The following example defines macros dotsfrom and dotsto, which put a dotted line between the locations. The locations are get from module zref-savepos of package zref, which provides an interface for the pdfsavepos feature of pdfTeX, which is also available in LuaTeX and XeTeX.
The first LaTeX run stores the positions in the .aux file as references and the next run will use the position values from the previous run. This requires two LaTeX runs.
The table is implemented by a simple tabular* for the whole line width and with glue between the columns to fill the space.
The setting of the dots via dotsfrom and dotsto would also
work in a tabbing environment or in lists.
The dotted line uses the code of @dottedtocline, which is used in the table of contents, for two reasons:
-
The space between the dots is not as narrow as in
dotfilland therefore less obtrusive. Also the space can be configured by redefining@dotsep. -
The code uses
leadersinstead ofcleaders(dotfill). Therefore
the dots are vertically aligned if they are in the same enclosing box.
However, this is not true here. Therefore, all enclosing boxes for the dots are starting vertically aligned at x coordinate zero.
The example shows the technique. But I have not wrapped the low level macros inside markup commands, because the target layout is not too clear
(alignment requirements, what about too long entries, how many categories, may the article name column use space of unused category columns, are the article groups independent with possible different positions for the middle column, multi-page tables, …?).
documentclass{article}
usepackage{zref-savepos}
providecommand{zsaveposx}{zsavepos}
newcounter{dotsfromto}
renewcommand*{thedotsfromto}{DFT@thevalue{dotsfromto}}
newcommand*{dotsfrom}{%
stepcounter{dotsfromto}%
leavevmode
zsaveposx{thedotsfromto f}%
}
makeatletter
newcommand*{dotsto}{%
leavevmode
zsaveposx{thedotsfromto t}%
zref@refused{thedotsfromto f}%
zref@refused{thedotsfromto t}%
ifnumzposx{thedotsfromto t}>zposx{thedotsfromto f}relax
llap{%
hbox to zposx{thedotsfromto t}sp{%
kernzposx{thedotsfromto f}sprelax
leadershbox{$m@th % from @dottedtocline
mkern@dotsep muhbox{.}mkern@dotsep mu%
$}hfill
}%
}%
fi
}
makeatother
begin{document}
noindent
begin{tabular*}{linewidth}{@{extracolsep{fill}}lcc@{}}
bfseries Article group 1 & & Cat.~No.\
Article 1dotsfrom & & dotsto ID\
Second articledotsfrom & &dotsto ID\[normalbaselineskip]
bfseries Group 2 & Cat.~No.~1 & Cat.~No.~2\
Productdotsfrom & dotsto ID1dotsfrom & dotsto ID2\
Another productdotsfrom & dotsto ID1dotsfrom & dotsto ID2
\[normalbaselineskip]
bfseries Article group 3 & & Cat.~No.\
Somethingdotsfrom & & dotsto ID\
Other thingdotsfrom & & dotsto ID\
end{tabular*}
end{document}

1.1. Исходные данные
На входе имеется
набор идентификаторов, которые
организуются в таблицу идентификаторов
по одному из двух методов:
-
Простое рехеширование.
-
Простой список.
Должна быть
предусмотрена возможность осуществления
многократного поиска идентификатора
в этой таблице. Список идентификаторов
задан в виде текстового файла. Длина
идентификатора ограничена 32 символами.
Требуется, чтобы
программа подсчитывала число коллизий
и среднее количество сравнений,
выполняемых при поиске идентификатора.
На основе анализа необходимо выбрать
лучший метод для использования в
дальнейшем.
1.2. Назначение таблиц идентификаторов
Проверка правильности
семантики и генерация кода требуют
знания характеристик идентификаторов,
используемых в программе на исходном
языке. Эти характеристики выясняются
из описаний и из того, как идентификаторы
используются в программе и накапливаются
в таблице символов, или таблице
идентификаторов. Любая таблица
идентификаторов состоит из набора
полей, количество которых равно числу
идентификаторов программы. Каждое поле
содержит в себе полную информацию о
данном элементе таблицы. Под идентификаторами
подразумеваются константы, переменные,
имена процедур и функций, формальные и
фактические параметры.
В данной работе
сравниваются два метода организации
таблицы идентификаторов: метод простого
рехеширования и метод простого списка.
Метод простого
рехеширования основан на хеш-адресации,
то есть на использовании значения,
возвращаемого хеш-функцией, в качестве
адреса ячейки из некоторого массива
данных. Хеш-функция вычисляется путем
выполнения над цепочкой символов
некоторых простых арифметических и
логических операций. Самой простой
хеш-функцией для символа является
ASCII-код символа.
В данной курсовой
работе принята хэш-функция суммаASCII-кодов первого
и пятого символов цепочки.
Сравниваемые в
данной работе методы организации таблицы
идентификаторов
простого рехеширования и простой список.
Ниже каждый метод рассмотрен подробнее.
1.3. Метод простого рехеширования
Согласно
данному методу, если
для элемента А
адрес
п()
= h|A|,
указывает
на уже занятую ячейку, то есть в случае
возникновения коллизии, необходимо
вычислить значение функции n1
=
h1|A|
и
проверить занятость ячейки по адресу
n1.
Если и она занята, то вычисляется
значение h2|A|.
И
так до тех пор, пока либо не будет найдена
свободная ячейка,
либо очередное значение hi|A|
не совпадет с h|A|.
В
последнем случае считается,
что таблица идентификаторов заполнена
и места в ней больше нет
выдается
сообщение об ошибке размещения
идентификатора в таблице.
Согласно методу
простого рехеширования:
hi(A)
= (h(A)+i) mod Nm,
где Nm
максимальное значение хэш-функции.
В данной курсовой
работе принята хэш-функция суммаASCII-кодов,
максимальное значение хэш-функции равно
512.
Поскольку при
заполнении таблицы идентификаторов
основными операциями являются добавление
элемента в таблицу и поиск элемента в
ней, на рис. 1 и рис. 2 представлены
блок-схемы этих операций для рассматриваемого
метода.
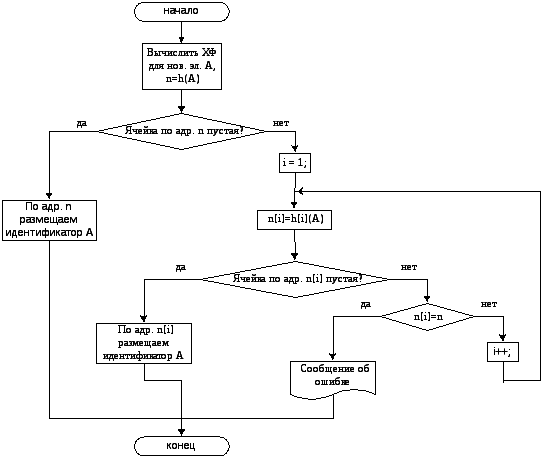
Рис. 1. Блок-схема добавления элемента
в таблицу идентификаторов по методу
простого рехеширования


Рис. 2. Блок-схема алгоритма поиска
элемента в таблице идентификаторов,
организованной по методу простого
рехеширования
Соседние файлы в папке ПЗ
- #
- #
- #
- #
02.05.2014880.64 Кб42ПЗ.doc
- #
Использование алгоритма Eclat в Python для частого анализа набора элементов для анализа корзины

В этой статье вы узнаете все, что вам нужно знать об алгоритме Eclat. Eclat означает кластеризацию классов эквивалентности и обход решетки снизу вверх и представляет собой алгоритм для анализа правил ассоциации (который также объединяет частый анализ набора элементов). .
Анализ ассоциативных правил и частый анализ наборов товаров легче всего понять в их приложениях для анализа корзины: здесь цель состоит в том, чтобы понять, какие продукты часто покупают вместе покупатели.
Эти правила ассоциации затем можно использовать, например, для рекомендательных систем (в случае покупок в Интернете) или для улучшения магазина при покупках в офлайн-магазинах.
Алгоритм ECLAT для интеллектуального анализа ассоциативных правил
Алгоритм ECLAT – не первый алгоритм поиска ассоциативных правил. Основным алгоритмом в домене является алгоритм априори. Поскольку алгоритм Априори является первым алгоритмом, который был предложен в данной области, он был улучшен с точки зрения вычислительной эффективности (т.е. они сделали более быстрые альтернативы).
ECLAT против роста FP против априори
Есть две более быстрые альтернативы алгоритму Apriori, которые являются современными: одна из них – FP Growth, а другая – ECLAT. Между FP Growth и ECLAT нет очевидного победителя с точки зрения времени выполнения: оно будет зависеть от разных данных и разных настроек в алгоритме.
Пример использования алгоритма ECLAT
Давайте теперь представим пример использования, чтобы сделать тему немного более практичной и прикладной. В этой статье мы возьмем небольшой набор данных о транзакциях ночного магазина. Для каждой транзакции у нас просто список продуктов.
Тот же набор данных использовался в предыдущих статьях для алгоритма априори и алгоритма роста FP, чтобы мы могли использовать их в качестве эталона и проверить, совпадают ли полученные результаты.
Исходный набор данных выглядит следующим образом:

Как видите, покупатели этого ночного магазина в основном покупают пиво, картофельные чипсы, вино и тому подобное, а также некоторые другие товары.
ECLAT: быстрее, но меньше показателей
Если вы уже знакомы с другими алгоритмами частого интеллектуального анализа наборов элементов или ассоциативных правил, есть небольшая вещь, которая может вас удивить. В то время как большинство алгоритмов содержат ряд ключевых показателей своих правил, ECLAT этого не делает.
Например, ECLAT не дает вам показателей уверенности и эффективности, которые необходимы для интерпретации в альтернативных моделях. С другой стороны, это позволяет модели быть быстрее: у пользователя есть выбор между скоростью и наличием большего количества показателей.
Как работает алгоритм ECLAT?
Давайте теперь перейдем к алгоритму ECLAT, повторив шаги алгоритма вручную.
Шаг 1. Составьте список идентификаторов транзакций (TID) для каждого продукта
Первый шаг – составить список, содержащий для каждого продукта список идентификаторов транзакций, в которых встречается этот продукт. Этот список представлен в следующей таблице.

Эти списки идентификаторов транзакций называются набором идентификаторов транзакций, также называемым набором идентификаторов транзакций.
Шаг 2 – Фильтр с минимальной поддержкой
Следующим шагом является определение значения, называемого минимальной поддержкой. Минимальная поддержка будет служить для фильтрации продуктов, которые встречаются не так часто, чтобы их можно было рассмотреть.
В текущем примере мы выберем значение 7 для минимальной поддержки. Как вы можете видеть в таблице на шаге 1, есть два продукта с набором TID, который содержит менее 7 транзакций: мука и масло. Поэтому мы их отфильтруем, и получим следующую таблицу:

Шаг 3. Вычислите набор идентификаторов транзакций для каждой пары продуктов.
Теперь перейдем к парам товаров. Мы в основном повторим то же самое, что и в шаге 1, но теперь для пар продуктов.
В алгоритме ECLAT интересно то, что этот шаг выполняется с помощью пересечения двух исходных наборов. Это отличает его от алгоритма Априори.
Алгоритм ECLAT работает быстрее, потому что гораздо проще определить пересечение набора идентификаторов транзакций, чем сканировать каждую отдельную транзакцию на наличие пар продуктов (как Apriori делает). На изображении ниже вы можете увидеть, как легко отфильтровать идентификаторы транзакций, общие для пары продуктов Wine и Cheese:

При пересечении для каждой пары продуктов (без учета продуктов, не получивших поддержки по отдельности) получается следующая таблица:

Шаг 4 – Отфильтруйте пары, которые не достигают минимальной поддержки
Как и прежде, нам нужно отфильтровать результаты, которые не достигают минимальной поддержки, равной 7. В результате остается только две пары продуктов: вино и сыр и пиво и картофельные чипсы.

Шаг 5 – Продолжайте до тех пор, пока вы можете создавать новые пары выше поддержки
С этого момента вы повторяете шаги как можно дольше. В текущем примере, если мы создадим продуктовые пары из трех продуктов, вы обнаружите, что нет ни одной группы из трех продуктов, которые достигают минимального уровня поддержки. Следовательно, правила ассоциации будут теми, что были получены на предыдущем шаге.
Алгоритм ECLAT в Python
Для этого упражнения мы будем использовать пакет pyECLAT в Python. Это очень простой в использовании пакет. Если вы работаете в среде Notebook, вы можете установить его следующим образом:
После установки пакета вам понадобится способ ввода данных. В этом случае давайте введем данные в виде списка списков. Каждая транзакция представлена в виде списка продуктов. Сделать это можно следующим образом:
Библиотека pyECLAT принимает в качестве входных данных фрейм данных. Вы можете просто преобразовать свой список транзакций во фрейм данных, а пакет pyECLAT позаботится обо всем остальном. Не проблема, что у вас много значений None в итоговом фрейме данных.
Вот как будут выглядеть данные:

Теперь, когда у вас есть данные, вам нужно указать ряд параметров алгоритма. Во-первых, вам нужно указать наименьший размер набора элементов, который вас интересует. В этом случае нас интересуют ассоциации продуктов, поэтому мы хотим исключить отдельные (1-элементные) наборы элементов: минимальный размер должен быть равен 2.
Нам также необходимо записать минимальное значение поддержки в процентах, что легко сделать, как показано в приведенном ниже коде.
Наконец, пакет pyECLAT хочет, чтобы мы указали максимальный размер. У нас нет максимального размера для наборов товаров (мы также были бы заинтересованы в крупных товарных ассоциациях). Поэтому берем максимальный размер транзакции.
Теперь, когда у нас есть все необходимые входные данные, мы, наконец, можем начать использовать пакет pyECLAT. Для этого есть два шага: вы сначала создаете экземпляр, а затем подбираете алгоритм. Сделать это можно следующим образом:
Метод fit возвращает две вещи: так называемые индексы правил ассоциации и так называемые поддерживаемые правила ассоциации . Как я объяснял ранее, метрик будет не так много. Единственное, что интересно здесь, это посмотреть на поддерживаемые правила, используя следующий код:
Вы увидите, что определены два правила: вино и сыр и пиво и картофельные чипсы:

Интерпретация
Интерпретация этого заключается в том, что в транзакциях нашего ночного магазина есть две относительно сильные комбинации продуктов. Люди часто вместе покупают вино и сыр. Люди также часто покупают вместе картофельные чипсы и пиво. Ясно, что было бы неплохо собрать эти продукты вместе, чтобы люди могли легко добраться до них обоих. Или, может быть, владелец магазина мог бы подумать о том, чтобы упаковать продукты в привлекательное предложение, чтобы еще больше повысить продажи этих продуктов.
Заключение
В этой статье вы узнали об алгоритме ECLAT как о быстром и эффективном методе интеллектуального анализа ассоциативных правил или частого анализа набора элементов. Вы видели, что, хотя он быстрее, он имеет меньше показателей, чем альтернативные методы, отчасти поэтому он быстрее.
В примере Python вы видели, как использовать пакет pyECLAT на примере данных транзакции из ночного магазина. Вы видели, как были обнаружены два ассоциативных правила и что владелец магазина мог сделать с такими знаниями.
Надеюсь, эта статья была для вас полезной. Благодарим за чтение. Следите за обновлениями, чтобы получать больше математических данных, статистики и данных!
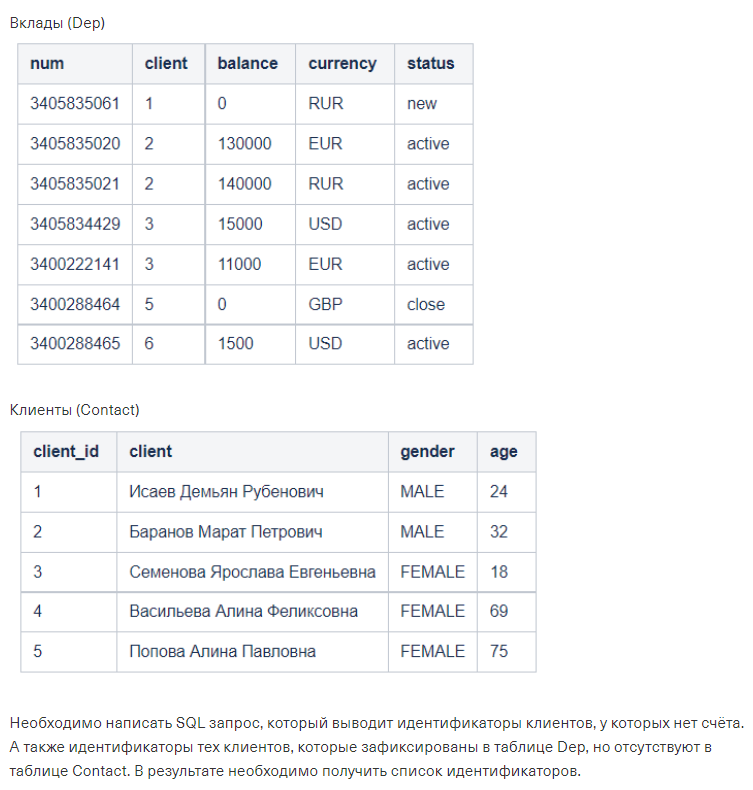
Необходимо написать SQL запрос, который выводит идентификаторы клиентов, у которых нет счёта. А также идентификаторы тех клиентов, которые зафиксированы в таблице Dep, но отсутствуют в таблице Contact. В результате необходимо получить список идентификаторов.
-
Вопрос заданболее года назад
-
1570 просмотров
SELECT client
FROM ( SELECT DISTINCT client
FROM Dep
UNION ALL
SELECT client_id
FROM Contact ) total
GROUP BY 1
HAVING COUNT(*) = 1SELECT
coalesce(contact.client_id, Dep.client) AS client_id
FROM
contact
FULL JOIN Dep ON contact.client_id = Dep.client
WHERE
contact.client_id is null
or Dep.client is null
GROUP BY
coalesce(contact.client_id, Dep.client)Пригласить эксперта
-
Показать ещё
Загружается…
19 мая 2023, в 00:55
3000 руб./за проект
18 мая 2023, в 23:42
1800 руб./за проект
18 мая 2023, в 22:57
500 руб./за проект
Минуточку внимания
Я пытаюсь выяснить, как составить список переменных или предпочтительно цикл, который идентифицирует идентификатор. Вот пример.
thumb1 = document.getElementById("image1");
Но вместо того, чтобы быть “image1”, я хочу, чтобы он прошел весь путь до изображения15. Я бы предпочел иметь цикл с кодом выше, который идентифицирует идентификатор от “image1” до “image15”. Я новичок в Javascript, поэтому любая помощь приветствуется! Спасибо!
03 март 2015, в 01:12
Поделиться
Источник
1 ответ
Вы могли бы сделать что-то вроде этого:
var elements = [];
for(var i = 1; i <= 15; i++) {
var id = "image" + i;
elements.push(document.getElementById(id));
}Но умнее всего было бы просто добавить один класс ко всем вашим элементам изображения и использовать его в сочетании с querySelectorAll:
var elements = document.querySelectorAll(".image");<div>
<img id="image1" class="image" />
<img id="image2" class="image" />
<img id="image3" class="image" />
</div>Will Reese
02 март 2015, в 21:41
Поделиться
Ещё вопросы
- 0Функция загрузки blogger.com uncaught referenceerror $ не определена
- 1Ошибка «закрыто гнездо» при попытке отправить / получить jxrpc через поток сокета
- 1Игнорируйте отсутствующие изображения в SVG с данными D3 и введите методы [дубликаты]
- 0JQuery триггер стека событий с течением времени
- 0загрузка файла JavaScript соответственно
- 0javascript, div мигает вместо исчезновения
- 0AngularJS продолжить цикл из индекса
- 0как показать сообщения проверки при отправке формы в угловых js
- 0Случай SQL-запроса с предложением Где / Имея
- 0Добавление в MySQL из формы Materialise
- 0Объединить два массива, если одно из значений равно ключу
- 0Невозможно войти в phpMyAdmin
- 0Как получить данные результата в запросе углового обещания?
- 1Методы для того, чтобы модуль узла возвращал «поток» данных?
- 0Получение history.js для запуска функции
- 0Совместное использование таблицы БД Mysql между разными учетными записями пользователей
- 0jQuery – объект Animate, которому был присвоен случайный идентификатор
- 0Сортировка массива структур
- 0получить доступ к главной таблице из реплики
- 0Как работает символ $ в jquery? [Дубликат]
- 0Элементы управления JQuery UI не работают после загрузки jquery.js после jquery.ui.js
- 1Является ли View или ViewModel ответственным за преобразование данных из модели, представляемой в пользовательском интерфейсе?
- 1Конвертировать декоратор в пользовательский виджет в DOJO?
- 0Использование Composer для автозагрузки Doctrine 1 в Zend Framework 2
- 1Окно подтверждения оповещения при отправке формы
- 0Разбор Json с помощью jQuery затруднен
- 0Извлечение JSON в транспортир и сравнение его с данными, отправленными из серверной части
- 0JQuery Назначение разницы ширины для элементов <li>
- 1Не могу загрузить файл в мое хранилище Firebase – ошибка 403 Запрещено
- 0Почему мое значение не обновляется в представлении директивы
- 1ошибка при использовании двойной универсальности
- 1Отправить токен в шапке (разные действия)
- 1Получить содержимое с помощью двух меток с помощью Casperjs
- 1Создать отображение из чисел в диапазон уникальных чисел
- 0AngularJS Directive Countup.JS получить данные из модели
- 1Как остановить службу переднего плана перед вызовом метода startForeground ()?
- 0Выбор элемента из многомерного массива
- 1Правильное отображение тенденций в matplotlib python, таких как электронные таблицы
- 1Открыть тип файла (xml) с помощью приложения clickonce
- 1(ASP.NET MVC4 C #) Вставьте UNICODE в SQL Server
- 0Дизайн базы данных – много таблиц с уникальными тегами или одна таблица со всеми из них?
- 0rand () и реализация Mersenne Twister C ++
- 0Как показать динамический контент на Ionic Custom POPUP
- 0Как найти повторяющееся значение значения столбца, используя mysql?
- 0Как использовать Apache Marmotta SPARQL веб-сервис API с AngularJS?
- 0Ссылаясь на корневой каталог
- 0Как я глобализирую и управляю массивом символов через функции
- 6Невозможно разместить запрошенные классы в одном файле dex, даже для более ранних коммитов, которые скомпилировались ранее
- 1получение покрытия кода через specflow
- 0Komodo 8.5: фрагменты PHP ‘block’ и ‘inline’ не работают там, где это необходимо

