Цифровой словарь от А до Я
Время на прочтение
5 мин
Количество просмотров 13K
Одной из самых полезных программ на ПК и смартфоне в моем понимании является электронный словарь. В те стародавние времена, когда я учил иностранный язык, каждое слово приходилось искать в бумажном словаре. Эту тривиальную операцию я проделывал сотни раз, а некоторые зловредные слова приходилось смотреть снова и снова, так как я успевал забыть их значение. Как это было обидно! То ли дело сейчас, вжух и перевод перед глазами на экране монитора. История поиска, на случай, если искомое слово не перешло из области кратковременной памяти в долгосрочную.
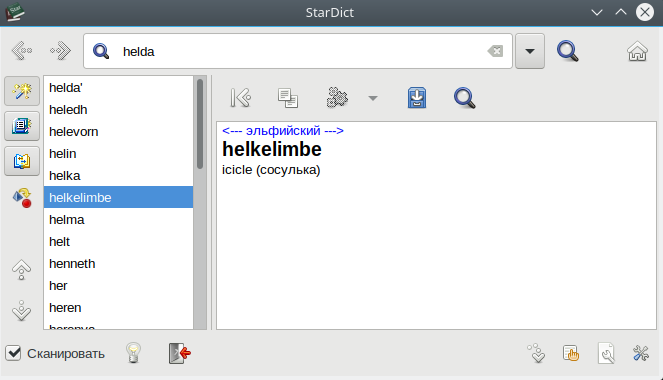
Давайте своими силами создадим электронный словарь для программ StarDict / GoldenDict. Для этого может понадобится много, или мало человеко-часов, в зависимости от качества исходного материала.
Шаг первый: OCR
В отличие от альпинизма при оцифровке словаря самый тяжелый шаг, не последний а первый. Если вам придется проводить OCR бумажного словаря с выцветшими страницами, напечатанного слишком мелко, с различными артефактами небрежного использования, или на экзотическом языке, то даже FineReader не сильно поможет. На некоторых страницах разница в длительности времени между ручным набором текста и OCR с корректировкой ошибок ничтожна.
Советую сохранять все в простых текстовых файлах, так как продвинутый поиск и исправление ошибок, расстановка тэгов, преобразование сортировки и прочие операции с текстовым массивом невообразимо осуществлять с бинарным фалом.
На этом шаге важно определиться со структурой словарных статей. В самом простом случае будет всего два поля: ключ и значение. Этого достаточно, но если нужна подсветка различных элементов статей, то тогда потребуется все такие элементы определенным образом маркировать.
Самое время немного поговорить о форматах. Существует много форматов электронных словарей, вот их список.
Все форматы мы здесь разбирать не будем, так как большинство из них проприетарные. Нас интересуют открытые стандарты и открытое ПО.
Dictd
Возникший в эпоху, когда сетевые TCP/IP протоколы беспрепятственно плодились и размножались dictd сейчас представляет лишь археологический интерес. Это клиент серверный протокол, использующий TCP порт 2628, определен в RFC 2229.
Исходный файл для словаря форматируется следующим образом.
:статья: объяснениеНапример, такой словарик
:catalysis: "increase in the rate of a chemical reaction due to the participation of an additional substance called a catalyst, which is not consumed in the catalyzed reaction and can continue to act repeatedly.
" <a href="is.gd/v6a22Q">ref</a>.
:deconstruction:
:rendered: eg. "rendered irrelevant."
:reading: cf. 'reading of'
:minor: a minor reading.Готовый файл для словаря создается командой dictfmt.
dictfmt --utf8 -s "Длинное имя словаря" -j dict-name < mydict.txtВ результате образуются 2 файла: dict-name.index и dict-name.dict. Из них первый очевидно индексный файл, с ним ничего делать не нужно, а второй можно сжать командой dictzip. Данная команда сжимает *.dict файл с помощью утилиты gzip. Сразу же возникает вопрос: а зачем оно тогда нужно, если есть обычный gzip?
Дело в том, что dictzip использует добавочные байты в заголовке архивного файлы для обеспечения псевдо-произвольного доступа к файлу.
Наконец файлы помещаются в профильные каталоги, т. к. /usr/lib/dict, перезагружаем службу dictd и вуаля. Синтаксис поиска прост, достаточно набрать
dict СЛОВО.
Пробежка по dictd ссылкам напоминает сафари по интернет сети 90-х, жив и еще лягается!
Sdict
Дерзкая попытка Алексея Семенова изменить мир к лучшему с помощью магии Perl в ту пору, когда Microsoft еще не крутил шашни с Linux и сообществом открытого ПО, а основной источник словарей были пиратки ABBYY Lingvo.
Заголовок исходного файла словаря.
<header>
title = Sample 1 test dictionary - dictionary name;
copyright = GNU Public License - copyright information;
version = 0.1 - version;
w_lang = en - language for words;
a_lang = fi - language for articles. For further information
about language codes refer 'C:Sdictsharedociso639.htm' file;
# charset = ... - use if your source file is not in UTF-8 encoding.
</header>Тело форматировано следующим образом:
word___articleМожно качнуть версию для ОС Symbian, если что. Проект более не жив, и даже сами словари можно почерпнуть лишь с Машины Времени.
XDXF
Ну все, завязываем с археологией и переходим к словарным форматам и программам годным для использования IRL.
XDXF имеет все преимущества и недостатки XML формата, каковым и является. Весь синтаксис формата и примеры можно обозреть тут.
Скелет словарного файла выгладит следующим образом, состоит из 2-х частей: meta_info и lexicon.
<xdxf ...>
<meta_info>
Вся информация про словарь: название, автор и пр.
</meta_info>
<lexicon>
<ar>статья 1</ar>
<ar>статья 2</ar>
<ar>статья 3</ar>
<ar>статья 4</ar>
...
</lexicon>
</xdxf>Есть огромное количество словарей в этом формате. Большим достоинством формата является то, что далее нет надобности ничего конвертировать. Программа GoldenDict распознает XDXF файлы наряду с большим количеством других поддерживаемых форматов.
TSV / StarDict
StarDict и клоны его это не столько про формат электронного словаря, сколько про качественное ПО просмотра, конвертации и создания таковых.
Для создания электронного словаря с помощью StarDict достаточно TSV файла, что я и выбрал для цифровой копии армяно-русского словаря.
Тем не менее возможно и кое-какое форматирования и разметка файла словаря, однако не идет ни в какое сравнение с XDXF.
a 1n2n3
b 4\5n6
c 789Формат определяет символ переноса строки n, в том случае, когда статья разбита на параграфы.
Шаг второй: корректировка
После первого шага скорее всего будут десятки, а то и сотни орфографических, грамматических и всяких прочих ошибок, странных символов и прочих артефактов OCR.
Особенность словарей в том, что проверка орфографии нужна одновременно по двум языкам. Даже сейчас в 2018-м удивительно мало текстовых редакторов и даже офисных пакетов умеют это нехитрое действие выполнять.
Не холивара для, рекомендую обработку теска производить с Vim. Если ваш любимый текстовый редактор справляется с этим не хуже, то и славно. С Vim достаточно команды.
:setlocal spell spelllang=en,ruдля проверки орфографии по двум словарям, в данном случае русском и английском. Далее список граблей.
- Сортировка текста работает абы как для не латинских локалей, особенно плохо там, где написание буквы требует более одного символа, как армянская
ու = ո + ւ. Необходимо в таких случаях самостоятельно сортировать список слов с помощью простенького Perl, или иного скрипта. - Поиск по шаблону также может работать неожиданно для некоторых локалей, даже если сам текст и консоль в UTF-8.
- При оцифровке печатного словаря нужно быть готовым не только к ошибкам оцифровки, но и ошибкам в самом печатном словаре. Их там может содержаться немало!
- Если название статьи пишется заглавными, то возможно следует перевести при оцифровке в нижний регистр. Не все буквы имеют символы в верхнем регистре, собственно не для всех локалей даже есть верхний регистр.
Шаг третий: компиляция словаря
Для формата XDXF, как уже было сказано, этот шаг не требуется. Просто запихнуть файл в папку /usr/share/goldendict, где программа подхватит его.
Для TSV файла, используется утилита stardict-editor, поставляемого с набором инструментов StarDict.

На выходе программа создает следующие файлы, наподобие древнего Dict.
- somedict.ifo
- somedict.idx либо somedict.idx.gz
- somedict.dict либо somedict.dict.dz
- somedict.syn (optional)
Файлы копируются в каталог /ysr/share/stardict/dic и на этом все.
P. S. Для мобильной платформы Android программа GoldenDict внезапно стал платной, однако в интернет сети все еще можно найти последнюю бесплатную версию программы.
Хотите стать мастером в Python? Тогда изучайте язык на практике. В этом материале рассказываем, как создать словарь на Python.
Интернет, с одной стороны, открывает доступ к большому объёму информации, но с другой, тормозит развитие. Согласитесь, изучая что-то новое, допустим, язык программирования Python, поиск ценных ресурсов занимает много сил и времени.
Из-за этого новички часто сдаются, переходят к чему-то более простому. Прежде чем мы пойдём дальше, нужно понять, что это не очередная статья из разряда «Как научиться программированию на Python с нуля», а нечто более ценное. За этим материалом последует ещё несколько, в каждом из которых мы покажем, как создаются Python-приложения, параллельно разбираясь с полезными для разработки и анализа данных навыками и инструментами.

Первое приложение, которое мы сделаем − интерактивный словарь на Python. Кажется, что это просто, но не заблуждайтесь.
Что будет делать наш словарь на Python? Его задача состоит в том, чтобы выводить на экран определение слова, которое задаст пользователь. В дополнение к этому, если пользователь сделает опечатку при вводе слова, программа предложит наиболее близкое слово, как обычно делает Google − «Вы имели в виду это вместо этого?». Ну а если у слова будет несколько определений, то программа выдаст все. Уже не так просто, правда?

Важно! Помимо изучения процесса создания приложения, обратите особое внимание на структуру кода.
Шаг №1 − Данные
Чтобы понимать принцип работы словаря, нужно определить, какие данные он будет использовать для выполнения действий − они представлены в формате JSON. Если вы уже знаете, что такое JSON, не бойтесь пропустить следующие несколько строк. Если же вы впервые услышали это слово или не уверены в своих знаниях, сейчас всё быстро объясним. Рекомендуем взглянуть вот на эти данные, потом мы их и будем использовать − раз и два.
Интересный факт: Каждую секунду генерируется примерно 2 500 000 000 000 000 000 байт данных
JSON, или JavaScript Object Notation, − это формат обмена данными, удобный как компьютерам, так и людям. Обычно он состоит из двух вещей − key и value. Представим, что key − это заброшенная территория, некто вынес постановление о том, что его нельзя использовать для строительства, например, вот это постановление примем за value. Если хотите вникнуть более серьёзно, посмотрите этот материал.
"заброшенный промышленный участок": ["Площадка не может быть использована для строительства".]
Теперь перейдём к коду. Сначала мы импортируем библиотеку JSON, а затем используем метод загрузки этой библиотеки для работы с нашими данными в формате .json. Важно понимать, что мы загружаем данные из .json формата, но храниться они будут в переменной “data” в виде dict — словаря Python. Если вы незнакомы с dict, можете представить их как хранилище данных.
import json
data = json.load(open("data.json"))
def retrive_definition(word):
return data[word]
word_user = input("Enter a word: ")
print(retrive_definition(word_user))
Как только данные будут загружены, создадим функцию, которая будет принимать слово и искать определение этого слова в данных. Достаточно просто.

Шаг №2 − Проверка на существование слова
Использование оператора if-else поможет вам проверить существует слово или нет. Если слово отсутствует в данных, просто сообщите об этом пользователю − в нашем случае, будет напечатано «Такого слова не существует, пожалуйста, проверьте, не ошиблись ли вы при вводе».
import json
data = json.load(open("dictionary.json"))
def retrive_definition(word):
if word in data:
return data[word]
else:
return ("The word doesn't exist, please double check it.")
word_user = input("Enter a word: ")
print(retrive_definition(word_user))

Шаг №3 – Учёт регистра
Каждый пользователь пишет по-своему. Одни пишут только строчными, другие используют ещё и заглавные. Для нас важно сделать так, чтобы результат для всех был одинаковым. Например, результаты по запросам «Rain» и «rain» будут идентичны. Чтобы сделать это, мы собираемся преобразовать слово, введенное пользователем, в строчную запись буквы, потому что наши данные имеют одинаковый формат. Сделать это можно с помощью метода lower() в Python.
Ситуация №1: Чтобы убедиться, что программа возвращает определение слов, начинающихся с заглавной буквы (например, Дели, Техас), мы также проверим наличие заглавных букв в условии else-if.
Ситуация №2: Чтобы убедиться, что программа возвращает определение аббревиатур (например, США, НАТО), мы также проверим прописные буквы.
import json
data = json.load(open("dictionary.json"))
def retrive_definition(word):
word = word.lower()
if word in data:
return data[word]
elif word.title() in data:
return data[word.title()]
elif word.upper() in data:
return data[word.upper()]
word_user = input("Enter a word: ")
print(retrive_definition(word_user))

Теперь словарь на Python может выполнять свою основную функцию − выдавать определение. Идём дальше, поможем пользователю найти слово, если он допустил ошибку при вводе.
Шаг №4 − Поиск близкого слова
Теперь, если пользователь сделал опечатку при вводе слова, вы можете предложить наиболее близкое слово и спросить, имел ли он его в виду. Мы можем сделать это с помощью библиотеки Python difflib. Для этого существует два метода, объясним, как работают оба, а чем пользоваться, выбирайте сами.
Метод 1 − Соответствие последовательности
Сначала мы импортируем библиотеку и извлекаем из нее метод. Функция SequenceMatcher() принимает всего 3 параметра. Первый − junk, что означает, что если в слове есть пробелы или пустые строки, в нашем случае это не так. Второй и третий параметры − это слова, между которыми вы хотите найти сходство. А последний метод выдаст вероятность того, что слово подобрано правильно.
import json
import difflib
from difflib import SequenceMatcher
data = json.load(open("dictionary.json"))
value = SequenceMatcher(None, "rainn", "rain").ratio()
print(value)

Как видите, сходство между словами «rainn» и «rain» составляет 0,89 или 89%. Это один из способов найти нужное слово. Но в той же библиотеке есть другой метод, который выбирает точное совпадение со словом напрямую, без определения вероятности.
Метод 2 − Получение близких совпадений
Метод работает следующим образом: первый параметр − это слово, для которого вы хотите найти близкие совпадения. Второй параметр − это список слов для сравнения. Третий указывает, сколько совпадений вы хотите в качестве вывода. Вы помните, что мы получили вероятность 0,89 в предыдущем методе? Последний метод использует это число, чтобы узнать, когда прекратить рассматривать слово как близкое совпадение (0,99 – самое близкое к слову). Эту цифру, порог, можно установить самостоятельно.
import json
import difflib
from difflib import get_close_matches
data = json.load(open("dictionary.json"))
output = get_close_matches("rain", ["help","mate","rainy"], n=1, cutoff = 0.75)
print(output)

Самое близкое слово из всех трех − rainy [rainy].
Шаг №5 – Возможно, вы имели в виду это?
Для удобства чтения я просто добавил часть кода if-else. Вы знакомы с первыми двумя утверждениями else-if, теперь разберемся с третьим. Сначала проверяется длина полученных близких совпадений. Функция получения близких совпадений принимает слово, введенное пользователем, в качестве первого параметра, и весь наш набор данных сопоставляется с этим словом. Здесь key − это слова в наших данных, а value − это их определение. [0] в операторе указывает на самое близкое среди всех совпадений.
if word in data:
return data[word]
elif word.title() in data:
return data[word.title()]
elif word.upper() in data:
return data[word.upper()]
elif len(get_close_matches(word, data.keys())) > 0:
return ("Did you mean %s instead?" % get_close_matches(word, data.keys())[0])

Да, об этом мы и говорили. Что теперь? Если это то слово, которое имел в виду пользователь, вы должны получить определение этого слова. Об этом далее
Шаг №6 − Получение определения
Ещё один if-else, и вот оно − определение нужного слова.
elif len(get_close_matches(word, data.keys())) > 0:
action = input("Did you mean %s instead? [y or n]: " % get_close_matches(word, data.keys())[0])
if (action == "y"):
return data[get_close_matches(word, data.keys())[0]]
elif (action == "n"):
return ("The word doesn't exist, yet.")
else:
return ("We don't understand your entry. Apologies.")

Шаг №7 − Вишенка на торте
Конечно, это дает нам определение слова «rain», но есть квадратные скобки и выглядит это не очень хорошо. Давайте удалим их и сделаем вид более чистым. Слово «rain» имеет более одного определения, вы заметили? Мы будем повторять вывод таких слов, имеющих более одного определения.
output = retrive_definition(word_user)
if type(output) == list:
for item in output:
print("-",item)
else:
print("-",output)
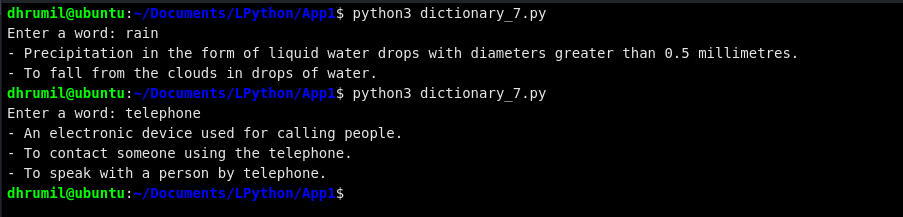
Выглядит намного лучше, не так ли? Ниже прикрепили весь код для справки. Не стесняйтесь изменять и обновлять его по своему усмотрению.
Итого
import json
from difflib import get_close_matches
data = json.load(open("data.json"))
def retrive_definition(word):
word = word.lower()
if word in data:
return data[word]
elif word.title() in data:
return data[word.title()]
elif word.upper() in data:
return data[word.upper()]
elif len(get_close_matches(word, data.keys())) > 0:
action = input("Did you mean %s instead? [y or n]: " % get_close_matches(word, data.keys())[0])
if (action == "y"):
return data[get_close_matches(word, data.keys())[0]]
elif (action == "n"):
return ("The word doesn't exist, yet.")
else:
return ("We don't understand your entry. Apologies.")
word_user = input("Enter a word: ")
output = retrive_definition(word_user)
if type(output) == list:
for item in output:
print("-",item)
else:
print("-",output)
Заключение
Вот мы и закончили создавать словарь на Python. Изучая одно, вы параллельно изучаете другие вещи, о которых даже не думали. Этот материал научил работе с данными JSON, основными функциями Python, библиотекой difflib и тому, как писать чистый код. Теперь попробуйте создать собственное приложение, с опорой на информацию из этого текста. Как закончите, переходите к новому материалу из цикла.
- Погружаемся в основы и нюансы тестирования Python-кода
- ООП на Python: концепции, принципы и примеры реализации
- 13 лучших книг по Python для начинающих и продолжающих
Источник: Создаём словарь на Python on Towards Data Science
Балалаева Елена Юрьевна
Национальный университет биоресурсов и природопользования Украины
кандидат педагогических наук, доцент кафедры журналистики и языковой коммуникации
Аннотация
Статья посвящена анализу концептуального этапа проектирования электронного словаря, на котором разрабатывают общую концепцию словаря: определяют его тип и назначение, устанавливают принципы описания лексикографического материала, проектирует функции, макро- и микроструктуру словаря, осуществляют отбор материала для него.
Balalajeva Olena Yurievna
National University of Life and Environmental Sciences of Ukraine
PhD in Pedagogy, Associate Professor
Abstract
The article is devoted to the analysis of the conceptual stage of designing an electronic dictionary, at which the general concept of the dictionary is developed: its type and purpose are determined, the principles for describing lexicographic material are established, the functions, macrostructure and microstructure of the dictionary are designed, and material is selected for it.
Библиографическая ссылка на статью:
Балалаева Е.Ю. Концептуальный этап создания электронного словаря // Гуманитарные научные исследования. 2021. № 3 [Электронный ресурс]. URL: https://human.snauka.ru/2021/03/42058 (дата обращения: 10.05.2023).
Несмотря на безусловную популярность электронных словарей в самых широких кругах пользователей, среди ученых нет единой точки зрения в отношении стадий проектирования этого лексикографического продукта. Более детально расписаны этапы создания словарей, предполагающие конкретные технические решения. Зачастую создание словаря движется не от концепции, а от имеющейся программной оболочки. Вместе с тем процедурам реализации словаря предшествуют весьма важные этапы. В частности, создание любого словаря должно начинаться с аналитического этапа, который предполагает анализ реальной ситуации на рынке лексикографической продукции в конкретной области и реальных потребностей пользователей, определение актуальности и целесообразности создания нового словаря, исследование факторов, влияющих на выбор его параметров.
Среди факторов, влияющих на параметры словаря и процесс его создания, различают собственно лексикографические и внешние. Первые связаны с удовлетворением потребностей пользователей словаря, вторые – корректируют проект словаря соответствии с реальными условиями [1, с. 66-70].
К лексикографическим относятся следующие факторы: пользователи, материал, с которым оперируют пользователи, характер этих операций, информационные потребности пользователей и потребности, связанные с особенностями поиска и восприятия информации. Внешними факторами считают ресурсы, требования сторон, предоставляющих эти ресурсы, ограничения, связанные с носителем информации.
На выбор предметной области словаря могут влиять: социальный заказ, уровень предметной компетенции составителя, наличие доступа к материалам, специфика выбранной отрасли.
На концептуальном этапе на основе анализа данных, полученных в ходе предварительного этапа, разрабатывают общую концепцию словаря: определяют его тип и назначение, устанавливают принципы описания лексикографического материала, проектирует функции, макро- и микроструктуру словаря, осуществляют отбор материала для него (первоисточники, печатные лексикографические работы, кодексы номенклатур, авторские наработки и т.д.).
Как замечает В. Широков, важным понятием для определения структуры словарных систем является предложенное Ю. Карауловым понятие лексикографического параметра – некоего «кванта» лингвистической информации, которая может иметь самостоятельный интерес для пользователя, но, как правило, выступает в комбинации с другими параметрами и находит свое специфическое выражение в словарях. Лексикографическим параметрам присущи определенные свойства, которые имеют универсальный характер и не зависят от типа словаря, а их значения характеризуются определенной спецификой конкретного языка. Количество лексикографических параметров в словарях варьируется от одного до нескольких десятков, причем эти колебания определяются не только целевой направленностью словаря, но и его ориентацией на пользователя [2, c. 13-15].
Словари в электронной форме, адресованные человеку, отличаются от бумажных словарей наличием в них технического инструмента, который позволяет предоставлять пользователю словарный контент, релевантный его запросу: морфологический и синтаксический анализ, полнотекстовый поиск, гипертекст, распознавание и синтез звука, а также позволяет предоставлять этот содержание различными способами: аудио, графические средства, последовательность предоставленного содержания. Поэтому в проектировании словарей, ориентированных на человека как конечного пользователя, необходимо учитывать и некоторые неинформационных потребности (эргономичную, экономическую и эстетическую) [1].
С одной стороны, электронный словарь является лексикографическим объектом, поэтому его создание может осуществляться на основе общих принципов описания лексикографических единиц [3]. В частности, В. Дубичинский называет пять основных принципов лексикографического описания:
1) преемственность лексикографических произведений – описание определенного словарного материала всегда опирается на имеющиеся лексикографические традиции;
2) значительная роль субъективного фактора в создании словарей;
3) обусловленность жестким прагматизмом;
4) нормативность в отборе лексики;
5) теоретическая и практическая многоплановость лексикографических произведений [4, с. 5].
С другой стороны, учитывая новую специфическую форму существования, электронные словари потребу формулировки новых принципов создания, к которым Л. Беляева относит модульность, динамичность, гибкость, сбалансированность и дружественность [5].
Важным типологическим параметром в проектировании любого словаря является функциональная обусловленность. По мнению В. Табанаковой, М. Ковязиной, доминантный параметр словаря отражают четыре универсальные функции: справочная (информативная), систематизирующая, учебная и нормативная [6].
Организация массива информации в словаре может иметь разнообразную и сложную структуру, единой общепринятой терминологии по структуре электронного словаря нет.
В. Широков отмечает, что традиционно словарную статью считают, как минимум, двухкомпонентной – в ней выделяют реестровую (левую) и интерпретационную (правую) части. Левая или реестровая, лексикографическая часть – это, как правило, любая единица языка, являющегося объектом лексикографирования. Множество таких единиц словаря определяет его реестр. Структура и содержание правой части словарной статьи зависит от типа словаря; здесь приводится лингвистическое описание соответствующей реестровая единицы (ее значение, перевод на другие языки, ударение, лексические, грамматические характеристики и др.) или содержится разнообразная информация о том, что она обозначает [2, с. 12].
Реестровые единицы в словаре связаны между собой многочисленными структурно-семантическими связями и в своей совокупности образуют определенную систему, которая реализует замыслы и цели его составителей. Кроме того, словарные статьи любого словаря должны иметь тождественные схемы описания однотипных элементов лексикографических структур. Совокупность правил, приемов и средств описания реестровых единиц создают метаязык словаря. Вместе с тем, В. Широков отмечает, что термины «левая» и «правая» части словарной статьи являются условными, поскольку в некоторых типах словарей наблюдается «чередования» или «смешения» элементов структур реестровой и интерпретационной частей [2, с. 13].
Этого же мнения придерживается И. Кудашев, который не только подчеркивает условность такого деления, но и замечает, что традиционная трактовка «левой» части как совокупности заглавных единиц и «правой» как совокупности словарных статей порождает ряд теоретических проблем [1, c. 32]. Левая часть словаря – это перечень определенных единиц: слова, термины, морфемы, словосочетания и пр. Эти единицы связаны между собой системными отношениями, а их перечень сортируются определенным образом (например, по алфавиту). Правая часть словаря содержит информацию о единицах левой части, а именно: толкование (значение), написание, произношение, грамматические и производные формы, функции, синонимы, этимологию, идиоматику, употребление, иноязычные соответствия, энциклопедическую информацию, справочные данные, систематическое описание и т.д. Исследователь предлагает рассматривать как «левую» часть любые единицы, о которых автор словаря сообщает релевантную при назначении словаря информацию, а как «правую» собственно эту информацию независимо от места расположения ее в словаре [там же, с. 33].
Ученые отмечают, что с развитием компьютерных технологий вопрос об упорядочении единиц словаря частично утратил актуальность [7], ведь в памяти компьютера словарь сохраняется в специфическом машинном представлении, а «вход» в словарь становится возможен практически через любой параметр или сочетание параметров. Н. Сивакова считает, что гипертекстовая структура электронного словаря заставляет переосмыслить традиционное понимание термина «композиция». В контексте электронного словаря композицией можно было бы назвать его меню или интерфейс. Но это лишь «внешнее» выявления композиции. Пользователь может создавать собственное композиционное решение, активизируя информационные зоны словаря в соответствии с личным запросом [8, c. 15].
По мнению И. Кудашева, проектирование структуры словаря целесообразно начинать с проектирования структуры микростатей – единиц словаря или единиц правой части информации о них. Прежде составляют классификацию микростатей, проектирует их наполнения и структуру, а затем объединяют. Микростатья единицы словаря с переводными соответствиями образует в многоязычном словаре самый тип словарной статьи [1, c. 364].
Лексикограф В. Дубичинский также считает словарную статью важнейшей частью словаря. микроструктура словаря, или модель комплексной словарной статьи может содержать следующие компоненты: заглавную единицу (слово, словосочетание, морфема, фразеологизм и т.д.), грамматическую характеристику (часть речи, род, число и т.д.), фонетическую характеристику (транскрипция, ударение, интонация), семантизацию заглавной единицы (толкование, дефиниция, переводной эквивалент, синонимы), сочетаемых информацию (словосочетания с заглавной единицей), фразеологические обороты, словообразовательную характеристику, этимологическую и историческую характеристики, иллюстрации по употреблению (словосочетания, предложения, цитаты), лексикографические отметки (грамматические, семантические, стилистические, специальные, эмоционально-экспрессивные, хронологические и т.д.), ссылки, энциклопедическую информацию [4, c. 4].
Форматом статьи электронного (компьютерного) словаря Е. Карпиловская считает модель организации, размещения и графического представления в словаре информации об описываемых в нем языковых объектах. Зонный принцип записи языковой информации является гибкой моделью, в которой каждому типу информации отведено отдельную зону и значимой является само наличие / отсутствие таких зон. Выработка такого формата составляет вместе с созданием базы данных и лексикографического процессора является неотъемлемой составляющей процесса создания электронного словаря [9, с. 49].
Л. Беляева рассматривает электронный словарь как базу данных, в которой каждая статья представлена как зонированный текст. Такой словарь должен иметь жесткую организацию и высокий уровень формализации представления данных [5].
Итак, создание электронного словаря предусматривает проектирование сложной системы в совокупности внутренних и внешних связей, организации ее компонентов. Единой жесткой схемы этапов проектирования электронного словаря не существует. Вместе с тем, важными этапами его создания, предшествующими технологическому, являются аналитический и концептуальный, пренебрежение которыми может привести к созданию продукта, не отвечающего требованиям современной лексикографии. Особенно тщательно следует подходить к разработке электронных словарей, предназначенных для использования в учебном процессе – игнорирование аналитического и концептуального этапов создания образовательного ресурса повышает дидактические риски его использования [10].
Библиографический список
- Кудашев И. С. Проектирование переводческих словарей специальной лексики. Helsinki: HU Print, 2007. 443 с.
- Лінгвістично-інформаційні студії: Праці Українського мовно-інформаційного фонду НАН України : у 5 т. . Т. 3 : Тлумачна лексикографія. Кн. 1. К.: Український мовно-інформаційний фонд, 2018. 276 с.
- Балалаєва О. Ю. Аналіз сутності поняття «електронний навчальний словник» // Проблеми сучасного підручника. 2014. Вип. 14. С. 26-33.
- Дубічинський В.В. Лексикографія: навч.-метод. посіб. Харків: НТУ «ХПІ», 2012. 66 с.
- Беляева Л. Н. Потенциал автоматизированной лексикографии и прикладная лингвистика // Известия РГПУ им. А.И. Герцена. 2010. № 134. С. 70-79.
- Табанакова В. Д., Ковязина М. А. Функциональная модель переводного специального словаря // Вестник ТюмГУ. 2006. № 4. С. 158–165.
- Лейчик В.М. Типология словарей на пороге XXI века. Вестник международного славянского университета. Харьков, 1999. Т. 2. № 4. С. 7–9.
- Сивакова Н. А. Лексикографическое описание английских и русских фитонимов в электронном глоссарии: автореф. дис. … канд. филол. наук. Тюмень, 2004.25 с.
- Карпіловська Є. А. Вступ до прикладної лінгвістики: комп’ютерна лінгвістика : підручник. Донецьк : Юго-Восток, 2006. 188 с.
- Балалаева Е.Ю. Дидактические риски использования электронных средств обучения // Непрерывное образование: XXI век. 2016. Вып. 4 (16) [Электронный ресурс]. URL: http://lll21.petrsu.ru/journal/article.php?id=3326
Количество просмотров публикации: Please wait
Все статьи автора «Балалаева Елена Юрьевна»
Hello, my friends!
Согласитесь, что было бы удобно, когда сам вносишь список слов, которые хочешь выучить, нежели искать это слово в словаре и делать лишние действия?
Сегодня я подобрала для вас приложения, которые помогут вам лично построить ваш английский словарь, а также они просты в использовании.
Оставайтесь со мной, потому что в конце я поделюсь с вами бонусным приложением, которое каждый день будет высылать вам новые и интересные слова для пополнения вашего запаса слов.

Для пользователей Android – Google Play
My Personal Dictionary
Приложение, где вы можете сами вбивать слова с их переводом. Также можете добавлять примеры предложений и картинки для более визуального запоминания. В приложении можете создавать категории по словам, то есть иметь сразу несколько словарей.
My Dictionary – Free: polyglot
Данное приложении имеет около 90 словарей на разных языках. Также есть функция построения своего личного словаря с автоматическим переводом добавленных слов. Бонусом в этом приложении служит функция тренировок. Вы можете выбрать один из 8 видов тренировок для заучивания слов.
My Personal Dictionary – Vocabulary Builder
Это приложение также позволяет вам построить свой словарь. Добавляйте слова и их перевод. Данное приложение не обязует вас иметь интернет, поэтому вы можете его использовать когда угодно. Также в этом приложении есть тренировка слов, где можете проверить, как хорошо знаете те или иные слова.
Для пользователей Apple – IOS
Тут у нас все кратко. Из всех приложений в этой категории я выделяю два.
My Words
Аналогично выше указанным приложением, это приложение позволяет добавлять ваши собственные слова в список. Также добавлена функция тренировок в виде тестов, аудирования, диктанта и карточек.
My Words – Learn New Words
Это одно из моих первых приложений для построения собственного словаря. В этом приложении вы также можете создавать несколько словарей по разным категориям. Тут вам надо самим добавлять слова и их перевод. В графе перевода можете также добавлять преложения. Также присутствует функция тренировок.
Бонусным приложением к вашим словарям будет английское приложение Vocabulary – Learn New Words. Вы отмечаете сколько раз в день, вы хотите получать новые слова, а также выбираете удобное для вас время. Приложение автоматически уведомляет вас о новом слове, где объяснение и пример предложения полностью на английском.
Приложение доступно и в App Store, и в Google Play
На этом мы заканчиваем с приложениями. Выберете то, что подходит именно для вас. Пользуйтесь приложением во время просмотра иностранных фильмов, прослушивания песен или чтения книг. Это очень полезный инструмент, который помогает вам оставаться более организованными.
Если статья была для вас полезной и интересной, то присоединяйтесь к каналу, делитесь своими мыслями, и как говорится: “Feel free to ask questions!”
Вестник Томского государственного университета. 2014. № 382. С. 6-10
ФИЛОЛОГИЯ
УДК 8Г374.2, 8Г374.7
Н.А. Агапова, Н. Ф. Картофелева
О ПРИНЦИПАХ СОЗДАНИЯ ЭЛЕКТРОННОГО СЛОВАРЯ ЛИНГВОКУЛЬТУРОЛОГИЧЕСКОГО ТИПА: К ПОСТАНОВКЕ ПРОБЛЕМЫ
Исследование выполнено в рамках государственного задания на выполнение НИР «Изучение историко-культурного наследия России (сибирский аспект)» (код проекта 2059).
Обосновывается актуальность создания электронных словарей различных типов; конкретизируются понятия «электронный словарь» и «электронный вариант словаря»; проводится сравнение информативных и навигационных возможностей традиционных бумажных и электронных лексикографических продуктов. Дается краткая характеристика существующих компьютерных словарей; рассматривается понятие «лингвокультурография»; намечаются перспективы создания словаря лингвокультурологического типа в электронном формате. Авторы выстраивают общую концепцию словаря, раскрывают содержание основных этапов работы над ним, презентуют базовый принцип организации материала в рамках создаваемого лексикографического продукта.
Ключевые слова: электронная лексикография; корпусная лингвистика; словарь компьютерного типа; лингвокультурология; этнолингвистика; лингвокультурография; народная примета; лингвокультурологический комментарий.
Лексикографическая практика является неотъемлемой и органичной частью науки о языке. При этом данные словаря могут быть использованы в качестве материалов исследования, и наоборот – сам словарь может выступать в качестве конечного результата, практического итога научной деятельности: «Словари обладают большими информативными возможностями и служат источником для теоретических построений и разработки других аспектов анализа. Существует и обратная связь “научная разработка – словарь”, при которой словарь представляет собой поле реализации той или иной научной концепции (например, теория мотивации, лингвоперсонология)» [1. С. 31-37].
Особую актуальность и востребованность в настоящее время приобрело такое направление, как компьютерная лексикография: сейчас разработка и создание электронных словарей, корпусов и баз данных являются наиболее продуктивными ее областями. Ценность данного направления заключается не только в разработке наглядных и удобных методов представления и классификации материала, но и в том, что электронные словари и компьютерные корпусы позволяют сохранить для дальнейшей обработки уже собранный (иногда – на протяжении очень долгого времени) материал, хранившийся ранее в менее удобной и неустойчивой к внешним воздействиям форме (бумажные картотеки, рукописные источники, аудио-, а также видеоносители, уязвимые перед внешними пагубными факторами, -аудиокассеты, видеокассеты, дискеты и т.д.).
Существует необходимость конкретизации терминов «компьютерная лексикография» и «электронный словарь»: как справедливо отмечает В.П. Селегей, «обычно подразумевается, что словарь на компьютере – это введенный в него бумажный словарь, снабженный удобными средствами поиска и отображения <…>. Компьютерная лексикография как область прикладной лингвистики, производящая такие словари, оказывается лишенной собственного языкового предмета. На ее долю оставляется только эффектная демон-
страция канонического содержания» [2]. Безусловно, необходимость перевода существующего массива словарей различных типов из бумажного формата в электронный назрела уже давно; данное направление сейчас достаточно успешно развивается в рамках отечественной лексикографии. Конечно, назвать это собственно научной деятельностью сложно, однако без предварительно проведенной технической работы невозможно получить готовый к исследованию материал – именно перевод информации в электронный формат является первым этапом работы с любым компьютерным корпусом. В отдельных случаях перевод данных в электронную форму сопровождается дополнительной и подчас весьма трудоемкой деятельностью. В качестве примера можно привести работу по переводу в электронный формат записей диалектной речи: это не только оцифровка самого материала (картотек, тетрадей), но и масштабная подготовительная работа, реализующаяся в виде разработки сложной системы метаразметки и ее применения в текстах, составляющих основу компьютерного диалектного корпуса [3].
В то же время словарь, существующий в электронном формате, – это не просто электронная (отсканированная, оцифрованная) версия уже созданного бумажного словаря, это полностью самостоятельный продукт, и форма его бытования логично продолжает и дополняет содержательную составляющую. Актуальным представляется замечание о том, что «компьютерная лексикография является особым направлением в практической лексикографии со своими собственными подходами не только к отображению, но и к содержанию словаря» [2].
Безусловно, электронный словарь – не только «особый лексикографический объект, в котором могут быть реализованы и введены в обращение многие продуктивные идеи, невостребованные по разным причинам в бумажных словарях» [Там же], но также и эффективный исследовательский инструмент, использование которого может способствовать более продуктивным
накапливанию и обработке информации. Кроме того, сами электронные словари в настоящее время всё чаще становятся объектом исследований. Обращение лингвистов к словарям именно этого типа, как справедливо отмечает О.С. Рублева, «объясняется тем, что в последнее время создается значительное количество электронных словарей, развивается всемирная сеть Интернет, информация хранится в электронном виде, но нет комплексного лингвистического описания электронных словарей и возможностей их использования пользователями в разных целях» [4. С. 3]. Между тем именно исследование возможностей использования электронных словарей в настоящее время представляется одним из наиболее продуктивных направлений данной сферы.
В.П. Селегей противопоставляет электронные словари традиционным, опираясь на несколько основополагающих принципов: исследователь называет их «антиномиями бумажной лексикографии». Во-первых, как отмечает автор, большой объем бумажного словаря (являющийся следствием богатой лексической базы и полноты словарных статей) выступает серьезным препятствием для удобного пользования: многотомный (или же просто очень объемный) словарь становится буквально непригодным для быстрого поиска информации – не говоря уже о том, что он абсолютно не мобилен в процессе использования. Таким образом, высокое качество словаря на содержательном уровне является непосредственной причиной низкого качества удобства его использования; в качестве примера автор приводит 20-томный Оксфордский словарь.
Вторая антиномия касается актуальности представленной в словаре информации: необходимо отметить, однако, что данное замечание справедливо в первую очередь для двуязычных (переводных) словарей, а также словарей терминологических: «Чрезвычайно долгий цикл создания и модификации фундаментальных бумажных словарей приводит к тому, что образ мира, который они фиксируют в системе своих значений, примеров и переводов, уже заметно отличается от действительности. Многие словари, основной корпус статей которых сформировался в языковой атмосфере середины века, представляют собой лексикографические музеи (а то и терминологические кладбища, если говорить о специализированных словарях)» [2].
Третье противоречие строится на асимметрии формы и содержания: исследователь говорит о том, что чем интереснее собственно лексикографическая концепция словаря, чем интегральнее средства описания лексических значений, тем уже его лексическая база.
Еще один недостаток бумажных (традиционных) словарей – отсутствие удобной навигации: в данном вопросе наиболее объективной представляется позиция пользователя, работающего со словарем; при этом чем больше объем словаря, тем сильнее данный недостаток проявляется. Основным навигационным инструментом, используемым в словарях, является способ расположения материала: в алфавитном порядке или по тематическому принципу. Возможен и смешанный вариант данных способов подачи материала. Этим возможности бумажного словаря исчерпываются.
Возможности компьютерной лексикографии позволяют успешно преодолеть перечисленные трудности и
противоречия. Так, первая «антиномия» в рамках электронной лексикографии разрешается благодаря возможности поместить большой объем данных на легкий и мобильный носитель информации, а также разместить созданный словарь (корпус) в сети Интернет. Таким образом, к словарю можно будет обращаться практически в любое время и любом месте. Неблагоприятные последствия, связанные с долгим циклом создания словаря, можно нейтрализовать, если программа, в которой создается лексикографический продукт, допускает возможность внесения новой информации и корректировки уже имеющейся. Эта же опция позволяет пополнять базу словаря: таким образом, лексикографический объект перестает быть статичным, застывшим во времени и пространстве, и получает возможность обновляться, если таковая потребность возникает.
В отличие от бумажной, электронная лексикография обладает весьма обширными навигационными возможностями. Помимо традиционных способов организации материала – в алфавитном порядке и по тематическому принципу – лексикограф получает возможность выстроить максимально удобные для пользователя словаря связи между объектами: лексикогра-фируемыми единицами, статьями, комментариями, списками источников и литературы, списком составителей и т. д.
О.С. Рублева продолжает мысль В.П. Селегея и создает развернутую классификацию достоинств (плюсов) электронных словарей (обширный объем словника, удобство и скорость поиска информации, наличие звуковой и графической иллюстрации слова, возможность самостоятельного заказа структуры словарной статьи через заданный путь поиска, возможность разностороннего раскрытия значения слова и др.) [4].
Наибольшее количество электронных лексикографических продуктов в настоящее время создается в области переводческой деятельности. Существовать переводные словари могут как в самостоятельном формате – в виде скачиваемой и устанавливаемой отдельной программы, так и в формате интерактивном, т.е. интегрированными в какой-либо электронный ресурс: иначе говоря, пользоваться таким словарем можно в режиме on-line, посетив нужный сайт в сети Интернет. Как правило, способы представления материала в таких словарях однотипны и достаточно просты: пользователю нужно в максимально короткие сроки получить точный перевод отдельной лексемы или выражения, это, в свою очередь, диктует специфику навигации: в таком словаре всегда есть поле для ввода переводимого слова и поле, в котором появляются перевод либо варианты перевода. Практически все двуязычные словари, существующие в электронном формате, подразумевают подобный способ работы с материалом. Специально для создания словарей переводческого типа компанией ABBYY – одним из наиболее известных в России разработчиков, занимающихся созданием электронных словарей, – был придуман язык DSL (Dictionary Specification Language) [5]. Широко известных аналогов данного языка в рамках российской электронной лексикографии в настоящий момент не применяется: связано это, прежде всего, с тем, что большинство компьютерных приложений для использования в
разных областях – и электронная лексикография не является исключением – до сих создается за рубежом.
Использование языка DSL возможно и для создания толковых словарей: способ представления материала по принципу «слово – толкование» аналогичен первоначальной схеме «слово – перевод»; меняется только наполнение словаря.
Однако давно назрела необходимость создания электронных словарей не только переводного и толкового, но и других типов: перечисленные ранее «антиномии бумажной лексикографии» актуальны для всех лексикографических областей; не являются исключением словари лингвокультурологического и этнолингвистического типов. Закономерным выглядит предположение о том, что организация материала в словарях этого типа предполагает принципиально иной подход, отличающийся от подхода к организации материала толковых и двуязычных словарей; следовательно, и создание компьютерных приложений для них будет строиться иных на принципах.
Некоторыми учеными предлагается объединять словари лингвокультурологического и этнолингвистического типов одним понятием – «лингвокультурогра-фия». В толковании этого термина мы идем вслед за О.К. Ансимовой, говорящей о том, что «объектом лингвокультурографии являются языковые и неязыковые (например, мимика, жесты) единицы, содержащие культурную информацию, знание которой необходимо для успешной коммуникации в рамках определенного лингвокультурного сообщества; предметом – параметры описания данных единиц в соответствующих словарях, т.е. их лексикографическая интерпретация» [6]. Словари такого типа диктуют более сложную – по сравнению с другими типами словарей – форму организации материала: связано это, прежде всего, с тем, что в поле зрения лексикографа наряду с собственно языковыми попадают неязыковые явления (обычаи, обряды, жесты, костюмы…), требующие особого подхода к возможности их представления в рамках словарной статьи. Это актуально для традиционного – бумажного – формата словаря и является не менее актуальным для электронной лингвокультурографии.
В то же время специфика материала, отображаемого в словаре лингвокультурологического типа, соединившись с навигационными и техническими возможностями компьютерной лексикографии, способна дать продуктивные результаты в виде не только удобно выстроенной навигации между материалом и иллюстрациями [7]. Использование медиа-приложений (видео-, аудиозаписей, анимированных приложений) является эффективным инструментом для иллюстрирования статей лингвокультурологического характера.
Представляется справедливым утверждение о том, что в рамках отечественной культурографии пока не создано полноценных компьютерных словарей. Однако электронные словари на материале русского языка создаются сейчас достаточно активно; определенным разнообразием отличаются типы создаваемых электронных лексикографических продуктов. Достаточно подробный список существующих электронных словарей размещен в рамках ресурса «Грамота.ру» [8]: так, в разделе «Словари русского языка» представлены, в
основном, словари толкового типа. Причем на равных с новыми – недавно созданными – словарями фигурируют и уже ставшие классическими словари, воплощенные в электронном варианте («Толковый словарь живого великорусского языка В.И. Даля» [9]; «Толковый словарь русского языка» под ред. Д.Н. Ушакова [10]). Отдельную группу формируют энциклопедические, терминологические словари и издания [8]; иноязычные словари и переводчики также достаточно широко представлены в рамках обозначенного электронного ресурса. Компьютерных словарей лингвокультурологического и этнолингвистического типов среди перечисленных на сайте словарей и справочников не встречается.
Авторы настоящей статьи видят своей целью разработку электронного словаря именно лингвокультурологического типа: в качестве примера такового было принято решение разработать и создать электронный словарь народных примет, призванный в компьютерном формате объединить корпус народных примет и лингвокультурологический комментарий, сопровождающий собранный материал. Воплощение этого проекта в жизнь предполагает разработку общей концепции словаря, структуры (модели) словарной статьи и принципов организации представленного в словаре материала, а также разработку компьютерного приложения, посредством которого данным словарем можно будет эффективно пользоваться как составителям словаря, так и читателям.
Уникальность заявленного проекта словаря заключается, с одной стороны, в его формальном воплощении – подобные типы словарей пока не представлены в рамках лингвокультурологических (как, впрочем, и филологических в целом) работ. Создание электронного словаря подобного типа позволит выработать и апробировать ряд универсальных принципов лексикографической работы с материалом, обладающим лингвокультурологической ценностью, прежде всего в области репрезентации такого материала в формате компьютерного словаря. С другой стороны, актуальность и научная ценность исследования заключаются в содержательной части словаря. Это связано, в свою очередь, с тем, что содержательное наполнение заявленного лексикографического продукта базируется на уникальном материале – корпусе народных примет, фиксируемых в рамках работы с разнообразными источниками, обладающих несомненной культурологической ценностью, создаваемом в течение нескольких лет и пополняемом до сих пор.
Работа над представленным лексикографическим продуктом включает в себя несколько базовых этапов.
Первый этап. Сбор материала, который выступит в качестве основы словаря; написание словарных статей, репрезентирующих лингвокультурологический комментарий. В настоящий момент этот этап в целом завершен [11].
Второй этап. Разработка общей концепции словаря; выбор формы существования словаря; составление программистом технического задания в соответствии с разработанной концепцией.
Третий этап. Выявление функциональных и нефункциональных требований, детализация технического задания на основе выявленных требований; написание словарных статей для электронного словаря.
Четвертый этап. Проектирование архитектуры компьютерного приложения с несколькими вариантами поиска и группировки материала, выбор средств разработки.
Пятый этап. Реализация электронного лингвокультурологического словаря народных примет на основе спроектированной архитектуры приложения. Разработка программной платформы словаря, позволяющей осуществлять поиск по заданным параметрам, проводить статистическую обработку материала, сохранение результатов поиска. Завершение разработки электронного ресурса: создание интуитивно понятного интерфейса и удобной навигации.
Шестой этап. Апробация созданного электронного словаря в рамках научных исследований, проводимых в сфере лингвокультурологии и смежных с ней научных областей, а также в сфере лексикографической практики (на базе кафедры русского языка и лаборатории общей и сибирской лексикографии филологиче-
ского факультета Национального исследовательского Томского государственного университета).
В качестве базового принципа организации материала в словаре решено использовать принцип ключевых слов, ставший уже традиционным при создании лексикографических продуктов различной направленности. Основное отличие данного принципа от способов организации материала в словарях, написанных на языке DSL, заключается в том, что он позволит выстроить максимально удобную навигацию между материалом (корпусом примет) и лингвокультурологическим комментарием, сопровождающим данный материал. Данный способ организации материала, структура словарной статьи, а также специфика технического воплощения представленного лексикографического продукта -особенности проектирования архитектуры приложения и выбранных средств разработки – будут подробным образом описаны в последующих работах авторов.
ЛИТЕРАТУРА
1. Демешкина Т.А. Лексикографическое направление в Томской диалектологической школе. Итоги и перспективы // Вестник Томского госу-
дарственного университетта. Филология. 2011. № 3. С. 31-37.
2. Селегей В.П. Электронные словари и компьютерная лексикография. ИЯЬ: http://www.lingvoda.ru/transforum/articles/selegey_a1.asp
3. Юрина Е.А. Томский диалектный корпус: в начале пути // Вестник Томского государственного университета. Филология. 2011. № 2. С. 58-63.
4. Рублева О.С. Слово в электронном словаре (с позиции пользователя электронными ресурсами) : автореф. дис. … канд. филол. наук. Тверь :
Тверской государственный университет, 2010. 20 с.
5. Ассоциация лексикографов Lingvo. ИЯЬ: http://www.lingvoda.rU/dictionaries/create.asp#p2
6. Анисимова О.К. Лингвокультурография как отдельная филиация общей лексикографии. И^: http://www.sociosphera.com/publi-cation/conference/2012/119/lingvokulturografiya_kak_otdelnaya_filiaciya_obwej_leksikografii/
7. Евсюкова Т.В. Лингвокультурологическая концепция словаря культуры : дис. … д-ра филол. наук. Нальчик, 2002. 304 с.: ил.
8. Грамота.ру. И^: http://www.gramota.ru/slovari/online
9. Даль В.И. Толковый словарь живого великорусского языка. И^: http://vidahl.agava.ru
10. Ушаков Д.Н. Толковый словарь русского языка. И^: http://ushdict.narod.ru
11. Агапова Н.А. Лингвокультурологический потенциал ключевого слова народной приметы : дис. … канд. филол. наук. Томск, 2013. 184 с. Статья представлена научной редакцией «Филология» 27 марта 2014 г.
ON THE PRINCIPLES OF CREATING AN ELECTRONIC DICTIONARY OF THE LINGUOCULTUROLOGICAL TYPE: RAISING THE PROBLEM
Tomsk State University Journal. No. 382 (2014), 6-10.
Agapova Nina A., Kartofeleva Natalia F. Tomsk State University (Tomsk, Russian Federation). E-mail: NinaAgapowa@yandex.ru, natconnor.neo@gmail.com
Keywords: computational lexicography; corpus linguistics; electronic dictionary; linguoculturology; ethnolinguistics; linguoculturogra-phy; national sign; linguoculturogical commentary.
Lexicographic practice is an essential and organic part of linguistics. Presently such a branch as computational lexicography has taken on special topicality and importance: development and implementation of electronic dictionaries, corpuses and databases are its most productive areas today. Undoubtedly, the need for converting the existing number of dictionaries of different kinds from paper to an electronic form appeared long ago: it is impossible to get some material prepared for work without any preliminary technical work -converting information to an electronic format is the first step of any activity with computer corpora. In particular cases data conversion may be accompanied by additional – and sometimes quite laborious – activities. Converting dialect speech records into an electronic format can be used for illustrative purposes: there is not only the digitization of the material itself (card indexes, notebooks, etc) but aslo huge preparation work realized with the development of a complex meta markup system and its adaptation in texts that form the basis of a computer dialect corpus. A dictionary existing in an electronic format is not just an electronic (scanned, digitized) version of a paper dictionary, it is a completely independent product, and its form of existence logically continues and supplements its content. At the present time, the greatest number of electronic lexicographic products is created in the area of translation industry. However, the need for creating Russian-language dictionaries of not only translational or explanatory types but also other types is obvious: linguoculturological and ethnolinguistic dictionaries are no exception. The authors of this paper aim at the development of an electronic dictionary of an indeed linguoculturological type: it was decided to develop and implement an electronic dictionary of national signs as an example which should unite the corpus of national signs and the linguoculturological commentary of the collected material in the electronic format. The realization of the project proposes the elaboration of the general concept of the dictionary, the structure (model) of a dictionary entry, and the principles of organisation of the material presented in the dictionary, and also it proposes the development of software to be conveniently and effectively used by dictionary compilers and readers. The originality of the project of the dictionary consists in, first of all, its physical implementation. The creation of an electronic dictionary of such a type allows elaborating and testing a series of universal principles for lexicorgaphic work with the material of linguoculturological value, including the representation of such a material in the computer dictionary format. On the other hand, the topicality and scientific value of the research consist in the
physical part of the dictionary as well. It, in its turn, concerns with the fact that the content of the announced lexicographic product is based on the unique material – the corpus of national signs fixed in the process of work with different sources, it has certain culturological value and was created during several years and it is still supplemented.
REFERENCES
1. Demeshkina T.A. Lexicographic studies of Tomsk Dialect School. Results and prospects. Vestnik Tomskogo gosudarstvennogo universiteta.
Filologiya — Tomsk State University Journal of Philology, 2011, no. 3 (15), pp. 31-37. (In Russian).
2. Selegey V.P. Elektronnye slovari i komp’yuternaya leksikografya [Electronic dictionaries and computer lexicography]. Available at: http://www.lingvoda.ru/transforum/articles/selegey_a1.asp.
3. Yurina Ye.A. Tomsk dialectal corpora: the starting point. Vestnik Tomskogo gosudarstvennogo universiteta. Filologiya — Tomsk State University
Journal of Philology, 2011, no. 2 (14), pp. 58-63. (In Russian).
4. Rubleva O.S. Slovo v elektronnom slovare (s pozitsii pol’zovatelya elektronnymi resursami). Avtoref. dis. kand. filol. Nauk [Word in an electronic
dictionary (by the user of electronic resources). Abstract of Philology Cand. Diss.]. Tver’: Tver’ State University Publ., 2010. 20 p.
5. Assotsiatsiya leksikografov Lingvo [Lingvo Lexicographer Association]. Available at: http://www.lingvoda.ru/dictionaries/create.asp#p2.
6. Ansimova O.K. Lingvokul’turografiya kak otdel’naya filiatsiya obshchey leksikografii [Linguoculturography as a separate filiation of general
lexicography]. Available at: http://www.sociosphera.com/publication/conference/2012/119/lingvokulturografiya_kak_otdelnaya_filiaciya_
obwej_leksikografii/.
7. Evsyukova T.V. Lingvokul’turologicheskaya kontseptsiya slovarya kul’tury. Dis. doktora filologicheskikh nauk [Linguoculturological concept of a
culture dictionary. Philology Dr. Diss.]. Nal’chik, 2002. 304 p.
8. Gramota.ru. Available at: http://www.gramota.ru/slovari/online/. (In Russian).
9. Dal’ V.I. Tolkovyy slovar’ zhivogo velikorusskogo yazyka [The Explanatory Dictionary of the Living Great Russian Language]. Available at:
http://www.vidahl.agava.ru/.
10. Ushakov D.N. Tolkovyy slovar’ russkogo yazyka [The Explanatory Dictionary of the Russian Language]. Available at: http://www.ushdict.narod.ru/.
11. Agapova N.A. Lingvokul’turologicheskiy potentsial klyuchevogo slova narodnoy primety. Dis. kandidata filologicheskikh nauk [Linguoculturological potential of the keyword of the folk sign. Philology Cand. Diss.]. Tomsk, 2013. 184 p.
Received: March 27, 2014
