Имеется библиотека с разного рода функциями, мне в этой библиотеки необходимо изменить 1 из функций .
Для поиска нужной функции я использовал IDA, которая мне выдала конкретный статичный адрес нужной мне функции – 0x1008F870 img;
Но при запуске программы, по этому адресу – ничего нету.По какой причине это происходит ?
В более ранних версиях этой же самой библиотеки, таких проблем нету, тот адрес что выдает ида можно использовать для инжекта. И если это своего рода динамичное построение, то каким образом IDA выдала именно такой адрес? Либо если это своего рода защита, как ее можно обойти ?И как мне тогда определить реальный адрес функции, который идет в память.
Я так же пытался ставить хук на Href .text:1008F870 sub_1008F870 proc near ; DATA XREF: .rdata:101B4C3Co Но это никакого результата не дало
0x00 start
; {EN} entry point, do nothing, just run _main {EN}
Статья для начинающих “воинов тьмы”, тех, кто хочет погрузиться в темную сторону силы: реверс-инжиниринг. На нашем “операционном столе” будет небольшой кустарный сервер, который работает по протоколу TCP/IP. Для анализа протокола обмена данными нам поможет стандарт де-факто в области реверса — IDA Pro.
Статей по реверс-инжинирингу и по IDA Pro уже написано немало (хотя и не столько, как по PHP), но поскольку процесс реверса — исследовательский, то мысли, как с “другого боку” подойти к задаче обратной разработки, полезны новичкам. По крайней мере, как автор, я руководствовался тем, чтобы изложить основные практики и техники, о которых говорю в первые дни всем стажерам и на первых парах курса по реверс-инжинирингу в университете.
Чего не будет в статье?
Поиска уязвимостей и разработки эксплоитов для Google Chrome или Apple iPhone… Поэтому если вы исследователь со стажем и с большим количеством CVE на счету, маловероятно, что вы найдете для себя что-то новое.

“Once you start down the dark path, forever will it dominate your destiny”.
Подопытный: crackme — не запускайте бинари на основной системе, лучше это делать на виртуалке!
Системные требования: виртуальная машина с установленной Windows 7/0xA
0x01 mov eax, ds:__stack_chk_guard
; {EN} Disclaimer {EN}
Практически вся статья написана относительно ассемблера и, соответственно, процессора x86, поэтому работа с памятью, условными переходами (флагами), инструкциями и т.п. будет описываться в контексте именно этого процессорного ядра. На момент чтения статьи считаем, что других процессорных архитектур не существует.

0x10 Что нам нужно, чтобы понять о чём пойдет речь?
; {EN} Setups prerequisites for the consequent execution {EN}
Чтобы статья была интересна и понятна, предполагается, что читатель знает:
- язык программирования C или C++;
- основы языка ассемблера x86;
- о существовании форматов исполняемых файлов (PE, ELF);
- о кадре стека функции, поверхностно — достаточно;
- как работать с сокетами;
- математический анализ;
- теорию ядерной физики.
Итак первое, что нам понадобится — сама IDA Pro от фирмы Hex-Rays (на русском произносится, как “ида про” или просто “ида”, для тех, кто любит соблюдать правила английского звучания “ай да про”, но звучит в русскоговорящей среде немного необычно). Вы можете скачать бесплатную версию для того, чтобы попробовать освоить реверс-инжиниринг, однако у неё есть ряд ограничений, среди которых: нельзя сохранять результат (в терминах IDA — базу данных) и подходит только для x86.
Второе, что нам понадобится — подопытный. Подойдет любой исполняемый файл (он же бинарник, он же файл с расширением *.exe для Windows), но рекомендуется взять тот, что прикреплен к статье. Если вы возьмёте свой бинарник, то лучше, если это будет скомпилированный для x86 файл (для первого раза не стоит брать собранные под x64 — в них ассемблер сложнее).
Третье — конечно же, хотя бы начальные знания языка ассемблера x86 (assembler language).

Чтобы осознанно копаться в программе и реверсить её, очень желательно знание языка ассемблера x86: инструкций (mov, lea, push/pop, call, jmp, арифметических и условных переходов), регистров и принципов работы процессора. Если их совсем нет, то настоятельно рекомендуется в начале изучить, например:
- подробно, на русском: Ассемблер. Уроки 2011 (не обращайте внимание, что дизайн из 90-х);
- кратко по ассемблеру, на английском: Guide to x86 Assembly;
- средне, что на самом деле видит процессор, на английском: A Guide To x86 Assembly.
Может показаться, что инструкций огромное количество. На самом деле достаточно понять порядка 10 штук, остальные мало чем отличаются. Смотреть референс по инструкциям можно здесь или же в самой документации на процессорное ядро (предпочтительней).
Примечание автора. Хочу отметить, что когда сам только начинал заниматься этим, ассемблер выглядел, как сейчас продолжает выглядеть regexp (регулярные выражения) — вроде все буквы знаешь, а в слова не складываются. Однако постепенно начал понимать, что делают инструкции и что происходит в процессоре.
Четвертое — 30 минут времени (хотя, может быть, 30 часов) и желание научиться.
0x20 Минутка философии или что такое IDA Pro и почему?
; {EN} Whatta hell? {EN}

Реверс-инжиниринг (или обратное проектирование) — “это процесс извлечения знаний из того, что когда-либо было сделано человеком… Фактически, реверс-инженер — исследователь (научный работник), с той лишь разницей, что разбирается в том, что получено не естественным образом, а кем-то создано” — Reversing: Secrets of Reverse Engineering, Eldad Eilam.
Что же в первую очередь нужно исследователю? Блокнот и ручка, чтобы вести и систематизировать полученные знания. Так, а при чем тут IDA? IDA — аббревиатура, которая расшифровывается как “интерактивный дизассемблер“. Ключевым и революционным в свое время было именно “интерактивный”. Это означает, что в результате работы вы получаете не просто длиннющий ассемблерный листинг, а что-то, где вы можете оставить свои заметки, то есть как будто это действительного листинг, но в котором можно сделать “заметочки на полях”, и они меняются по ходу всего листинга. Можно еще сравнить с функцией рефакторинга в современных программерских IDE — переименовали функцию в одном месте, она переименовалась везде, переменную — аналогично и т.д. Ваша задача как исследователя — из огромного массива сложно анализируемой информации оставить только важную и придать ей форму хорошо понятную для человека. Именно интерактивность IDA Pro и позволяет делать это очень эффективно, и на сегодняшний день никто её в этом не превосходит.
Стоит все же заметить, что с учетом постоянно возрастающей закрытой кодовой базы и напечатанного мартышками кода в интернете, программное обеспечение реверсить вручную и интерактивно становится все сложнее и сложнее. Из-за этого сейчас активно развиваются средства анализа кода, нацеленные на автоматизированную обработку — radare2 (что бы ни говорили адепты r2, интерактивный интерфейс Cutter не настолько интерактивен, как в IDA Pro). Более того, IDA Pro также очень хорошо автоматизирована с помощью встроенного в неё интерпретатора Python и API к нему.
И все-таки, как бы крут не был автоматизированный анализ, он не автоматический, то есть заменить на все 100% исследователя не может и рано или поздно исследователю нужно вступать в бой. Поэтому, когда все приготовления наконец-то закончены, приступаем к изучению IDA Pro! Начнём постепенно разбирать наш подопытный образец.

0x30 Смотрим на IDA Pro и познаем основы её интерфейса
; {EN}
; This function is too complex.
; Perhaps it interacts with user.
; But currently I am not sure about it.
; A lot of calls to Qt-framework.
; {EN}0x31 Загрузка бинарника в IDA Pro
Открываем IDA Pro. Перед нами после всех стартовых окошек (которые можно сразу же закрыть), появляется начальное окно программы. Все, что нужно сделать, — перетащить в него исследуемый бинарник. После этого в появившемся окне нажать кнопку “ОК”.
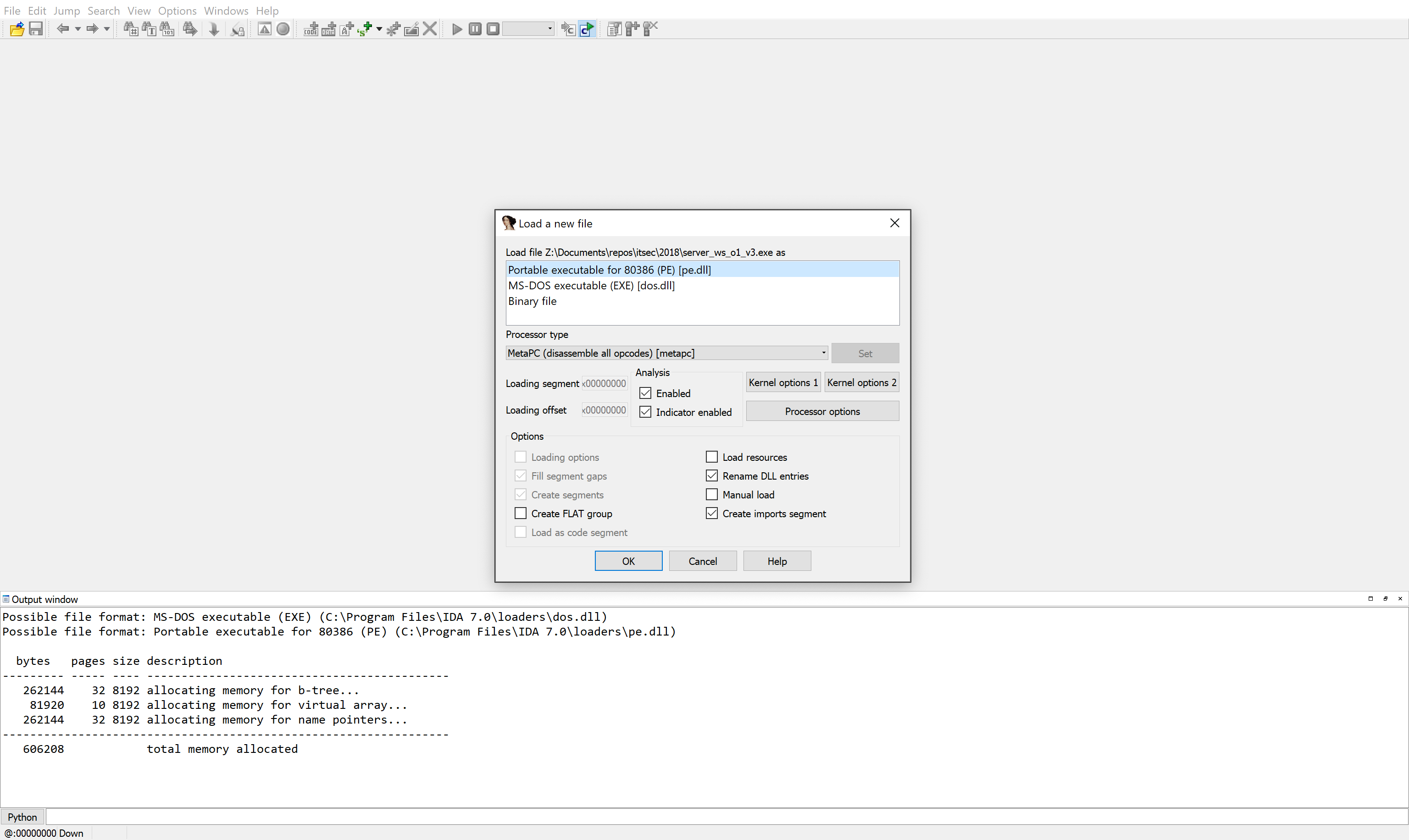
Главное окно IDA Pro при загрузке бинарника
В нашем случае (если вы грузили тот самый exe-файл в IDA, который приложен к статье) никаких настроек производить не нужно, IDA Pro сама распознает формат этого файла (PE, portable execute), а вот если туда кинуть прошивку или дамп из микросхемы памяти от, например, роутера, всё будет намного сложнее.
Какого-то единого стандарта хранения прошивки, можно сказать, нет. Каждый производитель сам для себя выбирает формат файла обновления, что даёт некоторую защиту от реверс-инжиниринга, так как, чтобы докопаться до кода, приходится сначала разобрать этот формат.
После извлечения из файла обновления, код сам по себе может быть размещен по какому угодно адресу в памяти устройства. Найти точку базирования кода — отдельная задача, заслуживающая своей статьи.
Что же касается дампа памяти, то на самой микросхеме может уже находится файловая система с учетом “скрамблинга” (перемешивания блоков на флеш-памяти с целью уменьшения износа). Собрать обратно эти блоки часто является не самой тривиальной задачей. Чтобы восстановить схему скрамблинга, необходимо реверсить сам скрамблер.
Скрамблер в студию
Знакомьтесь, так выглядит типичный алгоритм скрамблера (см. ниже). Причем на рисунке показана только “внешняя” функция, а в каждом из блоков может быть вызов еще такой же или чего-нибудь пострашнее.

Так выглядит граф потока выполнения скрамблера
0x32 Что нам IDA Pro показала?
После загрузки бинарника IDA Pro проводит его предварительный автоматический анализ: определяет функции, глобальные переменные, строки — всё, что можно автоматически вытащить из анализируемого файла. Анализ выполняется процессорным модулем IDA Pro (не путать с самим процессором). Фактически это плагин для IDA Pro (при желании можно написать свой на Python или C++). В нашем случае IDA использует так называемый Meta PC — вариант x86/x64, учитывающий большинство твиков, которые были добавлены в архитектуру от Intel и AMD. Автоматический анализ выполняется опять же на основе того, что есть полное описание формата файла, который мы загрузили в IDA, в нашем случае тот самый Portable Executable. Данный формат чётко указывает какие секции есть в файле, в какой из секций лежит код, где его точка входа, а в какой секции данные (константы или глобальные переменные). Как обычно, с прошивками такой финт не проходит и необходимо вручную размечать входной файл (или же писать loader-плагин для IDA, который сможет «рассовать» куски бинарника прошивки как нужно, после чего процессорный модуль IDA сможет приступить к анализу).
Автоматический анализ под капотом крайне сложная штука, но для каждой инструкции он состоит в следующем:
- декодирование инструкции из бинарного представления во внутреннее (analyze);
- связывание инструкции с учётом специфики её выполнения (emulate — не путать с эмуляцией, как, например, в QEMU);
- преобразование инструкции и аргументов в мнемонику.
Поверх этого с учётом информации и “связей” между инструкциями IDA выбирает путь для анализа следующего адреса, выполняя условный обход “дерева” инструкций от начальной точки анализа. За счёт того, что в стандартных форматах десктопных программ точка входа всегда известна (иначе загрузчик ОС не смог бы создать процесс из этого файла), IDA также может использовать эту информацию.
Следует отметить, что это очень общее описание того, что происходит на самом деле. Приведено оно с той целью, чтобы дать базовое понимание, что такое автоматический анализ, выполняемый в IDA.
Пару слов о том, как IDA Pro хранит результат реверса. После или во время автоматического анализа “проект” можно сохранить (если, конечно, у вас полная версия). IDA хранит результат анализа в виде специальной базы данных со своей структурой (нет, это не модная MongoDB) на жёстком диске. Она представляет собой один файл с расширением .idb (или .i64).
После того как автоматический анализ завершён, вы увидите окно, примерно такое, как на рисунке ниже. Основные элементы, на которые стоит обратить внимание начинающему исследователю, подписаны на самом скриншоте. Завершение автоматического анализа можно определить по надписе AU: Idle в левом нижнем углу IDA Pro.
UX/UI IDA Pro
GUI IDA Pro написан на Qt, поэтому, если вы когда-нибудь работали с приложениями, написанными на Qt, тут действуют те же самые правила:
- тотальный drag&drop окошек;
- все открывается в разных вкладках, которые можно переставлять как вам угодно. Иногда их можно случайно закрывать и потом долго искать меню, где открывается эта вкладка.
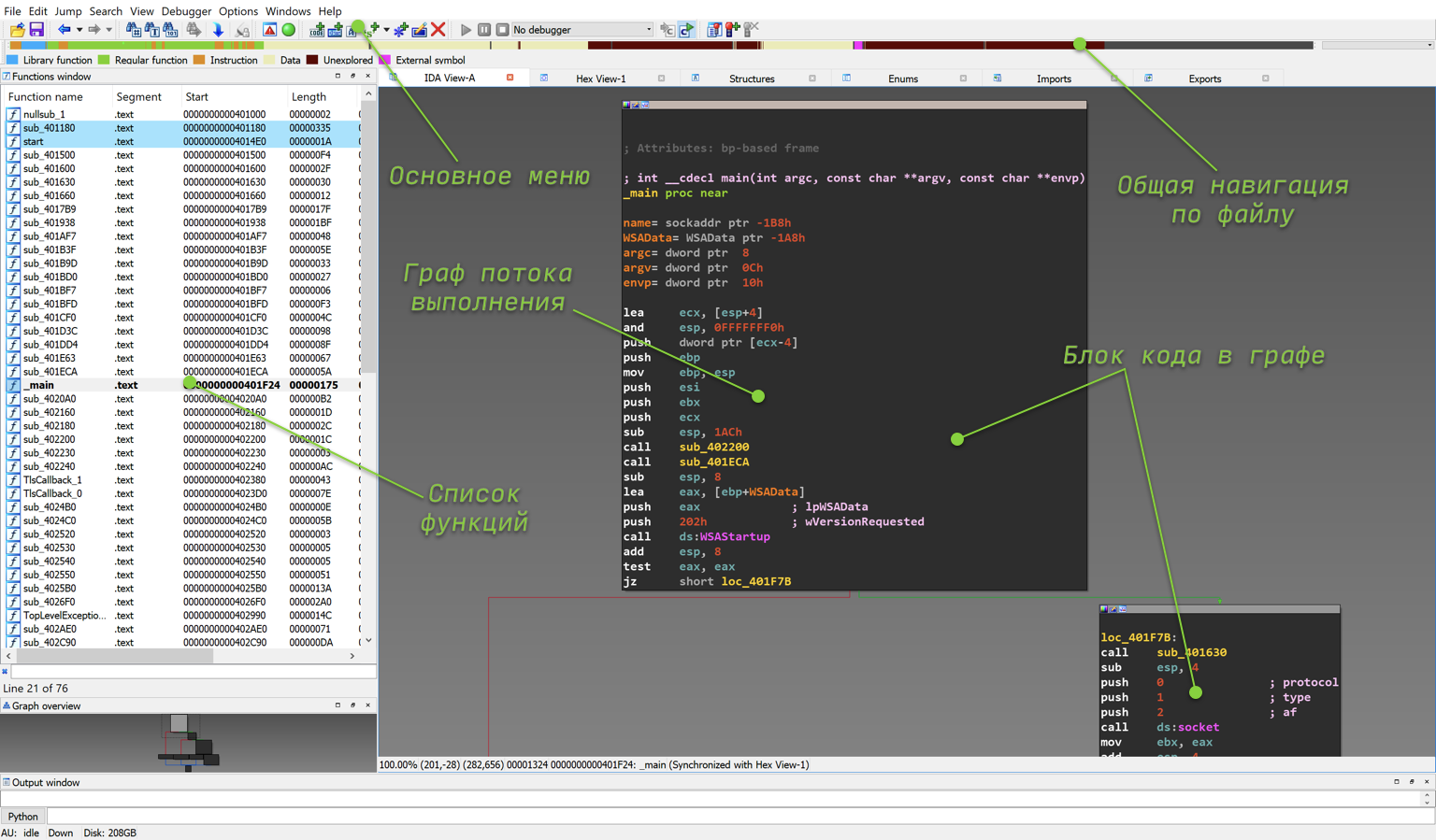
Граф потока выполнения функции main
Давайте рассмотрим основные окна, которые первоначально отображает нам IDA Pro.
- Граф потока выполнения — основной вид дизассемблера (можно сказать, представление в виде блок-схемы алгоритма функции). В нем отображаются инструкции процессора, полученные после дизассемблирования из бинарного вида. В этом графе показывается только одна функция. Каждая функция может быть разделена на блоки по инструкциям условного или безусловного перехода (пошли направо — один блок, налево — другой блок). Кроме этого вида есть и другой, где результат дизассемблирования отображается в виде сплошного листинга.
Proximity View
Есть и еще один вид, который называется Proximity View. Он отображает взаимосвязь между функциями и глобальными переменными.
Примечание автора. На мой взгляд, представление в виде графа более удобно, так как дает представление о структуре функции.
- Список функций — окно, в котором выводятся функции, которые нашлись в бинарнике. Это те самые функции, которые были написаны программистом при создании программы (не учитывая оптимизацию). Если разработчик при компиляции не убрал отладочную информацию (в gcc это опция -s) или вообще собрал программу с опцией -g, тогда мы увидим все имена функций точно в таком же виде, как и программист. Иначе IDA Pro отобразит их в виде sub_<виртуальный_адрес _функции>;
- Список строк (Strings) — не показан, но можно построить, нажав на SHIFT+F12. Одна из самых важных менюшек IDA Pro — в ней показаны все строки, которые есть в программе. Используя строки можно в некоторых случаях, найти всю интересующую нас функциональность.
0x33 Трогаем “лапой” IDA Pro
Наконец-то открыли бинарник и увидели, как это выглядит изнутри. Что же с ним делать и с чего начать реверс? С чего начать трогание нашего основного инструмента в реверсе, IDA Pro? Первое — виртуозное владение пианино горячими клавишами. Без знания горячих клавиш жизнь реверс-инженера скучна, так как сочетания клавиш сильно помогают её разнообразить и очень поднять эффективность и скорость реверса.

Когда только учишься работать в IDA Pro лучше постоянно держать перед глазами табличку (чит-шит, cheatsheet) с горячими клавишами. Ниже приведен пример моего чит-шита. Есть и официальный чит-шит от самой фирмы разработчика IDA Pro — Hexrays. Официальный чит-шит можно найти здесь, в нем больше сочетаний кнопок, но, на мой взгляд, на первое время будет достаточно того, что приведено на чит-шите ниже.

Где CTRL+S и CTRL+Z?
Внимательный читатель может заметить, что в этой таблице нет двух важных сочетаний клавиш. Первое — сохранение базы данных результатов реверса (CTRL+W, но в бесплатной версии сохранения нет), второе — undo. Так вот, забудьте про undo — его нет. Настоящие реверс-инженеры слишком суровы, чтобы использовать всем привычный CTRL+Z. Если серьезно, то функцию undo завезли только в версии 7.3 (бесплатная — 7.0), а всё потому что выполнить undo — не очень тривиальная задача. Дело в том, что какое-то изменение в базе данных IDA, внесенное пользователем, может привести к последующим множественным лавинным изменениям. Например, создание функции (make code) ведет к рекурсивному созданию всех вызываемых функций.
После того, как ознакомитесь с табличкой горячих кнопок, рекомендую попробовать некоторое время понажимать их в самой IDA Pro. При этом не стоит бояться, что вы что-то сломаете или перейдете “не туда”, потому что именно так и будет. Как и любую сложную систему, освоить IDA Pro до виртуозного владения за один вечер невозможно.
Пройдемся и заодно опробуем различные кнопки в IDA Pro.
0x33a Навигация по графу и листингу
Навигация — одна из самых простых и понятных задач, однако, чтобы не теряться в IDA Pro, следует потренироваться в следующем:
- перемещения по графу функции с помощью мыши;
- перейти на различные функции с помощью двойного нажатия мыши, вернуться обратно с помощью ESC и снова вперед с помощью CTRL+ENTER (нет в чит-шите — для продвинутых);
- переключения между графом и листингом — SPACE, если вдруг у вас включился другой вид (листинга);
- переход по перекрестным ссылкам: поставить указатель мыши на любое имя (функции или переменной) и нажать X. После этого вы увидите окно с другими инструкциями, которые ссылаются на это имя (или же указатель в памяти программы);
- прямой переход на имя или адрес (g): в открывшемся окне написать любое из существующих имен или же адрес (можно без 0x) из текущей база данных IDA Pro — вы перейдете на ту часть графа (листинга), где определено это имя.
0x33b Именование и заметки на полях
По изменению имен (рефакторингу) следует попробовать и отработать следующие действия:
- Переименование имен (для этого необходимо нажать мышью на имя и после этого N): функций, переменных (локальных и глобальных), регистров и меток. Постарайтесь разобраться, что можно переименовать, а что нет.
- Простановка комментариев к инструкциям. В целом все просто: выбрали строку, к которой хотим поставить комментарий, и нажали
;.
0x33c Представление данных (data representation)
Любую часть анализируемого бинарника можно представить в виде различных вариантов:
- байт (byte);
- слово (word);
- двойное слово (dword);
- указатель (offset);
- неопределенное (undefined);
- дизассемблированный код (code).
Иначе говоря, каждый адрес в бинарнике можно попытаться дизассемблировать, если получится — будет код, иначе просто данные (байт, слово и т.д.). По умолчанию, если не проводить никакого анализа (в том числе и автоматического), весь бинарник представляется IDA Pro как undefined. Можно сказать, что в процессе реверса или автоматического анализа происходит разметка того, как представить каждый из байтов загруженного бинарника. То, что мы с вами видим уже размеченным (причем практически все байт), является результатом автоматического анализа, который выполнила IDA Pro.
0x33d Отличие кода от функции
Отдельно можно отметить и представление кода:
- Код без функции (в таком случае IDA Pro не сможет построить граф);
- Функция (чтобы из кода создать функцию, необходимо нажать P).
Для большей части кода во время автоматического анализа IDA Pro сама распознает, где необходимо создать функции. Каким образом? За счет того, что если во время дизассемблирования встречается инструкция вызова (call), то анализатор однозначно может утверждать, что адрес, находящийся у этой инструкции в аргументе, — адрес начала функции.
Раз здесь спойлер, значит не все так просто
В реальности за счет использования различных техник защиты от реверса или просто из-за того, что мы грузим в IDA Pro прошивку и не знаем, где в ней начало кода, IDA Pro может начать дизассемблирование не с того адреса. Это приведет к тому, что будет получена инструкция call, хотя ее там и нет, а адрес “псевдоинструкции” call также не является началом никакой функции. Кроме того, какие-то данные, необходимые для работы программы, могут быть декодированы, как инструкции вызова — результат аналогичный.
0x33e Представление аргументов инструкций
Кроме представления каждого байта в виде различных вариантов указанных выше, можно по разному представить и аргументы большинства инструкций. Например, в инструкции записи числа в регистр mov eax, 0xFFFFFFFF второй аргумент может быть представлен, как в текущей записи, так и mov eax, -1. Для того, чтобы сменить вариант представления аргумента инструкции, необходимо нажать на него правой кнопкой мыши, и IDA Pro покажет возможные варианты представления.
0x33f Вспомогательные окна IDA Pro
В первую очередь стоит обратить внимание на Strings, Names, Functions, Hex Dump. Все эти окна можно открыть перейдя из строки меню View->Open Subviews.
0x40 Всего так много и как с этим работать?
; {EN}
; I think I found actual protocol parsing in function sub_401D3C
;
; But this function just chases bytes from corner to corner
; before actual parsing... we need to go deeper
; {EN}0x41 Что же мы будем делать?
Теперь, когда мы знаем на какие кнопки надо нажимать и приблизительно представляем как “под капотом” работает IDA Pro, давайте попробуем вернуться к нашей задаче и найти ту часть бинарника, которая отвечает за разбор протокола обмена данными подопытного сервера.
Если внимательно посмотреть на вкладку с перечнем функций, можно увидеть, что IDA нашла в нём всего лишь 76 функций, то есть это очень маленькая программа. Реальные программы и, тем более прошивки, могут состоять из сотни тысяч функций. При этом никогда не ставится задача «втупую» восстановить исходный код программы на 100% (по крайней мере в моей практике никогда такого не было). Среди прочего от реверса бывает нужно:
- Найти в протоколе ошибки. Для этого в программе необходимо искать места, связанные с получением данных извне;
- Разобрать некий протокол взаимодействия, чтобы, например, создать свой API;
- Пофиксить баг в чужой неподдерживаемой программной библиотеке (серьёзно, такое приходилось делать пару раз);
- Что-то ещё…
Таким образом, главная задача, которая стоит перед исследователем, — найти некоторые интересующие места программы. Иначе говоря, реверсить всё целиком зачастую не имеет смысла, да и процесс этот слишком трудоёмкий. Не стоит забывать, что обратный анализ кода занимает времени больше, чем его прямая разработка.
0x42 Иголка в стоге байт
; {RU}
; Ищем функцию получения данных извне;
; Ищем на неё ссылки;
; Если не нашли, пытаемся искать по логам (повторяем пп.1-3);
; {RU}Как же найти иголку в стоге сена? На самом деле, подходы практически такие же, как когда знакомишься с новым API или OpenSource-проектом, а вся документация в нем сделана в “doxygen”: пытаемся искать функции с вменяемыми именами или идём от API операционной системы.
Что не так с doxygen?
Наличие документации в doxygen — это отлично. Подразумевается, что это единственная документация, причем во время разработки программисты не всегда удосуживались написать комментарии к функции. То есть, все, что есть, — это HTML представление кода с именами функций и параметров (крайний случай).
Поскольку исходно сказано, что это TCP/IP-сервер, логично предположить, что данные будут “приезжать” в обработчик через recv, хотя в реальности могут быть использованы и другие функции. Например, recvfrom, или API более низкого уровня — самой ОСи (для Linux — read).
Заметка: кто хочет вспомнить/познакомиться с работой с сокетами в Си, тот читает Socket programming in c using TCP/IP.

Как сделать это в IDA Pro? Сначала нам нужен перечень всех имен (строк и имен функций, вкомпилированных в программу и импортируемых из библиотек). Для этого служит сочетание клавиш SHIFT+F4. После нажатия откроется вкладка с именами (Names).
На вкладке с именами можно воспользоваться поиском, точнее фильтром (в широком смысле, это более сложная функция с возможностью фильтрации строчек с помощью регекс выражения). Для того, чтобы вызвать поиск, необходимо, находясь во вкладке с именами, нажать сочетание клавиш CTRL+F. После этого внизу вкладки откроется строка ввода (как показано на рисунке). В эту строку необходимо написать часть слова, которое мы хотим найти (в нашем случае это будет recv), список сократится, и в нем останутся только те строки, в которых встречается заданное ключевое слово (на рисунке не показано).
Во второй колонке выводится адрес соответствующего имени. Для перехода на этот адрес в листинге следует дважды кликнуть по нему (или ENTER).
Заметка: переход назад в листинге выполняется по горячей клавише ESC.

Окно имен данного бинарника
И вот мы попадаем обратно в листинг. Теперь уже по адресу функции recv (вспоминаем, что recv в данном случае — библиотечная функция, и её код находится в динамической библиотеке).
Следующим шагом необходимо найти те места в программе, в которых происходит вызов функции recv. Для этого во время анализа IDA Pro создает перекрёстные ссылки между инструкцией вызова функции (или другим обращением к функции) и самой функцией. Чтобы посмотреть места, где используется функция, необходимо навести мышку на адрес (или имя), к которому мы хотим найти перекрёстные ссылки, и нажать кнопку X. Вслед за этим откроется окно, как на рисунке ниже. В окне будут перечислены все найденные перекрестные ссылки. Причем в колонке type используется следующая нотация:
- p[rocedure] — перекрёстная ссылка “по вызову”, то есть адрес (имя) используется в инструкции call;
- r[ead] — перекрёстная ссылка на чтение; в этом месте программы происходит чтение из данного адреса (имени);
- w[rite] — перекрёстная ссылка на запись; в этом месте программы происходит запись в данный адрес (имя).
В нашем случае ссылок всего две:
- Чтение адреса функции recv в регистр (тип r),
- Непосредственный вызов recv (тип p).
Можно заметить, что реально прямой перекрёстной ссылки на recv в инструкции вызова нет. Листинг вызова выглядит следующим образом:
push 0
push 1000h ; len
push ebx ; buf
push edi ; s
call esi ; recv <---- Вызов recv здесьКак видно из кода ассемблера, инструкция call выполняет переход по адресу из регистра esi. Во время автоматического анализа IDA отслеживает, какое значение было занесено в регистр esi, и делает вывод, что при выполнении call в регистре esi всегда будет адрес recv. Именно поэтому IDA создает перекрёстную ссылку на recv в этом адресе.

Перекрестные ссылки на recv
Выбираем из списка ссылку с типом p, и IDA перекидывает нас в граф (или листинг), где происходит вызов функции recv. Выше на экране — листинг IDA. Мы можем увидеть функцию, вызывающую recv: sub_401D3C.
Просто? Да. В данном случае. В реальности же может оказаться, что прямых ссылок нет, а вместо recv вызываются другие функции, или же данные сохраняются в какой-то буфер в структуре, и потом обрабатываются неизвестно где (но анализ всего этого — отдельная статья).
0x43 Делаем “заметки на полях”: sub_401D3C
; {EN} x_vserv_protocol {EN}
Что такое x_?
В нашей команде принято использовать префикс x_ для именования функций (от слова eXecutable), чтобы отличить поименованные вручную функции от автоматически поименнованных IDA Pro.
ax_ — префикс поименнованых функций скриптами (IDAPython);
v_ — префикс глобальных переменных (от слова Variable);
av_ — аналогично, но поименнованных скриптом (IDAPython).
Функция sub_401D3C в отличие от recv является частью данной программы. Поэтому можно исследовать, что происходит в этой части «подопытного».
Заметка: вообще исследование программы часто делится на два основных метода: статический и динамический анализ. Статика подразумевает, что весь анализ выполняется только на основе кода (без запуска программы), динамика — с учётом информации получаемой в дебаге.
В нашем случае проще было бы запустить подопытного в дебаге (англ. «debug» — отладка) и уже после этого начать изучать, что с ним происходит. Но, во-первых, чтобы поучиться мы проведем исследование чисто статикой: где-и-что делается в обработке сразу после получения данных из сокета. Во-вторых, прежде чем что-то запускать даже на виртуалке, я предпочитаю понять, чем это может закончиться
Ну и, как говорит теория эксперимента, прежде чем выполнять сам опыт, необходимо понимать, чем он может закончиться, и на что вообще надо будет смотреть во время фейерверка. Так и в нашем случае, прежде чем запустить программу, необходимо разобраться, в каких переменных ожидать какие данные, а всё то, что сложно понять сходу, добирать с помощью информации, полученной из динамики.

Место вызова функции recv
Начнем делать “заметки на полях”. Если окинуть взором функцию sub_401D3C, в которой мы очутились, можно увидеть в ней вызовы двух функций с неизвестными именами: sub_401CF0 и sub_401BFD. Кроме этого, мы видим и вызов функции puts — стандартная библиотечная функция из libc. Она выводит строку в стандартный поток вывода (stdout). Раз функция что-то печатает на экран, значит, должны быть и строки, из которых можно получить какую-то информацию!

Заметка: в предыдущем разделе мы нашли интересующую нас функцию по библиотечной функции recv. Однако “золотой жилой” являются строки. Просто пробежавшись взглядом по строкам в окне Strings (SHIFT+F12) или поискав в нём различные ключевые слова, можно извлечь очень много дополнительной информации о работе программы или же найти места, в которых происходит что-то интересное для нас как для реверс-инженеров. Никогда не пренебрегайте возможностью посмотреть на строки, которые остались в программе.
Даже не особо разбираясь в ассемблере, можно легко понять, что выводит конкретно здесь puts. В блоке по адресу 0x00401D64 (чтобы перейти в этот блок, нужно нажать кнопку g и вставить в окно указанный адрес) будет выведена строка “Received failed”, в блоке по адресу 0x00401D7A — “Client disconnected”, а в блоке 0x00401D9C — “VSERV protocol error…”. На основании этих строк можно сделать вывод, что данный сервер имеет внутреннее название VSERV (далее при именовании функций будем использовать такой идентификатор). Кроме этого нужно поименовать метки блоков по адресам:
- 0x00401D76 как RECV_SUCCESS;
- 0x00401D8C как CLIENT_NOT_DISCONNECTED.
Заметка: надо стараться именовать всё во время реверс-инжиниринга. Если вы натыкаетесь на функцию и у вас есть хотя бы малейшее предположение, что делает эта функция, — переименовывайте её. В будущем, когда натыкаетесь на эту же функцию, но при других обстоятельствах, вы будете помнить, что уже имели дело с ней, и она где-то была важна для вас. Также можете провести анализ её использования по нескольким случаям применения. Дальше по тексту уже не будет приводиться фраза: “надо переименовать”, предполагается, что это рефлекс.

Далее видно, что адрес 0x00401D54 — начало цикла, в котором сервер постоянно “крутится” и получает данные от клиента. Этот адрес можно назвать “RECV_LOOP”. Цикл в IDA Pro легко найти с помощью графового представления: стрелка перехода от нижнего блока (окончание цикла) к верхнему (начало цикла) выделяется жирным.
Хорошим вариантом для имени функции по адресу 0x00401D3C, в которой мы находимся, является, например, x_vserv_protocol. Видно, что в ней происходит приём данных от клиента, после чего вызываются две функции — в них будет либо полный разбор протокола, либо же предразбор (преобразование потока данных из TCP в “сообщения”). Из кода, который есть в функции x_vserv_protocol, невозможно сделать полноценный вывод, что же происходит внутри функций sub_401CF0 и sub_401BFD, поэтому давайте зайдем поочередно в каждую из них и попробуем понять их функциональное назначение (вернуться назад можно кнопкой ESC).

Не забываем переименовывать метки и имена функций
0x44 Делаем “заметки на полях”: sub_401CF0
; {EN} x_vserv_parse_header {EN}Начнем, пожалуй, с sub_401CF0, так как она идёт первая по ходу выполнения. Чтобы перейти в функцию, необходимо дважды нажать на неё мышью, в результате чего мы оказываемся в очень маленькой функции sub_401CF0. Граф её потока выполнения приведён на рисунке ниже. Судя только по общему виду графа (не вдаваясь в подробности ассемблера), сразу можно сделать вывод, что эта функция:
- На вход получает только один аргумент (причем, скорее всего, с помощью функции recv данные из TCP-сокета);
- Не имеет циклов и содержит одно ветвление (if-else);
- Вызывает две библиотечные функции memcmp и atoi;
- В одной из веток возвращается 0xFFFFFFFF (-1) в качестве результата;
- Проверяет сигнатуру в пришедших данных.
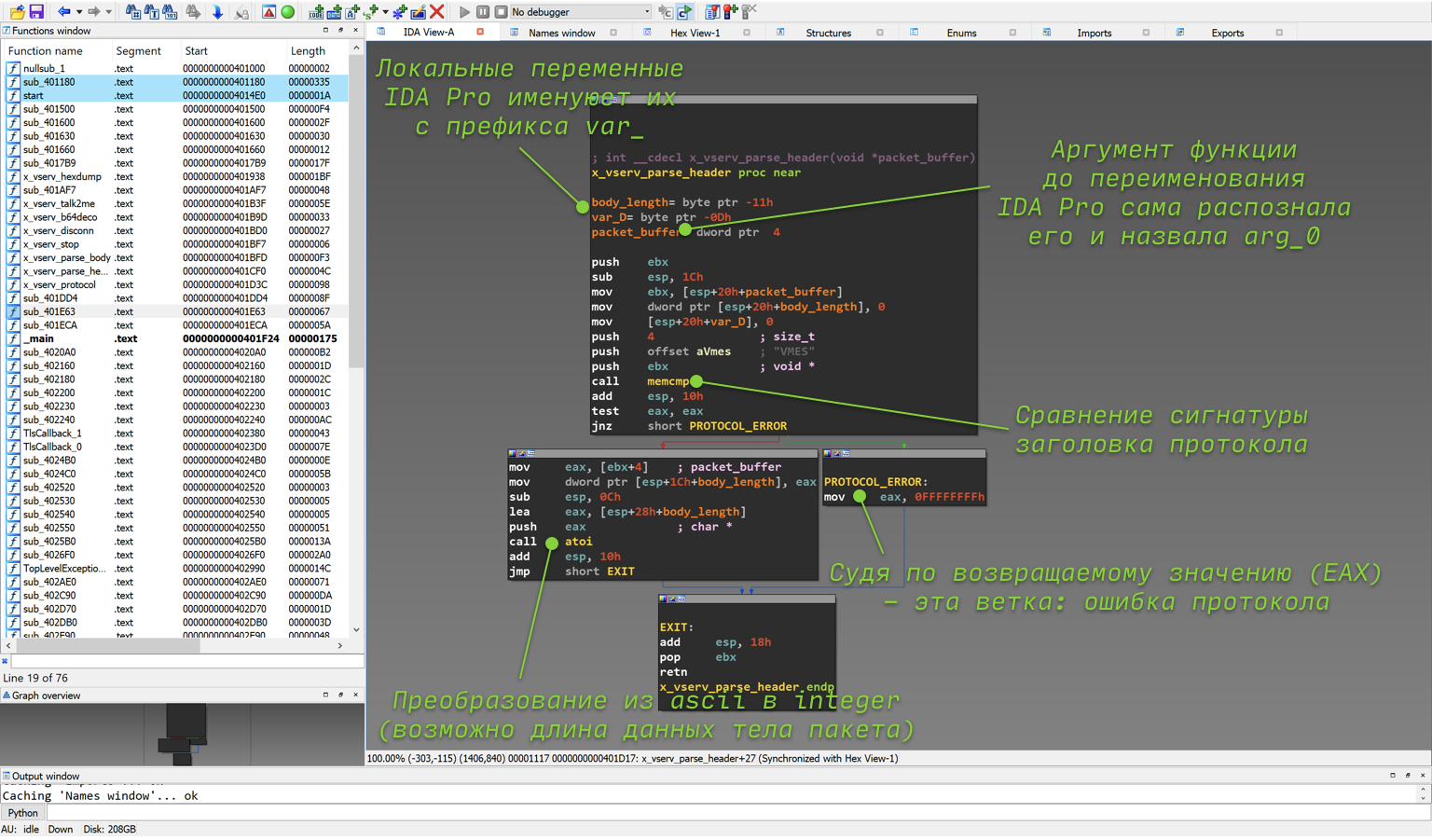
_Реверс функции sub_401CF0 она же x_vserv_parse_header_
Разберёмся по порядку, откуда что взялось.
0x44a Один аргумент и его назначение в функции sub_401CF0
Аргументы IDA пытается распознать сама (для этого она, точнее её конкретный процессорный модуль, использует знание о calling convention (соглашение о вызовах) и другие методы эвристики, но может ошибаться). Если аргумент передается через стек, а не через регистр (для x86 при соглашении о вызовах cdecl, которое используется чаще всего, это именно так), то такие смещения в стеке IDA Pro сама именует с префиксом arg_.
Заметка: передача аргументов и возврат значения из функции при компиляции целиком и полностью определяются соглашением о вызове функции (calling convention). В соглашении много нюансов, и самих вариантов соглашений довольно много (какой из них используется, определяется в том числе и компилятором). Основное, что нам сейчас нужно знать, — x86-аргументы передаются через стек (с помощью инструкции push), а возвращаемое значение через регистр eax (то, что на Си пишется после return).
Назначение аргумента. Почему на скриншоте агрумент уже назван packet_buffer? Разобраться с этим можно, взглянув на предыдущую функцию, а точнее на то, что ей передается в качестве аргумента. Для разъяснений ниже приведён еще один скриншот из функции x_vserv_protocol. Аргументом в функцию приходит значение из регистра ebx. Если нажать на ebx мышкой, IDA подсветит все его использования, за счёт чего можно легко найти предыдущее применение этого значения. Оно же передается в функцию recv (да, в ту самую) вторым аргументом (вспоминаем, что согласно соглашению о вызовах в стек аргументы в коде заносятся в «обратном порядке»).
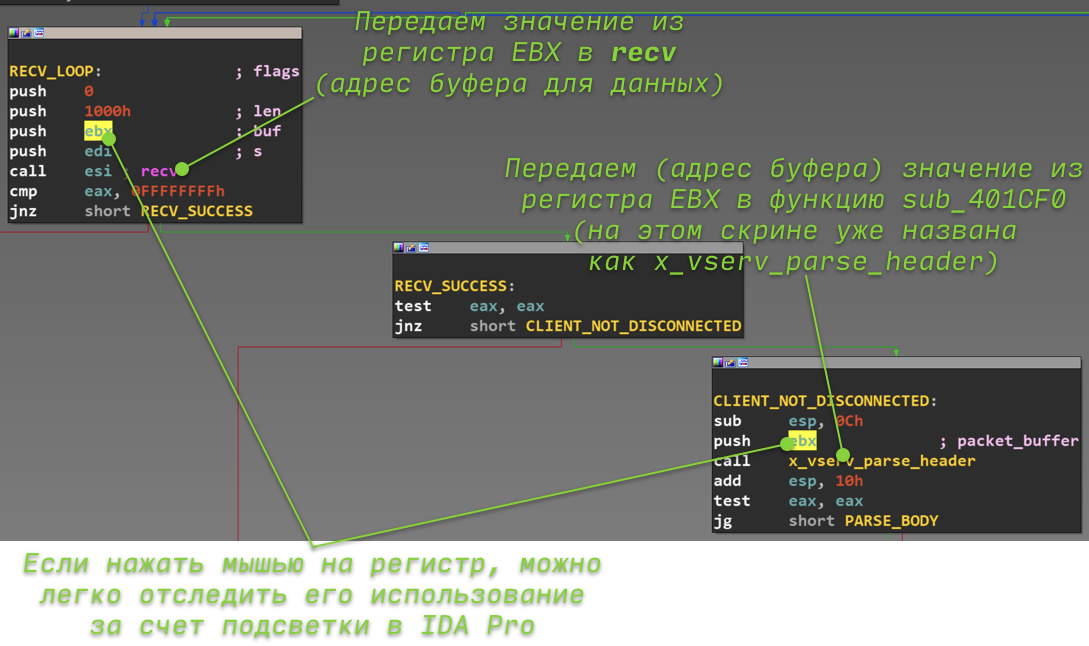
_Аргументы функции x_vserv_parse_header_
Следующим шагом (для тех, кто забыл определение функции recv) необходимо заглянуть в документацию на recv. Из неё станет понятно, что второй аргумент — адрес буфера, в который recv запишет принятые данные. Думаю, теперь очевидно, что единственный аргумент функции sub_401CF0 и есть адрес буфера с принятыми из TCP-сокета данными.
0x44b Функция sub_401CF0 не имеет циклов и содержит одно ветвление
Вспоминаем, как в IDA Pro быстро понять, есть ли в функции циклы или нет (стрелка от нижнего блока к верхнему). Аналогично смотрим на граф функции sub_401CF0 и делаем вывод, что в sub_401CF0 циклов нет.
Наверное, уже все догадались, что две выходящие стрелочки из блока в графе IDA Pro означают, что данный блок программы является частью if-else в исходном коде. Цвет стрелки означает следующее:
- Красный — путь выполнения программы, если переход не выполняется;
- Зеленый — если выполняется.
Выполнение перехода, в свою очередь, зависит от предыдущей инструкции. В анализируемой функции sub_401CF0 такое ветвление только одно, и чуть позже мы разберёмся, что же проверялось в исходном коде.
Заметка: обычно конструкция if-else после компиляции превращается в две инструкции (как минимум):
- Сравнение значений (эта инструкция выставит флаги процессора);
- Условный переход на основании выставленных флагов.
0x44c Функция sub_401CF0 вызывает две библиотечные memcmp и atoi
Если мы не помним определение и функциональное назначение библиотечных функций, их необходимо загуглить, так как эта информация позволит нам понять, что делает анализируемый код. Иногда названия API-функций могут быть совсем не очевидны и даже если считаете, что хорошо знаете ту или иную функцию, но возникла тень сомнения, лучше сразу посмотреть документацию, в данном случае на memcmp.
Примечание автора: иногда “fear … leads to suffering”, давным-давно, в одной забытой Галактике, я реверсил устройство и, находясь в режиме отладки при загрузке Линукса, наткнулся на вызов функции reboot. В тот момент, когда выполнение повернуло в ветку с этой функцией, я остановил отладку и начал разбираться, в чём проблема. На все разборки ушёл практически весь рабочий день. Под конец заглянув в документацию на reboot, я прочитал следующее: «or enables/disables the reboot keystroke». Победив «страх» и нажав на F8, находясь на функции reboot, я понял, что устройство не перезагрузилось, а продолжило выполняться… RTFM!
Довольно легко можно найти, что memcmp сравнивает два массива в памяти и на вход принимает указатели этих массивов и количество байт, которое необходимо «подвергнуть» сравнению. Вроде всё просто и понятно, а вот с возвращаемым значением не всё так очевидно, и новички в Си часто делают ошибку. Предполагают, что 0 — строки неравны, а 1 — строки равны. В реальности в случае равенства строк функция вернет 0, а если строки неравны, то либо > 0, либо < 0.
Вторая API-функция atoi преобразовывает число, записанное в ascii-строке, в integer. Соответственно, на вход приходит указатель на строку, а на выходе — целочисленное значение.
0x44d Собираем всё вместе и отвечаем на два оставшихся вопроса
Какие выводы можно сделать из анализа использования этих двух API-функций в исследуемой функции?
Во-первых, memcmp проверяет сигнатуру протокола (уникальную последовательность байт, чтобы «удостовериться», что пакет реально относится к заданному протоколу). Этот вывод можно сделать на основе того, что в функцию memcmp передается напрямую буфер с принятыми данными (постарайтесь отследить это сами), константная строка “VMES” и значение 4 (очевидно длина VMES). После этого, если сигнатура не нашлась, программа может повернуть в ветку, где в регистр eax заносится значение 0xFFFFFFFF (-1), или в ветку с atoi.
В данной случае используется функция memcmp, а не strcmp, хотя и сравниваются две строки, из-за того, что необходимо указать максимальную длину сигнатуры, 4 байта. Функция strcmp будет сравнивать до тех пор пока не встретит нуль-терминатор. Хотя у сигнатуры “VMES” нуль-терминатор идет последним, пятым символом, в пришедшем пакете — нуль-терминатор может быть где угодно. Из-за этого, даже если в пакете в начале будет эта сигнатура, strcmp определит эти строки как различающиеся.
Во-вторых, atoi, скорее всего, получает длину тела-сообщения (хотя напрямую это не следует из анализа только этой части кода). Взгляните внимательно и вы увидите, что atoi берёт из полученных данных кусок буфера — четыре байта следом за VMES (это можно понять, если разобрать ассемблер в блоке по адресу 0x00401D19) — и преобразует его в число. Результат преобразования atoi передается в eax. Таким образом, в eax на выходе из функции оказывается либо значение, полученное из принятых данных, либо -1. Также вспомним, что согласно соглашению о вызовах для x86 результат возврата функции находится в регистре eax, функция проверяет наличие сигнатуры в первых четырех байтах, если этих байтов в буфере нет — возвращает -1, иначе преобразует следующие четыре байта в число и возвращает его из функции. Что может быть лучше, чем описать код на естественном языке? Правильно, написать сам код:
char tmp[5] = { 0 };
if (memcmp(&buf[0], "VMES", 4) != 0)
return -1;
*(int*) tmp = *(int*)(&buf[4]);
return atoi(tmp);По началу код может показаться странным. Могут возникнуть такие вопросы, как: откуда буфер на 5 байт? Зачем он вообще здесь? Почему просто нельзя передать в atoi(buf + 4)? Начнем разбираться с последнего вопроса и для этого нам понадобится документация на atoi, а точнее на документация на strtol (если открыть доку на atoi, то она ссылается на strtol с указанием системы счисления 10). В ней сказано, что конвертация происходит, пока не будет встречен символ, который не подходит для данной системы счисления. То есть, для 10-ой системы это любой символ не из диапазона от 0 до 9. В ходе реверса в таких случаях, можно предположить, что автор программы хотел защититься от того, что в сервер могли отправить специально подобранный пакет, где это значение будет указано каким-угодно большим. Однако при этом (как увидим дальше) допустил другие ошибки. По итогу: копирование в отдельный буфер с нуль-терминатором позволит избежать проблемы неправильной конвертации ascii-строки.
Размер буфера в 5 байт можно определить, если заглянуть в стек программы (о котором подробнее чуть позже в статье): в списке переменных функции сразу за buffer_length идет переменная var_D (поэтому в стеке они распологаются друг за другом). В нее заносится 0 в самом начале функции, и больше эта переменная никак не изменяется. Поэтому var_D и есть нуль-терминатор.
На основании анализа предлагается дать функции гордое название x_vserv_parse_header (на скриншотах уже была переименована).
0x45 Делаем “заметки на полях”: sub_401BFD
; {EN} x_vserv_parse_body {EN}0x45a Немного о стеке и его кадре
Итак, мы дошли до последней неразобранной функции, чтобы целиком охватить «архитектуру» той части программы, которая отвечает за обработку протокола. Как и на предыдущем этапе реверса, начать следует с её аргументов. Обратимся к блоку функции x_vserv_protocol, который мы ранее поименовали как PARSE_BODY (для этого, как обычно, можно нажать g, вставить туда название блока и нажать ENTER). Перед вызовом самой функции видны две инструкции push, которые, очевидно, передают аргументы в нужную нам функцию sub_401BFD (на скринах она уже переименована в x_vserv_protocol_body). С этой целью взглянем на рисунок, приведенный ниже.

_Что за body_buffer?_
Первым аргументом передается адрес (так как используется инструкция lea) некой переменной (на скриншоте названа body_buffer). Вторым аргументом — то, что было получено из функции x_vserv_protocol_header (так как регистр eax передается в инструкцию push без изменений). Если со вторым аргументом все очевидно — число после atoi-преобразования, то с первым давайте разберёмся.
Чтобы понять, что такое body_buffer, следует обратить внимание на пару моментов:
- Каким образом получен указатель на буфер, который передается в recv;
- Структура стека функции x_vserv_protocol.
Указатель на буфер, передаваемый в recv, формируется довольно очевидно. Он передается вторым аргументом в recv и, следовательно, адрес буфера находится в регистре ebx перед вызовом функции recv (см. блок RECV_LOOP). Если нажать на ebx и отследить, какое значение заносится в него перед этим, то видно, что туда перекладывают регистр esp. Регистр esp является крайне важным (хотя все регистры важны) тем, что он всегда указывает на вершину стека и, кроме этого, неразрывно связан с push/pop. Конкретно в этом случае в esp хранится начало стекового буфера, что в исходном коде выглядело как:
char buffer[0x1000];
Заметка: почему так? Чтобы ответить, нужно разобраться с тем, что такое кадр стека, и как разложены локальные переменные, а также аргументы в стеке. Подробно тому, как располагаются данные в стеке лучше почитать по одной из ссылок в начале статьи, так как тема кадра стека сама по себе заслуживает отдельной статьи. Также можно почитать статью на Wikipedia.
Рассмотрим структуру стека (кадра или фрейма) функции x_vserv_protocol. Для отображения кадра стека в IDA Pro необходимо два раза нажать мышкой на одну из переменных, расположенных в стеке (на скриншотах — «рыжие» имена в самом начале функции). После этого вы увидите картинку, похожую на рисунок ниже.

Стековый кадр функции
Как было написано выше, указатель для приема данных через recv соответствует самому началу кадру стека (так как esp используется без смещения). В связи с этим можно поименовать (как обычно — кнопочкой N) верхушку как vmes_sign (в первых четырех байтах ожидается сигнатура “VMES”).
Следующие четыре байта — это байты, которые передаются в atoi в функции x_vserv_parse_header. Вывод о группе в четыре байта, можно сделать из первой инструкции левого блока функции x_vserv_parse_header (адрес 0x00401D19). Инструкция mov перекладывает именно четыре байта из [ebx+4] в регистр eax для последующего преобразования в atoi. Поскольку мы решили, что это длина тела пакета, поименуем их как vmes_body_len.
Теперь становится понятно, что после восьми описанных байт идут оставшиеся данные из TCP-пакета. Если вы разрабатывали клиент-серверное приложение, то очевидно, что эти оставшиеся данные — тело пакета, и его парсинг (разбор), скорее всего, будет в функции, вызываемой следом за x_vserv_parse_header. Собственно, эта функция на скриншотах практически сразу и была названа как x_vserv_parse_body.
0x45b Разбираем функцию разбора тела пакета
Вернёмся обратно в саму функцию (кнопка ESC) и соберём всё вместе. Первый аргумент для функции sub_401BFD (x_vserv_protocol_body — уже можно переименовать) — тело пакета, данные, пришедшие из TCP-сокета с помощью recv, за исключением первых восьми (судя по всему, первые восемь — заголовок пакета). Второй аргумент – данные, находящиеся по смещению +4 от начала пакета (предположительно, длина тела пакета) и «пропущенные» через atoi, чтобы получить из них число.
Заметка: если кто-то со знанием Stack BOF (он же Stack Buffer Overflow, оно же переполнение буфера в стеке) решил почитать статью, он наверняка уже учуял запах крови этого самого переполнения буфера в стеке. Из пользовательских данных берётся значение, которое преобразовывается в число. Если дальше нет валидации этих данных, жди беды переполнения.
Настала пора заглянуть в саму функцию x_vserv_protocol_body, граф которой показан на рисунке ниже.

_Граф функции x_vserv_protocol_body_
После долгих вечеров и дней реверс-инжиниринга граф функции в стиле «лесенки» практически сразу говорит о том, что в исходном коде была цепочка из if-else-if-else-if-else (возможно, также и switch). И действительно, если внимательно посмотреть на функцию, то хорошо видно, что в каждом из блоков берутся первые байты тела пакета и поочередно сравниваются с “HEXDUMP”, “TALK2ME”, “B64DECO”, “DISCONN”, “STOP!!!”. Если ничего из этого не нашлось, то в консоль выводится строка «Unknown command». Таким образом, понятно, что перечисленные выше строки — команды протокола. При обнаружении одной из них выполнение переходит на соответствующую функцию. Их можно поименовать следующим образом: x_vserv_hexdump, x_vserv_talk2me, x_vserv_b64deco, x_vserv_disconn, x_vserv_stop. Это и есть обработчики команд протокола.
0x45c Пощупаем некоторые обработчики команд vserv
Интересно отметить, что число, которое передано вторым аргументом, нигде не используется в этой функции напрямую, а только передается дальше в обработчики команд протокола. Кроме того, нет и валидации количества принятых данных, то есть программа считает, что ей обязательно пришёл пакет как минимум из 15 байт (хотя это может быть вовсе не так). Чтобы всё-таки убедиться, что второй аргумент, он же len, реально является числом, применяемым как размер данных, обратимся к одному из обработчиков x_vserv_hexdump. Интересующий нас кусок функции приведён на рисунке ниже.
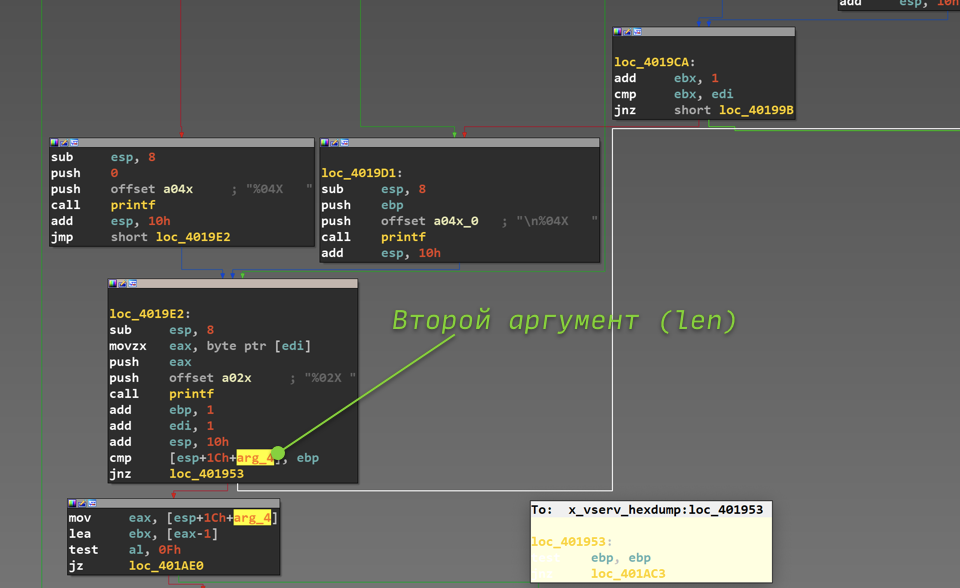
_Второй аргумент x_vserv_hexdump_
Из этого кода видно, что в функции есть некий счетчик, хранящийся в регистре ebp (вероятно, компилятору не хватило регистров общего назначения, обычно ebp не используется в качестве счётчика). Он сравнивается со вторым аргументом, и цикл завершается, когда значение счётчика достигает аргумента, то есть, какое значение мы указали в пакете, столько раз будет выполняться этот цикл.
0x45d Закругляемся на сегодня

0x50 Is this the end?
; {EN} x_vserv_parse_body {EN}Статья направлена на то, чтобы изложить максимально подробно базовую технику реверс-инжиниринга, которая была бы понятна новичку и он смог бы попробовать изучить другие бинарники. Конечно, мы не коснулись разбора алгоритмов, а фактически только посмотрели, как понять структуру программы и куда вообще лезть после того, как открыл её в IDA Pro.
Если вдруг эта статья окажется не 9-й жизнью котика реверс-инженера, он расскажет об анализе обработчиков протокола VSERV в IDA Pro, поможет написать для него клиент и вместе с читателем поищет уязвимость RCE (она там есть и лежит на поверхности) в этом сервере.

Изучение Ассемблера через IDA pro Link
ВАЖНО Снимок базы данных
- Позволяет вернуться в предыдущее состояние базы
- FILE->Take database snapshot->Enter snapshot description – создание снимка
- VIEW->Database snapshot manager->Restore – вернуться к выбранному состоянию
Изменение кода (плагин github Keypatch)
ПКМ->Keypatch->Patcher или Ctrl+Alt+K
Во второй ссылке находится файл keypatch.py,
который мы должны скопировать в каталог плагинов IDA
и затем можно установить keystone-0.9.1-python-win32.msi.
Кроме того, необходимо установить Microsoft VC ++,
библиотеку времени исполнения.
ФЛАГИ
Флаг Переноса (CF)
- При переполнении от взаимодействия дает 1 иначе 0
- Т.е. срабатывает при переносе
- cmp 0x30, 0x41 => CF = 1
- cmp 0x30, 0x29 => CF = 0
- sub 0x30, 0x41 => CF = 1
- add 0xFFFFFFFF, 1 => CF = 1
- sub 0x100, 0x40 => CF = 0
Флаг Переполнения (OF)
??????????????????????????????????????????????
??????????????????????????????????????????????
??????????????????????????????????????????????
??????????????????????????????????????????????
??????????????????????????????????????????????
??????????????????????????????????????????????
??????????????????????????????????????????????
??????????????????????????????????????????????
??????????????????????????????????????????????
??????????????????????????????????????????????
??????????????????????????????????????????????
??????????????????????????????????????????????
??????????????????????????????????????????????
??????????????????????????????????????????????
??????????????????????????????????????????????
??????????????????????????????????????????????
??????????????????????????????????????????????
Запомнить позицию в адресе (Mark Position)
- JUMP->MARK POSITION->NAME FOR MARK
Перейти к позиции в адресе
- JUMP->JUMP TO MARKED POSITION
Значение из функций возвращается в EAX
Системы счисления
- ДВОИЧНАЯ: Числа представляются двумя символами 0 и 1, вот почему она называется ДВОИЧНАЯ.
- ДЕСЯТИЧНАЯ: Все числа представляются с помощью 10 символов(от 0 до 9), вот почему она называется ДЕСЯТИЧНАЯ.
- ШЕСТНАДЦАТЕРИЧНАЯ: Все числа представляются с помощью символов от 0 до F ( от 0 до 9, далее A, B, C, D, E и F, или 16 символов в итоге).
- В нижней части IDA есть один коммандбар, чтобы исполнять команды PYTHON, он поможет переводить числа из одной системы в другую
- 0b означает двоичное представление числа
- 0x вначале числа конвертирует его в 16-ную систему : 0x45 = 69
- Для 16-ных hex() : hex(69) = 0x45
- Для двоичного bin() : bin(69) = 0b1000101
- Для символов chr() : chr(0x45) = E
- Для удобного управления преобразованиями в IDA есть калькулятор VIEW – CALCULATOR
- В 32-битных двоичных числах первый бит используется для знака числа, 0 = плюс, 1 = минус
- 7FFFFFFF : 2147483647 в десятичной (максимальное положительное число)
- FFFFFFFF : -1 в десятичной
- 80000000 : -2147483648 в десятичной (максимальное отрицательное число)
Возможности поиска (пункт SEARCH)
- next code – поиск след. кода : CODE
- next data – поиск след. данных : DATA
- next [un]explored – поиск след. [не]распознанного блока
- next immediate – поиск след. непосредственного значения
- next text – поиск совпадения по тексту
- sequance binary – поиск последовательности байт
- not function – поиск неразобранных функций
Data type
| Data Type | Bytes |
|---|---|
| BYTE, SBYTE | 1 |
| WORD, SWORD | 2 |
| DWORD, SDWORD | 4 |
| FWORD | 6 |
| QWORD | 8 |
| TBYTE | 10 |
Регистры 32-битные
- EAX – аккумулятор + 16 бит – AX(8 бит AH + AL)
- EBX – база + 16 бит – BX(8 бит BH + BL)
- ECX – счетчик + 16 бит – CX(8 бит CH + CL)
- EDX – данные + 16 бит – DX(8 бит DH + DL)
- ESP – указатель на вершину стека
- EBP – указатель на базу стека
- ESI – указатель на источник данных
- EDI – указатель на назначенные данные
Сегментные регистры
- CS – CODE Segment
- DS – DATA Segment
- SS – STACK Segment
- ES – Extra
- FS – Extra
- GS – Extra
IAT (таблица с адресами внешних функций, при запуске)
- .idata – раздел (розовые строки)
- IAT – пустой и заполняется при запуске программы
- extrn – означает что это внешняя функция
Инструкции
- OFFSET – передача самого адреса (не значения)
- dword_ – передача данных типа DWORD
- stru_ – передача данных типа структура
- loc_ – локальная метка
- sub_ – метка функции (ПКМ->Create function)
- Клавиша D – преобразование в DATA вид
- Клавиша A – преобразование в ASCII вид
MOV А, В (копирование из В в А)
Примеры :
- MOV EAX, EDI
- MOV EAX, 1
- MOV EAX, dword_46F908 – передача содержимого адреса
- MOV EAX, offset dword_46F908 – передача самого адреса
- MOV EAX, DWORD PTR DS:[46F908]
- MOV EAX, [EDI] – квадратные скобки если IDA не знает что в EDI
- MOV AL, 1
XCHG A, B (обмен значениями)
- XCHG EAX, ESI
- XCHG EAX, DS:dword_4020DC – обмен EAX c содержимым адреса 4020DC
PUSH (положить в стек)
- push 64h – положить в стек 0x64
- push eax – положить в стек значение из EAX
- push offset byte_4020E7 – положить в стек адрес памяти (например адрес начало строки)
Передача аргумента к функциям : PUSH offset xxxxx
POP (вытащить из стека)
- pop edi – вершина стека в edi (esp меняется на след. в стеке)
- pop esi
- pop ebx
Параметры в функциях в IDA
- В функциях обнаруженных IDA есть параметры.
- Передаются через PUSH который стоит перед вызовом функции(CALL)
- PUSH сохраняет эти значения(параметры) в стеке
00401170 var_24= byte ptr -24h 00401170 var_18= byte ptr -18h 00401170 var_14= dword ptr -14h 00401170 var_10= dword ptr -10h 00401170 var_C= dword ptr -0Ch 00401170 var_4= dword ptr -24 00401170 arg_0= dword ptr 8
LEA A, B (помещает указанный адрес из В в А)
- Никогда не получает доступ к содержимому В
- Либо адрес, либо результат работы операции между квадратными скобками в В.
- Используется чтобы получить адреса переменых в памяти или параметров.
- lea eax, [ebp+var_C] – ebp используется как база с адресом стека Lea решает операцию [EBP – var_C(0C)] – получим адрес переменной
- Lea eax, [4 + 5] – поместит 9 в eax, а не содержимое адреса 0x9, как это делает MOV
| LEA | Получает адрес переменной |
|---|---|
| MOV | Получает значение по адресу |
ADD A, B (сложение с результатом в А)
- А и В не должны быть в памяти в одно и то же время, в одной и той же инструкции
| A | Регистр | Содержимое ячейки памяти | |
|---|---|---|---|
| В | Регистр | Содержимое ячейки памяти | Константа |
- add al, 8
- add bx, ax
- add BYTE PTR DS: [eax], 7
SUB A, B (вычитает целое число В из А с результатом в А)
| A | Регистр | Содержимое ячейки памяти | |
|---|---|---|---|
| В | Регистр | Содержимое ячейки памяти | Константа |
- sub [ebp+arg_4], eax
- sub esp, 8
- esi, [eax+8]
INC A and DEC A (инкремент и декремент)
- inc eax
- dec eax
IMUL (умножение со знаком)
| A | Регистр | |
|---|---|---|
| В | Регистр | Содержимое ячейки памяти |
| С | Константа |
IMUL A, B (умножение А на В с результатом в А)
- IMUL eax, [ecx]
IMUL A, B, C (умножение В на С с результатом в А)
- IMUL esi, edi, 25
IDIV A (А – делитель)
- СУТЬ – Создает большое 64-битное число, старшая часть которого находится в EDX, а младшая в EAX. Делит значение на А и сохраняет результат в EAX, а остаток значения в EDX
- IDIV ecx – если EAX = 5, EDX = 0, ECX = 2, то выполнится деление 5 на 2. ИТОГ: EAX = 2, EDX = 1
Логические операции AND, OR, XOR
| A | Регистр | Содержимое ячейки памяти(ТОЛЬКО ОДИН) |
|---|---|---|
| В | Регистр | Содержимое ячейки памяти(ТОЛЬКО ОДИН) |
| A | B | AND | OR | XOR |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 0 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
AND A, B (логическое И с результатом в А)
- AND eax, 0F – 0F = 1111. В итоге нули во всех битах и нетронутые 4 последних бита
- Python>bin(0b11100111 & 0b1111) => 0b111
OR A, B (логическое ИЛИ с результатом в А)
- Python>0x54 | 0x34 => 116
XOR A, B (исключающее ИЛИ с результатом в А)
- Python>bin(0b111101 ^ 0b111101) => 0b0 (XOR)
NOT A (инверсия всех битов в А)
NEG A (превращает А в -А)
- Python>hex(~ 0x45+1) => -0x45
- Python>hex(~ -0x45+1) => 0x45
SHL A, B и SHR A, B (сдвиг байтов слева и справа в А с заменой нулями с другой стороны)
| A | Регистр | Содержимое ячейки памяти |
|---|---|---|
| В | 8-бит. регистр | Константа |
- SHL 0b1100, 2 => 0b0000
ROL A, B и ROR A, B (сдвиг байтов слева и справа в А с вращением битов)
- Биты которые уходят с одной стороны появляются с другой
- ROL 0b1100, 2 => 0b0011
JMP SHORT A (короткий переход вперед и назад – инструкция из 2 байт)
| 1 байт | ОПКОД перехода(JMP=0xEB) |
|---|---|
| 2 байт | Направление перехода |
- IDA: 00401324 EB 05 – JMP short loc_40132b
- ВАЖНО – Всегда добавляем размер инструкции при переходе
- Python>hex(0x401324 + 2 + 5) => 0x40132b – Начальный адрес инструкции + 2 (количество байт инструкции JMP SHORT) + 05 (значение второго байта)
- Максимальный переход вперёд будет равен 0x7F
- Максимальный переход назад будет равен 0x80
- Минимальный переход назад -1 = 0xFF
- В Python -0x80 в 16-ном значении равно 0xFFFFFF80
- Python>hex((0x401324 + 2 +0xFFFFFF80) & 0xFFFFFFFF) => 0x4012a6L
- Python>hex((0x401324 + 2 +0xFFFFFFff) & 0xFFFFFFFF) => 0x401325L
- Python>hex((0x401324 + 2 +0xFFFFFFfE) & 0xFFFFFFFF) => 0x401324L – Переход к начальной инструкции(Бесконечный цикл)
JMP A (длинный переход по адресу А)
- IDA: 004026AE E9 00 03 00 00 – JMP loc_4029B3
- Python>hex(0x4029b3 -0x4026ae -5) => 0x300(стоит рядом с опкодом Е9) – Где размер инструкции равен 5
- Python>hex(0x400000 -0x4026ae -5) => -0x26b3 = 0xFFFFD94D в итоге получается :
- IDA: 004026AE E9 4D D9 FF FF – JMP near ptr 400000h
Условные переходы
- ВАЖНО – после сравнение изменяются важные ФЛАГИ
Таблица условных переходов
| ASM | jne | je | ja | jna | jae | jnae | jb | jnb | jbe | jnbe | jg | jng | jge | jnge | jl | jnl | jle | jnle |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Hex | 75 0f85 | 74 0f84 | 77 0f87 | 0f86 | 0f83 | 0f82 | 0f82 | 0f83 | 0f86 | 0f87 | 0f8f | 0f8e | 0f8d | 0f8c | 0f8c | 0f8d | 0f8e | 0f8f |
CMP A, B (сравнение)
- CMP – вычитает оба регистра и если они равны, результатом будет 0. В переходе JZ, 0 активирует ФЛАГ Z = true то есть переход по зеленой стрелке, иначе переход по красной стрелке = false
- Пример : jz short loc_40124c
CALL (вызов функции)
- Сохраняет на ВЕРШИНЕ стэка адрес возврата
- call sub_4013d8
RET (возврат функции)
- Возврат к инструкции следующей за тем, где был вызов CALL
- Берёт адрес возврата сохраненный в стеке и переходит туда
- IDA : 004013fd retn – возврат из функции
Заметки по статическому анализу
Сегменты
- VIEW->OPEN SUBVIEW->SEGMENTS
Таблица SEGMENTS
| Name | Start | End | R(Read) | W(Write) | X(Exec) | D | L |
|---|---|---|---|---|---|---|---|
| Имя секции | Адрес начала | Адрес конца | Чтение | Запись | Выполнение | Отладчик | Загрузчик |
- Для ручной загрузки ЗАГОЛОВКА с адресом 0x400000 необходимо :
- При создании проекта включить галочку MANUAL LOAD
- Жмем ОК и YES
Все найденные строки IDA->VIEW->Open subviews->Strings
Hotkeys
| G | Переход к адресу памяти |
|---|---|
| D | Конвертация в data |
| A | Конвертация в ASCII |
| N | Переименовать(функцию) |
| X | Посмотреть ссылки вызова |
| Ctrl+Alt+K | Изменение кода |
| Ctrl+Alt+A | Сохранение нового кода |
| Ctrl+Alt+P | Patched bytes |
Введение в реверсинг с нуля используя IDA PRO. Часть 3
| Редактировалось 15 апр 2017
Загрузчик
Мы уже видели, что когда в IDA мы открываем исполняемый файл, тот же самый файл открывается в ЗАГРУЗЧИКЕ, который является статическим анализатором того же самого файла.Мы будем анализировать его части и характеристики, большая часть того, что мы видели до настоящего времени, будут применимы и к ЗАГРУЗЧИКУ и для ОТЛАДЧИКА. В случае, если что-то будет отличаться или не похоже на общий случай, я упомяну это.
Очевидно, то, что в ЗАГРУЗЧИКЕ программа абсолютно не выполняется, но она анализируется, и создаётся база данных с информацией этого файла, и это значительное отличие относительно ОТЛАДЧИКА.
В ЗАГРУЗЧИКЕ нет ни окна РЕГИСТРОВ, ни окна СТЕКА, ни списка модулей, которые загружены в память. Это вещи, существуют при выполнении и отладке программы.
После загрузки Cruehead Crackme (CRACKME.EXE), если мы посмотрим на список процессов , то увидим, что он не работает и никогда не выполняется, пока мы не откроем отладчик IDA.
Это очень полезно для определенного использования, например как анализ вредоноса, эксплоита и т.д. , потому что мы не всегда сможем получить доступ к некоторой функции, для этого мы должны изучить отладку, в то время как в ЗАГРУЗЧИКЕ мы можем проанализировать любую из функций программы, это не имеет значения, если мы не знаем как её вызывать и пользоваться ей.
Конечно, чтобы говорить о функциональном анализе, мы должны знать как используются регистры и инструкции, потому что несмотря на то, что мы не находимся под отладкой и не имеем окна с регистрами со значениями в каждый момент времени, инструкции используют их и мы должны понять их, чтобы знать то, что делает программа.
Что же такое регистры и для чего они используются?
Хорошему процессору нужны помощники в его задаче по выполнению программ.Регистры помогают ему в этом. Когда мы видем ассемблерные инструкции, мы видем, например, что они не могут сложить содержимое двух ячеек памяти напрямую. Процессор должен переместить одну из них в регистр, а затем сложить с другой ячейкой памяти. Это пример, но, конечно, у некоторых регистров есть более определенное использование. Давайте посмотрим.
32-разрядные регистры, которые используются – это: EAX, ECX, EDX, EBX, ESP, EBP, ESI, EDI и EIP . В конце курса будет часть, посвященная 64-битным.
Регистры общего назначения
EAX (Аккумулятор): Аккумулятор используется для таких инструкций как деление, умножение и некоторых инструкций формата, и также как регистр общего назначения.
EBX (База): Он может непосредственно работать с памятью, используется как база и также как регистр общего назначения.
ECX (Счетчик): ECX регистр общего назначения, который может использоваться в качестве счетчика для различных инструкций. Он также может иметь адрес смещения данных в памяти. Инструкции, которые используют счетчик, являются – цепочечные инструкции, инструкции смещения, ROR инструкции(циклические) и LOOP/LOOPD.
EDX (Данные): Это регистр общего назначения, который содержит часть результата умножения или деления. Он может также работать непосредственной с данными памяти.
EBP (Указатель на базу стека): EBP указывает на место в памяти. Почти всегда как база для аргументов и переменных функции, кроме того, он также регистр общего назначения.
EDI (Указатель на назначение): Часто, он указывает на адрес назначение результата в строковых цепочечных инструкциях. Он также регистр общего назначения.
ESI (Указатель на источник): Часто, он указывает на адрес источника в строковых цепочечных инструкциях. Как и EDI, ESI также работает как регистр общего назначения.
EIP: Указатель, который указывает на следующую инструкцию, которая будет выполнена.
ESP: Указатель, который указывает на верхушку части стека или пачку.
Подведём итог того, что я сказал.
Восемь регистров – EAX (аккумулятор), EBX (база), ECX (счетчик), EDX (данные), ESP (указатель на вершину стек), EBP (указатель на базу стека), ESI (указатель на источник данных ) и EDI (указатель на назначение данных).
Также там существуют 16-битные и 8-битные регистры , которые являются частями предыдущих регистров.
Если EAX равно 12345678
AX
это последние четыре цифры (16 бит)
AH это 5-я и 6-я цифра и AL две последние цифры (8 бит каждая)
Есть 16-разрядный регистр для младшей части регистра EAX называющийся AX и два 8-разрядных регистра называющихся AH и AL. Не существует специальных регистров для старшей части .
Эти регистры существуют в той же формы для EBX (BX, BH и BL), для ECX (CX, CH и CL) и это применимо почти ко всем регистрам (только у ESP есть 16-бит SP, но не SL из 8 битов)
Здесь Вы можете видеть регистры, такие как EAX, EDX, ECX, и EBX, которые имеют регистры из 16 и 8 битов и EBP, ESI, EDI и ESP, которые имеют 16-битные подрегистры.
Мы будем рассматривать и другие регистры, один из них важный вспомогательный регистр EFLAGS, который активирует свои флаги, которые принимают значения на основе решений в разные моменты выполнения программы, которые мы рассмотрим позже, сегментные регистры указывают на другие части исполняемого файла, такие как CS=CODE, DS=DATA и т.д.
Другая важная деталь, это размеры большинства используемых типов данных.
IDA управляет большим количеством данных, которые мы будем видеть постепенно, чтобы не усложнять обучение, важная вещь состоит в том, чтобы знать, что BYTE равен 1 байту в памяти, WORD 2 байтам и DWORD составляет 4 байта.
ИНСТРУКЦИИ
IDA
работает с синтаксисом инструкций, который не является самым простым в мире, большинство же людей используют дизассемблер OLLYDBG, который более прост и без кофеина (проще понять), несмотря на то, что OLLYDBG дает нам меньше информации.
Инструкции перемещения данных
MOV
MOV dest,src: Она копирует содержимое источника операнда (src) в место назначения (dest).Операция: dest ← src
Здесь есть несколько возможностей. Например, нам может понравиться первая возможность переместить значение одного регистра в другой.MOV EAX, EDI
В целом, мы можем перемещать из или в регистр непосредственно, принимая во внимание это EIP не может быть МЕСТОМ НАЗНАЧЕНИЯ или ИСТОЧНИКОМ в любой операции. Мы не можем сделать так
MOV EIP , EAX
Это не допустимо.Другая возможность состоит в том, чтобы переместить константу в регистр, например.
MOV EAX, 1
Другая возможность состоит в том, чтобы переместить значение адреса памяти, а не ее содержимое (Эти инструкции в изображении принадлежат другой программе, не CRACKME.exe, потому что они не были там, но есть в VEViewer.exe, файл приложен к этой части 3)
В этом случае, когда значение будет перемещено, оно является адресом памяти, слово OFFSET, указывает нам, что мы должны использовать адрес, но не его содержание.
Или если нажмём Q , оно становится таким
MOV EAX, 46f038
Эта ещё одна инструкция как в OLLY, но она не дает нам информации о содержимом этого адреса. Если мы щелкаем правой кнопкой по адресу 46F038, мы можем вернуться к исходной инструкции.
И она станет как прежде.
Что говорит мне эта дополнительная информация? Что IDA говорит мне о вышеупомянутом адресе памяти?
Если я открываю окно HEX DUMP и поищу упомянутый выше адрес, я вижу, что первично он равен нулю. Я знаю, что это DWORD, но я действительно не знаю что это, потому что он зависит от того, где он использует это значение в программе, что определяет тип этой переменной.
Если я вернусь к списку и дважды щелкну в этом адресе.
Здесь я буду видеть, что IDA говорит мне, что содержимое вышеупомянутого адреса DWORD, в окне дизассемблера IDA, когда мы видим область памяти, которая не является кодом, поскольку в этом случае принадлежит секции данных, конечно, первая колонка это адрес`а.
IDA говорит мне dword_46F038, это означает, что содержимое ячейки памяти равно DWORD, это похоже на разъяснения адреса слева, здесь есть тип данных dd, который является знакомым нам DWORD и потом значение, которое содержит вышеупомянутая ячейка памяти, является нулём.
IDA говорит мне, что программа использует этот адрес как DWORD и на правой стороне я вижу ссылки, где этот DWORD будет использоваться.
Там есть две ссылки, каждая стрелка, это одна из них и подведя курсор мыши над ней я могу видеть код, также если я нажму X на этом адресе, я увижу откуда сюда ссылается программа.
Первая, где читается адрес, где мы были ранее, вторая, записывает DWORD по адресу 0x46F038, вот почему IDA в первой инструкции говорит нам, что тот адрес указывает на DWORD, потому что тут была другая ссылка, которая получает доступ к ней и записывает этот DWORD и сейчас все чисто.
Так что, IDA в первоначальной инструкции не только сообщила мне, что собирается поместить адрес в регистр, но она также сказала мне, что этот адрес содержит DWORD, это что-то вроде бонуса.
Так что, когда мы видим, что говорится о числовых адресах, IDA помечает адрес как OFFSET и когда мы будем искать его содержимое, как в этом случае, оно будет равно нулю, она не использует квадратные скобки, если это числовой адрес.
Как ранее мы видели.
mov eax, offset dword_46F908
Эта инструкция поместит адрес 0x46F908 в EAXmov eax, dword_46F908
Эта инструкция поместит содержимое или значение, которое расположено в вышеупомянутой памяти.
Эта инструкция, которую помним по OLLY с квадратными скобками для, тех кто привык к этому отладчику.
MOV EAX,DWORD PTR DS:[46f908]
Или когда адрес имеет впереди слово OFFSET, он ссылается на этот самый адрес, а когда этого слова нет, то ссылается на значение полученное по этому адресу.Это просто случается, когда мы обращаемся к числовым адресам, если мы работает только с регистрами.
Здесь, инструкция использует квадратные скобки, потому что, очевидно, она не знает статически какое значение содержит регистр в этот момент, и она не знает на какой адрес будет указывать, чтобы получить больше информации .
Конечно, в этом случае, если EDI указывает например на 0x10000, упомянутая выше инструкция будет искать содержимое адреса памяти и оно будет скопировано в ECX.
Очень важно понимать, что когда IDA использует слово OFFSET перед адресом памяти она ссылается на это же числовое значение, а не на его содержимое, давайте рассмотрим ещё один пример.
Тут мы видим, что в EAX помещается значение 0x45f4d0, потому что впереди есть слово OFFSET и также она говорит мне, что упомянутый выше адрес содержит stru_, который является структурой.
В другом случае, в первой помеченной инструкции, перемещается содержимое 0x46fc50, которое DWORD ,а во второй, просто адрес, который равен числу 0x46FC50.
Мы видим, что значение вышеупомянутого адреса будет помещено в 0x42f302, если мы кликнем в 0x46fc50, давайте посмотрим, что там есть.
Мы видим, что инструкция помещает ноль, если другая инструкция не выполнилась и сохранила значение, которое я изменил, поскольку она показывает нам ссылки.
С помощью нажатия на X на ссылки, мы видим все ссылки, видим, что инструкция сохраняет DWORD по адресу.
Инструкция, которая выделена желтым цветом, сохраняет DWORD в вышеупомянутый адрес памяти, все другие или читают адрес смещения или читает само значение по адресу, там где нет слова смещение.
Конечно, константы можно также поместить в 16-ные и 8-ные регистры, которые мы видели ранее.
Эта инструкция помещает 1 в AL, оставляя остальную часть EAX со значением, которое было прежде. Тут просто изменяется самый младший байт.
Здесь, инструкция перемещает содержимое адреса памяти 0x459C24 в AX и говорит нам, что это WORD.
И мы видим, что первично здесь ноль, возможно, далее при выполнении программы он может быть изменен.
Здесь AX помещается в содержимое EBX, т. к. это регистр, то не знаем какое значение имеет регистр AX, IDA не может сказать больше, она использует квадратные скобки, чтобы указать что, записывается в содержимое адреса EBX.
Здесь, инструкция запишет значение AX в содержимое ESI+8.
Другой пример
Если я щелкну на страшное имя, оно приведет меня сюда
Мы знаем, что это IAT (таблица, которая сохраняет импортированные адреса функции, когда запускается программа), она почти всегда находится в разделе idata.
Если я ищу этот адрес в окне HEX DUMP, у него всё еще нет указателя на функции, потому что IAT заполняется, когда процесс запускается, а тут он ещё не запустился.
Если я пойду в OPTIONS->DEMANGLE NAMES и выберу NAMES будет намного лучше.
Префикс EXTRN подразумевает, что это ВНЕШНЯЯ импортированная функция.
Если мы прокрутим выше, мы видим, что программа говорит, что есть импортированные функции, которые принадлежат модулю DVCORE.dll и выше есть другие, которые принадлежат различным функциям.
Мы видели различные примеры MOV, которые Вы можете практиковать и видеть в IDA , в той программе, которую я приложил к уроку.
В 4-той части, мы продолжим и разберём больше инструкций.
Пока.
Рикардо Нарваха
Перевод на английский @IvinsonCLS
Перевод на русский Яша_Добрый_Хакер
Перевод специально для форума системного и низкоуровневого программирования – WASM.IN
18.02.2017

yashechka
Ростовский фанат Нарвахи
- Регистрация:
- 2 янв 2012
- Публикаций:
- 90
Комментарии
-
AhillesPeleevich 24 фев 2023
yashechka, благодарю за перевод, но прислушайся к критику ниже – вникай в то, что переводишь:
“AH это 5-я и 6-я цифра и AL две последние цифры (8 бит каждая)“.
Каждая цифра в регистре – это тетрада – половина байта – четыре бита, как указали ниже.
Из предыдущей строки “четыре цифры (16 бит)” тоже должно быть понятно (16 делим на 4).
У автора в скобках речь идёт о регистрах, а не о цифрах:
“AX is the last four digits (16 bits)
AH is the 5th and 6th digit and AL is the two last digits (8 bits each one)“
Так что предлагаю исправить на что-то типа: “8 бит каждый регистр“, чтобы начинающие не путались. -
Antora 31 июл 2018
Если я не ошибаюсь, значение по адресу поместится в eax, а не в 0x42f302 (ну а сам адрес в ecx):
“Мы видим, что значение вышеупомянутого адреса будет помещено в 0x42f302″ -
yashechka 14 май 2018
Основные ошибки исправленны, их можно видеть в комментариях. Если увидите что-то новое – пишите.
-
Aoizora 30 ноя 2017
И все переведено так убого и коряво. Прям лицо вирусной сцены, состоящей из недоучек.
-
Aoizora 30 ноя 2017
>Здесь AX помещается в содержимое EBX
>[EBX]
Складывается впечатление, что автор не понимает, что он переводит, и просто генерирует небрежный машинный перевод. Еще и какую-то статью про шеллкоды писать вздумал. Ты русский и английский язык для начала выучи. Наверно, еще и без работы сидишь, потому что C++ не осилил. -
Aoizora 29 ноя 2017
>AH это 5-я и 6-я цифра и AL две последние цифры (8 бит каждая)
>(8 бит каждая)
Что за чушь? AL содержит один байт. В байте 8 бит. Две 16-ричных цифры составляют байт, поэтому каждая цифра занимает 4 бита.
Нельзя же писать такую откровенную дезинформацию. Как вообще можно браться за перевод статей о реверсе, не имея фундаментальных знаний? -
yashechka 9 мар 2017
Будьте добры, скажите что не так.
-
Fail 8 мар 2017
При всем уважении к переводчику
") Просто вспомнилось
Просто вспомнилось— Что, очень плохо, да?
— Ну почему?
— Ну ты же всё повычёркивал.
— Ну, мелочи кое-какие… Например: «Коза кричала нечеловеческим голосом». Это я не мог оставить.
— Ну а каким?
— Да никаким. Просто кричала. -
yashechka 21 фев 2017
>Яшечка, дорогой, вы перевод хотя бы в Word то запихните, ну или спеллчекер в браузере включите.
Спасибо за дорого, Вы тоже дорогой, учту. -
TermoSINteZ 20 фев 2017
Яшечка, дорогой, вы перевод хотя бы в Word то запихните, ну или спеллчекер в браузере включите.
а то “мои глаза…”
>Регистры помогают ему в этом. Когда мы видем ассемблерные инструкции, мы видем…. -
yashechka 19 фев 2017
Готово. Если по тексту кому-нибудь что-то не нравиться – пишите, будем вместе исправлять.

Мы уже видели, что когда в IDA мы открываем исполняемый файл, тот же самый файл открывается в ЗАГРУЗЧИКЕ, который является статическим анализатором того же самого файла.
Мы будем анализировать его части и характеристики, большая часть того, что мы видели до настоящего времени, будут применимы и к ЗАГРУЗЧИКУ и для ОТЛАДЧИКА. В случае, если что-то будет отличаться или не похоже на общий случай, я упомяну это.
Очевидно, то, что в ЗАГРУЗЧИКЕ программа абсолютно не выполняется, но она анализируется, и создаётся база данных с информацией этого файла, и это значительное отличие относительно ОТЛАДЧИКА.
В ЗАГРУЗЧИКЕ нет ни окна РЕГИСТРОВ, ни окна СТЕКА, ни списка модулей, которые загружены в память. Это вещи, существуют при выполнении и отладке программы.
После загрузки Cruehead Crackme (CRACKME.EXE), если мы посмотрим на список процессов , то увидим, что он не работает и никогда не выполняется, пока мы не откроем отладчик IDA.
Это очень полезно для определенного использования, например как анализ вредоноса, эксплоита и т.д. , потому что мы не всегда сможем получить доступ к некоторой функции, для этого мы должны изучить отладку, в то время как в ЗАГРУЗЧИКЕ мы можем проанализировать любую из функций программы, это не имеет значения, если мы не знаем как её вызывать и пользоваться ей.
Конечно, чтобы говорить о функциональном анализе, мы должны знать как используются регистры и инструкции, потому что несмотря на то, что мы не находимся под отладкой и не имеем окна с регистрами со значениями в каждый момент времени, инструкции используют их и мы должны понять их, чтобы знать то, что делает программа.
Что же такое регистры и для чего они используются?
Хорошему процессору нужны помощники в его задаче по выполнению программ.
Регистры помогают ему в этом. Когда мы видем ассемблерные инструкции, мы видем, например, что они не могут сложить содержимое двух ячеек памяти напрямую. Процессор должен переместить одну из них в регистр, а затем сложить с другой ячейкой памяти. Это пример, но, конечно, у некоторых регистров есть более определенное использование. Давайте посмотрим.
32-разрядные регистры, которые используются – это: EAX, ECX, EDX, EBX, ESP, EBP, ESI, EDI и EIP . В конце курса будет часть, посвященная 64-битным.

Регистры общего назначения
EAX (Аккумулятор): Аккумулятор используется для таких инструкций как деление, умножение и некоторых инструкций формата, и также как регистр общего назначения.
EBX (База): Он может непосредственно работать с памятью, используется как база и также как регистр общего назначения.
ECX (Счетчик): ECX регистр общего назначения, который может использоваться в качестве счетчика для различных инструкций. Он также может иметь адрес смещения данных в памяти. Инструкции, которые используют счетчик, являются – цепочечные инструкции, инструкции смещения, ROR инструкции(циклические) и LOOP/LOOPD.
EDX (Данные): Это регистр общего назначения, который содержит часть результата умножения или деления. Он может также работать непосредственной с данными памяти.
EBP (Указатель на базу стека): EBP указывает на место в памяти. Почти всегда как база для аргументов и переменных функции, кроме того, он также регистр общего назначения.
EDI (Указатель на назначение): Часто, он указывает на адрес назначение результата в строковых цепочечных инструкциях. Он также регистр общего назначения.
ESI (Указатель на источник): Часто, он указывает на адрес источника в строковых цепочечных инструкциях. Как и EDI, ESI также работает как регистр общего назначения.
EIP: Указатель, который указывает на следующую инструкцию, которая будет выполнена.
ESP: Указатель, который указывает на верхушку части стека или пачку.
Подведём итог того, что я сказал.
Восемь регистров – EAX (аккумулятор), EBX (база), ECX (счетчик), EDX (данные), ESP (указатель на вершину стек), EBP (указатель на базу стека), ESI (указатель на источник данных ) и EDI(указатель на назначение данных).
Также там существуют 16-битные и 8-битные регистры , которые являются частями предыдущих регистров.
AX это последние четыре цифры (16 бит)

AH это 5-я и 6-я цифра и AL две последние цифры (8 бит каждая)

Есть 16-разрядный регистр для младшей части регистра EAX называющийся AX и два 8-разрядных регистра называющихся AH и AL. Не существует специальных регистров для старшей части .
Эти регистры существуют в той же формы для EBX (BX, BH и BL), для ECX (CX, CH и CL) и это применимо почти ко всем регистрам (только у ESP есть 16-бит SP, но не SL из 8 битов)

Здесь Вы можете видеть регистры, такие как EAX, EDX, ECX, и EBX, которые имеют регистры из 16 и 8 битов и EBP, ESI, EDI и ESP, которые имеют 16-битные подрегистры.

Мы будем рассматривать и другие регистры, один из них важный вспомогательный регистр EFLAGS, который активирует свои флаги, которые принимают значения на основе решений в разные моменты выполнения программы, которые мы рассмотрим позже, сегментные регистры указывают на другие части исполняемого файла, такие как CS=CODE, DS=DATA и т.д.
Другая важная деталь, это размеры большинства используемых типов данных.

IDA управляет большим количеством данных, которые мы будем видеть постепенно, чтобы не усложнять обучение, важная вещь состоит в том, чтобы знать, что BYTE равен 1 байту в памяти, WORD 2 байтам и DWORD составляет 4 байта.
IDA работает с синтаксисом инструкций, который не является самым простым в мире, большинство же людей используют дизассемблер OLLYDBG, который более прост и без кофеина (проще понять), несмотря на то, что OLLYDBG дает нам меньше информации.
Инструкции перемещения данных
MOV dest,src: Она копирует содержимое источника операнда (src) в место назначения (dest).
Здесь есть несколько возможностей. Например, нам может понравиться первая возможность переместить значение одного регистра в другой.

В целом, мы можем перемещать из или в регистр непосредственно, принимая во внимание это EIP не может быть МЕСТОМ НАЗНАЧЕНИЯ или ИСТОЧНИКОМ в любой операции. Мы не можем сделать так
Другая возможность состоит в том, чтобы переместить константу в регистр, например.

Другая возможность состоит в том, чтобы переместить значение адреса памяти, а не ее содержимое (Эти инструкции в изображении принадлежат другой программе, не CRACKME.exe, потому что они не были там, но есть в VEViewer.exe, файл приложен к этой части 3)

В этом случае, когда значение будет перемещено, оно является адресом памяти, слово OFFSET, указывает нам, что мы должны использовать адрес, но не его содержание.
Или если нажмём Q , оно становится таким

Эта ещё одна инструкция как в OLLY, но она не дает нам информации о содержимом этого адреса. Если мы щелкаем правой кнопкой по адресу 46F038, мы можем вернуться к исходной инструкции.

Что говорит мне эта дополнительная информация? Что IDA говорит мне о вышеупомянутом адресе памяти?

Если я открываю окно HEX DUMP и поищу упомянутый выше адрес, я вижу, что первично он равен нулю. Я знаю, что это DWORD, но я действительно не знаю что это, потому что он зависит от того, где он использует это значение в программе, что определяет тип этой переменной.

Если я вернусь к списку и дважды щелкну в этом адресе.

Здесь я буду видеть, что IDA говорит мне, что содержимое вышеупомянутого адреса DWORD, в окне дизассемблера IDA, когда мы видим область памяти, которая не является кодом, поскольку в этом случае принадлежит секции данных, конечно, первая колонка это адреса.
IDA говорит мне dword_46F038, это означает, что содержимое ячейки памяти равно DWORD, это похоже на разъяснения адреса слева, здесь есть тип данных dd, который является знакомым нам DWORD и потом значение, которое содержит вышеупомянутая ячейка памяти, является нулём.
IDA говорит мне, что программа использует этот адрес как DWORD и на правой стороне я вижу ссылки, где этот DWORD будет использоваться.

Там есть две ссылки, каждая стрелка, это одна из них и подведя курсор мыши над ней я могу видеть код, также если я нажму X на этом адресе, я увижу откуда сюда ссылается программа.

Первая, где читается адрес, где мы были ранее, вторая, записывает DWORD по адресу 0x46F038, вот почему IDA в первой инструкции говорит нам, что тот адрес указывает на DWORD, потому что тут была другая ссылка, которая получает доступ к ней и записывает этот DWORD и сейчас все чисто.

Так что, IDA в первоначальной инструкции не только сообщила мне, что собирается поместить адрес в регистр, но она также сказала мне, что этот адрес содержит DWORD, это что-то вроде бонуса.
Так что, когда мы видим, что говорится о числовых адресах, IDA помечает адрес как OFFSET и когда мы будем искать его содержимое, как в этом случае, оно будет равно нулю, она не использует квадратные скобки, если это числовой адрес.
mov eax, offset dword_46F908
Эта инструкция поместит адрес 0x46F908 в EAX
Эта инструкция поместит содержимое или значение, которое расположено в вышеупомянутой памяти.

Эта инструкция, которую помним по OLLY с квадратными скобками для, тех кто привык к этому отладчику.
MOV EAX,DWORD PTR DS:[46f908]
Или когда адрес имеет впереди слово OFFSET, он ссылается на этот самый адрес, а когда этого слова нет, то ссылается на значение полученное по этому адресу.
Это просто случается, когда мы обращаемся к числовым адресам, если мы работает только с регистрами.

Здесь, инструкция использует квадратные скобки, потому что, очевидно, она не знает статически какое значение содержит регистр в этот момент, и она не знает на какой адрес будет указывать, чтобы получить больше информации.
Конечно, в этом случае, если EDI указывает например на 0x10000, упомянутая выше инструкция будет искать содержимое адреса памяти и оно будет скопировано в ECX.
Очень важно понимать, что когда IDA использует слово OFFSET перед адресом памяти она ссылается на это же числовое значение, а не на его содержимое, давайте рассмотрим ещё один пример.

Тут мы видим, что в EAX помещается значение 0x45f4d0, потому что впереди есть слово OFFSET и также она говорит мне, что упомянутый выше адрес содержит stru_, который является структурой.

В другом случае, в первой помеченной инструкции, перемещается содержимое 0x46fc50, которое DWORD ,а во второй, просто адрес, который равен числу 0x46FC50.
Мы видим, что значение вышеупомянутого адреса будет помещено в 0x42f302, если мы кликнем в 0x46fc50, давайте посмотрим, что там есть.

Мы видим, что инструкция помещает ноль, если другая инструкция не выполнилась и сохранила значение, которое я изменил, поскольку она показывает нам ссылки.
С помощью нажатия на X на ссылки, мы видим все ссылки, видим, что инструкция сохраняет DWORD по адресу.

Инструкция, которая выделена желтым цветом, сохраняет DWORD в вышеупомянутый адрес памяти, все другие или читают адрес смещения или читает само значение по адресу, там где нет слова смещение.
Конечно, константы можно также поместить в 16-ные и 8-ные регистры, которые мы видели ранее.

Эта инструкция помещает 1 в AL, оставляя остальную часть EAX со значением, которое было прежде. Тут просто изменяется самый младший байт.

Здесь, инструкция перемещает содержимое адреса памяти 0x459C24 в AX и говорит нам, что это WORD.

И мы видим, что первично здесь ноль, возможно, далее при выполнении программы он может быть изменен.

Здесь AX помещается в содержимое EBX, т. к. это регистр, то не знаем какое значение имеет регистр AX, IDA не может сказать больше, она использует квадратные скобки, чтобы указать что, записывается в содержимое адреса EBX.

Здесь, инструкция запишет значение AX в содержимое ESI+8.

Если я щелкну на страшное имя, оно приведет меня сюда

Мы знаем, что это IAT (таблица, которая сохраняет импортированные адреса функции, когда запускается программа), она почти всегда находится в разделе idata.
Если я ищу этот адрес в окне HEX DUMP, у него всё еще нет указателя на функции, потому что IAT заполняется, когда процесс запускается, а тут он ещё не запустился.

Если я пойду в OPTIONS->DEMANGLE NAMES и выберу NAMES будет намного лучше.

Префикс EXTRN подразумевает, что это ВНЕШНЯЯ импортированная функция.
Если мы прокрутим выше, мы видим, что программа говорит, что есть импортированные функции, которые принадлежат модулю DVCORE.dll и выше есть другие, которые принадлежат различным функциям.

Мы видели различные примеры MOV, которые Вы можете практиковать и видеть в IDA , в той программе, которую я приложил к уроку.
В 4-той части, мы продолжим и разберём больше инструкций.
Автор оригинального текста — Рикардо Нарваха.
Перевод и адаптация на английский язык — IvinsonCLS.
Перевод и адаптация на русский язык — Яша Яшечкин.
Перевод специально для форума системного и низкоуровневого программирования – WASM.IN
