Самый простой способ выполнить поиск на странице в браузере — комбинация клавиш, позволяющие быстро вызвать интересующий инструмент. С помощью такого метода можно в течение двух-трех секунд найти требуемый текст на странице или отыскать определенное слово. Это удобно, когда у пользователя перед глазами большой объем информации, а поиск необходимо осуществить в сжатые сроки.
Горячие клавиши для поиска на странице для браузеров
Лучший помощники в вопросе поиска в браузере — горячие клавиши. С их помощью можно быстро решить поставленную задачу, не прибегая к сбору требуемой информации через настройки или иными доступным способами. Рассмотрим решения для популярных веб-обозревателей.
Internet Explorer
Пользователи Internet Explorer могут выполнить поиск по тексту с помощью комбинации клавиш Ctrl+ F. В появившемся окне необходимо ввести интересующую фразу, букву или словосочетание.
Google Chrome
Зная комбинацию клавиш, можно осуществить быстрый поиск текста в браузере на странице. Это актуально для всех веб-проводников, в том числе Google Chrome. Чтобы найти какую-либо информацию на страничке, необходимо нажать комбинацию клавиш Ctrl+F.

Mozilla Firefox
Для поиска какой-либо информации на странице жмите комбинацию клавиш Ctrl+F. В нижней части веб-обозревателя появляется поисковая строка. В нее можно ввести фразу или предложение, которое будет подсвечено в тексте на странице. Если необходимо найти ссылку через панель быстрого поиска, нужно войти в упомянутую панель, прописать символ в виде одиночной кавычки и нажать комбинацию клавиш Ctrl+G.
Opera
Теперь рассмотрим особенности поиска на странице в браузере Опера (сочетание клавиш). Для нахождения нужной информации необходимо нажать на Ctrl+F. Чтобы найти следующее значение, используется комбинация клавиш Ctrl+G, а предыдущее — Ctrl+Shift+G.

Yandex
Для поиска какой-либо информации через браузер Яндекс, необходимо нажать комбинацию клавиш Ctrl+F. После этого появляется окно, с помощью которого осуществляется поиск слова или фразы. При вводе система находит все слова с одинаковым или похожим корнем. Чтобы увидеть точные совпадения по запросу, нужно поставить отметку в поле «Точное совпадение».
Safari
Теперь рассмотрим, как открыть в браузере Сафари поиск по словам на странице. Для решения задачи жмите на комбинацию клавиш Command+F. В этом случае появляется окно, в которое нужно ввести искомое слово или словосочетание. Для перехода к следующему вхождению жмите на кнопку Далее с левой стороны.

Промежуточный вывод
Как видно из рассмотренной выше информации, в большинстве веб-проводников комбинации клавиш для вызова поиска идентична. После появления поискового окна необходимо прописать слово или нужную фразу, а далее перемещаться между подсвеченными элементами. Принципы управления немного отличаются в зависимости от программы, но в целом ситуация похожа для всех программ.
Как найти слова или фразы через настройки в разных браузерах?
Если под рукой нет информации по комбинациям клавиш, нужно знать, как включить поиск в браузере по словам через меню. Здесь также имеются свои особенности для каждого из веб-проводников.
Google Chrome
Чтобы осуществить поиск какого-либо слова или фразы на странице, можно использовать комбинацию клавиш (об этом мы говорили выше) или воспользоваться функцией меню. Для поиска на странице сделайте такие шаги:
- откройте Гугл Хром;
- жмите значок Еще (три точки справа вверху);
- выберите раздел Найти;

- введите запрос и жмите на Ввод;
- совпадения отображаются желтой заливкой (в случае прокрутки страницы эта особенность сохраняется).

Если нужно в браузере открыть строку поиска, найти картинку или фразу, сделайте такие шаги:
- откройте веб-проводник;
- выделите фразу, слово или картинку;
- жмите на выделенную область правой кнопкой мышки;
- осуществите поиск по умолчанию (выберите Найти в Гугл или Найти это изображение).

Применение этих инструментов позволяет быстро отыскать требуемые сведения.
Обратите внимание, что искать можно таким образом и в обычной вкладе и перейдя в режим инкогнито в Хроме.
Mozilla Firefox
Чтобы в браузере найти слово или фразу, можно задействовать комбинацию клавиш (об этом упоминалось выше) или использовать функционал меню. Для поиска текста сделайте следующее:
- жмите на три горизонтальные полоски;
- кликните на ссылку Найти на этой странице;
- введите поисковую фразу в появившееся поле (система сразу подсвечивает искомые варианты);
- выберите одно из доступных действий — Х (Закрыть поисковую панель), Следующее или Предыдущее (стрелки), Подсветить все (указываются интересующие вхождения), С учетом регистра (поиск становится чувствительным к регистру) или Только слова целиком (указывается те варианты, которые полностью соответствуют заданным).
Если браузер не находит ни одного варианта, он выдает ответ Фраза не найдена.
Выше мы рассмотрели, как найти нужный текст на странице в браузере Mozilla Firefox. Но бывают ситуации, когда требуется отыскать только ссылку на странице. В таком случае сделайте следующее:
- наберите символ одиночной кавычки, которая открывает панель быстрого поиска ссылок;
- укажите нужную фразу в поле Быстрый поиск (выбирается первая ссылка, содержащая нужную фразу);
- жмите комбинацию клавиш Ctrl+G для подсветки очередной ссылки с поисковой фразы.
Чтобы закрыть указанную панель, выждите некоторое время, а после жмите на кнопку Esc на клавиатуре или жмите на любое место в браузере.
Возможности Firefox позволяют осуществлять поиск на странице в браузере по мере набора фразы. Здесь комбинация клавиш не предусмотрена, но можно использовать внутренние возможности веб-проводника. Для начала нужно включить эту функцию. Сделайте следующее:
- жмите на три горизонтальные полоски и выберите Настройки;
- войдите в панель Общие;
- перейдите к Просмотру сайтов;
- поставьте отметку в поле Искать текст на странице по мере набора;
- закройте страничку.
Теперь рассмотрим, как искать в браузере по словам в процессе ввода. Для этого:
- наберите поисковую фразу при просмотре сайта;
- обратите внимание, что первое совпадение выделится;
- жмите Ctrl+G для получения следующего совпадения.
Закрытие строки поиска происходит по рассмотренному выше принципу — путем нажатия F3 или комбинации клавиш Ctrl+G.
Opera
Если нужно что-то найти на странице, которая открыта в Опере, можно воспользоваться комбинацией клавиш или кликнуть на значок «О» слева вверху. Во втором случае появится список разделов, в котором необходимо выбрать Найти. Появится поле, куда нужно ввести слово или фразу для поиска. По мере ввода система сразу осуществляет поиск, показывает число совпадений и подсвечивает их. Для перемещения между выявленными словами необходимо нажимать стрелочки влево или вправо.
Yandex
Иногда бывают ситуации, когда нужен поиск по буквам, словам или фразам в браузере Yandex. В таком случае также можно воспользоваться комбинацией клавиш или встроенными возможностями. Сделайте такие шаги:
- жмите на три горизонтальные полоски;
- войдите в раздел Дополнительно;
- выберите Найти.

В появившемся поле введите информацию, которую нужно отыскать. Если не устанавливать дополнительные настройки, система находит грамматические формы искомого слова. Для получения точного совпадения нужно поставить отметку в соответствующем поле. Браузер Яндекс может переключать раскладку поискового запроса в автоматическом режиме. Если он не выполняет этих действий, сделайте следующее:
- жмите на три горизонтальные полоски;
- войдите в Настройки;

- перейдите в Инструменты;
- жмите на Поиск на странице;
- проверьте факт включения интересующей опции (поиск набранного запроса в другой раскладке, если поиск не дал результатов).

Safari
В этом браузере доступна опция умного поиска. Достаточно ввести одну или несколько букв в специальном поле, чтобы система отыскала нужные фрагменты.
Итоги
Владея рассмотренными знаниями, можно скачать любой браузер и выполнить поиск нужного слова на странице. Наиболее удобный путь — использование комбинации клавиш, но при желании всегда можно использовать внутренние возможности веб-проводника.
Отличного Вам дня!
Содержание
- Дополнительные возможности поиска
- Поисковые подсказки
- Поиск по странице
- Горячие клавиши для поиска по странице
- Дополнительные возможности поиска
- Поисковые подсказки
- Поиск по странице
- Как сделать поиск по странице в Яндекс Браузере
- На компьютере
- Через меню
- Горячие клавиши
- С телефона
- Android
- iPhone
- Поиск на странице в браузере: комбинация клавиш и не только
- Поиск на странице в браузере
- Мини-приложения для 11
- Как отключить мини-приложения в 11
- Как вернуть старое контекстное меню в 11
- Не запускается PC Health Check на 11
- Не могу обновиться до 11
- Горячие клавиши для поиска на странице для браузеров
- Internet Explorer
- Google Chrome
- Mozilla Firefox
- Opera
- Yandex
- Safari
- Промежуточный вывод
- Как найти слова или фразы через настройки в разных браузерах?
- Google Chrome
- Mozilla Firefox
- Opera
- Yandex
- Safari
- Итоги
- Возможности поиска
- Умная строка
- Поиск по странице сайта
- Поиск по тексту
- Поиск по картинкам
- Поиск без интернета
- Возможности поиска
- Умная строка
- Поиск по странице сайта
- Поиск по тексту
- Поиск по картинкам
- Поиск без интернета
- Дополнительные возможности поиска
- Поисковые подсказки
- Поиск по странице
- Горячие клавиши для поиска по странице
- Дополнительные возможности поиска
- Поисковые подсказки
- Поиск по странице
Дополнительные возможности поиска
Подсказки Яндекс.Браузера помогут сформулировать поисковый запрос. А если вы выделите на странице любого сайта слово или словосочетание, Браузер покажет для них справку (быстрый ответ) прямо в контекстном меню.
Поисковые подсказки
— это варианты наиболее популярных запросов, которые начинаются с тех же символов, что и ваш запрос.
Вы можете уточнить запрос, дополнив текст выбранной подсказки.
Если адрес сайта введен с опечаткой, Браузер может предлагать исправления. Для этого:
Если вы не хотите видеть подсказки в браузере, отключите их:
Поиск по странице
Чтобы начать поиск по странице, используйте один из способов:
Если вам нужны только конкретные грамматические формы слова, без учета родственных форм, включите в диалоге поиска опцию Точное совпадение.
Горячие клавиши для поиска по странице
Дополнительные возможности поиска
Подсказки Яндекс.Браузера помогут сформулировать поисковый запрос. А если вы выделите на странице любого сайта слово или словосочетание, Браузер покажет для них справку (быстрый ответ) прямо в контекстном меню.
Поисковые подсказки
— это варианты наиболее популярных запросов, которые начинаются с тех же символов, что и ваш запрос.
Вы можете уточнить запрос, дополнив текст выбранной подсказки.

Если адрес сайта введен с опечаткой, Браузер может предлагать исправления. Для этого:
Если вы не хотите видеть подсказки в браузере, отключите их:
Поиск по странице
Чтобы начать поиск по странице, используйте один из способов:

Если вам нужны только конкретные грамматические формы слова, без учета родственных форм, включите в диалоге поиска опцию Точное совпадение.
Источник
Как сделать поиск по странице в Яндекс Браузере
Каждому пользователю, который пользуется браузером на постоянной основе, было бы не плохо владеть некоторыми навыками для удобства. Например, в Яндекс браузере можно осуществлять поиск по странице. Это очень полезная функция, если нужно быстро найти слово в предложении или само предложение в тексте. Сегодня мы более подробно разберем эту тему в статье. А именно поговорим о том, каким способами осуществляется поиск по странице в Яндекс браузере.
На компьютере
Поиск по странице в Яндекс браузере на компьютере можно разделить на две стороны. Это поиск с помощью комбинации клавиш и поиск через выпадающее меню. Далее мы разберем с вами оба случая более подробно.
Через меню
Итак, чтобы воспользоваться поисковиком по странице в Яндекс браузере, воспользуемся следующей инструкцией:
После выполнения инструкции, поисковое слово автоматически будет отображено желтым цветом, если оно найдено на странице.
Горячие клавиши
Также существует и несколько комбинаций клавиш для удобного поиска по странице. Выглядят они вот так:
Два последних пункта предназначены для перемещения к предыдущему или следующему запросу. Например, если вы нашли 10 запросов, то с помощью пункта 2 вы будете перемещаться от 1 до 10, а с помощью 3-го поиск будет осуществляться в обратном порядке.
С телефона
Комбинаций клавиш на телефоне никаких нет, поэтому будем использовать обычный поиск через меню приложения.
Android
iPhone
Как видите, поиск по странице в Яндекс браузере выполняется очень просто, но продуктивно. Это может сильно скоротать время поиска нужной информации на объемной странице. Таким образом, теперь вы можете быстро найти любое предложение или слово из текста на веб-странице. Удачи в изучении!
Источник
Поиск на странице в браузере: комбинация клавиш и не только

Поиск на странице в браузере

Мини-приложения для 11

Как отключить мини-приложения в 11

Как вернуть старое контекстное меню в 11

Не запускается PC Health Check на 11

Не могу обновиться до 11
Самый простой способ выполнить поиск на странице в браузере — комбинация клавиш, позволяющие быстро вызвать интересующий инструмент. С помощью такого метода можно в течение двух-трех секунд найти требуемый текст на странице или отыскать определенное слово. Это удобно, когда у пользователя перед глазами большой объем информации, а поиск необходимо осуществить в сжатые сроки.
Горячие клавиши для поиска на странице для браузеров
Лучший помощники в вопросе поиска в браузере — горячие клавиши. С их помощью можно быстро решить поставленную задачу, не прибегая к сбору требуемой информации через настройки или иными доступным способами. Рассмотрим решения для популярных веб-обозревателей.
Internet Explorer
Пользователи Internet Explorer могут выполнить поиск по тексту с помощью комбинации клавиш Ctrl+ F. В появившемся окне необходимо ввести интересующую фразу, букву или словосочетание.
Google Chrome
Зная комбинацию клавиш, можно осуществить быстрый поиск текста в браузере на странице. Это актуально для всех веб-проводников, в том числе Google Chrome. Чтобы найти какую-либо информацию на страничке, необходимо нажать комбинацию клавиш Ctrl+F.
Mozilla Firefox
Для поиска какой-либо информации на странице жмите комбинацию клавиш Ctrl+F. В нижней части веб-обозревателя появляется поисковая строка. В нее можно ввести фразу или предложение, которое будет подсвечено в тексте на странице. Если необходимо найти ссылку через панель быстрого поиска, нужно войти в упомянутую панель, прописать символ в виде одиночной кавычки и нажать комбинацию клавиш Ctrl+G.
Opera
Теперь рассмотрим особенности поиска на странице в браузере Опера (сочетание клавиш). Для нахождения нужной информации необходимо нажать на Ctrl+F. Чтобы найти следующее значение, используется комбинация клавиш Ctrl+G, а предыдущее — Ctrl+Shift+G.
Yandex
Для поиска какой-либо информации через браузер Яндекс, необходимо нажать комбинацию клавиш Ctrl+F. После этого появляется окно, с помощью которого осуществляется поиск слова или фразы. При вводе система находит все слова с одинаковым или похожим корнем. Чтобы увидеть точные совпадения по запросу, нужно поставить отметку в поле «Точное совпадение».
Safari
Теперь рассмотрим, как открыть в браузере Сафари поиск по словам на странице. Для решения задачи жмите на комбинацию клавиш Command+F. В этом случае появляется окно, в которое нужно ввести искомое слово или словосочетание. Для перехода к следующему вхождению жмите на кнопку Далее с левой стороны.
Промежуточный вывод
Как видно из рассмотренной выше информации, в большинстве веб-проводников комбинации клавиш для вызова поиска идентична. После появления поискового окна необходимо прописать слово или нужную фразу, а далее перемещаться между подсвеченными элементами. Принципы управления немного отличаются в зависимости от программы, но в целом ситуация похожа для всех программ.
Как найти слова или фразы через настройки в разных браузерах?
Если под рукой нет информации по комбинациям клавиш, нужно знать, как включить поиск в браузере по словам через меню. Здесь также имеются свои особенности для каждого из веб-проводников.
Google Chrome
Чтобы осуществить поиск какого-либо слова или фразы на странице, можно использовать комбинацию клавиш (об этом мы говорили выше) или воспользоваться функцией меню. Для поиска на странице сделайте такие шаги:
Если нужно в браузере открыть строку поиска, найти картинку или фразу, сделайте такие шаги:
Применение этих инструментов позволяет быстро отыскать требуемые сведения.
Обратите внимание, что искать можно таким образом и в обычной вкладе и перейдя в режим инкогнито в Хроме.
Mozilla Firefox
Чтобы в браузере найти слово или фразу, можно задействовать комбинацию клавиш (об этом упоминалось выше) или использовать функционал меню. Для поиска текста сделайте следующее:
Если браузер не находит ни одного варианта, он выдает ответ Фраза не найдена.
Выше мы рассмотрели, как найти нужный текст на странице в браузере Mozilla Firefox. Но бывают ситуации, когда требуется отыскать только ссылку на странице. В таком случае сделайте следующее:
Чтобы закрыть указанную панель, выждите некоторое время, а после жмите на кнопку Esc на клавиатуре или жмите на любое место в браузере.
Возможности Firefox позволяют осуществлять поиск на странице в браузере по мере набора фразы. Здесь комбинация клавиш не предусмотрена, но можно использовать внутренние возможности веб-проводника. Для начала нужно включить эту функцию. Сделайте следующее:
Теперь рассмотрим, как искать в браузере по словам в процессе ввода. Для этого:
Закрытие строки поиска происходит по рассмотренному выше принципу — путем нажатия F3 или комбинации клавиш Ctrl+G.
Opera
Если нужно что-то найти на странице, которая открыта в Опере, можно воспользоваться комбинацией клавиш или кликнуть на значок «О» слева вверху. Во втором случае появится список разделов, в котором необходимо выбрать Найти. Появится поле, куда нужно ввести слово или фразу для поиска. По мере ввода система сразу осуществляет поиск, показывает число совпадений и подсвечивает их. Для перемещения между выявленными словами необходимо нажимать стрелочки влево или вправо.
Yandex
Иногда бывают ситуации, когда нужен поиск по буквам, словам или фразам в браузере Yandex. В таком случае также можно воспользоваться комбинацией клавиш или встроенными возможностями. Сделайте такие шаги:
В появившемся поле введите информацию, которую нужно отыскать. Если не устанавливать дополнительные настройки, система находит грамматические формы искомого слова. Для получения точного совпадения нужно поставить отметку в соответствующем поле. Браузер Яндекс может переключать раскладку поискового запроса в автоматическом режиме. Если он не выполняет этих действий, сделайте следующее:
Safari
В этом браузере доступна опция умного поиска. Достаточно ввести одну или несколько букв в специальном поле, чтобы система отыскала нужные фрагменты.
Итоги
Владея рассмотренными знаниями, можно скачать любой браузер и выполнить поиск нужного слова на странице. Наиболее удобный путь — использование комбинации клавиш, но при желании всегда можно использовать внутренние возможности веб-проводника.
Источник
Возможности поиска
Вы можете искать информацию в интернете с помощью Умной строки, контекстного меню или голосом. Мобильный Яндекс.Браузер может также искать информацию по картинкам.
Умная строка
— это главный элемент Яндекс.Браузера, предназначенный для ввода адреса сайта и поиска информации. Умная строка расположена в нижней части браузера.
Когда вы смотрите сайт, Умная строка может исчезнуть, чтобы не занимать место на экране. Если вы хотите ее вернуть, нажмите на нижнюю границу браузера.
Браузер сам определит, что вам нужно — сайт или страница поисковой выдачи, и покажет результат.
Поиск по странице сайта
Поиск по тексту
Чтобы найти дополнительную информацию по интересующему вас вопросу:
Результат откроется в поисковой выдаче Яндекса.
Поиск по картинкам
Вы можете искать в браузере картинки, похожие на ваши, или сфотографировать объект и спросить у Алисы, что это такое. Для поиска используются алгоритмы компьютерного зрения Яндекса. В результатах поиска появятся точные копии вашей картинки и изображения с небольшими отличиями. Например, фотографии котят одной породы.
Чтобы найти изображения, похожие на:
Результат поиска откроется в Яндекс.Картинках.
Алиса распознает результат и предложит похожие изображения.
Поиск без интернета
Вы можете использовать поиск офлайн, если интернета нет или включен авиарежим.
Введите запрос. Браузер подберет подходящие ответы в словаре самых популярных поисковых запросов. В их числе — номера экстренных служб и организаций, информация из карточек Объектного ответа и т. д. Словарь хранится на смартфоне, обновляется автоматически по Wi-Fi и занимает 50–60 МБ.
Результаты поиска в офлайн-режиме состоят из сниппетов, в которых часто уже содержится ответ. Если вам нужны подробности — подождите, когда появится интернет, и под Умной строкой нажмите ссылку на онлайн-результаты.
Чтобы отключить поиск офлайн:
После этого словарь поисковых запросов удалится со смартфона.
Если вы не нашли информацию в Справке или у вас возникает проблема в работе Яндекс.Браузера, опишите все свои действия по шагам. Если возможно, сделайте скриншот. Это поможет специалистам службы поддержки быстрее разобраться в ситуации.
Возможности поиска
Вы можете искать информацию в интернете с помощью Умной строки, контекстного меню или голосом. Мобильный Яндекс.Браузер может также искать информацию по картинкам.
Умная строка
— это главный элемент Яндекс.Браузера, предназначенный для ввода адреса сайта и поиска информации. Умная строка расположена в нижней части браузера.
Когда вы смотрите сайт, Умная строка может исчезнуть, чтобы не занимать место на экране. Если вы хотите ее вернуть, нажмите на нижнюю границу браузера.
Браузер сам определит, что вам нужно — сайт или страница поисковой выдачи, и покажет результат.
Поиск по странице сайта
Браузер покажет все нужные слова на странице. Для перехода между ними используйте значки  и
и  . Чтобы закрыть поиск, нажмите слева значок
. Чтобы закрыть поиск, нажмите слева значок  .
.
Поиск по тексту
Чтобы найти дополнительную информацию по интересующему вас вопросу:
Результат откроется в поисковой выдаче Яндекса.
Поиск по картинкам
Вы можете искать в браузере картинки, похожие на ваши, или сфотографировать объект и спросить у Алисы, что это такое. Для поиска используются алгоритмы компьютерного зрения Яндекса. В результатах поиска появятся точные копии вашей картинки и изображения с небольшими отличиями. Например, фотографии котят одной породы.
Чтобы найти изображения, похожие на:
Результат поиска откроется в Яндекс.Картинках.
Алиса распознает результат и предложит похожие изображения.
Поиск без интернета
Вы можете использовать поиск офлайн, если интернета нет или включен авиарежим.
Введите запрос. Браузер подберет подходящие ответы в словаре самых популярных поисковых запросов. В их числе — номера экстренных служб и организаций, информация из карточек Объектного ответа и т. д. Словарь хранится на смартфоне, обновляется автоматически по Wi-Fi и занимает 50–60 МБ.
Результаты поиска в офлайн-режиме состоят из сниппетов, в которых часто уже содержится ответ. Если вам нужны подробности — подождите, когда появится интернет, и под Умной строкой нажмите ссылку на онлайн-результаты.
Чтобы отключить поиск офлайн:
После этого словарь поисковых запросов удалится со смартфона.
Если вы не нашли информацию в Справке или у вас возникает проблема в работе Яндекс.Браузера, опишите все свои действия по шагам. Если возможно, сделайте скриншот. Это поможет специалистам службы поддержки быстрее разобраться в ситуации.
Источник
Дополнительные возможности поиска
Подсказки Яндекс.Браузера помогут сформулировать поисковый запрос. А если вы выделите на странице любого сайта слово или словосочетание, Браузер покажет для них справку (быстрый ответ) прямо в контекстном меню.
Поисковые подсказки
— это варианты наиболее популярных запросов, которые начинаются с тех же символов, что и ваш запрос.
Вы можете уточнить запрос, дополнив текст выбранной подсказки.
Если адрес сайта введен с опечаткой, Браузер может предлагать исправления. Для этого:
Если вы не хотите видеть подсказки в браузере, отключите их:
Поиск по странице
Чтобы начать поиск по странице, используйте один из способов:
Если вам нужны только конкретные грамматические формы слова, без учета родственных форм, включите в диалоге поиска опцию Точное совпадение.
Горячие клавиши для поиска по странице
Дополнительные возможности поиска
Подсказки Яндекс.Браузера помогут сформулировать поисковый запрос. А если вы выделите на странице любого сайта слово или словосочетание, Браузер покажет для них справку (быстрый ответ) прямо в контекстном меню.
Поисковые подсказки
— это варианты наиболее популярных запросов, которые начинаются с тех же символов, что и ваш запрос.
Вы можете уточнить запрос, дополнив текст выбранной подсказки.
Если адрес сайта введен с опечаткой, Браузер может предлагать исправления. Для этого:
Если вы не хотите видеть подсказки в браузере, отключите их:
Поиск по странице
Чтобы начать поиск по странице, используйте один из способов:
Если вам нужны только конкретные грамматические формы слова, без учета родственных форм, включите в диалоге поиска опцию Точное совпадение.
Источник
Материал рассчитан на подготовленного читателя, знающего, что такое стоп-слова и операнды, чем ‘~~’ отличается от ‘&&’ и зачем их использовать. То есть на очень небольшую аудиторию. Полагаю, до конца дочитают только редкие энтузиасты и не менее редкие разработчики Яндекса. 🙂
Документация ни в коем случае не заменяет имеющуюся, а призвана ее исправить и дополнить. В отличие от официальной, она включает также разбор глюков и особенностей поиска, что поможет вам наконец-то ответить на вопрос «Блин, ну почему он не находит?» и найти несмотря ни на что.
Наличие заданного слова в результатах
Если какие-то слова должны быть в результатах, поставьте перед ними ‘+’.
Зачем. 1. Помогает со стоп-словами. Сейчас Яндекс, кажется, учитывает стоп-слова только в запросе из трех и менее слов (даже не операндов!). ‘+не покупай (samsung|lg)’ позволит найти негативные отзывы о продукции этих фирм (сравните с простым ‘не покупай (samsung|lg)’).
2. Помогает в случае «нестрогих соответствий». Запрос
‘индустриализация кемпинг ацтеки психоаналитик афтар’
предлагает страницы, на которых отсутствуют некоторые (на усмотрение Яндекса) из заданных слов. Если вы хотите, чтобы слово «ацтеки» обязательно присутствовало на найденных страницах, то запрос должен быть
‘индустриализация кемпинг +ацтеки психоаналитик афтар’
.
Исключение слова
‘~’ и ‘~~’ перед словом. Первый оператор следит, чтобы слова не было в пределах предложения, второй — чтобы его не было во всем документе.
Примечание к документации. Яндекс предлагает использовать ‘-‘. На мой взгляд, предпочтительней использовать ‘~~’, поскольку он логичнее выглядит в паре с ‘~’ и исключает стоп-слова (сравните, например: ‘иду шагаю москве -по’ и ‘иду шагаю москве ~ +по’).
Исключая стоп-слова, не забудьте ставить перед ними ‘+’, иначе можете наткнуться на глюк.
Решение проблемы омонимии
Слово употребить в начальной форме и поставить перед ним ‘!!’. Например, ‘!!дело рыбака’.
Зачем. Яндекс сознательно «путает», например, существительные ‘дело’ и ‘день’ — из-за глагола ‘деть’, который может принимать обе эти формы (что сделать? — деть, что сделало? — дело, что сделай? — день). Теоретически, приоритет должен даваться точной словоформе, но это почему-то не всегда срабатывает. Поэтому на запрос ‘дело рыбака’ вы получите сплошной «день рыбака». А вот на ‘!!дело рыбака’ — все формы именно этих слов.
Особенности. 1. Хитрый механизм при исключении форм слова. Например, по запросу ‘лужков ~~ !!лужков’ Яндекс все-таки найдет слово «Лужков», но при этом обязательно на странице будет присутствовать и другая форма слова «лужок».
2. Если одна из форм нужного слова одновременно является формой другого, приходится действовать исключением. Например, поискав ‘женить’, вы найдете также множество «Женю», «Женя» и «Жени». Запрос ‘!!женить’, понятно, не поможет от них избавиться. Поэтому исключать Евгения придется буквально: все формы слова «женить», кроме всех форм слова «женя» — ‘женить ~~ !!женя’.
Глюки. Увы, небольшой беспорядок в словаре Яндекса. Например, слово «режим» Яндекс почему-то считает формой слова «резать»: ‘!!резать видео’. И если наличие «режим» еще как-то можно оправдать безграмотностью создателей страниц, которые иногда именно так и пишут, то наличие «режимы» как формы слова «резать» — целиком на совести Яндекса.
Примечание. Если слово употреблено не в начальной форме и тем более не образует производных, то ‘!!’ будет примерно равно ‘!’. Пример: ‘!!выдавала’ и ‘!выдавала’.
Большие и маленькие
(спасибо </a></b></a> mackseem)
mackseem)
Всегда пишите все слова в запросе с маленькой буквы — не ошибетесь.
И вот почему.
Особенности. Слово, написанное большими буквами («НОУТБУК»), трактуется, как написанное маленькими, — как в запросе, так и на проиндексированных страницах. Т.е. для Яндекса «НОУТБУК» — это «ноутбук», а не «Ноутбук». Как следствие, запросом «купить Ноутбук» вы страницу с НОУТБУК’ом не найдете. Сравните, например, ‘Олег Слепынин’ и ‘олег слепынин’.
Печальная новость для товарных знаков: запрос ‘Артлебедев’ не найдет ‘АртЛебедев’-а (в слове присутствуют другие заглавные буквы). Сравните ‘система Adriver’ и ‘система adriver’ (попутно обратите внимание, как на сайте обычно пишут название системы).
Глюки. Яндекс дополнительно выдает документы, найденные по ссылке, при этом регистр букв игнорирует (пример).
Поиск слов в одном предложении
‘&’ между словами. Пример: ‘фотография & андерсон & джоли’.
Ошибки в документации. Яндекс уверяет, что «несколько набранных в запросе слов, разделенных пробелами, означают, что все они должны входить в одно предложение». Однако это уже давно не так: «Пробел между словами запроса означает, что слова должны находиться „не очень далеко“ друг от друга. Яндекс пытается определить, насколько тесно слова запроса связаны между собой. Сильно связанные слова ищутся в пределах одного предложения, менее тесно связанные слова — на расстоянии в несколько предложений и, наконец, несвязанным словам достаточно встретиться на одной странице, чтобы она была сочтена соответствующей запросу». К сожалению, и этот принцип соблюдается не всегда (см. ниже).
Поиск слов на одной странице
‘&&’ между словами. Применяется весьма часто.
Зачем.
1. Максимальное количество результатов. Пример: ‘фотография && андерсон && джоли’.
2. «Уточнение» запроса. Пример: ‘ремонт мобильный телефон && samsung && руб’.
3. Избавление от глюка, когда при использовании языка запросов Яндекс начинает искать слова в одном предложении (см. ниже). Пример: ‘(atmark|colorshift) && удобная’.
Любое из слов
Скобки и ‘|’ между словами: ‘(фото|фотография|фотоснимок|снимок) андерсон’.
Глюки. Если в запросе есть «ИЛИ», Яндекс начинает считать, что пробел — это поиск слов в одном предложении. Например, запросы ‘(atmark|colorshift) удобная’ и ‘(atmark|colorshift) & удобная’ эквивалентны, оба приводят к одинаковым результатам — нестрогим соответствиям. Сравните с ‘atmark удобная’ и ‘colorshift удобная’.
Наличие заданного слова в сниппетах
‘слово_в_сниппетах << (остальная_часть_запроса)’. Например, ‘сайт << лебедев’ — в сниппетах обязательно будет присутствовать слово «сайт».
Пример посложнее. Скажем, нужно найти резюме жителей Москвы со знанием французского языка, имеющих опыт работы с Windows, Linux и ЛВС. При этом уровень знания французского языка имеет первостепенное значение.
Строим исходный запрос — ‘$title(резюме) && +(москва | !095) && +французский && +лвс && +linux && +windows’. Яндекс выбирает слова для сниппетов как скрипт на душу положит, и слово «французский» попадает в них редко — придется открывать все страницы.
А можно и не открывать, а воспользоваться оператором ‘<<‘. ‘+французский << ($title(резюме) && +(москва | !095) && +лвс && +linux && +windows)’
Примечания. Спасибо Яндекс.Блогам, в которых впервые упоминается оператор ‘<<‘, хоть и совершенно в другом контексте. Ранее приходилось использовать оригинальный метод </a></b></a>sadovsky: ‘слово_в_сниппетах ~~ (слово_в_сниппетах ~~ (остальная_часть_запроса))’ (здесь обязательно сделайте паузу и оцените красоту решения). Например, сайт ~~ (сайт ~~ лебедев)’.
На самом деле, оператор работает несколько по-другому, однако побочный эффект — наличие слова в сниппетах — куда важнее его истинного предназначения.
Расстояние между словами
Почему-то
многие, даже продвинутые пользователи, недооценивают эту возможность. А зря.
В общем виде — оператор вида ‘/(n m)’ (n — минимальное, m — максимальное расстояние между словами). На практике в общем виде почти не используется. Вместо него используются запросы вида ‘поставщики /2 кофе’ (= слова либо идут подряд, либо через одно, неважно в каком порядке) — находит «поставщиков кофе», «поставщики пьют кофе», «кофе для поставщиков» и т. п.
Кроме того, весьма распространены запросы с жестко заданным расстоянием. Область их применения разнообразна:
- Самый полный словарь синонимов. Запросы вида ‘!надеемся +на /+2 !сотрудничество’ (= «надеемся на какое-то_слово сотрудничество»). Этому вопросу я посвятил отдельную страницу.
- Отчество. ‘памела /+2 андерсон’ — релевантность зашкаливает. Сравните с, хехе, ‘памела андерсон отчество’.
- Дата рождения. Как там обычно пишут? Гоголь Николай Андреич родился 15 ноября 1941 года. Считаем слова между «родился» и «года», получаем схему: ‘!платон родился /+4 !года’.
- И т.п.
Как ни странно, применение есть даже у /+0 (буквально — то же самое слово). С его помощью можно проверять работу морфологического модуля Яндекса. Например, ‘бруля /+0 брули’ — ага, Яндекс знает, что это формы одного слова. Убеждаемся, что форма !бруля есть в Сети, ставим в начальную форму, проверяем: !!бруль /+0 !бруля — действительно, «бруля» — это, с точки зрения Яндекса, форма слова «бруль». Аналогично, «тест» — форма слова «тесто», но никак не наоборот.
Глюки. ‘владимир /+0 путин’ и иже с ним.
Устойчивые словосочетания
Словосочетание в кавычках. Пример: ‘”красная шапочка”‘.
Особенности. Какой порядок слов в кавычках — в таком и будет искать Яндекс. Если в запросе, кроме словосочетания в кавычках, ничего нет — будет искать и в той же словоформе. Сравните “красными шапочками” и “красными шапочками” ~~ зелеными
Глюки. Как и в случае с «ИЛИ», Яндекс в запросе с кавычками начинает считать, что пробел — это поиск слов в одном предложении. Сравните “старик хоттабыч” терминатор и старик /+1 хоттабыч терминатор.
Устойчивые словосочетания с разными словоформами
‘/+1’ между словами (это частный случай использования оператора расстояния между словами).
Так,
‘”умная хорошая мальчики”‘
— 0 результатов, а
‘умная /+1 хорошая /+1 мальчики’
ищет все формы этих слов и находит множество страниц со словосочетанием «умный хороший мальчик».
Числа
К «словоформам» добавились «числоформы»: запрос ’03’ найдет «3», «03», «003» и т. д. Оператор ‘!’, как и полагается, позволяет искать точную «числоформу».
’17 01 2003′ (ищет также “17-01-2003”, “17/01/2003”) и ‘17.01.2003’ — разные запросы.
Глюки. Совпадение «числоформы» в запросе и в тексте, увы, не влияет на ранжирование. Запросы ‘107 0000’ (скорее, всего, ищется телефон) ‘107 000’ (очевидно, количество), 107 00 (часто цена), 107,0 (похоже на частоту радиостанции) для Яндекса эквивалентны.
Нафиг не надо
Лично мне лет за 6 не пригодились ни разу:
- Общий случай оператора расстояния между словами: ‘/(n m)’.
- Исключение порядка слов: ‘вакансии ~ /+1 студентов’.
Заявлено, но не работает
Операторы веса и уточнения запроса: ‘поисковые механизмы:5’, ‘компьютер <- телефон’.
Звучит заманчиво, но первое не работает, а принцип действия второго непонятен. Поэтому не использую.
Поиск спецсимволов
Нет, ‘C#’ и ‘C++’ Яндекс не ищет и искать в ближайшее время не собирается. Google is your friend.
Символ ‘№’ Яндекс то игнорирует, то автоматически переводит в ‘N’. Поэтому лучше ‘№’ вообще не использовать.
Поиск по маске
Яндекс не ищет слова с пропущенными буквами, как-то ‘Ян?екс’ или ‘Янде*’. Единственное исключение — поиск адреса (только для неизвестного окончания) и его вариации.
1. Поиск доменов — domain=”ya*”
2. Поиск авторов в Яндекс.Блогах — author=”kub*”
3. Поиск ссылок — link=”www.livejournal.com/community/kubok/458*”
4. И т.п.
Транслитерация
(спасибо </a></b></a>maksa)
Какая разница между словами «хоровод» и «xopoвog»? Она почти не видна, но первое слово написано по-русски, а во втором только одна русская буква — ‘в’, остальные же написаны латинским шрифтом. Яндекс учитывает «взаимозаменяемость» некоторых английских и русских букв, поэтому:
1. Оба запроса дадут почти на 100% одинаковые результаты: ‘хоровод’ и ‘xopoвog’
2. Оба запроса найдут страницы как с русским «хороводом», так и составленным частично из английских букв (отсюда вывод: иногда Яндекс может найти слово на странице, а Ctrl-F — нет, в Кубке был такой случай). По ссылке «Найденные слова» транслитерованные слова не подсвечиваются.
Следующие буквы взаимозаменяемы (полужирным выделены английские): e – е – ё, a – а, В – В (только прописные), c – с, e – е, g – д (только строчные), k – к, n – п (только строчные), o – о, p – р, u – и (только строчные), x – х, y – у.
Яндекс «транслитерует» слова, в которых есть хотя бы одна русская буква (noдapok)
Яндекс НЕ транслитерует слова: 1) в которых все буквы английские: ‘nogapok‘ (включая и слова, состоящие из одной буквы: ‘мне хорошо c тобой’); 2) в которых есть хотя бы одна цифра: ‘подарок1’ и ‘nодарок1′.
Если вам не нужна транслитерация, используйте ‘!’: ‘!поgарок’.
Особенности. 1. Не взаимозаменяемы: «0» (цифра) и «О» (буква). Украинская «і» (радіємо) и английская «i» (радiємо).
2. Яндекс транслитерует только в русскую сторону. Поэтому ‘samsunд’ ничего не найдет.
3. В запросе из одного слова приоритет отдается точной форме (т.е. если в запросе латиница, то и первые результаты будут с ней); результаты запросов из двух и более слов идентичны, вне зависимости от написания.
Поиск в элементах
Читайте оригинальную документацию. К ней есть только несколько замечаний.
Поиск на заданном сайте
Есть три основных способа поиска на сайте:
- оператор ‘#url=”адрес*”‘ в строке поиска (или аналогичный #host=”адрес*”);
- страница расширенного поиска (или аналогичный по действию параметр ‘surl=адрес’ в адресной строке);
- параметр ‘serverurl=адрес’ в адресной строке (или через форму «Проверить сайт»).
Как ни смешно, все три приводят к разным результатам. Главное отличие — это отношение каждого способа к поддоменам, «зеркалам» и адресу сайта с / без ‘www’. Где будет искать Яндекс, если указать ‘www.artlebedev.ru’? А если ‘artlebedev.ru’? а если ‘design.ru’? А если vilka.ru?
Иллюстрирующая табличка.
| www.artlebedev.ru | artlebedev.ru | design.ru | vilka.ru | |
| Оператор #url | есть, нужен еще один клик | нет | Находит сайты вида design.rusmedserv.com | нет |
| Страница расширенного поиска | есть | есть, также находит поддомены artlebedev.ru | Находит поддомены сайта design.ru | нет |
| Параметр serverurl | есть | есть | Находит результаты с сайта artlebedev.ru | Находит результаты с сайта artlebedev.ru |
Вдобавок, для другого сайта плюсы и минусы могут стоять совершенно в других местах. Поэтому часто приходится перебирать все три варианта.
В первом способе каждый раз нужно переходить по ссылке «еще с сайта» (удобно при поиске картинок, неудобно при обычном поиске).
Поиск на нескольких сайтах. Помимо очевидного ‘работа && (#url=”www.ko.by*” | #url=”www.superjob.ru*”)’ можно использовать параметр serverurl в адресной строке. Адреса сайтов — не более 10 — перечисляются через запятую.
Что интересно, во втором случае Яндекс выдаст список страниц,
по-видимому,
отсортированных так же, как и в основной выдаче. Поэтому можно сравнивать группу сайтов, узнавая, кто (и насколько страниц) выше по определенным ключевым словам.
Следствие. Хотите узнать, входит ли ваш сайт www.centrprofit.ru хотя бы в число первых 500 результатов по запросу ‘подбор персонала’? Нет проблем. Делаем запрос подбор персонала и смотрим, кто
на 500-м
месте. Ага, www.dnemsognem.ru (сейчас, скорее всего, другой сайт). Теперь сравниваем эти два сайта. yandex.ru/yandsearch?serverurl=www.dnemsognem.ru,www.centrprofit.ru&text=подбор+персонала. Ну, какой из этих сайтов стоит выше в выдаче? Вот
то-то.
Но, напоминаю, совпадение сортировки в группе сайтов и в общей выдаче — только гипотеза, требующая более внимательного изучения.
Особенности и глюки про поиске картинок. Поведение Яндекса здесь весьма оригинальное. Можно предположить, что по запросу ‘#url=”www.toster.ru*”‘ вы получите все картинки, размещенные на этом сайте. Это не совсем так. Т. е. картинки эти вы получите, но с небольшим довеском.
В качестве одного из аспектов отсечения дубликатов Яндекс для каждой картинки хранит список URL’ов, по которым она доступна. Когда вы требуете картинки с определенным URL’ом, то Яндекс ищет его по этому списку, но забывает учесть при выдаче результатов. Это приводит к тому, что Яндекс может найти картинки, которые и не расположены на toster.ru, и не загружаются с toster.ru. А находит он картинки, скопированные с него и размещенные на других сайтах (или наоборот, картинки, которые «Тостер» скопировал с других сайтов).
Поиск по частям домена
‘rhost’ — ищет по заданной доменной зоне.
Пример использования: ‘#rhost=”ru.narod*”‘ (обратите внимание на обратный порядок слов) — все сайты с адресом вида имя_сайта.narod.ru.
‘domain’ — ищет по любой части домена (не URL’а!).
Например, domain=”ufo” — найдет сайты вида ufo.ua, www.ufo.freenet.kz и ufo.city.tomsk.net.
«Найден по ссылке»
Примечание «найден по ссылке» в результатах означает, что на самом сайте слова из запроса не были найдены, зато на него кто-то такими словами ссылается.
Кто именно, можно узнать с помощью запроса anchor#link=”адрес”[слова]
Например, по запросу ‘найдётся +всё’ вылезает сайт yandex-rambler.ru с примечанием «найден по ссылке». Почему? Запрос anchor#link=”www.yandex-rambler.ru*”[найдётся +всё] подсказывает, что это результат обычного мусорообмена ссылками.
Чуть более забавный случай — наличие yandex.ru в результатах по запросу русская баня. Видимо, Яндекс считает, что одна ссылка с narod’ного сайта — это веский повод для попадания в Top-5.
Сохраненная в кеше Яндекса страница сайта
Чтобы докопаться до кеша, обычно нужно в результатах перейти по ссылке «показать найденные слова», а на открывшейся странице — по ссылке «сохраненная копия». Увы, Яндекс пытается загрузить страницу с найденными словами до последнего (дурная привычка), поэтому если страница не выдает ошибку, но и не загружается, то ждать ссылки на «сохраненную копию» вы будете очень-очень долго.
В такой ситуации нужно к адресу страницы с «найденными словами» приписать ‘&isu=1’ (пример).
Этот параметр, кстати, добавляет сам Яндекс, когда вы жмете по ссылке «сохраненная копия». Иногда приходится делать это за него.
Зачем. Особенно полезно в национальной русской забаве «Кубок Яндекса», когда 1000 человек ломятся в течение трех минут на одну страницу.
Примечание. Правда, гораздо лучше просто вбивать адрес страницы в поисковую строку Гугля и смотреть ‘Google’s cache’. Кеши у Гугля посимпатичнее будут.
Региональный поиск
Вариант 1 — страница расширенного поиска.
Вариант 2 — через параметр в адресной строке. За регион отвечает параметр ‘&rstr=-N’, где N — номер региона.
Вариант 3 — через оператор в запросе. Оператор вида ‘cat=(N)’, где N = 11000000 + номер региона. Например, для Таганрога (номер региона 971) запрос будет ‘достопримечательности && cat=(11000971)’
Вот база номеров регионов. Москва и Санкт-Петербург
почему-то
встречаются в ней дважды. Так вот, номера 243 и 244 — не работают.
Пример: вот только что вы были в Таганроге, сейчас вы в Объединенных Арабских Эмиратах, а через секунду окажетесь в прочих ближневосточных городах.
Примечания. Региональный поиск ищет только по сайтам, включенным в каталог, плюс некоторым региональным доменам (например, регион “Санкт-Петербург” присвоен сайтам с адресом *.spb.ru).
Лично я вообще не понимаю, зачем нужен этот региональный поиск и чем он лучше старого доброго ‘&& чукотка’. Но людям нравится.
Синтаксис
Иногда я иду в Гугль только потому что его синтаксис проще: ‘site:’, ‘inurl:’, ‘allintitle:’… У Яндекса — разнобой: #url=”значение*”, #hint=(значение), $title (значение)… Очень сложно запомнить, когда ставить скобки, а когда кавычки. Попытаюсь хоть немного упростить это нагромождение.
‘#’ — не нужен. ‘#abstract=(“скачать реферат”)’ и ‘abstract=(“скачать реферат”)’ дают одинаковый результат.
‘<<‘ в Яндекс.Блогах успешно заменяется на ‘&&’.
Безопасный поиск
Чтобы пореже натыкаться на «Искомая комбинация слов нигде не встречается», «нестрогие соответствия» и просто уменьшение количества результатов, вызванные неверным синтаксисом, используйте несколько нехитрых правил.
1. Всегда ставьте перед стоп-словами ‘+’ (а не то).
2. Отделяйте операторы поиска в элементах от слов запроса символами ‘&&’ (а не то, или даже).
3. По возможности, используйте в навороченных запросах ‘/+1’ вместо кавычек (а не то или вот еще).
Дисклеймер
Нет, я не работаю в Яндексе (с чего вы взяли?) и понятия не имею, что у него внутре, хотя подозреваю, что без неонки и думателя таки не обошлось.
Яндекс — отличный поисковик.
Написание поисковика — задача куда более сложная, чем кажется большинству. Гуглю придется очень постараться, чтобы сделать русскоязычный поиск с нормальным учетом морфологии.
Пример вполне себе типичного моего запроса в Яндекс: ‘$title (“англо русский”) && (domain=”forum*” | $title (форум|forum))’
Глюки действительны по состоянию на 29 ноября 2005 г. Каждую неделю
какие-то
глюки исправляются,
какие-то
появляются.
Еще раз, документация ни в коем случае не заменяет имеющуюся, а призвана ее исправить и дополнить.
Приведенная документация не является истиной в последней инстанции. «Истину вам предстоит найти самому» ©
Как пользоваться Яндекс поиском? Оказывается, мы многого не знаем о правильном котекстном поиске.

Язык запросов
Язык запросов позволяет точнее сформулировать ваш поисковый запрос. Наиболее популярные поисковые операторы представлены в фильтрах расширенного поиска, с остальными можно ознакомиться в следующих разделах Помощи:
• Морфология
• Поисковый контекст
• Документные операторы
МОРФОЛОГИЯ
При поиске с учетом морфологии принимаются во внимание: форма заданного слова (падеж, род, число, склонение и т. д.); часть речи (существительное, прилагательное, глагол и т. д.); регистр первой буквы слова запроса (заглавная или строчная).
По умолчанию Яндекс ищет все формы слова, указанного в запросе. Например, при запросе [рассказал] поиск будет производиться по глагольным формам: «рассказать», «расскажу», «рассказывать» и т. д., но не по однокоренным словам типа «рассказ», «рассказчик». При этом в поиске будут участвовать слова, начинающиеся как с заглавной, так и со строчной букв.
Для ограничения области поиска можно использовать специальные операторы, которые позволяют получить в выдаче только документы, содержащие запрашиваемое слово в заданной форме.
ПОИСКОВЫЙ КОНТЕКСТ
Вы можете конкретизировать поисковый запрос с помощью операторов, которые уточняют наличие и взаимное расположение запрашиваемых слов в документе. Яндекс ищет все формы слова, указанного в запросе. Исключение составляют случаи, когда используются операторы ! и «.
ДОКУМЕНТНЫЕ ОПЕРАТОРЫ
Уточнить поисковый запрос можно с помощью данных, относящихся к служебной информации о страницах. Например, можно ограничить поиск по тексту в заголовках документов, типу файла, хосту и т. д. Как правило, документный оператор указывается после текста поискового запроса и отделяется от него пробелом.
В одном запросе одновременно можно использовать несколько операторов, так же разделяя их пробелом. Например, [поиск site:www.yandex.ru mime:pdf]. При использовании операторов, где в качестве параметра задается имя хоста (url, host и rhost), следует указывать главное зеркало сайта. Например, [host:lib.ru], а не [host:www.lib.ru]. Узнать, является ли сайт главным зеркалом, можно добавив хост в базу Яндекса.
Подробнее в источнике: http://sneg5.com/nauka/internet/kak-polzovatsya-yandeks-poiskom.html
41,9 K
Никак. Ставлю кавычки для строго соответствия поиска по фразе – выдает что попало. На страницк дпже этой фразы… Читать дальше
Комментировать ответ…Комментировать…
Искусство понимать с полуслова. Расширение запроса в Яндексе
Время на прочтение
20 мин
Количество просмотров 30K
Сегодня мы расскажем о механизме, который позволяет поиску Яндекса находить именно то, что имел в виду пользователь, как бы кратко и небрежно он ни сформулировал свой запрос.
В мире поиска такой механизм называют расширением поискового запроса. Термин достаточно широкий, включает в себя переформулировки, синонимы, транслит и даже однокоренные слова (последние иногда ошибочно называют поддержкой морфологии).
Из каких частей этот механизм состоит? Что помогает ему угадывать? И почему на каждую из его редких ошибок приходятся тысячи запросов, на которых он сильно помог?


Почему нельзя просто так взять и расширить запрос.
Используя примитивные реализации поиска в небольшом интернет-магазине или на местном форуме, часто приходится переформулировать первоначальный запрос вручную — заменять слова на синонимы, варьировать падежи, времена глаголов и так далее.
Заметив это много лет назад, разработчики поисковых систем решили, что можно сильно упростить жизнь пользователю, если сразу, автоматически, искать не только заданный запрос, но и различные его вариации и переформулировки. Теперь уже никого не удивляет точная поисковая выдача в руках пользователя, не искушённого в премудростях составления поискового запроса — однако борьба за экономию времени и увеличение свободы при формулировании запроса продолжается.
Сегодня мы рассмотрим только механизмы расширения запроса, то есть дополнение исходного запроса другими словами. О способах изменения запроса (исправлении опечаток в слове «одноклассники» и словоизменении Брич-Муллу, Брич-Муллою) постараемся рассказать в другой раз.
Мы делим расширения на несколько видов, каждый из которых имеет параллели в лингвистике, но и по-своему отличается от своего прообраза:
Аббревиатуры (рф → Российская Федерация)
Раскрытие аббревиатур, пожалуй, самый обманчивый вид расширений — кажется на первый взгляд точным и однозначным («очевидно», «МГУ» — это «Московский Государственный Университет»), но быстро выясняется: есть и «Мордовский», и «Мариупольский», и «Международный Гуманитарный», и другие.
Мы различаем несколько типов аббревиатур:
- Акронимы («МГУ», «ОСАГО») — состоят из первых букв образующих их слов. У акронимов, особенно 2-3 буквенных — больше всего вариантов расшифровок. Чем больше неоднозначность акронима, тем меньший вес мы даём ему при ранжировании.
- Композитные («матмех», «сельхоз») — представляют собой части слов, как правило корни. Иногда корни соединяются дополнительной буквой (как “бензопила” = “бензиновая пила“)
- Пунктуационные («г.», «б/у», «р-н») — когда в состав аббревиатуры входит знак пунктуации.
- Отделение префиксов, каждый из которых сокращается до начальной буквы: «авто-», «мото-», «все-», «тепло-». Например, так получается «тэц» = “теплоэлектроцентраль”
Как учитывать региональность; как отсекать ложные гипотезы
Помимо многозначности, в этом виде расширений интересен учёт региональности, ведь в каждом регионе у аббревиатуры может быть своя расшифровка. Пользователи из «Мордовии», у которых есть свой «МГУ» (им. Огарёва), интересуются его московским тёзкой не меньше, чем жители других регионов России. Но региональных данных может оказаться мало, приходится подбирать баланс между местным объектом и его более известным аналогом из другого региона — чтобы было легко найти и тот, и другой.
При сборе вариантов расширений бывает немало ложных гипотез, с которыми мы боремся разными эвристиками:
- «фото» = “фотография Обамы” (при сокращении все слова фразы должны сокращаться до частей примерно одинаковой длины)
- “блага дарим” = “благодарим“, «маманя» = “мама аня” (одна гласная не может пропадать, как минимум целый слог)
- “химическая технология природных энергоносителей” = «хтн» (первая буква слова с отделяемым префиксом, «э», также должна присутствовать в аббревиатуре)
- «сгорел» = “скорее всего ремонту уже не подлежит” (много пропусков, первые буквы вне сокращения)
- «назой» = «назойливый» (сокращение из одного слова не переводится в столь длинное слово)
Транслитерация (Пежо → Peugeot)
В отличие от аббревиатур, тут интуиция оказывается права: на транслитерацию приходится несколько десятков процентов всей пользы от расширений. У неё хорошая точность и полнота; она хорошо помогает в любом контексте.
Пользователи не любят переключать раскладку на клавиатуре, а при поиске иностранной фамилии или населённого пункта проще набрать их по-русски («Демонжо» вместо «Demongeot» и «Кёльн» вместо «Cologne»), чем вспоминать правильное написание в оригинале. Нередка и обратная ситуация: жителям русскоязычных диаспор за рубежом привычнее общаться в форумах на русском, но с использованием транслита. Искать же по таким форумам нужно и для кириллических запросов. Транслитерация пригождается и когда слово запроса содержится в адресе найденного сайта.
На практике нам нужна даже не транслитерация, а так называемая практическая транскрипция — максимально близкая передача оригинального звучания средствами другого языка. Иначе, например, французские слова будут искажаться до неузнаваемости.
Реализация: по буквам, по слогам, по цепочкам (сегментам) гласных-согласных
Варианты реализации
Ограничимся поверхностным обзором, оставляя нюансы для самостоятельного поста. Самый известный и простой способ — транслитерация с помощью побуквенных правил. Есть несколько стандартов перевода между латиницей и кириллицей, большинство являются взаимно-однозначными (полностью или для почти всех букв). К сожалению, этот метод даёт очень плохое качество для имён — даже «Renault» и «Pegueot» никогда не станут «Рено» и «Пежо».
Более продвинутый способ — по слогам. Перевод каждого слога независимо от контекста работает довольно точно. Но есть сложности:
- В каждом языке свои правила деления на слоги, а их реализация с достаточно высокой точностью — нетривиальна.
- Одинаковые слоги тоже произносятся по-разному в разных языках, поэтому для каждого языка нужно досконально описать правила.
- По этим причинам особенно важно безошибочное определение языка
Метод сегментов
Мы выбрали третий путь, метод разбиения на сегменты. Сегмент — это группа подряд идущих гласных / согласных букв. Нужно найти большое количество примеров пар слов, когда мы достоверно знаем, что одно является транскрипцией другого. И по этим примерам, с помощью машинного обучения, построить правила преобразования одних сегментов в другие.
Вот как это работает. Для каждой пары из обучающей выборки слова разбиваются на сегменты. Для каждого примера правильной транскрипции между сегментами оригинального слова и его транскрипцией устанавливается соответствие — оказывается, практически во всех случаях число сегментов в русском и иностранном словах оказывается равным.
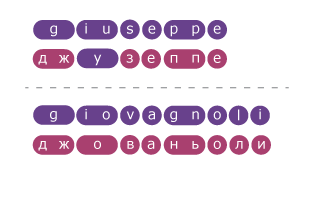
Далее, сегменты транскрипции с соответствующими сегментами оригинала поступают в обучающую выборку: как сами по себе, так и с окружающим контекстом (соседними сегментами). В результате машинное обучение определяет вероятности разных вариантов транскрипции каждого сегмента:
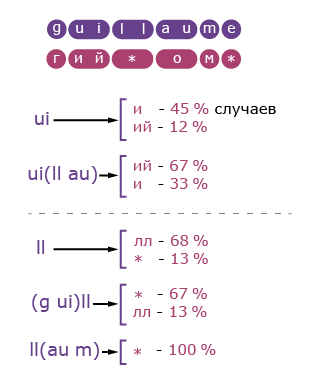
О неоднозначности сегментов
Тут есть пара хитростей, из-за которых сегменты могут оказаться не взаимно однозначными. Первая простая: некоторые слова начинаются с непроизносимых согласных, как «L’Humanite» > «Юманите». Такие сегменты переводятся в пустые. Вторая посложнее: в середине слова бывают «беглые» гласные (как в «stat
e
ment» не читается выделенная «e») или согласные (как в «guillaume» выше). С беглыми буквами помогает выравнивание по сегментам с помощью алгоритма Левенштейна: сначала устанавливаем побуквенное соответствие, а затем склеиваем рядом стоящие буквы в сегменты с учётом отличий разбиения слова на другом языке.
Из этого примера видно, что «й» правильнее считать гласной. А «ъ», «ь», дефис и апостроф мы считаем согласными — ведь они разрывают звучание.
О качестве
По нашему опыту, метод сегментов даёт самую лучшую точность. Он хорошо работает для всех распространённых языков — в том числе, для таких сложных, как китайский и вьетнамский (разумеется, в их буквенной записи). И даже позволяет с приемлемой точностью восстановить из русского написание на оригинальном языке. При этом метод не требует определения языка слова.
На тестовых коллекциях имен-фамилий, географических названий, популярных брендов и названиях музыкальных коллективов метод показывает точность до 99%. Если же оценивать точность на всём наборе гипотез, которые расширяются по реальным запросам и поисковому индексу, она падает по мере того, как мы увеличиваем словарь всё менее точными гипотезами. Сейчас пользователям доступны порядка 3 млн расширений на базе транслитерации, на них точность составляет около 90%.
Орфографические варианты (икея → икеа)
Орфоварианты — это слова, которые имеют идентичное значение, а писаться могут и так, и эдак, причём оба написания считаются грамотными.
Во-первых, это иностранные слова, которые записываются со слуха, и часто не имеют единственного канонического написания («ике
я
» / «ике
а
»; «толк
ие
н» / «толк
и
н»).
35 способов написать Scarlett Johansson
«скарлетт йоханссон»
«скарлетт йохансон»
«скарлет йоханссон»
«скарлет йоханссен»
«скарлетт джоханссон»
«скарлетт джохансон»
«скарлет йохонсон»
«скарлет йохансон»
«скарлет йоханнсон»
«скарелтт йоханссон»
«скарлетт йоханссен»
«скарлетт йоххансон»
«скарлет йохансен»
«скарлетт ёханссон»
«скарлетт йоханнсон»
«скарлет йохансан»
«скарлет джохансон»
«скарлетт йохансоон»
«скартлетт йоханссон»
«скарлетт йханссон»
«скарлетт йохассон»
«скарлетт йохансен»
«скарлет ёхансен»
«скарлет ехансен»
«скарлет джохэнсон»
«скарлетт йохансан»
«скарлетт йоанссон»
«скарлет йохенсон»
«скарлет иоханссон»
«скарлет ёхансон»
«скарлет ехансон»
«скарлет ёхансан»
«скарлетт джохэнссон»
«скарлетт йохансонн»
«скарлет джоханссон»
В отличие от транслитерации, тут мы имеем дело с парами на одном языке. Несколько слов, которые с помощью транскрипции можно привести к одному латиническому написанию, называются орфовариантами.
Во-вторых, русские слова, допускающие разные написания («бил
ья
рд» → «билл
иа
рд», «день рожден
и
я» → «день рожден
ь
я»)
Чем интересны орфоварианты?
Нужно отличать их от опечаток и падонкаффского сленга. А ещё бывает устаревшее написание.
- Нужно чётко разделять их с опечатками:
- для опечаток пользователь привык видеть явное сообщение: «В запросе была исправлена опечатка» и иметь возможность переключиться на поиск оригинального запроса. Для орфовариантов такое предупреждение будет неуместным, т.к. все возможные написания являются допустимыми.
- когда мы уверены, что пользователь опечатался, мы просто заменяем запрос на правильный. Для орфовариантов так делать нельзя, мы потеряем большую часть полезных документов с другим написанием («рожденья» вместо «рождения»). А вот расширять другими написаниями будет правильно. В отличие от опечаток — там неграмотные документы могут расстроить пользователя, задавшего запрос без ошибок.
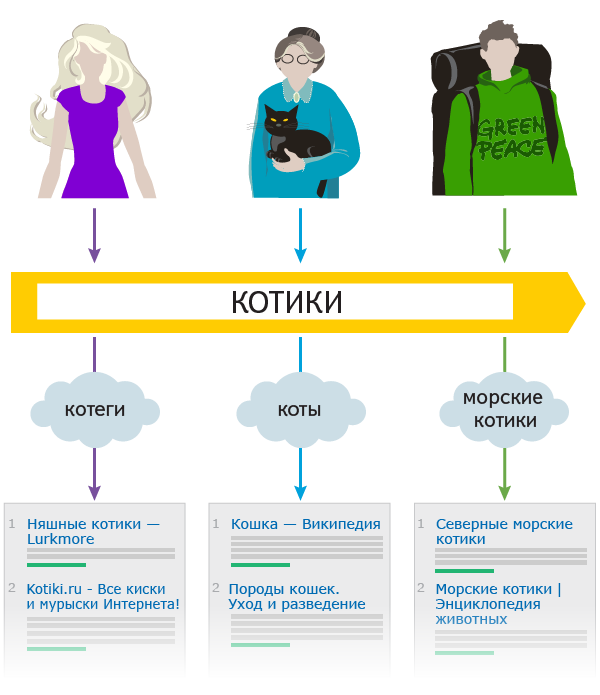
- Важно уметь отличать орфоварианты от интернет-сленга («падонкаффский / олбанский йезыг») и мемов («котеги»; «котэ»). Сленговые и общепринятые написания нельзя расширять друг другом:
- по запросу с мемом нельзя показывать документы с общеупотребимым написанием, они будут мешать интересующемуся мемом;
- и наоборот, если подмешивать к общеупотребительному написанию его аналоги-мемы, это будет ухудшать выдачу по запросам на «общечеловеческие» темы.
Благо, у сленга довольно специфический контекст использования, это помогает отличать его от орфовариантов.
Особняком стоит третий тип — устаревшее написание: «великодержавнаго», «благочестиваго» (например, «царя»). Благодаря расширениям находятся и оригинальные древнерусские тексты с параллельным переводом на современный язык, и сами переводы без оригинала — последние неподготовленному читателю легче распечатать и читать.
Словообразование (Москва-московский)
Описанные выше виды расширений (аббревиатуры, транслиты, словоизменение, орфоварианты) старались отражать точные слова запроса всеми возможными способами, считая смысл неприкосновенным. Но быстро стало понятно, что нужно смелее допускать смысловые добавки к исходному запросу. Так расширения пополнились словообразованием («моск
ва
метро» → «моск
овское
метро») и синонимами («бегемот» → «гиппопотам»).
Идея расширения по принципу словообразования состоит в добавлении к запросу однокоренных слов, включая даже другие части речи («моск
ва
метро» → «моск
овское
метро»).
Механизм словообразования зачастую называют просто морфологией, хотя это не совсем верно: кроме словообразования к морфологии относится и словоизменение (то самое «Брич-Муллою»). Словоизменение крайне редко добавляет к запросу новые смысловые оттенки, обычно оно ищет оригинальное слово запроса во всех формах (как говорят, «всю парадигму»), поэтому в этом посте мы его не затронем.
Словообразование, напротив, может добавлять семантически далекие варианты — вопреки общим соображениям, слова с одним корнем не обязаны быть близкими по смыслу. Лишь малое число типов словообразования оказывается на практике хорошими поисковыми расширениями, поэтому нужно быть аккуратными.
Несколько примеров
Среди полезных типов — <существительное> → <однокоренное прилагательное>, например «Москва» → «московский»: «мэр москвы» → «московский мэр». Но даже здесь есть свои тонкости, в первую очередь связанные с именованными сущностями:
- названиями организаций: [универмаг Москва] ≠ [универмаг Московский], в Москве это два разных магазина, оба весьма известные
- фамилиями людей: у чиновника, который работает в правительстве, может оказаться фамилия «Московский» — и это повлияет на запрос [Московский правительство]
- географическими названиями: в Подмосковье есть город «Московский» — для него запрос [Московский мэр] значит не то же самое, что [мэр москвы]
Пары <существительное> → <имя деятеля> («велосипед» → «велосипедист») — сильно уводят от смысла первоначального запроса. Если <существительное> → <прилагательное> «велосипед» → «велосипедный» полезно (например, [покупка велосипеда] → [велосипедный магазин]) — то «велосипед» → «велосипедист» ухудшит поиск, потому что по запросу [покупка велосипеда] в выдачу будет добавляться, например, документы про «посадку велосипедиста», про «травмы велосипедиста» и т.п.
- [занятие по рисованию]: хорошо расширить словом «рисовать», но плохо «рисовальщик»
- [зам командующего по тылу]: хорошо «тыловой», плохо «тыловик»
- [заказ мулине в Украине]: хорошо «заказывать», плохо «заказчик»
Аналогично, есть масса плохих примеров на смену рода. Возьмём «работник» → «работница»: если запрос [соглашение с работником] даёт широкий класс документов о любых предметах договорённостей, то расширяя его словом «работница», в выдачу попадают нежелательные документы, например про нормативную базу о выходе в декрет (которая с общим случаем про любого работника, скорее всего, не поможет).
Таким образом, схожесть слов по форме часто бывает обманчивой, и с точки зрения поиска содержание очень сильно меняется даже с самыми, казалось бы, невинными преобразованиями.
В других языках всё бывает иначе
Любопытно, что русский язык далеко не всегда оказывается самым сложным с точки зрения словообразования. Например, в турецком однокоренные слова с формально другим смыслом оказываются просто частью одной словарной парадигмы:
- «yüz» — сто, «yüzde» — процент,
- «top» — мяч/ядро, «topçu» — футболист/артиллерист.
И если в русском мы можем безболезненно использовать все формы того слова, для которого подготовили расширение — то в турецком приходится рассчитывать контекстную близость не между разными словами, а между формами одного и того же слова. И ограничивать использование далёких форм того же слова, чтобы не допускать искажений смысла.
Синонимы (мобильный → сотовый)
Можно ли взять за основу академические синонимы из традиционных словарей, и просто загрузить их в поиск? Ведь в словарях собраны обширные ряды надёжных синонимов.
Оказывается, поисковый язык совершенно не такой, как нормативный письменный.
Часто словари дают точные синонимы, но снабжают их стилистической пометой: арх., разг., науч., поэт. А некоторые слова, даже будучи современными и, формально, общеупотребительными, используются в письменной речи лишь в некоторых смыслах или жанрах:
- «волшебник» → «колдун»: второй употребляется преимущественно в фольклорных текстах, и только в негативном ключе
- «подъезд» → «парадное»: второй не используется в официальных адресах; ограничивает круг документов петербуржским регионом — по происхождению или месту действия.
- «врач» → «медик»: второй используется преимущественно для профиля образования, но не для обозначения профессии или вида услуги
- «дрессировщик» → «укротитель»: второй имеет дело только с опасными животными
В результате человек получит документы с ярко выраженной стилистикой (архаичные / научные / диалектные…), чем хотел — что не всегда будет полезно в решении его задач.
Поэтому мы ушли от чисто словарного, лингвистического понимания синонимов, гораздо лучше работает статистический поиск эквивалентов. Собираются любые варианты, которые могут не быть синонимами в академическом смысле, но помогают найти то, что пользователь ищет. Именно это и является главным критерием качества — полезность расширений для ранжирования (а не их словарная близость по смыслу).
Но и коллекции статистически собранных синонимов в традиционном смысле (как слов с идентичным значение) бывает мало. Для узкоспецифичных запросов, по которым в интернете чрезвычайно мало информации, бывает полезно заменить некоторые слова запроса на более общие понятия («гиперонимы»).
Пример замены общим; почему нельзя заменять общее частным
Например, запрос [конъюнктивит у цвергшнауцеров]: у слова «цвергшнауцер» есть очень точный синоним «цверг», но его добавление не сильно улучшит выдачу. Зато если добавить его обобщение на правах расширения, [конъюнктивит у собак], найдётся много полезного, ведь манипуляции по уходу и лечению похожи для разных пород собак.
А в обратную сторону, от общего к частному, расширять рискованно. Запросом [одежда для детей] разные пользователи ищут магазины для различных возрастов, поэтому будет правильнее всего показать максимально универсальные сайты, покрывающие весь возможный спектр разных ситуаций пользователя. Если мы будем пытаться расширять запрос более частными понятиями «школьник» или «младенец», это может осложнить пользователю решение его задачи.
Как собрать варианты расширений
В следующем разделе самое интересное — как расширения используются в поиске, но прежде давайте разберёмся, как мы готовим гипотезы расширений.
Из рассказанного выше легко догадаться, что варианты возможных расширений для наших нужд можно построить только через анализ реальных данных, существующих «в диком виде» в интернете. Отвечать на запрос пользователя нужно быстро, поэтому мы готовим такие варианты (т.н. «словарь расширений») заранее — а в момент поиска просто выбираем из готового словаря все пары для слов запроса.
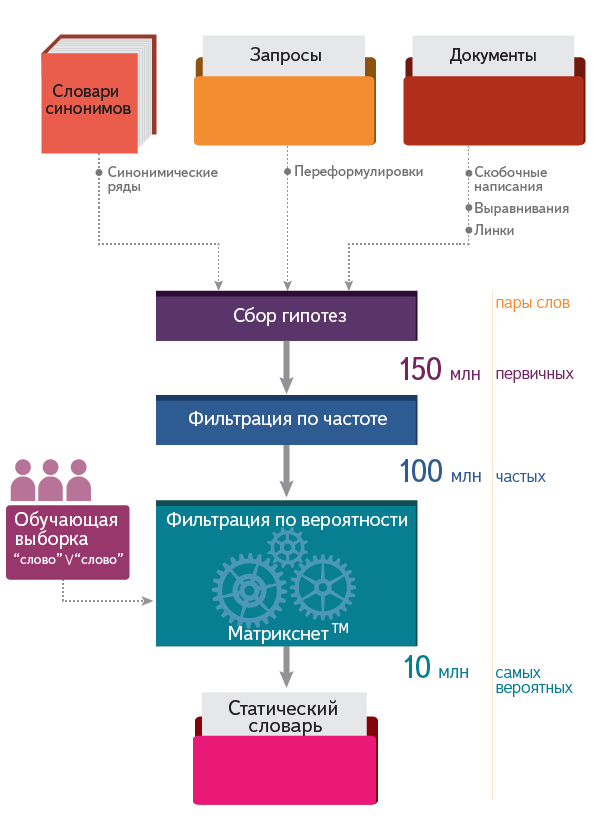
Сбор гипотез
Для составления словаря мы используем ряд источников:
 скобочные написания в документах: «Скарлетт Йохансон (Scarlett Johansson)»
скобочные написания в документах: «Скарлетт Йохансон (Scarlett Johansson)»- встречаемость обоих слов в одинаковых контекстах (N-граммах — цепочках из N подряд идущих слов: “… билетов в театр”: «цена» → «стоимость») — отдельно в текстах, отдельно в запросах. Её иногда называют «статистика взаимозаменяемости».
- ссылочные — когда несколько ссылок, ведущих на одну и ту же страницу, называются по-разному: «магазин велосипедов → веломагазин»
- параллельные тексты (размеченные с помощью машинного выравнивания)
Наш сервис машинного перевода обучается на так называемых параллельных текстах — парах «текст и его перевод», между которыми статистическими методами размечено соответствие предложений, словосочетаний и слов, означающих одно и то же. Такой переход одного слова в другое мы считаем хорошей гипотезой для расширения запроса. - пользовательские статистики — как часто пользователь пытается переформулировать запрос с использованием данной замены, и документы с какими синонимами к слову запроса предпочитает
- традиционные словари синонимов, другие словарные источники
- Wikipedia: для какого термина стоит перенаправление на другой термин
Для русского языка это даёт порядка 150 млн пар — гипотез расширений.
Частотная фильтрация
Пары, которые встречаются слишком редко и в запросах, и в текстах в интернете — не очень достоверный источник, поэтому после сбора гипотез мы ограничиваем их по частоте встречаемости.
Нет особого смысла и как-либо учитывать форму (падеж, склонение), в котором слово встретилось вместе с той или иной парой (по крайней мере, для русского языка). Поэтому мы оставляем единственную форму слова (как правило, начальную).
В результате этого обычно получается порядка 100 млн пар.
Отбор самых вероятных расширений
Но 100 млн сырых гипотез — это руда, которую нельзя просто отдать на этап обработки запроса.
Нет смысла помогать высокочастотным запросам; нужно исключать далёкие по смыслу замены
- Мы отбираем расширения, которые сильнее всего помогают пользователю. Ценность расширений напрямую зависит от частотности запроса. Для высокочастотных запросов у нас много различных данных, и добавление даже большого числа расширений практически не меняет ранжирования. А в случае запросов редких либо сформулированных с ошибкой вклад расширений в улучшение выдачи очень заметный — именно их и стараемся расширять прежде всего.
- Даже для нечастотных запросов нужно балансировать качество и скорость ответа на запрос. В идеале нужно расширять любой запрос максимально широким облаком расширений — и этап ранжирования выберет именно то, что действительно улучшает релевантность выдачи. На практике же размер облака приходится ограничивать ради скорости ответа — удаляя варианты, далёкие по смыслу от оригинала.
Как многое другое в этой теме, степень близости по смыслу расчитывается машинным обучением.
С одной стороны, для каждой гипотезы расширения (A, B) мы вычисляем порядка 60 факторов, которые так или иначе коррелируют с тем, что гипотеза являются полезным расширением. В числе этих факторов — контекстная близость, построенная на N-граммах; выбор пользователем одних и тех же документов по разным запросам; расстояние Левенштейна (например, для орфовариантов).
С другой стороны, специальные эксперты (асессоры) готовят обучающую выборку характерных примеров «какое слово B является хорошим расширением слова A, а какие пары недопустимо считать синонимичными».
Подготовка обучающей выборки — сложная задача, от её решения напрямую зависит качество итогового словаря. Даже опытные асессоры часто расходятся в оценке расширений. Асессорам приходится думать не только о близости слов с точки зрения языка, но и прогнозировать, как конкретная пара повлияет на полезность выдачи в целом сегменте запросов.
В результате этого отбора мы получаем 10 млн расширений — и этот «словарь» используется при обработке запросов. Об этом поговорим в следующем разделе.
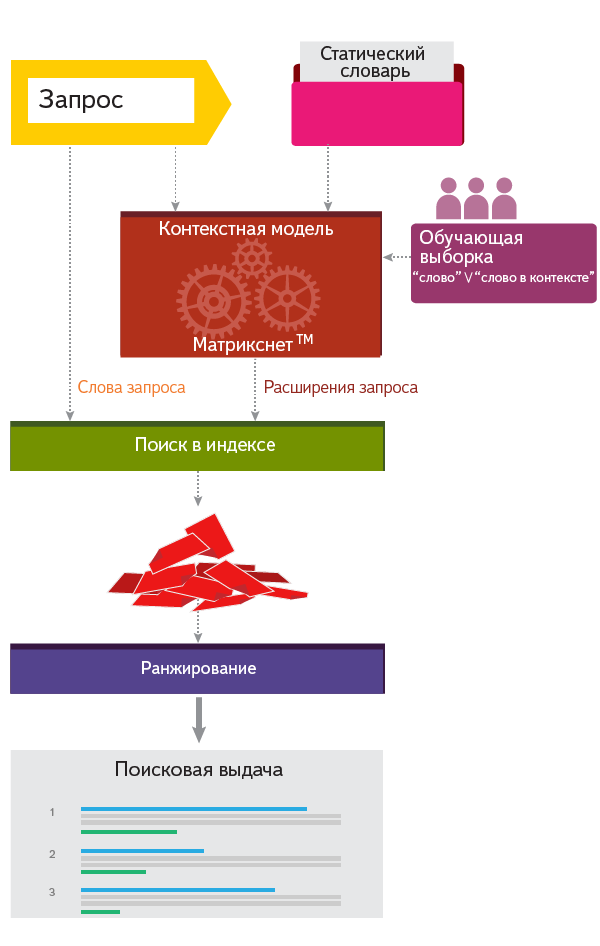
Как расширения участвуют в поиске
Получив от пользователя поисковый запрос, мы выбираем из словаря расширения, подходящие по контексту.
Например, [мгу] расширилось в [мгу ^ mgu ^ msu ^ «московский государственный университет»].
А уже по расширенному запросу поиск находит документы с различными вариантами формулировок, включая оригинальную («точную форму»). В ранжировании документов участвует множество факторов, учитывающих и оригинальное слово, и расширения. При прочих равных совпадение точной формы («мгу») более приоритетно, чем вхождение расширения (даже полного написания, как «московский государственный университет») — хотя другие факторы могут оказаться сильнее точного совпадения.
Мы стараемся подсвечивать в сниппетах не только слова запроса, но и все используемые синонимы, что помогает пользователю понять, почему он видит тот или иной документ.
Как определить, какие расширения уместны для данного запроса, а какие нет; что именно, в каких случаях и в каком объёме добавлять? Чем больше видов расширений, тем сложнее построить алгоритм их замешивания. Обычно начинают с подобранной вручную логики ветвлений и коэффициентов, а когда их становится слишком много — ищут качественно другой способ. По нашему опыту, сложную логику не получается развивать уже после первого десятка факторов: становится слишком трудоёмко подбирать параметры, чтобы рост одного показателя качества не оборачивался сравнимым падением другого. Не так давно мы возложили решение этой задачи на машинное обучение, что позволило быстрее добавлять новые факторы и на 20% повысило вклад расширений в качество поиска. Получившийся механизм мы назвали «контекстной моделью».
На каких факторах и примерах она работает
Модель, как и в случае с любым машинным обучением с учителем, опирается на примеры от экспертов (асессоров) и на факторы, с помощью которых эти примеры экстраполируются на любые другие случаи.
Основные признаки, используемые для определения уместности расширения:
- число слов в запросе и в расширении;
- насколько это редкие слова;
- тематика запроса;
- вид расширений (из перечисленных выше разделов) — тоже класифицируется автоматически;
- степень корреляции в текстах между словом запроса и расширениями (т.н. Mutual Information) — насколько часто они встречаются вместе.
Для наиболее характерных запросов асессоры размечают, какие варианты синонимов будут хорошим расширением в данном контексте, а какие плохим. Ведь в каких-то случаях можно дополнять запрос максимально, а в каких-то только заведомо «непортящими» расширениями.
В результате контекстной фильтрации из всех расширений, возможных для всех слов запроса, остаётся 27% пар, которые уместны именно для данного запроса.
Есть несколько больших классов запросов, контекст которых делает неуместным большинство расширений:
Имена собственные; цитаты; многозначные слова
- имена собственные:
[ООО Бегемот] → [ООО Гиппопотам] (хотя можно «повадки бегемотов» = «повадки гиппопотамов»)
[лодка ветерок цена] (хотя можно «легкий ветерок» = «легкий бриз») - точные цитаты. Вот чем могли бы расшириться известные фразы:
[мой дядя самых честных правил] → «дядечка, мужчина, дядько»; «наиболее»; «чистосердечный»; «кодекс, регламент, регулярность, стандарт, установленный порядок»
[все смешалось в доме Облонских] → «всякая, каждый, итого»; «домашний»; «здание», «постройка» - терминологические значения общеупотребительных слов — когда расхожее слово означает также ускоспецифическую вещь:
[монтёрская кошка]
[тормозной башмак]
Только если из запроса удалось понять, что слово встретилось в узкоспецифическом смысле, его можно расширить обобщающим термином («монтёрская кошка» → «монтёрское снаряжение»). - более широко, вообще многозначные (омонимичные) исходные слова. Примеры, почему их нельзя расширять:
[Приказ о назначении председателя ОСМД]: «назначении» → «предназначение»
[заставки на рабочий стол]: «стол» → «столик»
[как очистить картину написанную маслом]: «написанную» → «пишущий»
[феномен личности на конкретном примере]: «примере» → «задача»
[средняя зарплата дворника]: «дворник» → «щетка»
[гражданское общество]: «гражданский» → «незарегистрированный» (напр., «брак»)
[где взять выписку из домовой книги]: «взять» → «приобретать»
[тост на французском языке]: «тост» → «сухарик» (в запросе [тост] — в значении «речь во время застолья»)
Определение каждого класса «что нельзя расширять» также обеспечивается машинным обучением — на основе большого числа примеров от асессоров.
Подробнее о многозначных словах
Если слово многозначно, его можно расширять синонимами только к тому значению, которое подразумевалось в запросе. В противном случае мы испортим выдачу документами с кардинально другим смыслом, что может раздражить пользователя, и уж точно ему не поможет. То же правило верно в обратную сторону, когда однозначное слово расширяется многозначным.
Проблема в том, что операции снятия неоднозначности и подбора синонимов под конкретное значение слова подвержены большой ошибке, сделать их точными крайне сложно. Поэтому мы расширяем из или в многозначное слово в единственном случае: когда оба синонима применяются в интернете в одних и тех же контекстах, а значит и смыслах.
Подробнее об именах собственных
Имена собственные требуют особой аккуратности. Если опираться только на контекстную близость, то «МТС» и «Билайн», «Google» и «Яндекс», «ВКонтакте» и «Facebook» ведут себя как синонимы. И в случае Билайна, и в случае МТС пользователей интересуют одинаковые аспекты: «смс», «личный кабинет», «интернет», «тарифы», «роуминг». А при выборе сотового оператора они задают одинаковые запросы (тарифы, зона покрытия и т.п.), меняя только название компании — что неотличимо от классических переформулировок запроса синонимами.
Но примеры, в которых замена вроде «МТС» → «Билайн» действительно помогает лучше ответить на запрос пользователя, встречаются довольно редко. В подавляющем большинстве случаев такая замена не только не помогает, но и выглядит глупостью. Например:
(да простят нас коллеги за эту соринку — у себя мы интересного бревна не нашли)
Поэтому, когда дело касается имён собственных, мы стараемся сужать арсенал используемых расширений: транслиты и опечатки применяем без ограничений, а с синонимами действуем избирательно.
Как мы действуем с синонимами для имён собственных
Мы стремимся расширять имя объекта только когда уверены, что расширение является альтернативным обозначением его же (например, уменьшительно-ласкательными «Вконташа» → «Вконтакт» или разговорными «керосинка» → «РГУ нефти и газа»), а не названием другого объекта. Научить алгоритм отличать одно от другого непросто, как и достоверно определять, что первоначальный объект вообще является именем собственным. Мы учим автоматику различать имена собственные разных объектов на примерах от асессоров и данных Википедии: если в Википедии для каждого из наших слов существует собственная статья, это с большой вероятностью означает, что мы имеем дело с разными сущностями.
Учёт языка запроса
Обычно расширения предлагаются именно для того языка, на котором задан запрос. Но что если есть основания полагать, что пользователь понимает и другой язык, а результатов на нём существенно больше? Тогда разумно предложить документы на этом языке. Например, украинский запрос [в’язання схеми] можно расширить русским [вязание схемы], по которому в разы больше хороших результатов.
Качество расширений и качество поиска
Полнота результатов поиска — вот главная цель современных расширений: быть устойчивым к неточностям в формулировке запроса и терпимым к неумению пользоваться поиском; находить нужное как можно чаще, даже в самых неочевидных случаях.
Очень упрощённо, поиск как процесс состоит из двух основных этапов: фильтрация и ранжирование. Фильтрация отбирает из индекса документы, сколько-нибудь полезные для заданного запроса, ранжирование упорядочивает их по релевантности.
Механизм расширений — ключевой участник этапа фильтрации. Расширения находят все возможные замены, и ранжирование умеет выбрать из них то, что действительно будет полезно пользователю.
Поэтому ключевой параметр качества механизма расширений — полнота словаря возможных замен. Ради неё мы готовы давать даже неграмотные расширения, если они помогают пользователю найти нужное. Например, «war
k
raft» — неканоническое название (правильно «War
c
raft»), но какое-то время назад оно было очень распространено на геймерских форумах — и по некоторым запросам (вроде [варкрафт прохождение]) расширение «варкрафт» → «war
k
raft» позволяло найти то, что не удавалось найти без него.
Если расширение помогает найти нужное, нам не важна его «правильность», «грамотность» или «каноничность», даже академическая близость по смыслу к оригинальному запросу.
Следим за качеством расширений и до передачи в поиск, и в самом поиске
Но даже несмотря на то, что ранжирование очень терпимо к неполезным расширениям, мы предпочитаем перестраховываться и отдельно следим за качеством самих расширений ещё до их попадания в поиск. Всякий раз, когда мы внедряем какое-то изменение в расширениях, мы не только стремимся к бо́льшей полноте самих расширений, но и аккуратно смотрим, чтобы не упала их точность. Если метрика совокупного качества поиска оценивает отсутствие плохих результатов на первой странице выдачи, то собственная метрика качества расширений помогает исключать раздражающие расширения вообще из результатов поиска.
Как измерять качество расширений и поиска в целом
Мы пока не нашли достоверную метрику качества самих расширений относительно других поисковых систем, которая бы одновременно и походила на наши интуитивные оценки и основывалась на реальных ожиданиях пользователей (а не на умозрительных примерах). Поэтому мы руководствуемся совокупной оценкой качества поиска pfound. Она оценивает вероятность, что пользователь найдёт то, что искал, взятую в среднем по всему потоку запросов, задаваемых Яндексу. Для каждого запроса метрика суммирует полезность первых документов, показанных на выдаче — с поправкой на то, насколько высоко документ отранжирован. Чем ниже он на выдаче, тем меньше его вес в метрике — вероятность, что пользователь до него доберётся. Полезность каждого документа в контексте запроса мы оцениваем по оценкам от асессоров:
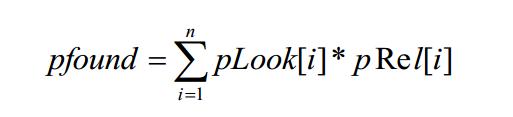
Здесь: pRel — релевантность i-того документа (вероятность того, что пользователь найдет ответ в этом документе). pLook — вероятность просмотра i-того документа в выдаче.
Мы надеемся, что расширения работают на то же благо, что и все остальные компоненты поиска. Собственный вклад расширений в совокупное качество поиска довольно существенный — он составляет несколько процентов. То есть, если очень сильно упрощать, в день несколько миллионов запросов к Яндексу получают качественный ответ исключительно благодаря расширениям. А тем или иным образом помогают в ответе они на 30% всего потока запросов в Яндекс, причём на 15% потока — дают ощутимое улучшение.
Литература
- Евгений Соловьёв, Тезаурусные расширения в информационном поиске. Яндекс, 2010 (презентация).
- Voorhees, Query Expansion using Lexical-Semantic Relations — автор одной из первых добилась улучшения результата на TREC при помощи расширений из WordNet.
- Jones et al. Generating Query Suggestions — как в Yahoo! решали проблему увеличения полноты поиска по рекламным объявлениям.
- Dang, Xue, Croft. Context-based Quasi-Synonym Extraction — сбор синонимов при помощи корпуса N-грамм (например, такого).
- Dang, Croft. Query Reformulation Using Anchor Text — пример использования статистики по приссылочным текстам для сбора расширений от Microsoft Research.
- Р.С. Гиляревский, Б.А. Старостин. Иностранные имена и названия в русском тексте. М., Высшая школа, 1985 — о практической транскрипции.
