Регулярные выражения в Python от простого к сложному

Решил я давеча моим школьникам дать задачек на регулярные выражения для изучения. А к задачкам нужна какая-нибудь теория. И стал я искать хорошие тексты на русском. Пяток сносных нашёл, но всё не то. Что-то смято, что-то упущено. У этих текстов был не только фатальный недостаток. Мало картинок, мало примеров. И почти нет разумных задач. Ну неужели поиск IP-адреса — это самая частая задача для регулярных выражений? Вот и я думаю, что нет.
Про разницу (?:…) / (…) фиг найдёшь, а без этого знания в некоторых случаях можно только страдать.
Плюс в питоне есть немало регулярных плюшек. Например, re.split может добавлять тот кусок текста, по которому был разрез, в список частей. А в re.sub можно вместо шаблона для замены передать функцию. Это — реальные вещи, которые прямо очень нужны, но никто про это не пишет.
Так и родился этот достаточно многобуквенный материал с подробностями, тонкостями, картинками и задачами.
Надеюсь, вам удастся из него извлечь что-нибудь новое и полезное, даже если вы уже в ладах с регулярками.
PS. Решения задач школьники сдают в тестирующую систему, поэтому задачи оформлены в несколько формальном виде.
Содержание
Регулярные выражения в Python от простого к сложному;
Содержание;
Примеры регулярных выражений;
Сила и ответственность;
Документация и ссылки;
Основы синтаксиса;
Шаблоны, соответствующие одному символу;
Квантификаторы (указание количества повторений);
Жадность в регулярках и границы найденного шаблона;
Пересечение подстрок;
Эксперименты в песочнице;
Регулярки в питоне;
Пример использования всех основных функций;
Тонкости экранирования в питоне (‘\\\\foo’);
Использование дополнительных флагов в питоне;
Написание и тестирование регулярных выражений;
Задачи — 1;
Скобочные группы (?:…) и перечисления |;
Перечисления (операция «ИЛИ»);
Скобочные группы (группировка плюс квантификаторы);
Скобки плюс перечисления;
Ещё примеры;
Задачи — 2;
Группирующие скобки (…) и match-объекты в питоне;
Match-объекты;
Группирующие скобки (…);
Тонкости со скобками и нумерацией групп.;
Группы и re.findall;
Группы и re.split;
Использование групп при заменах;
Замена с обработкой шаблона функцией в питоне;
Ссылки на группы при поиске;
Задачи — 3;
Шаблоны, соответствующие не конкретному тексту, а позиции;
Простые шаблоны, соответствующие позиции;
Сложные шаблоны, соответствующие позиции (lookaround и Co);
lookaround на примере королей и императоров Франции;
Задачи — 4;
Post scriptum;
Регулярное выражение — это строка, задающая шаблон поиска подстрок в тексте. Одному шаблону может соответствовать много разных строчек. Термин «Регулярные выражения» является переводом английского словосочетания «Regular expressions». Перевод не очень точно отражает смысл, правильнее было бы «шаблонные выражения». Регулярное выражение, или коротко «регулярка», состоит из обычных символов и специальных командных последовательностей. Например, d задаёт любую цифру, а d+ — задает любую последовательность из одной или более цифр. Работа с регулярками реализована во всех современных языках программирования. Однако существует несколько «диалектов», поэтому функционал регулярных выражений может различаться от языка к языку. В некоторых языках программирования регулярками пользоваться очень удобно (например, в питоне), в некоторых — не слишком (например, в C++).
Примеры регулярных выражений

Сила и ответственность
Регулярные выражения, или коротко, регулярки — это очень мощный инструмент. Но использовать их следует с умом и осторожностью, и только там, где они действительно приносят пользу, а не вред. Во-первых, плохо написанные регулярные выражения работают медленно. Во-вторых, их зачастую очень сложно читать, особенно если регулярка написана не лично тобой пять минут назад. В-третьих, очень часто даже небольшое изменение задачи (того, что требуется найти) приводит к значительному изменению выражения. Поэтому про регулярки часто говорят, что это write only code (код, который только пишут с нуля, но не читают и не правят). А также шутят: Некоторые люди, когда сталкиваются с проблемой, думают «Я знаю, я решу её с помощью регулярных выражений.» Теперь у них две проблемы. Вот пример write-only регулярки (для проверки валидности e-mail адреса (не надо так делать!!!)):
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[x01-x08x0bx0cx0e-x1fx21x23-x5bx5d-x7f]|\[x01-x09x0bx0cx0e-x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|[(?:(?:25[0-5]|
2[0-4][0-9]|[01]?[0-9][0-9]?).){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[x01-x08x0bx0cx0e-x1fx21-x5ax53-x7f]|\[x01-x09x0bx0cx0e-x7f])+)])А вот здесь более точная регулярка для проверки корректности email адреса стандарту RFC822. Если вдруг будете проверять email, то не делайте так!Если адрес вводит пользователь, то пусть вводит почти что угодно, лишь бы там была собака. Надёжнее всего отправить туда письмо и убедиться, что пользователь может его получить.
Документация и ссылки
- Оригинальная документация: https://docs.python.org/3/library/re.html;
- Очень подробный и обстоятельный материал: https://www.regular-expressions.info/;
- Разные сложные трюки и тонкости с примерами: http://www.rexegg.com/;
- Он-лайн отладка регулярок https://regex101.com (не забудьте поставить галочку Python в разделе FLAVOR слева);
- Он-лайн визуализация регулярок https://www.debuggex.com/ (не забудьте выбрать Python);
- Могущественный текстовый редактор Sublime text 3, в котором очень удобный поиск по регуляркам;
Основы синтаксиса
Любая строка (в которой нет символов .^$*+?{}[]|()) сама по себе является регулярным выражением. Так, выражению Хаха будет соответствовать строка “Хаха” и только она. Регулярные выражения являются регистрозависимыми, поэтому строка “хаха” (с маленькой буквы) уже не будет соответствовать выражению выше. Подобно строкам в языке Python, регулярные выражения имеют спецсимволы .^$*+?{}[]|(), которые в регулярках являются управляющими конструкциями. Для написания их просто как символов требуется их экранировать, для чего нужно поставить перед ними знак . Так же, как и в питоне, в регулярных выражениях выражение n соответствует концу строки, а t — табуляции.
Шаблоны, соответствующие одному символу
Во всех примерах ниже соответствия регулярному выражению выделяются бирюзовым цветом с подчёркиванием.
Квантификаторы (указание количества повторений)
Жадность в регулярках и границы найденного шаблона
Как указано выше, по умолчанию квантификаторы жадные. Этот подход решает очень важную проблему — проблему границы шаблона. Скажем, шаблон d+ захватывает максимально возможное количество цифр. Поэтому можно быть уверенным, что перед найденным шаблоном идёт не цифра, и после идёт не цифра. Однако если в шаблоне есть не жадные части (например, явный текст), то подстрока может быть найдена неудачно. Например, если мы хотим найти «слова», начинающиеся на СУ, после которой идут цифры, при помощи регулярки СУd*, то мы найдём и неправильные шаблоны:
ПАСУ13 СУ12, ЧТОБЫ СУ6ЕНИЕ УДАЛОСЬ.
В тех случаях, когда это важно, условие на границу шаблона нужно обязательно добавлять в регулярку. О том, как это можно делать, будет дальше.
Пересечение подстрок
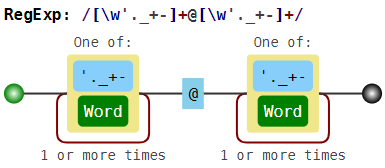
В обычной ситуации регулярки позволяют найти только непересекающиеся шаблоны. Вместе с проблемой границы слова это делает их использование в некоторых случаях более сложным. Например, если мы решим искать e-mail адреса при помощи неправильной регулярки w+@w+ (или даже лучше, [w'._+-]+@[w'._+-]+), то в неудачном случае найдём вот что:
foo@boo@goo@moo@roo@zoo
То есть это с одной стороны и не e-mail, а с другой стороны это не все подстроки вида текст-собака-текст, так как boo@goo и moo@roo пропущены.
Эксперименты в песочнице
Если вы впервые сталкиваетесь с регулярными выражениями, то лучше всего сначала попробовать песочницу. Посмотрите, как работают простые шаблоны и квантификаторы. Решите следующие задачи для этого текста (возможно, к части придётся вернуться после следующей теории):
- Найдите все натуральные числа (возможно, окружённые буквами);
- Найдите все «слова», написанные капсом (то есть строго заглавными), возможно внутри настоящих слов (аааБББввв);
- Найдите слова, в которых есть русская буква, а когда-нибудь за ней цифра;
- Найдите все слова, начинающиеся с русской или латинской большой буквы (
b— граница слова); - Найдите слова, которые начинаются на гласную (
b— граница слова);; - Найдите все натуральные числа, не находящиеся внутри или на границе слова;
- Найдите строчки, в которых есть символ
*(.— это точно не конец строки!); - Найдите строчки, в которых есть открывающая и когда-нибудь потом закрывающая скобки;
- Выделите одним махом весь кусок оглавления (в конце примера, вместе с тегами);
- Выделите одним махом только текстовую часть оглавления, без тегов;
- Найдите пустые строчки;
Регулярки в питоне
Функции для работы с регулярками живут в модуле re. Основные функции:
Пример использования всех основных функций
import re
match = re.search(r'ddDdd', r'Телефон 123-12-12')
print(match[0] if match else 'Not found')
# -> 23-12
match = re.search(r'ddDdd', r'Телефон 1231212')
print(match[0] if match else 'Not found')
# -> Not found
match = re.fullmatch(r'ddDdd', r'12-12')
print('YES' if match else 'NO')
# -> YES
match = re.fullmatch(r'ddDdd', r'Т. 12-12')
print('YES' if match else 'NO')
# -> NO
print(re.split(r'W+', 'Где, скажите мне, мои очки??!'))
# -> ['Где', 'скажите', 'мне', 'мои', 'очки', '']
print(re.findall(r'dd.dd.d{4}',
r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'))
# -> ['19.01.2018', '01.09.2017']
for m in re.finditer(r'dd.dd.d{4}', r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'):
print('Дата', m[0], 'начинается с позиции', m.start())
# -> Дата 19.01.2018 начинается с позиции 20
# -> Дата 01.09.2017 начинается с позиции 45
print(re.sub(r'dd.dd.d{4}',
r'DD.MM.YYYY',
r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'))
# -> Эта строка написана DD.MM.YYYY, а могла бы и DD.MM.YYYY
Тонкости экранирования в питоне ('\\\\foo')
Так как символ в питоновских строках также необходимо экранировать, то в результате в шаблонах могут возникать конструкции вида '\\par'. Первый слеш означает, что следующий за ним символ нужно оставить «как есть». Третий также. В результате с точки зрения питона '\\' означает просто два слеша \. Теперь с точки зрения движка регулярных выражений, первый слеш экранирует второй. Тем самым как шаблон для регулярки '\\par' означает просто текст par. Для того, чтобы не было таких нагромождений слешей, перед открывающей кавычкой нужно поставить символ r, что скажет питону «не рассматривай как экранирующий символ (кроме случаев экранирования открывающей кавычки)». Соответственно можно будет писать r'\par'.
Использование дополнительных флагов в питоне
Каждой из функций, перечисленных выше, можно дать дополнительный параметр flags, что несколько изменит режим работы регулярок. В качестве значения нужно передать сумму выбранных констант, вот они:
import re
print(re.findall(r'd+', '12 + ٦٧'))
# -> ['12', '٦٧']
print(re.findall(r'w+', 'Hello, мир!'))
# -> ['Hello', 'мир']
print(re.findall(r'd+', '12 + ٦٧', flags=re.ASCII))
# -> ['12']
print(re.findall(r'w+', 'Hello, мир!', flags=re.ASCII))
# -> ['Hello']
print(re.findall(r'[уеыаоэяию]+', 'ОООО ааааа ррррр ЫЫЫЫ яяяя'))
# -> ['ааааа', 'яяяя']
print(re.findall(r'[уеыаоэяию]+', 'ОООО ааааа ррррр ЫЫЫЫ яяяя', flags=re.IGNORECASE))
# -> ['ОООО', 'ааааа', 'ЫЫЫЫ', 'яяяя']
text = r"""
Торт
с вишней1
вишней2
"""
print(re.findall(r'Торт.с', text))
# -> []
print(re.findall(r'Торт.с', text, flags=re.DOTALL))
# -> ['Тортnс']
print(re.findall(r'вишw+', text, flags=re.MULTILINE))
# -> ['вишней1', 'вишней2']
print(re.findall(r'^вишw+', text, flags=re.MULTILINE))
# -> ['вишней2']
Написание и тестирование регулярных выражений
Для написания и тестирования регулярных выражений удобно использовать сервис https://regex101.com (не забудьте поставить галочку Python в разделе FLAVOR слева) или текстовый редактор Sublime text 3.
Задачи — 1
Задача 01. Регистрационные знаки транспортных средств
В России применяются регистрационные знаки нескольких видов.
Общего в них то, что они состоят из цифр и букв. Причём используются только 12 букв кириллицы, имеющие графические аналоги в латинском алфавите — А, В, Е, К, М, Н, О, Р, С, Т, У и Х.
У частных легковых автомобилях номера — это буква, три цифры, две буквы, затем две или три цифры с кодом региона. У такси — две буквы, три цифры, затем две или три цифры с кодом региона. Есть также и другие виды, но в этой задаче они не понадобятся.
Вам потребуется определить, является ли последовательность букв корректным номером указанных двух типов, и если является, то каким.
На вход даются строки, которые претендуют на то, чтобы быть номером. Определите тип номера. Буквы в номерах — заглавные русские. Маленькие и английские для простоты можно игнорировать.
Задача 02. Количество слов
Слово — это последовательность из букв (русских или английских), внутри которой могут быть дефисы.
На вход даётся текст, посчитайте, сколько в нём слов.
PS. Задача решается в одну строчку. Никакие хитрые техники, не упомянутые выше, не требуются.
Задача 03. Поиск e-mailов
Допустимый формат e-mail адреса регулируется стандартом RFC 5322.
Если говорить вкратце, то e-mail состоит из одного символа @ (at-символ или собака), текста до собаки (Local-part) и текста после собаки (Domain part). Вообще в адресе может быть всякий беспредел (вкратце можно прочитать о нём в википедии). Довольно странные штуки могут быть валидным адресом, например:
"very.(),:;<>[]".VERY."very@\ "very".unusual"@[IPv6:2001:db8::1]
"()<>[]:,;@\"!#$%&'-/=?^_`{}| ~.a"@(comment)exa-mple
Но большинство почтовых сервисов такой ад и вакханалию не допускают. И мы тоже не будем 🙂
Будем рассматривать только адреса, имя которых состоит из не более, чем 64 латинских букв, цифр и символов '._+-, а домен — из не более, чем 255 латинских букв, цифр и символов .-. Ни Local-part, ни Domain part не может начинаться или заканчиваться на .+-, а ещё в адресе не может быть более одной точки подряд.
Кстати, полезно знать, что часть имени после символа + игнорируется, поэтому можно использовать синонимы своего адреса (например, shаshkоv+spam@179.ru и shаshkоv+vk@179.ru), для того, чтобы упростить себе сортировку почты. (Правда не все сайты позволяют использовать “+”, увы)
На вход даётся текст. Необходимо вывести все e-mail адреса, которые в нём встречаются. В общем виде задача достаточно сложная, поэтому у нас будет 3 ограничения:
две точки внутри адреса не встречаются;
две собаки внутри адреса не встречаются;
считаем, что e-mail может быть частью «слова», то есть в boo@ya_ru мы видим адрес boo@ya, а в foo№boo@ya.ru видим boo@ya.ru.
PS. Совсем не обязательно делать все проверки только регулярками. Регулярные выражения — это просто инструмент, который делает часть задач простыми. Не нужно делать их назад сложными 🙂
Скобочные группы (?:...) и перечисления |
Перечисления (операция «ИЛИ»)
Чтобы проверить, удовлетворяет ли строка хотя бы одному из шаблонов, можно воспользоваться аналогом оператора or, который записывается с помощью символа |. Так, некоторая строка подходит к регулярному выражению A|B тогда и только тогда, когда она подходит хотя бы к одному из регулярных выражений A или B. Например, отдельные овощи в тексте можно искать при помощи шаблона морковк|св[её]кл|картошк|редиск.
Скобочные группы (группировка плюс квантификаторы)
Зачастую шаблон состоит из нескольких повторяющихся групп. Так, MAC-адрес сетевого устройства обычно записывается как шесть групп из двух шестнадцатиричных цифр, разделённых символами - или :. Например, 01:23:45:67:89:ab. Каждый отдельный символ можно задать как [0-9a-fA-F], и можно весь шаблон записать так:
[0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}
Ситуация становится гораздо сложнее, когда количество групп заранее не зафиксировано.
Чтобы разрешить эту проблему в синтаксисе регулярных выражений есть группировка (?:...). Можно писать круглые скобки и без значков ?:, однако от этого у группировки значительно меняется смысл, регулярка начинает работать гораздо медленнее. Об этом будет написано ниже. Итак, если REGEXP — шаблон, то (?:REGEXP) — эквивалентный ему шаблон. Разница только в том, что теперь к (?:REGEXP) можно применять квантификаторы, указывая, сколько именно раз должна повториться группа. Например, шаблон для поиска MAC-адреса, можно записать так:
[0-9a-fA-F]{2}(?:[:-][0-9a-fA-F]{2}){5}
Скобки плюс перечисления
Также скобки (?:...) позволяют локализовать часть шаблона, внутри которого происходит перечисление. Например, шаблон (?:он|тот) (?:шёл|плыл) соответствует каждой из строк «он шёл», «он плыл», «тот шёл», «тот плыл», и является синонимом он шёл|он плыл|тот шёл|тот плыл.
Ещё примеры
Задачи — 2
Задача 04. Замена времени
Вовочка подготовил одно очень важное письмо, но везде указал неправильное время.
Поэтому нужно заменить все вхождения времени на строку (TBD). Время — это строка вида HH:MM:SS или HH:MM, в которой HH — число от 00 до 23, а MM и SS — число от 00 до 59.
Задача 05. Действительные числа в паскале
Pascal requires that real constants have either a decimal point, or an exponent (starting with the letter e or E, and officially called a scale factor), or both, in addition to the usual collection of decimal digits. If a decimal point is included it must have at least one decimal digit on each side of it. As expected, a sign (+ or -) may precede the entire number, or the exponent, or both. Exponents may not include fractional digits. Blanks may precede or follow the real constant, but they may not be embedded within it. Note that the Pascal syntax rules for real constants make no assumptions about the range of real values, and neither does this problem. Your task in this problem is to identify legal Pascal real constants.
Задача 06. Аббревиатуры
Владимир устроился на работу в одно очень важное место. И в первом же документе он ничего не понял,
там были сплошные ФГУП НИЦ ГИДГЕО, ФГОУ ЧШУ АПК и т.п. Тогда он решил собрать все аббревиатуры, чтобы потом найти их расшифровки на http://sokr.ru/. Помогите ему.
Будем считать аббревиатурой слова только лишь из заглавных букв (как минимум из двух). Если несколько таких слов разделены пробелами, то они
считаются одной аббревиатурой.
Группирующие скобки (...) и match-объекты в питоне
Match-объекты
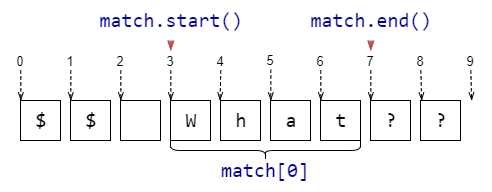
Если функции re.search, re.fullmatch не находят соответствие шаблону в строке, то они возвращают None, функция re.finditer не выдаёт ничего. Однако если соответствие найдено, то возвращается match-объект. Эта штука содержит в себе кучу полезной информации о соответствии шаблону. Полный набор атрибутов можно посмотреть в документации, а здесь приведём самое полезное.
Группирующие скобки (...)
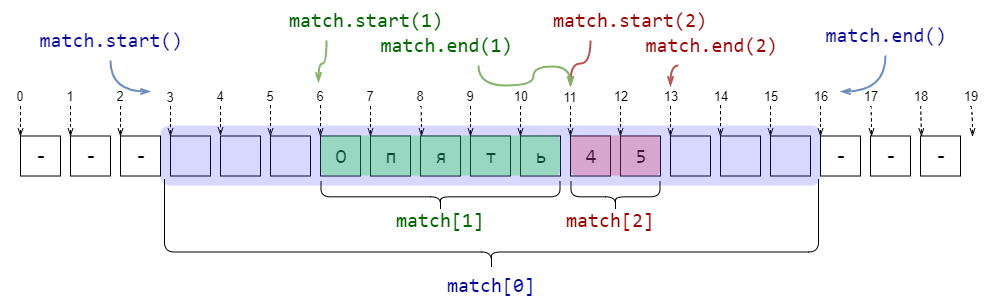
Если в шаблоне регулярного выражения встречаются скобки (...) без ?:, то они становятся группирующими. В match-объекте, который возвращают re.search, re.fullmatch и re.finditer, по каждой такой группе можно получить ту же информацию, что и по всему шаблону. А именно часть подстроки, которая соответствует (...), а также индексы начала и окончания в исходной строке. Достаточно часто это бывает полезно.
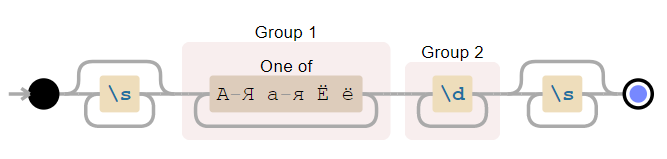
import re
pattern = r's*([А-Яа-яЁё]+)(d+)s*'
string = r'--- Опять45 ---'
match = re.search(pattern, string)
print(f'Найдена подстрока >{match[0]}< с позиции {match.start(0)} до {match.end(0)}')
print(f'Группа букв >{match[1]}< с позиции {match.start(1)} до {match.end(1)}')
print(f'Группа цифр >{match[2]}< с позиции {match.start(2)} до {match.end(2)}')
###
# -> Найдена подстрока > Опять45 < с позиции 3 до 16
# -> Группа букв >Опять< с позиции 6 до 11
# -> Группа цифр >45< с позиции 11 до 13
Тонкости со скобками и нумерацией групп.
Если к группирующим скобкам применён квантификатор (то есть указано число повторений), то подгруппа в match-объекте будет создана только для последнего соответствия. Например, если бы в примере выше квантификаторы были снаружи от скобок 's*([А-Яа-яЁё])+(d)+s*', то вывод был бы таким:
# -> Найдена подстрока > Опять45 < с позиции 3 до 16
# -> Группа букв >ь< с позиции 10 до 11
# -> Группа цифр >5< с позиции 12 до 13
Внутри группирующих скобок могут быть и другие группирующие скобки. В этом случае их нумерация производится в соответствии с номером появления открывающей скобки с шаблоне.
import re
pattern = r'((d)(d))((d)(d))'
string = r'123456789'
match = re.search(pattern, string)
print(f'Найдена подстрока >{match[0]}< с позиции {match.start(0)} до {match.end(0)}')
for i in range(1, 7):
print(f'Группа №{i} >{match[i]}< с позиции {match.start(i)} до {match.end(i)}')
###
# -> Найдена подстрока >1234< с позиции 0 до 4
# -> Группа №1 >12< с позиции 0 до 2
# -> Группа №2 >1< с позиции 0 до 1
# -> Группа №3 >2< с позиции 1 до 2
# -> Группа №4 >34< с позиции 2 до 4
# -> Группа №5 >3< с позиции 2 до 3
# -> Группа №6 >4< с позиции 3 до 4
Группы и re.findall
Если в шаблоне есть группирующие скобки, то вместо списка найденных подстрок будет возвращён список кортежей, в каждом из которых только соответствие каждой группе. Это не всегда происходит по плану, поэтому обычно нужно использовать негруппирующие скобки (?:...).
import re
print(re.findall(r'([a-z]+)(d*)', r'foo3, im12, go, 24buz42'))
# -> [('foo', '3'), ('im', '12'), ('go', ''), ('buz', '42')]
Группы и re.split
Если в шаблоне нет группирующих скобок, то re.split работает очень похожим образом на str.split. А вот если группирующие скобки в шаблоне есть, то между каждыми разрезанными строками будут все соответствия каждой из подгрупп.
import re
print(re.split(r'(s*)([+*/-])(s*)', r'12 + 13*15 - 6'))
# -> ['12', ' ', '+', ' ', '13', '', '*', '', '15', ' ', '-', ' ', '6']
В некоторых ситуация эта возможность бывает чрезвычайно удобна! Например, достаточно из предыдущего примера убрать лишние группы, и польза сразу станет очевидна!
import re
print(re.split(r's*([+*/-])s*', r'12 + 13*15 - 6'))
# -> ['12', '+', '13', '*', '15', '-', '6']
Использование групп при заменах
Использование групп добавляет замене (re.sub, работает не только в питоне, а почти везде) очень удобную возможность: в шаблоне для замены можно ссылаться на соответствующую группу при помощи 1, 2, 3, .... Например, если нужно даты из неудобного формата ММ/ДД/ГГГГ перевести в удобный ДД.ММ.ГГГГ, то можно использовать такую регулярку:
import re
text = "We arrive on 03/25/2018. So you are welcome after 04/01/2018."
print(re.sub(r'(dd)/(dd)/(d{4})', r'2.1.3', text))
# -> We arrive on 25.03.2018. So you are welcome after 01.04.2018.
Если групп больше 9, то можно ссылаться на них при помощи конструкции вида g<12>.
Замена с обработкой шаблона функцией в питоне
Ещё одна питоновская фича для регулярных выражений: в функции re.sub вместо текста для замены можно передать функцию, которая будет получать на вход match-объект и должна возвращать строку, на которую и будет произведена замена. Это позволяет не писать ад в шаблоне для замены, а использовать удобную функцию. Например, «зацензурим» все слова, начинающиеся на букву «Х»:
import re
def repl(m):
return '>censored(' + str(len(m[0])) + ')<'
text = "Некоторые хорошие слова подозрительны: хор, хоровод, хороводоводовед."
print(re.sub(r'b[хХxX]w*', repl, text))
# -> Некоторые >censored(7)< слова подозрительны: >censored(3)<, >censored(7)<, >censored(15)<.
Ссылки на группы при поиске
При помощи 1, 2, 3, ... и g<12> можно ссылаться на найденную группу и при поиске. Необходимость в этом встречается довольно редко, но это бывает полезно при обработке простых xml и html.
Только пообещайте, что не будете парсить сложный xml и тем более html при помощи регулярок! Регулярные выражения для этого не подходят. Используйте другие инструменты. Каждый раз, когда неопытный программист парсит html регулярками, в мире умирает котёнок. Если кажется «Да здесь очень простой html, напишу регулярку», то сразу вспоминайте шутку про две проблемы. Не нужно пытаться парсить html регулярками, даже Пётр Митричев не сможет это сделать в общем случае 🙂 Использование регулярных выражений при парсинге html подобно залатыванию резиновой лодки шилом. Закон Мёрфи для парсинга html и xml при помощи регулярок гласит: парсинг html и xml регулярками иногда работает, но в точности до того момента, когда правильность результата будет очень важна.
Используйте lxml и beautiful soup.
import re
text = "SPAM <foo>Here we can <boo>find</boo> something interesting</foo> SPAM"
print(re.search(r'<(w+?)>.*?</1>', text)[0])
# -> <foo>Here we can <boo>find</boo> something interesting</foo>
text = "SPAM <foo>Here we can <foo>find</foo> OH, NO MATCH HERE!</foo> SPAM"
print(re.search(r'<(w+?)>.*?</1>', text)[0])
# -> <foo>Here we can <foo>find</foo>
Задачи — 3
Задача 07. Шифровка
Владимиру потребовалось срочно запутать финансовую документацию. Но так, чтобы это было обратимо.
Он не придумал ничего лучше, чем заменить каждое целое число (последовательность цифр) на его куб. Помогите ему.
Задача 08. То ли акростих, то ли акроним, то ли апроним
Акростих — осмысленный текст, сложенный из начальных букв каждой строки стихотворения.
Акроним — вид аббревиатуры, образованной начальными звуками (напр. НАТО, вуз, НАСА, ТАСС), которое можно произнести слитно (в отличие от аббревиатуры, которую произносят «по буквам», например: КГБ — «ка-гэ-бэ»).
На вход даётся текст. Выведите слитно первые буквы каждого слова. Буквы необходимо выводить заглавными.
Эту задачу можно решить в одну строчку.
Задача 09. Хайку
Хайку — жанр традиционной японской лирической поэзии века, известный с XIV века.
Оригинальное японское хайку состоит из 17 слогов, составляющих один столбец иероглифов. Особыми разделительными словами — кирэдзи — текст хайку делится на части из 5, 7 и снова 5 слогов. При переводе хайку на западные языки традиционно вместо разделительного слова использую разрыв строки и, таким образом, хайку записываются как трёхстишия.
Перед вами трёхстишия, которые претендуют на то, чтобы быть хайку. В качестве разделителя строк используются символы / . Если разделители делят текст на строки, в которых 5/7/5 слогов, то выведите «Хайку!». Если число строк не равно 3, то выведите строку «Не хайку. Должно быть 3 строки.» Иначе выведите строку вида «Не хайку. В i строке слогов не s, а j.», где строка i — самая ранняя, в которой количество слогов неправильное.
Для простоты будем считать, что слогов ровно столько же, сколько гласных, не задумываясь о тонкостях.
Шаблоны, соответствующие не конкретному тексту, а позиции
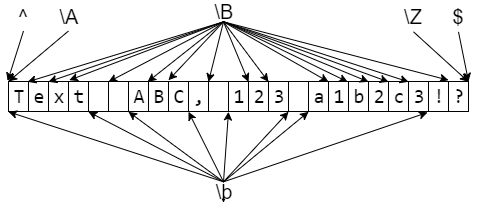
Отдельные части регулярного выражения могут соответствовать не части текста, а позиции в этом тексте. То есть такому шаблону соответствует не подстрока, а некоторая позиция в тексте, как бы «между» буквами.
Простые шаблоны, соответствующие позиции
Для определённости строку, в которой мы ищем шаблон будем называть всем текстом.Каждую строчку всего текста (то есть каждый максимальный кусок без символов конца строки) будем называть строчкой текста.
Сложные шаблоны, соответствующие позиции (lookaround и Co)
Следующие шаблоны применяются в основном в тех случаях, когда нужно уточнить, что должно идти непосредственно перед или после шаблона, но при этом
не включать найденное в match-объект.
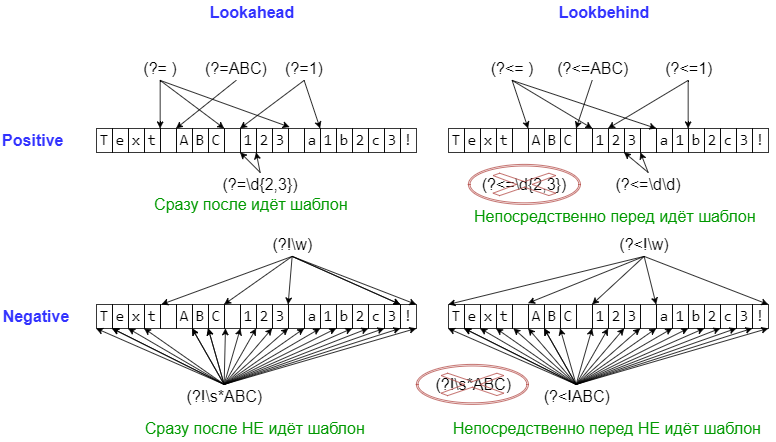
На всякий случай ещё раз. Каждый их этих шаблонов проверяет лишь то, что идёт непосредственно перед позицией или непосредственно после позиции. Если пару таких шаблонов написать рядом, то проверки будут независимы (то есть будут соответствовать AND в каком-то смысле).
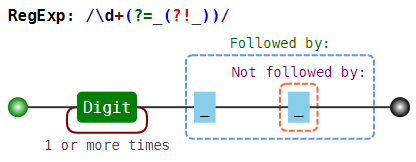
lookaround на примере королей и императоров Франции
Людовик(?=VI) — Людовик, за которым идёт VI
КарлIV, КарлIX, КарлV, КарлVI, КарлVII, КарлVIII,
ЛюдовикIX, ЛюдовикVI, ЛюдовикVII, ЛюдовикVIII, ЛюдовикX, …, ЛюдовикXVIII,
ФилиппI, ФилиппII, ФилиппIII, ФилиппIV, ФилиппV, ФилиппVI
Людовик(?!VI) — Людовик, за которым идёт не VI
КарлIV, КарлIX, КарлV, КарлVI, КарлVII, КарлVIII,
ЛюдовикIX, ЛюдовикVI, ЛюдовикVII, ЛюдовикVIII, ЛюдовикX, …, ЛюдовикXVIII,
ФилиппI, ФилиппII, ФилиппIII, ФилиппIV, ФилиппV, ФилиппVI
(?<=Людовик)VI — «шестой», но только если Людовик
КарлIV, КарлIX, КарлV, КарлVI, КарлVII, КарлVIII,
ЛюдовикIX, ЛюдовикVI, ЛюдовикVII, ЛюдовикVIII, ЛюдовикX, …, ЛюдовикXVIII,
ФилиппI, ФилиппII, ФилиппIII, ФилиппIV, ФилиппV, ФилиппVI
(?<!Людовик)VI — «шестой», но только если не Людовик
КарлIV, КарлIX, КарлV, КарлVI, КарлVII, КарлVIII,
ЛюдовикIX, ЛюдовикVI, ЛюдовикVII, ЛюдовикVIII, ЛюдовикX, …, ЛюдовикXVIII,
ФилиппI, ФилиппII, ФилиппIII, ФилиппIV, ФилиппV, ФилиппVI

Прочие фичи
Конечно, здесь описано не всё, что умеют регулярные выражения, и даже не всё, что умеют регулярные выражения в питоне. За дальнейшим можно обращаться к этому разделу. Из полезного за кадром осталась компиляция регулярок для ускорения многократного использования одного шаблона, использование именных групп и разные хитрые трюки.
А уж какие извращения можно делать с регулярными выражениями в языке Perl — поручик Ржевский просто отдыхает 🙂
Задачи — 4
Задача 10. CamelCase -> under_score
Владимир написал свой открытый проект, именуя переменные в стиле «ВерблюжийРегистр».
И только после того, как написал о нём статью, он узнал, что в питоне для имён переменных принято использовать подчёркивания для разделения слов (under_score). Нужно срочно всё исправить, пока его не «закидали тапками».
Задача могла бы оказаться достаточно сложной, но, к счастью, Владимир совсем не использовал строковых констант и классов.
Поэтому любая последовательность букв и цифр, внутри которой есть заглавные, — это имя переменной, которое нужно поправить.
Задача 11. Удаление повторов
Довольно распространённая ошибка ошибка — это повтор слова.
Вот в предыдущем предложении такая допущена. Необходимо исправить каждый такой повтор (слово, один или несколько пробельных символов, и снова то же слово).
Задача 12. Близкие слова
Для простоты будем считать словом любую последовательность букв, цифр и знаков _ (то есть символов w).
Дан текст. Необходимо найти в нём любой фрагмент, где сначала идёт слово «олень», затем не более 5 слов, и после этого идёт слово «заяц».
Задача 13. Форматирование больших чисел
Большие целые числа удобно читать, когда цифры в них разделены на тройки запятыми.
Переформатируйте целые числа в тексте.
Задача 14. Разделить текст на предложения
Для простоты будем считать, что:
- каждое предложение начинается с заглавной русской или латинской буквы;
- каждое предложение заканчивается одним из знаков препинания
.;!?; - между предложениями может быть любой непустой набор пробельных символов;
- внутри предложений нет заглавных и точек (нет пакостей в духе «Мы любим творчество А. С. Пушкина)».
Разделите текст на предложения так, чтобы каждое предложение занимало одну строку.
Пустых строк в выводе быть не должно. Любые наборы из полее одного пробельного символа замените на один пробел.
Задача 15. Форматирование номера телефона
Если вы когда-нибудь пытались собирать номера мобильных телефонов, то наверняка знаете, что почти любые 10 человек используют как минимум пяток различных способов записать номер телефона. Кто-то начинает с +7, кто-то просто с 7 или 8, а некоторые вообще не пишут префикс. Трёхзначный код кто-то отделяет пробелами, кто-то при помощи дефиса, кто-то скобками (и после скобки ещё пробел некоторые добавляют). После следующих трёх цифр кто-то ставит пробел, кто-то дефис, кто-то ничего не ставит. И после следующих двух цифр — тоже. А некоторые начинают за здравие, а заканчивают… В общем очень неудобно!
На вход даётся номер телефона, как его мог бы ввести человек. Необходимо его переформатировать в формат +7 123 456-78-90. Если с номером что-то не так, то нужно вывести строчку Fail!.
Задача 16. Поиск e-mail’ов — 2
В предыдущей задаче мы немного схалтурили.
Однако к этому моменту задача должна стать посильной!
На вход даётся текст. Необходимо вывести все e-mail адреса, которые в нём встречаются. При этом e-mail не может быть частью слова, то есть слева и справа от e-mail’а должен быть либо конец строки, либо не-буква и при этом не один из символов '._+-, допустимых в адресе.
Post scriptum
PS. Текст длинный, в нём наверняка есть опечатки и ошибки. Пишите о них скорее в личку, я тут же исправлю.
PSS. Ух и намаялся я нормальный html в хабра-html перегонять. Кажется, парсер хабра писан на регулярках, иначе как объяснить все те странности, которые приходилось вылавливать бинпоиском? 🙂
#статьи
- 5 окт 2022
-

0
Исчерпывающий гайд по работе с мощным инструментом для анализа и обработки строк.
Иллюстрация: Оля Ежак для SKillbox Media

Журналист, изучает Python. Любит разбираться в мелочах, общаться с людьми и понимать их.
Само словосочетание «регулярные выражения» звучит непонятно и выглядит страшно, но на самом деле ничего сложного в работе с ними нет. В этой статье мы познакомим вас с их логикой и основными принципами и научим разговаривать на языке шаблонов. В хорошем смысле слова.
Содержание:
- Что такое регулярные выражения
- Синтаксис регулярок
- Как ведётся поиск
- Квантификаторы и логическое ИЛИ при группировке
- Регулярные выражения в Python: модуль re и Match-объекты
- Жадный и ленивый пропуск
- Примеры и задачи
Представьте, что вы снова в школе, на уроке истории. Вам нужно решить итоговую контрольную работу по всем датам, которые проходили в четверти.
Но тут вас поджидает препятствие: все даты разбросаны по нескольким главам учебника по десятку страниц каждая. Читать полкниги в поисках нужных вам крупиц информации — такое себе удовольствие. Тем более когда каждая минута на счету.
К счастью, вы — человек неглупый (не зря же пошли в IT), тренированный и быстро соображающий. Поэтому моментально замечаете основные закономерности:
- даты обозначаются цифрами: арабскими, если это год и месяц, и римскими, если век;
- учебник — по истории позднего Средневековья и Нового времени, поэтому все даты, написанные арабскими цифрами, — четырёхсимвольные;
- после римских цифр всегда идёт слово «век».
Теперь у вас есть шаблон нужной информации. Остаётся лишь пролистать страницу за страницей и записать даты в смартфон (или себе на подкорку). Вуаля: пятёрка за четверть у вас в дневнике, а премия от родителей за отличную учёбу — в кармане.
По такому же принципу работают и регулярные выражения: они ведут поиск фрагментов текста по определённому шаблону. Если фрагмент совпадает с шаблоном — с ним можно работать.
Запишем логику поиска исторических дат в виде регулярных выражений (они ещё называются Regular Expressions, сокращённо regex или regexp). Выглядеть он будет так:
(?:d{4})|(?:[IVX]+ век)
Приятные новости: regex — настолько полезный и мощный инструмент, что поддерживается почти всеми современными языками программирования, в том числе и Python. Причём соответствующий синтаксис в разных языках очень схож. Так что, выучив его в одном языке, можно пользоваться им в других, практически не переучиваясь. Поехали.
С помощью regex можно искать как вполне конкретные выражения (например, слово «век» — последовательность букв «в», «е» и «к»), так и что-то более общее (например, любую букву или цифру).
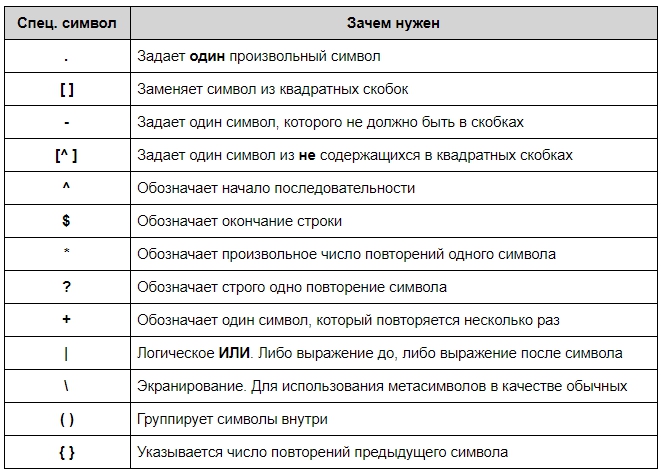
Для обозначения второй категории существуют специальные символы. Вот некоторые из них:
| Символ | Что означает | Пример использования шаблона | Пример вывода |
|---|---|---|---|
| . | Любой символ, кроме новой строки (n) | H.llo, .orld
20.. год |
Hello, world; Hallo, 2orld
2022 год, 2010 год |
| […] | Любой символ из указанных в скобках. Символы можно задавать как перечислением, так и указывая диапазон через дефис | [abc123]
[A-Z] [A-Za-z0-9] [А-ЯЁа-яё] |
а; 1
B; T A; s; 1 А; ё |
| [^…] | Любой символ, кроме указанных в скобках | [^A-Za-z] | з, 4 |
| ^ | Начало строки | ^Добрый день, | 0 |
| $ | Конец строки | До свидания!$ | 0 |
| | | Логическое ИЛИ. Регулярное выражение будет искать один из нескольких вариантов | [0-9]|[IVXLCDM] — регулярное выражение будет находить совпадение, если цифра является либо арабской, либо римской | 5; V |
| Экранирование. Помогает регулярным выражениям ориентироваться, является ли следующий за символ обычным или специальным | AdwZ — экранирование превращает буквы алфавита в спецсимволы.
[.] — экранирование превращает спецсимволы в обычные |
0 |
Важное замечание 1. Регулярные выражения зависимы от регистра, то есть «А» и «а» при поиске будут считаться разными символами.
Важное замечание 2. Буквы «Ё» и «ё» не входят в диапазон «А — Я» и «а — я». Так что, задавая русский алфавит, их нужно выписывать отдельно.
На экранировании остановимся подробнее. По умолчанию символы .^$*+? {}[]|() являются спецсимволами — то есть они выполняют определённые функции. Чтобы сделать спецсимволы обычными, их нужно экранировать .
Таким образом, . будет обозначать любой символ, а . — знак точки. Чтобы написать обратный слеш, его тоже нужно экранировать, то есть в регулярных выражениях он будет выглядеть так: \.
Обратная ситуация с некоторыми алфавитными символами. По умолчанию они считаются просто буквами, но при экранировании начинают играть роль спецсимволов.
| Символ | Что означает |
|---|---|
| d | Любая цифра. То же самое, что [0-9] |
| D | Любой символ, кроме цифры. То же самое, что [^0-9] |
| w | Любая буква, цифра и нижнее подчёркивание |
| W | Любой символ, кроме буквы, цифры и нижнего подчёркивания |
| s | Любой пробельный символ (пробел, новая строка, табуляция, возврат каретки и тому подобное) |
| S | Любой символ, кроме пробельного |
| A | Начало строки. То же самое, что ^ |
| Z | Конец строки. То же самое, что $ |
| b | Начало или конец слова |
| B | Середина слова |
| n, t, r | Стандартные строковые обозначения: новая строка, табуляция, возврат каретки |
Важное замечание. A, Z, b и B указывают не на конкретный символ, а на положение других символов относительно друг друга. Можно сказать, что они указывают на пространство между символами.
Например, регулярное выражение b[А-ЯЁаяё]b будет искать только те буквы, которые отделены друг от друга пробелами или знаками препинания.
Часто при записи регулярного выражения какая-то часть шаблона должна повторяться определённое количество раз. Число вхождений в синтаксисе regex задают с помощью квантификаторов. Они всегда помещаются после той части шаблона, которую нужно повторить.
| Символ | Что означает | Примеры шаблона | Примеры вывода |
|---|---|---|---|
| {} | Указывает количество вхождений, можно задавать единичным числом или диапазоном | d{4} — цифра, четыре подряд
d{1,4} — цифра, от одного до четырёх раз подряд d{2,} — цифра, от двух раз подряд d{,4} — цифра, от 0 до 4 раз подряд |
1243, 1876
1, 12, 176, 1589 22, 456, 988888 5, 15, 987, 1234 |
| ? | От нуля до одного вхождения. То же самое, что {0,1} | d? | 0 |
| * | От нуля вхождений. То же самое, что {0,} | d* | 0 |
| + | От одного вхождения. То же самое, что {1,} | d+ | 0 |
Теперь давайте ещё раз посмотрим на наше регулярное выражение для поиска дат по учебнику истории:
(?:d{4})|(?:[IVX]+ век)
В нём есть несколько дополнительных символов, о которых рассказано ниже, но начинка этого выражения уже понятна.
- d{4} — цифра, четыре подряд
- | — логическое ИЛИ
- [IVX]+ век — символ I, V или X, одно или более вхождений, пробел, слово «век»
Попрактиковаться в составлении регулярных выражений можно на сайте regex101.com. А мы разберём основные приёмы их использования и решим несколько задач.
Уточним ещё несколько терминов regex.
Регулярные выражения — это инструмент для работы со строками, которые и являются основной их единицей.
Строка представляет собой как само регулярное выражение, так и текст, по которому ведётся поиск.
Найденные в тексте совпадения с шаблоном называются подстроками. Например, у нас есть регулярное выражение м. (буква «м», затем любой символ) и текст «Мама мыла раму». Применяя регулярное выражение к тексту, мы найдём подстроки «ма», «мы» и «му». Подстроку «Ма» наше выражение пропустит из-за разницы в регистре.
Есть и более мелкая единица, чем подстрока, — группа. Она представляет собой часть подстроки, которую мы попросили выделить специально. Группы выделяются круглыми скобками (…).
Возьмём ту же строку «Мама мыла раму» и применим к ней следующее регулярное выражение:
(w)(w{3})
Оно значит: буквенный символ, выделенный группой, и за ним ещё три буквенных символа, также выделенных группой. Итого весь шаблон представляет собой четыре буквенных символа.
В нашем тексте это выражение найдёт три совпадения, в каждом из которых выделит две группы:
| Подстрока | Группа 1 | Группа 2 |
|---|---|---|
| Мама | М | ама |
| мыла | м | ыла |
| раму | р | аму |
Это помогает извлечь из найденной подстроки конкретную информацию, отбросив всё остальное. Например, мы нашли адрес, состоящий из названия улицы, номера дома и номера квартиры. Подстрока будет представлять собой адрес целиком, а в группы можно поместить отдельно каждый его структурный элемент — и потом обращаться к нему напрямую.
Группам можно давать имена с помощью такой формы: (? P<name>…)
Вот так будет выглядеть наш шаблон, ищущий четырёхбуквенные слова, если мы дадим имена группам:
?P<first_letter>w)(?P<rest_letters>w{3})
Уберём группы и упростим регулярное выражение, чтобы оно искало только подстроку:
w{4}
Немного изменим текст, по которому ищем совпадения: «Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке».
Регулярное выражение ищет четыре буквенных символа подряд, поэтому в качестве отдельных подстрок находит также «пило», «раме», «рабо», «тает», «лесо» и «пилк».
Исправьте регулярное выражение так, чтобы оно находило только четырёхбуквенные слова. То есть оно должно найти подстроки «мама», «мыла», «раму» и «папа» — и ничего больше.
Подсказка, если не можете решить задачу
Используйте символ b.
Важное замечание. При написании regex нужно помнить, что они ищут только непересекающиеся подстроки. Под шаблон w{4} в слове «работает» подходят не только подстроки «рабо» и «тает», но и «абот», «бота», «отае». Их регулярное выражение не находит, потому что тогда бы эти подстроки пересеклись с другими — а в regex так нельзя.
Нередко при использовании регулярных выражений требуется применить квантификатор либо логическое ИЛИ не к отдельному символу, а к целой группе. Именно так мы поступили в нашем шаблоне для поиска дат по учебнику истории:
(?:d{4})|(?:[IVX]+ век)
С помощью скобок мы сказали: выдайте совпадение, если в тексте присутствует хотя бы один из двух вариантов — либо год, либо век.
Важное замечание.? : в начале группы означает, что мы просим regex не запоминать эту группу. Если все группы открываются символами? :, то регулярные выражения вернут только подстроку и ни одной группы.
В Python это может быть полезно, потому что некоторые re-функции возвращают разные результаты в зависимости от того, запомнили ли регулярные выражения какие-то группы или нет.
Также к группам удобно применять квантификаторы. Например, имена многих дроидов в «Звёздных войнах» построены по принципу: буква — цифра — буква — цифра.
Вот так это выглядит без групп:
[A-Z]d[A-Z]d
И вот так с ними:
(?:[A-Z]d){2}
Особенно полезно использовать незапоминаемые группы со сложными шаблонами.
Чтобы работать с регулярными выражениями в Python, необходимо импортировать модуль re:
import re
Это даёт доступ к нескольким функциям. Вот их краткое описание.
| Функция | Что делает | Если находит совпадение | Если не находит совпадение |
|---|---|---|---|
| re.match (pattern, string) | Ищет pattern в начале строки string | Возвращает Match-объект | Возвращает None |
| re.search (pattern, string) | Ищет pattern по всей строке string | Возвращает Match-объект с первым совпадением, остальные не находит | Возвращает None |
| re.finditer (pattern, string) | Ищет pattern по всей строке string | Возвращает итератор, содержащий Match-объекты для каждого найденного совпадения | Возвращает пустой итератор |
| re.findall (pattern, string) | Ищет pattern по всей строке string | Возвращает список со всеми найденными совпадениями | Возвращает None |
| re.split (pattern, string, [maxsplit=0]) | Разделяет строку string по подстрокам, соответствующим pattern | Возвращает список строк, на которые разделила исходную строку | Возвращает список строк, единственный элемент которого — неразделённая исходная строка |
| re.sub (pattern, repl, string) | Заменяет в строке string все pattern на repl | Возвращает строку в изменённом виде | Возвращает строку в исходном виде |
| re.compile (pattern) | Собирает регулярное выражение в объект для будущего использования в других re-функциях | Ничего не ищет, всегда возвращает Pattern-объект | 0 |
Важное замечание. Напоминаем, что регулярные выражения по умолчанию ищут только непересекающиеся подстроки.
Для написания регулярных выражений в Python используют r-строки (их называют сырыми, или необработанными). Это связано с тем, что написание знака требует экранирования не только в регулярных выражениях, но и в самом Python тоже.
Чтобы программистам не приходилось экранировать экранирование и писать нагромождения обратных слешей, и придумали r-строки. Синтаксически они обозначаются так:
r'...'
Перечислим самые популярные из них.
Находит совпадение только в том случае, если соответствующая шаблону подстрока находится в начале строки, по которой ведётся поиск:
print (re.match (r'Мама', 'Мама мыла раму')) >>> <re.Match object; span=(0, 4), match='Мама'> print (re.match (r'мыла', 'Мама мыла раму')) >>> None
Как видим, поиск по шаблону «Мама» нашёл совпадение и вернул Match-объект. Слово же «мыла», хотя и есть в строке, находится не в начале. Поэтому регулярное выражение ничего не находит и возвращается None.
Ищет совпадения по всему тексту:
print (re.search (r'Мама', 'Мама мыла раму')) >>> <re.Match object; span=(0, 4), match='Мама'> print (re.search (r'мыла', 'Мама мыла раму')) >>> <re.Match object; span=(5, 9), match='мыла'>
При этом re.search возвращает только первое совпадение, даже если в строке, по которой ведётся поиск, их больше. Проверим это:
print (re.search (r'мыла', 'Мама мыла раму, а потом ещё раз мыла, потому что не домыла')) >>> <re.Match object; span=(5, 9), match='мыла'>
Возвращает итератор с объектами, к которым можно обратиться через цикл:
results = re.finditer (r'мыла', 'Мама мыла раму, а потом ещё раз мыла, потому что не домыла') print (results) >>> <callable_iterator object at 0x000001C4CDE446D0> for match in results: print (match) >>> <re.Match object; span=(5, 9), match='мыла'> >>> <re.Match object; span=(32, 36), match='мыла'> >>> <re.Match object; span=(54, 58), match='мыла'>
Эта функция очень полезна, если вы хотите получить Match-объект для каждого совпадения.
В Match-объектах хранится много всего интересного. Посмотрим внимательнее на объект с подстрокой «Мама», который нашла функция re.match:
<re.Match object; span=(0, 4), match='Мама'>
span — это индекс начала и конца найденной подстроки в тексте, по которому мы искали совпадение. Обратите внимание, что второй индекс не включается в подстроку.
match — это собственно найденная подстрока. Если подстрока длинная, то она будет отображаться не целиком.
Это, конечно же, не всё, что можно получить от Match-объекта. Рассмотрим ещё несколько методов.
Возвращает найденную подстроку, если ему не передавать аргумент или передать аргумент 0. То же самое делает обращение к объекту по индексу 0:
match = re.match (r'Мама', 'Мама мыла раму') print (match.group()) >>> Мама print (match.group(0)) >>> Мама print (match[0]) >>> Мама
Если регулярное выражение поделено на группы, то, начиная с единицы, можно вызвать группу отдельно от строки:
match = re.match (r'(М)(ама)', 'Мама мыла раму') print (match.group(1)) print (match.group(2)) >>> М >>> ама print (match[1]) print (match[2]) >>> М >>> ама #Методом group также можно получить кортеж из нужных групп. print (match.group(1,2)) >>> ('М', 'ама')
Если группы поименованы, то в качестве аргумента метода group можно передавать их название:
match = re.match (r'(?P<first_letter>М)(?P<rest_letters>ама)', 'Мама мыла раму') print (match.group('first_letter')) print (match.group('rest_letters')) >>> М >>> ама
Если одна и та же группа соответствует шаблону несколько раз, то в группу запишется только последнее совпадение:
#Помещаем в группу один буквенный символ, при этом шаблон представляет собой четыре таких символа. match = re.match (r'(w){4}', 'Мама мыла раму') print (match.group(0)) >>> Мама print (match.group(1)) >>> а
Возвращает кортеж с группами:
match = re.match (r'(М)(ама)', 'Мама мыла раму') print (match.groups()) >>> ('М', 'ама')
Возвращает кортеж с индексом начала и конца подстроки в исходном тексте. Если мы хотим получить только первый индекс, можно использовать метод start, только последний — end:
match = re.search (r'мыла', 'Мама мыла раму') print (match.span()) >>> (5, 9) print (match.start()) >>> 5 print (match.end()) >>> 9
Возвращает просто список совпадений. Никаких Match-объектов, к которым нужно дополнительно обращаться:
#В этом примере в качестве регулярного выражения мы используем правильный ответ на задание 0. match_list = re.findall (r'bw{4}b', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.') print (match_list) >>> ['Мама', 'мыла', 'раму', 'папа']
Функция ведёт себя по-другому, если в регулярном выражении есть деление на группы. Тогда функция возвращает список кортежей с группами:
match_list = re.findall (r'b(w{1})(w{3})b', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.') print (match_list) >>> [('М', 'ама'), ('м', 'ыла'), ('р', 'аму'), ('п', 'апа')]
Аналог метода str.split. Делит исходную строку по шаблону, а сам шаблон исключает из результата:
#Поделим строку по запятой и пробелу после неё. split_string = re.split (r', ', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.') print (split_string) >>> ['Мама мыла раму', 'а папа был на пилораме', 'потому что работает на лесопилке.']
re.split также имеет дополнительный аргумент maxsplit — это максимальное количество частей, на которые функция может поделить строку. По умолчанию maxsplit равен нулю, то есть не устанавливает никаких ограничений:
#Приравняем аргумент maxsplit к единице. split_string = re.split (r', ', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.', maxsplit=1) print (split_string) >>> ['Мама мыла раму', 'а папа был на пилораме, потому что работает на лесопилке.']
Если в re.split мы указываем группы, то они попадают в список строк в качестве отдельных элементов. Для наглядности поделим исходную строку на слог «па»:
#Помещаем буквы «п» и «а» в одну группу. split_string = re.split (r'(па)', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.') print (split_string) >>> ['Мама мыла раму, а ', 'па', '', 'па', ' был на пилораме, потому что работает на лесопилке.'] #Помещаем буквы «п» и «а» в разные группы. split_string = re.split (r'(п)(а)', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.') print (split_string) >>> ['Мама мыла раму, а ', 'п', 'а', '', 'п', 'а', ' был на пилораме, потому что работает на лесопилке.']
Требует указания дополнительного аргумента в виде строки, на которую и будет заменять найденные совпадения:
new_string = re.sub (r'Мама', 'Дочка', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.') print (new_string) >>> Дочка мыла раму, а папа был на пилораме, потому что работает на лесопилке.
Дополнительные возможности у функции появляются при применении групп. В качестве аргумента замены ему можно передать не строку, а ссылку на номер группы в виде n. Тогда он подставит на нужное место соответствующую группу из шаблона. Это очень удобно, когда нужно поменять местами структурные элементы в тексте:
new_string = re.sub (r'(w+) (w+) (w+),', r'2 3 1 –', 'Бендер Остап Ибрагимович, директор ООО "Рога и копыта"') print (new_string) >>> Остап Ибрагимович Бендер — директор ООО "Рога и копыта"
Используется для ускорения и упрощения кода, когда одно и то же регулярное выражение применяется в нём несколько раз. Её синтаксис выглядит так:
pattern = re.compile (r'Мама') print (pattern.search ('Мама мыла раму')) >>> <re.Match object; span=(0, 4), match='Мама'> print (pattern.sub ('Дочка', 'Мама мыла раму')) >>> Дочка мыла раму
Нередко в регулярных выражениях нужно учесть сразу много вариантов и опций, из-за чего их структура усложняется. А regex даже простые и короткие читать нелегко, что уж говорить о длинных.
Чтобы хоть как-то облегчить чтение регулярок, в Python r-строки можно делить точно так же, как и обычные. Возьмём наше выражение для поиска дат по учебнику истории:
re.findall (r'(?:d{4})|(?:[IVX]+ век)', text)
Его же можно написать вот в таком виде:
re.findall (r'(?:d{4})' r'|' r'(?:[IVX]+ век)', text)
Часто при написании регулярных выражений приходится использовать квантификаторы, охватывающие диапазон значений. Например, d{1,4}. Как регулярные выражения решают, сколько цифр им захватить, одну или четыре? Это определяется пропуском квантификаторов.
По умолчанию все квантификаторы являются жадными, то есть стараются захватить столько подходящих под шаблон символов, сколько смогут.
В некоторых случаях это может стать проблемой. Например, возьмём часть оглавления поэмы Венедикта Ерофеева «Москва — Петушки», записанную в одну строку:
Фрязево — 61-й километр……….64 61-й километр — 65-й километр…68 65-й километр — Павлово-Посад…71 Павлово-Посад — Назарьево……..73 Назарьево — Дрезна……………77 Дрезна — 85-й километр………..80
Нужно написать регулярное выражение, которое выделит каждый пункт оглавления. Для этого определим признаки, по которым мы будем это делать:
- Каждый пункт начинается с буквы или цифры (для этого используем шаблон w).
- Он может содержать внутри себя любой набор символов: буквы, цифры, знаки препинания (для этого используем шаблон .+).
- Он заканчивается на точку, после которой следует от одной до трёх цифр (для этого используем шаблон .d{1,3}).
Посмотрим в конструкторе, как работает наше выражение:
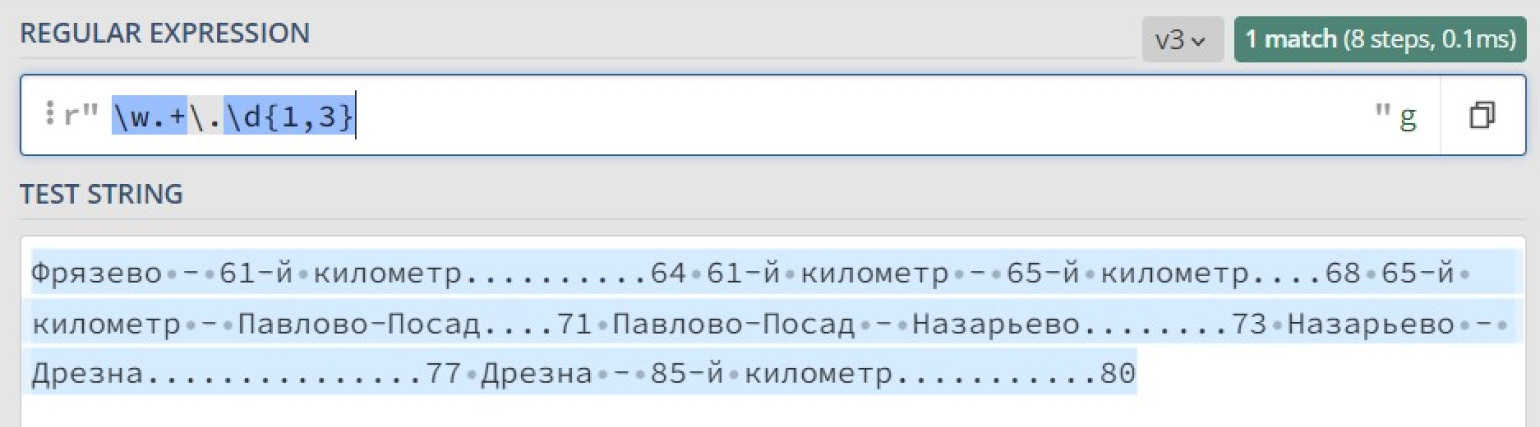
Что же произошло? Почему найдено только одно совпадение, причем за него посчитали весь текст сразу? Всё дело в жадности квантификатора +, который старается захватить максимально возможное количество подходящих символов.
В итоге шаблон w находит совпадение с буквой «Ф» в начале текста, шаблон .d{1,3} находит совпадение с «.80» в конце текста, а всё, что между ними, покрывается шаблоном .+.
Чтобы квантификатор захватывал минимально возможное количество символов, его нужно сделать ленивым. В таком случае каждый раз, находя совпадение с шаблоном ., регулярное выражение будет спрашивать: «Подходят ли следующие символы в строке под оставшуюся часть шаблона?»
Если нет, то функция будет искать следующее совпадение с .. А если да, то . закончит свою работу и следующие символы строки будут сравниваться со следующей частью регулярного выражения: .d{1,3}.
Чтобы объявить квантификатор ленивым, после него надо поставить символ ?. Сделаем ленивым квантификатор + в нашем регулярном выражении для поиска строк в оглавлении:
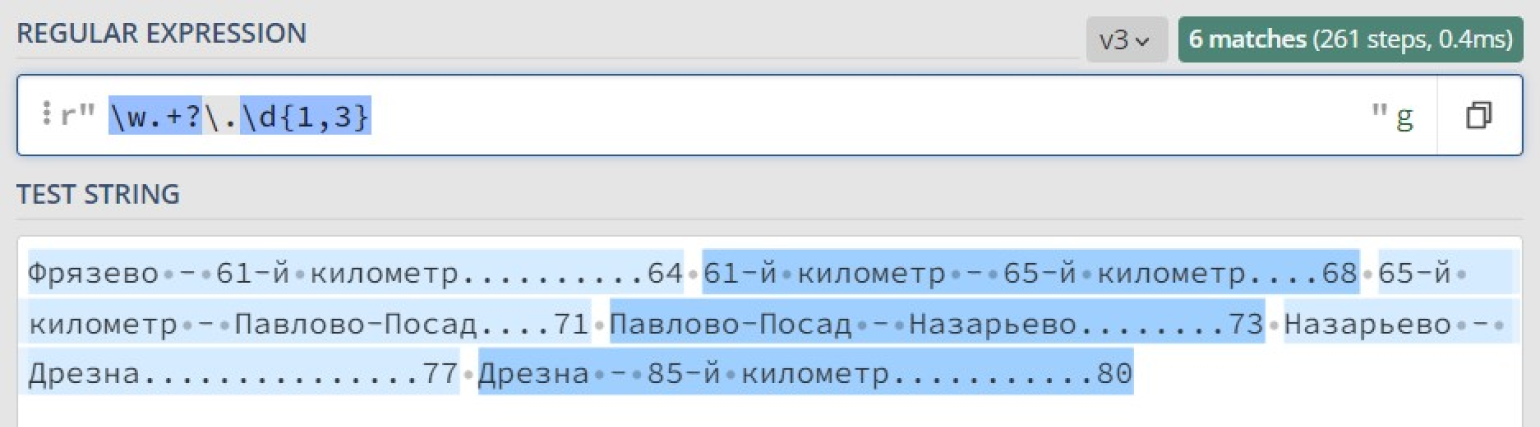
Теперь, когда мы уверены в правильности работы нашего регулярного выражения, используем функцию re.findall, чтобы выписать оглавление построчно:
content = 'Фрязево — 61-й километр..........64 61-й километр — 65-й километр....68 65-й километр — Павлово-Посад....71 Павлово-Посад — Назарьево........73 Назарьево — Дрезна...............77 Дрезна — 85-й километр...........80' strings = re.findall (r'w.+?.d{1,3}', content) for string in strings: print (string) #Результат на экране. >>> Фрязево — 61-й километр..........64 >>> 61-й километр — 65-й километр....68 >>> 65-й километр — Павлово-Посад....71 >>> Павлово-Посад — Назарьево........73 >>> Назарьево — Дрезна...............77 >>> Дрезна — 85-й километр...........80
В некоторых случаях одну и ту же задачу можно решить разными способами, используя разные возможности регулярок. Попробуйте решить следующие задачи самостоятельно. Возможно, у вас даже получится сделать это более эффективно.
При обнародовании судебных решений из них извлекают персональные данные участников процесса — фамилии, имена и отчества. Каждое слово в Ф. И. О. начинается с заглавной буквы, при этом фамилия может быть двойная.
Напишите программу, которая заменит в тексте Ф. И. О. подсудимого на N.
Подсудимая Эверт-Колокольцева Елизавета Александровна в судебном заседании вину инкриминируемого правонарушения признала в полном объёме и суду показала, что 14 сентября 1876 года, будучи в состоянии алкогольного опьянения от безысходности, в связи с состоянием здоровья позвонила со своего стационарного телефона в полицию, сообщив о том, что у неё в квартире якобы заложена бомба. После чего приехали сотрудники полиции, скорая и пожарные, которым она сообщила, что бомба — это она.
«Подсудимая N в судебном заседании» и далее по тексту.
Подсказка
Используйте незапоминаемую опциональную группу вида (? : …)? , чтобы обозначить вторую часть фамилии после дефиса.
Решение
#Сначала кладём в переменную string текст строки, по которой ведём поиск.
print (re.sub (r'[А-ЯЁ]w*'
r'(?:-[А-ЯЁ]w*)?'
r'(?: [А-ЯЁ]w*){2}', 'N', string))
Большинство адресов состоит из трёх частей: название улицы, номер дома и номер квартиры. Название улицы может состоять из нескольких слов, каждое из которых пишется с заглавной буквы. Номер дома может содержать после себя букву.
Перед названием улицы может быть написано «Улица», «улица», «Ул.» или «ул.», перед номером дома — «дом» или «д.», перед номером квартиры — «квартира» или «кв.». Также номер дома и номер квартиры могут быть разделены дефисом без пробелов.
Дан текст, в нём нужно найти все адреса и вывести их в виде «Пушкина 32-135».
Для упрощения мы не будем учитывать дома, которые находятся не на улицах, а на площадях, набережных, бульварах и так далее.
Добрый день!
Сегодня на выезды потребуется отправить трёх-четырёх специалистов, остальных держите в офисе. Некоторые заявки пришли на конкретных людей, но можно вызвать и других, смотрите по ситуации, как лучше их отправить, чтобы всех объездить сегодня.
Петрову П. П. попросили выехать по адресам ул. Культуры 78 кв. 6, улица Мира дом 12Б квартира 144. Смирнова С. С. просят подъехать только по адресу: Восьмого Марта 106-19. Без предпочтений по специалистам пришли запросы с адресов: улица Свободы 54 6, Улица Шишкина дом 9 кв. 15, ул. Лермонтова 18 кв. 93.
Все адреса скопированы из заявок, корректность подтверждена.
Культуры 78-6
Мира 12Б-144
Восьмого Марта 106-19
Свободы 54-6
Шишкина 9-15
Лермонтова 18-93
Подсказка
Используйте деление на группы, чтобы удобно выстроить структуру выражения. Попросите regex запоминать только нужные вам части адреса, чтобы функция не возвращала вам лишние подгруппы.
Решение
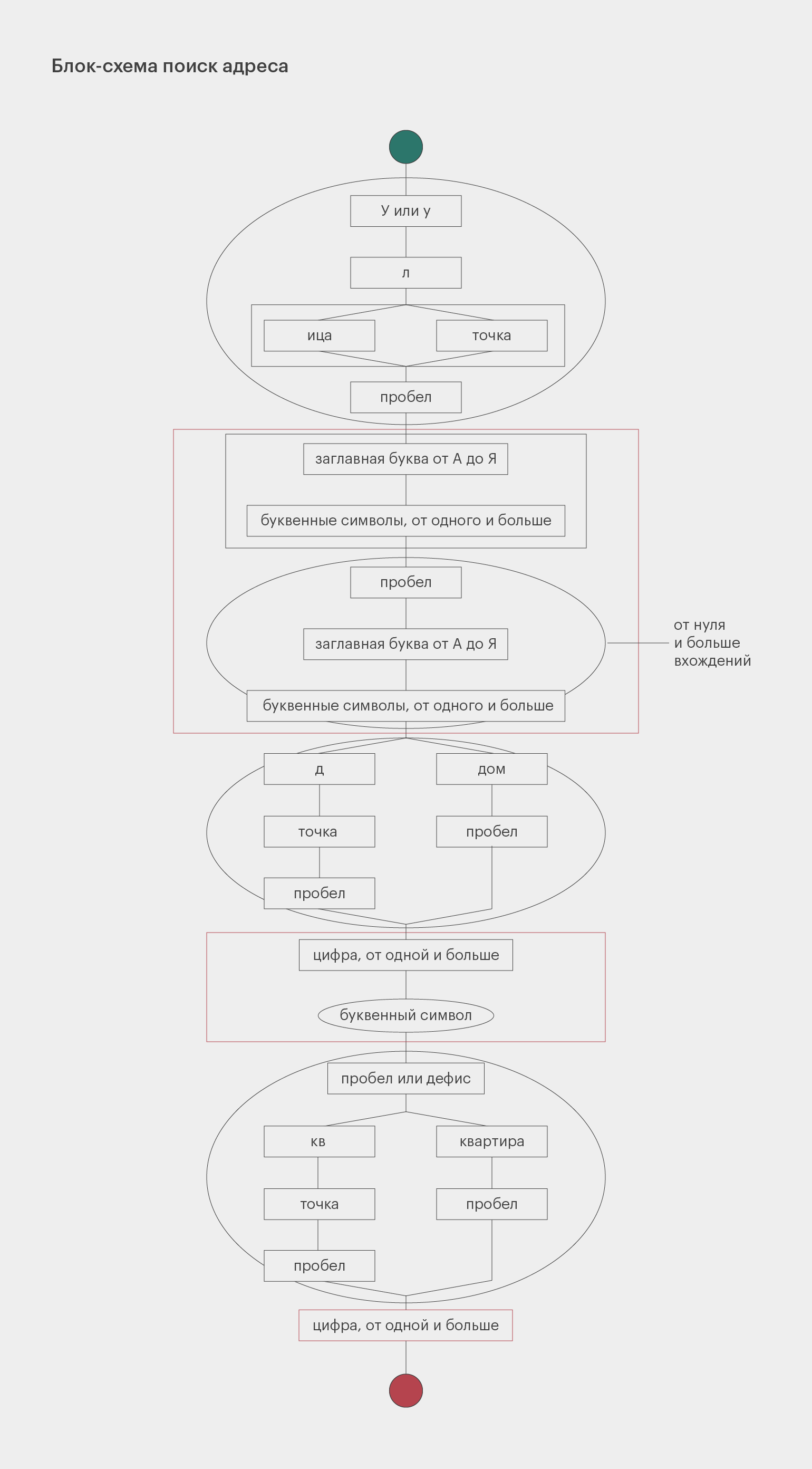
#Сначала кладём в переменную string текст строки, по которой ведём поиск.
pattern = re.compile (r'(?:[Уу]л(?:.|ица) )?'
r'((?:[А-ЯЁ]w+)(?: [А-ЯЁ]w+)*)'
r' (?:дом |д. )?'
r'(d+w?)'
r'[ -](?:квартира |кв. )?'
r'(d+)')
addresses = pattern.findall (text)
for address in addresses:
print (f'{address[0]} {address[1]}-{address[2]}')
Структура этого регулярного выражения довольно сложная. Чтобы в нём разобраться, посмотрите на схему. Прямоугольники обозначают обязательные элементы, овалы — опциональные. Развилки символизируют разные варианты, которые допускает наш шаблон. Красным цветом очерчены группы, которые мы запоминаем.
Писатели в поиске собственного неповторимого стиля нередко изобретают оригинальные творческие приёмы и неукоснительно им следуют. Например, Сергей Довлатов следил за тем, чтобы слова в предложении не начинались с одной и той же буквы.
Даны несколько предложений. Программа должна проверить, встречаются ли в каждом из них слова на одинаковую букву. Если таких нет, она печатает: «Метод Довлатова соблюдён». А если есть: «Вы расстроили Сергея Донатовича».
Важно. Чтобы регулярные выражения не рассматривали заглавные и прописные буквы как разные символы, передайте re-функции дополнительный аргумент flags=re.I или flags=re.IGNORECASE.
Здесь все слова начинаются с разных букв.
А в этом предложении есть слова, которые всё-таки начинаются на одну и ту же букву.
А здесь совсем интересно: символ «а» однобуквенный.
Метод Довлатова соблюдён
Вы расстроили Сергея Донатовича
Вы расстроили Сергея Донатовича
Подсказка
Чтобы указать на начало слова, используйте символ b.
Чтобы в каждом совпадении regex не старалось захватить максимум, используйте ленивый пропуск.
Чтобы найти повторяющийся символ, используйте ссылку на группу в виде 1.
Решение
#Сначала кладём в переменную string текст строки, по которой ведём поиск.
pattern = r'b(w)w*.*?b1'
match = re.search (pattern, string, flags=re.I)
if match is None:
print ('Метод Довлатова соблюдён')
else:
print ('Вы расстроили Сергея Донатовича')
Вернёмся к регулярному выражению, которое ищет даты в учебнике истории: (? :d{4})|(? : [IVX]+ век).
Оно в целом справляется со своей задачей, но также находит много ненужных чисел. Например, количество человек, которые участвовали в битве, тоже может быть описано четырьмя цифрами подряд.
Чтобы не получать лишние результаты, обратим внимание на то, как именно могут быть записаны годы. Есть несколько вариантов записи: 1400 год, 1400 г., 1400–1500 годы, 1400–1500 гг., (1400), (1400–1500).
Чтобы немного упростить задачу и не раздувать регулярное выражение, мы не будем искать конструкции «с такого-то по такой-то год» и «между таким-то и таким-то годом».
Важное замечание. Не забывайте про экранирование, если хотите использовать точки и скобки в качестве обычных, а не специальных символов. Так программа правильно поймёт, что вы имеете в виду.
Началом Реформации принято считать 31 октября 1517 г. — день, когда Мартин Лютер (1483–1546) прибил к дверям виттенбергской Замковой церкви свои «95 тезисов», в которых выступил против злоупотреблений Католической церкви. Реформация охватила практически всю Европу и продолжалась в течение всего XVI века и первой половины XVII века. Одно из самых известных и кровавых событий Реформации — Варфоломеевская ночь во Франции, произошедшая в ночь на 24 августа 1572 года.
Точное число жертв так и не удалось установить достоверно. Погибли по меньшей мере 2000 гугенотов в Париже и 3000 — в провинциях. Герцог де Сюлли, сам едва избежавший смерти во время резни, говорил о 70 000 жертв. Для Парижа единственным точным числом остаётся 1100 погибших во время Варфоломеевской ночи.
Этому событию предшествовали три других, произошедшие в 1570–1572 годах: Сен-Жерменский мирный договор (1570), свадьба гугенота Генриха Наваррского и Маргариты Валуа (1572) и неудавшееся покушение на убийство адмирала Колиньи (1572).
[‘1517 г.’, ‘(1483–1546)’, ‘XVI век’, ‘XVII век’, ‘1572 год’, ‘1570–1572 годах’, ‘(1570)’, ‘(1572)’, ‘(1572)’]
Решение
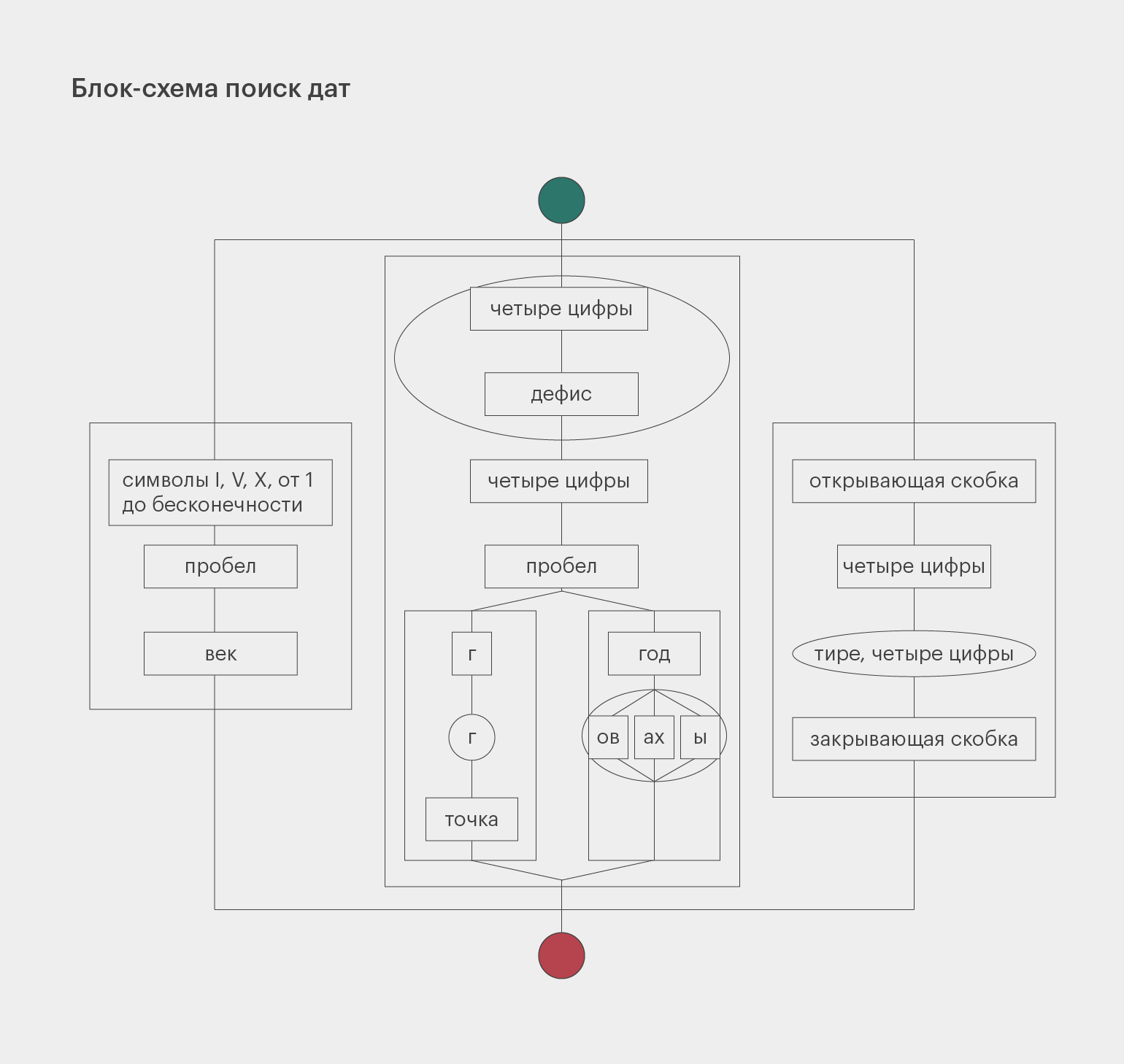
#Сначала кладём в переменную string текст строки, по которой ведём поиск.
pattern = re.compile (r'(?:(d{4}(?:-d{4})?))'
r'|'
r'(?:'
r'(?:d{4}-)?d{4} '
r'(?:'
r'(?:год(?:ы|ах|ов)?)'
r'|'
r'(?:гг?.)'
r')'
r')'
r'|'
r'(?:[IVX]+ век)')
print (pattern.findall (string))
Если вам сложно разобраться в структуре этого выражения, то вот его схема:

Научитесь: Профессия Python-разработчик
Узнать больше
Рассмотрим регулярные выражения в Python, начиная синтаксисом и заканчивая примерами использования.
Примечание Вы читаете улучшенную версию некогда выпущенной нами статьи.
- Основы регулярных выражений
- Регулярные выражения в Python
- Задачи
Основы регулярных выражений
Регулярками в Python называются шаблоны, которые используются для поиска соответствующего фрагмента текста и сопоставления символов.
Грубо говоря, у нас есть input-поле, в которое должен вводиться email-адрес. Но пока мы не зададим проверку валидности введённого email-адреса, в этой строке может оказаться совершенно любой набор символов, а нам это не нужно.
Чтобы выявить ошибку при вводе некорректного адреса электронной почты, можно использовать следующее регулярное выражение:
r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+(?:.[a-zA-Z0-9-]+)+$'По сути, наш шаблон — это набор символов, который проверяет строку на соответствие заданному правилу. Давайте разберёмся, как это работает.
Синтаксис RegEx
Синтаксис у регулярок необычный. Символы могут быть как буквами или цифрами, так и метасимволами, которые задают шаблон строки:
Также есть дополнительные конструкции, которые позволяют сокращать регулярные выражения:
- d — соответствует любой одной цифре и заменяет собой выражение [0-9];
- D — исключает все цифры и заменяет [^0-9];
- w — заменяет любую цифру, букву, а также знак нижнего подчёркивания;
- W — любой символ кроме латиницы, цифр или нижнего подчёркивания;
- s — соответствует любому пробельному символу;
- S — описывает любой непробельный символ.
Для чего используются регулярные выражения
- для определения нужного формата, например телефонного номера или email-адреса;
- для разбивки строк на подстроки;
- для поиска, замены и извлечения символов;
- для быстрого выполнения нетривиальных операций.
Синтаксис таких выражений в основном стандартизирован, так что вам следует понять их лишь раз, чтобы использовать в любом языке программирования.
Примечание Не стоит забывать, что регулярные выражения не всегда оптимальны, и для простых операций часто достаточно встроенных в Python функций.
Хотите узнать больше? Обратите внимание на статью о регулярках для новичков.
В Python для работы с регулярками есть модуль re. Его нужно просто импортировать:
import reА вот наиболее популярные методы, которые предоставляет модуль:
re.match()re.search()re.findall()re.split()re.sub()re.compile()
Рассмотрим каждый из них подробнее.
re.match(pattern, string)
Этот метод ищет по заданному шаблону в начале строки. Например, если мы вызовем метод match() на строке «AV Analytics AV» с шаблоном «AV», то он завершится успешно. Но если мы будем искать «Analytics», то результат будет отрицательный:
import re
result = re.match(r'AV', 'AV Analytics Vidhya AV')
print result
Результат:
<_sre.SRE_Match object at 0x0000000009BE4370>
Искомая подстрока найдена. Чтобы вывести её содержимое, применим метод group() (мы используем «r» перед строкой шаблона, чтобы показать, что это «сырая» строка в Python):
result = re.match(r'AV', 'AV Analytics Vidhya AV')
print result.group(0)
Результат:
AVТеперь попробуем найти «Analytics» в данной строке. Поскольку строка начинается на «AV», метод вернет None:
result = re.match(r'Analytics', 'AV Analytics Vidhya AV')
print result
Результат:
NoneТакже есть методы start() и end() для того, чтобы узнать начальную и конечную позицию найденной строки.
result = re.match(r'AV', 'AV Analytics Vidhya AV')
print result.start()
print result.end()
Результат:
0
2Эти методы иногда очень полезны для работы со строками.
re.search(pattern, string)
Метод похож на match(), но ищет не только в начале строки. В отличие от предыдущего, search() вернёт объект, если мы попытаемся найти «Analytics»:
result = re.search(r'Analytics', 'AV Analytics Vidhya AV')
print result.group(0)
Результат:
AnalyticsМетод search() ищет по всей строке, но возвращает только первое найденное совпадение.
re.findall(pattern, string)
Возвращает список всех найденных совпадений. У метода findall() нет ограничений на поиск в начале или конце строки. Если мы будем искать «AV» в нашей строке, он вернет все вхождения «AV». Для поиска рекомендуется использовать именно findall(), так как он может работать и как re.search(), и как re.match().
result = re.findall(r'AV', 'AV Analytics Vidhya AV')
print result
Результат:
['AV', 'AV']re.split(pattern, string, [maxsplit=0])
Этот метод разделяет строку по заданному шаблону.
result = re.split(r'y', 'Analytics')
print result
Результат:
['Anal', 'tics']В примере мы разделили слово «Analytics» по букве «y». Метод split() принимает также аргумент maxsplit со значением по умолчанию, равным 0. В данном случае он разделит строку столько раз, сколько возможно, но если указать этот аргумент, то разделение будет произведено не более указанного количества раз. Давайте посмотрим на примеры Python RegEx:
result = re.split(r'i', 'Analytics Vidhya')
print result
Результат:
['Analyt', 'cs V', 'dhya'] # все возможные участки.result = re.split(r'i', 'Analytics Vidhya',maxsplit=1)
print result
Результат:
['Analyt', 'cs Vidhya']Мы установили параметр maxsplit равным 1, и в результате строка была разделена на две части вместо трех.
re.sub(pattern, repl, string)
Ищет шаблон в строке и заменяет его на указанную подстроку. Если шаблон не найден, строка остается неизменной.
result = re.sub(r'India', 'the World', 'AV is largest Analytics community of India')
print result
Результат:
'AV is largest Analytics community of the World're.compile(pattern, repl, string)
Мы можем собрать регулярное выражение в отдельный объект, который может быть использован для поиска. Это также избавляет от переписывания одного и того же выражения.
pattern = re.compile('AV')
result = pattern.findall('AV Analytics Vidhya AV')
print result
result2 = pattern.findall('AV is largest analytics community of India')
print result2
Результат:
['AV', 'AV']
['AV']До сих пор мы рассматривали поиск определенной последовательности символов. Но что, если у нас нет определенного шаблона, и нам надо вернуть набор символов из строки, отвечающий определенным правилам? Такая задача часто стоит при извлечении информации из строк. Это можно сделать, написав выражение с использованием специальных символов. Вот наиболее часто используемые из них:
| Оператор | Описание |
|---|---|
| . | Один любой символ, кроме новой строки n. |
| ? | 0 или 1 вхождение шаблона слева |
| + | 1 и более вхождений шаблона слева |
| * | 0 и более вхождений шаблона слева |
| w | Любая цифра или буква (W — все, кроме буквы или цифры) |
| d | Любая цифра [0-9] (D — все, кроме цифры) |
| s | Любой пробельный символ (S — любой непробельный символ) |
| b | Граница слова |
| [..] | Один из символов в скобках ([^..] — любой символ, кроме тех, что в скобках) |
| Экранирование специальных символов (. означает точку или + — знак «плюс») | |
| ^ и $ | Начало и конец строки соответственно |
| {n,m} | От n до m вхождений ({,m} — от 0 до m) |
| a|b | Соответствует a или b |
| () | Группирует выражение и возвращает найденный текст |
| t, n, r | Символ табуляции, новой строки и возврата каретки соответственно |
Больше информации по специальным символам можно найти в документации для регулярных выражений в Python 3.
Перейдём к практическому применению Python регулярных выражений и рассмотрим примеры.
Задачи
Вернуть первое слово из строки
Сначала попробуем вытащить каждый символ (используя .)
result = re.findall(r'.', 'AV is largest Analytics community of India')
print result
Результат:
['A', 'V', ' ', 'i', 's', ' ', 'l', 'a', 'r', 'g', 'e', 's', 't', ' ', 'A', 'n', 'a', 'l', 'y', 't', 'i', 'c', 's', ' ', 'c', 'o', 'm', 'm', 'u', 'n', 'i', 't', 'y', ' ', 'o', 'f', ' ', 'I', 'n', 'd', 'i', 'a']Для того, чтобы в конечный результат не попал пробел, используем вместо . w.
result = re.findall(r'w', 'AV is largest Analytics community of India')
print result
Результат:
['A', 'V', 'i', 's', 'l', 'a', 'r', 'g', 'e', 's', 't', 'A', 'n', 'a', 'l', 'y', 't', 'i', 'c', 's', 'c', 'o', 'm', 'm', 'u', 'n', 'i', 't', 'y', 'o', 'f', 'I', 'n', 'd', 'i', 'a']Теперь попробуем достать каждое слово (используя * или +)
result = re.findall(r'w*', 'AV is largest Analytics community of India')
print result
Результат:
['AV', '', 'is', '', 'largest', '', 'Analytics', '', 'community', '', 'of', '', 'India', '']И снова в результат попали пробелы, так как * означает «ноль или более символов». Для того, чтобы их убрать, используем +:
result = re.findall(r'w+', 'AV is largest Analytics community of India')
print result
Результат:
['AV', 'is', 'largest', 'Analytics', 'community', 'of', 'India']Теперь вытащим первое слово, используя ^:
result = re.findall(r'^w+', 'AV is largest Analytics community of India')
print result
Результат:
['AV']Если мы используем $ вместо ^, то мы получим последнее слово, а не первое:
result = re.findall(r'w+$', 'AV is largest Analytics community of India')
print result
Результат:
[‘India’]Вернуть первые два символа каждого слова
Вариант 1: используя w, вытащить два последовательных символа, кроме пробельных, из каждого слова:
result = re.findall(r'ww', 'AV is largest Analytics community of India')
print result
Результат:
['AV', 'is', 'la', 'rg', 'es', 'An', 'al', 'yt', 'ic', 'co', 'mm', 'un', 'it', 'of', 'In', 'di']Вариант 2: вытащить два последовательных символа, используя символ границы слова (b):
result = re.findall(r'bw.', 'AV is largest Analytics community of India')
print result
Результат:
['AV', 'is', 'la', 'An', 'co', 'of', 'In']Вернуть домены из списка email-адресов
Сначала вернём все символы после «@»:
result = re.findall(r'@w+', 'abc.test@gmail.com, xyz@test.in, test.first@analyticsvidhya.com, first.test@rest.biz')
print result
Результат:
['@gmail', '@test', '@analyticsvidhya', '@rest']Как видим, части «.com», «.in» и т. д. не попали в результат. Изменим наш код:
result = re.findall(r'@w+.w+', 'abc.test@gmail.com, xyz@test.in, test.first@analyticsvidhya.com, first.test@rest.biz')
print result
Результат:
['@gmail.com', '@test.in', '@analyticsvidhya.com', '@rest.biz']Второй вариант — вытащить только домен верхнего уровня, используя группировку — ( ):
result = re.findall(r'@w+.(w+)', 'abc.test@gmail.com, xyz@test.in, test.first@analyticsvidhya.com, first.test@rest.biz')
print result
Результат:
['com', 'in', 'com', 'biz']Извлечь дату из строки
Используем d для извлечения цифр.
result = re.findall(r'd{2}-d{2}-d{4}', 'Amit 34-3456 12-05-2007, XYZ 56-4532 11-11-2011, ABC 67-8945 12-01-2009')
print result
Результат:
['12-05-2007', '11-11-2011', '12-01-2009']Для извлечения только года нам опять помогут скобки:
result = re.findall(r'd{2}-d{2}-(d{4})', 'Amit 34-3456 12-05-2007, XYZ 56-4532 11-11-2011, ABC 67-8945 12-01-2009')
print result
Результат:
['2007', '2011', '2009']Извлечь слова, начинающиеся на гласную
Для начала вернем все слова:
result = re.findall(r'w+', 'AV is largest Analytics community of India')
print result
Результат:
['AV', 'is', 'largest', 'Analytics', 'community', 'of', 'India']А теперь — только те, которые начинаются на определенные буквы (используя []):
result = re.findall(r'[aeiouAEIOU]w+', 'AV is largest Analytics community of India')
print result
Результат:
['AV', 'is', 'argest', 'Analytics', 'ommunity', 'of', 'India']Выше мы видим обрезанные слова «argest» и «ommunity». Для того, чтобы убрать их, используем b для обозначения границы слова:
result = re.findall(r'b[aeiouAEIOU]w+', 'AV is largest Analytics community of India')
print result
Результат:
['AV', 'is', 'Analytics', 'of', 'India']Также мы можем использовать ^ внутри квадратных скобок для инвертирования группы:
result = re.findall(r'b[^aeiouAEIOU]w+', 'AV is largest Analytics community of India')
print result
Результат:
[' is', ' largest', ' Analytics', ' community', ' of', ' India']В результат попали слова, «начинающиеся» с пробела. Уберем их, включив пробел в диапазон в квадратных скобках:
result = re.findall(r'b[^aeiouAEIOU ]w+', 'AV is largest Analytics community of India')
print result
Результат:
['largest', 'community']Проверить формат телефонного номера
Номер должен быть длиной 10 знаков и начинаться с 8 или 9. Есть список телефонных номеров, и нужно проверить их, используя регулярки в Python:
li = ['9999999999', '999999-999', '99999x9999']
for val in li:
if re.match(r'[8-9]{1}[0-9]{9}', val) and len(val) == 10:
print 'yes'
else:
print 'no'
Результат:
yes
no
noРазбить строку по нескольким разделителям
Возможное решение:
line = 'asdf fjdk;afed,fjek,asdf,foo' # String has multiple delimiters (";",","," ").
result = re.split(r'[;,s]', line)
print result
Результат:
['asdf', 'fjdk', 'afed', 'fjek', 'asdf', 'foo']Также мы можем использовать метод re.sub() для замены всех разделителей пробелами:
line = 'asdf fjdk;afed,fjek,asdf,foo'
result = re.sub(r'[;,s]',' ', line)
print result
Результат:
asdf fjdk afed fjek asdf fooИзвлечь информацию из html-файла
Допустим, нужно извлечь информацию из html-файла, заключенную между <td> и </td>, кроме первого столбца с номером. Также будем считать, что html-код содержится в строке.
Пример содержимого html-файла:
1NoahEmma2LiamOlivia3MasonSophia4JacobIsabella5WilliamAva6EthanMia7MichaelEmilyС помощью регулярных выражений в Python это можно решить так (если поместить содержимое файла в переменную test_str):
result = re.findall(r'd([A-Z][A-Za-z]+)([A-Z][A-Za-z]+)', test_str)
print result
Результат:
[('Noah', 'Emma'), ('Liam', 'Olivia'), ('Mason', 'Sophia'), ('Jacob', 'Isabella'), ('William', 'Ava'), ('Ethan', 'Mia'), ('Michael', 'Emily')]Адаптированный перевод «Beginners Tutorial for Regular Expressions in Python»
Что такое Regex
Регулярные выражения (Regex) – это строки, задающие шаблон для поиска определенных фрагментов в тексте. Помимо поиска, с помощью специальных Regex-шаблонов можно манипулировать текстовыми фрагментами – удалять и изменять подстроки частично или полностью.
Регулярные выражения состоят из набора литералов (букв и цифр) и метасимволов и выглядят примерно так: r'(https?://)?(www.)?youtube.(com|nl)/watch?v=([w-]+)(&.*?)?(?=[^-w&=%])'Используя метасимволы, можно создавать сложные шаблоны, содержащие специальные конструкции для работы с определенными последовательностями и группами символов.
Regex-выражения применяют для обработки текстовых данных, в том числе в скриптах для веб-скрапинга. Кроме того, Regex используют в составе OCR-приложений для очистки отсканированного текста.
Regex в Python
Большинство современных языков программирования поддерживают регулярные выражения, однако степень удобства использования Regex в разных языках варьируется. Python предоставляет простые и понятные методы для работы с регулярными выражениями. Все Regex инструменты находятся в модуле re, который входит в стандартный дистрибутив Python – достаточно импортировать его в свой проект:
import re
Для экранирования служебных символов в шаблонах поиска и замены используют два способа – обратный слэш и «сырые» строки r''. Второй метод предпочтительнее – он позволяет избежать нагромождения слэшей в шаблонах.
Основные функции Regex
re.match() – находит вхождение фрагмента в начале строки. Обычный формат использования – re.match(r'шаблон', строка):
import re
s = "утка крякает, кукушка кукует, петух кукарекает"
match = re.match(r'ку', s)
print(match)
Этот код вернет None, несмотря на то, что в строке есть 5 фрагментов «ку». Это происходит потому, что оба фрагмента расположены не в начале строки.
re.search() – находит первое вхождение фрагмента в любом месте и возвращает объект match. Если в строке есть другие фрагменты, соответствующие запросу, re.search их проигнорирует. У re.search есть дополнительные методы:
.span() – возвращает кортеж, содержащий начальную и конечную позиции искомого фрагмента.
.string – вернет строку, переданную в функцию re.search.
.group() – возвращает фрагмент строки, в котором было обнаружено совпадение.
#Пример использования re.search с дополнительными методами
import re
s = "oт топота копыт пыль по полю летит"
match = re.search(r'по', s)
print(match, match.span(), match.string, match.group(), sep='n')
#Вывод:
<re.Match object; span=(5, 7), match='по'>
(5, 7)
oт топота копыт пыль по полю летит
по
re.findall() – находит все вхождения фрагмента, в любом месте. Функция re.findall() учитывает регистр символов. Чтобы в результат вошли фрагменты с символами в другом регистре, применяют флаг re.IGNORECASE:
import re
s = "Не видно, ликвидны акции или неликвидны."
match = re.findall(r'не', s, re.I)
print(match)
re.split() – расщепляет строку по заданному шаблону. Количество расщеплений задается флагом – в этом примере от строки отделяется только первое слово:
import re
s = "Обладаешь ли ты налогооблагаемой благодатью?"
res = re.split(r' ', s, 1)
print(res)
re.sub() – заменяет фрагмент в соответствии с шаблоном:
import re
s = "Коала какао лениво лакала"
res = re.sub(r'коала', 'макака', s, flags=re.I)
print(res)
re.compile() – создает объект из регулярного выражения. Применяется, если один и тот же поисковый шаблон используется в коде несколько раз:
import re
st = re.compile('угнал')
res1 = st.findall("Карл у Клары угнал Maclaren, а Клара у Карла угнала Corvette.")
res2 = st.findall("Карл у Клары угнал кораллы, а Клара у Карла угнала кларнет.")
print(res1, res2, sep='n')
Все перечисленные выше примеры предназначены для выполнения самых простых задач по поиску и замене фрагментов текста. Возможности Regex в Python намного шире: шаблоны могут включать условия, учитывать (или игнорировать) группы символов и диапазоны значений. Для создания таких регулярных выражений используют специальные конструкции, состоящие из метасимволов.
Основные метасимволы в Regex
[] – используется для указания набора или диапазона символов – re.findall(r'[с-я]', "Камер-юнкер юркнул в бункер", re.I), re.findall(r'[аж]', "ажиотаж, мандраж, багаж").
– указывает на начало последовательности (мы рассмотрим их ниже) или экранирует служебные символы.
. – выбирает любой символ, кроме новой строки n.
^ – проверяет, начинается ли строка с определенного символа / слова / набора символов. Например, r'^Привет‘ проверит, начинается ли строка с «Привет». Метасимвол ^ в наборе [] имеет другое значение – проверяет, отсутствуют ли в строке определенные символы (подробнее об этом ниже).
$ – проверяет, заканчивается ли строка в соответствии с шаблоном r'До свиданья.$'.
* – ноль или больше совпадений с шаблоном r'ко.*аборация'.
+ – одно и более совпадений r'к.+ператив'.
? – ноль или одно совпадение r'ф.?нтастика'. Кроме того, нейтрализует «жадность» выражений, которые используют ., *, + для выбора любых символов.
{} – точное число совпадений r'Интерсте.{2}ар'.
| – любой из двух вариантов r'уйду|останусь'.
() – захватывает группу для дальнейших манипуляций – re.sub(r'(www)', r'1.', "wwwwear-gear.com").
<> – создает именованную группу – re.search('(?P<группа1>w+),(?P<группа2>w+),(?P<группа3>w+)', 'дом,улица,фонарь')
Последовательности
Знаком слэша обозначается специфическая последовательность символов.
A – проверяет, начинается ли строка с определенной последовательности символов. Например, re.findall(r"AДом", txt), проверит, начинается ли предложение со слова «Дом».
b – возвращает совпадение, если слово начинается или заканчивается нужной последовательностью символов. Выражение re.findall(r".comb", s) проверит, есть ли в строке хотя бы одно доменное имя зоны .com.
B – возвращает совпадение, если определенные символы есть в строке, но не в начале или не в конце слова – re.findall(r"Bро", 'розовая от мороза'), re.findall(r'инB', 'синий апельсин').
d – проверяет, что в строке есть цифры от 0 до 9 – re.findall("d", 'при пожаре звоните 112').
D – удостоверяет, что цифр в строке нет – re.findall("D", 'цифр нет').
s – проверяет наличие пробелов в строке – re.findall("s", "один пробел").
S – возвращает совпадение, если в строке есть любые символы, кроме пробелов – re.findall("S", "непустая строка").
w – проверяет, есть ли в строке «словесные» символы – знак нижнего подчеркивания, цифры и буквы – re.findall(r"w", "_\\").
W – возвращает совпадение по каждому «несловесному» символу – re.findall("W", "здесь есть такие символы!").
Z – проверит, заканчивается ли строка нужной последовательностью символов – re.findall("конецZ", "это конец").
Наборы и диапазоны символов
Наборы и диапазоны в регулярных выражениях заключены в квадратные скобки:
[есн] – проверит, есть ли в строке любой из указанных символов е, с или н – re.findall("[есн]", "здесь есть несколько символов из набора"). Наличие любой цифры из набора проверяется так же – [0169].
[а-е] – вернет совпадения по каждому символу из алфавитного диапазона – re.findall("[а-е]", "здесь есть символы из диапазона"). Таким же образом возвращает совпадения по диапазону цифр – [5-9]. Чтобы не использовать флаг re.IGNORECASE, диапазон можно указывать так – [а-еА-Е].
[^абвгд] – проверит наличие в строке символов, кроме указанных в наборе – re.findall("[^абвгд]", "АБВГДейка – детская передача", re.I).
[0-5][0-9] – возвращает совпадения по двузначным цифрам от 00 до 59 – re.findall("[0-5][0-9]", "будильник сработает в 07:45").
Флаги в Regex
Функциональность регулярных выражений расширяется за счет флагов:
| Краткий синтаксис | Полный синтаксис | Назначение |
| re.A | re.ASCII | Возвращает совпадения только по ASCII-символам вместо всей таблицы Unicode. |
| re.I | re.IGNORECASE | Игнорирует регистр символов. |
| re.M | re.MULTILINE | Используется совместно с метасимволами ^ и $. В первом случае возвращает совпадения в начале каждой новой строки n, во втором – в конце n. |
| re.S | re.DOTALL | Заставляет метасимвол . возвращать совпадения по абсолютно всем символам, включая n. Без этого флага точка . соответствует любому символу, кроме n. |
| re.X | re.VERBOSE | Разрешает комментарии в Regex-выражениях. |
| re.L | re.LOCALE | Учитывает региональные настройки при использовании w, W, b, B, s и S. Используется только при работе с байтовыми строками, не совместим с re.ASCII. |
Онлайн-конструкторы регулярных выражений
Чем сложнее регулярное выражение, тем труднее его правильно составить и протестировать. В интернете есть немало визуализаторов Regex, которые значительно упрощают эту задачу. Самый удобный ресурс – regex101. Сайт предоставляет справочную и отладочную информацию, позволяет визуально тестировать шаблоны для поиска и замены. Помимо Python, поддерживает PHP, Java, Golang и JavaScript.
Задача 1:
Написать регулярное выражение для извлечения из текста всех email-адресов.
Решение:
import re
s = 'По всем вопросам пишите на vasiliy-pupkin@gmail.com, или на secondemail@yandex.ru, отвечу сразу. Или пишите моему ассистенту secretary@gmail.com!'
emails = re.findall(r'[w.-]+@[w.-]+', s)
for email in emails:
print(email)
Задача 2:
Имеется файл transactions.txt, в котором даты указаны в формате MM/DD/YYYY, при этом в некоторых случаях месяц обозначен первыми тремя буквами: NOV, dec, JAN. Нужно привести даты к формату MM-DD-YYYY.
#формат дат в файле transactions.txt
nov/14/2021
dec/15/2021
12/16/2021
dec/17/2021
jan/03/2022
JAN/10/22
Решение:
import fileinput
import re
fn = "transactions.txt"
for line in fileinput.input(fn, inplace=True):
new_line = re.sub('(d{2}|[a-yA-Y]{3})/(d{2})/(d{2, 4})', r'1-2-3', line)
print(new_line)
#Содержимое файла после выполнения кода:
nov-14-2021
dec-15-2021
12-16-2021
dec-17-2021
jan-03-2022
JAN-10-2022
Задача 3:
Вводится последовательность строк. Нужно вывести строки, в которых фрагмент «кот» присутствует в качестве подстроки не менее 2 раз.
#Пример ввода
кот-кот
кот и кот
котофей
котейка кот
кот и котенок
Решение:
import re
import sys
for line in sys.stdin:
line = line.strip()
if re.search(r"кот.*?кот", line):
print(line)
Задача 4:
Дана последовательность строк. Нужно вывести те, в которых «кот» встречается в качестве отдельного слова.
#Пример ввода:
кот в сапогах
кошка и кот
котофей
котяра
Решение:
import re
import sys
for line in sys.stdin:
line = line.rstrip()
if re.search(r"bкотb", line):
print(line)
#Вывод
кот в сапогах
кошка и кот
Задача 5:
Вывести слова, состоящие из двух одинаковых слогов.
#Пример ввода
тартар
тик-так
сносно
варвар
барабан
Решение:
import re
import sys
for line in sys.stdin:
line = line.strip()
if re.search(r"b(w+)1b", line):
print(line)
#Вывод
тартар
сносно
варвар
Задача 6:
Вводится последовательность строк. В каждой строке нужно поменять местами две первые буквы в каждом слове, состоящем из двух и более букв.
#Пример ввода
это пример текста
в котором нужно поменять буквы
Решение:
import sys
import re
for line in sys.stdin:
line = line.rstrip()
print(re.sub(r'b(w)(w)', r"21", line))
#Вывод
тэо рпимер еткста
в октором унжно опменять убквы
Задача 7:
Напишите функцию для валидации мобильного номера в международном формате. Корректным считается представление номера в таком виде:
+7(912)15-16-896, 8(912)15-16-896
+79121516896, 89121516896
+7(912)151-68-96, 8(912)151-68-96
+7912-151-6896, 87912-151-6896
Решение:
import re
pattern = re.compile(r'(+7|8).*?(d{2,3}).*?(d{2,3}).*?(d{2}).*?(d{2})')
def isValid(number):
if re.match(pattern, number):
print("ДА")
else:
print("НЕТ")
isValid(input())
Задача 8:
Напишите программу для парсинга номеров телефонов с тестовой страницы.
Решение:
import urllib.request
from re import findall
url = "http://www.summet.com/dmsi/html/codesamples/addresses.html"
response = urllib.request.urlopen(url)
data = response.read()
s = data.decode()
phones = findall("(d{3}) d{3}-d{4}", s)
for number in phones:
print(number)
Задача 9:
Нужно извлечь все имена и фамилии из текста.
Решение:
import re
s = 'На встрече присутствовали: профессор Владимир Успенский, физик-ядерщик Сергей Ковалев, президент клуба Владимир Медведев и космонавт Юрий Титов.'
name = r"[А-Я][а-я]+,?s+"
last_name = r"[А-Я][а-я]+"
persons = re.findall(name + last_name, s)
for item in persons:
print(item)
Задача 10:
Нужно получить URL всех png и jpg изображений, использованных на главной странице proglib.io:
import re
import requests
def getURL(text):
urls = []
results = re.findall(r'(?:http:|https:)?//.*.(?:png|jpg)', text)
for x in results:
if not x.startswith('http:'):
x = 'http:' + x
urls.append(x)
return urls
def getImages(url):
resp = requests.get(url)
urls = getURL(resp.text)
print('urls', urls)
getImages('https://proglib.io')
Заключение
Regex в Python – мощный, гибкий, но достаточно сложный инструмент. Регулярные выражения сложно составлять, поддерживать и редактировать. При работе с текстовыми файлами Regex чаще всего можно заменить методами строк, а при парсинге, в большинстве случаев, использование XPath и CSS-селекторов окажется более эффективным.
***
Материалы по теме
- Регулярные выражения: 5 сервисов для тестирования и отладки
- Практическое введение в регулярные выражения для новичков
- Регулярные выражения: базовое знакомство для новичков
На чтение 15 мин Просмотров 8.6к. Опубликовано 11.08.2021
Содержание
- Введение в тему
- Введение в регулярные выражения
- Что такое шаблон регулярного выражения и как его скомпилировать
- Как разделить текст
- Поиск совпадений с использованием findall search и match
- Что делает re findall
- re search против re match
- Как заменить один текст на другой используя регулярные выражения
- Группы регулярных выражений
- Что такое жадное соответствие в регулярных выражениях
- Наиболее распространенный синтаксис и шаблоны регулярных выражений
- Примеры регулярных выражений
Введение в тему
Regex, или регулярные выражения – язык для работы с текстом. Он позволяет производить поиск, замену и другие операции. Этот язык встроен во многие другие языки программирования и является де-факто стандартным инструментом для большинства проектов, связанных с обработкой больших текстов.
Введение в регулярные выражения
Как уже говорилось, регулярные выражения присутствуют во множестве языков программирования, и, уж точно, во всех языках общего назначения. Не стал исключением и Python, в котором они представлены модулем стандартной библиотеки re.
Сфера применения этой библиотеки – всё, что связано с операциями над текстом: проверка пользовательского ввода, поиск на странице или в файле, анализ текстовой информации и многое другое. Но, будьте осторожны, использование этого инструмента требует определённых усилий. Не даром есть такая старая шутка: «Если у вас есть проблема, и вы собираетесь её решать с помощью регулярных выражений, тогда у вас будет уже две проблемы.»
Для начала работы с регулярными выражениями, необходимо импортировать модуль re в Ваш модуль.
Что такое шаблон регулярного выражения и как его скомпилировать
Ядром Regex являются шаблоны – синтаксис, позволяющий описывать текст: какой он длины, из каких символов состоит, в каком регистре и так далее. На основе таких шаблоном производится поиск в тексте.
Простой пример. Шаблон, который описывает один любой символ: «.?». Здесь точка означает любой символ, а вопросительный знак говорит о количестве – строго одно повторение.
Вы можете передать шаблон регулярного выражения в переменную, если планируете использовать его несколько раз. Для этого используется метод compile.
import re
regex = re.compile('.?')
# Теперь этот шаблон можно использовать из переменной
print(regex.findall('qwerty'))
# Вывод:
['q', 'w', 'e', 'r', 't', 'y', '']
Как разделить текст
В модуле re существует два метода разбиения строки по шаблону:
re.split и метод split объекта regex (который мы получаем методом compile). Второй метод предпочтительнее если Вы собираетесь использовать один и тот же шаблон много раз. Разберём, как они работают на примере:
import re
regex = re.compile('.')
text = 'Beautiful is better than ugly. '
'Explicit is better than implicit. '
'Simple is better than complex. '
'Complex is better than complicated. '
'Flat is better than nested.'
print('regex.split:', regex.split(text))
print('re.split:', re.split('.', text))
# Вывод:
regex.split: ['Beautiful is better than ugly', ' Explicit is better than implicit', ' Simple is better than complex', ' Complex is better than complicated', ' Flat is better than nested', '']
re.split: ['Beautiful is better than ugly', ' Explicit is better than implicit', ' Simple is better than complex', ' Complex is better than complicated', ' Flat is better than nested', '']
Как видите, работают он одинаково. Здесь мы экранировали точку обратной косой чертой чтобы модуль re воспринял её именно как точку, а не как любой символ.
Поиск совпадений с использованием findall search и match
Дальше мы рассмотрим, как искать участки текста, совпадающие с шаблоном регулярного выражения.
Что делает re findall
import re
regex = re.compile('is ......')
text = 'Beautiful is better than ugly. '
'Explicit is better than implicit. '
'Simple is better than complex. '
'Complex is better than complicated. '
'Flat is better than nested.'
print('regex.findall:', regex.findall(text))
# Вывод:
regex.findall: ['is better', 'is better', 'is better', 'is better', 'is better']
Метод findall ищет все участки текста, совпадающие с переданным шаблоном, и возвращает список, состоящий из найденных вхождений. В данном примере мы искали все участки, которые начинаются со слова ‘is’, пробела и шести любых символов после.
re search против re match
Метод match ищет по заданному шаблону в начале строки. Возвращает этот метод специальный объект, содержащий начальный и конечный индексы найденной подстроки:
import re
regex = re.compile('Beautiful')
text = 'Beautiful is better than ugly. '
'Explicit is better than implicit. '
'Simple is better than complex. '
'Complex is better than complicated. '
'Flat is better than nested.'
print('regex.match:', regex.match(text))
print('regex.match.start():', regex.match(text).start())
print('regex.match.end():', regex.match(text).end())
# Вывод:
regex.match: <re.Match object; span=(0, 9), match='Beautiful'>
regex.match.start(): 0
regex.match.end(): 9
Для того, чтобы вывести саму подстроку, придётся применить метод group:
import re
regex = re.compile('Beautiful')
text = 'Beautiful is better than ugly. '
'Explicit is better than implicit. '
'Simple is better than complex. '
'Complex is better than complicated. '
'Flat is better than nested.'
print('regex.match:', regex.match(text).group())
# Вывод:
regex.match: Beautiful
Метод search подобен функции match, но искать подстроки может в любом месте текста. Возвращает такой же объект, как и match.
import re
regex = re.compile('is .{6}')
text = 'Beautiful is better than ugly. '
'Explicit is better than implicit. '
'Simple is better than complex. '
'Complex is better than complicated. '
'Flat is better than nested.'
print('regex.search :', regex.search(text).group())
# Вывод:
regex.search : is better
Таким образом, отличие функций findall, search и match в способе поиска и возвращаемых значениях.
Как заменить один текст на другой используя регулярные выражения
Для замены одного фрагмента текста на другой используйте метод sub.
Тут, опять же существует два варианта:
import re
regex = re.compile('better')
text = 'Beautiful is better than ugly. '
'Explicit is better than implicit. '
'Simple is better than complex. '
'Complex is better than complicated. '
'Flat is better than nested.'# Первый вариант:
text = regex.sub('лучше', text)
print('regex.sub :', text)# Второй вариант:
text = re.sub('than', 'чем', text)
print('re.sub :', text)
# Вывод:
regex.sub : Beautiful is лучше than ugly. Explicit is лучше than implicit. Simple is лучше than complex. Complex is лучше than complicated. Flat is лучше than nested.
re.sub : Beautiful is лучше чем ugly. Explicit is лучше чем implicit. Simple is лучше чем complex. Complex is лучше чем complicated. Flat is лучше чем nested.
Группы регулярных выражений
Группы регулярных выражений — функция, позволяющая извлекать нужные объекты соответствия как отдельные элементы.
Если в шаблоне регулярного выражения встречаются скобки (…), то они становятся группирующими. Достаточно часто это бывает полезно.
import re
# Без группировки:
regex = re.compile(r'w{4,9}sis')
text = 'Beautiful is better than ugly. '
'Explicit is better than implicit. '
'Simple is better than complex. '
'Complex is better than complicated. '
'Flat is better than nested.'
print('regex.findall_1:', regex.findall(text))
# С группировкой:
regex = re.compile(r'(w{4,9})sis')
print('regex.findall_2:', regex.findall(text))
# Вывод:
regex.findall_1: ['Beautiful is', 'Explicit is', 'Simple is', 'Complex is', 'Flat is']
regex.findall_2: ['Beautiful', 'Explicit', 'Simple', 'Complex', 'Flat']
Что такое жадное соответствие в регулярных выражениях
Регулярные выражения могут быть жадными или ленивым. Если они жадные (это поведение по умолчанию), то они будут стараться найти как можно больший фрагмент текста, соответствующий шаблону.
Проще всего это понять на примере:
import re
regex = re.compile(r'.*.')
text = 'Beautiful is better than ugly. '
'Explicit is better than implicit.'
print('regex.findall:', regex.findall(text))
# Вывод:
regex.findall: ['Beautiful is better than ugly. Explicit is better than implicit.']
Как вы можете видеть, Regex показала совпадение до последней точки, хотя точка встречалась и в конце первой строки. Это и есть жадный поиск. Для того, чтобы активировать ленивое поведение, надо добавить в конец шаблона вопросительный знак. При ленивом поиске re будет останавливаться на каждой встреченной точке:
import re
regex = re.compile(r'.*?.')
text = 'Beautiful is better than ugly. '
'Explicit is better than implicit.'
print('regex.findall:', regex.findall(text))
# Вывод:
regex.findall: ['Beautiful is better than ugly.', ' Explicit is better than implicit.']
Наиболее распространенный синтаксис и шаблоны регулярных выражений
Ниже приведен список наиболее часто используемых шаблонов.
- Специальные символы,
- ‘.’ — любой символ;
- ‘^’ — началу строки;
- ‘$’ — конец строки;
- ‘*’ — 0 или более повторений;
- ‘+’ — 1 или более повторений;
- ‘?’ — 0 или 1 повторений;
- ‘*?’, ‘+?’,’??’ — ограничение жадности;
- ‘{m}’ — m повторений;
- ‘{m,n}’ — как можно больше повторений в промежутке от m до n ;
- ‘{m,n}?’ — как можно меньше повторений в промежутке от m до n;
- ‘’ — экранирование специальных символов;
- ‘[]’ — символьный класс;
- ‘|’ — или;
- ‘(…)’ — группа с захватом;
- Расширения регулярных выражений,
- ‘(?aiLmsux)’ — установка флагов регулярного выражения;
- ‘(?aiLmsux-imsx:…)’ — установка и удаление флагов;
- ‘(?:…)’ — группа без захвата;
- ‘(?P<name>…)’ — именованная группа;
- ‘(?P=name)’ — обратная ссылка на именованную группу;
- ‘(?#…)’ — комментарий;
- ‘(?=…)’ — опережающая позитивная проверка;
- ‘(?!…)’ — опережающая негативная проверка;
- ‘(?<=…)’ — позитивная ретроспективная проверка;
- ‘(?<!…)’ — негативная ретроспективная проверка;
- ‘(?(id/name)yes-pattern|no-pattern)’ — стараться соответствовать yes-pattern;
- Специальные последовательности.
- ‘number’ — соответствие группы с тем же номером;
- ‘A’ — только начало строки;
- ‘b’ — пустая строка (начало или конц слова);
- ‘B’ — пустая строка (НЕ начало или конец слова);
- ‘d’ — любая десятичная цифра;
- ‘D’ — НЕ десятичная цифра;
- ‘s’ — пробельный символ;
- ‘S’ — НЕ пробельный символ;
- ‘w’ — символы, которые могут быть частью слова;
- ‘W’ — символы, которые НЕ могут быть частью слова;
- ‘Z’ — только конец строки;
Примеры регулярных выражений
Любой символ кроме новой строки
import re
regex = re.compile(r'.')
text = 'Beautiful is better than ugly.'
print('regex.findall:', regex.findall(text))
# Вывод:
regex.findall: ['B', 'e', 'a', 'u', 't', 'i', 'f', 'u', 'l', ' ', 'i', 's', ' ', 'b', 'e', 't', 't', 'e', 'r', ' ', 't', 'h', 'a', 'n', ' ', 'u', 'g', 'l', 'y', '.']
Всё, кроме точек и пробелов
import re
regex = re.compile(r'[^s,^.]')
text = 'Beautiful is better than ugly.'
print('regex.findall:', regex.findall(text))
# Вывод:
regex.findall: ['B', 'e', 'a', 'u', 't', 'i', 'f', 'u', 'l', 'i', 's', 'b', 'e', 't', 't', 'e', 'r', 't', 'h', 'a', 'n', 'u', 'g', 'l', 'y']
Любая цифра
import re
regex = re.compile(r'd+')
text = 'Date: 2021-08-11'
print('regex.findall:', regex.findall(text))
# Вывод:
regex.findall: ['2021', '08', '11']
Все, кроме цифры
import re
regex = re.compile(r'D+')
text = 'Date: 2021-08-11'
print('regex.findall:', regex.findall(text))
# Вывод:
regex.findall: ['Date: ', '-', '-']
Любая буква или цифра
import re
regex = re.compile(r'w+')
text = 'Date: 2021-08-11'
print('regex.findall:', regex.findall(text))
# Вывод:
regex.findall: ['Date', '2021', '08', '11']
Все, кроме букв и цифр
import re
regex = re.compile(r'W+')
text = 'Date: 2021-08-11'
print('regex.findall:', regex.findall(text))
# Вывод:
regex.findall: [': ', '-', '-']
Только буквы
import re
regex = re.compile(r'[A-Za-z]+')
text = 'Date: 2021-08-11'
print('regex.findall:', regex.findall(text))
# Вывод:
regex.findall: ['Date']
Соответствие заданное количество раз
import re
regex = re.compile(r'w{4}')
# Четыре буквы подряд
text = 'Beautiful is better than ugly.'
print('regex.findall_1:', regex.findall(text))
# От пяти до семи
regex = re.compile(r'w{5,7}')
print('regex.findall_2:', regex.findall(text))
# Вывод:
regex.findall_1: ['Beau', 'tifu', 'bett', 'than', 'ugly']
regex.findall_2: ['Beautif', 'better']
1 и более вхождений
import re
regex = re.compile(r'w+t+w+')
# Слова с одной или более буквами t подряд
text = 'Beautiful is better than ugly.'
print('regex.findall:', regex.findall(text))
# Вывод:
regex.findall: ['Beautiful', 'better']
Любое количество вхождений (0 или более раз)
import re
regex = re.compile(r'u+t*w+')
# Слова с одной или более буквами t подряд
text = 'Beautiful is better than ugly.'
print('regex.findall:', regex.findall(text))
# Вывод:
regex.findall: ['utiful', 'ugly']
0 или 1 вхождение
import re
regex = re.compile(r'u+t?w+')
# Слова с одной или более буквами t подряд
text = 'Beautiful is better than ugly.'
print('regex.findall:', regex.findall(text))
# Вывод:
regex.findall: ['utiful', 'ugly']
Граница слова
Для определения границ слова, то есть такого места в тексте, где рядом расположен символ, из которого может состоять слово (w) и пробел (s), используют символ b.
Пример:
import re
# Первые две буквы каждого слова
regex = re.compile(r'bww')
text = 'Beautiful is better than ugly.'
print('regex.findall_1:', regex.findall(text))
# Последние две буквы каждого слова
regex = re.compile(r'wwb')
print('regex.findall_2:', regex.findall(text))
# Вывод:
regex.findall_1: ['Be', 'is', 'be', 'th', 'ug']
regex.findall_2: ['ul', 'is', 'er', 'an', 'ly']
