Время на прочтение
7 мин
Количество просмотров 278K
Продолжение перевода неофициальной документации Selenium для Python.
Перевод сделан с разрешения автора Baiju Muthukadan.
Оригинал можно найти здесь.
Содержание:
1. Установка
2. Первые Шаги
3. Навигация
4. Поиск Элементов
5. Ожидания
6. Объекты Страницы
7. WebDriver API
8. Приложение: Часто Задаваемые Вопросы
4. Поиск элементов
Существует ряд способов поиска элементов на странице. Вы вправе использовать наиболее уместные для конкретных задач. Selenium предоставляет следующие методы поиска элементов на странице:
- find_element_by_id
- find_element_by_name
- find_element_by_xpath
- find_element_by_link_text
- find_element_by_partial_link_text
- find_element_by_tag_name
- find_element_by_class_name
- find_element_by_css_selector
Чтобы найти все элементы, удовлетворяющие условию поиска, используйте следующие методы (возвращается список):
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
[Как вы могли заметить, во втором списке отсутствует поиск по id. Это обуславливается особенностью свойства id для элементов HTML: идентификаторы элементов страницы всегда уникальны. — Прим. пер.]
Помимо общедоступных (public) методов, перечисленных выше, существует два приватных (private) метода, которые при знании указателей объектов страницы могут быть очень полезны: find_element and find_elements.
Пример использования:
from selenium.webdriver.common.by import By
driver.find_element(By.XPATH, '//button[text()="Some text"]')
driver.find_elements(By.XPATH, '//button')
Для класса By доступны следующие атрибуты:
ID = "id"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"
4.1. Поиск по Id
Используйте этот способ, когда известен id элемента. Если ни один элемент не удовлетворяет заданному значению id, будет вызвано исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
</form>
</body>
<html>
Элемент form может быть определен следующим образом:
login_form = driver.find_element_by_id('loginForm')
4.2. Поиск по Name
Используйте этот способ, когда известен атрибут name элемента. Результатом будет первый элемент с искомым значением атрибута name. Если ни один элемент не удовлетворяет заданному значению name, будет вызвано исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
<input name="continue" type="button" value="Clear" />
</form>
</body>
<html>
Элементы с именами username и password могут быть определены следующим образом:
username = driver.find_element_by_name('username')
password = driver.find_element_by_name('password')
Следующий код получит кнопку “Login”, находящуюся перед кнопкой “Clear”:
continue = driver.find_element_by_name('continue')
4.3. Поиск по XPath
XPath – это язык, использующийся для поиска узлов дерева XML-документа. Поскольку в основе HTML может лежать структура XML (XHTML), пользователям Selenium предоставляется возможность посредоством этого мощного языка отыскивать элементы в их веб-приложениях. XPath выходит за рамки простых методов поиска по атрибутам id или name (и в то же время поддерживает их), и открывает спектр новых возможностей, таких как поиск третьего чекбокса (checkbox) на странице, к примеру.
Одно из веских оснований использовать XPath заключено в наличии ситуаций, когда вы не можете похвастать пригодными в качестве указателей атрибутами, такими как id или name, для элемента, который вы хотите получить. Вы можете использовать XPath для поиска элемента как по абсолютному пути (не рекомендуется), так и по относительному (для элементов с заданными id или name). XPath указатели в том числе могут быть использованы для определения элементов с помощью атрибутов отличных от id и name.
Абсолютный путь XPath содержит в себе все узлы дерева от корня (html) до необходимого элемента, и, как следствие, подвержен ошибкам в результате малейших корректировок исходного кода страницы. Если найти ближайщий элемент с атрибутами id или name (в идеале один из элементов-родителей), можно определить искомый элемент, используя связь «родитель-подчиненный». Эти связи будут куда стабильнее и сделают ваши тесты устойчивыми к изменениям в исходном коде страницы.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
<input name="continue" type="button" value="Clear" />
</form>
</body>
<html>
Элемент form может быть определен следующими способами:
login_form = driver.find_element_by_xpath("/html/body/form[1]")
login_form = driver.find_element_by_xpath("//form[1]")
login_form = driver.find_element_by_xpath("//form[@id='loginForm']")
- Абсолютный путь (поломается при малейшем изменении структуры HTML страницы)
- Первый элемент form в странице HTML
- Элемент form, для которого определен атрибут с именем id и значением loginForm
Элемент username может быть найден так:
username = driver.find_element_by_xpath("//form[input/@name='username']")
username = driver.find_element_by_xpath("//form[@id='loginForm']/input[1]")
username = driver.find_element_by_xpath("//input[@name='username']")
- Первый элемент form с дочерним элементом input, для которого определен атрибут с именем name и значением username
- Первый дочерний элемент input элемента form, для которого определен атрибут с именем id и значением loginForm
- Первый элемент input, для которого определен атрибут с именем name и значением username
Кнопка “Clear” может быть найдена следующими способами:
clear_button = driver.find_element_by_xpath("//input[@name='continue'][@type='button']")
clear_button = driver.find_element_by_xpath("//form[@id='loginForm']/input[4]")
- Элемент input, для которого заданы атрибут с именем name и значением continue и атрибут с именем type и значением button
- Четвертый дочерний элемент input элемента form, для которого задан атрибут с именем id и значением loginForm
Представленные примеры покрывают некоторые основы использования XPath, для более углубленного изучения рекомендую следующие материалы:
- W3Schools XPath Tutorial
- W3C XPath Recommendation
- XPath Tutorial — с интерактивными примерами
Существует также пара очень полезных дополнений (add-on), которые могут помочь в выяснении XPath элемента:
- XPath Checker — получает пути XPath и может использоваться для проверки результатов пути XPath
- Firebug — получение пути XPath — лишь одно из многих мощных средств, поддерживаемых этим очень полезным плагином
- XPath Helper — для Google Chrome
4.4. Поиск гиперссылок по тексту гиперссылки
Используйте этот способ, когда известен текст внутри анкер-тэга [anchor tag, анкер-тэг, тег «якорь» — тэг — Прим. пер.]. С помощью такого способа вы получите первый элемент с искомым значением текста тэга. Если никакой элемент не удовлетворяет искомому значению, будет вызвано исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<p>Are you sure you want to do this?</p>
<a href="continue.html">Continue</a>
<a href="cancel.html">Cancel</a>
</body>
<html>
Элемент-гиперссылка с адресом «continue.html» может быть получен следующим образом:
continue_link = driver.find_element_by_link_text('Continue')
continue_link = driver.find_element_by_partial_link_text('Conti')
4.5. Поиск элементов по тэгу
Используйте этот способ, когда вы хотите найти элемент по его тэгу. Таким способом вы получите первый элемент с указанным именем тега. Если поиск не даст результатов, будет возбуждено исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<h1>Welcome</h1>
<p>Site content goes here.</p>
</body>
<html>
Элемент заголовка h1 может быть найден следующим образом:
heading1 = driver.find_element_by_tag_name('h1')
4.6. Поиск элементов по классу
Используйте этот способ в случаях, когда хотите найти элемент по значению атрибута class. Таким способом вы получите первый элемент с искомым именем класса. Если поиск не даст результата, будет возбуждено исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<p class="content">Site content goes here.</p>
</body>
<html>
Элемент “p” может быть найден следующим образом:
content = driver.find_element_by_class_name('content')
4.7. Поиск элементов по CSS-селектору
Используйте этот способ, когда хотите получить элемент с использованием синтаксиса CSS-селекторов [CSS-селектор — это формальное описание относительного пути до элемента/элементов HTML. Классически, селекторы используются для задания правил стиля. В случае с WebDriver, существование самих правил не обязательно, веб-драйвер использует синтаксис CSS только для поиска — Прим. пер.]. Этим способом вы получите первый элемент удовлетворяющий CSS-селектору. Если ни один элемент не удовлетворяют селектору CSS, будет возбуждено исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
<html>
<body>
<p class="content">Site content goes here.</p>
</body>
<html>
Элемент “p” может быть определен следующим образом:
content = driver.find_element_by_css_selector('p.content')
На Sauce Labs есть хорошая документация по селекторам CSS.
От переводчика: советую также обратиться к следующим материалам:
- 31 CSS селектор — это будет полезно знать! — краткая выжимка по CSS-селекторам
- CSS селекторы, свойства, значения — отличный учебник параллельного изучения HTML и CSS
Перейти к следующей главе
Как вы, возможно, уже поняли, чтобы управлять элементами страницы, нам нужно сначала найти их. Selenium использует так называемые локаторы, чтобы находить элементы на веб-странице.
В Selenium есть 8 методов которые помогут в поиске HTML элементов:
| Цель поиска Используемый метод |
Пример | ||
| Поиск по ID find_element_by_id(“user”) |
|
||
| Поиск по имени find_element_by_name(“username”) |
|
||
| Поиск по тексту ссылки find_element_by_link_text(“Login”) |
|
||
| Поиск по частичному тексту ссылки find_element_by_partial_link_text(“Next”) |
|
||
| Поиск используя XPath find_element_by_xpath(‘//div[@id=”login”]/input’) |
|
||
| Поиск по названию тэга find_element_by_tag_name(“body”) |
|||
| Поиск по классу элемента find_element_by_class_name(“table”) |
|
||
| Поиск по CSS селектору find_element_by_css_selector(‘#login > input[type=”text”]’) |
|
Вы можете использовать любой из них, чтобы сузить поиск элемента, который вам нужен.
Запуск браузера
Тестирование веб-сайтов начинается с браузера. В приведенном ниже тестовом скрипте запускается окно браузера Firefox, и осуществляется переход на сайт.
|
from selenium import webdriver driver = webdriver.Firefox() driver.get(“http://testwisely.com/demo”) |
Используйте webdriver.Chrome и webdriver.Ie() для тестирования в Chrome и IE соответственно. Новичкам рекомендуется закрыть окно браузера в конце тестового примера.
Поиск элемента по ID
Использование идентификаторов — самый простой и безопасный способ поиска элемента в HTML. Если страница соответствует W3C HTML, идентификаторы должны быть уникальными и идентифицироваться в веб-элементах управления. По сравнению с текстами тестовые сценарии, использующие идентификаторы, менее склонны к изменениям приложений (например, разработчики могут принять решение об изменении метки, но с меньшей вероятностью изменить идентификатор).
|
driver.find_element_by_id(“submit_btn”).click() # Клик по кнопке driver.find_element_by_id(“cancel_link”).click() # Клик по ссылке driver.find_element_by_id(“username”).send_keys(“agileway”) # Ввод символов driver.find_element_by_id(“alert_div”).text # Получаем текст |
Поиск элемента по имени
Атрибут имени используются в элементах управления формой, такой как текстовые поля и переключатели (radio кнопки). Значения имени передаются на сервер при отправке формы. С точки зрения вероятности будущих изменений, атрибут name, второй по отношению к ID.
|
driver.find_element_by_name(“comment”).send_keys(“Selenium Cool”) |
Поиск элемента по тексту ссылки
Только для гиперссылок. Использование текста ссылки — это, пожалуй, самый прямой способ щелкнуть ссылку, так как это то, что мы видим на странице.
|
driver.find_element_by_link_text(“Cancel”).click() |
HTML для которого будет работать
|
<a href=“/cancel”>Cancel</a> |
Поиск элемента по частичному тексту ссылки
Selenium позволяет идентифицировать элемент управления гиперссылкой с частичным текстом. Это может быть полезно, если текст генерируется динамически. Другими словами, текст на одной веб-странице может отличаться при следующем посещении. Мы могли бы использовать общий текст, общий для этих динамически создаваемых текстов ссылок, для их идентификации.
|
# Полный текст ссылки “Cancel Me” driver.find_element_by_partial_link_text(“ance”).click() |
HTML для которого будет работать
|
<a href=“/cancel”>Cancel me</a> |
Поиск элемента по XPath
XPath, XML Path Language, является языком запросов для выбора узлов из XML документа. Когда браузер отображает веб-страницу, он анализирует его в дереве DOM. XPath может использоваться для ссылки на определенный узел в дереве DOM. Если это звучит слишком сложно для вас, не волнуйтесь, просто помните, что XPath — это самый мощный способ найти определенный веб-элемент.
|
# Клик по флажку в контейнере с ID div2 driver.find_element_by_xpath(“//*[@id=’div2′]/input[@type=’checkbox’]”).click() |
HTML для которого будет работать
|
<form> <div id=“div2”> <input value=“rules” type=“checkbox”> </div> </form> |
Некоторые тестеры чувствуют себя “запуганными” сложностью XPath. Тем не менее, на практике существует только ограниченная область для использования XPath.
Избегайте XPath из Developer Tool
Избегайте использования скопированного XPath из инструмента Developer Tool.
Инструмент разработчика браузера (щелкните правой кнопкой мыши, чтобы выбрать «Проверить элемент», чтобы увидеть) очень полезен для определения веб-элемента на веб-странице. Вы можете получить XPath веб-элемента там, как показано ниже (в Chrome):
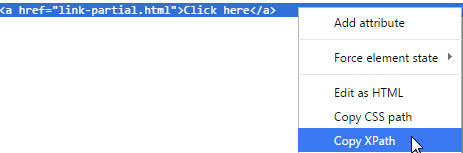
Скопированный XPath для второй ссылки «Нажмите здесь» в примере:
|
//*[@id=“container”]/div[3]/div[2]/a |
Этот метод работает. Тем не менее, этот подход не рекомендуется для постоянного применения, поскольку тестовый сценарий является довольно хрупким и изменчивым.
Попытайтесь использовать выражения XPath, которое менее уязвимо для структурных изменений вокруг веб-элемента.
Поиск элемента по имени тега
В HTML есть ограниченный набор имен тегов. Другими словами, многие элементы используют одни и те же имена тегов на веб-странице. Обычно мы не используем локатор tag_name для поиска элемента. Мы часто используем его с другими элементами в цепочке локаторах. Однако есть исключение.
|
driver.find_element_by_tag_name(“body”).text |
Вышеприведенная тестовая инструкция возвращает текстовое содержимое веб-страницы из тега body.
Поиск элемента по имени класса
Атрибут class элемента HTML используется для стилизации. Он также может использоваться для идентификации элементов. Как правило, атрибут класса элемента HTML имеет несколько значений, как показано ниже.
|
<a href=“back.html” class=“btn btn-default”>Cancel</a> <input type=“submit” class=“btn btn-deault btn-primary”> Submit </input> |
Вы можете использовать любой из них.
|
driver.find_element_by_class_name(“btn-primary”).click() # Клик по кнопки driver.find_element_by_class_name(“btn”).click() # Клик по ссылке # # |
Метод class_name удобен для тестирования библиотек JavaScript / CSS (таких как TinyMCE), которые обычно используют набор определенных имен классов.
|
driver.find_element_by_id(“client_notes”).click() time.sleep(0.5) driver.find_element_by_class_name(“editable-textarea”).send_keys(“inline notes”) time.sleep(0.5) driver.find_element_by_class_name(“editable-submit”).click() |
Поиск элемента с помощью селектора CSS
Вы также можете использовать CSS селектор для поиска веб-элемента.
|
driver.find_element_by_css_selector(“#div2 > input[type=’checkbox’]”).click() |
Однако использование селектора CSS, как правило, более подвержено структурным изменениям веб-страницы.
Используем find_elements для поиска дочерних элементов
Для страницы, содержащей более одного элемента с такими же атрибутами, как приведенный ниже, мы могли бы использовать XPath селектор.
|
<div id=“div1”> <input type=“checkbox” name=“same” value=“on”> Same checkbox in Div 1 </div> <div id=“div2”> <input type=“checkbox” name=“same” value=“on”> Same checkbox in Div 2 </div> |
Есть еще один способ: цепочка из find_element чтобы найти дочерний элемент.
|
driver.find_element_by_id(“div2”).find_element_by_name(“same”).click() |
Поиск нескольких элементов
Как следует из названия, find_elements возвращает список найденных элементов. Его синтаксис точно такой же, как find_element, то есть он может использовать любой из 8 локаторов.
Пример HTML кода
|
<div id=“container”> <input type=“checkbox” name=“agree” value=“yes”> Yes <input type=“checkbox” name=“agree” value=“no”> No </div> |
Выполним клик по второму флажку.
|
checkbox_elems = driver.find_elements_by_xpath(“//div[@id=’container’]//input[@type=’checkbox’]”) print(len(checkbox_elems)) # Результат: 2 checkbox_elems[1].click() |
Иногда find_element вылетает из-за нескольких совпадающих элементов на странице, о которых вы не знали. Метод find_elements пригодится, чтобы найти их.
I know that I can use methods such as:
find_elements_by_tag_name()
find_elements_by_id()
find_elements_by_css_selector()
find_elements_by_xpath()
But what I would like to do is simply get a list of all the element IDs that exist in the page, perhaps along with the tag type they occur in.
How can I accomplish this?
asked Nov 27, 2013 at 14:10
1
from selenium import webdriver
driver = webdriver.Firefox()
driver.get('http://google.com')
ids = driver.find_elements_by_xpath('//*[@id]')
for ii in ids:
#print ii.tag_name
print ii.get_attribute('id') # id name as string
answered Jan 14, 2015 at 19:42
russian_spyrussian_spy
6,3854 gold badges29 silver badges26 bronze badges
0
Not had to do this before, but thinking about it logically you could use XPath to do this (may be other ways, XPath is the first thing that appears into my head).
Use find_elements_by_xpath using the XPath //*[@id] (any element that has an ID of some sort).
You could then iterate through the collection, and use the .tag_name property of each element to find out what kind of element it is and the get_attribute("id") method/function to get that element’s ID.
Note: This is probably going to be quite slow. After all, you are asking for a lot of information.
answered Nov 27, 2013 at 14:52
ArranArran
24.6k6 gold badges68 silver badges77 bronze badges
There are various strategies to locate elements in a page. You can use the most
appropriate one for your case. Selenium provides the following method to
locate elements in a page:
- find_element
To find multiple elements (these methods will return a list):
- find_elements
Example usage:
from selenium.webdriver.common.by import By driver.find_element(By.XPATH, '//button[text()="Some text"]') driver.find_elements(By.XPATH, '//button')
The attributes available for the By class are used to locate elements on a page.
These are the attributes available for By class:
ID = "id" NAME = "name" XPATH = "xpath" LINK_TEXT = "link text" PARTIAL_LINK_TEXT = "partial link text" TAG_NAME = "tag name" CLASS_NAME = "class name" CSS_SELECTOR = "css selector"
The ‘By’ class is used to specify which attribute is used to locate elements on a page.
These are the various ways the attributes are used to locate elements on a page:
find_element(By.ID, "id") find_element(By.NAME, "name") find_element(By.XPATH, "xpath") find_element(By.LINK_TEXT, "link text") find_element(By.PARTIAL_LINK_TEXT, "partial link text") find_element(By.TAG_NAME, "tag name") find_element(By.CLASS_NAME, "class name") find_element(By.CSS_SELECTOR, "css selector")
If you want to locate several elements with the same attribute replace find_element with find_elements.
4.1. Locating by Id¶
Use this when you know the id attribute of an element. With this strategy,
the first element with a matching id attribute will be returned. If no
element has a matching id attribute, a NoSuchElementException will be
raised.
For instance, consider this page source:
<html> <body> <form id="loginForm"> <input name="username" type="text" /> <input name="password" type="password" /> <input name="continue" type="submit" value="Login" /> </form> </body> </html>
The form element can be located like this:
login_form = driver.find_element(By.ID, 'loginForm')
4.2. Locating by Name¶
Use this when you know the name attribute of an element. With this strategy,
the first element with a matching name attribute will be returned. If no
element has a matching name attribute, a NoSuchElementException will be
raised.
For instance, consider this page source:
<html> <body> <form id="loginForm"> <input name="username" type="text" /> <input name="password" type="password" /> <input name="continue" type="submit" value="Login" /> <input name="continue" type="button" value="Clear" /> </form> </body> </html>
The username & password elements can be located like this:
username = driver.find_element(By.NAME, 'username') password = driver.find_element(By.NAME, 'password')
This will give the “Login” button as it occurs before the “Clear” button:
continue = driver.find_element(By.NAME, 'continue')
4.3. Locating by XPath¶
XPath is the language used for locating nodes in an XML document. As HTML can
be an implementation of XML (XHTML), Selenium users can leverage this powerful
language to target elements in their web applications. XPath supports the
simple methods of locating by id or name attributes and extends them by opening
up all sorts of new possibilities such as locating the third checkbox on the
page.
One of the main reasons for using XPath is when you don’t have a suitable id or
name attribute for the element you wish to locate. You can use XPath to either
locate the element in absolute terms (not advised), or relative to an element
that does have an id or name attribute. XPath locators can also be used to
specify elements via attributes other than id and name.
Absolute XPaths contain the location of all elements from the root (html) and as
a result are likely to fail with only the slightest adjustment to the
application. By finding a nearby element with an id or name attribute (ideally
a parent element) you can locate your target element based on the relationship.
This is much less likely to change and can make your tests more robust.
For instance, consider this page source:
<html> <body> <form id="loginForm"> <input name="username" type="text" /> <input name="password" type="password" /> <input name="continue" type="submit" value="Login" /> <input name="continue" type="button" value="Clear" /> </form> </body> </html>
The form elements can be located like this:
login_form = driver.find_element(By.XPATH, "/html/body/form[1]") login_form = driver.find_element(By.XPATH, "//form[1]") login_form = driver.find_element(By.XPATH, "//form[@id='loginForm']")
- Absolute path (would break if the HTML was changed only slightly)
- First form element in the HTML
- The form element with attribute id set to loginForm
The username element can be located like this:
username = driver.find_element(By.XPATH, "//form[input/@name='username']") username = driver.find_element(By.XPATH, "//form[@id='loginForm']/input[1]") username = driver.find_element(By.XPATH, "//input[@name='username']")
- First form element with an input child element with name set to username
- First input child element of the form element with attribute id set to
loginForm - First input element with attribute name set to username
The “Clear” button element can be located like this:
clear_button = driver.find_element(By.XPATH, "//input[@name='continue'][@type='button']") clear_button = driver.find_element(By.XPATH, "//form[@id='loginForm']/input[4]")
- Input with attribute name set to continue and attribute type set to
button - Fourth input child element of the form element with attribute id set to
loginForm
These examples cover some basics, but in order to learn more, the following
references are recommended:
- W3Schools XPath Tutorial
- W3C XPath Recommendation
- XPath Tutorial
– with interactive examples.
Here is a couple of very useful Add-ons that can assist in discovering the XPath
of an element:
- xPath Finder –
Plugin to get the elements xPath. - XPath Helper –
for Google Chrome
4.4. Locating Hyperlinks by Link Text¶
Use this when you know the link text used within an anchor tag. With this
strategy, the first element with the link text matching the provided value will
be returned. If no element has a matching link text attribute, a
NoSuchElementException will be raised.
For instance, consider this page source:
<html> <body> <p>Are you sure you want to do this?</p> <a href="continue.html">Continue</a> <a href="cancel.html">Cancel</a> </body> </html>
The continue.html link can be located like this:
continue_link = driver.find_element(By.LINK_TEXT, 'Continue') continue_link = driver.find_element(By.PARTIAL_LINK_TEXT, 'Conti')
4.5. Locating Elements by Tag Name¶
Use this when you want to locate an element by tag name. With this strategy,
the first element with the given tag name will be returned. If no element has a
matching tag name, a NoSuchElementException will be raised.
For instance, consider this page source:
<html> <body> <h1>Welcome</h1> <p>Site content goes here.</p> </body> </html>
The heading (h1) element can be located like this:
heading1 = driver.find_element(By.TAG_NAME, 'h1')
4.6. Locating Elements by Class Name¶
Use this when you want to locate an element by class name. With this strategy,
the first element with the matching class name attribute will be returned. If
no element has a matching class name attribute, a NoSuchElementException
will be raised.
For instance, consider this page source:
<html> <body> <p class="content">Site content goes here.</p> </body> </html>
The “p” element can be located like this:
content = driver.find_element(By.CLASS_NAME, 'content')
4.7. Locating Elements by CSS Selectors¶
Use this when you want to locate an element using CSS selector
syntax. With this strategy, the first element matching the given CSS selector
will be returned. If no element matches the provided CSS selector, a
NoSuchElementException will be raised.
For instance, consider this page source:
<html> <body> <p class="content">Site content goes here.</p> </body> </html>
The “p” element can be located like this:
content = driver.find_element(By.CSS_SELECTOR, 'p.content')
Sauce Labs has good documentation on CSS
selectors.
При работе с Selenium если элемент на веб-странице не обнаруживаются общеизвестными локаторами locators, использующими значения атрибутов дерева DOM таких как id, class и name, то для его поиска используют либо CSS селекторы, либо локаторы XPath (XML Path).
Важным отличием локаторов, основанных на синктаксисе XPath от CSS селекторов является то, что используя XPath, мы можем при поиске нужного элемента перемещаться как вглубь иерархии дереву документа, так и возвращаться назад (вверх по дереву). Что касается CSS, то тут мы можем двигаться только в глубину. Это означает, например, что с XPath мы сможем найти родительский элемент по дочернему.
В этом руководстве мы познакомимся с некоторами особенностями языка ХРath применительно к практике использования выражений XPath для поиска сложных или динамически подгружаемых элементов, атрибуты которых также могут динамически изменяться (обновляться).
При рассмотрении примеров, я буду использовать следующий скрипт, который осуществляет поиск элементов на странице поиска Яндекса:
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import os
import time
from pprint import pprint
# тестовая страница, на которой мы ищем
target_page = "https://yandex.ru/"
# то самое выражение XPath, которое мы тестируем
xpath_testing = "//div[contains(@class, 'home-logo')]//child::*"
dir_current = os.getcwd()
driverLocation = dir_current + "chromedriver.exe"
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = Chrome(driverLocation, chrome_options=chrome_options)
data_text = driver.get(target_page)
time.sleep(3)
try:
elements_ = driver.find_elements(By.XPATH, xpath_testing)
for element_ in elements_:
pprint(f"Выбран элемент с тегом: "{element_.tag_name }"")
pprint(f"Содержимое атрибута class: "{element_.get_attribute('class')}"")
pprint(f"Текстовое содержимое элемента: {'Нет содержимого' if not element_.text else element_.text}")
except:
print('Элемент по заданному XPath выражению не найден :(')
finally:
driver.quit()
Переменной target_page присваивается строковое значение, содержащие адрес страницы, на которой мы будем осуществлять поиск элементов. Критерий поиска будем задавать с использованием XPath выражения, которое также в виде строки присваиваем переменной xpath_testing.
Содержание
- Коротко о XML и XPath
- Маршруты поиска
- Абсолютные пути
- Относительные пути
- Подстановочные выражения
- Предикаты
- Используем индексы для указания позиции элемента
- Используем логические операторы OR и AND в выражения XPath
- Используем функции языка XPath
- Функция text()
- Функция contains()
- Функция starts-with()
- Функция last()
- Функция position()
- Используем полные маршруты поиска элементов
- Ось предков (ancestor axis)
- Ось следующих одноуровневых узлов (following-sibling axis)
- Ось дочерних элементов (child axis)
- Ось следующих узлов (following axis)
- Ось предыдущих одноуровневых узлов (preceding-sibling axis)
- Ось предыдущих узлов (preceding axis)
- Ось потомков (descendant axis)
- Ось потомков, включая контекстный узел (descendant-or-self axis)
- Ось предков, включая контекстный узел (ancestor-or-self axis)
Коротко о XML и XPath
Некоторые разработчики ошибочно полагают, что язык Html является подмножеством XML, но на самом деле это не так, код на обоих языка не возможно комбинировать в одном документе. Так язык XML предназначен для хранения и передачи структурированных данных. В свою очередь HTML предназначен для их более или менее читаемого отображения. Самое существенное различие между HTML и XML в том, что в HTML есть предопределенные элементы и атрибуты, поведение которых так предопределено и ожидаемо, в то время как в XML такого нет. Кроме того существуют определенные различия в синктаксисе инструкций этих внешне схожих языков.
Однако есть у этих двух языков одно основное сходство, которое, в нашем случае, мы можем эффективно использовать для поиска маршрутов к нужным элементам на странице.
- HTML и XML документы состоят из элементов, каждый из которых включает «начальный тэг» (<element>), «конечный тэг» (</element>), а также информацию, заключенную между этими двумя тэгами (содержимое элемента).
- Элементы могут быть аннотированы атрибутами, содержащими метаданные об элементе и его содержимом.
- Любой документ представляет собой дерево, состоящее из узлов (элементов). Некоторые типы узлов могут содержать другие узлы.
- Существует единственный корневой узел, который в конечном счете включает в себя все остальные узлы.
Для выбора узлов и наборов узлов дерева документа и последующей обработки Xml использует особый язык XPath. XPath – это отличный от XML язык, используемый для идентификации определенных частей XML документов (элементов страницы). Применительно к html страницам XPath позволяет писать выражения, позволяющие получить, например, ссылку на первый элемент li неупордоченного списка ul, седьмой дочерний элемент третьего элемента div, ссылку а, содержащую строку «Купить по акции» и т. д. XPath позволяет получать ссылки на элементы по их положению на странице (дереве документа), положению относительно другого элемента, тегу, текстовому содержимому и другим критериям.
Согласно методологии XPath существует пять типов узлов, которые могут находиться в дереве документа на обычной html странице:
- Корневой узел;
- Узлы элементов;
- Текстовые узлы;
- Узлы атрибутов;
- Узлы комментариев.
В дальнейшем при формировании путей поиска к искомым элементам страницы мы будем иметь дело с первыми четырьмя типами узлов. И хотя технически мы можем обратиться, также и к узлу комментариев, расположенного в определенном элементе, рационального применения этой возможности при парсинге страниц нет и поэтому далее рассматриваться не будут.
Маршруты поиска
И хотя выражения XPath в Xml могут также возвращать числа, логические и строковые выражения, то есть производить обработку элементов и их содержимого. В Selenium используется лишь подмножество выражений XPath, называемых маршрутами поиска. Маршруты поиска указывают на определенный узел или набор узлов документа (элементов страницы), отвечающих заданным критериям поиска. Каждый маршрут поиска использует как минимум один шаг для идентификации узла или набора узлов документа. Этот набор может быть пустым, содержать один или содержать несколько узлов. Узел может быть корневым, узлом определенного элемента, атрибута, текста или комментария.
Абсолютные пути
Простейшим маршрутом поиска является тот, который указывает на корневой узел документа (страницы). Этот маршрут представляется простой наклонной чертой / и всегда обозначает одно и то же: корневой узел документа. Каждый документ имеет только один корневой узел, являющийся общим корнем дерева узлов. Корневой узел не имеет родительских узлов. Значением корневого узла является значение элемента документа.
С наклонной черты / всегда начинается абсолютный путь к элементу (маршрут поиска). Получить его можно используя либо специальные расширения браузера, либо так как это делается в браузере Chrome. Вызвать окно Chrome DevTools, выделить нужный элемент, кликнув правой клавишей мыши, вызвать контекстное меню, выбрать команду Copy , а затем Copy full XPath.

Абсолютный путь представляет собой полный и уникальный путь к элементу, начиная от корневого узла. Путь полученный выше описанным способом будет иметь следующий вид:
/html/body/div[1]/div[3]/div[3]/div/edvrt/aqwf/ftgr/fdpprt/fgn/dbgrsae/fwap/fwap/ftgr/div/fgn/dhtaq/div/div/div[1]/div[1]/a/div
Если вы используете в качестве тестируемого выражения XPath этот путь, и запустите на выполнение скрипт приведенный выше, то получите ссылку на логотип Яндекса, который находится на главной странице поисковика.
Абсолютный путь, по аналогии с абсолютным путем к любому файлу в файловой системе операционной системы, всегда однозначно указывает на нужный элемент. Однако у него есть один существенный недостаток: если разметка страницы изменится, то он с большой вероятностью может перестать работать. Особенно это актуально если на странице используется много различных интерактивных возможностей Javascript или анимаций элементов.
Отметим, что корневой элемент страницы имеет абсолютный путь (маршрут) /html и если в качестве XPath выражения мы введем просто ‘/’, то будет возбуждено исключения типа InvalidSelectorException с сообщением «Селектор некоректен. Результат поиска с использованием XPath выражения не возвратил объект элемента. Элемент не найден».
Вывод. Символ / объединяет различные шаги в составной маршрут поиска. Каждый шаг в маршруте является относительным по отношению к предшествующему. Если маршрут начинается с /, то путь является абсолютным, а его первый шаг является относительным по отношению к корневому узлу.
Относительные пути
Относительный путь начинается с двух наклонных черт и следующим за ним одиночным тегом нужного нам элемента. Он может идентифицировать элементы в любом месте веб-страницы. И это позволяет избегать необходимости писать весь длинный абсолютный XPath путь, и вы можете начать его с середины структуры документа страницы (DOM). Он позволяет выбрать все элементы, по заданному тегу на странице, удовлетворяющие указанному критерию поиска. Например, выражение XPath //li ссылается на все элементы li находящиеся на странице (в дереве DOM). Так относительный путь к логотипу Яндекса на странице поиска будет выглядеть следующим образом:
//div[@role = 'img']
Пусть вас пока не смущает выражение в квадратных скобках. Они называются предикатами и служат для сужения диапазона поиска элементов, то есть придания специфичности нашему маршруту поиска. Синтаксис предикатов и их использование мы рассмотрим в нашем руководстве далее. А пока отметим, выражение в квадратных скобках говорит нам о том, что искомый элемент div, должен иметь атрибут role со значением img.
Логично было бы думать, что при задании относительных путей можно задавать начальную точку поиска нужных элементов страницы или, как принято говорить в терминологии XPath контекстный узел. В этом случае маршрут поиска будет иметь следующий вид:
//ol[@class = 'list news__list']/li/a
Это XPath выражение позволяет получить пути к ссылкам из списка новостей, размещенного на главной странице поисковика Яндекс. Отметим, этот маршрут получился намного короче чем маршрут, использующий абсолютный путь, а также более понятна его логика. Также отметим, что значение атрибута класса элемента упорядоченного списка ol представляет собой строковое значение состоящее из двух имен соответствующих CSS классов. Если вы укажете в выражении наименование только одного из них, например, так //ol[@class = 'news__list'] ,то получите пустой набор элементов.
Попробуем теперь переписать выражение выше следующим образом:
//ol[@class='list news__list']//a
И мы получим точно такой же результат, как и для выражения выше. Фактически мы заменили все промежуточные элементы из пути к ссылкам на две наклонные черты // и упростили его вид. Таким образом можно убирать из пути к искомому элементу любое количество промежуточных шагов (элементов).
Вывод. В начале выражения XPath символы // по сути позволяют выбрать всех потомков корневого узла с указанным тегом. Например, выражение XPath //div выбирает в документе все элементы div. Если мы будем использовать символ // в маршруте для разделения отдельных шагов, то можем опускать промежуточные шаги сокращая при этом запись маршрута. Относительный путь Xpath всегда предпочтительнее, так как он является более логичным и понятным, а также устойчивым к динамическому изменению структуры дерева DOM страницы средствами движка Javascript.
Подстановочные выражения
Подстановочные выражения позволяют выбирать несколько типов элементов одновременно. Существуе два следующих вида подстановочных выражений, которые выможете использовать при парсинге страниц: * , @ *.
Звездочка * или астерикс соответствует любому узлу элемента, независимо от его типа. Звездочка * является одним из наиболее часто используемых подстановочных выражений, используемых в XPath выражениях в Selenium.
Символ @ указывает, что слдующий за ним идентификатор является наименованием атрибута элемента и используется для задания предикатов. Так выражение @ * мы можем использовать вместо любого имени атрибута.
Приведем некоторые примеры их использования.
//*– соответствует всем элементам, находящимся на странице (включая тег html).//div/*– соответствует всем элементам, являющимися непосредственными потомками элемента с тегомdiv.//input[@*]– соответствует всем элементам с тегомinput, которые имеют хотя бы один любой атрибут, при этом значение атрибута может быть любым, присутствовать или отсутствовать.//*[@*]– соответствует всем элементам на странице, имеющим хотя бы один атрибут.
Предикаты
Как мы уже знаем, что в общем случае выражение XPath может ссылаться более чем на один узел (элемент страницы), то есть метод, в котором оно используется будет возвравращать массив элементов. Иногда это именно то, что нам нужно, однако в некоторых случаях приходится «просеивать» его по определенным критериям, чтобы выбрать только некоторые из них. Для этих целей в XPath используется синктаксис предикатов. Каждый шаг в маршруте поиска может иметь свой предикат или даже несколько, который задает свой критерий выбора из текущего списка узлов на каждом шаге маршрута поиска. То есть на каждом шаге поиска могут существовать один или более предикатов. По сути предикат содержит логическое выражение, которое проверяется для каждого узла в полученном по указанному пути наборе элементов страницы. Если выражение ложно, этот узел удаляется из набора, в противном случае соответствено сохраняется.
Предикат – это часть выражения XPath, заключенная в квадратные скобки, которое следует в инструкции для шага поиска за критерием выбора узла (элемента). В общем виде выражение с предикатом будет выглядеть следующим образом:
//выбор_элементов[правило_предиката1][правило_предиката2][правило_предиката3]
Предположим, требуется найти кнопку для отправки поискового запроса на главной странице Яндекса. XPath выражение, которое позволяет это осуществить будет выглядеть следующим образом:
//div[@class='search2__button']/button[@role='button']
В начале на первом шаге выбираем все элементы div, для которых справедливо следующее логическое значение предиката: значение атрибута класса соответствует строке search2__button. На втором шаге выбираем у них элементы с тегом button, являющиеся их непосредственными потомками, у которых значение атрибута role содержит строковое значение button.
В следующем примере выбираем ссылку на корзину Яндекс Маркет, которая находится также на основной странице поисковика. Использование нескольких атрибутов в выражении XPath сужает поиск нужного элемента на странице до одного.
//а[@title='Корзина на Маркете'][@class='home-link market-cart']
Вывод. Механизм предикатов весьма полезен для сужения диапазона выбираемых на странице элементов по заданным критериям, который основан на логических выражениях. Используя предикаты мы можем задавать сколь угодно специфичные идентификаторы для искомых элементов.
Используем индексы для указания позиции элемента
С помощью синтаксиса индексов можно выбрать из набора элементов нужный, указав его номер в квадратных скобках по аналогии с синтаксисом массивов. В примере ниже мы получаем третий элемент из списка новостей на странице Яндекса.
//ol[@class='list news__list']/li[2] //ol[@class='list news__list']/li[2]//span[@class='news__item-content']
Второе выражение XPath позволянт получить у выбранного элемента списка элемент с тегом span, который содержит текстовое содержимое заголовока новости. Отметим, что индексы элементов начинают отсчитываться от 1, а не от 0, как принято для индексации массивов в языке Python.
Используем логические операторы OR и AND в выражения XPath
Логические оператры используются в инструкциях предикатов для комбинирования критериев поиска нужных элементов на странице.
В примере ниже приведены выражения для фильтрации ссылок на новости, которые показывают на странице поиска Яндекс.
//a[@rel='noopener' or @target='_blank'] //a[@rel='noopener' and @target='_blank'] //a[@rel='noopener' and @target='_blank' and contains(@class, 'home-link_black_yes')]
Как видно в предикате для фильтрации элементов можно применять сколько угодно логических операторов, а также комбинировать их с XPath функциями, которые рассмотрим ниже.
Функция text()
Функция XPath text() – это встроенная в синтаксис XPath Selenium функция, которая используется для поиска элементов на основе строкового значения, содержащегося в его текстовом узле. То есть если элемент имеет текстовое содержимое в виде строки, то элемент можно найти следующим образом:
<span class="button__text">Найти</span> //span[text()='Найти']
Функция contains()
Функция contains() часто используется в предикатах выражений XPath для случаев если значение атрибута элемента или его текстовое содержимое может динамически изменяться.
Например в значение атрибута класса элемента //element[@class='class1 class2'] средствами Javascript может быть добавлен для его анимации класс class3, а потом также динамически убран. При этом значение предиката в случае добавления нового класса станет ложным, то есть элемент не будет выбран. Для этого случая мы можем использовать функцию contains() следующим образом:
//element[contains(@class, 'class1 class2')]
Если выражение выбора элемента переписать в указанном выше виде, то мы ориентируясь на атрибут класса элемента будем выбирать его в любом случае.
Функция contains() позволяет находить элемент по текстовой подстроке значения атрибута или его текстового содержимого, как показано в примере XPath ниже.
//a[contains(@title, 'Корзина')] //span[contains(text(),'Найти')]
В примере мы нашли ссылку на корзину Яндекс маркета из примера выше по части значения атрибута title. А также по части текстового содержимого кнопку отправки запроса поисковику.
Функция starts-with()
Эта функция используется если нам известна первая часть (начальная подстрока) текстового содержимого искомого элемента на странице, либо часть значения его атрибута.
//a[starts-with(@title, 'Корзина')] //span[starts-with(text(),'Найти')]
Функция last()
Эта функция позволяет выбрать последний элемент (указанного типа) из набора элементов. Пример ее использования представлен ниже.
//ol[@class='list news__list']/li[last()]//span[@class='news__item-content']
Это выражение возвращает элемент, содержащий наименование последней новости из списка новостей со страницы поисковика Яндекс.
В следующем примере показано как можно получить предпоследнюю новость.
//ol[@class='list news__list']/li[last()-1]//span[@class='news__item-content']
Функция position()
Эта функция позволяет выбирать из полученного набора элементы в зависимости от указанного номера позиции. Начало отсчета позиции элемента, по аналогии с индексами также начинается с 1. Действие этой функции полностью идентично индексам, о которых мы говорили выше. В примере ниже представлены два эквивалентных по результату выполнения выражения.
//ol[@class='list news__list']/li[position()=1]")) //ol[@class='list news__list']/li[1]
Используем полные маршруты поиска элементов
До этого момента мы говорили о том, что в терминологии языка XPath называется сокращенными маршрутами поиска. Эти маршруты значительно проще для набора, менее многословны и знакомы большинству разработчиков. Кроме того, они являются именно теми выражениями XPath, которые лучше всего подходят для использования в простейших шаблонов поиска. Однако в XPath также предлагается полный синтаксис для маршрутов поиска, который более многословен, но, возможно, менее загадочен и определенно более гибок.
Так каждый шаг в полном маршруте поиска имеет две обязательные части: так называю ось и критерий узла (тег элемента), а также необязательную часть – предикаты. Ось указывает направление перемещения от контекстного узла для поиска следующих узлов. Критерий узла определяет, какие узлы будут выбраны на текущем шаге поиска вдоль этой оси. В полном маршруте они разделяются двумя двоеточиями ::.
По сути в сокращенном маршруте поиска ось и критерий узла объединены вместе. Например, следующий сокращенный маршрут поиска состоит из трех шагов.
//ol/li/a[@rel='noopener']
Первый шаг выбирает на странице элементы упорядоченных списков ol по оси дочерних узлов, второй – элементы li вдоль оси дочерних узлов, третий шаг – так же по оси дочерних узлов выбирает элементы ссылок a, а затем с помощью предиката выбирает из них только содержащие атрибут rel='noopener' с заданным значением . Если переписать это выражение в полной форме тот же маршрут поиска будет выглядеть следующим образом:
//child::ol/child::li/child::a[@rel='noopener']
Полные несокращенные маршруты поиска, как и сокращенные, могут быть также абсолютными, если начинаются с корневого узла.
В целом полная форма очень многословна и мало используется на практике. Однако она предоставляет одну исключительную возможность, которая делает эту форму записи XPAth выражений достойной внимания. Это единственный способ использования направлений осей поиска, по которым выражения XPath осуществляют выбор нужных элементов.
Так сокращенный синтаксис позволяет перемещаться по оси непосредственно дочерних узлов (child), оси атрибутов (attribute) и оси всех его потомков с включением контекстного узла (descendant-or-self). Полный синтаксис добавляет еще восемь осей, которые применимы для использования в XPath выражениях и поиска элементов на страницах с использованием Selenium:
Ось предков (ancestor axis)
Все узлы элементов, содержащие контекстный узел; родительский узел, родитель родителя, родитель родителя родителя и т.д. вверх вплоть до корневого узла в порядке, обратном расположению узлов в документе.
//div[text()='Маркет']//ancestor::a //div[text()='Маркет']//ancestor::*
В данном примере мы получаем ссылку на Яндекс Маркет по текстовому содержимому элемента div находящегося внутри нее. А следующее выражение позволяет выбрать последовательность всех предков этого элемента до корня документа /html.
Ось следующих одноуровневых узлов (following-sibling axis)
Все узлы элементов страницы, следующие за контекстным узлом и содержащиеся в том же узле родительского элемента, в том же порядке, в каком элементы расположены в документе.
//div[contains(@class, 'home-logo')]//following-sibling::div
В примере выше выражение выбирает блок div по содержимому атрибута класса, который содержит элементы строки ввода слов для поиска.
Ось дочерних элементов (child axis)
Ось содержит все дочерние узлы текущего контекстного, то есть выбирает все элементы, содержащиеся в текущем узле. В примере ниже будут выбраны все элементы находящиеся внутри блока div содержащего логотип Яндекса.
//div[contains(@class, 'home-arrow__search-wrapper')]//child::*
Ось следующих узлов (following axis)
Все узлы, следующие после контекстного узла, в том же порядке, в каком узлы присутствуют в документе. Отличием поиска вдоль этой оси от оси following-sibling является то, что будут выбраны все узлы (элементы) находящиеся в документе за закрывающим тегом контекстного узла. Так в аналогичном примере ниже будут выбраны все элементы div, следующие в документе за разметкой логотипа Яндекс. Сравните результаты поиска с примером выше.
//div[contains(@class, 'home-logo')]//following::div
Ось предыдущих одноуровневых узлов (preceding-sibling axis)
Выбирает все узлы, предшествующие контекстному узлу и содержащиеся в том же узле родительского элемента последовательно в обратном порядке.
//div[contains(@class, 'search2__input')]//preceding-sibling::input[@type='hidden']
В этом примере выражение позволяет выбрать скрытые поля в блоке со строкой основного поиска Яндекса.
Ось предыдущих узлов (preceding axis)
Все узлы, предшествующие началу контекстного узла, в порядке, обратном порядку в документе. Отличием поиска вдоль этой оси от оси following-sibling является то, что будут выбраны все узлы (элементы) находящиеся в документе перед открывающим тегом контекстного узла. Так в аналогичном примере ниже будут выбраны все элементы div, следующие в документе перед разметкой логотипа Яндекс. Сравните результаты поиска с примерами выше.
//div[contains(@class, 'home-logo')]//preceding::div
Ось потомков (descendant axis)
Поиск вдоль оси потомков descendant выбирает все дочерние элементы, а также их дочерние элементы «внуков». В примере ниже мы выбираем все элементы находящиеся в блоке со строкой поиска на главной странице Яндекса.
//div[contains(@class, 'home-arrow__search-wrapper')]//descendant::*
Ось потомков, включая контекстный узел (descendant-or-self axis)
Ее действие аналогично оси потомков descendant за исключением того, в набор будет включен и сам контекстный узел.
//div[contains(@class, 'home-arrow__search-wrapper')]//descendant-or-self ::*
Ось предков, включая контекстный узел (ancestor-or-self axis)
Все предки контекстного узла, включая сам контекстный узел. В примере ниже будут выбраны все предки элемента div блока с логотипом Яндекса, а также сам элемент.
//div[contains(@class, 'home-arrow__search-wrapper')]//ancestor-or-self::*
В этой статье мы рассмотрели основы использования синтаксиса XPath при составлении выражений для поиска элементов на странице. Отличительной особенностью такого поиска является то, что используется информация о структуре документа страницы, что позволяет более гибко составлять выражения маршрутов к искомым элементам в любом направлении от заданного контекстного узла. В отличии от использования CSS селекторов, которые позволяю осуществлять поиск только в глубину, выражения XPath позволяют выбирать как родительские узлы так и узлы предков выше до любого уровня вложенности.
Использование функций языка XPath позволяет находить элементы как по их текстовому содержимому, так и по содержимому их атрибутов. Существенно расширяют их возможности возможность использования логических выражений для комбинирования различных условий формирования маршрута поиска.
Надеюсь, что это руководство поможет вам разобраться с принципом использования XPath выражений при работе в Selenium Python. А также в дальнейшем послужит справочным пособием для разработки.
