Для того, чтобы найти ту или иную информацию в интернете, мы пользуемся поисковыми системами. Но откуда поисковик все знает?
Наверняка, данная информация будет полезна, поэтому решил раскрыть тему самым простым языком без сложных и непонятных терминов.
Сайт попадает в поисковую систему двумя способами: если найдет новый сайт по ссылке с других или же владелец сам добавляет свой ресурс в поисковик через специальный личный кабинет.
Поисковая машина является сложным механизмом, который состоит, как минимум, из трех условных частей, мы будем называть их роботами.
1. Поисковый робот
Также его называют «краулер» (Crawler — ползающее насекомое). Приходит на сайт, переходит по страницам и загружает информацию к себе на сервера.
Работа его похожа на работу паука, который ползает по паутине — в этом случае, он переходит по ссылкам внутри сайта и загружает к себе тот контент, который содержится на странице.
Такой робот буквально «живет» на сайтах. Как только поисковому счетчику (Метрика от Яндекса, аналитика от Google или же браузеру со встроенным поиском) станет известно о новой странице, робот тут же приходит на сайт, чтобы получить новую информацию. Все что просканировано, попадает уже к следующему роботу — индексатору.
2. Робот индексатор
Самая сложная часть поисковой системы, которая анализирует страницы, который нашел краулер и создает по ним индекс для поиска, а самое главное определяет порядок ранжирования того или иного сайта.
Ранжирование, если простыми словами объяснять, является местом в выдаче по определенному поисковому запросу, оно вычисляется для каждой страницы исходя из нескольких сотен факторов ранжирования, а также сравнивается с другими сайтами-конкурентами.
На ранжирование сайта и (или) конкретной страницы может влиять: уникальность текста, скорость работы сайта, качество контента, цитируемость сайта, поведение посетителя и еще много много различных факторов. Данные факторы подталкивают владельцу сайта к развитию и улучшению своего проекта.
Таким образом, создается естественная конкуренция между сайтами, ведь каждый владелец хочет чтобы его сайт посещало как можно больше людей. Всеми этими манипуляциями и занимается робот индексатор.
Рекомендую посмотреть: Надоела старая люстра – приобрел необычную
3. Сам поисковик
Который обеспечивает выдачу результатов поиска исходя из запроса пользователя, учитывая язык запросов и различные параметры — тип устройства (смартфон или компьютер), геолокацию и так называемый «пузырь фильтров». Например, если вы посещали ранее какой-либо сайт, то поисковик может вам помочь найти его быстрее.
По факту, сам поисковик это то, что вы видите после ввода запроса. В некоторых случаях поисковик дает возможность посмотреть сохраненную копию страницы, дату индексации документа, различную информацию о сайте и даже кнопку жалобы на результат поисковой выдачи.
Стоит понимать, что поисковая система не может 100% гарантировать индексацию сайта и информации, а еще она обязана подчиняться закону и удалять ссылки, которые противоречат законодательству.
Просто объяснил? Думаю да.
Но сама по себе поисковая система является очень сложным механизмом обработки данных и постоянно совершенствуется, чтобы дать конечному пользователю высокую релевантность запросов.
Поисковая система это тысячи серверов и сотни тысяч накопителей информации, которые расположены в дата центрах всего мира. И буквально каждый день добавляются все новые и новые мощности, чтобы мы легко смогли найти нужную информацию в сети.
Подписывайтесь, чтобы не пропустить новые публикации:
Телеграм-канал | Группа Вконтакте | Одноклассники
Поисковая система (поисковик) — это специальная программа, которая в ответ на запрос пользователя через веб-интерфейс (сайт) выдает список ресурсов, отсортированных по релевантности этому запросу.
Хорошая поисковая система предлагает материалы, которые наиболее корректно отвечают на запрос пользователя. При этом многие поисковики могут искать нужное не только по словам, но и по картинке или голосовому сообщению.
Прародителем всех поисковых систем считают программу Арчи — первый инструмент для поиска контента в интернете. Арчи предлагал пользователям архив со списком доступных файлов и возможностью поиска по ним.
Лишь в 1994 году появилась первая полноценная поисковая система — WebCrawler, которая стала индексировать не только названия файлов или заголовки страниц, но и их содержимое. А уже через три года, в 1997 году, на рынок вышли привычные нам Google и Яндекс — самые популярные поисковые системы в России, по данным Яндекс.радар.
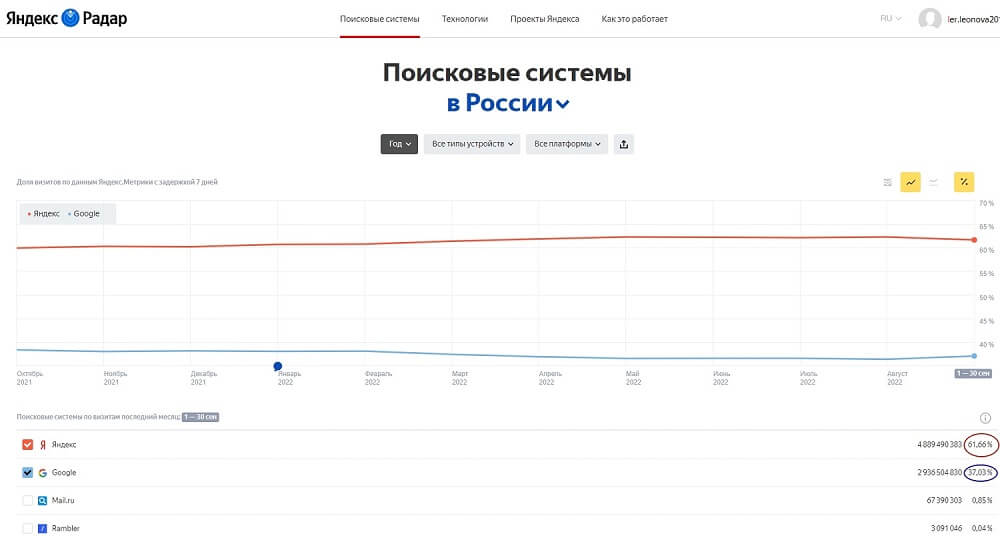
Если обратиться к мировой статистике, то здесь лидирует Google (84,8%), а «Яндекс» (1,06%) уходит на 6-е место.
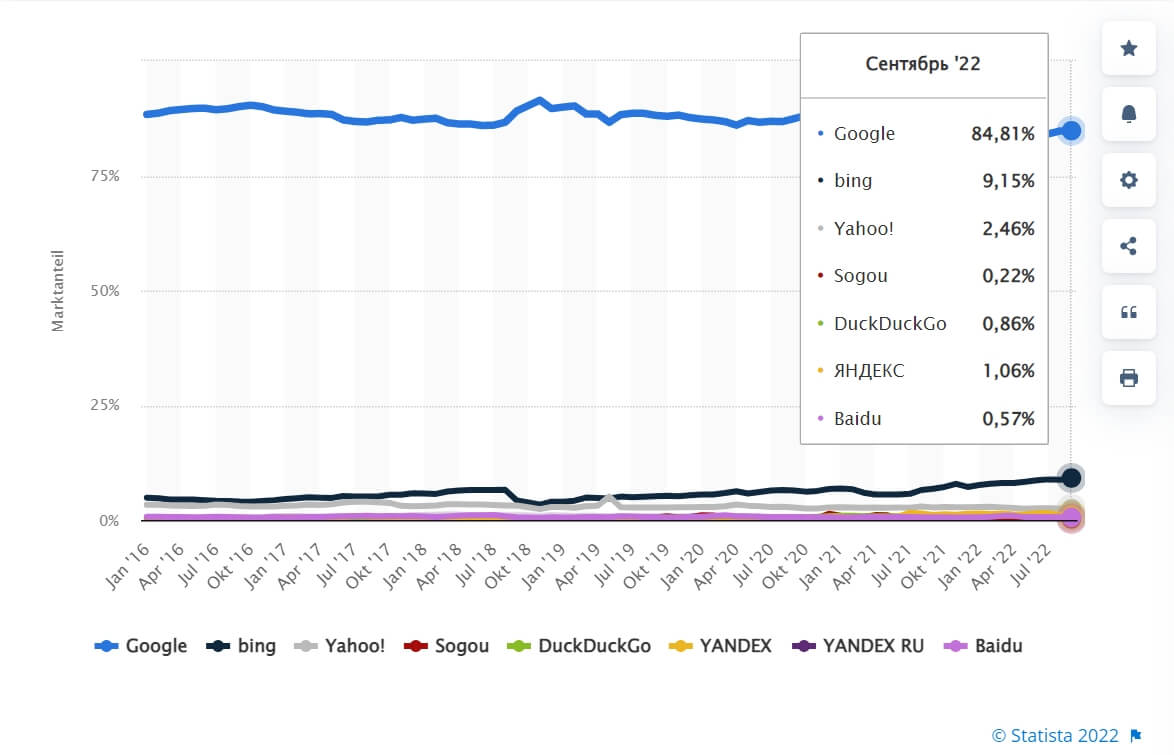
Доля рынка наиболее часто используемых поисковых систем по всему миру по состоянию на сентябрь 2022 г. Источник
Зачем нужна поисковая система
Без поисковых систем обычный пользователь вряд ли найдет в интернете нужную информацию, так как без них не будет привычного нам списка сайтов. Придется вручную вбивать адрес каждого ресурса, чтобы проверить, есть ли там то, что вы ищите. К счастью, алгоритмы поисковиков уже знают, какая информация есть на большинстве сайтов, и в ответ на запрос выдают список страниц, которые больше всего соответствуют этому запросу.
Кроме того, современные поисковые системы давно вышли за границы обычных поисковиков и превратились в целые экосистемы, которые помогают пользователям решать множество бытовых и бизнес-задач. В том же «Яндексе» есть электронная почта, маркетплейс, онлайн-кинотеатр, такси, доставка еды, карты, различные сервисы для бизнеса, а еще собственная платежная система и знакомый многим голосовой помощник Алиса.
У Яндекса столько разных сервисов, что они не поместились на одном экране даже мелким шрифтом
Этапы работы поисковиков
У каждой поисковой системы — свой алгоритм работы, который держится в строгом секрете. Однако условно весь процесс подбора нужной информации поисковиком можно разделить на три этапа: сканирование (поиск и сохранение страниц), индексация и ранжирование.
Сканирование
Чтобы поисковая система смогла найти нужную информацию в большом количестве сайтов, эти сайты должны быть ей известны, то есть прочитаны и сохранены в памяти.
Можно сравнить с библиотекой: если вы не знаете, какие книги стоят на полках и никогда не заглядывали в них, то вероятность того, что вы быстро сориентируетесь и найдете нужную цитату, равна нулю.
Поисковая система узнает о содержимом сайтов с помощью специального робота — краулера, или паука. Название происходит от английского crawler (ползающее насекомое, ползунок). Робот обходит все страницы, переходит по ссылкам и постепенно охватывает миллиарды веб-страниц в сети, сохраняет их и отправляет на индексацию.
Индексация
Следующий этап — подробный анализ загруженных страниц и добавление информации о том, какие сведения в них содержатся, в базу поисковой системы (создание индекса).
Индексный робот разбивает каждую сохраненную страницу на части (заголовки, текст, ссылки, теги html и т.д), изучает их содержимое, переваривает и структурирует. В результате получается упорядоченный список адресов страниц и размещенной на них информации.
По аналогии с библиотекой недостаточно знать, какие книги есть на полках. Важно составить подробный и удобный каталог, который расскажет, в каких книгах и на каких страницах искать нужную информацию.

Другой пример — предметный указатель в справочниках, который помогает без труда найти ответ на нужный вопрос. Все термины здесь размещены по алфавиту с указанием страниц, на которых они встречаются
Пока страница не проиндексирована, для поисковика она не существует. Поэтому важно, чтобы сайт был открыт для индексации. При необходимости можно закрыть от поисковых роботов отдельные страницы, например личный кабинет и корзину, чтобы они не попали в выдачу.
Как ускорить индексацию страниц
Если страница открыта для индексации, то самая распространенная причина того, что она не появляется в выдаче — она новая, и поисковый робот просто не успел ее проиндексировать.
В зависимости от характеристик сайта и возможностей поисковых роботов обновление или апдейт страниц может занять от нескольких минут до нескольких недель.
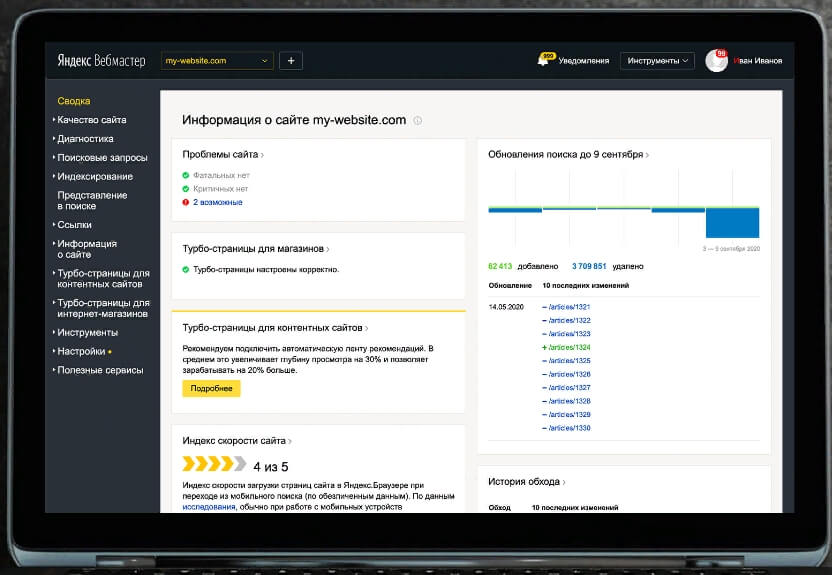
Проверить индексирование страницы можно в «Яндекс.Вебмастере» раздел «Индексирование», а в Google Search Console «Проверка URL».
Яндекс.Вебмастер помогает понять, виден ли сайт в поисковой выдаче
Также в «Яндекс Вебмастере» можно направить страницы сайта на индексацию вручную с помощью функции «Переобход страниц», а в Google Search Console — сделать запрос индексирования.
Ранжирование и поисковая выдача
Когда человек вводит запрос в поисковую строку, поисковик выбирает все страницы, которые имеют отношение к запросу, прогоняет их через свои алгоритмы и выдает список сайтов в определенном порядке. При этом чем выше сайт оказался в выдаче, тем лучше он соответствует запросу пользователя и требованиям поисковика.
Процесс сортировки сайтов по определенному списку критериев называется ранжированием. На результаты ранжирования влияет релевантность контента запросу, качество и удобство сайта, его технические и пользовательские характеристики и многое другое. Точный список критериев поисковые системы держат в секрете и постоянно обновляют свои алгоритмы.
По итогам ранжирования можно получить разные результаты поисковой выдачи:
- в разных поисковиках, так как используются различные критерии фильтрации;
- в разных регионах, так как в запросах учитывается местонахождение пользователя;
- на разных устройствах — в десктопной и мобильной версии, так как имеет значение удобство использования сайта на разных устройствах;
- по одинаковым запросам у разных пользователей, так как учитывается индивидуальная история поиска.
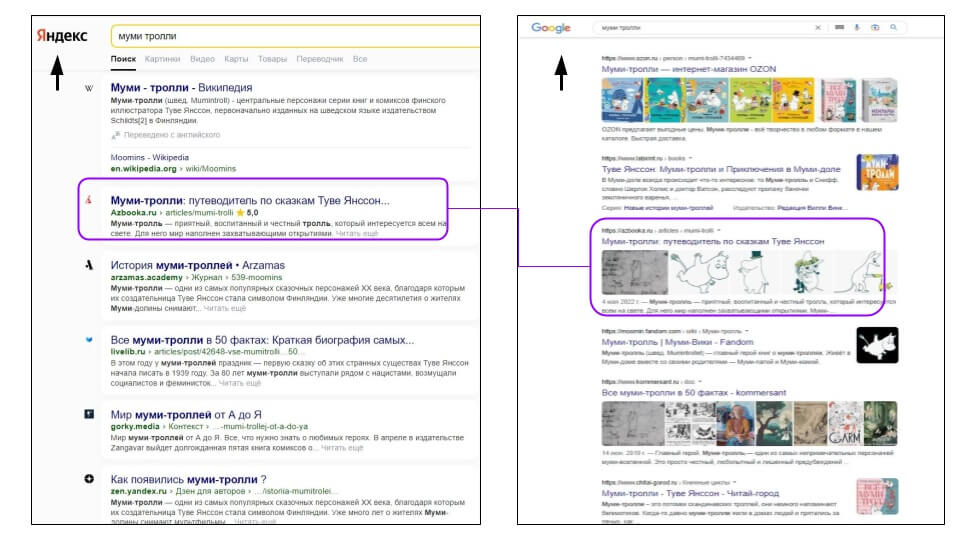
По запросу «Муми тролли» «Яндекс» и Google выдают разные результаты, на первой странице совпадает только один сайт из шести
Ранжирование позволяет пользователям быстрее получить нужную и достоверную информацию, а компаниям использовать поисковую выдачу для продвижения своего сайта.
Альтернативные поисковые системы
Большинству поисковых систем далеко до Яндекса и Гугла, и все же некоторые из них могут быть полезны в той или иной ситуации. Вот несколько примеров поисковиков, которые ориентируются на определенную нишу или предлагают больше конфиденциальности. Не только Яндекс и Google: 7 альтернативных поисковых систем
DuckDuckGo — поисковая система с открытым исходным кодом. Не собирает и не хранит данные о посетителях, а значит, обеспечивает максимальную конфиденциальность своим пользователям. Кроме того, Google и Яндекс стремятся персонализировать выдачу и учитывают предпочтения посетителя. В DuckDuckGo такого нет, поэтому поисковая выдача получается чуть более объективной. Например, через поисковик удобнее искать информацию на иностранном языке.
FindSounds — поисковик по звукам. Можно ввести текстовый запрос или загрузить образец. Запросы на русском не поддерживаются, но есть большой список русскоязычных тегов. Можно уточнить запрос, выбрав желаемый формат и качество звучания. Легко найти рев леопарда, жужжание осы, тикание часов и даже звук дыхания Дарта Вейдера. Все найденные звуки доступны для скачивания.
BoardReader — поиск по форумам, сервисам вопросов и ответов и другим сообществам. Специальные настройки помогут быстро найти посты и комментарии, которые соответствуют заданным критериям: языку, дате публикации и названию сайта.
Главные мысли

- Этап 1. Обход сайта
- Этап 2. Загрузка и обработка данных (индексирование)
- Этап 3. Формирование базы страниц, которые могут участвовать в поиске
- Этап 4. Формирование результатов поиска
- Вопросы и ответы
Чтобы ваш сайт начал отображаться в результатах поиска, Яндекс с помощью роботов должен узнать о его существовании.
Робот — это система, которая обходит страницы сайтов и загружает их в свою базу. У Яндекса есть множество роботов. Сохранение страниц в базу и их дальнейшая обработка с помощью алгоритмов называется индексированием. На основе загруженных данных формируются результаты поиска. Они регулярно обновляются, и позиции сайта могут меняться.
До того, как сайт попадет в результаты поиска, должно пройти несколько этапов:
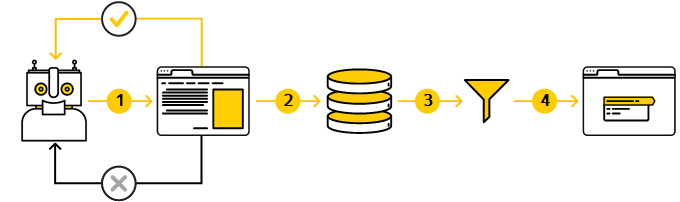
Этап 1. Обход сайта
Этап 2. Загрузка и обработка данных (индексирование)
Этап 3. Формирование базы страниц, которые могут участвовать в поиске
Этап 4. Формирование результатов поиска
Робот самостоятельно определяет, какие сайты и как часто нужно посещать, а также какое количество страниц следует обойти на каждом из них.
При обходе робот учитывает список уже известных страниц, который формируется на основе следующих данных:
-
ссылки, указанные в файле Sitemap;
-
объем страницы сайта — страницы больше 10 МБ не индексируются.
Роботы постоянно отслеживают появление новых ссылок, обновление контента уже загруженных страниц и их доступность. Это происходит до тех пор, пока:
-
ссылка размещена на вашем или стороннем сайте;
-
страница не запрещена для индексирования в файле robots.txt.
Когда робот пытается загрузить страницу сайта, он получает от сервера ответ с HTTP-статусом:
| Код HTTP-статуса | Примечание |
|---|---|
| 200 OK | Робот обойдет страницу. |
| 3XX | Роботу нужно обойти страницу, которая является целью редиректа. Подробнее об обработке редиректов. |
| 4XX и 5XX |
Страница с таким кодом не будет участвовать в поиске. Если до момента обращения робота она находилась в поиске, то будет удалена из него. Чтобы страница не выпала из поиска, настройте сервер так, чтобы он отвечал кодом 429. Робот обращаться к странице и проверять код ответа. Это может быть полезно, если из-за неполадок с CMS страница сайта выглядит некорректно. После исправления измените ответ сервера. Примечание. Если страница будет отвечать кодом 429 продолжительное время, это будет указывать, что сервер испытывает затруднения с нагрузкой. Следовательно это может снизить скорость обхода сайта. |
-
Диагностика — помогает убедиться в качестве сайта и исправить ошибки, если они есть.
-
Статистика обхода — показывает, какие страницы обошел робот и как часто он посещает сайт.
-
Как переиндексировать сайт — позволяет сообщить о новой странице сайта или об обновлении уже участвующей в поиске странице.
-
Региональность — помогает роботу правильно определить регион сайта и показывать его по .
-
Проверка ответа сервера — показывает, доступна ли для робота страница, которая должна быть проиндексирована.
Полезные инструменты
- Поддержка версии HTTP/2
-
Робот Яндекса поддерживает версию HTTP/2 . Протокол HTTP/2 ускоряет загрузку страниц, в том числе и на мобильных устройствах, что облегчает посетителям взаимодействие с сайтом. Также этот протокол уменьшает нагрузку на сервер и экономит трафик. На частоту обхода страниц и изменение позиций сайта в результатах поиска Яндекса протокол HTTP/2 напрямую не влияет.
Если вы используете HTTP/1.1, робот продолжит индексировать ваш сайт. Эти протоколы совместимы, поэтому конфликтов с настройками вашего сервера не будет.
Робот определяет содержание страницы и сохраняет ее в свою базу. Для этого он анализирует контент страницы, например:
-
Содержимое метатега description, элемента title и микроразметки Schema.org, которое может быть использовано для формирования сниппета страницы.
-
Директиву noindex в метатеге robots. Если она найдена, то страница не попадет в результаты поиска.
-
Атрибут rel=”canonical”, указывающий на адрес, который вы считаете приоритетным для отображения в поиске для группы одинаковых по содержанию страниц.
-
Текст, изображения и видео. Если робот определит, что контент нескольких страниц совпадает, он может признать их дублирующими.
-
Диагностика — помогает убедиться в качестве сайта и исправить ошибки, если они есть.
-
Статистика обхода — показывает, какие страницы обошел робот и как часто он посещает сайт.
-
Как переиндексировать сайт — позволяет сообщить о новой странице сайта или об обновлении уже участвующей в поиске странице.
Полезные инструменты
На основе собранной роботом информации алгоритмы определяют страницы, которые могут участвовать в результатах поиска. При этом алгоритмы учитывают множество факторов ранжирования и индексирования, благодаря которым принимается окончательное решение. Например, в базу не попадут закрытые от индексирования страницы или страницы-дубли.
Возможна ситуация, когда страница содержит оригинальный, структурированный текст, но алгоритм не добавляет ее в базу, так как вероятность ее попадания в зону видимости на поиске очень низкая. Например, из-за невостребованности пользователями или высокой конкуренции в данной теме.
Алгоритм определяет качество страницы, а именно:
-
насколько полно содержимое страницы отвечает на поисковый запрос (то есть является релевантной);
-
понятно и полезно ли ее содержимое для пользователя;
-
удобна ли страница (как структурирован текст, выделены абзацы и заголовки разного уровня и т. д.).
Если страница достаточно качественная, то она с большей вероятностью отобразится в результатах поиска. Таким образом, не все страницы сайта можно увидеть в поиске Яндекса. Также они могут исчезать из результатов поиска.
Как улучшить позиции сайта в поиске
-
Страницы в поиске — позволяет узнать, какие страницы сайта отображаются в результатах поиска или исключены из них. Также вы можете отслеживать наиболее важные для вас страницы.
-
Статистика запросов — помогает отслеживать количество показов вашего сайта и кликов на сниппет.
-
Все запросы и группы — отображает поисковые запросы, по которым ваш сайт отображается в результатах поиска. Также Вебмастер подберет для вас запросы, которые могут увеличить трафик на сайт, в том числе с помощью рекламы.
-
Диагностика — дает информацию о страницах без метатега description и элемента title.
-
Быстрые ссылки — помогает проверить, сформированы ли быстрые ссылки в сниппете, и настроить их.
Полезные инструменты
-
В результатах поиска не будет показываться дата рядом со страницами вашего сайта.
-
Робот не сможет получить информацию о том, обновилась ли страница сайта с момента последнего индексирования. Количество страниц, получаемых роботом с сайта за один заход, ограничено, поэтому изменившиеся страницы будут переиндексироваться реже.
Описание страницы в сниппете отличается от содержимого в description
В результатах поиска в качестве описания страницы используется текст, наиболее релевантный поисковому запросу: содержимое метатега Descripton или текст, размещенный на странице. Подробнее см. в разделе Отображение заголовка и описания сайта в результатах поиска.
В результатах поиска отображаются ссылки на внутренние фреймы сайта
Перед загрузкой страницы с помощью консоли браузера проверьте, открыт ли родительский фрейм с навигацией. Если он закрыт, откройте его.
Мой сервер не выдает last-modified
Даже если сервер не выдает дату последней модификации документа (last-modified), ваш сайт будет проиндексирован. Однако в этом случае следует учитывать следующее:
Как кодировка влияет на индексирование
Тип используемой на сайте кодировки не влияет на индексирование сайта. Если ваш сервер не передает в заголовке кодировку, робот Яндекса также определит ее самостоятельно.
Можно ли управлять частотой переиндексирования с помощью директивы Revisit-After?
Нет. Робот Яндекса ее игнорирует.
Яндекс индексирует сайт на иностранном домене?
Да. Сайты, содержащие страницы на русском, украинском, белорусском языках, индексируются автоматически. Ресурсы на английском, немецком и французском языках индексируются, если они могут быть интересны пользователям.
Как влияет на индексирование большое количество заданных параметров в URL и его длина
Большое количество заданных параметров в URL и повторяющихся вложенных директорий, а также слишком большая длина URL может привести к ухудшению индексирования сайта.
Максимальная длина URL — 1024 символов.
Индексирует ли робот архивы GZIP?
Да, робот индексирует архивы в формате GZIP (сжатие GNU ZIP).
Индексирует ли робот URL с якорем (#)?
Робот Яндекса не индексирует адреса страниц с якорем, кроме AJAX-страниц (с символом #!). Например, страница http://example.com/page/#title не попадет в базу робота, он проиндексирует страницу http://example.com/page/ (адрес до символа #).
Как робот индексирует страницы пагинации
Робот не учитывает атрибут rel со значениями prev и next. Поэтому страницы пагинации могут индексироваться и участвовать в поиске без ограничений.
Запрос «Поисковик» перенаправляется сюда; О людях см. Поисковое движение.

Поиск информации во Всемирной паутине был трудной и не самой приятной задачей, но с прорывом в технологии поисковых систем в конце 1990-х годов осуществлять поиск стало намного удобней
Поиско́вая систе́ма (англ. search engine) — алгоритмы и реализующая их совокупность компьютерных программ (в широком смысле этого понятия, включая аналоговые системы автоматизированной обработки информации первого поколения), предоставляющая пользователю возможность быстрого доступа к необходимой ему информации при помощи поиска в обширной коллекции доступных данных[1]. Одно из наиболее известных применений поисковых систем — веб-сервисы для поиска текстовой или графической информации во Всемирной паутине. Существуют также системы, способные искать файлы на FTP-серверах, товары в интернет-магазинах, информацию в группах новостей Usenet.
Для поиска информации с помощью поисковой системы пользователь формулирует поисковый запрос[2]. Работа поисковой системы заключается в том, чтобы по запросу пользователя найти документы, содержащие либо указанные ключевые слова, либо слова, как-либо связанные с ключевыми словами[3]. При этом поисковая система генерирует страницу результатов поиска. Такая поисковая выдача может содержать различные типы результатов, например: веб-страницы, изображения, аудиофайлы. Некоторые поисковые системы также извлекают информацию из подходящих баз данных и каталогов ресурсов в Интернете.
Для поиска нужных сведений удобнее всего воспользоваться современными поисковыми машинами, которые позволяют быстро обнаружить необходимые сведения и обеспечивают точность и полноту поиска. При работе с этими машинами достаточно задать ключевые слова, наиболее точно отражающие искомую информацию, или составить более сложный запрос из ключевых слов для уточнения области поиска. После ввода запроса на поиск вы получите список ссылок на документы в Интернете, обычно называемые web-страницами или просто страницами, в которых содержатся указанные ключевые слова. Обычно ссылки дополняются фрагментами текста из обнаруженного документа, которые часто помогают сразу определить тематику найденной страницы. Щёлкнув мышью на ссылке, можно перейти к выбранному документу.
Поисковая система тем лучше, чем больше документов, релевантных запросу пользователя, она будет возвращать. Результаты поиска могут становиться менее релевантными из-за особенностей алгоритмов или вследствие человеческого фактора[⇨]. По состоянию на 2020 год самой популярной поисковой системой в мире и, в частности, России является Google[источник не указан 703 дня].
По методам поиска и обслуживания разделяют четыре типа поисковых систем: системы, использующие поисковых роботов, системы, управляемые человеком, гибридные системы и мета-системы[⇨]. В архитектуру поисковой системы обычно входят:
- поисковый робот, собирающий информацию с сайтов сети Интернет или из других документов;
- индексатор, обеспечивающий быстрый поиск по накопленной информации;
- поисковик — графический интерфейс для работы пользователя[⇨].
История[править | править код]
| Хронология | ||
|---|---|---|
| Год | Система | Событие |
| 1993 | W3Catalog | Запуск |
| Aliweb | Запуск | |
| JumpStation[en] | Запуск | |
| 1994 | WebCrawler[en] | Запуск |
| Infoseek[en] | Запуск | |
| Lycos | Запуск | |
| 1995 | AltaVista | Запуск |
| Daum | Основание | |
| Open Text[en] Web Index | Запуск | |
| Magellan | Запуск | |
| Excite | Запуск | |
| SAPO | Запуск | |
| Yahoo! | Запуск | |
| 1996 | Dogpile[en] | Запуск |
| Inktomi[en] | Основание | |
| Рамблер | Основание | |
| HotBot[en] | Основание | |
| Ask Jeeves | Основание | |
| 1997 | Northern Light[en] | Запуск |
| Яндекс | Запуск | |
| 1998 | Запуск | |
| 1999 | AlltheWeb[en] | Запуск |
| GenieKnows[en] | Основание | |
| Naver | Запуск | |
| Teoma | Основание | |
| Vivisimo[en] | Основание | |
| 2000 | Baidu | Основание |
| Exalead[en] | Основание | |
| 2003 | Info.com[en] | Запуск |
| 2004 | Yahoo! Search | Окончательный запуск |
| A9.com[en] | Запуск | |
| Sogou[en] | Запуск | |
| 2005 | MSN Search | Окончательный запуск |
| Ask.com | Запуск | |
| Нигма | Запуск | |
| GoodSearch[en] | Запуск | |
| SearchMe[en] | Основание | |
| 2006 | wikiseek[en] | Основание |
| Quaero | Основание | |
| Live Search | Запуск | |
| ChaCha[en] | Запуск (бета) | |
| Guruji.com[en] | Запуск (бета) | |
| 2007 | wikiseek | Запуск |
| Sproose[en] | Запуск | |
| Wikia Search | Запуск | |
| Blackle.com[en] | Запуск | |
| 2008 | DuckDuckGo | Запуск |
| Tooby | Запуск | |
| Picollator[en] | Запуск | |
| Viewzi[en] | Запуск | |
| Cuil | Запуск | |
| Boogami[en] | Запуск | |
| LeapFish[en] | Запуск (бета) | |
| Forestle[en] | Запуск | |
| VADLO | Запуск | |
| Powerset | Запуск | |
| 2009 | Bing | Запуск |
| KAZ.KZ | Запуск | |
| Yebol[en] | Запуск (бета) | |
| Mugurdy[en] | Закрытие | |
| Scout[en] | Запуск | |
| 2010 | Cuil | Закрытие |
| Blekko | Запуск (бета) | |
| Viewzi | Закрытие | |
| 2012 | WAZZUB | Запуск |
| 2014 | Спутник | Запуск (бета) |
На раннем этапе развития сети Интернет Тим Бернерс-Ли поддерживал список веб-серверов, размещённый на сайте ЦЕРН[4]. Сайтов становилось всё больше, и поддерживать вручную такой список становилось всё сложнее. На сайте NCSA был специальный раздел «Что нового!» (англ. What’s New!)[5], где публиковали ссылки на новые сайты.
Первой компьютерной программой для поиска в Интернете была программа Арчи[en] (англ. archie — архив без буквы «в»). Она была создана в 1990 году Аланом Эмтэджем (Alan Emtage), Биллом Хиланом (Bill Heelan) и Дж. Питером Дойчем (J. Peter Deutsch), студентами, изучающими информатику в университете Макгилла в Монреале. Программа скачивала списки всех файлов со всех доступных анонимных FTP-серверов и строила базу данных, в которой можно было выполнять поиск по именам файлов. Однако, программа Арчи не индексировала содержимое этих файлов, так как объём данных был настолько мал, что всё можно было легко найти вручную.
Развитие и распространение сетевого протокола Gopher, придуманного в 1991 году Марком Маккэхилом (Mark McCahill) в университете Миннесоты, привело к созданию двух новых поисковых программ, Veronica[en] и Jughead[en]. Как и Арчи, они искали имена файлов и заголовки, сохранённые в индексных системах Gopher. Veronica (англ. Very Easy Rodent-Oriented Net-wide Index to Computerized Archives) позволяла выполнять поиск по ключевым словам большинства заголовков меню Gopher во всех списках Gopher. Программа Jughead (англ. Jonzy’s Universal Gopher Hierarchy Excavation And Display) извлекала информацию о меню от определённых Gopher-серверов. Хотя название поисковика Арчи не имело отношения к циклу комиксов «Арчи»[en], тем не менее Veronica и Jughead — персонажи этих комиксов.
К лету 1993 года ещё не было ни одной системы для поиска в вебе, хотя вручную поддерживались многочисленные специализированные каталоги. Оскар Нирштрасс (Oscar Nierstrasz) в Женевском университете написал ряд сценариев на Perl, которые периодически копировали эти страницы и переписывали их в стандартный формат. Это стало основой для W3Catalog, первой примитивной поисковой системы сети, запущенной 2 сентября 1993 года[6].
Вероятно, первым поисковым роботом, написанным на языке Perl, был «World Wide Web Wanderer» — бот Мэтью Грэя (Matthew Gray) из Массачусетского технологического института в июне 1993 года. Этот робот создавал поисковый индекс «Wandex». Цель робота Wanderer состояла в том, чтобы измерить размер всемирной паутины и найти все веб-страницы, содержащие слова из запроса. В 1993 году появилась и вторая поисковая система «Aliweb». Aliweb не использовала поискового робота, но вместо этого ожидала уведомлений от администраторов веб-сайтов о наличии на их сайтах индексного файла в определённом формате.
JumpStation[en], [7] созданный в декабре 1993 года Джонатаном Флетчером, искал веб-страницы и строил их индексы с помощью поискового робота, и использовал веб-форму в качестве интерфейса для формулирования поисковых запросов. Это был первый инструмент поиска в Интернете, который сочетал три важнейших функции поисковой системы (проверка, индексация и собственно поиск). Из-за ограниченности ресурсов компьютеров того времени индексация и, следовательно, поиск были ограничены только названиями и заголовками веб-страниц, найденных поисковым роботом.
Первой полнотекстовой индексирующей ресурсы при помощи робота («craweler-based») поисковой системой, стала система «WebCrawler»[en], запущенная в 1994 году. В отличие от своих предшественниц, она позволяла пользователям искать по любым словам, расположенным на любой веб-странице — с тех пор это стало стандартом для большинства поисковых систем. Кроме того, это был первый поисковик, получивший широкое распространение. В 1994 году была запущена система «Lycos», разработанная в Университете Карнеги — Меллон и ставшая серьёзным коммерческим предприятием.
Вскоре появилось множество других конкурирующих поисковых машин, таких как: «Magellan»[en], «Excite», «Infoseek»[en], «Inktomi»[en], «Northern Light»[en] и «AltaVista». В некотором смысле они конкурировали с популярными интернет-каталогами, такими как «Yahoo!». Но поисковые возможности каталогов ограничивались поиском по самим каталогам, а не по текстам веб-страниц. Позже каталоги объединялись или снабжались поисковыми роботами с целью улучшения поиска.
В 1996 году компания Netscape хотела заключить эксклюзивную сделку с одной из поисковых систем, сделав её поисковой системой по умолчанию на веб-браузере Netscape. Это вызвало настолько большой интерес, что Netscape заключила контракт сразу с пятью крупнейшими поисковыми системами (Yahoo!, Magellan, Lycos, Infoseek и Excite). За 5 млн долларов США в год они предлагались по очереди на поисковой странице Netscape[8][9].
Поисковые системы участвовали в «Пузыре доткомов» конца 1990-х[10]. Несколько компаний эффектно вышли на рынок, получив рекордную прибыль во время их первичного публичного предложения. Некоторые отказались от рынка общедоступных поисковых движков и стали работать только с корпоративным сектором, например, Northern Light[en].
Google взял на вооружение идею продажи ключевых слов в 1998 году, тогда это была маленькая компания, обеспечивавшая работу поисковой системы по адресу goto.com[en]. Этот шаг ознаменовал для поисковых систем переход от соревнований друг с другом к одному из самых выгодных коммерческих предприятий в Интернете[11]. Поисковые системы стали продавать первые места в результатах поиска отдельным компаниям.
Поисковая система Google занимает видное положение с начала 2000-х[12]. Компания добилась высокого положения благодаря хорошим результатам поиска с помощью алгоритма PageRank. Алгоритм был представлен общественности в статье «The Anatomy of Search Engine», написанной Сергеем Брином и Ларри Пейджем, основателями Google[13]. Этот итеративный алгоритм ранжирует веб-страницы, основываясь на оценке количества гиперссылок на веб-страницу в предположении, что на «хорошие» и «важные» страницы ссылаются больше, чем на другие. Интерфейс Google выдержан в спартанском стиле, где нет ничего лишнего, в отличие от многих своих конкурентов, которые встраивали поисковую систему в веб-портал. Поисковая система Google стала настолько популярной, что появились подражающие ей системы, например, Mystery Seeker[en](тайный поисковик).
К 2000 году Yahoo! осуществлял поиск на основе системы Inktomi. Yahoo! в 2002 году купил Inktomi, а в 2003 году купил Overture, которому принадлежали AlltheWeb[en] и AltaVista. Затем Yahoo! работал на основе поисковой системы Google вплоть до 2004 года, пока не запустил, наконец, свой собственный поисковик на основе всех купленных ранее технологий.
Фирма Microsoft впервые запустила поисковую систему Microsoft Network Search (MSN Search) осенью 1998 года, используя результаты поиска от Inktomi. Совсем скоро в начале 1999 года сайт начал отображать выдачу Looksmart[en], смешанную с результатами Inktomi. Недолго (в 1999 году) MSN search использовал результаты поиска от AltaVista. В 2004 году фирма Microsoft начала переход к собственной поисковой технологии с использованием собственного поискового робота — msnbot[en]. После проведения ребрендинга компанией Microsoft 1 июня 2009 года была запущена поисковая система Bing. 29 июля 2009 Yahoo! и Microsoft подписали соглашение, согласно которому Yahoo! Search работал на основе технологии Microsoft Bing. На момент 2015 года союз Bing и Yahoo! дал первые настоящие плоды. Теперь Bing занимает 20,1 % рынка, а Yahoo! 12,7 %, что в общем занимает 32,60 % от общего рынка поисковых систем в США по данным из разных источников.
Поиск информации на русском языке[править | править код]
В 1996 году был реализован поиск с учётом русской морфологии на поисковой машине Altavista и запущены оригинальные российские поисковые машины Рамблер и Апорт. 23 сентября 1997 года была открыта поисковая машина Яндекс. 22 мая 2014 года компанией Ростелеком была открыта национальная поисковая машина Спутник, которая на момент 2015 года находится в стадии бета-тестировании. 22 апреля 2015 года был открыт новый сервис Спутник. Дети специально для детей с повышенной безопасностью.
Большую популярность получили методы кластерного анализа и поиска по метаданным. Из международных машин такого плана наибольшую известность получила «Clusty»[en] компании Vivisimo[en]. В 2005 году в России при поддержке МГУ запущен поисковик «Нигма», поддерживающий автоматическую кластеризацию. В 2006 году открылась российская метамашина Quintura, предлагающая визуальную кластеризацию в виде облака тегов. «Нигма» тоже экспериментировала[14] с визуальной кластеризацией.
Как работает поисковая система[править | править код]

Высокоуровневая архитектура стандартного краулера
Основные составляющие поисковой системы: поисковый робот, индексатор, поисковик[15].
Как правило, системы работают поэтапно. Сначала поисковый робот получает контент, затем индексатор генерирует доступный для поиска индекс, и наконец, поисковик обеспечивает функциональность для поиска индексируемых данных. Чтобы обновить поисковую систему, этот цикл индексации выполняется повторно[15].
Поисковые системы работают, храня информацию о многих веб-страницах, которые они получают из HTML-страниц. Поисковый робот (англ. Crawler) — программа, которая автоматически проходит по всем ссылкам, найденным на странице, и выделяет их. Поисковый робот, основываясь на ссылках или исходя из заранее заданного списка адресов, осуществляет поиск новых документов, ещё не известных поисковой системе. Владелец сайта может исключить определённые страницы при помощи robots.txt, используя который можно запретить индексацию файлов, страниц или каталогов сайта.
Поисковая система анализирует содержание каждой страницы для дальнейшего индексирования. Слова могут быть извлечены из заголовков, текста страницы или специальных полей — метатегов. Индексатор — это модуль, который анализирует страницу, предварительно разбив её на части, применяя собственные лексические и морфологические алгоритмы. Все элементы веб-страницы вычленяются и анализируются отдельно. Данные о веб-страницах хранятся в индексной базе данных для использования в последующих запросах. Индекс позволяет быстро находить информацию по запросу пользователя[16].
Ряд поисковых систем, подобных Google, хранят исходную страницу целиком или её часть, так называемый кэш, а также различную информацию о веб-странице. Другие системы, подобные системе AltaVista, хранят каждое слово каждой найденной страницы. Использование кэша помогает ускорить извлечение информации с уже посещённых страниц[16]. Кэшированные страницы всегда содержат тот текст, который пользователь задал в поисковом запросе. Это может быть полезно в том случае, когда веб-страница обновилась, то есть уже не содержит текст запроса пользователя, а страница в кэше ещё старая[16]. Эта ситуация связана с потерей ссылок (англ. linkrot[en]) и дружественным по отношению к пользователю (юзабилити) подходом Google. Это предполагает выдачу из кэша коротких фрагментов текста, содержащих текст запроса. Действует принцип наименьшего удивления, пользователь обычно ожидает увидеть искомые слова в текстах полученных страниц (User expectations[en]). Кроме того, что использование кэшированных страниц ускоряет поиск, страницы в кэше могут содержать такую информацию, которая уже нигде более не доступна.
Поисковик работает с выходными файлами, полученными от индексатора. Поисковик принимает пользовательские запросы, обрабатывает их при помощи индекса и возвращает результаты поиска[15].
Когда пользователь вводит запрос в поисковую систему (обычно при помощи ключевых слов), система проверяет свой индекс и выдаёт список наиболее подходящих веб-страниц (отсортированный по какому-либо критерию), обычно с краткой аннотацией, содержащей заголовок документа и иногда части текста[16]. Поисковый индекс строится по специальной методике на основе информации, извлечённой из веб-страниц[12]. С 2007 года поисковик Google позволяет искать с учётом времени создания искомых документов (вызов меню «Инструменты поиска» и указание временного диапазона).
Большинство поисковых систем поддерживает использование в запросах булевых операторов И, ИЛИ, НЕ, что позволяет уточнить или расширить список искомых ключевых слов. При этом система будет искать слова или фразы точно так, как было введено. В некоторых поисковых системах есть возможность приближённого поиска[en], в этом случае пользователи расширяют область поиска, указывая расстояние до ключевых слов[16]. Есть также концептуальный поиск[en], при котором используется статистический анализ употребления искомых слов и фраз в текстах веб-страниц. Эти системы позволяют составлять запросы на естественном языке.
Полезность поисковой системы зависит от релевантности найденных ею страниц. Хоть миллионы веб-страниц и могут включать некое слово или фразу, но одни из них могут быть более релевантны, популярны или авторитетны, чем другие. Большинство поисковых систем использует методы ранжирования, чтобы вывести в начало списка «лучшие» результаты. Поисковые системы решают, какие страницы более релевантны, и в каком порядке должны быть показаны результаты, по-разному[16]. Методы поиска, как и сам Интернет со временем меняются. Так появились два основных типа поисковых систем: системы предопределённых и иерархически упорядоченных ключевых слов и системы, в которых генерируется инвертированный индекс на основе анализа текста.
Большинство поисковых систем являются коммерческими предприятиями, которые получают прибыль за счёт рекламы, в некоторых поисковиках можно купить за отдельную плату первые места в выдаче для заданных ключевых слов. Те поисковые системы, которые не берут денег за порядок выдачи результатов, зарабатывают на контекстной рекламе, при этом рекламные сообщения соответствуют запросу пользователя. Такая реклама выводится на странице со списком результатов поиска, и поисковики зарабатывают при каждом клике пользователя на рекламные сообщения.
Типы поисковых систем[править | править код]
Существует четыре типа поисковых систем: с поисковыми роботами, управляемые человеком, гибридные и мета-системы[17].
- системы, использующие поисковые роботы. Состоят из трёх частей: краулер («бот», «робот» или «паук»), индекс и программное обеспечение поисковой системы. Краулер нужен для обхода сети и создания списков веб-страниц. Индекс — большой архив копий веб-страниц. Цель программного обеспечения — оценивать результаты поиска. Благодаря тому, что поисковый робот в этом механизме постоянно исследует сеть, информация в большей степени актуальна. Большинство современных поисковых систем являются системами данного типа.
- системы, управляемые человеком (каталоги ресурсов). Эти поисковые системы получают списки веб-страниц. Каталог содержит адрес, заголовок и краткое описание сайта. Каталог ресурсов ищет результаты только из описаний страницы, представленных ему веб-мастерами. Достоинство каталогов в том, что все ресурсы проверяются вручную, следовательно, и качество контента будет лучше по сравнению с результатами, полученными системой первого типа автоматически. Но есть и недостаток — обновление данных каталогов выполняется вручную и может существенно отставать от реального положения дел. Ранжирование страниц не может мгновенно меняться. В качестве примеров таких систем можно привести каталог Yahoo, dmoz и Galaxy.
- гибридные системы. Такие поисковые системы, как Yahoo, Google, MSN, сочетают в себе функции систем, использующие поисковых роботов, и систем, управляемых человеком.
- мета-системы. Метапоисковые системы объединяют и ранжируют результаты сразу нескольких поисковиков. Эти поисковые системы были полезны, когда у каждой поисковой системы был уникальный индекс, и поисковые системы были менее «умными». Поскольку сейчас поиск намного улучшился, потребность в них уменьшилась. Примеры: MetaCrawler[en] и MSN Search.
Рынок поисковых систем[править | править код]
Google — самая популярная поисковая система в мире с долей на рынке 92,16 %. Bing занимает вторую позицию, его доля 2,88 %[18].
Самые популярные поисковые системы в мире[19]:
| Поисковая система | Доля рынка в июле 2014 | Доля рынка в октябре 2014 | Доля рынка в сентябре 2017 | Доля рынка в сентябре 2020[20] | Доля рынка в декабре 2021[21] |
|---|---|---|---|---|---|
| 68,69 % | 58,01 % | 69,24 % | 92,16 % | 91,94 % | |
| Bing | 17,17 % | 29,06 % | 12,26 % | 2,88 % | 2,86 % |
| Baidu | 6,22 % | 8,01 % | 6,48 % | 1,14 % | 1,37 % |
| Yahoo! | 6,74 % | 4,01 % | 5,19 % | 1,52 % | 1,5 % |
| AOL | 0,13 % | 0,21 % | 1,11 % | ||
| Excite | 0,22 % | 0,00 % | 0,00 % | ||
| Ask | 0,13 % | 0,10 % | 0,24 % |
Азия[править | править код]
В восточноазиатских странах и в России Google — не самая популярная поисковая система. В Китае, например, более популярна поисковая система Soso.
В Южной Корее поисковым порталом собственной разработки Naver пользуется около 70 % жителей[22] Yahoo! Japan и Yahoo! Taiwan — самые популярные системы для поиска в Японии и Тайване соответственно[23].
Россия и русскоязычные поисковые системы[править | править код]
Поисковой системой Google пользуются 50,3 % пользователей в России, Яндексом — 47,9 %[24].
Согласно данным LiveInternet в декабре 2017 года об охвате русскоязычных поисковых запросов[25]:
- Всеязычные:
- Google (42,9 %)
- Bing (0,3 %)
- Yahoo! (0,0 %) и принадлежащие этой компании поисковые машины: Inktomi[en], AltaVista, Alltheweb[en]
- Англоязычные и международные:
- AskJeeves[en] (механизм Teoma)
- Русскоязычные — большинство «русскоязычных» поисковых систем индексируют и ищут тексты на многих языках — украинском, белорусском, английском, татарском и других. Отличаются же они от «всеязычных» систем, индексирующих все документы подряд, тем, что, в основном, индексируют ресурсы, расположенные в доменных зонах, где доминирует русский язык, или другими способами ограничивают своих роботов русскоязычными сайтами.
- Яндекс (60,4 %)
- Mail.ru (3,5 %)
- Рамблер (0,2 %)
Некоторые из поисковых систем используют внешние алгоритмы поиска.
Количественные данные поисковой системы Google[править | править код]
Число пользователей Интернета и поисковых систем и требований пользователей к этим системам постоянно растёт. Для увеличений скорости поиска нужной информации крупные поисковые системы содержат большое количество серверов. Сервера обычно группируют в серверные центры (дата-центры). У популярных поисковых систем серверные центры разбросаны по всему миру.
В октябре 2012 года Google запустила проект «Где живёт Интернет», где пользователям предоставляется возможность познакомиться с центрами обработки данных этой компании[26].
О работе дата-центров поисковой системе Google известно следующее[27]:
- Суммарная мощность всех дата-центров Google, по состоянию на 2011 год, оценивалась в 220 МВт.
- Когда в 2008 году Google планировала открыть в Орегоне новый комплекс, состоящий из трёх зданий общей площадью 6,5 млн м², в журнале Harper’s Magazine подсчитали, что такой большой комплекс потребляет свыше 100 МВт электроэнергии, что сравнимо с потреблением энергии города с населением 300 000 человек.
- Ориентировочное число серверов Google в 2012 году — 1 млн.
- Расходы Google на дата-центры составили в 2006 году — $1,9 млрд, а в 2007 году — $2,4 млрд.
Размер всемирной паутины, проиндексированной Google на декабрь 2014 года, составляет примерно 4,36 миллиарда страниц[28].
Поисковые системы, учитывающие религиозные запреты[править | править код]
Глобальное распространение Интернета и увеличение популярности электронных устройств в арабском и мусульманском мире, в частности, в странах Ближнего Востока и Индийского субконтинента, способствовало развитию локальных поисковых систем, учитывающих исламские традиции. Такие поисковые системы содержат специальные фильтры, которые помогают пользователям не попадать на запрещённые сайты, например, сайты с порнографией, и позволяют им пользоваться только теми сайтами, содержимое которых не противоречит исламской вере.
Незадолго до мусульманского месяца Рамадан, в июле 2013 года, миру был представлен Halalgoogling[en] — система, выдающая пользователям только халяльные «правильные» ссылки[29], фильтруя результаты поиска, полученные от других поисковых систем, таких как Google и Bing. Двумя годами ранее, в сентябре 2011 года, был запущен поисковый движок I’mHalal, предназначенный для обслуживания пользователей Ближнего Востока. Однако этот поисковый сервис пришлось вскоре закрыть, по сообщению владельца, из-за отсутствия финансирования[30].
Отсутствие инвестиций и медленный темп распространения технологий в мусульманском мире препятствовали прогрессу и мешали успеху серьёзного исламского поисковика. Очевиден провал огромных инвестиций в веб-проекты мусульманского образа жизни, одним из которых был Muxlim[en]. Он получил миллионы долларов от инвесторов, таких как Rite Internet Ventures, и теперь — в соответствии с последним сообщением от I’mHalal перед его закрытием — выступает с сомнительной идеей о том, что «следующий Facebook или Google могут появиться только в странах Ближнего Востока, если вы поддержите нашу блестящую молодёжь»[источник не указан 905 дней].
Тем не менее исламские эксперты в области Интернета в течение многих лет занимаются определением того, что соответствует или не соответствует шариату, и классифицируют веб-сайты как «халяль» или «харам». Все бывшие и настоящие исламские поисковые системы представляют собой просто специальным образом проиндексированный набор данных либо это главные поисковые системы, такие как Google, Yahoo и Bing, с определённой системой фильтрации, использующейся для того, чтобы пользователи не могли получить доступ к харам-сайтам, таким как сайты о наготе, ЛГБТ, азартных играх и каким-либо другим, тематика которых считается антиисламской[источник не указан 905 дней].
Среди других религиозно-ориентированных поисковых систем распространёнными являются Jewogle — еврейская версия Google и SeekFind.org — христианский сайт, включающий в себя фильтры, оберегающие пользователей от контента, который может подорвать или ослабить их веру[31].
Персональные результаты и пузыри фильтров[править | править код]
Многие поисковые системы, такие как Google и Bing, используют алгоритмы выборочного угадывания того, какую информацию пользователь хотел бы увидеть, основываясь на его прошлых действиях в системе. В результате, веб-сайты показывают только ту информацию, которая согласуется с прошлыми интересами пользователя. Этот эффект получил название «пузырь фильтров»[32].
Всё это ведёт к тому, что пользователи получают намного меньше противоречащей своей точке зрения информации и становятся интеллектуально изолированными в своём собственном «информационном пузыре». Таким образом, «эффект пузыря» может иметь негативные последствия для формирования гражданского мнения[33].
Предвзятость поисковых систем[править | править код]
Несмотря на то, что поисковые системы запрограммированы, чтобы оценивать веб-сайты на основе некоторой комбинации их популярности и релевантности, в реальности экспериментальные исследования указывают на то, что различные политические, экономические и социальные факторы оказывают влияние на поисковую выдачу[34][35].
Такая предвзятость может быть прямым результатом экономических и коммерческих процессов: компании, которые рекламируются в поисковой системе, могут стать более популярными в результатах обычного поиска в ней. Удаление результатов поиска, не соответствующих местным законам, является примером влияния политических процессов. Например, Google не будет отображать некоторые неонацистские веб-сайты во Франции и Германии, где отрицание Холокоста незаконно[36].
Предвзятость может также быть следствием социальных процессов, поскольку алгоритмы поисковых систем часто разрабатываются, чтобы исключить неформатные точки зрения в пользу более «популярных» результатов[37]. Алгоритмы индексации главных поисковых систем отдают приоритет американским сайтам[35].
Поисковая бомба — один из примеров попытки управления результатами поиска по политическим, социальным или коммерческим причинам.
См. также[править | править код]
- Информационный поиск
- Статистика запросов
- Поисковый спам
- DataparkSearch
- Электронная библиотека#Списки библиотек и поисковые системы
- Семантическая паутина
- Система проверки правописания
Примечания[править | править код]
- ↑ Поисковая система / Д. В. Барашев, Н. С. Васильева, Б. А. Новиков // Большая российская энциклопедия : [в 35 т.] / гл. ред. Ю. С. Осипов. — М. : Большая российская энциклопедия, 2004—2017.
- ↑ Chu & Rosenthal, 1996, p. 129.
- ↑ Tarakeswar & Kavitha, 2011, p. 29.
- ↑ World-Wide Web Servers.
- ↑ What’s New.
- ↑ Oscar Nierstrasz.
- ↑ Archive of NCSA.
- ↑ Yahoo! And Netscape.
- ↑ Netscape, 1996.
- ↑ The dynamics of competition, 2001.
- ↑ Intro to Computer Science.
- ↑ 1 2 Google`s history.
- ↑ Брин и Пейдж, p. 3.
- ↑ Nigma.
- ↑ 1 2 3 Risvik & Michelsen, 2002, p. 290.
- ↑ 1 2 3 4 5 6 Knowledge Management, 2011.
- ↑ Tarakeswar & Kavitha, 2011, p. 29.
- ↑ NMS.
- ↑ Статистика.
- ↑ Search Engine Market Share Worldwide (англ.). StatCounter Global Stats. Дата обращения: 21 декабря 2020. Архивировано 10 декабря 2020 года.
- ↑ Search Engine Market Share Worldwide (англ.). StatCounter Global Stats. Дата обращения: 9 января 2022. Архивировано 10 декабря 2020 года.
- ↑ Naver.
- ↑ OII Web Team. Age of Internet Empires (англ.). Information Geographies. Дата обращения: 2 марта 2022. Архивировано 2 марта 2022 года.
- ↑ LiveInternet.
- ↑ Liveinternet. Дата обращения: 2 января 2018. Архивировано 19 февраля 2019 года.
- ↑ Where the Internet lives.
- ↑ Antula.
- ↑ World wide web size.
- ↑ Islam.
- ↑ I’mHalal. Дата обращения: 28 мая 2018. Архивировано 29 мая 2018 года.
- ↑ ChristianNews.
- ↑ Pariser, 2011.
- ↑ Auralist, 2012, p. 13.
- ↑ Segev, 2010.
- ↑ 1 2 Search engine coverage bias, 2004.
- ↑ Replacement of Google.
- ↑ Shaping the Web, 2000.
Литература[править | править код]
- Ашманов И. С., Иванов А. А. Продвижение сайта в поисковых системах. — М.: Вильямс, 2007. — 304 с. — ISBN 978-5-8459-1155-1.
- Байков В.Д. Интернет. Поиск информации. Продвижение сайтов. — СПб.: БХВ-Петербург, 2000. — 288 с. — ISBN 5-8206-0095-9.
- Колисниченко Д. Н. Поисковые системы и продвижение сайтов в Интернете. — М.: Диалектика, 2007. — 272 с. — ISBN 978-5-8459-1269-5.
- Ландэ Д. В. Поиск знаний в Internet. — М.: Диалектика, 2005. — 272 с. — ISBN 5-8459-0764-0.
- Ландэ Д. В., Снарский А. А., Безсуднов И. В. Интернетика: Навигация в сложных сетях: модели и алгоритмы. — M.: Либроком (Editorial URSS), 2009. — 264 с. — ISBN 978-5-397-00497-8.
- Chu H., Rosenthal M. Search engines for the World Wide Web: A comparative study and evaluation methodology (англ.) // Proceedings of the Annual Meeting of the American Society for Information Science : journal. — 1996. — Vol. 33. — P. 127—135.
- Gandal, Neil. The dynamics of competition in the internet search engine market. — 2001. — Vol. 19. — P. 1103–1117. — doi:10.1016/S0167-7187(01)00065-0.
- Introna L. D., Nissenbaum H.[en]. Shaping the Web: Why the Politics of Search Engines Matters (англ.) // The Information Society: An International Journal. — 2000. — Vol. 16. — doi:10.1080/01972240050133634.
- Jawadekar, Waman S. 8. Knowledge Management: Tools and Technology // Knowledge management: Text & Cases. — New Delhi: Tata McGraw-Hill Education Private Ltd, 2011. — С. 278. — 319 с. — ISBN 978-0-07-07-0086-4.
- Pariser E. The Filter Bubble: What The Internet Is Hiding From You. — NY: Penguin Group, 2011. — 257 с. — ISBN 978-0-14-196992-3.
- Risvik K. M., Michelsen R. Search engines and web dynamics (англ.) // Computer Networks : journal. — 2002. — Vol. 39, no. 3. — P. 289—302. Архивировано 29 ноября 2014 года.
- Segev El. Google and the Digital Divide: The Biases of Online Knowledge. — Oxford: Chandos Publishing. — 2010. — 171 с. — ISBN 978-1-84334-565-7.
- Tarakeswar M. K., Kavitha M. D. Search Engines:A Study (англ.) // Journal of Computer Applications (JCA) : journal. — 2011. — Vol. 4, no. 1. — P. 29—33. — ISSN 0974-1925.
- Vaughan L., Thelwall M. Search engine coverage bias: evidence and possible causes (англ.) // Information Processing & Management : journal. — 2004. — Vol. 40. — P. 693–707. — doi:10.1016/S0306-4573(03)00063-3.
- Zhang, Séaghdha, Quercia, Jambor. Auralist: introducing serendipity into music recommendation (англ.) // ACM WSDM. — 2012. — P. 13—22. — ISSN 978-1-4503-0747-5. — doi:10.1145/2124295.2124300. Архивировано 29 ноября 2014 года.
- Browser Deals Push Netscape Stock Up 7.8% (англ.) // Los Angeles Times : journal. — 1996.
Ссылки[править | править код]
- What’s New!: February, 1994. Home.mcom.com. Дата обращения: 14 мая 2012.
- World-Wide Web Servers. W3.org. Дата обращения: 14 мая 2012.
- The Anatomy of a Large-Scale Hypertextual Web Search Engine.
- Live Internet – Site Statistics. Live Internet. Дата обращения: 4 июня 2014.
- Arthur, Charles. The Chinese technology companies poised to dominate the world. The Guardian (3 июня 2014). Дата обращения: 4 июня 2014.
- Replacement of Google with Alternative Search Systems in China: Documentation and Screen Shots. Berkman Center for Internet & Society (2002).
- Emma Barnett. Koogle, a kosher Google, launches (англ.). The Telegraph (15 июня 2009). Дата обращения: 9 декабря 2014.
- Количество серверов Google составит 10 миллионов. ITUA.info. Дата обращения: 28 октября 2009.
- World wide web size.
Сегодня слово “поисковик” ассоциируется с Google. И не зря: это самая популярная поисковая система в мире. 9 из 10 людей используют Google, когда хотят найти информацию в Интернете.

Список популярных поисковых систем
В первой пятерке топовых поисковиков:
- Bing
- Baidu
- Yahoo!
- Яндекс
Разумеется, это далеко не все системы, которыми пользуются люди. Однако, из года в год они занимают первенство в рейтинге поисковиков, только время от времени местами меняются.
Зарубежные поисковики
Обратите внимание на зарубежные поисковые системы, о которых вы могли не слышать:
- About
- Find-It!
- Dogpile
- Arianna
- InfoSpace
- Internet Sleuth
- Jayde
- Lycos
- Meta Eureka
- Meta Crawler
- Qwant
Не игнорируйте этот список, если планируете работать с бурж аудиторией.
Поисковики без запретов
Наверняка, вы знаете, что в поисковых системах сложно пройти модерацию из-за большого количества ограничений. В таком случае приходят на помощь поисковики без запретов:
- DuckDuckGo
- not Evil
- YaCy
- Pipl
- Dogpile
- BoardReader
Перед тем, как настраивать контекстную рекламу, важно понять, как как работает поисковая система Яндекс, Google, Bing и т.д. Об этом мы и поговорим более детально ниже.
Как работают поисковые системы интернета? Разбираем, как работает поисковая система Google
Алгоритм работы поисковой системы состоит из 3-х функций. Поисковики:
- сканируют: находят в Интернете контент на каждом URL;
- индексируют: хранят и систематизируют контент. Как только страница попадает в индекс, она отображается в результате выполнения соответствующих запросов;
- ранжируют: предоставляют фрагменты контента, которые соответствуют запросу пользователя. Результаты упорядочены в порядке от наиболее релевантного к наименее релевантному.
Как работают алгоритмы гугл. Выясняем, что такое сканирование поисковыми системами
Сканирование — это процесс, с помощью которого поисковые системы обнаруживают обновленный контент в Интернете, например, новые сайты или страницы, изменения на сайтах и мертвые ссылки. Для этого поисковик использует программу, которую называют сканером, ботом или пауком (у каждой поисковой системы свой тип).
Он работает по алгоритму, чтобы определить, какие сайты сканировать и как часто. Контент бывает разным — это веб-страница, изображение, видео, PDF-файл и т.д. Независимо от формата контент обнаруживается по ссылкам.
Googlebot начинает с загрузки нескольких веб-страниц, а затем переходит по ссылкам на этих веб-страницах, чтобы найти новые URL-адреса. Перепрыгивая по пути ссылок, сканер находит релевантный материал и добавляет его в индекс Caffeine — базу обнаруженных URL-адресов. Так и открывается новый контент.
Что такое индекс поисковой системы
Поисковые системы обрабатывают и хранят информацию, которую находят, в индексе — базе данных контента. Как только поисковик обрабатывает каждую из просматриваемых страниц, он составляет индекс видимых слов и их расположение на каждой странице. По сути, это база данных из миллиардов веб-страниц.
Затем извлеченный контент сохраняется, а информация систематизируется и интерпретируется алгоритмом поисковой системы для измерения важности по сравнению с аналогичными страницами.
Благодаря этим серверам, пользователи получают доступ к интернет-страницам в доли секунды. Для хранения и сортировки информации требуется много места, поэтому у Microsoft и Google более миллиона серверов.
Рейтинг в поисковых системах. Как происходит Индексация сайта в Google?
После ввода ключевика в окно поиска системы проверяют страницы в индексе, чтобы те соответствовали запросу. Оценка этим страницам выставят на основе алгоритма, который состоит из сотен сигналов ранжирования.
Эти страницы (или изображения и видео) будут отображаться пользователю в зависимости от поставленной оценки.
Чтобы сайт занимал высокое место на страницах результатов поиска, важно убедиться, что поисковые системы правильно его сканируют и индексируют. В противном случае они не смогут ранжировать контент сайта в результатах поиска.
Ранжирование страницы включает в себя разные аспекты.
Не говоря уже о технических деталях, Google учится предоставлять информацию лучшим образом. Для этого Google сопоставляет различные факторы, к ним относятся:
- типология сайтов: рейтинг, который сделан поисковой системой, чтобы отличить один запрос от другого;
- контекст;
- время;
- макет: поисковая выдача покажет разные результаты в зависимости от цели поиска.
Типология сайтов
Как только пользователь набирает запрос, первое, что делает поисковая система, — это классифицирует его, чтобы получить типологию для запроса.
Например:
- сайты местных компаний;
- сайты для взрослых;
- новостные сайты и прочее.
Рейтинг меняется, но, тем не менее, он помогает определить, к какому «месту» принадлежит запрос.
Контекст
Поисковая система также учитывает контекст. Она извлекает релевантную информацию от пользователя, который вводит запрос, а также учитывает:
- социальные факторы;
- исторические факторы;
- экологические факторы;
- позицию;
- время;
- тип запроса.
После того, как система проанализирует показатели, человек получит полезный для него ответ.
Время
В работе стоит учитывать это соотношение времени выполнения и индексации контента.
По этой причине на результаты, например, «Первая мировая война» больше влияет источник, в то время как для «фильмы, которые уже вышли» поисковая система отдает приоритет свежести контента.
Макет результатов
Если ищет человек видео, то такой контент Google и будет показывать в поисковой выдаче.
Если цель поиска — тема, в которой много релевантных запросов, появляется поле «Люди также ищут».
И это также относится к другим элементам поисковой выдачи — темам и связанным поисковым запросам.
Подведем итоги
Google, Яндекс, Baidu и Microsoft и другие поисковики позволяют пользователям всего мира находить невообразимое количество информации. Так, сегодня поисковые системы — едва ли не самое совершенное техническое решение, которое видел мир.
В перспективе поисковики будут развиваться в сторону естественных интерфейсов, таких как голос и изображения. Сегодня работа систем, в основном, основана на ключевиках и тексте.
Продвижение в поисковиках — один из лучших способов привлечь и монетизировать аудиторию. Но чтобы конкурировать с другими платформами, важно понимать, как поисковая система обрабатывает контент и по каким принципам отображает его аудитории. Используйте советы из статьи, чтобы ваш сайт как можно лучше ранжировался и получил больше возможностей попасть на первые страницы поисковой выдачи.
Принеси в жертву лайк и шеринг во славу бога Рандома, и профитный конверт будет сопутствовать тебе всю неделю!
