Регулярные выражения. Всё проще, чем кажется
Время на прочтение
7 мин
Количество просмотров 71K
Всем доброго времени суток. Сегодня хочу рассказать максимум о регулярных выражениях: что они из себя представляют, как их писать, для чего нужны и т.д.
Информации о регулярках много, они разбросаны по разным сайтам и я решил собрать всё, касательно регулярок, в одну статью. Ну что-ж, приступим поскорее к делу 🙂
Содержание
-
Что такое регулярка и с чем ее едят?
-
Где писать регулярки?
-
Самые простые регулярки
-
Квантификаторы
-
Специальные символы квантификаторов
-
Специальные символы
-
Lookahead и lookbehind (опережающая и ретроспективная проверки)
-
Регулярные выражения в разных языках программирования
-
Заключение
Что такое регулярка и с чем ее едят?
Если по простому, регулярка- это некий шаблон, по которому фильтруется текст. Мы можем написать нужный нам шаблон (регулярку) и таким образом искать в тексте необходимые нам символы, слова и т.д. Также их используют, например, при заполнении поля E-mail на различных сайтах, т.е. создают шаблон по типу: someEmail@gmail.com. Это я взял как пример, не более. Теперь, разобравшись, что это, приступим к изучению. Обещаю, скучно не будет)
Где писать регулярки?
Регулярки мы можем писать как на специальных сайтах, так и используя какой-либо язык программирования. Синтаксис (правила написания регулярок) не привязан к какому-то отдельному языку программирования. Поэтому, изучив регулярные выражения, вы сможете пользоваться ими где захотите. Сначала, в рамках изучения, воспользуемся отличным сайтом, а как писать регулярные выражения в различных языках программирования, рассмотрим чуточку позже.
Сразу дам ссылку на сайт, чтобы вы могли уже писать вместе со мной https://www.regextester.com/
Коротко о том, как пользоваться сайтом. Сверху, в графе Regular Expression вы пишете само регулярное выражение, а под ним, в графе Test String вы пишете строку, которую вы хотите фильтровать. Если были найдены соответствия между регулярным выражением и текстом, в тексте эти соответствия будут помечены синим цветом, вы их сразу увидите, даже не сомневайтесь.
Самые простые регулярки
Перед тем, как писать регулярку, возьмем некоторый текст, чтобы мы не фильтровали пустоту. Допустим, у нас будет строка some text. И допустим мы хотим найти слово text. Для этого в саму регулярку мы должны написать просто слово text и он найдет его.

Вот и всё, надеюсь вы поняли регулярные выражения, спасибо за внимание…
Шутка конечно, это далеко не всё. Например, мы можем написать одну букву t, и он найдет все буквы t в тексте.
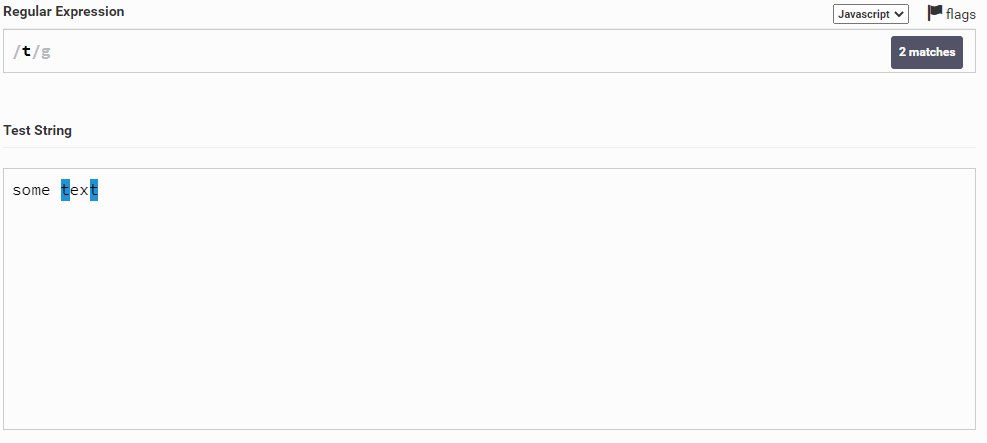
Таким образом вы можете просто указывать какие-то символы, но нам не всегда даются конкретные символы, а нужно написать какой-то шаблон. Сейчас этим и займемся.
Квантификаторы
Понимаю, звучит страшно, но на деле все просто. Сейчас разберемся.
С помощью квантификаторов мы можем указывать сколько раз должен повторяться тот или иной символ (ну или группа символов). Ниже приведу список квантификаторов с пояснением, а дальше попрактикуемся с ними.
-
{n} – символ повторяется ровно n раз
-
{m,n} – символ повторяется в диапазоне от m до n раз
-
{m,} – символ повторяется минимум m раз (от m и более)
Теперь посмотрим на примерах. Допустим у нас есть строка s ss sss ssss. И мы хотим выбрать слово, где буква s повторяется ровно 3 раза. Для этого мы можем написать так: s{3} – то есть пишем символ s, тем самым говоря, что хотим выбрать именно его, и рядом пишем {3}, говоря, что он должен повторяться ровно 3 раза. В результате будет найдено слово sss
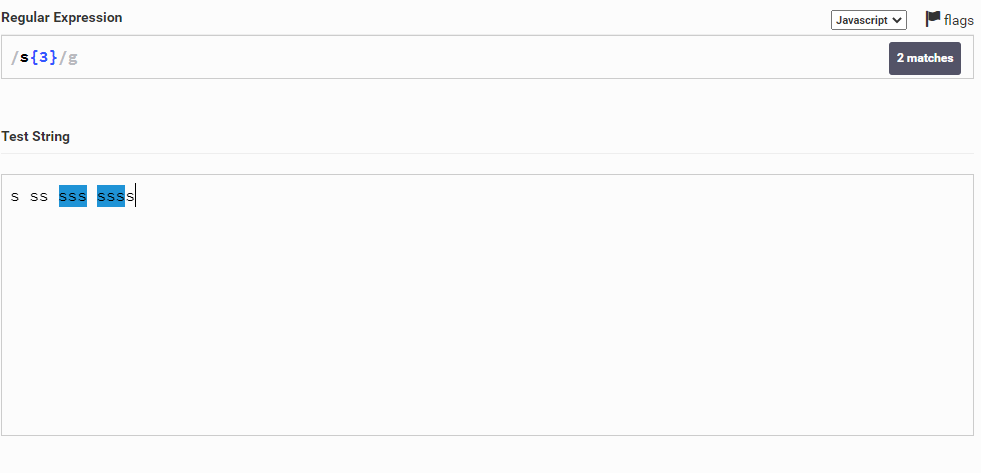
Почему же он взял еще ssss? Он взял не совсем его, а лишь его часть, так как в нем тоже есть 3 буквы s подряд. Дело в том, что регулярка не будет учитывать, отдельное это слово или нет. Пробелы тоже идут как символы! Поэтому будет выбран любой фрагмент, которому соответствует 3 идущие подряд буквы s
Едем дальше, допустим мы хотим выбрать фрагмент, где символ s будет от одного до трех раз. Для этого мы можем написать s{1,3} – опять же указываем s и пишем {1,3}, говоря, что нам нужно, чтобы этот символ повторялся от одного до трех раз.
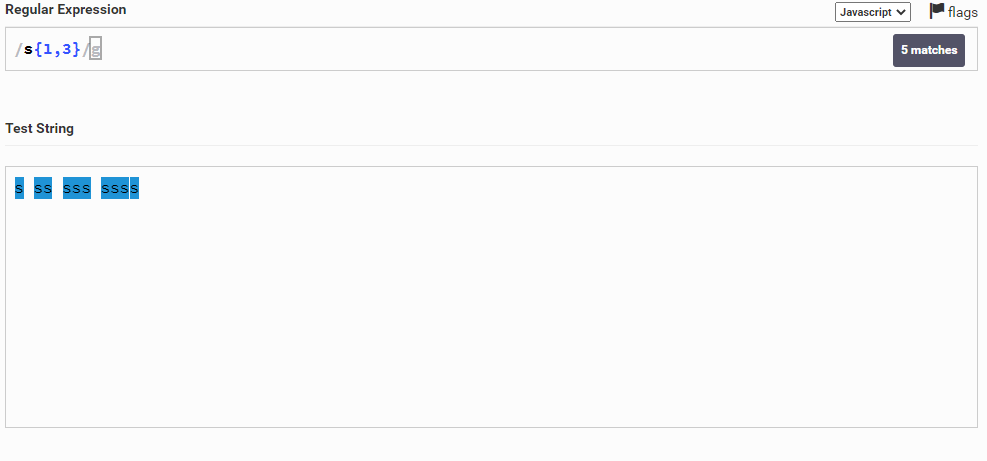
Интересный момент получается, он выбрал все. Почему же? Ответ: та же ситуация, что и в прошлый раз. Он увидел ssss, взял 3 идущие подряд s вместе и еще одну s, которая рядом, ведь она тоже соответствует регулярку (а ведь мы помним, что мы указали диапазон от одного до трех раз)
Ну и напоследок, давайте напишем шаблон, где символ s будет повторяться минимум три раза. Для этого напишем следующее: s{3,} ({3,} обозначает, что символ s будет повторяться от трех раз и до бесконечности).

Специальные символы квантификаторов
Есть уже готовые квантификаторы, которые обозначаются спец. символами. Вот они:
-
? ({0,1}) – символ повторяется 0 или 1 раз
-
* ({0,}) – символ повторяется от 0 раз и более
-
+ ({1,}) – символ повторяется от 1 и более раз
Давайте разбираться. Начнем со знака вопроса. Допустим у нас есть строка colour color и мы хотим найти либо colour, либо color. Мы можем написать так: colou?r.
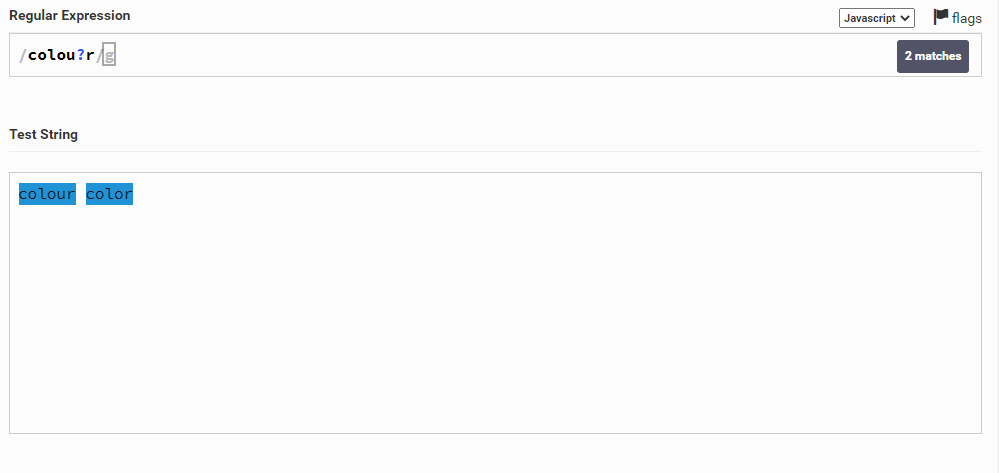
Что произошло? Мы указали, что идет последовательность символов colo, потом написали u? (тоже самое, что и u{0,1}). Это значит, что символ u повторяется 0 или 1 раз (то есть либо его нет вовсе (он не повторяется, то есть повторяется 0 раз), либо он есть, но только один (повторяется один раз)). Ну а потом указали, что после должен идти символ r. Поэтому colour соответствует, так как буква u повторяется 1 раз, а color – так как u вообще отсутствует (повторяется 0 раз). Видите, все просто 🙂
Давайте изменим строку и напишем что-то по типу colouuuuur color. И допустим мы хотим указать, что u должен либо не быть, либо быть сколько угодно раз. Для этого мы можем написать colou*r.
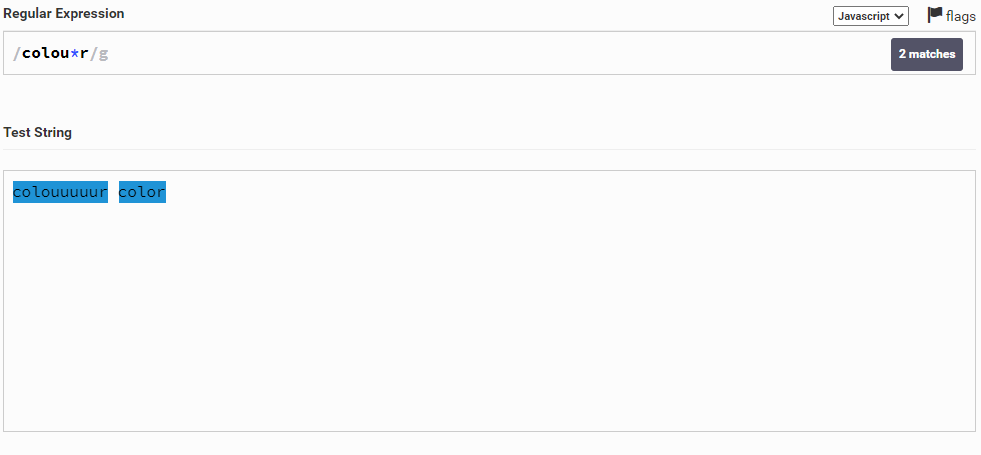
То есть либо u у нас нет, либо повторяется много раз.
Символ + работает почти также, за исключением того, что символ должен повторяться минимум 1 раз. То есть в данном случае слово color не будет соответствовать, так как там u не присутствует (то есть повторяется 0 раз, а у нас символ должен повторяться минимум 1 раз)

Специальные символы
Теперь поговорим о специальных символах, которые используются в регулярках. Тут все очень просто, так что можете сильно не переживать. Скрины прикреплять буду здесь не везде (тогда статья разрастется до безумных размеров). Так что заранее прошу меня понять и простить и попробовать сами.
-
. – одиночный символ
-
[] – набор символов, например [A-Z] обозначает все символы от A до Z
-
^ – начало строки
-
$ – конец строки
-
– экранирование
-
d – любая цифра
-
D – все, кроме цифр
-
s – пробелы
-
S – все, кроме пробелов
-
w – буква
-
W – все, кроме букв
-
[^someSymbol] – отрицание символа, соответсвие всем символам, кроме выбранного
Поговорим об одиночном символе. Это значит, что будет выбираться любой символ, который повторяется только один раз. Например, вернемся к нашей строке Some text и выберем букву t, после которой идет любой символ. Для этого напишем t.
Выберется te, так как после t идет один любой символ (в данном случае е)

Едем дальше. Допустим, у нас есть строка Some text12345 и мы хотим выбрать все буквы (только буквы, числа нам не нужны). Для этого мы можем написать следующее [A-Z,a-z] . Что же это значит? Это значит, что мы указали, что мы хотим выбрать все символы в диапазоне от A до Z (это мы выбираем все заглавные буквы) и, затем, через запятую, мы говорим о том, что хотим выбрать все символы от a до z (здесь мы выбираем все строчные символы).
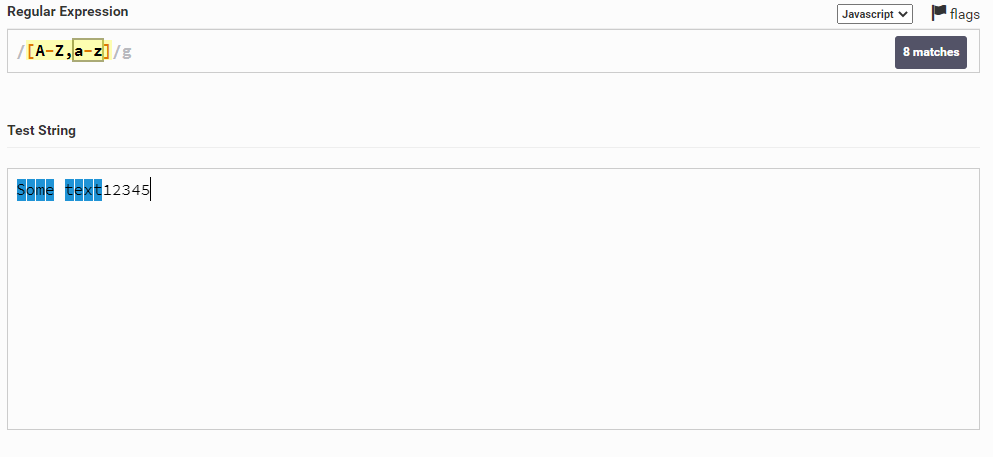
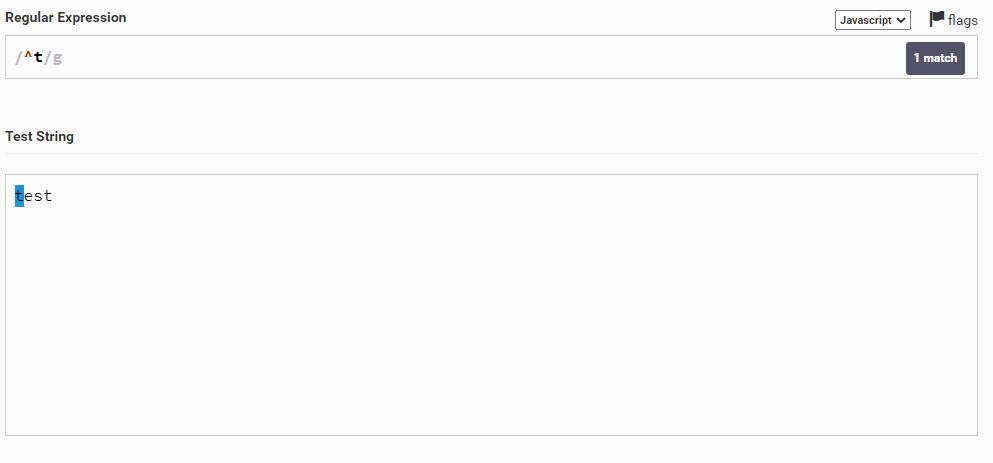
Теперь давайте возьмем слово test и выделим в нем первую букву t. Для этого мы можем написать ^t. То есть мы написали символ t и указали, что он должен находиться в самом начале строки. Важно поставить символ ^ перед нужным нам символом.
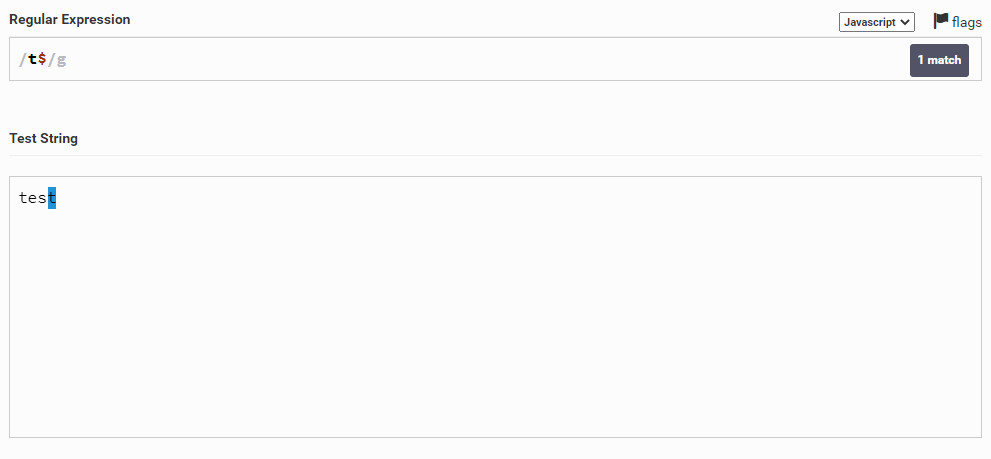
Теперь давайте сделаем наоборот и возьмем последнюю букву t. Для этого напишем t$. Важно, чтобы символ $ стоял после нужного нам символа.
Перейдем к экранированию. Звучит страшно, но на деле все проще простого. Например, в тексте some text. мы хотим выделить точку. Но ведь точка у нас уже зарезервирована как специальный символ (напоминаю, точка обозначает любой одиночный символ). И чтобы сделать так, чтобы точка на считалась как спец. символ мы можем написать . и тем самым говоря, что точка у нас будет как обычный символ.
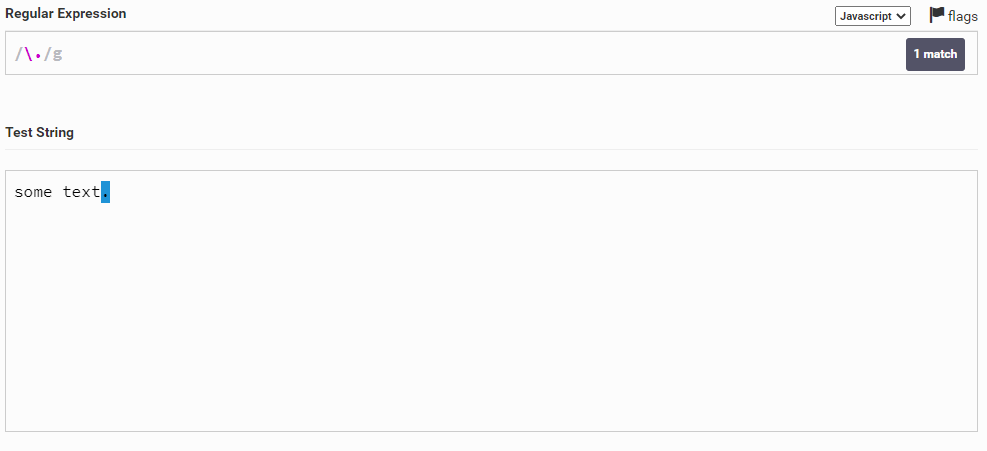
Теперь идут, простые вещи. d у нас обозначает любую цифру. Например в тексте some text123, если написать d у нас будут выделяться только цифры.
D делает все наоборот: берутся все символы, кроме цифр. То есть, если написать D будет браться все, кроме цифр (и пробелы, кстати, тоже).
s берет все пробелы, которые есть в строке, а S – наоборот, все, кроме пробелов.
w берет буквы, а W берет, все, кроме букв (в том числе и пробелы).
Теперь расскажу про еще одно применение символа ^. Его можно использовать как отрицание, тем самым исключая символ или группу символов. Например, в слове test мы хотим выбрать все, кроме буквы t и для этого мы можем написать так: [^t]
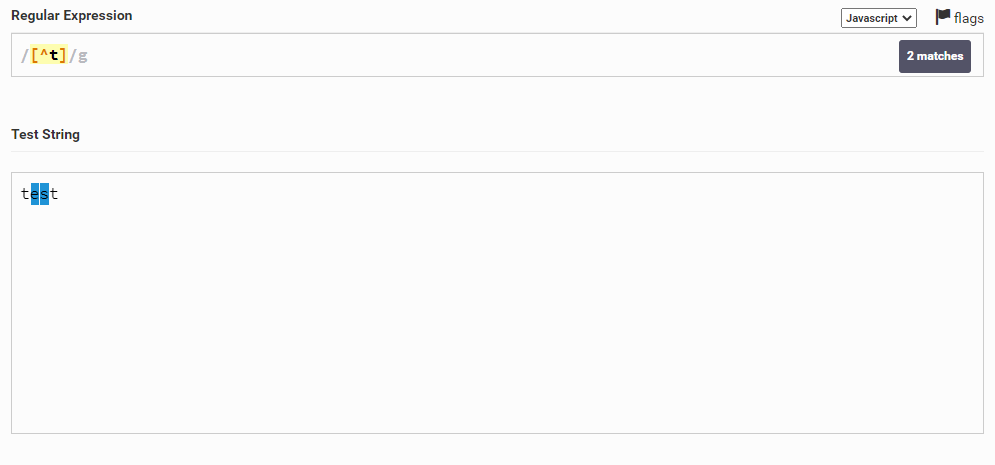
Именно в такой последовательности символ ^ будет обозначать отрицание.
Lookahead и lookbehind (опережающая и ретроспективная проверки)
Давайте разберемся, что это такое. Lookahead или же опережающая проверка позволяет выбрать символ или группу символов, если после него идет идет какой-либо символ или группа символов. Lookbehind или же ретроспективная проверка позволяет выбрать символ или группу символов, если до них идет какой-то символ или группа символов.
-
lookahead – опережающая проверка – X(?=Y) – найти Х, при условии, что после него идет Y
-
негативная опрережающая проверка – Х(?!Y)
-
lookbehind – ретроспективная проверка – (?<=Y)X – найти Х, при условии, что до него идет Y
-
негативная ретроспективная проверка – (?<!Y)Xo
Например, дана строка s sw sd st se и мы хотим выбрать букву s, после которой будет идти символ d. Для этого мы можем написать следующее: s(?=d). Таким образом мы как бы проверяем, будет ли идти после символ s символ d.
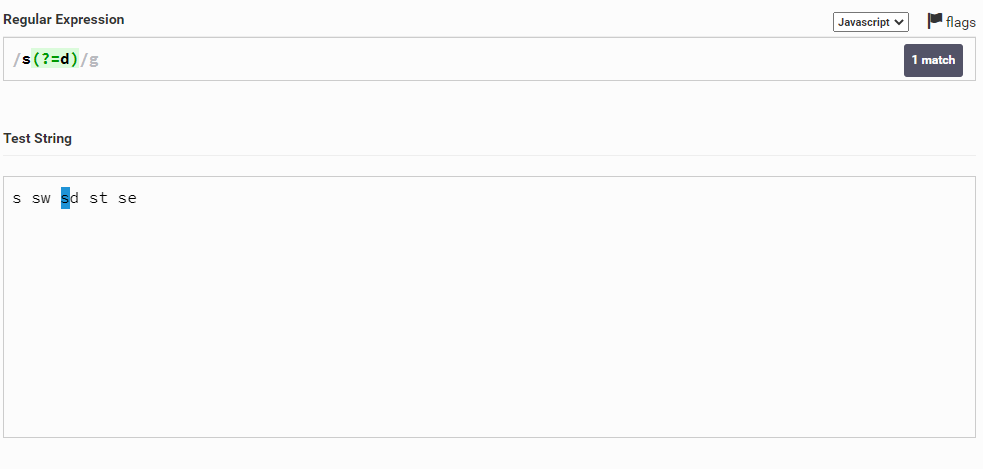
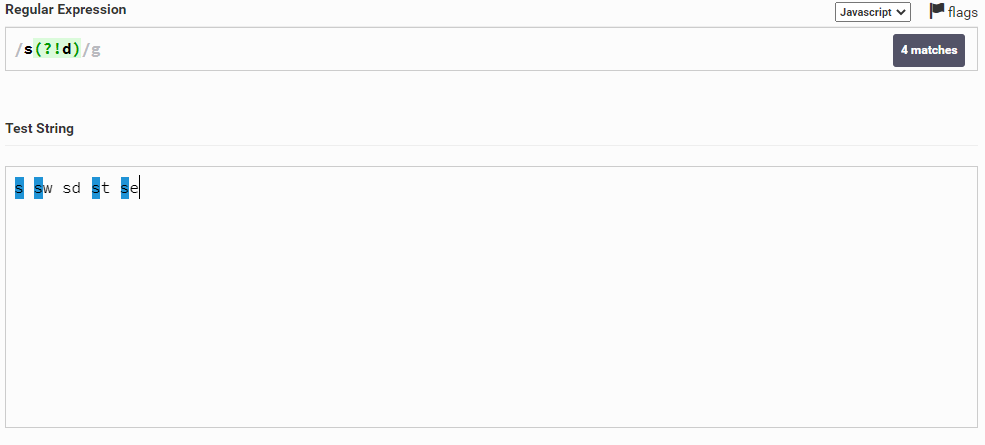
Также мы можем сделать наоборот и выбрать символ s, если после него НЕ идет символ d. Для этого вместо знака равно мы должны поставить восклицательный знак (!), т.е. написать вот так: s(?!d)
Теперь поговорим о lookbehind. Допустим, у нас есть строка s ws ds ts es и мы хотим выбрать символ s, до которого будет символ d. Для этого мы можем написать так: (?<=d)s
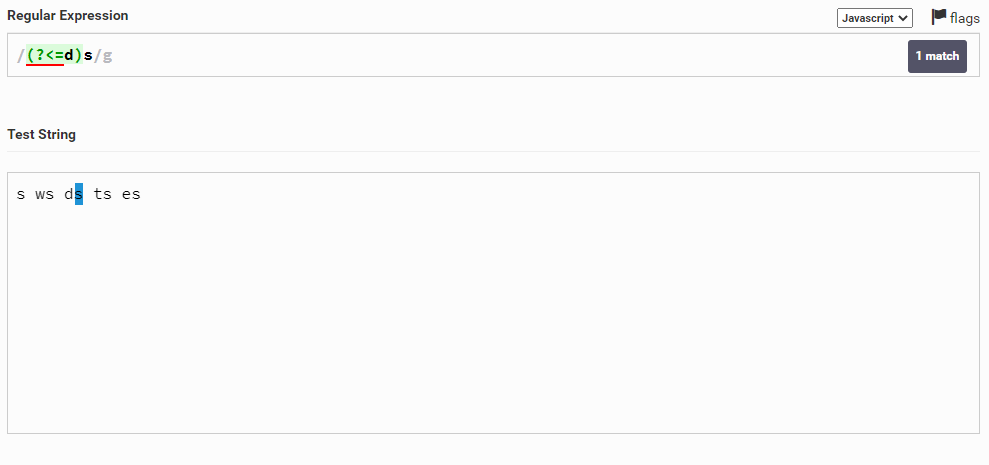
Почему же lookbehind подчеркивается красной линией? Дело в том, что lookbehind не всегда поддерживается и не везде такая регулярка будет работать. Нужно искать способ заменить этот lookbehind, но это зависит от поставленной задачи, поэтому нельзя сказать, как именно ее заменять. Будем надеяться, что в скором временем будет полная поддержка этой возможности.
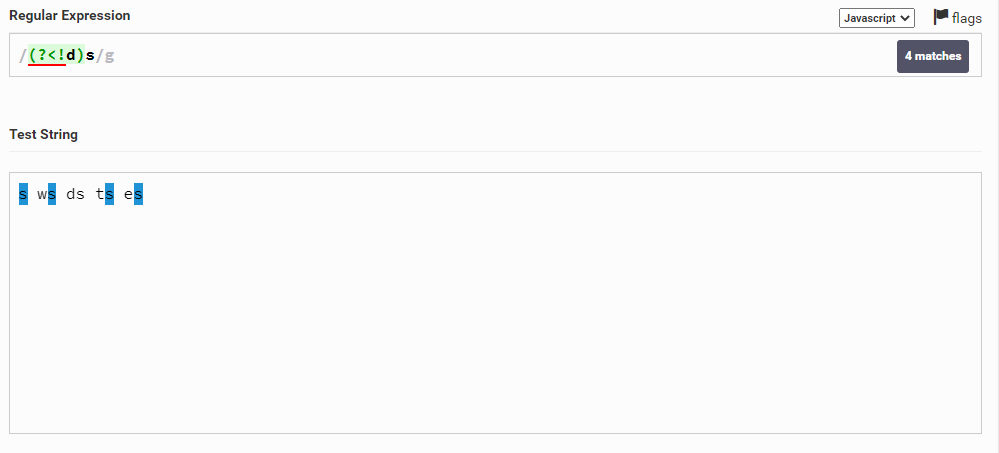
Чтобы сделать наоборот, то есть выбрать все символы s, до которых НЕ будет идти символ d, нужно опять же поменять знак равно на восклицательный знак: (?<!d)s
Регулярные выражения в разных языках программирования
Здесь я приведу примеры использования регулярных выражений в различных языках программирования. Заранее говорю, я не буду заострять внимание на синтаксисе языка программирования, так как это уже не касается данной темы
C#
string str = "some text";
Regex regex = new Regex(@"t$");
MatchCollection matches = regex.Matches(str);Здесь мы создаем строку с текстом, который хотим проверить, создаем объект класса Regex и в конструктор пишем нашу регулярку (как я и говорил, я не буду заострять внимание на том, что такое объект класса и конструктор). Потом создаем объект класса MatchCollection и от объекта regex вызываем метод Matches и в параметры передаем нашу строку. В результате все сопоставления будут добавляться в коллекцию matches.
Java
Pattern pattern = Pattern.compile("some text", Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher("t$");Здесь похожая ситуация. Создаем объект класса Pattern и записываем нашу строку. CASE_INSENSITIVE означает, что он не привязан к регистру (то есть нет разницы между заглавными и строчными символами). Создаем объект класса Matcher и пишем туда регулярку.
JavaScript
var regex = /d(b+)d/g;
var matches = regex.exec("cdbbdbsbz");Здесь тоже все просто. Вы создаете объект regex и пишете туда регулярку. И затем просто создаете объект matches, который будет являться коллекцией и вызываете метод exec и в параметры передаете строку.
Заключение
Итак, мы разобрали, что такое регулярные выражения, где они используются, как их писать и использовать в контексте языков программирования. Скажу сразу, написание регулярок приходит с опытом. Практикуйтесь, и я уверен: все у вас получится! А на этом я с вами прощаюсь. Спасибо за внимание и приятного всем дня)
P.S. Прошу строго не судить, это самая первая статья, которую я написал. Любая критика приветствуется.
Что такое регулярные выражения?
Давайте разберёмся, что же собой представляют регулярные выражения. Если вам когда-нибудь приходилось работать с командной строкой, вы, вероятно, использовали маски имён файлов. Например, чтобы удалить все файлы в текущей директории, которые начинаются с буквы «d», можно написать rm d*.
Регулярные выражения представляют собой похожий, но гораздо более сильный инструмент для поиска строк, проверки их на соответствие какому-либо шаблону и другой подобной работы. Англоязычное название этого инструмента — Regular Expressions или просто RegExp. Строго говоря, регулярные выражения — специальный язык для описания шаблонов строк.
Реализация этого инструмента различается в разных языках программирования, хоть и не сильно. В данной статье мы будем ориентироваться в первую очередь на реализацию Perl Compatible Regular Expressions.
Основы синтаксиса
В первую очередь стоит заметить, что любая строка сама по себе является регулярным выражением. Так, выражению Хаха, очевидно, будет соответствовать строка «Хаха» и только она. Регулярки являются регистрозависимыми, поэтому строка «хаха» (с маленькой буквы) уже не будет соответствовать выражению выше.
Однако уже здесь следует быть аккуратным — как и любой язык, регекспы имеют спецсимволы, которые нужно экранировать. Вот их список: . ^ $ * + ? { } [ ] | ( ). Экранирование осуществляется обычным способом — добавлением перед спецсимволом.
Набор символов
Предположим, мы хотим найти в тексте все междометия, обозначающие смех. Просто Хаха нам не подойдёт — ведь под него не попадут «Хехе», «Хохо» и «Хихи». Да и проблему с регистром первой буквы нужно как-то решить.
Здесь нам на помощь придут наборы — вместо указания конкретного символа, мы можем записать целый список, и если в исследуемой строке на указанном месте будет стоять любой из перечисленных символов, строка будет считаться подходящей. Наборы записываются в квадратных скобках — паттерну [abcd] будет соответствовать любой из символов «a», «b», «c» или «d».
Внутри набора большая часть спецсимволов не нуждается в экранировании, однако использование перед ними не будет считаться ошибкой. По прежнему необходимо экранировать символы «» и «^», и, желательно, «]» (так, [][] обозначает любой из символов «]» или «[», тогда как [[]х] — исключительно последовательность «[х]»). Необычное на первый взгляд поведение регулярок с символом «]» на самом деле определяется известными правилами, но гораздо легче просто экранировать этот символ, чем их запоминать. Кроме этого, экранировать нужно символ «-», он используется для задания диапазонов (см. ниже).
Если сразу после [ записать символ ^, то набор приобретёт обратный смысл — подходящим будет считаться любой символ кроме указанных. Так, паттерну [^xyz] соответствует любой символ, кроме, собственно, «x», «y» или «z».
Итак, применяя данный инструмент к нашему случаю, если мы напишем [Хх][аоие]х[аоие], то каждая из строк «Хаха», «хехе», «хихи» и даже «Хохо» будут соответствовать шаблону.
Предопределённые классы символов
Для некоторых наборов, которые используются достаточно часто, существуют специальные шаблоны. Так, для описания любого пробельного символа (пробел, табуляция, перенос строки) используется s, для цифр — d, для символов латиницы, цифр и подчёркивания «_» — w.
Если необходимо описать вообще любой символ, для этого используется точка — .. Если указанные классы написать с заглавной буквы (S, D, W) то они поменяют свой смысл на противоположный — любой непробельный символ, любой символ, который не является цифрой, и любой символ кроме латиницы, цифр или подчёркивания соответственно.
Также с помощью регулярных выражений есть возможность проверить положение строки относительно остального текста. Выражение b обозначает границу слова, B — не границу слова, ^ — начало текста, а $ — конец. Так, по паттерну bJavab в строке «Java and JavaScript» найдутся первые 4 символа, а по паттерну bJavaB — символы c 10-го по 13-й (в составе слова «JavaScript»).

Комикс про регулярные выражения с xkcd.ru
Диапазоны
У вас может возникнуть необходимость обозначить набор, в который входят буквы, например, от «б» до «ф». Вместо того, чтобы писать [бвгдежзиклмнопрстуф] можно воспользоваться механизмом диапазонов и написать [б-ф]. Так, паттерну x[0-8A-F][0-8A-F] соответствует строка «xA6», но не соответствует «xb9» (во-первых, из-за того, что в диапазоне указаны только заглавные буквы, во-вторых, из-за того, что 9 не входит в промежуток 0-8).
Механизм диапазонов особенно актуален для русского языка, ведь для него нет конструкции, аналогичной w. Чтобы обозначить все буквы русского алфавита, можно использовать паттерн [а-яА-ЯёЁ]. Обратите внимание, что буква «ё» не включается в общий диапазон букв, и её нужно указывать отдельно.
Квантификаторы
Вернёмся к нашему примеру. Что, если в «смеющемся» междометии будет больше одной гласной между буквами «х», например «Хаахаааа»? Наша старая регулярка уже не сможет нам помочь. Здесь нам придётся воспользоваться квантификаторами.
Примеры использования квантификаторов в регулярных выражениях
Обратите внимание, что квантификатор применяется только к символу, который стоит перед ним.
Некоторые часто используемые конструкции получили в языке RegEx специальные обозначения:

Спецобозначения квантификаторов в регулярных выражениях.
Таким образом, с помощью квантификаторов мы можем улучшить наш шаблон для междометий до [Хх][аоеи]+х[аоеи]*, и он сможет распознавать строки «Хааха», «хееееех» и «Хихии».
Ленивая квантификация
Предположим, перед нами стоит задача — найти все HTML-теги в строке
<p><b>Tproger</b> — мой <i>любимый</i> сайт о программировании!</p>Очевидное решение <.*> здесь не сработает — оно найдёт всю строку целиком, т.к. она начинается с тега абзаца и им же заканчивается. То есть содержимым тега будет считаться строка
p><b>Tproger</b> — мой <i>любимый</i> сайт о программировании!</pЭто происходит из-за того, что по умолчанию квантификатор работают по т.н. жадному алгоритму — старается вернуть как можно более длинную строку, соответствующую условию. Решить проблему можно двумя способами. Первый — использовать выражение <[^>]*>, которое запретит считать содержимым тега правую угловую скобку. Второй — объявить квантификатор не жадным, а ленивым. Делается это с помощью добавления справа к квантификатору символа ?. Т.е. для поиска всех тегов выражение обратится в <.*?>.
Ревнивая квантификация
Иногда для увеличения скорости поиска (особенно в тех случаях, когда строка не соответствует регулярному выражению) можно использовать запрет алгоритму возвращаться к предыдущим шагам поиска для того, чтобы найти возможные соответствия для оставшейся части RegExp. Это называется ревнивой квантификацией. Квантификатор делается ревнивым с помощью добавления к нему справа символа +. Ещё одно применение ревнивой квантификации — исключение нежелательных совпадений. Так, паттерну ab*+a в строке «ababa» будут соответствовать только первые три символа, но не символы с третьего по пятый, т.к. символ «a», который стоит на третьей позиции, уже был использован для первого результата.
Чуть больше о жадном, сверхжадном и ленивом режимах квантификации вы сможете узнать из статьи о регулярных выражениях в Java.
Скобочные группы
Для нашего шаблона «смеющегося» междометия осталась самая малость — учесть, что буква «х» может встречаться более одного раза, например, «Хахахахааахахооо», а может и вовсе заканчиваться на букве «х». Вероятно, здесь нужно применить квантификатор для группы [аиое]+х, но если мы просто напишем [аиое]х+, то квантификатор + будет относиться только к символу «х», а не ко всему выражению. Чтобы это исправить, выражение нужно взять в круглые скобки: ([аиое]х)+.
Таким образом, наше выражение превращается в [Хх]([аиое]х?)+ — сначала идёт заглавная или строчная «х», а потом произвольное ненулевое количество гласных, которые (возможно, но не обязательно) перемежаются одиночными строчными «х». Однако это выражение решает проблему лишь частично — под это выражение попадут и такие строки, как, например, «хихахех» — кто-то может быть так и смеётся, но допущение весьма сомнительное. Очевидно, мы можем использовать набор из всех гласных лишь единожды, а потом должны как-то опираться на результат первого поиска. Но как?…
Запоминание результата поиска по группе
Оказывается, результат поиска по скобочной группе записывается в отдельную ячейку памяти, доступ к которой доступен для использования в последующих частях регэкспа. Возвращаясь к задаче с поиском HTML-тегов на странице, нам может понадобиться не только найти теги, но и узнать их название. В этом нам может помочь регулярное выражение <(.*?)>.
<p><b>Tproger</b> — мой <i>любимый</i> сайт о программировании!</p>Результат поиска по всему регексу: «<p>», «<b>», «</b>», «<i>», «</i>», «</p>».
Результат поиска по первой группе: «p», «b», «/b», «i», «/i», «/i», «/p».
На результат поиска по группе можно ссылаться с помощью выражения n, где n — цифра от 1 до 9. Например выражению (w)(w)12 соответствуют строки «aaaa», «abab», но не соответствует «aabb».
Если выражение берётся в скобки только для применения к ней квантификатора (не планируется запоминать результат поиска по этой группе), то сразу после первой скобки стоит добавить ?:, например (?:[abcd]+w).
С использованием этого механизма мы можем переписать наше выражение к виду [Хх]([аоие])х?(?:1х?)*.

Перечисление
Чтобы проверить, удовлетворяет ли строка хотя бы одному из шаблонов, можно воспользоваться аналогом булевого оператора OR, который записывается с помощью символа |. Так, под шаблон Анна|Одиночество попадают строки «Анна» и «Одиночество» соответственно. Особенно удобно использовать перечисления внутри скобочных групп. Так, например (?:a|b|c|d) полностью эквивалентно [abcd] (в данном случае второй вариант предпочтительнее в силу производительности и читаемости).
С помощью этого оператора мы сможем добавить к нашему регулярному выражению для поиска междометий возможность распознавать смех вида «Ахахаах» — единственной усмешке, которая начинается с гласной: [Хх]([аоие])х?(?:1х?)*|[Аа]х?(?:ах?)+
Полезные сервисы
Потренироваться и/или проверить регулярное выражение на каком-либо тексте без написания кода можно с помощью таких сервисов, как RegExr, Regexpal или Regex101. Последний, вдобавок, приводит краткие пояснения к тому, как регулярка работает.
Разобраться, как работает регулярное выражение, которое попало к вам в руки, можно с помощью сервиса Regexper — он умеет строить понятные диаграмы по регуляркам.
RegExp Builder — визуальный конструктор функций JavaScript для работы с регулярными выражениями.
Больше инструментов можно найти в нашей подборке.
Задания для закрепления
Найдите время
Время имеет формат часы:минуты. И часы, и минуты состоят из двух цифр, пример: 09:00. Напишите RegEx выражение для поиска времени в строке: «Завтрак в 09:00». Учтите, что «37:98» — некорректное время.
Java[^script]
Найдет ли регулярка Java[^script] что-нибудь в строке Java? А в строке JavaScript?
Ответы: нет, да.
- В строке Java он ничего не найдёт, так как исключающие квадратные скобки в Java[^…] означают «один символ, кроме указанных». А после «Java» – конец строки, символов больше нет.
- Да, найдёт. Поскольку регэксп регистрозависим, то под [^script] вполне подходит символ «S».
Цвет
Напишите регулярное выражение для поиска HTML-цвета, заданного как #ABCDEF, то есть # и содержит затем 6 шестнадцатеричных символов.
Итак, нужно написать выражение для описания цвета, который начинается с «#», за которым следуют 6 шестнадцатеричных символов. Шестнадцатеричный символ можно описать с помощью [0-9a-fA-F]. Для его шестикратного повторения мы будем использовать квантификатор {6}.
#[0-9a-fA-F]{6}Разобрать арифметическое выражение
Арифметическое выражение состоит из двух чисел и операции между ними, например:
- 1 + 2
- 1.2 *3.4
- -3/ -6
- -2-2
Список операций: «+», «-», «*» и «/».
Также могут присутствовать пробелы вокруг оператора и чисел.
Напишите регулярку, которая найдёт, как всё арифметическое действие, так и (через группы) два операнда.
Регулярное выражение для числа, возможно, дробного и отрицательного: -?d+(.d+)?.
Оператор – это [+*/-]. Заметим, что дефис мы экранируем. Нам нужно число, затем оператор, затем число, и необязательные пробелы между ними. Чтобы получить результат в требуемом формате, добавим ?: к группам, поиск по которым нам не интересен (отдельно дробные части), а операнды наоборот заключим в скобки. В итоге:
(-?d+(?:.d+)?)s*([-+*/])s*(-?d+(?:.d+)?)Кроссворды из регулярных выражений
Такие кроссворды вы можете найти у нас.
Удачи и помните — не всегда задачу стоит решать именно с помощью регекспов («У программиста была проблема, которую он начал решать регэкспами. Теперь у него две проблемы»). Иногда лучше, например, написать развёрнутый автомат конечных состояний.
Задачи и их разборы с javascript.ru; в статье использованы комиксы xkcd.

Translations:
- English
- Español
- Français
- Português do Brasil
- 中文版
- 日本語
- 한국어
- Turkish
- Greek
- Magyar
- Polish
- Русский
- Tiếng Việt
- فارسی
- עברית
Что такое Регулярное выражение?
Регулярное выражение – это группа букв или символов, которая используется для поиска определенного шаблона в тексте.
Регулярное выражение – это шаблон, сопоставляемый с искомой строкой слева направо.
Термин «Регулярное выражение» сложно произносить каждый раз, поэтому, обычно, вы будете сталкиваться с сокращениями “регэкспы” или “регулярки”.
Регулярные выражения используются для замен текста внутри строк, валидации форм,
извлечений подстрок по определенным шаблонам и множества других вещей.
Представьте, что вы пишете приложение и хотите установить правила, по которым пользователь выбирает свой юзернейм. Мы хотим, чтобы имя пользователя содержало буквы, цифры, подчеркивания и дефисы. Мы также хотим ограничить количество символов в имени пользователя, чтобы оно не выглядело безобразно.
Для этого, используем следующее регулярное выражение:

Регулярное выражения выше может принимать строки john_doe,jo-hn_doe и john12_as.
Оно не валидирует Jo, поскольку эта строка содержит заглавные буквы, а также она слишком короткая.
Содержание
- Совпадения
- Метасимволы
- Точка
- Набор символов
- Отрицание набора символов
- Повторения
- Звёздочка
- Плюс
- Знак вопроса
- Фигурные скобки
- Скобочные группы
- Альтернация
- Экранирование
- Якоря
- Каретка
- Доллар
- Наборы сокращений и диапазоны
- Опережающие и ретроспективные проверки
- Положительное опережающее условие
- Отрицательное опережающее условие
- Положительное ретроспективное условие
- Отрицательное ретроспективное условие
- Флаги
- Поиск без учета регистра
- Глобальный поиск
- Мультистроковый поиск
- Жадные vs ленивые квантификаторы
1. Совпадения.
В сущности, регулярное выражение – это просто набор символов, который мы используем для поиска в тексте.
Например, регулярное выражение the состоит из буквы t, за которой следует буква h, за которой следует буква e.
"the" => The fat cat sat on the mat.
Запустить регулярное выражение
Регулярное выражение 123 соответствует строке 123. Регулярное выражение сопоставляется с входной строкой, сравнивая
каждый символ в регулярном выражении с каждым символом во входной строке по одному символу за другим. Регулярные выражения
обычно чувствительны к регистру, поэтому регулярное выражение The не будет соответствовать строке the.
"The" => The fat cat sat on the mat.
Запустить регулярное выражение
2. Метасимволы
Метасимволы это блоки, из которых строятся регулярные выражения. Метасимволы не означают что-то сами по себе,
вместо этого они интерпретируются для распознавания специальных групп символов. Некоторые метасимволы имеют
особые обозначения и пишутся в квадратных скобках. Существуют следующие метасимволы:
| Метасимволы | Описание |
|---|---|
| . | Точка соответствует любому отдельному символу, кроме разрыва строки. |
| [ ] | Класс символов. Находить любые символы заключенные в квадратных скобках. |
| [^ ] | Отрицание класа символов. Находить любые символы не заключенные в квадратных скобках. |
| * | Находить 0 или более повторений предыдущего символа. |
| + | Находить 1 или более повторений предыдущего символа. |
| ? | Сделать предыдущий символ необязательным. |
| {n,m} | Скобки. Находить по крайней мере “n” но не более чем “m” повторений предыдущего символа. |
| (xyz) | Группа символов. Находить только символы xyz в указанном порядке. |
| | | Чередование. Находить либо буквы до, либо буквы после символа. |
Экранирование. Позволяет находить зарезервированные символы: [ ] ( ) { } . * + ? ^ $ | |
|
| ^ | Обозначает начало пользовательского ввода. |
| $ | Обозначает конец пользовательского ввода. |
2.1 Точка
Точка . это простейший пример метасимвола. Метасимвол .
находит любой отдельный символ. Точка не будет находить символы перехода или перевода строки.
Например, регулярное выражение .ar обозначает: любой символ, за которым следуют буквы a и r.
".ar" => The car parked in the garage.
Запустить регулярное выражение
2.2 Набор символов.
Набор символов также называется классом символов. Квадратные скобки используются
для определения набора символов. Дефис используется для указания диапазона символов.
Порядок следования символов, заданный в квадратных скобках, не важен. Например,
регулярное выражение [Tt]he обозначает заглавную T или строчную t, за которой следуют буквы h и e.
"[Tt]he" => The car parked in the garage.
Запустить регулярное выражение
Точка внутри набора символов, однако, обозначает непосредственно точку, как символ.
Регулярное выражение ar[.] обозначает строчную a, за которой следует r, за которой следует . (символ точки).
"ar[.]" => A garage is a good place to park a car.
Запустить регулярное выражение
2.2.1 Отрицание набора символов
Знак вставки ^ обозначает начало строки, однако, когда вы вписываете его после открытия квадратных скобок, он отрицает набор символов.
Например, регулярное выражение [^c]ar обозначает любой символ, кроме c, за которым следуют буквы a и r.
"[^c]ar" => The car parked in the garage.
Запустить регулярное выражение
2.3 Повторения
Символы +, * или ? используются для обозначения того сколько раз появляется какой-либо подшаблон.
Данные метасимволы могут вести себя по-разному, в зависимости от ситуации.
2.3.1 Звёздочка
Символ * обозначает ноль или более повторений предыдущего совпадения.
Регулярное выражение a* означает ноль или более повторений предыдущего
строчного символа a. Если же символ появляется после набора или класса символов,
он находит повторения всего набора символов. Например, регулярное выражение [a-z]*
означает любое количество строчных букв в строке.
"[a-z]*" => The car parked in the garage #21.
Запустить регулярное выражение
Символы можно комбинировать, так, например, символ * может использоваться с метасимволом .
для поиска одной строки с произвольным содержанием .*. Символ * может использоваться
с символом пробела s, чтобы находить строки с символами пробела. Например, выражение
s*cats* означает: ноль или более пробелов, за которыми следует слово cat,
за которым следует ноль или более символов пробела.
"s*cats*" => The fat cat sat on the concatenation.
Запустить регулярное выражение
2.3.2 Плюс
Символ + соответствует одному или более повторению предыдущего символа. Например,
регулярное выражение c.+t означает строчную c, за которой следует по крайней мере один символ,
следом за которым идёт символ t. Стоит уточнить, что в данном шаблоне, t является последним t в предложении.
"c.+t" => The fat cat sat on the mat.
Запустить регулярное выражение
2.3.3 Знак вопроса
В регулярном выражении метасимвол ? делает предыдущий символ необязательным.
Этот символ соответствует нулю или одному экземпляру предыдущего символа.
Например, регулярное выражение [T]?he означает необязательную заглавную букву T, за которой следуют символы h и e.
"[T]he" => The car is parked in the garage.
Запустить регулярное выражение
"[T]?he" => The car is parked in the garage.
Запустить регулярное выражение
2.4 Фигурные скобки
В фигурных скобках, которые также называются квантификаторами, указывается,
сколько раз символ или группа символов могут повторяться. Например, регулярное выражение
[0-9]{2,3} означает совпадение не менее 2 но не более 3 цифр в диапазоне от 0 до 9.
"[0-9]{2,3}" => The number was 9.9997 but we rounded it off to 10.0.
Запустить регулярное выражение
Уберём второй номер (цифру 3), тогда, регулярное выражение [0-9]{2,} будет означать
совпадение 2 или более цифр. Если мы также удалим запятую, то регулярное выражение
[0-9]{3} будет означать совпадение точно с 3 цифрами.
"[0-9]{2,}" => The number was 9.9997 but we rounded it off to 10.0.
Запустить регулярное выражение
"[0-9]{3}" => The number was 9.9997 but we rounded it off to 10.0.
Запустить регулярное выражение
2.5 Скобочные группы
Скобочные группы это группы подшаблонов, которые написаны в круглых скобках
(...). Как мы уже говорили ранее в регулярном выражении, если мы поставим квантификатор
после символа, он будет повторять предыдущий символ. Но если мы поставим квантификатор после
скобочной группы, он будет искать всю группу. Например, регулярное выражение (ab)* соответствует
нулю или более повторений символа “ab”. Мы также можем использовать метасимвол чередования |
внутри скобочной группы. Например, регулярное выражение (c|g|p)ar означает поиск одной из строчных букв c,
g или p, за которыми следуют буквы a и r.
"(c|g|p)ar" => The car is parked in the garage.
Запустить регулярное выражение
Обратите внимание, что скобочные группы не только находят, но и захватывают символы для использования на родительском языке.
Родительским языком может быть python, javascript или практически любой язык, который реализует использование регулярных выражений как параметров функций.
2.5.1 Не запоминающие скобочные группы
Бывает так, что группу определить нужно, а вот запоминать их содержимое в массиве не требуется.
Подобный трюк осуществляется при помощи зарезервированной комбинации ?:
в круглых скобках (...). Например, регулярное выражение (?:c|g|p)ar будет находить такие же шаблоны как и
(c|g|p)ar, однако скобочная группа при этом создана не будет.
"(?:c|g|p)ar" => The car is parked in the garage.
Запустить регулярное выражение
Незапоминающиеся группы могут пригодиться, когда они используются в функциях поиска и замены,
или в сочетании со скобочными группами, например, для предпросмотра при создании скобочной группы или другого вида выходных данных,
смотрите также 4. Опережающие и ретроспективные проверки.
2.6 Альтернация
В регулярных выражениях, вертикальная черта | используется для определения альтернации (чередования).
Альтернация по своей сути похожа на оператор ИЛИ между логическими выражениями. Может создаться впечатление, что
чередование это то же самое, что и определение набора символов. Однако, большая разница между ними в том, что
набор символов работает на уровне конкретных символов, в то время как альтернация работает на уровне выражений.
Например, регулярное выражение (T|t)he|car объединяет два шаблона (заглавная T ИЛИ строчная t, с продолжением из h и e) и шаблон
(строчная c, затем строчная a, за которой следует строчная r). Таким образом, в поиске будет участвовать любой из данных шаблонов,
по аналогии с логической операцией ИЛИ в программировании и алгебре выражений.
"(T|t)he|car" => The car is parked in the garage.
Запустить регулярное выражение
2.7 Экранирование спецсимволов
Обратный слэш используется в регулярных выражениях для экранирования следующего символа.
Это позволяет формировать шаблоны с поиском зарезервированных символов, таких как { } [ ] / + * . $ ^ | ?.
Для использования спецсимвола в шаблоне необходимо указать символ перед ним.
Как упомянуто выше, символ . является зарезервированным и соответствует любому значению, кроме символа новой строки.
Бывают ситуации, когда необходимо найти точку в предложении, для таких случаев применимо экранирование. Рассмотрим выражение
(f|c|m)at.?, что соответствует следующему шаблону: строчный символ f, c или m, за которым следует строчные буквы a и t, с опциональной . точкой в конце.
"(f|c|m)at.?" => The fat cat sat on the mat.
Запустить регулярное выражение
2.8 Якоря
Понятие якорей в регулярных выражениях используется для обозначения проверок, является ли
соответствующий символ начальным или конечным символом входной строки. Якоря бывают двух типов:
Первый тип – Каретка ^, проверяет, является ли соответствующий символ начальным символом в тексте.
Второй тип – Доллар $, проверяет, является ли соответствующий символ последним символом входной строки.
2.8.1 Каретка
Символ каретки ^ используется для проверки, является ли соответствующий символ первым символом входной строки.
Если мы применяем следующее регулярное выражение ^a (если a является начальным символом) для строки abc,
совпадение будет соответствовать букве a. Если же мы используем регулярное выражение ^b на той же строке,
мы не получим совпадения, поскольку во входящей строке abc “b” не является первым символом. Рассмотрим другое
регулярное выражение: ^(T|t)he, обозначающее заглавную T или строчную t как первый символ, за которым следуют
символы букв h и e. Cоответственно:
"(T|t)he" => The car is parked in the garage.
Запустить регулярное выражение
"^(T|t)he" => The car is parked in the garage.
Запустить регулярное выражение
2.8.2 Доллар
Символ доллара $ используется для проверки, является ли соответствующий символ
последним символом входной строки. Например, регулярное выражение (at.)$ последовательность из
строчной a, строчной t, и точки ., ключевой момент в том, что благодаря доллару этот шаблон будет
находить совпадения только в том случае, если будет наблюдаться в конце строки. Например:
"(at.)" => The fat cat. sat. on the mat.
Запустить регулярное выражение
"(at.)$" => The fat cat. sat. on the mat.
Запустить регулярное выражение
3. Наборы сокращений и диапазоны
Регулярные выражения предоставляют сокращения для часто используемых наборов символов,
которые предлагают удобные сокращения для часто используемых регулярных выражений.
Наборы сокращенных символов следующие:
| Сокращение | Описание |
|---|---|
| . | Любой символ кроме символа новой строки |
| w | Поиск буквенно-цифрового диапазона символов: [a-zA-Z0-9_] |
| W | Поиск не буквенно-цифрового диапазона символов: [^w] |
| d | Поиск цифр: [0-9] |
| D | Поиск всего, что не является цифрой: [^d] |
| s | Поиск пробелов и символов начала строки: [tnfrp{Z}] |
| S | Поиск всего кроме пробелов и символов начала строки: [^s] |
4. Опережающие и ретроспективные проверки
Опережающие и ретроспективные проверки (в английской литературе lookbehind, lookahead) это особый вид
не запоминающих скобочных групп (находящих совпадения, но не добавляющих в массив).
Данные проверки используются когда мы знаем, что шаблон предшествует или сопровождается другим шаблоном.
Например, мы хотим получить цену в долларах $ из следующей входной строки
$4.44 and $10.88. Для этого используем следующее регулярное выражение (?<=$)[0-9.]*, означающее
получение всех дробных (с точкой .) цифр, которым предшествует знак доллара $. Существуют
следующие виды проверок:
| Символ | Описание |
|---|---|
| ?= | Положительное опережающее условие |
| ?! | Отрицательное опережающее условие |
| ?<= | Положительное ретроспективное условие |
| ?<! | Отрицательное ретроспективное условие |
4.1 Положительное опережающее условие
Положительное опережающее утверждение (assert) означает, что за первой частью выражения должно следовать
опережающее выражение (lookahead expression). (по аналогии с условиями, if (..) then (..)).
Возвращенное совпадение содержит только текст, который соответствует первой части выражения.
Для определения положительного опережающего условия используются круглые скобки. В этих скобках используется
знак вопроса со знаком равенства: (?=...). Опережающее выражение, записывается в скобках после знака равенства.
Рассмотрим пример регулярного выражения: (T|t)he(?=sfat), обозначающее опциональное наличие строчной t или заглавной T,
следом буквы h и e. В скобках, мы определяем положительное опережающее условие, которое сообщает движку регулярных выражений
информацию о том, что после шаблона The или the будет следовать слово fat.
"(T|t)he(?=sfat)" => The fat cat sat on the mat.
Запустить регулярное выражение
4.2 Отрицательное опережающее условие
Отрицательное опережающее условие работает по обратному принципу: используется, когда нам нужно получить
все совпадения из входной строки, за которыми НЕ следует определенный шаблон. Отрицательное опережающее условие
определяется таким же образом, как и позитивное, с той лишь разницей, что вместо равенства = мы ставим
восклицательный знак ! (отрицание) например: (?!...). Рассмотрим выражение (T|t)he(?!sfat), в котором мы
находим все The или the слова из входной строки, за которыми не следует слово fat.
"(T|t)he(?!sfat)" => The fat cat sat on the mat.
Запустить регулярное выражение
4.3 Положительное ретроспективное условие
Положительное ретроспективное условие используется чтобы найти все совпадения, которым предшествует
определенный шаблон. Условие определяется как (?<=...). Например, выражение (?<=(T|t)hes)(fat|mat) означает,
найти все слова fat или mat из входной строки, которым предшествует слово The или the.
"(?<=(T|t)hes)(fat|mat)" => The fat cat sat on the mat.
Запустить регулярное выражение
4.4 Отрицательное ретроспективное условие
Отрицательное ретроспективное условие используется чтобы найти все совпадения, которым НЕ предшествует
определенный шаблон. Условие определяется как (?<!...). Например, выражение (?<!(T|t)hes)(cat) означает
найти все слова cat из входной строки, которым не предшествует определенный артикль The или the.
"(?<!(T|t)hes)(cat)" => The cat sat on cat.
Запустить регулярное выражение
5. Флаги
Флаги, также называемые модификаторами, изменяют вывод регулярного выражения.
Эти флаги могут быть использованы в любом порядке или комбинации, и являются
неотъемлемой частью регулярных выражений.
| Флаг | Описание |
|---|---|
| i | Поиск без учета регистра |
| g | Глобальный поиск: поиск шаблона во всем входном тексте |
| m | Мультистроковый поиск: Якоря применяются к каждой строке. |
5.1 Поиск без учета регистра
Модификатор i используется для поиска без учета регистра. Например, регулярное выражение
/The/gi означает заглавную T следом строчные h и e. В конце регулярного выражения флаг i,
указывающий движку регулярных выражений игнорировать регистр. Помимо i, для поиска шаблона во
всем входном тексте, использован флаг g.
"The" => The fat cat sat on the mat.
Запустить регулярное выражение
"/The/gi" => The fat cat sat on the mat.
Запустить регулярное выражение
5.2 Глобальный поиск
Модификатор g используется для выполнения глобального сопоставления (найти все совпадения, а не останавливаться после первого).
Например, регулярное выражение /.(at)/g означает любой символ кроме символа новой строки, следом строчная a, далее строчная t.
Из-за использования флага g в конце регулярного выражения, теперь оно найдет все совпадения во входной строке, а не остановится на первом
(что является поведением по умолчанию).
"/.(at)/" => The fat cat sat on the mat.
Запустить регулярное выражение
"/.(at)/g" => The fat cat sat on the mat.
Запустить регулярное выражение
5.3 Мультистроковый поиск
Модификатор m используется для многострочного поиска. Как мы обсуждали ранее,
якоря (^, $) используются для проверки, является ли шаблон началом или концом входной строки.
Но если мы хотим, чтобы якоря работали в каждой строке, мы используем флаг m. Например,
регулярное выражение /at(.)?$/gm означает строчную a, следом строчная t и любой
символ кроме начала новой строки, идущий опционально (не обязательно). Из-за флага m механизм
регулярных выражений будет искать данный шаблон в конце каждой строки в тексте.
"/.at(.)?$/" => The fat
cat sat
on the mat.
Запустить регулярное выражение
"/.at(.)?$/gm" => The fat
cat sat
on the mat.
Запустить регулярное выражение
6. Жадные vs ленивые квантификаторы
По умолчанию регулярное выражение выполняет жадное сопоставление, то есть оно будет
искать совпадения как можно дольше. Мы можем использовать ? для ленивого поиска, который
будет стремиться быть как можно более коротким по времени.
"/(.*at)/" => The fat cat sat on the mat.
Запустить регулярное выражение
"/(.*?at)/" => The fat cat sat on the mat.
Запустить регулярное выражение
Содействие
- Вы можете открыть пулл реквест с улучшением
- Обсуждать идеи в issues
- Распространять ссылку на репозиторий
- Получить обратную связь через
Лицензия
MIT © Zeeshan Ahmad
![]()
Хочешь проверить свои знания по JS?
Подпишись на наш канал с тестами по JS в Telegram!
Решать задачи
×

Регулярное выражение (или regex) — это синтаксис, позволяющий находить строки, соответствующие определенным шаблонам. Это что-то вроде функционала поиска в тексте, только regex позволяют использовать квантификаторы, специальные символы и группы захвата для создания по-настоящему продвинутых шаблонов поиска.
Regex можно использовать во всех случаях, когда вам нужно запросить строковые данные. Примеры юзкейсов:
- анализ вывода командной строки
- парсинг пользовательского ввода
- проверка логов сервера или программы
- управление текстовыми файлами с последовательным синтаксисом, такими, как CSV
- чтение файлов конфигурации
- поиск в коде и рефакторинг кода
Теоретически, делать все это можно и без regex, но использование регулярок дает вам суперсилу в решении подобных задач.
Как выглядят регулярные выражения?
В простейшей форме regex может выглядеть так:

От редакции Techrocks. О сайте regex101 и других сайтах для изучения regex можно почитать в статье «Как, наконец, выучить Regex?».
В примере «Test» буквы test образуют шаблон, как при обычном поиске. Но регулярные выражения далеко не всегда столь просты. Вот regex, означающий «3 цифры, за которыми следует дефис, за которым идут 3 цифры, после которых идет еще дефис, а в конце идут 4 цифры».
Т.е. это формат записи телефонного номера:
^(?:d{3}-){2}d{4}$

Это регулярное выражение может показаться сложным, но, во-первых, к концу этой статьи вы научитесь читать подобные шаблоны, а во-вторых, это действительно сложный способ написания шаблона.
Фактически, большинство регулярных выражений можно написать по-разному. Например, выражение, приведенное выше, можно переписать более длинно, но при этом более читабельно:
^[0-9]{3}-[0-9]{3}-[0-9]{4}$
Большинство языков программирования предоставляют встроенные методы для поиска и замены строк с использованием regex. Но при этом в каждом языке может быть собственный синтаксис регулярок.
В этой статье мы остановимся на варианте regex в ECMAScript, который используется в JavaScript и имеет много общего с реализациями регулярных выражений в других языках.
Как читать (и писать) регулярные выражения
Квантификаторы
В регулярных выражениях квантификаторы указывают, сколько раз должен встретиться символ. Вот список квантификаторов:
a|b— или a, или b?— ноль или один+— один или больше*— ноль или больше{N}— ровно N раз (здесь N — число){N,}— N или больше раз (N — число){N,M}— от N до M раз (N и M — числа, при этом N < M)*?— ноль или больше, но после первого совпадения поиск нужно прекратить
Например, следующее регулярное выражение соответствует и строке «Hello», и строке «Goodbye»:
Hello|Goodbye
В то время как
Hey?
может означать как отсутствие y, так и одно вхождение y, и таким образом весь шаблон может соответствовать и «He», и «Hey».
Еще пример:
Hello{1,3}
Этот шаблон соответствует «Hello», «Hellooo», но не «Helloooo», потому что буква «о» может встречаться от 1 до 3 раз.
Квантификаторы можно комбинировать:
He?llo{2}
Здесь мы ищем строки, в которых «e» нет или встречается 1 раз, а «o» встречается ровно 2 раза. Таким образом, этот шаблон соответствует словам «Helloo» и «Hlloo».
Жадное соответствие
В списке квантификаторов в предыдущем разделе мы познакомились со значением символа +. Этот квантификатор означает один или больше символов. Таким образом, шаблон
Hi+
будет соответствовать как «Hi», так и «Hiiiiiiiiiiiiiiii». Это потому, что все квантификаторы по умолчанию «жадные».
Но вы можете сменить их поведение на «ленивое» при помощи символа ?.
Hi+?
Теперь шаблон будет соответствовать как можно меньшему числу «i». Символ + означает «один или больше», что в «ленивом» варианте превращается в «один». То есть, в строке «Hiiiiiiiiiii» шаблон совпадет только с «Hi».
Само по себе это не слишком полезно, но в сочетании с таким символом, как точка, становится важным.
Точка в регулярных выражениях используется для поиска любого символа.
Например, следующий шаблон соответствует и «Hillo», и «Hello», и «Hellollollo»:
H.*llo

Но что если в строке «Hellollollo» вам нужно совпадение только с «Hello»?
Нужно просто сделать поиск ленивым:
H.*?llo

Наборы
Квадратные скобки позволяют искать совпадение по целому набору символов, указанному в скобках. Например, шаблон
My favorite vowel is [aeiou]
совпадет со строками:
My favorite vowel is a My favorite vowel is e My favorite vowel is i My favorite vowel is o My favorite vowel is u
И ни с чем другим. [aeiou] — это набор, в регулярном выражении означающий «любой из указанных символов».
Вот список самых распространенных наборов:
[A-Z]— совпадает с любой буквой в верхнем регистре, от «A» до «Z»[a-z]— совпадает с любой буквой в нижнем регистре, от «a» до «z»[0-9]-любая цифра[asdf]— совпадает с «a», «s», «d» или «f»[^asdf]— совпадает с любым символом кроме «a», «s», «d» или «f»
Эти наборы можно комбинировать:
[0-9A-Z]— любой символ, являющийся либо цифрой, либо буквой от A до Z[^a-z]— любой символ, не являющийся буквой латинского алфавита в нижнем регистре
Символьные классы
Не каждый символ можно так легко идентифицировать. Скажем, найти буквы с использованием regex легко, а как насчет символа новой строки?
Примечание. Символ новой строки — это символ, который вы вводите, когда нажимаете Enter и переходите на новую строку.
.— любой символn— символ новой строкиt— символ табуляцииs— пробельный символ (включая t, n и некоторые другие)S— не-пробельный символw— любой «словообразующий» символ (буквы латинского алфавита в верхнем и нижнем регистре, цифры 0-9 и символ подчеркивания_)W— любой «несловообразующий» символ (класс символов, обратный классу w)b— граница слова, разделяетwиW, т. е. словообразующие и несловообразующие символы. Граница слова соответствует позиции, где за символом слова не следует другой символ слова.B— несловообразующая граница (класс, обратныйb). Несловообразующая граница соответствует позиции, в которой предыдущий и следующий символы являются символами одного типа: либо оба должны быть словообразующими символами, либо несловообразующими. Начало и конец строки считаются несловообразующими символами.^— начало строки$— конец строки\— символ «» в буквальном значении
Допустим, вы хотите удалить каждый символ, с которого начинается новое слово в строке. Вы можете использовать следующее регулярное выражение для поиска этих символов:
s.
А затем найденные символы можно заменить пустой строкой. Таким образом строка
Hello world how are you
превратится в
Helloorldowreou

Комбинирование наборов
Символьные классы сами по себе не слишком полезны, но их можно сочетать с наборами. Допустим, мы хотим удалить из строки любую букву в верхнем регистре или пробельный символ. Это можно написать так:
[A-Z]|s
Но s можно поместить и внутрь набора:
[A-Zs]

Границы слова
В списке символьных классов вы видели символ b, означающий границу слова. На нем стоит остановиться отдельно, потому что этот токен работает не как остальные.
Допустим, у вас есть строка «This is a string». Вы можете предположить, что символ границы слова соответствует пробелам между словами, но это не так. Он соответствует тому, что находится между буквой и пробелом.

Это может быть трудно понять. Но обычно никто и не ищет сами границы слов. Вместо этого можно написать, например, выражение для поиска целых слов:
bw+b

Это регулярное выражение интерпретируется следующим образом: «Граница слова, за которой следует один или больше словообразующих символов, за которыми следует другая граница слова».
Начало и конец строки
Еще два важных токена — ^ и $. Они означают начало и конец строки соответственно.
То есть, если вы хотите найти первое слово в строке, вы можете написать следующее выражение:
^w+
Оно соответствует одному или большему числу словообразующих символов, но только если они идут непосредственно в начале строки. Помните, что словообразующий символ это любая буква латинского алфавита в любом регистре, а также любая цифра и символ подчеркивания.

Аналогично, если вы хотите найти последнее слово в строке, ваше регулярное выражение может выглядеть так:
w+$

Но то, что символ $ обычно заканчивает строку, не означает, что после него не может идти других символов.
Допустим, мы хотим найти каждый пробельный символ между новыми строками для создания базового минификатора JavaScript-кода.
Мы можем написать следующее выражение, чтобы найти все пробелы после конца строки:
$s+

Экранирование символов
Хотя токены символьных классов очень полезны, иногда с ними возникают сложности. Например, когда нужно написать шаблон для поиска таких токенов в тексте.
Допустим, у вас есть строка в тексте статьи:
"Символ новой строки - 'n'"
Или вы хотите найти вообще все упоминания «n» в тексте. Тогда в шаблоне символ n нужно «экранировать»: поставить перед ним обратную косую черту:
\n
Как использовать regex
Ценность регулярных выражений не только в том, что они позволяют находить строки. Вы также можете использовать их для модификации строк и других действий с ними.
В разных языках программирования есть похожие методы для работы с regex. Мы используем JavaScript в качестве примера.
Создание регулярных выражений и поиск с их помощью
Для начала давайте посмотрим, как строятся регулярные выражения.
В JavaScript (и в некоторых других языках) мы помещаем regex в блоки //. Регулярное выражение для поиска буквы в нижнем регистре будет выглядеть так:
/[a-z]/
Этот синтаксис генерирует объект RegExp, который можно использовать со встроенными методами типа exec для поиска соответствий в строках.
/[a-z]/.exec("a"); // Возвращает ["a"]
/[a-z]/.exec("0"); // Возвращает null
Затем мы можем использовать это истиноподобие для определения, есть ли совпадение с regex (как в строке 3 примера, доступного по ссылке ниже).
Запустить код в песочнице.
Или мы можем вызвать конструктор RegExp со строкой, которую хотим конвертировать в регулярное выражение:
const regex = new RegExp("[a-z]"); // То же самое, что /[a-z]/
Замена строк при помощи регулярных выражений
Вы можете использовать regex для поиска и замены содержимого файлов. Скажем, вы хотите заменить любое приветствие на прощание. Можно сделать это так:
function youSayHelloISayGoodbye(str) {
str = str.replace("Hello", "Goodbye");
str = str.replace("Hi", "Goodbye");
str = str.replace("Hey", "Goodbye"); str = str.replace("hello", "Goodbye");
str = str.replace("hi", "Goodbye");
str = str.replace("hey", "Goodbye");
return str;
}
Но можно и проще, с использованием regex:
function youSayHelloISayGoodbye(str) {
str = str.replace(/[Hh]ello|[Hh]i|[Hh]ey/, "Goodbye");
return str;
}
Запустить код в песочнице
Но вы можете заметить, что при запуске youSayHelloISayGoodbye с «Hello, Hi there» регулярное выражение совпадает не больше, чем с одним вхождением:

Регулярное выражение /[Hh]ello|[Hh]i|[Hh]ey/, примененное к строке «Hello, Hi there», по умолчанию совпадет только с «Hello».
Мы ожидаем, что оно совпадет и с «Hello», и с «Hi», но этого не происходит.
Чтобы регулярное выражение «отловило» больше одного совпадения, нужно использовать особый флаг.
Флаги в regex
Флаг — это модификатор существующего регулярного выражения. При определении regex флаги всегда добавляются после замыкающего слэша.
Вот небольшой список доступных флагов:
g— глобально, больше одного совпаденияm— заставляет$и^соответствовать каждой новой строчке отдельноi— делает regex нечувствительным к регистру
Мы можем взять наше регулярное выражение:
/[Hh]ello|[Hh]i|[Hh]ey/
и переписать его, применив флаг нечувствительности к регистру:
/Hello|Hi|Hey/i
Это регулярное выражение будет соответствовать следующим словам:
Hello HEY Hi HeLLo
Также оно будет соответствовать любому другому варианту чередования заглавных и строчных букв.
Флаг глобального поиска для замены строк
Как уже говорилось, если вы производите замену при помощи regex без всяких флагов, заменен будет только первый результат поиска:
let str = "Hello, hi there!"; str = str.replace(/[Hh]ello|[Hh]i|[Hh]ey/, "Goodbye"); console.log(str); // В выводе будет "Goodbye, hi there"
Но если вы добавите флаг глобального поиска, будут найдены все соответствия шаблону:
let str = "Hello, hi there!"; str = str.replace(/[Hh]ello|[Hh]i|[Hh]ey/g, "Goodbye"); console.log(str); // В выводе будет "Goodbye, Goodbye there"
Использование флага глобального поиска в JavaScript
При использовании глобального поиска в JavaScript regex вы можете столкнуться со странным поведением.
Если вы многократно запустите exec с глобальным поиском, команда будет через раз возвращать null.

Как объясняет MDN,
«Объекты RegExp в JavaScript, когда у них установлены флаги global или sticky, являются stateful-объектами… Они хранят lastIndex из предыдущего сопоставления. Благодаря этому exec() может применяться для итерации по нескольким сопоставлениям в строке текста…»
Команда exec пытается начать поиск по lastIndex, продвигаясь вперед. Поскольку lastIndex имеет значение длины строки, exec будет пытаться сопоставить с вашим регулярным выражением "" — пустую строку, пока она не будет сброшена новой командой exec. Хотя эта особенность может быть полезна в определенных обстоятельствах, она часто сбивает с толку новичков.
Чтобы решить эту проблему, мы можем просто назначать значение 0 для lastIndex перед каждым запуском команды exec:

Группы в regex
При поиске совпадения с шаблоном может быть полезно искать больше одного сопоставляемого элемента за раз. Тут в игру вступают группы.
В примере ниже мы видим совпадение и с «Testing 123», и с «Tests 123» без дублирования «123» в выражении.
/(Testing|tests) 123/ig

Группы определяются при помощи скобок. Бывают они двух видов: группы захвата и незахватывающие группы (capture groups и non-capturing groups):
(…)— группа, соответствующая любым 3 символам(?:…)— незахватывающая группа, соответствующая любым 3 символам
Разница между этими группами ощутима тогда, когда речь идет о замене символов.
Например, используя приведенное выше выражение, при помощи JavaScript можно заменить текст с «Testing 234» и «tests 234»:
const regex = /(Testing|tests) 123/ig; let str = ` Testing 123 Tests 123 `; str = str.replace(regex, '$1 234'); console.log(str); // Testing 234nTests 234"
Мы используем $1 для обращения к первой группе захвата, (Testing|tests). Мы также можем сопоставить больше одной группы, скажем, сопоставлять одновременно (Testing|tests) и (123):
const regex = /(Testing|tests) (123)/ig; let str = ` Testing 123 Tests 123 `; str = str.replace(regex, '$1 #$2'); console.log(str); // Testing #123nTests #123"
Но это работает только с группами захвата.
Давайте заменим вот это:
/(Testing|tests) (123)/ig
на это:
/(?:Testing|tests) (123)/ig;
Теперь у нас только одна группа захвата — (123), и код, который мы использовали ранее, произведет другой результат:
const regex = /(?:Testing|tests) (123)/ig; let str = ` Testing 123 Tests 123 `; str = str.replace(regex, '$1'); console.log(str); // "123n123"
Запустить код в песочнице
Именованные группы захвата
Хотя группы захвата — отличная вещь, в них легко запутаться, когда их у вас несколько. Разница между $3 и $5 не всегда очевидна.
Для решения этой проблемы в регулярных выражениях есть концепция «именованных групп захвата».
(?<name>...) — здесь именованная группа с именем «name» соответствует любым 3 символам.
Например, можно создать группу с именем «num», которая будет соответствовать 3 цифрам:
Затем вы можете использовать эту группу для замены:
const regex = /Testing (?<num>d{3})/
let str = "Testing 123";
str = str.replace(regex, "Hello $<num>")
console.log(str); // "Hello 123"
Именованные обратные ссылки
Иногда бывает полезно сослаться на именованную группу захвата внутри самого запроса. В этом вам помогут «обратные ссылки».
k<name> — ссылка на именованную группу захвата «name» в поисковом запросе.
Скажем, вы хотите, чтобы выш шаблон совпадал со строкой
Hello there James. James, how are you doing?
но не со строкой
Hello there James. Frank, how are you doing?
Вы можете написать regex, где повторяется слово «James»:
/.*James. James,.*/
Но лучше написать так:
/.*(?<name>James). k<name>,.*/
Теперь имя жестко прописано только в одном месте.
Запустить код в песочнице.
Опережающие и ретроспективные группы
Опережающие (lookahead) и ретроспективные (lookbehind) группы — очень мощный инструмент, который часто понимают превратно.
Есть четыре разных типа опережающих и ретроспективных проверок:
(?!)— негативная опережающая проверка(?=)— позитивная опережающая проверка(?<=)— позитивная ретроспективная проверка(?<!)— негативная ретроспективная проверка
Суть lookahead — проверить, что за группой стоит или не стоит определенный шаблон (позитивная и негативная проверка).
Пример негативной опережающей проверки:
/B(?!A)/
Это выражение читается как «найди B, за которым НЕ следует A». Оно соответствует «В» в «BC», но не в «BA».

Это можно комбинировать с символами начала и конца строки, чтобы искать соответствия для целых строк. Например, следующее выражение соответствует любой строке, которая НЕ начинается с «Test»:
/^(?!Test).*$/gm

Мы можем изменить негативную опережающую проверку на позитивную и таким образом найти строки, которые начинаются с «Test»:
/^(?=Test).*$/gm

Итоги
Регулярные выражения — невероятно мощный инструмент, который можно использовать для всевозможных манипуляций со строками. Знание regex поможет вам проводить рефакторинг кодовых баз, вносить быстрые правки в скрипты и т. д.
Давайте вернемся к нашему regex, соответствующему номеру телефона. Попробуйте теперь прочитать это выражение:
^(?:d{3}-){2}d{4}$
Оно служит для поиска телефонных номеров:
555-555-5555
Здесь:
^и$используются для обозначения начала и конца строки- Незахватывающая группа нужна для поиска трех цифр, за которыми следует дефис.
- Эта группа повторяется дважды для соответствия
555-555-
- Эта группа повторяется дважды для соответствия
- Дальше мы ищем последние 4 цифры телефонного номера.
Надеюсь, эта статья дала вам начальное представление о regex.
Перевод статьи «The Complete Guide to Regular Expressions (Regex)».
-
Доступные статьи
-
IT-шное
-
Регулярные выражения за 15 минут
Регулярные выражения
Регулярные выражения (regular expressions) – это текстовый шаблон, который соответствует какому-то тексту. И всё? Да, это всё, для чего они нужны.
Что можно делать с помощью регулярных выражений:
- Проверять то, что вводит пользователь, чтобы быть уверенным в правильности данных (например, правильно ли пользователь ввёл email или ip-адрес).
- Разбирать большой текст на меленькие кусочки (например, выбирать данные из большого лога).
- Делать замены по шаблону (например, убирать непечатаемые символы из XML).
- Показывать невероятную крутость тем, кто не знает регулярных выражений.
Большинство современных языков программирования и текстовых редакторов (по моему личному мнению) поддерживают регулярные выражения. Поддержим их и мы.
/Быть или не быть/ugi ¶
Синтаксис регулярных выражений прост и логичен. Он разделяется на символ-разделитель (он идёт в начале и конце выражения, обычно это /), шаблон поиска и необязательные модификаторы.
Формальный синтаксис такой:
[разделитель][шаблон][разделитель][модификаторы]
Разделителем может быть любой символ, но обычно это / или ~. Важно лишь то, чтобы шаблон начинался и заканчивался одним и тем же разделителем. В самом конце регулярных выражений идут модификаторы, которые нужны, чтобы менять логику работы шаблонов (например делать регистронезависимый поиск).
Давайте разберём выражение /Быть или не быть/ugi:
/ - начальный символ-разделитель
Быть или не быть - шаблон поиска
/ - конечный символ-разделитель
ugi - модификаторы (UTF-8, global, case insensitive)
Данное регулярное выражение будет искать текст Быть или не быть не зависимо от регистра по всему тексту неограниченное количество раз. Модификатор u нужен для того, чтобы явно указать, что текст у нас в юникоде, то есть содержит символы, отличные от латиницы. Модификатор i включает регистронезависимый поиск. Модификатор g указывает поисковику идти до победного конца, иначе он остановится после первого удачного совпадения.
“Петя любит Дашу”.replace(/Дашу|Машу|Сашу/, “Катю”) ¶
Не трудно догадаться, что результатом работы js-выражения выше будет текст "Петя любит Катю". Даже, если Петя неровно дышит к Маше или Саше, то результат всё равно не изменится.
Рассмотрим базовые спец. символы, которые можно использовать в шаблонах:
| Символ | Описание | Пример использования | Результат |
|---|---|---|---|
| Символ экранирования или начала мета-символа | /путь/к/папке/ | Надёт текст путь/к/папке |
|
| ^ | Признак начала строки | /^Дом/ | Найдёт все строки, которые начинаются на Дом |
| $ | Признак конца строки | /родной$/ | Найдёт все строки, которые заканчиваются на родной |
| . | Точка означает любой символ, кроме перевода строки | /Петя ..бит Машу/ | Найдёт как Петя любит Машу, так и Петя губит Машу |
| | | Означает ИЛИ | /Вася|Петя/ | Найдёт как Васю, так и Петю |
| ? | Означает НОЛЬ или ОДИН раз | /Вжу?х/ | Найдёт Вжх и Вжух |
| * | Означает НОЛЬ или МНОГО раз | /Вжу*х/ | Найдёт Вжх, Вжух, Вжуух, Вжууух и т.д. |
| + | Означает ОДИН или МНОГО раз | /Вжу+х/ | Найдёт Вжух, Вжуух, Вжууух и т.д. |
Помимо базовых спец. символов есть мета-символы (или мета-последовательности), которые заменяют группы символов:
| Символ | Описание | Пример использования | Результат |
|---|---|---|---|
| w | Буква, цифра или _ (подчёркивание) | /^w+$/ | Соответствует целому слову без пробелов, например _Вася333_ |
| W | НЕ буква, цифра или _ (подчёркивание) | /Ww+W/ | Найдёт полное слово, которое обрамлено любыми символами, например @Петя@ |
| d | Любая цифра | /^d+$/ | Соответствует целому числу без знака, например 123 |
| D | Любой символ НЕ цифра | /^D+$/ | Соответствует любому выражению, где нет цифр, например Петя |
| s | Пробел или табуляция (кроме перевода строки) | /s+/ | Найдёт последовательность пробелов от одного и до бесконечности |
| S | Любой символ, кроме пробела или табуляции | /s+S/ | Найдёт последовательность пробелов, после которой есть хотя бы один другой символ |
| b | Граница слова | /bдомb/ | Найдёт только отдельные слова дом, но проигнорирует рядом |
| B | НЕ граница слова | /Bдомb/ | Найдёт только окночние слов, которые заканчиваются на дом |
| R | Любой перевод строки (Unix, Mac, Windows) | /.*R/ | Найдёт строки, которые заканчиваются переводом строки |
Нужно отметить, что спец. символы w, W, b и B не работают по умолчанию с юникодом (включая кириллицу). Для их правильной работы нужно указывать модификатор u. К сожалению, на окончание 2019 года JavaScript не поддерживает регулярные выражения для юникода даже с модификатором, поэтому в js эти мета-символы работают только для латиницы.
Ещё регулярные выражения поддерживают разные виды скобочек:
| Выражение | Описание | Пример использования | Результат |
|---|---|---|---|
| (…) | Круглые скобки означают под-шаблон, который идёт в результат поиска | /(Петя|Вася|Саша) любит Машу/ | Найдёт всю строку и запишет воздыхателя Маши в результат поиска под номером 1 |
| (?:…) | Круглые скобки с вопросом и двоеточием означают под-шаблон, который НЕ идёт в результат поиска | /(?:Петя|Вася|Саша) любит Машу/ | Найдёт только полную строку, воздыхатель останется инкогнито |
| (?P<name>…) | Задаёт имя под-шаблона | /(?P<воздыхатель>Петя|Вася|Саша) любит Машу/ | Найдёт полную строку, а воздыхателя запишет в результат под индексом 1 и ‘воздыхатель’ |
| [abc] | Квадратные скобки задают ЛЮБОЙ СИМВОЛ из последовательности (включая спец. символы w, d, s и т.д.) | /^[123]+$/ | Соответствует любому выражению 323323123, но не 54321 |
| [a-я0-9] | Если внутри квадратных скобок указать минус, то это считается диапазоном | /[A-Za-zА-Яа-яЁё0-9_]+/ | Аналог /w/ui для JavaScript |
| [abc-] | Если минус является первым или последним символом диапазона, то это просто минус | /[0-9+-]+/ | Найдёт любое целое числое с плюсом или минусом (причём не обязательно, чтобы минус или плюс были спереди) |
| [^…] | Квадратные скобки с “крышечекой” означают любой символ НЕ входящий в диапазон | /[^a-zа-я0-9 ]/i | Найдёт любой символ, который не является буквой, числом или пробелом |
| [[:class:]] | Квадратные скобки в квадратных скобках задают класс символов (alnum, alpha, ascii, digit, print, space, punct и другие) | /[^[:print:]]+/ | Найдёт последовательность непечатаемых символов |
| {n} | Фигурные скобки с одним числом задают точное количество символов | /w+н{2}w+/u | Найдёт слово, в котором две буквы н |
| {n,k} | Фигурные скобки с двумя числами задают количество символов от n до k | /w+н{1,2}w+/u | Найдёт слово, в котором есть одна или две буквы н |
| {n,} | Фигурные скобки с одним числом и запятой задают количество символов от n до бесконечности | /w+н{3,}w+/u | Найдёт слово, в котором н встречается от трёх и более раз подряд |
Как правильно писать регулярные выражения ¶
Прежде, чем садиться и писать регулярно выраженного кракена, подумайте, что именно вы хотите сделать. Регулярное выражение должно начинаться с мысли “Я хочу найти/заменить/удалить то-то и то-то”. Затем вам нужен исходный текст, который содержит как ПРАВИЛЬНЫЕ, так и НЕправильные данные. Затем вы открываете https://regex101.com/, вставляете текст и начинаете писать регулярное выражение. Этот замечательный инструмент укажет и покажет все ошибки, а также подсветит результаты поиска.
Для примера возьмём валидацию ip-адреса. Первая мысль должна быть: “Я хочу валидировать ip-адрес. А что такое ip-адрес? Из чего он состоит?”. Затем нужен список валидных и невалидных адресов:
# Валидные адреса
0.0.0.0
0.1.2.3
99.99.99.99
199.199.199.199
255.255.255.255
# Невалидные адреса
01.01.01.01
.1.2.3
1.2.3.
255.0.0.256
Валидный адрес должен содержать четыре числа (байта) от 0 до 255. Если он содержит число больше 255, это уже ошибка. Если бы мы делали валидацию на каком-либо языке программирования, то можно было бы разбить выражение на четыре части и проверить каждое число отдельно. Но регулярные выражения не поддерживают проверки больше или меньше, поэтому придётся делать по-другому.
Для начала упростим задачу: будем валидировать не весь ip-адрес, а только один байт. А байт это всегда есть либо одно-, либо дву-, либо трёхзначное число. Для одно- и двузначного числа шаблон очень простой – любая цифра. А вот для трёхзначного числа первая цифра либо единица, либо двойка. Если первая цифра единица, то вторая и третья могут быть от нуля до девяти. Если же первая цифра двойка, то вторая может быть только от нуля до пяти. Если первая цифра двойка и вторая пятёрка, то третья может быть только от ноля до пяти. Давайте формализуем:
# Валидация байта
от 0 до 9 d
от 10 до 99 [1-9]d
от 100 до 199 1dd
от 200 до 249 2[0-4]d
от 250 до 255 25[0-5]
Теперь, зная все диапазоны байта, можно объединить их в одно выражение через вертикальную палочку | (ИЛИ):
b(d|[1-9]d|1dd|2[0-4]d|25[0-5])b
Обратите внимание, что я использовал границу слова b, чтобы искать полные байты. Пробуем регулярку в деле:
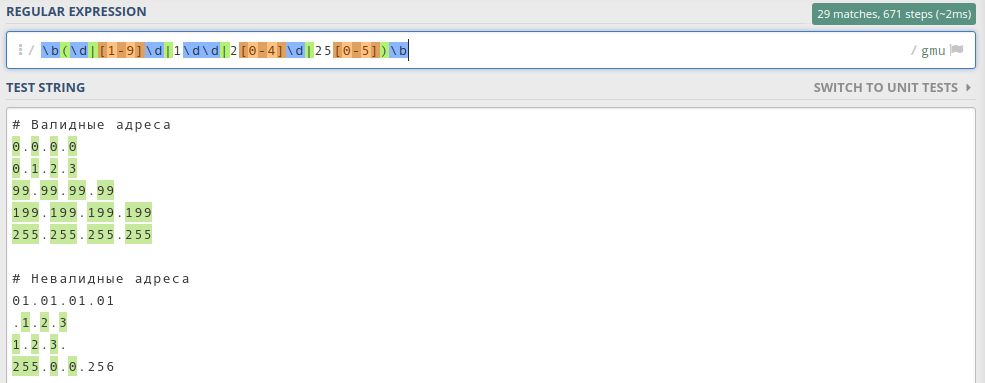
Как видим, все байты стали зелёненькими. Это значит, что мы на верном пути.
Осталось дело за малым: сделать так, чтобы искать четыре байта, а не один. Нужно учесть, что байты разделены тремя точками. То есть мы ищем три байта с точкой на конце и один без точки:
(b(d|[1-9]d|1dd|2[0-4]d|25[0-5])b.){3}b(d|[1-9]d|1dd|2[0-4]d|25[0-5])b
Результат выглядит так:
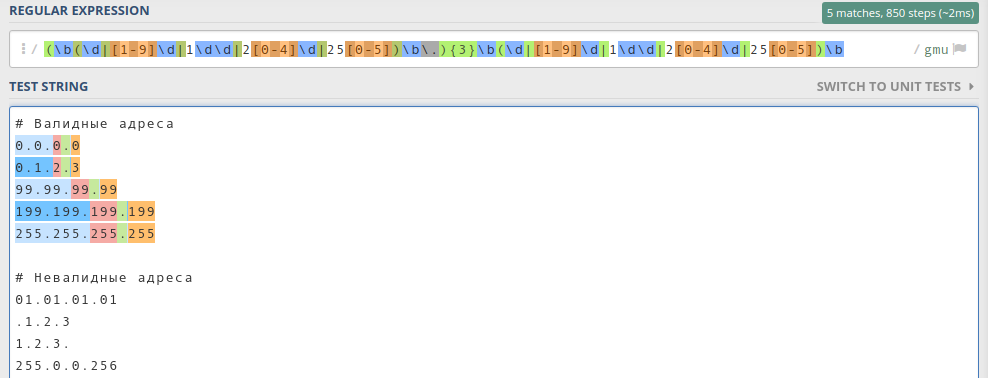
Подсветились только валидные ip-адреса, значит регулярное выражение работает корректно.
Если бы я сразу начал писать валидацию всего адреса, а не отдельного байта, то с большой долей вероятности допустил бы ошибку. Скопления скобочек, палочек и точечек трудно воспринимаются на глаз, поэтому задачу надо обязательно упрощать.
Практическое применение регулярных выражений ¶
Регулярными выражениями можно пользоваться не только для валидации, но и для обработки данных, например, в блокноте. Вот практический пример такой обработки: скопировать номера регионов и перевести в формат PHP-массива.
Your browser does not support HTML5 video.
Ссылки ¶
- https://regex101.com/ – сайт для тестирования регулярных выражений.
- https://linux.die.net/man/1/perlre – руководство по регулярным выражениям Perl.
- https://www.php.net/manual/ru/reference.pcre.pattern.syntax.php – регулярные выражения в PHP.
- https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Global_Objects/RegExp – регулярные выражения JavaScript.
Хорошая статья, мне понравилась. Оставлю отзыв!
