Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
In this article, we are going to discuss how to make a table in Python. Python provides vast support for libraries that can be used for creating different purposes. In this article we will talk about two such modules that can be used to create tables.
Method 1: Using Tabulate module
The tabulate() method is a method present in the tabulate module which creates a text-based table output inside the python program using any given inputs. It can be installed using the below command
pip install tabulate
Below are some examples which depict how to create tables in python:
Example 1
Python3
from tabulate import tabulate
mydata = [
["Nikhil", "Delhi"],
["Ravi", "Kanpur"],
["Manish", "Ahmedabad"],
["Prince", "Bangalore"]
]
head = ["Name", "City"]
print(tabulate(mydata, headers=head, tablefmt="grid"))
Output:
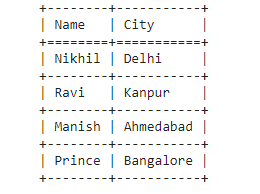
Example 2
Python3
from tabulate import tabulate
mydata = [
['a', 'b', 'c'],
[12, 34, 56],
['Geeks', 'for', 'geeks!']
]
print(tabulate(mydata))
Output:

Method 2: Using PrettyTable module
PrettyTable class inside the prettytable library is used to create relational tables in Python. It can be installed using the below command.
pip install prettytable
Example:
Python3
from prettytable import PrettyTable
myTable = PrettyTable(["Student Name", "Class", "Section", "Percentage"])
myTable.add_row(["Leanord", "X", "B", "91.2 %"])
myTable.add_row(["Penny", "X", "C", "63.5 %"])
myTable.add_row(["Howard", "X", "A", "90.23 %"])
myTable.add_row(["Bernadette", "X", "D", "92.7 %"])
myTable.add_row(["Sheldon", "X", "A", "98.2 %"])
myTable.add_row(["Raj", "X", "B", "88.1 %"])
myTable.add_row(["Amy", "X", "B", "95.0 %"])
print(myTable)
Output:
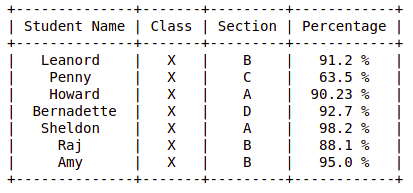
Last Updated :
22 Feb, 2022
Like Article
Save Article
In this document, you will learn how to create tables in Python, how to format them, and how parsing is useful. Python provides tabulate library to create tables and format them.
To install the tabulate library execute the below command on your system:
pip install tabulateWhat is Tabulate Module?
This module helps in pretty-print tabular data in Python; a library that helps in providing better command-line utility. The main usages of the module are:
- printing miniature sized tables without hassle or formatting tools. It requires only one function call, nor another formatting requirement. This module can easily understand how to frame the table.
- composing tabular data for lightweight plain-text markup: numerous output forms appropriate for additional editing or transformation
- readable presentation of diverse textual and numeric data: configurable number formatting, smart column alignment, alignment by a decimal point
It leverages a method called the tabulate() that takes a list containing n nested lists to create n rows table.
Program:
from tabulate import tabulate
table = [[‘Aman’, 23],[‘Neha’, 25],[‘Lata’, 27]]
print(tabulate(table))Output:
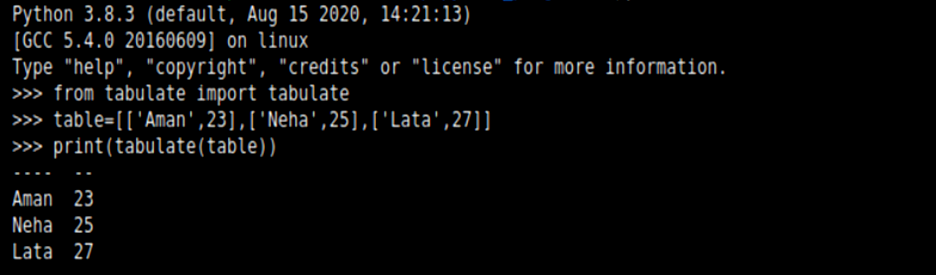
Explanation:
Here we have used the module Tabulate that takes a list of lists (also known as a nested list) and stored it under the object name table. Then we use the tabulate() method where we passed the table object (nested list). This will automatically arrange the format in a tabular fashion.
Table Headers
To get headers or column headings you can use the second argument in tabulate() method as headers. For example,
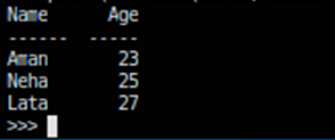
from tabulate import tabulate
table = [[‘Aman’, 23], [‘Neha’, 25], [‘Lata’, 27]]
print(tabulate(table), headers = [‘Name’, ‘Age’])Explanation:
Here we have used the module Tabulate that takes a list of lists (also known as a nested list) and stored it under the object name table. Then we use the tabulate() method where we passed the ‘table’ object (nested list). This time we take another parameter headers that takes two string values ‘Name’ and ‘Age’ that will be the title of the columns. This will automatically arrange the format in a tabular fashion.
Output:
In the list of lists, you can assign the first list for column headers containing all column headings, and assign headers’ value as “firstrow”.
Example:
from tabulate import tabulate
table = [['Name', 'Age'], ['Aman', 23], ['Neha', 25], ['Lata', 27]]
print(tabulate(table, headers = "firstrow" ))Output:

You can also pass a dictionary to tabulate() method where keys will be the column headings and assign headers’ value as “keys”.
Example:
from tabulate import tabulate
table = [['Name', 'Age'], ['Aman', 23], ['Neha', 25], ['Lata', 27]]
print(tabulate({"Name" : ['Aman', 'Lata', 'Neha'], 'Age' : [23, 25, 28]}, headers = 'keys'))Output:

Row Index
You can display the index column containing indexes for all rows in the table.
Example:
tabulate({"Name":['Aman', 'Lata', 'Neha'], 'Age': [23, 25, 28]}, headers = 'keys', showindex = True)Output:

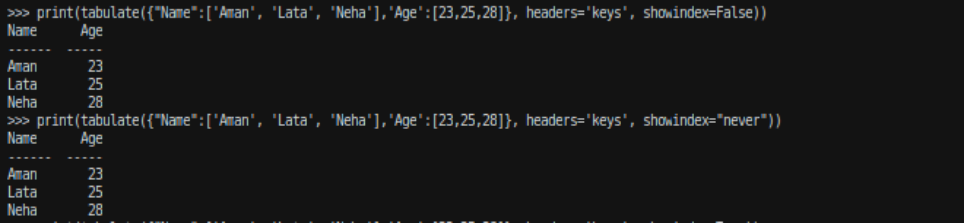
To hide the index column you can use showindex as ‘False’ or showindex as ‘never’.
Example:
tabulate({"Name":['Aman', 'Lata', 'Neha'], 'Age' : [23,25,28]}, headers = 'keys', showindex = "never")and,
tabulate({"Name":['Aman', 'Lata', 'Neha'],'Age':[23,25,28]}, headers = 'keys', showindex = False)Output:
To have a custom index column, pass an iterable as the value of showindex argument.
Example:
li=[2,4,6]
tabulate({"Name":['Aman', 'Lata', 'Neha'],'Age':[23,25,28]}, headers = 'keys', showindex = li)Output:

Number formatting
The tabulate() method allows you to display the specific count of numbers after a decimal point in a decimal number using floatfmt argument.
Example: Adding a new column Height in the above example:
table=tabulate({"Name":['Aman', 'Lata', 'Neha'],'Age':[23,25,28],'Height':[153.4567,151.2362,180.2564]}, headers='keys')Output:

Formatting the height values up to two digits:
tabulate({"Name":['Aman', 'Lata', 'Neha'],'Age':[23,25,28], 'Height':[153.4567,151.2362,180.2564]}, headers='keys', floatfmt='.2f')Output:

Table format
You can format the table in multiple ways using tablefmt argument. Following are a few of them:
- plain
- simple
- html
- jira
- psql
- github
- pretty
plain: It formats the table in a plain simple way without any outer lines:
Example:
tabulate({"Name":['Aman', 'Lata', 'Neha'],'Age':[23,25,28]}, headers='keys', tablefmt="plain")Output:

simple: It is the default formatting in tabulate() method that displays the table with one horizontal line below the headers:
Example:
tabulate({"Name":['Aman', 'Lata', 'Neha'],'Age':[23,25,28]}, headers='keys', tablefmt="simple")Output:

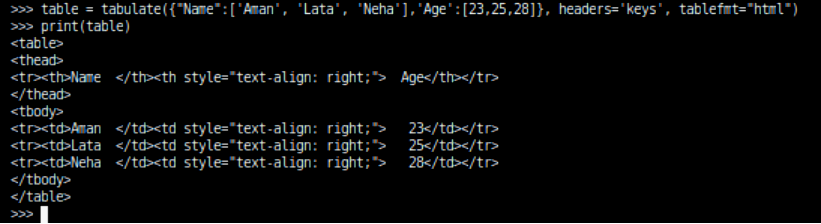
html: It displays the table in html code format:
Example:
tabulate({"Name":['Aman', 'Lata', 'Neha'],'Age':[23,25,28]}, headers='keys', tablefmt="html")Output:
jira: Displays the table in Atlassian Jira markup language format:
Example:
tabulate({"Name":['Aman', 'Lata', 'Neha'],'Age':[23,25,28]}, headers = 'keys', tablefmt = "jira")Output:

Psql: It displays the table in Postgres SQL form.
For example: tabulate({"Name":['Aman', 'Lata', 'Neha'],'Age':[23,25,28]}, headers='keys', tablefmt="psql")Output:

Github: It displays the table in GitHub mardown form.
For example: tabulate({"Name":['Aman', 'Lata', 'Neha'], 'Age':[23,25,28]}, headers = 'keys', tablefmt = "github")Output:

Pretty: Displays table in the form followed by PrettyTables library
For example: tabulate({"Name":['Aman', 'Lata', 'Neha'], 'Age':[23,25,28]}, headers='keys', tablefmt = "pretty")Output:

PrettyTable Module:
PrettyTable is another Python library that helps in creating simple ASCII tables. It got inspired by the ASCII tables generated and implemented in the PostgreSQL shell psql. This library allows controlling many aspects of a table, such as the the alignment of text, width of the column padding, or the table border. Also it allows sorting data.
Creating a Table using Python:
Creating a table in Python is very easy using the PrettyPrint library. Simply import the module and use its add_row() method to add multiple rows or create a table row-wise.
Example:
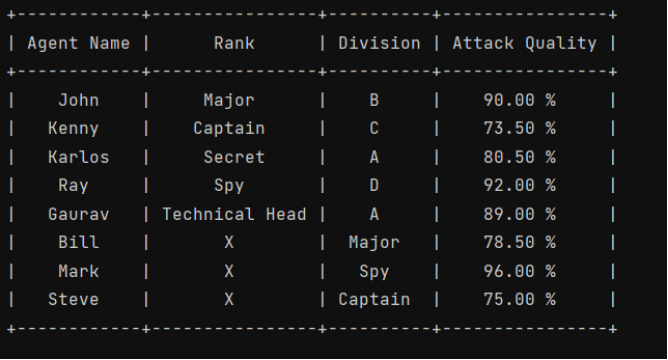
from prettytable import PrettyTable
myTab = PrettyTable(["Agent Name", "Rank", "Division", "Attack Quality"])
# Add rows
myTab.add_row(["John", "Major", "B", "90.00 %"])
myTab.add_row(["Kenny", "Captain", "C", "73.50 %"])
myTab.add_row(["Karlos", "Secret", "A", "80.50 %"])
myTab.add_row(["Ray", "Spy", "D", "92.00 %"])
myTab.add_row(["Gaurav", "Technical Head", "A", "89.00 %"])
myTab.add_row(["Bill", "X", "Major", "78.50 %"])
myTab.add_row(["Mark", "X", "Spy", "96.00 %"])
myTab.add_row(["Steve", "X", "Captain", "75.00 %"])
print(myTab)Output:
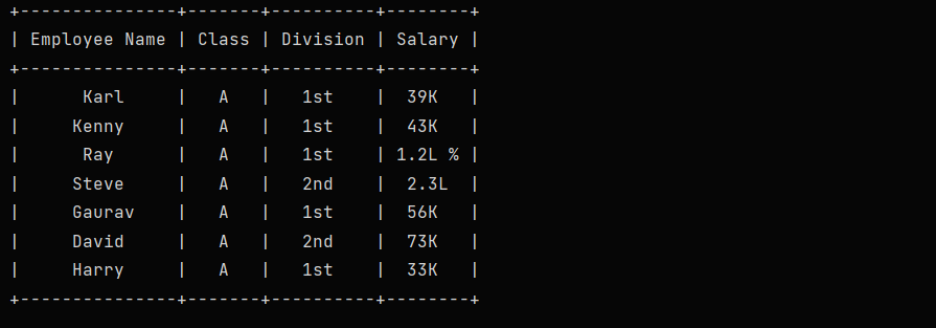
Example to create a table column-wise:
from prettytable import PrettyTable
columns = ["Employee Name", "Class", "Division", "Salary"]
myTab = PrettyTable()
# Add Columns
myTab.add_column(columns[0], ["Karl", "Kenny", "Ray", "Steve", "Gaurav", "David", "Harry"])
myTab.add_column(columns[1], ["A", "A", "A", "A", "A", "A", "A"])
myTab.add_column(columns[2], ["1st", "1st", "1st", "2nd", "1st", "2nd", "1st"])
myTab.add_column(columns[3], ["39K", "43K", "1.2L %", "2.3L", "56K", "73K", "33K"])
print(myTab)Output:
Conclusion:
Table plays a significant role in software development where the developer wants to create a formatted output. A lot of CLI-based software requires such formatting. Formatting through tabular form also helps in giving a crisp idea of the data so that the users can easily understand what the data wants to convey. Both these modules work well for representing data in tabular format. Web development using Python also requires these modules.
Таблицы pandas#
pandas.DataFrame — по сути дела таблица, на которую можно смотреть как на объединение столбцов pandas.Series с выравниванием по общему индексу.
import pandas as pd s1 = pd.Series({ "a": 1, "b": 2 }, dtype="Int8") s2 = pd.Series({ "b": "two", "c": "three" }) df = pd.DataFrame({ "s1": s1, "s2": s2 }) df
| s1 | s2 | |
|---|---|---|
| a | 1 | NaN |
| b | 2 | two |
| c | <NA> | three |
Таблицы изменяемы с точки зрения содержимого их ячеек, но лишь частично изменяемы с точки зрения размера: добавлять на месте можно только столбцы, но не строки.
Создание таблицы#
Как и в случае со столбцами, есть множество способов создать таблицу pandas из уже существующих объектов python. Большинство из них опираются на конструктор pandas.DataFrame.
Список списков или двухмерный массив NumPy#
Если ваши данные хранятся в виде списка списков, то на выходе каждый вложенный список будет соответствовать строке таблице.
data = [ ["a11", "a12", "a13"], ["a21", "a22", "a23"] ] df = pd.DataFrame(data) df
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | a11 | a12 | a13 |
| 1 | a21 | a22 | a23 |
По умолчанию генерируется RangeIndex и для строк и для столбцов таблицы.
print(f"{df.index=}, {df.columns=}")
df.index=RangeIndex(start=0, stop=2, step=1), df.columns=RangeIndex(start=0, stop=3, step=1)
Опциональными параметрами конструктора columns и index можно указать пользовательские значения.
df = pd.DataFrame(data, columns=["column 1", "column 2", "column 3"], index=["row 1", "row 2"]) df
| column 1 | column 2 | column 3 | |
|---|---|---|---|
| row 1 | a11 | a12 | a13 |
| row 2 | a21 | a22 | a23 |
Если вместо списка списков передавать двухмерный массив NumPy, то все будет работать точно также, кроме возможной потери типов.
import numpy as np data = np.array(data) df = pd.DataFrame(data, columns=["column 1", "column 2", "column 3"], index=["row 1", "row 2"]) df
| column 1 | column 2 | column 3 | |
|---|---|---|---|
| row 1 | a11 | a12 | a13 |
| row 2 | a21 | a22 | a23 |
Словарь#
Один самых удобных способов создавать таблицу в pandas — использовать словари.
Тут возможно два варианта.
-
ключи словаря — названия столбца, значение по ключу — содержимое соответствующего столбца;
-
ключи словаря — метки строк, значение по ключу — содержимое соответствующей строки.
По столбцам#
Первый вариант гораздо более распространен, поэтому его рассмотрим первым. Итак, ключи словаря станут названиями столбцов, значение по ключу — станет содержимым с соответствующим значением.
Будущие столбцы в словари могут быть представлены списком, массивом NumPy, а также столбцом pandas. При этом в случае списков и массивов NumPy накладывается требование на одинаковую длину всех столбцов, а также автоматически генерируется RangeIndex, если он не указан в явном виде опциональным параметром index.
col1 = np.array(["a11", "a21"]) col2 = ["a21", "a22"] col3 = "a31", "a32" d = { "column 1": col1, "column 2": col2, "column 3": col3 } df = pd.DataFrame(d, index=["a", "b"]) df
| column 1 | column 2 | column 3 | |
|---|---|---|---|
| a | a11 | a21 | a31 |
| b | a21 | a22 | a32 |
Если же содержимое будущих столбцов представлено в виде столбцов pandas, то индекс таблицы генерируется из индексов этих столбцов, а ограничение на одинаковую длину столбцов снимается: строки таблицы выравниваются по индексу.
import pandas as pd import numpy as np col1 = pd.Series([1, 2], index=["a", "b"]) col2 = pd.Series([3, 4], index=["b", "a"], dtype="Int64") col3 = pd.Series([5, 6, 7], index=["a", "b", "c"]) d = { 'column 1': col1, 'column 2': col2, 'column 3': col3, } df = pd.DataFrame(d) df
| column 1 | column 2 | column 3 | |
|---|---|---|---|
| a | 1.0 | 4 | 5 |
| b | 2.0 | 3 | 6 |
| c | NaN | <NA> | 7 |
По строкам#
Статический метод pandas.DataFrame.form_dict — более специализированный метод для создания таблицы из словаря. В примерах из предыдущего раздела этот метод сработает точно также, как и базовый конструктор класса, но наличие дополнительного опционального параметра orient (orientation) позволяет создавать таблицу из строк.
Если указать в качестве orient строку index, то ключи словаря будут восприниматься в качестве меток строк, а значение по ключу — содержимое строки с соответствующей меткой. Все остальное продолжает работать также, но с заменой меток и названий столбцов местами.
row1 = pd.Series([1, 2], index=["column 1", "column 2"]) row2 = pd.Series([3, 4], index=["column 2", "column 1"]) d = { "row1": row1, "row2": row2, } pd.DataFrame.from_dict(d, orient="index")
| column 1 | column 2 | |
|---|---|---|
| row1 | 1 | 2 |
| row2 | 4 | 3 |
Чтение таблиц с жесткого диска#
Библиотека pandas позволяет свободно оперировать с таблицами в формате csv, json, таблицами excel (потребуется установка дополнительной библиотеки, например, openpyxl), а также более продвинутыми бинарными форматами hdf5, apache parquet и многими другими форматами. Формат csv — один из самых простых и распространенных в научной среде, поэтому рассмотрим чтение таблиц средствами pandas именно на его примере.
Note
Все таблицы из этой лекции хранятся в репозитории с исходниками этого ресурса в папке по ссылке.
Предположим следующее содержимое хранится в текстовом файле planets.csv со следующим содержимым.
Название,Количество спутников,Масса,Группа,Кольца Меркурий,0,0.0055,земная группа,Нет Венера,0,0.815,земная группа,Нет Земля,1,1.0,земная группа,Нет Марс,2,0.107,земная группа,Нет Юпитер,62,317.8,газовый гигант,Да Сатурн,34,95.2,газовый гигант,Да Уран,27,14.37,ледяной гигант,Да Нептун,13,17.15,ледяной гигант,Да
Для чтения такой таблицы используется метод read_csv.
import os path = os.path.join("..", "..", "assets", "data", "tables", "planets.csv") planets = pd.read_csv(path) print(planets.info()) planets.head()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 8 entries, 0 to 7 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Название 8 non-null object 1 Количество спутников 8 non-null int64 2 Масса 8 non-null float64 3 Группа 8 non-null object 4 Кольца 8 non-null object dtypes: float64(1), int64(1), object(3) memory usage: 448.0+ bytes None
| Название | Количество спутников | Масса | Группа | Кольца | |
|---|---|---|---|---|---|
| 0 | Меркурий | 0 | 0.0055 | земная группа | Нет |
| 1 | Венера | 0 | 0.8150 | земная группа | Нет |
| 2 | Земля | 1 | 1.0000 | земная группа | Нет |
| 3 | Марс | 2 | 0.1070 | земная группа | Нет |
| 4 | Юпитер | 62 | 317.8000 | газовый гигант | Да |
В самом простом варианте использования функции read_csv
-
имена столбцов распознаются из первой строки файла (параметром
headerможно повлиять на это); -
в качестве индекса генерируется
RangeIndex(параметромindex_colможно выбрать столбец индекса таблицы); -
в качестве разделителя ожидается символ запятой “
,” (параметромsepможно на это повлиять); -
пропущенные значения заполняются значением “
np.nan” (параметромna_valuesможно указать, какие ещё значения интерпретировать, как пропущенные); -
столбцы с датами не распознаются (смотри страницу “Дата и время”).
Note
Метод DataFrame.head возвращает первые n строк таблицы. По умолчанию n равно 5, но можно указать явно и другое значение. Похожий по смыслу метод DataFrame.tail возвращает последние n строк.
Метод DataFrame.info печатает информацию о таблице. В частности, из вывода этой функции можно понять количество строк и столбцов, тип индекса таблицы, имя каждого столбца, тип данных и количество непропущенных значений в них.
Считаем эту таблицу ещё раз, указав в этот раз в качестве индекса столбец "Название".
planets = pd.read_csv(path, index_col="Название", sep=",") planets
| Количество спутников | Масса | Группа | Кольца | |
|---|---|---|---|---|
| Название | ||||
| Меркурий | 0 | 0.0055 | земная группа | Нет |
| Венера | 0 | 0.8150 | земная группа | Нет |
| Земля | 1 | 1.0000 | земная группа | Нет |
| Марс | 2 | 0.1070 | земная группа | Нет |
| Юпитер | 62 | 317.8000 | газовый гигант | Да |
| Сатурн | 34 | 95.2000 | газовый гигант | Да |
| Уран | 27 | 14.3700 | ледяной гигант | Да |
| Нептун | 13 | 17.1500 | ледяной гигант | Да |
Аналогично можно считывать данные из таблиц excel методом read_excel.
Методами to_csv и to_excel можно сохранить DataFrame в таблицу удобном формате (для сохранения в excel необходимо поставить библиотеку openpyxl или её аналоги).
Индексация#
Строки#
Для получения строк таблицы используются те же самые .loc и iloc (метки и порядковый номер соответственно).
print(planets.loc["Марс"]) print("_" * 80) print(planets.iloc[2])
Количество спутников 2 Масса 0.107 Группа земная группа Кольца Нет Name: Марс, dtype: object ________________________________________________________________________________ Количество спутников 1 Масса 1.0 Группа земная группа Кольца Нет Name: Земля, dtype: object
В ответ вы получаете объект pandas.Series соответствующей всей строке, при этом индекс этого объекта соответствует названиям столбцов. Если использовать срезы или список меток, то вы получите новую таблицу с, возможно, меньшим количеством строк.
Warning
Простые квадратные скобки “[]” не индексируют таблицу по строкам!
Столбцы#
Для получения столбца используется оператор “[]”.
planets["Количество спутников"]
Название Меркурий 0 Венера 0 Земля 1 Марс 2 Юпитер 62 Сатурн 34 Уран 27 Нептун 13 Name: Количество спутников, dtype: int64
Если в названии столбца нет пробелов и оно не совпадает ни с одним методом класса pandas.DataFrame, то можно использовать точечную нотацию. Хотя, конечно, в случае кириллицы это выглядит странно.
Название Меркурий 0.0055 Венера 0.8150 Земля 1.0000 Марс 0.1070 Юпитер 317.8000 Сатурн 95.2000 Уран 14.3700 Нептун 17.1500 Name: Масса, dtype: float64
Можно указывать список названий столбцов, чтобы извлечь сразу подтаблицу целиком.
planets[["Группа", "Кольца", "Масса"]]
| Группа | Кольца | Масса | |
|---|---|---|---|
| Название | |||
| Меркурий | земная группа | Нет | 0.0055 |
| Венера | земная группа | Нет | 0.8150 |
| Земля | земная группа | Нет | 1.0000 |
| Марс | земная группа | Нет | 0.1070 |
| Юпитер | газовый гигант | Да | 317.8000 |
| Сатурн | газовый гигант | Да | 95.2000 |
| Уран | ледяной гигант | Да | 14.3700 |
| Нептун | ледяной гигант | Да | 17.1500 |
Конкретные ячейки#
Для получения доступа сразу к конкретной ячейке используются методы DataFrame.at и DataFrame.iat.
-
метод DataFrame.at принимает на вход метку строки и название столбца, и возвращает значение ячейки, располагающейся на их пересечении.
-
метод DataFrame.iat принимает на вход номер строки и номер столбца, и возвращает значение ячейки, располагающейся на их пересечении.
print(f"{planets.at['Меркурий', 'Количество спутников']=}, {planets.iat[0, 0]=}")
planets.at['Меркурий', 'Количество спутников']=0, planets.iat[0, 0]=0
Однако, если метки строк и названия столбцов повторяются, то методом “.at” вместо значения одной ячейки вы можете получить или сразу pandas.Series или pandas.DataFrame.
duplicated_df = pd.DataFrame(data=[[1, 1], [1, 1]], index=["a", "a"], columns=["b", "b"]) duplicated_df
duplicated_df.at["a", "b"]
Добавление столбцов#
Добавление и изменение столбцов в таблицу похоже на добавление элементов в словарь. При этом данные автоматически выравниваются по индексу. В качестве примера добавим к таблице про планет столбец с данными про экваториальный диаметр. Обратите внимание, что планеты перечислены в порядке отличном от порядка таблицы, и далеко не все планеты есть в новом столбце. В итоговой таблицы все присутствующие значения выравниваются, а недостающие заменяются на NaN.
planets["Экваториальный диаметр"] = pd.Series({ "Венера": 0.949, "Сатурн": 9.449, "Земля": 1.0, "Меркурий": 0.382, }) planets
| Количество спутников | Масса | Группа | Кольца | Экваториальный диаметр | |
|---|---|---|---|---|---|
| Название | |||||
| Меркурий | 0 | 0.0055 | земная группа | Нет | 0.382 |
| Венера | 0 | 0.8150 | земная группа | Нет | 0.949 |
| Земля | 1 | 1.0000 | земная группа | Нет | 1.000 |
| Марс | 2 | 0.1070 | земная группа | Нет | NaN |
| Юпитер | 62 | 317.8000 | газовый гигант | Да | NaN |
| Сатурн | 34 | 95.2000 | газовый гигант | Да | 9.449 |
| Уран | 27 | 14.3700 | ледяной гигант | Да | NaN |
| Нептун | 13 | 17.1500 | ледяной гигант | Да | NaN |
В статье будут рассмотрены основы SQLite в Python. Это может быть полезным при работе с таблицами в процессе написания кода на Пайтоне. Особое внимание будет уделено:
- загрузке библиотек;
- созданию и соединению с базой данных;
- созданию таблиц БД;
- добавлению новых данных и запросам на их получение;
- удалению информации.
Согласно информации в Google, SQLite3 (часто называется просто SQLite) – часть стандартного Python-пакета, подключенного в версии 3.0. Чтобы использовать таблицы в коде языка, не придется ничего дополнительно устанавливать.

Выше – пример таблиц, с которыми предстоит работать далее в качестве «базы». Этот прием позволит без поиска дополнительной информации в Google освоить SQLite в Питоне.

Типы данных
SQLite3 в Python дает возможность создать таблицы с ограниченным типом данных. Этот спектр оказывается меньше, чем в других SQL, зато здесь более простая и понятная реализация.
Согласно источникам в Google, здесь поддерживаются такие типы данных:
- NULL – значение NULL;
- integer – целочисленные значения;
- text – текстовые данные;
- real – числа с плавающей точкой;
- blob – бинарное представление крупных элементов.
В SQLite отсутствуют другие привычные для SQL типы данных. Далее предстоит изучить основы работы с таблицами.
Начало работы с SQLite
Перед использованием SQLite необходимо загрузить соответствующую библиотеку. Для этого потребуется выполнить команду import.
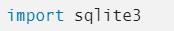
После этого предстоит создать базу данных, с которой будет проводиться дальнейшая работа. Выше можно увидеть команду загрузки, необходимую для выполнения операций с запросами и таблицами библиотеки.
Создание базы
Как официальная документация, так и свободные источники Google указывают на то, что перед созданием таблиц и выводом их на дисплей требуется сформировать базу информации. Без нее дальнейшие действия бесполезны. Разработчику попросту не с чем будет работать.
В рассматриваемой библиотеке поддерживаются несколько способов создания БД. Первый – это применение функции connect(). Ниже – пример того, как это делается в случае с «обычной» БД.

Здесь:
- Создан файл .db. Он выступает стандартным способом управления базой SQLite.
- Файл получил название orders. За соединение ответит переменная conn.
- После обработки строки будет создан объект connection и файл orders.db. Они разместятся в рабочей директории.
- Функция connect будет создавать соединение с базой SQLite. Источники Google указывают на то, что она также возвращает представляющий ее объект.
Иногда бывает так, что необходимо использовать не рабочую директорию, а другую. В этом случае необходимо воспользоваться такой командой:

Если файл уже имеется, функция connect подключится к нему и выведет соответствующие сведения. Перед строкой с путем установлен управляющий символ «r». В источниках Google подчеркивается, что с его помощью Питон понимает: речь идет о «сырой» строке. В ней слеши не отвечают за непосредственное экранирование.
Резидентная база
Сделать БД в SQLite не так трудно, как и сформировать таблицу, а затем вывести ее на устройство. Можно сделать «хранилище информации» в памяти устройства. Такой вариант подойдет для тестирования. Связано это с существованием базы непосредственно в оперативной памяти.

Знать о подобной концепции необходимо, но также предстоит учесть – этот подход на практике используется редко. Далее будет применяться первый вариант формирования «хранилища информации».
Объект cursor
Перед тем как сделать таблицу и начать работу с ней, потребуется обеспечить в БД объект cursor. Он поможет объединить элемент соединения с «хранилищем информации» и дает возможность формировать SQL-запросы.
Для хранения объекта необходимо воспользоваться переменной cur:

Запросы будут выполняться так:

Сами запросы помещаются в кавычки. Они могут быть тройными, одинарными или двойными. Первый вариант применим к особо длинным запросам, которые пишутся на нескольких строчках.
Создание таблиц
Вывод информации из таблиц возможен после их создания и заполнения. Ее структура будет представлена в следующем виде:
Первое, что необходимо делать – это сформировать таблицу users:

Здесь будут выполняться такие операции:
- Функция execute будет отвечать за запрос SQL.
- SQL сгенерирует таблицу users.
- Запись «If not exists» помогает при попытке повторного подключения к БД. Запрос проверит, существует ли соответствующая таблица. Если да – просмотрит ее на наличие изменений.
- Создаются несколько колонок: userid, fname, lname и gender. Userid выступит основным ключом.
- Изменения будут сохранены при помощи функции commit для объекта соединения.
Теперь можно сформировать вторую таблицу. Ее код предстанет в следующем виде:

После обработки предложенных скриптов база будет включать две таблицы. Чтобы вывести их содержимое в терминал, потребуется внести данные.
Добавление информации
Для добавления информации необходимо использовать объект cursor:

В Python часто приходится иметь дело с переменными, которые включают в себя числа. Пример – кортежи со сведениями о клиенте:

Что дальше? Если поискать ответ в том же Google, то мы увидим, что при необходимости загрузки в базу данных кортежа используется такой формат:

Все значения здесь заменены на знаки вопроса. Также добавлен параметр, включающий в себя добавляемые значения.
SQLite ожидает получения значения в формате кортежа, но это не обязательно. В переменной может быть список с кортежным набором. Несколько пользователей удастся добавить так:

Вместо обычной execute потребуется использование функции executemany:

Если использовать функцию в неизмененном виде, система подумает, что клиент передает в таблицу два объекта (кортежа), а не два кортежа, каждый из которых включает в себя некоторое количество значений для пользователей. В приведенном примере – 4. Из-за этого возникают конфликты и ошибки.
Загрузка
Вывод информации доступен после того, как она будет внедрена in tables. Для этого можно использовать скрипты:



Здесь можно увидеть полный текст скрипта. Также необходимо воспользоваться запросами:

Все это поможет подготовиться к выводу табличных данных через SQLite.
Получение информации
Выбор данных – это the wide theme. Он в SQL может реализовываться несколькими способами:
- через fetchone();
- при помощи fetchmany();
- через fetchall().
Каждый из предложенного числа запросов поддерживает свои особенности. Первый подход – fetchone(). Он позволяет вывести в терминал только один результат. Имеет формат:

При обработке получится следующий результат:

Функция fetchmany() – это wider-понятие. Она позволяет вывести много данных из заданной table. Вот пример с генерацией трех результатов:
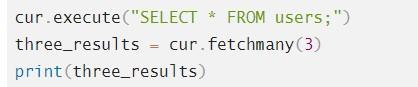
На экране высветится следующая информация:

Последний вариант – это fetchall(). Данная функция используется для полноценного выведения результатов. Применяется в отношении небольших таблиц. При обработке скрипта с fetchall() система выведет в терминале все табличные данные. Если их много, на реализацию запроса уйдет немало времени.

Выше – пример скрипта, который позволит увидеть всю информацию из users.
Объединение
Еще одной базовой операцией при работе с таблицами в Питоне является объединение нескольких tables. Этот вариант больше подойдет опытным разработчикам, решающим сложные задачи.

Вот пример генерации запроса, который включает в себя имя и фамилию каждого покупателя заказа. Этот вариант подойдет и для иных SQL-операций.
Удаление
Иногда может потребоваться удаление информации из SQL-table. Данная операция тоже относится к базовым. Она имеет простую и понятную структуру. Использует оператор Delete from.
На основании сформированной БД необходимо удалить пользователя. Пример – Parker. Для этого формируется запрос:

После этого потребуется сделать еще один запрос:

Он необходим для проверки грамотности работы команды delete. На экране появится пустой список, который подтвердит выполнение операции. В удаленном поле не будет никаких сведений.
Как быстро разобраться с SQLite
Python и SQLite – не самые сложные инструменты для работы с запросами и базами данных. Здесь можно увидеть подробный туториал по работе с таблицами.
Чтобы лучше и быстрее разобраться в выбранном направлении, рекомендуется закончить дистанционные онлайн-курсы. Пример – от образовательного центра OTUS. Все обучение организовано дистанционно. Пользователи смогут просмотреть вебинар в записи, если они отсутствовали во время прямых трансляций.
Дистанционные курсы подают информацию сжато и понятным языком. С их помощью в срок до года удастся разобраться с любым языком разработки и запросов. Гарантированы интересные домашние задания, а также богатая практика. В конце выдается электронный сертификат для подтверждения приобретенных навыков и умений.

