Кукусики!
Меня зовут Юля, и я Mobile QA в компании Vivid Money.
В тестировании уже давно — столько всего интересного видела. Но как показывает практика, проблемы и заботы у всех одинаковые. Разница только в анализе, подходах и реализации решений.
В этой статье я расскажу, КАК ОБЛЕГЧИТЬ ЖИЗНЬ ТЕСТИРОВЩИКУ ВО ВРЕМЯ РЕГРЕССА!
Расскажу по порядку:
-
Наши процессы (для полноты картины)
-
Основную проблему
-
Анализ
-
Методы решения, с полученными результатами
Немного о наших процессах
Итак, релиз приложений происходит раз в неделю. Один день закладывается на регрессионное тестирование, второй на smoke. Остальное время на разработку новых фич, исправление дефектов, написание и обновление документации, улучшение процессов.
Регрессионное тестирование — это набор тестов, направленных на обнаружение дефектов в уже протестированных, но затронутых изменениями, участках приложения.
Практически все позитивные сценарии проверки покрыты тест кейсами, которые ведутся в Allure TestOps.
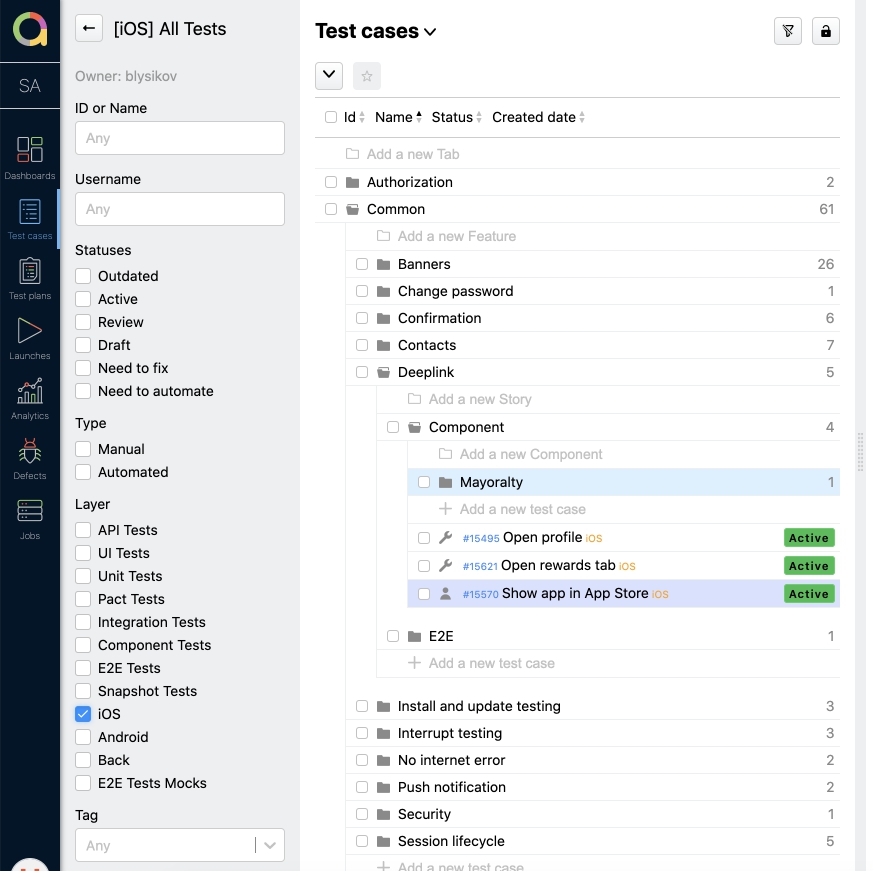
У каждой платформы (я имею ввиду iOS, Android) своя документация и автотесты, но все хранится в одном месте. Любой QA из команды может посмотреть и отредактировать их. Если добавляются новые кейсы, то они обязательно проходят ревью. Тестировщик Android проводит ревью для iOS, и наоборот. Это актуально для ручных тестов.
Про тест план для регресса
Для проведения регрессионного тестирования, составляется тест план с ручными тест кейсами и автотестами, отдельно для Android и iOS. Тестировщик собирает лаунч (запуск тест плана), в котором указывает версию релизной сборки и платформу. После создания лаунча, запускаются автотесты с выбранными кейсами, а ответственный за ручное тестирование назначает мануальные тест кейсы на себя. Каждый проходимый кейс отмечается статусом: Passed, Failed или Skipped. В ходе проверки сразу отображаются результаты.
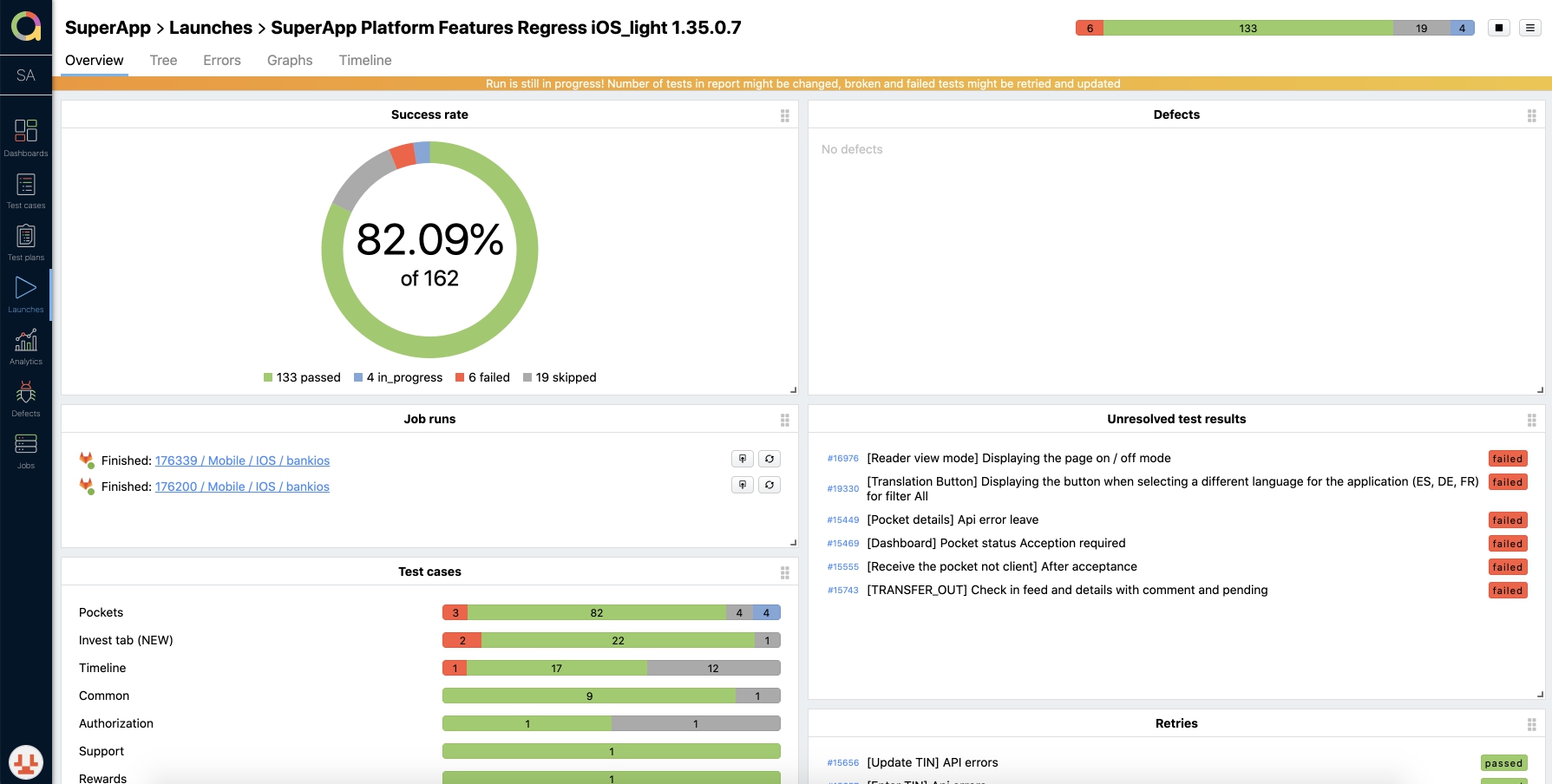
По окончании проверки лаунч закрывается. А на основании результов выносится решение о готовности к релизу. Вроде все классно и логично, но конечно же есть проблемы из-за которых грустят тестировщики

Определим проблему
Увеличение объема тестируемого функционала при проведении регресса, и выход из временных рамок.
Или — тест кейсов все больше и больше, а времени у нас только 8 часов максимум!
Раньше в тест план попадали все кейсы. А с добавлением нового функционала, тест план увеличился до 300 тестов и прохождение его стало занимать больше времени, чем было заложено. Мы перестали укладываться в рабочий день. В связи с этим было решено пересмотреть подход к тестированию, учитывая временные рамки и возможность сохранения качества.
Анализ и решение
Ручное тестирование перегружено из-за того, что с каждой новой фичей добавляются тест кейсы, они могут быть как простые, так и сложные (состоящие из переходов между экранами). Также приходилось проводить тестирование взаимодействия с бэкендом. Мы тратили много времени на такие проверки, особенно когда возникали баги и приходилось разбираться на чьей стороне проблемы.
Расписав слабые места, мы решили доработать подход к автоматизации, а еще воспользовались импакт-анализом для выделения методов решения.
Impact Analysis (импакт анализ) — это исследование, которое позволяет указать затронутые места в проекте при разработке новой или изменении старой функциональности.
Что же мы решили изменить, чтобы разгрузить ручное тестирование и сократить регресс:
-
Увеличение количества автотестов и разработка единого сценария перевода тест кейсов в автоматизацию
-
Разделение тестируемого функционала на фронтенд и бэкенд
-
Изменение подхода к формированию тест плана на регресс и смоук
-
Подключение автоматического анализа изменений, входящих в релизную сборку
Ниже я расскажу про каждый пункт более подробно и какие результаты были получены после введения.
Увеличение количества автотестов
Зачастую, когда в процессе тестирования хотят сократить время на регресс, начинают с автоматизации. Но у нас все этапы проходили параллельно. И естественно, часть проверок перешло в автоматизацию. Подробнее о том, как построен процесс автоматизации у нас в компании, будет расписано в другой статье.
Чтобы процесс был одинаковым для обеих платформ, была написана инструкция. В ней расписаны критерии перевода, шаги и инструменты. Я коротко распишу как происходит перевод тест кейсов в автоматизацию:
-
Определяется какие варианты проверок можно автоматизировать. Это делает ручной тестировщик самостоятельно, или обсудив с командой на митинге.
-
В Allure TestOps дорабатываются тест кейсы, например добавляется больше описания или json.
-
Переводятся соответствующие тест кейсы в статус need to automate (так же в Allure TestOps)
-
Создается задача в Youtrack. В ней описывается, что нужно автоматизировать. Прикладываются ссылки на тест кейсы из Allure TestOps. И назначается ответственный AQA.
-
Затем, задачи из Youtrack берутся в работу исходя из приоритетов. После того как изменения влиты в нужные ветки и прошли ревью, задачи закрываются, а тест кейсы в Allure переводятся в Automated со статусом Active. Ревью кода автотестов проводят разработчики.
Зачастую это происходит за несколько дней до следующего релиза, и ко дню проведения регресса, часть тест кейсов уже может быть автоматизирована.
Результаты:
-
Сокращение нагрузки на ручное тестирование.
-
Четкий и простой механизм перевода в автоматизацию. Все заняты – нет простоев.
-
Больше функционала покрыто автотестами, которые гоняются каждый день. Раньше обнаруживаются баги.
Backend и frontend отдельно
Автоматизация тестирования у нас разделена для backend и frontend.
Но есть E2E тесты, которые тестируют взаимодействие.
E2E (end-to-end) или сквозное тестирование — это когда тестируется вся система от начала до конца. Включает в себя обеспечение того, чтобы все интегрированные части приложения функционировали и работали вместе, как ожидалось.
Многие сквозные автотесты прогонялись со стороны мобильного тестирования, приходилось писать сложные тест кейсы. Зачастую они не проходили из-за проблем со стороны сервисов или на бэкенде.
Поработав в таком формате, мы решили, что много времени уходит на починку автотестов. И тогда E2E тесты приходится проходить вручную.
Было принято четко разделить функционал на модули с выделением логики на фронтенде и бэкенде. Оставить минимальное количество Е2Е тестов для ручного тестирования. Остальные сценарии упростить и автоматизировать. И так на бэкенде мы проверяем бизнес логику, а на клиенте корректное отображение данных от бэке и ui элементы.
Мы перестали запускать тесты на stable окружении и перевели их полностью на моки.
Это позволило нам определить области с наибольшей критичностью, сократить время ручного тестирования, сделать прогон автотестов более стабильным.
Для наглядности вот табличка:
|
Описание функционала |
Локализация тестов |
|
Простая валидация полей (например при смене пароля) |
клиент |
|
Размещение ui элементов на экране |
клиент |
|
Отрисовка ui элементов |
клиент |
|
Отображение информации от бэка |
клиент |
|
Навигация по экранам |
клиент |
|
Корректная обработка и отображение ошибок |
клиент |
|
Сложная валидация (например проверка формата TIN) |
бэк |
|
Сбор данных для профиля |
бэк |
|
Сбор и обработка данных по операциям |
бэк |
|
Создание и сохранение данных при работе с картами |
бэк |
|
Работа сервисов |
бэк |
|
Взаимодействие с БД |
бэк |
|
Обработка ошибок |
бэк |
Результаты
После разделения:
-
Стало проще локализовать проблему
-
Раньше определяются проблемы и соответственно решаются быстрее
-
Есть четкое разграничение зон ответственности. Нет лишних проверок на клиенте.
-
Автотесты стали гораздо стабильнее, т.к. не завязаны на сервисы, которые могут отваливаться в любой момент. (А этот любой момент обычно самый неподходящий)
-
Сократилось время на реализацию автотестов, не нужно добавлять json в тест кейсы дополнительно при написании
Отфильтровали тест кейсы в тест плане на регресс
Тест план на регресс формируется исходя из того, в каких блоках были внесены изменения, а также из основных постоянных сценариев проверки.
Для того, чтобы проще было формировать план, мы стали использовать теги.
Пример: Regress_Deeplink, Regress_Profile, Regress_CommonMobile
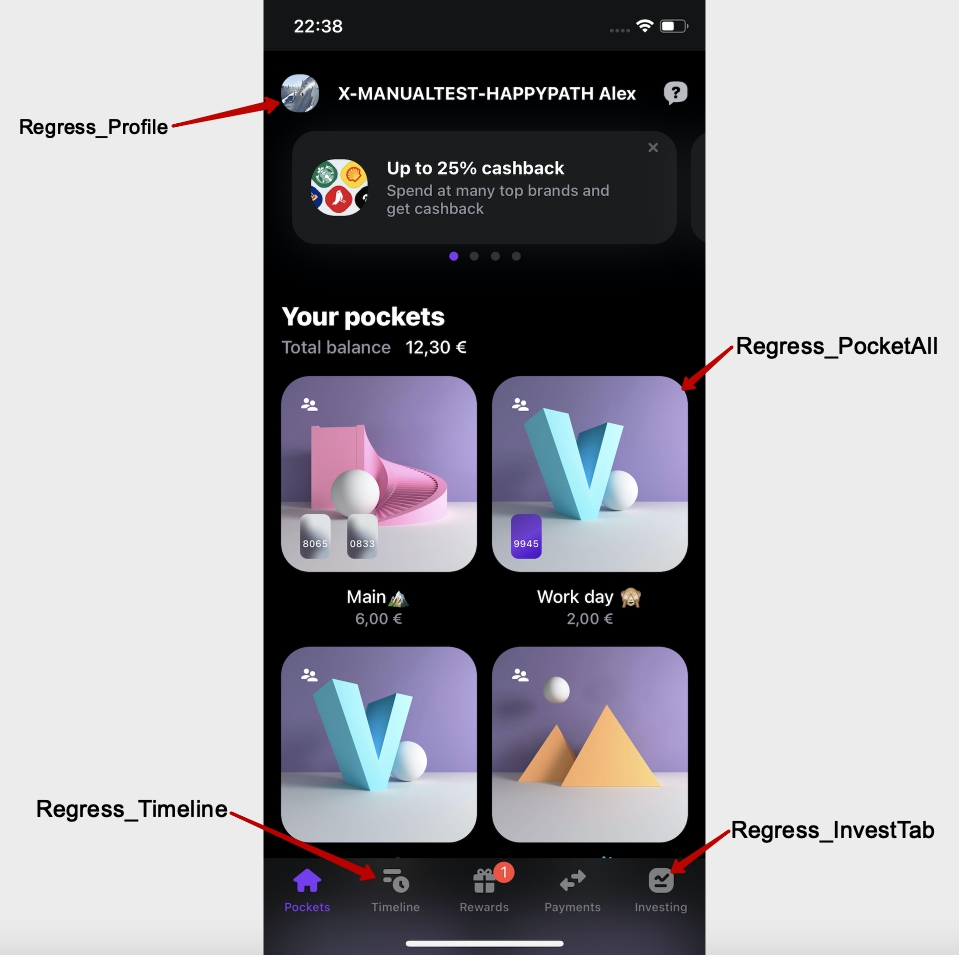
Теперь, все тест кейсы у нас поделены на блоки, которые отмечены определённым тегом! Есть также обязательные кейсы, которые входят в каждый тест план на регресс и отдельные тест кейсы для smoke-тестирования на проде.
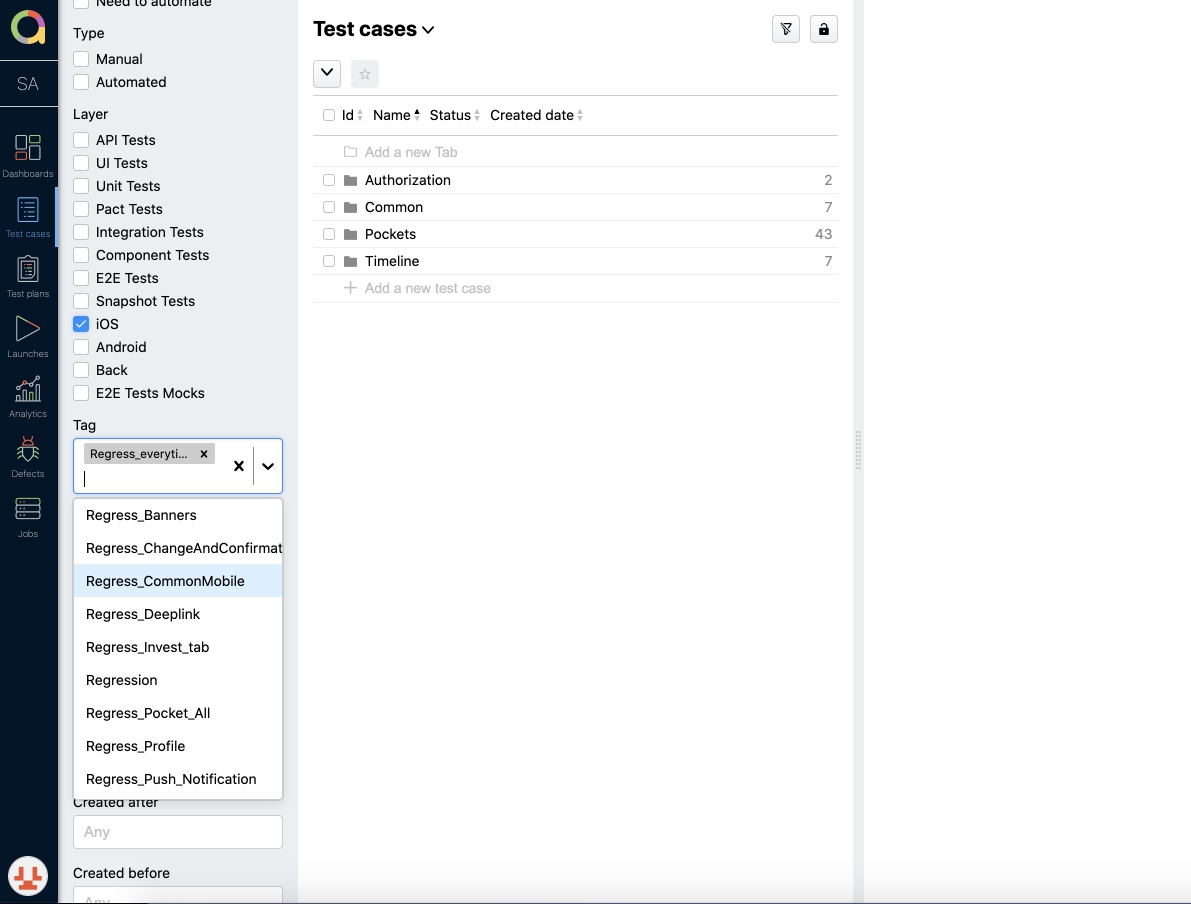
Это позволяет нам оперативно отфильтровать и быстро сформировать определённый план в соответствии с вносимыми изменениями, а не тратить время на проверку того, что не было затронуто.
Результаты
Введение дополнительного анализа, при формировании тест планов, помогло сократить общее время прохождения регрессионного тестирования всего до 2 часов с 8ми изначальных. У нас есть несколько тест планов — full и light. Обычно мы проходим light и он состоит из 98 кейсов (автотестов+ручных). Как видно на скрине, полный план регресса состоит из 297 тест кейсов!
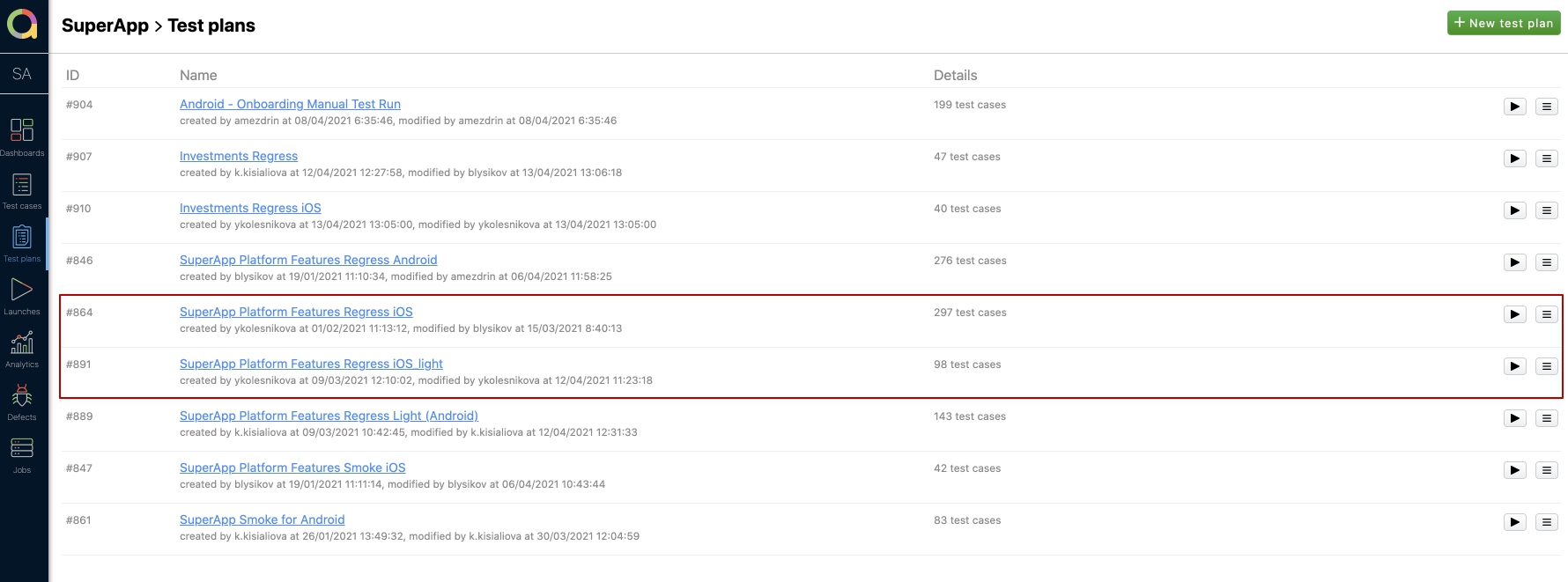
Время на прохождение Regress iOS light в среднем составляет около 2 часов, но когда изменения были только в паре модулей, то можно провести регресс и за час. Это большой плюс, потому что остается запас на багофиксы (если понадобится что-то срочно исправить). Также, в будущем, всегда есть возможность посмотреть по отчетам, в какой сборке что проверялось.
Разработали скрипт с анализом изменений и оповещением через Slack
Качество продукта полностью зависит от всех участников команды. Поэтому, чтобы точно понимать какой модуль был затронут, мы обратились к разработчикам с предложением информировать нас о том, какие изменения были внесены в выпускаемую версию.
Первое время нам приходилось напоминать, уточнять и указывать в задачах затрагиваемые блоки. С одной стороны, мы смогли облегчить регресс, выбирая только необходимые кейсы. Но с другой стороны, тратилось достаточно много времени на коммуникацию, и постоянные уточнения. Пропадала ясность, и не было полной уверенности в том, что проверяется всё необходимое.
Логически возникло следующее решение – сделать этот процесс автоматическим!
Был создан скрипт, который собирает информацию по коммитам. И далее, сформировав отчет о том, какие модули были затронуты, отправляет необходимую информацию в специальный канал Slack.
Скрипт работает просто:
-
После каждой сборки получает изменения между предыдущей версией приложения и коммитам, из которого собрался билд
-
Получает список файлов, которые отражают изменения в каком-то экране
-
Группирует эти изменения по фичам и командам, чтобы упростить жизнь тестировщикам
-
Посылаем сообщение в специальный Slack канал со всей информацией по изменениям
Результаты
Какие плюсы мы получили, подключив аналитику по сборкам:
-
Сократили время разработчиков на ручной анализ внесенных изменений
-
Снизили вероятность упустить из виду и недопроверить необходимый функционал
-
Упростили коммуникацию по данному вопросу
Естественно, было затрачено время на написание скрипта, и интеграцию его работы в Slack. Но, в дальнейшем, всем стало проще отслеживать вышеописанный процесс.
Коротко о главном
-
Использование тегов в тест кейсах и при формировании тест планов сократило объем тест плана, соответственно и время на тестирование.
-
Разработка и использование скрипта для оповещение об изменения дало возможность четко понимать какие модули были затронуты при разработке задач для релиза. Или при исправлении багов. Так же тестировщики перестали отвлекать разработчиков с такими вопросами.
-
Автоматизацией было покрыто около 46% тест кейсов, что сильно облегчило ручное тестирование. К тому же остается время на актуализацию кейсов и написание новых.
-
Разделение тестирования на backend и frontend помогло заранее определять локализацию проблем и своевременное исправление.
При создании качественного программного обеспечения необходимо не только написать строки кода, но и удостовериться, что в них нет ошибок. И если примитивные неисправности обнаруживаются в большинстве языков ещё на стадии компиляции, то более сложные необходимо искать уже при запуске приложений. Такой процесс называется тестированием. Он, в свою очередь, делится на целый ряд ветвлений, которые разнятся своим содержанием и особенностями ошибок. В рамках статьи будет рассмотрено, что такое регрессионное тестирование. Что оно собой представляет? Какие тесты здесь есть? Существует ли возможность автоматизации? Итак, что такое регрессионное тестирование? Поговорим подробнее.
Типы, виды, направления
Регрессионное тестирование (regression testing) – это механизм проверки, который направлен на обнаружение различных проблем в уже проверенных участках программ. Делается это не для окончательного убеждения в отсутствии неработающих участков кода, а чтобы найти и исправить регрессионные ошибки. Под ними понимают баги, которые появляются не во время написания программы, а при добавлении новых участков кода или исправлении допущенных ранее промахов в синтаксисе кода.

Подытожив всё сказанное, можно сделать вывод, что цель регрессионного тестирования – убедиться в том, что исправлении существующих проблем не привело к новым в уже проверенных участках кода программы. Различают два основных типа тестов:
- Функциональные.
- Нефункциональные.
Они могут быть выражены в виде:
- Скриптов.
- Наборов.
- Комплектов для запуска.
Что же, собственно, включает в себя регрессионное тестирование программного обеспечения? Проводится работа в 3 основных направлениях. А именно регрессия:
- Багов.
- Старых проблем.
- Побочных эффектов.
Функциональные тесты
Они основываются на функциях, которые выполняет система. Могут проводиться на компонентном, интеграционном, системном и приемочном уровнях. Два основных аспекта, по которым проводится тестирование:
- Требования.
- Бизнес-процессы.
При работе над требованиями необходимо составить список того, что должно быть протестировано. При этом желательно выделить приоритетные детали, чтобы определиться с направлением работы. Это необходимо, чтобы не оставить без внимания весь наиболее важный функционал. При тестировании «бизнес-процессов» упор делается именно на них, т. е. прогоняются сценарии каждодневной работы.

К преимуществам функциональной проверки следует отнести то, что программное обеспечение имитирует реальное использование системы. Но имеются и свои недостатки: так, программа может быть поддана избыточному тестированию. Также не исключено упущение логических ошибок в самом программном обеспечении.
Нефункциональные тесты
Данные виды тестов направлены на проверку всех свойств, которые не относят к функциям системы. Из них можно привести такие параметры:
- Надежность. Проводится проверка реакции на различные не предусмотренные ситуации.
- Производительность. Как работает система, которая поддаётся разным нагрузкам.
- Удобство. Насколько удобно работать с приложением, по мнению пользователя.
- Масштаб. Требования к изменению высоты и ширины приложения при работе с разными мониторами.
- Безопасность. Насколько защищены пользовательские данные, а также информация при передаче разными каналами.
- Портативность. Проверяется, работает ли приложение на разных платформах, и если да – на скольких.

Какие свойства системы могут быть исследованы в данных случаях? Всего их 4.
- Тестирование установки. Проверяется, насколько успешно удаётся поставить программу на компьютер, настроить её, а при надобности и удалить. Качественная настройка позволяет уменьшить риск потери данных пользователя или уменьшения (ухудшения) работоспособности приложения.
- Тестирования комфортности использования. Проверка разработанного программного обеспечения на удобство использования и понятность конечному пользователю.
- Конфигурационное тестирование. Подразумевает проверку работоспособности программы при установке разных системных настроек, а также экспериментирование с внутренними настройками программы.
- Тестирование на отказ и восстановление. Проверка работоспособности после возникновения ошибок. Оценивается реакция защитных свойств, а также то, какие данные и в каком объеме сохраняются после внезапного прекращения работы приложения.
Подытожив, следует сказать, что, хотя от нефункциональных тестов и не зависит проверка работоспособности приложения в плане выполнения поставленных задач, они позволяют говорить о таких свойствах, как надежность, производительность и безопасность программного обеспечения. Данные параметры характеризируют качество программы и тем или иным образом оставляют определённые впечатления у пользователя. Поэтому важность данного тестирования не меньше, чем у функционального.
Тест-кейсы
Тест-кейсами называют заготовки для проверки программного обеспечения. Они называются инструментами для автоматизированного тестирования. Это специальное программное обеспечение, с помощью которого специалист создаёт, отлаживает, выполняет и анализирует результаты прогона приложения через такие разработки:
- Тест-скрипты. Сюда относят комплекты инструкций, разработанные для проведения автоматических проверок отдельных частей программного обеспечения.
- Тестовые наборы. Это комбинации скриптов, которые проверяют определенные части программного обеспечения, которые объединены общим функционалом или целями.
- Тесты для запуска. Это комбинации различных скриптов или наборов для одновременного запуска при проверке программы.

Автоматизация регрессионных тестов
Автоматизация труда — одна из основ развития человечества в 21-м веке. Коснулась она и данной темы. Так, под автоматизированным тестированием программного обеспечения понимают процесс верификации ПО, во время которого основные функции и задачи, такие как запуск, инициализация и выполнение, а также анализ и выдача результатов, проводятся автоматически, с применением соответствующего инструментария. Это действие выполняется техническим специалистом, отвечающим за создание, отладку и поддержку в рабочем состоянии тест-скриптов, тестовых наборов и инструментария. Работа может проводиться с различным программным обеспечением, в том числе и регрессионное тестирование автоматизированных систем.

Регрессия багов
Под этим тестированием понимают поиск проблем, которые официально «были устранены», но есть основания полагать, что они до сих пор существуют. Особенность данного вида проверок заключается в том, что необходимо проверять все действия с определённым объектом в различных комбинациях. В первую очередь тестируют соответствие реальности сообщения об устранении проблемы по тому механизму, благодаря которому она была выявлена. Регрессионное тестирование верстки в данном случае помогает удостовериться в отсутствии нежелательных эффектов.

Регрессия старых ошибок
Под этим понимают выявление ситуаций, когда недавние изменения, внесенные в код программы, аннулировали исправления старых ошибок. Таким образом, они снова начинают быть активными. Поэтому при внесении изменения в код программного обеспечения необходимо начинать процессы тестирования с начала (при условии, конечно, что возникали проблемы с работоспособностью).
Регрессия побочного эффекта
Под нею понимают ситуации, когда недавнее изменение кода в одной части приложения сделало нерабочим некоторые или все другие части разрабатываемой программы. В качестве указания о наличии таких проблем служит отсутствие работоспособности в одной или нескольких частях программы. Задача тестера определить все проблемные места.

Подытожив всё написанное, что можно сказать про регрессионное тестирование? Что это теперь та тема, которая больше не должна вызывать вопросов. Осталось только освоить всё на практике.
Лекция №10.
Тема: Регрессионное тестирование.
План:
Цели и задачи регрессионного тестирования
Виды регрессионного тестирования
Управляемое регрессионное тестирование
Классификация тестов при отборе
Разновидности метода отбора тестов
Цели и задачи регрессионного тестирования
При корректировках программы необходимо гарантировать сохранение качества. Для этого используется регрессионное тестирование — дорогостоящая, но необходимая деятельность в рамках этапа сопровождения, направленная на перепроверку корректности измененной программы. В соответствии со стандартным определением, регрессионное тестирование — это выборочное тестирование, позволяющее убедиться, что изменения не вызвали нежелательных побочных эффектов, или что измененная система по-прежнему соответствует требованиям.
Главной задачей этапа сопровождения является реализация систематического процесса обработки изменений в коде. После каждой модификации программы необходимо удостовериться, что на функциональность программы не оказал влияния модифицированный код. Если такое влияние обнаружено, говорят о регрессионном дефекте. Для регрессионного тестирования функциональных возможностей, изменение которых не планировалось, используются ранее разработанные тесты. Одна из целей регрессионного тестирования состоит в том, чтобы, в соответствии с используемым критерием покрытия кода (например, критерием покрытия потока операторов или потока данных), гарантировать тот же уровень покрытия, что и при полном повторном тестировании программы. Для этого необходимо запускать тесты, относящиеся к измененным областям кода или функциональным возможностям.
Пусть T = {t1, t2, …, tN} — множество из N тестов, используемое при первичной разработке программы P, а  —подмножество регрессионных тестов для тестирования новой версии программы P’. Информация о покрытии кода, обеспечиваемом T’, позволяет указать блоки P’, требующие дополнительного тестирования, для чего может потребоваться повторный запуск некоторых тестов из множества
—подмножество регрессионных тестов для тестирования новой версии программы P’. Информация о покрытии кода, обеспечиваемом T’, позволяет указать блоки P’, требующие дополнительного тестирования, для чего может потребоваться повторный запуск некоторых тестов из множества  , или даже создание T» — набора новых тестов для P’ — и обновление T.
, или даже создание T» — набора новых тестов для P’ — и обновление T.
Другая цель регрессионного тестирования состоит в том, чтобы удостовериться, что программа функционирует в соответствии со своей спецификацией, и что изменения не привели к внесению новых ошибок в ранее протестированный код. Эта цель всегда может быть достигнута повторным выполнением всех тестов регрессионного набора, но более перспективно отсеивать тесты, на которыхвыходные данные модифицированной и старой программы не могут различаться. Результаты сравнения выборочных методов и метода повторного прогона всех тестов приведены в таблица 11.1.
| Таблица 11.1. Выборочное регрессионное тестирование и повторный прогон всех тестов. | |
| Повторный прогон всех тестов | Выборочное регрессионное тестирование |
| Прост в реализации | Требует дополнительных расходов при внедрении |
| Дорогостоящий и неэффективный | Способно уменьшать расходы за счет исключения лишних тестов |
| Обнаруживает все ошибки, которые были бы найдены при исходном тестировании | Может приводить к пропуску ошибок |
Задача отбора тестов из набора T для заданной программы P и измененной версии этой программы P’ состоит в выборе подмножества  для повторного запуска на измененной программе P’, где
для повторного запуска на измененной программе P’, где 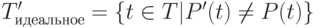 . Так как выходные данные P и P’ для тестов из множества
. Так как выходные данные P и P’ для тестов из множества  заведомо одинаковы, нет необходимости выполнять ни один из этих тестов на P’. В общем случае, в отсутствие динамической информации о выполнении P и P’ не существует методики вычисления множества T’идеальное для произвольных множеств P, P’ и T. Это следует из отсутствия общего решения проблемы останова, состоящей в невозможности создания в общем случае алгоритма, дающего ответ на вопрос, завершается ли когда-либо произвольная программа P для заданных значений входных данных. На практике создание T’идеальное возможно только путем выполнения на инструментированной версии P’ каждого регрессионного теста, чего и хочется избежать.
заведомо одинаковы, нет необходимости выполнять ни один из этих тестов на P’. В общем случае, в отсутствие динамической информации о выполнении P и P’ не существует методики вычисления множества T’идеальное для произвольных множеств P, P’ и T. Это следует из отсутствия общего решения проблемы останова, состоящей в невозможности создания в общем случае алгоритма, дающего ответ на вопрос, завершается ли когда-либо произвольная программа P для заданных значений входных данных. На практике создание T’идеальное возможно только путем выполнения на инструментированной версии P’ каждого регрессионного теста, чего и хочется избежать.
Реалистичный вариант решения задачи выборочного регрессионного тестирования состоит в получении полезной информации по результатам выполнения P и объединения этой информации с данными статического анализа для получения множестваT’реальное в виде аппроксимации T’идеальное. Этот подход применяется во всех известных выборочных методах регрессионного тестирования, основанных на анализе кода. Множество T’реальное должно включать все тесты из T, активирующие измененный код, и не включать никаких других тестов, то есть тест  входит в T’реальное тогда и только тогда, когда t задействует код P в точке, где в P’ код был удален или изменен, или где был добавлен новый код.
входит в T’реальное тогда и только тогда, когда t задействует код P в точке, где в P’ код был удален или изменен, или где был добавлен новый код.
Если некоторый тест t задействует в P тот же код, что и в P’, выходные данные P и P’ для t различаться не будут. Из этого следует, что если  , t должен задействовать некоторый код, измененный в P’ по отношению к P, то есть должно выполняться отношение
, t должен задействовать некоторый код, измененный в P’ по отношению к P, то есть должно выполняться отношение  . С другой стороны, поскольку не каждое выполнение измененного кода отражается на выходных значениях теста, могут существовать некоторые такие , что P(t) = P'(t). Таким образом, T’реальное содержит T’идеальное целиком и может использоваться в качестве его альтернативы без ущерба для качества тестируемого программного продукта.
. С другой стороны, поскольку не каждое выполнение измененного кода отражается на выходных значениях теста, могут существовать некоторые такие , что P(t) = P'(t). Таким образом, T’реальное содержит T’идеальное целиком и может использоваться в качестве его альтернативы без ущерба для качества тестируемого программного продукта.
Важной задачей регрессионного тестирования является также уменьшение стоимости и сокращение времени выполнения тестов.
Рассмотрим отбор тестов на примере рис. 11.1. Код, покрываемый тестами, выделен цветом и штриховкой. Легко заметить, что код, покрываемый тестом 1, не изменился с предыдущей версии, следовательно, повторное выполнение теста 1 не требуется. Напротив, код, покрываемый тестами 2, 3 и 4, изменился; следовательно, требуется их повторный запуск.

Рис. 11.1.Отбор тестов для множества T’.
…
Читайте также:
©2015-2022 poisk-ru.ru
Все права принадлежать их авторам. Данный сайт не претендует на авторства, а предоставляет бесплатное использование.
Дата создания страницы: 2016-04-11
Нарушение авторских прав и Нарушение персональных данных
Поиск по сайту:

Мы поможем в написании ваших работ!
Регрессионное тестирование — это дополнительный способ проверить программу, которая раньше уже прошла удачное тестирование. Регрессионное тестирование проводят в том случае, когда в уже протестированной программе были выполнены какие-либо изменения или исправления ошибок. Его цель — выявить и удостовериться, что внесенные в программу изменения никак не коснулись тех частей программ, которые остались без изменений.
Регрессионное тестирование
Бывают такие случаи, что после тестирования в программе обнаруживаются ошибки. Программу отправляют на доработку, чтобы ошибки исправили. Ошибки были исправлены путем внесения изменений в код программы. Однако эти изменения кода в какой-либо части программы могут косвенно задеть другую часть программы, которая до этого работала безупречно. То есть изменения в коде для устранения одних ошибок могут провоцировать возникновение ошибок в других частях кода. Регрессионное тестирование проводится как раз для выявления и устранения потенциальных ошибок, которых ранее в программе не было.
Такие ошибки могут получаться непреднамеренно. Разработчику дали установки, что исправить — он исправил. А то, что эти исправления могут спровоцировать ошибку в другом месте, может быть совсем не видно. Из этого следует, что регрессионное тестирование — это один из ключевых инструментов для обеспечения качества программы в случае внесения каких-либо исправлений в ее скрипты после уже проведенного удачного тестирования.
Когда проводят регрессионное тестирование
Итак, мы уже выяснили, что регрессионное тестирование запускают в том случае, когда были внесены какие-либо изменения в программный продукт. Это могут быть:
- исправления багов;
- умышленное изменение кода: добавление, изменение, удаление функций;
- внесение изменений в конфигурацию рабочего окружения: обновили PHP, Java, Linux, Windows, MySQL и т. д.;
- переезд на другие серверы;
- и др.
При этом изменения изменениям рознь. Не нужно запускать регрессионное тестирование, когда вносятся небольшие изменения в проект. Например, когда на сайте поменяли логотип или изменили формат даты. То есть из-за мелких изменений в проекте не стоит перепроверять весь сайт на наличие возможных багов. Если из-за изменения логотипа на сайте «ломается» весь ресурс, то тут вам тестирование не поможет. Тут нужно найти того «программиста», кто вам сделал сайт, и спросить у него, почему так происходит.
Преимущества и недостатки регрессионного тестирования
В качестве преимуществ можно отметить:
- улучшение конечного качества программного продукта;
- наличие регрессионных ошибок демонстрирует истинное качество программирования и архитектуры проекта: чем больше ошибок, тем хуже качество кода.
В качестве недостатков можно отметить:
- дорогие ошибки, потому что времени на поиск ошибок уделяется много, а их количество небольшое;
- рутинность, потому что приходится проходить одни и те же тесты много раз подряд.
Заключение
Регрессионное тестирование — это дополнительный гарант качества вашего программного продукта. Основная масса подобных тестов проходит «вручную», потому что, как ни странно, очень часто автоматизация регрессионного тестирования приводит к дополнительным финансовым затратам. В итоге получается, что проводить такие тесты дешевле руками молодых тестировщиков, чем автоматизированными решениями профессионалов тестирования.
В данной статье мы расскажем о виде тестирования, который обычно воспринимается как должное и редко вызывает вопросы. Однако, на наш взгляд, руководители ИТ-проектов должны знать, как и для чего проводится регрессионное тестирование. Понимание процесса даст возможность разработать грамотную стратегию, снизить расходы на тестирование и получить продукт высокого качества.
Начнём. Изменения в коде неизбежно сопровождают процесс разработки программного обеспечения. Добавляется новая функциональность, вносятся изменения в существующую, устраняются дефекты. При этом любые изменения могут затронуть уже существующую функциональность, которая исправно работала. Проверить, чтобы изменения не «поломали» рабочее ПО, – задача регрессионного тестирования.
Цель регрессионного тестирования – удостовериться в том, что существующая функциональность не была затронута изменениями в коде.
Приведём пример. Представьте, что ваша команда разработала простое приложение-фонарик. В приложении есть всего две функции: включение и выключение фонарика. Вы проводите тестирование функциональности, чтобы убедиться в правильной работе этих функций и приложения в целом. Результат тестирования положительный – вам не о чем беспокоиться.
Спустя какое-то время вы решаете усовершенствовать приложение, добавив в него функцию включения от того, что пользователь встряхивает телефон. Новая функциональность добавлена, проводится очередной раунд тестирования. Однако на этот раз вам необходимо проверить работоспособность не только новой функциональности, но и включения/выключения. А вдруг изменения затронули и её каким-то образом?
Этот пример демонстрирует место регрессионного тестирования в процессе разработки ПО.
Регрессионное тестирование и методологии управления проектами
Рассмотрим, как на проведение регрессионного тестирования влияет методология проекта. Возьмём для примера три самых популярных: гибкую, каскадную и гибридную.
Гибкая методология (Agile)
Разработка по Agile ведётся короткими итерациями (спринтами), продолжительностью 4–6 недель каждая. В конце каждой итерации заказчик получает готовый продукт, который может выполнять определённые функции. В идеале регрессионное тестирование проводится в конце каждого спринта, но на деле так происходит редко.
В чём трудность? Жёсткие дедлайны и задержки при разработке оставляют меньше времени на тестирование, чем требуется.
Решение. В конце каждого спринта проводится регрессионное тестирование с частичным покрытием, проверяются области, которые с большей долей вероятности могли быть затронуты разработкой. Перед крупными релизами проводится регрессионное тестирование всего продукта.
Каскадная методология (Waterfall)
Каскадная методология предполагает переход к следующему этапу только после полного завершения предыдущего. Таким образом, тестирование начинается после окончания разработки.
В чём трудность? Вносить изменения в готовый продукт – трудоёмкий и дорогостоящий процесс. Неудивительно, что каскадная модель применяется на небольших проектах с чёткими требованиями, которые не меняются в процессе разработки.
Решение. До того как начать процесс разработки, рекомендуется провести тестирование требований и убедиться, что они обладают всеми характеристиками качественных требований: единичностью, актуальностью, выполнимостью и т. д.
Рекомендуем доверять тестирование требований независимым специалистам, которые их объективно оценят и дадут рекомендации по оптимизации. Ведь устранение ошибок в требованиях – это исправление в тексте. Исправление ошибок в готовом продукте – это часы работы разработчиков и тестировщиков.
Гибридная методология
Все преимущества гибкой и каскадной методологий объединила в себе гибридная методология управления проектами. Этапы планирования и определения требований проходят согласно каскадной методологии, а этапы проектирования, разработки, внедрения и оценки – согласно гибкому подходу.
Соответственно, на разных стадиях проекта будет выполняться полное или частичное регрессионное тестирование.
7 стадий регрессионного тестирования
Независимо от того, какой методологии придерживаетесь вы, изменения ПО требуют выполнения регрессионного тестирования, состоящего из следующих стадий:
- Анализ внесённых изменений, требований и поиск областей, которые могли быть затронуты.
- Составление набора релевантных тест-кейсов для тестирования.
- Проведение первого раунда регрессионного тестирования.
- Составление отчета о дефектах.
Каждый дефект вносится в баг-трекинговую систему, описываются шаги для его воспроизведения. Если возможно, описание сопровождается видео, скриншотами.
- Устранение дефектов.
- Верификация дефектов.
На этой стадии QA-инженеры проверяют, действительно ли дефект исправлен. Если проблема остается, создаётся новый отчет. В некоторых случаях устранение дефекта подлежит обсуждению. Все критические и значительные дефекты должны быть устранены обязательно, а вот минорные, устранение которых требует больших затрат, могут быть оставлены. Особенно в тех случаях, если пользователю они не видны.
- Проведение второго круга регрессионного тестирования.
Исходя из опыта команды «Технологий качества», в среднем требуется не менее трёх раундов регрессионного тестирования для устранения всех дефектов и стабилизации приложения.
Регрессионное тестирование: ручное или автоматизированное?
На любом проекте регрессионные тесты – первые кандидаты на автоматизацию. Они запускаются регулярно, в большом количестве. Автоматизация позволяет не только сократить сроки тестирования, но и высвобождает ресурсы для более высокоуровневых задач, исследования приложения.
Однако несмотря на востребованность автоматизации, ручное регрессионное тестирование также имеет место быть.
Ручное тестирование
Внедрять автоматизацию на небольших проектах, которые длятся всего несколько месяцев, не всегда целесообразно: затраты могут не окупиться, а разработка автотестов лишь затянет сроки реализации проекта. В таком случае тестирование проводится вручную без каких-либо особых инструментов, за исключением баг-трекинговой системы, например, JIRA.
Однако если проект разрастается, функциональность ПО увеличивается с каждым последующим релизом, это влечёт за собой увеличение объемов тестирования. В таком случае стоит задуматься о привлечении специалистов по автоматизации.
Автоматизация тестирования
Решение об автоматизации принимает заказчик, а исполнение ложится на плечи профессиональных инженеров по автоматизации, которые обладают необходимым опытом, знают языки программирования.
Выгоду автоматизации тестирования нельзя недооценивать:
- Улучшается качество продукта.
- Ускоряется выпуск ПО на рынок.
- Оптимизируется стоимость тестирования.
Здесь история о том, как команда «Технологий качества» смогла на 40% уменьшить трудозатраты на регрессионное тестирование, внедрив автоматизацию.
Кстати, есть и такие проекты, на которых разумно совместить ручные проверки с автоматизированными. Все зависит от специфики программного продукта.
Подведём итог
Согласно отчёту World Quality Report 2017, в среднем 26% всего ИТ-бюджета компаний идет на тестирование. Опыт компании «Технологии качества» говорит о том, что 40–70% этих затрат приходится на регрессионное тестирование.
Если вы переведёте проценты в реальные деньги, то поймете, почему регрессионное тестирование заслуживает вашего внимания и требует тщательно продуманной стратегии. Выбор правильного подхода поможет эффективно обнаружить все проблемные места, устранить их, обеспечить высокое качество программного решения.
Как подобрать стратегию тестирования, оптимальную для вашего ПО? Спросите у нас! Получить бесплатную консультацию QA-специалиста.
2. Первичное и регрессионное тестирование.
Предположим, мы только что протестировали новую программу (пусть это будет просмотрщик графических файлов), все найденные баги были устранены и программа выпущена в продажу — состоялся релиз. Такое тестирование называется первичным и включает в себя тест-дизайн и прохождение тестов. При первичном тестировании имеет смысл, чтобы один человек занимался и тест-дизайном, и прохождением тестов, потому что при прохождении может потребоваться уточнение и изменение тестовых сценариев.
Однако разработчики не дремлют — они решили расширить функциональность программы (например, поддержку нового графического формата). Наряду с первичным тестированием новой функциональности нам нужно удостовериться, что уже существующая функциональность не была сломана — провести ее повторное, так называемое регрессионное тестирование. Регрессионное тестирование не включает в себя тест-дизайн, а значит, может выполняться менее опытными сотрудниками.
Таким образом, в большинстве проектов одна и та же функциональность регрессионно тестируется несколько раз — от релиза к релизу. Поэтому тесты необходимо документировать:
1. чтобы не вспоминать каждый раз, как тестировать ту или иную вещь,
2. чтобы регрессионное тестирование могли выполнять другие люди
3. чтобы после первичного тестирования можно было дать руководству отчет о том, что конкретно было протестировано.
3.Тестовая документация.
Тестовая документация состоит обычно из отдельных сценариев, которые называются тест-кейсами и могут быть для удобства объединены в группы или тест-сьюты.
Написание тестовой документации имеет много общего с написанием ПО: следует разбивать код на отдельные модули и избегать дублирования кода.
3.1. Что должна содержать тестовая документация и почему.
В общем случае, тестовая документация может содержать: заголовок, пошаговое описание, ожидаемый результат, критерий соответствия ожидаемого результата фактическому.
Тест-кейс должен обязательно содержать хотя бы ожидаемый результат (даже, может быть, без описания действий, которые к нему ведут). Например, «Программа должна уметь показывать файлы формата BMP». Такой тесткейс представляет собой просто перепечатку из документа с требованиями.
Однако, из такого тесткейса непонятно, как осуществить проверку. Человек, незнакомый с программой, может попросту не найти в ее интерфейсе, как показывать графические файлы, и напишет баг об отсутствии такой возможности.
Поэтому, кроме ожидаемого результата, необходимо еще пошаговое описание действий, которые позволят нам прийти к результату фактическому и сравнить его с ожидаемым.
Краткое описание тест-кейса имеет смысл вынести в заголовок.
Пример.
Заголовок: «Проверка того, что программа умеет показывать файлы формата BMP»
Шаг 1. Нажать кнопку «Выбрать файл»
Шаг 2. Выбрать файл с расширением BMP
Шаг 3. Нажать кнопку «Открыть»
Ожидаемый результат: содержимое файла показано в графическом виде, в полноэкранном режиме.
Здесь сравнение ожидаемого результата и фактического осуществить довольно просто, и критерий соответствия не нужен. Приведем более сложный пример:
Заголовок: «Проверка изменения домашнего телефона пользователя в ActiveDirectory»
Шаг 1. Нажать кнопку «Создать пользователя»
Шаг 2. Ввести имя пользователя, логин и пароль.
Шаг 3. Нажать кнопку OK
Шаг 4. Выбрать только что созданного пользователя в списке, кликнув на его логин.
Шаг 5. Нажать кнопку «Редактировать»
шаг 6. Ввести номер телефона в поле «Домашний телефон»
шаг 7. Нажать кнопку ОК
Ожидаемый результат: домашний телефон сохранился в ActiveDirectory.
Здесь ожидаемый результат было бы неплохо также расписать в виде последовательности шагов: как посмотреть в ActiveDirectory, что домашний телефон сохранился. Это и будет описанием критерия соответствия. Можно записать эти шаги здесь же, начиная с номера 8, и уточнить ожидаемый результат:
Шаг 8. Залогиниться на сервер AciveDirectory
Шаг 9. Открыть оснастку dsa.msc
Шаг 10. Найти пользователя по логину
Шаг 11. Посмотреть значение поля Home phone
Ожидаемый результат: это значение соответствует номеру телефона в поле «Домашний телефон»
Однако, строго говоря, эти шаги не являются частью тестируемого сценария. При изменении или удалении сценария эта инструкция может быть потеряна. Поэтому имеет смысл записать ее на специальном сайте — базе знаний (Knowledge Base, KB), а в тесткейсе дать ссылку на эту инструкцию.
Кроме того, если эта инструкция будет использована в других тесткейсах, нам не нужно будет ее каждый раз копировать, достаточно будет давать ссылку.
Таким образом, возвращаемся к предыдущему варианту и вставляем ссылку в поле «Ожидаемый результат»:
Ожидаемый результат: домашний телефон сохранился в ActiveDirectory (смотри ссылку)
3.2. Тестовые объекты и тестовые данные
Вышеприведенный тесткейс должен проверять редактирование телефона пользователя. Однако же первые три шага не относятся к редактированию телефона. Это вспомогательные шаги по созданию пользователя — мы создаем тестовый объект, объект, который мы будем использовать в тестах. Целесообразно вынести эти шаги в отдельную секцию «Setup», и описать более кратко:
Setup:
Создать пользователя.
Шаг 1. Открыть список пользователей.
Шаг 2. Выбрать пользователя в списке, кликнув на его логин.
Шаг 3. Нажать кнопку «Редактировать»
шаг 4. Ввести номер телефона в поле «Домашний телефон»
шаг 5. Нажать кнопку ОК
Ожидаемый результат: домашний телефон сохранился в ActiveDirectory.
Секцию Setup, как и Ожидаемый результат, тоже можно сделать гиперссылкой на соответствующую инструкцию. Таким образом, мы избавимся от дублирования информации в разных тестах и улучшим читабельность тестов и их поддержку, если в системе что-то поменяется. Вообще, процесс написания и поддержки тестовой документации имеет много общего с написанием и поддержкой программного обеспечения. Здесь так же важно избавляться от дублирования кода и выделять его в отдельные процедуры.
Часто один и тот же тесткейс следует выполнять с разными тестовыми данными. Например, если программа должна уметь показывать файлы в формате BMP, JPG и GIF, логично написать один тесткейс и указать в специальной секции, что выполняться он должен с использованием трех файлов разного формата. По аналогии с программированием — мы выносим название формата в параметр процедуры. Такой тесткейс называется data-driven — управляемый данными.
Тестовую документацию следует писать так, чтобы ее было легко поддерживать при изменениях в продукте!
Можно сказать, что хорошим стилем в написании тестовой документации является высокоуровневое описание действий, имеющее ссылки на пошаговое описание. Такая документация пригодна для использования как опытными (знакомыми с продуктом) тестировщиками, так и неопытными или аутсорсерами. Опытным тестировщикам не надо тратить время на чтение пошаговых инструкций (как правило, они их и так знают), а неопытные всегда смогут их прочитать.
Если же стоит задача написать тестовую документацию в кратчайшие сроки, приходится выбирать между пошаговым и высокоуровневым стилем (без ссылок). Как правило, следует выбирать высокоуровневый стиль, потому что, во-первых, так быстрее писать, а во-вторых, снабдить такой документ ссылками на пошаговое описание в дальнейшем будет проще, чем зарефакторить пошаговые инструкции.
3.3. Идентификатор тесткейса, приоритет, время прохождения
Тесткейсы полезно снабжать уникальными идентификаторами, чтобы можно было легко на них ссылаться.
Приоритет тесткейса — это его важность. Логично, что наиболее важные, критичные тесткейсы следует проходить в первую очередь, менее важные — во вторую и т.д., чтобы при нехватке времени пропускались менее необходимые вещи. Приоритет имеет смысл обозначать числом. Существует несколько методик расстановки приоритетов.
Целесообразно также указывать планируемое время прохождения тесткейса (при его создании) — для оценки трудозатрат на тестирование. Это время может быть скорректировано с учетом реальной истории прохождения. Например, если первоначально планируемое время составляло 10 минут, а реально кейс был пройден за 30 минут, это повод узнать у тестировщика, в чем была загвоздка и по результатам либо попросить его работать в 3 раза быстрее, либо скорректировать оценку.
3.4. История изменений и история прохождений
Опять же по аналогии с ПО, имеет смысл документировать все изменения в тестовой документации, чтобы можно было понять, почему, кто и когда их сделал. В простейшем случае тестовая документация может храниться в системе контроля версий, например CVS или SVN, в виде отдельного документа на каждый тесткейс или на группу кейсов, связанную по смыслу.
Однако этот способ не так удобен, как применение специализированных систем поддержки тестовой документации, например TestRail или Testlink. Такие системы имеют ряд дополнительных функций, связанных с прохождением тесткейсов:
1. возможность назначать тесткейсы сотрудникам для прохождения
2. возможность собирать статистику прохождений (фамилия сотрудника, потраченное время и найденные баги)
Я давно хотел написать о регрессионном тестировании. А тут и случай представился – 20 июня мы проведём сессию Weekend testing по этой теме.
Что это такое? Суть регрессионного тестирования в том, чтобы найти проблемы, возникшие в результате изменений продукта. Для тех, кто заинтересован в более формальном определении, могу посоветовать Wikipedia, MSDN, ISTQB.
Предположим, есть продукт, состоящий из множества частей:

При изменении одной из его частей могут возникнуть проблемы в других частях:

Либо добавление нового функционала приведет к ошибкам в старом:

Зачем нам проводить данный вид тестирования? Одна из очевидных причин – минимизировать регрессионные риски. То есть, риски того, что при очередном изменении продукт перестанет выполнять свои функции. Кстати, я не нашел термина “регрессионный риск”ни в англоязычной, ни в русскоязычной литературе. А мне он кажется удобным и “говорящим“, как говорящие фамилии у писателей.
С регрессионным тестированием плотно связана другая активность – импакт анализ (или иначе, анализ влияния изменений). Обычно под импакт анализом имеют в виду одно из следующих:
1) Попытку оценить регрессионные риски ещё на этапе планирования изменений (этим определением, по моему опыту, чаще пользуются менеджеры и разработчики);
2) Попытку определить объем регрессионного тестирования с учетом изменений, которые уже произошли (это определение чаще используют сами тестировщики).
В этом сообщении, говоря об импакт анализе, я буду иметь в виду второе определение. Кстати, у Пола Джеррарда есть серия статей, где более детально раскрывается понятие импакт анализа, причем не только с позиции тестировщика (см. список материалов внизу).
Очевидно, что от эффективности импакт анализа зависит эффективность регрессионного тестирования. Но не всегда тщательно проведенный импакт анализ позволяет сократить затраты на последующее тестирование. Проще вообще не проводить импакт анализ и выполнять одни и те же регрессионные тесты из релиза в релиз 🙂 Но это довольно смелое решение.
В табличке внизу я показал 3 разных случая – соотношение затрат на импакт анализа, на регрессионное тестирование и связанные с ними регрессионные риски:
 Обычно мы выбираем второй вариант, средний между двумя крайностями: регрессионным тестированием без импакт анализа (тем самым мы подвергаемся большим регрессионным рискам) и регрессионным тестированием со сверх тщательным импакт анализом (который отнимает много времени, но теоретически позволяет минимизировать регрессионные риски). Тем более импакт анализ, способный предвидеть все регрессионные баги, вряд ли вообще возможен, учитывая сложность современных продуктов.
Обычно мы выбираем второй вариант, средний между двумя крайностями: регрессионным тестированием без импакт анализа (тем самым мы подвергаемся большим регрессионным рискам) и регрессионным тестированием со сверх тщательным импакт анализом (который отнимает много времени, но теоретически позволяет минимизировать регрессионные риски). Тем более импакт анализ, способный предвидеть все регрессионные баги, вряд ли вообще возможен, учитывая сложность современных продуктов.
В данном сообщении я хотел бы помочь коллегам, столкнувшимся с задачей выбора стратегии регрессионного тестирования.
Во многом это напоминает другую задачу – составление тестовой стратегии в целом. Или просто я склонен находить параллели между этими задачами, потому что много писал про тестовую стратегию зимой (пост 1, пост 2, пост 3) и мой доклад на SQA days тоже был связан со стратегией тестирования 🙂
Процесс организации регрессионного тестирования выглядит для меня примерно так:
1. Сбор информации. Мы изучаем продукт и его окружение. Собираем информацию о релизах, о типичных изменениях в продукте, о критериях качества, о пропущенных в прошлом регрессионных багах.
2. Формирование стратегии. Мы принимаем решения по стратегии регрессионного тестирования, которая является общей для всех релизов.
3. Сбор информации о конкретном релизе. Мы опускаемся на более низкий уровень, на уровень релизов, и изучаем изменения в конкретном релизе.
4. Составление тест плана по регрессии. Мы принимаем решения по тестированию конкретного релиза. Этот шаг включает в себя и импакт анализ изменений.
5. Выполнение регрессии. Во время выполнения регрессионных тестов мы следим за процессом и анализируем найденные проблемы (или отсутствие проблем). Полученная информация используется для корректировки плана регрессии.
6. Работа над ошибками. После проведения тестирования мы анализируем регрессионные проблемы, которые прошли мимо нас, делаем выводы. Если у нас есть регрессионная библиотека тестов, то обновляем её с учетом последних изменений продукта.
Давайте рассмотрим эти шаги подробнее.
1 шаг: Сбор информации
Активности, которые мы проводим (или можем проводить) на данном этапе:
- Сессии исследовательского тестирования. Цель: изучить продукт.
- Составление структуры приложения. Мы можем проводить декомпозицию по фичам, структурную декомпозицию по модулям, из которых состоит продукт, а также другие типы разбиения продукта. Цель: изучить продукт и подготовить основу для импакт анализа и оценки покрытия.
- Построение модели приложения. Практически любой, даже очень сложный продукт, можно представить в виде рисунка, наглядно показывающего взаимодействие отдельных модулей. Цель: подготовить основу для импакт анализа.
- Составление списка критериев качества, важных для продукта.
- Изучение статистики регрессионных ошибок.
- Изучение типичных изменений продукта в среднестатистическом релизе.
- Изучение графика будущих релизов.
Отталкиваясь от информации, собранной на этом шаге, мы принимаем решения по стратегии регрессии.
2 шаг: Формирование стратегии
Решения, которые мы можем принимать:
- Будем ли мы составлять набор регрессионных тестов, специфичный для конкретного релиза, или у нас будет универсальный набор тестов.
- Кто будет проводить импакт анализ и на каких уровнях. Подробнее об уровнях импакт анализа – в статьях Пола Джеррарда (см. материалы внизу).
- Насколько полным и тщательным будет импакт анализ.
- Нужна ли нам библиотека регрессионных тестов.
- Если да, то как и когда мы будем обновлять эту библиотеку.
- Как мы будем измерять эффективность регрессионного тестирования.
- В частности, какие виды тестового покрытия будут для нас важны. А различных видов покрытия очень много 🙂
- Когда мы будем начинать регрессионное тестирование.
Когда эти высокоуровневые решения приняты, мы можем использовать эту стратегию для всех релизов. Для каждого релиза мы будем уточнять ее и дополнять необходимыми деталями, получая план регрессионного тестирования. Итак, мы опускаемся с высокого уровня (общего для всех релизов) на уровень конкретного релиза.
3 шаг: Сбор информации о конкретном релизе
Какая информация нам будет нужна:
- Список изменений, как минимум.
- Дата релиза.
- Доступность тестовых стендов / окружений в ходе тестирования.
- И другие вещи, важные при составлении тест плана для конкретного релиза.
Собранная информация будет использована дальше, когда мы будем составлять детальный план регрессионного тестирования.
4 шаг: Составление тест плана по регрессии
Какие решения мы принимаем на этом шаге:
- Как и когда проводить импакт анализ, кто будет это делать.
- Для каких изменений мы будем проводить импакт анализ.
- Каким будет список тестов для регрессионного тестирования. Формируется в результате импакт анализа.
- Какими будут приоритеты тестов.
- В каком формате мы будем хранить тесты (чеклисты, тест кейсы, тест идеи, другие).
- Каким будет график регрессионного тестирования.
- Как мы будем оценивать тестовое покрытие.
- Какой уровень тестового покрытия будет для нас достаточным.
- И другие.
Решений на этом этапе много. Мы часто действуем на опыте и используем решения, которые уже принимали в прошлом для похожих релизов.
На следующем шаге мы должны быть достаточно гибкими и уметь подстраиваться под ситуацию. Мы должны быть готовы к корректировке плана регрессии.
5 шаг: Выполнение регрессии
Что мы делаем во время выполнения регрессионных тестов:
- Анализируем найденные ошибки.
- Логичным будет уделить больше внимание тестированию той части системы, где возникает ошибка, и тех частей, что с ней связаны.
- Анализируем другие сигналы. Например, отсутствие найденных ошибок может быть полезной информацией для размышления.
- Оцениваем тестовое покрытие.
- Предоставляем отчетность по статусу регрессионного тестирования.
- Оцениваем реальность графика регрессионного тестирования.
- Меняем приоритеты тестов. Я явно указал эту активность как пример изменения плана, составленного раньше.
- Участвуем в триаже багов. Найденные проблемы нужно либо исправить в текущем релизе, либо перенести в будущий релиз. Обычно в триаже багов тестировщики принимают участие наряду с другими стейкхолдерами.
После окончания цикла регрессионного тестирования полезно выполнить еще один этап.
6 шаг: Работа над ошибками
Что он в себя включает:
- Анализ ошибок, которые были пропущены. Особенное внимание уделяется регрессионным ошибкам, то есть проблемам в старом функционале, возникшим в результате свежих изменений.
- Возможные изменения стратегии регрессионного тестирования.
- Обновление библиотеки регрессионных тестов. Если такая имеется. Обычно свежий функционал добавляется в регрессионную библиотеку, так как начиная со следующего цикла регрессии этот функционал будет уже старым.
Заключение
Вот такой план 🙂 Получилось не так много информации, как я ожидал. Я сознательно опустил такие крупные темы как: автоматизация регрессии, виды тестового покрытия.
Немного не хватает живого практического примера по использованию описанных шагов. Приходите на сессию викенд тестирования – там потренируемся!
Материалы (на английском):
- Paul Gerrard:
- Anti-Regression
Approaches: Impact Analysis and Regression Testing Compared/Combined –
Part I: Introduction & Impact Analysis - Anti-Regression Approaches – Part II: Regression Prevention and Detection Using Static Techniques
- Anti-Regression Approaches: Impact Analysis and Regression Testing Compared and Combined: Part III: Regression Testing

Регрессионное тестирование (regression testing) помогает убедиться в правильной работе системы и отсутствии снижения эффективности. Если вы хотите быть уверенными в том, что ваше приложение работает стабильно, регрессионный тест может вам в этом помочь.
В этой статье команда Technostacks подробно рассказывает о том, что такое регрессионное тестирование, какие есть методы и инструменты, и дает пошаговую инструкцию, как его проводить.
Нет времени читать статью? Найдите ее в нашем телеграм-канале и сохраните себе в «Избранном» на будущее.
Содержание статьи
Что такое регрессионное тестирование
Когда проводить регрессионное тестирование?
Как начать регрессионное тестирование: 5 шагов
4 инструмента для регрессионного тестирования
Katalon Studio
Selenium
Watir
Apache JMeter
Методы регрессионного тестирования
1. Полная регрессия
2. Выбор регрессионного теста
3. Приоритизация тест-кейсов
В чем разница между повторным тестированием и регрессионным тестированием?
Типы регрессионного тестирования
1. Модульное регрессионное тестирование
2. Частичная регрессия
3. Полная регрессия
Регрессионное тестирование и управление конфигурацией
Регрессионное тестирование в agile-среде
7 советов как выбрать регрессионное тестирование
Вместо заключения: важное о регрессионном тестировании
Что такое регрессионное тестирование
Проще говоря, регрессионное тестирование — это проверка работоспособности приложения после внесения модификаций и доработок. Оно позволяет убедиться, что внесенные изменения не нарушили должное функционирование системы.
Результатом изменений кода могут быть зависимости, дефекты и сбои. Регрессионное тестирование направлено на снижение этих рисков, чтобы уже созданный и протестированный код продолжал функционировать даже после внесения в него изменений.
Обычно приложение проходит несколько тестов, прежде чем изменения будут помещены в основную ветвь разработки. Последний этап, регрессионное тестирование, проверяет общее поведение продукта. Регрессионное тестирование обеспечивает общую стабильность и эффективность текущих функций.
Когда проводить регрессионное тестирование?
Регрессионное тестирование часто проводят в следующих ситуациях:
- выдвижение новых требований к существующей функции;
- добавление новой функции;
- исправление базы исходного кода в результате устранения бага;
- оптимизация исходного кода для повышения производительности;
- установка исправлений (патчей);
- изменения конфигурации.
Как начать регрессионное тестирование: 5 шагов
В организациях используются разные процедуры регрессионного тестирования. Тем не менее есть несколько основных шагов.
Шаг 1. Распознайте изменения исходного кода
Найдите измененные компоненты или модули и их влияние на текущие функции. Затем определите модификацию и оптимизацию в исходном коде.
Шаг 2. Установите приоритет этих изменений и требований к продукту
Далее упорядочьте эти изменения и спецификации продукта, чтобы упростить процедуру тестирования с помощью подходящих инструментов и сценариев тестирования.
Шаг 3. Установите критерии входа и точку входа
Перед запуском регрессионного теста убедитесь, что ваше приложение соответствует критериям приемлемости.
Шаг 4. Выберите точку выхода
Установите конечную точку или точку выхода для минимальных требований или критериев приемлемости, указанных на третьем шаге.
Шаг 5. Составьте план своих тестов
Наконец, составьте список всех тестовых компонентов и установите подходящее время выполнения.
4 инструмента для регрессионного тестирования
Katalon Studio
Katalon Studio — это решение для автоматизации, поддерживающее функциональное и регрессионное тестирование. Это комплексный набор инструментов для автоматизации тестирования сайтов, онлайн-сервисов и мобильных приложений.
Этот инструмент также позволяет выполнять сценарии в разных контекстах, браузерах и на разных устройствах. Настраиваемые отчеты о тестировании позволяют подробно оценить результаты тестирования и отправить их в виде вложений по электронной почте в форматах LOG, HTML, CSV и PDF.
Selenium
Selenium — это инструмент для автоматизации тестирования веб-приложений. Это по-прежнему один из лучших инструментов для кросс-платформенного и кросс-браузерного регрессионного тестирования. Selenium поддерживает управляемое данными тестирование (data-driven testing) и автоматизированные тестовые сценарии (automated test scripts), которые циклически перебирают наборы данных.
Данный инструмент подойдет масштабным группам по обеспечению качества с хорошо подкованными тестировщиками. Командам же небольшого и среднего размера требуется длительное обучение.
Watir
Watir — это инструмент с открытым исходным кодом для автоматизации тестирования веб-приложений, использующий библиотеки Ruby. Облегченный и адаптируемый пользовательский интерфейс упрощает разработку и управление тестами.
Для тестирования сайтов Watir предоставляет ряд функций для взаимодействия пользователя с системой, включая переход по ссылкам, заполнение форм и проверку текстов в нескольких браузерах.
Apache JMeter
Apache JMeter — это инструмент автоматизации тестирования с открытым исходным кодом, предназначенный для тестирования нагрузки и оценки производительности.
Он может выполнять широкий спектр функций тестирования, например поддерживать нагрузочные тесты и тесты производительности для нескольких различных приложений, серверов или протоколов, а также предлагать конечным пользователям полный набор регрессионных тестов.
Методы регрессионного тестирования
Существуют три наиболее известных метода реализации регрессионного тестирования: полная регрессия, выбор теста и приоритизация тест-кейсов.
1. Полная регрессия
В этом методе регрессионное тестирование используется во всех активных наборах тестов. Несмотря на то, что этот подход требует много времени и ресурсов, с его помощью вы гарантированно обнаружите и устраните все дефекты. Следовательно, метод полной регрессии работает лучше всего в тех случаях, когда программа модифицируется для новой платформы или языка либо обновляется операционная система.

Изображение: Firmbee.com для Unsplash
2. Выбор регрессионного теста
Регрессионное тестирование может ограничиваться только необходимыми компонентами, на которые могут повлиять изменения. Вы можете применить несколько более актуальных тест-кейсов, сосредоточившись на связных областях, что сократит время и работу, необходимые для проведения регрессионного тестирования.
3. Приоритизация тест-кейсов
Определите приоритеты тест-кейсов: какие из них будут запущены первыми в процедуре регрессионного тестирования. Приоритизация должна основываться на таких факторах, как процент сбоев, коммерческий эффект и постепенно внедряемые функции. Большое внимание также уделяется тест-кейсам для новых возможностей и клиентских компонентов.
В чем разница между повторным тестированием и регрессионным тестированием?
В типичном процессе разработки программного обеспечения повторное тестирование (retesting) предшествует процедурам регрессионного тестирования. Вот еще несколько основных отличий.
|
Повторное тестирование |
Регрессионное тестирование |
|
Направлено на исправление ошибки в исходном коде или на запуск определенного тест-кейса, который провалился во время финального выполнения |
Одна из основных задач — определить, не привели ли обновления или изменения к каким-либо новым дефектам в функционировании систем. Это действие гарантирует унификацию программного обеспечения |
|
Фокусируется исключительно на провалившихся тест-кейсах |
Предназначено для тестирования пройденных кейсов и выявления новых непредвиденных проблем |
|
Включает в себя верификацию ошибок |
Ключевой компонент — автоматизация, позволяющая максимально использовать потенциал возможностей вашего тест-кейса. Также устраняет любые базовые побочные эффекты, вызванные изменениями кода, наиболее экономичным способом |
Типы регрессионного тестирования
Для производства высококачественного программного обеспечения регрессионное тестирование сочетают с разными другими формами тестирования.
Перед их выполнением важно понять различия между функциональным тестированием, регрессионным тестированием и дымовым тестированием (smoke testing). Существуют разные типы регрессионного тестирования.
1. Модульное регрессионное тестирование
Модульное тестирование проверяет код в целом. Он использует ограниченный и устойчивый подход, блокируя сложные зависимости и взаимодействия за пределами рассматриваемого элемента кода.
2. Частичная регрессия
Этот тип регрессионного тестирования следует за анализом последствий. На протяжении этой процедуры тестирования старый код взаимодействует с более новым кодом. Это помогает определить, что система продолжает работать изолированно, как и предполагалось, даже после обновления кода.
3. Полная регрессия
Полное регрессионное тестирование часто происходит тогда, когда обновления программного обеспечения или изменения кода глубоко проникают в основу продукта. Оно полезно также в том случае, если текущий код претерпевает несколько модификаций. Это устраняет любые непредвиденные проблемы и предоставляет полный обзор системы.
Чтобы подтвердить, что сборка (новые строки кода) некоторое время не обновляется, реализуется форма «финального» регрессионного тестирования. После этого конечным потребителям будет доступна эта окончательная версия.
Регрессионное тестирование и управление конфигурацией
Управление конфигурацией играет важную роль в регрессионном тестировании в agile-средах. В контексте «гибкой разработки» код постоянно изменяется. Чтобы убедиться в справедливости регрессионного теста, примите во внимание следующее:
- На этапе регрессионного тестирования не допускаются никакие модификации кода.
- Регрессионный тест не должен оказывать влияния из-за изменений разработчиков.
- Запрещаются модификации базы данных.
- Для регрессионного тестирования необходимо выбрать изолированную базу данных.
Регрессионное тестирование в agile-среде
Как вы знаете, основу методологии agile составляют поэтапные и итерационные процессы. Спринты (sprints) — это короткие итерации, используемые для разработки программного обеспечения или других продуктов.
Большое количество спринтов приравнивается к многократным итерациям, а многократные итерации означают изменение исходного кода. Регрессионное тестирование играет ключевую роль в этой ситуации.
Подготовка к регрессионному тестированию должна начинаться в начале цикла разработки продукта (product development cycle) и продолжаться до этапа развертывания (deployment phase). В методологии agile регрессионное тестирование может выполняться одним из двух способов:
- Регрессия уровня спринта (sprint level regression). Этот тип регрессии выполняется для новых функций или улучшений, внесенных в последний спринт. Тест-кейсы выбираются в соответствии с новой добавленной функцией.
- Сквозная регрессия (end-to-end regression). Все тест-кейсы выполняются повторно для тестирования всех функций продукта. Короткие спринты — требование метода agile. Следовательно, выполнение регрессионного тестирования должно быть регулярным. Если делать это вручную, QA-специалистам придется нелегко. Автоматизация позволяет выявить распространенные проблемы, а также сократить время выполнения.
7 советов как выбрать регрессионное тестирование
Было замечено, что часто команда тестирования сообщает о большом количестве проблем прямо перед датой выпуска продукта. Перенос даты сдачи для устранения этих ошибок создает у клиентов плохой имидж. Это требует ранжирования тест-кейсов в порядке приоритета и продолжительности. Вот рекомендации, как приоритизировать тест-кейсы:
1. Выбирайте тест-кейсы, которые часто содержат ошибки
С учетом знаний и опыта, полученных в ходе предыдущих циклов регрессионного тестирования выбирайте тест-кейсы, которые часто вызывали ошибки.
2. Выбирайте тест-кейсы с особо важной функциональностью
Выбирайте тест-кейсы, охватывающие ключевые функции приложения. Например, ключевые функции мобильного банковского приложения — это «Перевод средств» и «Оплата счетов». В первую очередь можно сконцентрироваться на тестировании этих функций.
3. Выбирайте тест-кейсы, в которых происходят частые изменения кода
В раздел мобильного банкинга «Просмотр заявок» было добавлено нескольких запросов услуги. Это «увеличение лимита кредитной карты», «запрос чековой книжки», «запрос на привязку аккаунта» и «запрос на прекращение платежа по чеку». Чтобы обеспечить эту возможность, код менялся несколько раз. Необходимо расставить приоритеты и выбрать тест-кейсы, охватывающие эту возможность.

Изображение: Tran Mau Tri Tam ✪ для Unsplash
4. Охватите тестирование сквозных потоков
В этом разделе мы можем рассмотреть все сценарии сквозного интеграционного теста, в которых потоки модуля подвергаются тестированию от начала до конца. Например, сквозное тестирование отправки запроса на денежный перевод или добавления получателя в раздел оплаты счетов.
5. Тестируйте текстовые поля
Приложение отображает сообщение об ошибке и не позволяет пользователю перейти к следующей части, если он не заполнит обязательные поля формы. Это охватывает набор негативных тест-кейсов.
6. Выбирайте риск-ориентированный подход к тестированию
Риск-ориентированный подход к гибкому регрессионному тестированию включает в себя ранжирование тестировщиками тест-кейсов в соответствии с их приоритетом. Это сокращает время и усилия, необходимые для регрессионного тестирования. Набор регрессионных тестов делится на три группы:
- Высокий приоритет: эти тест-кейсы включают в себя важные функции и модули приложения, подверженные дефектам и недавним изменениям.
- Средний приоритет: сюда относят негативные тестовые сценарии. К этой области относятся тест-кейсы для проверки текстовых полей и сообщений об ошибках.
- Низкий приоритет: охватывают все оставшиеся функции приложения (включая пользовательский интерфейс и менее подверженные дефектам модули).
Набор гибких регрессионных тестов, выполняющийся после каждого спринта, всегда включает тест-кейсы с высоким и средним приоритетом. Регрессионное тестирование перед главным релизом может включать тест-кейсы с низким приоритетом.
Установка приоритетов позволяет agile-командам производить продукты более высокого качества, сокращая время и усилия, затрачиваемые на регрессионное тестирование.
7. Стремитесь к сотрудничеству
Эта стратегия предполагает совместную работу разработчиков и тестировщиков. Они могут помочь приоритизировать тест-кейсы для регрессии, основываясь на своих знаниях и опыте. Команда может координировать свои действия во время спринта с помощью скрам-доски регрессии, подробно описывающей области, над которыми работал каждый член команды.

Изображение: Jason Goodman для Unsplash
Например, согласно опыту разработчика, недавно реализованные модификации кода могут повлиять на область информации о состоянии счета пользователя. Он добавляет эту информацию на доску. После этого тестировщик может выбрать тест-кейсы для модуля «Состояние счета» и определить, сколько времени потребуется для выполнения этого модуля, сверившись с доской. В результате тестирование проходит быстрее и гораздо эффективнее.
Вместо заключения: важное о регрессионном тестировании
Регрессионное тестирование — надежный метод, но вместе с тем требующий много усилий и денег. По этой причине часто рекомендуют группировать тесты в наборы, соответствующие модулям программы.
Во время каждого сеанса тестирования тестировщики будут проверять только те модули, на которые повлияло обновление. Полностью отказаться от ручного тестирования невозможно. Вот полезные советы:
- Чаще обновляйте свой регрессионный пакет: пакет — это набор тест-кейсов, запускаемых при обновлении программы. Регрессионные тест-кейсы должны постоянно обновляться. Это занимает много времени.
- Многократно выполняйте эффективные тест-кейсы: запускайте тесты повторно, поскольку ваши регрессионные тесты могут содержать проблемы, выявленные ранее.
- Автоматизируйте: вы можете выполнять задачи быстрее с помощью автоматизированных технологий. Автоматизация — лучший способ ускорить выполнение тест-кейса. Поскольку обработка тест-кейсов утомительна, автоматическое регрессионное тестирование поможет тестировщикам сосредоточиться на более сложных тестах.
Высоких вам конверсий!
По материалам: technostacks.com. Автор: команда Technostacks
11-01-2023
Ты хочешь понять, что такое регрессионное тестирование, зачем оно нужно, почему про него говорят все тестировщики и при чем здесь автоматизация?
Тогда ты в правильном месте 🙂
В этой статье отвечаю на самые частые вопросы, связанные с этим типом тестирования.
Как обычно, начинаем с определений.
Что такое регрессионное тестирование?

Регрессионное тестирование (regression testing) это проверки ранее протестированной программы, выполняющиеся после изменения кода программы и/или ее окружения для получения уверенности в том, что новая версия программы не содержит дефектов в областях, не подвергавшихся изменениям.
Или в оригинале:
Regression testing — testing of a previously tested program following modification to ensure that defects have not been introduced or uncovered in unchanged areas of the software, as a result of the changes made. It is performed when the software or its environment is changed. [ISTQB Glossary]
Regression Testing является одним из двух видов тестирования, связанных с изменениями. [ISTQB FL]
Зачем нужно регрессионное тестирование?
Регрессионное тестирование необходимо для получения уверенности, что изменения ПО не коснулись и не сломали другие, не измененные, части ПО.

Здесь возникает вопрос: “Каким образом изменения одной части ПО могут сломать другие?”
Ответ: это загадка природы 🙂
На самом деле нет)
В мире не бывает идеальных вещей и все мы ошибаемся. ПО и программисты — не исключение.
Иногда, непреднамеренно, разработчик делая исправление в коде может повлиять на части приложения, о которых он никогда не слышал и не представлял, что они существуют и связаны каким-то образом.
Особенно часто эта проблема проявляется в проектах с низким уровнем качества кода, плохой архитектурой и большим техническим долгом.
Фредерик Брукс в своей книге «Мифический человеко-месяц» (1975) писал: «Фундаментальная проблема при сопровождении программ состоит в том, что исправление одной ошибки с большой вероятностью (20–50%) влечёт появление новой». [Куликов С., Базовый курс, 3-е издание]
Можно предположить, что в наше время вероятность появления ошибки — значительно меньше 20-50%, так как программы и среда разработки 1975 года сильно отличаются от современных.
Но, тем не менее, даже сегодня вероятность ошибки точно больше 0%.
Поэтому, регрессионное тестирование является ключевым инструментом обеспечения качества и должно использоваться практически на любом проекте.
Когда проводят регрессионное тестирование?
Регрессионное тестирование проводится после изменения кода программы (добавили / удалили / изменили) или изменения рабочего окружения (обновили версию PHP / Node JS / Java / Ubuntu / Windows / MySQL / MongoDB / переехали на новые сервера и т.п.)
Стоит отметить, что регрессионные тесты не нужно проводить после каждого изменения!
Например, вы изменили дату в футере сайта.
Нужно ли нам проходить 350 тест-кейсов и перепроверять весь сайт? — конечно же нет! Вы потратите свое время зря)
Такие исправления можно протестировать за 10 секунд используя самый простой чек-лист или сделав code review.
Если же такие исправления “ложат” / “ломают” сайт — вам срочно нужно задуматься о профессионализме разработчиков, это не нормально!
Или, другой пример. На одном из полей формы изменяется правило валидации: до этого максимальная длина строки равнялась 20 символам, а теперь нужно сделать 16.
Зачем после такой правки перепроверять весь сайт? (Вы не поверите, но существуют компании и команды, который до сих пор этим занимаются…)
Единственное, что нужно проверить — валидацию конкретно этого поля и, возможно, валидацию такого же поля на других формах (если они вообще существуют)
Если после изменения длины одного поля изменились правила валидации всех полей на сайте — поздравляю, у вас большие проблемы с профессионализмом разработчиков.
Вместо того, чтоб постоянно выполнять бесполезные проверки, лучше нанять более профессионального кодера. Через 2 месяца вы начнете экономить кучу денег.
При принятии решения о необходимости повторного тестирования вспоминаем принципы тестирования и задаем себе вопрос: ЧТО нам нужно проверять после этих изменений?
Какие плюсы регрессионного тестирования?
К плюсам можно отнести:
- повышение качества продукта (находим и исправляем новые дефекты)
- регрессионные дефекты показывают реальное качество кода / архитектуры системы и процесса разработки (чем больше дефектов — тем хуже код / процесс)
Выполнение повторного тестирования необходимо для анализа и улучшения качества продукта и рабочих процессов, чем, кстати, и занимаются настоящие QA Engineers.
Какие минусы регрессионного тестирования?
К минусам можно отнести:
- временные / денежные затраты (дефектов находим мало, времени тратим много, дефекты — “золотые”)
- рутина (очень немногие получают удовольствие от прохождения одних и тех же тестов по 100500 раз)
- “замыливание глаз” и парадокс пестицида
Пытаясь бороться с описанными выше минусами многие компании автоматизируют регрессионные проверки 🙂
Но, решает ли автоматизация эти проблемы? Или только усугубляет? Давайте разбираться…
Автоматизация и regression testing

Регрессионные тесты выполняются много раз и обычно проходят медленно, поэтому такие тесты — это серьезный кандидат на автоматизацию. [ISTQB FL]
На первый взгляд — выглядит логично. Но давайте посмотрим немного “глубже”.
Предположим, у нас есть небольшой проект и 50 тест-кейсов. Мы, после очередного видео / доклада — “Автоматизируй все!” — решаем их автоматизировать 🙂
Через 2 недели все готово: тесты проходят, все зеленое — класс, у нас авто-тесты, Agile и CI! (в видео сказали, что будет так)
…
Проходит 2 года. Количество тест-кейсов увеличилось в 20 раз, до 1,000. Иии…
Сравнение теоретического “до” и “после”:
До:
- 50 тестов
- 1,500$ на написание тестов (1 тест-кейс = 30$)
- среднее время прогона 50 * 6 сек = 5 минут
- затраты на 1 тестовый сервер = 200$ / мес
После:
- 1000 тестов
- 18,000$ на написание тестов (1 тест-кейс = 20$, стало проще, так как “основа” уже есть, но не 10$ — потому что старые тесты нужно постоянно поддерживать)
- среднее время прогона 1000 * 6 сек = 100 минут (!!!)
- затраты на 1 тестовый сервер = 200$ / мес
Решили ли мы проблемы, описанные выше? — нет.
Возможно, рутины стало чуть меньше. Но остальное — никуда не пропало + появилось новое:
- Очень высокие затраты на тестирование (автоматизаторы, сервера, поддержка, новые инструменты и т.п.)
- Очень большое время “прогона”
- Парадокс пестицида никуда не делся…
Теоретически, мы можем уменьшить время прогона, купив более мощные сервера, или подняв кластер (привет новый DevOps), но это сделает затраты еще большими…
И здесь появиться финансовый вопрос — а не дешевле ли нам иметь 5 джунов, которые будут проходить регрессионные тест-кейсы изо дня в день, за те же 100 минут? (Знакомо, да? Мы вернулись туда, откуда начали)
Парадокс автоматизации? Наверное, можно так сказать 🙂
Пытаясь уменьшить затраты — мы сделали их еще больше!
Давайте вспомним, что регрессионные тесты — это серьезный кандидат на автоматизацию.
Но! Серьезный кандидат != 100% автоматизация!
Поэтому, учитывая все, написанное выше, мы можем предложить решение проблем и сделать следующие выводы:
- Автоматизировать тесты нужно, но с умом
- Каждый тест-кейс, который автоматизируется, должен быть оценен с финансовой точки зрения (= экономить ресурсы)
- Отбор теста в регрессию — должен быть обдуманным процессом (ведь каждый новый тест-кейс увеличит время прогона)
- Запуск автоматизированных проверок — должен быть “умным”. Мы не должны перепроверять весь сайт и ждать 10-15-50 минут после нескольких правок в тексте!
Все эти проблемы решаются только настоящими специалистами, включая QA лидов, автоматизаторов и DevOps инженеров.
Поэтому в следующий раз хорошенько подумай, перед тем, как “автоматизировать все”.
И помни, что работа любого специалиста должна быть направлена на повышение эффективности работы и качества продуктов компании, а не на увеличение ее финансовых затрат!
Псс.. Несколько инструментов тестировщика, которые точно помогут тебе стать более эффективными, без автоматизации)
Резюме

В статье мы детально ознакомились с одним из типов тестирования, связанного с изменениями, а именно регрессионным тестированием.
Мы узнали что это такое, зачем оно необходимо, какие у него «плюсы» и «минусы», и что нам “готовит” автоматизация таких тест-кейсов.
Если у тебя есть вопросы / предложения / замечания — пиши нам!)
Если тебе интересна эта тема, и ты хочешь получать актуальную информацию о тестировании — подписывайся на наш Телеграм канал, там интересно: статьи, тесты, опросы, нет спама! 🙂
