Запуск рекламной кампании в маркетинге предполагает А/В-тестирование, однако не каждый проведенный тест будет показательным, а его результаты – значимыми для статистики. Одна из распространенных ошибок при проведении исследований – неправильное определение нормального размера выборки. Как следствие – запуск рекламы, которая не даст результатов, и зря потраченные деньги.
Что такое объем выборки
Объем выборки – это количество людей из общего числа целевой аудитории (ЦА) продукта или бренда, участвовавших в исследовании, или количество заполненных анкет, которые были учтены при подсчете результатов.
![]()
![]()

Термин «выборка» говорит о том, что из всей совокупности участников опроса проводится оценка лишь части ответов.
В зависимости от параметров проекта, которые были указаны изначально, выборка может быть разной. Например, при случайной выборке респонденты выбираются из целевой совокупности случайным образом.
Зачем необходимо рассчитывать
Объем выборки определяют перед запуском количественных исследований в маркетинге (например, контент-анализа), чтобы узнать, какое число представителей ЦА должно поучаствовать в тестировании, и получить достоверные результаты. Если данных о объеме выборки нет, это может стать причиной того, что исследователь получит некорректные результаты.
Для качественных исследований объем выборки не определяют. Также он неактуален, если речь идет о проведении пилотных, т. е. предварительных исследований.
Основные понятия определения
В определении размера выборки участвуют различные параметры:
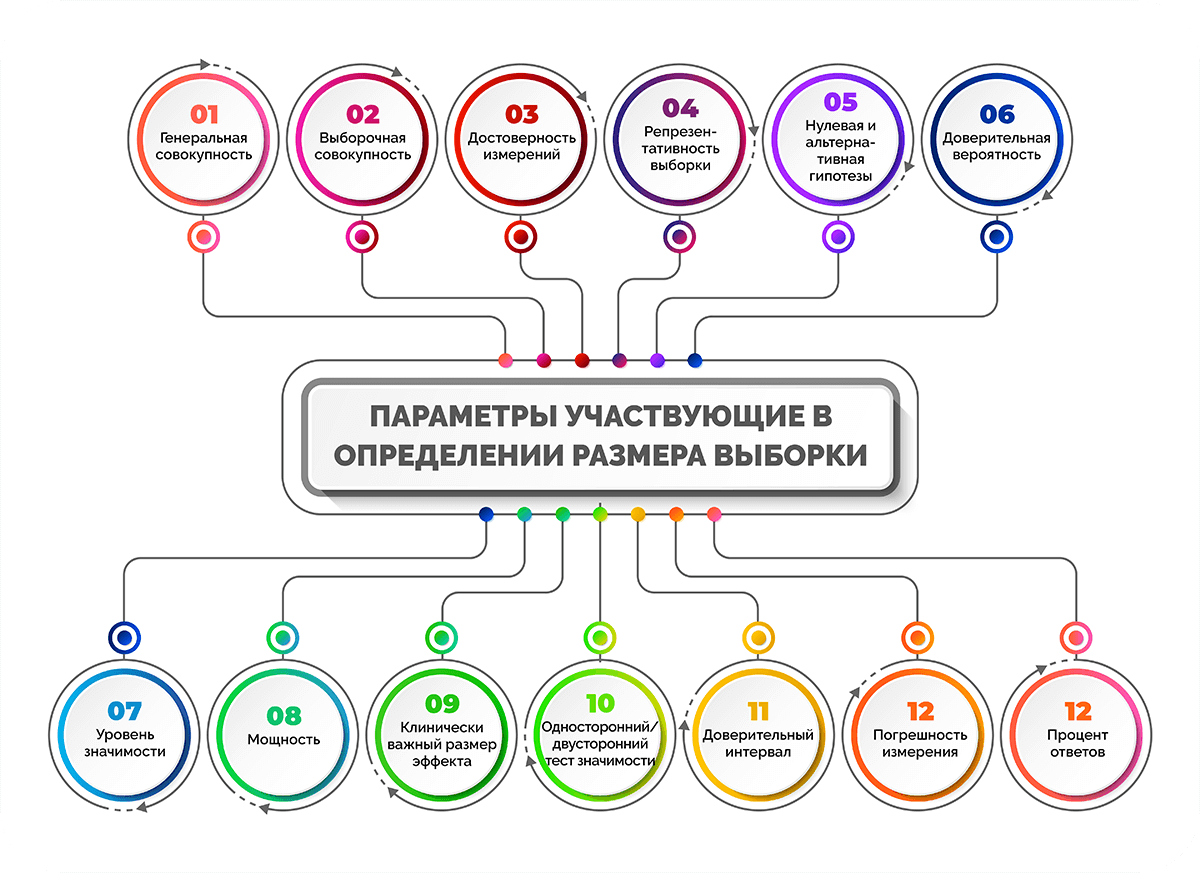
- генеральная совокупность;
- выборочная совокупность;
- достоверность измерений;
- репрезентативность выборки;
- нулевая и альтернативная гипотезы;
- доверительная вероятность;
- уровень значимости;
- мощность;
- клинически важный размер эффекта;
- односторонний / двусторонний тест значимости;
- доверительный интервал;
- погрешность измерения;
- процент ответов.
Разберем, что означают основные из них.
Генеральная совокупность
Генеральной совокупностью называется общее количество объектов наблюдения, которые обладают определенными общими признаками (возраст, пол, оборот, численность, доход и пр.) и о которых будут сделаны заявления после обработки результатов исследования.
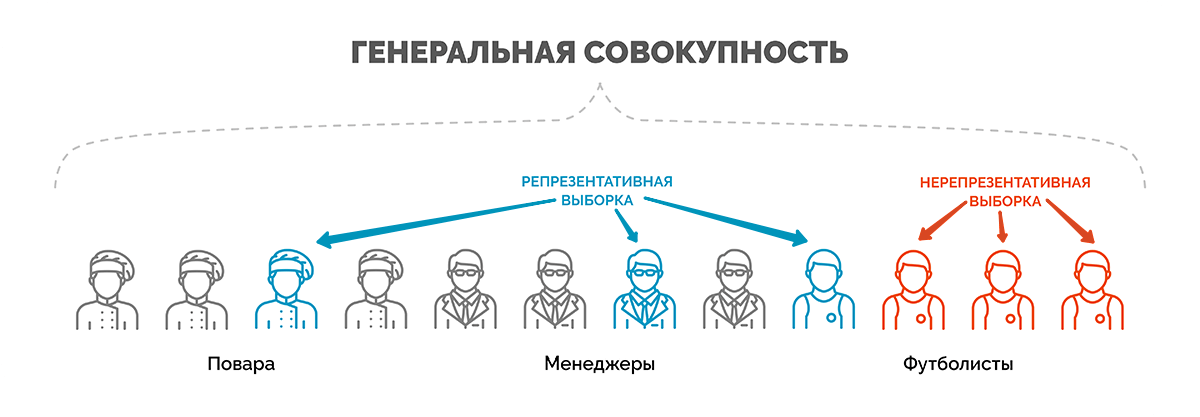
Объектами наблюдения могут быть люди, предприятия, домохозяйства, населенные пункты, отдельные малые социальные группы и т. д.
Если известно, что результаты опроса касаются всех жителей Москвы, то генеральная совокупность будет равна общей численности населения города, т. е. 13 млн человек (по данным 2021 года).
Оценивать свойства генеральный совокупностей, основываясь на выборочных методах, позволяет кривая нормального распределения.
Выборочная совокупность
Выборка или выборочная совокупность – это некоторая часть объектов из числа генеральной совокупности, отобранная для участия в исследовании с целью оценить распределение мнений и сделать итоговое заключение, которое будет распространяться на всю генеральную совокупность.
Характеристики выборочной совокупности должны корректно отражать параметры генеральной совокупности, т. е. обладать свойством репрезентативности. Только в данном случае заключение, сделанное исходя из результатов анализа выборки, будет с одинаковой вероятностью распространяться на представителей всей генеральной совокупности.
Выборка, состоящая из работников московских предприятий, не будет репрезентировать население города трудоспособного возраста и особенно все население столицы, т. к. не включает неработающих людей, женщин в декрете, удаленных сотрудников и т. д. Даже если мы будем увеличивать количество опрошенных работников столичных компаний, выборка все равно не сможет отразить характеристики генеральной совокупности, т. е. всего трудоспособного населения Москвы.
Погрешность измерений
Допустимая погрешность измерений – это процент возможной ошибки или отклонения результатов исследования, т. е. то значение, на которое истинный показатель может откланяться от значения, полученного в результате исследования.
Чем меньше погрешность, тем больше должна быть выборка.
Результаты опроса показали, что 60% опрощенных предпочитают делать покупки в сетевых магазинах. Предел погрешности 5% говорит о том, что в генеральной совокупности доля сторонников сетевых точек продаж может увеличиться или уменьшиться на 5% относительно уровня полученных 60%. Т. е. фактическое значение будет лежать в пределах значений от 55 до 65%.
Достоверность измерений
Уровень достоверности (надежности) измерений – это вероятность того, что полученные в результате исследования истинные результаты выбранного параметра генеральной совокупности находятся в пределах ее доверительного интервала (в примере выше это интервал 55-65%). Простыми словами, это степень уверенности в репрезентативности результатов.
Чем меньше доверительный интервал и выше заданный уровень достоверности, тем больше должна быть выборочная совокупность.
Если взять приведенный выше в статье пример с погрешностью в 5%, вы можете быть уверены в следующем: вероятность того факта, что от 55 до 65% людей предпочитают совершать покупки в сетевых магазинах, составляет не менее 95%.
Репрезентативность выборки
Под репрезентативностью понимают степень соответствия характеристик выборочной совокупности характеристикам генеральной совокупности, которые можно экстраполировать на всю популяцию.
- выборка, состоящая на 100% из автомобилистов Санкт-Петербурга, не репрезентирует всех жителей Санкт-Петербурга;
- выборка, состоящая только из российских фирм B2B с количеством сотрудников до 200 человек, не репрезентирует все компании страны, работающих в этом сегменте.
Исследование должно быть репрезентативным, если стоит задача по результатам количественного исследования сформировать представление о популяции в целом и правильно оценить ее. Если же исследование качественное или люди опрашиваются ради сбора мнений, предложений, идей, в этом случае репрезентативная выборка практически не играет роли.
Что влияет на результаты
Результаты тестирования могут изменяться под влиянием ряда факторов:
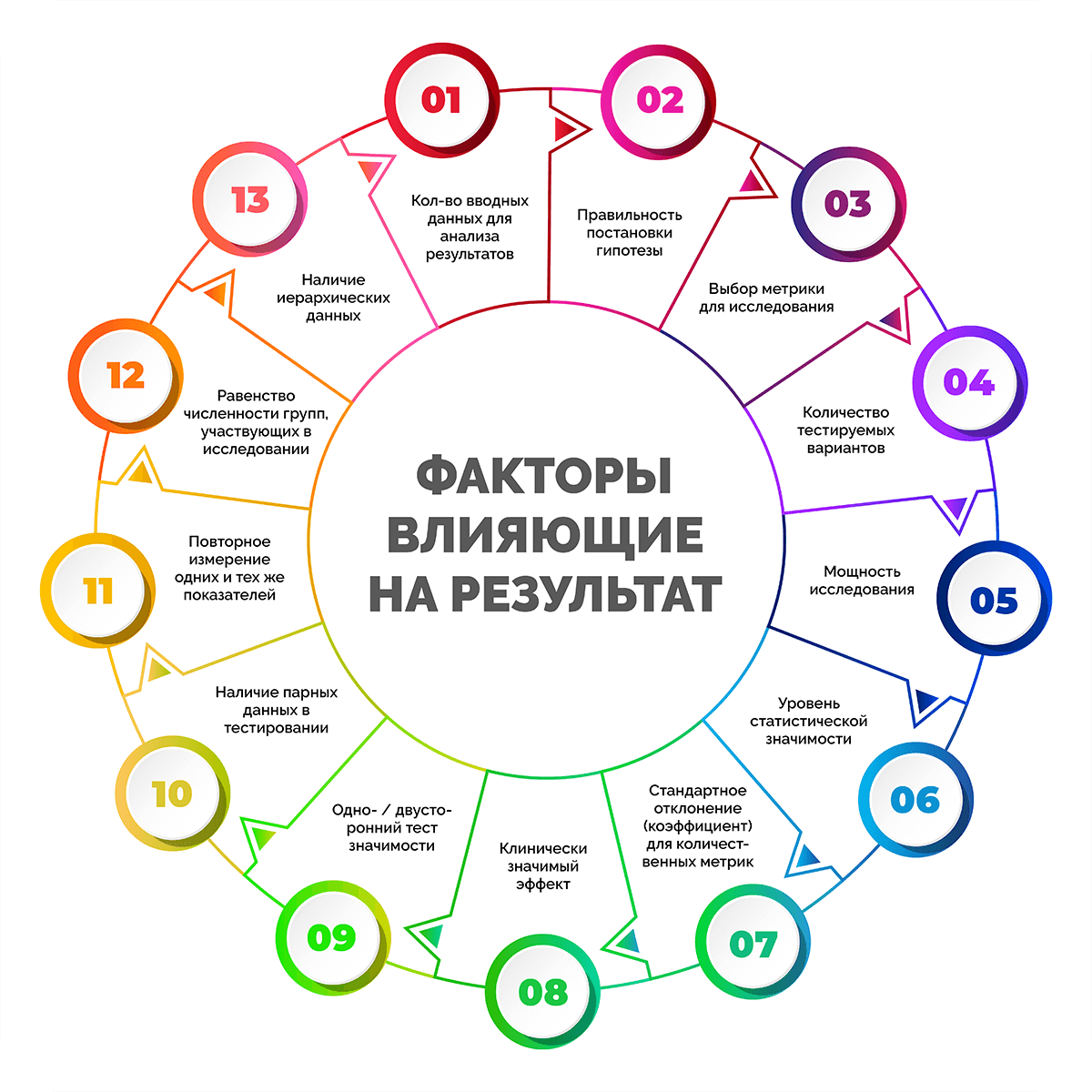
- количество вводных данных для анализа результатов;
- правильность постановки гипотезы;
- выбор той или иной метрики (показателя, переменных) для исследования;
- количество тестируемых вариантов;
- мощность исследования;
- уровень статистической значимости;
- стандартное отклонение (коэффициент) для количественных метрик;
- клинически значимый эффект;
- одно- / двусторонний тест значимости;
- наличие парных данных в тестировании;
- повторное измерение одних и тех же показателей;
- равенство численности групп, участвующих в исследовании;
- наличие иерархических данных.
Также расчет размера выборки может давать разные результаты, если анализ является:
- рандомизированным и контролируемым;
- рандомизированным и кластерным;
- нерандомизированным экспериментом вмешательства;
- исследованием эквивалентности;
- исследованием распространенности;
- обсервационным;
- изучением специфичности и чувствительности теста.
Нерандомизированные тестирования взаимосвязей или различий предполагают задействования в маркетинговых исследованиях выборки гораздо большего размера, чтобы при анализе было не сложно учесть влияние третьих факторов.
Типы выборок
Различают два типа выборок: вероятностные и невероятностные или детерминированные. Каждая группа включает в себя виды. Разберем, какие из них входят в каждый тип.
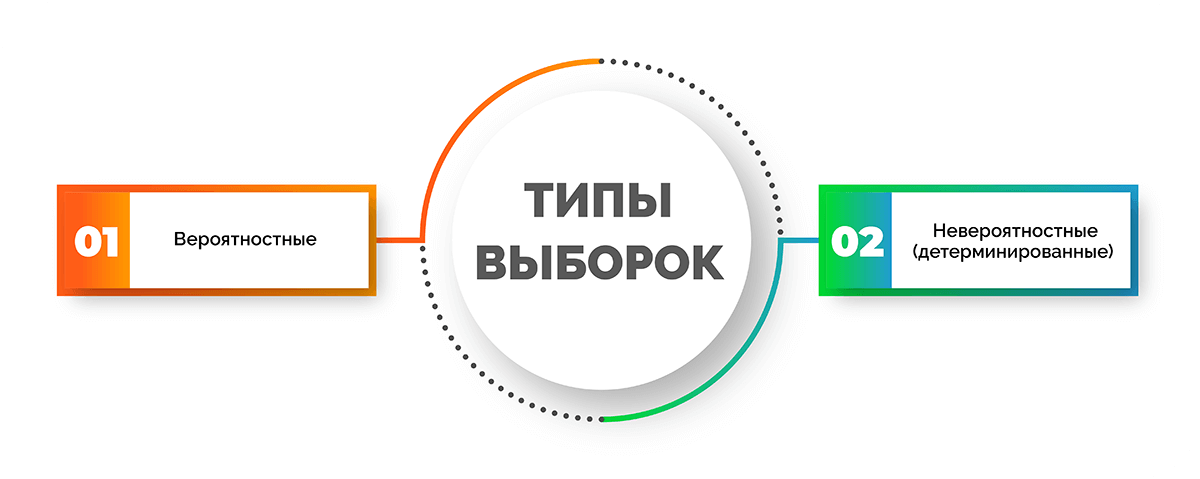
Вероятностные выборки:
- Случайная или простой случайный отбор – предполагает полный список элементов (отбираются при помощи таблицы случайных чисел), равную вероятность доступности всех из них и однородную генеральную совокупность;
- Механическая или систематическая – выступает в качестве разновидности случайной выборки, при этом упорядочивание происходит по тому или иному признаку, причем первый элемент отбирается случайно, затем с шагом n отбирается каждый последующий элемент;
- Стратифицированная или районированная – выборка используется при неоднородной генеральной совокупности, которая разделяется на страты (группы), в каждой из которых выполняется случайный отбор пропорционально их доле в генеральной совокупности;
- Серийная или кластерная, или гнездовая – единицами отбора выступают целые группы (гнезда или кластеры), которые могут попасть в выборку случайным образом, а все объекты внутри них подлежат сплошному исследованию.
Невероятностные (детерминированные) выборки:
- Квотная выборка – формируется несколько групп объектов, в каждой из которых зачастую пропорционально доле в генеральной совокупности задается определенное число объектов, которые нужно исследовать;
- Метод снежного кома – для формирования выборки каждый участник опроса предоставляет контакты своих знакомых; применяется для исследования труднодоступных групп респондентов;
- Стихийная выборка или выборка «первого встречного» – ее состав и размер заранее неизвестен и зависит от активности людей, опрос проводится среди самых доступных респондентов (интернет-опросы, опросы в журналах и газетах, анкеты на самозаполнение и т. д.);
- Выборка типичных случаев – для исследования отбираются отдельные представители генеральной совокупности, которым присуще среднее значение исследуемого признака.
Отбор в детерминированных выборках происходит не случайно, а по субъективным критериям: типичности, доступности, равного представительства каждой стороны и пр.
Расчет объема выборки
Расчет объема выборки – своего рода компромисс между требуемой мощностью исследования и возможностью реализовать его на практике с учетом имеющихся ресурсов и фокус-группы. При этом выбор метода расчета во многом определяется знаниями о параметрах и характеристиках изучаемых параметров.
Определить объем выборки можно двумя способами: по таблицам и с помощью формулы. Разберем эти методы.
По таблицам
Когда никаких данных о предстоящем исследовании нет, а сам эксперимент является инновационным, никто ранее ничего подобного не проводил и не предлагал решения, для определения объема выборки лучше выбрать табличный метод.
Ниже представлены различные методики. Выбор той или иной из них определяется имеющимися исходными данными или пожеланиями исследователя.
Таблица А. Определение объема выборки по методике К. А. Отдельновой
|
Уровень значимости |
Уровень точности |
||
|
Ориентировочное знакомство |
Исследование средней точности |
Исследование высокой точности |
|
|
0,01 |
100 |
225 |
900 |
|
0,05 |
44 |
100 |
400 |
Объем выборки указан в абсолютных значениях.
Таблица Б. Методика определения размера выборки В. И. Паниотто
|
Размер генеральной совокупности |
500 |
1000 |
2000 |
3000 |
4000 |
5000 |
10000 |
100000 |
∞ |
|
Объем выборки |
222 |
286 |
333 |
350 |
360 |
370 |
385 |
398 |
400 |
Данные указаны в единицах.
Таблица В. Методика N. Fox для определения объема выборки
|
Процент допускаемой ошибки |
Объем выборки в единицах |
|
10 |
88 |
|
5 |
350 |
|
3 |
971 |
|
2 |
2188 |
|
1 |
8750 |
Таблица Г. Определение размера согласно способу K. Mitra, S. Das, M. Mandal
|
Величина различий между основной и контрольной группами |
Уровень значимости |
Мощность |
Объем выборки |
|
0,2 |
0,5 |
80 |
586 |
|
0,2 |
0,1 |
80 |
773 |
|
0,2 |
0,5 |
90 |
746 |
|
0,4 |
0,5 |
80 |
146 |
|
0,4 |
0,1 |
80 |
193 |
|
0,4 |
0,5 |
90 |
186 |
|
0,6 |
0,5 |
80 |
65 |
|
0,6 |
0,1 |
80 |
86 |
|
0,6 |
0,5 |
90 |
83 |
По формулам
Объем выборки, достаточный для проведения новых исследований, определяется следующими параметрами:
- изменчивость признака;
- уровень доверия;
- размер эффекта.
Объем выборки всегда зависит от предполагаемой строгости эксперимента и изменчивости исследуемого признака.
Формула для оценки среднего значения размера выборки:
n = (z × σ / H)2, где:
n – размер выборки;
z – доверительный уровень (при р = 0,05 z = 1,96);
σ – стандартное отклонение;
Н – допустимая ошибка в натуральных величинах.
Формула для оценки доли выборки:

Где:
n – размер выборки;
z – доверительный уровень (при р = 0,05 z = 1,96);
p – доля признака (наибольшее значение достигается при р = 0,5);
H – допустимая ошибка в процентах.
Еще одна формула расчета объема выборки (чаще всего калькулятор размера выборки использует именно ее):

Где:
n – размер выборки;
z – нормированное отклонение;
p – вариация для выборки;
q = 1 – р;
е – допустимая ошибка.
Нормированное отклонение (z) определяется по таблице, зная основные значения доверительной вероятности (α).
|
α, % |
60 |
70 |
80 |
85 |
90 |
95 |
97 |
99 |
99,7 |
|
z |
0,84 |
1,03 |
1,29 |
1,44 |
1,65 |
1,96 |
2,18 |
2,58 |
3,0 |
Последняя формула расчета имеет особенности.
- Начинать считать размер выборки следует с проведения качественного анализа генеральной совокупности, чтобы выяснить степень схожести и близости исследуемых единиц совокупности относительно их географических, демографических, социальных и других характеристик.
- Рекомендуется предварительно выполнить пилотное исследование с целью определения приблизительного значения р.
- Если максимальная вариация р = 50%, то и значение q = 50%, что является наиболее худшим вариантом.
Пример расчета размера выборки
Маркетолог проводит исследование с целью определить, нужны ли компании визитки. Для этого промоутеру предстоит опросить потенциальных клиентов и задавать только один вопрос: «Вы пользуетесь визитками?». На что человек должен будет ответить «Да» или «Нет».
В таком случае размер выборки будет рассчитываться так. Принимаем, что уровень доверительности равен 95% (стандартное значение). При этом нормированное отклонение z составит 1,96. После предварительного анализа предположим, что 80% представителей генеральной совокупности дадут положительный ответ, а значит, р = 0,8. Соответственно, q = 1 – 0,8 = 0,2. Вероятность допустимой ошибки примем за 10%, т. е. e = 0,1. Теперь можно выполнить расчет.

Округлив значение, получаем размер выборки n = 62 человека. Соответственно, в опросе с заданными параметрами нужно задействовать 62 человека из числа целевой аудитории компании.
Подходы к определению размера выборки
Выделяют несколько подходов, которые позволяют установить объем выборки для проведения статистического исследования.
- Арбитражный подход. Объем выборки составляет определенный процент от генеральной совокупности. Например, 10% от общего количество потребителей.
- Традиционный подход. Выборка составляется на основе определенных норм, которые были выработаны в процессе проведенных ранее исследований. Подход игнорирует обстоятельства и условия, строгая логика отсутствует.
- Затратный подход. Объем выборки определяется в зависимости от стоимости сбора информации и возможных затрат на материалы для проведения исследования.
- Подход на основе использования доверительных интервалов. Размер выборки в этом случае рассчитывается по формуле, что обеспечивает высокую точность результата:
n = (p × q) / s2, где:
n – размер выборки;
p – вероятность того, что нужное событие наступит, %;
q = 100% – p;
s – стандартное отклонение, которое соответствует доверительному уровню.
Ошибки выборки
Объем выборки при массовом исследовании определяется двумя факторами:
- Точностью полученных данных или статистической погрешностью.
- Размером и количеством подгрупп, на которые будет разбита выборка при проведении анализа.
При любом исследовании, которое предполагает выборочный опрос респондентов из генеральной совокупности, может присутствовать погрешность данных или ошибка выборки. Выделяют два ее типа:
- случайная – обусловлена действием статистических законов, поэтому очень легко рассчитывается по формулам теории вероятности и математической статистики;
- систематическая – является следствием неточностей при проектировании выборки, определить ее степень смещения, направление и размер практически невозможно.
При расчете размера выборки важно так собрать данные, чтобы вероятность систематической ошибки в результате работы была минимальной.
Расчет случайной ошибки выборки зависит от объема последней, а также от степени однородности данных (дисперсии). Принцип такой: чем меньше дисперсия, тем меньше ошибка. Для расчета чаще всего используют онлайн калькуляторы.
Также выделяют:
- Ошибки первого рода – альфа-ошибка, при которой делается вывод о достоверности гипотезы, которая на самом деле неверна. Величина выбирается произвольно в диапазоне от 0 до 1, чаще всего это значение 0,05 или 0,01.
- Ошибки второго рода – бета-ошибка, при которой тот факт, что гипотеза неверна, остается не выявленным. Значение, как правило, устанавливается на уровне 0,2.
Расчет доверительного интервала
Для расчета доверительного интервала применяются достаточно простые формулы, выбор которых зависит от доли выборки в составе генеральной совокупности.
Если выборка значительно меньше генеральной совокупности:

Если выборка и генеральная совокупность сопоставимы:

В обеих формулах:
Δ – предельная ошибка выборки в процентах;
z – нормированное отклонение или z-фактор;
p – доля респондентов с наличием признака, который исследуется;
q – доля респондентов без исследуемого признака;
n – размер выборки;
N – объем генеральной совокупности (сколько всего респондентов).
Доверительный интервал удобно рассчитывать с помощью онлайн-калькулятора, который использует те же формулы, что мы привели выше. Просто введите необходимые переменные, и система рассчитает результат.
Расчет статистической значимости
Определить этот показатель проще всего с помощью онлайн-сервиса. Калькулятор позволяет проверить, существует ли статистически значимая разница между долями признака, которые были получены из независимых выборок.

Рассчитывать статистическую значимость можно только в том случае, если произведения (n × p) и (n × (1 – р)) превышают значение 5. При этом n – объем выборки, р – доля признака.
Часто задаваемые вопросы
Обычно размер выборки и ее статистическая значимость прямо пропорциональны, т. е. с ростом выборки получение случайных результатов сводится к минимуму. Важность статистической значимости зависит от определенной ситуации. Вот некоторые из них.
|
Ситуация |
Важность статистической значимости |
|
Опросы сотрудников |
Важна, т. к. повышает всесторонность выводов по итогам опроса. |
|
Опросы клиентов об уровне их удовлетворенности |
Не имеет значения, т. к. важен каждый ответ независимо от того, положительный он или отрицательный. |
|
Исследование рынка |
Имеет решающее значение, т. к. помогает сделать вывод о целевом рынке. |
|
Опросы об образовании |
Важна, если нужно использовать результаты исследования при внесении изменений в учебном заведении. |
|
Здравоохранение |
Помогает выявлять серьезные проблемы, делать выводы в исследованиях. Если же опрос проводится ради оценки удовлетворенности пациентов, то не имеет значения. |
|
Опросы для развлечения |
Не важна. |
Заданный размер выборки нужен для получения оценок с желаемым уровнем точности, если речь идет об исследовании распространенности в популяции конкретной характеристики.
- Мало просмотров.
- Узкая тематика.
- Низкий бюджет.
- Высокий бюджет.
Чтобы правильно рассчитать размер выборки и провести показательное исследование с учетом выдвинутых требований:
- наберитесь терпения и дождитесь, пока соберется требуемое количество респондентов;
- будьте последовательны и показывайте рекламу только ЦА в определенное время;
- устанавливайте высокий уровень достоверности при расчете выборки.
При определении объема выборки основную роль играет переменная исхода конкретного исследования. Если в расчет добавляются дополнительные важные переменные, то размер выборки должен позволять адекватно проанализировать их.
Это такое количество объектов исследования, которое позволит получить максимально точный и достоверный результат с предельно небольшой погрешностью. При этом его можно репрезентовать на более широкую аудиторию, в т. ч. по отношению к генеральной совокупности.
Заключение
Объем выборки – важный показатель, без которого невозможно провести адекватное исследование и сделать объективные выводы. Он отражает количество представителей целевой аудитории, которое будет принимать непосредственное участие в эксперименте, и требуется во всех случаях, когда стоит задача сделать определенные заключения по результатам опроса.
Нашли ошибку в тексте? Выделите нужный фрагмент и нажмите
ctrl
+
enter
 Приведенная ниже формула для расчета объема выборки используется в тех случаях, когда опрашиваемым (респондентам) задается только один вопрос, на который существует только два варианта ответа. Например: «Да» и «Нет», «Покупаю» и «Не покупаю», «Пользуюсь» и «Не пользуюсь». Конечно, данную формулу можно применять только при проведении простейших исследований. Если Вам нужно определить объем выборочной совокупности при проведении более масштабных исследований, например анкетирования, то следует использовать другие формулы.
Приведенная ниже формула для расчета объема выборки используется в тех случаях, когда опрашиваемым (респондентам) задается только один вопрос, на который существует только два варианта ответа. Например: «Да» и «Нет», «Покупаю» и «Не покупаю», «Пользуюсь» и «Не пользуюсь». Конечно, данную формулу можно применять только при проведении простейших исследований. Если Вам нужно определить объем выборочной совокупности при проведении более масштабных исследований, например анкетирования, то следует использовать другие формулы.
Содержание:
- формула с пояснениями;
- пример расчета объема выборки;
- нормированное отклонение (таблица);
- область применения;
- особенности формулы.
Простая формула для расчета объема выборки
Ниже приведена простая формула для расчета объема выборки для тех случаев когда на заданный вопрос возможны лишь два варианта ответа:

где: n – объем выборки;
z – нормированное отклонение, определяемое исходя из выбранного уровня доверительности (доверительного интервала, доверительной вероятности).
Этот показатель характеризует вероятность попадания ответов в специальный доверительный интервал — диапазон, границам которого соответствует определенный процент определенных ответов на некоторый вопрос.
Можно сказать, что уровень доверительности выражает вероятность того, что респонденты генеральной совокупности ответят так же, как и представители анализируемой выборки.
На практике доверительный интервал при проведении маркетинговых исследований часто принимают за 95% или 99%. Тогда значения z будут соответственно 1,96 и 2,58.
Также существует специальная таблица «Значение интеграла вероятностей», используя которую можно найти значение z для различных доверительных интервалов. Сокращенный вариант такой таблицы приведен ниже;
p – вариация для выборки, в долях.
Вариация характеризует величину схожести / несхожести ответов респондентов на вопрос. По сути, p — вероятность того, что респонденты выберут той или иной вариант ответа.
Допустим, если мы считаем, что четверть опрашиваемых выберут ответ «Да», то p будет равно 25%, то есть p = 0,25;
q = 1 – p.
Можно сказать, что q — это вероятность того, что респонденты не выберут анализируемый вариант ответа (в нашем примере ответят «Нет»). Например, если p = 0,25, то q = 1 – 0,25 = 0,75;
e – допустимая ошибка, в долях.
Значение допустимой ошибки заранее определяют исследователь и заказчик маркетингового исследования.
Пример расчета объема выборочной совокупности
Маркетинговая компания получила заказ на проведение социологического исследования с целью выявить долю курящих лиц в населении города. Для этого сотрудники компании будут задавать прохожим один вопрос: «Вы курите?». Возможных вариантов ответа, таким образом, только два: «Да» и «Нет».
Объем выборки в этом случае рассчитывается следующим образом. Уровень доверительности принимается за 95% (одно из стандартных значений для маркетинговых исследований), тогда нормированное отклонение z = 1,96. Проведя предварительный анализ населения города, вариацию принимаем за 50%, то есть условно считаем, что половина респондентов может ответить на вопрос о том, курят ли они — «Да». Тогда p = 0,5. Отсюда находим q = 1 – p = 1 – 0,5 = 0,5. исходя из требуемой заказчиком точности, допустимую ошибку выборки принимаем за 10%, то есть e = 0,1.
Подставляем эти данные в формулу и считаем:

Округлив расчетное значение, получаем объем выборки n = 96 человек.
Следовательно, для проведения исследования с заданными параметрами (уровень доверительности, допустимая ошибка) компании необходимо опросить 96 человек.
Значение нормированного отклонения для различных доверительных интервалов
В таблице приведены некоторые значения нормированного отклонения (z) для важнейших уровней доверительности, или, иначе, доверительной вероятности (α):
| α (%) | 60 | 70 | 80 | 85 | 90 | 95 | 97 | 99 | 99,7 |
|---|---|---|---|---|---|---|---|---|---|
| z | 0,84 | 1,03 | 1,29 | 1,44 | 1,65 | 1,96 | 2,18 | 2,58 | 3,0 |
Конечно, в таблице приведены значения z только для основных уровней доверительности. Полную версию таблицы можно найти в интернете.
Область применения простой формулы выборки
При проведении простых исследований, когда нужно получить ответ всего на один простой вопрос. При этом шкала ответов, как правило, дихотомического характера. То есть предлагаются (или подразумеваются) варианты ответов по типу «Да» — «Нет», «Черное» — «Белое», «Куплю» — «Не куплю», и т. д. Иными словами возможны лишь два варианта ответа на заданный вопрос.
Особенности формулы расчета размера выборки
Для рассмотренной нами простой формулы определения объема выборки можно выделить несколько характерных особенностей:
- перед тем, как рассчитывать объем выборки в данном случае желательно предварительно провести качественный анализ изучаемой генеральной совокупности. В частности установить степень схожести, близости изучаемых единиц совокупности в части их социальных, демографических, географических, иных характеристик. Также полезно провести пилотное (разведочное) исследование, чтобы установить приблизительную величину p;
- нужно иметь в виду, что максимальная изменчивость (вариация ответов) соответствует значению p = 50%, так как тогда q = 50% и p × q = 0,5 × 0,5 = 0,25. Это наихудший случай, все другие значения p дадут изменчивость меньшего размера (например, при p = 80%, p × q = 0,8 × 0,2 = 0,16; а при p = 10%, p × q = 0,1 × 0,9 = 0,09). Впрочем, данный показатель влияет на объем выборки не очень сильно.
Также стоит отметить, что существует ряд иных формул для определения объема выборки в случаях с дихотомической шкалой ответов на единственный вопрос. Для более сложных маркетинговых исследований применяются другие формулы.
Источники
- Голубков Е. П. Маркетинговые исследования: теория, методология и практика. – М.: Издательство «Финпресс», 1998.
Статья дополнена и доработана автором 10 дек 2020 г.
© Копирование любых материалов статьи допустимо только при указании прямой индексируемой ссылки на источник: Галяутдинов Р.Р.
Нашли опечатку? Помогите сделать статью лучше! Выделите орфографическую ошибку мышью и нажмите Ctrl + Enter.
Библиографическая запись для цитирования статьи по ГОСТ Р 7.0.5-2008:
Галяутдинов Р.Р. Формула выборки – простая // Сайт преподавателя экономики. [2020]. URL: https://galyautdinov.ru/post/formula-vyborki-prostaya (дата обращения: 18.05.2023).

Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p – ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p – ∆; p + ∆) = (20% – 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ – ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ – ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет
0,00
0,01
0,02
0,03
0,04 0,05
0,06
0,07
0,08
0,09
0,10
0,11
0,12
0,13
0,14
0,15
0,16
0,17
0,18
0,19
0,20
0,21
0,22
0,23
0,24
0,25
0,26
0,27
0,28
0,29
0,30
0,31
0,32
0,33
0,34
0,35
0,36
0,37
0,38
0,39
0,40
0,41
0,42
0,43
0,44
0,45
1,80
1,85
1,90
1,96
2,00
2,10
2,20
2,30
2,40
2,50
0,0000
0,0080
0,0160
0,0239
0,0319
0,0399
0,0478
0,0558
0,0638
0,0717
0,0797
0,0876
0,0955
0,1034
0,1113
0,1192
6,1271
0,1350
0,1428
0,1507
0,1585
0,1663
0,1741
0,1810
0,1897
0,1974
0,2051
0,2128
0,2205
0,2282
0,2358
0,2434
0,2510
0,2586
0,2661
0,2737
0,2812
0,2886
0,2961
0,3035
0,3108
0,3182
0,3255
0,3328
0,3401
0,3473
0,9281
0,9357
0,9426
0,9500
0,9545
0,9643
0,9722
0,9786
0,9836
0,9876
0,000
0,004
0,008
0,012
0,016
0,020
0,024
0,028
0,032
0,036
0,040
0,044
0,048
0,0515
0,0555
0,0595
0,0635
0,0675
0,0715
0,0755
0,0795
0,0830
0,0870
0,0910
0,0950
0,0985
0,1025
0,1065
0,1105
0,1140
0,1180
0,1215
0,1255
0,1295
0,1330
0,1370
0,1405
0,1445
0,1480
0,1515
0,1555
0,1590
0,1630
0,1665
0,1700
0,1735
0,4640
0,4680
0,4715
0,4750
0,4775
0,4820
0,4860
0,4895
0,4920
0,4940
0,46
0,47
0,48
0,49
0,50
0,52
0,54
0,56
0,58
0,60
0,62
0,64
0,66
0,68
0,70
0,72
0,74
0,76
0,78
0,80
0,82
0,84
0,86
0,88
0,90
0,92
0,94
0,96
0,98
1,00
1,05
1,10
1,15
1,20
1,25
1,30
1,35
1,40
1,45
1,50
1,55
1,60
1,65
1,70
1,75
2,60
2,70
2,80
2,90
3,00
3,20
3,40
3,60
3,80
4,00
5,00
0,3545
0,3616
0,3688
0,3759
0,3829
0,3969
0,4108
0,4245
0,4381
0,4515
0,4647
0,4778
0,4907
0,5035
0,5161
0,5285
0,5407
0,5527
0,5646
0,5763
0,5878
0,5991
0,6102
0,6211
0,6319
0,6424
0,6528
0,6629
0,6729
0,6827
0,7063
0,7287
0,7499
0,7699
0,7887
0,8064
0,8230
0,8385
0,8529
0,8664
0,8789
0,8904
0,9011
0,9109
0,9199
0,9907
0,9931
0,9949
0,9962
0,9973
0,9986
0,9993
0,9997
0,9999
0,99995
0,99999
0,1770
0,1810 0,1845 0,1880 0,1915 0,1985 0,2055 0,2125 0,2190 0,2255
0,2325 0,2390 0,2455 0,2520 0,2580 0,2640 0,2705 0,2765 0,2825
0,2880 0,2940 0,2995 0,3050 0,3105 0,3160 0,3210 0,3265 0,3315
0,3365 0,3415 0,3530 0,3645 0,3740 0,3850 0,3945 0,4030 0,4115
0,4190 0,4265 0,4330 0,4395 0,4450 0,4505 0,4555 0,4600
0,4955
0,4965 0,4975 0,4980 0,4986 0,4993 0,4996 0,4998 0,4999 0,4999
0,49999
План:
1. Задачи математической статистики.
2. Виды выборок.
3. Способы отбора.
4. Статистическое распределение выборки.
5. Эмпирическая функция распределения.
6. Полигон и гистограмма.
7. Числовые характеристики вариационного ряда.
8. Статистические оценки параметров
распределения.
9. Интервальные оценки параметров распределения.
1.
Задачи и методы математической статистики
Математическая статистика– это раздел математики, посвященный методам
сбора, анализа и обработки результатов статистических данных наблюдений для
научных и практических целей.
Пусть требуется
изучить совокупность однородных объектов относительно некоторого качественного
или количественного признака, характеризующего эти объекты. Например, если
имеется партия деталей, то качественным признаком может служить стандартность детали,
а количественным- контролируемый размер детали.
Иногда проводят
сплошное исследование, т.е. обследуют каждый объект относительно нужного
признака. На практике сплошное обследование применяется редко. Например, если
совокупность содержит очень большое число объектов, то провести сплошное
обследование физически невозможно. Если обследование объекта связано с его
уничтожением или требует больших материальных затрат, то проводить сплошное
обследование не имеет смысла. В таких случаях случайно отбирают из всей
совокупности ограниченное число объектов (выборочную совокупность) и подвергают
их изучению.
Основная задача
математической статистики заключается в исследовании всей совокупности по
выборочным данным в зависимости от поставленной цели, т.е. изучение
вероятностных свойств совокупности: закона распределения, числовых
характеристик и т.д. для принятия управленческих решений в условиях
неопределенности.
2.
Виды выборок
Генеральная совокупность – это совокупность объектов, из которой производится выборка.
Выборочная совокупность (выборка) – это совокупность случайно отобранных
объектов.
Объем совокупности –
это число объектов этой совокупности. Объем генеральной совокупности
обозначается N,
выборочной – n.
Пример:
Если из 1000
деталей отобрано для обследования 100 деталей, то объем генеральной
совокупности N =
1000, а объем выборки n =
100.
При составлении выборки можно поступить двумя
способами: после того, как объект отобран и над ним произведено наблюдение, он
может быть возвращен либо не возвращен в генеральную совокупность. Т.о. выборки
делятся на повторные и бесповторные.
Повторной называют выборку, при которой
отобранный объект (перед отбором следующего) возвращается в генеральную
совокупность.
Бесповторной называют выборку, при которой отобранный
объект в генеральную совокупность не возвращается.
На практике обычно
пользуются бесповторным случайным отбором.
Для того, чтобы по
данным выборки можно было достаточно уверенно судить об интересующем признаке
генеральной совокупности, необходимо, чтобы объекты выборки правильно его
представляли. Выборка должна правильно представлять пропорции генеральной
совокупности. Выборка должна быть репрезентативной (представительной).
В силу закона больших чисел можно утверждать,
что выборка будет репрезентативной, если ее осуществлять случайно.
Если объем
генеральной совокупности достаточно велик, а выборка составляет лишь
незначительную часть этой совокупности, то различие между повторной и
бесповторной выборками стирается; в предельном случае, когда рассматривается
бесконечная генеральная совокупность, а выборка имеет конечный объем, это
различие исчезает.
Пример:
В американском журнале
«Литературное обозрение» с помощью статистических методов было проведено исследование прогнозов
относительно исхода предстоящих выборов президента США в 1936 году.
Претендентами на этот пост были Ф.Д. Рузвельт и А. М. Ландон. В качестве
источника для генеральной совокупности исследуемых американцев были взяты
справочники телефонных абонентов. Из них случайным образом были выбраны 4
миллиона адресов., по которым редакция журнала разослала открытки с просьбой
высказать свое отношение к кандидатам на пост президента. Обработав результаты
опроса, журнал опубликовал социологический прогноз о том, что на предстоящих
выборах с большим перевесом победит Ландон. И … ошибся: победу одержал
Рузвельт.
Этот пример можно рассматривать, как пример нерепрезентативной выборки. Дело в
том, что в США в первой половине двадцатого века телефоны имела лишь зажиточная
часть населения, которые поддерживали взгляды Ландона.
3.
Способы отбора
На практике
применяются различные способы отбора, которые можно разделить на 2 вида:
1. Отбор не требует
расчленения генеральной совокупности на части (а) простой случайный
бесповторный; б) простой случайный повторный).
2. Отбор, при
котором генеральная совокупность разбивается на части. (а) типичный отбор;
б) механический отбор; в) серийный отбор).
Простым случайным
называют такой отбор, при котором объекты извлекаются по одному из всей
генеральной совокупности (случайно).
Типичным называют отбор, при котором объекты
отбираются не из всей генеральной совокупности, а из каждой ее «типичной»
части. Например, если деталь изготавливают на нескольких станках, то отбор
производят не из всей совокупности деталей, произведенных всеми станками, а из
продукции каждого станка в отдельности. Таким отбором пользуются тогда, когда
обследуемый признак заметно колеблется в различных «типичных» частях
генеральной совокупности.
Механическим называют отбор, при котором
генеральную совокупность «механически» делят на столько групп, сколько объектов
должно войти в выборку, а из каждой группы отбирают один объект. Например, если
нужно отобрать 20 % изготовленных станком деталей, то отбирают каждую 5-ую
деталь; если требуется отобрать 5 % деталей- каждую 20-ую и т.д. Иногда такой
отбор может не обеспечивать репрезентативность выборки (если отбирают каждый
20-ый обтачиваемый валик, причем сразу же после отбора производится замена
резца, то отобранными окажутся все валики, обточенные затупленными резцами).
Серийным называют отбор, при котором объекты
отбирают из генеральной совокупности не по одному, а «сериями», которые
подвергают сплошному обследованию. Например, если изделия изготавливаются
большой группой станков-автоматов, то подвергают сплошному обследованию
продукцию только нескольких станков.
На практике часто
применяют комбинированный отбор, при котором сочетаются указанные выше способы.
4.
Статистическое распределение выборки
Пусть из генеральной совокупности извлечена выборка, причем значение x1–наблюдалось
раз,
x2-n2
раз,… xk – nk
раз. n =
n1+n2+…+nk– объем
выборки. Наблюдаемые значения
называются вариантами, а
последовательность вариант, записанных в возрастающем порядке- вариационным
рядом. Числа наблюдений
называются
частотами (абсолютными частотами), а их отношения к объему выборки
– относительными частотами или статистическими вероятностями.

Если количество
вариант велико или выборка производится из непрерывной генеральной
совокупности, то вариационный ряд составляется не по отдельным точечным
значениям, а по интервалам значений генеральной совокупности. Такой
вариационный ряд называется интервальным.
Длины интервалов при этом должны быть равны.
Статистическим
распределением выборки
называется перечень вариант и соответствующих им частот или относительных
частот.
Статистическое
распределение можно задать также в виде последовательности интервалов и
соответствующих им частот (суммы частот, попавших в этот интервал значений)
Точечный
вариационный ряд частот может быть представлен таблицей:
|
xi |
x1 |
x2 |
… |
xk |
|
ni |
n1 |
n2 |
… |
nk |
Аналогично можно
представить точечный вариационный ряд относительных частот.
Причем:
Пример:
Число букв в
некотором тексте Х оказалось равным 1000. Первой встретилась буква «я», второй- буква «и», третьей- буква
«а», четвертой- «ю». Затем шли буквы
«о», «е», «у», «э», «ы».
Выпишем места,
которые они занимают в алфавите, соответственно имеем: 33, 10, 1, 32, 16, 6,
21, 31, 29.
После упорядочения
этих чисел по возрастанию получаем вариационный ряд: 1, 6, 10, 16, 21, 29, 31,
32, 33.
Частоты появления
букв в тексте: «а» – 75, «е» -87, «и»- 75, «о»- 110, «у»- 25, «ы»- 8, «э»- 3,
«ю»- 7, «я»- 22.
Составим точечный
вариационный ряд частот:

Пример:
Задано
распределение частот выборки объема n
= 20.
Составьте точечный
вариационный ряд относительных частот.
Решение:
Найдем
относительные частоты:
|
xi |
2 |
6 |
12 |
|
wi |
0,15 |
0,5 |
0,35 |
При построении интервального
распределения существуют правила выбора
числа интервалов или величины каждого интервала. Критерием здесь служит
оптимальное соотношение: при увеличении числа интервалов улучшается репрезентативность,
но увеличивается объем данных и время на их обработку. Разность
xmax – xmin между наибольшим и наименьшим значениями
вариант называют размахом выборки.
Для подсчета числа
интервалов k
обычно применяют эмпирическую формулу Стреджесса (подразумевая округление до
ближайшего удобного целого): k
= 1 + 3.322 lg n.
Соответственно,
величину каждого интервала h
можно вычислить по формуле
:
5.
Эмпирическая
функция распределения
Рассмотрим некоторую
выборку из генеральной совокупности. Пусть известно статистическое
распределение частот количественного признака Х. Введем обозначения: nx
– число наблюдений, при которых
наблюдалось значение признака, меньшее х; n – общее число наблюдений (объем
выборки). Относительная частота события Х<х равна
nx/n. Если х изменяется, то изменяется и относительная частота, т.е.
относительная частота nx/n–
есть функция от х. Т.к. она находится эмпирическим путем, то она называется
эмпирической.
Эмпирической функцией распределения
(функцией распределения выборки) называют функцию
,
определяющую для каждого х относительную частоту события Х<х.
где
число вариант, меньших х,
n– объем выборки.
В отличие от эмпирической функции
распределения выборки, функцию распределения F(x)
генеральной совокупности называют теоретической функцией распределения.
Различие между эмпирической и
теоретической функциями распределения состоит в том, что теоретическая функция F(x) определяет вероятность события Х<x , а эмпирическая
функция
F*(x) -относительную
частоту этого же события. Из теоремы Бернулли следует, что относительная
частота события Х<х , т.е
F*(x) стремится
по вероятности к вероятности F(x) этого события. Т.е.при
большом n F*(x)
и
F(x) мало отличаются друг от друга.
Т.о. целесообразно использовать
эмпирическую функцию распределения выборки для приближенного представления
теоретической (интегральной) функции распределения генеральной совокупности.
F*(x) обладает всеми свойствами F(x).
1. Значения
F*(x)
принадлежат
интервалу [0; 1].
2.
F*(x)
– неубывающая
функция.
3. Если
– наименьшая варианта, то
F*(x)= 0, при х
< x1
; если xk
– наибольшая варианта, то
F*(x)= 1, при х
> xk
.
Т.е.
F*(x) служит для
оценки F(x).
Если выборка задана вариационным рядом, то эмпирическая
функция имеет вид:
График эмпирической функции называется кумулятой.
Пример:
Постройте эмпирическую функцию по данному распределению
выборки.
Решение:
Объем выборки n = 12 + 18 +30 = 60. Наименьшая
варианта 2, т.е.
при х <
2. Событие X<6,
( x1= 2) наблюдалось 12 раз, т.е.
F*(x)=12/60=0,2 при 2 < x <
6. Событие Х<10, (
x1=2,
x2= 6) наблюдалось 12 + 18 = 30 раз, т.е. F*(x)=30/60=0,5
при 6 < x <
10. Т.к. х=10 наибольшая варианта, то F*(x) = 1
при х>10. Искомая эмпирическая функция имеет вид:
Кумулята:
Кумулята дает возможность
понимать графически представленную информацию, например, ответить на вопросы:
«Определите число наблюдений, при которых значение признака было меньше 6 или
не меньше 6. F*(6)=0,2
» Тогда число наблюдений, при которых
значение наблюдаемого признака было меньше 6 равно 0,2*n = 0,2*60 = 12. Число наблюдений, при
которых значение наблюдаемого признака было не меньше 6 равно (1-0,2)*n = 0,8*60 = 48.
Если задан интервальный вариационный
ряд, то для составления эмпирической функции распределения находят середины
интервалов и по ним получают эмпирическую функцию распределения аналогично
точечному вариационному ряду.
6. Полигон и гистограмма
Для наглядности строят различные графики
статистического распределения: полином и гистограммы
Полигон
частот- это ломаная, отрезки которой соединяют точки (
x1
;n1
), (
x2
;n2
),…, (
xk
; nk
), где
– варианты,
–
соответствующие им частоты.
Полигон
относительных частот- это ломаная, отрезки которой соединяют точки (
x1
;w1
), (x2
;w2
),…, (
xk
;wk
), где
xi–варианты,
wi –
соответствующие им относительные частоты.
Пример:
Постройте полином относительных
частот по данному распределению выборки:
Решение:
В случае
непрерывного признака целесообразно строить гистограмму, для чего интервал, в
котором заключены все наблюдаемые значения признака, разбивают на несколько
частичных интервалов длиной h
и находят для каждого частичного интервала ni – сумму частот вариант,
попавших в i-ый
интервал. (Например, при измерении роста человека или веса, мы имеем дело с
непрерывным признаком).
Гистограмма
частот- это ступенчатая фигура, состоящая из прямоугольников, основаниями
которых служат частичные интервалы длиною h, а высоты равны отношению
(плотность
частот).
Площадь i-го частичного
прямоугольника равна– сумме частот вариант i– го интервала, т.е. площадь
гистограммы частот равна сумме всех частот, т.е. объему выборки.
Пример:
Даны результаты изменения напряжения
(в вольтах) в электросети. Составьте вариационный ряд, постройте полигон и
гистограмму частот, если значения напряжения следующие: 227, 215, 230, 232,
223, 220, 228, 222, 221, 226, 226, 215, 218, 220, 216, 220, 225, 212, 217, 220.
Решение:
Составим вариационный ряд. Имеем n = 20, xmin=212
, xmax=232
.
Применим формулу
Стреджесса для подсчета числа интервалов.
.
Интервальный вариационный ряд
частот имеет вид:
|
|
|
Плотность частот |
|
212-216 |
3 |
0,75 |
|
216-220 |
3 |
0,75 |
|
220-224 |
7 |
1,75 |
|
224-228 |
4 |
1 |
|
228-232 |
3 |
0,75 |
Построим гистограмму частот:
Построим полигон частот, найдя предварительно середины
интервалов:
Гистограммой относительных
частот называют ступенчатую фигуру, состоящую из прямоугольников ,
основаниями которых служат частичные
интервалы длиною h, а
высоты равны отношению wi/h
(плотность
относительной частоты).
Площадь i-го частичного прямоугольника равна
– относительной частоте вариант, попавших в i– ый интервал. Т.е. площадь
гистограммы относительных частот равна сумме всех относительных частот, т.е.
единице.
7.
Числовые
характеристики вариационного ряда
Рассмотрим основные характеристики генеральной и выборочной
совокупностей.
Генеральным средним
называется среднее
арифметическое значений признака генеральной совокупности.
Для различных значений x1, x2
, x3
, …, xn.
признака
генеральной совокупности объема N
имеем:
Если
значения признака имеют соответствующие частоты N1
+N2
+…+Nk
=N,
то
Выборочным средним называется среднее арифметическое значений
признака выборочной совокупности.
Для различных значений x1, x2
, x3, …, xn
признака выборочной
совокупности объема n
имеем:
Если
значения признака имеют соответствующие частоты n1+n2+…+nk
= n,
то
Пример:
Вычислите выборочное среднее для выборки :
x1= 51,12;
x2= 51,07;
x3= 52,95; x4
=52,93;
x5= 51,1;x6
= 52,98; x7
= 52,29; x8
= 51,23; x9
= 51,07; x10
= 51,04.
Решение:
Генеральной дисперсией называется среднее арифметическое квадратов отклонений
значений признака Х генеральной совокупности от генерального среднего .
Для различных значений x1, x2, x3, …, xN
признака
генеральной совокупности объема N
имеем:
Если
значения признака имеют соответствующие частоты
N1+N2+…+Nk
=N,
то
Генеральным среднеквадратическим отклонением (стандартом)
называют квадратный корень из генеральной дисперсии
Выборочной дисперсией называется среднее
арифметическое квадратов отклонений наблюдаемых значений признака от среднего
значения.
Для различных значений
x1, x2, x3, …, xn
признака выборочной
совокупности объема n
имеем:
Если
значения признака имеют соответствующие частоты n1+n2+…+nk
= n,
то
Выборочным среднеквадратическим
отклонением (стандартом) называется квадратный корень из выборочной
дисперсии.
Пример:
Выборочная совокупность задана таблицей распределения. Найдите
выборочную дисперсию.
Решение:
Теорема: Дисперсия
равна разности среднего квадратов значений признака и квадрата общего среднего.
Пример:
Найдите дисперсию по данному распределению.
Решение:
8. Статистические оценки параметров распределения
Пусть генеральная совокупность исследуется по некоторой
выборке. При этом можно получить лишь приближенное значение неизвестного
параметра Q, который
служит его оценкой. Очевидно, что оценки могут изменяться от одной выборки к
другой.
Статистической
оценкой Q* неизвестного параметра
теоретического распределения называется функция f, зависящая от наблюдаемых значений
выборки. Задачей статистического оценивания неизвестных параметров по выборке
заключается в построении такой функции от имеющихся данных статистических
наблюдений, которая давала бы наиболее точные приближенные значения реальных,
не известных исследователю, значений этих параметров.
Статистические оценки делятся на
точечные и интервальные, в зависимости от способа их предоставления (числом или
интервалом).
Точечной
называют статистическую оценку параметра Q теоретического распределения определяемую одним значением
параметра Q*=f(x1, x2, …, xn), где x1, x2, …, xn – результаты эмпирических наблюдений над
количественным признаком Х некоторой выборки.
Такие оценки параметров, полученные по
разным выборкам, чаще всего отличаются друг от друга. Абсолютная разность /Q*-Q/ называют ошибкой выборки (оценивания).
Для того, чтобы статистические оценки
давали достоверные результаты об оцениваемых параметрах, необходимо, чтобы они
были несмещенными, эффективными и состоятельными.
Точечная
оценка, математическое ожидание которой равно (не равно) оцениваемому
параметру, называется несмещенной
(смещенной). М(Q*)=Q.
Разность М(Q*)-Q называют смещением или
систематической ошибкой. Для несмещенных оценок систематическая ошибка
равна 0.
Эффективной
называют такую статистическую оценку
Q*, которая при
заданном объеме выборки n
имеет наименьшую возможную дисперсию: D[Q*]min
(n=const). Эффективная оценка
имеет наименьший разброс по сравнению с другими несмещенными и состоятельными
оценками.
Состоятельной
называют такую статистическую оценку
Q*,
которая при n стремится по вероятности к оцениваемому
параметру Q,
т.е. при увеличении объема выборки n
оценка стремится по вероятности к истинному значению параметра Q.
Требование состоятельности
согласуется с законом больших числе: чем больше исходной информации об
исследуемом объекте, тем точнее результат. Если объем выборки мал, то точечная
оценка параметра может привести к серьезным ошибкам.
Любую выборку (объема n) можно рассматривать
как упорядоченный набор
x1, x2, …, xn независимых
одинаково распределенных случайных величин.
Выборочные средние для
различных выборок объема n из одной и той же генеральной
совокупности будут различны. Т. е. выборочное среднее можно рассматривать как
случайную величину, а значит, можно говорить о распределении выборочного
среднего и его числовых характеристиках.
Выборочное среднее
удовлетворяет всем накладываемым к статистическим оценкам требованиям, т.е.
дает несмещенную, эффективную и состоятельную оценку генерального среднего.
Можно доказать, что. Таким образом, выборочная дисперсия
является смещенной оценкой генеральной дисперсии, давая ее заниженное значение.
Т. е. при небольшом объеме выборки она будет давать систематическую ошибку. Для
несмещенной, состоятельной оценки достаточно взять величину
, которую называют исправленной
дисперсией. Т. е.
На практике для оценки генеральной дисперсии применяют исправленную
дисперсию при n
< 30. В остальных случаях (n>30) отклонение
от
малозаметно. Поэтому при больших значениях n
ошибкой смещения можно пренебречь.
Можно
так же доказать, что относительная
частота
ni / n является
несмещенной и состоятельной оценкой вероятности P(X=xi). Эмпирическая функция распределения F*(x) является несмещенной
и состоятельной оценкой теоретической функции распределения F(x)=P(X<x).
Пример:
Найдите
несмещенные оценки математического ожидания
и дисперсии по таблице выборки.
Решение:
Объем выборки n=20.
Несмещенной оценкой математического
ожидания является выборочное среднее.
Для вычисления несмещенной оценки
дисперсии сначала найдем выборочную дисперсию:
Теперь найдем
несмещенную оценку:
9.
Интервальные
оценки параметров распределения
Интервальной называется статистическая
оценка, определяемая двумя числовыми значениями- концами исследуемого
интервала.
Число> 0, при котором |Q–Q*|<
, характеризует точность интервальной
оценки.
Доверительным
называется интервал
, который с заданной вероятностью покрывает неизвестное значение параметра Q. Дополнение
доверительного интервала до множества всех возможных значений параметра Q называется критической областью. Если критическая
область расположена только с одной стороны от доверительного интервала, то
доверительный интервал называется односторонним:
левосторонним, если критическая область существует только слева, и правосторонним- если только справа. В
противном случае, доверительный интервал называется двусторонним.
Надежностью,
или доверительной вероятностью, оценки Q (с помощью Q*) называют вероятность,
с которой выполняется следующее неравенство: |Q–Q*|<
.
Чаще всего доверительную вероятность
задают заранее (0,95; 0,99; 0,999) и на нее накладывают требование быть близкой
к единице.
Вероятность
называют вероятностью
ошибки, или уровнем значимости.
Пусть |Q–Q*|<
, тогда
. Это означает, что с вероятностью
можно утверждать, что истинное значение
параметра Q
принадлежит интервалу. Чем меньше величина отклонения
, тем точнее оценка.
Границы (концы) доверительного интервала
называют доверительными границами, или
критическими границами.
Значения границ доверительного интервала
зависят от закона распределения параметра Q*.
Величину отклонения
равную половине ширины доверительного
интервала, называют точностью оценки.
Методы построения доверительных
интервалов впервые были разработаны американским статистом Ю. Нейманом.
Точность оценки
, доверительная вероятность
и
объем выборки n связаны между собой. Поэтому, зная
конкретные значения двух величин, всегда можно вычислить третью.
Нахождение
доверительного интервала для оценки математического ожидания нормального
распределения, если известно среднеквадратическое отклонение.
Пусть произведена выборка из генеральной
совокупности, подчиненной закону нормального распределения. Пусть известно
генеральное среднеквадратическое отклонение
, но неизвестно математическое ожидание
теоретического распределения a
().
Справедлива следующая формула:
Т.е.
по заданному значению отклонения
можно найти, с какой вероятностью неизвестное
генеральное среднее принадлежит интервалу. И наоборот. Из формулы видно, что при
возрастании объема выборки и фиксированной величине доверительной вероятности
величина
–
уменьшается, т.е. точность оценки увеличивается. С увеличением надежности
(доверительной вероятности), величина
-увеличивается,
т.е. точность оценки уменьшается.
Пример:
В результате испытаний
были получены следующие значения -25, 34, -20, 10, 21. Известно, что они
подчиняются закону нормального распределения с среднеквадратическим отклонением
2. Найдите оценку а* для математического ожидания а. Постройте для него 90%-ый
доверительный интервал.
Решение:
Найдем несмещенную
оценку
Тогда
Доверительный интервал
для а имеет вид: 4 – 1,47< a
< 4+ 1,47 или 2,53 < a
< 5, 47
Нахождение
доверительного интервала для оценки математического ожидания нормального
распределения, если неизвестно среднеквадратическое отклонение.
Пусть известно, что генеральная
совокупность подчинена закону нормального распределения, где неизвестны а и
. Точность доверительного интервала,
покрывающего с надежностью
истинное значение параметра а, в данном случае вычисляется по формуле:
, где n– объем выборки,
,– коэффициент Стьюдента (его следует
находить по заданным значениям n и
из
таблицы «Критические точки распределения Стьюдента»).
Пример:
В результате испытаний были получены
следующие значения -35, -32, -26, -35, -30, -17. Известно, что они подчиняются
закону нормального распределения. Найдите доверительный интервал для
математического ожидания а генеральной совокупности с доверительной вероятностью
0,9.
Решение:
Найдем несмещенную оценку
.
Найдем
.
Далее найдем
.
Тогда
Доверительный интервал примет вида (-29,2
– 5,62; -29,2 + 5,62) или (-34,82; -23,58).
Нахождение
доверительного интерла для дисперсии и среднеквадратического отклонения
нормального распределения
Пусть из некоторой генеральной
совокупности значений, распределенной по нормальному закону, взята случайная
выборка объема n <
30, для которой вычислены выборочные
дисперсии: смещенная
и
исправленная s2
. Тогда для нахождения интервальных
оценок с заданной надежностью
для генеральной дисперсии D генерального
среднеквадратического отклонения
используются следующие формулы.
или
,
Значения
– находят с помощью таблицы значений
критических точек распределения
Пирсона.
Доверительный интервал для дисперсии
находится из этих неравенств путем возведения всех частей неравенства в
квадрат.
Пример:
Было проверено качество 15 болтов.
Предполагая, что ошибка при их изготовлении подчинена нормальному закону
распределения, причем выборочное среднеквадратическое отклонение
равно 5 мм, определить с надежностью доверительный интервал для неизвестного
параметра
.
Решение:
Т. к. n = 15 <30, то воспользуемся формулой
.
Найдем пограничные значения вероятности
для .
Тогда:
Границы интервала представим в виде двойного неравенства:
Концы двустороннего доверительного
интервала для дисперсии можно определить и без выполнения арифметических
действий по заданному уровню доверия и объему выборки с помощью соответствующей
таблицы (Границы доверительных интервалов для дисперсии в зависимости от числа
степеней свободы и надежности). Для этого полученные из таблицы концы интервала
умножают на исправленную дисперсию s2
.
Пример:
Решим предыдущую задачу другим способом.
Решение:
Найдем исправленную
дисперсию:
По таблице «Границы
доверительных интервалов для дисперсии в зависимости от числа степеней свободы
и надежности» найдем границы доверительного интервала для дисперсии при k=14 и
: нижняя граница 0,513 и верхняя 2,354.
Умножим полученные
границы на
s2 и
извлечем корень (т.к. нам нужен доверительный интервал не для дисперсии, а для
среднеквадратического отклонения).
Как видно из примеров,
величина доверительного интервала зависит от способа его построения и дает
близкие между собой, но неодинаковые результаты.
При выборках достаточно
большого объема (n>30)
границы доверительного интервала для генерального среднеквадратического
отклонения можно определить по формуле:
Существует и другой
способ определения границы доверительного интервала для дисперсии, в основе
которого лежит выбор интервала, симметричного относительно
:
Причем
–
некоторое число, которое табулировано и приводится в соответствующей справочной
таблице.
Если 1- q<1, то формула имеет
вид:
Пример:
Решим предыдущую задачу третьим способом.
Решение:
Ранее было найдено s
= 5,17. q(0,95;
15) = 0,46 – находим по таблице.
Тогда:
