
Иногда перед программистом стоит не самая простая задача: найти все ссылки на странице с помощью PHP. Где это может быть нужно? Да, много где, например, при выводе одного сайта на другом. Для этого требуется вытащить из него все ссылки и заменить на другие. Также поиск ссылок используется при создании ЧПУ-ссылок, ведь нужно вытащить все старые ссылки и поставить заместо них новые. В общем, задач можно придумать много, но ключевой вопрос всего один: “Как найти все ссылки на странице через PHP?“. Об этом я и написал данную статью.
Кто имеет хотя бы маленький опыт, тут же скажет, что надо написать регулярное выражение и будет абсолютно прав. Действительно, простыми строковыми функциями данную задачу будет крайне трудно решить. Ведь каждый пишет по-разному, кто-то прописными бувами, кто-то строчными, кто-то ставит пробел после, например, знака “=“, а кто-то нет. У кого-то двойные кавычки, а у кого-то одинарные. В общем, разновидностей очень много. И единственная возможность предусмотреть максимум всего – это регулярное выражение.
<?php
/* $html - некий html-код некой страницы, n - это переход на новую строку (верстальщики иногда это делают) */
$html = "Текст <a href='page1.html'>ссылка</a> и снова <a hREF n ="page2.html" title=''>ссылка</a> конец";
/* Вызываем функцию, которая все совпадения помещает в массив $matches */
preg_match_all("/<[Aa][s]{1}[^>]*[Hh][Rr][Ee][Ff][^=]*=[ '"s]*([^ "'>s#]+)[^>]*>/", $html, $matches);
$urls = $matches[1]; // Берём то место, где сама ссылка (благодаря группирующим скобкам в регулярном выражении)
/* Выводим все ссылки */
for ($i = 0; $i < count($urls); $i++)
echo $urls[$i]."<br />";
?>
Самая сложная часть – это регулярное выражение, ради его публикации данная статья и создавалась, чтобы новичкам не пришлось писать нечто подобное. Хотя это и является очень полезным, но сразу новичок такое никогда не напишет, а для решения задачи это требуется. Конечно, данное регулярное выражение по поиску ссылок неидеальное (едва ли можно написать идеальное), но, думаю, что 99% ссылок будут найдены. А если код писал адекватный верстальщик, то все 100%. А как работать с найденными ссылками дальше, это уже отдельная история.
-

Создано 26.09.2012 10:08:17
-
Михаил Русаков

Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
-
Кнопка:
Она выглядит вот так:
-
Текстовая ссылка:
Она выглядит вот так: Как создать свой сайт
- BB-код ссылки для форумов (например, можете поставить её в подписи):

Not regexp, but finds it all and makes sure that they are not already encompassed in a tag already. It also checks to make sure that the link isn’t encapsulated in (), [], “” or anything else with an open and close.
$txt = "Test text http://hello.world Test text
http://google.com/file.jpg Test text https://hell.o.wor.ld/test?qwe=qwe Test text
test text http://test.test/test <a href="http://example.com">I am already linked up</a>
It was also done in 1927 (http://test.com/reference) Also check this out:http://test/index&t=27";
$holder = explode("http",$txt);
for($i = 1; $i < (count($holder));$i++) {
if (substr($holder[$i-1],-6) != 'href="') { // this means that the link is not alread in an a tag.
if (strpos($holder[$i]," ")!==false) //if the link is not the last item in the text block, stop at the first space
$href = substr($holder[$i],0,strpos($holder[$i]," "));
else //else it is the last item, take it
$href = $holder[$i];
if (ctype_punct(substr($holder[$i-1],strlen($holder[$i-1])-1)) && ctype_punct(substr($holder[$i],strlen($holder[$i])-1)))
$href = substr($href,0,-1); //if both the fron and back of the link are encapsulated in punctuation, truncate the link by one
$holder[$i] = implode("$href" target="_blank" class="link">http$href</a>",explode($href,$holder[$i]));
$holder[$i-1] .= "<a href="";
}
}
$txt = implode("http",$holder);
echo $txt;
Output:
Test text <a href="http://hello.world" target="_blank" class="link">http://hello.world</a> Test text
<a href="http://google.com/file.jpg" target="_blank" class="link">http://google.com/file.jpg</a> Test text <a href="https://hell.o.wor.ld/test?qwe=qwe" target="_blank" class="link">https://hell.o.wor.ld/test?qwe=qwe</a> Test text
test text <a href="http://test.test/test" target="_blank" class="link">http://test.test/test</a> <a href="http://example.com">I am already linked up</a>
It was also done in 1927 (<a href="http://test.com/reference" target="_blank" class="link">http://test.com/reference</a>) Also check this out:<a href="http://test/index&t=27" target="_blank" class="link">http://test/index&t=27</a>

От автора: не люблю каждый раз натыкаться на одни и те же грабли! Вот сегодня опять та тема, в которой никак не обойтись без регулярных выражений. Это и есть мои любимые «грабли». Но все равно я не сдамся, и чтобы с помощью PHP находить ссылки, я обойдусь без них!
Никуда без них не деться!
Нет уж, господа консерваторы! Я постараюсь уж как-нибудь реализовать парсинг документов без этого застарелого средства. Ну не хватает у меня терпения на составление шаблонов с помощью регулярных выражений. А когда терпение лопается, то рождаются другие более «ругательные» выражения :). Так что «грабли» в сторону – мы идем по собственному галсу!
Чтобы не опростоволоситься, нам потребуется сторонняя библиотека — Simple HTML DOM. Скачать ее можно по этой ссылке. Не беспокойтесь, версия хоть и старая, но работает. А главное, что это средство посвежее будет, чем выражения регулярные :).
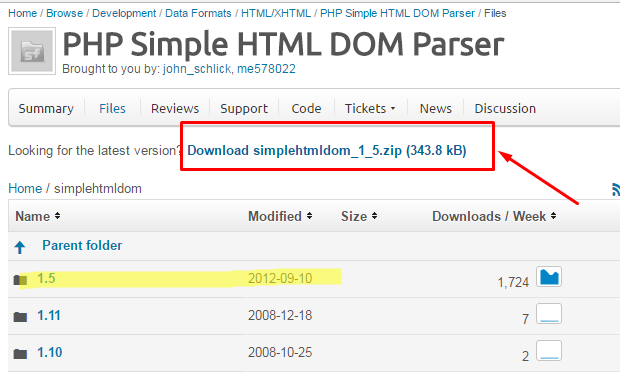
После распаковки помещаем файл simple_html_dom.php в папку со скриптом, чтоб легче было подключать. Все остальные файлы в принципе нас не интересуют, но пригодятся вам в будущем. Там есть и мануал, и примеры использования библиотеки.
Реализуем!
Напомню, что сегодня мы научимся, как найти ссылки PHP без «ужасных» регулярных выражений. Теперь нам осталось подключить скрипт библиотеки у себя в коде и просканировать указанную веб-страницу на наличие гиперссылок.
|
<?php include ‘simple_html_dom.php’; $razmetka = file_get_html(‘//test2.ru/’); foreach($razmetka–>find(‘a’) as $teg) echo $teg–>href . “<br>”; ?> |

Для доказательства действенности этого метода приведу код разметки «отпарсеной» страницы.

Сразу оговорюсь, что я не сканировал ничей сайт. Для демонстрации примера я использовал Денвер, а в нем стоит программная заглушка, которая не позволяет парсить удаленные хосты.
Еще пример!
Вот еще один вариант реализации, в котором нам также удастся обойтись без «граблей».
|
<?php $razmetka_html = file_get_contents(‘sample.html’); $dom = new DOMDocument; $dom–>loadHTML($razmetka_html); $tegi = $dom–>getElementsByTagName(“a”); foreach ($tegi as $teg) { echo $teg–>nodeValue.” “; echo $teg–>getAttribute(‘href’).“<br>”; echo “<br>”; } ?> |
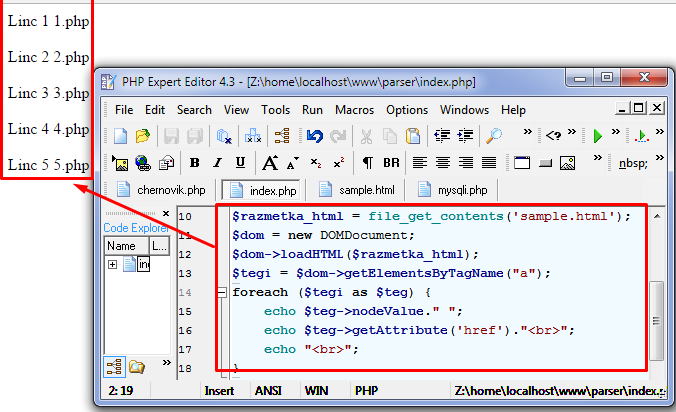
Разметка страницы, в которой с помощью PHP находили ссылки в тексте.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
<html> <head> <title>Sample</title> </head> <body> <div class=“menu”> <h2>Menu</h2> <ul> <li><a href=“1.php”>Linc 1</a></li> <li><a href=“2.php”>Linc 2</a></li> <li><a href=“3.php”>Linc 3</a></li> <li><a href=“4.php”>Linc 4</a></li> <li><a href=“5.php”>Linc 5</a></li> </ul> </div> <div class=“cont”> <p>PHP is a server scripting language</p> </div> </body> </html> |

Мне очередной раз удалось избавиться от своих «граблей» :). А вам?
Reading Time: 5 minutes
17,944 Views
Inside this article we will see the concept of find and extract all links from a HTML string in php. Concept of this article will provide very classified information to understand the things.
This PHP tutorial is based on how to extract all links and their anchor text from a HTML string. In this guide, we will see how to fetch the HTML content of a web page by URL and then extract the links from it. To do this, we will be use PHP’s DOMDocument class.
DOMDocument of PHP also termed as PHP DOM Parser. We will see step by step concept to find and extract all links from a html using DOM parser.
Learn More –
- How To Generate Fake Data in PHP Using Faker Library
- How to Generate Fake Image URLs in PHP Using Faker
- How to Generate Random Name of Person in PHP
- How to Get HTML Tag Value in PHP | DOMDocument Object
Let’s get started.
Example 1: Get All Links From HTML String Value
Inside this example we will consider a HTML string value. From that html value we will extract all links.
Create file index.php inside your application.
Open index.php and write this complete code into it.
<?php
// HTML String
$htmlString = "<html>
<head></head>
<body>
<a href='https://www.google.com/' title='Google URL'>Google</a>
<a href='https://www.youtube.com/' title='Youtube URL'>Youtube</a>
<a href='https://onlinewebtutorblog.com/' title='Website URL'>Online Web Tutor</a>
</body>
</html>";
//Create a new DOMDocument object.
$htmlDom = new DOMDocument;
//Load the HTML string into our DOMDocument object.
@$htmlDom->loadHTML($htmlString);
//Extract all anchor elements / tags from the HTML.
$anchorTags = $htmlDom->getElementsByTagName('a');
//Create an array to add extracted images to.
$extractedAnchors = array();
//Loop through the anchors tags that DOMDocument found.
foreach($anchorTags as $anchorTag){
//Get the href attribute of the anchor.
$aHref = $anchorTag->getAttribute('href');
//Get the title text of the anchor, if it exists.
$aTitle = $anchorTag->getAttribute('title');
//Add the anchor details to $extractedAnchors array.
$extractedAnchors[] = array(
'href' => $aHref,
'title' => $aTitle
);
}
echo "<pre>";
//print_r our array of anchors.
print_r($extractedAnchors);
Concept

Output
When we run index.php. Here is the output


Example 2: Get All Links From a Web Page
Inside this example we will use web page URL to get all links.
Create file index.php inside your application.
Open index.php and write this complete code into it.
<?php
$htmlString = file_get_contents('https://onlinewebtutorblog.com/');
//Create a new DOMDocument object.
$htmlDom = new DOMDocument;
//Load the HTML string into our DOMDocument object.
@$htmlDom->loadHTML($htmlString);
//Extract all anchor elements / tags from the HTML.
$anchorTags = $htmlDom->getElementsByTagName('a');
//Create an array to add extracted images to.
$extractedAnchors = array();
//Loop through the anchors tags that DOMDocument found.
foreach($anchorTags as $anchorTag){
//Get the href attribute of the anchor.
$aHref = $anchorTag->getAttribute('href');
//Get the title text of the anchor, if it exists.
$aTitle = $anchorTag->getAttribute('title');
//Add the anchor details to $extractedAnchors array.
$extractedAnchors[] = array(
'href' => $aHref,
'title' => $aTitle
);
}
echo "<pre>";
//print_r our array of anchors.
print_r($extractedAnchors);
Output
When we run index.php. Here is the output

We hope this article helped you to Find and Extract All links From a HTML String in PHP Tutorial in a very detailed way.
Buy Me a Coffee
Online Web Tutor invites you to try Skillshike! Learn CakePHP, Laravel, CodeIgniter, Node Js, MySQL, Authentication, RESTful Web Services, etc into a depth level. Master the Coding Skills to Become an Expert in PHP Web Development. So, Search your favourite course and enroll now.
If you liked this article, then please subscribe to our YouTube Channel for PHP & it’s framework, WordPress, Node Js video tutorials. You can also find us on Twitter and Facebook.
Всем привет! Есть шаблон сайта, но там ооооочень много сторонних ссылок. Можно ли с помощью php написать скрипт, который найдет все все все сторонние ссылки? Желательно указав номер строчки, где находится эта ссылка.
-
Вопрос заданболее трёх лет назад
-
117 просмотров
Пригласить эксперта
$file = file('файл_с_шаблоном.html');
foreach($file as $k => $v) {
preg_match_all('/href="(.*?)"/is', $v, $m, PREG_SET_ORDER);
foreach($m as $data) {
$hrefArr[]['strNum'] = ($k+1);
$hrefArr[]['href'] = $data[1];
}
}
/* print_r($hrefArr); */
foreach($hrefArr as $data) {
echo 'Найдена ссылка: '.$data['href'].' в строке: .'$data['strNum'].'<br>';
}-
Показать ещё
Загружается…
23 мая 2023, в 15:58
30000 руб./за проект
23 мая 2023, в 15:50
1000 руб./за проект
23 мая 2023, в 15:41
1000 руб./за проект
