В статистике есть целый набор показателей, которые характеризуют центральную тенденцию. Выбор того или иного индикатора в основном зависит от характера данных, целей расчетов и его свойств.
Что подразумевается под характером данных? Прежде всего, мы говорим о количественных данных, которые выражены в числах. Но набор числовых данных может иметь разное распределение. Под распределением понимаются частоты отдельных значений. К примеру, в классе из 23 человек 2 школьника написали контрольную работу на двойку, 5 – на тройку, 10 – на четверку и 6 – на пятерку. Это и есть распределение оценок. Распределение очень наглядно можно представить с помощью специальной диаграммы – гистограммы. Для данного примера получится следующая гистограмма.

Во многих случаях количество уникальных значений намного больше, а распределение похоже на нормальное. Ниже приведена примерная иллюстрация нормального распределения случайных чисел.

Итак, центральная тенденция. Если частоты анализируемых значений распределены по нормальному закону, то есть симметрично вокруг некоторого центра, то центральная тенденция определяется вполне однозначно – это есть тот самый центр, и математически он соответствует средней арифметической.
Как нетрудно заметить, в этом же центре находится и максимальная частота значений. То есть при нормальном распределении центральная тенденция есть не только средняя арифметическая, но и максимальная частота, которая в статистике называется модой или модальным значением.

На диаграмме оба значения центральной тенденции совпадают и равны 10.
Но такое распределение встречается далеко не всегда, а при малом числе данных – совсем редко. Чаще бывает так, что частоты распределяются асимметрично. Тогда мода и среднее арифметическое не будут совпадать.

На рисунке выше среднее арифметическое по-прежнему составляет 10, а вот мода уже равна 9. Что в таком случае считать значением центральной тенденции? Ответ зависит от поставленных целей анализа. Если интересует уровень, сумма отклонений от которого равна нулю со всеми вытекающим отсюда свойствами и последствиями, то это средняя арифметическая. Если нужно максимально частое значение, то это мода.
Итак, зачем нужна мода? Приведу пару примеров. Экономист планово-экономического отдела обувной фабрики интересуется, какой размер обуви пользуется наибольшим спросом. Средний размер обуви, скорее всего, здесь не подойдет, тем более, что число может получится дробным. А вот мода – как раз нужный показатель.
Расчет моды
Теперь посмотрим, как рассчитать моду. Мода – это то значение в анализируемой совокупности данных, которое встречается чаще других, поэтому нужно посмотреть на частоты значений и отыскать максимальное из них. Например, в наборе данных 3, 4, 6, 7, 3, 5, 3, 4 модой будет значение 3 – повторяется чаще остальных. Это в дискретном ряду, и здесь все просто. Если данных много, то моду легче всего найти с помощью соответствующей гистограммы. Бывает так, что совокупность данных имеет бимодальное распределение.

Без диаграммы очень трудно понять, что в данных не один, а два центра. К примеру, на президентских выборах предпочтения сельских и городских жителей могут отличаться. Поэтому распределение доли отданных голосов за конкретного кандидата может быть «двугорбым». Первый «горб» – выбор городского населения, второй – сельского.
Немного сложнее с интервальными данными, когда вместо конкретных значений имеются интервалы. В этом случае говорят о модальном интервале (при анализе доходов населения, например), то есть интервале, частота которого максимальна относительно других интервалов. Однако и здесь можно отыскать конкретное модальное значение, хотя оно будет условным и примерным, так как нет точных исходных данных. Представим, что есть следующая таблица с распределением цен.

Для наглядности изобразим соответствующую диаграмму.

Требуется найти модальное значение цены.
Вначале нужно определить модальный интервал, который соответствует интервалу с наибольшей частотой. Найти его так же легко, как и моду в дискретном ряду. В нашем примере это третий интервал с ценой от 301 до 400 руб. На графике – самый высокий столбец. Теперь нужно определить конкретное значение цены, которое соответствует максимальному количеству. Точно и по факту сделать это невозможно, так как нет индивидуальных значений частот для каждой цены. Поэтому делается допущение о том, что интервалы выше и ниже модального в зависимости от своей частоты имеют разные вес и как бы перетягивают моду в свою сторону. Если частота интервала следующего за модальным больше, чем частота интервала перед модальным, то мода будет правее середины модального интервала и наоборот. Давайте еще раз посмотрим на рисунок, чтобы понять формулу, которую я напишу чуть ниже.

На рисунке отчетливо видно, что соотношение высоты столбцов, расположенных слева и справа от модального определяет близость моды к левому или правому краю модального интервала. Задача по расчету модального значения состоит в том, чтобы найти точку пересечения линий, соединяющих модальный столбец с соседними (как показано на рисунке пунктирными линиями) и нахождении соответствующего значения признака (в нашем примере цены). Зная основы геометрии (7-й класс), по данному рисунку нетрудно вывести формулу расчета моды в интервальном ряду.
Формула моды имеет следующий вид.
![]()
Где Мо – мода,
x0 – значение начала модального интервала,
h – размер модального интервала,
fМо – частота модального интервала,
fМо-1 – частота интервала, находящего перед модальным,
fМо1 – частота интервала, находящего после модального.
Второе слагаемое формулы моды соответствует длине красной линии на рисунке выше.
Рассчитаем моду для нашего примера.
![]()
Таким образом, мода интервального ряда представляет собой сумму, состоящую из значения начального уровня модального интервала и отрезка, который определяется соотношением частот ближайших интервалов от модального.
Расчет моды в Excel
В настоящее время большинство вычислений делается в MS Excel, где для расчета моды также предусмотрена специальная функция. В Excel 2013 я таких нашел ажно 3 штуки.
МОДА – пережиток старых изданий Excel. Функция оставлена для совмещения со старыми версиями.
МОДА.ОДН – рассчитывает моду по заданным значениям. Здесь все просто. Вставили функцию, указали диапазон данных и «Ок».
МОДА.НСК – позволяет рассчитать сразу несколько модальных значений (одинаковых максимальных частот) для одного ряда данных, если они есть. Функцию нужно вводить как формулу массива, перед этим выделив количество ячеек равное количеству требуемых модальных значений. Иногда действительно модальных значений может быть несколько. Однако для этих целей предварительно лучше посмотреть на диаграмму распределения.
Моду для интервальных данных одной функцией в Excel рассчитать нельзя. То есть такая функция в готовом виде не предусмотрена. Придется прописывать вручную.
Следующая статья посвящена медиане.
До встречи на statanaliz.info.
Поделиться в социальных сетях:
Интервальный вариационный ряд и его характеристики
- Построение интервального вариационного ряда по данным эксперимента
- Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
- Выборочная средняя, мода и медиана. Симметрия ряда
- Выборочная дисперсия и СКО
- Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
- Алгоритм исследования интервального вариационного ряда
- Примеры
п.1. Построение интервального вариационного ряда по данным эксперимента
Интервальный вариационный ряд – это ряд распределения, в котором однородные группы составлены по признаку, меняющемуся непрерывно или принимающему слишком много значений.
Общий вид интервального вариационного ряда
| Интервалы, (left.left[a_{i-1},a_iright.right)) | (left.left[a_{0},a_1right.right)) | (left.left[a_{1},a_2right.right)) | … | (left.left[a_{k-1},a_kright.right)) |
| Частоты, (f_i) | (f_1) | (f_2) | … | (f_k) |
Здесь k – число интервалов, на которые разбивается ряд.
Размах вариации – это длина интервала, в пределах которой изменяется исследуемый признак: $$ F=x_{max}-x_{min} $$
Правило Стерджеса
Эмпирическое правило определения оптимального количества интервалов k, на которые следует разбить ряд из N чисел: $$ k=1+lfloorlog_2 Nrfloor $$ или, через десятичный логарифм: $$ k=1+lfloor 3,322cdotlg Nrfloor $$
Скобка (lfloor rfloor) означает целую часть (округление вниз до целого числа).
Шаг интервального ряда – это отношение размаха вариации к количеству интервалов, округленное вверх до определенной точности: $$ h=leftlceilfrac Rkrightrceil $$
Скобка (lceil rceil) означает округление вверх, в данном случае не обязательно до целого числа.
Алгоритм построения интервального ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Найти размах вариации (R=x_{max}-x_{min})
Шаг 2. Найти оптимальное количество интервалов (k=1+lfloorlog_2 Nrfloor)
Шаг 3. Найти шаг интервального ряда (h=leftlceilfrac{R}{k}rightrceil)
Шаг 4. Найти узлы ряда: $$ a_0=x_{min}, a_i=1_0+ih, i=overline{1,k} $$ Шаг 5. Найти частоты (f_i) – число попаданий значений признака в каждый из интервалов (left.left[a_{i-1},a_iright.right)).
На выходе: интервальный ряд с интервалами (left.left[a_{i-1},a_iright.right)) и частотами (f_i, i=overline{1,k})
Заметим, что поскольку шаг h находится с округлением вверх, последний узел (a_kgeq x_{max}).
Например:
Проведено 100 измерений роста учеников старших классов.
Минимальный рост составляет 142 см, максимальный – 197 см.
Найдем узлы для построения соответствующего интервального ряда.
По условию: (N=100, x_{min}=142 см, x_{max}=197 см).
Размах вариации: (R=197-142=55) (см)
Оптимальное число интервалов: (k=1+lfloor 3,322cdotlg 100rfloor=1+lfloor 6,644rfloor=1+6=7)
Шаг интервального ряда: (h=lceilfrac{55}{5}rceil=lceil 7,85rceil=8) (см)
Получаем узлы ряда: $$ a_0=x_{min}=142, a_i=142+icdot 8, i=overline{1,7} $$
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
п.2. Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
Относительная частота интервала (left.left[a_{i-1},a_iright.right)) – это отношение частоты (f_i) к общему количеству исходов: $$ w_i=frac{f_i}{N}, i=overline{1,k} $$
Гистограмма относительных частот интервального ряда – это фигура, состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – относительным частотам каждого из интервалов.
Площадь гистограммы равна 1 (с точностью до округлений), и она является эмпирическим законом распределения исследуемого признака.
Полигон относительных частот интервального ряда – это ломаная, соединяющая точки ((x_i,w_i)), где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Накопленные относительные частоты – это суммы: $$ S_1=w_1, S_i=S_{i-1}+w_i, i=overline{2,k} $$ Ступенчатая кривая (F(x)), состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – накопленным относительным частотам, является эмпирической функцией распределения исследуемого признака.
Кумулята – это ломаная, которая соединяет точки ((x_i,S_i)), где (x_i) – середины интервалов.
Например:
Продолжим анализ распределения учеников по росту.
Выше мы уже нашли узлы интервалов. Пусть, после распределения всех 100 измерений по этим интервалам, мы получили следующий интервальный ряд:
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
| (f_i) | 4 | 7 | 11 | 34 | 33 | 8 | 3 |
Найдем середины интервалов, относительные частоты и накопленные относительные частоты:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 |
| (S_i) | 0,04 | 0,11 | 0,22 | 0,56 | 0,89 | 0,97 | 1 |
Построим гистограмму и полигон:

Построим кумуляту и эмпирическую функцию распределения: 

Эмпирическая функция распределения (относительно середин интервалов): $$ F(x)= begin{cases} 0, xleq 146\ 0,04, 146lt xleq 154\ 0,11, 154lt xleq 162\ 0,22, 162lt xleq 170\ 0,56, 170lt xleq 178\ 0,89, 178lt xleq 186\ 0,97, 186lt xleq 194\ 1, xgt 194 end{cases} $$
п.3. Выборочная средняя, мода и медиана. Симметрия ряда
Выборочная средняя интервального вариационного ряда определяется как средняя взвешенная по частотам: $$ X_{cp}=frac{x_1f_1+x_2f_2+…+x_kf_k}{N}=frac1Nsum_{i=1}^k x_if_i $$ где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ X_{cp}=sum_{i=1}^k x_iw_i $$
Модальным интервалом называют интервал с максимальной частотой: $$ f_m=max f_i $$ Мода интервального вариационного ряда определяется по формуле: $$ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h $$ где
(h) – шаг интервального ряда;
(x_o) – нижняя граница модального интервала;
(f_m,f_{m-1},f_{m+1}) – соответственно, частоты модального интервала, интервала слева от модального и интервала справа.
Медианным интервалом называют первый интервал слева, на котором кумулята превысила значение 0,5. Медиана интервального вариационного ряда определяется по формуле: $$ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h $$ где
(h) – шаг интервального ряда;
(x_o) – нижняя граница медианного интервала;
(S_{me-1}) накопленная относительная частота для интервала слева от медианного;
(w_{me}) относительная частота медианного интервала.
Расположение выборочной средней, моды и медианы в зависимости от симметрии ряда аналогично их расположению в дискретном ряду (см. §65 данного справочника).
Например:
Для распределения учеников по росту получаем:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
$$ X_{cp}=sum_{i=1}^k x_iw_i=171,68approx 171,7 text{(см)} $$ На гистограмме (или полигоне) относительных частот максимальная частота приходится на 4й интервал [166;174). Это модальный интервал.
Данные для расчета моды: begin{gather*} x_o=166, f_m=34, f_{m-1}=11, f_{m+1}=33, h=8\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =166+frac{34-11}{(34-11)+(34-33)}cdot 8approx 173,7 text{(см)} end{gather*} На кумуляте значение 0,5 пересекается на 4м интервале. Это – медианный интервал.
Данные для расчета медианы: begin{gather*} x_o=166, w_m=0,34, S_{me-1}=0,22, h=8\ \ M_e=x_o+frac{0,5-S_{me-1}}{w_me}h=166+frac{0,5-0,22}{0,34}cdot 8approx 172,6 text{(см)} end{gather*} begin{gather*} \ X_{cp}=171,7; M_o=173,7; M_e=172,6\ X_{cp}lt M_elt M_o end{gather*} Ряд асимметричный с левосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|}=frac{2,0}{0,9}approx 2,2lt 3), т.е. распределение умеренно асимметрично.
п.4. Выборочная дисперсия и СКО
Выборочная дисперсия интервального вариационного ряда определяется как средняя взвешенная для квадрата отклонения от средней: begin{gather*} D=frac1Nsum_{i=1}^k(x_i-X_{cp})^2 f_i=frac1Nsum_{i=1}^k x_i^2 f_i-X_{cp}^2 end{gather*} где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ D=sum_{i=1}^k(x_i-X_{cp})^2 w_i=sum_{i=1}^k x_i^2 w_i-X_{cp}^2 $$
Выборочное среднее квадратичное отклонение (СКО) определяется как корень квадратный из выборочной дисперсии: $$ sigma=sqrt{D} $$
Например:
Для распределения учеников по росту получаем:
| $x_i$ | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
| (x_i^2w_i) – результат | 852,64 | 1660,12 | 2886,84 | 9826 | 10455,72 | 2767,68 | 1129,08 | 29578,08 |
$$ D=sum_{i=1}^k x_i^2 w_i-X_{cp}^2=29578,08-171,7^2approx 104,1 $$ $$ sigma=sqrt{D}approx 10,2 $$
п.5. Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
Исправленная выборочная дисперсия интервального вариационного ряда определяется как: begin{gather*} S^2=frac{N}{N-1}D end{gather*}
Стандартное отклонение выборки определяется как корень квадратный из исправленной выборочной дисперсии: $$ s=sqrt{S^2} $$
Коэффициент вариации это отношение стандартного отклонения выборки к выборочной средней, выраженное в процентах: $$ V=frac{s}{X_{cp}}cdot 100text{%} $$
Подробней о том, почему и когда нужно «исправлять» дисперсию, и для чего использовать коэффициент вариации – см. §65 данного справочника.
Например:
Для распределения учеников по росту получаем: begin{gather*} S^2=frac{100}{99}cdot 104,1approx 105,1\ sapprox 10,3 end{gather*} Коэффициент вариации: $$ V=frac{10,3}{171,7}cdot 100text{%}approx 6,0text{%}lt 33text{%} $$ Выборка однородна. Найденное значение среднего роста (X_{cp})=171,7 см можно распространить на всю генеральную совокупность (старшеклассников из других школ).
п.6. Алгоритм исследования интервального вариационного ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Построить интервальный ряд с интервалами (left.right[a_{i-1}, a_ileft.right)) и частотами (f_i, i=overline{1,k}) (см. алгоритм выше).
Шаг 2. Составить расчетную таблицу. Найти (x_i,w_i,S_i,x_iw_i,x_i^2w_i)
Шаг 3. Построить гистограмму (и/или полигон) относительных частот, эмпирическую функцию распределения (и/или кумуляту). Записать эмпирическую функцию распределения.
Шаг 4. Найти выборочную среднюю, моду и медиану. Проанализировать симметрию распределения.
Шаг 5. Найти выборочную дисперсию и СКО.
Шаг 6. Найти исправленную выборочную дисперсию, стандартное отклонение и коэффициент вариации. Сделать вывод об однородности выборки.
п.7. Примеры
Пример 1. При изучении возраста пользователей коворкинга выбрали 30 человек.
Получили следующий набор данных:
18,38,28,29,26,38,34,22,28,30,22,23,35,33,27,24,30,32,28,25,29,26,31,24,29,27,32,24,29,29
Постройте интервальный ряд и исследуйте его.
1) Построим интервальный ряд. В наборе данных: $$ x_{min}=18, x_{max}=38, N=30 $$ Размах вариации: (R=38-18=20)
Оптимальное число интервалов: (k=1+lfloorlog_2 30rfloor=1+4=5)
Шаг интервального ряда: (h=lceilfrac{20}{5}rceil=4)
Получаем узлы ряда: $$ a_0=x_{min}=18, a_i=18+icdot 4, i=overline{1,5} $$
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
Считаем частоты для каждого интервала. Получаем интервальный ряд:
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
| (f_i) | 1 | 7 | 12 | 6 | 4 |
2) Составляем расчетную таблицу:
| (x_i) | 20 | 24 | 28 | 32 | 36 | ∑ |
| (f_i) | 1 | 7 | 12 | 6 | 4 | 30 |
| (w_i) | 0,033 | 0,233 | 0,4 | 0,2 | 0,133 | 1 |
| (S_i) | 0,033 | 0,267 | 0,667 | 0,867 | 1 | – |
| (x_iw_i) | 0,667 | 5,6 | 11,2 | 6,4 | 4,8 | 28,67 |
| (x_i^2w_i) | 13,333 | 134,4 | 313,6 | 204,8 | 172,8 | 838,93 |
3) Строим полигон и кумуляту

Эмпирическая функция распределения: $$ F(x)= begin{cases} 0, xleq 20\ 0,033, 20lt xleq 24\ 0,267, 24lt xleq 28\ 0,667, 28lt xleq 32\ 0,867, 32lt xleq 36\ 1, xgt 36 end{cases} $$ 4) Находим выборочную среднюю, моду и медиану $$ X_{cp}=sum_{i=1}^k x_iw_iapprox 28,7 text{(лет)} $$ На полигоне модальным является 3й интервал (самая высокая точка).
Данные для расчета моды: begin{gather*} x_0=26, f_m=12, f_{m-1}=7, f_{m+1}=6, h=4\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =26+frac{12-7}{(12-7)+(12-6)}cdot 4approx 27,8 text{(лет)} end{gather*}
На кумуляте медианным является 3й интервал (преодолевает уровень 0,5).
Данные для расчета медианы: begin{gather*} x_0=26, w_m=0,4, S_{me-1}=0,267, h=4\ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h=26+frac{0,5-0,4}{0,267}cdot 4approx 28,3 text{(лет)} end{gather*} Получаем: begin{gather*} X_{cp}=28,7; M_o=27,8; M_e=28,6\ X_{cp}gt M_egt M_0 end{gather*} Ряд асимметричный с правосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|} =frac{0,9}{0,1}=9gt 3), т.е. распределение сильно асимметрично.
5) Находим выборочную дисперсию и СКО: begin{gather*} D=sum_{i=1}^k x_i^2w_i-X_{cp}^2=838,93-28,7^2approx 17,2\ sigma=sqrt{D}approx 4,1 end{gather*}
6) Исправленная выборочная дисперсия: $$ S^2=frac{N}{N-1}D=frac{30}{29}cdot 17,2approx 17,7 $$ Стандартное отклонение (s=sqrt{S^2}approx 4,2)
Коэффициент вариации: (V=frac{4,2}{28,7}cdot 100text{%}approx 14,7text{%}lt 33text{%})
Выборка однородна. Найденное значение среднего возраста (X_{cp}=28,7) лет можно распространить на всю генеральную совокупность (пользователей коворкинга).
Для
характеристики рядов
распределения (структуры
вариационных рядов), наряду со средней,
используются т. н. структурные
средние: мода и медиана.
Мода и медиана наиболее часто используются
в экономической практике.
Мода–
варианта, которая наиболее часто
встречается в ряду распределения
(в данной совокупности).
В дискретных вариационных
рядах мода определяется по наибольшей
частоте. Предположим товар А реализуют
в городе 9 фирм по следующим ценам
в рублях:
44;
43; 44; 45; 43; 46; 42; 46;43. Так как чаще всего
встречается цена 43 рубля, то она
и будет модальной.
При
характеристике социальных групп
населения по уровню дохода следует
использовать модальное значение, нежели
среднее. Средняя будет занижать одни
показатели и завышать другие — тем
самым осредняя (уравнивания) доходы
всех слоев населения.
В интервальных вариационных
рядах моду определяют приближенно по
формуле:
![]()
-
ХМ0 —
нижняя граница модального интервала; -
hMo –
величина (шаг, ширина) модального
интервала; -
f1 –
локальная частота интервала,
предшествующего модальному; -
f2 – локальная
частота модального интервала; -
f3 –
локальная частота интервала, следующего
за модальным.
Распределение
населения по уровню среднедушевого
месячного дохода
|
Среднедушевой |
Удельный |
Накопленная |
|
менее 1000-3000 3000-5000 5000-7000 7000-9000 9000 |
2,4 35,5 30,0 15,7 7,7 8,7 |
2,4 37,9 67,9 83,6 91,3 100,0 |
|
Всего |
100,0 |
Х |
Интервал
1000-3000 в данном распределении будет
модальным, т.к. он имеет наибольшую
частоту (f=35,5). Тогда по вышеуказанной
формуле мода будет равна:
![]()

На
графике (гистограмме распределения)
моду определяют следующим образом: по
оси ординат откладывают локальные
частоты, а по оси абсцисс -интервалы
либо центры интервалов. Выбирают самый
высокий столбик, которому соответствует
величина признака с наибольшей частотой
в ряду распределения.
Мода применяется
для решения некоторых практических
задач. Так, например, при изучении
товарооборота рынка берется модальная
цена, для изучения спроса на обувь,
одежду используют модальные размеры
обуви и одежды.
Медиана–
это численное значение признака у той
единицы совокупности, которая находится
в середине ранжированного ряда
(построенного в порядке возрастания,
либо убывания значений изучаемого
признака). Медиану иногда
называют серединной
вариантой,
т.к. она делит совокупность на две равные
части таким образом, чтобы по обе ее
стороны находилось одинаковое число
единиц совокупности. Если всем единицам
ряда присвоить порядковые номера, то
порядковый номер медианы будет
определяться по формуле (n+1):2 для
рядов, где n — нечетное.
Если же ряд с четным числом
единиц, томедианой будет
являться среднее значение между двумя
соседними вариантами, определенными
по формуле: n:2, (n+1):2, (n:2)+1.
В
дискретных вариационных рядах с нечетным
числом единиц совокупности — это
конкретное численное значение в середине
ряда.
Нахождение
медианы в интервальных вариационных
рядах требует предварительного
определения интервала, в котором
находится медиана, т.е. медианного интервала –
этот интервал характеризуется тем, что
его кумулятивная (накопленная) частота
равна полусумме или превышает полусумму
всех частот ряда.
![]()
-
XMe -нижняя
граница медианного интервала -
hMe
-величина
медианного интервала; -
SMe-1-сумма
накопленных частот интервала,
предшествующего медианному интервалу; -
fMe
-локальная
частота медианного интервала.
По
данным таблицы определим медианное
значение среднедушевого дохода. Для
этого необходимо определить какой
интервал будет медианным. Используем
формулу номера медианной единицы ряда,
т.е. середины:
![]()
Дробное
значение N (всегда при четном числе
членов) равное 50,5% говорит о том,
что середина ряда находится между 50% и 51%,
т.е. в третьем интервале. Иными словами:
медианным считается интервал, на который
впервые приходится более половины
суммы накопленных частот. Отсюда
медиана:
![]()

Для
того, чтобы определить графически
интервал, в котором находится медиана,
по оси ординат откладывают накопленные
частоты, а по оси абсцисс — центры
интервалов. Из точки на оси ординат,
которой соответствует 50.5% суммы
накопленных частот, проводят линию
параллельно оси абсцисс до пересечения
с кумулятой. Из точки пересечения
опускают перпендикуляр на ось абсцисс.
Соотношение
моды, медианы и средней арифметической
указывает на характер распределения
признака в совокупности, позволяет
оценить его асимметрию.
Если M0<Me<Х
— имеет место правосторонняя асимметрия.
Если же Х<Me<M0 –
левосторонняя асимметрия ряда. По
приведенному примеру можно сделать
заключение, что наиболее распространенным
является доход порядка 2715 руб. в
месяц. В то же время, более половины
населения располагает доходом
свыше 3807 руб., при среднем
уровне 4338 руб.

Из
соотношения этих показателей следует
сделать вывод о правосторонней асимметрии
распределения населения по уровню
среднедушевого денежного дохода:
![]()
Квартиль –это
четвертая часть совокупности, определяется
как и медиана, только сумму частот
необходимо разделить на 4, а при
определении квартильного интервала,
кумулятивная частота должна быть больше
или равна четверти суммы частот
совокупности.
Дециль –
делит совокупность на десять равных
частей. Определяется аналогично как и
квартиль, только сумму частот необходимо
разделить на 10.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
12.04.2015613.89 Кб24pr.doc
- #
- #
- #
- #
8.4. МОДА и МЕДИАНА (структурные средние)
Мода и медиана наиболее часто используемые в экономической практике структурные средние.
Мода – это величина признака (варианта), который наиболее часто встречается в данной совокупности, т.e. это варианта, имеющая наибольшую частоту.
В дискретном ряду мода определяется в соответствии с определением, т.е. это одна из вариант признака, которая в ряду распределения имеет наибольшую частоту.
Для интервального ряда моду находим по формуле (8.16), сначала по наибольшей частоте определив модальный интервал:

(8.16 – формула Моды)
где хо – начальная (нижняя) граница модального интервала;
h – величина интервала;
fМо – частота модального интервала;
fМо-1 – частота интервала, предшествующая модальному;
fМо+1– частота интервала следующая за модальным.
Медианой называется такое значение признака, которое приходится на середину ранжированного ряда, т.е. в ранжированном ряду распределения одна половина ряда имеет значение признака больше медианы, другая – меньше медианы.
В дискретном ряду медиана находится непосредственно по накопленной частоте, соответствующей номеру медианы.
В случае интервального вариационного ряда медиану определяют по формуле:
 (8.17 – формула Медианы)
(8.17 – формула Медианы)
где хо – нижняя граница медианного интервала;
NМе– порядковый номер медианы (Σf/2);
S Me-1 – накопленная частота до медианного интервала;
fМе – частота медианного интервала.
Пример вычисления Моды.
Рассчитаем моду и медиану по данным табл. 8.4.
Таблица 8.4 – Распределение семей города N по размеру среднедушевого дохода в январе 2018 г. руб.(цифры условные)
| Группы семей по размеру дохода, руб. | Число
семей |
Накоп-
ленные частоты |
в % к итогу |
| До 5000 | 600 | 600 | 6 |
| 5000-6000 | 700 | 1300
(600+700) |
13 |
| 6000-7000 | 1700 (fМо-1) | 3000 (S Me-1 )
(1300+1700) |
30 |
| 7000-8000
(хо) |
2500
(fМо) (fМе) |
5500 (S Me) | 55 |
| 8000-9000 | 2200 (fМо+1) | 7700 | 77 |
| 9000-10000 | 1500 | 9200 | 92 |
| Свыше 10000 | 800 | 10000 | 100 |
| Итого | 10000 | – | – |
Пример вычисления Моды. Найдем моду по формуле (8.16) см. обозначения в таблице, а h = 8000-7000=1000, т.е. получаем:

Пример вычисления Моды
Пример вычисления Медианы интервального вариационного ряда. Рассчитаем медиану по формуле (8.17):
1) сначала находим порядковый номер медианы: NМе = Σfi/2= 5000.
2) по накопленным частотам в соответствии с номером медианы определяем, что 5000 находится в интервале (7000 – 8000), далее значение медианы определим по формуле (8.17):

Пример вычисления Медианы
Вывод: по моде – наиболее часто встречается среднедушевой доход в размере 7730 руб., по медиане – что половина семей города имеет среднедушевой доход ниже 7800 руб., остальные семьи – более 7800 руб.
Пример .СРЕДНИЙ, МЕДИАННЫЙ И МОДАЛЬНЫЙ УРОВЕНЬ ДЕНЕЖНЫХ ДОХОДОВ НАСЕЛЕНИЯ ЦЕЛОМ ПО РОССИИ И ПО СУБЪЕКТАМ РОССИЙСКОЙ ФЕДЕРАЦИИ ЗА 2013 год см. по ссылке. Источник: оценка на основании данных выборочного обследования бюджетов домашних хозяйств и макроэкономического показателя денежных доходов населения
Соотношение моды, медианы и средней арифметической указывает на характер распределения признака в совокупности, позволяет оценить его асимметрию.
Если Мо<Ме<Х – имеет место правосторонняя асимметрия.
При Х<Ме<Мо следует сделать вывод о левосторонней асимметрии ряда.
Средние величины (арифметическая, гармоническая, геометрическая, квадратическая) см. по ссылке
Оценка статьи:
![]() Загрузка…
Загрузка…
3.1.4. Как вычислить среднюю, моду и медиану интервального ряда?
Начнём опять с ситуации, когда нам даны первичные статические данные:
Пример 10
По результатам выборочного исследования цен на ботинки в магазинах города получены следующие данные (ден. ед.):
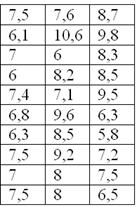
– это в точности числа из Примера 6. Но теперь нам нужно найти среднюю, моду и медиану.
Решение: чтобы найти среднюю по первичным данным, нужно
просуммировать все варианты и разделить полученный результат на объём совокупности:
![]() ден. ед.
ден. ед.
Эти подсчёты, кстати, займут не так много времени и при использовании оффлайн калькулятора. Но если есть Эксель, то,
конечно, забиваем в любую свободную ячейку:
=СУММ(, выделяем мышкой все числа, закрываем скобку ), ставим знак деления /, вводим число 30 и жмём Enter. Готово.
Что касается моды, то её оценка по исходным данным, становится непригодна. Хоть мы и видим среди чисел
одинаковые, но среди них запросто может найтись так 5-6-7 вариант с одинаковой максимальной частотой, например, частотой 2.
Поэтому модальное значение рассчитывается по сформированному интервальному ряду (см. ниже).
Чего не скажешь о медиане: забиваем в Эксель =МЕДИАНА(, выделяем мышью все числа, закрываем
скобку ) и жмём Enter: ![]() . Причём, здесь даже ничего
. Причём, здесь даже ничего
не нужно сортировать.
Но в Примере 6 я проводил сортировку совокупности по возрастанию (вспоминаем и сортируем), и это хорошая возможность
повторить формальный алгоритм отыскания медианы.
Делим объём выборки пополам:
![]() , и поскольку она состоит из чётного
, и поскольку она состоит из чётного
количества вариант, то медиана равна среднему арифметическому 15-й и 16-й варианты упорядоченного (!) вариационного
ряда:
![]() ден. ед.
ден. ед.
Ситуация вторая. Когда даны не первичные данные, а готовый интервальный ряд (что в учебных задачах бывает чаще).
Продолжаем анализировать этот же пример с ботинками, где по исходным данным был составлен ИВР. Для вычисления средней потребуются середины ![]() интервалов:
интервалов:
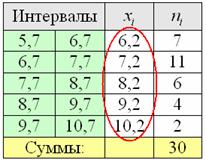
– чтобы воспользоваться знакомой формулой дискретного случая:
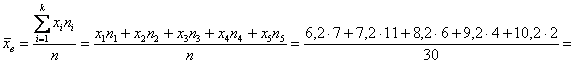
![]() – и это отличный результат! Расхождение с
– и это отличный результат! Расхождение с
более точным значением (![]() ), вычисленным по
), вычисленным по
первичным данным, составило всего 0,04!
Здесь мы использовали упомянутый ранее приём – приблизили интервальный ряд дискретным, и это приближение оказалось
весьма эффективным. Впрочем, с современными программами не составляет особого труда вычислить точное значение даже по
очень большому массиву первичных данных. Если они нам известны 😉
С другими центральными показателями всё занятнее.
Чтобы найти моду, нужно найти модальный интервал (с максимальной частотой) – в нашей задаче
это интервал ![]() с частотой 11, и воспользоваться
с частотой 11, и воспользоваться
следующей страшненькой формулой:
![]() , где:
, где:
![]() – нижняя граница модального интервала;
– нижняя граница модального интервала;
![]() – длина модального интервала;
– длина модального интервала;
![]() – частота модального интервала;
– частота модального интервала;
![]() – частота предыдущего интервала;
– частота предыдущего интервала;
![]() – частота следующего интервала.
– частота следующего интервала.
Таким образом:
![]() ден. ед. – как видите, «модная» цена на
ден. ед. – как видите, «модная» цена на
ботинки заметно отличается от среднего арифметического значения ![]() .
.
Не вдаваясь в геометрию формулы, просто приведу гистограмму относительных частот
и отмечу ![]() :
:
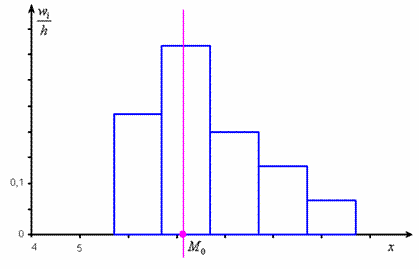
откуда хорошо видно, что мода смещена относительно центра модального интервала в сторону левого интервала
с бОльшей частотой. По той причине, что дешёвых ботинок больше. И, возможно, они тоже вполне себе модные.
Справочно остановлюсь на редких случаях:
– если модальный интервал крайний, то ![]() либо
либо ![]() ;
;
– если обнаружатся два смежных модальных интервала, например, ![]() и
и ![]() ,
,
то рассматриваем модальный интервал ![]() , при этом
, при этом
близлежащие интервалы (слева и справа) по возможности тоже укрупняем в два раза;
– если между модальными интервалами есть расстояние, то применяем формулу к каждому интервалу, получая тем самым две
или бОльшее количество мод.
Вот такой вот депеш мод 🙂
И медиана. Она рассчитывается чуть по менее страшной формуле. Для её применения
нужно найти медианный интервал – это интервал, содержащий варианту (либо 2 варианты), которая делит вариационный ряд на две
равные части.
Выше я рассказал, как определить медиану, ориентируясь на относительные накопленные частоты
![]() , здесь же сподручнее рассчитать
, здесь же сподручнее рассчитать
«обычные» накопленные частоты ![]() . Вычислительный
. Вычислительный
алгоритм такой же – первое значение сносим слева (красная стрелка), а каждое следующее получается как сумма
предыдущего с текущей частотой из левого столбца (зелёные обозначения в качестве примера):
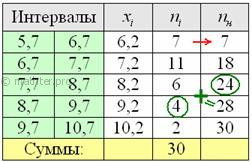
Всем понятен смысл чисел в правом столбце? – это количество вариант, которые успели «накопится» на всех «пройденных»
интервалах, включая текущий.
Поскольку у нас чётное количество вариант (30 штук), то медианным будет тот интервал, который содержит ![]() -ю и 16-ю варианту. И ориентируясь по накопленным частотам, легко
-ю и 16-ю варианту. И ориентируясь по накопленным частотам, легко
прийти к выводу, что эти варианты содержатся в интервале ![]() .
.
Формула медианы:
![]() , где:
, где:
![]() – объём статистической совокупности;
– объём статистической совокупности;
![]() – нижняя граница медианного
– нижняя граница медианного
интервала;
![]() – длина медианного интервала;
– длина медианного интервала;
![]() – частота медианного интервала;
– частота медианного интервала;
![]() – накопленная частота
– накопленная частота
предыдущего интервала.
Таким образом:
![]() ден. ед. – заметим, что медианное
ден. ед. – заметим, что медианное
значение, в отличие от моды, оказалось смещено правее, т.к. по правую руку находится значительное количество вариант:
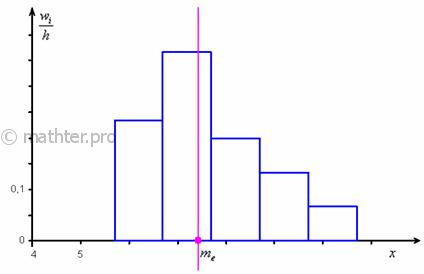
Справочно особые случаи:
– если медианным является крайний левый интервал, то ![]() ;
;
– если вариационный ряд содержит чётное количество вариант и две средние варианты попали в разные интервалы, то
объединяем эти интервалы, и по возможности удваиваем предыдущий интервал.
Ответ: ![]() ден. ед.
ден. ед.
По сравнению с предыдущей задачей ![]() ,
,
центральные показатели оказались заметно отличны друг от друга. Это говорит об асимметрии
(«скошенности») распределения цен, что хорошо видно по гистограмме и совершенно логично –
ботинок низкого и среднего ценового сегмента много, а премиального – мало.
Задание для тренировки:
Пример 11
Для изучения затрат времени на изготовление одной детали рабочими завода проведена выборка, в результате которой получено
следующее статистическое распределение:
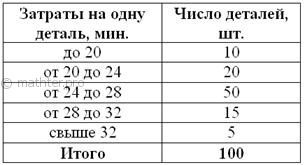
…да, тот самый завод Петровского 🙂 Найти среднюю, моду и медиану.
Решаем эту задачу в Экселе – все числа и инструкции уже там. Если нет Экселя, считаем на
калькуляторе, что в данном случае может оказаться даже удобнее. Образец решения, как обычно, в конце книги. Это, кстати, уже
каноничная «интервальная» задача, в которой исследуется непрерывная величина – время.
Что ещё можно сказать по теме?
Несмотря на разнообразия рассмотренных показателей, их всё равно бывает не достаточно. Существуют крайне неоднородные
совокупности, у которых варианты «кучкуются» во многих местах, и по этой причине средняя, мода и
медиана плохо характеризуют положение дел.
В таких случаях вариационный ряд дробят с помощью квартилей, децилей, а в упоротых специализированных исследованиях – и с
помощью перцентилей.
Квартили упорядоченного вариационного ряда – это варианты ![]() , которые делят его на 4 равные (по количеству вариант) части. Из чего
, которые делят его на 4 равные (по количеству вариант) части. Из чего
автоматически следует, что 2-я квартиль – есть в точности медиана: ![]() .
.
В тяжёлых случаях проводится разбиение на 10 частей – децилями ![]() – это варианты, который делят упорядоченный вариационный ряд на 10 равных (по
– это варианты, который делят упорядоченный вариационный ряд на 10 равных (по
количеству вариант) частей.
И в очень тяжелых случаях в ход пускается 99 перцентилей ![]() .
.
После разбиения вариационного ряда каждый участок исследуется по отдельности – рассчитываются локальные средние и другие
показатели.
В учебном курсе квартили, децили, перцентили встречаются редко, и посему я оставляю этот материал (их нахождение) для
самостоятельного изучения.
Ну а сейчас мы переходим к изучению второй группы статистических показателей:
 3.2. Показатели вариации
3.2. Показатели вариации
 3.1.3. Медиана
3.1.3. Медиана
| Оглавление |
