Введение
ALTER TABLE — один из самых незаменимых инструментов в работе с базами данных SQL. В этой статье мы рассмотрим SQL оператор ALTER TABLE и его применение. Узнаем, как добавить или удалить поля с помощью этого инструмента, и рассмотрим различные примеры его использования. В данной статье мы не будем рассматривать MS SQL и остановимся на синтаксисе наиболее популярной версии — MySQL.
Синтаксис оператора ALTER TABLE в SQL
Синтаксис оператора ALTER TABLE выглядит следующим образом:
ALTER TABLE название_таблицы [WITH CHECK | WITH NOCHECK]
{ ADD название_столбца тип_данных_столбца [атрибуты_столбца] |
DROP COLUMN название_столбца |
ALTER COLUMN название_столбца тип_данных_столбца [NULL|NOT NULL] |
ADD [CONSTRAINT] определение_ограничения |
DROP [CONSTRAINT] имя_ограничения}
Из этой записи мы видим, что сценариев применения данной команды достаточно много. Давайте рассмотрим их. В качестве примера мы будем использовать базу данных slcbookshelf, которую мы создавали в статье о первичных и внешних SQL ключах.
use slcbookshelf;
Добавление столбца в таблицу (ADD COLUMN)
Сейчас наша таблица выглядит следующим образом:
mysql> DESC books;
+---------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------------+--------------+------+-----+---------+-------+
| book_id | int | NO | | NULL | |
| book_name | varchar(255) | NO | | NULL | |
| book_category | varchar(255) | YES | | NULL | |
+---------------+--------------+------+-----+---------+-------+
3 rows in set (0.00 sec)
Давайте добавим в нашу таблицу новый столбец, в котором будет отображаться автор каждой книги:
ALTER TABLE books
ADD author NVARCHAR(50) NOT NULL;
Данным запросом мы создали в нашей таблице новый столбец authors с типом NVARCHAR и длиной в 50 символов, который не может принимать пустое значение. Если мы не знаем автора произведения, тогда наша команда будет иметь такой вид:
ALTER TABLE books
ADD author NVARCHAR(50) NOT NULL DEFAULT 'Неизвестен';
Теперь для существующих данных, для которых не заполнен столбец author, значение по умолчанию будет «Неизвестен».
Переименование столбца и таблицы
Переименование столбца (RENAME)
С помощью ALTER TABLE можно переименовать существующий столбец. Для этого выполните команду:
ALTER TABLE books
RENAME COLUMN author TO authors;
Переименование таблицы (RENAME)
При помощи ALTER TABLE можно переименовать таблицу. Выполняем запрос:
ALTER TABLE books
RENAME TO books_selectel;
Удаление столбца (DROP)
Чтобы удалить столбец из таблицы с помощью ALTER TABLE, требуется выполнить следующий запрос:
ALTER TABLE books
DROP COLUMN authors;
Изменение столбца (ALTER COLUMN)
Иногда бывают случаи, когда необходимо изменить уже созданный ранее столбец. Это действие можно выполнить с помощью команды ALTER TABLE. Для изменения существующего столбца необходимо выполнить такой запрос:
ALTER TABLE books
ALTER COLUMN book_category VARCHAR(200);
В данном примере мы изменили максимальное количество символов, которое может использоваться в полях столбца book_category с 255 до 200.
Также с помощью ALTER TABLE можно сделать действие сразу с несколькими столбцами. Чтобы изменить сразу несколько столбцов, вам потребуется использовать эту команду:
ALTER TABLE books
MODIFY book_category VARCHAR(200),
MODIFY book_name VARCHAR(200),
...
;
Таким запросом мы изменили сразу два столбца: book_category и book_name.
Изменение типа столбца
При помощи ALTER TABLE можно изменить тип столбца в таблице SQL. Изменение типа существующего столбца осуществляется при помощи команды:
ALTER TABLE books
ALTER COLUMN book_category NVARCHAR(200);
Выполнив эту команду, мы изменили тип book_category на NVARCHAR(200).
Добавление первичного и внешнего ключей при помощи ALTER TABLE
Вы можете определить существующий столбец в таблице в качестве первичного ключа с помощью команды ALTER TABLE. Запрос, добавляющий в таблицу первичный ключ, будет выглядеть следующим образом:
ALTER TABLE books
ADD PRIMARY KEY (book_id);
Аналогично при помощи ALTER TABLE можно добавить внешний ключ таблицы. Чтобы создать внешний ключ для таблицы MySQL выполните команду:
ALTER TABLE books ADD FOREIGN KEY (author_id) REFERENCES authors(author_id);
В результате выполнения этой команды поле author_id в таблице books будет внешним ключом для аналогичного поля в таблице authors.
Работа с ограничениями
Ограничения — специальные правила, которые применяются к таблице, чтобы ограничить типы данных в таблице. Ограничения очень важны, так как их правильное применение помогает обеспечить целостность данных в таблицах и наладить стабильную работу базы. Давайте рассмотрим одно из таких ограничений — ограничение CHECK. Применяя ограничения CHECK к столбцу таблицы, мы создаем правило, по которому при добавлении данных СУБД будет автоматически проверять их на соответствии заданным правилам.
Создание ограничения
Например, если нам необходимо, чтобы все клиенты в базе данных Customers имели возраст больше 21 года, мы можем установить следующее ограничение:
ALTER TABLE Customers
ADD CHECK (Age > 21);
При применении такого ограничения стоит учитывать, что если в столбце уже существуют данные, не соответствующие ограничению, то команда будет выполнена с ошибкой. Чтобы избежать подобного поведения, вы можете добавить ограничение со значением WITH NOCHECK. Таким образом, текущие значения столбца не вызовут ошибок при выполнении запроса при несоответствии ограничению:
ALTER TABLE Customers WITH NOCHECK
ADD CHECK (Age > 21);
Добавление ограничений с именами
Так как ограничений в таблицах может быть много, добавление имен к ограничениям может в значительной мере упростить будущую работу с таблицей. Создать имя для ограничения можно при помощи оператора CONSTRAINT:
ALTER TABLE Customers
ADD CONSTRAINT Check_Age_Greater_Than_Twenty_One CHECK (Age > 21);
Удаление ограничений
ALTER TABLE можно пользоваться и для удаления ограничений. Для удаления существующих ограничений необходимо выполнить следующую команду:
ALTER TABLE Customers
DROP Check_Age_Greater_Than_Twenty_One;
После выполнения этой команды ограничение перестанет применяться при добавлении новых данных в столбец.
Заключение
В данной статье мы с вами узнали что такое ALTER TABLE, рассмотрели работу с этой командой и научились вносить с ее помощью изменения в таблицы и столбцы, а также рассмотрели несколько примеров использования данной команды, которые сильно упростят будущую работу с базами данных.
Изменение таблицы
Последнее обновление: 09.07.2017
Возможно, в какой-то момент мы захотим изменить уже имеющуюся таблицу. Например, добавить или удалить столбцы, изменить тип столбцов, добавить или удалить ограничения.
То есть потребуется изменить определение таблицы. Для изменения таблиц используется выражение ALTER TABLE.
Общий формальный синтаксис команды выглядит следующим образом:
ALTER TABLE название_таблицы [WITH CHECK | WITH NOCHECK]
{ ADD название_столбца тип_данных_столбца [атрибуты_столбца] |
DROP COLUMN название_столбца |
ALTER COLUMN название_столбца тип_данных_столбца [NULL|NOT NULL] |
ADD [CONSTRAINT] определение_ограничения |
DROP [CONSTRAINT] имя_ограничения}
Таким образом, с помощью ALTER TABLE мы можем провернуть самые различные сценарии изменения таблицы. Рассмотрим некоторые из них.
Добавление нового столбца
Добавим в таблицу Customers новый столбец Address:
ALTER TABLE Customers ADD Address NVARCHAR(50) NULL;
В данном случае столбец Address имеет тип NVARCHAR и для него определен атрибут NULL. Но что если нам надо добавить столбец, который не должен принимать
значения NULL? Если в таблице есть данные, то следующая команда не будет выполнена:
ALTER TABLE Customers ADD Address NVARCHAR(50) NOT NULL;
Поэтому в данном случае решение состоит в установке значения по умолчанию через атрибут DEFAULT:
ALTER TABLE Customers ADD Address NVARCHAR(50) NOT NULL DEFAULT 'Неизвестно';
В этом случае, если в таблице уже есть данные, то для них для столбца Address будет добавлено значение “Неизвестно”.
Удаление столбца
Удалим столбец Address из таблицы Customers:
ALTER TABLE Customers DROP COLUMN Address;
Изменение типа столбца
Изменим в таблице Customers тип данных у столбца FirstName на NVARCHAR(200):
ALTER TABLE Customers ALTER COLUMN FirstName NVARCHAR(200);
Добавление ограничения CHECK
При добавлении ограничений SQL Server автоматически проверяет имеющиеся данные на соответствие добавляемым ограничениям. Если данные не соответствуют
ограничениям, то такие ограничения не будут добавлены. Например, установим для столбца Age в таблице Customers ограничение Age > 21.
ALTER TABLE Customers ADD CHECK (Age > 21);
Если в таблице есть строки, в которых в столбце Age есть значения, несоответствующие этому ограничению, то sql-команда завершится с ошибкой.
Чтобы избежать подобной проверки на соответствие и все таки добавить ограничение, несмотря на наличие несоответствующих ему данных,
используется выражение WITH NOCHECK:
ALTER TABLE Customers WITH NOCHECK ADD CHECK (Age > 21);
По умолчанию используется значение WITH CHECK, которое проверяет на соответствие ограничениям.
Добавление внешнего ключа
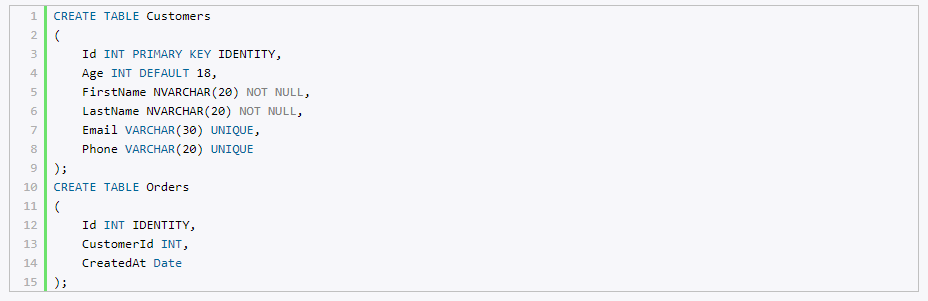
Пусть изначально в базе данных будут добавлены две таблицы, никак не связанные:
CREATE TABLE Customers ( Id INT PRIMARY KEY IDENTITY, Age INT DEFAULT 18, FirstName NVARCHAR(20) NOT NULL, LastName NVARCHAR(20) NOT NULL, Email VARCHAR(30) UNIQUE, Phone VARCHAR(20) UNIQUE ); CREATE TABLE Orders ( Id INT IDENTITY, CustomerId INT, CreatedAt Date );
Добавим ограничение внешнего ключа к столбцу CustomerId таблицы Orders:
ALTER TABLE Orders ADD FOREIGN KEY(CustomerId) REFERENCES Customers(Id);
Добавление первичного ключа
Используя выше определенную таблицу Orders, добавим к ней первичный ключ для столбца Id:
ALTER TABLE Orders ADD PRIMARY KEY (Id);
Добавление ограничений с именами
При добавлении ограничений мы можем указать для них имя, используя оператор CONSTRAINT, после которого указывается имя ограничения:
ALTER TABLE Orders
ADD CONSTRAINT PK_Orders_Id PRIMARY KEY (Id),
CONSTRAINT FK_Orders_To_Customers FOREIGN KEY(CustomerId) REFERENCES Customers(Id);
ALTER TABLE Customers
ADD CONSTRAINT CK_Age_Greater_Than_Zero CHECK (Age > 0);
Удаление ограничений
Для удаления ограничений необходимо знать их имя. Если мы точно не знаем имя ограничения, то его можно узнать через SQL Server Management Studio:
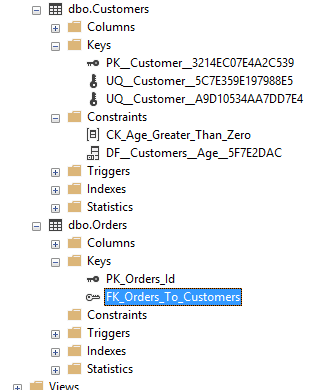
Раскрыв узел таблиц в подузле Keys можно увидеть названия ограничений первичного и внешних ключей. Названия ограничений внешних ключей
начинаются с “FK”. А в подузле Constraints можно найти все ограничения CHECK и DEFAULT. Названия ограничений CHECK начинаются с “CK”,
а ограничений DEFAULT – с “DF”.
Например, как видно на скриншоте в моем случае имя ограничения внешнего ключа в таблице Orders называется “FK_Orders_To_Customers”.
Поэтому для удаления внешнего ключа я могу использовать следующее выражение:
ALTER TABLE Orders DROP FK_Orders_To_Customers;
В этом материале я покажу, как вносятся изменения в таблицы в Microsoft SQL Server, под изменениями здесь подразумевается добавление новых столбцов, удаление или изменение характеристик уже существующих столбцов в таблице. По традиции я покажу, как это делается в графическом конструкторе среды SQL Server Management Studio и, конечно же, как это делается на языке T-SQL.

Напомню, в прошлых статьях я показывал, как создаются базы данных в Microsoft SQL Server, а также как создаются новые таблицы. Сегодня Вы узнаете, как изменить уже существующие таблицы в Microsoft SQL Server, при этом, как было уже отмечено, будет рассмотрено два способа изменения таблиц: первый – с помощью SQL Server Management Studio (SSMS), и второй – с помощью T-SQL.
Также я расскажу о некоторых нюансах и проблемах, которые могут возникнуть в процессе изменения таблиц, что, на самом деле, характерно для большинства случаев.
Заметка! Для комплексного изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL, в которых используется последовательная методика обучения и рассматриваются все конструкции языка SQL и T-SQL.
Содержание
- Исходные данные для примеров
- Изменение таблиц в конструкторе SQL Server Management Studio
- Изменение таблиц в Microsoft SQL Server на языке T-SQL (ALTER TABLE)
- Упрощенный синтаксис инструкции ALTER TABLE
- Добавление нового столбца в таблицу на T-SQL
- Удаление столбца из таблицы на T-SQL
- Задаем свойство NOT NULL для столбца на T-SQL
- Изменяем тип данных столбца на T-SQL
- Видео-инструкция по изменению таблиц в Microsoft SQL Server
Исходные данные для примеров
Сначала давайте определим исходные данные, а точнее таблицу, которую мы будем изменять. Допустим, это будет точно такая же таблица, которую мы использовали в прошлых статьях, а именно наша тестовая таблица Goods – она содержит информацию о товарах и имеет следующие столбцы:
- ProductId – идентификатор товара, столбец не может содержать значения NULL, первичный ключ;
- Category – ссылка на категорию товара, столбец не может содержать значения NULL, но имеет значение по умолчанию, например, для случаев, когда товар еще не распределили в необходимую категорию, в этом случае товару будет присвоена категория по умолчанию;
- ProductName – наименование товара, столбец не может содержать значения NULL;
- Price – цена товара, столбец может содержать значения NULL, например, с ценой еще не определились.
Если у Вас нет такой таблицы, то создайте ее и добавьте в нее несколько строк данных, например, следующей инструкцией.
--Создание таблицы с товарами
CREATE TABLE Goods (
ProductId INT IDENTITY(1,1) NOT NULL CONSTRAINT PK_ProductId PRIMARY KEY,
Category INT NOT NULL DEFAULT (1),
ProductName VARCHAR(100) NOT NULL,
Price MONEY NULL,
);
GO
--Добавление строк в таблицу
INSERT INTO Goods(Category, ProductName, Price)
VALUES (1, 'Системный блок', 300),
(1, 'Монитор', 200),
(2, 'Клавиатура', 100);
GO
--Выборка данных
SELECT * FROM Goods;
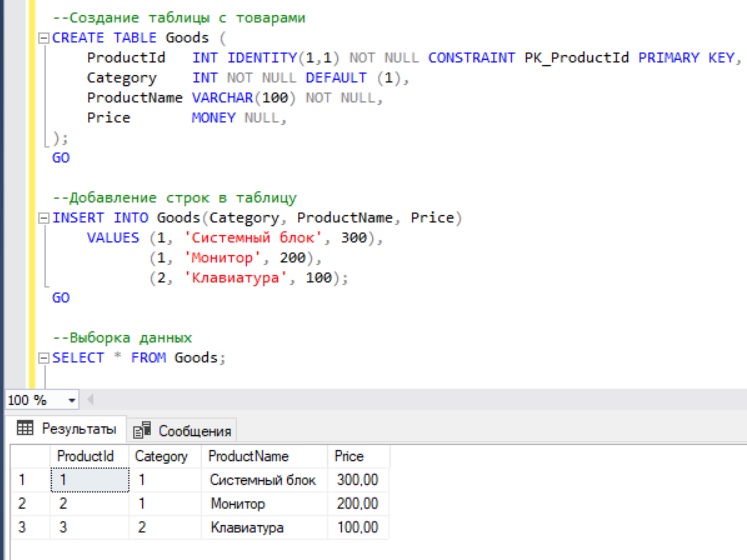
Данные мы добавили инструкцией INSERT INTO языка T-SQL.
Примечание! В качестве сервера у меня выступает версия Microsoft SQL Server 2017 Express, как ее установить, можете посмотреть в моей видео-инструкции.
Итак, давайте начнем.
Изменение таблиц в конструкторе SQL Server Management Studio
Сначала я покажу, как изменяются таблицы с помощью графического интерфейса SQL Server Management Studio, а изменяются они точно так же, как и создаются, с помощью того же самого конструктора.
Чтобы открыть конструктор таблиц в среде SQL Server Management Studio, необходимо в обозревателе объектов найти нужную таблицу и щелкнуть по ней правой кнопкой мыши, и выбрать пункт «Проект». Увидеть список таблиц можно в контейнере «Базы данных -> Нужная база данных -> Таблицы».
В итоге откроется конструктор таблиц, где Вы можете добавлять, удалять или изменять столбцы таблицы.
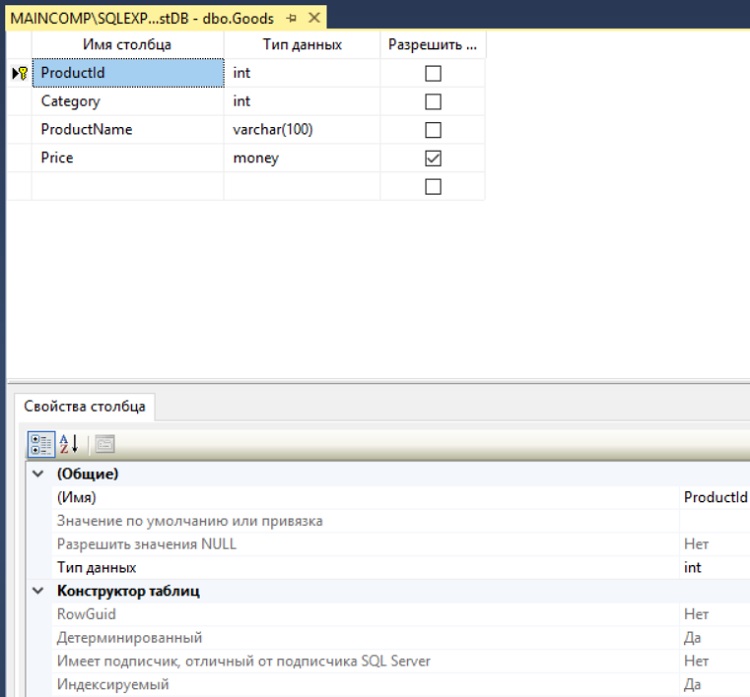
Важно! При работе в конструкторе с таблицей, в которой есть данные, обязательно стоит учитывать один очень важный момент, большинство изменений внести не получится, например, изменить свойства столбцов. Это связано с тем, что по умолчанию в конструкторе «Запрещено сохранение изменений, требующих повторного создания таблицы», именно так и называется параметр, который по умолчанию включён, за счет чего все соответствующие изменения будут блокироваться и, при попытке сохранить такие изменения, Вы будете получать, например, ошибки следующего характера
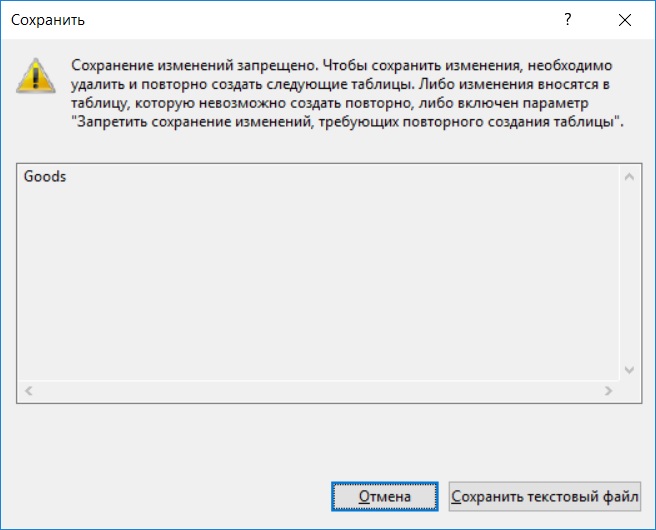
В случае если Вы работаете исключительно в конструкторе (если делать все то же самое с помощью T-SQL, то такая ошибка возникать не будет) и четко уверены в своих действиях, то этот параметр можно отключить. Для этого зайдите в меню «Сервис -> Параметры» и в разделе «Конструкторы -> Конструкторы таблиц и баз данных» снимите соответствующую галочку.
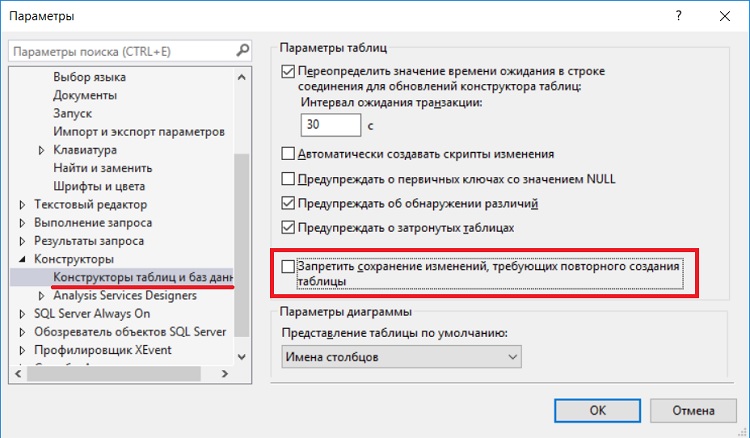

После чего данное ограничение будет снято, и Вы сможете вносить изменения в таблицы с помощью конструктора. При сохранении таблицы ошибок возникать уже не будет.
Как работать с конструктором, я думаю, понятно, например, для добавления нового столбца просто пишем название столбца в новую строку, выбираем тип данных и указываем признак, может ли данный столбец хранить значения NULL. Для сохранения изменений нажимаем сочетание клавиш «Ctrl+S» или на панели инструментов нажимаем кнопку «Сохранить» (также кнопка «сохранить» доступна и в меню «Файл», и в контекстном меню самой вкладки конструктора).
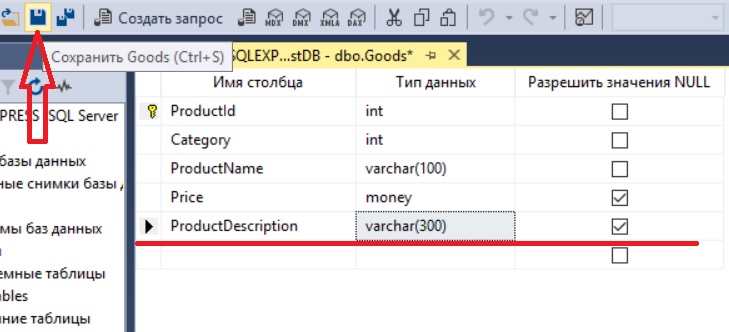
Для внесения изменений в существующие столбцы точно так же изменяем параметры, и сохраняем изменения.
Важно!
Во всех случаях, т.е. не важно с помощью конструктора или с помощью языка T-SQL, когда Вы будете вносить изменения в таблицы, в которых уже есть данные, важно понимать и знать, как эти изменения отразятся на существующих данных, и можно ли вообще применить эти изменения к данным.
Например, изменить тип данных можно, только если он явно преобразовывается без потери данных или в столбце нет данных вообще. Допустим, если в столбце с типом данных VARCHAR(100) есть данные, при этом максимальная длина фактических данных в столбце, к примеру, 80 символов, то изменить тип данных, без потери данных можно только в сторону увеличения или уменьшения до 80 символов (VARCHAR(80)).
Также если в столбце есть данные, при этом он может принимать значение NULL, а Вы хотите сделать его обязательным, т.е. задать свойство NOT NULL, Вам сначала нужно проставить всем записям, в которых есть NULL, значение, например, то, которое будет использоваться по умолчанию, или уже более детально провести анализ для корректной простановки значений.
Еще стоит отметить, что даже просто добавить новый столбец, который не должен принимать значения NULL, не получится, если в таблице уже есть записи, в таких случаях нужно сначала добавить столбец с возможностью принятия значения NULL, потом заполнить его данными, и уже потом обновить данный параметр, т.е. указать NOT NULL.
Изменение таблиц в Microsoft SQL Server на языке T-SQL (ALTER TABLE)
Теперь давайте я покажу, как изменять таблицы в Microsoft SQL Server на T-SQL. Все изменения в таблицы вносятся с помощью инструкции ALTER TABLE. Для начала давайте рассмотрим упрощённый синтаксис инструкции ALTER TABLE, чтобы Вы лучше понимали структуру тех запросов, которые мы будем рассматривать далее в примерах.
Упрощенный синтаксис инструкции ALTER TABLE
ALTER TABLE [Название таблицы] [Тип изменения] [Название столбца] [Тип данных]
[Возможность принятия значения NULL]
Добавление нового столбца в таблицу на T-SQL
Чтобы добавить новый столбец в таблицу, мы пишем инструкцию ALTER TABLE с параметром ADD, указываем название нового столбца (в нашем случае ProductDescription, т.е. описание товара), его тип данных и возможность принятия значения NULL (как было уже отмечено ранее, если в таблице есть строки, то сначала столбец должен принимать значения NULL).
ALTER TABLE Goods ADD ProductDescription VARCHAR(300) NULL; GO SELECT * FROM Goods;
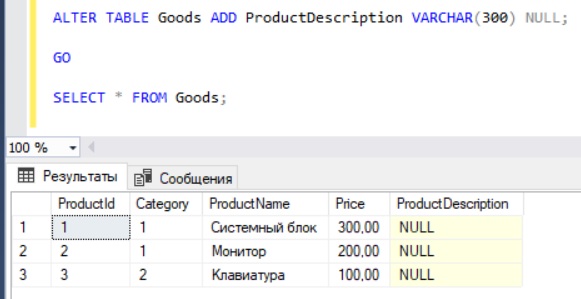
Удаление столбца из таблицы на T-SQL
Если Вам столбец не нужен, то его легко удалить (если он не участвует ни в каких связях) параметром DROP COLUMN, например, мы передумали добавлять новый столбец с описанием товара, и чтобы его удалить, пишем следующую инструкцию.
ALTER TABLE Goods DROP COLUMN ProductDescription; GO SELECT * FROM Goods;
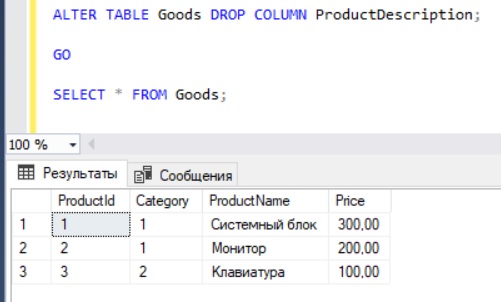
Задаем свойство NOT NULL для столбца на T-SQL
Если у Вас возникла необходимость сделать столбец обязательным, т.е. задать свойство NOT NULL для столбца, то для этого необходимо использовать параметр ALTER COLUMN, но обязательно помним о том, что в столбце уже должны быть заполнены все строки, т.е. отсутствовать значения NULL.
Допустим, в нашем случае цена стала обязательной, чтобы это реализовать в нашей таблице, пишем следующую инструкцию (просто указываем все фактические параметры столбца и изменяем тот, который нужно, в данном конкретном случае возможность принятия значения NULL).
ALTER TABLE Goods ALTER COLUMN Price MONEY NOT NULL;
Изменяем тип данных столбца на T-SQL
Для изменения типа данных столбца точно так же перечисляем все параметры столбца с изменением нужного, т.е. указываем новый тип данных.
Допустим, у нас возникла необходимость увеличить длину строки для хранения наименования товара (например, до 200 символов).
ALTER TABLE Goods ALTER COLUMN ProductName VARCHAR(200) NOT NULL;
У меня на этом все, надеюсь, материал был Вам полезен, пока!
Команда ALTER TABLE применяется в SQL при добавлении, удалении либо модификации колонки в существующей таблице. В этой статье будет рассмотрен синтаксис и примеры использования ALTER TABLE на примере MS SQL Server.

SQL-оператор ALTER TABLE способен менять определение таблицы несколькими способами:
• добавлением/переопределением/удалением столбца (column);
• модифицированием характеристик памяти;
• включением, выключением либо удалением ограничения целостности.
При этом пользователю нужно обладать системной привилегией ALTER ANY TABLE либо таблица должна находиться в схеме пользователя.
Меняя типы данных существующих columns либо добавляя их в БД-таблицу, следует соблюдать некоторые условия. Принято, что увеличение есть хорошо, а уменьшение — не очень. Существует ряд допустимых увеличений:
• добавляем новые столбцы в таблицу;
• увеличиваем размер столбца CHAR либо VARCHAR2;
• увеличиваем размер столбца NUMBER.
Нередко перед внесением изменений следует удостовериться, что в соответствующих columns все значения — это NULL-значения. Если выполняется операция над столбцами, которые содержат данные, следует найти либо создать область временного хранения данных. Можно создать таблицу посредством CREATE TABLE AS SELECT, где извлекаются данные из первичного ключа и изменяемых columns. Существует ряд допустимых изменений:
• уменьшаем размер столбца NUMBER (лишь при наличии пустого column для всех строк);
• уменьшаем размер столбца CHAR либо VARCHAR2 (лишь при наличии пустого column для всех строк);
• меняем тип данных столбца (аналогично, что и в первых двух пунктах).
При добавлении column с ограничением NOT NULL, администратор баз данных либо разработчик обязан учесть некоторые обстоятельства. Вначале следует создать столбец без ограничения, потом ввести значения во все строки. Далее, когда значения column будут уже не NULL, к нему можно будет применить ограничение NOT NULL. Но если column с ограничением NOT NULL хочет добавить юзер, то вернётся сообщение об ошибке, судя по которому таблица должна быть либо пустой, либо содержать в столбце значения для каждой имеющейся строки (после наложения на column NOT NULL-ограничения, в нём не смогут присутствовать значения NULL ни в одной из имеющихся строк).
Синтаксис ALTER TABLE на примере MS SQL Server
Рассмотрим общий формальный синтаксис на примере SQL Server от Microsoft:
ALTER TABLE имя_таблицы [WITH CHECK | WITH NOCHECK] { ADD имя_столбца тип_данных_столбца [атрибуты_столбца] | DROP COLUMN имя_столбца | ALTER COLUMN имя_столбца тип_данных_столбца [NULL|NOT NULL] | ADD [CONSTRAINT] определение_ограничения | DROP [CONSTRAINT] имя_ограничения}Итак, используя SQL-оператор ALTER TABLE, мы сможем выполнить разные сценарии изменения таблицы. Далее будут рассмотрены некоторые из этих сценариев.
Добавляем новый столбец
Для примера добавим новый column Address в таблицу Customers:
ALTER TABLE Customers ADD Address NVARCHAR(50) NULL;В примере выше столбец Address имеет тип NVARCHAR, плюс для него определён NULL-атрибут. Если же в таблице уже существуют данные, команда ALTER TABLE не выполнится. Однако если надо добавить столбец, который не должен принимать NULL-значения, можно установить значение по умолчанию, используя атрибут DEFAULT:
ALTER TABLE Customers ADD Address NVARCHAR(50) NOT NULL DEFAULT 'Неизвестно';Тогда, если в таблице существуют данные, для них для column Address добавится значение “Неизвестно”.
Удаляем столбец
Теперь можно удалить column Address:
ALTER TABLE Customers DROP COLUMN Address;Меняем тип
Продолжим манипуляции с таблицей Customers: теперь давайте поменяем тип данных столбца FirstName на NVARCHAR(200).
ALTER TABLE Customers ALTER COLUMN FirstName NVARCHAR(200);Добавляем ограничения CHECK
Если добавлять ограничения, SQL Server автоматически проверит существующие данные на предмет их соответствия добавляемым ограничениям. В случае несоответствия, они не добавятся. Давайте ограничим Age по возрасту.
ALTER TABLE Customers ADD CHECK (Age > 21);При наличии в таблице строк со значениями, которые не соответствуют ограничению, sql-команда не выполнится. Если надо избежать проверки и добавить ограничение всё равно, используют выражение WITH NOCHECK:
ALTER TABLE Customers WITH NOCHECK ADD CHECK (Age > 21);По дефолту применяется значение WITH CHECK, проверяющее на соответствие ограничениям.
Добавляем внешний ключ
Представим, что изначально в базу данных будут добавлены 2 таблицы, которые между собой не связаны:
Теперь добавим к столбцу CustomerId ограничение внешнего ключа (таблица Orders):
ALTER TABLE Orders ADD FOREIGN KEY(CustomerId) REFERENCES Customers(Id);Добавляем первичный ключ
Применяя определенную выше таблицу Orders, можно добавить к ней для столбца Id первичный ключ:
ALTER TABLE Orders ADD PRIMARY KEY (Id);Добавляем ограничения с именами
Добавляя ограничения, можно указать имя для них — для этого пригодится оператор CONSTRAINT (имя прописывается после него):
Удаляем ограничения
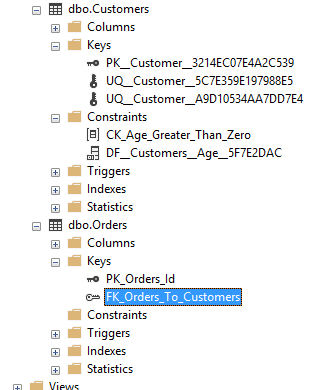
Чтобы удалить ограничения, следует знать их имя. Если с этим проблема, имя всегда можно определить с помощью SQL Server Management Studio:
Следует раскрыть в подузле Keys узел таблиц, где находятся названия ограничений для внешних ключей (названия начинаются с «FK»). Обнаружить все ограничения DEFAULT (названия начинаются с «DF») и CHECK («СК») можно в подузле Constraints.
Из скриншота видно, что в данной ситуации имя ограничения внешнего ключа (таблица Orders) имеет название “FK_Orders_To_Customers”. Здесь для удаления внешнего подойдёт такое выражение:
ALTER TABLE Orders DROP FK_Orders_To_Customers;Хотите знать про SQL Server больше? Добро пожаловать на курс “MS SQL Server Developer” в OTUS! Также вас может заинтересовать общий курс по работе с реляционными и нереляционными БД:
Источники:
• https://metanit.com/sql/sqlserver/3.6.php;
• https://sql-language.ru/alter-table.html.


| title | description | author | ms.author | ms.reviewer | ms.date | ms.service | ms.subservice | ms.topic | f1_keywords | helpviewer_keywords | dev_langs | monikerRange | |||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
ALTER TABLE (Transact-SQL) |
ALTER TABLE modifies a table definition by altering, adding, or dropping columns and constraints. ALTER TABLE also reassigns and rebuilds partitions, or disables and enables constraints and triggers. |
markingmyname |
maghan |
randolphwest |
07/25/2022 |
sql |
t-sql |
reference |
|
|
TSQL |
>=aps-pdw-2016||=azuresqldb-current||=azure-sqldw-latest||>=sql-server-2016||>=sql-server-linux-2017||=azuresqldb-mi-current |
ALTER TABLE (Transact-SQL)
[!INCLUDE sql-asdb-asdbmi-asa-pdw]
Modifies a table definition by altering, adding, or dropping columns and constraints. ALTER TABLE also reassigns and rebuilds partitions, or disables and enables constraints and triggers.
[!IMPORTANT]
The syntax for ALTER TABLE is different for disk-based tables and memory-optimized tables. Use the following links to take you directly to the appropriate syntax block for your table types and to the appropriate syntax examples:
Disk-based tables:
- Syntax
- Examples
Memory-optimized tables
- Syntax
- Examples
For more information about the syntax conventions, see Transact-SQL syntax conventions.
Syntax for disk-based tables
ALTER TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
{
ALTER COLUMN column_name
{
[ type_schema_name. ] type_name
[ (
{
precision [ , scale ]
| max
| xml_schema_collection
}
) ]
[ COLLATE collation_name ]
[ NULL | NOT NULL ] [ SPARSE ]
| { ADD | DROP }
{ ROWGUIDCOL | PERSISTED | NOT FOR REPLICATION | SPARSE | HIDDEN }
| { ADD | DROP } MASKED [ WITH ( FUNCTION = ' mask_function ') ]
}
[ WITH ( ONLINE = ON | OFF ) ]
| [ WITH { CHECK | NOCHECK } ]
| ADD
{
<column_definition>
| <computed_column_definition>
| <table_constraint>
| <column_set_definition>
} [ ,...n ]
| [ system_start_time_column_name datetime2 GENERATED ALWAYS AS ROW START
[ HIDDEN ] [ NOT NULL ] [ CONSTRAINT constraint_name ]
DEFAULT constant_expression [WITH VALUES] ,
system_end_time_column_name datetime2 GENERATED ALWAYS AS ROW END
[ HIDDEN ] [ NOT NULL ][ CONSTRAINT constraint_name ]
DEFAULT constant_expression [WITH VALUES] ,
start_transaction_id_column_name bigint GENERATED ALWAYS AS TRANSACTION_ID START
[ HIDDEN ] NOT NULL [ CONSTRAINT constraint_name ]
DEFAULT constant_expression [WITH VALUES],
end_transaction_id_column_name bigint GENERATED ALWAYS AS TRANSACTION_ID END
[ HIDDEN ] NULL [ CONSTRAINT constraint_name ]
DEFAULT constant_expression [WITH VALUES],
start_sequence_number_column_name bigint GENERATED ALWAYS AS SEQUENCE_NUMBER START
[ HIDDEN ] NOT NULL [ CONSTRAINT constraint_name ]
DEFAULT constant_expression [WITH VALUES],
end_sequence_number_column_name bigint GENERATED ALWAYS AS SEQUENCE_NUMBER END
[ HIDDEN ] NULL [ CONSTRAINT constraint_name ]
DEFAULT constant_expression [WITH VALUES]
]
PERIOD FOR SYSTEM_TIME ( system_start_time_column_name, system_end_time_column_name )
| DROP
[ {
[ CONSTRAINT ][ IF EXISTS ]
{
constraint_name
[ WITH
( <drop_clustered_constraint_option> [ ,...n ] )
]
} [ ,...n ]
| COLUMN [ IF EXISTS ]
{
column_name
} [ ,...n ]
| PERIOD FOR SYSTEM_TIME
} [ ,...n ]
| [ WITH { CHECK | NOCHECK } ] { CHECK | NOCHECK } CONSTRAINT
{ ALL | constraint_name [ ,...n ] }
| { ENABLE | DISABLE } TRIGGER
{ ALL | trigger_name [ ,...n ] }
| { ENABLE | DISABLE } CHANGE_TRACKING
[ WITH ( TRACK_COLUMNS_UPDATED = { ON | OFF } ) ]
| SWITCH [ PARTITION source_partition_number_expression ]
TO target_table
[ PARTITION target_partition_number_expression ]
[ WITH ( <low_priority_lock_wait> ) ]
| SET
(
[ FILESTREAM_ON =
{ partition_scheme_name | filegroup | "default" | "NULL" } ]
| SYSTEM_VERSIONING =
{
OFF
| ON
[ ( HISTORY_TABLE = schema_name . history_table_name
[, DATA_CONSISTENCY_CHECK = { ON | OFF } ]
[, HISTORY_RETENTION_PERIOD =
{
INFINITE | number {DAY | DAYS | WEEK | WEEKS
| MONTH | MONTHS | YEAR | YEARS }
}
]
)
]
}
| DATA_DELETION =
{
OFF
| ON
[( [ FILTER_COLUMN = column_name ]
[, RETENTION_PERIOD = { INFINITE | number {DAY | DAYS | WEEK | WEEKS
| MONTH | MONTHS | YEAR | YEARS }}]
)]
}
| REBUILD
[ [PARTITION = ALL]
[ WITH ( <rebuild_option> [ ,...n ] ) ]
| [ PARTITION = partition_number
[ WITH ( <single_partition_rebuild_option> [ ,...n ] ) ]
]
]
| <table_option>
| <filetable_option>
| <stretch_configuration>
}
[ ; ]
-- ALTER TABLE options
<column_set_definition> ::=
column_set_name XML COLUMN_SET FOR ALL_SPARSE_COLUMNS
<drop_clustered_constraint_option> ::=
{
MAXDOP = max_degree_of_parallelism
| ONLINE = { ON | OFF }
| MOVE TO
{ partition_scheme_name ( column_name ) | filegroup | "default" }
}
<table_option> ::=
{
SET ( LOCK_ESCALATION = { AUTO | TABLE | DISABLE } )
}
<filetable_option> ::=
{
[ { ENABLE | DISABLE } FILETABLE_NAMESPACE ]
[ SET ( FILETABLE_DIRECTORY = directory_name ) ]
}
<stretch_configuration> ::=
{
SET (
REMOTE_DATA_ARCHIVE
{
= ON (<table_stretch_options>)
| = OFF_WITHOUT_DATA_RECOVERY ( MIGRATION_STATE = PAUSED )
| ( <table_stretch_options> [, ...n] )
}
)
}
<table_stretch_options> ::=
{
[ FILTER_PREDICATE = { null | table_predicate_function } , ]
MIGRATION_STATE = { OUTBOUND | INBOUND | PAUSED }
}
<single_partition_rebuild__option> ::=
{
SORT_IN_TEMPDB = { ON | OFF }
| MAXDOP = max_degree_of_parallelism
| DATA_COMPRESSION = { NONE | ROW | PAGE | COLUMNSTORE | COLUMNSTORE_ARCHIVE} }
| ONLINE = { ON [( <low_priority_lock_wait> ) ] | OFF }
}
<low_priority_lock_wait>::=
{
WAIT_AT_LOW_PRIORITY ( MAX_DURATION = <time> [ MINUTES ],
ABORT_AFTER_WAIT = { NONE | SELF | BLOCKERS } )
}
[!NOTE]
For more information, see:
- ALTER TABLE column_constraint
- ALTER TABLE column_definition
- ALTER TABLE computed_column_definition
- ALTER TABLE index_option
- ALTER TABLE table_constraints
Syntax for memory-optimized tables
ALTER TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
{
ALTER COLUMN column_name
{
[ type_schema_name. ] type_name
[ (
{
precision [ , scale ]
}
) ]
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
}
| ALTER INDEX index_name
{
[ type_schema_name. ] type_name
REBUILD
[ [ NONCLUSTERED ] WITH ( BUCKET_COUNT = bucket_count )
]
}
| ADD
{
<column_definition>
| <computed_column_definition>
| <table_constraint>
| <table_index>
| <column_index>
} [ ,...n ]
| DROP
[ {
CONSTRAINT [ IF EXISTS ]
{
constraint_name
} [ ,...n ]
| INDEX [ IF EXISTS ]
{
index_name
} [ ,...n ]
| COLUMN [ IF EXISTS ]
{
column_name
} [ ,...n ]
| PERIOD FOR SYSTEM_TIME
} [ ,...n ]
| [ WITH { CHECK | NOCHECK } ] { CHECK | NOCHECK } CONSTRAINT
{ ALL | constraint_name [ ,...n ] }
| { ENABLE | DISABLE } TRIGGER
{ ALL | trigger_name [ ,...n ] }
| SWITCH [ [ PARTITION ] source_partition_number_expression ]
TO target_table
[ PARTITION target_partition_number_expression ]
[ WITH ( <low_priority_lock_wait> ) ]
}
[ ; ]
-- ALTER TABLE options
< table_constraint > ::=
[ CONSTRAINT constraint_name ]
{
{PRIMARY KEY | UNIQUE }
{
NONCLUSTERED (column [ ASC | DESC ] [ ,... n ])
| NONCLUSTERED HASH (column [ ,... n ] ) WITH ( BUCKET_COUNT = bucket_count )
}
| FOREIGN KEY
( column [ ,...n ] )
REFERENCES referenced_table_name [ ( ref_column [ ,...n ] ) ]
| CHECK ( logical_expression )
}
<column_index> ::=
INDEX index_name
{ [ NONCLUSTERED ] | [ NONCLUSTERED ] HASH WITH (BUCKET_COUNT = bucket_count)}
<table_index> ::=
INDEX index_name
{[ NONCLUSTERED ] HASH (column [ ,... n ] ) WITH (BUCKET_COUNT = bucket_count)
| [ NONCLUSTERED ] (column [ ASC | DESC ] [ ,... n ] )
[ ON filegroup_name | default ]
| CLUSTERED COLUMNSTORE [WITH ( COMPRESSION_DELAY = {0 | delay [Minutes]})]
[ ON filegroup_name | default ]
}
Syntax for Azure Synapse Analytics and Parallel Data Warehouse
-- Syntax for Azure Synapse Analytics and Parallel Data Warehouse
ALTER TABLE { database_name.schema_name.source_table_name | schema_name.source_table_name | source_table_name }
{
ALTER COLUMN column_name
{
type_name [ ( precision [ , scale ] ) ]
[ COLLATE Windows_collation_name ]
[ NULL | NOT NULL ]
}
| ADD { <column_definition> | <column_constraint> FOR column_name} [ ,...n ]
| DROP { COLUMN column_name | [CONSTRAINT] constraint_name } [ ,...n ]
| REBUILD {
[ PARTITION = ALL [ WITH ( <rebuild_option> ) ] ]
| [ PARTITION = partition_number [ WITH ( <single_partition_rebuild_option> ] ]
}
| { SPLIT | MERGE } RANGE (boundary_value)
| SWITCH [ PARTITION source_partition_number
TO target_table_name [ PARTITION target_partition_number ] [ WITH ( TRUNCATE_TARGET = ON | OFF )
}
[;]
<column_definition>::=
{
column_name
type_name [ ( precision [ , scale ] ) ]
[ <column_constraint> ]
[ COLLATE Windows_collation_name ]
[ NULL | NOT NULL ]
}
<column_constraint>::=
[ CONSTRAINT constraint_name ]
{
DEFAULT constant_expression
| PRIMARY KEY NONCLUSTERED (column_name [ ,... n ]) NOT ENFORCED -- Applies to Azure Synapse Analytics only
| UNIQUE (column_name [ ,... n ]) NOT ENFORCED -- Applies to Azure Synapse Analytics only
}
<rebuild_option > ::=
{
DATA_COMPRESSION = { COLUMNSTORE | COLUMNSTORE_ARCHIVE }
[ ON PARTITIONS ( {<partition_number> [ TO <partition_number>] } [ , ...n ] ) ]
| XML_COMPRESSION = { ON | OFF }
[ ON PARTITIONS ( {<partition_number> [ TO <partition_number>] } [ , ...n ] ) ]
}
<single_partition_rebuild_option > ::=
{
DATA_COMPRESSION = { COLUMNSTORE | COLUMNSTORE_ARCHIVE }
}
[!INCLUDEsynapse-analytics-od-supported-tables]
[!INCLUDEsql-server-tsql-previous-offline-documentation]
Arguments
database_name
The name of the database in which the table was created.
schema_name
The name of the schema to which the table belongs.
table_name
The name of the table to be altered. If the table isn’t in the current database or contained by the schema owned by the current user, you must explicitly specify the database and schema.
ALTER COLUMN
Specifies that the named column is to be changed or altered.
The modified column can’t be:
-
A column with a timestamp data type.
-
The ROWGUIDCOL for the table.
-
A computed column or used in a computed column.
-
Used in statistics generated by the CREATE STATISTICS statement. Users need to run DROP STATISTICS to drop the statistics before ALTER COLUMN can succeed. Run this query to get all the user created statistics and statistics columns for a table.
SELECT s.name AS statistics_name ,c.name AS column_name ,sc.stats_column_id FROM sys.stats AS s INNER JOIN sys.stats_columns AS sc ON s.object_id = sc.object_id AND s.stats_id = sc.stats_id INNER JOIN sys.columns AS c ON sc.object_id = c.object_id AND c.column_id = sc.column_id WHERE s.object_id = OBJECT_ID('<table_name>');
[!NOTE]
Statistics that are automatically generated by the query optimizer are automatically dropped by ALTER COLUMN. -
Used in a PRIMARY KEY or [FOREIGN KEY] REFERENCES constraint.
-
Used in a CHECK or UNIQUE constraint. But, changing the length of a variable-length column used in a CHECK or UNIQUE constraint is allowed.
-
Associated with a default definition. However, the length, precision, or scale of a column can be changed if the data type isn’t changed.
The data type of text, ntext, and image columns can be changed only in the following ways:
- text to varchar(max), nvarchar(max), or xml
- ntext to varchar(max), nvarchar(max), or xml
- image to varbinary(max)
Some data type changes may cause a change in the data. For example, changing a nchar or nvarchar column, to char or varchar, might cause the conversion of extended characters. For more information, see CAST and CONVERT. Reducing the precision or scale of a column can cause data truncation.
[!NOTE]
The data type of a column of a partitioned table can’t be changed.The data type of columns included in an index can’t be changed unless the column is a varchar, nvarchar, or varbinary data type, and the new size is equal to or larger than the old size.
A column included in a primary key constraint, can’t be changed from NOT NULL to NULL.
When using Always Encrypted (without secure enclaves), if the column being modified is encrypted with ‘ENCRYPTED WITH’, you can change the datatype to a compatible datatype (such as INT to BIGINT), but you can’t change any encryption settings.
When using Always Encrypted with secure enclaves, you can change any encryption setting, if the column encryption key protecting the column (and the new column encryption key, if you’re changing the key) support enclave computations (encrypted with enclave-enabled column master keys). For details, see Always Encrypted with secure enclaves.
column_name
The name of the column to be altered, added, or dropped. The column_name maximum is 128 characters. For new columns, you can omit column_name for columns created with a timestamp data type. The name timestamp is used if you don’t specify column_name for a timestamp data type column.
[!NOTE]
New columns are added after all existing columns in the table being altered.
[ type_schema_name. ] type_name
The new data type for the altered column, or the data type for the added column. You can’t specify type_name for existing columns of partitioned tables. type_name can be any one of the following types:
- A [!INCLUDEssNoVersion] system data type.
- An alias data type based on a [!INCLUDEssNoVersion] system data type. You create alias data types with the CREATE TYPE statement before they can be used in a table definition.
- A [!INCLUDEdnprdnshort] user-defined type, and the schema to which it belongs. You create user-defined types with the CREATE TYPE statement before they can be used in a table definition.
The following are criteria for type_name of an altered column:
- The previous data type must be implicitly convertible to the new data type.
- type_name can’t be timestamp.
- ANSI_NULL defaults are always on for ALTER COLUMN; if not specified, the column is nullable.
- ANSI_PADDING padding is always ON for ALTER COLUMN.
- If the modified column is an identity column, new_data_type must be a data type that supports the identity property.
- The current setting for SET ARITHABORT is ignored. ALTER TABLE operates as if ARITHABORT is set to ON.
[!NOTE]
If the COLLATE clause isn’t specified, changing the data type of a column causes a collation change to the default collation of the database.
precision
The precision for the specified data type. For more information about valid precision values, see Precision, Scale, and Length.
scale
The scale for the specified data type. For more information about valid scale values, see Precision, Scale, and Length.
max
Applies only to the varchar, nvarchar, and varbinary data types for storing 2^31-1 bytes of character, binary data, and of Unicode data.
xml_schema_collection
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEsql2008-md] and later) and [!INCLUDEssSDSfull].
Applies only to the xml data type for associating an XML schema with the type. Before typing an xml column to a schema collection, you first create the schema collection in the database by using CREATE XML SCHEMA COLLECTION.
COLLATE < collation_name >
Specifies the new collation for the altered column. If not specified, the column is assigned the default collation of the database. Collation name can be either a Windows collation name or a SQL collation name. For a list and more information, see Windows Collation Name and SQL Server Collation Name.
The COLLATE clause changes the collations only of columns of the char, varchar, nchar, and nvarchar data types. To change the collation of a user-defined alias data type column, use separate ALTER TABLE statements to change the column to a [!INCLUDEssNoVersion] system data type. Then, change its collation and change the column back to an alias data type.
ALTER COLUMN can’t have a collation change if one or more of the following conditions exist:
- If a CHECK constraint, FOREIGN KEY constraint, or computed columns reference the column changed.
- If any index, statistics, or full-text index are created on the column. Statistics created automatically on the column changed are dropped if the column collation is changed.
- If a schema-bound view or function references the column.
For more information, see COLLATE.
NULL | NOT NULL
Specifies whether the column can accept null values. Columns that don’t allow null values are added with ALTER TABLE only if they have a default specified or if the table is empty. You can specify NOT NULL for computed columns only if you’ve also specified PERSISTED. If the new column allows null values and you don’t specify a default, the new column contains a null value for each row in the table. If the new column allows null values and you add a default definition with the new column, you can use WITH VALUES to store the default value in the new column for each existing row in the table.
If the new column doesn’t allow null values and the table isn’t empty, you have to add a DEFAULT definition with the new column. And, the new column automatically loads with the default value in the new columns in each existing row.
You can specify NULL in ALTER COLUMN to force a NOT NULL column to allow null values, except for columns in PRIMARY KEY constraints. You can specify NOT NULL in ALTER COLUMN only if the column contains no null values. The null values must be updated to some value before the ALTER COLUMN NOT NULL is allowed, for example:
UPDATE MyTable SET NullCol = N'some_value' WHERE NullCol IS NULL; ALTER TABLE MyTable ALTER COLUMN NullCOl NVARCHAR(20) NOT NULL;
When you create or alter a table with the CREATE TABLE or ALTER TABLE statements, the database and session settings influence and possibly override the nullability of the data type that’s used in a column definition. Be sure that you always explicitly define a column as NULL or NOT NULL for noncomputed columns.
If you add a column with a user-defined data type, be sure to define the column with the same nullability as the user-defined data type. And, specify a default value for the column. For more information, see CREATE TABLE.
[!NOTE]
If NULL or NOT NULL is specified with ALTER COLUMN, new_data_type [(precision [, scale ])] must also be specified. If the data type, precision, and scale are not changed, specify the current column values.
[ {ADD | DROP} ROWGUIDCOL ]
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEsql2008-md] and later) and [!INCLUDEssSDSfull].
Specifies that the ROWGUIDCOL property is added to or dropped from the specified column. ROWGUIDCOL indicates that the column is a row GUID column. You can set only one uniqueidentifier column per table as the ROWGUIDCOL column. And, you can only assign the ROWGUIDCOL property to a uniqueidentifier column. You can’t assign ROWGUIDCOL to a column of a user-defined data type.
ROWGUIDCOL doesn’t enforce uniqueness of the values stored in the column and doesn’t automatically generate values for new rows that are inserted into the table. To generate unique values for each column, either use the NEWID or NEWSEQUENTIALID function on INSERT statements. Or, specify the NEWID or NEWSEQUENTIALID function as the default for the column.
[ {ADD | DROP} PERSISTED ]
Specifies that the PERSISTED property is added to or dropped from the specified column. The column must be a computed column that’s defined with a deterministic expression. For columns specified as PERSISTED, the [!INCLUDEssDE] physically stores the computed values in the table and updates the values when any other columns on which the computed column depends are updated. By marking a computed column as PERSISTED, you can create indexes on computed columns defined on expressions that are deterministic, but not precise. For more information, see Indexes on Computed Columns.
SET QUOTED_IDENTIFIER must be ON when you are creating or changing indexes on computed columns or indexed views. For more information, see SET QUOTED_IDENTIFIER (Transact-SQL).
Any computed column that’s used as a partitioning column of a partitioned table must be explicitly marked PERSISTED.
DROP NOT FOR REPLICATION
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEsql2008-md] and later) and [!INCLUDEssSDSfull].
Specifies that values are incremented in identity columns when replication agents carry out insert operations. You can specify this clause only if column_name is an identity column.
SPARSE
Indicates that the column is a sparse column. The storage of sparse columns is optimized for null values. You can’t set sparse columns as NOT NULL. Converting a column from sparse to nonsparse, or from nonsparse to sparse, locks the table for the duration of the command execution. You may need to use the REBUILD clause to reclaim any space savings. For additional restrictions and more information about sparse columns, see Use Sparse Columns.
ADD MASKED WITH ( FUNCTION = ‘ mask_function ‘)
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEsssql16-md] and later) and [!INCLUDEssSDSfull].
Specifies a dynamic data mask. mask_function is the name of the masking function with the appropriate parameters. Three functions are available:
- default()
- email()
- partial()
- random()
Requires ALTER ANY MASK permission.
To drop a mask, use DROP MASKED. For function parameters, see Dynamic Data Masking.
Add and drop a mask require ALTER ANY MASK permission.
WITH ( ONLINE = ON | OFF) <as applies to altering a column>
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEsssql16-md] and later) and [!INCLUDEssSDSfull].
Allows many alter column actions to be carried out while the table remains available. Default is OFF. You can run alter column online for column changes related to data type, column length or precision, nullability, sparseness, and collation.
Online alter column allows user created and autostatistics to reference the altered column for the duration of the ALTER COLUMN operation, which allows queries to run as usual. At the end of the operation, autostats that reference the column are dropped and user-created stats are invalidated. The user must manually update user-generated statistics after the operation is completed. If the column is part of a filter expression for any statistics or indexes then you can’t perform an alter column operation.
- While the online alter column operation is running, all operations that could take a dependency on the column (index, views, and so on.) block or fail with an appropriate error. This behavior guarantees that online alter column won’t fail because of dependencies introduced while the operation was running.
- Altering a column from NOT NULL to NULL isn’t supported as an online operation when the altered column is referenced by nonclustered indexes.
- Online ALTER isn’t supported when the column is referenced by a check constraint and the ALTER operation is restricting the precision of the column (numeric or datetime).
- The
WAIT_AT_LOW_PRIORITYoption can’t be used with online alter column. ALTER COLUMN ... ADD/DROP PERSISTEDisn’t supported for online alter column.ALTER COLUMN ... ADD/DROP ROWGUIDCOL/NOT FOR REPLICATIONisn’t affected by online alter column.- Online alter column doesn’t support altering a table where change tracking is enabled or that’s a publisher of merge replication.
- Online alter column doesn’t support altering from or to CLR data types.
- Online alter column doesn’t support altering to an XML data type that has a schema collection different than the current schema collection.
- Online alter column doesn’t reduce the restrictions on when a column can be altered. References by index/stats, and so on, might cause the alter to fail.
- Online alter column doesn’t support altering more than one column concurrently.
- Online alter column has no effect in a system-versioned temporal table. ALTER column isn’t run as online regardless of which value was specified for ONLINE option.
Online alter column has similar requirements, restrictions, and functionality as online index rebuild, which includes:
- Online index rebuild isn’t supported when the table contains legacy LOB or filestream columns or when the table has a columnstore index. The same limitations apply for online alter column.
- An existing column being altered requires twice the space allocation, for the original column and for the newly created hidden column.
- The locking strategy during an alter column online operation follows the same locking pattern used for online index build.
WITH CHECK | WITH NOCHECK
Specifies whether the data in the table is or isn’t validated against a newly added or re-enabled FOREIGN KEY or CHECK constraint. If you don’t specify, WITH CHECK is assumed for new constraints, and WITH NOCHECK is assumed for re-enabled constraints.
If you don’t want to verify new CHECK or FOREIGN KEY constraints against existing data, use WITH NOCHECK. We don’t recommend doing this, except in rare cases. The new constraint is evaluated in all later data updates. Any constraint violations that are suppressed by WITH NOCHECK when the constraint is added may cause future updates to fail if they update rows with data that doesn’t follow the constraint. The query optimizer doesn’t consider constraints that are defined WITH NOCHECK. Such constraints are ignored until they are re-enabled by using ALTER TABLE table WITH CHECK CHECK CONSTRAINT ALL. For more information, see Disable Foreign Key Constraints with INSERT and UPDATE Statements.
ALTER INDEX index_name
Specifies that the bucket count for index_name is to be changed or altered.
The syntax ALTER TABLE … ADD/DROP/ALTER INDEX is supported only for memory-optimized tables.
[!IMPORTANT]
Without using an ALTER TABLE statement, the statements CREATE INDEX, DROP INDEX, ALTER INDEX, and PAD_INDEX are not supported for indexes on memory-optimized tables.
ADD
Specifies that one or more column definitions, computed column definitions, or table constraints are added. Or, the columns that the system uses for system versioning are added. For memory-optimized tables, you can add an index.
[!NOTE]
New columns are added after all existing columns in the table being altered.
[!IMPORTANT]
Without using an ALTER TABLE statement, the statements CREATE INDEX, DROP INDEX, ALTER INDEX, and PAD_INDEX aren’t supported for indexes on memory-optimized tables.
PERIOD FOR SYSTEM_TIME ( system_start_time_column_name, system_end_time_column_name )
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEssSQL17] and later) and [!INCLUDEssSDSfull].
Specifies the names of the columns that the system uses to record the period of time for which a record is valid. You can specify existing columns or create new columns as part of the ADD PERIOD FOR SYSTEM_TIME argument. Set up the columns with the datatype of datetime2 and define them as NOT NULL. If you define a period column as NULL, an error results. You can define a column_constraint and/or Specify Default Values for Columns for the system_start_time and system_end_time columns. See Example A in the following System Versioning examples that demonstrates using a default value for the system_end_time column.
Use this argument with the SET SYSTEM_VERSIONING argument to make an existing table a temporal table. For more information, see Temporal Tables and Getting Started with Temporal Tables in Azure SQL Database.
As of [!INCLUDEssSQL17], users can mark one or both period columns with HIDDEN flag to implicitly hide these columns such that SELECT * FROM <table_name> doesn’t return a value for the columns. By default, period columns aren’t hidden. In order to be used, hidden columns must be explicitly included in all queries that directly reference the temporal table.
DROP
Specifies that one or more column definitions, computed column definitions, or table constraints are dropped, or to drop the specification for the columns that the system uses for system versioning.
[!NOTE]
Columns dropped in ledger tables are only soft deleted. A dropped column remains in the ledger table, but it is marked as a dropped column by setting sys.tables.dropped_ledger_table to 1. The ledger view of the dropped ledger table is also marked as dropped by setting sys.tables.dropped_ledger_view_column to 1. A dropped ledger table, its history table, and its ledger view are renamed by adding a prefix (MSSQL_DroppedLedgerTable, MSSQL_DropedLedgerHistory, MSSQL_DroppedLedgerView) and appending a GUID to the original name.ing
CONSTRAINT constraint_name
Specifies that constraint_name is removed from the table. Multiple constraints can be listed.
You can determine the user-defined or system-supplied name of the constraint by querying the sys.check_constraint, sys.default_constraints, sys.key_constraints, and sys.foreign_keys catalog views.
A PRIMARY KEY constraint can’t be dropped if an XML index exists on the table.
INDEX index_name
Specifies that index_name is removed from the table.
The syntax ALTER TABLE … ADD/DROP/ALTER INDEX is supported only for memory-optimized tables.
[!IMPORTANT]
Without using an ALTER TABLE statement, the statements CREATE INDEX, DROP INDEX, ALTER INDEX, and PAD_INDEX are not supported for indexes on memory-optimized tables.
COLUMN column_name
Specifies that constraint_name or column_name is removed from the table. Multiple columns can be listed.
A column can’t be dropped when it’s:
- Used in an index, whether as a key column or as an INCLUDE
- Used in a CHECK, FOREIGN KEY, UNIQUE, or PRIMARY KEY constraint.
- Associated with a default that’s defined with the DEFAULT keyword, or bound to a default object.
- Bound to a rule.
[!NOTE]
Dropping a column doesn’t reclaim the disk space of the column. You may have to reclaim the disk space of a dropped column when the row size of a table is near, or has exceeded, its limit. Reclaim space by creating a clustered index on the table or rebuilding an existing clustered index by using ALTER INDEX. For information about the impact of dropping LOB data types, see this CSS blog entry.
PERIOD FOR SYSTEM_TIME
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEsssql16-md] and later) and [!INCLUDEssSDSfull].
Drops the specification for the columns that the system will use for system versioning.
WITH <drop_clustered_constraint_option>
Specifies that one or more drop clustered constraint options are set.
MAXDOP = max_degree_of_parallelism
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEsql2008-md] and later) and [!INCLUDEssSDSfull].
Overrides the max degree of parallelism configuration option only for the duration of the operation. For more information, see Configure the max degree of parallelism Server Configuration Option.
Use the MAXDOP option to limit the number of processors used in parallel plan execution. The maximum is 64 processors.
max_degree_of_parallelism can be one of the following values:
1
Suppresses parallel plan generation.
>1
Restricts the maximum number of processors used in a parallel index operation to the specified number.
0 (default)
Uses the actual number of processors or fewer based on the current system workload.
For more information, see Configure Parallel Index Operations.
[!NOTE]
Parallel index operations aren’t available in every edition of [!INCLUDEssNoVersion]. For more information, see Editions and supported features of SQL Server 2016, and Editions and supported features of SQL Server 2017.
ONLINE = { ON | OFF } <as applies to drop_clustered_constraint_option>
Specifies whether underlying tables and associated indexes are available for queries and data modification during the index operation. The default is OFF. You can run REBUILD as an ONLINE operation.
ON
Long-term table locks aren’t held for the duration of the index operation. During the main phase of the index operation, only an Intent Share (IS) lock is held on the source table. This behavior enables queries or updates to the underlying table and indexes to continue. At the start of the operation, a Shared (S) lock is held on the source object for a short time. At the end of the operation, for a short time, an S (Shared) lock is acquired on the source if a nonclustered index is being created. Or, an SCH-M (Schema Modification) lock is acquired when a clustered index is created or dropped online and when a clustered or nonclustered index is being rebuilt. ONLINE can’t be set to ON when an index is being created on a local temporary table. Only single-threaded heap rebuild operation is allowed.
To run the DDL for SWITCH or online index rebuild, all active blocking transactions running on a particular table must be completed. When executing, the SWITCH or rebuild operation prevents new transactions from starting and might significantly affect the workload throughput and temporarily delay access to the underlying table.
OFF
Table locks apply for the duration of the index operation. An offline index operation that creates, rebuilds, or drops a clustered index, or rebuilds or drops a nonclustered index, acquires a Schema modification (Sch-M) lock on the table. This lock prevents all user access to the underlying table for the duration of the operation. An offline index operation that creates a nonclustered index acquires a Shared (S) lock on the table. This lock prevents updates to the underlying table but allows read operations, such as SELECT statements. Multi-threaded heap rebuild operations are allowed.
For more information, see How Online Index Operations Work.
[!NOTE]
Online index operations are not available in every edition of [!INCLUDEssNoVersion]. For more information, see Editions and supported features of SQL Server 2016, and Editions and supported features of SQL Server 2017.
MOVE TO { partition_scheme_name(column_name [ ,…n ] ) | filegroup | “default” }
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEsql2008-md] and later) and [!INCLUDEssSDSfull].
Specifies a location to move the data rows currently in the leaf level of the clustered index. The table is moved to the new location. This option applies only to constraints that create a clustered index.
[!NOTE]
In this context, default isn’t a keyword. It is an identifier for the default filegroup and must be delimited, as in MOVE TO “default” or MOVE TO [default]. If “default” is specified, the QUOTED_IDENTIFIER option must be ON for the current session. This is the default setting. For more information, see SET QUOTED_IDENTIFIER.
{ CHECK | NOCHECK } CONSTRAINT
Specifies that constraint_name is enabled or disabled. This option can only be used with FOREIGN KEY and CHECK constraints. When NOCHECK is specified, the constraint is disabled and future inserts or updates to the column are not validated against the constraint conditions. DEFAULT, PRIMARY KEY, and UNIQUE constraints can’t be disabled.
ALL
Specifies that all constraints are either disabled with the NOCHECK option or enabled with the CHECK option.
{ ENABLE | DISABLE } TRIGGER
Specifies that trigger_name is enabled or disabled. When a trigger is disabled, it’s still defined for the table. However, when INSERT, UPDATE, or DELETE statements run against the table, the actions in the trigger aren’t carried out until the trigger is re-enabled.
ALL
Specifies that all triggers in the table are enabled or disabled.
trigger_name
Specifies the name of the trigger to disable or enable.
{ ENABLE | DISABLE } CHANGE_TRACKING
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEsql2008-md] and later) and [!INCLUDEssSDSfull].
Specifies whether change tracking is enabled disabled for the table. By default, change tracking is disabled.
This option is available only when change tracking is enabled for the database. For more information, see ALTER DATABASE SET Options.
To enable change tracking, the table must have a primary key.
WITH ( TRACK_COLUMNS_UPDATED = { ON | OFF } )
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEsql2008-md] and later) and [!INCLUDEssSDSfull].
Specifies whether the [!INCLUDEssDE] tracks, which change tracked columns were updated. The default value is OFF.
SWITCH [ PARTITION source_partition_number_expression ] TO [ schema_name. ] target_table [ PARTITION target_partition_number_expression ]
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEsql2008-md] and later) and [!INCLUDEssSDSfull].
Switches a block of data in one of the following ways:
- Reassigns all data of a table as a partition to an already-existing partitioned table.
- Switches a partition from one partitioned table to another.
- Reassigns all data in one partition of a partitioned table to an existing non-partitioned table.
If table is a partitioned table, you must specify source_partition_number_expression. If target_table is partitioned, you must specify target_partition_number_expression. When reassigning a table’s data as a partition to an already-existing partitioned table, or switching a partition from one partitioned table to another, the target partition must exist and it must be empty.
When reassigning one partition’s data to form a single table, the target table must already exist and it must be empty. Both the source table or partition, and the target table or partition, must be located in the same filegroup. The corresponding indexes, or index partitions, must also be located in the same filegroup. Many additional restrictions apply to switching partitions. table and target_table can’t be the same. target_table can be a multi-part identifier.
Both source_partition_number_expression and target_partition_number_expression are constant expressions that can reference variables and functions. These include user-defined type variables and user-defined functions. They can’t reference [!INCLUDEtsql] expressions.
A partitioned table with a clustered columnstore index behaves like a partitioned heap:
- The primary key must include the partition key.
- A unique index must include the partition key. But, including the partition key with an existing unique index can change the uniqueness.
- To switch partitions, all nonclustered indexes must include the partition key.
For SWITCH restriction when using replication, see Replicate Partitioned Tables and Indexes.
Nonclustered columnstore indexes were built in a read-only format before [!INCLUDEssNoVersion] 2016 and for SQL Database before version V12. You must rebuild nonclustered columnstore indexes to the current format (which is updatable) before any PARTITION operations can be run.
SET ( FILESTREAM_ON = { partition_scheme_name | filestream_filegroup_name | “default” | “NULL” })
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEsql2008-md] and later). [!INCLUDEssSDSfull] doesn’t support FILESTREAM.
Specifies where FILESTREAM data is stored.
ALTER TABLE with the SET FILESTREAM_ON clause succeeds only if the table has no FILESTREAM columns. You can add FILESTREAM columns by using a second ALTER TABLE statement.
If you specify partition_scheme_name, the rules for CREATE TABLE apply. Be sure the table is already partitioned for row data, and its partition scheme uses the same partition function and columns as the FILESTREAM partition scheme.
filestream_filegroup_name specifies the name of a FILESTREAM filegroup. The filegroup must have one file that’s defined for the filegroup by using a CREATE DATABASE or ALTER DATABASE statement, or an error results.
“default” specifies the FILESTREAM filegroup with the DEFAULT property set. If there’s no FILESTREAM filegroup, an error results.
“NULL” specifies that all references to FILESTREAM filegroups for the table are removed. All FILESTREAM columns must be dropped first. Use SET FILESTREAM_ON = “NULL” to delete all FILESTREAM data that’s associated with a table.
SET ( SYSTEM_VERSIONING = { OFF | ON [ ( HISTORY_TABLE = schema_name . history_table_name [ , DATA_CONSISTENCY_CHECK = { ON | OFF } ] ) ] } )
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEsssql16-md] and later) and [!INCLUDEssSDSfull].
Either disables or enables system versioning of a table. To enable system versioning of a table, the system verifies that the datatype, nullability constraint, and primary key constraint requirements for system versioning are met. The system will record the history of each record in the system-versioned table in a separate history table. If the HISTORY_TABLE argument is not used, the name of this history table will be MSSQL_TemporalHistoryFor<primary_table_object_id>. If the history table does not exists, the system generates a new history table matching the schema of the current table, creates a link between the two tables, and enables the system to record the history of each record in the current table in the history table. If you use the HISTORY_TABLE argument to create a link to and use an existing history table, the system creates a link between the current table and the specified table. When creating a link to an existing history table, you can choose to do a data consistency check. This data consistency check ensures that existing records don’t overlap. Running the data consistency check is the default. Use the SYSTEM_VERSIONING = ON argument on a table that is defined with the PERIOD FOR SYSTEM_TIME clause to make the existing table a temporal table. For more information, see Temporal Tables.
HISTORY_RETENTION_PERIOD = { INFINITE | number {DAY | DAYS | WEEK | WEEKS | MONTH | MONTHS | YEAR | YEARS} }
Applies to: [!INCLUDEssSQL17] and [!INCLUDEssSDSfull].
Specifies finite or infinite retention for historical data in a temporal table. If omitted, infinite retention is assumed.
DATA_DELETION
Applies to: Azure SQL Edge only
Enables retention policy based cleanup of old or aged data from tables within a database. For more information, see Enable and Disable Data Retention. The following parameters must be specified for data retention to be enabled.
FILTER_COLUMN = { column_name }
Specifies the column, that should be used to determine if the rows in the table are obsolete or not. The following data types are allowed for the filter column.
- Date
- DateTime
- DateTime2
- SmallDateTime
- DateTimeOffset
RETENTION_PERIOD = { INFINITE | number {DAY | DAYS | WEEK | WEEKS | MONTH | MONTHS | YEAR | YEARS }}
Specifies the retention period policy for the table. The retention period is specified as a combination of a positive integer value and the date part unit.
SET ( LOCK_ESCALATION = { AUTO | TABLE | DISABLE } )
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEsql2008-md] and later) and [!INCLUDEssSDSfull].
Specifies the allowed methods of lock escalation for a table.
AUTO
This option allows [!INCLUDEssDEnoversion] to select the lock escalation granularity that’s appropriate for the table schema.
- If the table is partitioned, lock escalation will be allowed to the heap or B-tree (HoBT) granularity. In other words, escalation will be allowed to the partition level. After the lock is escalated to the HoBT level, the lock will not be escalated later to TABLE granularity.
- If the table isn’t partitioned, the lock escalation is done to the TABLE granularity.
TABLE
Lock escalation is done at table-level granularity whether the table is partitioned or not partitioned. TABLE is the default value.
DISABLE
Prevents lock escalation in most cases. Table-level locks aren’t completely disallowed. For example, when you’re scanning a table that has no clustered index under the serializable isolation level, [!INCLUDEssDE] must take a table lock to protect data integrity.
REBUILD
Use the REBUILD WITH syntax to rebuild an entire table including all the partitions in a partitioned table. If the table has a clustered index, the REBUILD option rebuilds the clustered index. REBUILD can be run as an ONLINE operation.
Use the REBUILD PARTITION syntax to rebuild a single partition in a partitioned table.
PARTITION = ALL
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEsql2008-md] and later) and [!INCLUDEssSDSfull].
Rebuilds all partitions when changing the partition compression settings.
REBUILD WITH ( <rebuild_option> )
All options apply to a table with a clustered index. If the table doesn’t have a clustered index, the heap structure is only affected by some of the options.
When a specific compression setting isn’t specified with the REBUILD operation, the current compression setting for the partition is used. To return the current setting, query the data_compression column in the sys.partitions catalog view.
For complete descriptions of the rebuild options, see ALTER TABLE index_option.
DATA_COMPRESSION
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEsql2008-md] and later) and [!INCLUDEssSDSfull].
Specifies the data compression option for the specified table, partition number, or range of partitions. The options are as follows:
NONE
Table or specified partitions aren’t compressed. This option doesn’t apply to columnstore tables.
ROW
Table or specified partitions are compressed by using row compression. This option doesn’t apply to columnstore tables.
PAGE
Table or specified partitions are compressed by using page compression. This option doesn’t apply to columnstore tables.
COLUMNSTORE
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEssSQL14] and later) and [!INCLUDEssSDSfull].
Applies only to columnstore tables. COLUMNSTORE specifies to decompress a partition that was compressed with the COLUMNSTORE_ARCHIVE option. When the data is restored, it continues to be compressed with the columnstore compression that’s used for all columnstore tables.
COLUMNSTORE_ARCHIVE
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEssSQL14] and later) and [!INCLUDEssSDSfull].
Applies only to columnstore tables, which are tables stored with a clustered columnstore index. COLUMNSTORE_ARCHIVE will further compress the specified partition to a smaller size. Use this option for archival or other situations that require less storage and can afford more time for storage and retrieval.
To rebuild multiple partitions at the same time, see index_option. If the table doesn’t have a clustered index, changing the data compression rebuilds the heap and the nonclustered indexes. For more information about compression, see Data Compression.
XML_COMPRESSION
Applies to: [!INCLUDEsssql22-md] and later, and [!INCLUDEssSDSfull] Preview.
Specifies the XML compression option for any xml data type columns in the table. The options are as follows:
ON
Columns using the xml data type are compressed.
OFF
Columns using the xml data type are not compressed.
ONLINE = { ON | OFF } <as applies to single_partition_rebuild_option>
Specifies whether a single partition of the underlying tables and associated indexes is available for queries and data modification during the index operation. The default is OFF. You can run REBUILD as an ONLINE operation.
ON
Long-term table locks aren’t held for the duration of the index operation. S-lock on the table is required in the beginning of the index rebuild and a Sch-M lock on the table at the end of the online index rebuild. Although both locks are short metadata locks, the Sch-M lock must wait for all blocking transactions to be completed. During the wait time, the Sch-M lock blocks all other transactions that wait behind this lock when accessing the same table.
[!NOTE]
Online index rebuild can set thelow_priority_lock_waitoptions described later in this section.
OFF
Table locks are applied for the duration of the index operation. This prevents all user access to the underlying table for the duration of the operation.
column_set_name XML COLUMN_SET FOR ALL_SPARSE_COLUMNS
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEsql2008-md] and later) and [!INCLUDEssSDSfull].
The name of the column set. A column set is an untyped XML representation that combines all of the sparse columns of a table into a structured output. A column set can’t be added to a table that contains sparse columns. For more information about column sets, see Use Column Sets.
{ ENABLE | DISABLE } FILETABLE_NAMESPACE
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEssSQL11] and later).
Enables or disables the system-defined constraints on a FileTable. Can only be used with a FileTable.
SET ( FILETABLE_DIRECTORY = directory_name )
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEssSQL11] and later). [!INCLUDEssSDSfull] doesn’t support FILETABLE.
Specifies the Windows-compatible FileTable directory name. This name should be unique among all the FileTable directory names in the database. Uniqueness comparison is case-insensitive, despite the SQL collation settings. Can only be used with a FileTable.
REMOTE_DATA_ARCHIVE
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEssSQL17] and later).
Enables or disables Stretch Database for a table. For more information, see Stretch Database.
[!IMPORTANT]
Stretch Database is deprecated in [!INCLUDE sssql22-md]. [!INCLUDE ssNoteDepFutureAvoid-md]
Enabling Stretch Database for a table
When you enable Stretch for a table by specifying ON, you also have to specify MIGRATION_STATE = OUTBOUND to begin migrating data immediately, or MIGRATION_STATE = PAUSED to postpone data migration. The default value is MIGRATION_STATE = OUTBOUND. For more information about enabling Stretch for a table, see Enable Stretch Database for a table.
Prerequisites. Before you enable Stretch for a table, you have to enable Stretch on the server and on the database. For more information, see Enable Stretch Database for a database.
Permissions. Enabling Stretch for a database or a table requires db_owner permissions. Enabling Stretch for a table also requires ALTER permissions on the table.
Disabling Stretch Database for a table
When you disable Stretch for a table, you have two options for the remote data that’s already been migrated to Azure. For more information, see Disable Stretch Database and bring back remote data.
-
To disable Stretch for a table and copy the remote data for the table from Azure back to SQL Server, run the following command. This command can’t be canceled.
ALTER TABLE <table_name> SET ( REMOTE_DATA_ARCHIVE ( MIGRATION_STATE = INBOUND ) ) ;
This operation incurs data transfer costs, and it can’t be canceled. For more information, see Data Transfers Pricing Details.
After all the remote data has been copied from Azure back to SQL Server, Stretch is disabled for the table.
-
To disable Stretch for a table and abandon the remote data, run the following command.
ALTER TABLE <table_name> SET ( REMOTE_DATA_ARCHIVE = OFF_WITHOUT_DATA_RECOVERY ( MIGRATION_STATE = PAUSED ) ) ;
After you disable Stretch Database for a table, data migration stops and query results no longer include results from the remote table.
Disabling Stretch doesn’t remove the remote table. If you want to delete the remote table, you drop it by using the Azure portal.
[ FILTER_PREDICATE = { null | predicate } ]
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEssSQL17] and later).
Optionally specifies a filter predicate to select rows to migrate from a table that contains both historical and current data. The predicate must call a deterministic inline table-valued function. For more information, see Enable Stretch Database for a table and Select rows to migrate by using a filter function – Stretch Database.
[!IMPORTANT]
If you provide a filter predicate that performs poorly, data migration also performs poorly. Stretch Database applies the filter predicate to the table by using the CROSS APPLY operator.
If you don’t specify a filter predicate, the entire table is migrated.
When you specify a filter predicate, you also have to specify MIGRATION_STATE.
MIGRATION_STATE = { OUTBOUND | INBOUND | PAUSED }
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEssSQL17] and later).
-
Specify
OUTBOUNDto migrate data from SQL Server to Azure. -
Specify
INBOUNDto copy the remote data for the table from Azure back to SQL Server and to disable Stretch for the table. For more information, see Disable Stretch Database and bring back remote data.This operation incurs data transfer costs, and it can’t be canceled.
-
Specify
PAUSEDto pause or postpone data migration. For more information, see Pause and resume data migration – Stretch Database.
WAIT_AT_LOW_PRIORITY
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEssSQL14] and later) and [!INCLUDEssSDSfull].
An online index rebuild has to wait for blocking operations on this table. WAIT_AT_LOW_PRIORITY indicates that the online index rebuild operation waits for low-priority locks, allowing other operations to carry on while the online index build operation is waiting. Omitting the WAIT AT LOW PRIORITY option is the same as WAIT_AT_LOW_PRIORITY ( MAX_DURATION = 0 minutes, ABORT_AFTER_WAIT = NONE).
MAX_DURATION = time [MINUTES ]
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEssSQL14] and later) and [!INCLUDEssSDSfull].
The wait time, which is an integer value specified in minutes, that the SWITCH or online index rebuild locks wait with low priority when running the DDL command. If the operation is blocked for the MAX_DURATION time, one of the ABORT_AFTER_WAIT actions will run. MAX_DURATION time is always in minutes, and you can omit the word MINUTES.
ABORT_AFTER_WAIT = [NONE | SELF | BLOCKERS } ]
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEssSQL14] and later) and [!INCLUDEssSDSfull].
NONE
Continue waiting for the lock with normal (regular) priority.
SELF
Exit the SWITCH or online index rebuild DDL operation currently being run without taking any action.
BLOCKERS
Kill all user transactions that currently block the SWITCH or online index rebuild DDL operation so that the operation can continue.
Requires ALTER ANY CONNECTION permission.
IF EXISTS
Applies to: [!INCLUDEssNoVersion] ([!INCLUDEsssql16-md] and later) and [!INCLUDEssSDSfull].
Conditionally drops the column or constraint only if it already exists.
RESUMABLE = { ON | OFF}
Applies to: [!INCLUDE sssql22-md] and later.
Specifies whether an ALTER TABLE ADD CONSTRAINT operation is resumable. Add table constraint operation is resumable when ON. Add table constraint operation is not resumable when OFF. Default is OFF. The RESUMABLE option can be used as part of the ALTER TABLE index_option in the ALTER TABLE table_constraint.
MAX_DURATION when used with RESUMABLE = ON (requires ONLINE = ON) indicates time (an integer value specified in minutes) that a resumable online add constraint operation is executed before being paused. If not specified, the operation continues until completion.
For more information on enabling and using resumable ALTER TABLE ADD CONSTRAINT operations, see Resumable table add constraints.
Remarks
To add new rows of data, use INSERT. To remove rows of data, use DELETE or TRUNCATE TABLE. To change the values in existing rows, use UPDATE.
If there are any execution plans in the procedure cache that reference the table, ALTER TABLE marks them to be recompiled on their next execution.
Changing the size of a column
You can change the length, precision, or scale of a column by specifying a new size for the column data type. Use the ALTER COLUMN clause. If data exists in the column, the new size can’t be smaller than the maximum size of the data. Also, you can’t define the column in an index, unless the column is a varchar, nvarchar, or varbinary data type and the index isn’t the result of a PRIMARY KEY constraint. See the example in the short section titled Altering a Column Definition.
Locks and ALTER TABLE
Changes you specify in ALTER TABLE implement immediately. If the changes require modifications of the rows in the table, ALTER TABLE updates the rows. ALTER TABLE acquires a schema modify (SCH-M) lock on the table to make sure that no other connections reference even the metadata for the table during the change, except online index operations that require a short SCH-M lock at the end. In an ALTER TABLE...SWITCH operation, the lock is acquired on both the source and target tables. The modifications made to the table are logged and fully recoverable. Changes that affect all the rows in large tables, such as dropping a column or, on some editions of [!INCLUDEssNoVersion], adding a NOT NULL column with a default value, can take a long time to complete and generate many log records. Run these ALTER TABLE statements with the same care as any INSERT, UPDATE, or DELETE statement that affects many rows.
Adding NOT NULL columns as an online operation
Starting with [!INCLUDEssSQL11] Enterprise Edition, adding a NOT NULL column with a default value is an online operation when the default value is a runtime constant. This means that the operation is completed almost instantaneously despite the number of rows in the table, because the existing rows in the table aren’t updated during the operation. Instead, the default value is stored only in the metadata of the table and the value is looked up, as needed, in queries that access these rows. This behavior is automatic. No additional syntax is required to implement the online operation beyond the ADD COLUMN syntax. A runtime constant is an expression that produces the same value at runtime for each row in the table despite its determinism. For example, the constant expression “My temporary data”, or the system function GETUTCDATETIME() are runtime constants. In contrast, the functions NEWID() or NEWSEQUENTIALID() aren’t runtime constants, because a unique value is produced for each row in the table. Adding a NOT NULL column with a default value that’s not a runtime constant is always run offline and an exclusive (SCH-M) lock is acquired for the duration of the operation.
While the existing rows reference the value stored in metadata, the default value is stored on the row for any new rows that are inserted and don’t specify another value for the column. The default value stored in metadata moves to an existing row when the row is updated (even if the actual column isn’t specified in the UPDATE statement), or if the table or clustered index is rebuilt.
Columns of type varchar(max), nvarchar(max), varbinary(max), xml, text, ntext, image, hierarchyid, geometry, geography, or CLR UDTS, can’t be added in an online operation. A column can’t be added online if doing so causes the maximum possible row size to exceed the 8,060-byte limit. The column is added as an offline operation in this case.
Parallel plan execution
In [!INCLUDEssEnterpriseEd11] and higher, the number of processors employed to run a single ALTER TABLE ADD (index-based) CONSTRAINT or DROP (clustered index) CONSTRAINT statement is determined by the max degree of parallelism configuration option and the current workload. If the [!INCLUDEssDE] detects that the system is busy, the degree of parallelism of the operation is automatically reduced before statement execution starts. You can manually configure the number of processors that are used to run the statement by specifying the MAXDOP option. For more information, see Configure the max degree of parallelism Server Configuration Option.
Partitioned tables
In addition to performing SWITCH operations that involve partitioned tables, use ALTER TABLE to change the state of the columns, constraints, and triggers of a partitioned table just like it’s used for nonpartitioned tables. However, this statement can’t be used to change the way the table itself is partitioned. To repartition a partitioned table, use ALTER PARTITION SCHEME and ALTER PARTITION FUNCTION. Additionally, you can’t change the data type of a column of a partitioned table.
Restrictions on tables with schema-bound views
The restrictions that apply to ALTER TABLE statements on tables with schema-bound views are the same as the restrictions currently applied when modifying tables with a simple index. Adding a column is allowed. However, removing or changing a column that participates in any schema-bound view isn’t allowed. If the ALTER TABLE statement requires changing a column used in a schema-bound view, ALTER TABLE fails and the [!INCLUDEssDE] raises an error message. For more information about schema binding and indexed views, see CREATE VIEW.
Adding or removing triggers on base tables isn’t affected by creating a schema-bound view that references the tables.
Indexes and ALTER TABLE
Indexes created as part of a constraint are dropped when the constraint is dropped. Indexes that were created with CREATE INDEX must be dropped with DROP INDEX. Use The ALTER INDEX statement to rebuild an index part of a constraint definition; the constraint doesn’t have to be dropped and added again with ALTER TABLE.
All indexes and constraints based on a column must be removed before the column can be removed.
When you delete a constraint that created a clustered index, the data rows that were stored in the leaf level of the clustered index are stored in a nonclustered table. You can drop the clustered index and move the resulting table to another filegroup or partition scheme in a single transaction by specifying the MOVE TO option. The MOVE TO option has the following restrictions:
- MOVE TO isn’t valid for indexed views or nonclustered indexes.
- The partition scheme or filegroup must already exist.
- If MOVE TO isn’t specified, the table is located in the same partition scheme or filegroup as was defined for the clustered index.
When you drop a clustered index, specify the ONLINE **=** ON option so the DROP INDEX transaction doesn’t block queries and modifications to the underlying data and associated nonclustered indexes.
ONLINE = ON has the following restrictions:
- ONLINE = ON isn’t valid for clustered indexes that are also disabled. Disabled indexes must be dropped by using ONLINE = OFF.
- Only one index at a time can be dropped.
- ONLINE = ON isn’t valid for indexed views, nonclustered indexes, or indexes on local temp tables.
- ONLINE = ON isn’t valid for columnstore indexes.
Temporary disk space equal to the size of the existing clustered index is required to drop a clustered index. This additional space is released as soon as the operation is completed.
[!NOTE]
The options listed under <drop_clustered_constraint_option> apply to clustered indexes on tables and can’t be applied to clustered indexes on views or nonclustered indexes.
Replicating schema changes
When you run ALTER TABLE on a published table at a [!INCLUDEssNoVersion] Publisher, by default, that change propagates to all [!INCLUDEssNoVersion] Subscribers. This functionality has some restrictions. You can disable it. For more information, see Make Schema Changes on Publication Databases.
Data compression
System tables can’t be enabled for compression. If the table is a heap, the rebuild operation for ONLINE mode will be single threaded. Use OFFLINE mode for a multi-threaded heap rebuild operation. For a more information about data compression, see Data Compression.
To evaluate how changing the compression state will affect a table, an index, or a partition, use the sp_estimate_data_compression_savings system stored procedure.
The following restrictions apply to partitioned tables:
- You can’t change the compression setting of a single partition if the table has nonaligned indexes.
- The
ALTER TABLE <table> REBUILD PARTITION… syntax rebuilds the specified partition. - The
ALTER TABLE <table> REBUILD WITH… syntax rebuilds all partitions.
Dropping NTEXT columns
When dropping columns using the deprecated NTEXT data type, the cleanup of the deleted data occurs as a serialized operation on all rows. The cleanup can require a large amount of time. When dropping an NTEXT column in a table with lots of rows, update the NTEXT column to NULL value first, then drop the column. You can run this option with parallel operations and make it much faster.
Online index REBUILD
To run the DDL statement for an online index rebuild, all active blocking transactions running on a particular table must be completed. When the online index rebuild launches, it blocks all new transactions that are ready to start running on this table. Although the duration of the lock for online index rebuild is short, waiting for all open transactions on a given table to complete and blocking the new transactions to start, might significantly affect the throughput. This can cause a workload slow-down or timeout and significantly limit access to the underlying table. The WAIT_AT_LOW_PRIORITY option allows DBAs to manage the S-lock and Sch-M locks required for online index rebuilds. In all three cases: NONE, SELF, and BLOCKERS, if during the wait time ( (MAX_DURATION =n [minutes]) ) there are no blocking activities, the online index rebuild is run immediately without waiting and the DDL statement is completed.
Compatibility support
The ALTER TABLE statement supports only two-part (schema.object) table names. In [!INCLUDEssnoversion], specifying a table name using the following formats fails at compile time with error 117.
server.database.schema.table.database.schema.table..schema.table
In earlier versions, specifying the format server.database.schema.table returned error 4902. Specifying the format .database.schema.table or the format ..schema.table succeeded.
To resolve the problem, remove the use of a four-part prefix.
Permissions
Requires ALTER permission on the table.
ALTER TABLE permissions apply to both tables involved in an ALTER TABLE SWITCH statement. Any data that’s switched inherits the security of the target table.
If you’ve defined any columns in the ALTER TABLE statement to be of a common language runtime (CLR) user-defined type or alias data type, REFERENCES permission on the type is required.
Adding or altering a column that updates the rows of the table requires UPDATE permission on the table. For example, adding a NOT NULL column with a default value or adding an identity column when the table isn’t empty.
Examples
| Category | Featured syntax elements |
|---|---|
| Adding columns and constraints | ADD * PRIMARY KEY with index options * sparse columns and column sets * |
| Dropping columns and constraints | DROP |
| Altering a column definition | change data type * change column size * collation |
| Altering a table definition | DATA_COMPRESSION * SWITCH PARTITION * LOCK ESCALATION * change tracking |
| Disabling and enabling constraints and triggers | CHECK * NO CHECK * ENABLE TRIGGER * DISABLE TRIGGER |
| Online operations | ONLINE |
| System versioning | SYSTEM_VERSIONING |
Adding columns and constraints
Examples in this section demonstrate adding columns and constraints to a table.
A. Adding a new column
The following example adds a column that allows null values and has no values provided through a DEFAULT definition. In the new column, each row will have NULL.
CREATE TABLE dbo.doc_exa (column_a INT) ; GO ALTER TABLE dbo.doc_exa ADD column_b VARCHAR(20) NULL ; GO
B. Adding a column with a constraint
The following example adds a new column with a UNIQUE constraint.
CREATE TABLE dbo.doc_exc (column_a INT) ; GO ALTER TABLE dbo.doc_exc ADD column_b VARCHAR(20) NULL CONSTRAINT exb_unique UNIQUE ; GO EXEC sp_help doc_exc ; GO DROP TABLE dbo.doc_exc ; GO
C. Adding an unverified CHECK constraint to an existing column
The following example adds a constraint to an existing column in the table. The column has a value that violates the constraint. Therefore, WITH NOCHECK is used to prevent the constraint from being validated against existing rows, and to allow for the constraint to be added.
CREATE TABLE dbo.doc_exd (column_a INT) ; GO INSERT INTO dbo.doc_exd VALUES (-1) ; GO ALTER TABLE dbo.doc_exd WITH NOCHECK ADD CONSTRAINT exd_check CHECK (column_a > 1) ; GO EXEC sp_help doc_exd ; GO DROP TABLE dbo.doc_exd ; GO
D. Adding a DEFAULT constraint to an existing column
The following example creates a table with two columns and inserts a value into the first column, and the other column remains NULL. A DEFAULT constraint is then added to the second column. To verify that the default is applied, another value is inserted into the first column, and the table is queried.
CREATE TABLE dbo.doc_exz (column_a INT, column_b INT) ; GO INSERT INTO dbo.doc_exz (column_a) VALUES (7) ; GO ALTER TABLE dbo.doc_exz ADD CONSTRAINT col_b_def DEFAULT 50 FOR column_b ; GO INSERT INTO dbo.doc_exz (column_a) VALUES (10) ; GO SELECT * FROM dbo.doc_exz ; GO DROP TABLE dbo.doc_exz ; GO
E. Adding several columns with constraints
The following example adds several columns with constraints defined with the new column. The first new column has an IDENTITY property. Each row in the table has new incremental values in the identity column.
CREATE TABLE dbo.doc_exe (column_a INT CONSTRAINT column_a_un UNIQUE) ; GO ALTER TABLE dbo.doc_exe ADD -- Add a PRIMARY KEY identity column. column_b INT IDENTITY CONSTRAINT column_b_pk PRIMARY KEY, -- Add a column that references another column in the same table. column_c INT NULL CONSTRAINT column_c_fk REFERENCES doc_exe(column_a), -- Add a column with a constraint to enforce that -- nonnull data is in a valid telephone number format. column_d VARCHAR(16) NULL CONSTRAINT column_d_chk CHECK (column_d LIKE '[0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]' OR column_d LIKE '([0-9][0-9][0-9]) [0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]'), -- Add a nonnull column with a default. column_e DECIMAL(3,3) CONSTRAINT column_e_default DEFAULT .081 ; GO EXEC sp_help doc_exe ; GO DROP TABLE dbo.doc_exe ; GO
F. Adding a nullable column with default values
The following example adds a nullable column with a DEFAULT definition, and uses WITH VALUES to provide values for each existing row in the table. If WITH VALUES isn’t used, each row has the value NULL in the new column.
CREATE TABLE dbo.doc_exf (column_a INT) ; GO INSERT INTO dbo.doc_exf VALUES (1) ; GO ALTER TABLE dbo.doc_exf ADD AddDate smalldatetime NULL CONSTRAINT AddDateDflt DEFAULT GETDATE() WITH VALUES ; GO DROP TABLE dbo.doc_exf ; GO
G. Creating a PRIMARY KEY constraint with index or data compression options
The following example creates the PRIMARY KEY constraint PK_TransactionHistoryArchive_TransactionID and sets the options FILLFACTOR, ONLINE, and PAD_INDEX. The resulting clustered index will have the same name as the constraint.
Applies to: [!INCLUDEsql2008-md] and later and [!INCLUDEssSDSfull].
USE AdventureWorks; GO ALTER TABLE Production.TransactionHistoryArchive WITH NOCHECK ADD CONSTRAINT PK_TransactionHistoryArchive_TransactionID PRIMARY KEY CLUSTERED (TransactionID) WITH (FILLFACTOR = 75, ONLINE = ON, PAD_INDEX = ON); GO
This similar example applies page compression while applying the clustered primary key.
USE AdventureWorks; GO ALTER TABLE Production.TransactionHistoryArchive WITH NOCHECK ADD CONSTRAINT PK_TransactionHistoryArchive_TransactionID PRIMARY KEY CLUSTERED (TransactionID) WITH (DATA_COMPRESSION = PAGE); GO
H. Adding a sparse column
The following examples show adding and modifying sparse columns in table T1. The code to create table T1 is as follows.
CREATE TABLE T1 ( C1 INT PRIMARY KEY, C2 VARCHAR(50) SPARSE NULL, C3 INT SPARSE NULL, C4 INT) ; GO
To add an additional sparse column C5, execute the following statement.
ALTER TABLE T1 ADD C5 CHAR(100) SPARSE NULL ; GO
To convert the C4 non-sparse column to a sparse column, execute the following statement.
ALTER TABLE T1 ALTER COLUMN C4 ADD SPARSE ; GO
To convert the C4 sparse column to a nonsparse column, execute the following statement.
ALTER TABLE T1 ALTER COLUMN C4 DROP SPARSE ; GO
I. Adding a column set
The following examples show adding a column to table T2. A column set can’t be added to a table that already contains sparse columns. The code to create table T2 is as follows.
CREATE TABLE T2 ( C1 INT PRIMARY KEY, C2 VARCHAR(50) NULL, C3 INT NULL, C4 INT) ; GO
The following three statements add a column set named CS, and then modify columns C2 and C3 to SPARSE.
ALTER TABLE T2 ADD CS XML COLUMN_SET FOR ALL_SPARSE_COLUMNS ; GO ALTER TABLE T2 ALTER COLUMN C2 ADD SPARSE ; GO ALTER TABLE T2 ALTER COLUMN C3 ADD SPARSE ; GO
J. Adding an encrypted column
The following statement adds an encrypted column named PromotionCode.
ALTER TABLE Customers ADD PromotionCode nvarchar(100) ENCRYPTED WITH (COLUMN_ENCRYPTION_KEY = MyCEK, ENCRYPTION_TYPE = RANDOMIZED, ALGORITHM = 'AEAD_AES_256_CBC_HMAC_SHA_256') ;
K. Adding a primary key with resumable operation
Resumable ALTER TABLE operation for adding a primary key clustered on column (a) with MAX_DURATION of 240 minutes.
ALTER TABLE table1 ADD CONSTRAINT PK_Constrain PRIMARY KEY CLUSTERED (a) WITH (ONLINE = ON, MAXDOP = 2, RESUMABLE = ON, MAX_DURATION = 240);
Dropping columns and constraints
The examples in this section demonstrate dropping columns and constraints.
A. Dropping a column or columns
The first example modifies a table to remove a column. The second example removes multiple columns.
CREATE TABLE dbo.doc_exb ( column_a INT, column_b VARCHAR(20) NULL, column_c DATETIME, column_d INT) ; GO -- Remove a single column. ALTER TABLE dbo.doc_exb DROP COLUMN column_b ; GO -- Remove multiple columns. ALTER TABLE dbo.doc_exb DROP COLUMN column_c, column_d;
B. Dropping constraints and columns
The first example removes a UNIQUE constraint from a table. The second example removes two constraints and a single column.
CREATE TABLE dbo.doc_exc (column_a INT NOT NULL CONSTRAINT my_constraint UNIQUE) ; GO -- Example 1. Remove a single constraint. ALTER TABLE dbo.doc_exc DROP my_constraint ; GO DROP TABLE dbo.doc_exc; GO CREATE TABLE dbo.doc_exc ( column_a INT NOT NULL CONSTRAINT my_constraint UNIQUE ,column_b INT NOT NULL CONSTRAINT my_pk_constraint PRIMARY KEY) ; GO -- Example 2. Remove two constraints and one column -- The keyword CONSTRAINT is optional. The keyword COLUMN is required. ALTER TABLE dbo.doc_exc DROP CONSTRAINT my_constraint, my_pk_constraint, COLUMN column_b ; GO
C. Dropping a PRIMARY KEY constraint in the ONLINE mode
The following example deletes a PRIMARY KEY constraint with the ONLINE option set to ON.
ALTER TABLE Production.TransactionHistoryArchive DROP CONSTRAINT PK_TransactionHistoryArchive_TransactionID WITH (ONLINE = ON) ; GO
D. Adding and dropping a FOREIGN KEY constraint
The following example creates the table ContactBackup, and then alters the table, first by adding a FOREIGN KEY constraint that references the table Person.Person, then by dropping the FOREIGN KEY constraint.
CREATE TABLE Person.ContactBackup (ContactID INT) ; GO ALTER TABLE Person.ContactBackup ADD CONSTRAINT FK_ContactBackup_Contact FOREIGN KEY (ContactID) REFERENCES Person.Person (BusinessEntityID) ; GO ALTER TABLE Person.ContactBackup DROP CONSTRAINT FK_ContactBackup_Contact ; GO DROP TABLE Person.ContactBackup ;
Altering a column definition
A. Changing the data type of a column
The following example changes a column of a table from INT to DECIMAL.
CREATE TABLE dbo.doc_exy (column_a INT) ; GO INSERT INTO dbo.doc_exy (column_a) VALUES (10) ; GO ALTER TABLE dbo.doc_exy ALTER COLUMN column_a DECIMAL (5, 2) ; GO DROP TABLE dbo.doc_exy ; GO
B. Changing the size of a column
The following example increases the size of a varchar column and the precision and scale of a decimal column. Because the columns contain data, the column size can only be increased. Also notice that col_a is defined in a unique index. The size of col_a can still be increased because the data type is a varchar and the index isn’t the result of a PRIMARY KEY constraint.
-- Create a two-column table with a unique index on the varchar column. CREATE TABLE dbo.doc_exy (col_a varchar(5) UNIQUE NOT NULL, col_b decimal (4,2)) ; GO INSERT INTO dbo.doc_exy VALUES ('Test', 99.99) ; GO -- Verify the current column size. SELECT name, TYPE_NAME(system_type_id), max_length, precision, scale FROM sys.columns WHERE object_id = OBJECT_ID(N'dbo.doc_exy') ; GO -- Increase the size of the varchar column. ALTER TABLE dbo.doc_exy ALTER COLUMN col_a varchar(25) ; GO -- Increase the scale and precision of the decimal column. ALTER TABLE dbo.doc_exy ALTER COLUMN col_b decimal (10,4) ; GO -- Insert a new row. INSERT INTO dbo.doc_exy VALUES ('MyNewColumnSize', 99999.9999) ; GO -- Verify the current column size. SELECT name, TYPE_NAME(system_type_id), max_length, precision, scale FROM sys.columns WHERE object_id = OBJECT_ID(N'dbo.doc_exy') ;
C. Changing column collation
The following example shows how to change the collation of a column. First, a table is created table with the default user collation.
CREATE TABLE T3 ( C1 INT PRIMARY KEY, C2 VARCHAR(50) NULL, C3 INT NULL, C4 INT) ; GO
Next, column C2 collation is changed to Latin1_General_BIN. The data type is required, even though it isn’t changed.
ALTER TABLE T3 ALTER COLUMN C2 varchar(50) COLLATE Latin1_General_BIN ; GO
D. Encrypting a column
The following example shows how to encrypt a column using Always Encrypted with secure enclaves.
First, a table is created without any encrypted columns.
CREATE TABLE T3 ( C1 INT PRIMARY KEY, C2 VARCHAR(50) NULL, C3 INT NULL, C4 INT) ; GO
Next, column ‘C2’ is encrypted with a column encryption key, named CEK1, and randomized encryption. For the following statement to succeed:
- The column encryption key must be enclave-enabled. Meaning, it must be encrypted with a column master key that allows enclave computations.
- The target SQL Server instance must support Always Encrypted with secure enclaves.
- The statement must be issued over a connection set up for Always Encrypted with secure enclaves, and using a supported client driver.
- The calling application must have access to the column master key, protecting
CEK1.
ALTER TABLE T3 ALTER COLUMN C2 VARCHAR(50) ENCRYPTED WITH (COLUMN_ENCRYPTION_KEY = [CEK1], ENCRYPTION_TYPE = Randomized, ALGORITHM = 'AEAD_AES_256_CBC_HMAC_SHA_256') NULL; GO
Altering a table definition
The examples in this section demonstrate how to alter the definition of a table.
A. Modifying a table to change the compression
The following example changes the compression of a nonpartitioned table. The heap or clustered index will be rebuilt. If the table is a heap, all nonclustered indexes will be rebuilt.
ALTER TABLE T1 REBUILD WITH (DATA_COMPRESSION = PAGE) ;
The following example changes the compression of a partitioned table. The REBUILD PARTITION = 1 syntax causes only partition number 1 to be rebuilt.
Applies to: [!INCLUDEsql2008-md] and later and [!INCLUDEssSDSfull].
ALTER TABLE PartitionTable1 REBUILD PARTITION = 1 WITH (DATA_COMPRESSION =NONE) ; GO
The same operation using the following alternate syntax causes all partitions in the table to be rebuilt.
Applies to: [!INCLUDEsql2008-md] and later and [!INCLUDEssSDSfull].
ALTER TABLE PartitionTable1 REBUILD PARTITION = ALL WITH (DATA_COMPRESSION = PAGE ON PARTITIONS(1)) ;
For additional data compression examples, see Data Compression.
B. Modifying a columnstore table to change archival compression
The following example further compresses a columnstore table partition by applying an additional compression algorithm. This compression reduces the table to a smaller size, but also increases the time required for storage and retrieval. This is useful for archiving or for situations that require less space and can afford more time for storage and retrieval.
Applies to: [!INCLUDEssSQL14] and later and [!INCLUDEssSDSfull].
ALTER TABLE PartitionTable1 REBUILD PARTITION = 1 WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE) ; GO
The following example decompresses a columnstore table partition that was compressed with COLUMNSTORE_ARCHIVE option. When the data is restored, it will continue to be compressed with the columnstore compression that’s used for all columnstore tables.
Applies to: [!INCLUDEssSQL14] and later and [!INCLUDEssSDSfull].
ALTER TABLE PartitionTable1 REBUILD PARTITION = 1 WITH (DATA_COMPRESSION = COLUMNSTORE) ; GO
C. Switching partitions between tables
The following example creates a partitioned table, assuming that partition scheme myRangePS1 is already created in the database. Next, a non-partitioned table is created with the same structure as the partitioned table and on the same filegroup as PARTITION 2 of table PartitionTable. The data of PARTITION 2 of table PartitionTable is then switched into table NonPartitionTable.
CREATE TABLE PartitionTable (col1 INT, col2 CHAR(10)) ON myRangePS1 (col1) ; GO CREATE TABLE NonPartitionTable (col1 INT, col2 CHAR(10)) ON test2fg ; GO ALTER TABLE PartitionTable SWITCH PARTITION 2 TO NonPartitionTable ; GO
D. Allowing lock escalation on partitioned tables
The following example enables lock escalation to the partition level on a partitioned table. If the table isn’t partitioned, lock escalation is set at the TABLE level.
Applies to: [!INCLUDEsql2008-md] and later and [!INCLUDEssSDSfull].
ALTER TABLE dbo.T1 SET (LOCK_ESCALATION = AUTO) ; GO
E. Configuring change tracking on a table
The following example enables change tracking on the Person.Person table.
Applies to: [!INCLUDEsql2008-md] and later and [!INCLUDEssSDSfull].
USE AdventureWorks; ALTER TABLE Person.Person ENABLE CHANGE_TRACKING ;
The following example enables change tracking and enables the tracking of the columns that are updated during a change.
Applies to: [!INCLUDEsql2008-md] and later.
USE AdventureWorks; GO ALTER TABLE Person.Person ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)
The following example disables change tracking on the Person.Person table.
Applies to: [!INCLUDEsql2008-md] and later and [!INCLUDEssSDSfull].
USE AdventureWorks; GO ALTER TABLE Person.Person DISABLE CHANGE_TRACKING ;
Disabling and enabling constraints and triggers
A. Disabling and re-enabling a constraint
The following example disables a constraint that limits the salaries accepted in the data. NOCHECK CONSTRAINT is used with ALTER TABLE to disable the constraint and allow for an insert that would typically violate the constraint. CHECK CONSTRAINT re-enables the constraint.
CREATE TABLE dbo.cnst_example ( id INT NOT NULL, name VARCHAR(10) NOT NULL, salary MONEY NOT NULL CONSTRAINT salary_cap CHECK (salary < 100000)) ; -- Valid inserts INSERT INTO dbo.cnst_example VALUES (1,'Joe Brown',65000) ; INSERT INTO dbo.cnst_example VALUES (2,'Mary Smith',75000) ; -- This insert violates the constraint. INSERT INTO dbo.cnst_example VALUES (3,'Pat Jones',105000) ; -- Disable the constraint and try again. ALTER TABLE dbo.cnst_example NOCHECK CONSTRAINT salary_cap; INSERT INTO dbo.cnst_example VALUES (3,'Pat Jones',105000) ; -- Re-enable the constraint and try another insert; this will fail. ALTER TABLE dbo.cnst_example CHECK CONSTRAINT salary_cap; INSERT INTO dbo.cnst_example VALUES (4,'Eric James',110000) ;
B. Disabling and re-enabling a trigger
The following example uses the DISABLE TRIGGER option of ALTER TABLE to disable the trigger and allow for an insert that would typically violate the trigger. ENABLE TRIGGER is then used to re-enable the trigger.
CREATE TABLE dbo.trig_example ( id INT, name VARCHAR(12), salary MONEY) ; GO -- Create the trigger. CREATE TRIGGER dbo.trig1 ON dbo.trig_example FOR INSERT AS IF (SELECT COUNT(*) FROM INSERTED WHERE salary > 100000) > 0 BEGIN print 'TRIG1 Error: you attempted to insert a salary > $100,000' ROLLBACK TRANSACTION END ; GO -- Try an insert that violates the trigger. INSERT INTO dbo.trig_example VALUES (1,'Pat Smith',100001) ; GO -- Disable the trigger. ALTER TABLE dbo.trig_example DISABLE TRIGGER trig1 ; GO -- Try an insert that would typically violate the trigger. INSERT INTO dbo.trig_example VALUES (2,'Chuck Jones',100001) ; GO -- Re-enable the trigger. ALTER TABLE dbo.trig_example ENABLE TRIGGER trig1 ; GO -- Try an insert that violates the trigger. INSERT INTO dbo.trig_example VALUES (3,'Mary Booth',100001) ; GO
Online operations
A. Online index rebuild using low-priority wait options
The following example shows how to perform an online index rebuild specifying the low-priority wait options.
Applies to: [!INCLUDEssSQL14] and later and [!INCLUDEssSDSfull].
ALTER TABLE T1 REBUILD WITH ( PAD_INDEX = ON, ONLINE = ON ( WAIT_AT_LOW_PRIORITY ( MAX_DURATION = 4 MINUTES, ABORT_AFTER_WAIT = BLOCKERS ) ) ) ;
B. Online alter column
The following example shows how to run an alter column operation with the ONLINE option.
Applies to: [!INCLUDEsssql16-md] and later and [!INCLUDEssSDSfull].
CREATE TABLE dbo.doc_exy (column_a INT) ; GO INSERT INTO dbo.doc_exy (column_a) VALUES (10) ; GO ALTER TABLE dbo.doc_exy ALTER COLUMN column_a DECIMAL (5, 2) WITH (ONLINE = ON) ; GO sp_help doc_exy; DROP TABLE dbo.doc_exy ; GO
System versioning
The following four examples will help you become familiar with the syntax for using system versioning. For additional assistance, see Getting Started with System-Versioned Temporal Tables.
Applies to: [!INCLUDEsssql16-md] and later and [!INCLUDEssSDSfull].
A. Add system versioning to existing tables
The following example shows how to add system versioning to an existing table and create a future history table. This example assumes that there’s an existing table called InsurancePolicy with a primary key defined. This example populates the newly created period columns for system versioning using default values for the start and end times because these values can’t be null. This example uses the HIDDEN clause to ensure no impact on existing applications interacting with the current table. It also uses HISTORY_RETENTION_PERIOD that’s available on [!INCLUDEsqldbesa] only.
--Alter non-temporal table to define periods for system versioning ALTER TABLE InsurancePolicy ADD PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo), ValidFrom datetime2 GENERATED ALWAYS AS ROW START HIDDEN NOT NULL DEFAULT SYSUTCDATETIME(), ValidTo datetime2 GENERATED ALWAYS AS ROW END HIDDEN NOT NULL DEFAULT CONVERT(DATETIME2, '9999-12-31 23:59:59.99999999') ; --Enable system versioning with 1 year retention for historical data ALTER TABLE InsurancePolicy SET (SYSTEM_VERSIONING = ON (HISTORY_RETENTION_PERIOD = 1 YEAR)) ;
B. Migrate an existing solution to use system versioning
The following example shows how to migrate to system versioning from a solution that uses triggers to mimic temporal support. The example assumes there’s an existing solution that uses a ProjectTask table and a ProjectTaskHistory table for its existing solution, that’s uses the Changed Date and Revised Date columns for its periods, that these period columns don’t use the datetime2 datatype and that the ProjectTask table has a primary key defined.
-- Drop existing trigger DROP TRIGGER ProjectTask_HistoryTrigger; -- Adjust the schema for current and history table -- Change data types for existing period columns ALTER TABLE ProjectTask ALTER COLUMN [Changed Date] datetime2 NOT NULL ; ALTER TABLE ProjectTask ALTER COLUMN [Revised Date] datetime2 NOT NULL ; ALTER TABLE ProjectTaskHistory ALTER COLUMN [Changed Date] datetime2 NOT NULL ; ALTER TABLE ProjectTaskHistory ALTER COLUMN [Revised Date] datetime2 NOT NULL ; -- Add SYSTEM_TIME period and set system versioning with linking two existing tables -- (a certain set of data checks happen in the background) ALTER TABLE ProjectTask ADD PERIOD FOR SYSTEM_TIME ([Changed Date], [Revised Date]) ALTER TABLE ProjectTask SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.ProjectTaskHistory, DATA_CONSISTENCY_CHECK = ON))
C. Disabling and re-enabling system versioning to change table schema
This example shows how to disable system versioning on the Department table, add a column, and re-enable system versioning. Disabling system versioning is required to modify the table schema. Do these steps within a transaction to prevent updates to both tables while updating the table schema, which enables the DBA to skip the data consistency check when re-enabling system versioning and gain a performance benefit. Tasks such as creating statistics, switching partitions, or applying compression to one or both tables doesn’t require disabling system versioning.
BEGIN TRAN /* Takes schema lock on both tables */ ALTER TABLE Department SET (SYSTEM_VERSIONING = OFF) ; /* expand table schema for temporal table */ ALTER TABLE Department ADD Col5 int NOT NULL DEFAULT 0 ; /* Expand table schema for history table */ ALTER TABLE DepartmentHistory ADD Col5 int NOT NULL DEFAULT 0 ; /* Re-establish versioning again*/ ALTER TABLE Department SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE=dbo.DepartmentHistory, DATA_CONSISTENCY_CHECK = OFF)) ; COMMIT
D. Removing system versioning
This example shows how to completely remove system versioning from the Department table and drop the DepartmentHistory table. Optionally, you might also want to drop the period columns used by the system to record system versioning information. You can’t drop either the Department or the DepartmentHistory tables while system versioning is enabled.
ALTER TABLE Department SET (SYSTEM_VERSIONING = OFF) ; ALTER TABLE Department DROP PERIOD FOR SYSTEM_TIME ; DROP TABLE DepartmentHistory ;
Examples: [!INCLUDEssazuresynapse-md] and [!INCLUDEssPDW]
The following examples A through C use the FactResellerSales table in the [!INCLUDEssawPDW] database.
A. Determining if a table is partitioned
The following query returns one or more rows if the table FactResellerSales is partitioned. If the table isn’t partitioned, no rows are returned.
SELECT * FROM sys.partitions AS p JOIN sys.tables AS t ON p.object_id = t.object_id WHERE p.partition_id IS NOT NULL AND t.name = 'FactResellerSales' ;
B. Determining boundary values for a partitioned table
The following query returns the boundary values for each partition in the FactResellerSales table.
SELECT t.name AS TableName, i.name AS IndexName, p.partition_number, p.partition_id, i.data_space_id, f.function_id, f.type_desc, r.boundary_id, r.value AS BoundaryValue FROM sys.tables AS t JOIN sys.indexes AS i ON t.object_id = i.object_id JOIN sys.partitions AS p ON i.object_id = p.object_id AND i.index_id = p.index_id JOIN sys.partition_schemes AS s ON i.data_space_id = s.data_space_id JOIN sys.partition_functions AS f ON s.function_id = f.function_id LEFT JOIN sys.partition_range_values AS r ON f.function_id = r.function_id and r.boundary_id = p.partition_number WHERE t.name = 'FactResellerSales' AND i.type <= 1 ORDER BY p.partition_number ;
C. Determining the partition column for a partitioned table
The following query returns the name of the partitioning column for table. FactResellerSales.
SELECT t.object_id AS Object_ID, t.name AS TableName, ic.column_id as PartitioningColumnID, c.name AS PartitioningColumnName FROM sys.tables AS t JOIN sys.indexes AS i ON t.object_id = i.object_id JOIN sys.columns AS c ON t.object_id = c.object_id JOIN sys.partition_schemes AS ps ON ps.data_space_id = i.data_space_id JOIN sys.index_columns AS ic ON ic.object_id = i.object_id AND ic.index_id = i.index_id AND ic.partition_ordinal > 0 WHERE t.name = 'FactResellerSales' AND i.type <= 1 AND c.column_id = ic.column_id ;
D. Merging two partitions
The following example merges two partitions on a table.
The Customer table has the following definition:
CREATE TABLE Customer ( id INT NOT NULL, lastName VARCHAR(20), orderCount INT, orderDate DATE) WITH ( DISTRIBUTION = HASH(id), PARTITION ( orderCount RANGE LEFT FOR VALUES (1, 5, 10, 25, 50, 100))) ;
The following command combines the 10 and 25 partition boundaries.
ALTER TABLE Customer MERGE RANGE (10);
The new DDL for the table is:
CREATE TABLE Customer ( id INT NOT NULL, lastName VARCHAR(20), orderCount INT, orderDate DATE) WITH ( DISTRIBUTION = HASH(id), PARTITION ( orderCount RANGE LEFT FOR VALUES (1, 5, 25, 50, 100))) ;
E. Splitting a partition
The following example splits a partition on a table.
The Customer table has the following DDL:
DROP TABLE Customer; CREATE TABLE Customer ( id INT NOT NULL, lastName VARCHAR(20), orderCount INT, orderDate DATE) WITH ( DISTRIBUTION = HASH(id), PARTITION ( orderCount RANGE LEFT FOR VALUES (1, 5, 10, 25, 50, 100 ))) ;
The following command creates a new partition bound by the value 75, between 50 and 100.
ALTER TABLE Customer SPLIT RANGE (75);
The new DDL for the table is:
CREATE TABLE Customer ( id INT NOT NULL, lastName VARCHAR(20), orderCount INT, orderDate DATE) WITH DISTRIBUTION = HASH(id), PARTITION ( orderCount (RANGE LEFT FOR VALUES (1, 5, 10, 25, 50, 75, 100))) ;
F. Using SWITCH to move a partition to a history table
The following example moves the data in a partition of the Orders table to a partition in the OrdersHistory table.
The Orders table has the following DDL:
CREATE TABLE Orders ( id INT, city VARCHAR (25), lastUpdateDate DATE, orderDate DATE) WITH (DISTRIBUTION = HASH (id), PARTITION ( orderDate RANGE RIGHT FOR VALUES ('2004-01-01', '2005-01-01', '2006-01-01', '2007-01-01'))) ;
In this example, the Orders table has the following partitions. Each partition contains data.
| Partition | Has data? | Boundary range |
|---|---|---|
| 1 | Yes | OrderDate < ‘2004-01-01’ |
| 2 | Yes | ‘2004-01-01’ <= OrderDate < ‘2005-01-01’ |
| 3 | Yes | ‘2005-01-01’ <= OrderDate< ‘2006-01-01’ |
| 4 | Yes | ‘2006-01-01′<= OrderDate < ‘2007-01-01’ |
| 5 | Yes | ‘2007-01-01’ <= OrderDate |
- Partition 1 (has data): OrderDate < ‘2004-01-01’
- Partition 2 (has data): ‘2004-01-01’ <= OrderDate < ‘2005-01-01’
- Partition 3 (has data): ‘2005-01-01’ <= OrderDate< ‘2006-01-01’
- Partition 4 (has data): ‘2006-01-01′<= OrderDate < ‘2007-01-01’
- Partition 5 (has data): ‘2007-01-01’ <= OrderDate
The OrdersHistory table has the following DDL, which has identical columns and column names as the Orders table. Both are hash-distributed on the id column.
CREATE TABLE OrdersHistory ( id INT, city VARCHAR (25), lastUpdateDate DATE, orderDate DATE) WITH (DISTRIBUTION = HASH (id), PARTITION ( orderDate RANGE RIGHT FOR VALUES ('2004-01-01'))) ;
Although the columns and column names must be the same, the partition boundaries don’t need to be the same. In this example, the OrdersHistory table has the following two partitions and both partitions are empty:
- Partition 1 (no data): OrderDate < ‘2004-01-01’
- Partition 2 (empty): ‘2004-01-01’ <= OrderDate
For the previous two tables, the following command moves all rows with OrderDate < '2004-01-01' from the Orders table to the OrdersHistory table.
ALTER TABLE Orders SWITCH PARTITION 1 TO OrdersHistory PARTITION 1;
As a result, the first partition in Orders is empty and the first partition in OrdersHistory contains data. The tables now appear as follows:
Orders table
- Partition 1 (empty): OrderDate < ‘2004-01-01’
- Partition 2 (has data): ‘2004-01-01’ <= OrderDate < ‘2005-01-01’
- Partition 3 (has data): ‘2005-01-01’ <= OrderDate< ‘2006-01-01’
- Partition 4 (has data): ‘2006-01-01′<= OrderDate < ‘2007-01-01’
- Partition 5 (has data): ‘2007-01-01’ <= OrderDate
OrdersHistory table
- Partition 1 (has data): OrderDate < ‘2004-01-01’
- Partition 2 (empty): ‘2004-01-01’ <= OrderDate
To clean up the Orders table, you can remove the empty partition by merging partitions 1 and 2 as follows:
ALTER TABLE Orders MERGE RANGE ('2004-01-01');
After the merge, the Orders table has the following partitions:
Orders table
- Partition 1 (has data): OrderDate < ‘2005-01-01’
- Partition 2 (has data): ‘2005-01-01’ <= OrderDate< ‘2006-01-01’
- Partition 3 (has data): ‘2006-01-01′<= OrderDate < ‘2007-01-01’
- Partition 4 (has data): ‘2007-01-01’ <= OrderDate
Suppose another year passes and you’re ready to archive the year 2005. You can allocate an empty partition for the year 2005 in the OrdersHistory table by splitting the empty partition as follows:
ALTER TABLE OrdersHistory SPLIT RANGE ('2005-01-01');
After the split, the OrdersHistory table has the following partitions:
OrdersHistory table
- Partition 1 (has data): OrderDate < ‘2004-01-01’
- Partition 2 (empty): ‘2004-01-01’ < ‘2005-01-01’
- Partition 3 (empty): ‘2005-01-01’ <= OrderDate
See also
- sys.tables
- sp_rename
- sp_help
- EVENTDATA
Next steps
- CREATE TABLE
- DROP TABLE
- ALTER TABLE column_constraint
- ALTER TABLE column_definition
- ALTER TABLE computed_column_definition
- ALTER TABLE index_option
- ALTER TABLE table_constraints
