
И вот наступает момент, когда уже пора приступить к этапу обработки голоса или вокала. Вокальные партии спеты, дубли отобраны, коррекция и тюнинг проведены – голосовая партия готовая – начинаем
Обработать голос – как правильно?
И снова надо вначале вносить ясность – о чём вообще речь и какие есть предустановки.
Перед тем, как начать писать эту статью, я почитал что пишут в аналогичных статьях в рунете и понял главную мысль которую я должен вам щас сказать в самом начале:
Никогда не воспринимайте подобные статьи (и эту тоже) как рецепт “вот так надо обрабатывать голос”. Толку от таких поучающих статей “компрессор крутим так, а эквалайзер так” – ноль рублей, ноль копеек. И снова риторический вопрос “Почему?” а потому что:
- у всех разные голоса, вокальные приёмы и условия записи – исходный материал в разных случаях совершенно разный и обрабатывать его нужно по-разному, единый рецепт тут не подойдёт, а наоборот всё испортит
- у разных песен разные задачи, стили, характеры и голоса в разных треках будут (и должны) звучать по разному, адекватно и соответственно стилю трека, его саунду и аранжировке
- у разных саундпродюсеров разные “уши”, разное вИдение того как должно звучать в итоге песня целиком и подгоняют они под свой вкус
- у каждого звукаря свой набор средств обработки и “фишечек” их применения, например кто то аналоговые приборы любит, а кто-то плагины для удобства, кто-то сильно жмёт, а кто-то поборник “динамики”
- ну и наконец: у треков разные задачи – какой то просто демка, какой то концертный плюс в клубе, какой то – микс для радиоэфира
А теперь перемножьте все эти варианты и обстоятельства и вы поймёте что это нереально внимать готовым рецептам. Они бесполезны и даже вредны. И казалось бы, всё, заканчивай статью, всё ясно, ничего не напишешь…. Но нет. Объяснить можно, но только когда всё объяснение строится на двух тезисах
- общие понятия какой то обработки без конкретики, просто на пальцах – как оно работает и вообще для чего нужно
- и наоборот: вот конкретный случай, который вот так захотелось мне обработать – при этом не претендовать на истину
И из чего уже можно что то намотать на ус, а лучше сделать общие выводы и применять уже всё это к своему материалу. Так правильнее. Да и потом – вопрос творческий: тут нет рецептов, волшебных кнопок и универсальных метод. Главное что бы слушалось хорошо, ухо не резало, не мешало музыке, текст читался и гармонировало с общей идеей и стилистикой трека. А уж какие там параметры компрессии, какой дилей и есть ли он вообще – совершенно пофик. Ухо – главный арбитр.
Голосовая обработка поэтапно
Буду писать языком который понятен в базовых основах людям мало-мальски занимающихся этим хотя бы поверхностно.
Этап первый – чистка
Убрать обработкой в записи то, что нельзя убрать при редактировании (конечно если это присутствует). Например сетевой гул. Понятно, что у нас в студии на записи этого нет, но мы же не рассматриваем конкретную запись у нас, а принципы работы вообще, в том числе и те моменты, когда мы работаем удалённо: нам присылают голосовой трек, а мы голос обрабатываем (если надо дальше – тюним, сводим и т.д.) а присылают разные по качеству записи. Итак, сетевой гул, обычно это 50 Гц + разной интенсивности обертоны. правится легко и быстро, любой нормальный эквалайзер с узкой полосой + гармоники Например вот такой:
Здесь отступаю от собственных правил “не умничать и не давать рецепты”, только потому что сетевой гул, если и присутствует, то он везде примерно одинаковый. Так же можно и вообще срезать частоты менее 50Гц. Настраивать фильтр, конечно, нужно по слуху.
Затем в по этому пункту при обработке голоса я смотрю на уровень DC offset: сигнал должен быть симметричным по амплитуде:

Если будет постоянная составляющая в сигнале то его “рисунок” сместится вверх или вниз относительно оси. Это происходит или из за каких- то особенностей аналоговой части тракта при записи с микрофона, или при каких то неккоректно сработавших оцифровке или предобработке. Это стоит делать потому то при начале и конце проигрывания будет раздаваться щелчок и потому что съедает часть итоговой громкости.
Справедливости ради стоит сказать что иногда бывает специфический звук который сам по себе не симметричный, например звук синта Roland TB303
Вот он так выглядит
Your browser does not support the audio element.
Но чота пипец мы отвлеклись )))
Также, если в файле есть щелчки можно убрать их вручную инструментом “карандаш” сгладив линию огибающей


Если есть равномерный шум, белый, розовый или коричневый (да да, они так и называются в зависимости от спектра) то можно на вокал при обработке “натравить” шумоподавитель, и как то попробовать задавить шум, хотя бы в паузах. Как правило ничего хорошего из этого не получается, теряются детали и читаемость, поэтому так важно на самом первом этапе записать голос максимально качественно.
Динамическая обработка вокала
Есть в треках, песнях и т.д. 2 вида динамики. Общая динамика это развитие трека, крещендо, тихие и кульминационные места – чисто художественные дела, которые являются лишь задумкой творца. И есть микродинамика: т.е. чередование, взаимосогласование и общее звучание частокола громких и тихих звуков, идущих друг за другом буквально в долях секунды. Напрмер партия басгитары. Все ноты одинаково громкие или ритмический рисунок задаётся чередованием громких и тихих нот. По-правильному будет, если эту партию и микродинамику сыграет басист, прущийся от грува, а не потом звукарь когда делает из скопища одинаковых ноты что то похожее на жизнь.
Совсем по иному это работает с голосом. Голос, вокальная партия – это текст. В тексте есть ударные и безударные слоги, есть звонкие и глухие согласные, есть шипящие и ещё мильён нюансов артикуляции. Громкие гласные генерируют в вокале как правило ноты, а вот произносимость и разборчивость дают те самые намного тише звучащие артикуляционные звуки. И вот тут и нужна динамическая обработка. Что это?
Это такой прибор регулирующий громкость: смотрит какая громкость у каждого звука и присваивает ему нужную громкость, которую мы хотим услышать. Теоретически можно ухитриться, извратиться и сделать так что громкие звуки будут звучать тише тех, которые были тихими, а стали громкими. НО это же неестесственно.

Вот посмотрите – это голос профессионального диктора. Вся суть его хорошо звучащего голоса, заключается в том, чтобы голос по громкости в макродинамике был одинаково горомкий. Не обязательно просто громкий, не всегда же он орёт, иногда есть ролик и тексты на шёпоте. Диктор или вокалист звучит профессионально, когда он сам по себе достигает такого мастерства, что все звуки которые он издаёт – одинаковые по громкости: и тогда голос или вокал звучит плотно, сильно и красиво.
Your browser does not support the audio element.
А вот это осцилограмма голоса просто ребёнка, у которого таких навыков нет: видно что не сопоставимы не то что гласныесогласные а даже гласные между собой и то разные, некоторые тише, некоторые громче…

Вот как звучит этот же самый отрезок который показан на осцилограмме:
Your browser does not support the audio element.
Что интересно – оба эти звука примерно одинаковые по громкости, однако всякий имеющий хотя бы одно ухо услышит, что первый голос слышно отчётливо и разборчиво безо всяких обработок (а голоса в примерах вообще никак не обработаны), а вот уже с ребёнком приходится уже чуть напрячься чтобы разобрать текст. И дело не в дикции. Дело именно в том, что эти тихие звуки и есть конкретные буквы. Громкие звуки лишь о-у-а-и-е, а вот те казалось бы незаметные тихони и задают информационную составляющую.
Но это всё фигня, интереснее что происходит дальше… 
Сами по себе эти файлы можно слушать, можно и разобрать вполне какой текст. Предоставленная сама себе запись самодостаточна и слушаема. НО! Как только это мы будем сводить с музыкой (а песня это и есть вокал наложенный на музыкальную подложку) – то гласные (особенно ударные гласные) слышны ещё будут, а вот тихие но гораздо более нужные буковки уже будут маскироваться музыкой и мы будем слышать голос, а что он говорит или поёт – ни хрена не понятно.
Вот вам оба голоса из тех же самых проектов, но только другие предложения чтобы текст был вам незнакомый а то вы уже текст подсознательно додумаете, только сверху наложена музыка
Your browser does not support the audio element.
Ну, понятно что музыка сделана специально громко чтобы пример был нагляднее, в реале так конечно никто не будет, но как это работает теперь вам ясно.
И вот чтобы при том же уровне громкости голоса или вокала было разборчивее и читаемее текст и нужна динамическая обработка вокала или голоса. Суть её уже вам ясна: надо сделать тихие звуки громче. Обычно это делается так: (очень грубо говоря) на какой то коэфициент (1.5, 2, 3, 4 или другой) убавляются громкие звуки (а тихие не трогаются) а потом на этот же коэфициент прибавляется общий уровень громкости. В итоге громкие звуки по громкости те же, а вот тихие стали громче во в столько раз, во сколько мы указали.
Вот пример: два дубля одного итого же фрагмента. применил компрессор с коэфициэнтом 1:4 и теперь ДО и ПОСЛЕ выглядят так:

Громкость у них одинаковая, а вот за счёт увеличенной громкости ранее тихих звуков, теперь кажется что после обработки стал гораздо громче. Отчасти это так – часть звукового файла после обработки голоса компрессором стала громче, но вот громкая часть осталась точно такой же по уровню.
вот как это теперь звучит:
Your browser does not support the audio element.
Да, конечно, пример для выпуклости с экстремальными настройками и сразу повылазили артефакты. Я же сразу сказал что когда выкрутишь такую обработку вокала то для уха это будет неестесственно и некрасиво. Это лишь пример чтоб – нагляднее было. Сразу становятся слышны и звуки в голосовой комнате и вздохи – слюни. В реальном голосе такого нет. Однако, не забывайте то, что мы это делаем не для голоса самого по себе, а для того чтобы “посадить его в микс”.
Без такой обработки голоса компрессором, сделать хорошую читаемость и разборчивость в плотной попсовой и особенно в качовой электронной колбасе – нереально. Это надо задирать общую громкость голоса так – что он будет как голый мужик на хоккейном катке торчать посреди зимы. Вот тут то и нужен компрессор. Все эти артефакты и вздохи, можно или вырезать вручную, или настроить тонко комрессор, или сделать это фишкой, а уже очень хорошо читаемый голос усадить глубоко в микс, не лишая фанеру грува и кача.
И вот тут уже все советы заканчиваются. Тут и начинается поле профессионального саундпродюсера который не мыслит цифрами или точными параметрами – всё подбирается индивидуально, на слух: как оно будет в общем, насколько все эти параметры
- громкость голоса,
- его уровень компрессии
- уровень “артикуляционной части”
- и баланс с фонограммой будут сходиться.
Тут и кроется волшебство этой обработки вокала. Можно голос сделать очень тихим но ясным, можно громким и взрывным, вторые голоса можно оставить только ноты а текст не слышен, а можно наоборот очень чёткий и “близкий – в ухо” энергичный шёпот. Динамическая обработка голоса – лично для меня давно перестал быть техническим инструментом накрутки параметров звука. Для меня он стал художественным инструментом, как эквалайзер или ревер.
Общий принцип работы динамической обработки, которая называется компрессия – уменьшение динамического диапазона сигнала, или, другими словами, уменьшение разницы между громкими и тихими звуками я вам описал, а вот как конкретно теперь что делать: это определяет только продюсер проекта по месту.
Остаётся лишь добавить в этом пункте, что вы теперь знаете – чем хороший дикторвокалист с данными отличается от профессионального: У хорошего есть хороший тембр, чисто поёт ноты, интонирует. А вот профессионал умеет сразу голосом все звуки выдавать ровные по громкости. У него компрессор уже в горле стоит. Стабильные, ровные нотки, без провалов, внезапных “вскриков”, бросаний и недоговариванийнедопеваний. Активное взятие звука и активное снятие. За счёт этого достигается сила, плотность, красота и мясо. А вот это уже твоя, исполнитель, работа.
Ух нифига себе я сколько уже написал, а ведь это только небольшая часть огромного раздела “динамическая обработка голоса”. Фуххх. выдохнул и продолжу.
А теперь от программных компрессоров в обработке вокала сделаем шаг назад.
Открою вам секрет (секретом на самом деле не являющимся, а для звукарей, так и вообще банальность): компрессор на вокал в частности или голос в общем применяется к сигналу ещё ДО записи его в комп. Сигнал с микрофона поступает на микрофонный предусилитель, который в подавляющем большинстве студий сочетает в себе, помимо предусиления слабенького микрофонного сигнала, ещё и компрессор (а до кучи ещё всякие плюшки). Отчасти эти плюшки действительно нужны, но, расскажу как это происходит обычно при выборе и покупке микрофонного преампа . В студию покупаем преамп, вроде как прибор, даже дорогой, а там блин всего 2 ручки чтоли будет: уровень входа и уровень выхода? Чота маловато. Давай уж на всю монтану, чтобы дофига крутилок было: компрессор, эквалайзер, диэссор, гейт и прочий зоопарк – всё равно же “деньгу плотим” )). Ну да ладно, я к этому ещё вернусь, а пока расскажу для чего это нужно в виде отдельного устройства (сдаётся мне что статья будет гигантской )
Сначала выскажу некие устоявшиеся общепринятые ништяки от аппаратных приборов обработки голоса в лице микрофонных предусилителей с компрессорами:
- благородное звучание аналоговых породистых студийных приборов
- музыкальность, корректность, фирмовость работы набортных инструментов обработки голоса, потому что в их разработке принимали участие знающие люди, а не абы кто
- наглядность кручения ручек и тактильная приятственность
- солидный список сетапа студии
- отлично смотрится рэковая стойка с этими красивыми штуками, ей богу – вот сами полюбуйтесь:
 И это в нашей студии (правда всё в одной, до того как стало 2 студии и оборудование разделили на 2 студии). А представляете какая красота в студиях с бюджетами в миллионы? )) Там я бы жить остался среди такой красоты:
И это в нашей студии (правда всё в одной, до того как стало 2 студии и оборудование разделили на 2 студии). А представляете какая красота в студиях с бюджетами в миллионы? )) Там я бы жить остался среди такой красоты:
 Вот вам сейчас наверное на мгновение показалось что я иронизирую и посмеиваюсь над этими мудрыми железками? Отнюдь. Я их и сам люблю, даже в студию напокупали, признаться, даже больше чем надо ) Да и вообще – я уже давно заприметил себе вот такой преамп и если бы нашёл клад, обязательно бы его купил и работал бы с ним:
Вот вам сейчас наверное на мгновение показалось что я иронизирую и посмеиваюсь над этими мудрыми железками? Отнюдь. Я их и сам люблю, даже в студию напокупали, признаться, даже больше чем надо ) Да и вообще – я уже давно заприметил себе вот такой преамп и если бы нашёл клад, обязательно бы его купил и работал бы с ним:
 Красавица Millenia STT-1. А всё почему, для чего такой прибор (и не только этот конкретно а вообще подобные ему микрофонные преампы) нужен в студии, что он даёт, как использовать?
Красавица Millenia STT-1. А всё почему, для чего такой прибор (и не только этот конкретно а вообще подобные ему микрофонные преампы) нужен в студии, что он даёт, как использовать?
ну, самое очевидное: пред-УСИЛИВАТЬ микрофонный сигнал. Задавая уровень как на входе чувствительностью, так и уровнем на выходе
- срезать ненужные низкие частоты, которых в голосе нет а в записи могут присутствовать. Например, фильтр до 80Гц. (то же самое касается и ненужных высоких частот)
- если надо, насыщать сигнал ламповыми гармониками подмешивая сатурацию
- “поджимать” динамический диапазон компрессором – вот как раз то самое о чём первая часть статьи
- приукрашивать тембр эквалайзером
- срезать выпирающие цикающие “ссс” или “ццц” диэссером (который кстати тоже является динамической обработкой голоса – компрессором, но только для узкого частотного диапазона в районе этих “ссс”)
- лимитировать уровень сигнала: ещё один прибор динамической обработки, позволяющий задавать предел по громкости
- отсекать звук ниже определённой громкости: пока не говорим – идёт тишина. Гейт называется
- наслаждаться внешним видом и эстетикой работы с ним
- внушать трепет и благоговение клиентам студии
Согласитесь, прибор который умеет всё это (или хотя бы часть этого) – очень желателен на студии. Так что, никакой иронии: как-нибудь я себе такой прикуплю Но лично для меня это носит вопрос не технологический, а развлекательно-эстетический. И сейчас объясню почему, но сначала расшифруем новые термины которые появились в этой статье:
Обработка голоса ламповым сатуратором
 Все наверное слышали мем “тёплый ламповый звук”, так вот это не только повод для хихиканий над аудиофилами, но в ряде случаев подобное применение весьма оправдано. Дело в том что лампа в режиме работы перегруза, плавно начинает “въезжать” в громкие пики звука, которые превышают определённый уровень своим окрашиванием: лампа начинает издавать характерный призвук “перегруза” одновременно компрессируя пики сигнал. И чем большие эти пики (или общий уровень сигнала) тем больше лампа начинает красить и компрессировать. При этом этот звук перегруза у лампы куда как приятнее на слух чем остальные виды перегруза: транзисторный или тем более цифровой клиппинг. Этот эффект называется дисторшн, но мы сейчас не о нём, а о динамической обработке, в частности голоса. Ну так вот: этот эффект можно использовать как своеобразный компрессор: там где сигнал ниже уровня, на котором лампа начинает подгружаться – сигнал чистый, там где выше – сигнал начинает поджиматься и подкрашиваться дополнительными гармониками, как правило приятными на слух. Эти гармоники уплотняют звук, добавляют новые частоты в спектр, лампа срезая пики выравнивает по громкости. Так что применять лампу тоже можно в нужной дозе, разумеется, без фанатизма. Делается это на преампах (и грелках при реампинге) двумя способами:
Все наверное слышали мем “тёплый ламповый звук”, так вот это не только повод для хихиканий над аудиофилами, но в ряде случаев подобное применение весьма оправдано. Дело в том что лампа в режиме работы перегруза, плавно начинает “въезжать” в громкие пики звука, которые превышают определённый уровень своим окрашиванием: лампа начинает издавать характерный призвук “перегруза” одновременно компрессируя пики сигнал. И чем большие эти пики (или общий уровень сигнала) тем больше лампа начинает красить и компрессировать. При этом этот звук перегруза у лампы куда как приятнее на слух чем остальные виды перегруза: транзисторный или тем более цифровой клиппинг. Этот эффект называется дисторшн, но мы сейчас не о нём, а о динамической обработке, в частности голоса. Ну так вот: этот эффект можно использовать как своеобразный компрессор: там где сигнал ниже уровня, на котором лампа начинает подгружаться – сигнал чистый, там где выше – сигнал начинает поджиматься и подкрашиваться дополнительными гармониками, как правило приятными на слух. Эти гармоники уплотняют звук, добавляют новые частоты в спектр, лампа срезая пики выравнивает по громкости. Так что применять лампу тоже можно в нужной дозе, разумеется, без фанатизма. Делается это на преампах (и грелках при реампинге) двумя способами:
- сигнал пропускается через ламповый каскад и крутится ручка гейна: степень вмешательства лампы
- сигнал дублируется на параллельный канал, где ручкой гейна настраивается степень вмешательства лампы в обработку голоса и отдельная ручка, которой подмешивается этот обработанный сигнал к основному
Этот метод обработки, а точнее сказать “украшения” звука, иногда неплохо слушается на голосе, хотя самый самое широкое его применение, конечно, гитары. Стоит так же сказать что в каскаде предусилителя в самом микрофоне тоже порой стоят лампы. Микрофон с таким каскадом так и называется: ламповый. И, кстати, не всегда это даёт положительный результат – ламповый мик+ ламповый преамп. Иногда этот “ламповый засер” даёт грязь, кашу и “переборщ”. Но в некоторых партиях это как раз и нужно. Так что всё по вкусу, и индивидуально. И вообще по теме лампы мной уже две статьи написано, гораздо более полных и подробных. Вот тут первая, а вот тут вторая. Просвещайтесь, а мы продолжим 
De-esser(диэссор) как обработка голоса
В зависимости от голоса или микрофона, в записанном голосе звучат неприятные звуки, иначе ещё называемые “сибилянты”: это звук “шшшш”, “сссс” и “цццц”, по возрастанию частоты. Кстати, у непрофессионалов эта проблема стоит острее. Помните почему? Потому что у них при пении и произношении нет “ровности громкости” и из за того что в голосе нет общего “силы и напор” цикалки торчат сильнее, как тополь на плющихе. Ситуация становится ещё хуже если используется “верхастый” микрофон. Это вообще отдельная головная боль для звукарей. Понапокупают микрофонов сравнивая сырую запись, и разумеется выбирают тот, в котором больше верхов, им кажется что он лучше звучит, а на самом деле там один “пыщь-пыщь” и “цык-цык”. Особенно я не люблю микрофоны Rode за эту их “фишечку”, ну и, соответственно, под замес и всех тех кто на неё ведётся. Недаром же все прутся по старым микам, 60-70х годов, и не потому что там были некие “технологии Аненербе”, а потому что тогда в эти игрушки “самый светлый” звук не играли и делали ровную частотку.
И вот когда эти две беды (исполнитель с неаккуратными верхами и верхастый микрофон) встречаются – получается дивный калейдоскоп, который потом разгребать и разгребать. Как только начинаешь осветвлять вокал – проблема умножается. И эквалайзером её исправить нельзя – начнёшь резать высокие частоты – срежутся все нафик. Причём сильнее всего пострадают аккуратно звучащие, а сибилянты всё равно торчать будут как бешенные. что же делать?
 Тут то и приходит на помощь прибор обработки голоса диэссер. Суть его простая – это тот же самый компрессор, но только он действует в узком участке спектра, например от 4кГц до 6кГц – там где голос “свистит” сильнее всего. Настраиваем нужный частотный диапазон, настраиваем уровень уменьшения громких звуков и вот уже корректный звук: голос тот же самый, а свистульки делаются тише в 1:2 или 1:4 раза в зависимости от выставленных настроек, ну или прямо указать на сколько дБ уменьшить нужный кусочек спектра.
Тут то и приходит на помощь прибор обработки голоса диэссер. Суть его простая – это тот же самый компрессор, но только он действует в узком участке спектра, например от 4кГц до 6кГц – там где голос “свистит” сильнее всего. Настраиваем нужный частотный диапазон, настраиваем уровень уменьшения громких звуков и вот уже корректный звук: голос тот же самый, а свистульки делаются тише в 1:2 или 1:4 раза в зависимости от выставленных настроек, ну или прямо указать на сколько дБ уменьшить нужный кусочек спектра.
Обработка голоса лимитером
Честно говоря, никакая это не обработка, это больше технический ограничитель по выходу из преампа чтобы на вход звуковой карты без перегруза сигнал шёл, но лимитер в студии вообще применяется широко. Основное его назначение лимитировать сигнал определённым значением уровня. Лимитер как и диэссер (и как последующий пункт: гейт) это частный случай (настройка) всё того же компрессора. Суть его в том, что во всём диапазоне громкости он в звук не вмешивается, и лишь начиная с определёного, как правило, высокого уровня громкости, всем пикам задаётся коэфициэнт уменьшения громкости 1:∞.
 Вот на скрине видны настройки компрессора работающего в режиме лимитера. Из него видно что можно подавать какой угодно по громкости сигнал, но при приближении к -10 дБ он будет ограничиваться, и хоть ты из штанов выпрыгни но более чем -10 дб на выходе из компрессора не получить.
Вот на скрине видны настройки компрессора работающего в режиме лимитера. Из него видно что можно подавать какой угодно по громкости сигнал, но при приближении к -10 дБ он будет ограничиваться, и хоть ты из штанов выпрыгни но более чем -10 дб на выходе из компрессора не получить.
Такой инструмент в преампе используется вместе (после) компрессора потому, что не всегда компрессора достаточно чтобы сгладить внезапный крик, например. если лимитер не использовать, дубль будет испорчен клиппингом, а лимитер позволит избежать артефакта. Ну а в сведении и в общей работе по обработке я как нибудь сподоблюсь написать отдельные статьи.
Я уж и так стараюсь покороче, но кажись не очень получается. Так что не будем терять время и приступим к следующему пункту:
Прибор или функция обработки gate (гейт)
Это тоже частный случай прибора динамической обработки, но только диаметрально противоположной по сути. Если смысл лимитера “ничто не должно быть громче определённого уровня” то у гейта наоборот: ничто не должно звучать всё что тише определённого уровня. Допустим у нас записан голос, а помимо голоса у нас там на записи всякая фигня в микрофон полезла – отражения комнаты, скрежет сверчков, шум… Голос у нас говорит или поёт в диапазоне от -30 до -10дБ. а всё что тише мы отсекаем настройками “всё что тише -30дБ = –∞дБ. В итоге у нас остаётся только голос, а всё остальное не звучит.
Все эти бесконечные пункты – это лишь поверхностный проход по такой глобальной теме как “динамическая обработка” о которой я могу писать часами и писать целые тома: насколько это интересный мир, где компрессор по-моему мнению король мира звука. (и это мы ещё не копнули тему экспандера, многополосной компрессии и его антипода – динамического эквалайзера).
Т.е. один только компрессор это целый класс устройств и обработок. Вот например это один и тот же компрессор, настраивая который по разному будет работать как разные устройства:

Это прибор динамической обработки который работает в режиме компрессора. Видно настройки, при которых при достижения уровня сигнала в -14дБ (и чуть ранее) сигнал уменьшается в 2.86 раза
 А это тот же прибор, с чуть более агрессивными настройками, но работающий лишь в диапазоне от 4кГц до 6.5кГц что даёт право называть его диэссером.
А это тот же прибор, с чуть более агрессивными настройками, но работающий лишь в диапазоне от 4кГц до 6.5кГц что даёт право называть его диэссером.
 Здесь же настройки таковы, что прибор динамической обработки работает в режиме лимитера. Громкость звука ограничивается -7дБ.
Здесь же настройки таковы, что прибор динамической обработки работает в режиме лимитера. Громкость звука ограничивается -7дБ.
 А здесь видно, что помимо работы лимитера, прибавляется ещё и функция гейта – всё что тише -29дБ перестаёт звучать.
А здесь видно, что помимо работы лимитера, прибавляется ещё и функция гейта – всё что тише -29дБ перестаёт звучать.
И разумеется все эти режимы работы можно совместить. При должном функционале прибора динамической обработки голос будет проходить все эти обработки и на выходе получим то что сами накрутили. А крутим с умом, по-вкусу
И вот сейчас подходим к тому, зачем я эту длиннющую телегу писал. Несмотря на то, что микрофонные преампы как правило оснащаются блоком динамической обработки (и не одним, например не редкость когда в одном преампе стоит сатуратор, компрессор, диэссор, экспандер, лимитер и гейт) при прочих равных я бы лично предпочёл писать звук без преампа
Сразу стоит сказать, что я “звукарь новой формации”, и мне весь этот благоговейный трепет перед аналоговыми и аппаратными приборами до лампочки. В моих студиях нет ни микшерного пульта (некоторых это кстати обескураживает) ни танцев с бубнами вокруг ламповых прибамбасов (хотя сами ламповые прибамбасы есть). Потому что я поборник “чистого исходника”:
Пишем звук как есть, а потом уже если надо обрабатываем, если надо, можем сбросить то что накрутили, и снова пересвестипереобработать.
Но сигнал с микрофона то в студии пишется через преамп на котором есть компрессор. Да. Но это вопрос не обработки, а вопрос удобства записи.
Дело в том, что человеческий голос обладает вполне большим динамическим диапазоном, и каждый раз крутить ручку уровня – утомительно. Проще немного усреднить уровень громкости и писать уже такой более комфортный для записи звук, чем каждый раз бояться: достаточно ли чувствительности для тихих мест в вокале, и не клипанёт ли в громких местах?
Но это лично мои предпочтения и стиль работы. У другого звукаря может быть другой. Например выстроил под себя настройки компрессирования, пишет скомпрессированный уже голос, а потом если надо ещё “дожимает” и “допиливает”.
Есть правда ещё отдельный вид чудиков, которые не знают как работать и знать не хотят, купили преамп, компрессором сигнал сжали, вроде поразборчивее и поплотнее – ну так и пусть будет. Особенно таких обормотов много среди тех кто видео занимаются Некоторые настолько тугие на ухо, что вообще никак звук не обрабатывают, прям так в видео вставляют Вот и сжаливаются порой студии и пишут голоса через преамп с компрессором… Ну да ладно )
Вот прикиньте чуваки – этот огромный блок был написан только лишь для того, чтобы объяснить вам, что в конвертор (звуковую картукомп) обычно приходит УЖЕ чуток (а где и не чуток) обработанный сигнал вокала или голоса. Т.е. я сейчас описывал примерно то что делает (или может делать) микрофонный предусилитель ДО записи сигнала. Это надо учитывать тоже.
И только теперь можно приступать к описанию того, с чего начали:
Обработка записи голоса или вокала
У нас в проекте аудиофайл с записанным вокалом, пропущенным в аналоговой части через микрофонный предусилитель с некими настройками предобработки. Обычно производители рекомендуют средние настройки крутилок (Long например прямо об этом говорит) а это, как правило уровень компрессии 1:4 для сигнала с порогом -20дБ. И вот этот звук мы уже начинаем “накручивать” в компьютере плагинами (как программными, так и аппаратными). Отдельные ценители могут пропускать этот сигнал опять через внешние обработки и на входе снова их записывать с обработкой. Но лично я так не делаю по нескольким причинам:
- самое первое – я не фанатею от аппаратных приборов обработки и считаю программные ничуть не уступающими
- это пипец как гемморойно разводить роутинг и раздувать объёмы проекта с сомнительной эффективностью
- невозможность постредактирования – опять заново переписывать только
- по-чуть чуть, но шумы копятся
В общем после записи звука на комп (а по-правильному надо говорить “после оцифровывания сигнала конвертором”), всю дальнейшую обработку голоса я веду в компе плагинами.
Итак с чего начать и какой тип и вид обработки должен идти за каким? Снова вас отсылаю к примеру аппаратных преампов: логика обработки вокала и последовательность операций общая во всех случах, именно поэтому примерно в такой же последовательности слева направо расположены блоки обработки и крутилок на лицевой панели микрофонных предусилителей и вообще голосовых процессоров: (микрофонный предусилитель Long Voice Master)
 цифрами обозначил блоки слева направо для их расшифровки: что это, для чего нужно, и почему именно в такой последовательности
цифрами обозначил блоки слева направо для их расшифровки: что это, для чего нужно, и почему именно в такой последовательности
- крутилка входного уровня сигнала, если будут какие то другие выбивающиеся из неких средних значений, то приборы динамической обработки голоса будут уже некорректно работать, или будут ли работать вообще, при очень маленьком входном уровне, например
- блок фильтра низких частот. нужно отрезать ненужные частоты, или мешающие работать последующим обработкам
- компрессор сужающий динамический диапазон
- диэссор, потому что для того чтобы резало ухо “ссскам” нужно совсем немного громкости, а мы убрали громкие и сибилянты начали выпирать, поэтому компрессим сибилянты отдельно ещё раз
- лимитер – режем звук чтобы не пропустить пики, которые возможно ещё остались
- эквалайзер – чтобы тембр отстроить так как нужно, добавить то чего уменьшилось после динамической обработки, и прибрать то, что вылезло наружу.
- фильтр высоких или низких – срезать ненужное в спектре
- ручка выходного уровня громкости
Так примерно в большинстве случаев и выстроена схема работы по обработке голоса: убираем ненужные частоты чтобы не мешать компрессору, а после ещё раз шлифануть звук эквалайзером до нужного нам тембра.
И чтобы закрыть этот монстрообразный по объёму пункт о динамике последний аспект, насчёт которого нет “правильного рецепта”, но есть некие хитрости:
Чем глубже мы хотим “посадить в микс” голос, тем сильнее его надо (а может и не надо – говорю же, нет универсальных советов) сжать при обработке вокала. Тут, конечно, всё индивидуально, но если у нас пробивные звуки например кричащий вокал, или основная фишка трека танцевальный ритм, то можно сжать голос посильнее и сделать его в целом потише. чтобы акцентировались другие грани трека. А если наборот, упор на голосе, или это акустическая песня в исполнении, например бардовская, то компрессии чуть чуть. Потому что и так голос на поверхности громче всего остального, нужна естественность и прозрачность. В особых случаях, например имитация “открытого воздуха” или театральной постановки – компрессии достаточно лишь той что была на преампе.
В обще всё рулится на слух, сообразно целям, задачам и условиям применения.
Ну хватит о динамике, перейдём к другим типам обработки вокала.
Эквализация или частотная обработка вокала.
 Этот пункт настолько простой и очевидный, что, признаться, я даже теряюсь что тут можно писать, кроме очевидного капитанства. Эквалайзер: прибор обработки голоса по частотам. Например, мы можем воздействовать на какую то конкретную частоту с определённой точностью её выборки и указать прибору – сделать всё в этой области в 2 раза тише (-6дБ). Хотя этот пример не жизненный, обычно наоборот – вырезается торчащая или резонирующая частота.
Этот пункт настолько простой и очевидный, что, признаться, я даже теряюсь что тут можно писать, кроме очевидного капитанства. Эквалайзер: прибор обработки голоса по частотам. Например, мы можем воздействовать на какую то конкретную частоту с определённой точностью её выборки и указать прибору – сделать всё в этой области в 2 раза тише (-6дБ). Хотя этот пример не жизненный, обычно наоборот – вырезается торчащая или резонирующая частота.
Всё потому, что спектр голоса человека определяется его резонаторными объёмами. Голосовые связки издают определённый тон – опорную частоту, ноту, а вот тембр голоса, делающий его индивидуальным (именно по нему мы отличаем голос одного человека от другого) определяется “конструктивной особенностью” человека. Разные объёмы грудной клетки, гортани, шеи, трахей, рта, мышц, особенности развития, их взаиморасположения и ещё кучи всяких факторов. В итоге получаем индивидуальный спектр голоса, который ещё до кучи и меняется в зависимости от исполнения вокала. Например, у меня, как у вокалиста и меня как диктора совершенные разные голоса. Потому что если дикторский по спектру более менее ровный, то в вокале с определённой громкостью начинают всё громче резонировать хрен его знает где расположенные резонаторы выдающие серединку. Именно поэтому я предпочитаю записывать свой вокал в микрофон Brauner VM-1 который густой, тёмный и даёт мало середины, а потом ещё и на этапе сведения дополнительно эти свербящие средние частоты резать приходится..
То же самое и с другими голосами: при обработке вокала эквалайзером приходится учитывать все эти индивидуальные особенности и исходить из правила “убирать недостатки и подчёркивать достоинства”, ну и конечно соотносить с общим звучанием в миксе. Переборщ, как правило, всегда хуже, чем недоборщ. Но бывает и так: отстроенный вокал, сам по себе хорошо звучащий, не звучит миксе. А голос, который удачно лежит в миксе и ничего не портит а наоборот обогащает общее звучание – сам по себе может быть обработан так что в соло звучит ужасно. В таких случаях лично я отдаю приоритет звучанию голосу в общем. Те настройки обработки при которых голос звучит хорошо вместе с остальными инструментами и есть верные.
“украшательские” обработки на вокал
Далее мы рассматриваем уже некие художественные приборы обработки вокала: фазовые, пространственные, и прочие спецэффекты.
В этом пункте уже просто можно обозначить “так обработать вокал тоже можно”. Они необязательны, а носят характер “рюшечек” хотя и весьма пользительных и желанных.
Такие устройства как хорус, фейзер и фленжер дают интересный призвук спецэффекта. Некие ужирнители, уплотнители, умножители. Звук чуток пошире, начинает причудливо плавать переливаясь “биением фаз”. По юности как то увлекался, ни трека без такого не было. А сейчас пришёл к выводу, что голос должен быть либо естесственным (что 99% песен) либо делать нарочитые спецэффекты (в остальных 1%) и накручивать на всю монтану. Советов давать не буду, они тут и не нужны – это чистое творчество, каждой крутит по вкусу.
Такие же приборы обработки всяких спецэффектов с причудливыми алгоритмами и их сочетанием, а так же “нарезатели” типа глитчеров. Каждый крутит сам и определяет нужны они или нет.
Но вот о чём отдельно стоит сказать так это об эффектах пространственной обработки вокала: дилей и ревер.
Дилей: задержка. эхо. упорядоченные повторы сигнала с определённой периодичностью и длиной хвоста. Эхо. Всё просто
Ревер: примерно то же самое, но с огромной кучей переотражений с разными задержками – этакое облако множества эх, в сумме дающих не эхо а некое пространство, объём.
 Эти два эффекта очень часто используются, потому что сухой обработанный вокал или голос хорош, но существует сам по себе. В вакууме, или прям в микрофоне. Без атмосферы, без пространства. В ряде жанров, стилей, миксов и творческих задумок это здорово звучит, а вот в ряде других работ, обязательно надо помещать голос в некую точку в пространстве, задавая атмосферу, для естесственности, красоты и слушаемости. А вот уже размеры этого пространства, глубина, цвет, степень – вот это уже снова индивидуально и без рецептов.
Эти два эффекта очень часто используются, потому что сухой обработанный вокал или голос хорош, но существует сам по себе. В вакууме, или прям в микрофоне. Без атмосферы, без пространства. В ряде жанров, стилей, миксов и творческих задумок это здорово звучит, а вот в ряде других работ, обязательно надо помещать голос в некую точку в пространстве, задавая атмосферу, для естесственности, красоты и слушаемости. А вот уже размеры этого пространства, глубина, цвет, степень – вот это уже снова индивидуально и без рецептов.
Важно также помнить, что этими приборами можно при обработке вокала задавать положение источника в пространстве микса. И если ручка панорамирования задаёт положение лишь влево-вправо, то крутя ручки настройки ревербератора можно делать голос “ближе-дальше”: ценное свойство, особенно если в песне несколько голосов, помимо основного. Можно хорошо обыграть это ревером.
Да и вообще, тут самый большой кусок в статье как обработать вокал достался компрессору и его вариантам. Конечно, это вызвано тем, что нужно было объяснить, что в комп запись вокала попадает уже частично обработанная микрофонным преампом, а попутно это многое разъяснило зачем вообще нужен компрессор уже на этапе обработки вокала.
По-хорошему, по каждому даже не прибору, а по случам применения каждого прибора можно написать отдельную статью с примерами, но это уж, для меня человека ленивого, трудновато Но как нибудь сподоблюсь и напишу.
Так что, примерное представление что делается на этапе обработки вокала, зачем это, сложно ли это или просто, вы уже имеете. Тем кто хочет делать сам – крутите ручки, слушайте, делайте выводы, пробуйте, ошибайтесь и снова пробуйте, никого не слушайте. Доверяйте только ушам. Звучит так как вы задумывали? Значит всё верно. Наплюйте на мнение всезнаек. Не всегда цель – идеально звучащая песня. Иногда при ужасных исходниках это принципиально недостижимо ). Главное достичь той цели к которой вы стремились. Помните – у всех вокруг разные уши и разные музыкальные пристрастия. Лекала одного, не могут и не должны подойти другому. Действуйте исходя из своих. Я например никогда не лезу со своими оценками в жанры в которых я мало что понимаю и не люблю. Например, рок. Что толку если я там расслышу что то, что мне покажется неправильным? Во первых я не в теме стиля. во вторых возможно у автора или саундпродюсера именно такая задумка и была. А те кто крутить ручки не хочет и не может (и это правильно – у каждого своя специализация) – обращайтесь. Всё как надо обработаем к взаимному удовольствию
С уважением, Дамир Command.com
К СПИСКУ СТАТЕЙ<<<———————->>>ПРЕДЫДУЩАЯ СТАТЬЯ

© студия звукозаписи «R-Records®»2018г.
Все статьи
Сегодня мы осветим такую тему как обработка голоса для песни. Если вы хотите заказать услугу обработки своего голоса, то можете сразу ознакомиться с нашими предложениями в разделе услуги и цены. Если же вас интересует самостоятельная обработка, то для вас эта статья. Итак, обо всем по порядку.

Чем обрабатывать голос
Сегодня все реже используются физические устройства для изменения голоса. В основном применяются их цифровые аналоги – цифровые плагины. При этом наблюдается некоторая преемственность, которая выражается в том, как выглядят интерфейсы таких плагинов: нередко они полностью имитируют классические электронные устройства, ставшие знаменитыми в звукорежиссерских кругах, поскольку применялись в известных студиях звукозаписи и позволяли добиться отличных результатов. Соответственно, производители плагинов обещают полное совпадение по звучание цифровых версий в сравнении с физическими (как правило, аналоговыми) приборами. Стоит ли на 100% доверять разработчикам плагинов в этом вопросе – это отдельная тема для обсуждений. Но очевидно, что сегодня можно добиваться хорошего звучания треков, используя исключительно компьютерные цифровые обработки, которые нередко обходятся дешевле, нежели физические устройства обработки, и отличаются большим удобством в использовании. Расскажем об основных плагинах, которые применимы для обработки голоса в песне.
Основные обработки
Компрессор. Нередко в цепи обработок этот эффект ставится в самом начале. Суть его работы в том, чтобы уменьшить динамический диапазон голосовой записи. Выражается это в том, что тихие звуки становятся громче. А изначально громкие звуки – наоборот, делаются тише. Компрессия вокала необходима, поскольку в большинстве случаев современные минусовки также подвергаются значительному сжатию динамического диапазона. И если не применять аналогичную обработку к голосу, он, как говорят звукорежиссеры, «не ляжет в микс», то есть будет слушаться чужеродно и неестественно, а в наиболее тихих местах будут ощущаться провалы, из-за которых невозможно будет расслышать часть слов. Существуют различные настройки компрессии в зависимости от особенностей голоса вокалиста и стилистики трека. К примеру, в современной поп- и рок-музыке компрессия может быть довольно агрессивной, позволяющей достичь очень «плотного» звучания голоса в песне. В академической музыке, отличающейся большим динамическим диапазоном, компрессор может быть очень мягким, сглаживающим лишь некоторые амплитудные пики с целью предотвращения клиппирования. Один из вариантов настройки компрессора приведен на иллюстрации ниже.

Эквалайзер. Этот эффект применяется для обработки голоса в песнях повсеместно. При этом самый лучший пример использования эквалайзера – это когда слушатель просто получает удовольствие от звучания голоса в песне и даже не догадывается, что изначально вокал звучал как-то иначе, и был подвергнут эквализации. Существует множество рекомендаций по эквализации голоса, в которых перечисляются такие термины, как «тело голоса», «теплота», «резкость», «презенс» и тд. Но слепо следовать таким рекомендациям не стоит. Дело в том, что сегодня существует огромное количество моделей микрофонов, и все, так или иначе, имеют отличия АЧХ (амплитудно-частотной характеристики). Соответственно, невозможно сформулировать какие-то универсальные рекомендации по применению обработки вокала эквалайзером. Также стоит учитывать, что голосовой аппарат у разных вокалистов имеет свои индивидуальные особенности. Поэтому при эквализации голоса в песне лучший совет будет: «не навреди». Слушайте записанный голос без обработки и сравнивайте его с референсными записями. И только если вы услышите, что имеются проблемы с АЧХ записанного вокала, тогда пробуйте исправлять их при помощи эквалайзера. Также стоит отметить, что заниматься эквализацией голоса стоит исключительно с применением студийных акустических мониторов в специально подготовленном помещении. Иначе легко допустить ошибку, даже ориентируясь на референсные треки. Один из вариантов легкой эквализации голоса в песне приведен на иллюстрации ниже.

Реверберация. Если вы, находясь в пустой комнате, хлопнете в ладоши, то услышите характерный призвук помещения, который быстро затихнет. Нередко этот призвук ошибочно называет эхом, но на самом деле это реверберация. Обработка голоса в песне с использованием ревербератора – очень частое явление. Дело в том, что вокал без этого эффекта слушается слишком «сухим», неестественным. Это неудивительно: запись голоса в студии происходит в помещении, стены которого отделаны звукопоглощающими материалами, поэтому микрофон практически не улавливает реверберацию вокальной комнаты или кабины. Соответственно, в процессе сведения трека эта недостающая реверберация добавляется в вокальный микс при помощи плагина, после чего голос звучит более естественно и приятно. Вы спросите: к чему такие сложности, почему нельзя просто записывать голос в помещении с естественной реверберацией? Дело в том, что такое решение не будет универсальным. В различных песенных треках, в зависимости от стилистики и поставленной творческой задачи, требуется совершенно разная реверберация: где-то едва заметная и с коротким «хвостом», где-то ярко выраженная и с долгим затуханием. И проще записать в студии совершенно «стерильный и сухой» голос, и уже потом, при сведении песни, пробовать различные варианты настроек ревербератора, добиваясь наилучшего варианта обработки. Один из примеров реверберации применительно к голосу приведен ниже.

Тюнинг. С тех пор, как в студиях звукозаписи появились компьютеры, такой эффект как тюнинг стал использоваться очень широко, произведя своего рода тихую революцию, позволившую записывать песни тем, кто, как говорится, не имеет ни слуха ни голоса. Тюнинг – это исправление фальшивых, неточных нот, или, иначе говоря, исправление неточного интонирования. Строго говоря, существуют также и специальные цифровые устройства, позволяющие исправлять неточные ноты, но все-таки самыми популярными сегодня являются именно компьютерные VST-плагины, которые позволяют очень эффективно исправлять голосовую фальшь. Среди прочих стоит упомянуть, прежде всего, Melodyne и Autotune. Если говорить коротко, то существует два основных режима редактирования голоса: ручной и автоматический. Ручной применяется в тех случаях, когда отклонения голоса по высоте очень значительны. Звукорежиссер кропотливо, нота за нотой, «рисует» правильную вокальную мелодию, в результате чего голос начинает звучать намного приятней. Впрочем, не все так радужно: если приходится «двигать» ноты по высоте в значительных пределах – до нескольких полутонов – это неминуемо сказывается на обработке: голос в песне звучит несколько «электронно», неестественно. Такова цена неумения петь правильные ноты самостоятельно. Автоматический режим тюнинга используется тогда, когда запись в целом сделана весьма достойно, но в некоторых местах имеются некоторые неточности интонирования (к примеру, не более четверти тона). Соответственно, автоматический режим подходит для опытных вокалистов с хорошо поставленным голосом и достаточно точным интонированием. Как нетрудно догадаться, применение автоматического тюнинга не требует значительного времени: программа делает обработку практически молниеносно. Все, что требуется после этого от звукорежиссера – это контрольное прослушивание трека, чтобы убедиться, что программа нигде не ошиблась и голос после обработки звучит так, как нужно. Ниже представлено изображение программы для тюнинга Melodyne.

Есть и другие эффекты, применимые к вокалу в музыкальных композициях и позволяющие «свести» вокал с минусом. Но мы перечислили самые основные. Если вы добавите их в цепочку и примените подходящие настройки, то гарантированно получите улучшение звучания. Надеемся, что теперь обработка голоса для песни стала для вас более понятной темой. Но, разумеется, прочтением статьи обойтись не получится: постоянно практикуйтесь, и вы обязательно достигнете высот в этом нелегком деле!
 Павел Медведев — Voice producer, продюсер, вокалист, автор песен, композитор, аранжировщик, хормейстер, преподаватель вокала, владелец студии звукозаписи Gold Word Corporation (ранее «New Voice»)
Павел Медведев — Voice producer, продюсер, вокалист, автор песен, композитор, аранжировщик, хормейстер, преподаватель вокала, владелец студии звукозаписи Gold Word Corporation (ранее «New Voice»)
Деятельность:
С 2003 по 2005 г. — вокалист группы «Фараоны» и «Hollywood» при ДК БАЗ (г.Краснотурьинск).
С 2005 по 2009 г. — педагог вокала в Уральском Государственном Педагогическом Университете.
С 2005 по 2009 г. — руководитель вокальной студии в Уральском Государственном Педагогическом Университете.
С 2008 по 2011 г. — работа voice продюссером в студии звукозаписи «Black vizards production».
С 2009 по 2012 г. — работа аранжировщиком и звукорежиссером в Уральской Государственной Консерватории им.Мусоргского при кафедре звукорежиссуры (директор кафедры Келлер Виталий Васильевич)
С 2009 по 2012 г. — работа аранжировщиком, автором, бек-вокалистом и voice продюссером при Уральской Государственной Консерватории им.Мусоргского. Был выпущен ряд релизов и компакт — дисков совместно с компанией «Монолит» и «Русский Шансон»
С 2009 по 2016 г. — voice — продюсирование таких исполнителей как: Александр Блик, Нина Ручкина, Андрей Бусыгин (Даль), Екатерина Жигера, Ульяна Синецкая, Анастасия Волочкова.
В 2009 г. — исполнитель главной роли «вора в законе» в мюзикле «Мурка».
С 2013 по 2014 г. — работа voice — продюсером, хормейстером и аранжировщиком на S.G.T.R.K. Media lab. с победителями телевизионного проекта «Битва хоров » (хор «Виктория»). Была спродюсированна новая концертная программа.
С 2013 по 2014 г. работа voice — продюсером и педагогом по вокалу в «Студия звезд» «Уральский Ералаш».
С 2013 по 2014 г. — возглавил филиал Уральской группы «Непоседы».
С 2013 г. — работа voice — продюсером в студии звукозаписи «Bastaz records».
С 2013 по 2015 г. — работа voice — продюсером в студии звукозаписи «Корпорация 11».
В 2014 г. — работа voice — продюсером, наставником и исполнителем одной из главных ролей в мюзикле «Реальный выпускной» совместно со звездами телевизионного канала ТНТ «Реальные пацаны».
С 2014 по 2015 г. — подготовка вокальных номеров для участников шоу «Уральские Пельмени».
В 2014 г. — открытие собственной студии звукозаписи «New Voice».
С 2014 г. по настоящее время работа voice — продюсером в собственной студии звукозаписи Gold Word Corporation (ранее «New Voice»).
С 2014 г. по настоящее время — благотворительная деятельность по voice — продюсированию детей инвалидов вместе с волонтерским движением «Время добра»
Работа с такими звездами российской и зарубежной эстрады как: «Boney — M», Сергей Ершов, Ариэль, «Веселые ребята», «Лейся песня», Аракс, «Карнавал», «Добры молодцы», «Красные маки», «Голубые гитары», «Шестеро молодых», Юрий Лоза, Анатолий Алешин, Валерий Ярушин, София Ротару, Вилли Токарев, Катя Лель, Евгения Отрадных, группа «Премьер — Министр», «Чай вдвоем», группа «Чайф», «Ногу свело», «Смысловые галлюцинации», Вячеслав Бутусов, Агата Кристи и другие.
Образование:
1. «Дирижер-хоровик-хормейстер» — Краснотурьинское Музыкальное Училище (неоконченное среднее)
2. «Дирижер — хоровик — хормейстер» — Уральский Государственный Педагогический Университет (специалитет)
3. Курсы звукорежиссуры от Келлера В.В. при Уральской Государственной Консерватории им.Мусоргского (с 2009 по 2012 г.)
Профессиональные навыки: Владение программами по созданию музыки: Cubase, Logic Pro X, Newendo, Sound Forge.
Владение музыкальными инструментами: фортепиано, акустическая гитара, электро — барабаны.
Создание оркестровой аранжировки и написание нотного текста; звукорежиссура; мастеринг; сведение
Исправление вокала на студии
В этой статье мы поговорим про исправление вокала (англ. vocal tuning). Что делать, если во время записи партии или дубля возникли трудности, но на их перезапись уже нет времени? Также бывает и так, что артист не до конца понимает, как ему нужно спеть, чтобы это звучало действительно хорошо. В этом случае записанный вокал стоит исправить уже после записи вокала на студии.

Опытный звукорежиссер никогда не пренебрегает коррекцией ритмики, т.к. неритмичная партия сильно сбивает слушателя и портит динамику музыкального произведения.ТопЗвук
Сразу следует отметить, что никакое студийное «волшебство» не поможет исправить совсем уж плохой вокал, поэтому стоить максимально постараться именно во время звукозаписи и меньше надеяться на следующий этап.
| Услуга | Стоимость | Способ оплаты |
|---|---|---|
| Запись голоса | 750 руб/час | Почасовая |
| Запись закадровой озвучки | 1000 руб/час | Почасовая |
| Запись инструментов | 750 руб/час | Почасовая |
| Создание барабанных партий | 750 руб/час | Почасовая |
| Сведение и мастеринг | 750 руб | Почасовая |
| RAP под минус | 3000 руб | Фиксированная |
| RAP под минус “Премиум” (с доп. эффектами) | 4000 руб | Фиксированная |
| Песня под минус “Лайт” (1 ч. записи + обработка без тюнинга) | 2500 руб | Фиксированная |
| Песня под минус “Премиум” (1 ч. записи + обработка и глубокий тюнинг) | 5000 руб | Фиксированная |
| Создание аранжировки | от 15.000 руб | Фиксированная |
| Создание минусовки | От 15.000 руб. | Фиксированная |
| Аренда студии без звукорежиссера | 700 руб/час | Почасовая |
Большинство программ и приборов тюнинга вокала до и после хорошо справляются с ошибками до +/- 2 тона. Далее начинаются весьма заметное на слух искажение голоса, появление неестественности и «роботизированности» в голосе, что недопустимо, если только не используется как специальный эффект. Следует отметить, что на 100% идеально попасть в ноту не могут даже опытные и очень хорошие вокалисты, поэтому даже качественный поставленный вокал требует проверки и некоторых исправлений.
Многие начинающие певцы имеют проблемы не только с попаданием в ноты, но и с ритмикой (зачастую так сказывается отсутствие практики занятий по метроном). Разумеется, после записи таких исполнителей приходится применять исправление вокала. В этом случае звукорежиссеры обязательно исправляют ритмические ошибки путем либо нарезки вокальной линии на большое количество фрагментов либо с помощью их растягивания/сжатия. Опытный звукорежиссер никогда не пренебрегает коррекцией ритмики, т.к. неритмичная партия сильно сбивает слушателя и портит динамику музыкального произведения.
Тюнинг голоса (до и после)
Можно ли исправить вокал
Нас часто спрашивают, можем ли мы обработать записанный дома трек, сделать исправление вокала, придать ему коммерческое и качественное звучание. С одной стороны, да, мы можем провести комплекс мер, направленных на улучшение звучания. Но результат будет несравним с материалом, записанным опытным специалистом у нас на студии с применением качественных микрофонов и оборудования (в том числе уникальных ламповых аппаратов).
Специалисты студии ТопЗвук имеют большой опыт звукозаписи и коррекции звукового материала. Мы знает, как работать с артистом, чтобы он остался доволен результатом. Помимо звукозаписи, коррекции и обработки, мы занимаемся сведением, мастерингом песни, саунд-продюсированием и созданием аранжировок в любых современных стилях музыки — рэп, рок, поп, электронная музыка, метал и многих других. Если требуется исправление вокала, обращайтесь в нашу студию!

Обновлено: 23.08.2021
Здравствуйте, уважаемые читатели. Недавно на своем блоге, я опубликовала статью под названием «Качественная обработка голоса в Adobe Audition», в которой я привела алгоритм действий, которым я пользуюсь, чтобы привести в порядок запись голоса. В комментариях к этой статье меня попросили привести конкретные примеры. Ну что ж, сейчас я вам покажу какими фильтрами и эффектами в программе Adobe Audition пользуюсь я, чтобы голосовой трек звучал качественно.
Голос до обработки
Начнем, с того, что запись осуществляется не в студийных условиях, а в кабинете, где стоит несколько системных блоков и кондиционер — конечно же все они очень шумят и создают помехи в записи. Если кондиционер еще можно выключить, то самый шумный системник, по стечению обстоятельств мой, выключить нельзя — иначе как записывать :-). Сразу хочу предупредить, что из-за этих условий избавиться от всех шумов не удастся, но при условии, что на трек будут наложены эффекты, типа эхо и реверберация, а фоном будет служить музыка, недостатки будут незаметны.
Микрофон: Perception 120.
Задача: Записать голосовое сопровождение для некоего ролика и наложить его на музыку. В качестве примера буду приводить отрывок.
Записанный трек звучит следующим образом:
Пошаговая обработка голоса
1 шаг. Откроем трек в программе Adobe Audition.
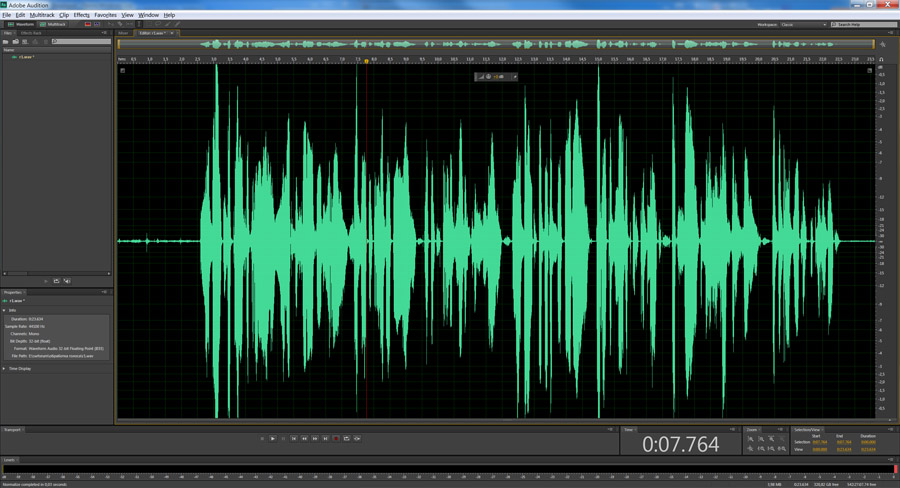
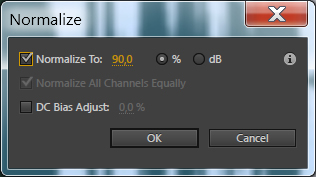
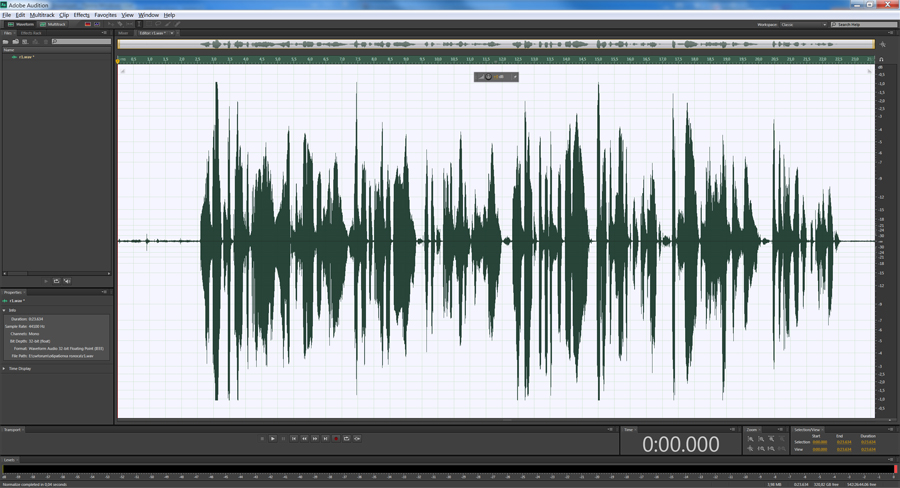
2 шаг. Выполним нормализацию. Процесс нормализации похож на перемещение ручки громкости, весь сигнал изменяется «неподвижным» количеством, вверх или вниз. При нормализации, система находит самый громкий пик и по нему уже выстраивает общий уровень, чтобы громкость звучания была оптимальной. Для этого в программе Adobe Audition выделите весь трек, нажатием клавиш Ctrl+A, при этом поле со звуковой дорожкой окрасится в белый цвет и выберите пункт меню Effects — Amplitude and Compression — Normaliza (Process). Появится диалоговое окно, в котором выставите вот такие настройки, (обычно я выбираю 90%):
Трек будет выглядеть вот так:
3 шаг. Избавимся от шумов. Для этого, пользуясь указателем мыши, выделим на треке небольшой кусочек шума, как здесь:
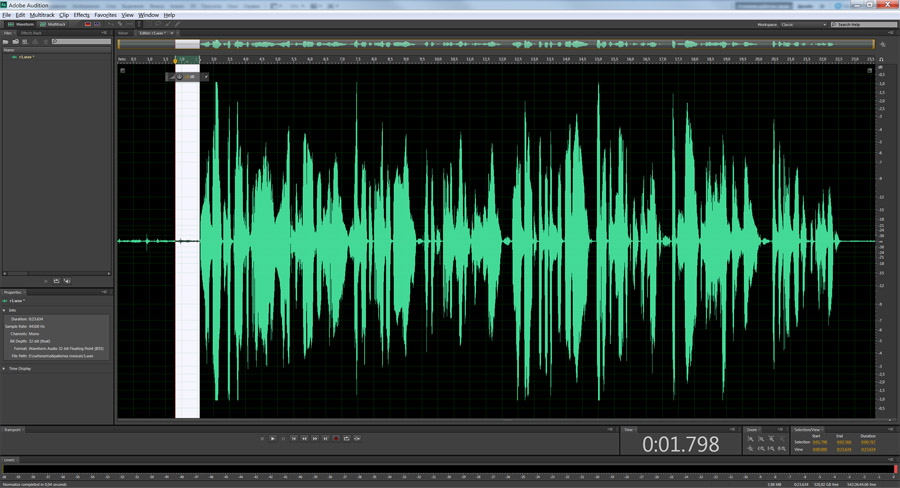
Вызовем пункт меню Effects — Noise Reduction / Restoration — Noise Reduction (process). Появится следующее диалоговое окно:
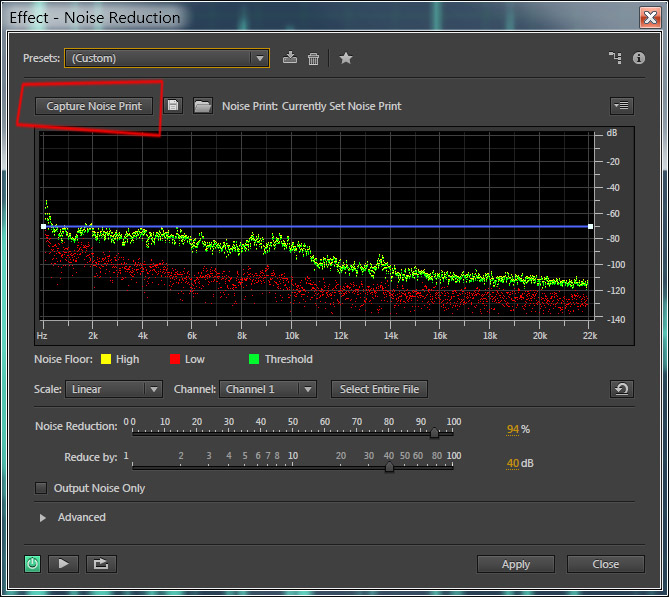
Здесь, нужно будет нажать на кнопку Capture Noise Print и в окне ниже появится график выделенного звукового сэмпла шума. Если данная кнопка не активна, то это означает, что вы выбрали слишком маленький кусочек шума, нужно закрыть диалоговое окно, выделить заново шум и вызвать эффект Noise Reduction. Смысл данного действия заключается в том, что программа запомнит частотную дорожку шума и попытается автоматически убрать все похожие частоты из трека. параметр Noise Reduction в 94% (можно и 100%, зависит от силы шума), остальное оставим по умолчанию и нажмем клавишу Applay.
Теперь обратите внимание, как будет выглядеть кусочек выделенного шума после применения эффекта. Звуковая волна стала практически прямой.
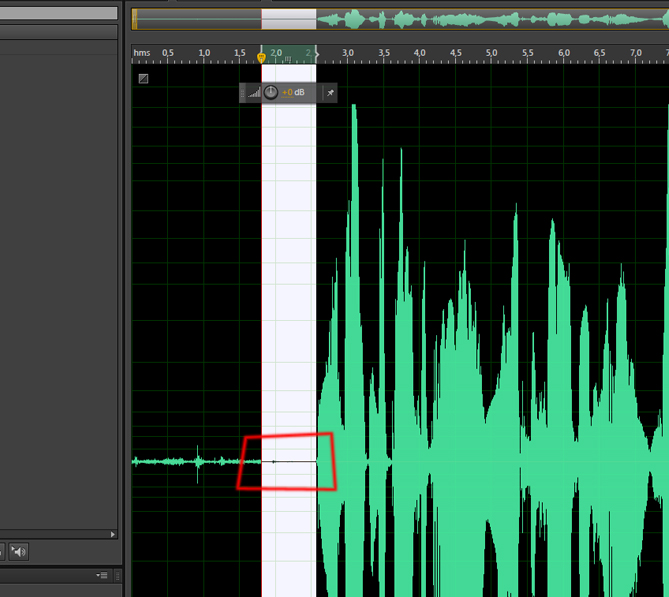
Теперь нужно избавиться от шумов во всем треке, для этого, выделим трек, нажав ctrl+A, вызовем тот же эффект и просто нажмем на кнопку Applay, образец шума будет использоваться старый, поэтому никаких настроек делать не надо. Трек будет выглядеть так:
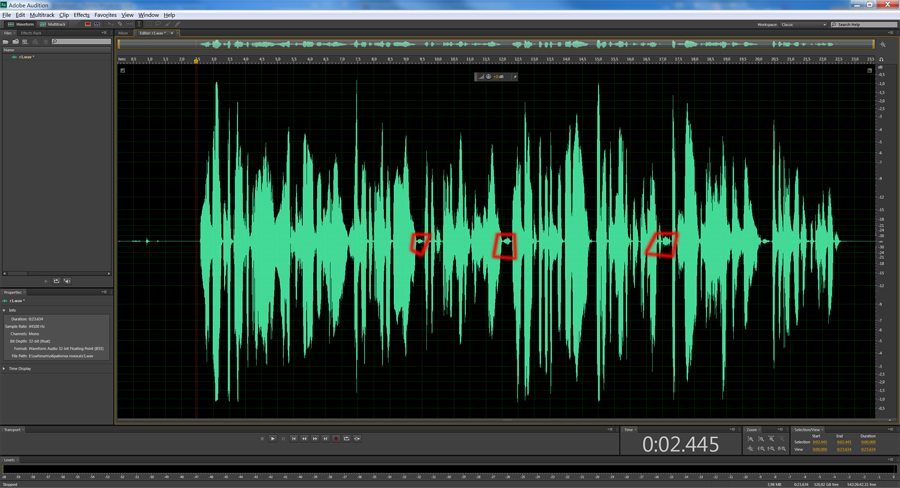
Обратите внимание, на выделенные красным цветом участки — это ненужные нам участки, на которые не подействовало шумоподавление, так как это запись дыхания. Избавимся от них вручную. Для этого выделим каждый из этих кусочков, щелкнем правой клавишей мыши и выберем пункт Silence.

4 шаг. Компрессия. Процесс изменения динамики звука, выравнивание его громкости, делающее громкий звук тише. По сути компрессор — это автоматический регулятор громкости. Компрессия — это один из важнейших этапов обработки звука, она позволяет «выделить», «уплотнить», «раскачать», «выровнять», акцентировать звук. Выберем пункт Effects — Amplitude and Compression — Dynamincs Processing. Появится диалоговое окно, в котором вы можете выбрать различные варианты настроек по умолчанию или задать свои настройки.
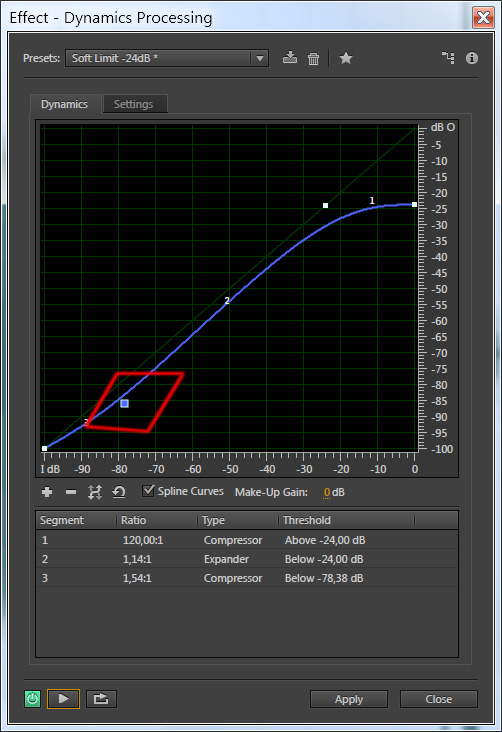
Я выбрала настройку Soft Limit -24dB и поэксперементировала с кривой — красным цветом выделена точка, которую я сдвинула. Вообще нужно всегда слушать к каким изменениям приводят ваши действия и выбирать то, что подходит по вашему слуху — универсальных настроек тут нет. А прослушать результат, вы всегда можете, не выходя из диалогового окна, нажав на клавишу Play в левом нижнем углу.
Если после компрессии наружу «вылезли» еще шумы, как показано ниже, то от них можно избавиться повторением алгоритма шумоподавления, по примеру шага 3.

5 шаг. Эквалайзер. Ну тут я бы не назвала его обязательным. Но все же. Попробуем поэксперементировать конкретными частотами. Выбираем Effects — Filter and EQ — Graphic Equalizer (30 Bands). Появится диалоговое окно, в котором вы можете настраивать конкретные частоты, пользуясь рекомендациями из прошлого урока «Качественная обработка голоса в Adobe Audition» или чисто интуитивно, каждый раз прослушивая результат изменений, как я и сделала:
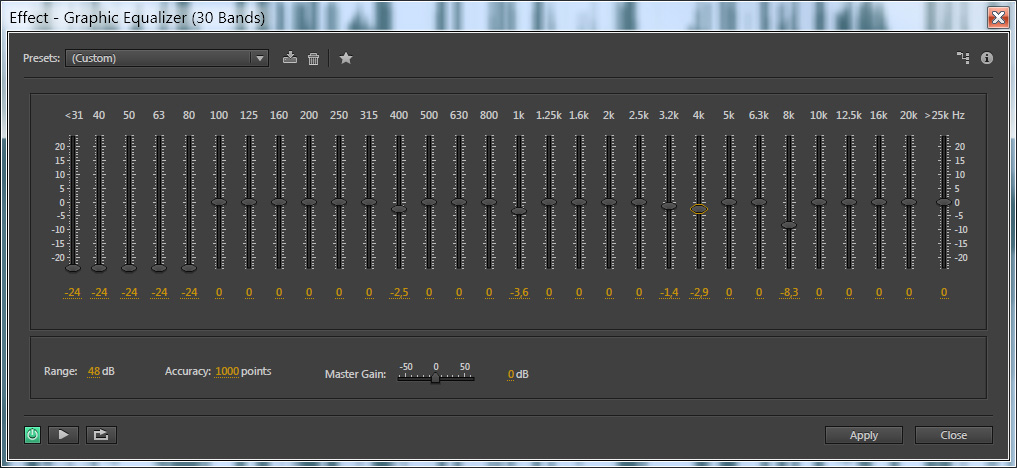
Голос после обработки
Теперь в принципе можно уже прослушать результат:
На этом я решила не останавливаться, поэтому:
6 шаг. Реверберация. Это эффект, который создаётся, когда какой либо звук звучит в замкнутом пространстве, в результате чего отражения от поверхностей стен вызывают большое количество эхо, затем звук медленно затухает по причине поглощения звуковых волн стенами и воздухом. Выберем пункт Effects — Reverb — Surround Reverd. Выставим значения так, чтобы было достигнуто желаемое звучание, не забываем прослушивать наши изменения. А у меня они такие:

В результате получилось следующее:
Надеюсь, моя статья оказалась для вас полезной. И не судите строго, так как все, что я сейчас показала я раскопала сама на просторах интернета без помощи профессионалов. Если вы считаете, что обладаете куда большими знаниями по качественной обработке голоса, то напишите о своем опыте в комментариях к данному посту. Будет очень интересно. Всего доброго!
Подписывайтесь на обновления блога «Дизайн в жизни»
по e-mail или социальных сетях
и мы обязательно опубликуем для вас еще больше полезной и интересной информации!
