|
№ п/п |
авт/ч |
№ п/п |
авт/ч |
№ п/п |
авт/ч |
№ п/п |
авт/ч |
|
1 |
2 |
26 |
5 |
51 |
8 |
76 |
10 |
|
2 |
2 |
27 |
5 |
52 |
8 |
77 |
10 |
|
3 |
2 |
28 |
5 |
53 |
9 |
78 |
10 |
|
4 |
2 |
29 |
5 |
54 |
9 |
79 |
10 |
|
5 |
2 |
30 |
5 |
55 |
9 |
80 |
11 |
|
6 |
3 |
31 |
5 |
56 |
9 |
81 |
11 |
|
7 |
3 |
32 |
6 |
57 |
9 |
82 |
11 |
|
8 |
3 |
33 |
6 |
58 |
9 |
83 |
11 |
|
9 |
3 |
34 |
6 |
59 |
9 |
84 |
12 |
|
10 |
3 |
35 |
6 |
60 |
9 |
85 |
13 |
|
11 |
3 |
36 |
6 |
61 |
9 |
86 |
13 |
|
12 |
3 |
37 |
6 |
62 |
9 |
87 |
13 |
|
13 |
3 |
38 |
7 |
63 |
9 |
88 |
14 |
|
14 |
4 |
39 |
7 |
64 |
10 |
89 |
14 |
|
15 |
4 |
40 |
7 |
65 |
10 |
90 |
16 |
|
16 |
4 |
41 |
7 |
66 |
10 |
91 |
16 |
|
17 |
4 |
42 |
7 |
67 |
10 |
92 |
18 |
|
18 |
4 |
43 |
7 |
68 |
10 |
93 |
19 |
|
19 |
4 |
44 |
7 |
69 |
10 |
94 |
21 |
|
20 |
4 |
45 |
7 |
70 |
10 |
95 |
21 |
|
21 |
4 |
46 |
8 |
71 |
10 |
96 |
22 |
|
22 |
4 |
47 |
8 |
72 |
10 |
97 |
26 |
|
23 |
5 |
48 |
8 |
73 |
10 |
98 |
28 |
|
24 |
5 |
49 |
8 |
74 |
10 |
99 |
31 |
|
25 |
5 |
50 |
8 |
75 |
10 |
100 |
35 |
1.3. Дискретный вариационный ряд
|
х, |
f |
|
2 |
5 |
|
3 |
8 |
|
4 |
9 |
|
5 |
9 |
|
6 |
6 |
|
7 |
8 |
|
8 |
7 |
|
9 |
11 |
|
10 |
16 |
|
11 |
4 |
|
12 |
1 |
|
13 |
3 |
|
14 |
2 |
|
16 |
2 |
|
18 |
1 |
|
19 |
1 |
|
21 |
2 |
|
22 |
1 |
|
26 |
1 |
|
28 |
1 |
|
31 |
1 |
|
35 |
1 |
|
Итого |
100 |
1.4. Построить интервальный вариационный ряд, подобрав наилучшее число интервалов.
i=(35-2/)6=5,5
|
Интервал |
f |
Хц |
Σf |
|
2 |
45 |
4,75 |
45 |
|
7,5 |
42 |
10,25 |
87 |
|
13,00 |
5 |
15,75 |
92 |
|
18,50 |
4 |
21,25 |
96 |
|
24,00 |
2 |
26,75 |
98 |
|
29,50 |
2 |
32,25 |
100 |
|
Итого |
100 |
i=(35-2)/7=4.71
|
Интервал |
f |
Хц |
Σf |
|
2 |
37 |
4,4 |
37 |
|
6,71 |
46 |
9,07 |
83 |
|
11,42 |
8 |
13,77 |
91 |
|
16,12 |
2 |
18,48 |
93 |
|
20,83 |
3 |
23,19 |
96 |
|
25,54 |
2 |
27,90 |
98 |
|
30,25 |
2 |
32,63 |
100 |
|
Итого |
100 |
i=(35-2)/8=4,13
|
Интервал |
f |
Хц |
Σf |
|
2 |
37 |
4,07 |
37 |
|
6,13 |
42 |
8,20 |
79 |
|
10,26 |
10 |
12,33 |
89 |
|
14,39 |
3 |
16,46 |
92 |
|
18,52 |
4 |
20,59 |
96 |
|
22,65 |
1 |
24,72 |
97 |
|
26,78 |
1 |
28,85 |
98 |
|
30,91 |
2 |
32,96 |
100 |
|
Итого |
100 |
1.5. Для каждого из полученных рядов
вычислить: среднюю арифметическую;
моду; медиану; показатели вариации
(размах вариации, среднее линейное и
среднее квадратическое отклонение,
дисперсию, коэффициент вариации).
Среднеарифметическая взвешенная.
Дискретный вариационный ряд.
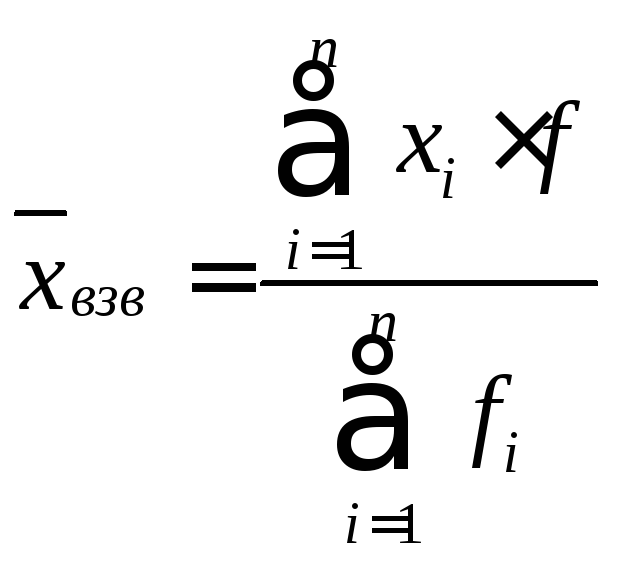 ,
,
где
Σxi∙fi – сумма произведений значений
признака и их частот;
Σfi – сумма всех частот.
Интервальный вариационный ряд.
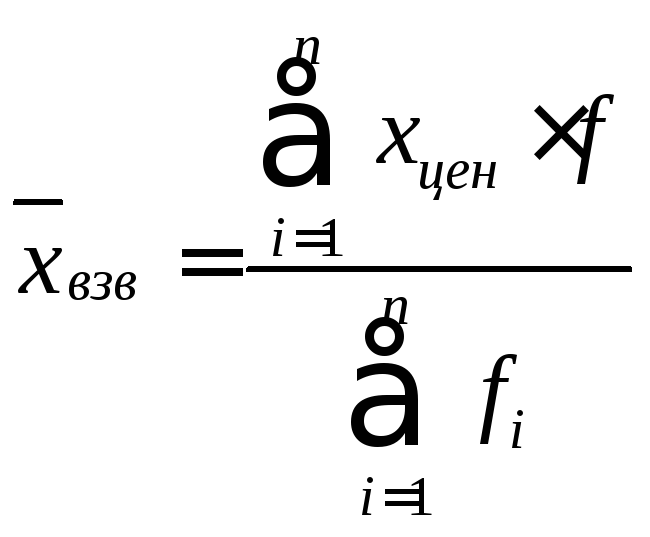 ,
,
где
Σxцен∙fi – сумма произведений центров
интервалов и их частот;
Σfi – сумма всех частот.
Мода.
Дискретный вариационный ряд.
Это вариант имеющий наибольшую частоту
f.
Интервальный вариационный ряд.
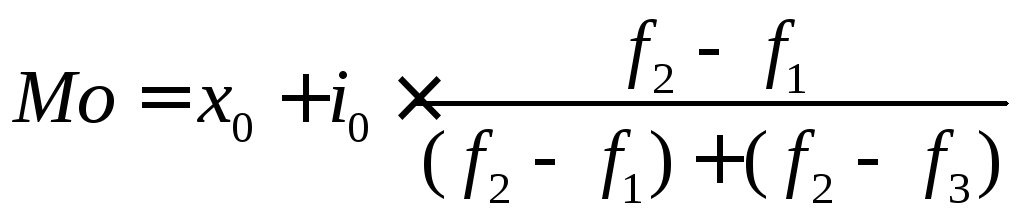 ,
,
где
х0 – нижняя граница модального интервала;
i0 – величина модального интервала;
f1, f2, f3 – частота интервала предшествующего,
модального и следующего за модальным.
Медиана.
Дискретный вариационный ряд.
Это вариант стоящий в центре ранжированного
ряда.
Интервальный вариационный ряд.
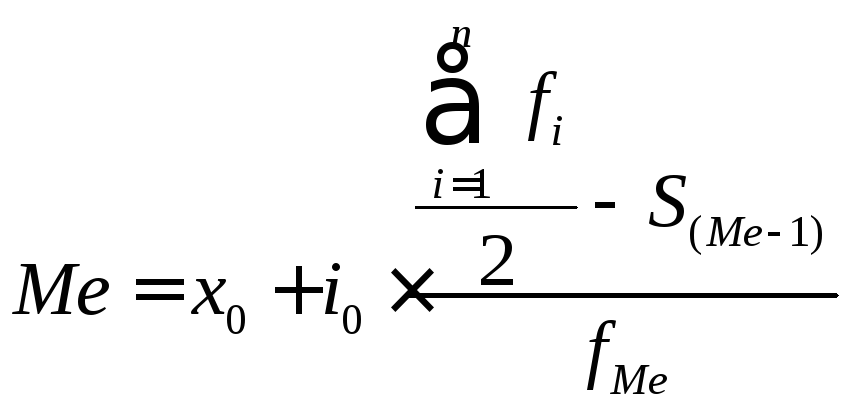 ,
,
где
х0 – нижняя граница медианного интервала;
i0 – величина медианного интервала;
Σfi – сумма всех частот;
S(Me – 1) – сумма накопленных частот
интервалов, предшествующих медианному;
fMe – частота медианного интервала.
Размах вариации.
![]()
Среднее линейное отклонение.
Дискретный вариационный ряд.
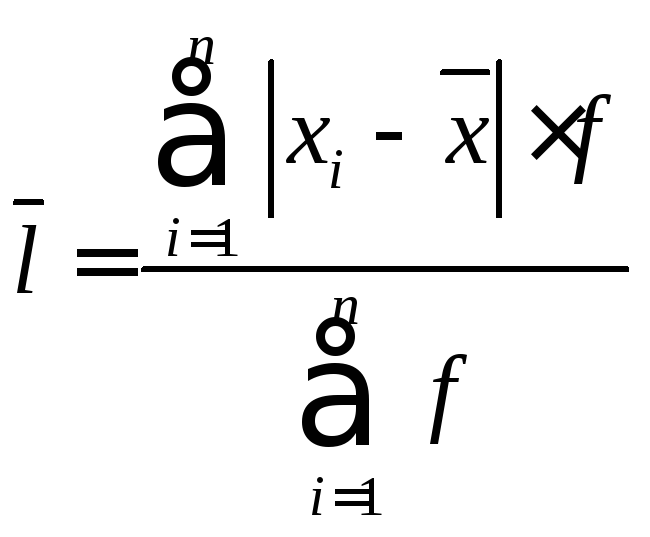
Интервальный вариационный ряд.
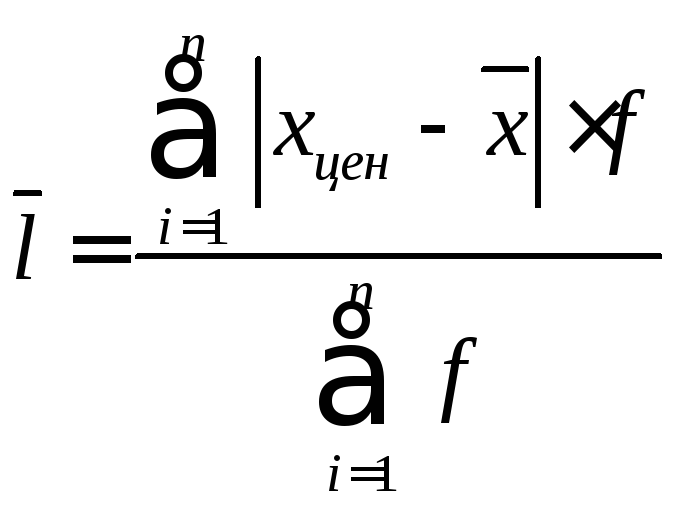
Дисперсия (средняя квадратов
отклонений).
Дискретный вариационный ряд.
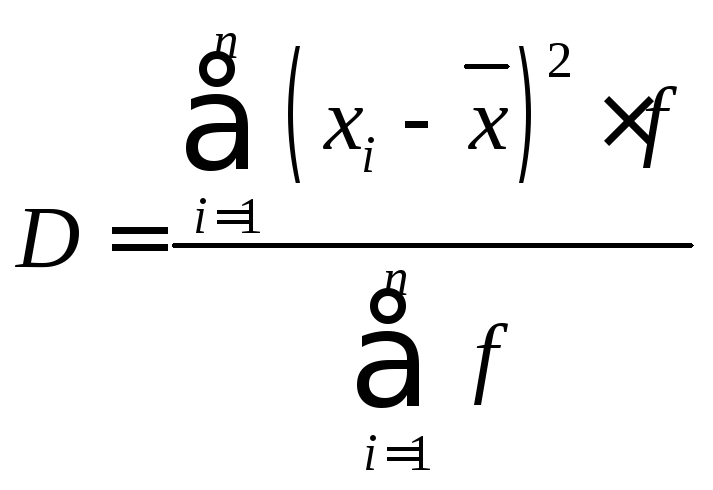
Интервальный вариационный ряд.
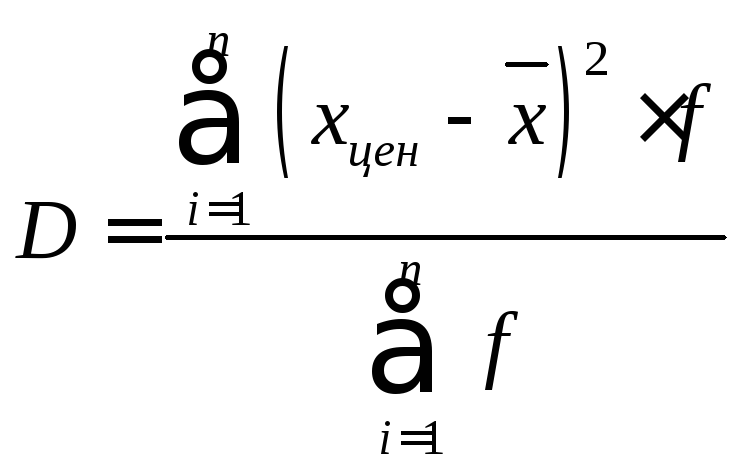
Среднее квадратическое отклонение.
![]()
Коэффициент вариации.
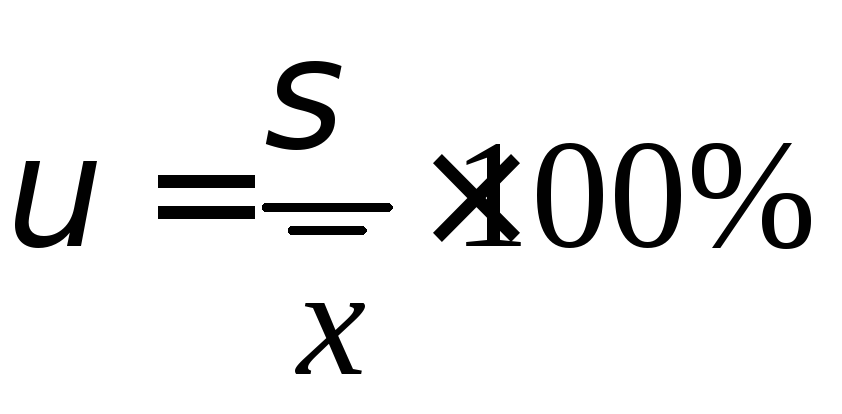
1.5.1 Для интервального вариационного
ряда.
Х=(45*4,75+42*10,25+5*15,75+4*21,25+2*26,75+2*32,25)/100=9,26
Мо=2+5,5*(45-0)
/ (45-0)+(45-42)=7,16
Ме=7,5+5,5*(50-45)/42=8,15
R=35-2=33
l=(4,75-9,26)+(10,25-9,26)+(15,75-9,26)+(21,25-9,26)+(26,75-9,26)+(32,25-9,26)/100=0,55
Dх=(4,75-9,26)2*45+(10,25-9,26)2*42+(15,75-9,26)2*5+(21,25-9,26)2*4+(26,75-9,26)2*2+(32,25-9,26)2*2/100=34,11
δх=(34,11)1/2=5,8
V=5.8/9.26*100=62,63
1.5.2 Для дискретного ряда
Х=2*5+3*8+4*9+5*9+6*6+7*8+8*7+9*11+10*16+11*4+12*1+13*3+14*2+16*2+18*1+19*1+21*2+22*1+26*1+28*1+31*1+35*1/100=8,98
Мо=10
Ме=8
R=35-2=33
l=(2-8,98)+(3-8,98)+(4-8,98)+(5-8,98)+(6-8,98)+(7-8,98)+(8-8,98)+
(9-8,98)+(10-8,98)+(11-8,98)+(12-8,98)+(13-8,98)+(14-8,98)+(16-8,98)+
(18-8,98)+(19-8,98)+(21-8,98)+(22-8,98)+(26-8,98)+(28-8,98)+
(31-8,98)+(35-8,98)/100=1,22
Dx=
(2-8,98)2+(3-8,98)2+(4-8,98)2+(5-8,98)2+(6-8,98)2+(7-8,98)2+(8-8,98)2+
(9-8,98)2+(10-8,98)2+(11-8,98)2+(12-8,98)2+(13-8,98)2+(14-8,98)2+
(16-8,98)2+(18-8,98)2+(19-8,98)2+(21-8,98)2+(22-8,98)2+(26-8,98)2+
(28-8,98)2+(31-8,98)2+(35-8,98)2/100=25,53
δх=(25,53)1/2=5,05
V=5,05/8,98*100=56,24
Соседние файлы в предмете Статистика
- #
- #
- #
- #
- #
Варианты для выполнения работы
I. Установление закономерностей, которым подчинены массовые случайные явления, основано на изучении методами теории вероятностей статистических данных — результатов наблюдений.
Почти все встречающиеся в жизни величины (урожайность сельскохозяйственных растений, продуктивности скота, производительность труда и заработная плата рабочих, объем производства продукции и т.д.) принимают неодинаковые значения у различных членов совокупности. Поэтому возникает необходимость в изучении их изменяемости. Это изучение начинается с проведения соответствующих наблюдений, обследований.
В результате наблюдений получают сведения о численной величине изучаемого признака у каждого члена данной совокупности.
Пример. Имеются данные о размере прибыли 100 коммерческих банков. Прибыль, млн. рублей.
| 30,2 | 51,9 | 43,1 | 58,9 | 34,1 | 55,2 | 47,9 | 43,7 | 53,2 | 34,9 |
| 47,8 | 65,7 | 37,8 | 68,6 | 48,4 | 67,5 | 27,3 | 66,1 | 52,0 | 55,6 |
| 54,1 | 26,9 | 53,6 | 42,5 | 59,3 | 44,8 | 52,8 | 42,3 | 55,9 | 48,1 |
| 44,5 | 69,8 | 47,3 | 35,6 | 70,1 | 39,5 | 70,3 | 33,7 | 51,8 | 56,1 |
| 28,4 | 48,7 | 41,9 | 58,1 | 20,4 | 56,3 | 46,5 | 41,8 | 59,5 | 38,1 |
| 41,4 | 70,4 | 31,4 | 52,5 | 45,2 | 52,3 | 40,2 | 60,4 | 27,6 | 57,4 |
| 29,3 | 53,8 | 46,3 | 40,1 | 50,3 | 48,9 | 35,8 | 61,7 | 49,2 | 45,8 |
| 45,3 | 71,5 | 35,1 | 57,8 | 28,1 | 57,6 | 49,6 | 45,5 | 36,2 | 63,2 |
| 61,9 | 25,1 | 65,1 | 49,7 | 62,1 | 46,1 | 39,9 | 62,4 | 50,1 | 33,1 |
| 33,3 | 49,8 | 39,8 | 45,9 | 37,3 | 78,0 | 64,9 | 28,8 | 62,5 | 58,7 |
Из данной таблицы видно, что интересующий нас признак (прибыль банков) меняется от одного члена совокупности к другому, варьирует. Варьирование есть изменяемость признака у отдельных членов совокупности.
Вариационным рядом называется последовательность вариант, записанных в возрастающем порядке и соответствующих им частот.
Число, показывающее, сколько раз повторяется в данной совокупности каждое значение признака, называется частотой.
Составим ранжированный вариационный ряд (выпишем варианты в порядке возрастания):
| 20,4 | 25,1 | 26,9 | 27,3 | 27,6 | 28,1 | 28,4 | 28,8 | 29,3 | 30,2 |
| 31,4 | 33,1 | 33,3 | 33,7 | 34,1 | 34,9 | 35,1 | 35,6 | 35,8 | 36,2 |
| 37,3 | 37,8 | 38,1 | 39,5 | 39,8 | 39,9 | 40,1 | 40,2 | 41,4 | 41,8 |
| 41,9 | 42,3 | 42,5 | 43,1 | 43,7 | 44,5 | 44,8 | 45,2 | 45,3 | 45,5 |
| 45,8 | 45,9 | 46,1 | 46,3 | 46,5 | 47,3 | 47,8 | 47,9 | 48,1 | 48,4 |
| 48,7 | 48,9 | 49,2 | 49,6 | 49,7 | 49,8 | 50,1 | 50,3 | 51,8 | 51,9 |
| 52,0 | 52,3 | 52,5 | 52,8 | 53,2 | 53,6 | 53,8 | 54,1 | 55,2 | 55,6 |
| 55,9 | 56,1 | 56,3 | 57,4 | 57,6 | 57,8 | 58,1 | 58,7 | 58,9 | 59,3 |
| 59,5 | 60,4 | 61,7 | 61,9 | 62,1 | 62,4 | 62,5 | 63,2 | 64,9 | 65,1 |
| 65,7 | 66,1 | 67,5 | 68,6 | 69,8 | 70,1 | 70,3 | 70,4 | 71,5 | 78,0 |
В нашем случае каждое значение признака (варианта вариационного ряда) повторилось только один раз, т.е. значение частоты для всех вариант равно единице. Перейдем к интервальному вариационному ряду, так как интересующий нас признак принимает дробные, практически не повторяющиеся значения.
Для этого необходимо определить число интервалов (классов) и длину интервала (классного промежутка), после чего произвести разноску, т.е. подсчитать для каждого интервала число вариант, попавших в него.
Количество классов устанавливают в зависимости от степени точности, с которой ведется обработка, и количества объектов в выборке. Считается удобным при объеме выборки (n) в пределах от 30 до 60 вариант распределять их на 6-7 классов, при n от 60 до 100 вариант — на 7-8 классов, при n от 100 и более вариант — на 9-17 классов.
Нужное количество групп также может быть ориентировочно вычислено по формуле Стерджесса:
![[k=1+3,322lgn]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-827d2afc3c23ef764fe96a262dc05464_l3.png "Rendered by QuickLaTeX.com")
где  — число групп (классов, интервалов) ряда распределения; n — объем выборки.
— число групп (классов, интервалов) ряда распределения; n — объем выборки.
Можно также использовать выражение:
![[k=sqrt{n}.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-c751034bcfa1dc301e6aa8cc4c208523_l3.png "Rendered by QuickLaTeX.com")
При  они дают примерно одинаковые результаты.
они дают примерно одинаковые результаты.
В рассматриваемом примере о размере прибыли коммерческих банков, n=100. Применяя формулу Стерджесса, получим:
![[k=1+3,322lg100=1+3,322cdot 2=7,644approx 8.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-c58a320e33430cf4c7533ebf191c3ab5_l3.png "Rendered by QuickLaTeX.com")
Однако  Таким образом, число интервалов может быть равно 8, 9, 10 и т.д.
Таким образом, число интервалов может быть равно 8, 9, 10 и т.д.
Нахождение нужного количества групп и их размеров часто бывает взаимообусловлено. Для того, чтобы как-то определиться с числом интервалов, найдем размах вариации — разность между наибольшей и наименьшей вариантой:
![[R=x_{max}-x_{min}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-aafc593639af68dbf52da085dd4d8c8c_l3.png "Rendered by QuickLaTeX.com")
где  — размах вариации,
— размах вариации,
 — наибольшее значение варьирующего признака,
— наибольшее значение варьирующего признака,
 — наименьшее значение варьирующего признака.
— наименьшее значение варьирующего признака.
Найдем размах вариации для рассматриваемой задачи:
![[R=78,0-20,4=57,6]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-56080b6ec34bbf2f588d137e9eaf87cb_l3.png "Rendered by QuickLaTeX.com")
Для того, чтобы найти длину интервала (величину классового промежутка) необходимо разделить размах вариации на число классов и полученную величину округлить таким образом, чтобы было удобно производить сначала разноску, а затем и различные вычисления. Рекомендую округлять до единиц, до которых округлены варианты в исходной таблице, в нашем случае до десятых.
![[happrox frac{R}{k}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-3e0b8eaa452c3f09d2f7f8090a3d7e36_l3.png "Rendered by QuickLaTeX.com")
Согласно формуле получаем
![[happrox frac{57,6}{8}=7,2]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-243ada79cae79e51927cddc6d6d38988_l3.png "Rendered by QuickLaTeX.com")
Теперь необходимо определиться с началом первого интервала. Для этого можно использовать формулу:
![[x_1approx x_{min}-frac{h}{2}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-5a6eab01e8fb5fc5d82b10533b954fc7_l3.png "Rendered by QuickLaTeX.com")
![[x_1approx 20,4-frac{7,2}{2}=16,8.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-f9ce5df5c222c16a62501fec5810487b_l3.png "Rendered by QuickLaTeX.com")
Замечание. За начало первого интервала можно принять некоторое значение, несколько меньшее или само значение . Далее в табличном виде я покажу оба варианта.
Прибавив к началу первого интервала (нижней границе) шаг, получим верхнюю границу первого интервала и одновременно нижнюю границу второго интервала. Выполняя последовательно указанные действия, будем находить границы последующих интервалов до тех пор, пока не будет получено или перекрыто .
Таким образом, верхняя граница одного интервала одновременно является нижней границей другого интервала. Чтобы не возникало сомнений, в какой интервал отнести варианту, попавшую на границу, условимся относить ее к верхнему интервалу.
Составим теперь рабочую таблицу для построения интервального вариационного ряда и произведем подсчет частот вариант, попавших в тот или иной интервал.
Как и обещал покажу две таблицы построения ряда:
1. Отсчет ведем от , т.е. нижняя граница первого интервала совпадает с .
|
Группы банков по размеру прибыли (границы интервалов) |
Количество банков, принадлежащих данной группе (частоты, |
Накопленные частоты,
|
| 20,4 — 27,6 | 4 | 4 |
| 27,6 — 34,8 | 11 | 15 |
| 34,8 — 42 | 16 | 31 |
| 42 — 49,2 | 21 | 52 |
| 49,2 — 56,4 | 21 | 73 |
| 56,4 — 63,6 | 15 | 88 |
| 63,6 — 70,8 | 10 | 98 |
| 70,8 — 78 | 2 | 100 |

2. Начало первого интервала определяем с помощью формулы:  .
.
|
Группы банков по размеру прибыли (границы интервалов) |
Количество банков, принадлежащих данной группе (частоты, |
Накопленные частоты,
|
| 16,8 — 24 | 1 | 1 |
| 24 — 31,2 | 9 | 10 |
| 31,2 — 38,4 | 13 | 23 |
| 38,4 — 45,6 | 17 | 40 |
| 45,6 — 52,8 | 23 | 63 |
| 52,8 — 60 | 18 | 81 |
| 60 — 67,2 | 11 | 92 |
| 67,2 — 74,4 | 7 | 99 |
| 74,4 — 81,6 | 1 | 100 |
Как мы видим в 1-м случае у нас получилось восемь интервалов, что полностью совпадает с результатом, который нам дала формула Стерджесса. Во втором случае у нас получилось девять интервалов, так как при поиске начала первого интервала пользовались специальной формулой.
Для дальнейшего исследования я буду пользоваться результатами второй таблицы, так как там ярко выражен модальный интервал (одна мода) и медиана практически точно попадает на середину вариационного ряда.
Мы получили интервальный вариационный ряд — упорядоченную совокупность интервалов варьирования значений случайной величины с соответствующими частотами попаданий в каждый из них значений величины.
II. Графическая интерпретация вариационных рядов.
| № п/п |
Границы интервалов,
|
Середины интервалов,
|
Частоты интервалов,
|
Относительные частоты
|
Плотность относит. частоты
|
Плотность частоты
|
| 1 | 16,8 — 24 | 20,4 | 1 | 0,01 | 0,001 | 0,139 |
| 2 | 24 — 31,2 | 27,6 | 9 | 0,09 | 0,013 | 1,250 |
| 3 | 31,2 — 38,4 | 34,8 | 13 | 0,13 | 0,018 | 1,806 |
| 4 | 38,4 — 45,6 | 42 | 17 | 0,17 | 0,024 | 2,361 |
| 5 | 45,6 — 52,8 | 49,2 | 23 | 0,23 | 0,032 | 3,194 |
| 6 | 52,8 — 60 | 56,4 | 18 | 0,18 | 0,025 | 2,500 |
| 7 | 60 — 67,2 | 63,6 | 11 | 0,11 | 0,015 | 1,528 |
| 8 | 67,2 — 74,4 | 70,8 | 7 | 0,07 | 0,010 | 0,972 |
| 9 | 74,4 — 81,6 | 78 | 1 | 0,01 | 0,001 | 0,139 |
 |
 |





Строим графики:





Далее найдем моду вариационного ряда:
![[M_o(X)=x_{M_o}+hfrac{(n_2-n_1)}{(n_2-n_1)+(n_2-n_3)}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-5618d73a38aaff5a278596c8af7758c8_l3.png "Rendered by QuickLaTeX.com")
где
 — начало модального интервала;
— начало модального интервала;
 — длина частичного интервала (шаг);
— длина частичного интервала (шаг);
 — частота предмодального интервала;
— частота предмодального интервала;
 — частота модального интервала;
— частота модального интервала;
 — частота послемодального интервала.
— частота послемодального интервала.
Определим модальный интервал — интервал, имеющий наибольшую частоту. Из таблицы видно, что модальным является интервал (45,6 — 52,8).
![[M_o(X)=45,6+7,2frac{(23-17)}{(23-17)+(23-18)}=]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-473f77b88c7bd6de3e31bd12541d8833_l3.png "Rendered by QuickLaTeX.com")
![[=45,6+7,2cdot frac{6}{6+5}=45,6+3,93=49,5]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-9122e42dfec05a0505617226d32d75df_l3.png "Rendered by QuickLaTeX.com")
Медиана
Для интервального ряда медиана находится по формуле:
![[M_e(X)=x_{M_e}+hfrac{0,5n-S_{M_{e}-1}}{n_{M_e}}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-c464daab40bab9748a191e3a00b95831_l3.png "Rendered by QuickLaTeX.com")
где
 — начало медианного интервала;
— начало медианного интервала;
— длина частичного интервала (шаг);
 — объем совокупности;
— объем совокупности;
 — накопленная частота интервала, предшествующая медианному;
— накопленная частота интервала, предшествующая медианному;
 — частота медианного интервала.
— частота медианного интервала.
Определим медианный интервал — интервал, в котором впервые накопленная частота превышает половину объема выборки.Так как объем выборки n=100, то n/2=50. По таблице найдем интервал, где впервые накопленные частоты превысят это значение. Таким является интервал (45,6 — 52,8).
Получаем,
![[M_e(X)=45,6+7,2frac{0,5cdot 100-40}{23}approx 48,7.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-d820d343bc16acd48af9d431995a7222_l3.png "Rendered by QuickLaTeX.com")
III. Расчет сводных характеристик выборки.
Для определения  составим расчетную таблицу. Для начала определимся с ложным нулем С. В качестве ложного нуля можно принять любую варианту. Максимальная простота вычислений достигается, если выбрать в качестве ложного нуля варианту, которая расположена примерно в середине вариационного ряда (часто такая варианта имеет наибольшую частоту).
составим расчетную таблицу. Для начала определимся с ложным нулем С. В качестве ложного нуля можно принять любую варианту. Максимальная простота вычислений достигается, если выбрать в качестве ложного нуля варианту, которая расположена примерно в середине вариационного ряда (часто такая варианта имеет наибольшую частоту).
Варианте, которая принята в качестве ложного нуля, соответствует условная варианта, равная нулю. В нашем случае С=49,2.
Равноотстоящими называют варианты, которые образуют арифметическую прогрессию с разностью h.
Условными называют варианты, определяемые равенством:
![[U_i=frac{(x_i-C)}{h}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-c6c24a440a025414d18ebe8781aa22b6_l3.png "Rendered by QuickLaTeX.com")
Произведем расчет условных вариант согласно формуле:
![[U_1=frac{20,4-49,2}{7,2}=-4]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-159a490fe276ae2b2a6081e4f9647090_l3.png "Rendered by QuickLaTeX.com")
![[U_2=frac{27,6-49,2}{7,2}=-3]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-a3e4e66d8520f3a12aa6519c36e69ba1_l3.png "Rendered by QuickLaTeX.com")
![[U_3=frac{34,8-49,2}{7,2}=-2]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-187afa35d11ed679a257edd766e3a0f1_l3.png "Rendered by QuickLaTeX.com")
![[U_4=frac{42-49,2}{7,2}=-1]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-929695d78c47d35b023c9dc2d11f5a3f_l3.png "Rendered by QuickLaTeX.com")
![[U_5=frac{49,2-49,2}{7,2}=0]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-aa956af961d374361e948bd16a3e1317_l3.png "Rendered by QuickLaTeX.com")
![[U_6=frac{56,4-49,2}{7,2}=1]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-fb490f3a7e06599bee2c19bcc67e4b9f_l3.png "Rendered by QuickLaTeX.com")
![[U_7=frac{63,6-49,2}{7,2}=2]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-8a98b7a3d0f9e4d9733242a9bf102866_l3.png "Rendered by QuickLaTeX.com")
![[U_8=frac{70,8-49,2}{7,2}=3]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-e9d062cda3a1324da90f6286b5542af0_l3.png "Rendered by QuickLaTeX.com")
![[U_9=frac{78-49,2}{7,2}=4]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-aa53c7e67e340a81ca72c0b720d8ca36_l3.png "Rendered by QuickLaTeX.com")
| N п/п |
Середины интервалов,
|
Частоты интервалов,
|
Условные варианты,
|
Произведения частот и условных вариант,
|
Произведения частот и условных вариант,
|
Произведения частот и условных вариант,
|
Произведения частот и условных вариант,
|
Произведения частот и условных вариант,
|
Произведения частот и условных вариант,
|
| 1 | 20,4 | 1 | -4 | -4 | 16 | -64 | 256 | 9 | 81 |
| 2 | 27,6 | 9 | -3 | -27 | 81 | -243 | 729 | 36 | 144 |
| 3 | 34,8 | 13 | -2 | -26 | 52 | -104 | 208 | 13 | 13 |
| 4 | 42 | 17 | -1 | -17 | 17 | -17 | 17 | 0 | 0 |
| 5 | 49,2 | 23 | 0 | 0 | 0 | 0 | 0 | 23 | 23 |
| 6 | 56,4 | 18 | 1 | 18 | 18 | 18 | 18 | 72 | 288 |
| 7 | 63,6 | 11 | 2 | 22 | 44 | 88 | 176 | 99 | 891 |
| 8 | 70,8 | 7 | 3 | 21 | 63 | 189 | 567 | 112 | 1792 |
| 9 | 78 | 1 | 4 | 4 | 16 | 64 | 256 | 25 | 625 |
|
 |
 |
 |
 |
 |
 |








Контроль:
![[sum n_i U_i^2 + 2sum n_iU_i+n=sum n_i{(U_i+1)}^2]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-bfe916445efb3e33681b87967ff3ee72_l3.png "Rendered by QuickLaTeX.com")
![[sum n_i U_i^2 + 2sum n_iU_i+n=307+2cdot (-9)+100=389]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-c979f642509fc9a23d3107e2a82fc723_l3.png "Rendered by QuickLaTeX.com")
![[sum n_i{(U_i+1)}^2=389]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-6b54236fb1d63f048c9dbec240de42d5_l3.png "Rendered by QuickLaTeX.com")
Контроль:
![[sum n_i U_i^4 + 4sum n_iU_i^3+6sum n_iU_i^2+4sum n_iU_i+n=sum n_i{(U_i+1)}^4]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-f07f4af98630f4642b04e2030e849232_l3.png "Rendered by QuickLaTeX.com")
![[sum n_i U_i^4 + 4sum n_iU_i^3+6sum n_iU_i^2+4sum n_iU_i+n=]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-fb86aec2d3151a542084e9e4805ecb1f_l3.png "Rendered by QuickLaTeX.com")
![[=2227+4cdot (-69)+6 cdot 307+4cdot (-9)+100=3857]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-81abf9514098d32eca4d80dbef425404_l3.png "Rendered by QuickLaTeX.com")
![[sum n_i{(U_i+1)}^4=3857]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-08ea4071bdd89be8534b6573048c6226_l3.png "Rendered by QuickLaTeX.com")
Равенство выполнено, следовательно вычисления произведены верно.
Вычислим условные моменты 1-го, 2-го, 3-го и 4-го порядков:
![[M_1^{*}=frac{sum n_iU_i}{n}=frac{-9}{100}=-0,09;]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-20762ac62aef7ff58d3d5a21f72d97fc_l3.png "Rendered by QuickLaTeX.com")
![[M_2^{*}=frac{sum n_iU_i^2}{n}=frac{307}{100}=3,07;]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-49fc1f9b0b295a1fc1aa27f267380093_l3.png "Rendered by QuickLaTeX.com")
![[M_3^{*}=frac{sum n_iU_i^3}{n}=frac{-69}{100}=-0,69;]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-dd8d7a50c08c5c1dd7b8a871e2493bde_l3.png "Rendered by QuickLaTeX.com")
![[M_4^{*}=frac{sum n_iU_i^4}{n}=frac{2227}{100}=22,27.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-8513720d7a2df45aaa7d99686e4d4436_l3.png "Rendered by QuickLaTeX.com")
Найдем выборочные среднюю, дисперсию и среднее квадратическое отклонение :
![[x_{B}=M_1^{*}cdot h+C=-0,09cdot 7,2+49,2=48,552;]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-01563ec6dda7fdedaa93513c74ff997e_l3.png "Rendered by QuickLaTeX.com")
![[D_{B}=(M_2^{*}-{(M_1^{*})}^2)h^2=(3,07-{(-0,09)}^2){7,2}^2approx 158,73.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-db67c404df7fbd10fcba1803dc1d9aef_l3.png "Rendered by QuickLaTeX.com")
![[sigma_{B}=sqrt{D_B}=sqrt{158,73}=12,6.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-d8d05199c63db71062b09ee4969f6df5_l3.png "Rendered by QuickLaTeX.com")
Также для оценки отклонения эмпирического распределения от нормального используют такие характеристики, как асимметрия и эксцесс.
Асимметрией теоретического распределения называют отношение центрального момента третьего порядка к кубу среднего квадратического отклонения:
![[a_s=frac{m_3}{sigma_B^3}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-b4a9bc811679794242a602b480953ec6_l3.png "Rendered by QuickLaTeX.com")
Асимметрия положительна, если «длинная часть» кривой распределения расположена справа от математического ожидания; асимметрия отрицательна, если «длинная часть» кривой расположена слева от математического ожидания. Практически определяют знак асимметрии по расположению кривой распределения относительно моды (точки максимума дифференциальной функции): если «длинная часть» кривой расположена правее моды, то асимметрия положительна, если слева — отрицательна.
Эксцесс эмпирического распределения определяется равенством:
![[e_k=frac{m_4}{sigma_B^4}-3]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-ebd36893c40d9e5760b22c5515404887_l3.png "Rendered by QuickLaTeX.com")
где  — центральный эмпирический момент четвертого порядка.
— центральный эмпирический момент четвертого порядка.
Для нормального распределения эксцесс равен нулю. Поэтому если эксцесс некоторого распределения отличен от нуля, то кривая этого распределения отличается от нормальной кривой: если эксцесс положительный, то кривая имеет более высокую и «острую» вершину, чем нормальная кривая; если эксцесс отрицательный, то сравниваемая кривая имеет более низкую и «плоскую» вершину, чем нормальная кривая. При этом предполагается, что нормальное и теоретическое распределения имеют одинаковые математические ожидания и дисперсии.
Вычисляем центральные эмпирические моменты третьего и четвертого порядков:
![[m_3=(M_3^*-3M_1^*M_2^*+2{(M_1^*)}^3)cdot h^3=51,3;]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-35fa469c4f36b2aae7705925a013be5e_l3.png "Rendered by QuickLaTeX.com")
![[m_4=(M_4^*-4M_3^*M_1^*+6M_2^*{(M_1^*)}^2-3{(M_1^*)}^4)cdot h^4=59580,97;]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-f687774454962c3d0e3377e6df0573e8_l3.png "Rendered by QuickLaTeX.com")
Найдем асимметрию и эксцесс:
![[a_s=frac{51,3}{{12,6}^3}=0,026]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-3ea65f54fb9839acecf06e17f7a04d64_l3.png "Rendered by QuickLaTeX.com")
![[e_k=frac{59580,97}{{12,6}^4}-3=-0,635]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-0ed5e864eda55df96619480c0a06a254_l3.png "Rendered by QuickLaTeX.com")
IV. Проверка гипотезы о нормальном распределении генеральной совокупности. Критерий согласия Пирсона.
Проверим генеральную совокупность значений размера прибыли банков по критерию Пирсона 
Правило. Для того, чтобы при заданном уровне значимости проверить нулевую гипотезу  : генеральная совокупность распределена нормально, надо сначала вычислить теоретические частоты, а затем наблюдаемое значение критерия:
: генеральная совокупность распределена нормально, надо сначала вычислить теоретические частоты, а затем наблюдаемое значение критерия:
![[chi^2_{nabl}=sum frac{ {(n_i-n_i^{'})}^2}{n_i^{'}}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-43685ed67e69272b6c950828a97acd89_l3.png "Rendered by QuickLaTeX.com")
и по таблице критических точек распределения , по заданному уровню значимости  и числу степеней свободы
и числу степеней свободы  найти критическую точку
найти критическую точку  , где s — количество интервалов.
, где s — количество интервалов.
Если  — нет оснований отвергнуть нулевую гипотезу.
— нет оснований отвергнуть нулевую гипотезу.
Если  — нулевую гипотезу отвергают.
— нулевую гипотезу отвергают.
Найдем теоретические частоты  , для этого составим следующую таблицу.
, для этого составим следующую таблицу.
|
Середины интервалов,
|
Частоты интервалов,
|
Произведем расчет,
|
Произведем расчет,
|
Значения функции Гаусса,
|
Произведем расчет,
|
Теоретические частоты,
|
| 20,4 | 1 | -28,152 | -2,23 | 0,0332 | 57 | 2 |
| 27,6 | 9 | -20,952 | -1,66 | 0,1006 | 57 | 6 |
| 34,8 | 13 | -13,752 | -1,09 | 0,2203 | 57 | 13 |
| 42 | 17 | -6,552 | -0,52 | 0,3485 | 57 | 20 |
| 49,2 | 23 | 0,648 | 0,05 | 0,3984 | 57 | 23 |
| 56,4 | 18 | 7,848 | 0,62 | 0,3292 | 57 | 19 |
| 63,6 | 11 | 15,048 | 1,19 | 0,1965 | 57 | 11 |
| 70,8 | 7 | 22,248 | 1,77 | 0,0833 | 57 | 5 |
| 78 | 1 | 29,448 | 2,34 | 0,0258 | 57 | 1 |
 |
 |





Вычислим  , для чего составим расчетную таблицу.
, для чего составим расчетную таблицу.
 |
 |
 |
 |
 |
 |
 |
 |
| 1 | 1 | 2 | -1 | 1 | 0,5 | 1 | 0,5 |
| 2 | 9 | 6 | 3 | 9 | 1,5 | 81 | 13,5 |
| 3 | 13 | 13 | 0 | 0 | 0 | 169 | 13 |
| 4 | 17 | 20 | -3 | 9 | 0,45 | 289 | 14,45 |
| 5 | 23 | 23 | 0 | 0 | 0 | 529 | 23 |
| 6 | 18 | 19 | -1 | 1 | 0,05 | 324 | 17,05 |
| 7 | 11 | 11 | 0 | 0 | 0 | 121 | 11 |
| 8 | 7 | 5 | 2 | 4 | 0,8 | 49 | 9,8 |
| 9 | 1 | 1 | 0 | 0 | 0 | 1 | 1 |
 |
100 | 100 |
Наблюдаемое значение критерия,
|
103,30 |

Контроль:
![[sumfrac{n_i^2}{n_i^{'}}-n=sum frac{{(n_i-n_i^{'})}^2}{n_i^'}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-6c32fcc2a5c6b3b4b603ae3d99533b4a_l3.png "Rendered by QuickLaTeX.com")
![[sumfrac{n_i^2}{n_i'}-n=103,3-100=3,3]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-a9fda2a1f7cb2dccff4e36db3eca149a_l3.png "Rendered by QuickLaTeX.com")
![[sum frac{{(n_i-n_i')}^2}{n_i'}=3,3]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-008fc9e192109f46116930043ed491f9_l3.png "Rendered by QuickLaTeX.com")
Вычисления произведены правильно.
Найдем число степеней свободы, учитывая, что число групп выборки (число различных вариант) s=9;
![[k=s-3=9-3=6.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-591c6b21dce56f5cf0fa9cd47789d7b6_l3.png "Rendered by QuickLaTeX.com")
По таблице критических точек распределения по уровню значимости  и числу степеней свободы k=6 находим
и числу степеней свободы k=6 находим 
Так как — нет оснований отвергнуть нулевую гипотезу. Другими словами, расхождение эмпирических и теоретических частот незначительное. Следовательно, данные наблюдений согласуются с гипотезой о нормальном распределении генеральной совокупности.
На рисунке построены нормальная (теоретическая) кривая по теоретическим частотам (зеленый график) и полигон наблюдаемых частот (коричневый график). Сравнение графиков наглядно показывает, что построенная теоретическая кривая удовлетворительно отражает данные наблюдений.

V. Интервальные оценки.
Интервальной называют оценку, которая определяется двумя числами — концами интервала, покрывающего оцениваемый параметр.
Доверительным называют интервал, который с заданной надежностью  покрывает заданный параметр.
покрывает заданный параметр.
Интервальной оценкой (с надежностью ) математического ожидания (а) нормально распределенного количественного признака Х по выборочной средней  при известном среднем квадратическом отклонении
при известном среднем квадратическом отклонении  генеральной совокупности служит доверительный интервал
генеральной совокупности служит доверительный интервал
![[x_B-frac{tsigma}{sqrt{n}}<a<x_B+frac{tsigma}{sqrt{n}},]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-9750e199194b01ecfa06ba1601feab7d_l3.png "Rendered by QuickLaTeX.com")
где  — точность оценки, n — объем выборки, t — значение аргумента функции Лапласа
— точность оценки, n — объем выборки, t — значение аргумента функции Лапласа  (см. приложение 2), при котором
(см. приложение 2), при котором  ;
;
при неизвестном среднем квадратическом отклонении (и объеме выборки n<30)
![[x_B-frac{t_{gamma}cdot S}{sqrt{n}}<a<x_B+frac{t_{gamma}cdot S}{sqrt{n}},]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-d9ee32ae620adb447d86d28cba84e871_l3.png "Rendered by QuickLaTeX.com")
![[S=sqrt{frac{n}{n-1}D_B}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-dfe89e1cead729b251b9981b9eac134b_l3.png "Rendered by QuickLaTeX.com")
где S — исправленное выборочное среднее квадратическое отклонение,  находят по таблице приложения по заданным n и .
находят по таблице приложения по заданным n и .
В нашем примере среднее квадратическое отклонение известно,  . А также
. А также  , ,
, ,  . Поэтому для поиска доверительного интервала используем первую формулу:
. Поэтому для поиска доверительного интервала используем первую формулу:
![[x_B-frac{tsigma}{sqrt{n}}<a<x_B+frac{tsigma}{sqrt{n}}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-600f869b70725152f297f8ba0a2459fa_l3.png "Rendered by QuickLaTeX.com")
Все величины, кроме t, известны. Найдем t из соотношения  По таблице приложения находим t=1,96. Подставив t=1,96, , , в формулу, окончательно получим искомый доверительный интервал:
По таблице приложения находим t=1,96. Подставив t=1,96, , , в формулу, окончательно получим искомый доверительный интервал:
![[48,55-frac{1,96cdot 12,6}{10}<a<48,55+frac{1,96cdot 12,6}{10}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-18be4f2ab8257c8e7f50af9fdc1766fa_l3.png "Rendered by QuickLaTeX.com")
![[48,55-2,47<a<48,55+2,47]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-268428dac12802b423e852d51d9dd03d_l3.png "Rendered by QuickLaTeX.com")
![[46,08<a<51,02]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-45b72334d0171fd5dd4329bd36b155b3_l3.png "Rendered by QuickLaTeX.com")
Интервальной оценкой (с надежностью ) среднего квадратического отклонения нормально распределенного количественного признака Х по «исправленному» выборочному среднему квадратическому отклонению S служит доверительный интервал
 (при q<1), (*)
(при q<1), (*)
 (при q>1),
(при q>1),
где q — находят по таблице приложения по заданным n и .
По данным и n=100 по таблице приложения 4 найдем q=0,143. Так как q<1, то, подставив  в соотношение (*), получим доверительный интервал:
в соотношение (*), получим доверительный интервал:
![[12,66(1-0,143)<sigma<12,66(1+0,143)]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-a4a65a9250ea6393a930f1b29215644f_l3.png "Rendered by QuickLaTeX.com")
![[10,85<sigma<14,47]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-f3d033cb268eca08d52ccfbe86fecd99_l3.png "Rendered by QuickLaTeX.com")
Составить ранжированный ряд в порядке возрастания по признаку, соответствующему варианту.
Составить типологическую, структурную и аналитическую

Составить ранжированный ряд в порядке возрастания по признаку, соответствующему варианту.
Составить типологическую, структурную и аналитическую группировки по 5-ти группам по признаку, соответствующему варианту.
Начертить графики полигон распределения, огива распределения, гистограмму, круговую диаграмму и кумуляту по признаку, соответствующему варианту.
По исходным данным ранжированного ряда рассчитать среднюю арифметическую, по группировке рассчитать среднюю арифметическую взвешенную, медиану по признаку, соответствующему варианту.
Рассчитать показатель вариации, используя исходные данные по признаку, соответствующему варианту.

Ранжированный ряд в порядке возрастания суммы выручки от реализации
№ предприятия Числен. рабочих, чел. Квалифиц. рабочие,чел
ФЗП, тыс. руб
Сумма выручки от реализ, тыс. руб. Сумма затрат на пр-во, тыс. руб.
18 225 175 26700 120000 175400
7 510 150 23000 120005 150500
16 345 325 35900 121005 325740
12 265 215 22000 122001 215700
1 460 300 37000 129500 103600
3 410 250 27000 135400 100000
9 580 400 39000 140000 400000
15 400 355 33700 145162 355240
5 320 300 28000 153700 150000
11 350 195 20000 160900 195800
19 365 225 27400 165400 225170
10 200 155 21600 178090 155070
4 305 250 29000 180540 135540
6 285 200 25000 185600 255000
13 275 180 24000 190350 180050
17 300 225 33156 192120 225170
2 480 380 39000 196700 127855
20 215 185 35000 199800 185470
14 320 165 23000 199999 165160
8 600 350 40000 200000 350400
Всего 7210 4980 589456 3236272 4176865
№ предприятия Сумма выручки от реализации, тыс. руб.
18 120000
7 120005
16 121005
12 122001
1 129500
3 135400
9 140000
15 145162
5 153700
11 160900
19 165400
10 178090
4 180540
6 185600
13 190350
17 192120
2 196700
20 199800
14 199999
8 200000
Всего 3236272
Проведем группировку предприятий по 5-ти группам
Величина интервала:
h=xmax-xmink
где h – величина отдельного интервала;
хmax – максимальное значение признака в исследуемой совокупности;
xmin – минимальное значение признака в исследуемой совокупности;
k – число групп.
h=200000-1200005=16 000 тыс. руб.
Группы предприятий
120000 – 136000
136000 – 152000
152000 – 168000
168000 – 184000
184000– 200000
№ предприятия Числен. рабочих, чел. Квалифицированные рабочие, чел. ФЗП, тыс. руб. Сумма выручки от реализации, тыс. руб. Сумма затрат на пр-во, тыс. руб.
18 225 175 26700 120000 175400
7 510 150 23000 120005 150500
16 345 325 35900 121005 325740
12 265 215 22000 122001 215700
1 460 300 37000 129500 103600
3 410 250 27000 135400 100000
∑ 2215 1415 171600 747911 1070940
9 580 400 39000 140000 400000
15 400 355 33700 145162 355240
∑ 980 755 72700 285162 755240
5 320 300 28000 153700 150000
11 350 195 20000 160900 195800
19 365 225 27400 165400 225170
∑ 1035 720 75400 480000 570970
10 200 155 21600 178090 155070
4 305 250 29000 180540 135540
∑ 505 405 50600 358630 290610
6 285 200 25000 185600 255000
13 275 180 24000 190350 180050
17 300 225 33156 192120 225170
2 480 380 39000 196700 127855
20 215 185 35000 199800 185470
14 320 165 23000 199999 165160
8 600 350 40000 200000 350400
∑ 2475 1685 219156 1364569 1489105
Всего 7210 4980 589456 3236272 4176865
Таблица 1.1
. – Типологическая группировка предприятий по сумме выручки от реализации
Группы предприятий по сумме выручки от реализации, тыс. руб. Число предприятия Сумма выручки от реализации, тыс. руб. Числен. рабочих, чел. Квалифицированные рабочие, чел. ФЗП, тыс. руб. Сумма затрат на пр-во, тыс. руб.
120000 – 136000 6 747911 2215 1415 171600 1070940
136000 – 152000 2 285162 980 755 72700 755240
152000 – 168000 3 480000 1035 720 75400 570970
168000 – 184000 2 358630 505 405 50600 290610
184000– 200000 7 1364569 2475 1685 219156 1489105
В целом по совокупности 20 3236272 7210 4980 589456 4176865
Таблица 1.2. – Структурная группировка предприятий по сумме выручки от реализации
Группы предприятий по сумме выручки от реализации, тыс. руб. Число предприятий В % к итогу
120000 – 136000 6 30
136000 – 152000 2 10
152000 – 168000 3 15
168000 – 184000 2 10
184000– 200000 7 35
В целом по совокупности 20 100
Выводы. В совокупности предприятий наибольшую долю составляют предприятия с наибольшей выручкой. Таких предприятий 7 единиц или 35%. Доля предприятий с наименьшей выручкой составляет 30% (6 предприятий).
Таблица 1.3. – Аналитическая группировка предприятий по сумме выручки от реализации
Группы предприятий по сумме выручки от реализации, тыс. руб. Число предприятий Числен. рабочих, чел. Квалифицированные рабочие, чел. ФЗП, тыс. руб. Сумма затрат на пр-во, тыс. руб.
Всего В среднем на одно предприятие Всего В среднем на одно предприятие Всего В среднем на одно предприятие Всего В среднем на одно предприятие
А 1 2 3=2/1 4 5=4/1 6 7=6/1 8 9=8/1
120000 – 136000 6 2215 369,2 1415 235,8 171600 28600 1070940 178490
136000 – 152000 2 980 490 755 377,5 72700 36350 755240 377620
152000 – 168000 3 1035 345 720 240 75400 25133,3 570970 190323,3
168000 – 184000 2 505 252,5 405 202,5 50600 25300 290610 145305
184000– 200000 7 2475 353,6 1685 240,7 219156 31308 1489105 212729,3
В целом по совокупности 20 7210 360,5 4980 249 589456 29472,8 4176865 208843,3
Выводы


- Составить расчет амортизации по объекту основного средства способом списания стоимости объекта пропорционально объему продукции
- Составить расчет и определить, имеет ли право организация в 2 квартале 2018 года:
1) - Составить расчёт на установление лимита остатка кассы и оформление разрешения на расходование наличных денег
- Составить расчет показателей к плану финансово-хозяйственной деятельности городской школы на планируемый год.
Исходные данные - Составить расчет по начислению НДФЛ и отразить бухгалтерские проводки.
В текущий период в пользу - Составить расчет расходов на приобретение продуктов питания, медикаментов и перевязочных средств на планируемый год.
- Составить расчет стипендиального фонда учреждения среднего профессионального образования на планируемый год. Указать код КОСГУ.
- Составить приказ на проведение инвентаризации.
2. Заполнить инвентаризационную опись товарно-материальных ценностей.
3. Заполнить сличительную ведомость товарно-материальных - Составить проводки и выполнить необходимые расчеты на основе следующих данных. Учет реализации по моменту
- Составить проводки по операциям.
2. Составить оборотно-сальдовый баланс.
3. Составить бухгалтерский баланс: 2 столбца, - Составить прогноз годовой доходности по каждой альтернативе. В бланке выполнения задания необходимо заполнить таблицы
- Составить прогноз состояния государственного бюджета, если в текущем году ВВП составляет 6011 тыс. ед.,
- Составить прогноз товарооборота аптеки на следующий год, учитывая, что:
в текущем году выполнение плана - Составить программу, печатающую значение true, если указанное высказывание является истинным, и false – в
Вариационный ряд может быть:
- дискретным, когда изучаемый признак характеризуется определенным числом (как правило целым).
- интервальным, когда определены границы «от» и «до» для непрерывно варьируемого признака. Интервальный ряд также строят если множество значений дискретно варьируемого признака велико.
Рассмотрим пример построения дискретного вариационного ряда.
Пример 1. Имеются данные о количественном составе 60 семей.

- Построить вариационный ряд и полигон распределения
- Решение.
- Алгоритм построения вариационного ряда:
- Откроем таблицы Excel.
Введем массив данных в диапазон А1:L5. Если вы изучаете документ в электронной форме (в формате Word, например), для этого достаточно выделить таблицу с данными и скопировать ее в буфер, затем выделить ячейку А1 и вставить данные – они автоматически займут подходящий диапазон.
Подсчитаем объем выборки n – число выборочных данных, для этого в ячейку В7 введем формулу =СЧЁТ(А1:L5). Заметим, что для того, чтобы в формулу ввести нужный диапазон, необязательно вводить его обозначение с клавиатуры, достаточно его выделить.
Определим минимальное и максимальное значение в выборке, введя в ячейку В8 формулу =МИН(А1:L5), и в ячейку В9: =МАКС(А1:L5).
Рис.1.1 Пример 1. Первичная обработка статистических данных в таблицах Excel

Далее, подготовим таблицу для построения вариационного ряда, введя названия для столбца интервалов (значений варианты) и столбца частот. В столбец интервалов введем значения признака от минимального (1) до максимального (6), заняв диапазон В12:В17.
Выделим столбец частот, введем формулу =ЧАСТОТА(А1:L5;В12:В17) и нажмем сочетание клавиш CTRL+SHIFT+ENTER
Рис.1.2 Пример 1. Построение вариационного ряда

Для контроля вычислим сумму частот при помощи функции СУММ (значок функции S в группе «Редактирование» на вкладке «Главная»), вычисленная сумма должна совпасть с ранее вычисленным объемом выборки в ячейке В7.
Построим полигон:
выделив полученный диапазон частот, выберем команду «График» на вкладке «Вставка». По умолчанию значениями на горизонтальной оси будут порядковые числа — в нашем случае от 1 до 6, что совпадает со значениями варианты (номерами тарифных разрядов).
Название ряда диаграммы «ряд 1» можно либо изменить, воспользовавшись той же опцией «выбрать данные» вкладки «Конструктор», либо просто удалить.
Пример 1. Построение полигона частот

Примечание: можно скачать готовый шаблон построение дискретного вариационного ряда в Excel
Следующая тема: Построение интервального вариационного ряда в Excel.
Источник: http://www.reshim.su/blog/variacionnyj_rjad/2014-08-23-500
Как сортировать данные в таблицах Excel (правильный способ)
Итак, нам вручили электронную таблицу Excel с тысячами строк внутри нее и вы понимаете, что все данные в неправильном порядке. Возможно, вам придется сортировать её на основе имен столбцов или путем сортировки данных от большего к меньшему.
На первый взгляд, сортировка данных в Excel задача простая, и приложение, безусловно, упрощает сортировку. Однако, более важно то, как вы можете отсортировать и изменить порядок данных в ваших листах. Вот три метода сортировки данных Excel, о которых вы узнаете в этом уроке:
- Сортировка данных всего в несколько кликов
- Установка нескольких, ступенчатых правил сортировки, таких как сортировка по алфавиту по состоянию, а затем по всё вместе.
- Создать полностью свои настройки сортировки, чтобы отсортировать данные с помощью любого установленного вами правила.
Сортировка данных иногда может казаться опасной; что, если вы отсортируете только один столбец и данные будут смещены? Я покажу вам, как избежать этого. Давайте начнем.
Как сортировать данные в электронной таблице Excel (короткое видео)
Этот скринкаст охватывает несколько методов сортировки ваших данных. Просмотрите этот трехминутный видеоролик, чтобы быстро изучить эти профессиональные техники работы Excel. Мы начнем с простой сортировки и перейдем к более продвинутым методам, чтобы вы всегда смогли отсортировать данные так, как вам нужно.
Читайте дальше пошаговое руководство по сортировке данных в электронных таблицах Excel с использованием простых и передовых методов.
Примеры данных (бесплатная загрузка рабочей книги Excel)
В рамках этого урока я создал книгу, с которой вы можете работать, изучая сортировку данных. Загрузите книгу бесплатно и используйте её во время изучения сортировки в Excel.
1. Простая сортировка в Excel
Сортировка может быть очень простой, всего пара кликов для перестановки данных в ваших таблицах. Давайте узнаем как.
В книге Excel, начните с нажатия на ячейку столбца, который вы хотите отсортировать. Теперь, убедитесь, что вы находитесь на вкладке Главная на ленте Excel’я и найдите кнопку Сортировка и фильтр на самой правой стороне этой панели.
Кнопка Сортировка и фильтр обитает в самой правый части вкладки Главная.
Заметьте, что в вариантах сортировки, вы можете отсортировать текст «А до Я» или «Я до А». Эти простые варианты помогут отсортировать данные в Excel В алфавитном или обратным порядках, в зависимости от того что вы выбрали.
Когда вы сортируете данные в Excel, сортируется вся строка. По сути, выбранный вами столбец будет «ключом», который Excel использует, чтобы решить, как сортировать данные, но каждая строка это запись, которая должна оставаться сгруппированной вместе.
В зависимости от данных, которые вы выбрали, можете произвести сортировку по алфавитному или числовому порядку. Если столбцы содержат числовые данные, вы можете отсортировать в порядке от малого к большому числу, текстовые данные сортируются в алфавитном порядке.
В примере выше, варианты сортировки изменились, потому что я выбрал столбец с цифрами.
Выполнить обычную сортировку на самом деле так просто. Просто кликните по данным, выберите вариант сортировки и Excel перестроит данные в таблице.
Я отсортировал данные в этой таблице на основе клиента всего в несколько кликов.
Дельный совет: попробуйте также сортировать, щелкнув правой кнопкой мыши внутри столбца и выбрав Сортировка, а затем указать способ сортировки исходных данных.
2. Как НЕ нужно сортировать данные в Excel
Не менее важно узнать, о самом опасном способе сортировки данных в Excel, такой метод может испортить ваши исходные данные.
Проблема возникает если в таблице много данных, а вы случайно отсортировали только один столбец данных. Каждая строка с данными в Microsoft Excel действительно похоже на запись, которая должна быть такой же по всей строке.
На изображении ниже, Я раскрасил строки, таким образом опасное место с сортировкой только одного столбца данных, будет выделено.
Я задал цвета строкам в этом примере, чтобы мы могли убедиться, что наши данные отсортированы правильно. Цвета должны проходить полностью через каждую строку без перерывов, если данные сортируются правильно.
Большая ошибка пользователей Excel заключается в выборе только одного столбца при сортировке и выборе неправильного параметра в следующем окне.
Excel даже пытается предупредить нас, показывая окно Обнаруженны данные вне указанного диапазона. Во всплывающем окне можно выбрать автоматически расширить выделенный диапазон (выберите это!) и сортировать в пределах указанного выделения.
Я всегда думал, что варианты, которые дает вам это окно, не совсем ясны. Просто знайте, что вы захотите использовать автоматически расширить выделенный диапазон, чтобы убедиться, что Excel затронет все столбцы при сортировке данных.
Для тестирования давайте посмотрим, что произойдет, если мы выберем один столбец и выберем тип сортировки сортировать в пределах указанного выделения.
Использование вариант сортировать в приделах указанного диапазона сортирует только один столбец данных, который обязательно разрушит вашу исходную электронную таблицу.
На скриншоте ниже вы можете видеть, насколько проблематичен этот тип сортировки. Так как столбец Amount Billed был отсортирован от наименьшего до наибольшего, все остальные столбцы остались на месте. Это означает, что наши данные больше не верны.
Как вы видите из несоответствия цветов, были отсортированы только данные в столбце Amount Billed, поэтому теперь таблица некорректна.
Таким образом, при сортировке данных есть два ключевых «НЕ»:
- Не начинайте, выделив один столбец в своей электронной таблице.
- Не используйте вариант сортировать в приделах указанного диапазона, если вы работаете не с одним столбцом, убедитесь, что вы расширили выделенный диапазон.
3. Расширенная сортировка данных Excel
До сих пор простая сортировка позволяла нам сортировать данные однотипно. Что, если мы хотим два типа данных в нашей сортировке?
Что, если мы хотим…
- Сортировка в алфавитном порядке по состоянию, а затем по области.
- Сортировка в алфавитном порядке по имени клиента, а затем по каждому типу проекта, который мы сделали для них.
- Сортировка клиентов в список по алфавиту, а затем по количеству для каждого отдельного проекта, от наибольшего до наименьшего.
Ответ на всё это — расширенная сортировка, при которой вы можете установить несколько уровней сортировки данных. Давайте рассмотрим последний пример, используя образцы данных.
Чтобы начать работу, щелкните где-нибудь внутри своих данных и найдите параметр Сортировка и фильтр, а затем выберите Настраиваемая сортировка.
Перейдите к расширенным параметрам сортировки, выбрав Сортировка и фильтр > Настраиваемая сортировка.
В этом окне мы можем добавить несколько уровней сортировки. Начните с нажатия на раскрывающийся список рядом с Сортировка и выберите столбец, который вы хотите отсортировать.
В моем случае я выберу Client в раскрывающемся меню и оставлю значение Сортировка равным Значения, а Порядок — От А до Я. На простом языке это отсортирует электронную таблицу Excel на основе алфавитного порядка.
Теперь давайте нажмем Добавить уровень. Это создаст новую строку в параметрах сортировки и позволит нам добавить второй уровень организации.
Теперь я могу выбрать Amount billed во втором раскрывающемся списке. Комбинация этих двух правил начнется путем сортировки на основе имени клиента, а затем суммы, выставленного счёта за каждый проект.
Вы можете продолжить добавлять столько уровней, сколько хотите в это окно расширенной сортировки. Последовательность строк имеет значение, т.е. вы можете переместить строку вверх для сортировки сначала по выставленному счету, например, а затем по клиенту.
Как только мы нажмем OK, Excel отсортирует таблицу на основе правил, которые мы создали в этом окне.
Совет: Для более продвинутой сортировки попробуйте в раскрывающимся меню Сортировка изменить тип сортировки на расширенные функции, такие как сортировка на основе цвета ячейки.
Расширенная сортировка позволяет создавать два уровня организации данных в вашей таблице. Если сортировки по одному фактору недостаточно, используйте расширенную сортировку, чтобы добавить больше возможностей.
Повторение и продолжение обучения
Сортировка это ещё одно умение, которое нужно держать в готовом виде в своей книге Excel. Когда вам нужно повторно сопоставить данные в электронной таблице, слишком много времени можно потратить для вырезания и вставки строк в определенном порядке, поэтому сортировка является обязательной.
Источник: https://business.tutsplus.com/ru/tutorials/how-to-sort-data-in-excel-spreadsheets—cms-28737
Построить ранжированный ряд пример. Как сделать ранжированный ряд в excel
Задание №1
На основании данных статистического наблюдения, приведенных в таблице построить ранжированный, интервальный и кумулятивный ряды распределения сельскохозяйственных предприятий по факторному признаку, изобразить их графически.
Провести сводку данных. Посредством метода группировок определите зависимость результативного признака в сельскохозяйственных предприятиях от факторного. Построить таблицы и графики зависимости. Вывод.
Решение:
Построение ранжированного ряда распределения предполагает расположение всех вариантов ряда в порядке возрастания изучаемого признака (качества почвы). Проведение сортировки производилось в программе ТП Excel с использованием функции «Сортировка».
Графическое изображение ранжированного ряда распределения
Линия на рис.1 носит название огива Гальтона. Данная огива имеет тенденцию плавного роста с небольшими скачками в некоторых точках. Для преобразования ранжированного ряда в интервальный лучше выполнить разбивку на группы вручную.
Построение интервального ряда распределения предприятий по изучаемому признаку предполагает определение числа групп (интервалов).
- Для расчета числа групп воспользуемся формулой:
- n=2 , где N-общее число единиц изучаемой совокупности.
n=2 Ig30 = 2,95424251?3.
Величина равного интервала вычисляется по формуле:
i = = = 16,33333
Кумулятивный ряд — это ряд в котором подсчитываются накопленные частоты. Он показывает, сколько единиц совокупности имеют значение признака не больше, чем данное значение, и вычисляется путем последовательного прибавления к частоте первого интервала частот последующих интервалов.
- Интервальный и кумулятивный ряды
- частота — число предприятий в группе;
- Удельный вес предприятий в группе — находится по формуле:
- (число предприятий в группе*100%)/ m, где m-число экспериментальных данных;
- Накопленная
частота — находится по формуле: число предприятий в предедущей группе+частота данной группы.
- Гистограмма частот
- Кумулята распределения качества почвы
- Сводные показатели
| № группы | Число предприятий в группе | Урожайность овощей открытого грунта (всего по группам) | Качество почвы (всего по группам) |
| II 61,33333-77,33333 | |||
| III 77,33333-94,1 |
Средние характеристики групп
| № Группы | Урожайность овощей открытого грунта | Качество почвы |
| II 61,33333-77,33333 | ||
| III 77,33333-94,1 | ||
| В среднем по совокупности |
- где, столбец «урожайность овощей» находится по формуле: У
У i (в группе)/ число предприятий в группе; - столбец «Качество почвы» находится по формуле: У Х i (в группе)/число предприятий в группе.
- Зависимость урожайности овощей открытого грунта от качества почвы.
- В рассматриваемом примере можно сделать вывод: с ростом качества почвы увеличивается урожайность овощей открытого грунта, следовательно можно предположить наличие прямой связи между рассматриваемыми параметрами.
Подобные документы
- Аналитическая группировка по факторному признаку. Построение вариационного частотного и кумулятивного рядов распределения на основе равно интервальной структурной группировки результативного признака – дивидендов, начисленных по результатам деятельности.контрольная работа , добавлен 07.05.2009 Основные показатели численности населения и его размещения по Калужской области. Построение ранжированного и интервального рядов распределения по одному группировочному факторному признаку. Анализ типических групп по показателям в среднем по совокупности.
Источник: https://netdenegnakino.ru/postroit-ranzhirovannyi-ryad-primer-kak-sdelat-ranzhirovannyi-ryad-v.html
Трюки и хитрости в Excel — Подсветка ряда данных в диаграмме. Часть 1
Всем привет! Друзья, случайно нашел в сети один очень интересный способ видопредставления диаграммы с подсветкой определенного значения. Спешу с вами поделиться этим чудом )) Только не буду выкладывать файлик пример, чтобы вы сами своими руками все сделали, так лучше запомнится. Информации будет много, поэтому разобью ее на три статьи, чтобы не было перегруза. Следите за обновлениями.
Недавно, я писал о том как без применения макросов можно настроить автообновление диаграммы. Если интересно, статью можно почитать здесь Как без формул и макросов сделать автообновление диаграммы?
Сегодня я хочу пошагово показать вам как сделать подсветку или выделить один ряд данных от остальных. Не переключайтесь, будет интересно ))
Шаг 1. Строим таблицу
Для начала составим таблицу. В статье про автообновление я строил таблицу по данным посещения игр на Чемпионате мира по футболу в наших городах. Продолжим с ней работать. В большинстве городов сыграно по 5 матчей, поэтому есть отличный повод сравнить среднюю посещаемость на стадионах. Данные я по прежнему брал с сайта Чемпионат.ком
Шаг 2. Выделяем необходимое значение
Затем в таблицу добавим еще один столбец и назовем его Подсветка. В данном столбце во всех строчках нам необходимо прописать функцию «НД()», которая возвращает значение без аргументов, т.е. создает ошибку.
Но в одной строчке, напротив самого большого значения просто скопируем данные. Цвет шрифта сделал светло серым, чтобы было наглядно понятнее. В нашем случае выделяется стадион «Лужники». У него наибольшая средняя посещаемость.
Не зря все таки на него столько денег потратили…..
Шаг 3. Строим диаграмму
Выделим только три столбца с данными которые необходимо нам отобразить. Затем нужно встать на одну из ячеек таблицы, перейти во вкладку Вставка и выбрать команду Гистограмма. В предложенном списке выберем Гистограмму с группировкой.
В результате у нас получается вот такая диаграмма.
Шаг 4. Делаем подсветку
Теперь самое главное. Для того чтобы выделить наш столбец в диаграмме, кликаем правой кнопкой на выделяющийся ряд данных и выбираем в списке контекстного меню «Формат ряда данных» . Затем в открывшемся окне «параметры ряда данных» в «перекрытии рядов» «с зазором» тянем бегунок вправо до 100%.
Нажимаем закрыть. Всё )) Вот так просто у нас получилось выделить «Лужники» из всех остальных стадионов.
На этом у меня всё. В следующей статье расскажу как подсветить ряд в зависимости от выбранного из списка стадиона. Тоже будет интересно и познавательно! Не пропустите!
Если вам понравился сегодняшний трюк, ставьте лайки и подписывайтесь на канал. Если хотите посмотреть еще уроки загляните в СОДЕРЖАНИЕ, обязательно еще что-нибудь присмотрите )) Спасибо!
Источник: https://zen.yandex.ru/media/id/5a25282b7800192677cc044f/5b3c8d32d75f2900a9562e31
