Для расширения возможностей анализа транзакционных данных с учетом временного аспекта, последовательности появления предметов и ориентированности на конкретного клиента существует задача Data Mining под названием «последовательные шаблоны». Рассмотрим ее подробнее.
- Введение
- Постановка задачи
- Поиск последовательных шаблонов
Введение
Во вводной статье раздела «Введение в анализ ассоциативных правил», рассказывалось, как ассоциативные правила применяются при анализе рыночной корзины. Целью такого анализа может быть поиск закономерностей в бизнес-процессах, выявление связей между продажами отдельных товаров и их групп, обнаружение типичных шаблонов покупок, прогнозирование объемов продаж и так далее.
Знания, полученные в процессе анализа, позволяют принимать решения, направленные на улучшение работы компании по самым разнообразным направлениям: оптимизация закупок, снижение издержек на доставку товаров, выявление целевых групп клиентов, определение ценовой политики и маркетинговой стратегии, стимулирование спроса и многое другое.
Одной из главных проблем, связанных с поиском ассоциативных правил, является необходимость обработки большого количества транзакций, каждая из которых содержит множество предметов (товаров). Если делать это с помощью прямого перебора, то на практике придется рассмотреть огромное количество возможных ассоциаций, что делает задачу неразрешимой. Для решения этой проблемы в 1994 г. Р. Агравал и Р. Шрикант предложили алгоритм поиска ассоциативных правил на транзакционных базах данных, получивший название Apriori. Алгоритм описан в статье «Apriori — масштабируемый алгоритм поиска ассоциативных правил».
Однако ассоциативные правила имеют следующие ограничения, которые не позволяют с их помощью охватывать некоторые аспекты анализа, представляющие большой практический интерес.
Во-первых, ассоциативные правила учитывают только факты совместного появления товаров и не учитывают временной аспект, а именно, последовательность появления товаров и динамику продаж. Если мы рассмотрим последовательность событий, таких, как рост или спад продаж определенного товара или услуги за несколько последовательных периодов времени, то можем сделать вывод, скажем, о готовности клиентов к покупке нового товара или услуги, о целесообразности стимулирования спроса и т.д. Для ввода в рассмотрение времени и последовательности появления товаров достаточно фиксировать в транзакции ее дату и время, что легко реализуется современными информационными системами.
Во-вторых, ассоциативные правила не являются клиентоориентированными, поскольку не связывают наборы предметов в транзакции с определенным клиентом. В то же время, с точки зрения анализа может представлять интерес исследование динамики продаж для отдельных клиентов. Для этого в транзакцию кроме предметного набора следует ввести идентификатор клиента. Такие транзакции называются клиентоориентированными (клиентскими) и образуют клиентоориентированные транзакционные базы данных, которые обязательно содержат поле идентификатора клиента. Возможность получения идентификаторов клиентов имеется, например, при торговле по кредитным картам, клиентским картам, дающим право на скидку.
Для расширения возможностей анализа транзакционных данных с учетом временного аспекта, последовательности появления предметов и ориентированности на конкретного клиента существует задача Data Mining под названием «последовательные шаблоны» (sequential pattern, time-serial sequential pattern).
Теория последовательных шаблонов во многом основана на теории ассоциативных правил и, по сути, является ее расширением. В частности, базовыми понятиями в ней также являются транзакция, предметный набор, частота набора, поддержка и т.д. Кроме этого, для поиска последовательных шаблонов широко используется адаптированный алгоритм Apriori и его модификации. Но при рассмотрении последовательных шаблонов необходимо учитывать ряд особенностей. Главная из них заключается в том, что если в ассоциативных правилах рассматривается только факт совместного появления товаров в одной транзакции, то последовательных шаблонах рассматривается последовательность появления товаров. Последовательный шаблон – это всегда последовательность появления предметов и их групп.
Интуитивно понятно, что типичной последовательностью (шаблоном) может быть только такая последовательность, которая встречается в базе данных достаточно часто. Поэтому при поиске последовательных шаблонов возникает та же проблема, что и при поиске ассоциативных правил. Большое число рассматриваемых предметов порождает огромное количество возможных последовательностей, что приводит к серьезным вычислительным затратам при использовании полного перебора. Но и здесь применим принцип антимонотонности — последовательности, содержащие редкие события, не могут быть частыми, что позволяет существенно снизить пространство поиска.
Применение последовательных шаблонов выходит за рамки анализа рыночной корзины. Они позволяют выявлять типичные последовательности событий в самых разнообразных предметных областях. Например, последовательность может содержать такие события, как покупку материалов для строительства дома: клиент покупает сначала материалы для фундамента, потом для стен, а затем для крыши.
При этом последовательность не обязательно должна быть непрерывной. В промежутке клиент может купить, например, окна, но типичная последовательность при этом сохранится. Анализ всех последовательностей покупок разными клиентами, позволит выявить наиболее типичные шаблоны. Знание таких последовательностей поможет стимулировать клиентов, предлагая им товары в порядке, установленном шаблоном.
Постановка задачи
Рассмотрим постановку задачи поиска последовательных шаблонов, используя задачу анализа рыночной корзины. Именно так она была изначально сформулирована в основополагающей статье Р. Агравала и Р. Шриканта «Mining Sequential Patterns», что позволит провести аналогии с ассоциативными правилами и выявить наиболее существенные различия. При этом будем придерживаться терминологии первоисточника.
Пусть имеется база данных D, в которой каждая запись представляет собой клиентскую транзакцию. Каждая транзакция содержит следующие поля: идентификатор клиента, дата/время транзакции, и набор купленных товаров. Введем ограничение, что ни один клиент не имеет двух или более транзакций, совершенных одновременно.
Введем несколько основных понятий. Предметный набор – это непустой набор предметов (товаров), появившихся в одной транзакции. Последовательность – это упорядоченный список предметных наборов. Последовательность будем заключать в треугольные скобки, а предметный набор — в круглые. Тогда, если обозначать предметы целыми числами, то предметные наборы будут записаны в виде (2,4,5),(1,3), а последовательность, содержащая эти наборы <(2,4,5),(1,3)>. Если предметы появились в одном наборе, это значит, что они были приобретены одновременно.
Обозначим предметный набор I=(i_1,i_2,…,i_m) (от англ. itemset — предметный набор, набор элементов) где i_j — предмет. Введём в рассмотрение последовательность S=I_1,I_2,…,I_m , где I_i — предметный набор.
Последовательность S_1 содержится в другой последовательности S_2, если все предметные наборы из S_1 содержатся в предметных наборах S_2 . Например, последовательность <(3);(4;5);(8)> содержится в последовательности <(7);(3,8);(9);(4,5,6);(8)>, поскольку (3)⊆(3,8), (4,5)⊆(4,5,6) и (8)⊆(8). Однако, <(3);(5)> ⊈ <(3,5)> и наоборот, поскольку в первой последовательности предметы 3 и 5 были куплены один за другим, а во второй – куплены совместно.
Последовательность S называется максимальной, если она не содержится в какой-либо другой последовательности.
Все транзакции одного клиента могут быть показаны в виде последовательности, в которой они упорядочены по дате, времени или номеру визита. Такие последовательности будем называть клиентскими. Формально это записывается следующим образом.
Пусть клиент совершил несколько упорядоченных во времени транзакций T_1,T_2,…,T_n . Тогда каждый предметный набор в транзакции T_i обозначим I(T_i) , а каждую клиентскую последовательность для данного клиента запишем как I(T_1),I(T_2),…,I(T_n) . Иными словами, клиентская последовательность – это последовательность предметных наборов, содержащихся во всех транзакциях, совершенных данным клиентом.
Последовательность S называется поддерживаемой клиентом, если она содержится в клиентской последовательности данного клиента. Тогда поддержка последовательности определяется как число клиентов, поддерживающих данную последовательность. Таким образом, понятие поддержки в теории последовательных шаблонов несколько отличается от аналогичного понятия теории ассоциативных правил.
Для базы данных клиентских транзакций задача поиска последовательных шаблонов заключается в обнаружении максимальных последовательностей среди всех последовательностей, имеющих поддержку выше заданного порога. Каждая такая максимальная последовательность и есть последовательный шаблон. Далее будем называть последовательности, удовлетворяющие ограничению минимальной поддержки, частыми последовательностями (по аналогии с часто встречающимися предметными наборами или популярными наборами в теории ассоциативных правил).
Рассмотрим базу данных, представленную в таблице 1.
Таблица 1 — База данных транзакций
Транзакции в базе данных упорядочены по кодам клиентов, а для каждого клиента — по дате транзакции. После преобразования исходной базы данных в набор клиентских последовательностей получим таблицу 2.
Таблица 2 — Клиентские последовательности
Зададимся уровнем минимальной поддержки 25%. В нашем примере ему будет удовлетворять любая последовательность, поддерживаемая как минимум двумя клиентами. Этому уровню поддержки будут удовлетворять две последовательности <(3); (9)> и <(3); (4,7)>, которые также являются максимальными.
В данном примере они и будут искомыми последовательными шаблонами. Последовательный шаблон <(3); (9)> поддерживается клиентами 1 и 4. Клиент 4 купил предметы (4, 7) между предметами 3 и 9, но поддерживает шаблон <(3); (9)>, поскольку шаблоны не обязательно являются непрерывными последовательностями. Шаблон <(3); (4, 7)> поддерживается клиентами 2 и 4. Клиент 2 купил предмет 6 между 4 и 7, но поддерживает данный шаблон, поскольку набор (4,7) является подмножеством (4,6,7).
Не удовлетворяет уровню минимальной поддержки последовательность <(1,2); (3)>, поскольку она поддерживается только клиентом 2. Последовательности <(3)>, <(4)>, <(7)>, <(9)>, <(3); (4)>, <(3); (7)> и <(4, 7)>, хотя и удовлетворяют минимальной поддержке, но не являются максимальными, поскольку содержатся в более длинных последовательностях.
Поиск последовательных шаблонов
Дополнительно введем несколько терминов. Длина последовательности – это число предметных наборов, которое в ней содержится. Последовательность длины k будем называть k -последовательностью. Поддержкой предметного набора I является число клиентов, которые приобрели входящие в него предметы в одной транзакции. Таким образом, предметный набор I и 1-последовательность I имеют одну и ту же поддержку.
Напомним, что в ассоциативных правилах предметный набор, удовлетворяющий уровню минимальной поддержки, называется частым или популярным. Обратим внимание, что любой предметный набор в частой последовательности также должен быть частым, на что указывает свойство антимонотонности. Следовательно, любая частая последовательность будет состоять только из частых предметных наборов.
Частые предметные наборы из таблицы 2 представлены в таблице 3.
Таблица 3 — Частые предметные наборы
Таблица 3 — Частые предметные наборы
Таким образом, процесс поиска последовательных шаблонов содержит следующие шаги.
Сортировка. Транзакции исходной базы данных сортируются по кодам клиентов, а транзакции каждого клиента — по дате, времени или номеру визита. Таким образом, исходная база данных преобразуется в базу данных клиентских последовательностей.
Поиск частых предметных наборов. Ищется множество всех частых предметных наборов F . Одновременно ищется множество всех частых 1-последовательностей, поскольку оно содержится в F .
Задача поиска частых предметных наборов на множестве клиентских транзакций использует несколько другое определение поддержки, а именно — число транзакций, в которых представлен данный предметный набор. В то время как в задаче поиска последовательных шаблонов — это число клиентов, купивших данный набор хотя бы в одной из транзакций.
Затем множество частых предметных наборов преобразуется в альтернативное представление в виде букв, целых чисел или двоичных последовательностей. Ранее мы установили, что частыми предметными наборами будут (3), (4), (7), (4,7) и (9), а возможное представление показано ниже в таблице 4. Использование такого представления в виде отдельных значений, позволяет упростить алгоритмическую реализацию задачи.
Преобразование. Нужно определить, какие из частых последовательностей содержатся в клиентской последовательности. Для этого каждая транзакция клиентской последовательности замещается множеством ее частых предметных наборов. Если транзакция не содержит ни одного частого предметного набора, то в результате преобразования она вообще исключается (отсекается) из рассмотрения.
Если клиентская последовательность не содержит ни одного частого предметного набора, то вся эта последовательность также исключается. После преобразования каждая клиентская последовательность будет представлена в виде множества частых предметных наборов (f_1, f_2,…, f_n) . В зависимости от объема доступной памяти преобразование может быть выполнено полностью над всеми данными, или выполняться «на лету» при чтении каждой клиентской последовательность в процессе прохода базы данных. Преобразование данных из таблицы 2 представлено в таблице 4.
Таблица 4 — Преобразование базы данных клиентских последовательностей
Таблица 4 — Преобразование базы данных клиентских последовательностей
Например, в процессе преобразования клиентской последовательности 2, набор (1,2) был исключен, поскольку не является частым, а набор (4,6,7) был заменен множеством частых предметных наборов {(4);(7);(4,7)}.
Поиск частых последовательностей. Используя множество частых предметных наборов, производится поиск частых последовательностей.
Поиск максимальных последовательностей. На данном этапе среди частых последовательностей производится поиск максимальных последовательностей. Иногда данный этап совмещают с предыдущим, чтобы уменьшить затраты времени на вычисление немаксимальных последовательностей.
Поиск частых последовательностей. Самым проблемным этапом процесса поиска последовательных шаблонов является поиск частых последовательностей, поскольку большое число предметных наборов требует рассмотрения огромного числа возможных последовательностей.
Общим свойством методов поиска значимых последовательностей является необходимость многократного прохода базы данных транзакций. Каждый проход начинается с исходного набора последовательностей, который используется для генерации новых потенциальных частых последовательностей, называемых последовательностями-кандидатами или просто кандидатами. Для этого вычисляется их поддержка и по завершении прохода определяется, являются ли обнаруженные кандидаты в действительности частыми. Обнаруженные частые последовательности-кандидаты станут исходными для нового прохода.
На первом проходе ищутся все 1-последовательности, удовлетворяющие условию минимальной поддержкой, полученные на этапе поиска частых предметных наборов. При этом возможно использование двух алгоритмов полного и частичного поиска. Алгоритм полного поиска ищет все частые последовательности, включая те, которые не являются максимальными. Немаксимальные последовательности затем должны быть исключены. Одним из таких алгоритмов полного поиска является алгоритм AprioriAll, основанный на алгоритме Apriori поиска ассоциативных правил.
Кроме этого, мы рассмотрим два алгоритма частичного поиска AprioriSome и DynamicSome. Эти алгоритмы работают только с максимальными последовательностями, что позволяет избежать обработки немаксимальных последовательностей.
Оба частичных алгоритма содержат две фазы: прямую и обратную. На прямой фазе находятся все частые последовательности определенных длин, а на обратной — все оставшиеся частые последовательности. Основное различие между алгоритмами заключается в процедуре, которую они используют для формирования последовательностей-кандидатов на прямой фазе. Алгоритм AprioriSome формирует кандидаты, используя только частые последовательности, найденные на предыдущем проходе, а затем делает проход для вычисления их поддержки.
Алгоритм DynamicSome генерирует кандидатов «на лету», используя частые последовательности, найденные на предыдущих проходах и клиентские последовательности, прочитанные из базы данных.
Эти алгоритмы подробно рассматриваются во второй части статьи.
Литература
- R. Agrawal and R. Srikant. Fast Algorithms for Mining Association Rules / In Proc. of the 20th Int’l Conference on Very Large Databases, Santiago, Chile, September 1994.
- R. Agrawal and R. Srikant. Mining Sequential Patterns / Journal Intelligent Systems, vol. 9, No.1, 1997, pp. 33 – 56.
- Srikant R, Agrawal R. Mining Sequential Patterns: Generalizations and Performance Improvements / In Proc. Int’l Conf Extending Database Technology. Springer (1996) 3-17.
Другие материалы по теме:
Поиск последовательных шаблонов. Часть 2
Введение в анализ ассоциативных правил
Выявление обобщенных ассоциативных правил
Apriori – масштабируемый алгоритм поиска ассоциативных правил
Цели урока:
1) Обучающая: рассмотреть алфавитный подход к измерению количества информации, научиться вычислять количество информации с точки зрения алфавитного подхода.
2) Развивающая: развитие у учащихся самостоятельности и познавательной активности.
3) Воспитывающая: воспитывать дисциплинированность, аккуратность, собранность.
Литература:
Для учителя:
1) Угринович Н. Д. «Информатика 8 класс»,
2) Заславская О. Ю., Левченко И. В. «Информатика: весь курс».
Для учеников:
1) Угринович Н. Д. «Информатика 8 класс».
Тип урока: ознакомление с новым материалом
План урока:
1. Организационный этап.
2. Актуализация знаний.
3. Подготовка учащихся к усвоению нового материала.
4. Этап получения новых знаний.
5. Этап обобщения и закрепления нового материала.
6. Рефлексия.
7. Заключительный этап.
Ход урока
1. Организационный этап.
Здравствуйте. Прежде чем мы приступим к уроку, хотелось бы, чтобы каждый из вас настроился на рабочий лад.
2. Актуализация знаний.
1) В чём заключается содержательный подход к измерению информации? (Количество информации — мера уменьшения неопределённости знаний при получении информационных сообщений.)
2) Какую минимальную единицу информации используют для измерения количества информации? (Бит)
3) Какую формулу используют для определения количества информации? (Формулу Хартли)
4) Производится бросание симметричной четырехгранной пирамидки. Какое количество информации мы получаем в зрительном сообщении о ее падении на одну из граней? (2 бита)
6) Из непрозрачного мешочка вынимают шарики с номерами и известно, что информационное сообщение о номере шарика несет 5 битов информации. Определите количество шариков в мешочке. (35)
3. Этап получения новых знаний.
Содержательный подход к измерению информации рассматривает информацию с точки зрения человека, как уменьшение неопределенности наших знаний.
Однако любое техническое устройство не воспринимает содержание информации. Поэтому в вычислительной технике используется другой подход к определению количества информации. Он называется алфавитным подходом.
При алфавитном подходе к определению количества информации отвлекаются от содержания (смысла) информации и рассматривают информационное сообщение как последовательность знаков определенной знаковой системы.
Проще всего разобраться в этом на примере текста, написанного на каком-нибудь языке. Для нас удобнее, чтобы это был русский язык.
Все множество используемых в языке символов будем традиционно называть алфавитом. Обычно под алфавитом понимают только буквы, но поскольку в тексте могут встречаться знаки препинания, цифры, скобки, то мы их тоже включим в алфавит. В алфавит также следует включить и пробел, т. е. пропуск между словами.
Алфавит — это множество символов, используемых при записи текста.
Мощность (размер) алфавита — это полное количество символов в алфавите.
Мощность алфавита обозначается буквой N.
Например:
· мощность алфавита из русских букв равна 33;
· мощность алфавита из латинских букв — 26;
· мощность алфавита текста набранного с клавиатуры равна 256 (строчные и прописные латинские и русские буквы, цифры, знаки арифметических операций, скобки, знаки препинания и т. д.);
· мощность двоичного алфавита равна 2.
При алфавитном подходе считается, что каждый символ текста имеет информационную емкость. Информационная емкость знака зависит от мощности алфавита.
Алфавит, с помощью которого записано сообщение состоит из N знаков. В простейшем случае, когда длина кода сообщения составляет один знак, отправитель может послать одно из N возможных сообщений, которое будет нести количество информации I.
Тогда в формуле
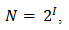
N — количество знаков в алфавите знаковой системы, I — количество информации, которое несет каждый знак.
Например, из формулы можно определить количество информации, которое несет знак в двоичной знаковой системе
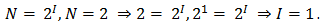
Информационная емкость знака двоичной знаковой системы составляет 1 бит.
Задача 1. Определите, какое количество информации несет буква русского алфавита (без буквы ё).
Решение:
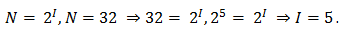
Буква русского алфавита несет 5 битов информации.
Формула 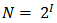 связывает между собой количество возможных событий и количество информации, которое несёт полученное сообщение. В рассматриваемой ситуации N — это количество знаков в алфавите, знаковой системы, а I — количество информации, которое несёт один знак.
связывает между собой количество возможных событий и количество информации, которое несёт полученное сообщение. В рассматриваемой ситуации N — это количество знаков в алфавите, знаковой системы, а I — количество информации, которое несёт один знак.
Сообщение состоит из последовательности знаков, каждый из которых несет определенное количество информации.
Количество информации в сообщении можно посчитать, умножив количество информации, которое несет один знак на количество знаков в сообщении.
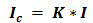
где 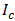 — количество информации в сообщении
— количество информации в сообщении
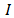 — количество информации, которое несет один знак
— количество информации, которое несет один знак
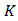 — количество знаков в сообщении
— количество знаков в сообщении
Давайте решим с вами задачу.
Задача 2. Какое количество информации содержит слово «ПРИВЕТ», если считать, что алфавит состоит из 32 букв?
Решение. Что нам требуется найти в данной задаче? Нам нужно найти какое количество информации содержит слово «ПРИВЕТ».
Что нам для этого дано?
Дано: количество знаков в сообщение и мощность алфавита.
Количество знаков в сообщении равно 6, а мощность данного алфавита равна 32.
Что нам нужно найти? Нам нужно найти какое количество информации содержит слово «ПРИВЕТ».
Посмотрим на наше сообщение, оно содержит несколько знаков, значит для того чтобы найти количество информации нашего сообщения, нам нужно умножив количество информации, которое несет один знак, на количество знаков в сообщении, т. е. воспользоваться формулой «и» суммарное равно «и» умножить на «к».
Но мы еще не можем воспользоваться формулой, т.к. не знаем какое количество информации несет один знак. Для этого воспользуемся формулой Хартли. Сообщение записано с помощью алфавита, мощность которого равна 32, т. е. N равно 32. Мы получили уравнение. Решив это уравнение, мы получили, что количество информации, которое несет один знак нашего алфавита, равно 5 бит. Зная количество информации, которое несет один знак нашего алфавита, и количество знаков в сообщении, мы можем найти какое количество информации содержит наше сообщение.
Итак, наше сообщение содержит 30 бит.
4. Этап обобщения и закрепления нового материала.
1) Какое количество информации содержит слово «ИНФОРМАТИКА», если считать, что алфавит состоит из 32 букв? (55 битов)
2) Определить количество информации, содержащееся в слове из 10 символов, если известно, что мощность алфавита равна 32 символам. (50 бит)
3) Сколько бит информации содержится в сообщении, состоящем из 5 символов, при использовании алфавита, состоящего из 64 символов. (6 битов)
4) Определить информативность сообщения «А + В = С», если для описания математических формул необходимо воспользоваться 64-символьным алфавитом. (30 бит)
5) Для представления числовых данных используют 16-ричный алфавит, включающий знаки математических действий. Сколько битов информации содержит выражение «32 * 5 = 160»? (32 бита)
6) Практическая работа № 2. «Тренировка ввода текстовой и числовой информации с помощью клавиатурного тренажера»
5. Рефлексия.
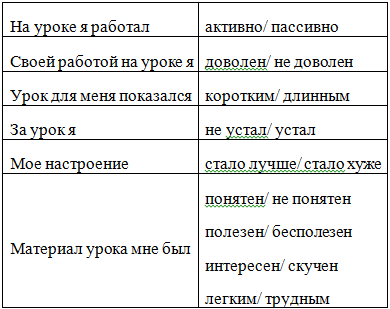
Data Mining позволяет обнаруживать в данных ранее неизвестную, скрытую от глаз информацию. Анализ последовательностей в Data Mining — один из методов, позволяющих достичь этой цели.

Анализ последовательностей в Data Mining — как самостоятельный, так и используемый совместно с другими методами вид анализа данных. Он использует выявленные последовательности для прогнозирования дальнейших событий и ситуаций. Если говорить о его месте среди основных методов анализа данных, то его применяют после методов регрессии и закономерностей. Всего аналитики выделяют шесть базовых методов анализа данных в Data Mining:
- кластеризацию,
- классификацию,
- регрессию,
- выявление закономерностей,
- выявление последовательностей,
- выявление отклонений.
Как используют Data Mining в компании Mail.ru?

Особенности анализа последовательностей в Data Mining
Data Mining предполагает различные варианты анализа последовательностей. Например, если речь идет об анализе последовательностей переходов со страницы на страницу клиентами компании, то тут возможны четыре варианта:
- отслеживание трафика пути к цели — при переходе клиентов к конечной точке ситуация считается положительной, при остановке на какой-либо из страниц, необходимо определить причину и устранить ее (некачественный контент, неинтересное предложение);
- сравнение разных путей трафика к цели — некоторые пути дают больший результат, другие — меньший; такой анализ позволяет понять, на совершение покупки влияет контент или качество товара/услуги;
- поиск циклов — позволяет увидеть, что клиенты не находят какую-то информацию и ищут ее на предыдущих страницах либо сравнивают данный вариант с предложением конкурентов;
- обзор всех вариантов выхода клиента с пути к покупки — такой анализ последовательности Data Mining позволяет найти слабые звенья цепи.
Средства анализа последовательностей Data Mining
Анализ последовательностей в Data Mining — ключ к скрытой информации в массиве данных:

Чем сложнее метод анализа, тем выше необходимость в профессиональных инструментах работы с данными. Любые процессы с Data Mining должны происходить, безусловно, в высокотехнологичных программах. Сегодня на рынке BI лидерами считаются Power BI, Qlik и Tableau. По уровню визуализации данных и доступности для всех типов сотрудников, вне зависимости от их технической подготовленности, лучшим из них считается отчетно-аналитическая программа Tableau.
Уровень визуализации данных настолько важен для работы с Data Mining, потому что позволяет увидеть тенденции и последовательности без изучения столбцов цифр, а на наглядных дашбордах. Именно эта особенность Tableau позволяет использовать программу аналитикам без технического образования. Анализ последовательностей Data Mining в отчетно-аналитической программе Tableau так же, как и другие методы анализа, можно выразить в виде диаграммы, графика, бар-чарта и сделать в соответствие с увиденным необходимые выводы.
Цифры о нас

Мы, компания АНАЛИТИКА ПЛЮС, с 2012 года помогаем нашим клиентам работать с данными – находить полезные инсайты и использовать эту информацию для увеличения прибыли компании.
За это время мы разработали и внедрили решения для различных отраслей и направлений бизнеса:
- анализ продаж,
- прогнозирование эффективности промо-акций,
- отслеживание воронки продаж по конкретной кампании с показателями конверсии на каждом этапе,
- сегментация по различным методам: ABC, RFM и т.д.,
- ключевые показатели интернет-маркетинга,
- анализ товара на складах,
- аналитика для отдела кадров (карточки сотрудников, обучение, анализ KPI и т.д.),
- анализ финансовых показателей
- и многое другое.
Хотите узнать, как провести анализ и сделать отчеты быстро?
Задачи, связанные с определением количества информации, занимают довольно большое место как в общем курсе 9-11 классов, так и при итоговой аттестации разного типа.
Обычно решение подобных задач не представляет трудности для учащихся с хорошими способностями к анализу ситуаций. Но большинство учеников поначалу путаются в понятиях и не знают, как приступить к решению.
Тем не менее, к 9-му классу учащиеся уже имеют определенный опыт решения задач по другим предметам (более всего – физика) с применением формул. Определить, что в задаче дано, что необходимо найти, и выразить одну переменную через другую – действия довольно привычные, и с ними справляются даже слабые ученики. Представляется возможным ввести некоторые дополнительные формулы в курсе информатики и найти общий стиль их применения в решении задач.
Оттолкнемся от одной из главных формул информатики – формулы Хартли N=2i. При ее использовании учащиеся могут еще не знать понятия логарифма, достаточно вначале иметь перед глазами, а затем запомнить таблицу степеней числа 2 хотя бы по 10-й степени.
При этом формула может применяться в решении задач разного типа, если правильно определить систему обозначений.
Выделим в системе задач на количество информации задачи следующих типов:
- Количество информации при вероятностном подходе;
- Кодирование положений;
- Количество информации при алфавитном подходе (кодирование текста);
- Кодирование графической информации;
- Кодирование звуковой информации
Все задачи группы A (в случае, если мы имеем дело с равновероятными событиями) решаются непосредственно по формуле Хартли с ее привычными обозначениями:
- N – количество равновероятных событий;
- i – количество бит в сообщении о том, что событие произошло,
Причем в задаче может быть определена любая из переменных с заданием найти вторую. В случае если число N не является непосредственно числом, представляющим ту или иную степень числа 2, количество бит нам необходимо определить «с запасом». Так для гарантированного угадывания числа в диапазоне от 1 до 100 необходимо задать минимально 7 вопросов (27=128).
Решение задач для случаев неравновероятных событий в этой статье не рассматривается.
Для решения задач групп B-E дополнительно введем еще одну формулу:
Q=k*i
и определим систему обозначений для задач разного типа.
Для задач группы B значение переменных в формуле Хартли таково:
- i – количество «двоичных элементов», используемых для кодирования;
- N – количество положений, которые можно закодировать посредством этих элементов.
Так:
- два флажка позволяют передать 4 различных сообщения;
- с помощью трех лампочек можно потенциально закодировать 8 различных сигналов;
- последовательность из 8 импульсов и пауз при передаче информации посредством электрического тока позволяет закодировать 256 различных текстовых знаков;
и т.п.
Рассмотрим структуру решения по формуле:
Задача 1: Сколько существует различных последовательностей из символов «плюс» и «минус» длиной ровно в пять символов?
Дано: i = 5
Найти: N
Решение: N = 25
Ответ: 5
Каждый элемент в последовательности для кодирования несет один бит информации.
Очевидно, что при определении количества элементов, необходимых для кодирования N положений, нас всегда интересует минимально необходимое для этого количество бит.
При однократном кодировании необходимого количества положений мы определяем необходимое количество бит и ограничиваемся формулой Хартли. Если кодирование проводится несколько раз, то это количество мы обозначаем как k и, определяя общее количество информации для всего кода (Q), применяем вторую формулу.
Задача 2: Метеорологическая станция ведет наблюдение за влажностью воздуха, результатом которых является целое число от 1 до 100%, которое кодируется посредством минимально возможного количества бит. Станция сделала 80 измерений. Какой информационный объем результатов наблюдений.
Дано: N = 100; k = 80
Найти: Q
Решение:
По формуле Хартли i = 7 (с запасом); Q = 80 * 7 = 560
Ответ: 560 бит
(Если в задаче даны варианты ответов с использованием других единиц измерения количества информации, осуществляем перевод: 560 бит = 70 байт).
Отметим дополнительно, что, если для кодирования используются нe «двоичные», а скажем, «троичные» элементы, то мы меняем в формуле основание степени.
Задача 3: Световое табло состоит из лампочек. Каждая из лампочек может находиться в одном из трех состояний («включено», «выключена» или «мигает»). Какое наименьшее количество лампочек должно находиться на табло, чтобы с его помощью можно было передать 18 различных сигналов.
В данном случае N = 18, основание степени – 3. Необходимо найти i. Если логарифмы еще не знакомы, определяем методом подбора – 5. Ответ: 5 лампочек
Далее рассмотрим решение задач на кодирование текстовой, графической и звуковой информации.
Здесь важно провести параллели:
Информация, которая обрабатывается на компьютере, должна быть представлена в виде конечного множества элементов (символ для текста, точка – для графики, фрагмент звуковой волны – для звука), каждый из которых кодируется отдельно с использованием заданного количества бит. Зависимость количества элементов, которые могут быть закодированы, от количества бит, отводимых, на кодирование одного элемента, как и раньше, определяем по формуле Хартли.
А путем умножения количества элементов (k) на «информационный вес» одного из них, определяем общее количество информации в текстовом, графическом, звуковом фрагменте (Q).
Каждую задачу можно решить, обозначив заданными переменными известные данные, и выразив одну переменную через другую. Только необходимо помнить, что непосредственно расчеты чаще всего производятся в минимальных единицах измерения (битах, секундах, герцах), а потом, если необходимо, ответ переводится в более крупные единицы измерения.
Рассмотрим конкретные примеры:
Алфавитный подход позволяет определить количество информации, заключенной в тексте. Причем под «текстом» в данном случае понимают любую конечную последовательность знаков, несущую информационную нагрузку. Поэтому обозначения переменных для задач группы C одинаково применимы как для задач на передачу обычной текстовой информации посредством компьютера (i = 8, N = 256 или i = 16, N = 16256) так и для задач на передачу сообщений посредством любых других алфавитов (здесь и далее используются разные названия, встречающиеся в задачах):
- i – количество бит, используемое для кодирования одного текстового знака, равнозначно: количество информации (в битах), в нем содержащееся, информационный «вес», информационный «объем» одного знака;
- N – полное количество знаков в алфавите, используемом для передачи сообщения, мощность алфавита;
- k – количество знаков в сообщении;
- Q – количество информации в сообщении (информационный «вес», «объем» сообщения), количество памяти, отведенное для хранения закодированной информации;
Задача 4: Объем сообщения – 7,5 кбайт. Известно, что данное сообщение содержит 7680 символов. Какова мощность алфавита?
Дано:
Q = 7,5 Кбайт = 7680 байт ( в данном случае нет необходимости перевода в биты);
k = 7680
Найти: N
Решение: i = Q / k = 1 байт = 8 бит; N = 28 = 256
Ответ: 256 знаков
Задача 5: Дан текст из 600 символов. Известно, что символы берутся из таблицы размером 16 на 32. Определите информационный объем текста в битах.
Дано:
k = 600; N = 16 * 32
Найти: Q
Решение:
N = 24 * 25 = 29; i = 9; Q = 600 * 9 = 5400 бит;
Ответ: 5400 бит
Задача 6: Мощность алфавита равна 64. Сколько кбайт памяти потребуется, чтобы сохранить 128 страниц текста, содержащего в среднем 256 символов на каждой странице?
Дано:
N = 64; k = 128 * 256
Найти: Q
Решение:
64 = 2i; i = 6; Q = 128 * 256 * 6 = 196608 бит = 24576 байт = 24 Кбайт;
Ответ: 24 Кбайт
Задача 7: Для кодирования нотной записи используется 7 значков-нот. Каждая нота кодируется одним и тем же минимально возможным количеством бит. Чему равен информационный объем сообщения, состоящего из 180 нот?
Дано:
N = 7; k = 180
Найти: Q
Решение:
7 = 2i; i = 3 (с запасом); Q = 180 * 3 = 540 бит;
Ответ: 540 бит
Рассматривая задачи групп D и E, вспоминаем, что при кодировании графики и звука производится дискретизация, то есть разбиение изображения на конечное множество элементов (пикселей) и звуковой волны на конечное множество отрезков, количество которых зависит от количества измерений в секунду уровня звука (частоты дискретизации) и времени звучания звукового файла.
То есть –
- общее количество элементов в графическом файле (k) равно разрешению изображения или разрешению экрана монитора, если изображение формируется на весь экран,
- общее количество элементов в звуковом файле (k) равно произведению частоты дискретизации на время звучания (важно при этом использовать в качестве единиц измерения минимальные единицы – герцы и секунды).
Рассмотрим всю систему обозначений для данного типа задач:
- i – количество бит, используемое для кодирования одного элемента изображения или звукового фрагмента, равнозначно: глубина цвета, звука;
- N – насыщенность цвета, равнозначно: количество цветов в палитре изображения, цветовое разрешение изображения; насыщенность звука (в задачах обычно не используется);
- k – количество точек в изображении, равнозначно: разрешение изображения (или экрана) или количество фрагментов дискретной звуковой волны (равно произведению частоты дискретизации на время звучания);
- Q – количество информации, содержащееся в графическом (звуковом) файле, равнозначно: информационный «объем», «вес» графического (звукового) файла, объем памяти (видеопамяти), необходимый для хранения заданного файла.
Задача 8: Для хранения растрового изображения размером 64 на 64 пикселя отвели 512 байтов памяти. Каково максимально возможное число цветов в палитре изображения?
Дано:
k = 64 * 64 = 212; Q = 512 байтов = 29 * 23 = 212 бит;
Найти: N
Решение:
i = Q / k = 212 / 212 = 1; N = 21 = 2
Ответ: 2 цвета
Задача 9: Сколько памяти нужно для хранения 64-цветного растрового графического изображения размером 32 на 128 точек?
Дано:
N = 64; k = 32 * 128;
Найти: Q
Решение:
i = 6 (по формуле Хартли); Q = 32 * 128 * 6 = 24576 бит = 3072 байт = 3 Кбайт
Ответ: 3 Кбайт
Задача 10: Оцените информационный объем моноаудиофайла длительностью звучания 1 минута, если глубина кодирования равна 16 бит при частоте дискретизации 8 кГц
Дано:
k = 60 * 8000; i = 16;
Найти: Q
Решение:
Q = 60 * 8000 * 16 = 7680000 бит = 960000 байт = 937,5 Кбайт
Ответ: 937,5 Кбайт
(Если файл стерео, Q будет больше в 2 раза).
Задача 11: Рассчитайте время звучания моноаудиофайла, если при 16-битном кодировании и частоте дискретизации 32 кГц его объем равен 625 Кбайт
Дано:
i = 16; k = 32000 * t; Q = 625 кбайт = 640000 байт = 5120000 бит;
Найти: t
Решение:
k = Q / i; k = 5120000 / 16 = 320000; t = 320000 / 32000 = 10 сек
Ответ: 10 секунд
В эту же схему укладывается решение задач на скорость передачи информации любого типа, если в хорошо известной учащимся формуле:
S = V * t принять S = Q (количество переданной информации вместо расстояния).
Задача 12: Сколько секунд потребуется обычному модему, передающему сообщения со скоростью 28800 бит/сек, чтобы передать цветное растровое изображение размером 640 на 480 пикселей, при условии, что цвет каждого пикселя кодируется тремя байтами?
Дано:
V = 28800 бит/сек; k = 640 * 480; i = 3 байт = 24 бит;
Найти: t
Решение:
t = S (Q) / V; Q = k * i = 640 * 480 * 24 = 7372800 бит; t = 7372800 / 28800 = 256 сек.
Ответ: 256 сек
В заключение отметим, что после определенной тренировки решения задач по формулам, многие учащиеся перестают нуждаться в их прописывании в задаче, сразу определяя порядок необходимых арифметических действий для ее решения.
 Абсолютно любая деятельность человека в современном мире, если речь идёт хотя бы о малейшем развитии и получении новой информации, предполагает поиск новых данных. Но просто искать информацию – это одно, а искать её профессионально и грамотно – это другое.
Абсолютно любая деятельность человека в современном мире, если речь идёт хотя бы о малейшем развитии и получении новой информации, предполагает поиск новых данных. Но просто искать информацию – это одно, а искать её профессионально и грамотно – это другое.
В этом уроке мы поговорим о том, что вообще представляет собой поиск информации, где и как следует искать информацию, как выбирать источники информации, анализировать их и проверять на достоверность, а также расскажем о правилах поиска информации в Интернете и работе с полученными данными.
Содержание:
- Что такое информационный поиск?
- Где искать информацию?
- Как выбирать достоверные источники?
- Тест «Источники информации»
- Немного из позитивизма
- Принципы отбора информации
- Правила поиска информации в Интернете
- Работа с полученной информацией: конспекты, ментальные карты, опорные схемы и блок-схемы
- Проверочный тест
Что такое информационный поиск?
Впервые понятие «информационный поиск» было употреблено в 1948 году американским математиком и специалистом в области компьютерных технологий Кельвином Муэрсом, но в общедоступной литературе оно начало встречаться лишь с 1950 года.
По сути, поиск информации является процессом выявления в определённом массиве текстовых документов тех данных, которые касаются конкретной темы и удовлетворяют указанным условиям, и в которых имеются необходимые сведения и факты (к примеру, вся необходимая информация по теме самообразования).
Состоит процесс поиска информации из нескольких последовательных этапов, посредством которых обеспечивается сбор данных, их обработка и предоставление. Как правило, поиск осуществляется следующим образом:
| ✔ | Определяется информационная потребность и формулируется запрос. |
| ✔ | Определяется комплекс источников, в которых может находиться нужная информация. |
| ✔ | Информация извлекается из выявленных источников. |
| ✔ | Происходит ознакомление с данными, и оцениваются результаты поиска. |
Но, несмотря на то, что на первом этапе нужно как можно правильнее определиться с тем, какую конкретно информацию вы собираетесь искать (а это может показаться первостепенным), наибольшую важность представляет именно второй этап, ведь определиться с тем, где искать информацию, на порядок сложнее.
Где искать информацию?
Вопрос о том, где искать информацию, действительно очень важен. И в первую очередь, по той причине, что XXI век – это век информационный. А это, в свою очередь, значит, что информационный поиск на настоящее время имеет свою специфику.
Давайте вспомним: в конце прошлого века и даже начале настоящего столетия с целью поиска информации люди обращались в специализированные заведения. К таким можно отнести библиотеки, архивы, картотеки и другие подобные органы информации. Но если в то время, чтобы отыскать информацию о том, что интересует, человеку нужно было собраться, выйти из дома, добраться до нужного места, заполнить заявку, отстоять очередь, чтобы её отдать, некоторое время подождать, пока нужная литература будет найдена, а затем провести несколько часов в поиске конкретной информации и её записи на бумагу, то сегодня все эти пункты можно обойти стороной, т.к. практически у каждого дома имеется компьютер и доступ в Интернет.
Исходя из этого, актуальные ещё в не таком далёком прошлом информационные базы (архивы, библиотеки и прочее) сегодня, если и не потеряли своей актуальности, то во всяком случае имеют гораздо меньшее количество клиентов.
Чтобы найти то, что нужно в Интернете, требуется просто ввести запрос в строке поискового сервиса (вспоминаем первый этап), нажать кнопку «Найти» и выбрать наиболее подходящий из предложенных вариантов – интернет-страниц. О поиске информации в Интернете мы продолжим говорить чуть позже, а пока заметим, что пренебрегать традиционными способами поиска информации всё же не стоит, и время от времени можно наведываться в библиотеку, картотеку или архив. Ко всем прочему, это позволит вам разнообразить свою деятельность, развеяться и провести время необычно, с пользой и интересом.
Говоря о подборе источников для поиска информации, нельзя не затронуть вопрос о достоверности, что говорит о необходимости уметь анализировать источники данных и определять те, которым можно доверять.
Как выбирать достоверные источники информации?
Любые рассуждения на тему того, какие источники могут быть, и какие следует считать достоверными, так или иначе, приведут нас к стилистическому пониманию источников информации, а их существует немалое количество. Представим лишь самые распространённые:
| ✔ | Научные исследования, имеющие под собой реальные доказательства, полученные эмпирическим путём. |
| ✔ | Научно-популярные размышления, включающие в себя как фактические эмпирические данные, так и субъективные точки зрения людей, являющихся специалистами в той или иной области. |
| ✔ | Философские трактаты и рассуждения, отличающиеся наибольшей оригинальностью, субъективностью и формой подачи. |
| ✔ | Художественная литература, служащая, как правило, источником информации – пищи для размышления, но не достоверных эмпирических данных. |
| ✔ | Публицистические произведения – категория произведений, которые посвящены актуальным явлениям и проблемам текущей социальной жизни. Нередко в таких произведениях можно отыскать немало достоверных данных и фактов. |
| ✔ | Средства массовой информации – комплекс органов публичной передачи информации, таких как телевидение, радио, журналы и газеты, а также Интернет. |
Всегда следует брать в расчёт то, что практически ни один источник информационных данных не может являться на 100% достоверным. Исключение составляют лишь научные исследования и, в некоторой степени, научно-популярные размышления, т.к., как уже и было подмечено, в них содержатся преимущественно факты, подтверждённые опытом и официально признанные научной общественностью (есть, конечно, и люди, и точки зрения, идущие вразрез с общепринятыми, но в данной статье частные случаи мы рассматривать не будем).
Информацию же из любых других источников следует подвергать тщательной проверке, дабы удостовериться в её актуальности и правдивости. Но прежде чем перейти непосредственно к принципам отбора информации, не будет лишним сказать о том, что для самого процесса информационного поиска является очень удобным и эффективным использование идей особого философского направления – позитивизма, т.к. благодаря этому в ряде случаев (особенно если это касается поиска конкретно научных данных) множество вопросов отпадают сами собой.
Тест «Источники информации»
Только что вы познакомились с описанием источников информации по признаку их достоверности. И теперь самое время проверить, удалось ли вам усвоить материал на должном уровне.
Ниже представлено пять вопросов, в каждом из которых содержится небольшой список источников информации. Ваша задача выбрать среди них те, которые могут считаться достоверными, и те, которые, наоборот, не могут.
Уверены, у вас получилось ответить на вопросы правильно. Если же нет, это вовсе не повод расстраиваться. Нужно лишь получить больше знаний. Впрочем, сделать это нужно в любом случае, и именно этим мы и предлагаем заняться дальше.
Совсем немного о позитивизме
Позитивизм является философским направлением в учении о методах и процедурах научной деятельности, в котором считается, что единственным источником истинного и действительного знания вообще являются только эмпирические (подтверждённые опытным путём) исследования.
Также позитивизм говорит о том, что философское исследование не несёт в себе познавательной ценности. Базовой предпосылкой позитивизма является то, что любые подлинные (они же позитивные) знания – это совокупность результатов специальных наук.
Основной же целью позитивизма является получение объективного знания, что возможно только через проверку информации на деле. Руководствуясь всем этим, мы снова можем вернуться к идее о том, что наиболее достоверными источниками информации являются научные исследования и научно-популярные размышления.
Вооружившись этим принципом как основным, можно начать использовать и другие.
Принципы отбора информации
Можно выделить несколько принципов отбора информации:
1
Принцип наглядности
Исследуемая информация, которая соответствует этому принципу, обладает следующими признаками:
- Информация доступна для восприятия и понимания
- Формируемые информацией образы достоверны, т.к. их можно смоделировать и установить их источники
- Основные понятия, объекты и явления могут быть продемонстрированы
- Информация соответствует запрашиваемым критериям
2
Принцип научности
Принцип научности подразумевает, что исследуемая информация соответствует современным научным данным. Если такое соответствие соблюдается, то появляется возможность обнаруживать неточности и ошибки, воспринимать другие точки зрения, руководствоваться собственной аргументацией и преобразовывать информацию, сопоставляя её с другой.
Вкратце критерии принципа научности можно выразить так:
- Данные соответствуют научным представлениям современности
- Если в массиве данных имеются ошибки и неточности, они не способны повлечь за собой искажения объективной картины, касающейся рассматриваемого вопроса
- Информация может иметь вид исторического документа, который показывает путь развития конкретного научного знания
3
Принцип актуальности
Согласно этому принципу, информация должна быть практичной, злободневной, соответствующей современным запросам, важной на текущий момент времени. Такая информация способна вызвать наибольший интерес, в отличие от неактуальной. Здесь нужно руководствоваться следующими соображениями:
- Желательно, чтобы информация была близка по времени и волновала исследователя
- Информация может представлять собой документ, который расширяет представление об исследуемом объекте
- Информация должна обладать исторической ценностью или быть важной по иным причинам
- Информация может являться классическим примером чего-либо, что знают все
4
Принцип систематичности
Если информация соответствует принципу систематичности, можно наблюдать её многократное повторение в той или иной интерпретации в рамках одного источника или в той же или другой подобной интерпретации в других источниках.
Таким образом, информация достойна внимания и может быть применена, если:
- Аналогичные данные можно найти в различных базах данных
- Различные интерпретации не разрушают целостность представлений об одной и той же проблеме
5
Принцип доступности
Нередко затруднения в поиске и обработке информации могут быть вызваны, во-первых, самим её содержанием, а, во-вторых, стилем, в котором она излагается. По этой причине, работая с информацией, необходимо учитывать, что:
- Информация должна быть не только доступной для понимания с точки зрения терминологии, но и расширять тезаурус исследователя, по причине чего она будет восприниматься интересной, но не банальной
- Информация должна соответствовать той терминологии, которой обладает исследователь, но освещать конкретную тему она должна с разных сторон
- Информация должна предполагать и дидактическую обработку, которая снимает терминологический барьер, другими словами, информацию можно адаптировать под себя, при этом сохранив её смысл
6
Принцип избыточности
Исследуемая информация должна позволять исследователю выделять основную мысль, находить скрытый смысл, если таковой имеется, приходить к пониманию авторской позиции, определять цели изложения и развивать умение соотносить содержание с назначением.
Принципы поиска информации, о которых мы поговорили, могут быть применены в работе с любыми источниками данных: книгами, документами, архивными материалами, газетами и журналами, а также интернет-сайтами. По сути, эти принципы универсальны, но здесь следует чётко понимать для себя, что для поиска информации в традиционных источниках их может быть вполне достаточно, но при поиске информации в сети Интернет во избежание ошибок необходимо соблюдать ещё один ряд правил.
Правила поиска информации в Интернете
Для опытного пользователя поиск информации в Интернете предельно прост, однако, для людей, столкнувшихся с вопросом автоматизированного информационного поиска впервые, этот процесс может показаться довольно сложным из-за обилия всевозможных поисковых операторов. Ниже мы рассмотрим простой поиск и расширенный поиск, а также укажем дополнительную информацию, которая будет полезна при поиске данных в Интернете.
Простой поиск информации в Интернете
Для начала стоит сказать, что наиболее популярной поисковой системой в мире является «Google». В России к нему добавляется «Яндекс», «Поиск@mail.ru» и «Rambler».
Чтобы найти нужную информацию, нужно просто внести в поисковую строку сервиса интересующий запрос, например «Иван Грозный» или «Как правильно водить машину», и нажать «Найти» или клавишу «Enter» на клавиатуре компьютера. В результате поисковик выдаст множество страниц, на которых представлена информация по запрашиваемому запросу. Обратите внимание на то, что наиболее актуальными считаются результаты, расположенные на первой странице поисковой системы.
Расширенный поиск информации в Интернете
По своему принципу расширенный поиск ничем не отличается от простого, кроме того, что можно указывать дополнительные параметры.
При помощи специальных фильтров у пользователя есть возможность задать дополнительные условия для своего запроса. Это может быть ограничение по региону, конкретному сайту, нужному языку, форме слова или фразы, дате размещения материала или типу файла.
Чтобы активировать эти функции, нужно щёлкнуть по специальному значку, расположенному на странице поисковика. Откроется дополнительное меню, где и задаются ограничения. Сбрасываются фильтры (ограничения) нажатием кнопки «Очистить» на странице поисковика.
Дополнительная информация
Каждый пользователь должен иметь в виду, что:
- Ограничение по региону запускает поиск в указанном регионе. В качестве стандарта (По умолчанию) обычно выдаются запросы по тому региону, откуда выходит в Сеть пользователь.
- Ограничение по форме запроса запускает поиск по тем документам, где слова имеют конкретно ту форму, которая стоит в запросе, однако порядок слов может меняться. Пользователь может задать регистр букв (заглавные или строчные), любую часть речи и форму, т.е. склонение, число, род, падеж и т.д. По умолчанию поисковые системы ищут все формы запрашиваемого слова, т.е. если задать «написал», поисковик будет искать «написать», «напишу» и т.п. Однокоренные слова поисковик искать не будет.
- Ограничение по сайту запускает поиск информации среди документов, имеющихся на конкретном сайте.
- Ограничение по языку запускает поиск информации на выбранном языке. Есть возможность установить поиск по нескольким языкам одновременно.
- Ограничение по типу файла запускает поиск по конкретному формату документа, т.е. при указании соответствующих расширений можно найти текстовые документы, аудио- и видеофайлы, документы, предназначенные для открытия специальными программами и редакторами и т.д. Есть возможность установить поиск по нескольким типам файлов одновременно.
- Ограничение по дате обновления запускает поиск по конкретной дате размещения документа. Пользователь может найти документ от конкретного числа, месяца и года, а также установить временной промежуток – тогда поисковик выдаст всю информацию, добавленную за этот период времени.
Этих правил будет достаточно для поиска информации в Интернете. Освоить его в состоянии любой человек, причём потребуется на это совсем немного времени – обычно хватает буквально 2-3 практических подходов.
Но что делать с найденной информацией, ведь весь её массив не обязателен для изучения? Неважно, как вы предпочитаете искать данные на интересующую тему – ходить в библиотеку или кликать по сайтам, одновременно попивая кофе – помимо того, что вы должны обладать навыками поиска, вы также должны уметь обрабатывать тот материал, который изучаете. И для этого как нельзя лучше подходит конспектирование и некоторые другие техники.
Работа с полученной информацией: конспекты, ментальные карты, опорные схемы и блок-схемы
Конспектирование по праву считается самым популярным и применяемым способом обработки информации. Учитывая это, мы решили уделить этому процессу наибольшее внимание, а по ментальным картам, опорным схемам и блок-схемам представить лишь ознакомительную информацию.
Что такое конспект?
Как все мы знаем, конспект представляет собой письменный текст, где последовательно и кратко излагаются основные моменты какого-либо источника информации. Конспектирование подразумевает приведение к определённой структуре сведений, взятых из оригинала. Основой этого процесса является систематизация данных. Заметки могут быть либо точными выдержками и цитатами, либо иметь форму свободного письма – главное, чтобы оставался смысл. Стиль, в котором выдерживается конспект, в большинстве случаев близок к первоисточнику.
Конспекты также различаются по видам, и чтобы можно было правильно применять тот вид конспекта, который в большей степени подходит выполняемой работе, эти виды нужно уметь различать.
Виды конспектов
Выделяют плановые конспекты, схематические плановые конспекты, текстуальные, тематические и свободные конспекты. Вкратце о каждом из них.
1
Плановый конспект
Основой планового конспекта является предварительно подготовленный материал, а сам конспект включает в себя заголовки и подзаголовки (пункты и подпункты). Каждый из заголовков сопровождается небольшим текстом, по причине чего имеет понятную структуру.
Плановый конспект в наибольшей мере соответствует подготовке к семинарам и публичным выступлениям. Чем чётче будет структура, тем более логично и полноценно можно будет донести информацию до адресата. По мнению специалистов, плановый конспект должен дополняться пометками, указывающими на использовавшиеся источники, ведь запомнить их все довольно сложно.
2
Схематический плановый конспект
Схематический плановый конспект состоит из пунктов плана, представленных в форме предложений-вопросов, на которые нужно ответить. При работе с информацией нужно вносить по несколько пометок под каждое из-предложений-вопросов. В таком конспекте будет отражена структура и внутренняя связь данных. Кроме того, этот вид конспектов помогает хорошо усвоить изучаемый материал.
3
Текстуальный конспект
Текстуальный конспект отличается от всех остальных максимальной насыщенностью, т.к. для его составления используются отрывки и цитаты из первоисточника. Его легко можно дополнить планом, терминами, понятиями и тезисами. Текстуальный конспект рекомендуется составлять тем, кто занят изучением литературы или науки, ведь здесь цитаты представляют особую важность.
Но и составляется этот вид конспектов непросто, т.к. необходимо уметь определять самые важные отрывки текста и цитаты так, чтобы, в конечном счете, они могли дать целостное представление об изученном материале.
4
Тематический конспект
Тематический конспект отличен от других более всего. Его смысл заключается в том, что освещается какая-либо конкретная тема, вопрос или проблема, а для его составления обычно используют целый ряд источников информации.
Посредством тематического конспекта лучше всего можно провести анализ исследуемой темы, раскрыть главные моменты и изучить их с разных ракурсов. Но нужно понимать, что для составления такого конспекта потребуется исследовать массу источников, чтобы суметь создать целостную картину – это является непременным условием действительно качественного материала.
5
Свободный конспект
Свободный конспект является лучшим выбором для людей, способных применять разные способы работы с информацией. В свободный конспект можно включить всё: тезисы, цитаты, отрывки текста, план, пометки, выписки и т.д. Необходимо только уметь быстро и грамотно излагать мысли и работать с материалом. Многие считают, что использование конспекта такой формы является самым полноценным и целостным.
Как только вы определились с тем, какой конспект вы будете составлять, можно приступать к самому процессу. Чтобы выполнить работу качественно, нужно руководствоваться определёнными правилами.
Правила составления конспекта
Таких правил несколько и все они предельно просты:
| 1 | Ознакомьтесь с текстом, выявите его основные особенности, характер, сложность; определите, есть ли в нём термины, которые вы видите впервые. Отметьте незнакомые понятия, места, даты, имена. |
| 2 | Узнайте всю необходимую информацию о том, что вам показалось незнакомым в тексте при первом прочтении. Наведите справки о людях и событиях. Узнайте значение терминов. Полученные данные обязательно зафиксируйте. |
| 3 | Прочтите текст повторно и проведите его анализ. Это поможет вам выделить основные моменты, разделить для себя информацию на отдельные блоки и наметить план конспекта. |
| 4 | Изучите отмеченные ранее основные моменты, составьте тезисы или выпишите отдельные фрагменты или цитаты (если их наличие не обязательно, то выразите авторскую мысль своими словами с сохранением смысла). При фиксации цитат и фрагментов обязательно помечайте, откуда взята информация, и кто является автором. |
| 5 | Если у вас есть возможность выражать авторские мысли своими словами, то старайтесь делать это так, чтобы даже большие объёмы данных были выражены в 2-3 предложениях. |
Применяя эти рекомендации на практике, вы овладеете навыком грамотного конспектирования, и фиксировать и обрабатывать информацию у вас будет получаться очень быстро и качественно (в качестве подспорья вы можете использовать дополнительный материал о методах конспектирования).
Помимо конспектов, для фиксации информации можно использовать и другие не менее интересные и эффективные методики.
Ментальные карты
Ментальные карты или, как их ещё принято называть, диаграммы связей, интеллект-карты, карты мыслей или ассоциативные карты являются таким методом структурирования информации, в котором используются графические записи, имеющие форму диаграмм.
Ментальные карты изображаются в виде древовидных схем, на которых присутствуют задачи, термины, факты и/или какие-либо иные данные, которые связаны ветвями. Ветви, как правило, отходят от главного (центрального) понятия.
Эффективность данного метода обусловлена тем, что его можно использовать в качестве удобного и простого инструмента управления информацией, для которого необходимо лишь наличие бумаги и карандаша (также можно использовать маркерную доску и маркеры).
Рекомендуем вам ознакомиться с подробным описанием метода ментальных карт.
Опорные схемы
Опорные схемы наглядно отображают интеллектуальную психологическую структуру человека, которая управляет его мышлением и поведением. Они позволяют изложить информацию при помощи логико-графического языка посредством значимых опор.
При составлении опорной схемы указывается её название, отмечаются ключевые понятия и схематически изображаются показатели и критерии, на основе которых производится группировка материала.
Этот вид структурирования информации очень удобен при подготовке к зачётам, экзаменам, семинарам. Его можно сопровождать конспектами и дополнительными пометками.
Блок-схемы
Блок-схемы – это ещё один действенный метод, помогающий структурировать информацию. Он представляет собой графические модели, которые описывают последовательность мыслительных операций.
Суть блок-схемы заключается в изображении отдельных шагов в форме блоков, имеющих различную форму. Все блоки соединяются друг с другом линиями-стрелками, которые указывают нужную последовательность мышления.
Чаще всего блок-схемы используются для работы с чётко структурированной информацией, когда все шаги являются конкретными. Каждый блок, имея свою форму, указывает на тот или иной мыслительный процесс, и ориентироваться по блок-схеме можно даже с минимальным количеством текстовых данных на ней. Удобно применять в качестве дополнительного инструмента.
В заключение
Как можно заключить, поиск информации и её обработка – это не только интересная, но и увлекательная деятельность. Если научиться применять этот навык с учётом всех особенностей, о которых мы сегодня поговорили, найти нужную информацию и использовать её в своих целях не будет составлять никакого труда, в особенности, если выполнить приемлемый для себя алгоритм действий несколько раз подряд.
В следующем уроке вы узнаете о том, почему в процессе самостоятельного обучения рекомендуется следовать конкретному плану, о том, как его составить, и на что нужно обратить внимание, чтобы обучение было максимально эффективным.
Проверьте свои знания
Если вы хотите проверить свои знания по теме данного урока, можете пройти небольшой тест, состоящий из нескольких вопросов. В каждом вопросе правильным может быть только один вариант. После выбора вами одного из вариантов система автоматически переходит к следующему вопросу. На получаемые вами баллы влияет правильность ваших ответов и затраченное на прохождение время. Обратите внимание, что вопросы каждый раз разные, а варианты перемешиваются.
Далее переходим к разговору о составлении плана.
← 1 Учебная мотивация3 Построение плана →
