To match any whole word you would use the pattern (w+)
Assuming you are using PCRE or something similar:

Above screenshot taken from this live example:
https://regex101.com/r/FGheKd/1
Matching any whole word on the commandline with (w+)
I’ll be using the phpsh interactive shell on Ubuntu 12.10 to demonstrate the PCRE regex engine through the method known as preg_match
Start phpsh, put some content into a variable, match on word.
el@apollo:~/foo$ phpsh
php> $content1 = 'badger'
php> $content2 = '1234'
php> $content3 = '$%^&'
php> echo preg_match('(w+)', $content1);
1
php> echo preg_match('(w+)', $content2);
1
php> echo preg_match('(w+)', $content3);
0
The preg_match method used the PCRE engine within the PHP language to analyze variables: $content1, $content2 and $content3 with the (w)+ pattern.
$content1 and $content2 contain at least one word, $content3 does not.
Match a number of literal words on the commandline with (dart|fart)
el@apollo:~/foo$ phpsh
php> $gun1 = 'dart gun';
php> $gun2 = 'fart gun';
php> $gun3 = 'farty gun';
php> $gun4 = 'unicorn gun';
php> echo preg_match('(dart|fart)', $gun1);
1
php> echo preg_match('(dart|fart)', $gun2);
1
php> echo preg_match('(dart|fart)', $gun3);
1
php> echo preg_match('(dart|fart)', $gun4);
0
variables gun1 and gun2 contain the string dart or fart. gun4 does not. However it may be a problem that looking for word fart matches farty. To fix this, enforce word boundaries in regex.
Match literal words on the commandline with word boundaries.
el@apollo:~/foo$ phpsh
php> $gun1 = 'dart gun';
php> $gun2 = 'fart gun';
php> $gun3 = 'farty gun';
php> $gun4 = 'unicorn gun';
php> echo preg_match('(bdartb|bfartb)', $gun1);
1
php> echo preg_match('(bdartb|bfartb)', $gun2);
1
php> echo preg_match('(bdartb|bfartb)', $gun3);
0
php> echo preg_match('(bdartb|bfartb)', $gun4);
0
So it’s the same as the previous example except that the word fart with a b word boundary does not exist in the content: farty.
Регулярные выражения (их еще называют regexp, или regex) — это механизм для поиска и замены текста. В строке, файле, нескольких файлах… Их используют разработчики в коде приложения, тестировщики в автотестах, да просто при работе в командной строке!
Чем это лучше простого поиска? Тем, что позволяет задать шаблон.
Например, на вход приходит дата рождения в формате ДД.ММ.ГГГГГ. Вам надо передать ее дальше, но уже в формате ГГГГ-ММ-ДД. Как это сделать с помощью простого поиска? Вы же не знаете заранее, какая именно дата будет.

А регулярное выражение позволяет задать шаблон «найди мне цифры в таком-то формате».
Для чего применяют регулярные выражения?
-
Удалить все файлы, начинающиеся на test (чистим за собой тестовые данные)
-
Найти все логи
-
grep-нуть логи
-
Найти все даты
-
…
А еще для замены — например, чтобы изменить формат всех дат в файле. Если дата одна, можно изменить вручную. А если их 200, проще написать регулярку и подменить автоматически. Тем более что регулярные выражения поддерживаются даже простым блокнотом (в Notepad++ они точно есть).

В этой статье я расскажу о том, как применять регулярные выражения для поиска и замены. Разберем все основные варианты.
Содержание
-
Где пощупать
-
Поиск текста
-
Поиск любого символа
-
Поиск по набору символов
-
Перечисление вариантов
-
Метасимволы
-
Спецсимволы
-
Квантификаторы (количество повторений)
-
Позиция внутри строки
-
Использование ссылки назад
-
Просмотр вперед и назад
-
Замена
-
Статьи и книги по теме
-
Итого
Где пощупать
Любое регулярное выражение из статьи вы можете сразу пощупать. Так будет понятнее, о чем речь в статье — вставили пример из статьи, потом поигрались сами, делая шаг влево, шаг вправо. Где тренироваться:
-
Notepad++ (установить Search Mode → Regular expression)
-
Regex101 (мой фаворит в онлайн вариантах)
-
Myregexp
-
Regexr
Инструменты есть, теперь начнём
Поиск текста
Самый простой вариант регэкспа. Работает как простой поиск — ищет точно такую же строку, как вы ввели.
Текст: Море, море, океан
Regex: море
Найдет: Море, море, океан
Выделение курсивом не поможет моментально ухватить суть, что именно нашел regex, а выделить цветом в статье я не могу. Атрибут BACKGROUND-COLOR не сработал, поэтому я буду дублировать регулярки текстом (чтобы можно было скопировать себе) и рисунком, чтобы показать, что именно regex нашел:

Обратите внимание, нашлось именно «море», а не первое «Море». Регулярные выражения регистрозависимые!
Хотя, конечно, есть варианты. В JavaScript можно указать дополнительный флажок i, чтобы не учитывать регистр при поиске. В блокноте (notepad++) тоже есть галка «Match case». Но учтите, что это не функция по умолчанию. И всегда стоит проверить, регистрозависимая ваша реализация поиска, или нет.
А что будет, если у нас несколько вхождений искомого слова?
Текст: Море, море, море, океан
Regex: море
Найдет: Море, море, море, океан

По умолчанию большинство механизмов обработки регэкспа вернет только первое вхождение. В JavaScript есть флаг g (global), с ним можно получить массив, содержащий все вхождения.
А что, если у нас искомое слово не само по себе, это часть слова? Регулярное выражение найдет его:
Текст: Море, 55мореон, океан
Regex: море
Найдет: Море, 55мореон, океан

Это поведение по умолчанию. Для поиска это даже хорошо. Вот, допустим, я помню, что недавно в чате коллега рассказывала какую-то историю про интересный баг в игре. Что-то там связанное с кораблем… Но что именно? Уже не помню. Как найти?
Если поиск работает только по точному совпадению, мне придется перебирать все падежи для слова «корабль». А если он работает по включению, я просто не буду писать окончание, и все равно найду нужный текст:
Regex: корабл
Найдет:
На корабле
И тут корабль
У корабля

Это статический, заранее заданный текст. Но его можно найти и без регулярок. Регулярные выражения особенно хороши, когда мы не знаем точно, что мы ищем. Мы знаем часть слова, или шаблон.
Поиск любого символа
. — найдет любой символ (один).
Текст:
Аня
Ася
Оля
Аля
Валя
Regex: А.я
Результат:
Аня
Ася
ОляАля
Валя

Точка найдет вообще любой символ, включая цифры, спецсисимволы, даже пробелы. Так что кроме нормальных имен, мы найдем и такие значения:
А6я
А&я
А я
Учтите это при поиске! Точка очень удобный символ, но в то же время очень опасный — если используете ее, обязательно тестируйте получившееся регулярное выражение. Найдет ли оно то, что нужно? А лишнее не найдет?
Точку точка тоже найдет!
Regex: file.
Найдет:
file.txt
file1.txt
file2.xls

Но что, если нам надо найти именно точку? Скажем, мы хотим найти все файлы с расширением txt и пишем такой шаблон:
Regex: .txt
Результат:
file.txt
log.txt
file.png1txt.doc
one_txt.jpg

Да, txt файлы мы нашли, но помимо них еще и «мусорные» значения, у которых слово «txt» идет в середине слова. Чтобы отсечь лишнее, мы можем использовать позицию внутри строки (о ней мы поговорим чуть дальше).
Но если мы хотим найти именно точку, то нужно ее заэкранировать — то есть добавить перед ней обратный слеш:
Regex: .txt
Результат:
file.txt
log.txt
file.png
1txt.doc
one_txt.jpg

Также мы будем поступать со всеми спецсимволами. Хотим найти именно такой символ в тексте? Добавляем перед ним обратный слеш.
Правило поиска для точки:
. — любой символ
. — точка

Поиск по набору символов
Допустим, мы хотим найти имена «Алла», «Анна» в списке. Можно попробовать поиск через точку, но кроме нормальных имен, вернется всякая фигня:
Regex: А..а
Результат:
Анна
Алла
аоикА74арплт
Аркан
А^&а
Абба

Если же мы хотим именно Анну да Аллу, вместо точки нужно использовать диапазон допустимых значений. Ставим квадратные скобки, а внутри них перечисляем нужные символы:
Regex: А[нл][нл]а
Результат:
Анна
Алла
аоикА74арплт
Аркан
А^&а
Абба

Вот теперь результат уже лучше! Да, нам все еще может вернуться «Анла», но такие ошибки исправим чуть позже.
Как работают квадратные скобки? Внутри них мы указываем набор допустимых символов. Это может быть перечисление нужных букв, или указание диапазона:
[нл] — только «н» и «л»
[а-я] — все русские буквы в нижнем регистре от «а» до «я» (кроме «ё»)
[А-Я] — все заглавные русские буквы
[А-Яа-яЁё] — все русские буквы
[a-z] — латиница мелким шрифтом
[a-zA-Z] — все английские буквы
[0-9] — любая цифра
[В-Ю] — буквы от «В» до «Ю» (да, диапазон — это не только от А до Я)
[А-ГО-Р] — буквы от «А» до «Г» и от «О» до «Р»
Обратите внимание — если мы перечисляем возможные варианты, мы не ставим между ними разделителей! Ни пробел, ни запятую — ничего.
[абв] — только «а», «б» или «в»
[а б в] — «а», «б», «в», или пробел (что может привести к нежелательному результату)
[а, б, в] — «а», «б», «в», пробел или запятая

Единственный допустимый разделитель — это дефис. Если система видит дефис внутри квадратных скобок — значит, это диапазон:
-
Символ до дефиса — начало диапазона
-
Символ после — конец
Один символ! Не два или десять, а один! Учтите это, если захотите написать что-то типа [1-31]. Нет, это не диапазон от 1 до 31, эта запись читается так:
-
Диапазон от 1 до 3
-
И число 1
Здесь отсутствие разделителей играет злую шутку с нашим сознанием. Ведь кажется, что мы написали диапазон от 1 до 31! Но нет. Поэтому, если вы пишете регулярные выражения, очень важно их тестировать. Не зря же мы тестировщики! Проверьте то, что написали! Особенно, если с помощью регулярного выражения вы пытаетесь что-то удалить =)) Как бы не удалили лишнее…
Указание диапазона вместо точки помогает отсеять заведомо плохие данные:
Regex: А.я или А[а-я]я
Результат для обоих:
Аня
Ася
Аля
Результат для «А.я»:
А6я
А&я
А я
^ внутри [] означает исключение:
[^0-9] — любой символ, кроме цифр
[^ёЁ] — любой символ, кроме буквы «ё»
[^а-в8] — любой символ, кроме букв «а», «б», «в» и цифры 8

Например, мы хотим найти все txt файлы, кроме разбитых на кусочки — заканчивающихся на цифру:
Regex: [^0-9].txt
Результат:
file.txt
log.txt
file_1.txt
1.txt

Так как квадратные скобки являются спецсимволами, то их нельзя найти в тексте без экранирования:
Regex: fruits[0]
Найдет: fruits0
Не найдет: fruits[0]
Это регулярное выражение говорит «найди мне текст «fruits», а потом число 0». Квадратные скобки не экранированы — значит, внутри будет набор допустимых символов.

Если мы хотим найти именно 0-левой элемент массива фруктов, надо записать так:
Regex: fruits[0]
Найдет: fruits[0]
Не найдет: fruits0
А если мы хотим найти все элементы массива фруктов, мы внутри экранированных квадратных скобок ставим неэкранированные!
Regex: fruits[[0-9]]
Найдет:
fruits[0] = “апельсин”;
fruits[1] = “яблоко”;
fruits[2] = “лимон”;
Не найдет:
cat[0] = “чеширский кот”;
Конечно, «читать» такое регулярное выражение становится немного тяжело, столько разных символов написано…

Без паники! Если вы видите сложное регулярное выражение, то просто разберите его по частям. Помните про основу эффективного тайм-менеджмента? Слона надо есть по частям.
Допустим, после отпуска накопилась гора писем. Смотришь на нее и сразу впадаешь в уныние:
— Ууууууу, я это за день не закончу!

Проблема в том, что груз задачи мешает работать. Мы ведь понимаем, что это надолго. А большую задачу делать не хочется… Поэтому мы ее откладываем, беремся за задачи поменьше. В итоге да, день прошел, а мы не успели закончить.
А если не тратить время на размышления «сколько времени это у меня займет», а сосредоточиться на конкретной задаче (в данном случае — первом письме из стопки, потом втором…), то не успеете оглянуться, как уже всё разгребли!

Разберем по частям регулярное выражение — fruits[[0-9]]
Сначала идет просто текст — «fruits».

Потом обратный слеш. Ага, он что-то экранирует.

Что именно? Квадратную скобку. Значит, это просто квадратная скобка в моем тексте — «fruits[»

Дальше снова квадратная скобка. Она не экранирована — значит, это набор допустимых значений. Ищем закрывающую квадратную скобку.

Нашли. Наш набор: [0-9]. То есть любое число. Но одно. Там не может быть 10, 11 или 325, потому что квадратные скобки без квантификатора (о них мы поговорим чуть позже) заменяют ровно один символ.
Пока получается: fruits[«любое однозназначное число»

Дальше снова обратный слеш. То есть следующий за ним спецсимвол будет просто символом в моем тексте.

А следующий символ — ]
Получается выражение: fruits[«любое однозназначное число»]

Наше выражение найдет значения массива фруктов! Не только нулевое, но и первое, и пятое… Вплоть до девятого:
Regex: fruits[[0-9]]
Найдет:
fruits[0] = “апельсин”;
fruits[1] = “яблоко”;
fruits[9] = “лимон”;
Не найдет:
fruits[10] = “банан”;
fruits[325] = “ абрикос ”;
Как найти вообще все значения массива, см дальше, в разделе «квантификаторы».
А пока давайте посмотрим, как с помощью диапазонов можно найти все даты.

Какой у даты шаблон? Мы рассмотрим ДД.ММ.ГГГГ:
-
2 цифры дня
-
точка
-
2 цифры месяца
-
точка
-
4 цифры года
Запишем в виде регулярного выражения: [0-9][0-9].[0-9][0-9].[0-9][0-9][0-9][0-9].
Напомню, что мы не можем записать диапазон [1-31]. Потому что это будет значить не «диапазон от 1 до 31», а «диапазон от 1 до 3, плюс число 1». Поэтому пишем шаблон для каждой цифры отдельно.
В принципе, такое выражение найдет нам даты среди другого текста. Но что, если с помощью регулярки мы проверяем введенную пользователем дату? Подойдет ли такой regexp?
Давайте его протестируем! Как насчет 8888 года или 99 месяца, а?
Regex: [0-9][0-9].[0-9][0-9].[0-9][0-9][0-9][0-9]
Найдет:
01.01.1999
05.08.2015
Тоже найдет:
08.08.8888
99.99.2000

Попробуем ограничить:
-
День месяца может быть максимум 31 — первая цифра [0-3]
-
Максимальный месяц 12 — первая цифра [01]
-
Год или 19.., или 20.. — первая цифра [12], а вторая [09]

Вот, уже лучше, явно плохие данные регулярка отсекла. Надо признать, она отсечет довольно много тестовых данных, ведь обычно, когда хотят именно сломать, то фигачат именно «9999» год или «99» месяц…
Однако если мы присмотримся внимательнее к регулярному выражению, то сможем найти в нем дыры:
Regex: [0-3][0-9].[0-1][0-9].[12][09][0-9][0-9]
Не найдет:
08.08.8888
99.99.2000
Но найдет:
33.01.2000
01.19.1999
05.06.2999

Мы не можем с помощью одного диапазона указать допустимые значения. Или мы потеряем 31 число, или пропустим 39. И если мы хотим сделать проверку даты, одних диапазонов будет мало. Нужна возможность перечислить варианты, о которой мы сейчас и поговорим.
Перечисление вариантов
Квадратные скобки [] помогают перечислить варианты для одного символа. Если же мы хотим перечислить слова, то лучше использовать вертикальную черту — |.
Regex: Оля|Олечка|Котик
Найдет:
Оля
Олечка
Котик
Не найдет:
Оленька
Котенка
Можно использовать вертикальную черту и для одного символа. Можно даже внутри слова — тогда вариативную букву берем в круглые скобки
Regex: А(н|л)я
Найдет:
Аня
Аля
Круглые скобки обозначают группу символов. В этой группе у нас или буква «н», или буква «л». Зачем нужны скобки? Показать, где начинается и заканчивается группа. Иначе вертикальная черта применится ко всем символам — мы будем искать или «Ан», или «ля»:
Regex: Ан|ля
Найдет:
Аня
Аля
Оля
Малюля

А если мы хотим именно «Аня» или «Аля», то перечисление используем только для второго символа. Для этого берем его в скобки.
Эти 2 варианта вернут одно и то же:
-
А(н|л)я
-
А[нл]я
Но для замены одной буквы лучше использовать [], так как сравнение с символьным классом выполняется проще, чем обработка группы с проверкой на все её возможные модификаторы.
Давайте вернемся к задаче «проверить введенную пользователем дату с помощью регулярных выражений». Мы пробовали записать для дня диапазон [0-3][0-9], но он пропускает значения 33, 35, 39… Это нехорошо!
Тогда распишем ТЗ подробнее. Та-а-а-ак… Если первая цифра:
-
0 — вторая может от 1 до 9 (даты 00 быть не может)
-
1, 2 — вторая может от 0 до 9
-
3 — вторая только 0 или 1
Составим регулярные выражения на каждый пункт:
-
0[1-9]
-
[12][0-9]
-
3[01]
А теперь осталось их соединить в одно выражение! Получаем: 0[1-9]|[12][0-9]|3[01]

По аналогии разбираем месяц и год. Но это остается вам для домашнего задания =)
Потом, когда распишем регулярки отдельно для дня, месяца и года, собираем все вместе:
(<день>).(<месяц>).(<год>)
Обратите внимание — каждую часть регулярного выражения мы берем в скобки. Зачем? Чтобы показать системе, где заканчивается выбор. Вот смотрите, допустим, что для месяца и года у нас осталось выражение:
[0-1][0-9].[12][09][0-9][0-9]
Подставим то, что написали для дня:
0[1-9]|[12][0-9]|3[01].[0-1][0-9].[12][09][0-9][0-9]
Как читается это выражение?
-
ИЛИ 0[1-9]
-
ИЛИ [12][0-9]
-
ИЛИ 3[01].[0-1][0-9].[12][09][0-9][0-9]
Видите проблему? Число «19» будет считаться корректной датой. Система не знает, что перебор вариантов | закончился на точке после дня. Чтобы она это поняла, нужно взять перебор в скобки. Как в математике, разделяем слагаемые.
Так что запомните — если перебор идет в середине слова, его надо взять в круглые скобки!
Regex: А(нн|лл|лин|нтонин)а
Найдет:
Анна
Алла
Алина
Антонина
Без скобок:
Regex: Анн|лл|лин|нтонина
Найдет:
Анна
Алла
Аннушка
Кукулинка

Итого, если мы хотим указать допустимые значения:
-
Одного символа — используем []
-
Нескольких символов или целого слова — используем |

Метасимволы
Если мы хотим найти число, то пишем диапазон [0-9].
Если букву, то [а-яА-ЯёЁa-zA-Z].
А есть ли другой способ?

Есть! В регулярных выражениях используются специальные метасимволы, которые заменяют собой конкретный диапазон значений:
|
Символ |
Эквивалент |
Пояснение |
|
d |
[0-9] |
Цифровой символ |
|
D |
[^0-9] |
Нецифровой символ |
|
s |
[ fnrtv] |
Пробельный символ |
|
S |
[^ fnrtv] |
Непробельный символ |
|
w |
[[:word:]] |
Буквенный или цифровой символ или знак подчёркивания |
|
W |
[^[:word:]] |
Любой символ, кроме буквенного или цифрового символа или знака подчёркивания |
|
. |
Вообще любой символ |
Это самые распространенные символы, которые вы будете использовать чаще всего. Но давайте разберемся с колонкой «эквивалент». Для d все понятно — это просто некие числа. А что такое «пробельные символы»? В них входят:
|
Символ |
Пояснение |
|
Пробел |
|
|
r |
Возврат каретки (Carriage return, CR) |
|
n |
Перевод строки (Line feed, LF) |
|
t |
Табуляция (Tab) |
|
v |
Вертикальная табуляция (vertical tab) |
|
f |
Конец страницы (Form feed) |
|
[b] |
Возврат на 1 символ (Backspace) |
Из них вы чаще всего будете использовать сам пробел и перевод строки — выражение «rn». Напишем текст в несколько строк:
Первая строка
Вторая строка
Для регулярного выражения это:
Первая строкаrnВторая строка
А вот что такое backspace в тексте? Как его можно увидеть вообще? Это же если написать символ и стереть его. В итоге символа нет! Неужели стирание хранится где-то в памяти? Но тогда это было бы ужасно, мы бы вообще ничего не смогли найти — откуда нам знать, сколько раз текст исправляли и в каких местах там теперь есть невидимый символ [b]?

Выдыхаем — этот символ не найдет все места исправления текста. Просто символ backspace — это ASCII символ, который может появляться в тексте (ASCII code 8, или 10 в octal). Вы можете «создать» его, написать в консоли браузера (там используется JavaScript):
console.log("abcbbdef");Результат команды:
adefМы написали «abc», а потом стерли «b» и «с». В итоге пользователь в консоли их не видит, но они есть. Потому что мы прямо в коде прописали символ удаления текста. Не просто удалили текст, а прописали этот символ. Вот такой символ регулярное выражение [b] и найдет.
См также:
What’s the use of the [b] backspace regex? — подробнее об этом символе
Но обычно, когда мы вводим s, мы имеем в виду пробел, табуляцию, или перенос строки.
Ок, с этими эквивалентами разобрались. А что значит [[:word:]]? Это один из способов заменить диапазон. Чтобы запомнить проще было, написали значения на английском, объединив символы в классы. Какие есть классы:
|
Класс символов |
Пояснение |
|
[[:alnum:]] |
Буквы или цифры: [а-яА-ЯёЁa-zA-Z0-9] |
|
[[:alpha:]] |
Только буквы: [а-яА-ЯёЁa-zA-Z] |
|
[[:digit:]] |
Только цифры: [0-9] |
|
[[:graph:]] |
Только отображаемые символы (пробелы, служебные знаки и т. д. не учитываются) |
|
[[:print:]] |
Отображаемые символы и пробелы |
|
[[:space:]] |
Пробельные символы [ fnrtv] |
|
[[:punct:]] |
Знаки пунктуации: ! ” # $ % & ‘ ( ) * + , -. / : ; < = > ? @ [ ] ^ _ ` { | } |
|
[[:word:]] |
Буквенный или цифровой символ или знак подчёркивания: [а-яА-ЯёЁa-zA-Z0-9_] |
Теперь мы можем переписать регулярку для проверки даты, которая выберет лишь даты формата ДД.ММ.ГГГГГ, отсеяв при этом все остальное:
[0-9][0-9].[0-9][0-9].[0-9][0-9][0-9][0-9]
↓
dd.dd.dddd
Согласитесь, через метасимволы запись посимпатичнее будет =))
Спецсимволы
Большинство символов в регулярном выражении представляют сами себя за исключением специальных символов:
[ ] / ^ $ . | ? * + ( ) { }
Эти символы нужны, чтобы обозначить диапазон допустимых значений или границу фразы, указать количество повторений, или сделать что-то еще. В разных типах регулярных выражений этот набор различается (см «разновидности регулярных выражений»).
Если вы хотите найти один из этих символов внутри вашего текста, его надо экранировать символом (обратная косая черта).
Regex: 2^2 = 4
Найдет: 2^2 = 4
Можно экранировать целую последовательность символов, заключив её между Q и E (но не во всех разновидностях).
Regex: Q{кто тут?}E
Найдет: {кто тут?}
Квантификаторы (количество повторений)
Усложняем задачу. Есть некий текст, нам нужно вычленить оттуда все email-адреса. Например:
-
test@mail.ru
-
olga31@gmail.com
-
pupsik_99@yandex.ru

Как составляется регулярное выражение? Нужно внимательно изучить данные, которые мы хотим получить на выходе, и составить по ним шаблон. В email два разделителя — собачка «@» и точка «.».

Запишем ТЗ для регулярного выражения:
-
Буквы / цифры / _
-
Потом @
-
Снова буквы / цифры / _
-
Точка
-
Буквы
Так, до собачки у нас явно идет метасимвол «w», туда попадет и просто текст (test), и цифры (olga31), и подчеркивание (pupsik_99). Но есть проблема — мы не знаем, сколько таких символов будет. Это при поиске даты все ясно — 2 цифры, 2 цифры, 4 цифры. А тут может быть как 2, так и 22 символа.
И тут на помощь приходят квантификаторы — так называют специальные символы в регулярных выражениях, которые указывают количество повторений текста.
Символ «+» означает «одно или более повторений», это как раз то, что нам надо! Получаем: w+@

После собачки и снова идет w, и снова от одного повторения. Получаем: w+@w+.
После точки обычно идут именно символы, но для простоты можно снова написано w. И снова несколько символов ждем, не зная точно сколько. Итого получилось выражение, которое найдет нам email любой длины:
Regex: w+@w+.w+
Найдет:
test@mail.ru
olga31@gmail.com
pupsik_99_and_slonik_33_and_mikky_87_and_kotik_28@yandex.megatron
Какие есть квантификаторы, кроме знака «+»?
|
Квантификатор |
Число повторений |
|
? |
Ноль или одно |
|
* |
Ноль или более |
|
+ |
Один или более |
Символ * часто используют с точкой — когда нам неважно, какой идет текст до интересующей нас фразы, мы заменяем его на «.*» — любой символ ноль или более раз.
Regex: .*dd.dd.dddd.*
Найдет:
01.01.2000
Приходи на ДР 09.08.2015! Будет весело!
Но будьте осторожны! Если использовать «.*» повсеместно, можно получить много ложноположительных срабатываний:
Regex: .*@.*..*
Найдет:
test@mail.ru
olga31@gmail.com
pupsik_99@yandex.ru
Но также найдет:
@yandex.ru
test@.ru
test@mail.

Уж лучше w, и плюсик вместо звездочки.
А вот есть мы хотим найти все лог-файлы, которые нумеруются — log, log1, log2… log133, то * подойдет хорошо:
Regex: logd*.txt
Найдет:
log.txt
log1.txt
log2.txt
log3.txt
log33.txt
log133.txt
А знак вопроса (ноль или одно повторение) поможет нам найти людей с конкретной фамилией — причем всех, и мужчин, и женщин:
Regex: Назина?
Найдет:
Назин
Назина
Если мы хотим применить квантификатор к группе символов или нескольким словам, их нужно взять в скобки:
Regex: (Хихи)*(Хаха)*
Найдет:
ХихиХаха
ХихиХихиХихи
Хихи
Хаха
ХихиХихиХахаХахаХаха
(пустота — да, её такая регулярка тоже найдет)
Квантификаторы применяются к символу или группе в скобках, которые стоят перед ним.
А что, если мне нужно определенное количество повторений? Скажем, я хочу записать регулярное выражение для даты. Пока мы знаем только вариант «перечислить нужный метасимвол нужное количество раз» — dd.dd.dddd.
Ну ладно 2-4 раза повторение идет, а если 10? А если повторить надо фразу? Так и писать ее 10 раз? Не слишком удобно. А использовать * нельзя:
Regex: d*.d*.d*
Найдет:
.0.1999
05.08.20155555555555555
03444.025555.200077777777777777
Чтобы указать конкретное количество повторений, их надо записать внутри фигурных скобок:
|
Квантификатор |
Число повторений |
|
{n} |
Ровно n раз |
|
{m,n} |
От m до n включительно |
|
{m,} |
Не менее m |
|
{,n} |
Не более n |
Таким образом, для проверки даты можно использовать как перечисление d n раз, так и использование квантификатора:
dd.dd.dddd
d{2}.d{2}.d{4}
Обе записи будут валидны. Но вторая читается чуть проще — не надо самому считать повторения, просто смотрим на цифру.
Не забывайте — квантификатор применяется к последнему символу!
Regex: data{2}
Найдет: dataa
Не найдет: datadata
Или группе символов, если они взяты в круглые скобки:
Regex: (data){2}
Найдет: datadata
Не найдет: dataa

Так как фигурные скобки используются в качестве указания количества повторений, то, если вы ищете именно фигурную скобку в тексте, ее надо экранировать:
Regex: x{3}
Найдет: x{3}
Иногда квантификатор находит не совсем то, что нам нужно.
Regex: <.*>
Ожидание:
<req>
<query>Ан</query>
<gender>FEMALE</gender>Реальность:
<req> <query>Ан</query> <gender>FEMALE</gender></req>Мы хотим найти все теги HTML или XML по отдельности, а регулярное выражение возвращает целую строку, внутри которой есть несколько тегов.
Напомню, что в разных реализациях регулярные выражения могут работать немного по разному. Это одно из отличий — в некоторых реализациях квантификаторам соответствует максимально длинная строка из возможных. Такие квантификаторы называют жадными.

Если мы понимаем, что нашли не то, что хотели, можно пойти двумя путями:
-
Учитывать символы, не соответствующие желаемому образцу
-
Определить квантификатор как нежадный (ленивый, англ. lazy) — большинство реализаций позволяют это сделать, добавив после него знак вопроса.
Как учитывать символы? Для примера с тегами можно написать такое регулярное выражение:
<[^>]*>
Оно ищет открывающий тег, внутри которого все, что угодно, кроме закрывающегося тега «>», и только потом тег закрывается. Так мы не даем захватить лишнее. Но учтите, использование ленивых квантификаторов может повлечь за собой обратную проблему — когда выражению соответствует слишком короткая, в частности, пустая строка.
|
Жадный |
Ленивый |
|
* |
*? |
|
+ |
+? |
|
{n,} |
{n,}? |

Есть еще и сверхжадная квантификация, также именуемая ревнивой. Но о ней почитайте в википедии =)
Позиция внутри строки
По умолчанию регулярные выражения ищут «по включению».
Regex: арка
Найдет:
арка
чарка
аркан
баварка
знахарка
Это не всегда то, что нам нужно. Иногда мы хотим найти конкретное слово.

Если мы ищем не одно слово, а некую строку, проблема решается в помощью пробелов:
Regex: Товар №d+ добавлен в корзину в dd:dd
Найдет: Товар №555 добавлен в корзину в 15:30
Не найдет: Товарный чек №555 добавлен в корзину в 15:30

Или так:
Regex: .* арка .*
Найдет: Триумфальная арка была…
Не найдет: Знахарка сегодня…
А что, если у нас не пробел рядом с искомым словом? Это может быть знак препинания: «И вот перед нами арка.», или «…арка:».
Если мы ищем конкретное слово, то можно использовать метасимвол b, обозначающий границу слова. Если поставить метасимвол с обоих концов слова, мы найдем именно это слово:
Regex: bаркаb
Найдет:
арка
Не найдет:
чарка
аркан
баварка
знахарка

Можно ограничить только спереди — «найди все слова, которые начинаются на такое-то значение»:
Regex: bарка
Найдет:
арка
аркан
Не найдет:
чарка
баварка
знахарка
Можно ограничить только сзади — «найди все слова, которые заканчиваются на такое-то значение»:
Regex: аркаb
Найдет:
арка
чарка
баварка
знахарка
Не найдет:
аркан
Если использовать метасимвол B, он найдем нам НЕ-границу слова:
Regex: BакрB
Найдет:
закройка
Не найдет:
акр
акрил
Если мы хотим найти конкретную фразу, а не слово, то используем следующие спецсимволы:
^ — начало текста (строки)
$ — конец текста (строки)
Если использовать их, мы будем уверены, что в наш текст не закралось ничего лишнего:
Regex: ^Я нашел!$
Найдет:
Я нашел!
Не найдет:
Смотри! Я нашел!
Я нашел! Посмотри!
Итого метасимволы, обозначающие позицию строки:
|
Символ |
Значение |
|
b |
граница слова |
|
B |
Не граница слова |
|
^ |
начало текста (строки) |
|
$ |
конец текста (строки) |
Использование ссылки назад
Допустим, при тестировании приложения вы обнаружили забавный баг в тексте — дублирование предлога «на»: «Поздравляем! Вы прошли на на новый уровень». А потом решили проверить, есть ли в коде еще такие ошибки.

Разработчик предоставил файлик со всеми текстами. Как найти повторы? С помощью ссылки назад. Когда мы берем что-то в круглые скобки внутри регулярного выражения, мы создаем группу. Каждой группе присваивается номер, по которому к ней можно обратиться.
Regex: [ ]+(w+)[ ]+1
Текст: Поздравляем! Вы прошли на на новый уровень. Так что что улыбаемся и и машем.

Разберемся, что означает это регулярное выражение:
[ ]+ → один или несколько пробелов, так мы ограничиваем слово. В принципе, тут можно заменить на метасимвол b.
(w+) → любой буквенный или цифровой символ, или знак подчеркивания. Квантификатор «+» означает, что символ должен идти минимум один раз. А то, что мы взяли все это выражение в круглые скобки, говорит о том, что это группа. Зачем она нужна, мы пока не знаем, ведь рядом с ней нет квантификатора. Значит, не для повторения. Но в любом случае, найденный символ или слово — это группа 1.
[ ]+ → снова один или несколько пробелов.
1 → повторение группы 1. Это и есть ссылка назад. Так она записывается в JavaScript-е.
Важно: синтаксис ссылок назад очень зависит от реализации регулярных выражений.
|
ЯП |
Как обозначается ссылка назад |
|
JavaScript vi |
|
|
Perl |
$ |
|
PHP |
$matches[1] |
|
Java Python |
group[1] |
|
C# |
match.Groups[1] |
|
Visual Basic .NET |
match.Groups(1) |
Для чего еще нужна ссылка назад? Например, можно проверить верстку HTML, правильно ли ее составили? Верно ли, что открывающийся тег равен закрывающемуся?

Напишите выражение, которое найдет правильно написанные теги:
<h2>Заголовок 2-ого уровня</h2>
<h3>Заголовок 3-ого уровня</h3>Но не найдет ошибки:
<h2>Заголовок 2-ого уровня</h3>Просмотр вперед и назад
Еще может возникнуть необходимость найти какое-то место в тексте, но не включая найденное слово в выборку. Для этого мы «просматриваем» окружающий текст.
|
Представление |
Вид просмотра |
Пример |
Соответствие |
|
(?=шаблон) |
Позитивный просмотр вперёд |
Блюдо(?=11) |
Блюдо11 Блюдо113
|
|
(?!шаблон) |
Негативный просмотр вперёд (с отрицанием) |
Блюдо(?!11) |
Блюдо1
Блюдо511 |
|
(?<=шаблон) |
Позитивный просмотр назад |
(?<=Ольга )Назина |
Ольга Назина
|
|
(?шаблон) |
Негативный просмотр назад (с отрицанием) |
(см ниже на рисунке) |
Анна Назина |

Замена
Важная функция регулярных выражений — не только найти текст, но и заменить его на другой текст! Простейший вариант замены — слово на слово:
RegEx: Ольга
Замена: Макар
Текст был: Привет, Ольга!
Текст стал: Привет, Макар!
Но что, если у нас в исходном тексте может быть любое имя? Вот что пользователь ввел, то и сохранилось. А нам надо на Макара теперь заменить. Как сделать такую замену? Через знак доллара. Давайте разберемся с ним подробнее.

Знак доллара в замене — обращение к группе в поиске. Ставим знак доллара и номер группы. Группа — это то, что мы взяли в круглые скобки. Нумерация у групп начинается с 1.
RegEx: (Оля) + Маша
Замена: $1
Текст был: Оля + Маша
Текст стал: Оля
Мы искали фразу «Оля + Маша» (круглые скобки не экранированы, значит, в искомом тексте их быть не должно, это просто группа). А замнили ее на первую группу — то, что написано в первых круглых скобках, то есть текст «Оля».
Это работает и когда искомый текст находится внутри другого:
RegEx: (Оля) + Маша
Замена: $1
Текст был: Привет, Оля + Маша!
Текст стал: Привет, Оля!

Можно каждую часть текста взять в круглые скобки, а потом варьировать и менять местами:
RegEx: (Оля) + (Маша)
Замена: $2 – $1
Текст был: Оля + Маша
Текст стал: Маша — Оля
Теперь вернемся к нашей задаче — есть строка приветствия «Привет, кто-то там!», где может быть написано любое имя (даже просто числа вместо имени). Мы это имя хотим заменить на «Макар».
Нам надо оставить текст вокруг имени, поэтому берем его в скобки в регулярном выражении, составляя группы. И переиспользуем в замене:
RegEx: ^(Привет, ).*(!)$
Замена: $1Макар$2
Текст был (или или):
Привет, Ольга!
Привет, 777!
Текст стал:
Привет, Макар!
Давайте разберемся, как работает это регулярное выражение.
^ — начало строки.
Дальше скобка. Она не экранирована — значит, это группа. Группа 1. Поищем для нее закрывающую скобку и посмотрим, что входит в эту группу. Внутри группы текст «Привет, »

После группы идет выражение «.*» — ноль или больше повторений чего угодно. То есть вообще любой текст. Или пустота, она в регулярку тоже входит.

Потом снова открывающаяся скобка. Она не экранирована — ага, значит, это вторая группа. Что внутри? Внутри простой текст — «!».

И потом символ $ — конец строки.
Посмотрим, что у нас в замене.
$1 — значение группы 1. То есть текст «Привет, ».

Макар — просто текст. Обратите внимание, что мы или включает пробел после запятой в группу 1, или ставим его в замене после «$1», иначе на выходе получим «Привет,Макар».

$2 — значение группы 2, то есть текст «!»

Вот и всё!
А что, если нам надо переформатировать даты? Есть даты в формате ДД.ММ.ГГГГ, а нам нужно поменять формат на ГГГГ-ММ-ДД.

Регулярное выражение для поиска у нас уже есть — «d{2}.d{2}.d{4}». Осталось понять, как написать замену. Посмотрим внимательно на ТЗ:
ДД.ММ.ГГГГ
↓
ГГГГ-ММ-ДД
По нему сразу понятно, что нам надо выделить три группы. Получается так: (d{2}).(d{2}).(d{4})
В результате у нас сначала идет год — это третья группа. Пишем: $3

Потом идет дефис, это просто текст: $3-
Потом идет месяц. Это вторая группа, то есть «$2». Получается: $3-$2

Потом снова дефис, просто текст: $3-$2-
И, наконец, день. Это первая группа, $1. Получается: $3-$2-$1

Вот и всё!
RegEx: (d{2}).(d{2}).(d{4})
Замена: $3-$2-$1
Текст был:
05.08.2015
01.01.1999
03.02.2000
Текст стал:
2015-08-05
1999-01-01
2000-02-03

Другой пример — я записываю в блокнот то, что успела сделать за цикл в 12 недель. Называется файлик «done», он очень мотивирует! Если просто вспоминать «что же я сделал?», вспоминается мало. А тут записал и любуешься списком.
Вот пример улучшалок по моему курсу для тестировщиков:
-
Сделала сообщения для бота — чтобы при выкладке новых тем писал их в чат
-
Фолкс — поправила статью «Расширенный поиск», убрала оттуда про пустой ввод при простом поиске, а то путал
-
Обновила кусочек про эффект золушки (переписывала под ютуб)
И таких набирается штук 10-25. За один цикл. А за год сколько? Ух! Вроде небольшие улучшения, а набирается прилично.
Так вот, когда цикл заканчивается, я пишу в блог о своих успехах. Чтобы вставить список в блог, мне надо удалить нумерацию — тогда я сделаю ее силами блоггера и это будет смотреться симпатичнее.

Удаляю с помощью регулярного выражения:
RegEx: d+. (.*)
Замена: $1
Текст был:
1. Раз
2. Два
Текст стал:
Раз
Два
Можно было бы и вручную. Но для списка больше 5 элементов это дико скучно и уныло. А так нажал одну кнопочку в блокноте — и готово!
Так что регулярные выражения могут помочь даже при написании статьи =)
Статьи и книги по теме
Книги
Регулярные выражения 10 минут на урок. Бен Форта — Очень рекомендую! Прям шикарная книга, где все просто, доступно, понятно. Стоит 100 рублей, а пользы море.
Статьи
Вики — https://ru.wikipedia.org/wiki/Регулярные_выражения. Да, именно ее вы будете читать чаще всего. Я сама не помню наизусть все метасимволы. Поэтому, когда использую регулярки, гуглю их, википедия всегда в топе результатов. А сама статья хорошая, с табличками удобными.
Регулярные выражения для новичков — https://tproger.ru/articles/regexp-for-beginners/
Итого
Регулярные выражения — очень полезная вещь для тестировщика. Применений у них много, даже если вы не автоматизатор и не спешите им стать:
-
Найти все нужные файлы в папке.
-
Grep-нуть логи — отсечь все лишнее и найти только ту информацию, которая вам сейчас интересна.
-
Проверить по базе, нет ли явно некорректных записей — не остались ли тестовые данные в продакшене? Не присылает ли смежная система какую-то фигню вместо нормальных данных?
-
Проверить данные чужой системы, если она выгружает их в файл.
-
Выверить файлик текстов для сайта — нет ли там дублирования слов?
-
Подправить текст для статьи.
-
…

Если вы знаете, что в коде вашей программы есть регулярное выражение, вы можете его протестировать. Вы также можете использовать регулярки внутри ваших автотестов. Хотя тут стоит быть осторожным.
Не забывайте о шутке: «У разработчика была одна проблема и он стал решать ее с помощью регулярных выражений. Теперь у него две проблемы». Бывает и так, безусловно. Как и с любым другим кодом.

Поэтому, если вы пишете регулярку, обязательно ее протестируйте! Особенно, если вы ее пишете в паре с командой rm (удаление файлов в linux). Сначала проверьте, правильно ли отрабатывает поиск, а потом уже удаляйте то, что нашли.

Регулярное выражение может не найти то, что вы ожидали. Или найти что-то лишнее. Особенно если у вас идет цепочка регулярок. Думаете, это так легко — правильно написать регулярку? Попробуйте тогда решить задачку от Егора или вот эти кроссворды =)
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
Примеры регулярных выражений
Приведенные ниже примеры показывают, как использовать и составлять простые регулярные выражения. Каждый пример содержит искомый текст, одно или несколько соответствующих ему регулярных выражений, а также примечания, поясняющие использование специальных символов и форматов.
- Поиск точной фразы
- Поиск слова или фразы из списка
- Поиск слова в разных вариантах написания или со специальными символами
- Поиск любого адреса электронной почты в определенном домене
- Поиск любого IP-адреса в определенном диапазоне
- Поиск буквенно-цифровой строки
Важно! Поддерживается только синтаксис RE2, который немного отличается от PCRE. Обратите внимание, что регулярные выражения по умолчанию вводятся с учетом регистра.
Примечание. На основе примеров, приведенных ниже, можно составлять более сложные регулярные выражения. Однако для поиска отдельных слов мы рекомендуем использовать параметры Соответствие содержания и Нежелательное содержание.
| Поиск точной фразы | |
|---|---|
| Пример использования | Поиск фразы сборник законов. |
| Примеры регулярных выражений | Пример 1: (W|^)сборникsзаконов(W|$)
Пример 2:(W|^)сборникs{0,3}законов(W|$) Пример 3: (W|^)сборник(и)s{0,3}законов{0,1}(W|$) |
| Примечания |
|
| Поиск слова или фразы из списка | |
|---|---|
| Пример использования | Поиск любого слова или фразы из приведенного ниже списка:
|
| Пример регулярного выражения | (?i)(W|^)(туфта|проклятие|убирайся|бред|чертsвозьми|зараза)(W|$) |
| Примечания |
|
| Поиск слова в разных вариантах написания или со специальными символами | |
|---|---|
| Пример использования | Поиск в нежелательных сообщениях слова “виагра” и нескольких вариантов его написания, например:
|
| Пример регулярного выражения | в[ие№][а@]гр[а@] |
| Примечания |
|
| Поиск любого адреса электронной почты в определенном домене | |
|---|---|
| Пример использования | Поиск любого адреса электронной почты в доменах yahoo.com, hotmail.com и gmail.com. |
| Пример регулярного выражения | (W|^)[w.-]{0,25}@(yahoo|hotmail|gmail).com(W|$) |
| Примечания |
|
| Поиск любого IP-адреса в определенном диапазоне | |
|---|---|
| Пример использования | Поиск любого IP-адреса в пределах диапазона 192.168.1.0–192.168.1.255. |
| Примеры регулярных выражений | Пример 1: 192.168.1. Пример 2: 192.168.1.d{1,3} |
| Примечания |
|
| Поиск буквенно-цифровой строки | |
|---|---|
| Пример использования | Поиск номеров заказов на покупку компании. Такие номера могут быть представлены в разном формате, например:
|
| Пример регулярного выражения | (W|^)po[#-]{0,1}s{0,1}d{2}[s-]{0,1}d{4}(W|$) |
| Примечания |
|
Эта информация оказалась полезной?
Как можно улучшить эту статью?
![]()
Хочешь проверить свои знания по JS?
Подпишись на наш канал с тестами по JS в Telegram!
Решать задачи
×

Регулярное выражение (или regex) — это синтаксис, позволяющий находить строки, соответствующие определенным шаблонам. Это что-то вроде функционала поиска в тексте, только regex позволяют использовать квантификаторы, специальные символы и группы захвата для создания по-настоящему продвинутых шаблонов поиска.
Regex можно использовать во всех случаях, когда вам нужно запросить строковые данные. Примеры юзкейсов:
- анализ вывода командной строки
- парсинг пользовательского ввода
- проверка логов сервера или программы
- управление текстовыми файлами с последовательным синтаксисом, такими, как CSV
- чтение файлов конфигурации
- поиск в коде и рефакторинг кода
Теоретически, делать все это можно и без regex, но использование регулярок дает вам суперсилу в решении подобных задач.
Как выглядят регулярные выражения?
В простейшей форме regex может выглядеть так:

От редакции Techrocks. О сайте regex101 и других сайтах для изучения regex можно почитать в статье «Как, наконец, выучить Regex?».
В примере «Test» буквы test образуют шаблон, как при обычном поиске. Но регулярные выражения далеко не всегда столь просты. Вот regex, означающий «3 цифры, за которыми следует дефис, за которым идут 3 цифры, после которых идет еще дефис, а в конце идут 4 цифры».
Т.е. это формат записи телефонного номера:
^(?:d{3}-){2}d{4}$

Это регулярное выражение может показаться сложным, но, во-первых, к концу этой статьи вы научитесь читать подобные шаблоны, а во-вторых, это действительно сложный способ написания шаблона.
Фактически, большинство регулярных выражений можно написать по-разному. Например, выражение, приведенное выше, можно переписать более длинно, но при этом более читабельно:
^[0-9]{3}-[0-9]{3}-[0-9]{4}$
Большинство языков программирования предоставляют встроенные методы для поиска и замены строк с использованием regex. Но при этом в каждом языке может быть собственный синтаксис регулярок.
В этой статье мы остановимся на варианте regex в ECMAScript, который используется в JavaScript и имеет много общего с реализациями регулярных выражений в других языках.
Как читать (и писать) регулярные выражения
Квантификаторы
В регулярных выражениях квантификаторы указывают, сколько раз должен встретиться символ. Вот список квантификаторов:
a|b— или a, или b?— ноль или один+— один или больше*— ноль или больше{N}— ровно N раз (здесь N — число){N,}— N или больше раз (N — число){N,M}— от N до M раз (N и M — числа, при этом N < M)*?— ноль или больше, но после первого совпадения поиск нужно прекратить
Например, следующее регулярное выражение соответствует и строке «Hello», и строке «Goodbye»:
Hello|Goodbye
В то время как
Hey?
может означать как отсутствие y, так и одно вхождение y, и таким образом весь шаблон может соответствовать и «He», и «Hey».
Еще пример:
Hello{1,3}
Этот шаблон соответствует «Hello», «Hellooo», но не «Helloooo», потому что буква «о» может встречаться от 1 до 3 раз.
Квантификаторы можно комбинировать:
He?llo{2}
Здесь мы ищем строки, в которых «e» нет или встречается 1 раз, а «o» встречается ровно 2 раза. Таким образом, этот шаблон соответствует словам «Helloo» и «Hlloo».
Жадное соответствие
В списке квантификаторов в предыдущем разделе мы познакомились со значением символа +. Этот квантификатор означает один или больше символов. Таким образом, шаблон
Hi+
будет соответствовать как «Hi», так и «Hiiiiiiiiiiiiiiii». Это потому, что все квантификаторы по умолчанию «жадные».
Но вы можете сменить их поведение на «ленивое» при помощи символа ?.
Hi+?
Теперь шаблон будет соответствовать как можно меньшему числу «i». Символ + означает «один или больше», что в «ленивом» варианте превращается в «один». То есть, в строке «Hiiiiiiiiiii» шаблон совпадет только с «Hi».
Само по себе это не слишком полезно, но в сочетании с таким символом, как точка, становится важным.
Точка в регулярных выражениях используется для поиска любого символа.
Например, следующий шаблон соответствует и «Hillo», и «Hello», и «Hellollollo»:
H.*llo

Но что если в строке «Hellollollo» вам нужно совпадение только с «Hello»?
Нужно просто сделать поиск ленивым:
H.*?llo

Наборы
Квадратные скобки позволяют искать совпадение по целому набору символов, указанному в скобках. Например, шаблон
My favorite vowel is [aeiou]
совпадет со строками:
My favorite vowel is a My favorite vowel is e My favorite vowel is i My favorite vowel is o My favorite vowel is u
И ни с чем другим. [aeiou] — это набор, в регулярном выражении означающий «любой из указанных символов».
Вот список самых распространенных наборов:
[A-Z]— совпадает с любой буквой в верхнем регистре, от «A» до «Z»[a-z]— совпадает с любой буквой в нижнем регистре, от «a» до «z»[0-9]-любая цифра[asdf]— совпадает с «a», «s», «d» или «f»[^asdf]— совпадает с любым символом кроме «a», «s», «d» или «f»
Эти наборы можно комбинировать:
[0-9A-Z]— любой символ, являющийся либо цифрой, либо буквой от A до Z[^a-z]— любой символ, не являющийся буквой латинского алфавита в нижнем регистре
Символьные классы
Не каждый символ можно так легко идентифицировать. Скажем, найти буквы с использованием regex легко, а как насчет символа новой строки?
Примечание. Символ новой строки — это символ, который вы вводите, когда нажимаете Enter и переходите на новую строку.
.— любой символn— символ новой строкиt— символ табуляцииs— пробельный символ (включая t, n и некоторые другие)S— не-пробельный символw— любой «словообразующий» символ (буквы латинского алфавита в верхнем и нижнем регистре, цифры 0-9 и символ подчеркивания_)W— любой «несловообразующий» символ (класс символов, обратный классу w)b— граница слова, разделяетwиW, т. е. словообразующие и несловообразующие символы. Граница слова соответствует позиции, где за символом слова не следует другой символ слова.B— несловообразующая граница (класс, обратныйb). Несловообразующая граница соответствует позиции, в которой предыдущий и следующий символы являются символами одного типа: либо оба должны быть словообразующими символами, либо несловообразующими. Начало и конец строки считаются несловообразующими символами.^— начало строки$— конец строки\— символ «» в буквальном значении
Допустим, вы хотите удалить каждый символ, с которого начинается новое слово в строке. Вы можете использовать следующее регулярное выражение для поиска этих символов:
s.
А затем найденные символы можно заменить пустой строкой. Таким образом строка
Hello world how are you
превратится в
Helloorldowreou

Комбинирование наборов
Символьные классы сами по себе не слишком полезны, но их можно сочетать с наборами. Допустим, мы хотим удалить из строки любую букву в верхнем регистре или пробельный символ. Это можно написать так:
[A-Z]|s
Но s можно поместить и внутрь набора:
[A-Zs]

Границы слова
В списке символьных классов вы видели символ b, означающий границу слова. На нем стоит остановиться отдельно, потому что этот токен работает не как остальные.
Допустим, у вас есть строка «This is a string». Вы можете предположить, что символ границы слова соответствует пробелам между словами, но это не так. Он соответствует тому, что находится между буквой и пробелом.

Это может быть трудно понять. Но обычно никто и не ищет сами границы слов. Вместо этого можно написать, например, выражение для поиска целых слов:
bw+b

Это регулярное выражение интерпретируется следующим образом: «Граница слова, за которой следует один или больше словообразующих символов, за которыми следует другая граница слова».
Начало и конец строки
Еще два важных токена — ^ и $. Они означают начало и конец строки соответственно.
То есть, если вы хотите найти первое слово в строке, вы можете написать следующее выражение:
^w+
Оно соответствует одному или большему числу словообразующих символов, но только если они идут непосредственно в начале строки. Помните, что словообразующий символ это любая буква латинского алфавита в любом регистре, а также любая цифра и символ подчеркивания.

Аналогично, если вы хотите найти последнее слово в строке, ваше регулярное выражение может выглядеть так:
w+$

Но то, что символ $ обычно заканчивает строку, не означает, что после него не может идти других символов.
Допустим, мы хотим найти каждый пробельный символ между новыми строками для создания базового минификатора JavaScript-кода.
Мы можем написать следующее выражение, чтобы найти все пробелы после конца строки:
$s+

Экранирование символов
Хотя токены символьных классов очень полезны, иногда с ними возникают сложности. Например, когда нужно написать шаблон для поиска таких токенов в тексте.
Допустим, у вас есть строка в тексте статьи:
"Символ новой строки - 'n'"
Или вы хотите найти вообще все упоминания «n» в тексте. Тогда в шаблоне символ n нужно «экранировать»: поставить перед ним обратную косую черту:
\n
Как использовать regex
Ценность регулярных выражений не только в том, что они позволяют находить строки. Вы также можете использовать их для модификации строк и других действий с ними.
В разных языках программирования есть похожие методы для работы с regex. Мы используем JavaScript в качестве примера.
Создание регулярных выражений и поиск с их помощью
Для начала давайте посмотрим, как строятся регулярные выражения.
В JavaScript (и в некоторых других языках) мы помещаем regex в блоки //. Регулярное выражение для поиска буквы в нижнем регистре будет выглядеть так:
/[a-z]/
Этот синтаксис генерирует объект RegExp, который можно использовать со встроенными методами типа exec для поиска соответствий в строках.
/[a-z]/.exec("a"); // Возвращает ["a"]
/[a-z]/.exec("0"); // Возвращает null
Затем мы можем использовать это истиноподобие для определения, есть ли совпадение с regex (как в строке 3 примера, доступного по ссылке ниже).
Запустить код в песочнице.
Или мы можем вызвать конструктор RegExp со строкой, которую хотим конвертировать в регулярное выражение:
const regex = new RegExp("[a-z]"); // То же самое, что /[a-z]/
Замена строк при помощи регулярных выражений
Вы можете использовать regex для поиска и замены содержимого файлов. Скажем, вы хотите заменить любое приветствие на прощание. Можно сделать это так:
function youSayHelloISayGoodbye(str) {
str = str.replace("Hello", "Goodbye");
str = str.replace("Hi", "Goodbye");
str = str.replace("Hey", "Goodbye"); str = str.replace("hello", "Goodbye");
str = str.replace("hi", "Goodbye");
str = str.replace("hey", "Goodbye");
return str;
}
Но можно и проще, с использованием regex:
function youSayHelloISayGoodbye(str) {
str = str.replace(/[Hh]ello|[Hh]i|[Hh]ey/, "Goodbye");
return str;
}
Запустить код в песочнице
Но вы можете заметить, что при запуске youSayHelloISayGoodbye с «Hello, Hi there» регулярное выражение совпадает не больше, чем с одним вхождением:

Регулярное выражение /[Hh]ello|[Hh]i|[Hh]ey/, примененное к строке «Hello, Hi there», по умолчанию совпадет только с «Hello».
Мы ожидаем, что оно совпадет и с «Hello», и с «Hi», но этого не происходит.
Чтобы регулярное выражение «отловило» больше одного совпадения, нужно использовать особый флаг.
Флаги в regex
Флаг — это модификатор существующего регулярного выражения. При определении regex флаги всегда добавляются после замыкающего слэша.
Вот небольшой список доступных флагов:
g— глобально, больше одного совпаденияm— заставляет$и^соответствовать каждой новой строчке отдельноi— делает regex нечувствительным к регистру
Мы можем взять наше регулярное выражение:
/[Hh]ello|[Hh]i|[Hh]ey/
и переписать его, применив флаг нечувствительности к регистру:
/Hello|Hi|Hey/i
Это регулярное выражение будет соответствовать следующим словам:
Hello HEY Hi HeLLo
Также оно будет соответствовать любому другому варианту чередования заглавных и строчных букв.
Флаг глобального поиска для замены строк
Как уже говорилось, если вы производите замену при помощи regex без всяких флагов, заменен будет только первый результат поиска:
let str = "Hello, hi there!"; str = str.replace(/[Hh]ello|[Hh]i|[Hh]ey/, "Goodbye"); console.log(str); // В выводе будет "Goodbye, hi there"
Но если вы добавите флаг глобального поиска, будут найдены все соответствия шаблону:
let str = "Hello, hi there!"; str = str.replace(/[Hh]ello|[Hh]i|[Hh]ey/g, "Goodbye"); console.log(str); // В выводе будет "Goodbye, Goodbye there"
Использование флага глобального поиска в JavaScript
При использовании глобального поиска в JavaScript regex вы можете столкнуться со странным поведением.
Если вы многократно запустите exec с глобальным поиском, команда будет через раз возвращать null.

Как объясняет MDN,
«Объекты RegExp в JavaScript, когда у них установлены флаги global или sticky, являются stateful-объектами… Они хранят lastIndex из предыдущего сопоставления. Благодаря этому exec() может применяться для итерации по нескольким сопоставлениям в строке текста…»
Команда exec пытается начать поиск по lastIndex, продвигаясь вперед. Поскольку lastIndex имеет значение длины строки, exec будет пытаться сопоставить с вашим регулярным выражением "" — пустую строку, пока она не будет сброшена новой командой exec. Хотя эта особенность может быть полезна в определенных обстоятельствах, она часто сбивает с толку новичков.
Чтобы решить эту проблему, мы можем просто назначать значение 0 для lastIndex перед каждым запуском команды exec:

Группы в regex
При поиске совпадения с шаблоном может быть полезно искать больше одного сопоставляемого элемента за раз. Тут в игру вступают группы.
В примере ниже мы видим совпадение и с «Testing 123», и с «Tests 123» без дублирования «123» в выражении.
/(Testing|tests) 123/ig

Группы определяются при помощи скобок. Бывают они двух видов: группы захвата и незахватывающие группы (capture groups и non-capturing groups):
(…)— группа, соответствующая любым 3 символам(?:…)— незахватывающая группа, соответствующая любым 3 символам
Разница между этими группами ощутима тогда, когда речь идет о замене символов.
Например, используя приведенное выше выражение, при помощи JavaScript можно заменить текст с «Testing 234» и «tests 234»:
const regex = /(Testing|tests) 123/ig; let str = ` Testing 123 Tests 123 `; str = str.replace(regex, '$1 234'); console.log(str); // Testing 234nTests 234"
Мы используем $1 для обращения к первой группе захвата, (Testing|tests). Мы также можем сопоставить больше одной группы, скажем, сопоставлять одновременно (Testing|tests) и (123):
const regex = /(Testing|tests) (123)/ig; let str = ` Testing 123 Tests 123 `; str = str.replace(regex, '$1 #$2'); console.log(str); // Testing #123nTests #123"
Но это работает только с группами захвата.
Давайте заменим вот это:
/(Testing|tests) (123)/ig
на это:
/(?:Testing|tests) (123)/ig;
Теперь у нас только одна группа захвата — (123), и код, который мы использовали ранее, произведет другой результат:
const regex = /(?:Testing|tests) (123)/ig; let str = ` Testing 123 Tests 123 `; str = str.replace(regex, '$1'); console.log(str); // "123n123"
Запустить код в песочнице
Именованные группы захвата
Хотя группы захвата — отличная вещь, в них легко запутаться, когда их у вас несколько. Разница между $3 и $5 не всегда очевидна.
Для решения этой проблемы в регулярных выражениях есть концепция «именованных групп захвата».
(?<name>...) — здесь именованная группа с именем «name» соответствует любым 3 символам.
Например, можно создать группу с именем «num», которая будет соответствовать 3 цифрам:
Затем вы можете использовать эту группу для замены:
const regex = /Testing (?<num>d{3})/
let str = "Testing 123";
str = str.replace(regex, "Hello $<num>")
console.log(str); // "Hello 123"
Именованные обратные ссылки
Иногда бывает полезно сослаться на именованную группу захвата внутри самого запроса. В этом вам помогут «обратные ссылки».
k<name> — ссылка на именованную группу захвата «name» в поисковом запросе.
Скажем, вы хотите, чтобы выш шаблон совпадал со строкой
Hello there James. James, how are you doing?
но не со строкой
Hello there James. Frank, how are you doing?
Вы можете написать regex, где повторяется слово «James»:
/.*James. James,.*/
Но лучше написать так:
/.*(?<name>James). k<name>,.*/
Теперь имя жестко прописано только в одном месте.
Запустить код в песочнице.
Опережающие и ретроспективные группы
Опережающие (lookahead) и ретроспективные (lookbehind) группы — очень мощный инструмент, который часто понимают превратно.
Есть четыре разных типа опережающих и ретроспективных проверок:
(?!)— негативная опережающая проверка(?=)— позитивная опережающая проверка(?<=)— позитивная ретроспективная проверка(?<!)— негативная ретроспективная проверка
Суть lookahead — проверить, что за группой стоит или не стоит определенный шаблон (позитивная и негативная проверка).
Пример негативной опережающей проверки:
/B(?!A)/
Это выражение читается как «найди B, за которым НЕ следует A». Оно соответствует «В» в «BC», но не в «BA».

Это можно комбинировать с символами начала и конца строки, чтобы искать соответствия для целых строк. Например, следующее выражение соответствует любой строке, которая НЕ начинается с «Test»:
/^(?!Test).*$/gm

Мы можем изменить негативную опережающую проверку на позитивную и таким образом найти строки, которые начинаются с «Test»:
/^(?=Test).*$/gm

Итоги
Регулярные выражения — невероятно мощный инструмент, который можно использовать для всевозможных манипуляций со строками. Знание regex поможет вам проводить рефакторинг кодовых баз, вносить быстрые правки в скрипты и т. д.
Давайте вернемся к нашему regex, соответствующему номеру телефона. Попробуйте теперь прочитать это выражение:
^(?:d{3}-){2}d{4}$
Оно служит для поиска телефонных номеров:
555-555-5555
Здесь:
^и$используются для обозначения начала и конца строки- Незахватывающая группа нужна для поиска трех цифр, за которыми следует дефис.
- Эта группа повторяется дважды для соответствия
555-555-
- Эта группа повторяется дважды для соответствия
- Дальше мы ищем последние 4 цифры телефонного номера.
Надеюсь, эта статья дала вам начальное представление о regex.
Перевод статьи «The Complete Guide to Regular Expressions (Regex)».
#статьи
- 5 окт 2022
-

0
Исчерпывающий гайд по работе с мощным инструментом для анализа и обработки строк.
Иллюстрация: Оля Ежак для SKillbox Media

Журналист, изучает Python. Любит разбираться в мелочах, общаться с людьми и понимать их.
Само словосочетание «регулярные выражения» звучит непонятно и выглядит страшно, но на самом деле ничего сложного в работе с ними нет. В этой статье мы познакомим вас с их логикой и основными принципами и научим разговаривать на языке шаблонов. В хорошем смысле слова.
Содержание:
- Что такое регулярные выражения
- Синтаксис регулярок
- Как ведётся поиск
- Квантификаторы и логическое ИЛИ при группировке
- Регулярные выражения в Python: модуль re и Match-объекты
- Жадный и ленивый пропуск
- Примеры и задачи
Представьте, что вы снова в школе, на уроке истории. Вам нужно решить итоговую контрольную работу по всем датам, которые проходили в четверти.
Но тут вас поджидает препятствие: все даты разбросаны по нескольким главам учебника по десятку страниц каждая. Читать полкниги в поисках нужных вам крупиц информации — такое себе удовольствие. Тем более когда каждая минута на счету.
К счастью, вы — человек неглупый (не зря же пошли в IT), тренированный и быстро соображающий. Поэтому моментально замечаете основные закономерности:
- даты обозначаются цифрами: арабскими, если это год и месяц, и римскими, если век;
- учебник — по истории позднего Средневековья и Нового времени, поэтому все даты, написанные арабскими цифрами, — четырёхсимвольные;
- после римских цифр всегда идёт слово «век».
Теперь у вас есть шаблон нужной информации. Остаётся лишь пролистать страницу за страницей и записать даты в смартфон (или себе на подкорку). Вуаля: пятёрка за четверть у вас в дневнике, а премия от родителей за отличную учёбу — в кармане.
По такому же принципу работают и регулярные выражения: они ведут поиск фрагментов текста по определённому шаблону. Если фрагмент совпадает с шаблоном — с ним можно работать.
Запишем логику поиска исторических дат в виде регулярных выражений (они ещё называются Regular Expressions, сокращённо regex или regexp). Выглядеть он будет так:
(?:d{4})|(?:[IVX]+ век)
Приятные новости: regex — настолько полезный и мощный инструмент, что поддерживается почти всеми современными языками программирования, в том числе и Python. Причём соответствующий синтаксис в разных языках очень схож. Так что, выучив его в одном языке, можно пользоваться им в других, практически не переучиваясь. Поехали.
С помощью regex можно искать как вполне конкретные выражения (например, слово «век» — последовательность букв «в», «е» и «к»), так и что-то более общее (например, любую букву или цифру).
Для обозначения второй категории существуют специальные символы. Вот некоторые из них:
| Символ | Что означает | Пример использования шаблона | Пример вывода |
|---|---|---|---|
| . | Любой символ, кроме новой строки (n) | H.llo, .orld
20.. год |
Hello, world; Hallo, 2orld
2022 год, 2010 год |
| […] | Любой символ из указанных в скобках. Символы можно задавать как перечислением, так и указывая диапазон через дефис | [abc123]
[A-Z] [A-Za-z0-9] [А-ЯЁа-яё] |
а; 1
B; T A; s; 1 А; ё |
| [^…] | Любой символ, кроме указанных в скобках | [^A-Za-z] | з, 4 |
| ^ | Начало строки | ^Добрый день, | 0 |
| $ | Конец строки | До свидания!$ | 0 |
| | | Логическое ИЛИ. Регулярное выражение будет искать один из нескольких вариантов | [0-9]|[IVXLCDM] — регулярное выражение будет находить совпадение, если цифра является либо арабской, либо римской | 5; V |
| Экранирование. Помогает регулярным выражениям ориентироваться, является ли следующий за символ обычным или специальным | AdwZ — экранирование превращает буквы алфавита в спецсимволы.
[.] — экранирование превращает спецсимволы в обычные |
0 |
Важное замечание 1. Регулярные выражения зависимы от регистра, то есть «А» и «а» при поиске будут считаться разными символами.
Важное замечание 2. Буквы «Ё» и «ё» не входят в диапазон «А — Я» и «а — я». Так что, задавая русский алфавит, их нужно выписывать отдельно.
На экранировании остановимся подробнее. По умолчанию символы .^$*+? {}[]|() являются спецсимволами — то есть они выполняют определённые функции. Чтобы сделать спецсимволы обычными, их нужно экранировать .
Таким образом, . будет обозначать любой символ, а . — знак точки. Чтобы написать обратный слеш, его тоже нужно экранировать, то есть в регулярных выражениях он будет выглядеть так: \.
Обратная ситуация с некоторыми алфавитными символами. По умолчанию они считаются просто буквами, но при экранировании начинают играть роль спецсимволов.
| Символ | Что означает |
|---|---|
| d | Любая цифра. То же самое, что [0-9] |
| D | Любой символ, кроме цифры. То же самое, что [^0-9] |
| w | Любая буква, цифра и нижнее подчёркивание |
| W | Любой символ, кроме буквы, цифры и нижнего подчёркивания |
| s | Любой пробельный символ (пробел, новая строка, табуляция, возврат каретки и тому подобное) |
| S | Любой символ, кроме пробельного |
| A | Начало строки. То же самое, что ^ |
| Z | Конец строки. То же самое, что $ |
| b | Начало или конец слова |
| B | Середина слова |
| n, t, r | Стандартные строковые обозначения: новая строка, табуляция, возврат каретки |
Важное замечание. A, Z, b и B указывают не на конкретный символ, а на положение других символов относительно друг друга. Можно сказать, что они указывают на пространство между символами.
Например, регулярное выражение b[А-ЯЁаяё]b будет искать только те буквы, которые отделены друг от друга пробелами или знаками препинания.
Часто при записи регулярного выражения какая-то часть шаблона должна повторяться определённое количество раз. Число вхождений в синтаксисе regex задают с помощью квантификаторов. Они всегда помещаются после той части шаблона, которую нужно повторить.
| Символ | Что означает | Примеры шаблона | Примеры вывода |
|---|---|---|---|
| {} | Указывает количество вхождений, можно задавать единичным числом или диапазоном | d{4} — цифра, четыре подряд
d{1,4} — цифра, от одного до четырёх раз подряд d{2,} — цифра, от двух раз подряд d{,4} — цифра, от 0 до 4 раз подряд |
1243, 1876
1, 12, 176, 1589 22, 456, 988888 5, 15, 987, 1234 |
| ? | От нуля до одного вхождения. То же самое, что {0,1} | d? | 0 |
| * | От нуля вхождений. То же самое, что {0,} | d* | 0 |
| + | От одного вхождения. То же самое, что {1,} | d+ | 0 |
Теперь давайте ещё раз посмотрим на наше регулярное выражение для поиска дат по учебнику истории:
(?:d{4})|(?:[IVX]+ век)
В нём есть несколько дополнительных символов, о которых рассказано ниже, но начинка этого выражения уже понятна.
- d{4} — цифра, четыре подряд
- | — логическое ИЛИ
- [IVX]+ век — символ I, V или X, одно или более вхождений, пробел, слово «век»
Попрактиковаться в составлении регулярных выражений можно на сайте regex101.com. А мы разберём основные приёмы их использования и решим несколько задач.
Уточним ещё несколько терминов regex.
Регулярные выражения — это инструмент для работы со строками, которые и являются основной их единицей.
Строка представляет собой как само регулярное выражение, так и текст, по которому ведётся поиск.
Найденные в тексте совпадения с шаблоном называются подстроками. Например, у нас есть регулярное выражение м. (буква «м», затем любой символ) и текст «Мама мыла раму». Применяя регулярное выражение к тексту, мы найдём подстроки «ма», «мы» и «му». Подстроку «Ма» наше выражение пропустит из-за разницы в регистре.
Есть и более мелкая единица, чем подстрока, — группа. Она представляет собой часть подстроки, которую мы попросили выделить специально. Группы выделяются круглыми скобками (…).
Возьмём ту же строку «Мама мыла раму» и применим к ней следующее регулярное выражение:
(w)(w{3})
Оно значит: буквенный символ, выделенный группой, и за ним ещё три буквенных символа, также выделенных группой. Итого весь шаблон представляет собой четыре буквенных символа.
В нашем тексте это выражение найдёт три совпадения, в каждом из которых выделит две группы:
| Подстрока | Группа 1 | Группа 2 |
|---|---|---|
| Мама | М | ама |
| мыла | м | ыла |
| раму | р | аму |
Это помогает извлечь из найденной подстроки конкретную информацию, отбросив всё остальное. Например, мы нашли адрес, состоящий из названия улицы, номера дома и номера квартиры. Подстрока будет представлять собой адрес целиком, а в группы можно поместить отдельно каждый его структурный элемент — и потом обращаться к нему напрямую.
Группам можно давать имена с помощью такой формы: (? P<name>…)
Вот так будет выглядеть наш шаблон, ищущий четырёхбуквенные слова, если мы дадим имена группам:
?P<first_letter>w)(?P<rest_letters>w{3})
Уберём группы и упростим регулярное выражение, чтобы оно искало только подстроку:
w{4}
Немного изменим текст, по которому ищем совпадения: «Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке».
Регулярное выражение ищет четыре буквенных символа подряд, поэтому в качестве отдельных подстрок находит также «пило», «раме», «рабо», «тает», «лесо» и «пилк».
Исправьте регулярное выражение так, чтобы оно находило только четырёхбуквенные слова. То есть оно должно найти подстроки «мама», «мыла», «раму» и «папа» — и ничего больше.
Подсказка, если не можете решить задачу
Используйте символ b.
Важное замечание. При написании regex нужно помнить, что они ищут только непересекающиеся подстроки. Под шаблон w{4} в слове «работает» подходят не только подстроки «рабо» и «тает», но и «абот», «бота», «отае». Их регулярное выражение не находит, потому что тогда бы эти подстроки пересеклись с другими — а в regex так нельзя.
Нередко при использовании регулярных выражений требуется применить квантификатор либо логическое ИЛИ не к отдельному символу, а к целой группе. Именно так мы поступили в нашем шаблоне для поиска дат по учебнику истории:
(?:d{4})|(?:[IVX]+ век)
С помощью скобок мы сказали: выдайте совпадение, если в тексте присутствует хотя бы один из двух вариантов — либо год, либо век.
Важное замечание.? : в начале группы означает, что мы просим regex не запоминать эту группу. Если все группы открываются символами? :, то регулярные выражения вернут только подстроку и ни одной группы.
В Python это может быть полезно, потому что некоторые re-функции возвращают разные результаты в зависимости от того, запомнили ли регулярные выражения какие-то группы или нет.
Также к группам удобно применять квантификаторы. Например, имена многих дроидов в «Звёздных войнах» построены по принципу: буква — цифра — буква — цифра.
Вот так это выглядит без групп:
[A-Z]d[A-Z]d
И вот так с ними:
(?:[A-Z]d){2}
Особенно полезно использовать незапоминаемые группы со сложными шаблонами.
Чтобы работать с регулярными выражениями в Python, необходимо импортировать модуль re:
import re
Это даёт доступ к нескольким функциям. Вот их краткое описание.
| Функция | Что делает | Если находит совпадение | Если не находит совпадение |
|---|---|---|---|
| re.match (pattern, string) | Ищет pattern в начале строки string | Возвращает Match-объект | Возвращает None |
| re.search (pattern, string) | Ищет pattern по всей строке string | Возвращает Match-объект с первым совпадением, остальные не находит | Возвращает None |
| re.finditer (pattern, string) | Ищет pattern по всей строке string | Возвращает итератор, содержащий Match-объекты для каждого найденного совпадения | Возвращает пустой итератор |
| re.findall (pattern, string) | Ищет pattern по всей строке string | Возвращает список со всеми найденными совпадениями | Возвращает None |
| re.split (pattern, string, [maxsplit=0]) | Разделяет строку string по подстрокам, соответствующим pattern | Возвращает список строк, на которые разделила исходную строку | Возвращает список строк, единственный элемент которого — неразделённая исходная строка |
| re.sub (pattern, repl, string) | Заменяет в строке string все pattern на repl | Возвращает строку в изменённом виде | Возвращает строку в исходном виде |
| re.compile (pattern) | Собирает регулярное выражение в объект для будущего использования в других re-функциях | Ничего не ищет, всегда возвращает Pattern-объект | 0 |
Важное замечание. Напоминаем, что регулярные выражения по умолчанию ищут только непересекающиеся подстроки.
Для написания регулярных выражений в Python используют r-строки (их называют сырыми, или необработанными). Это связано с тем, что написание знака требует экранирования не только в регулярных выражениях, но и в самом Python тоже.
Чтобы программистам не приходилось экранировать экранирование и писать нагромождения обратных слешей, и придумали r-строки. Синтаксически они обозначаются так:
r'...'
Перечислим самые популярные из них.
Находит совпадение только в том случае, если соответствующая шаблону подстрока находится в начале строки, по которой ведётся поиск:
print (re.match (r'Мама', 'Мама мыла раму')) >>> <re.Match object; span=(0, 4), match='Мама'> print (re.match (r'мыла', 'Мама мыла раму')) >>> None
Как видим, поиск по шаблону «Мама» нашёл совпадение и вернул Match-объект. Слово же «мыла», хотя и есть в строке, находится не в начале. Поэтому регулярное выражение ничего не находит и возвращается None.
Ищет совпадения по всему тексту:
print (re.search (r'Мама', 'Мама мыла раму')) >>> <re.Match object; span=(0, 4), match='Мама'> print (re.search (r'мыла', 'Мама мыла раму')) >>> <re.Match object; span=(5, 9), match='мыла'>
При этом re.search возвращает только первое совпадение, даже если в строке, по которой ведётся поиск, их больше. Проверим это:
print (re.search (r'мыла', 'Мама мыла раму, а потом ещё раз мыла, потому что не домыла')) >>> <re.Match object; span=(5, 9), match='мыла'>
Возвращает итератор с объектами, к которым можно обратиться через цикл:
results = re.finditer (r'мыла', 'Мама мыла раму, а потом ещё раз мыла, потому что не домыла') print (results) >>> <callable_iterator object at 0x000001C4CDE446D0> for match in results: print (match) >>> <re.Match object; span=(5, 9), match='мыла'> >>> <re.Match object; span=(32, 36), match='мыла'> >>> <re.Match object; span=(54, 58), match='мыла'>
Эта функция очень полезна, если вы хотите получить Match-объект для каждого совпадения.
В Match-объектах хранится много всего интересного. Посмотрим внимательнее на объект с подстрокой «Мама», который нашла функция re.match:
<re.Match object; span=(0, 4), match='Мама'>
span — это индекс начала и конца найденной подстроки в тексте, по которому мы искали совпадение. Обратите внимание, что второй индекс не включается в подстроку.
match — это собственно найденная подстрока. Если подстрока длинная, то она будет отображаться не целиком.
Это, конечно же, не всё, что можно получить от Match-объекта. Рассмотрим ещё несколько методов.
Возвращает найденную подстроку, если ему не передавать аргумент или передать аргумент 0. То же самое делает обращение к объекту по индексу 0:
match = re.match (r'Мама', 'Мама мыла раму') print (match.group()) >>> Мама print (match.group(0)) >>> Мама print (match[0]) >>> Мама
Если регулярное выражение поделено на группы, то, начиная с единицы, можно вызвать группу отдельно от строки:
match = re.match (r'(М)(ама)', 'Мама мыла раму') print (match.group(1)) print (match.group(2)) >>> М >>> ама print (match[1]) print (match[2]) >>> М >>> ама #Методом group также можно получить кортеж из нужных групп. print (match.group(1,2)) >>> ('М', 'ама')
Если группы поименованы, то в качестве аргумента метода group можно передавать их название:
match = re.match (r'(?P<first_letter>М)(?P<rest_letters>ама)', 'Мама мыла раму') print (match.group('first_letter')) print (match.group('rest_letters')) >>> М >>> ама
Если одна и та же группа соответствует шаблону несколько раз, то в группу запишется только последнее совпадение:
#Помещаем в группу один буквенный символ, при этом шаблон представляет собой четыре таких символа. match = re.match (r'(w){4}', 'Мама мыла раму') print (match.group(0)) >>> Мама print (match.group(1)) >>> а
Возвращает кортеж с группами:
match = re.match (r'(М)(ама)', 'Мама мыла раму') print (match.groups()) >>> ('М', 'ама')
Возвращает кортеж с индексом начала и конца подстроки в исходном тексте. Если мы хотим получить только первый индекс, можно использовать метод start, только последний — end:
match = re.search (r'мыла', 'Мама мыла раму') print (match.span()) >>> (5, 9) print (match.start()) >>> 5 print (match.end()) >>> 9
Возвращает просто список совпадений. Никаких Match-объектов, к которым нужно дополнительно обращаться:
#В этом примере в качестве регулярного выражения мы используем правильный ответ на задание 0. match_list = re.findall (r'bw{4}b', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.') print (match_list) >>> ['Мама', 'мыла', 'раму', 'папа']
Функция ведёт себя по-другому, если в регулярном выражении есть деление на группы. Тогда функция возвращает список кортежей с группами:
match_list = re.findall (r'b(w{1})(w{3})b', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.') print (match_list) >>> [('М', 'ама'), ('м', 'ыла'), ('р', 'аму'), ('п', 'апа')]
Аналог метода str.split. Делит исходную строку по шаблону, а сам шаблон исключает из результата:
#Поделим строку по запятой и пробелу после неё. split_string = re.split (r', ', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.') print (split_string) >>> ['Мама мыла раму', 'а папа был на пилораме', 'потому что работает на лесопилке.']
re.split также имеет дополнительный аргумент maxsplit — это максимальное количество частей, на которые функция может поделить строку. По умолчанию maxsplit равен нулю, то есть не устанавливает никаких ограничений:
#Приравняем аргумент maxsplit к единице. split_string = re.split (r', ', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.', maxsplit=1) print (split_string) >>> ['Мама мыла раму', 'а папа был на пилораме, потому что работает на лесопилке.']
Если в re.split мы указываем группы, то они попадают в список строк в качестве отдельных элементов. Для наглядности поделим исходную строку на слог «па»:
#Помещаем буквы «п» и «а» в одну группу. split_string = re.split (r'(па)', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.') print (split_string) >>> ['Мама мыла раму, а ', 'па', '', 'па', ' был на пилораме, потому что работает на лесопилке.'] #Помещаем буквы «п» и «а» в разные группы. split_string = re.split (r'(п)(а)', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.') print (split_string) >>> ['Мама мыла раму, а ', 'п', 'а', '', 'п', 'а', ' был на пилораме, потому что работает на лесопилке.']
Требует указания дополнительного аргумента в виде строки, на которую и будет заменять найденные совпадения:
new_string = re.sub (r'Мама', 'Дочка', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.') print (new_string) >>> Дочка мыла раму, а папа был на пилораме, потому что работает на лесопилке.
Дополнительные возможности у функции появляются при применении групп. В качестве аргумента замены ему можно передать не строку, а ссылку на номер группы в виде n. Тогда он подставит на нужное место соответствующую группу из шаблона. Это очень удобно, когда нужно поменять местами структурные элементы в тексте:
new_string = re.sub (r'(w+) (w+) (w+),', r'2 3 1 –', 'Бендер Остап Ибрагимович, директор ООО "Рога и копыта"') print (new_string) >>> Остап Ибрагимович Бендер — директор ООО "Рога и копыта"
Используется для ускорения и упрощения кода, когда одно и то же регулярное выражение применяется в нём несколько раз. Её синтаксис выглядит так:
pattern = re.compile (r'Мама') print (pattern.search ('Мама мыла раму')) >>> <re.Match object; span=(0, 4), match='Мама'> print (pattern.sub ('Дочка', 'Мама мыла раму')) >>> Дочка мыла раму
Нередко в регулярных выражениях нужно учесть сразу много вариантов и опций, из-за чего их структура усложняется. А regex даже простые и короткие читать нелегко, что уж говорить о длинных.
Чтобы хоть как-то облегчить чтение регулярок, в Python r-строки можно делить точно так же, как и обычные. Возьмём наше выражение для поиска дат по учебнику истории:
re.findall (r'(?:d{4})|(?:[IVX]+ век)', text)
Его же можно написать вот в таком виде:
re.findall (r'(?:d{4})' r'|' r'(?:[IVX]+ век)', text)
Часто при написании регулярных выражений приходится использовать квантификаторы, охватывающие диапазон значений. Например, d{1,4}. Как регулярные выражения решают, сколько цифр им захватить, одну или четыре? Это определяется пропуском квантификаторов.
По умолчанию все квантификаторы являются жадными, то есть стараются захватить столько подходящих под шаблон символов, сколько смогут.
В некоторых случаях это может стать проблемой. Например, возьмём часть оглавления поэмы Венедикта Ерофеева «Москва — Петушки», записанную в одну строку:
Фрязево — 61-й километр……….64 61-й километр — 65-й километр…68 65-й километр — Павлово-Посад…71 Павлово-Посад — Назарьево……..73 Назарьево — Дрезна……………77 Дрезна — 85-й километр………..80
Нужно написать регулярное выражение, которое выделит каждый пункт оглавления. Для этого определим признаки, по которым мы будем это делать:
- Каждый пункт начинается с буквы или цифры (для этого используем шаблон w).
- Он может содержать внутри себя любой набор символов: буквы, цифры, знаки препинания (для этого используем шаблон .+).
- Он заканчивается на точку, после которой следует от одной до трёх цифр (для этого используем шаблон .d{1,3}).
Посмотрим в конструкторе, как работает наше выражение:
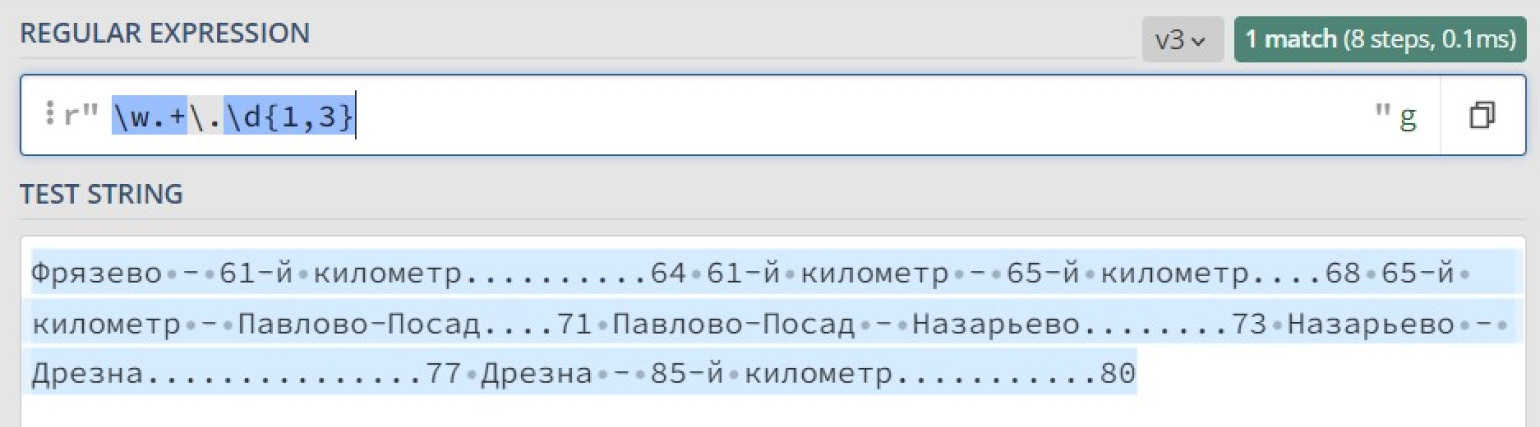
Что же произошло? Почему найдено только одно совпадение, причем за него посчитали весь текст сразу? Всё дело в жадности квантификатора +, который старается захватить максимально возможное количество подходящих символов.
В итоге шаблон w находит совпадение с буквой «Ф» в начале текста, шаблон .d{1,3} находит совпадение с «.80» в конце текста, а всё, что между ними, покрывается шаблоном .+.
Чтобы квантификатор захватывал минимально возможное количество символов, его нужно сделать ленивым. В таком случае каждый раз, находя совпадение с шаблоном ., регулярное выражение будет спрашивать: «Подходят ли следующие символы в строке под оставшуюся часть шаблона?»
Если нет, то функция будет искать следующее совпадение с .. А если да, то . закончит свою работу и следующие символы строки будут сравниваться со следующей частью регулярного выражения: .d{1,3}.
Чтобы объявить квантификатор ленивым, после него надо поставить символ ?. Сделаем ленивым квантификатор + в нашем регулярном выражении для поиска строк в оглавлении:
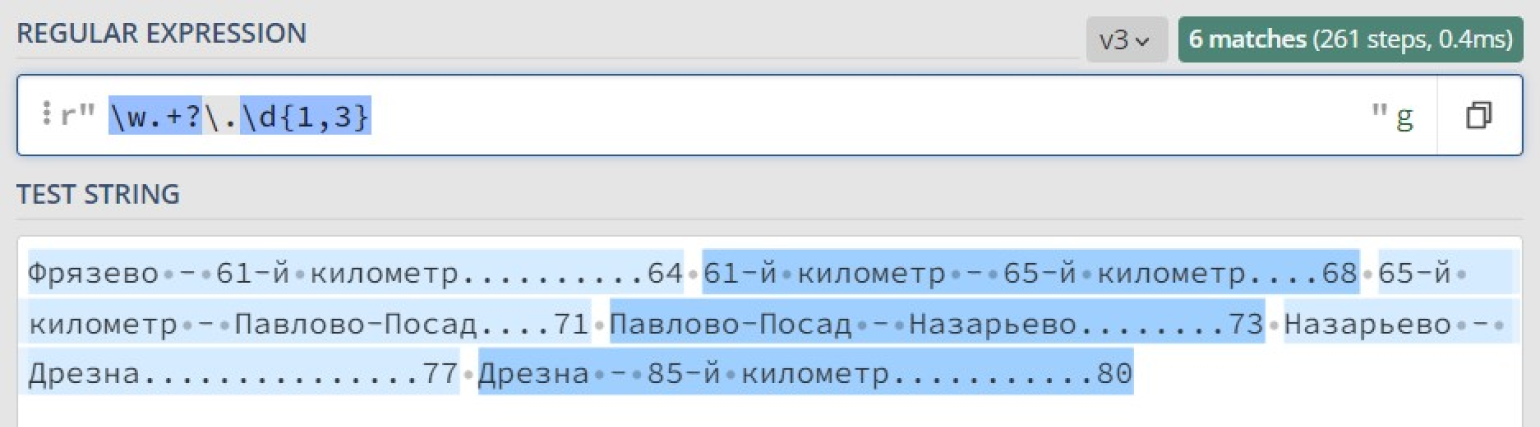
Теперь, когда мы уверены в правильности работы нашего регулярного выражения, используем функцию re.findall, чтобы выписать оглавление построчно:
content = 'Фрязево — 61-й километр..........64 61-й километр — 65-й километр....68 65-й километр — Павлово-Посад....71 Павлово-Посад — Назарьево........73 Назарьево — Дрезна...............77 Дрезна — 85-й километр...........80' strings = re.findall (r'w.+?.d{1,3}', content) for string in strings: print (string) #Результат на экране. >>> Фрязево — 61-й километр..........64 >>> 61-й километр — 65-й километр....68 >>> 65-й километр — Павлово-Посад....71 >>> Павлово-Посад — Назарьево........73 >>> Назарьево — Дрезна...............77 >>> Дрезна — 85-й километр...........80
В некоторых случаях одну и ту же задачу можно решить разными способами, используя разные возможности регулярок. Попробуйте решить следующие задачи самостоятельно. Возможно, у вас даже получится сделать это более эффективно.
При обнародовании судебных решений из них извлекают персональные данные участников процесса — фамилии, имена и отчества. Каждое слово в Ф. И. О. начинается с заглавной буквы, при этом фамилия может быть двойная.
Напишите программу, которая заменит в тексте Ф. И. О. подсудимого на N.
Подсудимая Эверт-Колокольцева Елизавета Александровна в судебном заседании вину инкриминируемого правонарушения признала в полном объёме и суду показала, что 14 сентября 1876 года, будучи в состоянии алкогольного опьянения от безысходности, в связи с состоянием здоровья позвонила со своего стационарного телефона в полицию, сообщив о том, что у неё в квартире якобы заложена бомба. После чего приехали сотрудники полиции, скорая и пожарные, которым она сообщила, что бомба — это она.
«Подсудимая N в судебном заседании» и далее по тексту.
Подсказка
Используйте незапоминаемую опциональную группу вида (? : …)? , чтобы обозначить вторую часть фамилии после дефиса.
Решение
#Сначала кладём в переменную string текст строки, по которой ведём поиск.
print (re.sub (r'[А-ЯЁ]w*'
r'(?:-[А-ЯЁ]w*)?'
r'(?: [А-ЯЁ]w*){2}', 'N', string))
Большинство адресов состоит из трёх частей: название улицы, номер дома и номер квартиры. Название улицы может состоять из нескольких слов, каждое из которых пишется с заглавной буквы. Номер дома может содержать после себя букву.
Перед названием улицы может быть написано «Улица», «улица», «Ул.» или «ул.», перед номером дома — «дом» или «д.», перед номером квартиры — «квартира» или «кв.». Также номер дома и номер квартиры могут быть разделены дефисом без пробелов.
Дан текст, в нём нужно найти все адреса и вывести их в виде «Пушкина 32-135».
Для упрощения мы не будем учитывать дома, которые находятся не на улицах, а на площадях, набережных, бульварах и так далее.
Добрый день!
Сегодня на выезды потребуется отправить трёх-четырёх специалистов, остальных держите в офисе. Некоторые заявки пришли на конкретных людей, но можно вызвать и других, смотрите по ситуации, как лучше их отправить, чтобы всех объездить сегодня.
Петрову П. П. попросили выехать по адресам ул. Культуры 78 кв. 6, улица Мира дом 12Б квартира 144. Смирнова С. С. просят подъехать только по адресу: Восьмого Марта 106-19. Без предпочтений по специалистам пришли запросы с адресов: улица Свободы 54 6, Улица Шишкина дом 9 кв. 15, ул. Лермонтова 18 кв. 93.
Все адреса скопированы из заявок, корректность подтверждена.
Культуры 78-6
Мира 12Б-144
Восьмого Марта 106-19
Свободы 54-6
Шишкина 9-15
Лермонтова 18-93
Подсказка
Используйте деление на группы, чтобы удобно выстроить структуру выражения. Попросите regex запоминать только нужные вам части адреса, чтобы функция не возвращала вам лишние подгруппы.
Решение
#Сначала кладём в переменную string текст строки, по которой ведём поиск.
pattern = re.compile (r'(?:[Уу]л(?:.|ица) )?'
r'((?:[А-ЯЁ]w+)(?: [А-ЯЁ]w+)*)'
r' (?:дом |д. )?'
r'(d+w?)'
r'[ -](?:квартира |кв. )?'
r'(d+)')
addresses = pattern.findall (text)
for address in addresses:
print (f'{address[0]} {address[1]}-{address[2]}')
Структура этого регулярного выражения довольно сложная. Чтобы в нём разобраться, посмотрите на схему. Прямоугольники обозначают обязательные элементы, овалы — опциональные. Развилки символизируют разные варианты, которые допускает наш шаблон. Красным цветом очерчены группы, которые мы запоминаем.
Писатели в поиске собственного неповторимого стиля нередко изобретают оригинальные творческие приёмы и неукоснительно им следуют. Например, Сергей Довлатов следил за тем, чтобы слова в предложении не начинались с одной и той же буквы.
Даны несколько предложений. Программа должна проверить, встречаются ли в каждом из них слова на одинаковую букву. Если таких нет, она печатает: «Метод Довлатова соблюдён». А если есть: «Вы расстроили Сергея Донатовича».
Важно. Чтобы регулярные выражения не рассматривали заглавные и прописные буквы как разные символы, передайте re-функции дополнительный аргумент flags=re.I или flags=re.IGNORECASE.
Здесь все слова начинаются с разных букв.
А в этом предложении есть слова, которые всё-таки начинаются на одну и ту же букву.
А здесь совсем интересно: символ «а» однобуквенный.
Метод Довлатова соблюдён
Вы расстроили Сергея Донатовича
Вы расстроили Сергея Донатовича
Подсказка
Чтобы указать на начало слова, используйте символ b.
Чтобы в каждом совпадении regex не старалось захватить максимум, используйте ленивый пропуск.
Чтобы найти повторяющийся символ, используйте ссылку на группу в виде 1.
Решение
#Сначала кладём в переменную string текст строки, по которой ведём поиск.
pattern = r'b(w)w*.*?b1'
match = re.search (pattern, string, flags=re.I)
if match is None:
print ('Метод Довлатова соблюдён')
else:
print ('Вы расстроили Сергея Донатовича')
Вернёмся к регулярному выражению, которое ищет даты в учебнике истории: (? :d{4})|(? : [IVX]+ век).
Оно в целом справляется со своей задачей, но также находит много ненужных чисел. Например, количество человек, которые участвовали в битве, тоже может быть описано четырьмя цифрами подряд.
Чтобы не получать лишние результаты, обратим внимание на то, как именно могут быть записаны годы. Есть несколько вариантов записи: 1400 год, 1400 г., 1400–1500 годы, 1400–1500 гг., (1400), (1400–1500).
Чтобы немного упростить задачу и не раздувать регулярное выражение, мы не будем искать конструкции «с такого-то по такой-то год» и «между таким-то и таким-то годом».
Важное замечание. Не забывайте про экранирование, если хотите использовать точки и скобки в качестве обычных, а не специальных символов. Так программа правильно поймёт, что вы имеете в виду.
Началом Реформации принято считать 31 октября 1517 г. — день, когда Мартин Лютер (1483–1546) прибил к дверям виттенбергской Замковой церкви свои «95 тезисов», в которых выступил против злоупотреблений Католической церкви. Реформация охватила практически всю Европу и продолжалась в течение всего XVI века и первой половины XVII века. Одно из самых известных и кровавых событий Реформации — Варфоломеевская ночь во Франции, произошедшая в ночь на 24 августа 1572 года.
Точное число жертв так и не удалось установить достоверно. Погибли по меньшей мере 2000 гугенотов в Париже и 3000 — в провинциях. Герцог де Сюлли, сам едва избежавший смерти во время резни, говорил о 70 000 жертв. Для Парижа единственным точным числом остаётся 1100 погибших во время Варфоломеевской ночи.
Этому событию предшествовали три других, произошедшие в 1570–1572 годах: Сен-Жерменский мирный договор (1570), свадьба гугенота Генриха Наваррского и Маргариты Валуа (1572) и неудавшееся покушение на убийство адмирала Колиньи (1572).
[‘1517 г.’, ‘(1483–1546)’, ‘XVI век’, ‘XVII век’, ‘1572 год’, ‘1570–1572 годах’, ‘(1570)’, ‘(1572)’, ‘(1572)’]
Решение
#Сначала кладём в переменную string текст строки, по которой ведём поиск.
pattern = re.compile (r'(?:(d{4}(?:-d{4})?))'
r'|'
r'(?:'
r'(?:d{4}-)?d{4} '
r'(?:'
r'(?:год(?:ы|ах|ов)?)'
r'|'
r'(?:гг?.)'
r')'
r')'
r'|'
r'(?:[IVX]+ век)')
print (pattern.findall (string))
Если вам сложно разобраться в структуре этого выражения, то вот его схема:

Научитесь: Профессия Python-разработчик
Узнать больше
