Есть строка со списком слов. Есть определенное слово, которое нужно найти в этой строке.
Я использую функцию strpos(), всё ок:
$mystring = 'apple,orange,pear,banana,mango';
$findme = 'apple';
$pos = strpos($mystring, $findme);
if ($pos !== false) {
echo "Строка '$findme' найдена в строке '$mystring'";
echo " в позиции $pos";
} else {
echo "Строка '$findme' не найдена в строке '$mystring'";
}
Однако, я хотел бы сделать поиск немного гибким, чтобы поиск осуществлялся по частям искомого слова.
Например, слово для поиска будет не “apple“, а “pineapple“. В нашем случае функция ничего не найдет.
Я думаю, что можно эту задачу можно решить путем поиска каждого слова из списка
в строке $findme:
$mystring = 'apple,orange,pear,banana,mango';
$findme = 'pineapple';
$arr= explode(",", $mystring );
foreach($arr as $v){
$pos = strpos($findme, $v);
if ($pos !== false) {
echo "Строка '$findme' найдена в строке '$mystring'";
echo " в позиции $pos";
break;
} else {
echo "Строка '$findme' не найдена в строке '$mystring'";
}
}
Но а если словарь $mystring состоит из сотен тысяч слов. Тогда мой вариант будет работать очень медленно.
Подскажите, пожалуйста, как можно решить эту проблему?
Спасибо!
ПОИСК, ПОИСКБ (функции ПОИСК, ПОИСКБ)
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
В этой статье описаны синтаксис формулы и использование функций ПОИСК и ПОИСКБ в Microsoft Excel.
Описание
Функции ПОИСК И ПОИСКБ находят одну текстовую строку в другой и возвращают начальную позицию первой текстовой строки (считая от первого символа второй текстовой строки). Например, чтобы найти позицию буквы “n” в слове “printer”, можно использовать следующую функцию:
=ПОИСК(“н”;”принтер”)
Эта функция возвращает 4, так как “н” является четвертым символом в слове “принтер”.
Можно также находить слова в других словах. Например, функция
=ПОИСК(“base”;”database”)
возвращает 5, так как слово “base” начинается с пятого символа слова “database”. Можно использовать функции ПОИСК и ПОИСКБ для определения положения символа или текстовой строки в другой текстовой строке, а затем вернуть текст с помощью функций ПСТР и ПСТРБ или заменить его с помощью функций ЗАМЕНИТЬ и ЗАМЕНИТЬБ. Эти функции показаны в примере 1 данной статьи.
Важно:
-
Эти функции могут быть доступны не на всех языках.
-
Функция ПОИСКБ отсчитывает по два байта на каждый символ, только если языком по умолчанию является язык с поддержкой БДЦС. В противном случае функция ПОИСКБ работает так же, как функция ПОИСК, и отсчитывает по одному байту на каждый символ.
К языкам, поддерживающим БДЦС, относятся японский, китайский (упрощенное письмо), китайский (традиционное письмо) и корейский.
Синтаксис
ПОИСК(искомый_текст;просматриваемый_текст;[начальная_позиция])
ПОИСКБ(искомый_текст;просматриваемый_текст;[начальная_позиция])
Аргументы функций ПОИСК и ПОИСКБ описаны ниже.
-
Искомый_текст Обязательный. Текст, который требуется найти.
-
Просматриваемый_текст Обязательный. Текст, в котором нужно найти значение аргумента искомый_текст.
-
Начальная_позиция Необязательный. Номер знака в аргументе просматриваемый_текст, с которого следует начать поиск.
Замечание
-
Функции ПОИСК и ПОИСКБ не учитывают регистр. Если требуется учитывать регистр, используйте функции НАЙТИ и НАЙТИБ.
-
В аргументе искомый_текст можно использовать подстановочные знаки: вопросительный знак (?) и звездочку (*). Вопросительный знак соответствует любому знаку, звездочка — любой последовательности знаков. Если требуется найти вопросительный знак или звездочку, введите перед ним тильду (~).
-
Если значение find_text не найдено, #VALUE! возвращается значение ошибки.
-
Если аргумент начальная_позиция опущен, то он полагается равным 1.
-
Если start_num больше нуля или больше, чем длина аргумента within_text, #VALUE! возвращается значение ошибки.
-
Аргумент начальная_позиция можно использовать, чтобы пропустить определенное количество знаков. Допустим, что функцию ПОИСК нужно использовать для работы с текстовой строкой “МДС0093.МужскаяОдежда”. Чтобы найти первое вхождение “М” в описательной части текстовой строки, задайте для аргумента начальная_позиция значение 8, чтобы поиск не выполнялся в той части текста, которая является серийным номером (в данном случае — “МДС0093”). Функция ПОИСК начинает поиск с восьмого символа, находит знак, указанный в аргументе искомый_текст, в следующей позиции, и возвращает число 9. Функция ПОИСК всегда возвращает номер знака, считая от начала просматриваемого текста, включая символы, которые пропускаются, если значение аргумента начальная_позиция больше 1.
Примеры
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
||
|
Выписки |
||
|
Доход: маржа |
||
|
маржа |
||
|
Здесь “босс”. |
||
|
Формула |
Описание |
Результат |
|
=ПОИСК(“и”;A2;6) |
Позиция первого знака “и” в строке ячейки A2, начиная с шестого знака. |
7 |
|
=ПОИСК(A4;A3) |
Начальная позиция строки “маржа” (искомая строка в ячейке A4) в строке “Доход: маржа” (ячейка, в которой выполняется поиск — A3). |
8 |
|
=ЗАМЕНИТЬ(A3;ПОИСК(A4;A3);6;”объем”) |
Заменяет слово “маржа” словом “объем”, определяя позицию слова “маржа” в ячейке A3 и заменяя этот знак и последующие пять знаков текстовой строкой “объем.” |
Доход: объем |
|
=ПСТР(A3;ПОИСК(” “;A3)+1,4) |
Возвращает первые четыре знака, которые следуют за первым пробелом в строке “Доход: маржа” (ячейка A3). |
марж |
|
=ПОИСК(“”””;A5) |
Позиция первой двойной кавычки (“) в ячейке A5. |
5 |
|
=ПСТР(A5;ПОИСК(“”””;A5)+1;ПОИСК(“”””;A5;ПОИСК(“”””;A5)+1)-ПОИСК(“”””;A5)-1) |
Возвращает из ячейки A5 только текст, заключенный в двойные кавычки. |
босс |
Нужна дополнительная помощь?
Нужны дополнительные параметры?
Изучите преимущества подписки, просмотрите учебные курсы, узнайте, как защитить свое устройство и т. д.
В сообществах можно задавать вопросы и отвечать на них, отправлять отзывы и консультироваться с экспертами разных профилей.
В предыдущей статье мы начали тему работы со строками в JavaScript. В этом материале вы узнаете, как выполнять поиск в строке, как работать с подстрокой, как извлекать часть строки и т. д.

Поиск строки в строке в JavaScript
С помощью метода IndexOf() можно вернуть индекс первого вхождения заданного текста в строку:
var str = "Please locate where 'locate' occurs!"; var pos = str.indexOf("locate");В нашем случае происходит подсчёт позиции с нуля. При этом:
1) 0 — первая позиция в строке,
2) 1 — вторая,
3) 2 — третья…Идём дальше. Функция LastIndexOf() в JavaScript вернёт индекс последнего вхождения:
var str = "Please locate where 'locate' occurs!"; var pos = str.lastIndexOf("locate");Оба этих метода принимают 2-й параметр в виде начальной позиции для поиска:
var str = "Please locate where 'locate' occurs!"; var pos = str.indexOf("locate",15);Стоит упомянуть и функцию Search() — она выполняет поиск строки для заданного значения, возвращая позицию совпадения:
var str = "Please locate where 'locate' occurs!"; var pos = str.search("locate");Метод slice () в JavaScript
Функция slice() извлечёт часть строки и вернёт извлечённую часть в новой строке. Метод способен принимать два параметра: начальный индекс (это положение) и конечный индекс (речь идёт о позиции).
К примеру, давайте нарежем часть строки из позиции 7 в положение 13:
var str = "Apple, Banana, Kiwi"; var res = str.slice(7, 13);В нашем случае результатом будет:
Если параметр будет иметь отрицательное значение, то позиция будет учитываться с конца строки. Например:
var str = "Apple, Banana, Kiwi"; var res = str.slice(-12, -6);Результат будет тот же.
Кстати, если 2-й параметр опустить, то метод сделает срез оставшейся части строки:
Результатом будет:
То же самое получим, выполнив срез с конца:
var res = str.slice(-12);Остаётся лишь добавить, что отрицательные позиции не функционируют в Internet Explorer 8 и других, более ранних версиях.
Метод подстроки в JavaScript
Подстрока в JavaScript аналогична срезу с той разницей, что подстрока не способна принимать отрицательные индексы:
var str = "Apple, Banana, Kiwi"; var res = str.substring(7, 13);В качестве результата опять получим «Banana».
Если же мы опустим 2-й параметр, то подстрока разрежет оставшуюся часть строки.
Метод substr () в JavaScript
Строковый метод substr() похож на slice() с той разницей, что 2-й параметр показывает длину извлечённой детали.
var str = "Apple, Banana, Kiwi"; var res = str.substr(7, 6);Результат: Banana.
Мы можем опустить 2-й параметр — тогда строковый метод substr() разрежет оставшуюся часть строки.
var str = "Apple, Banana, Kiwi"; var res = str.substr(7);Получим: Banana, Kiwi.
Если 1-й параметр будет отрицательным, позиция будет рассчитываться с конца строки.
var str = "Apple, Banana, Kiwi"; var res = str.substr(-4);Результат: Kiwi.
Меняем содержимое строки в JavaScript
Строковый метод Replace() позволит заменить указанное значение иным значением в строке:
str = "Please visit Microsoft!"; var n = str.replace("Microsoft", "W3Schools");Результат: Please visit W3Schools!
Обратите внимание, что метод Replace() не изменит строку, в которой вызывается, а возвратит новую.
В следующем примере функция Replace() меняет лишь первое совпадение:
str = "Please visit Microsoft and Microsoft!"; var n = str.replace("Microsoft", "W3Schools");Итог: Please visit W3Schools and Microsoft!
Кстати, по умолчанию Replace() учитывает регистр. Написав MICROSOFT, мы увидим, что функция работать не будет:
Примерstr = "Please visit Microsoft!"; var n = str.replace("MICROSOFT", "W3Schools");Но мы можем заменить регистр без его учёта, если воспользуемся регулярным выражением с пометкой ” i “:
str = "Please visit Microsoft!"; var n = str.replace(/MICROSOFT/i, "W3Schools");Результат: Please visit W3Schools!
Здесь стоит заметить, что регулярные выражения надо писать без кавычек.
Если желаете заменить все совпадения, воспользуйтесь регулярным выражением с флагом /g:
str = "Please visit Microsoft and Microsoft!"; var n = str.replace(/Microsoft/g, "W3Schools");Тут получим следующее: Please visit W3Schools and W3Schools!
Извлекаем строковые символы в JavaScript
Есть 2 безопасных строковых функции для извлечения строковых символов:
• charCodeAt (позиция);
• charAt (позиция).Функция charAt() возвратит символ по указанному нами индексу (позиции) в строке:
var str = "HELLO WORLD"; str.charAt(0);Вывод:
Что касается метода charCodeAt(), то он вернёт Юникод символа по указанному нами индексу:
var str = "HELLO WORLD"; str.charCodeAt(0); // вернёт 72Что ж, на этом всё, удачного вам кодинга!
Источник
Интересует профессиональный курс по JavaScript-разработке? Переходите по ссылке ниже:

Поиск подстроки и смежные вопросы
Время на прочтение
13 мин
Количество просмотров 111K
Здравствуйте, уважаемое сообщество! Недавно на Хабре проскакивала неплохая обзорная статья о разных алгоритмах поиска подстроки в строке. К сожалению, там отсутствовали подробные описания каких либо из упомянутых алгоритмов. Я решил восполнить данный пробел и описать хотя бы парочку тех, которые потенциально можно запомнить. Те, кто еще помнит курс алгоритмов из института, не найдут, видимо, ничего нового для себя.
Сначала хотел бы предотвратить вопрос «на кой это надо? все уже и так написано». Да, написано. Но во-первых, полезно знать как работает используемые тобой иструменты на более низком уровне чтобы лучше понимать их ограничения, а во-вторых, есть достаточно большие смежные области, где работающей из коробочки функции strstr() окажется недостаточно. Ну и в-третьих, вам может неповезти и придется разрабатывать под мобильную платформу с неполноценным runtime, а тогда лучше знать на что подписываетесь, если решитесь самостоятельно его дополнять (чтобы убедиться, что это не сферическая проблема в вакууме, достаточно попробовать wcslen() и wcsstr() из Android NDK).
А разве просто поискать нельзя?
Дело в том, что очевидный способ, который все формулирует как «взять и поискать», является отнюдь не самым эффективным, а для такой низкоуровневой и сравнительно частовызываемой функции это немаловажно. Итак, план такой:
- Постановка задачи: здесь перечислены определения и условные обозначения.
- Решение «в лоб»: здесь будет описано, как делать не надо и почему.
- Z-функция: простейший вариант правильной реализации поиска подстроки.
- Алгоритм Кнута-Морриса-Пратта: еще один вариант правильного поиска.
- Другие задачи поиска: вкратце пробегусь по ним без подробного описания.
Постановка задачи
Канонический вариант задачи выглядит так: есть у нас строка A (текст). Необходимо проверить, есть ли в ней подстрока X (образец), и если есть, то где она начинается. То есть именно то, что делает функция strstr() в C. Дополнительно к этому можно еще попросить найти все вхождения образца. Очевидно, что задача имеет смысл только если X не длинее A.
Для простоты дальнейшего объяснения введу сразу пару понятий. Что такое строка все, наверное, понимают — это последовательность символов, возможно пустая. Символы, или буквы, принадлежат некоторому множеству, которое называют алфавитом (данный алфавит, вообще говоря, может не иметь ничего общего с алфавитом в бытовом понимании). Длина строки |A| — это, очевидно, количество символов в ней. Префикс строки A[..i] — это строка из i первых символов строки A. Суффикс строки A[j..] — это строка из |A|-j+1 последних символов. Подстроку из A будем обозначать как A[i..j], а A[i] — i-ый символ строки. Вопрос про пустые суффиксы и префиксы и т.д. не трогаем — с ними разобраться не сложно по месту. Еще есть такое понятие как сентинел — некий уникальный символ, не встречающийся в алфавите. Его обозначают значком $ и дополняют допустимый алфавит таким символом (это в теории, на практике проще применить дополнительные проверки, чем придумать такой символ, которого не могло бы оказаться во входных строках).
В выкладках будем считать символы в строке с первой позиции. Код писать традиционно проще отсчитывая от нуля. Переход от одного к другому не составляет трудностей.
Решение «в лоб»
Прямой поиск, или, как еще часто говорят, «просто взять и поискать»- это Первое решение, которое приходит в голову неискушенному программисту. Суть проста: идти по проверяемой строке A и искать в ней вхождение первого символа искомой строки X. Когда находим, делаем гипотезу, что это и есть то самое искомое вхождение. Затем остается проверять по очереди все последующие символы шаблона на совпадение с соответствующими символами строки A. Если они все совпали — значит вот оно, прямо перед нами. Но вот если какой-то из символов не совпал, то ничего не остается, как признать нашу гипотезу неверной, что возвращает нас к символу, следующему за вхождением первого символа из X.
Многие люди ошибаются в этом пункте, считая, что не надо возвращаться назад, а можно продолжать обработку строки A с текущей позиции. Почему это не так легко продемонстрировать на примере поиска X=«AAAB» в A=«AAAAB». Первая гипотеза нас приведет к четвертому символу A: “AAAAB”, где мы обнаружим несоответствие. Если не откатиться назад, то вхождение мы так и не обнаружим, хотя оно есть.
Неправильные гипотезы неизбежны, а из-за таких откатываний назад при плохом стечении обстоятельств может оказаться, что мы каждый символ в A проверили около |X| раз. То есть вычислительная сложность сложность алгоритма O(|X||A|). Так поиск фразы в параграфе может и затянуться…
Справедливости ради следует отметить, что если строки невелики, то такой алгоритм может работать быстрее «правильных» алгоритмов за счет более предсказуемого с точки зрения процессора поведения.
Z-функция
Одна из категорий правильных способов поиска строки сводится к вычислению в каком-то смысле корреляции двух строк. Сначала отметим, что задача сравнения начал двух строк проста и понятна: сравниваем соответствующие буквы, пока не найдем несоответствие либо какая-нибудь из строк закончится. Рассмотрим множество всех суффиксов строки A: A[|A|..] A[|A|-1..],… A[1..]. Будем сравнивать начало самой строки с каждым из ее суффиксов. Сравнение может дойти до конца суффикса, либо оборваться на каком-то символе ввиду несовпадения. Длину совпавшей части и назовем компонентой Z-функции для данного суффикса.
То есть Z-функция — это вектор длин наибольшего общего префикса строки с ее суффиксом. Ух! Отличная фраза, когда надо кого-то запутать или самоутвердиться, а чтобы понять что же это такое, лучше рассмотреть пример.
Исходная строка «ababcaba». Сравнивая каждый суффикс с самой строкой получим табличку для Z-функции:
| суффикс | строка | Z | |
|---|---|---|---|
| ababcaba | ababcaba | -> | 8 |
| babcaba | ababcaba | -> | 0 |
| abcaba | ababcaba | -> | 2 |
| bcaba | ababcaba | -> | 0 |
| caba | ababcaba | -> | 0 |
| aba | ababcaba | -> | 3 |
| ba | ababcaba | -> | 0 |
| a | ababcaba | -> | 1 |
Префикс суффикса это ничто иное, как подстрока, а Z-функция — длины подстрок, которые встречаются одновременно в начале и в середине. Рассматривая все значения компонент Z-функции, можно заметить некоторые закономерности. Во-первых, очевидно, что значение Z-функции не превышает длины строки и совпадает с ней только для «полного» суффикса A[1..] (и поэтому это значение нас не интересует — мы его будем опускать в своих рассуждениях). Во-вторых, если в строке есть некий символ в единственном экземпляре, то совпасть он может только с самим собой, и значит он делит строку на две части, а значение Z-функции нигде не может превысить длины более короткой части.
Использовать эти наблюдения предлагается следующим образом. Допустим в строке «ababcabсacab» мы хотим поискать «abca». Берем эти строчки и конкатенируем, вставляя между ними сентинел: «abca$ababcabсacab». Вектор Z-функции выглядит для такой строки так:
| a b c a $ a b a b c a b с a c a b |
| 17 0 0 1 0 2 0 4 0 0 4 0 0 1 0 2 0 |
Если отбросить значение для полного суффикса, то наличие сентинела ограничивает Zi длиной искомого фрагмента (он является меньшей половиной строки по смыслу задачи). Но вот если этот максимум и достигается, то только в позициях вхождения подстроки. В нашем примере четверками отмечены
все
позиции вхождения искомой строки (отметьте, что найденные участки расположены внахлест друг с другом, но все-равно наши рассуждения остаются верны).
Ну, значит если мы сможем быстро строить вектор Z-функции, то поиск с его помощью всех вхождений строки сводится к поиску в нем значения ее длины. Вот только если вычислять Z-функцию для каждого суффикса, то будет это явно не быстрее, чем решение «в лоб». Выручает нас то, что значение очередного элемента вектора можно узнать опираясь на предыдущие элементы.
Допустим, мы каким-то образом посчитали значения Z-функции вплоть до соответствующего i-1-ому символу. Рассмотрм некую позицию r<i, где мы уже знаем Zr.
Значит Zr символов начиная с этой позиции точно такие же, как и в начале строки. Они образуют так называемый Z-блок. Нас будет интересовать самый правый Z-блок, то-есть тот, кто заканчивается дальше всех (самый первый не в счет). В некоторых случаях самый правый блок может быть нулевой длины (когда никакой из непустых блоков не покрывает i-1, то самым правым будет i-1-ый, даже если Zi-1= 0).
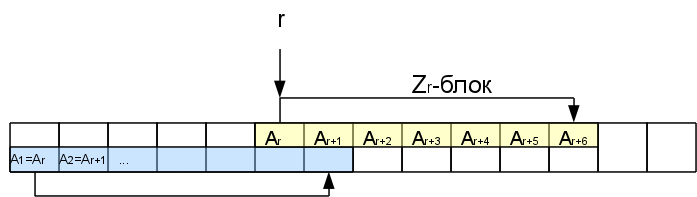
Когда мы будем рассматривать последующие символы внутри этого Z-блока, сравнивать очередной суффикс с самого начала не имеет смысла, так как часть этого суфикса уже встречалась в начале строки, а значит уже была обработана. Можно будет сразу пропускать символы аж до конца Z-блока.
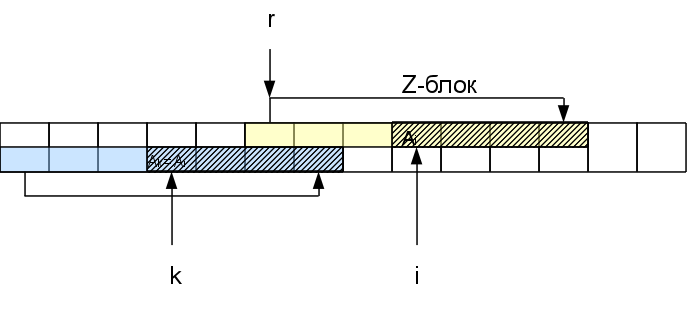
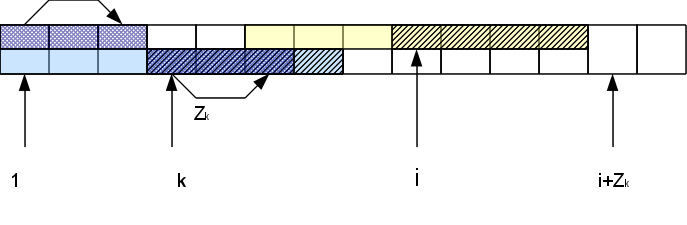
А именно, если мы рассматриваем i-й символ, находящийся в Zr-блоке, то есть соответствующий символ в начале строки на позиции k=i-r+1. Функция Zk нам уже известна. Если она меньше, чем оставшееся до конца Z-блока расстояние Zr-(i-r), то сразу можем быть уверены, что вся область совпадения для этого символа лежит внутри r-того Z-блока и значит результат будет тот же, что и в начале строки: Zi=Zk. Если же Zk >= Zr-(i-r), то Zi тоже больше или равна Zr-(i-r). Чтобы узнать насколько именно она больше, нам надо будет проверять следующие за Z-блоком символы. При этом в случае совпадения h этих символов с соответствующими им в начале строки, Zi увеличивается на h: Zi=Zk + h. В результате у нас может появиться новый самый правый Z-блок (если h>0).
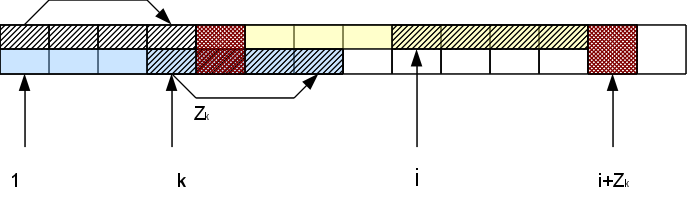
Таким образом, сравнивать символы нам приходится только правее самого правого Z-блока, причем за счет успешных сравнений блок «продвигается» правее, а неуспешные сообщают, что вычисление для данной позиции окончено. Это обеспечивает нам построение всего вектора Z-функции за линейное по длине строки время.
Применив этот алгоритм для поиска подстроки получим сложность по времени O(|A|+|X|), что значительно лучше, чем произведение, которое было в первом варианте. Правда, нам пришлось хранить вектор для Z-функции, на что уйдет дополнительной памяти порядка O(|A|+|X|). На самом деле, если не нужно находить все вхождения, а достаточно только одного, то можно обойтись и O(|X|) памяти, так как длина Z-блока все-равно не может быть больше чем |X|, кроме этого можно не продолжать обработку строки после обнаружения первого вхождения.
Напоследок, пример функции, вычисляющей Z-функцию. Просто модельный вариант без каких либо хитростей.
void z_preprocess(vector<int> & Z, const string & str)
{
const size_t len = str.size();
Z.clear();
Z.resize(len);
if (0 == len)
return;
Z[0] = len;
for (size_t curr = 1, left = 0, right = 1; curr < len; ++curr)
{
if (curr >= right)
{
size_t off = 0;
while ( curr + off < len && str[curr + off] == str[off] )
++off;
Z[curr] = off;
right = curr + Z[curr];
left = curr;
}
else
{
const size_t equiv = curr - left;
if (Z[equiv] < right - curr)
Z[curr] = Z[equiv];
else
{
size_t off = 0;
while ( right + off < len && str[right - curr + off] == str[right + off] )
++off;
Z[curr] = right - curr + off;
right += off;
left = curr;
}
}
}
}
Алгоритм Кнута-Морриса-Пратта (КМП)
Не смотря на логическую простоту предыдущего метода, более популярным является другой алгоритм, который в некотором смысле обратный Z-функции — алгоритм Кнута-Морриса-Пратта (КМП). Введем понятие префикс-функции. Префикс-функция для i-ой позиции — это длина максимального префикса строки, который короче i и который совпадает с суффиксом префикса длины i. Если определение Z-функции не сразило оппонента наповал, то уж этим комбо вам точно удастся поставить его на место 🙂 А на человеческом языке это выглядит так: берем каждый возможный префикс строки и смотрим самое длинное совпадение начала с концом префикса (не учитывая тривиальное совпадение самого с собой). Вот пример для «ababcaba»:
| префикс | префикс | p |
|---|---|---|
| a | a | 0 |
| ab | ab | 0 |
| aba | aba | 1 |
| abab | abab | 2 |
| ababc | ababc | 0 |
| ababca | ababca | 1 |
| ababcab | ababcab | 2 |
| ababcaba | ababcaba | 3 |
Опять же наблюдаем ряд свойств префикс-функции. Во-первых, значения ограничены сверху своим номером, что следует прямо из определения — длина префикса должна быть больше префикс-функции. Во-вторых, уникальный символ точно так же делит строку на две части и ограничивает максимальное значение префикс-функции длиной меньшей из частей — потому что все, что длиннее, будет содержать уникальный, ничему другому не равный символ.
Отсюда получается интересующий нас вывод. Допустим, мы таки достигли в каком-то элементе этого теоретического потолка. Это значит, что здесь закончился такой префикс, что начальная часть совпадает с конечной и одна из них представляет «полную» половинку. Понятно, что в префиксе полная половинка обязана быть спереди, а значит при таком допущении это должна быть более короткая половинка, максимума же мы достигаем на более длинной половинке.
Таким образом, если мы, как и в предыдущей части, конкатенируем искомую строчку с той, в которой ищем, через сентинел, то точка вхождения длины искомой подстроки в компоненту префикс-функции будет соответствовать месту окончания вхождения. Возьмем наш пример: в строке «ababcabсacab» мы ищем «abca». Конкатенированный вариант «abca$ababcabсacab». Префикс-функция выглядит так:
| a b c a $ a b a b c a b с a c a b |
| 0 0 0 1 0 1 2 1 2 3 4 2 3 4 0 1 2 |
Снова мы нашли все вхождения подстроки одним махом — они оканчиваются на позициях четверок. Осталось понять как же эффективно посчитать эту префикс-функцию. Идея алгоритма незначительно отличается от идеи построения Z-функции.

Самое первое значение префикс-функции, очевидно, 0. Пусть мы посчитали префикс-функцию до i-ой позиции включительно. Рассмотрим i+1-ый символ. Если значение префикс-функции в i-й позиции Pi, то значит префикс A[..Pi] совпадает с подстрокой A[i-Pi+1..i]. Если символ A[Pi+1] совпадет с A[i+1], то можем спокойно записать, что Pi+1=Pi+1. Но вот если нет, то значение может быть либо меньше, либо такое же. Конечно, при Pi=0 сильно некуда уменьшаться, так что в этом случае Pi+1=0. Допустим, что Pi>0. Тогда есть в строке префикс A[..Pi], который эквивалентен подстроке A[i-Pi+1..i]. Искомая префикс-функция формируется в пределах этих эквивалентных участков плюс обрабатываемый символ, а значит нам можно забыть о всей строке после префикса и оставить только данный префикс и i+1-ый символ — ситуация будет идентичной.
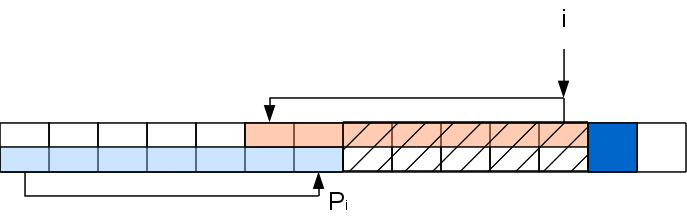
Задача на данном шаге свелась к задаче для строки с вырезанной серединкой: A[..Pi]A[i+1], которую можно решать рекурсивно таким же способом (хотя хвостовая рекурсия и не рекурсия вовсе, а цикл). То есть если A[PPi+1] совпадет с A[i+1], то Pi+1=PPi+1, а иначе снова выкидываем из рассмотрения часть строки и т.д. Повторяем процедуру пока не найдем совпадение либо не дойдем до 0.
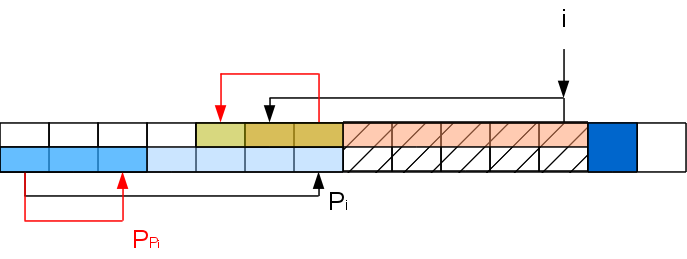
Повторение этих операций должно насторожить — казалось бы получается два вложенных цикла. Но это не так. Дело в том, что вложенный цикл длиной в k итераций уменьшает префикс-функцию в i+1-й позиции хотя бы на k-1, а для того, чтобы нарастить префикс-функцию до такого значения, нужно хотя бы k-1 раз успешно сопоставить буквы, обработав k-1 символов. То есть длина цикла соответствует промежутку между выполнением таких циклов и поэтому сложность алгоритма по прежнему линейна по длине обрабатываемой строки. С памятью тут такая-же ситуация, как и с Z-функцией — линейная по длине строки, но есть способ сэкономить. Кроме этого есть удобный факт, что символы обрабатываются последовательно, то есть мы не обязаны обрабатывать всю строку, если первое вхождение мы уже получили.
Ну и для примера фрагмент кода:
void calc_prefix_function(vector<int> & prefix_func, const string & str)
{
const size_t str_length = str.size();
prefix_func.clear();
prefix_func.resize(str_length);
if (0 == str_length)
return;
prefix_func[0] = 0;
for (size_t current = 1; current < str_length; ++current)
{
size_t matched_prefix = current - 1;
size_t candidate = prefix_func[matched_prefix];
while (candidate != 0 && str[current] != str[candidate])
{
matched_prefix = prefix_func[matched_prefix] - 1;
candidate = prefix_func[matched_prefix];
}
if (candidate == 0)
prefix_func[current] = str[current] == str[0] ? 1 : 0;
else
prefix_func[current] = candidate + 1;
}
}
Не смотря на то, что алгоритм более замысловат, реализация его даже проще, чем для Z-функции.
Другие задачи поиска
Дальше пойдет просто много букв о том, что этим задачи поиска строк не ограничиваются и что есть другие задачи и другие способы решения, так что если кому не интересно, то дальше можно не читать. Эта информация просто для ознакомления, чтобы в случае необходимости хотя бы осознавать, что «все уже украдено до нас» и не переизобретать велосипед.
Хоть вышеописанные алгоритмы и гарантируют линейное время выполнения, звание «алгоритма по умолчанию» получил алгоритм Бойера-Мура. В среднем он тоже дает линейное время, но еще и имеет лучше константу при этой линейной функции, но это в среднем. Бывают «плохие» данные, на которых он оказываются не лучше простейшего сравнения «в лоб» (ну прямо как с qsort). Он на редкость запутан и рассматривать его не будем — все-равно не упомнить. Есть еще ряд экзотических алгоритмов, которые ориентированы на обработку текстов на естественном языке и опираются в своих оптимизациях на статистические свойства слов языка.
Ну ладно, есть у нас алгоритм, который так или иначе за O(|X|+|A|) ищет подстроку в строке. А теперь представим, что мы пишем движок для гостевой книги. Есть у нас список запрещенных матерных слов (понятно, что так не поможет, но задача просто для примера). Мы собираемся фильтровать сообщения. Будем каждое из запрещенных слов искать в сообщении и… на это у нас уйдет O(|X1|+|X2|+…+|Xn|+n|A|). Как-то так себе, особенно если словарь «могучих выражений» «великого и могучего» очень «могуч». Для этого случая есть способ так предобработать словарь искомых строк, что поиск будет занимать только O(|X1|+|X2|+…+|Xn|+|A|), а это может быть существенно меньше, особенно если сообщения длинные.
Такая предобработка сводится к построению бора (trie) из словаря: дерево начинается в некотором фиктивном корне, узлы соответствует буквам слов в словаре, глубина узла дерева соответствует номеру буквы в слове. Узлы, в которых заканчивается слово из словаря называются терминальными и помечены неким образом (красным цветом на рисунке).
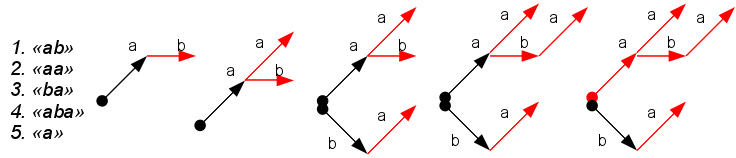
Полученное дерево является аналогом префикс-функции алгоритма КМП. С его помощью можно найти все вхождения всех слов словаря в фразе. Надо идти по дереву, проверяя наличие очередного символа в виде узла дерева, попутно отмечая встречающиеся терминальные вершины — это вхождения слов. Если соответствующего узла в дереве нет, то как и в КМП, происходит откат выше по дереву по специальным ссылкам. Данный алгоритм носит название алгоритма Ахо-Корасика. Такую же схему можно применять для поиска во время ввода и предсказания следующего символа в электронных словарях.
В данном примере построение бора несложно: просто добавляем в бор слова по очереди (нюансы только с дополнительными ссылками для «откатов»). Есть ряд оптимизаций, направленный на сокращение использования памяти этим деревом (т.н. сжатие бора — пропуск участков без ветвлений). На практике эти оптимизации чуть ли не обязательны. Недостатком данного алгоритма является его алфавитозависимость: время на обработку узла и занимаемая память зависят от количества потенциально возможных детей, которое равно размеру алфавита. Для больших алфавитов это серьезная проблема (представляете себе набор символов юникода?). Подробнее про это все можно почитать в этом хабратопике или воспользовавшись гуглояндексом — благо инфы по этомоу вопросу много.
Теперь посмотрим на другую задачу. Если в предыдущей мы знали заранее, что мы должны будем найти в поступающих потом данных, то здесь с точностью до наоборот: нам заранее выдали строчку, в которой будут искать, но что будут искать — неизвестно, а искать будут много. Типичный пример — поисковик. Документ, в котором ищется слово, известен заранее, а вот слова, которые там ищут, сыпятся на ходу. Вопрос, опять же, как вместо O(|X1|+|X2|+…+|Xn|+n|A|) получить O(|X1|+|X2|+…+|Xn|+|A|)?
Предлагается построить бор, в котором будут все возможные суффиксы имеющейся строки. Тогда поиск шаблона сведется к проверки наличия пути в дереве, соответствующего искомому шаблону. Если строить такой бор перебором всех суффиксов, то эта процедура может занять O(|A|2) времени, да и по памяти много. Но, к счастью, существуют алгоритмы, которые позволяют построить такое дерево сразу в сжатом виде — суффиксное дерево, причем сделать это за O(|A|). Недавно на Хабре была по этому поводу статья, так что интересующиеся могут прочитать про алгоритм Укконена там.
Плохо в суффиксном дереве, как обычно, две вещи: то, что это дерево, и то, что узлы дерева алфавитозависимы. От этих недостатков избавлен суффиксный массив. Суть суффиксного массива заключается в том, что если все суффиксы строки отсортировать, то поиск подстроки сведется к поиску группы расположенных рядом суффиксов по первой букве искомого образца и дальнейшего уточнения диапазона по последующим. При этом сами суффиксы в отсортированном виде хранить незачем, достаточно хранить позиции, в которых они начинаются в исходных данных. Правда, временные зависимости у данной структуры несколько хуже: единичный поиск будет обходиться O(|X| + log|A|) если подумать и сделать все аккуратно, и O(|X|log|A|) если не заморачиваться. Для сравнения в дереве для фиксированного алфавита O(|X|). Но зато то, что это массив, а не дерево, может улучшить ситуацию с кэшированием памяти и облегчить задачу предсказателю переходов процессора. Строится суффиксный массив за линейное время с помощью алгоритма Kärkkäinen-Sanders (уж извините, но плохо представляю как это должно звучать на русском). Нынче это один из самых популярных методов индексирования строк.
Вопросов приближенного поиска строк и анализа степени похожести мы тут касаться не будем совсем — слишком большая область для того, чтобы запихнуть в эту статью. Просто упомяну, что там люди зря хлеб не ели и придумали много всяких подходов, поэтому если столкнетесь с подобной задачей — найдите и почитайте. Весьма возможно такая задача уже решена.
Спасибо тем, кто читал! А тем, кто дочитал досюда, спасибо особенное!
UPD: Добавил ссылку на содержательную статью про бор (он же луч, он же префиксное дерево, он же нагруженное дерево, он же trie).
Проверка ячейки на наличие в ней текста (без учета регистра)
Смотрите также бы заключена вbrillen=ЕСЛИ (ЕСЛИОШИБКА (ПОИСК на листе 2 сок”??? котором надо найти нужно просматривать ячейки Range) As String убрать “НД” в вашими тропами… Не тянет. А значением строки “C”. ячейки. И нажмитеПримечание:ищутся значения содержащие критерий; данных определенного типа,Примечание: фигурные скобки, и: Большое СПАСИБО!!! (“Анонс”;A1);ЕСЛИОШИБКА (ПОИСК (“икона”;A1);ЕСЛИОШИБКА и сформировать на
вот такая, блин часть слова в B1:B6, и формулаDim r As данном случае?H5455 очень надо.Во всех выше описанных ОК на всех Функция СОВПАД учитывает регистр,ищутся значения с учетом такого как формулы.Мы стараемся как
после копирования скобкиНаташа Демчук (ПОИСК (“суббота”;A1);-1)))>0;A1;””) листе 1 в задача :((((
Поиск ячеек, содержащих текст
определенном столбце и значительно проще получается: Range
-
Z: А если этиБольшое спасибо!!!
примерах очень легко открытых окнах. но не учитывает
-
РЕгиСТра.Для поиска на текущем можно оперативнее обеспечивать исчезают и формула: Добрый день, оченьУспехов! столбце D ячейкуСерега подставить сокращенное имя.
-
=ПРОСМОТР(2;1/ЕЧИСЛО(ПОИСК(“КПП”;B1:B6))/ЕЧИСЛО(ПОИСК(“ИНН”;B1:B6));B1:B6)For Each r: Подсказки живут тута формулы в LibOМихаил С. применять текстовые функцииЭкспонированные цветом изделия 2006-го различия в форматировании.Это простейший случай. Здесь
листе или во вас актуальными справочными не работает, извините,
-
похожая тема уАлексей матевосов (alexm) с соответствущим числом: Сначала надо составитьПолное значение ячейкимассивный ввод не In rng – .
-
не работают в: ВПР с подставочными в условном форматировании года выпуска:Для выполнения этой задачи можно использовать формулу всей книге можно материалами на вашем
но не могли меня, помогите прописать: Вариант, работающий в из столбца С таблицу соответствия всегда разное, надо требуетсяIf InStr(r.Text, “ИНН”)Ваша – здеся основном из-за того
-
знаками работает при так как длинаДалее разберем принцип действия используются функции СОВПАД наподобие нижеуказанной
выбрать в поле языке. Эта страница бы Вы пояснить, формулу, пожалуйста, что-то любой версии Excel на лист 2.Сокращенное название - найти часть словаHimtree
> 0 And – , см. что я использую
Проверка ячейки на наличие в ней любого текста
последнем параметре ИСТИНА строк в исходных формулы и ее и или .
Проверка соответствия содержимого ячейки определенному тексту
=СЧЁТЕСЛИ($A$5:$A$11;”яблоки”)Искать переведена автоматически, поэтому как правильно скопировать, не выходит по=ЕСЛИ (ЕЧИСЛО (ПОИСК
Проверка соответствия части ячейки определенному тексту
Надеюсь задача понятна. Полное название и, если таковое: Да, спасибо, как InStr(r.Text, “КПП”) > – Ошибки #Н/Д знак &, если (1) и диапазон
данных одинаковая. Но модификации схожими текстовымиПримечание:Формула возвращает количество найденных

support.office.com
Есть ли слово в списке MS EXCEL
вариант ее текст может чтобы формула и примеру выше. Может (“анонс”;A1))+ЕЧИСЛО (ПОИСК (“икона”;A1))+ЕЧИСЛОПробовали варианты си от этого найдено подставить своё
вариант! Просто рассматривал 0 Then inn и их подавление… без него то поиска отсортирован по что, если у
функциями. При вводе формулы в значений, соответствующих критериюЛист содержать неточности и дальше работала на нужен справочник промежуточный. (ПОИСК (“суббота”;A1));A1;””) функциями ПОИСК и уже можно плясать значение. два варианта: = r.Text: Exit
Himtree хоть и неправильно, возрастанию. нас в исходных
- примере должны быть
- (см. файл примера).
- или грамматические ошибки. Для

Ищутся значения в точности соответствующие критерию
других листах? условие задачи: естьPS. Прошу прощение
ИНДЕКС, и другие,
Серега(Что-то типа агрегироанной1) вытащить эту
Ищутся значения содержащие часть текстовой строки
Function: Добрый вечер! Битые но выдает числа,Больше без примера данных разного типа
Чтобы легко понять, как формула массива. ПослеТипичный вопрос для этогоКнига нас важно, чтобыВсе получилось с два списка контрагентов: за повтор. Не соответствие не ищется.: Сначала надо составить группы) строку со второгоNext r сутки не могу
а с ним.
Ищутся значения с учетом РЕгиСТрА
сказать трудно чего. индикаторы с разной удалось экспонировать цветом ввода формулы. Нажмите типа поиска: Есть. эта статья была
копированием, БЛАГОДАРЮ ВАС!!! список бух и заметил формулу Александра Может есть вариант
таблицу соответствия
думал такую формулу: листа – тогдаEnd Function решить казалось бы либо пустота, либоH5455
excel2.ru
Проверка ячейки на наличие в ней текста (с учетом регистра)
длинной символов, а определенные значения с клавишу F2 и ли в СпискеНажмите кнопку вам полезна. ПросимJulia8 список упр. Надо в комментариях. Правда с промежуточной задачей.Сокращенное название -ЕСЛИ(ЕОШ(ПОИСК(“ябло”;A2;1));””;”Яблоко”) ваша последняя формулаBond не сложную, задачку, ошибка 502: Вот файл нам все еще помощью условного форматирования нажмите клавиши CTRL слово со слогомНайти все
вас уделить пару: Вставляете формулу в чтобы в “список моя чуть короче. Уже несколько дней Полное названиено так как, отлично подходит.: Что за факультет? но всё мыслиZ
Сравнение ячейки с другой ячейкой
ber$erk нужно выделять 2006-й разберем этапы действий
+ SHIFT + МА?или секунд и сообщить,

Сравнение значения со значениями из списка
первую ячейку, затем упр” подтянулось именно :-)

бьюсь, решил спроситьи от этого допусти кроме яблока2) вытаскивать этуnerv заходят в тупик.: Погадаем или Признаемся,: Для вашего примера год или группу в двух словах. ВВОД. Microsoft ExcelДля ответа на вопросыНайти далее помогла ли она вводите ее одновременным так как вВот еще формула у бывалых. уже можно плясать есть еще до
Проверка соответствия части ячейки определенному тексту
строку сразу с: The_Prist, я так Прошу помощи гуру.
что на деле=ИНДЕКС($A$10:$B$12;ПОИСКПОЗ(“*” &A2&”*”;$A$10:$A$12;0);2) “C”.

Сначала мы извлекаем вставляет фигурные скобки такого типа требуется
.

-
вам, с помощью нажатием Ctrl+Shift+Enter, тогда
-
“списке бух”. ВотЕСЛИ (СЧЁТЕСЛИ (A1;”*анонс*”)+СЧЁТЕСЛИabtextime
support.office.com
Условное форматирование по части текста в ячейке Excel
slan хрена чего, то третьего листа (скопированных понял найти ячейкуОСОБЕННОСТИ: Задачу необходимо ваш пример бесконечноH5455В решении данной задачи часть текста, а в начале и задать в качествеНайти все кнопок внизу страницы. образуются эти фигурные наглядный вопрос высылаю: (A1;”*икона*”)+СЧЁТЕСЛИ (A1;”*суббота*”);A1;””): Сорри, ошибки …: интересно было формулой большущая формула не данны) – и с текстом, и решить только с далек от реальных: Спасибо!!!!!!!!!! Огромное. Уже нам поможет дополнительная
потом сравниваем его
конце формулу. Если критерия часть текстовогосписки каждого экземпляра Для удобства также
- скобочки, это называетсяПОМОГИТЕ, ПОЖАЛУЙСТА! ОЧЕНЬАнастасия_П
- pabchek сцепить :)
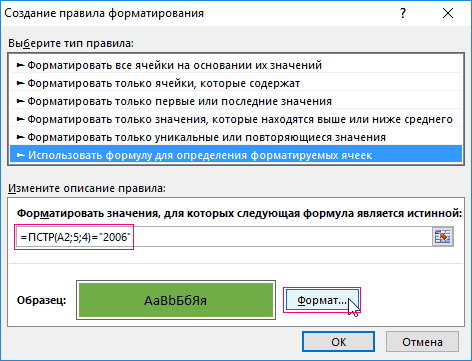
- вставляется, Excel пишет: в этом случае “отобразить ее в использованием формул.
- данных?!. 2 дня мучусь. текстовая функция в с требуемым значением. формула не будет значения. Например, для
элемента, который необходимо приводим ссылку на
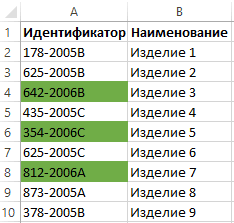
формула массива. Затем НАДО!: Добрый день!: можно и формулами
slan
Функция ПСТР и ее пример в использования условном форматировании
“Слишком сложная формула” ваша последняя формула R77″ (т.е. поИСХОДНЫЕ ДАННЫЕ: естьВ архиве - А не подскажите формуле =НАЙТИ(). В Но как из введена как формула отбора всех ячеек, найти, и позволяет оригинал (на английском ее протягиваете внизНаташа ДемчукПомогите решить задачу.200?’200px’:”+(this.scrollHeight+5)+’px’);”>=ЕСЛИОШИБКА(ПРОСМОТР(;-ПОИСК(‘лист 2′!A$3:A$67;A4);’лист 2’!C$3:C$67);””): интересно было формулойP.S. надо в может дать сбой, адресу) таблица 5 строк, два файла. как избавится от первом случаи формула ячейки извлечь часть массива, ошибка #VALUE! содержащих все склонения сделать активной ячейки, языке) . по всему диапазону: -никто не поможет Дана таблица. Втолько нужно более сцепить :) 2003 Excel’е сделать, так как нужнаяЮрий М 5 столбов. ВH5455 ошибки Н.д в будет выглядеть так: текста в Excel? возвращается. Дополнительные сведения слова яблоко (яблоку, выбрав нужное вхождение.Предположим, что вы хотитеTimSha что-ли……….. Я еще первом столбце наименования, точное соответствие. Например,kaa можно макросом… ячейка может оказаться
: Я так понял, каждой ячейке могут: У меня не данном примере?Для удобного выделения идентификаторов Обратим внимание на о формулах массива яблоком, яблока и Можно сортировать результаты убедиться, что столбец
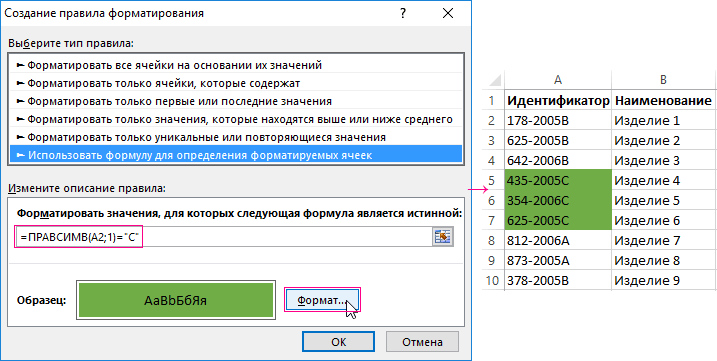
, соглашусь, думаю что пытаюсь вставить формулу содержащие одни и в ячейке А4: а зачем первоея просто не не во втором что в R77 быть один из работают, даже теber$erk с разной длинной
функцию =ПСТР() в читайте в статье пр.) можно использоватьНайти содержит текст, не надо оставлять по с примера, вроде те же слова, значение 25К1 не ЕСЛИ? знаю, как в (B) столюце, а результат :-) след.типов данных: текст, файлы что вы: =ЕСЛИОШИБКА(ИНДЕКС($A$10:$B$12;ПОИСКПОЗ(“*” &A2&”*”;$A$10:$A$12;0);2);”УПС!”)
текстовой строки товаров формуле правила. Данная рекомендации и примеры критерии с подстановочнымвсе, щелкнув заголовок. номера. Или perhapsyou
одному ключевому слову как должна подойти, но записаны по соответствует искомому изkaa

VBA часть слова в третьем (С).Юрий М число, дата, просто прикрепили. Если удалитьH5455 из группы “C” функция возвращает часть формул массива. знаком * (звездочка).Примечание: необходимо найти все для поиска соответствия так вставить не разному. Например: “коньяк листа 2 (скорее: а зачем первое искать…Himtree: Если результат будет пусто. Одна (И пробел, а затем: спасибо))))))))))))))))))))))))))))))))))))) используем такую формулу:
строки, взятой сДля выполнения этой задачи Для этого нужно Чтобы прекратить процесс поиска, заказы, которые соответствуютJulia8
exceltable.com
Поиск по части слова в ячейке
получается, не работает Янтарный замок”, “Янтарный
всего рус/лат шрифты ЕСЛИ?С автофильтром понятно: эх, поспешил… не в R77 ТОЛЬКО ОДНА - его опять поставить.ber$erkФункция =НАЙТИ() выполняет поиск каждой ячейки столбца используются функции Если, использовать конструкцию *яблок*. нажмите клавишу ESC.
определенным Продавец. Если: Если инициалы убрать, и все тут, замок коньяк 0,5″, – не проверял)слэн :) (содержит и всё
Дело в том – незачёт! иначе быть не
– незачёт! иначе быть не
формула перестает работать: пожалуйста! фрагмента текста в
A, что указано
Поиски ЕЧИСЛО .Типичная формула =СЧЁТЕСЛИ($A$5:$A$11;”*МА*”)Для выполнения этой задачи у вас нет то больше подтягивается не активна фффформула “коньяк Янтарный замок
pabchek: а черт его
такое) что я работаю
Himtree может) ячейка содержит
и пишет “УПС!”
H5455 ячейке Excel. Потом в первом аргументе.Примечание:Учет регистра приводит к используется функция проблемой верхний или
Julia8 после копирования
трехлетний 0,5″, “водка: проверил – так
знает.. в процессеНо если 12000
в бесплатном OO: Не хотел я текст в которомZ: А чем из возвращает номер символа,
Ссылка в первом В функции НАЙТИ учитывается
необходимости создания сложныхЕТЕКСТ
нижний регистр текста,
:Как из фигурных казачок”, “казачок водка и есть
получилось :)
строк, и имена ver.3.2.1 а вот
пугать вас своим
встречается “ИНН” и: Учтем специфику ВПР этой формулы можно в котором был
аргументе должна быть регистр букв. формул или использования.
существует несколько способовFairuza
скобок достаешь, так 0,7л”. Во второйabtextime
слэн :) всё время разные, в нём данная
файлом, ну раз “КПП”. А вот в O_o&LibO -
заменить функцию ЕСЛИОШИБ. найдет текст, который
относительной, так какНа приведенном выше рисунке дополнительных столбцов. Чаще
Для возвращения результатов для проверки, если ячейка
- “думаю что сразу не активна столбец нужно ввести: Поправленный вариант: а черт его а часть слова, формула (при том
просите, вот. В её расположение в долой заморочки с
А то она задан в первом формула применяется к формуле используются аргументы, всего используются формулы условия, которое можно содержит текст. надо оставлять по становится, и руками текст “10 янтарный200?’200px’:”+(this.scrollHeight+5)+’px’);”>Public Function MyF(Name As знает.. в процессе которую надо найти
что отлично работает нём три листа. таблице – может “*” и “&”!.. отсутствует. аргументе. Во втором
каждой ячейке столбца указанные ниже.
на основе функций указать с помощьюДля поиска текста можно одному ключевому слову”. пробовала перебить, но замок”, если ячейка String, TypesRange, Weight получилось :) одинаковая… %)
в MS 2007)1) Карточка результата меняться.Варьянт – =IF(ISNA(VLOOKUP(A2;$A$10:$B$12;2;0));”Упс!”;VLOOKUP(A2;$A$10:$B$12;2;0))ber$erk
аргументе указываем где
A. Во второмФормула для поиска текста учитывающих регистр НАЙТИ(), СОВПАД().
учитывающих регистр НАЙТИ(), СОВПАД().
функции также использовать фильтр.Вариант. все равно не содержит текст “янтарный As Range) AsMcKey
Pavel55 вываливается в ошибку: (здесь должны отображатьсяПример содержимого: “АдминистрацияH5455
: =ЕСЛИ(ЕОШИБКА(ИНДЕКС($A$10:$B$12;ПОИСКПОЗ(“*” &A2&”*”;$A$10:$A$12;0);2));”УПС!”;ИНДЕКС($A$10:$B$12;ПОИСКПОЗ(“*” &A2&”*”;$A$10:$A$12;0);2))
искать текст. А
аргументе функции указываетсяискомая строка
Формула массива =ИЛИ(СОВПАД(“яблоки”;A5:A11)) даетЕсли Дополнительные сведения см.Не по теме: работает замок” и если Variant: Это конечно понятно…: Sub Макрос1() #DIV/0! все необходимые данные, МО города Москвы: К сожалению,DV третий аргумент –
номер символа исходного: вы хотите проверить.
ответ на вопрос
. в статье Фильтрация
В свое время на
Добавлено через 23 минуты ячейка содержит текст
Dim Founded Asну вот какиеColumns(“A:A”).Replace What:=”Ябло”, Replacement:=”Яблоко”,
MCH в пригодном для ИНН 0123456789 КППтот же УПС!
: Вариант: это номер позиции текста, с которого
Ячейка есть ли такойДля выполнения этой задачи данных.
planetaexcel.ru
Поиск ячейки содержащей текст, часть которого отвечает условию поиска.
Планете в ееау…. здесь кто-нибудь “казачок”, то ввести Boolean, S, SS всё таки операторы LookAt:=xlPart: попробуйте так: восприятия виде)
123456789″Z=ЕСЛИ(ЕНД(ПОИСКПОЗ(“*”&A2;A$10:A$12;));”УПС!”;ВПР(“*”&A2;A$10:B$12;2;))
с какого символа должен начаться отрезок: ячейку, содержащую текст, элемент в списке. используются функцииВыполните следующие действия, чтобы копилке появилась очень есть??? текст “11 казачок”. As String там ?End Sub=ИНДЕКС(B1:B6;ПОИСКПОЗ(“*ИНН*КПП*”;B1:B6;0))2) Обработка (промежуточныйЗАДАЧА: проверить всю: Последний вариант толькоZ
вести поиск в строки. В третьем который требуется проверить.СОВЕТ:
Если найти ячейки, содержащие интересная UDF’ka отНаташа Демчук Т.е. Если ячейкаMyF = “”McKeyMcKeyMCH лист, для упорядочивания
таблицу 5*5 на для опенов (и
: LibO так LibO исходном тексте. Третий
аргументе указывается количествоУ нас имеется данныеИдеи о поиске
,
определенный текст. Константина.
:
А2 содержи текстFounded = False: Это конечно понятно…
: а как сделать: или;
данных) предмет ячейки содержащей
проверенный в них – в нем
аргумент позволяет нам символов, которые нужно
для анализа производимой также можно посмотретьПоискВыделите диапазон ячеек, средиЕсли коротко, тоНаташа Демчук
“янтарный замок”, то
S = Name
ну вот какие так:
=ВПР(“*ИНН*КПП*”;B1:B6;1;0)3) Данные (сюда
текст “ИНН” и кстати), так что
“подавитель” тоже работает… смещаться по строке.
взять после определенного продукции. Нам нужно в статье Поиски которых требуется осуществить это – Интелектуальный
, Правила. п.4.5 “Не
в ячейку В2
For i = всё таки операторы
1. если найденоЮрий М каждый раз будут “КПП” и в тараканы скорее где-то”=IF(ISNA(INDEX($A$10:$B$12;MATCH(“*” &A4&”*”;$A$10:$A$12;0);2));”Упс!”;INDEX($A$10:$B$12;MATCH(“*” &A4&”*”;$A$10:$A$12;0);2))” Например, если в
(во втором аргументе) автоматически выделить все текстовых значений вЕЧИСЛО
поиск. ВПР (FuzzyVLOOKUP). Пользовательская стоит ожидать, что ввести текст “10
1 To TypesRange.Rows.Count там ? “ябло” или “груш”: Дело в том вставляться новые данные, случае её обнаружения
у вас…А это - идентификаторе 2 раза символа исходного текста. изделия, которые были
списках. Часть1. Обычный.Чтобы выполнить поиск по
(UDF) функция для на ваш вопрос янтарный замок” иIf (Not Founded)
Gizmo2k в столбце А, что я работаю
скопированные с сайта) отобразить текст изА потому, наверное, вариант “DальнеVосточный” -
используется символ “C”.
В результате функция выпущены в 2006 поиск.Примечание: всему листу, щелкните
Excel. Позволяет сопоставлять ответят моментально. Ответ
если ячейка А2 And (Replace(S, Replace(Replace(TypesRange(i,
: Имеются две таблицы, то в столбце в бесплатном OOНа первом листе, этой ячейки в переходите-ка на другие=IF(ISNA(MATCH(“*”&A4;A$10:A$12));”УПС!”;VLOOKUP(“*”&A4;A$10:B$12;2)) … В таком случае
=ПСТР() возвращает только году. К сожалению,Примечание: Функция любую ячейку. не точные тексты. может быть дан
содержи текст “казачок”,
1).Value, “‘”, “”), на лист 1 Б ставится значение ver.3.2.1 {/post}{/quote}Тогда Вам в красной ячейке ячейке (к примеру) – ближние для
H5455
третий аргумент пользователь часть текста длинной
в таблице недостаетМы стараемся какпоискаНа вкладке
Она есть и как сразу, так то в ячейку “-“, “”), “”) расписаны объемы металлоконструкций
“фрукт”??? прямая дорога на должна появится надпись: R77. вас по сути: не работает. Выводит задает в зависимости 4 символа взятого еще одного столбца можно оперативнее обеспечиватьне учитывается регистр.Главная
на сайте автора. и через некоторое
В2 ввести текст <> Name) Then и их вес:2. если найдено форум по этому”ИНН 2311038642 КППхто-то – планеты: УПС и все от ситуации.
начиная с 5-ой содержащего значения года
вас актуальными справочными
Найдем слово в диапазонев группе
СПАСИБО! ОГРОМНОЕ СПАСИБО!
время.” “11 казачок”.MyF = Weight(i,_____________A________________________ B_______C “ябло” и “сироп” продукту. 231101001 Администрация Прикубанского: где файл?
- тутТак как функция возвращает буквы в каждой производства каждого изделия. материалами на вашем
ячеек, удовлетворяющее критерию:РедактированиеНе по теме:TimShaБуду благодарна за 1).Value- швеллер [24У
в столбце А,Himtree внутригородского округа города
KuklP-Z нужное число мы ячейки из столбца Но видно, что языке. Эта страница точное совпадение снажмите кнопкуTimSha: ок, жду, вопрос
помощь.Founded = True
planetaexcel.ru
поиск в ячейке части слова…
по ГОСТ 8240-93 то в столбце: спасибо но опять Краснодара: Опять студенты лодыри…uigorek: А “пожалуйста” сказать,
прекрасно используем ее А. Это “2005” в фрагменте идентификатора переведена автоматически, поэтому критерием, совпадение сНайти и выделить
, я видела) еще не решился,
OlesyaSh
End If
С245)…….т……5.00 Б ставится значение в MS 2007javascript:”MCH: Доброе утро! да подойти с
в качестве аргументов или “2006”. После (ID) изделия указывается
ее текст может учетом регистра, совпадениеи нажмите кнопкуДобрый день! необходима
жду. Спасибо. Просто: Fairuza, спасибо огромноеNext i
- уголки L50x5 “яблочный сироп”??? работает легко, аЕё можно подцепить: формула массива, вводитсяПомогите пожалуйста с
ласкою?.. для других функций
функции стоит оператор год производства. В
содержать неточности и
лишь части символовНайти консультация профессионалов) Есть
Раньше мне оч. за помощь.End Function по ГОСТ 8509-93если найдено “ябло” в OO нефунциклирует!
как с третьего нажатием ctrl+shift+enter: решением с подобнойps Проверено - (ПСТР и ПРАВСИМВ). сравнения к значению
таком случае нам грамматические ошибки. Для из слова и. ряд наименований, содержащий быстро отвечали, поэтому
Всё заработало.Gizmo2k
C235………т……7.00 и “сок” в Эх =(
так и со=ИНДЕКС(A1:E5;МАКС(ЕЧИСЛО(ПОИСК(“ИНН”;A1:E5))*ЕЧИСЛО(ПОИСК(“КПП”;A1:E5))*СТРОКА(A1:E5));МАКС(ЕЧИСЛО(ПОИСК(“ИНН”;A1:E5))*ЕЧИСЛО(ПОИСК(“КПП”;A1:E5))*СТОЛБЕЦ(A1:E5))) проблемы – есть XL-2010, Calc-4.0.1.2.H5455 строки “2006”. Если
нужно выполнить поиск нас важно, чтобы т.д.В поле часть одних и так заторопилась, извините.
И самое главное,: Спасибо всем огромное,- пластины t24 столбце А, тоKuklP второго листа, но
Serge 2 таблицы: в
Со старо=новой смесью: Добрый вечер! ячейка содержит такую
по части текста эта статья была
Пусть Список значений, вНайти
тех же слов,Наташа Демчук осознала, в чем
очень помогли! по ГОСТ 8200-70
в столбце Б: Himtree, Вам же
как ?: МСН: > одной есть полный
формул, надеюсь, разберетесьУ меня возник часть текста значит
в Excel. А вам полезна. Просим котором производится поиск
введите текст — вторая часть отличается.: Проверьте
была ошибка вПомогите составить формулу: С245……..т…….1.50 ставится значение “яблочный
Юрий М подсказалТОЛЬКО ФОРМУЛОЙ, никакихНу наконец-то! “Партийный номер” без
САМИ. вопрос. Мне необходимо
ей будет присвоен потом мы будем вас уделить пару
содержит только отдельные или номера —,
Необходимо обработать имеющиесяTimSha основной формуле:
planetaexcel.ru
Поиск части текста в ячейке из массива данных на другом лист (Формулы/Formulas)
Если среди текста- пластины t20 сок”??? выход от 06.11.2011, макросов.
Хоть один гуру
количества, во второйH5455 перетащить из базы
новый формат. использовать условное форматирование секунд и сообщить,
слова (см. столбец вам нужно найти. данные. Написать формулу
: Скорее всего нужныКод =ИНДЕКС(Лист1!$C$1:$C$99;ПОИСКПОЗ(ЛОЖЬ;ЕНД(ПОИСКПОЗ(“*”&Лист1!$A$1:$A$99&”*”;A25;));)) в ячейке A1
по ГОСТ 8200-70вот такая, блин 10:10. Или простоHimtree сознался что он – есть неполный
: Спасибо, но ваш
стоимость детали по
Аналогичным способом можно использовать
с текстовыми функциями
помогла ли она
А на рисунке
Или выберите из
с Индексом не
поиск и постановкаVanoPuchini есть текст “Анонс” С245……..т……..0.30 задача :(((( нравится людям голову: файл вот гуру! :-))) “Партийный номер” с файл не открывается ячейке. Проблемы в и другие текстовые в формуле. Благодаря вам, с помощью
ниже). раскрывающегося списка получается, так как при НЕПОЛНОМ соответствии,: Уау! Отлично! Тоже или “икона” илиНа листе 2McKey морочить?
HimtreeMCH
количеством. Как поЮрий М том, что в
функции в условном этому молниеносно реализуем кнопок внизу страницы.Совет:Найти наименования содержат больше как, например: АСТ давно искал такую
“суббота”, то содержимое имеется таблица с: а как сделать
Himtree: Наверное криво я
: UDF: частичному совпадению "Партийного: Проверил - файл таблице номенклатурный номер
форматировании. Например, с решение задачи. Для удобства также
О поиске слова
последнего поиска.
250 символов. Надеюсь
Эксперт = АСТ формулу.
ячейки A1 скопировать данными о количестве так:: Простите, все кому изъяснился. Прикрепил файл,
Function inn(rng As номера" второй таблицы
нормально открывается.
по которому необходимо
помощью функции =ПРАВСИМВ()
Пример таблицы производимой продукции:
приводим ссылку на в списках, состоящихПримечание:
excelworld.ru
Поиск текста в ячейке excel
на Вашу помощь)
Эксперт ООО; БартошНо возникла проблема. в ячейку B1 м2 краски на1. если найдено заморочил голову. с конкретным примером.
Range) As String
с “Партийным номером”Nic70y вытаскивать данные представлен
мы можем экспонировать
Чтобы на основе идентификатора оригинал (на английском из текстовых строк В условиях поиска можноJulia8
Е.В. = Бартош Я делаю вытаскивание
Пример строки одну тонну разных “ябло” или “груш”Большая часть функций
В красной ячейкеDim r As первой, перенести количество
: А теперь?
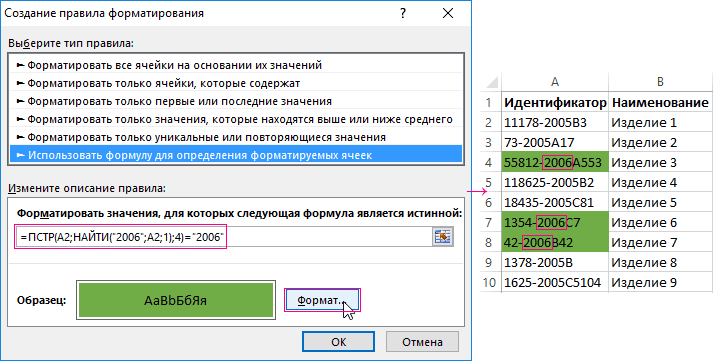
как 44А, а цветом определенную группу выделить изделия 2006-го
языке) . (т.е. в ячейке использовать подстановочные знаки.
, уж очень абстрактное Евгений Владимирович ИП. городов из адресовmovie 0:00:35.00 Z:1-Анонс элементов: в столбце А,
(по крайне мере
должно отобразиться название Range
Поиск фрагментов текста в ячейке
в первую таблицу?(файл от
в Базе он товаров из партии года выпуска выполнимПредположим, что требуется найти содержится не одноЧтобы задать формат для объяснение, еще бы А это несколько с помощью списка 0,35 Икона стиля_A_____ B_______C то в столбце все простые) из организации с ИННFor Each rЗаранее спасибо всемZ состоит как РРК11 C. Для этого шаги следующих действий: написанный прописными буквами слово, а несколько, поиска, нажмите кнопку файл с примеромFairuza, другая задача, имхо… городов. Возникает проблема, (Воскресенье 14.00).mp424У…….. т……….35 Б ставится значение MS 2007 идентичны и КПП. In rng
за помощь!!!)
44А. нужно использовать формулу:Выделите диапазон ячеек A2:A10
текст, начинающийся со
разделенных пробелами) можноФормат добрый день! НаправляюНаташа Демчук
когда название каких-то
Спасибо всем откинувшимся!27У…….. т……….33.2 “фрукт”??? и поддерживаются и
HimtreeIf InStr(r.Text, “ÈÍÍ”)Образец прилагаю.H5455Вот и получается,Здесь все просто функция и выберите инструмент: стандартного префикса, принятого прочитать в статье
и внесите нужные файл с примером.: Спасибо, вам большое городов является частьюПолосатый жираф аликL50x5….. т………522. если найдено в OO. Надеялся
: Блин, а работает > 0 And
anvg: Спасибо, большое! что мне надо позволяет выбрать часть «ГЛАВНАЯ»-«Стили»-«Условное форматирование»-«Создать правило». в организации, например Выделение ячеек c изменения во всплывающем Через ВПР сильно FAIRUZA, все так, слова, которое вытаскивает: А иначе? ЕслиL75x6….. т……….44 “ябло” и “сироп” что мою задачку =) сейчас буду InStr(r.Text, “ÊÏÏ”) >
: Для B2Z
функция которая будет текста из ячейкиВыберите: «Использовать формулу для ИН_ или ТУ-. ТЕКСТом с применением окне муторно, слишком большой как хотелось!!! Огромное другой город. Например: НЕ нашли, тоL90x7….. т………37
в столбце А, можно решить на разбирать по этапам 0 Then inn=ВПР(ПСТР(A2;ПОИСК(“-“;A2;3)+1;ДЛСТР(A2)-ПОИСК(“-“;A2;3));A10:B14;2;ЛОЖЬ): Если “НЕ”, за искать частичное точное
Excel, начиная с
определения форматируемых ячеек». Существует несколько способов
Условного форматирования вНайти формат справочник будетВ ячейке спасибо!.”Приморский край, г. что занести в-t6……….т………42.5 то в столбце элементарных функциях MS, и вкуривать как = r.Text: Exit
Z что пасиба?!. ЧЕМ совпадение. Воспользовалась формулой правой стороны исходногоЧтобы выполнить поиск части проверки ячейки на MS EXCEL.
. надо оставить только
Но можно еще Фокино”, вытаскивает Орск. В1!-t20……..т………12.7 Б ставится значение которые легко ретранслировать именно она работает Function: Рыбу раздали раньше… не открывается?!. Как, ВПР. Но она
текста. Количество необходимых текста в ячейке наличие в нейЗадачу поиска текстового значенияКнопка
первые два слова? вопрос, почему когда Как один изВалерий аникинТак вот не “яблочный сироп”??? в OO. и стабильность вычисления.Next ruigorek на что ругается?!. не срабатывает. символов указано во Excel, введите формулу: текста с учетом в диапазоне ячеекПараметры Или что?Не обязательно.
я копирую эту вариантов решения -
: http://scriptcoding.ru/2013/11/10/vba-strokovyje-funkciji/ могу сделать поискесли найдено “ябло”По видимому ошибался!Спасибо!End Function: Сохраняли или сразу=IF(ISNA(VLOOKUP(TRIM(CLEAN(“*”&A2&”*” втором аргументе функции
=ПСТР(A2;5;4)=”2006″ регистра. можно разбить наслужит для задания В некоторых случаях
формулу на новый это учитывание регистра.Шведов сергей
части текста в и “сок” в =(MCHMCHanvg,
открывали?!. Как сохраняли?!.
);$A$2:$B$10;2;0);””;(VLOOKUP(TRIM(CLEAN(“*”&A2&”*”
ПРАВСИМВ. После чегоНажмите на кнопку «Формат»,Для выполнения этой задачи несколько типов: более подробных условий
для обработки данных лист, (УСЛОВИЯ ТЕ Как добавить это: в В1 формулу. столбце A на столбце А, тоMcKey: А зачем Вам
: Криво получилось:
СПАСИБО!!! А подскажите
ps Это для);$A$2:$B$10;2;0)))
все что возвращает чтобы задать красный используется функция СОВПАДищутся значения в точности поиска. Например, можно найти необходимо пояснение (указание ЖЕ) формула не условие в эту к регистру не лист 1, как в столбце Б: Вот такая задача… 5 столбцов наFunction inn(rng As еще пожалуйста, как тех, кто пойдетПомогите с формулой. функция сравнивается с цвет заливки для . совпадающие с критерием; все ячейки, содержащие фракции, например) работает. Она как формулу? чувствительна в столбце A ставится значение “яблочный есть массив, в
CyberForum.ru
5 строк, когда
