
Описание
GIF

Этот инструмент будет искать упоминания городов в выбранном столбце и если встретит то запишет найденный город в первый свободный столбец
Поиск происходит по списку из ~2000 городов, поэтому время выполнения программы значительно увеличивается если вы анализируете большое количество строк
В списке содержатся города России, Украины и Белоруссии
Как установить?
Инструмент Города это часть SEO-Excel
6 комментариев к “Города”
-
Данная функция ищет на соответствие городам слова, которые идут или после спец.символов или после пробела. Но у меня задача найти на соответствие городу в списке хешТегов для инстаграмма, а там все слова написаны слитно, например: классноеКиноМосква, отличныйФильмСмоленск, заказатьБилетВКиноСочи и .т.д. и данный модуль на таких форматах не срабатывает, возможно это как-то подкрутить?))
-
Добавлено в версии 1.4.8

-
-
А можно добавить замену разных городов на один с учетом падежей? После сбора ключей получается винегрет из «купить в Москве, заказать в екб, прислать в Ростов, производитель в Самаре» и т.д. Пусть заменит на один нужный город, а потом удалим дубли и все варианты под регион готовы.
-
Хорошая идея, возьму на карандаш.
-
Спасибо. Очень буду ждать. Надоело вручную переименовывать города. Готов задонатить )
-
-
-
И добавьте плиз еще Казахстан, они бывает встречаются. Если списки замен в отдельном файле, то вообще круто, можно подправить или добавить, если что.

Комментирование закрыто, спасибо всем за помощь в разработке программы.
Вам нужно либо обучить распознаватель именных объектов (NER), либо вы можете создать свой собственный справочник.
Простой справочник, который я создал и использую для таких задач, как ваш:
# -*- coding: utf-8 -*-
import codecs
from lxml.html.builder import DT
import os
import re
from nltk.chunk.util import conlltags2tree
from nltk.chunk import ChunkParserI
from nltk.tag import pos_tag
from nltk.tokenize import wordpunct_tokenize
def sub_leaves(tree, node):
return [t.leaves() for t in tree.subtrees(lambda s: s.node == node)]
class Gazetteer(ChunkParserI):
"""
Find and annotate a list of words that matches patterns.
Patterns may be regular expressions in the form list of tuples.
Every tuple has the regular expression and the iob tag for this one.
Before applying gazetteer words a part of speech tagging should
be performed. So, you have to pass your tagger as a parameter.
Example:
>>> patterns = [(u"Αθήνα[ς]?", "LOC"), (u"Νομική[ς]? [Σσ]χολή[ς]?", "ORG")]
>>> gazetteer = Gazetteer(patterns, nltk.pos_tag, nltk.wordpunct_tokenize)
>>> text = u"Η Νομική σχολή της Αθήνας"
>>> t = gazetteer.parse(text)
>>> print(unicode(t))
... (S Η/DT (ORG Νομική/NN σχολή/NN) της/DT (LOC Αθήνας/NN))
"""
def __init__(self, patterns, pos_tagger, tokenizer):
"""
Initialize the class.
:param patterns:
The patterns to search in text is a list of tuples with regular
expression and the tag to apply
:param pos_tagger:
The tagger to use for applying part of speech to the text
:param tokenizer:
The tokenizer to use for tokenizing the text
"""
self.patterns = patterns
self.pos_tag = pos_tagger
self.tokenize = tokenizer
self.lookahead = 0 # how many words it is possible to be a gazetteer word
self.words = [] # Keep the words found by applying the regular expressions
self.iobtags = [] # For each set of words keep the coresponding tag
def iob_tags(self, tagged_sent):
"""
Search the tagged sentences for gazetteer words and apply their iob tags.
:param tagged_sent:
A tokenized text with part of speech tags
:type tagged_sent: list
:return:
yields the IOB tag of the word with it character, eg. B-LOCATION
:rtype:
"""
i = 0
l = len(tagged_sent)
inside = False # marks the I- tag
iobs = []
while i < l:
word, pos_tag = tagged_sent[i]
j = i + 1 # the next word
k = j + self.lookahead # how many words in a row we may search
nextwords, nexttags = [], [] # for now, just the ith word
add_tag = False # no tag, this is O
while j <= k:
words = ' '.join([word] + nextwords) # expand our word list
if words in self.words: # search for words
index = self.words.index(words) # keep index to use for iob tags
if inside:
iobs.append((word, pos_tag, 'I-' + self.iobtags[index])) # use the index tag
else:
iobs.append((word, pos_tag, 'B-' + self.iobtags[index]))
for nword, ntag in zip(nextwords, nexttags): # there was more than one word
iobs.append((nword, ntag, 'I-' + self.iobtags[index])) # apply I- tag to all of them
add_tag, inside = True, True
i = j # skip tagged words
break
if j < l: # we haven't reach the length of tagged sentences
nextword, nexttag = tagged_sent[j] # get next word and it tag
nextwords.append(nextword)
nexttags.append(nexttag)
j += 1
else:
break
if not add_tag: # unkown words
inside = False
i += 1
iobs.append((word, pos_tag, 'O')) # it an Outsider
return iobs
def parse(self, text, conlltags=True):
"""
Given a text, applies tokenization, part of speech tagging and the
gazetteer words with their tags. Returns an conll tree.
:param text: The text to parse
:type text: str
:param conlltags:
:type conlltags:
:return: An conll tree
:rtype:
"""
# apply the regular expressions and find all the
# gazetteer words in text
for pattern, tag in self.patterns:
words_found = set(re.findall(pattern, text)) # keep the unique words
if len(words_found) > 0:
for word in words_found: # words_found may be more than one
self.words.append(word) # keep the words
self.iobtags.append(tag) # and their tag
# find the pattern with the maximum words.
# this will be the look ahead variable
for word in self.words: # don't care about tags now
nwords = word.count(' ')
if nwords > self.lookahead:
self.lookahead = nwords
# tokenize and apply part of speech tagging
tagged_sent = self.pos_tag(self.tokenize(text))
# find the iob tags
iobs = self.iob_tags(tagged_sent)
if conlltags:
return conlltags2tree(iobs)
else:
return iobs
if __name__ == "__main__":
patterns = [(u"Αθήνα[ς]?", "LOC"), (u"Νομική[ς]? [Σσ]χολή[ς]?", "ORG")]
g = Gazetteer(patterns, pos_tag, wordpunct_tokenize)
text = u"Η Νομική σχολή της Αθήνας"
t = g.parse(text)
print(unicode(t))
dir_with_lists = "Lists"
patterns = []
tags = []
for root, dirs, files in os.walk(dir_with_lists):
for f in files:
lines = codecs.open(os.path.join(root, f), 'r', 'utf-8').readlines()
tag = os.path.splitext(f)[0]
for l in lines[1:]:
patterns.append((l.rstrip(), tag))
tags.append(tag)
text = codecs.open("sample.txt", 'r', "utf-8").read()
#g = Gazetteer(patterns)
t = g.parse(text.lower())
print unicode(t)
for tag in set(tags):
for gaz_word in sub_leaves(t, tag):
print gaz_word[0][0], tag
В if __name__ == "__main__": вы можете увидеть пример, где я делаю шаблоны в коде patterns = [(u"Αθήνα[ς]?", "LOC"), (u"Νομική[ς]? [Σσ]χολή[ς]?", "ORG")].
Позже в коде я прочитал файлы из каталога с именем Lists (поместите его в папку, где у вас есть код выше). Имя каждого файла становится тегом Gazetteer. Итак, создайте файлы типа LOC.txt с шаблонами для местоположений (LOC tag), PERSON.txt для лиц и т.д.
|
VistaSV30 496 / 276 / 72 Регистрация: 10.04.2012 Сообщений: 1,080 Записей в блоге: 2 |
||||
|
1 |
||||
Получить названия городов регулярным выражением02.12.2022, 00:34. Показов 496. Ответов 7 Метки python (Все метки)
Добрый день! Очень нерегулярно пользуюсь регулярными выражениями.
Спасибо!
0 |

|
iSmokeJC Am I evil? Yes, I am!
15975 / 8988 / 2601 Регистрация: 21.10.2017 Сообщений: 20,683 |
||||
|
02.12.2022, 09:31 |
2 |
|||
|
Решение
Очень нерегулярно пользуюсь регулярными выражениями.
идущих в списке после сл. Большекрипинская? Никак. Ты же по строкам циклом бегаешь. Ищи все города, потом из списка убирай ненужное. Или изначально список режь. ну или так
result Код ст. Усть-Бузулуцкая х.Большой Лычак р.п. Жирнов с. Средний Егорлык г. Белая Калитва, ул.Заводская, 14 п. М. Горького г. Ростов-на-Дону пгт. Сандата (субъект) пгт. Гвардейское пгт. Заозерное п. Цаган-Аман
1 |
 Сообщение было отмечено VistaSV30 как решение
Сообщение было отмечено VistaSV30 как решение


|
496 / 276 / 72 Регистрация: 10.04.2012 Сообщений: 1,080 Записей в блоге: 2 |
|
|
02.12.2022, 17:36 [ТС] |
3 |
|
?m для чего нужен этот шаблон? Не могу найти описание И еще. Астрахань ул. Волжская 11
0 |
|
iSmokeJC Am I evil? Yes, I am!
15975 / 8988 / 2601 Регистрация: 21.10.2017 Сообщений: 20,683 |
||||||||
|
02.12.2022, 17:50 |
4 |
|||||||
|
Решениеmultiline re.M Добавлено через 8 минут
выбрать названия городов из следующего списка? Оно?
Код Астрахань Большекрипинская Усть-Бузулуцкая Большой Лычак Средний Егорлык Белая Калитва Ростов-на-Дону Цаган-Аман Каштановский Добавлено через 3 минуты
1 |
|
496 / 276 / 72 Регистрация: 10.04.2012 Сообщений: 1,080 Записей в блоге: 2 |
|
|
02.12.2022, 17:50 [ТС] |
5 |
|
Еще “М. Горького” или его и подобные (Ст. Оскол, Б. Камень и т.п.) лучше отдельно выбирать?
0 |
|
Am I evil? Yes, I am!
15975 / 8988 / 2601 Регистрация: 21.10.2017 Сообщений: 20,683 |
|
|
02.12.2022, 17:54 |
6 |
|
Пофиксил. См. выше ))))
1 |
|
VistaSV30 |
|
03.12.2022, 10:00 [ТС] |
|
Не по теме: Получилось обработать почти все данные. Но, тем не менее, много приходится вручную доделывать. Просто невозможно предусмотреть все возможные варианты представления данных. Это, примерно, установленное количество вариантов, помноженное на количество возможных ошибок заполнения и помноженное на фантазию человека заполнявшего отчет.
0 |
|
Am I evil? Yes, I am!
15975 / 8988 / 2601 Регистрация: 21.10.2017 Сообщений: 20,683 |
|
|
03.12.2022, 10:40 |
8 |
|
VistaSV30, именно так. Если работать с регулярками, входной формат должен быть четко очерчен. А так, вариантов уронить регулярку, можно придумать множество.
0 |

Список городов по начальным буквам
После ввода первых 3х букв названия города скрипт осуществляет асинхронный поиск в базе данных и выдает список
населенных пунктов, начинающихся на введенные буквы. Список ограничен первыми найденными 10-ю городами(населенными пунктами).
Вы можете продолжить ввод, при этом список будет сокращаться, в нем будут оставаться только города(поселки, села, деревни),
которые начинаются на введенные буквы или выбрать с помощью мышки или клавиатуры город из списка.
В выпадающем списке выбрать город можно с помощью клавиши Enter или с помощью двойного клика мышкой.
При движении по списку с помощью стрелок вверх/вниз или одиночными нажатиями клавиши мыши на элементе списка,
в поле ввода подставляется выбранный город, при этом переход не осуществляется и список не обновляется.
В поле ввода input параметр AUTOCOMPLETE=”OFF” запрещает браузеру выводить свои подсказки с ранее выбранными городами.
Выпадающий список позиционируется относительно элемента ввода. При поиске не учитывается регистр вводимых букв.
Пример должен работать во всех браузерах.
Система использует общую базу с примером определения города по ip и выбора страна,
регион, город и с примером определения региона по номеру телефона.
Вы можете использовать API интерфейс и готовые бесплатные скрипты для интеграции себе на сайт такого выпадающего списка.
Ознакомьтесь с примером использования API выбора города.
Вы также можете приобрести скрипт и базу данных городов.
Подбор города для игры “в города”.
Поиск страны, области, района, города
Все гео-сервисы.
Содержание
- Комбинация клавиш для поиска в тексте и на странице
- Поиск по тексту в Ворде
- Поиск по словам и фразам через панель «Навигация»
- Расширенный поиск в Ворде
- Метод 1: Вкладка «Главная»
- Метод 2: Через окно «Навигация»
- Как найти слово в тексте Word
- Поиск слов в документе Word
- Замена слов по всему документу Word
- Поиск по тексту в Ворде
- Самый простой поиск в Word – кнопка «Найти»
- Расширенный поиск в Ворде
- Как в Word найти слово в тексте – Расширенный поиск
- Направление поиска
- Поиск с учетом регистра
- Поиск по целым словам
- Подстановочные знаки
- Поиск омофонов
- Поиск по тексту без учета знаков препинания
- Поиск слов без учета пробелов
- Поиск текста по формату
- Специальный поиск от Ворд
- Опции, которые не приносят пользы
- Как в Ворде в тексте быстро найти нужное слово
- Окно Навигация
- Расширенный поиск
Комбинация клавиш для поиска в тексте и на странице
Очень часто возникает необходимость найти какую-нибудь строчку, слово или абзац в длинном-длинном тексте на странице сайта, в текстовом документе, файле Word или таблице Excel. Можно, конечно, полазить по менюшкам и найти нужный пункт для вызова поискового диалогового окна. Но есть способ быстрее и удобнее — это специальная комбинация клавиш для поиска. В веб-браузерах, текстовых редакторах и офисных программах это — сочетание клавиш CTRL+F.

Нажав этим кнопки Вы вызовите стандартную для этого приложения форму поиска в тексте и на странице.
Причём комбинация клавиш поиска не зависит от версии программы или операционной системы — это общепринятый стандарт и от него практически никто не отходит!
Для того, чтобы найти что-то нужное через проводник Windows — необходимо воспользоваться несколько иной комбинацией клавиш для поиска — Win+F. Она относится к основным горячим клавишам Виндовс.
Для новичков поясню: кнопка Win — это специальная клавиша с логотипом Windows, расположенная в нижнем ряду кнопок клавиатуры компьютера. Она используется для вызова ряда функций Windows, в том числе и для поиска.
Источник
Поиск по тексту в Ворде
Бывают такие ситуации, когда в огромной статье нужно найти определённый символ или слово. Перечитывать весь текст – не вариант, необходимо воспользоваться быстрым способом – открыть поиск в Ворде. Существует несколько способов, с помощью которых можно легко совершать поиск по документу.
Поиск по словам и фразам через панель «Навигация»
Чтобы найти какую-либо фразу или слово в документе Ворд, надо открыть окно «Навигация». Найти данное окно можно с помощью шагов ниже:
Примечание. Поиск будет выдавать как точный вариант запроса фразы, так и производный. Наглядно можно увидеть на примере ниже.

Внимание. Если выделить определённое слово в тексте и нажать «Ctrl+F», то сработает поиск по данному слову. Причем в области поиска искомое слово уже будет написано.
Если случайно закрыли окно поиска, то нажмите сочетание клавиш «Ctrl+Alt+Y». Ворд повторно начнет искать последнюю искомую фразу.
Расширенный поиск в Ворде
Если понадобилось разыскать какой-то символ в определенном отрывке статьи, к примеру, знак неразрывного пробела или сноску, то в помощь расширенный поиск.
Метод 1: Вкладка «Главная»
Найти расширенный поиск можно нажав по стрелке на кнопке «Найти» во вкладке «Главная».

В новом окне в разделе «Найти» нужно кликнуть по кнопке «Больше». Тогда раскроется полный функционал данного поиска.

В поле «Найти» напишите искомую фразу или перейдите к кнопке «Специальный» и укажите нужный вариант для поиска.

Далее поставьте соответствующий вид документа, нажав по кнопке «Найти в», если нужно совершить поиск по всему документу то «Основной документ».

Когда надо совершить поиск по какому-то фрагменту в статье, изначально нужно его выделить и указать «Текущий фрагмент».

В окне «Найти и заменить» всплывет уведомление сколько элементов найдено Вордом.

Метод 2: Через окно «Навигация»
Открыть расширенный поиск можно через панель «Навигация».

Рядом со значком «Лупа» есть маленький треугольник, нужно нажать по нему и выбрать «Расширенный поиск».

Источник
Как найти слово в тексте Word
Word – одна из самых популярных программ для работы с текстом. Здесь пользователю доступны все возможные инструменты, которые только могут понадобиться при работе с текстовыми документами.
Одним из таких инструментов является поиск. В этой небольшой статье мы расскажем о том, как найти слово в тексте Word и при необходимости выполнить его замену по всему тексту. Статья будет актуальной для всех современных версий Word, включая Word 2007, 2010, 2013, 2016 и 2019.
Поиск слов в документе Word
Для того чтобы найти слово в тексте Word нужно перейти на вкладку « Главная » и нажать на кнопку « Найти » (в правом верхнем углу окна) или нажать комбинацию клавиш CTRL-F (F от английского Find).
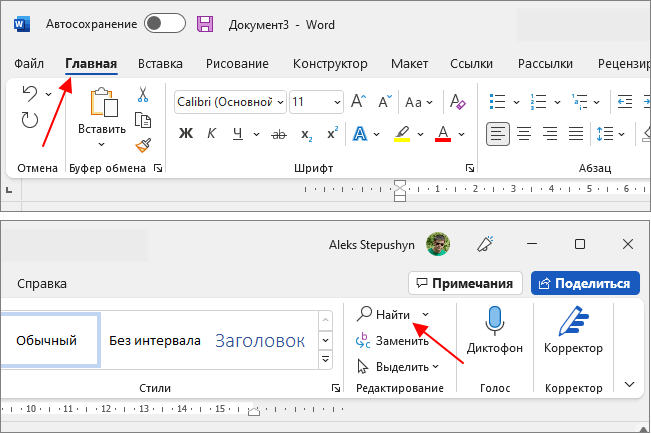
В результате откроется боковое меню « Навигация ». Здесь нужно ввести слово, которое вам нужно найти в тексте, и оно автоматически будет подсвечено в документе Word.
Также можно сначала выделить нужное слово в тексте и потом нажать на кнопку « Найти ». В этом случае выделенное слово сразу будет подставлено в поисковую строку.
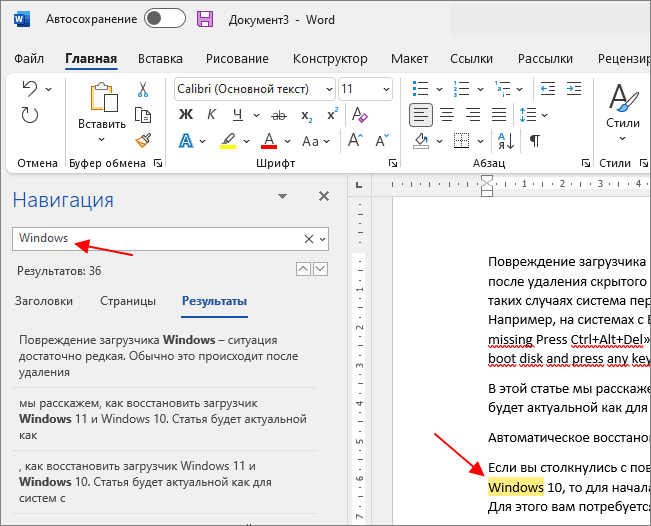
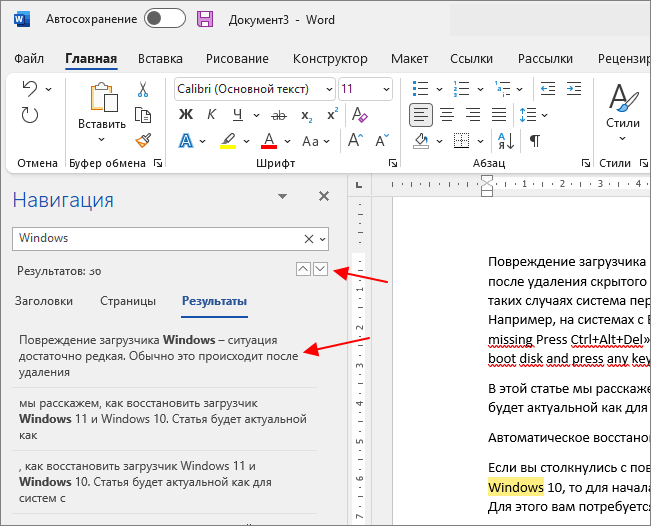
При этом в меню « Навигация » в блоке « Результаты » будет выведен список из отрывков текста, в которых было найдено введенное в поиск слово. Кликнув по найденному отрывку текста, вы сразу переместитесь к данному месту документа. Также для перемещения между найденными словами можно использовать небольшие стрелки под строкой поиска.
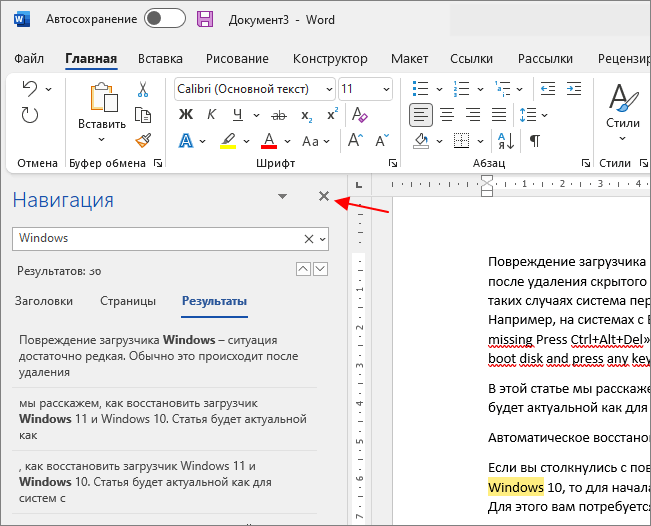
Для того чтобы закончить поиск достаточно просто закрыть меню « Навигация ».
В старых версиях программы Word при нажатии на кнопку « Найти » или использовании комбинации клавиш CTRL-F будет появляться всплывающее окно « Найти и заменить ».
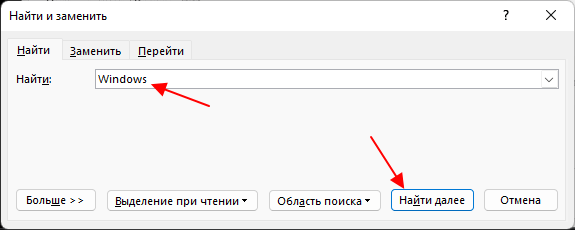
В этом случае нужно на вкладке « Найти » ввести искомое слово в поисковую строку и нажимать на кнопку « Найти далее » для того, чтобы перемещаться между найденными в документе словами.
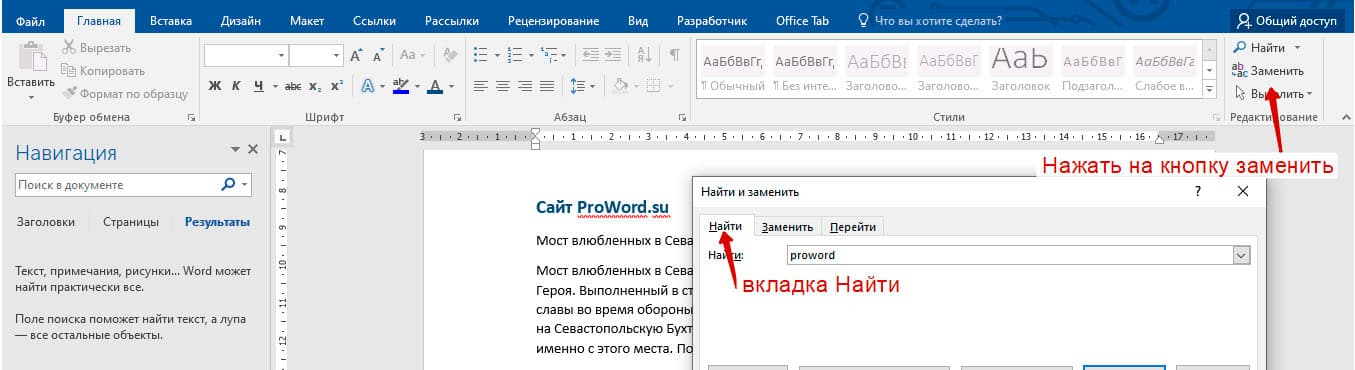
Замена слов по всему документу Word
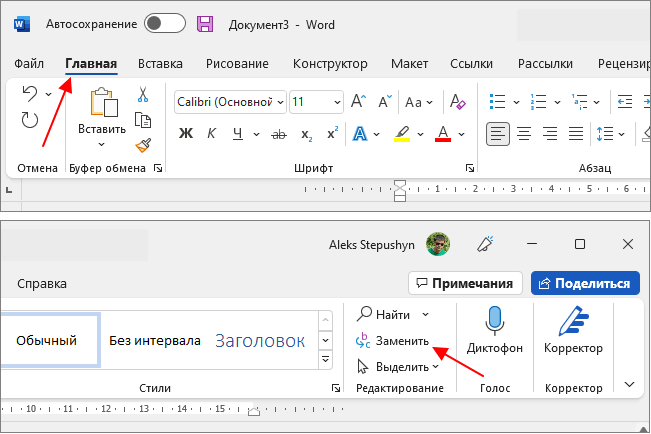
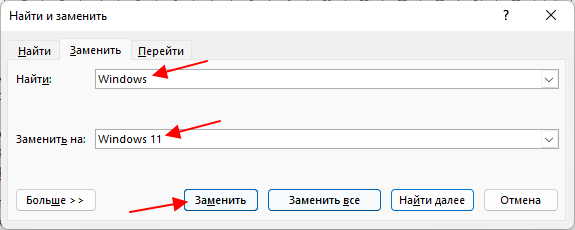
В результате откроется всплывающее окно « Найти и заменить ». Здесь на вкладке « Заменить » можно искать слова и автоматически заменять их на другие.
Для этого нужно ввести исходный текст в строку « Найти » и новый текст в строку « Заменить на ». После этого для замены нужно нажимать на кнопку « Заменить », если вы уверены и хотите заменить сразу все найденные отрывки текста, то можно нажать на кнопку « Заменить все ».
Если нажать на кнопку «Больше», то появятся дополнительные настройки замены текста.
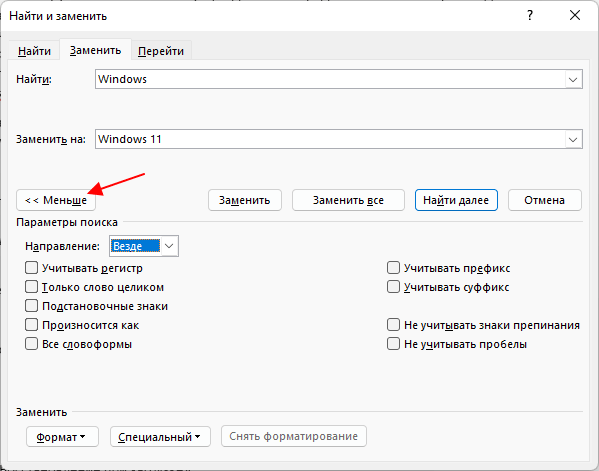
Здесь можно выбрать направление поиска, включить учет регистра (большие и маленькие буквы) и т. д.
Более подробно о поиске и замене в отдельной статье:
Источник
Поиск по тексту в Ворде
Работая с текстом, особенно с большими объемами, зачастую необходимо найти слово или кусок текста. Для этого можно воспользоваться поиском по тексту в Ворде. Существует несколько вариантов поиска в Word:
Самый простой поиск в Word – кнопка «Найти»
Самый простой поиск в ворде – это через кнопку «Найти». Эта кнопка расположена во вкладке «Главная» в самом правом углу.
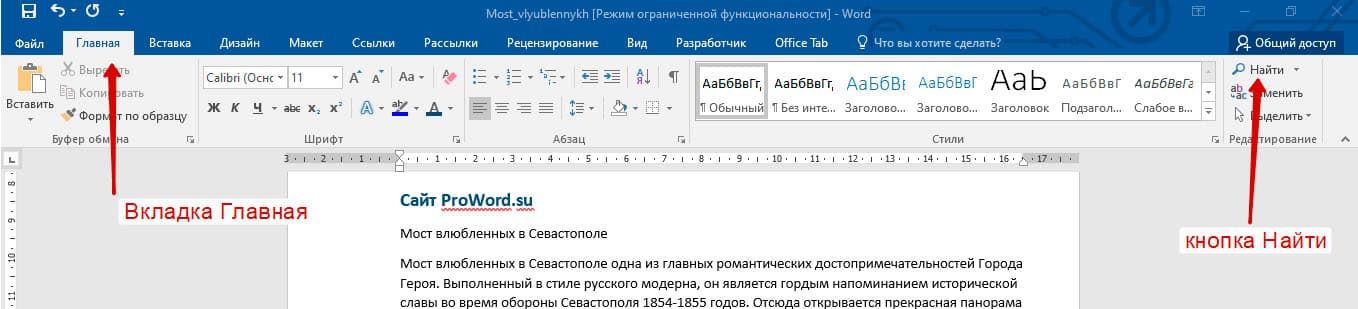
! Для ускорения работы, для поиска в Ворде воспользуйтесь комбинацией клавишей: CRL+F
После нажатия кнопки или сочетания клавишей откроется окно Навигации, где можно будет вводить слова для поиска.

! Это самый простой и быстрый способ поиска по документу Word.
Для обычного пользователя большего и не нужно. Но если ваша деятельность, вынуждает Вас искать более сложные фрагменты текста (например, нужно найти текст с синим цветом), то необходимо воспользоваться расширенной формой поиска.
Расширенный поиск в Ворде
Часто возникает необходимость поиска слов в Ворде, которое отличается по формату. Например, все слова, выделенные жирным. В этом как рас и поможет расширенный поиск.
Существует 3 варианта вызова расширенного поиска:
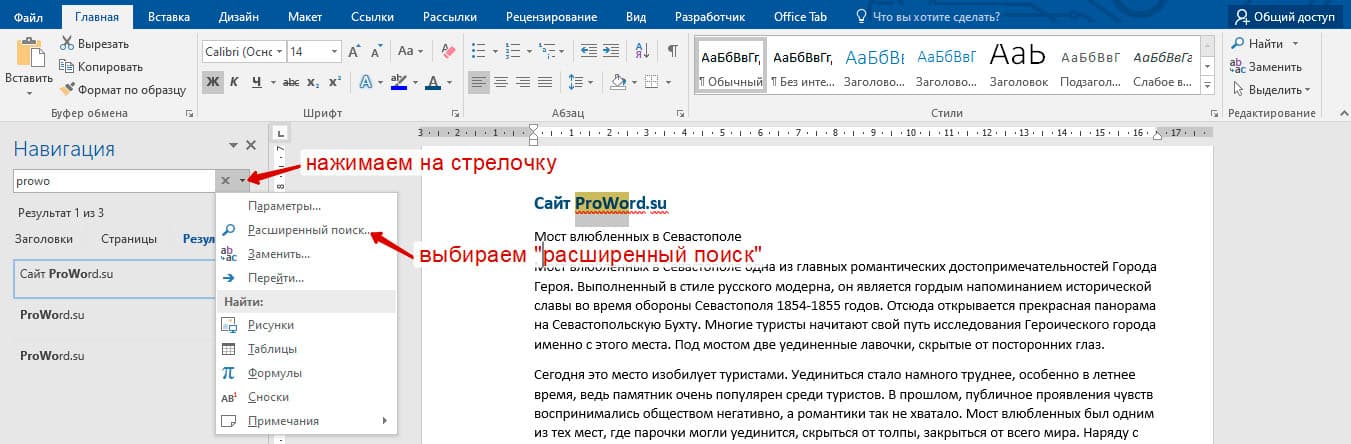
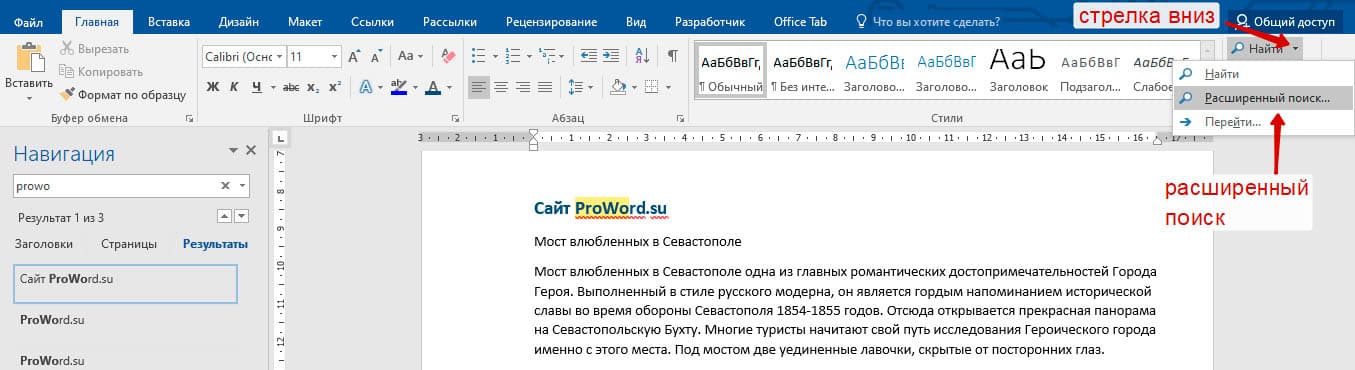
В любом случае все 3 варианта ведут к одной форме – «Расширенному поиску».
Как в Word найти слово в тексте – Расширенный поиск
После открытия отдельного диалогового окна, нужно нажать на кнопку «Больше»
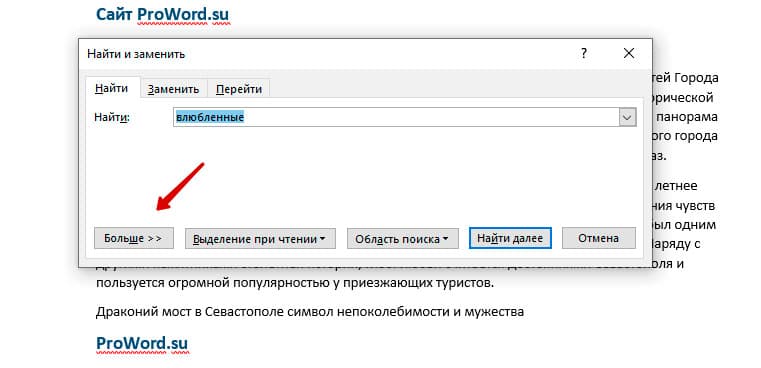
После нажатия кнопки диалоговое окно увеличится
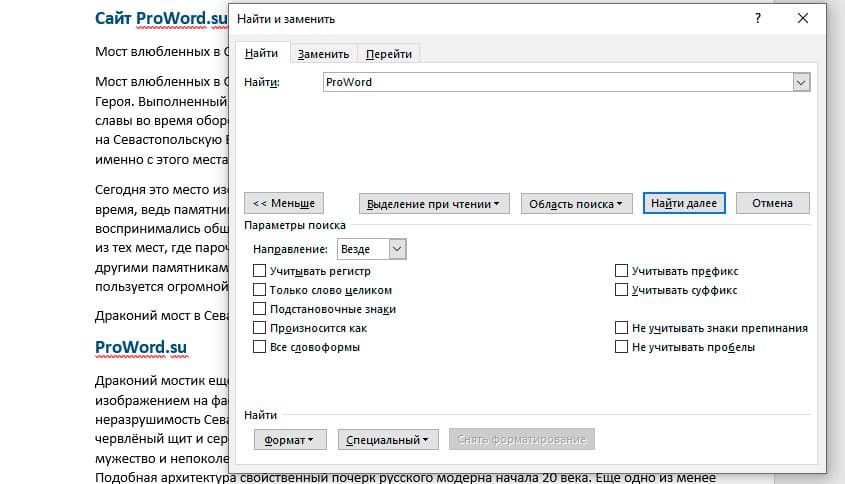
Перед нами высветилось большое количество настроек. Рассмотрим самые важные:
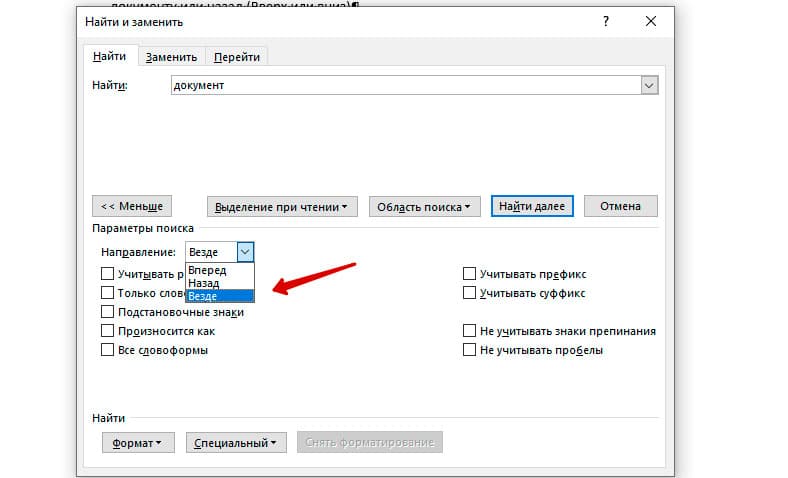
Направление поиска
В настройках можно задать Направление поиска. Рекомендовано оставлять пункт «Везде». Так найти слово в тексте будет более реально, потому что поиск пройдет по всему файлу. Еще существуют режимы «Назад» и «Вперед». В этом режиме поиск начинается от курсора и идет вперед по документу или назад (Вверх или вниз)
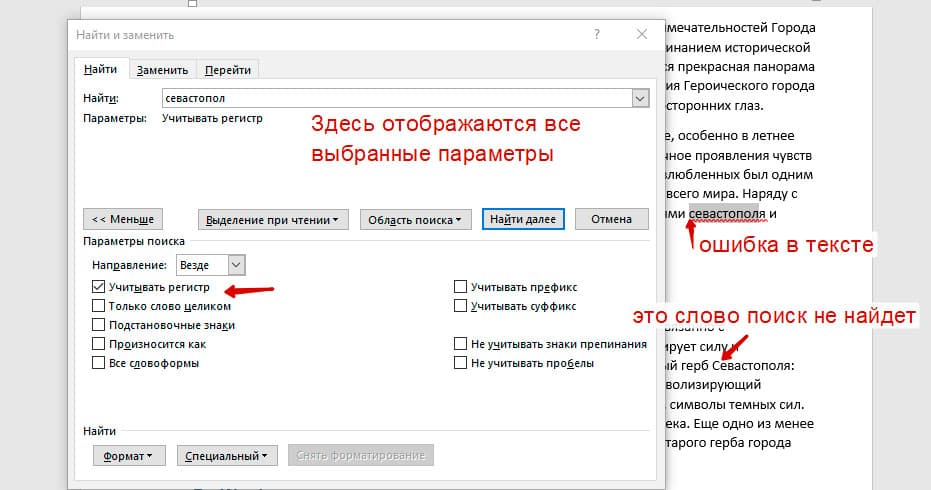
Поиск с учетом регистра
Поиск с учетом регистра позволяет искать слова с заданным регистром. Например, города пишутся с большой буквы, но журналист где-то мог неосознанно написать название города с маленькой буквы. Что бы облегчить поиск и проверку, необходимо воспользоваться этой конфигурацией:
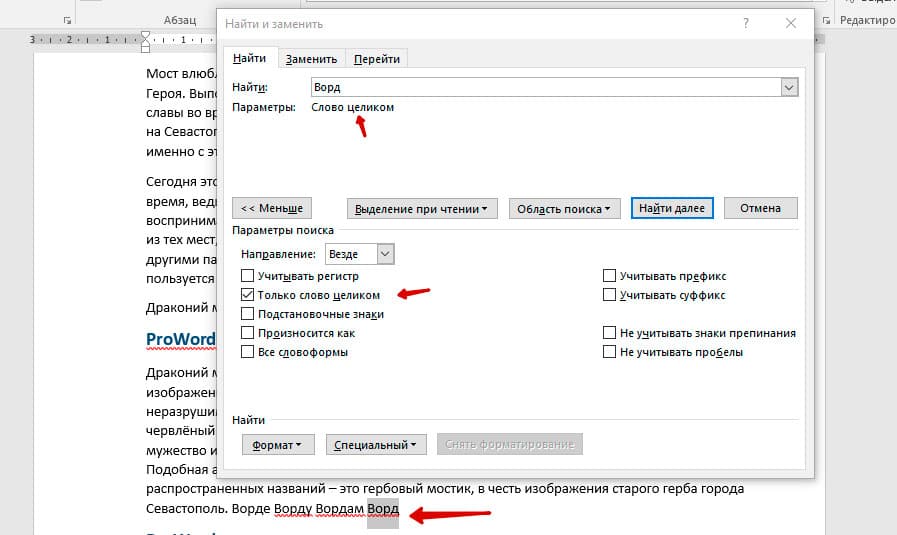
Поиск по целым словам
Если нажать на вторую галочку, «Только слово целиком», то поиск будет искать не по символам, а по целым словам. Т.е. если вбить в поиск только часть слова, то он его не найдет. Напимер, необходимо найти слово Ворд, при обычном поиске будут найдены все слова с разными окончаниями (Ворде, Ворду), но при нажатой галочке «Только слова целиком» этого не произойдет.
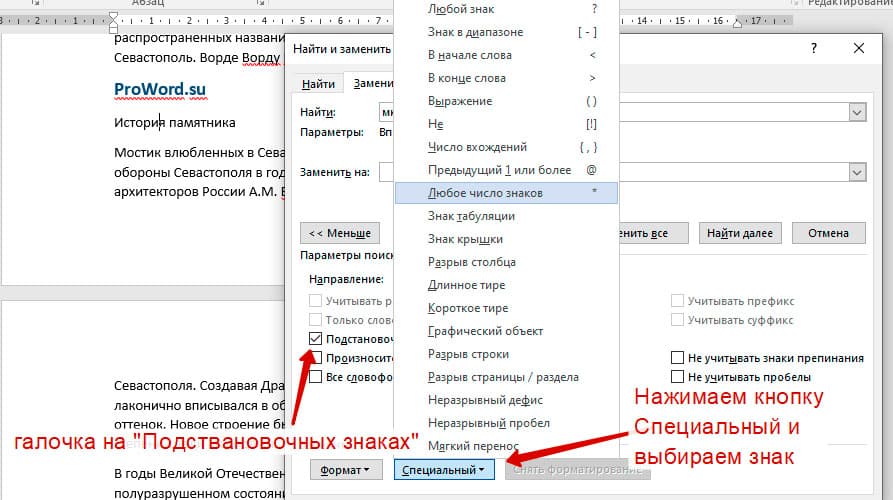
Подстановочные знаки
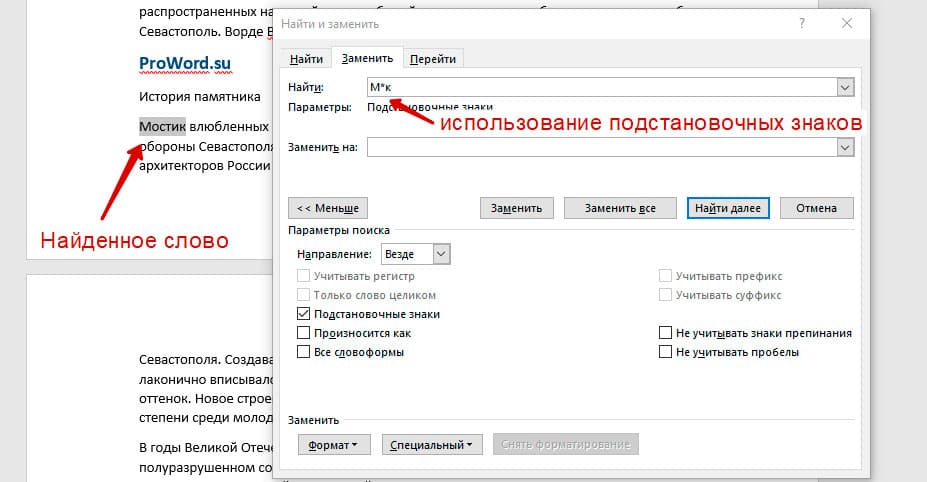
Более тяжелый элемент, это подстановочные знаки. Например, нам нужно найти все слова, которые начинаются с буквы м и заканчиваются буквой к. Для этого в диалоговом окне поиска нажимаем галочку «Подстановочные знаки», и нажимаем на кнопку «Специальный», в открывающемся списке выбираем нужный знак:
В результате Word найдет вот такое значение:
Поиск омофонов
Microsoft Word реализовал поиск омофонов, но только на английском языке, для этого необходимо выбрать пункт «Произносится как». Вообще, омофоны — это слова, которые произносятся одинаково, но пишутся и имеют значение разное. Для такого поиска необходимо нажать «Произносится как». Например, английское слово cell (клетка) произносится так же, как слово sell (продавать).
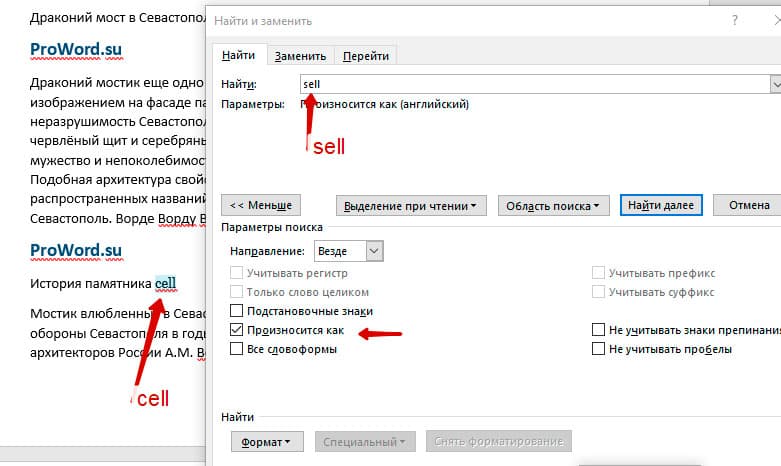
! из-за не поддержания русского языка, эффективность от данной опции на нуле
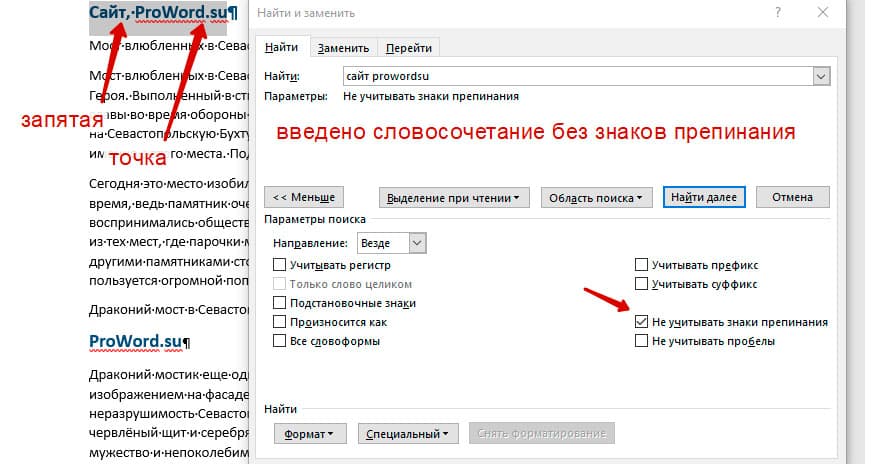
Поиск по тексту без учета знаков препинания
Очень полезная опция «Не учитывать знаки препинания». Она позволяет проводить поиск без учета знаков препинания, особенно хорошо, когда нужно найти словосочетание в тексте.
Поиск слов без учета пробелов
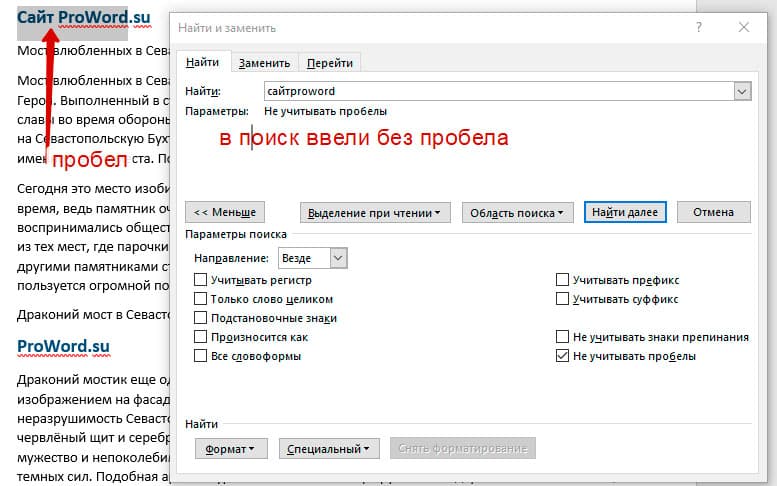
Включенная галочка «Не учитывать пробелы» позволяет находить словосочетания, в которых есть пробел, но алгоритм поиска Word как бы проглатывает его.
Поиск текста по формату
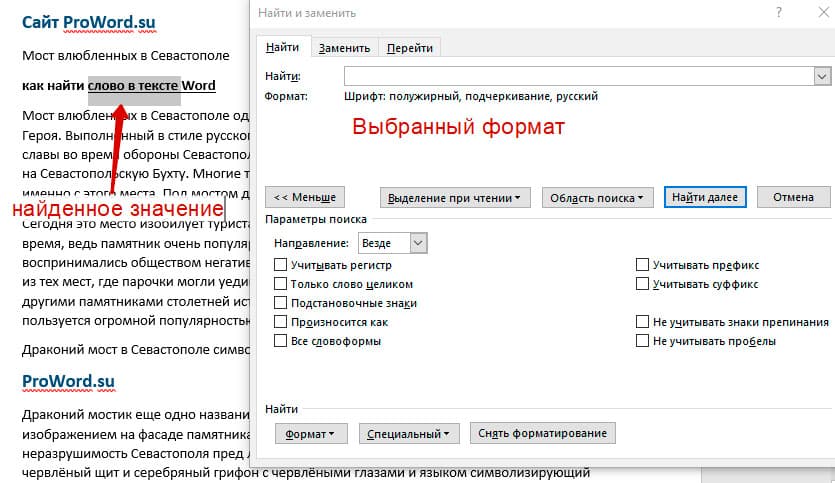
Очень удобный функционал, когда нужно найти текст с определенным форматированием. Для поиска необходимо нажать кнопку Формат, потом у Вас откроется большой выбор форматов:

Для примера в тексте я выделил Жирным текст «как найти слово в тексте Word». Весть текст выделен полужирным, а кусок текста «слово в тексте Word» сделал подчернутым.
В формате я выбрал полужирный, подчеркивание, и русский язык. В итоге Ворд наше только фрагмент «слово в тексте». Только он был и жирным и подчеркнутым и на русском языке.
После проделанных манипуляция не забудьте нажать кнопку «Снять форматирование». Кнопка находится правее от кнопки «Формат».
Специальный поиск от Ворд
Правее от кнопки формат есть кнопка «Специальный». Там существует огромное количество элементов для поиска
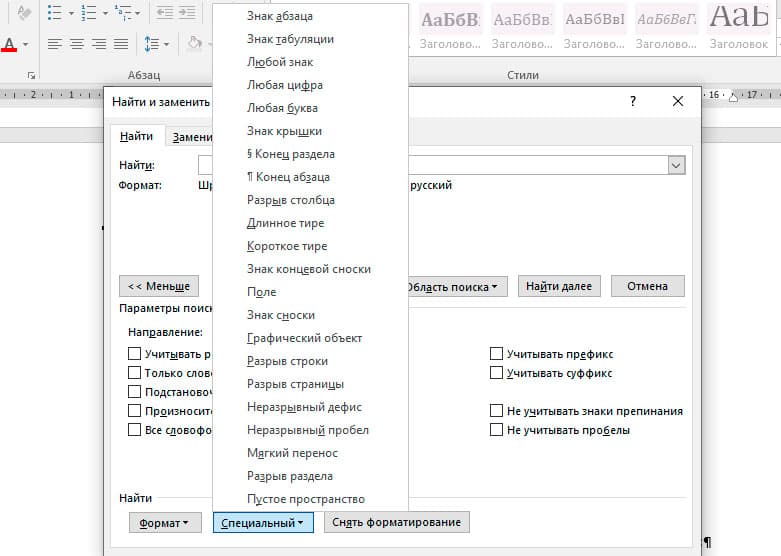
Через этот элемент можно искать:
Опции, которые не приносят пользы
!Это мое субъективное мнение, если у вас есть другие взгляды, то можете писать в комментариях.
Источник
Как в Ворде в тексте быстро найти нужное слово
После написания объемной статьи возникает необходимость найти неудачное слово или символ. Перечитывать весь документ достаточно трудоемкий процесс, который требует повышенного внимания и концентрации. Однако текстовый редактор Microsoft Office Word обладает функцией поиска. Данная статья о том, как в ворде найти слово в тексте.
Окно Навигация
Чтобы начать искать слова в тексте необходимо открыть панель навигации. Сделать это можно следующим образом:



В ворде запрограммированы горячие клавиши для быстрого вызова панели Навигация. Для этого необходимо одновременно нажать Ctrl+F.
Совет! Чтобы сразу найти повторяющиеся слова, выделяете одно и нажимаете сочетание кнопок Ctrl+F. Оно автоматически будет вписано в строку поиска.
Расширенный поиск
Расширенные поиск в ворде позволяет искать в тексте не только отрывки предложений, но и специальные знаки, а также скрытые символы форматирования.
Существует два способа вызова данной функции: через Найти во вкладке Главная или используя панель Навигация.
В первом случае необходимо выполнить следующие действия:



Во втором случае, в верхней строке нажимаете стрелку рядом со значком лупы и выбираете Расширенный поиск. Остальные действия аналогичны описанным в первом методе.

Совет! Для того, чтобы найти картинки, формулы или таблицы, рекомендуем использовать расширенный поиск из панели Навигации.
Дополнительно стоит отметить возможность в текстовом редакторе найти нужное слово и заменить его другим. Во вкладке Главная есть отдельная кнопка Заменить.

Меню выглядит следующим образом:

Заполняете нужные поля и нажимаете Заменить. Если предварительно хотите просмотреть искомые слова, то нажимаете на Найти далее и прорабатываете весь файл. Используя эту функцию можно за один раз поменять одинаковые слова на другие, что ускоряет процесс работы с документом.
Как видите, функция поиска слов и символов в ворд очень полезна и удобна. С ней легко справится даже новичок. Также этот инструмент позволяет искать ключевые слова в документе. А для более специфических условий рекомендуем использовать расширенный поиск, который позволяет искать специальные знаки, а также таблицы, рисунки и формулы.
Поделись с друзьями в соц.сети!
Источник
