| HTTP | |
|---|---|
| |
|
| Название | Hypertext Transfer Protocol |
| Уровень (по модели OSI) | Прикладной |
| Семейство | TCP/IP |
| Создан в | 1992 |
| Порт/ID | 80/TCP |
| Спецификация | RFC 124, RFC 1945, RFC 2616, RFC 2617, RFC 6266, RFC 7230, RFC 7240, RFC 8446. |
| Основные реализации (клиенты) | Веб-браузеры, например, Internet Explorer, Mozilla Firefox, Opera, Google Chrome, Яндекс.Браузер, Microsoft Edge и др. |
| Основные реализации (серверы) | Apache, IIS, nginx, Google Web Server и др. |
HTTP (англ. HyperText Transfer Protocol — «протокол передачи гипертекста») — протокол прикладного уровня передачи данных, изначально — в виде гипертекстовых документов в формате HTML, в настоящее время используется для передачи произвольных данных.
Основные свойства[править | править код]
Основой HTTP является технология «клиент-сервер», то есть предполагается существование:
- Потребителей (клиентов), которые инициируют соединение и посылают запрос;
- Поставщиков (серверов), которые ожидают соединения для получения запроса, производят необходимые действия и возвращают обратно сообщение с результатом.
HTTP в настоящее время повсеместно используется во Всемирной паутине для получения информации с веб-сайтов. В 2006 году в Северной Америке доля HTTP-трафика превысила долю P2P-сетей и составила 46 %, из которых почти половина — это передача потокового видео и звука[1].
HTTP используется также в качестве «транспорта» для других протоколов прикладного уровня, таких как SOAP, XML-RPC, WebDAV.
Основным объектом манипуляции в HTTP является ресурс, на который указывает URI (Uniform Resource Identifier) в запросе клиента. Обычно такими ресурсами являются хранящиеся на сервере файлы, но ими могут быть логические объекты или что-то абстрактное. Особенностью протокола HTTP является возможность указать в запросе и ответе способ представления одного и того же ресурса по различным параметрам: формату, кодировке, языку и т. д. (в частности, для этого используется HTTP-заголовок). Именно благодаря возможности указания способа кодирования сообщения клиент и сервер могут обмениваться двоичными данными, хотя данный протокол является текстовым.
HTTP — протокол прикладного уровня; аналогичными ему являются FTP и SMTP. Обмен сообщениями идёт по обыкновенной схеме «запрос-ответ». Для идентификации ресурсов HTTP использует глобальные URI. В отличие от многих других протоколов, HTTP не сохраняет своего состояния. Это означает отсутствие сохранения промежуточного состояния между парами «запрос-ответ». Компоненты, использующие HTTP, могут самостоятельно осуществлять сохранение информации о состоянии, связанной с последними запросами и ответами (например, «куки» на стороне клиента, «сессии» на стороне сервера). Браузер, посылающий запросы, может отслеживать задержки ответов. Сервер может хранить IP-адреса и заголовки запросов последних клиентов. Однако сам протокол не осведомлён о предыдущих запросах и ответах, в нём не предусмотрена внутренняя поддержка состояния, к нему не предъявляются такие требования.
Большинство протоколов предусматривает установление TCP-сессии, в ходе которой один раз происходит авторизация, и дальнейшие действия выполняются в контексте этой авторизации. HTTP же устанавливает отдельную TCP-сессию на каждый запрос; в более поздних версиях HTTP было разрешено делать несколько запросов в ходе одной TCP-сессии, но браузеры обычно запрашивают только страницу и включённые в неё объекты (картинки, каскадные стили и т. п.), а затем сразу разрывают TCP-сессию. Для поддержки авторизованного (неанонимного) доступа в HTTP используются cookies; причём такой способ авторизации позволяет сохранить сессию даже после перезагрузки клиента и сервера.
При доступе к данным по FTP или по файловым протоколам тип файла (точнее, тип содержащихся в нём данных) определяется по расширению имени файла, что не всегда удобно. HTTP перед тем, как передать сами данные, передаёт заголовок «Content-Type: тип/подтип», позволяющий клиенту однозначно определить, каким образом обрабатывать присланные данные. Это особенно важно при работе с CGI-скриптами, когда расширение имени файла указывает не на тип присылаемых клиенту данных, а на необходимость запуска данного файла на сервере и отправки клиенту результатов работы программы, записанной в этом файле (при этом один и тот же файл в зависимости от аргументов запроса и своих собственных соображений может порождать ответы разных типов — в простейшем случае картинки в разных форматах).
Кроме того, HTTP позволяет клиенту прислать на сервер параметры, которые будут переданы запускаемому CGI-скрипту. Для этого же в HTML были введены формы.
Перечисленные особенности HTTP позволили создавать поисковые машины (первой из которых стала AltaVista, созданная фирмой DEC), форумы и Internet-магазины. Это коммерциализировало Интернет, появились компании, основным полем деятельности которых стало предоставление доступа в Интернет (провайдеры) и создание сайтов.
Программное обеспечение[править | править код]
Всё программное обеспечение для работы с протоколом HTTP разделяется на три большие категории:
- Серверы как основные поставщики услуг хранения и обработки информации (обработка запросов);
- Клиенты — конечные потребители услуг сервера (отправка запроса);
- Прокси (посредники) для выполнения транспортных служб.
Для отличия конечных серверов от прокси в официальной документации используется термин «исходный сервер» (англ. origin server). Один и тот же программный продукт может одновременно выполнять функции клиента, сервера или посредника в зависимости от поставленных задач. В спецификациях протокола HTTP подробно описывается поведение для каждой из этих ролей.
Клиенты[править | править код]
Первоначально протокол HTTP разрабатывался для доступа к гипертекстовым документам Всемирной паутины. Поэтому основными реализациями клиентов являются браузеры (агенты пользователя). Для просмотра сохранённого содержимого сайтов на компьютере без соединения с Интернетом были придуманы офлайн-браузеры. При нестабильном соединении для загрузки больших файлов используются менеджеры закачек; они позволяют в любое время докачать указанные файлы после потери соединения с веб-сервером. Некоторые виртуальные атласы (такие как Google Планета Земля и NASA World Wind) тоже используют HTTP.
Нередко протокол HTTP используется программами для скачивания обновлений.
Целый комплекс программ-роботов используется в поисковых системах Интернета. Среди них веб-пауки (краулеры), которые производят проход по гиперссылкам, составляют базу данных ресурсов серверов и сохраняют их содержимое для дальнейшего анализа.
Исходные серверы[править | править код]
Основные реализации: Apache, Internet Information Services (IIS), nginx, LiteSpeed Web Server[en] (LSWS), Google Web Server, lighttpd.
Прокси-серверы[править | править код]
Основные реализации: Squid, UserGate, Multiproxy, Naviscope, nginx.
Структура HTTP-сообщения[править | править код]
Каждое HTTP-сообщение состоит из трёх частей, которые передаются в указанном порядке:
- Стартовая строка (англ. Starting line) — определяет тип сообщения;
- Заголовки (англ. Headers) — характеризуют тело сообщения, параметры передачи и прочие сведения;
- Тело сообщения (англ. Message Body) — непосредственно данные сообщения. Обязательно должно отделяться от заголовков пустой строкой.
Тело сообщения может отсутствовать, но стартовая строка и заголовок являются обязательными элементами. Исключением является версия 0.9 протокола, у которой сообщение запроса содержит только стартовую строку, а сообщения ответа — только тело сообщения.
Для версии протокола 1.1 сообщение запроса обязательно должно содержать заголовок Host.
Стартовая строка[править | править код]
Стартовые строки различаются для запроса и ответа. Строка запроса выглядит так:
GET URI— для версии протокола 0.9;Метод URI HTTP/Версия— для остальных версий.
Здесь:
- Метод (англ. Method) — тип запроса, одно слово заглавными буквами. В версии HTTP 0.9 использовался только метод
GET, список методов для версии 1.1 представлен ниже. - URI определяет путь к запрашиваемому документу.
- Версия (англ. Version) — пара разделённых точкой цифр. Например:
1.0.
Чтобы запросить страницу данной статьи, клиент должен передать строку (задан всего один заголовок):
GET /wiki/HTTP HTTP/1.0 Host: ru.wikipedia.org
Стартовая строка ответа сервера имеет следующий формат: HTTP/Версия КодСостояния Пояснение, где:
- Версия — пара разделённых точкой цифр, как в запросе;
- Код состояния (англ. Status Code) — три цифры. По коду состояния определяется дальнейшее содержимое сообщения и поведение клиента;
- Пояснение (англ. Reason Phrase) — текстовое короткое пояснение к коду ответа для пользователя. Никак не влияет на сообщение и является необязательным.
Например, стартовая строка ответа сервера на предыдущий запрос может выглядеть так:
HTTP/1.0 200 OK
Методы[править | править код]
Метод HTTP (англ. HTTP Method) — последовательность из любых символов, кроме управляющих и разделителей, указывающая на основную операцию над ресурсом. Обычно метод представляет собой короткое английское слово, записанное заглавными буквами. Обратите внимание, что название метода чувствительно к регистру.
Сервер может использовать любые методы, не существует обязательных методов для сервера или клиента. Если сервер не распознал указанный клиентом метод, то он должен вернуть статус 501 (Not Implemented). Если серверу метод известен, но он неприменим к конкретному ресурсу, то возвращается сообщение с кодом 405 (Method Not Allowed). В обоих случаях серверу следует включить в сообщение ответа заголовок Allow со списком поддерживаемых методов.
Кроме методов GET и HEAD, часто применяется метод POST.
OPTIONS[править | править код]
Используется для определения возможностей веб-сервера или параметров соединения для конкретного ресурса. В ответ серверу следует включить заголовок Allow со списком поддерживаемых методов. Также в заголовке ответа может включаться информация о поддерживаемых расширениях.
Предполагается, что запрос клиента может содержать тело сообщения для указания интересующих его сведений. Формат тела и порядок работы с ним в настоящий момент не определён; сервер пока должен его игнорировать. Аналогичная ситуация и с телом в ответе сервера.
Для того, чтобы узнать возможности всего сервера, клиент должен указать в URI звёздочку — «*». Запросы «OPTIONS * HTTP/1.1» могут также применяться для проверки работоспособности сервера (аналогично «пингованию») и тестирования на предмет поддержки сервером протокола HTTP версии 1.1.
Результат выполнения этого метода не кэшируется.
GET[править | править код]
Используется для запроса содержимого указанного ресурса. С помощью метода GET можно также начать какой-либо процесс. В этом случае в тело ответного сообщения следует включить информацию о ходе выполнения процесса.
Клиент может передавать параметры выполнения запроса в URI целевого ресурса после символа «?»:GET /path/resource?param1=value1¶m2=value2 HTTP/1.1
Согласно стандарту HTTP, запросы типа GET считаются идемпотентными[2]
Кроме обычного метода GET, различают ещё
- Условный
GET— содержит заголовкиIf-Modified-Since,If-Match,If-Rangeи подобные; - Частичный
GET— содержит в запросеRange.
Порядок выполнения подобных запросов определён стандартами отдельно.
HEAD[править | править код]
Аналогичен методу GET, за исключением того, что в ответе сервера отсутствует тело. Запрос HEAD обычно применяется для извлечения метаданных, проверки наличия ресурса (валидация URL) и чтобы узнать, не изменился ли он с момента последнего обращения.
Заголовки ответа могут кэшироваться. При несовпадении метаданных ресурса с соответствующей информацией в кэше — копия ресурса помечается как устаревшая.
POST[править | править код]
Применяется для передачи пользовательских данных заданному ресурсу. Например, в блогах посетители обычно могут вводить свои комментарии к записям в HTML-форму, после чего они передаются серверу методом POST и он помещает их на страницу. При этом передаваемые данные (в примере с блогами — текст комментария) включаются в тело запроса. Аналогично с помощью метода POST обычно загружаются файлы на сервер.
В отличие от метода GET, метод POST не считается идемпотентным[2], то есть многократное повторение одних и тех же запросов POST может возвращать разные результаты (например, после каждой отправки комментария будет появляться очередная копия этого комментария).
При результате выполнения 200 (Ok) в тело ответа следует включить сообщение об итоге выполнения запроса. Если был создан ресурс, то серверу следует вернуть ответ 201 (Created) с указанием URI нового ресурса в заголовке Location.
Сообщение ответа сервера на выполнение метода POST не кэшируется.
PUT[править | править код]
Применяется для загрузки содержимого запроса на указанный в запросе URI. Если по заданному URI не существует ресурса, то сервер создаёт его и возвращает статус 201 (Created). Если же ресурс был изменён, то сервер возвращает 200 (Ok) или 204 (No Content). Сервер не должен игнорировать некорректные заголовки Content-*, передаваемые клиентом вместе с сообщением. Если какой-то из этих заголовков не может быть распознан или недопустим при текущих условиях, то необходимо вернуть код ошибки 501 (Not Implemented).
Фундаментальное различие методов POST и PUT заключается в понимании предназначений URI ресурсов. Метод POST предполагает, что по указанному URI будет производиться обработка передаваемого клиентом содержимого. Используя PUT, клиент предполагает, что загружаемое содержимое соответствует находящемуся по данному URI ресурсу.
Сообщения ответов сервера на метод PUT не кэшируются.
PATCH[править | править код]
Аналогично PUT, но применяется только к фрагменту ресурса.
DELETE[править | править код]
Удаляет указанный ресурс.
TRACE[править | править код]
Возвращает полученный запрос так, что клиент может увидеть, какую информацию промежуточные серверы добавляют или изменяют в запросе.
CONNECT[править | править код]
Преобразует соединение запроса в прозрачный TCP/IP-туннель, обычно чтобы содействовать установлению защищённого SSL-соединения через нешифрованный прокси.
Коды состояния[править | править код]
Код состояния является частью первой строки ответа сервера. Он представляет собой целое число из трёх цифр[3]. Первая цифра указывает на класс состояния. За кодом ответа обычно следует отделённая пробелом поясняющая фраза на английском языке, которая разъясняет человеку причину именно такого ответа. Примеры:
201 Webpage Created 403 Access allowed only for registered users 507 Insufficient Storage
Клиент узнаёт по коду ответа о результатах его запроса и определяет, какие действия ему предпринимать дальше. Набор кодов состояния является стандартом, и они описаны в соответствующих документах RFC. Введение новых кодов должно производиться только после согласования с IETF. Клиент может не знать все коды состояния, но он обязан отреагировать в соответствии с классом кода.
В настоящее время выделено пять классов кодов состояния
| Код | Класс | Назначение |
|---|---|---|
1xx
|
Информационный
(англ. informational) |
Информирование о процессе передачи.
В HTTP/1.0 — сообщения с такими кодами должны игнорироваться. В HTTP/1.1 — клиент должен быть готов принять этот класс сообщений как обычный ответ, но ничего отправлять серверу не нужно. Сами сообщения от сервера содержат только стартовую строку ответа и, если требуется, несколько специфичных для ответа полей заголовка. Прокси-серверы подобные сообщения должны отправлять дальше от сервера к клиенту. |
2xx
|
Успех
(англ. Success) |
Информирование о случаях успешного принятия и обработки запроса клиента. В зависимости от статуса, сервер может ещё передать заголовки и тело сообщения. |
3xx
|
Перенаправление
(англ. Redirection) |
Сообщает клиенту, что для успешного выполнения операции необходимо сделать другой запрос (как правило по другому URI). Из данного класса пять кодов 301, 302, 303, 305 и 307 относятся непосредственно к перенаправлениям (редирект). Адрес, по которому клиенту следует произвести запрос, сервер указывает в заголовке Location. При этом допускается использование фрагментов в целевом URI.
|
4xx
|
Ошибка клиента
(англ. Client Error) |
Указание ошибок со стороны клиента. При использовании всех методов, кроме HEAD, сервер должен вернуть в теле сообщения гипертекстовое пояснение для пользователя.
|
5xx
|
Ошибка сервера
(англ. Server Error) |
Информирование о случаях неудачного выполнения операции по вине сервера. Для всех ситуаций, кроме использования метода HEAD, сервер должен включать в тело сообщения объяснение, которое клиент отобразит пользователю.
|
Заголовки[править | править код]
Заголовки HTTP (англ. HTTP Headers) — это строки в HTTP-сообщении, содержащие разделённую двоеточием пару параметр-значение. Формат заголовков соответствует общему формату заголовков текстовых сетевых сообщений ARPA (см. RFC 822). Заголовки должны отделяться от тела сообщения хотя бы одной пустой строкой.
Примеры заголовков:
Server: Apache/2.2.11 (Win32) PHP/5.3.0 Last-Modified: Sat, 16 Jan 2010 21:16:42 GMT Content-Type: text/plain; charset=windows-1251 Content-Language: ru
В примере выше каждая строка представляет собой один заголовок. При этом то, что находится до двоеточия, называется именем (англ. name), а что после него — значением (англ. value).
Все заголовки разделяются на четыре основных группы:
- General Headers («Основные заголовки») — могут включаться в любое сообщение клиента и сервера;
- Request Headers («Заголовки запроса») — используются только в запросах клиента;
- Response Headers («Заголовки ответа») — только для ответов от сервера;
- Entity Headers («Заголовки сущности») — сопровождают каждую сущность сообщения.
Именно в таком порядке рекомендуется посылать заголовки получателю.
Все необходимые для функционирования HTTP заголовки описаны в основных RFC. Если не хватает существующих, то можно вводить свои. Традиционно к именам таких дополнительных заголовков добавляют префикс «X-» для избежания конфликта имён с возможно существующими. Например, как в заголовках X-Powered-By или X-Cache. Некоторые разработчики используют свои индивидуальные префиксы. Примерами таких заголовков могут служить Ms-Echo-Request и Ms-Echo-Reply, введённые корпорацией Microsoft для расширения WebDAV.
Тело сообщения[править | править код]
Тело HTTP-сообщения (message-body), если оно присутствует, используется для передачи тела объекта, связанного с запросом или ответом. Тело сообщения отличается от тела объекта (entity-body) только в том случае, когда применяется кодирование передачи, что указывается полем заголовка Transfer-Encoding.
message-body = entity-body | <entity-body закодировано согласно Transfer-Encoding>
Поле Transfer-Encoding должно использоваться для указания любого кодирования передачи, применённого приложением в целях гарантирования безопасной и правильной передачи сообщения. Поле Transfer-Encoding — это свойство сообщения, а не объекта, и, таким образом, может быть добавлено или удалено любым приложением в цепочке запросов/ответов.
Правила, устанавливающие допустимость тела сообщения в сообщении, отличны для запросов и ответов.
Присутствие тела сообщения в запросе отмечается добавлением к заголовкам запроса поля заголовка Content-Length или Transfer-Encoding. Тело сообщения может быть добавлено в запрос, только когда метод запроса допускает тело объекта.
Включается или не включается тело сообщения в сообщение ответа — зависит как от метода запроса, так и от кода состояния ответа. Все ответы на запрос с методом HEAD не должны включать тело сообщения, даже если присутствуют поля заголовка объекта (entity-header), заставляющие поверить в присутствие объекта. Никакие ответы с кодами состояния 1xx (Информационные), 204 (Нет содержимого, No Content), и 304 (Не модифицирован, Not Modified) не должны содержать тела сообщения. Все другие ответы содержат тело сообщения, даже если оно имеет нулевую длину.
Примеры диалогов HTTP[править | править код]
Обычный GET-запрос
Запрос клиента:
GET /wiki/страница HTTP/1.1 Host: ru.wikipedia.org User-Agent: Mozilla/5.0 (X11; U; Linux i686; ru; rv:1.9b5) Gecko/2008050509 Firefox/3.0b5 Accept: text/html Connection: close (пустая строка)
Ответ сервера:
HTTP/1.1 200 OK Date: Wed, 11 Feb 2009 11:20:59 GMT Server: Apache X-Powered-By: PHP/5.2.4-2ubuntu5wm1 Last-Modified: Wed, 11 Feb 2009 11:20:59 GMT Content-Language: ru Content-Type: text/html; charset=utf-8 Content-Length: 1234 Connection: close (пустая строка) (запрошенная страница в HTML)
Аналогично выглядит ответ 203. Что существенно — непосредственно запрашиваемые данные отделены от HTTP-заголовков с помощью CR, LF, CR, LF.
Перенаправления
Предположим, что у вымышленной компании «Example Corp.» есть основной сайт по адресу «http://example.com» и домен-псевдоним «example.org». Клиент посылает запрос страницы «О компании» на вторичный домен (часть заголовков опущена):
GET /about.html HTTP/1.1 Host: example.org User-Agent: MyLonelyBrowser/5.0
Так как домен «example.org» не является основным и компания не собирается в будущем его использовать в других целях, их сервер вернёт код для постоянного перенаправления, указав в заголовке Location целевой URL:
HTTP/1.x 301 Moved Permanently
Location: http://example.com/about.html#contacts
Date: Thu, 19 Feb 2009 11:08:01 GMT
Server: Apache/2.2.4
Content-Type: text/html; charset=windows-1251
Content-Length: 110
(пустая строка)
<html><body><a href="http://example.com/about.html#contacts">Click here</a></body></html>
В заголовке Location можно указывать фрагменты как в данном примере. Браузер не указал фрагмент в запросе, так как его интересует весь документ. Но он автоматически прокрутит страницу до фрагмента «contacts», как только загрузит её. В тело ответа также был помещён короткий HTML-документ со ссылкой, с помощью которой посетитель попадёт на целевую страницу, если браузер не перейдёт на неё автоматически. Заголовок Content-Type содержит характеристики именно этого HTML-пояснения, а не документа, который находится по целевому URI.
Допустим, эта же компания «Example Corp.» имеет несколько региональных представительств по всему миру. И для каждого представительства у них есть сайт с соответствующим ccTLD. Запрос главной страницы основного сайта «example.com» может выглядеть так:
GET / HTTP/1.1 Host: example.com User-Agent: MyLonelyBrowser/5.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: ru,en-us;q=0.7,en;q=0.3 Accept-Charset: windows-1251,utf-8;q=0.7,*;q=0.7
Сервер принял во внимание заголовок Accept-Language и сформировал ответ со временным перенаправлением на российский сервер «example.ru», указав его адрес в заголовке Location:
HTTP/1.x 302 Found
Location: http://example.ru/
Cache-Control: private
Date: Thu, 19 Feb 2009 11:08:01 GMT
Server: Apache/2.2.6
Content-Type: text/html; charset=windows-1251
Content-Length: 82
(пустая строка)
<html><body><a href="http://example.ru">Example Corp.</a></body></html>
Обратите внимание на заголовок Cache-Control: значение «private» сообщает остальным серверам (в первую очередь прокси) что ответ может кэшироваться только на стороне клиента. В противном случае не исключено, что следующие посетители из других стран будут переходить всё время не в своё представительство.
Для перенаправления также используются коды ответа 303 (See Other) и 307 (Temporary Redirect).
Докачка и фрагментарное скачивание
Допустим, вымышленная организация предлагает скачать с сайта видео прошедшей конференции по адресу: «http://example.org/conf-2009.avi» — объёмом примерно 160 МБ. Рассмотрим, как происходит докачивание этого файла в случае сбоя и как менеджер закачек организовал бы многопоточную загрузку нескольких фрагментов.
В обоих случаях клиенты произведут свой первый запрос наподобие этого:
GET /conf-2009.avi HTTP/1.0 Host: example.org Accept: */* User-Agent: Mozilla/4.0 (compatible; MSIE 5.0; Windows 98) Referer: http://example.org/
Заголовок Referer указывает, что файл был запрошен с главной страницы сайта. Менеджеры закачек обычно тоже его указывают, чтобы эмулировать переход со страницы сайта. Без него сервер может ответить 403 (Access Forbidden), если не допускаются запросы с других сайтов. В нашем случае сервер вернул успешный ответ:
HTTP/1.1 200 OK Date: Thu, 19 Feb 2009 12:27:04 GMT Server: Apache/2.2.3 Last-Modified: Wed, 18 Jun 2003 16:05:58 GMT ETag: "56d-9989200-1132c580" Content-Type: video/x-msvideo Content-Length: 160993792 Accept-Ranges: bytes Connection: close (пустая строка) (двоичное содержимое всего файла)
Заголовок Accept-Ranges информирует клиента о том, что он может запрашивать у сервера фрагменты, указывая их смещения от начала файла в байтах. Если этот заголовок отсутствует, то клиент может предупредить пользователя, что докачать файл, скорее всего, не удастся.
Исходя из значения заголовка Content-Length, менеджер закачек поделит весь объём на равные фрагменты и запросит их по отдельности, организовав несколько потоков. Если сервер не укажет размер, то клиенту параллельное скачивание реализовать не удастся, но при этом он сможет докачивать файл, пока сервер не ответит 416 (Requested Range Not Satisfiable).
Допустим, на 84-м мегабайте соединение с Интернетом прервалось и процесс загрузки приостановился. Когда соединение с Интернетом было восстановлено, менеджер закачек автоматически послал новый запрос на сервер, но с указанием выдать содержимое с 84-го мегабайта:
GET /conf-2009.avi HTTP/1.0 Host: example.org Accept: */* User-Agent: Mozilla/4.0 (compatible; MSIE 5.0; Windows 98) Range: bytes=88080384- Referer: http://example.org/
Сервер не обязан помнить, какие и от кого запросы были до этого, и поэтому клиент снова вставил заголовок Referer, как будто это его самый первый запрос. Указанное значение заголовка Range говорит серверу: «Выдай содержимое от 88080384-го байта до самого конца». В связи с этим сервер вернёт ответ:
HTTP/1.1 206 Partial Content Date: Thu, 19 Feb 2009 12:27:08 GMT Server: Apache/2.2.3 Last-Modified: Wed, 18 Jun 2003 16:05:58 GMT ETag: "56d-9989200-1132c580" Accept-Ranges: bytes Content-Range: bytes 88080384-160993791/160993792 Content-Length: 72913408 Connection: close Content-Type: video/x-msvideo (пустая строка) (двоичное содержимое от 84-го мегабайта)
Заголовок Accept-Ranges здесь уже не обязателен, так как клиент уже знает об этой возможности сервера. О том, что передаётся фрагмент, клиент узнаёт по коду 206 (Partial Content). В заголовке Content-Range содержится информация о данном фрагменте: номера начального и конечного байта, а после слэша — суммарный объём всего файла в байтах. Обратите внимание на заголовок Content-Length — в нём указывается размер тела сообщения, то есть передаваемого фрагмента. Если сервер вернёт несколько фрагментов, то Content-Length будет содержать их суммарный объём.
Теперь вернёмся к менеджеру закачек. Зная суммарный объём файла «conf-2009.avi», программа поделила его на 10 равных секций.
Начальную менеджер загрузит при самом первом запросе, прервав соединение как только дойдёт до начала второго. Остальные он запросит отдельно. Например, 4-я секция будет запрошена со следующими заголовками (часть заголовков опущена — см. полный пример выше):
GET /conf-2009.avi HTTP/1.0 Range: bytes=64397516-80496894
Ответ сервера в этом случае будет следующим (часть заголовков опущена — см. полный пример выше):
HTTP/1.1 206 Partial Content Accept-Ranges: bytes Content-Range: bytes 64397516-80496894/160993792 Content-Length: 16099379 (пустая строка) (двоичное содержимое 4-й части)
Если подобный запрос отправить серверу, который не поддерживает фрагменты, то он вернёт стандартный ответ 200 (OK) как было показано в самом начале, но без заголовка Accept-Ranges.
- См. также частичные GET, байтовые диапазоны, ответ 206, ответ 416.
Основные механизмы протокола[править | править код]
Частичные GET[править | править код]
HTTP позволяет запросить не сразу всё содержимое ресурса, а только указанный фрагмент. Такие запросы называются частичные GET; возможность их выполнения необязательна (но желательна) для серверов. Частичные GET в основном используются для докачки файлов и быстрого параллельного скачивания в нескольких потоках. Некоторые программы скачивают заголовок архива, выводят пользователю внутреннюю структуру, а потом уже запрашивают фрагменты с указанными элементами архива.
Для получения фрагмента клиент посылает серверу запрос с заголовком Range, указывая в нём необходимые байтовые диапазоны. Если сервер не понимает частичные запросы (игнорирует заголовок Range), то он вернёт всё содержимое со статусом 200, как и при обычном GET. В случае успешного выполнения сервер возвращает вместо кода 200 ответ со статусом 206 (Partial Content), включая в ответ заголовок Content-Range. Сами фрагменты могут быть переданы двумя способами:
- В ответе помещается заголовок
Content-Rangeс указанием байтовых диапазонов. В соответствии с ними фрагменты последовательно помещаются в основное тело. При этомContent-Lengthдолжен соответствовать суммарному объёму всего тела; - Сервер указывает медиатип
multipart/byterangesдля основного содержимого и передаёт фрагменты, указывая соответствующийContent-Rangeдля каждого элемента (см. также «Множественное содержимое»[⇨]).
Условные GET[править | править код]
Метод GET изменяется на «условный GET», если сообщение запроса включает в себя поле заголовка If-Modified-Since. В ответ на «условный GET» тело запрашиваемого ресурса передаётся, только если он изменялся после даты, указанной в заголовке If-Modified-Since. Алгоритм определения этого включает в себя следующие случаи:
- Если статус ответа на запрос будет отличаться от «200 OK» или дата, указанная в поле заголовка «If-Modified-Since», некорректна, ответ будет идентичен ответу на обычный запрос GET.
- Если после указанной даты ресурс изменялся, ответ будет также идентичен ответу на обычный запрос GET.
- Если ресурс не изменялся после указанной даты, сервер вернет статус «304 Not Modified».
Использование метода «условный GET» направлено на разгрузку сети, так как он позволяет не передавать по сети избыточную информацию.
Согласование содержимого[править | править код]
Согласование содержимого (англ. Content Negotiation) — механизм автоматического определения необходимого ресурса при наличии нескольких разнотипных версий документа. Субъектами согласования могут быть не только ресурсы сервера, но и возвращаемые страницы с сообщениями об ошибках (403, 404 и т. п.).
Различают два основных типа согласований:
- Управляемое сервером (англ. server-driven).
- Управляемое клиентом (англ. agent-driven).
Одновременно могут быть использованы оба типа или каждый из них по отдельности.
В основной спецификации по протоколу (RFC 2616) также выделяется так называемое прозрачное согласование (англ. transparent negotiation) как предпочтительный вариант комбинирования обоих типов. Последний механизм не следует путать с независимой технологией Transparent Content Negotiation (TCN, «Прозрачное согласование содержимого», см. RFC 2295), которая не является частью протокола HTTP, но может использоваться с ним. У обоих существенное различие в принципе работы и самом значении слова «прозрачное» (transparent). В спецификации по HTTP под прозрачностью подразумевается, что процесс не заметен для клиента и сервера, а в технологии TCN прозрачность означает доступность полного списка вариантов ресурса для всех участников процесса доставки данных.
Управляемое сервером[править | править код]
При наличии нескольких версий ресурса сервер может анализировать заголовки запроса клиента, чтобы выдать, по его мнению, наиболее подходящую. В основном анализируются заголовки Accept, Accept-Charset, Accept-Encoding, Accept-Languages и User-Agent. Серверу желательно включать в ответ заголовок Vary с указанием параметров, по которым различается содержимое по запрашиваемому URI.
Географическое положение клиента можно определить по удалённому IP-адресу. Это возможно за счёт того что IP-адреса, как и доменные имена, регистрируются на конкретного человека или организацию. При регистрации указывается регион, в котором будет использоваться желаемое адресное пространство. Эти данные общедоступны, и в Интернете можно найти соответствующие свободно распространяемые базы данных и готовые программные модули для работы с ними (следует ориентироваться на ключевые слова «Geo IP»).
Следует помнить что такой метод способен определить местоположение максимум с точностью до города (отсюда определяется и страна).
При этом информация актуальна только на момент регистрации адресного пространства. Например, если московский провайдер зарегистрирует диапазон адресов с указанием Москвы и начнёт предоставлять доступ клиентам из ближайшего Подмосковья, то его абоненты могут на некоторых сайтах наблюдать, что они из Москвы, а не из Красногорска или Дзержинского.
Управляемое сервером согласование имеет несколько недостатков:
- Сервер только предполагает, какой вариант наиболее предпочтителен для конечного пользователя, но не может знать точно, что именно нужно в данный момент (например, версия на русском языке или английском).
- Заголовков группы Accept передаётся много, а ресурсов с несколькими вариантами — мало. Из-за этого оборудование испытывает избыточную нагрузку.
- Общему кэшу создаётся ограничение возможности выдавать один и тот же ответ на идентичные запросы от разных пользователей.
- Передача заголовков Accept также может раскрывать некоторые сведения о его предпочтениях, таких как используемые языки, браузер, кодировка.
Управляемое клиентом[править | править код]
В данном случае тип содержимого определяется только на стороне клиента.
Для этого сервер возвращает в ответе с кодом состояния 300 (Multiple Choices) или 406 (Not Acceptable) список вариантов, среди которых пользователь выбирает подходящий.
Управляемое клиентом согласование хорошо, когда содержимое различается по самым частым параметрам (например, по языку и кодировке) и используется публичный кэш.
Основной недостаток — лишняя нагрузка, так как приходится делать дополнительный запрос, чтобы получить нужное содержимое.
Прозрачное согласование[править | править код]
Данное согласование полностью прозрачно для клиента и сервера. В данном случае используется общий кэш, в котором содержится список вариантов, как для управляемого клиентом согласования. Если кэш понимает все эти варианты, то он сам делает выбор, как при управляемом сервером согласовании. Это снижает нагрузки с исходного сервера и исключает дополнительный запрос со стороны клиента.
В основной спецификации по протоколу HTTP механизм прозрачного согласования подробно не описан.
Множественное содержимое[править | править код]
Основная статья: MIME
Протокол HTTP поддерживает передачу нескольких сущностей в пределах одного сообщения. Причём сущности могут передаваться не только в виде одноуровневой последовательности, но и в виде иерархии с вложением элементов друг в друга. Для обозначения множественного содержимого используются медиатипы multipart/*. Работа с такими типами осуществляется по общим правилам, описанным в RFC 2046 (если иное не определено конкретным медиатипом). Если получателю не известно как работать с типом, то он обрабатывает его так же, как multipart/mixed.
Параметр boundary означает разделитель между различными типами передаваемых сообщений. Например, передаваемый из формы параметр DestAddress передаёт значение адреса e-mail, а следующий за ним элемент AttachedFile1 отправляет двоичное содержимое изображения формата .jpg
Со стороны сервера сообщения со множественным содержимым могут посылаться в ответ на частичные GET при запросе нескольких фрагментов ресурса. В этом случае используется медиатип multipart/byteranges.
Со стороны клиента при отправке HTML-формы чаще всего пользуются методом POST. Типичный пример: страницы отправки электронных писем со вложенными файлами. При отправке такого письма браузер формирует сообщение типа multipart/form-data, интегрируя в него как отдельные части, введённые пользователем, тему письма, адрес получателя, сам текст и вложенные файлы:
POST /send-message.html HTTP/1.1 Host: mail.example.com Referer: http://mail.example.com/send-message.html User-Agent: BrowserForDummies/4.67b Content-Type: multipart/form-data; boundary="Asrf456BGe4h" Content-Length: (суммарный объём, включая дочерние заголовки) Connection: keep-alive Keep-Alive: 300 (пустая строка) (отсутствующая преамбула) --Asrf456BGe4h Content-Disposition: form-data; name="DestAddress" (пустая строка) brutal-vasya@example.com --Asrf456BGe4h Content-Disposition: form-data; name="MessageTitle" (пустая строка) Я негодую --Asrf456BGe4h Content-Disposition: form-data; name="MessageText" (пустая строка) Привет, Василий! Твой ручной лев, которого ты оставил у меня на прошлой неделе, разодрал весь мой диван. Пожалуйста, забери его скорее! Во вложении две фотки с последствиями. --Asrf456BGe4h Content-Disposition: form-data; name="AttachedFile1"; filename="horror-photo-1.jpg" Content-Type: image/jpeg (пустая строка) (двоичное содержимое первой фотографии) --Asrf456BGe4h Content-Disposition: form-data; name="AttachedFile2"; filename="horror-photo-2.jpg" Content-Type: image/jpeg (пустая строка) (двоичное содержимое второй фотографии) --Asrf456BGe4h-- (отсутствующий эпилог)
В примере в заголовках Content-Disposition параметр name соответствует атрибуту name в HTML-тегах <INPUT> и <TEXTAREA>. Параметр filename равен исходному имени файла на компьютере пользователя. Более подробная информация о формировании HTML-форм и вложении файлов в RFC 1867.
История развития[править | править код]
- HTTP/0.9
- HTTP был предложен в марте 1991 года Тимом Бернерсом-Ли, работавшим тогда в CERN, как механизм для доступа к документам в Интернете и облегчения навигации посредством использования гипертекста. Самая ранняя версия протокола HTTP/0.9 была впервые опубликована в январе 1992 года (хотя реализация датируется 1990 годом). Спецификация протокола привела к упорядочению правил взаимодействия между клиентами и серверами HTTP, а также чёткому разделению функций между этими двумя компонентами. Были задокументированы основные синтаксические и семантические положения.
- HTTP/1.0
- В мае 1996 года для практической реализации HTTP был выпущен информационный документ RFC 1945, что послужило основой для реализации большинства компонентов HTTP/1.0.
- HTTP/1.1
- Современная версия протокола; принята в июне 1999 года[4]. Новым в этой версии был режим «постоянного соединения»: TCP-соединение может оставаться открытым после отправки ответа на запрос, что позволяет посылать несколько запросов за одно соединение. Клиент теперь обязан посылать информацию об имени хоста, к которому он обращается, что сделало возможной более простую организацию виртуального хостинга.
- HTTP/2
- 11 февраля 2015 года опубликованы финальные версии черновика следующей версии протокола. В отличие от предыдущих версий, протокол HTTP/2 является бинарным. Среди ключевых особенностей: мультиплексирование запросов, расстановка приоритетов для запросов, сжатие заголовков, загрузка нескольких элементов параллельно посредством одного TCP-соединения, поддержка проактивных push-уведомлений со стороны сервера[5].
- HTTP/3
- HTTP/3 — предлагаемый последователь HTTP/2[6][7], который уже используется в Веб на основе UDP вместо TCP в качестве транспортного протокола. Как и HTTP/2, он не объявляет устаревшими предыдущие основные версии протокола. Поддержка HTTP/3 была добавлена в Cloudflare и Google Chrome в сентябре 2019 года[8][9] и может быть включена в стабильных версиях Chrome и Firefox[10].
См. также[править | править код]
- Список кодов состояния HTTP
- Заголовки HTTP (список):
- Referer
- User-Agent
- Cookie
- Дайджест-аутентификация
- HTTP/2
- HTTPS
Примечания[править | править код]
- ↑ Объём HTTP-трафика впервые превысил P2P Архивная копия от 22 декабря 2007 на Wayback Machine // Компьюлента, 22 июня 2007 (Официальный документ от Ellacoya Networks Архивная копия от 22 июня 2007 на Wayback Machine).
- ↑ 1 2 HTTP/1.1: Method Definitions (англ.) (недоступная ссылка — история). Архивировано 23 июня 2012 года.
- ↑ См. первое предложение раздела «6.1.1 Status Code and Reason Phrase» в RFC 2068. На стр. 40 есть также объявление в формате расширенной БНФ-формы (Augmented BNF (англ.) (рус.) «
extension-code = 3DIGIT» для кодов расширений. - ↑ Впервые спецификация HTTP/1.1 была опубликована в январе 1997 RFC 2068; в современной версии RFC 2616 исправлены опечатки, местами улучшены терминология и оформление. Также разъяснено допустимое поведение клиента (браузера), сервера и прокси-серверов в некоторых сомнительных ситуациях. То есть версия 1.1 появилась всё-таки в 1997 году.
- ↑ HTTP/2 Draft. Дата обращения: 25 февраля 2015. Архивировано 20 февраля 2015 года.
- ↑ Bishop, Mike Hypertext Transfer Protocol Version 3 (HTTP/3) (англ.). tools.ietf.org (9 июля 2019). Дата обращения: 16 августа 2019. Архивировано 31 августа 2019 года.
- ↑ Cimpanu, Catalin. HTTP-over-QUIC to be renamed HTTP/3 | ZDNet (англ.), ZDNet. Архивировано 13 ноября 2018 года. Дата обращения: 10 августа 2020.
- ↑ Cimpanu, Catalin Cloudflare, Google Chrome, and Firefox add HTTP/3 support. ZDNet (26 сентября 2019). Дата обращения: 27 сентября 2019. Архивировано 26 сентября 2019 года.
- ↑ HTTP/3: the past, the present, and the future (англ.). The Cloudflare Blog (26 сентября 2019). Дата обращения: 30 октября 2019. Архивировано 26 сентября 2019 года.
- ↑ Firefox Nightly supports HTTP 3 – General – Cloudflare Community (19 ноября 2019). Дата обращения: 23 января 2020. Архивировано 6 июня 2020 года.
Ссылки[править | править код]
 Медиафайлы по теме HTTP на Викискладе
Медиафайлы по теме HTTP на Викискладе- RFC 1945 — HTTP/1.0 (Май 1996), включает версию 0.9
- RFC 2616 — HTTP/1.1 (Июнь 1999); см. также в виде PostScript и PDF;
- httpbis-http2-17 — HTTP/2 (11 февраля 2015) Окончательная спецификация
- «Разъяснение http/2» Даниэль Штенберг (рус.)
- Найденные опечатки в спецификации HTTP/1.1
- Перевод спецификации HTTP/1.1
- Первоначальный HTTP 0.9 Тима Бернерса-Ли (написан и издан в 1991 году)
- Ранняя версия исходного черновика версии 1.0 1992 года Тима Бернерса-Ли
- Пример последовательности HTTP-обмена Архивная копия от 5 августа 2012 на Wayback Machine между браузером и сервером
- Функционирование HTTP-сервера
Время на прочтение
9 мин
Количество просмотров 1.3M
Вашему вниманию предлагается описание основных аспектов протокола HTTP — сетевого протокола, с начала 90-х и по сей день позволяющего вашему браузеру загружать веб-страницы. Данная статья написана для тех, кто только начинает работать с компьютерными сетями и заниматься разработкой сетевых приложений, и кому пока что сложно самостоятельно читать официальные спецификации.
HTTP — широко распространённый протокол передачи данных, изначально предназначенный для передачи гипертекстовых документов (то есть документов, которые могут содержать ссылки, позволяющие организовать переход к другим документам).
Аббревиатура HTTP расшифровывается как HyperText Transfer Protocol, «протокол передачи гипертекста». В соответствии со спецификацией OSI, HTTP является протоколом прикладного (верхнего, 7-го) уровня. Актуальная на данный момент версия протокола, HTTP 1.1, описана в спецификации RFC 2616.
Протокол HTTP предполагает использование клиент-серверной структуры передачи данных. Клиентское приложение формирует запрос и отправляет его на сервер, после чего серверное программное обеспечение обрабатывает данный запрос, формирует ответ и передаёт его обратно клиенту. После этого клиентское приложение может продолжить отправлять другие запросы, которые будут обработаны аналогичным образом.
Задача, которая традиционно решается с помощью протокола HTTP — обмен данными между пользовательским приложением, осуществляющим доступ к веб-ресурсам (обычно это веб-браузер) и веб-сервером. На данный момент именно благодаря протоколу HTTP обеспечивается работа Всемирной паутины.
Также HTTP часто используется как протокол передачи информации для других протоколов прикладного уровня, таких как SOAP, XML-RPC и WebDAV. В таком случае говорят, что протокол HTTP используется как «транспорт».
API многих программных продуктов также подразумевает использование HTTP для передачи данных — сами данные при этом могут иметь любой формат, например, XML или JSON.
Как правило, передача данных по протоколу HTTP осуществляется через TCP/IP-соединения. Серверное программное обеспечение при этом обычно использует TCP-порт 80 (и, если порт не указан явно, то обычно клиентское программное обеспечение по умолчанию использует именно 80-й порт для открываемых HTTP-соединений), хотя может использовать и любой другой.
Как отправить HTTP-запрос?
Самый простой способ разобраться с протоколом HTTP — это попробовать обратиться к какому-нибудь веб-ресурсу вручную. Представьте, что вы браузер, и у вас есть пользователь, который очень хочет прочитать статьи Анатолия Ализара.
Предположим, что он ввёл в адресной строке следующее:
http://alizar.habrahabr.ru/
Соответственно вам, как веб-браузеру, теперь необходимо подключиться к веб-серверу по адресу alizar.habrahabr.ru.
Для этого вы можете воспользоваться любой подходящей утилитой командной строки. Например, telnet:
telnet alizar.habrahabr.ru 80
Сразу уточню, что если вы вдруг передумаете, то нажмите Ctrl + «]», и затем ввод — это позволит вам закрыть HTTP-соединение. Помимо telnet можете попробовать nc (или ncat) — по вкусу.
После того, как вы подключитесь к серверу, нужно отправить HTTP-запрос. Это, кстати, очень легко — HTTP-запросы могут состоять всего из двух строчек.
Для того, чтобы сформировать HTTP-запрос, необходимо составить стартовую строку, а также задать по крайней мере один заголовок — это заголовок Host, который является обязательным, и должен присутствовать в каждом запросе. Дело в том, что преобразование доменного имени в IP-адрес осуществляется на стороне клиента, и, соответственно, когда вы открываете TCP-соединение, то удалённый сервер не обладает никакой информацией о том, какой именно адрес использовался для соединения: это мог быть, например, адрес alizar.habrahabr.ru, habrahabr.ru или m.habrahabr.ru — и во всех этих случаях ответ может отличаться. Однако фактически сетевое соединение во всех случаях открывается с узлом 212.24.43.44, и даже если первоначально при открытии соединения был задан не этот IP-адрес, а какое-либо доменное имя, то сервер об этом никак не информируется — и именно поэтому этот адрес необходимо передать в заголовке Host.
Стартовая (начальная) строка запроса для HTTP 1.1 составляется по следующей схеме:
Метод URI HTTP/Версия
Например (такая стартовая строка может указывать на то, что запрашивается главная страница сайта):
GET / HTTP/1.1
Метод (в англоязычной тематической литературе используется слово method, а также иногда слово verb — «глагол») представляет собой последовательность из любых символов, кроме управляющих и разделителей, и определяет операцию, которую нужно осуществить с указанным ресурсом. Спецификация HTTP 1.1 не ограничивает количество разных методов, которые могут быть использованы, однако в целях соответствия общим стандартам и сохранения совместимости с максимально широким спектром программного обеспечения как правило используются лишь некоторые, наиболее стандартные методы, смысл которых однозначно раскрыт в спецификации протокола.
URI (Uniform Resource Identifier, унифицированный идентификатор ресурса) — путь до конкретного ресурса (например, документа), над которым необходимо осуществить операцию (например, в случае использования метода GET подразумевается получение ресурса). Некоторые запросы могут не относиться к какому-либо ресурсу, в этом случае вместо URI в стартовую строку может быть добавлена звёздочка (астериск, символ «*»). Например, это может быть запрос, который относится к самому веб-серверу, а не какому-либо конкретному ресурсу. В этом случае стартовая строка может выглядеть так:
OPTIONS * HTTP/1.1
Версия определяет, в соответствии с какой версией стандарта HTTP составлен запрос. Указывается как два числа, разделённых точкой (например 1.1).
Для того, чтобы обратиться к веб-странице по определённому адресу (в данном случае путь к ресурсу — это «/»), нам следует отправить следующий запрос:
GET / HTTP/1.1
Host: alizar.habrahabr.ru
При этом учитывайте, что для переноса строки следует использовать символ возврата каретки (Carriage Return), за которым следует символ перевода строки (Line Feed). После объявления последнего заголовка последовательность символов для переноса строки добавляется дважды.
Впрочем, в спецификации HTTP рекомендуется программировать HTTP-сервер таким образом, чтобы при обработке запросов в качестве межстрочного разделителя воспринимался символ LF, а предшествующий символ CR, при наличии такового, игнорировался. Соответственно, на практике бо́льшая часть серверов корректно обработает и такой запрос, где заголовки отделены символом LF, и он же дважды добавлен после объявления последнего заголовка.
Если вы хотите отправить запрос в точном соответствии со спецификацией, можете воспользоваться управляющими последовательностями r и n:
echo -en "GET / HTTP/1.1rnHost: alizar.habrahabr.rurnrn" | ncat alizar.habrahabr.ru 80
Как прочитать ответ?
Стартовая строка ответа имеет следующую структуру:
HTTP/Версия Код состояния Пояснение
Версия протокола здесь задаётся так же, как в запросе.
Код состояния (Status Code) — три цифры (первая из которых указывает на класс состояния), которые определяют результат совершения запроса. Например, в случае, если был использован метод GET, и сервер предоставляет ресурс с указанным идентификатором, то такое состояние задаётся с помощью кода 200. Если сервер сообщает о том, что такого ресурса не существует — 404. Если сервер сообщает о том, что не может предоставить доступ к данному ресурсу по причине отсутствия необходимых привилегий у клиента, то используется код 403. Спецификация HTTP 1.1 определяет 40 различных кодов HTTP, а также допускается расширение протокола и использование дополнительных кодов состояний.
Пояснение к коду состояния (Reason Phrase) — текстовое (но не включающее символы CR и LF) пояснение к коду ответа, предназначено для упрощения чтения ответа человеком. Пояснение может не учитываться клиентским программным обеспечением, а также может отличаться от стандартного в некоторых реализациях серверного ПО.
После стартовой строки следуют заголовки, а также тело ответа. Например:
HTTP/1.1 200 OK
Server: nginx/1.2.1
Date: Sat, 08 Mar 2014 22:53:46 GMT
Content-Type: application/octet-stream
Content-Length: 7
Last-Modified: Sat, 08 Mar 2014 22:53:30 GMT
Connection: keep-alive
Accept-Ranges: bytes
Wisdom
Тело ответа следует через два переноса строки после последнего заголовка. Для определения окончания тела ответа используется значение заголовка Content-Length (в данном случае ответ содержит 7 восьмеричных байтов: слово «Wisdom» и символ переноса строки).
Но вот по тому запросу, который мы составили ранее, веб-сервер вернёт ответ не с кодом 200, а с кодом 302. Таким образом он сообщает клиенту о том, что обращаться к данному ресурсу на данный момент нужно по другому адресу.
Смотрите сами:
HTTP/1.1 302 Moved Temporarily
Server: nginx
Date: Sat, 08 Mar 2014 22:29:53 GMT
Content-Type: text/html
Content-Length: 154
Connection: keep-alive
Keep-Alive: timeout=25
Location: http://habrahabr.ru/users/alizar/
<html>
<head><title>302 Found</title></head>
<body bgcolor="white">
<center><h1>302 Found</h1></center>
<hr><center>nginx</center>
</body>
</html>
В заголовке Location передан новый адрес. Теперь URI (идентификатор ресурса) изменился на /users/alizar/, а обращаться нужно на этот раз к серверу по адресу habrahabr.ru (впрочем, в данном случае это тот же самый сервер), и его же указывать в заголовке Host.
То есть:
GET /users/alizar/ HTTP/1.1
Host: habrahabr.ru
В ответ на этот запрос веб-сервер Хабрахабра уже выдаст ответ с кодом 200 и достаточно большой документ в формате HTML.
Если вы уже успели вжиться в роль, то можете теперь прочитать полученный от сервера HTML-код, взять карандаш и блокнот, и нарисовать профайл Ализара — в принципе, именно этим бы на вашем месте браузер сейчас и занялся.
А что с безопасностью?
Сам по себе протокол HTTP не предполагает использование шифрования для передачи информации. Тем не менее, для HTTP есть распространённое расширение, которое реализует упаковку передаваемых данных в криптографический протокол SSL или TLS.
Название этого расширения — HTTPS (HyperText Transfer Protocol Secure). Для HTTPS-соединений обычно используется TCP-порт 443. HTTPS широко используется для защиты информации от перехвата, а также, как правило, обеспечивает защиту от атак вида man-in-the-middle — в том случае, если сертификат проверяется на клиенте, и при этом приватный ключ сертификата не был скомпрометирован, пользователь не подтверждал использование неподписанного сертификата, и на компьютере пользователя не были внедрены сертификаты центра сертификации злоумышленника.
На данный момент HTTPS поддерживается всеми популярными веб-браузерами.
А есть дополнительные возможности?
Протокол HTTP предполагает достаточно большое количество возможностей для расширения. В частности, спецификация HTTP 1.1 предполагает возможность использования заголовка Upgrade для переключения на обмен данными по другому протоколу. Запрос с таким заголовком отправляется клиентом. Если серверу требуется произвести переход на обмен данными по другому протоколу, то он может вернуть клиенту ответ со статусом «426 Upgrade Required», и в этом случае клиент может отправить новый запрос, уже с заголовком Upgrade.
Такая возможность используется, в частности, для организации обмена данными по протоколу WebSocket (протокол, описанный в спецификации RFC 6455, позволяющий обеим сторонам передавать данные в нужный момент, без отправки дополнительных HTTP-запросов): стандартное «рукопожатие» (handshake) сводится к отправке HTTP-запроса с заголовком Upgrade, имеющим значение «websocket», на который сервер возвращает ответ с состоянием «101 Switching Protocols», и далее любая сторона может начать передавать данные уже по протоколу WebSocket.
Что-то ещё, кстати, используют?
На данный момент существуют и другие протоколы, предназначенные для передачи веб-содержимого. В частности, протокол SPDY (произносится как английское слово speedy, не является аббревиатурой) является модификацией протокола HTTP, цель которой — уменьшить задержки при загрузке веб-страниц, а также обеспечить дополнительную безопасность.
Увеличение скорости обеспечивается посредством сжатия, приоритизации и мультиплексирования дополнительных ресурсов, необходимых для веб-страницы, чтобы все данные можно было передать в рамках одного соединения.
Опубликованный в ноябре 2012 года черновик спецификации протокола HTTP 2.0 (следующая версия протокола HTTP после версии 1.1, окончательная спецификация для которой была опубликована в 1999) базируется на спецификации протокола SPDY.
Многие архитектурные решения, используемые в протоколе SPDY, а также в других предложенных реализациях, которые рабочая группа httpbis рассматривала в ходе подготовки черновика спецификации HTTP 2.0, уже ранее были получены в ходе разработки протокола HTTP-NG, однако работы над протоколом HTTP-NG были прекращены в 1998.
На данный момент поддержка протокола SPDY есть в браузерах Firefox, Chromium/Chrome, Opera, Internet Exporer и Amazon Silk.
И что, всё?
В общем-то, да. Можно было бы описать конкретные методы и заголовки, но фактически эти знания нужны скорее в том случае, если вы пишете что-то конкретное (например, веб-сервер или какое-то клиентское программное обеспечение, которое связывается с серверами через HTTP), и для базового понимания принципа работы протокола не требуются. К тому же, всё это вы можете очень легко найти через Google — эта информация есть и в спецификациях, и в Википедии, и много где ещё.
Впрочем, если вы знаете английский и хотите углубиться в изучение не только самого HTTP, но и используемых для передачи пакетов TCP/IP, то рекомендую прочитать вот эту статью.
Ну и, конечно, не забывайте, что любая технология становится намного проще и понятнее тогда, когда вы фактически начинаете ей пользоваться.
Удачи и плодотворного обучения!
#статьи
- 30 сен 2022
-

0
Рассказываем об одном из самых популярных интернет-протоколов, на котором работает весь современный веб — HTTP.
Иллюстрация: Оля Ежак для Skillbox Media

Любитель научной фантастики и технологического прогресса. Хорошо сочетает в себе заумного технаря и утончённого гуманитария. Пишет про IT и радуется этому.
Каждый раз, когда вы включаете компьютер и заходите почитать статьи о программировании, браузер посылает куда-то какие-то запросы. Он делает это беспрерывно, пока вы сидите в интернете. Что это за запросы и зачем они нужны? Давайте разбираться.
HTTP означает «протокол передачи гипертекста» (или HyperText Transfer Protocol). Он представляет собой список правил, по которым компьютеры обмениваются данными в интернете. HTTP умеет передавать все возможные форматы файлов — например, видео, аудио, текст. Но при этом состоит только из текста.
Например, когда вы вписываете в строке браузера www.skillbox.ru, он составляет запрос и отправляет его на сервер, чтобы получить HTML-страницу сайта. Когда сервер обрабатывает запрос, то он отправляет ответ, в котором написано, что всё «ок» и вот вам сайт.
Иллюстрация: Polina Vari для Skillbox Media
Протокол HTTP используют ещё с 1992 года. Он очень простой, но при этом довольно функциональный. А ещё HTTP находится на самой вершине модели OSI (на прикладном уровне), где приложения обмениваются друг с другом данными. А работает HTTP с помощью протоколов TCP/IP и использует их, чтобы передавать данные.
Кроме HTTP в интернете работает ещё протокол HTTPS. Аббревиатура расшифровывается как «защищённый протокол передачи гипертекста» (или HyperText Transfer Protocol Secure). Он нужен для безопасной передачи данных по Сети. Всё происходит по тем же принципам, как и у HTTP, правда, перед отправкой данные дополнительно шифруются, а затем расшифровываются на сервере.
Например, HTTPS используют во время ввода данных банковской карты или паролей на сайтах — да и в целом большинство современных сайтов используют именно его.
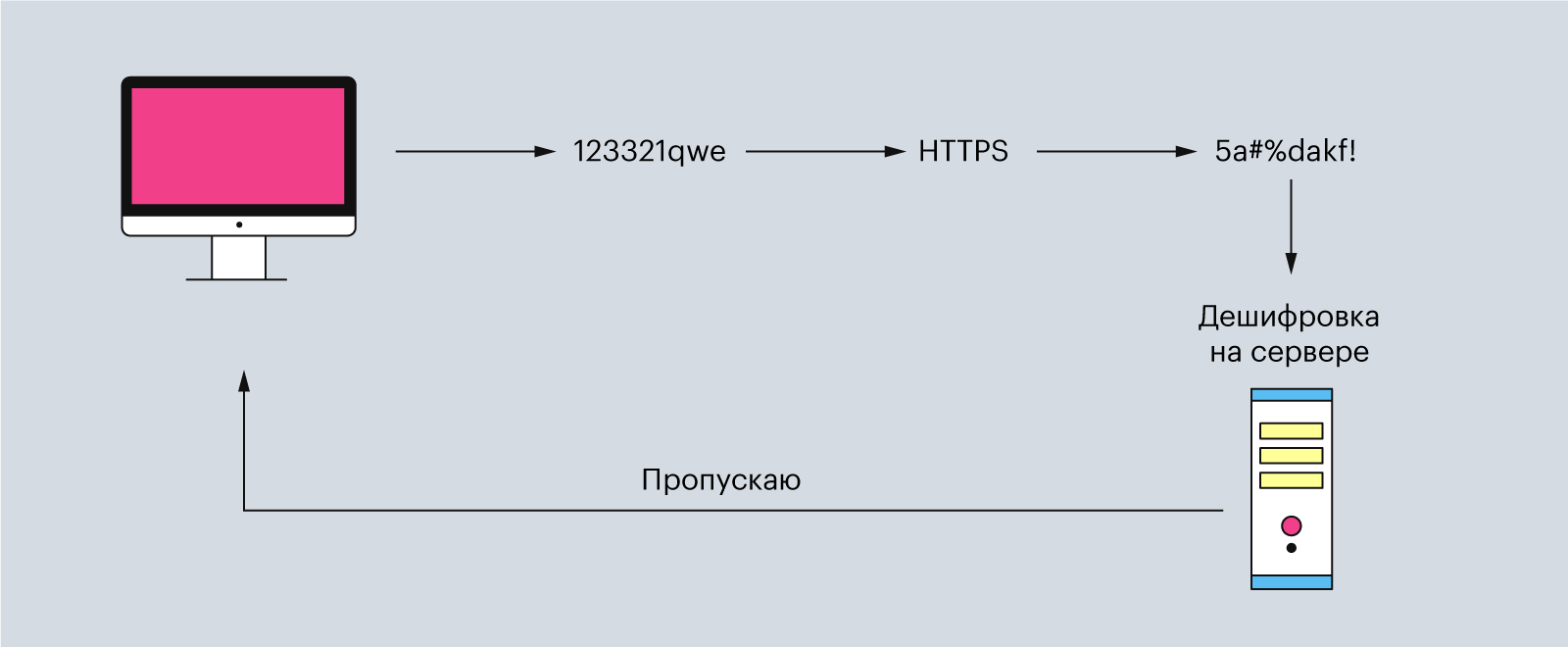
Иллюстрация: Polina Vari для Skillbox Media
HTTP состоит из двух элементов: клиента и сервера. Клиент отправляет запросы и ждёт данные от сервера. А сервер ждёт, пока ему придёт очередной запрос, обрабатывает его и возвращает ответ клиенту.
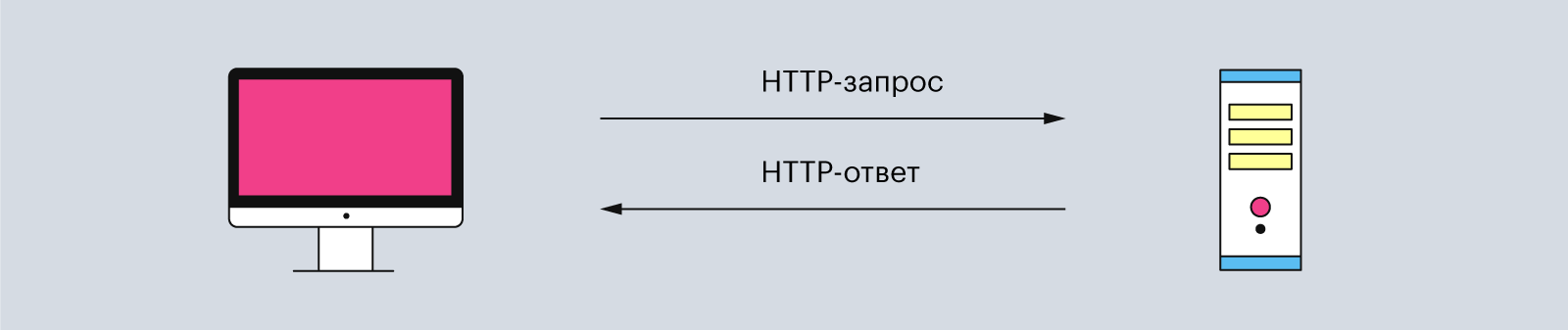
Иллюстрация: Polina Vari для Skillbox Media
Обычно эта связь между клиентом и сервером имеет посредников в виде прокси-серверов. Они нужны для разных операций — например, для безопасности и конфиденциальности, кэширования или распределения нагрузки на серверы.
Поэтому типичная процедура отправки HTTP-запроса от клиента выглядит так:
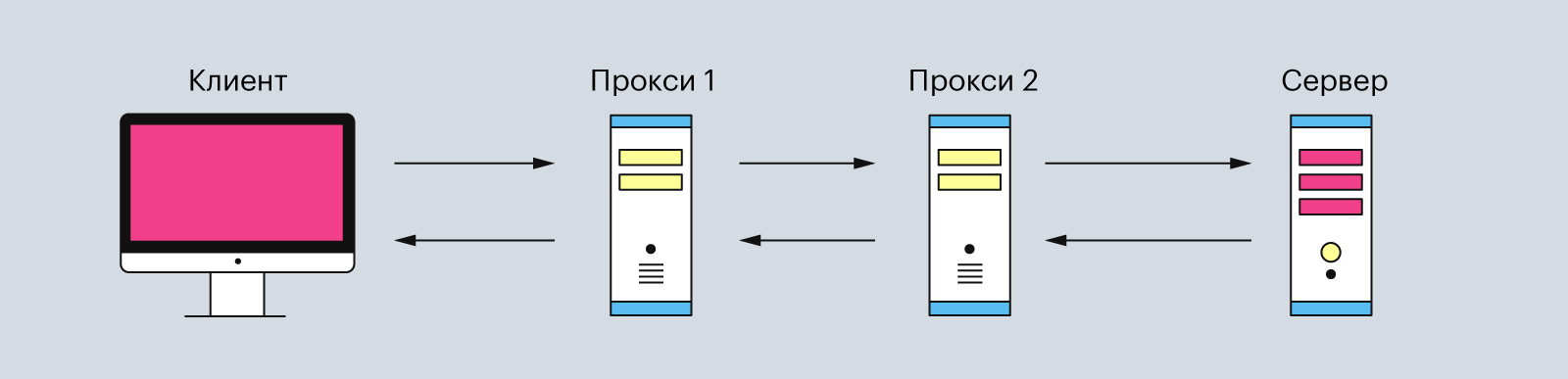
Иллюстрация: Polina Vari для Skillbox Media
Клиентом может быть любое устройство, через которое пользователь запрашивает данные. Часто в роли клиента выступает веб-браузер, программы для отладки приложений или даже командная строка. Главная особенность клиента — он всегда инициирует запрос.
Сервер — это устройство, которое обрабатывает запросы клиента. Он может состоять как из одного компьютера, так и из кластера. А ещё несколько виртуальных серверов могут находиться на одной физической машине.
Прокси-серверы — это второстепенные серверы, которые располагаются между клиентом и главным сервером. Они обрабатывают HTTP-запросы, а также ответы на них. Чаще всего прокси-серверы используют для кэширования и сжатия данных, обхода ограничений и анонимных запросов. И ещё — обычно между клиентом и основным сервером находится один или несколько таких прокси-серверов.
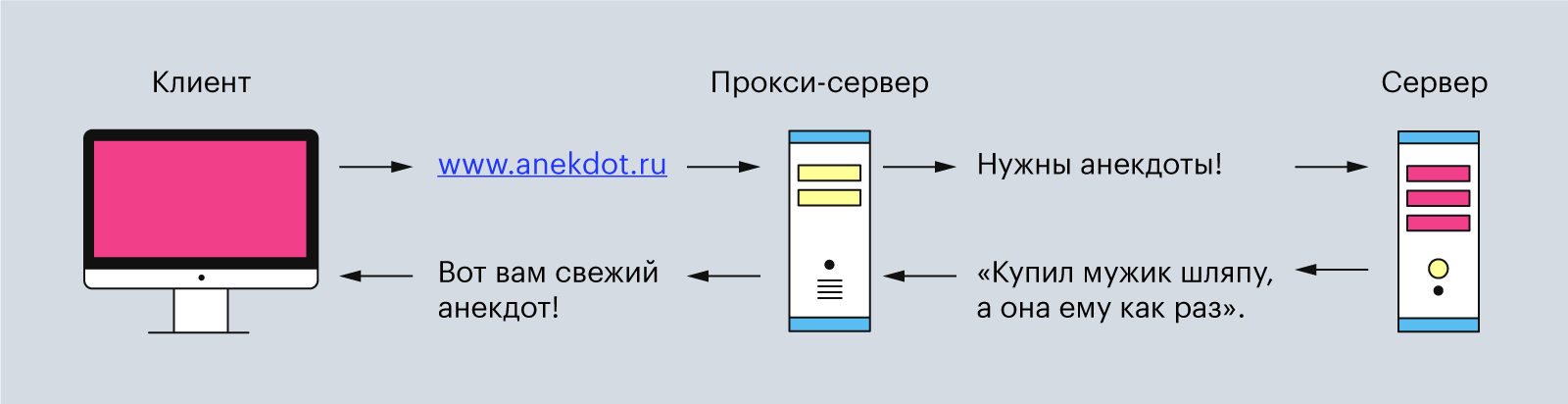
Иллюстрация: Polina Vari для Skillbox Media
Весь процесс передачи HTTP-запроса можно разбить на пять шагов. Давайте разберём их подробнее.
Чтобы отправить HTTP-запрос, нужно использовать URL-адрес — это «унифицированный указатель ресурса» (или Uniform Resource Locator). Он указывает браузеру, что нужно использовать HTTP-протокол, а затем получить файл с этого адреса обратно. Обычно URL-адреса начинаются с http:// или https:// (зависит от версии протокола).
Например, http://www.skillbox.ru — это URL-адрес. Он представляет собой главную страницу Skillbox. Но также в URL-адресе могут быть и поддомены — http://www.skillbox.ru/media. Теперь мы запросили главную страницу Skillbox Media.
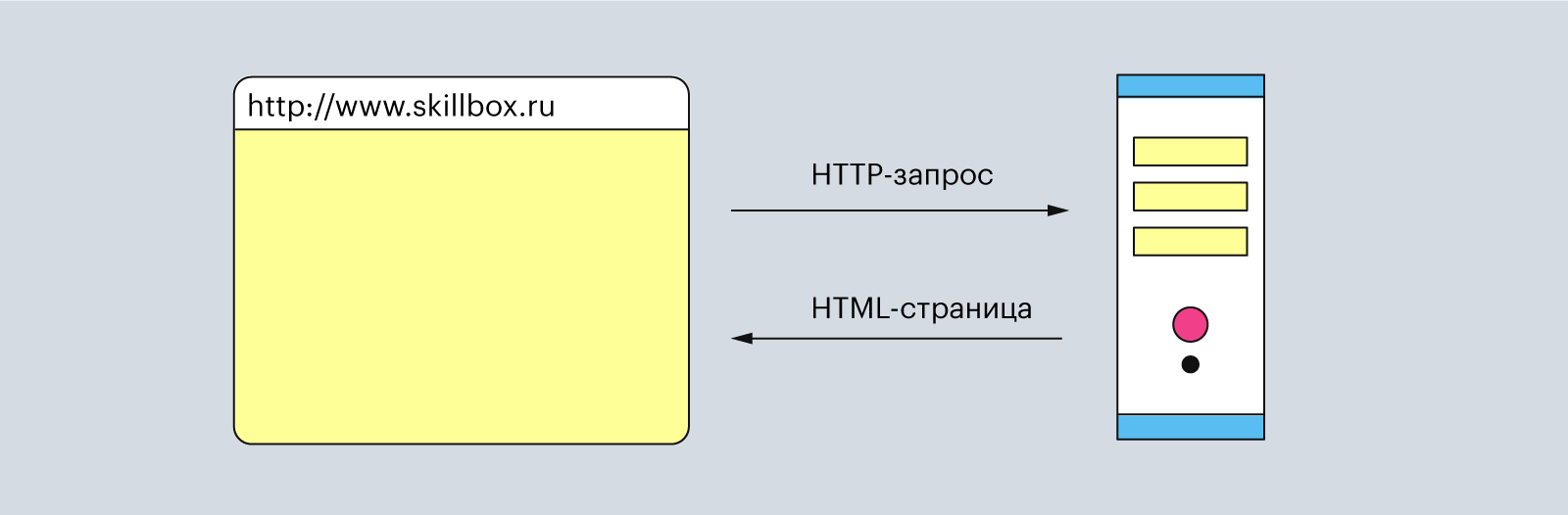
Иллюстрация: Polina Vari для Skillbox Media
Для пользователей URL-адрес — это набор понятных слов: Skillbox, Yandex, Google. Но для компьютера эти понятные нам слова — набор непонятных символов.
Поэтому браузер отправляет введённые вами слова в DNS, преобразователь URL-адресов в IP-адреса. DNS расшифровывается как «доменная система имён» (Domain Name System), и его можно представить как огромную таблицу со всеми зарегистрированными именами для сайтов и их IP-адресами.
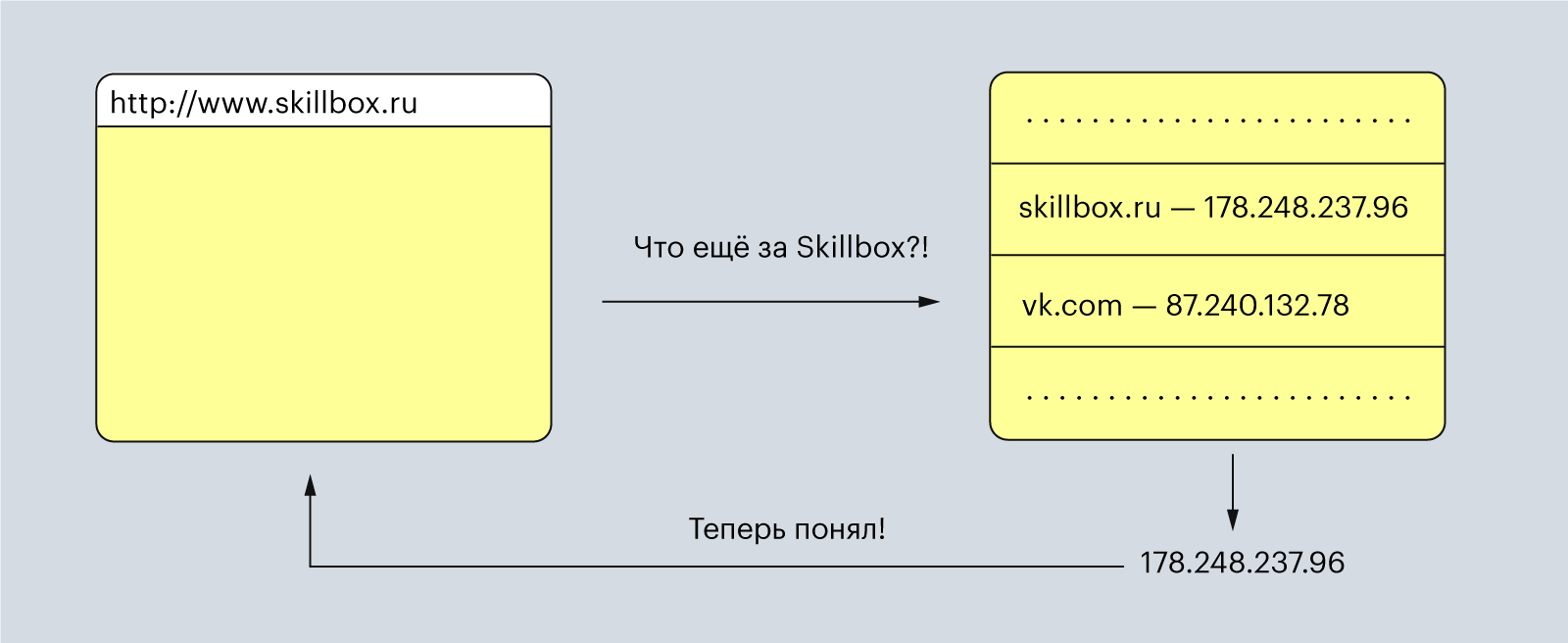
Иллюстрация: Polina Vari для Skillbox Media
DNS возвращает браузеру IP-адрес, с которым тот уже умеет работать. Теперь браузер начинает составлять HTTP-запрос с вложенным в него IP-адресом.
Сам HTTP-запрос может выглядеть так:

Здесь четыре элемента: метод — «GET», URI — «/», версия HTTP — «1.1» и адрес хоста — «www.skillbox.ru». Давайте разберём каждый из них подробнее.
Метод — это действие, которое клиент ждёт от сервера. Например, отправить ему HTML-страницу сайта или скачать документ. Протокол HTTP не ограничивает количество разных методов, но программисты договорились между собой использовать только три основных:
- GET — чтобы получить данные с сервера. Например, видео с YouTube или мем с Reddit.
- POST — чтобы отправить данные на сервер. Например, сообщение в Telegram или новый трек в SoundCloud.
- HEAD — чтобы получить только метаданные об HTML-странице сайта. Это те данные, которые находятся в <head>-теге HTML-файла.
URI расшифровывается как «унифицированный идентификатор ресурса» (или Uniform Resource Identifier) — это полный адрес сайта в Сети. Он состоит из двух частей: URL и URN. Первое — это адрес хоста. Например, www.skillbox.ru или www.vk.com. Второе — это то, что ставится после URL и символа / — например, для URI www.skillbox.ru/media URN-адресом будет /media. URN ещё можно назвать адресом до конкретного файла на сайте.
Версия HTTP указывает, какую версию HTTP браузер использует при отправке запроса. Если её не указывать, по умолчанию будет стоять версия 1.1. Она нужна, чтобы сервер вернул HTTP-ответ с той же версией HTTP-протокола и не создал ошибок с чтением у клиента.
Адрес хоста нужен, чтобы указать, с какого сайта клиент пытается получить данные. Адрес указывают в виде домена, но он сразу же меняется на IP-адрес перед отправкой запроса с помощью DNS.

Иллюстрация: Polina Vari для Skillbox Media
После получения и обработки HTTP-запроса сервер создаёт ответ и отправляет его обратно клиенту. В нём содержатся дополнительная информация (метаданные) и запрашиваемые данные.
Простой HTTP-ответ выглядит так:

Здесь три главные части: статус ответа — HTTP/1.1 200 OK, заголовки Content-Type и Content-Length и тело ответа — HTML-код. Рассмотрим их подробнее.
Статус ответа содержит версию HTTP-протокола, который клиент указал в HTTP-запросе. А после неё идёт код статуса ответа — 200, что означает успешное получение данных. Затем — словесное описание статуса ответа: «ок».
Всего статусов в спецификации HTTP 1.1 — 40. Вот самые популярные из них:
- 200 OK — данные успешно получены;
- 201 Created — значит, что запрос успешный, а данные созданы. Его используют, чтобы подтверждать успех запросов PUT или POST;
- 300 Moved Permanently — указывает, что URL-адрес изменили навсегда;
- 400 Bad Request — означает неверно сформированный запрос. Обычно это случается в связке с запросами POST и PUT, когда данные не прошли проверку или представлены в неправильном формате;
- 401 Unauthorized — нужно выполнить аутентификацию перед тем, как запрашивать доступ к ресурсу;
- 404 Not Found — значит, что не удалось найти запрашиваемый ресурс;
- 405 Forbidden — говорит, что указанный метод HTTP не поддерживается для запрашиваемого ресурса;
- 409 Conflict — произошёл конфликт. Например, когда клиент хочет создать дважды данные с помощью запроса PUT;
- 500 Internal Server Error — означает ошибку со стороны сервера.
Заголовки помогают браузеру разобраться с полученными данными и представить их в правильном виде. Например, заголовок Content-Type сообщает, какой формат файла пришёл и какие у него дополнительные параметры, а Content-Length — сколько места в байтах занимает этот файл.
Тело ответа содержит в себе сам файл. Например, сервер может вернуть код HTML-документа или отправить JPEG-картинку.

Иллюстрация: Polina Vari для Skillbox Media
Как только браузер получил ответ с веб-страницей, он отображает её с помощью внутреннего движка. И на этом весь процесс отправки и получение HTTP-запросов заканчивается, а клиент получает нужные ему данные.
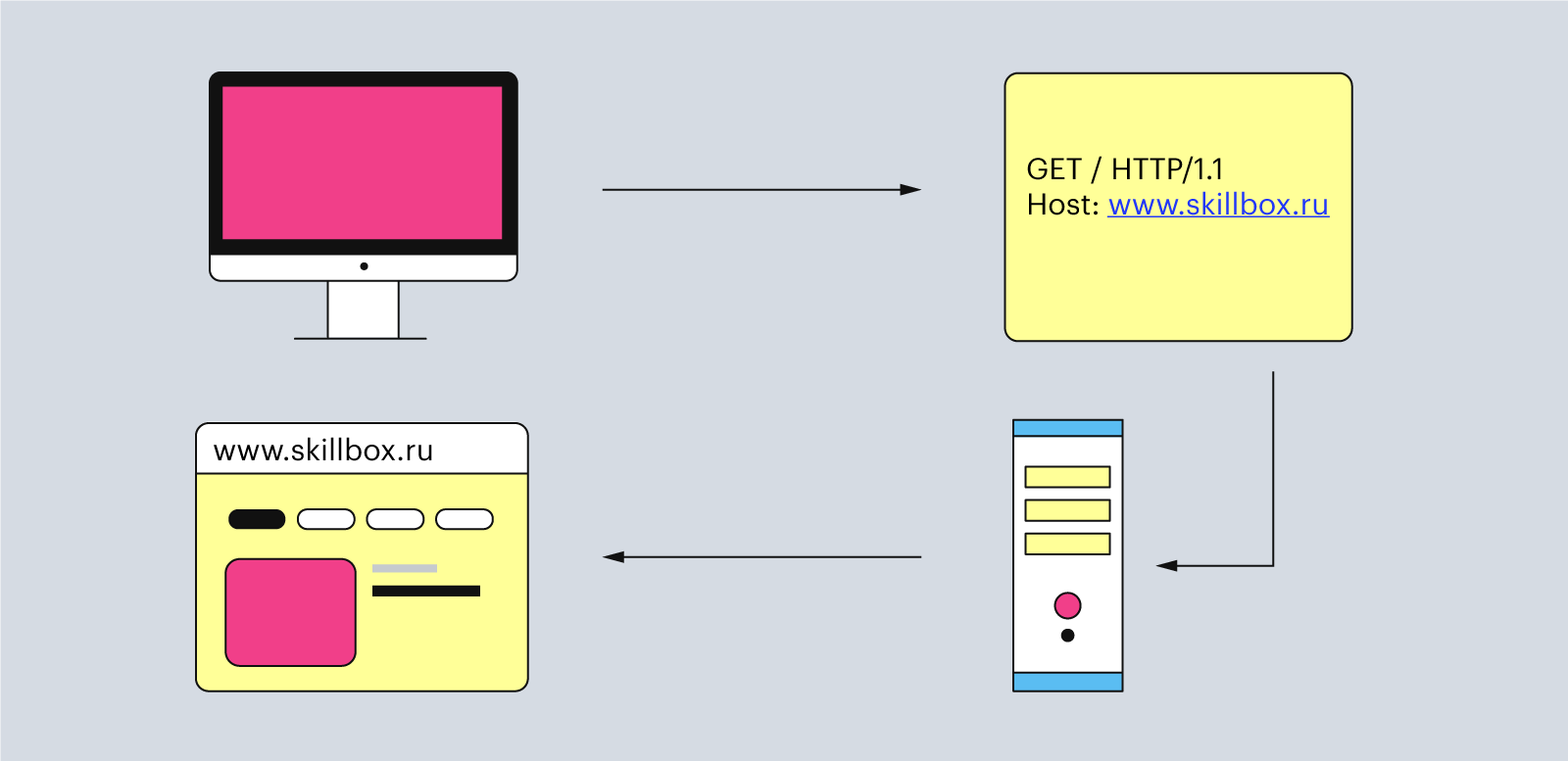
Иллюстрация: Polina Vari для Skillbox Media
- HTTP-протокол — это набор правил, по которым компьютеры обмениваются данными друг с другом. Его инициирует клиент (в данном случае — человек, заходящий в интернет с любого устройства), а обрабатывает сервер и возвращает обратно клиенту. Между ними могут находиться прокси-серверы, которые занимаются дополнительными задачами — шифрованием данных, перераспределением нагрузки или кэшированием.
- HTTP-запрос содержит четыре элемента: метод, URI, версию HTTP и адрес хоста. Метод указывает, какое действие нужно совершить. URI — это путь до конкретного файла на сайте. Версию HTTP нужно указывать, чтобы избежать ошибок, а адрес хоста помогает браузеру определить, куда отправлять HTTP-запрос.
- HTTP-ответ имеет три части: статус ответа, заголовки и тело ответа. В статусе ответа сообщается, всё ли прошло успешно и возникли ли ошибки. В заголовках указывается дополнительная информация, которая помогает браузеру корректно отобразить файл. А в тело ответа сервер кладёт запрашиваемый файл.

Научитесь: Профессия Веб-разработчик
Узнать больше
Большинство используемых нами веб- и мобильных приложений постоянно взаимодействуют с глобальной сетью. Почти все подобные коммуникации совершаются с помощью запросов по протоколу HTTP. Рассказываем о них подробнее.

Большинство используемых нами веб- и мобильных приложений постоянно взаимодействуют с глобальной сетью. Почти все подобные коммуникации совершаются с помощью запросов по протоколу HTTP. Рассказываем о них подробнее.
Базово о протоколе HTTP
HTTP (HyperText Transfer Protocol, дословно — «протокол передачи гипертекста») представляет собой протокол прикладного уровня, используемый для доступа к ресурсам Всемирной Паутины. Под термином гипертекст следует понимать текст, в понятном для человека представлении, при этом содержащий ссылки на другие ресурсы.
Данный протокол описывается спецификацией RFC 2616. На сегодняшний день наиболее распространенной версией протокола является версия HTTP/2, однако нередко все еще можно встретить более раннюю версию HTTP/1.1.
В обмене информацией по HTTP-протоколу принимают участие клиент и сервер. Происходит это по следующей схеме:
- Клиент запрашивает у сервера некоторый ресурс.
- Сервер обрабатывает запрос и возвращает клиенту ресурс, который был запрошен.
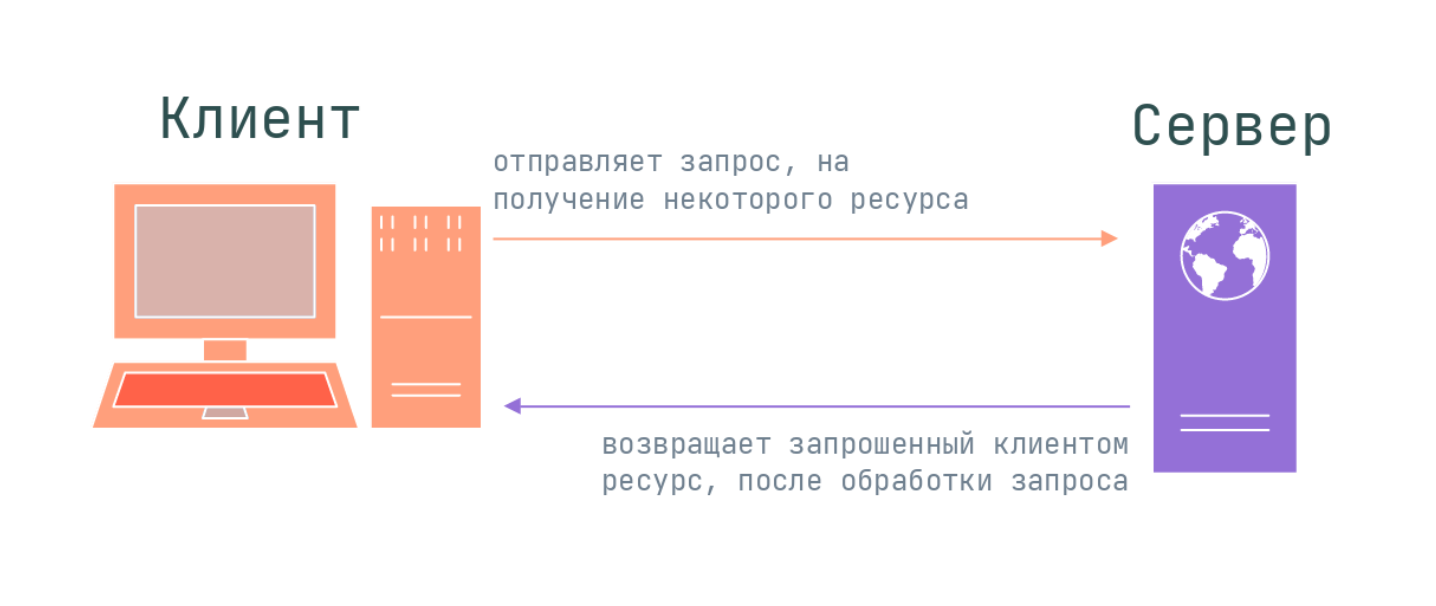
По умолчанию для коммуникации по HTTP используется порт 80, хотя вместо него может быть выбран и любой другой порт. Многое зависит от конфигурации конкретного веб-сервера.
Подробнее о протоколе HTTP читайте по ссылке →
HTTP-сообщения: запросы и ответы
Данные между клиентом и сервером в рамках работы протокола передаются с помощью HTTP-сообщений. Они бывают двух видов:
- Запросы (HTTP Requests) — сообщения, которые отправляются клиентом на сервер, чтобы вызвать выполнение некоторых действий. Зачастую для получения доступа к определенному ресурсу. Основой запроса является HTTP-заголовок.
- Ответы (HTTP Responses) — сообщения, которые сервер отправляет в ответ на клиентский запрос.
Само по себе сообщение представляет собой информацию в текстовом виде, записанную в несколько строчек.
В целом, как запросы HTTP, так и ответы имеют следующую структуру:
- Стартовая строка (start line) — используется для описания версии используемого протокола и другой информации — вроде запрашиваемого ресурса или кода ответа. Как можно понять из названия, ее содержимое занимает ровно одну строчку.
- HTTP-заголовки (HTTP Headers) — несколько строчек текста в определенном формате, которые либо уточняют запрос, либо описывают содержимое тела сообщения.
- Пустая строка, которая сообщает, что все метаданные для конкретного запроса или ответа были отправлены.
- Опциональное тело сообщения, которое содержит данные, связанные с запросом, либо документ (например HTML-страницу), передаваемый в ответе.
Рассмотрим атрибуты HTTP-запроса подробнее.
Стартовая строка
Стартовая строка HTTP-запроса состоит из трех элементов:
- Метод HTTP-запроса (method, реже используется термин verb). Обычно это короткое слово на английском, которое указывает, что конкретно нужно сделать с запрашиваемым ресурсом. Например, метод GET сообщает серверу, что пользователь хочет получить некоторые данные, а POST — что некоторые данные должны быть помещены на сервер.
- Цель запроса. Представлена указателем ресурса URL, который состоит из протокола, доменного имени (или IP-адреса), пути к конкретному ресурсу на сервере. Дополнительно может содержать указание порта, несколько параметров HTTP-запроса и еще ряд опциональных элементов.
- Версия используемого протокола (либо HTTP/1.1, либо HTTP/2), которая определяет структуру следующих за стартовой строкой данных.
В примере ниже стартовая строка указывает, что в качестве метода используется GET, обращение будет произведено к ресурсу /index.html, по версии протокола HTTP/1.1:
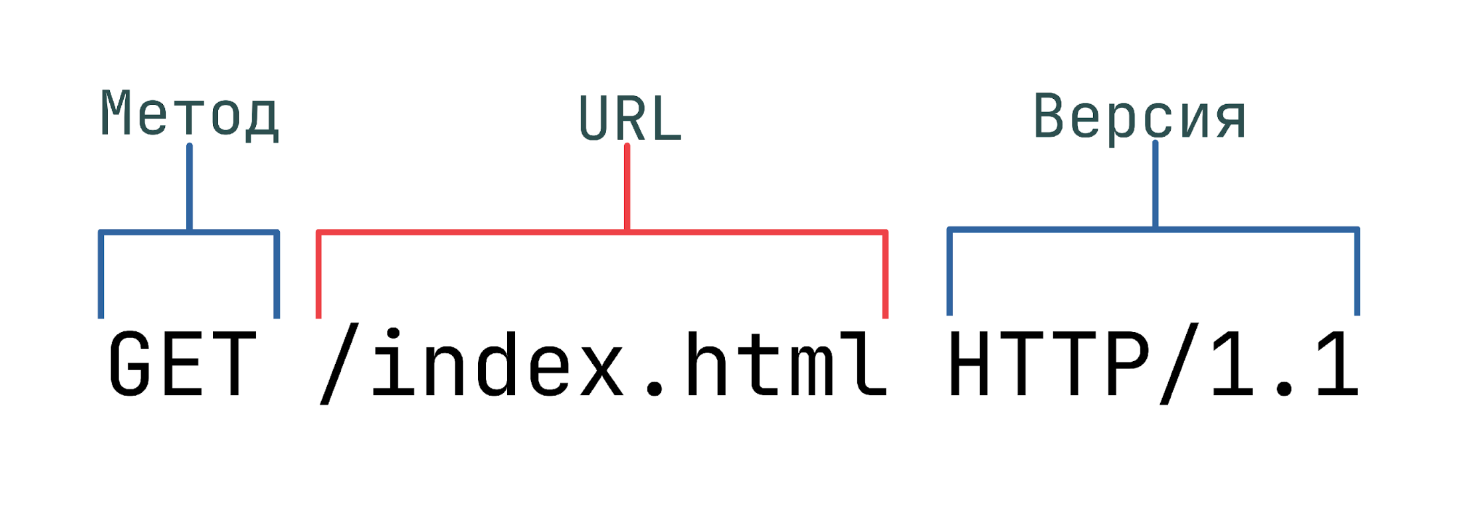
Разберемся с каждым из названных элементов подробнее.
Методы
Методы позволяют указать конкретное действие, которое мы хотим, чтобы сервер выполнил, получив наш запрос. Так, некоторые методы позволяют браузеру (который в большинстве случаев является источником запросов от клиента) отправлять дополнительную информацию в теле запроса — например, заполненную форму или документ.
Ниже приведены наиболее используемые методы и их описание:
Разберемся с каждым из названных элементов подробнее.
| Метод | Описание |
| GET | Позволяет запросить некоторый конкретный ресурс. Дополнительные данные могут быть переданы через строку запроса (Query String) в составе URL (например ?param=value).О составляющих URL мы поговорим чуть позже. |
| POST | Позволяет отправить данные на сервер. Поддерживает отправку различных типов файлов, среди которых текст, PDF-документы и другие типы данных в двоичном виде. Обычно метод POST используется при отправке информации (например, заполненной формы логина) и загрузке данных на веб-сайт, таких как изображения и документы. |
| HEAD | Здесь придется забежать немного вперед и сказать, что обычно сервер в ответ на запрос возвращает заголовок и тело, в котором содержится запрашиваемый ресурс. Данный метод при использовании его в запросе позволит получить только заголовки, которые сервер бы вернул при получении GET-запроса к тому же ресурсу. Запрос с использованием данного метода обычно производится для того, чтобы узнать размер запрашиваемого ресурса перед его загрузкой. |
| PUT | Используется для создания (размещения) новых ресурсов на сервере. Если на сервере данный метод разрешен без надлежащего контроля, то это может привести к серьезным проблемам безопасности. |
| DELETE | Позволяет удалить существующие ресурсы на сервере. Если использование данного метода настроено некорректно, то это может привести к атаке типа «Отказ в обслуживании» (Denial of Service, DoS) из-за удаления критически важных файлов сервера. |
| OPTIONS | Позволяет запросить информацию о сервере, в том числе информацию о допускаемых к использованию на сервере HTTP-методов. |
| PATCH | Позволяет внести частичные изменения в указанный ресурс по указанному расположению. |
URL
Получение доступа к ресурсам по HTTP-протоколу осуществляется с помощью указателя URL (Uniform Resource Locator). URL представляет собой строку, которая позволяет указать запрашиваемый ресурс и еще ряд параметров.
Использование URL неразрывно связано с другими элементами протокола, поэтому далее мы рассмотрим его основные компоненты и строение:
Поле Scheme используется для указания используемого протокола, всегда сопровождается двоеточием и двумя косыми чертами (://).
Host указывает местоположение ресурса, в нем может быть как доменное имя, так и IP-адрес.
Port, как можно догадаться, позволяет указать номер порта, по которому следует обратиться к серверу. Оно начинается с двоеточия (:), за которым следует номер порта. При отсутствии данного элемента номер порта будет выбран по умолчанию в соответствии с указанным значением Scheme (например, для http:// это будет порт 80).
Далее следует поле Path. Оно указывает на ресурс, к которому производится обращение. Если данное поле не указано, то сервер в большинстве случаев вернет указатель по умолчанию (например index.html).
Поле Query String начинается со знака вопроса (?), за которым следует пара «параметр-значение», между которыми расположен символ равно (=). В поле Query String могут быть переданы несколько параметров с помощью символа амперсанд (&) в качестве разделителя.
Не все компоненты необходимы для доступа к ресурсу. Обязательно следует указать только поля Scheme и Host.
Версии HTTP
Раз уж мы упомянули версию протокола как элемента стартовой строки, то стоит сказать об основных отличиях версий HTTP/1.X от HTTP/2.X.
Последняя стабильная, наиболее стандартизированная версия протокола первого поколения (версия HTTP/1.1) вышла в далеком 1997 году. Годы шли, веб-страницы становились сложнее, некоторые из них даже стали приложениями в том виде, в котором мы понимаем их сейчас. Кроме того, объем медиафайлов и скриптов, которые добавляли интерактивность страницам, рос. Это, в свою очередь, создавало перегрузки в работе протокола версии HTTP/1.1.
Стало очевидно, что у HTTP/1.1 есть ряд значительных недостатков:
- Заголовки, в отличие от тела сообщения, передавались в несжатом виде.
- Часто большая часть заголовков в сообщениях совпадала, но они продолжали передаваться по сети.
- Отсутствовала возможность так называемого мультиплексирования — механизма, позволяющего объединить несколько соединений в один поток данных. Приходилось открывать несколько соединений на сервере для обработки входящих запросов.
С выходом HTTP/2 было предложено следующее решение: HTTP/1.X-сообщения разбивались на так называемые фреймы, которые встраивались в поток данных.
Фреймы данных (тела сообщения) отделялись от фреймов заголовка, что позволило применять сжатие. Вместе с появлением потоков появился и ранее описанный механизм мультиплексирования — теперь можно было обойтись одним соединением для нескольких потоков.
Единственное о чем стоит сказать в завершение темы: HTTP/2 перестал быть текстовым протоколом, а стал работать с «сырой» двоичной формой данных. Это ограничивает чтение и создание HTTP-сообщений «вручную». Однако такова цена за возможность реализации более совершенной оптимизации и повышения производительности.
Заголовки
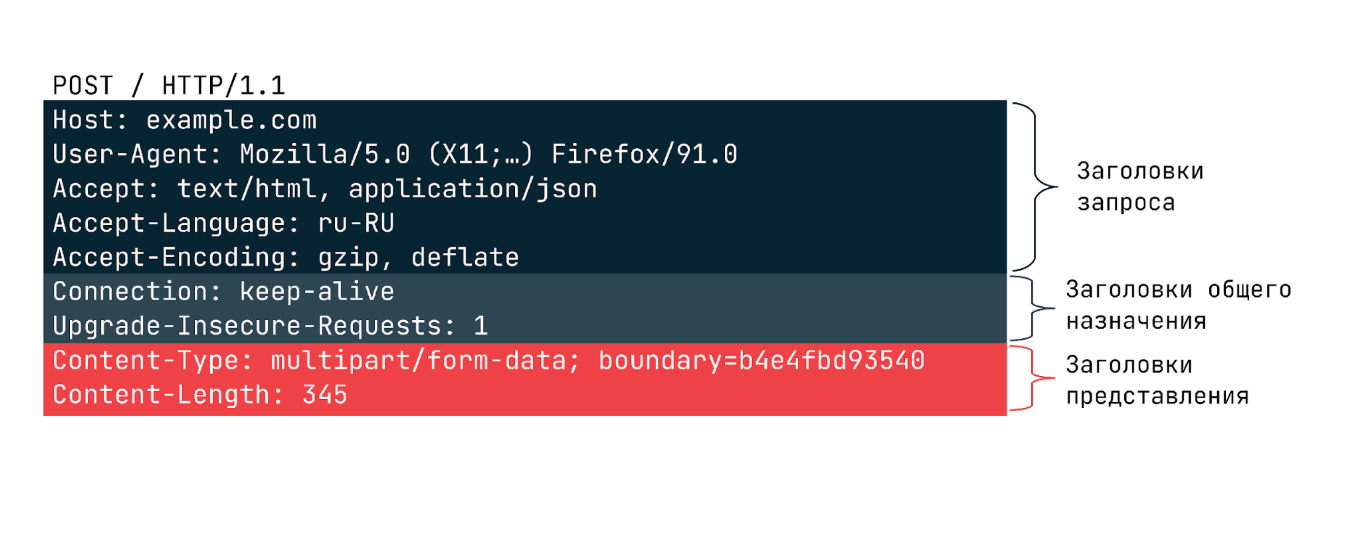
HTTP-заголовок представляет собой строку формата «Имя-Заголовок:Значение», с двоеточием(:) в качестве разделителя. Название заголовка не учитывает регистр, то есть между Host и host, с точки зрения HTTP, нет никакой разницы. Однако в названиях заголовков принято начинать каждое новое слово с заглавной буквы. Структура значения зависит от конкретного заголовка. Несмотря на то, что заголовок вместе со значениями может быть достаточно длинным, занимает он всего одну строчку.
В запросах может передаваться большое число различных заголовков, но все их можно разделить на три категории:
- Общего назначения, которые применяются ко всему сообщению целиком.
- Заголовки запроса уточняют некоторую информацию о запросе, сообщая дополнительный контекст или ограничивая его некоторыми логическими условиями.
- Заголовки представления, которые описывают формат данных сообщения и используемую кодировку. Добавляются к запросу только в тех случаях, когда с ним передается некоторое тело.
Ниже можно видеть пример заголовков в запросе:
Самые частые заголовки запроса
| Заголовок | Описание |
| Host | Используется для указания того, с какого конкретно хоста запрашивается ресурс. В качестве возможных значений могут использоваться как доменные имена, так и IP-адреса. На одном HTTP-сервере может быть размещено несколько различных веб-сайтов. Для обращения к какому-то конкретному требуется данный заголовок. |
| User-Agent | Заголовок используется для описания клиента, который запрашивает ресурс. Он содержит достаточно много информации о пользовательском окружении. Например, может указать, какой браузер используется в качестве клиента, его версию, а также операционную систему, на которой этот клиент работает. |
| Refer | Используется для указания того, откуда поступил текущий запрос. Например, если вы решите перейти по какой-нибудь ссылке в этой статье, то вероятнее всего к запросу будет добавлен заголовок Refer: https://selectel.ru |
| Accept | Позволяет указать, какой тип медиафайлов принимает клиент. В данном заголовке могут быть указаны несколько типов, перечисленные через запятую (‘ , ‘). А для указания того, что клиент принимает любые типы, используется следующая последовательность — */*. |
| Cookie | Данный заголовок может содержать в себе одну или несколько пар «Куки-Значение» в формате cookie=value. Куки представляют собой небольшие фрагменты данных, которые хранятся как на стороне клиента, так и на сервере, и выступают в качестве идентификатора. Куки передаются вместе с запросом для поддержания доступа клиента к ресурсу. Помимо этого, куки могут использоваться и для других целей, таких как хранение пользовательских предпочтений на сайте и отслеживание клиентской сессии. Несколько кук в одном заголовке могут быть перечислены с помощью символа точка с запятой (‘ ; ‘), который используется как разделитель. |
| Authorization | Используется в качестве еще одного метода идентификации клиента на сервере. После успешной идентификации сервер возвращает токен, уникальный для каждого конкретного клиента. В отличие от куки, данный токен хранится исключительно на стороне клиента и отправляется клиентом только по запросу сервера. Существует несколько типов аутентификации, конкретный метод определяется тем веб-сервером или веб-приложением, к которому клиент обращается за ресурсом. |
Тело запроса
Завершающая часть HTTP-запроса — это его тело. Не у каждого HTTP-метода предполагается наличие тела. Так, например, методам вроде GET, HEAD, DELETE, OPTIONS обычно не требуется тело. Некоторые виды запросов могут отправлять данные на сервер в теле запроса: самый распространенный из таких методов — POST.
Ответы HTTP
HTTP-ответ является сообщением, которое сервер отправляет клиенту в ответ на его запрос. Его структура равна структуре HTTP-запроса: стартовая строка, заголовки и тело.
Строка статуса (Status line)
Стартовая строка HTTP-ответа называется строкой статуса (status line). На ней располагаются следующие элементы:
- Уже известная нам по стартовой строке запроса версия протокола (HTTP/2 или HTTP/1.1).
- Код состояния, который указывает, насколько успешно завершилась обработка запроса.
- Пояснение — короткое текстовое описание к коду состояния. Используется исключительно для того, чтобы упростить понимание и восприятие человека при просмотре ответа.

Коды состояния и текст статуса
Коды состояния HTTP используются для того, чтобы сообщить клиенту статус их запроса. HTTP-сервер может вернуть код, принадлежащий одной из пяти категорий кодов состояния:
| Категория | Описание |
| 1xx | Коды из данной категории носят исключительно информативный характер и никак не влияют на обработку запроса. |
| 2xx | Коды состояния из этой категории возвращаются в случае успешной обработки клиентского запроса. |
| 3xx | Эта категория содержит коды, которые возвращаются, если серверу нужно перенаправить клиента. |
| 4xx | Коды данной категории означают, что на стороне клиента был отправлен некорректный запрос. Например, клиент в запросе указал не поддерживаемый метод или обратился к ресурсу, к которому у него нет доступа. |
| 5xx | Ответ с кодами из этой категории приходит, если на стороне сервера возникла ошибка. |
Полный список кодов состояния доступен в спецификации к протоколу, ниже приведены только самые распространенные коды ответов:
| Категория | Описание |
| 200 OK | Возвращается в случае успешной обработки запроса, при этом тело ответа обычно содержит запрошенный ресурс. |
| 302 Found | Перенаправляет клиента на другой URL. Например, данный код может прийти, если клиент успешно прошел процедуру аутентификации и теперь может перейти на страницу своей учетной записи. |
| 400 Bad Request | Данный код можно увидеть, если запрос был сформирован с ошибками. Например, в нем отсутствовали символы завершения строки. |
| 403 Forbidden | Означает, что клиент не обладает достаточными правами доступа к запрошенному ресурсу. Также данный код можно встретить, если сервер обнаружил вредоносные данные, отправленные клиентом в запросе. |
| 404 Not Found | Каждый из нас, так или иначе, сталкивался с этим кодом ошибки. Данный код можно увидеть, если запросить у сервера ресурс, которого не существует на сервере. |
| 500 Internal Error | Данный код возвращается сервером, когда он не может по определенным причинам обработать запрос. |
Помимо основных кодов состояния, описанных в стандарте, существуют и коды состояния, которые объявляются крупными сетевыми провайдерами и серверными платформами. Так, коды состояния, используемые Selectel, можно посмотреть здесь.
Заголовки ответа
Response Headers, или заголовки ответа, используются для того, чтобы уточнить ответ, и никак не влияют на содержимое тела. Они существуют в том же формате, что и остальные заголовки, а именно «Имя-Значение» с двоеточием (:) в качестве разделителя.
Ниже приведены наиболее часто встречаемые в ответах заголовки:
| Категория | Пример | Описание |
| Server | Server: ngnix | Содержит информацию о сервере, который обработал запрос. |
| Set-Cookie | Set-Cookie:PHPSSID=bf42938f | Содержит куки, требуемые для идентификации клиента. Браузер парсит куки и сохраняет их в своем хранилище для дальнейших запросов. |
| WWW-Authenticate | WWW-Authenticate: BASIC realm=»localhost» | Уведомляет клиента о типе аутентификации, который необходим для доступа к запрашиваемому ресурсу. |
Тело ответа
Последней частью ответа является его тело. Несмотря на то, что у большинства ответов тело присутствует, оно не является обязательным. Например, у кодов «201 Created» или «204 No Content» тело отсутствует, так как достаточную информацию для ответа на запрос они передают в заголовке.
Безопасность HTTP-запросов, или что такое HTTPs
HTTP является расширяемым протоколом, который предоставляет огромное количество возможностей, а также поддерживает передачу всевозможных типов файлов. Однако, вне зависимости от версии, у него есть один существенный недостаток, который можно заметить если перехватить отправленный HTTP-запрос:
Да, все верно: данные передаются в открытом виде. HTTP сам по себе не предоставляет никаких средств шифрования.
Но как же тогда работают различные банковские приложения, интернет-магазины, сервисы оплаты услуг и прочие приложения, в которых циркулирует чувствительная информация пользователей?
Время рассказать про HTTPs!
HTTPs (HyperText Transfer Protocol, secure) является расширением HTTP-протокола, который позволяет шифровать отправляемые данные, перед тем как они попадут на транспортный уровень. Данный протокол по умолчанию использует порт 443.
Теперь если мы перехватим не HTTP , а HTTPs-запрос, то не увидим здесь ничего интересного:
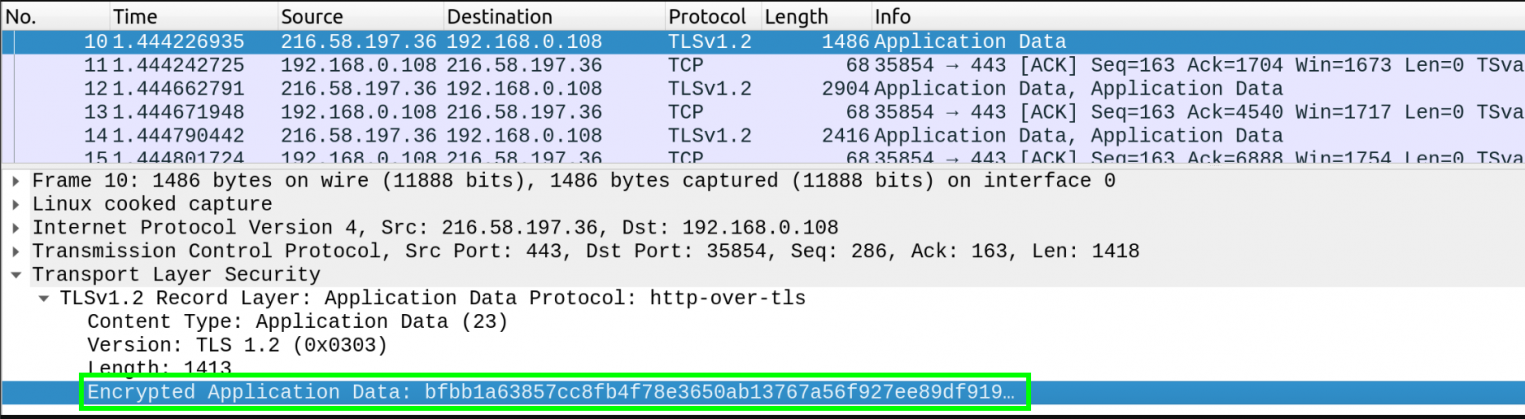
Данные передаются в едином зашифрованном потоке, что делает невозможным получение учетных данных пользователей и прочей критической информации средствами обычного перехвата.
Три межсетевых экрана для любых потребностей бизнеса.
Если хотите подробнее узнать о деталях работы протокола, читайте статью в нашем блоге →
Как отправить HTTP-запрос и прочитать его ответ
Теория это, конечно, отлично, но ничего так хорошо не закрепляет материал, как практика
Мы рассмотрим несколько способов, как написать HTTP-запрос в браузер, послать HTTP-запрос на сервер и получить ответ:
- Инструменты разработчика в браузере.
- Утилита cURL.
Инструменты разработчика
Основной программой на наших устройствах, которая работает с HTTP-протоколом, в большинстве случаев является браузер. Помимо обычных пользователей, с браузерами часто работают и разработчики веб-приложений. Именно их инструментами мы воспользуемся для работы с запросами и ответами.
По нажатию комбинации клавиш [Ctrl+Shift+I] или просто [F12] в подавляющем большинстве современных браузеров у нас откроется окно инструментов разработчика, которая представляет собой панель с несколькими вкладками. Нужная нам вкладка обычно называется Network. Перейдем в нее, а в адресной строке введем URL того сайта, на который хотим попасть. В качестве примера воспользуемся сайтом блога Selectel — https://selectel.ru/blog/.
После нажатия Enter сайт начнет загружаться, а открытая вкладка Network — заполняться различными элементами, начиная все больше напоминать приборную панель самолета.
Не спешите пугаться. Это всего лишь список ресурсов, которые нужны для правильного отображения и работы сайта.
Нажав на любой из них, мы можем увидеть детали обработки отправленного запроса:
В данном запросе, например:
- URL, к которому было совершено обращение — https://selectel.ru/blog,
- Метод, который был использован в запросе — GET,
- И в качестве кода возврата сервер вернул нам страницу с кодом статуса — 200 OK
Утилита cURL
Следующий инструмент, с помощью которого мы сможем послать запрос на тот или иной сервер, это утилита cURL.
cURL (client URL) является небольшой утилитой командной строки, которая позволяет работать с HTTP и рядом других протоколов.
Для отправки запроса и получения ответа мы можем воспользоваться флагом -v и указанием URL того ресурса, который мы хотим получить. «Схему» HTTP-запроса можно увидеть на скрине ниже:

После запуска утилита выполняет:
- подключение к серверу,
- самостоятельно разрешает все вопросы, необходимые для отправки запроса по HTTPs,
- отправляет запрос, содержимое которого мы можем видеть благодаря флагу -v,
- принимая ответ от сервера, отображает его в командной строке «как-есть».
Помимо этого, у данной утилиты есть огромное количество опций, которые предоставляют возможности по детальной настройке отправляемых запросов. Все эти возможности и делают ее такой популярной у веб-разработчиков и других специалистов, которым приходится работать с протоколом HTTP.
Заключение
HTTP представляет собой расширяемый протокол прикладного уровня, на котором работает весь веб-сегмент интернета. В данной статье мы рассмотрели принцип его работы, структуру, «компоненты» HTTP-запросов. Коснулись вопросов отличия версий протокола, HTTPs — его расширения, добавляющего шифрование. Разобрали устройство запроса, поняли, как можно отправить HTTP-запрос и получить ответ от сервера.
HTTP (HyperText Transfer Protocol — протокол передачи гипертекста) — символьно-ориентированный клиент-серверный протокол прикладного уровня без сохранения состояния, используемый сервисом World Wide Web.
Основным объектом манипуляции в HTTP является ресурс, на который указывает URI (Uniform Resource Identifier – уникальный идентификатор ресурса) в запросе клиента. Основными ресурсами являются хранящиеся на сервере файлы, но ими могут быть и другие логические (напр. каталог на сервере) или абстрактные объекты (напр. ISBN). Протокол HTTP позволяет указать способ представления (кодирования) одного и того же ресурса по различным параметрам: mime-типу, языку и т. д. Благодаря этой возможности клиент и веб-сервер могут обмениваться двоичными данными, хотя данный протокол является текстовым.
Структура протокола¶
Структура протокола определяет, что каждое HTTP-сообщение состоит из трёх частей (рис. 1), которые передаются в следующем порядке:
- Стартовая строка (англ. Starting line) — определяет тип сообщения;
- Заголовки (англ. Headers) — характеризуют тело сообщения, параметры передачи и прочие сведения;
- Тело сообщения (англ. Message Body) — непосредственно данные сообщения. Обязательно должно отделяться от заголовков пустой строкой.
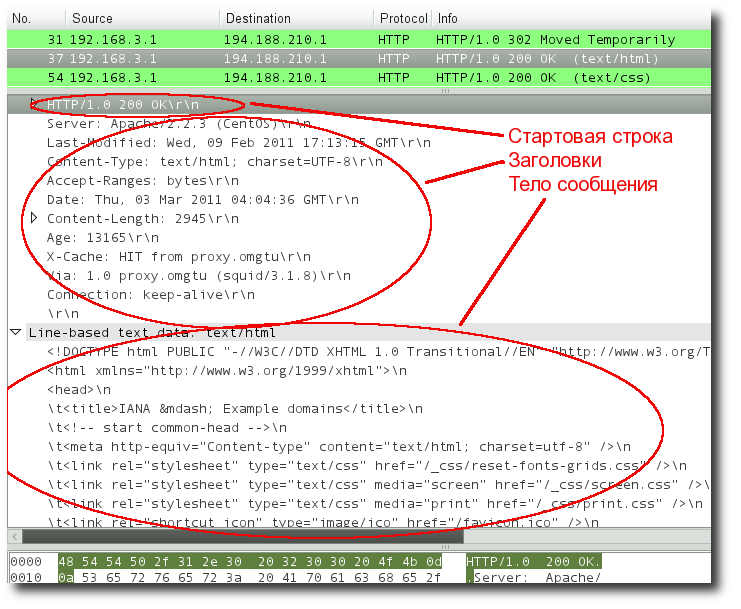
Рис. 1. Структура протокола HTTP (дамп пакета, полученный сниффером Wireshark)
Стартовая строка HTTP¶
Cтартовая строка является обязательным элементом, так как указывает на тип запроса/ответа, заголовки и тело сообщения могут отсутствовать.
Стартовые строки различаются для запроса и ответа. Строка запроса выглядит так:
Метод URI HTTP/Версия протокола
Пример запроса:
GET /web-programming/index.html HTTP/1.1
Стартовая строка ответа сервера имеет следующий формат:
HTTP/Версия КодСостояния [Пояснение]
Например, на предыдущий наш запрос клиентом данной страницы сервер ответил строкой:
HTTP/1.1 200 Ok
Методы протокола¶
Метод HTTP (англ. HTTP Method) — последовательность из любых символов, кроме управляющих и разделителей, указывающая на основную операцию над ресурсом. Обычно метод представляет собой короткое английское слово, записанное заглавными буквами (Табл. 1). Названия метода чувствительны к регистру.
Таблица 1. Методы протокола HTTP
| Метод | Краткое описание |
|---|---|
| OPTIONS |
Используется для определения возможностей веб-сервера или параметров соединения для конкретного ресурса. Для того чтобы узнать возможности всего сервера, клиент должен указать в URI звёздочку — «*». Запросы «OPTIONS * HTTP/1.1» могут также применяться для проверки работоспособности сервера (аналогично «пингованию») и тестирования на предмет поддержки сервером протокола HTTP версии 1.1. Результат выполнения этого метода не кэшируется. |
| GET |
Используется для запроса содержимого указанного ресурса. С помощью метода GET можно также начать какой-либо процесс. В этом случае в тело ответного сообщения следует включить информацию о ходе выполнения процесса. Согласно стандарту HTTP, запросы типа GET считаются идемпотентными[4] — многократное повторение одного и того же запроса GET должно приводить к одинаковым результатам (при условии, что сам ресурс не изменился за время между запросами). Это позволяет кэшировать ответы на запросы GET. Кроме обычного метода GET, различают ещё условный GET и частичный GET. Условные запросы GET содержат заголовки If-Modified-Since, If-Match, If-Range и подобные. Частичные GET содержат в запросе Range. Порядок выполнения подобных запросов определён стандартами отдельно. |
| HEAD |
Аналогичен методу GET, за исключением того, что в ответе сервера отсутствует тело. Запрос HEAD обычно применяется для извлечения метаданных, проверки наличия ресурса (валидация URL) и чтобы узнать, не изменился ли он с момента последнего обращения. Заголовки ответа могут кэшироваться. При несовпадении метаданных ресурса с соответствующей информацией в кэше копия ресурса помечается как устаревшая. |
| POST |
Применяется для передачи пользовательских данных заданному ресурсу. Например, в блогах посетители обычно могут вводить свои комментарии к записям в HTML-форму, после чего они передаются серверу методом POST и он помещает их на страницу. При этом передаваемые данные (в примере с блогами — текст комментария) включаются в тело запроса. Аналогично с помощью метода POST обычно загружаются файлы. В отличие от метода GET, метод POST не считается идемпотентным[4], то есть многократное повторение одних и тех же запросов POST может возвращать разные результаты (например, после каждой отправки комментария будет появляться одна копия этого комментария). При результатах выполнения 200 (Ok) и 204 (No Content) в тело ответа следует включить сообщение об итоге выполнения запроса. Если был создан ресурс, то серверу следует вернуть ответ 201 (Created) с указанием URI нового ресурса в заголовке Location. Сообщение ответа сервера на выполнение метода POST не кэшируется. |
| PUT |
Применяется для загрузки содержимого запроса на указанный в запросе URI. Если по заданному URI не существовало ресурса, то сервер создаёт его и возвращает статус 201 (Created). Если же был изменён ресурс, то сервер возвращает 200 (Ok) или 204 (No Content). Сервер не должен игнорировать некорректные заголовки Content-* передаваемые клиентом вместе с сообщением. Если какой-то из этих заголовков не может быть распознан или не допустим при текущих условиях, то необходимо вернуть код ошибки 501 (Not Implemented). Фундаментальное различие методов POST и PUT заключается в понимании предназначений URI ресурсов. Метод POST предполагает, что по указанному URI будет производиться обработка передаваемого клиентом содержимого. Используя PUT, клиент предполагает, что загружаемое содержимое соответствуют находящемуся по данному URI ресурсу. Сообщения ответов сервера на метод PUT не кэшируются. |
| PATCH |
Аналогично PUT, но применяется только к фрагменту ресурса. |
| DELETE |
Удаляет указанный ресурс. |
| TRACE |
Возвращает полученный запрос так, что клиент может увидеть, что промежуточные сервера добавляют или изменяют в запросе. |
| LINK |
Устанавливает связь указанного ресурса с другими. |
| UNLINK |
Убирает связь указанного ресурса с другими. |
Каждый сервер обязан поддерживать как минимум методы GET и HEAD. Если сервер не распознал указанный клиентом метод, то он должен вернуть статус 501 (Not Implemented). Если серверу метод известен, но он не применим к конкретному ресурсу, то возвращается сообщение с кодом 405 (Method Not Allowed). В обоих случаях серверу следует включить в сообщение ответа заголовок Allow со списком поддерживаемых методов.
Наиболее востребованными являются методы GET и POST — на человеко-ориентированных ресурсах, POST — роботами поисковых машин и оффлайн-браузерами.
Примечание
Прокси-сервер
Прокси – это транзитный сервер, перенаправляющий HTTP-трафик. Прокси-серверы используются для ускорения выполнения запросов путем кэширования веб-страниц. В локальной сети применяется как межсетевой экран и средство управления HTTP-трафиком (например, для блокирования доступа к некоторым ресурсам). В Интернете прокси часто используют для анонимизации запросов – в этом случае веб-сервер получает ip-адрес прокси-сервера, а не реального клиента. В современных браузерах можно задать целый список прокси и переключаться между серверами из этого списка по мере необходимости (обычно такая возможность доступна через расширения или плагины браузера).
Коды состояния¶
Код состояния информирует клиента о результатах выполнения запроса и определяет его дальнейшее поведение. Набор кодов состояния является стандартом, и все они описаны в соответствующих документах RFC.
Каждый код представляется целым трехзначным числом. Первая цифра указывает на класс состояния, последующие – порядковый номер состояния (рис 1.). За кодом ответа обычно следует краткое описание на английском языке.
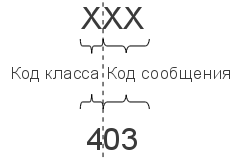
Рис. 1. Структура кода состояния HTTP
Введение новых кодов должно производиться только после согласования с IETF. Клиент может не знать все коды состояния, но он обязан отреагировать в соответствии с классом кода.
Применяемые в настоящее время классы кодов состояния и некоторые примеры ответов сервера приведены в табл. 2.
Таблица 2. Коды состояния протокола HTTP
| Класс кодов | Краткое описание |
|---|---|
| 1xx Informational (Информационный) |
В этот класс выделены коды, информирующие о процессе передачи. В HTTP/1.0 сообщения с такими кодами должны игнорироваться. В HTTP/1.1 клиент должен быть готов принять этот класс сообщений как обычный ответ, но ничего отправлять серверу не нужно. Сами сообщения от сервера содержат только стартовую строку ответа и, если требуется, несколько специфичных для ответа полей заголовка. Прокси-сервера подобные сообщения должны отправлять дальше от сервера к клиенту. Примеры ответов сервера: 100 Continue (Продолжать) 101 Switching Protocols (Переключение протоколов) 102 Processing (Идёт обработка) |
| 2xx Success (Успешно) |
Сообщения данного класса информируют о случаях успешного принятия и обработки запроса клиента. В зависимости от статуса сервер может ещё передать заголовки и тело сообщения. Примеры ответов сервера: 200 OK (Успешно). 201 Created (Создано) 202 Accepted (Принято) 204 No Content (Нет содержимого) 206 Partial Content (Частичное содержимое) |
| 3xx Redirection (Перенаправление) |
Коды статуса класса 3xx сообщают клиенту, что для успешного выполнения операции нужно произвести следующий запрос к другому URI. В большинстве случаев новый адрес указывается в поле Location заголовка. Клиент в этом случае должен, как правило, произвести автоматический переход (жарг. «редирект»). Обратите внимание, что при обращении к следующему ресурсу можно получить ответ из этого же класса кодов. Может получиться даже длинная цепочка из перенаправлений, которые, если будут производиться автоматически, создадут чрезмерную нагрузку на оборудование. Поэтому разработчики протокола HTTP настоятельно рекомендуют после второго подряд подобного ответа обязательно запрашивать подтверждение на перенаправление у пользователя (раньше рекомендовалось после 5-го). За этим следить обязан клиент, так как текущий сервер может перенаправить клиента на ресурс другого сервера. Клиент также должен предотвратить попадание в круговые перенаправления. Примеры ответов сервера: 300 Multiple Choices (Множественный выбор) 301 Moved Permanently (Перемещено навсегда) 304 Not Modified (Не изменялось) |
| 4xx Client Error (Ошибка клиента) |
Класс кодов 4xx предназначен для указания ошибок со стороны клиента. При использовании всех методов, кроме HEAD, сервер должен вернуть в теле сообщения гипертекстовое пояснение для пользователя. Примеры ответов сервера: 401 Unauthorized (Неавторизован) 402 Payment Required (Требуется оплата) 403 Forbidden (Запрещено) 404 Not Found (Не найдено) 405 Method Not Allowed (Метод не поддерживается) 406 Not Acceptable (Не приемлемо) 407 Proxy Authentication Required (Требуется аутентификация прокси) |
| 5xx Server Error (Ошибка сервера) |
Коды 5xx выделены под случаи неудачного выполнения операции по вине сервера. Для всех ситуаций, кроме использования метода HEAD, сервер должен включать в тело сообщения объяснение, которое клиент отобразит пользователю. Примеры ответов сервера: 500 Internal Server Error (Внутренняя ошибка сервера) 502 Bad Gateway (Плохой шлюз) 503 Service Unavailable (Сервис недоступен) 504 Gateway Timeout (Шлюз не отвечает) |
Заголовки HTTP¶
Заголовок HTTP (HTTP Header) — это строка в HTTP-сообщении, содержащая разделённую двоеточием пару вида «параметр-значение». Формат заголовка соответствует общему формату заголовков текстовых сетевых сообщений ARPA (RFC 822). Как правило, браузер и веб-сервер включают в сообщения более чем по одному заголовку. Заголовки должны отправляться раньше тела сообщения и отделяться от него хотя бы одной пустой строкой (CRLF).
Название параметра должно состоять минимум из одного печатного символа (ASCII-коды от 33 до 126). После названия сразу должен следовать символ двоеточия. Значение может содержать любые символы ASCII, кроме перевода строки (CR, код 10) и возврата каретки (LF, код 13).
Пробельные символы в начале и конце значения обрезаются. Последовательность нескольких пробельных символов внутри значения может восприниматься как один пробел. Регистр символов в названии и значении не имеет значения (если иное не предусмотрено форматом поля).
Пример заголовков ответа сервера:
Server: Apache/2.2.3 (CentOS) Last-Modified: Wed, 09 Feb 2011 17:13:15 GMT Content-Type: text/html; charset=UTF-8 Accept-Ranges: bytes Date: Thu, 03 Mar 2011 04:04:36 GMT Content-Length: 2945 Age: 51 X-Cache: HIT from proxy.omgtu Via: 1.0 proxy.omgtu (squid/3.1.8) Connection: keep-alive 200 OK
Все HTTP-заголовки разделяются на четыре основных группы:
- General Headers (Основные заголовки) — должны включаться в любое сообщение клиента и сервера.
- Request Headers (Заголовки запроса) — используются только в запросах клиента.
- Response Headers (Заголовки ответа) — присутствуют только в ответах сервера.
- Entity Headers (Заголовки сущности) — сопровождают каждую сущность сообщения.
Сущности (entity, в переводах также встречается название “объект”) — это полезная информация, передаваемая в запросе или ответе. Сущность состоит из метаинформации (заголовки) и непосредственно содержания (тело сообщения).
В отдельный класс заголовки сущности выделены, чтобы не путать их с заголовками запроса или заголовками ответа при передаче множественного содержимого (multipart/*). Заголовки запроса и ответа, как и основные заголовки, описывают всё сообщение в целом и размещаются только в начальном блоке заголовков, в то время как заголовки сущности характеризуют содержимое каждой части в отдельности, располагаясь непосредственно перед её телом.
В таблице 3 приведено краткое описание некоторых HTTP-заголовков.
Таблица 3. Заголовки HTTP
| Заголовок | Группа | Краткое описание |
|---|---|---|
| Allow | Entity | Список методов, применимых к запрашиваемому ресурсу. |
| Content-Encoding | Entity | Применяется при необходимости перекодировки содержимого (например, gzip/deflated). |
| Content-Language | Entity | Локализация содержимого (язык(и)) |
| Content-Length | Entity | Размер тела сообщения (в октетах) |
| Content-Range | Entity | Диапазон (используется для поддержания многопоточной загрузки или дозагрузки) |
| Content-Type | Entity | Указывает тип содержимого (mime-type, например text/html).Часто включает указание на таблицу символов локали (charset) |
| Expires | Entity | Дата/время, после которой ресурс считается устаревшим. Используется прокси-серверами |
| Last-Modified | Entity | Дата/время последней модификации сущности |
| Cache-Control | General | Определяет директивы управления механизмами кэширования. Для прокси-серверов. |
| Connection | General | Задает параметры, требуемые для конкретного соединения. |
| Date | General | Дата и время формирования сообщения |
| Pragma | General | Используется для специальных указаний, которые могут (опционально) применяется к любому получателю по всей цепочке запросов/ответов (например, pragma: no-cache). |
| Transfer-Encoding | General | Задает тип преобразования, применимого к телу сообщения. В отличие от Content-Encoding этот заголовок распространяется на все сообщение, а не только на сущность. |
| Via | General | Используется шлюзами и прокси для отображения промежуточных протоколов и узлов между клиентом и веб-сервером. |
| Warning | General | Дополнительная информация о текущем статусе, которая не может быть представлена в сообщении. |
| Accept | Request | Определяет применимые типы данных, ожидаемых в ответе. |
| Accept-Charset | Request | Определяет кодировку символов (charset) для данных, ожидаемых в ответе. |
| Accept-Encoding | Request | Определяет применимые форматы кодирования/декодирования содержимого (напр, gzip) |
| Accept-Language | Request | Применимые языки. Используется для согласования передачи. |
| Authorization | Request | Учетные данные клиента, запрашивающего ресурс. |
| From | Request | Электронный адрес отправителя |
| Host | Request | Имя/сетевой адрес [и порт] сервера. Если порт не указан, используется 80. |
| If-Modified-Since | Request | Используется для выполнения условных методов (Если-Изменился…). Если запрашиваемый ресурс изменился, то он передается с сервера, иначе – из кэша. |
| Max-Forwards | Request | Представляет механиз ограничения количества шлюзов и прокси при использовании методов TRACE и OPTIONS. |
| Proxy-Authorization | Request | Используется при запросах, проходящих через прокси, требующие авторизации |
| Referer | Request | Адрес, с которого выполняется запрос. Этот заголовок отсутствует, если переход выполняется из адресной строки или, например, по ссылке из js-скрипта. |
| User-Agent | Request | Информация о пользовательском агенте (клиенте) |
| Location | Response | Адрес перенаправления |
| Proxy-Authenticate | Response | Сообщение о статусе с кодом 407. |
| Server | Response | Информация о программном обеспечении сервера, отвечающего на запрос (это может быть как веб- так и прокси-сервер). |
В листинге 1 приведен фрагмент дампа заголовков при подключении к серверу http://example.org
Листинг 1. Заголовки HTTP
http://www.example.org/ GET http://www.example.org/ HTTP/1.1 Host: www.example.org User-Agent: Mozilla/5.0 (X11; U; Linux i686; ru; rv:1.9.2.13) Gecko/20101203 SUSE/3.6.13-0.2.1 Firefox/3.6.13 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: ru-ru,ru;q=0.8,en-us;q=0.5,en;q=0.3 Accept-Encoding: gzip,deflate Accept-Charset: windows-1251,utf-8;q=0.7,*;q=0.7 Keep-Alive: 115 Proxy-Connection: keep-alive HTTP/1.0 302 Moved Temporarily Date: Thu, 03 Mar 2011 06:48:28 GMT Location: http://www.iana.org/domains/example/ Server: BigIP Content-Length: 0 X-Cache: MISS from proxy.omgtu Via: 1.0 proxy.omgtu (squid/3.1.8) Connection: keep-alive ---------------------------------------------------------- http://www.iana.org/domains/example/ GET http://www.iana.org/domains/example/ HTTP/1.1 Host: www.iana.org User-Agent: Mozilla/5.0 (X11; U; Linux i686; ru; rv:1.9.2.13) Gecko/20101203 SUSE/3.6.13-0.2.1 Firefox/3.6.13 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: ru-ru,ru;q=0.8,en-us;q=0.5,en;q=0.3 Accept-Encoding: gzip,deflate Accept-Charset: windows-1251,utf-8;q=0.7,*;q=0.7 Keep-Alive: 115 Proxy-Connection: keep-alive HTTP/1.0 200 OK Server: Apache/2.2.3 (CentOS) Last-Modified: Wed, 09 Feb 2011 17:13:15 GMT Content-Type: text/html; charset=UTF-8 Accept-Ranges: bytes Date: Thu, 03 Mar 2011 04:04:36 GMT Content-Length: 2945 Age: 9858 X-Cache: HIT from proxy.omgtu Via: 1.0 proxy.omgtu (squid/3.1.8) Connection: keep-alive ....
Несколько полезных примеров php-скриптов, обрабатывающих HTTP-заголовки, приведены в статье «Использование файла .htaccess» (редирект, отправка кода ошибки, установка last-modified и т.п.).
Тело сообщения¶
Тело HTTP сообщения (message-body), если оно присутствует, используется для передачи сущности, связанной с запросом или ответом. Тело сообщения (message-body) отличается от тела сущности (entity-body) только в том случае, когда при передаче применяется кодирование, указанное в заголовке Transfer-Encoding. В остальных случаях тело сообщения идентично телу сущности.
Заголовок Transfer-Encoding должен отправляться для указания любого кодирования передачи, примененного приложением в целях гарантирования безопасной и правильной передачи сообщения. Transfer-Encoding – это свойство сообщения, а не сущности, и оно может быть добавлено или удалено любым приложением в цепочке запросов/ответов.
Присутствие тела сообщения в запросе отмечается добавлением к заголовкам запроса поля заголовка Content-Length или Transfer-Encoding. Тело сообщения (message-body) может быть добавлено в запрос только когда метод запроса допускает тело объекта (entity-body).
Все ответы содержат тело сообщения, возможно нулевой длины, кроме ответов на запрос методом HEAD и ответов с кодами статуса 1xx (Информационные), 204 (Нет содержимого, No Content), и 304 (Не модифицирован, Not Modified).
Контрольные вопросы¶
- В каком случае клиент получит от сервера ответ с кодом 418?
