Содержание
- Как сделать в Excel таблицу кубов?
- Функции для работы с кубами (справка)
- Аналитические функции в Excel (функции кубов)
- Функции кубов и сводные таблицы
- Простой способ получить функции кубов
- Функция КУБЗНАЧЕНИЕ()
- Написание формулы «с нуля»
- Синтаксис функции КУБЗНАЧЕНИЕ()
- Некоторые сведения о кубах OLAP и моделях данных Power Pivot
- Автозавершение в помощь
Как сделать в Excel таблицу кубов?
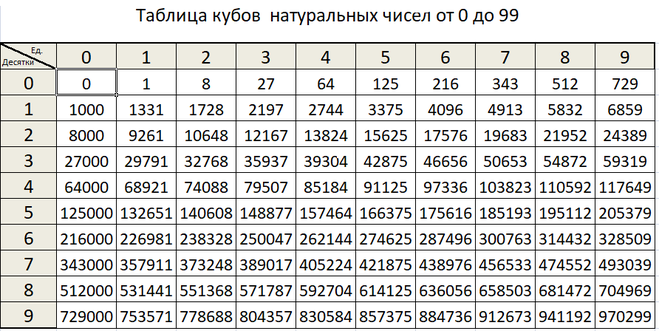
Как сделать в Эксель таблицу кубов натуральных чисел до 99
Какими формулами можно сделать таблицу кубов.
![]()
Если таблица начинается с клетки D4, то в эту клетку можно записать формулу:
=(( СТРОКА() — СТРОКА($D$4) )*10 + СТОЛБЕЦ( D4 ) — СТОЛБЕЦ( $D$4 ))^2
Далее эта формула растягивается на весь диапазон, сначала по вертикали, потом по горизонтали (или наоборот)
строка заголовка колонок формируется растянутой флормулой из ячейки D3 вправо
колонка заголовка строк формируется растянутой флормулой из ячейки C4 вниз
![]()
Бывает, возникает необходимость изменить масштаб всей таблицы, когда, например, что-то написано слишком мелким шрифтом. Это делается просто для удобства чтения. В этом случае можно масштаб регулировать при помощи бегунка в правом нижнем углу таблицы.
Как вариант, заходим во вкладку Вид, расположенную на панели инструментов, выбираем Масштаб. В новом окне остается только выбрать масштаб из предложенных или ввести свое значение масштаба.
В случае, когда масштаб требуется поменять для печати, действуем так:
1). В основном меню программы выбираем Файл — Печать — Параметры настраиваемого масштабирования.
2). Если таблицу следует уменьшить для печати, нам нужен масштаб меньше 100%.
3). Для увеличения размеров таблицы при распечатке, выбираем масштаб более 100%.
Если же просто нужно изменить размер ячеек, становимся на границу ячейки и раздвигаем границы.
![]()
Надо изменить параметры страницы. Измените, расстояния полей слева и справа. Измените, ширину и высоту столбцов. Сделайте предварительный просмотр страницы. Печатайте после предварительного просмотра и изменения параметров. Выделите текст с таблицами и печатайте выделенный текст после предварительного просмотра.
![]()
Для того, что добавленная строка автоматически появлялась в фильтре надо изменить порядок работы. Перед добавлением строки фильтр надо убрать, потом добавить нужную строку и вновь установить фильтр.
Дело в том, что Ваш первоначальный фильтр распространяется только на первоначальные данные и новую строку он не воспринимает.
![]()
Чтобы объявления с некоторыми телефонами не мешали просмотру остальных объявлений, необходимо вынести список этих телефонов на отдельный лист(например Лист3), а в таблице ввести поле, с формулой для определения количества слов из списка в тексте конкретной ячейки, тогда Вы сможете поставить фильтр и смотреть только нужные объявления или только ненужные.
Пример список телефонов для вычеркивания
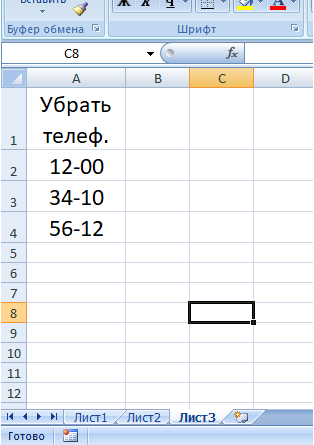
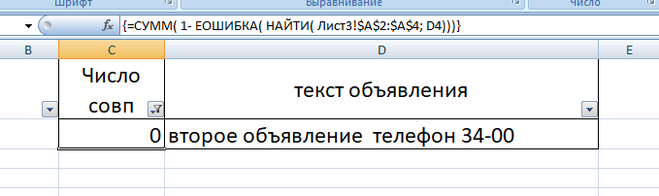
формула массива для количества появлений телефона из списка блокировки в объявлении (вводится через Ctrl+Shift+Enter):
=СУММ( 1- ЕОШИБКА( НАЙТИ( Лист3!$A$2:$A$4 ; D2)))
Эта формула массива растягивается на всю таблицу.
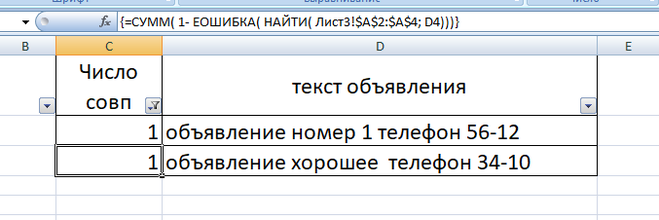
чтобы выделить строки прописываем формулу в условное форматирование для колонки 3 (С3 означает колонка 3):
применяем условное форматирование:

или можно поставить фильтр (пример без применения условного форматирования)

после применения фильтра можно выбрать только нужные строки:
можно использовать и условное форматирование и фильтр одновременно
![]()
Чтобы составить таблицу в Excel, особых усилий прилагать не придется, так как программа Excel и предназначена для работы с таблицами.
Сразу после открытия программы мы попадаем на готовый шаблон таблицы, в верхней части которой расположено меню с инструментами для работы.
Сама таблица Excel представляет из себя поле, составленное из отдельных ячеек. Можно сразу увидеть, что структура поля состоит из столбцов и строк, то есть это и есть таблица, которую можно далее преобразовывать так, как это необходимо в конкретном случае.
Столбцы и строки можно выделять и задавать общий формат ячеек, то есть определять их содержание – текстовое, числовое, процентное и так далее. В каждую ячейку можно вставить формулу расчета и связать ее с другими ячейками.
В коротком ответе невозможно изложить все тонкости работы с таблицей Excel, однако для начала нужно понять одно: исходная страница Excel – это и есть таблица.
Источник
Функции для работы с кубами (справка)
Важно: Вычисляемые результаты формул и некоторые функции листа Excel могут несколько отличаться на компьютерах под управлением Windows с архитектурой x86 или x86-64 и компьютерах под управлением Windows RT с архитектурой ARM. Дополнительные сведения об этих различиях.
Чтобы просмотреть подробную справку о функции, перейдите по нужной ссылке в представленном ниже списке.
Возвращает свойство ключевого показателя эффективности (КПЭ) и отображает его имя в ячейке. КПЭ представляет собой количественную величину, такую как ежемесячная валовая прибыль или ежеквартальная текучесть кадров, используемой для контроля эффективности работы организации.
Возвращает элемент или кортеж из куба. Используется для проверки существования элемента или кортежа в кубе.
Возвращает значение свойства элемента из куба. Используется для подтверждения того, что имя элемента внутри куба существует, и для возвращения определенного свойства для этого элемента.
Возвращает n-й, или ранжированный, элемент в множестве. Используется для возвращения одного или нескольких элементов в множестве, например лучшего продавца или 10 лучших студентов.
Определяет вычисляемое множество элементов или кортежей, отправляя выражение для множества в куб на сервере, который создает множество, а затем возвращает его в Microsoft Excel.
Возвращает число элементов в множестве.
Возвращает агрегированное значение из куба.
Источник
Аналитические функции в Excel (функции кубов)
Microsoft постоянно добавляет в Excel новые возможности в части анализа и визуализации данных. Работу с информацией в Excel можно представить в виде относительно независимых трех слоев:
- «правильно» организованные исходные данные
- математика (логика) обработки данных
- представление данных
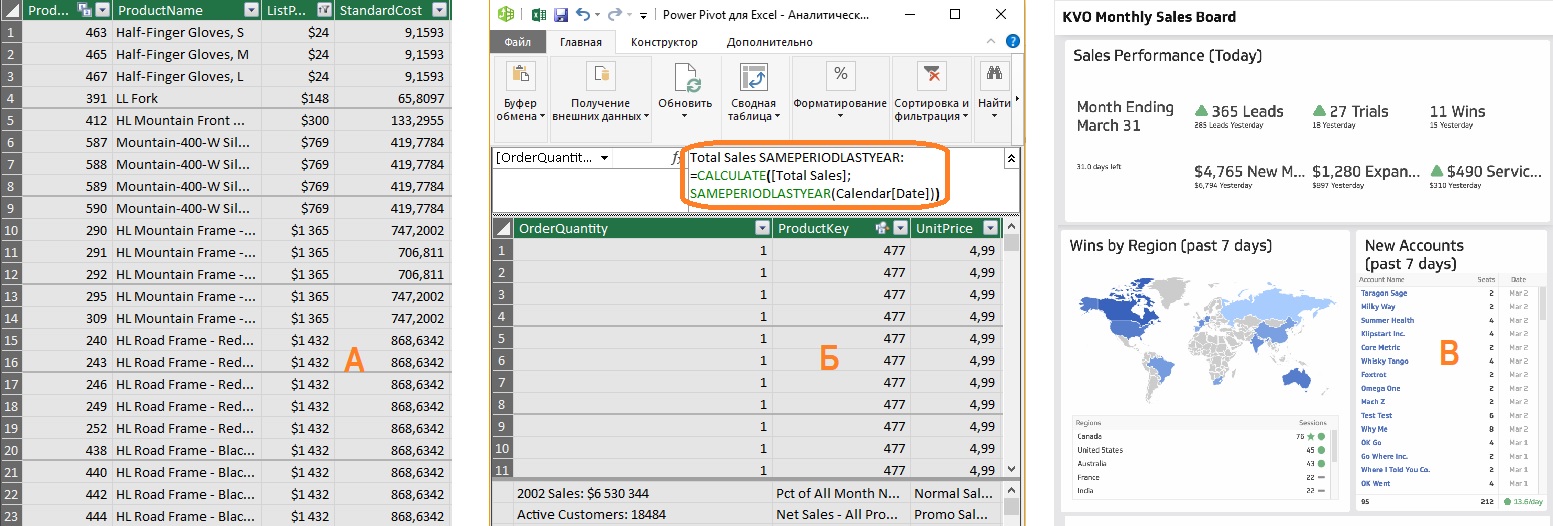
Рис. 1. Анализ данных в Excel: а) исходные данные, б) мера в Power Pivot, в) дашборд; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Скачать заметку в формате Word или pdf, примеры в формате Excel
Функции кубов и сводные таблицы
Наиболее простым и в тоже время очень мощным средством представления данных являются сводные таблицы. Они могут быть построены на основе данных, содержащихся: а) на листе Excel, б) кубе OLAP или в) модели данных Power Pivot. В последних двух случаях, помимо сводной таблицы, можно использовать аналитические функции (функции кубов) для формирования отчета на листе Excel. Сводные таблицы проще. Функции кубов сложнее, но предоставляют больше гибкости, особенно в оформлении отчетов, поэтому они широко применяются в дашбордах.
Дальнейшее изложение относится к формулам кубов и сводным таблицам на основе модели Power Pivot и в нескольких случаях на основе кубов OLAP.
Простой способ получить функции кубов
Когда (если) вы начинали изучать код VBA, то узнали, что проще всего получить код, используя запись макроса. Далее код можно редактировать, добавить циклы, проверки и др. Аналогично проще всего получить набор функций кубов, преобразовав сводную таблицу (рис. 2). Встаньте на любую ячейку сводной таблицы, перейдите на вкладку Анализ, кликните на кнопке Средства OLAP, и нажмите Преобразовать в формулы.
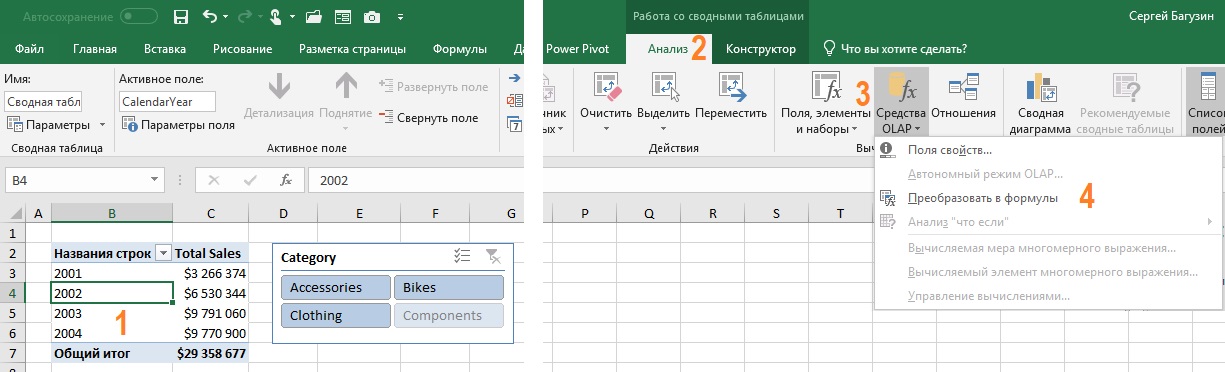
Рис. 2. Преобразование сводной таблицы в набор функций куба
Числа сохранятся, причем это будут не значения, а формулы, которые извлекают данные из модели данных Power Pivot (рис. 3). Получившуюся таблицу вы может отформатировать. В том числе, можно удалять и вставлять строки и столбцы внутрь таблицы. Срез остался, и он влияет на данные в таблице. При обновлении исходных данных числа в таблице также обновятся.
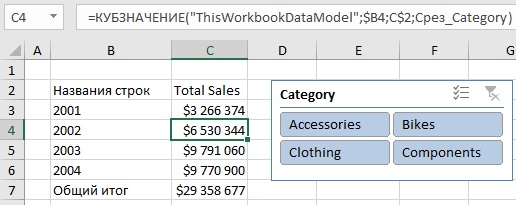
Рис. 3. Таблица на основе формул кубов
Функция КУБЗНАЧЕНИЕ()
Это, пожалуй, основная функция кубов. Она эквивалентна области Значения сводной таблицы. КУБЗНАЧЕНИЕ извлекает данные из куба или модели Power Pivot, и отражает их вне сводной таблицы. Это означает, что вы не ограничены пределами сводной таблицы и можете создавать отчеты с бесчисленными возможностями.
Написание формулы «с нуля»
Вам не обязательно преобразовывать готовую сводную таблицу. Вы можете написать любую формулу куба «с нуля». Например, в ячейку С10 введена следующая формула (рис. 4):
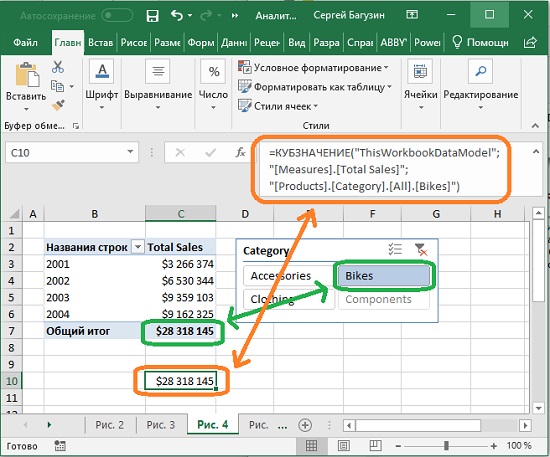
Рис. 4. Функция КУБЗНАЧЕНИЕ() в ячейке С10 возвращает продажи велосипедов за все годы, как и в сводной таблице
Маленькая хитрость. Чтобы удобнее было читать формулы кубов, желательно, чтобы в каждой строке помещался только один аргумент. Можно уменьшить окно Excel. Для этого кликните на значке Свернуть в окно, находящемся в правом верхнем углу экрана. А затем отрегулируйте размер окна по горизонтали. Альтернативный вариант – принудительно переносить текст формулы на новую строку. Для этого в строке формул поставьте курсор в том месте, где хотите сделать перенос и нажмите Alt+Enter.
Синтаксис функции КУБЗНАЧЕНИЕ()
Справка Excel абсолютно точна и абсолютно бесполезна для начинающих:
КУБЗНАЧЕНИЕ(подключение; [выражение_элемента1]; [выражение_элемента2]; …)
Подключение – обязательный аргумент; текстовая строка, представляющая имя подключения к кубу.
Выражение_элемента – необязательный аргумент; текстовая строка, представляющая многомерное выражение, которое возвращает элемент или кортеж в кубе. Кроме того, «выражение_элемента» может быть множеством, определенным с помощью функции КУБМНОЖ. Используйте «выражение_элемента» в качестве среза, чтобы определить часть куба, для которой необходимо возвратить агрегированное значение. Если в аргументе «выражение_элемента» не указана мера, будет использоваться мера, заданная по умолчанию для этого куба.
Прежде, чем перейти к объяснению синтаксиса функции КУБЗНАЧЕНИЕ, пару слов о кубах, моделях данных, и загадочном кортеже.
Некоторые сведения о кубах OLAP и моделях данных Power Pivot
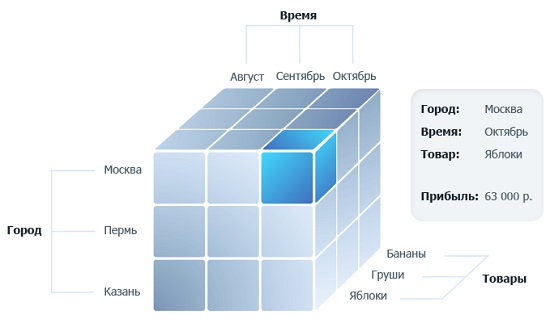
Кубы данных OLAP (Online Analytical Processing — оперативный анализ данных) были разработаны специально для аналитической обработки и быстрого извлечения из них данных. Представьте трехмерное пространство, где по осям отложены периоды времени, города и товары (рис. 5а). В узлах такой координатной сетки расположены значения различных мер: объем продаж, прибыль, затраты, количество проданных единиц и др. Теперь вообразите, что измерений десятки, или даже сотни… и мер тоже очень много. Это и будет многомерный куб OLAP. Создание, настройка и поддержание в актуальном состоянии кубов OLAP – дело ИТ-специалистов.
Аналитические формулы Excel (формулы кубов) извлекают названия осей (например, Время), названия элементов на этих осях (август, сентябрь), значения мер на пересечении координат. Именно такая структура и позволяет сводным таблицам на основе кубов и формулам кубов быть столь гибкими, и подстраиваться под нужды пользователей. Сводные таблицы на основе листов Excel не используют меры, поэтому они не столь гибки в целях анализа данных.
Power Pivot – относительно новая фишка Microsoft. Это встроенная в Excel и отчасти независимая среда с привычным интерфейсом. Power Pivot значительно превосходит по своим возможностям стандартные сводные таблицы. Вместе с тем, разработка кубов в Power Pivot относительно проста, а самое главное – не требует участия ИТ-специалиста. Microsoft реализует свой лозунг: «Бизнес-аналитику – в массы!». Хотя модели Power Pivot не являются кубами на 100%, о них также можно говорить, как о кубах (подробнее см. вводный курс Марк Мур. Power Pivot и более объемное издание Роб Колли. Формулы DAX для Power Pivot).
Основные компоненты куба – это измерения, иерархии, уровни, элементы (или члены; по-английски members) и меры (measures). Измерение – основная характеристика анализируемых данных. Например, категория товаров, период времени, география продаж. Измерение – это то, что мы можем поместить на одну из осей сводной таблицы. Каждое измерение помимо уникальных значений включает элемент [ALL], выполняющий агрегацию всех элементов этого измерения.
Измерения построены на основе иерархии. Например, категория товаров может разбиваться на подкатегории, далее – на модели, и наконец – на названия товаров (рис. 5б) Иерархия позволяет создавать сводные данные и анализировать их на различных уровнях структуры. В нашем примере иерархия Категория включает 4 Уровня.
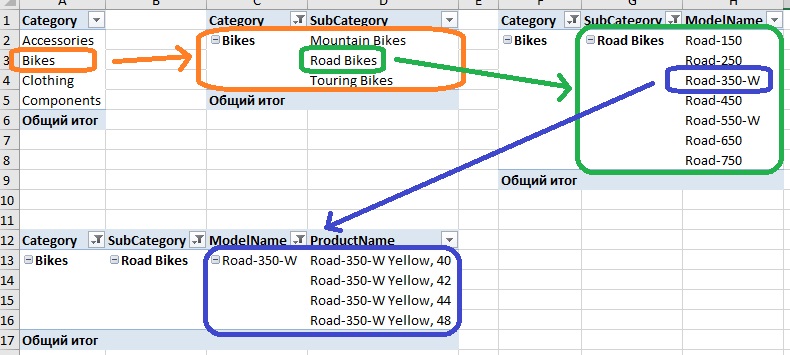
Рис. 5б. Иерархия категорий товаров
Элементы (отдельные члены) присутствуют на всех уровнях. Например, на уровне Category есть четыре элемента: Accessories, Bikes, Clothing, Components. Другие уровни имеют свои элементы.
Меры – это вычисляемые значения, например, объем продаж. Меры в кубах хранятся в собственном измерении, называемом [Measures] (см. ниже рис. 9). Меры не имеют иерархий. Каждая мера рассчитывает и хранит значение для всех измерений и всех элементов, и нарезается в зависимости от того, какие элементы измерений мы поместим на оси. Еще говорят, какие зададим координаты, или какой зададим контекст фильтра. Например, на рис. 5а в каждом маленьком кубике рассчитывается одна и та же мера – Прибыль. А возвращаемое мерой значение зависит от координат. Справа на рисунке 5а показано, что Прибыль (в трех координатах) по Москве в октябре на яблоках = 63 000 р. Меру можно трактовать, и как одно из измерений. Например, на рис. 5а вместо оси Товары, разместить ось Меры с элементами Объем продаж, Прибыль, Проданные единицы. Тогда каждая ячейка и будет каким-то значением, например, Москва, сентябрь, объем продаж.
Кортеж – несколько элементов разных измерений, задающие координаты по осям куба, в которых мы рассчитываем меру. Например, на рис. 5а Кортеж = Москва, октябрь, яблоки. Также допустимый кортеж – Пермь, яблоки. Еще один – яблоки, август. Не вошедшие в кортеж измерения присутствуют в нем неявно, и представлены членом по умолчанию [All]. Таким образом, ячейка многомерного пространства всегда определяется полным набором координат, даже если некоторые из них в кортеже опущены. Нельзя включить два элемента одного измерения в кортеж, не позволит синтаксис. Например, недопустимый кортеж Москва и Пермь, яблоки. Чтобы реализовать такое многомерное выражение потребуется набор двух кортежей: Москва и яблоки + Пермь и яблоки.
Набор элементов – несколько элементов одного измерения. Например, яблоки и груши. Набор кортежей – несколько кортежей, каждый из которых состоит из одинаковых измерений в одной и той же последовательности. Например, набор из двух кортежей: Москва, яблоки и Пермь, бананы.
Автозавершение в помощь
Вернемся к синтаксису функции КУБЗНАЧЕНИЕ. Воспользуемся автозавершением. Начните ввод формулы в ячейке:
Excel предложит все доступные в книге Excel подключения:
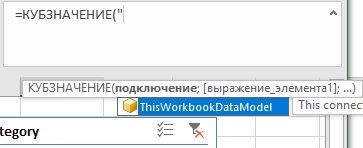
Рис. 6. Подключение к модели данных Power Pivot всегда называется ThisWorkbookDataModel
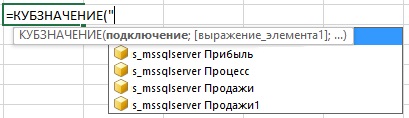
Рис. 7. Подключения к кубам
Продолжим ввод формулы (в нашем случае для модели данных):
Автозавершение предложит все доступные таблицы и меры модели данных:
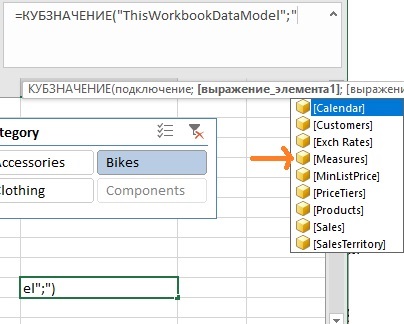
Рис. 8. Доступные элементы первого уровня – имена таблиц и набор мер (выделен)
Выберите значок Measures. Поставьте точку:
=КУБЗНАЧЕНИЕ( » ThisWorkbookDataModel » ; » [Measures].
Автозавершение предложит все доступные меры:
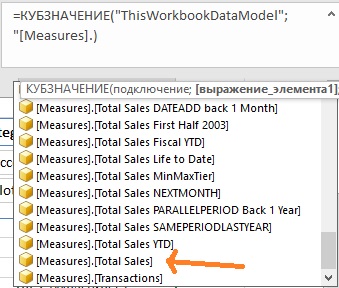
Рис. 9. Доступные элементы второго уровня в наборе мер
Выберите меру [Total Sales]. Добавьте кавычки, закрывающую скобку, нажмите Enter.
=КУБЗНАЧЕНИЕ( » ThisWorkbookDataModel » ; » [Measures].[Total Sales] » )
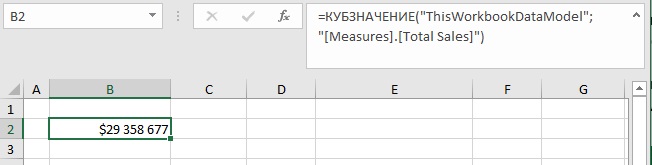
Рис. 10. Формула КУБЗНАЧЕНИЕ в ячейке Excel
Аналогичным образом можете добавить третий аргумент в формулу:
Источник
![]()
0
Как сделать в Эксель таблицу кубов натуральных чисел до 99
Какими формулами можно сделать таблицу кубов.
1 ответ:
![]()
0
0
Если таблица начинается с клетки D4, то в эту клетку можно записать формулу:
=(( СТРОКА() – СТРОКА($D$4) )*10 + СТОЛБЕЦ( D4 ) – СТОЛБЕЦ( $D$4 ))^2
Далее эта формула растягивается на весь диапазон, сначала по вертикали, потом по горизонтали (или наоборот)
строка заголовка колонок формируется растянутой флормулой из ячейки D3 вправо
=СТОЛБЕЦ( D3 ) – СТОЛБЕЦ( $D$3 )
колонка заголовка строк формируется растянутой флормулой из ячейки C4 вниз
=СТРОКА() – СТРОКА($C$4)
Читайте также
![]()
Бывает, возникает необходимость изменить масштаб всей таблицы, когда, например, что-то написано слишком мелким шрифтом. Это делается просто для удобства чтения. В этом случае можно масштаб регулировать при помощи бегунка в правом нижнем углу таблицы.
Как вариант, заходим во вкладку Вид, расположенную на панели инструментов, выбираем Масштаб. В новом окне остается только выбрать масштаб из предложенных или ввести свое значение масштаба.
<hr />
В случае, когда масштаб требуется поменять для печати, действуем так:
1). В основном меню программы выбираем Файл – Печать – Параметры настраиваемого масштабирования.
2). Если таблицу следует уменьшить для печати, нам нужен масштаб меньше 100%.
3). Для увеличения размеров таблицы при распечатке, выбираем масштаб более 100%.
<hr />
Если же просто нужно изменить размер ячеек, становимся на границу ячейки и раздвигаем границы.
![]()
Надо изменить параметры страницы… Измените, расстояния полей слева и справа… Измените, ширину и высоту столбцов…, Сделайте предварительный просмотр страницы. Печатайте после предварительного просмотра и изменения параметров. Выделите текст с таблицами и печатайте выделенный текст после предварительного просмотра.
УДАЧИ!
![]()
Для того, что добавленная строка автоматически появлялась в фильтре надо изменить порядок работы. Перед добавлением строки фильтр надо убрать, потом добавить нужную строку и вновь установить фильтр.
Дело в том, что Ваш первоначальный фильтр распространяется только на первоначальные данные и новую строку он не воспринимает.
![]()
Чтобы объявления с некоторыми телефонами не мешали просмотру остальных объявлений, необходимо вынести список этих телефонов на отдельный лист(например Лист3), а в таблице ввести поле, с формулой для определения количества слов из списка в тексте конкретной ячейки, тогда Вы сможете поставить фильтр и смотреть только нужные объявления или только ненужные.
Пример список телефонов для вычеркивания
формула массива для количества появлений телефона из списка блокировки в объявлении (вводится через Ctrl+Shift+Enter):
=СУММ( 1- ЕОШИБКА( НАЙТИ( Лист3!$A$2:$A$4 ; D2)))
Эта формула массива растягивается на всю таблицу.
чтобы выделить строки прописываем формулу в условное форматирование для колонки 3 (С3 означает колонка 3):
=ДВССЫЛ(“R”&СТРОКА()<wbr />&”C3”;0)>0
применяем условное форматирование:
или можно поставить фильтр (пример без применения условного форматирования)
после применения фильтра можно выбрать только нужные строки:
или только ненужные
можно использовать и условное форматирование и фильтр одновременно
![]()
Чтобы составить таблицу в Excel, особых усилий прилагать не придется, так как программа Excel и предназначена для работы с таблицами.
Сразу после открытия программы мы попадаем на готовый шаблон таблицы, в верхней части которой расположено меню с инструментами для работы.
Сама таблица Excel представляет из себя поле, составленное из отдельных ячеек. Можно сразу увидеть, что структура поля состоит из столбцов и строк, то есть это и есть таблица, которую можно далее преобразовывать так, как это необходимо в конкретном случае.
Столбцы и строки можно выделять и задавать общий формат ячеек, то есть определять их содержание – текстовое, числовое, процентное и так далее. В каждую ячейку можно вставить формулу расчета и связать ее с другими ячейками.
В коротком ответе невозможно изложить все тонкости работы с таблицей Excel, однако для начала нужно понять одно: исходная страница Excel – это и есть таблица.
Сводные таблицы Excel
В стандартной сводной таблице исходные данные хранятся на локальном жестком диске. Таким образом, вы всегда можете управлять ими и переорганизовывать их, даже не имея доступа к сети. Но это ни в коей мере не касается сводных таблиц OLAP. В сводных таблицах OLAP кеш никогда не хранится на локальном жестком диске. Поэтому сразу же после отключения от локальной сети ваша сводная таблица утратит работоспособность. Вы не сможете переместить в ней ни одного поля.
Если вам все же необходимо анализировать OLAP-данные после отключения от сети, создайте автономный куб данных. Автономный куб данных — это отдельный файл, который представляет собой кеш сводной таблицы и хранит OLAP-данные, просматриваемые после отключения от локальной сети. OLAP-данные, скопированные в сводную таблицу, можно распечатать, на сайте http://everest.ua подробно об этом рассказано.
Чтобы создать автономный куб данных, сначала создайте сводную таблицу OLAP. Поместите курсор в пределах сводной таблицы и щелкните на кнопке Средства OLAP (OLAP Tools) контекстной вкладки Параметры (Tools), входящей в группу контекстных вкладок Работа со сводными таблицами (PivotTable Tools). Выберите команду Автономный режим OLAP (Offline OLAP) (рис. 9.8).

Рис. 9.8. Создание автономного куба данных
На экране появится диалоговое окно настроек автономного куба данных OLAP. Щелкните в нем на кнопке Создать автономный файл данных (Create Offline Data File). Вы запустили мастер создания файла куба данных. Щелкните на кнопке Далее (Next), чтобы продолжить процедуру.
Cначала необходимо указать размерности и уровни, которые будут включаться в куб данных. В диалоговом окне необходимо выбрать данные, которые будут импортироваться из базы данных OLAP. Идея состоит в том, чтобы указать только те размерности, которые понадобятся после отключения компьютера от локальной сети. Чем больше размерностей укажете, тем больший размер будет иметь автономный куб данных.
Щелкните на кнопке Далее для перехода к следующему диалоговому окну мастера. В нем вы получаете возможность указать члены или элементы данных, которые не будут включаться в куб. В частности, вам не потребуется мера Internet Sales-Extended Amount, поэтому флажок для нее будет сброшен в списке. Сброшенный флажок указывает на то, что указанный элемент не будет импортироваться и занимать лишнее место на локальном жестком диске.
На последнем этапе укажите расположение и имя куба данных. В нашем случае файл куба будет назван MyOfflineCube.cub и будет располагаться в папке Work.
Файлы кубов данных имеют расширение .cub
Спустя некоторое время Excel сохранит автономный куб данных в указанной папке. Чтобы протестировать его, дважды щелкните на файле, что приведет к автоматической генерации рабочей книги Excel, которая содержит сводную таблицу, связанную с выбранным кубом данных. После создания вы можете распространить автономный куб данных среди всех заинтересованных пользователей, которые работают в режиме отключенной локальной сети.
После подключения к локальной сети можно открыть автономный файл куба данных и обновить его, а также соответствующую таблицу данных. Главный принцип гласит, что автономный куб данных применяется только для работы при отключенной локальной сети, но он в обязательном порядке обновляется после восстановления соединения. Попытка обновления автономного куба данных после разрыва соединения приведет к сбою.
Работа с файлами автономного куба
автономный файл куба (. cub) хранит данные в форме куба OLAP (Online Analytical Processing). Эти данные могут представлять часть базы данных OLAP на сервере OLAP или могут создаваться независимо от базы данных OLAP. Используйте автономный файл куба, чтобы продолжить работу с отчетами сводной таблицы и сводной диаграммы, если сервер недоступен или когда вы отключены от сети.
Примечание по безопасности: Будьте внимательны при использовании или распространении файла автономного куба, содержащего конфиденциальные или личные данные. Вместо файла куба рекомендуется сохранить данные в книге, чтобы можно было управлять доступом к данным с помощью функции управления правами. Дополнительные сведения можно найти в разделе Управление правами на доступ к данным в Office.
При работе с отчетом сводной таблицы или сводной диаграммы, основанными на исходных данных сервера OLAP, вы можете с помощью мастера автономного куба скопировать исходные данные в отдельный файл автономного куба на компьютере. Для создания этих автономных файлов необходимо, чтобы поставщик данных OLAP поддерживал такую возможность, например MSOLAP из служб Microsoft SQL Server Analysis Services, установленных на компьютере.
Примечание: Создание и использование файлов автономных кубов из служб Microsoft SQL Server Analysis Services регулируется термином и лицензированием установки Microsoft SQL Server. Ознакомьтесь с соответствующими сведениями о лицензировании версии SQL Server.
Работа с мастером автономного куба
Для создания файла автономного куба вы можете выбрать подмножество данных в базе данных OLAP с помощью мастера автономного куба, а затем сохранить это подмножество. В отчете не нужно включать все поля, включенные в файл, а также выбирать из них любые из них и поля данных, доступные в базе данных OLAP. Чтобы сохранить файл как минимум, вы можете включить только те данные, которые должны отображаться в отчете. Вы можете опустить все измерения и для большинства типов измерений вы также можете исключить сведения о более низком уровне и элементы верхнего уровня, которые не нужно отображать. Для всех элементов, которые вы включаете, поля свойств, доступные в базе данных для этих элементов, также сохраняются в автономном файле.
Перевод данных в автономный режим и их обратное подключение
Для этого сначала нужно создать отчет сводной таблицы или сводной диаграммы, основанный на базе данных сервера, а затем создать файл автономного куба из отчета. После этого вы можете переключить отчет между базой данных сервера и автономным файлом в любое время. Например, если вы используете портативный компьютер для работы в домашних и видеопоездках, а затем снова подключите компьютер к сети.
Ниже описаны основные шаги, которые следует выполнить для автономной работы с данными, а затем снова перевести данные в Интернет.
Создайте или откройте сводную таблицу или отчет сводной диаграммы, основанную на данных OLAP, к которым вы хотите получить доступ в автономном режиме.
Создание автономный файл куба на компьютере. В разделе Создание файла автономного куба из базы данных OLAP-сервера (ниже в этой статье).
Отключение от сети и работа с файлом автономного куба.
Подключитесь к сети и повторно подключите файл куба автономно. Ознакомьтесь с разделом Повторное подключение файла автономного куба к базе данных OLAP-сервера (ниже, в этой статье).
Обновление файла автономного куба с новыми данными и повторное создание автономного файла куба. Ознакомьтесь с разделом обновление и повторное создание файла автономного куба (ниже в этой статье).
БЛОГ
Только качественные посты
Что такое Сводные таблицы Excel и OLAP кубы
Смотрите видео к статье:
OLAP – это англ. online analytical processing, аналитическая технология обработки данных в реальном времени. Простым языком – хранилище с многомерными данными (Куб), еще проще – просто база данных, из которой можно получить данные в Excel и проанализировать с помощью инструмента Excel – Сводные таблицы.
Сводные таблицы – это пользовательский интерфейс для отображения многомерных данных. Иными словами — специальный вид таблиц, с помощью которых можно сделать практически любой отчет.
Чтобы было понятно, давайте сравним «Обычную таблицу» со «Сводной таблицей»
Обычная таблица:

Сводная таблица:

Основное отличие Сводных таблиц – это наличие окна «Список полей сводной таблицы», из которого можно выбирать нужные поля и получать любую таблицу автоматически!
Как пользоваться
Откройте файл Excel, который подключен к OLAP-кубу, например «BIWEB»:

Теперь, что это означает и как этим пользоваться?

Перетащите нужные поля, чтобы получить, например, такую таблицу:

«Плюсики» позволяют детализировать отчет. В этом примере «Бренд» детализируется до «Сокращенных названий», а «Квартал» до «Месяца», т.е. так:
Аналитические функции в Excel (функции кубов)
Microsoft постоянно добавляет в Excel новые возможности в части анализа и визуализации данных. Работу с информацией в Excel можно представить в виде относительно независимых трех слоев:
- «правильно» организованные исходные данные
- математика (логика) обработки данных
- представление данных
Рис. 1. Анализ данных в Excel: а) исходные данные, б) мера в Power Pivot, в) дашборд; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Скачать заметку в формате Word или pdf, примеры в формате Excel
Функции кубов и сводные таблицы
Наиболее простым и в тоже время очень мощным средством представления данных являются сводные таблицы. Они могут быть построены на основе данных, содержащихся: а) на листе Excel, б) кубе OLAP или в) модели данных Power Pivot. В последних двух случаях, помимо сводной таблицы, можно использовать аналитические функции (функции кубов) для формирования отчета на листе Excel. Сводные таблицы проще. Функции кубов сложнее, но предоставляют больше гибкости, особенно в оформлении отчетов, поэтому они широко применяются в дашбордах.
Дальнейшее изложение относится к формулам кубов и сводным таблицам на основе модели Power Pivot и в нескольких случаях на основе кубов OLAP.
Простой способ получить функции кубов
Когда (если) вы начинали изучать код VBA, то узнали, что проще всего получить код, используя запись макроса. Далее код можно редактировать, добавить циклы, проверки и др. Аналогично проще всего получить набор функций кубов, преобразовав сводную таблицу (рис. 2). Встаньте на любую ячейку сводной таблицы, перейдите на вкладку Анализ, кликните на кнопке Средства OLAP, и нажмите Преобразовать в формулы.
Рис. 2. Преобразование сводной таблицы в набор функций куба
Числа сохранятся, причем это будут не значения, а формулы, которые извлекают данные из модели данных Power Pivot (рис. 3). Получившуюся таблицу вы может отформатировать. В том числе, можно удалять и вставлять строки и столбцы внутрь таблицы. Срез остался, и он влияет на данные в таблице. При обновлении исходных данных числа в таблице также обновятся.
Рис. 3. Таблица на основе формул кубов
Функция КУБЗНАЧЕНИЕ()
Это, пожалуй, основная функция кубов. Она эквивалента области Значения сводной таблицы. КУБЗНАЧЕНИЕ извлекает данные из куба или модели Power Pivot, и отражает их вне сводной таблицы. Это означает, что вы не ограничены пределами сводной таблицы и можете создавать отчеты с бесчисленными возможностями.
Написание формулы «с нуля»
Вам не обязательно преобразовывать готовую сводную таблицу. Вы можете написать любую формулу куба «с нуля». Например, в ячейку С10 введена следующая формула (рис. 4):
Рис. 4. Функция КУБЗНАЧЕНИЕ() в ячейке С10 возвращает продажи велосипедов за все годы, как и в сводной таблице
Маленькая хитрость. Чтобы удобнее было читать формулы кубов, желательно, чтобы в каждой строке помещался только один аргумент. Можно уменьшить окно Excel. Для этого кликните на значке Свернуть в окно, находящемся в правом верхнем углу экрана. А затем отрегулируйте размер окна по горизонтали. Альтернативный вариант – принудительно переносить текст формулы на новую строку. Для этого в строке формул поставьте курсор в том месте, где хотите сделать перенос и нажмите Alt+Enter.
Рис. 5. Свернуть окно
Синтаксис функции КУБЗНАЧЕНИЕ()
Справка Excel абсолютно точна и абсолютно бесполезна для начинающих:
КУБЗНАЧЕНИЕ(подключение; [выражение_элемента1]; [выражение_элемента2]; …)
Подключение – обязательный аргумент; текстовая строка, представляющая имя подключения к кубу.
Выражение_элемента – необязательный аргумент; текстовая строка, представляющая многомерное выражение, которое возвращает элемент или кортеж в кубе. Кроме того, «выражение_элемента» может быть множеством, определенным с помощью функции КУБМНОЖ. Используйте «выражение_элемента» в качестве среза, чтобы определить часть куба, для которой необходимо возвратить агрегированное значение. Если в аргументе «выражение_элемента» не указана мера, будет использоваться мера, заданная по умолчанию для этого куба.
Прежде, чем перейти к объяснению синтаксиса функции КУБЗНАЧЕНИЕ, пару слов о кубах, моделях данных, и загадочном кортеже.
Некоторые сведения о кубах OLAP и моделях данных Power Pivot
Кубы данных OLAP (Online Analytical Processing — оперативный анализ данных) были разработаны специально для аналитической обработки и быстрого извлечения из них данных. Представьте трехмерное пространство, где по осям отложены периоды времени, города и товары (рис. 5а). В узлах такой координатной сетки расположены значения различных мер: объем продаж, прибыль, затраты, количество проданных единиц и др. Теперь вообразите, что измерений десятки, или даже сотни… и мер тоже очень много. Это и будет многомерный куб OLAP. Создание, настройка и поддержание в актуальном состоянии кубов OLAP – дело ИТ-специалистов.
Рис. 5а. Трехмерный куб OLAP
Аналитические формулы Excel (формулы кубов) извлекают названия осей (например, Время), названия элементов на этих осях (август, сентябрь), значения мер на пересечении координат. Именно такая структура и позволяет сводным таблицам на основе кубов и формулам кубов быть столь гибкими, и подстраиваться под нужды пользователей. Сводные таблицы на основе листов Excel не используют меры, поэтому они не столь гибки в целях анализа данных.
Power Pivot – относительно новая фишка Microsoft. Это встроенная в Excel и отчасти независимая среда с привычным интерфейсом. Power Pivot значительно превосходит по своим возможностям стандартные сводные таблицы. Вместе с тем, разработка кубов в Power Pivot относительно проста, а самое главное – не требует участия ИТ-специалиста. Microsoft реализует свой лозунг: «Бизнес-аналитику – в массы!». Хотя модели Power Pivot не являются кубами на 100%, о них также можно говорить, как о кубах (подробнее см. вводный курс Марк Мур. Power Pivot и более объемное издание Роб Колли. Формулы DAX для Power Pivot).
Основные компоненты куба – это измерения, иерархии, уровни, элементы (или члены; по-английски members) и меры (measures). Измерение – основная характеристика анализируемых данных. Например, категория товаров, период времени, география продаж. Измерение – это то, что мы можем поместить на одну из осей сводной таблицы. Каждое измерение помимо уникальных значений включает элемент [ALL], выполняющий агрегацию всех элементов этого измерения.
Измерения построены на основе иерархии. Например, категория товаров может разбиваться на подкатегории, далее – на модели, и наконец – на названия товаров (рис. 5б) Иерархия позволяет создавать сводные данные и анализировать их на различных уровнях структуры. В нашем примере иерархия Категория включает 4 Уровня.
Рис. 5б. Иерархия категорий товаров
Элементы (отдельные члены) присутствуют на всех уровнях. Например, на уровне Category есть четыре элемента: Accessories, Bikes, Clothing, Components. Другие уровни имеют свои элементы.
Меры – это вычисляемые значения, например, объем продаж. Меры в кубах хранятся в собственном измерении, называемом [Measures] (см. ниже рис. 9). Меры не имеют иерархий. Каждая мера рассчитывает и хранит значение для всех измерений и всех элементов, и нарезается в зависимости от того, какие элементы измерений мы поместим на оси. Еще говорят, какие зададим координаты, или какой зададим контекст фильтра. Например, на рис. 5а в каждом маленьком кубике рассчитывается одна и та же мера – Прибыль. А возвращаемое мерой значение зависит от координат. Справа на рисунке 5а показано, что Прибыль (в трех координатах) по Москве в октябре на яблоках = 63 000 р. Меру можно трактовать, и как одно из измерений. Например, на рис. 5а вместо оси Товары, разместить ось Меры с элементами Объем продаж, Прибыль, Проданные единицы. Тогда каждая ячейка и будет каким-то значением, например, Москва, сентябрь, объем продаж.
Кортеж – несколько элементов разных измерений, задающие координаты по осям куба, в которых мы рассчитываем меру. Например, на рис. 5а Кортеж = Москва, октябрь, яблоки. Также допустимый кортеж – Пермь, яблоки. Еще один – яблоки, август. Не вошедшие в кортеж измерения присутствуют в нем неявно, и представлены членом по умолчанию [All]. Таким образом, ячейка многомерного пространства всегда определяется полным набором координат, даже если некоторые из них в кортеже опущены. Нельзя включить два элемента одного измерения в кортеж, не позволит синтаксис. Например, недопустимый кортеж Москва и Пермь, яблоки. Чтобы реализовать такое многомерное выражение потребуется набор двух кортежей: Москва и яблоки + Пермь и яблоки.
Набор элементов – несколько элементов одного измерения. Например, яблоки и груши. Набор кортежей – несколько кортежей, каждый из которых состоит из одинаковых измерений в одной и той же последовательности. Например, набор из двух кортежей: Москва, яблоки и Пермь, бананы.
Автозавершение в помощь
Вернемся к синтаксису функции КУБЗНАЧЕНИЕ. Воспользуемся автозавершением. Начните ввод формулы в ячейке:
Excel предложит все доступные в книге Excel подключения:
Рис. 6. Подключение к модели данных Power Pivot всегда называется ThisWorkbookDataModel
Рис. 7. Подключения к кубам
Продолжим ввод формулы (в нашем случае для модели данных):
Автозавершение предложит все доступные таблицы и меры модели данных:
Рис. 8. Доступные элементы первого уровня – имена таблиц и набор мер (выделен)
Выберите значок Measures. Поставьте точку:
=КУБЗНАЧЕНИЕ( » ThisWorkbookDataModel » ; » [Measures].
Автозавершение предложит все доступные меры:
Рис. 9. Доступные элементы второго уровня в наборе мер
Выберите меру [Total Sales]. Добавьте кавычки, закрывающую скобку, нажмите Enter.
=КУБЗНАЧЕНИЕ( » ThisWorkbookDataModel » ; » [Measures].[Total Sales] » )
Рис. 10. Формула КУБЗНАЧЕНИЕ в ячейке Excel
Аналогичным образом можете добавить третий аргумент в формулу:
VBA в Excel Объект Excel.PivotTable и работа со сводными таблицами и кубами OLAP в Excel
10.8 Работа со сводными таблицами (объект PivotTable)
Объект Excel.PivotTable, программная работа со сводными таблицами и кубами OLAP в Excel средствами VBA, объект PivotCache, создание макета сводной таблицы
В процессе работы большинства предприятий накапливаются так называемые необработанные данные (raw data) о деятельности. Например, для торгового предприятия могут накапливаться данные о продажах товаров — по каждой покупке отдельно, для предприятий сотовой связи — статистика нагрузки на базовые станции и т.п. Очень часто менеджменту предприятия необходима аналитическая информация, которая генерируется на основе необработанной — например, посчитать вклад каждого вида товара в доходы предприятия или качество обслуживания в зоне данной станции. Из необработанной информации такие сведения извлечь очень тяжело: нужно выполнять очень сложные SQL-запросы, которые выполняются долго и часто мешают текущей работе. Поэтому все чаще в настоящее время необработанные данные сводятся вначале в хранилище архивных данных — Data Warehouse, а затем — в кубы OLAP, которые очень удобны для интерактивного анализа. Проще всего представить себе кубы OLAP как многомерные таблицы, в которых вместо стандартных двух измерений (столбцы и строки, как в обычных таблицах), измерений может быть очень много. Обычно для описания измерений в кубе используется термин «в разрезе». Например, отделу маркетинга может быть нужна информация во временном разрезе, в региональном разрезе, в разрезе типов продукта, в разрезе каналов продаж и т.п. При помощи кубов (в отличие от стандартных SQL-запросов) очень просто получать ответы на вопросы типа «сколько товаров такого-то типа было продано в четвертом квартале прошлого года в Северо-Западном регионе через региональных дистрибьюторов.
Конечно же, в обычных базах данных такие кубы не создать. Для работы с кубами OLAP требуются специализированные программные продукты. Вместе с SQL Server поставляется база данных OLAP от Microsoft, которая называется Analysis Services. Есть OLAP-решения от Oracle, IBM, Sybase и т.п.
Для работы с такими кубами в Excel встроен специальный клиент. По-русски он называется Сводная таблица (на графическом экране он доступен через меню Данные -> Сводная таблица), а по-английски — Pivot Table. Соответственно, объект, который представляет этот клиент, называется PivotTable. Необходимо отметить, что он умеет работать не только с кубами OLAP, но и с обычными данными в таблицах Excel или баз данных, но многие возможности при этом теряются.
Сводная таблица и объект PivotTable — это программные продукты фирмы Panorama Software, которые были приобретены Microsoft и интегрированы в Excel. Поэтому работа с объектом PivotTable несколько отличается от работы с другими объектами Excel. Догадаться, что нужно сделать, часто бывает непросто. Поэтому рекомендуется для получения подсказок активно использовать макрорекордер. В то же время при работе со сводными таблицами пользователям часто приходится выполнять одни и те же повторяющиеся операции, поэтому автоматизация во многих ситуациях необходима.
Как выглядит программная работа со сводной таблицей?
Первое, что нам потребуется сделать — создать объект PivotCache, который будет представлять набор записей, полученных с источника OLAP. Очень условно этот объект PivotCache можно сравнить с QueryTable. Для каждого объекта PivotTable можно использовать только один объект PivotCache. Создание объекта PivotCache производится при помощи метода Add() коллекции PivotCaches:
Dim PC1 As PivotCache
Set PC1 = ActiveWorkbook.PivotCaches.Add(xlExternal)
PivotCaches — стандартная коллекция, и из методов, которые заслуживают подробного рассмотрения, в ней можно назвать только метод Add(). Этот метод принимает два параметра:
- SourceType — обязательный, определяет тип источника данных для сводной таблицы. Можно указать создание PivotTable на основе диапазона в Excel, данных из базы данных, во внешнем источнике данных, другой PivotTable и т.п. На практике обычно OLAP есть смысл использовать только тогда, когда данных много — соответственно нужно специализированное внешнее хранилище (например, Microsoft Analysis Services). В этой ситуации выбирается значение xlExternal.
- SourceData — обязательный во всех случаях, кроме тех, когда значение первого параметра — xlExternal. Собственно говоря, определяет тот диапазон данных, на основе которого и будет создаваться PivotTable. Обычно принимает объект Range.
Следующая задача — настроить параметры объекта PivotCache. Как уже говорилось, этот объект очень напоминает QueryTable, и набор свойств и методов у него очень похожий. Некоторые наиболее важные свойства и методы:
- ADOConnection — возможность возвратить объект ADO Connection, который автоматически создается для подключения к внешнему источнику данных. Используется для дополнительной настройки свойств подключения.
- Connection — работает точно так же, как и одноименное свойство объекта QueryTable. Может принимать строку подключения, готовый объект Recordset, текстовый файл, Web-запрос. файл Microsoft Query. Чаще всего при работе с OLAP прописывается строка подключения напрямую (поскольку получать объект Recordset, например для изменения данных, большого смысла нет — источники данных OLAP практически всегда доступны только на чтение). Например, настройка этого свойства для подключения к базе данных Foodmart (учебная база данных Analysis Services) на сервере LONDON может выглядеть так:
PC1.Connection = «OLEDB;Provider=MSOLAP.2;Data Source=LONDON1;Initial Catalog = FoodMart 2000»
- свойства CommandType и CommandText точно так же описывают тип команды, которая передается на сервер баз данных, и текст самой команды. Например, чтобы обратиться на куб Sales и получить его целиком в кэш на клиенте, можно использовать код вида
- свойство LocalConnection позволяет подключиться к локальному кубу (файлу *.cub), созданному средствами Excel. Конечно, такие файлы для работы с «производственными» объемами данных использовать очень не рекомендуется — только для целей создания макетов и т.п.
- свойство MemoryUsed возвращает количество оперативной памяти, используемой PivotCache. Если PivotTable на основе этого PivotCache еще не создана и не открыта, возвращает 0. Можно использовать для проверок, если ваше приложение будет работать на слабых клиентах.
- свойство OLAP возвращает True, если PivotCache подключен к серверу OLAP.
- OptimizeCache — возможность оптимизировать структуру кэша. Изначальная загрузка данных будет производиться дольше, но потом скорость работы может возрасти. Для источников OLE DB не работает.
Остальные свойства объекта PivotCache совпадают с аналогичными свойствами объекта QueryTable, и поэтому здесь рассматриваться не будут.
Главный метод объекта PivotCache — это метод CreatePivotTable(). При помощи этого метода и производится следующий этап — создание сводной таблицы (объекта PivotTable). Этот метод принимает четыре параметра:
- TableDestination — единственный обязательный параметр. Принимает объект Range, в верхний левый угол которого будет помещена сводная таблица.
- TableName — имя сводной таблицы. Если не указано, то автоматически сгенерируется имя вида «СводнаяТаблица1».
- ReadData — если установить в True, то все содержимое куба будет автоматически помещено в кэш. С этим параметром нужно быть очень осторожным, поскольку неправильное его применение может резко увеличить нагрузку на клиента.
- DefaultVersion — это свойство обычно не указывается. Позволяет определить версию создаваемой сводной таблицы. По умолчанию используется наиболее свежая версия.
Создание сводной таблицы в первой ячейке первого листа книги может выглядеть так:
PC1.CreatePivotTable Range («A1»)
Сводная таблица у нас создана, однако сразу же после создания она пуста. В ней предусмотрено четыре области, в которые можно размещать поля из источника (на графическом экране все это можно настроить либо при помощи окна Список полей сводной таблицы — оно открывается автоматически, либо при помощи кнопки Макет на последнем экране мастера создания сводных таблиц):
- область столбцов — в нее помещаются те измерения («разрез», в котором будут анализироваться данные), членов которых меньше;
- область строк — те измерения, членов которых больше;
- область страницы — те измерения, по которым нужно только проводить фильтрацию (например, показать данные только по такому-то региону или только за такой-то год);
- область данных — собственно говоря, центральная часть таблицы. Те числовые данные (например, сумма продаж), которые мы и анализируем.
Полагаться на пользователя в том, что он правильно разместит элементы во всех четырех областях, трудно. Кроме того, это может занять определенное время. Поэтому часто требуется расположить данные в сводной таблице программным образом. Эта операция производится при помощи объекта CubeField. Главное свойство этого объекта — Orientation, оно определяет, где будет находиться то или иное поле. Например, помещаем измерение Customers в область столбцов:
PT1.CubeFields («[Customers]»).Orientation = xlColumnField
Затем — измерение Time в область строк:
PT1.CubeFields («[Time]»).Orientation = xlRowField
Затем — измерение Product в область страницы:
PT1.CubeFields («[Product]»).Orientation = xlPageField
И наконец, показатель (числовые данные для анализа) Unit Sales:
PT1.CubeFields(«[Measures].[Unit Sales]»).Orientation = xlDataField
Теперь сводная таблица создана и с ней вполне можно работать. Однако часто необходимо выполнить еще одну операцию — раскрыть нужный уровень иерархии измерения. Например, если нас интересует поквартальный анализ, то нужно раскрыть уровень Quarter измерения Time (по умолчанию показывается только самый верхний уровень). Конечно, пользователь может сделать это самостоятельно, но не всегда можно рассчитывать, что он догадается, куда щелкнуть мышью. Программным образом раскрыть, например, иерархию измерения Time на уровень кварталов для 1997 года можно при помощи объектов PivotField и PivotItem:
Многомерное представление данных в виде куба
Пользователь
получает естественную, интуитивно
понятную модель данных, организуя их в
виде многомерных кубов. Осями многомерной
системы координат служат основные
атрибуты анализируемого процесса.
Например, для продаж это могут быть
товар, регион, тип покупателя. В качестве
одного из измерений используется время.
На пересечениях осей – измерений находятся
данные, количественно характеризующие
процесс – меры. Это могут быть объемы
продаж в штуках или в денежном выражении,
остатки на складе, издержки и т. п.
В качестве
наглядного примера на рис. 20.2 показан
трехмерный куб. Мерами здесь являются
суммы продаж, а измерениями – время,
товар и место продажи. Измерения
представлены на определенных уровнях
группировки: товары группируются по
категориям, магазины – по странам, а
данные о времени совершения операций
– по месяцам.
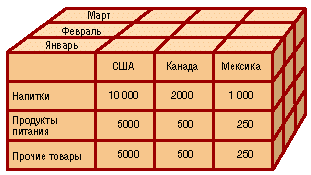
Рис.
20.2. Пример трехмерного куба
«Разрезание» куба
Даже трехмерный
куб сложно отобразить на экране компьютера
так, чтобы были видны значения интересующих
мер. Что уж говорить о кубах с количеством
измерений, большим трех? Для визуализации
данных, хранящихся в кубе, применяются,
как правило, привычные двумерные, т. е.
табличные, представления.
Двумерное
представление куба можно получить,
«разрезав» его поперек одной или
нескольких осей (измерений): фиксируем
значения всех измерений, кроме двух, –
и получаем обычную двумерную таблицу.
В горизонтальной оси таблицы (заголовки
столбцов) представлено одно измерение,
в вертикальной (заголовки строк) – другое,
а в ячейках таблицы – значения мер. При
этом набор мер фактически рассматривается
как одно из измерений – мы либо выбираем
для показа одну меру (и тогда можем
разместить в заголовках строк и столбцов
два измерения), либо показываем несколько
мер (и тогда одну из осей таблицы займут
названия мер, а другую – значения
единственного «неразрезанного»
измерения).
На рис.20.3
изображен двумерный срез куба для одной
меры – Продано
штук и двух
«неразрезанных» измерений – Место
продажи и
Время
.

Рис. 20.3. Двумерный
срез куба
Резюме
-
Оперативная
аналитическая обработка данных
(технология OLAP) предусматривает
динамический синтез, анализ и консолидацию
многомерных данных большого объема. -
Приложения OLAP
применяются в различных функциональных
областях, таких как планирование
расходов, анализ финансовых результатов,
анализ и прогнозирование сбыта,
аналитические исследования рынка и
сегментация рынков/клиентов. -
Основные
характеристики приложений OLAP включают
многомерные представления данных,
поддержку сложных вычислений и правильный
учет фактора времени. -
В базах данных
OLAP для хранения данных и представления
связей между ними используются
многомерные структуры. Многомерные
структуры проще всего представить в
виде кубов данных . Каждая сторона куба
рассматривается как отдельная
размерность.
21.
Документальные
БД
Реляционная
модель данных, в основе которой лежит
табличное представление данных, очень
хорошо подходит для создания
фактографических БД. Однако она может
с успехом использоваться и для разработки
документальных БД. В частности, хорошие
возможности для создания документальных
БД предоставляет современная СУБД SQL
Server.
Организация
данных и механизмы поиска в документальных
БД имеют существенные отличия, которые
обусловлены в первую очередь характером
хранимой и обрабатываемой информации.
Фактографические
системы хранят хорошо структурированные
сведения (факты). Соответственно и
запросы к ним носят более четкий
(определенный) характер. Например, запрос
к БД, содержащей сведения о сотрудниках
предприятия, может быть таким: найти
должность, оклад и телефон сотрудника
Иванова.
Документальные
системы хранят не факты, а документы,
содержащие эти факты. Соответственно
наш запрос о сотруднике может выглядеть
следующим образом: найти документы,
содержащие сведения о должности, окладе
и телефоне сотрудника Иванова.
Иными
словами, запись документальной базы
данных — это документ (обычно большого
размера), который задается как набор в
общем случае необязательных
полей
(например, аннотаций, глав, разделов,
подразделов и т.д.), для каждого из
которых определены имя и тип.
C
точки зрения поиска атомарным (семантически
значимым) элементом данных является
слово.
Вследствие
этого поисковые структуры строятся в
виде инвертированных файлов.
Обычно
система присваивает каждому документу
уникальный номер; каждому ключевому
слову документа ставится в соответствие
указатель на списки
экземпляров, являющихся
перечнем документов, в которых встречается
данное слово (то есть создается индекс).
Каждый список экземпляров содержит
заголовок, из которого можно узнать
число экземпляров слова во всем файле
документов, а также число документов,
в которых это слово встречается.
Поисковый
критерий (критерий поиска документов)
может включать в себя разные слова,
причем пользователь может потребовать,
чтобы заданное слово встречалось в
названии документа, аннотации, введении
или в каком-то конкретном параграфе.
Независимо
от содержания критерия отбора поиск
документа (в большинстве случаев)
осуществляется на уровне списка
экземпляров без необходимости входа в
файл документов.
Документальная
БД включает в себя как минимум три
области хранения данных, представляемые
из-за своего большого размера, как
правило, в виде файлов операционной
системы (в действительности их всегда
больше) :
-
файл
словаря, устанавливающий соответствие
между словом, встречающимся в БД, и
его кодом; -
инверсный
(инвертированный, обратный) список,
содержащий для каждого слова БД
список документов, его содержащих,
используется при текстовом поиске; -
текстовый
файл, содержащий собственно документы,
используется при выдаче (просмотре)
документов.
На
рис.21. 1 приведена принципиальная схема
организации поиска документов,
характерная для большинства
современных документальных БД.

Рис.21.
1 Принципиальная схема поиска документов
в документальных БД
Рассмотрим
пример упрощенной реализации
документальной БД в среде реляционной
СУБД. С логической точки зрения она
имеет «стандартную» структуру и включает
две компоненты: регистрационные
карты (РК)
и полные
тексты (ПТ).
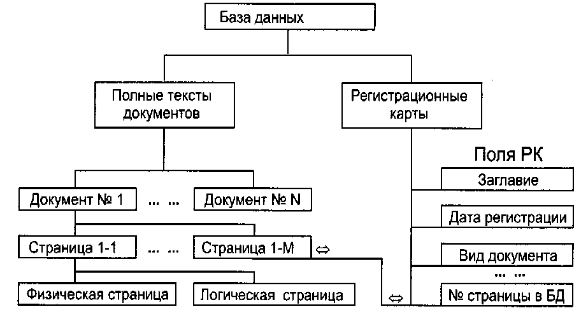
Рис.
21.2 Логическая структура документальной
БД
Регистрационные
карты представляют
собой форматированные записи, содержащие
относительно стандартный набор
библиографических данных, а также ссылку
на соответствующий полный текст
(рис.21.2).
Полные
тексты документов
состоят из страниц двух типов:
-
логических,
т. е. структурных единиц текста — пункт,
параграф, статья; -
физических
— принудительное разбиение длинного
неструктурированного текста на
фрагменты одинаковой длины.
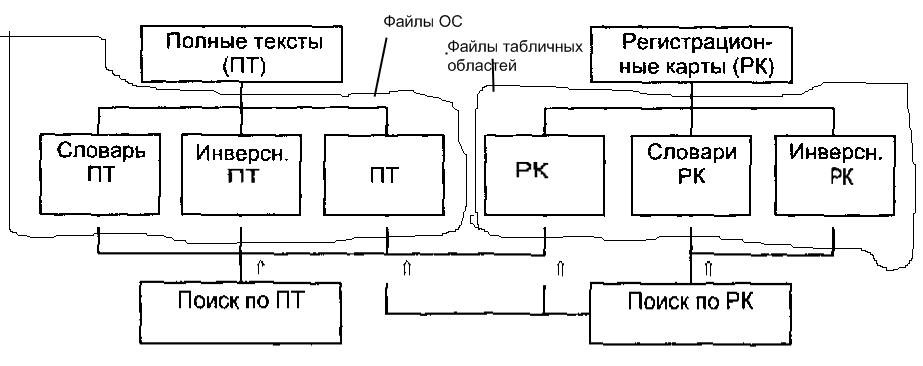
Рис21.
3 Физическая структура документальной
БД и виды поиска документов
Таблица
ПТ
— одна или несколько таблиц, в которых
содержатся полные тексты документов.
На логическом уровне образует
представленную на рис.2 иерархическую
структуру: БД, документ, страница.
Словарь
ПТ
— таблица представляет собой список
ключевых слов и стандартных словосочетаний
(например, «статья 256», «п. 13», «N
1400-РП»), извлеченных из текста,
сопровождаемых частотами появления.
Инверсная
таблица ПТ (или
инверсный список ПТ)
— таблица, содержащая список ключевых
слов и словосочетаний, сопровождаемых
номерами страниц.
Словарная
и инверсная таблицы используются для
сквозного полнотекстового поиска.
Таблица
РК
– таблица регистрационных карт,
каждая запись которой содержит заглавие,
дату регистрации, номер, вид документа,
ссылки на страницы полного текста (ПТ)
и другие поля.
Словарь
РК
– это таблица,
содержащая значения полей регистрационных
карт совместно с частотой появления и
ссылками на записи таблицы РК.
Инверсная
таблица РК
(или инверсный список РК)
содержит слова и словосочетания и
ссылки на записи таблицы РК.
Словарная
и инверсная таблицы используются для
поиска записей РК, с последующим
доступом к страницам полного текста
(ПТ).
Наряду
со словарем РК иногда может использоваться
словарь
синонимов,
служащий для обеспечения двуязычного
поиска в словарных таблицах.
Поиск
документов по БД может быть двух видов:
поиск по РК и поиск по ПТ.
Первый
вид поиска соответствует случаю, когда
пользователь что-то знает о документе,
например, название, автора, дату выпуска
и т.д. Самый простой случай, когда
пользователь знает все. Тогда просто
анализируется таблица РК, из нее
отбирается нужная регистрационная
карта, из которой отбирается указатели
на страницы полного текста документа.
Далее эти страницы выбираются из таблицы
ПТ.
Несколько
сложнее поиск в случае, когда пользователь
знает только часть атрибутов регистрационной
карты, например, только одно название
или только словосочетание из названия.
В этом случае предварительно анализируется
словарь и инверсная таблица РК, после
чего отыскивается сама РК.
Поиск
по ПТ соответствует ситуации, когда
пользователь ничего не знает о документе
и может указать только ключевые слова
для него. В этом случае прежде всего
используется инверсная таблица ПТ, из
которой отыскивается список страниц,
содержащих эти слова. Если такой список
оказывается очень велик, может быть
использован словарь ПТ, позволяющий
сократить его в соответствии с частотой
появления слов.
Несложно
видеть, что инверсные таблицы – это
таблицы адекватные по назначению и
структуре индексам. С той лишь разницей,
что они видны пользовательской программе,
а индексы нет. Именно возможность видеть
содержимое инверсной таблицы позволяет
пользовательской программе анализировать
его совместно со словарем ПТ.
Таблица
РК является обычной таблицей с символьными
полями.
Таблицы
словарей и инверсные таблицы содержат
данные типа BLOB:
то есть списки слов (словосочетаний) и
списки указателей хранятся не в самой
таблице, а в другой табличной области,
отличной от табличной области для
словаря или инверсного списка.
Таблица
ПТ содержит данные типа BFILE,
т.е. тексты страниц документов хранятся
в файлах операционной системы.
Лекция
10
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
16.09.2019717.31 Кб1lk.doc
Всего ответов: 1
В клетку (допустим A10) пишешь число “10”, в клетку ниже число “11”, выделяешь эти клетки, тащишь ползунок до клетки A99. Потом в клетке B10 пишешь “=A10^2”. тащишь ползунок с клетки B10 до клетки B99
Столбец “A” – это числа. Столбец “B” – это их квадраты
repatopt_zn
Начинающий

