Excel для Microsoft 365 Excel 2021 Excel 2019 Excel 2016 Еще…Меньше
Если у вас есть статистические данные с зависимостью от времени, вы можете создать прогноз на их основе. При этом в Excel создается новый лист с таблицей, содержащей статистические и предсказанные значения, и диаграммой, на которой они отражены. С помощью прогноза вы можете предсказывать такие показатели, как будущий объем продаж, потребность в складских запасах или потребительские тенденции.
Сведения о том, как вычисляется прогноз и какие параметры можно изменить, приведены ниже в этой статье.
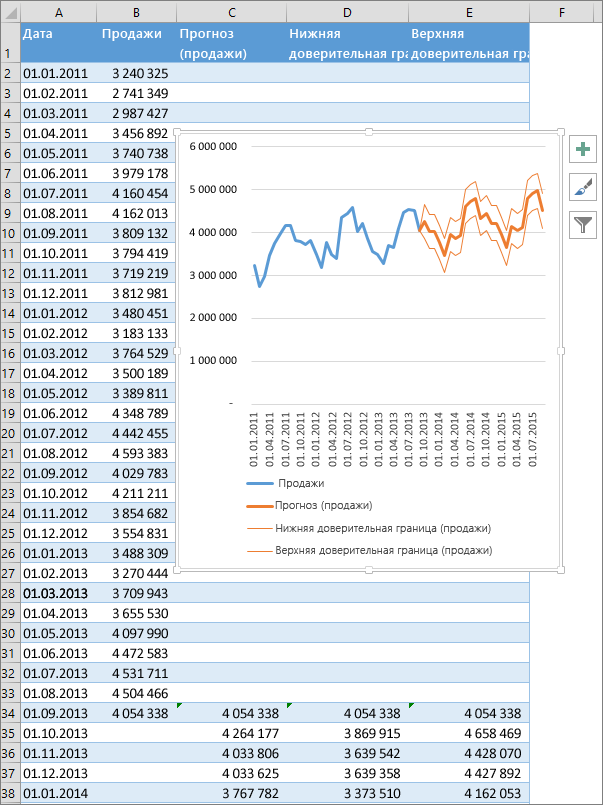
Создание прогноза
-
На листе введите два ряда данных, которые соответствуют друг другу:
-
ряд значений даты или времени для временной шкалы;
-
ряд соответствующих значений показателя.
Эти значения будут предсказаны для дат в будущем.
Примечание: Для временной шкалы требуются одинаковые интервалы между точками данных. Например, это могут быть месячные интервалы со значениями на первое число каждого месяца, годичные или числовые интервалы. Если на временной шкале не хватает до 30 % точек данных или есть несколько чисел с одной и той же меткой времени, это нормально. Прогноз все равно будет точным. Но для повышения точности прогноза желательно перед его созданием обобщить данные.
-
-
Выделите оба ряда данных.
Совет: Если выделить ячейку в одном из рядов, Excel автоматически выделит остальные данные.
-
На вкладке Данные в группе Прогноз нажмите кнопку Лист прогноза.

-
В окне Создание прогноза выберите график или гограмму для визуального представления прогноза.
-
В поле Завершение прогноза выберите дату окончания, а затем нажмите кнопку Создать.
В Excel будет создан новый лист с таблицей, содержащей статистические и предсказанные значения, и диаграммой, на которой они отражены.
Этот лист будет находиться слева от листа, на котором вы ввели ряды данных (то есть перед ним).

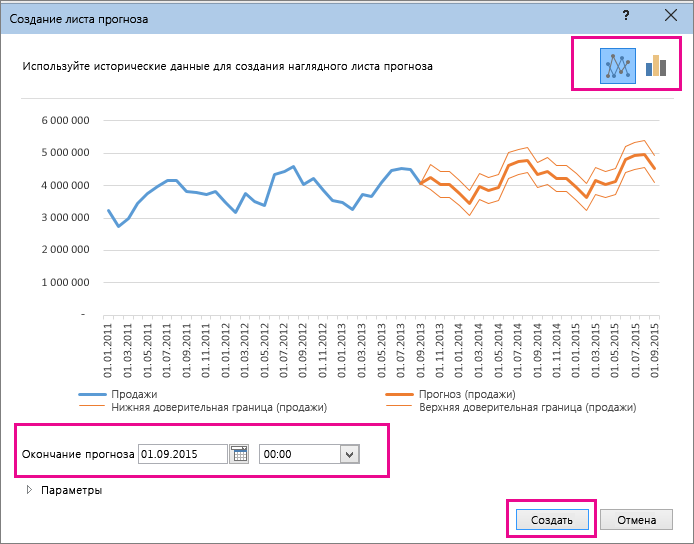
Настройка прогноза
Если вы хотите изменить дополнительные параметры прогноза, нажмите кнопку Параметры.
Сведения о каждом из вариантов можно найти в таблице ниже.
|
Параметры прогноза |
Описание |
|
Начало прогноза |
Выберите дату, с которой должен начинаться прогноз. При выборе даты начала, которая наступает раньше, чем заканчиваются статистические данные, для построения прогноза используются только данные, предшествующие ей (это называется “ретроспективным прогнозированием”). Советы:
|
|
Доверительный интервал |
Установите или снимите флажок Доверительный интервал, чтобы показать или скрыть его. Доверительный интервал — это диапазон вокруг каждого предсказанного значения, в который в соответствии с прогнозом (при нормальном распределении) предположительно должны попасть 95 % точек, относящихся к будущему. Доверительный интервал помогает определить точность прогноза. Чем он меньше, тем выше достоверность прогноза для данной точки. Доверительный интервал по умолчанию определяется для 95 % точек, но это значение можно изменить с помощью стрелок вверх или вниз. |
|
Сезонность |
Сезонность — это число для длины (количества точек) сезонного шаблона и автоматически обнаруживается. Например, в ежегодном цикле продаж, каждый из которых представляет месяц, сезонность составляет 12. Автоматическое обнаружение можно переопрепредидить, выбрав установить вручную и выбрав число. Примечание: Если вы хотите задать сезонность вручную, не используйте значения, которые меньше двух циклов статистических данных. При таких значениях этого параметра приложению Excel не удастся определить сезонные компоненты. Если же сезонные колебания недостаточно велики и алгоритму не удается их выявить, прогноз примет вид линейного тренда. |
|
Диапазон временной шкалы |
Здесь можно изменить диапазон, используемый для временной шкалы. Этот диапазон должен соответствовать параметру Диапазон значений. |
|
Диапазон значений |
Здесь можно изменить диапазон, используемый для рядов значений. Этот диапазон должен совпадать со значением параметра Диапазон временной шкалы. |
|
Заполнить отсутствующие точки с помощью |
Для обработки отсутствующих точек в Excel используется интерполяция, то есть отсутствующие точки будут заполнены в качестве взвешенного среднего значения соседних точек, если отсутствует менее 30 % точек. Чтобы нули в списке не были пропущены, выберите в списке пункт Нули. |
|
Использование агрегатных дубликатов |
Если данные содержат несколько значений с одной меткой времени, Excel находит их среднее. Чтобы использовать другой метод вычисления, например Медиана илиКоличество,выберите нужный способ вычисления из списка. |
|
Включить статистические данные прогноза |
Установите этот флажок, если хотите поместить на новом листе дополнительную статистическую информацию о прогнозе. При этом добавляется таблица статистики, созданная с помощью прогноза. Ets. Функция СТАТ и показатели, такие как коэффициенты сглаживания (“Альфа”, “Бета”, “Гамма”) и метрики ошибок (MASE, SMAPE, MAE, RMSE). |
Формулы, используемые при прогнозировании
При использовании формулы для создания прогноза возвращаются таблица со статистическими и предсказанными данными и диаграмма. Прогноз предсказывает будущие значения на основе имеющихся данных, зависящих от времени, и алгоритма экспоненциального сглаживания (ETS) версии AAA.
Таблицы могут содержать следующие столбцы, три из которых являются вычисляемыми:
-
столбец статистических значений времени (ваш ряд данных, содержащий значения времени);
-
столбец статистических значений (ряд данных, содержащий соответствующие значения);
-
столбец прогнозируемых значений (вычисленных с помощью функции ПРЕДСКАЗ.ЕTS);
-
два столбца, представляющие доверительный интервал (вычисленные с помощью функции ПРЕДСКАЗ.ЕTS.ДОВИНТЕРВАЛ). Эти столбцы отображаются только при проверке доверительный интервал в разделе Параметры.
Скачивание образца книги
Щелкните эту ссылку, чтобы скачать книгу с Excel FORECAST. Примеры функции ETS
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
Статьи по теме
Функции прогнозирования
Нужна дополнительная помощь?
Нужны дополнительные параметры?
Изучите преимущества подписки, просмотрите учебные курсы, узнайте, как защитить свое устройство и т. д.
В сообществах можно задавать вопросы и отвечать на них, отправлять отзывы и консультироваться с экспертами разных профилей.
Прогнозирование – хоть и неблагодарное, но необходимое дело и для решения таких задач в Microsoft Excel есть весьма приличный инструментарий – от простейших функций линейного тренда до навороченных статистических инструментов из надстройки Пакет Анализа (Analysis Toolpak). Одними из самых простых в реализации и при этом весьма эффективных являются функции прогнозирования по методу экспоненциального сглаживания.
Суть этого метода (если не вдаваться в математические подробности) можно объяснить относительно легко. Если бы мы, например, делали прогноз совсем примитивным способом по среднему арифметическому, то все исторические данные брались бы с одинаковым весом (в статистике этот метод “средней температуры по больнице” имеет, кстати, даже официальное название – “наивный прогноз”). При прогнозировании же по методу экспоненциального сглаживания принимается идея, что старые данные должны иметь вес меньше, чем новые. Изменение этого веса в зависимости от новизны или старости наших данных происходит по лавинообразной экспоненциальной кривой – отсюда и название методики.
В Microsoft Excel для её реализации есть две основные функции, появившиеся начиная с 2016-й версии Excel:
- ПРЕДСКАЗ.ETS (FORECAST.ETS) – вычисляет будущие спрогнозированные значения на основе исторических данных.
- ПРЕДСКАЗ.ETS.ДОВИНТЕРВАЛ (FORECAST.ETS.CONFINT) – вычисляет размах доверительного интервала – коридора погрешности, в пределах которого с заданной вероятностью наш прогноз должен сбыться.
Особенно приятно, что вводить вручную эти функции и их многочисленные аргументы совершенно не требуется – в Microsoft Excel для этого есть гораздо более удобный инструмент, получивший название Лист прогноза (Forecast Sheet). Давайте рассмотрим работу с ним на следующем примере.
В качестве исходных исторических данных возьмем с сайта AutoVercity реальную статистику по продажам автомобилей в России за 2019-2020 годы (все марки суммарно):

Представим на минуту, что сейчас конец 2020 года и мы хотим, используя эти данные, сделать помесячный прогноз продаж автомобилей на следующие полтора года. Выделим всю нашу таблицу и на вкладке Данные воспользуемся кнопкой Лист прогноза (Data – Forecast Sheet).

В открывшемся окне зададим следующие настройки:
- Дату завершения прогноза
- Сезонность – почти никогда корректно не определяется автоматически, к сожалению, так что лучше задать её вручную. В большинстве бизнесов она годовая (т.е. “узор” колебаний похожим образом повторяется из года в год), так что установим её равной 12 месяцам.
- Вероятность, с которой мы требуем попадания будущих фактических значений в коридор доверительного интервала. Чем больше эта вероятность, тем шире интервал (т.е. более размыт прогноз). Обычно используют значения 90-95%.
- В правом нижнем углу окна можно дополнительно выбрать реакцию на пустые ячейки (их можно заполнить нулями или средним соседних значений – интерполяцией) и на дубликаты (обычно их усредняют). Однако же, по возможности, лучше заранее подготовить исходные исторические данные, чтобы таких пробелов или дублей в них не было.
После нажатия на кнопку Создать будет сформирован новый лист с прогнозной таблицей и диаграммой, которая по ней построена:

В верхней части таблицы будут идти строки с историческими данными (синяя линия), а в момент их окончания произойдет переключение на три новых столбца с прогнозом функцией ПРЕДСКАЗ.ETS и верхней и нижней границами доверительного интервала, вычисленного с помощью функции ПРЕДСКАЗ.ETS.ДОВИНТЕРВАЛ.
Ссылки по теме
- Моделирование и оценка вероятности выигрыша в лотерею
- Оптимизация доставки в Excel с помощью Поиска решения (Solver)
- Быстрое добавление новых данных в диаграмму


КУРС
EXCEL ACADEMY
Научитесь использовать все прикладные инструменты из функционала MS Excel.
Любому бизнесу интересно заглянуть в будущее и правильно ответить на вопрос: «А сколько денег мы заработаем за следующий период?» Ответить на такого рода вопросы позволяют различные методики прогнозирования. В данной статье мы с вами рассмотрим несколько таких методик и произведем все необходимые расчеты в Excel. Еще больше про анализ данных в Excel мы рассказываем на нашем открытом курсе «Аналитика в Excel».
Постановка задачи
Исходные данные
Для начала, давайте определимся, какие у нас есть исходные данные и что нам нужно получить на выходе. Фактически, все что у нас есть, это некоторые исторические данные. Если мы говорим о прогнозировании продаж, то историческими данными будут продажи за предыдущие периоды.
Примечание. Собранные в разные моменты времени значения одной и той же величины образуют временной ряд. Каждое значение такого временного ряда называется измерением. Например: данные о продажах за последние 5 лет по месяцам — временной ряд; продажи за январь прошлого года — измерение.
Составляющие прогноза
Следующий шаг: давайте определимся, что нам нужно учесть при построении прогноза. Когда мы исследуем наши данные, нам необходимо учесть следующие факторы:
- Изменение нашей пронозируемой величины (например, продаж) подчиняется некоторому закону. Другими словами, в временном ряде можно проследить некую тенденцию. В математике такая тенденция называется трендом.
- Изменение значений в временном ряде может зависить от промежутка времени. Другими словами, при построении модели необходимо будет учесть коэффициент сезонности. Например, продажи арбузов в январе и августе не могут быть одинаковыми, т.к. это сезонный продукт и летом продажи значительно выше.
- Изменение значений в временном ряде периодически повторяется, т.е. наблюдается некоторая цикличность.
Эти три пункта в совокупность образуют регулярную составляющую временного ряда.
Примечание. Не обязательно все три элемента регулярной составляющей должны присутствовать в временном ряде.
Однако, помимо регулярной составляющей, в временном ряде присутствует еще некоторое случайное отклонение. Интуитивно это понятно – продажи могут зависеть от многих факторов, некоторые из которых могут быть случайными.
Вывод. Чтобы комплексно описать временной ряд, необходимо учесть 2 главных компонента: регулярную составляющую (тренд + сезонность + цикличность) и случайную составляющую.
Виды моделей
Следующий вопрос, на который нужно ответить при построении прогноза: “А какие модели временного ряда бывают?”
Обычно выделяют два основных вида:
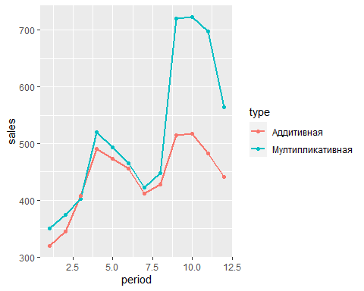
- Аддитивная модель: Уровень временного ряда = Тренд + Сезонность + Случайные отклонения
- Мультипликативная модель: Уровень временного ряда = Тренд X Сезонность X Случайные отклонения
Иногда также выделают смешанную модель в отдельную группу:
- Смешанная модель: Уровень временного ряда = Тренд X Сезонность + Случайные отклонения
С моделями мы определились, но теперь возникает еще один вопрос: «А когда какую модель лучше использовать?»
Классический вариант такой:
— Аддитивная модель используется, если амплитуда колебаний более-менее постоянная;
— Мультипликативная – если амплитуда колебаний зависит от значения сезонной компоненты.
Пример:
Решение задачи с помощью Excel
Итак, необходимые теоретические знания мы с вами получили, пришло время применить их на практике. Мы будем с вами использовать классическую аддитивную модель для построения прогноза. Однако, мы построим с вами два прогноза:
- с использованием линейного тренда
- с использованием полиномиального тренда
Во всех руководствах, как правило, разбирается только линейный тренд, поэтому полиномиальная модель будет крайне полезна для вас и вашей работы!
КУРС
EXCEL ACADEMY
Научитесь использовать все прикладные инструменты из функционала MS Excel.
Модель с линейным трендом
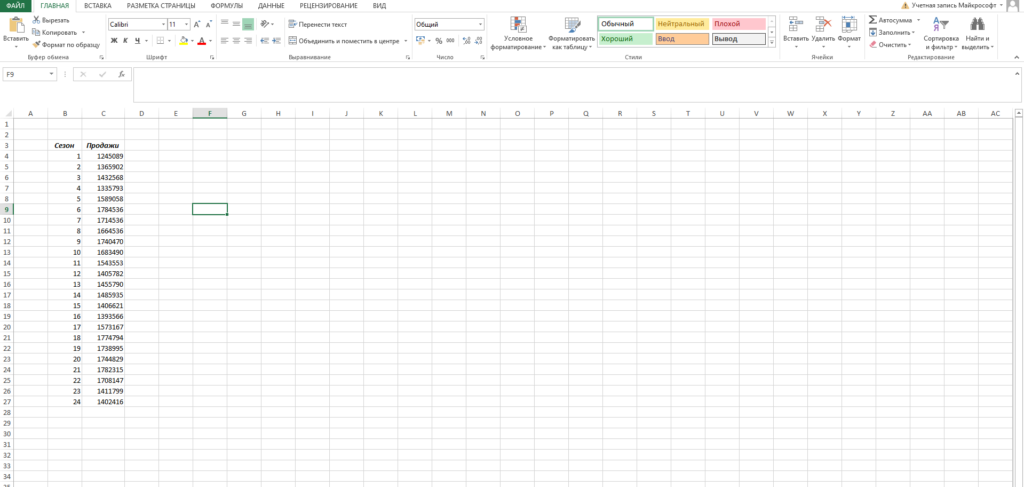
Пусть у нас есть исходная информация по продажам за 2 года:
Учитывая, что мы используем линейный тренд, то нам необходимо найти коэффициенты уравнения
y = ax + b
где:
- y – значения продаж
- x – номер периода
- a – коэффициент наклона прямой тренда
- b – свободный член тренда
Рассчитать коэффициенты данного уравнения можно с помощью формулы массива и функции ЛИНЕЙН. Нам необходимо будет сделать следующую последовательность действий:
- Выделяем две ячейки рядом
- Ставим курсор в поле формул и вводим формулу =ЛИНЕЙН(C4:C27;B4:B27)
- Нажимаем Ctrl+Shift+Enter, чтобы активировать формулу массива
На выходе мы получили 2 числа: первое — коэффициент a, второе – свободный член b.
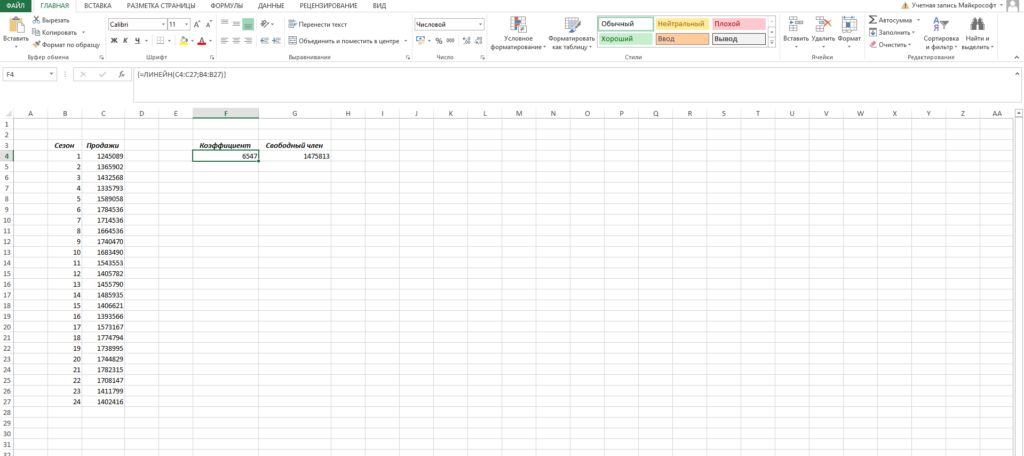
Теперь нам нужно рассчитать для каждого периода значение линейного тренда. Сделать это крайне просто — достаточно в полученное уравнение подставить известные номера периодов. Например, в нашем случае, мы прописываем формулу =B4*$F$4+$G$4 в ячейке I4 и протягиваем ее вниз по всем периодам.
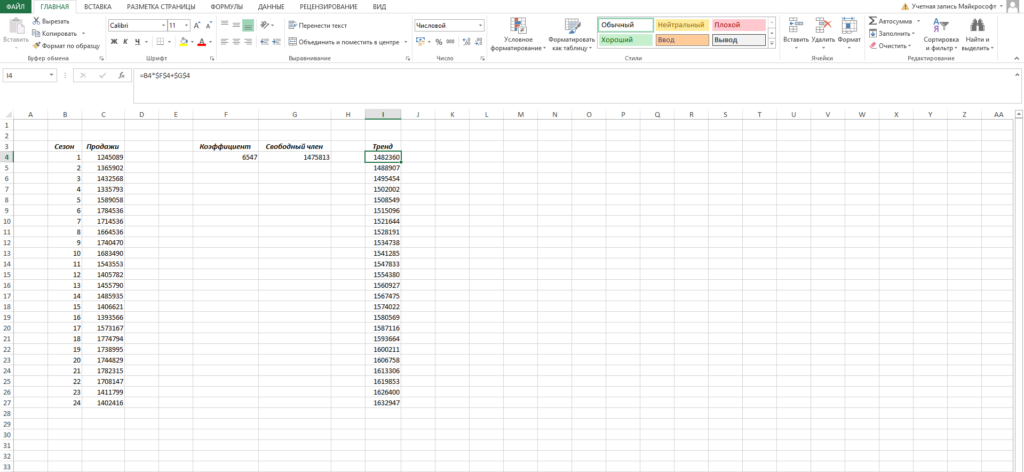
Нам осталось рассчитать коэффициент сезонности для каждого периода. Учитывая, что у нас есть исторические данные за два года, разумно будет учесть это при расчете. Можем сделать следующим образом: в ячейке J4 прописываем формулу =(C4+C16)/СРЗНАЧ($C$4:$C$27)/2 и протягиваем вниз на 12 месяцев (т.е. до J15).
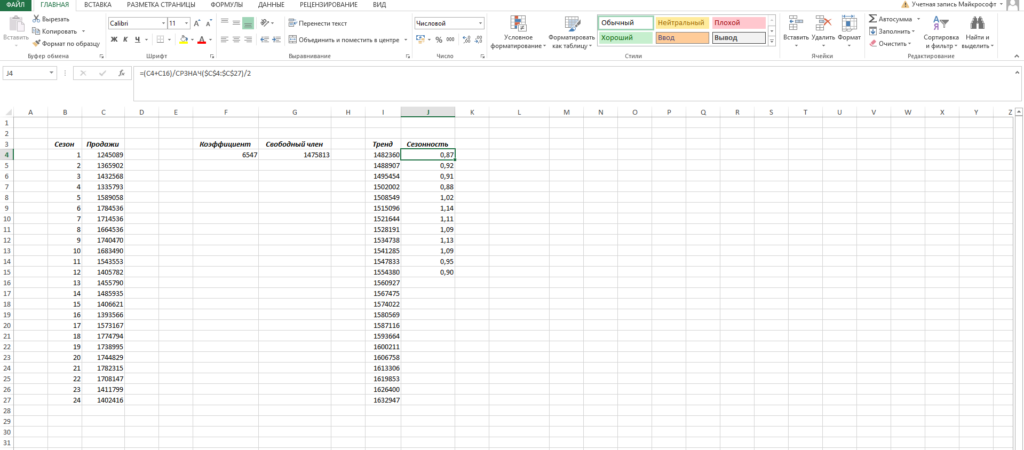
Что нам это дало? Мы посчитали, сколько суммарно продавалось каждый январь/каждый февраль и так далее, а потом разделили это на среднее значение продаж за все два периода.
То есть мы выяснили, как продажи двух январей отклонялись от средних продаж за два года, как продажи двух февралей отклонялись и так далее. Это и дает нам коэффициент сезонности. В конце формулы делим на 2, т.к. в расчете фигурировало 2 периода.
Примечание. Рассчитали только 12 коэффициентов, т.к. один коэффициент учитывает продажи сразу за 2 аналогичных периода.
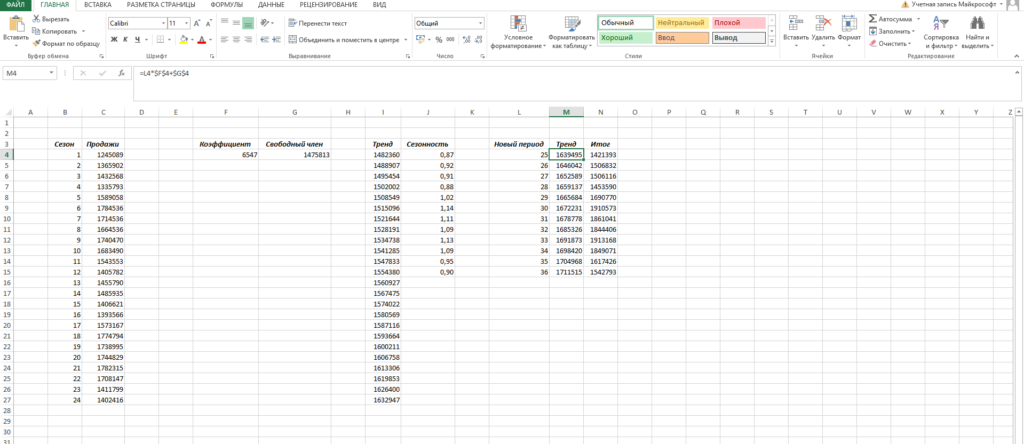
Итак, теперь мы на финишной прямой. Нам осталось рассчитать тренд для будущих периодов и учесть коэффициент сезонности для них. Давайте амбициозно построим прогноз на год вперед.
Сначала создаем столбец, в котором прописываем номера будущих периодов. В нашем случае нумерация начинается с 25 периода.
Далее, для расчета значения тренда просто прописываем уже известную нам формулу =L4*$F$4+$G$4 и протягиваем вниз на все 12 прогнозируемых периодов.
И последний штрих — умножаем полученное значение на коэффициент сезонности. Вуаля, это и есть итоговый ответ в данной модели!
Модель с полиномиальным трендом
Конструкция, которую мы только что с вами построили, достаточно проста. Но у нее есть один большой минус — далеко не всегда она дает достоверные результаты.
Посмотрите сами, какая модель более точно аппроксимирует наши точки — линейный тренд (прямая зеленая линия) или полиномиальный тренд (красная кривая)? Ответ очевиден. Поэтому сейчас мы с вами и разберем, как построить полиномиальную модель в Excel.
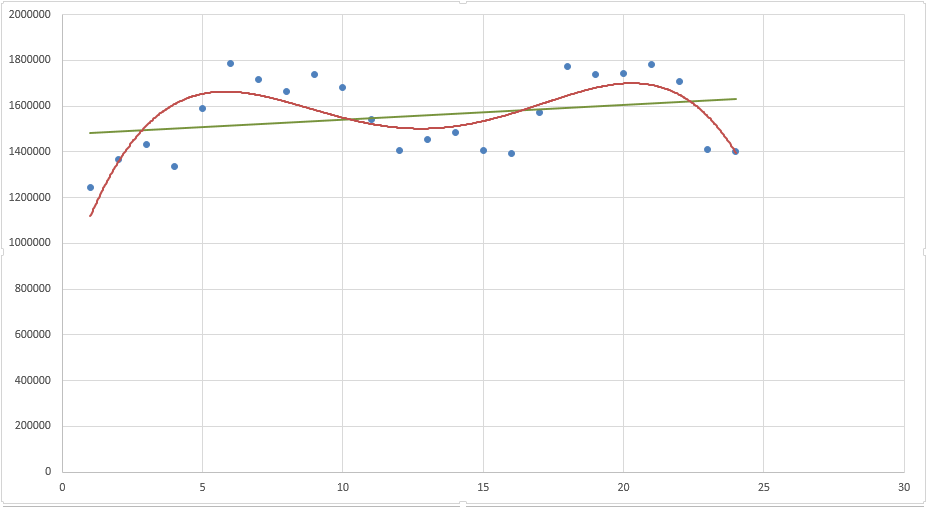
Пусть все исходные данные у нас будут такими же. Для простоты модели будем учитывать только тренд, без сезонной составляющей.
Для начала давайте определимся, чем полиномиальный тренд отличается от обычного линейного. Правильно — формой уравнения. У линейного тренда мы разбирали обычный график прямой:
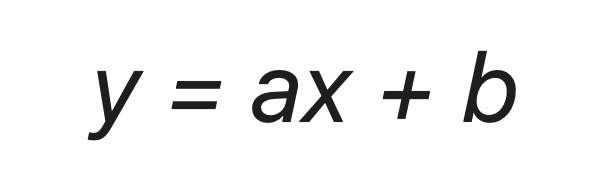
У полиномиального тренда же уравнение выглядит иначе:
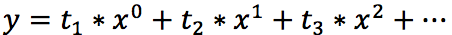
где конечная степень определяется степенью полинома.
Т.е. для полинома 4 степени необходимо найти коэффициенты уравнения:
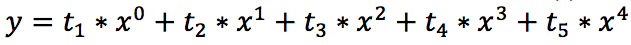
Согласитесь, выглядит немного страшно. Однако, ничего страшного нет, и мы с легкостью можем решить эту задачку с помощью уже известных нам методов.
- Ставим в ячейку F4 курсор и вводим формулу =ИНДЕКС(ЛИНЕЙН($C$4:$C$27;$B$4:$B$27^{1;2;3;4});1;1). Функция ЛИНЕЙН позволяет произвести расчет коэффициентов, а с помощью функции ИНДЕКС мы вытаскиваем нужный нам коэффициент. В данном случае за выбор коэффициента отвечает самый последний аргумент. У нас стоит 1 — это коэффициент при самой высокой степени (т.е. при 4 степени, коэффициент). Кстати, узнать о самых полезных математических формулах Excel можно в нашем бесплатном гайде «Математические функции Excel».
- Аналогично прописываем формулу =ИНДЕКС(ЛИНЕЙН($C$4:$C$27;$B$4:$B$27^{1;2;3;4});1;2) в ячейке ниже.
- Делаем такие же действия, пока не найдем все коэффициенты.
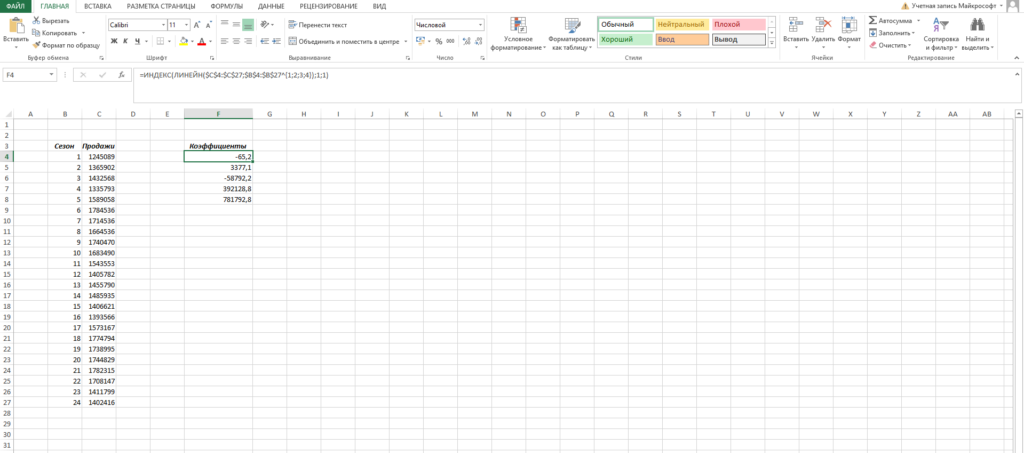
Кстати говоря, мы можем легко сами себя проверить. Давайте построим график наших продаж и добавим к нему полиномиальный тренд.
- Выделяем столбец с продажами
- Выбираем «Вставка» → «График» → «Точечный» → «Точечная диаграмма»
- Нажимаем на любую точку графика правой кнопкой мыши и выбираем «Добавить линию тренда»
- В открывшемся справа меню выбираем «Полиномиальная модель», меняем степень на 4 и ставим галочку на «Показывать уравнение на диаграмме»
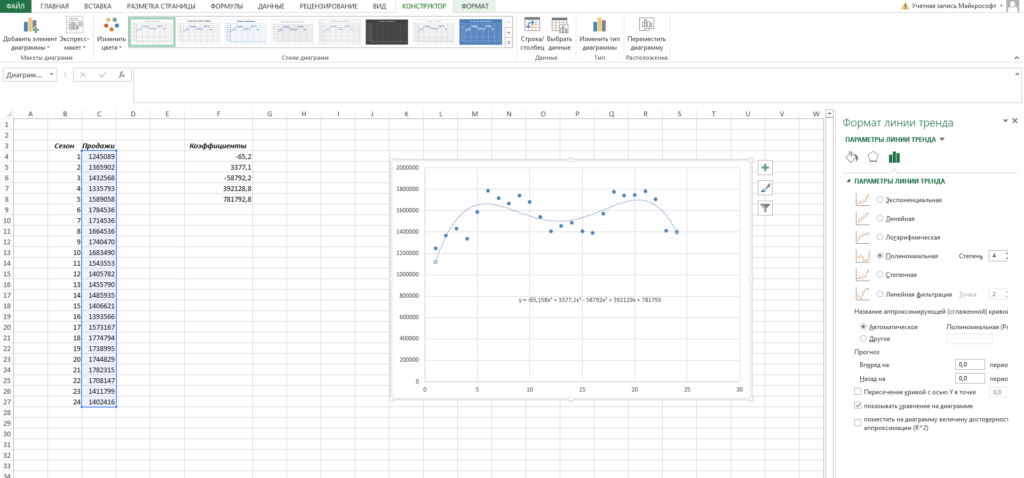
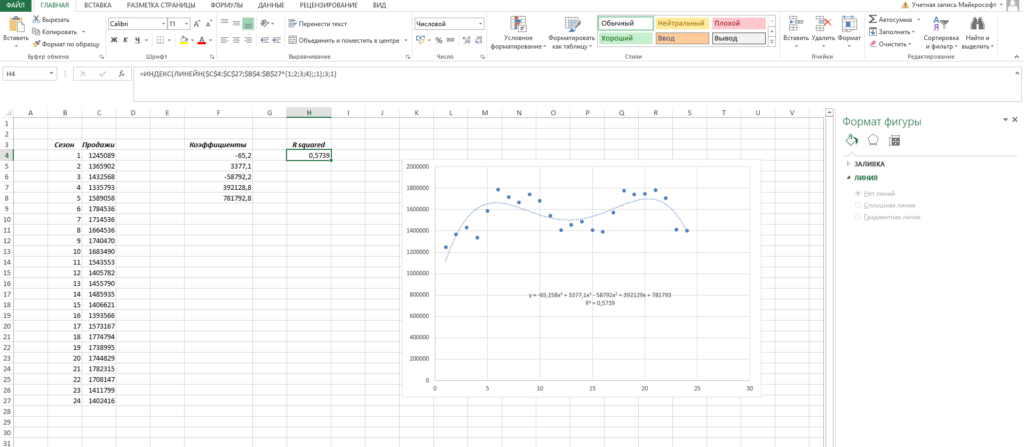
Теперь вы наглядно можете видеть, как рассчитанный тренд аппроксимирует исходные данные и как выглядит само уравнение. Можно сравнить уравнение на графике с вашими коэффициентами. Сходится? Значит сделали все верно!
Помимо всего прочего, вы можете сразу оценить точность аппроксимации (не полностью, но хотя бы первично). Это делается с помощью коэффициента R^2. Тут у вас снова есть два пути:
- Вы можете вывести коэффициент на график, поставив галочку «Поместить на диаграмму величину достоверности аппроксимации»
- Вы можете рассчитать коэффициент R^2 самостоятельно по формуле =ИНДЕКС(ЛИНЕЙН($C$4:$C$27;$B$4:$B$27^{1;2;3;4};;1);3;1)
Заключение
Мы с вами подробно разобрали вопрос прогнозирования — изучили необходимые термины и виды моделей, построили аддитивную модель в Excel с использованием линейного и полиномиального тренда, а также научились отображать результаты своих вычислений на графиках. Все это позволит вам эффективно внедрять полученные знания на работе, усложнять существующие модели и уточнять прогнозы. Чем большим количеством методов и инструментов вы будете владеть, тем выше будет ваш профессиональный уровень и статус на рынке труда.
Если вас интересуют еще какие-то модели прогнозирования — напишите нам об этом, и мы постараемся осветить эти темы в дальнейших своих статьях! Или запишитесь на курс «Excel Academy» от SF Education, где мы рассказываем про возможности Excel, необходимые для анализа.
Автор: Алексанян Андрон, эксперт SF Education
КУРС
EXCEL ACADEMY
Научитесь использовать все прикладные инструменты из функционала MS Excel.
Блог SF Education
Data Science
5 примеров экономии времени в Excel
Что для работодателя главное в сотруднике? Добросовестность, ответственность, профессионализм и, конечно же, умение пользоваться отведенным временем! Предлагаем познакомиться с очень нужными, на наш взгляд,…
Функция ПРЕДСКАЗ в Excel позволяет с некоторой степенью точности предсказать будущие значения на основе существующих числовых значений, и возвращает соответствующие величины. Например, некоторый объект характеризуется свойством, значение которого изменяется с течением времени. Такие изменения могут быть зафиксированы опытным путем, в результате чего будет составлена таблица известных значений x и соответствующих им значений y, где x – единица измерения времени, а y – количественная характеристика свойства. С помощью функции ПРЕДСКАЗ можно предположить последующие значения y для новых значений x.
Примеры использования функции ПРЕДСКАЗ в Excel
Функция ПРЕДСКАЗ использует метод линейной регрессии, а ее уравнение имеет вид y=ax+b, где:
- Коэффициент a рассчитывается как Yср.-bXср. (Yср. и Xср. – среднее арифметическое чисел из выборок известных значений y и x соответственно).
- Коэффициент b определяется по формуле:
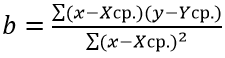
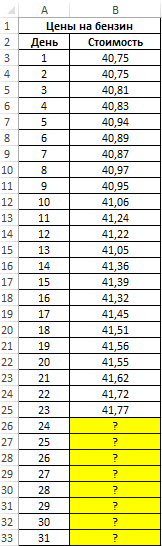
Пример 1. В таблице приведены данные о ценах на бензин за 23 дня текущего месяца. Согласно прогнозам специалистов, средняя стоимость 1 л бензина в текущем месяце не превысит 41,5 рубля. Спрогнозировать стоимость бензина на оставшиеся дни месяца, сравнить рассчитанное среднее значение с предсказанным специалистами.
Вид исходной таблицы данных:
Чтобы определить предполагаемую стоимость бензина на оставшиеся дни используем следующую функцию (как формулу массива):
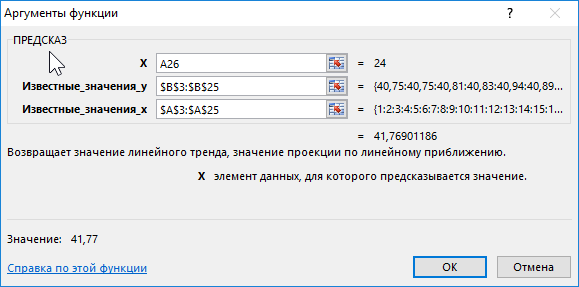
Описание аргументов:
- A26:A33 – диапазон ячеек с номерами дней месяца, для которых данные о стоимости бензина еще не определены;
- B3:B25 – диапазон ячеек, содержащих данные о стоимости бензина за последние 23 дня;
- A3:A25 – диапазон ячеек с номерами дней, для которых уже известна стоимость бензина.
Результат расчетов:
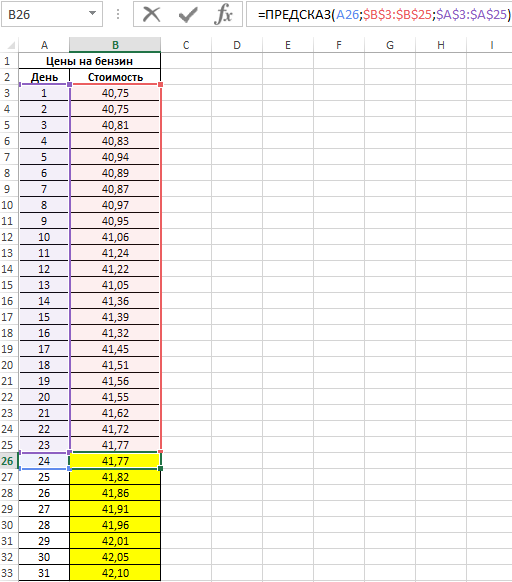
Рассчитаем среднюю стоимость 1 л бензина на основании имеющихся и расчетных данных с помощью функции:
=СРЗНАЧ(B3:B33)
Результат:
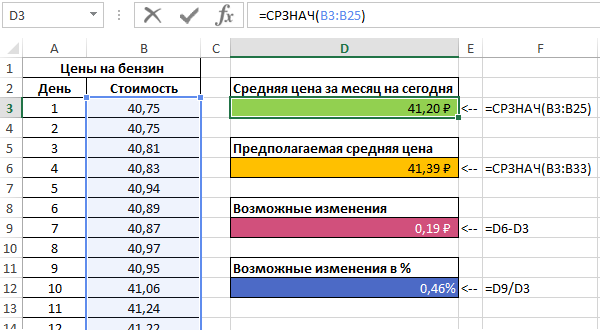
Можно сделать вывод о том, что если тенденция изменения цен на бензин сохранится, предсказания специалистов относительно средней стоимости сбудутся.
Анализ прогноза спроса продукции в Excel по функции ПРЕДСКАЗ
Пример 2. Компания недавно представила новый продукт. С момента вывода на рынок ежедневно ведется учет количества клиентов, купивших этот продукт. Предположить, каким будет спрос на протяжении 5 последующих дней.
Вид исходной таблицы данных:
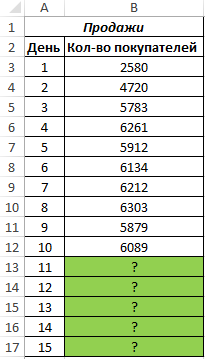
Как видно, в первые дни спрос был небольшим, затем он рос достаточно большими темпами, а на протяжении последних трех дней изменялся незначительно. Это свидетельствует о том, что основным фактором роста продаж на данный момент является не расширение базы клиентов, а развитие продаж с постоянными клиентами. В таких случаях рекомендуют использовать не линейную регрессию, а логарифмический тренд, чтобы результаты прогнозов были более точными.
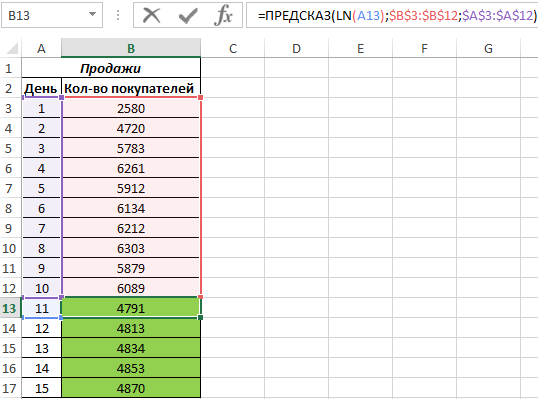
Рассчитаем значения логарифмического тренда с помощью функции ПРЕДСКАЗ следующим способом:
Как видно, в качестве первого аргумента представлен массив натуральных логарифмов последующих номеров дней. Таким образом получаем функцию логарифмического тренда, которая записывается как y=aln(x)+b.
Результат расчетов:
Для сравнения, произведем расчет с использованием функции линейного тренда:
И для визуального сравнительного анализа построим простой график.
Полученные результаты:
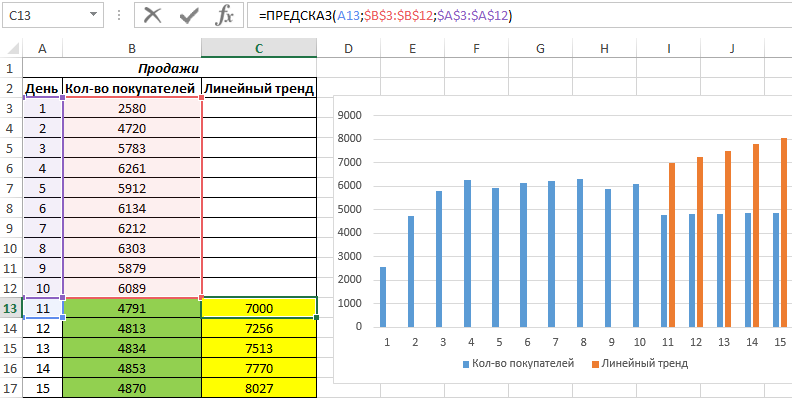
Как видно, функцию линейной регрессии следует использовать в тех случаях, когда наблюдается постоянный рост какой-либо величины. В данном случае функция логарифмического тренда позволяет получить более правдоподобные данные (более наглядно при большем количестве данных).
Прогнозирование будущих значений в Excel по условию
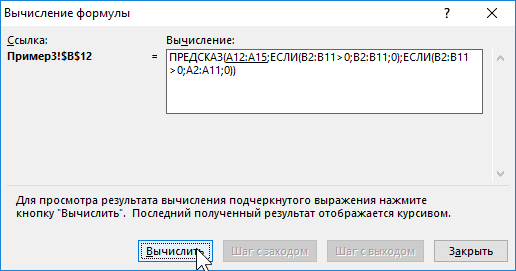
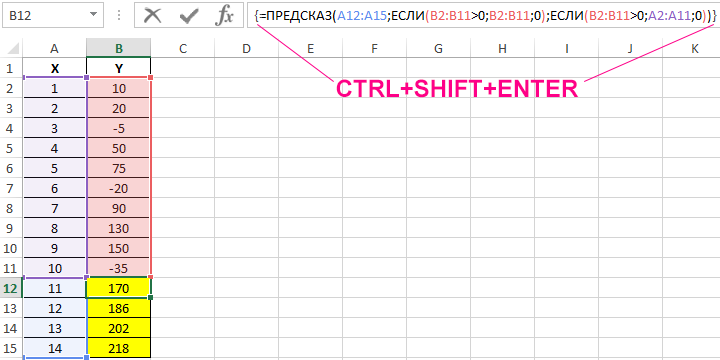
Пример 3. В таблице Excel указаны значения независимой и зависимой переменных. Некоторые значения зависимой переменной указаны в виде отрицательных чисел. Спрогнозировать несколько последующих значений зависимой переменной, исключив из расчетов отрицательные числа.
Вид таблицы данных:
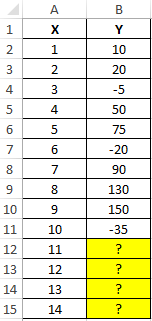
Для расчета будущих значений Y без учета отрицательных значений (-5, -20 и -35) используем формулу:
C помощью функций ЕСЛИ выполняется перебор элементов диапазона B2:B11 и отброс отрицательных чисел. Так, получаем прогнозные данные на основании значений в строках с номерами 2,3,5,6,8-10. Для детального анализа формулы выберите инструмент «ФОРМУЛЫ»-«Зависимости формул»-«Вычислить формулу». Один из этапов вычислений формулы:
Полученные результаты:
Особенности использования функции ПРЕДСКАЗ в Excel
Функция имеет следующую синтаксическую запись:
=ПРЕДСКАЗ(x;известные_значения_y;известные_значения_x)
Описание аргументов:
- x – обязательный для заполнения аргумент, характеризующий одно или несколько новых значений независимой переменной, для которых требуется предсказать значения y (зависимой переменной). Может принимать числовое значение, массив чисел, ссылку на одну ячейку или диапазон;
- известные_значения_y – обязательный аргумент, характеризующий уже известные числовые значения зависимой переменной y. Может быть указан в виде массива чисел или ссылки на диапазон ячеек с числами;
- известные_значения_x – обязательный аргумент, который характеризует уже известные значения независимой переменной x, для которой определены значения зависимой переменной y.
Примечания:
- Второй и третий аргументы рассматриваемой функции должны принимать ссылки на непустые диапазоны ячеек или такие диапазоны, в которых число ячеек совпадает. Иначе функция ПРЕДСКАЗ вернет код ошибки #Н/Д.
- Если одна или несколько ячеек из диапазона, ссылка на который передана в качестве аргумента x, содержит нечисловые данные или текстовую строку, которая не может быть преобразована в число, результатом выполнения функции ПРЕДСКАЗ для данных значений x будет код ошибки #ЗНАЧ!.
- Статистическая дисперсия величин (можно рассчитать с помощью формул ДИСП.Г, ДИСП.В и др.), передаваемых в качестве аргумента известные_значения_x, не должна равняться 0 (нулю), иначе функция ПРЕДСКАЗ вернет код ошибки #ДЕЛ/0!.
- Рассматриваемая функция игнорирует ячейки с нечисловыми данными, содержащиеся в диапазонах, которые переданы в качестве второго и третьего аргументов.
- Функция ПРЕДСКАЗ была заменена функцией ПРЕДСКАЗ.ЛИНЕЙН в Excel версии 2016, но была оставлена для обеспечения совместимости с Excel 2013 и более старыми версиями.
- Для предсказания только одного будущего значения на основании известного значения независимой переменной функция ПРЕДСКАЗ используется как обычная формула. Если требуется предсказать сразу несколько значений, в качестве первого аргумента следует передать массив или ссылку на диапазон ячеек со значениями независимой переменной, а функцию ПРЕДСКАЗ использовать в качестве формулы массива.
Хитрости »
23 Март 2017 158905 просмотров
Скачать файл, используемый в видеоуроке:
 Прогноз_продаж.xls (59,5 KiB, 35 032 скачиваний)
Прогноз_продаж.xls (59,5 KiB, 35 032 скачиваний)
Прогнозирование продаж является неотъемлемой частью при планировании работы коммерческих и финансовых служб, поэтому задача довольно актуальная. Вариантов построения прогнозов достаточное множество, но я хочу показать как сделать простой, но в то же время достаточно жизнеспособный прогноз «на скорую руку», без лишних телодвижений и поправок «на ветер»(читайте как: без кучи доп.расчетов, которые применяются для создания более точных прогнозов). Почему я это уточняю? Потому что на мой взгляд, каким бы точным ни был прогноз продаж – это всего лишь предположение и быть уверенным в том, что именно так и будет развиваться ход событий, никак нельзя.
И тем не менее при помощи встроенных в Excel функций мы можем построить довольно неплохой прогноз даже с учетом сезонности. Плюс я хочу показать как сделать не просто прогноз, а прогноз с отклонениями – пессимистичный и оптимистичный. С помощью подобной модели можно будет выстроить тактику продаж таким образом, чтобы постараться максимально «вписаться» в границы между пессимистичным и оптимистичным прогнозом.
А в довершение мы построим красивый график с прогнозом.
Исходные данные
Для расчета прогноза потребуются данные о продажах за ранние периоды. Чем больше данных, тем точнее будет прогноз. Желательно, чтобы были помесячные данные хотя бы за два года. На мой взгляд это тот минимум, на основании которого можно построить весьма точный прогноз с учетом прошлого опыта. Именно из таких данных и будем исходить. Предположим, что у нас есть данные с января 2013 года по август 2015, в табличном виде:

Нам необходимо рассчитать прогноз продаж на будущий год: с сентября 2015 по август 2016 и отразить это на графике. Я специально беру рваный период посреди года, чтобы показать, что начало прогноза может быть с любой даты.
Чтобы дальше в статье не запутать вас столбцами и где они должны быть добавлены, сразу приведу конечную структуру:

Т.е. у нас должно быть именно в указанном порядке 7 столбцов: Период; Продажи компании, руб.; Прогноз; Оптимистичный; Пессимистичный; Коэффициент сезонности; Отклонение. И чтобы все получилось они должны идти точно в таком же порядке, как на картинке выше.
Советую сразу создать все эти столбцы или скачать готовую модель для примера, чтобы дальше использовать именно её для пошагового выполнения описанных ниже действий:
Скачать файл:
В файле два листа:
- Исходные данные – только фактические данные по продажам, без доп.столбцов, чтобы можно было самостоятельно с нуля построить модель
- Прогноз – лист с готовыми функциями и графиком прогноза
В самый низ таблицы, после последней фактической даты, я добавил даты, на которые необходимо построить прогноз(от сен.2015 до авг.2016).
Расчет прогноза
Для расчета непосредственно прогноза в Excel есть специальная функция, которая основываясь на данных предыдущих периодов предсказывает вероятные значения для указанной даты. Она так и называется – ПРЕДСКАЗ(FORECAST). Функция основана на линейной регрессии и специально предназначена именно для прогнозирования продаж, потребления товара и пр. В столбец Прогноз (столбец C – сразу после столбца с суммами продаж) в ячейку
C34
записываем функцию (и распространяем на все прогнозируемые даты –
C34:C45
):
=ПРЕДСКАЗ(A34;$B$2:$B$33;$A$2:$A$33)
=FORECAST(A34,$B$2:$B$33,$A$2:$A$33)
Сама функция требует указания следующих входных данных:
- х – Дата, значение для которой необходимо спрогонозировать (A34)
- Известные значения y – ссылка на ячейки таблицы с суммами продаж за известные периоды ($B$2:$B$33)
- Известные значения x – ссылка на ячейки таблицы с дата продаж за известные периоды ($A$2:$A$33)
С одной стороны, мы уже имеем готовый прогноз, а с другой…Данная функция пока не учитывает фактор сезонности. А это в продажах в большинстве случаев немаловажный фактор. Поэтому желательно потратить еще чуточку времени и сделать так, чтобы прогноз получился еще больше приближен к реальности. Для учета фактора сезонности сначала необходимо вычислить коэффициент сезонности для каждого месяца. Для этого добавим в столбец Коэффициент сезонности следующую формулу:
=(($B$2:$B$13+$B$14:$B$25)/СУММ($B$2:$B$25))*12
=(($B$2:$B$13+$B$14:$B$25)/SUM($B$2:$B$25))*12
Формула вводится в ячейку как формула массива и сразу в 12 ячеек(чтобы получить коэффициенты для каждого месяца года). Для этого сначала выделяем ячейки F2:F13 -переходим в строку формул и вводим формулу выше. После указания верных ссылок на нужные ячейки завершаем ввод формулы одновременным нажатием трех клавиш: Ctrl+Shift+Enter. Если этого не сделать, то функция вернет значение ошибки #ЗНАЧ!(#VALUE!)
Подробнее про принцип работы формулы: она берет отдельно сумму каждого месяца за 2013 и 2014 год, складывает их. Делит полученное значение на общую сумму продаж за весь период целых месяцев(т.е. 24 месяца) и умножает на 12, чтобы получить коэффициент именно за один месяц. И так для каждого месяца. Т.е. для ячейки F2 расчет будет выглядеть следующим образом:
=((56 769+68 521)/ 1 542 293)*12
=((сумма за янв.2013 + сумма за янв.2014)/ общая сумма за два года(янв.2013 – дек.2014))*12
В результате для января получим коэффициент 0,974834224106574, для февраля – 0,989928632237843 и т.д. Я для наглядности назначил ячейкам процентный формат(правая кнопка мыши –Формат ячеек -вкладка Число –Процентный(Format cells –Number –Percent), два знака после запятой):

Теперь добавим учет этих коэффициентов для расчета прогноза в имеющуюся функцию ПРЕДСКАЗ(ячейки C34:C45):
=ПРЕДСКАЗ(A34;$B$2:$B$33;$A$2:$A$33)*ИНДЕКС($F$2:$F$13;МЕСЯЦ(A34))
=FORECAST(A34,$B$2:$B$33,$A$2:$A$33)*INDEX($F$2:$F$13,MONTH(A34))
Здесь применяется функция ИНДЕКС(INDEX), в которой первым аргументом указываем ссылку на 12 ячеек с коэффициентами сезонности($F$2:$F$13), а вторым – номер месяца, чтобы вернуть коэффициент именно для нужного месяца(для этого используем функцию МЕСЯЦ(MONTH), которая возвращает только номер месяца из указанной даты). Для сентября 2015 это будет выглядеть так:
=ПРЕДСКАЗ(A34; $B$2:$B$33; $A$2:$A$33)*ИНДЕКС({97,48%:98,99%:90,38%:94,66%:100,86%:99,02%:100,66%:110,39%:100,47%:104,82%:105,13%:97,14%}; 9)
Основную задачу выполнили – у нас есть прогноз на будущие периоды. Теперь осталось в дополнение к самому прогнозу, создать допустимые верхние и нижние границы, которые часто еще называют оптимистичный прогноз и пессимистичный(но по сути это просто возможное отклонение от прогнозных данных). Такой прогноз даст нам возможность более гибко планировать тактику на будущие периоды.
Для того, чтобы построить такие прогнозы необходимо рассчитать допустимое отклонение от прогнозируемых значений. Здесь так же будем использовать имеющиеся в Excel функции. В ячейку G2 запишем формулу:
=ДОВЕРИТ(0,05; СТАНДОТКЛОН(C34:C45); СЧЁТ(C34:C45))
=CONFIDENCE(0.05,STDEV(C34:C45),COUNT(C34:C45))
ДОВЕРИТ(CONFIDENCE) – возвращает доверительный интервал, используя нормальное распределение.
- алфа – уровень значимости для вычисления доверительного уровня. Используемое в формуле 0,05 означает доверительный уровень в 95%. В большинстве случаев это оптимальное значение
- станд_откл – стандартное отклонение генеральной совокупности. Должно быть известно. Но т.к. мы этими данными не располагаем – то это значение вычисляем при помощи функции СТАНДОТКЛОН(STDEV), передавая ей для расчетов спрогнозированные данные
- размер – указывается целое число, обозначающее количество данных для выборки. Как правило равно количеству спрогнозированных данных. У нас количество определяется функцией СЧЁТ, которая подсчитывает количество чисел в указанных ячейках.
Теперь в ячейки столбцов Оптимистичный и Пессимистичный(D и E), начиная со строки 34, запишем такие формулы:
Оптимистичный: =$C34+$G$2
Пессимистичный: =$C34-$G$2

Т.е. мы для оптимистичного прогноза берем сумму прогноза и прибавляем к ней сумму рассчитанного отклонения. А для пессимистичного, мы сумму отклонения вычитаем. Вот мы и получили все необходимые данные.
График
Но было бы кощунством с нашей стороны проделать такую работу и не использовать возможности Excel для построения красивого графика. Придется добавить немного шаманства(на деле, мы уже начали шаманить, когда стали записывать прогноз в отдельный столбец, а не продолжать его в том же столбце, что и фактические продажи). В ячейки C33, D33 и E33 скопируем значение из ячейки B33, чтобы они все имели одинаковые значения:

Теперь выделяем все данные (A1:E45), переходим на вкладку Вставка(Insert) – группа Диаграммы(Charts) –График(Line). И получим такую картину:

Наглядно и сразу понятно что к чему и чего можно ожидать.
- Синим – фактические продажи
- Оранжевый – прогноз
- Серый – Оптимистичный прогноз
- Желтый – Пессимистичный
Согласитесь, такой график смотрится достаточно эффектно и может украсить собой отчет для руководства. Особенно, если проявить немного фантазии и отформатировать график в соответствии с корпоративными цветами компании.
Быстрый прогноз в Excel 2016 и выше
Начиная с версии 2016 в Excel появилась замечательная возможность создать прогноз двумя кликами мыши. При этом сразу с оптимистичным и пессимистичным развитием событий и графиком. За основу возьмем все те же исходные данные из двух столбцов:
Выделяем необходимые данные из двух столбцов -переходим на вкладку Данные(Data) -группа Прогноз(Forecast) –Лист прогноза(Forecast Sheet):

В появившемся окне раскрываем пункт Параметры(Options) и настраиваем:

- Завершение прогноза(Forecase End) – указывается дата, которой должен заканчиваться прогноз. Я советую всегда проверять эту дату, т.к. по умолчанию Excel почти всегда выставляет некую среднюю дату, которая отличается от необходимой.
- Начало прогноза(Forecase Start) – указывается дата, с которой необходимо начать строить прогноз. Как правило это последняя дата фактических данных. Если указать дату, которая будет раньше последней даты фактических данных, то для построения прогноза будут использоваться данные только ДО этой даты (так же это называется “ретроспективным прогнозированием”).
- Доверительный интервал(Confidence interval) – этот пункт поможет понять, насколько точно построен прогноз. Чем больше будет доверительный интервал, тем меньше точность прогноза и чем меньше доверительный интервал – тем выше точность прогноза. Что вполне логично. По умолчанию определяется для 95% точек, хотя его можно изменить в соответствующем поле. Если интервал создавать не нужно – снять галочку.
- Сезонность(Seasonality) – как понятно из названия, отвечает за определение фактора сезонности. Лучше оставлять автоматическим, при котором сезонность определяется на основании всех точек месяцев(т.е. 12). Но если этот фактор необходимо рассчитывать из иного количества точек, то необходимо выбрать Установка вручную и указать нужное количество точек. Но следует учитывать, что если точек будет недостаточно – то прогноз может быть очень неточным и график в итоге будет иметь вид, далекий от ожидаемого.
- Диапазон временной шкалы(Timeline Range) – указывается диапазон значений с датами фактических продаж, на основании которых необходимо построить прогноз. По размерам должен совпадать с параметром Диапазон значений.
- Диапазон значений(Values Range) – указывается диапазон значений с суммами фактических продаж, на основании которых необходимо построить прогноз. По размерам должен совпадать с параметром Диапазон временной шкалы.
- Заполнить отсутствующие точки с помощью(Fill Missing Poins Using) – если каких-то данных не хватает(например, имеются пропуски в ячейках с суммами), то можно выбрать чем эти данные заполнить. По умолчанию используется интерполяция. Это означает, что отсутствующие данные вычисляется как взвешенное среднее соседних ячеек, если отсутствует менее 30 % точек. Если необходимо заполнять отсутствующие точки нулями, то необходимо выбрать из выпадающего списка пункт Нули.
- Объединить дубликаты с помощью(Aggregate Duplicates Using) – если в фактических данных есть повторяющиеся даты, то Excel объединит их в одну точку с этой датой, а в качестве суммы подставит среднее арифметическое для этой даты. Это оптимальный вариант, но так же допускается выбрать из списка и другую функцию: Количество, СЧЁТЗ, Максимум, Медиана, Минимум, Сумма.
- Включить статистические данные прогноза(Include Forecast Statistics) – при включении данного пункта на листе с таблицей графика правее основных данных будет создана таблица с дополнительной статистической информации о прогнозе. В таблице при помощи функции ПРЕДСКАЗ.ЕTS.СТАТ будут рассчитаны коэффициенты сглаживания (Альфа, Бета, Гамма), и метрики ошибок (MASE, SMAPE, MAE, RMSE).
После нажатия кнопки Создать(Create) будет создан новый лист, в котором будет создана таблица со всеми необходимыми данными и формулами и готовым графиком:

если при создании был отмечен пункт Включить статистические данные прогноза(Include Forecast Statistics), то правее таблицы основных данных будет так же создана таблица статистических данных:

Скачать файл:
Прогноз_продаж.xls (59,5 KiB, 35 032 скачиваний)
Так же см.:
Как быстро подобрать оптимальный вариант решения
Автообновляемая сводная таблица
Статья помогла? Поделись ссылкой с друзьями!
![]() Видеоуроки
Видеоуроки
Поиск по меткам
Access
apple watch
Multex
Power Query и Power BI
VBA управление кодами
Бесплатные надстройки
Дата и время
Записки
ИП
Надстройки
Печать
Политика Конфиденциальности
Почта
Программы
Работа с приложениями
Разработка приложений
Росстат
Тренинги и вебинары
Финансовые
Форматирование
Функции Excel
акции MulTEx
ссылки
статистика
