Несмещенная оценка выборочной дисперсии
Краткая теория
Пусть из генеральной совокупности в результате
независимых наблюдений над количественным
признаком
извлечена повторная выборка объема
:
При этом
Требуется по данным выборки оценить (приближенно найти) неизвестную
генеральную дисперсию
.
Если в качестве оценки генеральной дисперсии принять выборочную дисперсию, то
эта оценка будет приводить в систематическим ошибкам, давая заниженное значение
генеральной дисперсии. Объясняется это тем, что, как можно доказать, выборочная
дисперсия является смещенной оценкой
,
другими словами, математическое ожидание выборочной дисперсии не равно
оцениваемой генеральной дисперсии, а равно:
Легко «исправить» выборочную дисперсию так, чтобы ее математическое
ожидание было равно генеральной дисперсии. Достаточно для этого умножить
на дробь
.
Сделав это, получим исправленную дисперсию, которую обычно обозначают через
:
Исправленная дисперсия является, конечно, несмещенной оценкой
генеральной дисперсии. Действительно:
Итак, в качестве оценки генеральной дисперсии принимают
исправленную дисперсию:
Для оценки среднего квадратического
отклонения генеральной совокупности используют исправленное среднее квадратическое отклонение, которое равно квадратному корню
из исправленной дисперсии:
При достаточно больших значениях
объема выборки выборочная и исправленная
дисперсия отличаются мало. На практике используются исправленной дисперсией,
если примерно
.
Пример решения задачи
Задача
Найти
несмещенную выборочную дисперсию на основании данного распределения выборки.
Решение
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Выборочная дисперсия является смещенной оценкой генеральной дисперсии, поэтому в статистике применяют также исправленную выборочную дисперсию, которая является несмещенной оценкой генеральной дисперсии.
Сумма
частот:
Вычислим
среднюю:
Средняя квадратов:
Несмещенная
выборочная дисперсия:
Ответ:
Кроме этой задачи на другой странице сайта есть
пример расчета исправленной выборочной дисперсии и среднего квадратического отклонения для интервального вариационного ряда
Задача 55. Из генеральной совокупности извлечена выборка объема N, заданная вариантами ХI и соответствующими им частотами. Найти несмещенную оценку генеральной средней.
|
Варианта ХI |
2 |
5 |
7 |
10 |
|
Частота Ni |
16 |
12 |
8 |
14 |
Решение. Множество всех объектов, подлежащих изучению, называется Генеральной совокупностью. Множество случайно отобранных объектов называется выборочной совокупностью или Выборкой.
Для оценки неизвестных параметров теоретического распределения служат статистические оценки. Статистическая оценка, определяемая одним числом, называется Точечной оценкой.
Точечная статистическая оценка, математическое ожидание которой равно оцениваемому параметру при любом объеме выборки, называется Несмещенной оценкой. Статистическая оценка, математическое ожидание которой не равно оцениваемому параметру является Смещенной.
Несмещенной оценкой генеральной средней (математического ожидания) служит выборочная средняя
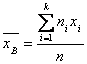 (1),
(1),
Где ХI – варианта выборки (элемент выборки); Ni – частота варианты ХI (число наблюдений варианты ХI); ![]() – объем выборки (число элементов совокупности).
– объем выборки (число элементов совокупности).
Объем данной выборки равен ![]() .
.
Далее по формуле (1) вычисляем несмещенную оценку генеральной средней:
![]()
Задача 56. По выборке объема N=41 найдена смещенная оценка генеральной дисперсии ![]() . Найти несмещенную оценку дисперсии генеральной совокупности.
. Найти несмещенную оценку дисперсии генеральной совокупности.
Решение. Смещенной оценкой генеральной дисперсии служит выборочная дисперсия
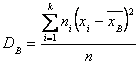
Несмещенной оценкой генеральной дисперсии является «исправленная дисперсия»
![]() или
или 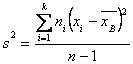
Таким образом, мы получаем искомую несмещенную оценку дисперсии генеральной совокупности:
![]()
Задача 57. Найти доверительный интервал для оценки с надежностью P=0,95 неизвестного математического ожидания A нормально распределенного признака Х генеральной совокупности, если даны генеральное среднее квадратическое отклонение S=5, выборочная средняя ![]() , а объем выборки N=25.
, а объем выборки N=25.
Решение. Интервальной оценкой называется интервал, покрывающий оцениваемый параметр. Доверительным интервалом является интервал, который с данной надежностью покрывает оцениваемый параметр.
Для оценки математического ожидания A нормально распределенного количественного признака Х по выборочной средней ![]() при известном среднем квадратическом отклонении s генеральной совокупности служит доверительный интервал
при известном среднем квадратическом отклонении s генеральной совокупности служит доверительный интервал
![]() ,
,
Где ![]() – точность оценки, T – значение аргумента функции Лапласа
– точность оценки, T – значение аргумента функции Лапласа ![]() (приложение, таблица 2).
(приложение, таблица 2).
В данной задаче T находим из условия ![]() . По таблице 2 определяем
. По таблице 2 определяем ![]() . Таким образом, T=1,96.
. Таким образом, T=1,96.
Далее получаем
![]()
Или ![]()
Задача 58. По данным N=9 независимых равноточных измерений некоторой физической величины найдены среднее арифметическое результатов измерений ![]() и исправленное среднее квадратическое отклонение S=6. Оценить истинное значение измеряемой величины при помощи доверительного интервала с надежностью
и исправленное среднее квадратическое отклонение S=6. Оценить истинное значение измеряемой величины при помощи доверительного интервала с надежностью ![]() =0,99.
=0,99.
Решение. Оценкой математического ожидания A нормально распределенного количественного признака Х в случае неизвестного среднего квадратического отклонения является доверительный интервал
![]() .
.
По таблице 3 приложения, по заданным N и ![]() находим
находим ![]() =3,36.
=3,36.
Таким образом
![]()
Окончательно получаем
![]()
Задача 59. Из генеральной совокупности извлечена выборка объема N. Оценить с надежностью ![]() =0,95 математическое ожидание A нормально распределенного признака Х генеральной совокупности по выборочной средней с помощью доверительного интервала.
=0,95 математическое ожидание A нормально распределенного признака Х генеральной совокупности по выборочной средней с помощью доверительного интервала.
|
Значение признака ХI |
-2 |
1 |
1 |
3 |
4 |
5 |
|
Частота Ni |
2 |
1 |
2 |
2 |
2 |
1 |
Решение. Объем данной выборки равен ![]()
![]()
По данным задачи находим выборочную среднюю:
![]()
Далее находим исправленное среднее квадратическое отклонение S:
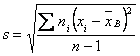
![]()
Для оценки математического ожидания A нормально распределенного количественного признака Х в случае неизвестного среднего квадратического отклонения служит доверительный интервал
![]() .
.
По таблице 3 приложения по заданным N и ![]() находим
находим ![]() =2,26.
=2,26.
Таким образом
![]()
Окончательно получаем
![]()
Задача 60. Построить полигон частот и эмпирическую функцию по данному распределению выборки:
|
Варианты ХI |
-3 |
0 |
1 |
4 |
6 |
7 |
|
Частоты Ni |
3 |
6 |
1 |
2 |
5 |
1 |
Решение. Полигоном частот называют ломаную, отрезки которой соединяют точки ![]() ;
; ![]() ;…;
;…;![]() , где ХI – варианты выборки, Ni – соответствующие им частоты.
, где ХI – варианты выборки, Ni – соответствующие им частоты.
Полигон частот для данного распределения изображен на рисунке 15.

Рис. 15
Эмпирической функцией распределения (функцией распределения выборки) называют функцию ![]() , определяющую для каждого значения X относительную частоту события
, определяющую для каждого значения X относительную частоту события ![]() :
:
![]() ,
,
Где ![]() – число вариант, меньших Х; N – объем выборки.
– число вариант, меньших Х; N – объем выборки.
Из определения следует, что ![]() .
.
Найдем эмпирическую функцию распределения.
Объем данной выборки равен ![]() =18.
=18.
Если ![]() , то
, то ![]() =0 (так как -3 – наименьшая варианта). Если
=0 (так как -3 – наименьшая варианта). Если ![]() , то значение
, то значение ![]() , а именно
, а именно ![]() наблюдалось 3 раза, следовательно,
наблюдалось 3 раза, следовательно, ![]() . При
. При ![]() значения
значения ![]() , а именно
, а именно ![]() и
и ![]() наблюдались 3+6=9 раз, следовательно,
наблюдались 3+6=9 раз, следовательно, ![]() .
.
Аналогично получаем, что при ![]() функция распределения
функция распределения ![]() ; при
; при ![]() функция распределения
функция распределения ![]() ; при
; при ![]() функция распределения
функция распределения ![]() . Далее, если
. Далее, если ![]() , то
, то ![]() (так как 7 – наибольшая варианта).
(так как 7 – наибольшая варианта).
Таким образом, эмпирическая функция распределения равна:

График полученной эмпирической функции распределения изображен на рисунке 16.
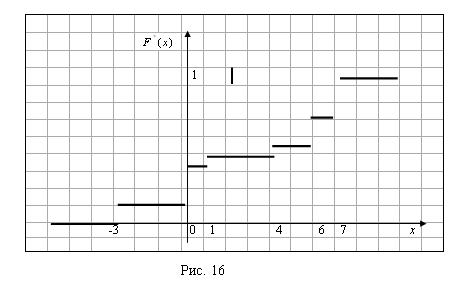
Задача 61. Найти методом сумм асимметрию и эксцесс по заданному распределению выборки объема N=100:
|
Варианта ХI |
48 |
52 |
56 |
60 |
64 |
68 |
72 |
76 |
80 |
84 |
|
Частота Ni |
2 |
4 |
6 |
8 |
12 |
30 |
18 |
8 |
7 |
5 |
Решение. Асимметрия ![]() эмпирического распределения определяется равенством:
эмпирического распределения определяется равенством:
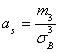 ,
,
Где ![]() – центральный эмпирический момент третьего порядка, вычисляемый по формуле:
– центральный эмпирический момент третьего порядка, вычисляемый по формуле: 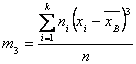
Эксцесс ![]() эмпирического распределения определяется равенством:
эмпирического распределения определяется равенством:
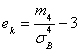 ,
,
Где ![]() – центральный эмпирический момент четвертого порядка, вычисляемый по формуле:
– центральный эмпирический момент четвертого порядка, вычисляемый по формуле: 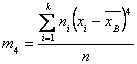
Асимметрия и эксцесс служат для оценки отклонения эмпирического распределения от нормального. Для нормального распределения эти характеристики равны нулю. Поэтому, если для изучаемого распределения асимметрия и эксцесс имеют небольшие значения, то можно предположить близость этого распределения к нормальному. Наоборот, большие значения асимметрии и эксцесса указывают на значительное отклонение от нормального. Кроме того, если эксцесс положительный, то распределение будет островершинным; если отрицательный, то распределение будет плосковершинным по сравнению с нормальным распределением.
Для практического расчета асимметрии и эксцесса непосредственно пользоваться вышеуказанными формулами довольно затруднительно, поэтому воспользуемся методом сумм. Составим расчетную таблицу 1, для этого:
1) Запишем варианты в первый столбец.
2) Запишем частоты во второй столбец; сумму частот (100) поместим в нижнюю клетку столбца.
3) В качестве ложного нуля С выберем варианту (68), которая имеет наибольшую частоту (в качестве С можно взять любую варианту, расположенную примерно в середине столбца); в клетках строки, содержащей ложный нуль, запишем нули; в четвертом столбце над и под уже помещенным нулем запишем еще по одному нулю.
4) В оставшихся незаполненными над нулем клетках третьего столбца (исключая самую верхнюю) запишем последовательно накопленные частоты:
2; 2+4=6; 6+6=12; 12+8=20; 20+12=32.
Сложив все накопленные частоты, получим число B1=72, которое поместим в верхнюю клетку третьего столбца. В оставшихся незаполненными под нулем клетках третьего столбца (исключая самую нижнюю) запишем последовательно накопленные частоты:
5; 5+7=12; 12+8=20; 20+18=38.
Сложив все накопленные частоты, получим число A1=75, которое поместим в нижнюю клетку третьего столбца.
5) Аналогично заполняется четвертый столбец, причем суммируют частоты третьего столбца. Сложив все накопленные частоты, расположенные над нулем, получим число B2=70, которое поместим в верхнюю клетку четвертого столбца. Сумма накопленных частот, расположенных под нулем, равна числу A2=59, которое поместим в нижнюю клетку четвертого столбца.
6) Для заполнения столбца 5 запишем нуль в клетке строки, содержащей ложный нуль (68); над этим нулем и под ним поставим еще по два нуля. В клетках над нулями запишем накопленные частоты, для чего просуммируем частоты столбца 4 сверху вниз; в итоге будем иметь следующие накопленные частоты:
2; 2+8=10; 10+20=30.
Сложив накопленные частоты, получим число B3=42, которое поместим в верхнюю клетку пятого столбца. В клетках под нулями запишем накопленные частоты, для чего просуммируем частоты столбца 4 снизу вниз; в итоге будем иметь следующие накопленные частоты:
5; 5+17=22.
Сложив накопленные частоты, получим число A3=27, которое поместим в нижнюю клетку пятого столбца.
7) Аналогично заполняется столбец 6, причем суммируют частоты столбца 5.
В итоге получим расчетную таблицу 1:
Расчетная таблица 1
|
1 |
2 |
3 |
4 |
5 |
6 |
|
ХI |
Ni |
B1=72 |
B2=70 |
B3=42 |
B4=14 |
|
48 |
2 |
2 |
2 |
2 |
2 |
|
52 |
4 |
6 |
8 |
10 |
12 |
|
56 |
6 |
12 |
20 |
30 |
0 |
|
60 |
8 |
20 |
40 |
0 |
0 |
|
64 |
12 |
32 |
0 |
0 |
0 |
|
68 |
30 |
0 |
0 |
0 |
0 |
|
72 |
18 |
38 |
0 |
0 |
0 |
|
76 |
8 |
20 |
37 |
0 |
0 |
|
80 |
7 |
12 |
17 |
22 |
0 |
|
84 |
5 |
5 |
5 |
5 |
5 |
|
N=100 |
A1=75 |
A2=59 |
A3=27 |
A4=5 |
Теперь найдем Di (I=1, 2, 3) и si (I=1, 2, 3, 4):
![]() ;
; ![]() ;
; ![]() ;
;
![]() ;
; ![]() ;
;
![]() ;
; ![]() .
.
Найдем условные моменты первого, второго, третьего и четвертого порядков:
![]() ;
; ![]() ;
;
![]() ;
;
![]() .
.
Найдем далее центральные эмпирические моменты третьего и четвертого порядков, учитывая, что шаг ![]() (разность между двумя соседними вариантами):
(разность между двумя соседними вариантами):
![]() ;
;

Так как дисперсия ![]() , то выборочное среднее квадратическое отклонение
, то выборочное среднее квадратическое отклонение ![]() .
.
Учитывая определения асимметрии и эксцесса, окончательно получаем:
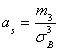
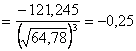 ;
; 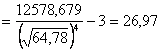 .
.
| < Предыдущая | Следующая > |
|---|
Т.к.
X1,
X2,…,Xn
– независимые, одинаково распределенные
случайные величины, то все они имеют
один и тот же закон распределения
вероятностей и одинаковые числовые
характеристики.
Среднее
выборочное
![]()
удовлетворяет
всем накладываемым к статистическим
оценкам требованиям, т.е. дает несмещенную,
эффективную и состоятельную оценку.
Действительно:
 . (3.7)
. (3.7)
Это
равенство следует из того, что все
значения xi
распределены одинаково с математическим
ожиданием
![]() .
.
Поэтому
![]() является несмещенной оценкой
является несмещенной оценкой
![]() .
.
В
то же время эта оценка является
состоятельной:
согласно
закону больших чисел, при увеличении
n,
величина
![]() сходится по вероятности к математическому
сходится по вероятности к математическому
ожиданию. Говорят, выборочное среднее
обладает свойством
статистической
устойчивости.
Оценим
по данным выборки неизвестную нам
генеральную дисперсию DГ.
Поступим аналогично, т.е. в качестве
оценки DГ
возьмем DВ.
Можно доказать, что математическое
ожидание DВ
равно
![]() .
.
Таким
образом, DВ
оказывается смещенной оценкой генеральной
дисперсии, давая заниженное
значение DГ.
Это значит, что при малых п,
ее использование приведет к систематическим
ошибкам. Для
несмещенной оценки DГ
достаточно взять величину
![]() ,
,
которую называютисправленной
дисперсией
и обозначают s2.
Тогда
![]() ,
,
![]() .
.
Т.о.,
математическое ожидание исправленной
дисперсии действительно равно дисперсии
генеральной совокупности и, значит, s2
– состоятельная оценка генеральной
дисперсии.
На
практике для оценки генеральной дисперсии
применяют исправленную дисперсию при
![]() .
.
В остальных случаях![]() ,
,
отклонениеDВ
от DГ
малозаметно. Поэтому при больших
значениях n
ошибкой “смещения” 1/n
можно пренебречь: т.к. при
![]() коэффициент
коэффициент![]() ,
,
т.е.s2
– состоятельная оценка.
Итак, несмещенная
оценка для дисперсии имеет вид
![]() (3.8)
(3.8)
для
выборки, заданной последовательностью
значений или таблицей относительных
частот.
Пусть
некоторая случайная величина X
имеет математическое ожидание MX=m
и дисперсию
DX=![]() .
.
В ходе эксперимента получена случайная
выборка из n
независимых испытаний случайной величины
X.
Тогда справедливы следующие утверждения.
1)
Среднее выборочное
![]() служит несмещенной и состоятельной
служит несмещенной и состоятельной
оценкой математического ожиданияMX.
2)
Если случайная величина X
распределена по нормальному закону с
параметрами N(m,),
то среднее выборочное
![]() также распределено нормально и имеет
также распределено нормально и имеет
минимальную дисперсию
![]() :
:
т.е.
![]() .
.
Поэтому среднее выборочное![]() – эффективная и состоятельная оценка
– эффективная и состоятельная оценка
математического ожидания.
3)
Выборочная дисперсия
![]() является
является
смещенной оценкой генеральной дисперсии![]() .
.
Несмещенной оценкой генеральной
дисперсии![]() является
является
«исправленная» дисперсия![]() ,
,
для получения которой необходимо
умножить![]() на так называемуюпоправку
на так называемуюпоправку
Бесселя
![]() .
.
Тогда
![]() .
.
«Исправленная»
выборочная дисперсия
![]() является состоятельной оценкой
является состоятельной оценкой
генеральной дисперсии![]() .
.
-
Если
известно m
– математическое ожидание случайной
величины X,
то выборочная дисперсия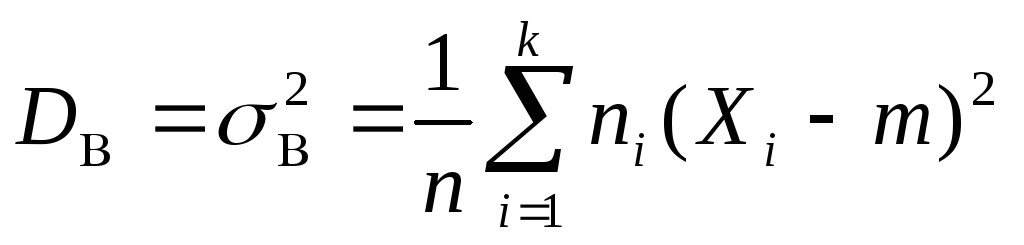 является несмещенной, состоятельной
является несмещенной, состоятельной
и эффективной оценкой генеральной
дисперсии .
. -
Относительная
частота
 является
является
несмещенной и состоятельной оценкой
вероятностиP(X=xi).
Эмпирическая функция распределения
 –
–
накопленная относительная частота –
является несмещенной и состоятельной
оценкой теоретической функции
распределенияF(x)=P(X<x).
Задача
5. Найти
несмещенные оценки математического
ожидания и дисперсии по таблице выборки:
|
xi |
2 |
6 |
12 |
|
ni |
3 |
10 |
7 |
Решение:
Из
таблицы имеем объем выборки n
= 20. Несмещенная оценка математического
ожидания есть среднее выборочное
![]() :
:
![]()
Для
вычисления несмещенной оценки дисперсии
сначала найдем выборочную дисперсию,
а затем несмещенную оценку – s2:
![]() ,
, ![]()
![]() .
.
|
хi |
2 |
6 |
12 |
|
|
0.15 |
0.5 |
0.35 |
Задача 6.
Найти несмещенные числовые характеристики
выборки, заданной таблицей:
Решение:
Среднее
выборочное
![]() является несмещенной оценкой генерального
является несмещенной оценкой генерального
среднего, а для вычисления несмещенной
дисперсии![]() предварительно вычислим смещенную
предварительно вычислим смещенную
дисперсию![]()
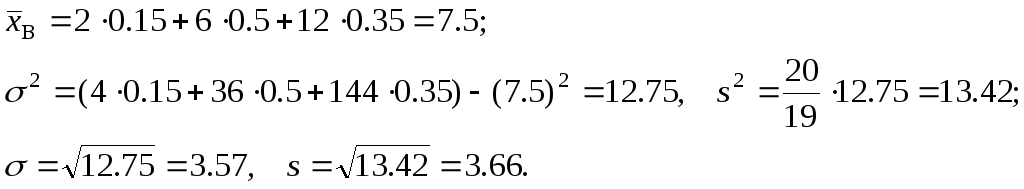
Легко видеть, что
задачи 5 и 6 задают одну и ту же выборку,
но в задаче 5 она задается таблицей
абсолютных частот, а в задаче 6 – таблицей
относительных частот:
![]() =
=![]() .
.
На
практике если значение вариант xi
– большие числа, то для облегчения
расчетов их представляют в виде суммы
некоторого постоянного числа с
и условной варианты ui,
как дополнения до
![]() ,
,
т.е.![]() .
.
Это значит, что задан некий новый
вариационный ряд для величиныU,
определенный по выборочным данным ui.
Поскольку выбор с
произволен, то лучше взять за с
значение, близкое к
![]() .
.
Тогда,![]() ,
,
а дисперсия не изменится, т.е.![]() ,
,
так как по свойствам дисперсии
![]() ,
,
где C
– const.
Тогда
![]() .
.
Аналогично
вычисляется несмещенная оценка дисперсии:
![]() . (3.9.)
. (3.9.)
Если
первоначальные варианты представлены
десятичными дробями, то их умножают на
постоянное число с=10k,
где k
– количество десятичных знаков. Тогда
условные варианты имеют вид
![]() ,
,
то есть дисперсия увеличилась в
![]() раз, согласно свойству дисперсии. Поэтому
раз, согласно свойству дисперсии. Поэтому![]() ,
,
а![]() .
.
Аналогично,
![]() . (3.10)
. (3.10)
Задача
7. Из генеральной
совокупности извлечена выборка. Найти
несмещенную оценку генеральной средней
и генеральной дисперсии.
|
xi |
3250 |
3270 |
3280 |
|
ni |
2 |
5 |
3 |
Решение:
1. Найдем
условную варианту и составим для нее
ряд распределений:
Пусть
с=3270,
тогда
![]() ,
,
|
ui |
-20 |
0 |
10 |
|
ni |
2 |
5 |
3 |
2.
Т.к. объем выборки n=10,
то
![]() ;
;![]() .
.
3.
Найдем выборочную дисперсию для
первоначальной варианты с помощью
условной варианты:
![]() .
.
4.
Найдем «несмещенную выборочную дисперсию»
– несмещенную оценку генеральной
дисперсии:
![]() .
.
То,
что выбор постоянной с
не влияет на значение дисперсии, следует
из соответствующего свойства, известного
теории вероятностей. Поэтому выбор
постоянной с
весьма условен и определяется удобством
расчета. Особенно это очевидно при очень
малых значениях V:
например, если среднеквадратичное
отклонение порядка 10-7,
а выборочное среднее порядка 107,
то затруднительно непосредственно
вычислить дисперсию, т.к. незначительная
разница будет меньше погрешности
округления на микрокалькуляторе. Т.о.,
на практике исходят из критерия удобства
дальнейших расчетов.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Содержание:
Точечные оценки:
Пусть случайная величина имеет неизвестную характеристику а. Такой характеристикой может быть, например, закон распределения, математическое ожидание, дисперсия, параметр закона распределения, вероятность определенного значения случайной величины и т.д. Пронаблюдаем случайную величину n раз и получим выборку из ее возможных значений 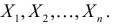
Существует два подхода к решению этой задачи. Можно по результатам наблюдений вычислить приближенное значение характеристики, а можно указать целый интервал ее значений, согласующихся с опытными данными. В первом случае говорят о точечной оценке, во втором – об интервальной.
Определение. Функция результатов наблюдений 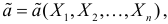
Для одной и той же характеристики можно предложить разные точечные оценки. Необходимо иметь критерии сравнения оценок, для суждения об их качестве. Оценка 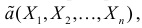 как функция случайных результатов наблюдений
как функция случайных результатов наблюдений 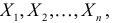 сама является случайной величиной. Значения
сама является случайной величиной. Значения 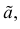 найденные по разным сериям наблюдений, могут отличаться от истинного значения характеристики
найденные по разным сериям наблюдений, могут отличаться от истинного значения характеристики 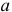 в ту или другую сторону. Естественно потребовать, чтобы оценка систематически не завышала и не занижала оцениваемое значение, а с ростом числа наблюдений становилась более точной. Формализация названных требований приводит к следующим понятиям.
в ту или другую сторону. Естественно потребовать, чтобы оценка систематически не завышала и не занижала оцениваемое значение, а с ростом числа наблюдений становилась более точной. Формализация названных требований приводит к следующим понятиям.
Определение. Оценка называется несмещенной, если ее математическое ожидание равно оцениваемой величине: 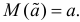 В противном случае оценку называют смещенной.
В противном случае оценку называют смещенной.
Определение. Оценка называется состоятельной, если при увеличении числа наблюдений она сходится по вероятности к оцениваемой величине, т.е. для любого сколь угодно малого 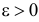
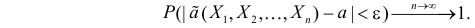
Если известно, что оценка 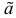 несмещенная, то для ее состоятельности достаточно, чтобы
несмещенная, то для ее состоятельности достаточно, чтобы
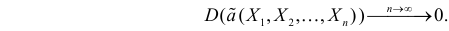
Последнее условие удобно для проверки. В качестве меры разброса значений оценки относительно 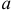 можно рассматривать величину
можно рассматривать величину 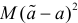 Из двух оценок предпочтительней та, для которой эта величина меньше. Если оценка имеет наименьшую меру разброса среди всех оценок характеристики, построенных по
Из двух оценок предпочтительней та, для которой эта величина меньше. Если оценка имеет наименьшую меру разброса среди всех оценок характеристики, построенных по 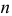 наблюдениям, то оценку называют эффективной.
наблюдениям, то оценку называют эффективной.
Следует отметить, что несмещенность и состоятельность являются желательными свойствами оценок, но не всегда разумно требовать наличия этих свойств у оценки. Например, может оказаться предпочтительней оценка хотя и обладающая небольшим смещением, но имеющая значительно меньший разброс значений, нежели несмещенная оценка. Более того, есть характеристики, для которых нет одновременно несмещенных и состоятельных оценок.
Оценки для математического ожидания и дисперсии
Пусть случайная величина имеет неизвестные математическое ожидание и дисперсию, причем 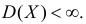 Если
Если 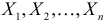 – результаты независимых наблюдений случайной величины, то в качестве оценки для математического ожидания можно предложить среднее арифметическое наблюдаемых значений
– результаты независимых наблюдений случайной величины, то в качестве оценки для математического ожидания можно предложить среднее арифметическое наблюдаемых значений 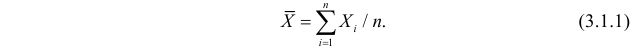
Несмещенность такой оценки следует из равенств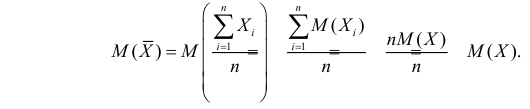
В силу независимости наблюдений 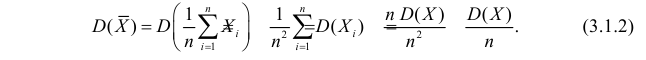
При условии 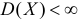 имеем
имеем 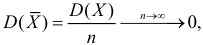 что означает состоятельность оценки
что означает состоятельность оценки  .
.
Доказано, что для математического ожидания нормально распределенной случайной величины оценка 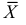 еще и эффективна.
еще и эффективна.
Оценка математического ожидания посредством среднего арифметического наблюдаемых значений наводит на мысль предложить в качестве оценки для дисперсии величину

Преобразуем величину 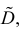 обозначая для краткости
обозначая для краткости 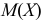 через
через 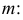
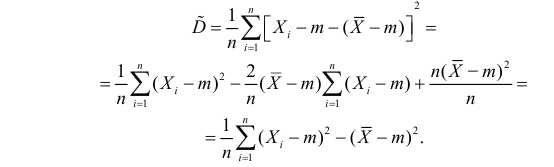
В силу (3.1.2) имеем 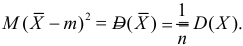 Поэтому
Поэтому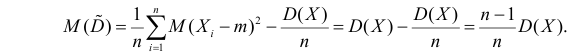
Последняя запись означает, что оценка 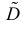 имеет смещение. Она систематически занижает истинное значение дисперсии. Для получения несмещенной оценки введем поправку в виде множителя
имеет смещение. Она систематически занижает истинное значение дисперсии. Для получения несмещенной оценки введем поправку в виде множителя 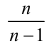 и полученную оценку обозначим через
и полученную оценку обозначим через 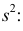
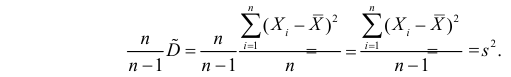
Величина
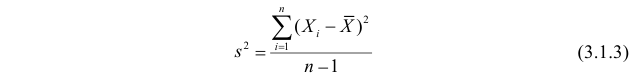
является несмещенной и состоятельной оценкой дисперсии.
Пример:
Оценить математическое ожидание и дисперсию случайной величины Х по результатам ее независимых наблюдений: 7, 3, 4, 8, 4, 6, 3.
Решение. По формулам (3.1.1) и (3.1.3) имеем 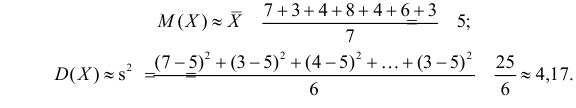
Ответ. 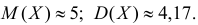
Пример:
Данные 25 независимых наблюдений случайной величины представлены в сгруппированном виде: 
Требуется оценить математическое ожидание и дисперсию этой случайной величины.
Решение. Представителем каждого интервала можно считать его середину. С учетом этого формулы (3.1.1) и (3.1.3) дают следующие оценки: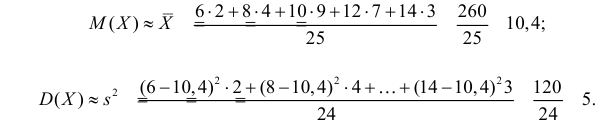
Ответ. 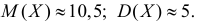
Метод наибольшего правдоподобия для оценки параметров распределений
В теории вероятностей и ее приложениях часто приходится иметь дело с законами распределения, которые определяются некоторыми параметрами. В качестве примера можно назвать нормальный закон распределения 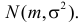 Его параметры
Его параметры 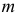 и
и 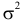 имеют смысл математического ожидания и дисперсии соответственно. Их можно оценить с помощью
имеют смысл математического ожидания и дисперсии соответственно. Их можно оценить с помощью 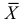 и
и 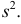 В общем случае параметры законов распределения не всегда напрямую связаны со значениями числовых 179 характеристик. Поэтому практический интерес представляет следующая задача.
В общем случае параметры законов распределения не всегда напрямую связаны со значениями числовых 179 характеристик. Поэтому практический интерес представляет следующая задача.
Пусть случайная величина Х имеет функцию распределения 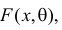 причем тип функции распределения F известен, но неизвестно значение параметра
причем тип функции распределения F известен, но неизвестно значение параметра 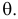 По данным результатов наблюдений нужно оценить значение параметра. Параметр может быть и многомерным.
По данным результатов наблюдений нужно оценить значение параметра. Параметр может быть и многомерным.
Продемонстрируем идею метода наибольшего правдоподобия на упрощенном примере. Пусть по результатам наблюдений, отмеченных на рис. 3.1.1 звездочками, нужно отдать предпочтение одной из двух функций плотности вероятности 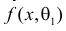 или
или 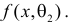
Из рисунка видно, что при значении параметра  такие результаты наблюдений маловероятны и вряд ли бы реализовались. При значении же
такие результаты наблюдений маловероятны и вряд ли бы реализовались. При значении же  эти результаты наблюдений вполне возможны. Поэтому значение параметра
эти результаты наблюдений вполне возможны. Поэтому значение параметра 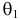 более правдоподобно, чем значение
более правдоподобно, чем значение 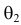 . Такая аргументация позволяет сформулировать принцип наибольшего правдоподобия: в качестве оценки параметра выбирается то его значение, при котором данные результаты наблюдений наиболее вероятны.
. Такая аргументация позволяет сформулировать принцип наибольшего правдоподобия: в качестве оценки параметра выбирается то его значение, при котором данные результаты наблюдений наиболее вероятны.
Этот принцип приводит к следующему способу действий. Пусть закон распределения случайной величины Х зависит от неизвестного значения параметра 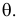 Обозначим через
Обозначим через 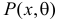 для непрерывной случайной величины плотность вероятности в точке
для непрерывной случайной величины плотность вероятности в точке 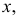 а для дискретной случайной величины – вероятность того, что
а для дискретной случайной величины – вероятность того, что 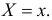 Если в
Если в 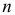 независимых наблюдениях реализовались значения случайной величины
независимых наблюдениях реализовались значения случайной величины 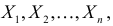 то выражение
то выражение 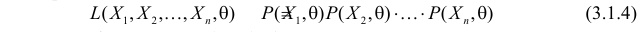
называют функцией правдоподобия. Величина 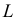 зависит только от параметра
зависит только от параметра 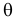 при фиксированных результатах наблюдений
при фиксированных результатах наблюдений 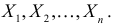 При каждом значении параметра
При каждом значении параметра 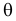 функция
функция 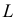 равна вероятности именно тех значений дискретной случайной величины, которые получены в процессе наблюдений. Для непрерывной случайной величины равна плотности вероятности в точке выборочного пространства
равна вероятности именно тех значений дискретной случайной величины, которые получены в процессе наблюдений. Для непрерывной случайной величины равна плотности вероятности в точке выборочного пространства 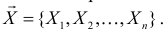
Сформулированный принцип предлагает в качестве оценки значения параметра выбрать такое 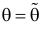 при котором принимает наибольшее значение. Величина
при котором принимает наибольшее значение. Величина 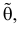 будучи функцией от результатов наблюдений
будучи функцией от результатов наблюдений 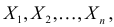 называется оценкой наибольшего правдоподобия.
называется оценкой наибольшего правдоподобия.
Во многих случаях, когда дифференцируема, оценка наибольшего правдоподобия находится как решение уравнения 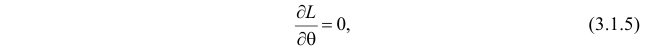
которое следует из необходимого условия экстремума. Поскольку 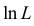 достигает максимума при том же значении
достигает максимума при том же значении 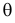 , что и , то можно решать относительно
, что и , то можно решать относительно 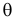 эквивалентное уравнение
эквивалентное уравнение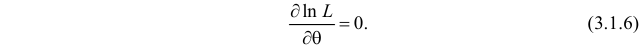
Это уравнение называют уравнением правдоподобия. Им пользоваться удобнее, чем уравнением (3.1.5), так как функция равна произведению, а – сумме, а дифференцировать проще.
Если параметров несколько (многомерный параметр), то следует взять частные производные от функции правдоподобия по всем параметрам, приравнять частные производные нулю и решить полученную систему уравнений.
Оценку, получаемую в результате поиска максимума функции правдоподобия, называют еще оценкой максимального правдоподобия.
Известно, что оценки максимального правдоподобия состоятельны. Кроме того, если для q существует эффективная оценка, то уравнение правдоподобия имеет единственное решение, совпадающее с этой оценкой. Оценка максимального правдоподобия может оказаться смещенной.
Метод моментов
Начальным моментом 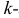 го порядка случайной величины Х называется математическое ожидание
го порядка случайной величины Х называется математическое ожидание 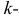 й степени этой величины, т.е.
й степени этой величины, т.е. 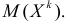 Само математическое ожидание считается начальным моментом первого порядка.
Само математическое ожидание считается начальным моментом первого порядка.
Центральным моментом 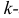 го порядка называется
го порядка называется 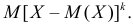 Очевидно, что дисперсия – это центральный момент второго порядка. Если закон распределения случайной величины зависит от некоторых параметров, то от этих параметров зависят и моменты случайной величины.
Очевидно, что дисперсия – это центральный момент второго порядка. Если закон распределения случайной величины зависит от некоторых параметров, то от этих параметров зависят и моменты случайной величины.
Для оценки параметров распределения по методу моментов находят на основе опытных данных оценки моментов в количестве, равном числу оцениваемых параметров. Эти оценки приравнивают к соответствующим теоретическим моментам, величины которых выражены через параметры. Из полученной системы уравнений можно определить искомые оценки.
Например, если Х имеет плотность распределения 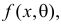 то
то 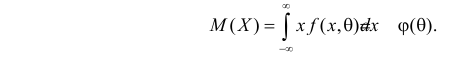
Если воспользоваться величиной 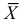 как оценкой для
как оценкой для 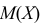 на основе опытных данных, то оценкой по методу моментов будет решение уравнения
на основе опытных данных, то оценкой по методу моментов будет решение уравнения 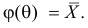
Пример:
Найти оценку параметра показательного закона распределения по методу моментов.
Решение. Плотность вероятности показательного закона распределения имеет вид 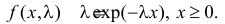 Поэтому
Поэтому 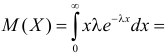
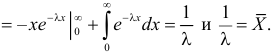 Откуда
Откуда 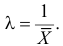
Ответ. 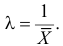
Пример:
Пусть имеется простейший поток событий неизвестной интенсивности 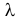 . Для оценки параметра
. Для оценки параметра 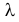 проведено наблюдение потока и зарегистрированы
проведено наблюдение потока и зарегистрированы 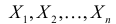 – длительности
– длительности 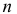 последовательных интервалов времени между моментами наступления событий. Найти оценку для
последовательных интервалов времени между моментами наступления событий. Найти оценку для 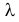 .
.
Решение. В простейшем потоке интервалы времени между последовательными моментами наступления событий потока имеют показательный закон распределения 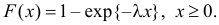 Так как плотность вероятности показательного закона распределения равна
Так как плотность вероятности показательного закона распределения равна 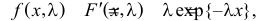 то функция правдоподобия (3.1.4) имеет вид
то функция правдоподобия (3.1.4) имеет вид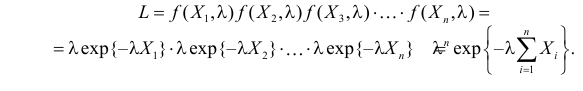
Тогда 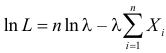 и уравнение правдоподобия
и уравнение правдоподобия 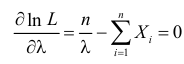 имеет решение
имеет решение 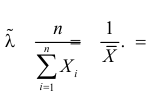
При таком значении 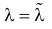 функция правдоподобия действительно достигает наибольшего значения, так как
функция правдоподобия действительно достигает наибольшего значения, так как 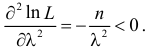
Ответ. 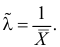
Определение. Пусть 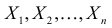 – результаты n независимых наблюдений случайной величины X. Если расставить эти результаты в порядке возрастания, то получится последовательность значений, которую называют вариационным рядом и обозначают:
– результаты n независимых наблюдений случайной величины X. Если расставить эти результаты в порядке возрастания, то получится последовательность значений, которую называют вариационным рядом и обозначают:

В этой записи 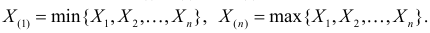
Величины 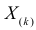 называют порядковыми статистиками.
называют порядковыми статистиками.
Пример:
Случайная величина Х имеет равномерное распределение на отрезке 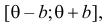 где
где 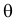 и
и 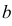 неизвестны. Пусть
неизвестны. Пусть 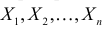 – результаты независимых наблюдений. Найти оценку параметра .
– результаты независимых наблюдений. Найти оценку параметра .
Решение. Функция плотности вероятности величины Х имеет вид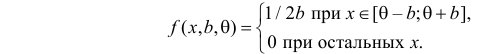
В этом случае функция правдоподобия 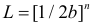 от явно не зависит. Дифференцировать по такую функцию нельзя и нет возможности записать уравнение правдоподобия. Однако легко видеть, что возрастает при уменьшении . Все результаты наблюдений лежат в
от явно не зависит. Дифференцировать по такую функцию нельзя и нет возможности записать уравнение правдоподобия. Однако легко видеть, что возрастает при уменьшении . Все результаты наблюдений лежат в 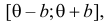 поэтому можно записать:
поэтому можно записать:
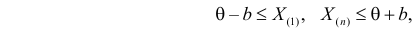
где 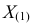 – наименьший, а
– наименьший, а 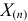 – наибольший из результатов наблюдений. При минимально возможном
– наибольший из результатов наблюдений. При минимально возможном
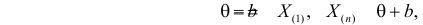
откуда 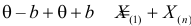 или
или 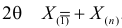
Оценкой наибольшего правдоподобия для параметра будет величина
Ответ. 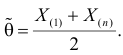
Пример:
Случайная величина X имеет функцию распределения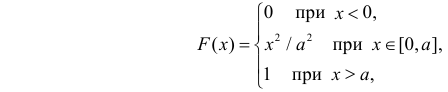
где 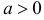 неизвестный параметр.
неизвестный параметр.
Пусть 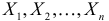 – результаты независимых наблюдений случайной величины X. Требуется найти оценку наибольшего правдоподобия для параметра
– результаты независимых наблюдений случайной величины X. Требуется найти оценку наибольшего правдоподобия для параметра 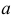 и найти оценку для M(X).
и найти оценку для M(X).
Решение. Для построения функции правдоподобия найдем сначала функцию плотности вероятности
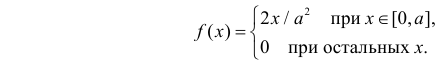
Тогда функция правдоподобия: 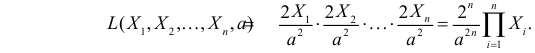
Логарифмическая функция правдоподобия: 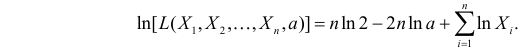
Уравнение правдоподобия

не имеет решений. Критических точек нет. Наибольшее и наименьшее значения находятся на границе допустимых значений 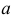 .
.
По виду функции можно заключить, что значение тем больше, чем меньше величина . Но не может быть меньше 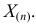 Поэтому наиболее правдоподобное значение
Поэтому наиболее правдоподобное значение 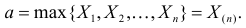
Так как 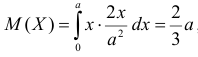 , то оценкой наибольшего правдоподобия для
, то оценкой наибольшего правдоподобия для 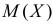 будет величина
будет величина 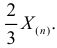
Ответ. 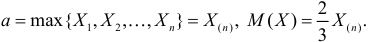
Пример:
Случайная величина Х имеет нормальный закон распределения 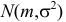 c неизвестными параметрами
c неизвестными параметрами 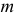 и
и 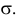 По результатам независимых наблюдений
По результатам независимых наблюдений 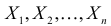 найти наиболее правдоподобные значения этих параметров.
найти наиболее правдоподобные значения этих параметров.
Решение. В соответствии с (3.1.4) функция правдоподобия имеет вид 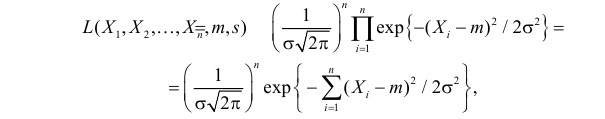
а логарифмическая функция правдоподобия: 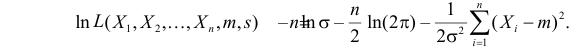
Необходимые условия экстремума дают систему двух уравнений: 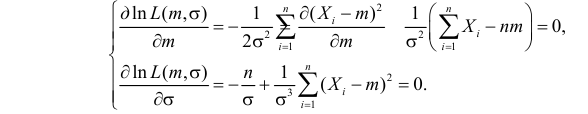
Решения этой системы имеют вид: 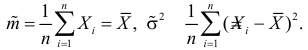
Отметим, что обе оценки являются состоятельными, причем оценка для 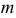 несмещенная, а для
несмещенная, а для 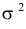 смещенная (сравните с формулой (3.1.3)).
смещенная (сравните с формулой (3.1.3)).
Ответ. 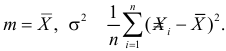
Пример:
По данным эксперимента построен статистический ряд:

Найти оценки математического ожидания, дисперсии и среднего квадратического отклонения случайной величины X.
Решение. 1) Число экспериментальных данных вычисляется по формуле:
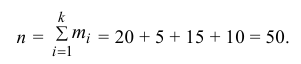
Значит, объем выборки n = 50.
2) Вычислим среднее арифметическое значение эксперимента:
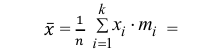
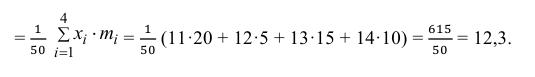
Значит, найдена оценка математического ожидания 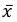 = 12,3.
= 12,3.
3) Вычислим исправленную выборочную дисперсию:
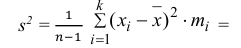
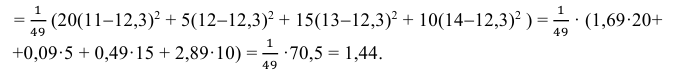
Значит, найдена оценка дисперсии: 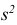 = 1,44.
= 1,44.
5) Вычислим оценку среднего квадратического отклонения:
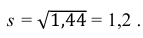
Ответ: 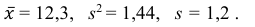
Пример:
По данным эксперимента построен статистический ряд:

Найти оценки математического ожидания, дисперсии и среднего квадратического отклонения случайной величины X.
Решение. По формуле
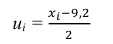
перейдем к условным вариантам:

Для них произведем расчет точечных оценок параметров:
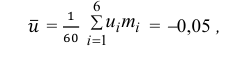
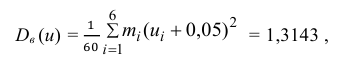
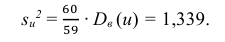
Следовательно, вычисляем искомые точечные оценки:
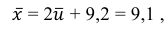
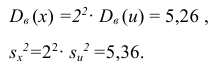
Ответ: 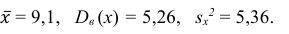
Пример:
По данным эксперимента построен интервальный статистический ряд:

Найти оценки математического ожидания, дисперсии и среднего квадратического отклонения.
Решение. 1) От интервального ряда перейдем к статистическому ряду, заменив интервалы их серединами 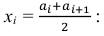

2) Объем выборки вычислим по формуле:
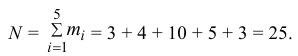
3) Вычислим среднее арифметическое значений эксперимента:
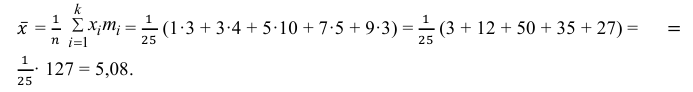
3) Вычислим исправленную выборочную дисперсию:
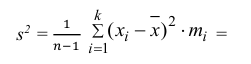
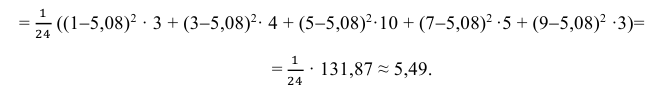
Можно было воспользоваться следующей формулой:
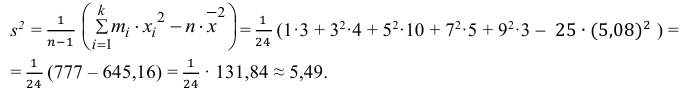
5) Вычислим оценку среднего квадратического отклонения:
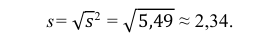
Ответ: 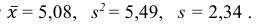
Пример:
Найти доверительный интервал с надежностью 0,95 для оценки математического ожидания M(X) нормально распределенной случайной величины X, если известно среднее квадратическое отклонение σ = 2, оценка математического ожидания 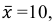 объем выборки n = 25.
объем выборки n = 25.
Решение. Доверительный интервал для истинного математического ожидания с доверительной вероятностью 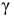 = 0,95 при известной дисперсии σ находится по формуле:
= 0,95 при известной дисперсии σ находится по формуле:
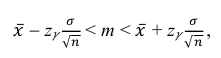
где m = M(X) – истинное математическое ожидание; 𝑥̅ − оценка M(X) по выборке; n – объем выборки; 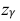 – находится по доверительной вероятности
– находится по доверительной вероятности 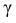 = 0,95 из равенства:
= 0,95 из равенства:
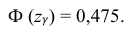
Из табл. П 2.2 приложения 2 находим: 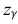 = 1,96. Следовательно, найден доверительный интервал для M(X):
= 1,96. Следовательно, найден доверительный интервал для M(X):
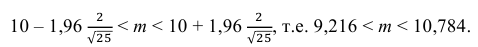
Ответ: (9,216 ; 10,784).
Пример:
По данным эксперимента построен статистический ряд:

Найти доверительный интервал для математического ожидания M (X) с надежностью 0,95.
Решение. Воспользуемся формулой для доверительного интервала математического ожидания при неизвестной дисперсии:
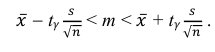
где n – объем выборки; 𝑥̅ оценка M(X); s – оценка среднего квадратического отклонения; 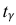 − находится по доверительной вероятности
− находится по доверительной вероятности 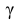 = 0,95.
= 0,95.
По числам 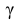 = 0,95 и n = 20 находим:
= 0,95 и n = 20 находим: 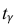 = 2,093.
= 2,093.
Теперь вычисляем оценки для M(X) и D(X):
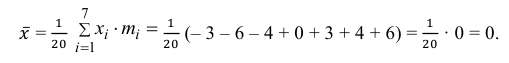
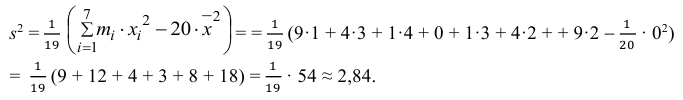
Следовательно, s ≈ 1,685. Поэтому искомый доверительный интервал математического ожидания задается формулой:
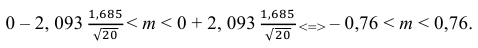
Ответ: (– 0,76; 0,76).
Пример:
По данным десяти независимых измерений найдена оценка квадратического отклонения 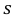 = 0,5. Найти доверительный интервал точности измерительного прибора с надежностью 99 %.
= 0,5. Найти доверительный интервал точности измерительного прибора с надежностью 99 %.
Решение. Задача сводится к нахождению доверительного интервала для истинного квадратического отклонения, так как точность прибора характеризуется средним квадратическим отклонением случайных ошибок измерений.
Доверительный интервал для среднего квадратического отклонения находим по формуле:
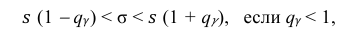
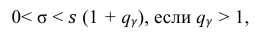
где 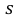 = 0,5 − оценка среднего квадратического отклонения;
= 0,5 − оценка среднего квадратического отклонения; 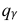 – число, определяемое из табл. П 2.4 приложения 2 по заданной доверительной вероятности
– число, определяемое из табл. П 2.4 приложения 2 по заданной доверительной вероятности 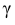 = 0,99 и заданному объему выборки n = 10.
= 0,99 и заданному объему выборки n = 10.
Находим: 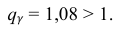
Тогда можно записать:
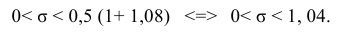
Ответ: (0; 1,04).
- Доверительный интервал для вероятности события
- Проверка гипотезы о равенстве вероятностей
- Доверительный интервал для математического ожидания
- Доверительный интервал для дисперсии
- Системы случайных величин
- Вероятность и риск
- Определения вероятности событий
- Предельные теоремы теории вероятностей
Приветствую посетителей блога statanaliz.info. В данной статье рассмотрим, что такое «выборочная несмещенная дисперсия».
Тема не нова, так как с таким показателями как размах значений, среднее линейное отклонение, дисперсия, среднеквадратичное (стандартное) отклонение, коэффициент вариации мы уже знакомы.
Понятие о сплошном и выборочном наблюдении
С точки зрения охвата объекта исследования, статистический анализ можно разделить на два вида: сплошной и выборочный. Сплошной статанализ предполагает изучение генеральной совокупности данных, то есть всего явления во всем его многообразии без распространения выводов на другие элементы, не входящие в анализируемую совокупность. Из названия данного типа явствует, что наблюдению подвергаются тотально все элементы. Результат анализа распространяется на всю генеральную совокупность без каких-либо допущений и поправок на ошибку. Данный тип статистического исследования является наиболее полным и точным, так как дополнительные знания почерпнуть уже неоткуда – информация собрана со всех элементов объекта исследования. Это бесспорный плюс.
Отличным примером сплошного наблюдения является перепись населения. «Всесоюзная перепись населения» — красиво звучало! Кстати, советская статистика, как и наука в целом, была одной из самых лучших в мире. Денег на проведение сплошных обследований не жалели, так как при СССР статистика выполняла свою прямую функцию – исследовала реальность, без чего невозможно было строить «светлое будущее». При этом советские ученые-статистики справедливо критиковали буржуазную статистику за то, что те скрывают от народа реальное положение дел и используют статистику для промывки мозгов. Об этом, кстати, писали и сами буржуи. Более практичный пример сплошного наблюдения – опрос жителей многоэтажного дома на предмет заваривания мусоропровода. Опрашиваются все, результат дает вполне однозначный ответ об отношении жителей к мусоропроводу. Ошибки в выводах маловероятны.
Как бы там ни было, у сплошного наблюдения есть отрицательное качество: на организацию и проведение исследования могут потребоваться значительные ресурсы. Одно дело взять пробу из партии товаров, другое – проверять всю партию. Одно дело опросить тысячу прохожих на улице, совсем другое – организовать перепись населения.
В противовес сплошному придумали выборочное наблюдение. Название метода точно отражает его суть: из генеральной совокупности отбирается и анализируется только часть данных, а выводы распространяют на всю генеральную совокупность. Отбор данных происходит таким образом, чтобы выборка была репрезентативной, то есть, сохранила внутреннюю структуру и закономерности генеральной совокупности. Если это условие не соблюдено, то дальнейший анализ во многом теряет смысл.
Сам анализ выборочных данных происходит так же, как и при сплошном наблюдении (рассчитываются различные показатели, делаются прогнозы и т.д.), только с поправкой на ошибку. Это значит, что рассчитывая тот или иной показатель, мы понимаем, что при повторной выборке его значение будет другим. К примеру, провели опрос общественного мнения. Опрос показал, что за кандидата N желают проголосовать 60% опрошенных. Если провести еще один такой же опрос, даже в том же месте, то результат будет отличаться. То есть, взяв первое значение 60%, следует понимать, что с той или иной вероятностью оно могло быть, скажем, и 58%, и 62%. Точность и разброс выборочных показателей зависят от характера данных и их количества.
У выборочного наблюдения есть один существенный плюс и один минус, однако по сравнению со сплошным наблюдением крайности меняются местами. Плюс заключается в том, что для проведения выборочного обследования требуется гораздо меньше ресурсов. Минус – в том, что выборочное наблюдение всегда ошибочно. Поэтому основная задача проведения выборочного наблюдения – добиться максимальной точности при приемлемых затратах на его проведение.
Выборочная несмещенная дисперсия
И вот, стало быть, дисперсия. Дисперсия, как и доля или средняя арифметическая, также меняет свое значение от выборки к выборке, но здесь есть интересная особенность. Дисперсия ведь рассчитывается от средней величины, а она в свою очередь, тоже рассчитывается по выборке, то есть является ошибочной. Как же это обстоятельство влияет на саму дисперсию?
Если бы мы знали истинную среднюю величину (по генеральной совокупности), то ошибка дисперсии была бы связана только с нерепрезентативностью, то есть с тем, что данные в выборке оказались бы ближе или дальше от средней, чем в целом по генеральной совокупности. При этом при многократном повторении данные стремились бы к своему реальному расположению относительно средней.
Выборочный показатель, который при многократном повторении выборки стремится к своему теоретическому значению, называется несмещенной оценкой. Почему оценкой? Потому что мы не знаем реальное значение показателя (по генеральной совокупности), и с помощью выборочного наблюдения пытаемся его оценить. Оценка показателя – это есть его характеристика, рассчитанная по выборке.
Теперь смотрим внимательно на выборочную среднюю. Выборочная средняя – это несмещенная оценка математического ожидания, так как средняя из выборочных средних стремится к своему теоретическому значению по генеральной совокупности. Где она расположена? Правильно, в центре выборки! Средняя всегда находится в центре значений, по которым рассчитана – на то она и средняя. А раз выборочная средняя находится в центре выборки, то из этого следует, что сумма квадратов расстояний от каждого значения выборки до выборочной средней всегда меньше, чем до любой другой точки, в том числе и до генеральной средней. Это ключевой момент. А раз так, то дисперсия в каждой выборке будет занижена. Средняя из заниженных дисперсий также даст заниженное значение. То есть при многократном повторении эксперимента выборочная дисперсия не будет стремиться к своему истинному значению (как выборочная средняя), а будет смещена относительно истинного значения по генеральной совокупности.
Отклонение выборочной средней от генеральной показано на рисунке.

Несмещенность оценки – одна из важных характеристик статистического показателя. Смещенная оценка показателя заранее говорит о тенденции к ошибке. Поэтому показатели стараются оценивать таким образом, чтобы их оценки были несмещенными (как у средней арифметической). Чтобы решить проблему смещенности выборочной дисперсии, в ее расчет вносят корректировку – умножают на n/(n-1), либо сразу при расчете в знаменатель ставят не n, а n-1. Получается так.
Выборочная смещенная дисперсия:
![]()
Выборочная несмещенная дисперсия:
![]()
Под выборочной дисперсией понимают, как правило, именно несмещенный вариант.
Теперь посмотрим на практическую сторону отличия смещенной и несмещенной дисперсии. Соотношение между выборочной и генеральной дисперсией составляет n/n-1. Несложно догадаться, что с ростом n (объема выборки) данное выражение стремится к 1, то есть разница между значениями выборочной и генеральной дисперсиями уменьшается.
Так, в выборке из 11 наблюдений относительная разница составляет 11/10 = 10%. При 21 наблюдениях, отличие сокращается до 5%, при 31 наблюдении – до 3,3%, при 51 – до 2%, при 101 – до 1%. Короче, при достаточно большой выборке данных (50 и выше наблюдений) относительная разница между смещенной и несмещенной дисперсией практически исчезает. Оценка параметра, когда с ростом выборки его отклонение от теоретического значения уменьшается, называется асимптотически несмещенной оценкой.
При переходе к среднеквадратичном отклонению по выборке (корень из выборочной дисперсии) разница становится еще меньше.
Таким образом, эффект смещенной дисперсии проявляется в небольших выборках. В больших выборках можно использовать генеральную дисперсию, что как бы не усложняет и не упрощает жизнь. Вручную сейчас никто не считает. Все легко посчитать в Excel. Но понимать различие в терминологии и в сути показателей все же следует.
Из данной статьи неплохо бы усвоить следующее.
1. Формула генеральной дисперсии в выборке дает смещенную оценку.
2. В знаменателе несмещенной оценки n-1 вместо n.
3. При большом объеме выборки (от 100 наблюдений) разница между смещенной и несмещенной дисперсиями практически исчезает.
4. Стандартное отклонение по выборке – это корень из выборочной дисперсии.
До новых встреч на блоге statanaliz.info.
Поделиться в социальных сетях:
