Функция
ЛИНЕЙН()
специально создана для оценки параметров линейной регрессии, а также для вывода регрессионной статистики (коэффициента детерминации, стандартных ошибок,
F
-статистики
и др.).
Функция
ЛИНЕЙН()
может использоваться для
простой регрессии
(в этом случае прогнозируемая переменная Y зависит от одной контролируемой переменной Х) и для
множественной регрессии
(Y зависит от нескольких Х).
Рассмотрим функцию на примере
простой регрессии
(оценивается
наклон
и
сдвиг
линии регрессии). Использование функции в случае
множественной регрессии
рассмотрено в соответствующей статье про
множественную регрессию
.
Функция
ЛИНЕЙН()
возвращает несколько значений, поэтому для вывода результатов потребуется несколько ячеек. Часто функцию вводят как
формулу массива
: нажатием клавиш
CTRL
+
SHIFT
+
ENTER
,
но, как будет показано ниже, для вывода результатов вычислений это не обязательно.
Функция работает в 2-х режимах. В простейшем случае, когда 4-й аргумент функции опущен или установлен ЛОЖЬ, функция возвращает только 2 значения — это оценки параметров модели: наклона a и сдвига b.
Для того, чтобы вычислить оценки:
- выделите 2 ячейки в одной строке,
- в
Строке формул
введите, например, =
ЛИНЕЙН(C23:C83;B23:B83)
- нажмите
CTRL
+
SHIFT
+
ENTER
.
В левой ячейке будет рассчитано значение
наклона
, в правой –
сдвига
.
Примечание
: В справке MS EXCEL результат функции
ЛИНЕЙН()
соответствующий
наклону
обозначается буквой m, а
сдвиг
– буквой b.
Примечание
: Без
формул массива
можно обойтись. Для этого нужно использовать функцию
ИНДЕКС()
, которая выведет нужное значение. Например, чтобы вывести величину
сдвига
линии регрессии введите формулу =
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1;2)
. Если 4-й аргумент функции опущен или установлен ЛОЖЬ, то функция
ЛИНЕЙН()
в возвращает массив значений вида 1х2 (т.е. 2 ячейки, расположенные в одной строке). Поэтому, для вывода величины
сдвига
прямой линии регрессии, первый аргумент функции
ИНДЕКС()
, который является номером строки, должен быть равен 1, а второй аргумент, номер столбца, должен быть равен 2. Чтобы вывести значение
наклона
линии регрессии формулу
=ЛИНЕЙН(C23:C83;B23:B83)
достаточно ввести просто как обычную формулу и нажать
ENTER
. Конечно, можно использовать и формулу
=ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1;1)
.
Теперь о втором, более сложном режиме функции. Этот режим нужно использовать, если требуется вывести дополнительную статистику (4-й аргумент функции должен быть установлен ИСТИНА). В этом случае функция
ЛИНЕЙН()
возвращает 10 значений в диапазоне 5х2 ячеек (5 строк и 2 столбца). Как и в более простом режиме, в первой строке возвращаются оценки параметров модели:
наклона
и
сдвига
.
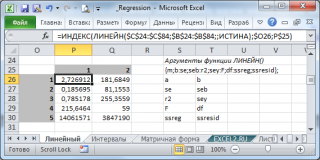
Чтобы ввести функцию как
формулу массива
выполните следующие действия:
- выделите диапазон 5х2 ячеек (2 столбца и 5 строк),
- в
Строке формул
введите формулу
ЛИНЕЙН($C$23:$C$83;$B$23:$B$83;;ИСТИНА)
- чтобы ввести формулу нажмите одновременно комбинацию клавиш
CTRL
+
SHIFT
+
ENTER
Примечание
: Чтобы обойтись без
формул массива
нужно использовать функцию
ИНДЕКС()
, которая выведет нужное значение. Например, чтобы вывести
коэффициент детерминации
R
2
введите формулу =
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3;1)
. 3 – это номер строки диапазона 5х2, а 1 – это номер столбца. В
файле примера на листе Линейный
в диапазоне
Q
26:
R
30
показано как вывести все значения, возвращаемые функцией
ЛИНЕЙН()
без
формул массива
.
Итак, установив 4-й аргумент равным ИСТИНА и введя функцию тем или иным способом, функция выведет:
- в строке 1:
оценки параметров модели
(наклон и сдвиг).
- в строке 2:
Стандартные ошибки для наклона и сдвига
. Ошибки обозначаются se и seb;
- в строке 3:
коэффициент детерминации
и
стандартную ошибку регрессии
. Обозначаются R
2
и SEy; - в строке 4:
значение F-статистики и число степеней свободы
. Обозначаются F и df;
- в строке 5: Суммы квадратов SSR, SSE определяющие
изменчивость объясненную и необъясненную моделью
(см. в статьеПростая линейная регрессия
разделы про коэффициент детерминации и
статью про F-тест
). В справке MS EXCEL SSR, SSE обозначаются как
ssreg
(Regression Sum of Squares) и
ssresid
(Residuals Sum of Squares) соответственно.
Примечание
: Разобраться в значениях, возвращаемых функцией
ЛИНЕЙН()
, можно лишь разобравшись в теории линейной регрессии.
В
файле примера
также приведены формулы, позволяющие сделать расчеты без функции
ЛИНЕЙН()
– см. диапазон
Q
34:
R
38
. Альтернативные формулы помогают разобраться в алгоритме расчета вышеуказанных статистических показателей.
Содержание
- Подключение пакета анализа
- Виды регрессионного анализа
- Линейная регрессия в программе Excel
- Разбор результатов анализа
- Вопросы и ответы

Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Подключение пакета анализа
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
- Перемещаемся во вкладку «Файл».
- Переходим в раздел «Параметры».
- Открывается окно параметров Excel. Переходим в подраздел «Надстройки».
- В самой нижней части открывшегося окна переставляем переключатель в блоке «Управление» в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «Перейти».
- Открывается окно доступных надстроек Эксель. Ставим галочку около пункта «Пакет анализа». Жмем на кнопку «OK».





Теперь, когда мы перейдем во вкладку «Данные», на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных».

Виды регрессионного анализа
Существует несколько видов регрессий:
- параболическая;
- степенная;
- логарифмическая;
- экспоненциальная;
- показательная;
- гиперболическая;
- линейная регрессия.
О выполнении последнего вида регрессионного анализа в Экселе мы подробнее поговорим далее.
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк. В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.
- Кликаем по кнопке «Анализ данных». Она размещена во вкладке «Главная» в блоке инструментов «Анализ».
- Открывается небольшое окошко. В нём выбираем пункт «Регрессия». Жмем на кнопку «OK».
- Открывается окно настроек регрессии. В нём обязательными для заполнения полями являются «Входной интервал Y» и «Входной интервал X». Все остальные настройки можно оставить по умолчанию.
В поле «Входной интервал Y» указываем адрес диапазона ячеек, где расположены переменные данные, влияние факторов на которые мы пытаемся установить. В нашем случае это будут ячейки столбца «Количество покупателей». Адрес можно вписать вручную с клавиатуры, а можно, просто выделить требуемый столбец. Последний вариант намного проще и удобнее.
В поле «Входной интервал X» вводим адрес диапазона ячеек, где находятся данные того фактора, влияние которого на переменную мы хотим установить. Как говорилось выше, нам нужно установить влияние температуры на количество покупателей магазина, а поэтому вводим адрес ячеек в столбце «Температура». Это можно сделать теми же способами, что и в поле «Количество покупателей».

С помощью других настроек можно установить метки, уровень надёжности, константу-ноль, отобразить график нормальной вероятности, и выполнить другие действия. Но, в большинстве случаев, эти настройки изменять не нужно. Единственное на что следует обратить внимание, так это на параметры вывода. По умолчанию вывод результатов анализа осуществляется на другом листе, но переставив переключатель, вы можете установить вывод в указанном диапазоне на том же листе, где расположена таблица с исходными данными, или в отдельной книге, то есть в новом файле.
После того, как все настройки установлены, жмем на кнопку «OK».






Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
В предыдущих заметках предметом анализа часто становилась отдельная числовая переменная, например, доходность взаимных фондов, время загрузки Web-страницы или объем потребления безалкогольных напитков. В настоящей и следующих заметках мы рассмотрим методы предсказания значений числовой переменной в зависимости от значений одной или нескольких других числовых переменных.
Материал будет проиллюстрирован сквозным примером. Прогнозирование объема продаж в магазине одежды.
Сеть магазинов уцененной одежды Sunflowers на протяжении 25 лет постоянно расширялась. Однако в настоящее время у компании нет систематического подхода к выбору новых торговых точек. Место, в котором компания собирается открыть новый магазин, определяется на основе субъективных соображений. Критериями выбора являются выгодные условия аренды или представления менеджера об идеальном местоположении магазина. Представьте, что вы — руководитель отдела специальных проектов и планирования. Вам поручили разработать стратегический план открытия новых магазинов. Этот план должен содержать прогноз годового объема продаж во вновь открываемых магазинах. Вы полагаете, что торговая площадь непосредственно связана с объемом выручки, и хотите учесть этот факт в процессе принятия решения. Как разработать статистическую модель, позволяющую прогнозировать годовой объем продаж на основе размера нового магазина?
Как правило, для предсказания значений переменной используется регрессионный анализ. Его цель — разработать статистическую модель, позволяющую предсказывать значения зависимой переменной, или отклика, по значениям, по крайней мере одной, независимой, или объясняющей, переменной. В настоящей заметке мы рассмотрим простую линейную регрессию — статистический метод, позволяющий предсказывать значения зависимой переменной Y
по значениям независимой переменной X
. В последующих заметках будет описана модель множественной регрессии, предназначенная для предсказания значений независимой переменной Y
по значениям нескольких зависимых переменных (Х 1 , Х 2 , …, X k
).
Скачать заметку в формате или , примеры в формате
Виды регрессионных моделей
где ρ
1
– коэффициент автокорреляции; если ρ
1
= 0 (нет автокорреляции), D
≈ 2; если ρ
1
≈ 1 (положительная автокорреляции), D
≈ 0; если ρ
1
= -1 (отрицательная автокорреляции), D
≈ 4.
На практике применение критерия Дурбина-Уотсона основано на сравнении величины D
с критическими теоретическими значениями d L
и d U
для заданного числа наблюдений n
, числа независимых переменных модели k
(для простой линейной регрессии k
= 1) и уровня значимости α. Если D < d L
, гипотеза о независимости случайных отклонений отвергается (следовательно, присутствует положительная автокорреляция); если D > d U
, гипотеза не отвергается (то есть автокорреляция отсутствует); если d L < D < d U
, нет достаточных оснований для принятия решения. Когда расчётное значение D
превышает 2, то с d L
и d U
сравнивается не сам коэффициент D
, а выражение (4 – D
).
Для вычисления статистики Дурбина-Уотсона в Excel обратимся к нижней таблице на рис. 14 Вывод остатка
. Числитель в выражении (10) вычисляется с помощью функции =СУММКВРАЗН(массив1;массив2), а знаменатель =СУММКВ(массив) (рис. 16).

Рис. 16. Формулы расчета статистики Дурбина-Уотсона
В нашем примере D
= 0,883. Основной вопрос заключается в следующем — какое значение статистики Дурбина-Уотсона следует считать достаточно малым, чтобы сделать вывод о существовании положительной автокорреляции? Необходимо соотнести значение D с критическими значениями (d L
и d U
), зависящими от числа наблюдений n
и уровня значимости α (рис. 17).

Рис. 17. Критические значения статистики Дурбина-Уотсона (фрагмент таблицы)
Таким образом, в задаче об объеме продаж в магазине, доставляющем товары на дом, существуют одна независимая переменная (k
= 1), 15 наблюдений (n
= 15) и уровень значимости α = 0,05. Следовательно, d L
= 1,08 и d
U
= 1,36. Поскольку D
= 0,883 < d L
= 1,08, между остатками существует положительная автокорреляция, метод наименьших квадратов применять нельзя.
Проверка гипотез о наклоне и коэффициенте корреляции
Выше регрессия применялась исключительно для прогнозирования. Для определения коэффициентов регрессии и предсказания значения переменной Y
при заданной величине переменной X
использовался метод наименьших квадратов. Кроме того, мы рассмотрели среднеквадратичную ошибку оценки и коэффициент смешанной корреляции. Если анализ остатков подтверждает, что условия применимости метода наименьших квадратов не нарушаются, и модель простой линейной регрессии является адекватной, на основе выборочных данных можно утверждать, что между переменными в генеральной совокупности существует линейная зависимость.
Применение
t
-критерия для наклона.
Проверяя, равен ли наклон генеральной совокупности β 1 нулю, можно определить, существует ли статистически значимая зависимость между переменными X
и Y
. Если эта гипотеза отклоняется, можно утверждать, что между переменными X
и Y
существует линейная зависимость. Нулевая и альтернативная гипотезы формулируются следующим образом: Н 0: β 1 = 0 (нет линейной зависимости), Н1: β 1 ≠ 0 (есть линейная зависимость). По определению t
-статистика равна разности между выборочным наклоном и гипотетическим значением наклона генеральной совокупности, деленной на среднеквадратичную ошибку оценки наклона:
(11)
t
= (b
1
–
β
1
) /
S b
1
где b
1
– наклон прямой регрессии по выборочным данным, β1 – гипотетический наклон прямой генеральной совокупности, ![]() , а тестовая статистика t
, а тестовая статистика t
имеет t
-распределение с n – 2
степенями свободы.
Проверим, существует ли статистически значимая зависимость между размером магазина и годовым объемом продаж при α = 0,05. t
-критерий выводится наряду с другими параметрами при использовании Пакета анализа
(опция Регрессия
). Полностью результаты работы Пакета анализа приведены на рис. 4, фрагмент, относящийся к t-статистике – на рис. 18.
Рис. 18. Результаты применения t
Поскольку число магазинов n
= 14 (см. рис.3), критическое значение t
-статистики при уровне значимости α = 0,05 можно найти по формуле: t L
=СТЬЮДЕНТ.ОБР(0,025;12) = –2,1788, где 0,025 – половина уровня значимости, а 12 = n
– 2; t U
=СТЬЮДЕНТ.ОБР(0,975;12) = +2,1788.
Поскольку t
-статистика = 10,64 > t U
= 2,1788 (рис. 19), нулевая гипотеза Н 0
отклоняется. С другой стороны, р
-значение для Х
= 10,6411, вычисляемое по формуле =1-СТЬЮДЕНТ.РАСП(D3;12;ИСТИНА), приближенно равно нулю, поэтому гипотеза Н 0
снова отклоняется. Тот факт, что р
-значение почти равно нулю, означает, что если бы между размерами магазинов и годовым объемом продаж не существовало реальной линейной зависимости, обнаружить ее с помощью линейной регрессии было бы практически невозможно. Следовательно, между средним годовым объемом продаж в магазинах и их размером существует статистически значимая линейная зависимость.

Рис. 19. Проверка гипотезы о наклоне генеральной совокупности при уровне значимости, равном 0,05, и 12 степенях свободы
Применение
F
-критерия для наклона.
Альтернативным подходом к проверке гипотез о наклоне простой линейной регрессии является использование F
-критерия. Напомним, что F
-критерий применяется для проверки отношения между двумя дисперсиями (подробнее см. ). При проверке гипотезы о наклоне мерой случайных ошибок является дисперсия ошибки (сумма квадратов ошибок, деленная на количество степеней свободы), поэтому F
-критерий использует отношение дисперсии, объясняемой регрессией (т.е. величины SSR
, деленной на количество независимых переменных k
), к дисперсии ошибок (MSE = S Y
X
2
).
По определению F
-статистика равна среднему квадрату отклонений, обусловленных регрессией (MSR), деленному на дисперсию ошибки (MSE): F
=
MSR
/
MSE
, где MSR =
SSR
/
k
, MSE =
SSE
/(n
– k – 1), k
– количество независимых переменных в регрессионной модели. Тестовая статистика F
имеет F
-распределение с k
и n
– k – 1
степенями свободы.
При заданном уровне значимости α решающее правило формулируется так: если F > F
U
, нулевая гипотеза отклоняется; в противном случае она не отклоняется. Результаты, оформленные в виде сводной таблицы дисперсионного анализа, приведены на рис. 20.

Рис. 20. Таблица дисперсионного анализа для проверки гипотезы о статистической значимости коэффициента регрессии
Аналогично t
-критерию F
-критерий выводится в таблицу при использовании Пакета анализа
(опция Регрессия
). Полностью результаты работы Пакета анализа
приведены на рис. 4, фрагмент, относящийся к F
-статистике – на рис. 21.

Рис. 21. Результаты применения F
-критерия, полученные с помощью Пакета анализа Excel
F-статистика равна 113,23, а р
-значение близко к нулю (ячейка Значимость
F
). Если уровень значимости α равен 0,05, определить критическое значение F
-распределения с одной и 12 степенями свободы можно по формуле F U
=F.ОБР(1-0,05;1;12) = 4,7472 (рис. 22). Поскольку F
= 113,23 > F U
= 4,7472, причем р
-значение близко к 0 < 0,05, нулевая гипотеза Н 0
отклоняется, т.е. размер магазина тесно связан с его годовым объемом продаж.

Рис. 22. Проверка гипотезы о наклоне генеральной совокупности при уровне значимости, равном 0,05, с одной и 12 степенями свободы
Доверительный интервал, содержащий наклон β 1 .
Для проверки гипотезы о существовании линейной зависимости между переменными можно построить доверительный интервал, содержащий наклон β 1 и убедиться, что гипотетическое значение β 1 = 0 принадлежит этому интервалу. Центром доверительного интервала, содержащего наклон β 1 , является выборочный наклон b
1
, а его границами — величины b 1 ±
t n
–2
S b
1
Как показано на рис. 18, b
1
= +1,670, n
= 14, S b
1
= 0,157. t
12
=СТЬЮДЕНТ.ОБР(0,975;12) = 2,1788. Следовательно, b 1 ±
t n
–2
S b
1
= +1,670 ± 2,1788 * 0,157 = +1,670 ± 0,342, или + 1,328 ≤ β 1 ≤ +2,012. Таким образом, наклон генеральной совокупности с вероятностью 0,95 лежит в интервале от +1,328 до +2,012 (т.е. от 1 328 000 до 2 012 000 долл.). Поскольку эти величины больше нуля, между годовым объемом продаж и площадью магазина существует статистически значимая линейная зависимость. Если бы доверительный интервал содержал нуль, между переменными не было бы зависимости. Кроме того, доверительный интервал означает, что каждое увеличение площади магазина на 1 000 кв. футов приводит к увеличению среднего объема продаж на величину от 1 328 000 до 2 012 000 долларов.
Использование
t
-критерия для коэффициента корреляции.
был введен коэффициент корреляции r
, представляющий собой меру зависимости между двумя числовыми переменными. С его помощью можно установить, существует ли между двумя переменными статистически значимая связь. Обозначим коэффициент корреляции между генеральными совокупностями обеих переменных символом ρ. Нулевая и альтернативная гипотезы формулируются следующим образом: Н 0
: ρ = 0 (нет корреляции), Н 1
: ρ ≠ 0 (есть корреляция). Проверка существования корреляции:

где r
= +
, если b
1
> 0, r
= –
, если b
1
< 0. Тестовая статистика t
имеет t
-распределение с n – 2
степенями свободы.
В задаче о сети магазинов Sunflowers r 2
= 0,904, а b 1
— +1,670 (см. рис. 4). Поскольку b 1
> 0, коэффициент корреляции между объемом годовых продаж и размером магазина равен r
= +√0,904 = +0,951. Проверим нулевую гипотезу, утверждающую, что между этими переменными нет корреляции, используя t
-статистику:

При уровне значимости α = 0,05 нулевую гипотезу следует отклонить, поскольку t
= 10,64 > 2,1788. Таким образом, можно утверждать, что между объемом годовых продаж и размером магазина существует статистически значимая связь.
При обсуждении выводов, касающихся наклона генеральной совокупности, доверительные интервалы и критерии для проверки гипотез являются взаимозаменяемыми инструментами. Однако вычисление доверительного интервала, содержащего коэффициент корреляции, оказывается более сложным делом, поскольку вид выборочного распределения статистики r
зависит от истинного коэффициента корреляции.
Оценка математического ожидания и предсказание индивидуальных значений
В этом разделе рассматриваются методы оценки математического ожидания отклика Y
и предсказания индивидуальных значений Y
при заданных значениях переменной X
.
Построение доверительного интервала.
В примере 2 (см. выше раздел Метод наименьших квадратов
) регрессионное уравнение позволило предсказать значение переменной Y
X
. В задаче о выборе места для торговой точки средний годовой объем продаж в магазине площадью 4000 кв. футов был равен 7,644 млн. долл. Однако эта оценка математического ожидания генеральной совокупности является точечной. для оценки математического ожидания генеральной совокупности была предложена концепция доверительного интервала. Аналогично можно ввести понятие доверительного интервала для математического ожидания отклика
при заданном значении переменной X
:
где  , =
, =
b
0
+
b
1
X i
– предсказанное значение переменное Y
при X
= X i
, S YX
– среднеквадратичная ошибка, n
– объем выборки, X
i
— заданное значение переменной X
, µ
Y
| X
=
X
i
– математическое ожидание переменной Y
при Х
= Х i
, SSX = 
Анализ формулы (13) показывает, что ширина доверительного интервала зависит от нескольких факторов. При заданном уровне значимости возрастание амплитуды колебаний вокруг линии регрессии, измеренное с помощью среднеквадратичной ошибки, приводит к увеличению ширины интервала. С другой стороны, как и следовало ожидать, увеличение объема выборки сопровождается сужением интервала. Кроме того, ширина интервала изменяется в зависимости от значений X
i
. Если значение переменной Y
предсказывается для величин X
, близких к среднему значению
, доверительный интервал оказывается уже, чем при прогнозировании отклика для значений, далеких от среднего.
Допустим, что, выбирая место для магазина, мы хотим построить 95%-ный доверительный интервал для среднего годового объема продаж во всех магазинах, площадь которых равна 4000 кв. футов:

Следовательно, средний годовой объем продаж во всех магазинах, площадь которых равна 4 000 кв. футов, с 95% -ной вероятностью лежит в интервале от 6,971 до 8,317 млн. долл.
Вычисление доверительного интервала для предсказанного значения.
Кроме доверительного интервала для математического ожидания отклика при заданном значении переменной X
, часто необходимо знать доверительный интервал для предсказанного значения. Несмотря на то что формула для вычисления такого доверительного интервала очень похожа на формулу (13), этот интервал содержит предсказанное значение, а не оценку параметра. Интервал для предсказанного отклика Y
X
=
Xi
при конкретном значении переменной X
i
определяется по формуле:

Предположим, что, выбирая место для торговой точки, мы хотим построить 95%-ный доверительный интервал для предсказанного годового объема продаж в магазине, площадь которого равна 4000 кв. футов:

Следовательно, предсказанный годовой объем продаж в магазине, площадь которого равна 4000 кв. футов, с 95%-ной вероятностью лежит в интервале от 5,433 до 9,854 млн. долл. Как видим, доверительный интервал для предсказанного значения отклика намного шире, чем доверительный интервал для его математического ожидания. Это объясняется тем, что изменчивость при прогнозировании индивидуальных значений намного больше, чем при оценке математического ожидания.
Подводные камни и этические проблемы, связанные с применением регрессии
Трудности, связанные с регрессионным анализом:
- Игнорирование условий применимости метода наименьших квадратов.
- Ошибочная оценка условий применимости метода наименьших квадратов.
- Неправильный выбор альтернативных методов при нарушении условий применимости метода наименьших квадратов.
- Применение регрессионного анализа без глубоких знаний о предмете исследования.
- Экстраполяция регрессии за пределы диапазона изменения объясняющей переменной.
- Путаница между статистической и причинно-следственной зависимостями.
Широкое распространение электронных таблиц и программного обеспечения для статистических расчетов ликвидировало вычислительные проблемы, препятствовавшие применению регрессионного анализа. Однако это привело к тому, что регрессионный анализ стали применять пользователи, не обладающие достаточной квалификацией и знаниями. Откуда пользователям знать об альтернативных методах, если многие из них вообще не имеют ни малейшего понятия об условиях применимости метода наименьших квадратов и не умеют проверять их выполнение?
Исследователь не должен увлекаться перемалыванием чисел — вычислением сдвига, наклона и коэффициента смешанной корреляции. Ему нужны более глубокие знания. Проиллюстрируем это классическим примером, взятым из учебников. Анскомб показал, что все четыре набора данных, приведенных на рис. 23, имеют одни и те же параметры регрессии (рис. 24).

Рис. 23. Четыре набора искусственных данных

Рис. 24. Регрессионный анализ четырех искусственных наборов данных; выполнен с помощью Пакета анализа
(кликните на рисунке, чтобы увеличить изображение)
Итак, с точки зрения регрессионного анализа все эти наборы данных совершенно идентичны. Если бы анализ был на этом закончен, мы потеряли бы много полезной информации. Об этом свидетельствуют диаграммы разброса (рис. 25) и графики остатков (рис. 26), построенные для этих наборов данных.

Рис. 25. Диаграммы разброса для четырех наборов данных
Диаграммы разброса и графики остатков свидетельствуют о том, что эти данные отличаются друг от друга. Единственный набор, распределенный вдоль прямой линии, — набор А. График остатков, вычисленных по набору А, не имеет никакой закономерности. Этого нельзя сказать о наборах Б, В и Г. График разброса, построенный по набору Б, демонстрирует ярко выраженную квадратичную модель. Этот вывод подтверждается графиком остатков, имеющим параболическую форму. Диаграмма разброса и график остатков показывают, что набор данных В содержит выброс. В этой ситуации необходимо исключить выброс из набора данных и повторить анализ. Метод, позволяющий обнаруживать и исключать выбросы из наблюдений, называется анализом влияния. После исключения выброса результат повторной оценки модели может оказаться совершенно иным. Диаграмма разброса, построенная по данным из набора Г, иллюстрирует необычную ситуацию, в которой эмпирическая модель значительно зависит от отдельного отклика (Х 8
= 19, Y
8
= 12,5). Такие регрессионные модели необходимо вычислять особенно тщательно. Итак, графики разброса и остатков являются крайне необходимым инструментом регрессионного анализа и должны быть его неотъемлемой частью. Без них регрессионный анализ не заслуживает доверия.

Рис. 26. Графики остатков для четырех наборов данных
Как избежать подводных камней при регрессионном анализе:
- Анализ возможной взаимосвязи между переменными X
и Y
всегда начинайте с построения диаграммы разброса. - Прежде чем интерпретировать результаты регрессионного анализа, проверяйте условия его применимости.
- Постройте график зависимости остатков от независимой переменной. Это позволит определить, насколько эмпирическая модель соответствует результатам наблюдения, и обнаружить нарушение постоянства дисперсии.
- Для проверки предположения о нормальном распределении ошибок используйте гистограммы, диаграммы «ствол и листья», блочные диаграммы и графики нормального распределения.
- Если условия применимости метода наименьших квадратов не выполняются, используйте альтернативные методы (например, модели квадратичной или множественной регрессии).
- Если условия применимости метода наименьших квадратов выполняются, необходимо проверить гипотезу о статистической значимости коэффициентов регрессии и построить доверительные интервалы, содержащие математическое ожидание и предсказанное значение отклика.
- Избегайте предсказывать значения зависимой переменной за пределами диапазона изменения независимой переменной.
- Имейте в виду, что статистические зависимости не всегда являются причинно-следственными. Помните, что корреляция между переменными не означает наличия причинно-следственной зависимости между ними.
Резюме.
Как показано на структурной схеме (рис. 27), в заметке описаны модель простой линейной регрессии, условия ее применимости и способы проверки этих условий. Рассмотрен t
-критерий для проверки статистической значимости наклона регрессии. Для предсказания значений зависимой переменной использована регрессионная модель. Рассмотрен пример, связанный с выбором места для торговой точки, в котором исследуется зависимость годового объема продаж от площади магазина. Полученная информация позволяет точнее выбрать место для магазина и предсказать его годовой объем продаж. В следующих заметках будет продолжено обсуждение регрессионного анализа, а также рассмотрены модели множественной регрессии.

Рис. 27. Структурная схема заметки
Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 792–872
Если зависимая переменная является категорийной, необходимо применять логистическую регрессию.
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
· линейной (у = а + bx);
· параболической (y = a + bx + cx 2);
· экспоненциальной (y = a * exp(bx));
· степенной (y = a*x^b);
· гиперболической (y = b/x + a);
· логарифмической (y = b * 1n(x) + a);
· показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
У = а 0 + а 1 х 1 +…+а к х к.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
1. Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».

2. Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
3. Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.

После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.
1. Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».

2. Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.

3. После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).

В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Известна тем, что она полезна в разных областях деятельности, включая и такую дисциплину, как эконометрика, где в работе используется данная программная утилита. В основном все действия практических и лабораторных занятий выполняют в Excel, которая существенно облегчает работу, давая подробные объяснения тех или иных действий. Так, один из инструментов анализа «Регрессия» применяется с целью подбора графика для набора наблюдений за счет метода наименьших квадратов. Рассмотрим, что представляет собой данный инструмент программы и в чем заключается его польза для пользователей. Ниже также предоставлена краткая, но понятная инструкция построения регрессионной модели.
Основные задачи и виды регрессии
Регрессия представляет собой зависимость между заданными переменными, за счет чего можно определить прогноз будущего поведения данных переменных. Переменные — это различные периодические явления, включая и поведение человека. Такой анализ программы Excel применяется для того, чтобы проанализировать воздействие на конкретную зависимую переменную значений одной или некоторым количеством переменных.
К примеру, на продажи в магазине влияет несколько факторов, включая ассортимент, цены и место локализации магазина. Благодаря регрессии в Excel можно определять степень влияния каждого из указанных факторов по результатам имеющихся продаж, а после применить полученные данные для прогнозирования продаж на другой месяц или для другого магазина, расположенного рядом.
Обычно регрессия представлена в виде простого уравнения, раскрывающего зависимости и силу связи между двумя группами переменных, где одна группа является зависимой или эндогенной, а другая — независимой или экзогенной. При наличии группы взаимосвязанных показателей зависимая переменная Y определяется исходя из логики рассуждений, а остальные выступают в роли независимых Х-переменных.
Основные задачи построения регрессионной модели заключаются в следующем:
- Отбор значимых независимых переменных (Х1, Х2, …, Xk).
- Выбор вида функции.
- Построение оценок для коэффициентов.
- Построение доверительных интервалов и функции регрессии.
- Проверка значимости вычисленных оценок и построенного уравнения регрессии.
Регрессионный анализ бывает нескольких видов:
- парный (1 зависимая и 1 независимая переменные);
- множественный (несколько независимых переменных).
Уравнения регрессии бывает двух видов:
- Линейные, иллюстрирующие строгую линейную связь между переменными.
- Нелинейные — уравнения, которые могут включать степени, дроби и тригонометрические функции.
Инструкция построения модели
Чтобы выполнить заданное построение в Excel, необходимо следовать указаниям:

Для дальнейшего вычисления следует использоваться функцию «Линейн ()», указывая Значения Y, Значения Х, Конст и статистику. После этого определите множество точек на линии регрессии с помощью функции «Тенденция» — Значения Y, Значения Х, Новые значения, Конст. При помощи заданных параметров вычислите неизвестное значение коэффициентов, опираясь на заданные условия поставленной задачи.
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2);
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
У = а 0 + а 1 х 1 +…+а к х к.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:


После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.


В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача:
Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» — первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» — второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.

Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
Пример:



Теперь стали видны и данные регрессионного анализа.
Статистическая обработка данных может также проводиться с помощью надстройки ПАКЕТ АНАЛИЗА
(рис. 62).
Из предложенных пунктов выбирает пункт «РЕГРЕССИЯ
» и щелкаем на нем левой кнопкой мыши. Далее нажимаем ОК.
Появится окно, показанное на рис. 63.

Инструмент анализа «РЕГРЕССИЯ
» применяется для подбора графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
Инструмент «Регрессия» использует функцию ЛИНЕЙН
.
Диалоговое окно «РЕГРЕССИЯ»
Метки Установите флажок, если первая строка или первый столбец входного диапазона содержит заголовки. Снимите этот флажок, если заголовки отсутствуют. В этом случае подходящие заголовки для данных выходной таблицы будут созданы автоматически.
Уровень надежности Установите флажок, чтобы включить в выходную таблицу итогов дополнительный уровень. В соответствующее поле введите уровень надежности, который следует применить, дополнительно к уровню 95%, применяемому по умолчанию.
Константа — ноль Установите флажок, чтобы линия регрессии прошла через начало координат.
Выходной интервал Введите ссылку на левую верхнюю ячейку выходного диапазона. Отведите как минимум семь столбцов для выходной таблицы итогов, которая будет включать в себя: результаты дисперсионного анализа, коэффициенты, стандартную погрешность вычисления Y, среднеквадратичные отклонения, число наблюдений, стандартные погрешности для коэффициентов.
Новый рабочий лист Установите переключатель в это положение, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A1. При необходимости введите имя для нового листа в поле, расположенном напротив соответствующего положения переключателя.
Новая рабочая книга Установите переключатель в это положение для создания новой книги, в которой результаты будут добавлены в новый лист.
Остатки Установите флажок для включения остатков в выходную таблицу.
Стандартизированные остатки Установите флажок для включения стандартизированных остатков в выходную таблицу.
График остатков Установите флажок для построения графика остатков для каждой независимой переменной.
График подбора Установите флажок для построения графика зависимости предсказанных значений от наблюдаемых.
График нормальной вероятности
Установите флажок, для построения графика нормальной вероятности.
Функция ЛИНЕЙН
Для проведения расчетов выделяем курсором ячейку, в которой хотим отобразить среднее значение и нажимаем на клавиатуре клавишу =. Далее в поле Имя указываем нужную функцию, например СРЗНАЧ
(рис. 22).
Функция ЛИНЕЙН
рассчитывает статистику для ряда с применением метода наименьших квадратов, чтобы вычислить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные и затем возвращает массив, который описывает полученную прямую. Можно также объединять функцию ЛИНЕЙН
с другими функциями для вычисления других видов моделей, являющихся линейными в неизвестных параметрах (неизвестные параметры которых являются линейными), включая полиномиальные, логарифмические, экспоненциальные и степенные ряды. Поскольку возвращается массив значений, функция должна задаваться в виде формулы массива.
Уравнение для прямой линии имеет следующий вид:
y=m 1 x 1 +m 2 x 2 +…+b (в случае нескольких диапазонов значений x),
где зависимое значение y — функция независимого значения x, значения m — коэффициенты, соответствующие каждой независимой переменной x, а b — постоянная. Обратите внимание, что y, x и m могут быть векторами. Функция ЛИНЕЙН
возвращает массив{mn;mn-1;…;m 1 ;b}. ЛИНЕЙН
может также возвращать дополнительную регрессионную статистику.
ЛИНЕЙН
(известные_значения_y; известные_значения_x; конст; статистика)
Известные_значения_y — множество значений y, которые уже известны для соотношения y=mx+b.
Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная.
Если массив известные_значения_y имеет одну строку, то каждая строка массива известные_значения_x интерпретируется как отдельная переменная.
Известные_значения_x — необязательное множество значений x, которые уже известны для соотношения y=mx+b.
Массив известные_значения_x может содержать одно или несколько множеств переменных. Если используется только одна переменная, то массивы_известные_значения_y и известные_значения_x могут иметь любую форму — при условии, что они имеют одинаковую размерность. Если используется более одной переменной, то известные_значения_y должны быть вектором (т. е. интервалом высотой в одну строку или шириной в один столбец).
Если массив_известные_значения_x опущен, то предполагается, что этот массив {1;2;3;…} имеет такой же размер, как и массив_известные_значения_y.
Конст — логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0.
Если аргумент «конст» имеет значение ИСТИНА или опущен, то константа b вычисляется обычным образом.
Если аргумент «конст» имеет значение ЛОЖЬ, то значение b полагается равным 0 и значения m подбираются таким образом, чтобы выполнялось соотношение y=mx.
Статистика — логическое значение, которое указывает, требуется ли вернуть дополнительную статистику по регрессии.
Если аргумент «статистика» имеет значение ИСТИНА, функция ЛИНЕЙН возвращает дополнительную регрессионную статистику. Возвращаемый массив будет иметь следующий вид: {mn;mn-1;…;m1;b:sen;sen-1;…;se1;seb:r2;sey:F;df:ssreg;ssresid}.
Если аргумент «статистика» имеет значение ЛОЖЬ или опущен, функция ЛИНЕЙН возвращает только коэффициенты m и постоянную b.
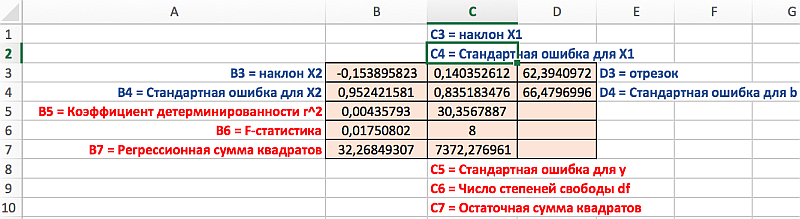
Дополнительная регрессионная статистика.(табл.17)
| Величина | Описание |
| se1,se2,…,sen | Стандартные значения ошибок для коэффициентов m1,m2,…,mn. |
| seb | Стандартное значение ошибки для постоянной b (seb = #Н/Д, если аргумент «конст» имеет значение ЛОЖЬ). |
| r2 | Коэффициент детерминированности. Сравниваются фактические значения y и значения, получаемые из уравнения прямой; по результатам сравнения вычисляется коэффициент детерминированности, нормированный от 0 до 1. Если он равен 1, то имеет место полная корреляция с моделью, т. е. различия между фактическим и оценочным значениями y не существует. В противоположном случае, если коэффициент детерминированности равен 0, использовать уравнение регрессии для предсказания значений y не имеет смысла. Для получения дополнительных сведений о способах вычисления r2, см. «Замечания» в конце данного раздела. |
| sey | Стандартная ошибка для оценки y. |
| F | F-статистика или F-наблюдаемое значение. F-статистика используется для определения того, является ли случайной наблюдаемая взаимосвязь между зависимой и независимой переменными. |
| df | Степени свободы. Степени свободы полезны для нахождения F-критических значений в статистической таблице. Для определения уровня надежности модели необходимо сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН. Для получения дополнительных сведений о вычислении величины df см. «Замечания» в конце данного раздела. Далее в примере 4 показано использование величин F и df. |
| ssreg | Регрессионная сумма квадратов. |
| ssresid | Остаточная сумма квадратов. Для получения дополнительных сведений о расчете величин ssreg и ssresid см. «Замечания» в конце данного раздела. |
На приведенном ниже рисунке показано, в каком порядке возвращается дополнительная регрессионная статистика (рис. 64).

Замечания:
Любую прямую можно описать ее наклоном и пересечением с осью y:
Наклон (m): чтобы определить наклон прямой, обычно обозначаемый через m, нужно взять две точки прямой (x 1 ,y 1) и(x 2 ,y 2); наклон будет равен (y 2 -y 1)/(x 2 -x 1).
Y-пересечение (b): Y-пересечением прямой, обычно обозначаемым через b, является значение y для точки, в которой прямая пересекает ось y.
Уравнение прямой имеет вид y=mx+b. Если известны значения m и b, то можно вычислить любую точку на прямой, подставляя значения y или x в уравнение. Можно также воспользоваться функцией ТЕНДЕНЦИЯ.
Если имеется только одна независимая переменная x, можно получить наклон и y-пересечение непосредственно, воспользовавшись следующими формулами:
Наклон: ИНДЕКС (ЛИНЕЙН(известные_значения_y; известные_значения_x); 1)
Y-пересечение: ИНДЕКС (ЛИНЕЙН (известные_значения_y; известные_значения_x); 2)
Точность аппроксимации с помощью прямой, вычисленной функцией ЛИНЕЙН, зависит от степени разброса данных. Чем ближе данные к прямой, тем более точной является модель, используемая функцией ЛИНЕЙН. Функция ЛИНЕЙН использует метод наименьших квадратов для определения наилучшей аппроксимации данных. Когда имеется только одна независимая переменная x, m и b вычисляются по следующим формулам:

где x и y – выборочные средние значения, например x = СРЗНАЧ (известные_значения_x), а y = СРЗНАЧ (известные_значения_y).
Функции аппроксимации ЛИНЕЙН и ЛГРФПРИБЛ могут вычислить прямую или экспоненциальную кривую, наилучшим образом описывающую данные. Однако они не дают ответа на вопрос, какой из двух результатов больше подходит для решения поставленной задачи. Можно также вычислить функцию ТЕНДЕНЦИЯ (известные_значения_y; известные_значения_x) для прямой или функцию РОСТ(известные_значения_y; известные_значения_x) для экспоненциальной кривой. Эти функции, если не задавать аргумент новые_значения_x, возвращают массив вычисленных значений y для фактических значений x в соответствии с прямой или кривой. После этого можно сравнить вычисленные значения с фактическими значениями. Можно также построить диаграммы для визуального сравнения.
Проводя регрессионный анализ, Microsoft Excel вычисляет для каждой точки квадрат разности между прогнозируемым значением y и фактическим значением y. Сумма этих квадратов разностей называется остаточной суммой квадратов (ssresid). Затем Microsoft Excel подсчитывает общую сумму квадратов (sstotal). Если конст = ИСТИНА или значение этого аргумента не указано, общая сумма квадратов будет равна сумме квадратов разностей действительных значений y и средних значений y. При конст = ЛОЖЬ общая сумма квадратов будет равна сумме квадратов действительных значений y (без вычитания среднего значения y из частного значения y). После этого регрессионную сумму квадратов можно вычислить следующим образом: ssreg = sstotal — ssresid. Чем меньше остаточная сумма квадратов, тем больше значение коэффициента детерминированности r2, который показывает, насколько хорошо уравнение, полученное с помощью регрессионного анализа, объясняет взаимосвязи между переменными. Коэффициент r2 равен ssreg/sstotal.
В некоторых случаях один или более столбцов X (пусть значения Y и X находятся в столбцах) не имеет дополнительного предикативного значения в других столбцах X. Другими словами, удаление одного или более столбцов X может привести к значениям Y, вычисленным с одинаковой точностью. В этом случае избыточные столбцы X будут исключены из модели регрессии. Этот феномен называется «коллинеарностью», поскольку избыточные столбцы X могут быть представлены в виде суммы нескольких неизбыточных столбцов. Функция ЛИНЕЙН проверяет на коллинеарность и удаляет из модели регрессии все избыточные столбцы X, если обнаруживает их. Удаленные столбцы X можно определить в выходных данных ЛИНЕЙН по коэффициенту, равному 0, и по значению se, равному 0. Удаление одного или более столбцов как избыточных изменяет величину df, поскольку она зависит от количества столбцов X, в действительности используемых для предикативных целей. Подробнее о вычислении величины df см. ниже в примере 4. При изменении df вследствие удаления избыточных столбцов значения sey и F также изменяются. Часто использовать коллинеарность не рекомендуется. Однако ее следует применять, если некоторые столбцы X содержат 0 или 1 в качестве индикатора указывающего, входит ли предмет эксперимента в отдельную группу. Если конст = ИСТИНА или значение этого аргумента не указано, функция ЛИНЕЙН вставляет дополнительный столбец X для моделирования точки пересечения. Если имеется столбец со значениями 1 для указания мужчин и 0 — для женщин, а также имеется столбец со значениями 1 для указания женщин и 0 — для мужчин, то последний столбец удаляется, поскольку его значения можно получить из столбца с «индикатором мужского пола».
Вычисление df для случаев, когда столбцы X не удаляются из модели вследствие коллинеарности происходит следующим образом: если существует k столбцов известных_значений_x и значение конст = ИСТИНА или не указано, то df = n – k – 1. Если конст = ЛОЖЬ, то df = n — k. В обоих случаях удаление столбцов X вследствие коллинеарности увеличивает значение df на 1.
Формулы, которые возвращают массивы, должны быть введены как формулы массива.
При вводе массива констант в качестве, например, аргумента известные_значения_x следует использовать точку с запятой для разделения значений в одной строке и двоеточие для разделения строк. Знаки-разделители могут быть различными в зависимости от параметров, заданных в окне «Язык и стандарты» на панели управления.
Следует отметить, что значения y, предсказанные с помощью уравнения регрессии, возможно, не будут правильными, если они располагаются вне интервала значений y, которые использовались для определения уравнения.
Основной алгоритм, используемый в функции ЛИНЕЙН
, отличается от основного алгоритма функций НАКЛОН
и ОТРЕЗОК
. Разница между алгоритмами может привести к различным результатам при неопределенных и коллинеарных данных. Например, если точки данных аргумента известные_значения_y равны 0, а точки данных аргумента известные_значения_x равны 1, то:
Функция ЛИНЕЙН
возвращает значение, равное 0. Алгоритм функции ЛИНЕЙН
используется для возвращения подходящих значений для коллинеарных данных, и в данном случае может быть найден по меньшей мере один ответ.
Функции НАКЛОН и ОТРЕЗОК возвращают ошибку #ДЕЛ/0!. Алгоритм функций НАКЛОН и ОТРЕЗОК используется для поиска только одного ответа, а в данном случае их может быть несколько.
Помимо вычисления статистики для других типов регрессии функцию ЛИНЕЙН можно использовать при вычислении диапазонов для других типов регрессии, вводя функции переменных x и y как ряды переменных х и у для ЛИНЕЙН. Например, следующая формула:
ЛИНЕЙН(значения_y, значения_x^СТОЛБЕЦ($A:$C))
работает при наличии одного столбца значений Y и одного столбца значений Х для вычисления аппроксимации куба (многочлен 3-й степени) следующей формы:
y=m 1 x+m 2 x 2 +m 3 x 3 +b
Формула может быть изменена для расчетов других типов регрессии, но в отдельных случаях требуется корректировка выходных значений и других статистических данных.
Лабораторная
работа №5
«Введение в
множественную регрессию»
Часто приходится
использовать несколько независимых
переменных (![]() )
)
для предсказания значения зависимой
переменной. В этих случаях для оценки
интересующей нас зависимости можно
применять либо вариант множественной
регрессии в Пакете
анализа,
либо функцию ЛИНЕЙН().
Множественная
регрессия предполагает, что зависимость
между y
и
![]()
описывается уравнением вида
![]()
Программа Excel
вычисляет значения Константы
и
![]()
для расчёта с помощью данного уравнения
как можно более точных (с точки зрения
минимизации суммы квадратов ошибок)
прогнозируемых значений.
Наша фабрика
производит три вида изделий. Как можно
предсказать производственные расходы
фабрики на основе количества выпускаемых
изделий?
На рабочем листе
Данные
содержатся текущие производственные
расходы за 19 месяцев, а также количество
штук изделия А, изделия В и изделия С,
выпускаемых каждый месяц (рис. 1).
Найдем наиболее
точный прогноз месячных производственных
расходов вида:
Месячные
производственные расходы = Константа+
+![]() (Произведенные
(Произведенные
изделия А)+ (1)
+![]() (Произведенные
(Произведенные
изделия В)+
+![]() (Произведенные
(Произведенные
изделия С).
Для этого щелкните
кнопкой мыши команду Анализ
данных в
меню Сервис
и в появившемся окне выберите вариант
Регрессия.
Заполните диалоговое окно Регрессия,
как показано на рис. 2.
Поле Входной
интервал Y,
B3:B22,
содержит зависимую переменную или
данные (включая заголовок Расходы),
значения которых мы хотим предсказать.
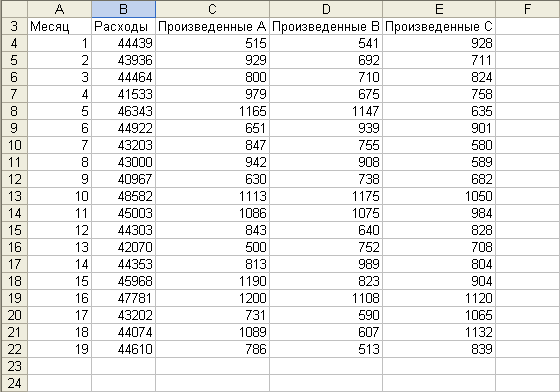
Рис. 1. Данные для
прогнозирования месячных текущих
производственных расходов
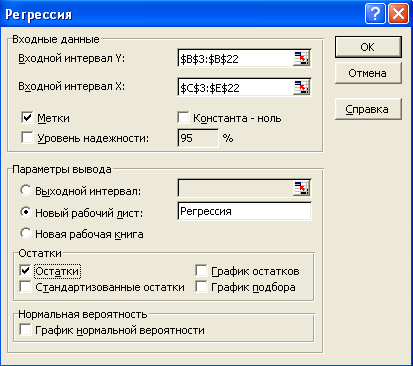
Рис. 2. Диалоговое
окно Регрессия
-
Поле Входной
интервал X,
C3:E22,
содержит данные или независимые
переменные (включая заголовки
ПроизведенныеА,
ПроизведенныеВ,
ПроизведенныеС),
которые мы хотим использовать в прогнозе. -
Поскольку и входной
диапазон x,
и входной диапазон y
включают заголовки, установлен флажок
Метки.
-
Результаты
размещаются на отдельном листе Регрессия. -
Установка флажка
Остатки
позволяет выводить для каждого наблюдения
предсказанное значение, рассчитанное
уравнением (1), и остаток, равный разности
наблюдаемого расхода и предсказанного
значения.
После нажатия
кнопки ОК
мы получим результат, показанный на
рис. 3 и 4.
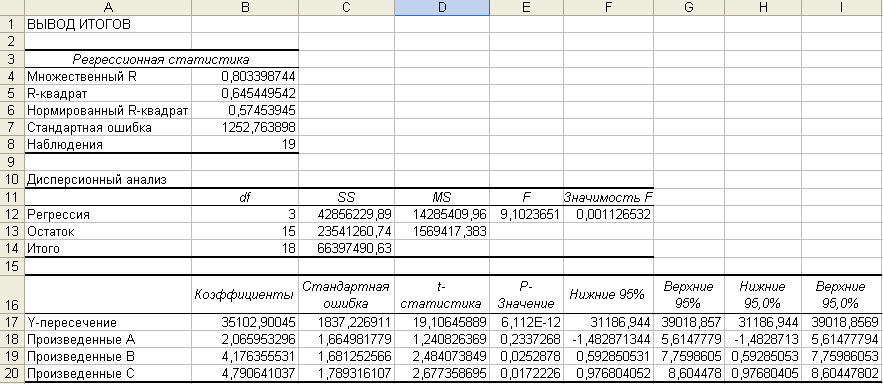
Рис. 3. Результат
расчёта исходной множественной регрессии

Рис. 4. Список
остатков исходной множественной
регрессии
Какое уравнение
прогнозирования можно считать лучшим.
Лучшим уравнением,
применяемым для прогнозирования месячных
расходов (столбец Коэффициенты),
считается следующее:
Прогнозируемые
месячные расходы = 35102.90+
+![]() (Произведенные
(Произведенные
изделия А)+
+![]() (Произведенные
(Произведенные
изделия В)+
+![]() (Произведённые
(Произведённые
изделия С).
Какие из независимых
переменных полезны для предсказания
месячных производственных расходов
Когда мы считаем
показатели регрессии для каждой
независимой переменной, выводится
показатель р-значение,
лежащее между 0 и 1. Любая независимая
переменная с р-значением
(столбец Е), меньшим или равным 0.15,
считается полезной для предсказания
значений зависимой переменной.
Следовательно, чем меньше р-значение,
тем сильнее влияние независимой
переменной на прогноз. У трёх независимых
переменных следующие р-значения:
0.23 (для Произведенные А), 0.025 (для
Произведенные В) и 0.017 (для Произведенные
С). Эти значения можно трактовать
следующим образом:
-
Когда для
предсказания месячных производственных
расходов используются переменные
Произведенные В и Произведенные С,
вероятность того, что переменная
Произведенные А повысит точность
прогноза, равна 77% (1-0.23). -
Когда для
предсказания месячных производственных
расходов используются переменные
Произведенные А и Произведенные С,
вероятность того, что переменная
Произведенные В повысит точность
прогноза, равна 97.5% (1-0.025). -
Когда для
предсказания месячных производственных
расходов используются переменные
Произведенные А и Произведенные В,
вероятность того, что переменная
Произведенные С повысит точность
прогноза, равна 98.3% (1-0.017).
Величины наших
р-значений
показывают, что переменная Произведенные
А не слишком усиливает прогнозирующую
способность переменных Произведенные
В и Произведенные С, т.е. если у нас есть
Произведенные В и Произведенные С, мы
можем предсказать месячные производственные
расходы примерно так же хорошо, как если
бы мы включили в прогноз ещё и переменную
Произведенные А в качестве независимой
переменной. Следовательно, мы можем
попробовать удалить из прогноза
независимую переменную Произведенные
А.
Скопируйте данные
на рабочий лист А
удалены и
удалите столбец Произведенные
А (столбец
С). Затем исправьте входной диапазон x
на C3:D22.
Результат представлен на листе Без
А (рис. 5 и
6).
У обеих переменных
Произведенные В и Произведенные С очень
низкие р-значения
(0.002 и 0.007). Они указывают на наличие у
обеих переменных значительной
прогнозирующей способности. С помощью
новых коэффициентов можно предсказать:
Прогнозируемые
месячные расходы = 35475+
+![]() (Произведенные
(Произведенные
В)+
+![]() (Произведенные
(Произведенные
С).

Рис. 5. Параметры
множественной регрессии без данных
независимой переменной Произведенные
А
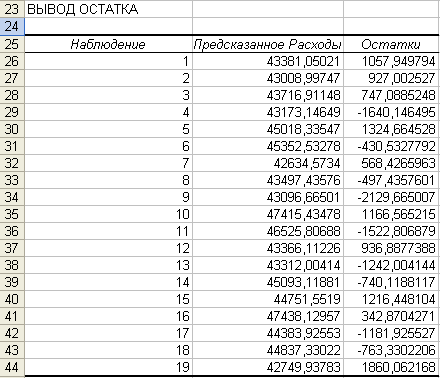
Рис. 6. Перечень
остатков, вычисленных после удаления
данных независимой переменной
Произведенные А
Насколько точны
прогнозы месячных производственных
расходов, основанные на объёме выпускаемой
продукции.
На рабочем листе
Без А
с параметрами регрессии в ячейке В5
приведен показатель достоверности
аппроксимации R2=0.61.
Подобное значение R2
указывает,
что переменные Произведенные В и
Произведенные С вместе обуславливают
61% колебаний месячных производственных
расходов. В параметрах первоначальной
регрессии, включающей независимую
переменную Произведенные А, R2=0.65.
Это означает, что включение независимой
переменной Произведенные А объясняет
только дополнительные 4% колебаний
текущих производственных расходов.
Столь малая разница согласуется с
решением удалить из анализа независимую
переменную Произведенные А.
В выходных параметрах
регрессии на листе Без
А, в ячейке
В7, стандартная ошибка регрессии с
независимыми переменными Произведенные
В и Произведенные С равна 1274. Мы
рассчитываем, что 68% наших прогнозов с
помощью нашей регрессии будут точны в
пределах одной стандартной ошибки, и
95% прогнозов с помощью множественной
регрессии будут определены с точностью
в пределах двух стандартных ошибок.
Любой прогноз, отличающийся от
действительного значения более чем на
2 стандартные ошибки, рассматривается
как выброс. Следовательно, если у
прогнозируемого значения текущих
производственных расходов ошибка 2548
(2![]() 1274),
1274),
руб., считаем это наблюдение выбросом.
В разделе остатков
регрессионного анализа даётся для
каждого наблюдения прогнозируемое
значение расходов и остаток, равный
реальным расходам, уменьшенным на
величину прогнозируемого значения
расходов. Например, для первого наблюдения
мы предсказали расходы, равные 43 381,10
руб. Остаток 1057,95 руб. означает, что
прогноз меньше реального значения на
1057,95 руб.
Расчёт показателей
множественной регрессии с помощью
функции ЛИНЕЙН().
У функции ЛИНЕЙН()
следующая синтаксическая запись
ЛИНЕЙН
(известные_значения_y;
известные_значения_x;ИСТИНА;ИСТИНА)
Если третий аргумент
равен ЛОЖЬ, в уравнении отсутствует
константа. Изменение четвёртого аргумента
на ЛОЖЬ приведет к пропуску расчёта
большого числа параметров регрессии,
и функция ЛИНЕЙН() вернёт только уравнение
множественной регрессии.
Для применения
функции ЛИНЕЙН() к m
независимым переменным на рабочем листе
А удалены
выделите диапазон F5:H9.
Введите формулу
=ЛИНЕЙН(B4:B22;
C4:D22;
ИСТИНА; ИСТИНА). Затем нажмите
<Ctrl>+<Shift>+<Enter>.
Результат представлен на рис. 7.
В строке 5 находится
описание уравнения прогнозирования
(коэффициенты приводятся справа налево,
начиная с константы):
Прогнозируемые
месячные расходы = 35475.3+
+![]() (Произведенные
(Произведенные
В)+![]() (Произведенные
(Произведенные
изделия С).
В строке 6 содержатся
стандартные ошибки приближенного
расчёта всех коэффициентов, но они не
слишком важны. В ячейке F7
приведено значение R2=0.61,
а в ячейке G7
– стандартная ошибка регрессии, равная
1274. В строках 8 и 9 содержится информация
(F-статистика,
степени свободы, регрессионная сумма
квадратов и остаточная сумма квадратов),
которая тоже не имеет большого значения.

Рис. 7. Применение
функции ЛИНЕЙН() для вычисления параметров
множественной регрессии
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Задача отыскания функциональной зависимости очень важна, поэтому для ее решения в MS Excel введен набор функций, основанных на методе наименьших квадратов. В качестве результата выдаются не только коэффициенты функции, приближающей данные, но и статистические характеристики полученных результатов.
Смысл выходной статистической информации функции ЛИНЕЙН
Функция ЛИНЕЙН рассчитывает статистику для ряда с применением метода наименьших квадратов, вычисляя прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные. Функция возвращает массив, который описывает полученную прямую.
Общий синтаксис вызова функции ЛИНЕЙН имеет следующий вид:
ЛИНЕЙН(известные_значения_y;известные_значения_x;конст;статистика)
Для работы с функцией необходимо заполнить как минимум 1 обязательный и при необходимости 3 необязательных аргумента:
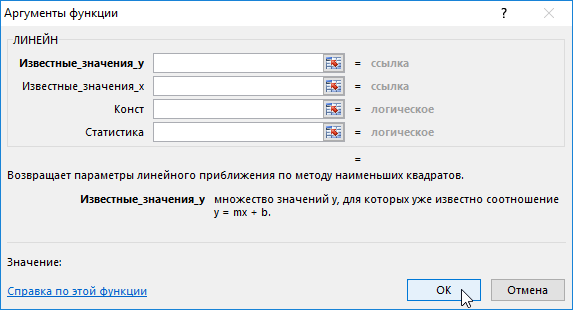
- Известные_значения_y − это множество значений y, которые уже известны для соотношения y=mx+b.
- Известные_значения_x − это множество известных значений x. Если этот аргумент опущен, то предполагается, что это массив {1; 2; 3; …} такого же размера, как и известные_значения_y.
- Конст − это логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0. Если в функции ЛИНЕЙН аргумент константа имеет значение ЛОЖЬ, то b полагается равным 0 и значения m подбираются так, чтобы выполнялось соотношение y = mx.
- Статистика − это логическое значение, которое указывает, требуется ли выдать дополнительную статистику по регрессии.
Примеры использования функции ЛИНЕЙН в Excel
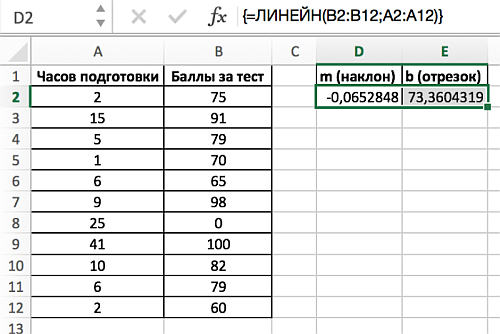
Для решения первой задачи – о соотношении часов подготовки студентов к тесту и результатов теста, как х и у соответственно, – необходимо применить следующий порядок действий (в связи с тем, что ЛИНЕЙН является функцией, которая возвращает массив):
- Выделите диапазон D2:Е2, так как функция ЛИНЕЙН возвращает массив из двух значений, расположенных по горизонтали, но не по вертикали.
- Введите известные значения y – баллы, которые студенты заработали на последнем тестировании (диапазон ячеек В2:В12).
- Затем введите известные значения х – количество часов, которые студенты потратили на подготовку к тестам (диапазон А2:А12).
- Опустите аргумент [конст].
- Опустите аргумент [статистика].
- Введите формулу с помощью Ctrl+Shift+Enter.
Результатом применения функции становится:
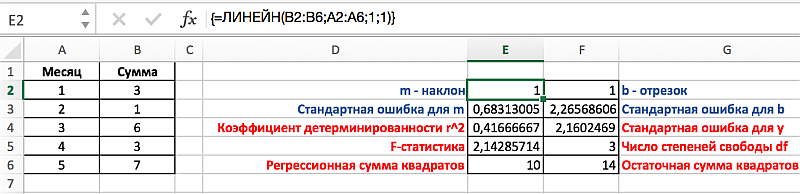
Теперь, на примере решения второй задачи, разберем необходимость в отображении не только наклона и отрезка, но и дополнительной статистики. Для примера, на диапазоне А1:В6 выстроим таблицу с соотношением у и х соответствующих сумме заработка студентом денежных средств за период в 5 месяцев. Так как мы имеем лишь одну переменную х, то необходимо выделить диапазон состоящий из двух столбцов и пяти строк. Важно отметить, что в том случае, если переменных х будет больше, то количество столбцов может изменяться соответственно их количеству, однако строк будет всегда 5.
Применительно к решаемой нами задаче, выделим диапазон Е2:F6, затем введем формулу аналогично предыдущей задаче, но в данном случае третьему и четвертому аргументу присвоим значение 1 соответствующее ИСТИНЕ. Для вывода параметров статистики функции ЛИНЕЙН необходимо нажат Ctrl+Shift+Enter, результат должен соответствовать следующему рисунку, на котором представлено обозначение дополнительных статистик:
Вернемся к примеру № 1, касающемуся зависимости между часами подготовки студентов к тесту и баллов за тест. Добавим к условию задачи данные о баллах за домашнее задание — представляющие дополнительную переменную х, что свидетельствует о необходимости применения множественной регрессии.
В случае множественной регрессии, когда значения «y» зависят от двух переменных «х», функция ЛИНЕЙН возвращает 12 статистик. На рисунке с модифицированной таблицей от 1 примера, представленном ниже используются следующие обозначения:
- y = зависимая переменная;
- x1 = независимая переменная 1 = баллы за домашнее задание;
- x2 = независимая переменная 2 = часы подготовки к тесту.
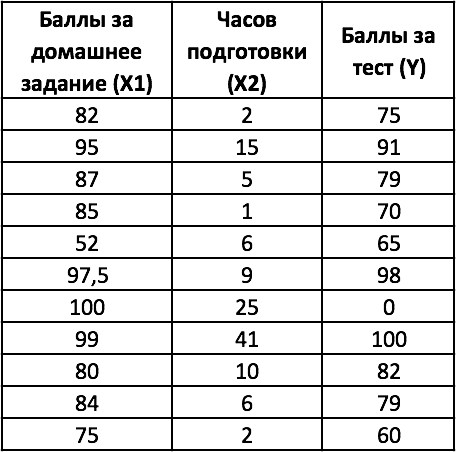
Чтобы выполнить множественную регрессию:
- Выделите диапазон В3:D7 (число столбцов = число переменных +1; число строк всегда равно 5).
- Наберите формулу =ЛИНЕЙН(D14:D24;B14:C24;1;1). Для аргумента известные_значения_х, выделите оба столбца значений x из диапазона В14:С24.
- Введите функцию с помощью клавиш Ctrl+Shift+Enter.
- Обратите внимание, что несмотря на то, что значения х1 указаны в диапазоне В14:С24 до значений х2, наклон сначала указан для х2.
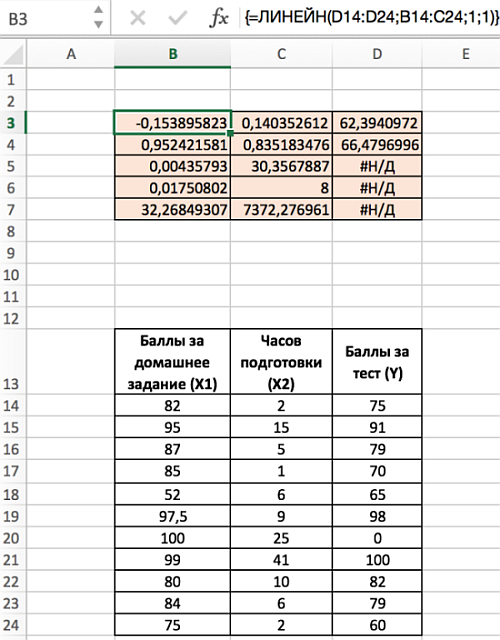
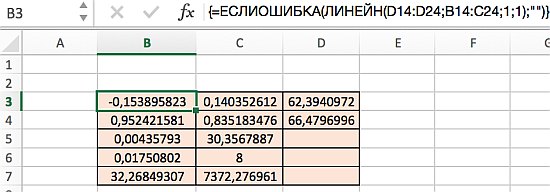
Диапазон D5:D7 содержит ошибку #Н/Д – значащую, что формула не может обнаружить значения для данных ячеек. Визуально наличие ошибки отвлекает от сути решения, поэтому далее предложим вариант избавления от нее. Так, если дополнить формулу содержащую функцию ЛИНЕЙН функцией ЕСЛИОШИБКА, то можно значительно улучшить вид таблицы, результат которой представлен ниже:
Распределение статистик в таблице их значение представлено на следующем рисунке:
Скачать примеры функции ЛИНЕЙН в Excel
В результате мы получили всю необходимую выходную статистическую информацию, которая нас интересует.
Проблемы
При использовании функции ЛИНЕЙН на листе в Microsoft Excel результаты статистического вывода могут возвращать неверные значения. Средство регрессия в окне “пакет анализа” может также возвращать неверные значения.
Причина
Результат, возвращаемый функцией ЛИНЕЙН, может быть неправильным, если выполняется одно или несколько из указанных ниже условий.
-
Диапазон значений x перекрывает диапазон значений y.
-
Количество строк в диапазоне входных данных меньше числа столбцов в общем диапазоне (x-value + y-Value).
-
Вы задаете нулевую константу (для третьего аргумента функции ЛИНЕЙН установите значение истина).
Обходное решение
Случай 1: диапазоны x-value и y перекрываются
Если диапазоны x-value и y перекрываются, функция ЛИНЕЙН возвращает неверные значения во всех ячейках результата. Нормальная статистическая вероятность запрещает значения в диапазонах x и y для перекрытия (повторяющиеся друг друга). Не перекрывают диапазоны x и y при ссылке на ячейки в формуле.Примечание. Средство регрессия предупреждает об этой проблеме и не продолжает работу. Вы можете использовать средство регрессия вместо функции ЛИНЕЙН. В Microsoft Office Excel 2007 вы можете найти инструмент регрессия, щелкнув анализ данных в группе анализ на вкладке данные . В Microsoft Office Excel 2003 и более ранних версиях Excel можно найти инструмент регрессия, выбрав пункт анализ данных в меню Сервис .
Случай 2: количество строк меньше числа столбцов x-Columns.
Статистические функции не действительны, так как количество строк должно быть меньше числа столбцов x (переменных). Количество строк данных должно быть больше количества столбцов данных (столбцов x и y).
Случай 3: указывается нулевая константа
Не указывайте нулевые константы (b = 0) в функции.
Дополнительная информация
Средство регрессия входит в пакет анализа. Пакет анализа — это программа надстройки Excel. Оно доступно при установке Microsoft Office или Excel. Прежде чем использовать средство регрессия в Excel, вы должны загрузить анализ ToolPak.To в Excel 2007, выполнив указанные ниже действия.
-
Нажмите кнопку Microsoft Office, затем нажмите кнопку Параметры Excel.
-
Выберите пункт надстройки, а затем в поле Управление выберите пункт надстройки Excel .
-
Нажмите кнопку Перейти.
-
В окне Доступные надстройки установите флажок Пакет анализа , а затем нажмите кнопку ОК.Примечание. Если в списке Доступные надстройки не указан Пакет анализа , нажмите кнопку Обзор , чтобы найти его.
Чтобы сделать это в Excel 2003 и более ранних версиях Excel, выполните указанные ниже действия.
-
В меню Сервисвыберите пунктнадстройки.
-
В диалоговом окне надстройки выберите Пакет анализаи нажмите кнопку ОК,Обратите внимание на то, что Пакет анализа не указан в поле Доступные надстройки, нажмите кнопку Обзор , чтобы найти его.
Ссылки
Статистические вычисления на цифровом компьютере. Уильям J. Hemmerle. Blaisdell компания публикации: 1967. Глава 3, “вычисления с несколькими регрессиями” и раздел 3.2.1, “теория для предварительной регрессии”.
Нужна дополнительная помощь?
Нужны дополнительные параметры?
Изучите преимущества подписки, просмотрите учебные курсы, узнайте, как защитить свое устройство и т. д.
В сообществах можно задавать вопросы и отвечать на них, отправлять отзывы и консультироваться с экспертами разных профилей.
Содержание
- При использовании функции линейная регрессия (ЛИНЕЙН) в Excel возвращается неверный результат
- Проблемы
- Причина
- Обходное решение
- Случай 1: диапазоны x-value и y перекрываются
- Случай 2: количество строк меньше числа столбцов x-Columns.
- Случай 3: указывается нулевая константа
- Дополнительная информация
- Ссылки
- Входной интервал содержит нечисловые данные что делать?
- Работа с инструментом «Регрессия» в Microsoft Excel
- Использование Пакета анализа EXCEL для построения простой линейной регрессионной модели
- Регрессия входной интервал содержит нечисловые данные
- Статистический анализ в excel Назначение и возможности пакета анализа
- Установка пакета анализа.
- Вызов пакета анализа
- Корреляция
- Регрессионный анализ. Построение статических однофакторных моделей
- Практическая работа 1. Регрессионный анализ. Построение статических однофакторных моделей.
- Часть I.
- Часть II.
- Варианты заданий к практической работе 1.
При использовании функции линейная регрессия (ЛИНЕЙН) в Excel возвращается неверный результат
Проблемы
При использовании функции ЛИНЕЙН на листе в Microsoft Excel результаты статистического вывода могут возвращать неверные значения. Средство регрессия в окне «пакет анализа» может также возвращать неверные значения.
Причина
Результат, возвращаемый функцией ЛИНЕЙН, может быть неправильным, если выполняется одно или несколько из указанных ниже условий.
Диапазон значений x перекрывает диапазон значений y.
Количество строк в диапазоне входных данных меньше числа столбцов в общем диапазоне (x-value + y-Value).
Вы задаете нулевую константу (для третьего аргумента функции ЛИНЕЙН установите значение истина).
Обходное решение
Случай 1: диапазоны x-value и y перекрываются
Если диапазоны x-value и y перекрываются, функция ЛИНЕЙН возвращает неверные значения во всех ячейках результата. Нормальная статистическая вероятность запрещает значения в диапазонах x и y для перекрытия (повторяющиеся друг друга). Не перекрывают диапазоны x и y при ссылке на ячейки в формуле.Примечание. Средство регрессия предупреждает об этой проблеме и не продолжает работу. Вы можете использовать средство регрессия вместо функции ЛИНЕЙН. В Microsoft Office Excel 2007 вы можете найти инструмент регрессия, щелкнув анализ данных в группе анализ на вкладке данные . В Microsoft Office Excel 2003 и более ранних версиях Excel можно найти инструмент регрессия, выбрав пункт анализ данных в меню Сервис .
Случай 2: количество строк меньше числа столбцов x-Columns.
Статистические функции не действительны, так как количество строк должно быть меньше числа столбцов x (переменных). Количество строк данных должно быть больше количества столбцов данных (столбцов x и y).
Случай 3: указывается нулевая константа
Не указывайте нулевые константы (b = 0) в функции.
Дополнительная информация
Средство регрессия входит в пакет анализа. Пакет анализа — это программа надстройки Excel. Оно доступно при установке Microsoft Office или Excel. Прежде чем использовать средство регрессия в Excel, вы должны загрузить анализ ToolPak.To в Excel 2007, выполнив указанные ниже действия.
Нажмите кнопку Microsoft Office, затем нажмите кнопку Параметры Excel.
Выберите пункт надстройки, а затем в поле Управление выберите пункт надстройки Excel .
Нажмите кнопку Перейти.
В окне Доступные надстройки установите флажок Пакет анализа , а затем нажмите кнопку ОК.Примечание. Если в списке Доступные надстройки не указан Пакет анализа , нажмите кнопку Обзор , чтобы найти его.
Чтобы сделать это в Excel 2003 и более ранних версиях Excel, выполните указанные ниже действия.
В меню Сервис выберите пунктнадстройки.
В диалоговом окне надстройки выберите Пакет анализаи нажмите кнопку ОК,Обратите внимание на то, что Пакет анализа не указан в поле Доступные надстройки, нажмите кнопку Обзор , чтобы найти его.
Ссылки
Статистические вычисления на цифровом компьютере. Уильям J. Hemmerle. Blaisdell компания публикации: 1967. Глава 3, «вычисления с несколькими регрессиями» и раздел 3.2.1, «теория для предварительной регрессии».
Источник
Входной интервал содержит нечисловые данные что делать?
Работа с инструментом «Регрессия» в Microsoft Excel
Открыв рабочую книгу и введя в нее исходные данные для построения уравнения регрессии, вызываем надстройку «Регрессия»: Данные — Анализ данных — Регрессия.
Диалоговое окно «Регрессия». В первое окно «Входной интервал Y» вводим данные объясняемой переменной — у, диапазон должен состоять из одного столбца. Во второе окно «Входной интервал X» вводим данные объясняющих переменных — х. На рис. П.1 представлены у. $С$2:$С$13, х: $В$2:$В$13. Длины интервалов должны быть одинаковы. Если строится уравнение множественной регрессии, то данные объясняющих переменных вводятся в окно «Входной интерват X» соответствующим образом. На рис. П.2 представлены у: $D$2:$D$13, xt—x2: $В2:$С$13. Максималь- ное число независимых объясняющих переменных равно 16.
![]()
Рис. П. 1. Задание парной регрессии
Ставим «галочку» в окно «Метки», если в отчете Microsoft Excel требуется знать, к какой из объясняющих переменных относятся результирующие данные.
Если исследователю не требуется константа Ь , то ставим «галочку» в окно «Константа — ноль». Линия регрессии пройдет через начало координат.
![]()
Рис. П.2. Задание множественной регрессии
«Уровень надежности». По умолчанию программа строит уравнение регрессии для доверительной вероятности (уровень надежности) 0,95. Если требуется другая величина, ставим «галочку» в окно «Уровень надежности» и в окно, помеченное символом «%», вводим требуемую величину уровня надежности десятичной дробью.
«Параметры вывода». Указываем, куда вывести результаты регрессионного анализа: на этом листе, как указано на обоих рисунках, на другой рабочий лист или в новую рабочую книгу.
«Остатки». Выбираем то, что требуется исследователю, и ставим «галочку». Можно одновременно пометить несколько окон. Подробная информация дана в справке но инструменту «Регрессия».
Заполнив диалоговое окно «Регрессия», нажимаем кнопку ОК. Программа выводит отчет «Вывод итогов» в виде трех таблиц (рис. П.З, приведено для двух объясняющих переменных).
Приведем описание таблиц (первых двух — в табл. П1.1 и П1.2 соответственно, третьей — в текстовом виде).
Описание первой таблицы
Наименование в отчете
Коэффициент множественной корреляции, индекс корреляции
Коэффициент детерминации, R 2
Скорректированный К 2
Наименование в отчете
Среднее квадратическое отклонение от модели
Рис. П.З. Результаты работы программы
Описание третьей таблицы
Данные первой строки относятся к коэффициенту уравнения регрессии Ь , данные второй строки — к коэффициенту Ьи третьей — к Ь2 и далее до коэффициента Ьт, но числу объясняющих переменных в уравнении.
Метки, если поставлена галочка в окно «Метки». У-пересечение для коэффициента/> , далее но всем объясняющим переменным.
Значения коэффициентов уравнения регрессии Ь , Ьь . Ьт.
Стандартная ошибка коэффициента регрессии 5^, 5Л). Sbm.
Статистическая значимость коэффициента регрессии (^-статистика) для а = 0,05 tw . tbm.
P-значение — это значение уровней значимости, соответствующее вычисленным ^статистикам коэффициентов.
Нижние 95% и Верхние 95% — это нижние и верхние границы 95%-ных доверительных интервалов для коэффициентов уравнения регрессии. Если в окно «Уровень надежности» не вводилось другое значение доверительной вероятности, то последние два столбца дублируют предыдущие два столбца. Если в окно «Уровень надежности» было введено другое значение доверительной вероятности у, то последние два столбца содержат значения соответственно нижней и верхней границы у-процентных доверительных интервалов.
Описание второй таблицы
df — число степеней свободы
SS — сумма квадратов
MS = SS/df — дисперсия на одну степень свободы
Использование Пакета анализа EXCEL для построения простой линейной регрессионной модели
history 26 января 2019 г.
- Группы статей
- Статистический анализ
Проведем простой регрессионный анализ с помощью надстройки MS EXCEL Пакет анализа .
Эффективно использовать надстройку Пакет анализа для целей регрессионного анализа могут только пользователи знакомые с теорией регрессионного анализа .
В данной статье решены следующие задачи:
- Показано как в MS EXCEL выполнить регрессионный анализ с помощью надстройки Пакет анализа (инструмент Регрессия), т.е. как вызвать надстройку и правильно заполнить входные данные;
- Даны пояснения по разделам отчета, формированного надстройкой.
В надстройке Пакет анализа для построения линейной регрессионной модели (как простой , так и множественной ) имеется специальный инструмент Регрессия .
![]()
После выбора этого инструмента откроется окно, в котором требуется заполнить следующие поля (см. файл примера лист Надстройка ):
![]()
- Входной интервалY : ссылка на массив значений переменной Y. Ссылку можно указать с заголовком. В этом случае, при выводе результатов надстройка использует Ваш заголовок (для этого в окне требуется установить галочку Метки );
- Входной интервал Х : ссылка на значения переменной Х. В случае множественной регрессии (несколько переменных Х) нужно указать все столбцы со значениями Х. В случае множественной регрессии ссылку рекомендуется делать на диапазон с заголовками (в окне требуется установить галочку Метки );
- Константа-ноль : если галочка установлена, то надстройка подбирает линию регрессии, проходящую через точку Y=0 ( сдвиг будет равен 0);
- Уровень надежности : Это значение используется для построения доверительных интервалов для наклона и сдвига . Уровень надежности = 1- альфа. Если галочка не установлена или установлена, но уровень значимости = 95%, то надстройка все равно рассчитывает границы доверительных интервалов, причем дублирует их. Если галочка установлена, а уровень надежности отличен от 95%, то рассчитываются 2 доверительных интервала : один для 95%, другой для введенного значения. Для демонстрации вышесказанного введем 90%;
- Выходной интервал: диапазон ячеек, куда будут помещены результаты вычислений. Достаточно указать левую верхнюю ячейку этого диапазона;
- Остатки : будут вычислены остатки модели , т.е. разница между наблюденными и предсказанными значениями Yi для всех наблюдений n;
- Стандартизированные остатки : Вышеуказанные значения остатков будут поделены на значение их стандартного отклонения ;
- График остатков : Будет построена точечная диаграмма : значения остатков для всех значений Хi;
- График подбора: Будет построена точечная диаграмма: точки данных (X;Y) и линия регрессии ;
- График нормальной вероятности: Будет построена точечная диаграмма с названием График нормального распределения . По сути — это график значений переменной Y, отсортированных по возрастанию .
В результате вычислений будет заполнен указанный Выходной интервал.
![]()
![]()
![]()
Тот же результат можно получить с помощью формул (см. файл примера лист Надстройка, столбцы I:T ):
![]()
Результаты вычислений, выполненных надстройкой, полностью совпадают с вычислениями сделанными нами в статье про простую линейную регрессию с помощью функций ЛИНЕЙН() , НАКЛОН() , ОТРЕЗОК() и др. Использование альтернативных формул помогает разобраться с алгоритмом расчета показателей регрессии.
Отчет, сформированный надстройкой, состоит из следующих разделов:
Раздел «Регрессионная статистика»:
- Множественный R. В случае простой линейной регрессии — это Коэффициент корреляции , функция КОРРЕЛ()
- R-квадрат . В случае простой линейной регрессии – это коэффициент детерминации , функция КВПИРСОН()
- Нормированный R-квадрат . См. про коэффициент детерминации .
- Стандартная ошибка . См. Стандартная ошибка регрессии ;
- Наблюдения . Количество значений Y.
Раздел « Дисперсионный анализ »:
- df – степени свободы (Degrees of Freedom).
- SS – сумма квадратов (Sum of Squares)
- MS – SS/df (MSR и MSE)
- F – значение статистики F (MSR/MSE)
- ЗначимостьF – p-значение, функция F.РАСП.ПХ()
- Коэффициенты : оценка параметров модели а и b. См. Оценка неизвестных параметров .
- Стандартная ошибка : Стандартные ошибки вышеуказанных статистик
- t-статистика : значение тестовой статистики t0. См. Проверка значимости взаимосвязи переменных
- P-Значение : См. Проверка значимости взаимосвязи переменных
- Нижние 95% и Верхние 95%: границы доверительных интервалов для оценок неизвестных параметров модели а и b .
Регрессия входной интервал содержит нечисловые данные
трюки • приёмы • решения
При импортировании данных из других источников вы, возможно, уже успели обнаружить, что Excel иногда некорректно импортирует значения. В частности, он может принять ваши числа за текст. И тогда, например, при суммировании диапазона значений формула СУММ возвращает 0 — хотя диапазон, по всей видимости, содержит числовые значения.
Часто Excel сообщает вам об этих «нечислах», отображая смарт-тег, который позволяет преобразовать текст в числа. Если смарт-тег не отображается, вы можете использовать следующий метод, чтобы указать Excel изменить эти «нечисловые» числа на их фактические значения. Выполните следующие действия.
- Активизируйте любую пустую ячейку на листе.
- Нажмите Ctrl+C, чтобы скопировать пустую ячейку.
- Выберите диапазон, содержащий проблематичные значения.
- Выберите Главная ► Буфер обмена ► Вставить ► Специальная вставка для открытия диалогового окна Специальная вставка.
- В окне Специальная вставка установите переключатель Операция в положение сложить.
- Нажмите кнопку ОК.
Excel ничего не добавит к значениям, но в процессе укажет этим ячейкам иметь фактические значения.
Входной интервал. Нужно ввести ссылку на интервал данных рабочего листа, подлежащих анализу. Excel также прелагает группирование входных данных по строкам или столбцам. Если во входной интервал включаются метки (заголовки строк или столбцов данных), необходимо установит флажок Метки,в противном случае Excel выдаст предупреждающее сообщение.
Метки. Если входной интервал не включает меток, снимите флажок Метки. Excel генерирует соответствующие метки данных для выходной таблицы (Строка 1, Строка 2, или Столбец 1, Столбец 2 и т.д.)
Выходные данные
Выходной интервал. Введите ссылку для верхней левой ячейки интервала, в который вы предполагаете вывести результирующую таблицу.
Новый рабочий лист. Этот параметр вставляет новый лист в рабочую книгу, где располагается текущий рабочий лист, и вставляет результаты в ячейку А1 нового листа. Используйте поле ввода рядом с параметром для задания имени нового листа.
Новая рабочая книга. Этот параметр создает новую рабочую книгу, добавляет новый рабочий лист и вставляет результаты в ячейку А1 нового листа.
Генерация случайных чисел
В имитационных моделях для описания реальных событий используются случайные величины и процессы. Когда имитационная модель рассчитывается на ЭВМ, то возникает необходимость реализации указанных процессов с максимально возможной точностью.
Для генерации случайных величин необходимо иметь возможность получать последовательность равномерно распределенных случайных чисел, т.е. чисел, которые ведут себя как независимые реализации или выборки случайной величины R, равномерно распределенной на единичном интервале [0,1]. Такие числа получают с помощью генераторов случайных чисел.
При помощи последовательности равномерно распределенных случайных чисел можно получить последовательности случайных величин, имеющих другие законы распределения.
Не нашли то, что искали? Воспользуйтесь поиском:
Лучшие изречения: Для студента самое главное не сдать экзамен, а вовремя вспомнить про него. 10663 — ![]() | 7824 —
| 7824 — ![]() или читать все.
или читать все.
Встроенные статистические функции используются для проведения статистического анализа данных.
Функция СРЗНАЧ вычисляет среднее арифметическое значение. Она игнорирует пустые, логические и текстовые ячейки и может использоваться вместо длинных формул. Например, для вычисления среднего значения данных в диапазоне ячеек В4:В15 можно использовать формулу:
Очевидно, что проще ввести = СРЗНАЧ(B4:B15).
Функция МЕДИАНА вычисляет медиану множества числовых значений.
Функция МОДА определяет значение, которое чаще других встречается во множестве чисел.
Функция МАКС вычисляет наибольшее значение в диапазоне.
Функция МИН вычисляет наименьшее значение в диапазоне.
Функция СЧЕТ определяет количество ячеек в заданном диапазоне, которые содержат числа, в том числе, даты и формулы, возвращающие числа.
Функции ДИСП и СТАНДОТКЛОН определяют дисперсию и стандартное отклонение чисел, в предположении что они образуют выборку.
Функции ДИСПР и СТАНДОТКЛОНП определяют дисперсию и стандартное отклонение для генеральной совокупности.
Функция НАКЛОН вычисляет коэффициент наклона линии линейной регрессии.
Функция ОТРЕЗОК вычисляет отрезок, отсекаемый на оси линией линейной регрессии.
Функция ПРЕДСКАЗ вычисляет теоретические значения y по линии линейной регрессии.
Если встроенных статистических функций недостаточно, можно обратиться к Пакету анализа .
Чтобы получить доступ к инструментам Пакета анализа необходимо:
· выполнить команду Сервис/Анализ данных;
· для использования инструмента анализа, выбрать его имя в списке и нажать кнопку ОК;
· заполнить открывшееся диалоговое окно (в большинстве случаев это означает задание входного диапазона с данными, которые вы собираетесь анализировать, указание верхней левой ячейки выходного диапазона, в который должны быть помещены результаты, и выбор нужных параметров. Группирование: установить переключатель в положение По столбцам или По строкам в зависимости от расположения данных во входном диапазоне. Установить переключатель в положение Метки в первой строке, если первая строка во входном диапазоне содержит названия столбцов или установить переключатель в положение Метки в первом столбце, если названия строк находятся в первом столбце входного диапазона. Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне будут созданы автоматически).
Если надстройка Анализ данных отсутствует, то ее можно подключить с помощью команды Сервис/Надстройки/Пакет анализа VBA ( Analysis ToolPak VBA ).
К инструментам Пакета анализа , например, относятся Описательная статистика , Корреляция , Регрессия .
Инструмент Описательная статистика предлагает таблицу основных статистических характеристик для одного или нескольких множеств входных значений ( Рис. 7.1 ):
Выходной интервал этого инструмента содержит следующие статистические характеристики: среднее, стандартная ошибка, медиана, мода, стандартное отклонение, дисперсия, коэффициент эксцесса, коэффициент асимметрии, интервал (размах), минимальное значение, максимальное значение, сумма, число значений, k -е наибольшее и наименьшее значения (для любого заданного значения k ) и уровень значимости для среднего. Установить флажок Итоговая статистика, если нужен полный список характеристик, в противном случае отметить конкретные характеристики, которые должны присутствовать в выходной таблице. Большинство из полученных характеристик, полученных с помощью пакета анализа Описательная статистика можно получить с помощью встроенных статистических формул.
Рис. 7 . 1 Диалоговое окно Описательная статистика
Корреляция используется для количественной оценки взаимосвязи двух наборов данных, представленных в безразмерном виде. Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть, большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция), или, наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (корреляция близка к нулю). В диалоговом окне Корреляция ( REF _Ref12174106 h * MERGEFORMAT Рис. 7.2 ) указывается Входной интервал – ссылка на диапазон, содержащий анализируемые данные. Ссылка должна состоять как минимум из двух смежных диапазонов данных, организованных в виде столбцов или строк.
Рис. 7 . 2 Диалоговое окно Корреляция
Регрессия используется для подбора графика линии регрессии. Параметры диалогового окна Регрессия ( Рис. 7.3 ):
Входной интервал Y – ссылка на диапазон анализируемых зависимых данных (диапазон должен состоять из одного столбца). Входной интервал X – ссылка на диапазон независимых данных, подлежащих анализу. Уровень надежности – установить флажок, чтобы включить в выходной диапазон дополнительный уровень. В соответствующее поле ввести уровень надежности, который будет использован дополнительно к уровню 95%, применяемому по умолчанию. Константа-ноль – установить флажок, чтобы линия регрессии прошла через начало координат. Остатки – установить флажок, чтобы включить остатки в выходной диапазон. Стандартизированные остатки – установить флажок, чтобы включить стандартизированные остатки в выходной диапазон. График остатков – установить флажок, чтобы построить диаграмму остатков для каждой независимой переменной. График подбора – установить флажок, чтобы построить диаграммы наблюдаемых и предсказанных значений для каждой независимой переменной. График нормальной вероятности – установить флажок, чтобы построить диаграмму нормальной вероятности.
Статистический анализ в excel Назначение и возможности пакета анализа
В состав MicrosoftExcelвходит пакет анализа, который позволяет осуществлять статистическую обработку данных в таблицах. В состав этого пакета входят разнообразные статистические методы. Способы применения их всех аналогичны, поэтому мы рассмотрим лишь некоторые из них: экспоненциальное сглаживание, корреляцию, скользящее среднее, регрессию.
Корреляция используется для количественной оценки взаимосвязи двух наборов данных, представленных в безразмерном виде. Корреляционный анализ дает возможность установить ассоциированы ли наборы данных по величине, то есть, большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция), или, наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (корреляция близка к нулю).
Скользящее среднее используется для расчета значений в прогнозируемом периоде на основе среднего значения переменной для указанного числа предшествующих периодов. Процедура может использоваться для прогноза сбыта, инвентаризации и других процессов. Мы спрогнозируем курс доллара США на основе данных за июль 1999 года.
Экспоненциальное сглаживание предназначается для предсказания значения на основе прогноза для предыдущего периода, скорректированного с учетом погрешностей в этом прогнозе. Использует константу сглаживания, по величине которой определяет, насколько сильно влияют на прогнозы погрешности в предыдущем прогнозе. Для константы сглаживания наиболее подходящими являются значения от 0,2 до 0,3. Эти значения показывают, что ошибка текущего прогноза установлена на уровне от 20 до 30 процентов ошибки предыдущего прогноза. Более высокие значения константы ускоряют отклик, но могут привести к непредсказуемым выбросам. Низкие значения константы могут привести к сдвигу аргумента для предсказанных значений.
Линейный регрессионный анализ заключается в подборе графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или более независимых переменных. Мы рассмотрим, как влиял на курс ЕВРО по отношению к рублю курс доллара США в июле 1999 года.
Установка пакета анализа.
Если в Microsoft Excel в меню Сервисотсутствует командаАнализ данных, то необходимо установить статистический пакет анализа данных.
Чтобы установить пакет анализа данных
В![]() менюСервисвыберите командуНадстройки. Если в списке надстроек нет пакета анализа данных, нажмите кнопкуОбзори укажите диск, папку и имя файла для надстройки пакет анализа, Analys32.xll (как правило, папка LibraryAnalysis) или запустите программу Setup, чтобы установить эту надстройку.
менюСервисвыберите командуНадстройки. Если в списке надстроек нет пакета анализа данных, нажмите кнопкуОбзори укажите диск, папку и имя файла для надстройки пакет анализа, Analys32.xll (как правило, папка LibraryAnalysis) или запустите программу Setup, чтобы установить эту надстройку.
Установите флажок Пакет анализа,выберите кнопкуOK.
Вызов пакета анализа
Чтобы запустить пакет анализа:
В меню Сервисвыберите командуАнализ данных.
В списке Инструменты анализавыберите нужную строку.
![]()
Корреляция
При выборе строки Корреляцияв диалоговом запросеАнализ данныхпоявляется следующее окно.
![]()
Входной интервал. Введите ссылку на ячейки, содержащие анализируемые данные. Ссылка должна состоять как минимум из двух смежных диапазонов данных, организованных в виде столбцов или строк. (Для этого нужно мышью щелкнуть по кнопке ![]() в правом конце строки, установить мышь в верхний правый угол диапазона анализируемых данных и, удерживая нажатой левую кнопку мыши, отбуксировать мышь в левый нижний угол диапазона, нажать клавишуEnter).
в правом конце строки, установить мышь в верхний правый угол диапазона анализируемых данных и, удерживая нажатой левую кнопку мыши, отбуксировать мышь в левый нижний угол диапазона, нажать клавишуEnter).
![]()
Группирование. Установите переключатель в положениеПо столбцамилиПо строкамв зависимости от расположения данных во входном диапазоне.
Метки в первой строке/Метки в первом столбце. Установите переключатель в положениеМетки в первой строке, если первая строка во входном диапазоне содержит названия столбцов. Установите переключатель в положениеМетки в первом столбце, если названия строк находятся в первом столбце входного диапазона. Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне будут созданы автоматически. (В других видах анализа этот флажок выполняет аналогичную функцию).
Выходной интервал. Введите ссылку на левую верхнюю ячейку выходного диапазона. Поскольку коэффициент корреляции двух наборов данных не зависит от последовательности их обработки, то выходная область занимает только половину предназначенного для нее места. Ячейки выходного диапазона, имеющие совпадающие координаты строк и столбцов, содержат значение 1, так как каждая строка или столбец во входном диапазоне полностью коррелирует с самим собой.
Новый лист. Установите переключатель, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A1. Если в этом есть необходимость, введите имя нового листа в поле, расположенном напротив соответствующего положения переключателя.
Новая книга. Установите переключатель, чтобы открыть новую книгу и вставить результаты анализа в ячейку A1 на первом листе в этой книге.
Смотри лист Корреляция в примере.
Вернитесь в текущий документ через Панель задач
результате программа сформирует таблицу с коэффициентами корреляции между выбранными совокупностями.
Регрессионный анализ. Построение статических однофакторных моделей
![]()
Практическая работа 1. Регрессионный анализ. Построение статических однофакторных моделей.
Содержательная постановка задачи. Имеется статистическая информация по центральному федеральному округу, которая представлена в таблице1:
Таблица 1. Число гостиниц и число ночевок в гостиницах
Наименование субъекта Федерации
Число гостиниц и аналогичных средств размещения, ед.
Число ночевок в гостиницах и аналогичных средствах размещения, тыс. ночевок
* — на базе данных Федеральной службы государственной статистики.
Пусть ряд наблюдений X — число гостиниц и аналогичных средств размещения, ряд наблюдений Y — число ночевок в гостиницах и аналогичных средствах размещения, тыс.
Часть I.
Построить точечную диаграмму, предварительно отсортировав таблицу; Выдвинуть гипотезу о виде функции зависимости; Рассчитать параметры модели регрессии, построить тренды; Оценить адекватность построенного уравнения по величине достоверности аппроксимации; Рассчитать теоретические значения по модели и построить графики фактических и расчетных данных. Создать отчет в Word по всем пунктам задания, используя экранные копии Excel. Написать вывод о виде функции зависимости, наилучшим образом описывающей модель.
Пример. В исходной таблице произведем сортировку по столбцу С (число гостиниц и аналогичных средств размещения) по возрастанию числа гостиниц.
![]()
Рис.1. Сортировка по возрастанию числа гостиниц
Отсортированная таблица представлена на рисунке 2:
![]()
Рис.2. Отсортированная таблица по возрастанию числа гостиниц
По отсортированным данным, используя мастер диаграмм, построим точечную диаграмму (диапазон ячеек С1:D19) (Рис.3).
![]()
Рис. 3. Диаграмма по отсортированной таблице
После построения диаграммы, вызовем контекстовое меню, щелкнув правой кнопкой мыши по одной из точек диаграммы, и выберем в нем команду Добавить линию тренда…(Рис. 4):
![]()
Рис. 4. Вкладка Параметры линии тренда
Во вкладке Параметры линии тренда выберем Линейная и отметим флаги показывать уравнение на диаграмме и поместить на диаграмму величину достоверности аппроксимации (R^2). Чем R2 ближе к 1, тем удачнее регрессионная модель. На диаграмме появляется линия тренда (Рис. 5).
![]()
Рис.5. Диаграмма с линейной линией тренда
Чаще всего выбор производится среди следующих функций:
у = ах + b — линейная функция;
у = ах2 + bх + с — квадратичная (полиномиальная) функция;
у = аln(х) + b — логарифмическая функция;
у = аеbх — экспоненциальная функция;
у = ахb — степенная функция.
Отобразим на диаграмме все возможные тренды (Рис. 6.).
![]()
Рис. 6. Диаграмма с построенными линиями тренда
Часть II.
Требуется: рассчитать основные характеристики случайных величин.
Для расчета основных характеристик случайных величин используются следующие функции: СРЗНАЧ() – возвращает среднее арифметическое своих аргументов, КОРЕНЬ() – возвращает значение квадратного корня, а также ДИСП() и КОРРЕЛ().
ДИСП() — Оценивает дисперсию по выборке (Рис.7).
Синтаксис функции: ДИСП(число1;число2; . ).
Число1, число2. — от 1 до 255 числовых аргументов, соответствующих выборке из генеральной совокупности.
![]()
Рис. 7. Аргументы функции, оценивающей дисперсию по выборке — Дисп()
КОРРЕЛ() – возвращает коэффициент корреляции между интервалами ячеек «массив1» и «массив2». Коэффициент корреляции используется для определения взаимосвязи между двумя свойствами. Например, можно установить зависимость между средней температурой в помещении и использованием кондиционера (Рис. 8).
Синтаксис функции: КОРРЕЛ(массив1;массив2).
Массив1 — это интервал ячеек со значениями, Массив2 — второй интервал ячеек со значениями.
![]()
Рис.8. Аргументы функции, возвращающей коэффициент корреляции Коррел()
Получим следующие результаты (Рис. 9):
![]()
Рис. 9. Результаты расчетов с использованием математических функций
Можно сделать вывод о том, что линейная зависимость между числом гостиниц и аналогичных средств размещения (ряд X) и числом ночевок в гостиницах и аналогичных средствах размещения (ряд Y) существует, т. к. коэффициент корреляции равен 0,93729 и ![]() .
.
Коэффициент корреляции значим, т. к. расчетный критерий Стъюдента больше табличного критерия: 10,7566 > 2.1190.
Рассчитаем коэффициент корреляции для исходных данных с помощью функции Корреляция пакета Анализ данных.
Вызвать окно Анализ данных можно с помощью команды Анализ данных меню Данные (Рис. 10).
![]()
Рис. 10. Анализ данных
Пакет Корреляция позволяет определить коэффициенты корреляции для n-го количества рядов данных. Выбор команды Корреляция вызывает окно Корреляция (Рис. 11).
![]()
Рис. 11. Окно Корреляция
Это окно содержит две панели Входные данные и Параметры вывода. Окно Входной интервал: предназначено для ссылки на диапазон, содержащий анализируемые данные. Эта ссылка должна состоять не менее чем из двух смежных диапазонов данных, расположенных по строкам или столбцам. Флаги Группирование: зависят от расположения данных в диапазоне. Флаг Метки в первой строке (Метки в первом столбце) устанавливается в том случае, если входной интервал включал название диапазонов. Если название диапазонов были включены в интервал, а данный флаг не выставлен, после нажатия кнопки Ок, Excel выдаст сообщение об ошибке «Входной интервал содержит нечисловые данные». Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне будут созданы автоматически.
Если результаты необходимо поместить на имеющемся листе, то нужно установить переключатель рядом с окном Выходной интервал:, а в самом окне следует ввести ссылку на левую верхнюю ячейку выходного диапазона.
Если установить переключатель рядом с окном Новый рабочий лист:, то в книге откроется новый лист и результаты анализа будут вставлены в него, начиная с ячейки A1. При необходимости в окно можно ввести имя нового листа. По умолчанию имя листа будет соответствовать следующему после последнего имеющегося в книге листа.
Если установить переключатель рядом с окном Новая рабочая книга, то откроется новая книга, и результаты анализа будут вставлены в нее, начиная с ячейки A1 на первом листе в этой книге.
Поскольку коэффициент корреляции двух наборов данных не зависит от последовательности их обработки, то выходная область занимает только половину предназначенного для нее места.
Ячейки выходного диапазона, имеющие совпадающие координаты строк и столбцов, содержат значение 1, так как каждая строка или столбец во входном диапазоне полностью коррелирует с самим собой.
Заполняем все необходимые поля окна Корреляция (Рис. 12).
Входной интервал – это данные, по которым необходимо провести корреляционный анализ, в данном случае это исходные данные по числу гостиниц и аналогичных средств размещения и числу ночевок в гостиницах и аналогичных средствах размещения (С2:D19). Строка 1 также указана во входном интервале, но в ней содержатся заголовки столбцов, поэтому ставим флаг Метки в первой строке.
В выходном интервале ставим Новый рабочий лист, в котором будут вынесены результаты расчета.
![]()
Рис. 12. Расчет коэффициента корреляции
Полученные данные абсолютно идентичны коэффициентам полученным с помощью функции КОРРЕЛ() (Рис. 13).
![]()
Рис. 13. Результаты расчета коэффициента корреляции
Пакет Описательная статистика предназначен для расчета основных статистических показателей. Окно Описательная статистика (Рис. 14) содержит:
![]()
Рис.14. Описательная статистика
панель Входные данные, аналогичную панели в окне Корреляция; панель Параметры вывода содержит указание на выходной интервал, аналогичный окну Корреляция; флаг Итоговая статистика обеспечивает вывод в выходной интервал среднего, стандартную ошибку (среднего), медиану, мода, стандартное отклонение, дисперсию выборки, эксцесс, асимметричность, интервал, минимум, максимум, сумму и количество значений; флаг Уровень надежности, установка которого выводит в выходной интервал строку для уровня надежности. Значение, введенное в поле, соответствует требуемому уровню надежности; флаг К-тый наименьший и К-тый наибольший, установка которых выводит в выходной интервал строки для k-го наибольшего и k-го наименьшего значения для каждого диапазона данных. В соответствующем окне необходимо ввести число k. Если k равно 1, эта строка будет содержать минимум или максимум из набора данных.
Далее вызовем функцию Описательная статистика из пакета Анализ данных (Рис. 15).
![]()
Рис. 15. Описательная статистика пакета Анализ данных
Выставив все необходимые флаги, нажимаем кнопку Ок, и получаем таблицу описательных статистик (Рис. 16).
![]()
Рис. 16. Таблица описательных статистик
Полученные данные совпадают с данными, рассчитанными с помощью математических функций (математическое ожидание по x и по y, дисперсия по x и по y, среднее квадратическое отклонение по x и по y).
Варианты заданий к практической работе 1.
Содержательная постановка задачи. Исходные данные:
построить точечную диаграмму, предварительно отсортировав таблицу; выдвинуть гипотезу о виде функции зависимости; рассчитать параметры модели регрессии, построить тренды; оценить адекватность построенного уравнения по величине достоверности аппроксимации; рассчитать теоретические значения по модели и построить графики фактических и расчетных данных. Создать отчет в Word по всем пунктам задания, используя экранные копии Excel. Написать вывод о виде функции зависимости, наилучшим образом описывающей модель.
Вариант 2. Имеется статистическая информация по Северо-Западному федеральному округу*, которая представлена в таблице:
Число гостиниц и аналогичных средств размещения
Число ночевок в гостиницах и аналогичных средствах размещения, тыс.
Источник
Эксель. Регрессия – входной интервал содержит нечисловые данные. Что делать?
Настя Черкасова
Просветленный
(32980),
закрыт
8 лет назад
через формат ячеек установила формат – числовой
что уже делать не знаю
регрессия не строится
Алекс Куха
Высший разум
(427098)
10 лет назад
– разделитель целой и др. часть м. б. неправильный
– вместо нуля стоит “О”
В общем, если есть такое сообщение, надо искать, иначе не отвяжется
Настя Черкасова Просветленный (32980)
10 лет назад
у меня столбцы Y и Х – может иметь значение, что некоторые числа в колонке Y с минусом?
Алекс Куха
Высший разум
(427098)
Надо смотреть конкретно. может между минусом и числом – пробел
Белая роза
Мыслитель
(6858)
4 года назад
Алекс Куха что значит разделить целой, я используя программу впервый раз, не понимаю вашего ответа, возникает такая же ошибка, уже весь интернет обыскала ища решение этой проблемы… но ничего нет
|
Ошибки в регрессии |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |




