В этой статье мы изучим особенности и структуру реляционных данных, а также увидим пример создания этих БД.

Рассмотрим проектирование, составим концептуальную модель данных. Узнаем, что такое объект и нормализация данных, обсудим, на что обратить внимание на этапе проектирования баз данных. Скучно не будет!
Таблица как важная часть реляционной БД
Всем известно, что реляционная база данных состоит из таблиц. При этом каждая таблица включает в себя столбцы (поля либо атрибуты) и строки (записи либо кортежи).
Таблицы в таких БД обладают следующими свойствами:
– столбцы размещаются в определённом порядке, формируемом при создании таблицы. Таблица может не иметь ни одной строки, однако хотя бы один столбец должен быть обязательно;
– в таблице не может быть 2-х одинаковых строк. Если вспомнить математику, то такие таблицы называют отношениями (relation). Именно поэтому данные БД и считаются реляционными;
– каждый столбец в пределах таблицы имеет уникальное имя, а все значения в одном столбце должны быть одного типа (дата, текст, число и т. п.);
– на пересечении строки и столбца может быть только атомарное значение (значение, не состоящее из группы значений). Таблицы, которые удовлетворяют этим условиям, считаются нормализованными.
Приведём пример
Допустим, вы хотите создать базу данных для интернет-форума. На форуме есть зарегистрированные пользователи, создающие темы и оставляющие сообщения в данных темах. Вся эта информация и должна размещаться в базе данных.
В теории всё можно расположить в одной таблице, а именно:
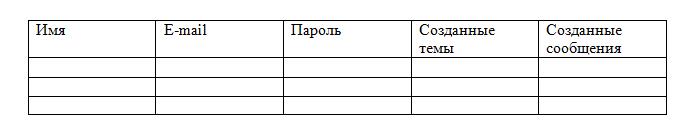
Однако такое расположение противоречит атомарности, причём в столбцах «Созданные сообщения» и «Созданные темы» возможно неограниченное число значений. Целесообразнее всего разбить таблицу на три:
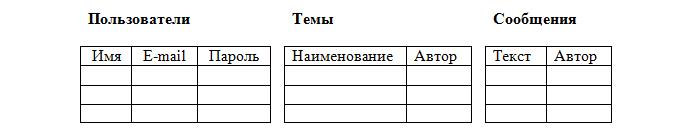
Теперь таблица «Пользователи» соответствует правилам. Но вот таблицы «Сообщения» и «Темы» — нет, т. к. не должно быть 2-х одинаковых строк. В нашем же случае один и тот же пользователь может написать 2 одинаковых сообщения:
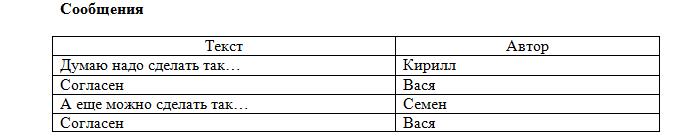
А ещё давайте вспомним о том, что каждое сообщение должно относиться к какой-нибудь теме. Для решения этого вопроса в реляционных базах данных используют ключи.
Ключи в БД
Первичный ключ (РК, primary key) — столбец, значения которого различны во всех строках. РК бывают логические (естественные) и суррогатные (искусственные).
Например, для таблицы «Пользователи» первичным ключом может быть столбец e-mail, т. к. не бывает 2-х пользователей с одним и тем же e-mail.
На практике для хранения и обработки данных рекомендуют применять суррогатные ключи (их использование позволит абстрагировать РК от реальных данных). Это важно, если пользователь, вдруг, сменит e-mail, а ведь первичные ключи нельзя менять.
Суррогатный ключ — это дополнительное поле в БД. Обычно это уникальный id (порядковый номер записи), хотя принцип может быть и другой, главное — уникальность.
Вносим первичные ключи в наши таблицы:

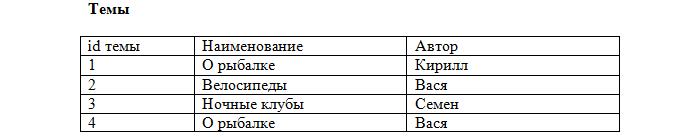
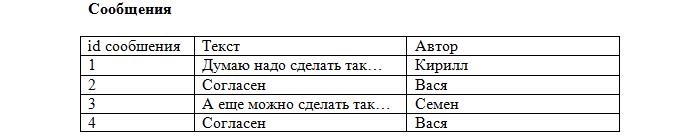
Заметьте, что каждая запись в таблице уникальна. Осталось лишь установить соответствие между сообщениями и темами, используя первичные ключи. Добавляем в таблицу с сообщениями ещё одно поле:

Теперь становится ясно, что сообщение id=2 относится к теме «О рыбалке» (id=4), которая создана Васей, а остальные принадлежат теме «О рыбалке», созданной Кириллом (id=1). Такое поле будет называться внешний ключ (FK, foreign key). При этом каждое значение данного поля сопоставляется с каким-либо первичным ключом из таблицы «Темы». В результате устанавливается однозначное соответствие между темами и сообщениями.
Ещё момент: допустим, добавляется новый пользователь по имени Вася.

Как узнать, какой же из «Васей» оставил сообщение? Для этого поля «Автор» в наших таблицах «Сообщения» и «Темы» мы тоже сделаем внешними ключами:
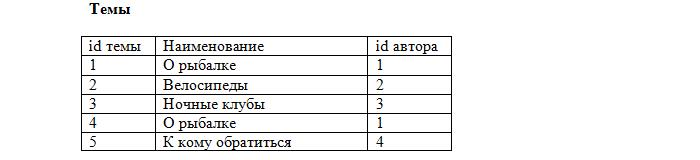

Итак, наша база данных фактически готова. Схематично она выглядит так:
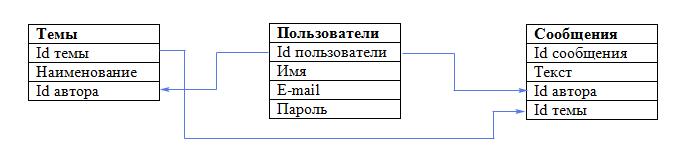
В этой небольшой базе данных лишь 3 таблицы. А что делать, если их 10 либо 200? Ясно, что всё не так просто. Именно поэтому любое проектирование реляционных баз данных начинается с разработки концептуальной модели данных.
Концептуальная модель базы данных
Под концептуальной моделью понимают отражение предметной области для разрабатываемой базы данных. Если не вдаваться в теорию, то речь идёт о некой диаграмме с общепринятыми обозначениями:
– вещи обозначаются прямоугольниками;
– атрибуты объекта овалами;
– связи в таблицах ромбами;
– мощность и направление связей стрелками (одинарными, двойными).
Простой пример — интернет-магазин. В нём есть товары, поставляемые поставщиками и заказываемые покупателями. Это три объекта и две связи:

Делая поставку, поставщик подтверждает её документами. Аналогично и с покупателем. Таким образом, и поставку, и покупку можно рассматривать в качестве самостоятельных объектов.
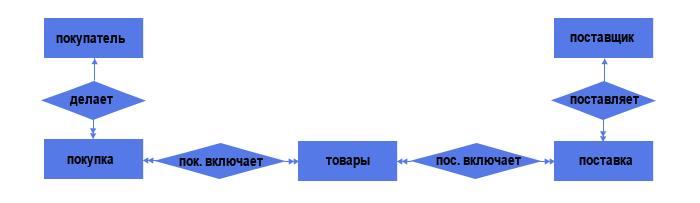
Итого 5 объектов и 4 связи. Из них:
– 2 связи типа «один ко многим» (один поставщик может делать несколько поставок; один покупатель может делать несколько покупок);
– 2 связи типа «многие ко многим» (каждая поставка может включать несколько товаров, причём одинаковый товар может быть в нескольких поставках; аналогичная ситуация по линии «Покупка — Товар»).
Но давайте вспомним, что связи типа «многие ко многим» недопустимы в реляционных моделях данных, поэтому такие связи надо менять на связи типа «один ко многим». Делаем это, добавляя промежуточный объект:
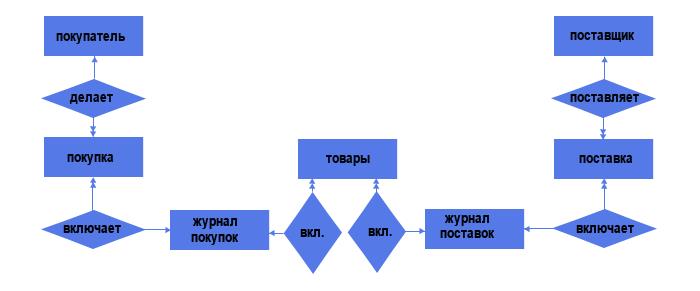
Видим, что в структуре появились ещё 2 объекта — «Журнал поставок» и «Журнал покупок» со связями типа «один ко многим» (каждый журнал может включать несколько поставок/покупок, но каждая поставка/покупка включает лишь один журнал).
Атрибуты таблицы
Каждый объект интернет-магазина имеет свои атрибуты:
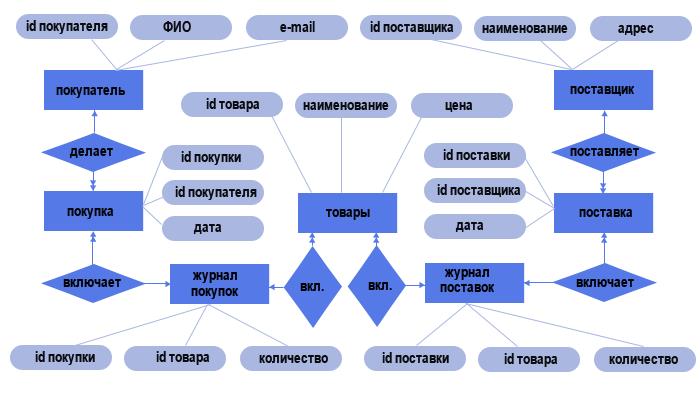
В результате мы создали концептуальную модель будущей базы данных. Точнее говоря, речь идёт лишь о части БД, т. к. мы не учли склады, сотрудников и т. п. Собственно, при обширной предметной области данные лучше разбить на несколько локальных областей. Как правило, объём должен быть в пределах 5-7 объектов. И лишь после создания локальных моделей выполняется их объединение в общую сложную схему. В нашем случае ограничимся созданной моделью. Однако теперь давайте преобразуем её в реляционную модель данных.
Проектирование реляционной базы данных. Преобразование модели в реляционную
Преобразование концептуальной модели данных в реляционную — важная часть проектирования БД. Процесс включает в себя:
– построение набора предварительных таблиц;
– указание РК;
– выполнение нормализации.
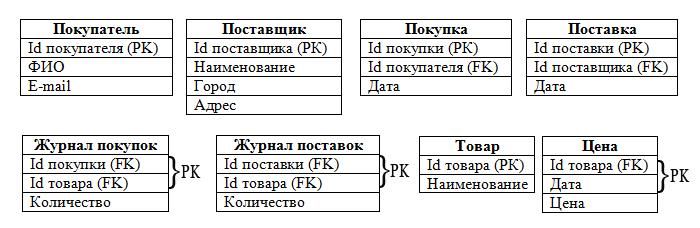
Из набора таблиц состоят наши объекты, а из полей таблиц — атрибуты объектов:
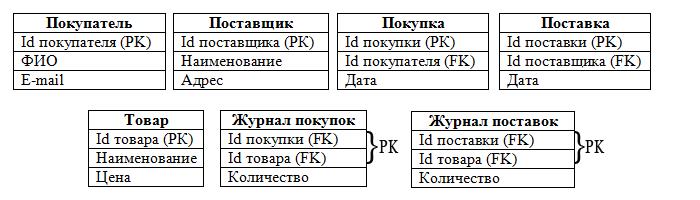
Итак, мы определились с таблицами, полями, РК и FK. Следует отметить, что в таблицах «Журнал покупок» и «Журнал поставок» РК составные, т. к. состоят из 2-х полей.
Что касается нормализации, то под ней понимают обратимый и пошаговый процесс, при котором исходная схема меняется другой схемой, в которой таблицы характеризуются более простой и логичной структурой. Это нужно по следующим причинам:
1. Устранение избыточности данных. Вспомним нашу таблицу:

Очевидно, что в поле «Темы» одни и те же названия встречаются регулярно. Для хранения таких данных нужны дополнительные ресурсы памяти. Кроме того, при дублировании данных можно допустить ошибку во время ввода значений атрибута, вследствие которой БД перейдёт в состояние несогласованности.
2. Устранение различных аномалий, связанных с обновлением, удалением, модификацией и пр. Пример аномалии модификации — чтобы поменять название темы, нам придётся смотреть все строки и менять название в каждой из них.
Нормализация бывает:
– 1-й нормальной формы (1НФ);
– 2НФ;
– 3НФ;
– НФБК (нормальной формы Бойса-Кодда);
– 4НФ;
– 5НФ.
Каждая форма накладывает определённые ограничения на данные разного уровня. В ходе нормализации база данных становится всё строже, подверженность аномалиям снижается.
Если говорить о реляционных базах данных, то минимум — это 1НФ. Однако в процессе проектирования специалисты по СУБД стремятся нормализовать базу хотя бы до уровня 3НФ, исключив тем самым избыточность данных и аномалии. Это важно, если мы стремимся получить качественный результат проектирования. Однако подробное описание нормализации данных выходит за рамки нашей статьи, поэтому давайте просто посмотрим, как будет выглядеть наша база на уровне 3НФ:
Итак, в процессе проектирования мы преобразовали концептуальную модель в реляционную. Следующий этап — реализация её в конкретной СУБД. Для этого потребуется как сама СУБД, так и знание языка SQL. Например, прекрасно подойдёт СУБД MySQL или какая-нибудь другая СУБД.
Подводим итоги проектирования
Проектирование БД — процесс небыстрый и достаточно трудоёмкий. Во время проектирования надо хорошо знать предметную область, учитывать все нюансы. Вся информация должна отображаться в виде таких элементов, как объекты, атрибуты, связи, причём проектирование успешно лишь тогда, когда всё сделано максимально рационально.
Вообще, взгляды на проектирование среди разработчиков могут различаться. Некоторые игнорируют теорию, руководствуясь лишь опытом и здравым смыслом. Другие во время проектирования отводят главную роль интуиции, считая проектирование искусством, которым владеют далеко не все. Как бы там ни было, знания никогда не бывают лишними.
Да, реляционная база данных — это не более чем хранилище, где хранятся данные. Однако от того, как грамотно вы его организуете, будет зависеть стабильность работы всего приложения, где используются эти самые данные.
В заключение, добавим, что умение проектировать базы вам никогда не помешает. А научиться всему этому вы сможете на нашем курсе «Реляционные СУБД». Ждём вас!

Время на прочтение
7 мин
Количество просмотров 404K
Перевод цикла из 15 статей о проектировании баз данных.
Информация предназначена для новичков.
Помогло мне. Возможно, что поможет еще кому-то восполнить пробелы.
Другие части: 4-6, 7-9, 10-13, 14-15.
Руководство по проектированию баз данных.
1. Вступление.
Если вы собираетесь создавать собственные базы данных, то неплохо было бы придерживаться правил проектирования баз данных, так как это обеспечит долговременную целостность и простоту обслуживания ваших данных. Данное руководство расскажет вам что представляют из себя базы данных и как спроектировать базу данных, которая подчиняется правилам проектирования реляционных баз данных.
Базы данных – это программы, которые позволяют сохранять и получать большие объемы связанной информации. Базы данных состоят из таблиц, которые содержат информацию. Когда вы создаете базу данных необходимо подумать о том, какие таблицы вам нужно создать и какие связи существуют между информацией в таблицах. Иначе говоря, вам нужно подумать о проекте вашей базы данных. Хороший проект базы данных, как было сказано ранее, обеспечит целостность данных и простоту их обслуживания.
Структурированный язык запросов (SQL).
База данных создается для хранения в ней информации и получения этой информации при необходимости. Это значит, что мы должны иметь возможность помещать, вставлять (INSERT) информацию в базу данных и мы хотим иметь возможность делать выборку информации из базы данных (SELECT).
Язык запросов к базам данных был придуман для этих целей и был назван Структурированный язык запросов или SQL. Операции вставки данных (INSERT) и их выборки (SELECT) – части этого самого языка. Ниже приведен пример запроса на выборку данных и его результат.
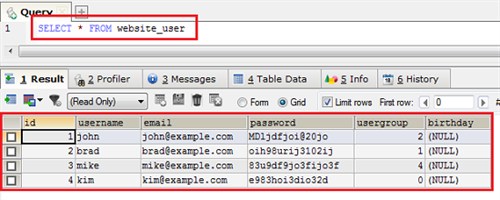
SQL – большая тема для повествования и его рассмотрение выходит за рамки данного руководства. Данная статья строго сфокусирована на изложении процесса проектирования баз данных. Позднее, в отдельном руководстве, я расскажу об основах SQL.
Реляционная модель.
В этом руководстве я покажу вам как создавать реляционную модель данных. Реляционная модель – это модель, которая описывает как организовать данные в таблицах и как определить связи между этими таблицами.
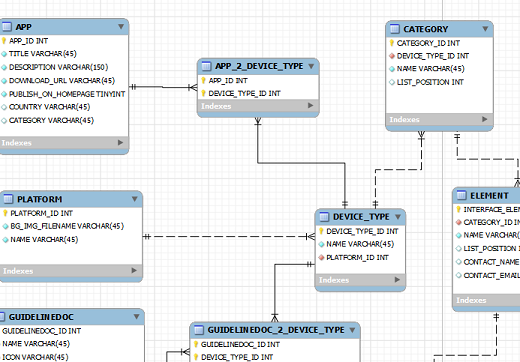
Правила реляционной модели диктуют, как информация должна быть организована в таблицах и как таблицы связаны друг с другом. В конечном счете результат можно предоставить в виде диаграммы базы данных или, если точнее, диаграммы «сущность-связь», как на рисунке (Пример взят из MySQL Workbench).
Примеры.
В качестве примеров в руководстве я использовал ряд приложений.
РСУБД.
РСУБД, которую я использовал для создания таблиц примеров – MySQL. MySQL – наиболее популярная РСУБД и она бесплатна.
Утилита для администрирования БД.
После установки MySQL вы получаете только интерфейс командной строки для взаимодействия с MySQL. Лично я предпочитаю графический интерфейс для управления моими базами данных. Я часто использую SQLyog. Это бесплатная утилита с графическим интерфейсом. Изображения таблиц в данном руководстве взяты оттуда.
Визуальное моделирование.
Существует отличное бесплатное приложение MySQL Workbench. Оно позволяет спроектировать вашу базу данных графически. Изображения диаграмм в руководстве сделаны в этой программе.
Проектирование независимо от РСУБД.
Важно знать, что хотя в данном руководстве и приведены примеры для MySQL, проектирование баз данных независимо от РСУБД. Это значит, что информация применима к реляционным базам данных в общем, не только к MySQL. Вы можете применить знания из этого руководства к любым реляционным базам данных, подобным Mysql, Postgresql, Microsoft Access, Microsoft Sql or Oracle.
В следующей части я коротко расскажу об эволюции баз данных. Вы узнаете откуда взялись базы данных и реляционная модель данных.
2. История.
В 70-х – 80-х годах, когда компьютерные ученые все еще носили коричневые смокинги и очки с большими, квадратными оправами, данные хранились бесструктурно в файлах, которые представляли собой текстовый документ с данными, разделенными (обычно) запятыми или табуляциями.

Так выглядели профессионалы в сфере информационных технологий в 70-е. (Слева внизу находится Билл Гейтс).
Текстовые файлы и сегодня все еще используются для хранения малых объемов простой информации. Comma-Separated Values (CSV) — значения, разделённые запятыми, очень популярны и широко поддерживаются сегодня различным программным обеспечением и операционными системами. Microsoft Excel – один из примеров программ, которые могут работать с CSV–файлами. Данные, сохраненные в таком файле могут быть считаны компьютерной программой.

Выше приведен пример того, как такой файл мог бы выглядеть. Программа, производящая чтение данного файла, должна быть уведомлена о том, что данные разделены запятыми. Если программа хочет выбрать и вывести категорию, в которой находится урок ‘Database Design Tutorial’, то она должна строчка за строчкой производить чтение до тех пор, пока не будут найдены слова ‘Database Design Tutorial’ и затем ей нужно будет прочитать следующее за запятой слово для того, чтобы вывести категорию Software.
Таблицы баз данных.
Чтение файла строчка за строчкой не является очень эффективным. В реляционной базе данных данные хранятся в таблицах. Таблица ниже содержит те же самые данные, что и файл. Каждая строка или “запись” содержит один урок. Каждый столбец содержит какое-то свойство урока. В данном случае это заголовок (title) и его категория (category).
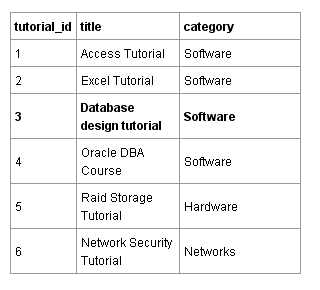
Компьютерная программа могла бы осуществить поиск в столбце tutorial_id данной таблицы по специфическому идентификатору tutorial_id для того, чтобы быстро найти соответствующие ему заголовок и категорию. Это намного быстрее, чем поиск по файлу строка за строкой, подобно тому, как это делает программа в текстовом файле.
Современные реляционные базы данных созданы так, чтобы позволять делать выборку данных из специфических строк, столбцов и множественных таблиц, за раз, очень быстро.
История реляционной модели.
Реляционная модель баз данных была изобретена в 70-х Эдгаром Коддом (Ted Codd), британским ученым. Он хотел преодолеть недостатки сетевой модели баз данных и иерархической модели. И он очень в этом преуспел. Реляционная модель баз данных сегодня всеобще принята и считается мощной моделью для эффективной организации данных.
Сегодня доступен широкий выбор систем управления базами данных: от небольших десктопных приложений до многофункциональных серверных систем с высокооптимизированными методами поиска. Вот некоторые из наиболее известных систем управления реляционными базами данных (РСУБД):
— Oracle – используется преимущественно для профессиональных, больших приложений.
— Microsoft SQL server – РСУБД компании Microsoft. Доступна только для операционной системы Windows.
— Mysql – очень популярная РСУБД с открытым исходным кодом. Широко используется как профессионалами, так и новичками. Что еще нужно?! Она бесплатна.
— IBM – имеет ряд РСУБД, наиболее известна DB2.
— Microsoft Access – РСУБД, которая используется в офисе и дома. На самом деле – это больше, чем просто база данных. MS Access позволяет создавать базы данных с пользовательским интерфейсом.
В следующей части я расскажу кое-что о характеристиках реляционных баз данных.
3. Характеристики реляционных баз данных.
Реляционные базы данных разработаны для быстрого сохранения и получения больших объемов информации. Ниже приведены некоторые характеристики реляционных баз данных и реляционной модели данных.
Использование ключей.
Каждая строка данных в таблице идентифицируется уникальным “ключом”, который называется первичным ключом. Зачастую, первичный ключ это автоматически увеличиваемое (автоинкрементное) число (1,2,3,4 и т.д). Данные в различных таблицах могут быть связаны вместе при использовании ключей. Значения первичного ключа одной таблицы могут быть добавлены в строки (записи) другой таблицы, тем самым, связывая эти записи вместе.
Используя структурированный язык запросов (SQL), данные из разных таблиц, которые связаны ключом, могут быть выбраны за один раз. Для примера вы можете создать запрос, который выберет все заказы из таблицы заказов (orders), которые принадлежат пользователю с идентификатором (id) 3 (Mike) из таблицы пользователей (users). О ключах мы поговорим далее, в следующих частях.
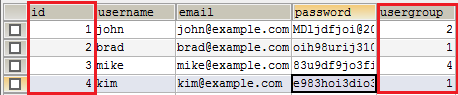
Столбец id в данной таблице является первичным ключом. Каждая запись имеет уникальный первичный ключ, часто число. Столбец usergroup (группы пользователей) является внешним ключом. Судя по ее названию, она видимо ссылается на таблицу, которая содержит группы пользователей.
Отсутствие избыточности данных.
В проекте базы данных, которая создана с учетом правил реляционной модели данных, каждый кусочек информации, например, имя пользователя, хранится только в одном месте. Это позволяет устранить необходимость работы с данными в нескольких местах. Дублирование данных называется избыточностью данных и этого следует избегать в хорошем проекте базы данных.
Ограничение ввода.
Используя реляционную базу данных вы можете определить какой вид данных позволено сохранять в столбце. Вы можете создать поле, которое содержит целые числа, десятичные числа, небольшие фрагменты текста, большие фрагменты текста, даты и т.д.
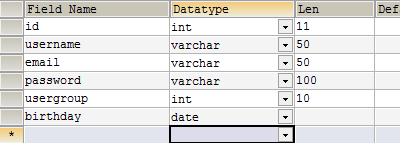
Когда вы создаете таблицу базы данных вы предоставляете тип данных для каждого столбца. К примеру, varchar – это тип данных для небольших фрагментов текста с максимальным количеством знаков, равным 255, а int – это числа.
Помимо типов данных РСУБД позволяет вам еще больше ограничить возможные для ввода данные. Например, ограничить длину или принудительно указать на уникальность значения записей в данном столбце. Последнее ограничение часто используется для полей, которые содержат регистрационные имена пользователей (логины), или адреса электронной почты.
Эти ограничения дают вам контроль над целостностью ваших данных и предотвращают ситуации, подобные следующим:
— ввод адреса (текста) в поле, в котором вы ожидаете увидеть число
— ввод индекса региона с длинной этого самого индекса в сотню символов
— создание пользователей с одним и тем же именем
— создание пользователей с одним и тем же адресом электронной почты
— ввод веса (числа) в поле дня рождения (дата)
Поддержание целостности данных.
Настраивая свойства полей, связывая таблицы между собой и настраивая ограничения, вы можете увеличить надежность ваших данных.
Назначение прав.
Большинство РСУБД предлагают настройку прав доступа, которая позволяет назначать определенные права определенным пользователям. Некоторые действия, которые могут быть позволены или запрещены пользователю: SELECT (выборка), INSERT (вставка), DELETE (удаление), ALTER (изменение), CREATE (создание) и т.д. Это операции, которые могут быть выполнены с помощью структурированного языка запросов (SQL).
Структурированный язык запросов (SQL).
Для того, чтобы выполнять определенные операции над базой данных, такие, как сохранение данных, их выборка, изменение, используется структурированный язык запросов (SQL). SQL относительно легок для понимания и позволяет в т.ч. и уложненные выборки, например, выборка связанных данных из нескольких таблиц с помощью оператора SQL JOIN. Как и упоминалось ранее, SQL в данном руководстве обсуждаться не будет. Я сосредоточусь на проектировании баз данных.
То, как вы спроектируете базу данных будет оказывать непосредственное влияние на запросы, которые вам будет необходимо выполнить, чтобы получить данные из базы данных. Это еще одна причина, почему вам необходимо задуматься о том, какой должна быть ваша база. С хорошо спроектированной базой данных ваши запросы могут быть чище и проще.
Переносимость.
Реляционная модель данных стандартна. Следуя правилам реляционной модели данных вы можете быть уверены, что ваши данные могут быть перенесены в другую РСУБД относительно просто.
Как говорилось ранее, проектирование базы данных – это вопрос идентификации данных, их связи и помещение результатов решения данного вопроса на бумагу (или в компьютерную программу). Проектирование базы данных независимо от РСУБД, которую вы собираетесь использовать для ее создания.
В следующей части подробнее рассмотрим первичные ключи.
Чтобы помочь начинающим аналитикам разобраться с основами SQL и реляционных баз данных, сегодня рассмотрим практический пример построения модели данных, заполнения таблиц значениями и генерации запросов к полученной базе. DDL-запросы для создания таблиц и примеры DML-запросов для наполнения их данными, а также выборки с условиями WHERE, GROUP BY, HAVING, операторы работы с датами и временем.
Проектирование реляционной модели (схемы базы данных)
Как я уже рассказывала здесь, системные и бизнес-аналитики часто сталкиваются с моделированием данных в рамках задачи разработки требований к ИС. Однако, зачастую простого концептуального моделирования, которое переводит ключевые сущности домена (предметной области) в плоскость программной системы, бывает недостаточно для разработки или более детального проектирования базы данных на физическом уровне. Основным фактором, определяющим ценность концептуальной модели, является возможность ее использования для дальнейшей работы. И чтобы повысить эту ценность, аналитику полезно понимать, какие именно потребности бизнеса позволит обеспечить разработанная им модель. Применительно к моделированию данных это примеры SQL-запросов.
Предположим, учебный центр, который предлагает курсы по 3-м направлениям: системный и бизнес-анализ, технологии Big Data, а также менеджмент, имеет данные о заявках слушателей на разные курсы.
Имеется каталог курсов и расписание их проведение, а также данные по потенциальным клиентам, подавшим заявки и тренерам, которые проводят курсы.
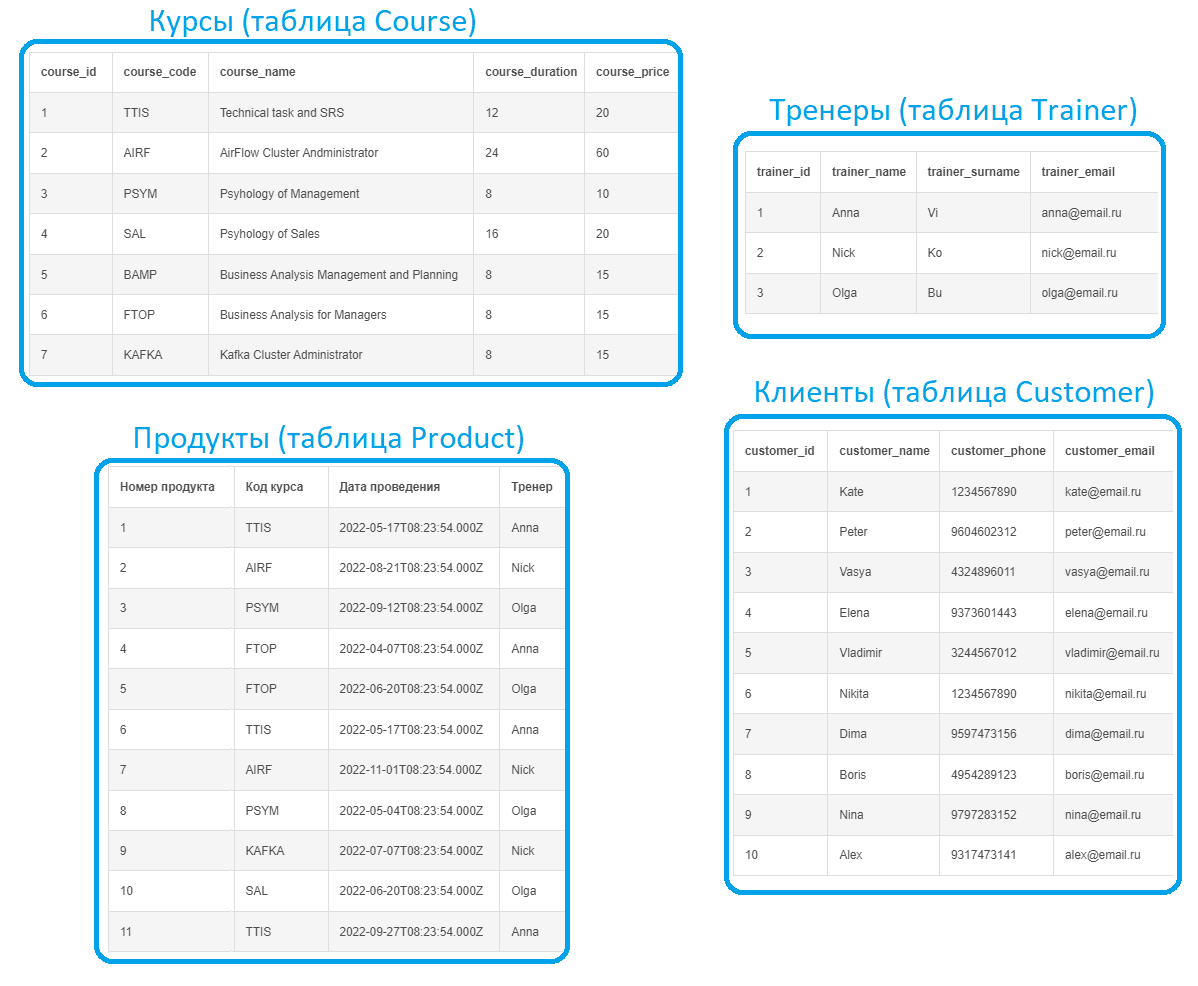
Реляционная модель данных, спроектированная для рассматриваемого случая, будет выглядеть следующим образом:
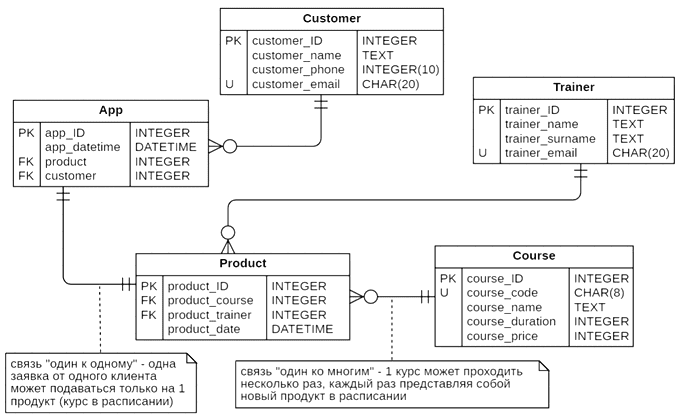
Выделено 5 сущностей, которые связаны между собой разными типами отношений. Каждая сущность в итоге представляет собой таблицу реляционной базы данных с набором столбцов, т.е. атрибутов или полей, каждое из которых содержит данные определенного типа. Поскольку база данных является реляционной, таблицы связаны между собой по ключам. Например, один тренер может вести несколько курсов. Таблица Course представляет собой каталог курсов, каждый из которых может проводиться несколько раз в разное время разными тренерами, что хранится в таблице Product. Один клиент (Customer) может подать много заявок, но каждая заявка может быть только по одному продукту.
Чтобы сократить избыточность данных в разных таблицах, проведена нормализация, т.е. приведение структуры данных к нормальной форме. В частности, данные клиентов хранятся не в таблице заявки, а выделены в отдельную таблицу Customer. Аналогичным образом данные о курсах и тренерах, которые их проводят содержатся не в таблице с расписанием (Product), а в отдельных таблицах. Это исключает транзитивную зависимость полей друг от друга. Чаще всего ER-модель приводят к 3-ей нормальной форме, когда каждая таблица атомарна и любой не ключевой атрибут в ней зависит только от первичного ключа.
В каждой таблице определен первичный ключ (Primary Key, PK),– столбец, каждое значение которого уникально и однозначно идентифицирует запись (строку) этой таблицы. Для ускорения работы базы данных в качестве первичного ключа обычно принимается целочисленный идентификатор, который реализуется автоматической генерацией поля ID с автоинкрементом, т.е. увеличением на 1 при создании новой записи. Большинство современных СУБД сами следят за этим, т.е. на уровне концептуального проектирования при описании модели предметной области, этот атрибут не обязательно добавлять в словарь данных.
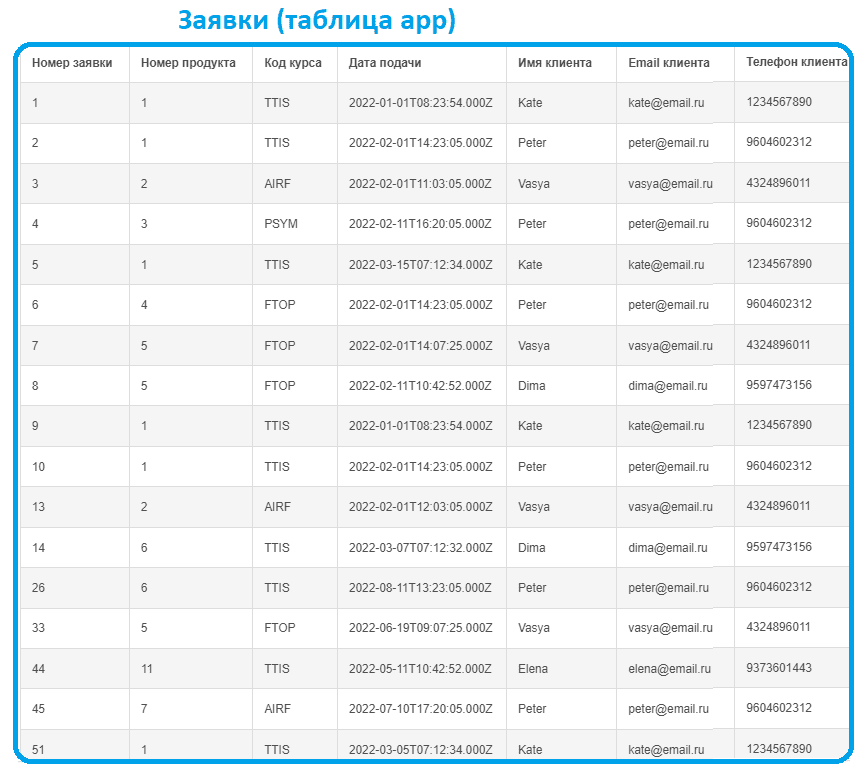
Связи между таблицами реализованы с помощью внешних ключей (Foreign Key, FK). Внешний (ссылочный) ключ показывает, что поведение записи в одной таблице (зависимой сущности) меняется при изменении или удалении записей из другой связанной таблицы (независимой сущности). Внешний ключ также нужен для объединения двух таблиц. Можно сказать, FK в одной таблице – это один или несколько столбцов, значения которых соответствуют PK в другой таблице. Связь между двумя таблицами задается через соответствие PK в одной таблице FK во второй. Например, в таблице App внешними ключами будут поля product и customer, соответствующие первичным ключам (id) в таблицах Product и Customer соответственно.
После проектирования схемы модели данных в редакторе StarUML, который я часто использую для разработки UML-диаграмм, с помощью расширения Postgresql DDL Extension for StarUML 2 для создания DDL-запросов к СУБД PostgreSQL, я получила набор SQL-команд по созданию таблиц:
CREATE TABLE public.course (
course_id integer NOT NULL,
course_code char(8) NOT NULL,
course_name text NOT NULL,
course_duration integer NOT NULL,
course_price integer NOT NULL,
PRIMARY KEY (course_id)
);
ALTER TABLE public.course
ADD UNIQUE (course_code);
CREATE TABLE public.customer (
customer_id integer NOT NULL,
customer_name text NOT NULL,
customer_phone char(10) NOT NULL,
customer_email char(20) NOT NULL,
PRIMARY KEY (customer_id)
);
ALTER TABLE public.customer
ADD UNIQUE (customer_email);
CREATE TABLE public.app (
app_id integer NOT NULL,
app_datetime timestamp with time zone NOT NULL,
product integer NOT NULL,
customer integer NOT NULL,
PRIMARY KEY (app_id)
);
CREATE INDEX ON public.app
(product);
CREATE INDEX ON public.app
(customer);
CREATE TABLE public.trainer (
trainer_id integer NOT NULL,
trainer_name text NOT NULL,
trainer_surname text NOT NULL,
trainer_email char(20) NOT NULL,
PRIMARY KEY (trainer_id)
);
ALTER TABLE public.trainer
ADD UNIQUE (trainer_email);
CREATE TABLE public.product (
product_id integer NOT NULL,
product_course integer NOT NULL,
product_trainer integer NOT NULL,
product_date timestamp with time zone NOT NULL,
PRIMARY KEY (product_id)
);
CREATE INDEX ON public.product
(product_course);
CREATE INDEX ON public.product
(product_trainer);
Автоматическая генерация DDL-запросов по спроектированной схеме сэкономила мне время на прописывание SQL-команд вручную, чтобы создать нужные таблицы, определить их атрибуты и связи между таблицами. Полученный код я внесла в бесплатный веб-движок тестирования SQL-запросов https://www.db-fiddle.com/, определив схему SQL. Там же внесла данные в мои таблицы с помощью следующих DML-запросов:
INSERT INTO app VALUES (1, '2022-01-01 10:23:54', 1, 1); INSERT INTO app VALUES (2, '2022-02-01 16:23:05', 1, 2); INSERT INTO app VALUES (3, '2022-02-01 13:03:05', 2, 3); INSERT INTO app VALUES (4, '2022-02-11 18:20:05', 3, 2); INSERT INTO app VALUES (5, '2022-03-15 09:12:34', 1, 1); INSERT INTO app VALUES (6, '2022-02-01 16:23:05', 4, 2); INSERT INTO app VALUES (7, '2022-02-01 16:07:25', 5, 3); INSERT INTO app VALUES (8, '2022-02-11 12:42:52', 5, 7); INSERT INTO app VALUES (9, '2022-01-01 10:23:54', 1, 1); INSERT INTO app VALUES (10, '2022-02-01 16:23:05', 1, 2); INSERT INTO app VALUES (13, '2022-02-01 14:03:05', 2, 3); INSERT INTO app VALUES (45, '2022-07-10 19:20:05', 7, 2); INSERT INTO app VALUES (51, '2022-03-05 09:12:34', 1, 1); INSERT INTO app VALUES (26, '2022-08-11 15:23:05', 6, 2); INSERT INTO app VALUES (33, '2022-06-19 11:07:25', 5, 3); INSERT INTO app VALUES (44, '2022-05-11 12:42:52', 11, 4); INSERT INTO app VALUES (14, '2022-03-07 09:12:32', 6, 7); INSERT INTO customer VALUES (1, 'Kate', 1234567890, 'kate@email.ru'); INSERT INTO customer VALUES (2, 'Peter', 9604602312, 'peter@email.ru'); INSERT INTO customer VALUES (3, 'Vasya', 4324896011, 'vasya@email.ru'); INSERT INTO customer VALUES (4, 'Elena', 9373601443, 'elena@email.ru'); INSERT INTO customer VALUES (5, 'Vladimir', 3244567012, 'vladimir@email.ru'); INSERT INTO customer VALUES (6, 'Nikita', 1234567890, 'nikita@email.ru'); INSERT INTO customer VALUES (7, 'Dima', 9597473156, 'dima@email.ru'); INSERT INTO customer VALUES (8, 'Boris', 4954289123, 'boris@email.ru'); INSERT INTO customer VALUES (9, 'Nina', 9797283152, 'nina@email.ru'); INSERT INTO customer VALUES (10, 'Alex', 9317473141, 'alex@email.ru'); INSERT INTO trainer VALUES (1, 'Anna', 'Vi', 'anna@email.ru'); INSERT INTO trainer VALUES (2, 'Nick', 'Ko', 'nick@email.ru'); INSERT INTO trainer VALUES (3, 'Olga', 'Bu', 'olga@email.ru'); INSERT INTO course VALUES (1, 'TTIS', 'Technical task and SRS', 12, 20); INSERT INTO course VALUES (2, 'AIRF', 'AirFlow Cluster Andministrator', 24, 60); INSERT INTO course VALUES (3, 'PSYM', 'Psyhology of Management', 8, 10); INSERT INTO course VALUES (4, 'SAL', 'Psyhology of Sales', 16, 20); INSERT INTO course VALUES (5, 'BAMP', 'Business Analysis Management and Planning', 8, 15); INSERT INTO course VALUES (6, 'FTOP', 'Business Analysis for Managers', 8, 15); INSERT INTO course VALUES (7, 'KAFKA', 'Kafka Cluster Administrator', 8, 15); INSERT INTO product VALUES (1, 1, 1, '2022-05-17 10:23:54'); INSERT INTO product VALUES (2, 2, 2, '2022-08-21 10:23:54'); INSERT INTO product VALUES (3, 3, 3, '2022-09-12 10:23:54'); INSERT INTO product VALUES (4, 6, 1, '2022-04-07 10:23:54'); INSERT INTO product VALUES (5, 6, 3, '2022-06-20 10:23:54'); INSERT INTO product VALUES (6, 1, 1, '2022-05-17 10:23:54'); INSERT INTO product VALUES (7, 2, 2, '2022-11-01 10:23:54'); INSERT INTO product VALUES (8, 3, 3, '2022-05-04 10:23:54'); INSERT INTO product VALUES (9, 7, 2, '2022-07-07 10:23:54'); INSERT INTO product VALUES (10, 4, 3, '2022-06-20 10:23:54'); INSERT INTO product VALUES (11, 1, 1, '2022-09-27 10:23:54');
Когда схема данных создана и таблицы наполнены, можно приступить к самому интересному: SQL-запросам на выборку нужных данных.
Разработка ТЗ на информационную систему по ГОСТ и SRS
Код курса
TTIS
Ближайшая дата курса
24 июля, 2023
Длительность обучения
12 ак.часов
Стоимость обучения
20 000 руб.
SQL-запросы для анализа данных
Напомню, для доступа к данным в реляционных СУБД используется язык структурированных запросов SQL (Structured Query Language) – декларативный язык программирования. Он содержит операторы определения данных (DDL), манипулирования данными (DML), определения доступа к данным (DCL) и управления транзакциями (TCL). Все эти операторы реализуют не только базовые CRUDL-операции, но и обеспечивают целостность и непротиворечивость информации. В рамках этой статьи мы рассматриваем только самые распространенные DDL- и DML-запросы. Например, следующий запрос покажет, сколько заявок подано на каждый курс:
SELECT course.course_code AS "Код курса",
course.course_name AS "Название курса",
count(*) AS aps_number
FROM app
JOIN product ON product.product_id=app.product
JOIN course ON course.course_id=product.product_course
GROUP BY app.product,
course.course_code,
course.course_name
ORDER BY aps_number DESC;
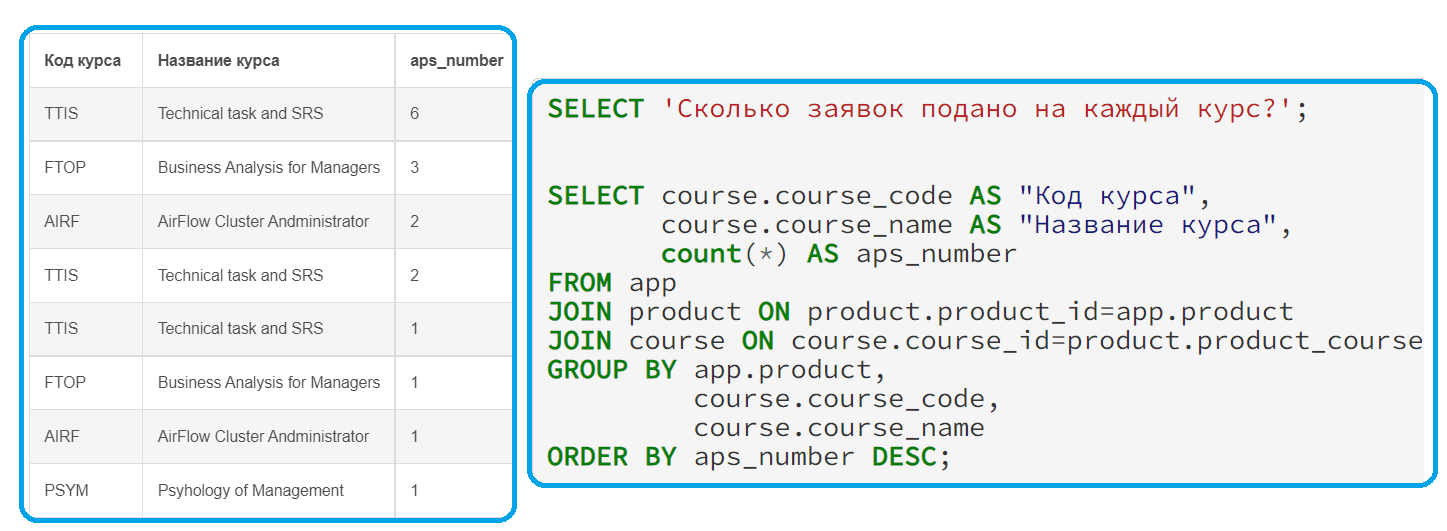
В этом запросе выполнено несколько соединений таблиц через оператор JOIN. Например, чтобы получить код и название курса, таблицу с заявками app нужно было соединить с таблицей продуктов, где указаны внешние ключи курсов, а не сами курсы. А чтобы получить название и код курса, пришлось выполнять соединение с таблицей курсов по внешним ключам, что указывается после ключевого слова ON. Для группировки заявок, поданных по одному и тому же курсу, в конце запроса добавлено выражение GROUP BY, в котором указаны поля группировки. В нашем случае некоторые из них совпадают с теми, что указаны в выборке после ключевого слова SELECT. Оператор COUNT(*) считает все строки таблицы с заявками. За сортировку по убыванию отвечает оператор ORDER BY с уточнением DESC.
Рассмотрим другой бизнес-запрос. Например, нужно определить, сколько денег на каком курсе заработает каждый тренер. На это ответит следующий SQL-запрос:
SELECT course.course_code AS "Код курса",
trainer.trainer_name AS "Тренер",
count(*)*(course.course_price) AS income
FROM product
JOIN app ON app.product=product.product_id
JOIN course ON course.course_id=product.product_course
JOIN trainer ON trainer.trainer_id=product.product_trainer
GROUP BY course.course_code,
trainer.trainer_name,
course.course_price
ORDER BY income DESC;

В этом SQL-запросе тоже появилась группировка, поскольку здесь выполняется агрегация строк по курсу. Поэтому встречается оператор GROUP BY с указанием полей, по которым выполняется группировка. Агрегатные функции, такие как расчет суммы, среднего или количества строк, выполняют вычисление на наборе ненулевых значений и возвращают одиночное значение. Исключением из этого правила является функция подсчета количества значений COUNT().
Также в запрос добавлен оператор сортировки по убыванию дохода от проведения курса, который вычисляется как произведение стоимости курса на количество поданных заявок. В свою очередь, количество заявок по определенному продукту, с которым связан курс, определяется через соединение с таблицей заявок.
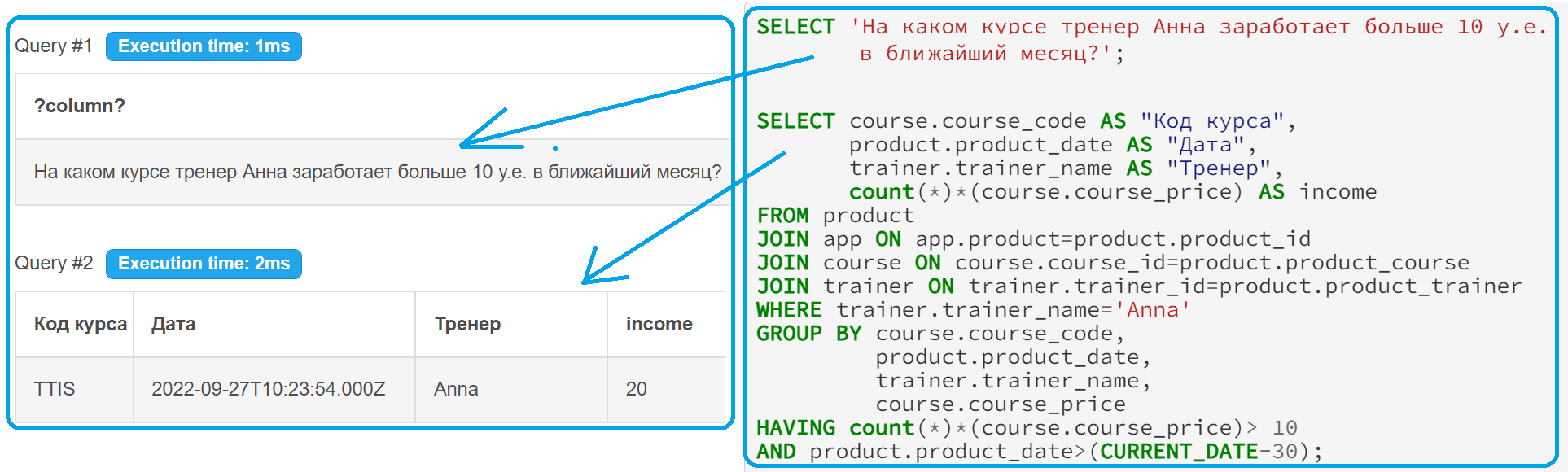
В заключение рассмотрим еще один пример с использованием группировки и фильтрации значений по агрегатным функциям через добавление HAVING после GROUP BY. Например, на каком курсе тренер Anna заработает больше 10 в ближайший месяц от текущей даты? Для этого используем следующий SQL-запрос:
SELECT 'На каком курсе тренер Анна заработает больше 10 у.е. в ближайший месяц?';
SELECT course.course_code AS "Код курса",
product.product_date AS "Дата",
trainer.trainer_name AS "Тренер",
count(*)*(course.course_price) AS income
FROM product
JOIN app ON app.product=product.product_id
JOIN course ON course.course_id=product.product_course
JOIN trainer ON trainer.trainer_id=product.product_trainer
WHERE trainer.trainer_name='Anna'
GROUP BY course.course_code,
product.product_date,
trainer.trainer_name,
course.course_price
HAVING count(*)*(course.course_price)> 10
AND product.product_date>(CURRENT_DATE-30);
Основы архитектуры и интеграции информационных систем
Код курса
OAIS
Ближайшая дата курса
29 июня, 2023
Длительность обучения
8 ак.часов
Стоимость обучения
15 000 руб.
Разумеется, в рамках это статьи не рассматривались все типы SQL-запросов и возможности этого языка. Наиболее эффективным способом освоить их будет самостоятельная работа с выполнением упражнений. Для этого есть множество открытых ресурсов, платных и бесплатных курсов, а также свободных и проприетарных инструментов. В частности, очень советую следующие онлайн-учебники и тренажеры:
- https://sql-academy.org/ru/guide
- https://learndb.ru/articles
- https://www.sql-ex.ru/
- https://stepik.org/course/63054/promo?search=882582677
Чтобы освоить все нюансы проектирования реляционных моделей и написания SQL-запросов к ним, также необходимо читать документацию и выполнять упражнения в соответствующей среде, развернув ее на своем компьютере. Например, для MySQL отлично подходит платформа MySQL Workbench (>https://www.mysql.com/products/workbench/), а для PostgreSQL можно использовать pgAdmin (>https://www.pgadmin.org/). Эти инструменты поддерживают как визуальное проектирование ER-модели, так и выполнение SQL-запросов. Они способны заменить целый набор инструментов, которые использовались при подготовке этой статьи:
- StarUML – среда разработки UML и ER-диаграмм;
- расширение Postgresql DDL Extension for StarUML 2 для создания DDL-запросов к СУБД PostgreSQL по спроектированной диаграмме;
- https://www.db-fiddle.com/ – онлайн-движок реляционных баз данных для тестирования, отладки и обмена фрагментами SQL-запросов;
- https://sqlformat.org/ – онлайн-форматер для операторов SQL, который делает код более читаемым;
- https://postgrespro.ru/docs/postgrespro/14/index – документация по Postgres Pro Standard, популярной объектно-реляционной СУБД.
В заключение отмечу, что проверить, как вы усвоили материал этой статьи можно бесплатно прямо на нашем сайте, выполнив интерактивный тест по основам баз данных и языку запросов SQL.
10 вопросов по основам теории баз данных и SQL: тест для начинающих
А подробнее познакомиться с основами реляционных СУБД и моделированием данных вам помогут курсы Школы прикладного бизнес-анализа в нашем лицензированном учебном центре обучения и повышения квалификации системных и бизнес-аналитиков в Москве:
- Основы архитектуры и интеграции информационных систем
- Разработка ТЗ на информационную систему по ГОСТ и SRS
Реляционные базы данных для чайников
Как правило, любое веб приложение можно разделить на 2 основные части: фронт-энд, где отображается вся информация сайта, и бэк-энд, где данная информация формируется и размещается. В этой статье мы поговорим о том, что такое реляционные базы данных, и как их проектировать.
База данных хранит записи в специально организованном виде, чтобы информацию можно было легко найти и извлечь. Любая БД состоит из одной или нескольких таблиц. Электронная таблица состоит из строк и столбцов. Все строки имеют одинаковые столбцы, а каждый столбец содержит данные. В общем, для лучшего понимания, определимся, что таблицы в БД очень похожи на те, что вы видели в Excel-е.

Табличные данные могут быть вставлены, восстановлены, обновлены и удалены. Для пакета этих операций была создана специальная аббревиатура CRUD (Create-Read-Update-Delete).
Реляционные базы данных – это базы, где вся информация хранится в таблицах, связанных друг с другом специальными отношениями. Эти отношения позволяют нам извлекать и объединять данные из одной или нескольких таблиц с помощью одного запроса.
Но всё это всего лишь слова. Для того чтобы действительно понять, что такое реляционные базы данных, вам нужно больше практиковаться. Давайте же начнём и посмотрим, с какими данными нам предстоит работать.
Шаг 1. Подготовка данных
Для того чтобы нам было с чем работать, я набрал в твиттере запрос “#databases” и сформировал таблицу из 10 записей:
Таблица 1
| full_name | username | text | created_at | following_username |
|---|---|---|---|---|
| Boris Hadjur | _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 | Scootmedia, MetiersInternet |
| Gunnar Svalander | GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 | klout, zillow |
| GE Software | GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 | DayJobDoc, byosko |
| Adrian Burch | adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 | CindyCrawford, Arjantim |
| Andy Ryder | AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 | MichaelDell, Yahoo |
| Andy Ryder | AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 | MichaelDell, Yahoo |
| Brett Englebert | Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 | RealSkipBayless, stephenasmith |
| Brett Englebert | Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 | RealSkipBayless, stephenasmith |
| Nimbus Data Systems | NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 | dellock6, rohitkilam |
| SSWUG.ORG | SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 | drsql, steam_games |
В первую очередь, давайте разберёмся с колонками:
- full_name: имя пользователя
- username: логин в Twitter-е
- text: текст твита
- created_at: время создания твита
- following_username: список пользователей, разделённых запятыми, которые подписались на этот твитт. Для краткости я сократил этот список до 2 имён.
Это реальные данные. Если хотите, вы можете их найти и обновить.
Хорошо. Теперь все наши данные находятся в одном месте. Даёт ли это нам возможность легко осуществить поиск по ним? Не совсем. Данная таблица далека от идеала. Во-первых, в некоторых столбцах у нас есть повторяющиеся записи: к примеру, в х “username” и “following_username”. Также колонка “following_username” нарушает правила реляционных моделей, т.к. её в ячейках присутствует более 1 значения (записи разделены запятыми).
К тому же у нас попадаются дубликаты и в строках.
Повторяющиеся данные действительно являются проблемой, т.к. они затрудняют процесс CRUD. К примеру, при поиске по данной таблице на обработку дубликатов будет уходить дополнительное время. К тому же, если пользователь обновит твитт, то нам нужно будет перезаписать все дубликаты.
Решение данной проблемы заключается в разделении Таблицы 1 на несколько таблиц. Давайте примемся за решение первой проблемы, а именно – устранение дубликатов в столбцах.
Шаг 2. Избавляемся от дубликатов в столбцах
Как было оговорено выше, столбцы “username” и “following_username” содержат дубликаты данных. Они возникли в результате того, что я хотел отобразить отношения между твиттами и пользователями. Давайте улучшим нашу структуру БД, разделив существующую таблицу на две: в одной будем хранить информацию, а в другой – отношения между записями.

Поскольку @Brett_Englebert подписан на @RealSkipBayless, то в таблице “following” отобразим это следующим образом: имя @Brett_Englebert поместим в колонку “from_user”, а @RealSkipBayless в “to_user.” Давайте посмотрим, как будет выглядеть таблица “following” после разделения Таблицы 1:
Таблица 2. following
| from_user | to_user |
|---|---|
| _DreamLead | Scootmedia |
| _DreamLead | MetiersInternet |
| GunnarSvalander | klout |
| GunnarSvalander | zillow |
| GEsoftware | DayJobDoc |
| GEsoftware | byosko |
| adrianburch | CindyCrawford |
| adrianburch | Arjantim |
| AndyRyder | MichaelDell |
| AndyRyder | Yahoo |
| Brett_Englebert | RealSkipBayless |
| Brett_Englebert | stephenasmith |
| NimbusData | dellock6 |
| NimbusData | rohitkilam |
| SSWUGorg | drsql |
| SSWUGorg | steam_games |
Таблица 3. users
| full_name | username | text | created_at |
|---|---|---|---|
| Boris Hadjur | _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 |
| Gunnar Svalander | GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 |
| GE Software | GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 |
| Adrian Burch | adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 |
| Andy Ryder | AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 |
| Andy Ryder | AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 |
| Brett Englebert | Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 |
| Brett Englebert | Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 |
| Nimbus Data Systems | NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 |
| SSWUG.ORG | SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 |
Уже лучше. Теперь в таблице “users” (Таблица 3) у нас хранится только информация о твиттах, а в таблице following (Таблица 2) – зависимость пользователей.
Основатель теории реляционных баз данных, Эдгар Кодд, назвал бы этот процесс (удаления повторений из столбцов таблиц) приведением БД к первой нормальной форме.
Шаг 3. Удаление повторений из строк
Теперь мы займёмся устранением других проблем, а именно, избавимся от дубликатов в строках таблицы “users”. Поскольку пользователи @AndyRyder5 и @Brett_Englebert разместили по несколько твиттов, то их имена в таблице “users” (Таблица 3) дублируются в колонке full_name. Данная проблема также решается разделением таблицы “users”.

Поскольку текст твитта и время его создания являются уникальными данными, то их мы поместим в одну и ту же таблицу. Также нам нужно указать связь между твитами и пользователями. Для этого я создал специальный столбец username.
Таблица 4. tweets
| username | text | created_at |
|---|---|---|
| _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 |
| GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 |
| GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 |
| adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 |
| AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 |
| AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 |
| Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 |
| Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 |
| NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 |
| SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 |
Таблица 5. users
| full_name | username |
|---|---|
| Boris Hadjur | _DreamLead |
| Gunnar Svalander | GunnarSvalander |
| GE Software | GEsoftware |
| Adrian Burch | adrianburch |
| Andy Ryder | AndyRyder5 |
| Brett Englebert | Brett_Englebert |
| Nimbus Data Systems | NimbusData |
| SSWUG.ORG | SSWUGorg |
После разделения в таблице users (Таблица 5) у нас присутствуют уникальные (не повторяющиеся) строки.
Данный процесс удаления дубликатов из строк называется приведением ко второй нормальной форме.
Шаг 4. Объединяем таблицы на основе ключей
Итак, в результате наших действий, Таблица 1 была разбита на 3 части: following (Таблица 2), tweets (Таблица 4), users (Таблица 5). Все дубликаты устранены. Для того чтобы в дальнейшем мы могли с лёгкостью извлекать данные из этой структуры, независимые друг от друга таблицы мы должны связать специальными отношениями, которые будут давать нам информацию о том, какому пользователю принадлежит какой твит, и кто на кого подписан.
Для создания связей между записями нам необходимо ввести уникальный идентификатор, который называется первичный ключ.
Вообще говоря, в Таблице 4 и 5 мы уже это сделали. В таблице “users” первичным ключом является колонка “username”, потому что логин пользователя должен быть уникальным значением и не может повторяться. В таблице “tweets” мы используем данный ключ для обозначения связи между пользователем и твитом. Колонка “username” в таблице “tweets” называется внешним ключом.
Если вы когда-то работали с базами данных, то у вас может возникнуть вопрос: можем ли мы использовать колонку “username” в качестве первичного ключа?
С одной стороны, это может упростить процесс поиска, ведь мы не используем никаких числовых ID. С другой стороны, что если пользователь захочет поменять свой логин? Это может привести к огромному количеству проблем. Для того чтобы не попасть в подобную ситуацию, лучше воспользоваться числовыми ID. Всё зависит от вашей системы. Если вы предоставляете вашим пользователям возможность менять логины, то лучше в качестве первичного ключа использовать автоинкрементированное числовое поле ID. В противном случае, колонка “username” вполне подойдёт для этой роли. Я оставлю всё как есть.
Давайте посмотрим на таблицу tweets (Таблица 4). Первичный ключ должен быть уникальным для каждой строки. Какую колонку в данной таблице мы можем выбрать для этой роли? Колонка “created_at” не подойдёт, т.к. в принципе 2 разных пользователя могут в одно и то же время опубликовать запись. С колонкой “text” та же история: два разных пользователя могут создать твит с текстом “Hello World”. Колонка “username” в данной таблице является внешним ключом для обозначения связи между пользователем и твитом. Итак, поскольку все возможные варианты нам не подходят, то лучшим решением будет добавление колонки id, которая будет первичным ключом для данной таблицы.
Таблица 6. tweets с колонкой id
| ID | username | text | created_at |
|---|---|---|---|
| 1 | _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 |
| 2 | GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 |
| 3 | GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 |
| 4 | adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 |
| 5 | AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 |
| 6 | AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 |
| 7 | Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 |
| 8 | Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 |
| 9 | NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 |
| 10 | SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 |
С таблицей following можем сделать то же самое, т.к. ни одна существующая колонка не подойдёт на роль первичного ключа. Колонки “from_user” и “to_user” являются внешними ключами и обозначают связь между подписками пользователей.
Итак, к этому моменту мы уже много чего сделали. Избавились от дублирующей информации в колонках и строках и выбрали для наших таблиц подходящие колонки на роль первичных и внешних ключей для обозначения зависимостей между данными. Данный процесс называется нормализацией и предназначен для приведения ваших таблиц под реляционную модель. Благодаря нормализации мы можем более простым образом реализовывать операции CRUD.
Ниже вы можете увидеть схему наших таблиц и связей между ними:

Системы Управления Базами Данных
Теперь, когда у нас есть реляционная БД, каким образом мы можем её имплементировать? Для этого мы можем воспользоваться системами управления базами данных (СУБД). Существует целый набор подобных программ, как платных, так и бесплатных. Среди платных можно выделить Oracle Database, IBM DB2 и Microsoft SQL Server. Бесплатные: MySQL, SQLite и PostgreSQL.
Чаще всего различные компании используют MySQL. Twitter в этом смысле – не исключение.
SQLite чаще используется при разработке приложений для iOS и Android, где хранится различного рода конфиденциальная информация. Браузер Google Chrome использует SQLite для хранения истории просмотров, кукисов, изображений…
PostgreSQL используется реже. Для неё существует полезное расширение PostGIS, которое делает данную СУБД удобной для хранения геолокационных данных. К примеру сервис OpenStreetMap исользует PostgreSQL.
Язык структурированных запросов (SQL)
После того, как вы выбрали подходящую для вас СУБД и установили её, следующим шагом было бы создание таблиц и управление данными. Для этого мы можем воспользоваться специальным языком SQL.
Создание БД development:
CREATE DATABASE development;
Создание таблицы Users:
CREATE TABLE users ( full_name VARCHAR(100), username VARCHAR(100) );
При создании полей нам необходимо указать тип хранимой информации и её размер. Колонки “full_name” и “username” будут типа VARCHAR, который предназначен для хранения строк символов. Размер 100 символов. Список всех типов вы можете найти тут.
Добавление записи:
INSERT INTO users (full_name, username)
VALUES ("Boris Hadjur", "_DreamLead");
Извлечение всех записей пользователя _DreamLead:
SELECT text, created_at FROM tweets WHERE username="_DreamLead";
Обновление записи:
UPDATE users SET full_name="Boris H" WHERE username="_DreamLead";
Удаление записи:
DELETE FROM users WHERE username="_DreamLead";
SQL очень похож на человеческий язык (английский). В каждом СУБД SQL обладает рядом собственных особенностей и различий, но в целом, все разновидности SQL похожи друг на друга.
Итог
В этом уроке мы разобрали процесс создания реляционной БД, взяли набор данных и распределили их по таблицам, согласно реляционной модели. Также мы быстро пробежались по существующим СУБД и языку SQL.
