Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
NaN stands for Not A Number and is one of the common ways to represent the missing value in the data. It is a special floating-point value and cannot be converted to any other type than float.
NaN value is one of the major problems in Data Analysis. It is very essential to deal with NaN in order to get the desired results.

Check for NaN Value in Pandas DataFrame
The ways to check for NaN in Pandas DataFrame are as follows:
- Check for NaN with isnull().values.any() method
- Count the NaN Using isnull().sum() Method
- Check for NaN Using isnull().sum().any() Method
- Count the NaN Using isnull().sum().sum() Method
Method 1: Using isnull().values.any() method
Example:
Python3
import pandas as pd
import numpy as np
num = {'Integers': [10, 15, 30, 40, 55, np.nan,
75, np.nan, 90, 150, np.nan]}
df = pd.DataFrame(num, columns=['Integers'])
check_nan = df['Integers'].isnull().values.any()
print(check_nan)
Output:
True
It is also possible to get the exact positions where NaN values are present. We can do so by removing .values.any() from isnull().values.any() .
Python3
Output:
0 False 1 False 2 False 3 False 4 False 5 True 6 False 7 True 8 False 9 False 10 True Name: Integers, dtype: bool
Method 2: Using isnull().sum() Method
Example:
Python3
import pandas as pd
import numpy as np
num = {'Integers': [10, 15, 30, 40, 55, np.nan,
75, np.nan, 90, 150, np.nan]}
df = pd.DataFrame(num, columns=['Integers'])
count_nan = df['Integers'].isnull().sum()
print('Number of NaN values present: ' + str(count_nan))
Output:
Number of NaN values present: 3
Method 3: Using isnull().sum().any() Method
Example:
Python3
import pandas as pd
import numpy as np
nums = {'Integers_1': [10, 15, 30, 40, 55, np.nan, 75,
np.nan, 90, 150, np.nan],
'Integers_2': [np.nan, 21, 22, 23, np.nan, 24, 25,
np.nan, 26, np.nan, np.nan]}
df = pd.DataFrame(nums, columns=['Integers_1', 'Integers_2'])
nan_in_df = df.isnull().sum().any()
print(nan_in_df)
Output:
True
To get the exact positions where NaN values are present, we can do so by removing .sum().any() from isnull().sum().any() .
Method 4: Using isnull().sum().sum() Method
Example:
Python3
import pandas as pd
import numpy as np
nums = {'Integers_1': [10, 15, 30, 40, 55, np.nan, 75,
np.nan, 90, 150, np.nan],
'Integers_2': [np.nan, 21, 22, 23, np.nan, 24, 25,
np.nan, 26, np.nan, np.nan]}
df = pd.DataFrame(nums, columns=['Integers_1', 'Integers_2'])
nan_in_df = df.isnull().sum().sum()
print('Number of NaN values present: ' + str(nan_in_df))
Output:
Number of NaN values present: 8
Last Updated :
30 Jan, 2023
Like Article
Save Article
You have a couple of options.
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(10,6))
# Make a few areas have NaN values
df.iloc[1:3,1] = np.nan
df.iloc[5,3] = np.nan
df.iloc[7:9,5] = np.nan
Now the data frame looks something like this:
0 1 2 3 4 5
0 0.520113 0.884000 1.260966 -0.236597 0.312972 -0.196281
1 -0.837552 NaN 0.143017 0.862355 0.346550 0.842952
2 -0.452595 NaN -0.420790 0.456215 1.203459 0.527425
3 0.317503 -0.917042 1.780938 -1.584102 0.432745 0.389797
4 -0.722852 1.704820 -0.113821 -1.466458 0.083002 0.011722
5 -0.622851 -0.251935 -1.498837 NaN 1.098323 0.273814
6 0.329585 0.075312 -0.690209 -3.807924 0.489317 -0.841368
7 -1.123433 -1.187496 1.868894 -2.046456 -0.949718 NaN
8 1.133880 -0.110447 0.050385 -1.158387 0.188222 NaN
9 -0.513741 1.196259 0.704537 0.982395 -0.585040 -1.693810
- Option 1:
df.isnull().any().any()– This returns a boolean value
You know of the isnull() which would return a dataframe like this:
0 1 2 3 4 5
0 False False False False False False
1 False True False False False False
2 False True False False False False
3 False False False False False False
4 False False False False False False
5 False False False True False False
6 False False False False False False
7 False False False False False True
8 False False False False False True
9 False False False False False False
If you make it df.isnull().any(), you can find just the columns that have NaN values:
0 False
1 True
2 False
3 True
4 False
5 True
dtype: bool
One more .any() will tell you if any of the above are True
> df.isnull().any().any()
True
- Option 2:
df.isnull().sum().sum()– This returns an integer of the total number ofNaNvalues:
This operates the same way as the .any().any() does, by first giving a summation of the number of NaN values in a column, then the summation of those values:
df.isnull().sum()
0 0
1 2
2 0
3 1
4 0
5 2
dtype: int64
Finally, to get the total number of NaN values in the DataFrame:
df.isnull().sum().sum()
5
В предыдущих разделах вы видели, как легко могут образовываться недостающие данные. В структурах они определяются как значения NaN (Not a Value). Такой тип довольно распространен в анализе данных.
Но pandas спроектирован так, чтобы лучше с ними работать. Дальше вы узнаете, как взаимодействовать с NaN, чтобы избегать возможных проблем. Например, в библиотеке pandas вычисление описательной статистики неявно исключает все значения NaN.
Если нужно специально присвоить значение NaN элементу структуры данных, для этого используется np.NaN (или np.nan) из библиотеки NumPy.
>>> ser = pd.Series([0,1,2,np.NaN,9],
... index=['red','blue','yellow','white','green'])
>>> ser
red 0.0
blue 1.0
yellow 2.0
white NaN
green 9.0
dtype: float64
>>> ser['white'] = None
>>> ser
red 0.0
blue 1.0
yellow 2.0
white NaN
green 9.0
dtype: float64
Фильтрование значений NaN
Есть несколько способов, как можно избавиться от значений NaN во время анализа данных. Это можно делать вручную, удаляя каждый элемент, но такая операция сложная и опасная, к тому же не гарантирует, что вы действительно избавились от всех таких значений. Здесь на помощь приходит функция dropna().
>>> ser.dropna()
red 0.0
blue 1.0
yellow 2.0
green 9.0
dtype: float64
Функцию фильтрации можно выполнить и прямо с помощью notnull() при выборе элементов.
>>> ser[ser.notnull()]
red 0.0
blue 1.0
yellow 2.0
green 9.0
dtype: float64
В случае с Dataframe это чуть сложнее. Если использовать функцию pandas dropna() на таком типе объекта, который содержит всего одно значение NaN в колонке или строке, то оно будет удалено.
>>> frame3 = pd.DataFrame([[6,np.nan,6],[np.nan,np.nan,np.nan],[2,np.nan,5]],
... index = ['blue','green','red'],
... columns = ['ball','mug','pen'])
>>> frame3
| ball | mug | pen | |
|---|---|---|---|
| blue | 6.0 | NaN | 6.0 |
| green | NaN | NaN | NaN |
| red | 2.0 | NaN | 5.0 |
>>> frame3.dropna()
Empty DataFrame
Columns: [ball, mug, pen]
Index: []
Таким образом чтобы избежать удаления целых строк или колонок нужно использовать параметр how, присвоив ему значение all. Это сообщит функции, чтобы она удаляла только строки или колонки, где все элементы равны NaN.
>>> frame3.dropna(how='all')
| ball | mug | pen | |
|---|---|---|---|
| blue | 6.0 | NaN | 6.0 |
| red | 2.0 | NaN | 5.0 |
Заполнение NaN
Вместо того чтобы отфильтровывать значения NaN в структурах данных, рискуя удалить вместе с ними важные элементы, можно заменять их на другие числа. Для этих целей подойдет fillna(). Она принимает один аргумент — значение, которым нужно заменить NaN.
>>> frame3.fillna(0)
| ball | mug | pen | |
|---|---|---|---|
| blue | 6.0 | 0.0 | 6.0 |
| green | 0.0 | 0.0 | 0.0 |
| red | 2.0 | 0.0 | 5.0 |
Или же NaN можно заменить на разные значения в зависимости от колонки, указывая их и соответствующие значения.
>>> frame3.fillna({'ball':1,'mug':0,'pen':99})
| ball | mug | pen | |
|---|---|---|---|
| blue | 6.0 | 0.0 | 6.0 |
| green | 1.0 | 0.0 | 99.0 |
| red | 2.0 | 0.0 | 5.0 |
Обучение с трудоустройством
Here are 4 ways to check for NaN in Pandas DataFrame:
(1) Check for NaN under a single DataFrame column:
df['your column name'].isnull().values.any()
(2) Count the NaN under a single DataFrame column:
df['your column name'].isnull().sum()
(3) Check for NaN under an entire DataFrame:
df.isnull().values.any()
(4) Count the NaN under an entire DataFrame:
df.isnull().sum().sum()
(1) Check for NaN under a single DataFrame column
In the following example, we’ll create a DataFrame with a set of numbers and 3 NaN values:
import pandas as pd
import numpy as np
data = {'set_of_numbers': [1,2,3,4,5,np.nan,6,7,np.nan,8,9,10,np.nan]}
df = pd.DataFrame(data)
print (df)
You’ll now see the DataFrame with the 3 NaN values:
set_of_numbers
0 1.0
1 2.0
2 3.0
3 4.0
4 5.0
5 NaN
6 6.0
7 7.0
8 NaN
9 8.0
10 9.0
11 10.0
12 NaN
You can then use the following template in order to check for NaN under a single DataFrame column:
df['your column name'].isnull().values.any()
For our example, the DataFrame column is ‘set_of_numbers.’
And so, the code to check whether a NaN value exists under the ‘set_of_numbers’ column is as follows:
import pandas as pd
import numpy as np
data = {'set_of_numbers': [1,2,3,4,5,np.nan,6,7,np.nan,8,9,10,np.nan]}
df = pd.DataFrame(data)
check_for_nan = df['set_of_numbers'].isnull().values.any()
print (check_for_nan)
Run the code, and you’ll get ‘True’ which confirms the existence of NaN values under the DataFrame column:
True
And if you want to get the actual breakdown of the instances where NaN values exist, then you may remove .values.any() from the code. So the complete syntax to get the breakdown would look as follows:
import pandas as pd
import numpy as np
data = {'set_of_numbers': [1,2,3,4,5,np.nan,6,7,np.nan,8,9,10,np.nan]}
df = pd.DataFrame(data)
check_for_nan = df['set_of_numbers'].isnull()
print (check_for_nan)
You’ll now see the 3 instances of the NaN values:
0 False
1 False
2 False
3 False
4 False
5 True
6 False
7 False
8 True
9 False
10 False
11 False
12 True
Here is another approach where you can get all the instances where a NaN value exists:
import pandas as pd
import numpy as np
data = {'set_of_numbers': [1,2,3,4,5,np.nan,6,7,np.nan,8,9,10,np.nan]}
df = pd.DataFrame(data)
df.loc[df['set_of_numbers'].isnull(),'value_is_NaN'] = 'Yes'
df.loc[df['set_of_numbers'].notnull(), 'value_is_NaN'] = 'No'
print (df)
You’ll now see a new column (called ‘value_is_NaN’), which indicates all the instances where a NaN value exists:
set_of_numbers value_is_NaN
0 1.0 No
1 2.0 No
2 3.0 No
3 4.0 No
4 5.0 No
5 NaN Yes
6 6.0 No
7 7.0 No
8 NaN Yes
9 8.0 No
10 9.0 No
11 10.0 No
12 NaN Yes
(2) Count the NaN under a single DataFrame column
You can apply this syntax in order to count the NaN values under a single DataFrame column:
df['your column name'].isnull().sum()
Here is the syntax for our example:
import pandas as pd
import numpy as np
data = {'set_of_numbers': [1,2,3,4,5,np.nan,6,7,np.nan,8,9,10,np.nan]}
df = pd.DataFrame(data)
count_nan = df['set_of_numbers'].isnull().sum()
print ('Count of NaN: ' + str(count_nan))
You’ll then get the count of 3 NaN values:
Count of NaN: 3
And here is another approach to get the count:
import pandas as pd
import numpy as np
data = {'set_of_numbers': [1,2,3,4,5,np.nan,6,7,np.nan,8,9,10,np.nan]}
df = pd.DataFrame(data)
df.loc[df['set_of_numbers'].isnull(),'value_is_NaN'] = 'Yes'
df.loc[df['set_of_numbers'].notnull(), 'value_is_NaN'] = 'No'
count_nan = df.loc[df['value_is_NaN']=='Yes'].count()
print (count_nan)
As before, you’ll get the count of 3 instances of NaN values:
value_is_NaN 3
(3) Check for NaN under an entire DataFrame
Now let’s add a second column into the original DataFrame. This column would include another set of numbers with NaN values:
import pandas as pd
import numpy as np
data = {'first_set_of_numbers': [1,2,3,4,5,np.nan,6,7,np.nan,8,9,10,np.nan],
'second_set_of_numbers': [11,12,np.nan,13,14,np.nan,15,16,np.nan,np.nan,17,np.nan,19]}
df = pd.DataFrame(data)
print (df)
Run the code, and you’ll get 8 instances of NaN values across the entire DataFrame:
first_set_of_numbers second_set_of_numbers
0 1.0 11.0
1 2.0 12.0
2 3.0 NaN
3 4.0 13.0
4 5.0 14.0
5 NaN NaN
6 6.0 15.0
7 7.0 16.0
8 NaN NaN
9 8.0 NaN
10 9.0 17.0
11 10.0 NaN
12 NaN 19.0
You can then apply this syntax in order to verify the existence of NaN values under the entire DataFrame:
df.isnull().values.any()
For our example:
import pandas as pd
import numpy as np
data = {'first_set_of_numbers': [1,2,3,4,5,np.nan,6,7,np.nan,8,9,10,np.nan],
'second_set_of_numbers': [11,12,np.nan,13,14,np.nan,15,16,np.nan,np.nan,17,np.nan,19]}
df = pd.DataFrame(data)
check_nan_in_df = df.isnull().values.any()
print (check_nan_in_df)
Once you run the code, you’ll get ‘True’ which confirms the existence of NaN values in the DataFrame:
True
You can get a further breakdown by removing .values.any() from the code:
import pandas as pd
import numpy as np
data = {'first_set_of_numbers': [1,2,3,4,5,np.nan,6,7,np.nan,8,9,10,np.nan],
'second_set_of_numbers': [11,12,np.nan,13,14,np.nan,15,16,np.nan,np.nan,17,np.nan,19]}
df = pd.DataFrame(data)
check_nan_in_df = df.isnull()
print (check_nan_in_df)
Here is the result of the breakdown:
first_set_of_numbers second_set_of_numbers
0 False False
1 False False
2 False True
3 False False
4 False False
5 True True
6 False False
7 False False
8 True True
9 False True
10 False False
11 False True
12 True False
(4) Count the NaN under an entire DataFrame
You may now use this template to count the NaN values under the entire DataFrame:
df.isnull().sum().sum()
Here is the code for our example:
import pandas as pd
import numpy as np
data = {'first_set_of_numbers': [1,2,3,4,5,np.nan,6,7,np.nan,8,9,10,np.nan],
'second_set_of_numbers': [11,12,np.nan,13,14,np.nan,15,16,np.nan,np.nan,17,np.nan,19]}
df = pd.DataFrame(data)
count_nan_in_df = df.isnull().sum().sum()
print ('Count of NaN: ' + str(count_nan_in_df))
You’ll then get the total count of 8:
Count of NaN: 8
And if you want to get the count of NaN by column, then you may use the following code:
import pandas as pd
import numpy as np
data = {'first_set_of_numbers': [1,2,3,4,5,np.nan,6,7,np.nan,8,9,10,np.nan],
'second_set_of_numbers': [11,12,np.nan,13,14,np.nan,15,16,np.nan,np.nan,17,np.nan,19]}
df = pd.DataFrame(data)
count_nan_in_df = df.isnull().sum()
print (count_nan_in_df)
And here is the result:
first_set_of_numbers 3
second_set_of_numbers 5
You just saw how to check for NaN in Pandas DataFrame. Alternatively you may:
- Drop Rows with NaN Values in Pandas DataFrame
- Replace NaN Values with Zeros
- Create NaN Values in Pandas DataFrame
При работе с Dataframe в Pandas можно столкнуться с ситуацией, когда данные не полные (отсутствует часть значений) и это не позволяет их анализировать. В этом уроке мы рассмотрим, как найти строки в Dataframe, у которых часть информации отсутствует.

Для начала давайте загрузим наш учебный пример:
import pandas as pd
url=’https://drive.google.com/file/d/1KXfupiJKql5Lc-D73KiiS_jEd_CNIW44/view?usp=sharing’
url2=’https://drive.google.com/uc?id=’ + url.split(‘/’)[-2]
df = pd.read_csv(url2)
df.info()
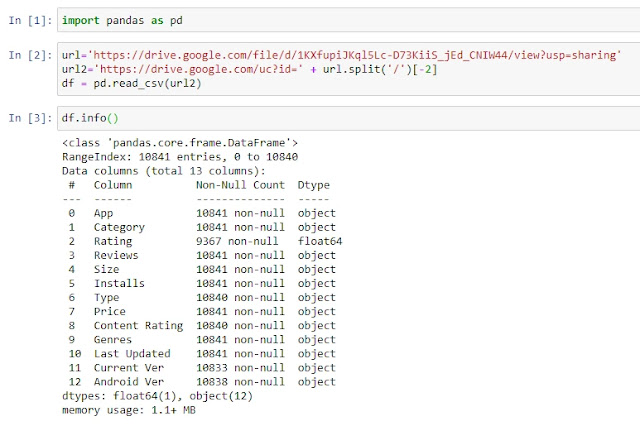
Это база данных по приложениям в Google Play и как вы видите, к примеру в столбце Rating, много пустых элементов.
Для отбора строк, где в одном указанном столбце, отсутствуют данные, мы можем воспользоваться стандартным инструментом фильтрации. К примеру, отберем те строки, по которым в столбце Current Ver нет информации:
df[df[‘Current Ver’].isnull()]
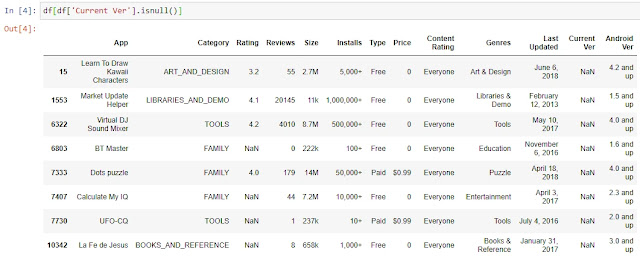
Однако, что делать, если нам нужно отобрать все строки, в которых хотя бы в одном из столбцов отсутствуют значения?
Для начала создадим новый Dataframe, в который поместим проверку на то, является ли информация в ячейке пустой или нет:
is_null = df.isnull()
Для каждой позиции мы получим результат False или True, где False – в ячейке есть данные, True – в ячейке NaN.
Как мы видели выше, в 15 строке у нас отсутствует информация о Current Ver, давайте проверим при помощи функции iloc, какие данные по 15 строке у нас в Dataframe is_null:
is_null.iloc[15,]

Все верно, по всем столбцам, кроме Current Ver, у нас False, а по столбцу Current Ver у нас True, так как в нем нет какой-либо информации.
Далее нам надо сформировать Series, которая нам послужит в дальнейшем фильтром, в которой значение True будет в случае, если хотя бы в одном столбце в строке нет данных, а False, если информация есть во всех столбцах:
row_with_null = is_null.any(axis=1)
Используя эту Series как фильтр, мы создаем новый Dataframe, в который переносим только те строки, в которых хотя бы в одном из столбцов есть NaN:
rows_with_null = df[row_with_null]
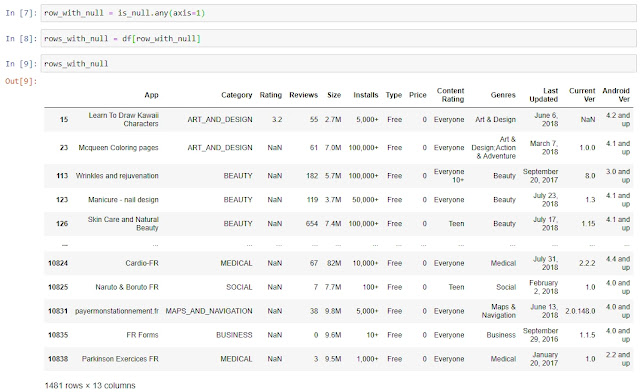
Готово, мы нашли все строки с отсутствующими данными в Dataframe. В качестве бонуса прикладываю
ноутбук
с текущего урока. Спасибо за внимание, комментарии приветствуются.
