных) атрибутов.
Для достижения большей производительности при выполнении часто вызываемых запросов может быть целесообразным подход сохранения многозначных атрибутов, чем вынесение их в отдельную таблицу. Например, если количество контактных телефонов у филиала компании невелико (до 10), эта величина постоянная и не увеличится со временем, то в таблице «Филиал» можно предусмотреть атрибуты «Номер телефона 1», …, «Номер телефона 10».
-
Создание сводных таблиц.
Если нагрузка на БД в часы пик велика, а период актуальности отчетов, составляемых на основании данных, – сутки и более, то следует подумать о включении в БД сводных таблиц, обновляемых в часы минимальной нагрузки на БД.
-
-
-
Перенос логической схемы данных в среду целевой СУБД.
Данная стадия включает в себя проектирование таблиц и связей между ними с учетом возможностей целевой СУБД. При этом проектировщик должен хорошо ориентироваться в функциональных возможностях СУБД, а именно поддерживает ли СУБД задание:
- доменов;
- первичных, альтернативных и внешних ключей;
- неопределенных (NULL) и обязательных (NOT NULL) значений;
- значений по умолчанию (DEFAULT);
- правил контроля целостности;
- хранимых процедур и триггеров.
Кроме этого, целевая СУБД должна поддерживать требуемые типы данных или иметь возможность адекватного их хранения. Стадия переноса также включает в себя модификацию логической схемы с учетом семантики и синтаксиса, принятой в целевой СУБД, а именно, соблюдение правил наименования таблиц, атрибутов, типов данных, описания триггеров, хранимых процедур и т. д.
-
Реализация бизнес-правил и анализ транзакций.
Реализацию бизнес-правил (сумма длин переходных кривых не должна быть более длины всей кривой) можно включить в SQL-операторы создания таблиц (CREATE TABLE опция CHECK для полей или таблицы в целом) или в триггеры (CREATE TRIGGER).
После реализации бизнес-правил необходимо проверить выполнимость и эффективность (время отклика, скорость выборки, объем задействованных данных) выполнения всех транзакций.
-
Разработка механизмов защиты.
Ввиду того, что работают с системой, как правило, несколько пользователей, необходимо продумать механизмы защиты данных от несанкционированного просмотра и модификации. В частности, с системой определения скоростей планируется работа разных пользователей: инженера службы пути; начальника службы пути, представителей других служб дороги и Департамента пути и сооружений ОАО «РЖД». Каждый из них должен быть наделен соответствующими полномочиями. Так, например, инженер службы пути «головой отвечает» за достоверность исходных данных и результаты расчетов. В связи с этим он должен быть наделен самыми широкими полномочиями. Другие пользователи должны иметь возможность только просмотра результатов расчета и формирования ведомостей.
Ниже рассматриваются два наиболее популярных способа обеспечения защиты данных.
-
Разработка пользовательских представлений (видов).
Представление пользователя включает в себя данные, необходимые конкретному пользователю для принятия решений или выполнения некоторого задания.
Представление в БД – динамический результат одной или более операций, выполненных над таблицами БД с целью получения новой сводной таблицы. Представление является виртуальной таблицей, которая реально в БД не существует, но создается по запросу (SELECT) определенного пользователя в результате выполнения этого запроса.
В БД представления создаются для упрощения запросов и для организации защиты. Например, с помощью представления можно ограничить доступ к отдельным атрибутам или записям некоторых типов пользователей.
-
Определение прав доступа (привилегий).
В СУБД, поддерживающих SQL, возможно выполнение запросов от имени определенного пользователя, которое задается администратором БД. Каждый пользователь обладает строго определенным набором прав (привилегий) в отношении конкретной таблицы или представления. Наделение правами выполняется с помощью оператора GRANT, отмена – REVOKE. Операции, на которые можно назначить права: SELECT, INSERT, DELETE и UPDATE. Кроме того, возможно задание передачи прав от одного пользователя к другому.
-
-
Организация мониторинга и настройка функционирования системы.
Мониторинг функционирования и достигнутого уровня производительности системы необходим с целью устранения ошибочных проектных решений или изменения требований к системе.
Первоначальный физический проект БД не следует понимать как нечто статическое. Он, скорее, является промежуточным звеном, предназначенным для оценки достигнутого уровня производительности системы. Большинство коммерческих СУБД предоставляет в распоряжение администратора БД набор утилит, предназначенных для наблюдения за функционированием системы и ее настройки.
На практике настройку БД никогда нельзя считать завершенной. На протяжении всего жизненного цикла системы необходимо постоянно вести наблюдение за уровнем ее производительности, что позволит своевременно реагировать на изменения, происходящие в окружающей среде. Внесение в БД изменений, предназначенных для повышения производительности одного из приложений, может отрицательно отразиться на работе другого приложения, возможно, более важного. Таким образом, внесение любых изменений в БД должно проводиться обдумано и осторожно с обязательным их тестированием.
Дополнительная литература
- Нормализация баз данных простыми словами
- Нормализация базы данных и ее формы
