Connecting to a Database
psql is a regular PostgreSQL client application. In order to connect to a database you need to know the name of your target database, the host name and port number of the server, and what user name you want to connect as. psql can be told about those parameters via command line options, namely -d, -h, -p, and -U respectively. If an argument is found that does not belong to any option it will be interpreted as the database name (or the user name, if the database name is already given). Not all of these options are required; there are useful defaults. If you omit the host name, psql will connect via a Unix-domain socket to a server on the local host, or via TCP/IP to localhost on machines that don’t have Unix-domain sockets. The default port number is determined at compile time. Since the database server uses the same default, you will not have to specify the port in most cases. The default user name is your operating-system user name, as is the default database name. Note that you cannot just connect to any database under any user name. Your database administrator should have informed you about your access rights.
When the defaults aren’t quite right, you can save yourself some typing by setting the environment variables PGDATABASE, PGHOST, PGPORT and/or PGUSER to appropriate values. (For additional environment variables, see Section 34.15.) It is also convenient to have a ~/.pgpass file to avoid regularly having to type in passwords. See Section 34.16 for more information.
An alternative way to specify connection parameters is in a conninfo string or a URI, which is used instead of a database name. This mechanism give you very wide control over the connection. For example:
$psql "service=myservice sslmode=require"$psql postgresql://dbmaster:5433/mydb?sslmode=require
This way you can also use LDAP for connection parameter lookup as described in Section 34.18. See Section 34.1.2 for more information on all the available connection options.
If the connection could not be made for any reason (e.g., insufficient privileges, server is not running on the targeted host, etc.), psql will return an error and terminate.
If both standard input and standard output are a terminal, then psql sets the client encoding to “auto”, which will detect the appropriate client encoding from the locale settings (LC_CTYPE environment variable on Unix systems). If this doesn’t work out as expected, the client encoding can be overridden using the environment variable PGCLIENTENCODING.
Entering SQL Commands
In normal operation, psql provides a prompt with the name of the database to which psql is currently connected, followed by the string =>. For example:
$ psql testdb
psql (15.3)
Type "help" for help.
testdb=>
At the prompt, the user can type in SQL commands. Ordinarily, input lines are sent to the server when a command-terminating semicolon is reached. An end of line does not terminate a command. Thus commands can be spread over several lines for clarity. If the command was sent and executed without error, the results of the command are displayed on the screen.
If untrusted users have access to a database that has not adopted a secure schema usage pattern, begin your session by removing publicly-writable schemas from search_path. One can add options=-csearch_path= to the connection string or issue SELECT pg_catalog.set_config('search_path', '', false) before other SQL commands. This consideration is not specific to psql; it applies to every interface for executing arbitrary SQL commands.
Whenever a command is executed, psql also polls for asynchronous notification events generated by LISTEN and NOTIFY.
While C-style block comments are passed to the server for processing and removal, SQL-standard comments are removed by psql.
Advanced Features
Variables
psql provides variable substitution features similar to common Unix command shells. Variables are simply name/value pairs, where the value can be any string of any length. The name must consist of letters (including non-Latin letters), digits, and underscores.
To set a variable, use the psql meta-command set. For example,
testdb=> set foo bar
sets the variable foo to the value bar. To retrieve the content of the variable, precede the name with a colon, for example:
testdb=> echo :foo
bar
This works in both regular SQL commands and meta-commands; there is more detail in SQL Interpolation, below.
If you call set without a second argument, the variable is set to an empty-string value. To unset (i.e., delete) a variable, use the command unset. To show the values of all variables, call set without any argument.
Note
The arguments of set are subject to the same substitution rules as with other commands. Thus you can construct interesting references such as set :foo 'something' and get “soft links” or “variable variables” of Perl or PHP fame, respectively. Unfortunately (or fortunately?), there is no way to do anything useful with these constructs. On the other hand, set bar :foo is a perfectly valid way to copy a variable.
A number of these variables are treated specially by psql. They represent certain option settings that can be changed at run time by altering the value of the variable, or in some cases represent changeable state of psql. By convention, all specially treated variables’ names consist of all upper-case ASCII letters (and possibly digits and underscores). To ensure maximum compatibility in the future, avoid using such variable names for your own purposes.
Variables that control psql‘s behavior generally cannot be unset or set to invalid values. An unset command is allowed but is interpreted as setting the variable to its default value. A set command without a second argument is interpreted as setting the variable to on, for control variables that accept that value, and is rejected for others. Also, control variables that accept the values on and off will also accept other common spellings of Boolean values, such as true and false.
The specially treated variables are:
AUTOCOMMIT-
When
on(the default), each SQL command is automatically committed upon successful completion. To postpone commit in this mode, you must enter aBEGINorSTART TRANSACTIONSQL command. Whenoffor unset, SQL commands are not committed until you explicitly issueCOMMITorEND. The autocommit-off mode works by issuing an implicitBEGINfor you, just before any command that is not already in a transaction block and is not itself aBEGINor other transaction-control command, nor a command that cannot be executed inside a transaction block (such asVACUUM).Note
In autocommit-off mode, you must explicitly abandon any failed transaction by entering
ABORTorROLLBACK. Also keep in mind that if you exit the session without committing, your work will be lost.Note
The autocommit-on mode is PostgreSQL‘s traditional behavior, but autocommit-off is closer to the SQL spec. If you prefer autocommit-off, you might wish to set it in the system-wide
psqlrcfile or your~/.psqlrcfile. COMP_KEYWORD_CASE-
Determines which letter case to use when completing an SQL key word. If set to
lowerorupper, the completed word will be in lower or upper case, respectively. If set topreserve-lowerorpreserve-upper(the default), the completed word will be in the case of the word already entered, but words being completed without anything entered will be in lower or upper case, respectively. DBNAME-
The name of the database you are currently connected to. This is set every time you connect to a database (including program start-up), but can be changed or unset.
ECHO-
If set to
all, all nonempty input lines are printed to standard output as they are read. (This does not apply to lines read interactively.) To select this behavior on program start-up, use the switch-a. If set toqueries, psql prints each query to standard output as it is sent to the server. The switch to select this behavior is-e. If set toerrors, then only failed queries are displayed on standard error output. The switch for this behavior is-b. If set tonone(the default), then no queries are displayed. ECHO_HIDDEN-
When this variable is set to
onand a backslash command queries the database, the query is first shown. This feature helps you to study PostgreSQL internals and provide similar functionality in your own programs. (To select this behavior on program start-up, use the switch-E.) If you set this variable to the valuenoexec, the queries are just shown but are not actually sent to the server and executed. The default value isoff. ENCODING-
The current client character set encoding. This is set every time you connect to a database (including program start-up), and when you change the encoding with
encoding, but it can be changed or unset. ERROR-
trueif the last SQL query failed,falseif it succeeded. See alsoSQLSTATE. FETCH_COUNT-
If this variable is set to an integer value greater than zero, the results of
SELECTqueries are fetched and displayed in groups of that many rows, rather than the default behavior of collecting the entire result set before display. Therefore only a limited amount of memory is used, regardless of the size of the result set. Settings of 100 to 1000 are commonly used when enabling this feature. Keep in mind that when using this feature, a query might fail after having already displayed some rows.Tip
Although you can use any output format with this feature, the default
alignedformat tends to look bad because each group ofFETCH_COUNTrows will be formatted separately, leading to varying column widths across the row groups. The other output formats work better. HIDE_TABLEAM-
If this variable is set to
true, a table’s access method details are not displayed. This is mainly useful for regression tests. HIDE_TOAST_COMPRESSION-
If this variable is set to
true, column compression method details are not displayed. This is mainly useful for regression tests. HISTCONTROL-
If this variable is set to
ignorespace, lines which begin with a space are not entered into the history list. If set to a value ofignoredups, lines matching the previous history line are not entered. A value ofignorebothcombines the two options. If set tonone(the default), all lines read in interactive mode are saved on the history list.Note
This feature was shamelessly plagiarized from Bash.
HISTFILE-
The file name that will be used to store the history list. If unset, the file name is taken from the
PSQL_HISTORYenvironment variable. If that is not set either, the default is~/.psql_history, or%APPDATA%postgresqlpsql_historyon Windows. For example, putting:set HISTFILE ~/.psql_history-:DBNAME
in
~/.psqlrcwill cause psql to maintain a separate history for each database.Note
This feature was shamelessly plagiarized from Bash.
HISTSIZE-
The maximum number of commands to store in the command history (default 500). If set to a negative value, no limit is applied.
Note
This feature was shamelessly plagiarized from Bash.
HOST-
The database server host you are currently connected to. This is set every time you connect to a database (including program start-up), but can be changed or unset.
IGNOREEOF-
If set to 1 or less, sending an EOF character (usually Control+D) to an interactive session of psql will terminate the application. If set to a larger numeric value, that many consecutive EOF characters must be typed to make an interactive session terminate. If the variable is set to a non-numeric value, it is interpreted as 10. The default is 0.
Note
This feature was shamelessly plagiarized from Bash.
LASTOID-
The value of the last affected OID, as returned from an
INSERTorlo_importcommand. This variable is only guaranteed to be valid until after the result of the next SQL command has been displayed. PostgreSQL servers since version 12 do not support OID system columns anymore, thus LASTOID will always be 0 followingINSERTwhen targeting such servers. LAST_ERROR_MESSAGELAST_ERROR_SQLSTATE-
The primary error message and associated SQLSTATE code for the most recent failed query in the current psql session, or an empty string and
00000if no error has occurred in the current session. ON_ERROR_ROLLBACK-
When set to
on, if a statement in a transaction block generates an error, the error is ignored and the transaction continues. When set tointeractive, such errors are only ignored in interactive sessions, and not when reading script files. When set tooff(the default), a statement in a transaction block that generates an error aborts the entire transaction. The error rollback mode works by issuing an implicitSAVEPOINTfor you, just before each command that is in a transaction block, and then rolling back to the savepoint if the command fails. ON_ERROR_STOP-
By default, command processing continues after an error. When this variable is set to
on, processing will instead stop immediately. In interactive mode, psql will return to the command prompt; otherwise, psql will exit, returning error code 3 to distinguish this case from fatal error conditions, which are reported using error code 1. In either case, any currently running scripts (the top-level script, if any, and any other scripts which it may have in invoked) will be terminated immediately. If the top-level command string contained multiple SQL commands, processing will stop with the current command. PORT-
The database server port to which you are currently connected. This is set every time you connect to a database (including program start-up), but can be changed or unset.
PROMPT1PROMPT2PROMPT3-
These specify what the prompts psql issues should look like. See Prompting below.
QUIET-
Setting this variable to
onis equivalent to the command line option-q. It is probably not too useful in interactive mode. ROW_COUNT-
The number of rows returned or affected by the last SQL query, or 0 if the query failed or did not report a row count.
SERVER_VERSION_NAMESERVER_VERSION_NUM-
The server’s version number as a string, for example
9.6.2,10.1or11beta1, and in numeric form, for example90602or100001. These are set every time you connect to a database (including program start-up), but can be changed or unset. SHOW_ALL_RESULTS-
When this variable is set to
off, only the last result of a combined query (;) is shown instead of all of them. The default ison. The off behavior is for compatibility with older versions of psql. SHOW_CONTEXT-
This variable can be set to the values
never,errors, oralwaysto control whetherCONTEXTfields are displayed in messages from the server. The default iserrors(meaning that context will be shown in error messages, but not in notice or warning messages). This setting has no effect whenVERBOSITYis set toterseorsqlstate. (See alsoerrverbose, for use when you want a verbose version of the error you just got.) SINGLELINE-
Setting this variable to
onis equivalent to the command line option-S. SINGLESTEP-
Setting this variable to
onis equivalent to the command line option-s. SQLSTATE-
The error code (see Appendix A) associated with the last SQL query’s failure, or
00000if it succeeded. USER-
The database user you are currently connected as. This is set every time you connect to a database (including program start-up), but can be changed or unset.
VERBOSITY-
This variable can be set to the values
default,verbose,terse, orsqlstateto control the verbosity of error reports. (See alsoerrverbose, for use when you want a verbose version of the error you just got.) VERSIONVERSION_NAMEVERSION_NUM-
These variables are set at program start-up to reflect psql‘s version, respectively as a verbose string, a short string (e.g.,
9.6.2,10.1, or11beta1), and a number (e.g.,90602or100001). They can be changed or unset.
SQL Interpolation
A key feature of psql variables is that you can substitute (“interpolate”) them into regular SQL statements, as well as the arguments of meta-commands. Furthermore, psql provides facilities for ensuring that variable values used as SQL literals and identifiers are properly quoted. The syntax for interpolating a value without any quoting is to prepend the variable name with a colon (:). For example,
testdb=>set foo 'my_table'testdb=>SELECT * FROM :foo;
would query the table my_table. Note that this may be unsafe: the value of the variable is copied literally, so it can contain unbalanced quotes, or even backslash commands. You must make sure that it makes sense where you put it.
When a value is to be used as an SQL literal or identifier, it is safest to arrange for it to be quoted. To quote the value of a variable as an SQL literal, write a colon followed by the variable name in single quotes. To quote the value as an SQL identifier, write a colon followed by the variable name in double quotes. These constructs deal correctly with quotes and other special characters embedded within the variable value. The previous example would be more safely written this way:
testdb=>set foo 'my_table'testdb=>SELECT * FROM :"foo";
Variable interpolation will not be performed within quoted SQL literals and identifiers. Therefore, a construction such as ':foo' doesn’t work to produce a quoted literal from a variable’s value (and it would be unsafe if it did work, since it wouldn’t correctly handle quotes embedded in the value).
One example use of this mechanism is to copy the contents of a file into a table column. First load the file into a variable and then interpolate the variable’s value as a quoted string:
testdb=>set content `cat my_file.txt`testdb=>INSERT INTO my_table VALUES (:'content');
(Note that this still won’t work if my_file.txt contains NUL bytes. psql does not support embedded NUL bytes in variable values.)
Since colons can legally appear in SQL commands, an apparent attempt at interpolation (that is, :name, :'name', or :"name") is not replaced unless the named variable is currently set. In any case, you can escape a colon with a backslash to protect it from substitution.
The :{? special syntax returns TRUE or FALSE depending on whether the variable exists or not, and is thus always substituted, unless the colon is backslash-escaped.name}
The colon syntax for variables is standard SQL for embedded query languages, such as ECPG. The colon syntaxes for array slices and type casts are PostgreSQL extensions, which can sometimes conflict with the standard usage. The colon-quote syntax for escaping a variable’s value as an SQL literal or identifier is a psql extension.
Prompting
The prompts psql issues can be customized to your preference. The three variables PROMPT1, PROMPT2, and PROMPT3 contain strings and special escape sequences that describe the appearance of the prompt. Prompt 1 is the normal prompt that is issued when psql requests a new command. Prompt 2 is issued when more input is expected during command entry, for example because the command was not terminated with a semicolon or a quote was not closed. Prompt 3 is issued when you are running an SQL COPY FROM STDIN command and you need to type in a row value on the terminal.
The value of the selected prompt variable is printed literally, except where a percent sign (%) is encountered. Depending on the next character, certain other text is substituted instead. Defined substitutions are:
%M-
The full host name (with domain name) of the database server, or
[local]if the connection is over a Unix domain socket, or[local:, if the Unix domain socket is not at the compiled in default location./dir/name] %m-
The host name of the database server, truncated at the first dot, or
[local]if the connection is over a Unix domain socket. %>-
The port number at which the database server is listening.
%n-
The database session user name. (The expansion of this value might change during a database session as the result of the command
SET SESSION AUTHORIZATION.) %/-
The name of the current database.
%~-
Like
%/, but the output is~(tilde) if the database is your default database. %#-
If the session user is a database superuser, then a
#, otherwise a>. (The expansion of this value might change during a database session as the result of the commandSET SESSION AUTHORIZATION.) %p-
The process ID of the backend currently connected to.
%R-
In prompt 1 normally
=, but@if the session is in an inactive branch of a conditional block, or^if in single-line mode, or!if the session is disconnected from the database (which can happen ifconnectfails). In prompt 2%Ris replaced by a character that depends on why psql expects more input:-if the command simply wasn’t terminated yet, but*if there is an unfinished/* ... */comment, a single quote if there is an unfinished quoted string, a double quote if there is an unfinished quoted identifier, a dollar sign if there is an unfinished dollar-quoted string, or(if there is an unmatched left parenthesis. In prompt 3%Rdoesn’t produce anything. %x-
Transaction status: an empty string when not in a transaction block, or
*when in a transaction block, or!when in a failed transaction block, or?when the transaction state is indeterminate (for example, because there is no connection). %l-
The line number inside the current statement, starting from
1. %digits-
The character with the indicated octal code is substituted.
%:name:-
The value of the psql variable
name. See Variables, above, for details. %`command`-
The output of
command, similar to ordinary “back-tick” substitution. %[…%]-
Prompts can contain terminal control characters which, for example, change the color, background, or style of the prompt text, or change the title of the terminal window. In order for the line editing features of Readline to work properly, these non-printing control characters must be designated as invisible by surrounding them with
%[and%]. Multiple pairs of these can occur within the prompt. For example:testdb=> set PROMPT1 '%[%033[1;33;40m%]%n@%/%R%[%033[0m%]%# '
results in a boldfaced (
1;) yellow-on-black (33;40) prompt on VT100-compatible, color-capable terminals. %w-
Whitespace of the same width as the most recent output of
PROMPT1. This can be used as aPROMPT2setting, so that multi-line statements are aligned with the first line, but there is no visible secondary prompt.
To insert a percent sign into your prompt, write %%. The default prompts are '%/%R%x%# ' for prompts 1 and 2, and '>> ' for prompt 3.
Note
This feature was shamelessly plagiarized from tcsh.
Command-Line Editing
psql uses the Readline or libedit library, if available, for convenient line editing and retrieval. The command history is automatically saved when psql exits and is reloaded when psql starts up. Type up-arrow or control-P to retrieve previous lines.
You can also use tab completion to fill in partially-typed keywords and SQL object names in many (by no means all) contexts. For example, at the start of a command, typing ins and pressing TAB will fill in insert into . Then, typing a few characters of a table or schema name and pressing TAB will fill in the unfinished name, or offer a menu of possible completions when there’s more than one. (Depending on the library in use, you may need to press TAB more than once to get a menu.)
Tab completion for SQL object names requires sending queries to the server to find possible matches. In some contexts this can interfere with other operations. For example, after BEGIN it will be too late to issue SET TRANSACTION ISOLATION LEVEL if a tab-completion query is issued in between. If you do not want tab completion at all, you can turn it off permanently by putting this in a file named .inputrc in your home directory:
$if psql set disable-completion on $endif
(This is not a psql but a Readline feature. Read its documentation for further details.)
The -n (--no-readline) command line option can also be useful to disable use of Readline for a single run of psql. This prevents tab completion, use or recording of command line history, and editing of multi-line commands. It is particularly useful when you need to copy-and-paste text that contains TAB characters.
На чтение 6 мин Просмотров 13.3к. Опубликовано 14.12.2021
PostgreSQL хранит данные таким образом, чтобы он был эффективным, надежным и простым в использовании и управлении для пользователя. Огромные компании используют эту систему управления базами данных в целях безопасности, чтобы защитить свои ценные данные от любых вторжений или вредоносных программ. В предыдущем руководстве мы узнали, как создавать таблицы в PostgreSQL, используя различные методы. В этой статье мы узнаем, как отображать таблицы в базе данных, которую мы создали ранее.
Содержание
- Различные методы отображения таблиц PostgreSQL
- Показать таблицы с помощью SQL Shell (psql) в PostgreSQL
- Показать таблицы с помощью pgAdmin4 в PostgreSQL
- Заключение
Различные методы отображения таблиц PostgreSQL
Вы создали большой проект для фирмы, который включает в себя множество баз данных и таблиц, теперь вам нужно внести изменения в конкретную таблицу, и вы не можете ее найти. Таблицы шоу PostgreSQL помогут вам найти таблицы, которые вы ищете. Нет специальной команды для отображения таблиц в PostgreSQL, как мы использовали для создания таблиц или нахождения максимального значения, но это можно сделать двумя разными способами:
- С помощью оболочки SQL (psql).
- Автор pgAdmin4.
Показать таблицы с помощью SQL Shell (psql) в PostgreSQL
Оболочка SQL psql — это терминал, в котором вы можете запускать запросы, и они направляются в PostgreSQL. Это происходит с установкой PostgreSQL, когда вы ее загружаете. Чтобы открыть оболочку SQL, найдите в своей системе «SQL Shell (psql)». После этого на вашем устройстве появится следующий экран:

После того, как вы вошли в оболочку SQL, переходите к следующему шагу. По умолчанию выбран сервер, т.е. localhost. Первоначально я выбрал базу данных по умолчанию, но мы можем изменить ее позже в командной строке. Порт по умолчанию — 5432, и я выбрал имя пользователя в качестве пользователя по умолчанию. Введите пароль, который вы создали при установке PostgreSQL. Когда мы вводим пароль, появится следующее сообщение, и вы будете введены в выбранную вами базу данных, то есть «Postgres».

Теперь, когда мы подключены к серверу «Postgres», мы войдем в конкретную базу данных, в которой мы хотим отображать таблицы в базе данных. Для этого выполните следующую команду, чтобы подключиться к конкретной базе данных, которую мы создали:
Обратите внимание: вы можете ввести имя базы данных по вашему выбору вместо «Testdb». Например, « c имя базы данных».
Мы занесены в нашу базу данных; теперь мы хотим узнать, сколько таблиц содержит база данных Testdb; выполните следующую команду, чтобы отобразить таблицы в базе данных «Testdb»:
Приведенная выше команда отобразит все таблицы, содержащиеся в базе данных Testdb, как:

Мы видим, что он показывает все таблицы в «Testdb» и те, которые мы создали для примеров в предыдущих статьях.
Если вам нужен размер и описание этой таблицы, вы можете запустить следующую команду, чтобы получить больше информации о таблице:
Приведенная выше команда дает следующий результат, который включает столбцы размера и описания, как показано:

Команда « dt +» покажет таблицы со всей информацией, включая имя таблицы, тип, владельца, сохраняемость, метод доступа, размер и описание.
Показать таблицы с помощью pgAdmin4 в PostgreSQL
Другой метод отображения таблиц в PostgreSQL — использование pgAdmin4. В PostgreSQL щелкните конкретную базу данных, таблицы которой вы хотите просмотреть, затем откройте инструмент запросов для отображения таблиц, существующих в базе данных. Вы можете просто использовать оператор Select для просмотра таблиц базы данных Testdb. Выполните следующий запрос, чтобы отобразить таблицы в PostgreSQL с помощью pgAdmin4:
# SELECT * FROM pg_catalog.pg_tables
WHERE
schemaname != ‘pg_temp_4’
AND schemaname!= ‘pg_catalog’
AND schemaname!= ‘information_schema’;
Здесь «pg_tables» используется для извлечения информации из таблиц, которые мы ищем в базе данных. Предложение «Где» фильтрует условие, которое мы установили для таблиц отображения. В «schemaname! = ’Pg_temp_4’» указано, что не выбирается «schemaname» в таблице, где оно равно «pg_temp_4». Условие «И» возвращает значения, если оба условия справа и слева определены как истинные.
Общий запрос будет выполняться следующим образом: сначала выберите из «pg_catalog.pg_tables» и не включайте «имя схемы» в таблицу как «pg_temp_4», «pg_catalog» и «information_schema». Вышеупомянутый запрос даст следующие результаты:

Все таблицы отображаются в выводе с использованием pgAdmin4, как и при использовании оболочки SQL (psql). Большинство результатов отфильтровываются из-за условия предложения «Где».
Если вы хотите отобразить все результаты, избегайте использования предложения «Где» в своем операторе.
Вы также можете изменить условие в соответствии с тем, что вы хотите отобразить в выводе. Например, я хочу отображать только таблицы, у которых «schemaname» равно «pg_temp_4», запустите этот запрос:
SELECT * FROM pg_catalog.pg_tables
WHERE
schemaname = ‘pg_temp_4’;
Это выберет только «pg_temp_4» из таблицы в базе данных «Testdb», которая отобразит этот вывод на экране:

Все таблицы с «schemaname» «pg_temp_4» показаны в приведенных выше результатах вывода.
Заключение
В этом руководстве мы нашли методы отображения таблиц в PostgreSQL с использованием двух разных методов. Сначала мы обсудили, как отображать таблицы с помощью инструмента оболочки SQL (psql); мы вошли в базу данных «Testdb», в которой мы использовали команду « dt» для отображения таблиц в этой базе данных. Для получения подробной информации мы использовали команду « dt +», чтобы получить размер и описание таблиц в «Testdb». Во-вторых, мы использовали pgAdmin4 для отображения таблиц в PostgreSQL. Вы можете использовать оператор Select для отображения таблиц в PostgreSQL с предложением Where. Предложение «Где» используется для указания условия для отображения определенных таблиц; если вы хотите отобразить все таблицы в своем выводе, тогда нет необходимости использовать предложение «Где».
Оба метода, которые мы использовали в этой статье, эффективны и просты в использовании. но первый метод отображения таблиц с использованием оболочки SQL (psql) позволяет сэкономить время, поскольку вам нужно написать команду меньшего размера. Второй метод является сравнительно масштабируемым, так как вы также можете указать условия в инструменте запросов для отображения отфильтрованных таблиц.
What is the best way to list all of the tables within PostgreSQL’s information_schema?
To clarify: I am working with an empty DB (I have not added any of my own tables), but I want to see every table in the information_schema structure.
Bonifacio2
3,3056 gold badges34 silver badges53 bronze badges
asked Feb 16, 2010 at 21:53
You should be able to just run select * from information_schema.tables to get a listing of every table being managed by Postgres for a particular database.
You can also add a where table_schema = 'information_schema' to see just the tables in the information schema.
answered Feb 16, 2010 at 22:08
RodeoClownRodeoClown
13.3k13 gold badges51 silver badges56 bronze badges
7
For listing your tables use:
SELECT table_name FROM information_schema.tables WHERE table_schema='public'
It will only list tables that you create.
alf
18.3k10 gold badges61 silver badges92 bronze badges
answered Aug 30, 2012 at 13:52
phsairesphsaires
2,1581 gold badge14 silver badges11 bronze badges
4
dt information_schema.
from within psql, should be fine.
answered Feb 16, 2010 at 22:31
The “z” COMMAND is also a good way to list tables when inside the interactive psql session.
eg.
# psql -d mcdb -U admin -p 5555
mcdb=# /z
Access privileges for database "mcdb"
Schema | Name | Type | Access privileges
--------+--------------------------------+----------+---------------------------------------
public | activities | table |
public | activities_id_seq | sequence |
public | activities_users_mapping | table |
[..]
public | v_schedules_2 | view | {admin=arwdxt/admin,viewuser=r/admin}
public | v_systems | view |
public | vapp_backups | table |
public | vm_client | table |
public | vm_datastore | table |
public | vmentity_hle_map | table |
(148 rows)
answered Jul 7, 2014 at 6:25
1
1.get all tables and views from information_schema.tables, include those of information_schema and pg_catalog.
select * from information_schema.tables
2.get tables and views belong certain schema
select * from information_schema.tables
where table_schema not in ('information_schema', 'pg_catalog')
3.get tables only(almost dt)
select * from information_schema.tables
where table_schema not in ('information_schema', 'pg_catalog') and
table_type = 'BASE TABLE'
answered Jan 21, 2019 at 1:34
hzhhzh
3012 silver badges8 bronze badges
4
You may use also
select * from pg_tables where schemaname = 'information_schema'
In generall pg* tables allow you to see everything in the db, not constrained to your permissions (if you have access to the tables of course).
answered May 16, 2013 at 7:09
TimofeyTimofey
2,4783 gold badges37 silver badges53 bronze badges
0
For private schema 'xxx' in postgresql :
SELECT table_name FROM information_schema.tables
WHERE table_schema = 'xxx' AND table_type = 'BASE TABLE'
Without table_type = 'BASE TABLE' , you will list tables and views
![]()
Chris
8,45710 gold badges34 silver badges51 bronze badges
answered Mar 1, 2014 at 17:43
germanlinuxgermanlinux
2,5011 gold badge20 silver badges8 bronze badges
If you want a quick and dirty one-liner query:
select * from information_schema.tables
You can run it directly in the Query tool without having to open psql.
(Other posts suggest nice more specific information_schema queries but as a newby, I am finding this one-liner query helps me get to grips with the table)
answered Feb 7, 2018 at 11:46
![]()
select * from information_schema.tables where table_schema = 'public' and table_type = 'BASE TABLE'
to get your tables only
answered Jan 3 at 12:47
V.J.V.J.
9183 gold badges18 silver badges37 bronze badges
Топ 10 самих популярных команд для управления сервером PostgreSQL для настоящих администраторов баз данных (DBA).
Большинство команд подходят как для консольной утилиты psql, так и для запуска через ваш клиент.
- Как найти самую большую таблицу в базе данных PostgreSQL?
- Как узнать размер всей базы данных PostgreSQL?
- Как узнать размер таблицы в базе данных PostgreSQL?
- Как узнать текущую версию сервера PostgreSQL?
- Как выполнить SQL-файл в PostgreSQL?
- Как отобразить список всех баз данных сервера PostgreSQL?
- Как отобразить список всех таблиц в базе данных PostgreSQL?
- Как показать структуру, индексы и прочие элементы выбранной таблицы в PostgreSQL?
- Как отобразить время выполнения запроса в консольной утилите PostgreSQL?
- Как отобразить все команды консольной утилиты PostgreSQL?
# SELECT
relname AS "table_name",
relpages AS "size_in_pages"
FROM
pg_class
ORDER BY
relpages DESC
LIMIT
1;
Результатом будет самая большая таблица (в примере testtable1) в страницах. Размер одной страницы равен 8KB (т.е. размер таблицы в примере — 2,3GB)
table_name | size_in_pages ----------------+--------------- testtable1 | 299211
2. Как узнать размер всей базы данных PostgreSQL?
# SELECT pg_database_size( 'sampledb' );
Результатом будет размер базы данных в байтах:
pg_database_size
------------------
27641546936
Если вы хотите получить размер в более читаемом («человеческом») формате — «оберните» результат в функцию pg_size_pretty():
# SELECT pg_size_pretty( pg_database_size( 'sampledb' ) );
Результат:
pg_size_pretty ---------------- 26 GB
Ну и сразу логичным будет показать все базы данных в читаемом («человеческом») виде, отсортированные от более больших к меньшим
# SELECT pg_database.datname as "database_name", pg_size_pretty(pg_database_size(pg_database.datname)) as size FROM pg_database ORDER by pg_database_size(pg_database.datname) DESC;
Результат:
database_name | size ----------------------+--------- sampledb | 45 GB loremdb_001 | 21 GB ipsumdb | 3358 MB
3. Как узнать размер таблицы в базе данных PostgreSQL?
# SELECT pg_size_pretty( pg_total_relation_size( 'testtable1' ) );
Результатом будет размер таблицы testtable1, включая индексы. Результат будет отображен сразу в удобном для чтения формате, а не в байтах.
pg_size_pretty ---------------- 4872 MB
Если вам нужно узнать размер таблицы без индексов, тогда следует выполнить такой запрос:
# SELECT pg_size_pretty( pg_relation_size( 'testtable1' ) );
Результат:
pg_size_pretty ---------------- 2338 MB
4. Как узнать текущую версию сервера PostgreSQL?
# SELECT version();
Результат будет подобным этому:
version ---------------------------------------------------------------------------------------------- PostgreSQL 9.3.1 on x86_64-unknown-linux-gnu, compiled by gcc (Debian 4.7.2-5) 4.7.2, 64-bit
5. Как выполнить SQL-файл в PostgreSQL?
Для данной цели существует специальная команда в консольной утилите:
# i /path/to/file.sql
Где /path/to/file.sql — это путь к вашему SQL-файлу. Обратите внимание, что он должен лежать в доступной для чтения пользователя postgres директории.
6. Как отобразить список всех баз данных сервера PostgreSQL?
Для данной цели существует специальная команда в консольной утилите:
# l
Результат:
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-------------+------------+-----------+-------------+-------------+---------------------------
sampledb | sampleuser | UTF8 | uk_UA.UTF-8 | uk_UA.UTF-8 | =Tc/sampleuser
| | | | | sampleuser=CTc/sampleuser
postgres | postgres | UTF8 | uk_UA.UTF-8 | uk_UA.UTF-8 |
template0 | postgres | UTF8 | uk_UA.UTF-8 | uk_UA.UTF-8 | =c/postgres
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | uk_UA.UTF-8 | uk_UA.UTF-8 | postgres=CTc/postgres
| | | | | pgsql=CTc/postgres
| | | | | =c/postgres
7. Как отобразить список всех таблиц в базе данных PostgreSQL?
Для данной цели существует специальная команда в консольной утилите что покажет список таблиц в текущей БД.
# dt
Результат:
List of relations Schema | Name | Type | Owner --------+-------------------------------+-------+-------- public | testtable1 | table | sampleuser public | testtable2 | table | sampleuser public | testtable3 | table | sampleuser public | testtable4 | table | sampleuser ...
8. Как показать структуру, индексы и прочие элементы выбранной таблицы в PostgreSQL?
Для данной цели существует специальная команда в консольной утилите:
# d testtable1
Где testtable1 — имя таблицы
Результат:
Table "public.testtable1"
Column | Type | Modifiers
--------------+------------------------+-----------
begin_ip | ip4 | not null
end_ip | ip4 | not null
begin_num | bigint | not null
end_num | bigint | not null
country_code | character(2) | not null
country_name | character varying(255) | not null
ip_range | ip4r |
Indexes:
"testtable1_iprange_index" gist (ip_range) WITH (fillfactor=100)
9. Как отобразить время выполнения запроса в консольной утилите PostgreSQL?
# timing
После чего все запросы станут отображаться в консольной утилите со временем выполнения.
Отключаются эти уведомления точно так же, как и включаются — вызовом:
# timing
10. Как отобразить все команды консольной утилиты PostgreSQL?
# ?
Это наверное самый важный пункт, т.к. любой DBA должен знать как вызвать эту справку 🙂
Это всё.
Удачи.
В сети много руководств по PostgreSQL, которые описывают основные команды. Но при погружении глубже в работу возникают такие практические вопросы, для которых требуются продвинутые команды.
Такие команды, или сниппеты, редко описаны в документации. Рассмотрим несколько на примерах, полезных как для разработчиков, так и для администраторов баз данных.
Получение информации о базе данных
Размер базы данных
Чтобы получить физический размер файлов (хранилища) базы данных, используем следующий запрос:
SELECT pg_database_size(current_database());Результат будет представлен как число вида 41809016.
current_database() — функция, которая возвращает имя текущей базы данных. Вместо неё можно ввести имя текстом:
SELECT pg_database_size('my_database');Для того, чтобы получить информацию в человекочитаемом виде, используем функцию pg_size_pretty:
SELECT pg_size_pretty(pg_database_size(current_database()));В результате получим информацию вида 40 Mb.
Перечень таблиц
Иногда требуется получить перечень таблиц базы данных. Для этого используем следующий запрос:
SELECT table_name FROM information_schema.tables
WHERE table_schema NOT IN ('information_schema','pg_catalog');information_schema — стандартная схема базы данных, которая содержит коллекции представлений (views), таких как таблицы, поля и т.д. Представления таблиц содержат информацию обо всех таблицах баз данных.
Запрос, описанный ниже, выберет все таблицы из указанной схемы текущей базы данных:
SELECT table_name FROM information_schema.tables
WHERE table_schema NOT IN ('information_schema', 'pg_catalog')
AND table_schema IN('public', 'myschema');В последнем условии IN можно указать имя определенной схемы.
Размер таблицы
По аналогии с получением размера базы данных размер данных таблицы можно вычислить с помощью соответствующей функции:
SELECT pg_relation_size('accounts');Функция pg_relation_size возвращает объём, который занимает на диске указанный слой заданной таблицы или индекса.
Имя самой большой таблицы
Для того, чтобы вывести список таблиц текущей базы данных, отсортированный по размеру таблицы, выполним следующий запрос:
SELECT relname, relpages FROM pg_class ORDER BY relpages DESC;Для того, чтобы вывести информацию о самой большой таблице, ограничим запрос с помощью LIMIT:
SELECT relname, relpages FROM pg_class ORDER BY relpages DESC LIMIT 1;relname — имя таблицы, индекса, представления и т.п.
relpages — размер представления этой таблицы на диске в количествах страниц (по умолчанию одна страницы равна 8 Кб).
pg_class — системная таблица, которая содержит информацию о связях таблиц базы данных.
Перечень подключенных пользователей
Чтобы узнать имя, IP и используемый порт подключенных пользователей, выполним следующий запрос:
SELECT datname,usename,client_addr,client_port FROM pg_stat_activity;Активность пользователя
Чтобы узнать активность соединения конкретного пользователя, используем следующий запрос:
SELECT datname FROM pg_stat_activity WHERE usename = 'devuser';Работа с данными и полями таблиц
Удаление одинаковых строк
Если так получилось, что в таблице нет первичного ключа (primary key), то наверняка среди записей найдутся дубликаты. Если для такой таблицы, особенно большого размера, необходимо поставить ограничения (constraint) для проверки целостности, то удалим следующие элементы:
- дублирующиеся строки,
- ситуации, когда одна или более колонок дублируются (если эти колонки предполагается использовать в качестве первичного ключа).
Рассмотрим таблицу с данными покупателей, где задублирована целая строка (вторая по счёту).
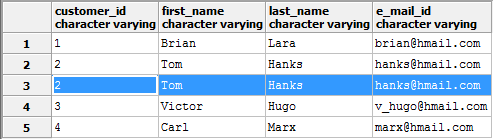
Удалить все дубликаты поможет следующий запрос:
DELETE FROM customers WHERE ctid NOT IN
(SELECT max(ctid) FROM customers GROUP BY customers.*);Уникальное для каждой записи поле ctid по умолчанию скрыто, но оно есть в каждой таблице.
Последний запрос требователен к ресурсам, поэтому будьте аккуратны при его выполнении на рабочем проекте.
Теперь рассмотрим случай, когда повторяются значения полей.
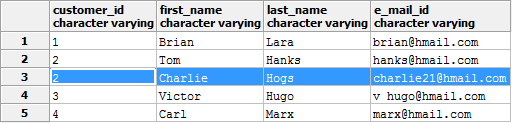
Если допустимо удаление дубликатов без сохранения всех данных, выполним такой запрос:
DELETE FROM customers WHERE ctid NOT IN
(SELECT max(ctid) FROM customers GROUP BY customer_id);Если данные важны, то сначала нужно найти записи с дубликатами:
SELECT * FROM customers WHERE ctid NOT IN
(SELECT max(ctid) FROM customers GROUP BY customer_id);
Перед удалением такие записи можно перенести во временную таблицу или заменить в них значение customer_id на другое.
Общая форма запроса на удаление описанных выше записей выглядит следующим образом:
DELETE FROM table_name WHERE ctid NOT IN (SELECT max(ctid) FROM table_name GROUP BY column1, [column 2,] );Безопасное изменение типа поля
Может возникнуть вопрос о включении в этот список такой задачи. Ведь в PostgreSQL изменить тип поля очень просто с помощью команды ALTER. Давайте для примера снова рассмотрим таблицу с покупателями.
Для поля customer_id используется строковый тип данных varchar. Это ошибка, так как в этом поле предполагается хранить идентификаторы покупателей, которые имеют целочисленный формат integer. Использование varchar неоправданно. Попробуем исправить это недоразумение с помощью команды ALTER:
ALTER TABLE customers ALTER COLUMN customer_id TYPE integer;Но в результате выполнения получим ошибку:
ERROR: column “customer_id” cannot be cast automatically to type integer
SQL state: 42804
Hint: Specify a USING expression to perform the conversion.
Это значит, что нельзя просто так взять и изменить тип поля при наличии данных в таблице. Так как использовался тип varchar, СУБД не может определить принадлежность значения к integer. Хотя данные соответствуют именно этому типу. Для того, чтобы уточнить этот момент, в сообщении об ошибке предлагается использовать выражение USING, чтобы корректно преобразовать наши данные в integer:
ALTER TABLE customers ALTER COLUMN customer_id TYPE integer USING (customer_id::integer);В результате всё прошло без ошибок:

Обратите внимание, что при использовании USING кроме конкретного выражения возможно использование функций, других полей и операторов.
Например, преобразуем поле customer_id обратно в varchar, но с преобразованием формата данных:
ALTER TABLE customers ALTER COLUMN customer_id TYPE varchar USING (customer_id || '-' || first_name);В результате таблица примет следующий вид:
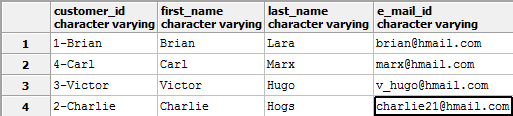
Поиск «потерянных» значений
Будьте внимательны при использовании последовательностей (sequence) в качестве первичного ключа (primary key): при назначении некоторые элементы последовательности случайно пропускаются, в результате работы с таблицей некоторые записи удаляются. Такие значения можно использовать снова, но найти их в больших таблицах сложно.

Рассмотрим два варианта поиска.
Первый способ
Выполним следующий запрос, чтобы найти начало интервала с «потерянным» значением:
SELECT customer_id + 1
FROM customers mo
WHERE NOT EXISTS
(
SELECT NULL
FROM customers mi
WHERE mi.customer_id = mo.customer_id + 1
)
ORDER BY customer_id;В результате получим значения: 5, 9 и 11.
Если нужно найти не только первое вхождение, а все пропущенные значения, используем следующий (ресурсоёмкий!) запрос:
WITH seq_max AS (
SELECT max(customer_id) FROM customers
),
seq_min AS (
SELECT min(customer_id) FROM customers
)
SELECT * FROM generate_series((SELECT min FROM seq_min),(SELECT max FROM seq_max))
EXCEPT
SELECT customer_id FROM customers;В результате видим следующий результат: 5, 9 и 6.
Второй способ
Получаем имя последовательности, связанной с customer_id:
SELECT pg_get_serial_sequence('customers', 'customer_id');И находим все пропущенные идентификаторы:
WITH sequence_info AS (
SELECT start_value, last_value FROM "SchemaName"."SequenceName"
)
SELECT generate_series ((sequence_info.start_value), (sequence_info.last_value))
FROM sequence_info
EXCEPT
SELECT customer_id FROM customers;Подсчёт количества строк в таблице
Количество строк вычисляется стандартной функцией count, но её можно использовать с дополнительными условиями.
Общее количество строк в таблице:
SELECT count(*) FROM table;Количество строк при условии, что указанное поле не содержит NULL:
SELECT count(col_name) FROM table;Количество уникальных строк по указанному полю:
SELECT count(distinct col_name) FROM table;Использование транзакций
Транзакция объединяет последовательность действий в одну операцию. Её особенность в том, что при ошибке в выполнении транзакции ни один из результатов действий не сохранится в базе данных.
Начнём транзакцию с помощью команды BEGIN.
Для того, чтобы откатить все операции, расположенные после BEGIN, используем команду ROLLBACK.
А чтобы применить — команду COMMIT.
Просмотр и завершение исполняемых запросов
Для того, чтобы получить информацию о запросах, выполним следующую команду:
SELECT pid, age(query_start, clock_timestamp()), usename, query
FROM pg_stat_activity
WHERE query != '<IDLE>' AND query NOT ILIKE '%pg_stat_activity%'
ORDER BY query_start desc;Для того, чтобы остановить конкретный запрос, выполним следующую команду, с указанием id процесса (pid):
SELECT pg_cancel_backend(procpid);Для того, чтобы прекратить работу запроса, выполним:
SELECT pg_terminate_backend(procpid);Работа с конфигурацией
Поиск и изменение расположения экземпляра кластера
Возможна ситуация, когда на одной операционной системе настроено несколько экземпляров PostgreSQL, которые «сидят» на различных портах. В этом случае поиск пути к физическому размещению каждого экземпляра — достаточно нервная задача. Для того, чтобы получить эту информацию, выполним следующий запрос для любой базы данных интересующего кластера:
SHOW data_directory;Изменим расположение на другое с помощью команды:
SET data_directory to new_directory_path;Но для того, чтобы изменения вступили в силу, требуется перезагрузка.
Получение перечня доступных типов данных
Получим перечень доступных типов данных с помощью команды:
SELECT typname, typlen from pg_type where typtype='b';typname — имя типа данных.
typlen — размер типа данных.
Изменение настроек СУБД без перезагрузки
Настройки PostgreSQL находятся в специальных файлах вроде postgresql.conf и pg_hba.conf. После изменения этих файлов нужно, чтобы СУБД снова получила настройки. Для этого производится перезагрузка сервера баз данных. Понятно, что приходится это делать, но на продакшн-версии проекта, которым пользуются тысячи пользователей, это очень нежелательно. Поэтому в PostgreSQL есть функция, с помощью которой можно применить изменения без перезагрузки сервера:
SELECT pg_reload_conf();Но, к сожалению, она применима не ко всем параметрам. В некоторых случаях для применения настроек перезагрузка обязательна.
Мы рассмотрели команды, которые помогут упростить работу разработчикам и администраторам баз данных, использующим PostgreSQL. Но это далеко не все возможные приёмы. Если вы сталкивались с интересными задачами, напишите о них в комментариях. Поделимся полезным опытом!
По материалам «10 Most Useful PostgreSQL Commands with Examples» и «15 Advanced PostgreSQL Commands with Examples»
