Время на прочтение
5 мин
Количество просмотров 1.1M
Введение
Язык SQL очень прочно влился в жизнь бизнес-аналитиков и требования к кандидатам благодаря простоте, удобству и распространенности. Из собственного опыта могу сказать, что наиболее часто SQL используется для формирования выгрузок, витрин (с последующим построением отчетов на основе этих витрин) и администрирования баз данных. И поскольку повседневная работа аналитика неизбежно связана с выгрузками данных и витринами, навык написания SQL запросов может стать фактором, из-за которого кандидат или получит преимущество, или будет отсеян. Печальная новость в том, что не каждый может рассчитывать получить его на студенческой скамье. Хорошая новость в том, что в изучении SQL нет ничего сложного, это быстро, а синтаксис запросов прост и понятен. Особенно это касается тех, кому уже доводилось сталкиваться с более сложными языками.
Обучение SQL запросам я разделил на три части. Эта часть посвящена базовому синтаксису, который используется в 80-90% случаев. Следующие две части будут посвящены подзапросам, Join’ам и специальным операторам. Цель гайдов: быстро и на практике отработать синтаксис SQL, чтобы добавить его к арсеналу навыков.
Практика
Введение в синтаксис будет рассмотрено на примере открытой базы данных, предназначенной специально для практики SQL. Чтобы твое обучение прошло максимально эффективно, открой ссылку ниже в новой вкладке и сразу запускай приведенные примеры, это позволит тебе лучше закрепить материал и самостоятельно поработать с синтаксисом.
Кликнуть здесь
После перехода по ссылке можно будет увидеть сам редактор запросов и вывод данных в центральной части экрана, список таблиц базы данных находится в правой части.
Структура sql-запросов
Общая структура запроса выглядит следующим образом:
SELECT ('столбцы или * для выбора всех столбцов; обязательно')
FROM ('таблица; обязательно')
WHERE ('условие/фильтрация, например, city = 'Moscow'; необязательно')
GROUP BY ('столбец, по которому хотим сгруппировать данные; необязательно')
HAVING ('условие/фильтрация на уровне сгруппированных данных; необязательно')
ORDER BY ('столбец, по которому хотим отсортировать вывод; необязательно')Разберем структуру. Для удобства текущий изучаемый элемент в запроса выделяется CAPS’ом.
SELECT, FROM
SELECT, FROM — обязательные элементы запроса, которые определяют выбранные столбцы, их порядок и источник данных.
Выбрать все (обозначается как *) из таблицы Customers:
SELECT * FROM CustomersВыбрать столбцы CustomerID, CustomerName из таблицы Customers:
SELECT CustomerID, CustomerName FROM CustomersWHERE
WHERE — необязательный элемент запроса, который используется, когда нужно отфильтровать данные по нужному условию. Очень часто внутри элемента where используются IN / NOT IN для фильтрации столбца по нескольким значениям, AND / OR для фильтрации таблицы по нескольким столбцам.
Фильтрация по одному условию и одному значению:
select * from Customers
WHERE City = 'London'Фильтрация по одному условию и нескольким значениям с применением IN (включение) или NOT IN (исключение):
select * from Customers
where City IN ('London', 'Berlin')select * from Customers
where City NOT IN ('Madrid', 'Berlin','Bern')Фильтрация по нескольким условиям с применением AND (выполняются все условия) или OR (выполняется хотя бы одно условие) и нескольким значениям:
select * from Customers
where Country = 'Germany' AND City not in ('Berlin', 'Aachen') AND CustomerID > 15select * from Customers
where City in ('London', 'Berlin') OR CustomerID > 4GROUP BY
GROUP BY — необязательный элемент запроса, с помощью которого можно задать агрегацию по нужному столбцу (например, если нужно узнать какое количество клиентов живет в каждом из городов).
При использовании GROUP BY обязательно:
- перечень столбцов, по которым делается разрез, был одинаковым внутри SELECT и внутри GROUP BY,
- агрегатные функции (SUM, AVG, COUNT, MAX, MIN) должны быть также указаны внутри SELECT с указанием столбца, к которому такая функция применяется.
Группировка количества клиентов по городу:
select City, count(CustomerID) from Customers
GROUP BY CityГруппировка количества клиентов по стране и городу:
select Country, City, count(CustomerID) from Customers
GROUP BY Country, CityГруппировка продаж по ID товара с разными агрегатными функциями: количество заказов с данным товаром и количество проданных штук товара:
select ProductID, COUNT(OrderID), SUM(Quantity) from OrderDetails
GROUP BY ProductIDГруппировка продаж с фильтрацией исходной таблицы. В данном случае на выходе будет таблица с количеством клиентов по городам Германии:
select City, count(CustomerID) from Customers
WHERE Country = 'Germany'
GROUP BY CityПереименование столбца с агрегацией с помощью оператора AS. По умолчанию название столбца с агрегацией равно примененной агрегатной функции, что далее может быть не очень удобно для восприятия.
select City, count(CustomerID) AS Number_of_clients from Customers
group by CityHAVING
HAVING — необязательный элемент запроса, который отвечает за фильтрацию на уровне сгруппированных данных (по сути, WHERE, но только на уровень выше).
Фильтрация агрегированной таблицы с количеством клиентов по городам, в данном случае оставляем в выгрузке только те города, в которых не менее 5 клиентов:
select City, count(CustomerID) from Customers
group by City
HAVING count(CustomerID) >= 5 В случае с переименованным столбцом внутри HAVING можно указать как и саму агрегирующую конструкцию count(CustomerID), так и новое название столбца number_of_clients:
select City, count(CustomerID) as number_of_clients from Customers
group by City
HAVING number_of_clients >= 5Пример запроса, содержащего WHERE и HAVING. В данном запросе сначала фильтруется исходная таблица по пользователям, рассчитывается количество клиентов по городам и остаются только те города, где количество клиентов не менее 5:
select City, count(CustomerID) as number_of_clients from Customers
WHERE CustomerName not in ('Around the Horn','Drachenblut Delikatessend')
group by City
HAVING number_of_clients >= 5ORDER BY
ORDER BY — необязательный элемент запроса, который отвечает за сортировку таблицы.
Простой пример сортировки по одному столбцу. В данном запросе осуществляется сортировка по городу, который указал клиент:
select * from Customers
ORDER BY CityОсуществлять сортировку можно и по нескольким столбцам, в этом случае сортировка происходит по порядку указанных столбцов:
select * from Customers
ORDER BY Country, CityПо умолчанию сортировка происходит по возрастанию для чисел и в алфавитном порядке для текстовых значений. Если нужна обратная сортировка, то в конструкции ORDER BY после названия столбца надо добавить DESC:
select * from Customers
order by CustomerID DESCОбратная сортировка по одному столбцу и сортировка по умолчанию по второму:
select * from Customers
order by Country DESC, CityJOIN
JOIN — необязательный элемент, используется для объединения таблиц по ключу, который присутствует в обеих таблицах. Перед ключом ставится оператор ON.
Запрос, в котором соединяем таблицы Order и Customer по ключу CustomerID, при этом перед названиям столбца ключа добавляется название таблицы через точку:
select * from Orders
JOIN Customers ON Orders.CustomerID = Customers.CustomerIDНередко может возникать ситуация, когда надо промэппить одну таблицу значениями из другой. В зависимости от задачи, могут использоваться разные типы присоединений. INNER JOIN — пересечение, RIGHT/LEFT JOIN для мэппинга одной таблицы знаениями из другой,
select * from Orders
join Customers on Orders.CustomerID = Customers.CustomerID
where Customers.CustomerID >10Внутри всего запроса JOIN встраивается после элемента from до элемента where, пример запроса:
Другие типы JOIN’ов можно увидеть на замечательной картинке ниже:

В следующей части подробнее поговорим о типах JOIN’ов и вложенных запросах.
При возникновении вопросов/пожеланий, всегда прошу обращаться!
SQL — язык структурированных запросов. Его создали в 1974 году, чтобы хранить и обрабатывать данные. Все реляционные СУБД — системы управления базами данных — используют его в качестве препроцессора для обработки команд. Сами же базы данных представляют наборы таблиц, где запись — это строка.
SQL в работе используют разработчики и тестировщики, чтобы улучшать сайт или приложение через грамотную работу с базами данных. Тестировщики таким образом помогают бизнесу принимать эффективные решения на основе данных. Маркетологи — глубже анализировать поведение пользователей.

Инженер-тестировщик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT
Узнать больше
Виды SQL-запросов
Ключевые слова этого языка делят на четыре логические группы.
1️⃣ DDL
Data Definition Language — язык определения данных. В него входят ключевые слова CREATE, DROP, RENAME и другие, которые относят к определению и манипулированию структурой базы данных. Их используют, чтобы создавать базы данных и описывать структуру, устанавливать, как размещать данные.
2️⃣ DML
Data Manipulation Language — язык манипулирования данными. В этой группе — запросы SELECT, INSERT, UPDATE, DELETE и другие. Их используют, чтобы изменять, получать, обновлять и удалять данные из базы.
3️⃣ DCL
Data Control Language — язык управления данными. К этой группе относят запросы разрешений, прав и различных ограничивающих доступ настроек. Например, GRANT или DENY.
4️⃣ TCL
Transaction Control Language — язык управления транзакциями. В эту группу входят все запросы, которые относят к управлению транзакциями и их жизненными циклами. Например, BEGIN TRANSACTION, ROLLBACK TRANSACTION, COMMIT TRANSACTION.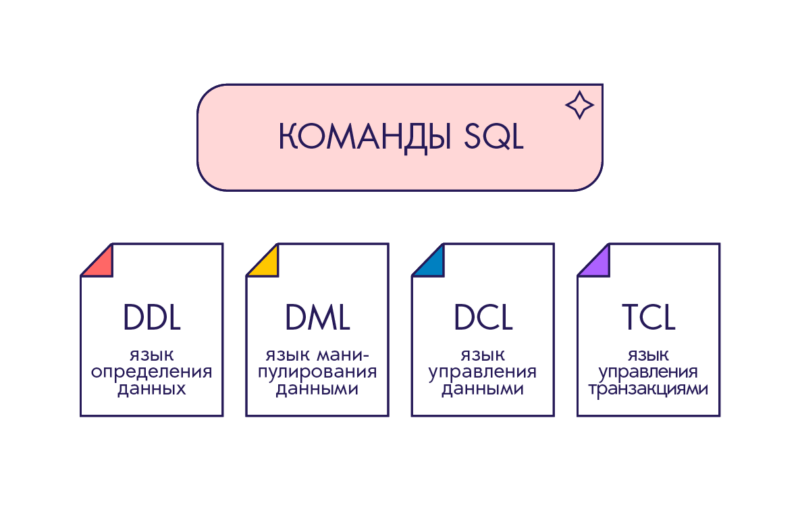
Структура SQL-запросов
Запросы на языке SQL последовательны: логика их составления почти не отличается от обычного предложения. Например, вы хотите отфильтровать записи, чтобы получить только те, где в первом столбце значение равно единице. А после получить значения второго и третьего столбцов в выборке. Предложение на такую команду будет следующее:
Выбрать Столбец2, Столбец3 из Таблица1, где Столбец1 равен одному
На SQL это выглядит похоже:
SELECT (Column2, Column3) FROM Table1 WHERE Column1 = 1
Простые запросы SQL
Ключевые слова
Их используют, чтобы составить запросы:
✔️ WHERE
Это ключевое слово отфильтровывает записи. Мы использовали его в абстрактном примере:
SELECT (Column2, Column3) FROM Table1 WHERE Column1 = 1
✔️ GROUP BY
Группирует записи выборки по значениям указанных столбцов. Это ключевое слово должно следовать после WHERE.
✔️ AND, OR и BETWEEN
AND или OR расширяют выборку, создаваемую с помощью WHERE. Либо сужают ее, если указать дополнительные значения. Ключевое слово BETWEEN позволяет указать диапазон значений, чтобы создать выборку.
✔️ LIMIT
Лимитирует количество значений выборки. Например, по указанным фильтрам получено 100 значений, а нужны только первые 10. Тогда применяют синтаксис LIMIT 10.
Команды
С них начинаются запросы.
Предположим, нам необходимо создать базу данных, чтобы хранить информацию о прочитанных книгах, извлекать и изменять данные. В примерах мы будем использовать самую простую СУБД — sqlite3 в среде Linux. Создайте базу данных командой sqlite3 demo.db — и сразу попадете в командную строку программы:
sqlite3 demo.db SQLite version 3.27.2 2019-02-25 16:06:06 Enter ".help" for usage hints. sqlite>
🚀 CREATE TABLE
Чтобы создать таблицу, используют команду CREATE TABLE. Если создаете таблицу с прочитанными книгами, вероятно, понадобятся три столбца: id, название и автор.
sqlite> CREATE TABLE Books (id INTEGER PRIMARY KEY, title CHAR(255), author CHAR(255)); sqlite> .tables Books
Команда .tables отображает список таблиц.
🚀 INSERT
Команда создает новые записи. Добавим три книги в нашу таблицу:
sqlite> INSERT INTO Books(title, author) VALUES
...> ("Язык SQL", "Неизвестный автор"),
...> ("SQL. Сборник рецептов", "Энтони Молинаро"),
...> ("Книга №3", "Без автора");
Указываем, в какие столбцы нужно вставить данные, игнорируя столбец id: он помечен как первичный ключ. Будет автоматически инкрементироваться, генерируя уникальные значения. В примере вставляем несколько записей за один запрос.
🚀 SELECT
Извлекает записи из таблицы:
sqlite> SELECT * FROM Books; 1|Язык SQL|Неизвестный автор 2|SQL. Сборник рецептов|Энтони Молинаро 3|Книга №3|Без автора
Каждая запись будет на новой строке, а значения столбцов — разделены вертикальной линией. Если, например, нужны не все, а определенные столбцы, то звездочку замените на названия столбцов через запятую:
sqlite> SELECT title, author FROM Books; Язык SQL|Неизвестный автор SQL. Сборник рецептов|Энтони Молинаро Книга №3|Без автора
🚀 UPDATE
Изменяет существующие записи. Чтобы использовать эту команду, укажите уникальный идентификатор изменяемой записи. Либо характеристику, по которой можно получить одну запись или группу из нескольких записей. Обновим авторов у первой и последней записи:
sqlite> UPDATE Books ...> SET author = "Unknown" ...> WHERE id = 1 OR id = 3; sqlite> sqlite> SELECT title, author FROM Books; Язык SQL|Unknown SQL. Сборник рецептов|Энтони Молинаро Книга №3|Unknown
🚀 DELETE
Удаляет записи из таблицы по поисковому запросу. Удалим книгу с id, равным двум:
sqlite> DELETE FROM Books WHERE id = 2; sqlite> sqlite> SELECT * FROM Books; 1|Язык SQL|Unknown 3|Книга №3|Unknown
🚀 DROP TABLE
Удаляет таблицы из базы данных. Создадим и удалим демонстрационную таблицу:
sqlite> CREATE TABLE Demo (id INTEGER PRIMARY KEY, text TEXT); sqlite> sqlite> .tables Books Demo sqlite> sqlite> DROP TABLE Demo; sqlite> sqlite> .tables Books
🚀 ALTER TABLE
Команда в сочетании с другими ключевыми словами изменяет названия таблиц или добавляет новые столбцы. Изменим название нашей таблицы Books:
sqlite> ALTER TABLE Books RENAME TO MyBooks; sqlite> sqlite> .tables MyBooks
Добавим в нее новый столбец is_finished с булевым значением:
sqlite> ALTER TABLE MyBooks ADD COLUMN is_finished BOOLEAN; sqlite> UPDATE MyBooks ...> SET is_finished = True; sqlite> sqlite> SELECT * FROM MyBooks; 1|Язык SQL|Unknown|1 3|Книга №3|Unknown|1
Агрегатные функции
Их используют, чтобы проводить дополнительные вычисления внутри полученной выборки:
✔️ COUNT(название_столбца) — возвращает количество строк выборки, где значение столбца не NULL.
✔️ SUM(название_столбца) — вычисляет и возвращает сумму значений в указанном столбце.
✔️ AVG(название_столбца) — вычисляет и возвращает среднее значение по столбцу.
✔️ MIN(название_столбца) — возвращает наименьшее значение для указанного столбца.
✔️ MAX(название_столбца) — возвращает наибольшее значение указанного столбца.
Вложенные подзапросы
Это SQL-запрос внутри другого SQL-запроса. Подзапросы помогают, если выборку фильтруют по значениям, которые тоже можно отфильтровать. Например, получим названия футбольных команд — участников соревнований с 2010 по 2020 годы:
SELECT DISTINCT club_name FROM clubs WHERE game_year = 2010 AND club_id IN (SELECT club_id FROM clubs WHERE game_year = 2020 );
Ключевое слово DISTINCT убирает из выборки дублирующиеся результаты.
Главное
- SQL используют в реляционных СУБД, где хранят данные в виде таблиц.
- Основные команды SQL делят на четыре логические группы: DDL, DML, DCL, TCL.
- С SQL можно создавать, читать, изменять и удалять данные. Например, чтобы создать таблицу, используют команду CREATE TABLE, извлечь записи — SELECT, удалить таблицу баз данных — DROP TABLE.
- Для дополнительных вычислений нужны агрегатные функции: вычислять и возвращать сумму, наименьшее и наибольшее значение для указанного столбца.
Узнайте, как решать бизнес-задачи с помощью SQL, на курсе Skypro «Аналитик данных». За 5-9 месяцев научитесь фильтровать, группировать и объединять данные из разных таблиц, проводить аналитические исследования, вычислять показатели из большого объема информации. Студенты участвуют в вебинарах и выполняют задания, разбирают реальные задачи на командных мастер-классах под руководством эксперта.
Добро пожаловать на первый урок по реляционным базам данных и языку SQL.
Реляционные базы данных представляют собой набор таблиц с информацией.
Вроде такой:
| id | name | count | price |
|---|---|---|---|
| 1 | Телевизор | 3 | 43200.00 |
| 2 | Микроволновая печь | 4 | 3200.00 |
| 3 | Холодильник | 3 | 12000.00 |
| 4 | Роутер | 1 | 1340.00 |
| 5 | Компьютер | 0 | 26150.00 |
Или такой:
| id | first_name | last_name | birthday | age |
|---|---|---|---|---|
| 1 | Дмитрий | Иванов | 1996-12-11 | 20 |
| 2 | Олег | Лебедев | 2000-02-07 | 17 |
| 3 | Тимур | Шевченко | 1998-04-27 | 19 |
| 4 | Светлана | Иванова | 1993-08-06 | 23 |
| 5 | Олег | Ковалев | 2002-02-08 | 15 |
| 6 | Алексей | Иванов | 1993-08-05 | 23 |
| 7 | Алена | Процук | 1997-02-28 | 18 |
Каждая таблица состоит из столбцов и строк.
Посмотрим внимательней на таблицу products, которая хранит данные о товарах в интернет-магазине. Таблица содержит 4 столбца: id, name, count и price. Каждый из столбцов отвечает за какой-то определенный тип информации: id — это уникальный номер товара, name — его имя, count — количество, price — цена.
Строка отвечает за конкретный товар в таблице. Если мы посмотрим на третью строку, то найдем там «Холодильник» с ценой 12 000 рублей в количестве 3 штук.
Другая таблица — это users, которая хранит данные о пользователях в системе. В таблице 5 столбцов: также уникальный номер пользователя id, имя, фамилия, возраст — age и дата рождения — birthday.
Как я уже говорил, каждый столбец отвечает за какую-то информацию и эта информация относится к определенному типу данных. Столбцы first_name и last_name строковые, age и id содержат числа, а birthday — дату.
Название столбца, его тип и порядок строго задаются на этапе создания таблицы. Об этом мы поговорим в других уроках.
А вот записи таблицы (или строки) заполняются в процессе её использования. Поэтому столбцов у нас жестко 5. А строк может быть сколько угодно. Зарегистрировался пользователь на сайте — добавили строку. Привезли новые товары в магазин — таблица растет.
Добавление, удаление, изменение или получение данных из таблиц, выполняется с помощью языка SQL.
- SQL
- — это язык общения с базами данных.
Давайте попробуем получить информацию из таблицы users. Для этого надо написать и выполнить такой SQL-запрос:
SELECT * FROM usersПолучили всех пользователей из таблицы users:
| id | first_name | last_name | birthday | age |
|---|---|---|---|---|
| 1 | Дмитрий | Иванов | 1996-12-11 | 20 |
| 2 | Олег | Лебедев | 2000-02-07 | 17 |
| 3 | Тимур | Шевченко | 1998-04-27 | 19 |
| 4 | Светлана | Иванова | 1993-08-06 | 23 |
| 5 | Олег | Ковалев | 2002-02-08 | 15 |
| 6 | Алексей | Иванов | 1993-08-05 | 23 |
| 7 | Алена | Процук | 1997-02-28 | 18 |
Рассмотрим SQL запрос подробнее.
Оператор SELECT говорит, что мы будем извлекать данные. После него идет список столцов, которые мы хотим получить. Если указать звездочку (*), как у нас, то получим все столбцы в том порядке, в котором они определены в таблице: id, first_name, last_name и тд. Далее идет конструкция FROM users, которая буквально означает ИЗ users.
То есть вся SQL конструкция читается как ВЫБРАТЬ все столбцы ИЗ таблицы users.
Теперь вместо звездочки напишем: last_name, first_name, birthday, чтобы у нас получился такой SQL-запрос:
SELECT last_name, first_name, birthday FROM usersЕсли его выполнить, то мы снова получим всех пользователей из таблицы users, но на этот раз только фамилию, имя и дату рождения. То есть записи все, а столбцы нет:
| id | last_name | first_name | birthday |
|---|---|---|---|
| 1 | Иванов | Дмитрий | 1996-12-11 |
| 2 | Лебедев | Олег | 2000-02-07 |
| 3 | Шевченко | Тимур | 1998-04-27 |
| 4 | Иванова | Светлана | 1993-08-06 |
| 5 | Ковалев | Олег | 2002-02-08 |
| 6 | Иванов | Алексей | 1993-08-05 |
| 7 | Процук | Алена | 1997-02-28 |
Кроме того, что мы получили не все столбцы, мы дополнительно изменили их порядок на тот, который нам удобен. В оригинальной таблице first_name стоит перед last_name, а у нас наоборот.
Еще обратите внимание, что результатом работы SQL запроса является таблица. То есть мы берем исходную таблицу, которая хранится в базе, и с помощью SQL запроса получаем другую таблицу — с теми данными, которые нам нужны.
И часто требуется получить не все данные, а только те, которые соответствуют какому-то условию. Давайте снова изменим наш SQL-запрос, чтобы он стал таким:
SELECT last_name, first_name, birthday FROM users WHERE age > 18Если его выполнить, то мы получим список пользователей которым уже исполнилось 19 лет:
| id | last_name | first_name | birthday |
|---|---|---|---|
| 1 | Иванов | Дмитрий | 1996-12-11 |
| 3 | Шевченко | Тимур | 1998-04-27 |
| 4 | Иванова | Светлана | 1993-08-06 |
| 6 | Иванов | Алексей | 1993-08-05 |
Конструкция WHERE позволяет фильтровать исходные данные в соответствии с нашими условиями. В данном случае мы получаем данные из таблицы users ГДЕ (WHERE) в столбце age значение больше 18.
Так как age — это числовой столбец, то его уместно сравнивать с числами. Если заменить знак больше на равно и снова запустить, то получим всех 18 летних пользователей. А если поставим >= , то получим совершеннолетних пользователей:
SELECT last_name, first_name, birthday FROM users WHERE age >= 18| id | last_name | first_name | birthday |
|---|---|---|---|
| 1 | Иванов | Дмитрий | 1996-12-11 |
| 3 | Шевченко | Тимур | 1998-04-27 |
| 4 | Иванова | Светлана | 1993-08-06 |
| 6 | Иванов | Алексей | 1993-08-05 |
| 7 | Процук | Алена | 1997-02-28 |
Как видите SQL запросы довольно просто составлять и читать. Язык создавался для того, чтобы им могли пользоваться люди, которые не умеют программировать.
А теперь самое время потренироваться в SQL, для этого к каждому уроку привязано несколько задач, которые вы можете решать в специальном тренажере прямо на сайте.
Следующий урок
Урок 2. Составные условия
В этом уроке вы узнаете как формировать сложные условия в SQL-запросах с использованием операторов AND и OR.
Посмотреть
Тарифы
-
-
56 видео-уроков
Более 7 часов видео
-
Дополнительные материалы
Схемы, методички, исходные коды
-
Возможность скачать видео
Смотреть уроки можно даже без интернета
-
Доступ к курсу навсегда
Можете освежить знания через год или два
-
271 практическое задание
Практические занятия на тренажере
-
Поддержка преподавателя
Помощь в решении заданий в течение 24 часов
-
Сертификат о прохождении курса
Подтверждение ваших навыков
-
Эталонные решения
Решения преподавателя
-
-
-
56 видео-уроков
Более 7 часов видео
-
Дополнительные материалы
Схемы, методички, исходные коды
-
Возможность скачать видео
Смотреть уроки можно даже без интернета
-
Доступ к курсу навсегда
Условия бесплатного тарифа могут измениться
-
271 практическое задание
Практические занятия на тренажере
-
Поддержка преподавателя
Помощь в решении заданий в течение 24 часов
-
Сертификат о прохождении курса
Подтверждение ваших навыков
-
Эталонные решения
Решения преподавателя
-
Регистрация
В этой статье мы рассмотрим некоторые базовые запросы SQL, с изучения которых стоит начинать новичкам в этом языке. Вы научитесь создавать базу данных и таблицы, вносить в них данные и делать выборки нужных сведений.

Аббревиатура SQL расшифровывается как «Structured Query Language» — язык структурированных запросов. С помощью этого языка вы можете работать с записями в базах данных.
SQL состоит из команд и декларативных ключевых слов, которые являются как бы инструкциями для базы данных.
При помощи команд SQL можно создавать и удалять таблицы в базах данных, добавлять в них данные или вносить изменения, искать и быстро находить нужные сведения.
В этой статье мы рассмотрим основные ключевые слова и операторы SQL и разберем, как с их помощью запрашивать конкретную информацию из базы данных.
Структура базы данных
Прежде чем мы начнем разбирать запросы, нужно, чтобы вы поняли иерархию базы данных.
База данных SQL — это набор взаимосвязанных сведений, хранящихся в таблицах. В каждой таблице есть столбцы, описывающие хранящиеся в них данные, и строки, в которых эти данные хранятся. Поле — это отдельный кусочек данных в строке. Чтобы найти нужные данные, мы должны написать, что именно мы хотим получить.
Возьмем для примера некую компанию, штат которой разбросан по всему миру. Допустим, у этой компании есть много баз данных. Чтобы увидеть их полный список, нужно набрать SHOW DATABASES;
Результат может выглядеть как-то так:
+--------------------+ | Databases | +--------------------+ | mysql | | information_schema | | employees | | test | | sys | +--------------------+
В каждой отдельной базе данных может быть много таблиц. Чтобы увидеть, какие таблицы есть в базе данных employees из нашего примера, нужно набрать SHOW TABLES in employees;. В таблицах могут содержаться данные по разным командам, что отражается в названиях: engineering, product, marketing, sales.
+----------------------+ | Tables_in_employees | +----------------------+ | engineering | | product | | marketing | | sales | +----------------------+
Все таблицы состоят из различных столбцов, описывающих данные.
Чтобы просмотреть столбцы таблицы Engineering, используйте Describe Engineering;. Каждый столбец этой таблицы может описывать какой-то один атрибут сотрудника, например: employee_id, first_name, last_name, email, country и salary.
Вывод:
+-----------+-------------------+--------------+ | Name | Null | Type | +-----------+-------------------+--------------+ |EMPLOYEE_ID| NOT NULL | INT(6) | |FIRST_NAME | NOT NULL |VARCHAR2(20) | |LAST_NAME | NOT NULL |VARCHAR2(25) | |EMAIL | NOT NULL |VARCHAR2(255) | |COUNTRY | NOT NULL |VARCHAR2(30) | |SALARY | NOT NULL |DECIMAL(10,2) | +-----------+-------------------+--------------+
Таблицы также состоят из строк — отдельных записей. В нашем примере в строках будут указаны id, имена, фамилии, email, зарплата и страны проживания сотрудников. Каждая строка будет касаться одного сотрудника, допустим, из команды Engineering.
Базовые запросы SQL
Все операции, которые можно осуществлять с данными, входят в понятие «CRUD».
CRUD расшифровывается как Create, Read, Update и Delete (создать, прочесть, обновить, удалить). Это четыре основных операции, которые мы осуществляем, делая запросы к базе данных.
Мы создаем информацию в базе (CREATE), мы читаем, получаем информацию из базы (READ), мы обновляем данные или осуществляем какие-то манипуляции с ними (UPDATE) и, при желании, можем удалять данные (DELETE).
Для осуществления различных операций с данными в SQL есть специальные ключевые слова (операторы). Ниже мы рассмотрим некоторые простые запросы SQL и их синтаксис.
Ключевые слова в SQL
CREATE DATABASE
Для создания базы данных с именем engineering мы используем следующий код:
CREATE DATABASE engineering;
CREATE TABLE
Синтаксис:
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
column3 datatype
);
Этот запрос создает новую таблицу в базе данных.
В нем задается имя таблицы, а также имена столбцов, которые нам нужны.
Что касается типов данных (datatype), они могут быть разными. Самые распространенные — INT, DECIMAL, DATETIME, VARCHAR, NVARCHAR, FLOAT и BIT.
В нашем примере запрос может быть таким:
CREATE TABLE engineering ( employee_id int(6) NOT NULL, first_name varchar(20) NOT NULL, last_name varchar(25) NOT NULL, email varchar(255) NOT NULL, country varchar(30), salary decimal(10,2) NOT NULL );
Таблица, созданная по этому запросу, будет выглядеть так:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | |
| |
ALTER TABLE
После создания таблицы мы можем изменять ее путем добавления столбцов.
Синтаксис:
ALTER TABLE table_name ADD column_name datatype;
Допустим, мы хотим добавить в только что созданную таблицу столбец с днями рождения сотрудников. Это можно сделать так:
ALTER TABLE engineering ADD birthday date;
Теперь таблица выглядит немного иначе:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | BIRTHDAY | |
| |
INSERT
Это ключевое слово служит для вставки данных в таблицы и создания новых строк. В аббревиатуре CRUD это соответствует букве C.
Синтаксис:
INSERT INTO table_name(column1, column2, column3,..) VALUES(value1, 'value2', value3,..);
Этот запрос создает новую запись в таблице, т. е. новую строку.
В части INSERT INTO мы указываем столбцы, которые хотим заполнить информацией. В VALUES указана информация, которую нужно сохранить.
При вставке строковых значений их нужно брать в одинарные кавычки.
Например:
INSERT INTO table_name(employee_id,first_name,last_name,email,country,salary) VALUES (1,'Timmy','Jones','timmy@gmail.com','USA',2500.00); (2,'Kelly','Smith','ksmith@gmail.com','UK',1300.00);
Теперь таблица будет выглядеть так:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | |
| 1 | Timmy | Jones | timmy@gmail.com | USA | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
SELECT
Это ключевое слово служит для выборки данных из базы. В CRUD эта операция соответствует букве R.
Синтаксис:
SELECT column1,column2 FROM table_name;
В нашем примере этот запрос будет выглядеть следующим образом:
SELECT first_name,last_name FROM engineering;
Результат:
+-----------+----------+ |FirstName | LastName | +-----------+----------+ | Timmy | Jones | | Kelly | Smith | +-----------+----------+
Ключевое слово SELECT указывает на конкретный столбец, из которого мы хотим выбрать данные.
В части FROM определяется сама таблица.
Вот еще один пример запроса SELECT:
SELECT * FROM table_name;
Астериск (звездочка) означает, что нам нужна вся информация из указанной таблицы (а не отдельный столбец).
WHERE
WHERE позволяет составлять более специфичные (конкретные) запросы.
Например, мы можем использовать WHERE, чтобы выбрать из нашей таблицы Engineering сотрудников с определенным уровнем зарплаты.
SELECT employee_id,first_name,last_name,email,country FROM engineering WHERE salary > 1500
Таблица из предыдущего примера:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | |
| 1 | Timmy | Jones | timmy@gmail.com | USA | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
Теперь вывод будет такой:
+-----------+----------+----------+----------------+------------+ |employee_id|first_name|last_name |email |country | +-----------+----------+----------+----------------+------------+ | 1| Timmy |Jones |timmy@gmail.com | USA | +-----------+----------+----------+----------------+------------+
Данные отфильтрованы, и нам показывается только то, что отвечает условию. То есть в выводе мы получаем только строки, где зарплата больше 1500.
Операторы AND, OR, BETWEEN в SQL
Эти операторы позволяют еще больше уточнить запрос. С их помощью можно добавить больше критериев в блоке WHERE.
Оператор AND принимает два условия, причем, чтобы строка попала в результат, оба условия должны быть истинными.
SELECT column_name
FROM table_name
WHERE column1 =value1
AND column2 = value2;
OR тоже принимает два условия, но чтобы строка попала в результат, достаточно истинности хотя бы одного.
SELECT column_name
FROM table_name
WHERE column_name = value1
OR column_name = value2;
Оператор BETWEEN отфильтровывает результаты в определенном диапазоне чисел или текста.
SELECT column1,column2 FROM table_name WHERE column_name BETWEEN value1 AND value2;
Все эти операторы можно комбинировать друг с другом.
Допустим, наша таблица выглядит так:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | |
| 1 | Timmy | Jones | timmy@gmail.com | USA | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
| 3 | Jim | White | jwhite@gmail.com | UK | 1200.76 |
| 4 | José Luis | Martìnez | jmart@gmail.com | Mexico | 1275.87 |
| 5 | Emilia | Fischer | emfis@gmail.com | Germany | 2365.90 |
| 6 | Delphine | Lavigne | lavigned@gmail.com | France | 2108.00 |
| 7 | Louis | Meyer | lmey@gmail.com | Germany | 2145.70 |
Если мы напишем такой запрос:
SELECT * FROM engineering
WHERE employee_id BETWEEN 3 AND 7
AND
country = 'Germany';
Мы получим следующий результат:
+------------+-----------+-----------+----------------+--------+--------+ |employee_id | first_name| last_name | email |country |salary | +------------+-----------+-----------+----------------+--------+--------+ |5 |Emilia |Fischer |emfis@gmail.com | Germany| 2365.90| |7 |Louis |Meyer |lmey@gmail.com | Germany| 2145.70| +------------+-----------+-----------+----------------+--------+--------+
Были выбраны все столбцы, где employee_id от 3 до 7, а страна проживания — Германия.
ORDER BY
Ключевое слово ORDER BY позволяет отсортировать выдачу по столбцам, указанным в SELECT.
Отсортированные результаты выводятся в порядке возрастания или убывания.
По умолчанию сортировка идет по возрастанию. Но мы можем указать желаемый порядок явно — при помощи команды ORDER BY column_name DESC | ASC .
SELECT employee_id, first_name, last_name,salary FROM engineering ORDER BY salary DESC;
В этом примере мы отсортировали зарплату сотрудников в команде engineering и представили вывод в порядке убывания числовых значений (DESC — от англ. descending — «нисходящий»).
GROUP BY
Ключевое слово GROUP BY в SQL позволяет комбинировать строки с идентичными и похожими данными.
Это полезно для приведения в порядок дублирующихся данных и записей, которые повторяются в таблице многократно.
SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name;
Здесь COUNT(*) подсчитывает все строки и возвращает число строк в указанной таблице, группируя строки-дубликаты.
От редакции Techrocks: о COUNT и других агрегатных функциях можно почитать в статье «Агрегатные функции в SQL: объяснение с примерами запросов».
LIMIT
При помощи LIMIT можно указать максимальное число строк, которые должны попасть в результат.
Это бывает полезно при работе с большими наборами данных. Если данных много, запрос может обрабатываться слишком долго. Но когда будет достигнут лимит результатов, обработка прекратится.
Синтаксис:
SELECT column1,column2 FROM table_name LIMIT number;
UPDATE
Ключевое слово UPDATE позволяет обновлять записи в таблице. В CRUD этой операции соответствует буква U.
Синтаксис:
UPDATE table_name
SET column1 = value1,
column2 = value2
WHERE condition;
В условии WHERE указывается запись, которую нужно отредактировать.
UPDATE engineering SET country = 'Spain' WHERE employee_id = 1
Прежде наша таблица выглядела так:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | |
| 1 | Timmy | Jones | timmy@gmail.com | USA | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
| 3 | Jim | White | jwhite@gmail.com | UK | 1200.76 |
| 4 | José Luis | Martìnez | jmart@gmail.com | Mexico | 1275.87 |
| 5 | Emilia | Fischer | emfis@gmail.com | Germany | 2365.90 |
| 6 | Delphine | Lavigne | lavigned@gmail.com | France | 2108.00 |
| 7 | Louis | Meyer | lmey@gmail.com | Germany | 2145.70 |
Теперь, после выполнения запроса, она выглядит так:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | |
| 1 | Timmy | Jones | timmy@gmail.com | Spain | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
| 3 | Jim | White | jwhite@gmail.com | UK | 1200.76 |
| 4 | José Luis | Martìnez | jmart@gmail.com | Mexico | 1275.87 |
| 5 | Emilia | Fischer | emfis@gmail.com | Germany | 2365.90 |
| 6 | Delphine | Lavigne | lavigned@gmail.com | France | 2108.00 |
| 7 | Louis | Meyer | lmey@gmail.com | Germany | 2145.70 |
Обновилась страна проживания сотрудника с id 1.
Обновить информацию можно и с помощью значений из другой таблицы. Для этого применяется ключевое слово JOIN.
UPDATE table_name
SET table_name1.column_name1 = table_name2.column_name1
table_name1.column_name2 = table_name2.column2
FROM table_name1
JOIN table_name2
ON table_name1.column_name = table_2.column_name;
DELETE
Ключевое слово DELETE служит для удаления записей из таблицы. В CRUD операция удаления представлена буквой D.
Синтаксис:
DELETE FROM table_name WHERE condition;
Пример с нашей таблицей:
DELETE FROM engineering WHERE employee_id = 2;
При выполнении запроса будет удалена запись о сотруднике с id 2 из команды engineering.
DROP COLUMN
Чтобы удалить из таблицы столбец, можно воспользоваться следующим кодом:
ALTER TABLE table_name DROP COLUMN column_name;
DROP TABLE
Для удаления всей таблицы выполните следующий запрос:
DROP TABLE table_name;
Итоги
В этой статье мы пробежались по самым базовым запросам, с которых начинают все новички в SQL.
Мы научились создавать таблицы и строки, группировать и обновлять данные и, наконец, удалять их. Попутно мы также разобрали SQL-запросы в привязке к операциям CRUD.
Перевод статьи «Learn SQL Queries – Database Query Tutorial for Beginners».
От редакции Techrocks. Вам также могут быть интересны другие статьи по теме SQL:
- Топ-30 вопросов по SQL на технических собеседованиях
- ТОП-10 сайтов, на которых можно потренировать SQL-запросы
- Порядок выполнения SQL-операций
- Выражение CASE в SQL: объяснение на примерах
Львиная доля мировой информации хранится в реляционных базах данных. Чтобы работать с ней, нужно владеть языком SQL-запросов.

Для решения многих стандартных задач не требуется быть SQL-виртуозом, достаточно изучить азы работы с базами:
- создание и редактирование таблиц;
- сохранение и обновление записей;
- выборка и фильтрация данных;
- индексирование полей.
Этими азами мы и займемся: разберем синтаксис SQL-запросов в теории и на реальных примерах. К счастью, язык баз данных очень похож на простые английские предложения, так что вы легко с ним справитесь.
Чтобы учиться эффективнее, сразу же закрепляйте новые знания практикой. Поиграть с SQL можно на этом замечательном ресурсе. В левой панели вы должны ввести весь код, относящийся к структуре базы данных. После этого начинайте экспериментировать с SELECT’ами в правом поле.
* В примерах используется SQL-синтаксис для MySQL 5.6. Запросы, предназначенные для разных СУБД, могут различаться.
Терминология
База данных состоит из таблиц, а таблица – из колонок и строк.
Каждая колонка, или поле таблицы, представляет собой конкретный вид информации, например, имя студента (строка) или зарплата сотрудника (число).
Каждая строка, или запись таблицы, – это описание конкретного объекта, например, студента или сотрудника.
Уровень: Новичок
Создание и редактирование таблиц
CREATE
Несложно догадаться, что оператор CREATE создает новую таблицу в базе. Ему нужно передать описания всех полей таблицы в формате:
название_поля тип_данных [атрибуты_поля]
Создадим таблицу с данными о собаках и их рационе питания:
# создать таблицу dogs с 5 полями разных типов CREATE TABLE rations ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(20) NOT NULL, weight INT DEFAULT 0, color VARCHAR(20), portion INT );
ALTER
Не всегда получается создать идеальную таблицу с первого раза. Не бойтесь вносить изменения, добавлять, удалять или изменять существующие поля:
# переименовать таблицу rations в portions ALTER TABLE rations RENAME TO portions; # добавить в таблицу portions числовое поле age ALTER TABLE portions ADD age INT; # удалить из таблицы portions поле color ALTER TABLE portions DROP COLUMN color; # переименовать поле name в dog_name ALTER TABLE portions CHANGE name dog_name VARCHAR(20) NOT NULL;
DROP и TRUNCATE
Оператор DROP удаляет таблицу из базы целиком:
# удалить таблицу portions DROP TABLE portions;
Если вам нужно удалить только записи, сохранив саму таблицу, воспользуйтесь оператором TRUNCATE:
# очистить таблицу portions TRUNCATE TABLE portions;
Атрибуты и ограничения
Можно ограничить диапазон данных, которые попадают в поле, например, запретить устанавливать в качестве возраста или веса отрицательные числа.
Самые распространенные в SQL ограничения целостности (CONSTRAINTS):
- DEFAULT – устанавливает значение по умолчанию;
- AUTO_INCREMENT – автоматически инкрементирует значение поля для каждой следующей записи;
- NOT NULL – запрещает создавать запись с пустым значением поля;
- UNIQUE – следит, чтобы поле или комбинация полей оставались уникальны в пределах таблицы;
- PRIMARY KEY – UNIQUE + NOT NULL. Первичный ключ должен однозначно идентифицировать запись таблицы, поэтому он должен быть уникальным и не может оставаться пустым;
- CHECK – проверяет значение поля на соответствие некоторому условию.
Ограничения можно добавлять при создании таблицы, а затем при необходимости добавлять/изменять/удалять. Они могут действовать на одно поле или комбинацию полей.
Первичный ключ, автоматический инкремент, NOT NULL и значение по умолчанию мы уже использовали в примере с собаками.
Решим новую задачу – составление списка президентов:
# уникальная комбинация страна + имя президента CREATE TABLE presidents ( country VARCHAR(20), name VARCHAR(50), age INT CHECK(age > 50), UNIQUE(country, name) );
Ограничение уникальности не позволит занести в таблицу одного и того же президента одной страны дважды. Кроме того, не попадут в список и слишком молодые политики.
Для добавления и удаления ограничений к существующим таблицам используйте оператор ALTER. Ограничениям можно давать имя, чтобы ссылаться на них впоследствии. Для этого предназначена конструкция CONSTRAINT.
CREATE TABLE presidents ( country VARCHAR(20), name VARCHAR(50), age INT ); # добавить именованное ограничение уникальности ALTER TABLE presidents ADD CONSTRAINT unique_president UNIQUE(country, name); # удалить именованное ограничение ALTER TABLE presidents DROP INDEX unique_president; # добавить неименованное ограничение уникальности ALTER TABLE presidents ADD UNIQUE(country, name); # добавить проверку значения ALTER TABLE presidents ADD CHECK (age > 50);
Еще одно удобное ограничение в SQL – внешний ключ (FOREIGN KEY). Он позволяет связать поля двух разных таблиц.
Для примера возьмем базу данных организации с таблицами сотрудников и отделов:
CREATE TABLE departments ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(20) ); # в поле departament будет храниться id одного из отделов, # перечисленных в таблице departments CREATE TABLE employees ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), department INT, salary INT, FOREIGN KEY (department) REFERENCES departments(id) );
Теперь в поле department таблицы employees нельзя будет указать произвольный отдел. Он обязательно должен содержаться в таблице departments.
Сохранение и обновление записей
INSERT
Добавить в таблицу новую запись (или даже сразу несколько) очень просто:
INSERT INTO portions (dog_name, weight, portion) VALUES ("Jack", 25, 250);
INSERT INTO portions (dog_name, weight, portion)
VALUES ("Max", 15, 180), ("Charlie", 37, 350);
Вы даже можете скопировать записи из одной таблицы и вставить их в другую одним запросом. Для этого нужно скомбинировать операторы INSERT и SELECT:
CREATE TABLE dogs( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(20) NOT NULL, weight INT DEFAULT 0 ); INSERT INTO dogs (name, weight) SELECT dog_name, weight FROM portions;
UPDATE
Оператор UPDATE используется для изменения существующих записей таблицы.
UPDATE employees SET salary = 0;
Вот так легким движением руки мы обнулили зарплату сразу у всех сотрудников.
Запрос можно уточнить, добавив секцию WHERE с условием отбора записей.
UPDATE employees SET salary = 0 WHERE name = "Ivan Ivanov";
С условиями мы подробно разберемся чуть позже, когда будем говорить о выборке данных из базы.
DELETE
Можно удалить из таблицы все записи сразу или только те, которые соответствуют некоторому условию:
DELETE FROM employees; # Ивана Иванова пора увольнять DELETE FROM employees WHERE name = "Ivan Ivanov";

Уровень: уверенный пользователь
Выборка и фильтрация данных
Для получения данных из базы служит оператор SELECT. В SQL есть множество способов отфильтровать именно те данные, которые вам нужны, а также отсортировать их и разбить по группам.
Вот небольшая демо-база, на которой вы можете попрактиковаться:
CREATE TABLE departments (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(20)
);
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
department INT,
salary INT,
boss INT
);
INSERT INTO departments (name)
VALUES ("administration"), ("accounting"),
("customer service"), ("finance"),
("legal"), ("logistics"),
("orders"), ("purchasing");
INSERT INTO employees (name, department, salary, boss)
VALUES ("John Doe", 1, 40000), ("Jane Smith", 1, 35000, 1),
("Fred Brown", 1, 48000, 1), ("Kevin Jones", 2, 36000),
("Josh Taylor", 2, 22000, 4), ("Alex Clark", 2, 29000, 5),
("Branda Evans", 2, 27000, 5), ("Anthony Ford", 4, 32000),
("David Moore", 4, 29000, 8), ("Scott Riley", 5, 20000),
("Chris Gilmore", 5, 28000, 10), ("Roberta Newman", 5, 33000, 11),
("Kenny Washington", NULL, 55000);
SELECT
# получить все поля из всех записей SELECT * FROM employees; # получить только имена и зарплаты всех работников SELECT name, salary FROM employees;
Можно переименовывать поля для вывода:
SELECT name as employee FROM employees;
Добавление условий:
# имена работников, зарплата которых выше 20 тысяч SELECT name FROM employees WHERE salary > 20000; # все сотрудники с запрлатой от 25 до 30 тысяч SELECT name FROM employees WHERE salary BETWEEN 25000 AND 30000; # все Джоны среди работников SELECT * FROM employees WHERE name LIKE "john%" # все сотрудники, кроме Джонов и Джонсов SELECT * FROM employees WHERE name NOT LIKE "john%" AND name NOT LIKE "%jones" # все сотрудники юридического отдела, администрации и бухгалтерии SELECT * FROM employees WHERE department IN [1, 2, 5] # все сотрудники, у которых нет начальников SELECT * FROM employees WHERE boss IS NULL
Сортировка:
# по уменьшению зарплаты SELECT name, salary FROM employees ORDER BY salary ASC; # по увеличению зарплаты SELECT name, salary FROM employees ORDER BY salary DESC;
Ограничение количества результатов:
# пять самых высокооплачиваемых работника SELECT name FROM employees ORDER BY salary DESC LIMIT 5; # все работники кроме пяти самых высокооплачиваемых SELECT name FROM employees ORDER BY salary DESC OFFSET 5;
Агрегатные функции и группировка
SQL позволяет привести несколько записей таблицы к некоторому единому значению:
# общее количество работников SELECT COUNT(*) FROM employees; # найти работника с максимальной зарплатой SELECT name, MAX(salary) FROM employees; # найти работника с минимальной зарплатой SELECT name, MIN(salary) FROM employees; # найти среднюю зарплату по предприятию SELECT AVG(salary) FROM employees; # найти сумму всех зарплат SELECT SUM(salary) FROM employees;
Агрегатные функции могут работать со всеми записями таблицы разом, а могут и с отдельными группами. Чтобы эти группы сформировать, используйте оператор GROUP BY:
# найти максимальную зарплату в каждом отделе SELECT department, MAX(salary) FROM employees GROUP BY department;
Полученные группы тоже можно отфильтровывать: для этого предназначена конструкция HAVING. Например, не будем учитывать в выборке отделы, в которых работает меньше трех человек:
SELECT department, MAX(salary) FROM employees GROUP BY department HAVING COUNT(*) > 3;
Объединение таблиц
Очень часто нужная вам информация хранится в разных таблицах – это обусловлено законами нормализации. Поэтому важно уметь объединять их.
В запросе, захватывающем несколько таблиц, нужно указать следующее:
- все интересующие вас поля, которые могут принадлежать разным таблицам;
- тип соединения;
- правило, по которому поля одной таблицы будут поставлены в соответствие полям другой таблицы.
Соединение бывает внутреннее (INNER) и внешнее (OUTER).
Внутреннее соединение
При внутреннем соединении вы получите в результате только те записи, для которых нашлось соответствие во всех таблицах.
SELECT employees.name, employees.salary, departments.name as department FROM employees INNER JOIN departments ON employees.department = departments.id;
SQL просмотрит каждую запись из таблицы employees и попытается поставить ей в соответствие каждую запись из таблицы departments. Если это удастся (id отделов совпадают), запись будет включена в результат, иначе – не будет.
Таким образом, вы не увидите Kenny Washington, у которого отдел не указан, а также все отделы, в которых нет сотрудников.
Если не указано условие для соединения таблиц, SQL создаст все возможные комбинации сотрудников и отделов.
Внешнее соединение
При внешнем соединении в результат попадают также записи без соответствий. При этом вы можете регулировать, из какой таблицы такие записи берутся, а из какой – нет.
Например, чтобы увидеть в результате Kenny Washington, потребуется левое внешнее соединение. Слово OUTER можно не указывать – соединение по умолчанию внешнее:
SELECT employees.name, employees.salary, departments.name as department FROM employees LEFT JOIN departments ON employees.department = departments.id;
Теперь в результате есть все данные из левой таблицы (employees), даже если для них нет соответствия.
Правое соединение соответственно проигнорирует Кенни, но выведет все пустые отделы:
SELECT employees.name, employees.salary, employees.department, departments.name FROM employees RIGHT JOIN departments ON employees.department = departments.id;
И наконец, полное внешнее соединение выведет и соответствия, и пустые отделы, и сотрудников без отдела.
SELECT employees.name, employees.salary, employees.department, departments.name FROM employees FULL JOIN departments ON employees.department = departments.id;
Декартово произведение
Оператор CROSS JOIN позволяет получить все возможные комбинации записей из двух таблиц:
SELECT * FROM employees CROSS JOIN departments;
Автосоединение
Кроме того, таблицу можно соединять с самой собой. Это пригодится, чтобы найти босса для каждого сотрудника. Сейчас в поле boss находится идентификатор другого сотрудника, необходимо вывести его имя:
SELECT e1.name, e1.department, e2.name as boss FROM employees e1 LEFT JOIN employees e2 ON e1.boss = e2.id
Благодаря использованию левого соединения мы можем вывести также сотрудников, не имеющих руководителей.
Объединение выборок
SQL позволяет сделать две отдельные выборки, а затем объединить их результаты по определенному правилу:
UNION
Объединить штатных и внештатных сотрудников
// без дублей (или со всеми дублями) SELECT * FROM employees UNION [ALL] SELECT * FROM freelancers;
INTERSECT
Найти всех сотрудников, которые участвуют в сборной предприятия по спортивной ходьбе
SELECT name FROM employees INTERSECT SELECT name FROM race_walking_team
MINUS
Найти всех сотрудников, которые не участвуют в сборной предприятия по спортивной ходьбе и заставить участвовать:
SELECT name FROM employees MINUS SELECT name FROM race_walking_team

Представления
Views, или представления, в SQL – это SELECT-запрос, который вы можете сохранить для дальнейшего использования. Один раз написали, а потом можете пользоваться полученной таблицей, которая – внимание! – всегда остается актуальной в отличие от результата обычных запросов.
У представлений есть еще одна важная миссия: обеспечение безопасности. Под view вы легко можете скрыть бизнес-логику и архитектуру базы и защитить свое приложение от нежелательных вторжений.
Представление может извлекать данные из одной или нескольких таблиц. Кроме того, при соблюдении ряда условий представление может быть изменяемым, то есть совершая операции над ним, можно изменять базовые таблицы.
// простое представление CREATE VIEW view(name, salary) AS SELECT name, salary FROM employees;
Если представление изменяемое, можно использовать при его создании CHECK OPTION для проверки изменений на соответствие некоторому предикату:
CREATE VIEW view(name, salary)
AS
SELECT name, salary
FROM employees WHERE salary > 30000
WITH CHECK OPTION;
// в такое представление не получится вставить следующую запись
INSERT INTO view (name, salary)
VALUES ("Jack Daniels", 25000);
Представления могут основываться как на таблицах базы, так и на других представлениях, образуя несколько уровней вложенности. С учетом этого предложение WITH можно расширить:
- WITH CASCADED CHECK OPTION – проверяет запросы на всех уровнях вложенности;
- WITH LOCAL CHECK OPTION – проверяет только “верхний” запрос.
CREATE VIEW view(name, salary)
AS
SELECT name, salary
FROM employees WHERE salary > 30000;
CREATE VIEW view2(name, salary)
AS
SELECT name, salary
FROM view WHERE salary > 10000
WITH LOCAL CHECK OPTION;
// строка будет вставлена в таблицу, но не будет видна в представлениях
INSERT INTO view2 (name, salary)
VALUES ("Jack Daniels", 15000);
Представление даже может ссылаться само на себя.
Чтобы удалить представление, используйте уже знакомый оператор DROP:
DROP VIEW view;
Индексы
Индексы – это специальный таблицы, которые позволяют ускорить поиск по базе данных. Их можно представить как алфавитный указатель в большой книге.
// создание индекса для двух полей CREATE INDEX index_name ON table(column1, column2);
Наличие индексов в базе ускоряет выполнение операций SELECT и вычисление условий WHERE. Но есть и обратная сторона медали: замедляются операции вставки и удаления данных, так как при этих изменениях необходимо пересчитывать индексы.
Триггеры
Триггеры в SQL – это процедуры, которые автоматически запускаются при выполнении определенной операции (INSERT/UPDATE/DELETE) – до (BEFORE) или после (AFTER) нее.
// создание триггера // бонус к зарплате каждому новому сотруднику DELIMITER $$ CREATE OR MODIFY TRIGGER bonuses BEFORE INSERT ON employees FOR EACH ROW BEGIN SET NEW.salary = NEW.salary+3000; END$$
Удалить существующий триггер можно с помощью оператора DROP:
DROP TRIGGER bonuses;
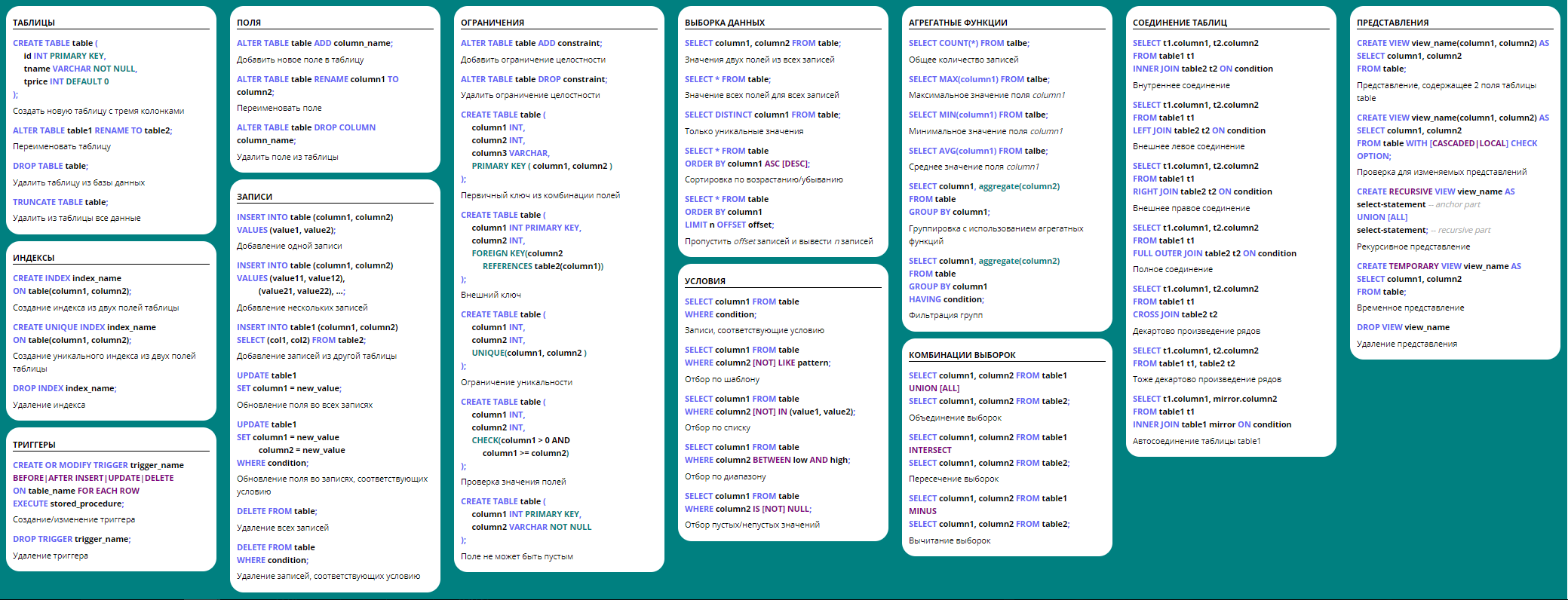
Удобные шпаргалки по SQL в pdf-формате.
Еще много интересных статей по SQL
- Супергеройское введение в SQL
- SQL-программирование: наиболее полный видеокурс
- Работа с PostgreSQL: от полного нуля до полного просветления
- ТОП-20 хитрых вопросов по SQL для собеседования
