Голосование за лучший ответ
Людвиг Фрезенбург
Знаток
(329)
13 лет назад
Таблицу в которую вводится значения х, у? чтобы потом построить график? Почетче сформулируй вопрос
Подставляешь в свое уравнение (например 2*х – 3 = у) значение х=0, и считаешь, ага 2*0-3=-3 и записываешь. в таблецу в столб х: 0, а в столбик у: -3, Потом можешь Игрик прировнять к нулю и подставить в уравнение и отсюда найти х. Например 2*х-3=0, отсюда х=3/2=1,5. и заполняешь дальше таблицу, х: 1.5, у: 0
Добрый Ээх
Профи
(902)
13 лет назад
пример линейная функция х=2у
х.. ..у
0… 0
1….2
2 …4
3… 6
т. е. пишешь любое значение Х, обычно 0, чтоб легче было, потом решаешь уравнение (ф-цию) , далее следующее значение Х.. . и т. д.
ну примерно так, хотя для линейной ф-ции достаточно двух точек.. .
А отличнице должно быть стыдно такое простое забывать.. . ))))))))))
Ghbdtn
Мастер
(1030)
13 лет назад
У= 2Х-4 например
подставляешь вместо Х какое-нибудь число например 3, У=2 х 3 – 4, У=6 – 4,У=2
Потом подставляешь вместо Х другие числа.
Строишь таблицу и подставляешь туда значения Х иУ .
Serega59
Ученик
(114)
3 года назад
это очень легко
рассмотрим функцию y=6x-5 подставляем вместо x любое число например (-3) тогда y=6*(-3)-5 решаем y=(-18)-5 и получаем что y=-23
Решение системы линейных уравнений графическим способом
ВИДЕО С ТЕОРИЕЙ:
Видео YouTube
ВИДЕО С РАЗБОРОМ ЗАДАНИЙ:
Видео YouTube
Система уравнений — это условие, состоящее в одновременном выполнении нескольких уравнений относительно нескольких (или одной) переменных.
Другими словами, если задано несколько уравнений с одной, двумя или больше неизвестными, и все эти уравнения (равенства) должны одновременно выполняться, такую группу уравнений мы называем системой.
Объединяем уравнения в систему с помощью фигурной скобки:

Графический метод
Недаром ответ записывается так же, как координаты какой-нибудь точки.
Ведь если построить графики для каждого уравнения в одной системе координат, решениями системы уравнений будут точки пересечения графиков.
Например, построим графики уравнений из предыдущего примера.
Пример 1
Для этого сперва выразим yyy в каждом уравнении, чтобы получить функцию (ведь мы привыкли строить функции относительно xxx):

⎧
⎪⎪⎪
⎪
Для того чтобы графически решить систему уравнений с двумя переменными нужно:
1) построить графики уравнений в одной системе координат;
2) найти координаты точек пересечения этих графиков (координаты точек пересечения графиков и есть решения системы);
Разберем это задание на примере.
Решить графически систему линейных уравнений.
Графическое решение системы уравнений с двумя переменными сводится к отыскиванию координат общих точек графиков уравнений.
Пример 2
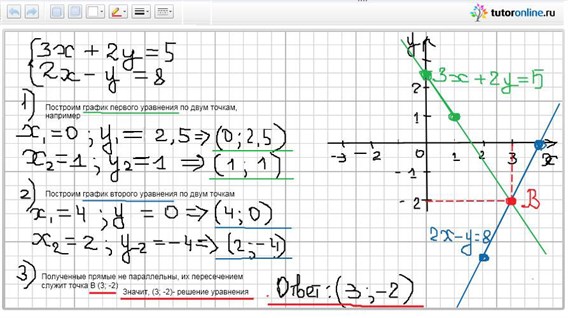
Графиком линейной функции является прямая. Две прямые на плоскости могут пересекаться в одной точке, быть параллельными или совпадать. Соответственно система уравнений может:
а) иметь единственное решение;
б) не иметь решений;
в) иметь бесконечное множество решений.
2) Решением системы уравнений является точка (если уравнения являются линейными) пересечения графиков.
Пример 3
Графическое решение системы 

Пример 4
Решить графическим способом систему уравнений.
 Графиком каждого уравнения служит прямая линия, для построения которой достаточно знать координаты двух точек. Мы составили таблицы значений х и у для каждого из уравнений системы.
Графиком каждого уравнения служит прямая линия, для построения которой достаточно знать координаты двух точек. Мы составили таблицы значений х и у для каждого из уравнений системы.
Прямую y=2x-3 провели через точки (0; -3) и (2; 1).
Прямую y=x+1 провели через точки (0; 1) и (2; 3).
Графики данных уравнений системы 1) пересекаются в точке А(4; 5). Это и есть единственное решение данной системы.
Ответ: (4; 5).
Пример 5
 Выражаем у через х из каждого уравнения системы 2), а затем составим таблицу значений переменных х и у для каждого из полученных уравнений.
Выражаем у через х из каждого уравнения системы 2), а затем составим таблицу значений переменных х и у для каждого из полученных уравнений.
Прямую y=2x+9 проводим через точки (0; 9) и (-3; 3). Прямую y=-1,5x+2 проводим через точки (0; 2) и (2; -1).
Наши прямые пересеклись в точке В(-2; 5).
Ответ: (-2; 5).
ОБЯЗАТЕЛЬНО: Познакомимся с видео, где нам объяснят как решаются системы линейных уравнений графическим способом. РАССКАЖУТ, КАК РЕШАТЬ СИСТЕМЫ ГРАФИЧЕСКИ.
Видео YouTube
ДОМАШНЯЯ РАБОТА: ВЫПОЛНЯТЬ ВСЕ ШАГИ ПОСТРОЕНИЯ, КАК ПОКАЗАНО В ВИДЕО РАЗБОРАХ И ПРИМЕРАХ. В УЧЕБНИКЕ ТЕОРИЯ НА СТРАНИЦАХ СТР 195-199. ВСЕ ИЗУЧИТЬ, ТЕМА ОЧЕНЬ ВАЖНАЯ.

In mathematics, a function defines a relationship between an independent variable and a dependent variable. In simple words, a function is a relationship between inputs and outputs in which each input is connected to exactly one output. If every element in set A has exactly one and only one image in set B, then the relation is said to be a function. Every function has a domain and a codomain, where a domain is a set of input values and a codomain, or range, is the set of possible output values for which the function is defined. The domain and codomain of a function are non-empty sets. If there exists a function from A → B and (a, b) ∈ f, then f (a) = b, where “a” is the image of “b” under “f” and “b” is the preimage of “b” under “f” and set A is the domain of the function and set B is its co-domain.
Examples of a function
- The formula for the circumference/perimeter of a circle is P = 2πr, where r is the radius of a circle. We can say that circumference/perimeter (P) is dependent on the radius (r) of the circle. In the language of functions, we say that P is defined as a function of r.
- The area (A) of a square A is a function of its side length. The dependence of A on s is given by A = 4s2.
Table Values of a Function
The table values of a function are referred to as the list of numbers that can be used to substitute for the given variable. By using this variable within the equation or in the other function, it is simple to determine the value of the other variable or the equation’s missing integer. In the table of values of a function, there are two kinds of variables, namely an independent variable and a dependent variable. For any equation of a function, an independent variable is selected independently to determine the value of a dependent variable, which is the output of the given function. The table of values is unique for every function. A graph of the given function can be plotted easily after the determination of the values of the independent and dependent variables. There are many uses and applications for tables of values of a function. These are used in the fields of mathematics, physics, and engineering.
How to make the Table of Values of a Function?
A function is typically represented by f(x), where x is the input, and its general representation is y = f(x).
- Create the table first, then choose a range of input values.
- In the left-hand side column, substitute each input value into the given equation.
- To determine the output value, evaluate the equation in the middle column. (A middle column is optional as the table of values just contains the input (independent variable) and output (dependent variable) pair.)
- Now, note down the output values in the right-hand side column.
Let us solve an example to understand the concept better.
Example: Write the table of the value for the function y = √x.
Here, the input is x and the output is y, where y = √x.
x value
Equation
y = √x
y value
0
y = √0 = 0
0
1
y = √1 = 1
1
4
y = √4 = 2
2
9
y = √9 = 3
3
16
y = √16 = 4
4
25
y = √25 = 5
5
Sample Problems
Problem 1: Write the table of values for the function y = 3x + 5.
Solution:
Here, the input is x and the output is y, where y = 3x + 5.
x value
Equation
y = 3x +5
y value
-2
y = 3(-2) + 5 = -6 + 5 = -1
-1
-1
y = 3(-1) + 5 = -3 + 5 = 2
2
0
y = 3(0) + 5 = 0 + 5 = 5
5
1
y = 3(1) + 5 = 3 + 5 = 8
8
2
y = 3(2) + 5 = 6 + 5 = 11
11
Problem 2: Write the table of values for the function P = 4s, where P is the perimeter of a square and a is its side length.
Solution:
Here, the input is s and the output is P, where P = 4s.
s value
Equation
P = 4s
P value
1
4 × 1 = 4
4
2
4 × 2 = 8
8
3
4 × 3 = 12
12
4
4 × 4 =16
16
5
4 × 5 = 20
20
Problem 3: Write the table of values for the function y = 2x + 3x.
Solution:
Here, the input is x and the output is y, where y = 2x + 3x .
x value
Equation
y = 2x + 3x
y value
-2
y = 2-2 + 3-2 = 1/22 + 1/32 = 1/4 + 1/9 = 13/36 = 0.3611
0.3611
-1
y = 2-1 + 3-1 = 1/2 + 1/3 = 5/6 = 0.834
0.834
0
y = 20 + 30 = 1 + 1 = 2
2
1
y = 21 + 31 = 2 + 3 = 5
5
2
y = 22 + 32 = 4 + 9 = 13
13
3
y = 23 + 33 = 8 + 27 = 35
35
Problem 4: Write the table values for the function y = cos x × sin x.
Solution:
Here, the input is x and the output is y, where y = cos x × sin x.
x value
Equation
y = cos x × sin x
y value
0°
y = cos 0 sin 0 = 1 × 0 = 0
0
30°
y = cos 30 sin 30 = √3/2 × 1/2 = 3/4
√3/4
45°
y = cos 45 sin 45 = 1/√2 × 1/√2 = 1/2
1/2
60°
y = cos 60 sin 60 = 1/2 × √3/2 = 3/4
√3/4
90°
y = cos 90 sin 90 = 0 × 1 = 0
0
180°
y = cos 180 sin 180 = -1 × 0 = 0
0
Problem 5: Write the table values for the function y = x2 – 5x + 6.
Solution:
Here, the input is x and the output is y, where y = x2 – 5x + 6.
x value
Equation
y = x2 – 5x + 6
y value
-3
y = (-3)2 – 5(-3) + 6 = 9 + 15 + 6 = 30
30
-2
y = (-2)2 – 5(-2) + 6 = 4 + 10 + 6 = 20
20
-1
y = (-1)2 – 5(-1) + 6 = 1 + 5 + 6 = 12
12
0
y = 02 – 5(0) + 6 = 0 – 0 + 6 = 6
6
1
y = 12 – 5(1) + 6 = 1 – 5 + 6 = 2
2
2
y = 22 – 5(2) + 6 = 4 – 10 + 6 = 10- 10 = 0
0
3
y = 32 – 5(3) + 6 = 9 – 15 + 6 = 15 – 15 = 0
0
Last Updated :
19 Jul, 2022
Like Article
Save Article
оглавление
- Что такое линейная структура?
- Что входит в линейную структуру?
- Что такое линейный стол?
- Что такое таблица последовательности? Классификация таблиц последовательности?
- Выполните следующие операции с таблицей динамической последовательности
- Полный код
- файл головы
- Исходный файл
- контрольная работа
Что такое линейная структура?
- Линейная структура – это набор упорядоченных элементов данных. Связь между элементами данных является взаимно однозначной, то есть, за исключением первого и последнего элементов данных, другие элементы данных соединяются встык.
- Обычно используемые линейные структуры: линейная таблица, стек, очередь, двойная очередь, массив, строка.
Что входит в линейную структуру?
В общем, «линейная структура» – это набор упорядоченных элементов данных, включая следующие:
- В наборе должен быть уникальный «первый элемент»;
- В наборе должен быть единственный «последний элемент»;
- За исключением последнего элемента, все элементы имеют уникальный «узел-преемник»;
- За исключением первого элемента, все элементы имеют уникальный «узел-предшественник».
Что такое линейный стол?
- Линейный список – это конечная последовательность из n элементов данных с одинаковыми характеристиками. Линейная таблица – это широко используемая на практике структура данных.Обычные линейные таблицы: таблица последовательностей, связанный список, стек, очередь, строка …
- Линейный стол логически представляет собой линейную структуру, то есть непрерывную прямую линию. Однако физическая структура не обязательно является непрерывной.Когда линейная таблица физически хранится, она обычно сохраняется в форме массива и цепной структуры.
Что такое таблица последовательности? Классификация таблиц последовательности?
-
Таблица последовательности представляет собой линейную структуру, в которой секция модулей хранения с непрерывными физическими адресами хранит элементы данных последовательно и обычно использует массивы хранения. Полное добавление, удаление, проверка и изменение данных в массиве.
-
Таблицу последовательности обычно можно разделить на:
- Таблица статической последовательности: используйте массивы фиксированной длины.
// Статическое хранилище таблицы последовательностей #define N 100 typedef int SLDataType; typedef struct SeqList { SLDataType array[N]; // массив фиксированной длины size_t size; // Количество действительных данных }SeqList;- Таблица динамической последовательности: используйте динамически развиваемое хранилище массива.
// Динамическое хранение таблицы последовательностей typedef struct SeqList { SLDataType* array; // Указываем на динамически развиваемый массив size_t size ; // Количество действительных данных size_t capicity ; // Размер емкости пространства }SeqList;
Выполните следующие операции с таблицей динамической последовательности
- Инициализация связанного списка
- Вставить узел со значением данных после последнего узла связанного списка s
- Удалить последний узел связанного списка s
- Вставить узел со значением данных перед первым узлом связанного списка s
- Удалить первый узел связанного списка s
- Вставить узел со значением data после позиции pos связанного списка
- Удалить узел в позиции pos в связанном списке s
- Найдите узел, значением которого являются данные в связанном списке, найдите адрес узла, который возвращает, в противном случае верните NULL
- Получить количество допустимых узлов в связанном списке
- Проверить, пуст ли связанный список
- Очистить действительные узлы в связанном списке
- Уничтожить связанный список
Полный код
файл головы
#pragma once
// таблица динамической последовательности
typedef int DataType;
typedef struct SeqList
{
DataType* _array;
int _capacity; // Общий размер таблицы последовательности
int _size; // Количество допустимых элементов в таблице последовательности
}SeqList, *PSeq;
//typedef struct SeqList SeqList;
//typedef struct SeqList* PSeqList;
// Инициализация таблицы последовательности
void SeqListInit(PSeq ps, int capacity);
// Вставляем элемент со значением данных в конец таблицы последовательности
void SeqListPushBack(PSeq ps, DataType data);
// удаляем последний элемент таблицы последовательности
void SeqListPopBack(PSeq ps);
// Вставляем элемент со значением данных в заголовок таблицы последовательности
void SeqListPushFront(PSeq ps, DataType data);
// Удаляем элемент во главе таблицы последовательности
void SeqListPopFront(PSeq ps);
// Вставляем элемент со значением данных в позицию pos таблицы последовательности
void SeqListInsert(PSeq ps, int pos, DataType data);
// Удаляем элемент в позиции pos в таблице последовательности
void SeqListErase(PSeq ps, int pos);
// Найдите элемент, значение которого является данными в таблице последовательности, найдите индекс элемента в таблице последовательности, в противном случае верните -1
int SeqListFind(PSeq ps, DataType data);
// Проверяем, пуста ли таблица последовательности, если она пуста, возвращаем ненулевое значение, если не пусто, возвращаем 0
int SeqListEmpty(PSeq ps);
// Возвращаем количество допустимых элементов в таблице последовательности
int SeqListSize(PSeq ps);
// Возвращаем размер таблицы последовательности
int SeqListCapacity(PSeq ps);
// Очищаем элементы в таблице последовательности
void SeqListClear(PSeq ps);
// Удаляем элемент с первым значением данных в таблице последовательности
void SeqListRemove(PSeq ps, DataType data);
// Таблица последовательности разрушения
void SeqListDestroy(PSeq ps);
// Расширение таблицы последовательностей
void CheckCapacity(PSeq ps);
void TestSeqList();
Исходный файл
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include "test.h"
// Инициализация таблицы последовательности
void SeqListInit(PSeq ps, int capacity) {
ps->_array = (DataType*)malloc(sizeof(DataType*) * capacity);
if (ps->_array == NULL) {
assert(0);
return;
}
ps->_capacity = capacity;
ps->_size = 0;
}
// Вставляем элемент со значением данных в конец таблицы последовательности
void SeqListPushBack(PSeq ps, DataType data) {
assert(ps);
// Таблица последовательности заполнена
CheckCapacity(ps);
ps->_array[ps->_size] = data;
ps->_size++;
//SeqListInsert(ps, ps->_size, data);
}
// удаляем последний элемент таблицы последовательности
void SeqListPopBack(PSeq ps) {
assert(ps);
if (SeqListEmpty(ps)) {
return;
}
ps->_size--;
//SeqListErase(ps, ps->_size-1);
}
// Вставляем элемент со значением данных в заголовок таблицы последовательности
void SeqListPushFront(PSeq ps, DataType data) {
assert(ps);
// Таблица последовательности заполнена
CheckCapacity(ps);
// Перемещаем все элементы в таблице последовательности на одну позицию назад
for (int i = ps->_size - 1; i >= 0; --i) {
ps->_array[i + 1] = ps->_array[i];
}
// Вставляем элемент
ps->_array[0] = data;
ps->_size++;
//SeqListInsert(ps, 0, data);
}
// Удаляем элемент во главе таблицы последовательности
void SeqListPopFront(PSeq ps) {
assert(ps);
for (int i = 0; i < ps->_size-1; ++i) {
ps->_array[i] = ps->_array[i+1];
}
ps->_size--;
//SeqListErase(ps, 0);
}
// Вставляем элемент со значением данных в позицию pos таблицы последовательности
void SeqListInsert(PSeq ps, int pos, DataType data) {
assert(ps);
if (pos<0 || pos>=ps->_size) {
return;
}
//CheckCapacity();
for (int i = ps->_size - 1; i >= pos; --i) {
ps->_array[i + 1] = ps->_array[i];
}
ps->_array[pos] = data;
ps->_size++;
}
// Удаляем элемент в позиции pos в таблице последовательности
void SeqListErase(PSeq ps, int pos) {
assert(ps);
if (pos < 0 || pos >= ps->_size) {
return;
}
for (int i = pos + 1; i < ps->_size; ++i) {
ps->_array[i - 1] = ps->_array[i];
}
ps->_size--;
}
// Найдите элемент, значение которого является данными в таблице последовательности, найдите индекс элемента в таблице последовательности, в противном случае верните -1
int SeqListFind(PSeq ps, DataType data) {
assert(ps);
for (int i = 0; i < ps->_size; ++i) {
if (ps->_array[i] == data) {
return i;
}
}
return -1;
}
// Проверяем, пуста ли таблица последовательности, если она пуста, возвращаем ненулевое значение, если не пусто, возвращаем 0
int SeqListEmpty(PSeq ps) {
assert(ps);
return ps->_size == 0;
}
// Возвращаем количество допустимых элементов в таблице последовательности
int SeqListSize(PSeq ps) {
return ps->_size;
}
// Возвращаем размер таблицы последовательности
int SeqListCapacity(PSeq ps) {
return ps->_capacity;
}
// Очищаем элементы в таблице последовательности
void SeqListClear(PSeq ps) {
assert(ps);
ps->_size = 0;
}
// Удаляем элемент с первым значением данных в таблице последовательности
void SeqListRemove(PSeq ps, DataType data) {
assert(ps);
SeqListErase(ps, SeqListFind(ps, data));
}
void SeqListRemoveAll(PSeq ps, DataType data) {
int pos = -1;
while (-1 != (pos = SeqListFind(ps, data))) {
SeqListErase(ps, pos);
}
// Временная сложность O (N ^ 2)
}
// Таблица последовательности разрушения
void SeqListDestroy(PSeq ps) {
if (ps->_array) {
free(ps->_array);
ps->_array = NULL;
ps->_capacity = 0;
ps->_size = 0;
}
}
// Расширение таблицы последовательностей
void CheckCapacity(PSeq ps) {
assert(ps);
if (ps->_size == ps->_capacity) {
int newCapacity = ps->_capacity * 2;
//realloc(p,size)
// Подать заявку на новое пространство
int* pTemp = (DataType*)malloc(sizeof(DataType*)*newCapacity);
if (pTemp == NULL) {
assert(0);
return;
}
// Копируем элементы
for (int i = 0; i < ps->_size; ++i) {
pTemp[i] = ps->_array[i];
}
// Освободить старое пространство
free(ps->_array);
//Обновить
ps->_array = pTemp;
ps->_capacity = newCapacity;
}
}
// Распечатать таблицу заказов
void SeqListPrint(PSeq ps) {
for (int i = 0; i < ps->_size; ++i) {
printf("%d ", ps->_array[i]);
}
printf("n");
}
//контрольная работа
void TestSeqList() {
SeqList s;
int pos = -1;
SeqListInit(&s, 10);
SeqListPushBack(&s, 1);
SeqListPushBack(&s, 2);
SeqListPushBack(&s, 3);
SeqListPushBack(&s, 4);
//SeqListPushBack(&s, 1);
//SeqListPushBack(&s, 2);
//SeqListPushBack(&s, 3);
//SeqListPushBack(&s, 4);
//SeqListPushBack(&s, 1);
//SeqListPushBack(&s, 2);
SeqListPrint(&s);
//printf("size=%dn", SeqListSize(&s));
//printf("capacity=%dn", SeqListCapacity(&s));
//SeqListPushBack(&s, 3);
//SeqListPushBack(&s, 4);
//printf("size=%dn", SeqListSize(&s));
//printf("capacity=%dn", SeqListCapacity(&s));
SeqListPopBack(&s);
SeqListPrint(&s);
SeqListPushFront(&s, 5);
SeqListPrint(&s);
SeqListPopFront(&s);
SeqListPrint(&s);
SeqListInsert(&s,2,4);
SeqListPrint(&s);
pos = SeqListFind(&s, 4);
if (pos != -1) {
printf("4 is in %d !n", pos);
}
else {
printf("4 is not in %d !n", pos);
}
SeqListErase(&s,2);
SeqListPrint(&s);
pos = SeqListFind(&s, 4);
if (pos != -1) {
printf("4 is in %d !n", pos);
}
else {
printf("4 is not in %d !n", pos);
}
SeqListRemove(&s,2);
SeqListPrint(&s);
printf("size=%dn", SeqListSize(&s));
printf("capacity=%dn", SeqListCapacity(&s));
SeqListDestroy(&s);
}
int main() {
TestSeqList();
system("pause");
return 0;
}
контрольная работа

113
5.1. Таблицы
Таблица
– это набор элементов, содержащих ключ
– отличительный признак для поиска
элемента, и тело
(сопутствующую информацию).
Примеры
таблиц.
а)
Таблица
значений функции:
ключ элемента – аргумент X, тело – значение
функции f(X);
б)
Словарь:
ключ – слово, тело – перевод слова;
в)
Телефонный
справочник:
ключ – имя владельца, тело – номер телефона;
г)
Таблица
имен
транслятора: ключ – имя какого-либо
объекта транслируемой программы, тело
– его характеристики (тип, размерность,
адрес, значение переменной и т. п.).
Везде,
где есть поиск информации, используются
таблицы. Трансляторы тратят на работу
с таблицами до 50 % времени.
Основные
операции над таблицами:
1.
Инициализация
(подготовка к работе);
2.
Поиск
элемента по ключу – основная операция
(входит в другие операции);
3.
Включение
в таблицу данного элемента;
4.
Исключение
из таблицы элемента с данным ключом;
5.
Изменение
в таблице тела элемента с данным ключом;
6.
Перебор
(например, вывод) элементов таблицы в
порядке, определяемом ключами.
Виды
таблиц: статическая
(постоянная) и динамическая
(меняющаяся при работе программы),
внутренняя
(в оперативной памяти) и внешняя
(во внешней памяти). Таблицу размещают
во внешней памяти, если ее необходимо
сохранять после работы программы или
она слишком велика для ОЗУ. Рассмотрим
основные методы организации внутренних
таблиц.
5.2. Линейные таблицы
Линейной
(последовательной) называют таблицу, в
которой производится линейный
поиск
(последовательный перебор элементов).
Линейные таблицы бывают упорядоченными
или неупорядоченными в виде вектора
или списка. Рассмотрим две из них на
примерах.
Таблица
в виде вектора
Пример
5.1.
Неупорядоченная
векторная таблица.
Задача:
составить программу подсчета количества
повторений каждого слова входного
текста. Результат вывести в лексикографическом
порядке.
Пример
работы:
Вход:
to
be
or
not
to
be
Выход:
Слово
Кол-во
be
2
not
1
or
1
to
2
Для
решения задачи нужна таблица, ключом в
которой служит слово, тело – количество
его повторений. Очередное слово ищется
в таблице. Если его там нет, оно включается
в таблицу, а если есть, то увеличивается
число повторений. Требуемые операции:
инициализация, поиск, включение, изменение
и вывод.
Для
примера используем неупорядоченную
линейную таблицу в виде вектора (рис.
5.1). Ключи размещены в ней в порядке
поступления. Тогда перед распечаткой
потребуется еще сортировка (упорядочивание)
таблицы.
|
Индекс |
t |
kol |
|||
|
|
0 |
To |
1 |
||
|
Длина |
1 |
Be |
1 |
||
|
│ |
2 |
Or |
1 |
||
|
Барьер |
Not |
||||
|
4 |
|||||
|
… |
. |
||||
|
DTMAX |
|||||
|
Рис. (при |

Ниже
показана нисходящая
разработка
программы на
псевдокоде.
Сначала алгоритм записывается укрупненно
с использованием неформальных обозначений
данных и операций, например:
Заполнение
таблицы t;
Если
данные или операции достаточно сложны
и не описаны в другом разделе пособия,
они затем детализируются через более
мелкие данные и операции в одном из
фрагментов программы с соответствующим
комментарием:
/*
Заполнение таблицы t */.
Так
продолжается, пока программа не станет
достаточно подробной. Этапы разработки
отделены горизонтальными линиями.
Алгоритм
5.1.
Подсчет количества повторений слов
текста с применением неупорядоченной
линейной таблицы в виде вектора
#include
<stdio.h>
void
main ()
{
1. Инициализация таблицы;
2.
Чтение текста и заполнение таблицы
слов;
3.
Сортировка таблицы по алфавиту;
4.
Вывод таблицы;
}
————————————————————————————————
Определение
данных:
#define
DTMAX 1001 /* Маx колич-во разных слов + 1 (для
барьера) */
#define
DSLMAX 21 /* Максимальная длина слова + 1
(для”) */
/*
Последовательная таблица в виде вектора:
t,kol,dt */
/*
(представлена параллельными массивами
t, kol) */
char
t[DTMAX][DSLMAX]; /* Слова
*/
int
kol[DTMAX]; /* Количество повторений */
int
dt; /* Длина таблицы (количество слов) */
————————————————————————————————
dt
= 0; /* 1. Инициализация
таблицы */
————————————————————————————————
int
sim; /* Текущий символ входного текста
*/
char
sl[DSLMAX]; /* Текущее слово входного текста
*/
…
/*
2. Чтение текста и заполнение таблицы
слов */
sim
= getchar(); /* 1-й символ текста */
while
(sim
!= EOF)
{
Чтение слова sl (и 1-го символа следующего
слова);
Корректировка
таблицы для прочитанного слова;
}
————————————————————————————————
int
j; /* Индекс символа в слове */
…
/*
Чтение слова sl (и 1-го символа следующего
слова) */
for
(j=0;
sim!=’
‘
&& sim!=’,’ && sim!=’.’ && sim!=’n’
&&
sim!=EOF; sim=getchar())
if
(j < DSLMAX-1) sl[j++] = sim;
sl[j]
= ”; /* Признак конца слова */
/*
Пропуск разделителей слов */
while
(sim==’
‘ || sim==’,’
|| sim==’.’
||
sim==’n’)
sim
= getchar();
————————————————————————————————
int
i;
/* Индекс текущего элемента таблицы
*/
/*
Корректировка таблицы для прочитанного
слова */
/*
Линейный поиск
с барьером слова sl
в таблице t
*/
strcpy
(t[dt],
sl);
/* Создание барьера == sl
*/
for
(i=0; strcmp(sl,t[i]); i++);
if
(i < dt) /* Нашли
t[i] == sl */
kol[i]++;
/* Изменение
количества повторений sl */
else
/* Не нашли */
/*
Включение
слова sl в таблицу */
if
(dt < DTMAX-1) /* Есть место */
kol[dt++]
= 1;
else
/* Таблица переполнена */
{
fprintf (stderr,
“nОшибка:
разных слов больше %d”
“nслово
‘%s’ не учитываетсяn”, DTMAX-1, sl);
}
Ускорить
поиск, избежав проверок в цикле на конец
таблицы, можно с помощью “барьера”
– элемента в конце таблицы, содержащего
искомый ключ. Плата за ускорение – память
для барьера.
—————————————————————————————————
int
L;
/* Длина просмотра сортировки */
/*
3. Сортировка
таблицы по алфавиту методом обмена */
for
(L=dt-1;
L>0;
L–)
/*
Просмотр элементов t[0]…t[l]
*/
for
(i=0; i<L; i++)
/*
Сортировка
пары
t[i] и
t[i+1] */
if
(strcmp(t[i],t[i+1]) > 0)
{
/* Обмен
t[i] <–> t[i+1] */
strcpy
(sl, t[i]); strcpy (t[i], t[i+1]); strcpy (t[i+1], sl);
/*
Обмен
kol[i] <–> kol[i+1] */
j
= kol[i]; kol[i] = kol[i+1]; kol[i+1] = j;
}
————————————————————————————————
/*
4. Вывод
(сортированной) таблицы */
printf
(“n%*s%s”,
DSLMAX,
“Слово “, “Кол-воn”);
for
(i=0; i<dt; i++)
printf
(“%-*s %5dn”, DSLMAX, t[i], kol[i]);
Таблицы
в виде списка
Пример
5.2.
Упорядоченная
линейная таблица в виде списка
(другой
метод решения задачи из примера 5.1).
Подсчитаем количество повторений слов
текста с помощью упорядоченной линейной
таблицы в виде списка с элементами
переменной длины, организованного с
помощью указателей.
При
нисходящей разработке программы на
псевдокоде приведем только фрагменты,
отличающиеся от примера 5.1. Упорядоченность
таблицы устраняет необходимость ее
сортировки (алгоритм зависит от структуры
данных!) – алг. 5.2:
Алгоритм
5.2.
Подсчет количества повторений слов
текста с применением упорядоченной
линейной таблицы в виде списка.
#include
<stdio.h>
#include
<stdlib.h>
void
main
()
{
1.
Инициализация таблицы;
2.
Чтение текста и заполнение таблицы
слов;
3.
Вывод таблицы;
}
Чтение
слов входного текста выполняется как
в примере 5.1. Отличаются лишь операции
с таблицей. На рис. 5.2 показана структура
упорядоченной таблицы в виде списка.
sled
kol
sl

Барьер
pt
 Указатель
Указатель
baryer
списка
DSLMAX символов
Рис.
5.2. Упорядоченная списковая таблица
с
барьером и элементами переменной длины
(при
поиске слова not входного текста: to be or
not to be)
Первый
фиктивный
элемент
списка
содержит указатель фактического начала
списка. Хранение указателя в фиктивном
элементе списка позволяет включать
элемент в начало списка так же, как в
его середину – упрощает операцию включения
(за счет памяти).
Последний
фиктивный элемент списка используется
как барьер
для устранения проверок на конец списка
в цикле поиска, подобно примеру 5.1. Это
упрощает и ускоряет поиск (тоже за счет
памяти).
Здесь
у барьера адрес постоянный и, чтобы не
копировать туда каждое слово, текущее
слово расположено в барьере! Изменяется
описание переменой sl, но не программа
чтения слова!
Поскольку
ключи упорядочены, и при встрече ключа,
превышающего искомый, поиск прекращается,
в качестве барьера можно было использовать
не только искомый ключ, но и код, состоящий
из единиц и заведомо превышающий любой
ключ.
Чтобы
обеспечить постоянство смещений адресов
полей внутри элемента списка, в начале
элемента размещены поля фиксированной
длины (sled и kol), а затем – поле переменной
длины sl (для языка высокого уровня это
может делать и сам компилятор).
Определение
данных
для
таблицы:
struct
el_tab /* Элемент таблицы (списка) */
{
struct el_tab *sled; /* Указатель следующего
элемента */
int
kol; /* Количество повторений */
char
sl[];
/* Слово */
};
struct
el_tab *pt; /* Указатель фиктивного начала
таблицы */
struct
el_tab *baryer; /* Указатель барьера */
char
*sl; /* Адрес текущего входного слова (в
барьере) */
—————————————————————————————————-
Пустая
таблица состоит из фиктивного элемента
и барьера.
/*
1. Инициализация
таблицы
*/
baryer
= malloc (sizeof(struct el_tab)
+
DSLMAX);
/* Место для слова и ” */
sl
= baryer->sl;
pt
= malloc (sizeof(struct el_tab));
pt->sled
= baryer;
/* Пустая таблица */
—————————————————————————————————-
struct
el_tab
*i,
/* Указатели текущего и */
ipr;
/*
предыдущего элементов таблицы */
/*
Корректировка таблицы для прочитанного
слова */
/*
Линейный поиск
с барьером слова sl
в таблице */
i
= pt->sled; ipr = pt;
while
(strcmp(sl,i->sl) > 0)
{
ipr=i;
i
= i->sled;
/* К следующему элементу списка */
}
if
(i!=baryer && strcmp(sl,i->sl)==0) /*Нашли
i->sl==sl */
i->kol
++; /* Изменение
количества повторений sl */
else
/* Не нашли */
{
/* Включение
слова sl в таблицу */
i
= malloc
(sizeof(struct
el_tab)
+
strlen(sl)+1);
/* Место для sl
и ” */
if
(i != NULL)
/* Есть место */
{
/* Создание нового элемента */
strcpy
(i->sl, sl); /* Слово sl – в новый элемент
*/
i->kol
= 1;
/*
Включение элемента в список после *ipr
*/
i->sled
= ipr->sled; ipr->sled = i;
}
else
/* Таблица
переполнена
*/
{
fprintf (stderr,
“nОшибка:
слишком много разных слов, ”
“слово
‘%s’ не учитываетсяn”, sl);
}
}
—————————————————————————————————-
/*
3. Вывод
таблицы */
printf
(“n%*s%s”,
DSLMAX,
“Слово “, “Кол-воn”);
i
= pt->sled; /* Указатель 1-го не фиктивного
элемента списка */
while
(i
!= baryer)
/* Не дошли до барьера */
{
printf (“%-*s %5dn”, DSLMAX, i->sl, i->kol);
i
= i->sled; /* К следующему элементу списка
*/
}
