17 авг. 2022 г.
читать 2 мин
Распределение частоты описывает, как часто разные значения встречаются в наборе данных. Это полезный способ понять, как значения данных распределяются в наборе данных.
К счастью, легко создать и визуализировать частотное распределение в Excel, используя следующую функцию:
=ЧАСТОТА(массив_данных,массив_бинов)
куда:
- data_array : массив необработанных значений данных
- bins_array: массив верхних пределов для бинов
В следующем примере показано, как использовать эту функцию на практике.
Пример: частотное распределение в Excel
Предположим, у нас есть следующий набор данных из 20 значений в Excel:
Во-первых, мы укажем Excel, какие верхние пределы мы хотели бы использовать для интервалов нашего частотного распределения. Для этого примера мы выберем 10, 20 и 30. То есть мы найдем частоты для следующих интервалов:
- от 0 до 10
- с 11 до 20
- от 21 до 30
- 30+
Далее мы будем использовать следующую функцию =FREQUENCY() для вычисления частот для каждого бина:
=ЧАСТОТА( A2:A21 , C2:C4 )
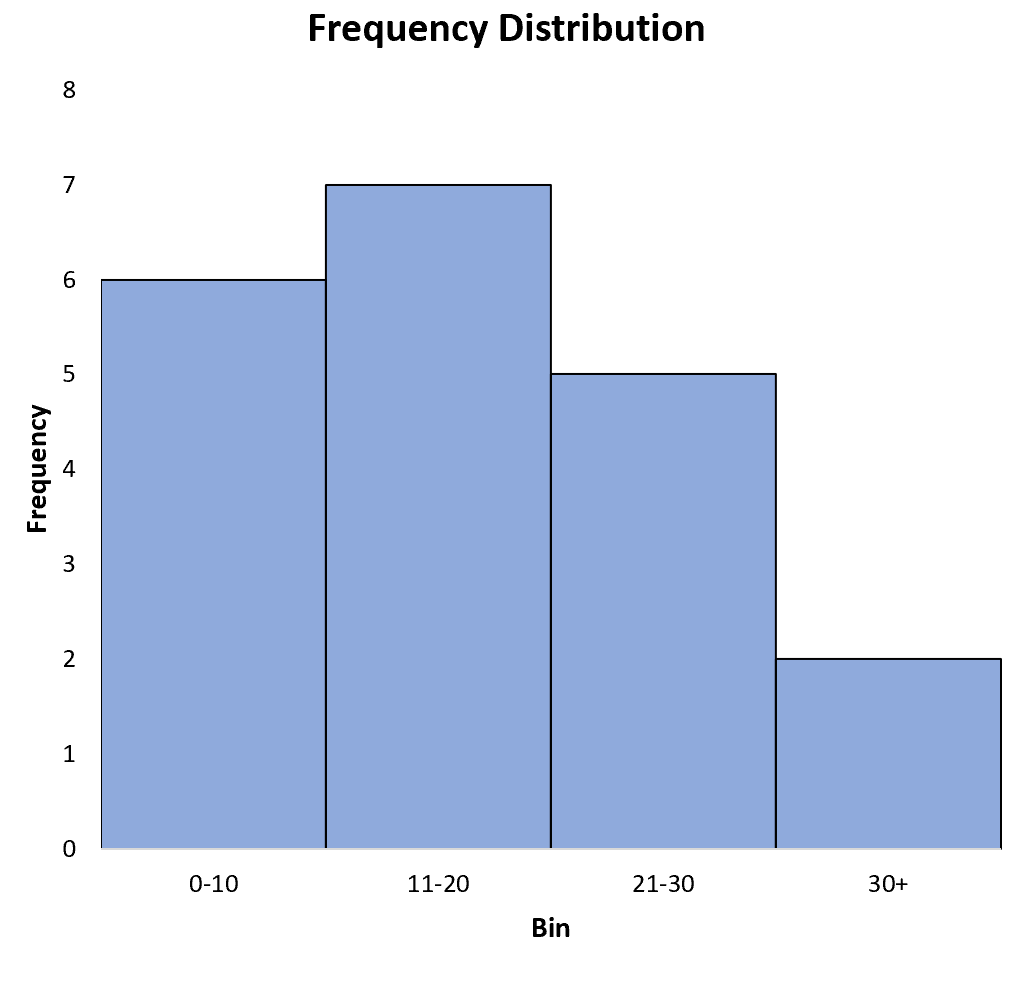
Вот результаты:
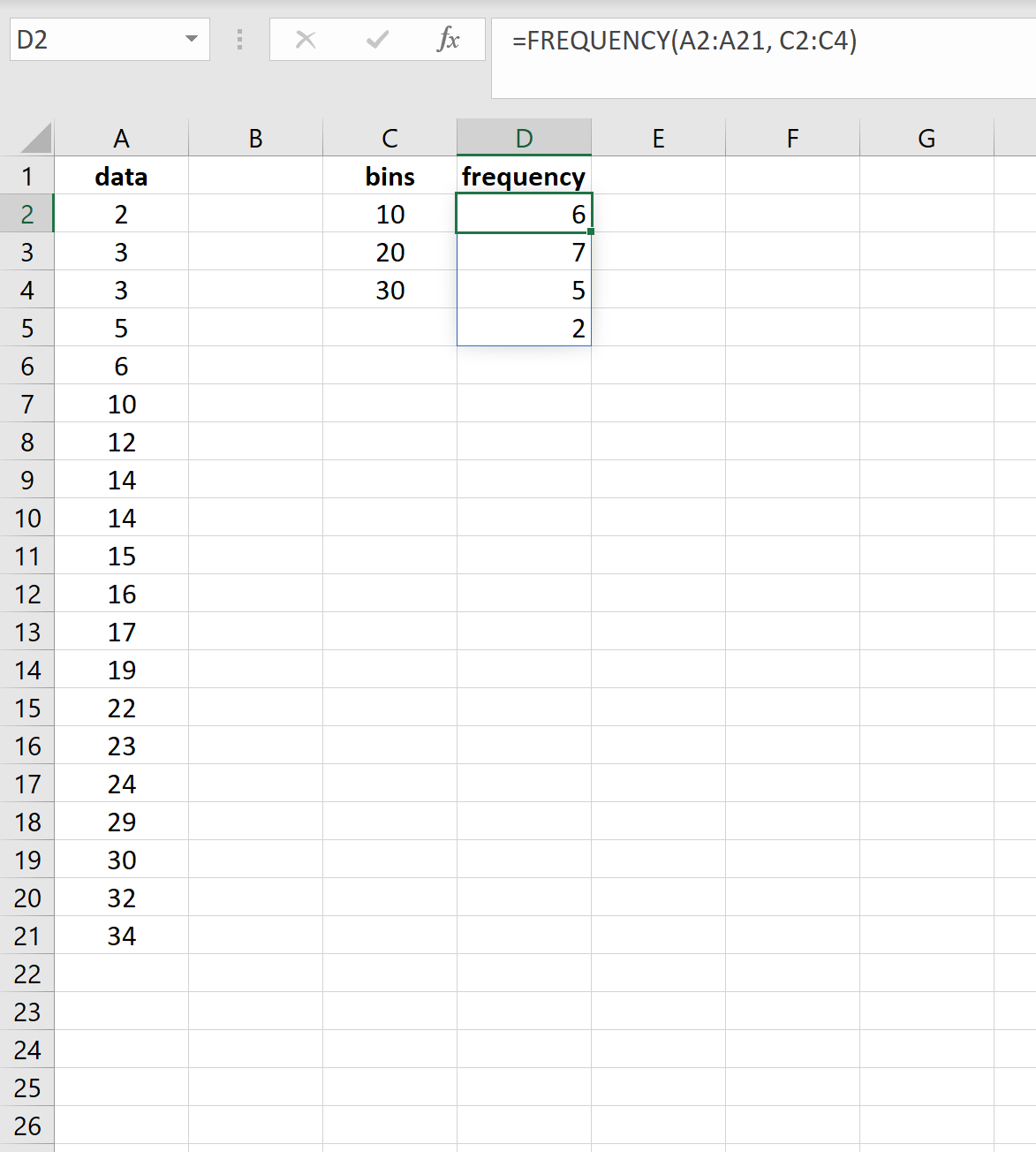
Результаты показывают, что:
- 6 значений в наборе данных находятся в диапазоне от 0 до 10.
- 7 значений в наборе данных находятся в диапазоне 11-20.
- 5 значений в наборе данных находятся в диапазоне 21-30.
- 2 значения в наборе данных больше 30.
Затем мы можем использовать следующие шаги для визуализации этого частотного распределения:
- Выделите частоты в диапазоне D2:D5 .
- Нажмите на вкладку « Вставка », затем нажмите на диаграмму под названием « Двухмерный столбец » в группе « Диаграммы ».
Появится следующая диаграмма, отображающая частоты для каждого бина:
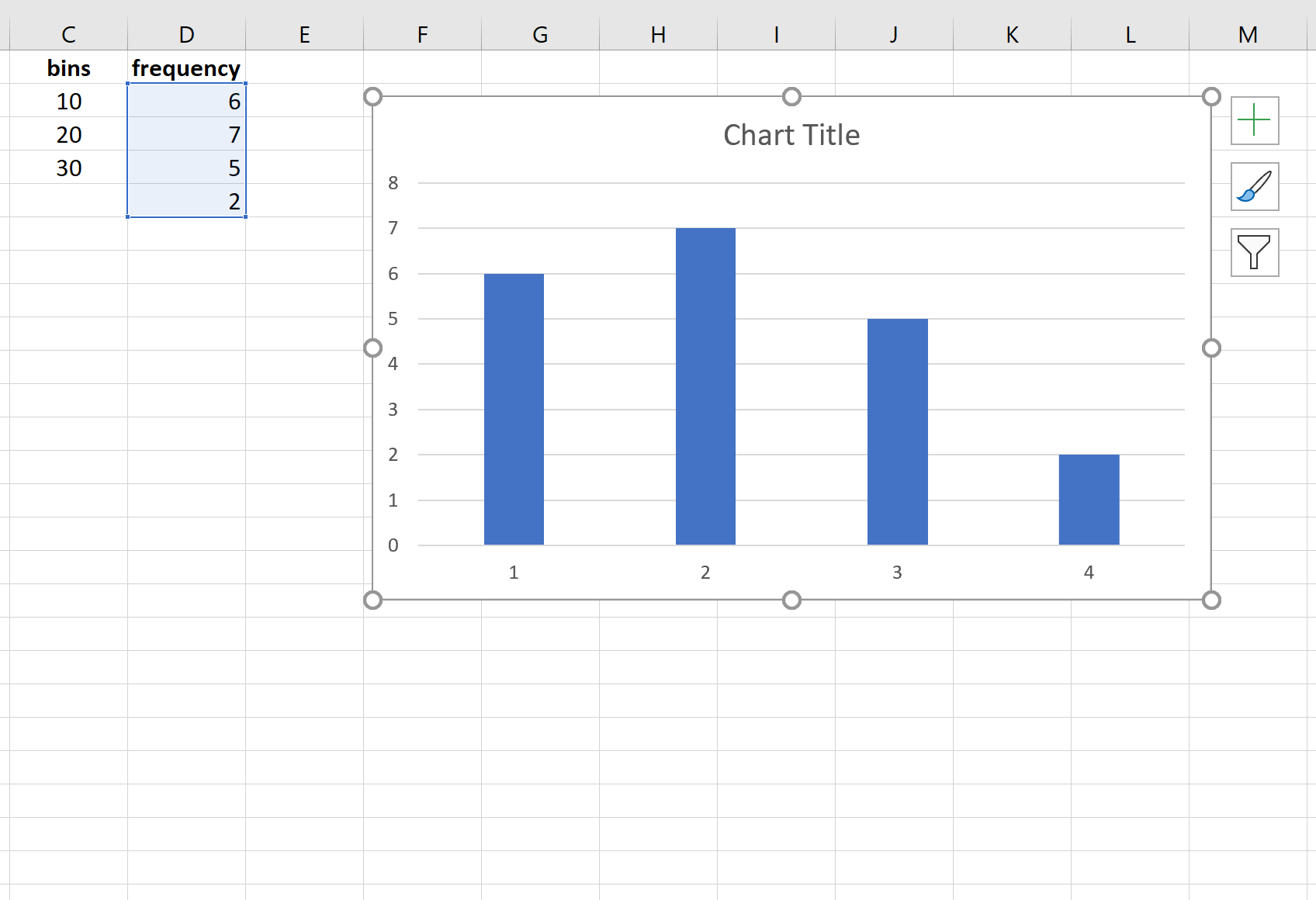
Не стесняйтесь изменять метки осей и ширину полос, чтобы сделать диаграмму более эстетичной:
Вы можете найти больше учебников по Excel здесь .
Написано
![]()
Замечательно! Вы успешно подписались.
Добро пожаловать обратно! Вы успешно вошли
Вы успешно подписались на кодкамп.
Срок действия вашей ссылки истек.
Ура! Проверьте свою электронную почту на наличие волшебной ссылки для входа.
Успех! Ваша платежная информация обновлена.
Ваша платежная информация не была обновлена.
Гистограмма распределения – это инструмент, позволяющий визуально оценить величину и характер разброса данных. Создадим гистограмму для непрерывной случайной величины с помощью встроенных средств MS EXCEL из надстройки Пакет анализа и в ручную с помощью функции
ЧАСТОТА()
и диаграммы.
Гистограмма (frequency histogram) – это
столбиковая диаграмма MS EXCEL
, в каждый столбик представляет собой интервал значений (корзину, карман, class interval, bin, cell), а его высота пропорциональна количеству значений в ней (частоте наблюдений).
Гистограмма поможет визуально оценить распределение набора данных, если:
- в наборе данных как минимум 50 значений;
- ширина интервалов одинакова.
Построим гистограмму для набора данных, в котором содержатся значения
непрерывной случайной величины
. Набор данных (50 значений), а также рассмотренные примеры, можно взять на листе
Гистограмма AT
в
файле примера.
Данные содержатся в диапазоне
А8:А57
.
Примечание
: Для удобства написания формул для диапазона
А8:А57
создан
Именованный диапазон
Исходные_данные.
Построение гистограммы с помощью надстройки
Пакет анализа
Вызвав диалоговое окно
надстройки Пакет анализа
, выберите пункт
Гистограмма
и нажмите ОК.
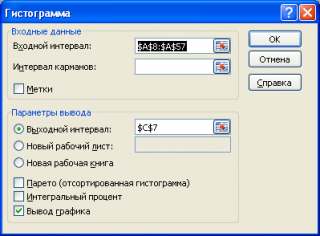
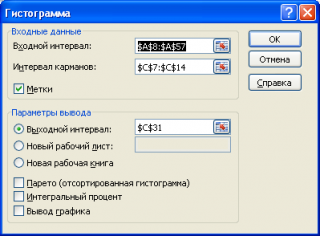
В появившемся окне необходимо как минимум указать:
входной интервал
и левую верхнюю ячейку
выходного интервала
. После нажатия кнопки
ОК
будут:
- автоматически рассчитаны интервалы значений (карманы);
- подсчитано количество значений из указанного массива данных, попадающих в каждый интервал (построена таблица частот);
-
если поставлена галочка напротив пункта
Вывод графика
, то вместе с таблицей частот будет выведена гистограмма.
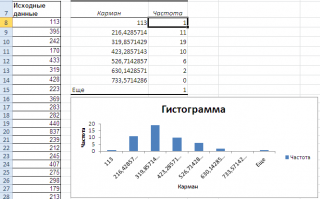
Перед тем как анализировать полученный результат –
отсортируйте исходный массив данных
.
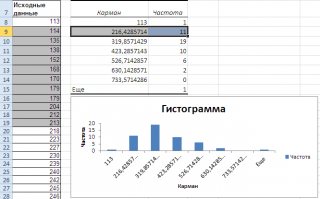
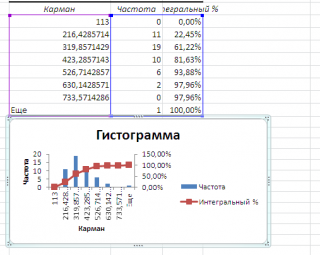
Как видно из рисунка, первый интервал включает только одно минимальное значение 113 (точнее, включены все значения меньшие или равные минимальному). Если бы в массиве было 2 или более значения 113, то в первый интервал попало бы соответствующее количество чисел (2 или более).
Второй интервал (отмечен на картинке серым) включает значения больше 113 и меньше или равные 216,428571428571. Можно проверить, что таких значений 11. Предпоследний интервал, от 630,142857142857 (не включая) до 733,571428571429 (включая) содержит 0 значений, т.к. в этом диапазоне значений нет. Последний интервал (со странным названием
Еще
) содержит значения больше 733,571428571429 (не включая). Таких значений всего одно – максимальное значение в массиве (837).
Размеры карманов одинаковы и равны 103,428571428571. Это значение можно получить так:
=(МАКС(
Исходные_данные
)-МИН(
Исходные_данные
))/7
где
Исходные_данные –
именованный диапазон
, содержащий наши данные.
Почему 7? Дело в том, что количество интервалов гистограммы (карманов) зависит от количества данных и для его определения часто используется формула √n, где n – это количество данных в выборке. В нашем случае √n=√50=7,07 (всего 7 полноценных карманов, т.к. первый карман включает только значения равные минимальному).
Примечание
:
Похоже, что инструмент
Гистограмма
для подсчета общего количества интервалов (с учетом первого) использует формулу
=ЦЕЛОЕ(КОРЕНЬ(СЧЕТ(
Исходные_данные
)))+1
Попробуйте, например, сравнить количество интервалов для диапазонов длиной 35 и 36 значений – оно будет отличаться на 1, а у 36 и 48 – будет одинаковым, т.к. функция
ЦЕЛОЕ()
округляет до ближайшего меньшего целого
(ЦЕЛОЕ(КОРЕНЬ(35))=5
, а
ЦЕЛОЕ(КОРЕНЬ(36))=6)
.
Если установить галочку напротив поля
Парето (отсортированная гистограмма)
, то к таблице с частотами будет добавлена таблица с отсортированными по убыванию частотами.
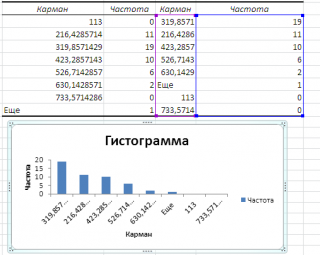
Если установить галочку напротив поля
Интегральный процент
, то к таблице с частотами будет добавлен столбец с
нарастающим итогом
в % от общего количества значений в массиве.
Если выбор количества интервалов или их диапазонов не устраивает, то можно в диалоговом окне указать нужный массив интервалов (если интервал карманов включает текстовый заголовок, то нужно установить галочку напротив поля
Метка
).
Для нашего набора данных установим размер кармана равным 100 и первый карман возьмем равным 150.
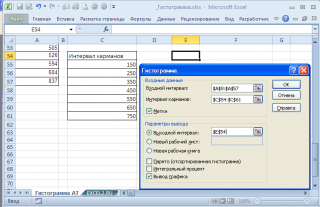
В результате получим практически такую же по форме
гистограмму
, что и раньше, но с более красивыми границами интервалов.
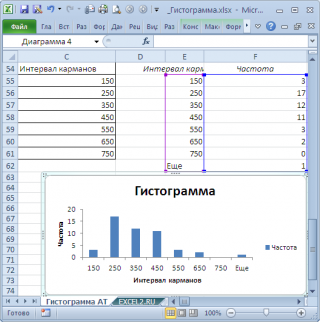
Как видно из рисунков выше, надстройка
Пакет анализа
не осуществляет никакого
дополнительного форматирования диаграммы
. Соответственно, вид такой гистограммы оставляет желать лучшего (столбцы диаграммы обычно располагают вплотную для непрерывных величин, кроме того подписи интервалов не информативны). О том, как придать диаграмме более презентабельный вид, покажем в следующем разделе при построении
гистограммы
с помощью функции
ЧАСТОТА()
без использовании надстройки
Пакет анализа
.
Построение гистограммы распределения без использования надстройки Пакет анализа
Порядок действий при построении гистограммы в этом случае следующий:
- определить количество интервалов у гистограммы;
- определить ширину интервала (с учетом округления);
- определить границу первого интервала;
- сформировать таблицу интервалов и рассчитать количество значений, попадающих в каждый интервал (частоту);
- построить гистограмму.
СОВЕТ
: Часто рекомендуют, чтобы границы интервала были на один порядок точнее самих данных и оканчивались на 5. Например, если данные в массиве определены с точностью до десятых: 1,2; 2,3; 5,0; 6,1; 2,1, …, то границы интервалов должны быть округлены до сотых: 1,25-1,35; 1,35-1,45; … Для небольших наборов данных вид гистограммы сильно зависит количества интервалов и их ширины. Это приводит к тому, что сам метод гистограмм, как инструмент
описательной статистики
, может быть применен только для наборов данных состоящих, как минимум, из 50, а лучше из 100 значений.
В наших расчетах для определения количества интервалов мы будем пользоваться формулой
=ЦЕЛОЕ(КОРЕНЬ(n))+1
.
Примечание
: Кроме использованного выше правила (число карманов = √n), используется ряд других эмпирических правил, например, правило Стёрджеса (Sturges): число карманов =1+log2(n). Это обусловлено тем, что например, для n=5000, количество интервалов по формуле √n будет равно 70, а правило Стёрджеса рекомендует более приемлемое количество – 13.
Расчет ширины интервала и таблица интервалов приведены в
файле примера на листе Гистограмма
. Для вычисления количества значений, попадающих в каждый интервал, использована
формула массива
на основе функции
ЧАСТОТА()
. О вводе этой функции см. статью
Функция ЧАСТОТА() – Подсчет ЧИСЛОвых значений в MS EXCEL
.
В MS EXCEL имеется диаграмма типа
Гистограмма с группировкой
, которая обычно используется для построения
Гистограмм распределения
.
В итоге можно добиться вот такого результата.
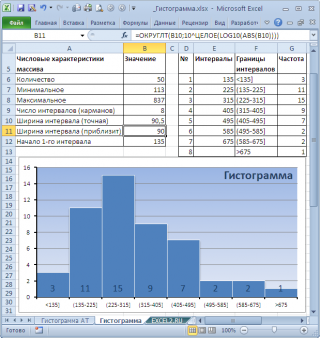
Примечание
: О построении и настройке макета диаграмм см. статью
Основы построения диаграмм в MS EXCEL
.
Одной из разновидностей гистограмм является
график накопленной частоты
(cumulative frequency plot).
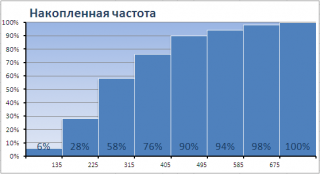
На этом графике каждый столбец представляет собой число значений исходного массива, меньших или равных правой границе соответствующего интервала. Это очень удобно, т.к., например, из графика сразу видно, что 90% значений (45 из 50) меньше чем 495.
СОВЕТ
: О построении
двумерной гистограммы
см. статью
Двумерная гистограмма в MS EXCEL
.
Примечание
: Альтернативой
графику накопленной частоты
может служить
Кривая процентилей
, которая рассмотрена в
статье про Процентили
.
Примечание
: Когда количество значений в выборке недостаточно для построения полноценной
гистограммы
может быть полезна
Блочная диаграмма
(иногда она называется
Диаграмма размаха
или
Ящик с усами
).
17 марта 2022 г.
Многие специалисты в различных отраслях используют Excel для создания и организации своих данных. Один из способов, которым профессионалы могут максимизировать использование программы, — это таблицы частотного распределения. Знание таблиц частотного распределения может помочь вам развить свои деловые навыки, навыки работы с компьютером и Excel. В этой статье мы обсудим, что такое таблица частотного распределения Excel, перечислим семь шагов, которые вы можете выполнить, чтобы создать ее, и подробно расскажем, как вы можете использовать их для повышения своих профессиональных навыков.
Распределение частоты Excel — это инструмент для просмотра того, как ваши данные варьируются в определенных диапазонах значений. Например, вы можете установить шкалу с категориями 1000, начиная с единицы и заканчивая 10 000, если вы работаете с числовыми значениями между этими конечными точками. Первая категория — «1–1 000», вторая — «1 001–2 000» с последовательностью до «9 001–10 000». Сама таблица сообщает вам, сколько значений находится в этих диапазонах. Например, у вас может быть 32 значения в первой категории, 23 в следующей и пять в последней.
Как сделать таблицу частотного распределения в Excel
Используя данные, которые вы собираете в электронной таблице Excel, вы можете создать сводную таблицу, а затем преобразовать эту таблицу в частотное распределение. Ниже приведены шаги, которые можно использовать для создания таблицы частотного распределения в Excel:
1. Вставьте сводную таблицу
После того, как вы введете данные, которые вы используете, в электронную таблицу Excel или получите электронную таблицу с уже содержащимися данными, вы можете создать сводную таблицу. Ниже приведены шаги, которые вы можете выполнить, чтобы создать сводную таблицу в Excel:
-
Выберите ячейку в вашем наборе данных.
-
Нажмите «Сводная таблица» на вкладке «Вставка» и в группе «Таблицы».
-
Нажмите «ОК», чтобы создать сводную таблицу с вашими данными.
После создания сводной таблицы Excel предложит вам инструкции по созданию нужной таблицы. Вы можете использовать эти указания, чтобы изменить внешний вид вашей таблицы частотного распределения.
2. Перетащите поля в соответствующие области.
Параметры диалогового окна Excel позволяют перемещать поля в разные области таблицы. В зависимости от того, как вы маркируете собираемые данные, могут отображаться различные параметры, которые вы можете выбрать. Например, если в вашем наборе данных есть столбец «Суммы» со значениями в валюте, вы можете выбрать поле с названием «Суммы». Когда вы выберете этот вариант, вы сможете указать, куда идет значение. Например, вы можете взять поле «Суммы» и поместить его как в область «Строки», так и в область «Значения».
Для частотного распределения используемые вами «Суммы» переходят в область «Строки» и область «Значения». Другие поля, которые у вас могут быть, включают элементы, к которым относятся значения валюты, и другую информацию об этих элементах. Для простого распределения частоты можно беспокоиться только о поле «Суммы». Если вы хотите вернуться и изменить таблицу распределения частот после ее создания, чтобы добавить дополнительную информацию, вы можете это сделать.
3. Перейдите к опции «Значение и настройки поля…».
После того, как вы укажете, где будут располагаться ваши категории в таблице, вы сможете получить доступ к опции «Значение и настройки полей…». Этот параметр позволяет изменить способ интерпретации сводной таблицей Excel имеющихся у вас значений. Чтобы перейти к этому параметру, выберите ячейку в столбце «Сумма» сводной таблицы, щелкните правой кнопкой мыши значение, затем выберите кнопку «Значение и параметры поля…». Это вызывает диалоговое окно, в котором у вас есть варианты того, как Excel вычисляет и суммирует выбранное вами поле. Некоторые параметры в этом разделе:
-
Сумма: общее числовое значение в левой соседней ячейке сводной таблицы.
-
Подсчет: сколько вхождений значения или диапазона значений происходит из значения или диапазона слева от ячейки в сводной таблице.
-
Среднее: среднее значение ваших сумм в левых смежных ячейках сводной таблицы.
-
Макс. Максимальное значение сумм в левых смежных ячейках сводной таблицы.
-
Мин.: наименьшее значение сумм в левых смежных ячейках сводной таблицы.
4. Выберите «Подсчет» и нажмите «ОК».
Чтобы создать таблицу распределения частот, вы хотите, чтобы Excel подсчитывал, сколько раз значение встречается в определенном диапазоне. Из списка опций «Количество» позволяет вам сделать это. После того, как вы выберете «Подсчет», нажмите «ОК», чтобы завершить свой выбор. Как только вы это сделаете, ваша сводная таблица может изменить значения во втором столбце в зависимости от того, сколько раз встречаются связанные значения в столбце слева. Например, если у вас есть три вхождения значения $107, правый столбец сводной таблицы генерирует значение «3» и помещает его в таблицу.
5. Перейдите к опции «Группа…».
Опция «Группировать…» позволяет группировать значения вместе, создавая определенные диапазоны. Например, вы можете создать диапазоны 5, 10, 100 или любое другое значение, которое вы считаете важным для своих данных. Чтобы найти параметр «Группировать…», выберите любую ячейку с меткой «Строки». Затем щелкните правой кнопкой мыши выбранную ячейку, чтобы открыть меню параметров. После этого выберите в этом меню кнопку «Группировать…».
6. Введите значения для распределения и нажмите «ОК».
В зависимости от данных, с которыми вы работаете, у вас могут быть разные значения для вашего распределения. Например, у небольшой организации может быть только несколько продуктов стоимостью от 5 до 200 долларов. Чтобы создать таблицу распределения того, сколько из этих товаров организация продает в течение маркетингового периода, вы можете выбрать раздел «Начало в» и ввести значение 1. Затем вы можете выбрать раздел «Окончание в» и ввести значение 200. Затем вы можете выбрать, насколько велики диапазоны, указав значение в разделе «По», например 25. Затем нажмите «ОК», чтобы применить ваши изменения.
Это создает восемь четных групп по 25 от 1 до 200 в сводной таблице, изменяя вашу таблицу. Это позволяет вам видеть, сколько значений встречается в каждом из этих диапазонов, а не для конкретных числовых значений. Наконец, ваша таблица частотного распределения завершена.
7. Сохраните электронную таблицу Excel
Есть несколько способов сохранить электронную таблицу Excel. Если вы ранее не сохраняли документ, вы можете перейти на вкладку «Файл» в левом верхнем углу программы Excel, выбрать его и нажать кнопку «Сохранить» или «Сохранить как». Кнопка «Сохранить» создает документ и автоматически сохраняет его на вашем компьютере. Кнопка «Сохранить как» позволяет выбрать имя файла и место его хранения на компьютере, что упрощает поиск документа.
Если вы уже сохранили свой документ ранее, вы можете использовать команду клавиатуры, чтобы сохранить новую версию электронной таблицы Excel. Вы можете нажать клавиши «Ctrl S», чтобы автоматически сохранить электронную таблицу, как если бы вы нажали кнопку «Сохранить». Это может помочь вам сэкономить время при обновлении таблицы новыми данными.
Использование для таблицы распределения частот
Вы можете использовать таблицу частотного распределения, чтобы сравнить количество значений в определенных диапазонах. Это поможет вам понять, с какой скоростью эти значения встречаются по сравнению друг с другом. Это может помочь компаниям сравнить, насколько сильно разные продукты или разные ценовые диапазоны влияют на их продажи. Вы также можете использовать таблицу частотного распределения для создания быстрых визуальных представлений для встреч.
Как создать гистограмму для таблицы распределения частот
Вы можете выбрать любую ячейку в таблице частотного распределения для визуального представления ваших данных. Как только вы это сделаете, перейдите в программе Excel на вкладку «Анализ». Под этой вкладкой есть несколько групп. Вам нужна группа «Инструменты». Это позволяет вам создать либо сводную диаграмму, либо другие типы сводных таблиц, которые Excel может вам порекомендовать. Вы хотите создать сводную диаграмму, поэтому нажмите на эту кнопку. Как только вы это сделаете, появится диалоговое окно, и вы можете просто нажать «ОК», чтобы создать визуальное представление вашей таблицы распределения частот.
По умолчанию Excel создает гистограмму, представляющую собой тип вертикальной гистограммы, которая показывает, как различные категории или диапазоны сравниваются друг с другом. Например, вы можете увидеть несколько диапазонов чисел, названия продуктов или другую информацию под синими полосами на диаграмме. Эти полосы могут иметь разную высоту в зависимости от того, сколько раз значение встречается в этой категории. Это означает, что вы можете предоставить другим специалистам быстрый способ просмотра созданных вами данных, не заходя в саму конкретную таблицу.
Обратите внимание, что ни одна из компаний, упомянутых в этой статье, не связана с компанией Indeed.
Построение рядов распределения
Любой ряд распределения характеризуется двумя элементами:
— варианта(хi) – это отдельные значения признака единиц выборочной совокупности. Для вариационного ряда варианта принимает числовые значения, для атрибутивного – качественные (например, х=«государственный служащий»);
— частота (ni) – число, показывающее, сколько раз встречается то или иное значение признака. Если частота выражена относительным числом (т.е. долей элементов совокупности, соответствующих данному значению варианты, в общем объеме совокупности), то она называется относительной частотойили частостью.
— дискретным, когда изучаемый признак характеризуется определенным числом (как правило целым).
— интервальным, когда определены границы «от» и «до» для непрерывно варьируемого признака. Интервальный ряд также строят если множество значений дискретно варьируемого признака велико.
Интервальный ряд может строиться как с интервалами равной длины (равноинтервальный ряд) так и с неодинаковыми интервалами, если это диктуется условиями статистического исследования. Например, может рассматриваться ряд распределения доходов населения со следующими интервалами:
где k – число интервалов, n – объем выборки. (Конечно, формула обычно дает число дробное, а в качестве числа интервалов выбирается ближайшее целое к полученному число.) Длина интервала в таком случае определяется по формуле
При работе в Excel для построения вариационных рядов могут быть использованы следующие функции:
— СЧЁТ(массив данных) – для определения объема выборки. Аргументом является диапазон ячеек, в котором находятся выборочные данные.
— СЧЁТЕСЛИ(диапазон; критерий) – может быть использована для построения атрибутивного или вариационного ряда. Аргументами являются диапазон массива выборочных значений признака и критерий – числовое или текстовое значение признака или номер ячейки, в которой оно находится. Результатом является частота появления этого значения в выборке.
Проиллюстрируем процесс первичной обработки данных на следующих примерах.
Пример 1.1. имеются данные о количественном составе 60 семей.
Построить вариационный ряд и полигон распределения
Рис.1.1 Пример 1. Первичная обработка статистических данных в таблицах Excel

Далее, подготовим таблицу для построения вариационного ряда, введя названия для столбца интервалов (значений варианты) и столбца частот. В столбец интервалов введем значения признака от минимального (1) до максимального (6), заняв диапазон В12:В17. Выделим столбец частот, введем формулу =ЧАСТОТА(А1:L5;В12:В17) и нажмем сочетание клавиш CTRL+SHIFT+ENTER

Для контроля вычислим сумму частот при помощи функции СУММ (значок функции S в группе «Редактирование» на вкладке «Главная»), вычисленная сумма должна совпасть с ранее вычисленным объемом выборки в ячейке В7.
Теперь построим полигон: выделив полученный диапазон частот, выберем команду «График» на вкладке «Вставка». По умолчанию значениями на горизонтальной оси будут порядковые числа — в нашем случае от 1 до 6, что совпадает со значениями варианты (номерами тарифных разрядов).
Название ряда диаграммы «ряд 1» можно либо изменить, воспользовавшись той же опцией «выбрать данные» вкладки «Конструктор», либо просто удалить.

Пример 1.2. Имеются данные о выбросах загрязняющих веществ из 50 источников:
| 10,4 | 18,6 | 10,3 | 26,0 | 45,0 | 18,2 | 17,3 | 19,2 | 25,8 | 18,7 |
| 28,2 | 25,2 | 18,4 | 17,5 | 41,8 | 14,6 | 10,0 | 37,8 | 10,5 | 16,0 |
| 18,1 | 16,8 | 38,5 | 37,7 | 17,9 | 29,0 | 10,1 | 28,0 | 12,0 | 14,0 |
| 14,2 | 20,8 | 13,5 | 42,4 | 15,5 | 17,9 | 19, | 10,8 | 12,1 | 12,4 |
| 12,9 | 12,6 | 16,8 | 19,7 | 18,3 | 36,8 | 15,0 | 37,0 | 13,0 | 19,5 |
Составить равноинтервальный ряд, построить гистограмму
Внесем массив данных в лист Excel, он займет диапазон А1:J5 Как и в предыдущей задаче, определим объем выборки n, минимальное и максимальное значения в выборке. Поскольку теперь требуется не дискретный, а интервальный ряд, и число интервалов в задаче не задано, вычислим число интервалов k по формуле Стерджесса. Для этого в ячейку В10 введем формулу =1+3,322*LOG10(B7).
Рис.1.4. Пример 2. Построение равноинтервального ряда

Полученное значение не является целым, оно равно примерно 6,64. Поскольку при k=7 длина интервалов будет выражаться целым числом (в отличие от случая k=6) выберем k=7, введя это значение в ячейку С10. Длину интервала d вычислим в ячейке В11, введя формулу =(В9-В8)/С10.
Рис.1.5. Пример 2. Построение равноинтервального ряда

Теперь заполним массив «карманов» при помощи функции ЧАСТОТА, как это было сделано в примере 1.
Рис.1.6. Пример 2. Построение равноинтервального ряда


Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
Если выбор количества интервалов или их диапазонов не устраивает, то можно в диалоговом окне указать нужный массив интервалов если интервал карманов включает текстовый заголовок, то нужно установить галочку напротив поля Метка. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
Расчет ширины интервала и таблица интервалов приведены в файле примера на листе Гистограмма . Для вычисления количества значений, попадающих в каждый интервал, использована формула массива на основе функции ЧАСТОТА() . О вводе этой функции см. статью Функция ЧАСТОТА() – Подсчет ЧИСЛОвых значений в MS EXCEL .

Для построений необходимо выделить всю таблицу вместе с заголовком и выполнить команду вкладка Вставка — инструмент Точечная. Выбираем вариант Точечная с гладкими кривыми и маркерами как более показательный.
| 10,4 | 18,6 | 10,3 | 26,0 | 45,0 | 18,2 | 17,3 | 19,2 | 25,8 | 18,7 |
| 28,2 | 25,2 | 18,4 | 17,5 | 41,8 | 14,6 | 10,0 | 37,8 | 10,5 | 16,0 |
| 18,1 | 16,8 | 38,5 | 37,7 | 17,9 | 29,0 | 10,1 | 28,0 | 12,0 | 14,0 |
| 14,2 | 20,8 | 13,5 | 42,4 | 15,5 | 17,9 | 19, | 10,8 | 12,1 | 12,4 |
| 12,9 | 12,6 | 16,8 | 19,7 | 18,3 | 36,8 | 15,0 | 37,0 | 13,0 | 19,5 |
Стиль и внешний вид гистограммы
После того, как вы создали гистограмму, вам может потребоваться внести корректировки в то, как выглядит ваш график. Для изменения дизайна и стиля используйте вкладку “Конструктор”. Эта вкладка отображается на Панели инструментов, когда вы выделяете левой клавишей мыши гистограмму. С помощью дополнительных настроек в разделе “Конструктор” вы сможете:
- добавить заголовок и другие дополнительные данные для отображения. Для того, чтобы добавить данные на график, кликните на пункт “Добавить элемент диаграммы”, затем, выберите нужный пункт из выпадающего списка:




Вы также можете использовать кнопки быстрого доступа к редактированию элементов гистограммы, стиля и фильтров:

Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
Получили следующий набор данных 18,38,28,29,26,38,34,22,28,30,22,23,35,33,27,24,30,32,28,25,29,26,31,24,29,27,32,24,29,29 Постройте интервальный ряд и исследуйте его. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
Например:
Для распределения учеников по росту получаем: begin S^2=fraccdot 104,1approx 105,1\ sapprox 10,3 end Коэффициент вариации: $ V=fraccdot 100textapprox 6,0textlt 33text $ Выборка однородна. Найденное значение среднего роста (X_)=171,7 см можно распространить на всю генеральную совокупность (старшеклассников из других школ).
Интервальный вариационный ряд и его характеристики: построение, гистограмма, выборочная дисперсия и СКО
- автоматически рассчитаны интервалы значений (карманы);
- подсчитано количество значений из указанного массива данных, попадающих в каждый интервал (построена таблица частот);
- если поставлена галочка напротив пункта Вывод графика , то вместе с таблицей частот будет выведена гистограмма.
Ряды распределения одна из разновидностей статистических рядов (кроме них в статистике используются ряды динамики), используются для анализа данных о явлениях общественной жизни. Построение вариационных рядов вполне посильная задача для каждого. Однако есть правила, которые необходимо помнить.
В статье подробно показано, что такое нормальный закон распределения случайной величины и как им пользоваться при решении практически задач.
Нормальное распределение в статистике
История закона насчитывает 300 лет. Первым открывателем стал Абрахам де Муавр, который придумал аппроксимацию биномиального распределения еще 1733 году. Через много лет Карл Фридрих Гаусс (1809 г.) и Пьер-Симон Лаплас (1812 г.) вывели математические функции.
Лаплас также обнаружил замечательную закономерность и сформулировал центральную предельную теорему (ЦПТ), согласно которой сумма большого количества малых и независимых величин имеет нормальное распределение.
Нормальный закон не является фиксированным уравнением зависимости одной переменной от другой. Фиксируется только характер этой зависимости. Конкретная форма распределения задается специальными параметрами. Например, у = аx + b – это уравнение прямой. Однако где конкретно она проходит и под каким наклоном, определяется параметрами а и b. Также и с нормальным распределением. Ясно, что это функция, которая описывает тенденцию высокой концентрации значений около центра, но ее точная форма задается специальными параметрами.
Кривая нормального распределения Гаусса имеет следующий вид.

График нормального распределения напоминает колокол, поэтому можно встретить название колоколообразная кривая. У графика имеется «горб» в середине и резкое снижение плотности по краям. В этом заключается суть нормального распределения. Вероятность того, что случайная величина окажется около центра гораздо выше, чем то, что она сильно отклонится от середины.

На рисунке выше изображены два участка под кривой Гаусса: синий и зеленый. Основания, т.е. интервалы, у обоих участков равны. Но заметно отличаются высоты. Синий участок удален от центра, и имеет существенно меньшую высоту, чем зеленый, который находится в самом центре распределения. Следовательно, отличаются и площади, то бишь вероятности попадания в обозначенные интервалы.
Формула нормального распределения (плотности) следующая.
![]()
Формула состоит из двух математических констант:
π – число пи 3,142;
е – основание натурального логарифма 2,718;
двух изменяемых параметров, которые задают форму конкретной кривой:
m – математическое ожидание (в различных источниках могут использоваться другие обозначения, например, µ или a);
σ2 – дисперсия;
ну и сама переменная x, для которой высчитывается плотность вероятности.
Конкретная форма нормального распределения зависит от 2-х параметров: математического ожидания (m) и дисперсии (σ2). Кратко обозначается N(m, σ2) или N(m, σ). Параметр m (матожидание) определяет центр распределения, которому соответствует максимальная высота графика. Дисперсия σ2 характеризует размах вариации, то есть «размазанность» данных.
Параметр математического ожидания смещает центр распределения вправо или влево, не влияя на саму форму кривой плотности.

А вот дисперсия определяет остроконечность кривой. Когда данные имеют малый разброс, то вся их масса концентрируется у центра. Если же у данных большой разброс, то они «размазываются» по широкому диапазону.

Плотность распределения не имеет прямого практического применения. Для расчета вероятностей нужно проинтегрировать функцию плотности.
Вероятность того, что случайная величина окажется меньше некоторого значения x, определяется функцией нормального распределения:
![]()
Используя математические свойства любого непрерывного распределения, несложно рассчитать и любые другие вероятности, так как
P(a ≤ X < b) = Ф(b) – Ф(a)
Стандартное нормальное распределение
Нормальное распределение зависит от параметров средней и дисперсии, из-за чего плохо видны его свойства. Хорошо бы иметь некоторый эталон распределения, не зависящий от масштаба данных. И он существует. Называется стандартным нормальным распределением. На самом деле это обычное нормальное нормальное распределение, только с параметрами математического ожидания 0, а дисперсией – 1, кратко записывается N(0, 1).
Любое нормальное распределение легко превращается в стандартное путем нормирования:
![]()
где z – новая переменная, которая используется вместо x;
m – математическое ожидание;
σ – стандартное отклонение.
Для выборочных данных берутся оценки:
![]()
Среднее арифметическое и дисперсия новой переменной z теперь также равны 0 и 1 соответственно. В этом легко убедиться с помощью элементарных алгебраических преобразований.
В литературе встречается название z-оценка. Это оно самое – нормированные данные. Z-оценку можно напрямую сравнивать с теоретическими вероятностями, т.к. ее масштаб совпадает с эталоном.
Посмотрим теперь, как выглядит плотность стандартного нормального распределения (для z-оценок). Напомню, что функция Гаусса имеет вид:
![]()
Подставим вместо (x-m)/σ букву z, а вместо σ – единицу, получим функцию плотности стандартного нормального распределения:
![]()
График плотности:

Центр, как и ожидалось, находится в точке 0. В этой же точке функция Гаусса достигает своего максимума, что соответствует принятию случайной величиной своего среднего значения (т.е. x-m=0). Плотность в этой точке равна 0,3989, что можно посчитать даже в уме, т.к. e0=1 и остается рассчитать только соотношение 1 на корень из 2 пи.
Таким образом, по графику хорошо видно, что значения, имеющие маленькие отклонения от средней, выпадают чаще других, а те, которые сильно отдалены от центра, встречаются значительно реже. Шкала оси абсцисс измеряется в стандартных отклонениях, что позволяет отвязаться от единиц измерения и получить универсальную структуру нормального распределения. Кривая Гаусса для нормированных данных отлично демонстрирует и другие свойства нормального распределения. Например, что оно является симметричным относительно оси ординат. В пределах ±1σ от средней арифметической сконцентрирована большая часть всех значений (прикидываем пока на глазок). В пределах ±2σ находятся большинство данных. В пределах ±3σ находятся почти все данные. Последнее свойство широко известно под названием правило трех сигм для нормального распределения.
Функция стандартного нормального распределения позволяет рассчитывать вероятности.
![]()
Понятное дело, вручную никто не считает. Все подсчитано и размещено в специальных таблицах, которые есть в конце любого учебника по статистике.
Таблица нормального распределения
Таблицы нормального распределения встречаются двух типов:
— таблица плотности;
— таблица функции (интеграла от плотности).
Таблица плотности используется редко. Тем не менее, посмотрим, как она выглядит. Допустим, нужно получить плотность для z = 1, т.е. плотность значения, отстоящего от матожидания на 1 сигму. Ниже показан кусок таблицы.

В зависимости от организации данных ищем нужное значение по названию столбца и строки. В нашем примере берем строку 1,0 и столбец 0, т.к. сотых долей нет. Искомое значение равно 0,2420 (0 перед 2420 опущен).
Функция Гаусса симметрична относительно оси ординат. Поэтому φ(z)= φ(-z), т.е. плотность для 1 тождественна плотности для -1, что отчетливо видно на рисунке.

Чтобы не тратить зря бумагу, таблицы печатают только для положительных значений.
На практике чаще используют значения функции стандартного нормального распределения, то есть вероятности для различных z.
В таких таблицах также содержатся только положительные значения. Поэтому для понимания и нахождения любых нужных вероятностей следует знать свойства стандартного нормального распределения.
Функция Ф(z) симметрична относительно своего значения 0,5 (а не оси ординат, как плотность). Отсюда справедливо равенство:
![]()
Это факт показан на картинке:

Значения функции Ф(-z) и Ф(z) делят график на 3 части. Причем верхняя и нижняя части равны (обозначены галочками). Для того, чтобы дополнить вероятность Ф(z) до 1, достаточно добавить недостающую величину Ф(-z). Получится равенство, указанное чуть выше.
Если нужно отыскать вероятность попадания в интервал (0; z), то есть вероятность отклонения от нуля в положительную сторону до некоторого количества стандартных отклонений, достаточно от значения функции стандартного нормального распределения отнять 0,5:
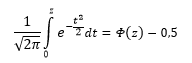
Для наглядности можно взглянуть на рисунок.

На кривой Гаусса, эта же ситуация выглядит как площадь от центра вправо до z.

Довольно часто аналитика интересует вероятность отклонения в обе стороны от нуля. А так как функция симметрична относительно центра, предыдущую формулу нужно умножить на 2:

Рисунок ниже.

Под кривой Гаусса это центральная часть, ограниченная выбранным значением –z слева и z справа.

Указанные свойства следует принять во внимание, т.к. табличные значения редко соответствуют интересующему интервалу.
Для облегчения задачи в учебниках обычно публикуют таблицы для функции вида:

Если нужна вероятность отклонения в обе стороны от нуля, то, как мы только что убедились, табличное значение для данной функции просто умножается на 2.
Теперь посмотрим на конкретные примеры. Ниже показана таблица стандартного нормального распределения. Найдем табличные значения для трех z: 1,64, 1,96 и 3.

Как понять смысл этих чисел? Начнем с z=1,64, для которого табличное значение составляет 0,4495. Проще всего пояснить смысл на рисунке.

То есть вероятность того, что стандартизованная нормально распределенная случайная величина попадет в интервал от 0 до 1,64, равна 0,4495. При решении задач обычно нужно рассчитать вероятность отклонения в обе стороны, поэтому умножим величину 0,4495 на 2 и получим примерно 0,9. Занимаемая площадь под кривой Гаусса показана ниже.

Таким образом, 90% всех нормально распределенных значений попадает в интервал ±1,64σ от средней арифметической. Я не случайно выбрал значение z=1,64, т.к. окрестность вокруг средней арифметической, занимающая 90% всей площади, иногда используется для проверки статистических гипотез и расчета доверительных интервалов. Если проверяемое значение не попадает в обозначенную область, то его наступление маловероятно (всего 10%).
Для проверки гипотез, однако, чаще используется интервал, накрывающий 95% всех значений. Половина вероятности от 0,95 – это 0,4750 (см. второе выделенное в таблице значение).

Для этой вероятности z=1,96. Т.е. в пределах почти ±2σ от средней находится 95% значений. Только 5% выпадают за эти пределы.

Еще одно интересное и часто используемое табличное значение соответствует z=3, оно равно по нашей таблице 0,4986. Умножим на 2 и получим 0,997. Значит, в рамках ±3σ от средней арифметической заключены почти все значения.

Так выглядит правило 3 сигм для нормального распределения на диаграмме.
С помощью статистических таблиц можно получить любую вероятность. Однако этот метод очень медленный, неудобный и сильно устарел. Сегодня все делается на компьютере. Далее переходим к практике расчетов в Excel.
В Excel есть несколько функций для подсчета вероятностей или обратных значений нормального распределения.

Функция НОРМ.СТ.РАСП
Функция НОРМ.СТ.РАСП предназначена для расчета плотности ϕ(z) или вероятности Φ(z) по нормированным данным (z).
=НОРМ.СТ.РАСП(z;интегральная)
z – значение стандартизованной переменной
интегральная – если 0, то рассчитывается плотность ϕ(z), если 1 – значение функции Ф(z), т.е. вероятность P(Z<z).
Рассчитаем плотность и значение функции для различных z: -3, -2, -1, 0, 1, 2, 3 (их укажем в ячейке А2).
Для расчета плотности потребуется формула =НОРМ.СТ.РАСП(A2;0). На диаграмме ниже – это красная точка.
Для расчета значения функции =НОРМ.СТ.РАСП(A2;1). На диаграмме – закрашенная площадь под нормальной кривой.

В реальности чаще приходится рассчитывать вероятность того, что случайная величина не выйдет за некоторые пределы от средней (в среднеквадратичных отклонениях, соответствующих переменной z), т.е. P(|Z|<z).

Определим, чему равна вероятность попадания случайной величины в пределы ±1z, ±2z и ±3z от нуля. Потребуется формула 2Ф(z)-1, в Excel =2*НОРМ.СТ.РАСП(A2;1)-1.

На диаграмме отлично видны основные основные свойства нормального распределения, включая правило трех сигм. Функция НОРМ.СТ.РАСП – это автоматическая таблица значений функции нормального распределения в Excel.
Может стоять и обратная задача: по имеющейся вероятности P(Z<z) найти стандартизованную величину z ,то есть квантиль стандартного нормального распределения.
Функция НОРМ.СТ.ОБР
НОРМ.СТ.ОБР рассчитывает обратное значение функции стандартного нормального распределения. Синтаксис состоит из одного параметра:
=НОРМ.СТ.ОБР(вероятность)
вероятность – это вероятность.
Данная формула используется так же часто, как и предыдущая, ведь по тем же таблицам искать приходится не только вероятности, но и квантили.

Например, при расчете доверительных интервалов задается доверительная вероятность, по которой нужно рассчитать величину z.

Учитывая то, что доверительный интервал состоит из верхней и нижней границы и то, что нормальное распределение симметрично относительно нуля, достаточно получить верхнюю границу (положительное отклонение). Нижняя граница берется с отрицательным знаком. Обозначим доверительную вероятность как γ (гамма), тогда верхняя граница доверительного интервала рассчитывается по следующей формуле.
![]()
Рассчитаем в Excel значения z (что соответствует отклонению от средней в сигмах) для нескольких вероятностей, включая те, которые наизусть знает любой статистик: 90%, 95% и 99%. В ячейке B2 укажем формулу: =НОРМ.СТ.ОБР((1+A2)/2). Меняя значение переменной (вероятности в ячейке А2) получим различные границы интервалов.

Доверительный интервал для 95% равен 1,96, то есть почти 2 среднеквадратичных отклонения. Отсюда легко даже в уме оценить возможный разброс нормальной случайной величины. В общем, доверительным вероятностям 90%, 95% и 99% соответствуют доверительные интервалы ±1,64, ±1,96 и ±2,58 σ.
В целом функции НОРМ.СТ.РАСП и НОРМ.СТ.ОБР позволяют произвести любой расчет, связанный с нормальным распределением. Но, чтобы облегчить и уменьшить количество действий, в Excel есть несколько других функций. Например, для расчета доверительных интервалов средней можно использовать ДОВЕРИТ.НОРМ. Для проверки статистической гипотезы о средней арифметической есть формула Z.ТЕСТ.
Рассмотрим еще пару полезных формул с примерами.
Функция НОРМ.РАСП
Функция НОРМ.РАСП отличается от НОРМ.СТ.РАСП лишь тем, что ее используют для обработки данных любого масштаба, а не только нормированных. Параметры нормального распределения указываются в синтаксисе.
=НОРМ.РАСП(x;среднее;стандартное_откл;интегральная)
x – значение (или ссылка на ячейку), для которого рассчитывается плотность или значение функции нормального распределения
среднее – математическое ожидание, используемое в качестве первого параметра модели нормального распределения
стандартное_откл – среднеквадратичное отклонение – второй параметр модели
интегральная – если 0, то рассчитывается плотность, если 1 – то значение функции, т.е. P(X<x).
Например, плотность для значения 15, которое извлекли из нормальной выборки с матожиданием 10, стандартным отклонением 3, рассчитывается так:

Если последний параметр поставить 1, то получим вероятность того, что нормальная случайная величина окажется меньше 15 при заданных параметрах распределения. Таким образом, вероятности можно рассчитывать напрямую по исходным данным.
Функция НОРМ.ОБР
Это квантиль нормального распределения, т.е. значение обратной функции. Синтаксис следующий.
=НОРМ.ОБР(вероятность;среднее;стандартное_откл)
вероятность – вероятность
среднее – матожидание
стандартное_откл – среднеквадратичное отклонение
Назначение то же, что и у НОРМ.СТ.ОБР, только функция работает с данными любого масштаба.
Пример показан в ролике в конце статьи.
Моделирование нормального распределения
Для некоторых задач требуется генерация нормальных случайных чисел. Готовой функции для этого нет. Однако В Excel есть две функции, которые возвращают случайные числа: СЛУЧМЕЖДУ и СЛЧИС. Первая выдает случайные равномерно распределенные целые числа в указанных пределах. Вторая функция генерирует равномерно распределенные случайные числа между 0 и 1. Чтобы сделать искусственную выборку с любым заданным распределением, нужна функция СЛЧИС.
Допустим, для проведения эксперимента необходимо получить выборку из нормально распределенной генеральной совокупности с матожиданием 10 и стандартным отклонением 3. Для одного случайного значения напишем формулу в Excel.
=НОРМ.ОБР(СЛЧИС();10;3)
Протянем ее на необходимое количество ячеек и нормальная выборка готова.
Для моделирования стандартизованных данных следует воспользоваться НОРМ.СТ.ОБР.
Процесс преобразования равномерных чисел в нормальные можно показать на следующей диаграмме. От равномерных вероятностей, которые генерируются формулой СЛЧИС, проведены горизонтальные линии до графика функции нормального распределения. Затем от точек пересечения вероятностей с графиком опущены проекции на горизонтальную ось.

На выходе получаются значения с характерной концентрацией около центра. Вот так обратный прогон через функцию нормального распределения превращает равномерные числа в нормальные. Excel позволяет за несколько секунд воспроизвести любое количество выборок любого размера.
Как обычно, прилагаю ролик, где все вышеописанное показывается в действии.
Скачать файл с примером.
Поделиться в социальных сетях:
