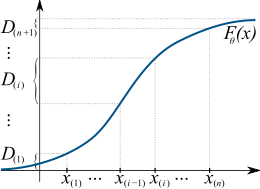
Метод максимального интервала пытается найти такую функцию распределения, чтобы интервалы, D(я), все примерно одинаковой длины. Это достигается за счет максимального увеличения их среднее геометрическое.
В статистика, оценка максимального интервала (MSE или же MSP), или же максимальный продукт оценки расстояния (MPS), – метод оценки параметров одномерного статистическая модель.[1] Метод требует максимизации среднее геометрическое из интервалы в данных, которые представляют собой различия между значениями кумулятивная функция распределения в соседних точках данных.
Концепция, лежащая в основе метода, основана на интегральное преобразование вероятности, в том, что набор независимых случайных выборок, полученных из любой случайной величины, должен в среднем быть равномерно распределен относительно кумулятивной функции распределения случайной величины. Метод MPS выбирает значения параметров, которые делают наблюдаемые данные как можно более однородными, в соответствии с определенной количественной мерой однородности.
Один из наиболее распространенных методов оценки параметров распределения по данным, метод максимальная вероятность (MLE) может давать сбой в различных случаях, например, при использовании определенных смесей непрерывных распределений.[2] В этих случаях может оказаться успешным метод оценки максимального интервала.
Помимо использования в чистой математике и статистике, сообщалось о пробных применениях метода с использованием данных из таких областей, как гидрология,[3] эконометрика,[4] магнитно-резонансная томография,[5] и другие.[6]
История и использование
Метод MSE был разработан независимо Расселом Ченгом и Ником Амином в Институт науки и технологий Уэльского университета, и Бо Раннеби в Шведский университет сельскохозяйственных наук.[2] Авторы пояснили, что из-за интегральное преобразование вероятности при истинном параметре «интервал» между каждым наблюдением должен быть равномерно распределен. Это означало бы, что разница между значениями кумулятивная функция распределения при последовательных наблюдениях должны быть равны. Это тот случай, который максимизирует среднее геометрическое таких расстояний, поэтому решение для параметров, которые максимизируют среднее геометрическое, приведет к «наилучшему» соответствию, как определено таким образом. Раннеби (1984) обосновали метод, продемонстрировав, что это оценка Дивергенция Кульбака – Лейблера, похожий на оценка максимального правдоподобия, но с более надежными свойствами для некоторых классов задач.
Существуют определенные распределения, особенно с тремя и более параметрами, у которых вероятность может стать бесконечным на определенных путях в пространство параметров. Использование максимального правдоподобия для оценки этих параметров часто приводит к сбоям, когда один параметр стремится к определенному значению, которое приводит к бесконечности вероятности, что делает другие параметры несовместимыми. Однако метод максимальных интервалов, зависящий от разницы между точками кумулятивной функции распределения, а не индивидуальных точек правдоподобия, не имеет этой проблемы и будет возвращать достоверные результаты по гораздо более широкому набору распределений.[1]
Распределения, которые, как правило, имеют проблемы с вероятностью, часто используются для моделирования физических явлений. Холл и др. (2004) стремятся анализировать методы смягчения последствий наводнений, что требует точных моделей воздействия наводнений на реки. Распределения, которые лучше моделируют эти эффекты, представляют собой трехпараметрические модели, которые страдают от проблемы бесконечного правдоподобия, описанной выше, что привело к исследованию Холлом процедуры максимального разнесения. Вонг и Ли (2006), при сравнении метода с максимальной вероятностью используйте различные наборы данных, начиная от набора самых старых возрастов смерти в Швеции между 1905 и 1958 годами до набора, содержащего максимальные годовые скорости ветра.
Определение
Учитывая iid случайный пример {Икс1, …, Иксп} размера п из одномерное распределение с непрерывной кумулятивной функцией распределения F(Икс;θ0), куда θ0 ∈ Θ – неизвестный параметр, который по оценкам, позволять {Икс(1), …, Икс(п)} быть соответствующим упорядоченный выборка, то есть результат сортировки всех наблюдений от наименьшего к наибольшему. Для удобства обозначим также Икс(0) = −∞ и Икс(п+1) = +∞.
Определить интервалы как «промежутки» между значениями функции распределения в соседних упорядоченных точках:[7]

Тогда оценщик максимального интервала из θ0 определяется как значение, которое максимизирует логарифм из среднее геометрическое интервалов между образцами:
![{hat {heta}} = {underset {heta in Theta} {operatorname {arg, max}}}; S_ {n} (heta), quad {ext {where}} S_ {n} (heta) = ln !! {sqrt [{n + 1}] {D_ {1} D_ {2} cdots D_ {n + 1}}} = {frac {1} {n + 1}} сумма _ {i = 1} ^ {n + 1} ln {D_ {i}} (гетта).](https://wikimedia.org/api/rest_v1/media/math/render/svg/9a31b5ecd6b17eba0ab4543bd2d844d706d1f573)
Посредством неравенство средних арифметических и геометрических, функция Sп(θ) ограничена сверху величиной −ln (п+1), поэтому максимум должен существовать хотя бы в супремум смысл.
Обратите внимание, что некоторые авторы определяют функцию Sп(θ) несколько иначе. Особенно, Раннеби (1984) умножает каждый Dя в раз (п+1), тогда как Ченг и Стивенс (1989) опустить1⁄п+1 поставьте множитель перед суммой и добавьте знак «-», чтобы превратить максимизацию в минимизацию. Поскольку это константы относительно θ, модификации не изменяют положение максимума функции Sп.
Примеры
В этом разделе представлены два примера расчета оценки максимального интервала.
Пример 1

Сюжеты бревно значение λ для упрощенного примера при оценке правдоподобия и интервала. Идентифицируются значения, для которых максимизированы как вероятность, так и интервал, оценки максимального правдоподобия и максимального интервала.
Предположим два значения Икс(1) = 2, Икс(2) = 4 были взяты из экспоненциальное распределение F(Икс;λ) = 1 – e−xλ, Икс ≥ 0 с неизвестным параметром λ > 0. Чтобы построить MSE, мы должны сначала найти интервалы:
| я | F(Икс(я)) | F(Икс(я−1)) | Dя = F(Икс(я)) − F(Икс(я−1)) |
|---|---|---|---|
| 1 | 1 – е−2λ | 0 | 1 – е−2λ |
| 2 | 1 – е−4λ | 1 – е−2λ | е−2λ – е−4λ |
| 3 | 1 | 1 – е−4λ | е−4λ |
Процесс продолжается поиском λ что максимизирует среднее геометрическое значение столбца «разница». Используя соглашение, которое игнорирует принятие (п+1) корень, это превращается в максимизацию следующего произведения: (1 – e−2λ) · (E−2λ – е−4λ) · (E−4λ). Сдача μ = e−2λ, проблема сводится к нахождению максимума μ5−2μ4+μ3. Дифференцируя, μ должен удовлетворить 5μ4−8μ3+3μ2 = 0. Это уравнение имеет корни 0, 0,6 и 1. Поскольку μ на самом деле е−2λ, он должен быть больше нуля, но меньше единицы. Поэтому единственное приемлемое решение –

что соответствует экспоненциальному распределению со средним значением1⁄λ ≈ 3,915. Для сравнения: оценка максимального правдоподобия λ является обратной величиной выборочного среднего, 3, поэтому λMLE = ⅓ ≈ 0.333.
Пример 2
Предполагать {Икс(1), …, Икс(п)} – это заказанный образец из равномерное распределение U(а,б) с неизвестными конечными точками а и б. Кумулятивная функция распределения: F(Икс;а,б) = (Икс−а)/(б−а) когда Икс∈[а,б]. Следовательно, индивидуальные интервалы задаются

Вычисление среднего геометрического, а затем логарифм, статистика Sп будет равно

Здесь только три члена зависят от параметров а и б. Дифференцируя по этим параметрам и решая полученную линейную систему, максимальные оценки интервалов будут

Это, как известно, равномерно минимальная дисперсия несмещенная (UMVU) оценки для непрерывного равномерного распределения.[1] Для сравнения, оценки максимального правдоподобия для этой проблемы  и
и  предвзяты и имеют более высокие среднеквадратичная ошибка.
предвзяты и имеют более высокие среднеквадратичная ошибка.
Характеристики
Последовательность и эффективность
Плотность

Распределение
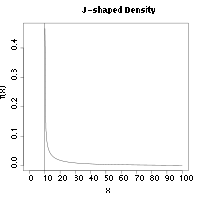
Оценка максимального интервала – это согласованная оценка в этом сходится по вероятности к истинному значению параметра, θ0, при увеличении размера выборки до бесконечности.[2] Непротиворечивость оценки максимального интервала сохраняется при гораздо более общих условиях, чем для максимальная вероятность оценщики. В частности, в случаях, когда базовое распределение имеет J-образную форму, максимальная вероятность не удастся, если MSE успешно.[1] Примером J-образной плотности является Распределение Вейбулла, в частности сдвинутый Вейбулл, с параметр формы меньше 1. Плотность будет стремиться к бесконечности при Икс приближается к параметр местоположения делает оценки других параметров несовместимыми.
Оценки максимального интервала также не ниже асимптотически эффективный в качестве оценок максимального правдоподобия, если таковые существуют. Однако MSE могут существовать в случаях, когда MLE отсутствуют.[1]
Чувствительность
Оценщики максимального разнесения чувствительны к близко разнесенным наблюдениям, и особенно к привязкам.[8] Данный

мы получили

Когда связи происходят из-за нескольких наблюдений, повторяющиеся интервалы (те, которые в противном случае были бы равны нулю) должны быть заменены соответствующей вероятностью.[1] То есть следует заменить  за
за  , в качестве
, в качестве

поскольку  .
.
Если ничья связана с ошибкой округления, Ченг и Стивенс (1989) предложите другой способ устранения последствий.[примечание 1]Данный р связанные наблюдения от Икся к Икся+р−1, позволять δ представляют ошибка округления. Тогда все истинные значения должны попадать в диапазон  . Соответствующие точки распределения теперь должны находиться между
. Соответствующие точки распределения теперь должны находиться между  и
и  . Ченг и Стивенс предлагают предположить, что округленные значения равны равномерно распределенный в этом интервале, определяя
. Ченг и Стивенс предлагают предположить, что округленные значения равны равномерно распределенный в этом интервале, определяя

Метод MSE также чувствителен к вторичной кластеризации.[8] Одним из примеров этого явления является случай, когда считается, что набор наблюдений исходит от одного нормальное распределение, но на самом деле происходит от смесь нормали разными средствами. Второй пример – когда считается, что данные поступают из экспоненциальное распределение, но на самом деле происходит от гамма-распределение. В последнем случае в нижней части хвоста могут быть меньшие расстояния. Высокая стоимость M(θ) будет указывать на этот вторичный эффект кластеризации и предполагает необходимость более внимательного изучения данных.[8]
Тест Морана
Статистика Sп(θ) также является формой Моран или статистика Морана-Дарлинга, M(θ), который можно использовать для тестирования степень соответствия.[заметка 2]Было показано, что статистика, определяемая как

является асимптотически нормальный, и что приближение хи-квадрат существует для небольших выборок.[8] В случае, если мы знаем истинный параметр  , Ченг и Стивенс (1989) показать, что статистика
, Ченг и Стивенс (1989) показать, что статистика  имеет нормальное распределение с
имеет нормальное распределение с

куда γ это Константа Эйлера – Маскерони что примерно равно 0,57722.[заметка 3]
Распределение также можно аппроксимировать распределением  , куда
, куда
 ,
,

в котором

и где  следует за распределение хи-квадрат с
следует за распределение хи-квадрат с  степени свободы. Поэтому для проверки гипотезы
степени свободы. Поэтому для проверки гипотезы  что случайная выборка значения поступают из распределения
что случайная выборка значения поступают из распределения  , статистика
, статистика  можно рассчитать. потом должен быть отклонен с значимость
можно рассчитать. потом должен быть отклонен с значимость  если значение больше, чем критическое значение соответствующего распределения хи-квадрат.[8]
если значение больше, чем критическое значение соответствующего распределения хи-квадрат.[8]
Где θ0 оценивается  , Ченг и Стивенс (1989) показало, что
, Ченг и Стивенс (1989) показало, что  имеет те же асимптотическое среднее и дисперсию, что и в известном случае. Однако используемый тестовый статистический показатель требует добавления поправочного члена смещения и составляет:
имеет те же асимптотическое среднее и дисперсию, что и в известном случае. Однако используемый тестовый статистический показатель требует добавления поправочного члена смещения и составляет:

куда  – количество параметров в оценке.
– количество параметров в оценке.
Обобщенный максимальный интервал
Альтернативные размеры и интервалы
Раннеби и Экстрём (1997) обобщил метод MSE для аппроксимации других меры помимо меры Кульбака – Лейблера. Экстрём (1997) далее расширил метод, чтобы исследовать свойства оценок с использованием интервалов более высокого порядка, где м– интервал порядка будет определен как  .
.
Многомерные распределения
Раннеби и др. (2005) обсудить расширенные методы максимального интервала для многомерный дело. Поскольку нет естественного порядка для  , они обсуждают два альтернативных подхода: геометрический подход, основанный на Клетки Дирихле и вероятностный подход, основанный на метрике «мяч ближайшего соседа».
, они обсуждают два альтернативных подхода: геометрический подход, основанный на Клетки Дирихле и вероятностный подход, основанный на метрике «мяч ближайшего соседа».
Смотрите также
- Дивергенция Кульбака – Лейблера
- Максимальная вероятность
- Распределение вероятностей
Примечания
- ^ Похоже, что в статье допущены незначительные опечатки. Например, в разделе 4.2, уравнение (4.1), замена округления для , не должно содержать термин журнала. В разделе 1 уравнение (1.2), определяется как сам интервал, а отрицательная сумма журналов . Если регистрируется на этом шаге, результат всегда ≤ 0, так как разница между двумя соседними точками на кумулятивном распределении всегда ≤ 1, и строго <1, если только две точки на опорах. Кроме того, в разделе 4.3 на стр. 392 расчет показывает, что это дисперсия который имеет оценку MPS 6,87, а не стандартное отклонение . – редактор
- ^ В литературе соответствующие статистические данные называются статистикой Морана или Морана-Дарлинга. Например, Ченг и Стивенс (1989) проанализировать форму куда определяется, как указано выше. Вонг и Ли (2006) используйте ту же форму. Тем не мение, Beirlant и др. (2001) использует форму , с дополнительным фактором внутри записанной суммы. Дополнительные факторы будут иметь значение с точки зрения ожидаемого среднего и дисперсии статистики. Для единообразия в этой статье будет по-прежнему использоваться форма Ченг и Амин / Вонг и Ли. – редактор
- ^ Вонг и Ли (2006) исключить Константа Эйлера – Маскерони из их описания. – редактор








Рекомендации
Цитаты
- ^ а б c d е ж Ченг и Амин (1983)
- ^ а б c Раннеби (1984)
- ^ Холл и др. (2004)
- ^ Анатольев и Косенок (2004)
- ^ Песяк (2014)
- ^ Вонг и Ли (2006)
- ^ Пайк (1965)
- ^ а б c d е Ченг и Стивенс (1989)
Процитированные работы
- Анатольев, Станислав; Косенок, Григорий (2005). «Альтернатива максимальной вероятности на основе расстояний» (PDF). Эконометрическая теория. 21 (2): 472–476. CiteSeerX 10.1.1.494.7340. Дои:10.1017 / S0266466605050255. Получено 2009-01-21.
- Beirlant, J .; Dudewicz, E.J .; Györfi, L .; ван дер Мейлен, E.C. (1997). «Непараметрическая оценка энтропии: обзор» (PDF). Международный журнал математических и статистических наук. 6 (1): 17–40. ISSN 1055-7490. Архивировано из оригинал (PDF) 5 мая 2005 г.. Получено 2008-12-31. Примечание: связанный документ является обновленной версией 2001 года.
- Cheng, R.C.H .; Амин, Н.А.К. (1983). «Оценка параметров в непрерывных одномерных распределениях со смещенным началом координат». Журнал Королевского статистического общества, серия B. 45 (3): 394–403. Дои:10.1111 / j.2517-6161.1983.tb01268.x. ISSN 0035-9246. JSTOR 2345411.CS1 maint: ref = harv (связь)
- Cheng, R.C.H; Стивенс, М.А. (1989). «Тест согласия с использованием статистики Морана с оценочными параметрами». Биометрика. 76 (2): 386–392. Дои:10.1093 / biomet / 76.2.385.CS1 maint: ref = harv (связь)
- Экстрём, Магнус (1997). «Обобщенные оценки максимального интервала». Университет Умео, факультет математики. 6. ISSN 0345-3928. Архивировано из оригинал 14 февраля 2007 г.. Получено 2008-12-30.CS1 maint: ref = harv (связь)
- Холл, M.J .; van den Boogaard, H.F.P .; Fernando, R.C .; Mynett, A.E. (2004). «Построение доверительных интервалов для частотного анализа с использованием методов передискретизации». Гидрология и науки о Земле. 8 (2): 235–246. Дои:10.5194 / hess-8-235-2004. ISSN 1027-5606.
- Печак, Томаш (2014). Оценка максимального интервала шума в данных МРТ с одной катушкой (PDF). Международная конференция IEEE по обработке изображений. Париж. стр. 1743–1747. Получено 2015-07-07.
- Пайк, Рональд (1965). «Промежутки». Журнал Королевского статистического общества, серия B. 27 (3): 395–449. Дои:10.1111 / j.2517-6161.1965.tb00602.x. ISSN 0035-9246. JSTOR 2345793.CS1 maint: ref = harv (связь)
- Раннеби, Бо (1984). «Метод максимального интервала. Метод оценки, относящийся к методу максимального правдоподобия». Скандинавский статистический журнал. 11 (2): 93–112. ISSN 0303-6898. JSTOR 4615946.CS1 maint: ref = harv (связь)
- Раннеби, Бо; Экстрём, Магнус (1997). «Оценка максимального интервала на основе различных показателей». Университет Умео, факультет математики. 5. ISSN 0345-3928. Архивировано из оригинал 14 февраля 2007 г.. Получено 2008-12-30.CS1 maint: ref = harv (связь)
- Раннеби, Бо; Джаммаламадакаб, С. Рао; Тетеруковский, Алексей (2005). «Оценка максимального интервала для многомерных наблюдений» (PDF). Журнал статистического планирования и вывода. 129 (1–2): 427–446. Дои:10.1016 / j.jspi.2004.06.059. Получено 2008-12-31.
- Вонг, Т.С.Т .; Ли, В.К. (2006). «Примечание об оценке распределений экстремальных значений с использованием максимального произведения расстояний». Временные ряды и связанные темы: памяти Чинг-Цзун Вэя. Конспект лекций Института математической статистики – Серия монографий. Бичвуд, Огайо: Институт математической статистики. С. 272–283. arXiv:математика / 0702830v1. Дои:10.1214/074921706000001102. ISBN 978-0-940600-68-3.CS1 maint: ref = harv (связь)
6.1 Сокращенная и тупиковая ДНФ
6.2 Метод импликантных матриц
Цель данного раздела – изложение основных методов построения минимальных дизъюнктивно нормальных форм.
6.1 Сокращенная и тупиковая ДНФ. В разделе 3 было показано, что любая булева функция может быть представлена дизъюнктивной нормальной формой. Следует отметить, что дизъюнктивная нормальная форма часто допускает упрощение. При этом путем различных тождественных преобразований получится дизъюнктивная нормальная форма, эквивалентная исходной, но содержащая меньшее число вхождений символов.
Дизъюнктивная нормальная форма называется Минимальной, если она включает минимальное число символов по сравнению со всеми другими эквивалентами ей дизъюнктивными нормальными формами.
Заметим, что если некоторый символ в формуле, скажем ![]() , встречается, например, два раза, то при подсчете числа символов в формуле он учитывается два раза.
, встречается, например, два раза, то при подсчете числа символов в формуле он учитывается два раза.
Основной вопрос данного параграфа – это как для произвольной булевой функции построить ей минимальную дизъюнктивную нормальную форму. Эта задача называется Проблемой минимизации булевых функций.
Существует тривиальный алгоритм построения минимальной ДНФ для произвольной булевой функции ![]() . Для этого все ДНФ, составленные из символов
. Для этого все ДНФ, составленные из символов ![]() упорядочиваются по числу букв и по порядку для каждой ДНФ Д проверяется соотношение
упорядочиваются по числу букв и по порядку для каждой ДНФ Д проверяется соотношение ![]() . Первая по порядку ДНФ, для которой это соотношение выполняется, есть, очевидно, минимальная ДНФ функции
. Первая по порядку ДНФ, для которой это соотношение выполняется, есть, очевидно, минимальная ДНФ функции ![]() .
.
Число различных ДНФ, составленных из переменных ![]() , равно
, равно ![]() .
.
Прежде чем доказать данное утверждение, приведем следующее определение.
Конъюнкция ![]() называется Элементарной, если
называется Элементарной, если ![]() при
при ![]() .
.
Число R называется Рангом элементарной конъюнкции. В случае r=0 конъюнкция называется Пустой и Полагается равной 1.
Так как каждая из N переменных ![]() либо не входит в элементарную, либо входят в нее с отрицанием, либо без отрицания, то число элементарных конъюнкций, составленных из
либо не входит в элементарную, либо входят в нее с отрицанием, либо без отрицания, то число элементарных конъюнкций, составленных из ![]() равно
равно ![]() . Ясно, что число различных ДНФ, составленных из переменной
. Ясно, что число различных ДНФ, составленных из переменной ![]() , равно числу подмножеств множества, из
, равно числу подмножеств множества, из ![]() элементов, т. е.
элементов, т. е. ![]() .
.
Рассмотрим геометрическую интерпретацию задачи минимизации булевых функций.
Обозначим через ![]() множество всех точек
множество всех точек ![]() , где
, где ![]() . Ясно, что
. Ясно, что ![]() – множество всех вершин единичного n-мерного куба.
– множество всех вершин единичного n-мерного куба.
Сопоставим каждой булевой функции ![]() Подмножество
Подмножество ![]() Из
Из ![]() , определенное следующим образом:
, определенное следующим образом:
![]()
Например, функции
|
X |
Y |
Z |
|
|
0 |
0 |
0 |
0 |
|
0 |
0 |
1 |
1 |
|
0 |
1 |
0 |
0 |
|
0 |
1 |
1 |
1 |
|
1 |
0 |
0 |
0 |
|
1 |
0 |
1 |
1 |
|
1 |
1 |
0 |
1 |
|
1 |
1 |
1 |
1 |
Соответствует подмножество ![]()
Вершин трехмерного единичного куба

Данное соответствие является взаимно однозначным и обладает следующими свойствами:
1) булевой функции ![]() Соответствует подмножество
Соответствует подмножество ![]() ;
;
2) булевой функции ![]() соответствует подмножество
соответствует подмножество ![]() ;
;
3) булевой функции ![]() соответствует подмножество
соответствует подмножество ![]() .
.
Докажем утверждение 2. Пусть ![]()
Отсюда ![]() .
.
Тогда ![]() .
.
А это значит, что ![]() .
.
Отсюда ![]() .
.
Пусть ![]() ДНФ, где
ДНФ, где ![]() – элементарные конъюнкции. Подмножество
– элементарные конъюнкции. Подмножество ![]() называется интервалом R-го ранга, если оно соответствует элементарной конъюнкции К R-го ранга. Как показано выше,
называется интервалом R-го ранга, если оно соответствует элементарной конъюнкции К R-го ранга. Как показано выше, ![]() . Итак, с каждой ДНФ функции F связано покрытие
. Итак, с каждой ДНФ функции F связано покрытие ![]() такими интервалами
такими интервалами ![]() , что
, что ![]() .
.
Пусть ![]() – ранг интервала
– ранг интервала ![]() . Тогда
. Тогда ![]() совпадает с числом букв в ДНФ
совпадает с числом букв в ДНФ ![]() функции
функции ![]() .
.
Теперь ясно, что задача построения минимальной ДНФ сводится к отысканию такого покрытия подмножества ![]() интервалами
интервалами ![]() , чтобы число
, чтобы число ![]() было наименьшим.
было наименьшим.
Интервал ![]() , содержащий
, содержащий ![]() , называется Максимальным для булевой функции, если не существует интервала
, называется Максимальным для булевой функции, если не существует интервала ![]() , такого, что
, такого, что ![]() .
.
Заметим, что соотношение ![]() выполняется тогда и только тогда, когда элементарная конъюнкция
выполняется тогда и только тогда, когда элементарная конъюнкция ![]() получается из элементарной конъюнкции К путем вычеркивания непустого числа сомножителей.
получается из элементарной конъюнкции К путем вычеркивания непустого числа сомножителей.
Очевидно, что каждый интервал ![]() из
из ![]() содержится в некотором максимальном интервале. Если
содержится в некотором максимальном интервале. Если ![]() – список всех максимальных интервалов подмножества
– список всех максимальных интервалов подмножества ![]() , то нетрудно видеть, что
, то нетрудно видеть, что ![]() .
.
ДНФ ![]() булевой функции f, соответствующая покрытию подмножества
булевой функции f, соответствующая покрытию подмножества ![]() всеми максимальными интервалами, называется Сокращенной ДНФ функции F.
всеми максимальными интервалами, называется Сокращенной ДНФ функции F.
Ясно, что сокращенная ДНФ для любой булевой функции f определяется однозначно.
Пример 1. Пусть ![]() . Обозначим
. Обозначим ![]() ,
, ![]() ,
, ![]() . Найдем соответствующие этим конъюнкциям интервалы
. Найдем соответствующие этим конъюнкциям интервалы ![]() ,
, ![]() ,
, ![]() .
.
Изобразим эти интервалы

Очевидно, что ![]() и
и ![]() – все максимальные интервалы. Интервал
– все максимальные интервалы. Интервал ![]() не является максимальным, ибо
не является максимальным, ибо ![]() . Следовательно, покрытию подмножества
. Следовательно, покрытию подмножества ![]() соответствует сокращенная ДНФ функции
соответствует сокращенная ДНФ функции ![]() , равная
, равная ![]() .
.
Данный геометрический подход дает и метод построения сокращенной ДНФ.
Теперь рассмотрим аналитический метод построения сокращенной ДНФ – метод Блейка. Этот метод основан на следующей теореме.
Теорема 1. Если в произвольной ДНФ булевой функции F произвести все возможные обобщения склеивания и устранить затем все элементарные поглощения, то в результате получиться сокращенная ДНФ функции F.
Следовательно, чтобы найти сокращенную ДНФ, надо к произвольной ДНФ данной функции применить правило обобщенного склеивания ![]() до тех пор, пока это возможно, а затем правило поглощения.
до тех пор, пока это возможно, а затем правило поглощения.
Пример 2. Найти сокращенную ДНФ для функции ![]() . Применяя правило обобщенного склеивания, получаем:
. Применяя правило обобщенного склеивания, получаем: ![]() .
.
Затем правило поглощения и находим сокращенную ДНФ: ![]() .
.
Рассмотрим еще один метод построения сокращенной ДНФ – метод Нельсона. Этот метод основан на следующей теореме.
Теорема 2. Если в произвольной КНФ булевой функции раскрыть все скобки в соответствии с дистрибутивным законом и устранить все элементарные поглощения, то в результате получится сокращенная ДНФ этой функции.
Пример 3. Найти сокращенную ДНФ для функции
![]()
После раскрытия скобок с помощью дистрибутивного закона, получаем:
![]() .
.
Так как ![]() ,
, ![]() , то имеем:
, то имеем:
![]() .
.
Далее, применяя правило поглощения, получаем сокращенную ДНФ:
![]() .
.
Рассмотрим табличный метод построения сокращенной ДНФ. Этот метод основан на составлении прямоугольной таблицы (минимизирующей карты).
Минимизирующие карты для булевых функций от трех и от четырех переменных изображены на следующих таблицах.
|
Z X y |
0 |
1 |
|
00 |
||
|
01 |
||
|
11 |
||
|
10 |
|
X4 X3 X1 X2 |
0 0 |
0 1 |
1 1 |
1 0 |
|
0 0 |
||||
|
0 1 |
||||
|
1 1 |
||||
|
1 0 |
Объединяя соседние клетки, соответствующие единичным значениям булевой функции f в максимальные интервалы, и сопоставляя им элементарные конъюнкции, получим сокращенную ДНФ. Отметим, что клетки, расположенные по краям таблицы, также считаются соседними. Покажем работу этого метода на следующем примере.
Пример 4. Найти сокращенную ДНФ для функции, заданной следующей таблицей.
|
X4 X3 X1 X2 |
0 0 |
0 1 |
1 1 |
1 0 |
|
0 0 |
1 |
1 |
0 |
1 |
|
0 1 |
0 |
1 |
1 |
0 |
|
1 1 |
1 |
1 |
1 |
0 |
|
1 0 |
0 |
1 |
0 |
0 |
В данной таблице объединены клетки в максимальные интервалы
![]()
![]()
![]()
![]()
![]() .
.
Этим интервалам соответствуют элементарные конъюнкции
![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]()
Следовательно, сокращенная ДНФ для данной функции имеет вид:
![]()
Построение сокращенной ДНФ есть только первый этап решения задачи минимизации булевой функции. В общем случае сокращенная ДНФ не является минимальной. Следующая теорема устанавливает связь между минимальной и сокращенной ДНФ.
Теорема 3. Минимальная ДНФ булевой функции получается из сокращенной ДНФ данной функции путем удаления некоторых элементарных конъюнкций.
Доказательство этого утверждения следует из того факта, что покрытие подмножества ![]() , отвечающее минимальной ДНФ, состоит только из максимальных интервалов. Действительно, если бы покрытие содержало не максимальный интервал, то его можно было бы заменить объемлющим максимальным интервалом. В результате этого сумма рангов интервалов данного покрытия уменьшилась бы, что противоречит предположению о минимальности ДНФ.
, отвечающее минимальной ДНФ, состоит только из максимальных интервалов. Действительно, если бы покрытие содержало не максимальный интервал, то его можно было бы заменить объемлющим максимальным интервалом. В результате этого сумма рангов интервалов данного покрытия уменьшилась бы, что противоречит предположению о минимальности ДНФ.
Покажем, что в классе монотонных функций понятия минимальной и сокращенной ДНФ совпадают.
Теорема 4. Сокращенная ДНФ монотонной булевой функции не содержит отрицаний переменных и является минимальной ДНФ этой функции.
Пусть К – элементарная конъюнкция, входящая в сокращенную ДНФ. Предположим, что К содержит отрицание переменных. Обозначим через ![]() произведение всех переменных, входящих в К без отрицания. Пусть
произведение всех переменных, входящих в К без отрицания. Пусть ![]() – набор переменных, в которых всем переменным, входящим в
– набор переменных, в которых всем переменным, входящим в ![]() , приписано значение 1, а всем остальным – значение 0. Ясно, что при этом наборе значение функции
, приписано значение 1, а всем остальным – значение 0. Ясно, что при этом наборе значение функции ![]() Равно 1. Элементарная конъюнкция
Равно 1. Элементарная конъюнкция ![]() обращается в 1 при всех наборах
обращается в 1 при всех наборах ![]() . Очевидно, что при этих наборах значение функции
. Очевидно, что при этих наборах значение функции ![]() также равно 1. Следовательно,
также равно 1. Следовательно, ![]() .
.
Получили противоречие с максимальностью интервала ![]() . Итак, сокращенная ДНФ булевой функции
. Итак, сокращенная ДНФ булевой функции ![]() Не содержит отрицаний переменных.
Не содержит отрицаний переменных.
Пусть ![]() – любая элементарная конъюнкция из сокращенной ДНФ. Конъюнкция К является единственной конъюнкцией сокращенной ДНФ, которая обращается в единицу в вершине с координатами
– любая элементарная конъюнкция из сокращенной ДНФ. Конъюнкция К является единственной конъюнкцией сокращенной ДНФ, которая обращается в единицу в вершине с координатами ![]() . Действительно, если бы в сокращенной ДНФ какая-нибудь другая элементарная конъюнкция
. Действительно, если бы в сокращенной ДНФ какая-нибудь другая элементарная конъюнкция ![]() обращалась в этой вершине в 1, то не содержала бы, во-первых, букв
обращалась в этой вершине в 1, то не содержала бы, во-первых, букв ![]() , и, во-вторых, букв
, и, во-вторых, букв ![]() . Поэтому в конъюнкцию
. Поэтому в конъюнкцию ![]() могли бы входить лишь буквы
могли бы входить лишь буквы ![]() , причем не все. Но тогда
, причем не все. Но тогда ![]() . Получили противоречие с максимальностью интервала
. Получили противоречие с максимальностью интервала ![]() . Следовательно, для любого максимального интервала
. Следовательно, для любого максимального интервала ![]() существует вершина куба
существует вершина куба ![]() , которая покрывается только этим интервалом. Поэтому из покрытия
, которая покрывается только этим интервалом. Поэтому из покрытия ![]() соответствующего сокращенной ДНФ, нельзя удалить ни одного из интервалов. Теперь, применяя предыдущую теорему, получаем требуемый результат.
соответствующего сокращенной ДНФ, нельзя удалить ни одного из интервалов. Теперь, применяя предыдущую теорему, получаем требуемый результат.
Следует отметить, что сокращенная ДНФ в большинстве случаев допускает дальнейшие упрощения за счет того, что некоторые элементарные конъюнкции могут поглощаться дизъюнкциями других элементарных конъюнкций. Действительно, в сокращенной ДНФ
![]()
Элементарная конъюнкция ![]() поглощается дизъюнкцией остальных элементарных конъюнкций, т. е.
поглощается дизъюнкцией остальных элементарных конъюнкций, т. е. ![]() .
.
Ввиду этого введем следующее определение.
Покрытие области истинности булевой функции максимальными интервалами называется Неприводимым, если после удаления из него любого интервала оно перестает быть покрытием. ДНФ булевой функции ![]() , соответствующая неприводимому покрытию, называется Тупиковой.
, соответствующая неприводимому покрытию, называется Тупиковой.
Теорема 5. Всякая минимальная ДНФ является тупиковой.
Доказательство этого утверждения следует из того, что покрытие, соответствующее минимальной ДНФ, является неприводимым.
Заметим, что булева функция может обладать несколькими различными минимальными ДНФ. Существуют также тупиковые ДНФ, не являющиеся минимальными ДНФ. Соответствующие примеры будут разобраны ниже.
Из того, что минимальная ДНФ является тупиковой, следует общая схема решения задачи минимизации булевых функций.
1. Выделяются все максимальные интервалы, и строится сокращенная ДНФ.
2. Строятся все тупиковые ДНФ.
3. Среди всех тупиковых ДНФ выделяются все минимальные ДНФ.
Рассмотрим алгоритм построения всех тупиковых ДНФ. Суть данного алгоритма состоит в следующем:
1) для булевой функции ![]() строим сокращенную ДНФ;
строим сокращенную ДНФ;
2) для каждой вершины ![]() из
из ![]() выделяем в сокращенной ДНФ функции F все такие элементарные конъюнкции
выделяем в сокращенной ДНФ функции F все такие элементарные конъюнкции ![]() , что
, что ![]() ;
;
3) составляем выражение вида
![]() (*)
(*)
4) применяем к выражению вида (*) законы дистрибутивности и поглощения. В результате получаем ![]() .
.
Теперь каждая ДНФ ![]() является тупиковой ДНФ функции
является тупиковой ДНФ функции ![]() .
.
Рассмотрим работу данного алгоритма на следующем примере.
Пример 5. Рассмотрим булеву функцию, заданную следующей таблицей:
|
X |
Y |
Z |
|
|
0 |
0 |
0 |
0 |
|
0 |
0 |
1 |
1 |
|
0 |
1 |
0 |
1 |
|
0 |
1 |
1 |
1 |
|
1 |
0 |
0 |
1 |
|
1 |
0 |
1 |
1 |
|
1 |
1 |
0 |
1 |
|
1 |
1 |
1 |
0 |
Найдем сокращенную ДНФ данной функции по методу Нельсона. Для этого составим КНФ данной функции ![]() .
.
Применяя законы дистрибутивности, получаем:
![]() .
.
Обозначим ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() .
.
![]()
Составляем выражение (*)
![]()
Преобразуем данное выражение к виду
![]() =
= ![]()
![]() =
=![]() .
.
Таким образом, ![]() имеет шесть тупиковых ДНФ:
имеет шесть тупиковых ДНФ:
![]()
![]()
![]()
![]()
![]()
![]()
Две из них ![]() и
и ![]() являются минимальными.
являются минимальными.
6.2 Метод импликантных матриц. Для булевой функции ![]() находим сокращенную ДНФ
находим сокращенную ДНФ ![]() . Построим для этой функции импликантную матрицу, представляющую собой таблицу, в вертикальные входы которой записываются
. Построим для этой функции импликантную матрицу, представляющую собой таблицу, в вертикальные входы которой записываются ![]() , а в горизонтальные
, а в горизонтальные ![]() .
.
|
|
|
… |
|
… |
|
|
|
|
||||||
|
|
||||||
|
… |
||||||
|
|
+ |
|||||
|
… |
||||||
|
|
Для каждой ![]() находим набор
находим набор ![]() такой, что
такой, что ![]() .
.
Клетку импликантной матрицы, образованную пересечением I-строки и J-столбца отметим крестиком.
Чтобы получить минимальную ДНФ заданной функции, достаточно найти минимальное число ![]() , которые совместно накрывают крестиками все столбцы импликантной матрицы.
, которые совместно накрывают крестиками все столбцы импликантной матрицы.
Пример 6. Найти минимальные ДНФ для функции
![]() .
.
Из предыдущего примера следует, что сокращенная ДНФ для данной функции ![]() . Очевидно, что
. Очевидно, что
![]() .
.
Строим импликантную матрицу
|
(0,0,1) |
(0,1,0) |
(0,1,1) |
(1,0,0) |
(1,0,1) |
(1,1,0) |
|
|
|
+ |
+ |
||||
|
|
+ |
+ |
||||
|
|
+ |
+ |
||||
|
|
+ |
+ |
||||
|
|
+ |
+ |
||||
|
|
+ |
+ |
Отсюда видно, что данная функция имеет два минимальные ДНФ:
![]() ;
; ![]() .
.
Вопросы для самоконтроля.
1. Дайте определение основных логических операций булевой алгебры.
2. Дайте определение булевой функции.
3. Что такое таблицы истинности булевой функции?
4. Каково число булевых функций от ![]() переменных?
переменных?
5. Какие булевы функции называются элементарными?
6. Дайте определение формулы алгебры логики.
7. Какие формулы алгебры логики называются равносильными?
8. Сформулируйте законы алгебры логики.
9. Какая формула алгебры логики называется двойственной к данной формуле алгебры логики?
10. Сформулируйте принцип двойственности.
11. Сформулируйте теорему о разложении и следствие из нее.
12. Дайте определение СДНФ.
13. Приведите алгоритмы построения СДНФ.
14. Дайте определение СКНФ.
15. Приведите алгоритмы построения СКНФ.
16. Дайте определение ДНФ.
17. Как найти ДНФ?
18. Дайте определение КНФ.
19. Как найти КНФ?
20. Какая формула алгебры логики называется тождественно истинной?
21. Какая формула алгебры логики называется тождественно ложной?
22. Какая формула алгебры логики называется выполнимой?
23. Что называется проблемой разрешимости?
24. Сформулируйте методы решения проблемы разрешения.
25. Что называется алгеброй Жегалкина?
26. Сформулируйте законы алгебры Жегалкина.
27. Что называется полиномом Жегалкина?
28. Сформулируйте алгоритмы построения полиномов Жегалкина.
29. Какая система булевых функций называется полной?
30. Что называется замыканием множества булевых функций?
31. Какой класс булевых функций называется замкнутым?
32. Дайте определение пяти важнейших замкнутых классов.
33. Сформулируйте теорему о полноте.
34. Сформулируйте алгоритм Поста.
35. Какая система булевых функций называется несократимой?
36. Каково максимальное возможное число функций в несократимой полной системе булевых функций?
37. Что такое релейно-контактная схема?
38. Почему любую булеву функцию можно изобразить в виде релейно-контактной схемы?
39. В чем состоит проблема анализа релейно-контактных схем?
40. В чем состоит проблема синтеза релейно-контактных схем?
41. Что такое логические элементы?
42. Приведите геометрическое изображение логических элементов.
43. Что такое логическая схема?
44. Что Вы понимаете под двоичным сумматором?
45. Какая ДНФ называется минимальной?
46. Чему равно число всех ДНФ от ![]() переменных?
переменных?
47. Сформулируйте тривиальный алгоритм построения МДНФ?
48. Что такое элементарная конъюнкция?
49. Что такое ранг элементарной конъюнкции?
50. Что называется интервалом элементарной конъюнкции?
51. Какой интервал называется максимальным?
52. Что называется областью истинности булевой функции?
53. Сформулируйте теорему об области истинности булевой функции.
54. Что называется покрытием области истинности булевой функции?
55. Какое число элементов содержится в интервале?
56. Какая ДНФ называется сокращенной?
57. В чем состоит геометрическая интерпретация задачи минимизации булевой функции?
58. Сформулируйте геометрический метод построения сокращенной ДНФ.
59. Сформулируйте метод Нельсона построения сокращенной ДНФ.
60. Сформулируйте метод Блейка построения сокращенной ДНФ.
61. Сформулируйте метод карт Карно построения сокращенной ДНФ.
62. Какая связь между МДНФ и сокращенной ДНФ?
63. Какое покрытие области истинности булевой функции называется неприводимым.
64. Какая ДНФ называется тупиковой?
65. Какая связь между МДНФ и тупиковой ДНФ?
66. Сформулируйте алгоритм построения всех тупиковых ДНФ.
67. Как строится импликантная матрица?
68. Сформулируйте алгоритм нахождения МДНФ методом импликантных матриц.
| < Предыдущая | Следующая > |
|---|
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Given a set of N intervals, the task is to find the maximal set of mutually disjoint intervals. Two intervals [i, j] & [k, l] are said to be disjoint if they do not have any point in common.
Examples:
Input: intervals[][] = {{1, 4}, {2, 3}, {4, 6}, {8, 9}}
Output:
[2, 3]
[4, 6]
[8, 9]
Intervals sorted w.r.t. end points = {{2, 3}, {1, 4}, {4, 6}, {8, 9}}
Intervals [2, 3] and [1, 4] overlap.
We must include [2, 3] because if [1, 4] is included then
we cannot include [4, 6].
Input: intervals[][] = {{1, 9}, {2, 3}, {5, 7}}
Output:
[2, 3]
[5, 7]
Approach:
- Sort the intervals, with respect to their end points.
- Now, traverse through all the intervals, if we get two overlapping intervals, then greedily choose the interval with lower end point since, choosing it will ensure that intervals further can be accommodated without any overlap.
- Apply the same procedure for all the intervals and print all the intervals which satisfy the above criteria.
Below is the implementation of the above approach:
C++
#include <bits/stdc++.h>
using namespace std;
#define ll long long int
bool sortbysec(const pair<int, int>& a,
const pair<int, int>& b)
{
return (a.second < b.second);
}
void maxDisjointIntervals(vector<pair<int, int> > list)
{
sort(list.begin(), list.end(), sortbysec);
cout << "[" << list[0].first << ", "
<< list[0].second << "]" << endl;
int r1 = list[0].second;
for (int i = 1; i < list.size(); i++) {
int l1 = list[i].first;
int r2 = list[i].second;
if (l1 > r1) {
cout << "[" << l1 << ", "
<< r2 << "]" << endl;
r1 = r2;
}
}
}
int main()
{
int N = 4;
vector<pair<int, int> > intervals = { { 1, 4 },
{ 2, 3 },
{ 4, 6 },
{ 8, 9 } };
maxDisjointIntervals(intervals);
return 0;
}
Java
import java.io.*;
import java.util.*;
public class GFG
{
static class Pair implements Comparable<Pair>
{
int first, second;
Pair(int f, int s)
{
first = f;
second = s;
}
@Override
public int compareTo(Pair o)
{
if(this.second > o.second)
return 1;
else if(this.second == o.second)
return 0;
return -1;
}
}
static void maxDisjointIntervals(Pair []list)
{
Collections.sort(Arrays.asList(list));
System.out.print("[" + list[0].first+ ", "
+ list[0].second+ "]" +"n");
int r1 = list[0].second;
for (int i = 1; i < list.length; i++) {
int l1 = list[i].first;
int r2 = list[i].second;
if (l1 > r1) {
System.out.print("[" + l1+ ", "
+ r2+ "]" +"n");
r1 = r2;
}
}
}
public static void main(String[] args)
{
int N = 4;
Pair []intervals = { new Pair(1, 4 ),
new Pair( 2, 3 ),
new Pair( 4, 6 ),
new Pair( 8, 9 ) };
maxDisjointIntervals(intervals);
}
}
Python3
def maxDisjointIntervals(list_):
list_.sort(key = lambda x: x[1])
print("[", list_[0][0], ", ", list_[0][1], "]")
r1 = list_[0][1]
for i in range(1, len(list_)):
l1 = list_[i][0]
r2 = list_[i][1]
if l1 > r1:
print("[", l1, ", ", r2, "]")
r1 = r2
if __name__ == "__main__":
N = 4
intervals = [ [ 1, 4 ], [ 2, 3 ],
[ 4, 6 ], [ 8, 9 ] ]
maxDisjointIntervals(intervals)
C#
using System;
using System.Collections.Generic;
class Program
{
static void Main(string[] args)
{
int N = 4;
List<Tuple<int, int>> intervals = new List<Tuple<int, int>>()
{
new Tuple<int, int>(1, 4),
new Tuple<int, int>(2, 3),
new Tuple<int, int>(4, 6),
new Tuple<int, int>(8, 9)
};
MaxDisjointIntervals(intervals);
}
private static void MaxDisjointIntervals(List<Tuple<int, int>> list)
{
list.Sort((a, b) => a.Item2.CompareTo(b.Item2));
Console.WriteLine("[" + list[0].Item1 + ", " + list[0].Item2 + "]");
int r1 = list[0].Item2;
for (int i = 1; i < list.Count; i++)
{
int l1 = list[i].Item1;
int r2 = list[i].Item2;
if (l1 > r1)
{
Console.WriteLine("[" + l1 + ", " + r2 + "]");
r1 = r2;
}
}
}
}
Javascript
<script>
function maxDisjointIntervals(list)
{
list.sort((a,b)=> a[1]-b[1]);
document.write( "[" + list[0][0] + ", "
+ list[0][1] + "]" + "<br>");
var r1 = list[0][1];
for (var i = 1; i < list.length; i++) {
var l1 = list[i][0];
var r2 = list[i][1];
if (l1 > r1) {
document.write( "[" + l1 + ", "
+ r2 + "]" + "<br>");
r1 = r2;
}
}
}
var N = 4;
var intervals = [ [ 1, 4 ],
[ 2, 3 ],
[ 4, 6 ],
[ 8, 9 ] ];
maxDisjointIntervals(intervals);
</script>
Output:
[2, 3] [4, 6] [8, 9]
Time Complexity: O(nlogn)
Auxiliary Space: O(1)
Last Updated :
20 Feb, 2023
Like Article
Save Article
Макеты страниц
 превышает
превышает  Может так оказаться, что верно и то и другое, но всегда должно быть справедливо по крайней мере одно из этих утверждений.
Может так оказаться, что верно и то и другое, но всегда должно быть справедливо по крайней мере одно из этих утверждений.
Мы будем изображать интервалы между  и между
и между  так, как это делалось выше.
так, как это делалось выше.

Фиг. 29.
Начертим треугольники  (фиг. 29) так, чтобы
(фиг. 29) так, чтобы  было параллельно
было параллельно  причем
причем  кроме того,
кроме того,  Продолжим
Продолжим  до пересечения в точке
до пересечения в точке  мы получим прямоугольник
мы получим прямоугольник  Интервалы между
Интервалы между  и между
и между  изображаются отрезками
изображаются отрезками  и
и  но
но  Поэтому сумма интервалов между
Поэтому сумма интервалов между  и между
и между  равна
равна  Интервал между
Интервал между  равен
равен 
Если  не равно
не равно  то треугольники
то треугольники  не будут подобны и соответственно углы
не будут подобны и соответственно углы  не будут равны между собой. Это означает, что отрезки
не будут равны между собой. Это означает, что отрезки  не лежат на одной прямой и, следовательно,
не лежат на одной прямой и, следовательно,  больше
больше  или
или 
Кроме того,  не может превосходить
не может превосходить  Таким образом, интервал между
Таким образом, интервал между  равен
равен

Находим
максимальные интервалы данной функции.
Их будет 4. Это четыре ребра: x1
![]()
,
x1
x2
, x2
x3
,
![]() x3
x3
.
Д ействительно,
ействительно,
данные интервалы являются допустимыми
и при удалении любого множителя получается
интервал грань, а допустимых граней для
данной функции нет. Других максимальных
интервалов для данной функции также не
существует.
Первый
этап завершен.
2 Этап:
Найти
все тупиковые покрытия.
![]() ;
;
![]() .
.
И
других тупиковых покрытий нет.
Действительно,
интервал
![]() обязан входить в любое покрытие , т.к.
обязан входить в любое покрытие , т.к.
только он покрывает вершину 100. Интервал![]() обязан входить в любое покрытие, т.к.
обязан входить в любое покрытие, т.к.
только он покрывает вершину 001. Остаются
два интервала![]() ;
;![]() , из которых достаточно взять только
, из которых достаточно взять только
один интервал , чтобы покрыть вершину
111. Сложность тупиковых покрытий
одинакова. Это и есть все минимальные
ДНФ данной функции.
Ответ:
![]()
Аналитический
метод нахождения всех минимальных ДНФ
функции.
2.3 Метод поиска всех максимальных интервалов заданной функции с помощью операции склеивания и сокращения.
I
. Метод нахождения сокращенной ДНФ
функции
![]() .
.
Метод
будет проходить по этапам.
На
начальном (нулевом) этапе рассматриваются
все допустимые интервалы ранга n,
т.е. СДНФ функции f
. На этапе i
ко всевозможным парам интервалов ранга
(n-i) вида
![]() ;
;![]() добавляется на интервалk
добавляется на интервалk
(![]() ;
;![]()
![]() ).
).
Предыдущая
операция называется склеиванием.
После чего применяется операция
поглощения: если есть пара интервалов![]() ;
;![]() , то интервал
, то интервал![]() удаляем.
удаляем.
После этого переходим к очередному
(i+1)–ому этапу. Если на этапеi
операция склеивания не применима ни к
каким интервалам, то алгоритм заканчивается
и множество полученных интервалов и
является в точности множеством всех
максимальных допустимых интервалов.
Рассмотрим
пример:






Этап
0.
![]()
![]()
![]() ;
;
![]()
![]()
![]() ;
;![]()
![]()
![]() ;
;![]()
![]()
![]() ;
;![]()
![]()
![]() – поглощение.
– поглощение.
Применяем
операцию склеивания ко всевозможным
интервалам.
(3-0)=3
1
и 2 , добавляем
![]()
![]() .
.
2
и 3, добавляем
![]()
![]()
2
и 4, добавляем
![]()
3
и 5, добавляем
![]()
![]()
4
и 5 , добавляем
![]()
![]()
После
применения операции поглощения будут
удалены все интервалы ранга 3.
![]()
![]() ,
,
![]()
![]() ,
,![]()
![]() ,
,![]()
![]() ,
,![]()
![]()
Этап
1.
Имеем
интервалы ранга 3-1=2 :
![]()
![]() ,
,![]()
![]() ,
,![]()
![]() ,
,![]()
![]() ,
,![]()
![]() и применяем операцию склеивания .
и применяем операцию склеивания .![]() дадут интервал
дадут интервал![]() .
.
После
применения операции поглощения получим
интервалы :
![]() ;
;![]()
![]() .
.
Этап
2.
Ко
всем интервалам ранга 2-1=1 применяем
операцию склеивания . В данном случае
она не применима. Алгоритм завершает
работу.
Все
максимальные интервалы :
![]() ,
,![]()
![]()
Корректность
алгоритма
.
Покажем,
что действительно алгоритм находит все
допустимые максимальные интервалы
функции f.
Утверждение
1 :
Все
интервалы, которые возникают на этапах
алгоритма являются допустимыми.
Действительно
для интервалов на начальном этапе это
утверждение справедливо, т.к. на начальном
этапе рассматриваются допустимые
интервалы максимального ранга.
Индуктивный
базис .
Пусть
интервал k возник в результате операции
склеивания двух допустимых интервалов
![]() и
и![]() .
.
Тогда интервалk
также является допустимым. Действительно,
набор, на котором конъюнкция K
равна 1 в компоненте, соответствующей
переменной x
может иметь произвольное значение 0 или
1, т. к. данная переменная не входит в
множество переменных рассматриваемой
конъюнкции K.
Тогда, если в этой компоненте набор
имеет единицу, то этот набор будет
единицей конъюнкции
![]() ,
,
а если в рассматриваемой компоненте
набор содержит 0, то тогда это есть
единица конъюнкции![]() .
.
Т. е. единицы конъюнкции K принадлежат
объединению единиц предыдущих двух
конъюнкций. И в силу допустимости этих
двух конъюнкций имеем![]() .
.
Тогда
справедливо
![]() ,
,
т. е. конъюнкцияK
– допустимый интервал.
Утверждение
2:
На входе i-ого этапа интервалы ранга
(n-i) в точности все допустимые интервалы
такого ранга, а интервалы большого
ранга есть в точности все максимальные
интервалы.
Докажем
данное утверждение методом индукции.
На
начальном (нулевом) этапе утверждение
справедливо. Интервалы ранга n
на этом этапе – это все допустимые
конъюнкции ранга n
функции f.
Допустим
утверждение справедливо для этапа i,
т. е. на входе этапа i
содержатся все допустимые интервалы
ранга (n–i),
а интервалы большего ранга есть в
точности все максимальные интервалы
такого ранга.
Рассмотрим
(i+1)
этап и докажем справедливость утверждения
для этого этапа.
Во-первых,
покажем, что любой допустимый интервал
ранга (n-(i+1))
содержится на входе этого этапа.
Рассмотрим
такой допустимый интервал k,
рассмотрим переменную x,
которая не входит в конъюнкцию этого
интервала. Тогда интервалы
![]() и
и![]() являются также допустимыми, т. к. любые
являются также допустимыми, т. к. любые
единицы данных интервалов являются
единицами допустимого интервала k.
Тогда
в силу предположения индукции, эти два
допустимых интервала ранга (n–i)
содержатся на входе этапа i.
После
применения операции склеивания к
рассматриваемым интервалам и получается
интервал k.
Во-вторых,
покажем, что интервалы большего ранга,
чем n–i-1
есть в точности все интервалы такого
ранга.
Рассмотрим
максимальный интервал ранга (n–i)k
и покажем, что он будет содержатся на
входе этапа i+1.
Действительно,
как допустимый интервал ранга (n–i)
по предположению индукции он содержался
на входе этапа i.
И этот интервал в силу своей максимальности
не мог быть поглощенным ни одним из
допустимых интервалов меньшего ранга
n–i-1.
А только допустимые интервалы возникают
на этапах алгоритма.
Поэтому
допустимый интервал k
будет сохранен на этапе i
и по этому будет содержатся на входе
этапа (i+1).
Верно
обратное утверждение, т. е. если интервал
k
ранга (n–i)
содержится на входе i+1
этапа, то этот интервал максимальный.
Действительно,
в силу доказанного данный интервал
допустимый и поэтому содержится на
входе этапа i,
и не был поглощен на i-ом этапе. Но тогда
все интервалы, которые получаются из
данного интервала удалением какого-либо
множителя будут недопустимыми, а поэтому
данный интервал является максимальным.
Поэтому доказано, что любой интервал
ранга n–i
является максимальным и наоборот любой
максимальный ранга n–i
содержится на входе i+1
этапа. Т. е. интервалы ранга n–i,
есть в точности все максимальные
интервалы такого ранга.
Для
интервалов большего ранга, чем (n–i)
утверждение о их максимальности следует
из утверждения базиса индукции этапа
i.
Ч.Т.Д.
Тогда
из данного утверждения корректность
алгоритма следует из справедливости
утверждения для последнего этапа.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
