
Добавил:
Вуз:
Предмет:
Файл:
Старый материал / Лабораторная работа №8 – Анализ качественных признаков.doc
Скачиваний:
41
Добавлен:
21.08.2018
Размер:
1.95 Mб
Скачать
Ход выполнения работы
-
Для решения поставленной задачи
необходимо сформировать таблицу
сопряженности (в нашем случае это
таблица 2х2). Для этого воспользуемся
возможностями сводной таблицы MS
Excel. -
Скопируем исходную таблицу
на лист 1 программы
MS Excel

-
Выделите всю таблицу.

-
Далее: вкладка
Вставка-Сводная таблица- Сводная
таблица-Ok


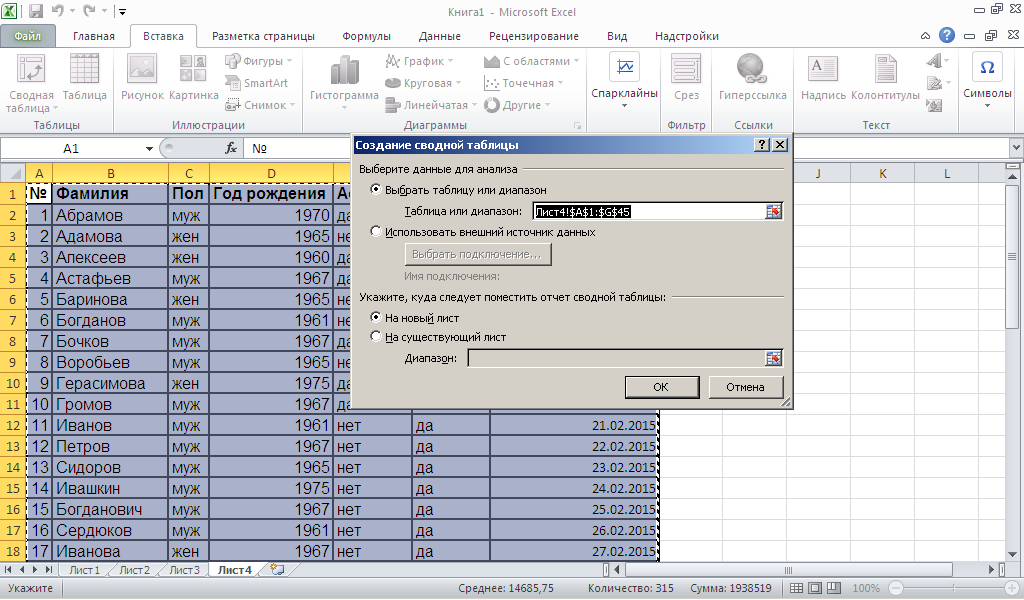
-
В появившемся макете сводной
таблице укажите название строк,
столбцов и значений
так, как показано на иллюстрациях ниже.


-
Для большей наглядности
сводной таблицы во вкладке Конструктор
укажите Макет отчета
как Показать в форме
структуры.
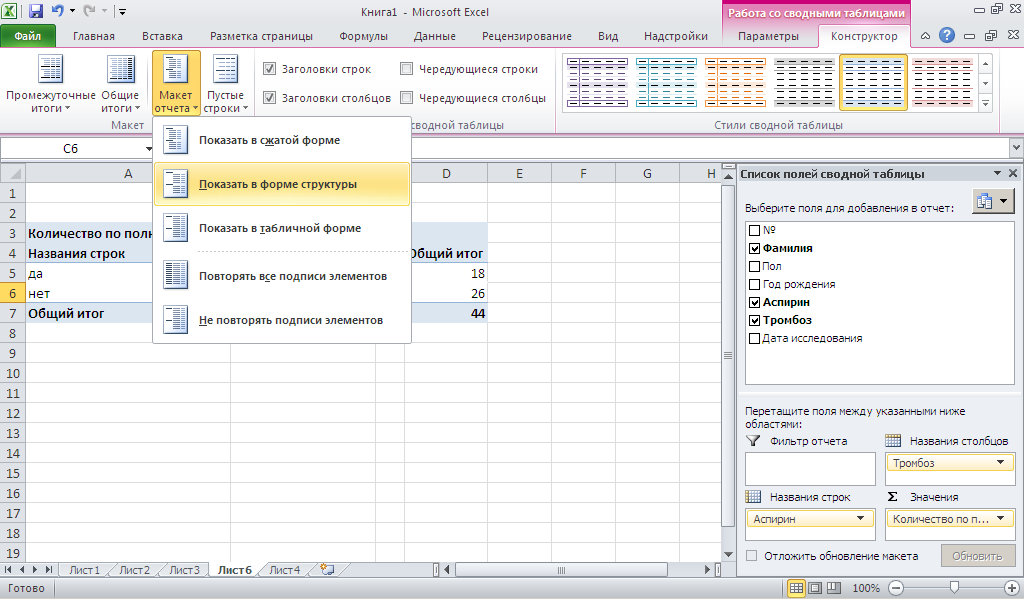
-
Получившуюся сводную таблицу
(таблица сопряженности) скопируйте в
отдельный документ Word
и при необходимости доофйормите ее.

-
В результате предыдущих
действий вы получили таблицу сопряженности
2х2, впринципе ее можно было бы получить
и вручную, но возможности сводной
таблицы Excel
значительно упрощают процесс построения.
Таблица сопряженности показывает
количество человек с тромбозом, которым
был введен аспирин и количество больных
тромбозом, которым вместо аспирина
давали плацебо. Как видно из таблицы
налицо явные преимущества аспирина.
Теперь видя только нужные для анализа
цифры необходимо оценить статистическую
значимость видимых различий. Воспользуемся
критерием хи-квадрат. -
Откройте программу Statistica,
создайте новый документ. -
Далее: Анализ-Непараметрическая
статистика-Таблицы 2х2…..


-
В появившемся окне введите
значения из полученной таблицы
сопряженности


-
Полученная таблица результата
анализа. Так как в нашем случае анализ
проводился таблицы сопряженности 2х2,
то необходимо учитывать поправку
Йейтса. Исходя из полученных значений
критерия хи-квадрат и вероятности p,
следует заключить, что видимые различия
в клетках таблицы сопряженности значимы.
Поэтому нулевая гипотеза отвергается.
Аспирин действительно положительно
влияет на снижение вероятности
возникновения тромбоза шунта.

Результат скопируйте в
документ Word.
Сделайте ваш собственный вывод.
-
Так как в подобного рода
анализе часто возникает потребность
в указании процентного соотношения в
таблице сопряженности, то вновь вернемся
к сводной таблице Excel.
И во вкладке Параметры
выберите Вычисления-Дополнительные
вычисления-%от общей суммы.
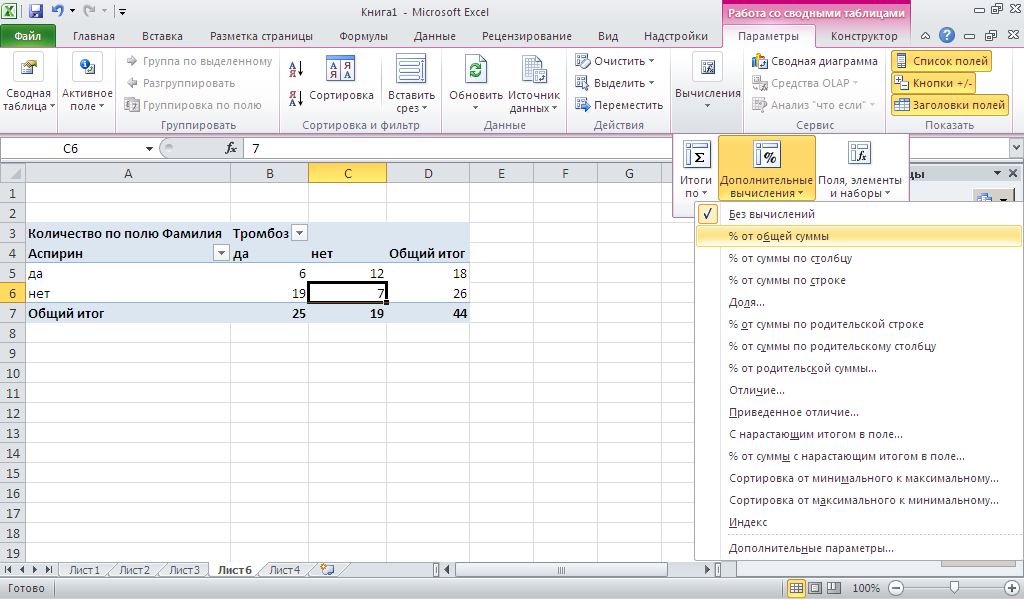
-
Полученный результат
скопируйте в документ Word

-
Постройте три типа сводных
диаграмм как указано ниже. Параметры-Сводная
диаграмма. Скопируйте
в отчет.


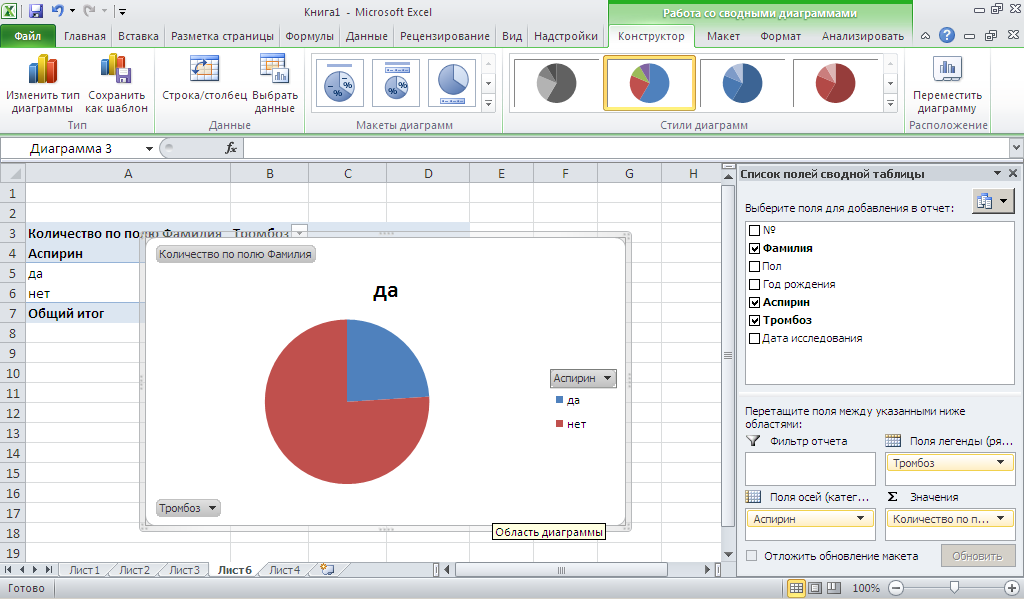

-
Сделайте выводы о проделанном анализе.
14
Соседние файлы в папке Старый материал
- #
- #
- #
- #
- #
- #
- #
- #
Для решения действительно важных исследовательских задач нужно пользоваться специализированными статистическими пакетами, но временами под рукой оказываются только офисные приложения. Табличный редактор Excel включает в себя ряд полезных инструментов, при помощи которых можно удовлетворительно решать простые задачи, стоящие перед социологом. Например, сводные таблицы дают возможность построить таблицу сопряженности с учетом взвешивания массива. Предположим, на одном из листов рабочей книги размещены данные опроса, причем в первой строке указаны имена переменных (В1, В2, И3 и т.д.). Добавьте к данным еще один столбец, в котором будут храниться весовые коэффициенты для наблюдений (если все респонденты имеют одинаковый вес, в нем будут находиться единицы). Пусть этот столбец имеет имя ВЕС. Теперь выберите ленту Вставка, Сводная таблица, Сводная таблица. В появившемся диалоговом окне выберите, если необходимо, таблицу или диапазон, в которых находятся данные, а также лист, на который будет помещена созданная таблица сопряженности, затем щелкните кнопку ОК. В появившемся списке полей сводной таблицы перетащите строковую переменную (например, В1) в поле Названия строк, столбцовую переменную (скажем, В2) в список Названия столбцов, а имя весовой переменной в поле Значения. На листе появится таблица с частотами и итогами. Чтобы заказать проценты, щелкните по элементу Сумма по полю ВЕС и в меню выберите пункт Параметры полей значений. Перейдите на вкладку Дополнительные вычисления и в выпадающем списке дополнительных вычислений установите Доля от суммы по строке, столбцу или Доля от общей суммы
Критерий независимости хи-квадрат используется для определения связи между двумя категориальными переменными. Примерами пар категориальных переменных являются: Семейное положение vs. Уровень занятости респондента; Порода собак vs. Профессия хозяина, Уровень з/п vs. Специализация инженера и др. При вычислении критерия независимости проверяется гипотеза о том, что между переменными связи нет. Вычисления будем производить с помощью функции MS EXCEL 2010
ХИ2.ТЕСТ()
и обычными формулами.
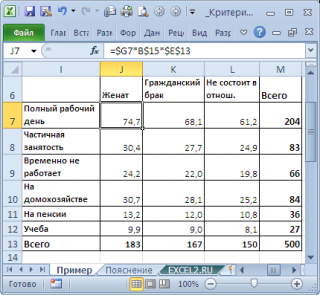
Предположим у нас есть
выборка
данных, представляющая результат опроса 500 человек. Людям задавалось 2 вопроса: про их семейное положение (женаты, гражданский брак, не состоят в отношениях) и их уровень занятости (полный рабочий день, частичная занятость, временно не работает, на домохозяйстве, на пенсии, учеба). Все ответы поместили в таблицу:
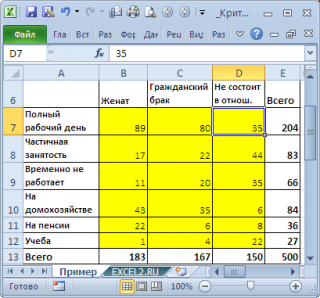
Данная таблица называется
таблицей сопряжённости признаков
(или факторной таблицей, англ. Contingency table). Элементы на пересечении строк и столбцов таблицы обычно обозначают O
ij
(от англ. Observed, т.е. наблюденные, фактические частоты).
Нас интересует вопрос «Влияет ли Семейное положение на Занятость?», т.е. существует ли зависимость между двумя методами классификации
выборки
?
При
проверке гипотез
такого вида обычно принимают, что
нулевая гипотеза
утверждает об отсутствии зависимости способов классификации.
Рассмотрим предельные случаи. Примером полной зависимости двух категориальных переменных является вот такой результат опроса:
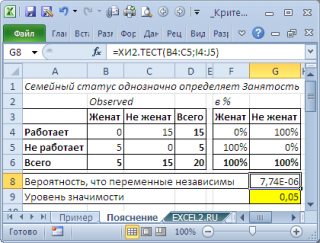
В этом случае семейное положение однозначно определяет занятость (см.
файл примера лист Пояснение
). И наоборот, примером полной независимости является другой результат опроса:
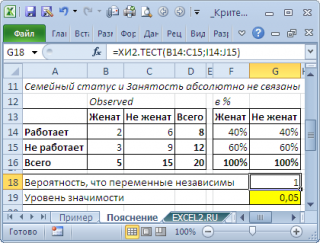
Обратите внимание, что процент занятости в этом случае не зависит от семейного положения (одинаков для женатых и не женатых). Это как раз совпадает с формулировкой
нулевой гипотезы
. Если
нулевая гипотеза
справедлива, то результаты опроса должны были бы так распределиться в таблице, что процент занятых был бы одинаковым независимо от семейного положения. Используя это, вычислим результаты опроса, которые соответствуют
нулевой гипотезе
(см.
файл примера лист Пример
).
Сначала вычислим оценку вероятности, того, что элемент
выборки
будет иметь определенную занятость (см. столбец u
i
):
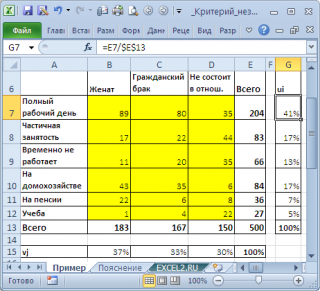
где
с
– количество столбцов (columns), равное количеству уровней переменной «Семейное положение».
Затем вычислим оценку вероятности, того, что элемент
выборки
будет иметь определенное семейное положение (см. строку v
j
).
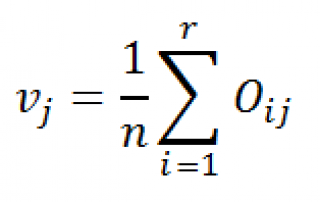
где
r
– количество строк (rows), равное количеству уровней переменной «Занятость».
Теоретическая частота для каждой ячейки E
ij
(от англ. Expected, т.е. ожидаемая частота) в случае независимости переменных вычисляется по формуле: E
ij
=n* u
i
* v
j
Известно, что статистика Х
2
0
при больших n имеет приблизительно
ХИ2-распределение
с (r-1)(c-1) степенями свободы (df – degrees of freedom):
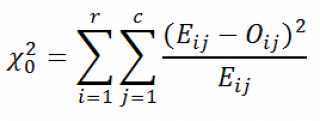
Примечание
: Вышеуказанная статистика при с=1 используется для вычисления
критерия согласия Пирсона ХИ-квадрат
(см. статью
Проверка гипотез критерием хи-квадрат Пирсона в MS EXCEL
).
Если вычисленное на основе
выборки
значение этой статистики «слишком большое» (больше порогового), то
нулевая гипотеза
отвергается. Пороговое значение вычисляется на основании
уровня значимости
, например с помощью формулы
=ХИ2.ОБР.ПХ(0,05; df)
.
Примечание
:
Уровень значимости
обычно принимается равным 0,1; 0,05; 0,01.
При
проверке гипотезы
также удобно вычислять
p-значение
, которое мы сравниваем с
уровнем значимости
.
p
-значение
рассчитывается с использованием
ХИ2-распределения
с (r-1)*(c-1)=df степеней свободы.
Если вероятность, того что случайная величина имеющая
ХИ2-распределение
с (r-1)(c-1)
степенями свободы
примет значение больше вычисленной статистики Х
2
0
, т.е. P{Х
2
(r-1)*(c-1)
>Х
2
0
}, меньше
уровня значимости
, то
нулевая гипотеза
отклоняется.
В MS EXCEL
p-значение
можно вычислить с помощью формулы
=ХИ2.РАСП.ПХ(Х
2
0
;df)
, конечно, вычислив непосредственно перед этим значение статистики Х
2
0
(это сделано в
файле примера
). Однако, удобнее всего воспользоваться функцией
ХИ2.ТЕСТ()
. В качестве аргументов этой функции указываются ссылки на диапазоны содержащие фактические (Observed) и вычисленные теоретические частоты (Expected).
Если
уровень значимости
>
p
-значения
, то означает это фактические и теоретические частоты, вычисленные из предположения справедливости
нулевой гипотезы
, серьезно отличаются. Поэтому,
нулевую гипотезу
нужно отклонить.
Использование функции
ХИ2.ТЕСТ()
позволяет ускорить процедуру
проверки гипотез
, т.к. не нужно вычислять значение
статистики
. Теперь достаточно сравнить результат функции
ХИ2.ТЕСТ()
с заданным
уровнем значимости
.
Примечание
: Функция
ХИ2.ТЕСТ()
, английское название CHISQ.TEST, появилась в MS EXCEL 2010. Ее более ранняя версия
ХИ2ТЕСТ()
, доступная в MS EXCEL 2007 имеет тот же функционал. Но, как и для
ХИ2.ТЕСТ()
, теоретические частоты нужно вычислить самостоятельно.
СОВЕТ
: О проверке других видов гипотез см. статью
Проверка статистических гипотез в MS EXCEL
.
В предыдущей заметке таблицы и диаграммы применялись для представления числовых данных. Однако часто данные носят не числовой, а категориальный характер. В этой заметке изучаются способы организации и представления категорийных данных в виде таблиц и диаграмм. [1]
Вернемся к анализу доходности взаимных фондов. Кроме среднегодовой доходности фонды характеризуются риском, связанном с инвестированием в эти фонды. Взаимные фонды могут иметь очень низкий, низкий, средний, высокий и очень высокий риск. При работе с категорийными переменными данные сначала заносятся в сводную таблицу, а затем графически представляются в виде гистограмм, круговых диаграмм или диаграмм Парето.
Сводная таблица
По внешнему виду сводная таблица для категорийных данных напоминает распределение частот для числовых данных. Чтобы проиллюстрировать процесс ее построения, рассмотрим данные о классификации взаимных фондов по уровню риска (рис. 1).

Рис. 1. Уровень риска 259 взаимных фондов. Частоты и процентные доли
Скачать заметку в формате Word или pdf, примеры в формате Excel2013
Линейчатая диаграмма
Информацию, содержащуюся в таблице (рис. 1), можно представить в виде линейчатой диаграммы (рис. 2), в которой каждая категория элементов изображается в виде столбца. Высота столбца равна частоте или процентной доле элементов выборки, относящихся к данной категории.

Рис. 2. Линейчатая диаграмма, отображающая уровень риска фондов
Круговая диаграмма
Существует еще один весьма популярный способ отображения информации, содержащейся в сводной таблице, — круговая диаграмма (рис. 3). При построении круговых диаграмм используется тот факт, что угол окружности равен 360°. Круг разделяется на секторы, углы которых соответствуют процентным долям каждой категории. Например, на рис. 3 показан сектор, соответствующий доле взаимных фондов с низким риском, которая равна 29,3%. При построении круговой диаграммы величина 360° умножается на 0,293. В результате образуется сектор, угол которого равен 105,6°. Как видим, круговая диаграмма позволяет отразить долю каждой категории в общем «пироге».

Рис. 3. Круговая диаграмма, отображающая уровень риска фондов
Цель графического представления данных — точность и ясность. Например, рис. 2 и 3 отображают одинаковую информацию. Какой из двух видов диаграмм предпочесть — дело вкуса. В частности, некоторые исследования показывают, что люди труднее воспринимают круговые диаграммы. Оказывается, человеку намного проще интерпретировать разницу между высотами столбцов в линейчатых диаграммах, чем углы секторов в круговых диаграммах. Обратите внимание на то, что по рис. 3 нелегко определить, какая из категорий фондов больше — с низким, средним или высоким уровнем риска. В то же время по линейчатой диаграмме легко определить, что доля фондов со средним уровнем риска больше, чем доли фондов с высоким и низким уровнями риска.
С другой стороны, круговые диаграммы четко демонстрируют, что сумма долей всех категорий равна 100%. Таким образом, выбор диаграммы является субъективным и часто зависит от предпочтений пользователя. Если необходимо сравнивать доли категорий, лучше применять линейчатые диаграммы. Если важно продемонстрировать вклад долей отдельных категорий в общий «пирог», лучше использовать круговые диаграммы.
Диаграмма Парето
Существует более информативный способ графического изображения категорийных данных — диаграмма Парето. Она особенно полезна, если количество категорий велико. Диаграмма Парето — это особая разновидность вертикальной диаграммы, в которой категории приводятся в порядке убывания их частот одновременно с полигоном накопленных частот. Это позволяет выделить наиболее важные категории из большого количества менее значимых групп. Диаграмма Парето получила широкое распространение при анализе производственных процессов и контроле качества (см., например, АВС-анализ и принцип Парето для бизнеса).
Например, для построения Диаграммы Парето на основе данных рис. 1, необходимо отсортировать строки по убыванию, и одновременно отобразить как количество фондов в каждой категории, так и интегральный процент (рис. 4).

Рис. 4. Диаграмма Парето, отображающая специфику фондов
Надо отметить, что в Excel2013 предоставляется стандартная возможность построения таких комбинированных диаграмм (рис. 5). Если же у вас Excel2007, то вам придется помучиться (см., например, Диаграмма Excel с двумя осями ординат).

Рис. 5. Построение комбинированной диаграммы
Представление двумерных категорийных данных
Довольно часто необходимо анализировать пары категорийных переменных. Для этого используют таблицы сопряженности признаков и нормированные диаграммы.
Таблица сопряженности признаков. Чтобы можно было одновременно анализировать две категорийные переменные, образующие пару, используются таблицы перекрестной классификации с двумя входами, или таблицы сопряженности признаков (их также называют факторными таблицами). Например, может возникнуть вопрос: существует ли зависимость между уровнем риска и платой, взимаемой фондами за осуществление продаж своих акций (рис. 6)?

Рис. 6. Таблица сопряженности признаков, содержащая данные об уровне риска и плате, взимаемой фондами за осуществление продаж своих акций
Чтобы выявить возможную зависимость между специализацией фонда и прейскурантом его комиссионных сборов, эти результаты сначала преобразуют в процентные доли, используя следующие три базиса:
- общую сумму (259 взаимных фондов);
- сумму по строкам (фонды, взимающие плату за продажу своих акций, и фонды без брокерской комиссии);
- сумму по столбцам (пять уровней риска).
Удобную возможность построения таблиц сопряжения дает опция Excel Сводные таблицы. Для начала нужно представить исходные данные в виде строк, в каждой из которых содержатся все исследуемые параметры (рис. 7). Далее выделяем область В3:D13, и проходим по меню Вставка → Сводная таблица. В открывшемся окне Создание сводной таблицы указываем на существующий лист и в поле Диапазон кликаем на ячейку, где мы хотели расположить левый верхний угол сводной таблицы, кликаем Ok. (Если вы хотите разместить сводную таблицу на отдельном листе, сразу после открытия окна Создание сводной таблицы, кликните Ok.)

Рис. 7. Построение сводной таблицы
Для настройки сводной таблицы просто перетащите строки из верхней части области Поля сводной таблицы в нижнюю, как указано на рис. 8.

Рис. 8. Настройка полей сводной таблицы
Логично расположить строки в сводной таблицы в порядке возрастания (или убывания) степени риска. Для этого надо по очереди выбрать каждую строку, выбрав ячейку в области Название строк (например, Очень высокий), кликнуть правой кнопкой мыши, и выбрать в контекстном меню Переместить, указав, куда именно переместить выбранную строку (рис. 9).

Рис. 9. Перетаскивание строк сводной таблицы
И, наконец, мы можем выбрать базис для анализа процентных долей. Встаньет в любую ячейку в области значений (рис. 10), кликните правой кнопкой мыши, и в открывшемся контекстном меню выберите Параметры полей значений.

Рис. 10. Параметр поля значений
В окне Параметры полей значений перейдите на закладку Дополнительные вычисления, и выберите одну из опций (рис. 11):
- % от общей суммы
- % от суммы по столбцу
- % от суммы по строке

Рис. 11. Выбор базиса процентной доли
Поскольку нас интересует корреляция между степенью риска и наличием комиссии, уместно выбрать опцию % от суммы по строке. Мы увидим, подчиняется ли закономерности доля фондов, взимающих комиссию, при переходе от фондов с очень высоким риском к фондам с очень низким риском (рис. 12). Явной тенденции обнаружить не удалось. [2]

Рис. 12. Доля фондов, взимающих комиссию по уровням риска
Нормированные диаграммы
Для визуализации двумерных категорийных данных часто строят нормированные диаграммы, то есть диаграммы, в которых высота столбиков равна 1 (100%) вне зависимости от общего числа случаев в той или иной категории. На рис. 13 представлен пример такой диаграммы (ось ординат охватывает значения от 0% до 100%, просто, масштаб диаграммы выбран таким образом, что отражается лишь часть этой области). Четко видна закономерность: доля трафика google выросла летом – осенью 2012 г. с 40 до 55%, а затем вновь упала до 40% (для меня остается загадкой, с чем это связано :)).

Рис. 13. Соотношение вклада google и yandex в поисковый трафик сайта baguzin.ru
Предыдущая заметка Представление категорийных данных в виде таблиц и диаграмм
Следующая заметка Искусство графического представления данных
К оглавлению Статистика для менеджеров с использованием Microsoft Excel
[1] Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 124–138
[2] Любопытно, что авторы книги такую закономерность (на тех же исходных данных) увидели 🙂
Создание таблиц сопряженности
-
Загрузите файл studium.sav.
-
Для создания таблиц сопряженности и вычисления меры связанности на их основе, выберите в меню команды Analyze (Анализ) ► Descriptive Statistics (Дескриптивные статистики) ►
Crosstabs… (Таблицы сопряженности). Откроется диалоговое окно Crosstabs (см. рис. 11.1).
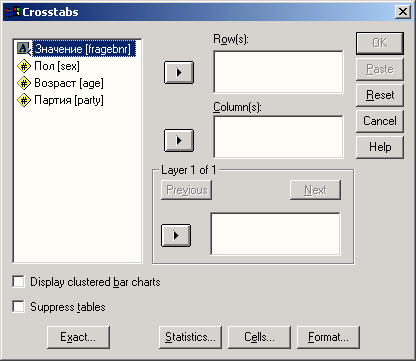
Рис. 11.1: Диалоговое окно Crosstabs (Таблицы cопряженности)
Список исходных переменных содержит переменные открытого файла данных. Здесь можно выбрать переменные для строк и столбцов таблицы сопряженности. Для каждого сочетания двух переменных
будет создана таблица сопряженности. Например, если в списке строк (Rows) находится три переменных, а в списке столбцов (Columns) — две, то мы получим 3 x 2 = 6 таблиц сопряженности.
Сначала мы построим таблицу сопряженности из переменных sex (пол) и psyche (психическое состояние). Поступите следующим образом:
-
Перенесите переменную sex в список строк (Rows), а переменную psyche — в список столбцов (Columns).
-
Щелкните на ОК, и будет создана таблица сопряженности в стандартном формате. В окне просмотра будут показаны следующие таблицы:
Case Processing Summary (Обработанные наблюдения)
| Cases (Случаи) | ||||||
| Valid (Допустимые) | Missing (Отсутствующие) | Total (Всего) | ||||
| N | Percent | N | Percent | N | Percent | |
| Пол * Психическое состояние | 106 | 98,1% | 2 | 1,9% | 108 | 100,0% |
Пол * Психическое состояние Crosstabulation (Таблица сопряженности)
Count (Число)
| Психическое состояние | Total | |||||
| Крайне неустойчивое | Неустойчивое | Устойчивое | Очень устойчивое | |||
| Пол | Женский | 16 | 18 | 9 | 1 | 44 |
| Мужской | 3 | 22 | 32 | 5 | 62 | |
| Total | 19 | 40 | 41 | 6 | 106 |
Первая таблица содержит информацию о числе самих наблюдений; два наблюдения содержат пропущенные значения по крайней мере в одной из двух участвующих переменных. Вторая таблица — это собственно
таблица сопряженности. Переменная “Психическое состояние” (psyche) является столбцовой переменной, так как каждое ее значение (крайне неустойчивое, устойчивое, …) отображается в отдельном столбце.
Переменная “Пол” (sex) — это переменная строк, так как каждое ее значение (женский, мужской) отображается в отдельной строке таблицы. Значение в каждой ячейке таблицы — количество наблюдений (частота).
Так, например, 16 респонденток оценивают свое психическое состояние как “крайне неустойчивое”, а 5 респондентов-мужчин — как “очень устойчивое”. Если для таблицы сопряженности приняты параметры
по умолчанию, в каждой ячейке отображается только абсолютная частота. Метки переменных и значений в таблице соответствуют определениям переменных в файле данных SPSS.
Числа в последней строке и в последнем столбце (Total) показывают суммы значений соответственно по строкам и столбцам. В данном примере суммы по строкам указывают,
что 44 (16+18+9+1) опрошенных — лица женского пола, а 62 — мужского. Суммы по столбцам показывают, что 19 опрошенных (16 + 3) оценивают свое психическое состояние как “крайне неустойчивое”,
40 как неустойчивое, 41 как устойчивое и 6 как “Очень устойчивое”. При анализе принимались в расчет 106 допустимых наблюдений. Полученные результаты мы можем интерпретировать следующим образом:
-
Из 106 опрошенных, которые учитывались при анализе, — 44 женщины и 62 мужчины.
-
16 женщин оценивают свою психику как “крайне неустойчивую”, тогда как для мужчин это количество составляет только 3.
-
Лишь одна женщина считает свое психическое состояние “очень устойчивым”, а мужчин с таким состоянием пятеро.
Даже первое впечатление, которое возникает при анализе таблицы сопряженности, свидетельствует о том, что зависимость между переменными Пол и Психическое состояние существует.
Женщины считают свое психическое состояние более неустойчивым, чем мужчины. Исследуем эту зависимость чуть более детально; для этого нам понадобится точно ответить на следующие вопросы:
-
Существует ли зависимость вообще?
-
Что можно сказать об интенсивности этой зависимости?
-
Что можно сказать о направлении и характере этой зависимости?
Более тщательно исследовать существование зависимости позволяет вычисление значений ожидаемых частот. Чтобы определить эти значения, выполните следующие действия:
-
Выберите в меню команды Analyze (Анализ) ► Descriptive Statistics (Дескриптивные статистики) ► Crosstabs… (Таблицы сопряженности).
В списке строк у нас должна стоять переменная sex, а в списке столбцов — переменная psyche. -
Щелкните на кнопке Cells… (Ячейки). Откроется диалоговое окно Crosstabs: Cell Display (Таблицы сопряженности: Отображение ячеек).
По умолчанию в ячейках таблицы сопряженности отображаются только наблюдаемые значения частот (Observed). В группе Counts (Частоты) можно выбрать один или более следующих вариантов отображения: -
Observed (Наблюдаемые): Будут отображаться наблюдаемые частоты. Это настройка по умолчанию.
-
Expected (Ожидаемые): Если установить этот флажок, будут отображаться ожидаемые частоты. Они вычисляются как произведение сумм соответствующей строки и столбца,
деленное на общую сумму частот. Например, ожидаемая частота для женщин с “крайне неустойчивым” психическим состоянием 7,9 = (16 + 18 + 9 + 1) x (16 + 3) / 106.
Рис. 11.2: Диалоговое окно Crosstabs: Cell Display
-
Установите флажок Expected.
-
Щелкните на кнопке Continue, а затем на ОК. Вы получите следующую таблицу сопряженности.
Пол * Психическое состояние Crosstabulation (Таблица сопряженности)
| Психическое состояние | Total | ||||||
| Крайне неустойчивое | Неустойчивое | Устойчивое | Очень устойчивое | ||||
| Пол | Женский | Count | 16 | 18 | 9 | 1 | 44 |
| Expected Count (Ожидаемое кол-во) | 7,9 | 16,6 | 17,0 | 2,5 | 44,0 | ||
| Мужской | Count | 3 | 22 | 32 | 5 | 62 | |
| Expected Count | 11,1 | 23,4 | 24,0 | 3,5 | 62,0 | ||
| Total | Count | 19 | 40 | 41 | 6 | 106 | |
| Expected Count | 19,0 | 40,0 | 41,0 | 6,0 | 106,0 |
Теперь под наблюдаемыми частотами (Count) появились ожидаемые значения Expected Count). Эти данные мы можем интерпретировать так:
Для значений переменной Психическое состояние “крайне неустойчивое” и “неустойчивое” абсолютная частота у опрашиваемых женщин выше, чем ожидаемая (16 и 7,9; 18 и 16,6),
тогда как при значениях “устойчивое” и “очень устойчивое” она ниже (9 и 17.0; 1 и 2,5).
У опрашиваемых мужчин мы находим противоположную тенденцию. Для значений “крайне неустойчивое” и “неустойчивое” абсолютная частота ниже, чем ожидаемая (3 и 11,1; 22 и 23,4),
тогда как для значений “устойчивое” и “очень устойчивое” она выше 32 и 24,0; 5 и 3,5). Эти результаты мы можем объединить в следующую таблицу:
| Крайне неустойчивое; неустойчивое | Очень устойчивое; устойчивое | |
| Женщины | Абс. частота > ожидаемой частоты | Абс. частота < ожидаемой частоты |
| Мужщины | Абс. частота < ожидаемой частоты | Абс. частота > ожидаемой частоты |
Таким образом, первоначальное впечатление, что женщины считают свое психическое состояние менее устойчивым, чем мужчины, подтверждается. Еще одну возможность выявления существования
зависимости между переменными дает вычисление остатков. Эти остатки являются показателем того, насколько сильно наблюдаемые и ожидаемые частоты отклоняются друг от друга.
Чтобы получить остатки частот, необходимо выполнить следующие действия:
-
Выберите в меню команды Analyze (Анализ) ► Descriptive Statistics (Дескриптивные статистики) ► Crosstabs… (Таблицы сопряженности).
В списке переменных строк должна была стоять переменная sex, а в списке переменных столбцов — переменная psyche. -
Щелкните на кнопке Cells… Флажки Observed и Expected следует оставить помеченными. В группе Residuals (Остатки) можно выбрать один или более следующих вариантов отображения:
-
Unstandardized (Ненормированные): Отображаются ненормированные остатки, то есть разность наблюдаемых (fo) и ожидаемых (fe) частот.
-
Standardized (Нормированные): Отображаются нормированные остатки. Для этого ненормированные остатки делятся на квадратный корень из ожидаемой частоты.
Нормированные остатки полезны при последующем проведении анализа тестов по критерию X2. -
Adjusted standardized (Уточненные нормированные): Нормированные остатки представляют собой отклонение наблюдаемой частоты от ожидаемой, измеренное в числе стандартных отклонений.
Вычисляются с учетом сумм по строкам и столбцам: -
Установите флажок Unstandardized.
-
Щелкните на кнопке Continue, а в главном диалоговом окне — на ОК. Вы получите следующую таблицу сопряженности.
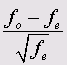
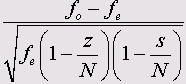
Где z — сумма по текущей строке, a s — сумма по текущему столбцу; N — общая сумма частот.
Пол * Психическое состояние Таблица сопряженности
| Психическое состояние | Total | ||||||
| Крайне неустойчивое | Неустойчивое | Устойчивое | Очень устойчивое | ||||
| Пол | Женский | Count | 16 | 18 | 9 | 1 | 44 |
| Expected Count | 7,9 | 16,6 | 17,0 | 2,5 | 44,0 | ||
| Residual (Остаток) | 8,1 | 1,4 | -8,0 | -1,5 | |||
| Мужской | Count | 3 | 22 | 32 | 5 | 62 | |
| Expected Count | 11,1 | 23,4 | 24,0 | 3,5 | 62,0 | ||
| Residual | -8,1 | -1,4 | 8,0 | 1,5 | |||
| Total | Count | 19 | 40 | 41 | 6 | 106 | |
| Expected Count | 19,0 | 40,0 | 41,0 | 6,0 | 106,0 |
Можно заметить, что каждый остаток равен разности наблюдаемой и теоретически ожидаемой частот в данной ячейке (например, в первой ячейке 16 – 7,9 = 8,1). Остатки делают еще более
заметной противоположную тенденцию самооценки у мужчин и женщин.
Таблицы сопряженности, которые мы рассмотрели выше, имеют тот недостаток, что в них приводятся только абсолютные значения. Чтобы узнать, насколько эти значения
важны по отношению к общему количеству, надо определить их процентную долю
для вычисления процентных значений выполните следующие действия:
-
Выберите в меню команды Analyze (Анализ) ► Descriptive Statistics (Дескриптивные статистики) ► Crosstabs… (Таблицы сопряженности)
-
Не изменяя прежних настроек, щелкните на кнопке Cells… Откроется диалоговое окно Crosstabs: Cell Display (Таблицы сопряженности: Отображение ячеек).
В группе Percentages (Проценты) можно выбрать один или более из нижеследующих вариантов отображения: -
Row (По строкам): Вычисляются процентные значения по строкам: количество наблюдений в каждой ячейке, отнесенное к сумме по строке.
-
Column (По столбцам): Вычисляются процентные значения по столбцам: количество наблюдений в каждой ячейке в отношении к сумме столбца.
-
Total (Полные): Вычисляются полные процентные значения: количество наблюдений в каждой ячейке, отнесенное к общей сумме наблюдений.
-
Установите флажки Row, Column и Total.
-
Щелкните на кнопке Continue, а в главном диалоговом окне — на ОК. В окне просмотра результатов будет получена таблица сопряженности, приведенная ниже.
Пол * Психическое состояние Таблица сопряженности
| Психическое состояние | Total | ||||||
| Крайне неустойчивое | Неустойчивое | Устойчивое | Очень устойчивое | ||||
| Пол | Женский | Count | 16 | 18 | 9 | 1 | 44 |
| Expected Count | 7,9 | 16,6 | 17,0 | 2,5 | 44,0 | ||
| % от Пол | 36,4% | 40,9% | 20,5% | 2,3% | 100,0% | ||
| % от Психическое состояние | 84,2% | 45,0% | 22,0% | 16,7% | 41,5% | ||
| % of Total | 15,1% | 17,0% | 8,5% | 0,9% | 41.5% | ||
| Residual | 8,1 | 1,4 | -8,0 | -1.5 | |||
| Мужской | Count | 3 | 22 | 32 | 5 | 62 | |
| Expected Count | 11,1 | 23,4 | 24,0 | 3,5 | 62,0 | ||
| % от Пол | 4,8% | 35,5% | 51,6% | 8.1% | 100,0% | ||
| % от Психическое состояние | 15,8% | 55,0% | 78,0% | 83,3% | 56,5% | ||
| % of Total | 2,8% | 20,8% | 30,2% | 4,7% | 58,5% | ||
| Residual | -8,1 | -1,4 | 8,0 | 1,5 | |||
| Тotal | Count | 19 | 40 | 41 | 6 | 106 | |
| Expected Count | 19,0 | 40,0 | 41,0 | 6,0 | 106,0 | ||
| % от Пол | 17,9% | 37,7% | 38,7% | 5,7% | 100.0% | ||
| % от Психическое состояние | 100,0% | 100,0% | 100,0% | 100,0% | 100,0% | ||
| % of Total | 17,9% | 37,7% | 38,7% | 5,7% | 100,0% |
В таблице дополнительно отображаются процентные значения частот по отношению к суммам строк, столбцов и общей сумме.
Возьмем для примера первую ячейку. Значения, содержащиеся в ней можно интерпретировать следующим образом:
-
16 из 44 женщин-респонденток или 36,4% от общего числа опрашиваемых охарактеризовали свое психическое состояние как “крайне неустойчивое”.
-
Из 19 респондентов с “крайне неустойчивым” состоянием 16 — женщины, что составляет 84,2%.
-
16 женщин-респонденток дали ответ “крайне неустойчивое”, что по отношению ко всей таблице (общему количеству респондентов) составляет 15,1%.
Можно также сделать следующие общие выводы:
-
36,4% женщин оценивают свою психику как “крайне неустойчивую”, тогда как среди мужчин эта доля составляет только 4,8%.
-
Среди опрашиваемых, оценивающих свою психику как “крайне неустойчивую”, женщины составляют 84,2%, а мужчины — лишь 15,8%.
-
77,3% (36,4% + 40,9%) женщин считают свое психическое состояние “крайне неустойчивым” или “неустойчивым”, в то время, как только 40,3% (4,8% + 35,5%) мужчин дают такую же оценку своего психического состояния.
-
22,8% (20,5% + 2,3%) женщин и 59,7% (51,6% + 8,1%) мужчин оценивают свою психику как “устойчивую” или “очень устойчивую”.
-
2,3% женщин оценивают свое психическое состояние как “очень устойчивое”, а среди мужчин эта доля составляет 8,1%.
-
Среди опрашиваемых, оценивающих свою психику как “очень устойчивую”, женщины составляют 16,7%, а мужчины — 83,3%.
На вопрос, существует ли зависимость между переменными sex и psyche, наиболее ясный ответ в данном примере дают процентные частоты по столбцам. Эти частоты сведены в следующую таблицу:
| Крайне неустойчивое | Неустойчивое | Устойчивое | Очень устойчивое | |
| Женский | 84,2 | 45,0 | 22,0 | 16,7 |
| Мужской | 15,8 | 55,0 | 78,0 | 83,3 |
Так как в нашем случае процентные распределения значительно различаются, мы могли сделать вывод о существовании статистической зависимости между признаками sex и psyche.
Значительно больше женщин, чем мужчин, оценивают свое психическое состояние как “крайне неустойчивое”, и значительно больше мужчин, чем женщин, оценивают свое психическое состояние как “очень устойчивое”.
Таким образом, наблюдается различие в оценках психического состояния, связанное с полом. Является ли это различие значимым, можно выяснить при помощи
хи-квадрат-теста.
Форматы таблиц сопряженности
Можно изменить порядок сортировки переменных строк в таблице сопряженности, щелкнув в диалоговом окне Crosstabs на кнопке Formal… (Формат).
Откроется диалоговое окно Crosstabs: Table Format (Таблицы сопряженности: Формат таблицы).
В группе Row Order (Порядок строк) можно выбрать один из следующих вариантов сортировки значений:
-
Ascending (По возрастанию): Значения переменных строк отображаются в порядке возрастания от наименьшего к наибольшему. Это настройка по умолчанию.
-
Descending (По убыванию): Значения переменных строк отображаются в порядке убывания от наибольшего к наименьшему.
Рис. 11.3: Диалоговое окно Crosstabs: Table Format
Применение переменных групп и слоев
Созданные выше таблицы сопряженности можно разделить по специальностям. Вполне может быть, что переменная fach (Специальность) оказывает влияние на зависимость между sex и psyche.
Чтобы выявить возможные различия, следует создать отдельные таблицы, в нашем случае — по одной таблице для каждой специальности. Такие таблицы могут выявить интересные различия между
отдельными специальностями. В рассматриваемом примере переменная fach играет роль переменной слоев. Анализ производится по группам, то есть для каждой группы — в нашем случае для каждой
специальности — составляется отдельная таблица сопряженности.
Чтобы задать переменную слоев, поступите так:
-
Выберите в меню команды Analyze (Анализ) ► Descriptive Statistics (Дескриптивные статистики) ► Crosstabs… (Таблица сопряженности). В списке строк у нас должна стоять переменная sex, а в списке столбцов — переменная psyche.
-
Перенесите переменную fach в список переменных слоев. В диалоговом окне это третий сверху список; он еще пуст. Диалоговое окно Crosstabs приобретет вид, показанный на рис. 11.4.
Рис. 11.4: Заполненное диалоговое окно Crosstabs
Можно выбрать другие уровни переменных слоев. Для каждой категории каждой из переменной слоев будет создана отдельная таблица сопряженности. Чтобы добавить новый слой,
щелкните на кнопке Next (Следующий). Каждый последующий уровень делит таблицу сопряженности на меньшие подгруппы. Переходить от одного слоя к другому можно при помощи кнопок Next и Previous (Предыдущий).
-
Щелкните на ОК. Вы получите таблицы сопряженности переменных sex и psyche отдельно для каждой специальности.
