Роботы Яндекса корректно обрабатывают robots.txt, если:
-
Размер файла не превышает 500 КБ.
-
Это TXT-файл с названием robots — robots.txt.
-
Файл размещен в корневом каталоге сайта.
-
Файл доступен для роботов — сервер, на котором размещен сайт, отвечает HTTP-кодом со статусом 200 OK. Проверьте ответ сервера
Если файл не соответствует требованиям, сайт считается открытым для индексирования.
Яндекс поддерживает редирект с файла robots.txt, расположенного на одном сайте, на файл, который расположен на другом сайте. В этом случае учитываются директивы в файле, на который происходит перенаправление. Такой редирект может быть удобен при переезде сайта.
Яндекс поддерживает следующие директивы:
| Директива | Что делает |
|---|---|
| User-agent * | Указывает на робота, для которого действуют перечисленные в robots.txt правила. |
| Disallow | Запрещает обход разделов или отдельных страниц сайта. |
| Sitemap | Указывает путь к файлу Sitemap, который размещен на сайте. |
| Clean-param | Указывает роботу, что URL страницы содержит параметры (например, UTM-метки), которые не нужно учитывать при индексировании. |
| Allow | Разрешает индексирование разделов или отдельных страниц сайта. |
| Crawl-delay |
Задает роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей. Рекомендуем вместо директивы использовать настройку скорости обхода в Яндекс Вебмастере. |
* Обязательная директива.
Наиболее часто вам могут понадобиться директивы Disallow, Sitemap и Clean-param. Например:
User-agent: * #указывает, для каких роботов установлены директивы
Disallow: /bin/ # запрещает ссылки из "Корзины с товарами".
Disallow: /search/ # запрещает ссылки страниц встроенного на сайте поиска
Disallow: /admin/ # запрещает ссылки из панели администратора
Sitemap: http://example.com/sitemap # указывает роботу на файл Sitemap для сайта
Clean-param: ref /some_dir/get_book.plРоботы других поисковых систем и сервисов могут иначе интерпретировать директивы.
Примечание. Робот учитывает регистр в написании подстрок (имя или путь до файла, имя робота) и не учитывает регистр в названиях директив.
Использование кириллицы запрещено в файле robots.txt и HTTP-заголовках сервера.
Для указания имен доменов используйте Punycode. Адреса страниц указывайте в кодировке, соответствующей кодировке текущей структуры сайта.
Пример файла robots.txt:
#Неверно:
User-agent: Yandex
Disallow: /корзина
Sitemap: сайт.рф/sitemap.xml
#Верно:
User-agent: Yandex
Disallow: /%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0
Sitemap: http://xn--80aswg.xn--p1ai/sitemap.xml-
В текстовом редакторе создайте файл с именем robots.txt и укажите в нем нужные вам директивы.
-
Проверьте файл в Вебмастере.
-
Положите файл в корневую директорию вашего сайта.
Пример файла. Данный файл разрешает индексирование всего сайта для всех поисковых систем.
В Вебмастере на странице «Диагностика сайта» возникает ошибка «Сервер отвечает редиректом на запрос /robots.txt»
Чтобы файл robots.txt учитывался роботом, он должен находиться в корневом каталоге сайта и отвечать кодом HTTP 200. Индексирующий робот не поддерживает использование файлов, расположенных на других сайтах.
Чтобы проверить доступность файла robots.txt для робота, проверьте ответ сервера.
Если ваш robots.txt выполняет перенаправление на другой файл robots.txt (например, при переезде сайта), Яндекс учитывает robots.txt, на который происходит перенаправление. Убедитесь, что в этом файле указаны верные директивы. Чтобы проверить файл, добавьте сайт, который является целью перенаправления, в Вебмастер и подтвердите права на управление сайтом.
Как правильно составить robots.txt и зачем он нужен, как закрыть индексацию через robots.txt и бесплатно проверить robots.txt с помощью онлайн-инструментов.
В статье:
-
Как поисковики сканируют страницу
-
Robots.txt для Яндекса и Google
-
Как составить robots.txt правильно
-
Инструменты для составления и проверки robots.txt
Как поисковики сканируют страницу
Роботы-краулеры Яндекса и Google посещают страницы сайта, оценивают содержимое, добавляют новые ресурсы и информацию о страницах в индексную базу поисковика. Боты посещают страницы регулярно, чтобы переносить в базу обновления контента, отмечать появление новых ссылок и их доступность.
Зачем нужно сканирование:
- Собрать данные для построения индекса — информацию о новых страницах и обновлениях на старых.
- Сравнить URL в индексе и в списке для сканирования.
- Убрать из очереди дублирующиеся URL, чтобы не скачивать их дважды.
Боты смотрят не все страницы сайта. Количество ограничено
краулинговым бюджетом, который складывается из количества URL, которое может просканировать бот-краулер. Бюджета на объемный сайт может не хватить. Есть риск, что краулинговый бюджет уйдет на сканирование неважных или «мусорных» страниц, а чтобы такого не произошло, веб-мастеры направляют краулеров с помощью файла robots.txt.
Боты переходят на сайт и находят в корневом каталоге файл robots.txt, анализируют доступ к страницам и переходят к карте сайта —
Sitemap, чтобы сократить время сканирования, не обращаясь к закрытым ссылкам. После изучения файла боты идут на главную страницу и оттуда переходят в глубину сайта.
Как узнать, попала ли страница сайта в индекс Яндекса или Google
Какие страницы краулер просканирует быстрее:
- Находятся ближе к главной.
Чем меньше кликов с главной ведет до страницы, тем она важнее и тем вероятнее ее посетит краулер. Количество переходов от главной до текущей страницы называется Click Distance from Index (DFI). - Имеют много ссылок.
Если многие ссылаются на страницу, значит она полезная и имеет хорошую репутацию. Нормальным считается около 11-20 ссылок на страницу, перелинковка между своими материалами тоже считается. - Быстро загружаются.
Проверьте скорость загрузки
инструментом, если она медленная — оптимизируйте код верхней части и уменьшите вес страницы.
Все посещения ботов-краулеров не фиксируют такие инструменты, как Google Analytics, но поведение ботов можно отследить в лог-файлах. Некоторые SEO-проблемы крупных сайтов можно решить с помощью
анализа лог-файлов который также поможет увидеть проблемы со ссылками и распределение краулингового бюджета.
Посмотреть на сайт глазами поискового бота
Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.txt.
Robots.txt — это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется “robots.txt“, название написано только строчными буквами, “Robots.TXT” и другие вариации не поддерживаются;
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.txt переведите все кириллические ссылки в Punycode с помощью любого Punycode-конвертера: “сайт.рф” — “xn--80aswg.xn--p1ai”.
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами —
http://web.site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
Яндекс поддерживает
стандарт исключений для роботов (Robots Exclusion Protocol). Веб-мастер может скрыть содержимое от индексирования ботами Яндекса, указав директиву “disallow”. Тогда при очередном посещении сайта робот загрузит файл robots.txt, увидит запрет и проигнорирует страницу. Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег “noindex” или “none”.
Google предупреждает, что robots.txt не предусмотрен для блокировки показа страниц в результатах выдачи. Он позволяет запретить индексирование только некоторых типов контента: медиафайлов, неинформативных изображений, скриптов или стилей. Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — “noindex” или атрибута “rel” со значением “nofollow”.
Если на этом или другом сайте есть ссылка на страницу, то она может оказаться в индексе, даже если к ней закрыт доступ в файле robots.txt.
Закройте доступ к странице паролем или “nofollow” , если не хотите, чтобы она попала в выдачу Google. Если этого не сделать, ссылка попадет в результаты но будет выглядеть так:

Такой вид ссылки означает, что страница доступна пользователям, но бот не может составить описание, потому что доступ к ней заблокирован в robots.txt.
Содержимое файла robots.txt — это указания, а не команды. Большинство поисковых ботов, включая Googlebot, воспринимают файл, но некоторые системы могут его проигнорировать.
Если нет доступа к robots.txt
Если вы не имеете доступа к robots.txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
На некоторых сторонних платформах управлять файлом robots.txt нельзя. К примеру, сервис Wix автоматически создает robots.txt для каждого проекта на платформе. Вы сможете посмотреть файл, если добавите в конец домена “/robots.txt”.
В файле будут элементы, которые относятся к структуре сайтов на этой платформе, к примеру “noflashhtml” и “backhtml”. Они не индексируются и никак не влияют на SEO.
Если нужно удалить из выдачи какие-то из страниц ресурса на Wix, используйте “noindex”.
Как составить robots.txt правильно
Файл можно составить в любом текстовом редакторе и сохранить в формате txt. В нем нужно прописать инструкцию для роботов: указание, каким роботам реагировать, и разрешение или запрет на сканирование файлов.
Инструкции отделяют друг от друга переносом строки.
Символы robots.txt
“*” — означает любую последовательность символов в файле.
“$” — ограничивает действия “*”, представляет конец строки.
“/” — показывает, что закрывают для сканирования.
“/catalog/” — закрывают раздел каталога;
“/catalog” — закрывают все ссылки, которые начинаются с “/catalog”.
“#” — используют для комментариев, боты игнорируют текст с этим символом.
User-agent: * Disallow: /catalog/ #запрещаем сканировать каталог
Директивы robots.txt
Директивы, которые распознают все краулеры:
User-agent
На первой строчке прописывают правило User-agent — указание того, какой робот должен реагировать на рекомендации. Если запрещающего правила нет, считается, что доступ к файлам открыт.
Для разного типа контента поисковики используют разных ботов:
- Google: основной поисковый бот называется Googlebot, есть Googlebot News для новостей, отдельно Googlebot Images, Googlebot Video и другие;
- Яндекс: основной бот называется YandexBot, есть YandexDirect для РСЯ, YandexImages, YandexCalendar, YandexNews, YandexMedia для мультимедиа, YandexMarket для Яндекс.Маркета и другие.
Для отдельных ботов можно указать свою директиву, если есть необходимость в рекомендациях по типу контента.
User-agent: * — правило для всех поисковых роботов;
User-agent: Googlebot — только для основного поискового бота Google;
User-agent: YandexBot — только для основного бота Яндекса;
User-agent: Yandex — для всех ботов Яндекса. Если любой из ботов Яндекса обнаружит эту строку, то другие правила User-agent: * учитывать не будет.
Sitemap
Указывает ссылку на
карту сайта — файл со структурой сайта, в котором перечислены страницы для индексации:
User-agent: * Sitemap: http://site.com/sitemap.xml
Некоторые веб-мастеры не делают карты сайтов, это не обязательное требование, но лучше составить Sitemap — этот файл краулеры воспринимают как структуру страниц, которые не можно, а нужно индексировать.
Disallow
Правило показывает, какую информацию ботам сканировать не нужно.
Если вы еще работаете над сайтом и не хотите, чтобы он появился в незавершенном виде, можно закрыть от сканирования весь сайт:
User-agent: * Disallow: /
После окончания работы над сайтом не забудьте снять блокировку.
Разрешить всем ботам сканировать весь сайт:
User-agent: * Disallow:
Для этой цели можно оставить robots.txt пустым.
Чтобы запретить одному боту сканировать, нужно только прописать запрет с упоминанием конкретного бота. Для остальных разрешение не нужно, оно идет по умолчанию:
User-agent: BadBot Disallow: /
Чтобы разрешить одному боту сканировать сайт, нужно прописать разрешение для одного и запрет для остальных:
User-agent: Googlebot Disallow: User-agent: * Disallow: /
Запретить ботам сканировать страницу:
User-agent: * Disallow: /page.html
Запретить сканировать конкретную папку с файлами:
User-agent: * Disallow: /name/
Запретить сканировать все файлы, которые заканчиваются на “.pdf”:
User-agent: * Disallow: /*.pdf$
Запретить сканировать раздел
http://site.com/about/:
User-agent: * Disallow: /about/
Запись формата “Disallow: /about” без закрывающего “/” запретит доступ и к разделу
http://site.com/about/, к файлу http://site.com/about.php и к другим ссылкам, которые начинаются с “/about”.
Если нужно запретить доступ к нескольким разделам или папкам, для каждого нужна отдельная строка с Disallow:
User-agent: * Disallow: /about Disallow: /info Disallow: /album1
Allow
Директива определяет те пути, которые доступны для указанных поисковых ботов. По сути, это Disallow-наоборот — директива, разрешающая сканирование. Для роботов действует правило: что не запрещено, то разрешено, но иногда нужно разрешить доступ к какому-то файлу и закрыть остальную информацию.
Разрешено сканировать все, что начинается с “/catalog”, а все остальное запрещено:
User-agent: * Allow: /catalog Disallow: /
Сканировать файл “photo.html” разрешено, а всю остальную информацию в каталоге /album1/ запрещено:
User-agent: * Allow: /album1/photo.html Disallow: /album1/
Заблокировать доступ к каталогам “site.com/catalog1/” и “site.com/catalog2/” но разрешить к “catalog2/subcatalog1/”:
User-agent: * Disallow: /catalog1/ Disallow: /catalog2/ Allow: /catalog2/subcatalog1/
Бывает, что для страницы оказываются справедливыми несколько правил. Тогда робот будет отсортирует список от меньшего к большему по длине префикса URL и будет следовать последнему правилу в списке.
Директивы, которые распознают боты Яндекса:
Clean-param
Некоторые страницы дублируются с разными GET-параметрами или UTM-метками, которые не влияют на содержимое. К примеру, если в каталоге товаров использовали сортировку или разные id.
Чтобы отследить, с какого ресурса делали запрос страницы с книгой book_id=123, используют ref:
“www.site. com/some_dir/get_book.pl?ref=site_1& book_id=123”
“www.site. com/some_dir/get_book.pl?ref=site_2& book_id=123”
“www.site. com/some_dir/get_book.pl?ref=site_3& book_id=123”
Страница с книгой одна и та же, содержимое не меняется. Чтобы бот не сканировал все варианты таких страниц с разными параметрами, используют правило Clean-param:
User-agent: Yandex Disallow: Clean-param: ref/some_dir/get_book.pl
Робот Яндекса сведет все адреса страницы к одному виду:
“www.example. com/some_dir/get_book.pl? book_id=123”
Для адресов вида:
“www.example2. com/index.php? page=1&sid=2564126ebdec301c607e5df”
“www.example2. com/index.php? page=1&sid=974017dcd170d6c4a5d76ae”
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: sid/index.php
Для адресов вида
“www.example1. com/forum/showthread.php? s=681498b9648949605&t=8243”
“www.example1. com/forum/showthread.php? s=1e71c4427317a117a&t=8243”
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s/forum/showthread.php
Если переходных параметров несколько:
“www.example1.com/forum_old/showthread.php?s=681498605&t=8243&ref=1311”
“www.example1.com/forum_new/showthread.php?s=1e71c417a&t=8243&ref=9896”
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s&ref/forum*/showthread.php
Host
Правило показывает, какое зеркало учитывать при индексации. URL нужно писать без “http://” и без закрывающего слэша “/”.
User-agent: Yandex Disallow: /about Host: www.site.com
Сейчас эту директиву уже
не используют, если в ваших robots.txt она есть, можно удалять. Вместо нее нужно на всех не главных зеркалах сайта поставить 301 редирект.
Crawl-delay
Раньше частая загрузка страниц нагружала сервер, поэтому для ботов устанавливали Crawl-delay — время ожидания робота в секундах между загрузками. Эту директиву можно не использовать, мощным серверам она не требуется.
Время ожидания — 4 секунды:
User-agent: * Allow: /album1 Disallow: / Crawl-delay: 4
Только латиница
Напомним, что все кириллические ссылки нужно перевести в Punycode с помощью любого конвертера.
Неправильно:
User-agent: Yandex Disallow: /каталог
Правильно:
User-agent: Yandex Disallow: /xn--/-8sbam6aiv3a
Пример robots.txt
Запись означает, что правило справедливо для всех роботов: запрещено сканировать ссылки из корзины, из встроенного поиска и админки, карта сайта находится по ссылке
http://site.com/sitemap, ref не меняет содержание страницы get_book:
User-agent: * Disallow: /bin/ Disallow: /search/ Disallow: /admin/ Sitemap: http://site.com/sitemap Clean-param: ref/some_dir/get_book.pl
Составить robots.txt бесплатно поможет
инструмент для генерации robots.txt от PR-CY, он позволит закрыть или открыть весь сайт для ботов, указать путь к карте сайта, настроить ограничение на посещение страниц, закрыть доступ некоторым роботам и установить задержку:

Для
проверки файла robots.txt на ошибки у поисковиков есть собственные инструменты:
Инструмент проверки файла robots.txt от Google позволит проверить, как бот видит конкретный URL. В поле нужно ввести проверяемый URL, а инструмент покажет, доступна ли ссылка.
Инструмент проверки от Яндекса покажет, правильно ли заполнен файл. Нужно указать сайт, для которого создан robots.txt, и перенести его содержимое в поле.
Файл robots.txt не подходит для блокировки доступа к приватным файлам, но направляет краулеров к карте сайта и дает рекомендации для быстрого сканирования важных материалов ресурса.
Вебмастер может направить поисковых ботов на страницы, которые считает обязательными для индексирования, и скрыть те, которых в выдаче быть не должно. Для этого предназначен файл robots.txt. Команда сервиса для анализа сайта PR-CY составила гайд об этом файле: для чего он нужен, из каких команд состоит, как составить его по правилам и проверить.
Зачем нужен robots.txt
С помощью этого файла можно повлиять на поведение ботов Яндекса и Google. Файл robots.txt содержит указания для краулеров, предназначенных для индексирования сайта. Он состоит из списка команд, которые рекомендуют либо просканировать, либо пропустить конкретные страницы или целые разделы сайта. Если боты «прислушаются» к этим пожеланиям, то не будут посещать закрытые страницы или индексировать определенный тип контента.
Закрывают обычно дублирующие страницы, служебные, неинформативные, страницы с GET-параметрами или просто неважные для пользователей.
Зачем это нужно:
- уменьшить количество запросов к серверу;
- оптимизировать краулинговый бюджет сайта — общее количество страниц, которое за один раз может посетить поисковый бот;
- уменьшить шанс того, что в выдачу попадут страницы, которые там не нужны.
Как надежно закрыть страницу от ботов
Поисковики не воспринимают robots.txt как список жестких правил, это только рекомендации. Даже если в robots стоит запрет, страница может появиться в выдаче, если на нее ведет внешняя или внутренняя ссылка.
Страница, доступ к которой запретили только в robots.txt, может попасть в выдачу и будет выглядеть так:
 Главная страница сайта в выдаче, но описание бот составить не смог
Главная страница сайта в выдаче, но описание бот составить не смог
Если вы точно не хотите, чтобы страница попала в индекс, недостаточно запретить сканирование в файле robots.txt. Один из вариантов, подходящий для служебных страниц, — запаролить ее. Бот не сможет просканировать содержимое страницы, если она доступна только пользователям, авторизованным через логин и пароль.
Если страницы нельзя закрыть паролем, но не хочется показывать их ботам, есть вариант применить директивы «noindex» и «nofollow». Для этого нужно добавить их в секцию <head> HTML-кода страницы:
<meta name="robots" content="noindex, nofollow"/>Чтобы робот правильно интерпретировал «noindex» и «nofollow» и не добавил страницу в индекс, не закрывайте одновременно доступ к ней в файле robots.txt. Так бот не получит доступа к странице и не увидит запрещающих директив.
Требования поисковых систем к файлу robots.txt
Каким должен быть файл, как его оформить и куда размещать — в этом и Яндекс, и Google солидарны:
- Формат — только txt.
- Вес — не превышающий 32 КБ.
- Название — строго строчными буквами «robots.txt». Никакие другие варианты, к примеру, с заглавной, боты не воспримут.
- Наполнение — строго латиница. Все записи должны быть на латинице, включая адрес сайта: если он кириллический, его нужно переконвертировать в punycode. Например, после конвертации запись сайта «окна.рф» будет выглядеть как «xn--80atjc.xn--p1ai». Ее и нужно использовать в командах.
- Исключение для предыдущего правила — комментарии вебмастера. Они могут быть на любом языке, поскольку специалист оставляет их для себя и коллег, а не для поисковых ботов. Для обозначения комментариев используют символ «#». Все, что указано после «#», роботы проигнорируют, поэтому следите, чтобы туда случайно не попали важные команды.
- Количество файлов robots.txt — должен быть один общий файл на весь сайт вместе с поддоменами.
- Местоположение — корневой каталог. У поддоменов файл должен быть таким же, только разместить его нужно в корневом каталоге каждого поддомена.
- Ссылка на файл — https://example.com/robots.txt (вместо https://example.com нужно указать адрес вашего сайта).
- Ссылка на robots.txt должна отдавать код ответа сервера 200 OK.
Подробные рекомендации для robots.txt от Яндекса читайте здесь, от Google — здесь.
Дальше рассмотрим, каким образом можно давать рекомендации ботам.
Как правильно составить robots.txt
Файл состоит из списка команд (директив) с указанием страниц, на которые они распространяются, и адресатов — имён ботов, к которым команды относятся.
Директиву Clean-param воспринимают только боты Яндекса, а в остальном в 2021 году команды для ботов Google и Яндекса одинаковы.
Основные обозначения файла
User-agent — какой бот должен прореагировать на команду. После двоеточия указывают либо конкретного бота, либо обобщают всех с помощью символа *.
Пример. User-agent: * — все существующие роботы, User-agent: Googlebot — только бот Google.
Disallow — запрет сканирования. После косого слэша указывают, на что распространяется команда запрета.
Пример:
Disallow: /blog/page-2.html
Пустое поле в Disallow означает разрешение на сканирование всего сайта:
User-agent: *
Disallow:
А эта запись запрещает всем роботом сканировать весь сайт:
User-agent: *
Disallow: /
Если речь идет о новом сайте, проследите, чтобы в файле robots.txt не осталась эта запись, после того как разработчики выложат сайт на рабочий домен.
Эта запись разрешает сканирование боту Google, а всем остальным запрещает:
User-agent: Googlebot
Disallow:
User-agent: *
Disallow: /
Отдельно прописывать разрешения необязательно. Доступным считается всё, что вы не закрыли.
В записях важен закрывающий косой слэш, его наличие или отсутствие меняет смысл:
Disallow: /about/ — запись закрывает раздел «О нас», доступный по ссылке https://example.com/about/
Disallow: /about — закрывает все ссылки, которые начинаются с «/about», включая раздел https://example.com/about/, страницу https://example.com/about/company/ и другие.
Каждому запрету соответствует своя строка, нельзя перечислить несколько правил сразу. Вот неправильный вариант записи:
Disallow: /catalog/blog/photo/
Правильно оформить их раздельно, каждый с новой строки и своим Disallow:
Disallow: /catalog/
Disallow: /blog/
Disallow: /photo/
Allow означает разрешение сканирования, с помощью этой команды удобно прописывать исключения. Для примера запись запрещает всем ботам сканировать весь альбом, но делает исключение для одного фото:
User-agent: *
Allow: /album/photo1.html
Disallow: /album/
А вот и отдельная команда для Яндекса — Clean-param. Директиву используют, чтобы исключить дубли страниц, которые могут появляться из-за GET-параметров или UTM-меток. Clean-param распознают только боты Яндекса. Вместо нее можно использовать Disallow, эту команду понимают в том числе и гуглоботы.
Допустим, на сайте есть страница page=1 и у нее могут быть такие параметры:
https://example.com/index.php?page=1&sid=2564126ebdec301c607e5df
https://example.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
Каждый образовавшийся адрес в индексе не нужен, достаточно, чтобы там была общая основная страница. В этом случае в robots нужно задать Clean-param и указать, что ссылки с дополнениями после «sid» в страницах на «/index.php» индексировать не нужно:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php
Если параметров несколько, перечислите их через амперсанд:
Clean-param: sid&utm&ref /index.php
Строки не должны быть длиннее 500 символов. Такие длинные строки — редкость, но из-за перечисления параметров такое может случиться. Если указание получилось сложным и длинным, его можно разделить на несколько. Примеры найдете в Справке Яндекса.
Sitemap — ссылка на карту сайта. Если карты сайта нет, запись не нужна. Сама по себе карта не обязательна, но если сайт большой, то лучше ее создать и дать ссылку в robots, чтобы ботам было проще разобраться в структуре.
Sitemap: https://example.com/sitemap.xml
Обозначим также два важных спецсимвола, которые используются в robots:
* — предполагает любую последовательность символов после этого знака;
$ — указывает на то, что на этом элементе необходимо остановиться.
Пример. Такая запись:
Disallow: /catalog/category1$
запрещает роботу индексировать страницу site.com/catalog/category1, но не запрещает индексировать страницу site.com/catalog/category1/product1.
Лучше не заниматься сбором команд вручную, для этого есть сервисы, которые работают онлайн и бесплатно. Инструмент для генерации robots.txt бесплатно соберет нужные команды: открыть или закрыть сайт для ботов, указать путь к sitemap, настроить ограничение на посещение избранных страниц, установить задержку посещений.
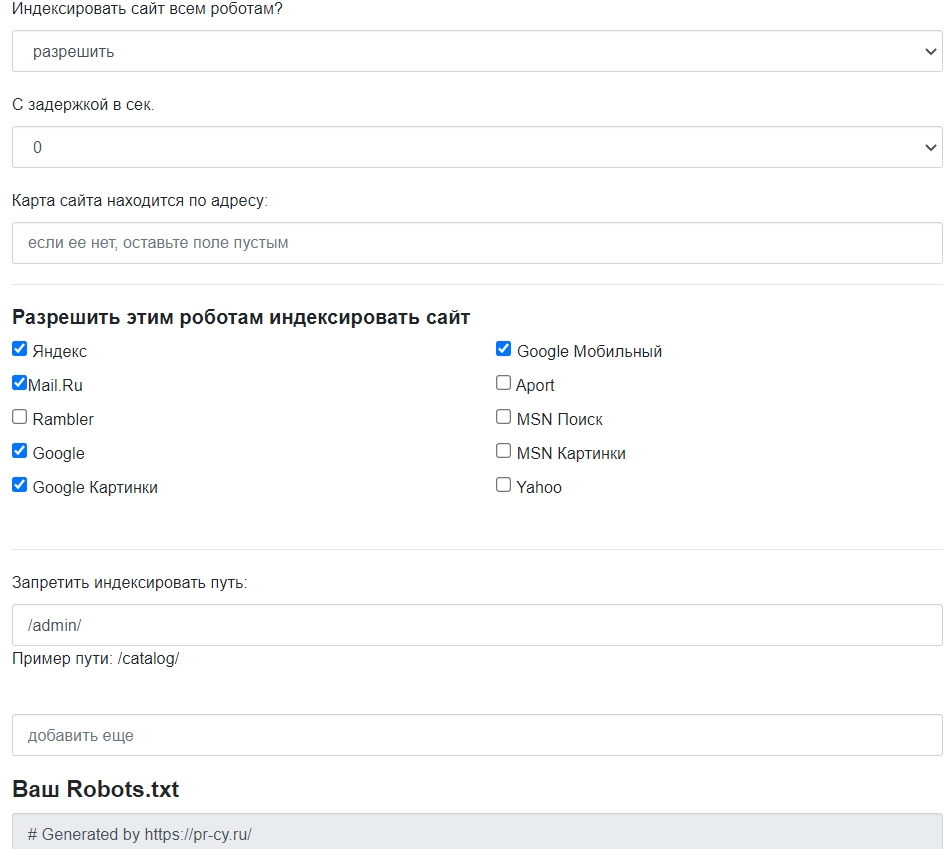 Настройки файла в инструменте
Настройки файла в инструменте
Есть и другие бесплатные генераторы файла, которые позволят быстро создать robots и избежать ошибок. У популярных движков есть плагины, с ними собирать файл еще проще. О них расскажем ниже.
Как проверить правильность robots.txt
После создания файла и добавления в корневой каталог будет не лишним проверить, видят ли его боты и нет ли ошибок в записи. У поисковых систем есть свои инструменты:
- Найти ошибки в заполнении robots — инструмент от Яндекса. Укажите сайт и введите содержимое файла в поле.
- Проверить доступность для ботов — инструмент от Google. Введите ссылку на URL с вашим robots.txt.
- Определить наличие файла robots.txt в корневом каталоге и доступность сайта для индексации — Анализ сайта от PR-CY. В сервисе есть еще 70+ тестов с проверкой SEO, технических параметров, ссылок и другого.
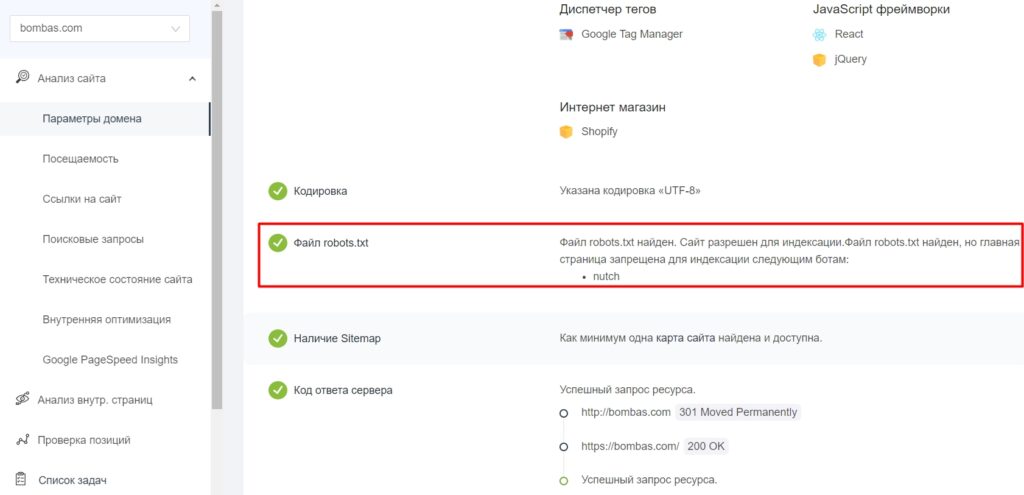 Фрагмент проверки сайта сервисом pr-cy.ru/analysis
Фрагмент проверки сайта сервисом pr-cy.ru/analysis
В «Важных событиях» отобразятся даты изменения файла.
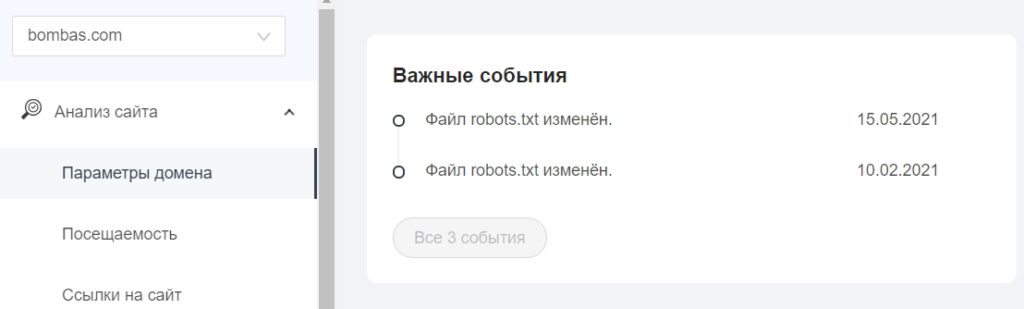 Оповещения в интерфейсе
Оповещения в интерфейсе
Правильный robots.txt для разных CMS: примеры готового файла
Файл robots.txt находится в корневой папке сайта. Чтобы создать или редактировать его, нужно подключиться к сайту по FTP-доступу. Некоторые системы управления (например, Битрикс) предоставляют возможность редактировать файл в административной панели.
Посмотрим, какие возможности для редактирования файла есть в популярных CMS.
WordPress
У WP много бесплатных плагинов, которые формируют robots.txt. Эта опция предусмотрена в составе общих SEO-плагинов Yoast SEO и All in One SEO, но есть и отдельные, которые отвечают за создание и редактирование файла, например:
- Robots.txt Editor,
- Virtual Robots.txt,
- WordPress Robots.txt optimization (+XML Sitemap).
Пример robots.txt для контентного проекта на WordPress
Это вариант файла для блогов и других проектов без функции личного кабинета и корзины.
User-agent: * # установили общие правила для роботов
Disallow: /cgi-bin # закрыли системную папку, которая находится на хостинге
Disallow: /? # обобщили все параметры запроса на главной странице сайта
Disallow: /wp— # все специальные WordPress-файлы: /wp-json/, /wp-content/plugins, /wp-includes
Disallow: *?s= # здесь и далее перечисление запросов поиска
Disallow: *&s=
Disallow: /search/
Disallow: */trackback # закрыли трекбеки — уведомления о появлении ссылки на статью
Disallow: */feed # новостные ленты полностью
Disallow: */rss # rss-ленты
Disallow: */embed # все встраивания
Disallow: /xmlrpc.php # файл API WP
Disallow: *utm*= # все ссылки, у которых прописаны UTM-метки
Disallow: *openstat= # все ссылки, у которых прописаны openstat-метки
Allow: */uploads # открыли доступ к папке с файлами uploads
Allow: /*/*.js # открыли доступ к js-скриптам внутри /wp-, уточнили /*/ для приоритета
Allow: /*/*.css # доступ к css-файлам внутри /wp-, также уточнили /*/ для приоритета
Allow: /wp-*.png # доступ к картинкам в плагинах, папке cache и других в формате png
Allow: /wp-*.jpg # то же самое для формата jpg
Allow: /wp-*.jpeg # для формата jpeg
Allow: /wp-*.gif # и для анимаций в gif
Allow: /wp-admin/admin-ajax.php # открыли доступ к этому файлу, чтобы не блокировать JS и CSS для плагинов
Sitemap: https://example.com/sitemap.xml # указали ссылку на карту сайта (вместо https://example.com нужно подставить сой домен)
Пример robots.txt для интернет-магазина на WordPress
Похожий файл, но со спецификой интернет-магазина на платформе WooCommerce на базе WordPress. Закрываем то же самое, что в предыдущем примере, плюс страницу корзины, а также отдельные страницы добавления в корзину и оформления заказа пользователем.
User-agent: *
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Disallow: /cart/
Disallow: /checkout/
Disallow: /*add-to-cart=*
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/sitemap.xml
1C-Битрикс
В модуле «Поисковая оптимизация» этой CMS начиная с версии 14.0.0 можно настроить управление файлом robots из административной панели сайта. Нужный раздел находится в меню Маркетинг > Поисковая оптимизация > Настройка robots.txt.
Пример robots.txt для сайта на Битрикс
Похожий набор рекомендаций с дополнениями, подразумевающими, что у сайта есть личный кабинет пользователя.
User-agent: *
Disallow: /cgi-bin # закрыли папку на хостинге
Disallow: /bitrix/ # закрыли папку с системными файлами Битрикс
Disallow: *bitrix_*= # GET-запросы Битрикс
Disallow: /local/ # другая папка с системными файлами Битрикс
Disallow: /*index.php$ # дубли страниц с index.php
Disallow: /auth/ # страница авторизации
Disallow: *auth=
Disallow: /personal/ # личный кабинет
Disallow: *register= # страница регистрации
Disallow: *forgot_password= # страница с функцией восстановления пароля
Disallow: *change_password= # страница с возможностью изменить пароль
Disallow: *login= # вход с логином
Disallow: *logout= # выход из кабинета
Disallow: */search/ # поиск
Disallow: *action= # действия
Disallow: *print= # печать
Disallow: *?new=Y # новая страница
Disallow: *?edit= # редактирование
Disallow: *?preview= # предпросмотр
Disallow: *backurl= # трекбеки
Disallow: *back_url=
Disallow: *back_url_admin=
Disallow: *captcha # страница с прохождением капчи
Disallow: */feed # новостные ленты
Disallow: */rss # rss-фиды
Disallow: *?FILTER*= # несколько популярных параметров фильтров в каталоге
Disallow: *?ei=
Disallow: *?p=
Disallow: *?q=
Disallow: *?tags=
Disallow: *B_ORDER=
Disallow: *BRAND=
Disallow: *CLEAR_CACHE=
Disallow: *ELEMENT_ID=
Disallow: *price_from=
Disallow: *price_to=
Disallow: *PROPERTY_TYPE=
Disallow: *PROPERTY_WIDTH=
Disallow: *PROPERTY_HEIGHT=
Disallow: *PROPERTY_DIA=
Disallow: *PROPERTY_OPENING_COUNT=
Disallow: *PROPERTY_SELL_TYPE=
Disallow: *PROPERTY_MAIN_TYPE=
Disallow: *PROPERTY_PRICE[*]=
Disallow: *S_LAST=
Disallow: *SECTION_ID=
Disallow: *SECTION[*]=
Disallow: *SHOWALL=
Disallow: *SHOW_ALL=
Disallow: *SHOWBY=
Disallow: *SORT=
Disallow: *SPHRASE_ID=
Disallow: *TYPE=
Disallow: *utm*= # все ссылки, имеющие метки UTM
Disallow: *openstat= # ссылки с метками openstat
Disallow: *from= # ссылки с метками from
Allow: */upload/ # открыли папку, где находятся файлы uploads
Allow: /bitrix/*.js # здесь и далее открыли скрипты js и css
Allow: /bitrix/*.css
Allow: /local/*.js
Allow: /local/*.css
Allow: /local/*.jpg # открыли доступ к картинкам в формате jpg и далее в других форматах
Allow: /local/*.jpeg
Allow: /local/*.png
Allow: /local/*.gif
Sitemap: https://example.com/sitemap.xml
OpenCart
У этого движка есть официальный модуль Редактирование robots.txt Opencart для работы с файлом прямо из панели администратора.
Пример robots.txt для магазина на OpenCart
CMS OpenCart обычно используют в качестве базы для интернет-магазина, поэтому пример robots заточен под нужды e-commerce.
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter=
Disallow: /*&filter=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: *page=*
Disallow: *search=*
Disallow: /cart/
Disallow: /forgot-password/
Disallow: /login/
Disallow: /compare-products/
Disallow: /add-return/
Disallow: /vouchers/
Sitemap: https://example.com/sitemap.xml
Joomla
Отдельных расширений, связанных с формированием файла robots.txt для этой CMS нет, система управления автоматически генерирует файл при установке, в нем содержатся все необходимые запреты.
Пример robots.txt для сайта на Joomla
В файле закрыты плагины, шаблоны и прочие системные решения.
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Allow: *.css
Allow: *.js
Sitemap: https://example.com/sitemap.xml
Поисковые системы воспринимают директивы в robots.txt как рекомендации, которым можно следовать или не следовать. Тем не менее, если в файле не будет противоречий, а на закрытые страницы нет входящих ссылок — у ботов не будет причин игнорировать правила. Пользуйтесь нашими инструкциями и примерами, и пусть в выдаче появляются только действительно нужные пользователям страницы вашего сайта.
Оптимизируйте свои подборки
Сохраняйте и классифицируйте контент в соответствии со своими настройками.
С помощью файла robots.txt вы можете указывать, какие файлы на вашем сайте будут видны поисковым роботам.
Файл robots.txt находится в корневом каталоге вашего сайта. Например, на сайте www.example.com он находится по адресу www.example.com/robots.txt. Он представляет собой обычный текстовый файл, который соответствует стандарту исключений для роботов
и содержит одно или несколько правил. Каждое из них запрещает или разрешает всем поисковым роботам или одному определенному из них доступ к определенному пути в домене или субдомене, в котором размещается файл robots.txt. Все файлы считаются доступными для сканирования, если вы не указали иное в файле robots.txt.
Ниже приведен пример простого файла robots.txt с двумя правилами.
User-agent: Googlebot Disallow: /nogooglebot/ User-agent: * Allow: / Sitemap: https://www.example.com/sitemap.xml
Пояснения:
-
Агенту пользователя с названием Googlebot запрещено сканировать любые URL, начинающиеся с
https://example.com/nogooglebot/. - Любым другим агентам пользователя разрешено сканировать весь сайт. Это правило можно опустить, и результат будет тем же. По умолчанию агенты пользователя могут сканировать сайт целиком.
-
Файл Sitemap этого сайта находится по адресу
https://www.example.com/sitemap.xml.
Более подробные сведения вы найдете в разделе Синтаксис.
Основные рекомендации по созданию файла robots.txt
Работа с файлом robots.txt включает четыре этапа.
- Создайте файл robots.txt
- Добавьте в него правила
- Опубликуйте готовый файл в корневом каталоге своего сайта
- Протестируйте свой файл robots.txt
Как создать файл robots.txt
Создать файл robots.txt можно в любом текстовом редакторе, таком как Блокнот, TextEdit, vi или Emacs. Не используйте офисные приложения, поскольку зачастую они сохраняют файлы в проприетарном формате и добавляют в них лишние символы, например фигурные кавычки, которые не распознаются поисковыми роботами. Обязательно сохраните файл в кодировке UTF-8, если вам будет предложено выбрать кодировку.
Правила в отношении формата и расположения файла
- Файл должен называться robots.txt.
- На сайте должен быть только один такой файл.
-
Файл robots.txt нужно разместить в корневом каталоге сайта. Например, на сайте
https://www.example.com/он должен располагаться по адресуhttps://www.example.com/robots.txt. Он не должен находиться в подкаталоге (например, по адресуhttps://example.com/pages/robots.txt). Если вы не знаете, как получить доступ к корневому каталогу сайта, или у вас нет соответствующих прав, обратитесь к хостинг-провайдеру. Если у вас нет доступа к корневому каталогу сайта, используйте альтернативный метод блокировки, например тегиmeta. -
Файл robots.txt можно разместить по адресу с субдоменом (например,
https://website.example.com/robots.txt) или нестандартным портом (например,https://example.com:8181/robots.txt). - Действие robots.txt распространяется только на пути в пределах протокола, хоста и порта, где он размещен. Иными словами, правило по адресу
https://example.com/robots.txtдействует только для файлов, относящихся к доменуhttps://example.com/, но не к субдомену, такому какhttps://m.example.com/, или другим протоколам, напримерhttp://example.com/. - Файл robots.txt должен представлять собой текстовый файл в кодировке UTF-8 (которая включает коды символов ASCII). Google может проигнорировать символы, не относящиеся к UTF-8, в результате чего будут обработаны не все правила из файла robots.txt.
Как написать правила в файле robots.txt
Правила – это инструкции для поисковых роботов, указывающие, какие разделы сайта можно сканировать. Добавляя правила в файл robots.txt, учитывайте следующее:
- Файл robots.txt состоит из одной или более групп (наборов правил).
-
Каждая группа может включать несколько правил, по одному на строку. Эти правила также называются директивами. Каждая группа начинается со строки
User-agent, определяющей, какому роботу адресованы правила в ней. - Группа содержит следующую информацию:
- К какому агенту пользователя относятся директивы группы.
- К каким каталогам или файлам у этого агента есть доступ.
- К каким каталогам или файлам у этого агента нет доступа.
- Поисковые роботы обрабатывают группы по порядку сверху вниз. Агент пользователя может следовать только одному, наиболее подходящему для него набору правил, который будет обработан первым. Если к одному агенту пользователя относится несколько групп, все они будут объединены в одну.
- По умолчанию агенту пользователя разрешено сканировать любые страницы и каталоги, доступ к которым не заблокирован правилом
disallow. -
Правила должны указываться с учетом регистра. К примеру, правило
disallow: /file.aspраспространяется на URLhttps://www.example.com/file.asp, но не наhttps://www.example.com/FILE.asp. -
Символ
#означает начало комментария. Во время обработки комментарии игнорируются.
Правила в файлах robots.txt, поддерживаемые роботами Google
-
user-agent:(обязательное правило, может повторяться в пределах группы). Определяет, к какому именно автоматическому клиенту (поисковому роботу) относятся правила в группе. С такой строки начинается каждая группа правил. Названия агентов пользователя Google перечислены в этом списке.
Используйте знак*, чтобы заблокировать доступ всем поисковым роботам (кроме роботов AdsBot, которых нужно указывать отдельно). Примеры:# Example 1: Block only Googlebot User-agent: Googlebot Disallow: / # Example 2: Block Googlebot and Adsbot User-agent: Googlebot User-agent: AdsBot-Google Disallow: / # Example 3: Block all crawlers except AdsBot (AdsBot crawlers must be named explicitly) User-agent: * Disallow: /
-
disallow:(каждое правило должно содержать не менее одной директивыdisallowилиallow). Указывает на каталог или страницу относительно корневого домена, которые нельзя сканировать агенту пользователя. Если правило касается страницы, должен быть указан полный путь к ней, как в адресной строке браузера. В начале строки должен быть символ/. Если правило касается каталога, строка должна заканчиваться символом/. -
allow:(каждое правило должно содержать не менее одной директивыdisallowилиallow). Указывает на каталог или страницу относительно корневого домена, которые разрешено сканировать агенту пользователя. Используется для того, чтобы переопределить правилоdisallowи разрешить сканирование подкаталога или страницы в закрытом для обработки каталоге. Если правило касается страницы, должен быть указан полный путь к ней, как в адресной строке браузера. В начале строки должен быть символ/. Если правило касается каталога, строка должна заканчиваться символом/. -
sitemap:(необязательная директива, которая может повторяться несколько раз или не использоваться совсем). Указывает на расположение файла Sitemap, используемого на сайте. URL файла Sitemap должен быть полным. Google не перебирает варианты URL с префиксами http и https или с элементом www и без него. Из файлов Sitemap роботы Google получают информацию о том, какой контент нужно сканировать и как отличить его от материалов, которые можно или нельзя обрабатывать.
Подробнее…Примеры:
Sitemap: https://example.com/sitemap.xml Sitemap: https://www.example.com/sitemap.xml
Все правила, кроме sitemap, поддерживают подстановочный знак * для обозначения префикса или суффикса пути, а также всего пути.
Строки, не соответствующие ни одному из этих правил, игнорируются.
Ознакомьтесь со спецификацией Google для файлов robots.txt, где подробно описаны все правила.
Как загрузить файл robots.txt
Сохраненный на компьютере файл robots.txt необходимо загрузить на сайт и сделать доступным для поисковых роботов. Специального инструмента для этого не существует, поскольку способ загрузки зависит от вашего сайта и серверной архитектуры. Обратитесь к своему хостинг-провайдеру или попробуйте самостоятельно найти его документацию (пример запроса: “загрузка файлов infomaniak”).
После загрузки файла robots.txt проверьте, доступен ли он для роботов и может ли Google обработать его.
Как протестировать разметку файла robots.txt
Чтобы убедиться, что загруженный файл robots.txt общедоступен, откройте в браузере окно в режиме инкогнито (или аналогичном) и перейдите по адресу файла. Пример: https://example.com/robots.txt. Если вы видите содержимое файла robots.txt, то можно переходить к тестированию разметки.
Для этой цели Google предлагает два средства:
- Инструмент проверки файла robots.txt в Search Console. Этот инструмент можно использовать только для файлов robots.txt, которые уже доступны на вашем сайте.
- Если вы разработчик, мы рекомендуем воспользоваться библиотекой с открытым исходным кодом, которая также применяется в Google Поиске. С помощью этого инструмента файлы robots.txt можно локально тестировать прямо на компьютере.
Как отправить файл robots.txt в Google
Когда вы загрузите и протестируете файл robots.txt, поисковые роботы Google автоматически найдут его и начнут применять. С вашей стороны никаких действий не требуется. Если вы внесли в файл robots.txt изменения и хотите как можно скорее обновить кешированную копию, следуйте инструкциям в этой статье.
Полезные правила
Ниже перечислено несколько правил, часто используемых в файлах robots.txt.
| Полезные правила | |
|---|---|
| Это правило запрещает сканировать весь сайт. |
Следует учесть, что в некоторых случаях URL сайта могут индексироваться, даже если они не были просканированы. User-agent: * Disallow: / |
| Это правило запрещает сканировать каталог со всем его содержимым. |
Чтобы запретить сканирование целого каталога, поставьте косую черту после его названия. User-agent: * Disallow: /calendar/ Disallow: /junk/ Disallow: /books/fiction/contemporary/ |
| Это правило позволяет сканировать сайт только одному поисковому роботу. |
Сканировать весь сайт может только робот User-agent: Googlebot-news Allow: / User-agent: * Disallow: / |
| Это правило разрешает сканирование всем поисковым роботам за исключением одного. |
Робот User-agent: Unnecessarybot Disallow: / User-agent: * Allow: / |
|
Это правило запрещает сканирование отдельной страницы. |
Например, можно запретить сканирование страниц User-agent: * Disallow: /useless_file.html Disallow: /junk/other_useless_file.html |
|
Это правило запрещает сканировать весь сайт за исключением определенного подкаталога. |
Поисковым роботам предоставлен доступ только к подкаталогу User-agent: * Disallow: / Allow: /public/ |
|
Это правило скрывает определенное изображение от робота Google Картинок. |
Например, вы можете запретить сканировать изображение User-agent: Googlebot-Image Disallow: /images/dogs.jpg |
|
Это правило скрывает все изображения на сайте от робота Google Картинок. |
Google не сможет индексировать изображения и видео, которые недоступны для сканирования. User-agent: Googlebot-Image Disallow: / |
|
Это правило запрещает сканировать все файлы определенного типа. |
Например, вы можете запретить роботам доступ ко всем файлам User-agent: Googlebot Disallow: /*.gif$ |
|
Это правило запрещает сканировать весь сайт, но при этом он может обрабатываться роботом |
Робот User-agent: * Disallow: / User-agent: Mediapartners-Google Allow: / |
Воспользуйтесь подстановочными знаками * и $, чтобы сопоставлять URL, которые заканчиваются определенной строкой.
|
Например, вы можете исключить все файлы User-agent: Googlebot Disallow: /*.xls$ |
Если не указано иное, контент на этой странице предоставляется по лицензии Creative Commons “С указанием авторства 4.0”, а примеры кода – по лицензии Apache 2.0. Подробнее об этом написано в правилах сайта. Java – это зарегистрированный товарный знак корпорации Oracle и ее аффилированных лиц.
Последнее обновление: 2023-02-24 UTC.
Robots.txt — документ, который нужен для индексирования и продвижения сайта. С помощью этого файла владелец сайта подсказывает поисковым системам, какие разделы ресурса нужно учитывать, а какие — нет. Объясняю особенности его составления и настройки такого текстового файла.
Кому нужен robots.txt
Если у сайта нет robots.txt, поисковые роботы считают все страницы ресурса открытыми для индексирования. Если файл есть, владелец сайта может запретить роботам индексировать определённые страницы.
Например, контентным ресурсам или медиа можно работать без robots.txt — тут все страницы участвуют в индексации.
На других ресурсах могут быть страницы, которые не нужно показывать поисковым роботам:
- Админ-панели сайта: пути, которые начинаются с /user, /admin, /administrator и т.д.
- Пустые страницы ресурса: если на них нет контента, в индексации они не помогут.
- Формы регистрации.
- Личные страницы в интернет-магазинах: кабинеты пользователей, корзины и т.д.
Как настроить файл robots.txt
Начну с основных параметров.
User-agent: Yandex
Disallow: catalog/
Allow: /catalog/cucumbers/
Sitemap: http://www.example.com/sitemap.xml
User-agent — указывает название робота, к которому применяется правило. Например, User-agent: Yandex означает, что правило применяется к роботу Яндекса.
А user-agent: * означает, что правило применяется ко всем роботам. Но о звёздочках поговорим ниже.
Основные типы роботов, которые можно указать в User-agent:
- Yandex. Все роботы Яндекса.
- YandexBot. Основной робот Яндекса
- YandexImages. Индексирует изображения.
- YandexMedia. Индексирует видео и другие мультимедийные данные.
- Google. Все роботы Google.
- Googlebot. Основной робот Google.
- Googlebot-Image. Индексирует изображения.
Disallow. Указывает на каталог или страницу ресурса, которые роботы индексировать не будут. Если нельзя индексировать конкретную страницу, например, определённый раздел в каталоге, нужно указывать полный путь к ней — как в поисковой строке браузера.
В начале строки должен быть символ /. Если правило касается каталога, строка должна заканчиваться символом /.
Например, disallow: /catalog/gloves. Так мы запретим индексацию раздела с перчаткам.
Если оставить disallow пустым, роботы будут индексировать все страницы сайта.
Allow. Указывает на каталог или страницу, которые можно сканировать роботу. Его используют, чтобы внести исключения в пункт disallow и разрешить сканирование подкаталога или страницы в каталоге, который закрыт для обработки.
Если требуется индексировать конкретную страницу, нужно указывать к ней полный путь. Как и в disallow. Например, allow: /story/marketing. Так мы разрешили индексировать статью о маркетинге.
Если правило касается каталога, строка должна заканчиваться символом /.
Если allow пустой, робот не будет индексировать никакие страницы.
Sitemap. Необязательная директива, которая может повторяться несколько раз или не использоваться совсем. Её используют, чтобы описать структуру сайта и помочь роботам индексировать страницы.
Лендингам и небольшим сайтам sitemap не нужен. А вот таким ресурсам без sitemap не обойтись:
- Cайтам без хлебных крошек (навигационных цепочек).
- Большим ресурсам. Например, если сайт содержит большой объём мультимедиа или новостного контента.
- Сайтам с глубокой вложенностью. Например, «Главная/Каталог/Перчатки/Резиновые».
- Молодым ресурсам, на которые мало внешних ссылок, — их роботам сложно найти.
- Сайтам с большим архивом страниц, которые изолированы или не связаны друг с другом.
Файл нужно прописывать в XML-формате. Создание sitemap — тема для отдельной статьи. Подробную инструкцию читайте на Google Developers или в Яндекс.Справке.
Основные моменты robots.txt разобрали. Теперь расскажу про дополнительные параметры, которые используют в коде.
Для начала посмотрим на robots.txt Unisender. Для этого в поисковой строке браузера пишем Unisender.com/robots.txt.
По такой же формуле можно проверять файлы на всех сайтах: URL сайта + домен/robots.txt.
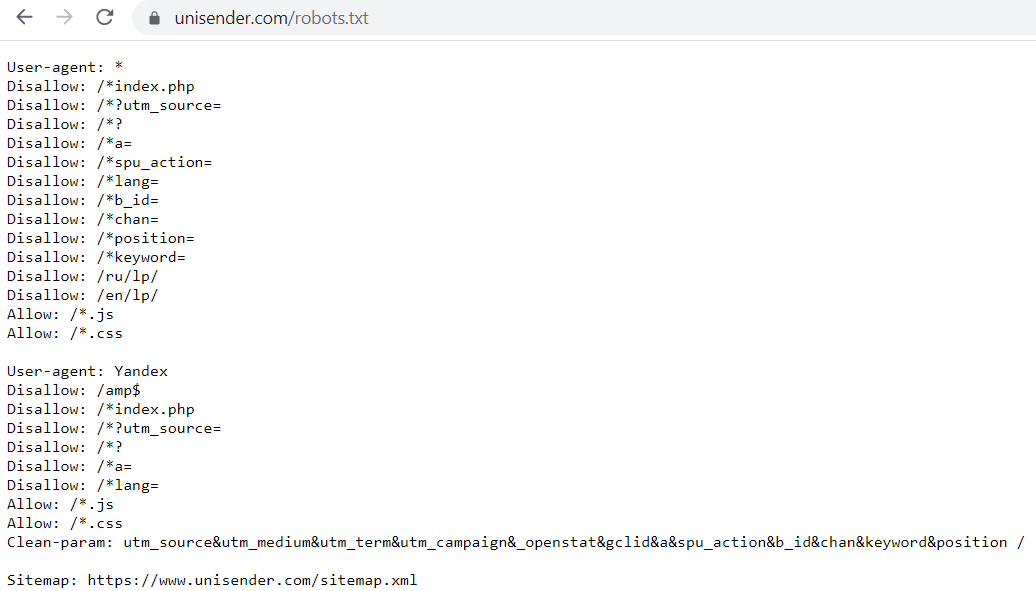
Robots.txt Unisender отличается от файла, который я приводил в пример. Дело в том, что здесь использованы дополнительные параметры:
Директива # (решётка) — комментарий. Решётки прописывают для себя, а поисковые роботы комментариев не видят.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Звёздочку роботы видят, а решётку — нет
Директива * (звёздочка) — любая последовательность символов после неё.
Например, если поставить звёздочку в поле disallow, то всё, что находится на её месте, будет запрещено.
User-agent: Yandex
Disallow: /example/* # запрещает ‘/example/blog’
# запрещает ‘/example/blog/test’
Disallow: */shop # запрещает не только ‘/shop’,
# но и ‘/example/shop’
Также и с полем allow: всё, что стоит на месте звёздочки, — разрешено для индексации.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Allow: */shop # разрешает не только ‘/shop’,
# но и ‘/example/shop’
Например, у Google есть особенность: компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. Вот как это нужно прописывать:
User-agent: Googlebot
Disallow: /site
Allow: *.css
Allow: *.js
Директива $ (знак доллара) — точное соответствие указанному параметру.
Например, использование доллара в disallow запретит доступ к определённому пути.
User-agent: Yandex
Disallow: /example # запрещает ‘/example’,
# запрещает ‘/example.html’
Disallow: /example$ # запрещает ‘/example’,
# не запрещает ‘/example.html’
# не запрещает ‘/example1’
# не запрещает ‘/example-new’
Таким способом можно исключить из сканирования все файлы определённого типа, например, GIF или JPG. Для этого нужно совместить * и $. Звёздочку ставим до расширения, а $ — после.
User-agent: Yandex
Disallow: / *.gif$ # вместо * могут быть любые символы,
# $ запретит индексировать файлы gif
Директива Clean-param — новый параметр Яндекс-роботов, который не будет сканировать дублированную информацию и поможет быстрее анализировать ресурс.
Дело в том, что из-за повторяющейся информации роботы медленнее проверяют сайт, а изменения на ресурсе дольше попадают в результаты поиска. Когда роботы Яндекса увидят эту директиву, не будут несколько раз перезагружать дубли информации и быстрее проверят сайт, а нагрузка на сервер снизится.
www.example.com/dir/get_card.pl?ref=site_1&card_id=10
www.example.com/dir/get_card.pl?ref=site_2&card_id=10
Параметр ref нужен, чтобы отследить, с какого ресурса сделан запрос. Он не меняет содержимое страницы, значит два адреса покажут одну и ту же страницу с книгой card_id=10. Поэтому директиву можно указать так:
User-agent: Yandex
Disallow:
Clean-param: ref /dir/get_card.pl
Робот Яндекса сведёт страницы к одной: www.example.com/dir/get_card.pl?card_id=10
Чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес:
User-agent: Yandex
Disallow:
Clean-param: utm
Директива Crawl-delay — устанавливает минимальный интервал в секундах между обращениями робота к сайту. Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами через точку.
User-agent: Yandex
Disallow:
Crawl-delay: 0.5
Для Яндекса максимальное значение в crawl-delay — 2. Более высокое значение можно установить инструментами Яндекс.Вебмастер.
Для Google-бота можно установить частоту обращений в панели вебмастера Search Console.
Директива Host — инструкция для робота Яндекса, которая указывает главное зеркало сайта. Нужна, если у сайта есть несколько доменов, по которым он доступен. Вот как её указывают:
User-agent: Yandex
Disallow: /example/
Host: example.ru
Если главное зеркало сайта — домен с протоколом HTTPS, его указывают так:
Как создать robots.txt
Способ 1. Понадобится текстовый редактор: блокнот, TextEdit, Vi, Emacs или любой другой. Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Способ 2. Создать на CMS с помощью плагинов — в этом случае robots.txt установится сам.
Если вы используете CMS хостинга, редактировать файл robots.txt не потребуется. Скорее всего, у вас даже не будет такой возможности. Вместо этого провайдер будет указывать поисковым системам, нужно ли сканировать контент, с помощью страницы настроек поиска или другого инструмента.
Способ 3. Воспользоваться генератором robots.txt — век технологий всё-таки.
Сгенерировать файл можно на PR-CY, IKSWEB, Smallseotools.
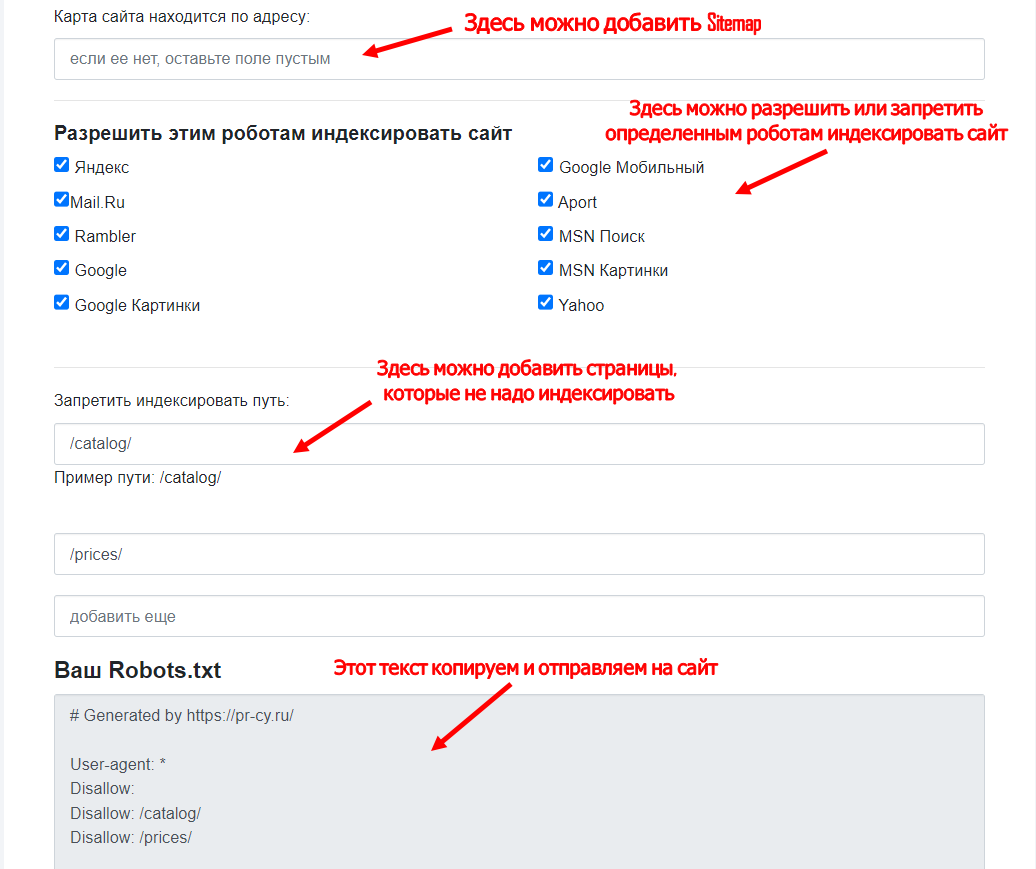
Создаём robots.txt на PR-CY
Требования к файлу robots.txt
Когда создадите текстовый файл, сохраните его в кодировке utf-8. Иначе поисковые роботы не смогут прочитать документ. После создания загрузите файл в корневую директорию на сайте хостинг-провайдера. Корневая директория — это папка public.html.
Папка, в которой нужно искать robots.txt. Источник
Если файла нет, его придётся создавать самостоятельно.
Как сделать файл robots.txt
Требования, которым должен соответствовать robots.txt:
- Каждая директива начинается с новой строки.
- Одна директива в строке, сам параметр также написан в одну строку.
- В начале строки нет пробелов.
- Нет кавычек в директивах.
- Директивы не нужно закрывать точкой или точкой с запятой.
- Файл должен называться robots.txt. Нельзя называть его Robots.txt или ROBOTS.TXT.
- Размер файла не должен превышать 500 КБ.
- robots.txt должен быть написан на английском языке. Буквы других алфавитов не разрешаются.
Если файл не соответствует одному из требований, весь сайт считается открытым для индексирования.
Как проверить правильность Robots.txt
Проверить robots.txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
Вот как это сделать:
- Перейдите на Яндекс.Вебмастер.
- В открывшееся окно вставьте текст robots.txt и нажмите проверить.
Проверяем robots.txt
Если файл написан правильно, Яндекс.Вебмастер не увидит ошибок.

Результаты анализа robots.txt
А если увидит ошибку — подсветит её и опишет возможную проблему.
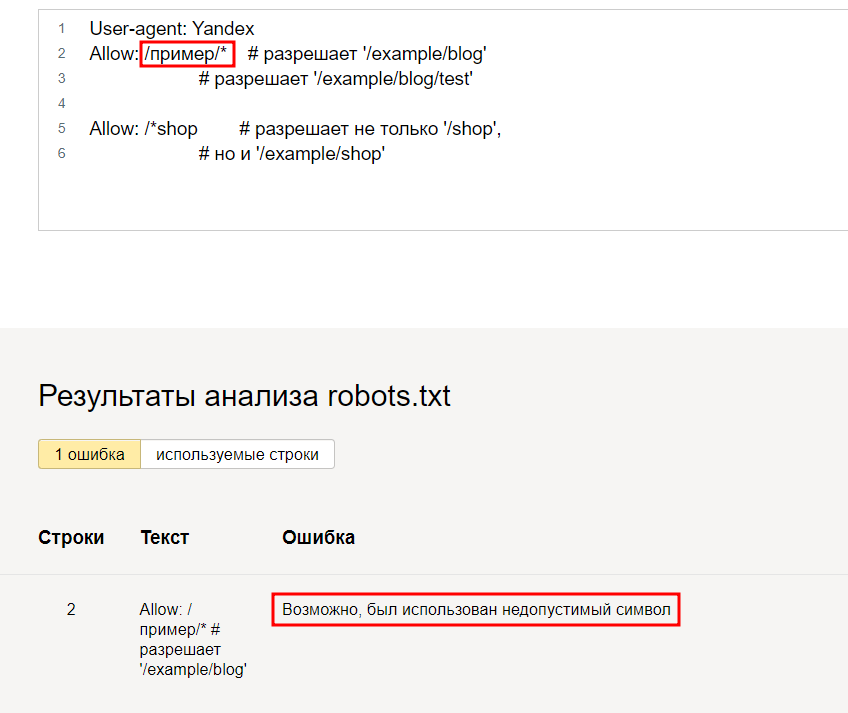
Так вебмастер помогает найти ошибки
На Яндекс.Вебмастер можно проверить robots.txt и по URL сайта. Для этого нужно указать запрос: URL сайта/robots.txt. Например, unisender.com/robots.txt.
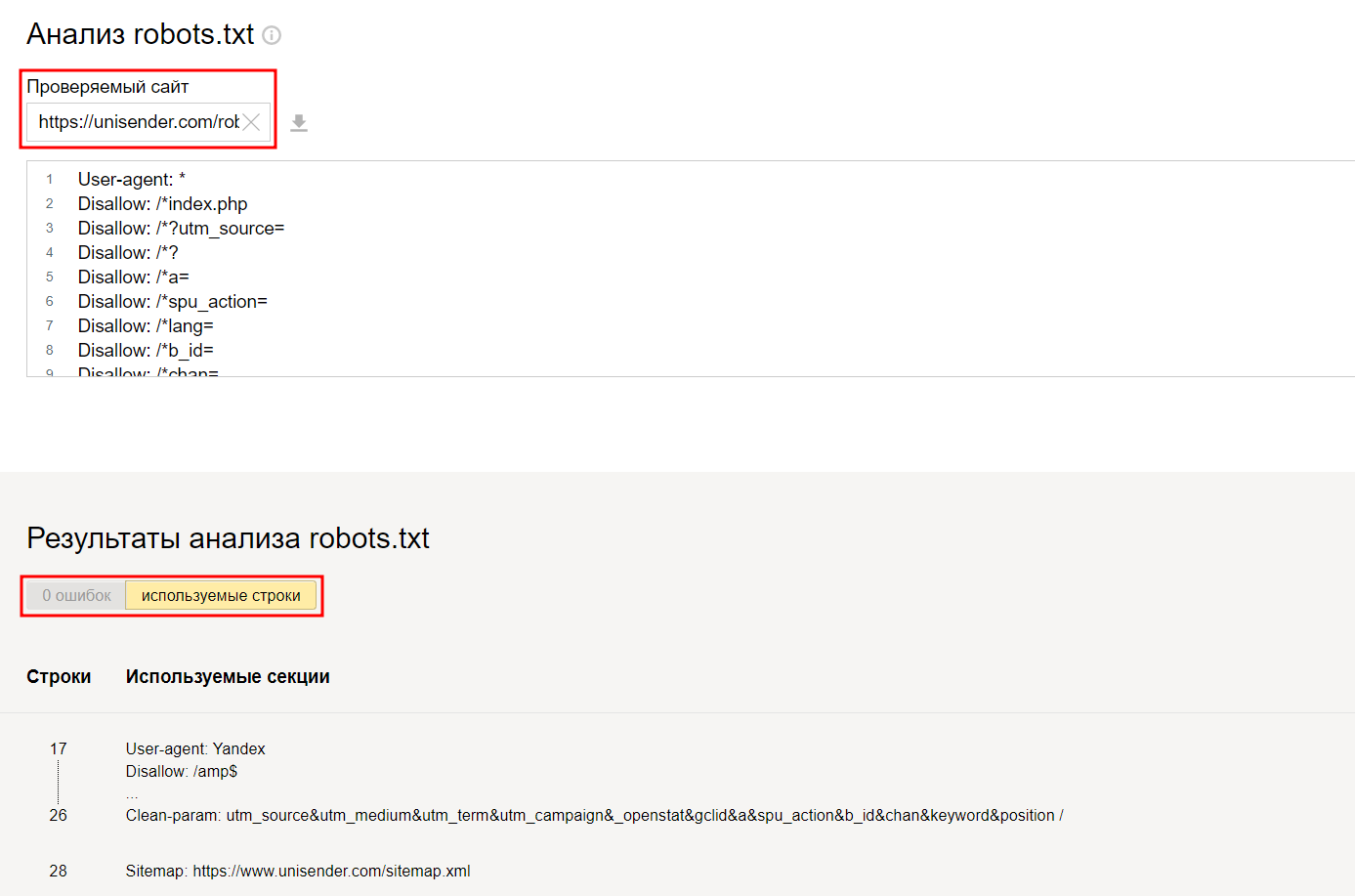
Unisender — robots.txt без ошибок
Ещё один вариант — проверить файл robots.txt через Google Search Console. Но сначала нужно подтвердить владение сайтом. Пошаговый алгоритм проверки robots.txt описан в видеоинструкции:
ЭКСКЛЮЗИВЫ ⚡️
Читайте только в блоге
Unisender
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
![]()
![]()
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни. Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
