Современная
перепись, дающая очень важный материал,
тем
не менее не обеспечивает полностью
потребности государства
в подробных данных о населении, а главное
получения их
в короткие сроки. Перепись, в силу того,
что она имеет всеобщий
характер, ограничивается относительно
краткой программой,
поэтому увеличение числа вопросов может
нанести ущерб
качеству ответов на них. Кроме того,
любое расширение
программы переписи требует большого
числа квалифицированных
счетчиков, что связано с дополнительными
затратами. Причем даже
при наличии современного оборудования
материалы переписи
нельзя обработать в короткий срок.
Подготовка их к обработке и полная
разработка занимают от двух до четырех
лет. При
этом разработка материалов по всем
нужным комбинациям признаков почти
никогда не производится вследствие ее
трудоемкости.
Для
преодоления названных трудностей в
современных переписях
широко пользуются выборочным методом,
который применяют
для: 1) Расширения программы переписи.
2) Получения предварительных
итогов переписи и ускорения разработки
материалов.
3) Дополнительной разработки материалов
переписи по более широкой программе.
4) Различного рода контрольных
мероприятий.
Расширение
программы переписи заключается в том,
что лицам,
отобранным или иным способом, задают
сверх обязательных
еще и дополнительные вопросы, содержание
их в большей
мере определяется дробностью
территориальной группировки.
Небольшой объем выборки не дает
возможности получить достаточно
представительные данные, дополнительные
вопросы которые
ставятся только части населения, касаются
миграции, числа
рожденных детей, места рождения, доходов
и т.д.
Сбop
сведений по выборочной программе
поручается счетчикам
всеобщей переписи или специально
подготовленному персоналу.
В зависимости от этого выборочный опрос
по более широкой
программе производится либо одновременно
с основной
переписью, либо через некоторое время,
обычно очень непродолжительное,
чтобы не нарушалась сопоставимость
данных. Однако
чаще всего дополнительные вопросы
выборочной части программы
переписи задают во время проведения
основной переписи,
только не всем, а лишь отобранным лицам.
Произвести
такой отбор в ходе самой переписи
непросто, т,
к. для этого нужно иметь основу выборки,
т.е. перечень единиц
изучаемой совокупности, из которого
следует отбирать заранее такого списка
обычно не бывает. Кроме того, необходимо
организовать отбор так, чтобы он был
строго объективным,
т.е. исключить возможность предпочтения
одних опрашиваемых
другим.
Во
всесоюзной переписи населения 1970г.
впервые был применен выборочный метод
для расширения программы. Отбор
значительно
облегчался тем, что каждый счетчик имел
записную книжку с полным перечнем всех
жилых помещений счетного участка
оставленным при предварительном обходе.
По записным книжкам из этого перечня
отбиралось каждое четвертое по
порядку жилое помещение. Отбор производился
в пределах инструкторского
участка, причем начало отсчета чередовалось
в зависимости
от номера участка : в участках №1 отбор
начинали с первого по порядку жилого
помещения, в участках №2-со второго
и т.д. Таким образом была применена
своеобразная форма районированного
отбора, причем отбиралось 25%жилых
помещений, или четвертая часть населения,
для отобранных жилых
помещений счетчики, кроме 2 основных
вопросов в опросные
листы включали 7 дополнительных: 1) место
работы; 2) занятие;
3) характер и продолжительность работы
в год перед переписью;
4) общественная группа; 5) продолжительность
проживания в данном
населенном пункте; 6) предыдущее место
постоянного жительства;
7) причина перемены места жительства.
Такой
порядок отбора оказался эффективным и
был сохранен
при переписи 1979 г. В программе этой
переписи первые II
вопросов ставились всем, а дополнительные
5-только постоянно
проживавшим в каждом четвертом по счету
жилом помещении,
дополнительные вопросы касались: 1)
места работы; 2) занятия;
3) общественной группы; 4) продолжительности
проживания в
данном населенном пункте; 5) для женщин
старше 16 лет числа рожденных
детей. Последний вопрос ставился впервые.
После
получения выборочных данных они
распространяются на
все население путем умножения каждого
выборочного показателя на коэффициент
распространения. Эта процедура довольно
сложная т.к. обычно применяется не один
коэффициент распространения
для всего населения, а ряд их по основным
группам
населения.
Выборочная
разработка применяется и в тех случаях,
когда
сплошная разработка по всем нужным
комбинациям признаков
слишком сложна и требует больших средств
и времени. Обычно она охватывает от
одного до нескольких процентов материала.
Выборочная разработка производится
также для более
подробного изучения материалов переписи
уже после того, как сплошная разработка
закончена, так обработка данных
переписи 1979 г. дала более подробные
сведения о составе семей, сочетаниях
характеристик супругов в супружеских
парах и др. Разработка проводилась по
экономическим районам.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
1 июля 2011
Elitarium.ru, 1 июля 2011г.
Предисловие редакции HT.ru:
Данная статья адресована, в первую очередь, маркетологам и социологам, которые занимаются проведением массовых опросов и исследований. Но нам бы хотелось, чтобы с этим материалом были знакомы наши hr-ы. Даже если Вы еще никогда не занимались проведением опросов в своей организации, поверьте, Вам предстоит когда-нибудь столкнуться с этой интереснейшей областью работы. И одной из первых проблем, которая встанет перед Вами, будет вопрос “Кого привлекать к опросу?”. Скажем так, данная статья не даст простого и четкого ответа на этот, в действительности, непростой вопрос. Но, прочитав ее, Вы сможете по-новому, осмысленнее и более профессионально взглянуть на тот фронт работ, который представляет собой проведение опросов. Например, Вы сможете предугадать, чьи ответы Вы получите в случае, когда опрос в организации будут проходить “все желающие”.
Редакция HT.ru
Автор статьи: Игopь Cтанислaвович Бepeзин, консультант по маркетинговым стратегиям, президент Гильдии мapкетoлoгов (г. Моcква).  Опрос и анкетирование являются ведущими, универсальными методами проведения социологических и маркетинговых исследований. Чаше всего, когда говорят о маркетинговом исследовании — сборе первичной информации, имеют в виду именно опрос или анкетирование, предполагающие прямое выяснение, непредвзятого мнения достаточно многочисленной группы респондентов.
Опрос и анкетирование являются ведущими, универсальными методами проведения социологических и маркетинговых исследований. Чаше всего, когда говорят о маркетинговом исследовании — сборе первичной информации, имеют в виду именно опрос или анкетирование, предполагающие прямое выяснение, непредвзятого мнения достаточно многочисленной группы респондентов.
Массовым считается опрос, в ходе которого путем личной беседы сотрудника исследовательской компании — интервьюера с носителями информации (респондентами), состоящей из нескольких десятков коротких вопросов, изучаются мнения нескольких сотен (тысяч) человек. Под анкетированием понимают безличную форму общения исследователей с носителями информации, при которой респонденты самостоятельно отвечают на вопросы анкеты, следуя содержащейся в ней инструкции и не вступая в непосредственный контакт с интервьюерами.
Конечной целью анкетирования и массового опроса является получение данных, характеризующих так называемую генеральную совокупность. Генеральная совокупность — это все представители какой-либо группы, носители какого-либо важного признака, например:
-
все российские избиратели;
-
все потенциальные потребители пива, проживающие в Перми;
-
все подростки (12-16 лет) Поволжского региона;
-
все учителя физики и химии, работающие в средних школах;
-
все домохозяйства, имеющие доход от 500 до 1 500 долл. в месяц;
-
все компании, занимающиеся розничной торговлей в Самаре и т. д. и т. п.
Для того чтобы опросить десятки или сотни тысяч, а тем более — миллионы человек (компаний), из которых может состоять генеральная совокупность, нужны сотни или даже тысячи интервьюеров. На проведение подобного исследования могут понадобиться десятки, если не сотни миллионов долларов и не менее полугода напряженной работы. Такое возможно только при переписи населения (проводящейся не чаще одного раза в 10 лет).
Однако в маркетинге этого и не требуется. Достаточно того, чтобы относительно небольшая выборка (от нескольких сотен до нескольких тысяч представителей) репрезентировала (выразила) мнение генеральной совокупности. Как такое возможно? На каком основании можно распространять данные, полученные от небольшой группы людей, на существенно (в десятки и сотни раз) большую группу? На основании гипотезы о том, что на поведение, знания, отношение потребителей к компании, товару, услуге или отдельных их компонентов оказывают влияние социально-демографические характеристики самих потребителей.
Иными словами, большинство представителей четко определенной социально-демографический группы будут сходным образом реагировать на внешние, в данном случае — рыночные стимулы: товар, цену, упаковку, рекламу и т. д. и т. п. И нет никакой необходимости опрашивать всех представителей этой группы, поскольку ее мнение (с допустимой погрешностью) может представить (репрезентировать) небольшая выборка из ее представителей.
Способы построения выборки
Существуют две группы методов построения выборки, в той или иной степени реализующих репрезентацию мнений и позиций генеральной совокупности: вероятностные и детерминированные.
Первая группа методов (вероятностные) базируется на использовании теории вероятности. В основе ее применения лежит постулат, что репрезентация будет достигнута в случае, если каждой единице генеральной совокупности обеспечено равновероятное попадание в выборку. Например, если генеральной совокупностью является все взрослое (16-85 лет) население города (200 тыс. человек), то каждому жителю должна быть обеспечена вероятность стать участником исследования(попасть в выборку), равная 1 / 200 000. В противном случае выборка будет не случайной, а смещенной, т. е. менее репрезентативной.
Реализовать это можно в случае, если все элементы генеральной совокупности могут быть тем или иным образом пронумерованы, а затем эти номера будут выбраны в определенной последовательности — «по воле случая». Например, в Москве около 2 500 средних школ, каждаяиз которых имеет свой номер. Мы могли бы выбрать наугад 100 номеров и провести опрос 100 директоров (завучей, учителей физики, классных руководителей 11-х классов и т. п.) в этих школах.
Эти 100 номеров мы можем выбрать с помощью таблицы или «генератора случайных чисел» (есть такая специальная компьютерная программа), а также с помощью «барабана» но принципу того, как это делается при проведении лотереи. Такие способы построения выборки называются «простой случайной выборкой». Каждый ее элемент отбирается независимо и имеет равную вероятность попасть в выборку.
Мы могли бы выбрать наугад любое число от 1 до 25, например— 12, а затем взять в выборку школы с номерами: 12, 37, 62, 87, 112, 137 и т. д. Такой метод построения называемся «систематической выборкой», первый элемент которой выбирается произвольно, а затем выбирают каждый i-й элемент.
Мы также могли бы сначала разделить эти школы на несколько страт (возможно, и пересекающихся), например, на школы физико-математические, спортивные, лингвистические и гуманитарные, а затем произвести случайную или систематическую выборку (по 20-30 школ) из каждой страты. Такой метод построения называется «стратифицированной выборкой».
Разновидностью стратифицированной выборки является «маршрутная выборка», суть реализации которой состоит в следующем. Город делится на 20-40 «секторов» по числу интервьюеров, задействованных и исследовании. Каждый интервьюер получает один сектор, маршрут обследования «своего» сектора и инструкцию по реализации простой случайной выборки. Например такую: «Начать обход с улицы Баумана, с дома № 2, третьего подъезда, второго этажа сверху, первой квартиры слева. Затем — дом № 4, второй подъезд, третий этаж, вторая квартира справа… Потом — переулок Комсомольский, нечетная сторона… Потом — тупик Коммунизма… и т. д.»
Наконец, мы могли бы разделить генеральную совокупность на непересекающиеся кластеры, к примеру, по муниципальным районам (их в Москве 125, и в каждом в среднем по 20 школ). Затем случайным образом выбрать пять районов и произвести обследование всех школ данного муниципального района. Такой метод построения называется «кластерной выборкой».
Тем не менее у вероятностных методов построения выборки есть один весьма существенный недостаток. Каждый из них исходит из предположения о том, что все элементы генеральной совокупности являются равнодоступными: и в «техническом» смысле (у всех есть телефон для телефонного опроса или доступ в Интернет), и в «психологическом», т. е. все респонденты с примерно равной вероятностью согласятся или откажутся принимать участие в исследовании. Однако это не так.
Граждане с относительно высокими доходами менее доступны для исследователей, чем те, чьи доходы невысоки. И нет никакой силы, которая могла бы заставить этих люден отвечать им вопросы социологов или маркетологов. Поэтому все выборки всегда смещены в сторону средне- и малообеспеченных групп населения. Во всех без исключения странах мира.
Менее образованные граждане идут на контакт с социологами менее охотно, чем лица с высшим образованием. Поэтому в большинстве выборок доля хорошо образованных граждан как правило существенно выше, чем в генеральной совокупности.
Никто из сотрудников исследовательских компаний не желает общаться с бомжами, алкоголиками, наркоманами, психо- и социопатами и прочими маргиналами. И у руководителя исследования нет решительно никаких возможностей заставить своих сотрудников делать это. А между прочим, к этим группам в России по взвешенным оценкам относится от 12 до 15% жителей Следовательно, любая выборка смещена в сторону «вменяемых» граждан.
Некоторые граждане боятся отвечать на вопросы, даже самые невинные. Таких людей немного, но они есть. А вот способов заставить их участвовать в опросе нет.
Наконец, есть люди, которые просто не желают участвовать в исследовании. У них есть время, они ничего не боятся, они все понимают, но на вопросы отвечать отказываются. И точка.
Таким образом, все выборки в маркетинге и социологии являются смещенными в сторону средне- и малообеспеченных, более образованных, контактных и вменяемых граждан. Они и репрезентируют общее мнение генеральной совокупности. И все исследователи рынка прекрасно это знают.
Преодолеть наложенные выше проблемы можно с помощью метода «квот», относящегося к детерминированным методам, при котором априори обеспечивается пропорциональное представительство носителей существенных признаков (пол, возраст, доход, образование и т. п.) генеральной совокупности в выборке.
Это наиболее эффективный, на наш взгляд, метод проведения массовых опросов. При его использовании существенно облегчается задача поиска корреляционных связей, сравнения различных типов (групп) потребителей между собой и экстраполяции выявленных закономерностей на генеральную совокупность.
Единственная, но весьма существенная трудность при реализации него метода состоит в том, что не всегда доподлинно известно распределение всех важных параметров в самой генеральной совокупности. В этом случае исследователь или консультант исследовательского проекта должен взять на себя смелость распределить квоты по своему усмотрению, в соответствии со своим видением, пониманием рынка.
Задача достижения строгой репрезентативности не всегда является важной. Иногда целесообразно воспользоваться существенно более простыми в реализации детерминированными методами:
-
нерепрезентативным, или произвольным, когда опрашивают того, кто «попался под руку» интервьюеру и согласился участвовать в опросе. Естественно, этот метод дает крайне ненадежные результаты. А вдруг под руку попадется рота солдат или команда баскетболисток! Однако его использование допустимо в исследованиях, носящих поисковый характер, не требующих большой точности, при проведении «пилотажа» анкеты. «Произвольность» можно компенсировать большим объемом выборки, из которой затем можно будет попробовать отобрать необходимое число «подходящих» анкет и составить уже из них репрезентативную в каких-то отношениях выборку;
-
поверхностным — когда отбор осуществляется по самым общим признакам, задаваемым исследователем интервьюерам в виде не очень строгого задания;
-
« воронки» — когда сначала отбираются наиболее «контактные», а затем среди них — наиболее «компетентные», подходящие респонденты;
-
« концентрации» — на представителях отдельных, сопоставимых сегментов рынка, среди которых проводят «сплошной» опрос. Например, школьный 11 «А» класс может представлять всех старшеклассников школы или даже города как «обычный», «типичный класс»;
-
«снежного кома» — когда начальная группа подбирается случайным образом, а дальнейший отбор ведется из кандидатов, указанных первыми респондентами, и т. д.
Достоверность и погрешности измерений
Под «достоверностью», уровнем достоверности понимают показатель вероятности того, что истинное значение изучаемого параметра генеральной совокупности попадет в доверительный интервал. Чем выше задаваемый уровень достоверности, тем больше должна быть выборка. Под доверительным интервалом понимают диапазон, в который попадет истинное значение изучаемого параметра генеральной совокупности при данном уровне достоверности. Чем он меньше, тем больше должна быть выборка.
К примеру, общероссийская городская выборка (14-65 лет) в 1 200 респондентов имеет доверительный интервал 4 процентных пункта при уровне достоверности 0,95. При ее проведении 15% участников опроса заявили, что за последние три месяца были в кинотеатре хотя бы один раз.
Эти данные позволяют нам утверждать с заданным уровнем достоверности, что от 11 до 19% жителей российских городов в возрасте от 14 до 65 лет были в кинотеатре хотя бы один раз за последние три месяца. Иными словами, можно сказать, что все значения между 11 и 19% в данном случае находятся в пределах «допустимой статистической погрешности». Если бы мы хотели задать доверительный интервал в 2 процентных пункта, то выборку (при прочих равных условиях) пришлось бы увеличить примерно в четыре раза.
Со стороны уровня достоверности эти данные означают, что если бы было проведено 100 независимых измерении (опросов) по 1200 респондентов в каждом, то в 95 из них значение доли ответов на вопрос о посещении кинотеатра не вышло бы за пределы доверительного интервала (в этом конкретном случае — 11-19%). А в пяти исследованиях или бы получены значения, выходящие за пределы доверительного интервала. Если бы нас устраивала достоверность на уровне 0,9, то опросить можно было бы 200 человек. Если нам нужна достоверность на уровне 0,99, то пришлось бы опросить более 10 тыс. человек.
Оптимальный размер выборки
Вот одна из формул расчета необходимого объема выборки, используемая при известном среднем отклонении (дисперсии) и заданных уровнях достоверности и точности:
N = (g2 * z2) / d2
где: N — искомый объем выборки; g — дисперсия признака, ожидаемое среднее отклонение получаемых результатов от ожидаемого среднего значения; z — коэффициент уровня достоверности (2 — для 0,95, 3 — для 0,99); d — уровень точности.
Допустим, мы изучаем поведение покупателей в продовольственном магазине, в частности, мы хотим определить среднюю сумму чека. Из бесед с владельцем магазина мы узнаем, что она может быть в районе 500-700 руб., а среднее отклонение (g) может составить 200 руб. В ходе опроса мы хотели бы определить среднее значение с точностью (d) до 20 руб. при уровне достоверности (z) в 0,95. Подставляем значения формулу и получаем:
40000 * 4 / 400 = 400.
То есть нам достаточно опросить 400 покупателей. Если бы мы хотели узнать среднюю сумму чека с точностью до 10 руб.. то нам пришлось бы опросить 1600 покупателей. Если бы при этом мы хотели получить уровень достоверности в 0,99, то количество покупателей, которых необходимо опросить, составило бы 3 500 человек. И наоборот: если нас устроила бы точность ±50 руб., то нам достаточно было бы опросить в заданных условиях всего 65 человек.
Практическое использование этой и других формул, которые здесь не будут приводиться, весьма затруднено следующими обстоятельствами:
-
Что делать, если мы не знаем даже приблизительно «ожидаемую среднюю» и среднюю дисперсию признака?
-
Что делать, если в анкете у нас 10 вопросов, по которым ожидаются различные средние, с различными средними дисперсиями?
-
Как быть в случае использования номинальных шкал?
-
Как быть в случае, если один вопрос предполагает два или три варианта ответа и т. д. и т. п.?
-
Для простых альтернативных вопросов по принципу «да/нет» используются одни формулы, для более сложных — другие.
-
Формулы необходимо корректировать в зависимости от количества столбцов в таблице «факторных распределении», а также в зависимости от распределения ответов (10 на 90 — это одно, а 45 на 55 — совсем другое дело).
-
Одни формулы учитывают размер генеральной совокупности, а другие (как приведенная выше) — нет. Есть много иных нюансов.
На практике сначала определяют количество респондентов, которое исследователи предполагают опросить с учетом временных и финансовых ограничений, задают уровень достоверности (обычно — 0,95), а затем уже рассчитывают доверительный интервал.
Определение необходимого и достаточного объема выборки происходит на основе опыта и неформальных «конвенций» исследователей между собой. Считается, и это многократно проверено на практике, что опрос 30-50 представителей конкретной, «узкой» социально-демографической группы населения, например «ярославских замужних женщин в возрасте 30-45 лет, имеющих одного ребенка, высшее образование и совокупный семейный доход в пределах от 1 500 до 3 000 долл. в месяц», можно распространять на всю эту группу, и допустимая ошибка (доверительный интервал) не превысит 4 процентных пунктов при уровне достоверности около 0,95.
Однако полученные данные нельзя распространять, например, на незамужних женщин того же возраста, имеющих такой же доход и уровень образования. А также на женщин, имеющих иной доход, возраст или уровень образования. И уж тем более — на мужчин.
Таким образом, если в задачу исследователя входит получение информации о мнениях, знаниях, поведении или отношении к некой проблеме всех ярославских женщин, и при этом все перечисленные выше социально-демографические факторы являются значимыми, необходимо построить такую выборку, в которой были бы представлены все «узко определенные» группы. В данном случае — две группы по семейному положению, три — по наличию и количеству детей, три возрастные, три доходные, две образовательные. Итого 108 групп, в каждой из которых должно быть не менее 30 представительниц. Всего — более 3 000 респондентов.
На самом деле едва ли найдется вопрос или проблема, на которые все пять факторов будут оказывать взаимное перекрестное воздействие. В большинстве случаев вполне можно было бы обойтись опросом 400-600 респонденток, а затем провести попарный (а не перекрестный) факторный анализ. То есть отдельно исследовать влияние факторов «возраст», «образование», «доход», «семейное положение», «дети». При этом выборка каждый раз разбивалась бы на две-три группы, наполнение которых было бы не меньше 100-150 респондентов.
Репрезентативная выборка, представляющая все население России, должна состоять из 3 600-9 000 человек и 180 групп (два пола, три возраста, два образовательных уровня, три доходные группы, пять типов поселений). Доверительный интервал будет в пределах ±3 процентных пункта. Это означает, что, к примеру, если 30% (12% или 45%) наших респондентов заявили, что регулярно употребляют в пищу майонез, то долю потребителей майонеза в России можно оценить в 27-33% (9-15 или 42-48% соответственно).
Размер выборки практически не зависит от размера генеральной совокупности. И в мегаполисе с населением более миллиона человек, и в уездном городе с населением в 35 тыс. человек для построения выборки, репрезентативной по одинаковому числу параметров, потребуется опросить одинаковое число респондентов.
От чего действительно зависит размер выборки — так это от числа параметров, по которым мы желаем добиться репрезентативности. Если нас устраивает репрезентативность только по полу и возрасту, то выборки в 400 человек в одном населенном пункте будет более чем достаточно. Если параметров три, количество респондентов придется увеличить до 600. Добиться репрезентативности выборки одновременно по пяти параметрам: полу, возрасту, доходу, образованию, сфере профессиональной деятельности — можно лишь на выборке из 1 000-1 200 человек в одном населенном пункте.
В вашей почте раз в неделю. А еще: новости, акции и мероприятия для HR.
Исследователей часто интересуют ответы на такие вопросы о популяциях , как:
- Какова средняя высота определенного вида растений?
- Каков средний вес определенного вида птиц?
- Какой процент жителей определенного города поддерживает определенный закон?
Один из способов ответить на эти вопросы — собрать данные о каждом отдельном человеке в интересующей популяции.
Однако это, как правило, слишком дорого и требует много времени, поэтому исследователи вместо этого берут выборку населения и используют данные из выборки, чтобы делать выводы о населении в целом.
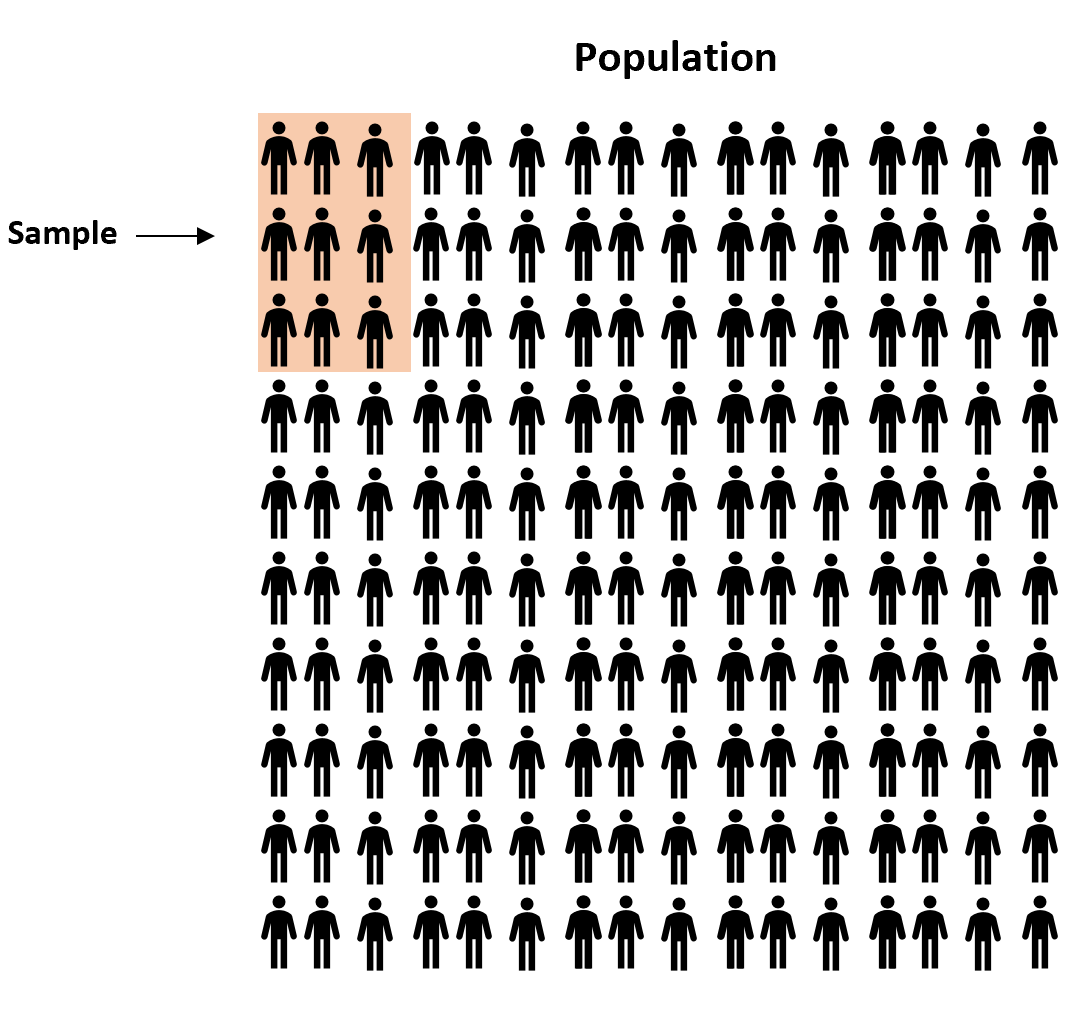
Существует множество различных методов, которые исследователи потенциально могут использовать для включения людей в выборку. Они известны как методы выборки .
В этом посте мы расскажем о наиболее часто используемых методах выборки в статистике, включая преимущества и недостатки различных методов.
Вероятностные методы выборки
Первый класс методов выборки известен как методы вероятностной выборки, поскольку каждый член совокупности имеет равную вероятность быть отобранным для включения в выборку.
Простая случайная выборка
Определение: Каждый член совокупности имеет равные шансы попасть в выборку. Произвольный выбор участников с помощью генератора случайных чисел или некоторых средств случайного выбора.
Пример: мы помещаем имена каждого ученика в классе в шляпу и случайным образом вытягиваем имена, чтобы получить выборку учеников.
Преимущество: Простые случайные выборки обычно репрезентативны для интересующей нас совокупности , поскольку каждый член имеет равные шансы быть включенным в выборку.
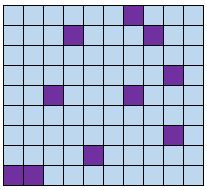
Стратифицированная случайная выборка
Определение: разделить население на группы. Случайным образом выберите несколько членов из каждой группы для включения в выборку.
Пример. Разделите всех учащихся в школе по их классам: первокурсников, второкурсников, младших и старших классов. Попросите 50 учащихся каждого класса заполнить анкету о школьных обедах.
Преимущество: стратифицированные случайные выборки обеспечивают включение в обследование представителей каждой группы генеральной совокупности.
Кластерная случайная выборка
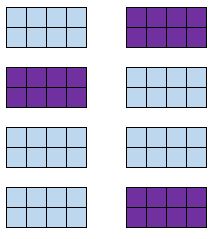
Определение: разбить популяцию на кластеры. Случайным образом выберите несколько кластеров и включите в выборку всех членов из этих кластеров.
Пример. Компания, организующая туры для наблюдения за китами, хочет опросить своих клиентов. Из десяти туров, которые они проводят один день, они случайным образом выбирают четыре тура и расспрашивают каждого клиента об их впечатлениях.
Преимущество: Кластерные случайные выборки включают каждого члена из некоторых групп, что полезно, когда каждая группа отражает совокупность в целом.
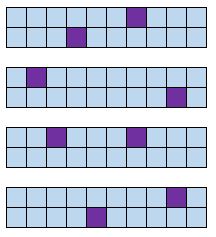
Систематическая случайная выборка

Определение: расположите каждого члена популяции в некотором порядке. Выбор случайной начальной точки и выбор каждого n -го члена для включения в выборку.
Пример: Учитель расставляет учеников в алфавитном порядке по их фамилиям, случайным образом выбирает начальную точку и выбирает каждого пятого ученика в выборку.
Преимущество: систематические случайные выборки обычно репрезентативны для интересующей нас совокупности , поскольку каждый член имеет равные шансы быть включенным в выборку.
Невероятностные методы выборки
Другой класс методов выборки известен как методы невероятностной выборки, потому что не каждый член совокупности имеет равную вероятность быть отобранным для включения в выборку.
Этот тип метода выборки иногда используется, потому что он намного дешевле и удобнее по сравнению с методами вероятностной выборки. Он часто используется во время исследовательского анализа, когда исследователи просто хотят получить первоначальное представление о популяции.
Однако выборки, полученные с помощью этих методов выборки, нельзя использовать для выводов о совокупностях, из которых они получены, поскольку обычно они не являются репрезентативными выборками.
Образец удобства
Определение: Выберите членов совокупности, которые легко доступны для включения в выборку.
Пример: Исследователь стоит днем перед библиотекой и опрашивает прохожих.
Недостаток: место и время суток будут влиять на результаты. Более чем вероятно, что выборка будет страдать от систематической ошибки недостаточного охвата, поскольку некоторые люди (например, те, кто работает в течение дня) не будут представлены в выборке в достаточной степени.
Образец добровольного ответа
Определение: Исследователь отправляет запрос на включение добровольцев в исследование, и представители населения добровольно решают, включаться в выборку или нет.
Пример: радиоведущий просит слушателей выйти в интернет и пройти опрос на его сайте.
Недостаток: люди, которые добровольно ответят , скорее всего, будут иметь более сильное мнение (положительное или отрицательное), чем остальная часть населения, что делает их нерепрезентативной выборкой. При использовании этого метода выборки выборка, скорее всего, будет страдать от систематической ошибки , связанной с отсутствием ответов — просто определенные группы людей с меньшей вероятностью дадут ответы.
Образец снежного кома
Определение: Исследователи набирают первоначальных субъектов для участия в исследовании, а затем просят этих первоначальных субъектов набрать дополнительных субъектов для участия в исследовании. При таком подходе размер выборки становится все больше и больше по мере того, как каждый дополнительный субъект набирает все больше испытуемых.
Пример: Исследователи проводят исследование людей с редкими заболеваниями, но трудно найти людей, которые действительно болеют этим заболеванием. Однако, если они могут найти только несколько первоначальных людей для участия в исследовании, они могут попросить их набрать других людей, которых они могут знать, через частную группу поддержки или с помощью других средств.
Недостаток: вероятно возникновение систематической ошибки выборки. Поскольку первоначальные испытуемые набирают дополнительных испытуемых, вполне вероятно, что многие из испытуемых будут иметь схожие черты или характеристики, которые могут быть нерепрезентативными для большей изучаемой группы. Таким образом, результаты выборки не могут быть экстраполированы на население.
Подробнее о снежном коме сэмплинга читайте здесь .
Целевой образец
Определение: Исследователи набирают людей, основываясь на том, кто, по их мнению, будет наиболее полезен в зависимости от цели их исследования.
Пример: Исследователи хотят узнать мнение людей в городе о потенциальном новом спортзале для скалолазания, размещенном на городской площади, поэтому они намеренно ищут людей, которые тусуются в других спортзалах для скалолазания по всему городу.
Недостаток: отдельные лица в выборке вряд ли будут репрезентативными для всего населения. Таким образом, результаты выборки не могут быть экстраполированы на население.
Визуальное представление процесса отбора проб
В статистика, гарантия качества, и методология обследования, отбор проб это выбор подмножества ( статистическая выборка ) лиц из статистическая совокупность оценить характеристики всего населения. Статистики пытаются представить в выборках рассматриваемую популяцию. Два преимущества выборки – это более низкая стоимость и более быстрый сбор данных, чем измерение всего населения.
Каждый наблюдение измеряет одно или несколько свойств (таких как вес, расположение, цвет) наблюдаемых тел, выделенных как независимые объекты или индивидуумы. В выборка обследования, к данным могут применяться веса для корректировки плана выборки, особенно в стратифицированная выборка.[1] Результаты из теория вероятности и статистическая теория используются для руководства практикой. В деловых и медицинских исследованиях выборка широко используется для сбора информации о населении.[2] Приемочный отбор используется для определения соответствия партии материала нормативным требованиям. технические характеристики.
Определение населения
Успешная статистическая практика основана на целенаправленной постановке задачи. При выборке это включает определение “Население “, из которых составлена наша выборка. Популяцию можно определить как включающую всех людей или предметы с характеристикой, которую вы хотите понять. Поскольку очень редко бывает достаточно времени или денег для сбора информации от всех или всех в популяции, цель становится поиск репрезентативной выборки (или подмножества) этой совокупности.
Иногда то, что определяет популяцию, очевидно. Например, производителю необходимо решить, будет ли партия материала производство имеет достаточно высокое качество, чтобы быть переданным заказчику, или подлежит утилизации или переработке из-за низкого качества. В этом случае партия – это популяция.
Хотя представляющая интерес совокупность часто состоит из физических объектов, иногда необходимо производить выборку во времени, пространстве или некоторой комбинации этих измерений. Например, при исследовании кадрового состава супермаркетов можно было бы изучить длину очереди в кассу в разное время, или исследование вымирающих пингвинов могло бы быть направлено на понимание того, как они используют различные охотничьи угодья с течением времени. Для измерения времени внимание может быть сосредоточено на периодах или дискретных событиях.
В других случаях исследуемая «популяция» может быть еще менее ощутимой. Например, Джозеф Джаггер изучал поведение рулетка колеса в казино в Монте-Карло, и использовал это для определения смещенного колеса. В данном случае «популяция», которую хотел исследовать Джаггер, представляла собой общее поведение колеса (т.е. распределение вероятностей его результатов по бесконечному количеству испытаний), в то время как его «выборка» была сформирована из результатов, наблюдаемых с этого колеса. Аналогичные соображения возникают при повторных измерениях некоторых физических характеристик, таких как электрическая проводимость из медь.
Такая ситуация часто возникает при поиске знаний о система причин из которых наблюдаемый население – это результат. В таких случаях теория выборки может рассматривать наблюдаемую популяцию как выборку из более крупной «суперпопуляции». Например, исследователь может изучить степень успеха новой программы «бросить курить» на тестовой группе из 100 пациентов, чтобы спрогнозировать эффекты программы, если она будет доступна по всей стране. Здесь суперпопуляция – это «все в стране, получившие доступ к этому лечению» – группа, которой еще не существует, поскольку программа еще не доступна для всех.
Популяция, из которой составлена выборка, может не совпадать с совокупностью, о которой требуется информация. Часто существует большое, но не полное перекрытие между этими двумя группами из-за проблем с фреймами и т. Д. (См. Ниже). Иногда они могут быть полностью отдельными – например, можно изучать крыс, чтобы лучше понять здоровье человека, или можно изучать записи людей, родившихся в 2008 году, чтобы делать прогнозы относительно людей, родившихся в 2009 году.
Время, затрачиваемое на уточнение выборки и вызывающей озабоченность совокупности, часто тратится не зря, потому что это порождает множество проблем, двусмысленностей и вопросов, которые в противном случае были бы упущены из виду на данном этапе.
Основа выборки
В самом простом случае, например при отборе партии материала из производства (приемочный отбор по партиям), наиболее желательно идентифицировать и измерять каждый отдельный элемент в совокупности и включать любой из них в нашу выборку. Однако в более общем случае это обычно невозможно или практически невозможно. Невозможно идентифицировать всех крыс в наборе всех крыс. Если голосование не является обязательным, невозможно определить, какие люди будут голосовать на предстоящих выборах (до выборов). Эти неточные совокупности не поддаются выборке ни одним из способов, указанных ниже, и к которым мы могли бы применить статистическую теорию.
В качестве лекарства мы ищем основа выборки который имеет свойство, позволяющее идентифицировать каждый элемент и включать любой из них в нашу выборку.[3][4][5][6] Самый простой тип фрейма – это список элементов совокупности (предпочтительно всего населения) с соответствующей контактной информацией. Например, в опрос общественного мнения возможные рамки выборки включают список избирателей и телефонный справочник.
А вероятностная выборка представляет собой выборку, в которой каждая единица в генеральной совокупности имеет шанс (больше нуля) быть выбранным в выборке, и эту вероятность можно точно определить. Комбинация этих характеристик позволяет производить объективные оценки совокупных итогов путем взвешивания единиц выборки в соответствии с их вероятностью отбора.
Пример: мы хотим оценить общий доход взрослых, живущих на данной улице. Мы посещаем каждое домохозяйство на этой улице, определяем всех проживающих там взрослых и случайным образом выбираем по одному взрослому из каждого домохозяйства. (Например, мы можем присвоить каждому человеку случайное число, сгенерированное из равномерное распределение от 0 до 1 и выберите человека с наибольшим номером в каждом домохозяйстве). Затем мы проводим собеседование с выбранным человеком и выясняем его доход.
Люди, живущие самостоятельно, обязательно будут выбраны, поэтому мы просто добавляем их доход к нашей оценке общей суммы. Но человек, живущий в семье из двух взрослых, имеет только один шанс из двух. Чтобы отразить это, когда мы подходим к такому дому, мы дважды подсчитываем доход выбранного человека к общей сумме. (Человек, который является выбранный из этого домохозяйства можно в общих чертах рассматривать как также представляющего человека, который не выбрано.)
В приведенном выше примере не у всех одинаковая вероятность выбора; выборку вероятности делает тот факт, что вероятность каждого человека известна. Когда каждый элемент населения делает имеют одинаковую вероятность выбора, это известно как дизайн с «равной вероятностью выбора» (EPS). Такие конструкции также называют «самовзвешенными», потому что всем отобранным единицам присваивается одинаковый вес.
Вероятностная выборка включает: Простая случайная выборка, Систематическая выборка, Стратифицированная выборка, Вероятность пропорциональна размеру выборки, и Кластер или Многоступенчатый отбор проб. Эти различные способы вероятностной выборки имеют две общие черты:
- Каждый элемент имеет известную ненулевую вероятность выборки и
- в какой-то момент включает случайный выбор.
Невероятностная выборка
Невероятностная выборка – это любой метод выборки, при котором некоторые элементы совокупности нет шанс выбора (иногда это называется «вне зоны покрытия» / «недостаточно защищен») или когда вероятность выбора не может быть точно определена. Он включает в себя выбор элементов на основе предположений об интересующей совокупности, которая формирует критерии для выбора. Следовательно, поскольку выбор элементов является неслучайным, не вероятностная выборка не позволяет оценить ошибки выборки. Эти условия порождают ошибка исключения, ограничивая объем информации, которую может предоставить выборка о совокупности. Информация о взаимосвязи между выборкой и совокупностью ограничена, что затрудняет экстраполяцию от выборки к генеральной совокупности.
Пример: мы посещаем каждую семью на данной улице и опрашиваем первого человека, открывшего дверь. В любом домохозяйстве с более чем одним жильцом это не вероятностная выборка, потому что некоторые люди с большей вероятностью откроют дверь (например, безработный, который проводит большую часть своего времени дома, с большей вероятностью ответит, чем работающий сосед по дому, который может быть на работе, когда звонит интервьюер), и рассчитывать эти вероятности нецелесообразно.
Методы недовероятностной выборки включают: удобная выборка, квотная выборка и целенаправленная выборка. Кроме того, эффекты отсутствия ответа могут превратиться в Любые вероятностный план в не вероятностный план, если характеристики неответа не до конца понятны, поскольку неполучение ответа эффективно изменяет вероятность каждого элемента быть выбранным.
Методы отбора проб
В рамках любого из типов фреймов, указанных выше, могут использоваться различные методы выборки, индивидуально или в комбинации. Факторы, обычно влияющие на выбор между этими конструкциями, включают:
- Характер и качество кадра
- Наличие вспомогательной информации об агрегатах на раме
- Требования к точности и необходимость измерения точности
- Ожидается ли подробный анализ образца
- Стоимость / операционные проблемы
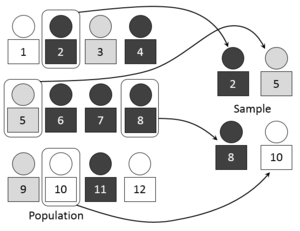
Простая случайная выборка
Визуальное представление выбора простой случайной выборки
В простой случайной выборке (SRS) заданного размера все подмножества основы выборки имеют равную вероятность быть выбранными. Таким образом, каждый элемент кадра имеет равную вероятность выбора: кадр не разделяется или разбивается на части. Кроме того, любой данный пара элементов имеет такой же шанс выбора, как и любая другая такая пара (и аналогично для троек и т. д.). Это сводит к минимуму предвзятость и упрощает анализ результатов. В частности, дисперсия между отдельными результатами в пределах выборки является хорошим индикатором дисперсии в генеральной совокупности, что позволяет относительно легко оценить точность результатов.
Простая случайная выборка может быть уязвима для ошибки выборки, потому что случайность выбора может привести к выборке, которая не отражает состав генеральной совокупности. Например, простая случайная выборка из десяти человек из данной страны будет в среднем дают пять мужчин и пять женщин, но в любом конкретном исследовании один пол будет представлен слишком далеко, а другой – недостаточно. Систематические и стратифицированные методы пытаются решить эту проблему путем «использования информации о совокупности» для выбора более «репрезентативной» выборки.
Кроме того, простая случайная выборка может быть обременительной и утомительной при выборке из большой целевой совокупности. В некоторых случаях исследователей интересуют вопросы исследования, специфичные для подгрупп населения. Например, исследователи могут быть заинтересованы в том, чтобы выяснить, применимы ли когнитивные способности как показатель эффективности работы в равной степени для разных расовых групп. Простая случайная выборка не может удовлетворить потребности исследователей в этой ситуации, потому что она не обеспечивает подвыборки населения, и вместо этого могут использоваться другие стратегии выборки, такие как стратифицированная выборка.
Систематическая выборка

Визуальное представление выбора случайной выборки с использованием методики систематической выборки
Систематическая выборка (также известная как интервальная выборка) основана на упорядочивании исследуемой совокупности в соответствии с некоторой схемой упорядочения и последующем выборе элементов через регулярные интервалы через этот упорядоченный список. Систематическая выборка включает случайное начало, а затем переходит к отбору каждого kth элемент с этого момента. В таком случае, k= (размер генеральной совокупности / размер выборки). Важно, чтобы начальная точка не была автоматически первой в списке, а вместо этого выбиралась случайным образом от первого до k-й элемент в списке. Простым примером может быть выбор каждого 10-го имени из телефонного справочника (выборка «каждое 10-е», также называемая «выборкой с пропуском 10»).
Пока отправная точка рандомизированный систематическая выборка – это вид вероятностная выборка. Его легко реализовать, и стратификация индуцированный может сделать его эффективным, если переменная, по которой упорядочен список, коррелируется с интересующей переменной. «Каждую 10-ю» выборку особенно полезно для эффективной выборки из базы данных.
Например, предположим, что мы хотим выбрать людей с длинной улицы, которая начинается в бедном районе (дом № 1) и заканчивается в дорогом районе (дом № 1000). Простой случайный выбор адресов с этой улицы может легко закончиться тем, что слишком много адресов из верхнего сегмента и слишком мало из нижнего (или наоборот), что приведет к нерепрезентативной выборке. Выбор (например) номера каждой 10-й улицы вдоль улицы гарантирует, что выборка будет равномерно распределена по длине улицы, представляя все эти районы. (Обратите внимание, что если мы всегда начинаем с дома №1 и заканчиваем в №991, выборка немного смещается в сторону нижнего предела; случайным образом выбирая начало между №1 и №10, это смещение устраняется.
Однако систематическая выборка особенно уязвима для периодичности в списке. Если периодичность присутствует, а период кратен или кратен используемому интервалу, то выборка особенно вероятна. ООНрепрезентативен для генеральной совокупности, что делает схему менее точной, чем простая случайная выборка.
Например, рассмотрим улицу, где все дома с нечетными номерами расположены на северной (дорогой) стороне дороги, а дома с четными номерами – на южной (дешевой) стороне. При указанной выше схеме выборки невозможно получить репрезентативную выборку; либо отобранные дома будут все быть с нечетной, дорогой стороны, или они будут все быть с четной и дешевой стороны, если только исследователь не знает заранее об этой предвзятости и избегает ее, используя пропуск, который обеспечивает переход между двумя сторонами (любой пропуск с нечетным номером).
Еще один недостаток систематической выборки состоит в том, что даже в сценариях, где она более точна, чем SRS, ее теоретические свойства затрудняют количественно оценить та точность. (В двух приведенных выше примерах систематической выборки большая часть потенциальной ошибки выборки связана с различиями между соседними домами – но поскольку этот метод никогда не выбирает два соседних дома, выборка не даст нам никакой информации об этом изменении.)
Как описано выше, систематическая выборка – это метод EPS, потому что все элементы имеют одинаковую вероятность выбора (в приведенном примере – один из десяти). это не «простая случайная выборка», потому что разные подмножества одного размера имеют разные вероятности выбора – например, набор {4,14,24, …, 994} имеет вероятность выбора один из десяти, но набор {4,13,24,34, …} имеет нулевую вероятность выбора.
Систематическая выборка также может быть адаптирована к подходу без EPS; для примера см. обсуждение примеров PPS ниже.
Стратифицированная выборка
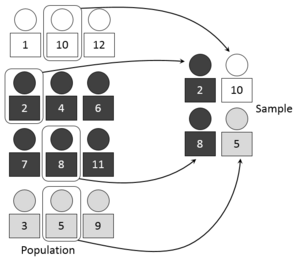
Визуальное представление выбора случайной выборки с использованием метода стратифицированной выборки
Когда совокупность включает несколько отдельных категорий, структура может быть организована по этим категориям в отдельные «страты». Затем каждая страта выбирается как независимая подгруппа, из которой случайным образом могут быть выбраны отдельные элементы.[3] Отношение размера этой случайной выборки (или выборки) к размеру генеральной совокупности называется фракция отбора проб. Стратифицированная выборка дает несколько потенциальных преимуществ.
Во-первых, разделение совокупности на отдельные независимые слои может позволить исследователям сделать выводы о конкретных подгруппах, которые могут быть потеряны в более обобщенной случайной выборке.
Во-вторых, использование метода стратифицированной выборки может привести к более эффективным статистическим оценкам (при условии, что страты выбираются на основе соответствия рассматриваемому критерию, а не наличия выборок). Даже если подход стратифицированной выборки не приводит к повышению статистической эффективности, такая тактика не приведет к меньшей эффективности, чем простая случайная выборка, при условии, что каждый слой пропорционален размеру группы в генеральной совокупности.
В-третьих, иногда данные более доступны для отдельных, ранее существовавших слоев населения, чем для всего населения; в таких случаях использование подхода стратифицированной выборки может быть более удобным, чем агрегирование данных по группам (хотя это потенциально может противоречить ранее отмеченной важности использования страт, релевантных критериям).
Наконец, поскольку каждая страта рассматривается как независимая совокупность, к разным слоям могут применяться разные подходы к выборке, что потенциально позволяет исследователям использовать подход, наиболее подходящий (или наиболее рентабельный) для каждой выявленной подгруппы в популяции.
Однако у использования стратифицированной выборки есть некоторые потенциальные недостатки. Во-первых, определение страт и реализация такого подхода может увеличить стоимость и сложность отбора выборки, а также привести к увеличению сложности оценок совокупности. Во-вторых, при изучении нескольких критериев стратифицирующие переменные могут быть связаны с одними, но не с другими, что еще больше усложняет план и потенциально снижает полезность страт. Наконец, в некоторых случаях (например, в планах с большим количеством слоев или в планах с указанным минимальным размером выборки для каждой группы) стратифицированная выборка потенциально может потребовать большей выборки, чем другие методы (хотя в большинстве случаев требуемый размер выборки будет не больше, чем требуется для простой случайной выборки).
- Подход стратифицированной выборки наиболее эффективен при выполнении трех условий.
- Изменчивость внутри пластов сведена к минимуму
- Изменчивость между пластами максимальна
- Переменные, по которым стратифицируется совокупность, сильно коррелируют с желаемой зависимой переменной.
- Преимущества перед другими методами отбора проб
- Сосредоточен на важных подгруппах населения и игнорирует нерелевантные.
- Позволяет использовать разные методы выборки для разных субпопуляций.
- Повышает точность / эффективность оценки.
- Позволяет лучше сбалансировать статистическую мощность тестов различий между слоями за счет выборки равных чисел из слоев, сильно различающихся по размеру.
- Недостатки
- Требуется выбор соответствующих переменных стратификации, что может быть затруднительно.
- Бесполезен, когда нет однородных подгрупп.
- Может быть дорого реализовать.
- Постстратификация
Стратификация иногда вводится после фазы выборки в процессе, называемом «постстратификация».[3] Этот подход обычно реализуется из-за отсутствия предварительных знаний о соответствующей стратифицирующей переменной или когда экспериментатор не имеет необходимой информации для создания стратифицирующей переменной на этапе выборки. Хотя этот метод подвержен ошибкам апостериорных подходов, он может дать несколько преимуществ в правильной ситуации. Реализация обычно следует простой случайной выборке. Помимо возможности стратификации по вспомогательной переменной, постстратификация может использоваться для реализации взвешивания, что может повысить точность оценок выборки.[3]
- Передискретизация
Выборка на основе выбора – одна из стратегий стратифицированной выборки. В выборке на основе выбора[7] данные стратифицируются по целевому объекту, и из каждого слоя берется выборка, так что редкий целевой класс будет более представлен в выборке. Затем модель строится на этом предвзятая выборка. Влияние входных переменных на целевой показатель часто оценивается с большей точностью с помощью выборки на основе выбора, даже если общий размер выборки меньше, чем у случайной выборки. Обычно результаты необходимо корректировать, чтобы скорректировать передискретизацию.
Выборка, пропорциональная вероятности и размеру
В некоторых случаях разработчик выборки имеет доступ к «вспомогательной переменной» или «измерению размера», которые, как считается, коррелируют с интересующей переменной для каждого элемента в генеральной совокупности. Эти данные можно использовать для повышения точности построения выборки. Один из вариантов – использовать вспомогательную переменную в качестве основы для стратификации, как обсуждалось выше.
Другой вариант – выборка с вероятностью, пропорциональная размеру («PPS»), при которой вероятность выбора для каждого элемента устанавливается пропорциональной его величине размера, максимум до 1. В простой схеме PPS эти вероятности выбора могут затем использоваться в качестве основы для Пуассоновская выборка. Однако это имеет недостаток, заключающийся в том, что размер выборки варьируется, и различные части генеральной совокупности могут по-прежнему быть чрезмерно или недопредставленными из-за случайного разброса выборок.
Теорию систематической выборки можно использовать для создания вероятности, пропорциональной размеру выборки. Для этого каждый счет в переменной размера рассматривается как единая единица выборки. Затем образцы идентифицируются путем выбора через равные промежутки времени среди этих подсчетов в пределах переменной размера. Этот метод иногда называют PPS-последовательной выборкой или выборкой денежных единиц в случае аудитов или судебно-медицинской экспертизы.
Пример: предположим, что у нас есть шесть школ с населением 150, 180, 200, 220, 260 и 490 учеников соответственно (всего 1500 учеников), и мы хотим использовать контингент учащихся в качестве основы для выборки PPS третьего размера. Для этого мы можем выделить первую школу с номерами от 1 до 150, вторую школу с 151 по 330 (= 150 + 180), третью школу с 331 по 530, и так далее, с последней школой (с 1011 по 1500). Затем мы генерируем случайное начало от 1 до 500 (равное 1500/3) и подсчитываем количество учащихся школ, кратное 500. Если бы случайное начало было 137, мы бы выбрали школы, которым были присвоены номера 137, 637 и 1137 г., т.е. первая, четвертая и шестая школы.
Подход PPS может повысить точность для данного размера выборки, сосредоточив выборку на крупных элементах, которые имеют наибольшее влияние на оценки совокупности. Выборка PPS обычно используется для обследований предприятий, где размер элементов сильно варьируется, а вспомогательная информация часто доступна – например, обследование, пытающееся измерить количество гостевых ночей, проведенных в отелях, может использовать количество номеров каждого отеля в качестве вспомогательной переменной. . В некоторых случаях более раннее измерение интересующей переменной может использоваться в качестве вспомогательной переменной при попытке произвести более текущие оценки.[8]
Выборочное обследование

Визуальное представление выбора случайной выборки с использованием техники кластерной выборки
Иногда более рентабельно отбирать респондентов в группы («кластеры»). Выборка часто группируется по географическому признаку или по временным периодам. (Почти все выборки в некотором смысле «сгруппированы» во времени – хотя это редко принимается во внимание при анализе.) Например, при обследовании домашних хозяйств в городе мы можем выбрать 100 городских кварталов, а затем опросить каждое домашнее хозяйство в пределах города. выбранные блоки.
Кластеризация может снизить командировочные и административные расходы. В приведенном выше примере интервьюер может совершить одну поездку, чтобы посетить несколько домашних хозяйств в одном квартале, вместо того, чтобы ездить в разные кварталы для каждого домашнего хозяйства.
Это также означает, что не нужно основа выборки перечисление всех элементов целевой совокупности. Вместо этого кластеры могут быть выбраны из кадра уровня кластера, при этом кадр уровня элемента создается только для выбранных кластеров. В приведенном выше примере для выборки требуется только карта города на уровне квартала для первоначального выбора, а затем карта уровня домохозяйства из 100 выбранных кварталов, а не карта всего города на уровне домохозяйства.
Кластерная выборка (также известная как кластерная выборка) обычно увеличивает вариабельность оценок выборки по сравнению с простой случайной выборкой, в зависимости от того, как кластеры отличаются друг от друга по сравнению с вариацией внутри кластера. По этой причине кластерная выборка требует большей выборки, чем SRS, для достижения того же уровня точности, но экономия средств за счет кластеризации может сделать этот вариант более дешевым.
Выборочное обследование обычно реализуется как многоступенчатый отбор проб. Это сложная форма кластерной выборки, в которой два или более уровня единиц встроены один в другой. Первый этап состоит из построения кластеров, из которых будет производиться выборка. На втором этапе выборка первичных единиц выбирается случайным образом из каждого кластера (вместо использования всех единиц, содержащихся во всех выбранных кластерах). На следующих этапах в каждом из этих выбранных кластеров выбираются дополнительные образцы единиц и так далее. Затем обследуются все конечные единицы (например, отдельные лица), выбранные на последнем этапе этой процедуры. Таким образом, этот метод, по сути, представляет собой процесс взятия случайных подвыборок из предыдущих случайных выборок.
Многоступенчатая выборка может существенно снизить затраты на выборку, когда необходимо будет составить полный список совокупности (до того, как можно будет применить другие методы выборки). Устраняя работу по описанию невыбранных кластеров, многоступенчатая выборка может снизить большие затраты, связанные с традиционной кластерной выборкой.[8] Однако каждая выборка не может быть полностью репрезентативной для всей генеральной совокупности.
Выборка квот
В квотная выборка, население сначала сегментируется на взаимоисключающий подгруппы, как и в стратифицированная выборка. Затем используется суждение для выбора предметов или единиц из каждого сегмента на основе определенной пропорции. Например, интервьюеру может быть предложено выбрать 200 женщин и 300 мужчин в возрасте от 45 до 60 лет.
Именно этот второй шаг делает методику маловероятной выборки. При квотной выборке выборка не производится.случайный. Например, у интервьюеров может возникнуть соблазн взять интервью у тех, кто выглядит наиболее полезным. Проблема в том, что эти образцы могут быть предвзятыми, потому что не у всех есть шанс отобрать. Этот случайный элемент – его величайшая слабость, и вопрос о соотношении квоты и вероятности является предметом споров в течение нескольких лет.
Минимаксная выборка
В несбалансированных наборах данных, где коэффициент выборки не соответствует статистике населения, можно повторно дискретизировать набор данных консервативным способом, называемым минимаксная выборка. Минимаксная выборка берет свое начало в Андерсон минимаксное соотношение, значение которого оказалось равным 0,5: в бинарной классификации размеры классов и выборок должны выбираться одинаково. Доказать, что это отношение является минимаксным, можно только в предположении LDA классификатор с гауссовыми распределениями. Понятие минимаксной выборки недавно разработано для общего класса правил классификации, называемых классовыми интеллектуальными классификаторами. В этом случае коэффициент выборки классов выбирается так, чтобы наихудшая ошибка классификатора по всей возможной статистике совокупности для априорных вероятностей класса была наилучшей.[9]
Случайный отбор проб
Случайный отбор проб (иногда известный как схватить, удобство или возможность выборки) – это тип не вероятностной выборки, который включает выборку из той части генеральной совокупности, которая находится поблизости. То есть население выбирается, потому что оно доступно и удобно. Это может быть через встречу с человеком или включение человека в выборку, когда кто-то встречает его, или выбранный путем поиска с помощью технических средств, таких как Интернет или по телефону.Исследователь, использующий такую выборку, не может с научной точки зрения делать обобщения об общей численности населения из этой выборки, потому что она не будет достаточно репрезентативной. Например, если бы интервьюер проводил такой опрос в торговом центре рано утром в определенный день, люди, с которыми он / она мог бы побеседовать, были бы ограничены теми людьми, которые были даны там в данное время, что не отражало бы мнения других членов общества в такой области, если бы опрос проводился в разное время суток и несколько раз в неделю. Этот тип выборки наиболее полезен для пилотного тестирования. Несколько важных соображений для исследователей, использующих удобные образцы, включают:
- Существуют ли элементы управления в плане исследования или эксперимента, которые могут помочь уменьшить влияние неслучайной удобной выборки, тем самым гарантируя, что результаты будут более репрезентативными для населения?
- Есть ли веские основания полагать, что конкретная удобная выборка будет или должна реагировать или вести себя иначе, чем случайная выборка из той же генеральной совокупности?
- Является ли вопрос, который задает исследование, тем, на который можно адекватно ответить, используя удобную выборку?
В исследованиях в области социальных наук выборка снежков аналогичная техника, при которой существующие предметы исследования используются для набора большего количества предметов в выборку. Некоторые варианты выборки методом снежного кома, такие как выборка, управляемая респондентами, позволяют рассчитывать вероятности выбора и являются методами вероятностной выборки при определенных условиях.
Добровольный отбор проб
Метод добровольной выборки – это разновидность маловероятной выборки. Добровольцы решают заполнить анкету.
Волонтеров можно пригласить через рекламу в социальных сетях.[10] Целевую аудиторию для рекламы можно выбрать по таким характеристикам, как местоположение, возраст, пол, доход, род занятий, образование или интересы, используя инструменты, предоставляемые социальной средой. Рекламное объявление может содержать сообщение об исследовании и ссылку на опрос. После перехода по ссылке и заполнения опроса волонтер отправляет данные для включения в выборку населения. Этот метод может охватить население всего мира, но ограничен бюджетом кампании. Волонтеры, не входящие в состав приглашенного населения, также могут быть включены в выборку.
На основании этой выборки трудно делать обобщения, поскольку она может не отражать всю совокупность. Часто волонтеры проявляют большой интерес к основной теме опроса.
Выборка перехвата линии
Выборка перехвата линии – это метод выборки элементов в области, при котором элемент выбирается, если выбранный отрезок линии, называемый «трансектом», пересекает элемент.
Выборка панелей
Выборка панелей – это метод первого выбора группы участников методом случайной выборки с последующим запросом у этой группы (потенциально одинаковой) информации несколько раз в течение определенного периода времени. Таким образом, каждый участник интервьюируется в двух или более временных точках; каждый период сбора данных называется «волной». Методика разработана социологом. Пол Лазарсфельд в 1938 году как средство обучения политические кампании.[11] Эта продольный Метод выборки позволяет оценить изменения в населении, например, в отношении хронических заболеваний, стресса на работе и еженедельных расходов на питание. Панельная выборка также может использоваться для информирования исследователей об изменениях здоровья внутри человека в связи с возрастом или для объяснения изменений в непрерывно зависимых переменных, таких как супружеское взаимодействие.[12] Было предложено несколько методов анализа данные панели, в том числе MANOVA, кривые роста, и структурное моделирование уравнение с запаздывающими эффектами.
Выборка снежка
Выборка снежка включает поиск небольшой группы первоначальных респондентов и их использование для набора большего числа респондентов. Это особенно полезно в тех случаях, когда популяция скрыта или трудна для подсчета.
Теоретическая выборка
|
Эта секция нуждается в расширении. Вы можете помочь добавляя к этому. (Июль 2015 г.) |
Теоретическая выборка[13] происходит, когда образцы отбираются на основе результатов уже собранных данных с целью развития более глубокого понимания данной области или разработки теорий. Могут быть выбраны крайние или очень конкретные случаи, чтобы максимизировать вероятность того, что явление действительно будет наблюдаемым.
Замена выбранных агрегатов
Схемы отбора проб могут быть без замены (‘WOR’ – ни один элемент нельзя выбрать более одного раза в одном и том же образце) или с заменой (‘WR’ – элемент может встречаться несколько раз в одном образце). Например, если мы ловим рыбу, измеряем ее и сразу же возвращаем в воду, прежде чем продолжить взятие пробы, это будет WR-план, потому что мы можем поймать и измерить одну и ту же рыбу более одного раза. Однако, если мы не вернем рыбу в воду или пометить и отпустить каждая рыба после поимки становится дизайном WOR.
Определение размера выборки
Формулы, таблицы и диаграммы степенной функции – хорошо известные подходы к определению размера выборки.
Шаги по использованию таблиц размера выборки
- Постулируйте величину интересующего эффекта, α и β.
- Проверить таблицу размеров выборки[14]
- Выберите таблицу, соответствующую выбранному α
- Найдите строку, соответствующую желаемой мощности
- Найдите столбец, соответствующий предполагаемой величине эффекта.
- Пересечение столбца и строки – это минимальный требуемый размер выборки.
Отбор проб и сбор данных
Хороший сбор данных включает:
- Следуя установленному процессу отбора проб
- Хранение данных в временном порядке
- Отмечать комментарии и другие контекстные события
- Запись неответов
Приложения отбора проб
Выборка позволяет выбрать правильные точки данных из более крупного набора данных для оценки характеристик всей совокупности. Например, ежедневно создается около 600 миллионов твитов. Необязательно просматривать все твиты, чтобы определить темы, обсуждаемые в течение дня, также нет необходимости просматривать все твиты, чтобы определить настроения по каждой из тем. Разработана теоретическая формулировка выборки данных Twitter.[15]
При производстве различные типы сенсорных данных, такие как акустика, вибрация, давление, ток, напряжение и данные контроллеров, доступны через короткие промежутки времени. Для прогнозирования времени простоя может не потребоваться просмотр всех данных, но выборки может быть достаточно.
Ошибки в выборочных опросах
В результатах опроса обычно есть ошибки. Общие ошибки можно разделить на ошибки выборки и ошибки, не связанные с выборкой. Термин «ошибка» здесь включает как систематические ошибки, так и случайные ошибки.
Ошибки и смещения выборки
Ошибки и смещения выборки вызваны дизайном выборки. Они включают:
- Критерий отбора: Когда истинные вероятности выбора отличаются от предполагаемых при вычислении результатов.
- Ошибка случайной выборки: Случайное изменение результатов из-за случайного выбора элементов в выборке.
Ошибка без выборки
Ошибки, не связанные с выборкой, – это другие ошибки, которые могут повлиять на окончательные оценки обследования, вызванные проблемами со сбором, обработкой или составлением выборки. Такие ошибки могут включать:
- Чрезмерное покрытие: включение данных из-за пределов населения
- Недостаточный охват: основа выборки не включает элементы в совокупности.
- Погрешность измерения: например когда респонденты неправильно понимают вопрос или затрудняются ответить
- Ошибка обработки: ошибки в кодировании данных
- Отсутствие ответа или предвзятость участия: невозможность получить полные данные от всех выбранных лиц
После отбора проб следует провести обзор.[кем? ] о точном процессе отбора проб, а не о предполагаемом, чтобы изучить любые эффекты, которые любые расхождения могут оказать на последующий анализ.
Конкретная проблема связана с отсутствие ответа. Существует два основных типа неполучения ответов:[16][17]
- единичный отказ от ответа (незавершение какой-либо части опроса)
- Отсутствие ответа на элемент (отправка или участие в опросе, но невыполнение одного или нескольких компонентов / вопросов опроса)
В выборка обследования, многие из лиц, определенных как часть выборки, могут не желать участвовать, у них нет времени участвовать (альтернативные издержки),[18] или администраторы опросов не смогли связаться с ними. В этом случае существует риск различий между респондентами и не респондентами, что приведет к смещению оценок параметров населения. Это часто решается путем улучшения дизайна опроса, предложения стимулов и проведения последующих исследований, в которых предпринимаются неоднократные попытки связаться с теми, кто не отвечает, и охарактеризовать их сходства и различия с остальной частью кадра.[19] Эффекты также можно смягчить путем взвешивания данных (при наличии эталонных показателей населения) или путем условного расчета данных на основе ответов на другие вопросы. Отсутствие ответа – особенно серьезная проблема при выборке в Интернете. Причины этой проблемы могут включать в себя неправильно составленные опросы,[17] чрезмерная съемка (или усталость от съемки),[12][20][нужна цитата для проверки ]и тот факт, что потенциальные участники могут иметь несколько адресов электронной почты, которые они больше не используют или не проверяют регулярно.
Обзорные веса
Во многих ситуациях доля выборки может варьироваться в зависимости от страты, и данные должны быть взвешены, чтобы правильно представить генеральную совокупность. Так, например, простая случайная выборка людей в Соединенном Королевстве может не включать некоторых из отдаленных шотландских островов, выборка которых будет чрезмерно дорогой. Более дешевым методом было бы использование стратифицированной выборки с городскими и сельскими стратами. Сельская выборка может быть недостаточно представлена в выборке, но при анализе должна быть соответствующим образом взвешена для компенсации.
В более общем плане, данные обычно следует взвешивать, если план выборки не дает каждому человеку равных шансов быть выбранным. Например, когда домохозяйства имеют равные возможности выбора, но опрашивается один человек в каждом домохозяйстве, это дает людям из больших домохозяйств меньшие шансы быть опрошенными. Это можно учесть с помощью весов обследования. Точно так же домохозяйства с более чем одной телефонной линией имеют больше шансов быть отобранными в выборке случайных цифр, и веса могут корректироваться с учетом этого.
Веса также могут служить другим целям, например, помогать исправлять неполучение ответов.
Методы получения случайных выборок
- Таблица случайных чисел
- Математические алгоритмы для генераторы псевдослучайных чисел
- Физические устройства рандомизации, такие как монеты, игральные карты или сложные устройства, такие как ЭРНИ
История
Случайная выборка по жребию – старая идея, несколько раз упоминавшаяся в Библии. В 1786 году Пьер Симон Лаплас оценил население Франции с помощью выборки, а также оценщик соотношения. Он также вычислил вероятностные оценки ошибки. Они не были выражены как современные доверительные интервалы но как размер выборки, который потребуется для достижения определенной верхней границы ошибки выборки с вероятностью 1000/1001. Его оценки использовали Теорема Байеса с униформой априорная вероятность и предположил, что его выборка была случайной. Александр Иванович Чупров представили выборочные опросы Императорская Россия в 1870-х гг.[нужна цитата ]
В США 1936 г. Литературный дайджест предсказание победы республиканцев в выборы президента пошло наперекосяк из-за тяжелого предвзятость [1]. Более двух миллионов человек ответили на исследование, указав свои имена через подписные листы журналов и телефонные справочники. Не было оценено, что эти списки были сильно смещены в сторону республиканцев, и итоговая выборка, хотя и очень большая, была глубоко ошибочной.[21][22]
Смотрите также
- Сбор информации
- Теория выборки Гая
- Проблема с немецким танком
- Оценка Хорвица – Томпсона
- Официальная статистика
- Оценка отношения
- Репликация (статистика)
- Механизм случайной выборки
- Ресэмплинг (статистика)
- Выборка (тематические исследования)
- Ошибка выборки
- Сортировка
Заметки
В учебнике Groves et alia дается обзор методологии обследования, включая недавнюю литературу по разработке вопросников (предоставлено когнитивная психология ) :
- Роберт Гровс, и др. Методология исследования (2-е изд. 2010 г. [2004 г.]) ISBN 0-471-48348-6.
Другие книги посвящены статистическая теория выборки обследования и требуют определенных знаний базовой статистики, как это обсуждается в следующих учебниках:
- Дэвид С. Мур и Джордж П. Маккейб (февраль 2005 г.). “Введение в практику статистики“(5-е издание). W.H. Freeman & Company. ISBN 0-7167-6282-X.
- Фридман, Дэвид; Пизани, Роберт; Purves, Роджер (2007). Статистика (4-е изд.). Нью-Йорк: Нортон. ISBN 978-0-393-92972-0. Архивировано из оригинал на 2008-07-06.
В базовой книге Шеаффера и других используются квадратные уравнения из школьной алгебры:
- Шеффер, Ричард Л., Уильям Менденхал и Р. Лайман Отт. Выборка элементарного обследования, Издание пятое. Бельмонт: Duxbury Press, 1996.
Больше математической статистики требуется для Лора, Сэрндала и др. И Кохрана (классический[нужна цитата ]):
- Кокран, Уильям Г. (1977). Методы отбора проб (Третье изд.). Вайли. ISBN 978-0-471-16240-7.
- Лор, Шэрон Л. (1999). Выборка: проектирование и анализ. Даксбери. ISBN 978-0-534-35361-2.
- Сярндал, Карл-Эрик, и Свенсон, Бенгт, и Ретман, Ян (1992). Выборка обследования с помощью модели. Springer-Verlag. ISBN 978-0-387-40620-6.CS1 maint: несколько имен: список авторов (ссылка на сайт)
Исторически важные книги Деминга и Киша по-прежнему ценны для понимания социологов (особенно о переписи населения США и Институт социальных исследований на университет Мичигана ):
- Деминг, У. Эдвардс (1966). Некоторая теория выборки. Dover Publications. ISBN 978-0-486-64684-8. OCLC 166526.
- Киш, Лесли (1995) Выборка обследования, Wiley, ISBN 0-471-10949-5
использованная литература
- ^ Ланс, П., Хаттори, А. (2016). Выборка и оценка. Веб: MEASURE Evaluation. С. 6–8, 62–64.CS1 maint: несколько имен: список авторов (ссылка на сайт)
- ^ Салант, Присцилла, И. Диллман и А. Дон. Как провести собственный опрос. № 300.723 S3. 1994 г.
- ^ а б c d Роберт М. Гровс; и другие. (2009). Методология исследования. ISBN 978-0470465462.
- ^ Лор, Шэрон Л. Выборка: проектирование и анализ.
- ^ Сэрндал, Карл-Эрик и Свенсон, Бенгт и Ретман, Янв. Выборка при помощи модели.CS1 maint: несколько имен: список авторов (ссылка на сайт)
- ^ Шеаффер, Ричард Л., Уильям Менденхал и Р. Лайман Отт. (2006). Выборка элементарного обследования.CS1 maint: несколько имен: список авторов (ссылка на сайт)
- ^ Scott, A.J .; Уайлд, Си-Джей (1986). «Подгонка логистических моделей под случай-контроль или выборку на основе выбора». Журнал Королевского статистического общества, серия B. 48 (2): 170–182. JSTOR 2345712.
- ^ а б
- Лор, Шэрон Л. Выборка: дизайн и анализ.
- Сэрндал, Карл-Эрик и Свенсон, Бенгт и Ретман, Янв. Выборка при помощи модели.CS1 maint: несколько имен: список авторов (ссылка на сайт)
- ^ Шахрох Исфахани, Мохаммад; Догерти, Эдвард (2014). «Влияние раздельной выборки на точность классификации». Биоинформатика. 30 (2): 242–250. Дои:10.1093 / биоинформатика / btt662. PMID 24257187.
- ^ Арияратне, Буддхика (30 июля 2017 г.). «Метод добровольной выборки в сочетании с рекламой в социальных сетях». heal-info.blogspot.com. информатика здоровья. Получено 18 декабря 2018.[ненадежный источник? ]
- ^ Лазарсфельд, П. и Фиске, М. (1938). «Панель» как новый инструмент измерения мнений. The Public Opinion Quarterly, 2 (4), 596–612.
- ^ а б Гровс и др. Методология исследования
- ^ «Примеры методов отбора проб» (PDF).
- ^ Коэн, 1988
- ^ Дипан Палгуна, Викас Джоши, Венкатесан Чакараварти, Рави Котари и Л. В. Субраманиам (2015). Анализ алгоритмов выборки для Twitter. Международная совместная конференция по искусственному интеллекту.CS1 maint: несколько имен: список авторов (ссылка на сайт)
- ^ Беринский, А. Дж. (2008). «Отсутствие ответа на опрос». В: W. Donsbach & M. W. Traugott (Eds.), Справочник по исследованию общественного мнения The Sage (стр. 309–321). Таузенд-Оукс, Калифорния: Sage Publications.
- ^ а б Диллман, Д. А., Элтинг, Дж. Л., Гровс, Р. М., и Литтл, Р. Дж. А. (2002). «Отсутствие ответа на опрос при разработке, сборе данных и анализе». В: Р. М. Гровс, Д. А. Диллман, Дж. Л. Элтинг и Р. Дж. А. Литтл (ред.), Отсутствие ответа на опрос (стр. 3–26). Нью-Йорк: Джон Вили и сыновья.
- ^ Диллман, Д.А., Смит, Дж. Д. и Кристиан, Л. М. (2009). Интернет, почта и смешанные опросы: индивидуальный метод разработки. Сан-Франциско: Джосси-Басс.
- ^ Веховар, В., Батагель, З., Манфреда, К.Л., и Залетель, М. (2002). «Отсутствие ответов в веб-опросах». В: Р. М. Гровс, Д. А. Диллман, Дж. Л. Элтинг и Р. Дж. А. Литтл (ред.), Отсутствие ответа на опрос (стр. 229–242). Нью-Йорк: Джон Вили и сыновья.
- ^ Портье; Уиткомб; Вайцер (2004). «Множественные опросы студентов и опрос на усталость». В Портер, Стивен Р. (ред.). Решение проблем опросного исследования. Новые направления институциональных исследований. Сан-Франциско: Джосси-Басс. стр. 63–74. Получено 15 июля 2019.
- ^ Дэвид С. Мур и Джордж П. Маккейб. “Введение в статистическую практику“.
- ^ Фридман, Дэвид; Пизани, Роберт; Первес, Роджер. Статистика.
дальнейшее чтение
- Чемберс, Р. Л., и Скиннер, К. Дж. (Редакторы) (2003), Анализ данных обследования, Wiley, ISBN 0-471-89987-9
- Деминг, У. Эдвардс (1975) О вероятности как основе действия, Американский статистик, 29 (4), стр. 146–152.
- Гай, П (2012) Отбор образцов из гетерогенных и динамических систем материалов: теории неоднородности, отбора образцов и гомогенизации, Elsevier Science, ISBN 978-0444556066
- Корн, Э.Л., Граубард, Б.И. (1999) Анализ медицинских обследований, Wiley, ISBN 0-471-13773-1
- Лукас, Сэмюэл Р. (2012). Дои:10.1007% 2Фс11135-012-9775-3 «За пределами доказательства существования: онтологические условия, эпистемологические последствия и подробные интервью».], Качество и количество, Дои:10.1007 / s11135-012-9775-3.
- Стюарт, Алан (1962) Основные идеи научного отбора проб, Hafner Publishing Company, Нью-Йорк[ISBN отсутствует ]
- Смит, Т. М. Ф. (1984). «Настоящее положение и возможные изменения: некоторые личные взгляды: выборочные опросы». Журнал Королевского статистического общества, серия A. 147 (150-летие Королевского статистического общества, номер 2): 208–221. Дои:10.2307/2981677. JSTOR 2981677.
- Смит, Т. М. Ф. (1993). «Популяции и отбор: ограничения статистики (Послание Президента)». Журнал Королевского статистического общества, серия A. 156 (2): 144–166. Дои:10.2307/2982726. JSTOR 2982726. (Портрет Т. М. Ф. Смита на странице 144)
- Смит, Т. М. Ф. (2001). «Столетие: выборочные опросы». Биометрика. 88 (1): 167–243. Дои:10.1093 / biomet / 88.1.167.
- Смит, Т. М. Ф. (2001). «100-летие биометрики: выборочные исследования». В Д. М. Титтерингтоне и Д. Р. Кокс (ред.). Биометрика: Сто лет. Издательство Оксфордского университета. С. 165–194. ISBN 978-0-19-850993-6.
- Уиттл, П. (Май 1954 г.). «Оптимальный профилактический отбор проб». Журнал Американского общества исследования операций. 2 (2): 197–203. Дои:10.1287 / opre.2.2.197. JSTOR 166605.
Стандарты
ISO
- ISO 2859 серия
- ISO 3951 серия
ASTM
- Стандартная практика ASTM E105 для вероятностного отбора проб материалов
- ASTM E122 Стандартная практика для расчета размера образца для оценки с заданной допускаемой ошибкой среднего значения для характеристики партии или процесса
- ASTM E141 Стандартная практика принятия доказательств, основанных на результатах вероятностного отбора проб
- Стандартная терминология ASTM E1402, относящаяся к отбору проб
- ASTM E1994 Стандартная практика использования процессно-ориентированных планов выборочного контроля AOQL и LTPD
- ASTM E2234 Стандартная практика отбора проб из потока продукции по атрибутам, индексируемым AQL
ANSI, ASQ
- ANSI / ASQ Z1.4
Федеральные и военные стандарты США
- MIL-STD-105
- MIL-STD-1916
внешние ссылки
 СМИ, связанные с Выборка (статистика) в Wikimedia Commons
СМИ, связанные с Выборка (статистика) в Wikimedia Commons

Автор: Игopь Cтанислaвович Бepeзин, консультант по маркетинговым стратегиям, президент Гильдии мapкетoлoгов (г. Моcква).
Опрос и анкетирование являются ведущими, универсальными методами проведения социологических и маркетинговых исследований. Чаше всего, когда говорят о маркетинговом исследовании — сборе первичной информации, имеют в виду именно опрос или анкетирование, предполагающие прямое выяснение, непредвзятого мнения достаточно многочисленной группы респондентов.
Массовым считается опрос, в ходе которого путем личной беседы сотрудника исследовательской компании — интервьюера с носителями информации (респондентами), состоящей из нескольких десятков коротких вопросов, изучаются мнения нескольких сотен (тысяч) человек. Под анкетированием понимают безличную форму общения исследователей с носителями информации, при которой респонденты самостоятельно отвечают на вопросы анкеты, следуя содержащейся в ней инструкции и не вступая в непосредственный контакт с интервьюерами.
Конечной целью анкетирования и массового опроса является получение данных, характеризующих так называемую генеральную совокупность. Генеральная совокупность — это все представители какой-либо группы, носители какого-либо важного признака, например:
- все российские избиратели;
- все потенциальные потребители пива, проживающие в Перми;
- все подростки (12-16 лет) Поволжского региона;
- все учителя физики и химии, работающие в средних школах;
- все домохозяйства, имеющие доход от 500 до 1 500 долл. в месяц;
- все компании, занимающиеся розничной торговлей в Самаре и т. д.
Чтобы опросить десятки или сотни тысяч, а тем более — миллионы человек (компаний), из которых может состоять генеральная совокупность, нужны сотни или даже тысячи интервьюеров. На проведение подобного исследования могут понадобиться десятки, если не сотни миллионов долларов и не менее полугода напряженной работы. Такое возможно только при переписи населения (проводящейся не чаще одного раза в 10 лет).
Однако в маркетинге этого и не требуется. Достаточно того, чтобы относительно небольшая выборка (от нескольких сотен до нескольких тысяч представителей) репрезентировала (выразила) мнение генеральной совокупности. Как такое возможно? На каком основании можно распространять данные, полученные от небольшой группы людей, на существенно (в десятки и сотни раз) большую группу? На основании гипотезы о том, что на поведение, знания, отношение потребителей к компании, товару, услуге или отдельных их компонентов оказывают влияние социально-демографические характеристики самих потребителей.
Иными словами, большинство представителей четко определенной социально-демографический группы будут сходным образом реагировать на внешние, в данном случае — рыночные стимулы: товар, цену, упаковку, рекламу и т. д. Нет никакой необходимости опрашивать всех представителей этой группы, поскольку ее мнение (с допустимой погрешностью) может представить (репрезентировать) небольшая выборка из ее представителей.
Способы построения выборки
Существуют две группы методов построения выборки, в той или иной степени реализующих репрезентацию мнений и позиций генеральной совокупности: вероятностные и детерминированные.
Первая группа методов (вероятностные) базируется на использовании теории вероятности. В основе ее применения лежит постулат, что репрезентация будет достигнута в случае, если каждой единице генеральной совокупности обеспечено равновероятное попадание в выборку. Например, если генеральной совокупностью является все взрослое (16-85 лет) население города (200 тыс. человек), то каждому жителю должна быть обеспечена вероятность стать участником исследования(попасть в выборку), равная 1 / 200 000. В противном случае выборка будет не случайной, а смещенной, т. е. менее репрезентативной.
Реализовать это можно в случае, если все элементы генеральной совокупности могут быть тем или иным образом пронумерованы, а затем эти номера будут выбраны в определенной последовательности — «по воле случая». Например, в Москве около 2 500 средних школ, каждая из которых имеет свой номер. Мы могли бы выбрать наугад 100 номеров и провести опрос 100 директоров (завучей, учителей физики, классных руководителей 11-х классов и т. п.) в этих школах.
Эти 100 номеров мы можем выбрать с помощью таблицы или «генератора случайных чисел» (есть такая специальная компьютерная программа), а также с помощью «барабана» но принципу того, как это делается при проведении лотереи. Такие способы построения выборки называются «простой случайной выборкой». Каждый ее элемент отбирается независимо и имеет равную вероятность попасть в выборку.
Мы могли бы выбрать наугад любое число от 1 до 25, например — 12, а затем взять в выборку школы с номерами: 12, 37, 62, 87, 112, 137 и т. д. Такой метод построения называемся «систематической выборкой», первый элемент которой выбирается произвольно, а затем выбирают каждый i-й элемент.
Мы также могли бы сначала разделить эти школы на несколько страт (возможно, и пересекающихся), например, на школы физико-математические, спортивные, лингвистические и гуманитарные, а затем произвести случайную или систематическую выборку (по 20-30 школ) из каждой страты. Такой метод построения называется «стратифицированной выборкой».
Разновидностью стратифицированной выборки является «маршрутная выборка», суть реализации которой состоит в следующем. Город делится на 20-40 «секторов» по числу интервьюеров, задействованных и исследовании. Каждый интервьюер получает один сектор, маршрут обследования «своего» сектора и инструкцию по реализации простой случайной выборки. Например такую: «Начать обход с улицы Баумана, с дома № 2, третьего подъезда, второго этажа сверху, первой квартиры слева. Затем — дом № 4, второй подъезд, третий этаж, вторая квартира справа… Потом — переулок Комсомольский, нечетная сторона… Потом — тупик Коммунизма… и т. д.»
Наконец, мы могли бы разделить генеральную совокупность на непересекающиеся кластеры, к примеру, по муниципальным районам (их в Москве 125, и в каждом в среднем по 20 школ). Затем случайным образом выбрать пять районов и произвести обследование всех школ данного муниципального района. Такой метод построения называется «кластерной выборкой».
Тем не менее у вероятностных методов построения выборки есть один весьма существенный недостаток. Каждый из них исходит из предположения о том, что все элементы генеральной совокупности являются равнодоступными: и в «техническом» смысле (у всех есть телефон для телефонного опроса или доступ в Интернет), и в «психологическом», т. е. все респонденты с примерно равной вероятностью согласятся или откажутся принимать участие в исследовании. Однако это не так.
Граждане с относительно высокими доходами менее доступны для исследователей, чем те, чьи доходы невысоки. И нет никакой силы, которая могла бы заставить этих люден отвечать им вопросы социологов или маркетологов. Поэтому все выборки всегда смещены в сторону средне- и малообеспеченных групп населения. Во всех без исключения странах мира.
Менее образованные граждане идут на контакт с социологами менее охотно, чем лица с высшим образованием. Поэтому в большинстве выборок доля хорошо образованных граждан как правило существенно выше, чем в генеральной совокупности.
Никто из сотрудников исследовательских компаний не желает общаться с бомжами, алкоголиками, наркоманами, психо- и социопатами и прочими маргиналами. У руководителя исследования нет решительно никаких возможностей заставить своих сотрудников делать это. А между прочим, к этим группам в России по взвешенным оценкам относится от 12 до 15% жителей. Следовательно, любая выборка смещена в сторону «вменяемых» граждан.
Некоторые граждане боятся отвечать на вопросы, даже самые невинные. Таких людей немного, но они есть. А вот способов заставить их участвовать в опросе нет.
Наконец, есть люди, которые просто не желают участвовать в исследовании. У них есть время, они ничего не боятся, они все понимают, но на вопросы отвечать отказываются. И точка.
Таким образом, все выборки в маркетинге и социологии являются смещенными в сторону средне- и малообеспеченных, более образованных, контактных и вменяемых граждан. Они и репрезентируют общее мнение генеральной совокупности. Все исследователи рынка прекрасно это знают.
Преодолеть наложенные выше проблемы можно с помощью метода «квот», относящегося к детерминированным методам, при котором априори обеспечивается пропорциональное представительство носителей существенных признаков (пол, возраст, доход, образование и т. п.) генеральной совокупности в выборке.
Это наиболее эффективный, на наш взгляд, метод проведения массовых опросов. При его использовании существенно облегчается задача поиска корреляционных связей, сравнения различных типов (групп) потребителей между собой и экстраполяции выявленных закономерностей на генеральную совокупность.
Единственная, но весьма существенная трудность при реализации него метода состоит в том, что не всегда доподлинно известно распределение всех важных параметров в самой генеральной совокупности. В этом случае исследователь или консультант исследовательского проекта должен взять на себя смелость распределить квоты по своему усмотрению, в соответствии со своим видением, пониманием рынка.
Задача достижения строгой репрезентативности не всегда является важной. Иногда целесообразно воспользоваться существенно более простыми в реализации детерминированными методами:
- нерепрезентативным, или произвольным, когда опрашивают того, кто «попался под руку» интервьюеру и согласился участвовать в опросе. Естественно, этот метод дает крайне ненадежные результаты. А вдруг под руку попадется рота солдат или команда баскетболисток! Однако его использование допустимо в исследованиях, носящих поисковый характер, не требующих большой точности, при проведении «пилотажа» анкеты. «Произвольность» можно компенсировать большим объемом выборки, из которой затем можно будет попробовать отобрать необходимое число «подходящих» анкет и составить уже из них репрезентативную в каких-то отношениях выборку;
- поверхностным — когда отбор осуществляется по самым общим признакам, задаваемым исследователем интервьюерам в виде не очень строгого задания;
- «воронки» — когда сначала отбираются наиболее «контактные», а затем среди них — наиболее «компетентные», подходящие респонденты;
- «концентрации» — на представителях отдельных, сопоставимых сегментов рынка, среди которых проводят «сплошной» опрос. Например, школьный 11 «А» класс может представлять всех старшеклассников школы или даже города как «обычный», «типичный класс»;
- «снежного кома» — когда начальная группа подбирается случайным образом, а дальнейший отбор ведется из кандидатов, указанных первыми респондентами, и т. д.
Достоверность и погрешности измерений
Под «достоверностью», уровнем достоверности понимают показатель вероятности того, что истинное значение изучаемого параметра генеральной совокупности попадет в доверительный интервал. Чем выше задаваемый уровень достоверности, тем больше должна быть выборка. Под доверительным интервалом понимают диапазон, в который попадет истинное значение изучаемого параметра генеральной совокупности при данном уровне достоверности. Чем он меньше, тем больше должна быть выборка.
К примеру, общероссийская городская выборка (14-65 лет) в 1 200 респондентов имеет доверительный интервал 4 процентных пункта при уровне достоверности 0,95. При ее проведении 15% участников опроса заявили, что за последние три месяца были в кинотеатре хотя бы один раз.
Эти данные позволяют нам утверждать с заданным уровнем достоверности, что от 11 до 19% жителей российских городов в возрасте от 14 до 65 лет были в кинотеатре хотя бы один раз за последние три месяца. Иными словами, можно сказать, что все значения между 11 и 19% в данном случае находятся в пределах «допустимой статистической погрешности». Если бы мы хотели задать доверительный интервал в 2 процентных пункта, то выборку (при прочих равных условиях) пришлось бы увеличить примерно в четыре раза.
Со стороны уровня достоверности эти данные означают, что если бы было проведено 100 независимых измерении (опросов) по 1200 респондентов в каждом, то в 95 из них значение доли ответов на вопрос о посещении кинотеатра не вышло бы за пределы доверительного интервала (в этом конкретном случае — 11-19%). А в пяти исследованиях или бы получены значения, выходящие за пределы доверительного интервала. Если бы нас устраивала достоверность на уровне 0,9, то опросить можно было бы 200 человек. Если нам нужна достоверность на уровне 0,99, то пришлось бы опросить более 10 тыс. человек.
Оптимальный размер выборки
Вот одна из формул расчета необходимого объема выборки, используемая при известном среднем отклонении (дисперсии) и заданных уровнях достоверности и точности:
N = (g2 * z2) / d2
где: N — искомый объем выборки; g — дисперсия признака, ожидаемое среднее отклонение получаемых результатов от ожидаемого среднего значения; z — коэффициент уровня достоверности (2 — для 0,95, 3 — для 0,99); d — уровень точности.
Допустим, мы изучаем поведение покупателей в продовольственном магазине, в частности, мы хотим определить среднюю сумму чека. Из бесед с владельцем магазина мы узнаем, что она может быть в районе 500-700 руб., а среднее отклонение (g) может составить 200 руб. В ходе опроса мы хотели бы определить среднее значение с точностью (d) до 20 руб. при уровне достоверности (z) в 0,95. Подставляем значения формулу и получаем:
40000 * 4 / 400 = 400.
То есть нам достаточно опросить 400 покупателей. Если бы мы хотели узнать среднюю сумму чека с точностью до 10 руб.. то нам пришлось бы опросить 1600 покупателей. Если бы при этом мы хотели получить уровень достоверности в 0,99, то количество покупателей, которых необходимо опросить, составило бы 3 500 человек. И наоборот: если нас устроила бы точность ±50 руб., то нам достаточно было бы опросить в заданных условиях всего 65 человек.
Практическое использование этой и других формул, которые здесь не будут приводиться, весьма затруднено следующими обстоятельствами:
- Что делать, если мы не знаем даже приблизительно «ожидаемую среднюю» и среднюю дисперсию признака?
- Что делать, если в анкете у нас 10 вопросов, по которым ожидаются различные средние, с различными средними дисперсиями?
- Как быть в случае использования номинальных шкал?
- Как быть в случае, если один вопрос предполагает два или три варианта ответа и т. д. и т. п.?
- Для простых альтернативных вопросов по принципу «да/нет» используются одни формулы, для более сложных — другие.
- Формулы необходимо корректировать в зависимости от количества столбцов в таблице «факторных распределении», а также в зависимости от распределения ответов (10 на 90 — это одно, а 45 на 55 — совсем другое дело).
- Одни формулы учитывают размер генеральной совокупности, а другие (как приведенная выше) — нет. Есть много иных нюансов.
На практике сначала определяют количество респондентов, которое исследователи предполагают опросить с учетом временных и финансовых ограничений, задают уровень достоверности (обычно — 0,95), а затем уже рассчитывают доверительный интервал.
Определение необходимого и достаточного объема выборки происходит на основе опыта и неформальных «конвенций» исследователей между собой. Считается, и это многократно проверено на практике, что опрос 30-50 представителей конкретной, «узкой» социально-демографической группы населения, например «ярославских замужних женщин в возрасте 30-45 лет, имеющих одного ребенка, высшее образование и совокупный семейный доход в пределах от 1 500 до 3 000 долл. в месяц», можно распространять на всю эту группу, и допустимая ошибка (доверительный интервал) не превысит 4 процентных пунктов при уровне достоверности около 0,95.
Однако полученные данные нельзя распространять, например, на незамужних женщин того же возраста, имеющих такой же доход и уровень образования. А также на женщин, имеющих иной доход, возраст или уровень образования. И уж тем более — на мужчин.
Таким образом, если в задачу исследователя входит получение информации о мнениях, знаниях, поведении или отношении к некой проблеме всех ярославских женщин, и при этом все перечисленные выше социально-демографические факторы являются значимыми, необходимо построить такую выборку, в которой были бы представлены все «узко определенные» группы. В данном случае — две группы по семейному положению, три — по наличию и количеству детей, три возрастные, три доходные, две образовательные. Итого 108 групп, в каждой из которых должно быть не менее 30 представительниц. Всего — более 3 000 респондентов.
На самом деле едва ли найдется вопрос или проблема, на которые все пять факторов будут оказывать взаимное перекрестное воздействие. В большинстве случаев вполне можно было бы обойтись опросом 400-600 респонденток, а затем провести попарный (а не перекрестный) факторный анализ. То есть отдельно исследовать влияние факторов «возраст», «образование», «доход», «семейное положение», «дети». При этом выборка каждый раз разбивалась бы на две-три группы, наполнение которых было бы не меньше 100-150 респондентов.
Репрезентативная выборка, представляющая все население России, должна состоять из 3 600-9 000 человек и 180 групп (два пола, три возраста, два образовательных уровня, три доходные группы, пять типов поселений). Доверительный интервал будет в пределах ±3 процентных пункта. Это означает, что, к примеру, если 30% (12% или 45%) наших респондентов заявили, что регулярно употребляют в пищу майонез, то долю потребителей майонеза в России можно оценить в 27-33% (9-15 или 42-48% соответственно).
Размер выборки практически не зависит от размера генеральной совокупности. И в мегаполисе с населением более миллиона человек, и в уездном городе с населением в 35 тыс. человек для построения выборки, репрезентативной по одинаковому числу параметров, потребуется опросить одинаковое число респондентов.
От чего действительно зависит размер выборки — так это от числа параметров, по которым мы желаем добиться репрезентативности. Если нас устраивает репрезентативность только по полу и возрасту, то выборки в 400 человек в одном населенном пункте будет более чем достаточно. Если параметров три, количество респондентов придется увеличить до 600. Добиться репрезентативности выборки одновременно по пяти параметрам: полу, возрасту, доходу, образованию, сфере профессиональной деятельности — можно лишь на выборке из 1 000 — 1 200 человек в одном населенном пункте.
Изучите полный цикл маркетинговых исследований в практическом курсе «Маркетинговые исследования»:

