Рассказываю о том как недавно довелось разрабатывать ПО для чтения книг FB2 онлайн
Нынче выдался хороший год. Есть несколько хороших проектов, которые я со временем непременно опубликую.
Сегодня я хочу рассказать как раз о таком проекте – онлайн-читалка для FB2 формата. Но сначала немного предыстории.
Начало разработки
Наш старый партнер – магазин OldieWorld решил развиваться дальше и разработать онлайн читалку для каталога своих книг.
Первым делом необходимо выбрать формат из доступных нам. Почти все книги имели формат FB2, EPUB, PDF, TXT. То есть выбрать мы можем FB2 или EPUB, так как они имеют данные разметки. Выбор был очевиден. Я выбрал FB2, так как мне он казался проще, все таки это по сути простой XML.
Как и любой другой разработчик я пошел в гугл искать готовые решения для парсинга FB2 формата. Но к великому сожалению готовых решений довольно мало. Единственный пакет, который мне показался взрослым – GitHub – tizis/FB2-Parser: Simple FB2 to HTML converter.
Но я не смог его завести.
В итоге намучившись с поиском готовых решений я принялся писать свой велосипед.
Разработка FB2 транслятора (Backend)
Первым делом пришла в голову мысль воспользоваться классом SampleXMLObject и поначалу это себя оправдывало. Я спокойно распарсил контент и описание книги, но выяснилось одно, но. Книга в формате FB2 содержит микро-разметку. Вот пример:

Мы видим
section – это страница или глава
p – параграф. Section может содержать еще овер-много section, а каждый другой тег title или p может содержать другую дичь в виде тегов empharsis, strong, poem и др.
Все это поставило точку на использовании SampleXMLObject ибо эта скотина конвертирует xml в достаточно плоский объект. То есть структура книги не сохраняется. А сохранение структуры очень важно, ибо для трансляции разметки как в книге необходимо много рекурсии.
Пришлось искать другие способы и благо таковы были. Я нашел для себя класс DOMDocument.
Мне он показался крайне экзотичным, но со своей задачей он справляется хорошо. Данный класс представляет XML файл в виде DOM дерева и содержит необходимые методы для перемещения по нему прямо как в JavaScript. Например, есть метод:
$body = $document->getElementsByTagName('body')Данный метод позволяет получить данные тега. Но не все так просто. Если вы попытаетесь получить тег таким образом, то вам выдадут экземпляр другого класса который уже называется DOMElement и содержит свои методы для работы.
Например, вы можете получить дочерние узлы:
$body->childNodesПолучить родителя:
$body->parentNodeПолучить текстовую ноду:
$body->nodeValueИзучив DOMDocument я принялся за работу. Пришлось потратить 5 полных рабочих дней, что бы выкатить рабочий прототип. Отдельной головной болью была разработка транслятора xml -> html. На текущий момент этот метод выглядит так:
/**
* Рекурсивно распарсить в html в узле DOM
* @param $element
* @return string|null
*/
protected function parseHtml($element, $clear_node = false): ?string
{
$content = '';
if (!isset($element->childNodes)) {
return null;
}
foreach ($element->childNodes as $child_element) {
$tag_start = '';
$tag_end = '';
$node = $child_element->nodeName;
// Обработка тегов (под каждый тег одно условие)
if ($node == 'Название тега') {
$tag_start = 'Открытие html тега';
$tag_end = 'Закрытие html тега';
}
// Не обрабатывать вложенную секцию
if ($node == 'section') {
continue;
}
// Вернуть чистый текст без обработки
if (isset($child_element->nodeValue) and $clear_node) {
$content .= $child_element->nodeValue;
continue;
}
// Если есть дочерние ноды вызвать рекурсивно
if ($child_element->childNodes->length) {
$content .= $tag_start . $this->parseHtml($child_element) . $tag_end;
} else {
$content .= ($tag_start . $child_element->nodeValue . $tag_end);
}
}
return $content;
}Работает достаточно просто. Мы можем передать секцию FB2 книги и на выходе получим html код в виде строки. Метод сам, рекурсивно обработает все дочерние узлы. Условия в этом методе проверяют имена тегов (узлов) и в зависимости от того какой тег в цикле устанавливают название тегов html и css классы.
На удивление обработка книги размеров 12мб занимает неприлично мало времени. Мне казалось такая дура будет жрать ресурсы, но на деле все куда проще. Но я все равно запилил кеширование тк., книги я получаю из приватного облака Amazon, поэтому кеш необходим, что бы пользователь не перекачивал книгу при каждом запросе.
В общем распарсить разметку было несложно, но что делать с картинками?
Оказывается картинки зашиты в формат и хранятся в виде бинарных данных. Вот как это выглядит.

Да выглядит ужасно. Но на деле все куда проще чем кажется с первого взгляда. Оказывается можно пропихнуть тегу атрибуту тега img src=bin и он это схавает. Конечно, код одной картинки это ДЕСЯТКИ ТЫСЯЧ таких символов и для любого разработчика будет сюрприз увидеть это в своем редакторе кода.
Я все же не извращенец, поэтому для улучшения результата просто кодируем эту простыню в base64. Сделать это не сложно (используется twig):
src="data:image/jpeg;base64,{{image}}"Это все премудрости формата.
Внешний вид приложения (FrontEnd)
Хотелось воплотить что-то по-настоящему удобное. Так как индексировать книжки нам не надо руки можно развязать, и построить интерфейс в виде SPA приложения.
Я терпеть не могу vue, angular, react хотя бы потому что я Backend разработчик. Да и эти фреймворки довольно тяжелые. Их избыточный функционал мне тоже не нужен.
А у кого нет таких минусов? Правильно, добро пожаловать в alpine.js.
С этим фреймворком я познакомился недавно переписывая интерфейс своей CRM системы. И функционал Alpine мне зашел. Плюс он до безобразия прост.
Дизайн решил сделать минималистичным в серо-белых тонах. Далее со скриншотами.

При переходе по ссылке на книгу нас встречает обложка. В данном примере у нас отрывок, поэтому есть кнопка купить. У зарегистрированного пользователя в этом месте кнопка – библиотека. Есть кнопка для перехода в полноэкранный режим.
Переключение страниц (глав) работает через кнопки в подвале, кнопке оглавление или кнопками на клавиатуре (A, D).

Шапка, подвал и боковая панель в постоянной фиксации. Это очень удобно. Если мы читаем книгу было бы грустно постоянно листать пол книги для доступа к элементам управления.

В настройках реализовано изменение размера текста, межстрочного интервала и ночная тема для вампиров. Все изменения происходят реактивно без каких либо перезагрузок. Спасибо Альпайну.
Зарегистрированный пользователь может не покидать читалку, выбор доступен прямо в интерфейсе.
Мобильный интерфейс полностью аналогичен по возможностям с десктопом. Более того концептуально он так же удобен.

Шапка, подвал, боковая панель зафиксированны.

Вот так выглядит выбор книги из библиотеки.

Оглавление

Настройки
В настоящий момент читалка готова, вы можете ее пощупать почитав бесплатную книжку в магазине олди – oldieworld.com/reader/demo/313.
Всем спасибо кто читает. Отдельно спасибо Миру Олди за доверие и многолетнее сотрудничество.
-
-
July 1 2013, 20:13
- История
- Литература
- Наука
- Cancel
правила составления ридера
КАК ДЕЛАТЬ РИДЕР
Структура ридера
Ридер состоит из трёх обязательных частей: исторические источники и произведения изобразительного искусства, художественная литература, научная литература.
Каждый текст ридера сопровождается:
1. Краткой исторической справкой, краткой информацией об авторе и минимальным комментарием к непонятным словам и фактам, в тексте упоминаемым
2. Датой написания текста
3. Правильно оформленным библиографическим описанием текста (даже если текст берётся из интернета)
4. Ключевыми словами текста. Рубрики ключевых слов, которые должны быть по максимуму отражены в списках ключевых слов после текстов:
a Хронология: век, дата, исторический период
b География: упоминаемые места
c Ключевые термины и категории
d Писатель
e Название произведения
f Литературные мотивы, сюжеты
g Имена (герои / исторические деятели)
Все тексты обязательно даются в сокращении – в тексте выделяется самое главное для темы ридера. Пропуски отмечаются знаком <…>.
В конце ридера приводится максимально полная библиография по теме ридера (в сам ридер включаются только основные тексты).
Факультативно: после каждого текста можно помещать «задания для самопроверки» — краткие вопросы на понимание прочитанного текста.
Советы по подготовке ридера
· Отбирать только самое важное и интересное.
· Ориентироваться не на первое найденное в интернете, а на надёжные (авторитетные в науке) источники.
· Запрещено использовать сайты рефератов и сочинений
by  skq ААС
skq ААС
Уровень сложности
Простой
Время на прочтение
13 мин
Количество просмотров 12K
Привет, Хабр!
Недавно мне для личных целей потребовалось написать читалку FB2. И сразу я столкнулась с тем, что информации по теме минимум. Палочка-выручалочка под названием ChatGPT выдал что-то невразумительное в ответ на довольно подробный запрос. К тому же, никаких готовых библиотек, чтобы по-быстренькому наваять ридер, я также не смогла обнаружить. Хотя искала долго и упорно, как Чубакка расческу.
Все это привело меня к закономерному выводу, что сначала нужно изучить формат FB2. А потом подумать, как прочитать его стандартными способами и вывести на экран. После того, как я немного разобралась со структурой FB2, начала догадываться, почему нет готовых библиотек. Дело в том, что этот формат довольно простой, и нет особой необходимости писать для него отдельную библиотеку. Можно довольно быстро наваять свой код, который будет читать практически все файлы FB2. И вы сможете убедиться в этом, если дочитаете статью до конца.
А раз все так просто, зачем я пишу эту статью? Для этого у меня есть две причины. Во-первых, это моя первая проба пера на Хабре. А во-вторых, возможно, это сэкономит кучу времени другому такому же новичку, как я. Ну, или пригодится какому-нибудь студенту, который пишет реферат.
Что из себя представляют файлы FB2
Итак, начнем с краткого описания формата. Откроем первый попавший под руку файл FB2 в блокноте, и мы увидим, что это обычный XML.

Стандартная структура файла включает три крупных блока:
<FictionBook>
<description>
Куча элементов с разной информацией о книге, такой как имя,
фамилия автора, название, краткое описание, обложка и т.д.
</description>
<body>
Собственно текст книги
</body>
<binary>
Base64 код картинки
</binary>
<binary>
...
</binary>
... еще много binary элементов
</FictionBook>Наша задача заключается в том, чтобы вытащить содержимое этих блоков. Контент из description и body можно, немного подредактировав, отобразить как html-код с помощью такого инструмента JavaFX, как WebView. А над binary-элементами придется сначала чуточку пошаманить. Дело в том, что они представляют собой бинарный код в формате Base64, что выглядит примерно так:

Иными словами, это огромный блок сплошных символов. И все это безобразие находится в конце файла FB2. Нам нужно будет не только извлечь весь этот код из FB2, но и отделить картинки друг от друга. А потом сохранить их как нормальные изображения в формате JPG, PNG или GIF.
Подготовка к работе над читалкой FB2
Итак, для работы нам понадобится среда разработки Eclipse IDE. У меня на момент написания статьи установлена версия 4.25.0. Наводим мышку на главное меню, нажимаем File, выбираем пункт New, а затем Project…

Далее в открывшемся окошке в разделе Maven выбираем Maven Project и жмем Next.

В следующем окне ставим галочку напротив пункта Create a simple project и снова жмем Next.

В окне под названием New Maven Project заполняем поля Group Id и Artifact Id примерно как на следующей картинке. После этого можно смело жать Finish.

Eclipse создаст новый проект, который появится в левой колонке под названием Package Explorer.

Потом щелкаем правой кнопкой мыши по строчке src/main/java, выбираем в выпавшем списке пункт New, а затем Package.

.Заполняем поле Name в открывшемся окне в точности как на картинке.

В левой колонке (Package Explorer) появится новая строка com.example. Клацаем по ней правой кнопкой мыши, выбираем пункт New, а затем Class. В появившемся окне заполняем поле Name как на картинке ниже. Также нужно поставить галочку в поле public static void main.

В центральной колонке откроется файл FbReader.java, в котором будем писать весь основной код. Также нам понадобится файл pom.xml. В него мы будем вставлять зависимости Maven. Они нужны для того, чтобы подключались все необходимые для работы программы плагины. Файл pom.xml также нужно открыть для редактирования. Для этого отыщите его в левой колонке (Package Explorer) и дважды щелкните по нему мышкой. Когда будете производить какие-либо изменения в этих файлах, не забывайте их сохранять (пункт верхнего меню File, затем Save All).
Чтобы программа работала корректно, нам нужно сделать еще пару настроек. В Package Explorer выберите пункт JRE System Library, а затем Properties.

Далее потребуется сменить версию JRE на JavaSE-1.8 (jdk-19.0.2). Если в списке у вас нет такого пункта, погуглите, чтобы узнать, как установить нужную версию. Мы на этом останавливаться сейчас не будем.

И последняя настройка. В Package Explorer (левая колонка) выбираем наш проект, жмем на него правой кнопкой мыши, открываем Properties, находим пункт Run/Debug Setting, затем жмем New…, выбираем Java Application и подтверждаем выбор, нажав на ОК.

В новом окне выбираем Main class (как на картинке).

Затем переходим на вкладку Arguments и заполняем поле VM Arguments так, как показано на картинке. Жмем ОК, а потом Apply and Close.

На этом предварительные настройки завершены. Можно переходить к написанию кода.
Пошаговое написание читалки FB2 на Java
I этап. Создание временной папки и файла для тестов
Первым делом создадим временную папку, в которую будем складывать ресурсы (картинки, временный файл с текстом и др.). Одновременно напишем метод для удаления временной папки после завершения работы программы.
Но сначала нужно найти какой-нибудь файл в формате FB2 для тестов и сохранить его в папку проекта. Сразу запишем путь к этому файлу в строковую переменную EPUB_FILE. Создадим метод для копирования файлов и воспользуемся им для переноса тестового FB2 во временную папку. Изменим расширение скопированного файла на txt.
Добавим следующий код в файл FbReader.java:
import java.awt.image.BufferedImage;
import java.io.BufferedReader;
import java.io.ByteArrayInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.StandardCopyOption;
import java.util.ArrayList;
import java.util.Base64;
import java.util.Base64.Decoder;
import javax.imageio.ImageIO;
import org.mozilla.universalchardet.UniversalDetector;
import javafx.application.Application;
import javafx.scene.Scene;
import javafx.scene.control.Alert;
import javafx.scene.control.Alert.AlertType;
import javafx.scene.layout.BorderPane;
import javafx.scene.web.WebEngine;
import javafx.scene.web.WebView;
import javafx.stage.Stage;
import javafx.stage.WindowEvent;
public class FbReader extends Application {
// Путь к тестовому файлу FB2
private static final String EPUB_FILE = "test.fb2";
public static void main(String[] args) {
launch(args);
}
public void start(Stage stage) throws Exception {
stage.setTitle("FBReader: программа для чтения книг FB2");
// Создаем временную папку в папке проекта
String filePath = new File("").getAbsolutePath();
Path tempDir = Files.createTempDirectory(Paths.get(filePath), "temp");
// Каталог, в который нужно сохранить все ресурсы
String outputDir = String.valueOf(tempDir) + "\";
// Создаем копию файла и переименовываем расширение в txt
try {
copyFile(new File(EPUB_FILE), new File(outputDir + "temp.txt"));
} catch (java.nio.file.NoSuchFileException e) {
Alert alert = new Alert(AlertType.WARNING);
alert.setTitle("Файл не найден");
alert.setHeaderText("Ошибка при открытии файла");
alert.setContentText("Такого файла не существует.");
alert.showAndWait();
File tmpFls = new File(String.valueOf(tempDir));
deleteDir(tmpFls);
}
}
// Метод для удаления временной папки
private static void deleteDir(File tmpFls) {
File[] contents = tmpFls.listFiles();
if (contents != null) {
for (File f : contents) {
if (! Files.isSymbolicLink(f.toPath())) {
deleteDir(f);
}
}
}
tmpFls.delete();
}
// Метод для копирования файла
public static void copyFile(File src, File dest) throws IOException {
Files.copy(src.toPath(), dest.toPath(), StandardCopyOption.REPLACE_EXISTING);
}
}Если программа не обнаружит наш тестовый FB2, она выкинет окошко (Alert) с сообщением о ненайденном файле и удалит временную папку.
На данном этапе потребуется добавить следующие зависимости в файл pom.xml:
<dependencies>
<dependency>
<groupId>org.openjfx</groupId>
<artifactId>javafx-controls</artifactId>
<version>16</version>
</dependency>
<dependency>
<groupId>org.openjfx</groupId>
<artifactId>javafx-graphics</artifactId>
<version>16</version>
</dependency>
<dependency>
<groupId>org.openjfx</groupId>
<artifactId>javafx-base</artifactId>
<version>16</version>
</dependency>
</dependencies>II этап. Сохранение в переменную всего содержимого FB2
После того, как мы создали временную папку для хранения ресурсов и переместили туда тестовый файл, нам нужно будет вытащить из него абсолютно все, что в нем есть. И на этом моменте у меня возникла первая сложность. Дело в том, что по умолчанию Java работает с текстами в кодировке UTF-8. А мой тестовый файлик был совсем в другой кодировке (Windows-1251). Подозреваю, что у других книг FB2 могут встречаться всякие разные варианты кодировок. Но это не точно.
Поэтому нам нужно программно определить кодировку файла, а затем перекодировать его содержимое в UTF-8. Добавим код в наш класс FbReader.java:
// Получение всего текста из файла temp.txt
String tempFilePath = outputDir + "temp.txt";
String charset = detectCharset(tempFilePath);
String content = readText(tempFilePath, charset);А еще напишем два метода, первый из которых служит для определения кодировки текстового файла. А второй — для чтения содержимого этого файла, извлечения данных, кодировки в UTF-8 и записи в переменную String.
// Метод для определения кодировки текстового файла
private static String detectCharset(String filePath) {
try (InputStream inputStream = new FileInputStream(filePath)) {
byte[] bytes = new byte[4096];
UniversalDetector detector = new UniversalDetector(null);
int nread;
while ((nread = inputStream.read(bytes)) > 0 && !detector.isDone()) {
detector.handleData(bytes, 0, nread);
}
detector.dataEnd();
return detector.getDetectedCharset();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
// Метод для чтения содержимого текстового файла, извлечения данных,
// кодировки в UTF-8 и записи в переменную String
private static String readText(String filePath, String charset) {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(
new FileInputStream(filePath), charset))) {
StringBuilder builder = new StringBuilder();
String line;
while ((line = reader.readLine()) != null) {
builder.append(line).append("n");
}
return builder.toString();
} catch (IOException e) {
e.printStackTrace();
}
return null;
} Чтобы все заработало как надо, в pom.xml добавим зависимость:
<dependency>
<groupId>com.googlecode.juniversalchardet</groupId>
<artifactId>juniversalchardet</artifactId>
<version>1.0.3</version>
</dependency>III этап. Извлечение текстового контента
Теперь, когда мы вытащили все содержимое FB2 файла, перекодировали его в UTF-8 и записали в строковую переменную, можно приступать к самому интересному. А именно, к извлечению частей текста и картинок. Для получения содержимого элементов description, body и binary мы будем использовать стандартные операции Java со строковыми переменными. На этом шаге займемся исключительно description и body.
Добавим следующий код в класс FbReader.java:
// Получение текста элемента description
int start = content.indexOf("<description>");
int end = content.lastIndexOf("</description>");
end = end + 14;
char[] dest = new char[end - start];
content.getChars(start, end, dest, 0);
String description = new String(dest);
description = description.replace("image l:href="#", "img src="file://"
+ tempDir.toString().replace("\","/") + "/");
// Получение текста между тегами body
int startBody = content.indexOf("<body>");
int endBody = content.lastIndexOf("</body>");
endBody = endBody + 7;
char[] dst = new char[endBody - startBody];
content.getChars(startBody, endBody, dst, 0);
String body = new String(dst);
body = body.replace("image l:href="#", "img src="file://"
+ tempDir.toString().replace("\", "/") + "/");Таким образом, мы получили содержимое элементов description и body из файла FB2. Одновременно с этим мы немножко подредактировали теги картинок, чтобы они корректно отображались в дальнейшем. Для этого нам понадобилось заменить невалидный для отображения в формате HTML код элементов image на соответствующие теги. Также мы прописали путь к картинкам, указав временную директорию. Именно в эту папку мы на следующем этапе и будем сохранять картинки.
IV этап. Извлечение картинок и сохранение во временную папку
На данном шаге нам придется хорошо постараться. Но все усилия будут не напрасны. Сначала мы вытащим из нашего многострадального текстового файла вообще все binary элементы и сохраним их в строковую переменную. Затем создадим цикл и два массива. Мы последовательно будем проходиться по всем элементам binary. Код Base64 изображений для каждого отдельного элемента будем сохранять в один массив, а имя файла картинки — во второй.
В конце мы сохраним картинки в нашу временную директорию. Но сначала перекодируем их из формата Base64 и получим байтовый массив. Это позволит нам получить отдельные файлы картинок в привычных форматах (JPG, PNG, GIF) и сохранить их во временную папку.
Вносим следующие изменения в класс FbReader.java:
// Получение текста со всеми картинками (binary)
int startBin = content.indexOf("<binary");
int endBin = content.lastIndexOf("</binary>");
if(startBin != -1 || endBin != -1) {
endBin = endBin + 9;
char[] dstb = new char[endBin - startBin];
content.getChars(startBin, endBin, dstb, 0);
String binContent = new String(dstb);
//System.out.println(binContent);
// Объявляем массивы для данных о картинках
ArrayList<String> binCode = new ArrayList<>();
ArrayList<String> binImg = new ArrayList<>();
// Получение отдельных binary
do {
int nextBin = binContent.indexOf("<binary");
int lastBin = binContent.indexOf("</binary>");
if(nextBin != -1) {
lastBin = lastBin + 9;
// Получение первой из оставшихся binary
char[] dstBin = new char[lastBin - nextBin];
binContent.getChars(nextBin, lastBin, dstBin, 0);
String binaryEl = new String(dstBin);
// Удаление текущей картинки из текста со всеми картинками
binContent = binContent.replace(binaryEl, "");
// Удаление закрывающего тега binary из текущей картинки
binaryEl = binaryEl.replace("</binary>", "");
// Получение строки с открывающим тегом binary
int findString = binaryEl.indexOf(">");
String tag = binaryEl.substring(0,findString + 1);
// Удаление открываюшего тега из картинки
binaryEl = binaryEl.replace(tag, "");
// Получение названия картинки
int findId = tag.indexOf("id=");
findId = findId + 4;
String imageName = tag.substring(findId);
int newFindId = imageName.indexOf(""");
String delText = imageName.substring(newFindId);
imageName = imageName.replace(delText, "");
// Кладем данные о картинках в массивы
binCode.add(binaryEl);
binImg.add(imageName);
} else {
break;
}
} while(binContent.indexOf("<binary") != -1);
// Сохраняем картинки во временную директорию temp
for(int i = 0; i < binCode.size(); i++) {
// Декодируем код Base64 картинок и сохраняем как байтовый массив
Decoder decoder = Base64.getMimeDecoder();
byte[] decodedBytes = decoder.decode(binCode.get(i));
try {
BufferedImage img = ImageIO.read(new ByteArrayInputStream(decodedBytes));
// Получаем расширения картинок
String extImage = "";
int extNum = 0;
extNum = binImg.get(i).indexOf(".");
extImage = binImg.get(i).substring(extNum + 1);
// В зависимости от расширения сохраняем в соответствующий формат
if(extImage.equals("jpg")) {
File outputfile = new File(outputDir + binImg.get(i));
ImageIO.write(img, "jpg", outputfile);
} else if(extImage.equals("png")) {
File outputfile = new File(outputDir + binImg.get(i));
ImageIO.write(img, "png", outputfile);
} else if(extImage.equals("gif")) {
File outputfile = new File(outputDir + binImg.get(i));
ImageIO.write(img, "gif", outputfile);
}
} catch (javax.imageio.IIOException e) {
e.printStackTrace();
}
}
}Можно выдохнуть, самое трудное позади. Остался последний этап. Но расслабляться пока все еще рано. Нам предстоит собрать весь контент книги воедино и отобразить его в окне так называемой сцены программы (Scene).
V этап. Вывод контента в окно программы
В качестве завершающих штрихов мы соединим текстовые части description и body, создадим сцену (Scene), добавим на нее браузерный элемент WebView. А в самом конце добавим код для удаления временной папки при закрытии окна программы. Для этого допишем следующие строчки в класс FbReader.java:
// Помещаем весь текстовый контент в одну переменную
String text = description + "n" + body;
// Создаем панель WebView для отображения HTML контента
WebView webView = new WebView();
WebEngine webEngine = webView.getEngine();
webEngine.loadContent(text);
// Замена встроенных стилей CSS на собственные
webEngine.setUserStyleSheetLocation("data:, @font-face {font-family: 'Open Sans', "
+ "sans-serif; src: local('Open Sans'), url(fonts/OpenSans-Regular.ttf);} "
+ "body {width: 90% !important; padding-left: 10px; font-size: 14pt; "
+ "font-family: 'Open Sans', sans-serif; line-height: 1.5;} "
+ "img {max-width: 90%; height: auto;}");
BorderPane borderPane = new BorderPane();
borderPane.setCenter(webView);
// Создание сцены и отображение окна
Scene scene = new Scene(borderPane);
stage.setScene(scene);
stage.show();
stage.setHeight(900);
borderPane.setPrefHeight(5000);
// Удаление временной папки при закрытии окна
stage.addEventFilter(WindowEvent.WINDOW_CLOSE_REQUEST, event -> {
File tmpFls = new File(tempDir.toString());
deleteDir(tmpFls);
});Добавим зависимость в pom.xml для корректной работы WebView:
<dependency>
<groupId>org.openjfx</groupId>
<artifactId>javafx-web</artifactId>
<version>17</version>
</dependency>На данном этапе меня поджидал еще один сюрприз. Когда я собрала весь контент и вывела его в окно программы, то обнаружила, что читать текст довольно сложно. Он выводился слишком мелким шрифтом, с небольшими интервалами между строками, буквально слипшимся. Обложки у некоторых книг вылазили за пределы окна, а полоса вертикального скроллинга скрывала пусть небольшую, но все же часть текста. Для того, чтобы устранить проблему, я прописала собственные стили CSS для окошка WebView.
Еще мне не понравился дефолтный шрифт с засечками. Я решила поменять его на Open Sans без засечек. Текст, написанный таким шрифтом, гораздо легче читается и воспринимается. Шрифт Open Sans или любой другой понравившийся можно скачать на сайте Google Fonts. Затем нужно будет создать папку Fonts в корневой директории проекта и положить туда TTF файл со шрифтом.
Запуск программы
Чтобы проверить, как все работает, нужно запустить программу. Для этого переходим в Package Explorer (левая колонка Eclipse), жмем правой кнопкой мыши на название нашего проекта, выбираем пункт выпавшего меню Run As, далее Java Application.

Откроется окно Select Java Application. В нем выбираем наш проект и жмем ОК.

Если вы сделали все правильно, должно открыться окно программы с текстом и картинками вашей электронной книги FB2.
Над чем еще можно поработать
Если есть желание, можно разобрать элемент description, вытащить из него имя автора, наименование, краткое описание книги, название файла обложки и другие параметры. А затем разложить их по переменным для дальнейшего использования. С этой задачей помогут справиться библиотеки JAXB или Jsoup, которые как раз и предназначены для работы с XML и HTML форматами. Я не стала так заморачиваться и выбрала путь попроще, потому что для моих целей этого было достаточно.
Что хочу сказать напоследок. Я новичок, поэтому прошу проявить милосердие и не кидаться помидорами, если есть чипсы. Буду рада, если в комментариях вы подскажете, как можно улучшить программу.
Если возникнут какие-либо проблемы, например, не сможете разобраться, куда вставлять тот или иной кусок кода, вы всегда можете скачать исходник и посмотреть на весь код целиком.
Исходный код проекта вы найдете тут.
инструкция по созданию
электронной книги
на компьютере
Как создать электронную книгу своими руками:
Про «смерть бумаги» говорят давно. Но печатные книги никуда не исчезают. Однако, электронные, тем временем, развиваются и множатся, превращаясь в отдельную нишу. Каждый год рынок цифровых книг в России растёт примерно в 2 раза. Сегодня, по некоторым данным, примерно каждый четвертый «человек читающий» выбирает digital-издания. Падает процент пиратства — выпуск книги в электронном формате обходится дешевле, а значит, потребителям приходится меньше выкладывать за неё из своего кармана. Но цена — далеко не единственное отличие электронного издания от традиционного.
Прошли те времена, когда многие утверждали, что читать с электронных носителей утомительнее, чем с бумажных. E-ink — электронные чернила — технология, которая позволила сделать процесс комфортным для глаз. Еще один пункт в копилку плюсов электронных книг. Использование ридеров и смартфонов экологичнее чтения бумажных изданий — деревья остаются в целости. Компактные размеры устройств для чтения при объемной памяти позволяют не выбирать одну-единственную книгу в отпуск, а взять целую библиотеку. Электронные закладки не выпадут, как бумажные. А цитаты можно не выписывать вручную, а «запомнить» с помощью пары кнопок. Электронное произведение можно настроить под себя — изменить размер шрифт: с бумажной такой фокус не пройдет. А необходимую литературу не приходится бегать и искать по разным магазинам — благодаря таким онлайн сервисам электронных и аудиокниг, как ЛитРес, читатели имеют доступ к неограниченному выбору книг.
Это если говорить об электронных изданиях с точки зрения читателей.

Для писателей digital-формат тоже имеет немало преимуществ
-
Во-первых, электронные версии книги просто не могут закончиться в магазине, то есть интерес читателей размер тиража не остановит.
-
Во-вторых, не нужно думать о точках сбыта своих творений и их доступности для читателей — скачать произведение они могут из любой точки планеты.
-
И в третьих, издать электронную книгу можно за неделю, а не за несколько месяцев, как с традиционным бумажным форматом.
Для чего нужна электронная книга
Первая книга была оцифрована почти полвека назад — с помощью самого мощного на тот момент компьютера была переведена в электронный формат Декларация независимости США. Идея копирования бумажных книг в «цифру» легла в основу проекта «Гутенберг» — предполагалось оцифровать и сохранить в электронной библиотеке всю мировую литературу. Однако проект вскоре закрылся из-за разногласий с правообладателями.
Сегодня выпуск электронной книги для авторов — самый простой способ познакомить с произведением аудиторию. В «цифре» публикуются и молодые авторы, и признанные писатели.
Для новичков выпуск электронных книг может стать карьерным трамплином — если не просто «выбрасывать» произведения в сеть, а публиковать на специализированных издательских площадках, к примеру, таких, как ЛитРес: Самиздат. Если произведения становятся популярными, их, а также их авторов, нередко замечают агенты и представители классических издательств, что позволяет публиковаться уже на бумаге — если именно это является конечной целью и мечтой.
Что важно учесть на этапе планирования электронной книги
Формат электронных книг предполагает, что текст будет по-разному отображаться на разных устройствах. Именно поэтому при оформлении электронной книги не нужно думать о размере и разметке страниц, крупности шрифта и других атрибутах, свойственных печатным изданиям.
Тем не менее, электронная книга должна быть комфортной для чтения — значит, надо подумать структуре текста и о цифровом формате сохранения файла, чтобы все буквы и рисунки остались на своих местах. А еще книга должна быть заметной для читателей — обложка в этом деле первый помощник.
Основные форматы электронных книг
На сегодняшний день форматов, которые используются для создания электронных книг, немало — около 10. Но это не означает, что кликать при сохранении документа стоит на любой из них. Авторам важно разбираться в типах файлов, чтобы быть уверенным, что их книга будет без ошибок открываться в большинстве ридеров.
В четверку наиболее распространенных и востребованных входят:
-
Это стандартный формат текстового редактора Word, который установлен, наверно, на всех компьютерах. В текст можно без опаски вставлять картинки, графики и таблицы. Доступность такого типа данных подкупает, однако читать файлы не всегда удобно: они много «весят», из-за этого могут долго открываться и обрабатываться ридерами.
-
Расшифровывается как FictionBook. Создан специально для верстки электронных книг и документов. Как утверждают некоторые специалисты, на сегодняшний день это самый распространенный формат в нашей стране. Он позволяет структурировать книгу — выделять главы, оформлять содержание, обложку и так далее. На русском языке в тексте можно делать переносы слов. Файлы «весят» немного и могут быть сконвертированы в другие форматы. Но для изданий с иллюстрациями подходит плохо — изображения на многих «читалках» могут не распознаваться. Плюс к тому, формат не предусмотрен для распространения за рубежом — его придумали отечественные разработчики. Но для русскоязычной аудитории это один из лучших вариантов. Именно с файлами этого типа работают верстальщики ЛитРес, которые готовят к электронной публикации книги крупнейших издательств России.
-
Название расшифровывается как Electronic Publication — этот тип файлов поддерживают все популярные ридеры — формат принят международной организацией International Digital Publishing Forum.
-
Ведущий формат для обмена электронными документами. Portable Document Format на всех устройствах открывается одинаково — он позволяет качественно объединять тексты и иллюстрации. Но и у него есть недостатки — текст в таком формате неадаптивен. То есть всегда показывается одинаково, а, значит, может быть неудобен для устройств с экраном небольшого размера — компактной «читалки» или смартфона. То есть скачивать произведения в таком варианте будут те, кто привык к такому типу файла, допустим, с экрана компьютера. А это существенно сужает аудиторию. Подробнее о формате мы рассказали в этой статье.
Программы и конвертеры форматов для создания электронных книг
Сегодня существует множество программ для создания и сохранения электронных книг — не обязательно устанавливать сложное и «тяжелое» ПО. Остановимся на самых доступных, функциональных и популярных программах.
-
Этот редактор можно назвать универсальным — он установлен практически на всех компьютерах — позволяет сохранять тексты в популярном формате docx, создавать структуру книги, добавлять иллюстрации. Функционал этого сервиса для большинства авторов достаточен. Онлайн-версии этого редактора есть и в бесплатных облачных сервисах, таких, как Облако. Mail и Яндекс. диск
-
Этот «виртуальный принтер» может печатать электронные издания прямо из файла Word — pdf-версия появляется буквально за несколько минут. При этом она будет профессионального уровня, то есть вполне подходит для создания электронных книг, а разобраться в устройстве сервиса может даже новичок. В программе можно добавить свои шрифты — это удобно, если в исходном документе используются какие-то нестандартные, которых может не быть на других устройствах — тогда документ всегда будет открываться, как планировал автор. В программе можно выставлять колонтитулы и номера страниц, создавать содержание и так далее.
-
Программа специализирована для создания и чтения электронных книг и учебников. Она проста в использовании (интерфейс схож с Microsoft Office), вместе с тем предлагает большое количество возможностей: от проверки орфографии и создания стилей до вставки иллюстраций таких образом, чтобы они не «утяжеляли» «вес» электронной книги в хранилище (а, значит, произведения открывались быстрее) до импорта и экспорта во множество форматов.
-
Это мощная программа со множеством возможностей, которой, в то же время, легко пользоваться. По мнению некоторых, по функциональности она превосходит все остальные программы для создания электронных книг. С помощью eBook Edit Pro можно устанавливать, в каком размере будет открываться книга у читателей, выбирать другие параметры. Настроек много, но разобраться помогает подробное справочное меню.
-
Это специализированный редактор электронных изданий. В нём можно управлять структурой документа, добавлять изображения в различных режимах, редактировать и проверять текст, выбирать элементы оформления, работать с отдельными разделами. Разобраться в его интерфейсе чуть сложнее, чем у предыдущих программ. Но подкупает широкий спектр возможностей — ведь программа «заточена» на работу именно с книгами.
-
Эту программу компьютерной вёрстки используют профессионалы в типографиях, но она подходит и для подготовки цифровых публикаций — конвертировать из неё можно в различные форматы. Однако такое ПО требовательно к техническим характеристикам компьютера — то есть поставить его можно не на любое устройство, а на более мощные агрегаты. Кроме того, функционал может быть избыточен для начинающих авторов.
Как сделать обложку для книги
Обложка — лицо книги, то, за что в первую очередь цепляется взгляд. Она может сыграть роль при выборе даже большую, чем название произведения и имя автора. Кто, как ни создатель произведения, лучше поймет, что в книге самое главное, что достойно оказаться на первом плане? Немаловажно соответствие обложки содержанию — важно не просто заманить читателя, а исполнить обещанное на обложке.
Заказать иллюстрацию можно у профессиональных дизайнеров и художников или подобрать самому — среди картинок в обычных поисковиках, представленных с открытой лицензией на использование (это можно увидеть в информации об изображениях).
В ЛитРес: Самиздат для обложки необходимо использовать файлы в формате PNG или JPG в цветовом пространстве RGB и в разрешении не меньше 2400 на 3405 пикселей.
Инструкция по созданию электронной книги
Создать электронную книгу так же просто, как новый документ в Microsoft Word (это, кстати, один из самых доступных сервисов для создания digital-изданий). Главной задачей для писателя остаётся написать текст. После — разбить на главы. И, при необходимости, добавить иллюстрации. Сохранить в правильном формате. А дальше — публиковать.
От места распространения зачастую зависит успех произведения и автора. Можно размещать его на личном авторском сайте или на собственных страницах в соцсетях. Но эффективнее — на специальной издательской площадке: так книга будет доступна максимально широкому потенциальному кругу читателей. К примеру, сайт ЛитРес: Самиздат позволяет авторам напрямую отправлять свои произведения в онлайн книжные магазины и получать авторское вознаграждение (если книга распространяется не бесплатно).
Чтобы опубликовать электронную книгу в ЛитРес: Самиздат нужно совершить всего 3 шага:
-
Зарегистрироваться в сервисе — указать почту и пароль, перейти по ссылке на почте в личный кабинет. И, по желанию, заполнить информацию об авторе и подтвердить профиль — это облегчит дальнейшую автоматическую публикацию от своего имени;
-
Загрузить текст книги — ЛитРес: Самиздат принимает файлы в форматах Docx и Fb2;
-
Заполнить сведения о книге, загрузить обложку и выбрать цену книги и пакет публикации. Пакет услуг зависит от типа лицензии, которую вы готовы дать. Если вы хотите размещать книгу не только на платформе ЛитРес: Самиздат, но и на других сервисах самопубликации, выбирать следует пакет с неисключительной лицензией. Если вы хотите опубликовать книгу с печатной версией print-on-demand, выбирайте пакет «Безлимитный» и ставьте галочку в пункте «Печатная версия».
После проверки книга автоматически появится в сетевых книжных магазинах, таких, как ЛитРес, Озон, Google Play, iBooks и многих других. После этого в личном кабинете можно будет следить за статистикой скачиваний и загружать новые книги.
Попробуйте, это просто!
Была ли данная статья полезна для Вас?
Post Views: 28 154
В настоящее время наиболее популярными и удобными способами чтения являются электронные книги. Их можно взять с собой куда угодно, они экономят бумагу, отображение текста в них можно настраивать так, как удобно читателю. По этим причинам появилось множество форматов электронных книг, основные из которых это EPUB, FB2 и MOBI. Всем известные DOC и TXT тоже являются форматами электронных книг, однако их возможности по сравнению с вышеуказанными весьма ограничены. У каждого из форматов есть свои преимущества, однако наиболее часто используемыми являются EPUB и FB2, причём второй популярен только у нас в России.
Одной из особенностей этих форматов является то, что для них нужна специальная программа, которая может работать с конкретным форматом. Поэтому в App Store или Google Play можно найти большое количество разнообразных читалок под все известные форматы. В этой статье мы попробуем написать свою собственную читалку электронных книг. Для этой цели мы воспользуемся специальной SDK от разработчиков FBReader, который доступен по следующей ссылке.
В сентябре этого года FBReader выпустили свой собственный SDK для Android, позволяющий создавать свои собственные читалки на его основе. FBReader SDK обладает большим функционалом, который включает в себя следующие возможности:
- Открытие любых файлов электронных книг (ePub, fb2, mobi, и так далее)
- Чтение метаданных из файла книги
- Особенности движка FBReader
- Возможность менять стиль текста книги
Кроме того, библиотека предоставляет и различные дополнительные возможности для реализации в приложениях, такие как:
- Выделение текста
- Закладки
- Поиск по тексту
- Оглавление
- Дополнительная навигация по тексту
- Поддержка сносок и гиперссылок
- Настройка яркости
Отдельно стоит отметить, что, хоть FBReader SDK и можно скачать с сайта бесплатно, после встраивания в приложение она будет работать в демо-режиме, который имеет полный функционал, но показывает только несколько первых страниц книги. Для того, чтобы получить полную версию библиотеки, нужно купить её на сайте разработчика и, следуя инструкциям, получить специальный ключ SDK, который затем добавляется в приложение.
В этой статье мы рассмотрим, как на основе FBReader SDK создать свою собственную читалку электронных книг и посмотрим её возможности.
Начнём с добавления SDK в свой проект. Для этого создадим новый проект с пустой активностью. В качестве минимального API укажем API 16.
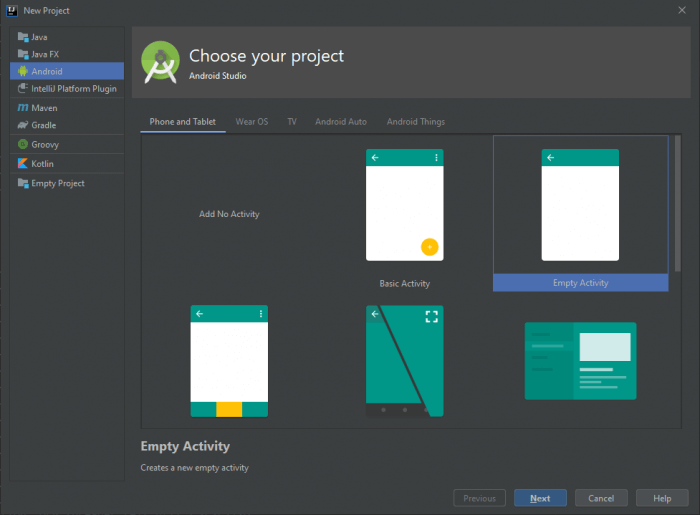
В файле build.gradle модуля проекта добавим в блок allprojects ссылку для скачивания нужных нам библиотек.
allprojects {
repositories {
...
maven {
url "https://sdk.fbreader.org/maven"
}
}
}
Затем в файле build.gradle модуля приложения добавим зависимости с библиотеками в блок dependencies.
dependencies {
...
implementation 'com.googlecode.json-simple:json-simple:1.1'
implementation 'org.fbreader:book:1.0.0-rc01'
implementation 'org.fbreader:config_client:1.0.0-rc01'
implementation 'org.fbreader:config_provider:1.0.0-rc01'
implementation 'org.fbreader:filesystem:1.0.0-rc01'
implementation 'org.fbreader:fontentry:1.0.0-rc01'
implementation 'org.fbreader:format_interface:1.0.0-rc01'
implementation 'org.fbreader:image:1.0.0-rc01'
implementation 'org.fbreader:intent:1.0.0-rc01'
implementation 'org.fbreader:language:1.0.0-rc01'
implementation 'org.fbreader:loader:1.0.0-rc01'
implementation 'org.fbreader:options:1.0.0-rc01'
implementation 'org.fbreader:text_client:1.0.0-rc01'
implementation 'org.fbreader:text_provider:1.0.0-rc01'
implementation 'org.fbreader:text_util:1.0.0-rc01'
implementation 'org.fbreader:text_view:1.0.0-rc01'
implementation 'org.fbreader:toc:1.0.0-rc01'
implementation 'org.fbreader:util:1.0.0-rc01'
implementation 'org.fbreader:view:1.0.0-rc01'
implementation 'org.fbreader:vimgadgets:1.0.0-rc01'
implementation 'org.fbreader:zip-amse:1.0.0-rc01'
}
Как вы можете заметить, здесь также присутствует библиотека «com.googlecode.json-simple:json-simple:1.1». Она пригодится чуть позже для работы с JSON-файлами.
Библиотек, входящих в FBReader SDK довольно много, однако они разделены так, чтобы можно было подключать только те, которые нужны для конкретного случая.
В этом же файле в блок android добавим следующие строки, которые должны обеспечить успешную сборку проекта.
android {
...
compileOptions {
sourceCompatibility JavaVersion.VERSION_1_8
targetCompatibility JavaVersion.VERSION_1_8
}
}
На сайте SDK разработчики также предоставляют исходный код различных компонентов, которые упрощают реализацию интерфейса. Скачаем его и добавим в проект. Для этого перенесём оттуда папку fbreader в папку своего проекта. После этого в файле settings.gradle пропишем эту папку и пути до нужных модулей.
include 'fbreader_extras'
project(':fbreader_extras').projectDir = new File('fbreader/extras')
include 'fbreader_styles'
project(':fbreader_styles').projectDir = new File('fbreader/styles')
include 'fbreader_text_extras'
project(':fbreader_text_extras').projectDir = new File('fbreader/text_extras')
Теперь добавим зависимости с ними в файле build.gradle модуля приложения.
dependencies {
...
implementation project(':fbreader_extras')
implementation project(':fbreader_styles')
implementation project(':fbreader_text_extras')
}
Когда IDE пересоберёт проект, мы увидим добавленные модули в списке слева.
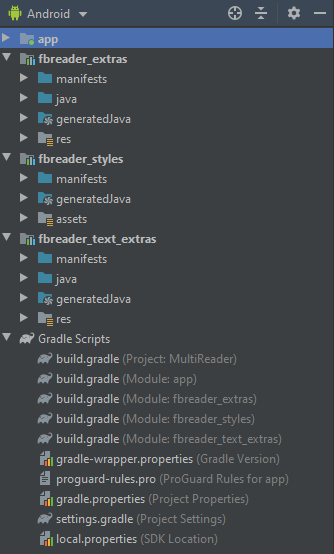
На этом подключение SDK завершено и можно приступать к непосредственно созданию приложения. В конце статьи у нас должна получиться простая читалка с двумя активностями, одна из которых будет отображать список электронных книг на устройстве, а вторая открывать выбранный файл.
Начнём с разметки. Для MainActivity добавим на экран компонент RecyclerView, который будет содержать собственно список файлов. Для этого добавим в файл layout/activity_main.xml следующий код.
<?xml version="1.0" encoding="utf-8"?>
<RelativeLayout
xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
tools:context=".MainActivity"
android:paddingRight="12dp"
android:paddingLeft="12dp"
>
<androidx.recyclerview.widget.RecyclerView
android:layout_width="match_parent"
android:layout_height="match_parent"
android:layout_marginTop="6dp"
android:id="@+id/rv_files"
/>
</RelativeLayout>
Теперь инициализируем этот объект в коде активности. Откроем файл MainActivity.java и добавим следующий код.
public class MainActivity extends AppCompatActivity {
private RecyclerView rvFiles;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
rvFiles = findViewById(R.id.rv_files);
rvFiles.setLayoutManager(new LinearLayoutManager(this));
}
}
Для того, чтобы работать с файлами, хранящимися на устройстве, нам потребуется запрашивать специальное разрешение. Добавим в манифест приложения AndroidManifest.xml следующие разрешения.
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="ru.androidtools.multireader">
<uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE"/>
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"/>
<application
android:allowBackup="true"
android:icon="@mipmap/ic_launcher"
android:label="@string/app_name"
android:roundIcon="@mipmap/ic_launcher_round"
android:supportsRtl="true"
android:theme="@style/AppTheme">
<activity android:name=".MainActivity">
<intent-filter>
<action android:name="android.intent.action.MAIN"/>
<category android:name="android.intent.category.LAUNCHER"/>
</intent-filter>
</activity>
</application>
</manifest>
Начиная с API 23 это разрешение необходимо запрашивать у пользователя в рантайме. Для этого при запуске приложения будем проверять версию Android на устройстве и при необходимости отправлять пользователю запрос на получение разрешения.
public class MainActivity extends AppCompatActivity {
...
private static final int REQUEST_PERMISSION = 101;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
rvFiles = findViewById(R.id.rv_files);
rvFiles.setLayoutManager(new LinearLayoutManager(this));
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.M) {
checkPermission();
} else {
generateList();
}
}
@TargetApi(Build.VERSION_CODES.M) private void checkPermission() {
if (ContextCompat.checkSelfPermission(this, Manifest.permission.WRITE_EXTERNAL_STORAGE)
== PackageManager.PERMISSION_GRANTED) {
generateList();
} else {
ActivityCompat.requestPermissions(this,
new String[] { Manifest.permission.WRITE_EXTERNAL_STORAGE }, REQUEST_PERMISSION);
}
}
}
Получить результат запроса можно, переопределив метод активности onRequestPermissionResult(). Если разрешение приложению было предоставлено, продолжаем дальнейшую работу.
@Override public void onRequestPermissionsResult(int requestCode, @NonNull String[] permissions,
@NonNull int[] grantResults) {
switch (requestCode) {
case REQUEST_PERMISSION: {
if (grantResults.length > 0 && grantResults[0] == PackageManager.PERMISSION_GRANTED) {
generateList();
}
break;
}
}
}
В методе generateList() мы будем искать нужные файлы на устройстве и отображать их в списке приложения. Для этого создадим AsyncTask, который будет выполнять всю работу в отдельном потоке и возвращать готовый список с найденными файлами. Добавим следующий код в MainActivity.
private void generateList() {
List<StorageBean> storageBeans = StorageUtils.getStorageData(this); // получение списка смонтированных карт памяти на устройстве
List<String> paths = new ArrayList<>();
if (storageBeans != null) {
for (StorageBean storageBean : storageBeans) {
paths.add(storageBean.getPath());
}
} else {
String path = Environment.getExternalStorageDirectory().getAbsolutePath();
paths.add(path);
}
ListFilesTask listFilesTask = new ListFilesTask(paths);
listFilesTask.setListener(new ListFilesTask.ListFilesListener() {
@Override public void onTaskCompleted(List<File> files) {
}
});
listFilesTask.execute();
}
static class ListFilesTask extends AsyncTask<Void, Void, List<File>> {
public interface ListFilesListener {
void onTaskCompleted(List<File> files);
}
private ListFilesListener listener;
private List<String> startPaths;
private List<File> files;
private boolean completed;
public ListFilesTask(List<String> startPaths) {
this.startPaths = new ArrayList<>(startPaths);
this.files = new ArrayList<>();
this.completed = false;
}
public void setListener(ListFilesListener listener) {
this.listener = listener;
if (completed && listener != null && files != null) {
listener.onTaskCompleted(files);
}
}
@Override protected List<File> doInBackground(Void... voids) {
List<File> fileList = new ArrayList<>();
for (String s : startPaths) {
searchFiles(fileList, new File(s));
}
return fileList;
}
@Override protected void onPostExecute(List<File> files) {
completed = true;
if (listener != null) {
listener.onTaskCompleted(files);
} else {
this.files = new ArrayList<>(files);
}
}
private void searchFiles(List<File> list, File dir) {
String epubPattern = ".epub";
String fb2Pattern = ".fb2";
File[] listFiles = dir.listFiles();
if (listFiles != null) {
for (File listFile : listFiles) {
if (listFile.isDirectory()) {
searchFiles(list, listFile);
} else {
if (listFile.getName().endsWith(epubPattern) || listFile.getName()
.endsWith(fb2Pattern)) {
list.add(listFile);
}
}
}
}
}
}
Полученный результат нужно отобразить. Для этого нам понадобится адаптер для RecyclerView и модель, в которой будут храниться данные элементов списка. Создадим простой класс BookFile, в котором мы будем хранить имя файла и путь до него на устройстве.
public class BookFile {
private String filename, path;
public BookFile(String filename, String path) {
this.filename = filename;
this.path = path;
}
public String getFilename() {
return filename;
}
public String getPath() {
return path;
}
@Override public int hashCode() {
return filename.hashCode() + path.hashCode();
}
@Override public boolean equals(Object obj) {
if (obj instanceof BookFile) {
BookFile bookFile = (BookFile) obj;
return this.filename.equals(bookFile.getFilename()) && this.path.equals(bookFile.getPath());
}
return false;
}
}
Теперь нам нужен адаптер, в который мы будем загружать список. Добавим разметку для элемента списка, для этого создадим файл layout/file_list_item.xml и добавим в него следующий код.
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout
xmlns:android="http://schemas.android.com/apk/res/android"
android:id="@+id/item_layout"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:layout_marginBottom="2dp"
android:layout_marginTop="2dp"
android:orientation="vertical"
android:paddingBottom="6dp"
android:paddingLeft="16dp"
android:paddingRight="16dp"
android:paddingTop="6dp"
>
<TextView
android:id="@+id/tv_filename"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:text="filename"
android:textSize="16sp"
/>
<TextView
android:id="@+id/tv_path"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:layout_marginTop="2dp"
android:text="path"
android:textSize="14sp"
/>
</LinearLayout>
Теперь создадим класс BooksAdapter, который будет наследовать от RecyclerView.Adapter<>. В нём нам нужно инициализировать элементы списка, загружая в них пути и имена файлов электронных книг. Таким образом, код адаптера будет выглядеть следующим образом.
public class BooksAdapter extends RecyclerView.Adapter<BooksAdapter.BookHolder> {
public interface BookListener {
void onBookOpen(BookFile bookFile);
}
private BookListener listener;
private List<BookFile> books;
public BooksAdapter(List<BookFile> books, BookListener listener) {
this.books = new ArrayList<>(books);
this.listener = listener;
}
@NonNull @Override public BookHolder onCreateViewHolder(@NonNull ViewGroup parent, int viewType) {
View view =
LayoutInflater.from(parent.getContext()).inflate(R.layout.file_list_item, parent, false);
return new BookHolder(view);
}
@Override public void onBindViewHolder(@NonNull BookHolder holder, int position) {
BookFile bookFile = books.get(position);
holder.bind(bookFile);
}
@Override public int getItemCount() {
return books.size();
}
class BookHolder extends RecyclerView.ViewHolder {
private LinearLayout itemLayout;
private TextView tvPath, tvName;
public BookHolder(@NonNull View itemView) {
super(itemView);
itemLayout = itemView.findViewById(R.id.item_layout);
tvName = itemView.findViewById(R.id.tv_filename);
tvPath = itemView.findViewById(R.id.tv_path);
}
public void bind(BookFile bookFile) {
tvPath.setText(bookFile.getPath());
tvName.setText(bookFile.getFilename());
itemLayout.setOnClickListener(new View.OnClickListener() {
@Override public void onClick(View view) {
listener.onBookOpen(bookFile);
}
});
}
}
}
Кроме того, между активностью и адаптером пробрасывается интерфейс, с помощью которого мы будем передавать в активность файл, который пользователь хочет открыть.
Вернёмся в главную активность. В методе generateList() мы запускаем AsyncTask и привязываем к нему слушатель, который должен вызывать метод onTaskCompleted() при завершении работы. В этом методе нам нужно составить список, отсортировать его по имени и передать в адаптер. Добавим сюда следующий код:
listFilesTask.setListener(new ListFilesTask.ListFilesListener() {
@Override public void onTaskCompleted(List<File> files) {
if (!isFinishing()) {
List<BookFile> bookFiles = new ArrayList<>();
for (File f : files) {
BookFile bookFile = new BookFile(f.getName(), f.getAbsolutePath());
if (!bookFiles.contains(bookFile)) bookFiles.add(bookFile);
}
Collections.sort(bookFiles, new Comparator<BookFile>() {
@Override public int compare(BookFile bookFile, BookFile t1) {
return bookFile.getFilename().compareToIgnoreCase(t1.getFilename());
}
});
rvFiles.setAdapter(new BooksAdapter(bookFiles, new BooksAdapter.BookListener() {
@Override public void onBookOpen(BookFile bookFile) {
}
}));
}
}
});
Теперь, запустив приложение, мы можем увидеть список файлов электронных книг, которые есть на устройстве.

Однако нам нужно этот файл открыть и прочитать, в этом нам и поможет FBReader SDK. Создадим новую активность, назовём её ReaderActivity. Теперь из скачанного исходного кода нам понадобится несколько классов. Откроем в папке с исходным кодом samples/extensions/src/main и скопируем себе в проект целиком папку res, за исключением res/layout/main.xml, и из java/org/fbreader/sample/extensions скопируем все классы, кроме MainActivity.java. Эти классы содержат готовые компоненты, которые помогут нам в создании читалки, при желании их можно модифицировать в соответствии с потребностями.
Теперь откроем layout/reader_activity.xml и добавим в него следующий код разметки.
<?xml version="1.0" encoding="utf-8"?>
<RelativeLayout
xmlns:android="http://schemas.android.com/apk/res/android"
android:id="@+id/widget_container"
android:layout_width="match_parent"
android:layout_height="match_parent"
>
<ru.androidtools.multireader.TextWidgetExt
android:id="@+id/text_widget"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:focusable="true"
android:scrollbars="vertical"
android:scrollbarAlwaysDrawVerticalTrack="true"
android:fadeScrollbars="false"
/>
<TextView
android:id="@+id/error_message"
android:textAppearance="?android:attr/textAppearanceLarge"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_centerInParent="true"
android:text="The app couldn't open the book"
android:visibility="gone"
/>
</RelativeLayout>
TextWidgetExt является обёрткой класса библиотеки TextWidget, этот класс является основным и именно он отображает содержимое книги.
Инициализируем теперь эти объекты в коде активности ReaderActivity.java.
public class ReaderActivity extends AppCompatActivity {
private TextWidgetExt widget;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_reader);
widget = findViewById(R.id.text_widget);
View errorView = findViewById(R.id.error_message);
widget.setVisibility(View.VISIBLE);
errorView.setVisibility(View.GONE);
}
}
Мы должны получить от главной активности путь до файла, который пользователь хочет открыть. Для этого мы будем передавать интент из одной активности в другую, содержащий нужный путь. Вернёмся в MainActivity.java и добавим код создания интента в метод onBookOpen() интерфейса адаптера.
rvFiles.setAdapter(new BooksAdapter(bookFiles, new BooksAdapter.BookListener() {
@Override public void onBookOpen(BookFile bookFile) {
Intent intent = new Intent(MainActivity.this, ReaderActivity.class);
intent.putExtra(ReaderActivity.EXTRA_PATH, bookFile.getPath());
startActivity(intent);
}
}));
После этого отправленный интент нам нужен получить в ReaderActivity.java при старте активности. Добавим в onCreate() запись пути файла.
...
public final static String EXTRA_PATH = "EXTRA_PATH";
private String filepath;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_reader);
widget = findViewById(R.id.text_widget);
View errorView = findViewById(R.id.error_message);
widget.setVisibility(View.VISIBLE);
errorView.setVisibility(View.GONE);
filepath = getIntent().getStringExtra(EXTRA_PATH);
}
}
Полученный путь мы передаём в метод setBook() у объекта TextWidgetExt. После этого он должен нам вернуть объект Book, который можно получить с помощью метода TextWidgetExt controller(). Если объект не будет равен null, значит загрузка содержимого прошла успешно и можно показать книгу пользователю.
...
private TextWidgetExt widget;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_reader);
...
try {
widget.setBook(BookLoader.fromFile(filepath, this, 1L));
Book book = widget.controller().book;
if (book != null) {
widget.invalidate();
widget.post(new Runnable() {
@Override public void run() {
widget.gotoPage(0);
setTitle(book.getTitle());
}
});
} else {
errorView.setVisibility(View.VISIBLE);
}
} catch (BookException e) {
e.printStackTrace();
errorView.setVisibility(View.VISIBLE);
}
}
Теперь, если запустить приложение, мы уже можем видеть содержимое книги, пролистывать его и работать с ним.

Однако это не весь функционал, на который способна данная SDK. Ранее мы добавляли файлы ресурсов: различные разметки, иконки и меню. Добавим меню в наше приложение, для этого в ReaderActivity.java переопределим метод onCreateOptionsMenu() и добавим в него следующий код.
@Override
public boolean onCreateOptionsMenu(final Menu menu) {
getMenuInflater().inflate(R.menu.app, menu);
return true;
}
Также переопределим методы onPrepareOptionsMenu() и onOptionsItemSelected() для работы с этим меню.
@Override
public boolean onPrepareOptionsMenu(final Menu menu) {
SearchView searchView = (SearchView) menu.findItem(R.id.menu_search).getActionView();
searchView.setOnQueryTextListener(new SearchView.OnQueryTextListener() {
@Override
public boolean onQueryTextChange(String query) {
return true;
}
@Override
public boolean onQueryTextSubmit(String query) {
widget.searchInText(query);
menu.findItem(R.id.menu_search).collapseActionView();
return true;
}
});
menu.findItem(R.id.menu_table_of_contents).setEnabled(TableOfContentsUtil.isAvailable(widget));
String name = widget.colorProfile().name;
menu.findItem(R.id.menu_color_profile_light).setChecked("defaultLight".equals(name));
menu.findItem(R.id.menu_color_profile_dark).setChecked("defaultDark".equals(name));
menu.findItem(R.id.menu_color_profile_dark_with_bg).setChecked("darkWithBg".equals(name));
menu.findItem(R.id.menu_color_profile_pink).setChecked("pink".equals(name));
return true;
}
@Override
public boolean onOptionsItemSelected(MenuItem item) {
BaseStyle baseStyle = widget.baseStyle();
switch (item.getItemId()) {
case R.id.menu_table_of_contents: {
final Intent intent = TableOfContentsUtil.intent(widget);
if (intent != null) {
startActivityForResult(intent, REQUEST_TABLE_OF_CONTENT);
}
break;
}
case R.id.menu_zoom_in:
baseStyle.fontSize.setValue(baseStyle.fontSize.getValue() + 2);
break;
case R.id.menu_zoom_out:
baseStyle.fontSize.setValue(baseStyle.fontSize.getValue() - 2);
break;
case R.id.menu_color_profile_light:
widget.setColorProfileName("defaultLight");
break;
case R.id.menu_color_profile_dark:
widget.setColorProfileName("defaultDark");
break;
case R.id.menu_color_profile_dark_with_bg:
widget.setColorProfileName("darkWithBg");
break;
case R.id.menu_color_profile_pink:
widget.setColorProfileName("pink");
break;
}
widget.clearTextCaches();
widget.invalidate();
return true;
}
Таким образом мы добавим в читалку меню, позволяющее нам:
- Менять размер текста
- Менять стиль текста
- Искать по тексту
- Открывать оглавление
По поводу оглавления стоит сказать отдельно. В коде, взятом из библиотеки, оглавление представлено в виде отдельной активности, мы её скопировали ранее, но не добавили в манифест. Поэтому откроем файл манифеста AndroidManifest.xml и зарегистрируем в нём новую активность.
<application
android:allowBackup="true"
android:icon="@mipmap/ic_launcher"
android:label="@string/app_name"
android:roundIcon="@mipmap/ic_launcher_round"
android:supportsRtl="true"
android:theme="@style/AppTheme">
...
<activity android:name=".TableOfContentsActivity"/>
</application>
Теперь при открытии оглавления через меню у нас будет запускаться новая активность, содержащая в себе оглавление открытой книги. Стоит отметить, что не все книги содержат такое оглавление, поэтому в таких случаях кнопка меню будет неактивна.
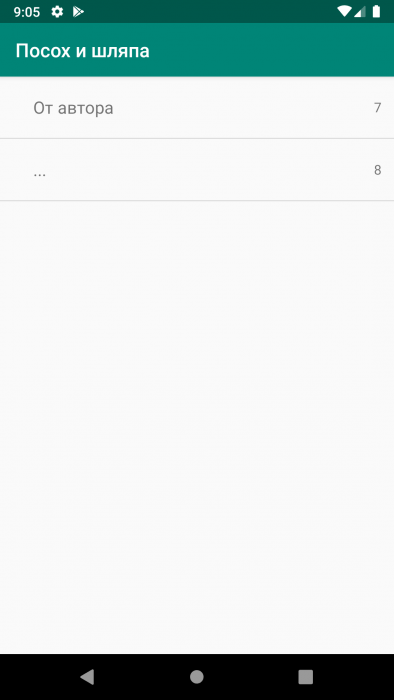
При выборе главы обратно в ReaderActivity будет возвращаться номер страницы, на которую нужно перейти. Чтобы получить этот результат, в ReaderActivity.java мы переопределим метод onActivityResult(), в который добавим следующий код.
public class ReaderActivity extends AppCompatActivity {
private final int REQUEST_TABLE_OF_CONTENT = 1;
...
@Override
protected void onActivityResult(int requestCode, int resultCode, Intent data) {
switch (requestCode) {
case REQUEST_TABLE_OF_CONTENT:
if (resultCode == RESULT_OK) {
int ref = data.getIntExtra(String.valueOf(TableOfContentsUtil.Key.reference), -1);
if (widget != null && ref != -1) {
widget.jumpTo(new FixedPosition(ref, 0, 0));
}
}
default:
super.onActivityResult(requestCode, resultCode, data);
}
}
Как можно увидеть, библиотека предоставляет разработчикам весь свой функционал, единственным ограничением бесплатной версии здесь является то, что она открывает только первые несколько страниц книги, о чём говорится при открытии книги.
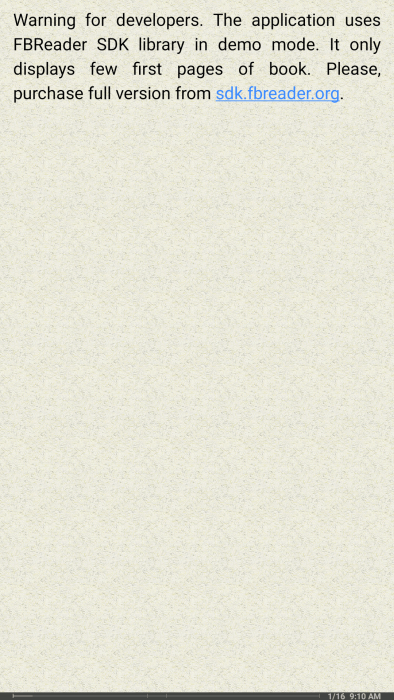
Если вы купили ключ SDK и хотите добавить его в своё приложение, вам понадобится в файле build.gradle модуля приложения добавить в блоке buildTypes следующий код.
buildTypes {
...
all {
resValue 'string', 'fbreader_sdk_key', 'put your fbreader sdk key here'
}
}
Не смотря на то, что движок FBReader достаточно мощный, а также учитывая графические ресурсы, добавляемые вместе с библиотекой, итоговый APK получился небольшого размера, что говорит о хорошей оптимизации библиотеки.
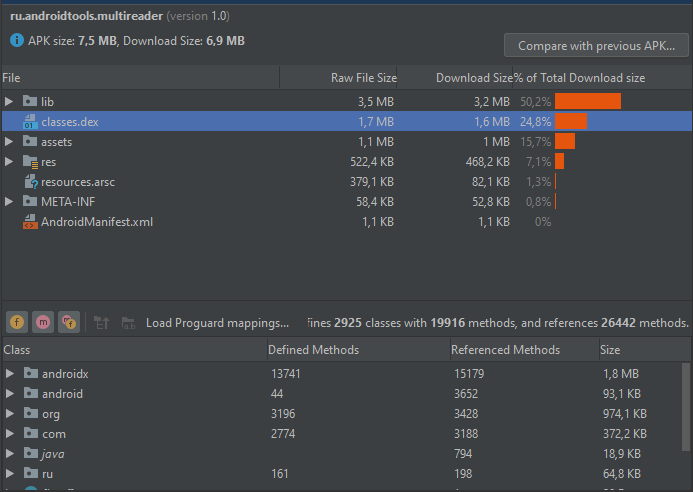
Итак, с помощью FBReader SDK и небольшого количества кода мы смогли создать простую читалку для электронных книг. Можно уже оставить как есть, либо продолжить модифицировать, изменяя интерфейс и дизайн так, как нужно разработчику. Пока что SDK есть только на Android, но разработчики планируют к концу года выпустить версию и для iOS.

