Подробная инструкция от руководителя оптимизаторов в «Ашманов и партнёры» Никиты Тарасова.
Семантическое ядро — основа поискового продвижения. Если допустить ошибки на этом этапе, дальнейшая работа по SEO пойдёт под откос. Это руководство поможет собрать семантику для проекта любого масштаба и ничего не упустить.
Этапы работы
Сбор семантического ядра состоит из четырёх последовательных этапов:
-
получение маркеров* и работа с ними;
-
парсинг запросов;
- чистка запросов;
- распределение запросов и кластеризация .
*Маркером (или маркерным запросом) называют слово или словосочетание наиболее точно отражающее суть конкретной страницы сайта. Обычно в качестве основного «маркерного» запроса для страницы берётся содержимое заголовка h1. У одной страницы может быть несколько маркерных запросов.
Получение маркеров и работа с ними
На рисунке изображена последовательность действий по подбору и обработке маркеров:
Собираем список заголовков h1
Собирать заголовки вручную долго и муторно, особенно если сайт состоит из тысяч страниц. Процесс можно автоматизировать и ускорить с помощью «пауков».
«Пауки» — программы, которые эмулируют роботов поисковых систем: обходят все страницы на сайте, получают список URL-адресов и заголовков h1. Список экспортируется в любой удобный формат, например, в Excel. Вот ссылки на наиболее популярные программы:
- Screaming Frog;
- Netpeak Spider;
- Xenu’s Link Sleuth.
Корректируем заголовки
Убедитесь, что собранные маркерные запросы обладают частотностью. Если частотность вызывает сомнения, сверьтесь с «Вордстатом», а потом скорректируйте запрос или найдите более частотный.
Не используйте несколько интентов (потребностей пользователей) для продвижения на одной странице. Например, на сайте магазина мебели есть раздел «Кресла и стулья». Но пользователи так не ищут, поэтому эффективней создать два отдельных раздела «Кресла» и «Стулья».
Не проектируйте структуру сайта так, чтобы в разных разделах дублировались одинаковые страницы, как на скриншоте ниже.
В примере выше для раздела «Душ» можно оставить ссылку на раздел «Смесители для ванны и душа», но она должна вести на страницу: http://www.domain.ru/catalog/vannaya/smesiteli-dlya-vanny-i-dusha/.
Не создавайте отдельные страницы под синонимичные группы запросов вроде «дешевые матрасы», «недорогие матрасы». Они могут быть восприняты поисковыми системами как нечёткие дубли. Это может привести к проблемам с индексацией сайта: часть страниц будет исключена из поиска.
Чтобы определить, какие запросы можно продвигать на одной странице, а какие — нет, воспользуйтесь сервисом кластеризации*.
*Кластеризация — принцип группировки запросов на основании общего числа URL в поисковой выдаче.
Суть кластеризации в том, чтобы изучить, как распределены запросы у сайтов, уже находящихся в верхней десятке поисковых систем. Для определения совместимости интентов идеально подойдёт такой сервис. А про методы кластеризации подробнее расскажу ниже.
Расширяем заголовки за счёт интентов и дополнительных слов
Когда мы получили маркеры, дальше собираем ключевые слова с помощью «Вордстата». Стоит учесть, что «Вордстат» отображает только 41 страницу со статистикой по запросу.
Если мы имеем дело с частотным маркером (например, «Диван»), то есть вероятность, что весь пул запросов мы не охватим.
Как видно, запросы ещё есть, но на следующей странице результаты не отображаются
Поэтому стоит подготовить список уточняющих запросов, характерных для конкретной тематики: например, «диван купить», «диван цена» и так далее.
Готовые тематические подборки можно найти на этой странице.
Получить маркеры, сцепленные с дополнительными словами, можно при помощи формулы =СЦЕПИТЬ(A1;” “;$E$1).
Маркеры не должны содержать символы .,”?!()- и другие знаки. Замените символы в Excel на пробел, используя сочетание клавиш Ctrl и H, а затем проверьте список маркерных запросов на орфографию.
Собираем заголовки с сайтов конкурентов
Проанализируйте сайты конкурентов, находящиеся в топе выдачи по интересующим вас запросам. В ходе анализа особенно интересно получить заголовки «теговых страниц», которые заточены под конкретный пользовательский интент.
Заголовки сайтов-конкурентов можно просканировать «пауками», о которых говорилось выше (например, Screaming frog SEO spider).
Этот подход поможет расширить структуру сайта и подобрать новые запросы для семантического ядра.
Нормализуем запросы
Под нормализацией понимается определение наиболее частотной формы запроса. Это нужно, чтобы не упустить запросы с высокой частотой, приносящие больше трафика на сайт.
Если запросов немного, они состоят из двух слов, то определить наиболее частотный запрос можно в «Вордстате» при помощи операторов: “[!поисковый !запрос]”.
Например:
Если запрос состоит из трех и более слов, а запросов больше ста, проверка вручную займёт много времени. Чтобы автоматически выявлять наиболее частотную словоформу, я сделал специальный парсер на базе А-parser.
Логика работы парсера в следующем:
- в «Вордстате» запросы выводятся в порядке убывания частоты;
- каждый запрос, подаваемый на вход, заключается в кавычки, тем самым анализируются все словоформы запроса;
- в качестве результата берётся первый запрос из левой колонки, то есть наиболее частотная из словоформ.
Как видно из примера ниже, наиболее частотной словоформой является «купить диван», что подтверждается точной частотой запросов из примеров выше.
Когда мы провели работы, описанные в разделе, у нас получается список маркерных запросов, удовлетворяющий следующим критериям:
- нет опечаток;
- нет символов и знаков препинания;
- все маркерные запросы частотные;
- часть маркеров содержит дополнительные слова и словосочетания, характерные для конкретной тематики;
- в списке присутствуют наиболее частотные словоформы запросов;
Парсинг запросов
Список маркеров, который мы получили, нужно расширить дополнительными словами — «хвостами». Это поможет нам максимально охватить семантику в поисковой нише, в которой продвигается сайт. Дополнительные слова можно взять из источников, указанных на схеме ниже.
Коротко разберу особенности некоторых источников.
Поисковые подсказки «Яндекса» и Google
Основное преимущество подсказок в том, что их база намного больше, чем база того же «Вордстата».
В подсказки попадают запросы, обладающие частотой, которые реально запрашивают пользователи. В «Вордстате» же есть доля мусорных и автосгенерированных запросов, не обладающих реальным поисковым спросом.
Подсказки в «Яндексе» можно получать в формате json. В этом случае каждой поисковой подсказке присваивается определенный тип.
Ниже приведены наиболее часто встречающиеся типы подсказок:
- B и T обозначают «обычные» подсказки;
- W — это перестановка слов;
- In — автодополнение;
- Pb — порно-подсказка;
- Nav — навигационный запрос;
- Rich — расширенная подсказка-сниппет, появляется для «Википедии»;
- Tail_word — как правило, означает, что подсказка дополняется не с конца, а с начала;
- Art, Fast_w, Fresh_console, Fast — неизвестные типы.
Например, после сбора можно сразу удалить все подсказки с типом «In», что существенно уменьшит число мусорных запросов. Для сбора подсказок с указанием типов я использую парсер.
«Яндекс.Вебмастер»
В «Вебмастере» есть раздел, в котором можно получить рекомендованные поисковые запросы. Достаточно нажать на кнопку и через некоторое время список будет доступен для скачивания.
«Яндекс.Метрика» и Google Analytics
Часть запросов можно выгрузить из отчёта «Яндекс.Метрики»: «Стандартные отчеты» → «Источники» → «Поисковые запросы».
В Google Analytics также есть данные о запросах, но с 2011 года Google начал шифровать запросы пользователей, поэтому собрать большой объём информации из данного источника не получится.
Готовые базы ключевых слов
На рынке есть готовые базы ключевых слов для различных тематик. Например:
- «Букварикс»;
- pastukhov.com.
У готовых баз есть два недостатка: они обновляются нерегулярно и содержат много мусорной и автосгенерированной семантики.
Тем не менее предпочтительнее использовать базу «Букварикс». Как показали исследования коллег из Rush Analytics, она содержит минимум мусорных запросов и к тому же бесплатная.
SaaS-решения
SaaS-решения (software as a service) помогают выгружать списки запросов, по которым находится в выдаче ваш сайт или сайты конкурентов. Ниже список наиболее популярных сервисов:
- keys.so;
- «Букварикс»;
- Spywords;
- Serpstat;
- Megaindex;
- Moab.tools.
Когда получим «хвосты» для маркерных запросов, нужно объединить данные из всех источников в один список и избавиться от дублей.
Для автоматизации сбора запросов можно воспользоваться программами:
- Key collector;
- A-parser.
И сервисами:
- Rush analytics;
- «Топвизор»;
- SE Ranking.
Чистка запросов
Удаляем мусорные фразы
В процессе сбора хвостов в списки неизбежно попадают мусорные запросы. Избавится от них можно с помощью функции «Стоп слова» программы Key collector.
В качестве стоп-слов можно использовать готовые тематические подборки.
С помощью функции «Анализ групп» можно найти и удалить нецелевую семантику.
Удаление низкочастотных запросов
Часть собранных запросов может быть автосгенерированными или низкочастотными (менее трех запросов). Если такие запросы попадут в семантическое ядро, то с высокой вероятностью для них будут созданы отдельные страницы на сайте. Значимого объема трафика они не принесут, но будут отнимать краулинговый бюджет.
Краулинговый бюджет — количество страниц, которые поисковый бот может обойти за период времени.
Нижний порог частоты запроса определяется отдельно для каждой тематики. Брать в работу микро- и низкочастотные запросы стоит лишь в исключительных ситуациях (например, если продукт супермаржинальный). Пример: разработка и внедрение ERP-систем, продажа нефтеперерабатывающего оборудования и так далее.
Для определения точной частоты запросов можно воспользоваться одной из программ — Key collector или A-parser, либо сервисами:
- Spyserp;
- Rush analytics;
- «Топвизор».
После чистки вы получите список целевых запросов, обладающих достаточной частотой.
Распределение запросов и кластеризация
Основная идея кластеризации — выяснить, как распределены запросы у сайтов, находящихся в первой десятке поисковой выдачи.
Наиболее широкое распространение данная методология получила около четырёх лет назад. Правда, некоторые оптимизаторы до сих пор предпочитают распределять запросы вручную, а зря.
Кластеризация позволяет решить ряд проблем при распределении запросов по страницам сайта. Она особенно полезна на больших объемах — от 1000 запросов и более.
Определяем тип запроса (коммерческий, информационный)
Запросы «пудра» и «пудра купить» на первый взгляд про одно и тоже. Но в первом случае поисковая выдача заполнена преимущественно информационными сайтами.
Исключение составляют два сайта: pudra.ru и «Подружка»: https://www.podrygka.ru/catalog/makiyazh/litso-1/pudra/. Их в расчет не берем, так как первый ранжируется за счет вхождения запроса в домен. А второй — за счёт своей популярности и больших объёмов прямого трафика на сайт.
По запросу «пудра купить» десятку результатов поисковой выдачи занимают в основном интернет-магазины.
Можно сделать вывод, что продвинуть оба запроса на одной странице не получится. Для продвижения запроса «пудра» нужна информационная статья с достаточным объемом текста и иллюстрациями. А для продвижения запроса «пудра купить» — небольшой текст и каталог товаров с ценами.
Результаты выдачи поисковых систем — особенно «Яндекса» — достаточно сильно типизированы. Выдача состоит либо преимущественно из коммерческих сайтов, либо из информационных. Кластеризация позволяет с большой точностью отделить коммерческие запросы от информационных.
Определяем типы страниц (главная, внутренняя)
Теперь проанализируем выдачу по запросы «люстры купить» и «люстры интернет-магазин», которые также похожи. Видно, что по запросу «люстры купить» топ занимают внутренние страницы сайтов, а по запросу «люстры интернет-магазин» — главные страницы.
Следовательно, по запросу «люстра купить» продвигаем внутренние страницы с каталогом люстр, а по запросу «люстры интернет магазин» — главную страницу сайта.
Определяем совместимость продвижения запросов на одной странице
На скриншоте ниже видно, что запросы «угловые диваны» и «недорогие диваны» не имеют между собой ни одного общего URL. Для достижения лучших результатов эти запросы стоит продвигать на отдельных страницах.
Кластеризация — инструмент аналитики, который не даёт готового решения. Он собирает данные в удобном отображении для дальнейшей постобработки и анализа.
Существует два метода кластеризации:
- Hard — используется для продвижения по позициям, а также для продвижения в конкурентных тематиках. Количество запросов в кластере меньше, но точность выше.
Условие, соблюдаемое при hard-кластеризации, — у всех запросов в кластере должен быть общий набор URL.
- Soft — в основном используется для трафикового продвижения. Количество запросов в кластере больше, но точность ниже.
Условие, соблюдаемое при soft-кластеризации, — запросы сравниваются на предмет общих URL у всех запросов в группе. Например, у запроса А есть общий набор URL с запросом В, у запроса В есть общий набор URL с запросом С.
Приведу несколько популярных сервисов кластеризации:
- Spyserp — сервис, платный;
- Rush analytics — сервис, платный;
- «Топвизор» — сервис, платный;
- coolakov.ru/tools/razbivka/ — сервис, бесплатный;
- Keyassort — программа, платная.
Для постобработки кластеризованной семантики можно воспользоваться бесплатной надстройкой для Excel.
Сбор семантики для больших проектов
Если проект содержит тысячи посадочных страниц, лучше собирать семантику отдельно для каждого раздела, учитывая приоритеты бизнеса и сезонность. А затем последовательно собирать семантическое ядро для двух–трёх разделов за каждую итерацию. Такой подход позволит собрать качественное семантическое ядро и не упустить целевые запросы
Если же собирать семантическое ядро сразу под весь проект, то на выходе получатся тысячи или даже десятки тысяч кластеров запросов, которые будет сложно обработать.
Как сохранить наследственность «Маркерный запрос — URL»
На первом шаге, описанном в статье, мы выгружали табличный список «Маркерный запрос — URL». Если сохранить URL после всех корректировок с маркерными запросами, то с помощью функции ВПР в Excel можно привязать часть URL-адресов к уже раскластеризованной семантике.
То есть — если маркерный запрос находится в кластере с другими запросами и у маркерного запроса уже известен URL, то можно считать, что все запросы кластера принадлежат к этому URL.
Не стоит бояться развивать структуру сайта. Если по результатам сбора запросов и их кластеризации вы понимаете, что под часть запросов не хватает посадочных страниц, лучше создать их или в крайнем случае отказаться от продвижения части запросов. Это будет эффективнее, чем вести несколько групп запросов (часто с несовместимыми интентами) на одну страницу сайта.
Один из этапов создания рекламной кампании — сбор семантического ядра. Оно включает в себя ключевые фразы пользователей, по которым будут показываться рекламные объявления. Релевантные ключевые слова и правильно написанный оффер — отличная возможность показать объявления целевой аудитории, привлечь клиентов и сэкономить бюджет. Как это сделать, читайте в инструкции по составлению семантического ядра от eLama.
Семантическое ядро для поисковых кампаний
1 этап. Сбор базовых ключевых слов
Прежде всего подумайте, какие слова характеризуют вашу нишу. Например, для интернет-магазина по продаже iPhone будут очевидны следующие слова: iPhone, айфон, купить, заказать и т. д. Для удобства записывайте слова в таблицу Excel.

Если у вас закончились идеи, то зайдите в yandex.wordstat.ru и посмотрите, что ищут при вводе, например, iPhone.

К собранному в Excel списку добавим слово «Цена».
Далее, найденные слова нужно скомпоновать. Это можно сделать через инструмент eLama «Комбинатор ключевых фраз»:

Полученные фразы мы будем использовать на следующем этапе.
Бесплатные кампании в Директе для старта
Для тех, кто раньше не запускал рекламу в Директе через eLama
Получить кампании
Этап 2. Подбор семантического ядра
Снова обратимся к сервису Wordstat и узнаем количество запросов пользователей по тому или иному слову. Это поможет в создании семантического ядра.
Установите расширение Yandex Wordstat Assistant для браузера, чтобы собрать запросы и их частотность быстрее:

Итак, получился список и одна свободная колонка, которая нужна для списка минус-слов.

Этап 3. Чистка семантического ядра
Теперь весь список ключевых слов нужно очистить от нерелевантных запросов, чтобы показывать рекламу только тем пользователям, которые ищут наши товары. Например, я не продаю iphone 7 в рассрочку в Минске, поэтому исключаю 7, минск, рассрочка. Содержащие эти слова и ключи стоит удалять сразу же, чтобы они случайно не попали в ключевые фразы.
Проще и удобнее это сделать в минусаторе eLama. Скопируйте собранную список семантики и вручную выделите все ненужные слова. В итоге у вас получится два списка: ключей и минус-слов. А еще в минусаторе можно применить готовый список минус-слов к списку ключевых фраз — инструмент найдет нерелевантные фразы и удалит их. Как работать с инструментом, читайте в другом нашем материале.
Можно продолжить работу в таблице, но так будет посложнее.

Если требуется удаление нескольких фраз, то сократите время поисков, используя фильтр Excel.

Для кампаний в Google Ads можно выбрать «Планировщик ключевых слов».

По сравнению с Wordstat он имеет больше функций, благодаря которым можно:
- узнать конкурентность ниши и процент показа объявлений;
- минимальные/максимальные ставки для показа объявлений внизу/вверху страницы.
В списке могут появиться фразы с минимальным различием, например, «iphone 8 в москве» и «iphone 8 купить спб». Для того, чтобы система показывала объявления, релевантные запросу, нужно провести кросс-минусацию, например, через eLama.
Для получения более точного результата попробуйте комбинировать все инструменты.
Этап 4. Заключительный
Теперь у вас есть отдельно список с ключевыми фразами и минус-словами. Вам нужно составить объявления таким образом, чтобы ключевая фраза была в первом или втором заголовке. Так вы сможете увеличить CTR объявления, а следовательно, уменьшить его стоимость.

Операторы и типы соответствия ключевых слов в Яндекс Директе и Google Ads
Операторы и типы соответствия необходимы для уточнения запросов пользователей. Например, вы создали акционное рекламное объявление, в котором говорите о продаже билетов из Москвы в Санкт-Петербург, то используйте оператор []. Таким образом, люди, которые хотят поехать из Санкт-Петербурга в Москву, не увидят ваше объявление.
Для экономии времени используйте «Комбинатор ключевых фраз», который автоматически добавит операторы +, ! в ваши списки. Под столбцами с собранным списком нажмите на «Дополнительно» и выберите оператор:

Если нужны типы соответствия/операторы, которых нет в «Комбинаторе ключевых фраз», то используйте Excel. Например, вы можете вставить оператор перед повторяющимся словом. Полный список операторов Яндекс.Директа есть на странице помощи, а для типов соответствия Google Ads — здесь.
Подбор ключевых слов для КМС и РСЯ
Ключевые фразы для РСЯ и КМС не нужно уточнять. Достаточно создать семантическое ядро с широкими ключевыми фразами, которые взаимосвязаны между собой. Если вы не уверены в собранных ключевых словах или боитесь мусорного трафика, то воспользуйтесь помощью Google Ads. Войдите в Аккаунт — Ключевые слова — Ключевые слова КМС или видео — введите свой сайт или услугу — система покажет релевантные ключи. Подобранные ключи можете использовать не только для КМС, но и для РСЯ.
Заключение
Сбор семантики — интересный, но в то же время сложный процесс. На каждом из этапов надо быть внимательным, чтобы не допустить нецелевых ключевых фраз. Однако следование подробной инструкции от eLama поможет сэкономить время на каждом этапе.

Советы
Как составить семантическое ядро сайта
Руководство с комментариями опытного сеошника
Семантическое ядро — список поисковых запросов, по которым пользователь может найти сайт. Его собирают для того чтобы понять интересы целевой аудитории, продумать структуру сайта и добавить ключи в текст.
В этом материале подробно разберемся с семантикой. В начале статьи будет теоретическая часть — что это такое, для чего нужно и когда сбор семантики лучше доверить специалисту. Во второй части будет пошаговая инструкция по сбору семантики. Если вам интересна именно эта часть — кликайте: пошаговая инструкция как составить семантическое ядро.
Статья написана под надзором Lead SEO в Unisender — Сергея Лукашевича. Если после статьи у вас останутся вопросы— задайте их в комментариях Сергею 🙂
Что такое семантическое ядро
Семантическое ядро — набор слов, фраз и запросов, которые характеризуют сайт, услугу или страницу в интернете. Использование таких слов на сайте позволит нам попасть в выдачу поисковика, хотя у самой семантики функции шире — о них чуть ниже.
Например, для интернет-магазина, который продает головные уборы, в семантическое ядро будут входить слова «купить шапку», «купить кепку», «шляпы дешево», «все ли шапки одного размера» и так далее.
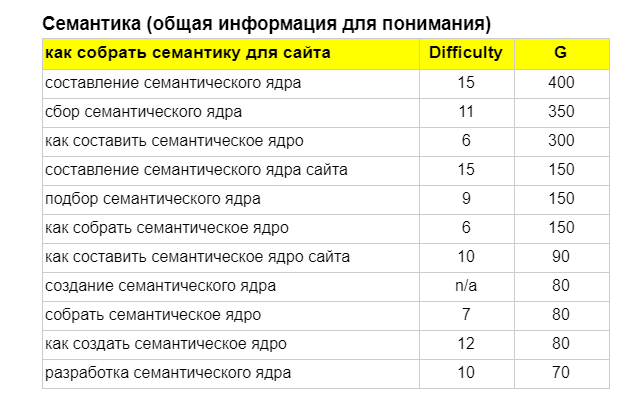
Вот так выглядит семантика для статьи, которую вы читаете. Скорее всего, если вы нашли эту статью в поиске, вы писали что-то подобное. Difficulty означает сложность запроса — чем выше, тем труднее попасть в топ выдачи. G означает частность — сколько таких запросов ищут в месяц
Для чего собирать семантическое ядро
Вот основные причины:
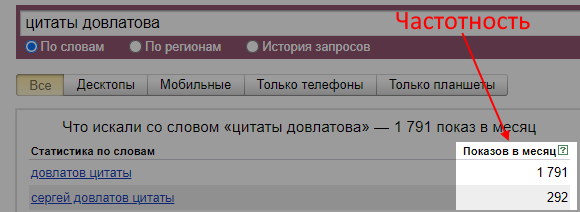
1. Исследовать интересы целевой аудитории. Анализ поисковых фраз — простой и достоверный способ узнать, как и что ищет человек: в поиске он не стесняется своих желаний. Более того, можно количественно отследить интерес людей к теме — в этом помогает частотность запросов в месяц:
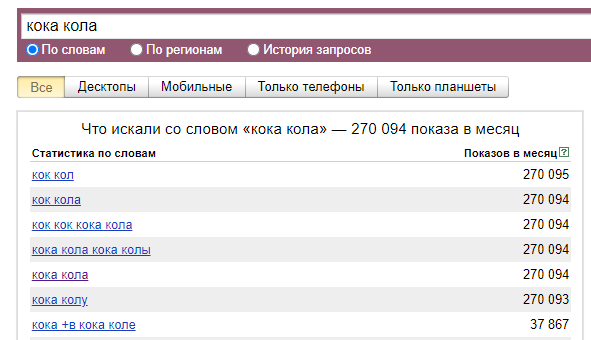
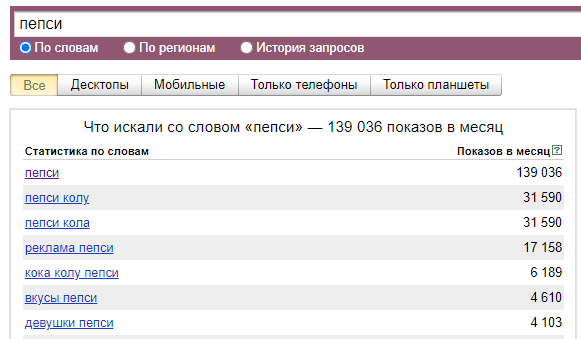
Кока кола популярнее Пепси. По данным Wordstat, запросов, связанных с ней, больше чем в два раза
Анализ семантического ядра дает подсказки в развитии бизнеса: закрыть непопулярные направления (их люди не ищут), открыть популярные — их часто ищут, а это потенциальный источник трафика и оплат.
Глобальная цель сбора семантики — понять, что хочет целевая аудитория, что ищут люди и как часто. Возможно, продукт который мы планируем выпустить или который уже есть — никому не нужен. В этом случае стоит сместить вектор развития в сторону популярных запросов.
2. Создать или доработать структуру сайта. Собранное семантическое ядро разбивается на кластеры. Кластер — группа запросов, которые поисковик считает одной темой и показывает по ней похожие результаты.
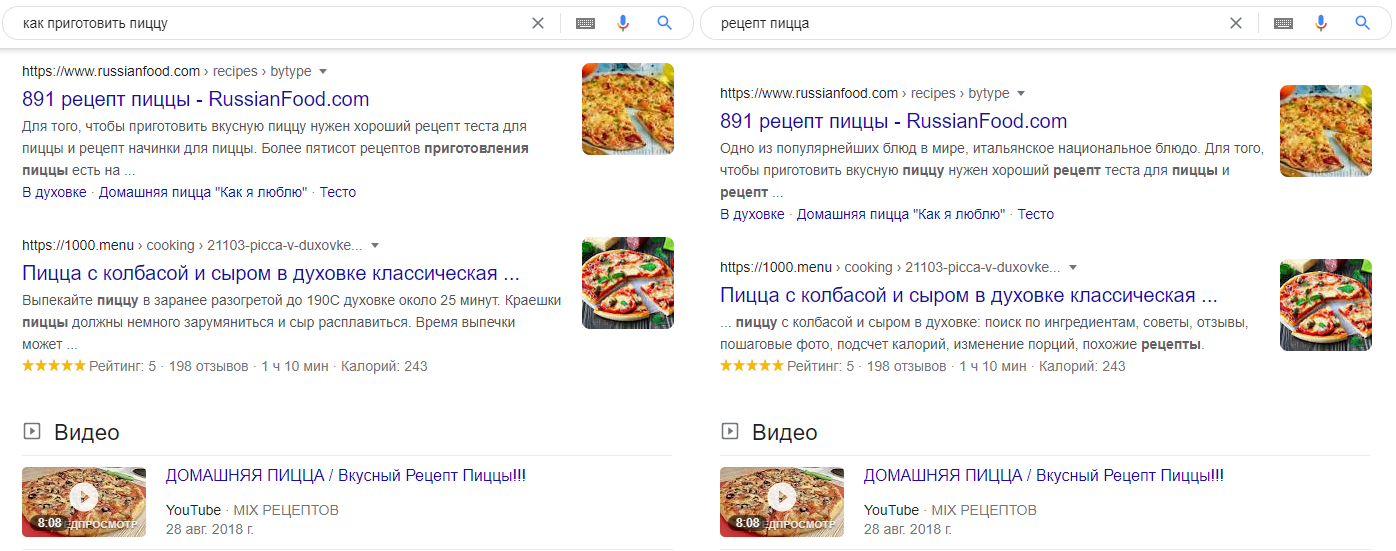
«Как приготовить пиццу» и «Рецепт пицца» — один кластер. Google выдает по этим запросам пересекающие результаты. Первые позиции совпадают полностью
Кластер — готовая идея для страницы в интернете или статьи. Разбив семантическое ядро на кластеры, мы получим грубую структуру сайта, основанную на интересах аудитории. Следуя этой структуре, мы становимся клиентоориентированными.
Семантика — практически неисчерпаемый источник идей для статей. Причем не просто статей, а статей по темам, на которые есть спрос. В блоге Unisender больше половины всех статей seo-оптимизированные. Эта статья тоже оптимизирована.
3. Оптимизировать текст под поиск. На основе семантического ядра к страницам прописывают заголовок, метатеги, описание статьи, структуру с H2 и H3 подзаголовками. А сама семантика — промежуточный этап в формировании ключевых слов (ключей). А глобально все это нужно для пассивного продвижения сайта в поиске.
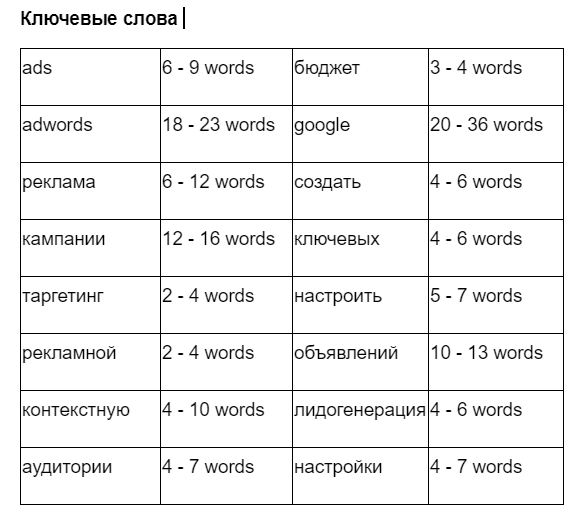
Ключи для статьи про контекстную рекламу. Справа от слова написано его рекомендуемое вхождение — сколько раз за статью оно должно быть использовано
Подбор ключей — совсем другой процесс, в котором сеошник анализирует текст конкурентов в выдаче по определенному кластеру. Через SEO-сервисы можно оценить, какие ключи и в каком количестве используются в их статьях. Если целиться на ключи конкурентов из первых мест выдачи, есть шанс, что и наш материал тоже попадет в топ.
Этап подбора ключей возможен только после составления семантического ядра и кластеризации — благодаря им, мы ищем конкурентов.
4. Отслеживать динамику страниц в поисковике. После того как собрано семантическое ядро мы можем следить за движением сайта в выдаче по определенным запросам. Например, в семантику попал запрос «как поставить мат двумя конями в шахматах». Мы написали статью на эту тему и теперь следим, как поисковик ранжирует ее.
Сначала статья будет выше сотой страницы в интернете, потом постепенно будет подниматься до тех пор, пока не достигнет первой страницы и высших строчек — это показатель того, что SEO-стратегия работает. Если же сайт застрял дальше второй-третьей страницы выдачи, мы что-то делаем неправильно. Возможно, неправильно подобраны ключи или есть другие фундаментальные проблемы. Кстати говоря, на пустой доске мат двумя конями поставить невозможно 🙂
А еще может выясниться, что по другим запросам из кластера сайт продвигается медленнее. Это повод докрутить текст, добавить ключей, оптимизировать некоторые предложения под отстающий запрос.
Семантика — это еще не все
Сбор семантики относится к SEO — оптимизации сайта под поисковую выдачу. Чем сайт оптимизированнее, тем выше вероятность, что он окажется на первой странице по ключевому запросу. Соответственно, тем больше переходов на сайт и целевых действий.
Кроме того, органика (люди, которые перешли на сайт по запросу из поисковика) бесплатна и пассивно приносит людей годами. Например, нашу статью про сокращаторы ссылок за полтора года прочитали 120 000 человек. При этом, мы не вкладывали денег в продвижение — просто правильно оптимизировали текст под поиск.
Сбор семантики — это только маленькая часть работы по SEO. На позицию сайта влияют его быстродействие, гигиена страниц, внешняя оптимизация, текстовая оптимизация и активность пользователей. Про все это подробнее можно почитать в нашем гиде по SEO. Если вы плохо ориентируетесь в поисковой оптимизации, рекомендую сначала изучать гид.
Когда семантическое ядро собирать самому, а когда лучше звать сеошника
Составление семантики — не самый сложный в мире процесс, однако в нем легко запутаться (особенно без опыта):
- Собрать много повторяющихся запросов.
- Упустить перспективные низкочастотные запросы.
- Неправильно отсеять нерелевантные запросы.
- Еще выше вероятность ошибиться на следующих этапах — кластеризации, анализе, формировании страниц в интернете.
Чем больше проект, тем выше вероятность ошибок.
Чем больше проект, тем больше нужд в специальном инструментарии
Я пользуюсь Ahrefs, SEMrush и другими. Они достаточно сложные и новичку в них будет сложно разобраться. В большом проекте может потребоваться сбор семантического ядра из 10 тысяч запросов (например, для крупного интернет-магазина) и развитая структура сайта с тысячами страниц.
Если ваш проект до 50 страниц, смело можете собирать семантику самостоятельно. Как минимум, это поможет определиться со структурой сайта и понять, на каких продуктах или услугах стоит сосредоточиться. А более тонкую работу можно оставить сеошнику, которого наймете позже.
Составление семантики — работа и она требует времени. Если вы плохо с этим знакомы, вам придется тратить время на изучение. Иногда целесообразнее сразу взять сеошника — пусть даже в рамках разового проекта.
На что обратить внимание при подборе ядра
Прежде чем собирать семантическое ядро, нужно синхронизироваться по некоторым терминам. Это теоретическая часть, чтобы лучше понимать инструкцию.
Частотность
Частотность показывает количество запросов в месяц. Запросы в семантическом ядре разделяются на высокочастотные, среднечастотные и низкочастотные. Высокочастотные ищут чаще, чем низкочастотные, а среднечастотные — что-то промежуточное между ними. Деление запросов на эти группы относительное и зависит от сферы. В каких-то сферах, 100 относится к низкочастотным, а в других — к высокочастотным.
Ранжирование
Ранжирование — сортировка сайтов в выдаче в зависимости от их рейтинга, который подсчитывают алгоритмы поисковика. Чем выше рейтинг сайта, тем лучше он ранжируется — занимает верхние строчки выдачи.
На рейтинг влияют текстовая оптимизация, адаптивность, скорость загрузки, внешние ссылки и другие параметры. Запущенный сайт с идеальными семантическим ядром не попадет в топ — поэтому не фокусируйтесь лишь на одном сборе семантики.
Конкурентность
Конкурентность запроса — величина, которая показывает сложность попасть в топ выдачи. Она зависит от конкурентов — чем их больше и чем качественные их сайты, тем сложнее будет идти продвижение.
Подробнее про конкуретность можете почитать здесь.
Опытные сеошники при сборе семантики указывают сложность (Difficulty). Если вы новичок — не парьтесь. Но если ваша ниша сильно конкурентная, опять же, нужен опытный сеошник.

Чем выше значение Difficulty, тем сложнее попасть в топ выдачи по этому запросу
Интент
Интент — это потребность пользователя, которую он хочет решить, когда вводит запрос. Некоторые запросы размыты, например, запрос «что такое осень» — пользователь хочет узнать, что такое осень или он ищет песню группы ДДТ?
Поисковики научились угадывать интент пользователя и даже по обобщенным запросам выдают нужное. И по запросу «что такое осень» все имеют в виду песню — это и показывает поисковик.
Учитывайте интент, иначе в ваше семантическое ядро попадут запросы, к которым вы не имеете отношения. Для этого просто внимательно просматривайте семантику на этапе чистки.
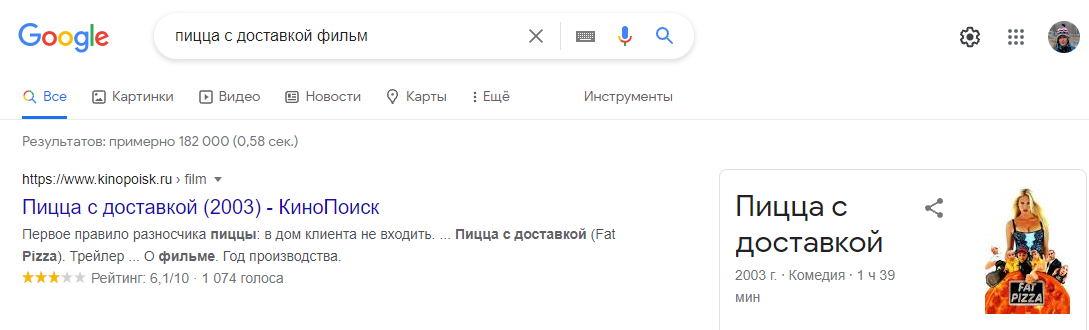
В мою семантику попал запрос «пицца с доставкой фильм». Не знал, что такой есть и поэтому было ощущение что запрос можно оставить. Но потом загуглил и вот — под пиццерию это не подходит
Геозависимость
Геозависимость — фича поисковиков, чтобы адаптировать выдачу под место проживания пользователя. Если вести «макдональдс адрес» — мне не покажут адреса фастфудов в Сыктывкаре, а покажут в моем городе.
Если у вас локальный бизнес, семантику нужно составлять с учетом геозависимости. Для этого в Яндекс Вордстат есть настройка по региону — информация будет выводиться только по нему. А если у вас онлайн бизнес, то на геозависимость можно не обращать внимания — в Вордстат по умолчанию выбраны все регионы. Но при желании можно добавить еще и страны СНГ.
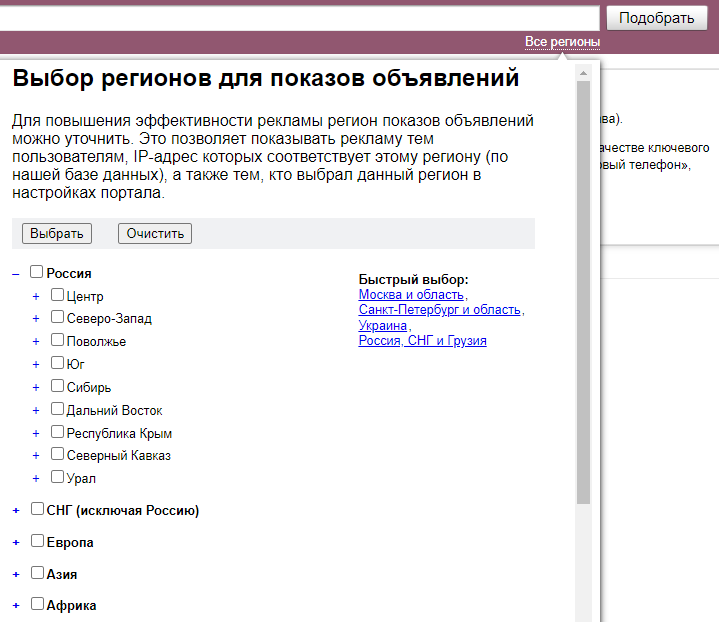
Можно выбрать как всю Россию, так и конкретный город или регион
Пошаговая инструкция как составить семантическое ядро
Подумайте, какие запросы характеризуют ваш сайт
Составление семантического ядра начинается с мозгового штурма. Ответьте на вопрос: если бы вы искали свой сайт в поисковике, то по каким запросам? Все идеи, которые придут в голову, записывайте в таблицу или текстовый документ.
Несколько советов, как охватить все интересные запросы:
- Созвонитесь с командой, особенно с теми, кто участвует в разработке продукта и делает сайт. Попросите их ответить на вопрос выше. Записывайте все идеи и фразы, которые придут в голову.
- Нужны запросы не только в рамках сайта в общем, но и в разрезе конкретных продуктов и частных вопросов клиентов. Например, сайт продает и устанавливает пластиковые окна. В семантику можно записать запросы «сколько стоит установка пластиковых окон» и «чем отличаются пластиковые окна». Такие запросы напрямую не связаны с нашими услугами, но все равно могут принести трафик, который позже конвертируется в клиентов.
- Забавный источник идей — отдел продаж и служба поддержки. Им всегда задают кучу вопросов и практически всегда эти вопросы популярны в поисковике.
Блог покроет информационные запросы и увеличит трафик на сайт
Даже если ваш сайт предполагается чисто коммерческим, я все равно рекомендую обратить внимание на информационные запросы, сделать под них специальные страницы или даже вынести в блог. Это в несколько раз ускорит продвижение и существенно увеличит трафик на сайт.
Блог ощутимо ест бюджет, особенно если организовывать собственную редакцию и налаживать регулярный выпуск материалов. Но это и не нужно — достаточно нескольких статей, которые бы отвечали на популярные запросы в поиске.
Производство статей можно отдать на аутсорс, а технически реализовать блог внутри домена несложно и недорого. В таком случае это будет лишь единовременным вложением, а не ежемесячной статьей расходов.
Теперь покажу на примере, что у вас должно получиться на этом этапе. В моем примере я собираю семантику для интернет-магазина пиццы в Оренбурге. Я сгенерировал такие запросы:
Сбор базовых ключевых слов
Все запросы, которые мы получили на прошлом этапе, поочередно вбиваем в Яндекс Wordstat или Букварикс. Все сервисы интуитивно понятны.
У Букварикс база Google и Яндекса, но я в нем не нашел функции фильтра по местности. У Яндекса это и есть, однако он раздражает вводом капчи после каждого запроса.
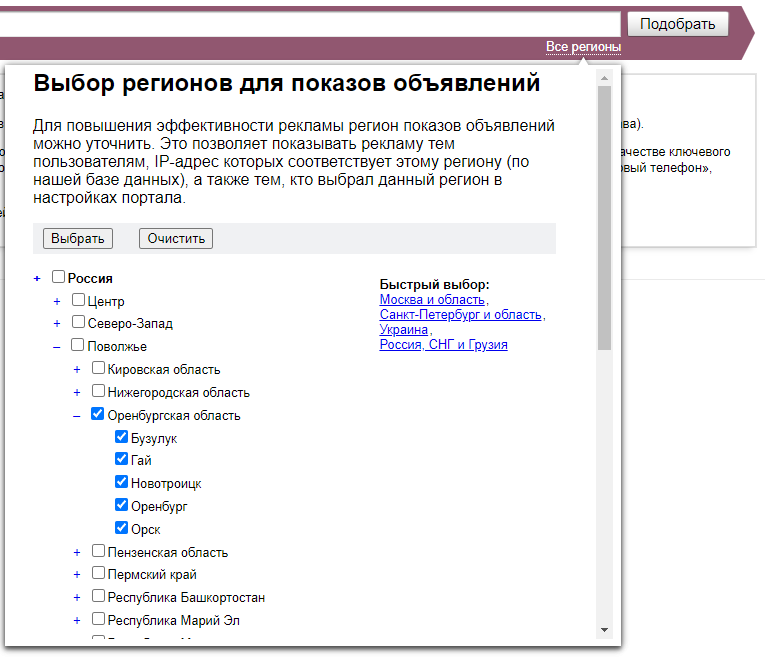
Выбор региона в Яндекс Вордстат
Поглядите, какая мне смешная капча попалась 🙂
Показываю на примере, как работаю с Яндекс Вордстат. Беру первый запрос из своего документа и ввожу его. Всю статистику из обоих столбцов копирую в Google Таблицы.
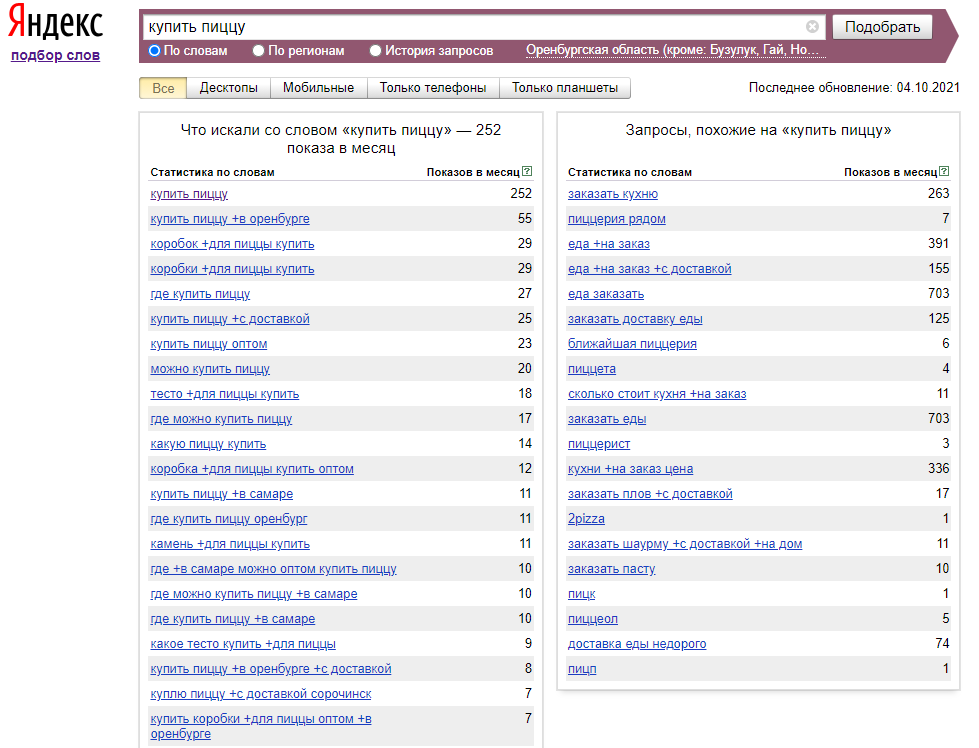
Статистика Яндекс Вордстат по запросу «купить пиццу» для Оренбурга
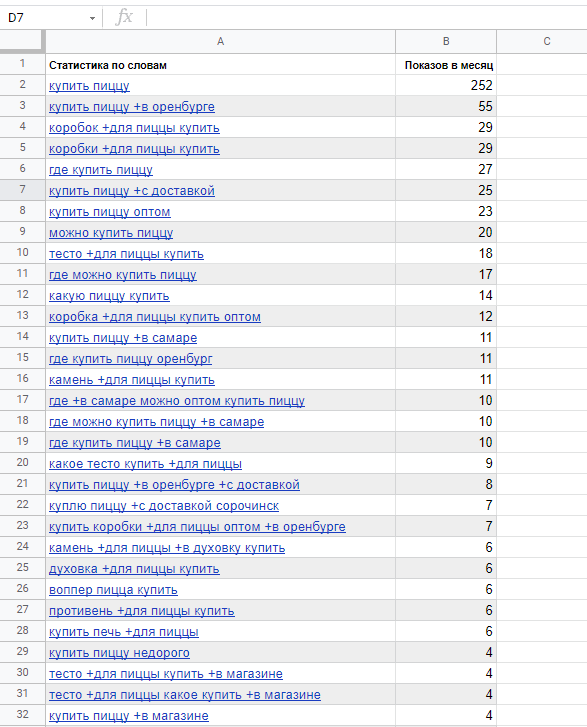
А вот так это выглядит в Google Таблицах
Располагайте запросы в один столбец. Пройдитесь по всем запросам из своего документа. Самые общие высокочастотные запросы пробейте дополнительно через Букварикс — в нем можно подсмотреть запросы, которые стоит поискать. Например:
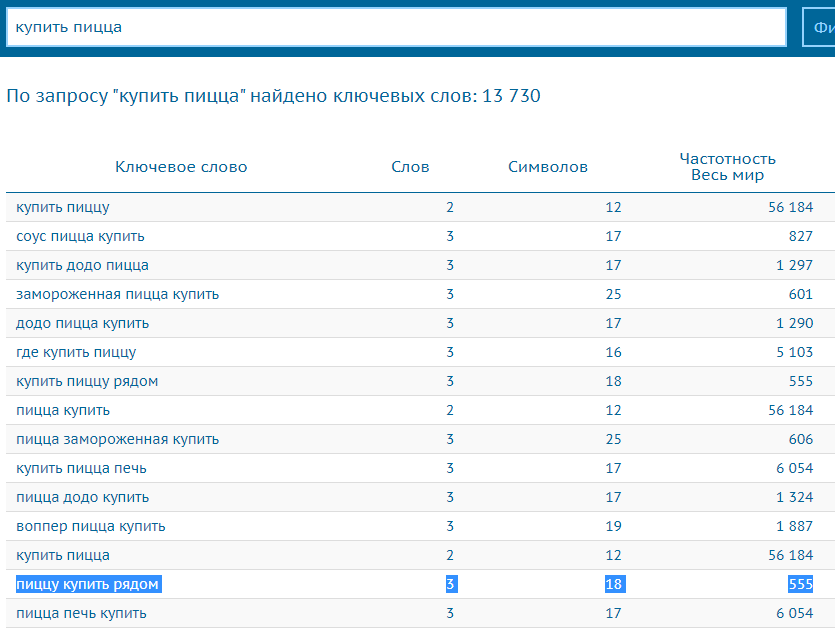
Я вбил общий запрос «купить пицца» и мне приглянулись фразы «пиццу купить рядом» и «воппер пицца купить» — последнюю часто ищут, видимо, какой-то тренд. В этот раз меня интуиция подвела: в Оренбурге «воппер пиццу» ищут 6 раз в месяц, что очень мало, а «купить пиццу рядом» не ищут вообще. Но тем не менее используйте Букварикс — это поможет вам отыскать другие перспективные запросы
Важно в процессе подбора запросов не переусердствовать. В какой-то момент это утратит смысл — в таблицу будут попадать фразы-синонимы, странная низкочастотка и другой мусор. Соблюдайте баланс — если расслабитесь слишком рано, не дойдете до перспективных среднечастотных запросов.
Как понять, что пора заканчивать собирать семантическое ядро — вопрос опыта. Тут нет идеального правила. По идее, вы сами почувствуете, что уже перебираете одно и то же — это сигнал, что вы финишировали.
Когда я только начал заниматься SEO, то любил собрать тонну запросов и копаться в них. Потом понимаешь, что это бессмыслица. Пускай лучше запросов будет меньше для каждой страницы, но они будут качественные и понятные.
Если сомневаетесь, можете собирать много запросов — мы все равно их удалим при чистке: просто это лишняя работа.
Анализ конкурентов
В интернете полно конкурентов — мы можем просканировать их через специальные сервисы и получить почти готовую семантику: важно отбирать только качественные страницы, которые высоко ранжируются в выдаче. Такие сервисы платные и разбирать в статье их функционал мы не будем. Если вам интересно, присмотритесь к следующим сервисам и изучите их самостоятельно:
- SEMRush
- Ahrefs
- Serpstat.
Почерпнуть идеи у конкурентов можно и без специализированных сервисов. Заходите на их сайт и внимательно изучайте — пощелкайте страницы в интернете и посмотрите, что пишут. Вы, скорее всего, отыщете запрос, который стоило бы включить в семантическое ядро, но который сами упустили из виду — обращайте внимание на заголовки страниц.
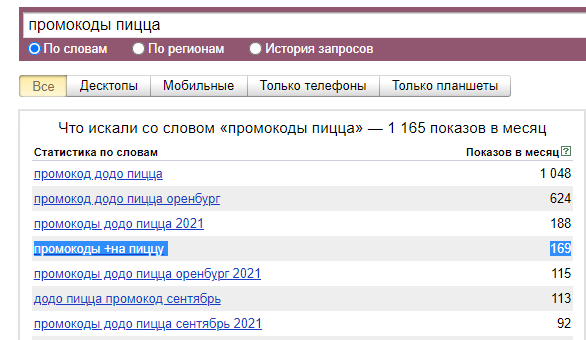
На одном сайте пиццерии я увидел раздел с акциями и стал копать в этом направлении. Попробовал запросы «пицца скидки» и «промокоды пицца». По последнему запросу неплохой результат — 169 запросов для Оренбурга, точно нужно взять. А по скидкам частотность меньше, но тоже можно использовать
Шлифуем семантику — сортируем, удаляем дубликаты и лишние символы
Удаление дубликатов. Некоторые запросы будут пересекаться. Нам они не нужны, поэтому удалим дубликаты через все тот же раздел «Данные»:
Выделяем таблицу и нажимаем вкладку «Данные», а в ней «Удалить повторы». Оставляем только столбец A — в котором содержатся сами запросы
Удалить плюсы. Они будут мешать на этапе кластеризации.
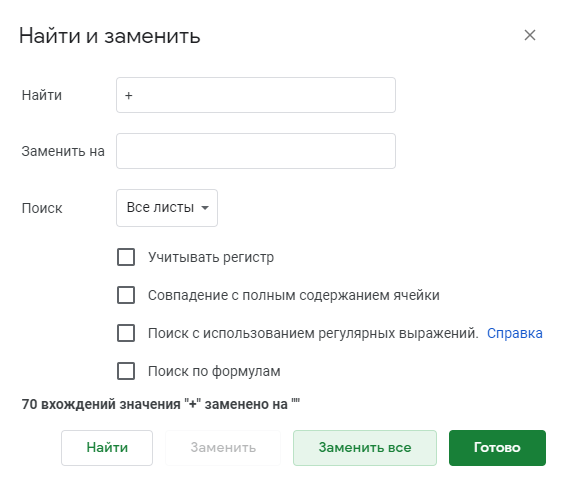
Нажмите Ctrl + F или Command + F на MacBook. В выпадающем меню выберите три точки. Либо в разделе «Правки» кликните «Найти и заменить». В поле «Найти» напишите «+», остальное оставьте без изменений. Нажмите на кнопку «Заменить все». Google удалит все плюсы из таблицы
Сортировка. Теперь всю таблицу отсортируем по убыванию частности. Отсортировать можно функционалом Google Таблиц. Этот шаг нужно повторить после следующего пункта «чистка нерелевантных запросов». При удалении запросов у нас появятся в случайных местах таблицы, а сортировка снова сведет всю семантику воедино.
Сортировка запросов по убыванию частотности. Выделяем таблицу, нажимаем «Данные» и кликаем по «Сортировать диапазон по столбцу B, Я → А». Если у вас частность не в столбце B, то сортируйте по другому столбцу
Чистка нерелевантных запросов
В семантическое ядро так или иначе попадут нерелевантные запросы — такие запросы не характеризуют наш сайт, а люди, когда их вводят, ищут совсем другое. От таких запросов нужно избавляться — трафика они не принесут.
Удаляем такие запросы:
- С упоминаниями конкурентов.
- С товарами или услугами, которые не оказываем.
- С упоминанием города, районов и улиц в которых не работаем.
- Запросы с ошибками. Даже если человек сделает ошибку в запросе, поисковик все равно переведет его на верный запрос.
- Фразы, которые вы не понимаете. С большой вероятностью это не имеет отношения к вашей компании.
- Запросы-синонимы, например, «купить смартфон» и «смартфон купить»
- Микрозапросы — их ищут ничтожно мало, такая сеошная погрешность. Зависит от сферы: например, если наша среднечастотка 200 запросов, то все запросы меньше 10 можно удалять. Тем более, если они похожи на уточнение основного запроса.
Давайте почистим ненужные ключи для нашего примера с пиццерией. Их получилось много:
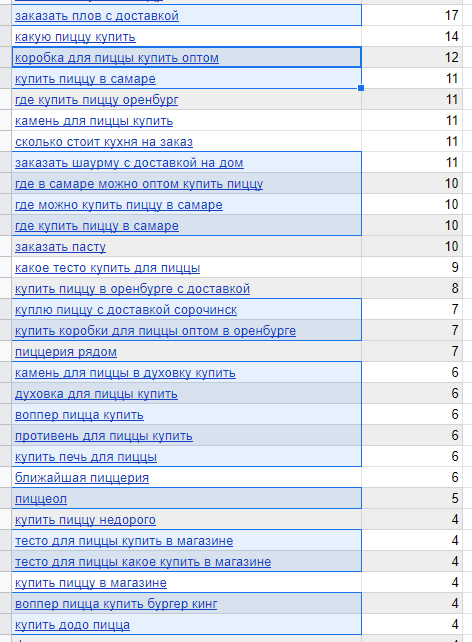
Плов и шаурму я не продаю. Печку, камень, противень, тесто и коробки для пиццы тоже. Воппер-пиццы нет в моем ассортименте. Удаляем.
Несмотря на то, что я смотрел запросы только по Оренбургу, в результаты Яндекс Вордстата подмешались левые запросы — пицца Сорочинск и Самара. Удаляем.
«Пиццеол» — непонятный запрос, который не прояснился даже после того, как я проверил в Google — удаляем. Еще на этот скриншот попала «Додо пицца» — конкурент. Конкурентов, гораздо больше, все они выше. Конкурентов удаляем, либо переносим их в другой документ: если планируете запускать контекстную рекламу — там пригодится такая семантика.
Еще встретился запрос «чудо пицца». Я сначала не понял, потом оказалось что это местная пиццерия. Поэтому важно удалять запросы, которые вы не понимаете. Для верности можете загуглить их.
Несколько примеров с запросами под удаление. Они выделены синим:



Если запрос перспективный, но у вас нет таких услуг — переносите его в скоринг-документ
При сборе семантики часто всплывают запросы, которые близки нашему бизнесу, но таких услуг у нас еще нет. Если эти запросы перспективны и их часто ищут люди — не удаляйте их, а перенесите в скоринг-документ. Это документ с идеями развития и масштабирования бизнеса с точки зрения SEO.
В нашем примере про пиццу такие запросы — суши и роллы. Люди часто ищут их вместе с пиццей, но если мы занимаемся одной только пиццей — нам они не подходят.
Чистка — рутинный процесс, который может занять много времени. Проверять семантическое ядро нужно вручную, а иногда запросов много — больше тысячи. Ну тут ничего не поделать.
Не игнорируйте информационные запросы
При чистке важно сохранять осознанность и не делать это действие на автомате — можете пропустить интересные запросы, которые стоило бы внедрить.
В примере про пиццерию я выяснил, что люди часто ищут рецепты для пиццы — это информационный запрос. Пиццерия вполне может запустить небольшой блог, в котором будет раскрывать похожие темы. Так мы привлечем больше трафика и познакомим аудиторию со своим брендом. Бизнесу ведь нужно повышать узнаваемость — это один из инструментов.
Конечно, если человек ищет рецепт пиццы, он хочет сам ее приготовить, но в конце статьи мы можем предложить человеку купить нашу пиццу, по рецепту который он искал. У человека уже появится лояльность к нашему бренду, а когда его пицца не получится, он закажет ее у нас 😁.
Другой интересный запрос, который я увидел — «рейтинг пиццерий». Мы можем на поддомене написать статью с рейтингом популярных оренбургских пиццерий. Похожую механику мы используем в Unisender: объективно сравниваем себя с конкурентами в статьях из базы знаний.
Если вы видите, что низкочастотные запросы повторяют основные запросы, только в них содержится странный хвост — их тоже можно удалять. В нашем примере про пиццу выяснилось что все запросы с частотой 10 и меньше можно убрать — они так или иначе копируют запросы, которые уже есть.
Также удаляйте запросы-синонимы, в которых слова из запроса одни и те же, но в другой последовательности. Например, «пицца доставка» и «доставка пицца. Их можно искать вручную, но удобнее делать через программу Key Collector (платная) — там есть функция «анализ неявных дублей».
Ссылка на Google-таблицу с семантикой сайта пиццы
На этом сбор семантики закончен. Теперь ее нужно разбить на кластеры.
Кластеризация
Напомню, кластеризация — деление семантического ядра на кластеры. Кластер — группа запросов, которую поисковик считает одной темой и выдает по ней пересекающиеся результаты.
Проверить кластеры можно вручную. В режиме инкогнито вбейте запросы и проверьте выдачу. Например, «заказать пиццу» и «купить пиццу» один кластер, выдача похожа.
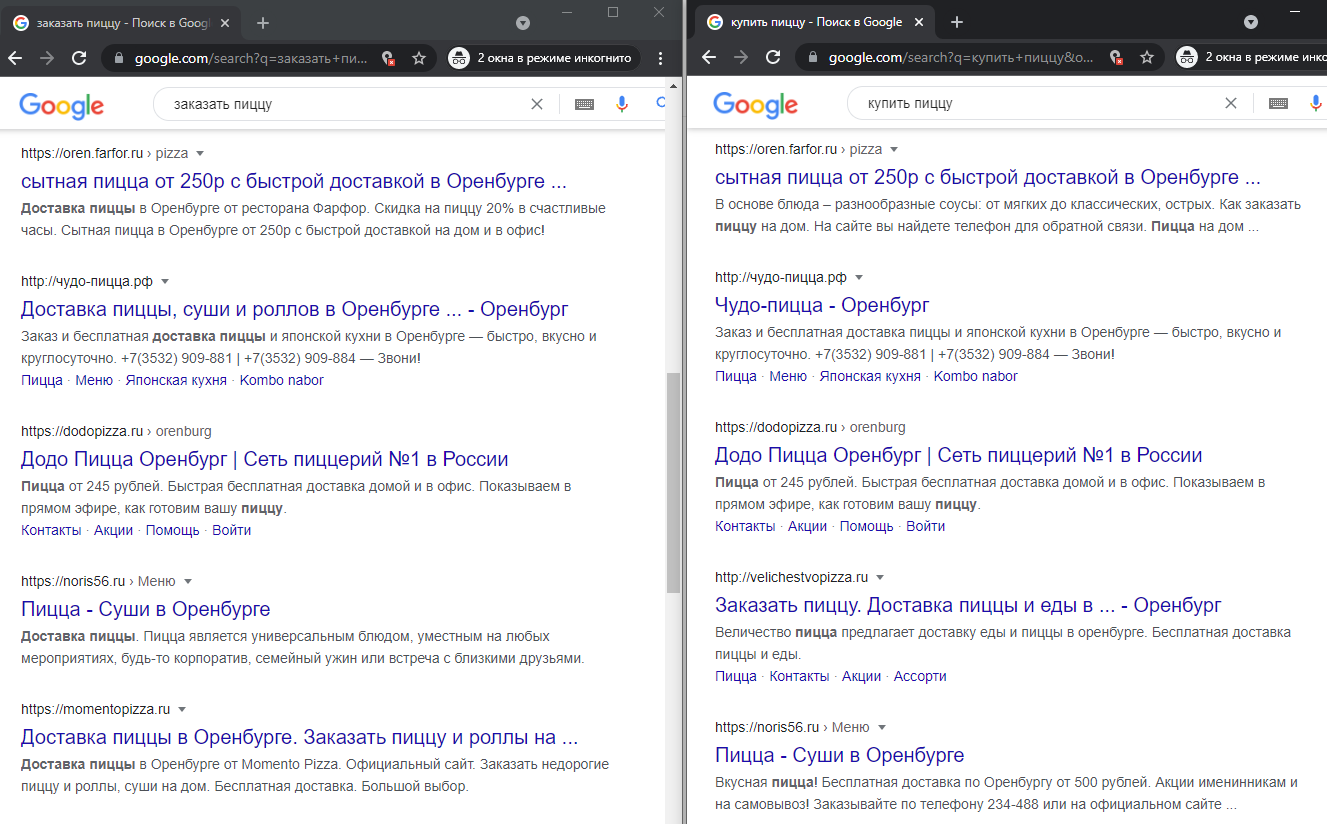
Проще всего кластеризовать семантику через специальные сервисы. Советуем KeyAssort — он платный, но с мощным функционалом. Еще можете присмотреться к KeyClusterer, этот уже бесплатный.
Далее будем кластеризовать семантическое ядро на примере KeyAssort. Принцип работы следующий: вы отдаете сервису свою семантику, он в зависимости от заданных параметров, проверяет пересечения, объединяет похожие запросы в кластеры и отдает вам. Вы можете посмотреть видео-инструкцию по работе с программой на официальном сайте, а я здесь кратко перескажу основные действия.
Приведенный ниже пример кластеризации — упрощенная схема. Более сложный и точный подход — когда мы берем частотность и сложность ключевого слова из платных сервисов.
Импорт. Чтобы программа все загрузила верно, лучше работать через шаблон. Скачать шаблон.
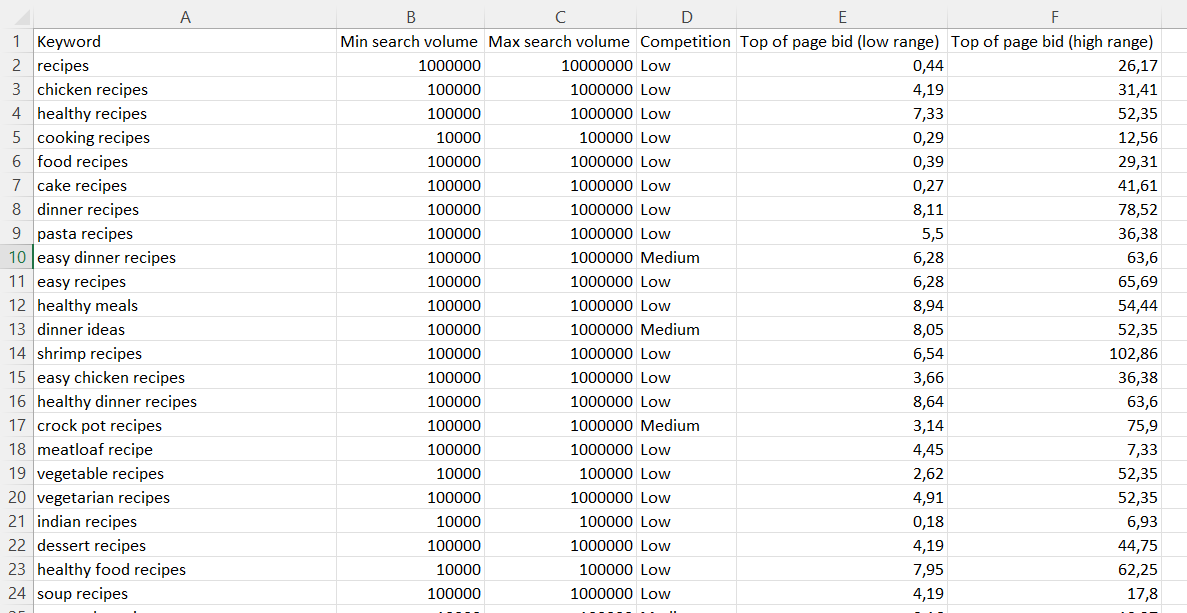
В первый столбец копируем запросы, а частотность копируем во второй и третий столбец (Mix search volume и Max search volume) — то есть их нужно продублировать. Поставьте значение «0» во всех остальных ячейках и «low» в Сompetition. Теперь импортируем:
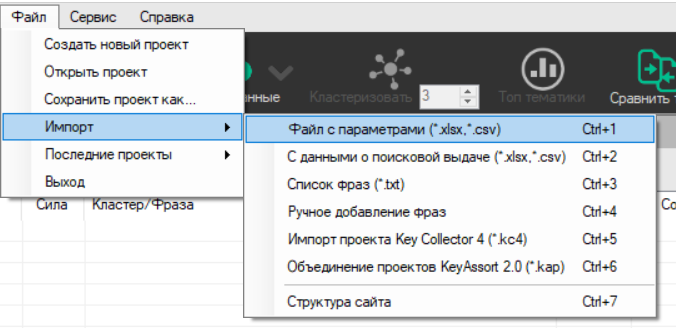
В меню нажимаем «Файл» — «Импорт» — «Файл с параметрами»
Следующие окна оставляем без изменений:
Сбор данных. Теперь нужно, чтобы программа проанализировала запросы и выявила среди них кластеры. Нажимаем «Собрать данные» в верхнем меню:
Так как мы работали с Яндекс Вордстат, то собираем по Яндексу
У нас около 200 запросов и сбор данных займет несколько минут. Чем больше семантика — тем больше времени.
Кластеризация. Нажимаем в верхнем меню «Кластеризация» и начинаем эксперименты с настройками. Цель — получить адекватную сборку кластеров . Мы можем менять вид кластеризации, силу группировки и другие параметры — подробнее об этом читайте в справке KeyAssort.
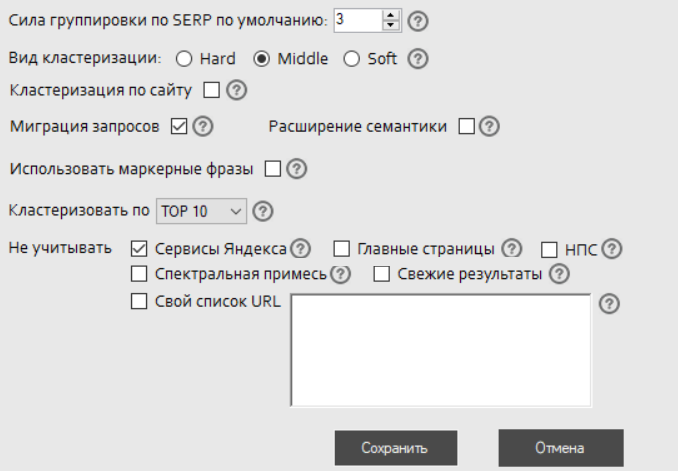
Настройка кластеризации
Меняйте настройки пока не увидите адекватную сборку кластеров. Иногда приходится вручную перебрасывать запросы из одного кластера в другой чтобы получить лучший результат.
В нашем примере получился такой результат:

В последнем кластере ошибка — это не статья в блоге, а страницы пиццы
Структура будущего сайта получилась точной, но большая часть запросов попала на главную страницу — это особенность региональных проектов.
Что дальше
Теперь у вас есть собранная и кластеризованная семантика. Можно:
- Продумать структуру сайта. Под каждый кластер — своя страница.
- Отслеживать движение сайта в выдаче по ключевым запросам.
- Подумать над созданием продуктов, которые близки нашему бизнесу.
- Писать технические задания с ключевыми словами и вставлять их в страницу — но это уже совсем другая тема, в этой статье мы ее касаться не будем.
Заключение
Статья получилась большой, пробежимся по основным выводам.
Что касается базовой теории:
- Семантика — набор запросов и фраз, которые характеризуют наш сайт или конкретную страницу.
- Семантика помогает продумать структура сайта, отслеживать продвижение сайта по ключевым запросам в поиске, а также это необходимый этап перед формированием сео-ключей. Собранное ядро — отличный советник по бизнес-идеям: на разработке каких продуктов и страниц, нужно сосредоточить внимание, а от каких наоборот отказаться.
- Если у вас не очень крупный проект, есть желание и время погрузиться в SEO — собрать семантику можно самостоятельно. В остальных случаях нужен сеошник хотя бы на разовый проект.
- Собранное семантическое ядро открывает путь к текстовой оптимизации страниц — добавлению SEO-ключей и метатегов, проработке структуры статьи, ее объема и другое. Это сложнее сбора семантики и тут нужные более глубокие знания. Скорее всего, придется звать сеошника и не факт, что его устроит собранная вами семантика.
Как собрать семантику за 6 шагов:
- Обсудите с коллегами и сотрудниками, какие запросы характеризуют ваш сайт. Ответьте на вопрос: «если бы вы искали свой сайт в поисковике, то по каким запросам?»
- Вбейте все фразы из предыдущего этапа в Яндекс Вордстат и скопируйте все предложенные запросы в Google Таблицы. Дополнительно используйте Букварикс.
- Посмотрите конкурентов — изучите их разделы, вам наверняка придет идея, как расширить свою семантику.
- Шлифовка и сортировка. Удаляем дубли, микрозапросы, символы «+» из Яндекс Вордстат.
- Чистка. Удаляем непонятные фразы и все, что наш сайт дать пользователю не может. Перспективные запросы, но которые сейчас не описывают наши услуги, переносим в скоринг-документ.
- Кластеризируем семантику через KeyClusterer.
SEO-продвижение не ограничивается одной лишь семантикой и текстовой оптимизацией — это более многогранный процесс, который охватывает работу с технической и контентной частью сайта. А еще желательно публиковаться на внешних ресурсах — блогах и каталогах. Подробности про всё SEO читайте в нашем гиде.
ЭКСКЛЮЗИВЫ ⚡️
Читайте только в блоге
Unisender
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
![]()
![]()
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни. Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
Обновил Сергей Алмакин.
Что такое семантическое ядро сайта
Сначала объясним простыми словами с помощью видео:
Рассказывает проект-менеджер «Текстерры» Иван Смирнов
Ну а теперь более подробно.

Органический поиск – самый эффективный источник привлечения трафика. Чтобы им пользоваться и сделать сайт видимым для посетителей «Яндекса» и Google, не нужно изобретать велосипед. Достаточно определить, чем интересуется ваша аудитория и как она ищет информацию. Эта задача решается построением семантического ядра.
Семантическое ядро – набор слов и словосочетаний, отражающих тематику и структуру сайта. Семантика – раздел языковедения, изучающий смысловую наполненность единиц языка. Поэтому термины «семантическое ядро» и «смысловое ядро» тождественны. Запомните эту реплику, она не даст вам скатиться до keyword stuffing, или напичкивания контента ключевыми словами.
Составляя смысловое ядро, вы отвечаете на глобальный вопрос: какую информацию можно найти на сайте. Поскольку одним из главных принципов бизнеса и маркетинга считается клиентоориентированность, на создание семантического ядра можно смотреть с другой стороны. Вам нужно определить, с помощью каких поисковых запросов пользователи ищут информацию, которая будет опубликована на сайте.
Построение смыслового ядра решает еще одну задачу. Речь идет о распределении поисковых фраз по страницам ресурса. Работая с ядром, вы определяете, какая страница точнее всего отвечает на конкретный поисковый запрос или группу запросов.
Есть два подхода к решению этой задачи. Первый предполагает создание структуры сайта по результатам анализа поисковых запросов пользователя. В этом случае семантическое ядро определяет каркас и архитектуру ресурса. Второй подход предполагает предварительное планирование структуры ресурса до анализа поисковых запросов. В этом случае семантическое ядро распределяется по готовому каркасу.
Оба подхода так или иначе работают. Но логичнее сначала планировать структуру сайта, а потом определять запросы, по которым пользователи смогут найти ту или иную страницу. В этом случае вы остаетесь проактивным: сами выбираете, что хотите рассказывать потенциальным клиентам. Если вы подгоняете структуру ресурса под ключи, то остаетесь объектом и реагируете на среду, а не активно ее меняете.
Здесь нужно четко подчеркнуть разницу между «сеошным» и маркетинговым подходом к построению ядра. Вот логика типичного оптимизатора старой школы: чтобы создать сайт, нужно найти ключевые слова и выбрать фразы, по которым просто попасть в топ выдачи. После этого необходимо создать структуру сайта и распределить ключи по страницам. Контент страницы нужно оптимизировать под ключевые фразы.
Вот логика бизнесмена или маркетолога: нужно решить, какую информацию транслировать аудитории с помощью сайта. Для этого необходимо хорошо знать свою отрасль и бизнес. Сначала нужно запланировать приблизительную структуру сайта и предварительный список страниц. После этого при построении семантического ядра надо узнать, как аудитория ищет информацию. С помощью контента необходимо отвечать на вопросы, которые задает аудитория.

Целевая аудитория: зачем знать своего клиента
К каким негативным последствиям приводит использование «сеошного» подхода на практике? Из-за развития по принципу «плясать от печки» падает информационная ценность ресурса. Бизнес должен формировать тренды и выбирать, что говорить клиентам. Бизнес не должен ограничиваться реакциями на статистику поисковых фраз и создавать страницы только ради оптимизации сайта под какой-то ключ.
Из-за особенностей подходов к продвижению представители старой школы SEO необоснованно отсеивают часть перспективных поисковых запросов. Это объясняется высокой конкурентностью или низким коэффициентом KEI, низкой частотностью, «мусорностью» ключей и т. д.
Мусорных или слишком конкурентных ключей не бывает. У нас в «Текстерре» кардинально другой подход к продвижению сайтов – упор идет на максимально широкое семантическое ядро.
Планируемый результат построения семантического ядра – это список ключевых запросов, распределенных по страницам сайта. Он содержит URL страниц, поисковые запросы и указание их частотности.
Продвинем ваш бизнес
В Google и «Яндексе», соцсетях, рассылках, на видеоплатформах, у блогеров
Подробнее

Как построить структуру сайта
Структура сайта представляет собой иерархическую схему страниц. С ее помощью вы решаете несколько задач: планируете логику подачи информации, обеспечиваете юзабилити и соответствие сайта требованиям поисковых систем.
Для создания структуры подойдет любой удобный инструмент: редактор таблиц, ваш любимый текстовый редактор – можно даже нарисовать от руки на листе бумаги. Главное, планируя иерархию будущего сайта, отвечать себе на два вопроса:
- Какую информацию вы хотите сообщить пользователям?
- Где лучше разместить тот или иной информационный блок?
Представьте, что у вас сайт небольшой кондитерской. Он включает информационные страницы, раздел публикаций и витрину или каталог продуктов. Визуально структура может выглядеть так:

Визуализация структуры сайта
Для дальнейшей работы с семантическим ядром оформите структуру сайта в виде таблицы. В ней укажите названия страниц и обозначьте их подчиненность. Также включите в таблицу колонки для указаний URL страниц, ключевых слов и их частотности. Колонки URL, «Ключи» и «Частотность» вы заполните позже. А сейчас – переходите к поиску ключевых слов.
Что нужно знать о ключевых словах
Чтобы подобрать семантическое ядро, вы должны понимать, что такое ключевые слова и какие ключи использует аудитория. С этими знаниями вы сможете корректно использовать один из инструментов для подбора ключевых слов.
Какие ключи использует аудитория
Ключи – это слова или фразы, которые используют потенциальные клиенты, чтобы найти необходимую информацию. Например, чтобы приготовить торт, пользователь вводит в поисковую строку запрос «наполеон рецепт с фото».
Ключевые слова классифицируются по нескольким признакам. По популярности выделяют высоко-, средне- и низкочастотные запросы. По разным данным, поисковые фразы объединяются в группы так:
- К низкочастотным относятся запросы с частотой показов до 100 в месяц. Некоторые специалисты включают в группу запросы с частотой до 1 000 показов.
- К среднечастотным относятся запросы с частотой до 1 000 показов. Иногда эксперты увеличивают порог до 5 000 показов.
- К высокочастотным запросам относятся фразы с частотой от 1 000 показов. Некоторые авторы считают высокочастотными ключи, имеющие от 5 000 или даже 10 000 запросов.
Разница в оценке частотности связана с разной популярностью тематик. Если вы создаете ядро для интернет-магазина, торгующего ноутбуками, фраза «купить ноутбук samsung» с частотой показа около 6 тыс. в месяц будет среднечастотной. Если вы создаете ядро для сайта спортивного клуба, запрос «секция айкидо» с частотой показов около 1 000 запросов будет высокочастотным.
Что нужно знать о частотности при составлении семантического ядра? По статистике, примерно две трети всех поисковых запросов низкочастотные. Поэтому нужно иметь максимально широкое семантическое ядро, которое должно постоянно расширяться за счет низкочастотных фраз.
Значит ли это, что высоко- и среднечастотные запросы можно игнорировать? Нет, вы не обойдетесь без них. Но в качестве основного ресурса для привлечения целевых посетителей рассматривайте низкочастотные ключи.
По потребностям пользователей ключи объединяются в такие группы:
- Информационные. Аудитория использует их, чтобы найти какие-то сведения. Примеры информационных запросов: «как правильно хранить выпечку», «как отделить желток от белка».
- Транзакционные. Пользователи вводят их, когда планируют совершить действие. К этой группе относятся ключи «купить хлебопечку», «скачать книгу рецептов», «заказать пиццу с доставкой».
- Прочие запросы. Речь идет о ключевых фразах, по которым сложно определить намерение пользователя. Например, когда человек использует ключ «торт», он может планировать купить кулинарное изделие или приготовить его самостоятельно. Кроме того, пользователь может интересоваться информацией о тортах: определением, признаками, классификацией и т. п.
Некоторые специалисты выделяют в отдельную группу навигационные запросы. С их помощью аудитория ищет информацию на конкретных сайтах. Вот несколько примеров: «ноутбуки связной», «сити экспресс отследить доставку», «зарегистрироваться в LinkedIn». Неспецифичные вашему бизнесу навигационные запросы при составлении семантического ядра можно игнорировать.
Как использовать этот способ классификации при построении семантического ядра? Во-первых, вы должны учитывать нужды аудитории при распределении ключей по страницам и создании контент-плана. Здесь все очевидно: публикации информационных разделов должны отвечать на информационные запросы. Здесь же должна быть большая часть ключевых фраз без выраженного намерения. На транзакционные вопросы должны отвечать страницы из разделов «Магазин» или «Витрина».
Во-вторых, следует помнить, что многие транзакционные вопросы относятся к коммерческим. Чтобы привлекать естественный трафик по запросу «купить смартфон Samsung», вам придется конкурировать с «Евросетью», «Эльдорадо» и другими бизнес-тяжеловесами. Избежать неравной конкуренции можно с помощью рекомендации, приведенной выше. Максимально расширяйте ядро и снижайте частотность запросов. Например, частотность запроса «купить смартфон Samsung Galaxy S6» на порядок ниже частотности ключа «Купить смартфон Samsung Galaxy».
Что нужно знать об анатомии поисковых запросов
Поисковые фразы состоят из нескольких частей: тела, спецификатора и хвоста. Это можно рассмотреть на примере.
Что можно сказать о запросе «торт»? По нему нельзя определить намерение пользователя. Он высокочастотный, что определяет высокую конкуренцию в выдаче. Использование этого запроса для продвижения принесет большую долю нецелевого трафика, что негативно сказывается на поведенческих метриках. Высокочастотность и неспецифичность запроса «торт» определяется его анатомией: он состоит только из тела.

Главная проблема семантики, которая мешает поисковому продвижению
Обратите внимание на запрос «купить торт». Он состоит из тела «торт» и спецификатора «купить». Последний определяет намерение пользователя. Именно спецификаторы указывают на принадлежность ключа к транзакционным или информационным. Посмотрите на примеры:
- купить торт;
- рецепты тортов;
- как подавать торт.
Иногда спецификаторы могут выражать прямо противоположные намерения пользователя. Простой пример: пользователи планируют купить или продать машину.
Теперь посмотрите на запрос «купить торт с доставкой». Он состоит из тела, спецификатора и хвоста. Последний не меняет, а детализирует намерение или информационную потребность пользователя. Посмотрите на примеры:
- купить торт онлайн;
- купить торт в Туле с доставкой;
- купить домашний торт в Орле.

Четко прослеживается интент главного запроса
В каждом случае видно намерение человека приобрести торт. А хвост ключевой фразы детализирует эту потребность.
Знание анатомии поисковых фраз позволяет вывести условную формулу подбора ключей для семантического ядра. Вы должны определить базовые термины, связанные с вашим бизнесом, продуктом и нуждами пользователей. Например, клиенты кондитерской фирмы интересуются тортами, выпечкой, печеньем, пирожными, капкейками и другими кондитерскими изделиями.
После этого вам нужно найти хвосты и спецификаторы, которые аудитория проекта использует с базовыми терминами. Благодаря «хвостатым» фразам вы одновременно увеличиваете охват и уменьшаете конкурентность ядра.
Системы аналитики
Если вы строите семантическое ядро для существующего сайта, воспользуйтесь системами аналитики «Яндекс.Метрика» или Google Analytics. С их помощью вы можете определить, какими поисковыми фразами пользуется существующая аудитория проекта.

В отчетах о поисковых запросах можно найти не только идеи ключевых слов, но и посмотреть подробную поведенческую статистику по уже существующим поисковым фразам
Данные о популярных поисковых запросах можно получить в кабинетах для вебмастеров «Яндекса» и Google. В Search Console информация находится в разделе «Поисковый трафик – Анализ поисковых запросов». В «Вебмастере» воспользуйтесь разделом «Поисковые запросы – Популярные запросы».
Сервисы анализа сайтов-конкурентов
Сайты конкурентов – отличный источник идей ключевых слов. Если вас интересует конкретная страница, определить поисковые фразы, под которые она оптимизирована, можно вручную. Чтобы найти основные ключи, обычно достаточно прочитать материал или проверить содержимое метатега keywords в коде страницы. Также вы можете воспользоваться сервисами семантического анализа текстов, например, Istio или Advego.

Получили список фраз без учета стоп-слов
Если вам необходимо проанализировать сайт целиком, воспользуйтесь сервисами комплексного конкурентного анализа:
- Searchmetrics – стоимость рассчитывается индивидуально.
- SpyWords – российский сервис, от 1 978 руб. в месяц.
- SEMrush – стоимость от 119,95 $ в месяц (подробный обзор ниже).

Searchmetrics позволяет собрать поисковые фразы, с помощью которых пользователи находят сайты конкурентов
Вы можете использовать и другие инструменты для сбора ключевых фраз. Вот несколько примеров: Google Trends, Wordtracker, WordStream, Ubersuggest, «Топвизор». Но не спешите освоить все сервисы и программы сразу. Если вы составляете семантическое ядро для собственного небольшого сайта, воспользуйтесь бесплатным инструментом, например, сервисом подбора ключевых слов «Яндекс» или планировщиком Google.
Как подобрать ключевые слова для семантического ядра
Процесс подбора ключевых фраз объединяется в несколько этапов. На первом вы определите базовые ключи, с помощью которых аудитория ищет ваш продукт или бизнес. Второй этап посвящен расширению семантического ядра. На третьем этапе вы удалите неподходящие поисковые фразы.
Определяем базовые ключи
Внесите в таблицу или запишите на бумаге общие поисковые фразы, связанные с вашим бизнесом и продуктами. Соберите коллег и проведите мозговой штурм. Фиксируйте все предложенные идеи без обсуждений.
Ваш список будет выглядеть примерно так:

Нашли главные запросы
Большинство ключей, которые вы записали, характеризуются высокой частотностью и низкой специфичностью. Чтобы получить средне- и низкочастотные поисковые фразы с высокой специфичностью, вам нужно максимально расширить ядро.
Расширяем семантическое ядро
Эту задачу вы будете решать с помощью инструментов для подбора ключевых слов, например, Wordstat. Если ваш бизнес имеет региональную привязку, в настройках выберите соответствующий регион.
С помощью сервиса подбора ключевых фраз вам необходимо проанализировать все записанные на предыдущем этапе ключи.

Получили множество вариаций по главному ключу
Скопируйте фразы из левой колонки Wordstat и вставьте в таблицу. Обратите внимание на правую колонку. В ней «Яндекс» предлагает фразы, которые люди использовали вместе с основным запросом. В зависимости от содержания, вы можете сразу выбрать подходящие ключи из правой колонки или скопировать список целиком. Во втором случае неподходящие запросы будут отсеяны на следующем этапе.
А результатом этого этапа работы будет список поисковых фраз для каждого базового ключа, который вы получили с помощью мозгового штурма. В списках могут быть сотни или тысячи запросов.

Внутри частотного ключа – множество других
Удаляем неподходящие поисковые фразы
Это самый трудозатратный этап работы с ядром. Вам необходимо вручную удалить из ядра неподходящие по смыслу поисковые фразы.
Не используйте в качестве критерия оценки ключей частотность, конкурентность или другие чисто «сеошные» метрики. Знаете, почему оптимизаторы старой школы считают мусорными те или иные поисковые фразы? Например, возьмите ключ «диетический торт». Сервис Wordstat прогнозирует для него 10 показов в месяц в регионе Вологодская область (без Вологды).

2 показа в месяц – значит показываемся по этой фразе только в Вологде, но не в области
Чтобы продвигать страницы по конкретным ключам, олдскульные сеошники покупали или арендовали ссылки. Кстати, некоторые специалисты используют этот подход до сих пор. Понятно, что поисковые фразы с низкой частотностью в большинстве случаев не окупают средства, потраченные на покупку ссылок.
Теперь посмотрите на фразу «диетические торты» глазами обычного маркетолога. Некоторые представители ЦА кондитерской фирмы действительно интересуются такими продуктами. Поэтому ключ можно и нужно включить в семантическое ядро. Если кондитерская готовит соответствующие продукты, фраза пригодится в разделе описаний товаров. Если фирма по каким-то причинам не работает с диетическими тортами, ключ можно использовать в качестве контент-идеи для информационного раздела.
Какие фразы можно смело исключать из списка?
- Ключи с упоминанием конкурирующих брендов.
- Ключи с упоминанием товаров или услуг, которые вы не продаете и не планируете продавать.
- Ключи с включением слов «недорого», «дешево», «со скидкой». Если вы не демпингуете, отсекайте любителей дешевого, чтобы не портить поведенческие метрики.
- Дублирующиеся ключи. Например, из трех ключей «торты на заказ на день рождения», «торты на заказ на день» и «торты на заказ на рождение» достаточно оставить первый.
- Ключи с упоминанием неподходящих регионов или адресов. Например, если вы обслуживаете жителей Северного района Череповца, вам не подходит ключ «торты на заказ индустриальный район».
- Фразы, введенные с ошибками или опечатками. Поисковые системы понимают, что пользователь ищет круассаны, даже если вводит в поисковую строку ключ «круассаны».
После удаления неподходящих фраз вы получили список запросов для базового ключа «торты на заказ». Такие же списки необходимо составить для других базовых ключей, полученных на этапе мозгового штурма. После этого переходите к группировке ключевых фраз.
Как группировать ключевые слова и строить карту релевантности
Поисковые фразы, с помощью которых пользователи находят или будут находить ваш сайт, объединяются в семантические кластеры. Это близкие по смыслу группы запросов. Например, в семантический кластер «Торт» входят все ключевые фразы, связанные с этим словом: рецепты тортов, заказать торт, фото тортов, свадебный торт и т. д.
Семантический кластер – это группа объединенных по смыслу запросов. Он представляет собой многоуровневую структуру. Внутри кластера первого порядка «Торт» есть кластеры второго порядка «Рецепты тортов», «Заказ тортов», «Фотографии тортов». Внутри кластера второго порядка «Рецепты тортов» теоретически можно выделить третий порядок кластеризации: «Рецепты тортов с мастикой», «Рецепты бисквитных тортов», «Рецепты песочных тортов». Число уровней в кластере зависит от обширности тематики. На практике в большинстве тематик достаточно внутри кластеров первого порядка выделить специфичные бизнесу кластеры второго порядка.

Теоретически семантический кластер может иметь много уровней. На практике работать придется с кластерами первого и второго уровней
Большую часть кластеров первого уровня вы определили во время мозгового штурма, когда записывали базовые ключевые фразы. Для этого достаточно разбираться в собственном бизнесе, а также подглядывать в схему сайта, которую вы составили до начала работы над семантическим ядром.
Очень важно корректно выполнить кластеризацию на втором уровне. Здесь поисковые фразы меняются с помощью спецификаторов, обозначающих намерения пользователей. Простой пример – кластеры «рецепты тортов» и «торты на заказ». Поисковые фразы первого используют люди, нуждающиеся в информации. Ключи второго кластера используют клиенты, желающие купить торт.
Поисковые фразы для кластера «торты на заказ» вы определили с помощью Wordstat и ручного отсева. Их необходимо распределить между страницами раздела «Торты».

Каждая страница соотносится с конкретным разделом сайта: о нас, условия, контакты, блог
Например, в кластере есть поисковые запросы «футбольные торты на заказ» и «торты на заказ футбольная тематика».

Футбольную тему можно развить
Если в ассортименте фирмы есть соответствующий продукт, в разделе «Торты из мастики» необходимо создать соответствующую страницу. Внесите ее в структуру сайта: укажите название, URL и поисковые фразы с частотностью.

Новая страница отправится в «кластер» «Торты из мастики»
С помощью сервиса «Подбор ключевых слов» или аналогичных инструментов посмотрите, какие еще поисковые фразы используют потенциальные клиенты, чтобы найти торты с футбольным оформлением. Внесите подходящие в список ключевых слов страницы.

Частотность единичная
В списке поисковых фраз кластера удобным вам способом отметьте распределенные ключи. Распределите оставшиеся поисковые фразы.
Если необходимо, меняйте структуру сайта: создавайте новые разделы и категории. Например, страница «торты на заказ щенячий патруль» должна войти в раздел «Детские торты». Одновременно она может входить в раздел «Торты из мастики».

Создаем новый раздел «Детские торты» и включаем в него страницу «Щенячий патруль». Тщательно отбираем фразы для каждого кластера
Обратите внимание на два момента. Во-первых, в кластере может не оказаться подходящих фраз для страницы, которую вы планируете создать. Это может произойти по разным причинам. Например, к ним относятся несовершенство инструментов сбора поисковых фраз или их некорректное использование, а также низкая популярность продукта.
Отсутствие в кластере подходящего ключа – не повод отказаться от создания страницы и продажи продукта. Например, представьте, что кондитерская фирма продает детские торты с изображением героев мультфильма «Свинка Пеппа». Если в список не попали соответствующие ключи, уточните потребности аудитории с помощью Wordstat или другого сервиса. В большинстве случаев подходящие запросы найдутся.

12 показов – единичные запросы, но использовать их можно
Во-вторых, даже после удаления лишних ключей в кластере могут остаться поисковые фразы, которые не подходят для созданных и запланированных страниц. Их можно игнорировать или использовать в другом кластере. Например, если кондитерская по каким-то причинам принципиально не продает торт «Наполеон», соответствующие ключевые фразы можно использовать в разделе «Рецепты».

Здесь можно найти отличные идеи для расширения семантики или нового контента для информационных разделов. Если вы не продаете «Наполеон», используйте популярный ключ в информационном разделе
После распределения всех ключей вы получите список существующих и запланированных страниц сайта с указанием URL, поисковых фраз и частотности. Что с ними делать дальше?
Сервисы для составления семантического ядра
Есть много инструментов для подбора ключевых слов. Вы можете построить ядро с помощью платных или бесплатных сервисов и программ. Выбирайте конкретное средство в зависимости от стоящих перед вами задач.
Key Collector
Вы не обойдетесь без этого инструмента, если занимаетесь интернет-маркетингом профессионально, развиваете несколько сайтов или составляете ядро для большого сайта. Вот список основных задач, которые решает программа:
- подбор ключевых слов. Key Collector собирает запросы через Wordstat «Яндекса»;
- парсинг поисковых подсказок;
- отсечение неподходящих поисковых фраз с помощью стоп-слов;
- фильтрация запросов по частоте;
- поиск неявных дублей запросов;
- определение сезонных запросов;
- сбор статистики из сторонних сервисов и платформ: Liveinternet.ru, «Метрика», Google Analytics, «Google Реклама», «Директ», «ВКонтакте» и другие;
- поиск релевантных запросу страниц.

Функциональность программы позволяет доскональную работу с любым, даже очень большим семантическим ядром
Key Collector – многофункциональный инструмент, который автоматизирует операции, необходимые для построения семантического ядра. Программа платная. Вы можете выполнить все действия, которые «умеет» Key Collector, с помощью альтернативных бесплатных инструментов. Но для этого вам придется использовать несколько сервисов и программ. Стоимость первой лицензии составляет 2 200 руб., второй-десятой – 2 700 руб.
SlovoEB
Это бесплатный инструмент от создателей Key Collector. Программа собирает ключевые слова через Wordstat, определяет частотность запросов, парсит поисковые подсказки. После запуска программы, в настройках, укажите логин и пароль от аккаунта «Директ». Не используйте основной аккаунт, так как «Яндекс» может заблокировать его за автоматические запросы.

Инструмент позволяет подобрать ключевые слова, а также автоматически выполнить некоторые задачи, связанные с анализом и группировкой запросов.
Сервис подбора ключевых слов «Яндекс»
Wordstat – бесплатный сервис, с помощью которого можно подобрать и проанализировать ключевые слова. Инструмент обладает такой функциональностью:
- Показывает статистику показов по ключевому слову, а также поисковым фразам, которые включают указанное ключевое слово. Вы можете проанализировать общие данные или данные о запросах мобильной аудитории.

- Показывает данные о запросах в региональном разрезе.
- Отображает данные о популярности запроса в динамике. Соответствующая информация доступна в разделе «История запросов».
- Показывает статистику только по указанной фразе и ее формам. Чтобы получить данные, возьмите ключ в кавычки.
- Отображает статистику для ключа без учета форм. Чтобы получить данные, добавьте перед поисковой фразой восклицательный знак.
- Отображает данные для ключа без учета минус-слов. Чтобы получить статистику для запроса «убить пересмешника» без учета слова «фильм», перед последним нужно поставить минус.
- Показывает статистику запросов с использованием выбранного предлога. Чтобы получить данные, поставьте перед предлогом знак «+».
- Показывает статистику по группе запросов. Чтобы получить информацию, укажите группы запросов в круглых скобках, а варианты ключей разделите знаком «|». Например, чтобы быстро получить статистику по запросам «заказать торт», «купить торт», «заказать капкейк», «купить капкейк», «заказать пирог» и «купить пирог», используйте указанную на иллюстрации конструкцию:
- Показывает статистику запросов с привязкой к указанным регионам.

Популярность запроса в динамике
С помощью сервиса Wordstat вы можете подобрать ключевые фразы, необходимые для построения семантического ядра. Используйте его, если готовы анализировать и группировать запросы вручную.
Планировщик ключевых слов Google
Используйте планировщик ключевых слов, чтобы построить семантическое ядро с учетом нужд пользователей поисковой системы Google. Например, логично использовать статистику Google в регионах, где этот поисковик доминирует.
Планировщик ключевых слов позволяет искать новые запросы по запросам, сайтам или тематикам. С помощью сервиса вы можете собрать статистику поисковых запросов. Также планировщик можно использовать для создания новых комбинаций запросов и прогнозирования трафика.

Есть данные не только по показам, но и по цене ставки (минимальной и максимальной)
Статистика запросов «Поиск Mail.ru»
Сервис показывает статистику запросов в третьем по популярности поисковике в Рунете. Информация представлена в разрезе пола и возраста пользователей. Доступна статистика за прошедший календарный месяц.

Статистика запросов Mail показывает данные в разрезе пола / возраста
Serpstat
Многофункциональный SEO-сервис, использование платное. Платная версия от 69 $.
С помощью Serpstat можно проанализировать ключевые фразы и подобрать средне- и низкочастотные запросы. Система работает с Google и «Яндекс». Пользователь указывает географию проекта.

Результаты анализа ключевой фразы с помощью Serpstat
По результатам анализа Serpstat выдает такие данные:
- частотность ключа;
- уровень конкуренции по шкале от 1 до 100;
- приблизительную стоимость перехода по контекстному объявлению;
- динамику популярности запроса в виде графика;
- список конкурентов в поисковой выдаче и в системах контекстной рекламы.
В разделе SEO-анализ можно подобрать для базового ключа дополнительные фразы. Serpstat выдает похожие фразы и поисковые подсказки. Здесь же можно увидеть список страниц из топа выдачи по выбранному запросу. Пользователь может оценить динамику видимости сайтов-конкурентов в выдаче по заданному ключу.

Сводка по видимости конкурентов
В разделе «Контент-маркетинг» можно получить «длиннохвостые» ключевые фразы и контент-идеи. Сервис по заданному базовому ключу собирает группы поисковых запросов. Например, в группе «как создание сайтов» содержатся популярные запросы типа «как начать создание сайта» или «как заработать создание сайтов». То есть Serpstat фактически генерирует готовые кластеры ключевых фраз.
«Мутаген»
С помощью сервиса можно искать ключевые фразы с высокой частотностью и низкой конкуренцией. «Мутаген» платный. Проверка конкуренции: 100 проверок 30 рублей. Парсер «Вордстат»: 1 запрос всего 2 копейки. Новым пользователям для доступа к бесплатным проверкам нужно хотя бы раз пополнить баланс.
Чтобы определить уровень конкуренции по ключу, сервис анализирует топ-30 сайтов в выдаче «Яндекса». Алгоритм и критерии проверки не разглашаются. Создатели «Мутагена» рекомендуют включать в семантическое ядро поисковые фразы с частотностью от 150 запросов в месяц и уровнем конкуренции не выше 5 баллов.

Подбираем семантику
SemRush
Платный комплексный инструмент поисковой аналитики. Цена: от 119.95 $ в месяц (от 99.95 $ в месяц при оплате за год). Есть встроенный инструмент Keyword Magic Tool. Он подбирает идеи ключевых фраз по базовому ключу, оценивает частотность фраз, стоимость перехода в «Google Рекламе», уровень конкуренции, выдачу Google по запросам на текущий момент. Собранные ключи можно экспортировать в таблицу или добавить в Keyword Analyzer для дальнейшего анализа.
В разделе «Анализ ключевых слов» можно получить данные по выбранным ключам:
- частотность ключа;
- распределение по регионам;
- динамика;
- стоимость в «Google Рекламе». Состояние SERP.
Данные можно экспортировать в формате PDF.

Анализ ключевого слова в SemRush
С помощью SemRush для базового ключа можно получить смежные запросы и просматривать историю объявлений в «Google Рекламе». В разделе Keyword Difficulty можно оценить уровень конкуренции по ключевому слову. Система оценивает по шкале от 1 до 100, насколько тяжело занять место в топе поисковой выдачи по выбранному ключу.
С помощью SemRush можно группировать ключи.
Keyword Tool
Платный инструмент для работы с ключевыми запросами. Сервис ищет идеи поисковых фраз для Google, YouTube, Bing, Amazon, App Store и eBay. Бесплатная версия отображает список ключей. Платная подписка дает доступ к частотности, динамике, стоимости в «Google Рекламе» и уровню конкуренции по выбранным ключам.
Платная и бесплатная версии поддерживают экспорт данных в форматах .xls или .csv. Платная подписка открывает доступ к инструменту анализа конкурентов.

Rush Analytics
Инструмент подбирает и кластеризирует ключевые фразы. Использование платное, тариф от 500 рублей в месяц.
Rush Analytics автоматически анализирует ключевые слова из сервиса «Подбор слов» «Яндекса». В настройках проекта можно указать параметры оценки ключей: добавить операторы, зафиксировать порядок слов. Собранные ключи и статистику можно экспортировать.
Rush Analytics собирает подсказки из «Яндекса», Google и YouTube. С их помощью можно расширить семантическое ядро. Собранные подсказки можно загрузить в таблицу.
С помощью Rush Analytics можно кластеризировать ключи. Данные можно выгрузить в таблицу.
В Rush Analytics есть функции генерации ТЗ на создание текстов с учетом собранных ключей.

Собранные с помощью Rush Analytics подсказки
SEMparser
Платный сервис кластеризации ключей. После регистрации доступен бесплатный тестовый пакет. Чтобы сгруппировать ключи, нужно загрузить таблицу и запустить проект.
Группы ключевых слов можно отредактировать вручную и экспортировать в таблицу. Также с помощью SEMparser можно получить параметры эталонных текстов из топа поисковой выдачи по выбранному запросу. Сервис автоматически генерирует ТЗ на создание текстов на основе результатов кластеризации и анализа поисковой выдачи.

Анализ текстов из топа выдачи и генерация ТЗ на создание текстов
JustMagic
Сервис представляет собой набор SEO-инструментов по работе с семантикой для профессионалов. Сервис платный, но есть бесплатный тариф с небольшим количеством лимитов на каждый месяц.
JustMagiс позволяет собрать семантическое ядро по собственным базам, на основе данных «Метрики», из «Вордстата» и поисковых подсказок «Яндекса».
Помимо сбора семантики, есть возможность ее кластеризации по топу «Яндекса» или Google. Дополнительно есть функции определения частотности по «Вордстату», тематики, коммерческости и геозависимости запроса.
Тем, кто составляет ТЗ для копирайтеров или готовит SEO-тексты, также могут пригодиться «Акварель»/«Акварель-генератор» (для работы с LSI) и «Текстовый анализатор» (для подсчета точных и неточных вхождений).

Один из самых мощных инструментов в своем роде. Здесь есть поддержка тематической классификации ключей, разные форматы групп, региональная зависимости, определение коммерческого интента
«Пиксель Тулс»
Pixel Tools – это набор 50 SEO-сервисов для профессионалов, 12 из которых представляют инструменты для работы с семантическим ядром. Некоторые доступны бесплатно, сразу после регистрации. Чтобы получить полный доступ, нужно будет покупать подписку.
С помощью «Пиксель Тулс» вы можете собрать запросы из Wordstat и «Яндекс.Вебмастера», а также подсказки «Яндекса», Google, YouTube и даже Avito. Есть отдельный инструмент для парсинга блока «Вместе с … ищут». Он находится в разделе «Инструменты» → «Семантическое ядро» → «Вместе с запросом ищут».

Результат работы такого инструмента, собраны ключи из блока
Подобранную разными способами семантику можно кластеризовать, плюс проверить на геозависимость и коммерческость, оценить интент (намерение/желание пользователя) по каждому запросу, удалить дубли.
SEOquick Tools
Сервис представляет собой сборку из 11 инструментов для SEO-аудита и оптимизации сайта. Работу с семантикой упростит кластеризатор ядра, который разбивает ключевые слова по группам, объединяет синонимы в один кластер, удаляет минус-слова и учитывает геозависимость. Умеет склонять слова и чистить дубли. Доступна ручная настройка.

Внешний вид ручной настройки кластеризатора
Кластеризатор SEOquick понимает файлы с Ahrefs, Serpstat, Semrush, Key Collector, «Планировщика», «Вордстата» и др. Есть возможность сохранять и загружать проекты для кластеризации. Обладает интуитивно понятным интерфейсом.
Click.ru
Это профессиональные инструменты для контекстной и таргетированной рекламы, которые также пригодятся для работы с семантикой и решения SEO-задач. Инструментарий доступен после регистрации в системе. Стоимость зависит от количества задач, по каждому инструменту есть бесплатные запросы.
Через пользовательский аккаунт вы можете подобрать ключи по контенту на собственном сайте, результатам анализа конкурентов и данным веб-аналитики. После – изучить популярность запросов в «Вордстате», расширить семантику за счет поисковых подсказок и фраз-ассоциаций. Затем – кластеризовать по «Яндексу» или Google.
Чтобы почистить СЯ от мусора, лишних символов и дублей, есть «Нормализатор». Для тех, кто работает с продвижением интернет-магазинов, будет полезен «Комбинатор». Решить задачу по оптимизации метатегов и заголовков поможет соответствующий парсер, достаточно загрузить в него список URL или карту сайта.

Так работает сбор частотностей Wordstat

600+ лучших инструментов для комплексного продвижения сайта
Что делать с семантическим ядром
Таблица с семантическим ядром должна стать дорожной картой и основным источником идей при составлении контент-плана. Посмотрите: у вас есть список с предварительным названием страниц и поисковыми фразами. Они определяют потребности аудитории. При составлении контент-плана вам остается уточнить название страницы или публикации. Включите в него основной поисковый запрос. Это не всегда самый популярный ключ. Кроме популярности, запрос в названии должен лучше всего отражать потребность аудитории страницы.
Остальные поисковые фразы используйте в качестве ответа на вопрос «о чем писать». Помните, вам не нужно во что бы то ни стало вписать все поисковые фразы в информационный материал или в описание продукта. Контент должен раскрывать тему и отвечать на вопросы пользователей. Еще раз обратите внимание: нужно фокусироваться на информационных потребностях, а не на поисковых фразах и их вписывании в текст.
Что нельзя делать с семантическим ядром, чтобы не превратиться в олдскульного сеошника
Про вписывание поисковых фраз вы уже знаете. Вот продолжение списка вредных действий. Обратите внимание, что это относится как к семантическому ядру, так и к работе над контент-стратегией. Не практикуйте следующее:
- Отказ от использования слишком конкурентных ключей. Чтобы привлекать трафик и продавать, вам не нужно обязательно попасть в топ по конкурентному запросу «туры в Египет». Оставьте фразу в семантическом ядре и используйте ее в качестве контент-идеи.
- Отказ от использования низкочастотных фраз. Как сказано выше, представители старой школы считают запросы мусорными, если они не окупают средств, вложенных в покупку или аренду ссылок. А вам нужно собрать как можно больше низкочастотных и ультранизкочастотных ключей. Они тоже станут вашими контент-идеями.
- Использование для оценки ключевых слов формул и коэффициентов. Например, коэффициент эффективности ключевых слов (KEI) представляет собой отношение популярности к конкурентности. Вы помните, что семантика – раздел языкознания? Оставьте формулы математикам. Иначе вы потеряете много ценных контент-идей, которые могут отсеяться вместе с ключами с якобы низкой эффективностью или KEI.
- Создание страниц ради запросов. Здесь долго объяснять не надо: в мире SEO часто встречаются отдельные страницы для запросов «купить торт» и «заказать торт». В реальной жизни под «купить» и «заказать» подразумевается одно намерение. Поэтому вам нужна одна страница.
- Попытка максимально автоматизировать построение семантического ядра. Да, чтобы собрать поисковые фразы, нужно использовать сервисы или программы. Да, для больших проектов Key Collector если не незаменимый инструмент, то оптимальное рабочее средство. Но даже оптимизаторы старой школы знают, что без тщательного ручного анализа ценность списка ключей невысока. Машина может собрать фразы и их характеристики, но только человек может проанализировать отрасль, реально оценить уровень конкуренции и спланировать информационные кампании. Последнее, кстати, связано с построением структуры сайта и распределением ключей.
- Избыточная фокусировка на сборе ключевых фраз. Небольшим новым проектам чаще всего не нужно шпионить за конкурентами, изучать поисковые подсказки, собирать ключи из разных поисковых систем. Чтобы получить контент-идеи, на первом этапе достаточно использовать один источник, например, статистику «Яндекса» или Google. Альтернативные источники ключей понадобятся, когда у вас возникнет дефицит идей и потребность расширять ядро.
Чтобы не превратиться в олдскульного оптимизатора, достаточно помнить, зачем вы строите ядро. Это поможет вам видеть дальше чисто технической процедуры сбора поисковых фраз.
Семантическое ядро: маркетинг или SEO
На самом деле здесь нет противоречия. Чтобы собрать поисковые фразы, нужно мыслить как бизнесмен или маркетолог и обладать некоторыми умениями оптимизатора.
- В первую очередь уделите внимание структуре сайта и решите, что вы хотите донести до клиентов.
- После этого разберитесь, как люди ищут информацию, которую вы планируете публиковать. Используйте сервисы и программы для подбора ключевых фраз, источники статистики и инструменты поискового шпионажа.
- Проанализируйте собранные ключи и удалите фразы, которые не подходят по смыслу. Сгруппируйте ключи и распределите по страницам сайта.
Теперь можно приступать к созданию контент-плана.
БЛОГ RU-CENTER
Чтобы сайт посещало больше людей и росла конверсия покупки, необходимо продвижение. Сделать продвижение эффективным помогает качественное семантическое ядро (СЯ). В этой статье расскажем, что же такое СЯ и чем оно полезно для вашего сайта. Вы узнаете о ключевых словах, поймете, как создается правильное ядро, и получите инструменты для сбора семантики.
Что такое семантическое ядро и зачем оно сайту
Семантическое ядро, сокращенно СЯ — это набор слов и словосочетаний для описания тематики сайта. Термин «семантическое ядро» вышел из раздела языкознания «семантика», который изучает смысл слов или речевых оборотов.
СЯ имеет определяющее значение для продвижения сайта: именно с него начинается работа над любым проектом. Без ядра невозможно запустить контекстную рекламу и создать SEO-стратегию. Структура сайта на основе СЯ помогает поисковикам лучше ранжировать ресурс и показывать пользователям релевантные результаты. Подробнее об этом в нашей статье «Как сделать правильную структуру сайта для SEO».
Анализ семантики позволяет изучить нишу, лучше понять клиента и использовать опыт конкурентов для развития собственного ресурса.
Ключевые слова и их виды
Чтобы создать ядро, нужно собрать пользовательские запросы к поисковикам. Эти запросы называются ключами. Например, чтобы узнать, как создать свой бизнес, пользователь введет в поиске «как открыть бизнес» — это и есть ключ.
Ключевые слова бывают:
● Низкочастотные (НЧ). Наименее популярные запросы; их регулярность — до 500 в месяц. Например, «купить квартиру в районе черемушки москва» — 112 запросов. По статистике, две трети запросов — низкочастотные. Конкуренция по таким фразам обычно меньше, чем по высокочастотным, поэтому продвигаться по ним легче и быстрее.
Но бывают исключения, когда низкочастотный запрос оказывается высококонкурентным. Как правило, такое происходит в специфических нишах. Например, «акриловые вывески» — это низкочастотный и узконаправленный ключ, но конкуренция в этой сфере большая. Все потому, что есть много ресурсов, которые производят акриловые и другие виды вывесок.
● Среднечастотные (СЧ). Это ключи частотностью от 500 до 5 000 показов в месяц. Например, «магазин чая в москве» — 2 716 запросов, «частная школа английского языка» — 2 964 запроса.
● Высокочастотные (ВЧ). Самые популярные поисковые запросы с частотой от 5 000 показов и выше. Например, «тур в египет» — 181 650 запросов в месяц, «купить смартфон самсунг» — 52 046 запросов.
Крупнейшие сайты делают акцент на ВЧ-запросах и вытесняют друг друга с первых позиций в выдаче. Такое продвижение стоит больших денег. Если вы не относитесь к компаниям-гигантам, то рекомендуется использовать малое количество ВЧ-запросов и сконцентрироваться на НЧ- и СЧ-запросах. Эти ключи выводить в топ проще всего.
Этапы сбора семантического ядра
Для начала необходимо понять, с каких ключевых слов люди переходят на ваш сайт, чем они интересуются. Далее вы должны расширить семантическое ядро и очистить его от лишних фраз. Самый последний этап — распределить ключи по группам.
Составляем базовые ключи
Запишите основные слова и словосочетания, которые описывают ваши продукты или услуги. Чтобы удобно оформить информацию и не упустить важное, советуем заносить данные в Excel или Google Таблицы.
Обычно на этом этапе собираются высокочастотные ключи с низкой уникальностью. Пример: мы открыли пиццерию в Мытищах и Королеве. Основное направление — доставка пиццы. За основу возьмем базовый ключ «доставка пиццы».
Расширяем ядро
Теперь нам нужно получить средне- и низкочастотные запросы. Здесь вам поможет сервис поиска ключей, например Яндекс Wordstat. С его помощью вы узнаете, насколько популярны слова, которые вы записали на первом этапе. Если ваш бизнес относится к определенной локации, выберите в настройках нужный регион. После того как вы введете запрос, сервис покажет две таблицы.
Слева видно, в каких вариациях люди пишут слова в поисковике. Нужно скопировать ключи из этой колонки и вставить их себе в таблицу. В колонке справа указаны фразы, которые похожи на ваши основные запросы. Подберите подходящие ключи из этой колонки и также вставьте в таблицу (на скриншотах выделены запросы, которые можно взять работу).
У вас получится список фраз для каждого базового запроса. В списках могут оказаться сотни или тысячи ключей.
Комбинируем слова. Увеличить ядро помогают запросы с уточняющими словами:
- «заказать», «цена», «стоимость», «доставка» и прочие;
- названия товаров, услуг;
- названия бренда, компании;
- информация о моделях и их характеристиках;
- акции, скидки, промокоды;
- запросы по срочности: быстрая, быстро, круглосуточно;
- по местам продажи: на дом, в офис;
- по мероприятиям и праздникам: на день рождения, Новый год, на корпоратив и прочие;
- по названию города, района доставки/обслуживания.
Изучаем конкурентов. Полезно знать и применять ключи, по которым ранжируются конкуренты. Это повышает видимость сайта в поисковой выдаче и контекстной рекламе. Определите лидеров ниши, и вы найдете у них качественные запросы. Есть специальные инструменты, которые делают эту работу автоматически и экономят время. Например, сервисы Serpstat, Мегаиндекс, Topvisor.
Регулярность расширения ядра зависит от тематики бизнеса, частоты обновления товаров и услуг, а также региона, в котором компания работает. Для сезонных сфер, например магазина трендовой одежды, обновлять ядро нужно не реже одного раза в сезон. Для новостных каналов — каждый день.
Удаляем лишние фразы
Это крайне трудоемкий этап создания семантического ядра. Не все варианты ключей, которые показали сервисы, подойдут вашему бизнесу. Нужно вручную убрать неподходящие по смыслу фразы.
Удаляйте запросы, которые содержат:
- Названия конкурентов. Для таких ключей поисковики ищут самый релевантный результат, а значит, сайт конкурента вам вряд ли обойти — он будет выше вас в выдаче. Упоминать другие бренды можно, только когда ресурс содержит материалы о конкуренте, например обзор его товара.
- Товары и услуги, которых у вас нет. Эти ключи не соответствуют ожиданию пользователя. Если использовать их на сайте, снижаются переходы по страницам и растут показатели отказов.
- Дубли. Например, из трех словосочетаний «подарок на день рождения», «подарок на день», «подарок на рождение», нужно сохранить только первое.
- Слова для другой локации. Например, если продаете только для жителей Измайловского района, вам не пригодится ключ с названием Останкинского района.
- Ошибки и опечатки. Поисковик знает, что человек ищет смартфон, даже если написано «смарфон». Поэтому на оптимизацию такие запросы не влияют.
Объединяем в группы
Готовое семантическое ядро следует хорошо структурировать. Метод, когда запросы разделяются на тематические группы, называется кластеризацией. Это важнейший этап, без которого семантическое ядро будет лишь набором не связанных между собой фраз.
Каждая группа запросов должна иметь свой интент — намерение пользователя. Выделяют следующие интенты:
- Информационные. С их помощью пользователи находят нужные сведения. Например, «как вложить деньги в акции», «как построить дом». Под такие запросы стоит писать посты и выкладывать их на сайт в разделе «Статьи» или «Блог».
- Транзакционные. Главные ключи для развития бизнеса. Это самые дорогие запросы для продвижения. Они используются, когда люди хотят совершить какое-то действие. Например, «купить автомобиль», «скачать книгу», «заказать роллы». Добавляйте их в разделы «Каталог», «Магазин», «Витрина».
- Навигационные. Эти запросы помогают найти конкретный ресурс или сайт. Например, «сайт госуслуг», «официальный сайт компании N». Размещайте их на тематических страницах: «Контакты», «Доставка», «О компании».
Кластеризацию можно проводить вручную или автоматически. Ручной метод удобен для небольшого ядра в пределах 500 запросов. Для крупного ядра лучше использовать специальные программы. За несколько минут они сделают то, на что у человека ушел бы месяц. При этом группировщики могут ошибаться, и идеальный результат получается, когда за ними перепроверяет человек.
Сервисы для кластеризации:
https://www.keys.so/ru/
https://just-magic.org/
https://seranking.ru/
https://arsenkin.ru/
https://ru.megaindex.com/a/keywords
Сервисы для создания семантического ядра
Key Collector
Многофункциональная программа, которая автоматизирует создание семантического ядра. Она подбирает запросы, быстро сегментирует и фильтрует ключи, собирает статистику и прочее. Приложение интегрировано с большим количеством сервисов, включая сервисы Яндекса и Гугла, что значительно упрощает работу.
Яндекс Wordstat
Бесплатный сервис, который помогает найти и проанализировать запросы пользователей Яндекса. С его помощью можно узнать, сколько людей в месяц ищет конкретную фразу, и увидеть ключи, схожие по смыслу с вашими.
Планировщик ключевых слов Google
Бесплатный сервис для подбора и группировки ключевых слов. Он также прогнозирует бюджет и результаты рекламной кампании.
Serpstat
Платная SEO-платформа для интернет-маркетинга. Она состоит пяти модулей: мониторинг позиций, анализ ссылок, анализ конкурентов, SEO-аудит сайта и анализ ключевых слов. Serpstat позиционирует себя как инструмент быстрого роста в SEO, PPC, контент-маркетинге и поисковой аналитике.
Megaindex
Платный сервис для автоматизированного продвижения сайтов. Он анализирует видимость запросов, по которым сайт занимает позиции в поисковой выдаче. Megaindex помогает выгрузить ключи топовых конкурентов и расширить ваше семантическое ядро.
Как использовать готовое семантическое ядро
Когда вы сделали кластеризацию, ядро готово к использованию. Собранная семантика позволяет:
- Создавать структуру сайта. На основе СЯ создаются страницы и разделы ресурса. Поисковые системы лучше индексируют такой сайт, а пользователи быстрее находят на нем нужную информацию.
- Делать контент. Используйте ключи, когда пишете материалы для сайта. Запросы помогают создавать полезный контент, который отвечает на вопросы людей и приводит к вам целевой трафик.
- Оптимизировать теги. Ключи используют для создания важнейших мета-тегов: основного заголовка (title) и описания страницы сайта (description). Поисковики сканируют эти элементы страниц и учитывают их при индексации. Правильно прописанные title и description улучшают позиции ресурса.
- Запускать контекстную рекламу. В платной выдаче Яндекса и Google ключи применяются для контекстной и баннерной рекламы. Чтобы собрать рекламные объявления, можно взять кластеры, которые вы подготовили для SEO, или же сделать отдельную сортировку ключей.
- Продвигать визуальное содержание. Если вы вставляете ключевые слова в названия и alt-теги изображений, то это повышает вероятность их появления в разделе «Картинки» у поисковиков.
Развивать другие каналы. Использовать ключи можно везде, где пользователи вводят запросы в строку поиска. Понимание запросов в конкретной нише помогает развивать ресурс в социальных сетях, YouTube, интернет-агрегаторах и прочих каналах.
Кратко: как не допустить ошибок при создании ядра
- Ищите любые способы пополнить СЯ качественными ключами. Если собирать только очевидные запросы и никак не расширять ядро, можно лишиться большой части трафика.
- Тематика ключей не должна обманывать пользователя. Если юзер зашел на сайт по фразе «установка windows», вряд ли он останется на нем, если страница рассказывает об установке macOS.
- Не стоит оставлять «пустые» ключи с крайне низкой или нулевой частотностью. Они почти неэффективны для продвижения ресурса.
- Регулярно обновляйте ядро и учитывайте сезонность. Некоторые запросы эффективны только в определенный период. Если какой-то ключ сейчас не работает, это не значит, что так будет всегда.
- Используйте несколько инструментов для создания СЯ. Когда вы ограничиваетесь каким-то одним сервисом, список запросов может оказаться неполным.
- Обязательно делайте кластеризацию. Именно этот этап превращает тысячи ключей в грамотную структуру, которая разбита на категории, страницы, статьи и т. д.
- Не используйте слишком много запросов на одной странице и не смешивайте разные тематики. Это снижает релевантность страницы и приводит нецелевой трафик. Важно, чтобы одна страница соответствовала одному интересу человека.
Подписывайтесь на наш блог на сайте nic.ru
