Без применения специализированных программ
Рассмотрим этапы формирования семантического ядра на основе сервиса Яндекс Вордстат (как им пользоваться). Будем использовать ручной метод сбора, который трудозатратен, при постоянной работе с семантикой целесообразно пользоваться профессиональными программами. Для понимания процессов разберем вариант сбора и обработки фраз без специлизированного софта и сервисов.
Возьмем направление «рольставни» для компании, которая занимается установкой защитных конструкций и их обслуживанием по Москве и области. В первую очередь актуальны запросы, которые формулируют люди, заинтересованные в покупке таких изделий или у которых возникли проблемы с эксплуатацией. Вводим маску в строку подбора, выбираем регион, например, Москва и область:

В колонке слева Wordstat показывает запросы пользователей, которые набирали со словом «рольставни». В правой колонке дополнительные запросы. Ориентируйтесь на левую колонку, скопируйте фразы и частоту в таблицу. Переходите по пагинации снизу на следующие странице и скопируйте предлагаемые варианты фраз.

Вордстат даёт 2000 запросов по одному направлению. На одной странице показывается 50 фраз, получается 20 страниц нужно пролистать. Для примера я собрал первые 350 фраз, получилась таблица:

Скачать файл Эксель-исходник
Группировка (кластеризация) запросов в семантическом ядре
После сбора запросов, группируем (кластеризируем). Для этого используют 3 вида кластеризации:
- по смыслу;
- по SERP;
- смешанный.
Разбивка «По смыслу» предполагает, что из запросов выделяется основной посыл, что хочет получить человек. В собранном перечне запросы делятся так:
- рольставни +в туалет
- рольставни +на окна
- сантехнические рольставни
- рольставни +в туалет купить
- рольставни +в санузел
- рольставни наружные
- рольставни +в туалет москва
- сантехнические рольставни +в туалет
- рольставни +на окна наружные
- рольставни +в туалет купить москва
- прозрачные рольставни
- рольставни сантехнические купить
- рольставни +в туалет цена
- рольставни +на окна цена
- рольставни +в санузел москва
- прозрачные рольставни +для веранды
Туалет: 1, 3, 4, 5, 7, 8, 10, 12, 13, 15. Так как санузел, туалет и сантехнический предполагает один вид помещения для установки.
Окна: 2, 6, 9, 14. Установка на окна предполагает, что рольставни буду наружными (запрос №6).
Прозрачные: 11, 16.
Кластеризация по «SERP» предполагает использование специализированной программы или сервиса (например, keyassort.ru). Получается, что это автоматизированный процесс. SERP – это результат поисковой выдачи, проще говоря ТОП-10. Алгоритм действий здесь такой:
- Выбранные фразы добавляются в программу.
- По каждому запросу программа проверяет ТОП-10 или ТОП-20 в Яндекс (Гугл) и сохраняет результат в таблице.
- Далее программа анализирует сохраненные данные и соотносит страницы в выдаче и фразы. И запросы, по которым встречаются одни и те же страницы сайтов в выдаче, объединяет в одну группу.
Такой способ кластеризации подходит для многотысячной семантики и экономит время. По опыту студии, в результате разбивки качество получаемых ядер низкое и требует корректировок.
Смешанный метод – «SERP» и здравый смысл. Применение двух способов одновременно. Случается, что разбив ядро по смыслу, остаются фразы, назначение которых спорно и их сложно объединить в группы. В этом случае снимается СЕРП и на основе анализа разбиваются фразы.
Популярный вопрос «сколько фраз должно быть в одном кластере?». Ограничений нет, от одного запроса до нескольких сотен. Студия DIUS ведет проекты, где одна страница ранжируется по 200-300 запросам. Бывает наоборот, что первоначально добавили в кластер 100 запросов, но при оптимизации зашли только 50. Тогда детально и подробно изучаем оставшиеся фразы, делим по дополнительным признакам и создаем под них новые разделы или оптимизируем другие страницы.
Но такой подход требует опыта, т.к. поисковики негативно относятся, когда под похожие запросы создаются две страницы. В этом случае понижаются позиции по обеим страницам. В этом случае, внимательно изучайте конкурентов в выдаче, возможно на одну страницу следует добавить вхождений.
Для группировки ядра по направлению «Рольставни» воспользуемся методом «По смыслу», т.к. фраз всего 350 и группировка не займет много времени.
Делим фразы по: типу продукции, назначению, параметрам (цвет, материал) и т.д. И также нужно будет отбросить ненужные фразы, назовем эту группу «мусор». В неё попадают нецелевые фразы, которые содержат слова:
- леруа мерлен;
- своими руками;
- фото и видео;
- города не из Московской области;
- бу, схемы, инструкции.
Просмотрев и задав кластер для каждого запроса, получаются следующие группы:

Из 350 подобранных фраз получилось 85 мусорных, остальные распределились на 36 групп по типам и назначению изделия. В первой колонке группа, во второй сколько содержит слов из 350 подобранных:
| Группа | Количество фраз |
| основная | 63 |
| туалет | 61 |
| область | 35 |
| на окна | 28 |
| гараж | 7 |
| прозрачные | 6 |
| монтаж | 5 |
| электропривод | 5 |
| ремонт | 4 |
| шкаф | 4 |
| фотопечать | 4 |
| ванная | 3 |
| дача | 3 |
| комната | 3 |
| дверь | 3 |
| терраса | 2 |
| алютех | 2 |
| балкон | 2 |
| дорхан | 2 |
| перфорированные | 2 |
| торговые | 2 |
| встроенные | 2 |
| веранда | 2 |
| беседка | 2 |
| двери | 1 |
| проем | 1 |
| внутренние | 1 |
| управление | 1 |
| поликарбонат | 1 |
| защитные | 1 |
| мебельные | 1 |
| антивандальные | 1 |
| паркинг | 1 |
| противопожарные | 1 |
| стеклянные | 1 |
| квартира | 1 |
| утепленные | 1 |
| мусор | 85 |
Полученные кластеры в свою очередь группируем по смыслу и получаем структуру сайта для оптимизации:
- Рольставни:
- Вид: прозрачные, поликарбонат, перфорированные, противопожарные, и т.д.
- Назначение: окна, двери, квартира, проем, торговые, мебельные, туалет, гараж, паркинг и т.д.
- Профиль: алютех, дорхан.
- Опции: с электроприводом, с фотопечатью.
- Сервис
- Ремонт
- Монтаж
Из 2000 фраз, которые выдает Вордстат по заданному слову, получится составить структуру сайт гораздо шире, чем приведенная в примере. Естественно ориентируйтесь на ключевики, которые характеризуют продукцию или услуги компании. Если какой-то тип продукции или услуг компания не производит отправляйте их в раздел «мусор».
Расширение семантического ядра в Wordstat
Как подсказывает вордстат на скрине выше, некоторые называют рольставни другим словом – «роллеты». Поэтому для расширения ядра получения дополнительных фраз по ним также собираются фразы:

И:

Эти фразы добавляются в созданные группы или по ним создаются новые. Поисковики понимают, что «рольставни» и «роллеты» – это одно и тоже, поэтому совмещайте их в одних целевых кластерах.
Расширение ядра при помощи поисковых подсказок Yandex.ru
Дополнительным способом расширения семантики используют такой метод как «поисковые подсказки». Когда пользователь Яндекса вводит запрос в строку, поисковик предлагает варианты, исходя из статистики популярных запросов, дополняющие слова:

Видно, что на запрос «рольставни» поисковик предлагает запросы, которые уже были отобраны из сервиса Вордстат. Ориентируйтесь на фразы из 3-4 слов:

Тогда получится дополнить ядро. Вручную собирать подсказки трудозатратно, для этого целесообразно использовать профессиональные программы по сбору семантики или сервисы. РашАналитикс помогает собирать подсказки. На сервисе предусмотрена бесплатная регистрация, и сразу даётся 200 баллов.
Для сбора добавьте фразы из 3-4 слов из семантического ядра. Задайте популярные мусорные слова, чтобы сервис автоматически из убрал из результатов: своими руками, бу, леруа мерлен. В результате получаем такие дополнительные слова из подсказок:

Полученные фразы чистим от мусорных и проверяем частоту через Вордстат:

Сколько запросов собирать в ядро
По сути ограничений нет, чем больше фраз подобрано в семантическое ядро, тем лучше будет проработан сайт с точки зрения структуры и содержания. Отталкиваясь от групп запросов оптимизатор формирует не только разделы, но и планирует контент. Посмотрим на 28 запросов в группе «Рольставни на окна»:

Ясно, что посетителей интересует:
- Цена такой конструкции.
- Варианты исполнения: с электроприводом или механические.
- Материалы изготовления: тканевые, металлические.
- Как устанавливают изделие.
- Для каких окон: квартиры, дачи, частный дом.
- Дополнительные функциональные свойства: защитные, антивандальные и т.д.
Каждый запрос в группе – это единица смысла, которую нужно отразить на созданной странице. Во-первых, это позволит употребить ключевые слова, что сделает сайт релевантным этому кластеру. Во-вторых, на странице будет опубликована полезная для посетителя информация.
Очистка семантики от мусора
При сборе многотысячного семантического ядра в список попадёт много нецелевых фраз:
- Тип продукции или схожий вид услуг, которыми компания не занимается. В случае с рольставнями, это материалы, из которых компания не производит изделия, либо дополнительные услуги – обслуживание, доставка, установка.
- В запросах часто появляются названия фирм конкурентов, когда пользователь пишет товар или услугу, и указывает название компании.
- У людей, проживающих в Москве и имеющих коттедж в другом регионе, например, Твери, отразится это в запросах, когда они будут заказывать рольставни, ворота и т.д. Указывая город в сервисе, вы задаете географию пользователей, интересы которых могут лежать за пределами этого региона.
- Также убирайте из ядра ошибочные написания и опечатки. Если раньше под такие запросы создавались страницы, то сейчас поисковые алгоритмы обнаружив опечатку исправляют её и выдача формируется по корректной словоформе. И если появятся новые ошибки в названиях, это значит, что в ближайшее время алгоритм это учтет.
От нецелевых запросов следует избавляться по следующим причинам:
- Если пользователь зайдет на сайт и обнаружит, что компания из другого региона – он закроет страницу. Это сказывается на поведенческих характеристиках сайта, в результате поисковик понизит в выдаче и по другим запросам, которые будут целевыми.
- Также это расценивается алгоритмами как поисковый спам, когда компания привлекает посетителей по запросам, задачи по которым она не решает.
- По некоторым запросам, типа «рейтинг компаний по рольставням», поисковики показывают сайты справочники, бизнес-каталоги, агрегаторы. По таким фразам не добраться до ТОП-10, если только не делать каталог организаций. Убрав их из ядра оптимизатор экономит время и ресурсы.
Как разбить семантическое ядро по типу запросов
Также стоит учесть разделение запросов по интенту пользователя:
- информационные;
- коммерческие.
Подробнее об этом в материале блога.
Для коммерческих запросов создаются разделы услуг, на которых предлагаются к продаже услуги и товары. Они называются коммерческими, т.к. предполагают, что у пользователя, при запросе прямое намерение купить или заказать продукцию, представленную на сайте. В таких запросах непосредственное название продукции или бренда, а также слова: купить, цена, заказать и т.п.
Информационные запросы подразумевают, что пользователь хочет получить сведения о пользовании продукцией, инструкций и т.п. В таких запросах часто фигурируют вопросы: как, какой, зачем, что лучше, почему и т.д. Для таких групп создается раздел статей на сайте, который отвечают на популярные вопросы людей перед покупкой, например, по рольставняим: как выбрать, какой профиль лучше и т.д. Формируется дополнительное ядро запросов для написания полезных материалов. Его собирают из Вордстат, добавив к фразе конструкцию «+как»:

Также с «+где», «+когда» и т.д.
При этом информационные запросы геонезависимые, поэтому регион ставьте Россия. Грамотное использование инфозапросов даёт целевые переходы из поисковиков, которые также конвертятся в обращения и покупки. Для этого используйте «Лестницу Бена Ханта» – подробней в статье.
Предлагаем создание
семантического ядра для сайта
Что делать с семантическим ядром после составления
Итак, семантика собрана, разбита на группы. Приступаем к завершающему и целевому действию – разработка структуры сайта и планирование содержания страниц.
Сначала еще раз посмотрите каждую группу, проверьте на соответствие ассортименту компании. На сколько формулировки соответствуют предлагаемым видам продукции или услуг.
Структура сайта на основе семантики
На основе семантического ядра разрабатываем структуру сайта:
- Главная страница под высокочастотные и прямые фразы. В случае с «Рольставни» – это: рольставни, рольставни купить / цена / заказать и т.д.
- Планируем разделы, в которые включаются виды продукции (услуг) и вспомогательные страницы (гарантии, отзывы, доставка, контактная информация, о компании) цель которых убедить посетителя в надежности представленной компании.
- Подразделы – группы запросов распределенные по видам, типам и т.д. В представленном примере «Рольставни» в разделе Профиль, будут 2 подраздела: Алютех и Дорхан, из которых производят изделия.
Содержание страниц
Как говорилось выше, семантика для маркетолога – это источник креатива и полезного контента. В запросах пользователя он видит какие проблемы хочет решить клиент и формирует содержание, которое вовлекает посетителя, цепляет и вызывает доверие, а также мотивирует оставить заявку, позвонить или заказать товар.
Превратитесь на время в маркетолога, изучите каждую фразу под микроскопом. Что подразумевает человек в запросе. Какие у него опасения и как их развеять. В какой формате человек хочет получить решение проблемы и как показать, что компания выполнит желаемое. Какие факторы принятия решения влияют на него и как их усилить на странице? Таким образом составится уникальный контент, полезный для посетителя с коммерческим эффектом.
Вывод
Ручное составление семантического ядра при помощи Яндекс Вордстат трудозатратное мероприятие. Оно подходит для разовой работы и для небольших сайтов. При профессиональном продвижении сайтов целесообразно приобрести программу Кей Коллектор, которая упрощает работы и сокращает время по формирование семантики в разы. При этом она позволяет детально работать с группой и каждым словом. Пример сбора ядра в Key Collector можете посмотреть здесь.
Время на прочтение
4 мин
Количество просмотров 197K
Хабр, привет!
Многие люди не знают, как работать с трендами в интернете, где их искать. Перед тем, как начинать бизнес не знают, где посмотреть будет ли этот бизнес вообще популярен и нужен ли он. Поэтому напишу полный туториал, чтобы закрыть все вопросы по этой тематике.
Работать мы будем со специальным сервисом по сбору поисковых запросов пользователей Яндекса Вордстатом, интерфейс которого довольно прост и понятен:
В начале, по традиции, поставлю цели:
- Понять весь функционал и научиться работать с Вордстатом;
- Как правильно собирать семантику с максимальной релевантностью и CTR >50%;
- Так как мы на Хабре, поработаем с API Wordstat напрямую.
Ключевая роль сервиса заключается в том, что он помогает оценить пользовательский интерес к трендам, различным тематикам и подобрать ключевые слова для контекстной рекламы.
Знакомство с сервисом
Для того, чтобы начать пользоваться Вордстатом нам необходимо авторизоваться в аккаунте Яндекса:

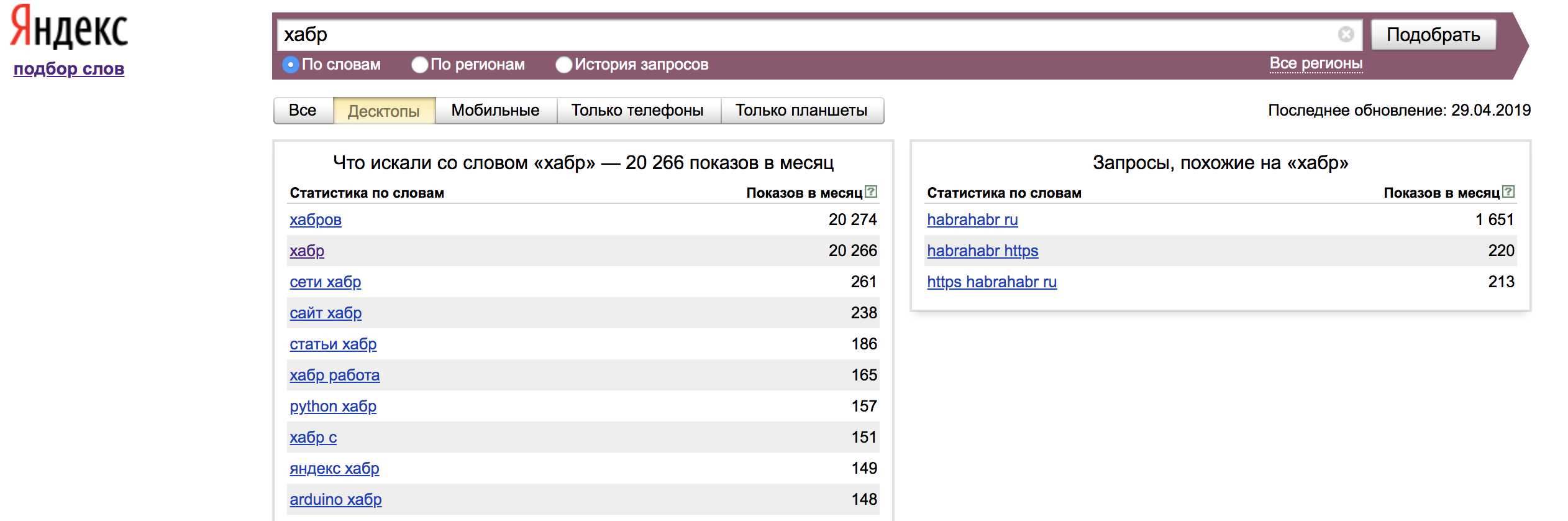
После авторизации мы можем пользоваться сервисом. Просмотр данных поисковых запросов нам доступен во вкладке «По словам»:
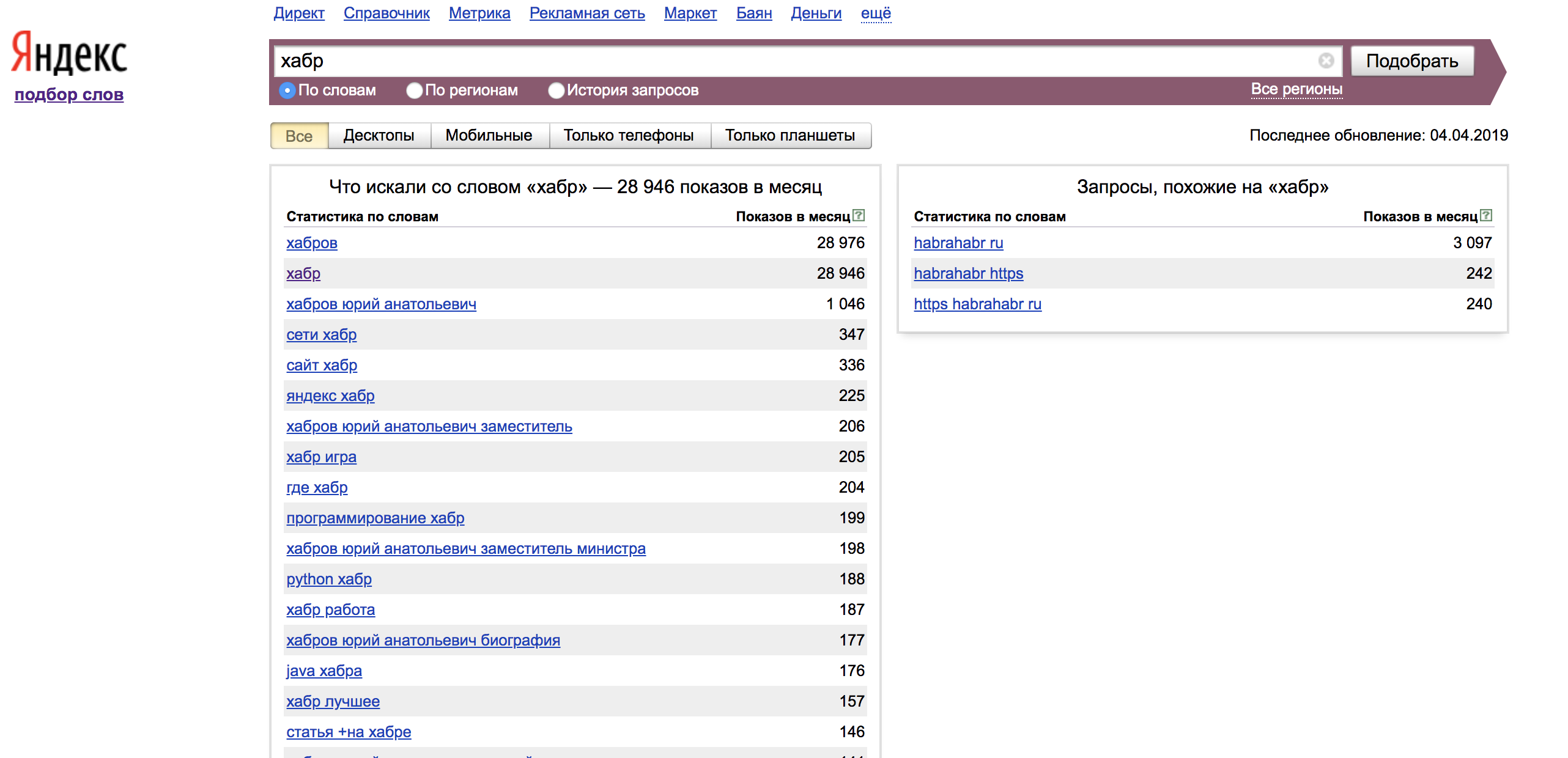
В левой колонке мы видим статистику по словам, которые были вместе с вашим поисковым запросом и показы в месяц по ним. Для того, чтобы мы нашли наше слово в точном соответствии мы должны использовать операторы. В правой колонке показываются похожие по смыслу запросы на заданную нами фразу.
Наглядный пример использования ключевых слов с операторами:
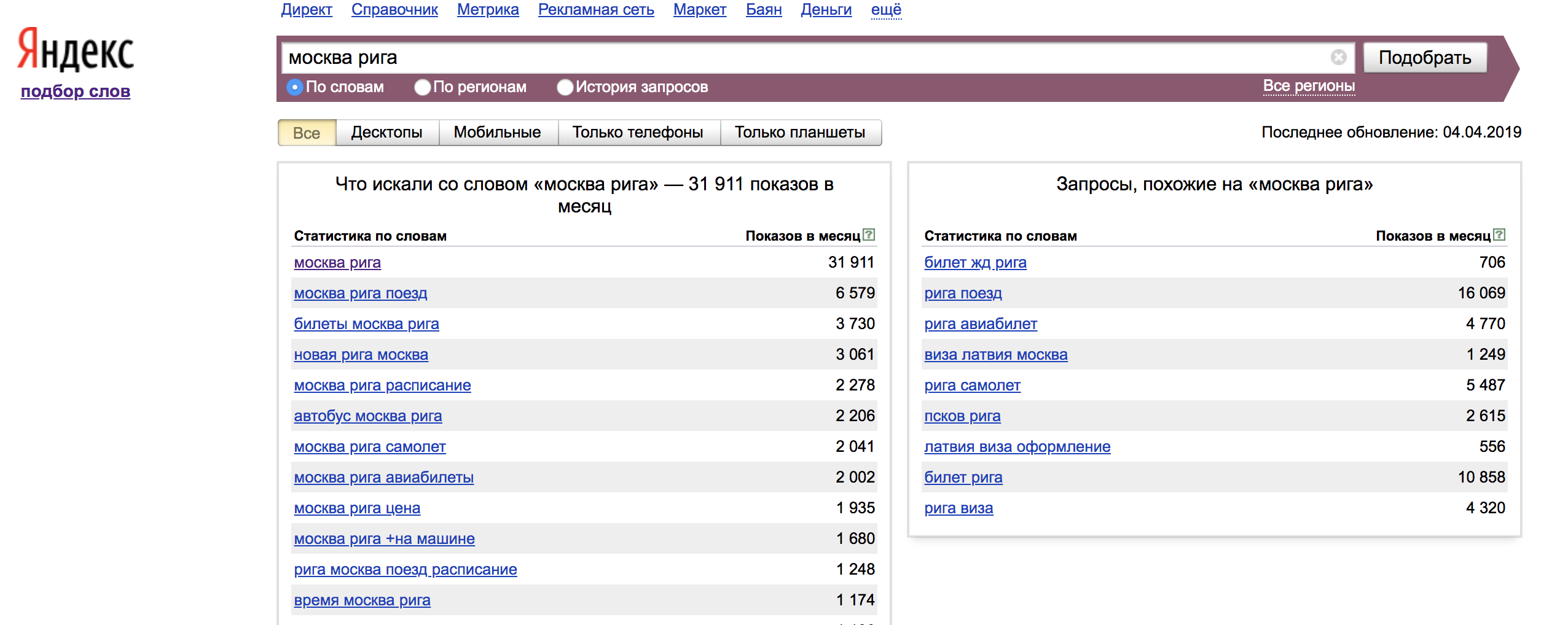
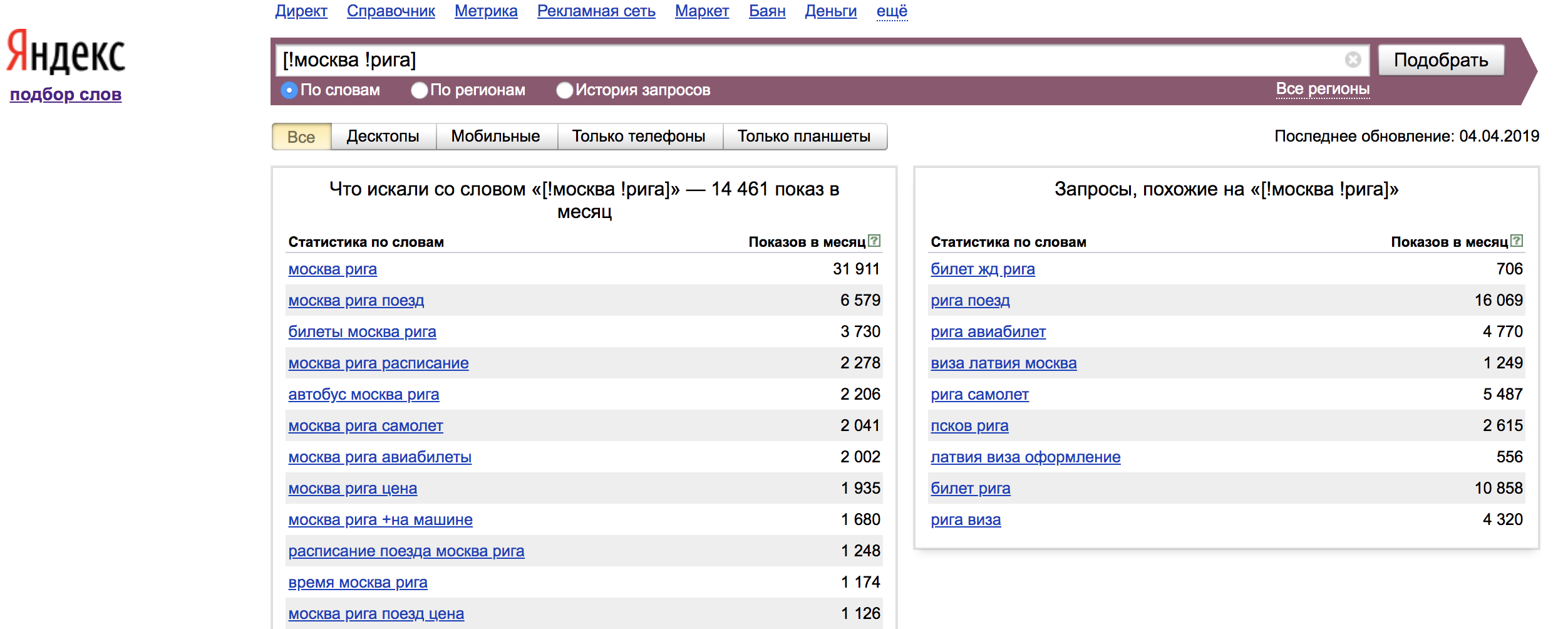
Оператор “!” — фиксирует форму слова (число, падеж, время);

Оператор “[]” — Фиксирует порядок слов. При этом учитываются все словоформы и стоп-слова.
Подробнее об операторах читаем здесь.
По умолчанию Вордстат показывает запросы по всем типам устройств. Настройки можно изменять: десктоп/мобайл/только телефоны/только планшеты. В нашем случае отфильтруем только десктопы.
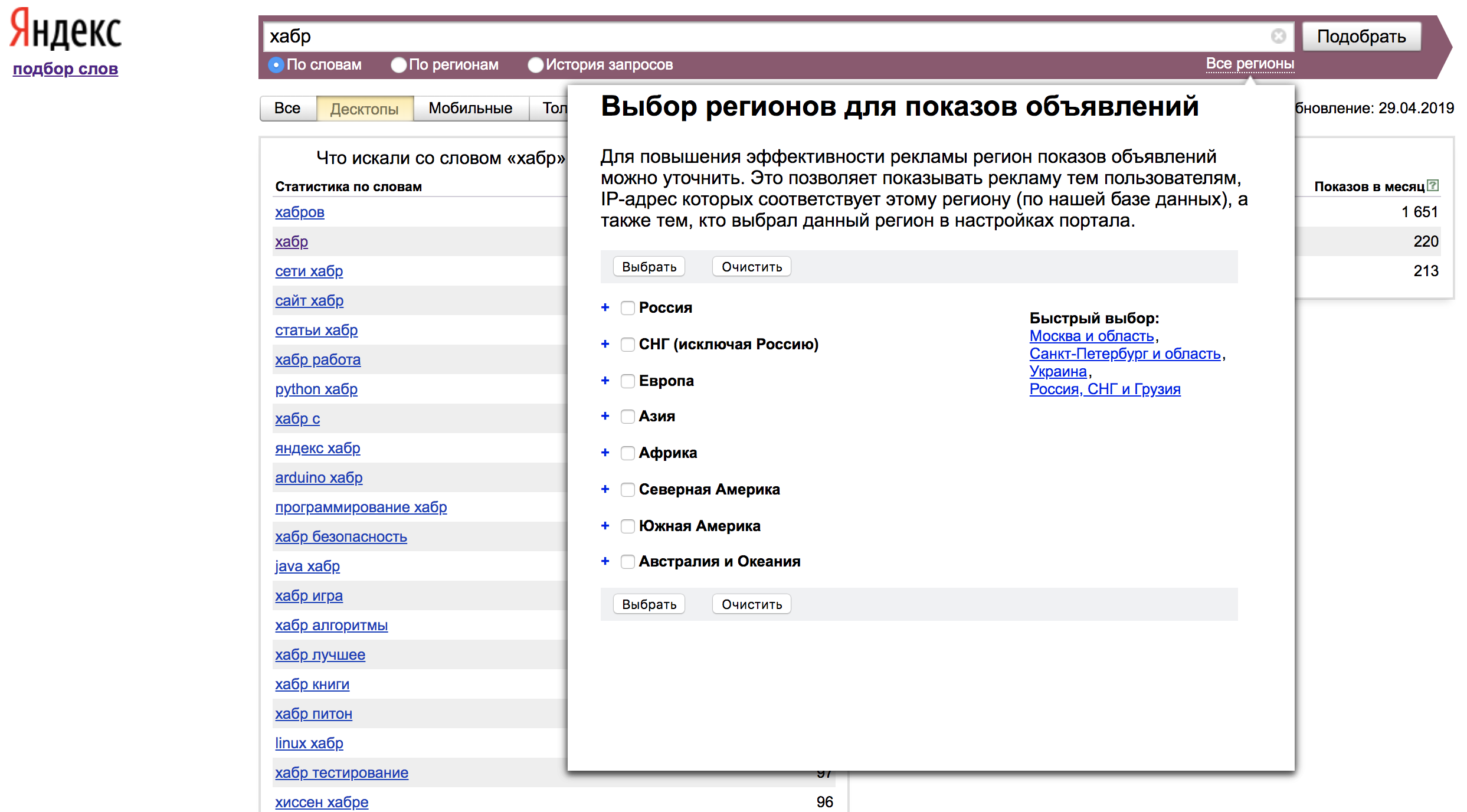
По умолчанию статистика показывается для всех регионов. Выбрать отображение статистики по интересующему нас региону можно во вкладке «Все регионы»:
Во вкладке «По регионам» отображаются данные со всех регионов, а также региональная популярность — доля, которую занимает регион в показах по слову, деленная на долю всех показов результатов поиска, пришедшихся на этот регион.
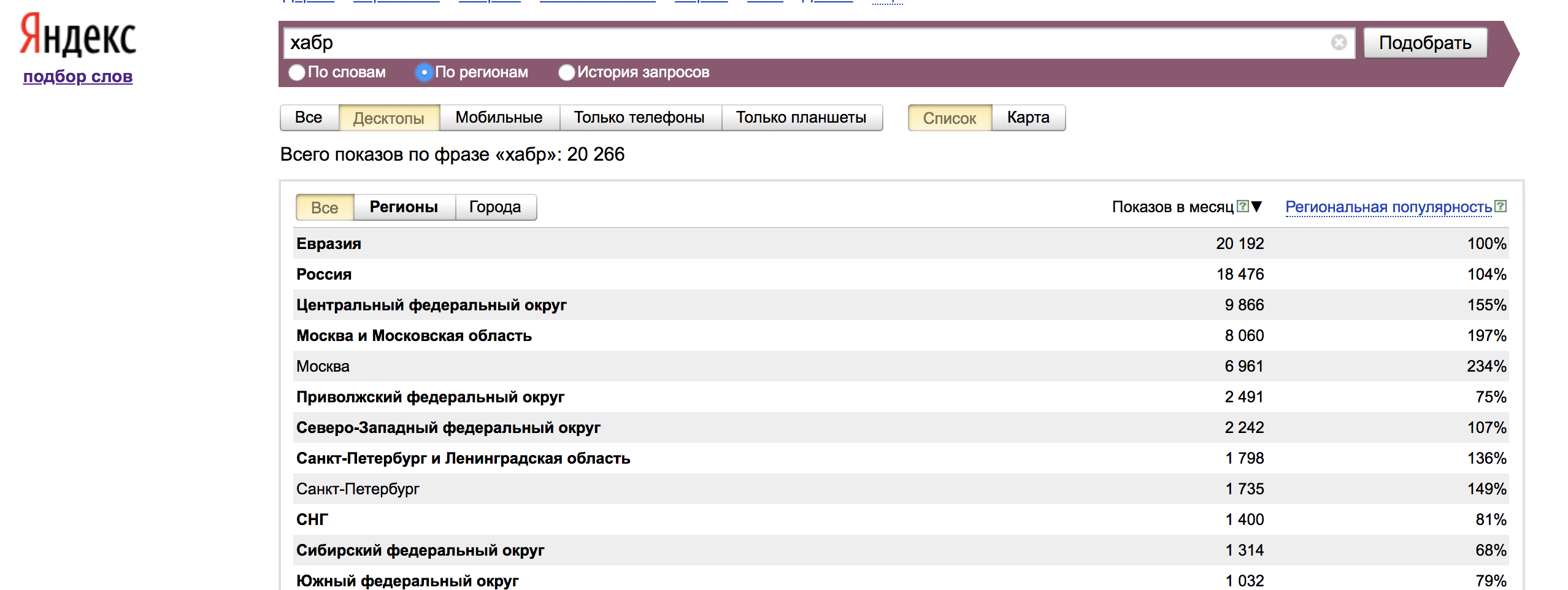
Для удобства эти же данные отображаются на карте:
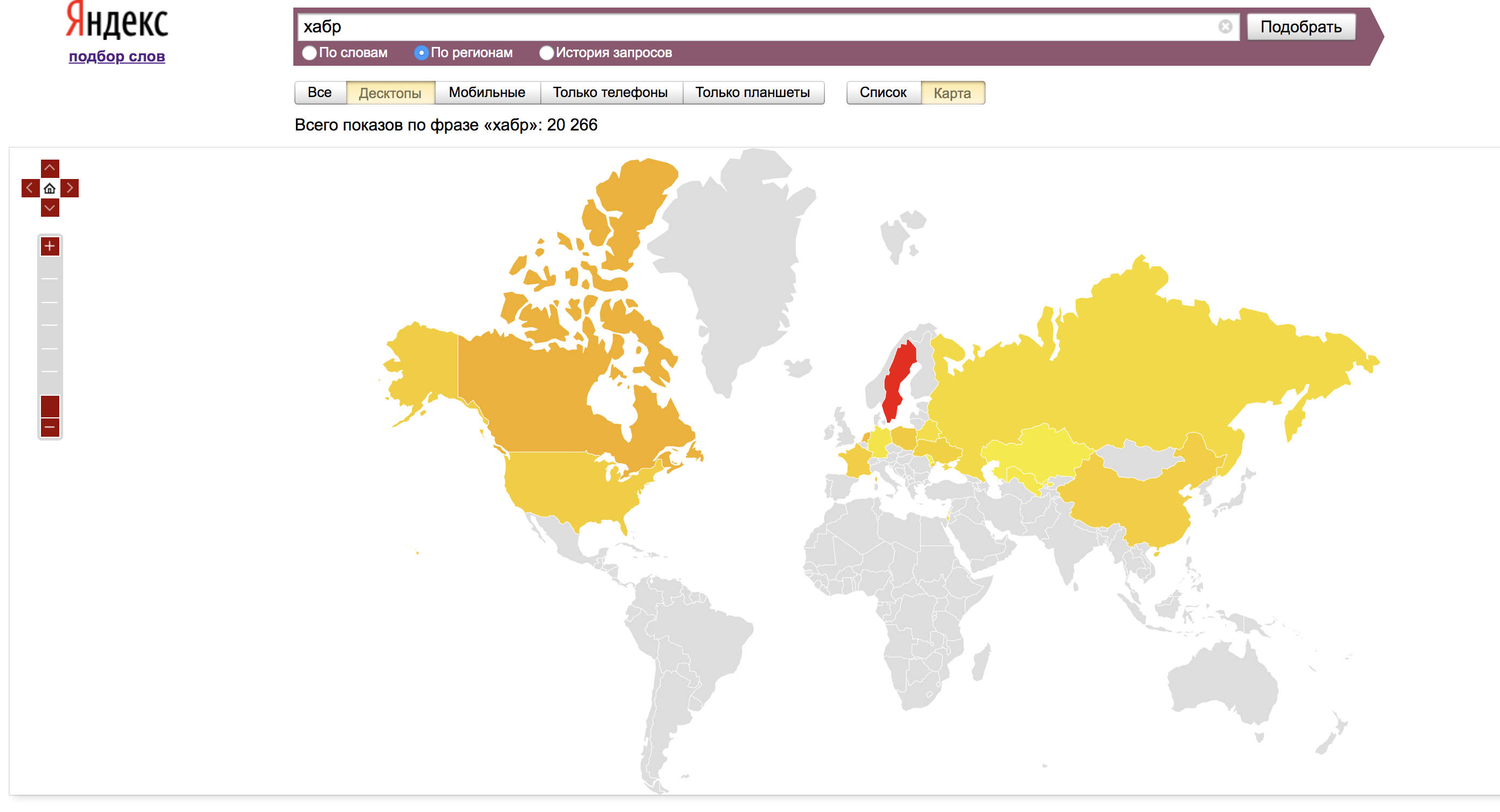
Во вкладке «История запросов» мы видим данные по запросу, обычно за 1,5 года. Здесь наглядно можем оценить тренды и влияние их на определенные запросы.
Статистику можно смотреть как в абсолютных значениях, так и в относительных. Для получения относительного значения абсолютная цифра нормируется на количество показов результатов поиска Яндекса за соответствующий месяц.
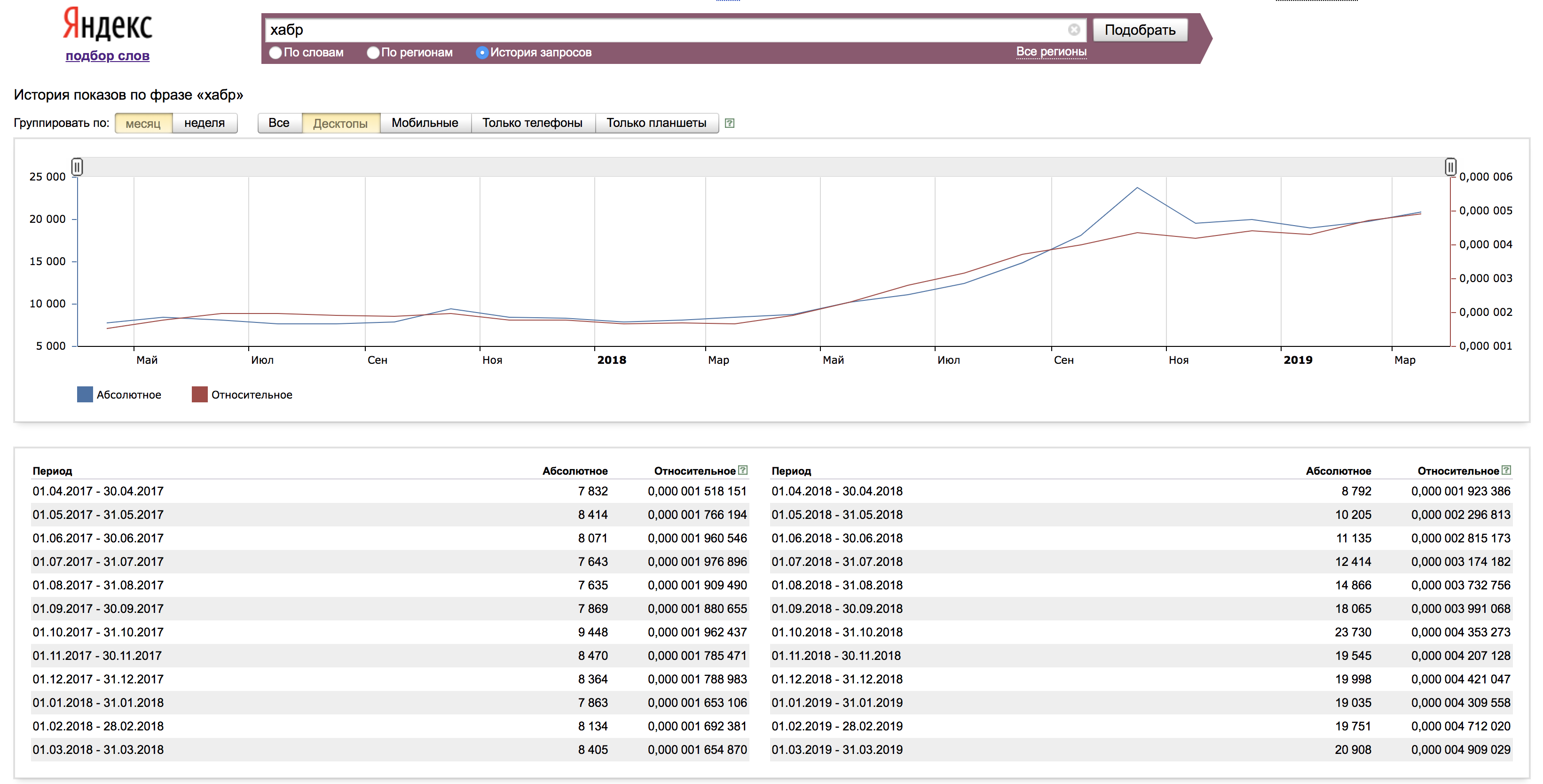
На этом изучение инструменты можно закончить и приступить к следующей нашей цели — правильный сбор семантического ядра.
Правильный сбор семантического ядра
В интернете уйма сервисов и способов для сбора семантического ядра, а также искусственного его создания. Мы не будем создавать велосипед и танцевать с бубном, а соберем семантику легко, просто и бесплатно.
Для того, чтобы нам собрать нашу семантику, первым делом мы скачиваем с официального сайта Яндекса Директ Коммандер последней версии.
После загрузки запускаем программу, логинимся и создаем (без разницы с каким названием) кампанию:
Добавляем группу объявлений (по прежнему нет смысле заморачиваться с его названием):
Переходим во вкладку «Подбор фраз», и вуаля! Это тот же самый Вордстат, только в программе Директ Коммандер. Логика работы с ним такая же, только в отличии от веб версии Вордстата здесь мы можем сразу указать минус слова:
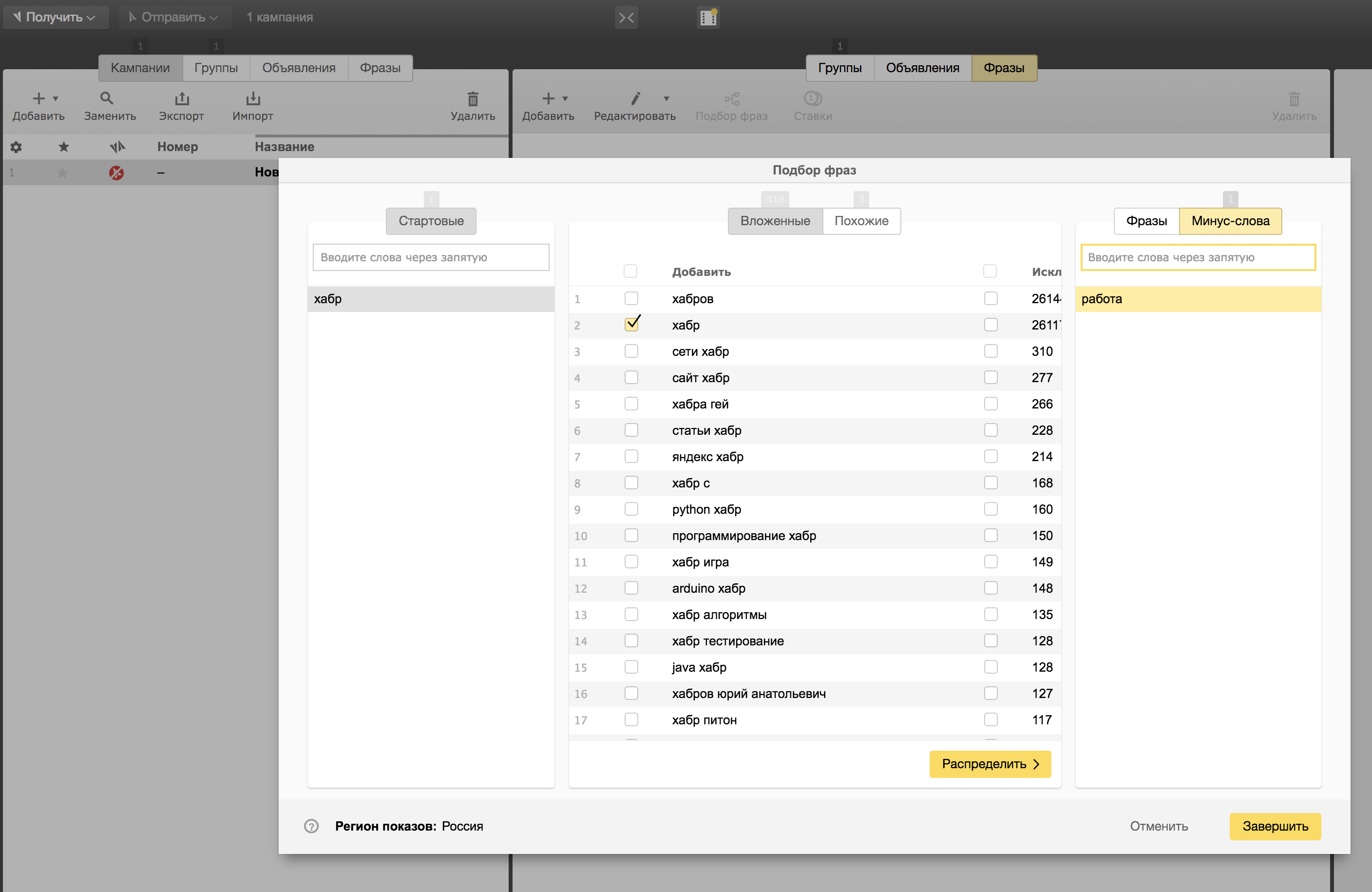
После того как мы тщательно отфильтруем весь список поисковых запросов от лишних запросов, можно приступать к экспорту нашей кампании в csv файл. Все, что остается нам сделать, это удалить лишние столбцы. Наше семантическое ядро находится в столбце «Фраза (с минус-словами)»:
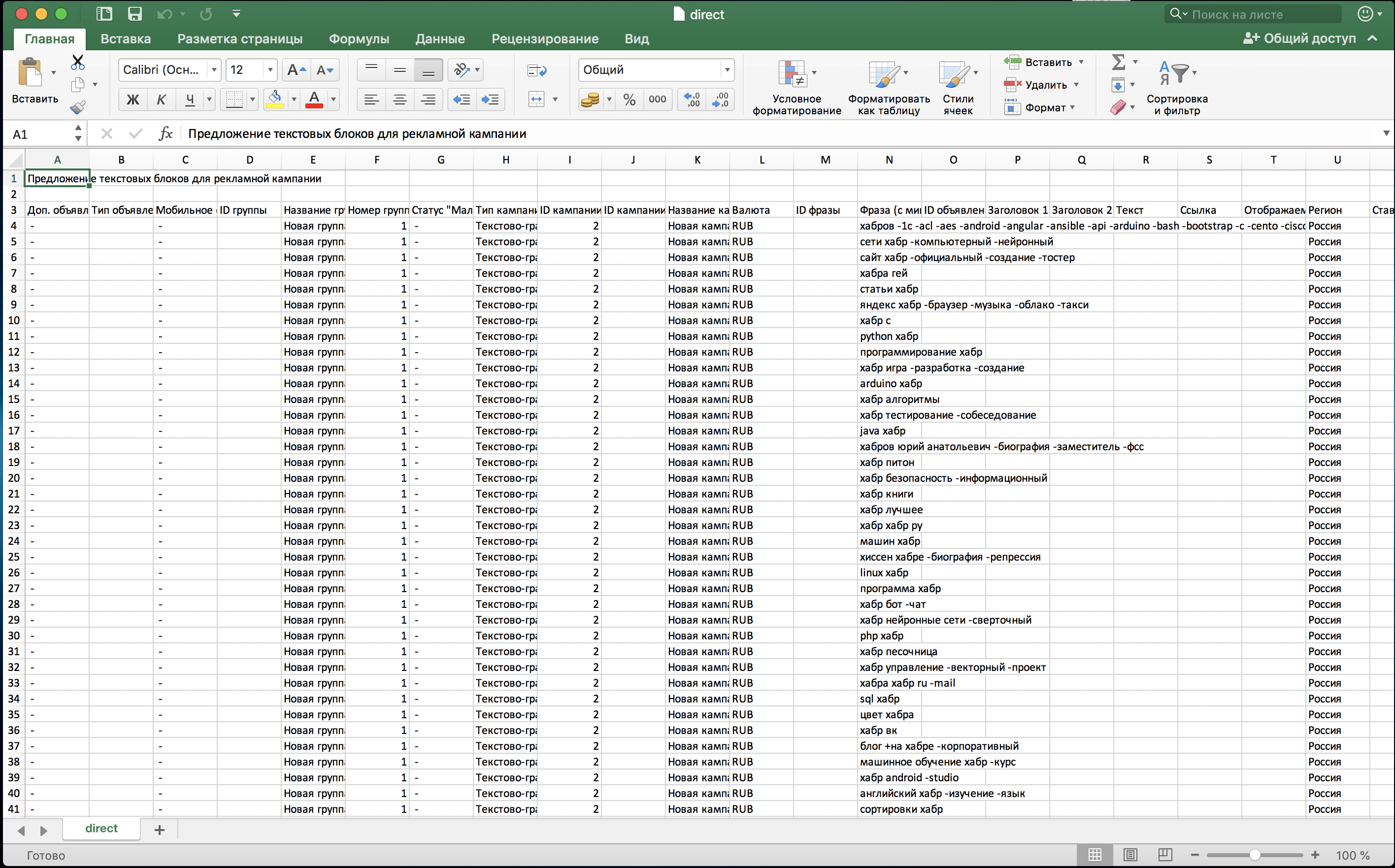
Плюсы сбора семантики таким способом:
- Охват запросов с частотностью до 1 в месяц;
- Не наращиваем искусственную семантику, в которой наверняка будут запросы, которых в реальной истории поиска на самом деле нет;
- Увеличиваем CTR объявлений максимально (конечно не только благодаря семантике, но и правильному разбиению объявлений по кластерам запросов и их текстам. Однако все это на основе нашей семантики);
- Клики становятся для нас дешевле;
- Это абсолютно бесплатно.
Работа с API Wordstat
Прежде чем начать, ознакомимся с базовой информацией из справки Яндекс Директа.
Справка по API Wordstat
Описание параметров
Обязательные GET параметры
request — Данные запроса
GET параметры
lr — код региона, если 0 — то все регионы
imp — если 1 — то важный запрос
Ответ содержит
status — Код статуса (0 — нет ошибок)
err_msg — Текст ошибок
data — Количество показов в месяц
Для указания региона используются коды из Яндекса. Скачать список регионов можно по ссылке
<?php
$array = array();
$array["user"] = '#логин_юзера';
$array["password"] = '123456';
$array["lr"] = "1";
$array["imp"]=1;
$array["request"] = "Хабр";
$content = file_get_contents("#url_user_auth".http_build_query($array));
$json = json_decode($content);
if( !is_object($json) ){
echo 'Не удалось разобрать данные';
exit();
}
if($json->status!=0){
echo $json->err_msg;
exit;
}
echo $json->data . " показов в месяц. ";
?>
Результат:
{«status»:0,«err_msg»:«OK»,«data»:«11284»,«date_update»:«29.04.2019»}
На этом все цели, которые мы поставили перед собой, в конце статьи были достигнуты.
Всем знаний!
Вы запустили контекстную рекламу, но получаете по своим объявлениям мало показов и переходов. Не спешите увеличивать рекламный бюджет или делать выводы о неэффективности контекста. Возможно, причина в том, что вы не уделили достаточно времени сбору семантического ядра.
Для чего нужно собрать семантическое ядро перед запуском контекста и как это сделать, рассказали в статье.
Семантическое ядро: что это такое, из чего оно состоит
Семантическое ядро – набор запросов пользователей, в ответ на которые им показываются объявления на поиске и в сетях Яндекса и Google.
Пользователи могут искать один и тот же товар или услугу по-разному. Они могут вводить общие запросы, например «купить смартфон». Могут вводить геозависимые запросы, например «Samsung А70 Москва», или информационные запросы: «Samsung А70 отзывы», «Samsung А70 цена», «лучшие смартфоны Samsung» и т. д. Все это важно учитывать при сборе семантики для максимального охвата целевой аудитории.
Также запросы делятся по частоте на:
- высокочастотные (ВЧ). Для больших сайтов – от 10 000 запросов в месяц. Для региональных – от 1000. Представляют собой общие запросы, которые состоят из 1–2 слов. Например, «инверторный кондиционер», «установка окон». Обычно по таким запросам ищут товары и услуги пользователи, которые находятся на начальной стадии воронки продаж;
- среднечастотные (СЧ). От 100 запросов в месяц. Состоят из 2–3 слов и представляют собой уточненные высокочастотные фразы. Например, «инверторный кондиционер Samsung», «вызов сантехника Ростов». По таким запросам ищут информацию пользователи, которые уже знакомы с товарами и услугами;
- низкочастотные (НЧ). От 1 запроса в месяц. Состоят из 3–6 слов. Это наиболее подробные запросы, по которым ищет товары теплая аудитория. Например, «холодильник Electrolux erf4113aow Москва».
Также отдельно выделяются транзакционные запросы. Эти запросы выражают намерение пользователя купить товар или заказать какую-то услугу. Например, «заказать разработку брендбука», «купить Samsung A70». По таким ключевым фразам осуществляет поиск горячая аудитория, у которой уже сформирована потребность в товаре и есть запрос на его покупку.
При сборе семантического ядра для контекста важно учитывать специфику рекламируемых товаров и услуг, частотность запросов и интересы пользователей.
Как собрать семантику с помощью Яндекс.Wordstat
Яндекс.Wordstat позволяет определить частотность запросов и расширить семантическое ядро. Покажем, как это сделать, на примере интернет-магазина, который планирует запустить рекламу велосипедов.
Заходим в Яндекс.Wordstat. Вводим запрос «горный велосипед» в поисковую строку.
Ниже показывается, сколько раз за месяц пользователи вводили эту фразу в поисковую строку. Всего – 156 190 раз. По умолчанию результат показывается по всем регионам.
Интернет-магазин находится в Москве и планирует показывать рекламу в этом регионе. Поэтому кликаем на надпись «Все регионы» и выбираем «Москва и область».
После этого Вордстат нам будет показывать статистику по запросам в данном регионе:
В левой колонке указываются основные запросы, а справа – похожие запросы.
Для поиска идей и сбора семантического ядра просматриваем весь список приведенных фраз и выбираем те фразы, которые относятся к предлагаемым услугам. Выписываем их в отдельную таблицу и указываем частотность по ним:
Если надо расширить семантику по какому-то запросу, то достаточно кликнуть на этот запрос в Яндекс.Wordstat: система покажет основные и похожие фразы по данному запросу.
Например, нажимаем на фразу «Горный велосипед gt»:
Инструмент показывает нам похожие запросы и статистику по ним:
Расширяем предложенными фразами нашу таблицу и получаем развернутую семантику по товарам, которые планируем рекламировать.
Таким образом, мы подобрали семантическое ядро для рекламной кампании горных велосипедов с помощью Яндекс.Wordstat.
Для сбора семантики с помощью этого инструмента нужно заранее подготовить опорный список фраз. В этом списке должны находиться товары/услуги компании, которые она будет рекламировать. Далее с помощью Вордстата рекламодатель может уточнить частотность запросов по этим фразам и расширить семантику по ним.
Для этого можно использовать полностью автоматизированные инструменты, которые избавляют от ручного сбора слов и отдельного уточнения данных по каждому.
Парсинг внутренней семантики сайта
Регистрируемся в Click.ru или авторизируемся в аккаунте. В главном меню выбираем «Инструменты» – «Семантика» – «Подбор слов и медиапланирование»:
Указываем основные данные: URL, рекламные системы, геотаргетинг. Оставляем галочки на автоматической корректировке фраз минус-словами и фиксации стоп-слов.
Кликаем на кнопку «Начать новый подбор». Система на основании контента сайта подобрала 680 ключевых слов. Такой большой список ключевиков объясняется широким ассортиментом.
В таблице также показана:
- частотность запросов с учетом региона;
- прогноз средней цены клика;
- прогноз кликов;
- прогноз бюджета.
Эти данные позволяют отобрать слова нужной частотности и спрогнозировать бюджет на рекламу.
Нажимаем на кнопку «Показать все»:
Просматриваем все слова. В списке собранных фраз есть повторяющиеся. Не будем удалять их вручную: система автоматически удалит их на этапе добавления ключевых слов в медиаплан.
Добавляем слова в медиаплан:
После клика по кнопке «Добавить в медиаплан» система показывает сообщение об обнаруженных дублях ключевых слов. Нажимаем «Удалить», чтобы очистить семантику от повторяющихся фраз:
После удаления дублей в медиаплан добавлено 482 слова:
Click.ru предоставляет широкий набор инструментов для работы с семантикой, объявлениями и оптимизацией рекламных кампаний. Сервис позволяет вести кампании Яндекс.Директа и Google Ads в едином окне. К тому же, их очень просто перенести из рекламных кабинетов.
Парсинг ключей конкурента
Для расширения семантического ядра проанализируем, по каким словам показывают рекламу ближайшие конкуренты. Сделать это можно прямо в медиаплане.
Для этого в автоматическом подборе слов выбираем опцию «Слова конкурентов». Всего система предлагает 5 конкурентов, которые также продают аналогичную продукцию. При необходимости можно удалить неподходящий сайты и добавить конкурентов вручную:
Всего система отобрала 1500 слов конкурентов. Кликаем на кнопку «Показать слова конкурентов»:
Мы видим, что частотность некоторых запросов очень высока. Например, запрос «купить велосипед» пользователи вводили 633 041 раз за месяц. По таким запросам нет смысла показывать рекламу, так как клики будут обходиться очень дорого.
Поэтому оставим запросы с максимальной частотностью 1000 запросов в месяц. Для этого в столбце «Частотность» задаем фильтр – от 10 до 1000 запросов в месяц.
Всего система отобрала 78 слов нужной частотности из 1500 фраз. Добавим их в медиаплан. Для этого устанавливаем галочку вверху таблицы и кликаем на кнопку «Добавить медиаплан»:
Система автоматически предлагает удалить дубли слов. Нажимаем «Удалить»:
Система добавила в медиаплан 75 слов:
Таким образом, с помощью автоматического подбора слов мы отобрали 482 фразы со своего сайта и 75 – с сайтов конкурентов. Всего мы получили 557 фраз.
Ручной подбор слов
Ручной подборщик находится над таблицей с результатами автоподбора. Для добавления в ручной подборщик слов из автоподбора отметим галочками необходимые слова и кликнем на «Добавить в ручной подбор»:
Система автоматически перенесет выбранные слова в ручной подборщик. Нажимаем «Развернуть список вложенных слов». Система подбирает ключи из левой колонки Wordstat, в которых присутствуют заданные в ручном подборе слова. В результате каждому опорному ключу соответствует группа вложенных запросов:
Выбираем ключевые слова, которыми хотим расширить нашу семантику, и добавляем их в медиаплан.
Далее просматриваем вложенные фразы по каждому ключевому слову и выбираем те ключевые слова, которые хотим добавить в медиаплан.
Результат – мы добавили еще 29 ключевых слов в медиаплан, дополнив наше семантическое ядро.
Результат подбора слов
В общей сложности с автоматическим подборщиком мы собрали 586 фраз (557 + 29). Для нишевого интернет-магазина этого достаточно.
Для дальнейшей работы с семантикой выгружаем выбранные слова в XLS-файл. Для этого внизу таблицы кликаем на кнопку «Выгрузка в XLS»:
Группировка ключевых слов
В Click.ru есть кластеризатор запросов. Кластеризатор собирает запросы с одинаковым интентом в одну группу. В результате проще сформировать группы объявлений, не упустив нужных ключевых запросов.
В главном левом меню выбираем «Семантика» – «Кластеризация запросов»:
В настройках указываем адрес сайта и название проекта:
Загружаем список ключевых запросов. Для этого нажимаем кнопку «Загрузить XLSX-файл» и добавляем слова, которые мы собрали в результате автоматического и ручного подбора. Также можно внести список фраз для проверки вручную.
Для более точной группировки фраз выберем профессиональную настройку. Она позволяет задавать одно или несколько условий, при которых точность кластеризации будет увеличиваться.
Кликаем на кнопку «Запустить кластеризацию». Через несколько минут становится доступным отчет в формате XLSX.
Отчет состоит из нескольких листов с такой информацией:
- сгруппированными запросами по кластерам в Яндексе/ Google;
- лидерами тематик в Яндексе/Google;
- исходными настройками.
Содержание отчета и его размеры зависят от количества запросов и заданных настроек.
В результате мы не только сформировали семантическое ядро, но и получили сгруппированные по кластерам запросы на основе результатов поисковой выдачи.
Сформировали семантику – что дальше
После сбора семантики в Click.ru можно автоматически создать объявления. Для этого кликаем под медиапланом на кнопку «Создать объявление»:
Система автоматически генерирует объявления по предложенным ключевым словам: формирует заголовок и текст, указывает цену, подбирает картинки и ключевые слова.
Остается только отредактировать подходящие объявления и запустить рекламную кампанию.
Семантическое ядро – это основа оптимизации любого сайта. Именно сбор семантического ядра должен проводиться в первую очередь. Нередко после составления списка запросов для продвижения приходиться перекраивать структуру сайта, добавляя новые страницы или меняя вложенность страниц, их иерархическую последовательность.
Для сбора семантики можно использовать самые разные сервисы. Есть для этого и специальные программы как бесплатные (тот же «Словоеб»),так и платные. В последнем варианте наибольшей популярностью пользуется КейКоллектор.
Однако не следует сбрасывать со счетов и сервисы от самой поисковой системы, которые дают возможность совершенно бесплатно собрать хорошее семантическое ядро. Далее поговорим о том, как составить семантику при помощи всем известного и совершенно бесплатного сервиса «ЯндексВордстат».

Виды запросов
Прежде всего, давайте определимся с тем, какие бывают запросы по частотности. Здесь выделяют три группы:
- высокочастотные;
- среднечастотные;
- низкочастотные.
Точно по такому же принципу различают запросы и по конкуренции. Само собой разумеется, что продвигать сайт по высококонкурентным запросам сложно, особенно, если это молодой ресурс и оптимизация только началась. Можно потратить огромное количество средств и времени на такое продвижение и получить минимум трафика и пользователей. А вот продвижение по НЧ и СЧ запросам, как правило, дает очень хорошие результаты.
Сбор ключевых слов
Собирать ключевые запросы – это дело долгое и нудное, но очень важное. От того, насколько качественно будет произведена данная операция, зависит эффективность самого семантического ядра и оптимизации в целом.
Интерфейс Вордстата настолько простой, что запутаться в нем, даже при желании, просто невозможно. В окне вводим тематику, которая нас интересует. Далее можно выбрать географию показов – по всей стране, по отдельным регионам или городам. Яндекс выдаст вам все запросы, которые вводили пользователи за последний месяц, и покажет число показов. Обратите внимание, что вы можете выбрать статистику показов в соответствии с устройствами пользователя – все или только мобильные.

Именно число показов и даст нам возможность определить конкурентность запросов. Обратите внимание, что изначально сервис вам покажет количество не точных вхождений, а общее число запросов за месяц, в которых встречалась ваша фраза. Собственно, это хорошо видно на самой странице – « что искали со (слово запроса)».

В Вордстате присутствуют свои инструменты (так называемый инструментарий) – т.е. операторы, помогающие посмотреть различную статистику по каждому запросу. Ниже представлен список операторов, поддерживаемых вордстатом:

Основные операторы, которыми есть смысл пользоваться – это ” ” (заключение в кавычки) и оператор “!” (восклицательный знак).
Оператор Кавычки позволяют увидеть, сколько раз искали за последний месяц именно вашу фразу без добавления дополнительных слов, но с изменяемыми окончаниями.
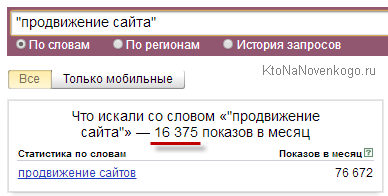
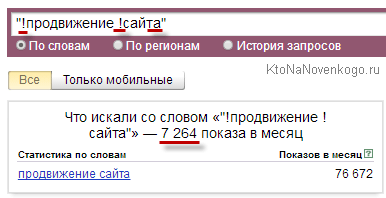
Для того чтобы отобрать точные вхождения, следует заключить запрос в кавычки и перед каждым словом проставить “!” – – «!продвижение !сайтов». Только в этом случае вы получите статистику именно по точным вхождениям.
Для наглядности сравним частотность запроса “продвижение сайтов” без операторов, в кавычках и с восклицательным знаком:

Как мы видим, общая частотность и точная частотность запроса “продвижение сайтов” разнится более чем в 10(!) раз.
Важность отбора целевых запросов
Из всех ключевых слов, которые получится отобрать, а их тысячи, следует оставить только те, которые точно отображают потребность вашего сайта. К примеру, если вы занимаетесь продажей сумок, то ключи типа «ремонт сумок», «пошить сумку своими руками», вам не подходят.
Нельзя забывать и про так называемые “Ассоциации” в Вордстате – правая колонка основного окна. Ассоциации показывают все похожие запросы, которые искали люди за последний месяц. Данный инструмент позволяет значительно расширить область вашего поиска и помогает найти максимальное количество различных формулировок одних и тех же запросов.

Операцию по отсеиванию лишнего нужно проводить до тех пор, пока не останутся только те ключи, которые максимально отражают представленность сайта в вашей нише.
Нужно изначально понимать, что составление нецелевых запросов просто не принесет вам заказов, не поможет продвинуть сайт и будет вести бесполезный трафик. Так, продвижение по запросу “как установить автомагнитолу” не поможет её продать, а только будет ухудшать поведенческие факторы при отсутствии соответствующих статей и форума.
Окончательный список ключей следует сгруппировать и распределить по конкретным страницам. Именно поэтому, нередко приходится добавлять новые страницы или менять структуру сайта.

Высокочастотные запросы следует использовать для продвижения главной страницы. Следует отметить, что если в семантическом ядре есть ключевые запросы, которые вам подходят, но нет контентной страницы, следует ее создать. Продвижение по средне- и низкочастотным запросам дает хороший трафик. Главное, не лепить все на одну страницу, в противном случае результата не получится никакого. Так, можно ли на вывеске магазина на улице поместить всё: продажу вешалок, туалетной бумаги, сантехники и эксклюзивных ёршиков и какой от этого будет результат? Так же и здесь. Лучше сделать несколько отдельных “вывесок” – в этом случае люди гарантированно увидят каждую из них.
Понять, какие из запросов есть смысл заключать в одну логическую группу можно исходя из анализа своих конкурентов, находящихся в ТОПе. Если они ранжируются высоко – значит поисковику такое распределение нравится и значит на них можно ориентироваться.
Группировка должна быть прежде всего логичной. Не нужно создавать 10 страниц под подобные ключи типа “пластиковые окна недорого”, “заказать пластиковые окна”, “пластиковые окна дешево” и т.п. – это будет явный переспам и в результате может повлечь негативные последствия.
Ручной процесс составления семантического ядра довольно длительный. Однако, это фундамент дальнейшей оптимизации и эффективности сайта. И не забывайте, что на сайте – важно прежде всего наличие хорошего контента, который будет действительно читаться и использоваться людьми. Откровенные SEO-тексты и переоптимизация никогда не смогут дать долговрочного результата.
Статистика запросов Яндекса и подбор ключевых слов в Вордстате для составления семантического ядра
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Сегодня я попробую рассказать вам о таком понятии, как семантическое ядро, во всяком случае попытаюсь, ибо тема довольно специфическая и вряд ли будет всем интересна, хотя…
В комментариях к статье Самостоятельное продвижение сайта меня вроде как попросили (или сделали замечание, что об этом не упомянул) написать о подборе ключевых слов и выделении целевых запросов в онлайн сервисе Вордстат от Яндекса, что я и попытаюсь сделать в этой публикации.

Если попробовать в двух словах описать назначение семантического ядра, то я бы сказал, что это очень похоже на составление блок схемы перед написанием программы. В нем вы намечаете те ключевые слова и словосочетания, по которым будет продвигаться ваш проект в целом, а также четко определяете, под какие именно поисковые запросы будут оптимизироваться те или иные страницы будущего или уже существующего сайта.
А потом уже по намеченной схеме вы будете планомерно создавать структуру будущего сайта и наполнять его материалами, одновременно оптимизируя их под заранее намеченные ключевики. В общем, работать над своим проектом с широко открытыми глазами завсегда лучше…
Онлайн сервис «Подбор слов» от Яндекса
Я понимаю, что публикаций на тему составления семантического ядра в интернете более чем достаточно. Но, как мне кажется, они написаны в основном теми, кто занимается этим делом профессионально, т.е. оптимизаторами из SEO контор или фрилансерами. Описанные ими методы довольно-таки интересны, ибо позволяют автоматизировать и упростить процесс сборки ядра, но лично на меня они нагоняют скуку при чтении.
Описываемые ими мелочи и нюансы помогают сэкономить время при большом потоке проектов, которые проходят через их руки, но вот если у вас стоит задача подбора ключевых слов для своего собственного сайта, то в большинстве случаев излишняя автоматизация может даже помешать, ибо можно что-то упустить или не учесть.
Тут, как мне кажется, спешить не надо. Например, я когда-то купил на бонусы Профит Партнера замечательную программу Key Collector. Вот. Покрутил ее, повертел, да и отложил на дальнюю полку. Почему? Да просто она не для меня — сложна в освоении и понимании полезности всего имеющегося в ней богатейшего функционала. По той же причине я пользуюсь Яндекс Метрикой, а не Гугл Аналитиксом.
Конечно, я не прав и надо было упереться рогом и добиться понимания всех имеющихся в Key Collector фишечек (полезных безусловно). Но в реалии, я скачал с сайта того же разработчика облегченную версию этой программы по подбору слов, правда под непрезентабельным названием Slovoeb (написанное русскими буквами оно не очень-таки и печатно).
Все, теперь работаю исключительно с ним, а Кей Колектор у меня в очередной раз после обновления системы заблокировался (в нем имеется привязка к конфигурации компьютера) и мне лень опять списываться с автором, чтобы его реанимировать.
Поэтому сегодня буду говорить только про ручное использование инструмента «Подбор слов» от Яндекса, про использования Slovoeb в целях быстрого получения статистики по тысячам ключевых фраз разом и отсеивание пустышек. Есть и другие инструменты, подобные Вордстату (о них можно прочитать в статье про работу со статистикой поисковых запросов Яндекса, Google и Рамблера), но они такой широкой популярности не снискали.
Вообще, конечно же, работа с Вордстатом до безобразия проста в плане теории, но достаточна муторна в плане практики. Кстати, не так давно у них поменялся дизайн, но не только. По субъективным ощущениям, скорость парсинга новой версии онлайн инструмента по подбору слов существенно увеличилась.
С чего начать? Со спокойного обдумывания сложившейся ситуации и того, что вы хотели бы получить в результате. У вас есть тематика вашего ресурса (будущего или уже имеющегося). Под эту тематику можете сходу подобрать десяток-другой фраз или слов, которые могут иметь к ней отношение. Как понять, какие именно из вертящихся у вас в голове фраз имеют перспективу?
Нужно посмотреть статистику их использования при обращении к поисковой системе Яндекс. Для этой цели и нужен Вордстат. Правда с недавних пор он доступен только для зарегистрированных пользователей, поэтому вам предварительно придется получить паспорт от Яндекса, а в нагрузку к нему еще и бесплатный почтовый ящик.
Если все это добро у вас уже есть, то не помешает вспомнить свои данные авторизации, ибо их придется вводить в Slovoeb для придания ему работоспособности. Дальше вводите ваш первый запрос в соответствующую форму на странице сервиса Подбор слов:
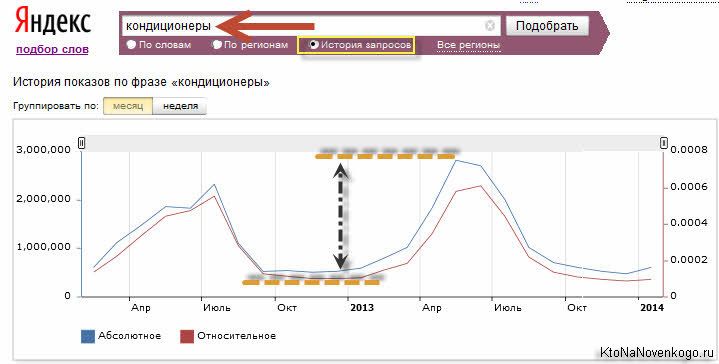
О, как много получилось. Вордстат выдает статистику по ключевым словам за последний календарный месяц. Значит за год можно будет получить число еще на порядок больше. Хотя это не совсем так. Одной из причин может являться колебание частотности запроса от времени года (т.е. сезонности).
Это можно проверить, переставив галочку в поле «История запросов». Для наглядности возьмем, действительно, что-то с ярко выраженной сезонностью, где частотность ввода данного ключевого слова в поисковую строку Яндекса в зависимости от времени года может меняться в шесть раз.
Если интересующий вас запрос имеет региональную привязку, то это тоже существенно повлияет на частоту его ввода в Яндекс. Для того, чтобы это понять, достаточно кликнуть по ссылке «Все регионы» и выбрать нужную вам географическую привязку.
Например, вот так будет выглядеть статистика по аудитории Яндекса, которая интересуется доставкой пиццы в маленьком городе.
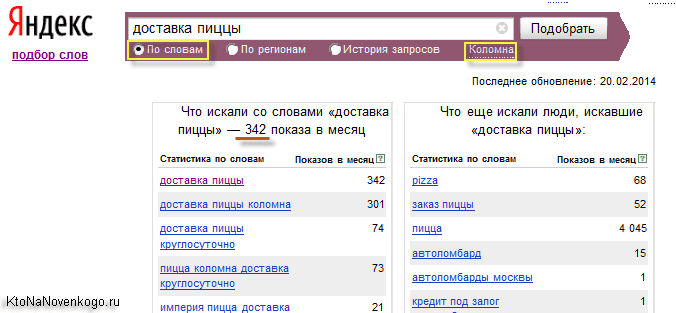
Кроме этого многие сеошники и владельцы сайтов проверяют позиции своих сайтов (например, в ТопВизоре) по всевозможным ключевым словам, и не всегда для этого используют свои лимиты в Яндекс XML. А это значит, что происходит накрутка (не специальная) частотности. Поэтому не стоит безоглядно верить цифрам этой статистики и не стоит ее воспринимать буквально.
Да и без этого все не так просто. Будь это статистика исключительно по использованию одного только этого слова (словосочетания), которое вы ввели, то все было бы замечательно. Но сервис подбора слов Яндекса при вводе в него запроса без каких-либо дополнительных операторов учитывает в показанной цифирьке все фразы, в которых данное словосочетание использовалось (в любой словоформе).
Например, если вернуться к первому скриншоту, то можно с уверенностью сказать, что почти 900 000 раз за месяц пользователи яндекса вводили запросы, в которых встречалось слово Joomla (например, «шаблоны для Joomla» или «самые популярные в мире сайты на системе управления сайтами Joomla»).
Данная статистика поможет вам оценить перспективу создания сайта или отдельного раздела на данную тематику, но вот при написании конкретных статей нужно будет использовать уже другие цифирьки, обладающие большей конкретикой. Где их взять? Хороший вопрос, на который мы сейчас и постараемся ответить.
Как собрать статистику реальной частотности запросов
Прежде, чем приступать к практике, хочу остановиться на тех операторах Вордстата, которые можно использовать в сервисе подбора ключевых слов Яндекса. Собственно, их совсем немного. Думаю, что никто не сможет рассказать о них лучше, чем собственный хелп этого сервиса.

Лично я использую только два из них — кавычки и восклицательный знак. Вы вольны поступать так, как считаете нужным.
Итак, кавычки заставляют поисковую систему делиться статистикой по вводу только данной фразы. Однако, при этом будут учтены все возможные словоформы содержащихся в ней слов (падежи, числа). Например, так:
А вот если поставить перед каждым словом из ключевой фразы по восклицательному знаку, то мы заставим Яндекс поделиться статистикой уже исключительно только по тем словоформам, которые были использованы в запросе. Например, так:
Странно, не правда ли? В три раза уменьшилась цифирька. А как же еще можно сформулировать данный запрос поисковой системе? Ну, если подумать, то скорее всего во множественном числе, тем более, что и оставшиеся цифирьки сразу видно куда подевались:
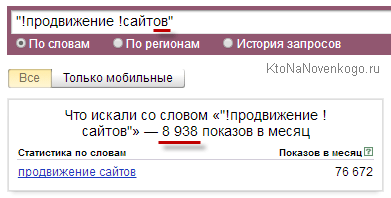
Ну вот, с теорией, считайте, покончили, пора приступать к практике. Все мои проекты носят информационный характер и поэтому сезонность и региональность запросов меня мало волнуют. Если у вас другая ситуация, то эти данные вам тоже придется учитывать, чтобы понимать перспективность.
Yandex Wordstat — что нужно учитывать при сборе семядра
Итак, давайте зайдем на этот чудо-сервис от Яндекса, который называется «статистика ключевых слов» и расположен по адресу Wordstat.Yandex.ru. Этот сервис создавался и позиционируется как незаменимый инструмент для работы с Яндекс Директом, а так же при SEO продвижении своего сайта под эту поисковую систему. Но по сути он стал мощнейшим инструментом для анализа ключевых слов в рунете.
Поэтому кроме своего прямого назначения Вордстат Яндекса с успехом можно так же использовать:
- При работе с Гугл Адвордсом
- Для поиска популярных хештегов в соцсетях
- Для получения данных о спросе на тот или иной товар
- Для построения структуры сайта
- Для поиска похожих слов
- Для проведения тестирования спроса на товары или услуги в другом регионе при поиске новых рынков сбыта
- Для анализа успешности проведения оффлайн рекламы, путем анализа частоты упоминаний брендовых слов
При всем этом интерфейс Вордстата, можно сказать, спартанский, но это, пожалуй, только к лучшему. Если хотите больше, то можно использовать различные программы для удаленной работы с этим сервисом, либо установить плагин типа Yandex Wordstat Assistant в свой браузер.
После введения Яндексом разделения результатов поиска в зависимости от региона, у вас появилась возможность посмотреть частоту ввода тех или иных поисковых запросов для каждого региона в отдельности (для этого нужно будет выбрать регион, перейдя на соответствующую вкладку).
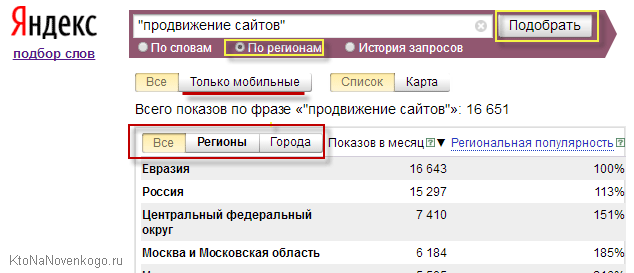
Если региональность вас не волнует, то имеет смысл смотреть статистику на первой вкладке без учета геозависимости. В принципе, это не так уж и важно на этапе изучения принципов составления семантического ядра для сайта. Равно, как и не так давно появившаяся возможность посмотреть отдельно статистику только по мобильным пользователям (использующих планшеты и смартфоны). Это может быть актуально в свете лавинного роста мобильного трафика.
В любом случае, вначале вам нужно будет выделить для себя ряд основных ключевых слов (масок) по тематике вашего будущего проекта, от которых мы уже начнем плясать дальше и подбирать с помощью вордстата Яндекса все остальные кючевики. Где их взять? Ну, просто подумайте или посмотрите на известных вам конкурентов в вашей нише (есть такой сервис Серпстат, который может в этом помочь).
Да и простая логика зачастую бывает очень полезной. Например, если ваш будущий сайт будет по тематике «Joomla», то для составления семантического ядра вполне логично будет ввести в Яндекс.Вордстат для начала это ключевое слово. Логика простая. Если сайт будет по СЕО, то исходных ключей может быть масса (SEO, продвижение сайтов, раскрутка, оптимизация и т.п.).
Ну, а мы в качестве примера возьмем другую фразу: «вордстат». Посмотрим, что данный онлайн-сервис скажет нам о самом себе. Тут сразу стоит сделать несколько замечаний.
Что необходимо знать и понимать для успешного использования ВордСтата
- Во-первых, для того, чтобы начать получать существенный приток посетителей по выбранному вами ключу, ваш сайт должен попасть в Топ 10 (за первой десяткой жизни, увы, практически нет) поисковой выдачи (серпа — см. толковый словарь начинающего SEO-шника). А представьте, что желающих (конкурентов) сотни, а то и тысячи. Поэтому семядро — это только необходимое условие успешности сайта, но вовсе не достаточное.
- Во-вторых, кроме этого сейчас практически для каждого пользователя формируется своя выдача, несколько отличная от того, что видит даже его сосед по этажу. Учитываются предпочтения и желания именно этого пользователя, если Яндексу удалось их ранее выявить (ну, и регион, конечно же, если запрос является геозависимым — например, «доставка пиццы»). Позиции в этом плане являются «средней температурой по больнице» и далеко не всегда приведут к ожидаемому притоку посетителей. Хотите увидеть истинную картину? Пользуйтесь режимом «Инкогнито» в вашем браузере.
- В-третьих, даже если вы попадете в Топ 10 выдачи (показываемой большинству ваших целевых пользователей), то число переходов на ваш сайт будет сильно зависеть от двух вещей: позиции (первая и десятая могут отличаться по кликабельности в десятки раз) и привлекательности вашего сниппета (информации о странице вашего сайта, отображаемой в выдаче по данному конкретному запросу).
- Выбранные вами для продвижения и формирования семантического ядра запросы попросту могут оказаться пустышками. Хотя пустышки и можно выявить и отсеять, но новички довольно часто попадаются на эту удочку. Как это увидеть и поправить читайте чуть ниже.
- Есть такая штука, как накрутка поисковых запросов. Мне лично не приходит в голову кому и зачем это нужно, но такие запросы встречаются. Начиная по ним продвижение вы не получите той посещаемости, на которую могли бы рассчитывать опираясь на данные Яндекс Вордстата. О способах выявления накруток опять же читайте чуть ниже.
- Уточняйте свой регион (если у вас региональных бизнес или региональные запросы) при просмотре статистики, иначе можете получить совершенно не соответствующую действительности картину.
- Обязательно учитывайте сезонность ваших запросов (если она есть) при анализе результатов продвижения. В Вордстате сезонность хорошо видна на вкладке «История запросов». Не стоит учитывать сезонные спады и подъемы, как фактор ваших неудач или успехов в продвижении.
- Работать непосредственно с интерфейсом сервиса удобно при небольшом количестве запросов, но потом это уже становится «пыткой». Поэтому главный вопрос успешного использования Wordstat — автоматизация рутинных операций. Как и чем автоматизировать будет описано ниже.
- Если научиться правильно пользоваться операторами Вордстата, то отдачу от него можно повысить в разы. Это и кавычки, и знак плюс, и понимание того, что выдает этот сервис при вводе не совсем обычных запросов. Об этом читайте ниже и в разделе «Секреты ЯнВо»
Напугал? Даже сам испугался, несмотря на то, что по сотням запросов (довольно-таки частотным) мой блог находится в Топе (и не в последнюю очередь благодаря тому, что я почти сразу начал работать опираясь на семантическое ядро, пусть и в несколько урезанном варианте — подбирая ключи под будущую статью непосредственно перед ее написанием). Но вот если бы сейчас начинал (даже с текущим опытом), то не поверил бы, что «удастся пробиться». Правда! Считаю, что по большей части повезло.
Операторы Вордстата в примерах
Итак, давайте поподробнее разберемся с двумя последними пунктами — запросами пустышками и накрутой. Готовы? Ну, тогда понеслась. Начнем с запросов-пустышек. Помните, какой пример мы использовали чуть выше? Введите слово ВОРДСТАТ в строку этого сервиса и нажмите на кнопку «Подобрать».
Так вот, нужно понимать, что отображаемая для этого слова (или любой другой фразы) цифра, вовсе не отражает реальное количество запросов этого ключа. Отображается (внимание!) общее число фраз запрашиваемых за месяц, в которых встречалось слово «Вордстат», а не количество запросов, включающих в себя одно это единственное слово (или словосочетание, в случае ввода вами ключевой фразы в форму Wordstat). Собственно, это понятно и из скриншота — «Что искали со словом…».
Но в Яндекс Вордстате есть соответствующий инструментарий, который позволяет отделить зерна от плевел (выявить пустышки или получить адекватную реальности информацию о частотности) и получить нужные нам данные. Это различные операторы, которые можете добавить в свой запрос и получить уточненный результат.
Операторы кавычки и восклицательный знак — отсев пустышек в Wordstat
Как вы можете видеть, основных операторов немного и главные из них, на мой взгляд, это заключение ключевой фразы в кавычки и простановка восклицательного знака перед словом. Хотя для высококонкурентных тематик может быть актуальным и новый оператор Wordstat в виде квадратных кавычек. Иногда бывает важно знать, как чаще всего пользователи расставляют слова в нужном вам запросе (например, «квартиру купить» или все же «купить квартиру»). Однако, я его пока не использую.
Итак, оператор Вордстата «кавычки» позволит подсчитать количество вводов в поисковую строку Яндекса именно этой фразы в течении месяца, но при этом будут учтены и подсчитаны все возможные ее словоформы — другое число, падеж и т.д. (например, не будут учтены запросы «Яндекс Вордстат», а только «Вордстат» в нашем примере). По сути, это то же самое, что мы рассматривали в статье про то, как искать в Яндексе. Цифра частотности после такой простейшей операции существенно уменьшится:
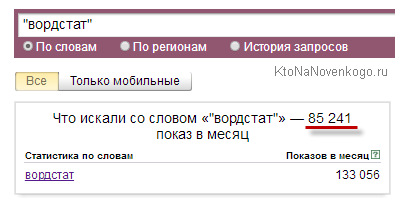
Т.е. такое количество раз за месяц в поисковую строку Яндекса пользователи вводили одно единственное слово ВОРДСТАТ во всех его словоформах (если они вообще имеют место быть). Конечно же, данный запрос вовсе не пустышка, а полноценный ВЧ, но бывают случаи, когда простое заключение фразы в кавычки снижает частотность с нескольких тысяч до нескольких десятков или даже единиц (например, пробейте фразу «заработок 100» в кавычках и без). Вот это действительно была пустышка.
Второй важный оператор в Wordstat — это восклицательный знак перед словом, который обяжет этот сервис подсчитывать только слова именно в таком варианте написания, в каком вы их ввели (без учета словоформ). Как я и предполагал, для слова «Joomla» установка оператора восклицательного знака никаких корректив не добавила, но это только из-за специфики данного конкретного ключевика.
Ну, а вот для ключевой фразы «продвижение сайта» разница будет очевидна и разительна:
И добавим «!» перед каждым словом без добавления пробела:
Откуда взялась такая разница в цифрах? Очевидно, что имеет место быть запрос(ы) с теми же самым ключевыми словами, но в другой словоформе, который отъедает оставшиеся цифирьки. Для нашего примера нетрудно догадаться, что это будет множественное число:
Таким образом вы можете, используя заключение фразы в кавычки и установив перед каждым из слов восклицательный знак, получить уже совсем другие значения частоты. Таким образом можно не только отсеять пустышки, но и получить представления о словоформах фразы, которые желательно будет употреблять в тексте почаще, а какие пореже (хотя и про синонимы не забывайте). Хотя, лично я сильной разницы при добавлении восклицательных знаков не увижу, поэтому довольствуюсь простыми кавычками.
Как быстро убрать мусор и оставить только целевые запросы
Есть еще один оператор позволяющий отсечь все лишнее и увидеть реальную частотность фразы. Это «+» перед словом. Он означает, что данное слово в фразе должно присутствовать обязательно. Зачем это может быть нужно? Ну, тут все дело в особенности работы поисковой системы Яндекс.
По умолчанию в ранжировании (а значит и в статистике Wordstat) не учитываются союзы, предлоги, междометия и т.п. слова. Делается это для упрощения, но зачастую нас интересует перспектива продвижения именно под фразу с предлогом или союзом. В этом случае и пригодится оператор «плюсик.»
Кстати, оператор «минус» позволит сразу же почистить ключевые слова от тех, что для вас являются нецелевыми. Например, такой вот запрос к ВордСтату сразу даст требуемый результат:
cмартфоны (+до|+с|+на) -скачать -игры -интернет -мтс -фото
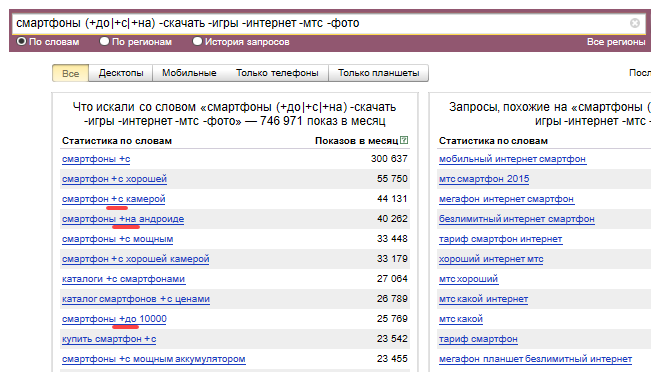
Тут, чтобы не повторять данный запрос три раза, применен оператор «вертикальная черта», который позволяет собрать фразы сразу с тремя предлогами (до, с, на). Ну, а слова с минусом (стоп-слова) нужны для очистки фраз от мусора.
Вот еще пример использования операторов для той же цели:
стиральные (машины|машинки) (samsung|самсунг) -ремонт -ошибки -отзыв -коды -видео -запчасти –неисправности
Очень удобно и быстро отсекается ненужное и экономится время.
Подбор ключевых слов в Яндекс Вордстате
Наверное, вам уже становится ясно, что те базовые ключевые фразы (маски), которые вы способны сформулировать сами, основываясь на будущей тематике вашего проекта, необходимо будет расширить с помощью Вордстата. И тут тоже есть как бы два направления в получении новых ключевиков для составления полноценного семантического ядра.
- Во-первых, вы можете воспользоваться теми расширенными вариантами, которые выдает Wordstat в левой колонке своего окна. Там будут приведены запросы, в которых присутствуют слова из вашей маски (например, «строительство», если у вашего проекта соответствующая тематика). Они будут отсортированы по убыванию частоты их употребления пользователями в поисковой строке Яндекса за месяц.
Что тут важно? Важно сразу же выделить те варианты расширенных ключей, которые будут являться для вашего проекта целевыми. Целевые — это такие запросы, по содержанию которых сразу становится ясно, что пользователь, вводящий его, ищет именно то, что вы можете ему предложить на своем сайте, который планируете продвигать.
Например, запрос «ядро» является сверхвысокочастотным, но совсем мне не нужным, ибо это абсолютно не целевой ключевик для данной публикации. Мало ли что ищут пользователи вводящие его в поисковой строке Яндекса, ну уж точно не «семантическое», которое, кстати, будет являться ярким примером целевого запроса по отношению к данной статье.
Но вам нужно выбирать целевые ключи применительно ко всему будущему сайту, хотя иногда бывает полезно продвигаться и по общим запросам, но это скорее исключение из правил.
Целевые фразы будут более низкочастотными и пользователи, пришедшие по ним с выдачи, смогут найти хоть что-то подобное тому, что они хотели найти, а значит не покинут сразу же ваш проект, тем самым ухудшив пользовательский фактор продвижения. Да и вам такие посетители очень важны, ибо они могут совершить требуемое вам действие (сделать покупку или заказать услугу).
Думаю, что про отбор именно таких ключевых слов из статистики Яндекса дальше говорить не нужно — вам и так все понятно. Единственное «но». Все фразы из правой колонки Вордстата вам опять же нужно проверить на пустышки, а именно, заключить их в кавычки (статистику с восклицательными знаками можно будет уже потом посмотреть и проанализировать). Если частотность не стремится к нулю, то добавляете ее в загашник.
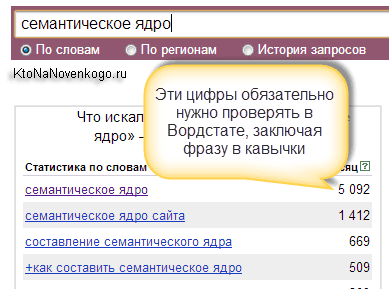
Вы наверное заметили, что по многим фразам список в левой колонке не ограничивается одной страницей (там есть внизу кнопка «далее»). Максимум, что выдает Вордстат — это по-моему 2000 запросов. И все их нужно будет проверить на пустышки. Справитесь? А ведь это только одна из многих «масок» (начальных ключей) вашего семантического ядра. Там ведь можно и «кони двинуть».
Но не расстраивайтесь, ибо есть способ автоматизировать подбор ключевых фраз в Slovoeb или Key Collector. По ссылке вы найдете подробнейшую статью, и если после этого еще что-то останется не понятно, то киньте в меня камень.
- Второй нюанс при подборе фраз для семантического ядра заключается в возможности использования так называемых ассоциаций из статистики Яндекс Вордстата. Эти самые ассоциативные запросы приводятся в правой колонке его основного окна.
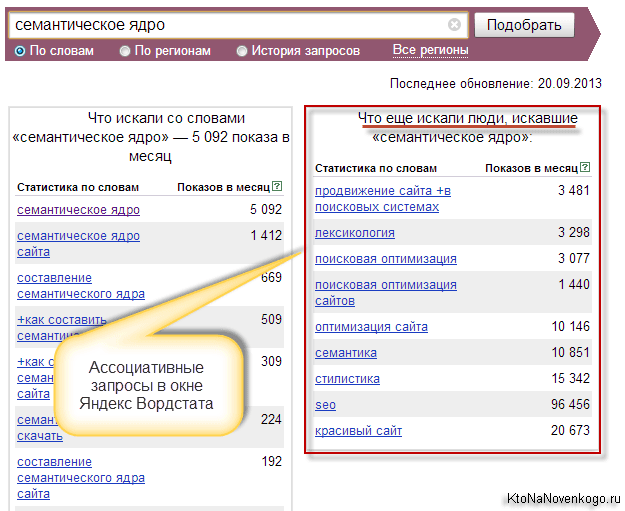
Тут, наверное, важно представлять, а как эти самые ассоциативные запросы в статистике Яндекса формируются и откуда берутся. Дело в том, что поисковик анализирует поведение пользователя, ищущего у него что-то.
Например, если пользователь после того (или перед тем) как набрать нашу ключевую фразу «семантическое ядро» вводил в поисковую строку еще какой-либо запрос (это называется за одну сессию поиска), то Яндекс может сделать предположение, что данные запросы как-то связаны между собой.
Если такая же ассоциативная связь будет наблюдаться и у некоторых других пользователей, то этот задаваемый вместе с основным запрос будет показан в правой колонке Wordstat. Ну, а вам остается только воспользоваться этими данными для расширения семантического ядра своего сайта.
Все ассоциации будут иметь указание частотности их запроса в течении месяца. Но она, естественно, будет общей, т.е. еще придется выявлять пустышки опять же проверяя все эти фразы взятые в кавычки (Slovoeb или Key Collector вам в помощь — читайте о них по приведенной чуть выше ссылке).
Некоторые из ассоциативных запросов наверняка приходили и вам в голову, но всегда найдутся и такие, которые вы упустили из вида. Ну, а чем больше целевых ключевых слов будет включать ваше семантическое ядро, тем большее количество правильных посетителей вы сможете привлечь на свой сайт при должном проведении внутренней и внешней оптимизации.
Итак, будем считать, что основываясь на базовых масках (ключевиках, явно определяющих тематику вашего будущего проекта) и возможностях Яндекс вордстата, вы смогли набрать достаточное количество фраз для семантического ядра. Теперь нужно будет четко разделить их по частоте использования.
Секретные техники работы с ВордСтатом
Конечно же, данный заголовок несколько ярковат, но все же, именно описанные ниже «секреты» могут помочь использовать этот инструмент на все 200%. Просто если этого не учитывать, то можно потратить время, деньги и усилия впустую.
Как увидеть накрутку поискового запроса в Wordstat
Однако очевидно, что по некоторым ключевым словам Wordstat выдает неправильную информацию. Связанно ли это с какими-либо вариантами накрутки и как определить такие пустышки я попробую пояснить. Конечно же, проверять все фразы таким образом может быть утомительно и, наверное, тут нужен просто опыт (чуйку), но это вполне работает.
Лично я исхожу из той предпосылки, что накручивают, как правило, не годами напролет, а значит отклонение от среднего значения частотности можно будет отследить на графике «История запроса» (переключатель прячется под строкой ввода запроса сервиса Yandex Wordstat). Например, недавно пробивал запросы связанные с «партнерской программой» и как раз столкнулся с накруткой (почти всех связанных с тематикой ключей).
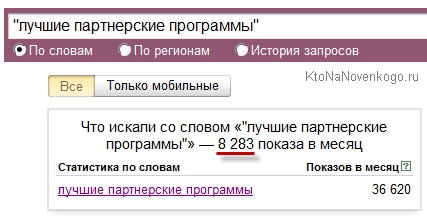
Просто с этими запросами я уже давно работаю и примерно знаю «расклад». Там ВЧ раз-два и обчелся, а тут что не ключ, то ВЧ. Но достаточно посмотреть на историю частотности этого запроса в Wordstat (кавычки только не забудьте предварительно убрать) и все становится ясно (крутить начали с начала лета):
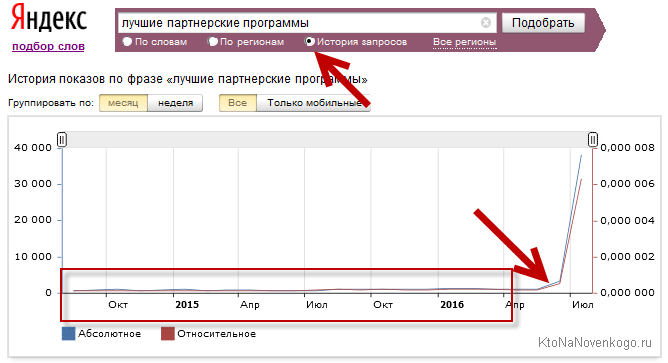
Причем, частотность запроса выросла чуть ли не на два порядка за несколько месяцев, а пару лет до этого была стабильна и даже сезонных колебаний особых не претерпевала. Явная накрутка — зачем не знаю, но крутят все сопутствующие ключи.
Как автоматизировать сбор ключевых слов в сервисе Яндекса
В принципе, можно работать и через вебинтерфейс, но очень уж это муторно. Есть программы (платные и бесплатные) подходящие для этой цели. Есть даже расширения для браузера, которые позволяют чуток победить рутину. Давайте их просто перечислю:
- Yandex Wordstat Assistant — устанавливаете его в свой браузер и при открытии страницы Вордстата слева появится модуль этого плагина.
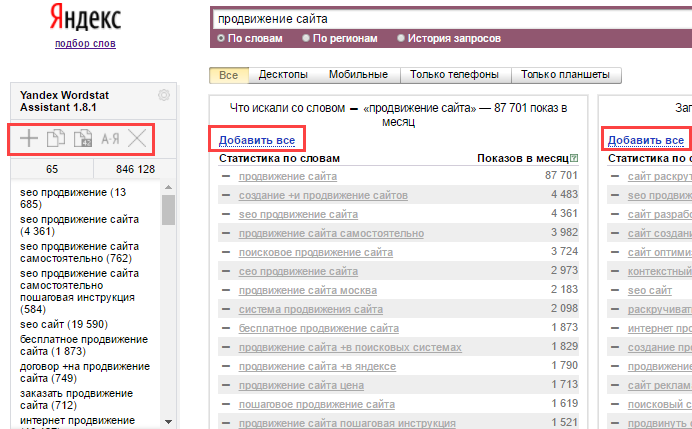
В него можно собирать открытые на странице ключевые слова (и из левой, и из правой колонки) с помощью появившихся над каждой колонкой кнопок «Добавить все», либо добавлять по одной фразе кликая по плюсику появившемуся перед фразами.
Перейдя на следующую страницу (либо введя новый запрос) можно будет продолжить сбор ключей. Из окна плагина их можно скопировать в буфер обмена и потом уже работать с ними в удобном редакторе. Так себе автоматизация, но все же лучше, чем ничего.
- Slovoeb — хорошая бесплатная программа с нехорошим названием. Вводите в нее набор «масок» и парсите всю выдачу Вордстата на нужную вам глубину. Можно так же собрать и данные правой по этим запросам, а так же поисковые подсказки.
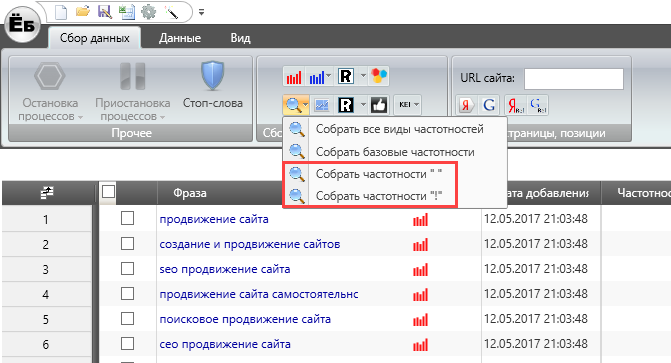
Для всех собранных таким образом фраз программа потом сама сможет собрать частотность (в кавычках, или в кавычках и с восклицательным знаком). Очень удобно, бесплатно, но сильно медлленно. Частотность для тысяч фраз программа будет собирать часами.
- Key Collector — платная версия предыдущей программы (не шибко дорогая, посему мною уже давно приобретенная).
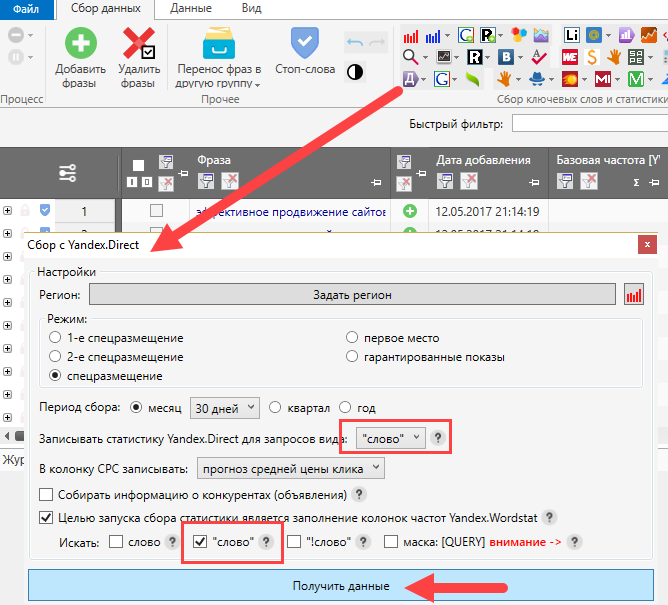
Key Collector имеет много дополнительных возможностей, но лично я использую в основном только быстрый сбор точной частотности. Делает он это очень быстро (тысячи запросов на считанные минуты).
Почему такая высокая частотность у запросов с повторяющимися словами?
Если вы уже более-менее погрузились в вопросы составления семядра и много спарсили запросов в Вордестате, то наверняка встречали странные запросы с повторяющимися словам, у которых почему-то высокая частотность даже при их заключении в кавычки и выставлении восклицательных знаков перед словами.
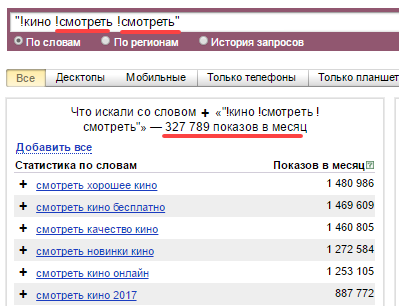
Даже если еще несколько раз добавить «смотреть», то частотность все равно останется практически такой же высокой. Так что же, верить Яндексу и оптимизировать статьи под такой бред? Ни в коем разе. Это еще один вид «пустышки». На самом деле, Wordstat воспринимает только одно из повторяющихся слов, а вот остальные «мысленно» заменяет другими возможными словами с таким же количеством знаков. В общем, несмотря на большие цифры обращать внимание на запросы с повторяющимися словами не стоит. Это фантом.
Принципы составления семантического ядра
При составлении семантического ядра вы не просто будете подбирать слова и фразы, а четко разделите их по тому, насколько часто их запрашивают у поисковиков и насколько эти запросы подойдут именно для вашего проекта. Зачем это нужно?
Во-первых, продвигаться по фразам, которые никого не интересуют, будет напрасным занятием, но главное не это. Дело в том, что организуя определенным образом внутреннюю линковку страниц своего будущего проекта, вы сможете добиться увеличения статического веса, например, у главной страницы и у страниц разделов или категорий. Таким образом, страницы, имеющие большой статический вес, будет актуально продвигать по более высокочастотным поисковым запросам.
А внутренние страницы сайта, статический вес которых не очень высок, можно оптимизировать под низкочастотные запросы (НЧ), которые, как я уже не раз упоминал, при удачном стечении обстоятельств можно продвинуть практически без привлечения внешней оптимизации (покупки обратных ссылок на эти статьи).
Но раз уж мы коснулись вопроса частотности запросов, без учета которого составить семантическое ядро у нас вряд ли получится, то я позволю себе немного напомнить вам об этом и о том, как определять их частоту. Итак, все запросы, которые пользователи набирают в поисковой строке Яндекса, Google или любой другой поисковой системы, можно довольно условно разделить на три группы:
- высокочастотные (ВЧ)
- среднечастотные (СЧ)
- низкочастотные (НЧ)
Отнести ключевую фразу к той или иной группе можно будет по количеству таких запросов, совершаемых пользователями в течении месяца. Но для разных тематик границы могут довольно существенно отличаться. Дело тут в том, что нас, по сути, при подборе ключевых слов интересует не частота ввода их пользователями, а то, насколько трудно будет продвинуться по ним (много ли оптимизаторов пытаются делать то же самое, что и вы).
Поэтому можно будет ввести еще три градации, которые для составления семантического ядра будут иметь большое значение:
- высококонкурентные (ВК)
- среднеконкурентные (СК)
- низкоконкурентные (НК)
Но вот определить конкурентность того или иного ключевого слова или фразы не всегда оказывается просто. Поэтому зачастую для упрощения проводят параллели и отождествляют ВК с ВЧ , СЧ с СК, а НЧ С НК. В большинстве случаев такое обобщение будет оправдано, но из любого правила, как известно, бывают исключения, и в некоторых тематиках НЧ могут оказаться выскоконкурентным, и вы это сразу же увидите по тому, как сложно будет продвинуться в ТОП по данным ключевикам.
Такие коллизии возможны в тематиках, где наблюдается сверхвысокая конкуренция и идет борьба за каждого отдельного посетителя, вытаскивая их даже по совсем низкочастотным запросам. Хотя это может быть присуще не только коммерческой тематике. Например, информационные сайты по тематике «WordPress» при составлении семантического ядра должны учитывать, что даже запросы с частотностью ниже 100 (ста показов в месяц) могут быть высоконкуренты по той простой причине, что сайтов по этой тематике тьма тьмущая, ибо даже такие «тупые дядьки» как я пытаются что-то писать по этой тематике.
Но мы не станем так глубоко вдаваться в детали и будем считать при составлении семантического ядра, что конкурентность (сколько оптимизаторов пытаются продвинуть свои проекты по этому ключу) и частотность (как часто их вводят в поисковую строку пользователи) находятся между собой в прямой зависимости. Ну, а частотность тех или иных ключевых слов мы уж как-нибудь определить сумеем, правда ведь?
Для этого можно использовать несколько сервисов статистики поисковых запросов, но мне больше всего по душе инструмент Яндекса. Раньше он предназначался только для пользователей сервиса Яндекс Директ, о котором я писал тут, чтобы рекламодатели могли правильно составлять тексты своих контекстных объявлений, учитывая, какие именно слова чаще всего спрашивают у этого поисковика пользователи.
Но потом доступ к онлайн сервису подбора ключевых слов под названием Яндекс Вордстат (Wordstat.Yandex.ru) был открыт для всех желающих, чем эти самые желающие и не преминули воспользоваться. Ну, а мы то чем хуже?
Что нужно учесть при сборке семантического ядра сайта
Раз уж речь зашла о перспективности. Сборка семантического ядра для сайта состоит из нескольких этапов:
- Подбор ключевых слов и определение их реальной частотности в Яндекс Вордстате (с использованием кавычек или их связки с восклицательными знаками). Ниже мы об этом поговорим поподробнее.
-
Определение перспективности продвижения по данным запросам. Что я имею в виду? Все довольно просто. Если данную фразу в свое семантическое ядро включили тысячи сайтов, то у вас будут проблемы с попаданием в ТОП 10, ибо конкурс слишком высок. Как оценить конкуренцию по вашим намеченным ключевым фразам, которые вы подобрали в Вордстате?
Можно набрать ее в Яндексе и посмотреть на число ответов, которое предлагает поисковая система по данному запросу. Вот пример низкоконкурентного варианта:
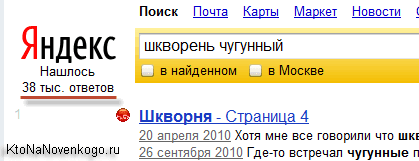
Принято считать, что по низкоконкурентным запросам Яндекс выдает меньше 100 000 результатов. Высококонкурентеные — более 1 000 0000. Ну, а все что по середине — это среднеконкурентные.
Если у вас подобранные ключевые запросы коммерческие, то можно будет посмотреть на данные по стоимости продвижения по ним, которые вам выдаст Мегаиндекс (читайте статью про бесплатные сервисы MegaIndex) или Сеопульт (платить за это не потребуется).
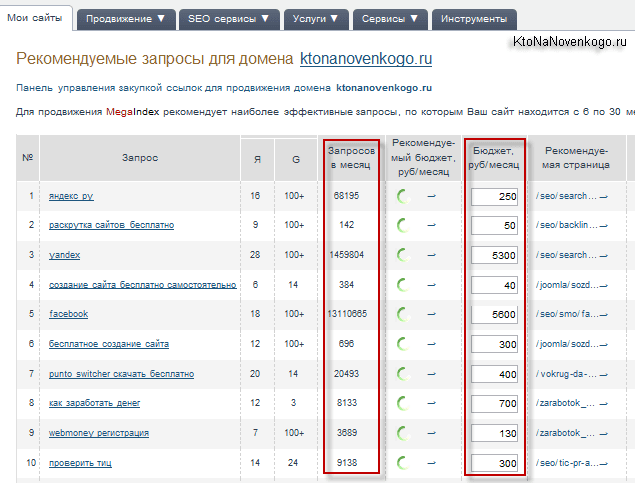
Эту же информацию умеет собирать с этих же и подобных им агрегаторов Кей Коллектор, о котором я упоминал в самом начале.
-
Вы должны распределить ключевые слова по страницам вашего сайта. Их можно группировать, чтобы не писать под каждое ключевое слово найденное в Вордстате отдельную статью. Определить, какие именно запросы можно объединять на одной вебстранице, а какие нельзя, вам помогут успешные конкуренты, которые попали в ТОП. Вообще, списывать у конкурентов не такая уж и плохая идея.
В случае информационных ресурсов для объединения запросов в одной статье нужно использовать обычную логику. Иногда бывает логичнее написать одну большую публикацию, а иногда — десяток маленьких. Какой вариант будет наиболее выигрышным проверить, скорее всего, получится только на практике. Собственно, можно это все совмещать, делая обзорную статью со ссылками на множество поясняющих.
При разработке семантического ядра очень важно с чего-то начать (за что-то зацепиться). Несколько ключевых фраз почерпнутых у ваших конкурентов, взятых из головы или же очевидно напрашивающихся, станут вашей отправной точкой. Но обязательно продолжайте процесс поиска и всегда имейте под рукой бумажку, чтобы можно было записать возникшую идею и потом посмотреть статистику в сервисе подбора слов от Яндекса, чтобы убедиться в ее состоятельности.
Из любого высокочастотного запроса можно с помощью Вордстата или Slovoeb получить десятки или даже сотни ключевых слов для ваших будущих статей. Как это сделать? Для начала нужно найти такие высокочастотники. Это самые очевидные фразы, которые используют пользователи при обращении к Яндексу, когда хотят получить ответ на вопрос по той тематике, в которой вы хотите подвязаться на создание сайта.
Например, для моего блога это могут быть слова Joomla, WordPress, продвижение сайтов, раскрутка сайтов, заработок и т.д. С них можно начинать. Но так поступают многие, поэтому было бы не плохо, если все приходящие вам идеи будущих статей вы пытались бы оформить в те запросы, по которым их могли бы найти пользователи Яндекса. Надо попытаться думать, как рядовой пользователь интернета задающий вопрос поисковику.
Да, еще про деление запросов на высокочастотные, низкочастотные и среднечастотные. Все это очень и очень условно. Если в вашей тематике вы смогли найти самую частотную ключевую фразу в статистике Яндекса с цифирькой 5000 (заключенной в кавычках, естественно), то в вашей теме запросы с частотой использования ниже 100 в месяц можно считать низкочастотными. А если в вашей теме ВЧ измеряются сотнями тысяч, то НЧ может быть все, что ниже 1000. Подробнее читайте про НЧ, СЧ, ВЧ и НК, СК, ВК поисковые запросы.
Подбор слов для семядра непосредственно в Яндекс Вордстате
Ладно. Воду лить можно долго. Давайте наберем запрос «Продвижение сайтов» в Вордстате и посмотрим, что он нам с вами сумеет подобрать.
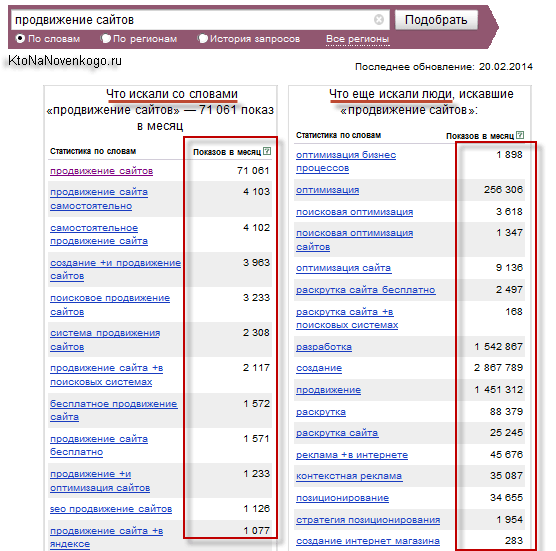
Замечательно. Мы получили кучу информации, которую теперь нужно будет попробовать как-то обработать. Яндекс нам подобрал слова на основе введенной нами фразы и распределил их по двух колонкам. Обе они очень важны.
В левой колонке Вордстата собраны все фразы, где непосредственно встречаются введенные ключевые слова. Справа от них отображается частотность их запроса у Яндекса его пользователями. Но не спешите радоваться, ибо частотность эта в большинстве случаев фейковая (что такое фейк). Т.е. написанные там цифры на самом деле могут быть фикцией.
Как же это проверить? Ну, первое что приходит в голову — открыть на новой вкладке браузера еще одно окно Вордстата и ввести в него все эти фразы из левой колонки по очереди, заключив их в кавычки.
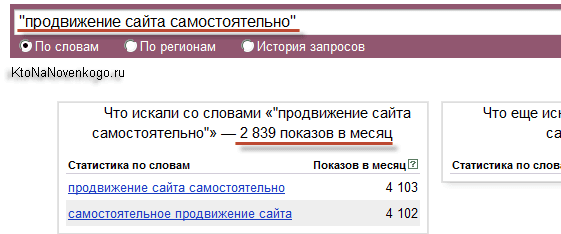
Вот тогда вы получите реальную статистику (ну, или более близкую к реальной). Можно скопировать эти фразы в вордовский или экселовский документ и добавить высчитанные таким образом частотности.
Просто? Теоретически да, но на практике, после проверки десятка фраз из левой колонки (с приведенного скриншота) в Вордстате, открытом в новой вкладке, вы захотите на все это забить и пойти напиться (ну или повеситься).
Рутина, она не всем доставляет удовольствие. А ведь левая колонка окна сервиса «Подбор слов» еще и имеет постраничную навигацию. Представляете, там может быть до 50 страниц, что в сумме даст 2000 подобранных ключевых фраз. И все их вручную надо будет проверить, заключив в кавычки. Пожалуй, что такое под силу единицам.
И это еще не все. Мы же забыли про правую колонку Вордстата Яндекса. А ведь это просто-таки замечательная штука. Там отображаются запросы тех же пользователей, что вводили фразу из правой колонки, сделанные ими в ту же самую поисковую сессию. Это позволит вам существенно расширить семантическое ядро сайта и порой даже в очень неожиданном направлении.
Что со всем этим богатством из правой колонки делать? Просмотреть ее содержимое и все фразы, что имеют отношения к вашей тематике, а затем пробить их во вновь открытой вкладке браузера с Вордстатом. В нашем примере в глаза бросается словосочетание «оптимизация сайта» с высокой (потенциально) частотностью.
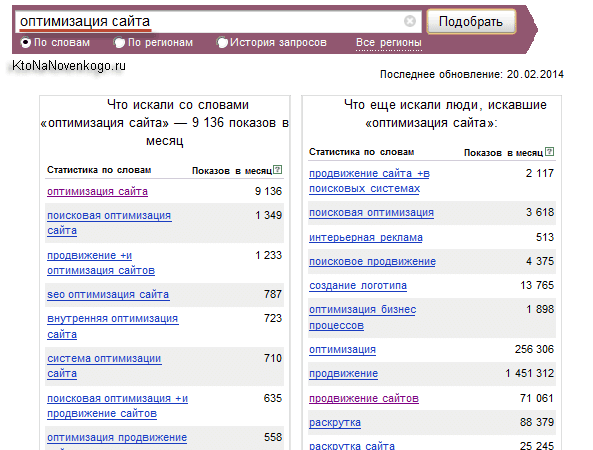
И что мы тут видим? А опять же много всего интересного. Из левой колонки нужно будет все фразы проверить на фейк с помощью заключения фразы в кавычки. А содержимое правой колонки можно проверить на нахождение там чего-то нового, чего вы еще не добавляли в свое семантическое ядро.
И так на протяжении многих часов можно сидеть с открытыми в разных вкладках браузера страницами сервис Яндекса «Подбор слов», чтобы ничего не упустить из потенциально возможных ключей и в то же время отсеять все пустышки. Через некоторое время, правда, вам захочется все это бросить, ибо усилия и усидчивость здесь нужны во истину не человеческие.
Вот именно на фоне подобных мучений ручного подбора ключевых слов и почувствуешь всю прелесть Key Collector, или его облегченной версии под названием Slovoeb. Какой же это кайф (без преувеличения) загнать в программу какой-нибудь пришедший вам в голову высокочастотный запрос, спарсить автоматически все страницы из левой колонки Вордстата, после чего также на автомате отсеять пустышки.
Полученный в результате список реально востребованных ключей можно будет отсортировать по убыванию частотности и сохранить в формате CSV для последующего анализа и разбивки по статьям. Кстати, процесс распределения ключевых слов по статьям можно тоже автоматизировать. Узнал об этом совершенно недавно из рассылки биржи ContentMonster (покупаю статьи последнее время в основном только у них).
Оказывается, что существует онлайн сервис KeyAssistant под эгидой этой биржи (он бесплатный, как я понял), который позволяет раскидать ключи по страницам, а страницы — по разделам. Объяснять его функционал довольно долго, поэтому предлагаю посмотреть «фильму» на тему и, возможно, оно вас заинтересует:
Ладно, это мы отвлеклись, а тем временем уже пора познакомиться с нашим сегодняшним героем с крайне непритязательным названием.
Как автоматизировать подбор слов из Яндекса в Slovoeb
Скачать Slovoeb можно по приведенной ссылке. Установки он не требует — достаточно распаковать скачанный архив и запустить файлик Slovoeb.exe
Сразу после запуска имеет смысл зайти в настройки программы, где на вкладках «Парсинг» — «Yandex Wordstat» в область «Настройки аккаунтов Yandex» нужно будет ввести хотя бы одну пару логин-пароль (разделенный двоеточием и без пробелов) для доступа к сервисам этой поисковой системы. Зачем? Я уже упоминал, что с недавних пор Вордстат позволяет собой пользоваться только авторизованным пользователям.
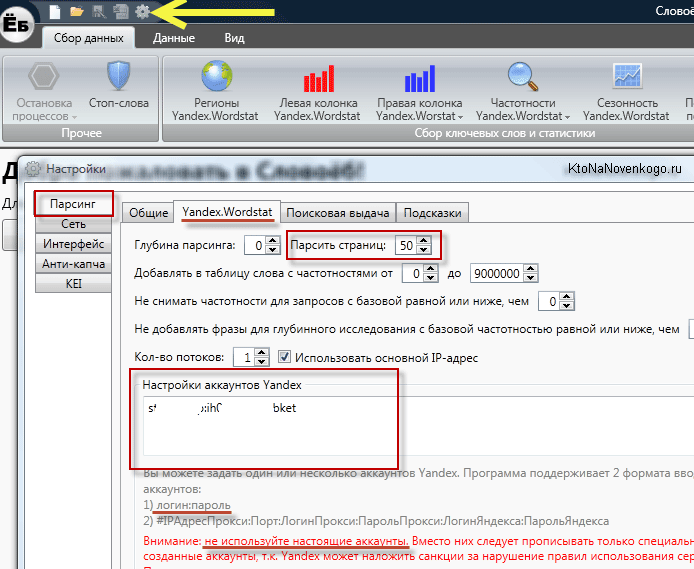
Обратите внимание, что аккаунты в Яндексе лучше будет создать новые (фейковые, т.е. не основные, где вы, например, работаете с РСЯ или деньгами). Почему? Парсить свою выдачу напрямую поисковик не разрешает (вместо этого предоставляет лимиты для работы XML выдачей), поэтому можно схватить бан аккаунта за проявление чрезмерной наглости.
Там же имеет смысл поставить максимальное количество страниц из левой колонки сервиса «Подбор слов» Яндекса, которое будет парситься (50). Это пригодится при пробивании ВЧ запросов, т.к. там может быть очень много возможных вариантов. Иногда даже на последней странице общая частотность равняется нескольким тысячам, что говорит о том, что не все ключи можно собрать с помощью Вордстата (к сожалению).
Если не хотите сильно нагружать и злить Яндекс, то на первой вкладке настроек «Общие» увеличьте диапазон таймаутов (перерывов между подачей запросов к поисковой системе).
Сохраняете настройки и жмете на кнопку «Создать проект», либо на «Открыть проект», если не закончили какую-то работу раньше.
Даете проекту название, после чего вводите в появившуюся строку интересую вам ключевую фразу или слово. Ввели? Хорошо, жмите на Энтер на клавиатуре.
Да, есть альтернативный вариант. Нажать на кнопочку «Левая колонка Yandex Wordstat» и ввести в открывшуюся форму сразу несколько фраз (по одной в строке), статистику по которым вы хотите спарсить. Потом жмете кнопку расположенную внизу и получаете за раз несколько списков слитых воедино.
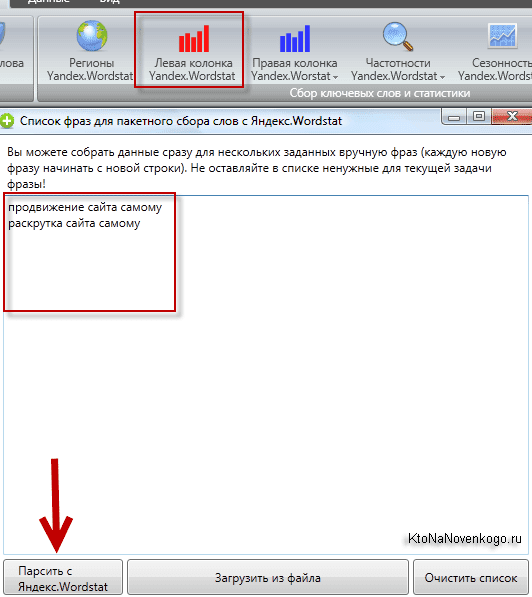
В современной версии Slovoeb придется подождать пяток или чуть меньше минут, пока он состыкуется с Вордстатом (это происходит только после запуска программы, а в дальнейшей работе таких задержек не будет).
Потом начнется парсинг левой колонки сервиса «Подбор слов» по данной фразе на ту глубину (число страниц), которое вы установили в настройках. У меня там всегда 50 установлено. В итоге получите не более 2000 ключей включающих ваше исходное словосочетание.
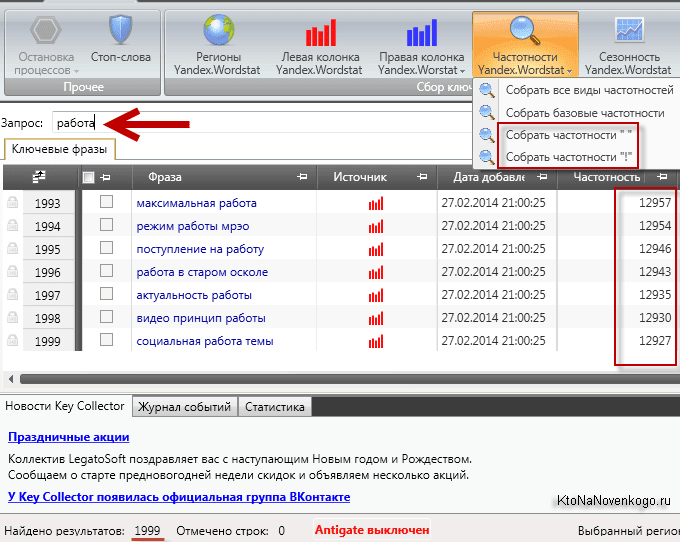
Для примера я взял супер ВЧ запрос «работа». Как видите, даже на последней странице Вордстата общая частотность фраз зашкаливает за десять тысяч. Следовательно, мы в этом случае не можем с помощью данного инструмента охватить весь пул запросов и многое остается за кадром. Вытащить «хвост» тоже, наверное, можно, но это уже гораздо сложнее и менее надежно.
Так, это мы просто спарсили ключи, но ведь нужно еще отделить зерна от плевел, т.е. понять, какие из этих ключевых слов имеет смысл дальше использовать в семантическом ядре, а какие отбросить в силу их крайне низкой реальной частотности. Последняя вычисляется благодаря заключению фразы в кавычки или еще с добавлением восклицательных знаков.
В Slovoeb для этого нужно будет всего лишь выбрать из выпадающего меню кнопки «Частотности Yandex.Wordstat» последний или предпоследний пункты. Разницу между ними вы уже должны понимать, поэтому выбирайте то, что считаете нужным. Я почему-то предпочитаю последний вариант, но это, возможно, излишне ограничивает результаты.
Пробивка реальной частотности в Slovoeb идет гораздо медленнее парсинга и что важно, не заходите в этом время в Вордстат через браузер, ибо выскочит капча, на которой данная программа у меня зависает. Возможно, что это проблема имеет место быть только на моем компьютере, но все же стоит предупредить.
За процессом проверки реальной частотности вы можете следить воочию — в соответствующей колонке в реальном времени будут появляться новые цифры. Хотя имеет смысл это дело пустить на самотек и пойти заняться чем-то более полезным, а в программу можно лишь периодически заглядывать. По окончании процесса сбора красный шестиугольник в верхнем левом углу станет серым.
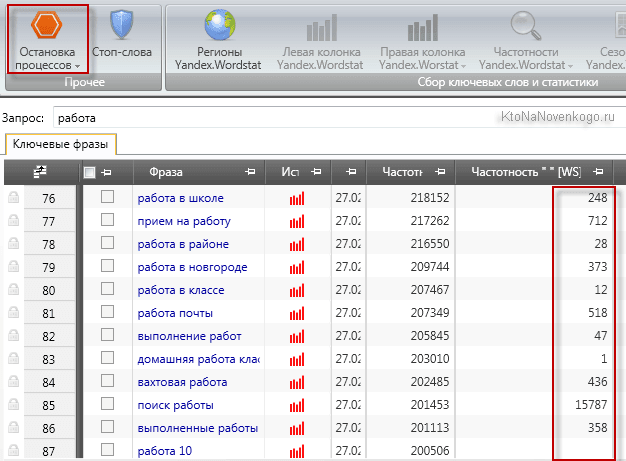
При желании вы сами можете остановить процесс, выбрав соответствующий пункт из контекстного меню этой кнопки. Проект можно будет сохранить, а Slovoeb закрыть. А потом опять открыть программу и сохраненный проект, после чего описанным выше способом продолжить сбор статистики. Очень удобно и, главное, просто до безобразия.
Вот. После окончания процесса вы можете отсортировать результаты по убыванию частотности, кликнув по заголовку столбца со статистикой фраз заключенных в кавычки, или с ними и восклицательными знаками перед каждым словом. Получится очень наглядно, ибо самые перспективные (пусть зачастую и не реальные в силу высокой конкуренции) запросы будут находиться вверху списка.
Советую сохранять все полученные в результате подбора ключевых слов списки в файл. Делается это в Slovoeb с помощью показанной на скриншоте иконки, расположенной в верхней части окна программы. Сохранение идет в формате CSV, который при желании можно открыть и обычным Экселем, главное указать правильный разделитель столбцов, чтобы все срослось.
Если не получается, то в настройках программы на вкладке «Интерфейс» — «Экспорт» выберете другой формат сохранения (xlsx). Там же можно посмотреть и разделитель используемый при экспорте в CSV.
Лишние столбцы в Экселе можно удалить (либо убрать в тех же самых настройках экспорта простым удалением галочек с не нужных вам столбцов — см. приведенный чуть выше скриншот), дабы они не снижали наглядность. Лично я оставляю только саму ключевую фразу и ее реальную частотность, а все остальное — в топку.
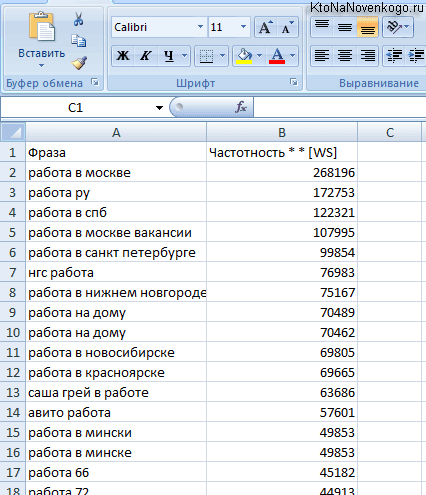
Собственно, с этими списками уже можно работать, что-то беря оттуда напрямую, а что-то опять пробивая через Вордстат на предмет получения новых ключей (например, не полную фразу, а встретившееся в ней слово или словосочетание, которое само по себе может породить массу вариантов). В общем, процесс весьма творческий и в силу его сильной автоматизации не шибко утомительный, особенно в сравнении с описанным выше ручным методом использования сервиса «Подбор слов».
Другие возможности Slovoeb по сбору статистики
Да, забыл еще упомянуть, что Slovoeb умеет собирать и поисковые подсказки. Это то, что выпадает при вводе запроса в поисковую строку Яндекса или Гугла.
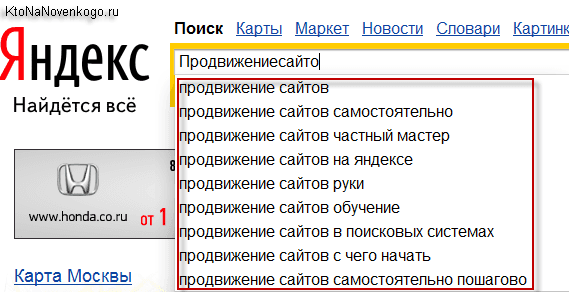
Среди них тоже могут содержаться вполне себе интересные варианты ключевиков, которые потом можно будет проверить описанным чуть выше способом на предмет реальной их частотности.
Раньше для этого существовала отдельная утилита (СловоДер) от того же разработчика (Александра Люстика), а сейчас этот функционал заключен в одной программе. Для сбора поисковых подсказок достаточно нажать соответствующую кнопку на панели инструментов Slovoeb.
В открывшемся окне нужно поставить галочки напротив тех поисковиков, откуда эти подсказки будут дергаться.
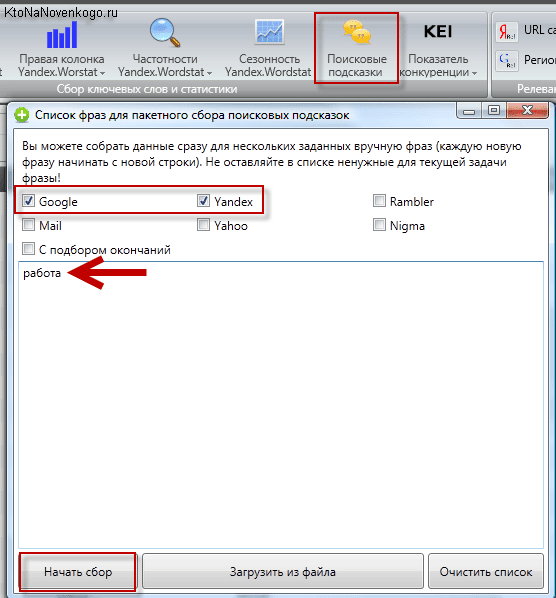
Собственно, следует также указать ключевые слова, для которых эти подсказки будут собираться и нажать кнопку «Начать сбор». Собранные ключи из подсказок добавятся к общему списку, чтобы потом можно было их все скопом проверить и собрать статистику частоты использования.
В общем списке они будут помечаться другим значком, чтобы вам было нагляднее с ними работать и различать парсинг Вордстата и поисковых подсказок.
Тоже самое касается и сбора слов из правой колонки Вордстата (Slovoeb умеет ее парсить тоже).
Чуть выше по тексту я говорил, что очень важно при сборке семантического ядра обращать внимание не только на частотность подобранных слов и фраз, но и на то, насколько высокая конкуренция существует в выдаче Яндекса и Гугла по данным запросам. Чем она выше, тем сложнее вам будет пробиться в ТОП.
Для ее оценки многие предлагают использовать число ответов поисковых систем, которые они дают на данный запрос. Чуть выше я писал об этом подробнее. Так вот, наша замечательная программа умеет парсить это самое число ответов из выдач Яндекса и Гугла.
Т.е. по всем собранным словам вы сможете пробить их конкурентность с помощью кнопочки KEI на панели инструментов Slovoeb:
Параметр KEI получается несколько утрированным и, чтобы на него опираться, лучше будет воспользоваться Key Collector (платная версия данной бесплатной программы с существенно более расширенным функционалом).
Как вы можете видеть, даже у упрощенной версии программы имеется довольно-таки богатый функционал. Что уж говорить о Key Collector. Другое дело — нужен ли вам этот функционал? Лично мне оказалось очень трудно выкроить время на его освоение, тем более, что я не видел в этом особых перспектив. Я не прав? Разубедите меня в комментариях тогда.
Тем не менее, не у всех есть время и силы на проведения подобной работы (сбор полного семядра), но делать ее все равно нужно обязательно. Однако, если есть спрос, то будет и предложение. Всегда найдутся люди, которые готовы будут проделать это за вас, другое дело, что они могут оказаться не всегда честными и исполнительными.
Позволю себе наглость и приведу в завершении видео, взятое с блога Максима Довженко, где он рассказывает про настройки и подбор слов в Slovoeb:
Завершаем составление семантического ядра
Как я говорил чуть выше, мы будем считать ВЧ по умолчанию и ВК, а значит для продвижения по ним нужно выбирать такие страницы своего сайта, которые будут иметь наибольший статический вес. Этот самый статический вес или PageRank набирается за счет входящих ссылок на эту страницу.
Важно понимать, что при его расчете не учитывается содержимое анкора ссылки и не важно то, внешняя она или внутренняя. Подробнее про статический и динамический веса, а также про анкоры читайте по приведенной ссылке.
Т.о. для продвижения по самым высокочастотным запросам (из составленного семантического ядра) наиболее подходит главная страница, ибо на нее, как правило, будут вести ссылки со всех других страниц вашего ресурса (при обычной структуре), а также и большинство внешних ссылок, особенно полученных естественным образом. Так что статический вес главной для большинства ресурсов будет самым высоким (раньше это можно было понять по показанию тулбарного значения Google PageRank, которое для нее будет завсегда выше, нежели, чем для внутренних, но сейчас Гугл решил перестать с нами делиться этой информацией).
При ранжировании сайтов в выдаче поисковые системы при прочих равных условиях (одинаковом качестве внутренней и внешней оптимизации) выше поставят ту страницу, чей статический вес больше. Посему, если вы выберете для продвижения по ВЧ внутреннюю страницу (с заведомо более низким статвесом), то конкуренты будут иметь перед вами преимущество, в случае продвижения ими по тем же ключевым словам, но уже главной страницы своего сайта. Хотя, лучшим способом будет анализ Топ 10 по нужному вам ключевику на предмет количества главных, которые участвуют в ранжировании (это, кстати, косвенно говорит о конкурентности запроса).
Если в структуре внутренней перелинковки вашего будущего проекта будут предусмотрены и другие страницы с большим статическим весом (разделы, категории и т.п.), то в семантическом ядре нужно будет отметить их как потенциальных кандидатов на оптимизацию под более-менее высоко- и среднечастотные запросы из подобранных вами.
Таким образом вы сможете использовать с пользой особенности распределения статического веса на вашем сайте и подобрать в соответствии с этим наиболее подходящие по частотности запросы для каждой из страниц, т.е. составить полностью семантическое ядро: подобрать пары запрос — страница.
Однако, при оптимизации страницы под продвижение по ВЧ или СЧ ключевой фразе, вы можете добавить еще и более низкочастотный ключевик, который будет получаться путем разбавления основного ключа. Но опять же, не все ключи можно сделать соседями на одной посадочной странице. Понять, какие можно использовать вместе, а какие нельзя, вам поможет анализ ваших прямых конкурентов в Топ 10 по основной ключевой фразе. Если они в Топе, то значит поиску их вариант семядра приходится по душе.
Однако, легко сказать, а сложно сделать. Попробуйте пробить выдачу по сотням (тысячам) запросов из вашего предварительного семантического ядра на предмет их совместимости или несовместимости. Тут уж точно «кони можно двинуть». Однако, я и тут приду вам на помощь, дав ссылку на подробную публикацию про распределение по страницам (кластеризацию) запросов из семядра. Реально все упрощает маленькая программка.
При внешней оптимизации (закупке и простановке ссылок с нужными анкорами) нужно опять же учитывать созданное семантическое ядро и проставлять бэклинки с учетом тех ключевых слов, под которые оптимизировалась данная страница вашего сайта. Не забудьте, что в эпоху Минусинска и Пингвина бэклинк с прямым вхождением лучше ставить один, но с очень жирного и тематического сайта, а «разбавки» безанкорами, названиями статьи и т.п. делать стоит побольше.
На практике ваше семантическое ядро будет представлять, наверное, довольно разветвленную схему страниц с подобранными для них ключевыми словами, под которые они будут оптимизированы и продвигаться. Там же будет прорисована схема внутренней перелинковки для накачки нужных страниц статическим весом.
В общем, будет включено и рассмотрено все что только можно, останется лишь начать строить (или переделывать) сайт по данному проекту (семантическому ядру). Лично я в последнее время всегда следую правилу о предварительном его составлении, ибо работать вслепую может оказаться не рентабельным занятием — силы потрачу, а те, кому материал будет интересен и полезен, так его и не найдут ни в Яндексе, ни в Гугле…
Если говорить об этом блоге, то перед написанием статьи я обязательно лезу в Вордстат и смотрю, как формулируют свои вопросы пользователи по той тематике, про которую планирую писать. Тем самым я с большей вероятностью найду своего читателя, который при удачной публикации может стать и постоянным. От этого никому не плохо, разве что только немного времени потратить приходится.
Ну, а в случае проекта по новой для вас тематике, и особенно, если вы начинающий оптимизатор, составление подобного ядра и подбор подходящих ключевых слов сможет вам существенно помочь и позволит избежать лишних ошибок. Тем не менее, не у всех есть время и силы на проведение подобной работы, но делать ее все равно нужно обязательно. Однако, если есть спрос, то будет и предложение. Всегда найдутся люди, которые готовы будут проделать это за вас, другое дело, что они могут оказаться не всегда честными и исполнительными.
