text ^@ text → boolean
Returns true if the first string starts with the second string (equivalent to the starts_with() function).
'alphabet' ^@ 'alph' → t
ascii ( text ) → integer
Returns the numeric code of the first character of the argument. In UTF8 encoding, returns the Unicode code point of the character. In other multibyte encodings, the argument must be an ASCII character.
ascii('x') → 120
btrim ( string text [, characters text ] ) → text
Removes the longest string containing only characters in characters (a space by default) from the start and end of string.
btrim('xyxtrimyyx', 'xyz') → trim
chr ( integer ) → text
Returns the character with the given code. In UTF8 encoding the argument is treated as a Unicode code point. In other multibyte encodings the argument must designate an ASCII character. chr(0) is disallowed because text data types cannot store that character.
chr(65) → A
concat ( val1 "any" [, val2 "any" [, …] ] ) → text
Concatenates the text representations of all the arguments. NULL arguments are ignored.
concat('abcde', 2, NULL, 22) → abcde222
concat_ws ( sep text, val1 "any" [, val2 "any" [, …] ] ) → text
Concatenates all but the first argument, with separators. The first argument is used as the separator string, and should not be NULL. Other NULL arguments are ignored.
concat_ws(',', 'abcde', 2, NULL, 22) → abcde,2,22
format ( formatstr text [, formatarg "any" [, …] ] ) → text
Formats arguments according to a format string; see Section 9.4.1. This function is similar to the C function sprintf.
format('Hello %s, %1$s', 'World') → Hello World, World
initcap ( text ) → text
Converts the first letter of each word to upper case and the rest to lower case. Words are sequences of alphanumeric characters separated by non-alphanumeric characters.
initcap('hi THOMAS') → Hi Thomas
left ( string text, n integer ) → text
Returns first n characters in the string, or when n is negative, returns all but last |n| characters.
left('abcde', 2) → ab
length ( text ) → integer
Returns the number of characters in the string.
length('jose') → 4
lpad ( string text, length integer [, fill text ] ) → text
Extends the string to length length by prepending the characters fill (a space by default). If the string is already longer than length then it is truncated (on the right).
lpad('hi', 5, 'xy') → xyxhi
ltrim ( string text [, characters text ] ) → text
Removes the longest string containing only characters in characters (a space by default) from the start of string.
ltrim('zzzytest', 'xyz') → test
md5 ( text ) → text
Computes the MD5 hash of the argument, with the result written in hexadecimal.
md5('abc') → 900150983cd24fb0d6963f7d28e17f72
parse_ident ( qualified_identifier text [, strict_mode boolean DEFAULT true ] ) → text[]
Splits qualified_identifier into an array of identifiers, removing any quoting of individual identifiers. By default, extra characters after the last identifier are considered an error; but if the second parameter is false, then such extra characters are ignored. (This behavior is useful for parsing names for objects like functions.) Note that this function does not truncate over-length identifiers. If you want truncation you can cast the result to name[].
parse_ident('"SomeSchema".someTable') → {SomeSchema,sometable}
pg_client_encoding ( ) → name
Returns current client encoding name.
pg_client_encoding() → UTF8
quote_ident ( text ) → text
Returns the given string suitably quoted to be used as an identifier in an SQL statement string. Quotes are added only if necessary (i.e., if the string contains non-identifier characters or would be case-folded). Embedded quotes are properly doubled. See also Example 43.1.
quote_ident('Foo bar') → "Foo bar"
quote_literal ( text ) → text
Returns the given string suitably quoted to be used as a string literal in an SQL statement string. Embedded single-quotes and backslashes are properly doubled. Note that quote_literal returns null on null input; if the argument might be null, quote_nullable is often more suitable. See also Example 43.1.
quote_literal(E'O'Reilly') → 'O''Reilly'
quote_literal ( anyelement ) → text
Converts the given value to text and then quotes it as a literal. Embedded single-quotes and backslashes are properly doubled.
quote_literal(42.5) → '42.5'
quote_nullable ( text ) → text
Returns the given string suitably quoted to be used as a string literal in an SQL statement string; or, if the argument is null, returns NULL. Embedded single-quotes and backslashes are properly doubled. See also Example 43.1.
quote_nullable(NULL) → NULL
quote_nullable ( anyelement ) → text
Converts the given value to text and then quotes it as a literal; or, if the argument is null, returns NULL. Embedded single-quotes and backslashes are properly doubled.
quote_nullable(42.5) → '42.5'
regexp_count ( string text, pattern text [, start integer [, flags text ] ] ) → integer
Returns the number of times the POSIX regular expression pattern matches in the string; see Section 9.7.3.
regexp_count('123456789012', 'ddd', 2) → 3
regexp_instr ( string text, pattern text [, start integer [, N integer [, endoption integer [, flags text [, subexpr integer ] ] ] ] ] ) → integer
Returns the position within string where the N‘th match of the POSIX regular expression pattern occurs, or zero if there is no such match; see Section 9.7.3.
regexp_instr('ABCDEF', 'c(.)(..)', 1, 1, 0, 'i') → 3
regexp_instr('ABCDEF', 'c(.)(..)', 1, 1, 0, 'i', 2) → 5
regexp_like ( string text, pattern text [, flags text ] ) → boolean
Checks whether a match of the POSIX regular expression pattern occurs within string; see Section 9.7.3.
regexp_like('Hello World', 'world$', 'i') → t
regexp_match ( string text, pattern text [, flags text ] ) → text[]
Returns substrings within the first match of the POSIX regular expression pattern to the string; see Section 9.7.3.
regexp_match('foobarbequebaz', '(bar)(beque)') → {bar,beque}
regexp_matches ( string text, pattern text [, flags text ] ) → setof text[]
Returns substrings within the first match of the POSIX regular expression pattern to the string, or substrings within all such matches if the g flag is used; see Section 9.7.3.
regexp_matches('foobarbequebaz', 'ba.', 'g') →
{bar}
{baz}
regexp_replace ( string text, pattern text, replacement text [, start integer ] [, flags text ] ) → text
Replaces the substring that is the first match to the POSIX regular expression pattern, or all such matches if the g flag is used; see Section 9.7.3.
regexp_replace('Thomas', '.[mN]a.', 'M') → ThM
regexp_replace ( string text, pattern text, replacement text, start integer, N integer [, flags text ] ) → text
Replaces the substring that is the N‘th match to the POSIX regular expression pattern, or all such matches if N is zero; see Section 9.7.3.
regexp_replace('Thomas', '.', 'X', 3, 2) → ThoXas
regexp_split_to_array ( string text, pattern text [, flags text ] ) → text[]
Splits string using a POSIX regular expression as the delimiter, producing an array of results; see Section 9.7.3.
regexp_split_to_array('hello world', 's+') → {hello,world}
regexp_split_to_table ( string text, pattern text [, flags text ] ) → setof text
Splits string using a POSIX regular expression as the delimiter, producing a set of results; see Section 9.7.3.
regexp_split_to_table('hello world', 's+') →
hello world
regexp_substr ( string text, pattern text [, start integer [, N integer [, flags text [, subexpr integer ] ] ] ] ) → text
Returns the substring within string that matches the N‘th occurrence of the POSIX regular expression pattern, or NULL if there is no such match; see Section 9.7.3.
regexp_substr('ABCDEF', 'c(.)(..)', 1, 1, 'i') → CDEF
regexp_substr('ABCDEF', 'c(.)(..)', 1, 1, 'i', 2) → EF
repeat ( string text, number integer ) → text
Repeats string the specified number of times.
repeat('Pg', 4) → PgPgPgPg
replace ( string text, from text, to text ) → text
Replaces all occurrences in string of substring from with substring to.
replace('abcdefabcdef', 'cd', 'XX') → abXXefabXXef
reverse ( text ) → text
Reverses the order of the characters in the string.
reverse('abcde') → edcba
right ( string text, n integer ) → text
Returns last n characters in the string, or when n is negative, returns all but first |n| characters.
right('abcde', 2) → de
rpad ( string text, length integer [, fill text ] ) → text
Extends the string to length length by appending the characters fill (a space by default). If the string is already longer than length then it is truncated.
rpad('hi', 5, 'xy') → hixyx
rtrim ( string text [, characters text ] ) → text
Removes the longest string containing only characters in characters (a space by default) from the end of string.
rtrim('testxxzx', 'xyz') → test
split_part ( string text, delimiter text, n integer ) → text
Splits string at occurrences of delimiter and returns the n‘th field (counting from one), or when n is negative, returns the |n|’th-from-last field.
split_part('abc~@~def~@~ghi', '~@~', 2) → def
split_part('abc,def,ghi,jkl', ',', -2) → ghi
starts_with ( string text, prefix text ) → boolean
Returns true if string starts with prefix.
starts_with('alphabet', 'alph') → t
string_to_array ( string text, delimiter text [, null_string text ] ) → text[]
Splits the string at occurrences of delimiter and forms the resulting fields into a text array. If delimiter is NULL, each character in the string will become a separate element in the array. If delimiter is an empty string, then the string is treated as a single field. If null_string is supplied and is not NULL, fields matching that string are replaced by NULL. See also array_to_string.
string_to_array('xx~~yy~~zz', '~~', 'yy') → {xx,NULL,zz}
string_to_table ( string text, delimiter text [, null_string text ] ) → setof text
Splits the string at occurrences of delimiter and returns the resulting fields as a set of text rows. If delimiter is NULL, each character in the string will become a separate row of the result. If delimiter is an empty string, then the string is treated as a single field. If null_string is supplied and is not NULL, fields matching that string are replaced by NULL.
string_to_table('xx~^~yy~^~zz', '~^~', 'yy') →
xx NULL zz
strpos ( string text, substring text ) → integer
Returns first starting index of the specified substring within string, or zero if it’s not present. (Same as position(, but note the reversed argument order.)substring in string)
strpos('high', 'ig') → 2
substr ( string text, start integer [, count integer ] ) → text
Extracts the substring of string starting at the start‘th character, and extending for count characters if that is specified. (Same as substring(.)string from start for count)
substr('alphabet', 3) → phabet
substr('alphabet', 3, 2) → ph
to_ascii ( string text ) → text
to_ascii ( string text, encoding name ) → text
to_ascii ( string text, encoding integer ) → text
Converts string to ASCII from another encoding, which may be identified by name or number. If encoding is omitted the database encoding is assumed (which in practice is the only useful case). The conversion consists primarily of dropping accents. Conversion is only supported from LATIN1, LATIN2, LATIN9, and WIN1250 encodings. (See the unaccent module for another, more flexible solution.)
to_ascii('Karél') → Karel
to_hex ( integer ) → text
to_hex ( bigint ) → text
Converts the number to its equivalent hexadecimal representation.
to_hex(2147483647) → 7fffffff
translate ( string text, from text, to text ) → text
Replaces each character in string that matches a character in the from set with the corresponding character in the to set. If from is longer than to, occurrences of the extra characters in from are deleted.
translate('12345', '143', 'ax') → a2x5
unistr ( text ) → text
Evaluate escaped Unicode characters in the argument. Unicode characters can be specified as XXXX+ (6 hexadecimal digits), XXXXXXu (4 hexadecimal digits), or XXXXU (8 hexadecimal digits). To specify a backslash, write two backslashes. All other characters are taken literally.XXXXXXXX
If the server encoding is not UTF-8, the Unicode code point identified by one of these escape sequences is converted to the actual server encoding; an error is reported if that’s not possible.
This function provides a (non-standard) alternative to string constants with Unicode escapes (see Section 4.1.2.3).
unistr('d061t+000061') → data
unistr('du0061tU00000061') → data
| Function | Return Type | Description | Example | Result |
|---|---|---|---|---|
|
int |
ASCII code of the first character of the argument. For UTF8 returns the Unicode code point of the character. For other multibyte encodings, the argument must be an ASCII character. | ascii('x') |
120 |
|
text |
Remove the longest string consisting only of characters in characters (a space by default) from the start and end of string |
btrim('xyxtrimyyx', 'xyz') |
trim |
|
text |
Character with the given code. For UTF8 the argument is treated as a Unicode code point. For other multibyte encodings the argument must designate an ASCII character. The NULL (0) character is not allowed because text data types cannot store such bytes. | chr(65) |
A |
|
text |
Concatenate the text representations of all the arguments. NULL arguments are ignored. | concat('abcde', 2, NULL, 22) |
abcde222 |
|
text |
Concatenate all but the first argument with separators. The first argument is used as the separator string. NULL arguments are ignored. | concat_ws(',', 'abcde', 2, NULL, 22) |
abcde,2,22 |
|
bytea |
Convert string to dest_encoding. The original encoding is specified by src_encoding. The string must be valid in this encoding. Conversions can be defined by CREATE CONVERSION. Also there are some predefined conversions. See Table 9.10 for available conversions. |
convert('text_in_utf8', 'UTF8', 'LATIN1') |
text_in_utf8 represented in Latin-1 encoding (ISO 8859-1) |
|
text |
Convert string to the database encoding. The original encoding is specified by src_encoding. The string must be valid in this encoding. |
convert_from('text_in_utf8', 'UTF8') |
text_in_utf8 represented in the current database encoding |
|
bytea |
Convert string to dest_encoding. |
convert_to('some text', 'UTF8') |
some text represented in the UTF8 encoding |
|
bytea |
Decode binary data from textual representation in string. Options for format are same as in encode. |
decode('MTIzAAE=', 'base64') |
x3132330001 |
|
text |
Encode binary data into a textual representation. Supported formats are: base64, hex, escape. escape converts zero bytes and high-bit-set bytes to octal sequences (nnn) and doubles backslashes. |
encode('1230001', 'base64') |
MTIzAAE= |
|
text |
Format arguments according to a format string. This function is similar to the C function sprintf. See Section 9.4.1. |
format('Hello %s, %1$s', 'World') |
Hello World, World |
|
text |
Convert the first letter of each word to upper case and the rest to lower case. Words are sequences of alphanumeric characters separated by non-alphanumeric characters. | initcap('hi THOMAS') |
Hi Thomas |
|
text |
Return first n characters in the string. When n is negative, return all but last |n| characters. |
left('abcde', 2) |
ab |
|
int |
Number of characters in string |
length('jose') |
4 |
|
int |
Number of characters in string in the given encoding. The string must be valid in this encoding. |
length('jose', 'UTF8') |
4 |
|
text |
Fill up the string to length length by prepending the characters fill (a space by default). If the string is already longer than length then it is truncated (on the right). |
lpad('hi', 5, 'xy') |
xyxhi |
|
text |
Remove the longest string containing only characters from characters (a space by default) from the start of string |
ltrim('zzzytest', 'xyz') |
test |
|
text |
Calculates the MD5 hash of string, returning the result in hexadecimal |
md5('abc') |
900150983cd24fb0 d6963f7d28e17f72 |
|
text[] |
Split qualified_identifier into an array of identifiers, removing any quoting of individual identifiers. By default, extra characters after the last identifier are considered an error; but if the second parameter is false, then such extra characters are ignored. (This behavior is useful for parsing names for objects like functions.) Note that this function does not truncate over-length identifiers. If you want truncation you can cast the result to name[]. |
parse_ident('"SomeSchema".someTable') |
{SomeSchema,sometable} |
|
name |
Current client encoding name | pg_client_encoding() |
SQL_ASCII |
|
text |
Return the given string suitably quoted to be used as an identifier in an SQL statement string. Quotes are added only if necessary (i.e., if the string contains non-identifier characters or would be case-folded). Embedded quotes are properly doubled. See also Example 43.1. | quote_ident('Foo bar') |
"Foo bar" |
|
text |
Return the given string suitably quoted to be used as a string literal in an SQL statement string. Embedded single-quotes and backslashes are properly doubled. Note that quote_literal returns null on null input; if the argument might be null, quote_nullable is often more suitable. See also Example 43.1. |
quote_literal(E'O'Reilly') |
'O''Reilly' |
|
text |
Coerce the given value to text and then quote it as a literal. Embedded single-quotes and backslashes are properly doubled. | quote_literal(42.5) |
'42.5' |
|
text |
Return the given string suitably quoted to be used as a string literal in an SQL statement string; or, if the argument is null, return NULL. Embedded single-quotes and backslashes are properly doubled. See also Example 43.1. |
quote_nullable(NULL) |
NULL |
|
text |
Coerce the given value to text and then quote it as a literal; or, if the argument is null, return NULL. Embedded single-quotes and backslashes are properly doubled. |
quote_nullable(42.5) |
'42.5' |
|
text[] |
Return captured substring(s) resulting from the first match of a POSIX regular expression to the string. See Section 9.7.3 for more information. |
regexp_match('foobarbequebaz', '(bar)(beque)') |
{bar,beque} |
|
setof text[] |
Return captured substring(s) resulting from matching a POSIX regular expression to the string. See Section 9.7.3 for more information. |
regexp_matches('foobarbequebaz', 'ba.', 'g') |
{bar}
(2 rows) |
|
text |
Replace substring(s) matching a POSIX regular expression. See Section 9.7.3 for more information. | regexp_replace('Thomas', '.[mN]a.', 'M') |
ThM |
|
text[] |
Split string using a POSIX regular expression as the delimiter. See Section 9.7.3 for more information. |
regexp_split_to_array('hello world', 's+') |
{hello,world} |
|
setof text |
Split string using a POSIX regular expression as the delimiter. See Section 9.7.3 for more information. |
regexp_split_to_table('hello world', 's+') |
hello
(2 rows) |
|
text |
Repeat string the specified number of times |
repeat('Pg', 4) |
PgPgPgPg |
|
text |
Replace all occurrences in string of substring from with substring to |
replace('abcdefabcdef', 'cd', 'XX') |
abXXefabXXef |
|
text |
Return reversed string. | reverse('abcde') |
edcba |
|
text |
Return last n characters in the string. When n is negative, return all but first |n| characters. |
right('abcde', 2) |
de |
|
text |
Fill up the string to length length by appending the characters fill (a space by default). If the string is already longer than length then it is truncated. |
rpad('hi', 5, 'xy') |
hixyx |
|
text |
Remove the longest string containing only characters from characters (a space by default) from the end of string |
rtrim('testxxzx', 'xyz') |
test |
|
text |
Split string on delimiter and return the given field (counting from one) |
split_part('abc~@~def~@~ghi', '~@~', 2) |
def |
|
int |
Location of specified substring (same as position(, but note the reversed argument order) |
strpos('high', 'ig') |
2 |
|
text |
Extract substring (same as substring() |
substr('alphabet', 3, 2) |
ph |
|
bool |
Returns true if string starts with prefix. |
starts_with('alphabet', 'alph') |
t |
|
text |
Convert string to ASCII from another encoding (only supports conversion from LATIN1, LATIN2, LATIN9, and WIN1250 encodings) |
to_ascii('Karel') |
Karel |
|
text |
Convert number to its equivalent hexadecimal representation |
to_hex(2147483647) |
7fffffff |
|
text |
Any character in string that matches a character in the from set is replaced by the corresponding character in the to set. If from is longer than to, occurrences of the extra characters in from are removed. |
translate('12345', '143', 'ax') |
a2x5 |
| Function | Return Type | Description | Example | Result |
|---|---|---|---|---|
|
|
int |
ASCII code of the first character of the argument. For UTF8 returns the Unicode code point of the character. For other multibyte encodings, the argument must be an ASCII character. |
ascii('x') |
120 |
|
|
text |
Remove the longest string consisting only of characters in characters (a space by default)from the start and end of string
|
btrim('xyxtrimyyx', 'xyz') |
trim |
|
|
text |
Character with the given code. For UTF8 the argument is treated as a Unicode code point. For other multibyte encodings the argument must designate an ASCII character. The NULL (0) character is not allowed because text data types cannot store such bytes. |
chr(65) |
A |
|
|
text |
Concatenate the text representations of all the arguments. NULL arguments are ignored. |
concat('abcde', 2, NULL, 22) |
abcde222 |
|
|
text |
Concatenate all but the first argument with separators. The first argument is used as the separator string. NULL arguments are ignored. |
concat_ws(',', 'abcde', 2, NULL, 22) |
abcde,2,22 |
|
|
bytea |
Convert string to dest_encoding. Theoriginal encoding is specified by src_encoding. Thestring must be valid in this encoding.Conversions can be defined by CREATE CONVERSION.Also there are some predefined conversions. See Table 9.10 for available conversions. |
convert('text_in_utf8', 'UTF8', 'LATIN1') |
text_in_utf8 represented in Latin-1encoding (ISO 8859-1) |
|
|
text |
Convert string to the database encoding. The original encoding is specified by src_encoding. Thestring must be valid in this encoding.
|
convert_from('text_in_utf8', 'UTF8') |
text_in_utf8 represented in the current database encoding |
|
|
bytea |
Convert string to dest_encoding.
|
convert_to('some text', 'UTF8') |
some text represented in the UTF8 encoding |
|
|
bytea |
Decode binary data from textual representation in string.Options for format are same as in encode.
|
decode('MTIzAAE=', 'base64') |
x3132330001 |
|
|
text |
Encode binary data into a textual representation. Supported formats are: base64, hex, escape.escape converts zero bytes and high-bit-set bytes tooctal sequences ( nnn) anddoubles backslashes. |
encode('1230001', 'base64') |
MTIzAAE= |
|
|
text |
Format arguments according to a format string. This function is similar to the C function sprintf.See Section 9.4.1. |
format('Hello %s, %1$s', 'World') |
Hello World, World |
|
|
text |
Convert the first letter of each word to upper case and the rest to lower case. Words are sequences of alphanumeric characters separated by non-alphanumeric characters. |
initcap('hi THOMAS') |
Hi Thomas |
|
|
text |
Return first n characters in the string. When nis negative, return all but last | n| characters.
|
left('abcde', 2) |
ab |
|
|
int |
Number of characters in string
|
length('jose') |
4 |
|
int |
Number of characters in string in the givenencoding. The stringmust be valid in this encoding. |
length('jose', 'UTF8') |
4 |
|
|
text |
Fill up the string to lengthlength by prepending the charactersfill (a space by default). If thestring is already longer thanlength then it is truncated (on theright). |
lpad('hi', 5, 'xy') |
xyxhi |
|
|
text |
Remove the longest string containing only characters fromcharacters (a space by default) from the start ofstring
|
ltrim('zzzytest', 'xyz') |
test |
|
|
text |
Calculates the MD5 hash of string,returning the result in hexadecimal |
md5('abc') |
900150983cd24fb0 d6963f7d28e17f72 |
|
|
text[] |
Split qualified_identifier into an array ofidentifiers, removing any quoting of individual identifiers. By default, extra characters after the last identifier are considered an error; but if the second parameter is false, then suchextra characters are ignored. (This behavior is useful for parsing names for objects like functions.) Note that this function does not truncate over-length identifiers. If you want truncation you can cast the result to name[].
|
parse_ident('"SomeSchema".someTable') |
{SomeSchema,sometable} |
|
|
name |
Current client encoding name | pg_client_encoding() |
SQL_ASCII |
|
|
text |
Return the given string suitably quoted to be used as an identifier in an SQL statement string. Quotes are added only if necessary (i.e., if the string contains non-identifier characters or would be case-folded). Embedded quotes are properly doubled. See also Example 43.1. |
quote_ident('Foo bar') |
"Foo bar" |
|
|
text |
Return the given string suitably quoted to be used as a string literal in an SQL statement string. Embedded single-quotes and backslashes are properly doubled. Note that quote_literal returns null on nullinput; if the argument might be null, quote_nullable is often more suitable.See also Example 43.1. |
quote_literal(E'O'Reilly') |
'O''Reilly' |
|
text |
Coerce the given value to text and then quote it as a literal. Embedded single-quotes and backslashes are properly doubled. |
quote_literal(42.5) |
'42.5' |
|
|
text |
Return the given string suitably quoted to be used as a string literal in an SQL statement string; or, if the argument is null, return NULL.Embedded single-quotes and backslashes are properly doubled. See also Example 43.1. |
quote_nullable(NULL) |
NULL |
|
text |
Coerce the given value to text and then quote it as a literal; or, if the argument is null, return NULL.Embedded single-quotes and backslashes are properly doubled. |
quote_nullable(42.5) |
'42.5' |
|
|
text[] |
Return captured substring(s) resulting from the first match of a POSIX regular expression to the string. SeeSection 9.7.3 for more information. |
regexp_match('foobarbequebaz', '(bar)(beque)') |
{bar,beque} |
|
|
setof text[] |
Return captured substring(s) resulting from matching a POSIX regular expression to the string. SeeSection 9.7.3 for more information. |
regexp_matches('foobarbequebaz', 'ba.', 'g') |
{bar}
(2 rows) |
|
|
text |
Replace substring(s) matching a POSIX regular expression. See Section 9.7.3 for more information. |
regexp_replace('Thomas', '.[mN]a.', 'M') |
ThM |
|
|
text[] |
Split string using a POSIX regular expression asthe delimiter. See Section 9.7.3 for more information. |
regexp_split_to_array('hello world', 's+') |
{hello,world} |
|
|
setof text |
Split string using a POSIX regular expression asthe delimiter. See Section 9.7.3 for more information. |
regexp_split_to_table('hello world', 's+') |
hello
(2 rows) |
|
|
text |
Repeat string the specifiednumber of times |
repeat('Pg', 4) |
PgPgPgPg |
|
|
text |
Replace all occurrences in string of substringfrom with substring to
|
replace('abcdefabcdef', 'cd', 'XX') |
abXXefabXXef |
|
|
text |
Return reversed string. | reverse('abcde') |
edcba |
|
|
text |
Return last n characters in the string. When nis negative, return all but first | n| characters.
|
right('abcde', 2) |
de |
|
|
text |
Fill up the string to lengthlength by appending the charactersfill (a space by default). If thestring is already longer thanlength then it is truncated.
|
rpad('hi', 5, 'xy') |
hixyx |
|
|
text |
Remove the longest string containing only characters fromcharacters (a space by default) from the end ofstring
|
rtrim('testxxzx', 'xyz') |
test |
|
|
text |
Split string on delimiterand return the given field (counting from one) |
split_part('abc~@~def~@~ghi', '~@~', 2) |
def |
|
|
int |
Location of specified substring (same asposition(, but note the reversedargument order) |
strpos('high', 'ig') |
2 |
|
|
text |
Extract substring (same assubstring()
|
substr('alphabet', 3, 2) |
ph |
|
|
bool |
Returns true if string starts with prefix.
|
starts_with('alphabet', 'alph') |
t |
|
|
text |
Convert string to ASCII from another encoding(only supports conversion from LATIN1, LATIN2, LATIN9,and WIN1250 encodings)
|
to_ascii('Karel') |
Karel |
|
|
text |
Convert number to its equivalent hexadecimalrepresentation |
to_hex(2147483647) |
7fffffff |
|
|
text |
Any character in string that matches acharacter in the from set is replaced bythe corresponding character in the toset. If from is longer thanto, occurrences of the extra characters infrom are removed.
|
translate('12345', '143', 'ax') |
a2x5 |
Summary: in this tutorial, we will introduce you to PostgreSQL substring function that extracts a substring from a string.
Introduction to PostgreSQL substring function
The substring function returns a part of string. The following illustrates the syntax of the substring function:
SUBSTRING ( string ,start_position , length )Code language: SQL (Structured Query Language) (sql)Let’s examine each parameter in detail:
- string is a string whose data type is char, varchar, text, etc.
- start_position is an integer that specifies where you want to extract the substring. If
start_positionequals zero, the substring starts at the first character of the string. Thestart_positioncan be only positive. Though in other database systems such as MySQL the substring function can accept a negativestart_position. - length is a positive integer that determines the number of characters that you want to extract from the string beginning at
start_position. If the sum ofstart_positionandlengthis greater than the number of characters in thestring, the substring function returns the whole string beginning atstart_position. The length parameter is optional. If you omit the length parameter, the substring function returns the whole string started atstart_position.
PostgreSQL substring examples
See the following examples:
SELECT
SUBSTRING ('PostgreSQL', 1, 8); -- PostgreS
SELECT
SUBSTRING ('PostgreSQL', 8); -- SQLCode language: SQL (Structured Query Language) (sql)In the first statement, we extract a substring that has length of 8 and it is started at the first character of the PostgreSQL string. we get PostgreS as the result. See the following picture:
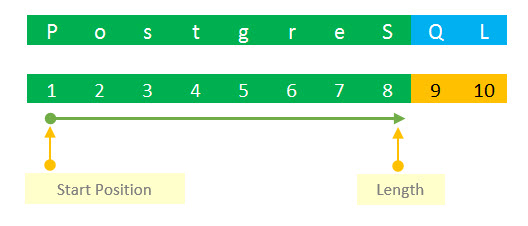
In the second statement, we extract a substring started at position 8 and we omit the length parameter. The substring is a string beginning at 8, which is SQL.
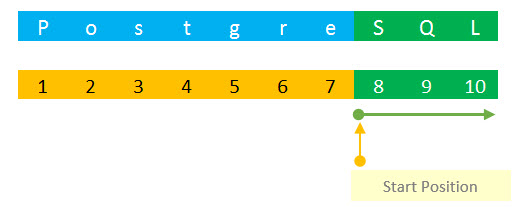
PostgreSQL provides another syntax of the substring function as follows:
substring(string from start_position for length);Code language: SQL (Structured Query Language) (sql)In this form, PostgreSQL puts three parameters into one. See the following example:
SELECT
SUBSTRING ('PostgreSQL' FROM 1 FOR 8); -- PostgreS
SELECT
SUBSTRING ('PostgreSQL' FROM 8); -- SQLCode language: SQL (Structured Query Language) (sql)The results are the same as the one in the first example.
In the following example, we query data from the customer table. We select last_name and first_name column. We get the initial name by extracting the first character of the first_name column.
SELECT
last_name,
SUBSTRING( first_name, 1, 1 ) AS initial
FROM
customer
ORDER BY
last_name;Code language: SQL (Structured Query Language) (sql)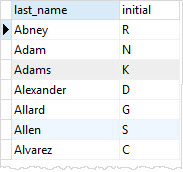
Extracting substring matching POSIX regular expression
In addition to the SQL-standard substring function, PostgreSQL allows you to use extract a substring that matches a POSIX regular expression. The following illustrates the syntax of the substring function with POSIX regular expression:
SUBSTRING(string FROM pattern)Code language: SQL (Structured Query Language) (sql)Or you can use the following syntax:
SUBSTRING(string,pattern);Code language: SQL (Structured Query Language) (sql)Note that if no match found, the substring function return a null value. If the pattern contains any parentheses, the substring function returns the text that matches the first parenthesized subexpression.
The following example extracts the house number (maximum 4 digits, from 0 to 9) from a string:
SELECT
SUBSTRING (
'The house no. is 9001',
'([0-9]{1,4})'
) as house_noCode language: SQL (Structured Query Language) (sql)![]()
Extracting substring matching a SQL regular expression
Besides POSIX regular expression pattern, you can use SQL regular expression pattern to extract a substring from a string using the following syntax:
SUBSTRING(string FROM pattern FOR escape-character)Code language: SQL (Structured Query Language) (sql)This form of substring function accepts three parameters:
string: is a string that you want to extract the substring.- escape-character: the escape character.
patternis a regular expression wrapped inside escape characters followed by a double quote (“). For example, if the character#is the escape character, the pattern will be#"pattern#". In addition, thepatternmust match the entirestring, otherwise, the substring function will fail and return aNULLvalue.
See the following examples:
SELECT SUBSTRING (
'PostgreSQL'
FROM
'%#"S_L#"%' FOR '#'
); -- SQL
SELECT SUBSTRING (
'foobar'
FROM
'#"S_Q#"%' FOR '#'
); -- NULLLCode language: SQL (Structured Query Language) (sql)PostgreSQL provides another function named substr that has the same functionality as the substring function.
Summary
- Use the PostgreSQL substring functions to extract substring from a string.
Was this tutorial helpful ?
- Use the
likeOperator toSELECTif String Contains a Substring Match in PostgreSQL - Use the
position()Function toSELECTif String Contains a Substring Match in PostgreSQL - Use the
similar toRegular Expression toSELECTif String Contains a Substring Match in PostgreSQL - Use the
substring()Function toSELECTif String Contains a Substring Match in PostgreSQL - Use the
PosixRegular Operators toSELECTif String Contains a Substring Match in PostgreSQL

Today, we will learn how to find a value in the PostgreSQL string and select it if it matches a specific condition.
Suppose you have a string carabc and want to see if it contains the value car or not. Thus, you would try to use a function that would tell you if such a substring exists in a string or not.
PostgreSQL provides three methods: like, similar to, and the Posix operator. We will discuss these in detail.
Use the like Operator to SELECT if String Contains a Substring Match in PostgreSQL
The like expression will return True if the string contains the specific sub-string; else, False. First, we create a table and insert some values into it:
create table strings(
str TEXT PRIMARY KEY
);
insert into strings values ('abcd'), ('abgh'), ('carabc');
Now, let’s select the abc values from this table.
select * from strings where str like 'abc';
When we run this, nothing happens. An empty table is displayed.
Why didn’t it return abcd and carabc from the table? Take a look at the statement below and try to see what happens:
select * from strings where str like 'abcd';
Output:

Thus, now you see that calling like tends to return results that are the exact copy of the string we are trying to match.
To match it to a substring, you need to add a % to the substring you are trying to match.
The following provides a better example of how to do that:
select * from strings where str like '%abc%';
Output:

The %x tells the query that we need to find the x in the string after some other values are located behind this x. If we wanted to find carabc, we would say %abc, and it would return carabc as car is appended before the abc.
But if we wanted to return abcd, we would use x% as d is appended after the x. Try this out yourself and see the results to get a better understanding!
Because we wanted to check if a string contains abc that could be either at the left, right or the middle, we used %abc% to return all such strings.
The like operator can also be written as ~~ and if not like, then use !~~.
Another expression is known as Ilike helps match strings without any case sensitivity. Meaning that if we use the statement:
select * from strings where str Ilike '%Abc%';
It would return the previous results even though abc is not equal to Abc as the a is capitalized in the substring.
Like the like operator, you can write Ilike as ~~* and not Ilike as !~~*.
Suppose you want to run a query to check the records in a table that match a particular string. If you want to compare abcde to the records in the table and return the row to which it matches, you can use:
select * from strings where 'abcd' like '%' || str || '%'
This would append the rows inside the str column to the syntax of %_str_%, and then we can compare each value inside and see which ones match.
Output:

To match a sub-string with some rogue character such as escape, %, or backslash /, , you can use,
select * from strings where 'abcd' like '%/abc'
This would return nothing as the function fails to eliminate the value %. This takes us to our next point, using the position function.
Use the position() Function to SELECT if String Contains a Substring Match in PostgreSQL
The position() function is a better alternative for checking if a substring exists within a string. This is defined under the operations for the string in the PostgreSQL documentation.
It returns the index of the found substring inside the main string. So if we were to find car in carabc, it would return 1.
In this way, we can see if any sub-string is present inside a string or not by checking the value of the returned index. If it is greater than 0, the sub-string exists; else, it doesn’t.
select * from strings where position(str in 'abcde') > 0
The above statement would return two values, a and abcd, as they both are present in abcde. You can manipulate this as needed.
Also, if you have any other character inside your sub-string such as %, it would skip that in the check and return accurate results, making it far better than the like expression.
select * from strings where position(str in '% abcde') > 0
Running the above will give the same results.
A possible replacement for the position expression can be strpos, which similarly works.
Use the similar to Regular Expression to SELECT if String Contains a Substring Match in PostgreSQL
The only difference between like and similar to is that the latter is a standard SQL definition used in various other DMBS.
select * from strings where position(str in 'abcde') > 0
This will return the same result as the like expression.
To use alternative matches, you can use:
select * from strings where str similar to '%(abc|a)%'
This will return all strings matching abc or a. When we run this query, we are returned with all strings in the table as each contains an a.
In case you want to disable any meta-characters in your matching substring, you can use a backslash to disable what we tend to call rogue characters inside a string.
Use the substring() Function to SELECT if String Contains a Substring Match in PostgreSQL
Another manipulation can be done to the substring() function as follows:
select * from strings where str ~~ substring(str similar '%abc%' escape '#')
The substring() returns the strings similar to abc in our case or contains abc. We then match the returned results to the str using the ~~ operator, short for like, and if they match, we select the results from the table.
This straightforward function even helps in dividing the string into separate parts can be seen in the syntax provided:
substring(string similar pattern escape escape-character)
or
substring(string from a pattern for escape-character)
or
substring(string, pattern, escape-character)
The escape-character tends to divide our string to be matched into different parts if it contains the escape-character at various points.
So if we run the statement:
select * from strings where str ~~ substring(str similar '#"abcd#"%' escape '#')
The '#"abcd#"%' will be divided into abcd, enclosed between two # characters. Thus, we can also find the matching string abcd.
Use the Posix Regular Operators to SELECT if String Contains a Substring Match in PostgreSQL

The above has been taken from a table described in the PostgreSQL documentation for Posix operators that perform the same match functions.
You can use the statement as follows to see if a string contains a sub-string or not:
select * from strings where str ~ 'abc'
This will return the values carabc and abcd.
You can even use the regexp_match(string, pattern [, flags]), which returns a null if no match is found. If a match is found, it will return an array with all the substrings matching a pattern.
To understand this, look at the following query:
select regexp_match('abdfabc', 'abd')
Output:

Using the another query,
select regexp_match('abdfabc', 'abf')
Output:

Now, you see how this expression finds a pattern and returns it. You can use this expression in a function, call the function for the select operation and then return all matching strings.
