Если робот Google не сможет получить доступ к вашей странице из-за правила в файле robots.txt, то она, скорее всего, не появится в результатах поиска Google, а если и появится, то без описания.
1. Проверьте, заблокирована ли страница в файле robots.txt
Если вы подтвердили право собственности на сайт в Search Console, сделайте следующее:
- Откройте инструмент проверки URL.
- Проверьте URL страницы, представленный в результате поиска Google.Должен быть выбран ресурс Search Console, который содержит этот URL.
- Найдите статус в разделе результатов проверки Индексирование страниц. Если там значится Заблокировано в файле robots.txt, то проблема подтверждена. Как ее устранить, описано далее.
Если вы не подтвердили право собственности на сайт в Search Console, сделайте следующее:
- Выполните поиск валидатора для файла robots.txt.
- Введите в валидаторе URL страницы, описание которой отсутствует. Это должен быть URL, указанный в результатах поиска Google.
- Если валидатор сообщает, что доступ к странице для робота Google запрещен, то проблема подтверждена. Как ее устранить, описано далее.
2. Измените правило
- Чтобы узнать, какое правило блокирует доступ к странице и где находится файл robots.txt, воспользуйтесь валидатором для robots.txt.
- Измените или удалите правило:
- Если вы пользуетесь сервисом веб-хостинга (например, если ваш сайт построен на Wix, Joomla или Drupal), мы не можем предоставить вам точное руководство по обновлению вашего файла robots.txt. Причина в том, что для каждого сервиса хостинга инструкции будут разными. Чтобы узнать, как разблокировать доступ Google к странице или сайту, поищите нужные сведения в документации своего хостинг-провайдера. Советуем выполнить поиск по запросу “robots.txt название_провайдера” или “открыть Google доступ к странице название_провайдера“. Пример: robots.txt Wix.
- Если у вас есть возможность вносить изменения непосредственно в файл robots.txt, удалите правило или обновите его иным образом с учетом синтаксиса robots.txt.
Эта информация оказалась полезной?
Как можно улучшить эту статью?
Адаптивность под мобильные устройства важна вне зависимости от тематики и функциональности веб-ресурса. Большинство из нас сталкивалось с неудобствами пользования различными интернет-ресурсами через планшет или смартфон по причине отсутствия в них адаптивности. Мелкий шрифт, частично скрывающийся за границами экрана контент или вся страница, перекрывающие друг друга элементы – это классика для множества сайтов.
Но даже при соблюдении правил адаптивного дизайна нужно понимать, что сайт посещают не только люди, но и роботы поисковых систем. И как ни странно, для этих неэмоциональных машин тоже важен данный показатель. Способность оценить, удобен ли сайт для просмотра на различных устройствах, дает возможность поисковой системе делать определенные выводы, что вполне может повлиять на ранжирование в поисковой выдаче – как позитивно, так и негативно.
Так как поисковые роботы смотрят и оценивают страницы ресурса не привычными для нас глазами, а по средствам загрузки и анализа кода страниц, они вполне могут увидеть и понять намного больше, чем представлено в визуальной части. Но, чтобы обеспечить корректное восприятие, необходимо правильно настроить файл robots.txt. Если вы не знаете, что это за файл такой и для чего предназначен, рекомендую прежде ознакомиться с этой статьей в нашем блоге. Очень важна именно индивидуальная настройка robots.txt под конкретный сайт. Таким образом, можно добиться корректного восприятия контента поисковыми системами.
Для максимально правильной настройки robots.txt для поискового робота Googlebot более опытными веб-мастерами и SEO-специалистами используется сервис Google Mobile-friendly.
Google Mobile-friendly: что это?
Представленный компанией Google инструмент для веб-разработчиков помогает определить, пригодна ли адаптивность сайта для отображения на мобильных устройствах и корректно ли ее воспринимает поисковый робот Googlebot.
Страница сервиса находится по адресу: https://search.google.com/test/mobile-friendly.
Максимально простой в использовании – достаточно лишь вставить ссылку на страницу тестируемого ресурса и нажать кнопку «Проверить страницу».
После недолгого ожидания получаем результат. Тут стоит заметить, что результат проверки для каждого сайта будет индивидуален, даже для отдельных страниц в рамках одного сайта. Поэтому желательно, кроме главной, проверить страницу категорий, товара, статьи и т. п.
Как пользоваться Mobile-friendly
Рассмотрим основные моменты в использовании сервиса на примере не адаптированного сайта.
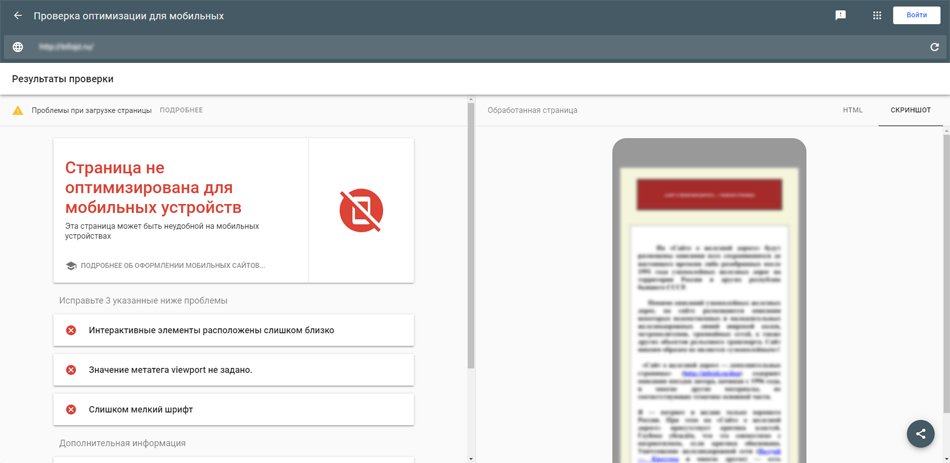
Интерфейс поделен на две части. Слева итог проверки, в данном случае – неутешительный вердикт о том, что страница не оптимизирована для мобильных устройств, а ниже список проблем, которые требуется исправить.
В данном случае необходимо увеличить шрифт до рекомендуемых 14pt, увеличить отступы между плотно расположенными элементами страницы (пункты меню, кнопки и т.п.) и обязательно добавить мета-тег viewport между <head> и </head>, пример: <meta name=”viewport” content=”width=device-width, initial-scale=1.0″>. Но нужно понимать, в этом случае приведенные рекомендации – не универсальный рецепт для любого сайта, настройка адаптивности должна быть индивидуальной.
Продолжим. Справа представление о том, как видит анализируемую страницу Googlebot. Здесь два режима: «Скриншот» – визуальное представление и «HTML» – полученный код страницы позволяет понять, актуальную ли версию страницы получает поисковый робот.
Вернемся к левой части, помимо вышесказанного, в самом верху есть кнопка «Подробнее» – открывает отчет о проверке.
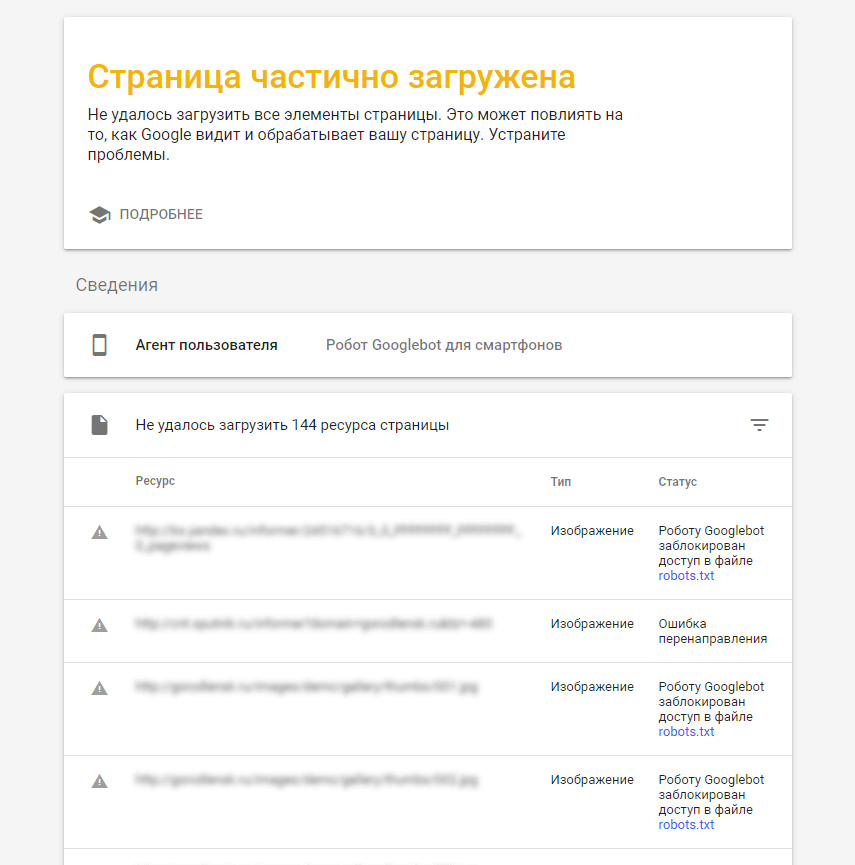
По различным причинам робот Googlebot может получить страницу не полностью. Сперва необходимо обратить внимание на колонку «Ресурс», так как проблема может находиться не только на проверяемом сайте, но и на стороннем. Чаще всего это различные скрипты (счетчики метрики, кнопки соц. сетей и т. п.), CDN-сервисы и прочие ресурсы.
К сожалению, повлиять самостоятельно на такой род ошибок не удастся, разве что попытаться связаться с администратором ресурса и попросить принять необходимые меры по исправлению. Мы же рассмотрим исправление ошибок на стороне своего сайта.
Исправление ошибки «Роботу Googlebot заблокирован доступ к файлу»
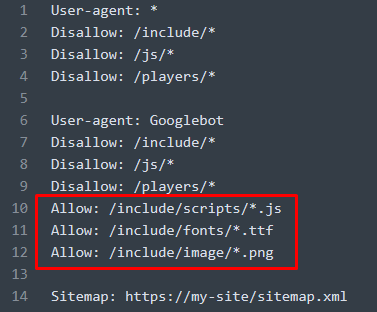
Решение проблемы рассмотрим на примере заведомо корректно настроенного User-agent: *
Тут все просто: необходимо открыть файл robots.txt в текстовом редакторе, добавить юзер-агента для поискового робота Google: User-agent: Googlebot. Скопировать все директивы Disallow у User-agent: * и вставить для User-agent: Googlebot.
Для поискового робота Googlebot добавить директивы Allow, открывающие доступ к ресурсам с данной ошибкой.
Пример:
Исправление «Ошибка перенаправления»
Происходит, как правило, когда ресурс, на который направляет ссылка (изображение, скрипт, файл), пытается произвести редирект, но Googlebot может неправильно это интерпретировать или просто отказаться его исполнять. Например, веб-сайт работает по защищенному протоколу безопасности https, но в ссылке указан – http.
Чтобы убедиться в предположении, стоит воспользоваться любым сервисом по проверке ответа сервера и проанализировать проблемную ссылку, после чего найти ее у себя на сайте и исправить согласно конечному редиректу. Или связаться с администратором ссылаемого ресурса и попробовать решить проблему совместно.
Исправление «Другая ошибка» в Mobile-friendly
Эта ошибка часто встречается даже на хорошо оптимизированных сайтах. Причины появления таких ошибок бывают различными. Это может быть ограничением отдачи контента поисковику на стороне сайта или сервера, либо внутренним лимитом на загрузку контента на стороне Googlebot. Как вариант, можно вставить ссылку на проверяемую страницу в поле поисковика Google и открыть сохраненную копию.
Если проблемный контент отображается в сохраненной странице, то беспокоиться тут не о чем, так как поисковик его видит. В ином случае стоит связаться со своим хостинг-провайдером, описать суть проблемы и попытаться совместно ее решить.
Заключение
Инструмент Mobile-friendly от компании Google – отличный помощник веб-мастера или SEO-специалиста. Ранее он был частью интерфейса Google Webmaster, но обрел самостоятельность и успешно помогает в настройке оптимизации сайта.
Знайте, что если вам необходима профессиональная помощь в проведении адаптации и оптимизации своего интернет-ресурса, вы можете обратиться к нам за помощью.
Несколько дней назад, очень большое количество сайтов получили письмо в панели Google Search Console (Google Webmasters) со следующей проблемой: «Googlebot не может получить доступ к файлам CSS и JS на сайте …» (англ. «Googlebot cannot access CSS and JS files on …»).

Поскольку Google пишет, что сайт может потерять позиции, при условии дальнейшей блокировки этих ресурсов сайта, то необходимо прислушаться к этой рекомендации и открыть все запрашиваемые для индексации файлы для поискового робота Google.
Кроме этого, про эту проблему четко написано в справке Google https://support.google.com/webmasters/answer/35769?hl=ru#technical_guidelines

Поэтому, давайте рассмотрим детальную инструкцию как устранить данную проблему.
1. Определяем какие ресурсы нужно открыть для индексации
Для выполнение данного пункта мы заходим в Google Search Console https://www.google.com/webmasters/tools/home?hl=ru и выбираем нужный сайт.
После этого, нажимаем на вкладку «Сканирование» и «Посмотреть как Googlebot»

и нажимаем «ПОЛУЧИТЬ И ОТОБРАЗИТЬ»

И переходим на последнюю строчку с результатами сканирования

В результате мы получаем:
— отображение того как сейчас видит поисковый робот Google и как эту же страницу увидят пользователи сайта

— список ресурсов с причиной по которой Googlebot не может получить доступ и, соответственно, которые нужно открыть для индексации:

2. Получаем строки для добавления в свой robots.txt
Копируем полученную таблицу, вставляем (с использованием функции вставки без форматирования) данную таблицу в Excel и делаем сортировку по колонке с URL.
Через «Найти и заменить» удаляем домен из URL и выделяем уникальные папки (или в некоторых случаях папку + определенный тип файлов), которые необходимо открыть для индексации.
Через данную функции добавляем разрешающую команду индексации =CONCATENATE(«Allow: «;A2) (или =СЦЕПИТЬ(«Allow: «;A2) ) и, в итоге, получаем строки которые нужно добавить в роботс:

3. Проверяем свой роботс.тхт с обновленными инструкциями
Перед заливкой нового robots.txt нужно проверить созданные инструкции на ошибки и все ли файлы мы открыли. Для этого лучше всего воспользоваться сервисом проверки роботса от Яндекса https://webmaster.yandex.ua/robots.xml, так как там сразу можно указать список адресов, которые нужно проверить:

Если вы всё правильно сделали, то получите уведомление, что все нужные ресурсы открыть для индексации:

Если все нормально, то обновляем свой файл на сервере.
4. Повторяем итерации 1-3, пока есть заблокированные ресурсы
Как оказалось, Google сразу отображает НЕ ВСЕ ресурсы которые нужно открыть для индексации.
При повторной проверке, мы можем получить такую картину:


Где видим, что для индексации нужно открыть еще и изображения. Поэтому, повторяем пункты 2. и 3. для новых ресурсов.
В итоге, мы должны получить нормальное отображение сайта для Googlebot’а:

Единственный нюанс, что в списке ресурсов могут оказаться файлы к которым Гугл не может получить доступ:

5. Проверяем доступность всех ресурсов для Mobile: smartphone
После этого, также делаем проверку на доступность всех ресурсов и для Mobile: smartphone – робота: для этого при проверке выбираем соответствующее значение и нажимаем «Получить и отобразить».

На данном сайте и для мобильного бота все ресурсы оказались доступны, поэтому, дополнительных действий не нужно было проводить.
Примеры что нужно добавить для стандартных движков:
WordPress
Allow: /wp-content/themes/*.css
Allow: /wp-content/plugins/*.css
Allow: /wp-content/uploads/*.css
Allow: /wp-content/themes/*.js
Allow: /wp-content/plugins/*.js
Allow: /wp-content/uploads/*.js
Allow: /wp-includes/css/
Allow: /wp-includes/js/
Allow: /wp-includes/images/
Универсальное решение для всех CMS
Allow: /*.js
Allow: /*.css
Allow: /*.jpg
Allow: /*.gif
Allow: /*.png
Joomla
Allow: /templates/*.css
Allow: /templates/*.js
Allow: /components/*.css
Allow: /components/*.js
Allow: /media/*.js
Allow: /media/*.css
Allow: /plugins/*.css
Allow: /plugins/*.js
DLE
Allow: /engine/classes/*.css
Allow: /engine/classes/*.js
Allow: /templates/Название шаблона/style/*.css
Allow: /templates/Название шаблона/js/*.js
Заключение
В данной статье мы постарались максимально подробно расписать как исправить ошибку «Googlebot не может получить доступ к файлам CSS и JS на сайте …».
Поэтому, если вы получили данное уведомление от Google, рекомендуем прислушаться к этим рекомендациям и открыть необходимые файлы для индексации.
PS: Если у вас возникли трудности, то задавайте в комментариях будем помогать с решением уникальных проблем.
Оцените статью

 (73 оценок, средняя: 4,73 из 5)
(73 оценок, средняя: 4,73 из 5)
![]() Загрузка…
Загрузка…
Вот здесь пустых строк быть не должно:
User-agent: Googlebot Disallow: /wp-admin Disallow: /wp-json/ Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: */author/* Disallow: */feed/ Disallow: */feed Disallow: /?feed= Disallow: /*search* Disallow: /trackback Disallow: */trackback/ Disallow: */comments/ Disallow: /?replytocom* Disallow: */tag/* Disallow: *?* Disallow: /*?p=* Disallow: /*?s=* Disallow: /kontaktyi Disallow: /page Disallow: */page/ Allow: /wp-content/uploads/ Allow: /*.js Allow: /*.css Allow: /wp-content/themes/*.css Allow: /wp-content/plugins/*.css Allow: /wp-content/uploads/*.css Allow: /wp-content/themes/*.js Allow: /wp-content/plugins/*.js Allow: /wp-content/uploads/*.js Allow: /wp-includes/css/ Allow: /wp-includes/js/ Allow: /wp-includes/images/
Вы выделяете поискового бота, потом даете ему правила, потом пустая строка, будто бы будут правила для другого бота, но бот не задан! Вы думаете, что Гугл настолько умный, что поймет, что это просто вебмастер косячнул и оставил пустые строки, и их не нужно учитывать? А вы уверены, что ему нужно понимать эту белиберду? А как воспримут непонятные правила после пустых строк остальные поисковые боты?
Пустые строки используются только для разделения блоков правил для разных пауков и для отделения, например, правила для указания положения карты сайта.
Здравствуйте, уважаемые читатели блога Goldbusinessnet.com! Требования поисковых систем ужесточаются, и нам приходится с этим мириться. Сейчас наступает новый этап, когда для достижения максимального эффекта при продвижении сайта в Гугле необходимо предоставить его роботу (Googlebot) доступ ко всем ресурсам, которые так или иначе формируют отображение страниц вебсайта в браузере.
Оглавление
- Как и где узнать, с каких конкретно ресурсов следует снять блокировку
- Каким образом обеспечить доступ Googlebot с помощью редактирования robots.txt
Что же это за ресурсы? Все очень просто – это, прежде всего, файлы каскадных таблиц стилей CSS, скрипты JavaScript (JS), различного рода изображения и видео. Все эти файлики, отвечающие за полновесный вид сайта, вполне могут быть заблокированы в robots.txt.

Чтобы выполнить требования Гугла, необходимо все выше упомянутые ресурсы разблокировать для Googlebot, чтобы обеспечить своему вебсайту максимальные преференции при ранжировании в Google. Как это осуществить практически, мы и рассмотрим чуть ниже.
Какие ресурсы нужно разблокировать для Гугл бота и зачем это нужно
Думаю, многие вебмастера в свое время уже получили сообщение от Google, начало которого было примерно следующим: «Googlebot не может получить доступ к файлам CSS и JS…» (на английском это звучит как «Googlebot cannot access CSS and JS files…»).
Ну и далее шло предупреждение о том, что в случае, если проблема не будет решена, то позиции сайта могут серьезно пострадать. Обычно в подобных случаях Гугл не шутит. Поэтому всем, кто пока не озаботился исправить ситуацию, рекомендую сделать это в ближайшее время, поскольку блокировка части файлов для бота Гугла может сулить неприятности.
Зачем же Google требует открыть доступ к файлам стилей, скриптов и других ресурсов для своих роботов? Дело в том, что в связи с изменением некоторых алгоритмов ранжирования (все средства на совершенствование поисковой выдачи) Гугл желает получить в том же виде, как они отображаются для пользователей. Это поможет корректно оценивать их содержание.
Стили CSS, как известно, отвечают за внешний вид вебстраниц, изображения являются частью, а JS скрипты определяют функционал вебресурса. Кроме того, очень важной частью контента являются изображения (определяемые графическими файлами), которые также должны быть открыты для робота Гугла.
Это поможет мировому лидеру поиска в том числе правильно ранжировать сайты, где установлен адаптивный дизайн для просмотра на мобильных устройствах. Кстати, возможность просматривать страницы на малых экранах даст дополнительное преимущество вашему проекту. Перейдите по этой ссылке и посмотрите, что говорит по этому поводу сам Google.
Для того, чтобы проанализировать, ситуацию в отношении своего сайта и определить, какие именно ресурсы недоступны для Googlebot, перейдите в соответствующий аккаунт панели вебмастеров (сейчас этот сервис носит название Search Console), выберите нужный вебсайт, после чего войдите во вкладку «Просмотреть как Googlebot» раздела «Сканирование»:

Там необходимо дописать URL любой вебстраницы, поскольку адрес главной уже указан (если желаете проверить домашнюю страницу проекта, то и дописывать ничего не надо). Затем жмете кнопку «Получить и отобразить». После этого появится строка с результатом сканирования, где спустя некоторое время будет отображаться статус «Частично выполнено». Щелкаете по этой строчке:

В итоге получите картинки для сравнения: слева будет вид исследуемой вебстраницы глазами бота Гугла, а справа – обычного пользователя (во вкладке «Отображение»):

Как говорится, “найдите 10 отличий”. Как видите, робот и юзер совершенно по-разному визуально воспринимают данную вебстраницу. Поэтому нужно предпринять такие действия, которые бы позволили бы стереть различия и тем самым угодить мистеру Google.
После того, как вы получите сравнительные скриншоты странички сайта для робота и для пользователей, внизу будут представлены ссылки на все ресурсы, к которым закрыт доступ (обычно это стили CSS, скрипты и изображения, о чем я упоминал выше) в файле robots.txt (тут полновесная информация об этом важнейшем файле для WordPress):

Да-да, опять этот многострадальный роботс.тхт, о который сломано столько копий. Но ничего не поделаешь, жизнь заставляет вновь редактировать его. Чуть ниже мы рассмотрим, как изменить robots.txt для сайта, работающего под управлением Вордпресс, в очередной раз, чтобы удовлетворить требования Гугла.
Редактирование robots.txt (для WordPress) с целью открытия доступа роботу Гугла
Итак, для снятия блокировки необходимых файлов нужно открыть соответствующие позиции в роботсе. Для начала давайте проанализируем список URL, которые были получены после сканирования одной из страниц моего блога (смотрите предыдущий скриншот выше).
Обратите внимание, что все закрытые ресурсы можно разделить на две части: расположенные на исследуемом сайте (связанные с этой группой элементы выделены красным подчеркиванием или рамкой) и находящиеся на сторонних вебресурсах: блоки контекстной рекламы Adsense (как настроить объявления в системе Адсенс), Рекламной сети Яндекса РСЯ, счетчики посещаемости, кнопки социальных сетей (в этом, этом, этом и этом материалах все о социальных кнопочках) и т.д.
Для первых даны ссылки на инструмент проверки файла роботс.тхт. Благодаря этому в любой момент можно проверить текущее состояние выбранного ресурса. Скажем, сканирование произведено до того, как вы предприняли меры по исправлению ситуации, а после совершения этих действий вы решили посмотреть, насколько изменилась ситуация, нажав на этот линк:

Если все сделано корректно, то вы увидите, что этот файл на самом деле теперь доступен:

Попутно можно убедиться в корректности составленного robots (отсутствии ошибок и предупреждений). Это тоже немаловажно и непосредственно может оказать влияние на степень эффективности продвижения вашего проекта.
Теперь о второй группе заблокированных ресурсов, то бишь тех файлах, которые размещены на сторонних вебсайтах. Напротив каждого из них есть ссылка непосредственно на роботс. Но его изменить, мы, конечно, не можем и вообще повлиять на ситуацию с этой стороны мы не в силах.
Гугл советует в этом случае обратиться к владельцам вебресурсов с просьбой разблокировать нужные файлы. Естественно, в подавляющем большинстве случаев такой шаг обречен на неудачу. Другой вариант: постараться просто удалить со своего сайта часть элементов, связанных со сторонними сайтами.
Но, как вы понимаете, такое тоже не всегда возможно. Ведь та же реклама РСЯ, например, очень важна с точки зрения получения дохода. Различные счетчики (скажем, того же сервиса аналитики Yandex Метрика) тоже не выглядят лишними. Поэтому пока приходится мириться с таким положением вещей. Тем более, Google, по слухам, довольно лояльно относится к тому, что ресурсы со сторонних проектов заблокированы.
Однако, все файлы, которые вебмастер в силах открыть для робота, должны быть обязательно разблокированы. Поэтому предпримем необходимые действия лишь в отношении тех ресурсов, которые связаны с собственным сайтом и доступ к которым можно беспрепятственно регулировать.
Если снова взглянуть на картинку с закрытыми ресурсами (пред-предыдущий скриншот), то можно обратить внимание, что все они (таблицы стилей, скрипты и изображения) находятся в директориях:
/wp-includes /wp-content/plugins /wp-content/themes
Вполне логично, что именно к этим папкам и следует открыть Гугл боту доступ. По крайней мере, я так и сделал, хотя это довольно грубый метод. Точнее, просто удалил Disallow в отношении данных директорий:

Безусловно, существуют и более изысканные варианты, например, указание целевой разрешающей директивы Allow непосредственно для каждого ресурса, но я не стал кардинально менять структуру своего robots.txt, в конце концов результат достигнут. Поэтому окончательный вариант в меру универсального файла robots.txt для стандартного блога Вордпресс с учетом последних гугловских указаний выглядит по моей версии таким образом:
User-agent: Mediapartners-Google Disallow: User-agent: * Disallow: /cgi-bin Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /wp-admin Disallow: /wp-content/cache Disallow: /xmlrpc.php User-agent: Yandex Disallow: /cgi-bin Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /xmlrpc.php Host: goldbusinessnet.com Sitemap: /sitemap.xml
Хотя нужно быть готовым к тому, что это далеко не окончательный вариант. Я, например, не исключаю, что Яндекс последует примеру своего главного конкурента и тоже потребует от владельцев интернет-ресурсов нечто похожее. Так что в этом месте ставим не точку, а многоточие.
Ну а в доказательство того, что предпринятые мною действия принесли положительный результат, даю результат проверки той же странички в разделе «Просмотреть как Googlebot» уже после редактирования роботса:

А вот как выглядит теперь перечень закрытых для бота ресурсов:

Как видите, остались только лишь те, доступом к которым я не могу управлять. Впрочем, возможно, в дальнейшем некоторые связанные с ними элементы я уберу с сайта для минимизации числа неугодных Гуглу файлов. Хотя, с другой стороны, бросается в глаза блок Google Adsense, который закрыт для бота. Получается, что Гугл скрывает от своих же роботов элементы собственной контекстной рекламы?
Но если разобраться, то все логично. Ведь роботы Адсенса, которые призваны сканировать страницы вебсайтов партнеров для корректного отображения рекламных блоков, не имеют никакого отношения к основному роботу (это утверждает сам Google). Аминь.
Ну и в свете современных веяний не лишним будет проверить, насколько соответствует рекомендациям Гоогле вид страниц сайта при просмотре на малых мониторах. Для этого в той же вкладке «Посмотреть как Googlebot» для проверки нужно выбрать из выпадающего меню вместо «ПК» пункт «Mobile: Smartfone»:

Я после данного тестирования оказался удовлетворен, поскольку ни одного заблокированного ресурса в списке среди тех, на которые я мог бы повлиять, не оказалось. А как дела обстоят у вас? Хотелось бы активного обмена мнениями в комментариях по данной теме, поскольку важность ее трудно переоценить. В заключение видео от Мэтта Каттса о пользе инструмента «Посмотреть как Гугл бот»:
