Неканонические страницы в Поиске
Часто на сайтах присутствуют страницы с разными URL, но с одинаковым или очень похожим содержанием. С помощью атрибута rel=«canonical» вебмастера могут указать, какая страница является «канонической» — предпочтительной для индексации и появления в результатах поиска. Остальные, неканонические версии как правило в поиск не попадают.
Наши исследования показывают, что страницы, размеченные как неканонические могут быть полезны, а их наличие в поиске может влиять на качество и полноту ответа на запрос пользователя. Например, если для темы форума владелец сайта указал канонической страницу с началом ветки, то многие важные и нужные ответы, которые были даны пользователями позже, в поиск не попадают. Другой пример: бывает, что какое-то литературное произведение разбито на страницы и в качестве канонической прописана первая страница. В результате сайт не находится по запросу-цитате, соответствующей тексту за пределами первой странице. Поэтому теперь в поиске неканонические страницы будут появляться чаще.
Они будут показаны в том случае, если они более релевантны запросу и их контент существенно отличался от канонической версии во время сканирования роботом. В Вебмастере такие страницы можно увидеть на странице «Страницы в поиске» с пометкой «Неканоническая». Помимо этого статуса мы начали показывать статусы «Каноническая» и «Каноническая страница не указана» для всех страниц, попавших в поиск.

Если канонические страницы настроены на сайте без ошибок, то никаких дополнительных действий от вебмастера не требуется. Для сайтов, имеющих много неканонических страниц, которые сильно отличались от канонических, возможен прирост количества страниц в Поиске. Впрочем, канонические страницы по-прежнему попадают в поиск гораздо чаще и имеют более высокий приоритет при показе в результатах поиска. Объем трафика для каждого конкретного сайта существенно не изменится.
Команда Поиска
P. S. Подписывайтесь на наши каналы
Блог Яндекса для Вебмастеров
Канал Яндекса о продвижении сайтов на YouTube
Канал для владельцев сайтов в Яндекс.Дзен
Что делать, если в индекс попадают неканонические страницы?
В данной статье поговорим про канонические страницы, и разберем, почему неканонические попадают в поиск Яндекса. А также стоит ли менять карту сайта, если в ней указаны ссылки на оба варианта, или атрибута rel=canonical будет достаточно.
Для начала, нужно сказать, что не слишком важно, указаны ли страницы в карте сайта или нет — Яндекс использует этот файл в основном для того, чтобы узнать, какие новые страницы вообще появились. И в общем особого приоритета тем, которые там есть,.не дает, поэтому вряд ли они залетают в индекс только потому, что ссылки есть в карте. Но можно на всякий случай и убрать, если не хотите рисковать, вдруг поисковик всё же как-то использует эти сведения, хотя по наблюдениям такого и нет.
Почему попадают в индекс
Яндекс не так давно решил, что часть неканонических страниц имеют достаточную важность и значимость для пользователя, чтобы могли попадать в индекс. И этот алгоритм работает не очень хорошо, многие бесполезные для людей страницы теперь часто залетают в индекс. Возможно через 1-2 года они этот алгоритм починят, и он станет работать нормально.
Что можно делать
Во-первых, можно ничего не делать. То есть, раз Яндекс посчитал эти страницы достаточно значимыми, то можно надеяться, что их нахождение в индексе никак не повлияет.
Хотя, конечно, особо на это уповать не стоит. Лучше все же, если явно бесполезные страницы попадают в индекс, для начала посмотреть, отчего или вопреки чему это происходит — допустим, они не были закрыты от индексации, но были закрыты canonical, то есть по идее не должны были индексироваться.
Классический пример таких страниц — это пагинация. И стоит смотреть, действительно ли страницы пагинации могут принести пользу, при попадании в индекс ранжируются ли они по каким-либо запросам, мелькают ли хоть где-то, показываются ли хотя бы на 50 местах. И если показываются, то действительно ли будут лучшим ответом внутри сайта на те запросы, по которым они выходят. В 9 из 10 случаев ответ — нет. Почти всегда это полумусорные страницы, которые не являются лучшим ответом на запрос пользователя внутри сайта, поэтому желательно что-то сделать, как-то закрыть их.
Если такое происходит массово — например, есть такие проекты, где 20 страниц пагинации, и несмотря на то, что они были закрыты canonical, они влетели в индекс. Это много, и Яндекс сам же потом рано или поздно признает их мусорными, и это потом может повлияет на представление поисковика о сайте в целом. Точно также, если бы вы сами сделали такое, что индексировались бы пустые страницы или страницы пагинации — позже это могло бы негативно сказаться на продвижении сайта. Поэтому можно с этими страницами что-то делать:
- закрывать их более жестко от индексации: либо все страницы пагинации – например, в robots или через метатег “robots”=”noindex”;
- можно закрыть не все, а только те, что проиндексировались. Каноникл оставить на тех, что не попали в индекс, а которые попали, закрыть более жестко через noindex;
- можно сделать их более похожими на первую страницу. Например, если на первой есть текст, а на остальных нет, на первой заголовок, а на остальных «страница 2», «страница 3»,.. — можно это исправить, подогнать по формату так, чтобы были похожи, и посомтреть, что получится, как Яндекс на это отреагирует.
Если до этого у вас применялся каноникал, то это все основные способы, как можно избежать попадания неканонических старниц в индекс. Как правило, неканонические страницы в индексе — это не проблема, но если их объем становится большой (10-30%), то уже можно и даже желательно самые бесполезные из индекса выкидывать, потому как иначе сам Яндекс на всю эту ситуацию и отреагирует негативно.
Более подробно в других статьях, которые есть на нашем сайте
В данной статье поговорим про канонические страницы, и разберем, почему неканонические попадают в поиск Яндекса. А также стоит ли менять карту сайта, если в ней указаны ссылки на оба варианта, или атрибута rel=canonical будет достаточно.
Для начала, нужно сказать, что не слишком важно, указаны ли страницы в карте сайта или нет — Яндекс использует этот файл в основном для того, чтобы узнать, какие новые страницы вообще появились. И в общем особого приоритета тем, которые там есть,.не дает, поэтому вряд ли они залетают в индекс только потому, что ссылки есть в карте. Но можно на всякий случай и убрать, если не хотите рисковать, вдруг поисковик всё же как-то использует эти сведения, хотя по наблюдениям такого и нет.
Почему попадают в индекс
Яндекс не так давно решил, что часть неканонических страниц имеют достаточную важность и значимость для пользователя, чтобы могли попадать в индекс. И этот алгоритм работает не очень хорошо, многие бесполезные для людей страницы теперь часто залетают в индекс. Возможно через 1-2 года они этот алгоритм починят, и он станет работать нормально.
Что можно делать
Во-первых, можно ничего не делать. То есть, раз Яндекс посчитал эти страницы достаточно значимыми, то можно надеяться, что их нахождение в индексе никак не повлияет.
Хотя, конечно, особо на это уповать не стоит. Лучше все же, если явно бесполезные страницы попадают в индекс, для начала посмотреть, отчего или вопреки чему это происходит — допустим, они не были закрыты от индексации, но были закрыты canonical, то есть по идее не должны были индексироваться.
Классический пример таких страниц — это пагинация. И стоит смотреть, действительно ли страницы пагинации могут принести пользу, при попадании в индекс ранжируются ли они по каким-либо запросам, мелькают ли хоть где-то, показываются ли хотя бы на 50 местах. И если показываются, то действительно ли будут лучшим ответом внутри сайта на те запросы, по которым они выходят. В 9 из 10 случаев ответ — нет. Почти всегда это полумусорные страницы, которые не являются лучшим ответом на запрос пользователя внутри сайта, поэтому желательно что-то сделать, как-то закрыть их.
Если такое происходит массово — например, есть такие проекты, где 20 страниц пагинации, и несмотря на то, что они были закрыты canonical, они влетели в индекс. Это много, и Яндекс сам же потом рано или поздно признает их мусорными, и это потом может повлияет на представление поисковика о сайте в целом. Точно также, если бы вы сами сделали такое, что индексировались бы пустые страницы или страницы пагинации — позже это могло бы негативно сказаться на продвижении сайта. Поэтому можно с этими страницами что-то делать:
-
закрывать их более жестко от индексации: либо все страницы пагинации – например, в robots или через метатег “robots”=”noindex”;
-
можно закрыть не все, а только те, что проиндексировались. Каноникл оставить на тех, что не попали в индекс, а которые попали, закрыть более жестко через noindex;
-
можно сделать их более похожими на первую страницу. Например, если на первой есть текст, а на остальных нет, на первой заголовок, а на остальных «страница 2», «страница 3»,.. — можно это исправить, подогнать по формату так, чтобы были похожи, и посомтреть, что получится, как Яндекс на это отреагирует.
Если до этого у вас применялся каноникал, то это все основные способы, как можно избежать попадания неканонических старниц в индекс. Как правило, неканонические страницы в индексе — это не проблема, но если их объем становится большой (10-30%), то уже можно и даже желательно самые бесполезные из индекса выкидывать, потому как иначе сам Яндекс на всю эту ситуацию и отреагирует негативно.
Если на сайте есть страница, доступная по нескольким адресам, а также страницы с одинаковым или схожим содержимым, робот Яндекса может посчитать их дублями. Тогда он объединит страницы в группу дублей и выберет для показа в результатах поиска только одну из них — наиболее информативную и релевантную поисковым запросам. Такая страница называется канонической.
Вы можете указать роботу страницу, предпочитаемую для показа в результатах поиска, с помощью атрибута rel=”canonical”. Также вы можете указать канонический адрес, если хотите изменить адрес сайта — с префиксом www или без него, протоколом HTTP или HTTPS.
Внимание. Робот Яндекса воспринимает указание на канонический адрес как рекомендацию и может проигнорировать его в нескольких случаях.
- Как указать канонический адрес страницы
- Как изменить адрес сайта с помощью канонического адреса
- Случаи, когда канонический адрес не учитывается
- Вопросы и ответы
Добавьте канонический адрес страницы с помощью атрибута rel=”canonical” одним из способов:
Например, страница доступна по двум адресам: www.example.com/pages?id==2 и www.example.com/blog.
Если предпочитаемый адрес — /blog, добавьте в HTML-код страницы /pages?id=2 элемент link:
<link rel="canonical" href="http://www.example.com/blog"/>Например, на сайте есть PDF-файл, доступный по нескольким адресам: www.example.com/offer/file.pdf и www.example.com/files/file.pdf. Если предподчитаемый адрес — /offer/file.pdf, настройте сервер так, чтобы он передавал в HTTP-заголовке страницы /files/file.pdf следующее:
Link: <http://www.example.com/offer/file.pdf>; rel="canonical"Примечание. Указывайте канонический адрес в пределах одного домена. В качестве канонического адреса задавайте абсолютный путь, например http://example.com/blog/.
Страница, на которой размещен атрибут rel=”canonical” с адресом другой страницы, считается неканонической.
Робот узнает об изменениях при обходе сайта. Если канонический адрес указан верно и робот не проигнорировал указание, неканоническая страница пропадет из результатов поиска. Убедиться в том, что страница удалена из поиска, можно в Вебмастере на странице (блок Исключённые страницы).
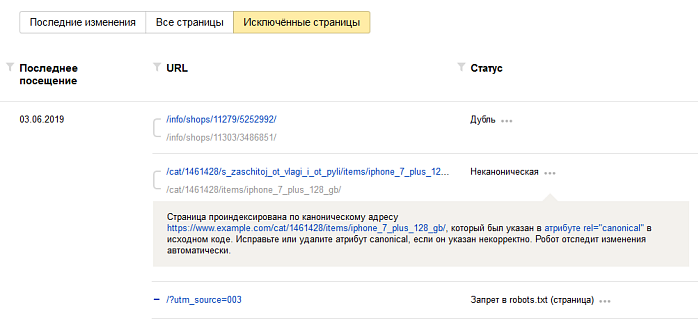
Робот игнорирует указания, если содержимое канонической страницы значительно отличается от содержимого неканонической. В этом случае в поиске может участвовать неканоническая страница. Чтобы проверить это, перейдите на страницу .
Чтобы исключить из поиска неканоническую страницу, адрес которой содержит GET-параметры или метки (UTM, from и т. д.), добавьте директиву Clean-param в файл robots.txt. В другом случае используйте директиву Disallow.
Вы можете указать канонический адрес, если хотите изменить адрес сайта:
-
на домен с префиксом www или без него;
-
с протоколом HTTPS или HTTP.
Робот воспримет канонический адрес как редирект на новое главное зеркало и объединит две версии сайта в одну группу. Для этого в HTML-код или в HTTP-заголовок каждой страницы старого сайта добавьте ссылку на аналогичную страницу нового с атрибутом rel=”canonical”. Например, вы меняете адрес http://example.com на https://example.com. На странице http://example.com/main/ нужно указать:
<link rel="canonical" href="https://example.com/main"/>Если атрибут будет указывать на другую страницу, робот может посчитать это различием в структуре сайтов. В таком случае переезд будет невозможен.
При смене адреса убедитесь, что контент старого и нового сайтов совпадает. Подробнее см. инструкцию по переезду.
Примечание. Если атрибут добавлен только на отдельные страницы, он не будет указывать на главное зеркало.
Робот Яндекса не учтет канонический адрес, если:
-
На момент обхода неканонические страницы более полно отвечают на запрос пользователя, и их контент существенно отличается от канонических. Если вы уверены, что такие страницы не будут полезны пользователям в поиске, запретите индексирование в файле robots.txt.
-
Канонический адрес недоступен для робота — перенаправляет на другую страницу или закрыт от индексирования. Это значит, что он не сможет участвовать в поиске. Тогда вместо канонического адреса может участвовать неканонический, если он доступен для робота.
-
В качестве канонического адреса указан URL в другом домене или поддомене.
-
Указано несколько канонических адресов.
-
Указана цепочка канонических адресов. Например, для адреса example.com/1 каноническим адресом является example.com/2, в то время как для адреса example.com/2 указан канонический адрес example.com/3.
Атрибут rel=”canonical” указывает на страницу, на которой размещен. Это ошибка?
Нет. Если на странице атрибут rel=”canonical” указывает на эту же страницу, робот посчитает ее канонической.
Как вернуть неканоническую страницу в поиск
Если страница была исключена из поиска как неканоническая, значит, в ее HTML-коде или HTTP-заголовке робот нашел атрибут rel=”canonical” с указанием на канонический адрес. Удалите это указание и проверьте, что индексирование страницы, которую вы хотите вернуть в поиск, не запрещено.
Если у вас остались вопросы об использовании атрибута rel=”canonical”, укажите в форме ниже примеры страниц, с которыми возникли проблемы.
Неканоническая страница – это страница веб-сайта, которая не существует в иерархии страниц сайта, и не имеет структуры внутренних ссылок, указывающих на нее. Такие страницы необходимы для решения определенных задач, но не являются основными страницами сайта. Неканонические страницы могут быть созданы для отображения рекламы, справочных материалов, партнерских предложений и других вспомогательных функций. В этой статье мы рассмотрим, что такое неканоническая страница, как она может помочь в продвижении сайта, и как правильно ее создать.
Что такое неканоническая страница сайта
Оглавление статьи
- 1 Что такое неканоническая страница сайта
- 2 Как прописывается каноническая ссылка на сайте
- 3 Как ненканоническая и каноническая ссылка влияет на продвижение сайта
- 4 Пример дублирования URL страницы
- 5 Откуда берутся неканонические страницы на сайте
- 6 Каноническая страница rel=canonical как прописывать
- 7 Выводы
- 8 Вместо заключения
Неканоническая страница – это страница, которая не имеет структуры внутренних ссылок и не включена в иерархию страниц сайта. Это может быть страница, созданная для отображения рекламы, справочных материалов, партнерских предложений и других вспомогательных функций. Такие страницы не являются основными страницами сайта и не содержат контента, необходимого для продвижения сайта.
Не сложно догадаться, что неканоническая ссылка на сайте это обратная сторона канонической.
Как прописывается каноническая ссылка на сайте
В HTML коде каноническая ссылка прописывается так: <link rel=»canonical» href=»ссылка« />
Как ненканоническая и каноническая ссылка влияет на продвижение сайта
На крупных WEB сайтах (и не только) существует большое количество дублирующих страниц. Похожие URL дублируют друг друга, создавая внутри сайта огромное количество одинаковых страниц, тем самым путая пользователей и усложняя работу поисковых роботов.
Чаще всего, такие дубли массово встречаются в интернет магазинах, и если владелец сайта с помощью атрибута rel=»canonical» не указал Яндекс боту какие страницы и товары на сайте являются основными, то Yandex и Google сделают это сами, исключив из индексации дубляж. Вот пример такого исключения в Яндексе:
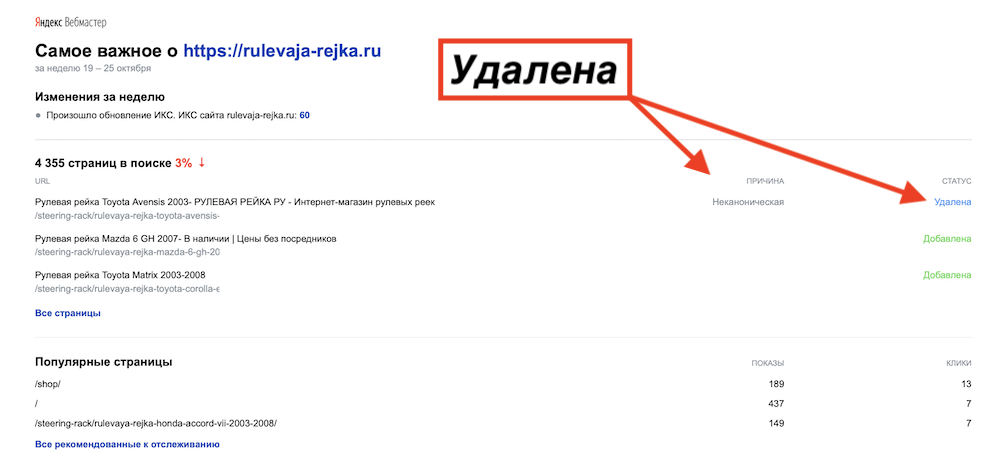
Очень частая ситуация, когда из-за дублирования карточек товаров и страниц интернет-магазина, Яндекс исключает их из выдачи, а владелец сайта не может понять, почему интернет-магазин не продаёт. А по факту, просто не указана основная страница атрибутом rel=»canonical».
Пример дублирования URL страницы
Атрибут rel=canonical был впервые был анонсирован компанией Google в феврале 2009 года. Яндекс его также начал использовать, но позже. Данный атрибут указывает Google и Yandex ботам предпочтение в индексации, той или иной страницы, в том случае, если на сайте таких одинаковых страниц несколько.
Допустим есть две страницы с такими URL:
1) https://www.stroytechservis.ru/remont-magazinov.html
2) https://www.stroytechservis.ru/remont-magazinov.html?id=4535
В этом случае первая страница является основной на сайте, а вторая дублирующей. Если для роботов не прописать основную страницу атрибутом rel=»canonical», то роботы могут её исключить из индексации, а вы этого даже не будете знать.
Соответственно такая страница не будет показываться в поисковой выдаче и приводить на сайт целевых клиентов. Отсюда и возникает важность обозначения канонических страниц на сайтах и интернет-магазинах.
У каждого сайта и интернет магазина дублирующих страниц очень много и с ними нужно бороться. Представьте интернет-магазин с 20 000 товаров у которого страница дублируется несколько раз. В глазах поисковых роботов этот магазин будет иметь 60 000 страниц (условно). Представляете, как этот дубляж подпортит репутацию сайту и ухудшит SEO продвижение? Надеюсь понятно объяснил!
Откуда берутся неканонические страницы на сайте
Неканонические страницы генерируются автоматически, системами управления сайта (CMS), такими как Вордпресс, Модэкс, Тильда, Джумла, Опенкад итд. Полное исключение дублирования достигается на рукописных сайтах с чистым HTML.
Вот, что говорят по этому поводу Google и Яндекс:

Если Вы не хотите, чтобы поисковые системы самовольно определяли важность страниц, товаров и услуг на ваших сайтах, обязательно указывайте rel=canonical.
Каноническая страница rel=canonical как прописывать
После появления атрибута rel=canonical прошло уже очень много времени и практически все системы управления сайтами позволяют прописывать внутри себя канонические ссылки и исключать неканонические.
К примеру в CMS WordPress, у меня это делается автоматически за счет плагина Yoast SEO. Но если к примеру нужно поменять пагинацию, то делается это в дополнительных настройках плагина в этой графе:
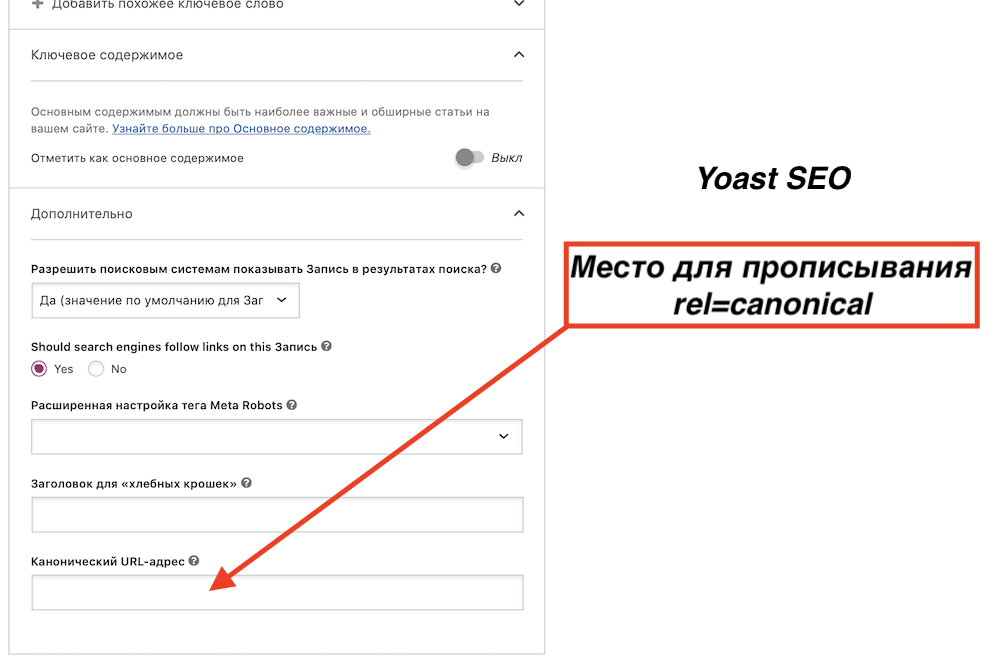
В коде элемента по умолчанию данная страница выглядет так:
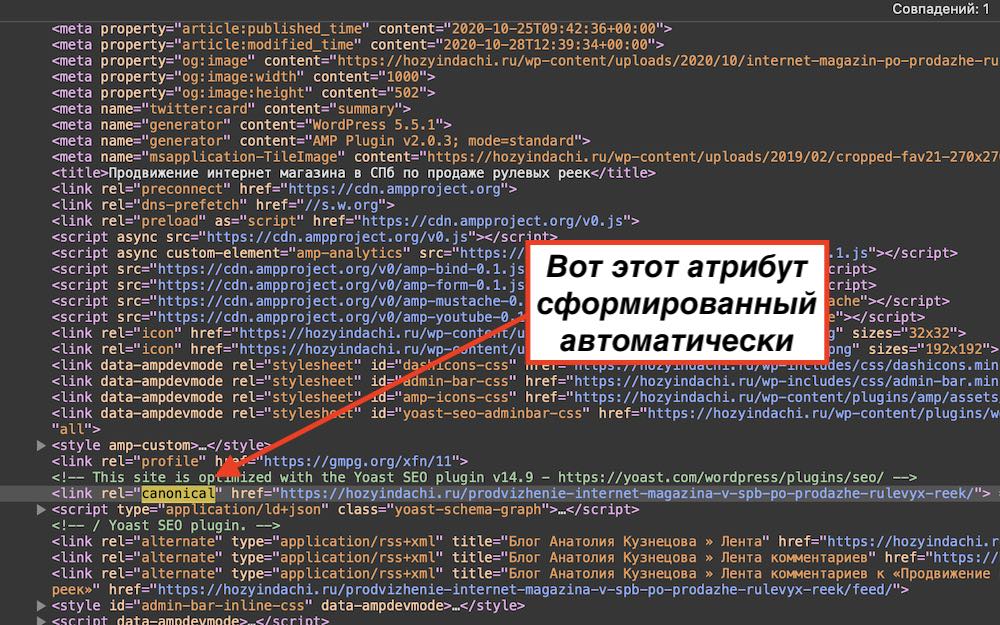
Ну надеюсь теперь Вы поняли, что такое канонические и неканонические ссылки, как их прописывать и как они влияют на продвижение сайта в Яндекс и Google.
Выводы
Неканонические страницы могут помочь в SEO продвижении сайта, если они содержат ссылки на основные страницы сайта и созданы с соблюдением всех необходимых правил. Оптимизация неканонической страницы помогает повысить ее релевантность и видимость в поисковых результатах, что может привести к увеличению трафика на сайт и улучшению его позиций в поисковых системах.
Вместо заключения
Хотите выйти в ТОП10 Яндекс и долго там оставаться? Продвигайте свои сайты и интернет-магазины исключительно белыми SEO методами! Не умеете? Могу научить! Тем, кто хочет разобраться во всех премудростях SEO, предлагаю посетить мои курсы по SEO обучению, которые я провожу индивидуально, в режиме онлайн по скайпу.
Для тех, у кого нет времени проходить обучение и самостоятельно заниматься продвижением своих интернет-магазинов, предлагаю и в этом вопросе помощь. Я могу взять ваш сайт на SEO продвижение и за несколько месяцев вывести его в ТОП10 Яндекс.
Для того чтобы убедиться в моей экспертности, предлагаю ознакомиться с моими последними SEO кейсами и только после этого заказать у меня SEO продвижение. Ниже на видео один из примеров успешного продвижения строительного сайта в Санкт-Петербурге.
