Cправка – Search Console
Войти
Справка Google
- Справочный центр
- Сообщество
- Search Console
- Политика конфиденциальности
- Условия предоставления услуг
- Отправить отзыв
Тема отзыва
Информация в текущем разделе Справочного центра
Общие впечатления о Справочном центре Google
- Справочный центр
- Сообщество
Search Console
Аналогичная проблема с сайтом. Только проблема в том, что писать по 1000 символов для каждого логотипа невыгодно. Моим решением было создать отдельный блок с ссылками страниц, которые не проиндексированы и просквозить в подвале, вынести URL этих страниц в отдельный sitemap для отслеживания индексации. Индексация улучшилась. Еще как вариант пробовать через API отправлять в индекс по 200 страниц в день.
Могу только высказать предположение, что мало контента на страницах, попробуйте для теста на пару непроиндексированных страниц вроде /7-klass/algebra/makarychev/nomer-349 добавить уникального текста на 1000 знаков. И посмотреть через неделю-две, будет индексировать или нет. Вполне возможно, он просто “склеивает” похожие на его взгляд страницы.
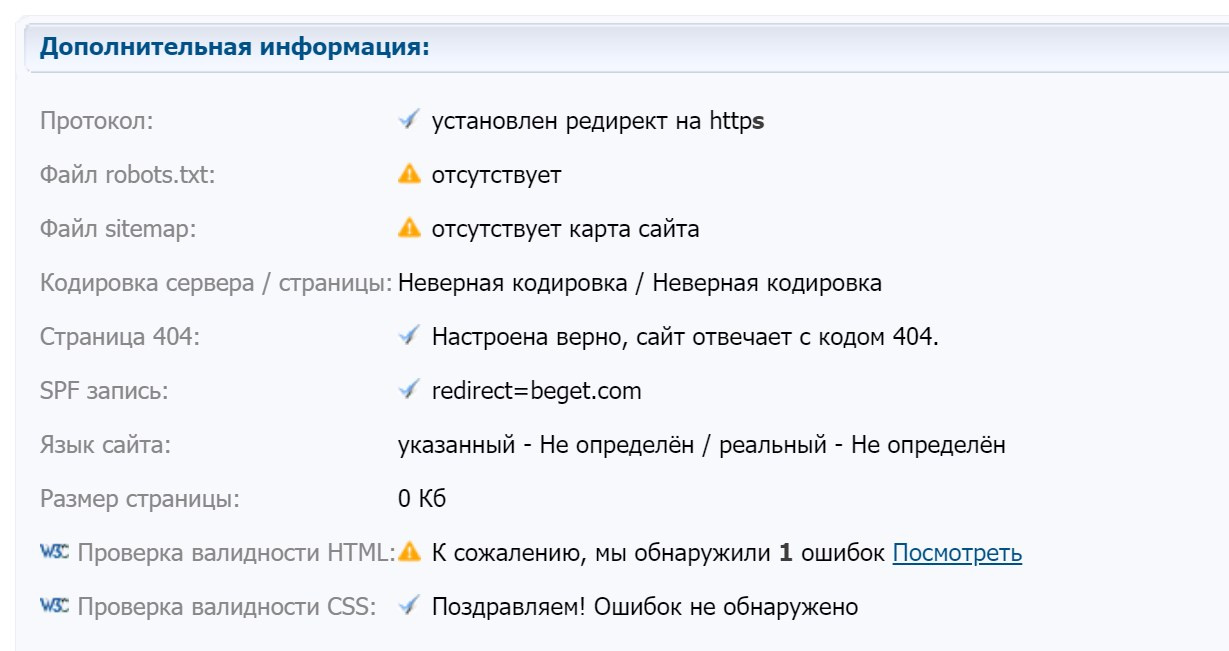
А вот cy-pr.com не видит у вас ни сайтмепа, ни роботса… Почему так, интересно. И на кодировку ругается.
Можете для проверки попробовать способ в первом ответе на ваш вопрос. Если получится, то как вариант можете через сервис распознавания текста перенести все эти задания в реальный контент. Это будет наиболее быстрый способ решить проблему.
Мне кажется, дело не в проценте уникальности страниц. У меня такая же проблема есть страницы побольше, есть поменьше. Недавно писал большую хорошую статью, и она тоже не индексируется. Так что возможно дело в чём-то другом.
Привет! У меня Гугл начал удалять из индекса столетние несуществующие страницы после того, как я ускорил сайт. Что уже прогресс, я считаю.
То же самое.
В работе 3 сайта. Причём если с одним из них можно было бы объяснить это тем, что контента маловато, то со вторым это объяснение не пройдёт – сайт под бурж, контента достаточно.
С уникальностью всё в порядке, похожих страниц нет, ошибок в консоли не наблюдается, в т.ч. в мобильной версии.
И самое интересное – индексация новых статей прекратилась почти одновременно на всех трёх сайтах.
Статус в консоли тот же, что и у тс – “обнаружена, не проиндексирована” .
Индексации нет как таковой уже 4 месяца, т.е. с июля-августа. До этого всё индексировалось почти влёт.
Я думаю, это как-то связано со следующим
Поисковики всё меньше становятся похожи на поисковики…
Да это бан! сайт под какой-то из фильтров гугла угодил! посмотрел сайт – там (там одна строка текста)…. и таких 8 тысяч страниц…… такие сайты даже лет 10 назад в бан улетали – а теперь алгоритмы сложнее….
У нас на сайте аналогично Яндекс кушает отлично, а вот Google очень медленно 🙁
Пришли к выводу, что все таки нужно больше уникального текста и контента добавлять
Всем привет.
В Google данная проблема объясняется тем что бот не смог проанализировать страницу и временно перенес это мероприятие на потом.
У меня на сайте не так много страниц. По итогу всего 3 страницы проиндексированы, остальные – нет. Страницы с портфолио и прочими основными (весь контент уникальный) имеет статус “Обнаружена, не проиндексирована”.
В Search Console только что вручную поставил пару страниц в очередь на принудительное индексирование.
Посмотрим, что из этого выйдет.
Начал заниматься интернет-магазином в конце ноября, там трафика вообще не было, был какой-то фронт с шаблона рандомного натянутый на самописную цмс и наполнение товаром с описаниями и структурой другого сайта. В начале декабря релизнулся новый дизайн, структура и т.д., сейчас пишется контент постоянно и обновляется старый. На старте работы по 10-20 уников в сутки заходили, сейчас застой полный и тянет ошибки в консоли еще с марта 21 года, когда там было, что я расписал выше. Канониклы настроены, редиректы работаю, ссылки ставятся качественные и органические, DR по ахрефсу вырос с 0.2 до 5, по началу все норм было, новый контент в течении 2 дней в индексе был, а сейчас за месяц только 1 статья появилась, а старые выпали.
Была такая проблема. Что характерно, началась после того как решил привести сайт под все рекомендации гугла… После того как переназначил приоритеты в карте сайта для страниц, часть ранее популярных страниц резко удалились с поиска вообще. А новые не добавлялись в индексацию. Начал играться приоритетами и картина немного исправилась…
У меня та же проблема с конца ноября 2021 года – ВСЕ новые страницы – “Обнаружено, не проиндексировано” со статусом “Исключено”. Причем не индексируются как обычные страницы (например, с описанием процесса покупки), так и карточки товаров. А те страницы, которые уже есть в индексе, Гугл обходит исправно и никаких проблем нет.
Ища решение проблемы, наткнулся на иностранный форум. Там обсуждали эту же проблему, но произошла она 2 года назад. Тогда вопрос решился тем, что это оказался косяк Гугла, который он публично признал и исправил. Похоже, что сейчас проблема в этом же. Я забил и просто жду.
Вот что в гугл рекомендуют:
https://support.google.com/webmasters/thread/13936…
Как правило, Google не сразу индексирует новые сайты. Подождите или запросите сканирование и индексирование. Также стоит отметить, что Google сканирует миллиарды сайтов и некоторые может пропустить. Чаще всего это происходит по следующим причинам:
- Другие сайты редко ссылаются на ваши страницы.
- Если сайт новый, Google может не успеть отсканировать его.
- Структура сайта затрудняет сканирование.
- При попытке сканирования произошла ошибка.
- Сверьтесь с приведенным контрольным списком и убедитесь, что вы выполнили хотя бы необходимый минимум условий для появления сайта в Google.
- Предотвратите перегрузку сервера, сделав ваш сервер и сайт быстрее;
- Поставьте ссылки на новые страницы вашего сайта на видном месте, например с главной страницы;
- Избегайте использования на своем сайте ненужных URL-адресов, таких как бесконечные URL-адреса календаря или фильтров и сортировок со всеми возможными комбинациями для страниц категорий.
У меня проблема решена. Интересно как у других. Не знаю то ли все само собой разрешилось, то ли мои действия повлияли – я улучшил значение Core Web Vitals, в частности CLS. После этого страницы начали индексироваться как прежде. Хотя может быть и простым совпадением.
Я в середине января с такой проблемой столкнулся – при чём на всех сайтах одновременно. Т.е. от содержимого страниц это вообще никак не зависит. Почитал форумы – советовали Гугл API. Ну поставил
плагин – прогнал страницы и да все страницы влетели в индекс почти мгновенно. Но почему-то с 16 марта этот способ перестал работать – страницы отправляюца в гугл, но результата нет.
У меня на сайте все было тоже самое. Где то с конца марта перестали страницы индексироваться “Обнаружена, не проиндексирована Статус: Исключено”. Много думал чего, предпринимал и ничего так прям сильно не помогало. Но потом через google cloud API прогнал страницы и да все страницы влетели в индекс примерно через несколько дней.. я так решил проблему.
Публикация обновлена 17 ноября 2021 года. Мы добавили опыт и рекомендации экспертов MOZ по исправлению ошибок индексации: “обнаружена, не проиндексирована”, “просканирована, не проиндексирована”.
Вебмастера часто сталкиваются с проблемой отказа индексации страниц Google-поиском. В Search Console появляется ошибка “обнаружена, не проиндексирована”, “просканирована, не проиндексирована”. При этом не указываются ни приблизительные сроки индексации, ни возможные причины, тогда как в других поисковых системах проблемы с индексацией этих же страниц нет. Мы собрали несколько способов, которые помогают вебмастерам быстрее проиндексировать страницы с такой ошибкой.
Что говорит Google об ошибке “обнаружена, не проиндексирована”
Cправка Google указывает, что:

Исходя из этого вебмастеру не нужно предпринимать никаких действий, чтобы проиндексировать страницы. Но по сообщениям на форумах вебмастеров и оптимизаторов сроки индексации могут растягиваться от нескольких недель до никогда.
Так как Google не дает практических путей решения проблемы, вебмастера экспериментируют. Вот самые эффективные методы.
Основные причины и решения ошибок индексации страниц
Некоторые вебмастера полагают, что причиной проблем с индексацией становятся лишь технические факторы страницы. Но это не всегда и в большинстве случаев не так. Простой эксперимент MOZ показал, что 15% страниц популярных интернет-магазинов США не попадают в индекс.
Ошибка: обнаружена, не проиндексирована
Это одна из самых сложных ошибок для устранения, так как причинами может быть что угодно: от качества контента до краулингового бюджета.
Чаще такая ошибка возникает на товарных страницах интернет-магазинов.
Краулинговый бюджет — это максимальное количество страниц одного сайта, которое может просканировать Google за один визит. Большое количество новых и/или обновленных страниц приводит к тому, что Google не справляется с объемом и оставляет остаток на потом.
Вторая распространенная причина появления ошибки — шаблонность страниц. Google определяет, что страницы определенного шаблона на сайте низкого качества, и предпочитает не индексировать их.
Работа с этой ошибкой требует определенных знаний и опыта. Что нужно проверить:
- нет ли определенного шаблона страниц, которые Google не индексирует. Это важно, так как в индекс могут не попадать целые категории товаров;
- очередь новых страниц на индексацию;
- краулинговый бюджет, который вполне могут занимать страницы результатов поиска или фильтров, где Google тратит много времени.
Далее опишем несколько нестандартных решений для ошибки “обнаружена, не проиндексирована”.
1. Перенос на новый URL
Зарубежный вебмастер Дэн Шур (@dan_shure в Твиттере) решил проблему с непроиндексированными страницами путем переноса контента на новый URL. При этом контент оставался неизменным (скопирован), а вот сам URL немного изменен. Для эксперимента вебмастер оставил одну страницу с этой ошибкой без изменений, вторую перенес на новый адрес. Страница на новом URL попала в индекс в течение нескольких часов, а неизмененная страница так и осталась с ошибкой (на тот момент уже более 10 дней).
Вебмастер отмечает, что подача заявок на переобход и отправка URL на индексацию вручную результатов не давали.
Джон Мюллер прокомментировал ситуацию так:
Такая ошибка часто возникает на сайтах, находящихся на грани допустимого качества. Это значит, что вам надо убедить Google в том, что страница стоит добавления в индекс.Для этого сайт должен быть “улетным” (awesome).
Это самая размытая рекомендация Google, потому как указанная характеристика весьма субъективна.
Мюллер предупреждает, что технические манипуляции, чтобы ввести страницу в индекс, не всегда эффективны. Так как добавленная страница может точно также через несколько дней снова вылететь из индекса.
К слову, вторая страница из эксперимента также успешно была проиндексирована после переноса на новый URL.
2. Обновить контент
Другие вебмастера видят проблему в самом контенте, что подтверждает рекомендацию Мюллера. Обнаруженные и не проиндексированные страницы содержат мало контента, он недостаточно информативен и полезен.
Рекомендация: дополнить страницу уникальным контентом в достаточном объеме (от 1000 символов). При этом контент должен быть полезным и информативным, а не техническим дополнением.
3. Проверить контент на уникальность
Мы не знаем, как Google определяет уникальность. Но даже разные инструменты могут показать разный процент проверки одного и того же текста. Ошибку “обнаружена, не проиндексирована” чаще получают страницы с контентом пограничной уникальности. Если какой-то из инструментов показывает низкий процент, стоит доработать страницу, дополнив ее уникальным и полезным текстом.
4. Получить внешнюю ссылку на страницу
Переход по внешним ссылкам — один из методов Google для обнаружения новых страниц. При этом ссылка с хорошего, авторитетного сайта оценивается поиском как голос “за” сайт, что станет дополнительным маркером важности непроиндексированной страницы.
Экспериментировать можно как с внутренними ссылками, прокачав неиндексируемую страницу линками с главной и тематических страниц, так и внешними ссылками.
5. Нагрузка на сервер
Это самый очевидный способ устранения проблемы с индексацией, который работает, но не во всех случаях.
Если страница получила ошибку “обнаружена, не проиндексирована”, стоит проверить хостинг и нагрузку на сервер и устранить причины ее повышения.
Ошибка: просканирована, но пока не проиндексирована
Google указывает, что робот просканировал страницу, но она не внесена в индекс. При этом отправлять повторный запрос на сканирование не надо. Из опыта экспертов MOZ такая ошибка часто вызвана проблемой качества содержания. Учитывая темпы появления новых интернет-магазинов, Google становится более избирательным в том, что вносит в индекс, а что нет.
Если страница получила такой статус, то надо проверить следующее:
- уникальность основных тегов Title и Description. а также основного содержания страницы
- не скопирован ли контент из внешних источников
- не дублируется ли контент в пределах сайта
- заблокирован ли доступ Google к некачественному, неоригинальному контенту на сайте.
Расскажите, случалась ли в вашей практике такая ошибка? Какие методы помогли ее устранить?
Эта статья также доступна на нашем Дзен-канале!

Когда ваш проект начинает расти и у него появляются тысячи публикаций, следует очень внимательно следить за его индексацией, так как сколько бы вы не создавали новых страниц, их отсутствие в поисковом индексе не приведет вам читателя и будет бессмысленным. На минувшем месяце я на одном из своих крупных проектов наткнулся на интересую ситуацию, я выпустил цикл новых статей, отправил их на ручную индексацию Google и забыл, какого же было мое удивление, когда я их не обнаружил в индексе гугла, а в Яндексе все появилось буквально через минуту. Начав копать я обнаружил, что они имеют статус “Страница Обнаружена, не просканирована“. Давайте разбираться из-за чего они получили такой статус и как это исправить.
Что означает статус “Страница Обнаружена, не просканирована”
В Google Search Console есть раздел “Покрытие” в котором вебмастер может отслеживать состояние страниц на его ресурсе:
- Ошибка – Это самое важное из данного представления
- Без ошибок, но есть предупреждения
- Страниц без ошибок – их должно быть максимальное количество
- Исключено – тут нужно особенно изучить все, так как там могут быть проблемы.
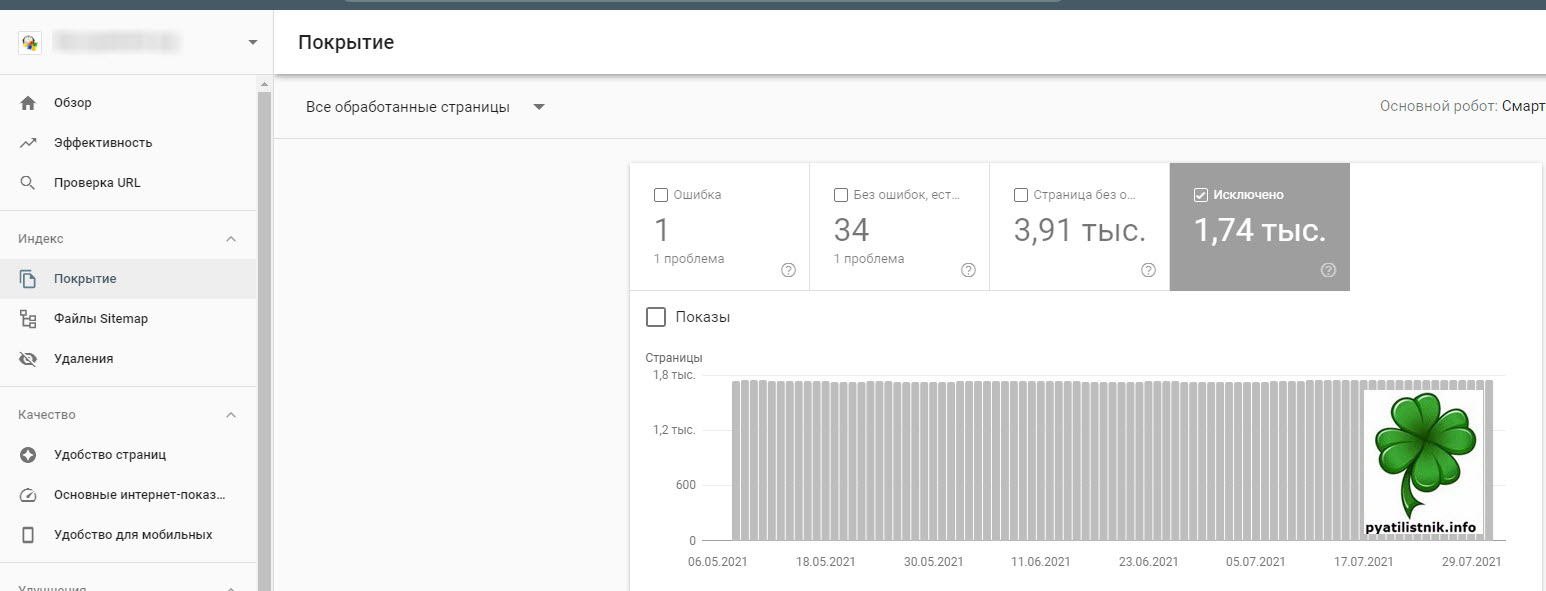
Если пролистать немного ниже, заведомо выбрав пункт “Исключено“, то можно очень детально посмотреть состав исключенных страниц, тут то я и обнаружил раздел с “Страница Обнаружена, не просканирована“.
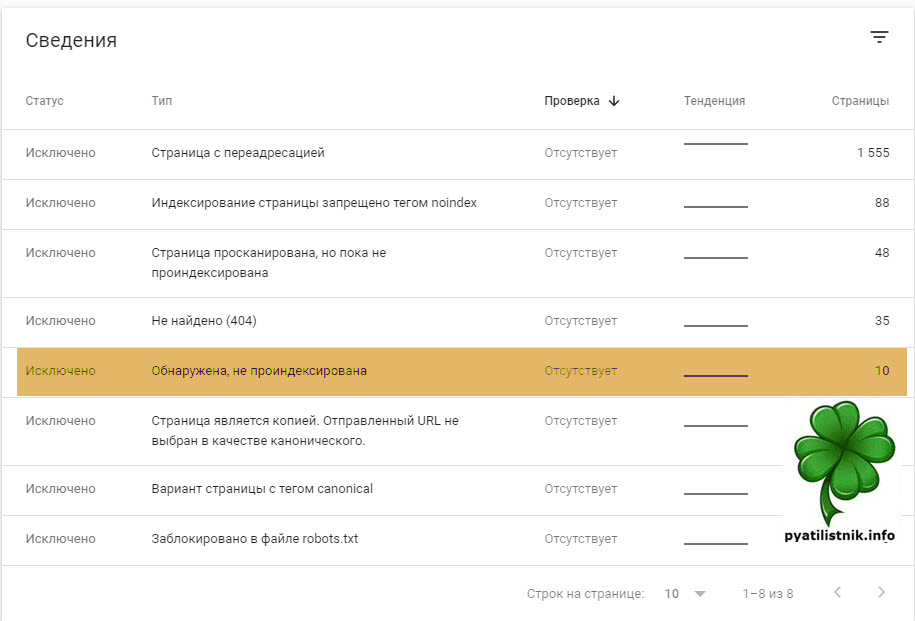
Перейдите в него и вы увидите состав данных страниц, вот мои бывшие примеры:
- http://pyatilistnik.org/how-to-turn-your-photos-into-a-beautiful-movie/
- http://pyatilistnik.org/dell-r740-server-testing/
- http://pyatilistnik.org/netapp-create-aggregate-command-line-howto/
- http://pyatilistnik.org/skachat-ibm-advanced-settings-utility-asu-9-63-dlya-linux/
- http://pyatilistnik.org/how-to-install-the-operating-system-on-the-dell-r740/
- http://pyatilistnik.org/error-rac0509-the-server-temporalily-unavailable/
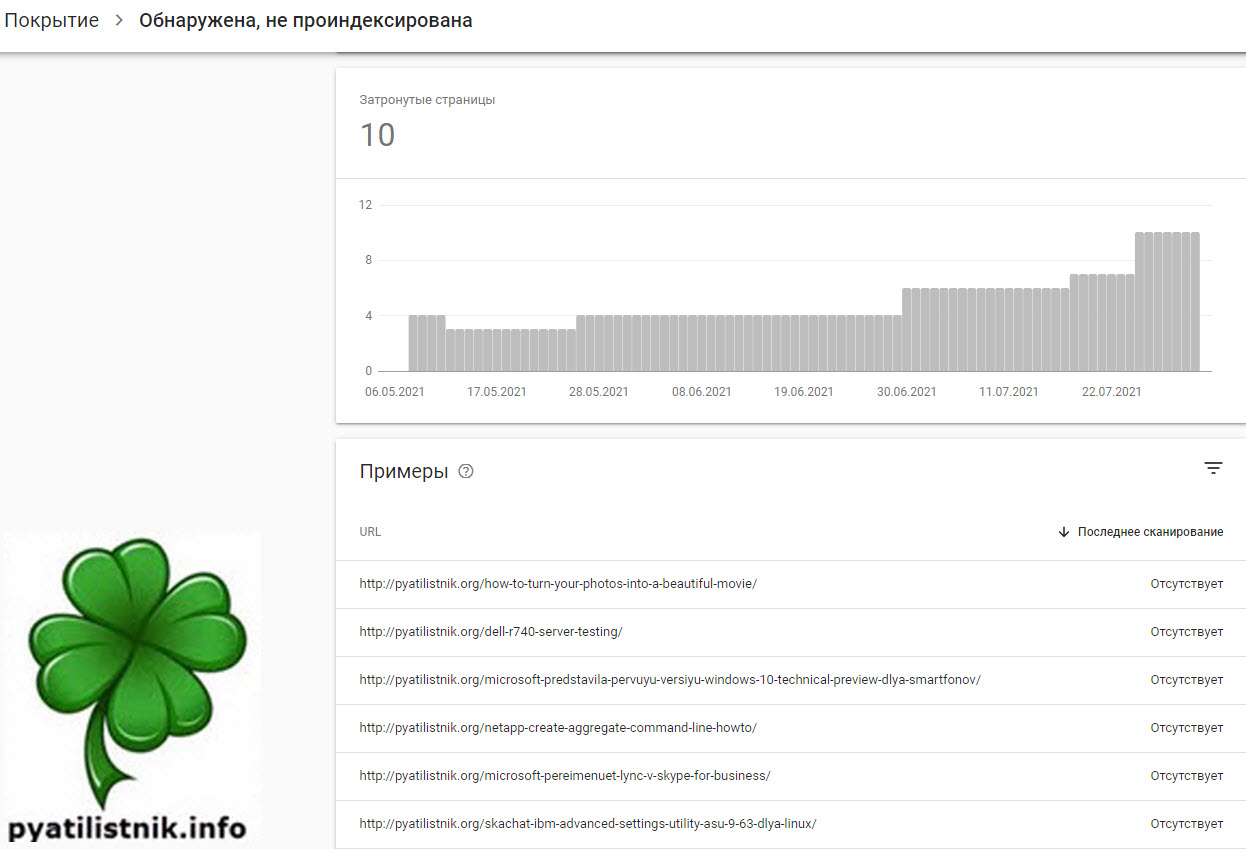
Что значит обнаружена, не проиндексирована – Это сообщение означает, что мы нашли страницу, но пока не добавили ее в индекс Google. Обычно это объясняется тем, что роботу Google не удалось просканировать сайт, поскольку это могло привести к чрезмерной загрузке ресурса, и сканирование было перенесено на более поздний срок. Именно поэтому в отчете не указывается дата последнего сканирования.(https://support.google.com/webmasters/answer/7440203?hl=ru)
Поиск проблем и причин
Когда при индексации вы видите подобный статус страницы, то с большой вероятностью когда пришел Google-bot отвечающий за сканирование ваших страниц, он осознал, что создает большую нагрузку на ваш ресурс. Дабы его не положить он откладывает данный процесс на неизвестное время и старается вас меньше напрягать. Что это значит для нас, это очень плохо, так как страницы не будут индексироваться, значит не будет трафика и далее заработка.
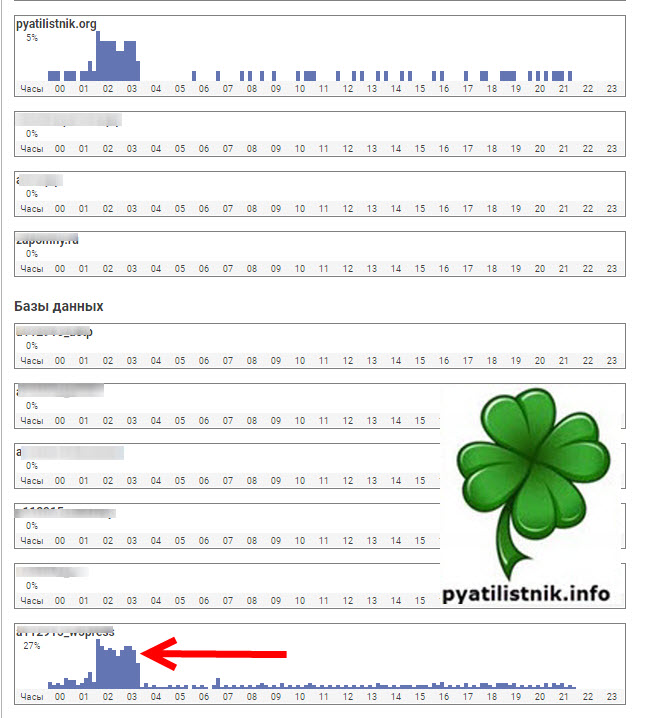
Что делать, нужно смотреть нагрузку на сайт. Первым делом вам необходимо зайти на ваш сервер или хостинг и проанализировать логи. В моем случае, это хостинг. Открыв админку, я увидел сильную нагрузку на сайт и на базу данных, выглядело это вот так. Обычно в пиковые значения нагрузка на БД не превышала 5-6%, что меня очень заинтересовало.
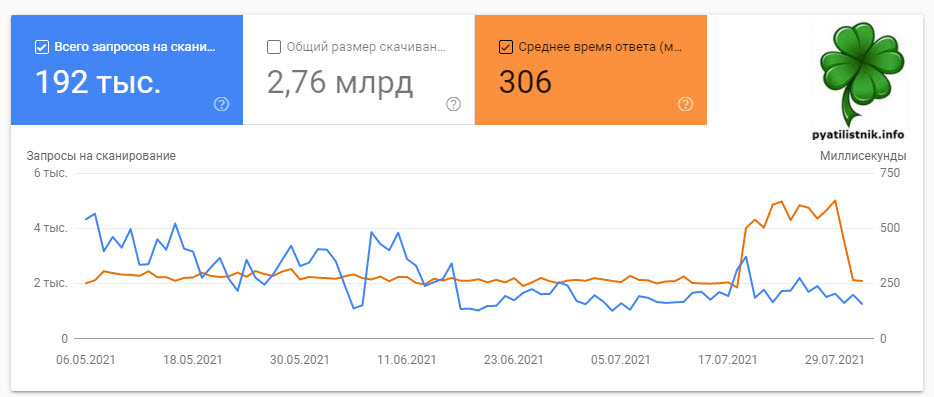
Далее я пошел в отчеты в Google Search Console. Раздел “Настройки – Статистика сканирования“. Нажмите “Открыть отчет“.
Нас будет интересовать среднее время ответа, это по сути аналог PING, при обращении к хосту. Как видите у меня он в среднем был 260, а затем резко подскочил до 700. Потом то, я нашел причину и он уменьшился, как вы видите по графику, но это успело повлиять на ресурс, и бот стал слегка осторожнее при обходе.
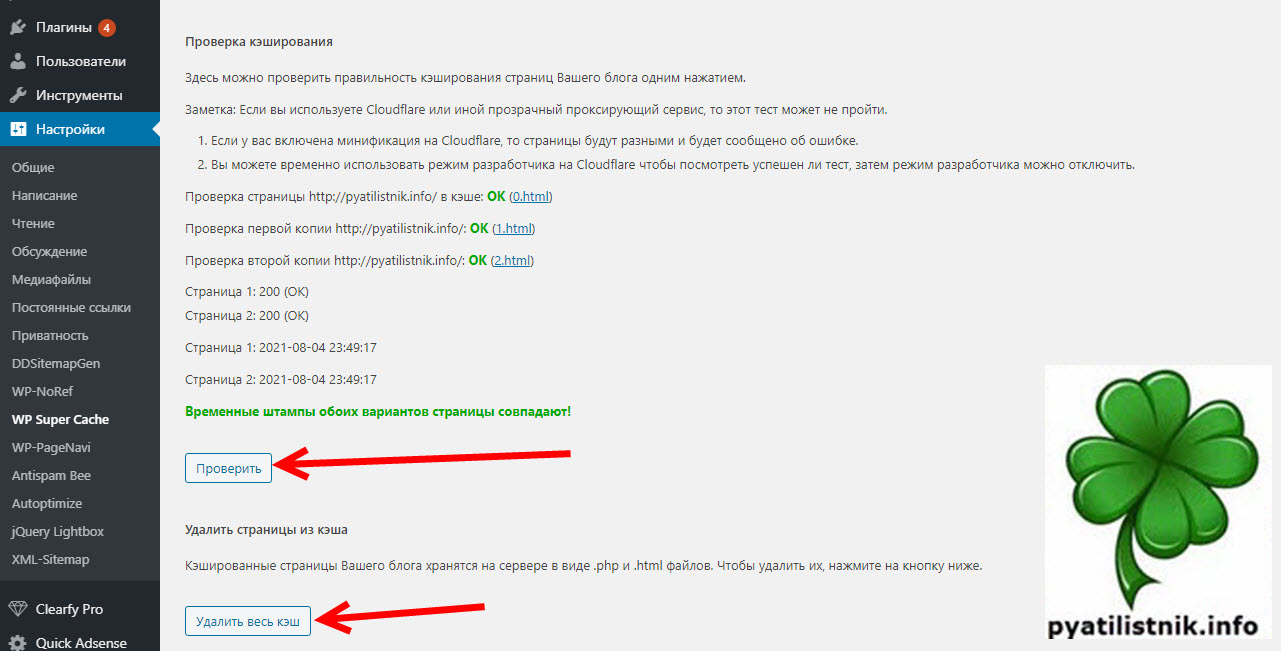
Вспоминая хронологию действий я понял, что причиной всему стало обновление плагина WordPress под названием WP Super Cache. И реально я заметил, что на хостинге в статистике была нагрузка, так как будто сайт работает без кэширующего плагина. Что я сделал, я полностью удалил кэш, а затем провел его тестирование, в итоге штампы совпадают, значит все хорошо.
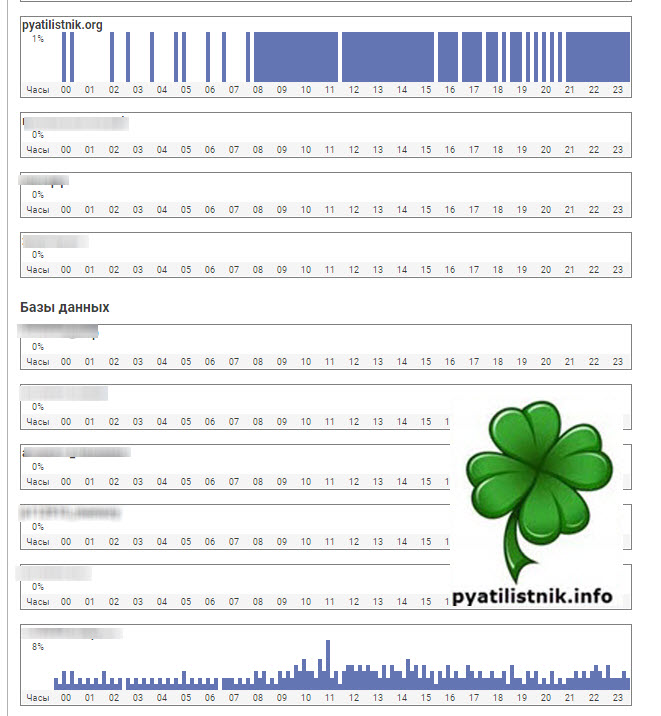
На следующий день я проверил статистику по нагрузке на хостинге, в итоге увидел привычную картину.
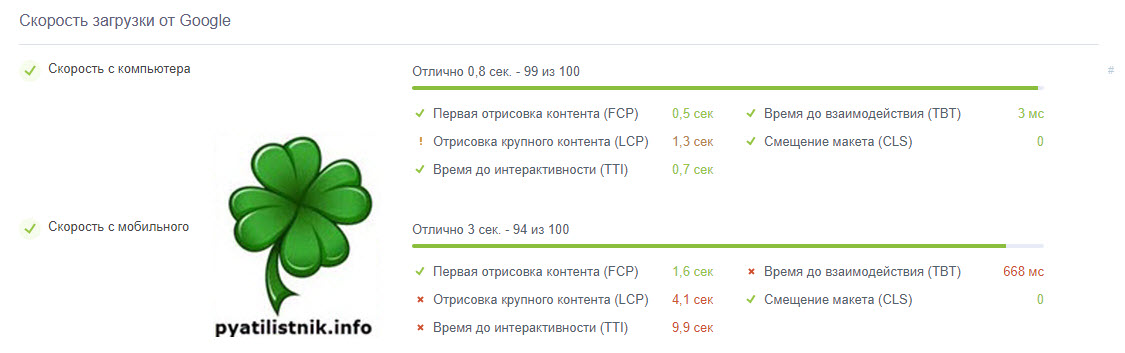
Так же я проверил скорость загрузки сайта в Google через сервис, в итоге все вернулось в зеленую зону.
Дополнительно
- Обязательно учитывайте свой краулинговый бюджет сайта, постарайтесь, чтобы у вас если страницы не изменяются, то отдавался 304 код и заголовок Last Modified. Это можно увидеть в отчете.
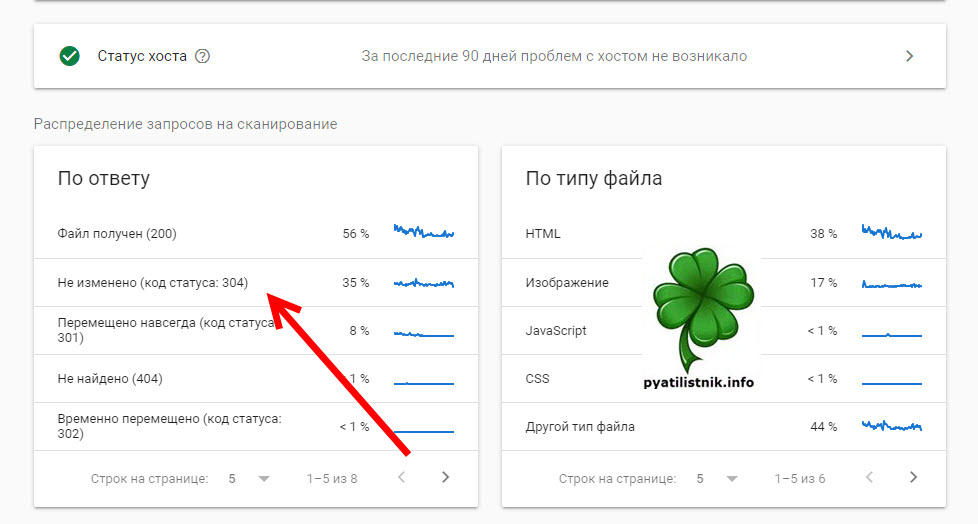
Проверить заголовок Last Modified можно на вот этом ресурсе “https://lastmodified.ru/“. Например, я проверю статью “Какими компаниями владеет Сбербанк”.
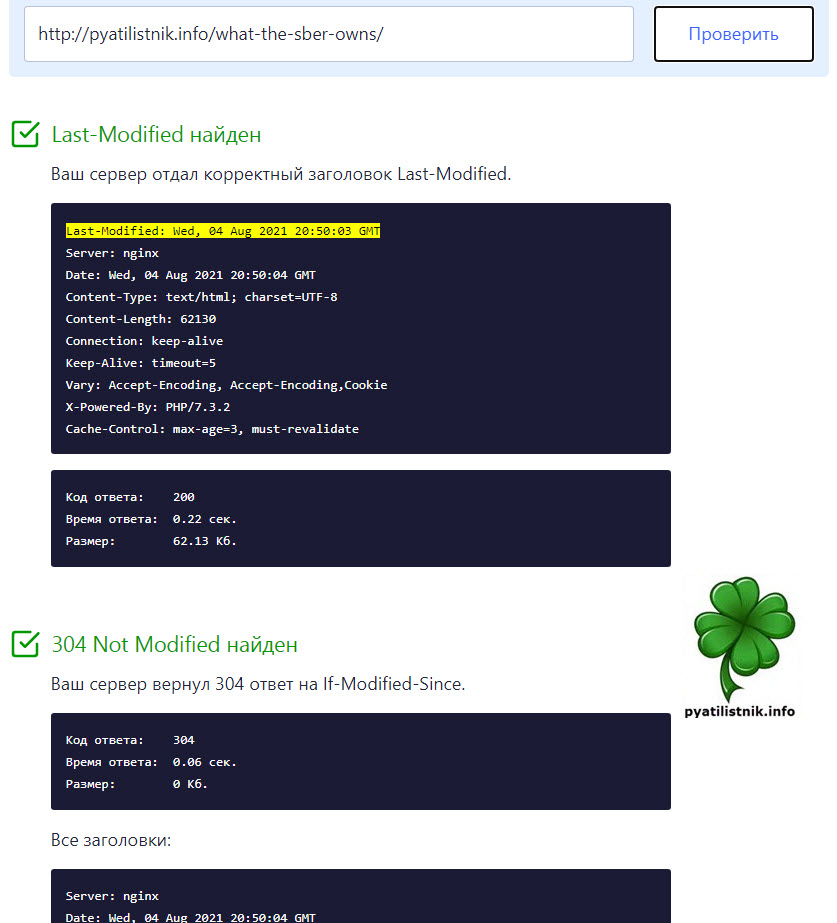
Ваш сервер отдал корректный заголовок Last-Modified.
Last-Modified: Wed, 04 Aug 2021 20:50:03 GMT Server: nginx Date: Wed, 04 Aug 2021 20:50:04 GMT Content-Type: text/html; charset=UTF-8 Content-Length: 62130 Connection: keep-alive Keep-Alive: timeout=5 Vary: Accept-Encoding, Accept-Encoding,Cookie X-Powered-By: PHP/7.3.2 Cache-Control: max-age=3, must-revalidateКод ответа: 200 Время ответа: 0.22 сек. Размер: 62.13 Кб.
- Уменьшите количество 404 страниц, удостоверьтесь, что они не индексируются
- Создайте правильный файл robots.txt, чтобы исключить от индексации разные технические страницы.
- Постарайтесь нарастить ссылочную массу, на страницы у которых статус “Страница Обнаружена, не просканирована”
- Создайте карту сайта в формате XML
- Попробуйте уменьшить количество страниц, если среди них есть незначимые
Через некоторое время ваши выпавшие из индексации страницы появятся в индексе, можете периодических их пытаться засунуть в ручную Google Search Console через кабинет.
Автор: Томек Рудзки (Tomek Rudzki) – специалист по техническому SEO, R&D-менеджер Onely.
В справочной документации Google определяет этот статус так:
«Страница просканирована, но пока не проиндексирована. В дальнейшем она может быть проиндексирована, а может и остаться в текущем состоянии; вновь отправлять этот URL на сканирование не нужно».
Обычно это объяснение не сильно помогает, особенно если это касается важной для бизнеса страницы. Google не проясняет, что именно случилось, и что может сделать владелец сайта. Он лишь говорит, что Googlebot просканировал страницу, но по какой-то причине решил ее не индексировать.
Согласно нашим данным, статус «Страница просканирована, но пока не проиндексирована» – это самая частая ошибка в отчете об индексировании. Это значит, что вы или уже сталкивались с ней, или столкнетесь в будущем.
Очень важно решить эту проблему максимально быстро: если страница не проиндексирована, она не будет появляться в результатах поиска и не получит органического трафика из Google.
В этой статье мы рассмотрим возможные причины возникновения этой ошибки и разберемся, как их устранить.
Где найти этот статус
Этот статус можно увидеть в отчете об индексировании и в инструменте проверки URL в Search Console.
Отчет об индексировании
URL со статусом «Страница просканирована, но пока не проиндексирована» относится к категории исключенных, и Google не считает отсутствие этой страницы в индексе ошибкой.
В Справке этот статус определяется так:
«Исключено. Страница не проиндексирована, скорее всего потому, что таково было ваше решение. В частности, это может быть связано с тем, что страница исключена вами при помощи директивы noindex или является копией уже проиндексированной канонической страницы».
Прим. ред.: интересно, что в англоязычной версии Справки упор делается на решение Google, а не владельца сайта: «These pages are typically not indexed, and we think that is appropriate. These pages are either duplicate of indexed pages, or blocked from indexing by some mechanism on your site, or otherwise not indexed for a reason that we think is not an error». При переводе этот смысл потерялся, но именно на него ориентируется автор статьи.
После клика по статусу «Страница просканирована, но пока не проиндексирована» отображается список всех таких URL. В первую очередь нужно будет заняться теми страницами, которые являются наиболее ценными для сайта.
Отчет также можно выгрузить. Однако экспортировать можно лишь до 1000 URL. Если затронуто больше страниц, то можно увеличить количество экспортируемых URL, отфильтровав их по Sitemap. Например, если у сайта два файла Sitemap, в каждом из которых по 1000 URL, то их можно будет скачать по отдельности.
Инструмент проверки URL
Найти страницы со статусом «Страница просканирована, но пока не проиндексирована» также можно с помощью инструмента проверки URL в Search Console.
Верхний раздел отчета показывает, может ли страница быть найдена в Google. Если в отчете об индексировании проверяемый URL отнесен к категории «Исключено», то инструмент сообщит, что страница отсутствует в индексе, но это не связано с ошибкой.
Ошибка в отчетности: страница на самом деле может быть проиндексирована
Заметив статус «Страница просканирована, но пока не проиндексирована», первое, что нужно сделать – проверить, действительно ли страницы нет в индексе. Нередко можно увидеть, что страница помечена как просканированная, тогда как инструмент проверки URL показывает, что на самом деле она проиндексирована.
Инструмент проверки URL также позволяет получить более детальную информацию о конкретной странице, включая:
- Ошибки индексации;
- Ошибки структурированных данных;
- Оптимизация для мобильных и т.д.
Также можно просмотреть загруженные ресурсы (например, JavaScript), запросить индексацию и увидеть обработанную версию страницы.
Важно помнить, что данные о статусе индексации страницы в отчете об индексировании и инструменте проверки URL могут не совпадать. Согласно Google, это связано с тем, что в отчете об индексировании данные обновляются немного по-другому и медленнее, чем в инструменте проверки URL. Однако это не всегда задержка. Иногда это баг в работе отчетности.
В сентябре мы заметили, что некоторые из наших проиндексированных статей получили статус «Страница просканирована, но не проиндексирована» в Search Console. Это определенно не было задержкой, поскольку также были затронуты и более старые статьи.
Вскоре после этого на проблему обратили внимание и другие специалисты, в том числе Лили Рэй (Lily Ray):
Others have already tweeted about this, but I’m seeing many examples of URLs in GSC’s “Crawled, Not Indexed” report (with recent crawl dates) that are, in fact, indexed URLs.
Inspecting individual URLs often results in the below message.
Thoughts @danielwaisberg @googlesearchc? pic.twitter.com/i1XfcvldEq
— Lily Ray 😏 (@lilyraynyc) 28 сентября 2021 г.
Что делать в такой ситуации и какому отчету доверять
Как правило, инструмент проверки URL показывает более актуальные данные, чем отчет об индексировании. Поэтому, выбирая между этими двумя отчетами, ориентируйтесь на данные инструмента проверки URL.
Причины возникновения такой ошибки и как ее устранить
Теперь давайте перейдем к сути проблемы: почему появляется этот статус, и что можно сделать, чтобы страницы были проиндексированы.
Google не дает четкого ответа, почему страница получила такой статус, но есть несколько возможных причин, по которым он может появиться. В их числе:
- Задержка индексации
- Страница не соответствует стандартам качества
- Страница была деиндексирована
- Проблема с архитектурой сайта
- Проблемы с дублированным контентом
Задержка индексации
Для индексации нужно время. Интернет бесконечно велик, и Google должен определить, какие страницы будут проиндексированы в первую очередь.
В своей статье Ultimate Guide to Indexing SEO мы показали, сколько времени обычно требуется страницам на популярных сайтах для индексации. Вот некоторые результаты из нашего исследования:
- Google индексирует только 56% индексируемых URL через 1 день после публикации.
- Через 2 недели индексируется 87% URL-адресов.
Если вы только что опубликовали страницу, вполне нормально, если она пока не проиндексирована. Нужно немного подождать, и она появится в индексе.
Решение
Вы не можете повлиять на сканирование и индексирование страницы в краткосрочной перспективе, но есть несколько вещей, которые помогут сайту в более долгосрочном периоде:
- Создайте стратегию индексирования, чтобы помочь Google приоритизировать нужные страницы на сайте. Для этого следует решить, какие страницы должны индексироваться, и выбрать лучшие методы сообщить об этом Google.
- Убедитесь, что на те страницы, которые для вас важны, есть внутренние ссылки. Это поможет Google найти эти страницы и лучше понять их контекст.
- Создайте хорошо оптимизированную карту сайта. Перечислите в ней самые ценные URL. Google будет использовать этот файл в качестве дорожной карты и сможет быстрее находить страницы.
Страница не соответствует стандартам качества
Google не может индексировать все страницы в интернете. Хранилище ограничено и поэтому необходимо фильтровать низкокачественный контент.
Цель Google – предоставлять пользователям страницы высокого качества, которые лучше всего отвечают их намерению. Это значит, что если страница более низкого качества, то Google может ее проигнорировать, чтобы оставить место для более качественного контента. И мы ожидаем, что в будущем стандарты качества будут лишь ужесточаться.
Решение
Как владелец сайта, вы должны убедиться, что каждая страница содержит контент высокого качества. Проверьте, может ли страница удовлетворить намерение пользователя, и добавьте качественный контент при необходимости.
В справочном руководстве по ключевым обновлениям Google предлагает список вопросов, которые помогают определить ценность контента. Вот некоторые из них:
- Размещены ли на сайте оригинальные материалы (факты, репортажи, исследования, аналитика)?
- Содержит ли ваш сайт глубокую аналитику или интересные и неочевидные факты?
- Если взят контент из других источников, то переработан ли он в достаточной мере, чтобы представлять существенную ценность в таком виде?
- Готовы ли вы поделиться такой страницей с друзьями, добавить ее в закладки или порекомендовать другим пользователям?
Кроме того, вы можете воспользоваться советами по качественному контенту из Руководства для асессоров Google. Хотя этот документ ориентирован прежде всего на асессоров, чтобы они могли оценивать качество сайтов, вебмастера могут использовать его для улучшения собственных ресурсов.
UGC-контент
Генерируемый пользователями контент тоже может быть проблемой с точки зрения качества. Например, у вас есть форум, и кто-то задает вопрос. Если на момент сканирования ответов в теме не было, то Google может квалифицировать эту страницу как низкокачественный контент – несмотря на то, что такие ответы могут появиться в будущем.
Как защититься от такой ситуации?
Сервис вопросов и ответов Quora разработал отличную стратегию на этот случай: любой неотвеченный вопрос имеет префикс /unanswered/ в URL. Например:
Файл robots.txt блокирует все страницы с префиксом /unanswered/. В итоге Googlebot не может их сканировать. Как только в теме появляется ответ, URL меняется и становится доступным для сканирования.
Таким образом Quora блокирует доступ к потенциально низкокачественному контенту, генерируемому пользователями.
Google удалил страницу из индекса
URL может получить статус «Страница просканирована, но не проиндексирована», если страница была проиндексирована, но со временем Google решил удалить ее из индекса.
Почему страницы могут выпадать из индекса? Google может заменять их на более качественный контент.
Index selection, while it’s largely about (RAM/flash/disk) space, it’s tightly tied to quality of content. If we have tons of free space available, we’re more likely to index crappier content. If we don’t, we might deindex stuff to make space for higher quality docs. pic.twitter.com/jRMkEqdft0
— Gary 鯨理/경리 Illyes (@methode) 15 мая 2020 г.
Также важно следить за обновлениями поисковых алгоритмов. Деиндексация может стать результатом одного из таких апдейтов.
Выпадение страниц из индекса также может быть связано со сбоем на стороне Google. Такие ситуации тоже возможны. Например, Google как-то удалил из индекса сайт Search Engine Land потому что ошибочно решил, что он был взломан.
Решение
Решение для деиндексированных страниц тесно связано с их качеством. Следите за тем, чтобы страница предоставляла качественный и актуальный контент. Не думайте, что если страница проиндексирована, то больше ничего с ней делать не нужно. Продолжайте отслеживать и внедряйте изменения и улучшения при необходимости.
«Если после определенного ключевого обновления эффективность страниц снизилась, это не значит, что с ними что-то не так. Они не нарушают наши рекомендации для вебмастеров, и к ним не применялись никакие меры – ни вручную, ни автоматически. Ключевые обновления не нацелены на конкретные страницы и сайты. Они предназначены для того, чтобы наши системы могли в целом лучше оценивать контент», – объяснили в Google.
Прим. ред. В англоязычной версии документа, опять же, смысл немного другой: «Убедитесь, что предлагаете максимально качественный контент. Это то, что наши алгоритмы стремятся вознаграждать».
После устранения проблем отправьте запрос на повторную индексацию этих URL, чтобы Google быстрее увидел изменения.
Проблемы с архитектурой сайта
Когда сотрудника Google Джона Мюллера спросили о возможных причинах, по которым страница может иметь статус «просканирована, но пока не проиндексирована», он упомянул еще одну возможную причину – плохую структуру сайта.
You can’t force pages to be indexed — it’s normal that we don’t index all pages on all websites. It’s not an issue with “that page”, it’s more site-wide. Creating a good site structure and making sure the site is of the highest quality possible is essentially the direction.
— 🐐 John 🐐 (@JohnMu) 28 июня 2021 г.
Например, на сайте есть страница хорошего качества, но Google может найти ее только через файл Sitemap. Googlebot может посетить эту страницу и просканировать ее, но поскольку внутренних ссылок нет, он может решить, что эта страница менее ценная, чем другие. На сайте нет никакой семантической или структурной информации, которая помогла бы ему должным образом оценить страницу. И это может быть одной из причин, по которой Google решил сосредоточиться на других страницах, а эту оставить без индексации после сканирования.
Решение
Хорошая архитектура сайта является ключом к тому, чтобы максимально увеличить шансы на индексацию. Продуманная структура позволяет роботам поисковых систем обнаруживать контент и лучше понимать взаимосвязь между страницами.
Вот почему так важно обеспечить хорошую архитектуру сайта и внутренние ссылки на ту страницу, которую нужно проиндексировать.
Дублированный контент
В октябре 2021 года SEO-консультант Адам Гент (Adam Gent) поделился интересным кейсом. Его страница получала статус «Просканирована, но пока не проиндексирована», поскольку Google посчитал ее дубликатом.
Google хочет предоставлять уникальный и ценный контент своим пользователям. Поэтому, когда при сканировании он видит, что некоторые страницы идентичны или практически идентичны, то может индексировать лишь одну из них.
Обычно страницы, не попавшие в индекс по этой причине, в отчете об индексировании получают статус «Страница является копией», однако не всегда. Иногда Google присваивает им статус «Страница просканирована, но пока не проиндексирована».
Почему Google может выбирать этот статус, до конца не понятно. Одно из возможных объяснений состоит в том, что этот статус может измениться в будущем, когда Google увидит, что есть более подходящий URL.
Также причина может быть в ошибке: Google может попросту ошибиться при назначении статуса. Такая ситуация более сложная, поскольку статус «Страница просканирована, но пока не проиндексирована» не дает столько информации, как специальный статус для дублированного контента.
Как проверить, показывается ли дубликат в результатах поиска:
- Перейдите на страницу, которая не проиндексирована, и скопируйте небольшой фрагмент текста.
- Возьмите его в кавычки и выполните поиск по этому запросу в Google.
- Проанализируйте результаты. Если в выдаче присутствует другой URL с этим текстом, значит ваша страница не индексируется, потому что Google выбрал другой URL.
Решение
Прежде всего, убедитесь, что создаете оригинальные страницы. Если необходимо, добавьте уникальный контент.
К сожалению, избежать появления дублированного контента не всегда возможно (например, если есть мобильная и десктопная версия сайта). У нас не так много контроля над тем, что появляется в результатах поиска, но мы можем дать Google некие подсказки о том, какая версия является оригиналом.
Если вы видите, что Google индексирует много дублированного контента, то проверьте следующие элементы:
- Канонические теги. Эти HTML-теги сообщают поисковым системам, какие версии страниц являются оригиналами.
- Внутренние ссылки. Убедитесь, что внутренние ссылки указывают на оригинальный контент. Google может использовать это как индикатор важности страницы.
- Файлы Sitemap. Убедитесь, что в них содержится только каноническая версия страницы.
Помните, что это только подсказки, и Google не обязан им следовать. В случае, описанном Адамом Гентом, Google выбрал для индексации RSS-фид, хотя многие сигналы указывали на другой URL. Адам решил проблему, настроив ошибку 404, чтобы оставалась только оригинальная версия. Он также настроил HTTP-заголовок X-Robots-Tag на всех URL фидов таким образом, чтобы запретить их индексацию.
«Страница просканирована, но пока не проиндексирована» vs «Обнаружена, не проиндексирована»
Статус «Страница просканирована, но пока не проиндексирована» часто путают с другой проблемой индексации в отчете об индексировании: «Обнаружена, не проиндексирована».
Оба статуса показывают, что страница не проиндексирована. Однако в первом случае Google уже посетил страницу, а во втором – поисковик знает об URL, но пока его не просканировал.
Если вы видите статус «Обнаружена, не проиндексирована», попробуйте выяснить, почему Google не смог или не захотел просканировать эту страницу. Например, этот статус может указывать на проблемы с качеством сайта в целом, бюджетом сканирования или перегрузкой сервера.
Подводим итоги
Статус «Страница просканирована, но пока не проиндексирована» часто связывают с качеством страницы, но в действительности он может указывать на множество других проблем, таких как плохая архитектура сайта или дублированный контент.
Что сделать, чтобы избавиться от этого статуса:
- Добавьте на страницы уникальный и ценный контент. После этого отправьте заявку на повторное сканирование. Так поисковик сможет быстрее заметить изменения.
- Проверьте архитектуру сайта и убедитесь, что на ценные страницы есть внутренние ссылки.
- Решите, какие страницы должны и не должны индексироваться Google. Помогите поисковой системе приоритизировать более ценные URL.
